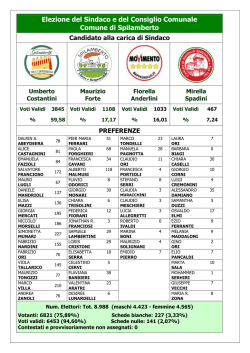
Strumenti matematici per la statistica descrittiva
Gli strumenti matematici, che saranno illustrati, consentono di effettuare l’elaborazione
dei
dati : questa fase dell’indagine statistica, consiste nella trasformazione dei dati grezzi rilevati,
in nuovi dati, ricavati matematicamente, dotati della proprietà di essere sintetici, indicativi
ed interpretabili ai fini della scoperta delle leggi che regolano il fenomeno in oggetto.
Questo metodo di indagine scientifica, che è caratteristico delle discipline sperimentali, è il
metodo induttivo: con tale metodo si passa dal particolare all’universale; infatti, dall’osservazione di alcuni fatti particolari, si giunge a formulare una regola, o legge, universale, cioè
valida per tutti gli altri fatti analoghi, ma non osservati direttamente.
1. Indici di posizione centrale o medie
1.1 Media aritmetica
1.2 Media geometrica
1.3 Media quadratica
1.4 Media armonica
1.5 Moda
1.6 Mediana
2. Indici di dispersione o di variabilità
2.1 Range o campo di variazione
2.2 Scarto semplice medio
2.3 Scarto quadratico medio
2.4 La distribuzione normale
2.5 Indici relativi di variabilità
3. Rapporti statistici (numeri indici)
4. Metodo dei minimi quadrati - interpolazione
5. Statistica bivariata - Correlazione e regressione
1
1. Indici di posizione centrale o medie
Definizione: un valore medio di un insieme di dati numerici {x1, x2, ., xn } è un
particolare numero, risultato di una opportuna operazione-funzione f(x1, x2, ., xn),
che, da solo, è capace di rappresentare sinteticamente l’intero insieme dei predetti dati
e che, per scopi prefissati, è ad esso sostituibile, cioè è quel numero che sostituito
alle x i lascia invarito il risultato operato dalla f.
Gli indici di posizione centrale o medie assumono sempre un valore (numero) compreso
tra il minimo ed il massimo dei dati cnsiderati:
min {xi } 6 numero 6 Max{xi }
1.1 Media aritmetica
Si definisce media aritmetica di più numeri, quel valore che sostituito ai dati, lascia
invariata la loro somma.
•
La media aritmetica (semplice) dell’ insieme di dati numerici {x1, x2, ., xn } è:
Pn
xi
x1 + x2 + . + xn
µ=
= i=1
n
n
Esempio - Calcola la media aritmetica µ dei dati riportati nella seguente tabella:
Discipline
Ita. Lat. Ingl. Fra. Sto. Fil. Sci. Mat. Fis. Ed.A. Ed.F
Voti di Masssimo 7
6
8
8
8
7
7
6
6
8
9
µ=
•
7+6+8+8+8+7+7+6+6+8+9
F 7, 27
11
La media aritmetica ponderata dell’ insieme di dati numerici {x1, x2, ., xn }, aventi
ciascuno il corrispondente peso {p1, p2, ., pn } è:
Pn
x1 · p1 + x2 · p2 + . + xn · pn
i=1 xi · pi
= P
µ=
n
p
p1 + p2 + . + pn
i=1 i
Esempio - Calcola la media aritmetica ponderata µ dei dati riportati nella seguente
tabella:
verifiche di Mat.
Voti di Masssimo
Peso dei voti
µ=
1^ 2^ 3^ 4^ 5^
7
6 8
8
9
1 0,7 0,5 1
0,3
7 · 1 + 6 · 0, 7 + 8 · 0, 5 + 8 · 1 + 8 · 0, 3
F 7, 31
1 + 0, 7 + 0, 5 + 1 + 0, 3
2
•
Definizione: le differenze (x1 − µ), (x2 − µ), , (xn − µ) tra ciascun dato e la media
aritmetica si chiamano scarti semplici degli xi da µ.
Proprietà
•
La somma degli scarti è nulla:
(x1 − µ)+(x2 − µ)+...+(xn − µ)=
Pn
i=1
(x1 − µ) = 0
La relazione si dimostra e si comprende facilmente, infatti gli scarti positivi e quelli
negativi si neutralizzano a vicenda.
•
Se su ciascuno degli n valori {x1, x2, , xn } si opera la trasformazione
yi = axi +b
(a e b ∈ R)
si ottiene
µ y = aµ + b
1.2 Media geometrica
Si definisce media geometrica di più numeri, quel valore che sostituito ai dati, lascia
invariato il loro prodotto.
