文字列
コンピュータ内部での文字の表現
英数字の場合
コンピュータ内部では全データは数値として扱われる。そのため、文字には対応する数値が割り
振られており、これを基にしてプログラムは動作する。文字と数値の対応表にはアスキーコード表
というものがあり、この表では英数字と記号に 0~127 の整数がそれぞれ割り当てられている。以
下に一例を示す。
表1.アスキーコードの一例
文字
16 進数
10 進数
a
0x61
97
A
0x41
65
+
0x2B
43
1
0x31
49
プログラムでアスキーコードの値を確かめたければ、以下のようにすればよい。
プログラム例1
#include <stdio.h>
int main(void)
{
char c;
c = 'L';
printf("L = %d\n", c);
return 0;
}
出力
L = 76
文字型変数(char)は 1 バイト(8 ビット)のデータが格納でき、格納できる値は-127~128 までの整
数である。そのため、文字型変数1つで表現できるのは最大 256 種類の文字となる。
日本語の場合
日本語のように多くの文字を使う際には 256 種類しか表現できないコードでは対応出来ない。そ
のため、日本語はアスキーコードとは異なる文字コードが使われる。代表的なのが、
日本語 euc
shift-jis
JIS コード
Unicode
extend unix code の略。主に linux、UNIX で使われている。
主に Windows、machintosh で使われている。
日本工業規格 JIS(Japanse Industrial Standards)が定めたコード。
全ての文字の対応付けを行っている。
である。例えば、
「秋」という漢字は、表2のようになっている。
表2.各コードでの"秋"。C 言語の場合、先頭に 0x とつく数字は 16 進数を表す。
コード
16 進数
10 進数
日本語 EUC
0xbda9
48553
shift-jis
0x8f48
36680
jis コード
0xbda9
48553
ユニコード
0x79cb
31179
-1-
英数字と日本語では 1 文字を表現するために必要な情報量が異なる。英数字は 1 バイトで十分であ
るが、日本語は 2 バイト必要である。
文字の記憶方法
英数字 1 文字の場合(文字型変数)
英数字 1 文字の場合、文字型変数を用いる。次のように宣言をすれば、変数名 a の文字を入れる
箱が用意される。この箱の容量は、1 バイトである。
char a;
型名の char と言うのは、character(文字)の略である。この変数に、文字を格納するのは簡単で、
a = 'A';
とすればよい。格納したい文字をシングルクォーテーションで囲んで、代入演算子(=)を使う。文字
型変数のイメージを図1に示す。
‘A’
a
図1 文字型変数 a を用意して、それに’ A’を格納。この箱の大きさは、1 バイトなので、日本語を
入れることはできない。
表示まで含めた文字型変数を使ったプログラムは、次のようになる。
プログラム例2
#include <stdio.h>
int main( void )
{
char a;
a = ‘A’;
printf("%c\n", a);
// 文字型の変数
// 代入
// 表示
return 0;
}
出力
A
英数字の文字列の場合(文字型配列)
文字型配列の使い方
次に、いくつかの英数字で構成される文字列の場合について述べる。このようなときは文字型の
配列のデータ構造を使う。以前、同じ型の数値データが複数ある場合、int 型あるいは double 型
の配列を使ったのと同じである。文字型の配列を使うときには、次のように宣言する。
char a[10];
これで 10 個の文字を格納できるメモリの領域が確保できる。しかし、実際に入れることができる
文字数は 9 文字である。文字列の最後の文字の後に、文字列終了の記号を入れることになるため、
1 文字分少なくなる。文字列終了の記号は、’¥0’という文字が使われ、これを NULL 文字と言う。
いろいろな方法で、この文字型の配列に文字を格納することができる。まずは、配列の要素毎に
-2-
文字を入れる方法がある。
プログラム例3
#include <stdio.h>
int main( void )
{
char a[6];
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
