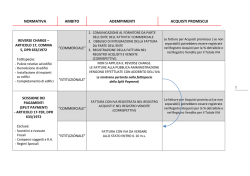
Corso di Laurea in Ingegneria Informatica Corso di Calcolatori Elettronici Anno accademico 2013-‐2014 Prof. Angelo Marcelli Appunti per le lezioni1 LE INTERFACCE DI INGRESSO/USCITA Le interfacce di ingresso/uscita consentono di collegare al calcolatore dispositivi in grado di interagire con il mondo esterno per realizzare le operazioni di ingresso/uscita previste dal programma. Sono esempi di dispositivi la tastiera, il mouse, il monitor ma anche un’unità a disco, una scheda grafica, un sintetizzatore di suoni. Sono esempi di operazioni di ingresso/uscita la lettura di un carattere da tastiera o delle coordinate del mouse, la visualizzazione di un carattere sul monitor, come anche la lettura o scrittura di un file. Le interfacce di ingresso/uscita sono rappresentate dal blocco denominato I/O nel modello di riferimento dell’architettura di un calcolatore elettronico adottato nelle lezioni del corso. Come si evince dal modello, l’accesso a questo blocco avviene in maniera analoga a quanto avviene per la memoria: sull’address bus viene fornito l’indirizzo del registro cui si vuole accedere e sul databus viene fornito il contenuto letto dal (o da scrivere nel) registro indirizzato. Indirizzamento Lo spazio degli indirizzi per le interfacce di ingresso/uscita può essere disgiunto dallo spazio degli indirizzi di memoria o incluso in esso. Nel primo caso si parla di independent I/O space, nel secondo di memory mapped I/O space. I processori che adottano la prima soluzione, ad esempio i processori Intel, prevedono istruzioni specifiche per l’ingresso/uscita, il cui formato è del tipo IN reg_proc, port OUT port, reg_proc dove reg_proc identifica il registro del processore e port l’indirizzo del registro di ingresso/uscita. Poichè gli spazi degli indirizzi di memoria e di ingresso/uscita sono separati, lo stesso indirizzo può indicare un registro di memoria o un registro di ingresso/uscita. Per distinguere i casi, durante l’esecuzione delle istruzioni di I/O, la CPU disabilita la memoria e abilita le interfacce, in modo tale che quando il valore di port viene scritto sull’address bus il registro selezionato sarà un registro allocato su di una interfaccia. 1 Per segnalare errori o suggerire commenti inviare una mail all’indirizzo [email protected] avente in oggetto: appunti i/o I processori che adottano la seconda soluzione, tra i quali il MIPS, non prevedono istruzioni di ingresso/uscita, essendo il trasferimento da/verso le interfacce realizzato mediante le istruzioni di lettura/scrittura in memoria, il cui formato è del tipo: LOAD reg_proc, memoria STORE memoria, reg_proc In questo caso, all’atto dell’istallazione dell’interfaccia vengono assegnati ai suoi registri degli indirizzi e l’azione combinata dell’hardware (della MMU) e del sistema operativo garantisce che quando uno degli indirizzi assegnati ai registri delle interfacce viene scritto sull’address bus venga disabilitata la memoria e abilitate le interfacce di ingresso/uscita. Dunque, le interfacce sono viste dal processore in maniera del tutto analoga alla memoria, ma vi è una importante differenza tra i due: mentre nel caso della memoria il contenuto di ogni registro che appartiene allo spazio degli indirizzi del programma può essere modificato solo dalle azioni eseguite dalla CPU (durante l’esecuzione delle istruzioni del programma), nel caso delle interfacce il contenuto di un registro può essere modificato anche dal dispositivo. E’ dunque necessario che le azioni eseguite dalla CPU e quelle eseguite dal dispositivo siano in qualche modo sincronizzate, per garantire la corretta evoluzione della computazione. Le istruzioni necessarie a implementare il meccanismo di sincronizzazione tra l’evoluzione della CPU e quella del dispositivo per il tramite dell’interfaccia, costituiscono il driver del dispositivo. L’architettura dell’interfaccia specifica i circuiti logici elementari e le connessioni necessari a consentire alla CPU e al dispositivo di modificare il contenuto dei registri dell’interfaccia. La realizzazione di una operazione di ingresso/uscita richiede quindi la cooperazione tra hardware (l’architettura dell’interfaccia) e software (le istruzioni del driver). Architettura Per definizione, l’interfaccia deve assolvere una duplice funzione: fornire alla CPU una rappresentazione del dispositivo nei termini del modello di programmazione (registri indirizzabili da programma) e computare la rappresentazione dello stato del dispositivo. La prima funzione è assolta rappresentando il dispositivo attraverso due registri: il registro dati, che rappresenta il registro nel quale trasferire il dato proveniente dalla CPU, ovvero dal quale trasferire il dato diretto verso la CPU, e un registro di stato, nel quale vengono memorizzate le informazioni necessarie per la sincronizzazione. La seconda funzione