Si utilizza la media geometrica quando ha senso moltiplicare fra loro i dati ststistici,
per esempio nella ricerca del taso medio nella capitalizzazione composta o quando, in
generale, i dati variano in progressione geometrica.
•
La media geometrica (semplice) dell’ insieme di dati numerici {x1, x2, , xn } è:
√
xG = n x1 · x2 · · xn
Esempio - Nel 2010 un bene costava C1=2000 euro; nel 2011 si è registrato un
aumento del 10%, che porta al costo C2; nel 2012 un ulteriore aumento del 15%, che
porta al costo C3 e nel 2013 un aumento del 9%, che porta al costo C4 (aumenti sempre
riferiti all’anno precedente).
Calcolare il costo C4 di quel bene nel 2013 e l’aumento medio annuo i% (media degli
aumenti i1%=10%, i2%=15%, i3%=9%):
C2=C1+C1·0, 1 = C1(1 + 0, 1) = C1 · 1, 1;
C3 = C2 · 1, 15;
C4=C3·1, 09
quindi C4=2000 · 1, 1 · 1, 15 · 1, 09 = 2757,70;
Per determinare l’aumento medio annuo i si deve risolvere l’equazione
2000(1 + i)3 = 2757, 70
r
1+i=3
(dalla legge della capitalizzazione composta)
2000 · 1, 1 · 1, 15 · 1, 09 √
= 3 1, 1 · 1, 15 · 1, 09 = 1, 113 ⇒ i=0, 113
2000
Pertanto l’aumento medio annuo è stato dell’ 11,3%.
3
,
i%=11,3%
Osservo che
•
√
3
1, 1 · 1, 15 · 1, 09
è la media geometrica di (1+i1), (1+ i2), (1+ i3).
La media geometrica ponderata dell’ insieme di dati numerici {x1, x2, ., xn }, aventi
ciascuno il corrispondente peso {p1, p2, , pn } è:
p
Pn
xG = N x1p1 · x2p2 · · xnpn
con N = i=1 pi
Proprietà
•
La media geometrica (semplice o ponderata)di n numeri positivi coincide con la
media aritmetica (semplice o ponderata) degli n logaritmi dei singoli numeri:
Log xG=
•
log x1 + log x2 + . + log xn
n
La media geometrica delle potenze {xh1 , xh2 , , xhn } è (xG)h .
1.3 Media quadratica
Si definisce media quadratica di più numeri, quel valore che sostituito ai dati, lascia
invariata la somma dei loro quadrati.
Si usa quando ha interesse calcolare un valore medio di superfici.
•
La media quadratica (semplice) dell’ insieme di dati numerici {x1, x2, ., xn } è:
r Pn
r
2
x21 + x22 + + x2n
i=1 xi
=
xQ =
n
n
Esempio - Si hanno tre quadrati di lamiera di uguale spessore con i lati di 11 cm,
7 cm e 19 cm.
Calcolare il lato l di tre quadrati uguali fra loro in modo che la superficie totale sia
invariata:
r
112 + 72 + 192
l 2+l 2+l 2 = 112 + 72 + 192
⇒ l=
= 13, 30 cm
3
•
La media quadratica ponderata dell’ insieme di dati numerici {x1, x2, ., xn }, aventi
ciascuno il corrispondente peso {p1, p2, ., pn } è:
sP
s
n
2
2
2
2
x1 · p1 + x2 · p2 + + xn · pn
i=1 xi · pi
Pn
P
xQ =
=
n
p
p
i=1 i
i=1 i
1.4 Media armonica
4
Si definisce media armonica di più numeri, quel valore che sostituito ai dati, lascia
invariata la somma dei reciproci.
Si applica quando ha senso calcolare il reciproco dei dati, per es (velocità media,
resistenze in parallelo, capacità in serie, potere di acquisto medio di una moneta ...).
•
La media armonica (semplice) dell’ insieme di dati numerici {x1, x2, ., xn } è:
xA =
•
n
n
=P
1
1
1
1
n
+ +
+
i=1
x1 x2
xn
xi
La media armonica ponderata dell’ insieme di dati numerici {x1, x2, ., xn }, aventi
ciascuno il corrispondente peso {p1, p2, ., pn } è:
Pn
Pn
i=1 pi
i=1 pi
x A = p1 p2
pn = Pn pi
+ +
+
i=1 x
xn
x1 x2
i
Esempio 1 - Un automobilista ha percorso 150 km alla velocità di 75 km/h, poi 270
km alla velocità di 90km/h ed infine 400 km alla velocitò di 80 km/h.
