Calcolo delle Probabilit`a
Alfredo Pulvirenti
November 3, 2014
Concetti di Base
Eventi
Assiomi
Probabilit`a condizionata
Teorema di Bayes
Variabili aleatorie
Discrete
Varianza e deviazione standard
Distribuzioni discrete notevoli
Distribuzione di Bernoulli
Distribuzione Binomiale
Distribuzione Uniforme
Distribuzione Geometrica
Distribuzione Binomiale negativa
Distribuzione di Poisson
Variabili aleatorie continue
Distribuzione uniforme
Distribuzione Normale
Distribuzione Esponenziale
Variabili Aleatorie Congiunte
Distribuzione Marginale
Distribuzioni multivariate
distribuzione Normale Multivariata
Gli Eventi
I
EVENTI: entit`a caratterizzate da aleatoriet`a, qualcosa che
pu`o verificarsi oppure no
La Juventus vincer`a il campionato anche quest’anno?
Gli Eventi
I
EVENTI: entit`a caratterizzate da aleatoriet`a, qualcosa che
pu`o verificarsi oppure no
La Juventus vincer`a il campionato anche quest’anno?
I
Gli eventi si indicano con le lettere maiuscole dell’alfabeto
latino
E1 = “La Juventus vincer`a il campionato anche quest’anno”
E¯1 = “La Juventus non vince`a il campionato quest’anno”
Gli Eventi
I
EVENTI: entit`a caratterizzate da aleatoriet`a, qualcosa che
pu`o verificarsi oppure no
La Juventus vincer`a il campionato anche quest’anno?
I
Gli eventi si indicano con le lettere maiuscole dell’alfabeto
latino
E1 = “La Juventus vincer`a il campionato anche quest’anno”
E¯1 = “La Juventus non vince`a il campionato quest’anno”
I
Si chiama evento complementare ad E il verificarsi di tutto ci`o
che non `e E e si indica con E¯
I
Si indica con la lettera dell’alfabeto greco Ω l’insieme di tutti i
possibili risultati di un esperimento, per esperimento si intende
una prova il cui esito `e incerto. Viene anche chiamato evento
certo o spazio campionario
E1 =Vince la Juve, E2 =Vince l’Inter, E3 =Vince il Napoli,
E4 = Vince il Milan . . . Ω `e l’insieme di tutti gli eventi Ei ,
peri = 1, . . . ., 20
Eventi
`
Al verificarsi di un evento viene associata una PROBABILITA
P(E1 ) = Probabilit`a che la Juventus vinca il campionato
Se chiedessimo di assegnare questa probabilit`a a un tifoso della
Juve, a un tifoso dell’Inter (che pensa sempre che quest’anno sia
quello buono), a un tifoso del Torino, o a una persona oggettiva,
tecnicamente preparata a livello calcistico otterremmo 4 valori
diversi di probabilit`a
Come `e possibile assegnare correttamente la probabilit`a agli eventi?