è realizzata definendo la rappresentazione del dispositivo in termini di variabili logiche (di ingresso e di uscita) e implementando le relazioni logiche tra le variabili di stato, di ingresso e di uscita, come per qualsiasi macchina sequenziale. Questa funzione è specifica per ogni dispositivo e dunque questa parte dell’architettura dell’interfaccia deve essere progettata con specifico riferimento al dispositivo da collegare e alle sue modalità di funzionamento. Il driver Compito fondamentale del driver è quello di garantire il trasferimento sincronizzato dei dati tra la CPU e l’interfaccia di ingresso/uscita. In questo contesto, sincronizzato significa che il dato che la CPU intende acquisire è effettivamente disponibile nel registro dati ovvero che l’interfaccia è disponibile ad accettare il dato che la CPU intende inviare, rispettivamente per le operazioni di ingresso e le operazioni di uscita. Il trasferimento può essere tempificato in modo sincrono o asincrono. Il primo modo di tempificazione è possibile quando l’evoluzione della CPU e quella dell’interfaccia avvengono sulla base di un segnale di sincronizzazione condiviso, di modo che è possibile utilizzare tale segnale per determinare in quale istante di tempo il dato richiesto/fornito dalla CPU può essere effettivamente letto/scritto. Ad esempio, nel caso in cui il segnale di sincronizzazione sia il clock che determina l’evoluzione della CPU (o da questo derivato) si può calcolare il numero di cicli di clock che intercorrono dal momento in cui è stata inviata la richiesta di leggere un dato al momento in cui il dato è reso disponibile dall’interfaccia e può dunque essere letto dalla CPU. Il secondo modo di sincronizzazione è l’unico possibile quando la CPU e il dispositivo evolvono in maniera indipendente, senza che vi sia un segnale di sincronizzazione. In questo caso, deve essere previsto lo scambio di informazioni per la sincronizzazione, il cui scopo è quello di informare la CPU in merito all’evoluzione del dispositivo, in modo che il trasferimento del dato avvenga al momento opportuno. Il trasferimento sincrono, quando realizzabile, risulta particolarmente indicato in caso di dispositivi il cui tempo di risposta è costante e risulta tanto più efficiente quanto minore è il tempo di attesa (della CPU), in quanto con questa modalità di sincronizzazione la CPU resta impegnata per tutta la durata del trasferimento. Il modo più semplice per implementare il trasferimento sincrono è quello di inserire dopo l’istruzione che richiede il dato e prima di leggere il dato stesso un numero di istruzioni di NOP tale che al termine della loro esecuzione sia trascorso il tempo necessario a garantire che il dato sia disponibile per il trasferimento. Il trasferimento asincrono, viceversa, risulta particolarmente indicato in tutti quei casi in cui il tempo di risposta del dispositivo varia in funzione dello stato del dispositivo stesso e/o del tipo di richiesta. Inoltre, esso consente di utilizzare il meccanismo delle interruzioni per liberare la CPU dalla necessità di rimanere in attesa del completamento del trasferimento. Nel caso di trasferimento asincrono, il protocollo utilizzato per la sincronizzazione è denominato handshake, e prevede che, prima di effettuare il trasferimento da/verso il registro dati dell’interfaccia, la CPU invii una richiesta di trasferimento all’interfaccia, aspetti una risposta positiva da parte dell’interfaccia e quindi esegua le istruzioni necessarie al trasferimento del dato. Poichè nel modello di interfaccia che abbiamo considerato lo stato dell’interfaccia è rappresentato nel registro di stato, il trasferimento effettivo del dato dovrà avvenire solo quando lo stato rappresentato nel registro è quello previsto. Come detto, lo stato può essere modificato dalla CPU per effetto delle istruzioni contenute nel driver, ma anche dal dispositivo. Dunque, prima di effettuare un trasferimento è necessario che il driver controlli se lo stato rappresentato nel registro di stato (che chiameremo stato attuale) è quello previsto (che chiameremo stato atteso) quando deve essere effettuato il trasferimento. In caso positivo, il trasferimento avviene e la computazione prosegue. In caso negativo, viceversa, l’evoluzione del programma che ha richiesto di effettuare l’operazione di ingresso/uscita deve avvenire in modo da “aspettare” l’evoluzione del dispositivo. D’altro canto, la CPU, terminata l’esecuzione dell’istruzione con la quale verifica se lo stato attuale è quello previsto, eseguirà l’istruzione il cui indirizzo è contenuto nel program counter. Se il confronto da esito positivo, il program counter contiene già il valore corretto, che nella fattispecie è quello dell’istruzione che segue il confronto. Il problema della sincronizzazione si riduce quindi a determinare qual è l’indirizzo dell’istruzione da eseguire nel caso in