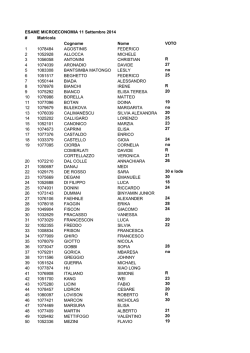
Università degli Studi di Napoli Federico II
Master di I° Livello in
Tecnologie per il CAlcolo Scientifico ad Alte
Prestazioni - CASAP
Tesi di Master
Tecniche e metodologie di imputazione singola per
dataset non normali
Relatori
Candidato
Prof. Roberto Bellotti
Dt.ssa Sonia Sabina Tangaro
Giulia De Luca
matr. Z62000002
Anno Accademico 2012-2013
Indice generale
1 Elementi di teoria: mancate risposte e imputazione singola...................................5
1.1 Il problema dei missing data...........................................................................5
1.2 Il concetto di non risposta ...............................................................................5
1.2.1 Meccanismo generatore dei dati mancanti ..............................................6
1.3 Imputazione dei dati mancanti ........................................................................8
1.4 Metodi deduttivi .............................................................................................8
1.4.1 Imputazione con media campionaria........................................................9
1.4.2 Imputazione con regressione predittiva....................................................9
1.5 Metodi stocastici .........................................................................................10
1.5.1 Imputazione con regressione casuale.....................................................11
1.5.2 Imputazione tramite algoritmo EM........................................................11
2 Materiali e metodi.................................................................................................16
2.1 Cosa è l'EGDI................................................................................................16
2.2 Descrizione del problema..............................................................................17
2.3 Dettagli implementativi.................................................................................18
2.3.1 3.1 Media incondizionata.......................................................................18
2.3.2 Regressione...........................................................................................20
2.3.3 Regressione stocastica............................................................................22
2.3.4 Stima a massima verosimiglianza.........................................................24
2.3.4.1 Stima a massima verosimiglianza dell'indice HCI....................................25
Giulia De Luca Z62000002
di 54
2.3.4.2 Stima a massima verosimiglianza dell'indice OSI....................................26
2.3.4.3 Stima a massima verosimiglianza dell'indice II........................................26
2.3.4.4 Imputazione dei missing...........................................................................28
2.4 Matlab per le applicazioni statistiche............................................................29
3 Conclusioni...........................................................................................................31
3.1 Metodi di analisi............................................................................................31
3.2 Visualizzazione grafica dei risultati...............................................................31
3.3 Indici numerici...............................................................................................38
3.4 Valutazioni incrociate....................................................................................41
APPENDICE B.........................................................................................................44
Indice delle illustrazioni
Illustrazione 1: Scatter plot dei valori di OSI imputati e osservati...........................19
Illustrazione 2: Scatter plot dei valori di HCI imputati e osservati...........................22
Illustrazione 3: Scatter plot dei valori di II imputati e osservati...............................24
Illustrazione 4: Istogramma dei valori di HCI..........................................................25
Illustrazione 5: Istogramma dei valori di OSI...........................................................26
Illustrazione 6: Istogramma dei valori di II...............................................................27
Illustrazione 7: Istogramma ricostruito dei valori di II.............................................27
Illustrazione 8: Scatter plot dei valori di II imputati e osservati...............................29
Illustrazione 9............................................................................................................32
Illustrazione 10..........................................................................................................33
Illustrazione 11..........................................................................................................33
Illustrazione 12..........................................................................................................34
Illustrazione 13..........................................................................................................34
Illustrazione 14..........................................................................................................35
Giulia De Luca Z62000002
di 54
Illustrazione 15..........................................................................................................36
Illustrazione 16..........................................................................................................36
Illustrazione 17..........................................................................................................37
Illustrazione 18..........................................................................................................37
Illustrazione 19: ........................................................................................................41
Indice delle tabelle
Tabella 1:distribuzione percentuali di missing..........................................................18
Tabella 2: medie campionarie...................................................................................19
Tabella 3: Parametri della GEV................................................................................25
Tabella 4: Parametri della gamma.............................................................................26
Tabella 5: Parametri della gaussiana.........................................................................28
Tabella 6: Valori attesi della funzioni di distribuzione di probabilità gev, gamma,
normale......................................................................................................................28
Tabella 7: Performance nel caso di 6,8% missing.....................................................39
Tabella 8: Performance case delection per 13 missing.............................................39
Tabella 9: Performance nel caso di 25,8% missing...................................................40
Tabella 10: Performance case delection con 49 missing...........................................40
Giulia De Luca Z62000002
di 54
Tabella 11: Indice err calcolato per ogni variabile....................................................42
1 Elementi di teoria: mancate risposte e imputazione
singola
1.1 Il problema dei missing data
Il problema dei dati mancanti è molto molto sentito nelle scienze economicosociali, ambito in cui somministrazione di questionari è una delle tecniche più
utilizzata per
raccogliere dati e informazioni.
problema, non esiste un’unica tecnica o
Data le forte dipendenza dal
approccio al problema, ma ogni
esperimento rappresenta un caso a sé. Nel caso il problema dei dati mancanti sia
irrisolvibile per via fisica (utilizzando diversi strumenti per la misura dei dati), la
quantità e la distribuzione dei dati mancanti (missing data), la struttura dei dati e la
natura delle variabili coinvolte, saranno l’unica indicazione in base alla quale
prendere decisioni. Nella letteratura sono presenti svariate tecniche e metodologie
per poter affrontare il problema dei dati mancanti come ad esempio i lavori di Rubin
[1]e Schafer[2]. Prima di parlare dei metodi per il trattamento dei dati mancanti e
quindi per la generazione delle imputazioni è doveroso introdurre alcune questioni
metodologiche fondamentali come il concetto di non risposta, la notazione, il
meccanismo generatore dei dati mancanti.
1.2 Il concetto di non risposta
Il termine non-risposta si riferisce ad un insieme di situazioni in cui il dato non
viene rilevato. Si parla di non risposta ogni qualvolta non si riesce ad ottenere il
dato su una o più variabili di interesse per una o più unità campionarie. In
conseguenza di ciò si ha un incremento nella variabilità degli stimatori, dovuta ad
Giulia De Luca Z62000002
di 54
una riduzione della base campionaria di analisi e alle eventuali applicazioni di
metodi per il trattamento della stessa. Si distinguono due tipi di non risposta la non
risposta totale e la non risposta parziale. La non risposta totale si riferisce al caso in
cui non si ha nessuna informazione disponibile rilevata per unità campionarie.
Mentre la non risposta parziale indica il caso in cui le informazioni rilevate sono tali
da essere ritenute accettabili, ma alcune informazioni risultano mancanti. Le
metodologie che si adottano per trattare le due tipologie di mancata risposta sono
sostanzialmente diverse. In questo lavoro verrà trattato il caso delle non risposte
parziali.
1.2.1
Meccanismo generatore dei dati mancanti
Sia Y una matrice di dimensione n × p di dati non completamente osservata,
indichiamo con θ la parte osservata di Y con Y m la parte mancante di Y .
Supponiamo inoltre che R sia la matrice di dimensione n × p degli indicatori di
risposta, i cui elementi assumono valore zero o uno a seconda che il corrispondente
elemento di
Y sia mancante o osservato. Euristicamente si può stabilire che
meccanismo generatore dei dati mancanti è MAR (Missing At Random) se la
probabilità che una data osservazione sia mancante dipende da Y o ma non da Y .
Un caso particolare di meccanismo MAR è il meccanismo MCAR (Missing
Completely At Random), in questo caso la probabilità che una data osservazione sia
mancante non dipende né da Y o né da Y m ; i dati mancanti sono essenzialmente un
campione casuale dei dati osservabili. Se il processo generatore dei dati mancanti è
MAR e il parametro del meccanismo generatore dei dati mancanti ed il parametro
del modello sui dati completi sono distinti, allora il processo generatore dei dati
mancanti è ignorabile. Formalmente assumere un meccanismo MAR implica che la
distribuzione di R può dipendere da Y o ma non da Y m .