PROPRIETA’ FORMALI
La probabilit`a non `e mai un numero negativo, verr`a assegnata
probabilit`a 0 agli eventi che ci si aspetta che non si verifichino
(evento quasi impossibile) e probabilit`a 1 all’eventi che ci si
aspetta che si verifichino (evento certo)
Siccome ogni evento Ei `e contenuto in Ω
0 < P(Ei ) < P(Ω) = 1
P(Ω) = P(“tutto quello che pu`
o accadere”) = P(“evento certo”) = 1
PROPRIETA’ FORMALI
Se due eventi E1 e E2 non possono verificarsi contemporaneamente
(la loro intersezione coincide con l’insieme vuoto) diremo che sono
incompatibili,
E1 ∩ E2 = ∅ ⇐⇒ P(E1 ∩ E2 ) = 0
Se si vuole calcolare la probabilit`a che si verifichi l’evento E1
oppure l’evento E2 (E1 unito E2 ) e i due eventi sono incompatibili
allora la probabilit`a dell’unione `e uguale alla somma delle
probabilit`a
P(E1 ∪ E2 ) = P(E1 ) + P(E2 )
ASSIOMI
E’ possibile riassumere quanto visto fino ad ora negli assiomi di
Kolmogorov
1.∀E ⊂ Ω, P(E ) > 0
2.P(Ω) = 1
3.Se E1 ∩ E2 = ∅ allora P(E1 ∪ E2 ) = P(E1 ) + P(E2 )
Alcune regole
E ∪ E¯ = Ω
Quindi
P(E ) + P(E¯) = 1
ne segue
P(E ) = 1 − P(E¯)
Se E1 ∩ E2 6= ∅ si ha
P(E1 ∪ E2 ) = P(E1 ) + P(E2 ) − P(E1 ∩ E2 )
Eventi elementari
Insiemi contenenti un solo elemento. In generale possiamo
partizione lo spazio degli eventi in
Ω = {ω1 , ω2 , . . . , ωn }
Se gli eventi elementari sono tutti equiprobabili
P({ω1 }) = P({ω2 }) = . . . = P({ωn })
Possiamo definire la probabilit`a di un qualsiasi evento E composto
da pi`
u eventi elementari come
P(E ) =
# casi favorevoli (all’evento)
# casi possibili (all’esperimento)
Probabilit`a condizionata
Se abbiamo due eventi E1 ed E2 e ne conosciamo le probabilit`a
P(E1 ) e P(E2 ). Possiamo chiederci il verificarsi di un evento varia
la probabilit`a di verificarsi dell’altro
P(E1 |E2 ) =
P(E1 ∩ E2 )
P(E2 )
dato P(E2 ) > 0.
Esempio. E1 = ‘estrarre un numero pari’ ; E2 = ‘estrarre un
numero ≥ 4’ P(E1 ) = 3/6 ; P(E2 ) = 3/6 La probabilit`a di estrarre
un numero pari cambia se si sa che il numero estratto `e ≥ 4?
P(E1 |E2 ) =
P({4, 6})
2/6
2
P(E1 ∩ E2 )
=
=
=
P(E2 )
P({4, 5, 6})
3/6
3
Eventi indipendenti
Dati due eventi E1 ed E2 si dicono indipendenti se la probabilit`a di
verificarsi dell’uno rimane invariata quando si `e verificato l’altro.
P(E1 |E2 ) = P(E1 ) e P(E2 |E1 ) = P(E2 )
Ne segue che
P(E1 ∩ E2 ) = P(E1 )P(E2 )
Principio delle probabilit`a totali
Se A1 , A2 , . . . , Ak sono una partizione di Ω (Ai ∩ Aj = ∅,
∪ki Ai = Ω) ed E `e un qualsiasi altro evento definiamo l’operazione
di marginalizzazione
P(E ) =
k
X
i=1
P(E ∩ Ai ) =
k
X
i=1
P(E |Ai )P(Ai )
Teorema di Bayes
Se A1 , A2 , . . . , Ak sono una partizione di Ω ed E `e un qualsiasi
altro evento
P(E |Ai )P(Ai )
P(Ai |E ) = Pk
i=1 P(E |Ai )P(Ai )
Se si sa che si `e verificato l’evento E si `e in grado di calcolare la
probabilit`a che si sia verificato l’evento Ai . Dato l’effetto `e
possibile calcolare la probabilit`a della causa che lo ha generato
(probabilit`a a posteriori). E’ come se le conoscenze a priori su Ai a
seguito del verificarsi dell’evento E venissero aggiornate. La
probabilit`a a priori P(Ai ) diventa una probabilit`a a posteriori
P(Ai |E )
Esempio
Un nuovo farmaco funziona nel 60% dei pazienti con una
particolare patologia. Nel 40% dei pazienti con la medesima
patologia il farmaco non funziona. Tra i pazienti in cui il farmaco
funziona il 50% ha un particolare marcatore positivo. Tra i pazienti
in cui il farmaco non funziona, il marcatore `e sempre negativo.
