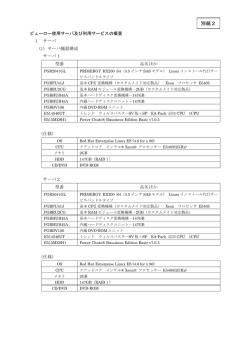
導入事例 インテル® Xeon Phi ™ コプロセッサー インテル® Xeon® プロセッサー E5 ファミリー、 インテル ® Xeon Phi ™ コプロセッサーを搭載したスーパーコンピューターの導入 メニーコア・プロセッサーで ピーク演算性能 1PFLOPS の スーパーコンピューターを実現 計算機科学・情報科学の先進的研究に活用 課 題 • 科学と計算機科学を融合した「学際計算科学」を支援する高速システムのニーズ拡大 • メニーコア・プロセッサーの技術の蓄積 ソリューション • インテル® Xeon® プロセッサー E5 ファミリー • インテル® Xeon Phi™ コプロセッサー • C++/Fortran プログラマーおよび MPI 開発者向け総合ツール「インテル® Cluster Studio XE」 導入効果 • ピーク演算性能 1.001PFLOPS のスーパーコンピューター「COMA(PACS-IX)」の導入 • メニーコアを採用した次世代スーパーコンピューターのコーディングやチューニングの研究開発 筑波大学計算科学研究センター 2 台目 となるペタフロップス・スパコンの 運用開始 筑波大学計算科学研究センター 所在地:茨城県つくば市天王台 1-1-1 筑 波大学筑波キャンパス 設置:2014 年 4 月 1 日 事業内容:学際計算科学の推進、超高速 計算機システムおよび超高速ネットワーク 技術の開発、超高速シミュレーションおよ び大規模データ解析や情報技術の応用研 究、計算科学を担う人材の育成、学際共同 利用プログラムの運営 http://www.ccs.tsukuba.ac.jp/ 科学と計算機科学を融合した「学際計算科 学」を推進する筑波大学計算科学研究セン ター(以下、計算科学研究センター)は、ピー ク演算性能 1.001PFLOPS のスーパーコン (コマ、パッ ピューター「COMA(PACS-IX)」 クス・ナイン)を導入し、2014 年 4 月から運 用を開始しています。CPU には、インテル ® Xeon® プロセッサー E5 ファミリーを 2 基、 CPU を補助する演算加速装置にインテル ® Xeon Phi™ コプロセッサーを 2 基 搭 載し た計算ノードを合計 393 台結合し、超並列 PC クラスターを実現しています。ピーク演算 性能 1.001PFLOPS は、インテル ® Xeon Phi™ コプロセッサーを採用したスパコンとし ては国内最高性能(2014 年 6 月時点)を 誇ります。 計算科学研究センターでは、新型スパコンの 「COMA」と、2012 年 に 運 用 を 開 始した GPU を演算加速装置とする 1.166PFLOPS のスパコン「HA-PACS」の 2 つによって、最 先端の計算科学研究を推進しているほか、 高性能計算分野のプロフェッショナル育成に 向けた学生・大学院生の教育に活用してい ます。 国立大学の情報センターでは唯一 計算機を用いた科学研究を自ら推進 計算科学研究センターは、1992 年に設立 された計算物理学研究センターを前身とし、 2004 年に改組拡充されて現在の体制とな りました。2010 年には、文部科学省共同利 用・共同研究拠点「先端学際計算科学共同 研究拠点」に認定されています。現在は、科 学と計算機科学の連携を強化した「学際共 同利用プログラム」のもとで、全国の研究機 関にセンター計算機を提供するとともに、学 際計算科学推進のための研究集会開催支 援、研究者招聘支援など研究者や学生向け の交流支援や、エクサスケールのスパコン開 発に向けた調査研究を行っています。 計算機システム運用委員長であり副センター 長の朴泰祐氏は、 「科学分野の研究者にスパ コンを利用してもらう情報センターとしての役 割ばかりでなく、国立大学としては唯一、各 種計算科学分野の教員・研究者を多数有し、 計算機を用いた科学研究やアプリケーション 開発、そして計算機自体の開発を自ら推進 メニーコアを実現するインテル® Xeon Phi™ コプロセッサーが、科学と計算機科学を融合した 「学際計算科学」に貢献 「多数の CPU コアを 1 つの チップに搭載し、 PCI Express* バス経由で CPU にアタッチできる インテル® Xeon Phi ™ コプロセッサー は、スパコンの高い コスト・パフォーマンス、 パワー・パフォーマンス、 スペース・パフォーマンスを 実現します」 筑波大学計算科学研究センター 教授 計算機システム運用委員長・副センター長 朴 泰祐 氏 していることに、他大学の計算機センターに はない特色があります。 