Giulia De Luca Z62000002
di 54
p (R∣Y o ,Y m )= p(R∣Y o)
(1)
Nel caso del meccanismo MCAR si ha invece:
p ( R∣Y o ,Y m )= p(R)
(2)
La definizione formale di ignorabilità del meccanismo dei dati mancanti è stata
formulata da Rubin e Schafer ed è la seguente: siano φ e φ ' rispettivamente i
parametri del modello dei dati ed i parametri del meccanismo generatore dei dati
mancanti, se tali parametri sono distinti, ovvero la conoscenza dell’uno non fornisce
alcuna informazione sull’altro, ed il meccanismo è MAR, ne consegue che il
meccanismo dei dati mancanti è ignorabile. Tale assunzione è di fondamentale
importanza in quanto permette di stimare il parametro incognito senza specificare
la distribuzione dei dati mancanti. Nella maggior parte delle situazioni, in cui i dati
mancanti provengono da un processo di non risposta, la natura del processo
generatore non è facilmente verificabile, tuttavia ci sono situazioni nelle quali
possiamo avere la certezza sullo stato di ignorabilità del processo.
Il pattern dei dati mancanti (missing data pattern) vieni definito come la l'insieme
ordinato degli stati di risposta associato alla matrice dei dati Y , la matrice R
definisce il pattern dei dati mancanti. Un caso particolare di pattern di dati mancanti
è il pattern monotono. Siano Y 1, Y 2, ... ,Y p le variabili ordinate misurate, si definisce
pattern monotono quando si verifica la mancanza della variabile Y j unità implica
che tutte le variabili che seguono Y k , k >j , siano mancanti per tutte le unità.
Di contro, nel caso in cui una variabile Y j è osservata per una particolare unità
anche tutte le variabili antecedenti Y k , k <j , risultano osservate per tutte le unità.
Giulia De Luca Z62000002
di 54
1.3 Imputazione dei dati mancanti
Nel trattamento delle mancate risposte parziali la procedura comunemente
utilizzata, al fine al fine di ripristinare la completezza della matrice dei dati, è
l’imputazione, la quale consiste nell’assegnazione di un valore sostitutivo del dato
mancante.
Svariati sono i metodi di imputazione disponibili in letteratura e in linea del tutto
generale si posso distinguere tre classi di metodi:
•
Metodi deduttivi: il valore imputato è ricostruito da relazioni o informazioni
note.
•
Metodi deterministici: imputazioni ripetute per unità aventi le stesse
caratteristiche generano sempre i medesimi valori imputati.
•
Metodi stocastici, nei quali imputazioni ripetute per unità aventi le stesse
caratteristiche possono produrre differenti valori imputati; si caratterizzano
per la presenza di una componente aleatoria, corrispondente ad uno schema
probabilistico associato al particolare metodo d’imputazione prescelto
Ad eccezione fatta dei metodi deduttivi, tutti i metodi di imputazione per le mancate
risposte si basano, esplicitamente o implicitamente, sull'ipotesi che il meccanismo
generatore dei dati mancanti sia MAR. Nel
seguito verranno in dettaglio alcuni
dei metodi di imputazione più utilizzati.
1.4 Metodi deduttivi
Questa tipologia di metodi si fonda sulla possibilità di sfruttare le informazioni
presenti nell'insieme dei dati in modo da poter ricavare il valore da sostituire al dato
mancante da una o più variabili ausiliarie. Si tratta di metodi la cui applicazione
dipende fortemente dei fenomeni studiati e che richiedono la costruzione di modelli
di comportamento specifici del fenomeno in oggetto sviluppati da esperti del
dominio. Il grave difetto di tale imputazione è essere molto legato a valutazioni
soggettive e spesso dipende dal grado di conoscenza del tipo di dati trattati. Nessun
Giulia De Luca Z62000002
di 54
metodo generalizzato
permette di effettuare automaticamente imputazioni
deduttive. Necessariamente algoritmi “ad hoc” devono essere sviluppati
per
implementare i modelli di imputazione voluti.
1.4.1
Imputazione con media campionaria
Questo metodo appartiene ai metodi deterministici e consiste nella sostituzione
sostituiscono di tutte le mancate risposte con un unico valore, corrispondente la
media calcolata campionaria calcolata sul totale dei rispondenti. E’ un metodo che
può essere utilizzato solo per le variabili quantitative, per le variabili qualitative al
posto del valore medio si può imputare la moda. L'utilizzo tipico di tale
metodologia si riduce solo ai casi in cui il numero dei dati mancanti per ciascuna
variabile è ridotto in cui è ragionevole supporre
una relazione debole
tra le
variabili. Gli ovvi vantaggi di tale metodo sono la preservazione la media dei
rispondenti ed la sua estrema facilita computazionale.
Di contro gli svantaggi non sono trascurabili, infatti:
•
introduce una seria distorsione nella distribuzione della variabile creando un
picco artificiale in corrispondenza del suo valore medio
•
non restituisce buoni risultati nella stima della varianza
•
provoca distorsioni nelle relazioni tra le variabili.
1.4.2
Imputazione con regressione predittiva
Anche questo secondo metodo è un metodo deterministici. Si basa sull'utilizzo dei
valori dei rispondenti per stimare i parametri di una regressione per la variabile
d'interesse y su prefissate variabili ausiliarie considerate esplicative di y . I valori
della variabile y sono, inseguito imputati come valori estrapolati dell’equazione di
regressione. Le variabili ausiliarie possono essere sia di natura quantitativa che
qualitativa. Se la variabile
Giulia De Luca Z62000002
y
è quantitativa generalmente sono utilizzate
di 54
regressioni lineari:
y m=β r 0+∑ j β rj z mij
(3)
Nel caso in cui, invece, la variabile y sia qualitativa, si possono adottare modelli
log-lineari o logistici. Una variazione di questo metodo utilizza la suddivisione in
classi dei dati; in tal modo diversi modelli possono essere adottati in ogni classe.
Il metodo dell'imputazione con regressione ben si adatta a situazioni in cui la
variabile sulla quale effettuare l’imputazione è quantitativa oppure binaria oltre che
ovviamente essere fortemente correlata con altre variabili. Si presta molto meno nei
casi in cui le variabili qualitative presentano numerose modalità. Si può fare uso di
un numero elevato di variabili, sia quantitative che qualitative, in modo da ridurre,
più che con altri metodi, la distorsioni generate dalle mancate risposte. Tale metodo,
nonostante preservi le relazioni delle variabili usate nel modello, introduce
distorsioni nella distribuzione della variabile ed essendo un metodo deterministico,
ha una scarsa attitudine nel preservare la variabilità delle distribuzioni marginali.
Nel caso in cui si applichi il metodo suddividendo in classi i dati, è necessario
stimare molti modelli diversi tra loro, tanti quante sono le celle di imputazione il
che può richiedere la conoscenze tecniche molto specifiche per la messa a punto di
modelli appropriati. Essendo un metodo parametrico, richiede assunzioni sulle
distribuzioni delle variabili per evitare il rischio che possano essere imputati valori
non permessi.
1.5 Metodi stocastici
Un altra classe di metodi, più complessa, è l’imputazione di valori stocastici,
provenienti da una distribuzione teorica o
empirica. Tramite
questi ultimi si
ottengono risultati più soddisfacenti in termini di distribuzioni marginali dei dati
completi ed è possibile ridurre le distorsioni statistiche. Gli errori standard calcolati
Giulia De Luca Z62000002
di 54
risultano essere più veritieri rispetto alle stime con metodi deterministici.
1.5.1
Imputazione con regressione casuale
Il metodo della regressione predittiva può essere reso stocastico, in pratica i valori
da imputare sono ottenuti dalla regressione predittiva a cui viene aggiunto un
termine residuo εij . A seconda delle assunzioni fatte, i residui vengo determinati in
diversi modi, alcuni criteri possono essere:
•
assumendo che i residui siano omoschedastici e normalmente distribuiti, essi
possono essere generati casualmente da una distribuzione normale con media
pari a zero e varianza pari a quella residua della regressione.
•
nel caso si assuma che i residui siano generati dalla stessa distribuzione non
nota, possono essere selezionati casualmente dai residui dei rispondenti.