Calcolare la velocità media v :
v=
820
150 + 270 + 400
=
= 82 km/h.
150 270 400 2 + 3 + 5
+
+
90
80
75
Esempio 2 - La formula per la capacità C equivalente a quella di n condensatori
C1, C2, ..., Cn collegati in serie è:
C=
1
1
1
1
+
+
.+
C1 C2
Cn
quindi la capacità equivalente è
⇒ C=
1
n
·
1
1
n 1
+
+
.+
C1 C2
Cn
la media armonica delle capacità
n
.
Proprietà
•
La somma degli scarti dei singoli valori dalla media armonica è nulla.
Osservazione: per un insieme di dati numerici positivi {x1, x2,
seguente relazione:
xA6xG 6 µ 6 x Q
5
.,
xn }, vale la
1.5 La moda
Definizione: si dice moda o valore normale di una distribuzione di frequenze,
la modalità o il valore della variabile al quale corrisponde la massima frequenza.
Una distribuzione statistica può avere più mode o anche nessuna:
La distribuzione 1,2,2,2,3,5,5 ha moda 2
La distribuzione 1,2,2,2,3,5,5,5 ha moda 2 e 5
La distribuzione 1,1,2,2,3,3,5,5 non ha moda perchè nessun termine ha frequenza
maggiore di altri.
Esempio - Dalla seguente tabella si evince che la moda della variabile spesa è
2500 euro.
N. famiglie
1
0
5
4
Spesa per ferie (euro) 1500 2000 2500 3000
1.6 La mediana
Definizione: data una successione di valori x1, x2, , xn, ordinati in senso non
decrescente, si dice mediana il valore che bipartisce la successione, ossia il
valore non inferiore a metà dei valori e non superiotre all’altra metà.
Esempi - Trovare la mediana per le seguenti distribuzioni :
n. dispari di dati 5, 7, 11, 13, 15
n. pari di dati 5, 7, 11, 13, 15, 17
mediana 11
11 + 13
mediana
= 12 .
2
2. Indici di dispersione o di variabilità
La varabilità è l’attitudine che la grandezza in oggetto ha di assumere valori più o
meno diversi fra loro.
In pratica, dopo aver calcolato uno o più valori medi, i dati rilevati si possono presentare in modo più o meno disperso attorno a tali valori medi, quindi si cerca di
evidenziare e descrivere in modo sintetico tale dispersione mediante oppurtuni indici.
Esempio - Analizziamo i dati riportati nella seguente tabella:
voti nelle prove scritte di matematica di tre allievi
Filippo
Ilaria
Pietro
5
4
3
Grafici delle frequenze dei voti:
6
6
5
4
6
7
8
7
8
9
Si nota che, a parità di media aritmetica (µ = 6), le tre successioni di voti presentano
una misura diversa della variabilità - dispersione attorno a tale valore medio:
i voti di Filippo sono quelli meno dispersi, mentre i voti di Pietro sono i più dispersi
o a variabilità più alta.
Poichè nessuno dei valori medi è in grado di dare informazioni sulla misura della variabilità dei dati, è necessario introdurre indici appropriati, detti indici di dispersione
o di variabilità.
2.1 Range o campo di variazione (d)
Def.: il campo di variazione d è dato dalla differenza tra il dato massimo ed il dato
minimo; tale dato equivale al minimo intervallo che contiene tutti i dati.
d = Max{xi } − min {xi }
Esempio: il campo di variazione dei voti
- di Filippo è d = 7 - 5 = 2,
- di Ilaria è
d = 8 - 4 = 4,
- di Pietro è d = 9 - 3 = 6.
2.2 Scarto semplice medio (S)
Def.: lo scarto semplice medio S è uguale alla media aritmetica, semplice o ponderata,
dei valori assoluti degli scarti di ciascun dato xi dalla media aritmetica µ.
7
|x1 − µ| + |x2 − µ| + . + |xn − µ|
S=
cioè S =
n
S=
Pn
|xi − µ| ·
i=1P
n
pi
i=1
pi
Pn
i=1
|xi − µ|
n
(media ponderata)
Osservazione: si dimostra e si comprende facilmente che
Pn
i=1
(xi − µ)
= 0.
n
Esempio: lo scarto semplice medio dei voti
- di Filippo è S =
|5 − 6| + |6 − 6| + |6 − 6| + |7 − 6| 2 1
= = = 0,5
4
4 2
- di Ilaria è
|4 − 6| + |5 − 6| + |7 − 6| + |8 − 6| 6 3
= = = 1,5
4 2
4
S=
- di Pietro è S =
|3 − 6| + |4 − 6| + |8 − 6| + |9 − 6| 10 5
=
= =2, 5.
