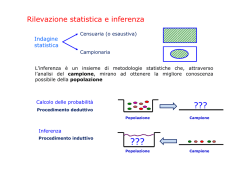
Supponiamo che un fabbricante stia introducendo un nuovo tipo di
batteria per un’automobile elettrica. La durata osservata xi delle
i-esima batteria `e la realizzazione (valore assunto) di una variabile
aleatoria Xi . Si pu`o assumere che le Xi abbiano la stessa
distribuzione incognita. Per ottenere informazioni sulla
distribuzione si costruiscono e mettono in funzione un certo numero
n di batterie. La durata di ciascuna batteria fornisce l’insieme di
dati x1 , x2 , .., xn . La media campionaria della durata `e
x1 + .... + xn
n
Le lettere maiuscole Xi indicano la variabili aleatorie (prima
dell’esperimento), quelle minuscole xi ne indicano le realizzazione
(il numero ottenuto dopo l’esperimento).
¯
xn =
E’ naturale chiedersi alcune cose sulla media campionaria ¯
xn
• c’entra qualcosa con il valore atteso µ delle variabili Xi ?
• posso dire che legge ha, ossia come `e distribuita?
Alla prima domanda risponder`a la Legge dei Grandi Numeri. Se
n `e ”molto” grande, ¯
xn sar`a molto prossima a µ (vedremo poi
quanto prossima).
Rispondere alla seconda domanda in generale non `e semplice, ma
se n `e ”abbastanza” grande con buona approssimazione `e una
realizzazione di una variabile normale per il Teorema del Limite
Centrale (vedremo poi come determinarne i parametri).
Siano X1 , X2 ,...., Xn ,... variabili aleatorie indipendenti e tutte con
la stessa distribuzione, con valore atteso E(X1 ) = ... = E(Xn )=
µ e stessa varianza var (Xi )=σ 2 , i = 1, 2..., n.
Sia Yn = X1 + ... + Xn , per la propriet`a della media:
E(Yn ) = E(X1 ) + E(X2 )... + E(X2 )= nµ
e per le propriet`a della varianza
var(Yn ) = var(X1 ) + var(X2 ) + ..var(Xn )= nσ 2
Si ha inoltre che
¯ n = X1 + ... + Xn = Yn
X
n
n
per cui
¯ n ) = µ,
E(X
¯ n ) = σ 2 /n
var(X
Esercizio. I risultati di un test sul livello di potassio nel sangue di
un individuo variano sia a causa dell’imprecisione dello strumento
di misurazione, sia perch`e il livello stesso varia nel tempo.
Sappiamo che per un certo individuo le letture successive del livello
di potassio oscillano intorno a un valore atteso µ con deviazione
standard σ = 0.3. Quattro letture specifiche generano i dati
3.6,
3.9,
3.4,
3.5
La media campionaria per il livello medio di potassio per questa
persona `e
3.6 + 3.9 + 3.4 + 3.5
= 3.6
4
mentre la deviazione standard della media campionaria `e
σ
0.3
√ =
= 0.15
2
n
LEGGE DEI GRANDI NUMERI
¯ n , che ha sempre valore atteso µ, ha
Si vede che la variabile X
varianza inversamente proporzionale ad n (ossia uguale a σ/n).
Nel limite n → ∞ (ossia per n molto grande) la varianza diventa
nulla, questo significa che la media campionaria diventa una
variabile certa con valore µ.
Questo risultato `e pi`
u correttamente descritto dal seguente
teorema:
Teorema. Si dimostra (ma non qui) che per n → ∞ e per ogni a
strettamente positivo:
¯ n − µ| > a → 0
P |X
¯n sia diversa da µ diventa nulla
In altre parole la probabilit`a che X
quando n diventa molto grande. Con un certo abuso di termini e di
¯n → µ quando n → ∞.
notazione) possiamo dire che X
¯n − µ| > a ' 0.
Se n `e grande ma non infinito si avr`a : P |X
Cosa significa?
