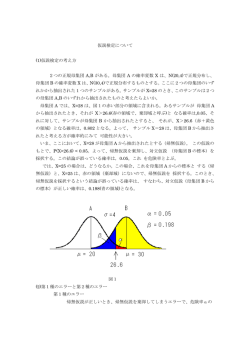
統計学Ⅱ(2016) 10章 1 母集団と標本 10章 標本抽出と標本分布 1.母集団と標本 (1) 視聴率調査 (2) 有限母集団と無限母集団 (3) データと母集団 2.標本抽出法 (1) 全数調査と標本調査 (2) 無作為抽出と有意抽出 (3) 単純無作為抽出法 (4) 層別抽出法 (5) 多段抽出法 (6) 系統抽出法 (7) その他の抽出法 3.標本平均 X の標本分布 (1) 標本平均の標本分布の例 (2) 標本平均 X の標本分布の平均 (3) 標本平均の標本分布の分散 (4) 有限母集団からの標本平均 X の 標本分布 教科書 224-231ページ 4.統計量の標本分布と比率への応用 (1) 標本分布の考え方 (2) 統計量とパラメータ,推定量と推 定値 (3) 標本比率の標本分布 (4) 標本比率の標本分布の平均と分 散 5.中心極限定理 (1) 母集団分布が正規分布の場合 (2) 中心極限定理 (3) 中心極限定理の応用 (1) 視聴率調査 名古屋地区である番組をみた人がどのくらいの割合 かを表す 例:ある番組の視聴率が20%であった 名古屋地区の20%の人が,その番組を見ていた ⇒? 6. t 分布 (1) t 統計量とt 分布 (2) t 分布表 7.歪度統計量と尖度統計量の分布 ◆ ◆ 自分は調査されていない 名古屋地区に住んでいる人すべてを調査してない 参考:視聴率調査は:ビデオリサーチによる http://www.videor.co.jp/index.htm 視聴率調査の対象 視聴率調査のしくみ 人 名古屋地区全体(愛知,岐阜,三重の大部分) .... .... ... .... ... .. .. .... ..... ... .... .... .. .... ... .. ..... ... ... ... 調査世帯 (600世帯) 標本抽出 .... .... ... .... .. . .. 名古屋市 岐阜県 2,263,894 1,021,227 2,080,773 737,151 三県合計 20%の視聴率 愛知県の30市6郡7町,岐阜県の14市4郡4町,三重県の5市1郡4町 対象は約375万2千世帯(約922万2千人) 600 0.00016 0.016% しか調査していない 3752000 抽出率 母集団と標本 費用,時間,労力・・・ 標本 (sample) (2) 有限母集団と無限母集団 母集団 (population) 本当にしりたい対象(ex.視聴率の名古屋地区全体) 通常は,調査不可能 実際に知ることができる対象(ex.600世帯) 特定の調査対象を何らかの基準によって選ぶ ほとんどの統計調査は,標本調査 標本から得られた結果=データ 母集団の大きさ:N 標本の大きさ(データの個数):n 視聴率調査・・・母集団の大きさNは有限 ⇒有限母集団 母集団から,どのように標本を選ぶか 標本抽出法 (10章) 標本の結果から,母集団を情報をどのように予想するか 統計的推論:推定 (11章),(仮説)検定 (12章) 全数調査をすれば,母集団の情報を知ることができる 無限母集団 母集団の大きさNが無限 ◆ 標本調査における課題 704,607 資料:総務省「平成22年国勢調査」 あくまでも調査した 本当に知りたいが視聴率(わからない) 世帯の20% 1,854,724 11,228,891 4,144,501 視聴率の調査対象エリアは,3県のすべてではない ?% 世帯数 7,410,719 2,933,802 三重県 推定 口 愛知県 ◆ サイコロで1の目が出る確率を推定する ある工場で生産される電球の寿命時間の平均を推定する Nが有限であっても, Nが十分大きければ無限母集団と みなす 第1章(14-15ページ)参照 1 統計学Ⅱ(2016) 10章 統計学の基本的な考え方 2 標本抽出法 教科書 231-238ページ データ=母集団から抽出された標本とみなす 実際に標本抽出されたデータ そうでないデータ (1) 全数調査と標本調査 全数調査(センサス) 視聴率,失業率… ◆ 母集団全体を調査する 実施はむずかしい 例:総務省「国勢調査」・「経済センサス」 ◆ GDP,株価,為替レート,試験の得点・・・ ◆ ※ このようなデータも母集団からの標本とみなす (母集団を想定する) cf. 