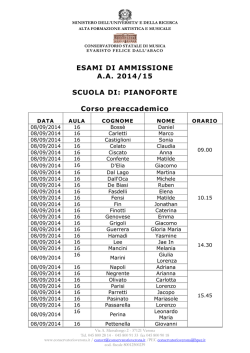
Res User Meeting 2014 con la partecipazione di Scriviamo insieme il futuro Cristina Vecchietti Research for Enterprise Systems Direttore Applicazioni e Architetture Il “Data Meaning Discovery” - Scenari e applicazioni Data Meaning Discovery - Scenari e applicazioni Perché Data Meaning Discovery … perché il significato funzionale dei dati non è più così scontato (ammesso che lo sia mai stato) • Nell’ evoluzione dei grandi sistemi verso il mondo distribuito, al decentramento delle applicazioni fa seguito anche se con ritmi più lenti, il decentramento dei dati. • Sempre più frequentemente le nuove applicazioni vengono acquisite come prodotti di mercato, con maintenance esterno all’organizzazione . • Di conseguenza, all’interno dell’organizzazione, diventa sempre più complesso acquisire la conoscenza delle nuove basi dati, soprattutto sul piano funzionale. • Il ricorso alla naming di archivi ed informazioni elementari come criterio di orientamento ad un possibile significato viene ancor più vanificato in caso di pacchetti applicativi presenti sul mercato internazionale. • Il problema diventa più evidente quando sono i comparti aziendali di estrazione tecnico-sistemistica a doversi fare carico, a volte impropriamente, di operazioni sui dati che ne richiedono la conoscenza funzionale. 3 Data Meaning Discovery - Scenari e applicazioni Perché Data Meaning Discovery 4 Data Meaning Discovery - Scenari e applicazioni Quando e a chi serve conoscere il significato dei dati ... e quali dati … restringiamo il perimetro d’interesse • La risposta più istintiva sarebbe probabilmente : sempre / a tutti / ogni tipo di dato… Contestualizziamo perciò la tematica ad un ambito specifico, seguendo il filo conduttore della Data Governance • Quando … – In occasione di attività e progetti in cui occorre riconoscere l’appartenenza ad una specifica classe (metadato), di una o più informazioni di cui si ignora il significato. – E’ il caso tipico dei progetti di mascheratura dove » Sono note e limitate le classi di dati “riservati” (es. dati anagrafici e codici di uso corrente) » Sono identificabili come appartenenti a tali classi un numero limitato di informazioni, presenti su archivi primari (Anagrafe Generale) » Più difficilmente identificabili le informazioni riservate, distribuite su archivi secondari o di procedure collaterali / decentrate – Con una diversa finalità, il discovery può applicarsi ad attività di controllo di qualità dei dati » in questo caso è certo il significato dell’informazione, ovvero la sua classe di appartenenza, ma potrebbe non essere altrettanto certo il grado di rispondenza del contenuto alle caratteristiche di classe attese. (es. un campo Codice Fiscale potrebbe contenere un valore sintatticamente errato) 5 Data Meaning Discovery - Scenari e applicazioni Quando e a chi serve conoscere il significato dei dati ... e quali dati … restringiamo il perimetro d’interesse • • A chi serve … – Agli applicativi che si trovano a prendere in carico la gestione di nuove procedure o nuove versioni o estensioni di procedure esistenti, senza averne potuto approfondire il disegno dati – A ruoli trasversali che normalmente supportano l’applicativo sul fronte dati, quali Data administrator e Database administrator , o ruoli di natura prevalentemente tecnico-sistemistica che su specifiche problematiche (come il masking appunto) operano in luogo degli applicativi … Quali dati – Le possibili rappresentazioni dei dati che transitano in un’organizzazione medio-grande sono estremamente variegate. – Riportiamo pertanto il perimetro d’interesse ai dati di business dell’organizzazione, in particolare ai dati strutturati che si trovano nelle basi dati operative delle applicazioni. 