cui il confronto da esito negativo. Le soluzioni al problema della sincronizzazione, dunque, non possono che essere due: fare in modo che nel program counter venga caricato un indirizzo in corrispondenza del quale inizi una sequenza di istruzioni che “tenga occupata” la CPU senza fare avanzare l’evoluzione del programma, ovvero interrompere l’esecuzione del programma che ha richiesto l’operazione di ingresso/uscita fino a quando lo stato attuale del dispositivo sia quello previsto e quindi riprendere l’esecuzione del programma che aveva richiesto l’operazione di ingresso/uscita a partire dall’istruzione immediatamente successiva a quella (di confronto) che aveva originato l’interruzione. Nel primo caso si dice che le operazioni di ingresso/uscita sono sincronizzate da programma, nel secondo caso che esse sono sincronizzate mediante le interruzioni. Nel caso di sincronizzazione da programma, la sequenza di istruzioni necessaria sarà del tipo: leggi dal registro di stato lo stato attuale se lo stato attuale è diverso dallo stato previsto salta a leggi trasferisci dal/nel registro dati In questo modo, la CPU legge il contenuto del registro di stato finchè esso non assume il valore desiderato e quindi effettua il trasferimento. Questa soluzione è di semplice realizzazione, nel senso che non richiede all’interfaccia nessuna funzione specifica oltre a quella di modificare il contenuto del registro di stato per effetto delle informazioni fornite dal dispositivo, ma rende la computazione inefficiente quando il tempo necessario al dispositivo per modificare lo stato della computazione è molto grande rispetto al tempo impiegato dal processore per eseguire le istruzioni di lettura e confronto. In tal caso, infatti, le istruzioni del ciclo saranno ripetute molte volte, consumando cicli macchina senza che avanzi lo stato della computazione del programma. Se, ad esempio, il driver fosse quello che acquisisce i caratteri da tastiera e lo stato previsto fosse quello corrispondente a “è stato premuto un tasto”, anche in presenza di una persona con buona velocità di scrittura, il ciclo verrebbe eseguito milioni di volte tra l’acquisizione di un carattere e il successivo. Nel caso di sincronizzazione mediante le interruzioni, la sequenza di istruzioni sarà del tipo: leggi dal registro di stato lo stato attuale se lo stato attuale è diverso dallo stato previsto interruzione trasferisci dal/nel registro dati In questo modo, la CPU legge una volta sola il contenuto del registro di stato e se lo stato attuale non è quello previsto genera un’interruzione. Il meccanismo delle interruzioni provvede a salvare il valore del program counter (che contiene l’indirizzo dell’istruzione di trasferimento) e caricare nel program counter l’indirizzo della ISR, la quale metterà il driver in attesa di una interruzione da parte del dispositivo e quindi deciderà quale programma mettere in esecuzione. Quando lo stato del dispositivo diviene quello atteso, l’interfaccia genera un segnale di interruzione. Il meccanismo delle interruzioni, riconosciuta la causa dell’interruzione, caricherà nel program counter il valore precedentemente salvato, di modo che l’esecuzione del driver possa procedere con l’istruzione di trasferimento del dato, come desiderato. Questa soluzione è più efficiente della precedente perchè “libera” la CPU dall’eseguire il ciclo di istruzioni necessarie alla sincronizzazione, recuperando cicli macchina che possono essere impiegati per far avanzare l’esecuzione di altri programmi, ma richiede che l’interfaccia sia dotata dei circuiti necessari a generare le interruzioni ed inoltre utilizza una parte dei cicli macchina recuperati per eseguire le istruzioni della ISR necessarie a salvare e ripristinare lo stato del driver ed eventualmente a riconoscere la causa delle interruzioni, se tale riconoscimento non è effettuato dall’hardware delle interruzioni. Nota: Il numero di cicli macchina spesi per eseguire le istruzioni della ISR rappresenta un limite invalicabile per la sincronizzazione mediante interruzioni, che non può essere usata se lo stato del dispositivo può cambiare in un intervallo di tempo uguale a (o minore di) quello necessario ad eseguire le istruzioni della ISR. In tal caso, infatti, appena terminata l’esecuzione delle istruzioni della ISR necessarie a gestire l’interruzione generata dal driver si verificherebbe l’interruzione generata dall’interfaccia, che riattiverebbe la ISR, rendendo vano il ricorso alle interruzioni perchè i cicli macchina recuperati sarebbero tutti spesi per il servizio dell’interruzione (e dunque per la sincronizzazione), senza nessun vantaggio sulle prestazioni complessive del sistema. In conclusione, la scelta del meccanismo di sincronizzazione dipende essenzialmente dalla differenza di velocita tra la CPU e il dispositivo: maggiore è tale differenza, maggiore è la convenienza