Dato un paziente con il marcatore negativo, qual `e la probabilit`a
che sia un paziente in cui il farmaco funziona?
Variabile Aleatoria
Una variabile aleatoria o variabile casuale o variabile random
associa un valore numerico unico ad ogni possibile risultato nello
spazio di campionamento.
Formalmente una variabile aleatoria `e una funzione reale dallo
spazio di campionamento che chiameremo S verso i numeri reali.
Le variabili aleatorie vengono denotate con lettere maiuscole (es.
X o Y ) ed il valore assunto ad una variabile aleatoria viene
indicato lettere minuscole dell’alfabeto (es. x o y ).
Le variabili aleatorie possono essere continue o discrete.
Variabili aleatorie discrete
Una variabile aleatoria `e discreta se i valori che pu´o assumere sono
finiti (o numerabili). I possibili valori assunti dalla variabile
possono essere elencati come x1 , x2 , · · · . Supponiamo di voler
calcolare la probabilit`a P(X = x) per ogni valore x. La collezione
di queste probabilit`a pu´
o essere vista come una funzione di X . La
funzione massa di probabilit`a di X `e definita come:
fX (x) = P(X = x)
fX gode delle seguenti propriet`a:
1. fX (xi ) ≥ 0 per i = 1, · · · , n
Pn
2.
i=1 fX (xi ) = 1
∀ x
Esempio
Distribuzione di una variabile aleatoria ottenuta dal lancio di due
dadi. Assumiamo che vengano lanciati due dati. Qual `e la
distribuzione della somma?
Sia X la somma dei due numeri ottenuti dal lancio dei due dadi.
La funzione di massa di probabilit`a si deriva elencando tutti i
possibile 36 risultati che risultano ugualmente probabili e contando
i risultati tali che X = x per x = 2, 3, · · · , 12. Ne segue che:
f (x) = P(X = x) =
num volte che X = x
36
Si ottiene quindi:
X
f (x)
2
3
4
5
6
7
8
9
10
11
12
1
36
2
36
3
36
4
36
5
36
6
36
5
36
4
36
3
36
2
36
1
36
Valore atteso di una variabile aleatoria discreta
Il valore atteso o media di una variabile aleatoria discreta X si
denota con E (X ), o con µX o semplicemente µ ed ´e definito come:
X
E (X ) = µ =
xf (x) = x1 f (x1 ) + x2 f (x2 ) + · · ·
x
La varianza di una variabile casuale si denota con Var (X ), σX2 o σ 2
ed ´e definita come:
Var (X ) = E (X − µ)2
La varianza ´e il quadrato della somma delle differenze tra ogni
possibile valore e µ pesati con le rispettive probaiblit´a. Rappresenta
la dispersione della variabile aleatoria attorno al valore medio.
E (X − µ)2 = E (X 2 + 2µX + µ2 ) =
E (X 2 ) − 2µE (X ) + µ2 = E (X 2 ) − 2µ2 + µ2 =
E (X 2 ) − µ2
La deviazione standard:
SD(X ) =
p
Var (X )
La covarianza:
Cov (X , Y ) = E [(X − µx )(Y − µy )] =
E (XY ) − µx µy = E (XY ) − E (X )E (Y )
Distribuzioni discrete notevoli: Distribuzione di Bernoulli
I
Variabile aleatoria che assume solo due valori, es. 0 e 1, viene
chiamata variabile aleatoria di Bernoulli.
I
Utile per modellare situazioni dicotomiche.
I
Un esperimento con un risultato dicotomico `e chiamato
Bernoulli trial.
Supponiamo che un prodotto di un processo di produzione possa
essere normale o difettoso. Sia p la frazione di prodotti difettosi.