6 Data Meaning Discovery - Scenari e applicazioni DMD System: principi e funzioni … perché Data Meaning Discovery System • Nasce da nostre esperienze pregresse e da requirement di clienti interessati alla mascheratura in contesti di difficoltà a localizzare punti e modalità d’intervento. • E’ una componente di analisi dei contenuti degli archivi, volta a fornire il significato più probabile dei singoli campi in essi contenuti. • Seleziona dagli archivi operativi campioni di dati, ridotti ma rappresentativi, consentendo così di contenere significativamente i tempi di elaborazione • DMD è una componente LUW in grado di analizzare – – Tabelle DB2 su Zos Tabelle di DBMS dipartimentali » Oracle » SQLServer » DB2 UDB » MySQL – Il sistema è aperto a trattare file sequenziali e file CSV. 7 Data Meaning Discovery - Scenari e applicazioni DMD System: principi e funzioni Basi del riconoscimento del dato Il riconoscimento della “Data Class” può avvenire in modalità diverse a seconda della tipologia di campo • In base al grado di matching delle parole contenute nel campione rispetto ad un insieme di elementi precostituito e certificato di valori (parole o keyword) – Es. parole di Nomi propri, Cognomi, Denominazioni societarie … – Statistic Data Value STATISTIC LOOKUP TABLE • In base al grado di matching dei valori contenuti rispetto ad un dominio predefinito di codici – Es. Codici provincia , Codici nazione, Codice Fiscale Comune … – Domain Data Value DOMAIN LOOKUP TABLE • In base alla prevalente rispondenza dei valori contenuti rispetto ad un formalismo riconosciuto – Codice fiscale, Partita IVA, Credit Card … – Specific Data Value SPECIFIC DISCOVERY FUNCTION 8 Data Meaning Discovery - Scenari e applicazioni DMD System: principi e funzioni Dipendenza dal contesto: flessibilità e adattamento • In una estrema variabilità del contesto di lavoro: – – – – • Strutture dei dati Scopi del riconoscimento Dipendenza territoriale / linguistica … Il sistema deve essere flessibile e adattabile: – Parametrizzazione dell’ambito del discovery » » » » » DBMS Archivi Campi Tipologie di analisi Ampiezza del campione su cui si vuole attuare il processo – Esternalizzazione degli oggetti e dei processi dipendenti dal contesto : » Statistic Lookup Tables » Domain Lookup Tables » Specific Discovery Functions 9 Data Meaning Discovery - Scenari e applicazioni DMD System: principi e funzioni Fruibilità dei risultati • In un’ottica di servizio ad utenti diversi e con esigenze variegate, DMD System si pone l’obiettivo di costituire un supporto efficace per immediatezza e fruibilità delle sue rilevazioni. • Riscontro immediato sulla ricognizione del significato funzionale, con rapporti di elaborazione di tipo “volatile” (testo) per ogni campo degli archivi analizzati – Rapporto di sintesi per ogni dataclass per cui è stato richiesto il riconoscimento – Log esteso opzionale • Capitalizzazione dei dati rilevati in forma strutturata e persistente su base dati relazionale, aperta ad interrogazioni e ed elaborabile ai fini decisionali: il DMD Repository – disponibile su DB2 / ORACLE / SQL Server / MYSql • Dotazione nativa di evidenze di base ottenibili dal Repository. 