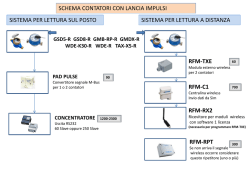
Introduzione - I
◮
Comunicazioni Wireless
◮
Sequenze in Sistemi a Spettro Espanso
◮
Universita’ Politecnica delle Marche
A.A. 2013-2014
◮
◮
A.A. 2013-2014
Comunicazioni Wireless
1/47
Introduzione - II
◮
Comunicazioni Wireless
2/47
Il singolo bit della sequenza di spreading e’ tipicamente chiamato chip e
ha durata TC .
BWDSSS e’ proporzionale a T1C = T1b = N · T1b = N· BW
Le caratteristiche e le prestazioni dei diversi sistemi SS dipendono
fortemente dalle proprieta’ di specifiche sequenze in uso nei sistemi
stessi.
Nel Frequency Hopping SS (FH-SS), tali sequenze prendono il nome
di sequenze di hopping, e definiscono la successione dei valori di
frequenza sui quali la trasmissione deve saltare
◮
Nel Direct Sequence SS (DS-SS), tali sequenze prendono il nome di
sequenze di spreading, e determinano l’allargamento spettrale del
segnale trasmesso, oltre che le prestazioni del sistema multi-utente,
come nel caso DS Code Division Multiple Access (DS CDMA)
◮
Nei sistemi CDMA le sequenze hanno un ruolo importante anche
nelle procedure di sincronizzazione, con le quali si cerca di
determinare l’istante ottimo di campionamento del segnale ricevuto
per ottenere le migliori prestazioni
Nei sistemi asincroni, l’espansione di banda e la separazione degli
utenti possono essere ottenute con famiglie di sequenze diverse,
rispettivamente chiamate di spreading e di scrambling
A.A. 2013-2014
Il ricevitore puo’ determinare quale parte del segnale totale proviene
da uno specifico utente, guardando ai soli segnali che presentano
uno specifico spreading pattern (profilo di spreading)
Sfruttando le proprieta’ specifiche delle tecniche SS, la capacita’ per
unita’ di banda non viene ridotta, bensi’ puo’ anche essere
incrementata
DS-SS
◮
◮
A.A. 2013-2014
I sistemi a Spettro Espanso (Spread Spectrum - SS) espandono
l’informazione da trasmettere su una banda molto maggiore
dell’inverso del data rate
Questo, a prima vista, sembra contraddittorio, dato che per
incrementare l’efficienza spettrale di una trasmissione si cerca, al
contrario, di trasmettere la maggiore quantita’ di informazione
possibile, per unita’ di banda
L’apparente paradosso si risolve quando si considera che i segnali
generati da differenti utenti possono essere espansi nello spettro in
differenti maniere, consentendo cosi’ a piu’ utenti di trasmettere
simultaneamente nella stessa banda di frequenze
Comunicazioni Wireless
N
N, lunghezza della sequenza di spreading, e’ chiamato anche spreading
factor e rappresenta il fattore di espansione di banda dovuto
all’operazione di spreading.
3/47
A.A. 2013-2014
Comunicazioni Wireless
4/47
DS-CDMA
Requisiti
L’obiettivo primario delle sequenze (o codici) di spreading e’ quello di
conseguire l’espansione in banda del segnale d’informazione. Tuttavia cio’
deve essere ottenuto tenendo presenti alcuni requisiti, che determinano la
scelta delle sequenze di spreading:
◮ le sequenze di spreading devono presentare buone proprieta’ di
auto-correlazione
◮
◮
◮
◮
le sequenze di spreading devono presentare buone proprieta’ di
cross-correlazione
◮
◮
Comunicazioni Wireless
5/47
Sequenze di spreading e sistemi SS
◮
◮
◮
Comunicazioni Wireless
6/47
Sequenze di spreading per DS-SS
le sequenze di hopping sono tipicamente scelte in alfabeti N-ari, dove
N e’ il numero di frequenze sulle quali la trasmissione puo’ saltare
il criterio di progetto per le sequenze di hopping e’ basato sulla
massimizzazione della distanza di Hamming tra le sequenze, dato che
l’interferenza si verifica quando due o piu’ trasmettitori saltano sulla
stessa frequenza
l’associazione tra la sequenza di hopping e le frequenze in uso in un
sistema FH-SS e’ arbitraria e puo’ essere agevolmente cambiata nel
tempo, rendendo cosi’ piu’ complessa l’intercettazione delle
trasmissioni
Sono due le categorie principali di sequenze di spreading per DS-SS:
1) sequenze pseudo-noise (PN), anche dette pseudorandom:
◮
◮
◮
◮
sistemi DS-SS:
◮
◮
◮
A.A. 2013-2014
A.A. 2013-2014
sistemi FH-SS:
◮
◮
consentire l’accesso multiplo usando differenti codici di spreading
(sistemi commerciali)
adeguata cardinalita’ della famiglia di sequenze scelta
L’auto-correlazione e’ una misura della randomicita’ della sequenza,
ovvero della sua somiglianza ad una sequenza casuale; una sequenza
ideale e casuale risulta incorrelata a versioni shiftate di se stessa.
Il rumore aggiunto dal canale viene sottoposto all’operazione di spreading
al ricevitore: questo costituisce un vantaggio, infatti ne viene aumentata
la banda ma ridotta l’ampiezza.