4
2
4
Intepretazione dei risultati: mediamente i voti
- di Filippo si discostano dalla media (6) di una frazione pari a 1/2 di voto,
- di Ilaria si discostano dalla media di una frazione pari a 3/2 di voto,
- di Pietro si discostano dalla media di una frazione pari a 5/2 di voto,
quindi i voti di di Pietro, discostandosi dalla media del 6, mediamente di 2,5, presentano un grado di variabilità maggiore (sono più dispersi ) di quelli di Ilaria e di
Filippo. I voti di Filippo sono i meno dispersi.
2.3 Varianza e scarto quadratico medio (σ 2, σ)
Def.: la varianza σ 2 è la media aritmetica, semplice o ponderata, dei quadrati degli
scarti.
Pn
(xi − µ)2
(x1 − µ)2 + (x2 − µ)2 + . + (xn − µ)2
2
2
σ =
cioè σ = i=1
n
n
Pn
(xi − µ)2 · pi
σ 2 = i=1 Pn
(media ponderata)
pi
i=1
Osservazione: si dimostra facilmente che
σ 2 = µx2 − µ2
infatti, indicando con µx2 la media aritmetica degli x2i :
Pn
Pn
Pn
x2i
xi
(xi − µ)2
2
i=1
i=1
=
− 2µ i=1 + µ2 = µx2 − 2µ2 + µ2 = µx2 − µ2 .
σ =
n
n
n
8
Quindi la varianza è uguale alla differenza fra la media aritmetica semplice o ponderata dei quadrati dei termini e il quadrato della media.
Def.: lo scarto quadratico medio σ (deviazione standard) è la radice quadratata della
varianza, cioè la media quadratica, semplice o ponderata, degli scarti dei valori dalla
media aritmetica.
r
(x1 − µ)2 + (x2 − µ)2 + . + (xn − µ)2
σ=
cioè
n
r Pn
2
i=1 (xi − µ)
σ=
n
σ=
sP
n
(xi − µ)2 ·
i=1 P
n
pi
i=1
pi
(media ponderata)
Esempio : cinque successive rilevazioni della temperatura di una giornata hanno
fornito il seguente insieme di dati:
x 0C 18 22 24 28 30 , determinare:
a) la media aritmetica µ ;
b) il campo di variazione d;
c) lo scarto semplice medio S;
d) lo scarto quadratico medio σ .
Per rispondere ai quesiti conviene compilare la seguente tabella:
dati
x
18
22
24
28
30
µ = 24, 4
scarti
x-µ
-6,4
-2,4
-0,4
+3,6
P +5,6
(x − µ) = 0
val. ass. scarti
|x-µ|
scarti al quadrato
(x-µ)2
6,4
2,4
0,4
3,6
P 5,6
|x − µ| = 18, 4
40,96
5,76
0,16
12,96
31,36
P
(x − µ)2 = 91, 20
quindi, ecco le risposte:
a) µ = 24, 4 - 24, 4 0C è la temperatura media della giornata;
b) d=xmax − xmin = 30-18=12 - 12 0C è il campo di variazione (escursione termica);
18, 4
= 3, 68 - 3, 68 0C è di quanto le temperature rilevate si discostano
5
mediamente dal loro valor medio 24, 4 0C;
c) S=
9
r
91, 20
= 4, 27 - 4, 27 0C è un altro indice di variabilità che dice, con
5
risultato diverso, di quanto le temperature rilevate si discostano mediamente dal
loro valor medio.
d) σ =
Osservazioni sull’importanza dello scarto quadratico medio:
Lo scarto quadratico medio σ (deviazione standard, scarto tipico) è il più importante
tra tutti gli indici di variabilità, preferibile al campo di variazione d, perchè troppo
grossolano, e allo scarto semplice medio S, perchè σ:
a) è più sensibile di S, dimostrandosi capace di percepire più intensamente anche
lievissimi mutamenti della variabilità;
b) è maggiore di S, cosicchè consente di evidenziare meglio anche le più piccole
differenze delle variabilità allorchè si confrontano due insiemi di dati statistici;
c) è molto importante per lo studio di quella notevole distribuzione di frequenze
che è la distribuzione normale.
2.4 La distribuzione normale
Esempio di distribuzione di frequenze di tipo normale.
Analizzare il grafico della distribuzione delle frequenze dei seguenti dati (risultato di un
test d’ingresso, assegnato ad un campione casuale di 100 studenti iscritti al 1 anno di Ingegneria):
voti
2
frequenze 3
3
5
4
7
5 6 7 8 9
22 26 22 7 5
10
3
Istogramma corrispondente alla tabella:
analisi del grafico:
•
•
6 + 15 + 28 + 110 + 156 + 154 + 56 + 45 + 30
= 6),
100
media (µ =
e valgono 6;
il grafico è a forma di campana;
10
moda e mediana coincidono
•
la maggior parte dei voti è addensata nelle vicinanze della media.