10 Data Meaning Discovery - Scenari e applicazioni DMD System: flow dell’attività di discovery Fase preliminare e fase operativa Identificazione DataClass Identificazione Archivi / Campi “Anchor Point” Identificazione Archivi oggetto di discovery Screening campi candidabili Elaborazione della Discovery Session Parametrizzazione della Discovery Session Alimentazione iniziale Statistic Lookup Customizzazione Domain Lookup e Specific Functions Analisi dei risultati Attribuzione delle dataclass più probabili Ritaratura Statistic Lookup (Autoapprendimento) RESTART 11 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - fase preliminare Nomi / Cognomi Identificazione DataClass Toponimi Codici Fiscali Identificazione Archivi / Campi “Anchor Point” Identificazione DataClass Screening campi candidabili 12 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - fase operativa • • • Alimentazione iniziale Statistic Lookup L’identificazione delle lookup tables necessarie dipende dalle classi di dato oggetto del discovery. Le lookup in dotazione nativa a DMD System potrebbero non essere del tutto applicabili . Il sistema può sopperire con automatismi di alimentazione iniziale delle Lookup tables di tipo statistico, basandosi sugli “anchor point” dichiarati in fase d’impianto: es. gli archivi di Anagrafe Generale di cui sono noti i campi “sensibili” che rappresentano la fonte dl processo. Value ROSSI MÜLLER FERRARI SCHMIDT COLOMBO SCHNEIDER BIANCHI FISCHER RUSSO MEYER ESPOSITO WEBER … Frequency 0,65978% 0,57332% 0,38849% 0,48326% 0,36917% 0,39198% 0,31036% 0,33814% 0,30993% 0,29965% 0,20347% 0,25768% … Value GIUSEPPE MARK GIOVANNI FRANK ANTONIO KARL MARIO PETER FRANCESCO BRIGIT MARIA KRISTEN … Cognomi Nomi Frequency 3,7870% 2,8024% 2,6387% 2,2165% 2,4461% 2,0547% 2,1314% 1,8756% 2,0753% 1,7432% 1,9935% 1,6745% … 13 DMD admin Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - fase operativa La Discovery Session • La Discovery Session si configura come un’iterazione di Discovery Unit • Discovery Unit: l’unità minima autoconsistente di discovery riferita ad un singolo archivio. • E’ un contenitore logico che consente all’utente di raggruppare le elaborazioni di discovery di più archivi, sulla base di propri criteri, di tipo funzionale o tecnico, es: – appartenenza alla stessa applicazione – appartenenza allo stesso database – per owner – per pattern di naming – liste di data type – … Discovery Session PARM TAB01 PARM TAB02 ... PARM TAB03 14 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - fase operativa Esempio di Discovery Unit - Struttura tabella candidata • Da catalogo : TBM123C – no remarks COLNAME FLD001 FLD002 FLD003 FLD004 FLD005 FLD006 FLD007 FLD008 FLD009 FLD010 FLD011 FLD012 FLD013 FLD014 COLNO KEYSEQ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 COLTYPE LENGTH SCALE 0 DECIMAL 0 CHAR 0 CHAR 0 CHAR 0 CHAR 0 DATE 0 CHAR 0 CHAR 0 CHAR 0 CHAR 0 CHAR 0 CHAR 0 CHAR 0 CHAR 9 11 16 1 50 4 2 30 20 50 20 3 16 30 NULLS DEFAULT REMARKS 0Y 0N 0N 0N 0N 0Y 0Y 0N 0N 0N 0N 0N 0N 0N Y N N N N Y Y N N N N N N N 15 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - fase operativa Esempio di Discovery Unit : DataClass di interesse per persona fisica – Campi candidati • • • Nome ( campo dedicato) Cognome(campo dediicato) Cognome e nome (stesso campo) • • • Toponimo Comune Provincia • • • Codice Fiscale Partita IVA Credit Card COLNAME COLTYPE LENGTH SCALE FLD001 FLD002 FLD003 FLD004 FLD005 FLD006 FLD007 FLD008 FLD009 FLD010 FLD011 FLD012 FLD013 FLD014 DECIMAL CHAR CHAR CHAR CHAR DATE CHAR CHAR CHAR CHAR CHAR CHAR CHAR