2014/10/22
2014年10月22日 15:00-15:50
組み込みシステムシンポジウム2014 (ESS2014)
チュートリアル
今日の話: PyCoRAMについて
n 高位合成技術とメモリシステム抽象化を用いた
アクセラレータIPコア開発のためのフレームワーク
PyCoRAMによる
Pythonを用いたポータブルな
FPGAアクセラレータ開発
l キーワード: FPGAアクセラレータ・IPコア設計・Python-Verilog
高位合成・メモリシステム抽象化・AXI4インターコネクト
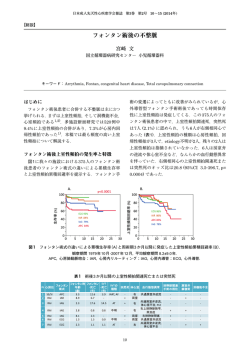
Modeled in RTL
(Verilog HDL) User
I/O
GPIO
PyCoRAM IP
User Logic
CoRAM
Register
CoRAM
Channel
高前田(山崎) 伸也
奈良先端科学技術大学院大学 情報科学研究科
E-mail: shinya_at_is_naist_jp
2014-10-22
CoRAM
Memory
CoRAM
Stream
Master
DMAC
Master
DMAC
Shinya T-Y, NAIST
Control
Thread
Memory Access
Pattern
in Python
FSM
CoRAM
IoChannel
Slave
DMAC
2
PyCoRAM and Pyverilog are released for public!
n PyCoRAM
はじめに
l http://shtaxxx.github.io/PyCoRAM/
n Pyverilog
l http://shtaxxx.github.io/Pyverilog/
2014-10-22
Shinya T-Y, NAIST
3
2014-10-22
Shinya T-Y, NAIST
4
1
2014/10/22
Heterogeneous Computing
Multicore (Intel Corei7)
FPGAs in Anywhere
n As an LSI verification platform
GPU (NVIDIA GeForce)
OoO
Core
OoO
Core
OoO
Core
OoO
Core
L2
L2
L2
L2
l Testing the LSI functions,
before the actual fabrication
• It enables longer behavior simulations
than SW-based simulators
L3 Cache
L2 Cache
DDR3 DRAM
GDDR5 DRAM
n As a final product
l Vision processing
FPGA (Xilinx Virtex-7)
Manycore (Intel Xeon Phi)
l Network router
l Broadcasting
DDR3 DRAM
l Stock Trading
(High Frequency Trading (HFT))
DDR3 DRAM
l Oil mining
5
Shinya T-Y, NAIST
2014-10-22
FPGA Board Overview
Digilent Atlys
FPGA: Xilinx Spartan-6 LX45
Size: Pipelined CPU ×4
Price: 20,000yen (Academic)
Xilinx VC707 Evaluation Board
(400,000yen)
FPGA (Xilinx Virtex-7)
DDR3 SODIMM DRAM
(Memory)
Stock Trading
Shinya T-Y, NAIST
6
Digilent ZedBoard
FPGA: Xilinx Zynq-7020
Size: Pipelined CPU ×8 (+ ARM DualCore)
Price: 50,000yen (Academic)
SD Card
Power In
Ethernet
2014-10-22
2014-10-22
Object
Detection
PCI-express
(Connected to PC)
Shinya T-Y, NAIST
7
2014-10-22
Shinya T-Y, NAIST
8
2
2014/10/22
ScalableCore System
FPGA: Xilinx Spartan-6 ×100
Size: Pipelined CPU x200?
Price: 1,000,000yen?
アプリケーションのポータビリティ
n どうやって様々なプラットフォームをサポートするか?
l プラットフォーム毎に特性が違うL
• ロジックサイズ・メモリサイズ・
メモリインターフェース・I/O・・・
Digilent Atlys
(Xilinx Spartan-6 LX45)
ScalableCore System (our FPGA system)
(Xilinx Spartan-6 LX16 × 128-node)
9
Shinya T-Y, NAIST
2014-10-22
IPコアベースのシステム開発
Xilinx ML605
(Xilinx Virtex-6 LX240T)
Shinya T-Y, NAIST
2014-10-22
10
どうやってアクセラレータIPを実装するか?
n IPコアを開発・追加して繋げばシステム完成J
n 普通にHDLでアクセラレータを実装するのは芸が無い
l 標準的なインターコネクトでIPコア達を接続
l というかいろいろ面倒で嫌だ!