Perchè il termine “normale”
Tutte le volte che una distribuzione di frequenze porta ad una situazione simile a
quella presentata nell’esempio, si dice che essa è una distribuzione normale, perchè la
sua rappresentazione grafica tende al grafico (campana perfetta) della funzione normale di Gauss, in grado di descrivere molti fenomeni nel campo della fisica, della
medicina-biologia, della sociologia, della psicologia, che si distribuiscono “normalmente” con frequenze più elevate nei valori centrali e con frequenze progressivamente
minori verso gli estremi della variabile.
E’ detta anche curva degli errori accidentali in quanto, soprattutto nelle discipline
fisiche, la distribuzione degli errori commessi nel misurare ripetutamente una stessa
grandezza, è molto bene approssimata da questa curva.
Funzione normale di Gauss:
(x− µ)
−
1
y= √
· e 2σ2
σ 2π
2
Caratteristiche della curva di Gauss (gaussiana)
a) è simmetrica rispetto al valore medio µ;
b) media, moda e mediana coincidono;
c) è asintotica, con asintoto la retta y=0
lim f (x) = 0 ;
x→±∞
d) è crescente per x<µ, decrescente per x>µ ;
e) presenta due punti di flesso per x=µ ± σ ;
f) l’area sotto la curva vale 1, essendo 1 la probabilità che si verifichi un valore x
nell’intervallo ]-∞ ;+∞[;
g) posizione, forma e distribuzione delle frequenze sono caratterizzate da µ e σ:
11
12
2.5 Indici relativi di variabilità
Gli indici d, S, σ sono espressi nella stessa unità di misura dei dati da elaborare,
quindi servono per confrontare le variabilità di dati omogenei.
Per confrontare successioni di dati non omogenei si devono usare gli indici relativi
di variabilità:
d
• campo di variazione relativo:
dr =
µ
•
scarto semplice medio relativo:
Sr =
S
µ
•
scarto quadratico medio relativo:
σr =
σ
µ
Facendo riferimento ai dati dell’esempio precedente (in 2.3), si ottiene:
•
campo di variazione relativo:
dr =
12 0C
= 0, 49
24, 4 0C
•
scarto semplice medio relativo:
Sr =
3, 68 0C
= 0, 15
24, 4 0C
•
scarto quadratico medio relativo:
σr =
4.26 0C
= 0, 17
24, 4 0C
Esempio : data la seguente distribuzione di frequenze riguardante una successione
di 10 voti, determinare:
a) la media aritmetica dei voti;
b) la misura della variabilità dei voti, mediante l’uso della deviazione standard (scarto
q.m.);
c) il confronto delle variabilità delle due successioni di dati riportate nella tabella
dell’esempio 1 e nella seguente.
dati (voti) x
frequenze f
5
1
6
5
7
2
8
2
P4
5 + 30 + 14 + 16
i=1 xi · fi
a) media ponderata dei voti
µ= P
=
= 6, 5
4
10
·fi
i=1
sP
r
n
(xi − µ)2 · fi
8, 50
i=1P
b) deviazione standard
σ=
=
= 0, 92
n
f
10
i=1 i
13
scarti
x-µ
-1,5
-0,5
+0,5
P +1,5
(x − µ) = 0
scarti al quadr.
(x-µ)2
1
5
2
P 2
f = 10
2,25
0,25
0,25
2,25
prodotti
(x-µ)2 · f
frequenze
f
2,25
1,25
0,50
4,50
P
(x − µ)2 · f = 8, 5
c) Per confrontare le variabilità dei due insiemi non omogenei di dati, si devono
usare gli indici relativi di variabilità:
σ 4, 26 0C
per le temperature dell’esempio 1 si ha σr = =
= 0, 17 ,
µ 24, 4 0C
per i voti dell’esempio 2 si ha σr =
σ 0, 92
=
= 0, 14 .
µ
6, 5
Conclusione: gli indici relativi ci informano, in riferimento ai dati analizzati, che
la variabilità delle temperature è maggiore di quella dei voti.
Nessun confronto, fra dati non omogenei, è possibile mediante gli indici assoluti.
3. Numeri Indici
I numeri indici sono rapporti, espressi in percentuali, fra intensità di un certo
fenomeno in tempi o in luoghi diversi e possono essere:
a) numeri indici a base fissa che si calcolano scegliendo un dato come base (o il primo,
o l’ultimo, o un valore medio) e dividendo gli altri dati per la base, moltiplicandolo
il risultato per 100;
b) numeri indici a base mobile (soprattutto per serie storiche), che si ricavano
prendendo, per ciascuno, come base il dato precedente.
