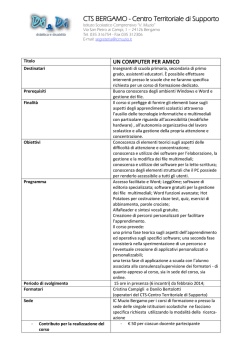
Università degli studi di Salerno
Facoltà: Lingue e letterature straniere
Corso di laurea: Lingue e culture straniere
Tesi in: Linguistica applicata
Dividing CLIPS' Phonemic Layer into Syllables
An SPP Based Syllabification Program with Python/NLTK
Relatore: Prof.ssa Renata Savy
Correlatore: Dott.ssa Marina Lops
Candidato: Luca Iacoponi
Matricola: 4310200182
Ad Andrea, la mia memoria;
a Marina, il mio presente
Table of Contents
ABSTRACT.................................................................................................................7
ACKNOWLEDGEMENTS......................................................................................10
1 SYLLABLE AND SYLLABIFICATION............................................................11
1 Syllable..........................................................................................................................11
1. Syllable Structure..................................................................................................................11
2. Syllable Weight.....................................................................................................................14
2 Syllabification ..............................................................................................................15
1. Orthographic Syllabification.................................................................................................15
2. Sonority Scale.......................................................................................................................16
3. Sonority Distance .................................................................................................................19
4. Phonotactical Constraints......................................................................................................19
5. Internal Evidence..................................................................................................................20
6. External Evidence.................................................................................................................21
7. Comparison of Principles......................................................................................................22
8. Conclusion............................................................................................................................24
3 From SPE to Optimality ...............................................................................................25
1. SPE Rules..............................................................................................................................25
2. The Syllable in SPE..............................................................................................................26
3. Autosegmental Theory..........................................................................................................27
4. Autosegmental Syllabification..............................................................................................29
5. Metrical Phonology...............................................................................................................35
6. Foot, mora and P-Word.........................................................................................................39
7. Optimality Basic Principles..................................................................................................40
8. Optimality Procedure............................................................................................................41
9. Optimality Formalisation......................................................................................................42
10. Syllabification in OT...........................................................................................................44
4 Conlcusion....................................................................................................................47
1. Definitions of syllable...........................................................................................................47
2. Which Syllabification?..........................................................................................................49
2 AUTOMATIC SYLLABIFICATION..................................................................50
1 Input, Model and Purposes............................................................................................50
1. Written or Spoken Language.................................................................................................51
2. Transcriptions........................................................................................................................52
3. Software Purposes.................................................................................................................54
4. Epistemology........................................................................................................................55
5. Data Driven - Rule Based.....................................................................................................57
2 Data Driven Models......................................................................................................60
1. Artificial Neural Networks....................................................................................................60
2. Calderone's ANN...................................................................................................................65
3. Look-up Procedure................................................................................................................69
3 Rule based Models........................................................................................................72
1. Computational OT ................................................................................................................72
2. Hammond's Algorithms ........................................................................................................74
3. Others OT Implementations..................................................................................................81
4. Cutugno et al. (2001)............................................................................................................82
4 Conclusion....................................................................................................................84
3 CLIPS.....................................................................................................................85
1 Transcription.................................................................................................................86
1. Transcription Principles........................................................................................................86
2. Annotated Transcription........................................................................................................88
3. Transcription Procedure........................................................................................................91
4. Labelling...............................................................................................................................92
5. Phonological Layer...............................................................................................................96
2 Diatiopic, Diamesic and Diaphasic Variation................................................................99
1. Northern Italy Cities..............................................................................................................99
2. Dialogic...............................................................................................................................101
3. Read Speech........................................................................................................................103
4. Radio and TV......................................................................................................................103
5. Telephonic...........................................................................................................................105
6. Orthophonic........................................................................................................................107
7. Corpus structure..................................................................................................................108
4 SYLLABIFICATION PROGRAM....................................................................110
1 Python and NLTK........................................................................................................110
1. Python .................................................................................................................................110
2. NTLK..................................................................................................................................112
2 Implementation............................................................................................................113
1. Syllabification.....................................................................................................................113
2. CLIPS's STD.......................................................................................................................115
3. Core SY...............................................................................................................................117
4. Phonological Syllabification...............................................................................................123
3 Final Developing.........................................................................................................125
1. Corpus Reader.....................................................................................................................125
2. SY and NLTK......................................................................................................................130
3. NTLK and SY.....................................................................................................................133
4. Further studies.....................................................................................................................141
5 CONCLUSION....................................................................................................143
APPENDIX A: SONORITY SCALE.....................................................................148
APPENDIX B: SAMPLE SYLLABIFICATION OUTPUT................................149
APPENDIX C: PHONOLOGICAL SYLLABIFICATION.................................150
BIBLIOGRAPHY....................................................................................................151
Illustration Index
Tree representation of a CVC syllable................................................................................................12
Tree representation of the Italian syllable structure...........................................................................13
Syllable weight representation in moraic theory................................................................................14
Sonority representation of the word 'candle'......................................................................................17
Sonority representation of the word 'gatto'.........................................................................................17
Fake nasal assimilation rule................................................................................................................26
SPE rule for French [e] and [ɛ] alternance........................................................................................27
SPE rule for French [e] and [ɛ] alternance including syllabe...........................................................27
1 to 1 correspondence between melodic and skeletal tier..................................................................30
Example of a 2 to 1 correspondence between melodic and skeletal tier............................................31
Example of 1 to 2 correspondence between melodic and skeletal tier...............................................31
N-Placement.......................................................................................................................................33
CV Rule..............................................................................................................................................33
Onset Rule..........................................................................................................................................33
Coda Rule...........................................................................................................................................33
Autsegmental syllabification step for the word 'pastrocchio'.............................................................35
Metrical three for the word 'compitare'..............................................................................................38
Phonological hierarchy.......................................................................................................................39
Simple Artificial Neural Network unit...............................................................................................61
Articial Neural Network unit..............................................................................................................62
Artificial Neural Network with three hidden layers...........................................................................64
Feedforward Neural Network.............................................................................................................64
Phonoctactic and syllabic window.....................................................................................................68
Attraction values for the word 'sillaba'...............................................................................................68
Attraction values for the word 'pasta'.................................................................................................69
Hammond's candidate encoding for the word 'apa'............................................................................74
Hammond's second algorithm rule formalisation...............................................................................80
DG utterance filename example.........................................................................................................93
Word sì 'yes' labelling on WaveSurfer................................................................................................95
Syllable Cumulative Frequency Distribution Plot............................................................................138
Index of Tables
Rhyme, assonance, consonance and alliteration.................................................................................12
Sonority Hierarchy.............................................................................................................................18
Coursil's Sonority Scale......................................................................................................................18
Syllabification of the French word 'moustique' according to Coursil (1992).....................................18
Davis (1990) Sonority Scale for Italian..............................................................................................19
A comparison of possible CC cluster division strategies...................................................................23
Autosegmental Syllabification Algorithm for Italian.........................................................................33
Hypotetycal language 1 tableau..........................................................................................................43
Hypotetycal language 2 tableau..........................................................................................................43
Hypotetycal language 2 tableau..........................................................................................................44
Tableau for the syllabification of 'pasta'.............................................................................................45
Tableau for the syllafication of the word 'studente'............................................................................46
Tableau for the syllafication of the word 'klok'..................................................................................46
Corpora based studies until 1991.......................................................................................................56
Important differences between rationalism and empiricism...............................................................58
Rule based and data driven models....................................................................................................59
Number of candidates if epenthesis and deletion are considered by Gen .........................................73
Example of an unparsed Hammond's tableau.....................................................................................76
Number of evaluations for a 10X5 tableau.........................................................................................79
Number of evaluations reduction using fatal violations.....................................................................79
CLIPS corpus summary (Savy and Cutugno 2009)...........................................................................85
Semi-lexical phenomena....................................................................................................................89
Non lexical phenomena......................................................................................................................89
Interjections........................................................................................................................................89
Non verbal and non lexical phenomena.............................................................................................90
Operator comments............................................................................................................................90
Transcript units...................................................................................................................................92
Transcript and labelled transcript unit................................................................................................93
SAMPA vowel set for CLIPS.............................................................................................................96
SAMPA consonant set for CLIPS.......................................................................................................97
Transcript symbols used in STD........................................................................................................98
Final location sites with codes..........................................................................................................100
Italian networks audience sharing....................................................................................................103
Minutes of recording distribution on RD and TV............................................................................104
ABSTRACT
La sillaba è tra le unità fonologiche più controverse della linguistica moderna. Quasi
ignorata dalla fonologia generativa classica, ha assunto un'importanza decisiva nella teoria
fonologica autosegmentale e nei suoi successivi sviluppi (fonologia metrica e prosodica,
Government Phonology ecc.). Parallelemente, in ambito ingenieristico, l'unità sillabica conquista
rilevanti spazi di interesse a partire degli anni Novanta, quando alcuni studi rivelano che a livello
psicolinguistico e fonetico-acustico, la sillaba costituisce un'importante unità sub-lessicale per
l'accesso al lessico e la segmentazione del continuum fonico.
Mentre è riscontrabile una certa omogeneità nella definizione di struttura sillabica,
l'argomento più controverso in ambito linguistico concerne l'individuazione dei principi che
determinano la distribuzione dei confini sillabici. Teorie e principi si sovrappongono in una babele
in cui l'ambiguità delle analisi empiriche non permette di avallare con sicurezza nessuna delle
ipotesi proposte. La sillaba puo' essere definita in termini di preferenze fonotattiche, in base alla
sonorità intrinseca dei fonemi che la compongono, secondo criteri distribuzionali e statistici,
ciascuna definizione implicando un particolare tipo di algoritmo, tecnica o principio di
sillabificazione diverso. Se esista o meno un principio universale ed una sillabificazione
fonologicamente determinata non ci è possibile al momento affermarlo con sicurezza. Un
programma per la sillabificazione come quello sviluppato nella tesi terrà tuttavia conto della
problematica, partendo dal presupposto che solo alcune sillabazioni sono certe, mentre le altre sono
possibili, incerte, improbabili o impossibili in base a quanto i vari principi divergono da un'unica
soluzione. Le scelte finali quindi, sia a livello linguistico che computazionale, saranno dettate
soprattutto dall'obiettivo finale della tesi: la creazione di un programma per sillabificazione
fonologica di un corpus di parlato allineato al segnale.
Nel capitolo I, si delinea a grandi linee lo status della sillaba nello sviluppo delle teorie
fonologiche moderne: in un primo momento si è cercato di fornire una descrizione della sillaba in
accordo con le teorie fonologiche non lineari che ne prevedono una strutturazione interna. Nella
seconda sezione, si è mostrato in ambito prevalentemente storico l'approccio al problema da diverse
prospettive, da quella generativa classica a l'Optimality Theory, mostrando come da semplice tratto
fonemico la sillaba sia divenuta unità fonologica fondamentale in numerose teorie fonologiche
contemporanee. Nella terza sezione, diverse rappresentazioni e assunti teorici hanno portato a
delineare alcune metodologie e principi di sillabificazione, che sembrano confermare l'assunto
secondo cui ad un nucleo di processi fonologici deterministicamente definito si oppone una
periferia in cui l'applicazione dei fenomeni fonologici risultà più vacua ed incerta. Nel capitolo II,
una breve introduzione epistemologica si propone di costituire l'assunto per la descrizione di due
modelli computazionali: uno di tipo simbolico o definito dalla codifica computazionale di regole
fonologiche, e un altro sub-simbolico, basato invece sull'estrapolazione da corpora di regolarità e
strutture prevalentemente fonotattiche. I principi e le teorie illustrati nel primo capitolo vengono
coniugati con i modelli computazionali analizzati, conducendo ad un'analisi critica sulla
compatibilità e coerenza dei modelli computazionali con le teorie fonologiche. Analizzato lo stato
dell'arte della disciplina in ambito sia linguistico che informatico, nel capitolo III viene descritto il
corpus CLIPS. L'argomento merita un capitolo a sé in quanto il principio e le finalità del corpus
stesso, e quindi dei dati da sottoporre ad analisi, definiranno la scelta dei principi di sillabificazione
adottati durante la fase di progettazione del programma. Oggetto della sillabificazione è il livello
fonematico del corpus, allineato temporalmente al segnale. Inoltre, come evidenziato nel documento
di presentazione del corpus, uno degli obiettivi di un corpus di parlato quale CLIPS è “la
predisposizione di strumenti applicativi che servano come base per la realizzazione di sistemi di
riconoscimento del parlato e di produzione di voce sintetica di buona qualità.” Si è quindi scelto di
prediligere un tipo di sillabificazione di tipo semi-acustico. Il principio di sonorità è stato notato
essere l'unico tra quelli analizzati in letteratura a riflettersi nel segnale, in particolare sotto il profilo
dell'energia. L'applicazione stretta del principio su una sequenza fonematica prevedeva comunque la
risoluzione di alcuni problemi di sillabificazione, alcuni ampiamente trattati in letteratura (nessi sC,
geminate), altri meno discussi (risillabificazione, sequenze di vocoidi). Alla base delle scelte vi è
stata l'aderenza a fondamentali esigenze linguistiche, riflessa nell'adozione di un principio
ampiamente supportato dalla fonologia, e le finalità del programma, ovvero la sillabificazione di un
corpus di parlato allineato al segnale. La soluzione più semplice ed elegante è consistita
nell'applicare senza eccezioni il principio di sonorità e rilegare invece nell'assunto ampiamente
accettato in letteratura che la scala di sonorità ammette variazioni linguospecifiche. Si è quindi
constatato che cambiando il valore di sonorità dei fonemi /s/ e /r/ le sillabificazioni ottenute
presentavano un'ottima organicità e che, anche nei casi dei nessi più problematici, si ottenevano dei
risultati molto incoraggianti sia a livello linguistico che computazionale. Perfino nella
sillabificazione dei nessi non nativi, nonostante si sia deciso a priori di non tenerne conto per motivi
teorici di indecidibilità e di praticità, in quanto completamente assenti nel corpus. Sempre
attenendosi al suddetto principio, le finalità del sillabificatore hanno spinto a prediligere la
tautosillabicità all'eterosillabicità dei nessi sC e delle geminate. Favorendo la prima infatti si è
ottenuto una minore varietà di sillabe, si è evitato il problema dell'extrasillabicità tout court, si è
ottenuta la possibilità di riconoscere e distinguere a posteriori le sillabe geminate da quelle scempie,
si è ridotta la variabilità delle strutture sillabiche presenti nel corpus. Seppur discutibile a livello
puramente fonologico, la soluzione adottata si è dimostrata essere la più valida per le finalità del
sillabificatore, che in tal modo è in grado di associare il maggior numero di informazioni possibili al
minor numero di porzioni di segnale e senza dover ricorrere a regole, eccezioni o risillabificazione
post-lessicale per includere i segmenti extrasillabici. Le sillabificazioni ottenute sono perfettamente
adatte all'analisi automatica del segnale, permettendo di soddisfare uno degli scopi fondamentali del
progetto CLIPS: la possibilità di disporre di un'importante risorsa per il trattamento automatico del
parlato.
Ciononostante, per verificare il valore innanzitutto fonologico dei principi adottati, è stato
necessario dimostrare la corretta sillabificazione delle geminate e dei nessi sC, trattati come
tautosillabici per meglio attenersi alle finalità del programma. Il principio di sonorità è stato quindi
considerato nella sua forma restrittiva, che prevede l'unità sillabica fintanto che la sonorità decresce,
escludendo quindi i casi di sonorità piatta. Rispettando questa interpretazione del principio, si è
ottenuta una sillabificazione perfettamente aderente alla teoria fonologica, ivi incluso il rispetto
dell'eterosillabicità di nessi sC e geminate, senza introdurre eccezioni o modifiche di sorta al
principio e alla scala di sonorità precedentemente proposti. I risultati ottenuti si dimostrano essere
ancora più importanti a livello linguistico: il solo principio di sonorità predice un sistema di
sillabificazioni avallato dalla letteratura fonologica, senza alcuna eccezione se non le variazioni
ammesse alla scala di sonorità. Non è necessario assumere che i parlanti ricorrano ad operazioni
aritmetiche per determinare la sillabificazione di alcun nesso, né introdurre ulteriori principi o
condizioni contestuali. Inoltre, mantenendo la stessa scala di sonorità e cambiando il valore di /s/ da
1 a 0 si ottiene l'interpretazione tautosillabica del nesso sC, anche in questo caso non risultante in
segmenti extrasillabici all'interno di parola, come già descritto nel caso di /e.kstra/. L'ipotesi di
Bertinetto (1999) sullo slittamento diacronico del nesso sC da eterosillabico a tautosillabico,
potrebbe quindi, sotto questa prospettiva, essere giustificato e spiegato in termini di perdita di
sonorità del fonema /s/.
Il programma è stato sviluppato in Python, insieme ad un'interfaccia ad hoc basata su NLTK
che permette l'interazione, la codifica e l'analisi dei dati presenti nel corpus. Un maggiore
approfondimento di alcune problematiche è sicuramente necessario, ma i risultati ottenuti aprono
sicuramente la strada a numerose altre possibilità di studio ed ambiti di applicazione.
ACKNOWLEDGEMENTS
11
ACKNOWLEDGEMENTS
First and foremost I would like to thank my advisor, Renata Savy, for her patience, support
and advice. My profound ammiration goes to her for having introduced me to Linguistics. Thanks
to Franco Cutugno, for his continuous support and for opening his NLP laboratory to me. Without
them this thesis would never have come about.
I will never sufficiently thanks all my friends, especially Rocco and Gabriele. They have
helped me in so many ways it would double size this thesis to thank them as they would deserve.
Thanks also to Carmen and Vito, that made me graduate, to the whole 'Poznan cool egg' group for
giving me the best generative holiday of my life, to my new friends in Pisa and to the old ones in
Warsaw. Thanks to my family for supporting me.
Thanks to Jerzy Rubach, Piotr Banski, Markus Poechtrager, David Pesetsky and to all the
scholars who have given me hints and stimuli. A special thanks also goes to Karolina Iwan for the
endless discussions of Optimality Theory.
Syllable and Syllabification
1
1
12
Syllable and Syllabification
Syllable
The term ‘syllable’ is defined by the Merriam-Webster dictionary as “a unit of spoken
language that is next bigger than a speech sound and consists of one or more vowel sounds alone or
of a syllabic consonant alone or of either with one or more consonant sounds preceding or
following.” The definition of syllable is controversial as much as the concept itself. To define the
term the adjective syllabic is used and there is no clue on how to distinguish phonematic sequences
from syllables. As I will show in this chapter, the definition of the Merrian-Webster reflects two
main points regarding a phonological debate that has not lasted yet: what is the syllable and how to
define its boundaries. In this paragraph, I will introduce basic concepts about syllable structure. In
the second paragraph, various syllabification principles will be analysed. In the third paragraph, I
will show how the concept of syllable has evolved through some phonological theories.
1.
Syllable Structure
While a linear approach to the syllable was adopted by linear phonologies, for instance in
structuralism, SPE and in otehr notable examples such as Kahn (1976), Clements and Keyser
(1983), the binary structure in image 1.1 could be considered the most found in the phonological
theories treated on this chapter1. It is made of:
➢
the onset, which is one or more consonants preceding the nucleus
➢
the nucleus, which is obligatory in all languages and constitutes the core of the syllable.
Usually vowels in the form of monophthong, diphthong, or triphthong. Some languages may
also allow sonorants as nuclei2:
➢
the coda, which is one or more consonants following the nucleus in the syllable;
1 Other notably descriptions are moraic (Hyman 1985, Prince 1986, Hayes 1989) and ternary branching : σ → Onset
Nucleus Coda (Hockett 1955, Haugen 1956, Davis 1985)
2 For example the word 'little' in RP.
Syllable and Syllabification
13
➢
the rime, which is obligatory and group together nucleus and coda;
➢
the syllable, which include rime and onset. It is generally indicated with a σ (sigma).
Image 1.1: Tree representation of a CVC syllable3
Nonlinear representation of the syllabe was inspired by a new approach to phonology4, and helped
improving the formalisation of other known phonological processes. Syllable structure for example
was used to describe how two words echo one another by means of rhyme, assonance, consonance
and alliteration. Rhyming words will have the same rime in the last syllable, an assonance could be
described as two words having the same last syllable nucleus and so forth (see table 1.1).
Example
Onset
Nucleus
Coda
Rhyme
pill, mill
Different
Same
Same
Assonance
cap, hat
Different
Same
Different
Consonance
silly, Sally
Same
Different
Same
Alliteration
silly, solar
Same
Different
Different
Table 1.1: Rhyme, assonance, consonance and alliteration
To represent the structure of syllables, phonemic segments are usually reduced both to 'C' for
consonantal phonemes or as 'V' to indicate vowels. More specific phonemic properties (such as
features) may be used according to the referring theory to describe phonotactic constraints on
syllabic position (see image 1.2).
3 This hierarchical representation of the syllable was proposed by the autosegmental theory.
4 I will focus on Autosegmental theories later on this chapter.
Syllable and Syllabification
14
Image 1.2: Tree representation of the Italian syllable structure5
It has been argued that preferred syllable structures are either CV or V and CV structure has
even been considered as a Linguistic Universal by Blevins (1995). Recent works on Government
Phonology also suggest that first some kind of templatic languages are CV only and then, as in
Lowenstamm (1996), that “syllable structure universally, i.e., regardless of whether the language is
templatic or not, reduces to CV”. CV In Italian, French and Spanish CV structure has at least 50%
frequency (Vogel, 1993) and it is universally the least marked, so that in some languages no other
configuration is allowed. For example, in Boumaa Fijian all syllables are either CV or V and if a
word is loaned from other languages epenthetic segments might be added to reduce to those syllable
structures. This is the case of loanwords such as koloko and aoopolo, from the English cloak and
apple (Zec, 1995). On the other hand, some languages allow syllables with complex onsets and
codas. For example, English syllables can be sCCVCCC and word-finally even more can occur in
the coda; German syllables can be SCCVCCC like in springst. However, in most cases codas are
severely restricted. In Lardil and Ponepean languages, syllables are maximally CVC with restricted
coda, and many Chinese languages are CGVC. In Italian, syllables can be maximally sCCVC,
within the coda generally limited to sonorants or /s/. However, some Italian words, such as the
5 adapted from Nespor, 1993
Syllable and Syllabification
15
acronym CAP. /kap/ - 'post code', or borrowings from Germanic languages (e.g., en. /kart/) may
include non-sonorant or complex codas, thus resulting in possible sCCVCC structures.
2.
Syllable Weight
Syllables can be furthermore grouped according to their weight. A heavy syllable is VV(V)6,
V: or VC, that is, the rime contains more than one segments. A light syllable instead has no coda
and a simple nucleus (i.e., composed by either a short vowel, a sonorant, or generally by a single
segment). For example V and xCV syllable are considered light syllables. In some languages only
the nucleus account for the weight of the syllable. In such a language, a syllable with a coda – as
CVC – would be considered light as well. Traditionally it was supposed that weight criteria - even if
they may differ from language to language – are uniform in the same language (McCarthy and
Prince 1986, Hayes 1989). In a recent study Matthew Gordon (2004) argued that '[…] weight
criteria are frequently non-uniform within a given language.' (Hayes, 1989; Goldsmith 1999)
Syllable weight may be represented differently according to the given theory. I will take as
an indicative example the representation of syllable weight in moraic theory. Image 1.3 shows three
syllables, two heavy – CVVC and CVC – and a light CV. Mu (Greek: μ) indicates a segment
weight. The first syllable is heavy because the vowel is long and therefore bimoraic; the second
syllable because has two segments in the coda and then two moras.
Image 1.3: Syllable weight representation in moraic theory
Syllable weight has played an important role in recent studies, in particular to describe stress
6 Dipthong, triphthong or a long vowel
Syllable and Syllabification
16
assignment (Waltermire, 2004) and African tonal languages. It also had a crucial role in classical
metric and has been used for the description of some important Italian phonological phenomena
such as Raddoppiamento Sintattico, il/lo allomorphy and vowel lenghtening (see paragraph 2).
2
Syllabification
Syllabification can be simply defined as the separation of a word into syllables. In this paragraph I
will start by analysing theoretical effort of prescriptive grammarians to define some syllabification
rules that could be useful to divide orthographic words into syllables. I will show that while these
principles are mostly non-linguistic in English, where spelling differs greatly from the
pronunciation, in Italian they are closer to phonological principles and empirical evidence.
Descriptive linguistics have tried to formulate some formal principles to account for the syllable
division problem. But while counting the number of syllable of a word is a simple task for any
speaker of a language, the description of this speaker ability and an accurate identification of
syllable boundaries is still a debated problem. I will also show results of some experiments based on
corpora and on speaker competence that are supposed to give a psycholinguistic value to syllable
division. Finally, I will summarise in a table how each of these approaches results on dividing
consonantal clusters (on which there is the most disagreement). In paragraph 3 I will analyse how
these principles (in particular the descriptive ones) have been formalised in generative theories.
1.
Orthographic Syllabification
In English, as an effect of the very weak correspondence between sounds and letters in the
spelling, orthographic and natural syllabification are usually fairly different. The word ‘learning’ for
example is syllabicated learn-ing instead of lear-ning, despite the fact that, in spoken language, the
word would have been syllabified as the latter. Orthographic syllabification is mostly nonphonological and is considers not only the phonemic sequence, but also the etymology of the word,
its morphological constituents, the ambiguity of possible pronunciation due to spelling
Syllable and Syllabification
17
idiosyncrasies and so on.These syllabifications are the ones taught at school and used in music
scores or in written texts. The same problem arises for Italian. Most of the dictionaries that display
syllabic information are controversial (McCrary, 2004) and adopt the following rules, as indicated
in prescriptive grammars or dictionaries (Sabatini and Coletti, 1997; Serianni, 1989; Lesina, 1986)7:
➢
CV.CV - if only a consonant precede the nucleus, the consonant goes in the incipit;
➢
VC.CV - geminates are separated, one belong to the preceding nucleus, the other to the
following;
➢
V.CCxV8 - if intra-vocalic consonants are different and CCV is word-initial the cluster
belong to the second syllable;
➢
VC.CxV - if CCV does not appear word-initially the cluster is divided after the first
consonant, which goes in the coda9;
➢
Vx - vowels are never divided if they form a diphtong (CVVC). On the other hand, if they
form a hiatus they are divided. xV.Vx. Glides always belong to the following vowel syllable
(i.e., go in the coda);
➢
x.sCx - 's' before a consonant, if it is not geminated, always belongs to the incipit of the
following syllable.
These rules have had a few importance in formal linguistics. Their formal weakness lies in
the fact that they are not justified by any internal or external phonological evidence but they are
imposed as a set of rules to take as they come.
7 These rules are used to divide graphemes. However, digrams and trigrams are considered as a single unit and always
belong to the same syllable.
8 With 'x' I indicate one or more optional occurrence of the previous symbol. For example Cx indicates that a
consonant may be followed by zero, one or more consonants.