A.A. 2013-2014
rendere il segnale utile piu’ possibile simile a rumore (noise-like),
prevenire l’intercettazione del segnale, ridurre l’impatto di interferenti
intenzionali (sistemi militari)
migliorare la sincronizzazione al ricevitore
conseguire reiezione del multipath
le sequenze in uso in sistemi DS-SS sono tipicamente binarie
la selezione delle sequenze nei sistemi DS-CDMA e’ basata sulle
proprieta’ di auto- e cross-correlazione
l’associazione tra sequenza di spreading e utente non puo’ essere
cambiata nel tempo a meno di interventi radicali nel sistema e cio’
rende le sequenze di spreading in DS-CDMA piu’ suscettibili a
intercettazione
Comunicazioni Wireless
progettate per le loro proprieta’ di auto-correlazione
rendono i segnali difficili da intercettare ma facilmente determinabili
dai ricevitori autorizzati
ad un osservatore esterno appaiono come sequenze random, ma sono
generate da mediante algoritmi deterministici
hanno lunghezza finita e sono periodiche; si distinguono in long
codes (periodo >> symbol period) e short codes (lunghezza ∼
=
symbol period). Tipicamente si scelgono in modo da avere lunghezza
pari al symbol period.
2) sequenze ortogonali: utilizzate nello spreading quando lo scopo
primario dell’uso del DS-SS e’ l’accesso multiplo, e il sistema
mantiene il sincronismo tra gli utenti
7/47
A.A. 2013-2014
Comunicazioni Wireless
8/47
Proprieta’ di sequenze di spreading - I
Proprieta’ di sequenze di spreading - II
Le due principali proprieta’ di interesse nella discussione delle sequenze di
spreading sono la auto-correlazione e la cross-correlazione.
Supponiamo di rappresentare una sequenza di spreading binaria di
lunghezza N (periodo) come: s = s0 , s1 , . . . , sN−1 , dove ogni si e’ tale
che si ∈ [0, 1].
Per il calcolo di auto- e cross-correlazione, si passa alla notazione
bipolare, per la quale definiamo ai = 2 · si − 1 ∀i = 0 . . . N − 1, ovvero:
si = 1 → ai = 1, e si = 0 → ai = −1, quindi ai ∈ [−1, +1].
Funzione di auto-correlazione periodica discreta normalizzata per
una sequenza a:
N−1
1 X
ai ai+n
(1)
Caa [n] =
N
Funzione di cross-correlazione periodica discreta normalizzata per
due sequenze a1 e a2 aventi stessa lunghezza N:
Ca1 a2 [n] =
Caratteristiche ideali desiderate: (
9/47
Proprieta’ di sequenze di spreading - III
Comunicazioni Wireless
◮
cross-correlazione: Ca1 a2 [n] = 0, ∀ n
A.A. 2013-2014
Comunicazioni Wireless
10/47
Le sequenze di spreading che noi ricerchiamo devono presentare le
seguenti proprieta’:
◮
essere semplici da generare
avere buone proprieta’ di auto-correlazione
avere buone proprieta’ di cross-correlazione
◮
fornire un sufficiente numero di sequenze nel set
◮
dove M e’ la cardinalita’ del set S e N e’ la lunghezza delle sequenze. Il
bound rappresenta il limite inferiore alla cross-correlazione tra due
sequenze qualunque in uno stesso set.
Infine, da notare che essendo le sequenze periodiche di periodo N, anche
le funzioni di auto- e cross-correlazione discrete sono periodiche:
A.A. 2013-2014
se n = 0
se n =
6 0
auto-correlazione: Caa [n] =
Proprieta’ desiderate
La cross-correlazione tra due sequenze in un set S e’ limitata
inferiormente dal cosidetto Welch bound. Ovvero, definendo la massima
cross-correlazione Cmax = maxa1 ,a2 ∈S,n {|Ca1 a2 [n]|}, risulta:
r
M −1
(3)
Cmax ≥
MN − 1
Ca1 a2 [n] = Ca1 a2 [n + N]
1,
0,
◮
Nei sistemi sincroni, i valori Ca1 a2 [n] per n 6= 0 non sono di interesse, ed e’ possibile
garantire che sia Ca1 a2 [n] = 0 a patto che la cardinalita’ della famiglia di sequenze non
sia maggiore della lunghezza delle sequenze stesse, ma in sistemi asincroni la
cross-correlazione delle sequenze non puo’ essere portata a zero. Proprieta’ di
cross-correlazione ideali sono utili nei sistemi ad accesso multiplo cosi’ come per
mutliplare differenti data streams sullo stesso segnale.
Questa espressione consente di calcolare la funzione di auto-correlazione
discreta normalizzata e periodica, perche’ appunto calcolata sull’intero
periodo (ovvero sull’intera lunghezza) della sequenza.
Comunicazioni Wireless
(2)
i=0
i=0
A.A. 2013-2014
N−1
1 X
a1,i a2,i+n
N
◮
(4)
11/47
A.A. 2013-2014
Comunicazioni Wireless
12/47
Sequenze Pseudonoise - I
◮
◮
◮
◮
Sequenze Pseudonoise - II
Uno dei principali attributi dei segnali SS e’ la loro somiglianza a
rumore bianco per un ricevitore non autorizzato. Per tale motivo,
questi segnali devono presentare livelli bassi di densita’ spettrale di
potenza, e idealmente la loro densita’ spettrale di potenza assume
un profilo piatto.