このような取り組みを 『学際計算科学』として定め、幅広い計算科 学の探究を行っているところが、計算科学研 究センターの大きな特長です」 と説明します。 「学際計算科学」とは、超高速計算機と高速 ネットワークを中心的な研究手段とし、計算 機を活用する科学研究者、ハードウェア、ソフ トウェア、アルゴリズム、プログラミングの研 究を行う計算機科学の研究者、データやメ ディア処理の研究を行う情報科学の研究者 の 3 者が、それぞれの分野を融合しながら 革新的な応用研究を行うものです。計算科 学研究センターでは、長年にわたる共同研 究体制を構築しながら、基礎科学分野におけ る高速シミュレーション、大規模データ解析、 情報技術の応用研究などを進めてきました。 現在は、ペタフロップスを実現した「COMA」 や「HA-PACS」を活用し、素粒子、宇宙、原 子核、物質、生命、地球環境の各分野におけ る計算科学の研究発展とブレイクスルーを目 指しています。 高いコスト・パフォーマンスと パワー・パフォーマンスを評価して インテル® Xeon Phi™ コプロセッサー を採用 近年は CPU の高速化・高性能化により、超 並列 PC クラスターの性能は著しい進歩を遂 げています。しかし、限られた電力とスペース の中で演算性能を高めていくためには、従来 のように CPU を積み重ねてノードを増やし ていくだけでは限界があります。計算科学研 究センターでは、CPU を補助する演算加速 装置による低電力・高性能なスパコンの研究 を進める中で、1 つのチップに多数のコアを 集積したメニーコア・プロセッサー(MIC)に 着目。2012 年からインテルが MIC のアー キテクチャーの評価のために開始した「Intel MIC Beta Program」に参加しながら、性 能評価とチューニングに関する研究を続け てきました。そして、インテル ® Xeon Phi ™ コプロセッサーの製品化を受けて、いち早く COMA の導入を決定します。 「61 個 の CPU コアを 1 チップに搭 載した インテル ® Xeon Phi ™ コプロセッサーは、汎 用バスである PCI Express* を介して CPU にアタッチするだけで、テラフロップスの性 能が引き出せる特長があり、高いコスト・パ フォーマンスを実現します。また、電力 1 ワッ トあたりの性能であるパワー・パフォーマンス が高く、スペース・パフォーマンスにも優れて います」 (朴氏)。 インテル ® Xeon Phi ™ コプロセッサーのもう 1 つのメリットとして、インテル ® Xeon® プロ セッサーと同じアーキテクチャーを踏襲した、 プログラマビリティーの高さが挙げられます。 朴 氏は、 「 既 存のプログラム資 産を無 駄に せず、新しいことを覚えなくてもそのままプロ グラムが作れる安心感があります。今までど おり C++ や For tran でプログラムを書いた り、Open MP が使えたりするので、将来を 見据えたプログラム開発が可能です」と述べ ています。 また、計 算 科 学 研 究センターは、2013 年 に東京大学情報基盤センターと共同で次期 スーパーコンピューター・システムを設 計し 共同運営・管理するための組織「最先端共 同 HPC 基盤施設(JCAHPC)」を設置して、 2015 年 度を目 標に、東 京 大 学 情 報 基 盤 センターの柏キャンパス内に数十 PFLOPS クラスの超 大 型スパコンを導 入することを 計画しています。メニーコア・プロセッサーを 搭載した COMA は、次世代スパコンのコー ディングやチューニングの研究開発を行う実 験システムとしての役割も担っているといえ ます。 1 つの CPU に 2 基の MIC ボードを 片寄せして高速性能を確保 計算科学研究センターが導入した「COMA」の 名称は、Cluster Of Many-core Architecture processor の 略 である 一 方、CO M A は 代 表的な銀河団の 1 つである「かみのけ座」 の英語名に由来し、星の集まりである銀河 ( M a ny Co re )、銀河の集まりである銀河 団( C lu s t e r )をイメージしています。同時 に計算科学研究センターの歴代のスパコン PAC S シリーズの 9 世代目のマシンとなる ことから PAC S - I X のコード名が併用されま した。 COMA は、計算ノード数 393 台からなる並 列システムで、1 つの計算ノードは 1CPU あ 筑波大学計算科学研究センターと 東京大学情報基盤センターによる 「最先端共同 HPC 基盤施設 (JCAHPC)」 たり 10 コアを有するインテル® Xeon® プロ セッサー E5-2670v2(2.50GHz)2 基 と、 1MIC あたり 61 コアを有するインテル® Xeon Phi ™ コプロセッサー 7110P を 2 基搭載して います。