•
se linearità e l'additività delle componenti del modello di regressione non
sono certe, i residui potrebbero essere presi dai rispondenti con i valori delle
variabili ausiliarie più simili a quelli dell'osservazione incompleta. In tal
modo, se il rispondente ha lo stesso insieme di valori del non rispondente, il
metodo si riduce ad assegnare il valore del rispondente al non rispondente
1.5.2
Imputazione tramite algoritmo EM
Nel caso si possa specificare un modello probabilistico è possibile stimare i suoi
parametri attraverso funzioni di massima verosimiglianza. Se f (X o , X mj∣θ) è la
distribuzione di probabilità congiunta dei valori osservati e di quelli mancanti, si
definisce verosimiglianza rispetto ai dati osservati la funzione:
L(θ∣X o)∝f (X o∣θ)=∫ f (X o , X m∣θ)dX m
(4)
Affinché si possano effettuare inferenze sui parametri utilizzando soltanto i valori
Giulia De Luca Z62000002
di 54
osservati, evitando di esplicitare un modello per le non risposte, occorre che il
meccanismo di mancata risposta sia ignorabile. Si consideri infatti, la distribuzione
congiunta dei dati X e delle variabili indicatrici M , se sussiste la decomposizione
Ωθ φ=Ωθ×Ωφ , essa può essere fattorizzata come segue:
f (X o , X m , M∣θ , φ)=f (M , X o , X m∣φ)f ( X o , X m∣θ)
(5)
Analizzando i soli dati osservati, la funzione di verosimiglianza per la stima dei
parametri sarà data da:
L(θ , φ∣X o , M )∝∫ f ( M∣X o , X m , φ) f ( X o , X m∣θ)dX m
(6)
Supponendo che il meccanismo generatore delle mancate risposte non dipenda dai
valori mancanti condizionatamente a quelli osservati, ovvero se vale la condizione
(2) o la condizione (1), si ottiene:
L(θ , φ∣X o , M )∝f ( M∣X o , φ)∫ f ( X o , X m∣θ)dX m
=f (M∣X o , φ)f ( X o∣θ)L(θ∣X o )
(7)
I valori che massimizzano la funzione (6) risultano gli stessi che massimizzano
anche la funzione (7), quindi le inferenze possono essere effettuate sulla
verosimiglianza dei soli dati osservati. L' ipotesi di trascurabilità del meccanismo
generatore dei dati mancanti, ciò non assicura che
la massimizzazione della
verosimiglianza sia un problema di semplice soluzione. Infatti, è estremamente
difficile, a meno che la matrice dei dati sia di tipo monotono, trovare soluzioni
analitiche
per le equazioni di massima verosimiglianza. Per superare questo
ostacolo viene utilizzato l'algoritmo numerico Expectation-Maximization (EM).
Tale metodo iterativo consente, di ottenere le stime di massima verosimiglianza dei
parametri in presenza di dati incompleti, riconducendo l'analisi ad un problema di
stima per dati completi.
Partendo da una stima iniziale t =0 , l'algoritmo ad ogni ciclo t applica i due
Giulia De Luca Z62000002
di 54
seguenti passi:
passo-E: viene calcolato il valore atteso della funzione di log-verosimiglianza dei
(t )
dati completi Q(θ∣θ ) , integrando la log-verosimiglianza dei dati completi rispetto
alla distribuzione dei dati mancanti condizionata ai valori osservati e alle stime
correnti dei parametri θ(t)
Q(θ∣θ(t ))=∫ ln L(θ∣X o , X m )f ( X m∣X o ,θ(t ))dX m
(8)
Passo-M: si determinano le nuove stime θ(t+1 ) , massimizzando la funzione
(t )
Q(θ∣θ ) rispetto a θ :
θ(t+1 )=arg maxθ Q(θ∣θ(t) )
(9)
L'algoritmo genera una successione {θ(t ) }t =1,2 ,... che sotto alcune ipotesi di regolarità
converge alla stima di massima verosimiglianza dei parametri. L'applicazione
dell'EM porta al seguente risultato fondamentale:
Q(θ(t +1)∣θ(t ))⩾Q(θ(t)∣θ(t) )→ln L(θ(t +1)∣X o )⩾ln L(θ(t)∣X o)
(10)
Poiché la distribuzione congiunta dei valori mancanti e dei valori osservati può
essere fattorizzata come:
f ( X o , X m∣θ)=f (X o∣θ)f (X m∣X o , θ)
(11)
considerando la corrispondente scomposizione della log-verosimiglianza, si
ottiene:
Giulia De Luca Z62000002
di 54
ln L(θ∣X o , X m)=ln L(θ∣X o )+ln f (θ∣X o , X m)
(12)
La log-verosimiglianza dei dati osservati può riformulata come:
ln L(θ∣X o)=ln L(θ∣X o , X m ) ln L( X m∣X o , θ)
(13)
Prendendo il valore atteso di entrambi i membri, rispetto alla distribuzione dei dati
mancanti, condizionata ai valori osservati e alle stime correnti (t) si ha:
ln L(θ∣X o)=Q(θ∣θ(t) ) H (θ∣θ (t ))
(14)
H (θ∣θ(t) )=∫ ln ( f ( X m∣X o ,θ) ) f ( X m∣X o , θ(t ) ) dX m
(15)
con
La differenza tra i valori di ln L(θ∣X o) in tra due successive iterazioni è data da:
ln L(θ(t+1)∣X o ) ln L(θ(t)∣X o)=Q(θ(t+1 )∣θ(t )) Q (θ(t )∣θ(t ) )
+H (θ(t )∣θ(t) ) H (θ(t +1)∣θ(t ) )
Risulta sussistere
Q(θ(t +1)∣θ(t )) ≥ Q(θ(t)∣θ(t) )
(16)
per il passo-M, mentre per la
(t) (t )
(t +1) (t)
disuguaglianza di Jensen si ha H (θ ∣θ ) ≥ H ( θ ∣θ ) .
Nel contesto delle mancate risposte parziali, l'algoritmo EM è utilizzato per la stima
dei parametri del modello attraverso il quale vengono successivamente effettuate le
imputazioni dei valori non osservati. Tali imputazioni possono essere effettuate in
due modi diversi:
•
Generazione casuale: i dati vengono completati generando i valori dalla
Giulia De Luca Z62000002
di 54
distribuzione di probabilità condizionata dai valori osservati e dai parametri
stimati con l'algoritmo EM, P ( X m∣X o , θ̂ ) .
•
Imputazione tramite media condizionata: i dati mancanti vengono imputati
mediante i valori attesi condizionati ai valori osservati e alle stime
individuate, E [ X m∣X o , θ̂ ] .
Essendo un metodo deterministico, il secondo approccio è preferibile se si vogliono
stimare quantità univariate lineari nei dati come medie o totali. Nel caso si è
interessati alla stima di parametri distribuzionali legati alle relazioni di
interdipendenza tra le variabili, conviene utilizzare un metodo stocastico come
l'imputazione mediante generazione casuale[2].
Giulia De Luca Z62000002
di 54
2 Materiali e metodi
2.1 Cosa è l'EGDI
Uno dei principali scopi della pubblica amministrazione è fornire al cittadino dei servizi di
utilità pubblica. Lo sviluppo di nuove tecnologie di comunicazione e la crescente
importanza di internet obbliga le autorità nazionali a fornire un sempre più crescente
numeri di servizi online[3]: si parla perciò di e-governament. Esso è il sistema di gestione
digitalizzata della pubblica amministrazione, il quale consente di trattare la
documentazione e di gestire i procedimenti con sistemi informatici, grazie all’uso delle
tecnologie della comunicazione e dell'informazione (ICT), allo scopo di ottimizzare il
lavoro degli enti e di offrire agli utenti servizi più rapidi[4].
Per misurare le capacità di sviluppo dell'e-governament delle nazioni è stato creato un
indice composito “E-GOVERNMENT DEVELOMENT INDEX”(EGDI), che è la
media pesata di tre altri tre indici, al loro volta compositi, di seguito elencati:
•
Human capital index
•
Online service index
•
Infrastructure index
Ai fini di una maggiore chiarezza espositiva indicheremo in seguito i tre indici Human
capital index, Online service index e Infrastructure index con i loro acronimi, ossia
rispettivamente con HCI,OSI, II.
L'EGDI è calcolato come:
EGDI =0,34 x OSI +0,33 X HCI+0,33 X II
A partire dalla sua creazione nel 2003, tale indice viene
annualmente per
(17)
calcolato e aggiornato
193 paesi dall'UNPAP (United Nations Public Administration
Programme)[5].
Giulia De Luca Z62000002
di 54
2.2 Descrizione del problema
Obiettivo del lavoro di tesi era confrontare le diverse tecniche di imputazione
singola per ricostruire i valori assunti da un indice composito, EGDI, che non era
osservato per tutti i paesi.
Il dataset assegnato può essere rappresentato come una matrice rettangolare le cui
righe rappresentano i paesi per ciascuno dei quali sono indicati i valori di
HCI,OSI,II, e le cui colonne sono le variabili stesse:
HCI
Paese 1 ?
Paese 2
.
.
.
?
OSI
II
?
?
?
Paese N
?
La matrice consta di 193 entries, ciascuna corrispondente a un determinato paese.