Quindi la probabilit`a che preso un prodotto casualmente dal
processo di produzione sia difettoso `e P(X = ”Difettoso”) = p.
Conseguentemente P(X = ”Normale”) = 1 − p.
Quindi una variabile casuale di Bernoulli pu`
o essere definita come
X = 1 se il prodotto `e difettoso, X = 0 se il prodotto `e normale
con la seguente funzione massa di probabilit`a:
p
se x = 1
f (x) = P(X = x) =
q = 1 − p se x = 0
La media e la varianza sono calcolate come segue:
E (X ) = 0 × P(X = 0) + 1 × P(X = 1) = 0(1 − p) + 1(p) = p
Var (X ) = E (X 2 ) − E (X )2 = p(1 − p)
Distribuzione Binomiale
I
Alcuni esperimenti possono essere visti come una sequenza di
Bernoulli trial indipendenti e distribuiti in modo identico, dove
ogni risultato `e ”successo” o ”fallimento”.
I
Il numero totale di successi da questo esperimento `e pi`
u
interessante del risultato individuale.
I
Se fissiamo n prove indipendenti, dove ogni prova ha la stessa
probabilit`a di successo p allora la somma di queste Bernulli
trial danno luogo alla distribuzione di probabilit`a Binomiale.
I
I
I
La forma generale di una distribuzione Binomiale di una
variabile aleatoria X con parametri n e p denotata con
X ∼ Bin(n, p).
La probabilit`a di ottenere x successi e n − x fallimenti in una
particolare sequenza `e p x (1 − p)n−x poich`e i tentativi sono
indipendenti.
I possibili modi in cui otteniamo x successi su n prove sono
ottenuti dalle combinazioni di questi.
Quindi la distribuzione Binomiale `e data da
n
f (x) = P(X = x) =
p x (1 − p)n−x
x
Notiamo che f (0) = P(X = 0) = (1 − p)n ed
f (n) = P(X = n) = p n . La media e la varianza
E (X ) = E [Y1 ] + E [Y2 ] + · · · + E [Yn ] = np
Var (X ) = Var [Y1 ] + Var [Y2 ] + · · · + Var [Yn ] = np(1 − p)
Figure : Distribuzione binomiale. (a) n = 20, p = 0.5. (b)
n = 20, p = 0.25.
Distribuzione Ipergeometrica
I
Supponiamo che un contenga N palline, delle quali n sono
rose e N − n sono bianche.
I
Supponiamo di estrarre m palline dall’urna in modo casuale e
senza reimmissione.
I
Definiamo una variabile aleatoria X come numero di palline
rosse estratte dall’urna.
n
N −n
x
m−x
x = A, A + 1, . . . , B
P(X = x) =
N
m
Dove A = max(0, n + m − N) e B = min(n, m)
Distribuzione Uniforme
I
La pi`
u semplice distribuzione di probabilit`a discreta `e la
distribuzione uniforme.
I
X ha una distribuzione uniforme se tutti i valori di X sono
a, a + 1, · · · , a + b − 1, per due costanti intere a e b e la
probabilit`a che X assuma uno di questi possibili b valori `e 1/b.
Quindi la distribuzione uniforme `e data da:
f (x) = P(X = x) =
E [X ] = a + b−1
2
2 −1
VAR[X ] = b 12
1
per x = a, a + 1, · · · , a + b − 1
b
Distribuzione Geometrica
I
Supponiamo di lanciare una monetina fino a quando non
otteniamo per la prima volta testa.
I
Assumiamo che i tentativi siano indipendenti ed ogni lancio ha
una distribuzione di Bernoulli con parametro p.