In altre parole, i segnali SS devono avere una funzione di
auto-correlazione ideale Rx (τ ) = δ(τ ), ovvero una funzione di
auto-correlazione data da una delta di Dirac.
Ovviamente i segnali reali non possono avere banda infinita quindi
non presenteranno una funzione di auto-correlazione ideale come la
delta di Dirac.
Considerando lo schema classico di un sistema DS-SS, per poter
perfettamente invertire l’operazione di spreading al ricevitore,
mediante una correlazione, la funzione di auto-correlazione della
sequenza di spreading dovrebbe idealmente essere una delta di
Dirac, in modo che la convoluzione del segnale d’informazione
originale con la concatenazione di spreader e despreader restituisca
la sequenza originale.
A.A. 2013-2014
Comunicazioni Wireless
Quanto prima esposto significa richiedere che per una sequenza di
spreading (a risulti:
1, se n = 0
Caa [n] =
0, se n 6= 0
avendo in precedenza utilizzato la definizione di auto-correlazione
normalizzata (rispetto alla lunghezza delle sequenze).
Nella pratica la proprieta’ di auto-correlazione ideale puo’ soltanto essere
approssimata. In particolare, un gruppo specifico di sequenze PN, dette
sequenze a massima lunghezza, o m-sequenze, forniscono le seguenti
proprieta’:(
1,
se n = 0, lN
Caa [n] =
− N1 , se n 6= 0, lN
l e’ un intero
13/47
m-sequenze
A.A. 2013-2014
Comunicazioni Wireless
14/47
Rappresentazione polinomiale di m-sequenze - I
Le m-sequenze sono generate mediante registri a scorrimento lineari
retroazionati (Linear Feedback Shift Register, LFSR) nella configurazione
a massima lunghezza, per la quale, indicato con m il numero di celle del
registro, la lunghezza delle m-sequenze vale N = 2m − 1. Sono infatti
2m − 1 le possibili configurazioni delle celle del registro, escludendo la
configurazione tutta nulla, non ammessa a causa della linearita’ delle
operazioni di generazione delle sequenze.
La sequenza puo’ essere specificata come:
g (p) = 1 + α1 p + α2 p 2 + . . . + αm−1 p m−1 + p m
(5)
sulla base della struttura del registro, come mostrato in figura:
La figura illustra anche il calcolo del bit di retroazione
A.A. 2013-2014
Comunicazioni Wireless
15/47
A.A. 2013-2014
Comunicazioni Wireless
16/47
Rappresentazione polinomiale di m-sequenze - II
Proprieta’ delle m-sequenze
Utilizzando la rappresentazione polinomiale delle m-sequenze e’ possibile individuare i
cosiddetti polinomi primitivi che consentono, dato un LFSR di grado n, ovvero a n
celle, di generare la/e m-sequenza/e esistenti, per qualunque configurazione iniziale
delle celle del registro esclusa quella tutta nulla.
La tabella di seguito mostra i polinomi primitivi (in rappresentazione ottale) che
consentono di generare m-sequenze di lunghezza N da 3 a 1023 bit.
Proprieta’ di sequenze PN deterministiche:
◮ bilanciamento: la frequenza relativa di 1 e di 0 nella sequenza deve essere la
stessa e circa pari a 1/2
◮ lunghezza delle corse: la lunghezza delle corse di 1 e 0 deve essere tale che meta’
delle corse hanno lunghezza 1, 1/4 delle corse ha lunghezza 2, 1/8 delle corse ha
lunghezza 3, etc
◮ proprieta’ ritardo e somma (dealy & add): se la sequenza viene shiftata di un
numero non nullo di elementi, la sequenza risultante avra’ un ugual numero di
concordanze e discordanze con la sequenza originale
Proprieta’ delle m-sequenze:
◮ Una m-sequenza ha 2m−1 bit 1, e 2m−1 − 1 bit 0
◮ Facendo scorrere una finestra di dimensione m lungo un periodo di una
m-sequenza si trova che essa contiene tutte le possibili m-ple binarie, ad
eccezione della m-pla tutta nulla
◮ La m-sequenza contiene: una corsa di 1 di lunghezza m, una corsa di 0 di
lunghezza m − 1, una corsa di 1 e una corsa di 0 di lunghezza m − 2, etc
Esempio: per n = 6, il polinomio [103] in notazione ottale corrisponde alla notazione
binaria [1000011]; poiche’ la notazione usata rappresenta i polinomi come
[gn gn−1 . . . g0 ], il polinomio generatore dato equivale a: g (p) = 1 + p + p 6 . Ogni
polinomio puo’ essere usato per generare una m-sequenza e il suo reciproco un’altra
m-sequenza.
A.A. 2013-2014
Comunicazioni Wireless
◮ La somma modulo-2 di una m-sequenza con una versione shiftata di se stessa
produce un’altra versione shiftata della stessa m-sequenza
17/47
Auto-correlazione di m-sequenze
A.A. 2013-2014
Comunicazioni Wireless
18/47
Cross-correlazione di m-sequenze - I
Esempio di auto-correlazione di una m-sequenza di lunghezza N = 31
(m = 5)
A.A. 2013-2014
Comunicazioni Wireless
19/47
◮
La cross-correlazione tra una sequenza PN (m-sequenza) e il rumore
e’ bassa, e questa proprieta’ e’ utile al ricevitore, per filtrare via il
rumore in ingresso. Il rumore e’ un segnale random quindi ha
auto-correlazione pari a 0 per qualunque valore dello shift del
segnale stesso.
