Amazon DynamoDB
開発者ガイド
API Version 2012-08-10
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB: 開発者ガイド
Copyright © 2017 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any
manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other
trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to,
or sponsored by Amazon.
Amazon DynamoDB 開発者ガイド
Table of Contents
Amazon DynamoDB とは ............................................................................................................... 1
仕組み ................................................................................................................................. 2
コアコンポーネント ...................................................................................................... 2
DynamoDB API ............................................................................................................ 9
命名ルールおよびデータ型 ............................................................................................ 11
読み込み整合性 ........................................................................................................... 16
プロビジョニングされたスループット ............................................................................ 16
パーティションとデータ分散 ......................................................................................... 19
SQL から NoSQL へ ........................................................................................................... 23
SQL か NoSQL か ...................................................................................................... 23
データベースにアクセスする ......................................................................................... 25
テーブルの作成 ........................................................................................................... 26
テーブルに関する情報の取得 ......................................................................................... 28
テーブルへのデータの書き込み ..................................................................................... 29
テーブルからデータを読み込む ..................................................................................... 32
インデックス管理 ........................................................................................................ 37
テーブルのデータ変更 .................................................................................................. 40
テーブルからデータを削除する ..................................................................................... 42
テーブルの削除 ........................................................................................................... 43
DynamoDB のセットアップ .......................................................................................................... 44
DynamoDB (ダウンロード可能バージョン) のセットアップ ....................................................... 44
DynamoDB のダウンロードと実行 ................................................................................. 44
ローカルエンドポイントの設定 ..................................................................................... 46
使用に関する注意事項 .................................................................................................. 47
DynamoDB (ウェブサービス) のセットアップ .......................................................................... 48
AWS にサインアップする ............................................................................................. 48
AWS アクセスキー ID およびシークレットアクセスキーの取得 .......................................... 48
DynamoDB へのアクセス ............................................................................................................. 50
コンソールを使用する .......................................................................................................... 50
項目と属性を操作する .................................................................................................. 52
テーブルを監視する ..................................................................................................... 56
CloudWatch アラームを設定する ................................................................................... 57
DynamoDB ストリーム とトリガーの管理 ....................................................................... 57
CLI の使用 ......................................................................................................................... 58
AWS CLI のダウンロードと設定 .................................................................................... 59
DynamoDB での AWS CLI の使用 ................................................................................. 59
ダウンロード可能な DynamoDB での AWS CLI の使用 ..................................................... 60
API の使用 ......................................................................................................................... 61
DynamoDB を使用したプログラミング ........................................................................................... 62
DynamoDB の AWS SDK サポートの概要 ............................................................................... 62
プログラム用インターフェイス ............................................................................................. 64
低レベル インターフェイス .......................................................................................... 64
ドキュメント インターフェイス .................................................................................... 65
オブジェクト永続性インターフェイス ............................................................................ 66
DynamoDB 低レベル API ..................................................................................................... 68
リクエストの形式 ........................................................................................................ 70
レスポンスの形式 ........................................................................................................ 70
データ型記述子 ........................................................................................................... 71
数値データ ................................................................................................................. 72
バイナリデータ ........................................................................................................... 72
エラー処理 ......................................................................................................................... 72
エラーコンポーネント .................................................................................................. 73
エラーメッセージおよびコード ..................................................................................... 73
アプリケーションのエラー処理 ..................................................................................... 76
エラーの再試行とエクスポネンシャルバックオフ ............................................................. 76
API Version 2012-08-10
iv
Amazon DynamoDB 開発者ガイド
バッチオペレーションとエラー処理 ............................................................................... 77
DynamoDB 用の高レベルプログラミングインターフェイス ....................................................... 78
Java: DynamoDBMapper .............................................................................................. 78
.NET ドキュメントモデル ........................................................................................... 116
.NET: オブジェクト永続性モデル ................................................................................. 138
コードサンプルの実行 ........................................................................................................ 165
サンプルデータのロード ............................................................................................. 166
Java コードサンプル .................................................................................................. 171
.NET コードサンプル ................................................................................................. 173
PHP コードサンプル .................................................................................................. 175
DynamoDB の操作 ..................................................................................................................... 178
テーブルの操作 ................................................................................................................. 178
プライマリキーの指定 ................................................................................................ 179
テーブルの読み書き要件 ............................................................................................. 179
キャパシティーユニットの計算 .................................................................................... 181
テーブルのリストと情報を取得する .............................................................................. 183
DynamoDB のタグ付け ............................................................................................... 184
テーブルの操作 : Java ................................................................................................ 186
テーブルの操作 : .NET ................................................................................................ 191
テーブルの操作 : PHP ................................................................................................ 198
項目の操作 ....................................................................................................................... 204
概要 ......................................................................................................................... 205
項目を読み込む ......................................................................................................... 206
項目を書き込む ......................................................................................................... 206
バッチオペレーション ................................................................................................ 207
アトミックカウンタ ................................................................................................... 207
条件付きの書き込み ................................................................................................... 208
式を使用した項目の読み取りと書き込み ....................................................................... 210
項目の操作 : Java ...................................................................................................... 228
項目の操作 : .NET ...................................................................................................... 250
項目の操作 : PHP ...................................................................................................... 274
クエリおよびスキャンの使用 ............................................................................................... 287
Query ...................................................................................................................... 287
スキャン .................................................................................................................. 289
クエリまたはスキャンからの結果のフィルタリング ........................................................ 289
クエリおよびスキャンオペレーションによって消費されるキャパシティーユニット ............. 290
ページ単位の出力件数を指定 ....................................................................................... 290
制限 ......................................................................................................................... 290
応答での項目のカウント ............................................................................................. 291
読み込み整合性 ......................................................................................................... 291
クエリおよびスキャンのパフォーマンス ....................................................................... 292
並列スキャン ............................................................................................................ 292
クエリ ..................................................................................................................... 294
スキャニング ............................................................................................................ 310
インデックスの使用 ........................................................................................................... 333
グローバルセカンダリインデックス .............................................................................. 336
ローカルセカンダリインデックス ................................................................................. 383
ストリームの使用 .............................................................................................................. 426
DynamoDB ストリーム におけるエンドポイント ............................................................ 427
ストリームの有効化 ................................................................................................... 428
ストリームの読み込みと処理 ....................................................................................... 429
DynamoDB ストリーム Kinesis Adapter を使用したストリームレコードの処理 ................... 430
チュートリアル : DynamoDB ストリーム の低レベルの API ............................................. 443
クロスリージョン レプリケーション ............................................................................. 450
DynamoDB ストリーム と AWS Lambda のトリガー ...................................................... 451
認証とアクセスコントロール ....................................................................................................... 460
認証 ................................................................................................................................. 460
アクセスコントロール ........................................................................................................ 461
API Version 2012-08-10
v
Amazon DynamoDB 開発者ガイド
アクセス管理の概要 ........................................................................................................... 462
Amazon DynamoDB リソースおよびオペレーション ....................................................... 462
リソース所有権について ............................................................................................. 463
リソースへのアクセスの管理 ....................................................................................... 463
ポリシー要素の指定 : アクション、効果、プリンシパル .................................................. 464
ポリシーでの条件の指定 ............................................................................................. 465
アイデンティティベースのポリシー (IAM ポリシー) を使用する ................................................ 465
コンソールのアクセス許可 .......................................................................................... 466
Amazon DynamoDB での AWS 管理 (事前定義) ポリシー ................................................ 466
お客様が管理するポリシーの例 .................................................................................... 467
DynamoDB API の権限リファレンス .................................................................................... 473
関連トピック ............................................................................................................ 477
条件の使用 ....................................................................................................................... 477
概要 ......................................................................................................................... 477
条件の指定: 条件キーの使用 ........................................................................................ 480
関連トピック ............................................................................................................ 488
ウェブアイデンティティフェデレーションの使用 ................................................................... 488
ウェブアイデンティティフェデレーションに関するその他のリソース ................................ 488
ウェブアイデンティティフェデレーションのポリシー例 .................................................. 489
ウェブアイデンティティフェデレーションを使用するための準備 ...................................... 491
ウェブアイデンティティフェデレーションを使用するアプリケーションの記述 ................... 492
Amazon DynamoDB のモニタリング ............................................................................................ 495
モニタリングツール ........................................................................................................... 496
自動化ツール ............................................................................................................ 496
手動ツール ............................................................................................................... 496
Amazon CloudWatch でのモニタリング ................................................................................ 497
メトリクスとディメンション ....................................................................................... 497
メトリクスの使用 ...................................................................................................... 508
アラームの作成 ......................................................................................................... 509
AWS CloudTrail を使用した DynamoDB オペレーションのログ記録 .......................................... 511
CloudTrail での DynamoDB 情報 ................................................................................. 512
DynamoDB ログファイルエントリの概要 ...................................................................... 512
他の AWS のサービスとの統合 .................................................................................................... 518
Amazon Redshift との統合 .................................................................................................. 518
Amazon EMR との統合 ...................................................................................................... 519
概要 ......................................................................................................................... 520
チュートリアル: Amazon DynamoDB および Apache Hive の使用 ..................................... 520
Hive に外部テーブルを作成します。 ............................................................................. 527
HiveQL ステートメントの処理 ..................................................................................... 529
DynamoDB でのデータのクエリ .................................................................................. 530
Amazon DynamoDB でデータを出し入れする ................................................................ 532
パフォーマンスの調節 ................................................................................................ 544
Amazon Data Pipeline との統合 .......................................................................................... 548
データをエクスポートおよびインポートデータするための前提条件 ................................... 550
DynamoDB から Amazon S3 にデータをエクスポートする .............................................. 554
Amazon S3 から DynamoDB にデータをインポートする ................................................. 555
トラブルシューティング ............................................................................................. 556
AWS Data Pipeline と DynamoDB 用の定義済みテンプレート .......................................... 557
DynamoDB での制限 .................................................................................................................. 558
キャパシティーユニットとプロビジョニングされるスループット .............................................. 558
キャパシティーユニットサイズ .................................................................................... 558
プロビジョニングされたスループットの最小値と最大値 .................................................. 559
プロビジョニングされるスループットを増やす .............................................................. 559
プロビジョニングされるスループットを減らす .............................................................. 559
テーブル .......................................................................................................................... 560
テーブルのサイズ ...................................................................................................... 560
アカウントあたりのテーブル数 .................................................................................... 560
セカンダリインデックス ..................................................................................................... 560
API Version 2012-08-10
vi
Amazon DynamoDB 開発者ガイド
テーブルごとのセカンダリインデックス ....................................................................... 560
テーブルあたりの射影されたセカンダリインデックス属性 ............................................... 560
パーティションキーおよびソートキー ................................................................................... 560
パーティションキーの長さ .......................................................................................... 560
パーティションキーの値 ............................................................................................. 560
ソートキーの長さ ...................................................................................................... 561
ソートキー値 ............................................................................................................ 561
名前付けルール ................................................................................................................. 561
テーブル名およびセカンダリインデックス名 ................................................................. 561
属性名 ..................................................................................................................... 561
データ型 .......................................................................................................................... 561
文字列 ..................................................................................................................... 561
数値 ......................................................................................................................... 562
バイナリ .................................................................................................................. 562
アイテム .......................................................................................................................... 562
項目のサイズ ............................................................................................................ 562
ローカルセカンダリインデックスを持つテーブルの項目サイズ ......................................... 562
属性 ................................................................................................................................. 562
項目あたりの属性名と値のペア .................................................................................... 562
リスト、マップ、またはセットの値の最大数 ................................................................. 563
属性値 ..................................................................................................................... 563
入れ子の属性の深さ ................................................................................................... 563
式パラメーター ................................................................................................................. 563
長さ ......................................................................................................................... 563
演算子およびオペランド ............................................................................................. 563
予約語 ..................................................................................................................... 563
DynamoDB ストリーム ....................................................................................................... 563
DynamoDB ストリーム のシャードの同時リーダー ......................................................... 563
ストリームが有効なテーブルの最大書き込みキャパシティー ............................................ 564
API 固有の制限 ................................................................................................................. 564
ベストプラクティス ................................................................................................................... 565
テーブルのベストプラクティス ............................................................................................ 565
項目のベストプラクティス .................................................................................................. 565
クエリとスキャンのベストプラクティス ............................................................................... 566
ローカルセカンダリインデックス のベストプラクティス ......................................................... 566
グローバルセカンダリインデックス のベストプラクティス ...................................................... 566
テーブルの操作のガイドライン ............................................................................................ 566
テーブル内のすべての項目に対して均一なデータアクセスを実現する設計 ......................... 567
パーティションの動作について .................................................................................... 569
急激に増大するキャパシティーは控えめに使用する ........................................................ 573
データアップロード時に書き込みアクティビティを分散する ............................................ 573
時系列データへのアクセスパターンを理解する .............................................................. 574