ノード単体のピーク演算性能は CPU が 0.4TFLOPS、MIC が 2.147TFLOPS で、 合わせて 2.547TFLOPS。システム全体の ピーク演算性能は、CPU が 157.2TFLOPS、 MIC が 843.8TFLOPS で、 トータルで 1.001 PFLOPS となります。 筑波大学計算科学研究センターと東京 大学情報基盤センターは、東京大学柏 キャンパスの東京大学情報基盤センター 内に、両機関の教職員が中心となって設 計するスパコンシステムを設置し、2015 年 4 月以降の運用開始を目標に、新しい スパコンの導入に向けた活動を始めまし た。このような施設を設置し、スパコンを 共同運営・管理するのは国内初めての試 みです。 筑波大学計算科学 研究センター 教授 計算機システム運用 委員長・副センター長 朴 泰祐 氏 3 つのオペレーション・パターンで 計算ノードの並列実行をサポート また、すべての計算ノードはイーサネットと比 べて数 10 倍の通信性能を持つ高速ネット ワーク(InfiniBand* FDR)による 相 互 結 合 網で結ばれ、あらゆる計 算ノード間で均 等な並列処理を実行します。ストレージは、 R AID-6 による 総 容 量 1.5PB の Lustre ファイル サーバーを 採 用 し、InfiniBand* FDR を介してすべての計算ノードから自由に アクセスすることが可能です。 COMA の オ ペ レーション は、CPU の み、 MIC のみ、CPU と MIC の MIX の 3 つのジョ ブが用意され、以下の用途での利用を想定 しています。 ・CPU のみ 2014 年 2 月に運 用を終えた前 世 代のス パコン「T2K-Tsukuba」の マルチコア 用 プログラム(+MPI)をサポート。インテル ® Xeon® プロセッサー E5-2670v2 の全 20 コア分のうち 16 コアを使用する。 「計算ノードは、インテル® Xeon Phi™ コプロ セッサー 7110P を搭載した 2 基の MIC ボー ドと、InfiniBand* FDR のネットワーク・ボー ドを、1 基のインテル ® Xeon® プロセッサー E5-2670v2 に片寄せして、コプロセッサー とネットワーク・ボード間の高速通信性能を確 保し、1 基のインテル ® Xeon® プロセッサー E5-2670v2 は単独で利用することで高速 性能を維持している点が特長です」 (朴氏)。 ・MIC のみ インテル ® Xeon® プロセッサー E5-2670v2 の 4 コアと、インテル® Xeon Phi ™ コプロセッ サー 7110P の 2 基(61 コア ×2)を利 用。 計算ノード構成(System Block Diagram) DDR-III DIMM CPU1 CPU2 P0 P1 QPI Intel E5-2670v2 Intel E5-2670v2 8G 10 IVB CORE 10 IVB CORE P1 P0 DDR-III DDR-III Internal COM Port Header #1 #0 QPI 8G #1 PCI DMI2 4GB/s DMI2 LANE1/2/3/4 PCI LANE5 LANE6 C602 PCH SAS Parts #0~3 SATA Parts #0~5 2 in Rear SPI SATA2 3.0Gb/s For Parts #2~5 SATA3 6.0Gb/s SSB-A or B USB 2.0 SATA3 6.0Gb/s S-SATA3 #6~#9 LAN I350/X540 I-SATA3 #2~#5 BMC WPCM450 VGA DMI2 SIO W83527 For Parts 0/1 I-SATA3 #0/#1 InfiniBand* FDR SLOT 5 USB IPMI LAN #1 PCI-E X8 G3 PCI-E X4 Gen2 VGA #3 SLOT 5 PCI-E X8 SLOT 2 PCI-E X16 SLOT 1 PCI-E X16 Intel® Xeon Phi™ 7110p SLOT 1/2 #2 #1-4 #1-3 #1-2 #1-1 DDR-III DIMM #0-4 #0-3 #0-2 #0-1 ●システム構成 - ノード構成 ・ CPU:インテル® Xeon® プロセッサー E5-2670v2 (2.5GHz)×2 ・ MIC:インテル® Xeon Phi™ コプロセッサー 7110P×2 ・メモリー:CPU64GB 、MIC16GB ・ネットワーク:InfiniBand* FDR - ノード数:393 - ピーク性能 ・ CPU:157.2TFLOPS ・ MIC:843.8.2TFLOPS ・ TOTAL:1.001PFLOPS 筑波大学計算科学研究センターと東京大 学情報基盤センターは、京都大学の学術 情報メディアセンターの 3 センターからな る「T2K オープンスパコン・アライアンス」 を通して、各大学のスパコンの共同仕様 を策定・調達するプロジェクトを実施して きた歴史があります。