◮
La cross-correlazione tra due diverse m-sequenze e’ bassa (dovrebbe
essere 0 o quasi nulla).
◮
Questa proprieta’ e’ alla base delle applicazioni CDMA, poiche’
consente al ricevitore di discriminare i segnali SS generati da
differenti m-sequenze; consente di sfruttare l’elevata
cross-correlazione del segnale SS con la m-sequenza corretta, e la
bassa cross-correlazione tra il segnale SS e sequenze m differenti da
quella usata al trasmettitore.
A.A. 2013-2014
Comunicazioni Wireless
20/47
Cross-correlazione di m-sequenze - II
Altre proprieta’
Esempio di cross-correlazione tra due m-sequenze di lunghezza 31
◮ Una proprieta’ interessante ed utile delle m-sequenze riguarda la loro
decimazione: decimando una m-sequenza di un fattore q, la sequenza che si
ottiene ha periodo N/MCD(N, q), dove MCD indica il massimo comun divisore
◮ Di conseguenza, se MCD(N, q) = 1, otteniamo una m-sequenza che ha la stessa
lunghezza di quella originale
◮ La m-sequenza cosi’ ottenuta non e’ necessariamente una nuova m-sequenza ma
puo’ essere una versione shiftata di quella originale (diversa fase)
◮ Se prendiamo due m-sequenze di lunghezza N = 2n − 1, b e v = b[q], in cui
q = 2k + 1 oppure q = 22k − 2k + 1, per valori interi di k, e e =MCD(n, k) e’
tale che n/e e’ un valore dispari, allora la cross-correlazione periodica tra b e v e’
a tre valori
◮ Quando n 6= 0mod4, esistono delle coppie specifiche di m-sequenze, chiamate
coppie preferite, per le quali i tre valori assunti dalla cross-correlazione
periodica
risultano pari a: −1/N, −1/N(1 + 2⌊(n+2)/2⌋ ), 1/N(2⌊(n+2)/2⌋ − 1) , dove ⌊.⌋
e’ la funzione floor
◮ Le m-sequenze che costituiscono coppie preferite sono importanti nella
generazione delle sequenze di Gold
◮ Una limitazione all’uso delle m-sequenze, specie in sistemi DS-CDMA, e’ la
bassa cardinalita’ dei loro set, come mostrato nella Tabella seguente
A.A. 2013-2014
Comunicazioni Wireless
21/47
Cardinalita’ di m-sequenze
A.A. 2013-2014
22/47
Sequenze di Gold
◮
◮
◮
◮
◮
A.A. 2013-2014
Comunicazioni Wireless
Comunicazioni Wireless
23/47
A.A. 2013-2014
Sebbene le m-sequenze abbiano ottime proprieta’ di
auto-correlazione, come abbiamo visto, non risultano molto adatte
all’uso in sistemi CDMA a causa della bassa cardinalita’ dei loro set.
Nel 1967, Gold dimostro’ che alcune coppie di m-sequenze, dette
preferite, hanno un buon comportamento in termini di
cross-correlazione (che risulta a tre valori) e possono essere
combinate per formare sequenze chiamate di Gold.
Piu’ precisamente, si possono generare N + 2 sequenze di Gold da
una coppia di m-sequenze preferite di lunghezza N = 2n − 1.
Se b1 e b2 rappresentano la coppia di m-sequenze preferite, il set di
sequenze
di Gold e’ dato da: G (b1 , b2 ) =
b1 , b2 , b1 ⊕ b2 , b1 ⊕ Tb2 , b1 ⊕ T 2 b2 , . . . b1 ⊕ T N−1 b2 , dove T
rappresenta l’operazione di shift della sequenza rispetto all’originale.
Alcune delle sequenze cosi’ ottenute non sono piu’ a massima
lunghezza.
La cross-correlazione periodica normalizzata tra due qualunque
sequenze
della famiglia cosi’generata assume sempre tre valori:
1
n+1
− N , − N1 t(n), N1 (t(n) − 2) , dove t(n) = 2 2 + 1 per n dispari, e
n+2
t(n) = 2 2 + 1 per n pari.
Comunicazioni Wireless
24/47
Generazione di sequenze di Gold di lunghezza 31 - esempio
Auto- e cross-correlazione di sequenze di Gold - esempio
Il vantaggio di usare le sequenze di Gold sulle m-sequenze sta nel poter aumentare la
cardinalita’ del set e controllare i valori di cross-correlazione. Tuttavia, le prestazioni di
auto-correlazione peggiorano, come mostrato nella figura seguente per il caso n = 6
Affinche’ le m-sequenze scelte siano le preferite, devono soddisfare le seguenti
condizioni:
In particolare, i valori di auto-correlazione fuori aggancio sono piu’ alti che nel caso
delle m-sequenze, e assumono gli stessi tre valori in precedenza indicati per la
cross-correlazione
◮ n 6= 0mod4, ovvero n dispari, oppure n = 2mod4
◮ b2 = b1 [q], con q dispari oppure q = 2k + 1 o q = 22k − 2k + 1 per k intero
◮ MCD(n, k)=1 per n dispari, e MCD(n, k)=2 per n = 2mod4
A.A. 2013-2014
Comunicazioni Wireless
25/47
Sequenze di Kasami
A.A. 2013-2014
◮ Come precedentemente illustrato, il Welch bound ci dice che la cross-correlazione
tra due qualsiasi
qsequenze di un set a cardinalita’ M e’ limitata inferiormente dal
M−1
. Quindi, per set di sequenze relativamente numerosi
valore Cmax =
MN−1
q
1
(M >> 1), la cross-correlazione sara’ sempre maggiore di un valore ∼
.