人気の高い項目をキャッシュに格納する ....................................................................... 575
プロビジョニングされたスループットを調整するときにワークロードの均一性を考慮する .... 575
大規模環境でのアプリケーションのテスト .................................................................... 576
項目の操作のガイドライン .................................................................................................. 577
大規模な設定属性の代わりに 1 対多のテーブルを使用する .............................................. 577
複数テーブルの使用による多様なアクセスパターンのサポート ......................................... 578
大量の属性値を圧縮する ............................................................................................. 579
Amazon S3 に大量の属性値を格納する ......................................................................... 580
大量の属性を複数の項目に分割する .............................................................................. 580
クエリおよびスキャンのガイドライン ................................................................................... 581
読み込みアクティビティの急激な増大の回避 ................................................................. 581
並列スキャンの利用 ................................................................................................... 583
ローカルセカンダリインデックス のガイドライン .................................................................. 584
インデックスの使用は控えめにする .............................................................................. 584
射影を慎重に選択する ................................................................................................ 584
フェッチを回避するための頻繁なクエリの最適化 ........................................................... 585
API Version 2012-08-10
vii
Amazon DynamoDB 開発者ガイド
スパースなインデックスの利用 .................................................................................... 585
項目コレクションの拡張の監視 .................................................................................... 586
グローバルセカンダリインデックス のガイドライン ............................................................... 586
ワークロードが均一になるようにキーを選択する ........................................................... 586
スパースなインデックスの利用 .................................................................................... 587
グローバルセカンダリインデックス を使用したすばやい検索 ........................................... 587
結果整合性のある読み込みレプリカを作成する .............................................................. 587
付録 ......................................................................................................................................... 589
サンプルテーブルとデータ .................................................................................................. 589
サンプルデータファイル ............................................................................................. 590
サンプルテーブルの作成とデータのアップロード ................................................................... 599
サンプルテーブルの作成とデータのアップロード – Java ................................................. 600
サンプルテーブルの作成とデータのアップロード – .NET ................................................. 608
サンプルテーブルの作成とデータのアップロード – PHP ................................................. 617
AWS SDK for Python(Boto)を使用したサンプルアプリケーション ......................................... 626
ステップ 1: ローカルにデプロイおよびテストを実行する ................................................. 627
ステップ 2: データモデルと実装の詳細を調べる ............................................................. 630
ステップ 3: 本稼働環境でのデプロイ ............................................................................ 637
ステップ 4: リソースをクリーンアップする ................................................................... 644
DynamoDB 用の追加のツールとリソース .............................................................................. 644
Amazon DynamoDB Storage Backend for Titan ............................................................. 645
Amazon DynamoDB 用 Logstash プラグイン ................................................................. 668
DynamoDB の予約語 .......................................................................................................... 668
レガシー条件パラメータ ..................................................................................................... 678
AttributesToGet ......................................................................................................... 679
AttributeUpdates ........................................................................................................ 680
ConditionalOperator ................................................................................................... 681
Expected .................................................................................................................. 682
KeyConditions ........................................................................................................... 685
QueryFilter ................................................................................................................ 687
ScanFilter ................................................................................................................. 689
レガシー パラメータを使用した条件書き込み ................................................................ 690
現在の低レベル API バージョン (2012-08-10) ........................................................................ 696
前バージョンの低レベル API (2011-12-05) ............................................................................ 697
BatchGetItem ............................................................................................................ 697
BatchWriteItem .......................................................................................................... 703
CreateTable .............................................................................................................. 708
DeleteItem ................................................................................................................ 713
DeleteTable .............................................................................................................. 717
DescribeTables ......................................................................................................... 721
GetItem .................................................................................................................... 724
ListTables ................................................................................................................. 726
PutItem .................................................................................................................... 728
Query ...................................................................................................................... 734
スキャン .................................................................................................................. 743
UpdateItem ............................................................................................................... 754
UpdateTable ............................................................................................................. 760
ドキュメント履歴 ...................................................................................................................... 764
API Version 2012-08-10
viii
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB とは
これは Amazon DynamoDB 開発者ガイド です。
Amazon DynamoDB は、完全に管理された NoSQL データベースサービスで、高速かつ予測可能なパ
フォーマンスとシームレスな拡張性を提供します。DynamoDB を使用すると、分散データベースの運
用とスケーリングに伴う管理作業をまかせることができるため、ハードウェアのプロビジョニング、
設定と構成、レプリケーション、ソフトウェアパッチ適用、クラスタースケーリングなどを自分で行
う必要はなくなります。
DynamoDB では、任意の量のデータを保存および取得できるデータベーステーブルを作成し、任意の
レベルのリクエストトラフィックを処理できます。ダウンタイムやパフォーマンスの低下を発生させ
ずに、テーブルのスループット容量を拡張または縮小し、AWS マネジメントコンソールを使用して、
リソースの利用率とパフォーマンスメトリクスをモニタリングできます。
DynamoDB は十分な数のサーバー間でデータとトラフィックを自動的に分散し、一貫した高速なパ
フォーマンスを維持したまま、スループットとストレージの要件に対応します。すべてのデータは
SSD (Solid State Disk) に保存され、1 つの AWS リージョン内の複数のアベイラビリティーゾーン間
で自動的にレプリケートすることによって、高い可用性とデータ堅牢性を実現します。
最初に以下のセクションを読むことをお勧めします。
• Amazon DynamoDB: 仕組み (p. 2)—DynamoDB の基本的な概念を学習します。
• DynamoDB のセットアップ (p. 44)—DynamoDB (ダウンロード可能バージョンまたはウェブ
サービス) をセットアップする方法を学習します。
• DynamoDB へのアクセス (p. 50)—コンソール、CLI、または API を使用して DynamoDB にアク
セスする方法を学習します。
アプリケーション開発の詳細については、以下を参照してください。
• DynamoDB および AWS SDK を使用したプログラミング (p. 62)
• DynamoDB の操作 (p. 178)
Note
言語固有のチュートリアルとサンプルコードを「Amazon DynamoDB 入門ガイド」で参照
することもできます。AWS SDK は、さまざまな言語で利用できます。詳細なリストについ
ては、「Tools for Amazon Web Services」を参照してください。
API Version 2012-08-10
1
Amazon DynamoDB 開発者ガイド
仕組み
パフォーマンスを最大にしてスループットコストを最小にするための推奨事項をすばやく見つけるに
は、「DynamoDB のベストプラクティス (p. 565)」を参照してください。DynamoDB リソースにタ
グ付けする方法については、「DynamoDB のタグ付け (p. 184)」を参照してください。
最後に、リレーショナルデータベース管理システム (RDBMS) データベースを識別し、DynamoDB に
移行する場合は、「RDBMS から Amazon DynamoDB への移行のベストプラクティス」を参照してく
ださい。
Amazon DynamoDB: 仕組み
以下のセクションでは、Amazon DynamoDB サービスコンポーネントと、それらの対話方法の概要を
示します。
この概要を読んだ後は、「テーブルの作成とサンプルデータのロード (p. 166)」セクションの操作を
お試しください。このセクションでは、サンプルテーブルを作成し、データをアップロードして、い
くつかの基本的なデータベース操作を実行します。
言語固有のチュートリアルとサンプルコードを「Amazon DynamoDB 入門ガイド」で参照することも
できます。
トピック
• DynamoDB コアコンポーネント (p. 2)
• DynamoDB API (p. 9)
• 命名ルールおよびデータ型 (p. 11)
• 読み込み整合性 (p. 16)
• プロビジョニングされたスループット (p. 16)
• パーティションとデータ分散 (p. 19)
DynamoDB コアコンポーネント
DynamoDB では、テーブル、項目、および属性が、操作するコアコンポーネントです。テーブルは項
目の集合であり、各項目は属性の集合です。DynamoDB はプライマリキーを使用してテーブルの各項
目を一意に識別し、セカンダリインデックスを使用してクエリの柔軟性を高めます。DynamoDB スト
リーム を使用して、DynamoDB テーブルのデータ変更イベントをキャプチャできます。
DynamoDB には制限があります。詳細については、「DynamoDB での制限 (p. 558)」を参照してく
ださい。
トピック
• テーブル、項目、属性 (p. 2)
• プライマリキー (p. 5)
• セカンダリインデックス (p. 6)
• DynamoDB ストリーム (p. 8)
テーブル、項目、属性
DynamoDB の基本コンポーネントは次のとおりです。
• テーブル – 他のデータベース管理システムと同様、DynamoDB はデータをテーブルに保存しま
す。テーブルは、データのコレクションです。たとえば、個人の連絡先情報を保存するために使用
できる People (以下に示す) というテーブルの例を参照してください。
API Version 2012-08-10
2
Amazon DynamoDB 開発者ガイド
コアコンポーネント
• 項目 – 各テーブルには複数の項目が含まれています。項目は、他のすべての項目間で一意に識別可
能な属性のグループです。DynamoDB の項目は、多くの点で他のリレーショナルデータベースシス
テムの行、レコード、またはタプルに似ています。例の People テーブルでは、各項目は人を表し
ます。
• 属性 – 各項目は 1 つ以上の属性で構成されます。属性は、基盤となるデータ要素であり、そ
れ以上分割する必要がないものです。DynamoDB 内の属性は、多くの点で他のデータベー
スシステムのフィールドや列に似ています。たとえば、People サンプルテーブルの項目に
は、PersonID、LastName、FirstName のような名前の属性が含まれます。
次の図は、いくつかの項目と属性の例を含む、People という名前のテーブルを示しています。
People テーブルについて、以下の点に注意してください。
• テーブルの各項目には一意の識別子があります。これは、テーブルの他のすべての項目からその項
目を区別するプライマリキーです。People テーブルで、プライマリキーは 1 つの属性 (PersonID)
で構成されます。
• プライマリキー以外、People テーブルはスキーマレスです。つまり、属性またはデータ型を事前
に定義する必要はありません。各項目は、独自の固有の属性を持つことができます。
• 属性のほとんどはスカラーです。つまり、1 つの値のみを持つことができます。文字列と数値はス
カラーの一般的な例です。
• 項目の一部には、入れ子の属性 (Address) があります。DynamoDB は深さが最大 32 レベルの入れ
子の属性をサポートします。
以下は、音楽コレクションを継続して追跡するために使用できる、Music という名前の別のサンプル
テーブルです。
API Version 2012-08-10
3
Amazon DynamoDB 開発者ガイド
コアコンポーネント
Music テーブルについて、以下の点に注意してください。
• Music のプライマリキーは 2 つの属性 (Artist および SongTitle) で構成されます。テーブルの
各項目にはこれら 2 つの属性が必要です。Artist および SongTitle の組み合わせにより、テー
ブルの各項目が他のすべての項目から区別されます。
• プライマリキー以外、Music テーブルはスキーマレスです。つまり、属性またはデータ型を事前に
定義する必要はありません。各項目は、独自の固有の属性を持つことができます。
• 項目の 1 つに、入れ子の属性 (PromotionInfo) があります。これには、入れ子の他の属性が含ま
れます。DynamoDB は深さが最大 32 レベルの入れ子の属性をサポートします。
詳細については、「DynamoDB でのテーブルの操作 (p. 178)」を参照してください。
API Version 2012-08-10
4
Amazon DynamoDB 開発者ガイド
コアコンポーネント
プライマリキー
テーブルを作成する場合には、テーブル名に加えて、テーブルのプライマリキーを指定する必要があ
ります。プライマリキーはテーブルの各項目を一意に識別するため、テーブル内の 2 つの項目が同じ
キーを持つことはありません。
DynamoDB は 2 種類の異なるプライマリキーをサポートします。
• パーティションキー – パーティションキーという 1 つの属性で構成されたシンプルなプライマリ
キー。
DynamoDB は、パーティションキーの値を内部ハッシュ関数への入力として使用します。ハッシュ
関数からの出力により、項目が保存されるパーティション (DynamoDB 内部の物理ストレージ) が決
まります。
パーティションキーのみを含むテーブルでは、2 つの項目が同じパーティションキー値を持つこと
はできません。
「テーブル、項目、属性 (p. 2)」で説明されている People テーブルは、シンプルなプライマリ
キー (PersonID) があるテーブルの例です。この項目に値 PersonId を指定すると、People テー
ブルの任意の項目にすぐにアクセスできます。
• パーティションとソートキー – 複合プライマリキーと呼ばれるこのキーのタイプは、2 つの属性で
構成されます。最初の属性はパーティションキーであり、2 番目の属性はソートキーです。
DynamoDB は、パーティションキーの値を内部ハッシュ関数への入力として使用します。ハッシュ
関数からの出力により、項目が保存されるパーティション (DynamoDB 内部の物理ストレージ) が決
まります。同じパーティションキーを持つすべての項目は、ソートキー値でソートされてまとめて
保存されます。
パーティションキーとソートキーがあるテーブルでは、2 つの項目が同じパーティションキー値を
持つこともできます。ただし、それらの 2 つの項目には別のソートキー値が必要です。
「テーブル、項目、属性 (p. 2)」で説明されている Music テーブルは、複合プライマリキー
(Artist および SongTitle) があるテーブルの例です。この Music テーブルの任意の項目には、
その項目の Artist および SongTitle 値を指定すればすぐにアクセスできます。
複合プライマリキーは、データのクエリを実行するときに柔軟性を高めます。たとえば、Artist
の値のみを指定した場合、DynamoDB はそのアーティストのすべての曲を取得します。Artist の
値と SongTitle の範囲を指定し、特定のアーティストの曲のサブセットのみを取得することもで
きます。
Note
項目のパーティションキーは、そのハッシュ属性とも呼ばれます。ハッシュ属性という用語
は、DynamoDB が内部のハッシュ関数を使用し、パーティションキーの値に基づいてパー
ティション間でデータ項目を均等に分散することに由来しています。
項目のソートキーは、範囲属性とも呼ばれます。範囲属性という用語は、ソートキー値で並
べ替えられた順に、DynamoDB が同じパーティションキーを持つ項目どうしを物理的に近く
に保存する方法に由来しています。
各プライマリキー属性はスカラー値 (単一値のみを保持できる) である必要があります。プライマリ
キー属性に許可される唯一のデータ型は、文字列、数値、またはバイナリです。他のキー以外の属性
では、このような制限はありません。
API Version 2012-08-10
5
Amazon DynamoDB 開発者ガイド
コアコンポーネント
セカンダリインデックス
テーブルで 1 つ以上のセカンダリインデックスを作成できます。セカンダリインデックス では、プラ
イマリキーに対するクエリに加えて、代替キーを使用して、テーブル内のデータのクエリを行うこと
ができます。DynamoDB ではインデックスを使用する必要はありませんが、インデックスを使用する
と、データのクエリを実行するときにアプリケーションの柔軟性が高まります。
DynamoDB では、次の 2 種類のインデックスをサポートしています。
• Global secondary index – テーブルと異なるパーティションキーとソートキーを持つインデックス。
• ローカルセカンダリインデックス – テーブルと同じパーティションキーと、異なるソートキーを持
つインデックス。
テーブルあたり最大 5 個のグローバルセカンダリインデックスと 5 個のローカルセカンダリインデッ
クスまで定義できます。
前に示した Music サンプルテーブルでは、Artist (パーティションキー) または Artist および
SongTitle (パーティションキーとソートキー) によってデータ項目にクエリを実行できます。Genre
および AlbumTitle によってデータにクエリを実行する場合はどうでしょうか。これを行うには、こ
れらの属性にインデックスを作成し、Music テーブルのクエリと同様に、インデックスにクエリを実
行できます。
次の図は、GenreAlbumTitle という新しいインデックスがある Music サンプルテーブルを示してい
ます。
API Version 2012-08-10
6
Amazon DynamoDB 開発者ガイド
コアコンポーネント
GenreAlbumTitle インデックスについて、以下の点に注意してください。
• 各インデックスはテーブルに属します。これをインデックスの基本テーブルと呼びます。前述の例
では、Music が GenreAlbumTitle インデックスの基本テーブルです。
• DynamoDB はインデックスを自動的に維持します。基本テーブルの項目を追加、更新、または削除
すると、DynamoDB はそのテーブルに属するすべてのインデックスの対応する項目を追加、更新、
または削除します。
• インデックスを作成するときは、基本テーブルからインデックスにコピーまたは射影される属性を
指定します。少なくとも、DynamoDB は基本テーブルからインデックスにキー属性を射影します。
これは GenreAlbumTitle のケースで、Music テーブルのキー属性のみがインデックスに射影され
ます。
API Version 2012-08-10
7
Amazon DynamoDB 開発者ガイド
コアコンポーネント
GenreAlbumTitle インデックスにクエリを実行し、特定のジャンルのすべてのアルバム (たとえ
ば、すべての Rock アルバム) を検索できます。また、インデックスにクエリを実行して、特定のジャ
ンル内のすべてのアルバムのうち、特定のアルバムタイトル (たとえば、タイトルが文字 H で始まる
すべての Country アルバム) のみを検索することもできます。
詳細については、「セカンダリインデックスを使用したデータアクセス性の向上 (p. 333)」を参照し
てください。
DynamoDB ストリーム
DynamoDB ストリーム は、DynamoDB テーブルのデータ変更イベントをキャプチャするオプション
の機能です。これらのイベントに関するデータは、ほとんどリアルタイムに、イベントの発生順にス
トリームに表示されます。
各イベントはストリームレコードによって表されます。テーブルでストリームを有効にする
と、DynamoDB ストリーム は次のいずれかのイベントが発生するたびに、ストリームレコードを書
き込みます。
• 新しい項目がテーブルに追加された場合、ストリームはすべての属性を含む項目全体のイメージを
キャプチャします。
• 項目が更新された場合、ストリームは項目で変更された属性について、「前」と「後」のイメージ
をキャプチャします。
• テーブルから項目を削除する場合、ストリームは項目が削除される前に項目全体のイメージを取得
します。
各ストリームレコードには、テーブルの名前、イベントのタイムスタンプ、およびその他のメタデー
タも含まれます。ストリームレコードには 24 時間の有効期間があり、その後はストリームから自動
的に削除されます。
DynamoDB ストリーム は AWS Lambda と共に使用してトリガーを作成できます。これは、スト
リームで関心のあるイベントが発生するたびに自動的に実行されるコードです。たとえば、会社の
顧客情報を含む Customers テーブルがあるとします。新規の各顧客に、歓迎の E メールを送信す
るとします。そのテーブルでストリームを有効にし、そのストリームを Lambda 関数に関連付けま
す。Lambda 関数は、新しいストリームレコードが表示されるたびに実行されますが、Customers
テーブルに追加された新しい項目を処理するのみです。EmailAddress 属性を持つ項目につい
て、Lambda 関数は Amazon Simple Email Service (Amazon SES) を呼び出してそのアドレスに E
メールを送信します。
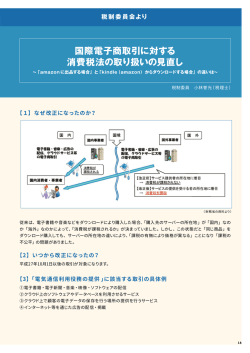
このシナリオを以下に図で示します。
API Version 2012-08-10
8
Amazon DynamoDB 開発者ガイド
DynamoDB API
Note
この例で、最後の顧客 Craig Roe は、EmailAddress がないために E メールを受信しないこ
とに注意してください。
トリガーに加えて、DynamoDB ストリーム は AWS リージョン内および AWS リージョン間のデータ
レプリケーション、DynamoDB テーブル内のデータのマテリアライズされたビュー、Amazon Kinesis
のマテリアライズされたビューを使用したデータ分析など、数多くの強力なソリューションを可能に
します。
詳細については、「DynamoDB ストリーム を使用したテーブルアクティビティのキャプ
チャ (p. 426)」を参照してください。
DynamoDB API
DynamoDB を使用するには、アプリケーションでいくつかの簡単な API オペレーションを使用する必
要があります。以下に、カテゴリー別にこれらのオペレーションの概要を示します。
トピック
• コントロールプレーン (p. 10)
• データプレーン (p. 10)
• DynamoDB ストリーム (p. 11)
API Version 2012-08-10
9
Amazon DynamoDB 開発者ガイド
DynamoDB API
コントロールプレーン
コントロールプレーンの操作では、DynamoDB テーブルを作成、管理できます。また、インデック
ス、ストリーム、およびテーブルに依存する他のオブジェクトを操作できます。
• CreateTable – 新しいテーブルを作成します。オプションで、1 つ以上のセカンダリインデックス
を作成し、テーブルに対して DynamoDB ストリーム を有効にできます。
• DescribeTable – プライマリキーのスキーマ、スループット設定、インデックス情報など、テー
ブルに関する情報を返します。
• ListTables – リストのすべてのテーブルの名前を返します。
• UpdateTable – テーブルまたはそのインデックスの設定を変更、テーブルの新しいインデックスを
作成または削除、またはテーブルの DynamoDB ストリーム 設定を変更します。
• DeleteTable – テーブルとそのすべての依存オブジェクトを DynamoDB から削除します。
データプレーン
データプレーンオペレーションでは、テーブルのデータで、作成、読み込み、更新、および削除
(CRUD とも呼ばれます) アクションを実行できます。一部のデータプレーンオペレーションでも、セ
カンダリインデックス からデータを読み込むことができます。
データの作成
• PutItem – テーブルに単一の項目を書き込みます。プライマリキー属性を指定する必要があります
が、その他の属性を指定する必要はありません。
• BatchWriteItem – 25 個の項目をテーブルに書き込みます。これは、PutItem を複数回呼び出
すよりも効率的です。アプリケーションで項目を書き込むために、1 回のネットワークラウンドト
リップのみで済むためです。また、BatchWriteItem を使用して、1 つ以上のテーブルから複数の
項目を削除することもできます。
データの読み取り
• GetItem – テーブルから単一の項目を取り出します。目的の項目のプライマリキーを指定する必要
があります。項目全体またはその属性のサブセットのみを取り出すことができます。
• BatchGetItem – 1 つ以上のテーブルから 100 個の項目を取り出します。これは、GetItem を複数
回呼び出すよりも効率的です。アプリケーションで項目を読み込むために、1 回のネットワークラ
ウンドトリップのみで済むためです。
• Query – 特定のパーティションキーがあるすべての項目を取り出します。パーティションキーの値
を指定する必要があります。項目全体またはその属性のサブセットのみを取り出すことができま
す。オプションで、ソートキーの値に条件を適用し、同じパーティションキーがあるデータのサブ
セットだけを取り出すことができます。テーブルにパーティションキーとソートキーの両方を持つ
テーブルがある場合、テーブルでこのオペレーションを使用できます。また、インデックスにパー
ティションキーとソートキーの両方がある場合、インデックスでこのオペレーションを使用できま
す。
• Scan – 指定されたテーブルまたはインデックスのすべての項目を取り出します。項目全体またはそ
の属性のサブセットのみを取り出すことができます。オプションでフィルタリング条件を適用する
と、関心のある値のみを返し、残りは破棄できます。
データの更新
• UpdateItem – 項目の 1 つ以上の属性を変更します。変更する項目のプライマリキーを指定する必
要があります。新しい属性を追加したり、既存の属性を変更または削除したりできます。ユーザー
定義の条件を満たす場合にのみ更新が成功するように、条件付きの更新を実行できます。オプショ
API Version 2012-08-10
10
Amazon DynamoDB 開発者ガイド
命名ルールおよびデータ型
ンで、アトミックカウンタを実装できます。このカウンタは、他の書き込みリクエストを妨害する
ことなく、数値属性をインクリメントまたはデクリメントします。
データの削除
• DeleteItem – テーブルから単一の項目を削除します。削除する項目のプライマリキーを指定する
必要があります。
• BatchWriteItem – 1 つ以上のテーブルから最大 25 個の項目を削除します。これは、DeleteItem
を複数回呼び出すよりも効率的です。アプリケーションで項目を削除するために、1 回のネット
ワークラウンドトリップのみで済むためです。また、BatchWriteItem を使用して、1 つ以上の
テーブルに複数の項目を追加することもできます。
DynamoDB ストリーム
DynamoDB ストリーム オペレーションでは、テーブルのストリームを有効または無効にし、スト
リームに含まれるデータ変更レコードにアクセスすることができます。
• ListStreams – すべてのストリームのリスト、または特定のテーブルのストリームのみを返しま
す。
• DescribeStream – Amazon リソースネーム (ARN)、アプリケーションが最初のいくつかのスト
リームレコードの読み込みを開始できる場所など、ストリームに関する情報を返します。
• GetShardIterator – シャードイテレーターを返します。これは、ストリームからレコードを取得
するためにアプリケーションが使用するデータ構造です。
• GetRecords – 特定のシャードイテレーターを使用して 1 つ以上のストリームレコードを取得しま
す。
命名ルールおよびデータ型
このセクションでは、DynamoDB の命名規則と、DynamoDB がサポートするさまざまなデータ
型について説明します。データタイプに適用される制限があります。詳細については、「データ
型 (p. 561)」を参照してください。
トピック
• 名前付けルール (p. 11)
• データ型 (p. 12)
名前付けルール
DynamoDB のテーブル、属性、および他のオブジェクトには名前が必要です。名前は有意義で簡潔
である必要があります。たとえば、Products、Books、Authors などの名前は見ればすぐわかりま
す。
DynamoDB の命名規則は次のとおりです。
• すべての名前は UTF-8 を使用してエンコードする必要があり、大文字と小文字が区別されます。
• テーブル名とインデックス名の長さは 3~255 文字で、次の文字のみを含めることができます。
• a-z
• A-Z
• 0-9
• _ (下線)
API Version 2012-08-10
11
Amazon DynamoDB 開発者ガイド
命名ルールおよびデータ型
• - (ダッシュ)
• . (ドット)
• 属性名の長さは 1~255 文字である必要があります。
予約語と特殊文字
その他のデータベース管理システムと同様、DynamoDB には予約語と特殊文字のリストがあります。
• DynamoDB の予約語の一覧については、「DynamoDB の予約語 (p. 668)」を参照してください。
• DynamoDB では、# (ハッシュ) および: (コロン) に特別な意味があります。
DynamoDB では、命名目的でこれらの予約語と特殊文字を使用することができますが、お勧めしませ
ん。これは、式でこれらの名前を使用するたびに、プレースホルダー変数を定義する必要があるため
です。
詳細については、「属性の名前および値でのプレースホルダーの使用 (p. 213)」を参照してくださ
い。
データ型
DynamoDB では、テーブル内の属性に対してさまざまなデータ型がサポートされています。データ型
は次のように分類できます。
• スカラー型 – スカラー型は 1 つの値を表すことができます。スカラー型は、数値、文字列、バイナ
リ、ブール、および null です。
• ドキュメント型 – ドキュメント型は、JSON ドキュメントで見られるもののように、入れ子の属性
を持つ複雑な構造を表すことができます。ドキュメント型は、リストとマップです。
• セット型 – セット型は複数のスカラー値を表すことができます。セット型は、文字セット、数値
セット、およびバイナリセットです。
テーブルまたは セカンダリインデックス を作成するときは、各プライマリキー属性 (パーティション
キーとソートキー) の名前とデータ型を指定する必要があります。さらに、各プライマリキー属性は、
文字列、数値、またはバイナリとして定義する必要があります。
DynamoDB は NoSQL データベースであり、スキーマレスです。つまり、プライマリキー属性以外
に、テーブルの作成時に属性またはデータ型を定義する必要はありません。これに対して、リレー
ショナルデータベースでは、テーブルの作成時に各列の名前とデータ型を定義する必要があります。
ここでは、各データ型についてJSON 形式の例を挙げて説明します。
スカラー型
スカラー型は、数値、文字列、バイナリ、ブール、および null です。
文字列
文字列は、UTF-8 バイナリエンコードの Unicode です。文字列の長さは、0 より大きい必要があ
り、DynamoDB 項目の最大サイズ 400 KB によって制限されます。
プライマリキー属性を文字列型属性として定義する場合、以下の制約がさらに適用されます。
• シンプルなプライマリキーの場合、最初の属性値 (パーティションキー) の最大長は 2048 バイト で
す。
• 複合プライマリキーの場合、2 番目の属性値 (ソートキー) の最大長は 1024 バイト です。
API Version 2012-08-10
12
Amazon DynamoDB 開発者ガイド
命名ルールおよびデータ型
DynamoDB は、基礎となる UTF-8 文字列エンコードのバイトを使用して文字列を照合し、比較しま
す。たとえば、「a」(0x61) は「A」(0x41) より大きく、「¿」(0xC2BF) は 「z」(0x7A) より大きいで
す。
Example
"Bicycle"
文字列データ型を使用して、日付またはタイムスタンプを表すことができます。これを行う 1 つの方
法は、これらの例に示すように、ISO 8601 文字列を使用することです。
• 2016-02-15
• 2015-12-21T17:42:34Z
• 20150311T122706Z
詳細については、http://en.wikipedia.org/wiki/ISO_8601 を参照してください。
数値
数値は、正、負、または 0 とすることができます。数値は最大 38 桁の精度であり、これを超えると
例外が発生します。
• 正の範囲: 1E-130~9.9999999999999999999999999999999999999E+125
• 負の範囲: -9.9999999999999999999999999999999999999E+125~-1E-130
DynamoDB では、数値は可変長で表されます。先頭と末尾の 0 は切り捨てられます。
すべての数値はネットワーク経由で文字列として DynamoDB に送信され、言語やライブラリ間の互
換性が最大になります。ただし、DynamoDB は算術演算では数値を数値型属性として扱います。
Note
数値の精度が重要な場合は、数値型から変換する文字列を使用して、DynamoDB に数値を渡
します。
Example
300
数値データ型を使用して、日付またはタイムスタンプを表すことができます。これを行う 1 つの方法
は、エポック時間 (1970 年 1 月 1 日の 00:00:00 UTC 以降の秒数) を使用することです。たとえば、
エポック時間 1437136300 は、2015 年 7 月 17 日の 12:31:40 UTC を表します。
詳細については、http://en.wikipedia.org/wiki/Unix_time を参照してください。
バイナリ
バイナリ型の属性には、圧縮テキスト、暗号化データ、イメージなど、任意のバイナリデータが保存
されます。DynamoDB は、バイナリ値を比較するたびに、各バイナリデータを符号なしとして扱いま
す。
API Version 2012-08-10
13
Amazon DynamoDB 開発者ガイド
命名ルールおよびデータ型
バイナリ属性の長さは 0 より大きい必要があり、DynamoDB 項目の最大サイズ 400 KB によって制限
されます。
プライマリキー属性をバイナリ型属性として定義する場合、以下の制約がさらに適用されます。
• シンプルなプライマリキーの場合、最初の属性値 (パーティションキー) の最大長は 2048 バイト で
す。
• 複合プライマリキーの場合、2 番目の属性値 (ソートキー) の最大長は 1024 バイト です。
アプリケーションは、DynamoDB に送信する前に、base64 エンコード形式のバイナリ値をエンコー
ドする必要があります。DynamoDB は、これらの値を受信すると、データを符号なしバイト配列にデ
コードし、それをバイナリ属性の長さとして使用します。
Example
次に示しているのはバイナリ属性の例であり、Base64 でエンコードされたテキストを使用していま
す。
dGhpcyB0ZXh0IGlzIGJhc2U2NC1lbmNvZGVk
ブール
ブール型の属性には、true または false が格納されます。
Example
true
Null
Null は不明または未定義の状態の属性を表します。
Example
NULL
ドキュメント型
ドキュメント型は、リストとマップです。これらのデータ型は、相互に入れ子にして、最大 32 レベ
ルの深さまで複雑なデータ構造を表すことができます。
値を含む項目が DynamoDB のサイズ制限 (400 KB) 内である限り、リストまたはマップの値の最大数
の制限はありません。
属性値は空の文字列または空のセット (文字列セット、数値セット、またはバイナリセット) にす
ることはできません。ただし、空のリストおよびマップは許可されます。詳細については、「属
性 (p. 562)」を参照してください。
リスト
リスト型の属性には、順序付きの値のコレクションを保存できます。リストは角括弧で囲まれます:
[ ... ]
API Version 2012-08-10
14
Amazon DynamoDB 開発者ガイド
命名ルールおよびデータ型
リストは JSON 配列に似ています。リスト要素に保存できるデータ型に制限はなく、リスト要素の要
素が同じ型である必要はありません。
次の例は、2 つの文字列と数が含まれるリストを示します。
Example
FavoriteThings: ["Cookies", "Coffee", 3.14159]
Note
DynamoDB では、要素が深い入れ子になっていても、リスト内の個々の要素を操作できま
す。詳細については、「ドキュメントパス (p. 212)」を参照してください。
マップ
マップ型属性は、順序なしの名前と値のペアのコレクションを保存できます。マップは中括弧で囲ま
れます: { ... }
マップは、JSON オブジェクトと同様です。マップの要素に保存できるデータ型に制限はなく、マッ
プの要素が同じ型である必要はありません。
マップは DynamoDB で JSON ドキュメントを保存するのに最適です。以下の例は、文字列、数値、
別のマップを含む入れ子のリストを要素とするマップを示しています。
Example
{
Day: "Monday",
UnreadEmails: 42,
ItemsOnMyDesk: [
"Coffee Cup",
"Telephone",
{
Pens: { Quantity : 3},
Pencils: { Quantity : 2},
Erasers: { Quantity : 1}
}
]
}
Note
DynamoDB では、要素が深い入れ子になっていても、マップ内の個々の要素を操作できま
す。詳細については、「ドキュメントパス (p. 212)」を参照してください。
セット
DynamoDB は、数値、文字列、またはバイナリ値のセットを表す型をサポートします。セット内のす
べての要素は、同じ型である必要があります。たとえば、数値セット型の属性は数値のみを含むこと
ができ、文字列セットは文字列のみを含むことができるなどです。
API Version 2012-08-10
15
Amazon DynamoDB 開発者ガイド
読み込み整合性
値を含む項目が DynamoDB のサイズ制限 (400 KB) 内である限り、セットの値の最大数の制限はあり
ません。
設定内の各値は一意である必要があります。設定内の値の順序は保持されません。したがって、アプ
リケーションは、設定内の要素の特定の順序に依存することはできません。最後に、DynamoDB では
空白のセットはサポートされていません。
Example (文字セット、数値セット、バイナリセット)
["Black", "Green" ,"Red"]
[42.2, -19, 7.5, 3.14]
["U3Vubnk=", "UmFpbnk=", "U25vd3k="]
読み込み整合性
Amazon DynamoDB は、世界中の複数の AWS リージョンで利用できます。各リージョンは完全に
独立していて、他の AWS リージョンから分離されています。たとえば、us-east-1 リージョンに
People というテーブルがあり、us-west-2 リージョンに People という名前の別のテーブルがある
場合、これらは 2 つの完全に異なるテーブルであると見なされます。DynamoDB を利用できるすべて
の AWS リージョンのリストについては、アマゾン ウェブ サービス全般のリファレンスのAWS リー
ジョンとエンドポイントを参照してください。
各 AWS リージョンは、複数のそれぞれ独立した場所で構成されており、これらの場所はアベイラビ
リティーゾーンと呼ばれます。各アベイラビリティーゾーンは、他のアベイラビリティーゾーンにお
ける障害の影響は受けず、同じリージョン内の他のアベイラビリティーゾーンに対して、低コスト、
低レイテンシーでネットワーク接続できます。これにより、リージョンの複数のアベイラビリティー
ゾーン間でデータの迅速なレプリケーションが可能になります。
アプリケーションが DynamoDB テーブルにデータを書き込み、HTTP 200 応答 (OK) を受け取ると、
データのすべてのコピーが更新されます。データは、すべてのストレージの場所で結果的に整合性が
保たれます (通常は 1 秒以内)。
DynamoDB は結果整合性と強力な整合性のある読み込みをサポートします。
結果整合性のある読み込み
DynamoDB テーブルからの読み込みオペレーションの応答には、最近の書き込みオペレーションの結
果が反映されていないことがあります。応答には古いデータが含まれる場合があります。少し時間が
たってから読み込みリクエストを繰り返すと、応答で最新のデータが返されます。
強力な整合性のある読み込み
強力な整合性のある読み込みをリクエストすると、DynamoDB は成功した以前のすべての書き込み
オペレーションからの更新が反映された最新データの応答を返します。強力な整合性のある読み込み
は、ネットワークの遅延または停止があった場合には利用できなくなる可能性があります。
Note
DynamoDB は、特に指定がない限り、結果的に整合性のある読み込みを使用します。読み取
りオペレーション (GetItem、Query、Scan など) では ConsistentRead パラメーターが提