ad utilizzare il meccanismo delle interruzioni, anche tenendo conto dei cicli macchina che vengono spesi per eseguire le istruzioni della ISR. Esempio Un esempio riepilogativo Progettare un’interfaccia e scriverne il driver per collegare al processore MIPS un sistema di irrigazione costituito da 8 dispositivi. Il protocollo che descrive l’interazione tra la CPU, l’interfaccia e i dispositivi è il seguente: -‐ la CPU invia all’interfaccia il segnale START; -‐ quando riceve START l’interfaccia, se disponibile, invia alla CPU il segnale ACK; -‐ se la CPU non riceve ACK entro 5 secondi dall’invio di START, deasserisce START e termina l’operazione; -‐ quando riceve ACK, la CPU invia il segnale GO e scrive sul data bus il codice identificativo del dispositivo da attivare e la durata (in secondi) dell’irrigazione; -‐ quando riceve GO, l’interfaccia attiva il dispositivo selezionato e si rende non disponibile a ricevere altre richieste; -‐ al termine del periodo di irrigazione, l’interfaccia disattiva il dispositivo selezionato, invia alla CPU il segnale END e si rende disponibile ad accettare nuove richieste; -‐ quando riceve il segnale END, la CPU deasserisce START e termina l’operazione. Si facciano tutte le ipotesi che si ritengono opportune, purchè non in contrasto con le specifiche assegnate. A. Progetto dell’interfaccia Per il progetto dell’interfaccia si possono seguire delle linee guida che seguono dalle considerazioni svolte in precedenza a proposito dell’architettura: . Esse si articolano in 7 punti, come di seguito. 1. Individuare i segnali di ingresso e di uscita lato processore e lato dispositivo Dall’analisi del protocollo si evince che: -‐ Gli ingressi lato CPU sono START e GO -‐ Non ci sono ingressi lato dispositivo -‐ -‐ Le uscite lato CPU sono ACK ed END Le uscite lato dispositivo sono i segnali di attivazione dei singoli dispositivi che possiamo chiamare ON(i), dove l’indice i individua l’i-‐esimo dispositivo. 2. Scrivere le relazioni logiche per le variabili di uscita lato processore e lato dispositivo ricavandole dal protocollo Le relazioni logiche per le variabili di uscita, in maiuscolo, si ricavano anch’esse dal protocollo: ACK= START and interfaccia_disponibile END= GO and tempo_trascorso ON(i) = GO and indice_dispositivo In queste relazioni, i termini in grassetto denotano l’operazione logica tra le variabili, la cui implementazione dipende dalle scelte che saranno fatte nella definizione del datapath in merito alle macchine elementari che lo costituiscono. Le variabili logiche in corsivo rappresentano le variabili di stato dell’interfaccia e dunque dovranno essere calcolate dall’interfaccia e memorizzate nel registro di stato. La variabile in minuscolo è uno dei dati traferiti sul data bus. 3. Definire la dimensione e la struttura del registro di stato Il registro di stato deve contenere i seguenti bit di stato: S: bit di start, asserito dalla CPU; si suppone che occupi la posizione 0 del registro G: bit di go, asserito dalla CPU; si suppone che occupi la posizione 1 del registro A: bit di ack, asserito dall’interfaccia; si suppone che occupi la posizione 2 del registro E: bit di end, asserito dall’interfaccia; si suppone che occupi la posizione 3 del registro. D: bit di interfaccia disponibile, asserito dall’interfaccia; si suppone che occupi la posizione 4 del registro T: bit di tempo trascorso, asserito dall’interfaccia; si suppone occupi la posizione 5 del registro La dimensione del registro di stato è pertanto fissata in 1 byte e i bit di posto 6 e 7 non sono utilizzati. Si fa inoltre l’ipotesi che il bit meno significativo del databus (DB0) corrisponda al bit meno significativo del registro di stato (RS0) e così via per gli altriregistro sia realizzato mediante flip-‐flop di tipo D. 4. Definire la dimensione e la struttura del registro dati Il registro dati deve consentire il trasferimento del codice del dispositivo da attivare e del tempo di irrigazione. Bisogna quindi definire la dimensione in bit di tali dati. Per il codice del dispositivo, si può assumere che esso sia rappresentato con 3 bit, essendo 8 il numero massimo di dispositivi collegabili. Per il tempo di irrigazione è necessario fissare un limite massimo, non essendo questo definito dalla specifiche. E’ importante osservare che questa scelta di progetto introduce un limite sulle caratteristiche dell’interfaccia che non potrà essere utilizzata per periodi di irrigazione maggiori del limite. D’altra parte, la dimensione del registro dati deve essere congruente con uno dei tipi previsti dal linguaggio macchina, che nel caso del MIPS sono byte, halfword e word. Data la natura dell’applicazione, un registro dati a 8 bit (corrisponde a fissare un limite di 255 secondi) è inadeguato, mentre un registro dati a 16 bit consente di fissare un limite di 65535 secondi, pari a circa 18 ore, che può ritenersi adeguato in molte applicazioni. Poichè il protocollo specifica che la CPU invia il codice identificativo e la durata del periodo di irrigazione, si può ipotizzare un registro dati di 3 byte, di cui 1 per il codice identificativo e 2 per la durata del periodo di irrigazione. 