CHAR 9 11 16 1 50 4 2 30 20 50 20 3 16 30 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - fase operativa DMD admin Discovery Unit – Esempio: parametrizzazione EntityTableName=RESADD.TBM123C ConnectionParms … Field=FLD001,DECIMAL,9,0 Field=FLD002,CHAR,11,0 Field=FLD003,CHAR,16,0 Field=FLD005,CHAR,50,0 Field=FLD007,CHAR,2,0 Field=FLD008,CHAR,30,0 Field=FLD009,CHAR,20,0 Field=FLD010,CHAR,50,0 Field=FLD011,CHAR,20,0 Field=FLD013,CHAR,16,0 Field=FLD014,CHAR,30,0 LookupFile=Look-Stats-Cognomi LookupFile=Look-Stats-Nomi LookupFile=Look-Stat-Nomi-Cognomi LookupFile=Look-Dom-Province LookupFile=Look-Stats-Comuni LookupFile=Look-Stats-Toponimi SpecificValueClass=CodiceFiscale SpecificValueClass=PartitaIva SpecificValueClass=CreditCard MaxLines=1000 AnalysisOutputFile=TBM123C-DB2-OUT.tx PARAMETRI DI LOCALIZZAZIONE TABELLA DICHIARAZIONE CAMPI CANDIDATI DICHIARAZIONE • LOOKUP (Statistic e Domain) • SPECIFIC DISCOVERY FUNCTIONS MAX NUMERO DI RIGHE • Riferito al campione da analizzare. • Il sistema preleva un numero di righe nell’intorno del valore indicato intervallandole opportunamente NOME FILE ESTERNO dove riversare la Reportistica “volatile” 17 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - uso delle rilevazioni TBM123C.FLD005 Affinity Index 4 5 18 TOPONIMO COMUNE Analisi TBM123C.FLD005 9 NOME COGNOME COGNOME E NOME 13 50 40 30 Affinity Index 20 Affinity Index Confidence 10 0 TOPONIMO COMUNE NOME COGNOME Value Data Class COGNOME E NOME 18 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - uso delle rilevazioni TBM123C.FLD008 Affinity Index 1 2 NOME 2 Analisi TBM123C.FLD008 3 COGNOME E NOME COGNOME 19 TOPONIMO COMUNE 45 40 35 30 25 Affinity Index 20 15 Affinity Index Confidence 10 5 0 NOME COGNOME E COGNOME NOME TOPONIMO COMUNE Value Data Class 19 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - uso delle rilevazioni Discovery Unit – Esempio : Sintesi risultati da Repository, valori massimi degli indicatori* ? ? ? ? COLNAME COLTYPE LENGTH SCALE FLD001 FLD002 FLD003 FLD004 FLD005 FLD006 FLD007 FLD008 FLD009 FLD010 FLD011 FLD012 FLD013 FLD014 DECIMAL CHAR CHAR CHAR CHAR DATE CHAR CHAR CHAR CHAR CHAR CHAR CHAR CHAR 9 11 16 1 50 4 2 30 20 50 20 3 16 30 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Field Name DataClass SDtClass Observations frequency SDtClass Observations number FLD002 PartitaIva 88% 14 FLD003 CodiceFiscale 98% 926 Field Name DataClass Affinity Index Affinity Index Confidence FLD005 COGNOME E NOME 18 50 FLD007 SIGLA PROVINCIA 70 27 FLD008 COMUNE 19 44 FLD014 COMUNE 3 93 FLD014 NOME 3 93 * Esclusi i valori logicamente nulli 20 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - uso delle rilevazioni Discovery Unit – Esempio : Verifica sui dati FLD002 FLD003 FLD005 FLD007 FLD008 CAPASSO COSTANZA MARTIN SIRO SANTAROSSA TOBIA LOMBARDI NUCCIO DE ROSA ISABEL CORAZZA ALEX MARIANI DONATELLA BELTRAME GIACINTA ROSSI ALOISIO MI EE PC VA VB TO NA MI MILANO CASABLANCA CASTELL' ARQUATO LEGGIUNO SANGIANO OMEGNA 0 VARESE TORINO NAPOLI MONZA MRNPRZ64T08E734G BRBPFR63B14Z216G NTNJTH81B10L682U GRBNEE59A28I725M BRTSBN73S23I073W DRIKRA72B26D869Q PDRLBR57D30E014K PRDDNL75B57C665L CSDMYA71L49G337Q FRRRCE66A17L736U MARINELLI PATRIZIO BARBERO PIERFERDINANDO ANTONINI JONATHAN GRUBER ENEA BARTOLINI SABINO DI IORIO AKIRA PEDROTTI ILDEBRANDO PARODI DANIELA CASADEI MAYA FERRERO ERIC VA EE VA RC NA VA ME TO PR VE LUINO MALVAR VARESE SIDERNO MARINA SAN PAOLO BEL SITO GALLARATE GIARDINI NAXOS CHIVASSO PARMA VENEZIA CodiceFiscale Cognome