供されます。このパラメーターを true に設定すると、DynamoDB はオペレーション中に強い
整合性のある読み込みを使用します。
プロビジョニングされたスループット
トピック
API Version 2012-08-10
16
Amazon DynamoDB 開発者ガイド
プロビジョニングされたスループット
• 読み込みキャパシティーユニット (p. 17)
• 書き込みキャパシティーユニット (p. 18)
• リザーブドキャパシティーの購入 (p. 19)
テーブルを作成する場合は、読み込みと書き込み用に予約するプロビジョンドスループット容量を指
定します。DynamoDB では、低レイテンシーで一貫したスループットパフォーマンスを実現するため
に必要なリソースを予約します。また、プロビジョンドスループット設定を変更し、必要に応じて容
量を増減できます。
DynamoDB では、キャパシティーユニットの観点で、プロビジョンドスループット要件を指定しま
す。次のガイドラインを使用して、プロビジョンドスループットを決定します。
• 1 つの読み込みキャパシティーユニットは、最大サイズ 4 KB の項目について、1 秒あたり 1 回の
強力な整合性のある読み込み、あるいは 1 秒あたり 2 回の結果的に整合性のある読み込みを表し
ます。4 KB より大きい項目を読み込む必要がある場合、DynamoDB は追加の読み込みキャパシ
ティーユニットを消費する必要があります。必要な読み込みキャパシティーユニットの最大数は、
項目のサイズと、結果整合性のある読み込みまたは強力な整合性のある読み込みが必要かどうかに
よって異なります。
• 1 つの書き込みキャパシティーユニットは、最大でサイズが 1 KB までの項目について、1 秒あたり
1 回の書き込みを表します。1 KB より大きい項目を書き込む必要がある場合、DynamoDB は追加
の書き込みキャパシティーユニットを消費する必要があります。必要な書き込みキャパシティーユ
ニットの合計数は、項目サイズに応じて異なります。
セカンダリインデックスがあるテーブルの場合、DynamoDB はさらにキャパシティーユニットを消費
します。たとえば、1 つの 1 KB の項目をテーブルに追加するときに、その項目にインデックス付きの
属性が含まれている場合には、テーブルへの書き込み用とインデックスへの書き込み用の 2 つの書き
込みキャパシティーユニットが必要になります。詳細については、以下のトピックを参照してくださ
い。
• プロビジョニングされたスループットに関する考慮事項(ローカルセカンダリインデック
ス) (p. 389)
• プロビジョニングされたスループットに関する考慮事項(グローバルセカンダリインデック
ス) (p. 342)
アプリケーションの読み込みまたは書き込みリクエストが、テーブルにプロビジョニン
グされたスループットを超えると、DynamoDB がそれらのリクエストを制限する可能
性があります。これが発生すると、リクエストは HTTP 400 コード (Bad Request) と
ProvisionedThroughputExceededException で失敗します。AWS SDK には、制限されたリク
エストを再試行するための組み込みサポートがあります。ただし、エラー処理コードでエクスポネン
シャルパックオフロジックの使用を検討することをお勧めします。詳細については、「エラーの再試
行とエクスポネンシャルバックオフ (p. 76)」を参照してください。
AWS マネジメントコンソール を使用して、プロビジョニングされたスループットと実際のスルー
プットをモニタリングし、制限されているリクエストがあるかどうか判断できます。また、トラ
フィックの変化を予測し、プロビジョニンドキャパシティー設定を変更できます。
読み込みキャパシティーユニット
項目のサイズが 4 KB よりも小さい場合、それぞれの読み込みキャパシティーユニットでは、1 秒あ
たり 1 回の強力な整合性のある読み込みか、1 秒あたり 2 回の結果整合性のある読み込みが得られま
す。
たとえば、テーブルから 1 秒あたり 80 項目を読み込むとします。項目のサイズが 3 KB で、強い整合
性のある読み込みが必要であるとします。このシナリオでは、読み込みごとに 1 つのプロビジョニン
グされた読み込みキャパシティーユニットが必要です。これを判断するには、次の例に示すようにオ
ペレーションの項目サイズを 4 KB で除算し、次に最も近い整数に切り上げます。
API Version 2012-08-10
17
Amazon DynamoDB 開発者ガイド
プロビジョニングされたスループット
3 KB / 4 KB = 0.75 --> 1
このシナリオでは、テーブルのプロビジョングされた読み込みスループットを 80 読み込みキャパシ
ティーユニットに設定する必要があります。
1 read capacity unit per item × 80 reads per second = 80 read capacity units
強い整合性のある読み込みの代わりに結果的に整合性のある読み込みが必要な場合は、40 個の読み込
みキャパシティーユニットのみをプロビジョニングする必要があります。
項目が 4 KB より大きい場合は、項目サイズを次の 4 KB 境界に切り上げる必要があります。たとえ
ば、1 秒あたり 100 個の強い整合性のある読み込みを実行し、項目のサイズが 6 KB であるとしま
す。最初に、次に示すように項目ごとに必要な読み込みキャパシティーの数を判断し、それを最も近
い整数に切り上げる必要があります。
6 KB / 4 KB = 1.5 --> 2
結果は項目あたり 2 つの読み込みキャパシティーユニットになります。ここで、この数値を、1 秒あ
たりの強い整合性のある読み込み数で乗算します。
2 read capacity units per item × 100 reads per second = 200
したがって、テーブルのプロビジョニングされた読み込みキャパシティーユニットを 200 に設定する
必要があります (強い整合性のある読み込みの代わりに結果的に整合性のある読み込みが必要な場合
は、100 個の読み込みキャパシティーユニットのみをプロビジョニングする必要があります)。
単一の項目を読み込むには、GetItem オペレーションを使用します。複数の項目を読み込む場
合、BatchGetItem を使用してテーブルから最大 100 項目を取り出すことができます。
Query および Scan オペレーションを使用して、1 つのリクエストによってテーブルまたはインデッ
クスから連続する複数の項目を取り出すことができます。これらのオペレーションで、DynamoDB は
処理済みの項目の累積サイズを使用して、プロビジョニングするスループットを計算します。たとえ
ば、Query オペレーションによって 1 KB の項目を 100 個取り出した場合、読み込みキャパシティー
の計算は、GetItem または BatchGetItem を使用して個別に取り出した場合のように (100 × 4 KB)
= 100 読み込みキャパシティーユニットにはなりません。代わりに、合計は後に示すように 25 読み込
みキャパシティーユニットのみになります。
(100 * 1024 bytes = 100 KB) / 4 KB = 25 read capacity units
詳細については、「キャパシティーユニットの計算 (p. 181)」を参照してください。
書き込みキャパシティーユニット
項目のサイズが 1 KB より小さい場合、それぞれの書き込みキャパシティーユニットでの書き込み数
は 1 秒あたり 1 回になります。たとえば、テーブルに 1 秒あたり 100 項目を書き込み、項目のサイズ
が 512 バイトであるとします。このシナリオでは、書き込みごとに 1 つのプロビジョニングされた書
き込みキャパシティーユニットが必要です。これを判断するには、オペレーションの項目サイズを 1
KB で除算し、次に最も近い整数に切り上げます。
512 bytes / 1 KB = 0.5 --> 1
このシナリオでは、テーブルのプロビジョニングされた書き込みスループットを 100 書き込みキャパ
シティーユニットに設定する必要があります。
API Version 2012-08-10
18
Amazon DynamoDB 開発者ガイド
パーティションとデータ分散
1 write capacity unit per item × 100 writes per second = 100 write capacity
units
項目が 1 KB より大きい場合は、項目サイズを次の 1 KB 境界に切り上げる必要があります。たとえ
ば、1 秒あたり 10 個の書き込みを実行し、項目のサイズが 1.5 KB であるとします。最初に、次に示
すように項目あたりの必要な書き込みキャパシティーユニットの数を判断し、最も近い整数に切り上
げます。
1.5 KB / 1 KB = 1.5 --> 2
結果は項目あたり 2 つの書き込みキャパシティーユニットになります。ここでは、これを 1 秒あたり
の書き込み数で乗算します。
2 write capacity units per item × 10 writes per second = 20 write capacity
units
したがって、このシナリオではテーブルのプロビジョニングされた書き込みキャパシティーユニット
を 20 に設定する必要があります。
1 つの項目を操作するためには、必要に応じて PutItem、UpdateItem、または DeleteItem オペ
レーションを使用します。また、BatchWriteItem を使用して、1 つのオペレーションで最大 25 項
目を配置または削除することができます。(BatchWriteItem は PutItem および DeleteItem オペレー
ションはサポートしますが、UpdateItem はサポートしないことにご注意ください。)
リザーブドキャパシティーの購入
DynamoDB では、「Amazon DynamoDB 料金表」に説明されているように、リザーブドキャパシ
ティーを購入することができます。リザーブドキャパシティーでは、1 回限りの前払い料金を支払
い、期間中、最小使用レベルを支払う契約を結びます。読み込みキャパシティーユニットおよび書
き込みキャパシティーユニットを事前に予約することで、オンデマンドのプロビジョニングされたス
ループット設定と比べて大幅なコスト削減を実現できます。
リザーブドキャパシティを管理するには、DynamoDB コンソールに移動し、[Reserved Capacity] を
選択します。
Note
ユーザーがリザーブドキャパシティーを表示または購入できないようにしながら、コン
ソールの他の部分にはアクセスを許可することができます。詳細については、「Amazon
DynamoDB に対する認証とアクセスコントロール (p. 460)」の「リザーブドキャパシティの
提供タイプを購入するためのアクセス許可」を参照してください。
パーティションとデータ分散
DynamoDB はデータをパーティションに保存します。パーティションは、Solid State Drive (SSD) に
よってバックアップされ、AWS リージョン内の複数のアベイラビリティーゾーン間で自動的にレプ
リケートされる、テーブル用のストレージの割り当てです。パーティション管理は完全に DynamoDB
によって処理され、お客様はパーティションを管理する必要はありません。
テーブルを作成するときに、テーブルの最初のステータスは CREATING になります。このフェーズの
間に、DynamoDB はテーブルに十分なパーティションを割り当て、プロビジョニングされたスルー
プット要件に対応できるようにします。テーブルのステータスが ACTIVE に変わったらテーブルデー
タの書き込みと読み取りを開始できます。
API Version 2012-08-10
19
Amazon DynamoDB 開発者ガイド
パーティションとデータ分散
DynamoDB は次の状況でテーブルに追加のパーティションを割り当てます。
• テーブルのプロビジョニングされたスループット設定を、既存のパーティションがサポートできる
以上に増やした。
• 既存のパーティションが容量いっぱいになり、より多くのストレージ領域が必要になった。
詳細については、「パーティションの動作について (p. 569)」を参照してください。
パーティション管理は自動的にバックグラウンドで自動的に発生し、アプリケーションに対して透過
的です。テーブルは利用可能な状態のままで、プロビジョニングされたスループット要件を完全にサ
ポートします。
DynamoDB のインデックスもパーティションで構成されます。インデックスのデータは、基本テーブ
ルのデータとは別に保存されますが、インデックスパーティションはテーブルパーティションと同様
に動作します。
データ分散: パーティションキー
テーブルにシンプルなプライマリキー (パーティションキーのみ) がある場合、DynamoDB はパーティ
ションキーの値に基づいて、各項目を保存および取得します。
DynamoDB は項目をテーブルに書き込むため、パーティションキーの値を内部ハッシュ関数への入力
として使用します。ハッシュ関数からの出力値によって、項目が保存されるパーティションが決まり
ます。
テーブルから項目を読み取るには、項目に対するパーティションキーの値を指定する必要がありま
す。DynamoDB はこの値をハッシュ関数への入力として使用して、項目が見つかるパーティションを
提供します。
次の図は、複数のパーティションにまたがる Pets という名前のテーブルを示しています。テーブル
のプライマリキーは AnimalType です (このキー属性のみが表示されます)。DynamoDB はそのハッ
シュ関数を使用して、新しい項目を保存する場所を決定します (この場合は文字列 Dog のハッシュ値
に基づく)。項目はソート順に保存されないことに注意してください。各項目の場所は、そのパーティ
ションキーのハッシュ値によって決まります。
API Version 2012-08-10
20
Amazon DynamoDB 開発者ガイド
パーティションとデータ分散
Note
DynamoDB は、パーティション数にかかわらず、テーブルのパーティションにまたがる項目
の均一な分散に対して最適化されません。テーブルの項目数に対して大きな個別の値を持つ
ことができるパーティションキーを選択することをお勧めします。詳細については、「テー
ブルの操作のガイドライン (p. 566)」を参照してください。
データ分散: パーティションキーおよびソートキー
テーブルに複合プライマリキー (パーティションキーとソートキー) がある場合、DynamoDB は「デー
タ分散: パーティションキー (p. 20)」に説明されているのと同じ方法でパーティションキーのハッ
シュ値を計算します。ただし、パーティションキーの値が同じすべての項目は、ソートキー値によっ
て並べ替えられて物理的に近くに配置されます。
テーブルに項目を書き込むため、DynamoDB はパーティションキーのハッシュ値を計算し、項目を含
めるパーティションを決定します。そのパーティションで、パーティションキーの値が同じ複数の項
目がある可能性があるため、DynamoDB は同じパーティションキーを持つ項目をソートキーで昇順に
ソートして保存します。
テーブルから項目を読み込むには、パーティションキーの値とソートキーの値を指定する必要があり
ます。DynamoDB は、パーティションキーのハッシュ値を計算し、項目が見つかるパーティションを
提供します。
目的の項目に同じパーティションキー値がある場合、単一の操作 (Query) でテーブルから複数の項
目を読み取ることができます。DynamoDB はそのパーティションキー値を持つすべての項目を返し
API Version 2012-08-10
21
Amazon DynamoDB 開発者ガイド
パーティションとデータ分散
ます。オプションでソートキーに条件を適用し、特定範囲内の値を持つ項目だけを返すことができま
す。
Pets テーブルに、AnimalType (パーティションキー) と Name (ソートキー) で構成される複合プライ
マリキーがあるとします。次の図は、パーティションキー値が Dog で、ソートキー値が Fido の項目
を書き込む DynamoDB を示しています。
DynamoDB は、Pets テーブルから同じ項目を読み取るため、ハッシュ値 Dog を計算し、これらの
項目が保存されたパーティションを提供します。次に、DynamoDB は、Fido が見つかるまでソート
キーの属性値をスキャンします。
AnimalType が Dog のすべての項目を読み込むには、ソートキーの条件を指定しないで Query オペ
レーションを発行できます。デフォルトでは、項目は保存されている順序 (つまり、ソートキーによっ
て昇順でソート) で返されます。オプションで、代わりに降順をリクエストできます。
Dog 項目の一部のみにクエリを実行するには、ソートキーに条件を適用できます (たとえば、Dog が
Name~A の範囲内である K 項目のみ)。
Note
DynamoDB テーブルには、パーティションキーの値ごとに個別のソートキー値の数に上限は
ありません。Dog テーブルに数十億の Pets 項目を保存する必要がある場合、DynamoDB は
自動的に十分なストレージを割り当てて、この要件に対応します。
API Version 2012-08-10
22
Amazon DynamoDB 開発者ガイド
SQL から NoSQL へ
SQL から NoSQL へ
アプリケーション開発者なら、リレーショナルデータベース管理システム (RDBMS) および構造化ク
エリ言語 (SQL) を使用した経験があるかもしれません。 Amazon DynamoDB を使い始めると、多く
の類似点があると同時に、異なる点も多くあることに気づきます。 このセクションでは、SQL ステー
トメントを同等の DynamoDB オペレーションと比較、対比しながら、一般的なデータベースタスク
について説明します。
NoSQL は、可用性が高く、スケーラブルで、高パフォーマンス用に最適化された、非リレーショナル
データベースシステムについて説明するのに使用される用語です。 NoSQL データベース (DynamoDB
など) は、リレーショナルモデルの代わりに、キーと値のペアやドキュメントストレージなど、データ
管理のための代替モデルを使用します。 詳細については、http://aws.amazon.com/nosql をご覧くださ
い。
Note
このセクションの SQL の例は、MySQL のリレーショナルデータベース管理システムと互換
性があります。
このセクションの DynamoDB 例では、JSON 形式のオペレーションのパラメーターと共に
DynamoDB オペレーションの名前を表示します。 これらのオペレーションを使用するコード
サンプルについては、Amazon DynamoDB 入門ガイド を参照してください。
トピック
• SQL か NoSQL か (p. 23)
• データベースにアクセスする (p. 25)
• テーブルの作成 (p. 26)
• テーブルに関する情報の取得 (p. 28)
• テーブルへのデータの書き込み (p. 29)
• テーブルからデータを読み込む (p. 32)
• インデックス管理 (p. 37)
• テーブルのデータ変更 (p. 40)
• テーブルからデータを削除する (p. 42)
• テーブルの削除 (p. 43)
SQL か NoSQL か
現在のアプリケーションには今までになく厳しい要件があります。 たとえば、あるオンラインゲーム
を、小数のユーザーおよび非常に小さいデータ量で開始するかもしれません。 しかし、ゲームが成功
すれば、それは基盤となるデータベース管理システムのリソースを簡単に上回ります。 ウェブベース
のアプリケーションに、数百、数千、数百万の同時ユーザーがいて、テラバイトあるいはそれ以上の
新しいデータが毎日生成される、というのはよくあることです。 そのようなアプリケーションのデー
タベースの場合は、1 秒あたり数万 (あるいは数十万) の読み取り/書き込みの処理が必要です。
Amazon DynamoDB は、これらのワークロードに適しています。 開発者として、少量のプロビジョニ
ングされたスループットで開始し、アプリケーションの人気が出てくるにつれて、徐々に増加させる
ことができます。 DynamoDB は、大量のデータや多数のユーザーの処理をシームレスにスケーリン
グできます。
次の表はリレーショナルデータベース管理システム (RDBMS) と DynamoDB の、高レベルな相違点を
示します。
API Version 2012-08-10
23
Amazon DynamoDB 開発者ガイド
SQL か NoSQL か
特徴
リレーショナルデータベース管
理システム (RDBMS)
Amazon DynamoDB
最適なワークロード
アドホッククエリ、データウェ
アハウス、OLAP (オンライン
分析処理)。
ソーシャルネットワーク、ゲー
ム、メディア共有、IoT (Internet
of Things) を含む、ウェブス
ケールアプリケーションです。
データモデル
リレーショナルモデルには、
データを、テーブル、行、列
に正規化する、明確に定義さ
れたスキーマが必要です。 さ
らに、関係のすべては、テーブ
ル、列、インデックスおよび他
のデータベースのエレメント間
で定義されます。
DynamoDB はスキーマレスで
す。 すべてのテーブルに、各
データ項目を一意に識別する
プライマリキーが必要ですが、
他の非キー属性のような制約
はありません。 DynamoDB
は、JSON ドキュメントを含む
構造化データまたは半構造化
データを管理できます。
データアクセス
SQL (構造化クエリ言語) は、
データを保存および取得するた
めの基準です。 リレーショナ
ルデータベースにはデータベー
ス駆動型アプリケーションの開
発を簡素化するためのツールが
豊富ですが、これらのツールは
すべて、SQL を使用します。
AWS マネジメントコンソール
または AWS CLI を使用して
DynamoDB を操作し、アドホッ
クタスクを実行できます。 ア
プリケーションでは、オブジェ
クトベースでドキュメント中
心、または低レベルのインター
フェイスを使用しながら、AWS
Software Development Kit (SDK)
を活用し、DynamoDB を操作で
きます。
パフォーマンス
リレーショナルデータベース
は、ストレージに最適化されて
いますので、パフォーマンスは
通常、ディスクサブシステムに
よって異なります。 開発者と
データベース管理者は、ピーク
パフォーマンスを達成するため
に、クエリ、インデックスおよ
びテーブルの構造を最適化する
必要があります。
DynamoDB は、コンピューティ
ングに最適化されていますの
で、パフォーマンスは主に、
基盤となるハードウェアとネッ
トワークレイテンシーの機能で
す。 マネージド型サービスとし
て、DynamoDB は、これらの実
装の詳細からアプリケーション
を隔離し、堅牢で高パフォーマ
ンスなアプリケーションの設計
と構築に集中できるようにしま
す。
スケーリング
より高速なハードウェアでス
ケールアップするのが最も簡単
です。 データベーステーブル
が分散システムの複数のホスト
にまたがることは可能ですが、
この場合、追加の投資が必要
です。 リレーショナルデータ
ベースは、スケーラビリティに
上限を課すファイルの数とサイ
ズが最大サイズです。
DynamoDB は、ハードウェア
の分散型クラスターを使用して
スケールアウトできるように設
計されています。 この設計によ
り、レイテンシーの増加なしで
スループットを強化することが
できます。 顧客がスループット
要件を指定すると、DynamoDB
は、その要件に対応するため
に十分なリソースを割り当てま
す。 テーブル単位の項目数、お
よびそのテーブルの合計サイズ
に上限はありません。
API Version 2012-08-10
24
Amazon DynamoDB 開発者ガイド
データベースにアクセスする
データベースにアクセスする
アプリケーションがデータベースにアクセスする前に、そのアプリケーションがデータベースを使用
する権限があることが認証され、アプリケーションが認可されているアクションのみを実行できるよ
うに承認される必要があります。
次の図は、クライアントとリレーショナルデータベースおよび DynamoDB とのやり取りを示しま
す。
次の表にクライアントのやり取りのタスクについての詳細があります。
特徴
リレーショナルデータベース管
理システム (RDBMS)
Amazon DynamoDB
データベースにアクセスするた
めのツール
ほとんどのリレーショナルデー
タベースは、コマンドラインイ
ンターフェース (CLI) を提供し
ており、アドホックな SQL ス
テートメントを入力して、結果
をすぐに見ることができます。
ほとんどの場合、アプリケー
ションコードを書き込みます。
AWS マネジメントコンソール
または AWS Command Line
Interface (AWS CLI) を使用し
て、アドホックなリクエストを
DynamoDB に送信し、結果を表
示することもできます。
データベースに接続
アプリケーションプログラム
は、データベースを使用した
ネットワーク接続を確立し、維
持します。 アプリケーション
が終了すると、接続を終了しま
す。
DynamoDB は、ウェブサービ
スで、その操作はステートレ
スです。 アプリケーションは
永続的ネットワーク接続を維
持する必要はありません。 代
わりに、DynamoDB の操作は
HTTP(S) リクエストおよびレス
ポンスを使用して行われます。
認証
アプリケーションが認証される
までデータベースに接続できま
せん。 RDBMS は認証自体を
DynamoDB に対するすべての
リクエストは、その特定のリ
クエストを認証する暗号署名
API Version 2012-08-10
25
Amazon DynamoDB 開発者ガイド
テーブルの作成
特徴
リレーショナルデータベース管
理システム (RDBMS)
Amazon DynamoDB
実行できますし、ホストのオペ
レーティングシステムやディレ
クトリサービスにこのタスクを
オフロードすることもできま
す。
と共に使用しなければなりませ
ん。 AWS SDK は、署名の作成
とリクエストの署名に必要なす
べての論理を提供します。 詳
細については、AWS General
Reference の AWS API リクエ
ストの署名を参照してくださ
い。
承認
アプリケーションは承認された
アクションのみ実行できます。
データベース管理者またはアプ
リケーション所有者は、SQL
GRANT および REVOKE ステー
トメントを使用して、データ
ベースオブジェクト (テーブル
など)、データ (テーブル内の行
など)、特定の SQL ステートメ
ントを発行する機能へのアクセ
スを制御できます。
DynamoDB では、AWS Identity
and Access Management (IAM)
によって承認が処理されます。
DynamoDB リソース (テーブ
ルなど) にアクセス許可を付
与する IAM ポリシーを書き
込み、IAM ユーザーとロー
ルがそのポリシーを使用でき
るようにします。 IAM はま
た、DynamoDB テーブルの個々
のデータ項目のきめ細かなア
クセス制御を特徴とします。
詳細については、「Amazon
DynamoDB に対する認証とアク
セスコントロール (p. 460)」を
参照してください。
リクエストを送信
アプリケーションは、実行する
すべてのデータベース操作に対
する SQL ステートメントを発
行します。 SQL ステートメン
トを受信すると、RDBMS は構
文を確認し、操作を実行するた
めの計画を作成し、計画を実行
します。
アプリケーションは、HTTP(S)
リクエストを DynamoDB に
送信 します。 リクエスト
には、パラメーターととも
に、DynamoDB の名前と実
行する操作が含まれます。
DynamoDB は、リクエストを迅
速に実行します。
レスポンスを受信
RDBMS は SQL ステートメ
ントから結果を返します。 エ
ラーがある場合は、RDBMS は
エラー状況とエラーメッセージ
を返します。
DynamoDB は、操作の結果を
含む HTTP(S) レスポンスを
返します。 エラーがある場合
は、DynamoDB は、HTTP エ
ラー状況およびエラーメッセー
ジを返します。
テーブルの作成
テーブルは、リレーショナルデータベースおよび DynamoDB の基本的なデータ構造です。 リレー
ショナルデータベース管理システム (RDBMS) では、作成時に、テーブルのスキーマを定義する必要
があります。 これに対して、DynamoDB テーブルは、プライマリキー以外は schemaless— ですか
ら、テーブル作成時に属性やデータ型を定義する必要はありません。
SQL
次の例に示すように、CREATE TABLE ステートメントを使用して、テーブルを作成します。
CREATE TABLE Music (
API Version 2012-08-10
26
Amazon DynamoDB 開発者ガイド
テーブルの作成
Artist VARCHAR(20) NOT NULL,
SongTitle VARCHAR(30) NOT NULL,
AlbumTitle VARCHAR(25),
Year INT,
Price FLOAT,
Genre VARCHAR(10),
Tags TEXT,
PRIMARY KEY(Artist, SongTitle)
);
このテーブルのプライマリキーは、Artist および SongTitle で構成されます。
テーブルの列とデータ型すべて、およびテーブルのプライマリキーを定義する必要があります。 (こ
れらの定義は、ALTER TABLE ステートメントを使用して、必要に応じて後で変更することができま
す。)
多くの SQL 実装では、CREATE TABLE ステートメントの一部として、テーブルのストレージ仕様を
定義することができます。 他に明記されていない限り、テーブルはデフォルトのストレージ設定で作
成されます。 本稼働環境では、データベース管理者は最適なストレージパラメーターを特定すること
もできます。
DynamoDB
CreateTable アクションを使用してテーブルを作成し、次に示すように、パラメーターを指定しま
す。
{
TableName : "Music",
KeySchema: [
{
AttributeName: "Artist",
KeyType: "HASH", //Partition key
},
{
AttributeName: "SongTitle",
KeyType: "RANGE" //Sort key
}
],
AttributeDefinitions: [
{
AttributeName: "Artist",
AttributeType: "S"
},
{
AttributeName: "SongTitle",
AttributeType: "S"
}
],
ProvisionedThroughput: {
ReadCapacityUnits: 1,
WriteCapacityUnits: 1
}
}
このテーブルのプライマリキーは、Artist (パーティションキー) および SongTitle (ソートキー) で構成
されています。
CreateTable に以下のパラメーターを提供する必要があります。
API Version 2012-08-10
27
Amazon DynamoDB 開発者ガイド
テーブルに関する情報の取得
• TableName – テーブルの名前.
• KeySchema – プライマリキーに使用される属性。 詳細については、「テーブル、項目、属
性 (p. 2)」および「プライマリキー (p. 5)」を参照してください。
• AttributeDefinitions – キースキーマ属性のデータ型。
• ProvisionedThroughput – このテーブルに必要な 1 秒あたりの読み取り/書き込み数。
DynamoDB は、スループット要件を常に満たすように、十分なストレージとシステムリソースを
確保しています。 これらは、UpdateTable アクションを使用して、必要に応じて後で変更できま
す。 DynamoDB がストレージ割り当てを完全に管理しているため、テーブルのストレージ要件を
指定する必要はありません。
Note
CreateTable を使用したコードサンプルについては、Amazon DynamoDB 入門ガイド を参
照してください。
テーブルに関する情報の取得
テーブルが仕様に従って作成されたことを確認できます。 リレーショナルデータベースでは、すべて
テーブルのスキーマが表示されます。 DynamoDB テーブルはスキーマレスであるため、プライマリ
キー属性のみが表示されます。
SQL
ほとんどのリレーショナルデータベース管理システム (RDBMS) では、列、データ型、プライマリ
キー定義などのテーブルの構造を説明できます。 SQL にはこれを行うための標準的な方法はありませ
ん。 ただし、データベースシステムの多くが DESCRIBE コマンドを提供しています。 MySQL からの
例を示します。
DESCRIBE Music;
すべての列名、データ型、サイズを含むテーブルの構造を返します。
+------------+-------------+------+-----+---------+-------+
| Field
| Type
| Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| Artist
| varchar(20) | NO
| PRI | NULL
|
|
| SongTitle | varchar(30) | NO
| PRI | NULL
|
|
| AlbumTitle | varchar(25) | YES |
| NULL
|
|
| Year
| int(11)
| YES |
| NULL
|
|
| Price
| float
| YES |
| NULL
|
|
| Genre
| varchar(10) | YES |
| NULL
|
|
| Tags
| text
| YES |
| NULL
|
|
+------------+-------------+------+-----+---------+-------+
このテーブルのプライマリキーは、Artist および SongTitle で構成されます。
DynamoDB
DynamoDB には、同様の DescribeTable アクションがあります。 次に示すように、唯一のパラ
メーターは、テーブル名です。
{
API Version 2012-08-10
28
Amazon DynamoDB 開発者ガイド
テーブルへのデータの書き込み
TableName : "Music"
}
DescribeTable からの返信は、次のようになります。
{
"Table": {
"AttributeDefinitions": [
{
"AttributeName": "Artist",
"AttributeType": "S"
},
{
"AttributeName": "SongTitle",
"AttributeType": "S"
}
],
"TableName": "Music",
"KeySchema": [
{
"AttributeName": "Artist",
"KeyType": "HASH" //Partition key
},
{
"AttributeName": "SongTitle",
"KeyType": "RANGE" //Sort key
}
],
...
DescribeTable は、情報も返します。 テーブル、プロビジョニングされたスループット設定、概算
項目数とそのほかのメタデータのインデックスについて。
テーブルへのデータの書き込み
リレーショナルデータベースのテーブルには、データの行が含まれます。 行は列で構成されます。
DynamoDB テーブルには、項目が含まれます。 項目は属性で構成されます。
このセクションでは、テーブルに 1 つの行 (または項目) を書き込む方法を説明します。
SQL
リレーショナルデータベースのテーブルは、行と列で構成される、2 つのディメンションのデータ構
造です。 一部のデータベース管理システムは、通常、ネイティブ JSON または XML データ型を使用
する半構造化データのサポートを提供します。 ただし、実装の詳細はベンダー間で変わります。
SQL では、INSERT ステートメントを使用して、テーブルに行を追加します。
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Year, Price, Genre,
Tags)
VALUES(
'No One You Know', 'Call Me Today', 'Somewhat Famous',
API Version 2012-08-10
29
Amazon DynamoDB 開発者ガイド
テーブルへのデータの書き込み
2015, 2.14, 'Country',
'{"Composers": ["Smith", "Jones","Davis"],"LengthInSeconds": 214}'
);
このテーブルのプライマリキーは、Artist および SongTitle で構成されます。 これらの列の値を指定す
る必要があります。
Note
この例では、タグ列を使用して、音楽テーブル内の曲に関する半構造化データを保存しま
す。 タグ列を MySQL で 65535 文字まで格納できる TEXT 型として定義しました。
DynamoDB
Amazon DynamoDB では、PutItem アクションを使用して、テーブルに項目を追加します。
{
TableName: "Music",
Item: {
"Artist":"No One You Know",
"SongTitle":"Call Me Today",
"AlbumTitle":"Somewhat Famous",
"Year": 2015,
"Price": 2.14,
"Genre": "Country",
"Tags": {
"Composers": [
"Smith",
"Jones",
"Davis"
],
"LengthInSeconds": 214
}
}
}
このテーブルのプライマリキーは、Artist および SongTitle で構成されます。 これらの属性の値を指定
する必要があります。
この PutItem 例に関する主要事項を示します。
• DynamoDB は、JSON を使用してドキュメントのネイティブサポートを提供します。 これにより
DynamoDB はタグなどの半構造化データを保存するのに最適になります。 また、JSON ドキュメン
ト内からデータを取得および操作できます。
• 音楽テーブルには、プライマリキー (Artist および SongTitle) 以外には事前定義された属性はありま
せん。
• ほとんどの SQL データベースはトランザクション指向です。 INSERT ステートメントを発行す
ると、データ変更は、COMMIT ステートメントを発行するまで永続的ではありません。 Amazon
DynamoDB によって、PutItem アクションの効果は、DynamoDB が HTTP 200 ステータスコード
(OK) で応答する場合、永続的になります。
Note
PutItem を使用したコードサンプルについては、Amazon DynamoDB 入門ガイド を参照し
てください。
API Version 2012-08-10
30
Amazon DynamoDB 開発者ガイド
テーブルへのデータの書き込み
次に、PutItem の他の例をいくつか示します。
{
TableName: "Music",
Item: {
"Artist": "No One You Know",
"SongTitle": "My Dog Spot",
"AlbumTitle":"Hey Now",
"Price": 1.98,
"Genre": "Country",
"CriticRating": 8.4
}
}
{
TableName: "Music",
Item: {
"Artist": "No One You Know",
"SongTitle": "Somewhere Down The Road",
"AlbumTitle":"Somewhat Famous",
"Genre": "Country",
"CriticRating": 8.4,
"Year": 1984
}
}
{
TableName: "Music",
Item: {
"Artist": "The Acme Band",
"SongTitle": "Still In Love",
"AlbumTitle":"The Buck Starts Here",
"Price": 2.47,
"Genre": "Rock",
"PromotionInfo": {
"RadioStationsPlaying":[
"KHCR", "KBQX", "WTNR", "WJJH"
],
"TourDates": {
"Seattle": "20150625",
"Cleveland": "20150630"
},
"Rotation": "Heavy"
}
}
}
{
TableName: "Music",
Item: {
"Artist": "The Acme Band",
"SongTitle": "Look Out, World",
"AlbumTitle":"The Buck Starts Here",
"Price": 0.99,
"Genre": "Rock"
}
API Version 2012-08-10
31
Amazon DynamoDB 開発者ガイド
テーブルからデータを読み込む
}
Note
PutItem に加えて、Amazon DynamoDB は、同時に複数の項目に書き込むための
BatchWriteItem アクションもサポートします。
テーブルからデータを読み込む
SQL では、SELECT ステートメントを使用して、テーブルから 1 つ以上の行を取得します。 WHERE
句を使用して、返されたデータを調べます。
DynamoDB は、データ読み取りのために次のオペレーションを提供します。
• GetItem – テーブルから単一の項目を取り出します。これは、項目の物理的な場所に直接ア
クセスできるため、単一の項目を読み取るのには最も効率的な方法です。 (DynamoDB はま
た、BatchGetItemオペレーションを提供するため、単一の操作で、最大 100GetItem 呼び出しを
実行できます。)
• Query – 特定のパーティションキーがあるすべての項目を取り出します。これらの項目内では、
ソートキーに条件を適用し、データのサブセットのみ取得できます。 Query は、データが格納さ
れているパーティションに、すばやく効率的にアクセスできます。 (詳しくは、パーティションと
データ分散 (p. 19) を参照してください)。
• Scan – 指定されたテーブルで、すべての項目を取り出します。 (大量のリソースシステムを消費す
るため、このオペレーションは大きなテーブルでは使用しないでください。)
Note
リレーショナルデータベースでは、SELECT ステートメントを使用して、複数のテーブルから
データを結合し、その結果を返すことができます。 結合は、リレーショナルモデルにおいて
必須です。 結合を効率的に実行するために、データベースおよびアプリケーションは、継続
的にパフォーマンスの調整をする必要があります。
DynamoDB は、非リレーショナル NoSQL データベースのため、テーブルの結合はサポート
されません。 その代わり、アプリケーションは一度に 1 つのテーブルからデータを読み込み
ます。
次のセクションでは、データを読み込むための異なるユースケースおよびこれらのタスクをリレー
ショナルデータベースと DynamoDB を使って実行する方法を説明します。
トピック
• プライマリキーを使用して項目を読み取る (p. 32)
• テーブルに対するクエリの実行 (p. 34)
• テーブルをスキャンする (p. 36)
プライマリキーを使用して項目を読み取る
データベースの一般的なアクセスパターンの 1 つは、テーブルから単一項目を読み取ることです。 目
的の項目のプライマリキーを指定する必要があります。
SQL
SQL では、SELECT ステートメントを使用して、テーブルからデータを取得します。 結果の 1 つ以上
の列 (* オペレーター を使用すれば、すべて) をリクエストできます。 WHERE 句は返される行を決定
します。
API Version 2012-08-10
32
Amazon DynamoDB 開発者ガイド
テーブルからデータを読み込む
音楽テーブルから 1 つの行を取得する SELECT ステートメントを次に示します。 WHERE 句はプライ
マリキー値を指定します。
SELECT *
FROM Music
WHERE Artist='No One You Know' AND SongTitle = 'Call Me Today'
列のサブセットのみを取得するようにこのクエリを変更できます。
SELECT AlbumTitle, Year, Price
FROM Music
WHERE Artist='No One You Know' AND SongTitle = 'Call Me Today'
このテーブルのプライマリキーが、Artist および SongTitle で構成されていることに注意してくださ
い。
DynamoDB
DynamoDB は、プライマリキーにより項目を取得するための GetItem アクションを提供します。
GetItem は、項目の物理的な場所への直接アクセスを提供するため非常に能率的です。 (詳しく
は、パーティションとデータ分散 (p. 19) を参照してください)。
デフォルトでは、GetItem は、すべての属性を含む項目全体を返します。
{
TableName: "Music",
Key: {
"Artist": "No One You Know",
"SongTitle": "Call Me Today"
}
}
一部の属性のみが返されるように、ProjectionExpression パラメーターを追加できます。
{
TableName: "Music",
Key: {
"Artist": "No One You Know",
"SongTitle": "Call Me Today"
},
"ProjectionExpression": "AlbumTitle, Year, Price"
}
このテーブルのプライマリキーが、Artist および SongTitle で構成されていることに注意してくださ
い。
DynamoDB GetItem アクションは非常に効率的です。プライマリキー値を使用して、該当する項目
の正確な格納場所を特定し、そこから直接取得します。 SQL SELECT ステートメントは、プライマリ
キー値によって項目を取得する場合、同様に効率的です。
SQL SELECT ステートメントは多くの種類のクエリおよびテーブルスキャンをサポートします。
DynamoDB は Query および Scanアクションで、同様の機能を提供しています。テーブルに対するク
エリの実行 (p. 34) および テーブルをスキャンする (p. 36) を参照してください。
SQL SELECT ステートメントは、テーブルの結合を実行でき、同時に複数のテーブルからデータを取
得できます。 データベーステーブルが正規化され、テーブル間の関係が明確である場合、結合は最も
API Version 2012-08-10
33
Amazon DynamoDB 開発者ガイド
テーブルからデータを読み込む
効果的です。 ただし、1 つの SELECTステートメントであまりに多くのテーブルを結合すると、アプ
リケーションパフォーマンスが影響を受けます。 データベースレプリケーション、マテリアライズド
ビュー、またはクエリの書き換えを使用して、このような問題を回避できます。
DynamoDB は、非リレーショナルデータベースです。 したがって、テーブルの結合はサポートされ
ません。 リレーショナルデータベースから既存のアプリケーションを DynamoDB に移行する場合、
結合の必要を排除するためデータモデルを非正規化する必要があります。
Note
GetItem を使用したコードサンプルについては、Amazon DynamoDB 入門ガイド を参照し
てください。
テーブルに対するクエリの実行
もう 1 つの一般的なアクセスパターンは、クエリ条件に基づき、テーブルから複数の項目を読み込む
ことです。
SQL
SQL SELECT ステートメントは、キー列、非キー列、または任意の組み合わせに対してクエリを実行
できます。 WHERE句は、次の例に示すように、返される行を決定します。
/* Return a single song, by primary key */
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle = 'Call Me Today';
/* Return all of the songs by an artist */
SELECT * FROM Music
WHERE Artist='No One You Know';
/* Return all of the songs by an artist, matching first part of title */
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle LIKE 'Call%';
/* Return all of the songs by an artist, with a particular word in the
title...
...but only if the price is less than 1.00 */
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle LIKE '%Today%'
AND Price < 1.00;
このテーブルのプライマリキーが、Artist および SongTitle で構成されていることに注意してくださ
い。
DynamoDB
DynamoDB Query アクションにより、同様の方法でデータを取得できます。 Queryアクションは、
データが保存されている物理的な場所にすばやく効率的にアクセスすることができます。 (詳しく
は、パーティションとデータ分散 (p. 19) を参照してください)。
API Version 2012-08-10
34
Amazon DynamoDB 開発者ガイド
テーブルからデータを読み込む
Query は、複合プライマリキー (パーティションキーとソートキー) のある任意のテーブルで使用でき
ます。 パーティションキーに対して等価条件を指定する必要があります。必要に応じて、ソートキー
に対して別の条件を指定できます。
KeyConditionExpression パラメーターは、クエリを実行するキー値を指定します。 オプションの
FilterExpression を使用して、結果が返される前に、そこから特定の項目を削除できます。
DynamoDB では、式パラメーター (KeyConditionExpression および FilterExpressionなど) で
ExpressionAttributeValues をプレースホルダーとして使用する必要があります。 これは、実行
時に、実際の値を SELECT ステートメントに置き換えるリレーショナルデータベースでの バインド変
数の使用と似ています。
このテーブルのプライマリキーが、Artist および SongTitle で構成されていることに注意してくださ
い。
次に DynamoDB の Query 例を示します。
// Return a single song, by primary key
{
TableName: "Music",
KeyConditionExpression: "Artist = :a and SongTitle = :t",
ExpressionAttributeValues: {
":a": "No One You Know",
":t": "Call Me Today"
}
}
// Return all of the songs by an artist
{
TableName: "Music",
KeyConditionExpression: "Artist = :a",
ExpressionAttributeValues: {
":a": "No One You Know"
}
}
// Return all of the songs by an artist, matching first part of title
{
TableName: "Music",
KeyConditionExpression: "Artist = :a and begins_with(SongTitle, :t)",
ExpressionAttributeValues: {
":a": "No One You Know",
":t": "Call"
}
}
// Return all of the songs by an artist, with a particular word in the
title...