Esempio:
I numeri indici a base fissa mettono in evidenza, meglio dei dati grezzi, la variazione
dei dati rispetto alla base.
I numeri indici a base mobile evidenziano la variazione di un dato rispetto al dato
precedente.
14
4. Metodo dei minimi quadrati - interpolazione
Il metodo dei minimi quadrati è una tecnica molto utile per determinare la funzione
che rappresenti nel migliore dei modi la relazione che può esistere fra due grandezze
X e Y delle quali si conoscono alcuni valori o dati rilevati.
Procedimento:
a) si rilevano i dati (xi; yi) delle grandezze X e Y (per es.: X peso applicato e Y
allungamento di una molla);
b) si rappresentano le n coppie di dati (xi; yi) mediante tabella e diagramma a
dispersione;
c) il diagramma a dispersione suggerisce quale tipo di funzione scegliere per
l’interpolazione, di solito
polinomiale di 1o grado - y = ax + b
2o grado - y = ax2 + bx + c
3o grado - y = ax3 + bx2 + cx + d
4o grado - y = ax4 + bx3 + cx2 + dx + e
esponenziale - y = a·bx
logaritmica - y = a·lnx + b
iperbole -
y=
1
,
ax + b
ecc. ...
d) Scelta la funzione, si calcolano i parametri a, b, c, ... mediante formule
note, ricavate dall’applicazione di un fondamentale teorema di analisi alla
condizione di accostamento: per ottenere la migliore funzione interpolante
(o perequatrice) è necessario e sufficiente determinare i valori dei parametri
a, b, c, ... in modo che sia minima la somma dei quadrati delle differenze fra
i valori rilevati yi e i valori teorici yˆi :
Pn
(yi − yˆi)2 = minima
i=1
( per la funzione polinomiale di 10 grado:
Pn
i=1
(yi − axi − b)2 = minima )
e) Calcolo del coefficiente di determinazione ρ2 (R2) , che indica quanto il
modello scelto (funzione interpolante) è aderente al fenomeno oggetto di studio
(dati rilevati).
Per l’interpolazione lineare R2 è semplicemente il quadrato del coefficiente di
correlazione:
15
2
ρ =
σxy
σx · σ y
2
con
σxy = cov(X; Y ) =
0 6 ρ2 6 1
Pn
i=1
(xi − µx)(yi − µ y )
n
ρ2 =1 indica un adattamento perfetto del modello ai dati;
ρ2 = 0 indica che il modello utilizzato non si adatta ai dati rilevati.
Esempio 1
Data la seguente tabella di dati rilevati per le grandezze X eY, mediante foglio
di calcolo, tracciare il diagramma a dispersione, richiedendo al software di
calcolare la funzione interpolante e il relativo coefficiente di determinazione.
Soluzione
Osserva come l’interpolazione lineare si adatti meglio, rispetto a quella
16
logaritmica, ai dati della tabella: R2lineare > R2logaritmica
Formule per l’interpolazione lineare
(polinomio di primo grado)
Scelta la funzione del tipo y = ax + b si determinano i parametri a e b
mediante le seguenti formule:
P
P
P
n xiyi −
xi ·
yi
P
P
(∗) calcolato il coeff. ang. a, si ottiene b
a=
2
2
( x i)
P ny xi −
P
xi
i
−a
⇒ b = µ y − a µx ⇒ y = ax − µ y − aµx
b=
n
n
Concludendo l’equazione della retta interpolante fra punti noti è:
y − µ y = a(x − µx)
Osservazioni
•
•
Il punto di coordinate (µx , µ y) è il baricentro della distribuzione.
la formula (∗) può essere scritta in modo più semplice in termini di
′
′
scarti xi = xi−µx e yi = yi−µ y :
P ′ ′
xy
σxy
a = P i′ i2 = 2 .
σx
xi
Esempio 2
Calcolare la retta interpolante e il relativo coefficiente di determinazione R2
per i dati riportati nella tabella dell’esempio 1.
Soluzione
′
′
′
′
xi e yi sono gli scarti: xi =(xi − µx); yi =(yi − µ y )
17
a=
σxy 10, 5
=
F 0, 636364
σx2 16, 5
⇒ equazione retta : y − µ y = a(x − µx)
y = 0, 636364x − 0, 636364 · 7+5 ;
y = 0, 636364x + 0.545455
2
σxy
(10, 5)2
ρ2 =
=
F 0, 954545 ⇒ ρ2 F 1 indica un buon
σx · σ y
16, 5 · 7
adattamento del modello ai dati.