• 演算とメモリアクセスのスケジューリングロジック
l EDAツールが自動的にインターコネクトと(いくつかの)
デバイス依存のインターフェースを生成してくれるから楽ちん
– ダブルバッファリングとか面倒
• メモリシステムの制御回路
– HDLでステートマシンを書くのは面倒だし間違えやすい
IP-core List
• デバッグが面倒
FPGA
CPU
IP-core
Instances
HW
Acc
l でもパイプラインの振る舞いはサイクルレベルで定義したい
HW
Acc
• FPGAで性能を出すには高稼働率のパイプラインが重要
Interconnect
Ether
Interconnect
DRAM
I/F
– だから計算ロジックはHDLで書きたい
– 高位合成だとチューンがイマイチ難しい
PCI-E
n 抽象化されたメモリシステムが使えると幸せそう
DRAM
2014-10-22
Xilinx Platform Studio (XPS)
Shinya T-Y, NAIST
CoRAMメモリアーキテクチャ
11
2014-10-22
Shinya T-Y, NAIST
12
3
2014/10/22
CoRAM [Chung+,FPGA’11]
What “Runs” CoRAM?
n FPGAアクセラレータのためのメモリ抽象化
RTL conversion
l 高位モデルによるメモリ管理でアクセラレータをポータブルに
Core Logic
• ソフトウェアのモデルによるメモリアクセスパターンの記述
Architecture
Microarchitecture
Read/Write
CoRAM
Memory
Read
Write
HW Kernels
(Computing Logics)
2014-10-22
Off-chip
Memory
Fabric
FPGA
Manage
Control Logic
Network-on-Chip
Memory Translation (TLBs)
Memory Interfaces and Caches
Control Threads
(Memory Access
Pattern)
Shinya T-Y, NAIST
Cluster DMA
Control Logic
Abstracted
On-chip Memories
Cluster DMA
CoRAM
Channel
Fabric
Communication
FIFOs (Registers)
Control
thread
programs
SRAM
• 計算カーネルとメモリアクセスの分離
Read/Write
From
CoRAM Tutorial
@FPGA’13
6/19/2013
13
High-level synthesis
from C to RTL
using LLVM
CONNECT
NoC generator
CoRAM Tutorial
18
14
Shinya T-Y, NAIST
2014-10-22
Motivation: CoRAM for Modern EDKs
n CoRAMのメモリ抽象化を今時のEDKで使いたい
l 標準的なインターコネクト( AMBA AXI4)に繋ぎたい
l そうすれば他の普通のIPコアとも簡単に共存できそう
Portable application
design with CoRAM
PyCoRAM
Cooperation with standard IP-cores
Accelerator logic
Standard IP-core
CPU core
CoRAM
Abstraction
Standard On-chip Interconnect
Device-dependent Interfaces
2014-10-22
Shinya T-Y, NAIST
15
2014-10-22
Shinya T-Y, NAIST
16
4
2014/10/22
PyCoRAM [Takamaeda+,CARL’13]
オリジナルのCoRAMとの比較
CoRAM
n ベンダーEDK向けのPythonベースのCoRAM実装
l 出来上がったIPコアをEDKでポチポチつなげばシステム完成!
n 特徴
C
Python
Supported
Memory Operations
(Blocking/Non-Blocking)
Read/Write
(Blocking/Non-Blocking)
Read/Write
On-chip Interconnect
CONNECT NoC [FPGA’12]
AMBA AXI4
FSM Granularity
in Control Thread
LLVM-IR
Python AST Node
l Pythonでのコントロールスレッド記述
• Pythonで簡単にメモリアクセスパターンを記述できる
– 独自の高位合成コンパイラでPython記述からVerilog HDLのRTLを合成
l AMBA AXI4インターコネクトのサポート
Generate Statement
Support for User logics
No
Yes
Supported FPGAs
Xilinx ML605
Altera Terasic DE-4
Any FPGAs
supporting AXI Bus
# Lines of Code
11,682 lines
(w/o CONNECT)
4,947 lines
(w/o Pyverilog)
• Xilinx Platform Studio (XPS)などを用いたIPコアベースの開発を支援
l 計算ロジックの複雑なデザインに対応
• ハードウェアデザイン解析・生成のための
オープンソースツールキットPyverilogを活用
17
Shinya T-Y, NAIST
2014-10-22
PyCoRAMマイクロアーキテクチャ
GPIO
User
I/O
CoRAM
Register
CoRAM
Channel
2014-10-22
CoRAM
Memory
CoRAM
Stream
Master
DMAC
Master
DMAC
Shinya T-Y, NAIST
FSM: Finite State Machine
LLVM-IR: Low Level Virtual Machine Intermediate Representation
AST: Abstract Syntax Tree
Shinya T-Y, NAIST
2014-10-22
18
PyCoRAMマイクロアーキテクチャ
PyCoRAM IP
User Logic
PyCoRAM
Language
for Control-Thread
l 計算カーネルのRTL記述とメモリアクセスパターンの
Python記述からAXI4 IPコアを自動合成
Modeled in RTL
(Verilog HDL) User