例題10.1 標本調査 標本調査の例 関東・関西・名古屋地区:600世帯(名古屋地区は以前は250世帯) 九州,札幌,仙台地区など:200世帯 抽出される標本 母集団を代表するものでなければならない ⇒特定の集団に偏った標本はよくない 例 ◆ 視聴率調査で,特定の年齢層だけを標本に選ぶ ◆ 街頭インタビュー ◆ 大統領選挙の例・・・ 失業率:総務省「労働力調査」 (2) 無作為抽出と有意抽出 視聴率調査 母集団:全国の15歳以上人口(約1億1千万人) 標本:約10万人 家計の所得・貯蓄など:総務省「家計調査」 母集団:全国の約5018万世帯 (平成22年国勢調査による) =二人以上の世帯(3506万世帯)+単身者世帯(1512万世帯) 標本:約9000世帯 ◆ 母集団のすべてではなく,その一部を調査する ほとんどが標本調査 理由:データ=標本とみなすことによって様々 な統計的手法を適用することができる 費用,時間・・・ ⇒特定の人に偏らないように,標本をいかに抽 二人以上の世帯:8076世帯+単身者世帯:673世帯 出するかを考える その他ほとんどの調査(内閣支持率,様々なアンケート調査, 「民間給与実態統計調査」・・・) ランダムサンプリングと有意抽出 くじびきの原理で抽出 ⇒ランダム・サンプリング(無作為抽出法) 無作為(確率的)に標本を抽出 有意抽出(ランダム・サンプリング以外の抽出) 確率的に標本抽出するのではない 恣意的に標本を抽出 ◆ ◆ ◆ (3) 単純無作為抽出法 偏りのない標本をどのように抽出するか 街頭インタビュー,ヒアリング インターネットによる調査 調査対象を募集する(モニター募集など)・・・ 偏った標本なので,母集団の推定が効率的に行えない ランダム・サンプリングから得られた標本だと,標本から母 集団への推定がうまくいく 偏りのない標本を抽出する ⇒特定の人が選ばれやすくならないようにする ⇒どの標本も選ばれる確率が等しくなるように標本 を抽出する =くじびきの原理 ⇒ 単純無作為抽出法 (Simple Random Sampling) SRS,シンプル・ランダム・サンプリング 単にランダム・サンプリングと呼ぶこともある 独立性を確保できる 2 統計学Ⅱ(2016) 10章 (単純)無作為抽出の抽出方法 乱数の利用 1.母集団に番号をつける 2.母集団の番号ぶんだけのくじをつくる 3.よくかきまぜて,調査する数(標本の大きさ) だけくじをひく 4.選ばれた番号を標本として,調査対象とする 実際はくじのかわりに,乱数(表)が用いられる 乱数における数字 (ex. 234ページ 表10‐1) 数字の並び方に特定の規則はない ◆ 出やすい数字はない –1ケタの数:0‐9までの10個の数字の出てくる 頻度はほぼ同じ –2ケタの数:00‐99までの100個の数字が出て くる頻度はほぼ同じ 以下同様に,3ケタ,4ケタ・・・ ◆ 並びやすい数字はない – ex. 1のあとに2が出やすいなどはない (1のあとの数字は,どの数字もほぼ同じ頻度で出現 する) ランダム・サンプリングの例 乱数で同じ番号が出てきたら? (例)母集団400人から5人の標本を選ぶ 1. 母集団に 1,2,・・・,400の番号を振る 2. 乱数表の適当な箇所をスタート地点に選ぶ(サイコロを 振る,目をつぶって指をあてる・・・) ex.サイコロを2回振ったら5と3が出た ⇒5行目,3個目の数字からスタート 3. スタート地点から3ケタずつ数字を拾う 母集団の大きさが400で3ケタだから 401よりも大きい数字だったら飛ばす 400以下の数字が5個出てくるまで数字を拾っていく 192,035,(424),120,309,(928),133 Excelでの乱数発生: RAND関数,RANDBETWEEN関数 同じ番号が選ばれた場合の対処の仕方 1. 2回目(あるいはそれ以上)以降は飛ばす 重複を許さない抽出(非復元抽出) 2. 同じ番号の人は2人分とみなす 重複を許す抽出(復元抽出) どちらの方法でもよい ※ 有限母集団と無限母集団の項を参照 有限母集団における抽出: 復元抽出と非復元抽出の例 母集団=5人(有限母集団) 視聴率調査を考え,5人のうち3人が ある番組を見ていたとする ⇒母集団の視聴率=0.6 p 0 .6 2人の標本を抽出する 重複を許さない抽出(非復元抽出) 母集団 a b c d e ○ ○ ○ × × 1人目を抽出するとき,母集団の視聴率は0.6 もしbが選ばれたら,2人目を抽出するときの母集団視聴率は0.5 ⇒同一の母集団視聴率から標本を選べない 復元抽出と非復元抽出 簡単な例 重複を許す抽出(復元抽出)・・・無限母集団と同じ 1人目を抽出しても,母集団に戻して2人目を抽出する 常に同一の視聴率から標本を抽出でき,独立性も確保される(iid) 実際には重複を許さない抽出がとられることが多い(同じ 人は選ばない 理論的には重複を許す抽出の方が正しい 有限母集団における標本の選び方 同じ対象を重複して選んでもよい ⇒重複を許す抽出(復元抽出)・・・無限母集団と同じ 同じ対象を2度選ぶことはしない ⇒重複を許さない抽出(非復元抽出) 標本 ・ ・ 非復元抽出だと iid にならない 同一の母集団からの抽出 独立性 iid ⇒復元抽出の方が理論的には望ましい ただしNが十分大きければ,非復元抽出でも,iidと考える ことができる 3 統計学Ⅱ(2016) 10章 ランダム・サンプリングの問題点 (4) 層化抽出法(層別抽出法) ランダム・サンプリング・・・偏りのない標本抽出の基本 しかし,結果として,偏った標本となり得る (くじなので,何が起こるのかはわからない.ex.