=
N
◮
n
massima per un set di sequenze
q di Gold di lunghezza N = 2 − 1 e’ circa pari a
q
2
4
per n dispari, e a circa
per n pari (assumendo N = 2n − 1 ∼
= 2n ).
N
N
Quindi, la cross-correlazione massima
per
le
sequenze
di
Gold
supera
il limite di
√
Welch per almeno un fattore 2.
◮
◮ Da quanto visto sulle sequenze di Gold, si puo’ mostrare che la cross-correlazione
◮ Un’altra famiglia di sequenze puo’ essere costruita a partire dalle m-sequenze, e
sono le sequenze di Kasami, che hanno una cardinalita’ pari a 2n/2 per una
lunghezza N = 2n − 1 e una funzione di cross-correlazione a tre valori.
Purtroppo, sebbene questo set di sequenze soddisfi il Welch bound,
non e’ un set molto numeroso, ed e’ infatti chiamato Kasami small
set.
◮
Un set piu’ ampio di sequenze di Kasami, il cosiddetto large set,
puo’ essere ottenuto includendo le sequenze di Gold e il Kasami
small set, a patto che mod(n, 4) = 2. Si ottengono cosi’ in totale
M = 23n/2 + 2n/2 sequenze, di lunghezza N = 2n − 1, tali che sia la
autoche la cross-correlazione
o assumono i tre valori possibili:
n
−1±2n/2 −1±2n/2+1
.
−1/N, N ,
N
−1/N, −1/N(2n/2 + 1), 1/N(2n/2 − 1) , e soddisfa il Welch bound.
Comunicazioni Wireless
27/47
Le sequenze di Kasami sono generate in maniera simile alle Gold. Si
parte con una m-sequenza b di lunghezza N = 2n − 1 e n pari.
Decimando b per il fattore 2n/2 + 1, si ottiene una seconda
m-sequenza b’ che ha lunghezza 2n/2 − 1. Sommando modulo-2 b e
le 2n/2 − 1 versioni shiftate di b’ si ottiene un set di 2n/2 − 1
sequenze.
Includendo la sequenza originale b si ottiene la cardinalita’ M = 2n/2 .
◮
◮ Precisamente, la cross-correlazione di sequenze di Kasami puo’ assumere valori
A.A. 2013-2014
26/47
Generazione di sequenze di Kasami
◮
in:
Comunicazioni Wireless
A.A. 2013-2014
Comunicazioni Wireless
28/47
Generazione di sequenze PN: sommario
Sequenze ortogonali
◮
Alcuni sistemi ad accesso multiplo e applicazioni di multiplexing
richiedono l’uso di sequenze a cross-correlazione nulla. Cio’ e’
possibile a patto che il sistema sia sincrono o adattivo. Nel primo
caso, le sequenze e le forme d’onda sono dette ortogonali.
◮
Nei set di sequenze ortogonali, tutte le cross-correlazioni tra coppie
di sequenze del set sono nulle.
◮
In sistemi CDMA, si usano sequenze ortogonali sia a lunghezza fissa
che variabile; ogni utente utilizza una sequenza che lo rende
ortogonale a tutti gli altri utenti.
Le famiglie di sequenze piu’ usate e note sono le sequenze di Walsh
e le sequenze OVSF (Orthogonal Variable Spreading Factor).
◮
A.A. 2013-2014
Comunicazioni Wireless
29/47
Sequenze di Walsh - I
A.A. 2013-2014
Comunicazioni Wireless
30/47
Comunicazioni Wireless
32/47
Sequenze di Walsh - II
Le sequenze ortogonali di uso piu’ comune sono quelle cosiddette di
Walsh, o Walsh-Hadamard, perche’ basate sull’uso di matrici di
Hadamard per la loro generazione. Le matrici di Hadamard sono formate,
per i ≥ 0, come:
I codici di Walsh di lunghezza 2i sono cosi’ ottenuti dalle righe della matrice di
Hadamard H2i . Le righe della matrice di Hadamard sono ortogonali, cosi’ possono
essere usate per formare 2i codici di spreading ortogonali. la lunghezza di queste
sequenze puo’ soltanto essere una potenza di 2. Inoltre, e’ importante sottolineare che
l’ortogonalita’ si mantiene soltanto se i codici sono propriamente allineati nel tempo,
ovvero se il sistema e’ sincrono. Quando l’allineamento non c’e’, le prestazioni di
cross-correlazione diventano molto povere. Allo stesso tempo, questi codici non hanno
buone prestazioni in termini di auto-correlazione, che puo’ essere molto diversa e
lontana da quella ideale, come mostrato nella slide seguente.