I
La variabile X definita come il numero totale di lanci della
monetina ha una distribuzione geometrica con parametro p.
f (x) = P(X = x) = P(T ) × P(T ) × P(T ) × · · · × P(T ) × P(H) =
= (1 − p)x−1 p
E (X ) = 1/p
Var (X ) = 1−p
p2
Figure : Distribuzione geometrica
Memoeryless property
Una variabile aleatoria geometrica X ha la propriet`a di
”dimenticarsi” del passato. Se il primo successo non `e arrivato
dopo il tentativo s-esimo, la probabilit`a che non accadr`a per
almeno altri t tentativi `e la stessa di quella che parte da zero.
Ovvero ottenere il primo successo dopo t tentativi.
P(X = s + t|X > s) = P(X = t)
Distribuzione Binomiale negativa
I
I
I
La distribuzione Binomiale negativa calcola il numero di
successi in un prefissato numero di Bernoulli trial con
probabilit`a p.
Definiamo una variabile aleatoria X come il numero di lanci di
una moneta per ottenere m volte testa.
P(X = x) `e la probabilit`a che i primi x − 1 tentativi risultino
in m − 1 successi e x − m fallimenti in un qualche ordine ed il
trial x-esimo sia successo
x −1
f (x) = P(X = x) =
p m (1 − p)x−m
m−1
per x = m, m + 1, m + 2, · · · .
E (X ) =
Var (X ) =
m
p
m(1 − p)
p2
Figure : Distribuzione binomiale negativa, m = 10, p = 0.75
Distribuzione di Poisson
I
La distribuzione di Poisson `e adatta a descrivere
un’importante classe di fenomeni in cui:
I
I
I
n grande;
p probabilit`a di successo piccola;
si verificano mediamente λ successi.
Una variabile causale X che ha questa distribuzione `e chiamata di
Poisson con parametro λ.
X ∼ Pois(λ) `e data da:
f (x) = P(X = x) =
e −λ λx
per x = 0, 1, 2, . . .
x!
La distribuzione di Poisson `e una buona approssimazione della
distribuzione binomiale quando n −→ ∞, p −→ 0, np −→ λ .
E [X ] = Var [X ] = λ.
Figure : Distribuzione di Poisson, λ = 5
Figure : Riepilogo distribuzioni discrete
Variabili aleatorie continue
I
Una variabile aleatoria continua pu`
o assumere valori da uno o
pi`
u intervalli di numeri reali.
I
Per essa non pu`o definirsi una funzione di massa di probaiblit`a
poich`e i valori sono non numerabili (infiniti).
I
Viene definito il concetto di densit`a di probaiblit`a tale che
l’area sotto la curva della funzione f (x) rappresenta la
probaiblit`a.
Variabili aleatorie continue
La densit`a di probabilit`a di una variabile aleatoria X continua `e
una funzione che soddisfa:
Z x
FX (x) =
fX (t)dt ∀ x
−∞
dove FX (x) `e chiamata funzione cumulativa di probabilit`a di una
variabile aleatoria ed `e definita da
FX (x) = PX (X ≤ x)
∀ x
Il valore atteso di una variabile aleatoria continua `e
Z
E (X ) = µ = xf (x)dx
x
E (X ) ´e definita come il baricentro di X .
Figure : Funzione cumulativa di probabilit`a, ottenuta come area sotto la
curva
Distribuzione uniforme
X ha una distribuzione uniforme sull’intervallo [a, b] (X U[a, b]) ha
la funzione densit`a:
1
a≤x ≤b
b−a
f (X ) =
0
altrimenti
E (X ) =
a+b
2
Var (X ) =
(b−a)2
12
Distribuzione Normale (Gaussiana)
I
La pi`
u importante distribuzione continua `e la distribuzione
Normale o Gaussiana.
I
La distribuzione normale `e utilizzata per modellare diversi
fenomeni reali.
I
Spesso si assume che i dati in esame abbiano una
distribuzione normale. Ovvero che questi assumono un
andamento riconducibile ad una Gaussiana.