女子だけが選 ばれる) 母集団を代表する保障はない 母集団の完全なリストも必要になる ⇒ ランダム・サンプリングを若干修正した標本抽出法 が考えられている ☆ ☆ ☆ 層化(層別)抽出法 多段抽出法 系統抽出法・・・ 事前に母集団をいくつかのグループ(層) に分ける 各グループ(層)ごとにランダム・サンプリ ングを行う 標本の大きさは,母集団の各層の大きさ に比例させる ⇒母集団に関する事前の情報を利用する ※ 実際には,これらの方法がよく用いられている .... .... ... .... ... .. .. .... ..... ... .... .... .. .... ... .. ..... ... ... ... 層化抽出法におけるグループ(層) 層化抽出法 ランダムサンプリング ランダムサンプリング 母集団 ランダムサンプリング .... .... ... .... .. . .. ランダムサンプリング 標本 ex. 学生の通学時間調査 ・ 全学の男女比が8:2であれば ・ 200人の標本をとるとすると ⇒ 男160人,女40人の標本 分析の結果に大きな影響を与えると思われる主な属性で,母 集団をグループ分けをする 都市階級 地域 事業所規模(従業員規模) 性別 年齢・・・ 大きな影響を与えない属性は用いない 層は細かくしすぎない 例 総務省「家計調査」 ◆ • 結果として,偏った標本になることはない • しかし,純粋なシンプル・ランダム・サンプリングとは異なる 国税庁「民間給与実態統計調査」 ◆ 地域を先に抽出する(ランダム・サンプリングによる) ex.市町村の抽出⇒調査区の抽出 選ばれた地域の中で,ランダムサンプリングによって, 世帯・個人を抽出する 多段抽出法の利点 母集団に割り振られた番号を,一定の間隔で選 んでいく 例: 800人から20人を選ぶ →800÷20=40人に1人ずつ抽出する 調査地域が散らばらない ◆ 時間・費用などの面から効率的 母集団の完全なリストは必要ない 1~40, 41~80, 81~120, ・・・,761~800からそれぞれ 1人を抽出 最初の番号を,1から40の中から乱数で選択 ex.17 17,57,97,・・・,777を標本として抽出 より一般的に・・・ 例.総務省統計局「家計調査」 市町村の抽出→国勢調査の調査区を抽出→世帯を抽出 市町村の抽出は層化抽出 ⇒ 層化3段抽出 従業員規模によって,事業所を抽出 (6)系統抽出法 (5) 多段抽出法 県庁所在地,政令指定都市,都市階級と地域によって,市町村を 層別して抽出(都道府県はなく,県庁所在地) 間隔=母集団の大きさ÷標本の大きさ m N / n 最初の番号は乱数で選択(1~mより1つ選択=K) 選択された乱数に間隔を加えていく 系統抽出法=等間隔抽出法 系統抽出法の例 K , K m, K 2m, , K ( n 1)m 視聴率調査(ウェブサイト参照)・・・ 4 統計学Ⅱ(2016) 10章 教科書 238-244ページ (7) その他の標本抽出法 3 標本平均 X の標本分布 確率比例抽出法 RDD ・・・ 様々な標本調査法については, 島崎哲彦・大竹延幸編(2013) 『社会調査の実際』学文社 いずれの標本抽出法も,ランダム・サンプリングが基本に なっている N=100の母集団から大きさn=8 の標本を抽出 抽出される標本の組合せを考 える 重複を許す抽出 繰り返し標本を抽出すると,各 標本で標本平均を計算するこ とができる 60, 14, : 52 x 38.375 母集団 N=100 1, 2, 3, : : 99, 100 標本2 51, 5, : x 53.625 82 母集団 母集団分布 標本=データ x1, x2, : : xn X1, X2, : : Xn .... .... ... .... ... .. ... .... .... .. .... ... .. ..... ... ... ... X1の分布=母集団分布 X2 X2の分布=母集団分布 x 確率変数:X 1 , X 2 ,, X n 標本 ... . .. . .. 