9 Note that in Italian the coda allows only one consonant. Hence, VCCxV will always be syllabified as V.CCxV or
VC.CxV
Syllable and Syllabification
2.
18
Sonority Scale
The first formal principle to be found in the literature is probably the Sonority Sequencing
Principle (SSP). The SSP is based on the Sonority Hierarchy10 (SH), which ranks phones by
sonority. In articulatory phonetics least sonorous phones are the ones produced with a minor
opening of the vocal tract while in acoustic phonetics they are described as characterised by a minor
magnitude. The syllable is then defined as a sequence of speech consisting of a sonority peak and
margins of sonority which decrease. Image 1.4 shows a possible SH and the syllabification of the
word 'candle' in accordance with it. (Selkirk, 1984; Jespersen, 1904; Sievers, 1876). A common and
longly disputated problem in Italian is whether geminates are tautosyllabic or heterosyllabic.
Generally, a strict interpretation of this principles would require them to be divided as the segments
would otherwise form a sonority plateau and therefore sonority would not decrease (Image 1.5). But
at the acoustic and articulatory level Italian geminates are evidently a single unit, which could be
hardly divided. It is evident that in languages like Italian, geminates11 are realised whithing the same
“chest pulse” and at the acoustic level the energy keeps decreasing without interruption during the
production of the entire sequence.
Image 1.4: Sonority representation of the word 'candle'
10 The term Sonority Scale is also used.
11 Produced as a long consonantal sound. In other languages each consonant is produced with a single and complete
articulation of the sound, i.e., [an.na] instead of Italian [an:a]. In this case, even at an acoustic and articulatory level,
geminates are probably heterosyllabic.
Syllable and Syllabification
19
Image 1.5: Sonority representation of the word 'gatto'
Sonority
Type
Voiced
1 (lowest)
Plosives
no
yes
2
Affricates
no
yes
3
Fricatives
no
yes
4
Nasals
yes
5
Liquids
yes
6
Approximants
yes
7
High vowels
yes
8 (highest) Non-high vowels
yes
Table 1.2: Sonority Hierarchy
Sonority
Segments
Sonority
Segments
1
Occlusives
5
Glides
2
Fricatives
6
High vowels
3
Nasals
7
Medium vowels
4
Liquids
8
Low vowels
Table 1.3: Coursil's Sonority Scale
Syllable and Syllabification
20
Coursil's (1992) syllabification system for French was based on a SH more similar to
Saussure's (1914). Table 1.3 shows that the author divided vowels in three groups and used vocal
tract aperture to discriminate sonorities. To each segment in the sequence was assigned a binary
value (called plosion value) which could be 1 if the sonority decreased or 0 if not. Syllable
boundaries were then placed whenever this value changed from 1 to 0. For example the French
word moustique 'moustique' was syllabified 'mus.tik' as in table 1.4.
m u s t i k
Aperture ranks
3 6 2 1 6 1
Plosion values
0 1 1 0 1 1
Table 1.4: Syllabification of the French word 'moustique' according to Coursil (1992)
3.
Sonority Distance
A SH proposed by Davis (1990) for Italian is showed in table 1.5. According to Davis
(1990), in Italian a consonant cluster violates the sonority principle and is heterosyllabic if the
distance between two phoneme is less than four. Otherwise the cluster is tautosyllabic. VCCxV will
be syllabified as VC.Cx if the sonority of C1 => 4, V.CCxV if s(C1)- (C1) > 4. For example the
word padre 'father' will be syllabified as pa.dre, because the sonority distance between /d/ and /r/
reaches +4:
/padre/ → Sonority(p) – Sonority(r) ≥ 4 → tautosyllabic→ pa.dre
While 'pasta' as pas.ta:
/pasta/ → Sonority(s) – Sonority(t) < 4 → heterosyllabic→ pas.ta
A similar principle was also used by Peereman's (1998) on his syllabification model for
French. According to his sonority scale, the distance necessary to have syllable boundary is three.
Principle based on an relative interpretation of the SH are generally called Sonority Distance
Principles.
Syllable and Syllabification
21
Sonority
Segments
Phones
1
Voiceless stops
/p, t, k/
2
Voiced stops
/b, d, g/
3
Noncoronal fricatives
/f, v/
4
Coronal fricatives
/s, S/
5
Coronal Nasal
/n/
7
Noncoronal Nasal
/m/
8
Liquids
/r,l/
9
Vowels
/a, e, i, o, u/
Table 1.5: Davis (1990) Sonority Scale for Italian
4.
Phonotactical Constraints
Other widely accepted syllabification principles are based on phonotactical assumptions.
The main point, as expressed by Pulgram (1970), Hooper (1972), Kahn (1976) lies in the fact that
possible codas or onsets are only that phonotactically possible word-initially or word-finally. This
principle is based on two assumptions: firstly that only medial clusters that could be analysed as a
word-final followed by word-initial exist in language and secondly that speaker intuition tends to
divide syllable in units that match these phonotactical constraints. This same principle was
developed by Kahns into the Maximum Onset Principles (MOP) which regulate the distribution of
ambiguous intervocalic consonant cluster. This principle is based on the fact that CV syllables are
the preferred ones (i.e., the least marked) in all languages. For example, this principle accounts for
the division of V.CV instead of VC.V. Ambiguous intervocalic consonant clusters are also
syllabified according to the principle. For instance, in a sequence VCCV the application of the MOP
will give V.CCV if CCV is a possible word-initial cluster or VC.CV otherwise.
5.
Internal Evidence
Studies have justified the necessity of the syllable in the phonological theory by discussing
phenomena that for the best description would require this unit to be postulated 12. In Italian
12 I will give an example in the next paragraph, where phonoogical theories will be threated
Syllable and Syllabification
22
literature most work has been based on three phonological processes: Raddoppiamento Sintattico
(RS), Vowel Lengthening and il/lo Allomorphy.
➢
Raddoppiamento Sintattico (RS): the gemination of a word initial consonant if the preceding
word meets some conditions which vary from Italian variety to variety. RS is syllable
sensitive because – in some theories - only tautosyllabic clusters on the second word seems
to undergo the RS. For example, metà [s]carpa vs metà [k:]oso. (Vogel, 1982; Chierchia,
1982, 1986; Repetti 1989, 1991)
➢
Vowel Lenghtening: the lengthening of a vowel if it is stressed, not word final and belongs
to an open syllable. For example ['ka:.sa], but ['kar.ta] or ['pas.ta]. (Chierchia, 1982, 1986;
Nespor and Vogel, 1986; Nespor, 1993; Vogel, 1977, 1982).
➢
il/lo allomorphy: the selection of the definite article allomorph il or lo before various word
initial consonant cluster. lo is claimed to heterosyllabic cluster while il prefers
tautosyllabicity. For example, [los.karpone] but [il.korpo] (Davis, 1990; Marotta, 1993)
The convergence of multiple phonological processes on the same syllable structure is argued
to provide evidence for the claimed syllabifications. For example, in a VCCV sequence, supposed
that vowel lengthening occurs on open syllable only, the syllabification would be V.CCV13 if V is
lengthened on that context or VC.CV otherwise.
6.
External Evidence
Various efforts have been made in the literature to give external evidence to language
syllabification and structure. For example, Bertinetto (1999) analysed how the sC cluster is treated
by 20 speakers from the University of Pisa using some permutation tasks (syllable reduplication and
substitution) and found that, despite the descriptive phonological prevision14, sC are treated more
13 Note that the vowel lengthening in Italian, requires the stress to be assigned. will not indicate stresses for the sake of
simplicity by now.
14 Previous study analysing the convergence of il/lo allomorphy, RS and vowel lenghtening brought to a generally
agreed heterosyllabicity for sC clusters.
Syllable and Syllabification
23
like a tautosyllabic cluster V.sC. Caldognetto also got contrastive results analysing a corpus of 2500
speech errors. In fact, while for consonant substitution tautosyllabic sC cluster was suggested, in
deletion and insertion errors heterosyllabic clusters were probably detected by speakers.
An exhaustive study on consonant cluster syllabification was recently made by McCrary
(2004). Using various tasks she tested a 51 Pisan subjects. The experiments aimed to verify:
➢
how native speakers treat consonant clusters
➢
if segment duration (vowel lengthening and RS) and definite article allomorphy (the three
phonological process listed in the previous section) really converge on syllable structure
According to McCrary (2004) the results obtained shows that “the standard syllable-based analyses
of consonant cluster divisions, definite article allomorphy and segment duration are not supported
by the experimental evidence.” In a previous study Steriade (1999) argued that syllable division
experiments are influence by phonotactical knowledge of the speaker, in particular for the division
of consonantal clusters. Word edge knowledge is claimed to be used to divide words in syllables, so
that given a syllable-initial/final segment there is a word of which the first/final segment is the
syllable-initial/final segment. According to the theory, speakers should show uncertainty about the
syllabification of Italian /s/ because the phoneme is a possible word-initial and word-final segment.
The theory seems to be partially confirmed by McCrary (2004) which states that the word-based
syllables strategy and the phonotactical-constraint satisfaction strategy appear to be adopted by
speakers, as it emerge from the result of his tests. In fact he states that “ […] ambiguous and
contrastive syllabification were given in the case the two principles contrasted ”
7.
Comparison of Principles
I show in table 1.6 all consonant clusters analysed and tested by McCrary (2004) and I will
compare them with syllabification obtained by the application of the other principles in the
paragraph. I will start with native clusters (i.e., Cl, sC, sL, sN, LC, NC) where major accordance is
Syllable and Syllabification
24
given and then I will proceed to the more problematic non-native clusters. A brief summary of the
proposals follows:
➢
MOP: Maximum Onset Principle includes word-initial condition. In a CC cluster if CC is
word initial then the cluster is tautosyllabic. For example is syllabified as pa.dre, as /dr/ is a
possible word initial cluster.
➢
SSP: sonority decrease from nucleus to margins. For example, mir.to as /t/ is less sonorous
than /r/. But la.dro because /r/ is more sonorous than /d/.
➢
SD: if the sonority distance according to Davis' SH is major than 4 the cluster is
tautosyllabic. pas.ta is heterosyllabic because the distance between /s/ and /t/ is +3.
➢
Experimental evidence: the first value indicates how many speaker treated the cluster as
tautosyllabic, the second as mixed and the third as heterosyllabic. The pattern is
tauto/mixed/hetero as for the cluster /nd/ which is indicated as 12/22/22.
➢
Dictionary: DISC syllabification is also given.
Syllable and Syllabification
Cluster
Experiment
SSP
SDistance
Garzanti
CL:pl,kl, aeroplano,
pr,tr,kr, padre,litro,
dr...
ecc.
40/2/5
tauto
pa.dre
yes
tauto
pa.dre
6
tauto
pa.dre
tauto
pa.dre
sC:sp,st, caspita,
sk,sb
pasta,kasko,
ecc.
25/6/16
tauto
pa.sta
no
hetero
pas.ta
3
hetero
pas.ta
tauto
pa.sta
sL:sl sr
20/11/16
tauto?
di.slessia
yes
tauto
di.slessia
3
hetero
tauto
dis.lessia di.slessi
a
sN:sn, sm nichilismo,
masnada,
bisnonno,
18/4/25
hetero?
bis.nonno
yes
tauto
bi.snonno
1
hetero
bis.nonno
tauto
bi.snonno
LC:rp,rt, korpo,
rk,lp,lt, arto,arko,
lk
alto, ecc.
0/0/47
hetero
ar.to
no
hetero
ar.to
6
tauto
ar.to
hetero
ar.to
Cn:pn,
tn, kn
9/12/26
hetero
tek.nika
yes
tauto
te.knika
4
tauto
te.knika
hetero
tek.nica
CT:pt, kt sinaptico,
ektoplasma
penectomia
7/16/24
hetero
sinap.tiko
no
hetero
sinap.tiko
0
hetero
hetero
sinap.tiko sinap.tik
o
Cs:ps,ks
micropsia,
kapsula,
rokstar
8/11/28
hetero
kap.sula
yes
tauto
ka.psula
3
hetero
kap.sula
tauto
ka.psula
ft
lifta,lifting
, nafta
9/10/28
hetero
naf.ta
no
hetero
naf.ta
2
hetero
naf.ta
hetero
naf.ta
tl
atletico,
atlante,
genetliako
26/12/9
tauto
a.tlante
yes
tauto
a.tlante
6
tauto
a.tlante
tauto
a.tlante
GM:dm,gm
kadmio,
segmento,
dogma
6/10/31
hetero
dog.ma
yes
tauto
do.gma
4
tauto
do.gma
hetero
dog.ma
bn
abnorme,
abnegare,
subnukleare
4/15/28
hetero
ab.norme
yes
tauto
a.bnorme
3
hetero
ab.norme
hetero
ab.norme
afnio
8/16/23
hetero
af.nio
yes
tauto
a.fnio
2
hetero
af.nio
hetero
af.nio
fn
Word ex.
25
bislakko,
dislessiko,
israele
apnea, etnia,
teknika
Table 1.6: A comparison of possible CC cluster division strategies (adapted from McCrary 2004)
Syllable and Syllabification
8.
26
Conclusion
Unanimous syllabifications are given for CL, LC, NC. The most interesting aspect of that
consensus is the fact that there are also the only clusters in which speaker operated an omogeneus
and unanimous division. For the CL cluster 40 people syllabified it as tautosyllabic, only two gave
mixed responses and five threated it as heterosyllabic. Other clusters are even clearer showing
0/2/45 for LC clusters and an impressive 0/0/47 for NC. The fact that the consensus from
phonological theories coincide with experimental evidence only in this cases demonstrates that
there is a real convergence between the principles and that phonological basis probably exist.
Other interesting cases are the ones which concern the syllabification of sC cluster. I have
already cited studies on which the contrastant treatment of sC arised from the analysis of
phonological phenomena, corpora and experiments. Considering table 1.6 further evidence of
syllabification discrepancies is given. It is interesting to note that the only divergent phonological
principles are the experimental and the dictionary. The syllabification of sC as tautosyllabic might
then be due to an interference of the orthographic syllabification learned at school. Additional
evidence to such hypotesis comes from the fact that children tend to split out the cluster and to the
special place of /s/ on the syllable structure (remember it can go in the coda even if it is not a
sonorant) and from the various experiments and studies already cited. In the next paragraph we will
also show how an algorithm based on phonotactical context confirm the uncertain behaviour of sC.
Various syllabification techniques have been proposed in this paragraph, but while there is
convergence on detecting syllable number and a core area on which syllabification is easily
predictable, some cases are still debated and unresolved. The reason to this uncertain syllabification
might be due to various factors:
•
the non deterministic nature of phonology or linguistics itself, thus leading to a broad
theoretical discussion I wanted to avoid;
Syllable and Syllabification
•
27
to the non necessity of the speaker to face that problem, that is to have the possibility to
have rules which do not account for every possible cases of a language, simply because they
are not relevant to that language or do not occur frequently enough, that might be the case of
non native clusters which do not appear even once in CLIPS;
•
to the interference or interaction of various component in speakers' competence and
knowledge of its language, such as the phonotactic ability, the sonority scale principle and
orthographic hints, as is in my opinion clearly emerges from McCrary (2004) data;
•
a diachronic change in act in the language, such as for the sC cluster, whom ambiguity is
argued by Bertinetto (1999) to be due to a diachronic shift of the cluster from
heterosyllabicity to tautosyllabicity.
Syllable and Syllabification
3
From SPE to Optimality
1.
SPE Rules
28
Most of the classical generative phonology (based on SPE15) was based on the analyses of
the discrepancies between Mental and Surface representation. Mental or Underlying
Representation (UR) includes unpredictable and contrastive language information, while the
Surface Representation systematic and predictable one. The discrepancies between Surface and
Mental representations are accounted in derivation using a set of rules (whose order of application
has to be specified) which, applied to the UR will result in the surface form. Rules are formalised in
formulas similar to the following:
A → B / C__ D
Which could be paraphrased as:
A becomes B if preceded by C and followed by D.
Each rule defines a Structural Description, which consists of a class of possible context - CAD in
this case - and of a Structural Changes, which are the derivation rules to apply when the context is
met. Variables are usually expressed in the form of distinctive features or phones, but other symbols
are also found (the first two loaned from the Chomsky and Halle's syntax works):
➢
# indicating a word margin
➢
+ indicating a morpheme boundary
➢
C or V indicating a consonant or a vowel
For example, the nasal assimilation rule for Italian was described by the rule in image 1.6 which
could be paraphrased as following. Total Nasal Assimilation: nasals totally assimilate the
following sonorant traits before morpheme boundaries.
15 The Sound Pattern of English (1968), Chomsky and Halle's phonology work which stands as a landmark for any
generative work on Phonology.
Syllable and Syllabification
29
Image 1.6: Nasal assimilation rule
Features with Greek letters indicate that the two segments share the same value. For
example, if [αant] is positive in the context the derived segment will have the same value. As the
name of the rule suggests, assimilation consist on the assimilation of some traits by an adiacent
segment.
The derivation of the word /illegale/ would be the following:
//in+legale//
UR
/il+legale/
Total Nasal Assimilation
/illegale/
Surface Representation
2.
The Syllable in SPE
The application of SPE principles to the most various languages, made an unlikely context
appear more recurrently than expected. For example, the alternance in France of [e] and [ɛ] (e.g.,
ins[eR]é, ins[ɛR] and ins[ɛR]sion) was described with the rule in image 1.7. But the same rule
does not apply to many words which match the CC context, such as [mepRiz]er, [səvr]er and so
forth. Moreover, even in typologically different languages the same context frequently recurred. For
instance, English dark and clear /r/ alternate in the same context as well as many phonological
phenomena in Turkish, such as epenthesis, final devoicing and vowel shortening (Clements and
Keyser, 1983). The recurrence of these two unrelated contexts (word-margin or a consonant) in
different languages can not be casual. The adoption of the syllable provided the most elegant
solution to the problem. For example, the French rule can be rewritten as in image 1.8, with the
Syllable and Syllabification
30
dollar sign ($) marking a syllable boundary. Still, linear representation of the syllable was soon
abandoned by most authors in favour of an nonlinear one.
Image 1.7: SPE rule for French [e] and [ɛ] alternance
Image 1.8: SPE rule for French [e] and [ɛ] alternance including syllabe
3.
Autosegmental Theory
During the '70, numerous studies about tones and phonological phenomena which spanned
across multiple segments (such as vowel and nasal harmony) led some linguists to rethink Chomsky
and Halle's theory. For instance, in SPE tones were usually assigned to a segment (generally a
vowel), but many coeval studies about African tone languages showed that tones can be assigned to
a phone, a sequence of phones, a syllable or a phonological word and that the deletion of a segment
would not eventually lead to the deletion of the tone itself (this property being called stability).
Rules still apply (on section 1.2.7 I will show that the Optimality Theory will replace rules with
constraints) but instead of thinking the phonetic representation as a single sequence of segments the
autosegmental theory propose them as a set of autosegments (where auto stands for autonomous,
independent). On such view, phonological representations consist of more then one linear sequence
of segments; each linear sequence constitutes а separate tier of autosegments, also called planes.
The autosegmental theory can be dated back to the framework that John Goldsmith
Syllable and Syllabification
31
submitted in 1976 at the Massachusetts Institute of Technology. Goldsmith developed а formal
account of ideаs thаt hаd been sketched in eаrlier work by severаl linguists, notаbly by Bloch
(1948), Hockett (1955) аnd Firth (1948). Goldmith stated that “phonological representations consist
of more than one linear sequence of segments; each linear sequence constitutes a separate tier”. The
realisation of a segment implies the coordination and the simultaneity of the tiers. In other words,
each tier has to be associated and finally converge on a chronological linear sequence. This tier is
called the skeleton. The skeleton is represented by using neutral X-slots, in which no features or
articulatory properties changes16. Instead, X-slots organise autosegments into temporal units. For
this reason the skeleton is also called timing tier. Note that at no point different tiers merge. The
planes instead are linked together and organised by association lines, which indicate that different
autosegments are simultaneous. Tiers and association lines are always organised according to hard
constraints, which can never be violated. Association lines are drawn according to a series of
principles called Well-Formedness Constraints (Clements and Goldsmith, 1984) and are supposed
to be universal in their specific domain. We have already stated that WFCs can not violate Hard
Constraints. However, some Soft Constraints might be specified. Unlike hard constraints, these
can be violated. If a derivation violates a soft constraints it is not marked as ill-formed. Instead a
Repair Mechanism is specified. In this way phonological phenomena are described 'in terms of
rule that delete and reorganize the various autosegment, through the readjustments of association
lines'. The difference with the SPE lies in the fact that derivation was made by applying a sequence
of rules which directly changed features of linear segments. We will see an example of
autosegmental derivation in the following section.
16 In some literature, mostly on that concerning tones and syllables, it is possible to mark the skeletal tier with C or V
instead of X-slots. I will be using such notation too when necessary.
Syllable and Syllabification
4.
32
Autosegmental Syllabification
In this section I will start by showing the new autosegmental representation of the syllable
(after Goldsmith 1976, 1984; McCarthy 1979, 1981; J. Trommer 2008). Then, I will propose a
minimalistic description of Italian syllabification in an autosegmental fashion. To describe the
Italian syllabification at least two tiers of representation in addition to the skeleton are necessary:
➢
melody: the articulators described in term of features;
➢
syllable: organising X-slots into syllable structure;
The melodic tier is linked to the skeleton according to the following WFCs:
➢
Every skeletal node is linked to a melodic node
➢
Every melodic node is linked to a skeletal node
➢
Every melodic node should be associated to at most one skeletal node
The following Soft Constraint determines whether a segment in the melodic tier is correctly
associated with an X-slot:
➢
Every skeletal node should be associated to at most one melodic node
A Repair Algorithm account for constraints violation:
1. If there are unassociated S-nodes and M-nodes:
Associate S-nodes and M-nodes 1:1 from left to right
2. Else: If there are unassociated S-nodes:
Associate every unassociated S-node S to the M-node to
which the S-node immediately preceding S is associated
Association lines links the melodic to the skeleton tiers straightly. In fact, most of the time
the realisation of a segment in the melodic tier is represented as a single unit in the skeleton, that is
Syllable and Syllabification
33
without violating any constraints. But there are cases in which articulators are not linked one-to-one
to the skeleton and soft constraints are violated. Generally, these combinations are possible17.
➢
one-to-one: this is the commonest case. Each set of traits distinguishes a unit in the
skeleton, like in the representation of the word cane 'dog' (Image 1.9):
Image 1.9: 1 to 1 correspondence between melodic and skeletal tier
➢
many-to-one: even if affricates are considered a single phoneme, the articulation of
affricates is complex, as it implies that the trait [± continuant] changes within the phoneme .
For example, the articulation of /ts/ can be described as the sequence of [t] followed by [s].
The trait [± continuant] shifts in fact from a negative to a positive value in the melodic tier.
However, since in Italian phonological system the sound behaves as a single unit, in the
skeletal tier the affricate /ts/ will be represented as a single segment. Affricates are
represented as in image 1.10.
Image 1.10: Example of a 2 to 1 correspondence between melodic and skeletal tier
17 Others configurations are possible as well, like 0 → many and many → 0 but will not be treated here.
Syllable and Syllabification
➢
34
one-to-many: In Italian an open and debated problem regards the syllabification of
geminates. Following the traditional autosegmental approach, geminates are considered a
single unit in the melodic tier, but as two X-slots. In fact, there is no distinctive feature
change during the articulation of geminates, that is articulators and distinctive features
remain the sames during the production of the speech sound. On the other hand, as
consonantal length in Italian has a phonological and a phonetic value (it serves to
differentiate minimal pairs and is determined by an effective percepted lengthen of the
segment in contrast with same non-geminate segment appearing on the same context) the
melodic segment will be linked to two X-slots as proposed by Danesi (1985) to resolve the
problem of geminate syllabification in Italian. For example, the word 'gatto' is represented as
in the image 1.11:
Image 1.11: Example of 1 to 2 correspondence between melodic and skeletal tier
Well-formedness rules accounting the association of the syllabic to the skeleton tier require
an higher degree of complexity. We will use as the a principle the Sonority distance based on Davis
(90). To correctly represent simplified syllabification in Italian we will need at least the following
rules, adapted from Rubach (1990) proposal for Polish. Rules are stated in their correct order of
application in table 1.7 and an example is given in image 1.12.
Yet, the application of those principles may result in unlinked segment. A repair Mechanism
would be necessary for words which violate the Sonority Scale Principle on word margins like
Syllable and Syllabification
35
skala 'ladder', or for syllable with a complex coda (sport)18. For the last case extrasyllabicity may be
assumed and the segment directly linked to the phonological word, for the former a recursive Onset
rule before Coda Rule might be hypotised (in this case we will have word margin resyllabification
as well). For example, the phrase la skala (the ladder) will be syllabified according to the following
rules:
N-Placement > CV Rule > Onset Rule (Blocked by SSP) > Coda Rule (add /s/ to the first
syllabe) > las.ka.la
If the phoneme /s/ in the word scala is considered extrasyllabic a rule or the repair algorithm stated
above will link it to the phonological word or to the following syllable onset. For example:
N-Placement > CV Rule > Onset Rule (Blocked by SSP) > Coda Rule (No segment, skip) >
Complex Onset Rule19 > ska.la
18 According to Rubach (1986), floating segments are typically not present in the phonetic representation.
19 Complex Onset put other segment in the onset, a positive constraint may allow for specific phonotactical
configuration, such as sCCV syllable in Italian and overcome the SSP.
Syllable and Syllabification
Rule
36
Representation
1
N-Placement: for every vowel on the
melody tier place an N20 in the
syllabic tier
2
CV Rule : If there is something to
the left of an N, it is included
into the onset. In any case, a N”
node is created.
3
Onset Rule: put the remaining
consonants on the onset as long as
they do not violate the Sonority
Scale Principle. It may apply
several times(optional)
4
Coda Rule: put the remaining
consonant in the coda.(optional)
Table 1.7: Autosegmental Syllabification Algorithm for Italian
20 N indicates a node. It is possible to rename the node according to syllable structure consitutents. In this case, the
correspondence is the following:
N → Nucleus
N' → Rime
N'' → Syllable
Syllable and Syllabification
37
An example of the application of the algortihm for the syllabifaction of 'pastrocchio' is following:
Syllable and Syllabification
38
Image 1.12: Autsegmental syllabification step for the word 'pastrocchio'
5.
Metrical Phonology
On a first stage autosegmental theory was used to describe tonal features. However, by the
mid '80 autosegmental theory became a full theory capable of represent all kind of phonological
features. The success of the theory contributed to the creation of two other nonlinear theories: the
metrical and the prosodic phonology. But while Autosegmental phonology began when linguists
failed to account for tonal phenoma in some African languages, metrical phonology was introduced
when the available instruments for the analysis of stress patterns became insufficient.
So forth, generative phonology had represented prominence as a feature [±accent], assigned by
Syllable and Syllabification
39
rules during the derivation to individual vowels as a segmental feature21.
