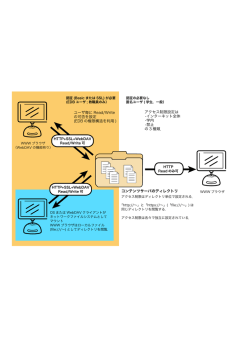
分散ストレージを用いた 実行環境とデータの分離 TIS 株式会社 2016/02/24 License This Document is licensed under a Creative Commons Attribution 4.0 International Public License. License Summary: http://creativecommons.org/licenses/by/4.0/ 1. はじめに .................................................................................................................. 5 2. 背景 ......................................................................................................................... 6 2.1. Blue Green Deployment................................................................................. 6 2.1.1. 2.2. Blue Green Deployment のメリット・デメリット .................................. 6 Immutable Infrastructure ............................................................................. 7 2.2.1. Immutable Infrastructure のメリット・デメリット ............................... 7 3. 課題 ......................................................................................................................... 8 4. 検証の目的 ............................................................................................................... 8 5. 分散ストレージを用いた実行環境とデータの分離 ................................................... 9 5.1. 分散ストレージ ............................................................................................... 9 5.2. 分散ストレージを用いたデータ分離の概要 ..................................................... 9 6. 比較検証するソフトウェア .................................................................................... 10 6.1. DRBD9 ......................................................................................................... 10 6.1.1. 概要と特徴 ............................................................................................. 10 6.1.2. アーキテクチャ ...................................................................................... 10 6.2. GlusterFS ..................................................................................................... 12 6.2.1. 概要と特徴 ............................................................................................. 12 6.2.2. アーキテクチャ ...................................................................................... 12 6.3. Ceph ............................................................................................................. 13 6.3.1. 概要と特徴 ............................................................................................. 13 6.3.2. アーキテクチャ ...................................................................................... 13 6.4. 3 製品の機能比較 .......................................................................................... 14 7. 検証内容 ................................................................................................................ 15 7.1. 運用環境切り替え検証................................................................................... 15 7.1.1. 想定する運用フロー ............................................................................... 15 7.2. 拡張性検証 .................................................................................................... 17 7.3. 耐障害性検証................................................................................................. 17 7.4. 性能検証 ........................................................................................................ 18 7.4.1. ファイルシステムへの Read/Write 性能検証 ......................................... 19 7.4.2. PostgreSQL の実行可能トランザクション数 ......................................... 20 8. 環境情報 ................................................................................................................ 21 8.1. ハードウェア環境.......................................................................................... 21 8.2. OS 情報 ......................................................................................................... 21 8.3. ソフトウェアのバージョン情報 .................................................................... 21 8.4. 各ソフトウェアの検証時の基本構成 ............................................................. 22 9. 検証結果 ................................................................................................................ 24 9.1. 運用環境切り替え検証................................................................................... 24 9.1.1. DRBD9................................................................................................... 24 9.1.2. GlusterFS .............................................................................................. 25 9.1.3. Ceph....................................................................................................... 26 9.1.4. 3 つのストレージを比較した考察 ........................................................... 28 9.2. 拡張性検証 .................................................................................................... 29 9.2.1. DRBD9................................................................................................... 29 9.2.2. GlusterFS .............................................................................................. 29 9.2.3. Ceph....................................................................................................... 30 9.2.4. 3 つのストレージを比較した考察 ........................................................... 31 9.3. 耐障害性検証................................................................................................. 32 9.3.1. DRBD9................................................................................................... 32 9.3.2. GlusterFS .............................................................................................. 35 9.3.3. Ceph....................................................................................................... 38 9.3.4. 9.4. 3 つのストレージを比較した考察 ........................................................... 40 性能検証 ........................................................................................................ 41 9.4.1. ファイルの Read / Write 性能 ................................................................ 41 9.4.1.1. 実データの位置の違いによる性能変化 ................................................ 41 9.4.1.2. 台数拡張による性能変化 ..................................................................... 47 9.4.1.3. 非同期並列数による性能変化 .............................................................. 52 9.4.2. 分散ストレージ上の PostgreSQL ........................................................... 56 9.4.2.1. 実行トランザクション総数 ................................................................. 56 9.4.2.2. 台数拡張による実行トランザクション総数の変化 .............................. 58 9.4.3. 性能検証全体の考察 ............................................................................... 60 10. まとめ .................................................................................................................. 