標本 ... . .. . .. ・ ・ ・ x 45 実現する前の確率 変数として,標 本平均を考える x X x 1 X1 X 2 X n n ・ ・ ・ X の標本分布 標本平均 X の標本分布の例 例 教科書練習問題3(262ページ) N=4の母集団(0,10,40,90)から n=2の標本を抽出(重複 を許す抽出) n=2 ・・・・・・ x1 実現値(データ): x1 , x2 , , xn ... . .. . .. N=4 X1 x 標本 標本200 58, 38, : 52 確率変数 X 標本 x1 , x2 . .. . xn 母集団 標本1 ⇒その分布を標本平均 X の標 表10‐2,図10‐3 本分布という .... .... ... .... ... .. ... .... .... .. .... ... .. ..... ... ... ... 標本抽出法=ランダム・サンプリングが基本 標本の結果から,母集団の情報をどのように 予想(推定)するか 標本分布という考え方をもとに推定などを行う 標本分布の イメージ (1) 標本平均の標本分布の例 (238‐241ページ) 知りたいのは母集団の情報 母集団から,どのように標本を選ぶか などを参考のこと 基本的な考え方:データ=母集団からの標本 x2 データx1, x2, ・・・,xnの背後に確率変数X1, X2, ・・・,Xnを考える(母集団) X1, X2, ・・・,Xnに共通の母集団分布を想定する(iid) 0 10 40 90 0,0 n=2 0,10 x 0 x 5 ・ ・ ・ ・ ・ ・ 5 統計学Ⅱ(2016) 10章 母集団分布と特性値(通常は未知) i x i -μ xi 1 2 3 4 合計 平均 2 (x i -μ ) 0 10 40 90 答. 母平均 μ=35 母分散 σ2=1225 母標準偏差 σ=35 分散 2 標準偏差 階級 0 - 20 20 - 40 40 - 60 60 - 80 80 - 100 合計 母集団分布 度数 2 0 1 0 1 4 母集団分布 3 2 1 0 20 40 標本平均の標本分布の平均と分散 X 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 合計 平均 0 5 20 45 5 10 25 50 20 25 40 65 45 50 65 90 X -35 -30 -15 10 -30 -25 -10 15 -15 -10 5 30 10 15 30 55 0 560 35 分散 標準偏差 標本平均の標本分布の平均は母平均に等しい 60 80 100 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 標本平均 X の標本分布の =母平均μ 平均=35 n 2 1225 2 母平均μ=35 母分散σ2=1225 母標準偏差σ=35 標本平均 0 10 40 90 0 10 40 90 0 10 40 90 0 10 40 90 0 5 20 45 5 10 25 50 20 25 40 65 45 50 65 90 標本平 X 均の標 本分布 階級 0 以上 - 20 未満 20 - 40 40 - 60 60 - 80 80 - 100 合計 度数 4 4 5 2 1 16 相対度数 0.25 0.25 0.3125 0.125 0.0625 1.00 標本平均の標本分布 6 標本平均の標本分布 0.4 0.3 4 0.2 2 0.1 0 0 20 40 60 80 100 20 40 60 80 100 X 標本平均 X の標本分布の 平均=μ(母平均) 分散=612.5 母分散σ2 母集団:0,10,40,90 →16通りの x 標本平均 X の標本分布 分散= 2 有限母集団(重複を許 さない抽出)の場合は 244ページ参照 (Nが大きければ同じ 結論) n 2 標準偏差= n n 標準偏差=24.75… 分散は母分散よりも小さい 平均すると,もとのデータよ り真ん中に集まる x1, x2,・・・, xn :iidデータ(ランダム・サンプリングによる ⇒ X1, X2,・・・, Xn :iid (互いに独立に同一の分布に従う) 標本平均の標本分布の平均 1 E ( X ) E ( X 1 X 2 X n ) n 1 E ( X 1 ) E ( X 2 ) E ( X n ) n 1 n n E( X1) E( X 2 ) E( X n ) 標本平均 X の標本分布の意味 x によって を推定する根拠を与える 1個1個の x は を当てることはできない (3) 標本平均の標本分布の分散 標本) 標本 0 0 0 0 10 10 10 10 40 40 40 40 90 90 90 90 母平均μ=35 母分散σ2=1225 母標準偏差σ=35 (2) 標本平均の標本分布の平均 標本番号 