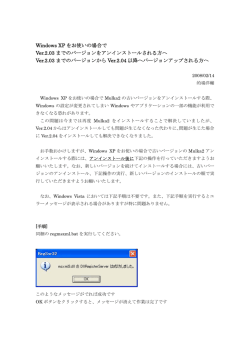
ICS-08B-449 カメラと距離センサーを用いた 自律移動ミュージアムガイドロボット 指導教員 久野 義徳教授 平成 20 年 2 月 18 日提出 工学部情報システム工学科 04TI049 星野 豪 埼玉大学 理工学研究科・工学部 久野研究室 埼玉県さいたま市桜区下大久保 255 概要 人間がコミュニケーションを計る際、話し手と聞き手の ”距離 ”によって親しみ やすさを与えたり、逆に不快感を与えるということは誰もが経験的に知っているし、 また多くの社会学者の研究対象になってきた。それら人間間の ”距離 ”に加え、美 術館における展示物等 ”この ”などの指示語をもって会話、議論の対象物となりえ る物を交えてのコミュニケーションにおいても ”距離 ”は重要な要素である。展示 物への知識、理解をもった学芸員(話し手) と、理解を持たない鑑賞者(聞き手)、 および展示物の大きさ、それら 3 事象の ”距離 ”は聞き手の展示物への集中度、理 解度、学芸員の説明のしやすさへ大きな影響を及ぼすものである。 本論文では美術館で鑑賞者 1 名に対し、美術作品の解説を行い鑑賞を支援する ミュージアムガイドロボットシステムを想定し、スムーズな説明開始を可能にする ガイドロボットの接近方法、及び誘導位置、誘導動作等の実装、提案する。本研究 では学芸員の観察により誘導位置は展示物 (絵画) の大きさによることが解った。ま た誘導位置導くまでの移動の方法としてビジュアルフィードバックを導入すること が有効であることが解った。 目次 論文概要 i 第 1 章 序論 1 1.1 背景 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2 問題点の整理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 1.3 解決方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 1.3.1 展示物情報の保持 . . . . . . . . . . . . . . . . . . . . . . . . 5 1.3.2 ビジュアルフィードバック . . . . . . . . . . . . . . . . . . . 6 第 2 章 調査実験 2.1 7 調査実験概要 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.1.1 学芸員の観察 . . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.1.2 調査実験からの考察 . . . . . . . . . . . . . . . . . . . . . . 9 第 3 章 画像処理 10 3.1 画像処理ライブラリ 3.2 正面カメラ 3.3 . . . . . . . . . . . . . . . . . . . . . . . . . . 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 右方向カメラ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 3.3.1 矩形検知法 . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 3.3.2 4 隅テンプレートマッチング法 . . . . . . . . . . . . . . . . . 13 i 第 4 章 提案システム 16 4.1 目標 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 4.2 ハードウェア概要 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 4.2.1 ガイドロボット . . . . . . . . . . . . . . . . . . . . . . . . . 21 4.2.2 USB カメラ . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 4.3 ソフトウェア概要 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 4.4 ガイドロボットの動作 . . . . . . . . . . . . . . . . . . . . . . . . . 26 実装で明らかになった問題点 . . . . . . . . . . . . . . . . . 26 4.4.1 第 5 章 実験 5.1 5.2 29 実験 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 5.1.1 目的 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 5.1.2 方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 5.1.3 結果と考察 . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 実験 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 5.2.1 目的 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 5.2.2 方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 5.2.3 結果と考察 . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 第 6 章 終わりに 35 6.1 まとめ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 6.2 今後の課題 35 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 謝辞 37 参考文献 38 ii 表目次 2.1 絵の大きさと鑑賞者との距離 . . . . . . . . . . . . . . . . . . . . . 9 4.1 移動決定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 4.2 Robovie-R ver.2 仕様 . . . . . . . . . . . . . . . . . . . . . . . . . 21 4.3 距離センサー 仕様 . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 4.4 R pro for notebooks 性能表 . . . . . . . . . . . . . . . . . . . Qcam⃝ 25 iii 図目次 2.1 鑑賞者を探す学芸員 2.2 説明を始める学芸員と鑑賞者 3.1 正面顔取得 . . . . . . . . . . . . . . . . . . . . . . . . . . 8 . . . . . . . . . . . . . . . . . . . . . 