Paper
zz
Explore Categories
Log in
Create new account
No category
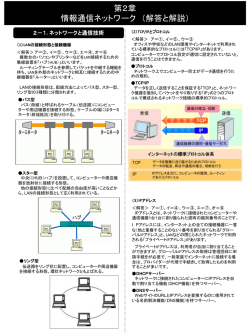
長距離高速通信のための TCP 性能改善技術の動向
Download
Report
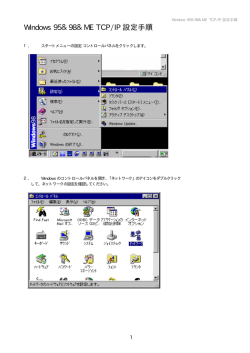
Windows 95&98&ME TCP/IP 設定手順
準2級解答-見本(PDF
Travelport Smartpoint 仕様書
IPv6対応 組み込み向けTCP/IPプロトコルスタック
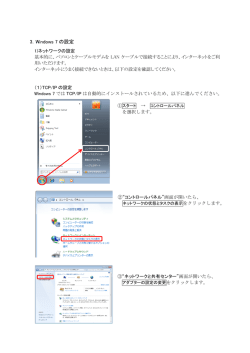
ネットワーク設定
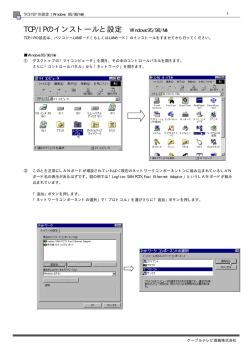
TCP/IPのインストールと設定 Windows95/98/Me
「流通システム開発センター」に申請し
Datataker データロガー DT80
PDF: 858 kB - セイコーソリューションズ株式会社
NSM10ご利用にあたって - NetSHAKERシリーズサポート
© Copyright 2026 Paperzz
About Paperzz
DMCA / GDPR
Report