// ...but only if the price is less than 1.00
{
TableName: "Music",
KeyConditionExpression: "Artist = :a and contains(SongTitle, :t)",
API Version 2012-08-10
35
Amazon DynamoDB 開発者ガイド
テーブルからデータを読み込む
FilterExpression: "price < :p",
ExpressionAttributeValues: {
":a": "No One You Know",
":t": "Today",
":p": 1.00
}
}
Note
Query を使用したコードサンプルについては、Amazon DynamoDB 入門ガイド を参照してく
ださい。
テーブルをスキャンする
SQL では、WHERE 句なしの SELECT ステートメントは、テーブルのすべての行を返します。
DynamoDB では、スキャンオペレーションが同じことを行います。 どちらの場合も、全ての、また
は一部の項目を取得できます。
SQL または NoSQL データベースのいずれを使用するにしても、スキャンは大量のシステムリソース
を消費するので、控え目に使用する必要があります。 スキャンが適切 (小さなテーブルをスキャンす
るなど) または不可避 (データの一括エクスポートの実行など) な場合はあります。 しかし、一般的な
ルールとして、スキャンを実行しないようアプリケーションを設計する必要があります。
SQL
SQL では WHERE 句を指定せずに、SELECT ステートメントを使用してテーブルをスキャンし、データ
のすべてを取得することができます。 結果の 1 つ以上の列をリクエストできます。 または、ワイル
ドカード文字「*」を使用するなら、すべての列をリクエストできます。
次に例を示します。
/* Return all of the data in the table */
SELECT * FROM Music;
/* Return all of the values for Artist and Title */
SELECT Artist, Title FROM Music;
DynamoDB
DynamoDB は、同じように機能する Scan アクションを提供します。 次に例を示します。
// Return all of the data in the table
{
TableName: "Music"
}
// Return all of the values for Artist and Title
{
TableName: "Music",
ProjectionExpression: "Artist, Title"
}
API Version 2012-08-10
36
Amazon DynamoDB 開発者ガイド
インデックス管理
Scan アクションは、結果に表示しない項目を破棄する FilterExpression パラメーターも提供しま
す。 FilterExpression は、テーブル全体がスキャンされた後で、結果が返される前に適用されま
す。 (これは大きなテーブルでは推奨されません。ごくわずかな一致する項目のみが返ってくる場合で
も、Scan 全体にたいして課金されます。)
Note
Scan を使用するコードサンプルに関しては、Amazon DynamoDB 入門ガイド を参照してく
ださい。
インデックス管理
インデックスは代替のクエリパターンへのアクセスを付与し、クエリを高速化できます。 このセク
ションでは、SQL と DynamoDB におけるインデックスの作成と使用を比較します。
リレーショナルデータベースまたは DynamoDB のいずれを使用するにしても、インデックスの作成
は慎重に判断する必要があります。 テーブルに書き込みが発生するたびに、テーブルのインデックス
はすべて、更新する必要があります。 大きなテーブルでの書き込み量が多い環境では、大量のシステ
ムリソースを消費する可能性があります。 読み取り専用または読み取りがほとんどの環境では、これ
は大きな問題にはなりません。ただし、インデックスがアプリケーションによって実際に使用されて
おり、ただ容量を取っていることがないよう確認する必要があります。
トピック
• インデックスの作成 (p. 37)
• インデックスのクエリの実行およびスキャン (p. 39)
インデックスの作成
SQL
リレーショナルデータベースでは、インデックスは、テーブルの異なる列に対して高速にクエリを実
行できるデータ構造です。 CREATE INDEXSQL ステートメントを使用して、既存のテーブルにイン
デックスが追加し、インデックスを作成する列を指定します。 インデックスの作成後は、通常どおり
テーブルのデータにクエリを実行できますが、テーブル全体をスキャンする代わりに、テーブルの指
定された行を迅速に検索するため、データベースがインデックスを使用することができます。
インデックスの作成後は、データベースが維持します。 テーブルのデータを変更した場合は、イン
デックスが自動的に変更され、テーブル内の変更を反映します。
MySQL では、このようなインデックスを作成できます。
CREATE INDEX GenreAndPriceIndex
ON Music (genre, price);
DynamoDB
DynamoDB では、同様の目的のため、セカンダリインデックス を作成し、使用できます。
DynamoDB のインデックスはリレーショナルな対応物とは異なります。 セカンダリインデックス を
作成すると、パーティションキーおよびソートキーのように、キー属性を指定する必要があります。
セカンダリインデックス を作成した後、テーブルを使ってするのと同じように、Query を実行または
Scan できます。 DynamoDB に、クエリオプティマイザはありませんので、セカンダリインデックス
は、Query を実行するか、Scan するときにのみ使用されます。
DynamoDB では、次の 2 種類のインデックスをサポートしています。
API Version 2012-08-10
37
Amazon DynamoDB 開発者ガイド
インデックス管理
• グローバルセカンダリインデックス - インデックスのプライマリキーは、テーブルからの任意の 2
つの属性になります。
• ローカルセカンダリインデックス - インデックスのパーティション キーは、テーブルのパーティ
ションキーと同じである必要があります。 ただし、ソートキーは、他の任意の属性にすることがで
きます。
DynamoDB を使えば、セカンダリインデックス のデータは結果的にテーブルと整合性が取れます。
テーブルまたは local secondary index. での強い整合性を持つ Query または Scan アクションをリク
エストできます。 ただし、グローバルセカンダリインデックスは結果整合性のみをサポートします。
UpdateTable アクションを使用し、GlobalSecondaryIndexUpdates: を指定して、既存のテーブ
ルに グローバルセカンダリインデックス を追加できます。
{
TableName: "Music",
AttributeDefinitions:[
{AttributeName: "Genre", AttributeType: "S"},
{AttributeName: "Price", AttributeType: "N"}
],
GlobalSecondaryIndexUpdates: [
{
Create: {
IndexName: "GenreAndPriceIndex",
KeySchema: [
{AttributeName: "Genre", KeyType: "HASH"}, //Partition
key
{AttributeName: "Price", KeyType: "RANGE"}, //Sort key
],
Projection: {
"ProjectionType": "ALL"
},
ProvisionedThroughput: {
"ReadCapacityUnits": 1,"WriteCapacityUnits": 1
}
}
}
]
}
UpdateTable に以下のパラメーターを提供する必要があります。
• TableName - インデックスが関連付けられるテーブル。
• AttributeDefinitions - インデックスのキースキーマ属性用のデータ型。
• GlobalSecondaryIndexUpdates - 作成するインデックスに関する詳細。
• IndexName - インデックスの名前。
• KeySchema - インデックスプライマリキーに使用する属性。
• Projection - テーブルからインデックスにコピーされる属性。 この場合、ALL は、すべての属
性がコピーされることを意味します。
• ProvisionedThroughput - このインデックスに必要な 1 秒あたりの読み取り/書き込み数。 (こ
れは、テーブルのプロビジョニングされたスループット設定とは異なります。)
このオペレーションの一部は、テーブルから新しいインデックスにデータをバックフィリングするこ
とを含みます。 バックフィリング中、テーブルは使用可能なままになります。 ただし、インデックス
は Backfilling 属性が true から false に変わるまで、準備ができていません。 DescribeTable ア
クションを使用して、この属性を表示できます。
API Version 2012-08-10
38
Amazon DynamoDB 開発者ガイド
インデックス管理
Note
UpdateTable を使用するコードサンプルに関しては、Amazon DynamoDB 入門ガイド を参
照してください。
インデックスのクエリの実行およびスキャン
SQL
リレーショナルデータベースでは、インデックスを直接使用しません。 代わりに、SELECT ステート
メントの発行により、テーブルでクエリを実行し、クエリオプティマイザは任意のインデックスを利
用できます。
クエリオプティマイザは、使用できるインデックスを評価し、クエリを高速化するためにそれらを使
用できるかを決定するリレーショナルデータベース管理システム (RDBMS) のコンポーネントです。
クエリを高速化するためにインデックスが使用できる場合、RDBMS は最初にインデックスにアクセ
スし、それを使用してテーブルのデータを特定します。
GenreAndPriceIndex を使用してパフォーマンスを向上できる SQL ステートメントを次に示します。
ここでは、音楽テーブルに十分なデータがあり、クエリオプティマイザが、テーブル全体にスキャン
するのではなく、このインデックスを使用することを前提にします。
/* All of the rock songs */
SELECT * FROM Music
WHERE Genre = 'Rock';
/* All of the cheap country songs */
SELECT Artist, SongTitle, Price FROM Music
WHERE Genre = 'Country' AND Price < 0.50;
DynamoDB
DynamoDB では、テーブルで実行するのと同じように、インデックスに対して直接 Query オペレー
ションを実行します。 TableName と IndexName の両方を指定する必要があります。
以下に、DynamoDB の GenreAndPriceIndex に対するクエリをいくつか示します。 (このインデック
スのキースキーマは、ジャンルと価格で構成されています。)
// All of the rock songs
{
TableName: "Music",
IndexName: "GenreAndPriceIndex",
KeyConditionExpression: "Genre = :genre",
ExpressionAttributeValues: {
":genre": "Rock"
},
};
// All of the cheap country songs
{
TableName: "Music",
API Version 2012-08-10
39
Amazon DynamoDB 開発者ガイド
テーブルのデータ変更
IndexName: "GenreAndPriceIndex",
KeyConditionExpression: "Genre = :genre and Price < :price",
ExpressionAttributeValues: {
":genre": "Country",
":price": 0.50
},
ProjectionExpression: "Artist, SongTitle, Price"
};
この例では ProjectionExpression を使用して、属性すべてではなく、一部のみを結果に表示する
ことを示します。
また、テーブルで実行するのと同じように、セカンダリインデックス で Scan オペレーションを実行
できます。 次に示すのは、GenreAndPriceIndex に対するスキャンです。
// Return all of the data in the index
{
TableName: "Music",
IndexName: "GenreAndPriceIndex"
}
テーブルのデータ変更
SQL 言語はデータ変更のための UPDATE ステートメントを提供します。 DynamoDB
は、UpdateItem オペレーションを使用して、同じようなタスクを実行します。
SQL
SQL では、UPDATE ステートメントを使用して、1 つ以上の行を変更します。 SET 句は、1 つ以上の
行に新しい値を指定し、WHERE 句は変更する行を決定します。 例を示します。
UPDATE Music
SET RecordLabel = 'Global Records'
WHERE Artist = 'No One You Know' AND SongTitle = 'Call Me Today';
WHERE 句に行が一致しない場合、UPDATE ステートメントは何も実行しません。
DynamoDB
DynamoDB では、UpdateItem アクションを使用して、単一の項目を変更します。 (複数の項目を変
更する場合は、複数の UpdateItem オペレーションを使用する必要があります。)
例を示します。
{
TableName: "Music",
Key: {
"Artist":"No One You Know",
"SongTitle":"Call Me Today"
},
UpdateExpression: "SET RecordLabel = :label",
ExpressionAttributeValues: {
":label": "Global Records"
}
API Version 2012-08-10
40
Amazon DynamoDB 開発者ガイド
テーブルのデータ変更
}
変更する項目の Key 属性と、属性値を指定する UpdateExpression を指定する必要があります。
UpdateItem は、個々の属性を置き換えるのではなく、項目全体を置き換えます。
UpdateItem は、「アップサート」操作のように動作します。項目はテーブルにある場合更新されま
すが、更新されない場合は、新しい項目が追加されます (挿入)。
UpdateItem は、条件付き書き込みをサポートしており、特定の ConditionExpression が true と
評価された場合のみ、オペレーションが成功します。 たとえば、次の UpdateItem アクションは、
曲の価格が 2.00 以上でない限り、更新を実行しません。
{
TableName: "Music",
Key: {
"Artist":"No One You Know",
"SongTitle":"Call Me Today"
},
UpdateExpression: "SET RecordLabel = :label",
ConditionExpression: "Price >= :p",
ExpressionAttributeValues: {
":label": "Global Records",
":p": 2.00
}
}
UpdateItem はまた、アトミックカウンター、または増加減少する数値型の属性をサポートしていま
す。 アトミックカウンターは多くの点で SQL データベースのシーケンスジェネレーター、IDENTITY
列、または自動インクリメントフィールドと似ています。
曲が再生された回数を追跡するために新しい属性 (Plays) を初期化する UpdateItem アクションの例
を次に示します。
{
TableName: "Music",
Key: {
"Artist":"No One You Know",
"SongTitle":"Call Me Today"
},
UpdateExpression: "SET Plays = :val",
ExpressionAttributeValues: {
":val": 0
},
ReturnValues: "UPDATED_NEW"
}
ReturnValues パラメーターは、更新された任意の属性の新しい値を返す、UPDATED_NEW に設定さ
れています。 この場合は、0 (ゼロ) を返します。
ユーザーがこの曲を再生するたびに、次の UpdateItem アクションを使用して Plays を 1 ずつ増分で
きます。
{
TableName: "Music",
Key: {
"Artist":"No One You Know",
API Version 2012-08-10
41
Amazon DynamoDB 開発者ガイド
テーブルからデータを削除する
"SongTitle":"Call Me Today"
},
UpdateExpression: "SET Plays = Plays + :incr",
ExpressionAttributeValues: {
":incr": 1
},
ReturnValues: "UPDATED_NEW"
}
Note
UpdateItem を使用したコードサンプルについては、Amazon DynamoDB 入門ガイド を参照
してください。
テーブルからデータを削除する
SQL では、DELETE ステートメントは、テーブルから 1 つ以上の行を削除します。 DynamoDB
は、DeleteItem オペレーションを使用して、一度に 1 つの項目を削除します。
SQL
SQL では、DELETE ステートメントを使用して、1 つ以上の行を削除します。 WHERE 句は、変更する
行を決定します。 例を示します。
DELETE FROM Music
WHERE Artist = 'The Acme Band' AND SongTitle = 'Look Out, World';
WHERE 句を変更して、複数行を削除できます。 たとえば、次に示すように、特定のアーティストのす
べての曲を削除できます。
DELETE FROM Music WHERE Artist = 'The Acme Band'
Note
WHERE 句を省略すると、データベースはテーブルからすべての行を削除しようとします。
DynamoDB
DynamoDB では、DeleteItem アクションを使用して、テーブルからデータを一度に 1 項目ずつ削除
します。 項目のプライマリキー値を指定する必要があります。 例を示します。
{
TableName: "Music",
Key: {
Artist: "The Acme Band",
SongTitle: "Look Out, World"
}
}
Note
DeleteItem に加えて、Amazon DynamoDB は、同時に複数の項目を削除するための
BatchWriteItem アクションをサポートします。
API Version 2012-08-10
42
Amazon DynamoDB 開発者ガイド
テーブルの削除
DeleteItem は、条件付き書き込みをサポートしており、特定の ConditionExpression が true
と評価された場合のみ、オペレーションが成功します。 たとえば、次の DeleteItem アクションは
RecordLabel 属性がある場合のみ項目を削除します。
{
TableName: "Music",
Key: {
Artist: "The Acme Band",
SongTitle: "Look Out, World"
},
ConditionExpression: "attribute_exists(RecordLabel)"
}
Note
DeleteItem を使用したコードサンプルについては、Amazon DynamoDB 入門ガイド を参照
してください。
テーブルの削除
SQL では、DROP TABLE ステートメントを使用して、テーブルを削除します。 DynamoDB で
は、DeleteTable オペレーションを使用します。
SQL
不要になったテーブルを完全に廃棄する場合、SQL の DROP TABLE ステートメントを使用します。
DROP TABLE Music;
テーブルは削除された後、復元できません。 (一部のリレーショナルデータベースは DROP TABLE オ
ペレーションを取消すことができますが、これはベンダー固有の機能であり、一般的には実装されて
いません。)
DynamoDB
DynamoDB には、同様のアクションがあります。DeleteTable 次の例では、テーブルは完全に削除
されます。
{
TableName: "Music"
}
Note
DeleteTable を使用したコードサンプルについては、Amazon DynamoDB 入門ガイド を参
照してください。
API Version 2012-08-10
43
Amazon DynamoDB 開発者ガイド
DynamoDB (ダウンロード可
能バージョン) のセットアップ
DynamoDB のセットアップ
Amazon DynamoDB ウェブサービスに加え、AWS では、コンピュータでローカルに実行できるダウ
ンロード可能なバージョンの DynamoDB を提供しています。DynamoDB (ダウンロード可能または
ウェブサービス) をセットアップするには、次のセクションを参照してください。
トピック
• DynamoDB (ダウンロード可能バージョン) のセットアップ (p. 44)
• DynamoDB (ウェブサービス) のセットアップ (p. 48)
DynamoDB (ダウンロード可能バージョン) の
セットアップ
ダウンロード可能なバージョンの DynamoDB では、実際に Amazon DynamoDB ウェブサービスにア
クセスせずに、アプリケーションを記述できます。代わりに、データベースはコンピュータ上で自己
完結型となります。
このローカルバージョンの DynamoDB により、プロビジョニングされたスループット、データスト
レージ、およびデータ転送料金を節約できます。 また、アプリケーションを開発している間インター
ネットに接続しておく必要はありません。 ただし、本稼働環境でアプリケーションをデプロイする場
合、Amazon DynamoDB ウェブサービスを使用できるように簡単な調整を加えることができます。
トピック
• DynamoDB のダウンロードと実行 (p. 44)
• ローカルエンドポイントの設定 (p. 46)
• 使用に関する注意事項 (p. 47)
DynamoDB のダウンロードと実行
ダウンロード可能なバージョンの DynamoDB は、実行可能な .jar ファイルとして提供されます。
Windows、Linux、Mac OS X、および Java をサポートする他のプラットフォームで動作します。以
下のステップに従って DynamoDB をコンピューターにダウンロードして実行します。
1.
以下のリンクから無料で DynamoDB をダウンロードします。
API Version 2012-08-10
44
Amazon DynamoDB 開発者ガイド
DynamoDB のダウンロードと実行
• .tar.gz 形式: https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.tar.gz
• .zip 形式: https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip
Important
ダウンロード可能なバージョンの DynamoDB は他の場所で入手できる場合もあります
が、最新バージョンであることは保証されません。確実に最新バージョンを入手するに
は、上に示したいずれかのリンクを使用します。
お使いのコンピュータ上の DynamoDB では、Java Runtime Environment (JRE) バージョ
ン 6.x 以降が必要です。それよりも古い JRE バージョンでは動作しません。DynamoDB
(ダウンロード可能バージョン) は、AWS Toolkit for Eclipse の一部としても入手できま
す。詳細については、「AWS Toolkit for Eclipse」を参照してください。
2.
アーカイブをダウンロードしたら、内容を抽出し、抽出されたディレクトリを任意の場所にコ
ピーします。
3.
コンピュータで DynamoDB を開始するには、コマンドプロンプトウィンドウを開
き、DynamoDBLocal.jar を抽出したディレクトリに移動し、次のコマンドを入力します。
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar sharedDb
DynamoDB が実行中のウィンドウに、ときどき診断メッセージが表示されます。
DynamoDB は、停止するまで受信リクエストを処理します。DynamoDB を停止するには、コマ
ンドプロンプトウィンドウで Ctrl+C を入力します。
コマンドラインオプション
DynamoDB コンピュータの実行は次のコマンドラインオプションを使用します :
• -cors value - JavaScript で CORS (Cross-Origin Resource Sharing) のサポートを有効にします。
特定のドメインのカンマ区切りの "許可" リストを指定する必要があります。-cors のデフォルト設
定は、パブリックアクセスを許可するアスタリスク(*)です。
• -dbPath value – DynamoDB がそのデータベースファイルを書き込むディレクトリ。このオ
プションを指定しない場合、ファイルは現在のディレクトリに書き込まれます。-dbPath と inMemory の両方を同時に指定することはできません。
• -delayTransientStatuses - DynamoDB で特定のオペレーションの遅延を発生させま
す。DynamoDB は、テーブルやインデックスでの作成/更新/削除オペレーションなど、一部のタ
スクをほぼ瞬時に実行できます。ただし、実際の DynamoDB サービスでは、それらのタスクには
より多くの時間が必要です。このパラメーターを設定すると、DynamoDB は Amazon DynamoDB
ウェブサービスの動作をより正確にシミュレートできます(現在、このパラメータではステータス
が CREATING または DELETING のグローバルセカンダリインデックスに対してのみ遅延が発生し
ます)。
• -help — 使用方法の概要とオプションを出力します。
• -inMemory — DynamoDB は、データベースファイルを使用する代わりにメモリで実行されま
す。DynamoDB を停止したとき、保存されるデータはありません。-dbPath と -inMemory の両方
を同時に指定することはできません。
• -optimizeDbBeforeStartup — コンピュータで DynamoDB を開始する前に、基になるデータ
ベーステーブルを最適化します。このパラメータを使用するときは、-dbPath も指定する必要があ
ります。
• -port value – DynamoDB がアプリケーションと通信するために使用するポート番号。このオプ
ションを指定しない場合、デフォルトポートは 8000 になります。
API Version 2012-08-10
45
Amazon DynamoDB 開発者ガイド
ローカルエンドポイントの設定
Note
DynamoDB は、デフォルトではポート 8000 を使用します。ポート 8000 を使用できない場
合、このコマンドにより例外がスローされます。-port オプションを使用すると、異なる
ポート番号を指定できます。DynamoDB ランタイムオプション (-port) の詳細なリストを
表示するには、次のコマンドを入力します。
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar help
• -sharedDb - DynamoDB は、認証情報とリージョンごとに別のファイルを使用する代わりに、単一
のデータベースファイルを使用します。-sharedDb を指定すると、すべての DynamoDB クライア
ントは、リージョンと認証情報の設定にかかわらず、テーブルの同じセットを操作します。
ローカルエンドポイントの設定
AWS SDK およびツールは、デフォルトで Amazon DynamoDB ウェブサービスのエンドポイントを使
用します。 ローカルで DynamoDB を実行しながら AWS SDKとツールを使用するには、ローカルエ
ンドポイントを指定する必要があります:
http://localhost:8000
AWS Command Line Interface
AWS CLI を使って、コンピュータで実行中の DynamoDB を操作できます。 たとえば、テーブルの作
成とサンプルデータのロード (p. 166) の手順すべてを AWS CLI を使って実行できます。
ローカルで実行中の DynamoDB にアクセスするには、AWS CLI で --endpoint-url パラメーター
を使用します。 次の例では、AWS CLI を使用して、コンピュータにある DynamoDB のテーブルを一
覧表示します。
aws dynamodb list-tables --endpoint-url http://localhost:8000
Note
AWS CLI はデフォルトのエンドポイントとしてダウンロード可能なバージョンの DynamoDB
を使用できません。このため、各 CLI コマンドで --endpoint-url を指定する必要がありま
す。
AWS SDK
エンドポイントを指定する方法は、使用しているプログラミング言語と AWS Software Development
Kit (SDK) によって異なります。 以下のセクションでは、各種言語でこれを行う方法について説明し
ます。
• Java: AWS リージョンとエンドポイントの設定 (p. 172)
• .NET: AWS リージョンとエンドポイントの設定 (p. 175)
• PHP: AWS リージョンとエンドポイントを設定 (p. 176)
Note
他のプログラミング言語の例については、Amazon DynamoDB 入門ガイド を参照してくださ
い。 入門ガイドにあるコード例はすべて、ダウンロード可能なバージョンの DynamoDB を使
用しています。
API Version 2012-08-10
46
Amazon DynamoDB 開発者ガイド
使用に関する注意事項
使用に関する注意事項
エンドポイントを除き、システムの DynamoDB で実行するアプリケーションは Amazon DynamoDB
ウェブサービスでも動作します。ただし、以下に注意する必要があります。
• -sharedDb オプションを使用すると、DynamoDB は shared-local-instance.db という名前の単一の
データベースファイルを作成します。DynamoDB に接続するすべてのプログラムはこのファイルに
アクセスします。このファイルを削除すると、保存されたすべてのデータを失うことになります。
• -sharedDb を省略する場合のデータベースファイルの名前は、myaccesskeyid_region.db で、アプ
リケーション設定に表示されるとおりの AWS アクセスキー ID とリージョンが使用されます。この
ファイルを削除すると、保存されたすべてのデータを失うことになります。
• -inMemory オプションを使用する場合、DynamoDB はデータベースファイルの書き込みを行いま
せん。代わりに、すべてのデータがメモリに書き込まれ、DynamoDB を終了するときにデータは保
存されません。
• -optimizeDbBeforeStartup オプションを使用する場合は、-dbPath パラメータも指定
し、DynamoDB がそのデータベースファイルを見つけられるようにする必要があります。
• DynamoDB 用の AWS SDK では、アプリケーション設定でアクセスキーの値と AWS リージョン
の値を指定する必要があります。-sharedDb または -inMemory オプションを使用していない限
り、DynamoDB はこれらの値を使用してローカルデータベースファイルに名前を付けます。
ローカルに実行するためにこれらが有効な AWS 値である必要はありませんが、使用しているエン
ドポイントを変更するだけで、クラウドでコードを後で実行できるように、有効な値を使用するこ
とをお勧めします。
ローカルで実行される DynamoDB と Amazon DynamoDB
ウェブサービスの違い
ダウンロード可能なバージョンの DynamoDB は、できるだけ密接に Amazon DynamoDB ウェブサー
ビスをエミュレートしようとします。ただし、これは以下のように Amazon DynamoDB サービスとは
異なります。
• リージョンと個別の AWS アカウントは、クライアントレベルでサポートされません。
• プロビジョニングされたスループット設定は無視されます。ただし、この設定は CreateTable オ
ペレーションで必要です。 CreateTable の場合、プロビジョニングされた読み込みおよび書き込
みスループットに対して任意の数値を指定できます。ただし、この数値は使用されません。1 日に
何回でも UpdateTable を呼び出すことができます。ただし、プロビジョニングされたスループッ
ト値の変更は無視されます。
• 読み込みおよび書き込みオペレーションの速度は、コンピュータの速度によってのみ制限を受け
ます。CreateTable、UpdateTable、および DeleteTable オペレーションはすぐに実行されま
す。テーブルの状態は常に ACTIVE です。テーブルやグローバルセカンダリインデックスでプロビ
ジョニングされたスループット設定のみを変更する UpdateTable オペレーションは、すぐに発生
します。UpdateTable オペレーションがグローバルセカンダリインデックスを作成または削除す
る場合、それらのインデックスは、通常の状態(CREATING や DELETING など)に移行してから
ACTIVE 状態になります。この間、テーブルは ACTIVE のままになります。
• 読み込みオペレーションには結果整合性があります。ただし、コンピュータで実行されている
DynamoDB の速度が原因で、実際には、ほとんどの読み込みに強い整合性があるように見えます。
• 消費されたキャパシティーユニットは追跡されません。オペレーションレスポンスでは、キャパシ
ティーユニットの代わりに、null が返されます。
• 項目コレクションのメトリクスは追跡されず、項目コレクションのサイズも同様です。オペレー
ションレスポンスでは、項目コレクションのメトリクスの代わりに、null が返されます。
• DynamoDB では、結果セットごとに、返されるデータに 1 MB の制限があります。 DynamoDB
ウェブサービスはこの制限を適用し、ダウンロード可能バージョンの DynamoDB も同様です。た
だし、インデックスのクエリを実行しているとき、DynamoDB サービスは、射影されたキーと属性
API Version 2012-08-10
47
Amazon DynamoDB 開発者ガイド
DynamoDB (ウェブサービス) のセットアップ
のサイズだけを計算します。一方で、ダウンロード可能バージョンの DynamoDB は、項目全体の
サイズを計算します。
• DynamoDB ストリーム を使用している場合、シャードが作成される速度が異なる可能性がありま
す。DynamoDB ウェブサービスでは、シャードの作成動作はテーブルパーティションアクティビ
ティの影響を部分的に受けます。一方、DynamoDB をローカルに実行する場合にはテーブルパー
ティションがありません。 どちらの場合も、シャードはエフェメラルのため、アプリケーションが
シャードの動作の影響を受けることはありません。
DynamoDB (ウェブサービス) のセットアップ
DynamoDB ウェブサービスを使用するには:
1. AWS にサインアップする (p. 48)
2. AWS アクセスキー ID およびシークレットアクセスキーの取得 (p. 48) (プログラムで
DynamoDB にアクセスするために使用)。
Note
DynamoDB コンソールのみを使用して DynamoDB とやり取りする場合、アクセスキー ID
やシークレットアクセスキーは必要なく、「コンソールを使用する (p. 50)」に進むこと
ができます。
AWS にサインアップする
DynamoDB を使用するには、AWS アカウントが必要です。アカウントを持っていない場合は、サイ
ンアップ時に作成するための画面が表示されます。サインアップした AWS サービスの料金は、その
サービスを使用しない限り発生することはありません。
AWS にサインアップするには
1.
https://aws.amazon.com/ を開き、[AWS アカウントの作成] を選択します。
2.
オンラインの手順に従います。
サインアップ手順の一環として、通話呼び出しを受け取り、電話のキーパッドを用いて PIN を入
力することが求められます。
AWS アクセスキー ID およびシークレットアクセス
キーの取得
DynamoDB ウェブサービスを使用するには、事前に AWS アクセスキーおよびシークレットキーを取
得する必要があります。
アクセスキー ID とシークレットアクセスキーを取得するには
アクセスキーはアクセスキー ID と秘密アクセスキーからなり、AWS に対するプログラムによるリク
エストに署名するときに使用されます。アクセスキーがない場合は、AWS マネジメントコンソール
を使用して作成することができます。AWS ルートアカウントのアクセスキーの代わりに、IAM のアク
セスキーを使用することをお勧めします。IAM では、AWS アカウントでの AWS サービスとリソース
へのアクセスを安全に制御できます。
API Version 2012-08-10
48
Amazon DynamoDB 開発者ガイド
AWS アクセスキー ID および
シークレットアクセスキーの取得
Note
アクセスキーを作成するには、必要な IAM アクションを実行するアクセス許可が必要です。
詳細については、『IAM ユーザーガイド』の「パスワードポリシーと認証情報を管理する
IAM ユーザーアクセス許可の付与」を参照してください。
1.
2.
IAM コンソールを開きます。
ナビゲーションペインで [Users] を選択します。
3.
IAM のユーザー名 (チェックボックスではありません) を選択します。
4.
5.
[Security Credentials] タブを選択し、次に [Create Access Key] を選択します。
アクセスキーを参照するには、[Show User Security Credentials] を選択します。認証情報は以下
のようになります。
• アクセスキー ID:AKIAIOSFODNN7EXAMPLE
• シークレットアクセスキー: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
6.