5. Statistica bivariata - Correlazione e regressione
La statistica unidimensionale si occupa di studiare una sola variabile o mutabile. La
statistica bidimensionale o bivariata si occupa dello studio congiunto di due caratteri
distinti. In particolare il problema è quello di vedere se esiste fra essi un legame
associativo e in caso positivo di misurarne l’entità.
Il caso più importante è la classificazione rispetto a due caratteri (voto in storia e in
matematica per gli allievi di una classe, peso e altezza per gli atleti di una certa disciplina); le
distribuzioni di frequenza, per rilevazioni di questo tipo, si rappresentano con tabelle
a doppia entrata, che possono essere:
a) di contingenza se i due caratteri sono entrambi qualitativi (mutabile statistica
doppia); es.: distribuzione degli abitanti di una regione per provincia e sesso;
b) di correlazione se i due caratteri sono entrambi quantitativi (variabile statistica
es.: distribuzione delle abitazioni di una città per numero dei vani e per
numero dei componenti della famiglia;
doppia);
c) miste se uno dei due caratteri è quantitavo e l’altro e qualitativo; es.: distribuzione
dei suicidi in una regione per età e per sesso.
Esempio di tabella mista:
distribuzione delle frequenze di un campione di allievi di un istituto scolastico, per
numero di lingue straniere conosciute e per le modalità magro regolare, grasso:
Da ogni tabella a doppia entrata si possono ricavare due tabelle a semplice entrata
riguardante ognuno dei due caratteri. Infatti, se si considerano i valori dei totali dei
dati di riga e dei totali di ogni colonna, si hanno due tabelle a semplice entrata che
vengono dette distribuzioni marginali:
18
Dalla tabella a doppia entrata e tenendo conto delle distribuzioni marginali, si può
valutare se i caratteri considerati sono indipendenti:
Def.: Due caratteri A e B sono indipendenti se le frequenze relative del carattere
A (p.es. peso) si mantengono ugualmente distribuite in tutte le modalità con cui
compare il carattere B(p.es. lingue straniere conosciute) e viceversa.
Per esempio, considerato il carattere y di A, si ha
f2,1 f2,2 f2,3
=
=
e f2,1 + f2,2 + f2,3 = A2 .
B1
B2
B3
Segue inoltre il teorema:
se due caratteri sono indipendenti, allora fi,k=
Ai · Bk
, con N il totale del campione;
N
fi,n
fi,1 fi,2
=
=
per tutta la
dimostrazione: se i caratteri sono indipendenti, allora
B2
Bn
B1
riga i-esima, quindi si può scrivere
Pn
j=1
fi,j =
fi,k Pn
fi,k
·N
Bk ⇒Ai =
j=1
Bk
Bk
⇒ fi,k =
Ai · Bk
N
I due caratteri considerati nell’esempio sono indipendenti, infatti:
e dal teorema, per esempio f2,3 =
A2 · B3 46 · 11
A1 · B2 23 · 18
=
F
6; f1,2 =
=
F 5.
N
N
84
84
Correlazione e regressione
Nella Statistica descrittiva è importante lo studio della connessione che è la ricerca
di eventuali relazioni, di dipendenza ed interdipendenza, intercorrenti tra due variabili
statistiche X, Y; esso prende il nome di
19
•
•
correlazione se lo scopo è quello di accertare ed esprimere l’intensità del legame di
interdipendenza tra le variabili, cioè di vedere se esse si influenzano reciprocamente,
ed allora si sceglirà, come mezzo tecnico, un indice (coefficiente di correlazione ρ);
regressione se lo scopo è quello di ricercare ed illustrare legami di dipendenza fra
le variabili X, Y, determinando, con il metodo dei minimi quadrati, una funzione,
detta funzione di regressione, che permetta di valutare le variazioni della Y al
variare della X e viceversa.
Se la funzione prescelta è la retta si parlerà di regressione lineare.
Calcolo della Correlazione
Per misurare la variabilità congiunta di due varibili X e Y si introduce la covarianza
di X e di Y:
Pn
(xi − µx)(yi − µ y)
σxy = cov(X; Y ) = i=1
n
o anche
σxy = µxy − µx · µ y
con
µxy =
Pn
xi · yi
n
i=1
La covarianza è il valor medio del prodotto degli scarti corrispondenti di X e di Y e
si usa per definire il coefficiente di correlazione lineare di Bravais-Pearson,
che viene assunto come indice:
ρ=
cov(X; Y )
σxy
=
σx · σ y
σx · σ y
Il coefficiente di correlazione di Bravais-Pearson è il rapporto fra la covarianza e il
prodotto degli scarti quadratici medi di X e Y.