In some cases, stress was further indicated using a discrete numeric scale, defined by syntactic
structures, which came along a single phonetic dimension (Chomsky and Halle, 1968; Halle and
Keyser, 1971;. The following digits were used to mark stresses:
➢
0 – for unstressed vowels
➢
1 – to indicate primary stress
➢
n > 1 for other stresses, with higher numbers indicating a weaker stress
For example, the phrase 'black board'22 is described in the following terms:
And the compound name 'blackbord' as following:
The differences reflect the syntactic structure of the two constituents:
blackboard [[black]A [board]N]N
black board [black]A [board]N]NP
To discuss the intonational system of English, in his doctoral dissertation Liberman (1975)
proposed a new representation of the phonological hierarchy. He organised segments into groups of
relative prominence and into different levels, and assumed stress as a supreasegmental feature.
Stress patterns are then described as a sequence of weaker and stronger constituents, which belong
to different domains and which finally converge on the syllable level. To represent this organisation
21 Another simplification is presented here. In SPE in fact most important stress assigment ru les are at least two: CSR
which applies to strings dominated by a lexical category and NSR to strings dominated by phrasal category
22 In this and in the following examples I will always assume a normal stress. Emphatic stress will not be considered
as it would require a further investigation into pragmatics and marked stress patterns.
Syllable and Syllabification
40
of phonological constituents; units are displayed in trees similar to those used by autosegmental
phonology. The metrical tree for the Italian verb compitare 'to spell out' (Image 1.13) is an
interesting example to show how different stress levels are organised in the representation. As it
emerge from the tree, constituents belong to different levels and are organised into groups of
relative preminence whitin each level. The previous tree included three levels at which strong and
weak constituents are juxtaposed. Those are the phonological word (P-Word or ω), the foot (f) and
the syllables (σ). The syllable dominated only by strong constituents (all up the tree) is called
Designated Terminal Element (DTE) – red in the prervious tree - and is the one bearing the primary
stress.The geometry of metrical tree is defined by principles, which may differ among authors (as
well as the layout). For example, in Vogel (1986) a rule states 'trees have an n-ary ramification', but
some theories may assume a restricted binary represantion only.
Image 1.13: Metrical tree for the word 'compitare'
Syllable and Syllabification
41
To represent different levels of prominence, the metrical grid is also used.
X
X
X
X
X
X
X
com
pi
ta
re
The more Xs in a column the more prominent the syllable is. The syllable with the major
number of Xs is the DTE. The three levels showed above are not the only the ones included in the
theory. The necessity of new levels and units was generally justified when it appears as domain of
application of phonological phenomena. Moreover, as explicited in the phonological grid, in
metrical phonology each level defines an additional word accentual level. For a comprehensive list
of levels see image 1.1423 (adapted from Selkirk, 1986; Vogel and Nespor, 1986).
Image 1.14: Phonological hierarchy24
23 Phonologists may disagree on the arrangement and inclusion of units in the hierarchy. As it is of no interest for this
thesis arguing the existence of any level, I will assume that the necessity of every level is justified.
24 In this thesis I will not focus on units from P-Word upwards. Instead, in the next section I will better illustrate the
mora and the foot level, which are important for some syllable based phonological analysis.
Syllable and Syllabification
6.
42
Foot, mora and P-Word
As said, vowel lenghtening and RS is argued to be triggered by the FOOTBIN25 constraint,
which states that Feet must be binary at either the mora or syllable level (McCrary 2002; Prince and
Smolensky; 1993; Vogel 1982). For example, in the case of 'kasa' vowel lenghtning occurs to avoid
FOOTBIN violation. A light stressed syllable lenghtens to create a bimoraic heavy syllables
[L] → [H]:
In the case of 'pasta' instead there is no vowel lenghtening , therefore /s/ is assumed etherosyllabic.
In fact, the /s/ being in the coda results in a syllable which is already heavy and do not need to
lenghten. The same is true for all the other hetherosyllab clusters, such as [kar.ta] and [al.to].
Word final stressed vowel do not undergo vowel lenghtening because of another
rule/constraint which forbids word-final long vowels (Vogel 1982, Chierchia 1982, 1986, Davis
1990). Therefore, 'papà' is CVCV, while 'papa' CV:CV. To satisfy the foot binarity principle then,
the consonant following the stressed vowel is lenghtned instead of the vowel itself. Concerning
syllabification the same is true for RS. Argued tautosyllabic consonants do not cause RS as the
heavy syllable is given by the resyllabification of the consonant which goes in the coda. In 'metà
morto' RS double the second word first consonant. Foot binarity violates light stressed syllable but
being vowel lenghtening forbidden word-finally resylabification puts /m/ in the coda, which results
in the the form cit.tàm.mor.ta. On the other hand, in 'ctttà sporca' stressed /a/ is lenghtened by
resyllabification of /s/: cit.[tàs].por.ca.
7.
Optimality Basic Principles
As showed in 1.3.1, SPE linguistic investigation aimed “ to explicate the system of
predicates used to analyse inputs — the possible Structural Descriptions of rules — and to define
the operations available for transforming inputs — the possible Structural Changes of rules. ”
25 The description of these phenomena is simplified but mostly complete according to cited authors. Others have
analysed the same phenomena following different theories (eg. expressing them in term of rules) and obtaining different
results. However, only this solution is reported in the thesis due to its fundamental importance in syllable division.
Syllable and Syllabification
43
(Prince and Smolensky, 2004). However the necessity and the importance of well-formedness
constraints became crucial in many important works especially in morphology and phonology for
example by Bach and Wheeler (1981) Broselow (1982), Goldsmith (1990) and many others. The
place of these constraints in the phonological system and theirs interaction was obscure and did not
assume that constraints in language are highly conflicting.
According to Prince and Smolensky (2004) the first necessary step forward a new theory
was to abandon a couple of presuppositions: first, to abandon the theory that “it is possible for a
grammar to narrowly and parochially specify the Structural Description and Structural Change of
rules” (Prince and Smolensky, 2004); second, it also to abandon the theory that “constraints are
language-particular statements of phonotactical truth” (Prince and Smolensky, 2004). Instead of
these, they support the idea that the grammar should contain these constraints with means of
resolving these conflicts. In other words, one of the major innovation the theory allowed in
formalising linguistics process is the systematic use of constraints instead of rules. One of the most
ambitious goal of the theory was to create a set universal constraints. The task is still of course
unmet, but theoretically possible. In SPE instead given that each well-formedness constraints had to
surface or at least be level true (remember that the application of a rule was compulsory), it was
harder to imagine a universal set of constraints lying in the UG. In Optimality theory UG provides a
set of general constraints. The way in which languages differ would then lie only in the hierarchy on
which such constraints are ranked.
8.
Optimality Procedure
In Prince and Smolensky (2004) the procedure is schematically represented like this:
a. Gen (Ink)
→
b. H-Eval(Outi, 1∢i ∢∞ ) →
{Outi, Out2, …}
{Outreal}
Syllable and Syllabification
44
Gen contains representational principles and their relations. For example, according to syllable
theory a sigma which always dominates the rime. Given an input – Gen(Ink) – Gen generates a
number of outputs. The input H-heval – H-eval() - is then constituted by Gen outputs, in a number
comprised between 1 and infinite. H-vel will give the best candidate in the output according to the
set of constraints called CON.
To paraphrase the procedure illustrated above we can say that:
1. given an input, a set of possible candidates are generated by a GEN function, in accordance
with the unit representational principles.
2. The EVAL function - following a set of hierarchically ranked constraints (CON) - evaluate
each candidate.
3. The optimal candidate26 is then chosen so that a violation of a higher-ranked constraint is
always worse than a violation of a lower-ranked, that is the most harmonic one.
Two basic assumptions of the OT is that the Gen generates for a given output by freely applying
basic structural resources of the theory; and, second, that constraints are typically universal and of
general formulation, with disagreements over the wellformedness of analyses (Prince & Smolensky
2002). These two are among the Universal Grammar and both are simple and general.
9.
Optimality Formalisation
An OT procedure is formalised using a 'tableau'. As example I will assume a hypothetical
language in which the UR /ABCD/ surface as [ABC]. Optimal candidate are indicated using an
arrow hand right.
Hypothetical Lаnguаge 1:/АBCD/ ☞ [АBC]
26 'The degree to which a possible analysis satisfies the set of conflicting well-formedness constraints will be referred
to as the Harmony of that analysis […] The actual output is the most harmonic analysis of all, the optimal one.'
Syllable and Syllabification
45
We assume CON contains two constraints:
DEP: All segments must be underlying
Con1: C must not precede D
The ranking of rules is represented with this notation and is generally included for reference before
the tableau:
H-ranked >> Mid-Ranked >> Low-Ranked …
The procedure will then be formalised as the following:
DEP >> Con1
/ABCD/
DEP
i.
[ABCD]
ii.
☞[ABC]
Con1
!*
*
Table 1.8: Hypotetycal language 1 tableau
In the first column the input /ABCD/ is indicated, in the second possible candidates –
[ABC], [ABCD]. Third and fourth columns are more interesting. DEP and Con1 indicate the
constraints. If a representation violates a constraint, the corresponding cell is marked with an
asterisk (*). If it is a fatal constraints, which means it is the higher-ranked an exlamation mark (!) is
added before the asterisk. Shadowed cells are not necessary to the choice of optimal candidate. The
entire Co1 row is shadowed because DEP was violated and hence, being Con1 lower ranked, such
constraints violation are not evaluated by EVAL to choose the Optimal candidate. As I said,
languages differs only in CON, so supposing an Hypothetical language 2, with the same constraints
but the ranking reversed the optimal form would be ABC in this case.
Syllable and Syllabification
46
Con1 >> DEP
/ABCD/
Con1
i.
[ABC]
ii.
☞[ABCD]
Dep
!*
*
Table 1.9: Hypotetycal language 2 tableau
10.
Syllabification in OT
It is worth to say that the theory was proposed by Prince and Smolensky (1993) using
syllabification as working example. We will do the same, but instead of exploring exotic languages
I will use examples taken from Italian and see how OT would determine the best syllabified output.
In paragraph 1.2 I showed that the universally accepted syllabification for Cl and Cn clusters is
tautosyllabic (e.g., pa.dre, li.tro). Two general syllable constraints can account for this
syllabification.
-COD
Syllables do not have codas.
COMPLEXONSET
Syllables do not have complex onset
The ranking of the two constraints would determine whether Cl and Cn cluster are treated as
tautosyllabic or heterosyllabic in a language. If we rank COMPLEXONSET above NOCODA (i.e.,
COMPLEXONSET >> NOCODA) we will have an erroneous heterosyllabic division in Italian,
resulting in syllabification like pad.re and lit.ro. We would instead have the reversed ranking (see
table 1.10).
For more complex cases we may need to formalise the Sonority Principle according to Davis (90).
SD+4
Syllable do not contains cluster with a sonority distance < 4
Syllable and Syllabification
47
To allow an heterosyllabic syllabification of clusters like SC (e.g., pas.ta, kas.ta), SD+4 has to be
ranked before NOCODA (table 1.11). (McCrary, 2002)
NOCODA >> COMPLEX ONSET
/litro/
-COD
i.
☞ li.tro
ii.
lit.ro
COMPLEX ONSET
*
!*
Table 1.10: Hypotetycal language 2 tableau
SD+4 >> NOCODA
/pasta/
SD+4
i.
☞ pas.ta
ii.
pa.sta
-COD
*
!*
Table 1.11: Tableau for the syllabification of 'pasta'
SD+4, COMPLEX ONSET and -COD are called syllable structure constraints. The
application of these constraints to the Eval input allow to choose the optimal syllable structure, for
example VC.CV instead of V.CCV. But in many languages phenomena like ephentesis and deletion
are structural. Then Gen has to generate candidates which include epenthesised and deleted
segments27. This candidate will be then evaluated against a class of constraints which define the
correspondence28 of segments in the input to segments in the output. This kind of constraints are
called faithfulness constraints and determine the relation between output structure and input. We
assume that in Italian syllable structure do not force segments to be deleted or inserted 29. Two
faithfulness constraints PARSE and FILL are then assumed and higher ranked to avoid epenthesis
the former and deletion the latter. (McCrary, 2002)
27 The Gen module candidate generation problem will further discussed on III.3
28 The concept of correspondence was formalised by McCarthy and Prince (1995) and will be deeper discussed in the
next section
29 This does not mean that ephentesis and deletion phenomena do not occur at all in Italian.
Syllable and Syllabification
48
FILL
Syllable positions must be filled with underlying segments.
PARSE
Underlying segments must be parsed into syllable structure
PARSE >> FILL >> SD+4 >> -COD
/
studente/
PARSE
i.
tu.den.te
ii.
es.tu.den.te
iii.
☞ stu.den.te
FILL
SD+4
-COD
!*
!*
*
*
Table 1.12: Tableau for the syllafication of the word 'studente'
In the first paragraph we have seen that some languages codas and onset are severly limited.
For example, in the case of loaning epenthesis fulfilled the onset in Bouma Fijian. In this case,
unlike Italian, FILL is ranked below structural constraints.
-COD >> FILL
/klok/
-COD
i.
klok
ii.
☞ koloko
FILL
!*
*
Table 1.13: Tableau for the syllafication of the word 'klok'
Other constraints might be necessary in Italian, like ONS, which states that 'syllable must
have onsets' and the HNUC (nuclear harmony constraints) which specify that a higher sonority
nucleus is more harmonic than one of lower sonority. However, a complete analysis of Italian
syllable constraints (and of any language) is still an open and complex problem and unfortunately
can not be treated here.
Syllable and Syllabification
4
Conlcusion
1.
Definitions of syllable
49
So far I have considered the place of the syllable in phonological theories (mostly
generative) and how it is identified. It is now possible to better expose the problem of syllable
definition. A good literature review is to be found on Cutugno et al. (2001). From a phonological
perspective I have showed that systematic studies about the syllable began in the 70', with the
investigation of suprasegmental phonomena. In theories such as the autosegmental, the metrical and
the prosodic phonology, the syllable is then defined as a phonological unit, because domain of
phonological process. Blevins and Goldsmith (1995) echo this aspect by saying:
“The first argument for the syllable as a phonological constituent derives from the fact that there
are phonological process and/or constraints which take the syllable as their domain of
application.”
Trubeckoj (1958) had already recognised the syllable as domain of prosodic phenomena, but
in metrical phonology it becomes the building block of the rhythm, prosody, poetic meter and stress
patterns of languages. For example, in Hooper (1972) says that the syllable “always has a prosodic
function – i.e., it is the phonological unit that carries the tone, stress or length”.
Fudge (1969) argues that the syllable has both a prosodical and a phonoctactical function and
Goldsmith refers to syllables in term of possible words:
“ […] the syllable is a linguistic construct tightly linked to the notion of possible word in each
natural language, thought not, striclty speaking, reducible to it.”
Finally, a phonological sonority scale serves as a fundamental principle for syllabification in
many theories, based on the fact that each phoneme has an intrisic sonority it is possible to define
the phonological syllable as in Bloomfield (1983):
Syllable and Syllabification
50
“In any succession of phonemes there will thus be an up-and-down of sonority […] evidently some
of phonemes are lore sonorous than the phonemes (or the silence) which immediately precede or
follow […] any such phoneme is a 'crest of sonority' or a 'syllabic'; the other phonemes are 'nonsyllabic.”
Note that the sonority has an important place to the definition of the syllable both in acoustic
phonetics, i.e., the energy of the sound wave, and in articulatory phonetics, as a result of the vocal
trait aperture. Concerning these two phonetic field in fact, the definition of the syllable is different
and consider other aspects of the concrete realisation of the syllable in speech production.
From an articulatory perspective the syllable was defined by Stetson (1951) as consisting of
“a single chest pulse usually made audible by the vocal folds.” The same principle is found on Pike
(1955), which says that “physiologically syllables may also be called chest pulse.” Sausurre,
Grammont and Sommerfelt definition of the syllable also considers physiological observation:
“ […] en principe il y a une syllabe nouvelle là ou l'on passe d'une tension décroissante à une
tension croissante ou là où il y a une interruption dans une série de tension décroissantes ou
croissantes.” Saussure (1922)
Malmberg (1971) highlight from an acoustic perspective that elements of a phonetic sequence are
attracted and influence one another whithin different degree of strenght.
To sum up, it is necessary to distinguish between the concrete expression and the abstact
representation of the syllable. For the former, the articulatory and the acoustic dimension is to be
considered. In the first case the syllable is defined as a 'chest pulse' or as continuous 'puff of air', in
the second the only studied realisation of the syllable is to be found on the sound wave energy. At
an abstract, phonological level, different principles have been proposed. Some argue that the
syllable is influenced or completely depends on phonotactics or in terms attraction between
phonemes, other assume a phonological scale of sonority, with different variations and exceptions,
Syllable and Syllabification
51
others argue all of these to have some place and so on. How syllable and syllabification are
integrated in a phonological system, their role and function also varies among theories.
2.
Which Syllabification?
I have showed how the concept of syllable itself is debated and evolved fast during three
decades. Different approaches, theoretical assumptions and aims may lead to different definition of
the syllable and therefore to different syllabifications. Any serious approach to the syllable however
would require at least one of the theory to be taken into account and different syllabification
techniques may be preferred or allowed in accordance with the chosen theory. As we seen in
paragraph 2 there is no convergence on a unique syllabification principle. However, choosing the
best syllabification system for a language is not a totally arbitrary task. The system has to be
systematic and organic, and each choice has to be justified and harmonic with the rest of the system.
Some syllabification principle may not be suited for particular theories or just do not fit together
with principles of different nature. An acoustic approach to syllable division will probably require
the sonority principle to be considered, while a phonological syllabification will never be based on
orthographic rules. Different syllabification principles are harldy comparable, as no gold standard
exists. This conceptual assumption may lack among some scholars, in particular computer
scientists, leading to conclusions that evidently need to be revised. In the next chapter I will give to
examples of this misunderstanding. On the other hand, I will show that the algorithm I will be
implementing takes into account the linguistic problematic of syllabifcation and therefore results in
a concrete and organic solution to those problems.
Automatic Syllabification
2
1
52
Automatic Syllabification
Input, Model and Purposes
In chapter I, I have analysed various syllabification principles basing my investigation both
on phonological and orthographic forms. However, most Natural Language Processing (NLP)
studies are based on raw speech recording data. In fact, in NLP the importance of the syllable
became evident when syllabic units appeared to give optimal results in automatic speech
recognition and in text-to-speech systems (Laurinčiukaitė and Lipeika, 2006; Ostendorf,1999; King
et al., 1998, 1991). In linguistics, evidence emerged from various psycholinguistic experiments,
arguing the importance of the syllable as sub-lexical unit in lexical access and in speech
segmentation (Willem, Levelt et al., 1999; J Segui et al., 1984, 1991; Cutler and Norris, 1986,
1988). However, The problems that an acoustic computational approach to syllable division has to
face are various. The interaction between signal recognition and syllable description may lead to
ambiguous context and the manipulation of speech recording data add a great degree of complexity
to the system. In linguistics the study of phonetic representation of the signal is of particular
interest, especially in the field of statistical analysis and contrastive description of language
varieties (see chapter III). It is possible to discover correlates between the physical characteristics of
the signal and their linguistic properties, how the production may vary among speakers,
coarticulation phenomena and so on.
In the first chapter I have showed that defining a general and unique syllabification principle
is impossible. No gold standard exists and syllabification techniques, principles and representations
may vary within the same theory. However, in order to proceed, it is necessary to make some
operative decisions, having in mind the purposes of the algorithm. Input structure, model, and
finally possible uses of the program are the necessary choices that has to be made before starting
implementing any system. Note that these three elements are necessairily related. For example, if
Automatic Syllabification
53
you want to develop an orthographic syllabification software, the input will be orthographic and the
model possibly rule based.
1.
Written or Spoken Language
A first choice has then to be made between two different input structures. In this study, as I
prefer to face phonological problems directly related to syllabification, I will not work directly on
recordings; the algorithm input will be a sequence of strings.
➢
Raw speech recording: the sound wave is analysed and a syllabification algorithm
distinguish acoustic syllable boundaries. The syllabified output may be used for speech
recognition or for prosodic analysis.
➢
Sequence of strings: the input is made of a sequence of strings.
Another important differentiation has to be made between orthographic and phonological
data. Most word processors include a syllabification function which allows to divide a document or
a word into syllables. The obtained syllabification will be orthographic and, as said in chapter I, will
probably diverge from the phonological one. The syllabification module implemented in the word
processor can look up in a dictionary – that is generally the case of English - or implement a set of
rules for languages which allow the syllabification to be automatically obtained from the
orthographic form (e.g., Italian). Phonological transcripts of spoken language are a more genuine
form to work on. As said in chapter I, the syllable is a phonological unit and there is more interest in
studying it if the data are spoken language transcripts. It is possible in this case to analyse segmental
and suprasegmental phenomena, to obtain statistical information on effective syllable usage, to
exploit the obtained syllabification for signal analysis application. Finally, the recent possibility to
exploit corpus of spoken language makes this new field particularly interesting.
➢
written text, such as a journal article, a paper, a romance. This will be probably parsed
according to orthographic syllabification rules and most phonological phenomena not
Automatic Syllabification
54
accounted (such as pause, resyllabification).
➢
Transcription of spoken language:. This is normally considered the genuine data to work on
by descriptive linguistics and the one in which natural syllabification is more relevant.
2.
Transcriptions
Different kinds of transcription exist, but only orthographic, phonetic and phonological ones
will likely be used for syllabification. Being syllabification a phonological phenomenon, it would
better requires phone or phonemes as unit to be parsed. Graphemes do not belong to the any of
these domains and therefore such kind of syllabification would be of little or no interest in
descriptive linguistics. However, it could still be possible to exploit orthographic texts for
phonological analysis. The syllabification system will likely include a module which perform a
grapheme-to-phoneme conversion or take a transcribed form as input. Given an orthographic
transcription you will then have the following procedures:
1. Convert graphemes to phonemes
2. syllabify phoneme segments
3. convert syllabified segments back into graphemes (optional).
Note that in this case a phonological transcription will always be preferred. Phonological
transcripts in fact usually include information useful to syllabification (such as stress, pauses), while
a converted text could not in any case provide such kind of data.
Phonological transcripts can include different information. The transcription for instance
may have been broad or narrow. Generally, it is useful to dispose of as many information as
possible. This does not mean that any element of the transcription is relevant to syllabification. A
study has to be made in order to discriminate relevant information and to account for its role in the
syllabification procedure (see chapter IV). The phonetic transcription is the most difficult to be
Automatic Syllabification
55
processed as it will present additional boundary identification problems similar to the ones that
speech recognition has to face. Phenomena like epenthesis and deletion will have to be treated as
well as segment assimilation, modification and so on. Moreover, most of the work done on
syllabification analysis has been made by generative linguistics which - as said on chapter I – does
not account for non-systematic, performance related phenomena. To sum up, possible transcript to
be used as input for the syllable division program can be:
➢
Orthographic: an orthographic transcript is converted into phonemes, divided in syllable
and eventually converted back to the original orthographic form. A phonological transcript
would be better used instead if available.
➢
Phonological: the preferred transcript form. It may contain various phonological
information in addition to the sequence of phonemes. A preliminary study has to be made to
discriminate relevant information and determine its role on syllabification.
➢
Phonetic: this is the most complex one as various phonetic phenomena may render the
sequence difficult to syllabify. Moreover, traditional syllabification literature assumed the
syllable as a phonological unit. It is then difficult to bend the syllabification to nonphonological principles.
3.
Software Purposes
Depending on the future use of the program, different solutions might be more suitable or
even necessary during the development of the software. This is a very important point but it is
usually neglected. One of the common assumption by computer scientists is that a unique and
universal syllabification procedure is possible, and therefore an algorithm can be described as doing
a syllable division task better than another (Marchand et al., 2009a, 2009b; Weerasinghe et al.,
2005). While a solution can be faster and more precise within a specific domain, as we have been
seeing so forth is impossible for various reasons. I will better illustrate these problematic by the end
Automatic Syllabification
56
of the chapter. What is important to state now it is that is necessary to be aware of the final use of
the algorithm before developing it. In fact, as we will see in the rest of this chapter, syllabification
principles, procedures and computational models will not only be more suited for specific tasks, but
in certain cases a necessary choice. In general, three major approaches are possible:
➢
Speaker Behaviour Investigation: this kind of algorithm should simulate the linguistic
behaviour of the speaker, possibly simulating his/her idiosyncrasies as well as getting light
on the psycholinguistic aspects of the problematic. Data Driven method are the most
indicated for this kind of programs.
➢
Theory investigation: in this case we try to implement a phonological theory. The manual
application of a theory to a certain amount of data (e.g. Optimality theory, see section 1.3.9)
can be tedious and error prone. An automatic approach will allow to better and faster analyse
a lager number of data. This could also be helpful to test particular aspect of a theory in
order to clarify or confute them. We can also get statistical results by applying the theory on
a corpus or discover new problematics during the development of the program.
➢
Engineering goal: that is if we need a syllabification program for a specific engineering or
linguistic task, for example divide orthographic words into a syllable to obtain an automatic
hypenator or to syllabify corpora in order obtain statistically relevant information and data.
In this case, it is possible to give limited importance to the most controversial linguistic
debates if they are irrelevant to the the final application of the program and eventually bend
the theory to suit pratical needs. This concept will be further explained in chapter IV as the
program I will develop will basically be of this type.
4.
Epistemology
From an epistemological perspective, it may be interesting to summarise a long-lasting
Automatic Syllabification
57
debate about the nature of language, which will allow me to introduce an important differentiation
between two broad types of computational models and of linguistic theories. The debate has ancient
roots but in modern linguistics it has began in 1957 after the publication of Buhrrus Skinner's Verbal
Behavior. Explicitly against structuralists (Edward Titchener) and functionalists (James R. Angell),
Skinner proposed a theory of language which is based only on explicit behaviour, that is the
experience and the production of the speaker. Knowledge is all supposed to be given by cognitive
connections which are strengthened in case of positive stimuli or weakened after negative
feedbacks. Noam Chomsky (1959) review of VB demolished Skinner thesis and served as
background of his future generative theory (Chomsky, 1965; Chomsky and Halle, 1968).
Experience is not the solely source of knowledge, but constitute a stimulus to the activation of
parameters of an innate and general faculty of language.
“ It seems plain that language acquisition is based on the child's discovery of what from a formal
point of view is a deep and abstract theory - a generative grammar of his language.” (Chomsky,
1965)
Chomsky's theories weakened for a couple of decades any linguistic work directly based on natural
data. Nonetheless, many fields of linguistic – such as phonetic and language acquisition - still
required to work on speaker production, as demonstrated by table 2.1 (McEnery and Andrew
Wilson 2001), which highlights how corpora based studies have multiplied during these two
decades.