Control
Thread
I/O
GPIO
PyCoRAM IP
User Logic
CoRAM
Register
CoRAM
Channel
FSM
CoRAM
IoChannel
Slave
DMAC
19
2014-10-22
CoRAM
Memory
CoRAM
Stream
Master
DMAC
Master
DMAC
Shinya T-Y, NAIST
Control
Thread
Memory Access
Pattern
in Python
FSM
CoRAM
IoChannel
Slave
DMAC
20
5
2014/10/22
PyCoRAMマイクロアーキテクチャの実装
GPIO
User
I/O
PyCoRAMマイクロアーキテクチャの実装
GPIO
PyCoRAM IP
User Logic
User
I/O
Control
Thread
CoRAM
Register
CoRAM
Channel
CoRAM
Stream
Master
DMAC
Master
DMAC
Slave
DMAC
Master I/F
Master I/F
Slave I/F
CoRAM
Channel
CoRAM
IoChannel
Master:
メモリ等へ能動
的にアクセス
Control
Thread
FSM
CoRAM
Memory
CoRAM
Stream
Master
DMAC
Master
DMAC
Slave
DMAC
Master I/F
Master I/F
Slave I/F
Interconnect (AXI4/Avalon)
FPGA
CoRAM
Register
FSM
CoRAM
Memory
CoRAM
IoChannel
Slave:
プロセッサ等から
読み書きされる
Interconnect (AXI4/Avalon)
FPGA
DRAM Controller
21
Shinya T-Y, NAIST
2014-10-22
PyCoRAM IP
User Logic
2014-10-22
DRAM Controller
Shinya T-Y, NAIST
22
PyCoRAMにおける開発フロー
n 計算カーネルのRTLとPythonでのコントロールスレッド
記述からIPコアパッケージを生成
l 生成されたIPコアは通常のEDAフローで利用可能
RTL Conversion
User-logic
(Verilog HDL)
Control
Threads
(Python)
Portable
Application
Design
2014-10-22
Logic
Hierarchy
Analysis
Control
Signal
Insertion
Python-toVerilog
Compilation
Control
Signal Port
Addition
IP-core
generation
with AXI4
Interface
PyCoRAMHLS
Tool-chain
Python-to-Verilog
Shinya T-Y, NAIST
IP-core
Packing
(RTL,
.mpd,
and
.pao)
Top design
synthesis with
AXI4
PyCoRAMの使い方
IP-core
Integration
on EDK
Synthesis
FPGA
Bit
File
Vendor EDA Flow
23
2014-10-22
Shinya T-Y, NAIST
24
6
2014/10/22
PyCoRAMにおけるIPコアの作り方・でき方
計算ロジックにおけるCoRAMオブジェクト
n 2種類のファイルを用意する
n CoRAMオブジェクトはブロックRAMやFIFOとして扱う
l Verilog HDL: 計算ロジック
l 一般的なメモリとよく似たインターフェース
• CoRAMと外部を接続するインターフェースは自動的に追加される
l Python: コントロールスレッド(メモリアクセスパターン)
CoramMemory1P�
#(�
.CORAM_THREAD_NAME("thread_name"),�
.CORAM_ID(0),�
.CORAM_ADDR_LEN(ADDR_LEN),�
.CORAM_DATA_WIDTH(DATA_WIDTH)�
)�
inst_memory�
(.CLK(CLK),�
.ADDR(mem_addr),�
.D(mem_d),�
.WE(mem_we),�
.Q(mem_q)�
);�
l いくつかのパラメータで特性を指定
def calc_sum(times):�
ram = CoramMemory(idx=0, datawidth=32, size=1024)�
channel = CoramChannel(idx=0, datawidth=32)�
addr = 0�
sum = 0�
for i in range(times):�
ram.write(0, addr, 128)�
channel.write(addr)�
sum += channel.read()�
addr += 128 * (32/8)�
print(‘sum=’, sum)�
calc_sum(8)�
• スレッド名,ID,データ幅,アドレス幅,スキャッターギャザー等
n PyCoRAMが自動的にIPコアのパッケージを作成
l Python-Verilog高位合成とRTL変換を自動で行う
2014-10-22
25
Shinya T-Y, NAIST
Pythonによるコントロールスレッド
User
I/O
• ユーザロジックとコントロールスレッド
との間のトークンのやりとり
Shinya T-Y, NAIST
26
l CoramMemory
Control
Thread
• Block RAM that the data is replaced by the control thread
l CoramInStream
CoRAM
Channel
CoRAM
Memory
• Input FIFO from off-chip DRAM
FSM
l CoramOutStream
DMAC
• Output FIFO to off-chip DRAM
n ユーザロジックとコンロールスレッド間のチャネル
0� def calc_sum(times):�
ram = CoramMemory(idx=0, datawidth=32, size=1024)�
1�
channel = CoramChannel(idx=0, datawidth=32)�
2�
addr = 0�
3�
sum = 0�
4�
for i in range(times):�
5�
ram.write(0, addr, 128)� # Transfer (off-chip DRAM to BRAM)