T2K オープンスパ コンの仕様は、調達コストの低減と、ベン ダー依存からの脱却によるシステム性能 強化を目的に、ハードウウェアのオープン 性、ユーザーに依存しないオープン性と いった「オープン性」の理念に基づいて作 成されたものです。JCAHPC の設置はそ れを一歩推し進めたもので、高性能スパ コンの設計開発と運転・運営を 2 つの大 学の情報センターが共同で行い、最先端 の計算科学を推進することを目的として います。 スパコンシステムの設計・開発では、既存 のスパコン製品にとらわれず、メニーコア・ プロセッサーを利用した最先端のシステ ムを設計し、さらにソフトウェアの核となる 技術である、OS、プログラミング言語、数 値計算ライブラリーなどを他の組織とも連 携しながら研究開発していく方針が定め られています。 インテルコンパイラーが提供するオフロード 機能を利用して演算の 1 部を M I C 上でオ フロード実行させ、処理速度を高めることも 可能。 ・CPU+MIC すべての計算リソース(CPU+MIC)をノード 単位で丸ごと占有。ハイブリッド・プログラム、 MIC のネイティブモードや Symmetric モー ドなどで利用する。 プログラム環 境は、インテルの Linux* 版 の開発ツール「インテル ® Cluster Studio XE」を採用し、研究者がそれぞれ、インテル ® For tran コンパイラー / インテル ® C++ コン パイラー、インテル ® MPI ライブラリーを利用 してプログラムを作成しています。朴氏は「プ ログラムによってはフリーのコンパイラーが効 果的な場合もあるため、コンパイラーやライブ ラリーには特定の製品を指定せず、研究者 がそれぞれ自由に選択して利用できる運用 体制を整えています」 と述べています。 素粒子理論、生命科学をはじめとした 計算科学アプリケーション開発に活用 COMA は、計算科学研究センターが独自に 先進的科学計算科学・計算工学研究を支援 する「学際共同利用プログラム」において、全 国の研究者が無償で利用できます。また、文 部科学省が進める「HPCI プログラム」での 無償利用、さらには全国の研究者が有償で 利用する「大規模一般利用プログラム」も用 意されています。 計算科学研究センターに所属する研究者は、 素粒子理論分野、分野宇宙物理学分野、生 命科学、物質科学分野、地球環境、計算情 報など各分野の計算科学アプリケーション 開発に、 「COMA」の高速並列計算を活かし た研究を行っています。2012 年に先行して 運用を開始した大規模並列 GPU クラスター 「HA-PACS」と、COMA の 使 い 分 けに つ いて朴氏は次のように語ります。 「研究内容による使い分けはありません。研 究者の好みに応じて選択していただき、研究 内容を精査したうえで、学際共同利用プロ グラムをご利用いただいています。ただし、 HA-PACS は、GPU 向けにコーディングさ れたプログラムを必要とするため、GPU に 最適化されたプログラムを動かすことが多く なります。それに対してインテル ® アーキテク チャーを採用した COMA は、汎用性が高く、 より多くのプログラムを走らせることができま す」 (朴氏) 大学院の学生に高性能計算の 講義を行い、計算科学の手法で 計算ができる人材を育成 COMA は現在、学際計算科学を推進する計 算科学研究センターの学生教育にも活用さ れています。朴氏は、 「今の日本は、自分でプ ログラムが作れる科学分野の研究者が、海 外と比べて圧倒的に不足しているのが現状 です。そこで、さまざまな研究分野の計算プ ログラムを研究者自らが作成し、計算科学の 手法で計算ができる人材をより多く育成して いくために、大学院の学生に対して高性能計 算手法や、高性能計算リテラシーの授業を 行っています。その他にも、高性能計算の概 論に関する集中講義を 40 人、50 人の大学 院生を集めて毎年開催し、高性能計算の知 識を持つ人材を送り出す取り組みを進めてい ます」 と述べています。 海外からの留学生が全編英語だけで講義 の受講や単位の取得ができる教育プログラム 「グローバル 30(G30)」においても留学生 に対して COMA や HA-PACS などのスパ コンに関する授業を実施し、高度な教育サー ビスを提供していく予定です。 