61 1. はじめに 近年、Blue Green Deployment や Immutable Infrastructure という、本番環境への修正・ 変更を本番環境に対して直接行わない運用の考え方が注目されている。特に、Immutable Infrastructure は、本番環境の構築をコード化することで自動化して、修正・変更点を適用 した環境が容易に作成できるようにすることで、修正・変更適用前の環境の入れ替え・破 棄できるようになり、環境の破棄と生成が容易であるクラウド上での運用に向いている。 Immutable Infrastructure を実現した運用では、本番環境を止めずに新しい環境のテスト ができる、障害復旧が容易である、テスト環境と本番環境の差異を無くす、などのメリッ トがある。 しかし、Immutable Infrastructure は変更の度に新しい環境を構築しているため、log や DB などの、継続利用したいデータが存在する場合はデータを新しい環境に移行する必要が ある。 この問題を解決する方法として、継続利用したいデータを共有ディスク上に格納して、 本番環境とデータを分離するという方法が考えられる。また、データ共有の方法として分 散ストレージが注目されている。しかし、Immutable Infrastructure と分散ストレージを 組み合わせた運用方法や、運用上の課題などは現在明らかにされていない。 この文書は、分散ストレージの性能・拡張性・耐障害性などの実運用上の課題を Immutable Infrastructure をユースケースとして検証を行い、結果をまとめたものである。今回、分散 ストレージを実現する OSS として DRBD9、GlusterFS、Ceph の 3 種類を用いて比較検 証した。 2. 背景 運用中 ver.1 2.1. Blue Green Deployment Blue Green Deployment は、同じ環境が構築された Blue と Green という 2 つの環境を用意して、本番環 ルーター ユーザ 待機中 1 境を修正・変更の適用された環境へルータなどを用い ルーター ユーザ 2 Blue 環境 修正を反映する 確認を行う。Blue 環境の動作確認後、ルータによって、 ルータで運用環境 を切り替える ユーザのリクエストを受け付ける運用環境を Green 環 境から Blue 環境へ切り替えて、更新が反映された Blue 環境での運用を始める(図 1)。 もし、動作確認では見つからなかった予期せぬ不具 ver.2 Green 環境 ver.1 ルーター ユーザ 3 図1 Blue 環境 ver.2 合が、Blue 環境で本番環境に昇格後発覚した場合は、 以前に稼働していた Green 環境に切り戻すことが可 ver.1 ver.1 Green 環境が本番環境で運用中に、修正・変更があ く、待機している Blue 環境に変更を適用して、動作 Blue 環境 Green 環境 て切り替える運用の考え方である。 った場合は、稼働中の Green 環境に適用するのではな Green 環境 Blue Green Deployment 能である。 Blue Green Deployment を実現した運用を行うことで、動作テスト環境をそのまま本番 環境に昇格することが可能であるため、サービス停止時間を通常の運用よりも短くするこ とが可能である。また、障害復旧も今まで動いていた環境に切り戻すことでサービスを再 開することが可能であるため、障害復旧時間も短くすることができる。 この Blue Green Deployment を発展させたアプローチとして Immutable Infrastructure がある。 2.1.1. Blue Green Deployment のメリット・デメリット メリット サービスを運用しながら、本番環境へ影響を与えずに動作確認を行うことができ る。 サービスの停止時間を短くできる。 動作確認した新環境をそのまま本番環境にすることが可能 不具合が起こった場合、旧本番環境に戻すことが可能 デメリット 運用状況によっては、環境を二つ用意することになるため、単純に費用が二倍に なる。 待機している環境への更新方法が、通常の運用と同じであるため、自動化するこ とが難しい。 2.2. Immutable Infrastructure Immutable Infrastructure はマシンに環境を構築したら、ソフトウェア構成は直接変更を 行わないという考え方である。マシン内の環境に修正・更新が必要になった場合、別のマ シンに修正・更新を適用した新環境を一から構築する。その後、Blue Green Deployment のように新環境の動作確認ができたら、新環境を本番環境に昇格させる。旧環境は新環境 の動作確認が終了次第、破棄する。本番環境に異常が発生した場合は、新たに環境を構築 しなおすことで対応する。 この運用方法は、環境構築のコードによる自動化を前提としており、マシンの生成・破棄 を容易に行うことができるクラウド上で用いられることが多い。 従来 変更 変更 変更・修正があるたびに 現在の環境に反映させる マシンA 構築 更新 修正 時間 変更・修正があるたびに 変更を反映させた 新しい環境を再構築する 破棄 マシンA 再構築! 破棄 再構築! マシンB マシンC Immutable Infrastructure 変更後に不具合がなければ 以前の環境を破棄する 不具合があれば 前環境にロールバックする 図 2 Immutable Infrastructure 2.2.1. Immutable Infrastructure のメリット・デメリット メリット 実質的な運用コストが 1 環境のみですむ コード化による自動化が可能 環境再構築を毎回 1 から行っているため、環境構築の理解に属人性がない サーバの切り戻し・障害復旧が容易 動作確認した新環境をそのまま本番環境にすることが可能であるため、サービス の停止時間を短くできる デメリット 運用環境をマシンごと切り替えるため、DB などの継続的に利用したいデータが破 棄されてしまう。 データをバックアップするなどの対策が必要 3. 課題 Immutable Infrastructure を 実 現 し た 運 用 を 行 い た い 。 し か し 、 Immutable Infrastructure に DB などを対象とすると継続利用したいデータが破棄されてしまうとい う問題がある。この問題を解決する方法として、バックアップを取る方法がある。しかし、 バックアップ作成にデータ量によっては時間がかかる、バックアップを展開する新環境で のバージョン間互換を考える必要がある、バックアップ対象外のデータ(log 等)があるとそ れらのデータは消えてしまう、という問題が新たに考えられる。 問題を解決する別の方法として、継続利用したいデータを共有ディスク上に格納して、 本番環境とデータを分離するという方法が考えられる。そして、現在注目されているデー タ共有の方法として分散ストレージがある。今回、分散ストレージを使用しデータ共有を 行う方法を考える。 4. 検証の目的 Immutable Infrastructure を実現する運用で分散ストレージを用いて、実行環境とデ ータの分離を実現する。実現するにあたっての性能・実運用上の課題である以下の項目に ついて検証を行う。 分散ストレージを用いて、実行環境とデータの分離を実現することができるのか。 分散ストレージ環境の構築方法、および分散ストレージクラスタの拡張方法の確認 分散ストレージを利用した場合の、読み込み書き込み性能の確認。 分散ストレージの耐障害性・可用性の確認 5. 分散ストレージを用いた実行環境とデータの分離 5.1. 分散ストレージ 近年、ネットワークで接続された複数のストレージ群、もしくはストレージを持つ複数 のマシンを一つのストレージとして見せることができる、分散ストレージソフトウェアが 多数開発されている。これらのソフトウェアは、オープンソースで開発されているものも ある。分散ストレージは、拡張性に優れている。例えば、小さな構成で始めて、容量を増 やしたくなった場合、分散ストレージクラスタへマシンを追加して容量を増やすことが可 能である。分散ストレージは複数ノードで、1 つのストレージを構成するために、クラスタ 内のノードが 1 つ落ちても、別のノードに Replication されているデータを使うことが可能 であり、可用性が高いといえる。また、分散ストレージ上のデータは各ノードへ再配置可 能であり、負荷分散を行うことも可能である。 5.2. 分散ストレージを用いたデータ分離の概要 サービス実行環境と log や DB などのデータを分離する。構築した新環境が、分散ストレ ージをマウントすることで、本番環境で使用していた DB 等のデータを引き継ぎ、利用す ることを可能にする。分散ストレージを用いることで、1 ボリューム内のデータに複数ノー ドからアクセスすることができれば、本番環境切り替え時にサービス停止時間無しで移行 できると考える。 6. 比較検証するソフトウェア 比較検証を行う、ソフトウェアの詳細を示す。 6.1. DRBD9 6.1.1. 概要と特徴 DRBD (Distributed Replicated Block Device)は LINBIT 社によって開発された、ネット ワークを介して、ブロックデバイスのリアルタイムレプリケーションを実現可能としたソ フトウェアである。2015 年 6 月に DRBD の最新バージョンとしてリリースされたのが DRBD9 である。DRBD8 までは 1 対 1 の単純な Replication であったが、DRBD9 からは 複数ノード間の Replication が可能になった。さらに新機能としてマウント処理と連動した 自動昇格、などが実装されている。また、DRBD8 では実装されていなかった、local storage を持たず、他ノードにあるデータへアクセス可能なノードである drbd client が利用できる ようになった。DRBD は、GPLv2 ライセンスで提供されている。 6.1.2. アーキテクチャ DRBD9 を構成する要素を以下に挙げる。 Resource 特定の複製されたデータセットの総称。 Resource name と Volumes を持つ Volumes クライアントがアクセスできる仮想ボリューム。Volume 単 位でレプリケートされる drbdctrl volume DRBD の管理情報が格納されている Volume。 server node Resource が割り当てられているストレージノード。 client node drbdctrl volume を持つ、または drbdctrl volume と通信が できるサーバ。上記のノードと通信を行い、ファイル操作 を行う。 Primary role client node からのデータ読み書きを受け付ける node クラスタ内に基本的に一台のみ Secondary role Primary からの同期処理のみを受け付ける node DRBD client node drbdctrl block device mount drbdctrl server1 Secondary DRBD drbdctrl server2 Secondary server 0 Primary 図 3 DRBD9 の構成 DRBD9 は、 基本的には作成した Resource 内の Volumes(仮想ブロックデバイスとして見 える)へファイルシステムを構築してから使用する。ファイルシステム構築後、Volumes を マウントすることでデータの読み書きを行う。この時、マウントしたノードは Primary role である。Primary と Secondary の変更は、ノードが Volumes をマウント、アンマウント する時に変更され、Volumes をマウントしているノードが Primary となる。Primary が Volumes にデータを書き込むと、書き込んだ内容が Secondary のストレージに Replication される。Volumes からデータを読み込むときは、複数の Secondary から分散読み込みを行 うことができる。DRBD9 は Volumes 単位で Replication される。 6.2. GlusterFS 6.2.1. 概要と特徴 GlusterFS は、Red Hat 社により開発されている、ファイルベースの分散ファイルシス テムを実現したソフトウェアである。GlusterFS はオープンソース版だけでなく、商用版 の Red Hat Gluster Storage が発売・サポートされている。オープンソースの GlusterFS は LGPLv3 と GPLv2 のデュアルライセンスで提供されている。 6.2.2. アーキテクチャ GlusterFS を構成する要素を以下に挙げる。 Volume 各ノードのデータ格納領域を論理的に 1 つにまとめて、 1 ファイルシステムとして扱う仮想ボリューム Volume は以下の 4 種類を組み合わせて作成できる。 Distribute, Replicated, Striped, Disperse Brick 各ノードが持つデータ格納領域(ファイルシステム内のデ ィレクトリ)ファイルはこの Brick 内に格納される。 server node Brick を持つストレージノード。 client node 上記のノード内のデータにアクセスを行い、ファイル操作 を行う。 Volume GlusterFS は、各 Server node 上の複数 の Brick を論理的に一つにまとめることで、 Volume を作成する。作成された Volume は client node からマウントされることで 利用可能になる。 Volume に対しては GlusterFS client、 Server node client node nfs client or gluster client もしくは nfs client からアクセス可能であ Brick server 1 Server node る。 Volume は Brick のまとめ方により、複数 server 0 のタイプの構成を作成することができる。 Brick server2 4 つの volume タイプは以下のような特徴 を持つ 図 4 GlusterFS の構成 Distributed:保存したファイルが、Volume 内の Brick のいずれか一つに格納される。 Replicated:保存したファイルが、Volume 内の全ての Brick に格納される。 Striped:保存したファイルが、指定したストライプ数に分割・分散され格納される。 Disperse:保存したファイルが RAID5 のように分散配置される。 この 4 タイプをそれぞれ組み合わせることで自身の望む分散ストレージを構築可能である。 GlusterFS は Brick 単位で Replication される。 6.3. Ceph 6.3.1. 概要と特徴 Ceph は、Red Hat 社により開発されている、ブロック、オブジェクト、ファイルシステ ムの 3 種類のインターフェースに対応した分散ストレージを実現するソフトウェアである。 