Ciascuna entry è composta da un vettore i cui elementi sono i valori, calcolati per
ciascun paese, dei tre indici (HCI,OSI,II). Inoltre è fornito anche il valore di EGDI,
derivato da questi.
Per tre dei centonovanta-tre paesi non è fornito il valore di EGDI e dell'indice II
necessario al suo calcolo, per cui sono stati tolti dall'analisi. In definitiva la matrice
utilizzata è composta da 190 entries.
A partire da tale dataset, sono stati eliminati in maniera casuale diverse percentuali
di elementi per ciascuno dei tre indici. In particolare si sono eliminati i missing
ottenendo un pattern univariato, ossia per ognuna delle entry della matrice è stato
tolto un solo valore degli indici, mentre gli altri due sono stati lasciati invariati.
Si sono considerati le seguenti percentuali di missing:
•
6,8% (13 missing)
Giulia De Luca Z62000002
di 54
•
25,8% (49 missing)
La tabella che segue spiega in che modo sono stati distribuiti i i missing tra i diversi
indici.
Missing
HCI
Missing
OSI
6
16
Missing
II
3
17
Totale numero di
missing
4
16
13
49
Tabella 1:distribuzione percentuali di missing
Utilizzando le classificazioni introdotta da Rubin(1976), e quindi considerando le
procedure di missingness come fenomeno probabilistico, i missing data sono stati
considerati MCAR (Missing completely at random): ciò è perfettamente in linea con
la procedura adottata per generare le risposte mancanti.
Sono state implementate diverse tecniche di imputazione singola per ricostruire il
dataset costituito dai valori di HCI,OSI e II. Con tali valori imputati si è ricostruito
il valore EGDI per le non risposte. La bontà dei diversi metodi di imputazione
singola è stata valutata confrontando il dataset completo contenente i valori di
EGDI e il dataset contenete i valori osservati e imputati di tale indice.
2.3 Dettagli implementativi
Sono state utilizzate quattro diverse tecniche di imputazione singola:
1. sostituzione del valore medio incondizionato
2. regressione
3. regressione stocastica
4. stima a massima verosimiglianza
2.3.1
3.1 Media incondizionata
Per ciascuna variabile HCI,OSI e II, valutate separatamente dalle altre, sono stati
considerati i singoli dataset e se ne è calcolata la media campionaria con la funzione
“mean” di matlab e con tale valore si sono imputate le non riposte. Le medie
campionarie stimate sono riassunti in tabella:
Giulia De Luca Z62000002
di 54
numero di
missing
13 missing
49 missing
HCI
OSI
II
0,7223
0,7251
0,4355
0,4278
0,3233
0,3252
Tabella 2: medie campionarie
Come si nota le stime delle medie campionarie differiscono di poco nei due casi con
differenti percentuali di missing.
Questo metodo introduce una seria distorsione nelle distribuzioni della variabili
(HCI,OSI,II), creando un picco artificiale in corrispondenza dei rispettivi valori
medi. Ciò si nota anche nello scatter plot sotto, che rappresenta i valori di indice
OSI imputati e osservati.
Illustrazione 1: Scatter plot dei valori di OSI imputati e osservati
Ovviamente tale distorsione è più evidente nel caso con maggiori missing, al
contrario nel caso in cui i dati non rispondenti sono in numero esiguo è molto meno
evidente.
Giulia De Luca Z62000002
di 54
2.3.2
Regressione
Tale metodo è stato implementato nel modo seguente:
il dataset con gli osservati e non osservati è stato privato di tutte le entries che
contenevano un missing, al fine di ottenere un dataset con osservazioni complete.
Successivamente questi dati rispondenti sono stati utilizzati per stimare i parametri
della regressione
B0, B1, B 2 per la ciascuna delle variabili
separatamente
(HCI,OSI,II) sulle altre due considerate esplicative della prima. Le determinazioni
della variabile (alternativamente HCI,OSI, II) sono, state poi, imputate con valori
stimati dell’equazione di regressione :
y 1=Bo +B1∗y 2∗B2∗y 3 dove
y 1, y 2
y 1 sono alternativamente HCI,OSI,II e
sono rispettivamente (OSI,II),(HCI,II),(HCI,OSI).
I coefficienti di regressioni sono stati calcolati utilizzando la funzione “mvnrmle” di
matlab.
Tale funzione considera la
pari
y1 come una variabile aleatoria gaussiana di media
̄B ̄y e matrice di covarianza
Ĉ , dove
̄B è
[ B 0, B1, B2 ]
e
̄y è
[1 , y1 , y 2 ]T .
In tale ottica i dati osservati di
tale variabile aleatoria e quindi
y1
possono essere visti come realizzazione di
̄
B ̄y e
Ĉ sono ottenuti massimizzando la
funzione di log-verosimiglianza. Si utilizza un approccio iterativo che nel caso in
esame coincide con la regressione ai minimi quadrati implementata in matlab con la
funzione “regress”.
Di seguito sono riportati i risultati ottenuti :
Giulia De Luca Z62000002
di 54
I caso:13 missing
HCI i=0,7159+0,7159∗OSI i 0,0045∗II i
OSI i=0,0820+0,7927∗HCI i 0,0026∗II i
II i=0,1070+0,5234∗HCI i 0,0084∗OSI i
(18)
II caso: 49 missing
HCI i=0,7169+0,0065∗OSI i 0,0013∗II i
OSI i=0,4104+0,0065∗HCI i 0,0058∗II i
II i=0,2808+0,0149∗HCI i 0,0153∗OSI i
(19)
Come si nota nel caso con quarantanove missing, le variabili sembrano essere non
correlate, infatti i coefficienti angolari per ciascuna formula di regressione sono un
ordine di grandezza se non addirittura due ordini di grandezza più piccoli
dell'intercetta. Anche in questo caso perciò si altera le funzioni di distribuzione di
probabilità delle variabili che risultano più smussate.
Giulia De Luca Z62000002
di 54
Illustrazione 2: Scatter plot dei valori di HCI imputati e osservati
2.3.3
Regressione stocastica
La regressione stocastica è stata implementata nello stesso modo in cui si è stato
stato svolto il metodo precedente con la sola differenza che a ciascun elemento del
della variabile dipendente (alternativamente HCI, OSI , II) della formula di
regressione nel dataset completamente osservato è stato sommato un numero
estrapolato a caso in intervallo
[ σ σ ] dove
σ è la varianza della funzione di
distribuzione di probabilità della variabile dipendente, stimata mediante il metodo
di stima a massima verosimiglianza descritto nel paragrafo successivo. In altre
parole si è svolta la seguente operazione:
y 1+ε=B o+B1∗y 2∗B 2∗y 3 dove
Giulia De Luca Z62000002
ε è un numero pescato a caso nell'intervallo
di 54
[ σσ] .
Di seguito sono riportati i risultati.
I caso:13 missing
HCI i=0,6943 0,0005∗OSI i 0,0152∗II i
OSI i=0,0647 0,7988∗HCI i 0,0084∗II i
II i=0,0855+0,5651∗HCI i 0,0170∗OSI i
(20)
II caso:49 missing
HCI i=0,7159 0,0024∗OSI i 0,0045∗II i
OSI i=0,0820 0,7927∗HCI i 0,0026∗II i
II i=0,1070+0,5234∗HCI i 0,0084∗OSI i
(21)
In questo caso rispetto al caso precedente si evidenzia meglio la correlazione tra gli
indici. Nello specifico le variabili OSI e II sembrano essere correlate con l'indice
HCI, che sembra al contrario indipendente dalle alle altre due. Si noti ad esempio il
grafico di seguito: i valori di OSI imputati sono differenti l'uno dall'altro, al
contrario i valori di HCI imputati variano di poco l'uno dall'altro.
Giulia De Luca Z62000002
di 54
Illustrazione 3: Scatter plot dei valori di II imputati e osservati
2.3.4
Stima a massima verosimiglianza
La stima a massima verosimiglianza è stata condotta considerando i tre indici
statisticamente indipendenti tra loro, ossia considerando la funzione di distribuzione
di probabilità congiunta delle tre variabili come il prodotto delle funzioni di
distribuzioni di probabilità marginali. In altre parole si sono considerate le variabili
separatamente, private dei missing: il problema multivariato è stato ricondotto a tre
problemi univariati.
In prima battuta si sono valutati gli istogrammi delle tre variabili. Poi sulla base di
questi si sono stimate le funzioni di distribuzione.