8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 3.2 矩形検知結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 3.3 テンプレートマッチング成功 . . . . . . . . . . . . . . . . . . . . . 14 3.4 テンプレートマッチング失敗 . . . . . . . . . . . . . . . . . . . . . 14 3.5 画像とピクセルの関係 . . . . . . . . . . . . . . . . . . . . . . . . . 15 4.1 かぐわしき大地 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 4.2 テンプレート元画像 . . . . . . . . . . . . . . . . . . . . . . . . . . 17 4.3 左上テンプレート画像 . . . . . . . . . . . . . . . . . . . . . . . . . 18 4.4 右上テンプレート画像 . . . . . . . . . . . . . . . . . . . . . . . . . 18 4.5 左下テンプレート画像 . . . . . . . . . . . . . . . . . . . . . . . . . 18 4.6 右下テンプレート画像 . . . . . . . . . . . . . . . . . . . . . . . . . 18 4.7 相対位置概要 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 4.8 右カメラでの動作決定 . . . . . . . . . . . . . . . . . . . . . . . . . 20 4.9 Robovie-R ver.2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 4.10 手軸改造後 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 4.11 指差し動作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 iv 4.12 ハンドジェスチャー . . . . . . . . . . . . . . . . . . . . . . . . . . 22 4.13 センサーマップ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 4.14 移動機構概観 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 4.15 移動機構概観-ベルト . . . . . . . . . . . . . . . . . . . . . . . . . . 24 R pro for notebooks . . . . . . . . . . . . . . . . . . . . . . . 4.16 Qcam⃝ 25 4.17 カメラ 4 台 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 4.18 システム概要 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 4.19 実行例 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 4.20 実行例 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 4.21 統合実験の様子 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 5.1 デッドレコニング . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 5.2 ビジュアルフィードバック . . . . . . . . . . . . . . . . . . . . . . . 30 5.3 デッドレコニング誤差絶対値グラフ . . . . . . . . . . . . . . . . . . 31 5.4 ビジュアルフィードバック絶対値グラフ . . . . . . . . . . . . . . . 31 5.5 Y 軸ずれの平均誤差 . . . . . . . . . . . . . . . . . . . . . . . . . . 32 5.6 実験 2 誘導可能範囲 . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 v 第1章 序論 人間がコミュニケーションをとる際、人間間の距離は重要な役割を果たす。西出 [1] は対人距離において、密接距離、個人的距離、社会的距離、公共距離の 4 つの状 態があるといっている。ロボットで実装する際にも同じことが言え、発見した時か らの、声掛け、接近方法、接近スピード、ルート、誘導動作、立ち位置の設定など の考えなしに円滑なコミュニケーションの導入は果たせない。 現在ではキーボード、マウスなどに頼らないタッチパネル、音声入力といった様々 なユーザーインターフェースが考案実用化されているが、そのどれもが、操作者が 人であるのに対し、相手がコンピュータであるという前提に立っている。操作者は 相手がコンピュータであるという認識の下操作し、例え通信相手が人であるチャッ ト、テレビ電話等においてもおよそ、人対人のコミュニケーションとかけ離れてい る様子が観察できる。人型のロボットを用いることによる利点は、人がロボットを ユーザーインターフェースとして扱わず、人対人で行われるコミュニケーションと 同等の反応を期待出来ることである。 以降では、ミュージアムガイドロボットについての背景、移動機構および、それ に伴う自己位置の同定、また画像処理等の人、ロボット間のコミュニケーションの 円滑な導入に関する、現在行われている研究の背景の一例を示す。 1.1 背景 現在情報通信技術の発展は日進月歩であり、その急速な発展と普及は我々の生活 環境を大きく変化させた。一方でその急速な普及は、お年寄りを始めとした情報弱 者という言葉を生み出すほど操作者の知識、技能によっての恩恵となってしまい、 そのインタラクションの難しさ、多岐におよぶ煩雑さは人と機械の未だ未完成な関 係を浮き彫りにしている。人と人とのコミュニケーションを機械が阻害するという 現象さえも起こってしまっている。 1 かつて人は一定距離を離れると相手とコミュニケーションをとる手段を持たなかっ た。この不便さが狼煙や、手紙といった通信手段を普及させ、機械の発展とともに、 電信、電話、ポケベル、携帯電話、テレビ電話、インターネットと進化を続け、距 離、時間の壁を越えてのコミュニケーションを可能にした。現在も進化を続ける通 信手段は、より身近に、低価格で、鮮明にといいた指標で進化を続けていくであろ う。がしかし大変便利である電話やテキストのみのやり取りでは、通信しあう人と 人の間で共有している知識以外の共に作り上げていく情報 (共創情報) を扱うのに 大変に不自然さ、違和感を感じる。テレビ電話にしても共有している知識以外の情 報にはあまり優位がなく、対象物を交えての議論などは捗りにくいといえる。