A.A. 2013-2014
Comunicazioni Wireless
31/47
A.A. 2013-2014
Sequenze OVSF - I
Sequenze OVSF - II
Un altro limite delle sequenze di Walsh e’ dovuto al fatto che esse richiedono che tutti
i segnali nello stesso sistema presentino lo stesso spreading factor, cioe’ diano luogo
alla stessa espansione di banda. Tuttavia, in alcune applicazioni, specie legate alla
trasmissione di segnali multimediali, puo’ essere richiesta una certa flessibilita’
nell’avere data rate multipli, mantenendo pero’ fissa la chip rate.
Siamo dunque anche interessati a sequenze che si mantengano ortogonali anche a
fronte di fattori di spreading variabili. Vengono cosi’ introdotte le sequenze OVSF,
anch’esse basate sulle matrici di Hadamard, ma assegnate secondo una albero binario,
come mostrato in figura.
◮ Sequenze appartenenti a rami differenti dell’albero, alla stessa profondita’, sono
ortogonali. Inoltre, una sequenza di lunghezza 2k−i e’ ortogonale ad una
sequenza di lunghezza 2k se e solo se essa non discende dalla prima. Se la
lunghezza massima e’ N = 2k , le sequenze possono essere assegnate dalla
lunghezza 1 alla N, tuttavia ogni sequenza di lunghezza 2k−i elimina 2i
sequenze di lunghezza 2k dalla possibilita’ di utilizzo.
◮ Nella figura precedente, N = 16, quindi ci sono 16 sequenze, in totale, di
massima lunghezza che possono essere assegnate agli utenti. Supponiamo che si
debba assegnare una sequenza di lunghezza 24−2 = 4. Per ciascuna sequenza di
lunghezza 4, ci sono due sequenze di lunghezza 8, e quattro sequenze di
lunghezza 16, che non sono ortogonali ad essa, perche’ discendono dalla
medesima sequenza. Per ottenere ortogonalita’, non possiamo assegnare
sequenze che discendono da una sequenza gia’ assegnata ad un utente.
◮ Per ciascun codice di lunghezza 4 che viene assegnato ad un utente, dobbiamo
pertanto eliminare due codici di lunghezza 8, e quattro di lunghezza 16.
Rimangono comunque sei sequenze di lunghezza 8, e dodici di lunghezza 16 che
sono disponibili perche’ ortogonali alla sequenza di lunghezza 4 originariamente
scelta.
A.A. 2013-2014
Comunicazioni Wireless
33/47
Sequenze OVSF - III
A.A. 2013-2014
◮
A.A. 2013-2014
34/47
Approccio Multiple-Spreading
◮
◮
Comunicazioni Wireless
In questo modo, utenti con differenti guadagni di spreading (ovvero
differenti spreading factors) possono rimanere ortogonali, a patto che
i loro segnali siano sincronizzati nel tempo. L’ortogonalita’ tra codici
di lunghezza diversa viene verificata sulle varie parti della sequenza
di lunghezza maggiore, rispetto a quella di lunghezza minore (es: se
A e’ formato da due chip, e B da quattro, A e B sono ortogonali se
la cross-correlazione di A con la prima parte di B e’ zero, e se e’
nulla la cross-correlazione di A con la seconda parte di B).
Le sequenze ortogonali consentono di ottenere la perfetta
soppressione dell’interferenza multi-utente al ricevitore, se i segnali
sono trasmessi su canale AWGN. Viceversa, in canali multipath, la
delay dispersion distrugge l’ortogonalita’ delle sequenze in uso. In tal
caso il ricevitore puo’ accettare l’interferenza addizionale (indicata
come fattore di ortogonalita’), oppure utilizzare un filtro di
equalizzazione che elimini la delay dispersion prima di eseguire la
correlazione e la separazione degli utenti.
Comunicazioni Wireless
◮
◮
◮
◮
35/47
A.A. 2013-2014
Quando occorre aumentare la capacita’ di sistemi multi-utente,
come i sistemi cellulari, si puo’ adottare il cosiddetto approccio
Multiple-Spreading, o Layered-Spreading, usando cioe’ diversi set di
sequenze di spreading, e piu’ operazioni di spreading sullo stesso
segnale.
Tipicamente si attua una prima operazione di spreading usando
codici ortogonali, in modo da conseguire l’ortogonalita’ mutua tra
tutti gli utenti della stessa cella. Queste sequenze sono anche dette
channelization codes.
L’ulteriore spreading dell’informazione d’utente avviene mediante
una sequenza PN che agisce come codice di scrambling, fornendo
mutua randomicita’ e bassa cross-correlazione tra utenti che stanno
in celle diverse.
Questo approccio richiede banda sufficiente, perche’ ogni operazione
di spreading aumenta il rate, ma e’ efficace per decodificare gli utenti
nella stessa cella, e ridurre l’interferenza tra utenti in celle diverse.
Un caso d’uso e’ il CDMA combinato con FDMA: ogni sottobanda
in cui risulta suddivisa l’intera banda disponibile viene gestita con
accesso multiplo CDMA tra piu’ utenti.