L’asserzione vale per ogni a strettamnte positivo. Per fissare le
idee immaginiamo che sia molto piccolo, ad esempio a = 0.01.
µ −a
µ
µ +a
La probabilit`
a che la media campionaria osservata x¯n cada
fuori dall’intervallo colorato in figura `
e trascurabile (' 0) se n
`
e abbastanza grande.
La probabilit`
a che la media campionaria osservata x¯n cada
dentro l’intervallo colorato in figura `
e ' 1 se n `
e abbastanza
grande.
MEDIA TEORICA ' MEDIA OSSERVATA
La legge dei grandi numeri dice che il valore osservato
¯n = (X1 + .. + Xn )/n
x¯n = (x1 + .. + xn )/n della variabile aleatoria X
`e con grande probabilit`a vicino a µ se n `e grande.
Quindi se non conosco µ, ne posso dare una stima con x¯n che `e
¯n . Se n `e grande, la
una realizzazione della statistica campionaria X
¯n e µ siano ”molto diversi” `e quasi zero.
probabilit`a che X
Si noti che µ `e la media teorica a priori di ciascuna osservazione
(un parametro della distribuzione delle Xi ) mentre
x¯n = (x1 + .. + xn )/n `e una media a posteriori delle osservazioni.
IL TEOREMA DEL LIMITE CENTRALE
Siano X1 , X2 ,...., Xn ,... variabili aleatorie indipendenti e tutte con
la stessa distribuzione, con valore atteso E(X1 ) = ... = E(Xn )=
µ e stessa varianza var (Xi )=σ 2 , i = 1, 2..., n.
Sia Yn = X1 + ... + Xn , abbiamo visto che:
E(Yn )= nµ
var(Yn )= nσ 2
Teorema. Per le propriet`a del valore atteso e della varianza, la
variabile
− nµ
¯ n = Yn √
Z
σ n
ha media 0 e varianza 1. Inoltre si dimostra (ma non qui) che
per n sufficientemente grande (nel limite n → ∞) ha
distribuzione normale.
In altre parole, nel limite n → ∞
− nµ
¯ n = Yn √
Z
→ N(0, 1) = Z
σ n
¯ n < x) `e
Quindi per n grande (ma non infinito) la probabilit`a P(Z
circa uguale a P(Z < x) dove Z `e una normale standard N(0, 1).
Se vogliamo calcolare probabilit`
a relative a Z¯n possiamo
utilizzare quelle relative a N(0,1) come approssimazione.
¯n possiamo anche scrivere
Tenendo presente che Yn /n = X
¯ −µ
¯ n = Xn √
→ N(0, 1) = Z
Z
σ/ n
¯n `e la statistica
Si ricordi ancora una volta che in questo contesto X
campionaria di cui la x¯n `e una realizzazione (risultato di una
misurazione o esperimento). Anche Y¯n e Zn sono statistiche
campionarie.
DISTRIBUZIONE DELLE MEDIA CAMPIONARIA
(VARIANZA NOTA)
Anche la somma di n variabili identicamente distribuite `e
approssimativamente normale, infatti:
√
√
√
¯ n + nµ ' σ n N(0, 1) + nµ = N(nµ, σ n)
Yn = σ n Z
La media campionaria `e anch’essa approssimativamente normale:
√
¯ n = Yn ' √σ N(0, 1) + µ 'N(µ, σ/ n).
X
n
n
Il valore atteso µx¯n della media camionaria `e uguale a µ mentre
√
la varianza σx¯n della media campionaria `e uguale a σ/ n e quindi
decresce come l’inverso della radice quadrata della dimensione del
campione. Come abbiamo visto con la legge dei grandi numeri, per
un ipotetico campione infinito, la media campionaria coincide
identicamente con µ.
E IN PRATICA?
Il Teorema del limite centrale lascia aperta la questione di quanto
il campione debba essere numeroso affinch`e l’approssimazione
sia valida.