Una variabile aleatoria X ha una distribuzione normale con
parametri µ e σ 2 , denotata con X ∼ N(µ, σ 2 ) `e una funzione di
densit`a di probabilit`a definita come segue:
(x−µ)2
1
f (x) = √ e − 2σ2
σ 2π
con −∞ < x < ∞, −∞ < µ < ∞ e σ > 0.
Figure : Distribuzione Gaussiana
Una distribuzione normale particolarmente importante `e la
distribuzione normale standard. Per questa distribuzione abbiamo
che µ = 0 e σ 2 = 1. Una qualsiasi distribuzione normale pu`o
essere ricondotta ad una normale standard, sottraendo la media e
dividendo per la deviazione standard Se X ∼ N(µ, σ 2 ), allora
Z = X σ−µ ∼ N(0, 1). Il valore osservato z di Z `e chiamato spesso
score.
z2
1
φ(z) = √ e − 2
2π
La normale standard `e simmetrica rispetto all’origine. La funzione
di ripartizione
Z z
Φ(z) = P(Z ≤ z) =
φ(y )dy
−∞
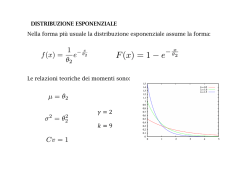
Distribuzione Esponenziale
La distribuzione esponenziale `e una distribuzione di probabilit`a che
si pu`o incontrare spesso con dati di varia natura. La distribuzione
esponenziale usata per modellare il tempo di vita p analoga alla
distribuzione geometrica nel caso discreto. X ∼ exp(λ)
f (x) = λe −λx
La funzione cumulativa di probabilit`a `e
FX (x) = 1 − e −λx
E (X ) =
1
λ
Var (X ) =
1
λ2
Figure : Distribuzione Esponenziale
Anche la distribuzione esponenziale presenta la caratteristica
memory less.
P(X > s + t|X > s) = P(X > t)
Distribuzione Chi-quadro
Siano Xi , i = 1, 2, · · · , n variabili aleatorie con distribuzione
normale N(0, 1) stocasticamente indipendenti tra loro. La variabile
aleatoria:
X = X12 + X22 + X32 + X42 + . . . , +Xn2
`e detta χ2 con n gradi di liberata. Si prova che X `e
(
0,
se t < 0
n
fX (t) =
1 2 n2 −1
1
1
t
exp − 2 t , se t ≥ 0
Γ( n2 ) 2
R +∞
Con Γ(α) = 0 e −x x α−1 dx funzione Gamma di Eulero. Si
dimostra che E [X ] = n Var [X ] = 2n.
Figure : Chi-quadro
T di Student
I
siano Z ∼ N(0, 1) e Y ∼ χ2n due variabili aletorie indipendenti.
I
La variabile aleatoria
Z
X =q
Y
n
`e distribuita secondo la distribuzione T di Student con n gradi
di libert`a.
I
si dimostra che X ha la seguente densit`a di probabilit`a
− 21 (n+1)
Γ n+1
t2
2 √1
1+
fX (t) =
n
nπ
Γ n2
con
E [X ] = 0 se n > 1
n
Var [X ] = n−1
se n > 2.
Variabili Aleatorie Congiunte
I
Nella maggior parte delle situazioni sperimentali e reali non si
osserver`a solo l’andamento di una variabile casuale.
I
Ad esempio consideriamo un esperimento creato per ottenere
informazioni riguardo le caratteristiche di salute di una
popolazione.
I
Saranno quindi rilevate diverse caratteristiche per ogni
individuo e sar`a usato un campione di individui.
I
Ogni singola osservazione di una caratteristica sar`a modellata
come l’osservazione di una particolare variabile aleatoria.
I
Quindi nasce l’esigenza di modellare pi`
u variabili aleatorie
contemporaneamente.
I
Solitamente viene associata pi`
u di una variabile aleatoria ad
un particolare risultato. Ricordiamo l’esempio della banca
dove la solvibilit`a era espressa in funzione degli introiti mensili
e dei risparmi posseduti dal richiedente.