[Download Credentials] を選択し、安全な場所にキーを保存します。
秘密キーは AWS マネジメントコンソール ではもう確認できなくなります。コピーは 1 つだ
けです。アカウントを保護するために秘密キーは内緒にしておき、メールでも送信しないで
ください。また、所属している組織外にこの情報を公開してはいけません。もし AWS または
Amazon.com を名乗る人物から問い合わせがあった場合でも、この情報は開示しないでくださ
い。Amazon のスタッフまたは関係者がこの情報を尋ねることは決してありません。
関連トピック
• IAM とは何ですか?」(IAM ユーザーガイド)
• AWS セキュリティ認証情報(AWS General Reference)
API Version 2012-08-10
49
Amazon DynamoDB 開発者ガイド
コンソールを使用する
DynamoDB へのアクセス
コンソール、CLI、または API を使用して DynamoDB にアクセスできます。
トピック
• コンソールを使用する (p. 50)
• CLI の使用 (p. 58)
• API の使用 (p. 61)
コンソールを使用する
DynamoDB AWS マネジメントコンソールには、https://console.aws.amazon.com/dynamodb/home か
らアクセスできます。コンソールでは次のことが可能です。
• テーブルを作成、更新、削除する。スループットカリキュレーターでは、利用率に関する情報を入
力すると、リクエストが必要になるキャパシティーユニットの見積りが得られる。
• テーブルに保存されている項目を表示し、項目の追加、更新、削除を行う。
• テーブルのクエリを行う。
• テーブルの容量の利用率をモニタリングするアラームを設定する。
• CloudWatch のリアルタイムグラフで、テーブルの主要なモニタリングメトリクスを表示する。
• 各テーブルに対して設定されているアラームを表示し、カスタムアラームを作成する。
コンソールには、最初のテーブルの作成を求める初期画面が表示されます。
API Version 2012-08-10
50
Amazon DynamoDB 開発者ガイド
コンソールを使用する
コンソールでテーブルを作成するための詳細な手順については、「テーブルの作成とサンプルデータ
のロード (p. 166)」を参照してください。
テーブルを表示するには、コンソールの左側のナビゲーションペインから、[Tables] を選択します。
項目を操作するには、テーブル名の 1 つを選択し、[Items] タブを選択します。ここでテーブルのクエ
リを行うこともできます。詳細については、「項目と属性を操作する (p. 52)」を参照してくださ
い。
API Version 2012-08-10
51
Amazon DynamoDB 開発者ガイド
項目と属性を操作する
項目と属性を操作する
トピック
• 項目の追加 (p. 52)
• 項目の削除 (p. 54)
• 項目の更新 (p. 55)
• 項目のコピー (p. 55)
DynamoDB コンソールを使用して、テーブルの項目を追加、変更、削除できます。
項目の追加
1.
コンソールの左側のナビゲーションペインから、[Tables] を選択します。
2.
対象のテーブル名を選択し、[Items] タブを選択します。次のスクリーンショットでは、[Reply]
テーブルが表示されています。
3.
[Create Item] を選択します。
[Create item] ウィンドウでは、必要なプライマリキー属性値を入力することができます。テーブ
ルにセカンダリインデックスがある場合は、インデックスプライマリキーの値も入力する必要が
あります。
次のスクリーンショットは、Reply テーブル (Id および ReplyDateTime) のプライマリキー属性を
示しています。テーブル (PostedBy-Message-Index) にグローバルセカンダリインデックスがあ
るため、そのプライマリキー属性 (PostedBy および Message) も必要です。
API Version 2012-08-10
52
Amazon DynamoDB 開発者ガイド
項目と属性を操作する
4.
さらに属性を追加するには、[Message] の左側にあるアクションメニューを選択します。アク
ションメニューで、[Append] を選択し、目的のデータ型を選択します。
API Version 2012-08-10
53
Amazon DynamoDB 開発者ガイド
項目と属性を操作する
表示されたフィールドに新しい属性の名前と値を入力します。
さらに属性を追加する場合は、必要な回数だけこの手順を繰り返します。
5.
項目の設定が完了したら、[Save] を選択して新しい項目をテーブルに追加します。
項目の削除
1.
コンソールの左側のナビゲーションペインから、[Tables] を選択します。
2.
対象のテーブル名を選択し、[Items] タブを選択します。
3.
削除する 1 つ以上の項目を選択し、[Actions | Delete] を選択します。
API Version 2012-08-10
54
Amazon DynamoDB 開発者ガイド
項目と属性を操作する
4.
[Delete Item?] ダイアログボックスで、[Yes, Delete] を選択します。
項目の更新
1.
コンソールの左側のナビゲーションペインから、[Tables] を選択します。
2.
対象のテーブル名を選択し、[Items] タブを選択します。
3.
更新する項目を選択し、[Actions | Edit] を選択します。
4.
[Edit Item] ウィンドウで、目的の属性または値を変更します。
5.
項目の設定が完了したら、[Save] を選択して項目をテーブルに書き込みます。
項目のコピー
既存の項目を選択してコピーし、コピーされた項目を新しいプライマリキーとともに保存できます。
1.
コンソールの左側のナビゲーションペインから、[Tables] を選択します。
2.
対象のテーブル名を選択し、[Items] タブを選択します。
3.
コピーする項目を選択し、[Actions | Duplicate] を選択します。
4.
[Copy Item] ウィンドウで、目的の属性または値を変更します。
API Version 2012-08-10
55
Amazon DynamoDB 開発者ガイド
テーブルを監視する
テーブルのプライマリキー属性用に、別の値を選択する必要があります。セカンダリインデック
スが存在する場合、インデックスのプライマリキー属性の値も選択する必要があります。
5.
項目の設定が完了したら、[Save] を選択して項目をテーブルに書き込みます。
テーブルを監視する
選択したテーブルの CloudWatch メトリクスを表示するには、[Metrics] タブを選択します
。
任意のグラフを選択すると、特定のメトリクスについて詳しく調べることができます。
[Metrics] ページには、テーブルのパフォーマンスのわかりやすい概要が表示されます。テーブル
に関連付けられたその他のメトリクスを表示するには、[View all CloudWatch metrics] を選択して
CloudWatch コンソールに移動します。
DynamoDB の CloudWatch メトリクスの詳細については、「Amazon DynamoDB のモニタリン
グ (p. 495)」を参照してください。
API Version 2012-08-10
56
Amazon DynamoDB 開発者ガイド
CloudWatch アラームを設定する
CloudWatch アラームを設定する
DynamoDB コンソールを使用して、テーブルの CloudWatch アラームを作成および管理できま
す。CloudWatch アラームは、プロビジョニングされたスループット設定を長時間超えているテーブ
ルなど、注意が必要になる可能性があるイベントについて通知します。
テーブルの CloudWatch アラームに対応するには、[Alarms] タブを選択します。
このページでは、テーブルの既存の CloudWatch アラームを変更するか、[Create alarm] を選択して新
しい CloudWatch アラームを作成できます。
CloudWatch アラームは、特定の CloudWatch メトリックスが特定の期間のしきい値に達したときに
トリガーされます。
アラームの設定の詳細については、CloudWatch コンソールで CloudWatch ヘルプを参照する
か、CloudWatch ドキュメントを参照してください。
DynamoDB ストリーム とトリガーの管理
テーブルで DynamoDB ストリーム を有効または無効にできます。これを行うには、[Overview] タブ
に移動し、[Manage Stream] を選択します。
Note
DynamoDB ストリーム および AWS Lambda トリガーの詳細については、「DynamoDB スト
リーム を使用したテーブルアクティビティのキャプチャ (p. 426)」 を参照してください。
API Version 2012-08-10
57
Amazon DynamoDB 開発者ガイド
CLI の使用
[Manage Stream] ウィンドウでは、このテーブルのストリームを有効にできます。 また、ストリーム
に表示されるデータ変更に関する詳細レベルを選択することもできます。
すでにテーブルでストリームが有効になっている場合、[Manage Stream] ウィンドウで、これを無効
にできます。
[Triggers] タブでは、AWS Lambda 関数をテーブルのストリーム (有効になっている場合) と関連付け
ることができます。このタブを使用して、対象となるイベントがテーブルのストリームに表示される
たびに呼び出される既存の Lambda 関数を選択 (または新しい関数を作成) します。
CLI の使用
AWS Command Line Interface (AWS CLI) を使用すると、複数の AWS のサービスをコマンドライン
から制御したり、スクリプトで自動化したりできます。テーブルの作成など、その場限りのオペレー
ションに AWS CLI を使用できます。また、ユーティリティスクリプト内に DynamoDB オペレーショ
ンを埋め込むときにも使用できます。
コンピュータで AWS CLI を設定する前に、AWS アクセスキー ID とシークレットキーを最初に入手
します。詳細については、「AWS アクセスキー ID およびシークレットアクセスキーの取得 (p. 48)」
を参照してください。
API Version 2012-08-10
58
Amazon DynamoDB 開発者ガイド
AWS CLI のダウンロードと設定
DynamoDB AWS CLI で使用できるすべてのコマンドの完全な一覧については、http://
docs.aws.amazon.com/cli/latest/reference/dynamodb/index.html を参照してください。
トピック
• AWS CLI のダウンロードと設定 (p. 59)
• DynamoDB での AWS CLI の使用 (p. 59)
• ダウンロード可能な DynamoDB での AWS CLI の使用 (p. 60)
AWS CLI のダウンロードと設定
AWS CLI は、http://aws.amazon.com/cli で入手でき、Windows、Mac、または Linux で動作しま
す。AWS CLI をダウンロードした後でインストールし、設定するには、次の操作を実行します。
1.
2.
AWS Command Line Interface ユーザーガイド に移動します。
AWS CLI をインストールし、AWS CLI を設定する手順に従います。
DynamoDB での AWS CLI の使用
コマンドラインの形式は、DynamoDB オペレーション名の後に、そのオペレーションのパラメーター
が続きます。 AWS CLI では、パラメータ値の短縮構文および JSON をサポートしています。
たとえば、次のコマンドでは、Music という名前のテーブルを作成します。パーティションキーは
Artist で、ソートキーは SongTitle です。(読みやすくするために、このセクションの長いコマンド
は、複数の行に分かれています)。
aws dynamodb create-table \
--table-name Music \
--attribute-definitions \
AttributeName=Artist,AttributeType=S \
AttributeName=SongTitle,AttributeType=S \
--key-schema AttributeName=Artist,KeyType=HASH
AttributeName=SongTitle,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1
次のコマンドでは、新しい項目をテーブルに追加します。この例では、短縮構文と JSON を組み合わ
せて使用しています。
aws dynamodb put-item \
--table-name Music \
--item \
'{"Artist": {"S": "No One You Know"}, "SongTitle": {"S": "Call Me
Today"}, "AlbumTitle": {"S": "Somewhat Famous"}}' \
--return-consumed-capacity TOTAL
aws dynamodb put-item \
--table-name Music \
--item \
'{"Artist": {"S": "Acme Band"}, "SongTitle": {"S": "Happy Day"},
"AlbumTitle": {"S": "Songs About Life"}}' \
--return-consumed-capacity TOTAL
aws dynamodb put-item \
--table-name Music \
--item '{ \
API Version 2012-08-10
59
Amazon DynamoDB 開発者ガイド
ダウンロード可能な DynamoDB での AWS CLI の使用
"Artist": {"S": "Acme Band"}, \
"SongTitle": {"S": "Happy Day"}, \
"AlbumTitle": {"S": "Songs About Life"} }' \
--return-consumed-capacity TOTAL
コマンドラインで、有効な JSON を作成するのは難しい場合があります。ただし、AWS CLI
は、JSON ファイルを読み込むことができます。たとえば、key-conditions.json という名前のファイ
ルに格納されている次の JSON スニペットがあるとします。
{
"Artist": {
"AttributeValueList": [
{
"S": "No One You Know"
}
],
"ComparisonOperator": "EQ"
},
"SongTitle": {
"AttributeValueList": [
{
"S": "Call Me Today"
}
],
"ComparisonOperator": "EQ"
}
}
次のように、AWS CLI を使用して、Query リクエストを発行できます。この例では、keyconditions.json ファイルの内容は、--key-conditions パラメータに使用されます。
aws dynamodb query --table-name Music --key-conditions file://keyconditions.json
DynamoDB で AWS CLI を使用する方法に関するドキュメントについては、http://
docs.aws.amazon.com/cli/latest/reference/dynamodb/index.html を参照してください。
ダウンロード可能な DynamoDB での AWS CLI の使
用
AWS CLI は、コンピュータで実行中の DynamoDB を操作できます。これを有効にするには、各コマ
ンドに --endpoint-url パラメーターを追加します。
--endpoint-url http://localhost:8000
次の例では、AWS CLI を使用して、ローカルデータベースのテーブルを一覧表示します。
aws dynamodb list-tables --endpoint-url http://localhost:8000
DynamoDB がデフォルト(8000)以外のポート番号を使用している場合、それに応じて -endpoint-url 値を変更する必要があります。
Note
AWS CLI はデフォルトのエンドポイントとしてダウンロード可能なバージョンの DynamoDB
を使用できません。このため、各コマンドで --endpoint-url を指定する必要があります。
API Version 2012-08-10
60
Amazon DynamoDB 開発者ガイド
API の使用
API の使用
AWS マネジメントコンソールおよび AWS コマンドラインインターフェイスを使用して、DynamoDB
をインタラクティブに操作できます。ただし、DynamoDB を最大限に活用するためには、AWS SDK
を使用してアプリケーションコードを記述できます。詳細については、「DynamoDB および AWS
SDK を使用したプログラミング (p. 62)」を参照してください。
API Version 2012-08-10
61
Amazon DynamoDB 開発者ガイド
DynamoDB の AWS SDK サポートの概要
DynamoDB および AWS SDK を使
用したプログラミング
この章では、開発者に関連するトピックを取り上げます。代わりにコードサンプルを実行する場合
は、「この開発者ガイドのコードサンプルの実行 (p. 165)」を参照してください。
トピック
• DynamoDB の AWS SDK サポートの概要 (p. 62)
• プログラム用インターフェイス (p. 64)
• DynamoDB 低レベル API (p. 68)
• エラー処理 (p. 72)
• DynamoDB 用の高レベルプログラミングインターフェイス (p. 78)
• この開発者ガイドのコードサンプルの実行 (p. 165)
DynamoDB の AWS SDK サポートの概要
次の図は、AWS SDK を使用する DynamoDB アプリケーションプログラミングの概要を示していま
す。
API Version 2012-08-10
62
Amazon DynamoDB 開発者ガイド
DynamoDB の AWS SDK サポートの概要
1. 使用しているプログラミング言語用の AWS SDK を使用してアプリケーションを作成します。AWS
SDK は、さまざまな言語で利用できます。詳細なリストについては、「Tools for Amazon Web
Services」を参照してください。
2. 各 AWS SDK には、DynamoDB を使用するために 1 つ以上のプログラムインターフェイスが用意
されています。使用可能なインターフェイスは、使用するプログラミング言語および AWS SDK に
よって異なります。
3. AWS SDK は低レベル DynamoDB API で使用するための HTTP(S) リクエストを構築します。
4. AWS SDK は、DynamoDB エンドポイントにリクエストを送信します。
5. DynamoDB は、リクエストを実行します。リクエストが成功した場合、DynamoDB により応答
コード HTTP 200 (OK) が返されます。リクエストが失敗した場合、DynamoDB により HTTP エ
ラーコードとエラーメッセージが返されます。
6. AWS SDK は、応答を処理し、アプリケーションに反映させます。
各 AWS SDK は、次のものを含むアプリケーションに重要なサービスを提供しています。
• HTTP(S) リクエストをフォーマットし、リクエストパラメーターをシリアル化します。
• 各リクエストの暗号署名を生成します。
• リクエストを DynamoDB エンドポイントに送信し、DynamoDB からのレスポンスを受信します。
• これらのレスポンスから結果を抽出します。
• エラーが発生した場合には、基本的な再試行ロジックを実行します。
これらのタスクのコードを書く必要はありません。
API Version 2012-08-10
63
Amazon DynamoDB 開発者ガイド
プログラム用インターフェイス
Note
インストール手順とドキュメントを含む、AWS SDK の詳細については、「アマゾン ウェブ
サービスのツール」を参照してください。
プログラム用インターフェイス
すべての AWS SDK には、DynamoDB を使用するために 1 つ以上のプログラムインターフェイスが
用意されています。これらのインターフェイスは、シンプルな低レベルの DynamoDB ラッパーから
オブジェクト指向永続化層までを含みます。利用できるインターフェイスは、使用するプログラミン
グ言語および AWS SDK によって異なります。
以下のセクションでは、AWS SDK for Java を例として使用し、利用できるインターフェイスの一部
を取り上げています。(すべての AWS SDK ですべてのインターフェイスが使用できるわけではありま
せん)。
トピック
• 低レベル インターフェイス (p. 64)
• ドキュメント インターフェイス (p. 65)
• オブジェクト永続性インターフェイス (p. 66)
低レベル インターフェイス
すべての言語固有の AWS SDK には、低レベルの DynamoDB API リクエストとよく似たメソッドを
持つ、DynamoDB の低レベルインターフェイスが用意されています。
API Version 2012-08-10
64
Amazon DynamoDB 開発者ガイド
ドキュメント インターフェイス
場合によっては、属性のデータ型を、data type descriptors (p. 71) を使用して、文字列を S あるい
は数字を N などのように指定する必要があります。
Note
低レベルインターフェイスは、すべての言語固有 AWS SDK で使用できます。
次の Java プログラムには、AWS SDK for Java の低レベルインターフェイスを使用します。プログラ
ムは Music テーブル内の曲の GetItem リクエストを発行し、曲がリリースされた年を出力します。
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient クラスは、DynamoDB 低レベ
ルインターフェイスを実装します。
package com.amazonaws.codesamples;
import java.util.HashMap;
import
import
import
import
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.model.AttributeValue;
com.amazonaws.services.dynamodbv2.model.GetItemRequest;
com.amazonaws.services.dynamodbv2.model.GetItemResult;
public class MusicLowLevelDemo {
public static void main(String[] args) {
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
HashMap<String, AttributeValue> key = new HashMap<String,
AttributeValue>();
key.put("Artist", new AttributeValue().withS("No One You Know"));
key.put("SongTitle", new AttributeValue().withS("Call Me Today"));
GetItemRequest request = new GetItemRequest()
.withTableName("Music")
.withKey(key);
try {
GetItemResult result = client.getItem(request);
if (result != null) {
AttributeValue year = result.getItem().get("Year");
System.out.println("The song was released in " +
year.getN());
} else {
System.out.println("No matching song was found");
}
} catch (Exception e) {
System.err.println("Unable to retrieve data: ");
System.err.println(e.getMessage());
}
}
}
ドキュメント インターフェイス
多くの AWS SDK には、ドキュメント インターフェイスがあり、テーブルおよびインデックスでデー
タプレーンオペレーション (作成、読み込み、更新、削除) を実行できます。ドキュメント インター
API Version 2012-08-10
65
Amazon DynamoDB 開発者ガイド
オブジェクト永続性インターフェイス
フェイスに、data type descriptors (p. 71) を指定する必要はありません。データ型は、データその
もののセマンティクスによって暗示されます。これらの AWS SDK には、JSON ドキュメントとネイ
ティブな DynamoDB データ型を簡単に変換できるメソッドが用意されています。
Note
ドキュメントインターフェイスは、AWS SDK for Java、.NET、Node.js、およびブラウザの
JavaScript で使用できます。
次の Java プログラムには、AWS SDK for Java のデータ型ドキュメント インターフェイスを使用し
ます。プログラムは Music テーブルを表す Table オブジェクトを作成し、オブジェクトが曲を取得
する GetItem を使用するようにします。その後、プログラムは、その曲がリリースされた年を出力
します。
com.amazonaws.services.dynamodbv2.document.DynamoDB クラスは、DynamoDB ドキュメン
ト インターフェイスを実装します。DynamoDB が低レベルクライアント (AmazonDynamoDBClient)
にラッパーとしてどのように機能するかに注意してください。
package com.amazonaws.codesamples.gsg;
import
import
import
import
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.GetItemOutcome;
com.amazonaws.services.dynamodbv2.document.Table;
public class MusicDocumentDemo {
public static void main(String[] args) {
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
DynamoDB docClient = new DynamoDB(client);
Table table = docClient.getTable("Music");
GetItemOutcome outcome = table.getItemOutcome(
"Artist", "No One You Know",
"SongTitle", "Call Me Today");
int year = outcome.getItem().getInt("Year");
System.out.println("The song was released in " + year);
}
}
オブジェクト永続性インターフェイス
AWS SDK の一部には、直接データプレーンオペレーションを実行しない、オブジェクト永続性イン
ターフェイスが用意されています。代わりに、DynamoDB テーブルおよびインデックスに項目を表す
オブジェクト作成し、これらのオブジェクトとのみやり取りします。これにより、データベース中心
のコードではなく、オブジェクト中心のコードを記述できます。
Note
オブジェクト永続性インターフェイスは、AWS SDK for Java および AWS SDK for .NET で
使用できます。詳細については、「DynamoDB 用の高レベルプログラミングインターフェイ
ス (p. 78)」を参照してください。
API Version 2012-08-10
66
Amazon DynamoDB 開発者ガイド
オブジェクト永続性インターフェイス
次の Java プログラムは、DynamoDBMapper という AWS SDK for Java のオブジェクト永続性イン
ターフェイスを使用します。MusicItem クラスは、Music テーブル内の項目を表します。
package com.amazonaws.codesamples;
import
import
import
import
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBAttribute;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBHashKey;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBRangeKey;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTable;
@DynamoDBTable(tableName="Music")
public class MusicItem {
private String artist;
private String songTitle;
private String albumTitle;
private int year;
@DynamoDBHashKey(attributeName="Artist")
public String getArtist() { return artist;}
public void setArtist(String artist) {this.artist = artist;}
@DynamoDBRangeKey(attributeName="SongTitle")
public String getSongTitle() { return songTitle;}
public void setSongTitle(String songTitle) {this.songTitle = songTitle;}
@DynamoDBAttribute(attributeName = "AlbumTitle")
public String getAlbumTitle() { return albumTitle;}
public void setAlbumTitle(String albumTitle) {this.albumTitle =
albumTitle;}
@DynamoDBAttribute(attributeName = "Year")
public int getYear() { return year; }
public void setYear(int year) { this.year = year; }
}
次に、MusicItem オブジェクトをインスタンス化し、DynamoDBMapper の load() メソッドを使用
して曲を取得できます。その後、プログラムは、その曲がリリースされた年を出力します。
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapper クラス
は、DynamoDB オブジェクト永続性インターフェイスを実行します。DynamoDBMapper が低レベル
クライアント (AmazonDynamoDBClient) にラッパーとしてどのように機能するかに注意してくださ
い。
package com.amazonaws.codesamples;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapper;
public class MusicMapperDemo {
public static void main(String[] args) {
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
DynamoDBMapper mapper = new DynamoDBMapper(client);
MusicItem keySchema = new MusicItem();
keySchema.setArtist("No One You Know");
API Version 2012-08-10
67
Amazon DynamoDB 開発者ガイド
DynamoDB 低レベル API
keySchema.setSongTitle("Call Me Today");
try {
MusicItem result = mapper.load(keySchema);
if (result != null) {
System.out.println(
"The song was released in "+ result.getYear());
} else {
System.out.println("No matching song was found");
}
} catch (Exception e) {
System.err.println("Unable to retrieve data: ");
System.err.println(e.getMessage());
}
}
}
DynamoDB 低レベル API
トピック
• リクエストの形式 (p. 70)
• レスポンスの形式 (p. 70)
• データ型記述子 (p. 71)
• 数値データ (p. 72)
• バイナリデータ (p. 72)
API Version 2012-08-10
68
Amazon DynamoDB 開発者ガイド
DynamoDB 低レベル API
DynamoDB 低レベル API は、Amazon DynamoDB 用のプロトコルレベルのインターフェイスです。
このレベルでは、すべての HTTP リクエストは、適切な形式で有効なデジタル署名がある必要があり
ます。
AWS SDK は、低レベル DynamoDB API リクエストをユーザーに代わって作成し、DynamoDB から
のレスポンスを処理します。 これにより、低レベルの詳細ではなく、アプリケーションロジックに専
念することができます。 ただし、低レベル DynamoDB API の動作方法についての基本的な知識も役
立ちます。
低レベル DynamoDB API の詳細については、Amazon DynamoDB API Reference を参照してくださ
い。
Note
DynamoDB ストリーム には、DynamoDB とは別に独自の低レベル API があり、AWS SDK
で完全にサポートされています。
詳細については、「DynamoDB ストリーム を使用したテーブルアクティビティのキャプ
チャ (p. 426)」を参照してください。低レベルの DynamoDB ストリーム API について
は、DynamoDB ストリーム API リファレンス を参照してください
低レベル DynamoDB API は、ワイヤプロトコル形式として、JavaScript Object Notation (JSON) を使
用しています。 JSON では、データ値とデータ構造が両方同時にわかるように、データが階層で示さ
れます。 名前と値のペアは、name:value の形式で定義されます。データ階層は、名前と値のペアを
ブラケットで囲み、ネストする形で定義します。
API Version 2012-08-10
69
Amazon DynamoDB 開発者ガイド
リクエストの形式
DynamoDB は、ストレージ形式としてではなく、トランスポートプロトコルとしてのみ、JSON を使
用しています。 AWS SDK は、DynamoDB へのデータ送信に JSON を使用し、DynamoDB は JSON
で応答しますが、DynamoDB が JSON 形式でデータを永続的に保存することはありません。
Note
JSON に関する詳細については、JSON.org のウェブサイト 「JSON の入門」 を参照してく
ださい。
リクエストの形式
DynamoDB 低レベル API は、HTTP POST リクエストを入力として受け付けます。 AWS SDK はこれ
らのリクエストを作成します。
ペットという名のテーブルに、AnimalType (パーティションキー)、Name (ソートキー) によって構成
されるキースキーマがあるとします。 これらの属性は両方とも文字列型になります。 ペットからある
項目を取り出すために、AWS SDKは次に示すようなリクエストを作成します。
POST / HTTP/1.1
Host: dynamodb.<region>.<domain>;
Accept-Encoding: identity
Content-Length: <PayloadSizeBytes>
User-Agent: <UserAgentString>
Content-Type: application/x-amz-json-1.0
Authorization: AWS4-HMAC-SHA256 Credential=<Credential>,
SignedHeaders=<Headers>, Signature=<Signature>
X-Amz-Date: <Date>
X-Amz-Target: DynamoDB_20120810.GetItem
{
"TableName": "Pets",
"Key": {
"AnimalType": {"S": "Dog"},
"Name": {"S": "Fido"}
}
}
このリクエストに関して以下の点に注意してください。
• Authorization ヘッダーには、DynamoDB がリクエストを認証するのに必要な情報が含まれてい
ます。 詳細については、『アマゾン ウェブ サービス全般のリファレンス』 の 「AWS API リクエ
ストの署名」 と 「署名バージョン 4 の署名プロセス」 を参照してください。
• X-Amz-Target ヘッダーには、DynamoDB オペレーションの名前が含まれます : GetItem。 (これ
は、低レベル API バージョンと共に示されます。この場合は 20120810 となります。)
• リクエストのペイロード (本文) には、JSON 形式で、オペレーションのパラメーターが含まれま
す。 GetItem オペレーションでは、パラメーターは TableName と Key です。
レスポンスの形式
リクエストを受け取ったら、DynamoDB が処理しレスポンスを返します。 上に示したリクエストに
対して、HTTP レスポンスペイロードには、この例のようにオペレーションからの結果が含まれます:
HTTP/1.1 200 OK
x-amzn-RequestId: <RequestId>
x-amz-crc32: <Checksum>
API Version 2012-08-10
70
Amazon DynamoDB 開発者ガイド
データ型記述子
Content-Type: application/x-amz-json-1.0
Content-Length: <PayloadSizeBytes>
Date: <Date>
{
"Item": {
"Age": {"N": "8"},
"Colors": {
"L": [
{"S": "White"},
{"S": "Brown"},
{"S": "Black"}
]
},
"Name": {"S": "Fido"},
"Vaccinations": {
"M": {
"Rabies": {
"L": [
{"S": "2009-03-17"},
{"S": "2011-09-21"},
{"S": "2014-07-08"}
]
},
"Distemper": {"S": "2015-10-13"}
}
},
"Breed": {"S": "Beagle"},
"AnimalType": {"S": "Dog"}
}
}
この時点で、AWS SDK は、さらに処理するためにアプリケーションに応答データを返します。
Note
DynamoDB がリクエストを処理できない場合、HTTP エラーコードとメッセージを返しま
す。 AWS SDK は、これらを例外の形でアプリケーションに伝達します。 詳細については、
「エラー処理 (p. 72)」を参照してください。
データ型記述子
低レベル DynamoDB API のプロトコルは、各属性がデータ型記述子に伴われる必要があります。
データ型記述子は、各属性を解釈する方法を DynamoDB に伝えるトークンです。
リクエストの形式 (p. 70)とレスポンスの形式 (p. 70)には、データ型記述子が使用されている例
が示されています。 GetItem リクエストは、ペットキースキーマ属性AnimalType と Name のため
の S を文字列で指定します。 GetItem レスポンスには、文字列 (S)、数値 (N)、マップ (M)、リスト
(L) の属性のあるペット項目が含まれます。
DynamoDB データ型記述子の一覧を次に示します。
• S – 文字列
• N – 数値
• B – バイナリ
• BOOL – Boolean
• NULL – Null
API Version 2012-08-10
71
Amazon DynamoDB 開発者ガイド
数値データ
• M – マップ
• L – リスト
• SS – 文字列セット
• NN – 数値セット
• BB – バイナリセット
Note
DynamoDB データ型の詳細な説明については、データ型 (p. 12) を参照してください。
数値データ
プログラミング言語により、提供される JSON のサポートのレベルが異なります。 場合によって
は、JSONドキュメントを検証し解析するにあたり、サードパーティーのライブラリを使用すること
もできます。
JSON Number 型に基づいて構築されたサードパーティーライブラリもあり、int や long、または
double など独自の型を提供しています。 ただし、では他のデータ型に正確にマッピングされない
DynamoDB; のネイティブ数値データ型が使用されるため、このようなデータ型の区別が競合の原因
になる可能性があります。 加えて、多くの JSON ライブラリでは固定精度の数値は処理されず、小数
点を含む数字列は自動的に倍精度浮動小数点データ型であると推定されます。
これらの問題を解決するために、DynamoDB ではデータ損失のない単一の数値型が用意されていま
す。誤って倍精度の値に暗黙的変換が行われないように、DynamoDB では数値のデータ転送には文字
列が使用されます。 この方法によって、01、2、03 などの値を適切な順序で配置するなど、適切な並
べ替えセマンティクスを維持しながら、柔軟に属性値を更新することが可能になります。
数値の精度がアプリケーションにとって重要な場合は、数値を文字列に変換してから、DynamoDB に
渡します。
バイナリデータ
DynamoDB ではバイナリ属性がサポートされています。ただし JSON では、ネイティブではバ
イナリデータのエンコードがサポートされていません。リクエストでバイナリデータを送信す