5. Definire il datapath per il trasferimento dati con la CPU Il datapath relativo al trasferimento CPU-‐interfaccia si ricava dal fatto che deve essere possibile leggere (ACK e END) e scrivere (START e GO) nel registro di stato e scrivere (il codice identificativo e la durata) nel registro dati. Ricordando che nel caso del MIPS i registri sono memory mapped, ne segue lo schema rappresentato in celeste in figura 1. Per semplicità, sono riportate solo le uscite del decodificatore che corrispondono all’indirizzo del registro di stato e del registro dati, essendo tutte le altre non utilizzate. 6. Definire il datapath per il trasferimento dati con il dispositivo Il datapath relativo al trasferimento interfaccia-‐dispositivo si ricava osservando che è necessario l’invio dei segnali ON(i), che devono essere asseriti per tutta la durata del tempo di irrigazione. L’indice i del dispositivo si ottiene decodificando il codice identificativo del dispositivo fornito dalla CPU e contenuto nel registro dati: ON(i)=DEC(codice_identificativo). Lo schema risultante è rappresentato in rosso in figura 1. 7. Implementare le relazioni logiche e tempificare il funzionamento del datapath A. Variabili di uscita L’implementazione della relazione logica per il calcolo della variabile A si ottiene mediante una porta AND tra il bit S e il bit D del registro di stato: A=S AND D Nota: Se si usano dei flip-‐flop D per l’implementazione del registro di stato, l’equazione definisce direttamente l’ingresso al flip-‐flop, mentre se si usano flip-‐flop RS le equazioni che descrivono gli ingressi al flip-‐flop sono R=NOT(S) OR NOT(D), S=S AND D L’implementazione della relazione logica per il calcolo della variabile E si ottiene mediante una porta AND tra il bit G e il bit T del registro di stato: E=G AND T Nota: Se si usano dei flip-‐flop D per l’implementazione del registro di stato, tale equazione definisce direttamente l’ingresso al flip-‐flop, mentre se si usano flip-‐flop RS le equazioni che descrivono gli ingressi al flip-‐flop sono R=NOT(G) OR NOT(T), S=G AND T Ricordando che l’uscita di un decodificatore assume valore significativo solo quando l’ingresso di abilitazione è asserito, l’implementazione della relazione logica per il calcolo delle variabili ON(i) si ottiene utilizzando il bit G come segnale di abilitazione del decodificatore: EN=G Le reti logiche per il calcolo delle variabili di uscita sono riportate in verde in figura 1. B. Variabili di stato e tempificazione Per il corretto funzionamento dell’interfaccia è necessario imporre che: -‐ il bit D assuma il valore 1 inizialmente e quando l’interfaccia non è impegnata a controllare un dispositivo di irrigazione, mentre deve assumere il valore 0 quando l’interfaccia è impegnata. Dal protocollo si evince che durante il controllo G=1 e T=0, quindi: D=NOT(G) OR T Nota: Se si usano dei flip-‐flop di D per l’implementazione del registro di stato, tale equazione definisce direttamente l’ingresso al flip-‐flop D. Se si usano flip-‐flop RS le equazioni che descrivono gli ingressi al flip-‐flop sono R=G AND NOT(T), S=NOT(G) OR T. -‐ il bit T assuma il valore 0 inizialmente e durante tutta la durata dell’irrigazione e che assuma il valore 1 quando il periodo di irrigazione termina. -‐ il bit G assuma il valore 0 inizialmente e al termine dell’irrigazione. Per implementare la variabile T la scelta più naturale è quella di usare un contatore modulo 216 la cui frequenza di clock è pari a 1 hz, visto che la durata è espressa in secondi. Il contatore deve precaricato al valore pari alla durata dell’irrigazione quando inizia l’irrigazione e contare a decrescere. Ricordando che gli ingressi di load e reset del contatore sono sempre attivi mentre l’avanzamento del conteggio avviene solo se il contatore è abilitato, segue che: I=registro dati load=G EN=NOT(D) u/d=0 Per garantire che T=0 all’inizio del conteggio successivo, il contatore deve essere resettato quando viene generato il segnale ACK, quindi reset=A In queste condizioni, l’uscita div si alza al termine del periodo di irrigazione. Quindi: T=div Le uscite U e ripple non sono utilizzate. Nota: Se si usano flip-‐flop D per l’implementazione del registro di stato, D=div, mentre se si usano flip-‐flop RS le equazioni che descrivono gli ingressi al flip-‐flop sono R= NOT(div), S=div. Per quanto riguarda G, esso assume il valore 1 per effetto del segnale GO e deve assumere il valore 0 quando il conteggio termina. Dunque G=GO AND NOT(T) Nota: Se si usano flip-‐flop D per l’implementazione del registro di stato, tale equazione definisce direttamente l’ingresso al