Automatic Syllabification
58
Period
Studies
to 1965
10
1966-1971
20
1971-1975
30
1976-1980
80
1981-1981
160
1985-1991
320
Table 2.1: Corpora based studies until 1991
During the 90's the critics to Chomskian model become numerous and important. Many
argued for the lack of precision on the definition of fundamental concepts, such as that of the
language faculty: what is this faculty made of? has it a corresponding biological structure? what
kind of knowledge is it involved? But more conceptual fall-backs have been argued. For example,
the ability of the speaker to recognise and exploit statistically systematic phenomena have been
demonstrated and theorised in many recent studies (Cleeremans et al., 1998, 1993, 1991). Other
works, such as Tomasello's (2005, 2003), argue that hypothesis about language, during children
language acquisition period, are made after a statistical extrapolation of linguistic data and are not
due to any innate ability. Sampson (2002) criticised the generative introspective methodology,
which is based on data which are artificial and impossible to observe. Finally, many studies made
on first language acquisition seem to invalidate the fundamental chomskian thesis of the poverty of
the stimulus. According to this principle, an innate faculty of language has to be assumed as long
as children are not exposed to such an amount of data which could possibly allow for a language to
be learned. Yet, many studies have demonstrated that even the rarest syntactic structures are heard
with a certain frequency by children and that the majority of child wrong linguistic production is
corrected by the parent or receives a negative feedback On the other hand, correct sentences are
usually recast and extended by adult speaker. (Bohannon. and Stanowicz, 1988; Bohannon et al.,
1990a, 1990b; Gordon, 1990). (Markie, 2008; Russel, 2008; Griffiths 2009)
Automatic Syllabification
5.
59
Data Driven - Rule Based
In the next two paragraphs I will be showing two computational models, called data driven
and rule based. The main difference between these two approaches reflect the epistemological
debate cited in the previous section: the former consists in a series of rule and procedures hard
coded in the program, the latter acquires knowledge from a set of given data. Most of the
syllabification principles I have analysed in chapter I, were all based on set of rules or constraints,
whose application to a given input led to the syllabified output. The choice was due to the fact that
most of the work recently done about syllable and syllabification has been based on generative
theories. However, the recent development of NLP and computational linguistics granted the
possibility of implementing learning machines which demonstrated good results even on real-life
tasks, such as speech recognition and text-to-speech systems. Connectionist theories have been
implemented into Artificial Neural Networks and widely used in several NLP applications (Kasabov
et al., 2002; Dale et al., 2001; Amari and Kasabov, 1998; Kasabov, 1996; Goldsmith, 1994, 1992).
The main differences which distinguish the two epistemological assumptions are summarised in
table 2.2.
Automatic Syllabification
60
Rationalist
(Generative)
Empiricist
Knowledge
The faculty of Language
is innate, universal,
equally present among
men and overall could
not be learned or
forgotten (but acquired
during defined
childhood development
periods). A Universal
Grammar and a language
organ (which refers to
a specific cognitive
organ) allow the
speaker to develop a
specific language.
Human being has no
language specific
organs. Instead, other
developed abilities
(mainly the ability to
share the attention
with others and to
statistically infers
pattern and
regularities) allowed
the exploitation of
complex sign systems
such as the language.
Learning
Few stimuli suffice to
activate the proper
parameters (this term
may differ from theory
to theory) in the
Universal Grammar.
A great deal of stimuli
is necessary in order
to infer patterns from
a language.
Production
Performance or speaker
production has little
or
no
influence
on
language description.
Speaker language
production constitute
the basis of the
analysis as it is what
determine speaker
language ability
itself.
Table 2.2: Important differences between rationalism and empiricism
I have highlighted three particularly important differences for our analysis of algorithmic
models. The first row shows that knowledge for a rationalist is innate 30 while for an empiricist it is
acquired through experience. Computationally, we can express this concept by saying that a
knowledge (in our case concerning the syllable and syllabification) is hard-coded a priori in a rulebased program while in a data driven patterns are derived by a training set. In other words a rulebased algorithm will include in its structure any information required for that knowledge while data
30 This particular school of thought is called innativism and is the most used definition used to describe generative
linguistics. However, being an innatist does not strightly implies being a non-empiricist. Many simplifications are
assumed on this exposition.
Automatic Syllabification
61
driven will infer it. Concerning the example of syllabification the programmer will have to code
rules and procedures necessary for an input to be syllabified, such as 'if the sonority of an x segment
is major than the sonority of a y segment put a syllable boundary'. Data driven models will of
course have to include some kind of information, but unlike the rule-based this will not directly
affect the studied process or knowledge. The coded algorithm will be more general and the
programmer will have to provide only a set of statistical or simply context dependent rules and a
training set. The application of such rules to the data will result in a set of patterns which will
eventually correspond to the previously cited hard-coded rules. A first setback is evident: rule-based
models do not require any kind of linguistic data to be developed while for data-driven models a
corpus or a collection of specific linguistic data is required. For some models such a corpus could
not be available and the data collection could be more time-consuming than the development of the
program itself. The application of the knowledge is similar for the two models. Generally an input is
required and according to the knowledge coded or inherited by the algorithm an output is given. In
the case of data-driven method the output could be used for further training. Table 2.3 summarises
the cited procedure.
Rule Based
Data Driven
Pre-processing data
Nothing
A corpus or a
collection of
linguistic data.
Imprinting
Set of rules
(parameters or
procedures) are
specified by the
programmer.
The learning machine
infers knowledge and
patterns from given
data using few
statistical operations.
Operations
Rules or constraints
apply to the given
input. No other
knowledge is
incorporated.
Resulted patterns/
knowledge applies to
the given input. The
output may contribute
to strengthen or create
other knowledge.
Table 2.3: Rule based and data driven models
Automatic Syllabification
2
62
Data Driven Models
In this paragraph I will briefly expose some data driven models. In the first section I will
show the model for Italian syllabification proposed by Calderone and Bertinetto (2006). In the
second section a small literature review is proposed, on which other possible implementations are
cited with no warranty of completeness.
1.
Artificial Neural Networks
The term Data Driven was used to indicate a very broad and general category of
computational models. Connectionism belongs to this category. The term connectionism is
generally used to define an approach to information processing which is based on the design and
architecture of brain. In this paragraph I will discuss Artificial Neural Networks (ANN)31: a
computational model which simulate structures and functions of biological neural networks. ANN
are useful in linguistics for at least three cases:
➢
when we do not dispose of an algorithmic solution. This is the case of the syllable division,
as showed in chapter I, where multiple possible syllabifications and principle contrast. In
this case ANNs can be used to pick out structures from linguistic data;
➢
when we dispose of noisy data and we want to normalise or generalise them. (This could be
useful to analyse speech recordings);
➢
when we want to simulate the speaker behaviour32 in certain context or phenomena. Again,
this is the case of syllabification as showed in 1.2.8 where empirical evidence showed
discrepancies on how cluster division is handled by speakers.
Data Driven model's disadvantages are:
➢
ANNs need training to operate;
31 Not all ANNs are connectionist and not all connectionist models are ANNs.
32 Note that biological neural network orders of magnitude more complex than any artificial neural network so far
realised. The results obtained are just an idealisation of the possible cognitive process involved.
Automatic Syllabification
➢
63
data collection and ANN's tuning may be time-consuming;
An ANN – and generally a connectionist model – consists of four parts – unit, activation,
connection and connection weight - each of which correspond to a particular structure of process
in the biological neural network. Units are generally indicated by circles while connections are
represented as arrows, to indicate the direction of information and therefore distinguish input from
output (image 2.1). Units and connections are in an ANN what neurons and synapses are in a
biological neural network.
Image 2.1: Simple Artificial Neural Network unit
One of the characteristics of natural neural networks is the simplicity both in the nature of
the signals and in their transmission. To convey an information each neuron receives an input,
which is composed by the other neurons electric signals, and propagates the output to other
neurons if its stronger enough to break the synaptic cleft threshold. Connections weight among
neurons might be excitatory or inhibitory and stronger or weaker, thus affecting in different ways
the amount of action potential transmitted. The huge number of neurons permit the complex
operations of animal's brain.
Artificial neural networks works in a similar way. Generally, units compute the input from other
neurons and, given a threshold, forward it to other neurons. The synaptic weight may differentiate
among weaker and stronger inhibitory (negative value) or excitatory (positive value) connections,
Automatic Syllabification
64
generally by multiplying each input before they are summed up33. The procedure is schematically
presented as following:
1. The unit (neuron) receives input from connected units → x1, x2, x3 ... Xi
2. Each input is multiplied for the synaptic weight (the strength of the connection) xiwi
3. multiplied input is summed up
Image 2.2: Artificial Neural Network unit
So the resulted value Vk is obtained by the sum of each input multiplied by its synaptic weight:
Vk = W1X1 + W2X2 + W3X3 + WkjXj... In mathematical terms, it is described by the following
formula:
Before having this value fired to other neurons an activation function squashes this value in a
range which is generally 1 to 0 or -1 to 1. This is to avoid that the output of a unit never exceeds the
actrivation value.
33 This kind of model is called McCulloch and Pitts model (MCP).
Automatic Syllabification
65
Neurons are organised in various layers, for example the cerebral cortex is organised into 6 layers.
In a common ANN model, called feed-forward network, units are organised in three group or
layers34(image 2.3):
➢
the input layers, which receives as input raw information fed into the network (called bias).
➢
hidden layer, which computes the input and construct its representation inside the network
itself
➢
output layers, which send resulting information outside the network
Depending on the way communication occurs among layer a first major distinction is
possible between two types of networks:
➢
Feedforward: signal is transmitted from one layer to another. Recursion in the same layer
or back to other layer is not allowed (image 2.4).
➢
Feedback: signal is transmitted to any layer. This kind of networks are dynamic because the
signal does not follow a path to an end, as for the feed-forward, but units keep sending it
until an equilibrium is found and activation values do not change anymore.
What makes ANNs interesting, especially in linguistics, is their ability to learn. In fact, even if
connection strengths can be manually hard-coded on each units of the network generally ANNs are
trained before being used. Training a network consists on altering units' connection weights until
the difference between desired and obtained output is minimal. The cost function determines the
mismatch between desired and obtained output. The modification of connection weights usually
consists on a variant of the Hebbian learning rule. This basically says that if two units are active
simultaneously their interconnection is strengthened according to a learning rate value. The error
derivative of the weight (EW) indicates how the error changes as each connection weight is
modified. Various algorithm are used to calculate this value, but the the most common is the back34 Note that more than one hidden layer may be used:
Automatic Syllabification
66
propagation algorithm (Rumelhar et al.,1986). Basically, at a first stage the error at the output unit
is calculated. The error is then back-propagated to previous hidden layers and their weights altered
accordingly.
Image 2.3: Artificial Neural Network with three hidden layers
Image 2.4: Feedforward Neural Network
In general, three learning methods are used: supervised learning, on which the input and the
desired output is given, unsupervised learning, where only the input is given and the network
organises itself, and the reinforcement learning, which could be considered an intermediate variant
of the two. I will focus on the first method, as it will be used on the network I will be studying in
Automatic Syllabification
67
the next section. In supervised learning a set of pairs (x,y) containing an input and the desired
output is given by a teacher. Connection weights are then altered in order to obtain the optimal
configuration.
2.
Calderone's ANN
Many ANN models have been used for syllable division such as generic neural algorithm
(Oudeyer, 2001), dynamic systems (Laks, 1995), recursive networks (Stonaiov and Nerbonne,
1998) and so forth. I will concentrate on Calderone (2006), which propose a feed-forward neural
network, trained with a back-propagation. A correlation between syllable structure and phonoctactic
principles have already been argued in Chapter I. The main assumption of the algorithm lies in the
fact that syllabification is governed by the speaker phonotactical competence. Clusters which tend
to occur together will be considered stronger than segments which do not. These associations,
which are defined by the phonotactical knowledge of the speaker will then determine syllable
structure and syllabification process. Neighboring segments are described in terms of attraction and
the syllabification as the process which divides segment distant from each others or gather together
segments strongly attracted. For example, suppose that /r/ and /a/ have a linking value of x. /r/ and
/t/, which are less phonotactically related will have a value y < x. The speaker's knowledge of these
values is determined by its exposition to linguistic data and to its ability to determine statistical
inference. Syllabification will result by this ability. The algorithm is based on a small corpus of 83
words35 for 51 syllable configurations. Each segment was then described according to the following
phonological classes (manner of articulation mostly): V (vowel), G (glide), L (liquid), N (nasal), F
(fricative), O (occlusive) and A (include) dental affricates and palatal geminates). For example, the
phonological classes of segments in the word cane 'dog' would be following:
35 An English and a Spanish corpus are also considered in the paper but I will concentrate only on Italian.
Automatic Syllabification
68
k
a
n
e
O
V
N
V
Each segment was represented by a binary array Vi (where i is the number of the segment in the
corpus) of seven segments, made by the focus segment and by the three segments on its right and on
its left.
Vi = (Vi – 4, Vi – 3 … Vi, Vi + 1 … Vi + 4)
If a position is not occupied by any segment the position is filled with a Null value. The focus
segment is also saved as Null. Given the example above for the word cane, this is how the vector of
the second segment /a/ would appear if the word was the first element of the corpus. Note that there
is only one segment /c/ before the focus segment, the other position as well as the focus /a/ are Null.
V1 = (Null, Null, O, Null, N, V, Null)
For example, the arrays necessary to describe the word kane would be these four.
K
V0 = (Null, Null, Null, Null, V, N, V )
A
V1 = (Null, Null, O, Null, N, V, Null )
N
V2 = ( Null, O, A, Null, V, Null, Null )
E
V3 = (O, A, N, Null, Null, Null, Null )
As said, the network was trained using a supervised learning (see 2.2.1). For the input the
phonoctactic vectors described above were given. For the output the teacher chose syllabification
Automatic Syllabification
69
vectors of the same length and nature of the input (image 2.5).
Image 2.5: Phonoctactic and syllabic window
The network was trained using a feedforward network with no hidden layers and a backpropagation algorithm to change the unit's pseudo-random initial connection weights.
The learning machine trained, the ANN is able to determine the attraction values of an input
sequence. The syllable is then composed by groups of segments which are strongly attracted one to
another. For example, the word sillaba 'syllable' could be represented as governed by the following
attraction values (image 2.6).
Image 2.6: Attraction values for the word 'sillaba'
The system obtained a 99.2% syllabification accuracy for input contained in the training set,
but most important showed the most interesting results on clusters that were not included in the
Automatic Syllabification
70
training set. For example, the learning machine was not directly trained to handle sC clusters. Given
it as an input it clearly reflects its ambiguous behaviour (see chapter 1) and the reason why it could
be treated both as tautosyllabic or a etherosyllabic by speakers. There is a very small difference
between the two attraction values and therefore the /s/ could both be parset in the coda or in the
onset of the following syllable. Image 2.7 shows the attraction values of the word pasta:
Image 2.7: Attraction values for the word 'pasta'
3.
Look-up Procedure
Not all data-driven methods are ANNs. For example, another commonly used method,
which derives from automatic pronunciation systems, consists on building a table (a lattice or a
database) containing the phonotactical context of the words in the training set and then compare the
input to the table in order to have it syllabified. Generally, the form of units in the table and the
matching functions distinguish this kind of algorithm. The three algorithms I will propose here are
all instances of lazy learning. In artificial intelligence lazy learning (Atkeson et al., 1997) is
distinguished by eager learning because it defers processing of the examples until a query is made
to the system. One of the outstanding advantages of lazy learning is the ease with which algorithms
can be transferred to new tasks. In fact, all three methods studied here were originally designed for
automatic pronunciation but are readily modified to perform syllabification.
One of the first model was proposed Weijters (1991) as an automatic pronunciation system
and then adapted for syllabification by Daelemans and van den Bosch (1997, 1992a, 1992b). The
Automatic Syllabification
71
training set is constituted by syllabified words, which are stored in a look-up table in the form of
N-Grams36. Each N-Gram is constituted by a focus character and by its left and right context. The
'N' in N-Gram indicates the length of the gram. For example, to allow each character to be a focus
the six 4-Grams of the word <kidney> would be:
<– kid>, <kidn>, <idne>, <dney>, <ney –>, <ey – –>
Each N-gram is stored in a table, including its juncture class, which specify whether or not
there is a syllable boundary ob the focus character. To syllabify an input, each entry in the look-up
table is compared to the input. A match value is then assigned to each N-Gram depending on how
much a context is similar to the input. Note that context positions are weighted, this means that not
every position in the N-Gram will affect the match value in the same way. Generally, focus
character weights more than right contexts, which weights more that left contexts. With the
algorithm 15 sets of weights are given and are stored in a table. (Daelemans and van den Bosch,
1992)
This is the algorithmm as it appears in (Weijters, 1991) and describes how two N-Grams, the
input (NgramT) and the one in the look-up table (NgramS) are compared. Each character in the
input NgramT is compared with the ones in in the table NgramS. If two characters are identical, the
MatchValue is increased by the weight of its context position.
FindMatchValue(weights, NgramT, NgramS)
MatchValue := 0
for i := 1 to length(weights) do
if (NgramT[i] = NgramS[i]) then
36 n-gram is a subsequence of n items from a given sequence.
Automatic Syllabification
72
MatchValue := MatchValue + weights[i]
end if
end for
The N-Gram with the highest MatchValue will then be used to syllabify the input, according
to its juncture classes. For example, for the word midnight the closest N-Grams will be <kidn>, as it
differs only by one character to <midn> and is also in the rightward context (which has the less
weight). As a juncture class is indicated in the look-up table afer the <d> in <kidn> (highlighted in
image ) the syllable boundary is placed in the same position on the input, thus resulting in <mid|
night>.
The look-up procedure was modified by Daelemans, van den Bosch and Weijters (1997). Basically,
the procedure remains the same, but weights are not pre-defined. Instead each weight is calculated
with a function which determines how much a position contributes to determine the placement of
syllable boundary.
Automatic Syllabification
3
73
Rule based Models
This chapter will expose some Rule Based syllabification systems. I will start by showing
how it is possible within a theory (OT) to adopt different solution and get different results. Then, I
will analyse a program which tries to integrate OT and autosegmental theory. I will finally consider
an Italian syllabigfication algorithm based on the SH principle.
1.
Computational OT
The main problem an OT based algorithm has to face is how to implement the OT
generation component. Potentially, Gen could create a huge set of candidates if epenthesis and
insertion are considered. For example, if epenthesis is assumed in the generation of the threesegments word 'pin' candidates, epenthetic segments could go in each of the space showed here:
_p_i_n_
2n+1 candidates would have to be generated, in our example 23+1 = 16.
The same is true for deleted segments, the candidate set for the same word would be the following:
pin, pi, pn, p, in, n, i.
But the two phenomena have to be considered together. Table 2.3 (Hammond, 1997) illustrates the
number of the candidate set for the segment number with the phenomena considered alone and
together.
segment
epenthesis
deletion
both
1
4
1
4
2
8
3
16
3
16
7
52
4
32
15
160
5
64
31
484
6
128
63
1456
Table 2.4: Number of candidates if epenthesis and deletion are considered by Gen
Automatic Syllabification
74
Each candidate will then have to be multiplied for the number of possible syllabified
candidate to evaluate, resulting in an enormous candidate set. Various solutions to the problem have
been adopted in the literature which will be analysed in the following section. According to
Hammond (1997) a generator or a parser could be implemented: 'A generator would map input
forms onto properly syllabified output forms. A parser would take output forms and map them onto
input forms.' In other words, a generator would provide the set of candidates required by the
syllabificator to be generated and evaluated them in the same module. A Parser instead will take the
already generated form as input (epenthesis and deletion will not have to be considered by the
parser which will parse already generated form), avoiding the problem of oversized candidate set.
Implementing the parser would then be easier as its generator component will have to generate only
syllabified candidates. In the case of the parser, syllabified output will also have to be checked
against a few number of constraints as faithfulness constraints will be redundant. Nonetheless, even
for parsers the problem of big candidate sets has to be resolved. In the case of four phonemes,
possible syllabification are 8:
XXXX, X.XXX, XX.XX, XXX.X, X.XX.X, XX.X.X, X.X.XX, X.X.X.X.
Supposing that there are 6 syllabification constraints we will have at least 4*8 = 48 evaluations to
be done.
2.
Hammond's Algorithms
The first program I will analyse is Hammond's (1995). Hammond's program is a parser, so
he avoids the faithfulness problem by assuming that it has already been treated by another module
(and therefore ignoring it). To further reduce syllabified candidates, Hammond uses what he calls
the local programming. The Eval module of his program analyses only a segment at each cycle,
evaluating as possible candidates for the segment only four states o (onset), n (nucleus), c (coda) u
(unsyllabified). For the word 'apa', there would only be a set of 43 = 12 candidates, as showed in 2.8.
Automatic Syllabification
75
Image 2.8: Hammond's candidate encoding for the word 'apa'
The program aimed to simulate in a Optimality approach, English and French syllabification
differences. This is an important point because, unlike its second algorithm did not aim to be
universal even within the two languages. Given an input, each segment is parsed in a linear fashion
from the rightmost character until the end. Each time possible values (candidates) are assigned to
the segment until the syllabification is reached. The relevant constraints indicated by Hammond to
highlight cases of different syllabifications in French and English are the following:
PARSE
all segments must be syllabified
NOONSET
stressless syllables do not have onset
ONSET
syllables have an onset
The three are ranked differently in English and French. The former ranks:
PARSE>>NOONSET>>ONSET
While the latter:
PARSE>>>>ONSET>>NOONSET
The constraints are coded as the following:
Automatic Syllabification
76
PARSE → &parse
eliminates 'u' if other parses are available
ONSET → &onset
eliminates 'c' as an option if the current segment is a vowel
NOONSET → &nonoonset
eliminates 'o' as an option for the preceding segment if the current segment is stressless
vowel
The algorithm work as following37:
1 CV skeleton is firstly generated:
a→V
2 Candidates for each segments are generated:
oncu
V
Which will result as the following In a tableau:
/x/
PARSE
i.
o
ii.
n
iii.
c
iv.
u
ONSET
NOONSET
Table 2.5: Example of an unparsed Hammond's tableau
37 For each algorithm presented in this section I will describe only operations relevant to syllabification. Function that
remove stress, verify correct inputs or allow to choose various parameters are ignored.
Automatic Syllabification
77
3 A first set of 'housekeeping' constraints are applied, this includes constraints such as:
a) vowels can not be onset or codas
b) consonants can not be nuclei
c) word-initial consonants can't be codas
d) word-final consonants can't be onset
...
4 The violation of a) will eliminate c and o as possible candidate.
un
V
5 The next passage eliminates u if a constraint applies, that is the case:
n
V
6) Others specific constraints will then apply, we will see how in the next segment as this
one is already syllabified as a nucleus. (7) Finally, the segment is converted in the corresponding
phoneme (V → /a/) and the constraints evaluation re-applied.
n
a
The following segment /p/ is more interesting as it is an intervocalic consonants and will be
syllabified differently in English and French. 1, 2, 3c, 4 will result in the following segment:
co
C
Automatic Syllabification
78
&donoonset can not apply now as it needs to consider the following vowel, we will then have the
following sequence:
co
Sp
If we assumed the /apa/ was an English word the algorithm evaluates the candidates according to
three constraints shown above for English (5a):
➢
&doparse
➢
&donoonset
Otherwise (5b) will apply:
➢
&doparse;
➢
&doonsetS
➢
&donoonset;
In French ONSET is higher ranked:
PARSE>>>>ONSET>>NOONSET
therefore &donoonset applies first and 'c' is eliminated resulting In the following syllabification:
n
o
n
a
p
a
a.pa
In the case of an English word, /a/ &donoonset applies first
PARSE>>>>ONSET>>NOONSET
Automatic Syllabification
79
&dononset applies and eliminates 'o' as an option .The resulted syllabification will be the following:
n
o
n
a
p
a
ap.a
Second Hammond's algorithm (1997) aimed to be describe English syllabification entirely.
This determined the necessity to overcome some limitations that the previous proposal had. The
linear approach was in fact insufficient. The problem were solved by introducing two important
changes. The programmings shifted to a declarative approach. Perl, which is an interpreted
language, is replaced by Prolog, which allows a set of relations to be indicated and the constraints
to simultaneously apply on the input. Concerning the candidate set problem, a cyclic CON-EVAL
loop will not permit constraints to be evaluated if a higher ranked constraint is violated first. For
example, if we assume a set of 10 candidates to be evaluated against 5 constraints we will need 50
cycles to evaluate each candidate:
A
1
B
!*
C
*
2
!*
3
!*
4
D
*
*
*
!*
5
*
6
*
7
!*
10
!*
*
8
9
E
*
S
!*
*
!*
Table 2.6: Number of evaluations for a 10X5 tableau
Automatic Syllabification
80
In Hammond's program once a constraint eliminates a candidate (because of a violation of a highest
ranked constraint), remaining cells are shadowed and not computed.
A
1
B
!*
D
!*
3
!*
4
!*
*
**
*
!*
*
*
**
6
!*
7
!*
8
*
9
*
10
E
*
2
5
C
!*
**
*!
*
Table 2.7: Number of evaluations reduction using fatal violations
Constraints are implemented like in the previous algorithm and their application results in
the pruning of possible candidates [oncu]. The rules are represented in formal statements that say
that structural option alpha ([oncu]) is removed from element of X type38 (image 2.9):
Image 2.9: Hammond's second algorithm rule formalisation
Once the input is given it is converted into a prolog list. For example, the word /apa/ would be
converted to the following: [a,p,a]
38 As I said this algorithm aimed to be universal and allow for a more exhaustive description of syllabification.
Constraints are more in number than in the previous example and better generalised. Here I give only a contrastive
example to show main differences with the first Hammond solution.
Automatic Syllabification
81
As for the previous algorithm Gen pairs each element with the candidate set:
[a/[o,n,c,u],p/[o,n,c,u,a/[o,n,c,u]]
Which could be represented as in the following
a
p
a
o
o
o
n
n
n
c
c
c
u
u
u
Each constraint will then prune away possible candidates. The previous housekeeping constraints
will result with the following grid:
a
p
a
o
n
n
c
Two constraints may apply now, ONSET and NOCODA. In English the former is higher-ranked.
Hence, the 'c' is pruned away and the resulting syllabification grid is:
p
a
o
n
n
Automatic Syllabification
3.
82
Others OT Implementations
Other approaches have handled the potentially infinite candidate set problem differently.
One of the first attempt to implement OT computationally was made by Black (1993). However, the
model did not strictly simulate the OT, but was rather inspired by it. Major differences concern the
Generator component which created candidates according to a set of rules. Constraints, then,
operate more or less as repair-mechanism triggers. Ellison (1995) implemented the model using
automata and representing the output of Gen and the constraints with regular expressions. Similar
to Ellisson's are the models proposed by Eisner (1997). Tesar proposals (1995, 1998) are based on
the technique of dynamic programming. To explain this model suppose that you have to go from
point A to Z. You can divide the path in two, and say in each half there are three paths. A dynamic
programming approach would split the problem and calculate first the distance to the three points in
the first half, save the result in a table, and then will proceed resolving the problem. In Tesar then
the input is parsed segment by segment considering previous segment best candidate and its
structural position. The works I have discussed so far does even does not treat autosegmental
representations at all (Tesar, 1995a; Hammond, 1995, 1997) or does so in a cursory way (Ellison,
1995, Eisner, 1997). Heiberg (1999) instead develop a program which implement the OT tied to the
autosegmental representation. An object-oriented approach was used so that, as put by MacLennan
(1986) for object-oriented programming, “the code is organized in the way that reflects the natural
organization of the problem”. This allows the code to reflect the theory and then to be easily
modified in order to experiment various kind of simulations. The model was not designed for the
syllabifaction, but an implementation of such a process is possible and extremely interesting.