るには、Base64 形式でエンコードする必要があります。 DynamoDB はリクエストを受け取る
と、Base64 データをバイナリに復号します。
DynamoDB で使用される Base64 エンコーディングスキームは、Internet Engineering Task Force
(IETF) のウェブサイト RFC 4648 に記載されています。
エラー処理
このセクションでは、ランタイムエラーとその処理方法について説明します。 また、DynamoDB 特
有のエラーメッセージとコードについて説明します。
トピック
• エラーコンポーネント (p. 73)
• エラーメッセージおよびコード (p. 73)
• アプリケーションのエラー処理 (p. 76)
• エラーの再試行とエクスポネンシャルバックオフ (p. 76)
• バッチオペレーションとエラー処理 (p. 77)
API Version 2012-08-10
72
Amazon DynamoDB 開発者ガイド
エラーコンポーネント
エラーコンポーネント
プログラムがリクエストを送信すると、DynamoDB は処理を試行します。 リクエストが成功した場
合、DynamoDB は要求されたオペレーションからの結果とともに、成功の HTTP ステータスコード
(200 OK) を返します。
リクエストが正常に行われなかった場合、DynamoDB はエラーを返します。 それぞれのエラーに
は、次の三つのコンポーネントがあります:
• HTTP ステータスコード (400 など)。
• 例外の名前 (ResourceNotFoundException など)。
• エラーメッセージ (Requested resource not found: Table: tablename not found な
ど)。
AWS SDK によりアプリケーションにエラーが伝達されるため、適切なアクションを実行できます。
たとえば、Java プログラムでは、 ResourceNotFoundException を処理する try-catch ロジック
を記述できます。
AWS SDK を使用していない場合は、DynamoDB からの低レベルのレスポンスの内容も解析する必要
があります。 以下に、そのようなレスポンスの例を示します。
HTTP/1.1 400 Bad Request
x-amzn-RequestId: LDM6CJP8RMQ1FHKSC1RBVJFPNVV4KQNSO5AEMF66Q9ASUAAJG
Content-Type: application/x-amz-json-1.0
Content-Length: 240
Date: Thu, 15 Mar 2012 23:56:23 GMT
{"__type":"com.amazonaws.dynamodb.v20120810#ResourceNotFoundException",
"message":"Requested resource not found: Table: tablename not found"}
エラーメッセージおよびコード
DynamoDB によって返される例外のリストを HTTP ステータスコードごとに次に示します。 再試
行してもいいですかがはいであれば、同じリクエストを再度送信できます。 再試行してもいいです
かがいいえであれば、新しいリクエストを送信する前に、クライアント側で問題を修正する必要があ
ります。
HTTP ステータスコード 400
HTTP ステータスコード400は、認証の失敗、必須パラメーターの欠落、またはテーブルにプロビジョ
ニングされているスループットの超過などのリクエストに関連した問題があることを示しています。
リクエストを再度送信する前に、アプリケーションで問題を修正する必要があります。
AccessDeniedException
メッセージ: アクセスが拒否されました。
クライアントがリクエストに正しく署名しませんでした。AWS SDKを使用する場合、リクエスト
は自動的に署名されます。それ以外の場合、AWS General Reference にある「Signature Version
4 Signing Process」を参照してください。
再試行してもいいですか。 いいえ
ConditionalCheckFailedException
メッセージ: 条件付きリクエストが失敗しました。
API Version 2012-08-10
73
Amazon DynamoDB 開発者ガイド
エラーメッセージおよびコード
false と評価された条件を指定しました。 たとえば、項目に条件付き更新を実行しようとしたかも
しれませんが、属性の実際の値は、条件の予期される値と一致しませんでした。
再試行してもいいですか。 いいえ
IncompleteSignatureException
メッセージ: リクエストの署名が AWS 基準に適合しません。
リクエストの署名に、必要なすべての要素が含まれていませんでした。 AWS SDKを使用する
場合、リクエストは自動的に署名されます。それ以外の場合、AWS General Reference にある
「Signature Version 4 Signing Process」を参照してください。
再試行してもいいですか。 いいえ
ItemCollectionSizeLimitExceededException
メッセージ : コレクションサイズが超過しました。
local secondary indexがあるテーブルの場合、同じパーティションキー値を持つ項目のグループ
が、10 GB の最大サイズ制限を超過しました。項目コレクションの詳細については、「項目コレ
クション (p. 391)」を参照してください。
再試行してもいいですか。 はい
LimitExceededException
メッセージ : 特定のサブスクライバに対するオペレーションが多すぎます。
同時オペレーションのコントロールプレーンが多すぎます。 CREATING、DELETINGまた
はUPDATINGの状態のテーブルやインデックスの累積数が、10 を超えることはできません。
再試行してもいいですか。 はい
MissingAuthenticationTokenException
メッセージ : リクエストには、有効な(登録済みの)AWS Access Key ID が含まれている必要が
あります。
リクエストに、必要な認証ヘッダーが含まれていないか、または正しい形式ではありません。
「DynamoDB 低レベル API (p. 68)」を参照してください。
再試行してもいいですか。 いいえ
ProvisionedThroughputExceededException
メッセージ : 1 つのテーブルまたは 1 つ以上のグローバルセカンダリインデックスのプロビジョ
ンドスループットが許容されている最大値を超えました。 プロビジョンドスループットと消費ス
ループットのパフォーマンスメトリクスを表示するには、「Amazon CloudWatch console」を参
照してください。
例: リクエストの頻度が多すぎます。DynamoDB の AWS SDK は、この例外を受け取ったリクエ
ストを自動的に再試行します。リクエストは最終的に成功しますが、再試行キューが大きすぎて
終了しない場合もあります。exponential backoff (p. 76) を使用して、リクエストの頻度を少な
くします。
再試行してもいいですか。 はい
ResourceInUseException
メッセージ : 変更しようとしているリソースは使用中です。
API Version 2012-08-10
74
Amazon DynamoDB 開発者ガイド
エラーメッセージおよびコード
例: 既存のテーブルを再作成しようとしたか、CREATING 状態にあるテーブルを削除しようとしま
した。
再試行してもいいですか。 いいえ
ResourceNotFoundException
メッセージ : リクエストされたリソースは存在しません。
例: リクエストされたテーブルが存在しないか、ごく初期の CREATING 状態にあります。
再試行してもいいですか。 いいえ
ThrottlingException
メッセージ : リクエストの速度が、許容されているスループットを超えています。
CreateTable、UpdateTable、DeleteTable オペレーションの実行が速すぎる場合、次の例外
が返されることがあります。
再試行してもいいですか。 はい
UnrecognizedClientException
メッセージ : アクセスキー ID またはセキュリティトークンが無効です。
リクエスト署名が間違っています。最も可能性の高い原因は、AWS アクセスキー ID またはシー
クレットキーが無効であることです。
再試行してもいいですか。 はい
ValidationException
メッセージ : 発生した特定のエラーにより異なります
このエラーは、必須パラメータが指定されていない、値が範囲外である、データ型が一致しな
い、などいくつかの理由で発生します。エラーメッセージに、エラーを引き起こしたリクエスト
の特定部分に関する詳細が含まれています。
再試行してもいいですか。 いいえ
HTTP ステータスコード 5xx
HTTP ステータスコード 5xx は、アマゾン ウェブ サービスで解決する必要のある問題を示していま
す。 これは一時的なエラーかもしれず、その場合はリクエストを再試行することで成功する場合があ
ります。 それ以外の場合、サービスに運用上の問題があるかどうかを確認するために、「AWS サー
ビス状態ダッシュボード」を参照してください。
内部サーバーエラー (HTTP 500)
DynamoDB でリクエストを処理できませんでした。
再試行してもいいですか。 はい
Note
項目の操作中に内部サーバーエラーが発生することがあります。これはテーブルの存続期
間中に発生すると予想されます。失敗したリクエストは速やかに再試行できます。
Service Unavailable (HTTP 503)
DynamoDB は現在利用できません。 (これは一時的な状態です。)
API Version 2012-08-10
75
Amazon DynamoDB 開発者ガイド
アプリケーションのエラー処理
再試行してもいいですか。 はい
アプリケーションのエラー処理
アプリケーションをスムーズに実行するには、エラーを見つけ、エラーに対応するロジックを組み込
む必要があります。 一般的な方法には、try-catchブロックやif-thenステートメントの使用など
があります。
AWS SDK は独自に再試行とエラーチェックを実行します。AWS SDK の使用中にエラーが発生した
場合は、エラーコードと説明が問題のトラブルシューティングに役立ちます。
また、レスポンスにRequest IDが表示されます。 Request IDは、AWS サポートを使用して問題を
診断することが必要な場合に便利です。
次の Java コードスニペットは、DynamoDB テーブルから項目の削除を試み、基本的なエラー処理を
実行します。 (この場合、ユーザーにはリクエストが失敗したとだけ通知されます)。
Table table = dynamoDB.getTable("Movies");
try {
Item item = table.getItem("year", 1978, "title", "Superman");
if (item != null) {
System.out.println("Result: " + item);
} else {
//No such item exists in the table
System.out.println("Item not found");
}
} catch (AmazonServiceException ase) {
System.err.println("Could not complete operation");
System.err.println("Error Message: " + ase.getMessage());
System.err.println("HTTP Status:
" + ase.getStatusCode());
System.err.println("AWS Error Code: " + ase.getErrorCode());
System.err.println("Error Type:
" + ase.getErrorType());
System.err.println("Request ID:
" + ase.getRequestId());
} catch (AmazonClientException ace) {
System.err.println("Internal error occured communicating with DynamoDB");
System.out.println("Error Message: " + ace.getMessage());
}
このコードスニペットでは、try-catchの構成は二つの異なるタイプの例外を処理します:
• AmazonServiceException — クライアントリクエストが DynamoDB に正しく送信された
が、DynamoDB がリクエストを処理できず、代わりにエラーレスポンスを返した場合にスローされ
ます。
• AmazonClientException — クライアントがサービスからレスポンスを取得できなかったか、ク
ライアントがサービスからレスポンスを解析できなかった場合にスローされます。
エラーの再試行とエクスポネンシャルバックオフ
特定のリクエストの処理中には、DNS サーバー、スイッチ、ロードバランサーなど、ネットワーク上
のさまざまなコンポーネントが原因でエラーが発生する可能性があります。ネットワーク環境内でこ
れらのエラー応答を処理する一般的な手法としては、クライアントアプリケーションに再試行を実装
する方法が挙げられます。この手法によってアプリケーションの信頼性が向上し、開発者のオペレー
ションコストが軽減されます。
API Version 2012-08-10
76
Amazon DynamoDB 開発者ガイド
バッチオペレーションとエラー処理
各 AWS SDK は、自動的に再試行ロジックを実装しています。 必要に応じて再試行パラメーターを変
更できます。 たとえば、エラーが発生したら再試行が許可されない、Fail-Fast 方式を要求する Java
アプリケーションについて考えてみましょう。 AWS SDK for Java では、ClientConfiguration ク
ラスを使用して maxErrorRetry の値を 0 に設定することで、再試行を無効にできます。 詳細につい
ては、AWS SDK ドキュメントのご使用のプログラミング言語の項目を参照してください
AWS SDK を使用していない場合は、サーバーエラー (5xx) を受け取る元のリクエストを再試
行する必要があります。ただし、クライアントエラー (4xx、ThrottlingException または
ProvisionedThroughputExceededException 以外) は、再試行する前にリクエスト自体を修正し
て問題を解決する必要があることを示しています。
単純な再試行に加えて、各 AWS SDK は効果的なフロー制御を行うために、エクスポネンシャルバッ
クオフアルゴリズムを実装します。エクスポネンシャルバックオフは、再試行間の待機時間を累進的
に長くして、連続的なエラー応答を受信するという概念に基づいています。たとえば、1 回目の再試
行の前に最大 50 ミリ秒、2 回目の前に最大 100 ミリ秒、3 回目の前に最大 200 ミリ秒のようになり
ます。ただし 1 分を経過してもリクエストが成功しない場合は、問題の原因はリクエストの速度では
なく、プロビジョニングしたスループットをリクエストのサイズが超えたためである可能性がありま
す。1 分程度で再試行が停止するように最大回数を設定します。リクエストが失敗した場合は、プロ
ビジョニングしたスループットオプションを調べてください。詳細については、「テーブルの操作の
ガイドライン (p. 566)」を参照してください。
Note
AWS SDK には自動再試行ロジックとエクスポネンシャルバックオフが実装されています。
ほとんどのエクスポネンシャルバックオフアルゴリズムは、衝突の連続を防ぐためにジッター (ランダ
ム化された遅延) を使用します。この場合は、そうした衝突を回避しようとしていないので、乱数を使
用する必要はありません。ただし、同時クライアントを使用すると、ジッターはリクエストを迅速に
処理する助けになります。詳細については、「Exponential Backoff and Jitter」のブログ投稿を参照し
てください。
バッチオペレーションとエラー処理
DynamoDB 低レベル API は、バッチオペレーションの読み書きをサポートします。 BatchGetItem
は、1 つ以上のテーブルからの項目の読み込み、BatchWriteItem は、1 つ以上のテーブルでの
項目の入力や削除に使用します。 これらのバッチオペレーションはバッチ以外の DynamoDB オペ
レーションのラッパーとして実装されています。 つまり、BatchGetItem は、バッチの項目ごとに
GetItem を一度呼び出します。 同様に、BatchWriteItem は、DeleteItem または PutItem を必
要に応じてバッチの項目ごとに呼び出します。
バッチオペレーションではバッチの個々のリクエストのエラーが許容されます。たとえば、5 つの項
目を読み込む BatchGetItem リクエストの場合を考えます。基礎となる GetItem リクエストの一部
が失敗した場合でも、BatchGetItem オペレーション全体が失敗することはありません。 一方、5 つ
の項目の読み込みがすべて失敗した場合は、BatchGetItem 全体が失敗します。
バッチオペレーションでは、失敗した個々のリクエストについて情報が返されるため、問題を診断
し、オペレーションを再試行できます。BatchGetItem の場合、問題のあるテーブルとプライマリ
キーがリクエストの UnprocessedKeys パラメーターで返されます。BatchWriteItem の場合、同
様の情報は UnprocessedItems で返されます。
読み込みまたは書き込みの失敗の原因として最も可能性が高いのは、帯域幅調整で
す。BatchGetItem の場合、バッチリクエストの 1 つ以上のテーブルに、オペレーションをサポート
するための十分なプロビジョンド読み込みキャパシティーがなくなります。BatchWriteItem の場
合、1 つ以上のテーブルに、十分なプロビジョンド書き込みキャパシティーがなくなります。
DynamoDB によって未処理の項目が返された場合は、それらの項目に対してバッチオペレーションを
再試行する必要があります。ただし、エクスポネンシャルバックオフアルゴリズムを使用することを
強くお勧めします。すぐにバッチオペレーションを再試行した場合、基礎となる読み込みまたは書き
API Version 2012-08-10
77
Amazon DynamoDB 開発者ガイド
DynamoDB 用の高レベルプロ
グラミングインターフェイス
込みリクエストはやはり、個々のテーブルに対する帯域幅調整により失敗することがあります。エク
スポネンシャルバックオフアルゴリズムを使用してバッチオペレーションを遅らせた場合は、バッチ
の個々のリクエストが成功する可能性がはるかに高くなります。
DynamoDB 用の高レベルプログラミングイン
ターフェイス
AWS SDK は、Amazon DynamoDB を操作するための低レベルインターフェイスをアプリケーション
に提供します。このクライアント側の クラスとメソッドは、低レベルの DynamoDB API に直接対応
しています。ただし、多くの開発者は、複雑なデータ型をデータベーステーブルの項目にマッピング
する必要があるときに、切断、つまり "インピーダンス不整合" を感じています。低レベルデータベー
ス インターフェイスでは、開発者は、データベーステーブルからオブジェクトデータを読み込むまた
は書き込むメソッド、およびその反対の読み込みまたは書き込みを行うメソッドを記述する必要があ
ります。オブジェクト型とデータベーステーブルの組み合わせごとに別途必要なコードの量は、対処
しきれないほど多いように思われます。
開発を簡素化するために、AWS SDK for Java と AWS SDK for .NET には、高レベルの抽象化を備え
た別のインターフェイスが用意されています。DynamoDB 用の高レベルインターフェイスにより、プ
ログラムのオブジェクトと、そのオブジェクトのデータを格納するデータベーステーブルとの間の関
係を定義できます。このマッピングを定義した後に、save、load、delete などの単純なオブジェク
トメソッドを呼び出すと、下位の低レベル DynamoDB オペレーションが自動的に呼び出されます。
これにより、データベース中心のコードではなく、オブジェクト中心のコードを記述できます。
DynamoDB 用の高レベルプログラミングインターフェイスは、AWS SDK for Java と AWS SDK
for .NET に用意されています。
Java
• Java: DynamoDBMapper (p. 78)
.NET
• .NET ドキュメントモデル (p. 116)
• .NET: オブジェクト永続性モデル (p. 138)
Java: DynamoDBMapper
トピック
• サポートされているデータの種類 (p. 81)
• DynamoDB 用の Java 注釈 (p. 82)
• DynamoDBMapper クラス (p. 87)
• DynamoDBMapper のオプションの設定 (p. 94)
• 例: CRUD オペレーション (p. 95)
• 例: バッチ書き込みオペレーション (p. 97)
• 例: クエリおよびスキャン (p. 102)
• バージョン番号を使用したオプティミスティックロック (p. 110)
• 任意データのマッピング (p. 112)
AWS SDK for Java は DynamoDBMapper クラスを提供し、クライアント側クラスを DynamoDB テー
ブルにマッピングできるようにします。DynamoDBMapper を使用するには、DynamoDB テーブル内
API Version 2012-08-10
78
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
の項目と、コードの対応するオブジェクトインスタンス間の関係を定義します。DynamoDBMapper ク
ラスでは、テーブルへのアクセス、さまざまな作成、読み取り、更新、削除 (CRUD) オペレーション
の実行、およびクエリを行うことができます。
Note
DynamoDBMapperクラスでは、テーブルを作成、更新、または削除することはできません。
これらのタスクを実行するには、代わりに低レベル SDK for Java インターフェイスを使用し
ます。詳細については、「テーブルの操作 : Java (p. 186)」を参照してください。
SDK for Java には一連の注釈タイプが用意されているので、クラスをテーブルにマッピングできま
す。たとえば、Id がパーティションキーになった ProductCatalog テーブルがあるとします。
ProductCatalog(Id, ...)
次の Java コードに示すように、クライアントアプリケーション内のクラスを ProductCatalog テーブ
ルにマッピングすることができます。このコードスニペットでは、CatalogItem という名前の Plain
Old Java Object (POJO) を定義しています。このオブジェクトは、注釈を使用して、オブジェクト
フィールドを DynamoDB 属性名にマッピングします。
package com.amazonaws.codesamples;
import java.util.Set;
import
import
import
import
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBAttribute;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBHashKey;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBIgnore;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTable;
@DynamoDBTable(tableName="ProductCatalog")
public class CatalogItem {
private
private
private
private
private
Integer id;
String title;
String ISBN;
Set<String> bookAuthors;
String someProp;
@DynamoDBHashKey(attributeName="Id")
public Integer getId() { return id;}
public void setId(Integer id) {this.id = id;}
@DynamoDBAttribute(attributeName="Title")
public String getTitle() {return title; }
public void setTitle(String title) { this.title = title; }
@DynamoDBAttribute(attributeName="ISBN")
public String getISBN() { return ISBN; }
public void setISBN(String ISBN) { this.ISBN = ISBN; }
@DynamoDBAttribute(attributeName = "Authors")
public Set<String> getBookAuthors() { return bookAuthors; }
public void setBookAuthors(Set<String> bookAuthors) { this.bookAuthors =
bookAuthors; }
@DynamoDBIgnore
public String getSomeProp() { return someProp;}
API Version 2012-08-10
79
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
public void setSomeProp(String someProp) {this.someProp = someProp;}
}
前述のコードでは、@DynamoDBTable 注釈によって、CatalogItem クラスが ProductCatalog テー
ブルにマッピングされています。個々のクラスインスタンスは、テーブル内の項目として格納できま
す。クラス定義では、@DynamoDBHashKey 注釈によって Id プロパティがプライマリキーにマッピン
グされます。
デフォルトでは、クラスプロパティはテーブル内の同じ名前属性にマッピングされます。プロパティ
Title および ISBN は、テーブル内の同じ名前属性にマッピングされます。
対応する項目の属性名に一致しないクラスプロパティ名を定義した場合は、@DynamoDBAttribute
注釈を明示的に追加して、マッピングを指定する必要があります。前述の例では、各プロパティに
@DynamoDBAttribute 注釈を追加することで、プロパティ名が「テーブルの作成とサンプルデータ
のロード (p. 166)」で作成したテーブルに確実に一致し、このガイド内の他のコード例で使用されて
いる属性名との整合性がとられています。
クラス定義には、テーブル内のどの属性にもマッピングされないプロパティを含めることもで
きます。これらのプロパティを特定するには、@DynamoDBIgnore 注釈を追加します。前述
の例では、SomeProp プロパティが @DynamoDBIgnore 注釈によってマーキングされていま
す。CatalogItem インスタンスをテーブルにアップロードしたとき、DynamoDBMapper インスタン
スに SomeProp プロパティは追加されません。また、このマッパーは、テーブルから項目を取り出す
ときにこの属性を返しません。
マッピングクラスを定義した後で、DynamoDBMapper メソッドを使用して、そのクラスのインスタン
スを Catalog テーブルの対応する項目に書き込むことができます。次のコードスニペットは、この手
法を示しています。
AmazonDynamoDBClient client = new AmazonDynamoDBClient(new
ProfileCredentialsProvider());
DynamoDBMapper mapper = new DynamoDBMapper(client);
CatalogItem item = new CatalogItem();
item.setId(102);
item.setTitle("Book 102 Title");
item.setISBN("222-2222222222");
item.setBookAuthors(new HashSet<String>(Arrays.asList("Author 1", "Author
2")));
item.setSomeProp("Test");
mapper.save(item);
次のコードスニペットでは、項目を取り出し、その属性の一部にアクセスする方法を示します。
CatalogItem partitionKey = new CatalogItem();
partitionKey.setId(102);
DynamoDBQueryExpression<CatalogItem> queryExpression = new
DynamoDBQueryExpression<CatalogItem>()
.withHashKeyValues(partitionKey);
List<CatalogItem> itemList = mapper.query(CatalogItem.class,
queryExpression);
for (int i = 0; i < itemList.size(); i++) {
System.out.println(itemList.get(i).getTitle());
System.out.println(itemList.get(i).getBookAuthors());
API Version 2012-08-10
80
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
}
DynamoDBMapper は、Java 内で DynamoDB データを操作するための直観的で自然な方法を提供しま
す。また、オプティミスティックロック、自動生成されるパーティションキーとソートキーの値、オ
ブジェクトのバージョニングなど、複数の組み込み機能があります。
サポートされているデータの種類
このセクションでは、サポートされているプリミティブな Java データ型、コレクション、および任
意データ型について説明します。
DynamoDB では、次のプリミティブなデータ型とプリミティブなラッパークラスがサポートされてい
ます。
• String
• Boolean, boolean
• Byte, byte
• Date(ISO8601 ミリ秒精度文字列、UTC に転換)
• Calendar(ISO8601 ミリ秒精度文字列、UTC に転換)
• Long, long
• Integer, int
• Double, double
• Float, float
• BigDecimal
• BigInteger
DynamoDB では、Java Set コレクションタイプがサポートされています。マッピングされているコレ
クションのプロパティが Set ではない場合には、例外がスローされます。
次の表に、前述の Java 型が DynamoDB 型にどのようにマッピングされるかを示します。
Java 型
DynamoDB の型
すべての数値型
N(数値型)
文字列
S (文字列型)
Boolean
N (数値型)、0 または 1。
または、@DynamoDBNativeBooleanType を
使用して Java のブール型を DynamoDB BOOL
データ型にマッピングできます。詳細について
は、「DynamoDB 用の Java 注釈 (p. 82)」を
参照してください。
ByteBuffer
B(バイナリ型)
日付
S(文字列型)。Date の値は、ISO-8601 形式の
文字列として格納されます。
Set コレクション型
SS(文字列セット)型、NS(数値セット)型、
または BS(バイナリセット)型。
また、SDK for Java は DynamoDB 用の任意のデータ型のマッピングもサポートしています。たとえ
ば、クライアントで独自の複合型を定義できます。複合型に対して DynamoDBMarshaller インター
API Version 2012-08-10
81
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
フェイスと @DynamoDBMarshalling 注釈を使用して、マッピングを記述します (任意データのマッ
ピング (p. 112))。
DynamoDB 用の Java 注釈
このセクションでは、クラスとプロパティをテーブルと属性にマッピングするときに使用できる注釈
について説明します。
対応する Javadoc ドキュメントについては、「AWS SDK for Java API Reference」の「Annotation
Types Summary」を参照してください。
Note
次の注釈では、DynamoDBTable と DynamoDBHashKey だけが必須です。
トピック
• DynamoDBAttribute (p. 82)
• DynamoDBAutoGeneratedKey (p. 82)
• DynamoDBDocument (p. 83)
• DynamoDBHashKey (p. 84)
• DynamoDBIgnore (p. 85)
• DynamoDBIndexHashKey (p. 85)
• DynamoDBIndexRangeKey (p. 85)
• DynamoDBMarshalling (p. 85)
• DynamoDBNativeBoolean (p. 85)
• DynamoDBRangeKey (p. 86)
• DynamoDBTable (p. 86)
• DynamoDBVersionAttribute (p. 87)
DynamoDBAttribute
テーブルの属性にプロパティをマッピングします。デフォルトでは、各クラスのプロパティ
が、同じ名前の項目属性にマッピングされます。ただし名前が同じでない場合は、この注釈を
使用して属性にプロパティをマッピングすることができます。次の Java コードスニペットで
は、DynamoDBAttribute によって、BookAuthors プロパティがテーブル内の 属性名にマッピング
されています。Authors
@DynamoDBAttribute(attributeName = "Authors")
public List<String> getBookAuthors() { return BookAuthors; }
public void setBookAuthors(List<String> BookAuthors) { this.BookAuthors =
BookAuthors; }
DynamoDBMapper では、テーブルにオブジェクトを保存する際に、 を属性名として使用していま
す。Authors
DynamoDBAutoGeneratedKey
パーティションキーまたはソートキーのプロパティは、自動生成済みとしてマーキングされま
す。DynamoDBMapper は、これらの属性を保存するときにランダムな UUID を生成します。String プ
ロパティには、自動生成済みのキーとしてマーキングできます。
次のスニペットは、自動生成されたキーの使用方法を示しています。
@DynamoDBTable(tableName="AutoGeneratedKeysExample")
API Version 2012-08-10
82
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
public class AutoGeneratedKeys {
private String id;
private String payload;
@DynamoDBHashKey(attributeName = "Id")
@DynamoDBAutoGeneratedKey
public String getId() { return id; }
public void setId(String id) { this.id = id; }
@DynamoDBAttribute(attributeName="payload")
public String getPayload() { return this.payload; }
public void setPayload(String payload) { this.payload = payload; }
public static void saveItem() {
AutoGeneratedKeys obj = new AutoGeneratedKeys();
obj.setPayload("abc123");
// id field is null at this point
DynamoDBMapper mapper = new DynamoDBMapper(dynamoDBClient);
mapper.save(obj);
System.out.println("Object was saved with id " + obj.getId());
}
}
DynamoDBDocument
DynamoDB ドキュメントとしてシリアル化できるクラスを示します。
たとえば、JSON ドキュメントをマップ型 (M) の DynamoDB 属性にマッピングしたいとします。次の
コードスニペットでは、マップ型の入れ子の属性 (Pictures) を含む項目を定義します。
public class ProductCatalogItem {
private Integer id; //partition key
private Pictures pictures;
/* ...other attributes omitted... */
@DynamoDBHashKey(attributeName="Id")
public Integer getId() { return id;}
public void setId(Integer id) {this.id = id;}
@DynamoDBAttribute(attributeName="Pictures")
public Pictures getPictures() { return pictures;}
public void setPictures(Pictures pictures) {this.pictures = pictures;}
// Additional properties go here.
@DynamoDBDocument
public static class Pictures {
private String frontView;
private String rearView;
private String sideView;
@DynamoDBAttribute(attributeName = "FrontView")
public String getFrontView() { return frontView; }
public void setFrontView(String frontView) { this.frontView =
frontView; }
API Version 2012-08-10
83
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
@DynamoDBAttribute(attributeName = "RearView")
public String getRearView() { return rearView; }
public void setRearView(String rearView) { this.rearView =
rearView; }
@DynamoDBAttribute(attributeName = "SideView")
public String getSideView() { return sideView; }
public void setSideView(String sideView) { this.sideView =
sideView; }
}
}
次に、次のコードスニペットに示すように、新しい ProductCatalog 項目を、Pictures とともに保存で
きます。
ProductCatalogItem item = new ProductCatalogItem();
Pictures pix = new Pictures();
pix.setFrontView("http://example.com/products/206_front.jpg");
pix.setRearView("http://example.com/products/206_rear.jpg");
pix.setSideView("http://example.com/products/206_left_side.jpg");
item.setPictures(pix);
item.setId(123);
mapper.save(item);
その結果、ProductCatalog 項目は次のようになります (JSON 形式)。
{
"Id" : 123
"Pictures" : {
"SideView" : "http://example.com/products/206_left_side.jpg",
"RearView" : "http://example.com/products/206_rear.jpg",
"FrontView" : "http://example.com/products/206_front.jpg"
}
}
DynamoDBHashKey
テーブルのパーティションキーにクラスプロパティをマッピングします。このプロパティは、スカ
ラー文字列型、数値型、バイナリ型のいずれかである必要があります。コレクション型は使用できま
せん。
Id がプライマリキーである ProductCatalog テーブルがあるとします。次の Java コードスニペット
では、CatalogItem クラスを定義し、その Id プロパティを @DynamoDBHashKey タグを使用して
ProductCatalog テーブルのプライマリキーにマッピングしています。
@DynamoDBTable(tableName="ProductCatalog")
public class CatalogItem {
private Integer Id;
@DynamoDBHashKey(attributeName="Id")
public Integer getId() {
return Id;
API Version 2012-08-10
84
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
}
public void setId(Integer Id) {
this.Id = Id;
}
// Additional properties go here.