6�
channel.write(addr)�
# Notification to User-logic
7�
sum += channel.read()� # Wait for Notification from User-logic
8�
addr += 128 * (32/8)�
9�
print(‘sum=’, sum)�
# $display Verilog system task
10�
�
11� calc_sum(8)�
2014-10-22
(b) CoRAM Channel
Shinya T-Y, NAIST
n データ置き場(メモリ・ストリーム)
User Logic
• オンチップCoRAMメモリとオフチップDRAM
との間のDMA転送によるデータ移動
l CoRAMチャネル(read/write)
(a) CoRAM Memory
サポートされているPyCoRAMオブジェクト
n CoRAMオブジェクトに対する処理を記述する
l CoRAMメモリ(read/write)
2014-10-22
CoramMemory1P�
#(�
.CORAM_THREAD_NAME("thread_name"),�
.CORAM_ID(0),�
.CORAM_ADDR_LEN(ADDR_LEN),�
.CORAM_DATA_WIDTH(DATA_WIDTH)�
)�
inst_memory�
(.CLK(CLK),�
.ADDR(mem_addr),�
.D(mem_d),�
.WE(mem_we),�
.Q(mem_q)�
);�
CoramChannel�
#(�
.CORAM_THREAD_NAME("thread_name"),�
.CORAM_ID(0),�
.CORAM_ADDR_LEN(CHANNEL_ADDR_LEN),�
.CORAM_DATA_WIDTH(CHANNEL_DATA_WIDTH)�
)�
inst_channel�
(.CLK(CLK),�
.RST(RST),�
.D(comm_d),�
.ENQ(comm_enq),�
.FULL(comm_full),�
.Q(comm_q),�
.DEQ(comm_deq),�
.EMPTY(comm_empty)�
);�
l CoramChannel
• FIFO between user-logic and control-thread
l CoramRegister
• Latch between user-logic and control-thread
n 他のIPコア・プロセッサからアクセスできるスレーブチャネル
l CoramIoChannel
• (AXI4/Avalon) Slave interface
27
2014-10-22
Shinya T-Y, NAIST
28
7
2014/10/22
計算ロジック (1): I/Oポート
例: 配列の和を求めるアクセラレータ
n 1-CoRAM+1-Threadの簡単なハードウェア
l CoRAMメモリにDRAM(など)からデータを読み込む
l コントロールスレッドでオンチップ-オフチップ間のデータ転送
パターンを表現
Computing Logic (Verilog HDL)
クロック(CLK)とリセット(RST)
以外に専用のI/Oは不要
CoRAM
Memory 0
A
+
Control Logic
CoRAMメモリのための信号
(BRAMと同じインターフェース)
Control
Thread
(Python)
sum
CoRAMチャネルのための信号
(FIFOと同じインターフェース)
CoRAM
Channel 0
ステートマシン用変数
2014-10-22
Shinya T-Y, NAIST
29
計算ロジック (2): パイプライン/FSM
2014-10-22
Shinya T-Y, NAIST
30
計算ロジック (3): 子インスタンス
CoRAMメモリ
(BRAMと同じインターフェース)
CoRAMチャネル
(FIFOと同じインターフェース)
CoRAMチャネルから読み出し
(コントロールスレッドから受信)
2014-10-22
CoRAMチャネルに書き込み
(コントロールスレッドに通知)
Shinya T-Y, NAIST
31
2014-10-22
Shinya T-Y, NAIST
32
8
2014/10/22
コントロールスレッド (Python)
コンパイル
ram (CoRAMメモリ)とchannel (CoRAMチャネル)の宣言
CoRAMメモリにDMA転送したり
CoRAMチャネルから読んだり書いたり
2014-10-22
Shinya T-Y, NAIST
33
シミュレーション結果
2014-10-22
Shinya T-Y, NAIST
2014-10-22
Shinya T-Y, NAIST
34
シミュレーション結果(波形)
35
2014-10-22
Shinya T-Y, NAIST
36
9
2014/10/22
評価
n 評価項目: メモリバンド幅利用率
l メモリ抽象化の下でも高いメモリ性能を達成できることを示す
n セットアップ
l FPGAボード2種
• Digilent Atlys
評価
– Spartan-6 LX45
– DDR2-800 DRAM 128MB (1.2GB/s*)
*300MHz動作のため
– AXI4 128-bit, 100MHz (1.6GB/s)
Digilent Atlys
(Xilinx Spartan-6 LX45)
• Xilinx ML605
– Virtex-6 LX240T
– DDR3-800 DRAM 512MB (6.4GB/s)
– AXI4 256-bit, 200MHz (6.4GB/s)
l EDK
• Xilinx Platform Studio (14.6)
37
Shinya T-Y, NAIST
2014-10-22
評価用アプリケーション
n 結構良い感じでメモリバンド幅を使えている
l 2つのCoRAMメモリをダブルバッファで利用
l Atlys: 85.5% (@ 16-byte)
l SIMD幅 (=同時に計算する要素数) を変化させてその影響を観測
l ML605: 84.9% (@ 64-byte)
• 4, 8, 16, 32, 64 (bytes)
n 100%使い切れていない理由
Output
l 各DMACのトランザクションがシーケンシャルになっているから
• 結果,メモリアクセスレイテンシが性能にダイレクトに影響
+
s3
s2
s1
s0
+
+
+
+
D[3]
D[2]
D[1]
D[0]
Bandwidth Utilization
MUX
MUX
2014-10-22
D[2]
D[1]
D[0]
from DMA Controller 0
大幅に改善!