Comunicazioni Wireless
36/47
CDMA e progettazione delle sequenze - sintesi
Proposte alternative
Riassumendo quanto visto fin qui, possiamo dire che la selezione delle sequenze di
spreading ha effetti sostanziali sulle prestazioni di un sistema CDMA. In generale, le
proprieta’ da considerare sono:
Le famiglie di sequenze trattate nelle slides precedenti sono ormai ben
note e di uso tradizionale nei sistemi CDMA e DS-SS. E’ possibile
tuttavia esplorare delle soluzioni alternative, che facciano uso di famiglie
differenti di sequenze, sempre binarie, individuate sulla base di una o piu’
proprieta’ tra quelle piu’ volte citate. In particolare, sono due le famiglie
di sequenze in fase di studio per applicazioni DS-SS e DS-CDMA:
◮ auto-correlazione: idealmente, a shift nullo l’AC dovrebbe essere pari al numero
di chip della sequenza (N), e valere zero per ogni altro valore dello shift (i
cosiddetti side-lobes). Una buona auto-correlazione consente di migliorare la
sincronizzazione, inoltre le proprieta’ della auto-correlazione influenzano la
interferenza inter-chip in un ricevitore Rake (l’uscita del correlatore e’ la somma
delle ACF degli echi ritardati, per cui la presenza di un picco spurio di AC puo’
essere interpretata come un ulteriore contributo multipath);
◮ cross-correlazione: idealmente, le sequenze usate dovrebbero essere ortogonali,
per annullare l’interferenza inter-utente. Nei sistemi asincroni, l’ortogonalita’
deve essere garantita per valori arbitrari di ritardo tra i diversi utenti;
◮
sequenze binarie di De Bruijn
◮
sequenze binarie ricavate da generatori caotici
◮ numero di sequenze: in un sistema CDMA tentiamo di allocare il maggior
numero di utenti, e questo richiede famiglie di sequenze di una certa cardinalita’.
Il numero di sequenze ortogonali non puo’ superare la lunghezza delle sequenze
stesse, altrimenti occorre accettare un degrado delle prestazioni legato a una
cross-correlazione tra sequenze di utenti differenti che risulta diversa da zero.
A.A. 2013-2014
Comunicazioni Wireless
37/47
Sequenze binarie di De Bruijn - I
A.A. 2013-2014
Comunicazioni Wireless
38/47
Sequenze binarie di De Bruijn - II
La tabella seguente illustra l’impressionante cardinalita’ offerta dalle sequenze binarie
di De Bruijn, a parita’ di span, rispetto alle altre sequenze binarie ben note fin qui
analizzate.
◮ Una sequenza binaria di De Bruijn di span n ha lunghezza pari a 2n ed e’ tale
per cui, se osservata ciclicamente muovendo una finestra ideale di lunghezza n
sopra la sequenza, essa contiene esattamente tutte le possibili n-ple binarie,
inclusa la n-pla tutta nulla, senza ripetizioni.
◮ Questa definizione ricorda da vicino quella di una m-sequenza; la differenza
sostanziale risiede nel fatto che le sequenze binarie di De Bruijn vengono
generate mediante registri a scorrimento retroazionati di tipo NON lineare, nei
quali, cioe’, la funzione di feedback e’ tipicamente una funzione booleana non
lineare, che non si compone di sole somme e moltiplicazioni modulo-2. Per
questo, la generazione di una sequenza di De Bruijn puo’ anche prevedere un
registro inizialmente configurato con tutte le sue celle poste a zero.
◮ Tuttavia, non tutte le sequenze generate da un NFSR (Non-linear Feedback Shift
Register) sono sequenze di De Bruijn; per poter essere tali, devono verificare la
proprieta’ sopra enunciata. E’ possibile dimostrare che il numero totale di
n−1
sequenze di De Bruijn binarie di span n e’ dato da: M = 22 −n .
A.A. 2013-2014
Comunicazioni Wireless
A fronte di tante sequenze disponibili, tuttavia, e’ necessaria un’attenta opera di
selezione, per ricavare le sequenze adatte agli scopi di un sistema CDMA. Inoltre, le
sequenze di De Bruijn pongono un problema ancora in parte irrisolto, legato alla
complessita’ degli algoritmi fin qui proposti per la loro generazione, trattandosi di
schemi che procedono dapprima generando tutte le possibili sequenze binarie di
lunghezza 2n e poi selezionando quelle che soddisfano la definizione precedentemente
data.
39/47
A.A. 2013-2014
Comunicazioni Wireless
40/47
Sequenze binarie di De Bruijn - proprieta’ di correlazione
Auto-correlazione sequenze di De Bruijn
Andamento delle funzioni di auto-correlazione periodica di tutte le 2048 sequenze
binarie di De Bruijn di span 5.
Le sequenze binarie di De Bruijn presentano alcune caratteristiche interessanti per le
loro proprieta’ di auto- e cross-correlazione. Per l’auto-correlazione:
P
Caa
[k] = 2n
per
k=0
P
Caa
[k] = 0
per
P
Caa
1 ≤ |k| ≤ n − 1
[k] 6= 0
per
|k| = n
P
Caa
Si dimostra inoltre che
[k] ≡ 0 mod 4 per tutti i valori di k, per ogni arbitraria
sequenza a di periodo N = 2n , con n ≥ 2. Se si esclude il picco a k = 0, le funzioni di
auto-correlazione di tutte le sequenze di De Bruijn sono simmetriche rispetto al valore
centrale.
Un aspetto peculiare e interessante, tuttora oggetto di studio, e’ la seconda tra le
proprieta’ di auto-correlazione, che denota l’ esistenza di una cosiddetta Zero
Correlation Zone (ZCZ) intrinseca nella natura stessa delle sequenze.