Ceph はオープンソース版だけでなく、商用版の Red Hat Ceph Storage が発売・サポート されている。オープンソース版の Ceph は一部のファイルを除いて LGPLv2.1 ライセンス で提供されている。 6.3.2. アーキテクチャ Ceph を構成する項目を以下に挙げる。 OSD(Object Storage Device) ファイルデータやメタデータをオブジェクトとして格納 される。 実際にデータの読み書きを行うプロセスは Object Storage Daemon (osd)という。 Monitor クラスタ全体を監視するプロセス。1 クラスタ内に 3 ノー ド以上稼働させて、冗長化することを推奨されている。 MDS(Meta Data Server) CephFS のディレクトリの階層構造などのメタデータを OSD に格納するプロセス。CephFS を使用する時に必要。 client node OSD、Monitor、MDS と通信を行い、ファイル操作を行 う。 Ceph は、ファイルデータやメタ データをオブジェクト単位で管理し ている。すべてのデータは,OSD 上に 格納される。Monitor はデータの場 所やクラスタ内のプロセスの死活情 報など、のクラスタの情報を管理し ている。 client node は、まず Monitor にク ラスタの情報を問い合わせてから、 OSD に対してデータの操作を行う。 Ceph では、ブロックデバイスとし 図 5 Ceph の構成 てアクセスできる CephRBD と Ceph が提供しているファイルシステムである CephFS の 2 種類のデータアクセス方法がある。 CephFS では、MDS を用いて、ファイルシステムの階層構想などのメタデータを OSD に 格納している。 6.4. 3 製品の機能比較 DRBD9、GlusterFS、Ceph の 3 点について、機能面で比較した表を以下に示す。 DRBD9 GlusterFS Ceph Linux Linux Linux クライアントの ブロックデバイス ファイルシステム、 ファイルシステム、 アクセス方法 nfs ブロックデバイス Replication 方 完全ミラーリング ボリュームの組み合わ オブジェクト単位 式 せによる Replication 単 ボリューム ブリック オブジェクト単位 稼働する OS 位 (ブロックデバイス) 同期単位 同期・非同期 同期・非同期 同期・非同期 選択可能 選択可能 選択可能 データ再配置 手動 手動 自動 最小構成 2台 2台 3 台(設定で変更可能) スナップショ 有 有 有 drbdmanage 複数のコマンド群 Ceph-deploy LINBIT クラスタスタッ Red Hat Gluster Storage Red Hat Ceph Storage ット 設定管理ツー ル 商用サポート ク 7. 検証内容 今回の検証では、運用環境切り替え検証、拡張性検証、耐障害性検証、性能検証の 4 つ の検証を行う。 7.1. 運用環境切り替え検証 分散ストレージを用いて、データと実行環境を分離した運用を行う。今回の検証では、 7.1.1 の 2 つの想定した運用フローに沿って、Immutable Infrastructure の考え方に基づい た運用における環境切り替えが実現可能かどうか検証を行う。 具体的には、PostgreSQL のバージョンを 9.4.4 から 9.4.5 へのアップデートを行い、そ の後不具合が見つかったという想定で切り戻しを行う。 運用フローを通して、以下の点の調査を行う。 異なるノード間でデータの引き継ぎが可能か。 引き継いだデータに対して、Read・Write 可能か。 環境移行時のサービス停止時間があるか。 7.1.1. 想定する運用フロー 今回想定するサービス運用環境は、一台のみで PostgreSQL が動いている。 今回の運用フローは、環境構築や切り替えを自動化するコードの作成は省略し、すべて手 作業で行った。 前提条件として以下の 4 点がある。 前提条件 1:DB サーバ 1 台、分散ストレージクラスタ 3 台の構成で運用している 前提条件 2:分散ストレージ上に継続使用したいデータが格納されている 前提条件 3:PostgreSQL の新旧のバージョン間には互換性がある 前提条件 4:運用中のノードは極力止めずに、新しい変更を適用済みのノードへ切り替える 今回の検証で想定した運用フローを以下に示す。 i. 変更を新環境に適用し正常な動作確認後、旧環境からの切り替えを行う運用 PostgreSQL のマイナーバージョンアップを行う。 運用中のノードはノード A、新しい環境を適用済みのノードはノード B とする。 ① ノード B 上に同一の環境を構築して更新を適用する。 ② ノード A で使用している分散ストレージボリュームを、ノード B にもマウントする。 ③ ノード B で分散ストレージボリューム上の、本番データに対して、読み込み・書き込 み可能がテストする。 ④ ノード B からデータが正常に読み込み・書き込み可能であることを確認後、ユーザの アクセス先をノード A からノード B に切り替える。 ⑤ サービス運用環境がノード B に移行後、問題がなければノード A のサービスを停止す る。 ⑥ ノード A の分散ストレージボリュームをアンマウントする。 ii. 本番環境に切り替え後に問題が発生した場合に、旧環境に切り戻しする運用 i. の作業の続きで、環境切り替え後に、ノード B からのデータ操作に異常が発見された 前提とする。また、旧運用環境のノード A は廃棄してないものとする。 ① ノード B で実行中のサービスを停止し、分散ストレージボリュームをアンマウントす る。 ② ノード A へ分散ストレージボリュームをマウントする。 ③ ノード A へ分散ストレージ上のデータを読み込み・書き込みが可能か確かめる。 ④ ノード A をサービス運用ノードに変更する。 ⑤ ノード B の環境を削除する。 7.2. 拡張性検証 分散ストレージにデータを書き込みながら、サービスの停止時間無しで、分散ストレー ジクラスタにノードを追加することができるか確認する。 今回の検証では、分散ストレージクラスタ 3 台の構成に、ノードを 1 台クラスタへ追加 する。ノード追加時には、分散ストレージクラスタ外から pg_bench を用いて、常時分散ス トレージへ書き込み続けている状態にする。 pg_bench が異常終了もしくは応答待ち状態になれば、分散ストレージへ新規ノードを追 加時に稼働中のサービスに影響が出たものとする。また、pg_bench が正常終了、且つ実行 トランザクションに漏れがなければ、リアルタイムに新規ノードの追加が可能と判断する。 7.3. 耐障害性検証 サービスが分散ストレージへデータを書き込み中に、障害が発生した時の影響と障害か らの復旧方法を検証する。検証環境の分散ストレージクラスタの構成台数は 3 台で行う。 今回は以下のケースで確認した。 NIC 障害 サービスが分散ストレージへデータを書き込み中に、分散ストレージクラスタ内のノー ドの NIC を落とした場合の検証を行う。NIC は ifdown コマンドを用いて落とす。NIC を 落とすノードのパターンとしては、以下のパターンを行う。 分散ストレージクライアントがマウントしている 1 ノード 前記以外の 1 ノード 全ノード 正常シャットダウン サービスが分散ストレージへデータを書き込み中に、分散ストレージクラスタ内の全て のノードが正常シャットダウンされた時の確認を行う。シャットダウンは shutdown コマ ンドを用いた。 1 ノード異常終了 サービスが分散ストレージへデータを書き込み中に、分散ストレージクラスタ内のノー ドが、電源を物理的に切断された時の確認を行う。異常終了させるノードのパターンは以 下のケースで確認した。 分散ストレージクライアントがマウントしている 1 ノード、 前記以外の 1 ノード 7.4. 性能検証 今回の性能検証では、分散ストレージに対してリアルタイムに数 MB~数十 GB 程度のフ ァイルが読み書きされる場合と、分散ストレージ上で PostgreSQL を動かしたした場合を ユースケースとして考える。 上記ユースケースのもとで、各ソフトウェアで構築したストレージに対して、ファイル システムへの Read/Write 性能と、 PostgreSQL の実行可能トランザクション数を計測した。 今回の検証では、本番環境も含めて分散ストレージクラスタを構築している時と分離し ている時の性能の違い(図 6)と、分散ストレージクラスタの台数拡張による性能変化につい て計測した(図 7)。 検証用 アプリケーション 検証用 アプリケーション 分散ストレージクラスタ 分散ストレージクラスタ 図 6 検証イメージ:ストレージクラスタ内・外での性能変化 検証用 アプリケーション 検証用 アプリケーション 分散ストレージクラスタ 分散ストレージクラスタ 検証用 アプリケーション 分散ストレージクラスタ 図 7 検証イメージ:台数変化による性能変化 今回行った性能検証時の、性能にかかわるパラメータの設定は、すべてデフォルト値で 行った。そのため、Ceph の Replication 数はデフォルト値の 3 で固定され、GlusterFS と DRBD9 は、台数拡張に伴って Replication 数が増えている。 7.4.1. ファイルシステムへの Read/Write 性能検証 分散ストレージ上へのファイル書き込みと読み込みについて計測を行った。 計測にはベンチマークツールの fio を使用した。 以下に、fio を用いてファイルサイズ 10GB の単一ファイルを読み込む時のコマンド例を示す。 fio -name=random-read_10G -ioengine=libaio ¥ -group_reporting ¥ --directory=/mnt/t_volume ¥ --output=/result/ random_read_10G.txt ¥ --rw=randread ¥ --iodepth=16 ¥ -numjobs=1 ¥ --direct=1 ¥ --bs=4k ¥ --runtime=180 ¥ --size=10g ¥ 今回の検証では、ファイルサイズを変更した場合と、非同期アクセス数を変更した場合の 検証を行った。 A) ファイルサイズ変更時 ファイルアクセス方法 (rw) sequential read/write, random read/write ファイルサイズ (size) 10240MB, 5120MB, 1024MB, 512MB, 16MB 非同期アクセス数 (iodepth) 16 同時書き込み数 (numjobs) 1 ブロックサイズ (bs) 4KB 実行時間 (runtime) 3分 B) 非同期 Read/Write 数による違いの計測 ファイルアクセス方法 (rw) random read/write ファイルサイズ (size) 1024MB 非同期アクセス数 (iodepth) 1, 16, 32 同時書き込み数 (numjobs) 1 ブロックサイズ (bs) 4KB 実行時間 (runtime) 3分 上記に明記しなかった値は fio のデフォルト値を用いた。 7.4.2. PostgreSQL の実行可能トランザクション数 分散ストレージ上にデータがある PostgreSQL の 3 分間に実行されたトランザクション 数の計測を行う。さらに、分散ストレージクラスタの台数拡張による性能変化と、分散ス トレージのクライアントが、分散ストレージクラスタ内にいる場合と、クラスタ外にいる 場合の性能変化も調べた。 計測には、ベンチマークツールの pg_bench を用いた。実行するトランザクションは、以 下の SQL である。 i. pgbench_accounts を 1 件更新 ii. pgbench_accounts から 1 件検索 iii. pgbench_history に 1 件行を追加 DB への同時接続数の違いによる性能変化を計測するため、セッション数が 1, 5, 10, 50, 100 の場合で計測を行った。 8. 環境情報 今回の検証で用いた環境情報を以下に示す。 8.1. ハードウェア環境 CPU:Intel(R) Xeon(R) CPU E5506 @ 2.13GHz 4 core/8 thread Memory Size:48GB SSD250GB ストレージは RAID 0 を上記 SSD2 枚で構成している。 8.2. OS 情報 CentOS CentOS Linux release 7.1.1503 kernel version 3.10.0-229.20.1.el7.x86_64 8.3. ソフトウェアのバージョン情報 DRBD9 今回、DRBD9 の git の master branch から clone したものを使用した。 DRBD version 9.0.0 11 月 1 日更新 (git_hash=ece72f515db06d78f1603c452d38d1f943648eb4) drbdmanage version 0.5.0 9 月 29 日更新 (git_hash=c5f39e2511d40329ae66783e6476a6c41c273440) drbd-utils version 8.9.4 11 月 1 日更新 (git_hash=13f1450d0aa5af7466977f4c8be77794817b578e) GlusterFS ブロックデバイス上のファイルシステムは ext4 を用いた。 GlusterFS version 3.7.6 Ceph ceph version 0.94.3 ceph-deploy version 1.5.26 PostgreSQL version 9.4.5 運用検証時のみ 9.4.4 も同時に使用した ブロックデバイス上のファイルシステムは ext4 を用いた。 8.4. 各ソフトウェアの検証時の基本構成 DRBD9 PostgreSQL を実行する環境も含めて、すべてのノードが drbdctrl ボリュームを 持つ。 client PostgreSQL DRBD9 fio CentOS drbdctrl マウント Server 分散ストレージクラスタ DRBD9 DRBD9 DRBD9 CentOS CentOS CentOS drbdctrl data drbdctrl data drbdctrl 図 8 DRBD9 の検証時基本構成 data GlusterFS 各ノードは一つのブリックを持つ client PostgreSQL GlusterClient fio CentOS マウント Server 分散ストレージクラスタ Gluster Server Gluster Server Gluster Server CentOS CentOS CentOS Brick Brick Brick 図 9 GlusterFS の検証時基本構成 Ceph 各ノードで、OSD、Monitor を動かす CephFS を使用する時は上記 2 つに加えて、MDS を動かす client PostgreSQL Ceph client fio CentOS マウント Server 分散ストレージクラスタ Monitor OSD CentOS data Monitor OSD CentOS Monitor OSD CentOS data 図 10 Ceph の検証時基本構成 data 9. 