(現在評価中)
D[3]
D[2]
D[1]
D[0]
from DMA Controller 1
Shinya T-Y, NAIST
CoRAM
Memory
1
1
Atlys (Spartan-6)
Bandwidth Utilization
sum
D[3]
38
結果:メモリバンド幅利用率
n 配列の和を求める
CoRAM
Memory
0
Xilinx ML605
(Xilinx Virtex-6 LX240T)
Shinya T-Y, NAIST
2014-10-22
0.8
0.6
0.4
0.2
0
4
39
2014-10-22
8
16
SIMD size [byte]
32
Shinya T-Y, NAIST
1
ML605 (Virtex-6)
0.8
0.6
0.4
0.2
0
4
8
16
32
SIMD size [byte]
64
40
10
2014/10/22
高性能コンピュータシステム設計コンテスト
n 競技内容
l 指定のFPGAボード上に
指定のアプリケーションを処理可能な
計算機システムを実装し処理時間を競う
応用その1
行列積・ステンシル
アクセラレータ
l 指定FPGAボード
• Digilent Atlys (Xilinx Spartan6 LX45)
• Terasic DE2-115 (Altera Cyclone 4) など
n 結果
l 第1回:準優勝
• 自作MIPSコア+アクセラレータ2種
– 高前田(山崎) 伸也, 吉瀬 謙二: メモリ抽象化フレームワークPyCoRAMを
用いたソフトプロセッサ混載FPGAアクセラレータの開発
l 第2回:3位
• Microblaze+アクセラレータ2種
– 田ノ元 正和, 枝元 正寛, 竹内 昌平, 高前田(山崎) 伸也: IPコア開発フレー
ムワークPyCoRAMを用いたHW/SW協調FPGAアクセラレータの開発
41
Shinya T-Y, NAIST
2014-10-22
ベンチマークアプリケーション4種
42
Shinya T-Y, NAIST
2014-10-22
第2回コンテスト用アクセラレータ構成
アプリケーション
説明
メモリシステムへの要求
310_sort
整数ソート
低レイテンシ
320_mm
行列積(整数)
高バンド幅
330_stencil
ステンシル計算(9点・整数)
高バンド幅
340_spath
最短経路問題
低レイテンシ
n PyCoRAMでIPコア2種を実装
l MicroblazeからはAXI4スレーブ経由でメモリマップドI/Oで制御
exStick
FPGA (Spartan-6 LX45)
UART
Loader
Microblaze
5-stage
32KB Local memory
8KB D-Cache
UART
Loader
Logic
Matrix-Mult
Accelerator
Control
Thread
CoRAM Abstraction
行列積・ステンシル計算
ソート・最短経路問題
MM
Logic
Cthread
MM
CoRAM Abstraction
Stencil
Accelerator
Stencil
Logic
Cthread
Stencil
CoRAM Abstraction
専用アクセラレータ向き
AXI4-lite Interconnect (32-bit, Shared bus)
専用アクセラレータは面倒
AXI4 Interconnect (128-bit, Crossbar)
CPUコア+専用アクセラレータが良さそう
2014-10-22
Shinya T-Y, NAIST
DRAM Controller (DDR2-800 16-bit (1.6GB/s))
43
2014-10-22
DRAM
(128MB)
Shinya
T-Y, NAIST
44
11
2014/10/22
行列積アクセラレータ
ステンシル計算アクセラレータ
n 行列A・B・Cの各行をCoRAMメモリに格納
n 元配列の3行と結果配列の1行をCoRAMメモリに格納
l DRAMとの間のデータ転送をコントロールスレッドが担当
l DRAMとの間のデータ転送をコントロールスレッドが担当
l 毎サイクル乗算パイプラインにデータを投入
l 毎サイクル加算・除算パイプラインに3点分のデータを投入
• 過去3サイクルの入力値の合計を9で割る(3点×3サイクル=9点)
l 行列Bの転送と演算をダブルバッファリング
l 計算1行分毎に結果を書き戻して元配列の次の1行を読み込む
l SIMD幅をメモリバンド幅を使い切るようにチューニング
Control
Thread
(Python)
Computing Logic (Verilog HDL)
CoRAM
Memory 0
+
8-stage
Multiply
Pipeline
A
CoRAM
Memory 1
C
+
sum
Control Logic
CoRAM
Memory 1
CoRAM
Memory 0
check
sum
CoRAM
Memory 2
×
B
Computing Logic (Verilog HDL)
CoRAM
Channel 0
CoRAM
Memory 2
I/O
Channel
d0
d1
d2
+
+
check
sum
/
45
Shinya T-Y, NAIST
2014-10-22
CoRAM
Memory 3
rslt
41-stage
Add-Divide
Pipeline
Control Logic
2014-10-22
Control
Thread
(Python)
CoRAM
Channel 0
Shinya T-Y, NAIST
I/O
Channel
46
性能(第2回コンテスト)
n データ転送時間を含む総時間
n リファレンスデザインと比較して大幅な速度向上
l 行列積・ステンシル・最短経路(ソフト実装)では
データ転送に要する時間が殆ど
応用その1
グラフ処理
アクセラレータ
• 僅差だった・・・?J
50.00
40.00
30.00
Atlys Ref
40.96
38.85
29.99
DE2 Ref
42.99
42.28
26.06
40.66
35.44
25.72
PyCoMA
52.17
100.00
44.64
80.00
25.73
20.00
10.00
70.00
60.00
50.00
40.00
62.78
86.00
DE2 Ref
PyCoMA
69.90
63.66
65.22
50.93
55.99
54.28
37.24
26.23
30.00
25.94
25.70
20.00
10.00