=
=
=
=
=
=
// 文字型の配列
'A';
'k';
'i';
't';
'a';
'\0';
printf( "%s\n", a );
// 表示
return 0;
}
出力
Akita
実際、この方法で文字を代入することはまれであるが、文字列のある特定の要素を操作するには
有効である。あるいは、変数の宣言と同時に初期化するのであれば、以下のような書き方もある。
char a[10] = {'A', 'k', 'i', 't', 'a', '\0'};
これは配列の初期化の方法で習った通常の初期化方法である。しかし、文字列については特に、
以下のような形式も許されている。
char a[10] = "Akita";
文字列の終了を表す NULL 文字は省略して書くことになるが、この場合、a[5]には自動的に'\0'
が代入される。また、これらは配列の初期化のルールに従うので、配列の要素数を省略した以下の
形も使用可能である。
char a[] = {'A', 'k', 'i', 't', 'a', '\0'};
char a[] = "Akita";
これらは配列の要素数が自動的にカウントされることになり、この場合では要素数が 6 になる。
注意点として、次に示す間違った使用例がある。
char a[10];
a = "Akita";
この場合では、a は配列の先頭アドレスを取り扱っているので、コンパイルエラーとなる。次に
文字列を操作するライブラリを用いて、配列に文字を代入する方法を紹介する。具体的には、次の
ようにする。
strcpy(a, "Akita");
-3-
これで配列に文字が格納できる。ただし、この方法を使う場合は、プログラムの最初に#include
<string.h>とライブラリをインクルードする必要がある。また、stdio.h のインクルードだけで良
い方法もある。
sprintf(a, "Akita");
printf 関数とよく似ており、書式指定することでもう少し複雑な処理も可能であるが、詳しい
説明は省略する。文字型配列のイメージは、図2のようになる。
‘A’
a[0]
‘k’
a[1]
‘i’
a[2]
‘t’
a[3]
‘a’
a[4]
‘\0’ 不明 不明 不明 不明
a[5]
a[6]
a[7]
a[8]
a[9]
図2 文字型の配列 a[10]を用意して、それに"Akita"を格納。一つの箱には、一つの英数字しか入
れられない。そして、最後に\0 が入る。
配列に格納された文字列を表示するプログラムは次のようになる。
プログラム例4
#include <stdio.h>
int main(void)
{
char a[10];
sprintf(a, "Akita" );
printf( "%s\n", a );
/* 文字型の変数 */
/* 代入 */
/* 表示 */
return 0;
}
出力
Akita
※注意
配列を使う場合、そのサイズはプログラマが決めなくてはならない。そのサイズを超えて代入す
るような操作をすると、エラーメッセージを出して止まる。通常は十分大きいサイズで使う。
日本語の場合
文字型配列の使い方
文字型の場合、それに格納できるデータは 1 バイトである。一方、日本語の場合、文字は 2 バ
イトで表現する。そのため、日本語は 2 個の文字型のデータ領域に 1 個の文字を格納している。文
字型の配列に日本語の文字を格納する方法は、アルファベットの場合とほとんど同じである。従っ
て、以下のようになる。
strcpy(a, "秋田");
sprintf(a, "秋田");
ただし、a[0]='秋';のような代入はできない。a[0]は 1 バイトで、日本語の「秋」は 2 バイトだか
らである。文字型配列のイメージは、図 3 のようになる。
-4-
bd
a9
c5
c4
a[0]
a[1]
a[2]
a[3]
秋
‘\0’ 不明 不明 不明 不明 不明
a[4]
a[5]
a[6]
a[7]
a[8]
a[9]
田
図3 文字型の配列 a[10]を用意して、それに"秋田"を格納。日本語の場合、 2 つの箱で 1 つの文
字が入る。そして、最後に’¥0’が入る。
表示方法もアルファベットと同じである。
プログラム例5
#include <stdio.h>
int main(void)
{
char a[10];
sprintf(a, "秋田");
printf("%s\n", a);
return 0;
}
出力
秋田
※注意