検証結果 今回行った、運用環境切り替え検証、拡張性検証、耐障害性検証、性能検証の 4 つの検証 結果を示す。 9.1. 運用環境切り替え検証 3 つの分散ストレージソフトウェアについて、想定した運用フロー通りに運用環境を切り 替えることができたか結果を示す。 9.1.1. DRBD9 DRBD9 で デ ー タ と 実行 環 境 の 分 離 を 行 っ た。 想 定 し た 運 用 フ ロ ーは 、 実 行 中 の PostgreSQL のプロセスを止め、 Volume にどのノードからもマウントされていないという、 制約付きで実現可能であることを確認した。 DRBD9 は、想定した運用フローを実現するために、以下の制約が必要となった。 DRBD9 の制約事項 DRBD9 は 1 ボリュームに対して、複数ノードからの通常マウントは現在(2015 年 12 月)許容されていない。このため、マウントするノードを切り替える時、ボ リュームはどのノードからもマウントされていない状態でなければならない。 アンマウントするときに PostgreSQL のプロセスが動いているとボリュームのア ンマウントができないため、マウントするノードを切り替える時、PostgreSQL のプロセスは停止しなければならない。 DRBD9 は複数ノードからの書き込みができないため、運用環境切り替え時に、サービス の停止時間がどうしても発生する。なので、想定した Immutable Infrastructure を実現す る運用はできないと思われる。 サービス停止時間を許容する運用フローならば、サービス停止時間や障害発生時の環境の 切り戻しは Volume のアンマウント、マウントを行うだけであるため、短時間で行うことが できる。 表 1 DRBD9:運用フロー実行結果 検証結果 データの引き継ぎ 可能 引き継ぎ後のデータの Read 可能 引き継ぎ後のデータの Write 可能 サービス停止時間 有 運用環境の切り戻し 可能 運用環境の切り戻し時間 有 備考 今回の検証では約 1 分未満 サービス停止時間と同じ 9.1.2. GlusterFS GlusterFS でデータと実行環境の分離を行った。想定した運用フローは、実行中の PostgreSQL のプロセスを止めるという制約付きで、実現可能であることを確認した。今回 発生した制約は、GlusterFS ではなく PostgreSQL 側の問題であることも確認した。 GlusterFS に対して、想定した運用フローを実現するために、制約は必要でなかった。 しかし、PostgreSQL は GlusterFS 上で動かすとき、以下の制約が必要であることがわか った。 PostgreSQL の制約事項 複数ノードからマウントされている状態で、PostgreSQL をそれぞれのノードで起動する と、PostgreSQL の data ディレクトリ内の.pid ファイルの整合性が取れなくなり、 PostgreSQL の操作ができなくなってしまう。このため、環境を切り替える時、PostgreSQL のプロセスは、すべてのノードで停止しなければならない。 上記、pid ファイルの整合性の対策として、pid ファイルを data ディレクトリから分離 することを考えた。しかし、他ノードからの DB への書き込みは、書き込んだノード以外 から読み込むことができなかったため、他の対策が必要である。 GlusterFS は 、 PostgreSQL を ユ ー ス ケ ー ス と し た 場 合 、 想 定 し た Immutable Infrastructure を実現する運用はできないと思われる。PostgreSQL 以外のユースケースな らば実現できる可能性があるかもしれない。 今回の結果は GlusterFS クライアントでマウントする時、NFS マウントする時のどちら でも同様の実行結果だった。 複数ノードからの同時マウントは、1 ファイルに同時書き込みを行おうとすると、結果が 時系列的に更新の新しい方を優先されてしまい、時系列的にそれ以前のものは破棄される という結果を得た。つまり、無理に複数ノードから書き込みをせずに、書き込みを行って いるノード以外は読み込みしか行わないという運用ルールが必要であると考える。 表 2 GlusterFS:運用フロー実行結果 検証結果 データの引き継ぎ 可能 引き継ぎ後のデータの Read 可能 引き継ぎ後のデータの Write 可能 サービス停止時間 有 備考 PostgreSQL が原因で発生 今回の検証では約 1 分未満 運用環境の切り戻し 可能 運用環境の切り戻し時間 有 サービス停止時間と同じ 9.1.3. Ceph 想定した運用フローは CephFS では GlusterFS と同じ、実行中の PostgreSQL のプロセ スを止めるという制約付きで、実現可能であることを確認した。 Ceph RBD では、複数ノードからの書き込みを行うと、データに不整合が発生したため DRBD9 と同じ制約付きで、実現可能であることを確認した。 CephFS CephFS マウントでは GlusterFS の制約事項と同じ PostgreSQL が原因で、環境を切り 替える時、PostgreSQL のプロセスをすべてのノードで停止しなければならない。 CephFS は 、 PostgreSQL を ユ ー ス ケ ー ス と し た 場 合 、 想 定 し た Immutable Infrastructure を実現する運用はできないと思われる。PostgreSQL 以外のユースケースな らば実現できる可能性があるかもしれない。 表 3 Ceph(CephFS):運用フロー実行結果 検証結果 データの引き継ぎ 可能 引き継ぎ後のデータの Read 可能 引き継ぎ後のデータの Write 可能 サービス停止時間 有 備考 PostgreSQL が原因で発生 今回の検証では約 1 分未満 運用環境の切り戻し 可能 運用環境の切り戻し時間 有 サービス停止時間と同じ Ceph RBD Ceph RBD では、RBD マウントを複数ノードから行うと、1 ノードでのファイル更新はす べてのノードに適用されず、データに不整合が発生するため、以下の制約が必要となる。 Ceph RBD の制約事項 RBD でマウントするノードを切り替える時、ボリュームがどのノードにもマウント されていない状態でなければならない。 CephRBD は複数ノードからの書き込みを行うとデータに不整合が発生する。複数ノードか らの書き込みを防止するために、サービスの停止時間がどうしても発生する。なので、想 定した Immutable Infrastructure を実現する運用はできないと思われる。 表 4 Ceph(RBD):運用フロー実行結果 検証結果 データの引き継ぎ 可能 引き継ぎ後のデータの Read 可能 引き継ぎ後のデータの Write 可能 サービス停止時間 有 運用環境の切り戻し 可能 運用環境の切り戻し時間 有 備考 今回の検証では約 1 分未満 サービス停止時間と同じ 9.1.4. 3 つのストレージを比較した考察 DRBD9 と CephRBD といった、ブロックデバイスへマウントを行う場合、複数ノードか らの Write を同時に行うことができない。しかし、クラスタ内に Primary がいない場合に 限って Read Only で複数ノードからマウントできることを確認した。このため、Immutable Infrastructure を実現する運用はできないが、データの読み込みのみを行うことは可能で あるため、ユースケースによっては実現できるかもしれないと考える。 GlusterFS client、GlusterFS nfs、CephFS は、今回の PostgreSQL の場合にサービス 停止時間が発生してしまう。このため、PostgreSQL をユースケースとした場合は、厳密な Immutable Infrastructure を実現する運用はできない。しかし、複数ノードからのデータ 操作を許容するサービスならば、Immutable Infrastructure を実現する運用が実現できる と考える。 7.1.1 で示した、今回の運用フローでは、環境移行前のチェックに本番環境が読み書きし ている分散ストレージ上の領域を新規環境から並行して参照している。このため、格納さ れているデータはエラーが発生すると汚染されてしまう可能性がある。データ汚染回避の 対策として、テストをデータの Read だけにすることが考えられる。それ以外の対策として、 各分散ストレージでスナップショット等のバックアップをあらかじめ作成する、検証環境 に、本番環境で使用しているブロックデバイスのコピーを行うこともデータ汚染対策とし て考えられる。 結論として、分散ストレージを使用した Immutable Infrastructure を実現する運用は難 しく、実現できるのは限られた場合のみになると考えられる。 9.2. 拡張性検証 3 つの分散ストレージソフトウェアについて、クラスタへのノードの追加がサービス無停 止で可能であるか検証した結果を示す。 9.2.1. DRBD9 DRBD9 はサービス無停止で、ノードの追加が可能であることを確認した。拡張中もデー タの読み書きが正常に行われていることも確認できた。 拡張手順 DRBD9 でのノードの拡張手順を示す。 i. ii. クラスタ内のノードが、クラスタへ新規にノードを追加する(add-node)。 追加ノードに移したいボリュームを割り当てる(assign)。 iii. データの同期が終わるまで待つ。 iv. 領域を解放したいノードは、追加ノードに割り当て済みのボリュームを未割り当て (unassign)にする。 今回の手順では、各ノードが持つデータ量を均一にするためにデータの再配置も行った。 これは、DRBD9 は自動でデータの再配置を行わないためである 拡張後のデータ同期の時間は、40GB のボリュームでは約 5~8 分程度の時間がかかった。 今回の拡張検証で起こった現象として、unassign を実行する操作で、pg_bench トラン ザクションで内の pg_history への insert 処理が約 10 秒間待たされる現象が発生した。こ の原因は、unassign したノードからの keep-alive packet の受信待ちが原因で発生したと考 えられる。約 10 秒の待ち時間以外は、読み書きの性能は低下していなかった。 9.2.2. GlusterFS GlusterFS はサービス無停止で、ノードの追加が可能であることを確認した。拡張中も データの読み書きが正常に行われていることも確認できた。GlusterFS マウント、nfs マウ ントのどちらの場合でも同様の結果を得ることができた。 今回の検証では、Replication モードでクラスタを組み拡張を行った。 拡張手順 GlusterFS でのノードの拡張手順を示す。 i. ii. クラスタへ新規にノードを追加する(peer)。 追加ノードで、ブリック用のディレクトリを作成する。 iii. ボリュームに追加ノードを割り当て。(add-brick と Replication 数を 4 に増やす) iv. データの同期を待つ。 GlusterFS は同期の進捗状況を出力する方法が確認できなかった。このため、データ同 期の可否は、追加ノードのブリック内にファイルがあるかどうかで確かめた。 実際に拡張を行い、特に問題なくノード拡張を行うことができた。データの同期時間は、 計測できなかったが、同期が行われていることは確認した。 9.2.3. Ceph Ceph はサービス無停止で、ノードの追加が可能であることを確認した。CephFS、RBD のどちらも、拡張が可能であることを確認した。しかし、トランザクションの処理性能が、 ノードの追加後のデータ再配置を行う間、性能低下することを確認した。 拡張手順 Ceph でのノードの拡張手順を示す。 i. 新規に追加するノードで、Ceph 用のユーザ作成、Ceph 用ディレクトリを作成する ii. ceph-deploy を行うノードで、hosts ファイルの編集、新規追加ノードへ鍵の配布を 行う。 iii. ceph-deploy を行うノードが新規に追加するノードに、Monitor の作成、OSD の作 成・起動を行う。 iv. データの同期を待つ。 Ceph でノードを拡張した直後から、pg_bench の秒間実行トランザクション数が減少し ていた。具体的には、ノード追加前は約 111 トランザクション/sec で処理していたが、ノー ドを追加した直後から約 5 トランザクション/sec になってしまっていた。この原因としては、 データの再配置がクラスタ内で行われていたためと考えられる。 9| 2| 3| 1 | 78430 | -871 | 2015-11-25 11:31:13.997294 | 1 | 6545 | 1072 | 2015-11-25 11:31:14.000818 | 1 | 43748 | -1477 | 2015-11-25 11:31:14.00452 | 1| 3| 9| 6| 7| 8| 10 | 1| 4| 6| 1| 5| 8| 9| 1 | 65051 | 4070 | 2015-11-25 11:31:14.4214 | 1 | 51055 | -2440 | 2015-11-25 11:31:14.549549 | 1 | 5702 | 2580 | 2015-11-25 11:31:14.952268 | 1 | 47368 | 1155 | 2015-11-25 11:31:15.129388 | 1 | 7294 | 1215 | 2015-11-25 11:31:15.409634 | 1 | 76919 | -1980 | 2015-11-25 11:31:15.597786 | 1 | 56773 | 4159 | 2015-11-25 11:31:15.702991 | 1 | 79827 | -4835 | 2015-11-25 11:31:15.913404 | 1 | 25253 | 74 | 2015-11-25 11:31:16.120762 | 1 | 70723 | 2546 | 2015-11-25 11:31:16.294528 | 1 | 11048 | 658 | 2015-11-25 11:31:16.455919 | 1 | 15096 | -555 | 2015-11-25 11:31:16.65371 | 1 | 6563 | -1959 | 2015-11-25 11:31:16.825237 | 1 | 27071 | 4998 | 2015-11-25 11:31:17.000395 | … pg_bench の実行後、データの再配置にかかった時間は、今回の検証で用意した 40GB の ボリュームに対して、約 5~7 分の時間がかかった。 今回、3 分間 pg_bench を実行したため、観測できなかったが、より長い時間計測すると、 データの再配置終了後にトランザクション実行性能が元に戻る可能性がある。 9.2.4. 3 つのストレージを比較した考察 DRBD9 は現在データの自動再配置機能は存在しないため、他のソフトウェアと比べて手 間がかかる。