石黒 ら [2][3] はこの共創情報の自然な把握や理解が人間間のコミュニケーションにおい て大きな部分を占めていると指摘し、人間の場合と同じ共創情報を創りえる人型の ロボットの開発を行った。テレビ電話にしても共有している知識以外の情報にはあ まり優位がなく、対象物を交えての議論などは捗りにくいといえる。 この事実は従来の人‐人の間のコミュニケーションに議論の対象物 (展示物) と加 えた人‐人‐対象物の 3 事象の関係は、同じ場にいることが求められているという ことである。詳しくは「この、その、あれ、どれ」といった指示語を共有できる空 間にいることが求められている。指示語は意識することなく各々距離によって割り 振って使われているが、指示語が共有させる対象物の話者、聞き手の整合を取るに は上記の 3 事象における距離が重要になる。 ロボット-人間コミュニケーションについても近年盛んに研究が行なわれており、 三菱重工の wakamaru[4]、SONY の QRIO[5] や NEC の PaPeRo[6] 等人に似せた、 または親しみの持ちやすい見た目で、人間のような動きをしている印象を与えるも のも増えてきた。ガイドロボットとしては minerva[7][8] という特徴として、 「移動」 「センシング」 「自己位置同定」などの高度な機能を有し、簡易なウェブ上でのイン ターフェースからの遠隔操作、自律移動などを実現している。ガイドロボットとし ての研究は展示物間の安全かつ効率のよい移動の研究が主で、展示物のインタラク ティブな説明を重視してはこなかった。本研究室 [9] ではガイドロボットのインタ ラクティブな説明に重きを置いている。 前述の人間が自然に行なう距離の調節をロボットで行なうことを考えた時、あら かじめ部屋や対象物などの環境情報を持っているか、もしくは環境に適応する能力 が求められる。初めに見た部屋の状態を記憶し、その情報にもとづいて全ての行動 を行なうとしたら、人や物の移動、もしくはロボット本体の強制移動 (誘拐問題) に より、すぐに正常な動作を行なえなくなってしまう。これを補うために、ロボット には学習能力を持たせ、初期状態にの記憶のみに頼らないで、環境の変化に適応で きるようにすることが正常な動作には必要にになる。 2 さらにカメラからの画像情報を視覚情報として受け取るロボットにおいて人間の 視覚とロボットの画像処理能力とのギャップを埋める工夫が必要になる。佐藤ら [10] は有効な画像であるか検証が重要であると述べている。例えば、人は自分の知識と して持っているものを見た時、ある程度向き、大きさが異なろうと、または一部が 隠されて見えなくても推測し、認識可能である。人にとって当たり前なことである が、ロボットにとってはおおきな障害となってしまう。ロボットの視覚は、カメラ からの画像を処理し、様々な処理を加え、特徴量を抽出し、自らの記憶してある情 報との照らし合わせることで得られる。単純な形状(丸、四角など) であれば、物 体認識も可能であるが、複雑な形状の物(椅子、机、ファックス) などは向きによっ て見え方が大きく異なるし、単純に表現できないため認識は極めて困難である。画 像データのみからの物体の認識は、遠近や認識すべき物体の一部が隠された時など 誤認識を起こしやすい。画像処理の計算機上での計算コストはかなり大きく、効率 のよい画像処理法、画像取得方法も考慮しなくてはならない。これらの解決策が必 要である。 また鑑賞者-ロボットという関係だけでなく、ロボットの操作側の人-ロボットの 関係においても理解しやすいインターフェースを備えることも必要になる。複雑な コマンドや、キーボード操作が必要であれば、操作者側に熟練が必要になるし、人 型のロボットを用いている利点さえなくなってしまう。操作側の技能や熟練が必要 であれば、捜査側は人間ガイドを置く方が簡単で手早いと判断するだろう。 実際のガイドロボットを想定した場合、ひとつの展示物を説明できるだけでは利 用価値が無く、複数の展示物を説明できなくてはならないし、また鑑賞者を見つけ た場合に、待機しているだけでは横柄な印象を与えやすい。それらを解決するため に「移動」、またそれに伴う「警戒」といった機能を持たなくてはならない。移動 の方法にも近年着目される点であり、従来のキャタピラのようなものから、タイヤ を制御するもの、空中に浮かんでいるものに加え、より人間らしい 2 足歩行をする 本田技研工業の ASIMO[11] なども開発されている。目的どおりに移動を行う移動 機構の正確性は元より、障害物回避などに距離センサーも用い、その正確性も求め られる。まだ移動に関しては自己位置推測機能が非常に重要である。 具体的に展示物を解説するミュージアムガイドロボットとして、動作するロボッ トを想定し、前述した問題を解決するための研究を行った。展示物を鑑賞している 鑑賞者を見つけ、近づき、展示物との距離、相手との距離を考慮にいれた誘導動作 を行うという、ガイドの導入部分が本研究の領域である。移動ロボットの研究にお いて、画像からのロボットの自己位置同定、移動方法の研究が主となり、様々な研 究がこの分野では行われている。 3 1.2 問題点の整理 前項で鑑賞者-ガイド (人、ロボット)-展示物間の距離の重要性は述べたが、その距 離についての情報を得る必要がある。それらの距離を左右するものとして施設的要 因 (採光、柵)、配置的要因 (壁、隣の展示物との関係)、また人的要因 (ガイド各々、 鑑賞者の身長、視力など) があげられる。それらの要因を影響をあまり受けないよ うな環境を考え、3 事象のみの空間での観察が必要になるだろう。誘導動作につい ても同様である。 一般的に自己位置推定を行うにはデッドレコニングが用いられる。デッドレコニ ングとは移動機構をロータリーエンコーダによって制御することで、ロータリーエ ンコーダの内界センサの値を用いて、車輪などの回転角速度を逐次記録計算してい くことで、自己位置を推定する方法である。しかしデッドレコニングが誤差が累積 してゆくという大きな欠点を持ち、累積誤差を軽減し、自己位置推定の精度を高め るような様々な研究が行われているものの、根本的な解決は未だ見ない。またロボッ トが強制的に動かされた時の自己位置推定には決定的に弱い (誘拐問題)。誘拐問題 の解決のために、今まで記録してきたロータリーエンコーダーの値やセンサの値を リセットするセンサリセット法があげられるが、非常に大味な操作であることは否 めない。上田ら [12] は誘拐時間や状況によって近距離誘拐、長距離誘拐などに分け、 10 センチごとに重みを設定したパーティクルフィルタにによる自己位置推定とセン サリセット法を組み合わせることで致命的位置誤りからの回復に成果を挙げたが、 マッピングやフィルタ設定へかける時間は非常に長い。 あらかじめ地図情報を持たない室内でロボットを移動させ、そのソナー情報に よって地図を作成し、自己位置を推定するという方法も数多くなされている。しか し多くの場合地図作成のために多くの時間、労力を必要としたり、人、物などが障 害となり運用経路をしなければならない場合の地図の再作成、自己位置の推定し直 すプログラムの修正等も問題になってしまう。超音波センサ等の外界センサで、意 図的に解りやすいランドマークを置き、それらを認識することで自己位置推定を行 う方法もあるが、ランドマークは意図的に配置され、認識もしやすく作られている ため、現実的ではないと言える。 GPS 等の利用という手段もあるが、最低でも 10 センチ単位の距離情報が欲しい 本研究において、数メートル単位の情報しか得られない GPS は不適切と言える。 