計算科学研究センターでは今後、COMA を さまざまな研究分野で活用しながら、メニー コア・プロセッサーの性能研究を継続し、高 いパフォーマンスを実現するためのノウハウと 知見を獲得していくことを目指しています。さ らに、2015 年度の導入を予定している計算 科学研究センターと東京大学情報基盤セン ターが共同で運営するメニーコア・プロセッ サーを中心としたスパコンの実現に向けて、 調査、性能評価を続けていく方針です。 最後に朴氏は、インテルに対して「エクサフ ロップスを実現するために、さまざまな分野 におけるスパコン技術の検証・評価のフィー ドバックを期待しています」と述べています。 インテルはインテル ® Xeon® プロセッサーお よびインテル® Xeon Phi ™ コプロセッサーの 性能強化、MIC アーキテクチャーの進化を通 して、計算科学研究センターが進める学際 計算科学の発展を支えていきます。 インテル® Xeon Phi ™ コプロセッサーに 関する詳しい情報は、 下記のサイトをご覧ください。 http://www.intel.co.jp/XeonPhi 性能に関するテストや評価は、特定のコンピューター・システム、コンポーネント、またはそれらを組み合わせて行ったものであり、このテストによるインテル製品の性能の概算の値を表しているものです。システム・ハー ドウェア、 ソフトウェアの設計、構成などの違いにより、実際の性能は掲載された性能テストや評価とは異なる場合があります。システムやコンポーネントの購入を検討される場合は、ほかの情報も参考にして、パフォー マンスを総合的に評価することをお勧めします。インテル製品の性能評価についてさらに詳しい情報をお知りになりたい場合は、 「インテル・パフォーマンス - ベンチマークの限界」を参照してください。インテルは、本 資料で参照している第三者のベンチマーク・データまたは Web サイトの設計や実装について管理や監査を行っていません。本資料で参照している Web サイトまたは類似の性能ベンチマーク・データが報告されてい るほかの Web サイトも参照して、本資料で参照しているベンチマーク・データが購入可能なシステムの性能を正確に表しているかを確認されるようお勧めします。 インテル ® コンパイラーは、互換マイクロプロセッサー向けには、 インテル製マイクロプロセッサー向けと同等レベルの最適化が行われない可能性があります。これには、 インテル ® ストリーミング SIMD 拡張命令 2(イン インテル ® ストリーミング SIMD 拡張命令 3(インテル ® SSE3)、 ストリーミング SIMD 拡張命令 3 補足命令(SSSE3)命令セットに関連する最適化およびその他の最適化が含まれます。 インテルでは、 テル ® SSE2)、 インテル製ではないマイクロプロセッサーに対して、最適化の提供、機能、効果を保証していません。本製品のマイクロプロセッサー固有の最適化は、インテル製マイクロプロセッサーでの使用を目的としています。イン テル ® マイクロアーキテクチャーに非固有の特定の最適化は、インテル製マイクロプロセッサー向けに予約されています。この注意事項の適用対象である特定の命令セットの詳細は、該当する製品のユーザー・リファ レンス・ガイドを参照してください。 この文書は情報提供のみを目的としています。この文書は現状のまま提供され、いかなる保証もいたしません。ここにいう保証には、商品適格性、他者の権利の非侵害性、特定目的への適合性、また、あらゆる提案 書、仕様書、見本から生じる保証を含みますが、これらに限定されるものではありません。インテルはこの仕様の情報の使用に関する財産権の侵害を含む、いかなる責任も負いません。また、明示されているか否かに かかわらず、また禁反言によるとよらずにかかわらず、いかなる知的財産権のライセンスも許諾するものではありません。 Intel、インテル、Intel ロゴ、Xeon、Xeon Inside、Xeon Phi、Xeon Phi Inside は、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。 * その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。 インテル株式会社 〒 100-0005 東京都千代田区丸の内 3-1-1 http://www.intel.co.jp/ ©2014 Intel Corporation. 2014 年 7 月 無断での引用、転載を禁じます。 330732-001 JA JPN/1407/PDF/SE/ESS/FN
© Copyright 2026 Paperzz