Giulia De Luca Z62000002
di 54
2.3.4.1 Stima a massima verosimiglianza dell'indice HCI
Illustrazione 4: Istogramma dei valori di HCI
Per stimare la funzione di distribuzione di questo indice è stato utilizzato il tool
statistico di matlab “dfittool”. Tra le varie funzioni di distribuzione di probabilità si
è scelta quella a cui corrispondeva un valore della funzione di log-verosimiglianza
più elevato.
Successivamente, considerata la forma di tale distribuzione e i valori dei parametri
stimati, è stato effettuato un test del chi-quadro per valutare se effettivamente la
stima ottenuta fosse effettivamente compatibile con i dati.
La funzione di distribuzione che meglio si adattava ai dati è risultata una
generalized extreme value (Appendice A), i cui parametri sono riassunti in tabella.
numero di missing k
µ
6 -0,7009
16 -0,6801
0,2166
0,2093
σ
0,6931
0,6950
Tabella 3: Parametri della GEV
I parametri, essendo la differenza della percentuale di missing molto vicine per
ciascun indice, quasi coincidono nei due casi.
Giulia De Luca Z62000002
di 54
2.3.4.2 Stima a massima verosimiglianza dell'indice OSI
Illustrazione 5: Istogramma dei valori di OSI
Per la stima della distribuzione di tale indice si è effettuato lo stesso procedimento
spiegato sopra. La funzione di probabilità stimata è stata con una gamma:in tabella
sono riassunti valori dei parametri.
α
θ
numero di missing
3
17
3,15
3,16
0,14
0,14
Tabella 4: Parametri della gamma
2.3.4.3 Stima a massima verosimiglianza dell'indice II
Per questo indice la stima della forma della distribuzione è stata condotta in modo
differente. Dall'istogramma, rappresentato in figura, si è notata una certa
somiglianza con la forma di una mezza campana di una distribuzione gaussiana con
media nulla.
Giulia De Luca Z62000002
di 54
Illustrazione 6: Istogramma dei valori di II
Pertanto si è aumentato la dimensionalità del dataset di valori dell'indice II in modo
da ottenere istogramma l'istogramma che segue:
Illustrazione 7: Istogramma ricostruito dei valori di II
Si è effettuato un test del chi-quadro per saggiare l'ipotesi che i dati si distribuissero
secondo una gaussiana. Tale test ha dato risultato positivo.
A tal punto si è utilizzata la stima a massima verosimiglianza per stimare i parametri
di questa distribuzione, di seguito riportati.
Giulia De Luca Z62000002
di 54
numero di
missing
µ
σ
4
16
0,0000
0,0000
0,4122
0,41
Tabella 5: Parametri della gaussiana
Anche in questo caso i parametri della funzione non differiscono nei due casi.
2.3.4.4 Imputazione dei missing
Per l'imputare i missing di ogni distribuzione sono stati considerati due modalità:
1. imputazione con il valore medio della funzione di distribuzione di probabilità
2. imputazione con un valore a caso estrapolato dalla funzione di distribuzione
di probabilità
Nel primo caso a ciascun valore di missing è stato sostituito il valore medio della
distribuzione a cui esso appartiene.
numero di
missing
13 missing
49 missing
media
media OSI media II
HCI
0,3068
0,4355 0,3231
0,3063
0,4278 0,3252
Tabella 6: Valori attesi della funzioni di distribuzione di probabilità gev, gamma, normale
Riprendendo
la
tabella
relativa
all'imputazione
con
il
valore
medio
incondizionato(tabella 2) si nota che se il valore di media campionaria per gli indici
OSI e II si avvicinano molto alla stima della media delle funzioni di distribuzioni di
probabilità, nel caso dell'indice HCI se ne distanzia molto. Ciò è da attribuire alla
presenza nel dataset di valori estremi di HCI, nei confronti dei quali la media
campionaria è fortemente sensibile.
Nel secondo caso i missing sono stati imputati utilizzando le funzioni matlab di
generazioni di numeri casuali
a partire da una funzione di distribuzione di
probabilità nota.
Le funzioni di distribuzione di probabilità stimate hanno supporto che ricopre tutto
l'insieme reale, ma gli indici, invece, variano in un intervallo di ampiezza unitaria,
pertanto si è stati attenti ad escludere eventuali numeri casuali fuori da
Giulia De Luca Z62000002
di 54
tale
intervallo.
Rispetto all'imputazione con il valore medio campionario e valore medio stimato
con la massima verosimiglianza si preserva la variabilità dei dati stesse, come
mostrato in figura.
Illustrazione 8: Scatter plot dei valori di II imputati e osservati
2.4 Matlab per le applicazioni statistiche
Il software Matlab è molto applicato nel campo ingegneristico e scientifico ma
ancora non è utilizzato in ambito statistico, nonostante contenga un pacchetto
relativamente completo con implementate funzioni statistiche.
Di seguito verranno indicati i principali strumenti utilizzati per il lavoro di tesi.
Stimatori
Il software Matlab mette a disposizione funzioni che permettono di stimare la
Giulia De Luca Z62000002
di 54
media, la varianza e curtosi campionarie
che possono essere richiamate
direttamente con i comandi “mean” e “var”, “kurtosis”.
Stima a massima verosimiglianza
Matlab offre
algoritmi numerici che permettono, conosciuta la forma di una
distribuzione di probabilità di un campione univariato, di fare inferenza sui
parametri di tale distribuzione. Infatti a partire dalle funzioni log-verosimiglianza
delle diverse funzioni di probabilità che sono note in letteratura e a partire da una
stima iniziale dei parametri, implementa l'algoritmo Nelder–Mead per trovare il
massimo di tali funzioni multiparametriche.
Inoltre mette a disposizioni il tool “dfittool” un'interfaccia grafica per importare i
dati dal workspace, fittare diverse distribuzioni e disegnarle.
Generatori di numeri casuali
Sono disponibili routine che permettono di estrarre numeri casuali a partire da una
distribuzione univariata o multivariata. Esse sfruttano tale proprietà:
a partire da sequenze di numeri pseudo-casuali, che sono effettivamente distribuiti
uniformemente, U in
[0,1]
e una funzione di ripartizione invertibile F, la
variabile casuale X = F−1(U) è distribuita secondo F .
Giulia De Luca Z62000002
di 54
3 Conclusioni
3.1 Metodi di analisi
Al fine di condurre delle analisi riguardanti le performance dei diversi metodi di
imputazione singola, si sono scelte due differenti strade:
•
visualizzazione grafica dei risultati
•
valutazioni di indici numerici
La visualizzazione grafica presenta il vantaggio di essere di facile e soprattutto di
immediata comprensione, però non permette un'analisi quantitativa ed è più
sensibile alla soggettività dell'occhio dell'osservatore: questo è il motivo per cui ci si
è affidati anche ad indici numerici.
3.2 Visualizzazione grafica dei risultati
Di seguito sono riportati i grafici relativi ai risultati
dell'imputazione singola
dell'EGDI per ciascun metodo utilizzato, con due diverse percentuali di missing.
Nel primo caso il dataset comprendente il valore di EGDI calcolato per
centonovanta paesi è stato privato di
tredici valori, nel secondo caso di
quarantanove. Per ciascuno dei metodi utilizzati si è scelto di plottare il valore
imputato
in
funzione
del
valore
reale,
ossia
i
punti
di
coordinate
(EGDI_IMPUTATO,EGDI_REALE): ciò per rendere visivamente l'ammontare
dello scostamento tra il singolo valore imputato e il valore osservato. Infatti, se le
tecniche utilizzate permettessero, per assurdo, di recuperare in maniera esatta il
valore non noto, i punti si distribuirebbero nel piano cartesiano sulla retta bisettrice
del primo e secondo quadrante, caratteristica della trasformazione identica.
Giulia De Luca Z62000002
di 54
I caso:13 missing data
Sostituzione con il valore di media incondizionata
Illustrazione 9
Giulia De Luca Z62000002
di 54
Regressione non stocastica
Illustrazione 10
Regressione stocastica
Illustrazione 11
Giulia De Luca Z62000002
di 54
Verosimiglianza con imputazione del valore medio
Illustrazione 12
Verosimiglianza con valori casuali
Illustrazione 13
Giulia De Luca Z62000002
di 54
II caso:49 missing data
Sostituzione con il valore di media incondizionata
Illustrazione 14
Giulia De Luca Z62000002
di 54
Regressione non stocastica
Illustrazione 15
Regressione stocastica
Illustrazione 16
Giulia De Luca Z62000002
di 54
Verosimiglianza con imputazione del valore medio
Illustrazione 17
Verosimiglianza con valori casuali
Illustrazione 18
Giulia De Luca Z62000002
di 54
Qualitativamente, si nota che, la dispersione intorno alla bisettrice del primo e
secondo quadrante è maggiore nel caso con di presenza dei soli 13 missing: le
tecniche garantiscono risultati migliori nel caso di un numero maggiore di missing.