多くの移動ロボットの研究では視覚を用いて外界の状況を把握しようという試み を行っており、ロボットの位置推定方法として、ランドマークを用いるモデルベー スト (model-based) アプローチ、シーン全体を利用するビューベースト (view-based) 4 アプローチに大別される。 モデルベーストアプローチは 2 次元画像から、エッジやコーナーなどの特徴を抽 出し、パターン認識を行う。しかし 2 次元画像において、幾何学的特徴を精度良く 抽出するのは容易でない。そこで実験空間内にランドマークを配置し、推定を行う 方法がよく用いられる。ランドマークは 記憶機能付きのマークを用いており、既知 の地図空間では効果を期待できる。しかし、複雑な実験環境下において 2 次元画像 からランドマークの抽出は難しい。橋場ら [13] はロボットを等速直線運動させたと きの正面カメラ画像の上下左右の周縁のみを 2 次元展開した画像を用いることで計 算資源の節約と高度な自己位置推定能力を実現したものの、廊下など一定のコース では力を発揮するものの、広い室内空間などではマップ作成はやはり時間が掛かり すぎる。 一方ビューベーストアプローチは、2 次元画像の見え方をそのまま利用されるた め、より画像を直接的に使用できる。ノイズの多い実画像から複雑な形状をもつ物 体の認識を期待できるが、データ量や計算量の観点からあまり現実的でなかった。 やがてハードの性能の向上とともに、画像処理のスピードも向上し、人間が記録映 像の単純な照合を行っているという認識もあいまって、注目を集めている。このよ うにモデルベーストとビューベーストは一長一短があり、あくまでシーンにおいて の使い分けが必要になる。 2 次元画像のみに位置同定機能をゆだねるのは、危険が多く、実際の物体に対し反 応をするセンサを用いなければ、ガイドロボットとしての安全とはいえないだろう。 1.3 解決方法 前項の問題の解決を図るために、導入する手法を示す。 • 展示物情報の保持 • ビジュアルフィードバック 1.3.1 展示物情報の保持 ガイドロボットなので展示物に関する情報を準備しておかなくてはならない。絵 画ならば、作者、題名に始まり、時代背景から絵の意味するものまで細部にいたる まで把握しておく。本研究ではガイドロボットが直接絵画の解説をするまでは行っ 5 ていないが、展示物の情報で必ず持っていなければいけないものとして絵画のサイ ズが上げられる。展示物を解説するに適した位置があるということは述べたが、そ れは展示物の縦、横の長さが決めるものであった。詳しく第は 2 章に後術する。 1.3.2 ビジュアルフィードバック 主に、移動機構の不正確さを補う目的で導入する。誘導時に用いる。ガイドロボッ トの側面を写すように固定されたカメラの画像を用いる。 人を見つけ、近づいてゆき、絵の説明に適した位置まで誘導しなければいけない が、移動機構は思い通りに正確に絵の正面まで誘導できない。それはデッドレコニ ングによる室内の 2 次元座標の保持の不可能を示している。そこで解決のために、 ビジュアルフィードバックをもちいる。 ガイドロボットは後退しながら絵の説明に適した位置の少し手前付近まで、鑑賞 者を付いてこさせる。そして、側面カメラの情報により適した位置とのズレを把握 し、目標まで修正するという手法である。ビジュアルフィードバックは精度の悪い 移動機構について、非常に有効な手段であり、デッドレコニングによるズレを考慮 に入れなくても良く、また地図情報についても詳細は必要にならない。また、実験 空間内の詳細な座標を持たないことで、ロボットが強制的に移動させられたときの リカバリーや、絵の一部が障害物、人などで隠されてしまったときの動作の不確か さといった欠点があるものの、一対一での説明であるのでこれを採用する。 6 第2章 調査実験 第 1 章では、人との距離、展示物のとの位置関係、人型ユーザーインターフェー スへの人としての反応の重要性について述べた。本章ではガイドロボットでの実装 を考えた時に、目標とすべき手本の動きをする学芸員の動き、またそのときの鑑賞 者、展示物の位置関係等についての調査を行った。様々な大きさの展示物 (絵画に限 る)、壁の位置、鑑賞者の人数、個々の学芸員によらない傾向の観察を目的に行った。 2.1 調査実験概要 学芸員が展示物を 1 対 1 で説明している様子を撮影する。そのときの鑑賞者の発 見から、誘導、説明位置、絵の大きさなどを記録してゆく。この様子は、倉敷にあ る大原美術館 [14] の協力のもと撮影、記録を行った。 2.1.1 学芸員の観察 鑑賞している絵画の大きさ、また鑑賞者、学芸員の立ち位置を記録した。以下の 図 2.1、図 2.2 は実験の様子を示したものであり、女性の学芸員が鑑賞者を見つけ、 説明を開始する様子を示している。ここで女性の学芸員はパブロ・ピカソの “骸骨 のある静物” という絵に着いて説明を行なっている。表 2.1 はその結果を示したも のである。 7 図 2.1: 鑑賞者を探す学芸員 図 2.2: 説明を始める学芸員と鑑賞者 8 2.1.2 調査実験からの考察 表 2.1 より、鑑賞者の観察位置は個別差はあるものの、およそ絵画の対角線の長 さ分以上は離れていることが解る。これは絵画を鑑賞する点で、全体の印象を確か める「全体を眺める」という行為と、絵画の中の局所「一部に注目する」という行 為をどちらも行なえることが重要であり、そのための距離感であると考えられる。 大きな絵画であればあるほど、「全体を眺める」という行為には距離を絵画からの 距離をとらねばならないという経験上からも明らかであるだろう。 その他に鑑賞者を見つけ近づいてゆく接近動作、 「詳しく説明しましょうか?」な どという問いかけ、また展示物の前への誘導という 3 つの段階を必ずこの順序で行っ ている。大きな特徴として 1. 学芸員は絵の前を必要以外横切らない 2. 説明開始時には学芸員が質問をかける 3. 誘導位置が展示物ごとにことなるが、絵ごとに特徴がとれる 1 については絵画の鑑賞の邪魔をしないことが目的であることは明白である。2 は、作者の出生地、または時代背景等について質問することで、鑑賞者の知識の程 度を把握し、その後の説明の難度を変えようといった狙いや、また鑑賞者と打ち解 けやすい現場の空気を作ることで、自由で柔軟な発想を鑑賞者にもって欲しいから だと思われる。3 については前項の考察に載せたとおりの理由がある。これらの特 徴をガイドロボットでの実装へ生かしてゆく。 表 2.1: 絵の大きさと鑑賞者との距離 作品タイトル 作者 対角線 [cm] Annunciation EL GRECO 174.6 Still Life with a Skull P ablo P ICASSO 199.2 Still Life with a Skull P ablo P ICASSO 199.2 Bird Cage P ablo P ICASSO 248.0 Wood Cutter F erdinand HODLER 192.0 深海の情景 古賀春江 200 9 観測距離 [cm] 200 155 210 257 190 180 第3章 画像処理 本章では本研究で行った画像処理法について記す。 3.1 画像処理ライブラリ 画像処理ライブラリとしては Intel 社の OpenCV(v1.0)[17] を使用した。