Se le variabili Xi sono variabili gaussiane il problema non si pone
perch´e qualsiasi combinazione lineare di variabili gaussiane `e
anch’essa gaussiana. In tal caso, la distribuzione di Xn `e gaussiana
per ogni n (quella di Z¯n `e normale standard). Altrimenti si accetta
la seguente regola pratica.
• Se la legge delle X1 , . . . ,Xn non `e troppo asimmetrica, a livello
empirico si `e stabilito che n ≥ 30 va bene.
Per convincerci dell’asserzione consideriamo il caso in cui la
distribuzione delle Xi `e esponenziale (non importa qui sapere la
definizione). Confrontiamo i grafici delle densit`
a delle somme
standardizzate di queste variabili indipendenti per n = 5, n = 10
n = 20 e n = 50 con il grafico di una N(0, 1).
In blu la N(0, 1), in azzurro la Z¯5 , in magenta la Z¯10 , in celeste la
Z¯20 e in violetto la Z¯50 .
Esercizio. Il livello di colesterolo nel sangue di una popolazione
di lavoratori ha una media 202 e una deviazione standard 14.
Viene selezionato un campione di 36 lavoratori, si approssimi la
probabilit`
a che la media campionaria dei loro livelli di
colesterolo sia compresa tra 198 e 206.
¯36 ha distribuzione approssimatemente normale con valore atteso
X
√
√
µ = 202 e deviazione standard σ/ n = 14/ 36 = 7/3, quindi
¯36 − 202
X
Z¯36 =
' N(0, 1) = Z
7/3
206 − 202 7/3
7/3
' P(−1.714 < Z < 1.714) = φ(1.714) − φ(−1.714) = 0.913
¯36 < 206) = P
P(198 < X
198 − 202
< Z¯36 <
dove φ `e la solita funzione di distribuzione della normale standard.
RIASSUMENDO
Per un campione di numerosit`a n estratto da una popolazione con
distribuzione di media µ e varianza σ si ha che
I
I
I
I
I
µx¯n = µ per ogni n,
√
σx¯n = σ/ n per ogni n,
¯n `e distribuita normalmente per ogni n se le Xi sono
X
gaussiane,
¯n `e distribuita quasi normalmente se n `e grande (n > 30)
X
anche se le Xi non sono gaussiane.
¯n → µ quando n → ∞ (non realizzabile in pratica).
X
Si noti che la media campionaria `e approssima il parametro µ ma la
√
sua precisione (σx¯n = σ/ n) viene definita in base ad una varianza
σ nota. Vedremo cosa fare quando la varianza `
e incognita.
STIME PUNTUALI
Definizione 1
Se la stima di un parametro della distribuzione delle Xi `
e data
da un singolo numero ottenuto dalle misurazioni relative a un
campione, tale valore `
e detto stima puntuale del parametro.
Esempio La media campionaria osservata x¯n `e una stima del
parametro µ della distribuzione delle variabili aleatorie Xi . Il
numero (stima) x¯n `e una realizzazione dello stimatore Xn .
¯n ha valore atteso µ, quindi, in questo caso, il valore
La statistica X
atteso dello stimatore `e uguale al parametro che si vuole stimare.
Definizione 2
Uno stimatore con valore atteso uguale al parametro che si
vuole stimare si dice corretto (o non distorto).
¯ n = (X1 + .. + Xn )/n `
La media campionaria X
e quindi uno
stimatore corretto di µ.
Definizione 3
Se due statistiche sono entrambe stimatori corretti di un
parametro, la statistica con minore varianza `
e detta
stimatore pi`
u efficiente.
La stima ottenuta con la media campionaria `e tanto pi`
u accurata
tanto pi`
u il campione `e numeroso. Infatti x¯n `e un valore osservato
¯n la cui varianza `e σ/n. Pertanto se si considerano due
di X
¯m `
campioni di taglia m e n con m > n si avra che X
e pi`
u
¯
efficiente di Xn nello stimare il parametro µ.
In seguito potremo confrontare con l’efficienza di altri stimatori
corretti diversi dalla media campionaria.
© Copyright 2026 Paperzz