}
DynamoDBIgnore
DynamoDBMapper インスタンスに対して、関連するプロパティを無視するように指示します。テーブ
ルにデータを保存する場合、DynamoDBMapper ではこのプロパティがテーブルに保存されません。
DynamoDBIndexHashKey
グローバルセカンダリインデックスのパーティションキーにクラスプロパティをマッピングします。
このプロパティは、スカラー文字列型、数値型、バイナリ型のいずれかである必要があります。コレ
クション型は使用できません。
この注釈は、グローバルセカンダリインデックスの Query を実行する必要がある場合に使用しま
す。インデックス名(globalSecondaryIndexName)を指定する必要があります。クラスプロ
パティの名前がインデックスのパーティションキーと異なる場合、そのインデックス属性の名前
(attributeName) も指定する必要があります。
DynamoDBIndexRangeKey
グローバルセカンダリインデックスまたはlocal secondary indexのソートキーにクラスプロパティを
マッピングします。このプロパティは、スカラー文字列型、数値型、バイナリ型のいずれかである必
要があります。コレクション型は使用できません。
この注釈は、local secondary indexまたはグローバルセカンダリインデックスの Query を実行
し、インデックスキーを使用して結果を絞り込む必要がある場合に使用します。インデックス名
(globalSecondaryIndexName または localSecondaryIndexName)を指定する必要がありま
す。クラスプロパティの名前がインデックスのソートキーと異なる場合、そのインデックス属性の名
前 (attributeName) も指定する必要があります。
DynamoDBMarshalling
カスタムマーシャラーを使用するクラスプロパティを識別します。この注釈を
DynamoDBMarshaller クラスと一緒に使用すると、独自の任意のデータ型を DynamoDB によって
ネイティブにサポートされているデータ型にマッピングできます。詳細については、「任意データの
マッピング (p. 112)」を参照してください。
DynamoDBNativeBoolean
クラスの boolean (または Boolean) 属性を、ネイティブな DynamoDB BOOL データ型として扱うこ
とを示します。
たとえば、CatalogItem を使用して、ProductCatalog テーブルに項目をマッピングするこ
とができます。属性 (InStock) の 1 つをブール型としてモデリングするには、次のように
DynamoDBNativeBoolean 注釈を使用します。
@DynamoDBTable(tableName="ProductCatalog")
public class CatalogItem {
private String Id;
private Boolean inStock;
API Version 2012-08-10
85
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
@DynamoDBHashKey(attributeName="Id")
// Getters and setters for Id go here
@DynamoDBNativeBoolean
@DynamoDBAttribute(attributeName = "InStock")
public boolean getInStock() { return inStock; }
public void setInStock(boolean inStock) { this.inStock = inStock; }
// Additional properties go here.
}
Note
以前のバージョンの DynamoDBMapper で、ブール属性は DynamoDB の Number データ型
(N) として表され、1 は true、0 は false と解釈されました。テーブルからデータを読み込むす
べてのアプリケーションが、更新されたバージョンの DynamoDBMapper を使用していない限
り、DynamoDBNativeBoolean の注釈を使用しないでください。
DynamoDBRangeKey
テーブルのソートキーにクラスプロパティをマッピングします。このプロパティは、スカラー文字列
型、数値型、バイナリ型のいずれかである必要があります。コレクション型は使用できません。
プライマリキーが複合の場合 (パーティションキーとソートキー)、このタグを使用して、クラス
フィールドをソートキーにマッピングできます。たとえば、フォーラムスレッドからの返信を格納す
る Reply テーブルがあるとします。各スレッドには多数の返信がある可能性があります。したがって
このテーブルのプライマリキーは、ThreadId と ReplyDateTime の両方になります。ThreadId がパー
ティションキーで、ReplyDateTime がソートキーです。次の Java コードスニペットでは、Reply ク
ラスを定義して Reply テーブルにマッピングしています。ここでは、@DynamoDBHashKey タグと
@DynamoDBRangeKey タグの両方を使用して、プライマリキーにマッピングされるクラスプロパティ
を識別しています。
@DynamoDBTable(tableName="Reply")
public class Reply {
private Integer id;
private String replyDateTime;
@DynamoDBHashKey(attributeName="Id")
public Integer getId() { return id; }
public void setId(Integer id) { this.id = id; }
@DynamoDBRangeKey(attributeName="ReplyDateTime")
public String getReplyDateTime() { return replyDateTime; }
public void setReplyDateTime(String replyDateTime) { this.replyDateTime =
replyDateTime; }
// Additional properties go here.
}
DynamoDBTable
DynamoDB でターゲットテーブルを識別します。たとえば次の Java コードスニペットで
は、Developer クラスを定義して、DynamoDB の People テーブルにマッピングしています。
@DynamoDBTable(tableName="People")
public class Developer { ...}
API Version 2012-08-10
86
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
@DynamoDBTable 注釈は継承できます。Developer クラスから継承された新しいクラスも、People
テーブルにマッピングされます。たとえば、Developer クラスから継承された Lead クラスを作成し
たとします。Developer クラスを People テーブルにマッピングしたことで、Lead クラスオブジェ
クトも同じテーブルに格納されます。
@DynamoDBTable もオーバーライドできます。デフォルトで Developer クラスから継承された新し
いクラスは、同じ People テーブルにマッピングされます。ただし、このデフォルトのマッピングは
オーバーライドできます。たとえば、Developer クラスから継承したクラスを作成した場合には、次
の Java コードスニペットに示すように、@DynamoDBTable 注釈を追加することで、別のテーブルに
明示的にマッピングできます。
@DynamoDBTable(tableName="Managers")
public class Manager extends Developer { ...}
DynamoDBVersionAttribute
オプティミスティックロックのバージョン番号を格納するためのクラスプロパティを識別しま
す。DynamoDBMapper は、新しい項目を保存するときにこのプロパティにバージョン番号を割り当
てます。バージョン番号は項目を更新するたびに増えていきます。サポートされているのは番号によ
るスカラー型だけです。データ型の詳細については、「データ型 (p. 12)」を参照してください。バー
ジョニングの詳細については、「バージョン番号を使用したオプティミスティックロック (p. 110)」
を参照してください。
DynamoDBMapper
クラス
DynamoDBMapper クラスは、DynamoDB のエントリポイントです。このクラスから DynamoDB エ
ンドポイントにアクセスして、各種のテーブル内のデータにアクセスし、項目に対してさまざまな
CRUD オペレーションを実行し、テーブルに対するクエリやスキャンを実行することができます。こ
のクラスは、DynamoDB を操作するために以下のメソッドを提供します。
対応する Javadoc ドキュメントについては、『AWS SDK for Java API Reference』の
「DynamoDBMapper」を参照してください。
トピック
• save (p. 88)
• load (p. 88)
• delete (p. 88)
• query (p. 88)
• queryPage (p. 90)
• scan (p. 90)
• scanPage (p. 91)
• parallelScan (p. 91)
• batchSave (p. 92)
• batchLoad (p. 92)
• batchDelete (p. 92)
• batchWrite (p. 93)
• count (p. 93)
• generateCreateTableRequest (p. 93)
• createS3Link (p. 93)
• getS3ClientCache (p. 94)
API Version 2012-08-10
87
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
save
指定したオブジェクトがテーブルに保存されます。このメソッドで必要なパラメータは、保存するオ
ブジェクトだけです。DynamoDBMapperConfig オブジェクトを使用して、オプションの設定パラ
メータを入力できます。
同じプライマリキーを持つ項目が存在しない場合は、このメソッドによってテーブル内に新しい項
目が作成されます。同じプライマリキーを持つ項目が存在する場合は、その既存の項目が更新されま
す。パーティションキーとソートキーが String 型で、@DynamoDBAutoGeneratedKey によって注釈
が付けられている場合、初期化しなければ、ランダムな UUID (Universally Unique Identifier) が与えら
れます。@DynamoDBVersionAttribute によって注釈が付けられたバージョンフィールドは、バー
ジョンが 1 ずつ増えていきます。さらに、バージョンフィールドが更新されるかキーが生成される
と、オペレーションの結果として、渡されたオブジェクトが更新されます。
デフォルトでは、マッピングされたクラスプロパティに対応する属性だけが更新されます。項目に含
まれるその他の既存の属性は更新されません。ただし、SaveBehavior.CLOBBER を指定すると、項
目が完全に上書きされるようにすることができます。
mapper.save(obj, new
DynamoDBMapperConfig(DynamoDBMapperConfig.SaveBehavior.CLOBBER));
バージョニングを有効にした場合は、クライアント側とサーバー側で項目のバージョンが一致する必
要があります。ただし、SaveBehavior.CLOBBER オプションを使用する場合は、バージョンを一致
させる必要はありません。バージョニングの詳細については、「バージョン番号を使用したオプティ
ミスティックロック (p. 110)」を参照してください。
load
テーブルから項目を取り出します。取り出す項目のプライマリキーを入力する必要がありま
す。DynamoDBMapperConfig オブジェクトを使用して、オプションの設定パラメータを入力できま
す。たとえば次の Java ステートメントに示すように、オプションで強力な整合性のある読み込みを
リクエストして、このメソッドによって最新の項目の値だけを取り出すようにすることができます。
CatalogItem item = mapper.load(CatalogItem.class, item.getId(),
new
DynamoDBMapperConfig(DynamoDBMapperConfig.ConsistentReads.CONSISTENT));
デフォルトでは、DynamoDB では結果整合性のある値を持つ項目が返されます。DynamoDB の結果
整合性モデルの詳細については、「読み込み整合性 (p. 16)」を参照してください。
delete
テーブルから項目を削除します。マッピングされたクラスのオブジェクトインスタンスを渡す必要が
あります。
バージョニングを有効にした場合は、クライアント側とサーバー側で項目のバージョンが一致する必
要があります。ただし、SaveBehavior.CLOBBER オプションを使用する場合は、バージョンを一致
させる必要はありません。バージョニングの詳細については、「バージョン番号を使用したオプティ
ミスティックロック (p. 110)」を参照してください。
query
テーブルまたはセカンダリインデックスのクエリを実行します。複合プライマリキー (パーティショ
ンキーおよびソートキー) が存在する場合にのみ、テーブルまたはインデックスにクエリを実行できま
す。このメソッドでは、ソートキーに適用されるパーティションキー値とクエリフィルタを指定する
必要があります。フィルタ式には、条件と値が含まれています。
API Version 2012-08-10
88
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
フォーラムスレッドの返信を格納する Reply というテーブルがあるとします。各スレッドの件名
については、0 以上の返信を受け取ることができます。Reply テーブルのプライマリキーは、Id
および ReplyDateTime フィールドで構成されます。Id がプライマリキーのパーティションキー
で、ReplyDateTime がソートキーです。
Reply ( Id, ReplyDateTime, ... )
ここで、Reply クラスと DynamoDB の対応する Reply テーブル間のマッピングを作成したとします。
次の Java コードスニペットでは、DynamoDBMapper を使用して特定のスレッド件名に対する過去 2
週間のすべての返信を検索しています。
String forumName = "DynamoDB";
String forumSubject = "DynamoDB Thread 1";
String partitionKey = forumName + "#" + forumSubject;
long twoWeeksAgoMilli = (new Date()).getTime() - (14L*24L*60L*60L*1000L);
Date twoWeeksAgo = new Date();
twoWeeksAgo.setTime(twoWeeksAgoMilli);
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'");
String twoWeeksAgoStr = df.format(twoWeeksAgo);
Map<String, AttributeValue> eav = new HashMap<String, AttributeValue>();
eav.put(":v1", new AttributeValue().withS(partitionKey));
eav.put(":v2",new AttributeValue().withS(twoWeeksAgoStr.toString()));
DynamoDBQueryExpression<Reply> queryExpression = new
DynamoDBQueryExpression<Reply>()
.withKeyConditionExpression("Id = :v1 and ReplyDateTime > :v2")
.withExpressionAttributeValues(eav);
List<Reply> latestReplies = mapper.query(Reply.class, queryExpression);
このクエリでは、Reply オブジェクトのコレクションが返されます。
デフォルトでは、query メソッドによって、「遅延ロード」されたコレクションが返されます。最初
に結果が 1 ページのみ返され、必要に応じて、さらに次ページを要求するサービス呼び出しが行われ
ます。一致するすべての項目は、latestReplies コレクションを反復的に処理するだけで取得でき
ます。
インデックスにクエリを実行するには、最初にインデックスをマッパークラスとしてモデリングする
必要があります。Reply テーブルに、PostedBy-Message-Index という名前のグローバルセカンダリ
インデックスがあるとします。このインデックスのパーティションキーは PostedBy キーで、ソート
キーは Message です。インデックス内の項目のクラス定義は次のようになります。
@DynamoDBTable(tableName="Reply")
public class PostedByMessage {
private String postedBy;
private String message;
@DynamoDBIndexHashKey(globalSecondaryIndexName = "PostedBy-MessageIndex", attributeName = "PostedBy")
public String getPostedBy() { return postedBy; }
public void setPostedBy(String postedBy) { this.postedBy = postedBy; }
@DynamoDBIndexRangeKey(globalSecondaryIndexName = "PostedBy-MessageIndex", attributeName = "Message")
API Version 2012-08-10
89
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
public String getMessage() { return message; }
public void setMessage(String message) { this.message = message; }
// Additional properties go here.
}
@DynamoDBTable 注釈は、このインデックスが Reply テーブルに関連付けられていることを示
します。@DynamoDBIndexHashKey 注釈はインデックスのパーティションキー (PostedBy) を示
し、@DynamoDBIndexRangeKey はインデックスのソートキー (Message) を示します。
ここで、DynamoDBMapper を使用してインデックスにクエリを実行し、特定のユーザーによって
投稿されたメッセージのサブセットを取得できます。クエリを実行するインデックスを DynamoDB
に知らせるため、withIndexName を指定する必要があります。次のコードスニペットでは、グ
ローバルセカンダリインデックスにクエリを実行します。グローバルセカンダリインデックスは結
果的に整合性のある読み込みをサポートしますが、強い整合性のある読み込みをサポートしないた
め、withConsistentRead(false) を指定する必要があります。
HashMap<String, AttributeValue> eav = new HashMap<String, AttributeValue>();
eav.put(":v1", new AttributeValue().withS("User A"));
eav.put(":v2", new AttributeValue().withS("DynamoDB"));
DynamoDBQueryExpression<PostedByMessage> queryExpression = new
DynamoDBQueryExpression<PostedByMessage>()
.withIndexName("PostedBy-Message-Index")
.withConsistentRead(false)
.withKeyConditionExpression("PostedBy = :v1 and
begins_with(Message, :v2)")
.withExpressionAttributeValues(eav);
List<PostedByMessage> iList =
queryExpression);
mapper.query(PostedByMessage.class,
このクエリでは、PostedByMessage オブジェクトのコレクションが返されます。
queryPage
テーブルまたはセカンダリインデックスのクエリを実行し、一致する結果を 1 ページ返しま
す。query メソッドと同様、パーティションキー値とソートキー属性に適用されるクエリフィルタを
指定する必要があります。ただし、queryPage では、データの最初の "ページ"、つまり、1 MB 内に
収まるデータ量だけが返されます。
scan
テーブル全体またはセカンダリインデックスがスキャンされます。オプションで
FilterExpression を指定して結果セットをフィルタリングできます。
フォーラムスレッドの返信を格納する Reply というテーブルがあるとします。各スレッドの件名
については、0 以上の返信を受け取ることができます。Reply テーブルのプライマリキーは、Id
および ReplyDateTime フィールドで構成されます。Id がプライマリキーのパーティションキー
で、ReplyDateTime がソートキーです。
Reply ( Id, ReplyDateTime, ... )
Reply テーブルに Java クラスをマッピングした場合は、DynamoDBMapper を使用してテーブルをス
キャンできます。たとえば、以下の Java コードスニペットは、Reply テーブル全体をスキャンし、
特定の年の返信のみを返します。
API Version 2012-08-10
90
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
HashMap<String, AttributeValue> eav = new HashMap<String, AttributeValue>();
eav.put(":v1", new AttributeValue().withS("2015"));
DynamoDBScanExpression scanExpression = new DynamoDBScanExpression()
.withFilterExpression("begins_with(ReplyDateTime,:v1)")
.withExpressionAttributeValues(eav);
List<Reply> replies =
mapper.scan(Reply.class, scanExpression);
デフォルトでは、scan メソッドによって、「遅延ロード」されたコレクションが返されます。最初に
結果が 1 ページのみ返され、必要に応じて、さらに次ページを要求するサービス呼び出しが行われま
す。一致するすべての項目は、replies コレクションを反復的に処理するだけで取得できます。
インデックスをスキャンするには、最初にインデックスをマッパークラスとしてモデリングする必要
があります。Reply テーブルに、PostedBy-Message-Index という名前のグローバルセカンダリイン
デックスがあるとします。このインデックスのパーティションキーは PostedBy キーで、ソートキー
は Message です。このインデックスのマッパークラスを「query (p. 88)」セクションに示しま
す。ここで、@DynamoDBIndexHashKey および @DynamoDBIndexRangeKey 注釈を使用して、イン
デックスパーティションキーとソートキーを指定します。
次のコードスニペットは、PostedBy-Message-Index をスキャンします。スキャンフィルタを使用し
ないので、インデックス内のすべての項目が返されます。
DynamoDBScanExpression scanExpression = new DynamoDBScanExpression()
.withIndexName("PostedBy-Message-Index")
.withConsistentRead(false);
List<PostedByMessage> indexItems = mapper.scan(PostedByMessage.class,
scanExpression);
Iterator<PostedByMessage> indexItems = iList.iterator();
scanPage
テーブルまたはセカンダリインデックスがスキャンされ、一致する結果が 1 ページ返されます。scan
メソッドと同様に、オプションで FilterExpression を指定して結果セットをフィルタリングでき
ます。ただし、scanPage では、データの最初の "ページ"、つまり、1 MB 内に収まるデータ量だけが
返されます。
parallelScan
テーブルまたはセカンダリインデックス全体の並列スキャンが実行されます。テーブルの論理セグメ
ントの数と、結果をフィルタするスキャン式を指定します。parallelScan では、スキャンタスク
が複数のワーカーに分割され、論理セグメントごとに 1 つのワーカーが割り当てられます。ワーカー
は、データを並列に処理し、結果を返します。
次の Java コードスニペットでは、Product テーブルに対して並列スキャンを実行します。
int numberOfThreads = 4;
Map<String, AttributeValue> eav = new HashMap<String, AttributeValue> ();
eav.put(":n", new AttributeValue().withN("100"));
DynamoDBScanExpression scanExpression = new DynamoDBScanExpression()
.withFilterExpression("Price >= :n")
.withExpressionAttributeValues(eav);
API Version 2012-08-10
91
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
List<Product> scanResult = mapper.parallelScan(Product.class, scanExpression,
numberOfThreads);
parallelScan の使い方を示す Java コードサンプルについては、「例: クエリおよびスキャ
ン (p. 102)」を参照してください。
batchSave
AmazonDynamoDB.batchWriteItem メソッドに対する 1 つ以上の呼び出しを使用して、1 つ以上の
テーブルにオブジェクトを保存します。このメソッドでは、トランザクション保証はなされません。
次の Java コードスニペットでは、2 つの項目(書籍)が ProductCatalog テーブルに保存されていま
す。
Book book1 = new Book();
book1.id = 901;
book1.productCategory = "Book";
book1.title = "Book 901 Title";
Book book2 = new Book();
book2.id = 902;
book2.productCategory = "Book";
book2.title = "Book 902 Title";
mapper.batchSave(Arrays.asList(book1, book2));
batchLoad
テーブルのプライマリキーを使用して、1 つ以上のテーブルから複数の項目を取り出します。
次の Java コードスニペットでは、2 つの異なるテーブルから 2 つの項目を取り出します。
ArrayList<Object> itemsToGet = new ArrayList<Object>();
ForumItem forumItem = new ForumItem();
forumItem.setForumName("Amazon DynamoDB");
itemsToGet.add(forumItem);
ThreadItem threadItem = new ThreadItem();
threadItem.setForumName("Amazon DynamoDB");
threadItem.setSubject("Amazon DynamoDB thread 1 message text");
itemsToGet.add(threadItem);
Map<String, List<Object>> items = mapper.batchLoad(itemsToGet);
batchDelete
AmazonDynamoDB.batchWriteItem メソッドに対する 1 つ以上の呼び出しを使用して、1 つ以上
のテーブルからオブジェクトを削除します。このメソッドでは、トランザクション保証はなされませ
ん。
次の Java コードスニペットでは、2 つの項目(書籍)が ProductCatalog テーブルから削除されてい
ます。
Book book1 = mapper.load(Book.class, 901);
Book book2 = mapper.load(Book.class, 902);
mapper.batchDelete(Arrays.asList(book1, book2));
API Version 2012-08-10
92
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
batchWrite
AmazonDynamoDB.batchWriteItem メソッドに対する 1 つ以上の呼び出しを使用して、1 つ以上の
テーブルに対してオブジェクトの保存および削除を行います。このメソッドではトランザクション保
証はなされず、バージョニング(条件付き入力または削除)もサポートされません。
次の Java コードスニペットでは、新しい項目が Forum テーブルと Thread テーブルに書き込ま
れ、ProductCatalog テーブルから項目が削除されています。
// Create a Forum item to save
Forum forumItem = new Forum();
forumItem.name = "Test BatchWrite Forum";
// Create a Thread item to save
Thread threadItem = new Thread();
threadItem.forumName = "AmazonDynamoDB";
threadItem.subject = "My sample question";
// Load a ProductCatalog item to delete
Book book3 = mapper.load(Book.class, 903);
List<Object> objectsToWrite = Arrays.asList(forumItem, threadItem);
List<Book> objectsToDelete = Arrays.asList(book3);
mapper.batchWrite(objectsToWrite, objectsToDelete);
count
指定されたスキャン式の値を求め、一致する項目数を返します。項目データは返されません。
generateCreateTableRequest
DynamoDB テーブルを表す POJO クラスを解析し、そのテーブルの CreateTableRequest を返し
ます。
createS3Link
Amazon S3 のオブジェクトへのリンクを作成します。バケット名とキー名を指定する必要がありま
す。キー名によって、バケット内のオブジェクトを一意に識別します。
createS3Link を使用するには、マッパークラスでゲッターメソッドとセッターメソッドを定義する
必要があります。次のコードスニペットでは、これを示しており、新しい属性とゲッター/セッターメ
ソッドを CatalogItem クラスに追加しています。
@DynamoDBTable(tableName="ProductCatalog")
public class CatalogItem {
...
public S3Link productImage;
....
@DynamoDBAttribute(attributeName = "ProductImage")
public S3Link getProductImage() {
return productImage;
}
public void setProductImage(S3Link productImage) {
API Version 2012-08-10
93
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
this.productImage = productImage;
}
...
}
次の Java コードでは、Product テーブルに書き込まれる新しい項目を定義しています。この項目に
は、製品イメージへのリンクがあり、そのイメージデータは Amazon S3 にアップロードされていま
す。
CatalogItem item = new CatalogItem();
item.id = 150;
item.title = "Book 150 Title";
String myS3Bucket = "myS3bucket";
String myS3Key = "productImages/book_150_cover.jpg";
item.setProductImage(mapper.createS3Link(myS3Bucket, myS3Key));
item.getProductImage().uploadFrom(new File("/file/path/book_150_cover.jpg"));
mapper.save(item);
S3Link クラスには、他にも、Amazon S3 のオブジェクトを操作するためのさまざまなメソッドが用
意されています。詳細については、「Javadocs for S3Link」を参照してください。
getS3ClientCache
Amazon S3 にアクセスするための基礎となる S3ClientCache を返します。S3ClientCache
は、AmazonS3Client オブジェクトのスマートマップです。複数のクライアントがある場
合、S3ClientCache によって、リージョン別にクライアントを整理しやすくなり、新しい Amazon S3
クライアントをオンデマンドで作成できます。
DynamoDBMapper のオプションの設定
DynamoDBMapper のインスタンスを作成すると、そのインスタンスには、特定のデフォルトの動作が
あります。DynamoDBMapperConfig クラスを使用して、このデフォルトの動作をオーバーライドで
きます。
次のコードスニペットでは、カスタム設定を使用して DynamoDBMapper を作成します。
ClasspathPropertiesFileCredentialsProvider cp =
new ClasspathPropertiesFileCredentialsProvider();
AmazonDynamoDBClient client = new AmazonDynamoDBClient(cp);
DynamoDBMapperConfig mapperConfig = new DynamoDBMapperConfig(
DynamoDBMapperConfig.SaveBehavior.CLOBBER,
DynamoDBMapperConfig.ConsistentReads.CONSISTENT,
null, //TableNameOverride - leaving this at default setting
DynamoDBMapperConfig.PaginationLoadingStrategy.EAGER_LOADING
);
DynamoDBMapper mapper = new DynamoDBMapper(client, mapperConfig, cp);
詳細については、「AWS SDK for Java API Reference」の「DynamoDBMapperConfig」を参照してく
ださい。
API Version 2012-08-10
94
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
DynamoDBMapperConfig のインスタンスに対して、次の引数を指定できます。
• DynamoDBMapperConfig.ConsistentReads 列挙値:
• EVENTUAL – マッパーインスタンスは、結果整合性のある読み込みリクエストを使用します。
• CONSISTENT – マッパーインスタンスは、強力な整合性のある読み込みリクエストを使用しま
す。このオプションの設定は、load、query、または scan オペレーションに対して使用でき
ます。強力な整合性のある読み込みは、パフォーマンスと請求に関連しています。詳細について
は、DynamoDB の製品の詳細ページを参照してください。
マッパーインスタンスに読み込み整合性の設定を指定しない場合、デフォルトは EVENTUAL になり
ます。
• DynamoDBMapperConfig.PaginationLoadingStrategy 列挙値 – query または scan からの結
果など、ページ分割されたデータのリストをマッパーインスタンスが処理する方法を制御します。
• LAZY_LOADING – マッパーインスタンスは、可能な限りデータをロードし、ロードされたすべて
の結果をメモリに維持します。
• EAGER_LOADING – マッパーインスタンスは、リストが初期化されるとすぐにデータをロードし
ます。
• ITERATION_ONLY – イテレータを使用する場合にのみ、リストから読み込むことができます。反
復中、リストは、前のすべての結果をクリアしてから、次のページをロードすることで、最大 1
ページのロードされた結果をメモリに維持するようにします。つまり、リストを反復できるのは
1 回だけです。メモリのオーバーヘッドを低減するために、大きい項目を処理するときにこの方
法を使用することをお勧めします。
マッパーインスタンスにページ分割ロードの方法を指定しない場合、デフォルトは LAZY_LOADING
になります。
• DynamoDBMapperConfig.SaveBehavior 列挙値 – 保存オペレーション中にマッパーインスタン
スが属性を処理する方法を指定します。
• UPDATE – 保存オペレーション中、すべてのモデル化された属性は更新され、モデル化されていな
い属性は影響を受けません。プリミティブな数値型(byte、int、long)は 0 に設定されます。オ
ブジェクト型は null に設定されます。
• CLOBBER – 保存オペレーション中、モデル化されていない属性も含め、すべての属性をクリア
し、置き換えます。このオペレーションは、項目を削除し、再作成することで実行されます。ま
た、バージョン付きフィールドの制約は無視されます。
マッパーインスタンスに保存動作を指定しない場合、デフォルトは UPDATE になります。
• DynamoDBMapperConfig.TableNameOverride オブジェクト – クラスの DynamoDBTable 注釈
によって指定されたテーブル名を無視し、代わりに、提供する別のテーブル名を使用するように
マッパーインスタンスに指示します。これは、実行時にデータを複数のテーブルに分割する場合に
役立ちます。
必要に応じて、オペレーションごとに DynamoDBMapper のデフォルトの設定オブジェクトをオー
バーライドできます。
例: CRUD オペレーション
次の Java コード例では、Id、Title、ISBN、および Authors プロパティを指定して、CatalogItem
クラスを宣言しています。これらのプロパティは、注釈を使用して、DynamoDB の ProductCatalog
テーブルにマッピングされています。このコード例では、次に DynamoDBMapper を使用して、書籍
オブジェクトを保存し、取り出し、更新し、書籍項目を削除します。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセク
ションに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード
済みであることを前提としています。
API Version 2012-08-10
95
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
以下の例を実行するための詳しい手順については、「Java コードサンプル (p. 171)」を参照
してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.datamodeling;
import
import
import
import
java.io.IOException;
java.util.Arrays;
java.util.HashSet;
java.util.Set;
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBAttribute;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBHashKey;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapper;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapperConfig;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTable;
public class DynamoDBMapperCRUDExample {
static AmazonDynamoDBClient client = new AmazonDynamoDBClient(new
ProfileCredentialsProvider());
public static void main(String[] args) throws IOException {
testCRUDOperations();
System.out.println("Example complete!");
}
@DynamoDBTable(tableName="ProductCatalog")
public static class CatalogItem {
private Integer id;
private String title;
private String ISBN;
private Set<String> bookAuthors;
//Partition key
@DynamoDBHashKey(attributeName="Id")
public Integer getId() { return id; }
public void setId(Integer id) { this.id = id; }
@DynamoDBAttribute(attributeName="Title")
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
@DynamoDBAttribute(attributeName="ISBN")
public String getISBN() { return ISBN; }
public void setISBN(String ISBN) { this.ISBN = ISBN;}
@DynamoDBAttribute(attributeName = "Authors")
public Set<String> getBookAuthors() { return bookAuthors; }
public void setBookAuthors(Set<String> bookAuthors)
{ this.bookAuthors = bookAuthors; }
@Override
public String toString() {
API Version 2012-08-10
96
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
return "Book [ISBN=" + ISBN + ", bookAuthors=" + bookAuthors
+ ", id=" + id + ", title=" + title + "]";
}
}
private static void testCRUDOperations() {
CatalogItem item = new CatalogItem();
item.setId(601);
item.setTitle("Book 601");
item.setISBN("611-1111111111");
item.setBookAuthors(new HashSet<String>(Arrays.asList("Author1",
"Author2")));
// Save the item (book).