本研究で は USB カメラを 2 台使用し、ガイドロボットの正面を撮影する USB カメラの画像 を用いて鑑賞者を探索し、ガイドロボットの右横を撮影するカメラの画像を用いて 展示物 (絵画) の把握に利用した。 3.2 正面カメラ 正面カメラで取得した画像に用いる画像処理を示す。正面カメラの役割は、正面 方向の風景の取得と共に、人の観察である。待機状態の時に正面カメラで顔を探し 続ける。画面の大きさは 320 × 240 である。顔を認識し、安定すると、顔のある方 向へと体を向け、誘導動作を始める目安にした。図 3.1 は顔認識の様子を示したも のである。 10 図 3.1: 正面顔取得 3.3 右方向カメラ ガイドロボットの右方向を撮影する USB カメラを設置した。この右方向カメラ の画像を用いて、絵画の補足を試みる。右方向カメラは人間であれば誘導の後退動 作の時に、首を振り、やや後ろにある絵画の位置を確認し、目的地を再確認すると いう行為を一瞬で行うが、ガイドロボットで実装するに当たり、正面カメラでの画 像取得を行おうとすると、首や体の回転動作に時間が掛かる上、回転直後の振動が 精巧な画像取得を妨げてしまうために、観察用に導入した。このカメラ画像を用い ることで展示物の認識を行い、画像内の展示物の座標の 4 隅の座標を得られる。4 隅の座標の関係からガイドロボットと絵画の距離、ズレを把握する。 以下に絵画を認識する方法を述べる。展示物から絵画へと対象物を固定すること で絵画のもつ特徴が挙げられる。 • 多くの絵画は矩形をしている • 矩形の絵画は壁にまっすぐ掛かっている • 額と背景の壁などは大きく異なっている これらの特徴を捕らえるために矩形検知とテンプレートマッチングという二つの 方式を比較した。結果を後に記す。 3.3.1 矩形検知法 画像中から展示物、ここでは絵画を含む矩形を探すことで、対象の展示物の候補 をピックアップすることを試みた。額は静止画において、常に大まかな矩形で表現 11 でき、また矩形の静止画中の 4 頂点座標が判明することで距離判別に生かせる。以 下に矩形検知の操作を示す。 静止画取得 ノイズを除去 画像を cvPyrDown にて 1/2 に縮小し、cvPyrUp にて 2 倍に 拡大することでノイズを除去する。 2 値化適当な値を閾値にして 2 値化を行う。 輪郭線集出 cvFindContours で輪郭線リストを取得する。 輪郭線を直線近似 cvApproxPoly で対象輪郭線を直線に近似する。 近似した図形が四角形 (辺 の数=4) でなければ対象外とする。 妥当な矩形か? cvContourArea で面積を求め、 「最小矩形サイズ」より小さい場合は除外する。 cvCheckContourConvexity で、交差しているか凹型の四角形は除外する。 画像 の四隅付近に2頂点以上ある場合は除外する。(画面全体が選択されることを抑止 するため) 4 点の角度が 90 度±「最大角度誤差」の範囲でない場合は除外する。 (台形や平行四辺形を除外するため) 有効な矩形が見つかった場合の取捨選択基準点 (回転角度が最も小さくなる 左下の角) を選択する。また複数見つかった場合には、もっとも大きい矩形を選択 する。 実際に矩形検知をおこなった様子を示したのが図 3.2 である。緑色の矩形で近似 された領域と絵を一致させたいのだが、周囲の矩形のものを取り込んでしまったり、 また額と絵の関係を区別するのが非常に難しい。 12 図 3.2: 矩形検知結果 3.3.2 4 隅テンプレートマッチング法 次に 4 隅テンプレートマッチング法について述べる。これはあらかじめ目的地で撮 影しておいたテンプレート画像をから、絵画の額を含めた 4 隅の微小テンプレートを 抽出し、それぞれにテンプレートマッチングを行う。4 つの微小テンプレート画像の 座標関係によって、画像中から絵画を取得を計る。テンプレートマッチングの処理は OpenCV(ver.1.0) のライブラリから cvMatchTemplate を用いた。cvMatchTemplate については次に述べる。 void cvMatchTemplate( const CvArr* image, const CvArr* templ, CvArr* result, int method ); image テンプレートマッチングを行う画像。8 ビットか 32 ビット浮動小数点型でなけれ ばならない。 templ 探索用テンプレート。画像より大きくてはならない、かつ画像と同じタイプであ る必要がある。 result 比較結果のマップ。シングルチャンネルの 32 ビット浮動小数点型データ。image が W × H で templ が w × h ならば、 result は W-w+1 × H-h+1 のサイズが必要。 method テンプレートマッチングの方法 (以下を参照)。 13 templ を、image 全体に対してスライドさせ、それとサイズ w × h で重なる領域 とを指定された方法で比較し、その結果を result に保存する。 以下に、この関数で指定可能な比較手法を表す式を示す。 (I は画像を、T はテン プレートを、R は結果をそれぞれ表す。総和計算は、以下のようにテンプレートと (または) 画像領域に対して行われる。x’=0..w-1, y’=0..h-1)。 中でも最小値を返す。 method = CV TM SQDIFF: R(x, y) = sumx,y [T (x′ , y ′ ) − I(x + x′ , y + y ′ )]2 (3.1) ここでは重ねたテンプレート中の座標の値と、入力画像の座標の値の2乗誤差を 求め、最小値をだした領域をマッチング領域とする。 4 隅テンプレートマッチング法の操作を以下に記す。 画像取得 4 隅微小テンプレート画像のロード 2 値化 テンプレートマッチング 返り値が最小になるものを保存 、 を微小 4 隅テンプレート画像全てに行う 結果画像を出力 図 3.3 と図 3.4 は実際に 4 隅テンプレートマッチングを行った結果画像である。 図 3.3: テンプレートマッチング成功 図 3.4: テンプレートマッチング失敗 14 4 隅テンプレートマッチングは微小テンプレートの作成や、テンプレートマッチ ングを 4 回繰り返す手間はあるものの、矩形検知法に比べ、4 隅のひとつを隠され ても絵の妥当性の判断ができという利点がある。また絵全体でなく 4 隅をとらえる ことで、斜めから撮影した画像に生じるねじれにも広い範囲で認識できる。よって ここでは 4 隅テンプレートマッチング法にて絵画の認識、座標の取得を行う。静止 画像中の絵の取れ方によってその後のガイドロボットの移動動作を決定する。 上記の条件において取得したポール・ゴーギャンの「かぐわしき大地」4.1 の画 像中での大きさ、ピクセルについて記録を行う。使用画像は 640 × 480 ピクセルの 静止画を利用した。図 3.5 は絵画とガイドロボットとの距離、絵画正面に配置した ガイドロボットが取得した静止画像中の絵画の大きさの関係をグラフにしたもので ある。 図 3.5: 画像とピクセルの関係 絵画の大きさは変わらないので、画像中に取得した絵画の左右両端のピクセル数 が解れば、実空間ので絵画とガイドロボットの大まかな距離はわかる。 15 第4章 提案システム ここでは、学芸員が鑑賞者へ展示物のガイドを始めるまでの導入、アプローチの モデルを提案する。ガイドの対象となる展示物、絵画はポール・ゴーギャンの「か ぐわしき大地」(図 4.1) とした。事前に大原美術館の学芸員の方にガイドするため の文章を作ってもらっている。 