母集団:0,10,40,90 ( X )2 1225 900 225 100 900 625 100 225 225 100 25 900 100 225 900 3025 9800 612.5 24.75 標本平均の標本分布(無限母集団) 42=16通りの標本が考えられる 標本平均の標本分布の分散は,母集団分 布の分散より小さい 分散の大きさ 1 1 Var( X ) Var ( X 1 X 2 X n ) 2 Var( X 1 X 2 X n ) n n 1 2 Var( X 1 ) Var( X 2 ) Var( X n ) n 1 1 2 2 2 2 2 2 n 2 n n n Var ( X 1 ) Var ( X 2 ) Var ( X n ) 2 6 統計学Ⅱ(2016) 10章 標本平均の標本分布の特徴 (1):平均 実現した個々の x はμと等しくない しかし,X の標本分布の平均はμに等しい 一般的に 標本平均の標本分布の特徴 (2) :分散 x 個々の x は μ と等しくない →正確には μ を当てることはできない →全体としてみれば(平均すれば), X は μ をうまくあてている X の標本分布の分散は → X をμの推定値として用いる根拠を与える ※但し,実際には1つの標本, x が実現する 2 n →nを大きくすれば,分散は小さくなる 分散が小さくなると,実現する x は μに近づいていく Xの標本分布 X 教科書 245-250ページ 4 統計量の標本分布と比率への応用 標本平均の標本分布の特徴(3):分布の形 (1) 標本分布の考え方 標本平均,標本分散・・・ y h x1 , x2 ,, xn 母集団分布は左右対称の分布 標本平均の標本分布は左右対称になる 母集団分布は左右対称のきれいな形の分布をし ていなくても・・・ 標本平均の標本分布はほぼ左右対称になる 母集団分布 標本平均 X の標本分布 (2) 統計量とパラメータ,推定量と推定値 標本からある特性値を計算するための公式 統計量は確率変数 統計量の実現値y=h(x1, x2,・・・, xn) 母集団の特性値(本当に知りたいこと;未知) 母(集団)平均,母(集団)比率,母(集団)分散 推定量(estimator):パラメータを推定する ための統計量 確率変数ではない(既知) パラメータ 確率変数 推定値(estimate):推定量の実現値 確率変数ではない x1, x2,・・・, xn は X1, X2,・・・, Xn から一定の確率 で実現した Y=h(X1, X2,・・・, Xn)も確率変数で,確率分布を もつ=標本分布 (sampling distribution) パラメータと統計量の例 統計量: Y=h(X1, X2,・・・, Xn) 実現値(データ)の関数 データを実現させる確率変数を考える 母集団の情報 (未知) 母比率 p 母平均μ 2 母分散 母標準偏差 : 推定 パラメータ 母集団における特性値 (本当に知りたい値だが,未知) 確率変数 標本比率 X 標本平均 X 標本分散 S 2 標本標準偏差 S : 標本の情報 (既知):確率 変数の実現値 pˆ x s2 s 統計量 7 統計学Ⅱ(2016) 10章 比率と平均 1,0データの平均と分散 比率は,1 ‐ 0データの平均 例 コインの5回投げたら2回表が出た 表が出る比率(割合)=2/5=0.4 Xi:表が出たら1,裏が出たら0をとる変数 5回のうち2回表がでた⇒1,1,0,0,0 1 – 0データの平均: 1 1 0 0 0 2 (母)比率がpのとき 平均:p 分散:p(1-p)=pq , 5 5 , n ⇒標本比率は標本平均 X で表せる X X i n i 1 ただし,P ( X i 1) p, P ( X i 0) 1 p q Xiの平均=p Xiの分散=pq 標本比率の標本分布の平均と分散 ~標本平均の場合とほとんど同じ 0.36 0.36 0.16 0.16 0.16 1.2 0.24 p pq ex. p=0.8の場合, 分散=pq=0.8×(1-0.8)=0.8×0.2=0.16 標本番号 標本比率=標本平均 1 Xi ・・・ 1か0をとる確率変数 X i 0 1 ( x i p) 2 0.6 0.6 -0.4 -0.4 -0.4 0 分散 pがわかれば分散もわかる(パラメータは1つ) (3) 標本比率の標本分布 標本比率の標本分布 xi p 1 1 0 0 0 2 0.4 教科書 150ページ参照 したがって標本分布も比率と平均ではほとんど 同じ xi 1 2 3 4 5 合計 平均 0.4 比率 比率と平均は同じもの (ただし,q=1-p) i 平均=母平均=母比率 p 分散=母分散(pq)÷n 