4.
Cutugno et al. (2001)
Previous algorithms constituted an attempt to implement a phonological theory
computationally, in particular the autosegmental and the OT. However, another approach might be
only based on some of the syllabification principles proposed in the first chapter and on their
Automatic Syllabification
83
application to the input in a linear fashion. The most interesting algorithm is to be found in
Cutugnoi et al. (2001), most importantly because its purpose is very similar to the program I am
trying to realise. The algorithm is based on the SSP and on the same SH I will use (with some
modification) for my program. The algorithm was designed to syllabify a portion of AVIP, a spoken
language corpus labelled in a way very similar to CLIPS (see chapter III). The corpus is constituted
by a collection of recordings with time-aligned phonetic and phonemic transcriptions. These layers
were syllabified using the algorithm and then compared with an automatic syllabification done on
the signal. The pseudocode used to describe the algorithm is the following:
ASSIGN a sonority value to each phoneme.
{find least sonorous segments}
FOR EACH phoneme
IF (sonority is minor than the preceeding phoneme sonority)
AND
(sonority is equal or major than the following phoneme sonority)
THEN: the phoneme is a least sonorous segment
END FOR
FOR EACH least sonorous segment
{a sonorant not followed by a vowel}
IF phoneme sonority > 9 AND the following phoneme sonority < 18
THEN: it is the preceeding syllable end
ELSE: it is the beginning of the following syllable
First it parses the input and gets the least sonorous phone/phonemes of the sequence. Then, for each
of these segments it puts a syllable boundary before the segment in case of a sonorant not followed
by a vowel or after the segment everywhere else (for examples and discussion see 4.2.3).
Automatic Syllabification
4
84
Conclusion
In various essays, percentage indicating syllabification accuracy is stated. This is the case of
Marchand (1999), which compares different syllabification algorithms to demonstrate that data
driven model is better suited than rule based syllabification systems. However, as clearly
demonstrated so forth in this chapter, principles are likely to contrast and using dictionaries as gold
standard is probably not a relevant parameter to argue that a syllabification algorithm is better than
another. Data driven algorithms are trained with the syllabified words that will be used for the
comparison and the fact that they get better results is obvious. For example, Marchand (1999)
argues that Hammond algorithms can correctly syllabify only a 30% of words. But Hammond's
implementation is based on the OT theory, which resulting application may be fairly different from
any syllabification given in a dictionary. The same is true when he considers Fisher's
implementation of Kahn's theory (Kahn, 1976). The correct syllabification should be compared with
the result obtained by a human doing the syllabification by hand and following the same principles
(as in an Weerasinghe et al., 2005). In this case the performance and accuracy of an algorithmic
solution can be tested, but not the accuracy of the syllabification itself. Different algorithms may be
used to obtain different results and therefore the algorithm must be based on the principle which
better reflect the primary use of the software.
CLIPS
85
3
CLIPS
CLIPS (http://clips.unina.it) is the largest corpus of spoken Italian ever collected39. It
contains more than 100 hours of recording and 1 million words totaling more than 20GB of storage
space (1). It is annotated and balanced to give broad dialectal coverage (Savy and Cutugno, 2009).
Unlike many other corpora collected for specific purposes, CLIPS aims to give a general
representation of Italian. A detailed socio-economic and sociolinguistic analysis (2) has been made
to obtain a corpus representative of Italian, with the full understanding that Italian is notorious for
its peculiar diatopic variability (Lepschy, 1977; Bruni, 1992). In fact, language may differ greatly
from region to region and the standard language is hardly spoken even on national television.
CLIPS is also structured into five sub-corpora, for diamesic and diaphasic variation and includes
time-aligned orthographic, phonemic, phonetic and sub-phonetic labelling of the recordings (Savy
and Cutugno, 2009). One of the main purpose of the corpus was to provide a support which could
be used for statistical and probabilistic language analysis, especially in the field of speech
processing applications. For this reason, particular attention was given to the phonetic correlation
between data representation and acoustic signal.
Diatopic
Textual
Dialogic
Read speech
Radio and TV
Telephonic
Orthophonic
15 sites
15 sites
15 sites
15 sites
standard
map-task
read senences
Auto
read sentences
Woz
word list
90+180
broadcast
talk show
commercials
culture
333RD+240TV
1077+7628
2400+1200
Units
spot
difference
120+120
the word list
Transcription
30%
30%
30%
100%
100%
Labelling
10%
10%
10%
3,5%
16%
Table 3.1: CLIPS corpus summary (Savy and Cutugno 2009)
39 In fact, the corpus I refer to is only a part of a largest project whose name is CLIPS. For simplicity, I will keep using
this notation to indicate only 'the spoken language corpus of the CLIPS project'.
CLIPS
1
Transcription
1.
Transcription Principles
86
The importance of corpus transcription has been argued by various authors (Gibbon et al.,
1997; Ide, 1996). A corpus of spoken language which contains only raw speech recordings can be
used only for a limited number of applications. Transcription of corpus recordings in fact allows to
drastically increment the possibility to exploit the corpus itself for studies otherwise particularly
time-consuming or even impossible. On the other hand, the main setback of corpus transcription
lies in the fact that it requires a great amount of human work to be done. For this reason, it was
chosen to transcribe only a portion of each corpus, but to an amount sufficient for statistical based
analysis and for application support, being this kind of approach possible only by disposing and
comparing a great number of structured data.
Recording transcription implies an encoding operation, which means giving a permanent
representation and an interpretation of the raw data (i.e., speech recordings). By assuring a
unique transcript it is possible to give warranties that any study made on it will be reproducible,
comparable and consistent with other studies made using the same corpus transcripts. If raw data of
a corpus has to be kept unaltered to avoid obtaining different results within a change of the corpus
itself - the same is true for transcriptions. By providing a unique transcription standard - that is
always using the same set of graphic symbols and procedures to describe a phenomena - the
representation of data will always be the same.
The principles of consistency is to be applied also on a technical ground. It is in fact
recommended to refer to a single set of symbols and transcription procedures to keep the research
consistent, organic and save time to researchers. For the same reason , it is recommended to adopt
already well known and widely accepted standards from other corpora. CLIPS was created after the
experience of ATIS, SPEECHDAT, POLYPHONE, PHONDAT e VERBMOBIL (Kohler et al.,
CLIPS
87
1995) and of other Italian corpora such as AVIP and API . In particular, VERBMOBIL was used as
a basic reference because similar to CLIPS for 'purposes, materials and procedures' (Savy, 2007).
Clips transcription design was mainly based on Edwards (1993) principles of category design,
readability and computational tractability. According to Edwards categories must be:
➢
systematically discriminable: for every case in the data it has to be clear whether a category
applies or not;
➢
exhaustive: for each case in the data there must be a category which applies;
➢
systematically contrastive: each category must determine other category boundaries.
The principle of readability states that a transcription to be readable has to have satisfy these
conditions:
➢
the temporal sequence of the events has to be reflected on the spatial sequence of the text
➢
similar events are to be kept spatially closer to each other, qualitatively different events
visually separate.
➢
prerequisite information for the understanding of an event has to be placed following a
logical priority
➢
categories are encoded in an iconic way so that a human reader can easily recover their
meaning.
Finally, the principle of computational tractability states that the encoding has to be systematic
and predictable.
CLIPS
2.
88
Annotated Transcription
So far I have talked about corpus transcription in general. To be more precise, CLIPS is
distributed with annotated transcripts of recordings. This means that transcripts not only consist
of lexical information but also contain labels used to describe semi-lexical, non lexical and non
vocal phenomena. As said on paragraph 3.1.1, one of the main purposes of the project was to obtain
a corpus that could be used for the automatic computation of the acoustic signal. For this reason,
among all possible phenomena that could be described and annotated, it was chosen to focus only
on those that altered or interfered with the acoustic signal itself (Savy, 2007). All symbols used in
the annotated transcript are listed on the following tables (3.2 - 3.6). Note that all transcribed words
are lowercase, except for acronyms (all capitals) and proper name (first letter capital). To transcribe
a sequence of letters (as in the case of acronyms) if the letters are pronounced in their phonetic
spelling (e.g., AVIP pronounced as /'avip/) every letter is transcribed between slashes (/A/ /V/ /I/
/P/). In case of spelling pronunciation (AVIP - pronounced in Italian /a/ /vu/ /i/ /pi/) each letter is
transcribed in its spelling form, so AVIP was transcribed A-Vu-I-P. Finally, any other comment by
the operator concerning the alteration of the acoustic signal is added between square brackets, and
its duration indicated by braces. For example, in the case of a sentence in dialect the comment
[dialect] and the target sequence are included between braces as in the example:
{[dialect] ka ditto ?}
If only an element of the transcription has to be described by the comment, the comment is added
between square brackets just after the element itself and no braces is required. For example, in the
following case only the word guaglio 'guy' is indicated as a dialectal form:
ho detto guagliò [dialect]
CLIPS
89
Symbol
Phenomema
Example
+
Uncompleted words
(disfluences)
non lo vedo → non lo ve+
_
Word internal interruptions
mon_tato
*
Lapsus linguae, pronunciation
errors
altalenante → altanelante
/
False starts
ma tu / dove sta la figura?40
<unclear> Unclear word or sequence
ho <unclear>
?
interrogative sentence
vieni ?41
!
exclamation
vieni !
,
semantic/syntactic boundary
no , non mi sembra
/LETTER/
phonetic pronunced acronomys
/A/ /V/ /I/ /P/)
-
spelled acronyms
A-Vu-I-Pi
Table 3.2: Semi-lexical phenomena
Symbol
Phenomena
Example
<sp> or <lp>
Short or long pause
vedi <lp> la macchina?
<P>
Long pause, ends an utterance
ma tu <P> no, vabbè42
<eeh> or <ehm>
Full pause and full nasal pause
la <ehm> macchina
<CC> or <VV>
Final segment lenghtening
allora<aa>...; con<nn>
<cc>
Word initial segment lenghtening
<ss>sì
Table 3.3: Non lexical phenomena
Symbol
<eh>,
<ah>
<mh>,
<mhmh>, <'mbè>
Phenomema
<ahah>, Assent labels, <'mbè?> is used to ask a
question, like English 'so what?'
<oh>
Ends and begins of a sub-task (DG)
<ah!>, <oh!>, <eh!>
Exclamation
Table 3.4: Interjections
40 but you … where is the picture?
41 Note the blank space between word and symbols (?!,)
42 but you... no, right
CLIPS
90
Symbol
Phenomema
<laugh>,<cough>, <breath>, <inspiration>, Non verbal phenomena
<tongue-click>, <clear-throath>
<vocal>
Others non verbal
<i.talkers>
Background voice noise
<NOISE>
Non vocal noise
<MUSIC>
Background music (RD and TV)
#TURN#
turn overlapping
{TURN}
turn overlapping
Table 3.5: Non verbal and non lexical phenomena
Symbol
Phenomema
[dialect]
dialect sequence
[foreign word]
foreign word
[screaming] and others
other comments
Table 3.6: Operator comments
As the temporal continuity of the signal had to be segmented and further labeled with
reference to the spectrogram (see paragraph 4), annotations indicate any audible phenomena,
overlapping speaker utterances included. If only one acoustic event overlapped with another, the
two were indicated between braces, the overlapping segment on the left and the overlapped
sequence on the right.
1. no deve andare verso la sinistra del foglio <sp> cancella e vai verso
{<laugh> sinistra}
2. fatto questo<oo> {<NOISE> <lp>} sei arrivata
In 1. the word sinistra 'left' is said laughing. In 2. a noise is present during a long pause of the
speaker. In case of turn overlapping (i.e., two speakers talking at the same time) the following
notation was used in both speakers turns:
CLIPS
91
➢
a hash indicates the begin of the overlapping portion (#);
➢
the hash is followed by the turn indicator between inequality signs <> (e.g., <F#8> means
follower, turn 8);
➢
the overlapping sequence is transcribed (<lp> sulla);
➢
another hash indicates the end of the overlapping sequence (#);
➢
the same is done on the other speaker turn transcription.
p1G#7: #<F#8> <lp> sulla# sinistra <sp> c'è scritto fiume
p2F#8: #<G#7> no# <lp> non c'è
This example indicates that during a speaker 1 long pause followed by the word sulla, speaker 2
says the word no.
3.
Transcription Procedure
The first operation was to individuate a segmentation unit which could make the
transcription easy to access, describe, codify (annotation and labelling) and consult. Units reflect
the characteristics of each sub-corpus item, which means that not all sub-corpus recording will be
divided in portion of the same nature (table 3.7). Each transcription is included into a TXT file
(unicode)43.
Corpus
Transcription Unit
Dialogic
Dialog
Radio and TV
Transmission
Telephonic
Call
Read speech
List's item (word or sentence)
Orthophonic
List's item (word or sentence)
Table 3.7: Transcript units
43 A complete description of each sub-corpus file name format is to be found on the corresponding sub-corpus section
on paragraph 3.3.
CLIPS
92
Each transcription file begins with a header, which includes all information about recording,
speakers and transcription. CLIPS header layout is conform to the SAM standard (Gibbon et al.,
1997). It follows the header schema, divided in four sections: text information, speaker information,
transcription information and recording information.Finally, each candidate recording was
transcribed in four phases.
1. Lexical transcription: all lexical elements of the recording are transcribed within turn
indicators. Numbers , acronyms, dialectal and short forms are transcribed according to their
pronunciation.
2. Annotation: comments and annotation are added to the transcription.
3. Overlaps: particular attention was given to turn overlapping and transcription partially
revised.
4. Revision: transcription revision was made on a regular basis by different operators.
4.
Labelling
The labelling procedure aimed to give a phonetic, phonemic, sub-phonetic and orthographic
time-aligned representation of the signal (Savy and Cutugno, 2009). Transcripts were used as a
basis for labelling portions of each sub-corpora. First, transcript files were divided into smaller units
according to their corpus characteristics (table 3.11)
Corpus
Transcription Unit
Labelled transcript unit
Dialogic
dialogue
Turn
Radio and TV
Transmission
Utterance
Telephonic
Call
Instruction
Read speech
List's item (word or sentence) word or sentence
Orthophonic
List's item (word or sentence) word or sentence
Table 3.8: Transcript and labelled transcript unit
CLIPS
93
Each labelled transcript name was then composed by the name of the original transcription
followed by a descriptor of the labelled unit. For example, the transcript of the dialogue
DgmtA01T.txt is divided in turn and each turn labelled. Labelled transcription file names will be
constituted by the original transcription file name (DgmtA01T) followed by speaker and turn
indicator (_p2G#1), resulting in files such as DgmtA01T_p2G#1. Image 3.1 describes a dialogic
utterance filename by its components.
Image 3.1: DG utterance filename example
One of the main purposes of the project was to obtain a corpus that could be used for
automatic speech processing. Therefore the whole annotation and labelling procedures focused on
the phonetic description. Concerning transcripts, any acoustic event present in the signal was
transcribed in its temporal succession. As far as labelling is concerned, not only the temporal
succession was preserved, but all relevant information was time-aligned with the signal. To do this,
a modified version of WaveSurfer (software website: http://www.speech.kth.se/wavesurfer/, version
used for CLIPS: http://www.clips.unina.it/downloads/wavsxclips.zip) was used to read and label the
spectrogram at different levels. (Savy, 2007b) In CLIPS, five different layers were labelled:
➢
ACS: sub-phonemic layer used for the description of occlusives and affricates. It contains
CLIPS
94
the begin of the silence phase, its end and the end of the release phase;
➢
PHN: phonetic transcription enriched with diacritics and annotation of various phonological
phenomena;
➢
STD: standard phonological transcription.
➢
WRD: orthographic transcription.
➢
ADD: includes operator comment, turn overlapping, and other non lexical phenomena left
out from other levels (such as <vocal>, <NOISE>)
Image 3.2 shows how labels appears on WaveSurfer. The output of the program is saved by
Wavesurfer as text files. File extensions indicate which layer was labelled (for example .phn for
phonetic transcription). On a label file every line is divided in three colums, which contain a TIMIT
sample indicating the begin, the end and the content of the label.
Image 3.2: word sì 'yes' labelling on WaveSurfer
Note that the first label of such a file can be two underscores (__) or two underscores followed by
the percentage sign (__%) in the case it was impossible to determine the exact beginning of the turn.
This is an example of an STD TIMIT.
CLIPS
95
0 159 __
159 9808 ok"Ei
9808 11734 <sp>
11734 16008 v"ai
16008 17382 un
17382 20189 p020189 27405 dZ"u
At the phonological level, each label basically corresponds to a word. Therefore, each line describes
a word, giving the temporal indication of its begin, its end and its phonological representation. For
example, the second line label the signal from TIMIT 159 to 9808 as the word /oK”Ej/.
5.
Phonological Layer
STD files contain word phonemic transcription 44(Savy, 2007b). In CLIPS a word is defined as a
sequence of letters separated by a blank space. Words separated by an apostrophe (and forms
syntactically identical to those) are grouped together as a single unit. The alphabet used for the
transcription is SAMPA. The list of symbols used to indicate vowels is given in table 3.9, for
consonants see 3.10.45 Most of the tags used in the orthographic transcript were both not transcribed
(i.e., the orthographic form is kept unaltered) or not included at all in STD (see table 3.11). For
example, turns and turn overlapping were not included at all in STD. On the other hand, false starts
were included but not transcribed phonemically. In the sequence no, non ca+ capisco 'No, I don't
understand' ca+ is kept in its orthographic form (instead of being transcribed as 'ka+') at STD and
the comma not included. The sequence then will be transcribed as no non ca+ kap”isko.
44 In this thesis I will focus only on CLIPS STD layer (see chapter 4 for explanation).
45 http://www.phon.ucl.ac.uk/home/sampa
CLIPS
96
SAMPA
Description
IPA example transcription Translation
i
Front, Close
i
fino
[f”ino]
thin
e
Front, Close-mid
e
pera
[p”era]
pear
E
Front, Open-mid
ɛ
meta
[m”Eta]
half
a
Front, Open
a
nata
[n”ata]
born (fem.)
O
Back, Open-mid, rounded
ɔ
nota
[n”Ota]
note
o
Back, Close-mid, rounded o
voto
[v”oto]
vote
u
Back, Close, rounded)
unico
[“uniko]
unic
u
Table 3.9: SAMPA vowel set for CLIPS
Transcription
STD
element between bracekts <> Not transcribed
dialectal and foreign words Not transcribed
parole troncate
Not transcribed
intterrupted words
Not transcribed
false starts
Non transcribed46
lapsus linguae
Not transcribed
punctuation
Not included
turn overlapping symbols
Not included
Table 3.10: Transcript symbols used in STD
46 False starts are followed by a slash '/' on transcriptions, which was not included on STD. For example 'non ca+ /' is
simply transcribed as non 'non ca+'
CLIPS
97
SAMPA
Description
IPA example
transcribed
English
p
occlusive,labial
p
palla
[p“alla]
ball
b
occlusive,labial,voiced
b
bolla
[b“olla]
ball
t
occlusive,dental
t
tana
[t”ana]
liar
d
occlusive,dental,voiced
d
dado
[d”ado]
dice
k
occlusive,palatal,
k
cane
[k”ane]
dog
g
occlusive,palatal,voice
d
g
gatto
[g”atto]
cat
ts
affricate,dental
ʦ
zio
azione
lo zio
[ts”io]
[atts”ione]
[lotts”io]
uncle
action
the uncle
dz
affricate,dental,voiced
ʣ
zolla
mezzo
la zona
[dz”Olla]
[m”Eddzo]
[laddz”Ona]
clod
half
zone
tS
affricate,dental
ʧ
cena
[tS”ena]
dinner
dZ
affricate,dental,voiced
ʤ
giro
[dZ”iro]
turn
f
fricative,labiodental
f
faro
[f”aro]
lighthouse
v
fricative,labiodental,
voiced
v
vano
[v”ano]
vain
s
fricative,alveolar
s
sale
[s”ale]
salt
z
fricative,alveolar,voic
ed
z
sbaglio
[zb”aLLo]
mistake
S
fricative,palatal
ʃ
sciarpa
[S”arpa]
pesce
[p“eSSe]
è sciolto [ESS”Olto]
scarf
fish
melted
m
nasal,labial
m
mamma
[m”amma]
mommy
n
nasal,alveolar
n
nonna
[n”Onna]
grandmather
J
nasal, palatal
ɲ
gnomo
legno
lo gnomo
[J”Omo]
[l”eJJo]
[l”oJJOmo]
gnome
wood
the gnome
r
vibrant,alveolar
r
rana
[r”ana]
frog
l
lateral,alveolar
l
lana
[l”ana]
wool
L
lateral,palatal
ʎ
paglia
[p”aLLa]
straw
j
semivowel, palatal
j
ieri
[j”Eri]
yesterday
w
semivowel, labial
w
nuovo
[nw”Ovo]
new
Table 3.11: SAMPA consonant set for CLIPS
The following two elements, not present on the transcript, were added in STD: dash, in the case of
words with apostrophe due to apocope and inverted commas '' to mark le lexical stress.
CLIPS
2
Diatiopic, Diamesic and Diaphasic Variation
1.
Diatopy
98
CLIPS aims to give a broad dialectal coverage of Italian. For this reason, fifteen cities were
chosen according to results of a detailed sociolinguistic and socioeconomic study (Sobrero and
Tempesta, 2007). The study has taken into account both static (percentage of agriculture, industry,
service and GDP section composition) and dynamic economic values (annual GDP increment).
Other parameters were also considered, each of them with a different weight or importance on
efining the representativeness of candidate locations. The most important indicator was the presence
and the demand of economic (such as transportation, communication, energy, water management)
and social infrastructures (such as education, health, sport, culture). In addition to this, other
parameters were also considered such as consistency and demographic dynamism, urban typology,
economic importance of the city, both at regional and national level.The 15 highest ranked cities
according to these parameters were: Milano, Bologna, Modena, Parma, Reggio Emilia, Firenze,
Brescia, Roma, Vicenza, Torino, Trieste, Ravenna, Bergamo, Verona, Venezia. All these cities lie in
northern Italy. A further grouping has considered four other parameters: GDP, GDP increment
during the period of 1951-1991,cities with a specific economic vocation (agriculture > 20; industry
> 40%, services > 70%) and low unemployment rate.Cities which shared the following
characteristics were then grouped together. Each city was further described according to its
population size. The 25 lowest ranked cities resulted by the application of the socio-economic
analyses in the previous section all lie in Southern Italy. Being the least dynamic cities , they were
compared and chosen according to different criteria, like specific economic vocation and high
unemployment rate (major than the area average value). From those cities, a list of cities was
chosen to be representative for the geographic, socio-economic and linguistic variation of Italian.
This final list was further modified in order to further balance the number of cities representative of
CLIPS
99
each italian region. The resulting 15 cities, chosen as collection sites, are shown in table 3.12. The
table also contains the abbreviated form (code) used in CLIPS file names and headers. Speakers
from these collection sites were then chosen so that the samples could be organic and representative
of the population analysed. To reduce the influence of uncontrollable variables, the chosen speakers
had to fulfill the following requirements:
➢
age: between 18 and 30 years old
➢
social and cultural status: at least middle-high
➢
education: undergraduate or college students
➢
city: born and risen in the target city by parents of that same city.
Location
Code
Linguistic Area
Turin
T
Gallo-Italica
Milan
M
Gallo-Italica
Bergamo
D
Gallo-Italica
Venice
V
Veneta
Parma
E
Gallo-Italica
Genova
G
Gallo-Italica
Florence
F
Toscana
Perugia
O
Mediana
Rome
R
Mediana
Naples
N
Meridionale
Bari
B
Meridionale
Lecce
L
Merid. estrema
Catanzaro
H
Merid. estrema
Palermo
P
Merid. estrema
Cagliari
C
Sarda
Table 3.12: Final location sites with codes
CLIPS
2.
100
Dialogic
CLIPS is also structured into 5 diamesic/diaphasic layers (Savy 2009): dialogic, read speech,
radio and TV, telephonic and orthophonic. In the end of each sub-corpus sections I will resume all
important information about corpus transcription and labelling notation.
The dialogic corpus is composed by 240 dialogues of high quality semi-spontaneous speech
recordings. It is important to note that, unlike other corpora of spoken Italian, the project aimed to
obtain sufficiently good recordings, so that the acoustic and the phonetic analysis of the signal could
be possible (Savy, 2007). To reach this result and obtain at the same time a spontaneous speech,
elicitation techniques were used to reduce the observer's paradox argued by Labov (1977):
"[...] the researcher has to observe how people speak when they are not being observed.”
A speaker aware of being recorded for linguistic purposes in fact will probably overcontrol his/her
speech, thus leading to an artificial linguistic behaviour. On the other hand, a hidden recording apart from rising any kind of privacy and legal issue - will inevitably result in a great loss of quality,
probably to such an extent to make the phonetic analysis of the signal hardly possible. Elicitation
techniques are used and consist on shifting the attention of the speaker from the form to the content
of what is being said. The elicited dialogue is therefore spontaneous but at the same time of high
quality because recorded on a controlled environment. This kind of techniques also allows the
linguist to have the speaker focus on a particular subject, thus reducing the linguistic complexity
(syntactic, pragmatic and lexical) of the speech. The elicitation techniques used in CLIPS are based
on two non-linguistic tasks, which require two speakers to achieve a goal by exchanging verbal
instructions (also called instruction giving dialogues). Two types of elicitation techniques were
used: map task and spot the difference. Map task was introduced by Brown et al. (1984) and
developed by the HCRC of Edimburgh for the acquisition of the HCRC map task corpus (Anderson
et al. 1992). Each speaker disposes of a map consisting of a collection of objects. A path is drawn
CLIPS
101
on the instruction giver's (Speaker 1) map. The instruction follower (speaker 2) then will have to
follow giver's instructions in order to draw the same path on his/her map. Some minor differences
on the location of the objects allow for more spontaneousness and variety. Still, the dialogue is
unbalanced. The giver will have longer turns and the entire dialogue will show a fixed structure and
a limited pragmatic variation. To avoid the balancing problem, CLIPS maps were drawn so that
only half of the path is represented on each map. This way each speaker will be follower and giver
during the same recording session. In order to obtain less structured dialogue a second elicitation
technique has been used based on the spot the difference task. Two speakers are given two pictures
and have to discover the differences between them. Note that in the both cases – map task and spot
the difference - speakers can not see each others. Thus, only verbal language can be used to
communicate. Task's pictures were chosen according to some specific criteria based on a previous
work on infant audiometry by Cutugno et al. (2001). The words to be chosen had to be known by 3year-old children, had to be easy to represent with simple pictures and to be among the most
frequent of the Italian lexicon. Dialogue transcription are characterised by turn indicators and turn
overlapping. The former mark the begin of a turn and indicates speaker and turn number. For the
latter see paragraph 3.1.