目標、ハードウェア概要、ソフトウェア概要についてそれぞれ述べてゆく。 図 4.1: かぐわしき大地 16 4.1 目標 ガイドロボットの状態により以下の 7 つのモードに分ける。 1. 2. 3. 4. 5. 6. 7. 空間情報取得 待機状態 声掛け動作 接近動作 誘導動作 ビジュアルフィードバック動作 説明開始 1.空間情報取得 1 の空間情報取得では、あらかじめ説明対象の展示物の大きさ、障害物の存在など を把握しておく。この実験空間では展示物の周囲は広く、障害などは無いものと仮 定しておく。そして事前情報の展示物の大きさから、説明に適した場所を割り出し、 その点へと移動、その点から撮影した展示物の画像を保持しておく (図 4.2)。画像 からは展示物ここでは絵の四隅をテンプレート画像 (図 4.3、図 4.4、図 4.5、図 4.6) として切り出し、4 隅テンプレート画像のそれぞれの画像中の座標を保持しておく。 図 4.2: テンプレート元画像 17 図 4.3: 左上テンプレート画像 図 4.4: 右上テンプレート画像 図 4.5: 左下テンプレート画像 図 4.6: 右下テンプレート画像 2.待機状態 待機状態において、ガイドロボットは説明したい展示物の付近、他の展示物の鑑 賞の邪魔にならないようなデッドスペースに位置どる。鑑賞者、ガイドロボット、 展示物のそれぞれの位置関係は図 4.7 のようになっている。 図 4.7: 相対位置概要 そして周囲を見渡す動作 (首を左右に振る、体を回転させる) でガイドロボットの 周囲の人々へアベイラビリティを示しつつ、正面カメラで顔認識を行なう。画像中 に顔を認識し、安定しているようであれば、取得した顔が展示物の説明を受けたそ うな鑑賞者であるとみなす。 18 3.声掛け動作 2で認識した顔がある方向へ、ガイドロボットの正面を向ける。待機状態で行なっ ていたアベイラビリティを示す行為は終了する。そこで「よろしかったら説明いた しましょうか?」などと音声を再生する。音声を再生することでガイドロボットが 唐突に接近してくる恐怖をなくし、親しみを持たせる。 4.接近動作正面方向へ前進する。この時距離センサーにより 80 から 100 セン チくらいに近づくにとどめる。また常に距離センサーは稼動させ、異常接近の際に は行動をやめる。 5.誘導動作 手のひらを差し出すハンドジェスチャー (図 4.12) を行い、回転することで展示物 の方向へ空間があることを示し、誘導動作を開始する。「こちらへどうぞ」という 音声を再生し、 展示物の正面への誘導を行う。この後退動作は接近動作で進んだ座 標情報と説明場所の座標で決めるが、誤差を考慮に入れ、少し手前で6へと移る。 6.ビジュアルフィードバック動作 5で出た説明位置と現在位置の誤差を埋めるべく、展示物を観察することで現在 位置を取得する。絵の見え方によって微調整を行い、事前に撮影してあったテンプ レート画像の情報との差により、細かく移動を繰り返し修正する。(図 4.8, 表 4.1) また絵が取れない場合は、修正回数が 5 回未満の場合は、数センチ後退する。これ は絵がカメラの撮影範囲に入っていないことが考えられるためである。 また振動による影響を考慮し、絵が認識できないときは間をおいて認識を試みる ようにする。続けて絵が認識できなかった場合は致命的な誤差が発生しているもの としてその後の行動を行わない。 19 図 4.8: 右カメラでの動作決定 表 4.1: 移動決定 状態 動作 絵が取れない (1 度目) 絵が取れない (2 度目) 絵左端のみ取得 絵を画面右に取得 テンプレート画像やや右で取得 テンプレート画像とほぼ同じ テンプレート画像やや左で取得 絵右端のみ取得 もう 1 度取得を試みる 迷子状態 大きく後退 やや大きく後退 小さく後退 説明開始 小さく前進 やや大きく前進 20 7.説明開始 6で事前に計算していた位置に誘導を行えていたら説明を開始する。シナリオは 事前に準備していたものである。 4.2 ハードウェア概要 この章では研究で使用するガイドロボットの紹介を行う。 4.2.1 ガイドロボット 本研究で使用するガイドロボットは ATR(知的ロボティクス研究所)[16] で開発さ れた図 4.9 の Robovie-R ver.2(表 4.2) を使用する。このガイドロボットに全身に 29 の自由度を持ち、人間のような動きを表現できる。また触覚センサ、距離センサ、 全方位カメラ、両眼カメラ等で周囲の状況を得ることが出来る。また、プロセッサ として上下 2 台の PC を持っている。開発は Visual C++ 6.0 を用いて行った。本 研究室では以前からガイドロボットとして Robovie-R ver.2 を使用してきたが、以 前の球状の手から図 4.10 のように 5 本の指を持った手へと変わっている。片手は手 首、5 指の 6 の自由度を持っている。これにより、以前は曖昧だった志向性を、図 4.11 指差し、図 4.12 のようなハンドジェスチャーなどでより明確に表現できるよう になった。 名称 全高 全幅 全長 重量 自由度 稼働時間 表 4.2: Robovie-R ver.2 仕様 ロボビーアール (Robovie-R Ver.2) 1100mm 560mm 500mm 57.0kg(本体重量 39.5kg/バッテリ重量 8.75kg × 2) 29 自由度 最大 3 時間 21 図 4.9: Robovie-R ver.2 図 4.10: 手軸改造後 図 4.11: 指差し動作 図 4.12: ハンドジェスチャー 22 センサー Robovie-R ver.2 は胸部正面 6 方向、足元全周囲 24 方向、計 30 の距離センサーを 搭載している。距離センサーの主な仕様は表 4.3 に記す。 表 4.3: 距離センサー 仕様 製品名 GP2Y0D02Yk0F メーカー SHARP 測定範囲 200 - 1500mm 使用個数 胸部 6 方向、足元 24 方向 測定方式 PSD 使用波 赤外線 出力方式 アナログ電圧出力 この赤外線を用いる光位置センサーと呼ばれる形式の距離センサーの特徴として、 光のスポットの光量の重心を求めることができる。求めた重心からセンサー距離を 割り出せる。出力はアナログ電圧を採用していることで、理論的には分解能は無限 であるが、ここでは 10−2 mm にとどまっている。また探索範囲は 200-1500mm に限 られるだけではなく、距離センサーからの垂直な直線上しか探索可能でない。つま り足元 24 方向のセンサーも一般的なソナーと異なり、厳密に全方位を把握するの ではなく、実際探索可能距離に人が立っていてもセンサー間の隙間に位置を取るこ とも多く、信頼性に乏しい。(図 4.13) そのうえ実際には外乱光や、反射素材の影響 を大きく受け、それほど精度は高くはならず、このことからもセンサー以外の環境 判断材料が必要といえる。 図 4.13: センサーマップ 23 移動機構 移動機構としては Robovie-R ver.2 内蔵のものを用いた。この移動機構は RobovieR ver.2 本体の他の 27 自由度と共にモーションファイルの再生や、モーションファ イルによらない非同期的制御も可能になっている。移動機構の概観は図 4.14 のよう であり、左車輪、右車輪それぞれの回転量、回転にかけるステップ数で制御できる。 