Si dimostra che esiste un bound al valore massimo di auto-correlazione fuori aggancio
(per k 6= 0) dato da:
n +
2
P
, for 1 ≤ k ≤ N − 1
[k] ≤ 2n − 4
0 ≤ max Caa
2n
dove [x]+ indica il piu’ piccolo intero maggiore o uguale a x.
A.A. 2013-2014
Comunicazioni Wireless
41/47
Cross-correlazione sequenze di De Bruijn
A.A. 2013-2014
Comunicazioni Wireless
42/47
Sequenze binarie da generatori caotici
Valgono proprieta’ analoghe a quelle indicate per l’auto-correlazione: date due
sequenze a1 e a2 , incluse a1 = a2 , di span n e periodo N, la funzione di
cross-correlazione Ca1 a2 [k], per 0 ≤ k ≤ N − 1, esibisce le seguenti proprieta’:
N−1
X
Ca1 a2 [k]
=
Ca1 a2 [N − k] , per 0 ≤ k ≤ N − 1
Ca1 a2 [k]
=
0
Ca1 a2 [k]
≡
0 mod 4, per n ≥ 2, ∀k
k=0
Vale inoltre il seguente bound:
−2n ≤ Ca1 a2 [k] ≤ 2n − 4, per 0 ≤ k ≤ N − 1
A.A. 2013-2014
Comunicazioni Wireless
43/47
A.A. 2013-2014
Comunicazioni Wireless
44/47
Bibliografia - I
Bibliografia - II
◮
L. Welch, Lower bounds on the maximum cross-correlation of
signals, IEEE Transactions on Information Theory, vol. IT-20, pp.
397-399, May 1974.
◮
D. Sarwate and M. Pursley, Crosscorrelation properties of
pseudorandom and related sequences, Proceedings of the IEEE, vol.
68, pp. 593-619, May 1980.
◮
R. Gold, Optimum binary sequences for spread spectrum
multiplexing, IEEE Transactions on Information Theory, vol. IT-13,
pp. 619-621, October 1967.
T. Kasami, Weight distribution formula for some class of cyclic
codes, University of Illinois-Urbana Technical Report R-285, April
1966.
◮
◮
A.A. 2013-2014
Spinsante, S., Gambi, E., Warty, C., Mattigiri, S., Yu, R.W. Analysis
of spreading codes in conjunction with ambiguity function for inter
vehicular communication (2013) IEEE Vehicular Technology
Conference, ISSN: 15502252 ISBN: 9781467361873 DOI:
10.1109/VTCFall.2013.6692104
◮
Warty, C., Mattigiri, S., Gambi, E., Spinsante, S. De Bruijn
sequences as secure spreading codes for wireless communications
(2013) Proceedings of the 2013 International Conference on
Advances in Computing, Communications and Informatics, ICACCI
2013, art. no. 6637190, pp. 315-320. ISBN: 9781467362153 DOI:
10.1109/ICACCI.2013.6637190
Spinsante, S., Gambi, E. De bruijn binary sequences and spread
spectrum applications: A marriage possible? (2013) IEEE Aerospace
and Electronic Systems Magazine, 28 (11), art. no. 6678491, pp.
28-39. ISSN: 08858985 DOI: 10.1109/MAES.2013.6678491
◮
J. Lindholm, An analysis of the pseudo-randomness properties of
subsequences of long m-sequences, IEEE Transactions on
Information Theory, vol. IT-15, 1968.
Comunicazioni Wireless
45/47
Disponibilita’ di tesi sull’argomento
Vedere il sito: http://www.tlc.dii.univpm.it/blog/ - available theses
Sequenze di spreading per comunicazioni a spettro espanso (T,M)
◮ T: implementazione di algoritmi per la generazione di sequenze di spreading
appartenenti a famiglie gia’ individuate (caotiche, Zadoff-Chu, De Bruijn binarie
e/o multi-livello). Analisi e confronto tra le sequenze, sulla base di proprieta’ di
interesse gia’ individuate. Linguaggio di programmazione: MATLAB.
◮ M: analisi dello stato dell’arte relativo a sistemi di telecomunicazione
wired/wireless operanti con tecniche a spettro espanso; selezione di un sistema
di interesse; individuazione delle famiglie di sequenze in uso; proposta di
soluzioni adoperanti sequenze alternative. Attivita’ di simulazione e verifica delle
prestazioni mediante programmi in MATLAB.
Sistemi di scrambling e soluzioni innovative (T,M)
◮ T: implementazione di algoritmi per lo scrambling usati in differenti sistemi di
telecomunicazione (LTE, DVB, etc). Analisi e confronto tra le prestazioni, sulla
base di proprieta’ di interesse gia’ individuate. Linguaggio di programmazione:
MATLAB.
◮ M: analisi dello stato dell’arte relativo alle tecniche di scrambling in LTE-A;
individuazione delle principali proprieta’ e prestazioni; proposta di soluzioni
adoperanti schemi alternativi. Attivita’ di simulazione e verifica delle prestazioni
mediante programmi in MATLAB.
A.A. 2013-2014
◮
Comunicazioni Wireless
47/47
A.A. 2013-2014
Comunicazioni Wireless
46/47
© Copyright 2026 Paperzz