配列のサイズに気を付ける必要がある。日本語はアルファベットとは異なり、サイズは 2 倍とな
る。さらに、文字列の終わりを示す’¥0’を加えた配列の要素数が必要である。
文字列のキーボードからの入力
文字列をキーボードから入力する方法を示す。まずは、使い慣れている scanf である。
プログラム例6
#include <stdio.h>
int main(void)
{
char a[100];
scanf("%s", a);
printf("%s\n", a);
return 0;
}
出力例(斜体は入力)
Akita
Akita
上記のように使用することができる。文字列をキーボードから入力し、Enter ボタンを押すと、’\n’
が’¥0’に置き換えられた上で、配列 a に格納される。ただし、注意が必要で、”This is a pen”と入
力すると、最初の空白までが区切りとみなされてしまい、”This”までしか読み込まれない。1 行全
-5-
て入力する方法としては gets がある。
プログラム例7
#include <stdio.h>
int main(void)
{
char a[100];
gets(a);
printf("%s\n", a);
return 0;
}
出力例(斜体は入力)
This is a pen
This is a pen
この方法だと、1 行全てが入力され、また、’\n’は’¥0’に置き換えられる。ただし、この方法でも
注意が必要で、配列で確保された文字数以上を入力すると、問題が生じる可能性(メモリ破壊)が
あり、使用する場合には気をつけなくてはならない。そのため、次回で習う「fgets」で入力文字
数を制限する方が良いが、今回は十分なサイズの配列でプログラムを組むことで対応する。
入力される空白の数があらかじめ分かっている場合には以下のように scanf を利用することもで
きる。
プログラム例8
#include <stdio.h>
int main(void)
{
char a[10], b[10], c[10], d[10];
scanf("%s %s %s %s", a, b, c, d);
printf("%s %s %s %s\n", a, b, c, d);
return 0;
}
出力例(斜体は入力)
This is a pen
This is a pen
-6-
演習
プログラム例 1~例7を作成し、実行しなさい。
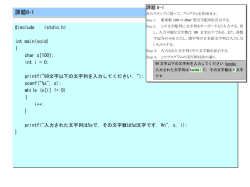
課題 9
kadai9-1 以下のプログラムを作成、実行し、結果について考察しなさい。提出物はソースファイ
ルを印刷したものである。その考察を印刷した余白に書くこと。
#include <stdio.h>
int main(void)
{
char a[] = {'T', 'A', 'K', 'E'};
printf("%s\n", a);
return 0;
}
kadai9-2 以下のプログラムを作成、実行しなさい。また、gets を scanf に変えたものを作成し、
その際に起こる問題を考察しなさい。考察は印刷物の余白に書くこと。
#include <stdio.h>
int str_length(char a[]);
int main(void)
{
char str[100];
int length;
printf("英文を入力して下さい:");
gets(str);
length = str_length(str);
printf("文字列の長さは%dです\n", length);
return 0;
}
int str_length(char a[])
{
int i;
for(i = 0; a[i] != '\0'; i++)
;
// '\0'が出現するまでiをカウントアップ
// 何もしない
return i;
// for文を抜けた後のiが文字列の長さになる
}
提出日:課題 9 は続きがあるので、後で指定する。
-7-
基数について
数値を表現する際に、各桁の重み付けの基礎として用いる数を「基数」と呼ぶ。私たちが一般的
に使用している 10 進数の場合、右から順に「1 の位」
「10 の位」
「100 の位」というように 10 倍ご
とに桁が繰り上がるため、
「基数は 10」となる。同様に、2 進数、8 進数、16 進数の基数は、それ
ぞれ 2、8、16 となる。例えば 2 進数の場合、右から順に「1 の位」
「2 の位」
「4 の位」
「8 の位」の