しかし概観からも解るように、アクチュエーターから両車輪に駆動を伝える部 分が、図 4.15 のようにゴム製のベルトになっており、このゴム製のベルトが伸縮、 空転してしまうことによる車輪の回転の誤差が大きな問題になってしまっている。 Robovie-R ver.2 自体の重みがバッテリーなどによって大きく変わり、重心が高い と急激な停止動作の際転倒の危険がある上、ベルトのたわみ、伸縮が一定ではなく なってしまう。また気温や駆動部によりゴム製ベルトの伸縮率の変化も見逃せない。 図 4.14: 移動機構概観 4.2.2 図 4.15: 移動機構概観-ベルト USB カメラ 前述のガイドロボットの正面方向、右方向を撮影するカメラとして、logicool 社 R の Qcam⃝pro for notebooks[15](図 4.16) を使用した。この USB カメラは非常に小 さく、またドライバソフト内での撮影画像の上下左右の反転、明るさ補正、ピント の自動調節などの機能を有し、画像取得後の画像操作を減らせるという大きな利点 R がある。Qcam⃝pro for notebooks の性能は表 4.4 のようである。他の遠隔操作ガ イドロボット等の機能との実現のために 4 台のカメラを仕様している。(図 4.17) 24 R pro for notebooks 図 4.16: Qcam⃝ R pro for notebooks 性能表 表 4.4: Qcam⃝ フォーカス 10cm ∼ ∞ 画像センサー True 200 万画素 ビデオキャプチャー 最大 200 万画素 静止画キャプチャー 最大 800 万画素 フレームレート 最大 30 フレーム / 秒 図 4.17: カメラ 4 台 25 4.3 ソフトウェア概要 ここでは提案の実現するためのプログラムなどソフトウェア面について述べる。 図 4.18: システム概要 4.4 ガイドロボットの動作 前述のガイドロボットの動きを実装したものの動きを示す。図 4.19 のように画面 に絵画とそのテンプレートマッチング結果を映しながらヴィジュアルフィードバッ ク動作を行い、適切な位置まで誘導する。(図 4.20) 図 4.21 は遠隔操作、指差しなど リモートモードも組み込んだ統合実験の様子である。 4.4.1 実装で明らかになった問題点 潜在恐怖 誘導時、また実際に説明を始めた後での身振り手振りで鑑賞者に触れない距離、 また向きなどを考慮にいれなくてはならない。同時に Robovie-R ver.2 の動作時に 26 図 4.19: 実行例 1 図 4.20: 実行例 2 27 図 4.21: 統合実験の様子 は非常に大きい駆動音がなってしまい、鑑賞者へ大きなストレスを与えてしまう。 これらを考慮に入れ、ガイドロボットはあまり早い動作を行わないように設定する。 また機械的動作の反復は人間との違いを浮き彫りにする点で好ましくないので、出 来るだけ避けるようにした。 移動時間 ガイドロボットで移動行動を行うと、どうしても振動が生じてしまう。この振動 は USB カメラの取得画像に大きな影響を与えてしまう。画像がぶれることで、認 識対象を誤ったり、把握できなかったりもする。よって移動行動と移動行動の間に はカメラが振動による影響を受けない時間分あける必要がある。 28 第5章 実験 本章では、ガイドロボットが人間へ誘導を行い、提案した手法が有効であるか検 証する実験について述べる。 5.1 実験 1 ビジュアルフィードバックを用いることで誘導の精度についての有意差があるの かを検証する実験を行った。 5.1.1 目的 本研究ではガイドロボット移動時に対象物とのカメラ画像をもちいたビジュアル フィードバック動作のロボットへの導入を提案している。ビジュアルフィードバッ ク動作を用いることで従来のデッドレコニングを用いた動作との比較検討をする。 5.1.2 方法 図のように人 (鑑賞者)、ガイドロボット、絵画が配置された実験空間を考える。 本実験において、初期位置は説明位置と同じものとする。待機場所から一定の距離 に立つ人を向かえに行き、胸部距離センサーを用いて止まるという。そして説明場 所へ戻る。動作は前進と後退しか行わない。ビジュアルフィードバック、またはデッ ドレコニングによって初期位置に戻った際のそのときの誤差を記録してゆく。それ ぞれに 10 回ずつこの動作を繰り返して 1 回の試行とし、それぞれ 3 回ずつ行う。 29 5.1.3 結果と考察 図 5.1、図 5.2 はそれぞれの誤差を記録したものである。図 5.3、図 5.4 はデッド レコニングを用いた場合、ビジュアルフィードバックを用いた場合の誤差の絶対値 を示したものである。1-3 回目の試行に関してはデッドレコニングを用いたほうが 誤差が少なくなっている。 図 5.1: デッドレコニング 図 5.2: ビジュアルフィードバック これはビジュアルフィードバック動作に関しては取得画像とテンプレート画像の 4 隅の座標が完全に一致することが難しく、説明位置判断に関して、与えた許容範 囲が大きかったためと考えられる。この許容範囲の縮小と微調整動作の分割を行え ば改善されるだろう。 しかしその後の反復ではビジュアルフィードバックを用いた試行が優位差が見ら れる。もっとも大きく異なるのはビジュアルフィードバックによる試行では N 回目 より N + 1 回目の反復に誤差の改善が見られることがあるという点である。デッド レコニングによる動作では誤差の改善は見られなかった。デッドレコニングでは正 30 図 5.3: デッドレコニング誤差絶対値グラフ 図 5.4: ビジュアルフィードバック絶対値グラフ 31 比例的に誤差が蓄積していくのに対し、ビジュアルフィードバックではある程度ず れが蓄積すると改善がみられる。 図 5.5: Y 軸ずれの平均誤差 またY軸のずれ分に注目する。図 5.5 はデッドレコニング、ビジュアルフィード バックそれぞれのY軸のみのずれの誤差の絶対値をグラフにしたものである。ビジュ アルフィードバックが優位であることがわかるが、実験 1 では前後の動き、理論上 はX軸上のみの移動となっているはずである。しかしY軸のずれは発生してしまい、 このずれは予定軌道からのずれであるとも言える。このずれをビジュアルフィード バックは反復途中で減少させているのがわかる。 したがって反復回数が増えるにつれてのビジュアルフィードバック動作が優位で あると考察される。 5.2 実験 2 実験 1 ではビジュアルフィードバックを用いた移動がデッドレコニングを用いた 移動より反復動作に優位なことが解った。次に様々なシチュエーションへの導入を 図る。 32 5.2.1 目的 実際に美術館では鑑賞者は常に同じ位置から絵画を鑑賞している訳でも、ガイド が常に同じ位置から絵画や鑑賞者を探し、誘導するわけではなく、臨機応変に対応 している。ガイドロボットについても同様に臨機応変に誘導できるようユーティリ ティー性を持たなければならない。実験 2 では続いて一般性を検証する。 5.2.2 方法 右方向カメラが絵を認識できる範囲に初期位置を置き、そこから様々な方向へと お迎え動作を行い、誘導を目指す。ただし角度によってテンプレート画像の変更は 認め、左右対称な事象は割愛する。そして右方向カメラでビジュアルフィードバッ クを行えない範囲、不安定な範囲、可能な範囲と 3 つの指標に分類する。 5.2.3 結果と考察 図 5.6: 実験 2 誘導可能範囲 安定した範囲で誘導動作を行えたものは図 5.6 の矢印の方向である。矢印の長さ がそれぞれお迎えに行く距離を示している。