3.3 Indici numerici
Per confrontare il comportamento dei diverse tecniche di imputazione in funzione in
modo numerici, si è utilizzato l'indice di Willmott, così definito:
N
∑ ( Pi
d =1
Oi )k
i=1
N
∑ (∣Pi
O∣+∣O i O∣) k
i=1
dove :
Pi
è il valore imputato all'i-esimo missing
Oi
è il valore osservato per i-esimo missing
N
O è la media dei dati osservati completi,ossia
O=1 / N ∑ Oi con N numero dei
i=1
dati osservati
k è un numero adimensionale che può assumere valore 1 o 2.
Di seguito sono riportate le tabelle con i diversi risultati.
Fissata la percentuale di missing, i diversi metodi di imputazioni sono stati
confrontati valutando somma degli scarti tra il valore imputato e quello osservato:
err=∑ ∣Pi Oi∣
Giulia De Luca Z62000002
di 54
I caso:13 missing
metodo
media
regressione
regressione_stocastica
verosimiglianza(media)
verosimiglianza(casuale)
EGDI_reale
media
0,4937
0,3229
0,5157
0,4893
0,5763
0,4954
Indice di
Indice di
Willmott
Willmott
err
(k=1)
(k=2)
0,0390
0,9950
0,9975
0,039
0,9868
0,9990
0,0295
0,9924
0,9948
0,0393
0,9489
0,9157
0,0425
0,9932
0,9969
varianza
1,0419
1,0601
1,2882
1,4294
1,1392
0,0416
Tabella 7: Performance nel caso di 6,8% missing
Dalla tabella si nota che la migliore stima della media del dataset EGDI è ottenuto
con con la tecnica di sostituzione del valore medio incondizionato, tuttavia con tale
metodo di sottostima la varianza.
D'altra parte buoni risultati, in termini di stima del valore atteso, si sono ottenuti
anche con il metodo a massima verosimiglianza, imputando le mancate risposte
parziali con il valore medio della funzione di distribuzione di probabilità. La
varianza è, tuttavia, sottostima anche in questo caso.
La migliore stima della varianza è ottenuta imputando i dati mancanti estrapolando
a caso campioni dalla funzione di distribuzioni di probabilità delle variabili.
Vale la pena notare che in realtà stime più precisa della media e della varianza del
dataset EGDI sono ottenute semplicemente eliminando dal dataset i valori mancanti.
In letteratura[6] è noto che qualora l'ammontare dei missing rispetto al dataset
completo sia inferiore al 5%, migliori performance si ottengono con la tecnica del
case delection, ossia eliminando dall'analisi i missing data. Poiché i dati mancanti
sono solo tredici, costituiscono cioè il solo 6,8% del dataset completo, si può
ipotizzare che tale comportamento sia da imputare alla esiguità dei valori missing.
Giulia De Luca Z62000002
di 54
metodo
case
delection
media
varianza
0,4965
0,0414
Tabella 8: Performance case delection per 13 missing
D'altra parte valutando le prestazioni dei diversi metodi
in termini
generali(considerando l'indice err o di Willmott), si denota che quasi tutti hanno un
comportamento simile. Per quasi tutti i metodi utilizzati l'agreement index, sia per
k=1 che per k=2, si avvicina a 1. Valori leggermente diversi sono ottenuti per
l'imputazione con il valore medio delle funzioni di distribuzioni di probabilità delle
variabili.
Interessanti risultano invece i risultati ottenuti per la stima della varianza del dataset
EGDI sostituendo i missing dati con valori estrapolati in maniera casuale dalle
funzioni di distribuzione di probabilità stimate: senza dubbio è il metodo che meglio
stima questo parametro.
II caso:49 missing
Indice di
Indice di
metodo
media
varianza
Willmott
Willmott
err
(k=1)
(k=2)
media
0,4925
0,0332
0,9989
0,9971
regressione
0,3231
0,0586
0,9988
0,9979
regressione_stocastica
0,5092
0,0294
0,9980
0,9968
verosimiglianza(media)
0,4809
0,0339
0,9741
0,9175
verosimiglianza(casuale)
0,4889
0,0304
0,9897
0,9863
EGDI_reale
0,4954
3,8238
3,8009
4,1208
4,6369
5,5861
0,0416
Tabella 9: Performance nel caso di 25,8% missing
Anche in questo caso valgono le considerazioni precedenti. La migliore stima del
valore medio si ottiene con la sostituzione di media incondizionata, pur se si
sottostima la varianza.
Tuttavia questa volta la tecnica case delection, come ben riassunto nella tabella
sottostante, non offre le migliori prestazioni in termini di stima di media e varianza.
Giulia De Luca Z62000002
di 54
Infatti l'ammontare del numero di missing è pari al 25,8%.
metodo
media
varianza
case delection
0,4854 0,1896
Tabella 10: Performance case delection con 49 missing
3.4 Valutazioni incrociate
Dal grafico che segue, si nota, che sia per valori di missing parti al 6,8% che 26,8%
rispetto al totale di valori osservati, l'andamento dell'indice di Wilmott è lo stesso.
Illustrazione 19:
Si sono indicati con A il metodo con media incondizionata, B il metodo di regressione
semplice, C regressione stocastica, D valore medio della funzione di distribuzione di
probabilità, E valori casuali a partire dalla funzione di distribuzione di probabilità
Le tecniche di imputazione singola risulta essere più performante con numero di
missing più elevati. In effetti è già stato notato che nel caso di soli 13 valori di
Giulia De Luca Z62000002
di 54
missing il case delection è la migliore alternativa.
Si nota inoltre che che la stima a massima verosimiglianza ha, rispetto alle altre
tecniche, un peggiore comportamento. Questo è da imputare ai dati stessi, che
risultano essere abbastanza variabili: la stima della deviazione standard del dataset
completo contente i valori di EGDI è pari a 0.2039. Considerando che il valore di
EGDI varia in un intervallo [0,1], è evidente l'elevata dispersione dei dati.
Ricordiamo che l'imputazione dei valori di EGDI non è stata effettuata direttamente,
ma considerando che esso è la media pesata di tre diversi indici, si sono imputati i
valori di tali indici e poi si calcolato il valore di EGDI con la nota formula(16).
Per ciascuno dei tre indici, considerati statisticamente indipendenti tra loro, si sono
considerate le funzioni di massima verosimiglianza. La distribuzione dell'indice
HCI è stata modellata con una genalized extreme value. Tale distribuzione presenta
una coda a sinistra non trascurabile (asimmetria a sinistra), pertanto stima bene i
valori intorno al valore medio, ma non quelli che sia allontanano da essa anche se
di poco. Ciò risulta tanto più evidente si considera che la stima della curtosi del
dataset composto dai valori di HCI è pari a -1,0254 a fronte di quella di una
gaussiana pari a 3. La distribuzione è pertanto una distribuzione platicurtica.
A prova che ad essere problematico è proprio l'indice HCI e non gli altri due, si
sono riportati in tabella la somma degli scarti in valore assoluto tra il valore
imputato con la media della funzioni di distribuzione e il valore osservato per ogni
indice(err).
indice
err
HCI
OSI
II
6,2425 3,9792 3,6625
Tabella 11: Indice err calcolato per ogni variabile
Si noti che, essendo l'EGDI calcolato con una media pesata dei tre indici, l'indice err
calcolato considerando i valori imputati di questo indice risulta minore rispetto al
massimo valore assunto dell'indice err per ciascuno indici di cui è funzione.
Più in generale le elevate performance delle diverse tecniche di imputazione singola
utilizzate sono da attribuire a due cause:
Giulia De Luca Z62000002
di 54
1. l'elevata dispersione dei dati
2. l'errore commesso nell'imputare le non risposte nel dataset contenente i
valori di EGDI è un terzo rispetto a quello commesso nell'imputare i missing
degli indice HCI,OSI e II.
Questi sono i due motivi per cui i risultati ottenuti discordanti non poco da quello
che intuitivamente ci sarebbe aspettato, ossia che i metodi non deterministici
dessero migliori risultati.
