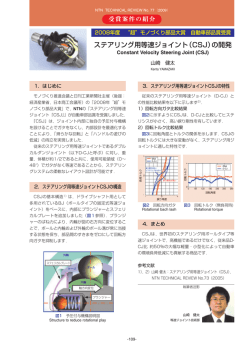
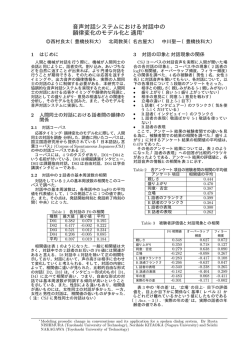
特集 学生の研究活動報告−国内学会大会・国際会議参加記 14 第 2 回若手研究者フォーラム∼音声言語処理について語ろう∼ に参加して 久 木 一 平 Ippei HISAKI 情報メディア学専攻修士課程 2年 従来の音響モデル,言語モデルをそのまま使用して 1.はじめに も高い認識精度が得られない可能性が高い.このよ 私は,2011 年 3 月 5 日から 2011 年 3 月 6 日まで うな背景に基づき,小学校授業音声に含まれる話し 静岡県にある熱海ニューフジヤで行われた「第 2 回 言葉表現と子ども向け表現の言語的特徴をモデル化 若手研究者フォーラム∼音声言語処理について語ろ するための言語モデルについて研究を行う. う∼」に参加しました.私は,「小学校授業の音声 認識の研究」という題目でポスター発表を行いまし 4.音声認識用言語モデルの学習データ 話し言葉表現と子ども向け表現をモデル化するた た. めに,話し言葉表現には日本語話し言葉コーパス 2.研究概要 (CSJ)を,子ども向け表現には子ども向けの Web 近年,大学といった高等教育では音声を保存した サイト(子どもコーパス)を用いた.日本語話し言 上で字幕や話者情報などのメタデータを付与して保 葉コーパスは日本で利用できる大規模な話し言葉コ 存・活用する音声ドキュメント処理の研究が盛んに ーパスである.子ども向けの Web サイトには「NHK 行われている.一方で,学問の基礎を学ぶ初等教 週間こどもニュース」と「Yahoo! きっず」を用い 育,特に小学校において,ICT を利用した教育の導 た.「NHK 週刊こどもニュース」からはサイト内の 入が推進されている.しかし,音声ドキュメント処 「ニュースまるわかり」および「とことんシラベタ 理に基づく教材作成などの試みはほとんど行われて ーズ」を対象に 2006 年 1 月から 2010 年 12 月末ま いない.本研究では,小学校授業音声を対象とし, でのデータを収集し,「Yahoo! きっず」からはサイ 音声ドキュメント処理の重要な基礎的技術である音 ト内の「Yahoo! きっずニュース」を対象に 2010 年 声認識について研究を行う.具体的には,小学校授 9 月から 2010 年 12 月末までのデータを収集した. 業の言語的特徴のモデル化,つまり言語モデルの学 習について研究を行う. 5.語彙の設定 はじめに小学校授業の音声認識のための語彙につ 3.小学校授業の特徴 いて検討を行う.13 件の授業を対象に適切な語彙 小学校授業は子どもが理解できるようにすすめら を検討した.まず,小中学校での教育上で基本とな れるため,子どもに馴染みがない語は基本的に使用 る語彙を集めた『新阪本教育基本語彙』を検討し されず,教師の発話スタイルは自発的な話し言葉で た.本研究では小学校低学年と小学校高学年のラベ あり,呼びかけや確認が多い傾向がある.これまで ルがつけられたものについて検討した.小学校低学 の話し言葉の音声認識の研究が対象としていた大人 年の語彙サイズは 4047 語であり,未知語率は 25.21 向けの音声とは言語的にも音響的にも異なるため, %であった.小学校高学年の語彙サイズは 9002 語 ― S-75 ― であり,未知語率は 19.70% であった.話し言葉表 現および子ども向け表現が多数カバーされていない 6.言語モデルの作成 前章で述べた語彙に基づき言語モデルを学習す ため,未知語率が高くなった. 次に,子どもコーパスについて検討した.収集し る.学習データには子どもコーパスと CSJ を使用 た単語から異なる単語を抽出し,収集したデータに した.さらに,各コーパスで学習した言語モデルを 2 回以上出現するもののみを用いて語彙を作成し 確率ベースで混合することで混合言語モデルを作成 た.語彙サイズは 9902 語であり,未知語率は 8.94 した.言語モデルは 13 件の授業に対するテストセ %と新阪本教育基本語彙より低い値であるが,話し ットパープレキシティで評価した.表 1 に各言語モ 言葉表現がカバーされていないため十分な未知語率 デルのテストセットパープレキシティを示す.表 1 でないと考えられる. より,混合することで大幅にテストセットパープレ 次に,CSJ について検討した.出現頻度が一定回 キシティを改善できることがわかる.これは子ども 以上の単語を選択して語彙を作成した.出現頻度が コーパスによる子ども向け表現のモデル化と CSJ 59 回未満の単語を使用しないことで語彙サイズが による話し言葉表現のモデル化ができていることが 約 5000 語であり,未知語率は 7.18% であった.579 わかる. 回未満 の 単 語 を 使 用 し な い こ と で 語 彙 サ イ ズ が 語彙サイズによらず,CSJ による言語モデルと子ど 1000 語であり,未知語率は 18.14% であった.出現 もコーパスによる言語モデルの混合比が 7 : 3 のと 頻度を 579 回以上のものにしても未知語率が 2 割程 きに,最も低いパープレキシティであった. 度あり,小学校授業で用いられる語の多くは CSJ で学習可能と考えられる. 表1 テストセットパープレキシティ 最後に,各コーパスから作成した語彙を混合し, 混合割合 言語モデル用の語彙を作成し,各語彙の未知語率を 調べた.図 1 に未知語率と語彙サイズの関係を示 CSJ:子ども 5k 20 k 0 : 10 467.8 724.5 6:4 186.9 277.0 7:3 184.8 275.4 8:2 185.3 277.7 10 : 0 352.51 542.32 子どもコーパス す.本研究では従来の新聞読み上げの音声認識タス クに習い,語彙が 5000 と 20000 程度で語彙を作成 混合言語モデル し,音声認識用の言語モデルを作成する.本研究で は,5000 程度の場合には CSJ のみの語彙を使 用 語彙サイズ CSJ し,20000 程度の場合には未知語率が低い CSJ と 子どもコーパスからの語彙を使用する. 7.まとめ 小学校授業の音声認識のために言語モデルを検討 した.CSJ を用いた話し言葉表現のモデル化と子ど も向け Web サイトを用いた子ども向け表現のモデ ル化の効果を示した. 8.おわりに 今回,ポスター発表を行いました.研究の参考と なる意見を多く頂くことができ,今後も頑張って行 図1 語彙サイズとテストセット 13 件の未知語率 きたいと考えています. ― S-76 ―
© Copyright 2026 Paperzz