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 a a a a a b b b b b c c c c c d d d d d e e e e e 標本 データ a b c d e a b c d e a b c d e a b c d e a b c d e 合計 平均 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 標本比率 1 1 0 0 0 1 1 0 0 0 1 1 0 0 0 1 1 0 0 0 1 1 0 0 0 1.0 1.0 0.5 0.5 0.5 1.0 1.0 0.5 0.5 0.5 0.5 0.5 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 0.5 0.5 0.0 0.0 0.0 10.0 0.4 例:教科書練習問題4,263ページ 母集団 N=5 (1,1,0,0,0) 母比率 (平均) p=0.4 母分散 pq=0.4×0.6=0.24 ただし,q=1-p 標本 母集団 ※標本平均の 場合と同様 a b c p 0 .4 d e 標本比率 X の標本分布 ・ ・ ○ ○ × × × 14 平均=0.4 =母比率p 12 10 8 分散=0.12 母分散pq 6 4 2 0 0 標準偏差=0.34… 0.5 1 pq 0.6 0.4 n n 2 2 教科書 250-255ページ 5 中心極限定理 (4) 標本比率の標本分布の平均と分散 標本比率 X の標本分布の 平均=p(母比率) 分散= pq n 標準偏差= (1) 母集団分布が正規分布の場合 データ: iid データであること (q 1 p) pq n 母集団分布 X の標本分布 平均 分散 2 2 分布の形 正規分布 n 正規分布 8 統計学Ⅱ(2016) 10章 (2) 中心極限定理 標本平均 母集団分布が一般の場合 データ: iid データ nが大きい 分散 分布の形 X の標本分布の平均=μ,分散 n 正規分布 ? n n Z X ~N (0,1) n 条件: X1,X2,・・・,Xn:iid n:大きい 標本平均 X の標本分布 標本n ... . .. . .. 母集団N x x z n x x z n x z 標本n ... . .. . .. .... .... ... .... ... .. ... .... .... .. .... ... .. ..... ... ... ... 標本n ... . .. . .. 標本n ... . .. . .. X ・ ・ ・ x n データが独立に同一の分布から抽出され(iidデータ) 標本の大きさnが十分大きいとき 母集団分布がどのような形の分布でも, X Z n は標準正規分布N(0,1)で近似できる x z n x ・ ・ ・ の標本分布~ N ( , 2 n Z~N (0,1) ) n が大きければ,X は 正規分布 • 標本比率 X の標本分布 の 平均=p(母比率) N ( p, pq ) で近似 n できる X を基準化 Z Xp ~N (0,1) pq n 教科書 253ページ 中心極限定理 標本平均 X の標本分布 N ( , 母集団分布 2 n Zの分布 ) N (0,1) 0 (3) 中心極限定理の応用 標本比率に関する中心極限定理 pq 分散= n pq 標準偏差= n 2 標準偏差 →Zの平均は0,分散は1(標準偏差は1) また,X は正規分布にしたがうので,Zも正規分 布にしたがう=中心極限定理 2 2 母集団分布 中心極限定理の イメージ 平均 の基準化 X →基準化する Z n X の標本分布 母集団分布 X p.254 例題10.2 母集団 .... .... ... .... ... .. .. .... ....... . .... .... .. .... ... .. ..... ... ... ... 0.5% 2 4 2% 標本 n=25 .... .... ... .... .. . .. P ( X 0) P( X P( Z n 0 0 0 .5 2 25 n ) ) P( Z 1.25) 0.8944 9 統計学Ⅱ(2016) 10章 教科書 255-261ページ 6 t 分布 (1) t 統計量と t 分布 イメージ 母集団N Xi~N(μ,σ2) のとき iid X ~N (0,1) Z n ⇒ ただし,μとσは一般に未知 t 統計量の S2 1 n ( X i X )2 n i 1 .... .... ... .... ... .. ... .... .... .. .... ... .. ..... ... ... ... ⇒ σを計算可能な値で置き換える S S2 標本標準偏差S ⇒ 置き換えた値を T とする μを推定するため (nもn-1で置き換える) (11章で利用) X T S n 1 標本n ... . .. . .. X の標本分布 x 基準化 z 標本n ... . .. . .. z x x n 標本n ... . .. . .. x z 標本n ... . .. . .. ・ ・ ・ T : t 統計量 σをsで置き換え x n x z ・ ・ ・ N ( , 2 n ) x n t x s n 1 t x s n1 t x s n1 x t x s n 1 n ・ ・ ・ ・ ・ ・ Z~N (0,1) T ~ 自由度 n-1のt分布 t 分布の形状 t 統計量と t 分布 X t 分布は,自由度(データ数)によって形が変わる t 統計量 T S n 1 は,標準正規分布(0,1) ではなく,自由度m=n‐1の t 分布に従う t 分布では,標準正規分布より,0から離れた値 をとる確率が高い(スソの厚い分布) 左右対称の分布で,平均は0 Tm X S n 1 と書くこともある 自由度=n-1 E Tm 0 m m2 2 1 m2 Var Tm 自由度が大きくなると,t 分布は標準正規分布に近づく • t 分布:データが少ないとき(小標本)に利用される • データ数が多ければ,標準正規分布 N(0,1) を用いて 構わない( t 分布と標準正規分布で結果に大差ない) (2) t 分布表 (435ページ) 各自由度に対して, P(Tm< c)=0.95 などに対するcの値を与える 0.95 自由度によって分布の 形が変わるから この数字が t 分布 表に入っている 例 自由度10の場合 P(T<1.812)=0.95 P(T<2.764)=0.99 P(T<2.228)=0.975 a P(-2.228 <T<2.228)=0.95 10 統計学Ⅱ(2016) 10章 10 章 標本抽出と標本分布 練習問題 1.234 ページの表 10-1 の乱数表を用いて,シンプル・ランダムサンプリングにより 5000 人の中から 4 人の標本を抽出せよ.ただし,スタートする場所は,当日の月を列番号, 日の下一桁を行番号として用いよ. また,Excel の乱数の関数を利用して,同様の抽出を行え. 2.教科書の練習問題1(262 ページ) 3.教科書の練習問題2(262 ページ) .さらに「視聴率調査」 ,「家計調査」についても同 様の問いに答えよ. 4.母集団が 15,23,47,87 という4つの数字からなるとき,次の問いに答えよ. (1) 母集団の平均,分散,標準偏差を求めよ. i xi 1 2 3 4 合計 平均 x i -μ 2 (x i -μ ) 1 N 15 23 47 87 2 分散 標準偏差 N x i i 1 N 1 N ( x ) i 2 i 1 (2) この母集団から重複を許す大きさ 2 (n=2) の標本を抽出することを考える.このとき, すべての可能な標本を書き出し,それぞれの標本平均を求めよ.(2)の標本平均を度数分 布にまとめよ(階級は,0-20,20-40,40-60,60-80,80-100). (3) (2)の標本平均を度数分布にまとめよ(階級は,0-20,20-40,40-60,60-80,80-100). (4) (2)で求めた標本平均の標本分布の平均,分散,標準偏差を求めよ. (2) (3) 標本番号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 標本 標本平均 標本平均 0 以上 - 20 未満 20 - 40 40 - 60 60 - 80 80 - 100 合計 度数 11 統計学Ⅱ(2016) 10章 5.母集団が 8,12,24,44 という4つの数字からなるとき,次の問いに答えよ. (1) 母集団の平均,分散,標準偏差を求めよ. (2) この母集団から重複を許す大きさ 2 (n=2) の標本を抽出することを考える.このとき, すべての可能な標本を書き出し,それぞれの標本平均を求めよ. (3) (2)の標本平均を度数分布にまとめよ(階級は,0-10,10-20,20-30,30-40,40-50). (4) (2)で求めた標本平均の標本分布の平均,分散,標準偏差を求めよ. i 1 2 3 4 合計 平均 xi x i -μ 2 (x i -μ ) 8 12 24 44 分散 標準偏差 (3) 標本平均 0 以上 - 10 未満 10 - 20 20 - 30 30 - 40 40 - 50 合計 度数 (2) 標本番号 標本 標本平均 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 6.