0.00
0.00
sort
mm
stencil
spath
リファレンスデータ
2014-10-22
Atlys Ref
90.00
Execution Time [sec]
Execution Time [sec]
60.00
sort
mm
stencil
spath
第1回コンテスト決勝データ
Shinya T-Y, NAIST
47
2014-10-22
Shinya T-Y, NAIST
48
12
2014/10/22
PyCoRAMを用いたダイクストラIPコア
ダイクストラ法アクセラレータ[高前田+,CPSY2014-07]
n PyCoRAMを使って演算モジュールはVerilog HDLで実装
メモリアクセス制御はPythonで実装
n 不規則なメモリアクセスパターンを持つアプリにおける
PyCoRAM適用可能性を明らかにする
User Definition (Modeled in Verilog HDL and Python)
Control Threads (Modeled in Python)
l 規則的なメモリアクセスパターンを持つアプリケーション
(行列積・ステンシル)はバンド幅律速
l メモリアクセスレイテンシの影響が大きいアプリで使えるの?
• まずは実装してみましょう
n 今回の題材:グラフ処理
l 最短経路探索(ダイクストラ法)
• ボトルネックになりそうな箇所
Mark Visited
Cthread
Mark Visited
Cthread
Next Node Addr
Update
Node
Mark Visited
OutStream
OutStream
Read Node
Cthread
Priority Queue Cthread
Read Edge
Read Node
Priority Queue
OutStream
InStream
InStream
Edge
Page
Addr
InStream
Next Node Cost
FSM
Dijkstra
Logic
(Modeled in Verilog
HDL)
Cost
Next Node Cost
Main
CThread
Next Node Addr
Node Addr
Node
Addr
Read Edge
Cthread
+
Generated by
PyCoRAM
– 未訪問ノードの管理→距離をキーとした優先度キュー
– 隣接ノード情報(コスト・親ノード)の読み書き→ページング
DMAC
DMAC
DMAC
DMAC
DMAC
DMAC
AXI4-lite
Slave Interfaces
AXI4 Master Interfaces
49
Shinya T-Y, NAIST
2014-10-22
PyCoRAMを用いたダイクストラIPコア
PyCoRAMを用いたダイクストラIPコア
n ステージ2:ノード情報読み出し
OutStream
Read Edge
Read Node
Priority Queue
OutStream
InStream
InStream
Edge
Page
Addr
InStream
DMAC
DMAC
Next Node Cost
DMAC
+
DMAC
Shinya T-Y, NAIST
FSM
Dijkstra
Logic
(Modeled in Verilog
HDL)
Cost
Next Node Cost
AXI4 Master Interfaces
2014-10-22
Next Node Addr
Node Addr
Node
Addr
Main
CThread
DMAC
DMAC
User Definition (Modeled in Verilog HDL and Python)
Mark Visited
Read Edge
Cthread
Mark Visited
Cthread
Slave I/F
AXI4-lite
Slave Interfaces
Mark Visited
Cthread
Update
Node
Mark Visited
OutStream
OutStream
Read Node
Cthread
Priority Queue Cthread
Next Node Addr
Generated by
PyCoRAM
Update
Node
OutStream
Control Threads (Modeled in Python)
Read Node
Cthread
Priority Queue Cthread
Next Node Addr
Generated by
PyCoRAM
User Definition (Modeled in Verilog HDL and Python)
Control Threads (Modeled in Python)
Mark Visited
Cthread
50
Shinya T-Y, NAIST
2014-10-22
n ステージ1: 最小コストノード取り出し
Mark Visited
Cthread
Slave I/F
InStream
InStream
2014-10-22
Edge
Page
Addr
InStream
DMAC
DMAC
Next Node Cost
DMAC
+
DMAC
Shinya T-Y, NAIST
FSM
Dijkstra
Logic
(Modeled in Verilog
HDL)
Cost
Next Node Cost
AXI4 Master Interfaces
51
Read Edge
Read Node
Priority Queue
OutStream
Main
CThread
Next Node Addr
Node Addr
Node
Addr
Read Edge
Cthread
DMAC
DMAC
Slave I/F
AXI4-lite
Slave Interfaces
52
13
2014/10/22
PyCoRAMを用いたダイクストラIPコア
PyCoRAMを用いたダイクストラIPコア
n ステージ3:ノードに訪問済みフラグ書き込み
n パイプライン動作:(1)エッジ読み出し→
(2)隣接ノード読み出し→(3)隣接ノード更新
Next Node Addr
Control Threads (Modeled in Python)
Read Node
Cthread
Priority Queue Cthread
Update
Node
Mark Visited
OutStream
OutStream
Read Edge
Read Node
Priority Queue
Node
Addr
InStream
Edge