e nome Prov Comune CPSCTN72P54F205Q MRTSRI68R20Z330X SNTTBO40L03C145H LMBNCC39R30E511E DRSSBL75R66G062E 91434921242 CRZLXA60E02L682T MRNDTL43S51L219U BLTGNT71A62F839S RSSLSA66C04F704X PartitaIva FLD009 FLD010 FLD011 3332767084 FLD013 FLD014 AO7764625 MILANO 332745553 3406659507 3470334192 0118993265 3398547300 3338392845 3474349427 3396832236 331776170 AJ7184387 SESTO S. GIOVANNI AO598289 SAN PAOLO B. 3381816774 0521772662 0521754362 41000634660 ERIC96.FERR@G AK9438147 COMUNE DI MAIL.COM VENEZIA Num Tel. E-Mail Num Tel. Num. Doc. Ente Emiss. Dataclass non richieste Ambiguo 21 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - uso delle rilevazioni Discovery Unit – Gli indicatori di rilevanza - Statistic & Domain Data Value Class • AFFINITY INDEX Indicatore numerico del grado di affinità dell'informazione rispetto alla DataClass. I valori possono variare da 0 a 100. • AFFINITY INDEX CONFIDENCE Indicatore numerico del grado di affidabilità con cui è stato determinato il valore dell'Affinity index associato. I valori possono variare da 0 a 100. • La valutazione dell’Affinity index non può essere disgiunta da quella dall'Affinity index confidence per la stessa DataClass: inoltre deve essere confrontata con le analoghe valutazioni ottenute sullo stesso campo per le altre DataClass indicate. • Il processo di riconoscimento si riconduce pertanto alla rilevazione del valore relativo più elevato fra tutti gli Affinity index calcolati per una determinata colonna, avvalorato da un Affinity index confidence massimo o prossimo al massimo fra quelli rilevati. 22 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - uso delle rilevazioni Discovery Unit – Gli indicatori di rilevanza - Specific Data Value Class • L’approccio di analisi varia rispetto ai precedenti perché si basa non sul confronto con valori di riferimento, bensì sulla base del grado di rispondenza strutturale o formale a una specifica data class, tipicamente codici di interesse che possiedono una struttura riconoscibile, come codice fiscale, partita IVA, codice di carta di credito. Cambiano pertanto anche gli indicatori. • OBSERVATIONS FREQUENCY Indicatore di maggior rilievo per questa classe , fornisce il rapporto fra il numero dei riscontri positivi sul totale dei valori analizzati • OBSERVATIONS NUMBER Completa il precedente fornendo un dato quantitativo assoluto dei riscontri positivi. 23 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - I Log di dettaglio su stampa Discovery Unit – Esempio: istogramma dei valori rilevati (specific value) Column name: FLD003 Data type: 1 Precision: 16 Scale: 0 Length: 16 Nullable: 0 Candidate key: 1 Num values: 948 Min value: 2nd Min value: 01110250337 2nd Max value: ZZISST65P02H119R Max value: ZZLRTI66H69F065Z SIGLA PROVINCIA: Affinity index = 0 - Affinity index confidence = 100 COGNOME: Affinity index = 0 - Affinity index confidence = 100 COMUNE: Affinity index = 0 - Affinity index confidence = 100 NOME: Affinity index = 0 - Affinity index confidence = 100 COGNOME E NOME: Affinity index = 0 - Affinity index confidence = 100 TOPONIMO: Affinity index = 0 - Affinity index confidence = 100 -- Specific values histogram follows -Data class: CodiceFiscale --||--Frequency: 97.679% --||-- Number of observations: 926 Look-Stats-Cognomi Look-Stats-Nomi Look-Stat-Nomi-Cognomi Look-Dom-Province Look-Stats-Comuni Look-Stats-Toponimi SpecificValueClass=CodiceFiscale SpecificValueClass=PartitaIva SpecificValueClass=CreditCard 24 Data Meaning Discovery - Scenari