Proprietà dell’indice di correlazione lineare:
−1 6 ρ 6 1
•
ρ = −1
la correlazione è perfetta inversa (o negativa)
•
−1 < ρ < 0
la correlazione è inversa (o negativa)
•
ρ=0
non esiste correlazione lineare
•
0< ρ<1
la correlazione è diretta (o positiva)
•
ρ=1
la correlazione è perfetta diretta (o positiva)
20
N.B. se non esiste correlazione lineare (ρ = 0) potrebbe, però, sussistere una correlazione curvilinea.
Esempio 3
Calcolare la covarianza e il coefficiente di correlazione per le variabili X e Y con i
dati riportati nella tabella dell’esempio 1.
Soluzione
Calcolo delle medie aritmentice µx e µ y :
µx =
1 + 3 + 4 + 6 + 8 + 9 + 11 + 14
8
=7 ;
µy =
1+2+4+4+5+7+8+9
8
=5
Calcolo gli scarti quadratici medi σx e σ y :
r Pn
q
√
(xi − µx)2
(1 − 7)2 + (3 − 7)2 + . + (14 − 7)2
=
= 16, 5 F 4, 062
8
n
r Pn
2 q
√
(1 − 5)2 + (2 − 5)2 + . + (9 − 5)2
i=1 (yi − µ y )
=
=
7 F 2, 646
σy =
8
n
σx =
i=1
Calcolo la covarianza σ xy = cov(X;Y):
Pn
(xi − µx)(yi − µ y)
(1 − 7) · (1 − 5) + (3 − 7) · (2 − 5) + . + (14 − 7) · (9 − 5)
=
= 10, 5
σxy = i=1
8
n
Calcolo il coefficiente di correlazione ρ :
ρ=
σxy
cov(X; Y )
10, 5
=
F
F 0, 977
σx · σ y
σx · σ y
4, 062 · 2, 646
21
0 < ρ < 1 e anche ρ F 1 , quindi fra i dati rilevati, relativi alle grandezze X e
Y, vi è una buona correlazione diretta (o positiva).
Calcolo della Regressione lineare
Date due variabili statistiche X e Y con associati n dati rilevati xi e y i ci si prefigge
di determinare una funzione matematica, in questo contesto di tipo lineare, che
esprima la relazione fra tali variabili:
y = ax +b
′
x = ay + b
retta di regressione di y in x e, se ha senso logico anche
′
retta di regressione di x in y.
Si procede applicando le seguenti formule, ricavate mediante il metodo dei minimi
quadrati:
P ′ ′
xy
σxy
y − µ y = a(x − µx)
con
a = P i′ i2 = 2
σx
xi
a è il coefficiente di regressione di y in x
P ′ ′
xy
′
′
σxy
x − µx = a (y − µ y )
con
a = P i′ i2 = 2
σy
yi
′
a è il coefficiente di regressione di x in y
Osservazioni:
•
•
le rette di regressione lineare passano per il baricentro (µx; µ y) e rendono minima
la somma dei dei quadrati degli scarti.
ρ=
√
σxy
′
=± a·a .
σx · σ y
22
Esempio 4
La seguente distribuzione doppia rappresenta il peso in kg di un neonato nei primi
12 mesi:
a) rappresentare il grafico a dispersione;
b) trovare le coordinate del baricentro;
c) calcolare la covarianza;
d) determinare l’equazione della retta di regressione di y in x (la regressione di x in
y non ha senso logico) e il coefficiente di determinazione ρ2 .
Soluzione
a) Grafico a dispersione
Per rispondere ai quesiti b,c,d basta compilare la seguente tabella:
′
′
′
′
xi e yi sono gli scarti: xi =(xi − µx); yi =(yi − µ y)
23
b) Coordinate del baricentro: (µx ; µ y ) → (6, 50; 6, 23)
Pn
(xi − µx)(yi − µ y )
= 5,80
c) Covarianza: σxy = cov(X; Y ) = i=1
n
d) Retta di regressione di y in x e coefficiente di determinazione:
y − µ y = a(x − µx)
P ′ ′
xy
σxy
5, 80
a = P i′ i2 = 2 =
F 0, 4866
11, 92
σx
xi
con
y − 6, 23 F 0, 4866(x − 6, 50) → y F 0, 4866x +3, 06697
2
(5, 80)2
σ
xy
=
ρ2 =
F 0, 957 ⇒ R2 F 1 indica un buon
11, 92 · 2, 95
σx · σ y
adattamento del modello ai dati.
24
© Copyright 2026 Paperzz