母集団が 30,50,60,70,90 という 5 つの数字からなるとき,問5と同様の問いに答えよ (階級は,0-20,20-40,40-60,60-80,80-100). 7.母集団の大きさを N=4,標本の大きさを n=2 とし,母比率を 0.25 とする(たとえば, 視聴率調査を考え,4 人を a~d とすると,a がある番組をみた,b,c,d がみていないとする). みた場合に 1,みていない場合に 0 という数値を与えるものとする. (1) 1,0 で表された母集団の平均と分散を求めよ. (2) この母集団から重複を許す大きさ 2 (n=2) の標本を抽出することを考える.このとき, すべての可能な標本を書き出し,それぞれの標本比率を求めよ(次ページ). (3) 標本比率を度数分布にまとめよ. (4) 求めた標本比率の標本分布の平均,分散,標準偏差を求めよ. 12 統計学Ⅱ(2016) 10章 標本番号 標本 標本比率 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 標本比率 0.0 0.5 1.0 合計 度数 8.母集団の大きさを N=5,標本の大きさを n=2 とし,母比率を 0.6 とする.この母集団 から重複を許す大きさ 2 (n=2) の標本を抽出するとき,問7と同様の問いに答えよ. 9.問4について,この母集団から重複を許さない大きさ 2 (n=2) の標本を抽出することを 考える.このとき,問4(2)~(4)と同様の問いに答えよ. 10. 問7で重複を許さない大きさ 2 (n=2) の標本を抽出するとき,問7の(1)~(4)と同様の 問に答えよ. 11. 教科書の練習問題6(263 ページ) 12. 教科書の練習問題7(263 ページ) 13. 教科書の練習問題8(264 ページ) 14. 教科書の練習問題9(264 ページ) 15. 次の値を満たす a を求めよ.ただし,T は自由度 8 の t 分布に従うとする. (1) P (T a ) 0.95 (3) P (T a ) 0.99 ( 2) P ( a T a ) 0.95 (4) P ( a T a ) 0.99 16. T が自由度 5 の t 分布に従う場合,16 と同じ問いに答えよ. 17. 教科書の練習問題 10(264 ページ) 18. 次の確率を求めよ.ただし,T は自由度 12 の t 分布に従うとする. (1) P (T 1.782) ( 4) P ( 2.179 T 2.179) (2) P (1.782 T 1.782) (5) P (T 3.055) (3) P (T 2.179) (6) P (3.055 T 3.055) 13 統計学Ⅱ(2016) 10章 19.次の( )に最もよくあてはまる記号(または数式),語句,数値を答えよ.ただし, 無限母集団から大きさ n の標本(データの個数が n ,ただし n 2 )を互いに独立に無作為 に抽出することを考え,母平均を ,母分散を 2 ,母比率を p ,q 1 p ,標本平均を X , 2 標本分散を S とする. (1) ある番組の視聴率調査を5人に対して行い,その番組を見ていたら 1,見ていなか ったら 0 という数値を与えるものとする.その結果,0,0,0,1,0 というデータが得ら a )%である.また,5 個のデータの平均は( れた.このとき視聴率は( 分散は( (2) b ), c )である. 標本平均 X の標本分布の平均は( d ),分散は( e ),標準偏差は( f ) である. (3) 標本平均 X を基準化した Z 標準偏差は( (4) X の分布の平均は( g ),分散は( h ), n i )である. n が十分大きければ, (3)の Z は( j )分布で近似することができる.これは( k ) 定理と呼ばれる. (5) 標本比率 X の標本分布の平均は( l ),分散は( m ),標準偏差は( n ) である. (6) 標本比率 X を基準化した Z 準偏差は( (7) X (l ) の分布の平均は( (n) ),分散は( p ),標 q )である. 母集団分布を正規分布とするとき, 従う.また( o X は自由度( r )の( s )分布に S n 1 s )分布は,自由度が大きい場合, ( t )分布で近似することが できる. (8) ( u )とは,すべての標本が等しい確率で抽出されるような標本抽出法である. (9) ( v )とは,母集団を地域,都市階級,従業員規模,年齢などでグループ分けし, それぞれのグループで( (10) ( w u )によって標本を抽出する方法である. )とは,母集団に割り振られた番号を等間隔で選び,標本を抽出する方法 である. 14
© Copyright 2026 Paperzz