Page
Addr
InStream
InStream
Generated by
PyCoRAM
DMAC
Next Node Cost
DMAC
DMAC
FSM
Dijkstra
Logic
(Modeled in Verilog
HDL)
Cost
Next Node Cost
Main
CThread
Next Node Addr
Node Addr
OutStream
Read Edge
Cthread
+
DMAC
DMAC
DMAC
Slave I/F
AXI4-lite
Slave Interfaces
AXI4 Master Interfaces
Mark Visited
Cthread
Mark Visited
Cthread
Next Node Addr
Update
Node
Mark Visited
OutStream
OutStream
優先度付きキュー(ヒープ)
Cost
3
Next Node Cost
Next Node Cost
DMAC
DMAC
Microblaze
Control
Thread
(Modeled
in Python
DMAC
BRAM
Memory Bus (To DRAM)
Out
3-stage
16KB Local memory
2KB I-Cache
2KB D-Cache
d, 20
a, 40
e, 50
DMAC
Slave I/F
AXI4-lite
Slave Interfaces
54
UART
Loader
Logic
Priority
Queue
Read
Node
Read
Edge
CThread
Update
Node
CThread
Mark
Visited
CThread
Update
Node
Mark
Visited
Main
Control
Tread
Dijkstra Logic
Control
Thread
Read
Edge
CoRAM Abstraction
AXI4-lite Interconnect (32-bit, Shared bus)
BRAM
Zone
AXI4 Interconnect (128-bit, Crossbar)
DRAM Controller (DDR2-800 16-bit (1.6GB/s))
DMAC
Shinya T-Y, NAIST
DMAC
Dijkstra
Logic
(Modeled in Verilog
HDL)
f, 45
DMA requests
2014-10-22
Read
Node
CThread
CoRAM Abstraction
b, 30
In
Priority
Queue
CThread
UART Loader
Channel
FIFO
Child
1
Dijkstra Accelerator
Priority Queue Logic (Modeled in Verilog HDL)
Parent
2
FSM
Host PC
FPGA
(Spartan-6 LX45)
l コストが小さいノード群を格納する BRAM
Right
DMAC
InStream
n ホストからUART経由で制御・グラフ構築にMicroblaze
l 外部へ書き込むための CoramOutChannel
Left
+
Edge
Page
Addr
Shinya T-Y, NAIST
2014-10-22
l 外部から読み出すための CoramInChannel
Compare Logic
InStream
評価環境:FPGAシステム
n CoRAMメモリ x2 + BRAM x1
FSM
InStream
Main
CThread
Read Edge
Read Node
Priority Queue
Node
Addr
Read Edge
Cthread
Next Node Addr
Node Addr
OutStream
DMAC
Read Node
Cthread
Priority Queue Cthread
AXI4 Master Interfaces
53
Shinya T-Y, NAIST
2014-10-22
User Definition (Modeled in Verilog HDL and Python)
Mark Visited
Cthread
Generated by
PyCoRAM
User Definition (Modeled in Verilog HDL and Python)
Control Threads (Modeled in Python)
Mark Visited
Cthread
DRAM (128MB)
55
2014-10-22
Shinya T-Y, NAIST
56
14
2014/10/22
実装の詳細
評価
n FPGAボード実機で評価
n AXI4インターコネクト:4構成
l ボード: Digilent Atlys
l クロスバー2種:パイプラインレジスタ等を持つ高性能タイプ
• FPGA: Spartan-6 LX45
• C128: 128ビット幅
• C32: 32ビット幅
• DRAM: DDR2-800 (1.6GB/s), 128MB
l 共有バス2種:リソース使用量を優先した省エリアタイプ
l ツール: Xilinx PlanAhead 14.7, XPS 14.7
• S128: 128ビット幅
n 汎用PC上と比較
• S32: 32ビット幅
l Intel Core i7 3770K (3.5GHz), DDR3-1600 (12.8GB/s ×2)
n AXI4バスでは異なるマスターポート間では
Read/WriteのIn-order順番が保証されていない
l Linux (Ubuntu 14.04), gcc 4.8.2 (-O3)
n グラフ
l 先にバスにリクエストが発行したからといって
必ず先に処理されるわけではない
l XORSHIFT乱数を用いてランダムに生成
l 特に Write → Read の依存関係には注意が必要
l ノード数: 5000,エッジ数: 100000
l 解決策
• より大規模なグラフはデバッグが間に合わなかったので
今後の課題ということで・・・
• AXI4バスの設定で書き込みポートのPriorityを高くする
57
Shinya T-Y, NAIST
2014-10-22
実行時間
58
Shinya T-Y, NAIST
2014-10-22
実行時間
n FPGA上の実装は汎用PCと比べて25倍程度低速L
l メモリバンド幅あたりの性能でも1.5倍程度悪い・・・
n FPGAでの実行時間を比べてみると直感と真逆の結果
l なぜか?