3.
Read Speech
The read speech corpus contains 16 hours of recording (De Masi, 2007). It is divided in two
categories: word list reading and sentence reading. The list of sentences was created using the
following procedures. A list of lemmas was firstly obtained by merging four frequency lexicon:
➢
Frequency Lexicon of Spoken Italian (LIP)
➢
Frequency Lexicon of Contemporary Italian (LIF)
➢
Italian Electronic Dictionary (VELI)
➢
Basic Lexicon (LE)
CLIPS
102
Function words, adverbs (the correspondent adjectives were instead kept) and other ambiguous
categories (possessives, indefinites and numerals) were all removed from the list. The 70 remaining
words with the highest usage index were then chosen to create the 20 micro-textes of the sentence
list.
The word list instead is simply constituted by the name of the objects drawn in the map task and
spot the difference maps.
4.
Radio and TV
To be representative and balanced, the Radio and TV sub-corpus is structured for diamesic,
diaphasic and diatopic variance. To account for the diatopic variance, 20% of the data was taken
from national channels, the rest 80% from regional television. The proportion of contacts between
national and regional television was not respected in order to obtain a balanced representation of
diatopic variation. A faithful representation would have penalised too much regional networks (see
table 3.13 for percentages). Even national televisions in fact are characterised by a minor diatopic
variance. In particular, middle Italian and southern Italian traits are dominant on RAI programs
while northern Italian traits are more frequent on MEDIASET network (A. Sobrero, 2007);
Network
Percentage
Rai
25,00%
Mediaset
35-40%
Syndications
15,00%
Private networks
20-25%
Table 3.13: Italian networks audience sharing
Concerning the diamesic variation it has been noted (Dardano, 1994; Rivola, 1989) that
radiophonic and television language show basically the same properties in Italian. For this reason, it
was chosen to collect 50% of the corpus from television and the other 50% from the radio.
CLIPS
103
Four other categories were introduced to account for the diamesic variation:
Entertainment: very high audience and contains live calls, which are of particular interest
➢
due to their spontaneousness.
➢
Broadcast: important for the audience and for the language used, very close to written text.
➢
Culture: contains less data because of the few audience and of the diaphasic variation
similar to the broadcast
Advertisement: the high audience and the peculiarities of the advertisement language were
➢
considered as a positive factor, but the spare attention given by the audience as well as the
minor linguistic influence on the audience brought the authors to limit the amount of
collected data.
Table 3.14 resumes the variables listed above; 50% of the data comes from television, the other
50% from the radio.
Typology
Talk show
Local radios
for every
node
15'
Local TV,
for every
node
RAI
(total)
Mediaset
(total)
15'
50'
50'
Advertisement 5'
5'
15'
15'
Broadcast
2'
2'
15'
15'
Culture
3'
3'
10'
10'
Total
25'
25'
90'
90'
Table 3.14: Minutes of recording distribution on RD and TV
5.
Telephonic
The Telephonic corpus contains recordings of calls from simulated tourists to a virtual
assistance service. Each speaker from the 15 cities of the corpus received 10 scenarios, which
contain information about the request that should be given to stem (Di Carlo and D'anna, 2007). For
example, a possible scenario is the following:
CLIPS
104
“You are at home. You are calling Hotel Excelsior in Paris to book a triple non-smoker room, with
view, shower, and a strongbox. You are booking for the week of Christmas, for three friends of
yours. Your credit card number is 7497 3792 1801 9340.”
The user would call the assistance system and ask for the service indicated. Two different
modalities of interaction were used: automatic and Wizard of Oz (WoZ). The former did not
require a human operator to be present and was used when Wizard of Oz modality was not possible.
Once received the call, the automatic system will proceed to the following operations:
➢
take the call;
➢
recognise the DTMF that the user will digit to indicate the scenario;
➢
record the request;
➢
end the call.
The Wizard of Oz mode required the presence of an operator. In addition to the basic operation
showed above, the operator was able to send messages to the client and to record information based
on the scenario. When a call was received, the operator had to fill a form with the information
received by the client. For example, for the scenario above, the form would be the following:
Identity:
Username
Obligatory information:
Room size
Check-in date
Check-out date
Credit card number
Facultative information:
Room with view
Bathroom service
CLIPS
105
Strongbox
Room for smoker
Arrival time
To ask facultative information the operator could interactively send recorded messages.
Recorded messages could also be used to ask a request to be repeated (in case of unclear
instructions or lack of relevant information) or to conclude the call. Note that any message sent by
the operator was recorded using a synthetised voice in order to keep the client aware that he/she is
interacting with an automatic speaker and not with a human. The entire procedure is the following:
➢
the client calls;
➢
the OC receives the call;
➢
the client is asked to digit the number of the scenario, the numer is saved on a logfile;
➢
stem starts the recording;
➢
the client gives the instructions of the scenario;
➢
if an operator is present (WoZ):
•
he may ask to recast the instruction by sending a recorded message
•
messages from the operator will be saved in a log file
•
he fills in the module of the scenario
•
the client concludes his/her scenario
➢
the recording ends
➢
a good-bye message is sent
➢
the call is terminated
CLIPS
6.
106
Orthophonic
The read speech corpus contains a list of words and sentences read by non-professional
speakers of Italian. The orthophonic corpus consists of the same item read by professional
speakers. The aim of the orthophonic corpus was to obtain a corpus of high quality recordings,
parallel to the read speech, which could be representative of standard Italian. Ten professional
speakers were chosen (5 males and 5 females) to read and repeat three times in an anecoic
chamber47 the twenty sentences previously cited. Being the items of the read speech corpus chosen
according to lexical criteria only, the original corpus was extended with another list of sentences
which could provide a phonetic coverage of Italian phonotactic clusters. Thus, the corpus could be
used as a basis for the evaluation of verbal communication and codification systems. With reference
to the SQEG (Speech Quality Expert Group) , ITU (International Telecommunication Union) and
the expert European group of the ETSI (European Telecommunications Standards Institute) another
list of 120 short sentences was added.
7.
Corpus structure
The structure of the corpus can be summarised as following:
➢
dialogic (DG)
• map task (mt)
• spot the difference (td)
➢
sentence read (LF)
➢
map task words reading (LM)
➢
spot the difference words reading (LT)
➢
Radio (RD)
47 Istituto Superiore C.T.I., viale America 201 - Rome. For technical information please refer to the original document:
CLIPS
107
• culture (dc)
• entertainment (it)
• broadcast (is)
• advertisement (pb)
➢
Television (TV) - as RD (see above)
➢
Telephonic (TL):
• Automatic (A)
• Wizard of Oz (M)
➢
sentence reading (LP)
➢
balanced sentence reading (LB)
Syllabification Program
4
1
Python and NLTK
1.
Python
108
Syllabification Program
Guido Von Rossum (2000), the ideator and main developer of Python describes Python as
“an interpreted, object-oriented, high-level programming language with dynamic semantics”.
Python was chosen as the programming language for this project for various reasons. First, it is
particularly suited for Rapid Application Development. Python programs are typically shorter
then equivalent Java or C++ programs and the development eventually faster. Python's built-in
high-level data types and dynamic typing do not require variable declaration, allow operators to be
overloaded, save human typing time, code lines and avoid memory allocation bugs (overhead of
buffer overruns, pointer-aliasing problems, malloc/free memory leaks and so on). Moreover, being
Python an interpreted programming language, debugging is usually fast and trouble-free. It is
possible to edit the code by including print statements, test it and obtain a clear stack trace. A
powerful source level debugger written in Python also “ allows inspection of local and global
variables, evaluation of arbitrary expressions, setting breakpoints, stepping through the code a line
at a time and so on ”. Second, Python is known for being elegant. Its very clear syntax and
semantics, the use of indentation, transparent operator symbols and many other features make the
code reusable and easy to understand, learn and customise. For example, even the debated use of
indentation instead of braces reduces the number of variability in the code (e.g., there are at least
three different conventions for the placement of braces in C), its visual complexity and therefore the
entire readability of the program. Third, Python is portable: according to the documentation it runs
on many Unix variants, on the Mac, and on PCs under MS-DOS, Windows, Windows NT, and OS/2
and it is included in most Linux and BSD distributions (such as Debian Lenny, Ubuntu). Fourth,
python includes an extensive and documented standard library which provides powerful general
Syllabification Program
109
purpose modules and a big collection of libraries and packages that could be easily used and
included in one's code. Fifth, Python is widely used in academia and in industrial applications by
many major brands (such as Yahoo, Google, Firaxis games, Rackspace) and in many application
domains such as software development, arts, business, education, biology, chemistry, engineering.
Finally, “Python is absolutely free, even for commercial use (including resale) ” and its licence is
certified as Open Source by the Open Source initiative48 (http://www.python.org/psf/license/).
(Rossum and Drake 2003, 2000, 1993; Rossum et al.,1994)
Python is a very powerful language and for computational linguistic tasks it provides all the
necessary tools even for the most advanced applications49. For example, ConceptNet
(http://web.media.mit.edu/~hugo/conceptnet/) is the largest freely available commonsense
knowledgebase and is used in dozens new innovative research projects at MIT and elsewhere.
(Havasi et al., 2007; Liu and Singh, 2004) However, as any other programming langugage, some
structural choices rendered some functionalities unavailable or discouraged. The one major
drawback with Python is code run-time speed. Python code is supposed to run slower than
equivalent programs in C++ and Java. This is mainly due to its memory manager and to dynamic
typing (cf. above). However, with the exception of some applications where speed optimisation and
control of memory usage is a prerogative (scientific computing, kernel hacking and so on), the loss
in speed is in most cases irrelevant with today's machine efficiency and would be negligible in our
software. (Raymond, 2000)
48 All software used to write this thesis (OpenOffice.org 3.1), the scripts (vim) as well as the Operating System
(Debian Lenny) and all programs are free or open source.
49 Hence there is no necessity to discuss about technical details such as the lack of tail recursion (see
http://neopythonic.blogspot.com/2009/04/tail-recursion-elimination.html) in this thesis
Syllabification Program
2.
110
NTLK
Before implementing it was necessary to find a method to manage CLIPS data. It was
important to have a program that could store corpus data without losing information, but at the same
time allows to easily manage it. We needed in fact an interface between and the corpus that could
fetch all necessary information from the corpus and make it available to. TIMIT and transcripts had
to be kept available, as well as the possibility to find and read the audio samples associated with
each transcripts and their recording information. To do this, we could choose between two
possibilities: write a parser from scratch or try to look for a project that had already implemented
such kind of CR. The latter choice was preferred and NLTK's TIMIT corpus reader (hereforward
CR) was used as a basis.
NLTK (Natural Language Tool-kit) “ is a suite of program modules ,datasets, tutorials and
exercises, covering symbolic and statistical natural language processing ” (Loper and Bird, 2002;
Loper, 2004). It is widely used in the most prestigious university NLP courses (including at the
MIT, UPENN, University of Edinburgh) and in research systems (Liddy and McCracken, 2005;
Sætre et al., 2005). According to Loper (2004), the main requirements for the tool-kit design have
been ease of use, consistency (in data structures and interfaces), extensibility (the tool kit includes
now a lot of third party modules), documentation and simplicity. In addition to these characteristics
we decided to choose NLTK for various reasons. First of all it is entirely developed in Python. As
said before this was the programming language we intended to use for the development of . Even if
it is possible to use Python as a glue language by having it to interact with other languages, a fully
consistent implementation was preferred. NLTK was also designed with simplicity and and
extensibility in mind. NLTK is distributed under the GNU General Public licence and all
documentation under a Creative Commons non-commercial licence. This allows to customised and
extend NLTK to include the corpus reader and in a consistent and elegant way. UNIX's divide and
conquer philosophy was also privileged. UNIX design principle of organising complexity by
Syllabification Program
111
breaking it into parts permits to have a main application actively developed and rich of functions
(NLTK), a small syllabification program which could be easily modified and adapted to other
languages leaving the other components untouched, and a simple interface between the two (CR).
NLTK will allow us to analyse and interact with the corpus in an autonomous way. In fact, it will be
possible to exploit NLTK's structures and functionalities in the same way directly on the corpus or
in syllabified data. and the CR were designed so that they could be used by NLTK without issues as
will simple permit to dispose of a new token. A token is a linguistic unit used by NLTK as a basic
processing unit. In our case it will be a syllable, a phone, a phoneme or a word depending on the
case. The main functions will be used on different tokens in an identical way, with no issue of
compatibility.
Syllabification Program
2
Implementation
1.
Syllabification
112
In this paragraph I will illustrate the final syllabification procedure and make important
choices on how the specific problems of Italian syllabification will be treated and why. In chapter I
showed various syllabification principles and procedures and demonstrated that different theories
may lead to different assumptions on the nature of the syllable. As it is not the purpose of this thesis
to draw out a brand new phonological theory it is necessary to make choices on the basis of
available theories and principles. The aim of this thesis is to write a syllabification program, the
algorithm I will show in the next paragraph has engineering goals (it does not aim to demonstrate,
confute, simulate a linguistic theory, see 2.1) and therefore the main design principle will be
practical. This argumentation is controversial, but actually lays out an important theoretical
assumption. As said in chapter II it is important to make design choices so that they can reflect the
nature of the problem. The syllabification program will be used to syllabify CLIPS time-aligned
transcripts. In the scope of the corpus itself it was important to find a principle that could rely on the
acoustic properties of the signal so that the phonological syllabification and syllabification on the
signal could be as closer as possible. Remember that a syllable in an acoustic domain is defined in
term of its energy. The phonological principle which better reflects this property is then the SSP.
Still, we had to face various problems. The basic design principle I used was however to keep the
procedure as simple as possible. This is not only for practical reasons (a neat transparent, bug free
code) but also because the analysis of the signal would not allow for phonological restrictions. For
example, in the case of the SD+4 principle, it would be necessary while working on the signal to
determine if there is a sonority distance in terms of energy major or minor than four between two
consonants, which is impossible if we do not want to abstract that portion of the signal to its
corresponding phoneme. While it is easier, on an abstract phonological level, given two phonemes,
Syllabification Program
113
to obtain their relative sonority distance it is almost impossible to get a precise relative distance at
the acoustic level as it would require at least the phonological class to be detected. The main reason
to use the syllable in NLP was because it allowed to ease speech recognition tasks by using a unit
which was not as hard to recognise and variable as the phone. Going back to segment recognition to
determine the relative sonority of a portion of signal would require a segmental analysis, which is
what we wanted to avoid. Finally, the principle of simplicity means to have the least number of
segments associated with their corresponding signal portion.
In the case of a sC clusters for example we want every sCC clusters recognised as the same
sequence everywhere. That would not be the case of a heterosyllabic division. sCC would be kept
togeter word-initallly but split up word internally as in Vs.CC. The same with geminates. By
keeping them together the opposition between minimal pairs as pap.pa and pa.pa would be clearer
because the contrasting segment appears in one syllable and it's consistent with its representation on
the signal. Moreover, in the case of etherosyllabic geminates, it would have been harder in the
signal to detect and split the two segments up. The signal is continuous and it would have added a
lot of arbitrariness and complexity to the algorithm to decide where to put syllable boundary.
Concerning non native cluster syllabification it was chosen to have them syllabified by the SSP
without adding useless complexity to the algorithm. The underlying linguistic debate is probably the
most controversial and sometimes considered irrelevant even from a phonological perspective.
Moreover, the frequency of these clusters in spoken language (and in the lexicon) is so spare that it
does not really need to be accounted (cf 4.3.4). Finally, concerning diphthongg syllabification we
used the strict definition of hiatus adopted by Fiorelli (1941) and Canepari (2004). According to
these authors, in Italian a hiatus is given only by vowel clusters stressed in the second vowel (e.g.
/ka”ino/, /be”ato/, /pa”ura/). Again, in the signal a concrete rise in energy is visible only in that case.
In the other cases we did not consider it sufficient to have the vowel constitutes a nucleus.
Syllabification Program
2.
114
CLIPS's STD
In chapter III, I have described only the phonemic transcription layer (STD). As a first stage of
work in fact it was decided that a syllabification of sub-lexical level (PHN basically) would be too
problematic to start with. A test simulation was made within the PHN but overwhelming presence
of deletion, epenthesis and assimilation phenomena which had to be treated showed that obtained
syllables were too far from being accurate for any possible application. Nonetheless, the importance
of a phonetic syllabification is still evident. The PHN labels correspond to phones while phonemic
labelling to phonological words, which means that at a phonological level we have word boundary
TIMITs only. It is then impossible to obtain an automatic correspondence between acoustic syllable
boundaries and syllabification obtained through SY, due to the lack of temporal indication at a
lexical level. For example, suppose we want to syllabify the word 'ka.za'. At the phonetic level we
would have the TIMIT of all phones, so that it would possible to trace syllable boundary between 'a'
and 'z' back to the signal. At a phonemic level however we would dispose only of word boundary
TIMITs. Without any temporal indication on where the phones 'a' and 'z' are, we would not be able
to individuate the signal portion of syllable. The WRD level was also not implemented because, as
explained in chapter 2, we did not want to implement an orthographic syllabification program and
there is no reason to use orthographic transcripts if the corresponding phonemic transcription is
available for syllabification. One of the reason is that the phonemic transcription allowed us to
dispose of phonological information useful for syllabification.
In particular, the algorithm relied on transcript labels to determine a syllabification that
could correspond to real acoustic syllable in the signal. For example, in case of pauses between
words, re-syllabification does not apply as there is avoid between two segments which was
considered as an evidence of syllable boundary. Pauses inside words instead were considered
disfluences, labelled with an underscore _ and therefore not transcribed (all the sequences not
transcribed in STD were not syllabified, cf 3.1.5). Lexical stress was used only to distinguish hiatus
Syllabification Program
115
from diphthongs. If two vowels are separated by a stress label (“) they will be considered
heterosyllabic (cf. previous section) and divided. Dashes used to indicate apostrophes were stripped
off because word boundaries were not considered during sentence syllabification (simulating the
natural re-syllabification) and therefore the whole sentence was treated as a single sequence of
phonemes ([l-albero] is the same as [lalbero] due to re-syllabification).
3.
Core SY
As I will be showing in the next section, SY contains two functions used to pre-process and
eventually purge the input. The core syllabification function however was implemented so that it
could simply take a sequence as input and give the same sequence with syllables separated by dots
as output. The input can be any phonemic sequence (word, phrases, sentences and so on).
input: 'lakarta' → do_syllabify() → output: 'la.kar.ta'
The original implementation of the algorithm (Cutugno et al., 2001) was divided in two parts, the
first one parsed the sequence and stored the indexes of least sonorous elements:
def do_syllabify(sequence, verbose=0):
""" Divide a phonematic sequence in syllables """
if son(sequence[i]) < son(sequence[prevchar]) and \
son(sequence[i]) <= son(sequence[nextchar]):
less_son.append(i)
Another portion of code then implemented the rest of the algorithm as the following:
# it is a sonorant
if config.getint('Sonorities', sequence[ph_index]) > 9:
# it is not followed by a vowel or semivowel, coda
Syllabification Program
116
if config.getint('Sonorities', sequence[nextchar]) < 15:
syllable_boundaries.append(nextchar)
# followed by a vowel or semivowel, incipit
else:
syllable_boundaries.append(ph_index)
else:
# not a sonorant, incipit
syllable_boundaries.append(ph_index)
In my opinion, this solution was not the best one, from a computational and overall from a
linguistic point of view. In particular, it treated sonorants in a different way from other segments
and required a lot of code whose behaviour was hard to predict. In fact, three semantic bugs were
found. In case of sonorants geminates, the algorithm put a syllable boundary between the two
segments. In case of other geminates it did not. For example, the word gallo 'cock' was syllabified
as gal.lo while gatto 'cat' as ga.tto. This could not be acceptable. A solution was to use relative
indexes. In the case of geminates have the algorithm consider them as a single unit.
nextchar = ph_index + 1
if sequence[ph_index] == sequence[nextchar]:
nextchar += 1
Another correction had to be made to include semi-vowels while evaluating structural
position of sonorants. In fact, V.SGV behaves exactly the same way as V.SV and not as VS.CV. For
example, 'karje' had to be syllabifiedd as ka.rje and not as kar.je.
Finally, the sCC cluster was syllabified as s.CC at the beginning of a word or even as
V.Cs.CC between two consonants as in word like /ekstra/ (syllabified [ek.s.tra]). The left alone /s/
Syllabification Program
117
was recognised as a syllabic nucleus or better as extra-syllabic because left out from adjacent
syllables. This kind of clusters had to be purged and other lines included. The resulting code lacked
elegance, did not really reflect the nature of the phonological phenomena and a lot of code to be
added to handle situations where the original algorithm failed.
The original purpose of the algorithm was to implement the SSP, which benefits of being a simple
and universal principle. But if the principle is universal, it is widely accepted that some variations
can be found across language in the SH. Instead of modifying the code, the algorithm or the
principle itself, what I had to look for was some possible variations in the SH. The result was that
by slightly changing the sonority value of /l/ so that it could be less sonorous than /r/ and by setting
the sonority value of /s/ to 1 (see previous section) the principle could be implemented in only three
lines of code and gave good results. It required no messy exception handling instructions, no crazy
sonorant restrictions, gave the desired syllabification for sC cluster, geminates and hiatus, and an
elegant and transparent design50. Table 4.2 shows how some words were syllabified by the two
algorithms. It follows the only three lines of code needed.
if son(sequence[i]) < son(sequence[prevchar]) and \
son(sequence[i]) <= son(sequence[nextchar]):
less_son.append(i)
Note that sonorities are specified in a configuration file and parsed using the module ConfigParse:
def son(phone):
return config.getint('Sonorities', phone)
50 I have been argued that this is a programming hack. It is and it is not only this. I am not arguing here that /s/ has a
sonority value of 1 in phonology nor that the tautosyllabic syllabification is the correct one. What I am saying is that
I assumed no phonologic framework but found an algorithm that had to work on the signal and I am pretty sure this
is the best way to do it, both in implementation and in design. In addition to this, keeping it as simple as possible,
and demonstrating that is possible to obtain a syllabification in Italian by only tuning sonority values the SSP
remains universal and simple.
Syllabification Program
118
For the sonority.cfg see APPENDIX A (divided in two colums to save space). Hashes indicate
comments. An integer is assigned to each phoneme used in CLIPS. Typos are also handled as in the
case of 0 (zero) used instead of O (capital <o>), 'c' instead of 'k' and so on. Symbols are also
included and assigned a sonority value for compatibility. More work is necessary to handle CLIPS
labels. In case of stress, if adjacent segments are vowels in the form V"V, a syllable boundary is
placed between the two vowels V."V.
if itis(sequence[prevchar], 'V') and itis(sequence[nextchar], 'V'):
syllable_boundaries.append(i)
The syllabification of most relevant Italian clusters by the program is given in APPENDIX B.The
opaque interaction with the CR is interesting as well. The CF (cf. next section) can provide four
types of data: a list of words, a list of sentences, one word or one sentence. The syllabify function
recognises the input and provide the syllabification of the sequence. For example, in the case of a
sentence the CR return a list which contains a list of strings for each sentence [[Sentece1],
[Sentence2]]. Each sentence is then represented as a list of strings (words) [S1[W1, W2,
W3]S2['W1','W2']]. The list is parsed and every sentence is turned into a string made by the
sequence of all the words in the sentence and given as argument of do_syllabify(). If syllabify is
called with the option 'rich' it will print non transcribed portion of the sentence between parenthesis
(such as disfluences). Otherwise, it will just ignore them. Comments are always ignored:
# it is a sentence
for word in sequence:
# ignore comments
if '[' in sequence or '<' in sequence:
continue
elif '+' in word:
if not rich:
Syllabification Program
119
continue
else:
# save the word and substitute it with a '+'
oldwords.append(word)
word = re.sub(r'.*\+', '+', word)
nsequence.append(word)
# syllabify the sequence
tmp_syllabified = do_syllabify(''.join(nsequence), verbose)
if rich:
for word in oldwords:
# put the non transcribed words back between parenthesis
tmp_syllabified = re.sub(r'\+', '.(' + word[:-1] + ')', tmp_syllabified, 1)
# if the sentence begins with a '.' strip it off
if tmp_syllabified[0] == '.':
tmp_syllabified = tmp_syllabified[1:]
The two additional functions are cvsyll(word, ph_class = 0) and itis(). The former take a
string (syllabified or not) and return its syllable structure. If ph_class is set to 0 the phonological
class of each sentence is given, otherwise the CV structure of syllable. For example, the word 'ka.za'
will return as 'OV.FV' if ph_class is specified or as 'CV.CV' if set to 0. The Phonological class used
are: Occlusives, Fricative... cvsyll uses itis() to determine whether a phone is a consonant or a
vowel and eventually its phonological class. If the argument query specify a phonological class itis
return 1 if the phone belongs to that class or 0 if not. To determine the phonological class the
sonority values used in sonority.cfg are used. These two functions are particularly useful to abstract
statistical analysis as we will see in the next section.
def itis(phone , query = 0):
""" query == CLASS return 1 if a phone belongs to the desired class
query == 0 return C or V
query == 1 return ph class of a phone """
Syllabification Program
120
try:
config.getint('Sonorities', phone)
except:
return 0
if son(phone) in [99, 0]:
# symbols
phoneis = 'X'
elif 27 > son(phone) > 18:
# vowels
phoneis = 'V'
elif 19 > son(phone) > 14:
# glides
phoneis = 'G'
elif 15 > son(phone) > 9:
Another useful function is demo_syll(). By simply running the function demo_syll(), it is
possible to get a set of example syllabifications (APPENDIX B). The set is thought so that only
representative examples of relevant sequences are syllabified, as for example geminates, sC cluster,
non native clusters, and so on. This might be particular useful, especially for linguists. In fact, it is
possible to make any change to the algorithm or simply to the sonority scale and immediately see
how the change has affected the whole syllabification system.
4.
Phonological Syllabification
A controversial aspect of the syllabification program was the treatment of geminates. Even if some
authors assumes the opposite (De Gregorio, 1935; Martinet, 1975 and others), evidence clearly
shows that Italian speakers recognise geminates as heterosyllabic segments (for a recent and
complete analysis see Loporcaro, 1996).