ように 2 倍ごとに桁が繰り上がる。ここで、10 進数の「100」を 8 桁の 2 進数で表すことを考える。
10 進数を 2 進数へ変換するには、10 進数で表現された数値を 2 進数の基数「2」で割っていく。割
り切れれば 0 を、割り切れなければ余りの 1 を記入し、その商をまた 2 で割っていく。
2
2
2
2
2
2
2
) 100
) 50 ……0
) 25 ……0
) 12 ……1
) 6 ……0
) 3 ……0
) 1 ……1
0 ……1
並べる順番
商が 0 になったところで、余りを下から並べる。並べると「1100100」となる。ここでは、8 桁
と指定されていたので、一番左に 0 を付けて、
「01100100」である。余りを並べる順番(下から)
に気を付けること。
バイトとビット
人間は 10 進数を使うが、コンピュータ内部では 2 進数が使われている。C 言語では 10 進数の他
に、8 進数と 16 進数が利用できるが、ビット単位での演算を行いたいときには、2 進数との対応が
つきやすい 16 進数が良く利用される。それぞれの対応は、以下の表のようになる。
10 進数
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2 進数
0
1
10
11
100
101
110
111
1000
1001
1010
1011
1100
1101
1110
1111
10000
10001
10010
10011
10100
16 進数
0
1
2
3
4
5
6
7
8
9
a
b
c
d
e
f
10
11
12
13
14
11111111
ff
1111111111111111
…
…
…
65535
…
…
…
255
ffff
…
…
…
基数を変えた場合の整数の表し方
以下に要点を述べる。
-8-
・2 進数の 1 桁を 1 ビット(bit)と言う。これで、0 と 1 の整数を表すことができる。
・2 進数の 8 桁、即ち 8 ビットで、1 バイト(byte)になる。これは、10 進数だと、
0~255 までの整数を表すことができる。16 進数だと、0~ff までの整数を表せる。
・2 バイトの場合、10 進数だと、0~65535 までの整数を表せる。16 進数だと、
0~ffff までの整数を表せる。
実際のコンピュータの世界では、バイトにキロバイトとかメガバイトとかの補助単位がつく。こ
れは、自然科学で使われる補助単位と少し異なるので、注意が必要である。
キロ
KB
メガ
MB
ギガ
GB
210 1024 バイト
2 20 1048576 バイト
230 1073741824 バイト
アスキーコード
アスキーコード表を以下に表に載せておく。この表から数字(10 進数)を計算する方法は、次の
ようにする。
1. 対応する文字の上位 3 ビットの値を探す。
2. 次に下位 4 ビットを探す。
3. 対応する整数の計算を行う。計算方法は 16 ( 上位 3 ビット ) 16 ( 下位 4 ビット )
である。ただし、A=10, B=11,・・・, F=15 である。
1
0
具体的な例で表すと、大文字の'L'は、4C なので
161 4 160 12 76
となる。
0
1
2
3
4
5
6
7
8
9
A
B
C
D
E
F
0
NUL
SOH
STX
ETX
EOT
ENQ
ACK
BEL
BS
HT
LF
VT
FF
CR
SO
SI
1
DLE
DC1
DC2
DC3
DC4
NAK
SYN
ETB
CAN
EM
SUB
ESC
FS
GS
RS
US
2
SP
!
"
#
$
%
&
'
(
)
*
+
,
.
/
3
0
1
2
3
4
5
6
7
8
9
:
;
<
=
>
?
4
@
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
5
P
Q
R
S
T
U
V
W
X
Y
Z
[
¥
]
^
_
6
`
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
7
p
q
r
s
t
u
v
w
x
y
z
{
|
}
~
DEL
アスキーコード表:表の縦の列に割り振っている数字(0~7)は上位 3 ビットで、横の列に割り振っ
ている英数字(0~F)は下位 4 ビット を表す。表中の 2 文字以上のものは文字ではなく、制御コー
ドと呼ばれる特殊文字である。
-9-
© Copyright 2026 Paperzz