flip-‐flop. Se si usano flip-‐flop RS le equazioni che descrivono gli ingressi al flip-‐flop sono R=T, S=GO. Le reti logiche per il calcolo delle variabili di stato e la tempificazione sono riportate in arancione in figura 1. CS R/W Address Bus Decoder EN DB1 (GO) T D E A G S EN div EN 0 D e c o d e r u/d clk reset I load ON0 ON1 ON7 1 Hz 15 0 7 0 Data Bus Figura 1. Architettura dell’interfaccia. In azzurro il datapath per il trasferimento da/verso il processore; in rosso il datapath per il trasferimento verso i dispositivi; in verde le reti logiche per il calcolo delle variabili di uscita; in arancio le reti logiche per il calcolo delle variabili di stato e la tempificazione. Il registro di stato e il registro dati sono realizzati con flip-flop di tipo D. B. Il driver Per la progettazione e implementazione del driver è necessario conoscere il modo nel quale sono rappresentate le informazioni nel registro di stato, la dimensione del registro dati, la loro allocazione in memoria e la tecnica di sincronizzazione. Mentre le prime due devono essere comunque specificate, la definizione delle ultime due può essere lasciate al progettista del driver. Come nel caso del progetto dell’architettura, anche per il driver si possono definire delle linee guida alla progettazione che seguono dalle oseervazioni svolte in precedenza. 1. Definizione del registro di stato Dalla specifiche dell’interfaccia che abbiamo progettato in precedenza si evince che il registro di stato ha la seguente struttura: T D E A G S 2. Definizione registro dati Dalla specifiche dell’interfaccia che abbiamo progettato in precedenza si evince che sono disponibili due registri dati, di dimensione byte e halfword, rispettivamente per il codice del dispositivo da attivare ed il tempo di irrigazione, che possono essere mappati in due registri dati come segue: Tempo Irrigazione (8-‐15) Tempo Irrigazione (0-‐7) ID dispositivo 3. Allocazione in memoria Nel processore MIPS, i registri di I/O sono mappati in memoria negli indirizzi compresi tra 0xFFFF0000 2 0xFFFFFFFF e lo spazio di indirizzamento è byte addressable. Non essendo fornite specifiche in merito, supporremo i registri allocati nello spazio degli indirizzi come segue: Registro Stato Dati -‐ ID Dati-‐ Tempo LSB Dati-‐ Tempo MSB Indirizzo 0xFFFF0000 0XFFFF0001 0xFFFF0002 0xFFFF0003 Nota: Il modo in cui abbiamo mappato in memoria i registri inciderà sulla scrittura del driver ed in particolare sul tipo di istruzione che utilizzeremo per leggere e scrivere i dati dai vari registri: • per leggere/scrivere il registro di stato dovremo utilizzare una lb/sb • per scrivere l'ID del dispositivo da attivare dovremo utilizzare una sb • per scrivere il Tempo di Irrigazione dovremo utilizzare una sh Gli indirizzi possono essere trattati come costanti, ma anche essere considerati come parametri passati in ingresso al driver tramite registri o stack. Nell’implementazione che segue, li tratteremo come costanti. Il codice identitifcativo del dispositivo da attivare (ID) e il tempo di irrigazione possono essere passati al driver dal chiamante tramite registri o stack, oppure possono essere delle costanti. Nell’implementazione che segue li passeremo tramite i registri $a0 e $a1 4. Sincronizzazione Non essendo specificata la tecnica di sincronizzazione, nel’implementazione che segue utilizzeremo la sincronizzazione da programma. .data .text # step 0: inizializzazione Carichiamo, rispettivamente, nei registri s0, s1, s2 gli indirizzi che puntano al byte del registro di stato, al byte che codifica l'ID e all'half word che rappresenta il tempo di irrigazione. Essendo registri NON modificabili, ne salviamo lo stato sullo stack addi $sp,$sp, -‐16 sw $s0,0($sp) # salva il contenuto di $s0 sw $s1, 4($sp) # salva il contenuto di $s1 sw $s2, 8($sp) # salva il contenuto di $s2 sw $ra, 12($sp) # salva indirizzo di ritorno li $s0, 0xFFFF0000 # carica indirizzo registro di stato li $s1, 0xFFFF0001 # carica indirizzo registro dati per ID li $s2, 0xFFFF0002 # carica indirizzo registro dati per Tempo di Irrigazione #step 1: invia START senza alterare lo stato attuale dell'interfaccia, che potrebbe trovarsi occupata a gestire una richiesta precedente lb $t0, 0($s0) # legge il registro di stato ori $t0,$t0,1 # modifica il contenuto del registro di stato (ora presente in t0) mettendo ad 1 il solo bit di start sb $t0,0($s0) # invio START #step 2: In attesa di ACK attiva il timer Per implementare il meccanismo di time-‐out dobbiamo: • conoscere la frequenza del clock del processore e calcolare quanti colpi di clock corrispondono a 5 secondi; • contare il numero di colpi di clock dall'avvio del timer; • verificare che il segnale di ACK si alzi prima che siano trascorsi i 5 minuti. Dalla documentazione dei primi modelli di MIPS a 32 bit con pipeline, risulta che la frequenza del clock è 20 MHz, ovvero il periodo è di 50 