e applicazioni Flow dell’attività di discovery - I Log di dettaglio su stampa Discovery Unit – Esempio: istogramma dei valori rilevati (statistic value) Look-Stats-Cognomi Look-Stats-Nomi Look-Stat-Nomi-Cognomi Look-Dom-Province Look-Stats-Comuni Look-Stats-Toponimi SpecificValueClass=CodiceFiscale SpecificValueClass=PartitaIva SpecificValueClass=CreditCard Column name: FLD005 Num values: 2262 Min value: ABBASSI MOHAMED NACEUR BEN 2nd Min value: ABEYSINGHE HERATH MUDIYANSELAG 2nd Max value: ZOUHIRI ABDERRAZZAK Max value: ZUNINO NICO SIGLA PROVINCIA: Affinity index = 0 - Affinity index confidence = 46 COGNOME: Affinity index = 13 - Affinity index confidence = 48 COMUNE: Affinity index = 5 - Affinity index confidence = 49 NOME: Affinity index = 9 - Affinity index confidence = 47 COGNOME E NOME: Affinity index = 18 - Affinity index confidence = 50 TOPONIMO: Affinity index = 4 - Affinity index confidence = 50 TOPONIMO(TIPO): Affinity index = 0 - Affinity index confidence = 46 Persona Giuridica: Affinity index = 0 - Affinity index confidence = 46 -- Values histogram follows -Frequency: 1.415% --||-- Number of observations: 32 --||-- Value(s): DI Frequency: 1.194% --||-- Number of observations: 27 --||-- Value(s): DE Frequency: 0.928% --||-- Number of observations: 21 --||-- Value(s): ROSSI Frequency: 0.707% --||-- Number of observations: 16 --||-- Value(s): LUCA Frequency: 0.663% --||-- Number of observations: 15 --||-- Value(s): MARIA Frequency: 0.575% --||-- Number of observations: 13 --||-- Value(s): FRANCESCO;MARCO Frequency: 0.531% --||-- Number of observations: 12 --||-- Value(s): EL;RICCI Frequency: 0.486% --||-- Number of observations: 11 --||-- Value(s): ANTONIO;FERRARI;MARINO Frequency: 0.442% --||-- Number of observations: 10 --||-- Value(s): GIOVANNI;MANCINI;STEFANO Frequency: 0.398% --||-- Number of observations: 9 --||-- Value(s): ANDREA;PAOLO;ROBERTO Frequency: 0.354% --||-- Number of observations: 8 --||-- Value(s): COLOMBO Frequency: 0.309% --||-- Number of observations: 7 --||-- Value(s): BRUNO;CONTI;GIORDANO;MARIO;MARTINO;MAURIZIO;MORO;SANTORO ... Frequency: 0.044% --||-- Number of observations: 1 --||-- Value(s): AB;ABDALLAH;ABDELAZIZ;ABDELHAKIM; . . . ZOCCHEDDU;ZORAN;ZOUHIRI;ZULIMO;ZUNINO 25 Data Meaning Discovery - Scenari e applicazioni DMD System: sinergie per la Data Governance DMD System e Daisy / Daisy DM • Oggi DMD System e le soluzioni RES Suite per il subsetting e il data masking sono componenti separate. • Le Discovery Sessions possono essere attivate preliminarmente come elaborazioni propedeutiche all’impostazione di progetti soprattutto di mascheratura dei dati . • La componente amministrativa a supporto delle attività preliminari di parametrizzazione delle discovery session è in fase di sviluppo. • La disponibilità della soluzione nella sua configurazione completa , come previsto dai piani di realizzazione approvati , si avrà con il rilascio della RES Suite Enterprise Version 1.0. • Nell’ambito della RES Suite EV 1.0, DMD System verrà integrato nella Suite per la Data Governance, al fine di poter sviluppare le più efficaci sinergie con le soluzioni per il Subsetting / Data Masking e per la Data Quality. 26 Res User Meeting 2014 con la partecipazione di Scriviamo insieme il futuro Research for Enterprise Systems Cristina Vecchietti Direttore Applicazioni e Architetture [email protected] RES Viale Piero e Alberto Pirelli, 6 - 20126 Milano IT: +39 02 3657 0593 IT M +39 335 371053 Grazie
© Copyright 2026 Paperzz