これは安定範囲と表される領域までお 33 迎えを行ったものがビジュアルフィードバックによる調整が可能になっていると考 えられる。またカメラの絵画認識可能範囲は 60 度程度とも考えられる。これは同 時にカメラの取り付け角、位置によって大きく依存してしまう事実も示している。 図 5.6 のガイドロボットの左後方、図の右端から鑑賞している人に関しては、誘導 の仕方が左右対称である必要もでてくる。 34 第6章 終わりに 本章では,本研究のまとめと今後の課題について述べる。 6.1 まとめ 本研究では美術館で行われた相互行為である展示物の説明の導入を記録観察する ことにより、鑑賞者-ガイドロボット-展示物間の関係が展示物の大きさによって定 まることが解った。ガイドロボットが適切な鑑賞者の鑑賞位置、ガイドの説明位置 へのスムーズな誘導動作を行うことでのその後の相互行為を行いやすくするべく、 ガイドロボットのビジュアルフィードバックを用いた誘導動作を提案した。4 隅に テンプレートマッチングを行い、ねじれや取得ミスなどの影響が発生しにくくなっ た上、誘導動作においてはビジュアルフィードバックを用いることでの一定の精度 と、反復性の向上が望める事が解った。誘導可能な範囲や初期位置については絵画 認識用のカメラの向きに大きく依存してしまうこともわかった。 6.2 今後の課題 実際に美術館でのデモを行うことを考慮すると、センサーを使っての安全管理の 向上が求められる。全方位センサー警戒や手動での遠隔緊急停止といった機能を実 装しなくてはならない。 またビジュアルフィードバック動作の速度向上も望まれる。現在では 1 メートル 足らずの移動動作も 10 秒近くかかってしまい、絵画への興味をそいでしまうこと もあるだろう。 また右方向にカメラを限定しているために、実験 2 のように誘導可能な範囲が非 常に狭くなり、柔軟性がない。右方向カメラを限定しているのは、右手で絵画を指 35 差すモーションファイルしか用意してなかったためであり、左で指差しするモーショ ンファイルを用意できれば誘導可能範囲は大きく広がるし、全方位カメラも取り入 れられればさらに自由度が広がるだろう。 「説明いたしましょうか?」とイントロダクションを行った後にも問題がある。 現在は相手の反応を読まずに強引に「こちらへどうぞ」と誘導を始めてしまう。こ れでは相互行為を誘発しやすいとは言えず、改善するために音声認識や、相手のう なづき、拒否の首振りに反応できる機能も実装してゆかなくてはならない。 そして最後に全ての機能を統合した上での評価実験やその方法を検討しなければ ならない。 36 謝辞 研究ならびに生活面においてご指導を賜りました久野義徳教授、小林貴訓助教に 深く感謝致します.並びにエスノメソドロジー的見地に基づいた発話については埼 玉大学教養学部山崎研究室の皆様にご協力をいただきました。この場を借りてお礼 申し上げます。 また,先輩としていつもよきアドバイスをくださいました,定塚氏,笛木氏をは じめとする研究室の皆様,そして同期学生の皆様,並びに私を暖かく見守って頂い た両親はじめとする周囲のすべての皆様に深く感謝致します. 37 参考文献 [1] 西出 和彦, ”人と人との間の距離”, 人間の心理・生態からの建築計画 (1), 建築 と実務, No. 5, pp. 95–99, 1985 [2] 神田崇行,石黒浩,小野哲雄,今井倫太,前田武志,中津良平 (2001).研究用 プラットフォームとしての日常移動型ロボット”Robovie”の開発. 『電子情報通信学会論文誌』,Vol.J84-D-I,No.3,pp.1-10. [3] 小野哲雄,今井倫太,石黒浩,中津良平 (2001).“身体表現を用いた人とロボッ トの共創対話” 『情報処理学会論文誌』,Vol.42,No.6,pp.1348-1358. [4] “wakamaru.net” http://www.mhi.co.jp/kobe/wakamaru/ [5] “Sony Japan | QRIO” http://www.sony.co.jp/SonyInfo/QRIO/ [6] NEC ホームページ http://www.nec.co.jp/ [7] Sebastian Thrun, Maeren Bennewitz, Wolfram Burgard, Armin B.Cremers, Frank Dellaert, Dieter Fox Dirk Hahnel, Chaeles Rosenberg, Nicholas Roy, Jamieson Schulte, Dirk Schulz: “MINERVA:A Second-Generation Museum Tour-Guide Robot””, Proc. of the IEEE International Conference on Robotics and Automation (ICRA’99), (1999) [8] Wolfram Burgard, Armin B.Cremers, Dieter Fox, DIrkHahnel, Gerhard Lakemeyer, Dirk Schulz, Walter Steiner, Sebastian Thrun: “Experiences with an Interractive Museum Tour-Guide Robot”,ACM Artifical Intelligence Volume 114 , Issue 1-2 (October 1999) [9] Yoshinori Kuno, Kazuhisa Sadazuka, Michie Kawashima, Sachie Tsuruta, Keiichi Yamazaki and Akiko Yamazaki:“Effective Head Gestures for Museum Guide Robots in Interaction with Humans”in proc.RO-M AN 08, 2007,pp 151156 38 [10] 佐藤徳孝, 城間直司, 小島稔, 稲見昌彦, 松野文俊: “遠隔操作ロボットにおける有 効な提示カメラ画像の検証”, 第 22 回 日本ロボット学会学術講演会,3A27,(2004) [11] “ASIMO SPECIAL SITE,” http://www.honda.co.jp/ASIMO/ [12] 上田隆一, 新井民夫, 浅沼和範, 梅田和昇, 大隈久: “パーティクルフィルタを利 用した自己位置推定に生じる致命的な推定誤りからの回復法” 『日本ロボット 学会誌』JRSV Vol.23 No.4 pp.466-473, (November 2005) [13] 橋場参生, 吉川毅, 鈴木慎一: “画像情報を用いた屋内移動ロボットの自己位置 推定方法”” 北海道立工業試験場報告 No.301, (2002) [14] “大原美術館” http://www.ohara.or.jp/ R pro for notebooks [15] Logicool 社製 Qcam⃝ http://www.logicool.com/ [16] ATR(知能ロボティクス研究所) http://www.irc.atr.jp/productRobovie/robovie-r2-e.html [17] “Open Source Computer Vision Library” http://www.intel.com/technology/computing/opencv/index.htm 39
© Copyright 2026 Paperzz