Se X e Y sono variabili aleatorie discrete la loro distribuzione di
probabilit`a congiunta `e
f (x, y ) = P(X = x, Y = y )
questa distribuzione di probabilit`a soddisfa:
fP
(x,P
y) ≥ 0
x
y f (x, y ) = 1
Analogamente il caso continuo
Rf (x,
R y) ≥ 0
x y f (x, y )dxdy = 1
Distribuzione Marginale
I
Una distribuzione congiunta pu`
o dare informazioni sul
comportamento di un vettore causale (X , Y ).
I
Inoltre da informazioni riguardo l’andamento separato delle
variabili individuali.
Definiamo fX (x) distribuzione di probabilit`a marginale di X per
enfatizzare il fatto che `e una distribuzione di X ma nel contesto di
una distribuzione di probabilit`a congiunta (X , Y ). Definiamo
quindi due distribuzioni marginali
X
g (x) = P(X = x) =
f (x, y )
y
h(y ) = P(Y = y ) =
X
f (x, y )
x
Analogamente nel caso continuo con l’integrazione.
Distribuzioni multivariate
I
Quando si hanno pi`
u di due variabili aleatorie si parla di
distribuzione multivariata.
I
Abbiamo X1 , X2 , · · · , Xn variabili casuali. f (x1 , x2 , · · · , xn )
I
Le distribuzioni multivariate sono una naturale estensione
delle distribuzioni bivariate.
I
Se X = (X1 , · · · , Xn ) `e un vettore casuale la distribuzione
congiunta di X `e data dalla seguente funzione
fX (x) = fX (x1, · · · , xn ) = P(X1 = x1 , · · · , Xn = xn ).
Per un qualsiasi insieme A
P(X ∈ A) =
X
f (X )
x∈A
Nel caso di vettori continui analogo con l’integrazione su tutte le
dimensioni Xi .
La marginalizzazione `e analoga al caso bivariato, sommando su
tutte le variabili eccetto quella sulla quale si intente marginalizzare.
Si effettua analogamente la proabilit`a condizionata di
(Xk+1 , . . . , Xn ) dati (X1 , · · · Xk )
f (xk+1 , · · · , xn |x1 , · · · , xk ) =
f (x1 , · · · , xn )
f (x1 , · · · , xk )
L’indipendenza delle variabili
f (x1 , · · · , xn ) = f (x1 ) × f (x2 ) × · · · f (xn ).
Supponiamo di avere delle variabili casuali X1 , · · · Xn con varianza
σ12 , · · · , σn2 e supponiamo che la covarianza a delle coppie sia
σij = Cov (Xi , Xj ) per 1 ≤ i 6= j ≤ k. Definiamo la matrice di
covarianza
2
σ1 σ12 · · · σ1n
σ21 σ 2 · · · σ2n
2
Σ= .
..
..
.
.
.
.
.
.
.
σn1 σn2 · · ·
σn2
Σ e’ una matrice simmetrica. Se Σ `e definita positiva esistono due
matrici ortogonali U e V tali che
UΣV = D = diag (λ1 , λ2 , · · · , λn ) con λi chiamati autovalori i
quali rappresentano la dispersione corrispondente ad ogni direzione
degli autovettori.
Analogamente possiamo definire la matrice di correlazione.
ρij = Corr (Xi , Xj ) per 1 ≤ i 6= j ≤ k. Definiamo la matrice di
covarianza
1 ρ12 · · · ρ1n
ρ21 1 · · · ρ2n
R= .
..
..
..
..
.
.
.
ρn1 ρn2 · · ·
1
distribuzione Normale Multivariata
fX (x1 , · · · , xN ) =
1
1
exp(− (x − µ)T Σ−1 (x − µ))
2
2π N/2 |Σ|
1
2
© Copyright 2026 Paperzz