nsec . Di conseguenza 5 secondi equivalgono a 10^8 colpi di clock. lb $t0, 0($s0) andi $t0, $t0, 4 # legge lo stato # effettua l'and bit a bit tra il contenuto del registro di stato e la maschera 00000100. Quando ACK=0, in $t0 avremo 0, quando ACK=1, in $t0 avremo 4 (00000100) # se ACK=1 va allo step 3 beq $t0,4, STEP3 #segmento di codice per implementare meccanismo di time-‐out move $t2,0 # azzera contatore li $t3, 100000000 # inizializza valore di fine conteggio (5 secondi) LOOP_TIMER: slt $t4, $t2,$t3 # t4 =1 se il contatore non ha raggiunto il valore di fine conteggio beq $t4,$zero, TIMEOUT lb $t0, 0($s0) # legge lo stato andi $t0, $t0, 4 # effettua l'and bit a bit tra il contenuto del registro di stato e la maschera 00000100. Quando ACK=0, in $t0 avremo 0, quando ACK=1, in $t0 avremo 4 (00000100) addi $t2, $t2, 10 # incrementa il contatore di 10 perché tanti sono i cicli di clock necessari per eseguire le 5 istruzioni precedenti su una pipeline a 5 stadi con propagazione tra stadio EX e stadio ID. Se posizionassimo questa istruzione tra la lb e la andi risolveremmo la dipendenza tra i dati senza la necessità di introdurre uno stallo e aggiungeremmo 9 e non 10 beq $t0, $zero, LOOP_TIMER #step 3: Invia dati e GO STEP3: sb $a0, 0($s1) # invia ID sh $a1, 0($s2) # invia il tempo di irrigazione lb $t0, 0($s0) # legge il contenuto del registro di stato ori $t0, $t0, 2 # or bit a bit con 00000010 per asserire GO sb $t0, 0($s0) # invia GO #step 4: Attesa di END LOOP_END: lb $t0, 0($s0) # legge il contenuto del registro di stato andi $t0, $t0, 8 #effettua l'and bit a bit tra il contenuto del registro di stato e la maschera 00001000. Quando END=0, in $t0 avremo 0, quando END=1, in $t0 avremo 8 (00001000) beq $t0, $zero, LOOP_END andi $t0, $t0, 48 # and con la maschera 00110000 per non modificare i bit D e T del registro di stato sb $t0, 0($s0) # ripristina le condizioni iniziali dell’interfaccia j TERMINA_OPERAZIONI #reset per time_out TIMEOUT: andi $t0,$t0,254 # and bit a bit con 1111 1110 per non modificare lo stato sb $t0,0($t0) # deasserisce START #ripristina e termina TERMINA_OPERAZIONI: lw $s0,0($sp) lw $s1, 4($sp) lw $s2, 8($sp) lw $ra, 12($sp) addi $sp,$sp, 16 jr $ra Commenti conclusivi Nello svolgimento dell’esempio sono state fatte alcune ipotesi, compatibili con le specifiche assegnate. Ne potrebbero essere fatte altre, altrettanto valide. A. Architettura Si potrebbe ipotizzare di usare un solo registro dati a 16 bit, di cui 3 per ID e 13 per il Tempo di Irrigazione. In questo caso occorre modificare anche il driver, il quale dovrà “impacchettare” in una halfword il codice identificativo e la durata che presumibilmente saranno allocate in una variabile di tipo byte e di tipo halfword, rispettivamente. Naturalmente, con questa scelta si riduce la durata massima dell’intervallo di irrigazione. Si potrebbe anche scegliere di codificare le configurazioni del registro di stato in maniera piu0’ compatta, senza associare ad ogni segnale un bit esplicito, ma codificando tutte le possibili configurazione dello stato in maniera implicita, ricorrendo ad un numero di bit pari al log2 [numero delle configurazioni] del registro di stato. Questa scelta riduce la dimensione del registro di stato ma richiede di esprimere le variabili di uscita e di stato in funzione di tutte le variabili di stato. Anche ij questo caso occorre modificare il driver nelle parti che calcoano le configurazioni che devono essere caricate neò regsitro di stato o in quelle che verificano se il registro contiene una data configurazione. Si potrebbe ancora implementare il meccanismo di time-‐out utilizzando il contatore a crescere, facendolo partire da 0 all’inizio del conteggio e generando un segnale di time-‐out quando il valore del conteggio è pari alla durata desiderata. Per generare questo segnale, si potrebbe utilizzare un comparatore che confronti l’uscita U del contatore con la durata desiderata e la cui uscita egout rappresenterebbe il segnale di time-‐out desiderato. Con questa soluzione, l’ingresso di load non è più necessario, perchè il contatore non deve essere precaricato e l’uscita div non rappresenta più il segnale di fine conteggio. Valgono ancora le considerazioni in merito agli ingressi di abilitazione e di reset. Questa modifica non richiede modifiche del driver, essendo interna ad una funzione (quella di conteggio) dell’architettura dell’interfaccia, in analogia a quanto succede con implementazioni diverse di una subroutine che non ne modifichino la sequenza di chiamata/ritorno. B. Driver Le costanti 100000000, 1, 4, 8, 16, 48, 254 possono essere anche caricate nell'area di memoria riservata ai dati statici: .data TEMPO_MAX: .word 100000000 START: .byte 1 ACK: .byte 4 GO: .byte 2 END: .byte 8 ANNULLA_OP: .byte 254 RESET: .byte 48 .text ..... Per il loro caricamento dovrebbe quindi essere usata l’istruzione