If the syllabifications so far given by the program might be considered phonologically erroneous
because of this aspect, the proposed SSP and the SH are perfectly able to describe and predict the
correct phenomenon. The algorithm so far described put a syllable boundary if there is a decreasing
Syllabification Program
121
sonority and therefore, in the case of geminates, it keeps the two identical segments together in the
onset as there is no sonority shift in a broad sense. However, as noted on 1.2.2, a strict or exclusive
interpretation of the SSP implies that because sonority does not decrease throughout syllable
margins in the case of a sonority plateau, two identical segments have to belong to different
syllables. By strictly applying this interpretation of the principle you get a different syllabification,
in particular that of geminates, which becomes heterosyllabic. The resulting syllabification system
shows no idiosyncrasies and perfectly reflects Italian phonological theory. The output of the
demo_syll() function (see APPENDIX C) shows all relevant cluster syllabifications that result from
the application of this principle. It is important to note that no resyllabification or exceptions is
required. By changing the SH and applying the SSP you get two possible syllabifications: one that
prefers tautosyllabicity and seems to be more usable on an acoustic-computational ground, the other
which is phonological and results by the strict interpretation of the SSP. The algorithm is identical
to the first one, thus demonstrating that the core principles have not changed, with the exception
that a syllable boundary is placed even if two phonemes have the same sonority (while in the other
one it was required a sonority shift).
if son(sequence[i]) <= son(sequence[prevchar]) and \
son(sequence[i]) < son(sequence[nextchar]):
Even more interesting is the fact that even the sC cluster is treated as heterosyllabic with
the strict implementation of the SSP, thus reflecting the hypothesis of most literature discussed so
far. Most important, sC cluster does not cause extrasyllabicity word-internally with this SH and
SSP, as in the word /ekstra/, syllabified as /e.ks.tra/. In fact, the literature has never accounted,
especially for Italian, of phenomena of extrasyllabicity which do not occur on word margins, which
instead would result from the application of the SSP using the standard sonority value for /s/. By
using the exclusive or phonological interpretation of the SSP and the same SH I used so far, you get
Syllabification Program
122
divided geminates, heterosyllabic sC cluster and no word-internal extrasyllabicity. A further
evidence which may justify the special sonority of /s/, and overall avoid the necessity of other
principles, is the fact that by changing the sonority value of /s/ from 1 to 0 you get a tautosyllabic
syllabification of the cluster and no extrasyllabicity (i.e., /E.kstra/, /stra.no/, /pa.sta/). In this case, it
is easy to justify the ambgious behaviour of the cluster only in terms of sonority. Davis (1990)
proposed a principle based on the assumption that speakers resolve an arithmetic operation to
determine if a value of 4 in the sonority distance is reached to determine whether to put or not a
syllable boundary. My hypothesis is that there is no principle that make the speaker able to do such
a fine-grained distinction between arbitrary sonority distances. The SD principle for Italian was
justified by il/lo allomorphy, but as noted by notable authors such as Bertinetto (1999), proposed
data is quite controversial. Moreover, as demonstrated in 1.2.7 (cf. McCrary, 2004), in the cases
where a few sonority distance, cluster syllabification is particularly ambiguous and it is hard to
determine where to put a syllable boundary in a sequence of vocoids possibly because there is no
clear sonority shift. I assume then that Davis (1990) himself indirectly constitutes an evidence that
Italian speakers are better able to distinguish between high sonority distances to determine correct
syllabification. The sonority of /s/ might be 1, 0, or might be changing diachronically from 1 to 0.
Its ambiguity lies in the fact that this little sonority shift/difference causes the cluster to be
heterosyllabic or tautosyllabic.
Syllabification Program
3
Final Developing
1.
Corpus Reader
123
Instead of reinventing the wheel and to keep compatibility among programs it was decided
to build a CR based on the NLTK TIMIT one. The main methods and classes are kept and with
future reference to a possible merging of the two CRs, I have tried to keep the code compatible. To
do this it was necessary to modify the directory structure of CLIPS so that it could be parsed in the
same way as the TIMIT one. The script onlineclips.py allows to download the entire corpus from
Internet and prepare it to be processed by the CR. As it is impossible to directly download fileeee of
the corpus via HTTP, GNU wget is used by onlineclips.py as web-crawler to get the URls
downloadable files of the corpus. Within the CR we will have access to all information contained in
the corpus. Most important, the CR will codify the data so that it can be processed and manipulated
by Python and NLTK. As we will see, this will also mean to be able to have any sequence
syllabified and processed. First it is necessary to load the CR.
>>> from nltk.corpus import clips
Now we can operate using the imported object methods. clips.utteranceids(corpus) return a
list containing the id of the specified corpus. Instead of getting all the ids we can choose to get only
a part of it, let's say the first the first five utterance ids of the dialogic corpus:
>>> item = clips.utteranceids()[5:10]
And print them to see the the content of the list.
>>> print clips.fileids('txt')[5:10]
['DGmtA01L_p1F/115.txt', 'DGmtA01L_p1F/117.txt', 'DGmtA01L_p1F/119.txt',
'DGmtA01L_p1F/121.txt', 'DGmtA01L_p1F/123.txt']
Syllabification Program
124
Now it is possible to easily get all information from the chosen items as showed in the following
examples.
Phones:
>>> print clips.phonemes(item)
['akk"anto%', '%a', 'sin"istra', '__%', '%t"utto%', '%"alla', 'sin"istra%', 'margi+', 's"i', 's"i']
Orthographic words (the 'u' before the strings stands for unicode):
>>> print clips.words(item)
[u'accanto', u'a', u'sinistra', u'tutto', u'alla', u'sinistra', u'margi+', u'si', u's\xec']
To codify the character print the single element instead of a the list representation:
for word in clips.words(item):
....:
print word,
accanto a sinistra tutto alla sinistra margi+ si sì
Orthographic words with TIMIT:
>>> print clips.word_times(item)
[(u'accanto%', 8264, 20419), (u'%a', 20419, 21789), (u'sinistra', 21789, 37007), (u'__%', 0, 694),
(u'%tutto%', 694, 6333), (u'%alla', 6333, 10477), (u'sinistra%', 10477, 25731), (u'margi+', 37599,
47610), (u'si', 10016, 16372), (u's\xec', 3013, 8870)]
Syllabification Program
125
Phonemes with timit:
>>> print clips.phoneme_times(item)
[('akk"anto%', 8264, 20419), ('%a', 20419, 21789), ('sin"istra', 21789, 37007), ('__%', 0, 694),
('%t"utto%', 694, 6333), ('%"alla', 6333, 10477), ('sin"istra%', 10477, 25731), ('margi+', 37599,
47610), ('s"i', 10016, 16372), ('s"i', 3013, 8870)]
Sentences with TIMIT:
>>> print clips.sent_times(item)
[('akk"anto%', 8264, 20419), ('%a', 20419, 21789), ('sin"istra', 21789, 37007), ('__%', 0, 694),
('%t"utto%', 694, 6333), ('%"alla', 6333, 10477), ('sin"istra%', 10477, 25731), ('margi+', 37599,
47610), ('s"i', 10016, 16372), ('s"i', 3013, 8870)]
Play a sentence
>>> clips.play(item)
Play from the first and the third word
>>> clips.play(item, clips.ut_start(item,0), clips.ut_end(item,2))
If you leave $start out the beginning of the sentence is assumed, for $end the end.
>>> clips.play(item, clips.ut_start(item,4))
You can also play one or more phones, in this case from the second to the fifth ([kanto])
>>> clips.play(item, clips.ut_start(item,1), clips.ut_end(item,4), phone = 1)
Syllabification Program
126
print a tree containing the orthographic and the phonemic transcription of a sentence:
>>>for tree in clips.phone_trees(item):
…
print tree
(S
(__% __%)
(%quindi %kw"indi)
(bisogna biz"OJJa)
(prepararsi prepar"arsi)
(per per)
(metter m"etter)
(le le)
(piante% pj"ante%)
(%in %in)
(condizione kondittsj"one)
(di di)
(autodifese autodif"eze))
These methods combined together are extremely powerful. This simple script prints the entire
corpus:
# import clips corpus reader
from nltk.corpus import clips
# all the utterances in the corpus
item = clips.utteranceids()
Syllabification Program
# for every sentence
for it in item:
print it + ":"
# print the sentence with timit indicators
print clips.sent_times(it)
# for every word in the sentence print phonemic and orthographic transcription
# with timit
for word, phone in zip(clips.word_times(it), clips.phoneme_times(it)):
print "%s -> %s" % (phone, word)
Output:
DGmtA01L_p1F/203:
[('o"kay % %tSisj"amo', 0, 35656)]
('o"kay', 3543, 15284) -> (u'okay', 3543, 15284)
('%tSi', 23086, 27684) -> (u'%ci', 23086, 27684)
('sj"amo', 27684, 35656) -> (u'siamo', 27684, 35656)
DGmtA01L_p1G/1:
[('all"oram"arko', 0, 31267)]
('all"ora', 9865, 17344) -> (u'allora', 9865, 17344)
('m"arko', 17344, 31267) -> (u'Marco', 17344, 31267)
127
Syllabification Program
2.
128
SY and NLTK
SY can be used from the command line by specifying the sequence to syllabify as an argument:
$ python syllable.py 'colore'
co.lo.re
In case the argument verbose is specified it will print to the standard output the entire syllabification
procedures:
>>> do_syllabify('lakarta', verbose = 1)
lakarta
Trovato minimo di sonorita: k
Trovato minimo di sonorita: t
Confini di sillaba: [2, 5]
la.kar.ta
It is also possible to run the program without argument. In this case the user will be prompted for
the word to syllabify and the syllabification procedure shown.
$ python syllable.py
Sequenza fonematica da dividere in sillabe: colore
colore
Trovato minimo di sonorita: l
Trovato minimo di sonorita: r
Confini di sillaba: [2, 4]
co.lo.re
Sequenza fonematica da dividere in sillabe: kasa
...
The most interesting use of SY is possible by exploiting the interaction between SY, NLTK
and CLIPS, which allows to syllabify any part of the corpus, interactively query it and get statistical
and categorical information with ease. In the next sections I will finally show how the three
components can be combined together, how the SY can be exploited to syllabify the corpus and
Syllabification Program
129
how to use syllabified data with NLTK. First, import two modules, one is the CR the other the SY.
>>> import syllable
>>> from ntlk.corpus import clips
Now it is possible to query the corpus and syllabify the output. As said in the previous
section the CR returns data types depending on the linguistic unit to parse. However, SY is designed
to syllabify any input received by the CR despite its nature. First, we define an object item which
contains the ids of a corpus unit, in this case the fifth dialogue of DG.
>>> item = clips.utteranceids('DG')[5]
You can get each word syllabified by using the method syllabify().
>>> syllable.syllabify(clips.phonemes(item))
['a.kk"an.to', 'a', 'si.n"i.stra']
If a sentence has to be syllabified, it is considered as a sequence of phonemes and syllabification
applies without considering word boundaries.
>>> syllable.syllabify(clips.sents(item))
['a.kk"an.toa.si.n"i.stra']
As yo can see the sequence toa is considered as a single unit do to re-syllabification You can also
syllabify each word separately.
>>> for word in clips.phonemes(item):
...
print syllable.syllabify(word)
...
['a.kk"an.to']
['a']
['si.n"i.stra']
Syllabification Program
130
Or syllabify a single word and use the verbose mode.
>>> syllable.syllabify(clips.phonemes(item)[0], verbose = 1)
single word: akk"anto
Confini di sillaba: [1, 6]
a.kk"an.to
['a.kk"an.to']
Finally, it is possible to display the TIMIT as well as any other information available in the desired
layout. For example, this simple code will display the entire sentence, its syllabification, the
phonological transcription of each word, the orthographic transcription and its TIMIT.
print clips.sent_times(item), ' > ', syllable.syllabify(clips.sents(item))
for word, phoneme, syll in zip(clips.word_times(item), clips.phoneme_times(item), \
syllable.syllabify(clips.phonemes(item))):
print word[0], word[1], '-', word[2], ':', phoneme[0], '>', syll
Output:
[('akk"anto% %asin"istra', 0, 37007)] > 'a.kk"an.to%%a.si.n"i.stra'
accanto% 8264 - 20419 : akk"anto% > a.kk"an.to
%a 20419 - 21789 : %a > a
sinistra 21789 - 37007 : sin"istra > si.n"i.stra
3.
NTLK and SY
This paragraph will expose the potentiality of NLTK, SY and CLIPS and will only serve as a
demonstration of what could be done with them 51. To have NLTK interacting with both the corpus
and SY allows to exploit NLTK functionalities to analyse CLIPS. In this paragraph I will explore
NLTK statistical processing , a feature of particular interest in corpus linguistic. CLIPS was
51 Note that all data given in this paragraph does not prove any linguistic theory. It can be exploited in linguistic
analsys but that would require them to be discussed and analysed. Moreover, I will be using only a sample portion of
CLIPS and not the entire corpus.
Syllabification Program
131
designed as a support for automatic speech processing applications but also for statistical analysis of
Italian spoken language. Note that I will show only some of the functionalities featured by NLTK
and use them on a syllabified output. But it is always possible to do the same kind of processing at a
lexical, phonological, phonetic level as well as investigate other NLTK features that I will not
discuss here (for a complete reference see S. Bird, 2009). For example, a phonotactic study of
Italian could be particularly interesting in relation to the syllable. In this case you will be using the
phonological or the phonetic layer instead of the syllable. In paragraph 4.2 we said that non native
clusters in Italian spoken language are so rare that could be ignored. This simple script gives us a
clue about it52.
import nltk
from nltk import FreqDist
from nltk.corpus import clips
import syllable, re
item = clips.utteranceids('DG')
clusters = ['pr', 'sp', 'rt', 'pt', 'ft', 'fn', 'pn']
for cluster in clips.phonemes(item):
m = re.search(r'(pr|sp|rt|pt|ft|fn|pn)', cluster)
if m:
clusters.append(m.group())
fdist1 = FreqDist(clusters)
fdist1.tabulate()
pr
866
rt
656
sp
515
ft
1
pt
1
pn
1
fn
1
52 In order to have all the results showed in the table they had to be set to 1. In fact, the real result shows that there is
none of the non native clusters in the corpus!
Syllabification Program
132
Before working on CLIPS syllables it is recommended to add a new layer SYL to the
corpus. This way the CR will have direct access to CLIPS syllables and wont have to syllabify and
store the entire corpus (which could be particularly time consuming) every time the program is run.
The new layer will have the characteristics of all other layers and will be saved as text files in
TIMIT format. It is strongly recommended to use this approach on research. In fact, being the
corpus transcripts permanent and immutable there is no reason to process them if no change of the
corpus is made. Moreover, as said before, this will create another representation of the corpus at a
syllabic layer and will allow all the benefits argued for the other transcripts. In this paragraph I will
syllabify the corpus on the fly, keeping SY and the CR separated. This because the operation is
slightly more complicated than having a syllabic layer integrated with the corpus and because it
would better show the functioning of SY itself.
The first operation to do is to syllabify the entire corpus. This could be done by creating a
list containing the desired syllabified units (such as phonemes and sentences). To reduce the
processing time we will process only the first 100 units of the DG corpus. Note that the verbose
argument indicates that we do not want any message on stdout.
item = clips.utteranceids('DG')[:1000]
std_words = [syll for syll in syllable.syllabify(clips.phonemes(item), verbose = -1 )]
std_sentences = [syll for syll in syllable.syllabify(clips.sents(item), verbose = -1 )]
The two lists will look like the following:
>>> std_words[10:20]
['s"i', '".io', '"O', 'un', 'p"e.tti.ne', '"a.lla', 'm".ia', 'si.n"i.stra', 'lon.t"a.no', 's"i']
>>> sent_sylls[1:4]
['s".i."E.kko.nO.non.tSe.l".O%%".io.nO', 's".i."E.kko.nO.non.tSe.l".O%%".io.nO.s"i.s"i.s".i.".io
%%".O%%un.p"e.tti.ne%%"a.lla.m".ia.si.n"i.stra.lon.t"a.no', 's".i."E.kko.nO.non.tSe.l".O%
%".io.nO.s"i.s"i.s".i.".io%%".O%%un.p"e.tti.ne%%"a.lla.m".ia.si.n"i.stra.lon.t"a.no.s"i']
Syllabification Program
133
It is also possible to have syllbification to be done on phonological classe or CV structures by using
the cvsyll() function:
classed_words = [syllable.cvsyll(syll,1) for syll in syllable.syllabify(clips.phonemes(item),
verbose = -1 )]
cv_words = [syllable.cvsyll(syll) for syll in syllable.syllabify(clips.phonemes(item),verbose=-1 )]
The content of the lists would then be the following:
>>> cv_words[:10]
['CV', 'V.CCV', 'CV', 'CVC', 'CCV', 'CV', '.VV', 'CV', 'CV', 'CV']
>>> classed_words[:10]
['OV', 'V.OOV', 'SV', 'SVS', 'OOV', 'SV', '.VV', 'SV', 'OV', 'OV']
NTLK's frequency module does statistics using elements of a list. In other words, to have the
module count syllables (or any linguistic units) we need that each element of the list corresponds to
a syllable (or to any desired linguistic unit).The following code first joins all the string of the list
(i.e. words or sentences) in a single list using a dot as separator and then splits it up in
correspondence of every dot. For example, ['ka.za', 'di', 'lu.ka'] first will be merged in
['ka.za.di.lu.ka'] and then divided back into ['ka', 'za', 'di', 'lu', 'ka'].
# create a list whose elements are syllables
w_sylls = [syll for syll in '.'.join(std_words).split('.')]
c_sylls = [syll for syll in '.'.join(classed_words).split('.')]
cv_sylls = [syll for syll in '.'.join(cv_words).split('.')]
s_sylls = [syll for syll in '.'.join(sent_sylls).split('.')]
Now it is possible to have the lists processed by the NLTK's FreqDist module. First of all we have
to import it and initialise a frequency object.
from nltk import FreqDist
fdist1 = FreqDist(w_sylls)
Syllabification Program
134
The object methods will allow us to dispose of frequency information and graphs. These
next lines of code will allow us to easily obtain generic statistical information, in this case of
CLIPS's syllabified phonemic transcripts. Note the frequency of 'si', 'no', 'la' syllables in the DG
corpus which is probably lexical.
print "Computed syllables: ", fdist1.N()
print "100 most frequent syllables"
for i in range(10, 101, 10):
vocabulary1 = fdist1.keys()[i-10:i]
print i-10, '-', i ,vocabulary1
print "Most frequent syllable:", fdist1.max()
print "Recurrences:", fdist1[fdist1.max()]
print "Frequency:", fdist1.freq(fdist1.max())
And this is the output:
Computed syllables: 12585
100 most frequent syllables
0 - 10 ['a', 's"i', 'o', 'lla', 'la', 'e', 'no', 'na', 'te', 're']
10 - 20 ['tto', 'le', 'stra', 'di', 'vi', 'il', 'ra', '"E', 'ne', 'to']
20 - 30 ['k"Ei', 's"o', 'in', 'ta', 'd"e', 'pra', 'si', 'll"o', 's"O', 'nO']
30 - 40 ['n"i', 'ti', 'ssa', '"u', 'un', 'do', 'ma', 'io', 'ke', 'm"a']
40 - 50 ['"a', 'tSi', 'p"a', 'ko', '"', 'non', 'da', 'so', 'd"E', 'kki']
50 - 60 ['va', 'v"Er', 'lle', 'kw"e', 'tra', 'p"Oi', 'mo', 't"or', 'me', 'r"o']
60 - 70 ['pj"u', 'tu', 'd"a', 'tSe', 'ri', 'sso', 't"i', 'se', 'm"en', 'li']
70 - 80 ['tta', 'pa', 'po', '"O', 'l"O', 'al', 'del', 've', 'tS"E', 'l"i']
80 - 90 ['per', 'v"a', 'ro', 'st"E', '"ai', 'vo', 'f"a', 'ka', 'd"', 'ue']
90 - 100 ['tti', 'kko', 'v"ai', 'tro', 'rri', 'm"E', 'tSo', 'd"o', 'kkj"a', 'Li']
Most frequent syllable: a
Recurrences: 379
Frequency: 0.0301152165276
Syllabification Program
135
It is also possible to obtain frequency and cumulative freqeuency distribution plots (image 4.1 and
4.2).
print "Syllable Frequency Distribution Plot..."
fdist1.plot(25)
print "Syllable Cumulative Frequency Distribution Plot..."
fdist1.plot(25, cumulative=True)
The argument of the function specifies the number of results showed in the plots. You can
get simple frequency information on the object but also more complex and personalised one in a
very clear and elegant way thanks to python. In this example we will create a first list containing
only syllable lengths, initialise another frequency object and get frequency information. The
function tabulate() will format the results in a table.
len_sylls = [len(syll) for syll in cv_sylls if 0 < len(syll) < 6]
fdist2 = FreqDist(len_sylls)
print 'Most frequent syllable lengths'
fdist2.tabulate()
The result will be the following. The method tabulate formats the output in a table.
Most frequent syllable lengths
2
3
1
4
5
6660 3893 1344
563
46
Syllabification Program
Image 4.1: Syllable Frequency Distribution Plot.
Image 4.2: Syllable Cumulative Frequency Distribution Plot.
136
Syllabification Program
137
You may also use the phnoological class list to get the structure of most frequent long
syllables (which contain more than two elements). Again, the code will be very clear. you will just
have to create a list containing only syllable longer than 2 and initialise another FreqDist object.
long_sylls = [syll for syll in c_sylls if len(syll) > 2]
fdist4 = FreqDist(long_sylls)
print '10 Most frequent long syllables (l > 2)', fdist4.keys()[:10]
Output:
10 Most frequent long syllables (l > 2) ['OOV', 'SSV', 'OVS', 'OSV',
'OGV', 'OVV', 'SVS', 'OOSV', 'FVS', 'OOVS']
Another interesting NLTK feature is the conditional frequency module. CLIPS is well
structured and conditional frequency can be used to obtain highlight differences between different
linguistic variaties (diatopic, diaphasic and so on). In the next example I will use the function
clips.corpinfo() to obtain a list of CLIPS sub-corpora (such as 'DG', 'TV', 'TL'). These corpora will
be paired with CV syllabification of their data. The resulting pairs will be used to create a FreqDist
object with the same characteristic as the previous ones. Note that only the first 200 occurrences of
each corpus are processed.
cv_syllsP = [(subc, syllable.cvsyll(syll))
for subc in clips.corpinfo('subcorpora')
for syll in '.'.join(syllable.syllabify(clips.phonemes(clips.utteranceids(subc)[:200]),
verbose = -1 )).split('.')]
The pairs will look like the following:
>>> for pair in cv_syllsP[-3:]:
…
print pair
('DG', 'CV')
('DG', 'CCV')
Syllabification Program
138
This time we will have to initialise a conditional FreqDist object.
cfd = nltk.ConditionalFreqDist(cv_syllsP)
The object will give the possibility to control the conditions once initialised. For example, we may
want to obtain the number of occurrences of a particular element in a sub-corpus
>>> print 'CV occurences in DG:', cfd['DG']['CV']
CV occurences in DG: 1291
Or get a plot of syllable structure occurrences in the various sub-corpora. We can also specify the
conditions argument to select only particular sub corpora to compare at once:
4.
Further studies
The aim of this thesis was to design and implement a robust system for the automatic
syllabification of CLIPS. In the last section I showed how this system can be exploited to get
statistical information and how to create a SYL layer in a completely automatic fashion. But SY and
the CR constitute just the basis for the future investigation of the subject. Python and NLTK allows
an unlimited number of possibilities and a great versatility that could be exploited for the linguistic
analysis of CLIPS. Moreover, the phonological syllabification could be used as a reference or as a
basis for syllabification of PHN. To have a syllabified phonetic transcription of the corpus will
allow the segmentation of the signal and therefore the possibility to exploit it in numerous ways.
For example, an ANN can be trained using phonetic syllables and their corresponding signal portion
for speech recognition, to describe the acoustic characteristics of most frequent syllables or for textto-speech systems.
Conclusion
139
5
Conclusion
On the first chapter, I have showed that different syllabification principles and definition
have been proposed for Italian. The biggest problem lays on how to divide particular sequences of
two segments, in other words on whether some types of clusters are heterosyllabic or tautosyllabic.
Syllabification principles basically diverge only on the syllabification of sC cluster, geminates,
sequence of vocoids and non native clusters. Depending on the theory, these conflicts are resolved
by means of diffent interacting constraints (Optimality Theory), converging levels of representation
(Autosegmental representation), exceptions or variations of a principle (Sonority Distance principle)
and so on. However, because of various interacting factors, such as the phonotactic knowledge of
speakers, the few occurrences of non native clusters, the rules learned at school for orthographic
syllabification, a possible grey area of unpredictable phenomena or a change in act in the language
it has been difficult to give experimental or external evidence to support a definitive principle or
syllabification.
In the second chapter, two computational models are presented in the light of the ever lasting
epistemological and linguistic debate of empiricism versus rationalism. The brief literature review
shows how different models can be more suited to reflect phonological theories and principles.
However, as a result of chapter I investigation, I conclude that in most cases the accuracy results
given by authors is fallacious. As no gold standard exists, it is illogical to argue that percentage of
syllabification is 'correct'. In my opinion, the only way to test such kind of algorithms is to verify
the obtained syllabification against the expected one, that is compare it with a corpus of
syllabification which results by the application of the same principles by a human. In this case the
performance and accuracy of an algorithmic solution can be tested, but not the accuracy of the
syllabification itself. For example, Marchand (1999) to argue the superiority of data driven against
rule based models argues that Hammond algorithms can correctly syllabify only 30% of words
Conclusion
140
while its data driven algorithm can do fairly better. But its data driven algorithms are trained using
dictionary syllabifications and then tested back against dictionaries. The division between testing
data and training data is obviously maintained, but has argued in chapter I, syllabification given by
dictionaries is among the least reliable from a phonological perspective and it has few value to
compare it with a computational implementation of the OT theory. This is the reason why some
authors avoid giving such kind of information or summarise them in the correct terms. In order to
determine the best syllabification principles or solutions the purposes of the research play a
fundamental role. A model which will be used to get light on a phonological theory would be
different by an algorithm developed for engineering goals or for speaker behaviour investigation.
In chapter III, I describe CLIPS, the largest Italian corpus of spoken language. One of its
most relevant characteristics is the fact to come with a time aligned phonological, phonetic, subphonetic and lexical transcription. I decided to work on the phonological transcription because, as
said in the previous chapter, the orthographic would be irrelevant to analyse and the phonetic is too
much complex at a first stage (such as segment alteration, epenthesis, deletion). One of the main
purpose of the corpus was to provide a support which could be used for statistical and probabilistic
language analysis, especially in the field of speech processing applications.