Giulia De Luca Z62000002
di 54
APPENDICE B
Di seguito sono riportati le righe del dataset con almeno un missing imputato
utilizzando le diverse tecniche di imputazioni singola. In rosso sono indicati i valori
imputati.
I caso: 13 missing
Imputazione con media campionaria
HCI
OSI
II
0,7223 0,3791
0,7223 0,5817
0,7223 0,2484
0,7223 0,3660
0,7223 0,8431
0,7223 0,4837
0,7089 0,4355
0,1723 0,4355
0,9494 0,4355
0,8751 0,5621
0,9467 0,8824
0,8971 0,7516
0,2576 0,1699
EGDI
0,2173 0,4389
0,4179 0,5740
0,2772 0,4143
0,1239 0,4037
0,8225 0,7964
0,3215 0,5089
0,2638 0,4690
0,0645 0,2262
0,8356 0,7371
0,3233 0,5866
0,3233 0,7191
0,3233 0,6583
0,3233 0,2495
Regressione non stocastica
HCI
OSI
II
0,7153 0,3791
0,7200 0,5817
0,7158 0,2484
0,7134 0,3660
0,7290 0,8431
0,7177 0,4837
0,7089 0,4068
0,1723 0,4251
0,9494 0,4175
0,8751 0,5621
0,9467 0,8824
0,8971 0,7516
0,2576 0,1699
Giulia De Luca Z62000002
0,2173
0,4179
0,2772
0,1239
0,8225
0,3215
0,2638
0,0645
0,8356
0,2975
0,3138
0,3056
0,3104
EGDI
0,4366
0,5733
0,4122
0,4008
0,7986
0,5074
0,4593
0,2227
0,7310
0,5781
0,7160
0,6524
0,2452
di 54
Regressione stocastica
HCI
OSI
III
EGDI
0,6974 0,3791 0,2173 0,4307
0,7003 0,5817 0,4179 0,5668
0,6984 0,2484 0,2772 0,4064
0,6960 0,3660 0,1239 0,3950
0,7064 0,8431 0,8225 0,7912
0,6989 0,4837 0,3215 0,5012
0,7089 0,3289 0,2638 0,4328
0,1723 0,3126 0,0645 0,1844
0,9494 0,2413 0,8356 0,6711
0,8751 0,5621 0,2082 0,5486
0,9467 0,8824 0,1831 0,6728
0,8971 0,7516 0,2549 0,6357
0,2576 0,1699 0,4306
0,28
Stima a massima verosimiglianza(imputazione con il valore medio)
HCI
OSI
II
0,3068 0,3791
0,3068 0,5817
0,3068 0,2484
0,3068 0,3660
0,3068 0,8431
0,3068 0,4837
0,7089 0,4355
0,1723 0,4355
0,9494 0,4355
0,8751 0,5621
0,9467 0,8824
0,8971 0,7516
0,2576 0,1699
Giulia De Luca Z62000002
EGDI
0,2173 0,3018
0,4179 0,4369
0,2772 0,2772
0,1239 0,2666
0,8225 0,6593
0,3215 0,3718
0,2638 0,4690
0,0645 0,2262
0,8356 0,7371
0,3231 0,5865
0,3231 0,7190
0,3231 0,6582
0,3231 0,2494
di 54
Stima a massima verosimiglianza (imputazione con valore casuale)
HCI
OSI
II
0,8810 0,3791
0,5377 0,5817
0,9210 0,2484
0,9898 0,3660
0,7701 0,8431
0,9310 0,4837
0,7089 0,7089
0,1723 0,1723
0,9494 0,9494
0,8751 0,5621
0,9467 0,8824
0,8971 0,7516
0,2576 0,1699
EGDI
0,2173 0,4913
0,4179 0,5131
0,2772 0,4799
0,1239 0,4920
0,8225 0,8122
0,3215 0,5778
0,2638 0,3778
0,0645 0,1859
0,8356 0,7481
0,1694 0,5358
0,0590 0,6319
0,31 0,4489
0,2128 0,2130
II caso: 49 missing
Imputazione con il valore di media campionaria
HCI
OSI
II
0,7251 0,2941
0,7251 0,3333
0,7251 0,8562
0,7251 0,3791
0,7251 0,5425
0,7251 0,5752
0,7251 0,5817
0,7251 0,2484
0,7251 0,9608
0,7251 0,3660
0,7251 0,2288
0,7251 0,1830
0,7251 0,8431
0,7251 0,1373
0,7251 0,2418
0,7251 0,4837
0,3113 0,4278
0,7572 0,4278
0,9332 0,4278
0,7089 0,4278
Giulia De Luca Z62000002
0,0454
0,1019
0,8615
0,2173
0,8772
0,6697
0,4179
0,2772
0,8342
0,1239
0,0411
0,5648
0,8225
0,0744
0,2069
0,3215
0,1118
0,1595
0,5531
0,2638
EGDI
0,3543
0,3862
0,8147
0,4399
0,7132
0,6559
0,5750
0,4152
0,8413
0,4046
0,3307
0,4879
0,7974
0,3105
0,3898
0,5099
0,2851
0,4480
0,6359
0,4664
di 54
0,8969
0,9134
0,1723
0,8057
0,7590
0,8182
0,4521
0,9347
0,7862
0,9494
0,8696
0,6841
0,9007
0,6463
0,9232
0,5554
0,8751
0,5588
0,9467
0,8971
0,6151
0,9982
0,6533
0,1103
0,8129
0,2576
0,7830
0,8228
0,7434
0,4278
0,4278
0,4278
0,4278
0,4278
0,4278
0,4278
0,4278
0,4278
0,4278
0,4278
0,4278
0,4278
0,2549
0,3725
0,3007
0,5621
0,6013
0,8824
0,7516
0,2876
0,7843
0,3137
0,1961
0,5163
0,1699
0,4837
0,0523
0,4248
0,6460
0,3555
0,0645
0,7192
0,0425
0,5375
0,0597
0,7870
0,1968
0,8356
0,5147
0,2886
0,8135
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,6546
0,5642
0,2236
0,6487
0,4099
0,5928
0,3143
0,7136
0,4698
0,7345
0,6023
0,4664
0,7111
0,4073
0,5386
0,3928
0,5872
0,4962
0,7198
0,6589
0,4081
0,7034
0,4296
0,2104
0,5511
0,2501
0,5302
0,3966
0,4971
Regressione non stocastica
HCI
OSI
II
0,7184 0,2941
0,7186 0,3333
0,7222 0,8562
0,7190 0,3791
0,7207 0,5425
0,7206 0,5752
0,7203 0,5817
0,7185 0,2484
0,7227 0,9608
Giulia De Luca Z62000002
EGDI
0,0454 0,3520
0,1019 0,3841
0,8615 0,8137
0,2173 0,4379
0,8772 0,7118
0,6697 0,6544
0,4179 0,5734
0,2772 0,4130
0,8342 0,8404
di 54
0,7188
0,7180
0,7185
0,7221
0,7176
0,7183
0,7197
0,3113
0,7572
0,9332
0,7089
0,8969
0,9134
0,1723
0,8057
0,7590
0,8182
0,4521
0,9347
0,7862
0,9494
0,8696
0,6841
0,9007
0,6463
0,9232
0,5554
0,8751
0,5588
0,9467
0,8971
0,6151
0,9982
0,6533
0,1103
0,8129
0,2576
0,7830
0,8228
0,7434
0,3660
0,2288
0,1830
0,8431
0,1373
0,2418
0,4837
0,4122
0,4175
0,4730
0,4199
0,4144
0,4203
0,4188
0,4178
0,4207
0,4204
0,4176
0,4184
0,4181
0,4133
0,4748
0,4193
0,4208
0,2549
0,3725
0,3007
0,5621
0,6013
0,8824
0,7516
0,2876
0,7843
0,3137
0,1961
0,5163
0,1699
0,4837
0,0523
0,4248
Giulia De Luca Z62000002
0,1239
0,0411
0,5648
0,8225
0,0744
0,2069
0,3215
0,1118
0,1595
0,5531
0,2638
0,6460
0,3555
0,0645
0,7192
0,0425
0,5375
0,0597
0,7870
0,1968
0,8356
0,5147
0,2886
0,8135
0,2876
0,2990
0,2976
0,2939
0,2986
0,3024
0,2985
0,3089
0,3058
0,2987
0,3001
0,3060
0,2934
0,3007
0,3045
0,2961
0,4025
0,3283
0,4857
0,7964
0,3081
0,3875
0,5080
0,2798
0,4445
0,6513
0,4638