la invece della li. Ad esempio, per inviare il segnale START si avrebbe: la $t2, START lb $t2, 0($t2) lb $t0, 0($s0) or $t0,$t0,$t2 sb $t0,0($s0) Si potrebbe anche supporre che gli indirizzi dei registri non siano costanti I cui valori sono noti al tempo della compilazione, ma parametri che vengono passati al driver attraverso i regisitri $a0, ... $a3 ovvero sullo stack. Evidentemente, anche queste assunzioni richiedono di modificare lo step 0 del driver in maniera conseguenziale. Per quanto attiene alla sincronizzazione, si sarebbe potuto ipotizzare l’uso del meccanismo delle interruzioni. Perchè ciò sia possibile, bisogna supporre che i segnali ACK ed END rappresentino altrettante richieste di interruzione, il cui servizio comporta la ripresa del driver. L’uso di tale meccanismo per la sincronizzazione prevista nelo step 2 richiede cautela. Infatti, l’attesa dell’ACK mediante il meccanismo delle interruzioni così come descritto in precedenza, dovrebbe essere implementata come segue: lb $t0,0($s0) # legge lo stato andi $t0, $t0, 4 # effettua l'and bit a bit tra il contenuto del registro di stato e la maschera 00000100. Quando ACK=0, in $t0 avremo 0, quando ACK=1, in $t0 avremo 4 (00000100) tnei $t0,4 In questo modo, però, se ACK non è stato asserito quando viene effettuata la load, l’istruzione tnei genera un’interruzione, per effetto della quale l’esecuzione del driver viene sospesa e riprende solo quando ACK viene effettivamente asserito, rendendo impossibile implementare il meccanismo di time-‐out. Dunque tale meccanismo deve essere gestito dalla ISR. Le modalità con cui avviene la gestione del time-‐out dipendono dal sistema operativo e quindi esulano dai contenuti del corso. Ai nostri fini, supporremo che questa funzionalità può essere richiesta alla ISR mediante una Syscall. Supporremo inoltre che il valore che specifica il servizio “i/o con time out” sia 60, che con questo codice di interruzione la ISR vada a leggere dal registro $a0 il valore (in secondi) del time-‐out e che quando il servizio dell’interruzione termina la ISR restituisca in $v0 il valore 1 se ACK viene asserito prima che scatti il time-‐out, 0 altrimenti. In queste ipotesi, la sequenza di istruzioni per implementare lo step 2 diventa: #step 2: In attesa di ACK o del timer lb $t0,0($s0) # legge lo stato andi $t0, $t0, 4 # effettua l'and bit a bit tra il contenuto del registro di stato e la maschera 00000100. Quando ACK=0, in $t0 avremo 0, quando ACK=1, in $t0 avremo 4 (00000100) li $v0,60 # specifica la causa di interruzione move $a3, $t3 # carica in $a3 la durata (in secondi) del time-‐out syscall # invoca la ISR move $t0, $v0 # carica in $t0 il valore ritornato da ISR be $t0,0,STEP # ACK è stato asserito j TIMEOUT # time-‐out Per quanto riguarda lo step 4, l’implementazione è una immediata applicazione delle considerazioni svolte in precedenza e la sequenza di istruzioni per implementare lo step 4 diventa: #step 4: Attesa di END lb $t0, 0($s0) # legge il contenuto del registro di stato andi $t0, $t0, 8 #effettua l'and bit a bit tra il contenuto del registro di stato e la maschera 00001000. Quando END=0, in $t0 avremo 0, quando END=1, in $t0 avremo 8 (00001000) teq $t0, $zero andi $t0, $t0, 48 # and con la maschera 00110000 per non modificare i bit D e T del registro di stato sb $t0, 0($s0) # ripristina le condizioni iniziali dell’interfaccia j TERMINA_OPERAZIONI E’ importante notare che, avendo scelto di implementare la sincronizzazione mediante le interruzioni nelle ipotesi fatte, la gestione del time-‐out è stata demandata alla ISR e dunque possone essere eliminati dall’interfaccia il contatore e la rete logica che genera i segnali necessari alla sua tempificazione, così come non è più necessario il flip-‐flop T del registro di stato. D’altro canto, si potrebbe interpretare anche il segnale T come richiesta di interruzione, lasciando inalterata l’architettura dell’interfaccia e supponendo che il servizio di questa interruzione comporti il caricamento in $v0 del valore 0, il posizionamento a 0 della maschera di interruzioni dell’interfaccia (per evitare che dopo che è scattato il time-‐out possa generarsi un’altra interruzione dovuta all’asserimento di ACK) e la ripresa del driver, mentre il servizio dell’interruzione richiesta da END comporti il caricamento in $v0 del valore 1, , il posizionamento a 0 della maschera di interruzioni dell’interfaccia (per evitare che dopo che è stato asserito ACK possa generarsi un’altra interruzione dovuta al time-‐out) e la ripresa del driver. In conclusione, la progettazione di una interfaccia e/o del relativo driver devono discendere in maniera rigorosa dalle specifiche assegnate. Qualora queste ultime non fossero complete, sarà il progettista a completarle mediante ipotesi opportune che devono comunque essere compatibili con le specifiche assegnate.
© Copyright 2026 Paperzz