For this reason and to exploit the time-aligned representation of the signal it was decided in
chapter IV to design an SSP based model. The SSP was chosen because it was the only
phonological principle to rely on a property that could be be traced back to the signal, in particular
to the energy profile. A similar system was also developed by Cutugno et al. (2001) and applied to a
portion of an annotated spoken language corpus. However, the application of the principle resulted
in evidently erroneous syllabifications, for example, words such as Carlo 'Charles' were syllabified
as /ka.rlo/ by the strict application of the SH. To avoid similar problems, a conditional statement
treated sonorants as an exception, relying on syllable structure and segments neighborhood,
Conclusion
141
following an approach similar to the normativist proposed syllabification rules for Italian
enumerated on chapter I. Again, this approach led to unacceptable syllabifications. Geminates were
divided in the case of sonorants and kept together in other cases (/gal.lo/ 'cock' vs /ga.tto/ 'cat'), /s/
remained extrasyllabic and in some cases the algorithm returned syllable without nucleus. Of
particular interest was the extrasyllabicity of the /s/ both word-marginally as in strano 'strange'
/s.tra.no/ and word-internally as in extra 'extra' /ek.s.tra/, which I will show being not suited for this
kind of system. In addition to this, the four issues of Italian syllabification (i.e., sC clusters,
geminates, non native clusters, sequence of vocoids) were not sufficiently discussed. The solution I
adopted was based on two assumptions: the system had to rely on a general phonological principle,
which had to apply without exception to all possible cases; great importance should be given to the
purpose of the software, that is the syllabification of time-aligned phonological transcription of a
corpus created for speech application support. To avoid the syllabification problems derived by the
strict application of the SSP, as showed in Cutugno et al. (2001), it was noted that it suffice to
simply change the sonority value of /l/ (cf. APPENDIX A) and apply the SSP straightforward to this
scale to get only acceptable syllabification (cf. APPENDIX B). In fact, while the SSP is considered
to be universal, it is widely accepted in literature that the SH accept intralinguistic variation. By
changing the sonority value of a phone, it has been possible to apply the principle without clumsy
exceptions. Tautosyllabicity was preferred both for sC clusters and geminates. Concerning the
former, this is the only case of conflict with the phonological theory. I believe in fact that from a
phonological perspective, geminates are heterosyllabic in Italian, but it was necessary for the
purpose of the program to keep them on the same syllable. Tautosyllabicity is in fact preferred on
automatic signal segmentation system. First, it is hard to determinte the syllable boundary position
in the production of non continuous phones, as there is no margin of decreasing sonority. Therefore,
it is also impossible to divide the signal in two identical units. Second, by chosing such
syllabification it is possible to distinguish without contextual information which syllables derive
Conclusion
142
from geminates; third, less variability in syllable structure and types is obtained, being the same
sequence always included in the same syllable and therefore always associated to the same portion
of the signal. For these reasons and to avoid discrepancies on the syllabification system sC cluster
was syllabified as tautosyllabic. By simply changing the sonority value of /s/ it has also been
possible to avoid extrasyllabicity both word internally and word-marginally, resulting in /stra.no/
instead of /s.trano/ and in /ek.stra/ instead of /ek.s.tra/ and again to obtain all the advantages stated
for the geminates syllabification. This point is particularly important for speech applications,
because otherwise the floating extrasyllabic phone would have had to be reassigned, again by
means of exceptions, additional rules or even post-lexical resyllabification, to an adjacent syllable
to have it correctly analysed.
However, to demonstrate that the principle discussed so far is relevant first of all on a
phonological perspective, the theory has to be able to handle geminates and sC clusters correctly, to
explain the reason of the sC cluster ambiguity and eventually give further evidence over the change
made to the SH. As noted on 1.2.7, in the strict interpretation of the SSP, syllable boundary is placed
only if sonority does not decrease, that comprehends the case of a sonority plateau. The application
of this simple observation lead to a phonological syllabification system, which success on treating
geminates and sC cluster as heterosyllabic with no changes. The SSP and SH are kept unchanged,
but the obtained syllabification (APPENDIX C) reflects the one predicted by the phonological
theory. The advantages of this solution are even more important on a phonological theory. Only a
single principle is used to account for the syllabification system of Italian and no arithmetic
operation on sonorities have to be postulated to justify specific cases (cf. SD principle). For this
reason, the theory may have a legitimate cognitive value and eventually be confirmed by the
ambiguous behaviour of sC cluster: by changing the sonority of /s/ from 1 to 0 in fact the
tautosyllabic syllabification of the sC cluster is obtained, but with no word-internal extrasyllabicity
(e.g., /e.kstra/). Within the theory, the possible diachronic shift of sC cluster syllabification from
Conclusion
143
tautosyllabicity to heterosyllabicity argued by Bertinetto (1999) can simply be explained in terms
of a sonority loss of the phoneme /s/.
By changing the sonority value of two phonemes it was possible to obtain an organic and
effective syllabification system which entirely relies on the SSP, without the necessity of rules,
exceptions or relative sonority values. The obtained syllabification is perfectly suited for
phonological analyses and most important for automatic signal processing, especially to train
speech recognition or text to speech systems, this allowing to exploit CLIPS for its original purpose.
The syllabificator as well as the corpus corpus reader have been developed, tested and are free and
available to be downloaded and used for any kind of research. Further studies are obviously
necessary, but this study can constitute an optimal basis for a multitude of possible future works and
applications.
APPENDIX A: Sonority scale
144
APPENDIX A: SONORITY SCALE
[Sonorities]
# Affricates
# Vowels
dZ = 6
a = 26
dz = 6
E = 24
tS = 4
O = 24
ts = 4
e = 22
# Stops
o = 22
b=3
i = 19
d=3
u = 19
g=3
Q = 19
p=1
# Approximants
t=1
j = 18
k=1
y = 18
s=1
w = 18
# Symbols
#Sonorants
- = 99
L = 14
% = 99
r = 14
" = 99
l = 12
_=0
m = 11
n = 11
# Fricatives
v=9
z=9
Z=8
f=7
S=7
h=7
APPENDIX B: SAMPLE SYLLABIFICATION OUTPUT
APPENDIX B: SAMPLE SYLLABIFICATION OUTPUT
CL clusters (pl, kr, dr etc.):
['pa.dre']
['li.tro']
['ka.pra']
LC clusters (lp, rt, rp etc.):
['kol.pa']
['ar.to']
['ar.pa']
Sc cluster:
['pa.sta']
['stra.no']
['E.kstra']
Geminates:
['ga.tto']
['ga.llo']
Second vowel stressed, hiatus:
['pa."u.ra']
['pao.lo']
Non native clusters:
['di.sle.ssia']
['bi.sno.nno']
['te.kni.ka']
['si.na.pti.ko']
['ka.psu.la']
['naf.ta']
['a.tlan.te']
['do.gma']
['a.bnor.me']
['a.fnio']
145
APPENDIX C: PHONOLOGICAL SYLLABIFICATION
APPENDIX C: PHONOLOGICAL SYLLABIFICATION
CL clusters (pl, kr, dr etc.):
['pa.dre']
['li.tro']
['ka.pra']
LC clusters (lp, rt, rp etc.):
['kol.pa']
['ar.to']
['ar.pa']
Sc cluster:
['pas.ta']
['s.tra.no']
['Eks.tra']
Geminates:
['gat.to']
['gal.lo']
Second vowel stressed, hiatus:
['pa."u.ra']
['pao.lo']
Non native clusters:
['di.sles.sia']
['bi.snon.no']
['te.kni.ka']
['si.nap.ti.ko']
['kap.su.la']
['naf.ta']
['a.tlan.te']
['do.gma']
['a.bnor.me']
['a.fnio']
146
Bibliography
147
Bibliography
Adsett, C.R., Marchand, Y. & Kes˘ elj, V., 2009. Syllabification rules versus data-driven methods in
a language with low syllabic complexity: The case of Italian. Computer Speech &
Language.
Amari, S.I. & Kasabov, N., 1998. Brain-like computing and intelligent information systems,
Springer-Verlag Singapore Pte. Limited.
Anderson, A.H. et al., 1992. The HCRC map task corpus, Human Communication Research Centre.
Atkeson, C.G., Moore, A.W. & Schaal, S., 1997. Locally weighted learning. Artificial Intelligence
Review, 11(1), 11–73.
Bach, E. & Wheeler, D., 1981. Montague phonology: a first approximation. University of
Massachusetts Occasional Papers in Linguistic, 7, 27–45.
Bertinetto, P.M., 1999, La sillabazione dei nessi sC in Italiano: un'eccezione alla tendenza
'universale'. In Fonologia e morfologia dell'italiano e dei dialetti d'Italia: atti del XXXI
Congresso della Società di linguistica italiana. pagg. 71-96.
Bird, S., 2005. NLTK-Lite: Efficient scripting for natural language processing. Dans Proceedings of
the 4th International Conference on Natural Language Processing (ICON). pp. 11–18.
Bird, S., Klein, E. & Loper, E., 2009. Natural Language Processing with Python, Oreilly &
Associates Inc.
Bird, S. & Loper, E., 2004. NLTK: the natural language toolkit. Proceedings of the ACL
demonstration session, 214–217.
Black, H.A., 1993. Constraint-Ranked Derivation A Serial Approach to Optimization, University of
California, Santa Cruz.
Bibliography
148
Blevins, J. & Goldsmith, J., 1995. The syllable in phonological theory. 1995, 206–244.
Bloch, B., 1948. A set of postulates for phonemic analysis. Language, 3–46.
Bloomfield, L. & Kess, J.F., 1983. An introduction to the study of language, J. Benjamins Pub Co.
Bonomi, A., Falcone, M. & Barone, A., 2007. Definizione e caratterizzazione di un database vocale
ortofonico realizzato da parlanti professionisti in camera anecoica. Available at:
http://www.clips.unina.it/downloads/8_definizione%20database%20ortofonico.pdf.
Broselow, E., 1982. On predicting the interaction of stress and epenthesis. Glossa, 16(2), 115–132.
Brown, G. et al., 1984. Teaching talk: Strategies for production and assessment, Cambridge:
Cambridge University Press.
Bruni, F., 1992. L'italiano nelle regioni: lingua nazionale e identità regionali, Utet.
Calderone, B. & Bertinetto, P.M., 2006. La sillaba come stabilizzatore di forze fonotattiche. Una
modellizzazione.
Camilli, A., 1941. Pronuncia e grafia dell’italiano, ed. Piero Fiorelli, Firenze, Sansoni, 3(1965), 1.
Canepari, L., 1999. Il MaPI, Manuale di pronuncia italiana, Zanichelli.
Cerrato, L., 2007a. Tecniche di elicitazione dialogica. Available at:
http://www.clips.unina.it/downloads/2_tecniche%20di%20elicitazione%20dialogica.pdf.
Cerrato, L., 2007b. Sulle tecniche di elicitazione di dialoghi di parlato semi-spontaneo. Available at:
http://www.clips.unina.it/downloads/2_tecniche%20di%20elicitazione%20dialogica.pdf.
Chierchia, G., 1986. Length, syllabification and the phonological cycle in Italian. Journal of Italian
Linguistics, 8(1), 5–33.
Chomsky, N., 1996. A review of BF Skinner's Verbal Behavior. Readings in language and mind,
413–441.
Bibliography
149
Chomsky, N., 1965. Aspects of the Theory of Syntax, MIT press.
Chomsky, N., 1959. review of Skinner's' Verbal Behaviour'. Language, 35(1).
Chomsky, N., 2002. Syntactic structures, Walter de Gruyter.
Chomsky, N. & Halle, M., 1968. The sound pattern of English.
Clements, G.N. & Goldsmith, J.A., 1984. Autosegmental studies in Bantu tone, Foris Pubns USA.
Clements, G.N. & Keyser, S.J., 1983. CV Phonology. A Generative Theory of the Syllabe.
Linguistic Inquiry Monographs Cambridge, Mass., (9), 1–191.
Cutler, A. et al., 1986. The syllable's differing role in the segmentation of French and English.
Journal of memory and language(Print), 25(4), 385–400.
Cutler, A. & Norris, D., 1988. The role of strong syllables in segmentation for lexical access.
Journal of Experimental Psychology: Human perception and performance, 14(1), 113–121.
Cutugno, F., Passaro, G. & Petrillo, M., 2001. Sillabificazione fonologica e sillabificazione fonetica.
Dans Atti del XXXIII, Congresso della Società di Linguistica Italiana, Bulzoni Roma. pp.
205–232.
Cutugno, F., Prosser, S. & Turrini, M., 2000. Audiometria Vocale, Bloomington, MN: GN ReSound.
Cutugno, F., 2006. Criteri per le liste di lettura. Available at:
http://www.clips.unina.it/downloads/4_criteri%20per%20le%20liste%20di%20lettura.pdf.
Cutugno, F., 2007a. Criteri per la definizione delle mappe, esempi di mappe e di vignette per il
gioco delle differenze. Available at: http://www.clips.unina.it/downloads/3_definizione%20mappe
%20e%20vignette.pdf.
Cutugno, F., 2007b. Criteri per la digitalizzazione del materiale audio CLIPS. Available at:
Bibliography
150
http://www.clips.unina.it/downloads/7_criteri%20per%20la%20digitalizzazione.pdf.
Cutugno, F., 2007c. Specifiche quantitative e indicazioni sulle modalità di registrazione relative alla
raccolta di parlato: dialoghi, corpus letto e parlato radiotelevisivo. Available at:
http://www.clips.unina.it/downloads/6_modalit%C3%A0%20di%20registrazione
%20abc.pdf.
D‘Imperio, M. & Rosenthall, S., 1998. Phonetics and Phonology of Italian Main Stress. Dans
Twenty-Eighth Linguistics Symposium on Romance Languages, University Park, Penn.
Daelemans, W. & Van Den Bosch, A., 1992. Generalization performance of backpropagation
learning on a syllabification task. Dans Proceedings of the 3rd Twente Workshop on
Language Technology. pp. 27–38.
Daelemans, W. & Van Den Bosch, A., 1997. Language-independent data-oriented grapheme-tophoneme conversion. Progress in speech synthesis, 77–89.
Daelemans, W. & Van den Bosch, A., 1992. A neural network for hyphenation. Artificial Neural
Networks, 2, 1647–1650.
Dale, R., Moisl, H. & Somers, H., 2001. Handbook of natural language processing. Computational
Linguistics, 27(4), 602–603.
Danesi, M., 1985. The Italian geminate consonants and recent theories of the syllable. Toronto
Working Papers in Linguistics, 6(0).
Dardano, M., 1994. Profilo dell’italiano contemporaneo. Storia della lingua italiana, 343–430.
De Masi, S., 2007. Criteri per la predisposizione delle liste di lettura. Available at:
http://www.clips.unina.it/downloads/4_criteri%20per%20le%20liste%20di%20lettura.pdf.
Bibliography
151
Di Carlo, A. & D'Anna, L., 2007. Definizione del contenuto del corpus telefonico e linee guida per
la
raccolta.
Available
at:
http://www.clips.unina.it/downloads/10_definizione%20del
%20corpus%20telefonico.pdf.
Edwards, J.A., 1993. Principles and contrasting systems of discourse transcription. Talking data:
Transcription and coding in discourse research, 3–31.
Eisner, J., Efficient generation in primitive Optimality Theory.
Ellison, T.M., 1994. Phonological derivation in optimality theory. Dans Proceedings of the
Fifteenth International Conference on Computational Linguistics. pp. 1007–1013.
Falcone, M., Barone, A. & Alessandro, B., 2007. Definizione del database ortofonico in camera
anecoica.
Available
at:
http://www.clips.unina.it/downloads/9_descrizione%20del
%20corpus%20ortofonico.pdf.
Firth, J.R., 1957. Papers in linguistics, 1934-1951, Oxford University Press.
Firth, J.R., 1948. Sounds and peosodies . Transactions of the Philological Society, 47(1), 127–152.
Fudge, E.C., 1969. Syllables. Journal of Linguistics, 253–286.
Gibbon, D., Moore, R. & Winski, R., 1997. Handbook of standards and resources for spoken
language systems, Walter de Gruyter.
Goldsmith, J., 1992. ‘Local modelling in phonology. Connectionism: Theory and Practice, Oxford
University Press, Oxford.
Goldsmith, J., 1994. A dynamic computational theory of accent systems. Perspectives in Phonology,
1–28.
Goldsmith, J.A., 1990. Autosegmental and metrical phonology, Basil Blackwell.
Goldsmith, J.A., 1976. Autosegmental phonology, Indiana University Linguistics Club.
Bibliography
152
Goldsmith, J.A., 1999. Phonological theory: the essential readings, Blackwell Pub.
Gordon, M., 2004. Syllable weight. Phonetically based phonology, 277–312.
Halle, M. & Keyser, S.J., 1971. English stress. Its form, its growth, and its role in verse. New York
etc.: Harper” Row.
Hammond, M., 1997. Parsing in OT. Ms., University of Arizona (ROA-222).
Hammond, M., 1995. Syllable parsing in English and French. Arxiv preprint cmp-lg/9506003.
Hayes, B., 1989. Compensatory lengthening in moraic phonology. Linguistic inquiry, 253–306.
Heiberg, A.J., 1999. Features in Optimality Theory: A computational model. THE UNIVERSITY
OF ARIZONA.
Hockett, C.F. & Francis, C., 1955. A manual of phonology, Waverly Press.
Hooper, J.B., 1972. The syllable in phonological theory. Language, 525–540.
Ide, N., Priest-Dorman, G. & Veronis, J., 1996. Corpus encoding standard. URL http://www. cs.
vassar. edu/CES, 3.
Jespersen, O., 1913. Lehrbuch der Phonetik, BG Teubner.
Kahn, D., 1976. Syllable-based generalizations in English phonology, Indiana University
Linguistics Club.
Kasabov, N.K., 2003. Evolving connectionist systems: Methods and applications in bioinformatics,
brain study and intelligent machines, Springer Verlag.
Kasabov, N.K., 1996. Foundations of neural networks, fuzzy systems, and knowledge engineering,
The MIT press.
King, S. et al., 1998. Speech recognition via phonetically featured syllables. Dans Fifth
International Conference on Spoken Language Processing.
Bibliography
153
King, S. & Taylor, P., 2000. Detection of phonological features in continuous speech using neural
networks. Computer Speech and Language, 14(4), 333–353.
Kohler, K.J., P\ätzold, M. & Simpson, A., 1995. From scenario to segment: the controlled
elicitation, transcription, segmentation and labelling of spontaneous speech. Arbeitsberichte
Phonetik Kiel, 29, 7.
Labov, W., 1972. Some principles of linguistic methodology. Language in society, 97–120.
Laks, B., 1995. A connectionist account of French syllabification. Lingua, 95(1-3), 51–76.
Laporte, E., Phonetic syllables in French: combinatorics, structure and formal definitions. Acta
Linguistica Academiae Scientarum Hungaricae, 41, 175.
Laurinčiukaitė, S. & Lipeika, A., 2006. Syllable-Phoneme based Continuous Speech Recognition.
ELEKTRONIKA IR ELEKTROTECHNIKA, 6, 70.
Lepsky, A. & Lepsky, G., 1977. The Italian Language Today, London: Hutchinson.
Lesina, R., 1986. Il manuale di stile, Zanichelli.
Levelt, W.J., Roelofs, A. & Meyer, A.S., 1999. A theory of lexical access in speech production.
Behavioral and brain sciences, 22(01), 1–38.
Loper, E. & Bird, S., 2002. NLTK: The natural language toolkit. Dans Proceedings of the ACL
Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing
and Computational Linguistics. pp. 62–69.
Loporcaro, M. 1996. On the analysis of geminates in Standard Italian and Italian dialects. Natural
Phonology: The State of the Art, 153-187.
Lowenstamm, J., 1996. CV as the only syllable type. Current trends in Phonology. Models and
Methods, edited by Jacques Durand & Bernard Laks, 419–441.
Bibliography
154
Malmberg, B., 1971. Phonétique générale et romane: Études en allemand, anglais, espagnol et
français, Mouton.
Marchand, Y., Adsett, C.R. & Damper, R.I., 2009. Automatic syllabification in English: A
comparison of different algorithms. Language and Speech, 52(1), 1.
Marotta, G., 1993. Selezione dell'articolo e sillaba in Italiano: un'unterazione totale? Studi di
grammatica italiana, 15, 255–296.
McCarthy, J. & Prince, A., 1986. Prosodic Phonology. Ms. University of Massachusetts, Amherst
and Brandeis University.
McCarthy, J., 1981.A prosodic theory of nonconcatenative morphology.Linguistic inquiry, 373-418.
McCarthy, J.J., 1979. On stress and syllabification. Linguistic Inquiry, 443–465.
McCarthy, J.J. & Prince, A., 1995. Faithfulness and reduplicative identity. John J. McCarthy, 44.
McCrary, K.M., 2004. Reassessing the Role of the Syllable in Italian Phonology: An Experimental
Study of Consonant Cluster Syllabification, Definite Article Allomorphy and Segment
Duration. UNIVERSITY OF CALIFORNIA Los Angeles.
McEnery, T., Wilson, A. & Barnbrook, G., 2001. Corpus linguistics, Edinburgh.
Mehler, J., Dommergues, J.Y. et al., 1981. The syllable's role in speech segmentation. Journal of
Verbal Learning & Verbal Behavior. Vol, 20(3), 298–305.
Mehler, J., Segui, J. & Frauenfelder, U., 1981. The role of the syllable in language acquisition and
perception. The cognitive representation of speech. Amsterdam: North Holland.
Nespor, M., 1993. Fonologia, Il Mulino.
Nespor, M. & Vogel, I., 1979. Clash avoidance in Italian. Linguistic Inquiry, 467–482.
Bibliography
155
Nespor, M. & Vogel, I., 1982. Prosodic domains of external sandhi rules. The structure of
phonological representations, 1, 225–255.
Ostendorf, M., 1999. Moving beyond the ‘beads-on-a-string’model of speech. Dans Proc. IEEE
ASRU Workshop. pp. 79–84.
Oudeyer, P., 2001. The Epigenesis of Syllable Systems: an Operational Model. Language, 167–171.
Prince, A., 1990. Quantitative consequences of rhythmic organization. CLS, 26(2), 355–398.
Prince, A. & Smolensky, P., 2004. Optimality theory, Blackwell.
Prince, A. & Smolensky, P., 1993. Optimality Theory: Constraint interaction in generative grammar.
Pulgram, E., 1970. Syllable, word, nexus, cursus, Mouton.
Raymond, E.S., 2000. Why Python. Linux Journal, 73.
Repetti, L.D., 1989. The bimoraic norm of tonic syllables in Italo-Romance. UCLA.
Rivola, R., 1989. La lingua dei notiziari radiotelevisivi nella Svizzera italiana.
van Rossum, G. & de Boer, J., 1991. Interactively testing remote servers using the Python
programming language. CWI Quarterly, 4(4), 283–303.
van Rossum, G. & Drake Jr, F.L., 1993. Python library reference, Technical report, CWI,
Amsterdam.
van Rossum, G. & Drake Jr, F.L., 2000. Python reference manual, iUniverse.
van Rossum, G. & Drake, F.L., 2003. Python language reference. Network Theory Ltd.
van Rossum, G. & others, 1994. Python programming language. CWI, Department CST, The
Netherlands.
Rubach, J., 1986. Abstract vowels in three dimensional phonology: the yers. The Linguistic Review,
Bibliography
156
5, 247–280.
Rubach, J. & Booij, G., 1990. Syllable structure assignment in Polish. Phonology, 121–158.
Sabatini, F., 1997. DISC: dizionario italiano Sabatini Coletti, Giunti.
Saussure, F. et al., 1922. Cours de linguistique générale, Payot, Paris.
Savy, R., 2007a. Specifiche per la trascrizione ortografica annotata dei testi raccolti. Available at:
http://www.clips.unina.it/downloads/11_specifiche%20trascrizione%20ortografica.pdf.
Savy,
R.,
2007b.
Specifiche
per
l'etichettatura
dei
livelli
segmentali. Available
at:
http://www.clips.unina.it/downloads/12_specifiche%20di%20etichettatura.pdf.
Segui, J., 1984. The syllable: A basic perceptual unit in speech processing. Attention and
performance X: Control of language processes, Hillsdale, Erlbaum, 125–149.
Segui, J., Dupoux, E. & Mehler, J., 1991. The role of the syllable in speech segmentation, phoneme
identification, and lexical access.
Segui, J., Frauenfelder, U. & Mehler, J., 1981. Phoneme monitoring, syllable monitoring and lexical
access. British Journal of Psychology, 72(4), 471–477.
Selkirk, E., 1986. On derived domains in sentence phonology. Phonology Yearbook, 371–405.
Selkirk, E.O., 1980. On prosodic structure and its relation to syntactic structure, Indiana University
Linguistics Club.
Selkirk, E.O., 1984. Phonology and syntax: The relation between sound and structure.
Serianni, L. & Castelvecchi, A., 1989. Grammatica italiana, UTET.
Sievers, E., 1876. Grundzüge der Lautphysiologie zur Einführung in das Studium der Lautlehre der
indogermanischen Sprachen, Breitkopf und H\ärtel.
Sj\ölander, K. & Beskow, J., 2000. Wavesurfer-an open source speech tool. Dans Sixth
Bibliography
157
International Conference on Spoken Language Processing.
Skinner, B.F. & Frederic, B., 1957. Verbal behavior, Appleton-Century-Crofts New York.
Sobrero, A., 2007. Articolazione diatopica, diamesica e diafasica del corpus Radiotelevisivo.
Available at: http://www.clips.unina.it/downloads/5_articolazione%20del%20RTV.pdf.
Sobrero, A. & Tempesta, I., 2007. Definizione delle caratteristiche generali del corpus: informatori,
località. Available at: http://www.clips.unina.it/downloads/1_scelta%20informatori%20e
%20localit%C3%A0.pdf.
Soetre, R. et al., 2005. gProt: annotating protein interactions using Google and gene ontology.
Lecture notes in computer science, 3683, 1195.
Steriade, D., 1999. Alternatives to syllable-based accounts of consonantal phonotactics. Dans
Proceedings of the 1998 Linguistics and Phonetics Conference. pp. 205–245.
Stetson, R.H., Kelso, J.A. & Munhall, K.G., 1988. RH Stetson's Motor Phonetics, Little Brown and
Company.
Stoianov, I., Nerbonne, J. & Bouma, H., 1998a. Modelling the phonotactic structure of natural
language words with Simple Recurrent Networks. Dans Computational Linguistics in the
Netherlands, 1997: Proceedings: CLIN Meeting (8th: 1997: Nijmegen, Netherlands). p. 77.
Stoianov, I., Nerbonne, J. & Bouma, H., 1998b. Modelling the phonotactic structure of natural
language words with Simple Recurrent Networks. Dans Computational Linguistics in the
Netherlands, 1997: Proceedings: CLIN Meeting (8th: 1997: Nijmegen, Netherlands). p. 77.
Tesar, B., 1995. Computing optimal forms in Optimality Theory: Basic syllabification. Ms.,
University of Colorado and Rutgers University.(ROA-52).
Tesar, B. & Smolensky, P., 1998. Learnability in optimality theory. Linguistic Inquiry,29, 229–268.
Bibliography
158
Trommer, J., 2008. Syllable-counting allomorphy by indexed constraints. Talk given at OCP, 5.
Trubeckoj, N.S., 1958. Grundz\üge der Phonologie, Vandenhoeck & Ruprecht.
Vennemann, T., 1988. Preference laws for syllable structure and the explanation of sound change:
With special reference to German, Germanic, Italian, and Latin, Mouton de Gruyter.
Waltermire, M., 2004. The effect of syllable weight on the determination of spoken stress in
Spanish. Laboratory approaches to Spanish phonology, 171–191.
Weerasinghe, R., Wasala, A. & Gamage, K., 2005. A rule based syllabification algorithm for
Sinhala. Lecture notes in computer science, 3651, 438.
Weijters, A., 1991. A simple look-up procedure superior to NETtalk. Dans Proceedings of the
International Conference on Artificial Neural Networks, Espoo, Finland.
Zec, D., 1995. Sonority constraints on syllable structure. Phonology, 85–129.
© Copyright 2026 Paperzz