0,6501
0,5616
0,2205
0,6453
0,4075
0,5903
0,3109
0,7104
0,4665
0,7296
0,6182
0,4635
0,7088
0,3949
0,5300
0,3837
0,5769
0,4874
0,7122
0,6501
0,4027
0,6970
0,4208
0,2021
0,5448
0,2396
0,5221
0,3898
0,4875
di 54
Regressione stocastica
HCI
OSI
II
0,7014 0,2941
0,7014 0,3333
0,7009 0,8562
0,7012 0,3791
0,7003 0,5425
0,7008 0,5752
0,7012 0,5817
0,7009 0,2484
0,7011 0,9608
0,7014 0,3660
0,7013 0,2288
0,7003 0,1830
0,7010 0,8431
0,7011 0,1373
0,7010 0,2418
0,7012 0,4837
0,3113 0,1847
0,7572 0,5240
0,9332 0,1822
0,7089 0,1852
0,8969 0,4196
0,9134 0,3792
0,1723 0,5309
0,8057 0,4380
0,7590 0,8097
0,8182 0,8002
0,4521 0,3112
0,9347 0,5428
0,7862 0,7668
0,9494 0,4126
0,8696 0,2965
0,6841 0,5266
0,9007 0,5611
0,6463 0,2549
0,9232 0,3725
0,5554 0,3007
0,8751 0,5621
0,5588 0,6013
0,9467 0,8824
0,8971 0,7516
Giulia De Luca Z62000002
EGDI
0,0454 0,3464
0,1019 0,3784
0,8615 0,8067
0,2173 0,4320
0,8772 0,7050
0,6697 0,6478
0,4179 0,5671
0,2772 0,4072
0,8342 0,8333
0,1239 0,3968
0,0411 0,3228
0,5648 0,4797
0,8225 0,7894
0,0744 0,3026
0,2069 0,3818
0,3215 0,5020
0,1118 0,2024
0,1595 0,4807
0,5531 0,5524
0,2638 0,3839
0,6460 0,6518
0,3555 0,5477
0,0645 0,2586
0,7192 0,6521
0,0425 0,5398
0,5375 0,7195
0,0597 0,2747
0,7870 0,7527
0,1968 0,5851
0,8356 0,7293
0,5147 0,5576
0,2886 0,5000
0,8135 0,7565
0,3098 0,4022
0,1570 0,4831
0,4700 0,4406
0,2436 0,5603
0,2944 0,4860
0,1596 0,6651
0,4346 0,6950
di 54
0,6151
0,9982
0,6533
0,1103
0,8129
0,2576
0,7830
0,8228
0,7434
0,2876
0,7843
0,3137
0,1961
0,5163
0,1699
0,4837
0,0523
0,4248
0,2608
0,2722
0,3679
0,5200
0,3439
0,3033
0,1875
0,5725
0,2847
0,3868
0,6859
0,4436
0,2747
0,5573
0,2428
0,4847
0,4782
0,4837
Stima a massima verosimiglianza (imputazione con il valore atteso)
HCI
OSI
II
0,3063 0,2941
0,3063 0,3333
0,3063 0,8562
0,3063 0,3791
0,3063 0,5425
0,3063 0,5752
0,3063 0,5817
0,3063 0,2484
0,3063 0,9608
0,3063 0,3660
0,3063 0,2288
0,3063 0,1830
0,3063 0,8431
0,3063 0,1373
0,3063 0,2418
0,3063 0,4837
0,3113 0,4278
0,7572 0,4278
0,9332 0,4278
0,7089 0,4278
0,8969 0,4278
0,9134 0,4278
0,1723 0,4278
0,8057 0,4278
0,7590 0,4278
0,8182 0,4278
0,4521 0,4278
0,9347 0,4278
0,7862 0,4278
Giulia De Luca Z62000002
EGDI
0,0454 0,2161
0,1019 0,2480
0,8615 0,6765
0,2173 0,3017
0,8772 0,5750
0,6697 0,5177
0,4179 0,4368
0,2772 0,2770
0,8342 0,7031
0,1239 0,2664
0,0411 0,1924
0,5648 0,3497
0,8225 0,6592
0,0744 0,1723
0,2069 0,2516
0,3215 0,3716
0,1118 0,2851
0,1595 0,4480
0,5531 0,6359
0,2638 0,4664
0,6460 0,6546
0,3555 0,5642
0,0645 0,2236
0,7192 0,6487
0,0425 0,4099
0,5375 0,5928
0,0597 0,3143
0,7870 0,7136
0,1968 0,4698
di 54
0,9494
0,8696
0,6841
0,9007
0,6463
0,9232
0,5554
0,8751
0,5588
0,9467
0,8971
0,6151
0,9982
0,6533
0,1103
0,8129
0,2576
0,7830
0,8228
0,7434
0,4278
0,4278
0,4278
0,4278
0,2549
0,3725
0,3007
0,5621
0,6013
0,8824
0,7516
0,2876
0,7843
0,3137
0,1961
0,5163
0,1699
0,4837
0,0523
0,4248
0,8356
0,5147
0,2886
0,8135
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,3252
0,7345
0,6023
0,4664
0,7111
0,4073
0,5386
0,3928
0,5872
0,4962
0,7197
0,6589
0,4081
0,7034
0,4296
0,2104
0,5511
0,2501
0,5302
0,3966
0,4971
Stima a massima verosimiglianza(imputazione con valori casuali)
HCI
OSI
II
0,9160 0,2941
0,6411 0,3333
0,8630 0,8562
0,5126 0,3791
0,9075 0,5425
0,5137 0,5752
0,8027 0,5817
0,6940 0,2484
0,8946 0,9608
0,7647 0,3660
0,7580 0,2288
0,9254 0,1830
0,6865 0,8431
0,7384 0,1373
0,9699 0,2418
0,3293 0,4837
0,3113 0,3113
0,7572 0,7572
Giulia De Luca Z62000002
0,0454
0,1019
0,8615
0,2173
0,8772
0,6697
0,4179
0,2772
0,8342
0,1239
0,0411
0,5648
0,8225
0,0744
0,2069
0,3215
0,1118
0,1595
EGDI
0,4173
0,3585
0,8602
0,3698
0,7734
0,5861
0,6006
0,4050
0,8972
0,4177
0,3415
0,5540
0,7846
0,3149
0,4706
0,3792
0,2030
0,4596
di 54
0,9332
0,7089
0,8969
0,9134
0,1723
0,8057
0,7590
0,8182
0,4521
0,9347
0,7862
0,9494
0,8696
0,6841
0,9007
0,6463
0,9232
0,5554
0,8751
0,5588
0,9467
0,8971
0,6151
0,9982
0,6533
0,1103
0,8129
0,2576
0,7830
0,8228
0,7434
0,9332
0,7089
0,8969
0,9134
0,1723
0,8057
0,7590
0,8182
0,4521
0,9347
0,7862
0,9494
0,8696
0,6841
0,9007
0,2549
0,3725
0,3007
0,5621
0,6013
0,8824
0,7516
0,2876
0,7843
0,3137
0,1961
0,5163
0,1699
0,4837
0,0523
0,4248
Giulia De Luca Z62000002
0,5531
0,2638
0,6460
0,3555
0,0645
0,7192
0,0425
0,5375
0,0597
0,7870
0,1968
0,8356
0,5147
0,2886
0,8135
0,1851
0,3912
0,2957
0,9429
0,0687
0,6963
0,5285
0,0918
0,3213
0,1586
0,2870
0,02
0,0363
0,5865
0,0026
0,2829
0,6002
0,6015
0,5494
0,5823
0,1866
0,5751
0,3461
0,5475
0,4329
0,8957
0,3714
0,8057
0,5997
0,5065
0,6558
0,2389
0,5604
0,3831
0,7911
0,4115
0,8422
0,7260
0,3310
0,7021
0,3746
0,1978
0,4385
0,1548
0,6164
0,2902
0,4831
di 54
Bibliografia
1: Rubin RB, Inference and missing data,
2: Joseph L.Schafer, John W. Graham, Missing Data:Our View of State of Art,
3: United Nations (2012), E-Government Survey 2012. E-Government for the People ,
4: Marco Mancaralla, eJustice amministrativa in Europa,
5: UN Public Administration Programme, United Nations E-Government Survey 2010,
6: JRC European Commission, Handbook on Constructing on Composite Indicators,
Giulia De Luca Z62000002
di 54
Giulia De Luca Z62000002
di 54
© Copyright 2026 Paperzz