さらに、ボリュームの再配置による領域の確保は、あらかじめ使用するボリ ュームを細かく分けておく必要がある。同期時間は DRBD9 のデータボリュームのサイズ によって変化していると考える。理由として、ボリューム内にデータが入っていない場合 でも、今回の検証ではデータ同期に 5 分程度の時間がかかっていたためである。 GlusterFS は今回、何も問題なくノードの拡張ができた。今回検証を行わなかったが Replicated に Distributed や Striped モードを組み合わせた場合や、Disperse モードを使 用した場合にはデータの再配置を手動で行う必要がある。このデータの再配置を行う時、 Ceph と同様にデータの再配置による処理性能低下が発生する可能性がある。 Ceph は、秒間の実行トランザクション数が大きく減少するという結果が出た。性能低下の 理由は、Ceph がデータの自動再配置が原因である可能性が高い。性能低下してしまうので、 Ceph のクラスタを拡張する時は、処理性能の低下による影響の少ない夜中などに行うこと が望ましいと考えられる。 9.3. 耐障害性検証 3 つの分散ストレージソフトウェアについて、以下の観点で耐障害性と障害復旧方法を検証 した。今回、障害が発生したノードは障害ノードと呼ぶ。 NIC 障害 分散ストレージクライアントがマウントしている 1 ノードで発生 DRBD9 と CephRBD は除く 前記以外の 1 ノードで発生 全ノードで発生 正常シャットダウン 1 ノード異常終了 分散ストレージクライアントがマウントしている 1 ノードで発生 DRBD9 と CephRBD は除く 前記以外の 1 ノードで発生 9.3.1. DRBD9 1 ノード NIC 障害 1 ノード NIC 障害の場合、障害発生による、クラスタへの影響は観測されず、pg_bench は正常終了した。障害が発生したノードは NIC の回復後に drbdmanage server の再起動を 行うと、クラスタの状態が復旧することを確認した。 NIC を止めると、正常に動作しているクラスタ内のノードで`drbdmanage list-node` コ マンドを実行すると、障害ノードの State が OFFLINE になっていることが確認できる。 障害ノードで NIC の ifup を行い、回復しても State に変化はなかった。 復旧方法は、drbdmanage shutdown コマンドと drbdmanage startup コマンドを実行 すると障害ノードの State が正常に戻り、データの同期が開始された。 pg_bench の pgbench_history を確認したところ、トランザクション実行時のタイムスタ ンプが障害発生直後から 10 秒ほど待ちが発生し、その後正常に読み書きされていることが 確認できた。この 10 秒という時間は DRBD9 の keep-alive packet の送信間隔と一致して いた。設定で keep-alive packet の送信間隔を変更すると、変更した時間と同じ時間だけ、 タイムスタンプの飛びを確認できた。 全ノード NIC 障害 全ノードで NIC を止めると、client node は Volume にアクセスできなくなり、pg_bench は異常終了し、PostgreSQL も異常停止していた。すべてのノードで NIC の回復と drbdmanage server プロセスの再起動を行い、 PostgreSQL を再起動することで復旧した。 全ノード NIC 障害時のログ node-pclient01 で pg_bench を実行している間に、node-01,node-02,node-03 の NIC を止める `````````````````````````````````````````````````````````````````````````````````````````````````````````` ````````````````````````` bash-4.2$ /usr/pgsql-9.4/bin/pgbench -c 1 -T 360 test starting vacuum...end. Client 0 aborted in state 13: PANIC: ログファイル 00000001000000080000000D を fdatasync できませんでした: 入 力/出力エラーです transaction type: TPC-B (sort of) scaling factor: 1 query mode: simple number of clients: 1 number of threads: 1 duration: 360 s number of transactions actually processed: 2220 latency average: 162.162 ms tps = 61.184189 (including connections establishing) tps = 61.190113 (excluding connections establishing) bash-4.2$ exit exit [root@node-pclient01 inamoto]# drbdsetup status .drbdctrl role:Secondary volume:0 disk:UpToDate volume:1 disk:UpToDate node-01 connection:Connecting node-02 connection:Connecting node-03 connection:Connecting pg_volume role:Primary disk:Diskless node-01 connection:Connecting node-02 connection:Connecting node-03 connection:Connecting t_volume role:Secondary disk:Diskless node-01 connection:Connecting node-02 connection:Connecting node-03 connection:Connecting ```````````````````````````````````````````````````````````````````````````````````````` 一度 unmount としてから、再度マウントすると、node-pclient01 から PostgreSQL を止めることができる PostgreSQL を停止し、再び起動すると、またデータを触ることができるようになる。 ````````````````````````````````````````````````````````````````````````````````````````````` [root@node-pclient01 inamoto]# umount /var/lib/pgsql/9.4/ [root@node-pclient01 inamoto]# mount /dev/drbd100 /var/lib/pgsql/9.4/ [root@node-pclient01 inamoto]# su postgres [root@node-pclient01 inamoto]# su postgres bash-4.2$ cd bash-4.2$ /usr/pgsql-9.4/bin/pg_ctl -D /var/lib/pgsql/9.4/data/ -l logfile start pg_ctl: 他のサーバが動作中の可能性がありますが、とにかく postmaster の起動を試みます。 サーバは起動中です。 クライアントノード以外の全てのノードで NIC を止めると、ストレージに書き込むこと ができなくなり、pg_bench は I/O エラーで停止する。また、PostgreSQL のプロセスが停 止しており、マウントしているボリュームが自動的にアンマウントされていた。分散スト レージ内の全てのノードを 1 ノード NIC 障害の時と同じ手順で回復行い、その後クライア ントがボリュームを再マウントする。そして、PostgreSQL を起動することで障害前の状態 に戻った。 全ノード正常シャットダウン 分散ストレージクラスタ内の全てのノードが正常シャットダウンされた場合、全ノード NIC 障害と同様に、client node は Volume にアクセスできなくなり、pg_bench は異常終 了し、PostgreSQL も異常停止していた。 シャットダウンされたノードを再び起動して、全ノード NIC 障害と同じ復旧手順をとるこ とで、環境は復旧した。 1 ノード異常終了 1 ノード異常終了の場合、1 ノード NIC 障害の場合同様に、障害発生による、クラスタ への影響は観測されず、pg_bench は正常終了した。 障害ノードの電源を再び起動した後は、他の障害からの復旧と同じで、drbdmanage server プロセスを起動することで障害前の状態に復旧した。 9.3.2. GlusterFS 1 ノード NIC 障害 1 ノード NIC 障害が発生すると、glusterfs client、nfs client のどちらでも、クラスタは 障害ノードが認識できなくなるが、実行中の pg_bench は正常終了した。障害が発生したノ ードは NIC の回復と glusterd プロセスの再起動を行うことで、元の状態にクラスタが復旧 した。 1 台の NIC を止めると、 gluster peer status で出てくる障害ノードの State が disconnect となり、gluster vol status を見ると動作中のプロセス一覧から削除されていた。障害発生 後も pg_bench はトランザクションの消失なしに正常終了した。 障害ノードの NIC を回復すると、障害ノードが gluster peer と gluster vol status どち らからも認識された。しかし、gluster vol status の Online 項目だけは No になっていた。 NIC 回復後に、 障害ノードで、glusterd を restart すると、 ボリュームのステータスの Online 状況も Yes になり、分散ストレージクラスタが元の状態に戻った。GlusterFS client、nfs のどちらでも同様の結果になった。 正常な状態 [root@node-01 inamoto]# gluster vol status Status of volume: pg_volume Gluster process TCP Port RDMA Port Online Pid -----------------------------------------------------------------------------Brick 10.255.195.57:/export/sda3/brick/pg_v olume 49153 0 Y 16018 Brick 10.255.195.58:/export/sda3/brick/pg_v olume 49153 0 Y 15320 Brick 10.255.195.59:/export/sda3/brick/pg_v olume 49153 0 Y 15108 NFS Server on localhost 2049 0 Y 16875 Self-heal Daemon on localhost N/A N/A Y 16883 NFS Server on 10.255.195.60 2049 0 Y 31577 Self-heal Daemon on 10.255.195.60 N/A N/A Y 31585 NFS Server on 10.255.195.58 2049 0 Y 15965 Self-heal Daemon on 10.255.195.58 N/A N/A Y 15973 NFS Server on 10.255.195.59 2049 0 Y 15710 Self-heal Daemon on 10.255.195.59 N/A N/A Y 15718 Task Status of Volume pg_volume -----------------------------------------------------------------------------There are no active volume tasks Volume t_volume is not started NIC 停止直後 [root@node-01 inamoto]# gluster vol status Status of volume: pg_volume Gluster process TCP Port RDMA Port Online Pid -----------------------------------------------------------------------------Brick 10.255.195.57:/export/sda3/brick/pg_v olume 49153 0 Y 16018 Brick 10.255.195.58:/export/sda3/brick/pg_v olume 49153 0 Y 15320 NFS Server on localhost 2049 0 Y 16875 Self-heal Daemon on localhost N/A N/A Y 16883 NFS Server on 10.255.195.60 2049 0 Y 31577 Self-heal Daemon on 10.255.195.60 N/A N/A Y 31585 NFS Server on 10.255.195.58 Self-heal Daemon on 10.255.195.58 2049 N/A 0 N/A Y Y 15965 15973 Task Status of Volume pg_volume -----------------------------------------------------------------------------There are no active volume tasks Volume t_volume is not started [root@node-01 inamoto]# gluster peer status Number of Peers: 3 Hostname: 10.255.195.58 Uuid: 2bd9632d-f502-4f54-8f3e-1bd36fc20e4f State: Peer in Cluster (Connected) Hostname: 10.255.195.59 Uuid: a8e0d916-7983-41db-aab8-a0f7321a9f45 State: Peer in Cluster (Disconnected) Hostname: 10.255.195.60 Uuid: e6df1c93-6f37-4bce-a748-39d2af7ce2cf State: Peer in Cluster (Connected) [root@node-01 inamoto]# NIC 復帰直後 [root@node-01 inamoto]# gluster vol status Status of volume: pg_volume Gluster process TCP Port RDMA Port Online Pid -----------------------------------------------------------------------------Brick 10.255.195.57:/export/sda3/brick/pg_v olume 49153 0 Y 16018 Brick 10.255.195.58:/export/sda3/brick/pg_v olume 49153 0 Y 15320 Brick 10.255.195.59:/export/sda3/brick/pg_v olume N/A N/A N N/A NFS Server on localhost 2049 0 Y 16875 Self-heal Daemon on localhost N/A N/A Y 16883 NFS Server on 10.255.195.60 2049 0 Y 31577 Self-heal Daemon on 10.255.195.60 N/A N/A Y 31585 NFS Server on 10.255.195.58 2049 0 Y 15965 Self-heal Daemon on 10.255.195.58 N/A N/A Y 15973 NFS Server on 10.255.195.59 2049 0 Y 15710 Self-heal Daemon on 10.255.195.59 N/A N/A Y 15718 Task Status of Volume pg_volume -----------------------------------------------------------------------------There are no active volume tasks Volume t_volume is not started [root@node-01 inamoto]# gluster peer status Number of Peers: 3 Hostname: 10.255.195.58 Uuid: 2bd9632d-f502-4f54-8f3e-1bd36fc20e4f State: Peer in Cluster (Connected) Hostname: 10.255.195.59 Uuid: a8e0d916-7983-41db-aab8-a0f7321a9f45 State: Peer in Cluster (Connected) Hostname: 10.255.195.60 Uuid: e6df1c93-6f37-4bce-a748-39d2af7ce2cf State: Peer in Cluster (Connected) マウント先ノードの NIC 障害 分散ストレージクラスタのマウント先ノードで NIC 障害が発生した場合、nfs client の時 は pg_bench が待ち状態になることを観測した。glusterfs client の時は pg_bench が待ち状 態になる場合と、正常終了する場合の 2 パターン観測した。復旧方法は、どの場合も障害 ノードで glusterd プロセスの再起動によって復旧する 分散ストレージクラスタのマウント先ノードが NIC 障害の場合、nfs client の時、 pg_bench が応答待ちの状態になってしまい、pg_bench を止めなければ障害復旧できない 状態になった。pg_bench を止めなければ、gluster サーバの各ノードが互いに認識してく れないため、pg_bench の読み書きの停止は必須である。glusterfs client の時は、pg_bench が正常終了する場合と pg_bench が待ち状態になる 2 パターンを確認した。 復旧方法はどちらの場合も、障害ノードの glusterd プロセスの再起動を行うことで復旧 する。 しかし、 ここでの glusterd の再起動は systemctl restart では復旧せず、 systemctl stop と systemctl start を順番に実行することが必要である。 障害発生後、起こる現象が 2 パターン発生した。これは、内部的には分散ストレージク ラスタ内の 3 台のうちの、どれか 1 台に書き込みを行っていた可能性があると考える。例 えば、マウント先ノードに書き込んでいた場合は pg_bench が待ち状態になり、マウント先 ノードではないところに書き込んでいた場合は正常終了した可能性がある。 全ノード NIC 障害 全ノード NIC 障害の場合、すべてのノードからクラスタを認識できなくなり、pg_bench は異常終了し、PostgreSQL も異常停止した。復旧方法は、すべての障害ノードで NIC を 回復し、glusterd プロセスの再起動を行う。その後、PostgreSQL を再起動することで復旧 した。 全ノードで NIC 障害が発生すると、すべての障害ノードはクラスタを組んでいる、他ノ ードを認識できなくなり。pg_bench は障害発生時に I/O エラーを出して、PostgreSQL は 異常終了していた。 すべての障害ノードで NIC を復旧した時、各ノードは互いに認識しているが、Volume への接続はできていないという状態になった。その後、glusterd プロセスを systemctl stop と systemctl start で再起動を行うことで、各ノードがクラスタ内の他ノードを認識した。 分散ストレージ側の復旧が終了したら、PostgreSQL を再び起動することで復旧は完了した。 全ノード正常 shutdown 分散ストレージの全ノードを正常 shutdown した時、 全ノード NIC 障害の場合と同様に、 すべてのノードからクラスタを認識できなくなり、pg_bench は異常終了し、PostgreSQL も異常停止した。復旧も、全ノード NIC 障害の場合と同様の手順で行った。 1 ノード異常終了 1 ノード異常終了の場合、1 ノード NIC 障害と同様に、glusterfs client、nfs client のど ちらでも、クラスタは障害ノードが認識できなくなるが、実行中の pg_bench は正常終了し た。障害発生ノードの電源をいれて、glusterd プロセスを起動することで復旧する。 9.3.3. Ceph 1 ノード NIC 障害 1 ノード NIC 障害の場合、ceph クラスタは WARN 状態になったが、pg_bench は正常終 了した。障害発生ノードの NIC を回復するだけで復旧した。 ceph health コマンドで出てくる、ceph の状態が NIC を止めると WARN 状態になる。 これはデフォルトの設定で Monitor と OSD がそれぞれ 3 台以上なければ異常となる設定だ からである。ceph_health が WARN でも pg_bench は正常に終了した。 pg_bench 終了後、障害ノードの NIC を回復すると、クラスタに認識されデータの同期 が始まり、データ同期が終了すると WARN 状態が解消され復旧が完了した。 今回の検証では CephFS、RBD のどちらでも同様の結果になった。 マウント先ノードの NIC 障害 CephFS マウントの場合、マウントポイントが存在するため、マウント先ノードの NIC 障害を検証した。今回の障害でも、1 ノード NIC 障害と同様に、ceph クラスタは WARN 状態になったが、pg_bench は正常終了した。1 ノード NIC 障害と同様の方法で復旧した。 マウントポイントの NIC を落としても正常に終了した理由としては、Monitor プロセス を複数ノードで冗長化しているためと考える。 全ノード NIC 障害 全ノード NIC 障害の場合 CephFS、CephRBD のどちらでも、pg_bench が待ち状態にな った。障害ノードの NIC をすべて回復することで復旧した。 全ノードの NIC を止めると、pg_bench が待ち状態になった。pg_bench の実行は 180 秒 に設定していたが、10 分以上たっても待ち状態のまま、pg_bench は終了されなかった。 pg_bench の待ち状態が続いている間に、全ノードの NIC を回復すると pg_bench の待ち 状態が治ることを確認した。I/O エラーで pg_bench が異常終了という動きはなかった。 ここで、pg_bench を実行時間ではなく、総実行トランザクション数を指定して、同様の障 害を発生させると、障害発生時に同様の待ちが発生した。その後、全ノードの NIC を復旧 すると、復旧してすぐに残りのトランザクションが途中から実行され、指定したトランザ クション数の実行が完了したことを確認した。 NIC 障害は、NIC を回復するだけで復旧が可能だった。これは、各ノードに Monitor ノ ードがあるため、Monitor 間で一貫性を保持するアルゴリズムが動作しているためと考える。 今回の検証では CephFS、RBD のどちらでも同様の結果になった。 全ノード正常 shutdown 全ノードを正常シャットダウンすると、CephFS、CephRBD のどちらでも、pg_bench が待ち状態になった。復旧方法としては、Ceph に関連する、全てのプロセスを全てのノー ドで再起動を行うことで復旧した。 全ノードを正常シャットダウンすると、全ノード NIC 障害と同様に pg_bench が待ち状 態になった。 全ノードの電源を再び起動しても復旧せず、すべてのノードの osd が down していた。 さらに、データのリカバリが 66%で止まってしまい、待つだけでは復旧できなかった。警 告メッセージとして、障害ノードの Monitor の時刻に差異がある、というものが出ていた め、ntpd の restart を行ったが治らなかった。最後に Ceph の Monitor プロセスを再起動 することで、 データのリカバリが終わり、 osd の状態が up になった。 今回の検証では CephFS、 RBD のどちらでも同様の結果になった。 1 ノード異常終了 1 ノード異常終了の場合、1 ノード NIC 障害と同様に、Ceph クラスタは WARN 状態に なったが、pg_bench は正常終了した。復旧方法としては、Ceph に関連する、全てのプロ セスを全てのノードで再起動を行うことで復旧した。 1 ノードを強制終了後、再び電源を入れると障害ノードの osd の状態は up になるが、 ceph_health は WARN になり「障害ノードの Monitor の時刻に差異がある」 、という警告 メッセージを出していた。この警告メッセージは全ノード正常 shutdown と同様のメッセ ージであるため、Ceph のプロセスを再起動することで治る。今回の検証では CephFS、RBD のどちらでも同様の結果になった。 9.3.4. 3 つのストレージを比較した考察 今回の検証では、1 ノード障害の時は PostgreSQL の停止は起こらず、データの破損等は 確認されなかった。また、全ノード障害では、障害発生直前までのデータは DB に格納さ れていることを確認した。ここから、今回の障害パターンでの耐障害性は DRBD9、 GlusterFS、Ceph ともに高いと考える。 障害復旧に関しては DRBD9、GlusterFS、Ceph どの場合でも、プロセスの再起動で障 害から復旧することを確認した。 9.4. 性能検証 今回の性能検証では、分散ストレージに対してリアルタイムに 1MB~数 GB 程度のファ イルが読み書きされるファイルサーバとして使用する場合と、分散ストレージ上で PostgreSQL を動かしたした場合を考える。 計測は、DRBD9、GlusterFS(Replicated モード)、CephRBD、CephFS の 4 種類の分散 ストレージと local-disk の計 5 種類を対象とする。CephFS は Stable では無い(2015 年 12 月現在)ため、ベストなパフォーマンスでは無いが参考値として記載する。 9.4.1. ファイルの Read / Write 性能 DRBD9、GlusterFS、Ceph の 3 つについて、ファイルの Read / Write 性能を実データの 位置の違い、クラスタの台数拡張、非同期アクセス数の 3 つの観点で性能変化を計測した。 9.4.1.1. 実データの位置の違いによる性能変化 本番環境を含めて分散ストレージクラスタを構築している場合と、分散ストレージが完 全に本番環境と分離している場合の性能変化について比較検証を行う。 読み書きを行う単一ファイルのファイルサイズは 1GB と 10GB の 2 パターンとする。今 回の検証では、以下の表のように読み書き方法を設定して計測を行った。 テスト名 ファイルサイズ アクセス方法 seq_w_1GB 1 GB sequential write seq_w_10GB 10 GB sequential write seq_r_1GB 1 GB sequential read seq_r_10GB 10 GB sequential read rand_w_1GB 1 GB random write rand_w_10GB 10 GB random write rand_r_1GB 1 GB random read rand_r_10GB 10 GB random read DRBD9 ストレージクラスタ内からのデータアクセスの方が、性能はよい。さらに、local-disk と 比較しても、性能低下が小さいことがわかる。 (IOPS) 35000 DRBD9_out_cluster 30000 DRBD9_in_cluster 25000 local_disk 20000 15000 10000 5000 0 図 11 DRBD9:クラスタ内のデータ位置による性能の違い (IOPS) DRBD9_out_cluster DRBD9_in_cluster local_disk seq_w_1GB 9326 12991 13945 seq_w_10GB 9353 13025 13940 seq_r_1GB 22225 27923 29799 seq_r_10GB 21011 29823 29804 rand_w_1GB 7124 8772 13954 rand_w_10GB 5731 6238 7524 rand_r_1GB 22569 27094 29836 rand_r_10GB 21480 28331 29853 GlusterFS sequential write の性能がストレージクラスタ内からのアクセスの時、 local-disk の write 性能を超えている。sequential read、random write でストレージクラスタ外からのデータ アクセスが、クラスタ内からのデータアクセス性能に若干勝っている。 (IOPS) Gluster:gluster_out_cluster 35000 Gluster:gluster_in_cluster local_disk 30000 25000 20000 15000 10000 5000 0 図 12 GlusterFS:クラスタ内のデータ位置による性能の違い (IOPS) Gluster:gluster_out_cluster Gluster:gluster_in_cluster local_disk seq_w_1GB 9558 14325 13945 seq_w_10GB 9560 13697 13940 seq_r_1GB 2436 1922 29799 seq_r_10GB 2464 1906 29804 rand_w_1GB 3987 4299 13954 rand_w_10GB 4071 3849 7524 rand_r_1GB 899 2572 29836 rand_r_10GB 885 2628 29853 Ceph RBD ストレージクラスタ内からのデータアクセスの方が、性能はよい。 (IOPS) 35000 Ceph:RBD_out_cluster Ceph:RBD_in_cluster 30000 local_disk 25000 20000 15000 10000 5000 0 図 13 Ceph RBD:クラスタ内のデータ位置による性能の違い (IOPS) Ceph:RBD_out_cluster Ceph:RBD_in_cluster local_disk seq_w_1GB 1616 1660 13945 seq_w_10GB 1615 1664 13940 seq_r_1GB 6774 7020 29799 seq_r_10GB 6690 7276 29804 rand_w_1GB 3487 3450 13954 rand_w_10GB 2680 2662 7524 rand_r_1GB 14581 16079 29836 rand_r_10GB 14382 16822 29853 CephFS 参考値として計測したが、良い結果を得ることはできなかった。 (IOPS) 35000 Ceph:ceph_out_cluster Ceph:ceph_in_cluster 30000 local_disk 25000 20000 15000 10000 5000 0 図 14 CephFS:クラスタ内のデータ位置による性能の違い (IOPS) Ceph:FS_out_cluster Ceph:FS_in_cluster local_disk seq_w_1GB 342 362 13945 seq_w_10GB 337 353 13940 seq_r_1GB 1284 1502 29799 seq_r_10GB 1272 1547 29804 rand_w_1GB 329 345 13954 rand_w_10GB 302 313 7524 rand_r_1GB 1075 1319 29836 rand_r_10GB 983 1187 29853 考察 DRBD9 の実データがクラスタ内にある場合は、local-disk と比べてデータアクセス性能 の差はほぼないという結果だった。これは、Read/Write 共にクラスタ内にある場合は、一 番近いローカルにあるデータに Read/Write を行ったためではないかと思われる。また、実 データがクラスタ外にある場合もデータアクセス性能の低下は、クラスタ内にある場合と 比べて 2~3 割程度の低下にとどまっていた。ここから、DRBD9 は性能面からいうと実デ ータがクラスタ内外どちらにあっても local-disk の代替を十分に果たせると考える。 GlusterFS は、今回の検証では、いくつかの検証項目で実データがクラスタ内にある場 合よりも、クラスタ外にある場合の方が、性能は良いという結果を得た。しかし、差は若 干なので計測時の誤差である可能性が高い。また、今回の検証環境では、GlusterFS は sequential write 以外は良い結果を得ることができなかった。これは、Replication モード のみを利用しているため、同期処理に時間がかかったためではないかと考える。 Ceph は、実データがクラスタ内外にある場合の差が少なかったが、やはり、クラスタ内 に実データがある場合の方が、アクセス性能は良かった。しかし、この差も誤差である可 能性が高い。write 時の性能が低い原因としては、データの分散配置を行っているためでは ないかと考える。 9.4.1.2. 台数拡張による性能変化 分散ストレージクラスタを構成する、ノード数が拡張された時の性能変化を計測した。 台数拡張とともに、Read/Write するファイルサイズを変えた時の性能変化も計測した。 Sequential write の時 台数拡張による sequential write の計測結果が以下のグラフである。 すべてのソフトウェアについて、台数拡張を行うことで性能の低下を計測した。 (IOPS) 12000 16MB 5120MB 512MB 10240MB 1024MB 10000 8000 6000 4000 2000 0 3 4 5 3 DRBD9 4 5 3 GlusterFS 4 5 3 4 CephRBD 5 (台数) Cephfs 図 15 台数拡張による性能変化:Sequential write (IOPS) file size 16MB 512MB 1024MB 5120MB 10240MB 台数 DRBD9 GlusterFS CephRBD Cephfs 3 9309 9321 9326 9345 9353 4 7025 7043 7039 7040 7041 5 5610 5627 5625 5626 5617 3 9309 9554 9558 9561 9560 4 7062 7168 7170 7166 7171 5 5680 5734 5736 5734 5728 3 1605 1621 1616 1612 1615 4 1622 1608 1596 1614 1608 5 1529 1585 1576 1586 1565 3 344 342 342 343 337 4 337 341 341 342 337 5 348 348 351 349 346 Sequential read の時 台数拡張による sequential read の計測結果が以下のグラフである。 DRBD9 が若干だが台数拡張による性能向上が見られた。 (IOPS) 30000 16MB 512MB 1024MB 5120MB 10240MB 25000 20000 15000 10000 5000 0 3 4 5 3 DRBD9 4 5 3 GlusterFS 4 5 3 4 CephRBD 5 (台数) Cephfs 図 16 台数拡張による性能変化:Sequential read (IOPS) file size 16MB 512MB 1024MB 5120MB 10240MB 台数 DRBD9 GlusterFS CephRBD Cephfs 3 19320 22378 22225 22160 21011 4 21787 25075 25148 25227 24901 5 22382 23848 23100 23933 24628 3 2420 2412 2436 2476 2464 4 2368 2543 2553 2530 2560 5 2435 2458 2478 2588 2660 3 6511 6662 6774 6692 6690 4 6491 6578 6618 6743 6749 5 6390 6198 6165 6192 6298 3 1303 1285 1284 1284 1272 4 1284 1246 1252 1262 1277 5 1263 1294 1298 1300 1285 Random write の時 台数拡張による random write の計測結果が以下のグラフである。Ceph_RBD と、若干 だが Cephfs の 2 つが台数拡張による、性能向上を計測した。これは、Ceph の Replication 数が 3 台から変化していないためである。 (IOPS) 10000 9000 16MB 512MB 5120MB 10240MB 1024MB 8000 7000 6000 5000 4000 3000 2000 1000 0 3 4 5 3 DRBD9 4 5 3 GlusterFS 4 5 3 CephRBD 4 5 (台数) Cephfs 図 17 台数拡張による性能変化:Random write (IOPS) file size 16MB 512MB 1024MB 5120MB 10240MB 台数 DRBD9 GlusterFS CephRBD Cephfs 3 9330 7433 7124 6466 5731 4 7001 6227 6153 5714 5028 5 5610 5395 5318 4970 4393 3 3923 4150 3987 4151 4071 4 3424 3907 3565 3702 3538 5 3747 3174 3279 3195 3433 3 2888 3613 3487 3078 2680 4 3126 4165 4042 3520 3158 5 3093 4408 4277 3823 3439 3 330 331 329 313 302 4 340 323 324 301 291 5 342 321 319 306 294 Random read の時 台数拡張による random read の計測結果が以下のグラフである。 GlusterFS 以外は台数拡張による若干の性能向上を確認できた。 (IOPS) 30000 16MB 5120MB 512MB 10240MB 1024MB 25000 20000 15000 10000 5000 0 3 4 5 3 DRBD9 4 5 3 GlusterFS 4 5 3 CephRBD 4 5 (台数) Cephfs 図 18 台数拡張による性能変化:Random read (IOPS) file size 16MB 512MB 1024MB 5120MB 10240MB 台数 DRBD9 GlusterFS CephRBD Cephfs 3 21787 21309 22569 21632 21480 4 22021 25352 24403 24614 24639 5 22260 24814 24742 24750 24233 3 1469 940 899 898 885 4 1395 938 881 893 890 5 1479 931 904 894 890 3 11221 14220 14581 14405 14382 4 11941 16381 15076 15937 16041 5 10893 16147 16957 16673 16768 3 1129 1118 1075 992 983 4 1158 1143 1083 1007 995 5 1221 1187 1138 1041 1025 考察 DRBD9 と GlusterFS の二つは、台数拡張に伴って Replication 数を増やした。この 2 つのソフトウェアは、Sequential, Random ともに write 時の性能が低下している。 これは、クラスタ内のノード増加により、ネットワークを介して、他ノードに送信す るデータ量が増えたため発生したのではないかと考える。ネットワークがボトルネッ クになっている場合の、性能低下を予防する方法として、ネットワーク帯域をより広 いものにすることが考えられる。もしくは、ファイルの read が頻繁に起こり、write 処理は少ないユースケースならば、local-disk と比較した時の性能低下の影響を最小限 に抑えて利用することができると考える。 CephRBD と、CephFS は台数拡張によって、write の性能も向上している。これは、 Ceph の Replication 数が 3 台から変化していないため、ネットワークのボトルネック を最小限にできたためではないかと思われる。 DRBD9 は、台数拡張に伴って Read 性能が向上している。これは、DRBD9 は分散 読み込み機能があるためではないかと思われる。このため、より大規模なクラスタを 用いて比較検証する必要がある。 9.4.1.3. 非同期並列数による性能変化 非同期並列アクセス数を変更した時の計測結果を示す。今回の検証では、以下の表のよう に読み書き方法を設定して計測を行った。 テスト名 rand 非同期並列アクセス数 1 rand-QD16 16 rand-QD32 32 今回の計測では IOPS ではなく平均帯域幅(KB/second)で比較を行った。 Write の時 非同期並列数が増加することで、CephRBD、DRBD の書き込み性能の向上を計測できた。 local-disk と Gluster nfs は非同期数が 1 から 16 に増加した時に、大幅な性能向上を計測 した。しかし、非同期並列数が 16 から 32 に増加した時の性能変化は計測されていない。 平均帯域幅(KB/s) 60000 DRBD9_in Gluster_in Gluster_nfs CephRBD_out Cephfs_out 50000 DRBD9_out Gluster_out CephRBD_in Cephfs_in local 40000 30000 20000 10000 0 rand rand-QD16 rand-QD32 非同期並列書き込み数 図 19 非同期並列書き込み数による違い (KB/sec) DRBD9_in rand DRBD9_out Gluster_in Gluster_out Gluster_nfs 4772 5909 18489 16552 2108 rand-QD16 35088 28498 17198 15950 9811 rand-QD32 55305 37148 18419 14693 8084 CephRBD_in CephRBD_out 1304 1235 1397 1316 13757 rand-QD16 13800 13949 1381 1372 55820 rand-QD32 15624 15837 1398 1324 55740 rand Cephfs_in Cephfs_out local Read の時 Write の時とほぼ同様の傾向が計測された。 平均帯域幅(KB/s) 140000 120000 DRBD9_in Gluster_in Gluster_nfs CephRBD_out DRBD9_out Gluster_out CephRBD_in Cephfs_in 100000 80000 60000 40000 20000 0 rand rand-QD16 rand-QD32 非同期並列読み込み数 図 20 非同期読み込み数による違い (KB/sec) DRBD9_in rand DRBD9_out Gluster_in Gluster_out Gluster_nfs 14244 5777 3501 1833 5289 rand-QD16 108380 90278 10288 3597 47817 rand-QD32 111267 112207 10478 3563 46960 CephRBD_in CephRBD_out 5126 4411 5184 4487 17403 rand-QD16 64318 58326 5278 4301 119346 rand-QD32 68732 64267 5240 4330 114736 rand Cephfs_in Cephfs_out local 考察 非同期読み書き数が 16 から 32 に変わった時、全体的に読み書き性能の変化が少な かった。