l クロスバーよりも共有バスの方が高性能!
• データセットが小さい・OoOプロセッサのMLP抽出能力は凄い
500.0
498.9
l バス幅が狭い方が高性能!
n なぜか?
492.7
413.4
400.0
l 共有バスの方が
レイテンシが短い
404.3
25x
300.0
l バス幅が短い方が
レイテンシが短い
200.0
100.0
l 必要なモノ:
高バンド幅ではなく
短レイテンシ
16.2
0.0
500.0
498.9
C32
S128
Shinya T-Y, NAIST
S32
492.7
413.4
404.3
S128
S32
400.0
300.0
200.0
100.0
16.2
0.0
C128
C128
2014-10-22
600.0
Execution Time [msec]
Execution Time [msec]
600.0
C32
x86
x86
59
2014-10-22
Shinya T-Y, NAIST
60
15
2014/10/22
今後の展望
n ロジックのモデリング方式
l コンピューティングロジックもHDLで書きたくない
l 計算カーネルに特化したマルチパラダイム処理系・DSL?
まとめ
• MyHDLとの連携方式を実装中
n 静的解析による性能・電力チューニング
l より少ないエフォートでより高いメモリ性能
l 電力効率の高いネットワーク・システム構成の自動選択
n 実アプリケーションへの適用
l イーサネット直結系のオフローダ(ストリーム処理?)
l ストレージ直結系のアクセラレータ(ビッグデータ?)
Shinya T-Y, NAIST
2014-10-22
61
2014-10-22
Shinya T-Y, NAIST
62
63
2014-10-22
Shinya T-Y, NAIST
64
まとめ
n PyCoRAM: 高位合成技術とメモリシステム抽象化を用い
たアクセラレータIPコア開発のためのフレームワーク
n 開発したツール・フレームワークはgithubにて公開中
l PyCoRAM: http://shtaxxx.github.io/PyCoRAM/
l Pyverilog: http://shtaxxx.github.io/Pyverilog/
Modeled in RTL
(Verilog HDL) User
I/O
GPIO
PyCoRAM IP
User Logic
CoRAM
Register
CoRAM
Channel
CoRAM
Memory
2014-10-22
Master
DMAC
CoRAM
Stream
Master
Shinya
T-Y, NAIST
DMAC
Control
Thread
Memory Access
Pattern
in Python
FSM
CoRAM
IoChannel
Slave
DMAC
16
2014/10/22
Pyverilog: Python-based Hardware Design
Processing Tool-kit for Verilog HDL
PyCoRAMの実装と動作環境
Parser
n ピュアなPythonによる実装
module TOP
(input CLK,
input RST,
output rslt, …
l 全体で4947行で実装できたのでコンパクト!
• Python-Verilogコンパイラ: 3828行
Verilog HDL
Code
Lexical
Analyzer
Code
Generator
Syntax
Analyzer
AST
AST
module TOP
(input CLK,
input RST,
output rslt, …
Verilog HDL
Code
• RTLトランスレータ: 769行
l Verilog HDLのRTL静的解析にはPyverilogを利用
Dataflow Analyzer
• Python-based Hardware Design Processing Tool-kit for Verilog HDL
Module
Analyzer
• 全体で12665行とかなりコンパクト
Signal
Analyzer
Bind
Analyzer
l コード生成にはJinja2 (テキストテンプレートエンジン)を利用
Visualizer
Dataflow
• テンプレート用テキストファイルが8000行くらい
Graphical
Output
Optimizer
n 動作環境:LinuxかMacを推奨
l Python 3.3 (or later)
Control-flow Analyzer
l Icarus Verilog 0.9.6 (or later)
State
Machine
Pattern
Matcher
l Jinja2 (2.7 or later)
2014-10-22
65
Shinya T-Y, NAIST
2014-10-22
Input
Active
Condition
Analyzer
Output
Control-flow
Shinya T-Y, NAIST
66
Visualizerの出力
Dataflow
2014-10-22
Shinya T-Y, NAIST
State
Machine
67
17
© Copyright 2026 Paperzz