これは、非同期数 16 の時点で、帯域幅がほぼ最大になっていたためだと考え られる。 非同期アクセス数を増やすことで、DRBD9 と CephRBD は性能の大幅な向上を確認 できた。このため、DRBD9 と CephRBD は非同期アクセスによって、データアクセス の待ち時間を短くできるユースケースでの利用が向いていると考える。 GlusterFS と CephFS は非同期並列アクセス数を増やすことによる性能向上を観測 できなかった。理由として、どちらもファイルシステムを提供しているためではない かと思うが、原因はわからない。 9.4.2. 分散ストレージ上の PostgreSQL DRBD9、GlusterFS、Ceph の 3 つについて、PostgreSQL の 3 分間の実行トランザクショ ン総数とクラスタの台数拡張に伴う性能変化について検証した。 9.4.2.1. 実行トランザクション総数 3 分間に実行されるトランザクション数について、セッション数を変えた時の結果が以下 のグラフである。 DRBD9 以外はセッション数の増加に伴って性能が向上している。 2500000 3 分 間 の 実 行 ト ラ ン ザ ク シ ョ ン 総 数 2000000 1500000 1000000 500000 local Gluster_in CephRBD_in Cephfs_out 0 0 10 20 30 DRBD9_in Gluster_out CephRBD_out 40 50 60 DRBD9_out Gluster_nfs Cephfs_in 70 80 90 100 セッション数 図 21 実行トランザクション数 (3 分間の実行トランザクション総数) 1 5 10 50 100 local 164163 613604 991992 2054566 2040401 DRBD9_in 125235 528134 978573 2044045 1803509 DRBD9_out 118039 500402 890742 1939256 1718944 Gluster_in 47774 140840 278130 916395 1063770 Gluster_out 44914 128199 259101 908733 1103260 Gluster_nfs 64076 221284 425832 1570102 1734222 CephRBD_in 48715 160032 314196 1222669 1304450 CephRBD_out 46681 147292 284975 1184476 1485733 Cephfs_in 49116 161193 319099 1199787 1299788 Cephfs_out 47183 146884 283900 1176312 1456148 考察 DRBD9 のみ性能の低下がセッション数 50 と 100 の間で計測された。このため、DRBD9 は並列数にピークが存在する可能性があると考えた。 試しにセッション数を 10 単位で再計測を行った。結果、セッション数 40 がピークで、セ ッション数 50 以上では少しずつ性能低下していることがわかった。さらに細かく調べてみ ると、今回の検証環境ではセッション数 45 か 46 が DRBD9 のピークであることがわかっ た。DRBD9 は PostgreSQL と組み合わせる場合、性能低下を避けるためにセッション数の 制限を設けるなどの対策が必要になると考える。 2500000 最大 トランザクション数 2000000 1500000 1000000 500000 0 1 10 20 30 40 50 60 70 80 90 100 (セッション数) 図 22 DRBD9:セッション数のピーク Ceph と GlusterFS については、100 セッションでもピークを観測できなかったが、セッ ション数 50 から 100 の間の変化量が少ないため、セッション数 100 以上からは、一定値に 収束して性能増加が伸び悩むのではないかと考える。 Ceph は、CephRBD、CephFS のどちらでも、ファイルの Read/Write 性能の時よりも、 local-disk と比べた場合の性能低下の割合が低い。これは、Ceph への Read/Write は、今 回の検証で使用したデフォルトの設定との相性が良かったためかもしれない。 9.4.2.2. 台数拡張による実行トランザクション総数の変化 3 分間に実行されるトランザクション数について、クラスタの台数を拡張した時の結果が 以下のグラフである。Ceph 以外は台数拡張によって性能低下している。 (3分間の実行総トランザクション数) 2500000 1 5 10 3 4 50 100 2000000 1500000 1000000 500000 0 3 4 5 DRBD9 3 4 GlusterFS 5 3 4 5 GlusterFS_nfs 5 3 CephRBD 4 5 (台数) Cephfs 図 23 台数拡張による実行トランザクション数の違い (3 分間の実行トランザクション総数) 1 5 10 50 100 3 118039 512272 890742 1939256 1718944 4 107414 455242 785683 1705162 1546984 5 99987 463820 770196 1704952 1556573 3 44914 128199 259101 908733 1103260 4 42211 116041 225097 819789 1018370 5 41917 107002 207418 746991 950170 3 64076 221284 425832 1570102 1734222 4 30804 90643 178675 835060 1089143 5 29378 86014 166562 775024 1031081 3 46681 147292 284975 1184476 1485733 4 46263 145082 280444 1169416 1470150 5 46936 147321 287854 1199648 1500692 3 47183 146884 283900 1176312 1304450 4 46320 145111 281027 1171365 1463925 5 47652 149301 286441 1199047 1499378 セッション数 台数 DRBD9 GlusterFS GlusterFS_nfs CephRBD Cephfs 考察 DRBD9 と GlusterFS の二つは、ノード数増加によって性能が低下している。ノード数 増加による性能低下の原因は、ファイルの読み書きと同じ原因で、クラスタ内のノード増 加により、ネットワークを介した他ノードに送信するデータ量が増えたためと考えられる。 クラスタを構成する台数が増えても、DRBD9 についてはセッション数 50 から 100 に増 加すると性能が低下しているため、セッション数のピーク値に変化はないのではないかと 思われる。 PostgreSQL 動かすにあたって、DRBD9 は台数拡張を行っても、分散 Read による性能 向上が今回の検証では確認できなかった。ここから、DRBD9 上で PostgreSQL を使う場合 は、想定するトランザクションの処理数と Replication 数のバランスを考えて組み合わせる 必要があると思われる。今回は 5 台までしか拡張していないが、台数をさらに拡張すれば 性能が上がり始める可能性があるかもしれない。 GlusterFS は今回の検証環境では read 性能がボトルネックとなって、性能の向上が伸び 悩んだのではないかと思われる。しかし、セッション数が 100 以上の時は DRBD9 以上の 実行トランザクション数だったため 、セッション数が 100 以上と多い場合には、GlusterFS 上で PostgreSQL を動かす組み合わせが、DRBD9 よりもいいのかもしれない。 9.4.3. 性能検証全体の考察 繰り返しになるが、今回の検証ではすべてのソフトウェアについて、処理性能にかかわ るパラメータはすべてデフォルト値で行った。 そのうえで 3 者を見比べると、DRBD9 は各種パラメータのチューニングを行わなくても、 ファイルの Read Write、実行トランザクション数共に local-disk に迫る性能を出している ことがわかる。これは、DRBD8 でも高速であった Replication の性能が、複数台の Replication になった DRBD9 でも有効に働いているためだと思われる。ここから、 local-disk への読み書きとの性能差を極力なくしたい場合には、DRBD9 を使用することが、 有効だと思われる。しかし、複数ノードからの読み込み書き込みがない場合に限る。 GlusterFS は、sequential write の性能が local-disk の書き込みとほぼ同程度の性能であ る。しかし、read に関しては、今回の環境では local-disk と比べると 1 割程度の read 性能 だった。このため、GlusterFS は sequential write がよく使用され、読み込みよりも書き 込みの方がよく行われるサービスに向いていると考える。また、ボリュームタイプが問題 であるとも考えた。今回使用した Replicated モードでは、データの分散読み込み機能がな く、分散読み込みを行うには、Distributed モードなどの、別のボリュームタイプを組み合 わせて使用する必要があるのではないかと考える。 Ceph はファイルの Read/Write を行う場合よりも、PostgreSQL と組み合わせて使用し た方が、local-disk と比較した場合の性能低下の割合が低かった。PostgreSQL のセッショ ン数の増加と非同期アクセス数の増加傾向を見ると、Ceph は並列度を上げると local-disk の性能に近づくことがわかった。今回の結果から、Ceph はデータアクセスの並列数が多い ユースケースで使用することで、性能を限界まで発揮できるのではないかと考える。 10. まとめ Immutable Infrastructure を実現した運用に分散ストレージを用いて、データと実行環 境の分離を行った場合の検証を行った。結果として、同時書き込みの必要性・可能性がな いデータでなければ、Immutable Infrastructure を実現した運用が可能であると考えられ る。GlusterFS、Ceph は同時書き込みや読み込みを行うことが可能であるが、今回の検証 で使用した PostgreSQL は複数ノードからの同時書き込みを行うことができないため、本 番環境の切り替え時に、PostgreSQL を止めてから分散ストレージを付け替えるという制約 が必要であるとわかった。Immutable Infrastructure を実現した運用で分散ストレージを 用いる場合は、分離するデータとしては設定ファイルなどの static なデータや、web サー ビスでユーザがアップロードしたデータなどの同時書き込みが発生しないデータであれば 有用な使い方が可能であると考えられる。また、DRBD9 は複数ノードからの 1 ボリューム へのアクセスが許可されていない。このため、今回の PostgreSQL ではない場合でも、同 時マウントができず、サービス停止時間が環境切り替え時にどうしても発生してしまうの で、Immutable Infrastructure を実現した運用は現時点ではサービス停止無しでは難しい という結論が出た。 今回使用した各製品を比較すると、DRBD9 は複数ノードから 1 ボリュームに、同時にマ ウントできない点がネックであると感じた。複数ノードから同時にデータの Read を行うこ とができれば、待機しているノードが運用中の本番データを用いて、読み込みを行う、と いう限定的ではあるが動作確認を行うことが可能となり、分散ストレージ上のデータをよ り柔軟に扱うことが可能になると考える。DRBD9.1 では Dual Primary の機能が安定板と して実装予定されているので、Immutable Infrastructure を実現した運用にも使えるよう になるかもしれない。ファイルの Read/Write やトランザクション実行などの性能はデフォ ルトの設定でも、他の分散ストレージを凌ぎ、local-disk への Read/Write に迫る勢いであ るので、本番環境の停止が許容されるような運用であれば、データの Read/Write 性能は従 来の local-disk とほぼ変わらずに使用できると考える。 GlusterFS は複数ノードからのデータ書き込みに制約を持たせる必要があると感じた。 GlusterFS は複数ノードからの同時書き込みが、警告は出るが書き込めてしまい、正しく 反映されないという問題がある。このため、複数ノードから書き込みを行う時は同時に行 わない、書き込みは 1 ノードだけに限定する、本番環境からできるデータ操作は Read のみ を行う、といったデータ操作に制約を持たせることが必要であると考える。Read/Write 性 能に関しては、デフォルト設定では Read 性能が低かったが、fio のブロックサイズ等のチ ューニングを行うことで Read 性能の向上を確認した。実際に使う場合にはブロックサイズ 等のチューニングを行うことで Read 性能を引き上げることが必要であると考える。今回行 わなかったが、GlusterFS ほかのボリュームグループでの検証も必要であると考える。 Ceph は、同時書き込みを行う場合、CephFS と RBD で違う結果を得た。CephFS の場 合は、複数ノードから同じファイルを開こうとすると、ファイルを開く操作が遅かった方 は Read Only になる。RBD の場合だと、同時書き込みを行うことが可能だが、最終的には 更新した内容はどちらか片方の更新しか反映されていない。このため、複数ノードから使 用する場合は CephFS を利用するのが安全であると考える。 性能面では、デフォルトの設定で、今回の検証で Read/Write 性能が全体的に local-disk に比べて読み書き性能が低いという問題があると感じた。Ceph RBD は GlusterFS と同等 な Write 性能を出すことができているため、それほど高いスループットが要求されない分 野ならば使用できると考える。Ceph のいい点としては、データの再配置を自動で行うこと が可能である点、ブロックデバイスとファイルシステムという 2 種類のデータアクセス方 法を用意している点があげられる。CephFS はチューニングを行った場合でもあまり良い性 能を出すことができていなかった。今回の検証の時点では、CephFS はまだ安定版ではない ので、2016 年にリリース予定の安定版に期待である。
© Copyright 2026 Paperzz