DynamoDBMapper mapper = new DynamoDBMapper(client);
mapper.save(item);
// Retrieve the item.
CatalogItem itemRetrieved = mapper.load(CatalogItem.class, 601);
System.out.println("Item retrieved:");
System.out.println(itemRetrieved);
// Update the item.
itemRetrieved.setISBN("622-2222222222");
itemRetrieved.setBookAuthors(new
HashSet<String>(Arrays.asList("Author1", "Author3")));
mapper.save(itemRetrieved);
System.out.println("Item updated:");
System.out.println(itemRetrieved);
// Retrieve the updated item.
DynamoDBMapperConfig config = new
DynamoDBMapperConfig(DynamoDBMapperConfig.ConsistentReads.CONSISTENT);
CatalogItem updatedItem = mapper.load(CatalogItem.class, 601,
config);
System.out.println("Retrieved the previously updated item:");
System.out.println(updatedItem);
// Delete the item.
mapper.delete(updatedItem);
// Try to retrieve deleted item.
CatalogItem deletedItem = mapper.load(CatalogItem.class,
updatedItem.getId(), config);
if (deletedItem == null) {
System.out.println("Done - Sample item is deleted.");
}
}
}
例: バッチ書き込みオペレーション
次の Java コード例では、Book、Forum、Thread、および Reply クラスが宣言さ
れ、DynamoDBMapper クラスを使用して、DynamoDB テーブルにマッピングされています。
API Version 2012-08-10
97
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
このコードは、以下のバッチ書き込みオペレーションを示しています。
• ProductCatalog テーブルに書籍項目を入力する batchSave
• ProductCatalog テーブルから項目を削除する batchDelete
• Forum および Thread テーブルに対して項目を入力または削除する batchWrite
この例で使用されているテーブルの詳細については、「テーブルの作成とサンプルデータのロー
ド (p. 166)」を参照してください。次のサンプルをテストするための詳しい手順については、
「Java コードサンプル (p. 171)」を参照してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.datamodeling;
import
import
import
import
import
import
java.text.SimpleDateFormat;
java.util.ArrayList;
java.util.Arrays;
java.util.HashSet;
java.util.List;
java.util.Set;
import
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBAttribute;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBHashKey;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapper;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapperConfig;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBRangeKey;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTable;
public class DynamoDBMapperBatchWriteExample {
static AmazonDynamoDBClient client = new AmazonDynamoDBClient(new
ProfileCredentialsProvider());
static SimpleDateFormat dateFormatter = new SimpleDateFormat("yyyy-MMdd'T'HH:mm:ss.SSS'Z'");
public static void main(String[] args) throws Exception {
try {
DynamoDBMapper mapper = new DynamoDBMapper(client);
testBatchSave(mapper);
testBatchDelete(mapper);
testBatchWrite(mapper);
System.out.println("Example complete!");
} catch (Throwable t) {
System.err.println("Error running the
DynamoDBMapperBatchWriteExample: " + t);
t.printStackTrace();
}
}
private static void testBatchSave(DynamoDBMapper mapper) {
API Version 2012-08-10
98
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
Book book1 = new Book();
book1.id = 901;
book1.inPublication = true;
book1.ISBN = "902-11-11-1111";
book1.pageCount = 100;
book1.price = 10;
book1.productCategory = "Book";
book1.title = "My book created in batch write";
Book book2 = new Book();
book2.id = 902;
book2.inPublication = true;
book2.ISBN = "902-11-12-1111";
book2.pageCount = 200;
book2.price = 20;
book2.productCategory = "Book";
book2.title = "My second book created in batch write";
Book book3 = new Book();
book3.id = 903;
book3.inPublication = false;
book3.ISBN = "902-11-13-1111";
book3.pageCount = 300;
book3.price = 25;
book3.productCategory = "Book";
book3.title = "My third book created in batch write";
System.out.println("Adding three books to ProductCatalog table.");
mapper.batchSave(Arrays.asList(book1, book2, book3));
}
private static void testBatchDelete(DynamoDBMapper mapper) {
Book book1 = mapper.load(Book.class, 901);
Book book2 = mapper.load(Book.class, 902);
System.out.println("Deleting two books from the ProductCatalog
table.");
mapper.batchDelete(Arrays.asList(book1, book2));
}
private static void testBatchWrite(DynamoDBMapper mapper) {
// Create Forum item to save
Forum forumItem = new Forum();
forumItem.name = "Test BatchWrite Forum";
forumItem.threads = 0;
forumItem.category = "Amazon Web Services";
// Create Thread item to save
Thread threadItem = new Thread();
threadItem.forumName = "AmazonDynamoDB";
threadItem.subject = "My sample question";
threadItem.message = "BatchWrite message";
List<String> tags = new ArrayList<String>();
tags.add("batch operations");
tags.add("write");
threadItem.tags = new HashSet<String>(tags);
// Load ProductCatalog item to delete
API Version 2012-08-10
99
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
Book book3 = mapper.load(Book.class, 903);
List<Object> objectsToWrite = Arrays.asList(forumItem, threadItem);
List<Book> objectsToDelete = Arrays.asList(book3);
DynamoDBMapperConfig config = new
DynamoDBMapperConfig(DynamoDBMapperConfig.SaveBehavior.CLOBBER);
mapper.batchWrite(objectsToWrite, objectsToDelete, config);
}
@DynamoDBTable(tableName="ProductCatalog")
public static class Book {
private int id;
private String title;
private String ISBN;
private int price;
private int pageCount;
private String productCategory;
private boolean inPublication;
//Partition key
@DynamoDBHashKey(attributeName="Id")
public int getId() { return id; }
public void setId(int id) { this.id = id; }
@DynamoDBAttribute(attributeName="Title")
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
@DynamoDBAttribute(attributeName="ISBN")
public String getISBN() { return ISBN; }
public void setISBN(String ISBN) { this.ISBN = ISBN; }
@DynamoDBAttribute(attributeName="Price")
public int getPrice() { return price; }
public void setPrice(int price) { this.price = price; }
@DynamoDBAttribute(attributeName="PageCount")
public int getPageCount() { return pageCount; }
public void setPageCount(int pageCount) { this.pageCount =
pageCount;}
@DynamoDBAttribute(attributeName="ProductCategory")
public String getProductCategory() { return productCategory; }
public void setProductCategory(String productCategory)
{ this.productCategory = productCategory; }
@DynamoDBAttribute(attributeName="InPublication")
public boolean getInPublication() { return inPublication; }
public void setInPublication(boolean inPublication)
{ this.inPublication = inPublication; }
@Override
public String toString() {
return "Book [ISBN=" + ISBN + ", price=" + price
+ ", product category=" + productCategory + ", id=" + id
+ ", title=" + title + "]";
}
API Version 2012-08-10
100
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
}
@DynamoDBTable(tableName="Reply")
public static class Reply {
private String id;
private String replyDateTime;
private String message;
private String postedBy;
//Partition key
@DynamoDBHashKey(attributeName="Id")
public String getId() { return id; }
public void setId(String id) { this.id = id; }
//Sort key
@DynamoDBRangeKey(attributeName="ReplyDateTime")
public String getReplyDateTime() { return replyDateTime; }
public void setReplyDateTime(String replyDateTime)
{ this.replyDateTime = replyDateTime; }
@DynamoDBAttribute(attributeName="Message")
public String getMessage() { return message; }
public void setMessage(String message) { this.message = message; }
@DynamoDBAttribute(attributeName="PostedBy")
public String getPostedBy() { return postedBy; }
public void setPostedBy(String postedBy) { this.postedBy = postedBy;}
}
@DynamoDBTable(tableName="Thread")
public static class Thread {
private String forumName;
private String subject;
private String message;
private String lastPostedDateTime;
private String lastPostedBy;
private Set<String> tags;
private int answered;
private int views;
private int replies;
//Partition key
@DynamoDBHashKey(attributeName="ForumName")
public String getForumName() { return forumName; }
public void setForumName(String forumName) { this.forumName =
forumName; }
//Sort key
@DynamoDBRangeKey(attributeName="Subject")
public String getSubject() { return subject; }
public void setSubject(String subject) { this.subject = subject; }
@DynamoDBAttribute(attributeName="Message")
public String getMessage() { return message; }
public void setMessage(String message) { this.message = message; }
@DynamoDBAttribute(attributeName="LastPostedDateTime")
API Version 2012-08-10
101
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
public String getLastPostedDateTime() { return lastPostedDateTime; }
public void setLastPostedDateTime(String lastPostedDateTime)
{ this.lastPostedDateTime = lastPostedDateTime; }
@DynamoDBAttribute(attributeName="LastPostedBy")
public String getLastPostedBy() { return lastPostedBy; }
public void setLastPostedBy(String lastPostedBy) { this.lastPostedBy
= lastPostedBy;}
@DynamoDBAttribute(attributeName="Tags")
public Set<String> getTags() { return tags; }
public void setTags(Set<String> tags) { this.tags = tags; }
@DynamoDBAttribute(attributeName="Answered")
public int getAnswered() { return answered; }
public void setAnswered(int answered) { this.answered = answered; }
@DynamoDBAttribute(attributeName="Views")
public int getViews() { return views; }
public void setViews(int views) { this.views = views; }
@DynamoDBAttribute(attributeName="Replies")
public int getReplies() { return replies; }
public void setReplies(int replies) { this.replies = replies; }
}
@DynamoDBTable(tableName="Forum")
public static class Forum {
private String name;
private String category;
private int threads;
//Partition key
@DynamoDBHashKey(attributeName="Name")
public String getName() { return name; }
public void setName(String name) { this.name = name; }
@DynamoDBAttribute(attributeName="Category")
public String getCategory() { return category; }
public void setCategory(String category) { this.category =
category; }
@DynamoDBAttribute(attributeName="Threads")
public int getThreads() { return threads; }
public void setThreads(int threads) { this.threads = threads;}
}
}
例: クエリおよびスキャン
API Version 2012-08-10
102
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
このセクションの Java コード例では、次のクラスを定義して、DynamoDB 内のテーブルにマッピン
グしています。サンプルテーブル作成の詳細については、「テーブルの作成とサンプルデータのロー
ド (p. 166)」を参照してください。
• Book クラスは ProductCatalog テーブルにマッピングされます。
• Forum、Thread、および Reply クラスは、同じ名前テーブルにマッピングされます。
この例では DynamoDBMapper インスタンスを使用して、さらに次のクエリとスキャンオペレーショ
ンを実行しています。
• Id によって書籍を取得します。
ProductCatalog テーブルでは Id がプライマリキーになっています。プライマリキーの一部にソート
キーは含まれていません。したがって、テーブルのクエリを行うことはできません。項目は Id 値を
使用して取得できます。
• Reply テーブルに対して次のクエリを実行します。
Reply テーブルのプライマリキーは、Id と ReplyDateTime 属性で構成されていま
す。ReplyDateTime はソートキーです。したがってこのテーブルではクエリを実行できます。
• 過去 15 日間に投稿されたフォーラムスレッドに対する返信を検索する
• 特定の日付範囲の間に投稿されたフォーラムスレッドに対する返信を検索する
• ProductCatalog テーブルをスキャンし、価格が指定した値より低い書籍を検索します。
パフォーマンス上の理由から、スキャンオペレーションではなくクエリを使用するようにしてくだ
さい。ただし、場合によってはテーブルをスキャンする必要があります。データ入力エラーがあ
り、書籍の価格の 1 つが 0 未満に設定されたとします。この例では、ProductCategory テーブルを
スキャンして、価格が 0 未満である書籍項目(ProductCategory は書籍)を検索しています。
• ProductCatalog テーブルのパラレルスキャンを実行して特定のタイプの自転車を検索します。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセク
ションに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード
済みであることを前提としています。
以下の例を実行するための詳しい手順については、「Java コードサンプル (p. 171)」を参照
してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.datamodeling;
import
import
import
import
import
import
import
java.text.SimpleDateFormat;
java.util.Date;
java.util.HashMap;
java.util.List;
java.util.Map;
java.util.Set;
java.util.TimeZone;
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBAttribute;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBHashKey;
API Version 2012-08-10
103
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
import com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapper;
import
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBQueryExpression;
import com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBRangeKey;
import com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBScanExpression;
import com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTable;
import com.amazonaws.services.dynamodbv2.model.AttributeValue;
public class DynamoDBMapperQueryScanExample {
static AmazonDynamoDBClient client = new AmazonDynamoDBClient(new
ProfileCredentialsProvider());
public static void main(String[] args) throws Exception {
try {
DynamoDBMapper mapper = new DynamoDBMapper(client);
// Get a book - Id=101
GetBook(mapper, 101);
// Sample forum and thread to test queries.
String forumName = "Amazon DynamoDB";
String threadSubject = "DynamoDB Thread 1";
// Sample queries.
FindRepliesInLast15Days(mapper, forumName, threadSubject);
FindRepliesPostedWithinTimePeriod(mapper, forumName,
threadSubject);
// Scan a table and find book items priced less than specified
value.
FindBooksPricedLessThanSpecifiedValue(mapper, "20");
// Scan a table with multiple threads and find bicycle items with
a specified bicycle type
int numberOfThreads = 16;
FindBicyclesOfSpecificTypeWithMultipleThreads(mapper,
numberOfThreads, "Road");
System.out.println("Example complete!");
} catch (Throwable t) {
System.err.println("Error running the
DynamoDBMapperQueryScanExample: " + t);
t.printStackTrace();
}
}
private static void GetBook(DynamoDBMapper mapper, int id) throws
Exception {
System.out.println("GetBook: Get book Id='101' ");
System.out.println("Book table has no sort key. You can do GetItem,
but not Query.");
Book book = mapper.load(Book.class, 101);
System.out.format("Id = %s Title = %s, ISBN = %s %n", book.getId(),
book.getTitle(), book.getISBN() );
}
private static void FindRepliesInLast15Days(DynamoDBMapper mapper,
API Version 2012-08-10
104
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
String forumName,
String threadSubject) throws
Exception {
System.out.println("FindRepliesInLast15Days: Replies within last 15
days.");
String partitionKey = forumName + "#" + threadSubject;
long twoWeeksAgoMilli = (new Date()).getTime() (15L*24L*60L*60L*1000L);
Date twoWeeksAgo = new Date();
twoWeeksAgo.setTime(twoWeeksAgoMilli);
SimpleDateFormat dateFormatter = new SimpleDateFormat("yyyy-MMdd'T'HH:mm:ss.SSS'Z'");
dateFormatter.setTimeZone(TimeZone.getTimeZone("UTC"));
String twoWeeksAgoStr = dateFormatter.format(twoWeeksAgo);
Map<String, AttributeValue> eav = new HashMap<String,
AttributeValue>();
eav.put(":val1", new AttributeValue().withS(partitionKey));
eav.put(":val2", new
AttributeValue().withS(twoWeeksAgoStr.toString()));
DynamoDBQueryExpression<Reply> queryExpression = new
DynamoDBQueryExpression<Reply>()
.withKeyConditionExpression("Id = :val1 and ReplyDateTime
> :val2")
.withExpressionAttributeValues(eav);
List<Reply> latestReplies = mapper.query(Reply.class,
queryExpression);
for (Reply reply : latestReplies) {
System.out.format("Id=%s, Message=%s, PostedBy=%s %n,
ReplyDateTime=%s %n",
reply.getId(), reply.getMessage(), reply.getPostedBy(),
reply.getReplyDateTime() );
}
}
private static void FindRepliesPostedWithinTimePeriod(
DynamoDBMapper mapper,
String forumName,
String threadSubject) throws Exception {
String partitionKey = forumName + "#" + threadSubject;
System.out.println("FindRepliesPostedWithinTimePeriod: Find replies
for thread Message = 'DynamoDB Thread 2' posted within a period.");
long startDateMilli = (new Date()).getTime() (14L*24L*60L*60L*1000L); // Two weeks ago.
long endDateMilli = (new Date()).getTime() - (7L*24L*60L*60L*1000L);
// One week ago.
SimpleDateFormat dateFormatter = new SimpleDateFormat("yyyy-MMdd'T'HH:mm:ss.SSS'Z'");
dateFormatter.setTimeZone(TimeZone.getTimeZone("UTC"));
String startDate = dateFormatter.format(startDateMilli);
String endDate = dateFormatter.format(endDateMilli);
API Version 2012-08-10
105
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
Map<String, AttributeValue> eav = new HashMap<String,
AttributeValue>();
eav.put(":val1", new AttributeValue().withS(partitionKey));
eav.put(":val2", new AttributeValue().withS(startDate));
eav.put(":val3", new AttributeValue().withS(endDate));
DynamoDBQueryExpression<Reply> queryExpression = new
DynamoDBQueryExpression<Reply>()
.withKeyConditionExpression("Id = :val1 and ReplyDateTime
between :val2 and :val3")
.withExpressionAttributeValues(eav);
List<Reply> betweenReplies = mapper.query(Reply.class,
queryExpression);
for (Reply reply : betweenReplies) {
System.out.format("Id=%s, Message=%s, PostedBy=%s %n,
PostedDateTime=%s %n",
reply.getId(), reply.getMessage(), reply.getPostedBy(),
reply.getReplyDateTime() );
}
}
private static void FindBooksPricedLessThanSpecifiedValue(
DynamoDBMapper mapper,
String value) throws Exception {
System.out.println("FindBooksPricedLessThanSpecifiedValue: Scan
ProductCatalog.");
Map<String, AttributeValue> eav = new HashMap<String,
AttributeValue>();
eav.put(":val1", new AttributeValue().withN(value));
eav.put(":val2", new AttributeValue().withS("Book"));
DynamoDBScanExpression scanExpression = new DynamoDBScanExpression()
.withFilterExpression("Price < :val1 and ProductCategory
= :val2")
.withExpressionAttributeValues(eav);
List<Book> scanResult = mapper.scan(Book.class, scanExpression);
for (Book book : scanResult) {
System.out.println(book);
}
}
private static void FindBicyclesOfSpecificTypeWithMultipleThreads(
DynamoDBMapper mapper,
int numberOfThreads,
String bicycleType) throws Exception {
System.out.println("FindBicyclesOfSpecificTypeWithMultipleThreads:
Scan ProductCatalog With Multiple Threads.");
Map<String, AttributeValue> eav = new HashMap<String, AttributeValue>
();
eav.put(":val1", new AttributeValue().withS("Bicycle"));
eav.put(":val2", new AttributeValue().withS(bicycleType));
API Version 2012-08-10
106
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
DynamoDBScanExpression scanExpression = new DynamoDBScanExpression()
.withFilterExpression("ProductCategory = :val1 and BicycleType
= :val2")
.withExpressionAttributeValues(eav);
List<Bicycle> scanResult = mapper.parallelScan(Bicycle.class,
scanExpression, numberOfThreads);
for (Bicycle bicycle : scanResult) {
System.out.println(bicycle);
}
}
@DynamoDBTable(tableName="ProductCatalog")
public static class Book {
private int id;
private String title;
private String ISBN;
private int price;
private int pageCount;
private String productCategory;
private boolean inPublication;
@DynamoDBHashKey(attributeName="Id")
public int getId() { return id; }
public void setId(int id) { this.id = id; }
@DynamoDBAttribute(attributeName="Title")
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
@DynamoDBAttribute(attributeName="ISBN")
public String getISBN() { return ISBN; }
public void setISBN(String ISBN) { this.ISBN = ISBN; }
@DynamoDBAttribute(attributeName="Price")
public int getPrice() { return price; }
public void setPrice(int price) { this.price = price; }
@DynamoDBAttribute(attributeName="PageCount")
public int getPageCount() { return pageCount; }
public void setPageCount(int pageCount) { this.pageCount =
pageCount;}
@DynamoDBAttribute(attributeName="ProductCategory")
public String getProductCategory() { return productCategory; }
public void setProductCategory(String productCategory)
{ this.productCategory = productCategory; }
@DynamoDBAttribute(attributeName="InPublication")
public boolean getInPublication() { return inPublication; }
public void setInPublication(boolean inPublication)
{ this.inPublication = inPublication; }
@Override
public String toString() {
return "Book [ISBN=" + ISBN + ", price=" + price
+ ", product category=" + productCategory + ", id=" + id
+ ", title=" + title + "]";
API Version 2012-08-10
107
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
}
}
@DynamoDBTable(tableName="ProductCatalog")
public static class Bicycle {
private int id;
private String title;
private String description;
private String bicycleType;
private String brand;
private int price;
private List<String> color;
private String productCategory;
@DynamoDBHashKey(attributeName="Id")
public int getId() { return id; }
public void setId(int id) { this.id = id; }
@DynamoDBAttribute(attributeName="Title")
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
@DynamoDBAttribute(attributeName="Description")
public String getDescription() { return description; }
public void setDescription(String description) { this.description =
description; }
@DynamoDBAttribute(attributeName="BicycleType")
public String getBicycleType() { return bicycleType; }
public void setBicycleType(String bicycleType) { this.bicycleType =
bicycleType; }
@DynamoDBAttribute(attributeName="Brand")
public String getBrand() { return brand; }
public void setBrand(String brand) { this.brand = brand; }
@DynamoDBAttribute(attributeName="Price")
public int getPrice() { return price; }
public void setPrice(int price) { this.price = price; }
@DynamoDBAttribute(attributeName="Color")
public List<String> getColor() { return color; }
public void setColor(List<String> color) { this.color = color; }
@DynamoDBAttribute(attributeName="ProductCategory")
public String getProductCategory() { return productCategory; }
public void setProductCategory(String productCategory)
{ this.productCategory = productCategory; }
@Override
public String toString() {
return "Bicycle [Type=" + bicycleType + ", color=" + color + ",
price=" + price
+ ", product category=" + productCategory + ", id=" + id
+ ", title=" + title + "]";
}
}
API Version 2012-08-10
108
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
@DynamoDBTable(tableName="Reply")
public static class Reply {
private String id;
private String replyDateTime;
private String message;
private String postedBy;
//Partition key
@DynamoDBHashKey(attributeName="Id")
public String getId() { return id; }
public void setId(String id) { this.id = id; }
//Range key
@DynamoDBRangeKey(attributeName="ReplyDateTime")
public String getReplyDateTime() { return replyDateTime; }
public void setReplyDateTime(String replyDateTime)
{ this.replyDateTime = replyDateTime; }
@DynamoDBAttribute(attributeName="Message")
public String getMessage() { return message; }
public void setMessage(String message) { this.message = message; }
@DynamoDBAttribute(attributeName="PostedBy")
public String getPostedBy() { return postedBy; }
public void setPostedBy(String postedBy) { this.postedBy = postedBy;}
}
@DynamoDBTable(tableName="Thread")
public static class Thread {
private String forumName;
private String subject;
private String message;
private String lastPostedDateTime;
private String lastPostedBy;
private Set<String> tags;
private int answered;
private int views;
private int replies;
//Partition key
@DynamoDBHashKey(attributeName="ForumName")
public String getForumName() { return forumName; }
public void setForumName(String forumName) { this.forumName =
forumName; }
//Range key
@DynamoDBRangeKey(attributeName="Subject")
public String getSubject() { return subject; }
public void setSubject(String subject) { this.subject = subject; }
@DynamoDBAttribute(attributeName="Message")
public String getMessage() { return message; }
public void setMessage(String message) { this.message = message; }
@DynamoDBAttribute(attributeName="LastPostedDateTime")
public String getLastPostedDateTime() { return lastPostedDateTime; }
API Version 2012-08-10
109
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
public void setLastPostedDateTime(String lastPostedDateTime)
{ this.lastPostedDateTime = lastPostedDateTime; }
@DynamoDBAttribute(attributeName="LastPostedBy")
public String getLastPostedBy() { return lastPostedBy; }
public void setLastPostedBy(String lastPostedBy) { this.lastPostedBy
= lastPostedBy;}
@DynamoDBAttribute(attributeName="Tags")
public Set<String> getTags() { return tags; }
public void setTags(Set<String> tags) { this.tags = tags; }
@DynamoDBAttribute(attributeName="Answered")
public int getAnswered() { return answered; }
public void setAnswered(int answered) { this.answered = answered; }
@DynamoDBAttribute(attributeName="Views")
public int getViews() { return views; }
public void setViews(int views) { this.views = views; }
@DynamoDBAttribute(attributeName="Replies")
public int getReplies() { return replies; }
public void setReplies(int replies) { this.replies = replies; }
}
@DynamoDBTable(tableName="Forum")
public static class Forum {
private String name;
private String category;
private int threads;
@DynamoDBHashKey(attributeName="Name")
public String getName() { return name; }
public void setName(String name) { this.name = name; }
@DynamoDBAttribute(attributeName="Category")
public String getCategory() { return category; }
public void setCategory(String category) { this.category =
category; }
@DynamoDBAttribute(attributeName="Threads")
public int getThreads() { return threads; }
public void setThreads(int threads) { this.threads = threads;}
}
}
バージョン番号を使用したオプティミスティックロック
オプティミスティックロックとは、更新(または削除)しているクライアント側の項目
が、DynamoDB の項目と確実に同じになるようにするための方法です。この方法を使用すると、デー
タベースの書き込みは、他のユーザーの書き込みによって上書きされないように保護されます。逆の
場合も同様に保護されます。
オプティミスティックロックを使用する場合、各項目には、バージョン番号として機能する属性があ
ります。項目をテーブルから取り出すと、アプリケーションは、その項目のバージョン番号を記録し
API Version 2012-08-10
110
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
ます。サーバー側のバージョン番号が変更されていない場合のみ、項目を更新できます。バージョン
の不一致がある場合、他のユーザーが先に項目を変更したことを意味します。項目のバージョンが古
いため、更新は失敗します。その場合は、単純に更新をやり直します。もう一度項目を取り出して、
それを更新してください。オプティミスティックロックによって、他のユーザーが行った変更を誤っ
て上書きしないようにすることができます。また、自分が行った変更を他のユーザーが誤って上書き
しないようにすることもできます。
オプティミスティックロックをサポートするために、AWS SDK for Java では
@DynamoDBVersionAttribute 注釈が提供されています。テーブルのマッピングクラスで、バー
ジョン番号を保存する 1 つのプロパティを指定し、この注釈を使用してそのプロパティをマーキング
します。オブジェクトを保存すると、DynamoDB テーブルの対応する項目に、バージョン番号を格納
する属性が作成されます。DynamoDBMapper では、最初にオブジェクトを保存したときにバージョン
番号が割り当てられ、項目を更新するたびにバージョン番号が自動的にインクリメントされます。更
新または削除リクエストは、クライアント側のオブジェクトのバージョンが、DynamoDB テーブルの
項目の対応するバージョン番号に一致する場合のみ成功します。
たとえば次の Java コードスニペットでは、複数のプロパティを持つ CatalogItem クラスを定義し
ています。Version プロパティは @DynamoDBVersionAttribute 注釈でタグ付けされています。
@DynamoDBTable(tableName="ProductCatalog")
public class CatalogItem {
private
private
private
private
private
private
Integer id;
String title;
String ISBN;
Set<String> bookAuthors;
String someProp;
Long version;
@DynamoDBHashKey(attributeName="Id")
public Integer getId() { return id; }
public void setId(Integer Id) { this.id = Id; }
@DynamoDBAttribute(attributeName="Title")
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
@DynamoDBAttribute(attributeName="ISBN")
public String getISBN() { return ISBN; }
public void setISBN(String ISBN) { this.ISBN = ISBN;}
@DynamoDBAttribute(attributeName = "Authors")
public Set<String> getBookAuthors() { return bookAuthors; }
public void setBookAuthors(Set<String> bookAuthors) { this.bookAuthors =
bookAuthors; }
@DynamoDBIgnore
public String getSomeProp() { return someProp;}
public void setSomeProp(String someProp) {this.someProp = someProp;}
@DynamoDBVersionAttribute
public Long getVersion() { return version; }
public void setVersion(Long version) { this.version = version;}
}
@DynamoDBVersionAttribute 注釈は、Long や Integer などの、null が許容された型を提供する
プリミティブラッパークラスによって得られた、null が許容された型に適用できます。
API Version 2012-08-10
111
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
オプティミスティックロックは、次の DynamoDBMapper メソッドに対して次のような影響がありま
す。
• save – 新しい項目に対して、DynamoDBMapper は初期バージョン番号 1 を割り当てます。項目を
取り出し、その項目の 1 つ以上のプロパティを更新して変更を保存する場合には、クライアント側
とサーバー側のバージョン番号が一致する場合のみ、保存が成功します。DynamoDBMapper によっ
てバージョン番号が自動的にインクリメントされます。
• delete – delete メソッドは 1 つのオブジェクトをパラメータとして指定し、項目を削除する前に
DynamoDBMapper がバージョンチェックを実行します。バージョンチェックは、リクエスト内で
DynamoDBMapperConfig.SaveBehavior.CLOBBER を指定して無効にすることができます。
DynamoDBMapper 内のオプティミスティックロックの内部実装では、DynamoDB の条件付き更新
と条件付き削除サポートが使用されます。
オプティミスティックロックの無効化
オプティミスティックロックを無効にするには、DynamoDBMapperConfig.SaveBehavior
列挙値を UPDATE から CLOBBER に変更します。その場合は、バージョンチェックを省略する
DynamoDBMapperConfig インスタンスを作成して、そのインスタンスをすべてのリクエストで使用
します。DynamoDBMapperConfig.SaveBehavior とその他のオプションの DynamoDBMapper パラ
メータの詳細については、「DynamoDBMapper のオプションの設定 (p. 94)」を参照してくださ
い。
ロック動作は、特定のオペレーションだけに設定することもできます。たとえば次の
Java コードスニペットではDynamoDBMapper を使用してカタログ項目を保存していま
す。オプションの DynamoDBMapperConfig パラメータを save メソッドに追加すること
で、DynamoDBMapperConfig.SaveBehavior を指定しています。
DynamoDBMapper mapper = new DynamoDBMapper(client);
// Load a catalog item.
CatalogItem item = mapper.load(CatalogItem.class, 101);
item.setTitle("This is a new title for the item");
...
// Save the item.
mapper.save(item,
new DynamoDBMapperConfig(
DynamoDBMapperConfig.SaveBehavior.CLOBBER));
任意データのマッピング
サポートされている Java 型(「サポートされているデータの種類 (p. 81)」を参照)に加え
て、DynamoDB 型に直接マッピングされない、アプリケーション内の型を使用できます。これらの
型をマッピングするには、複合型を文字列のインスタンスに、またその反対に変換する実装を指定
し、@DynamoDBTypeConverted 注釈を使用して複合型のアクセサーメソッドに注釈を付ける必要が
あります。コンバーターコードは、オブジェクトが保存またはロードされるときにデータを変換しま
す。これは、複合型を消費するすべてのオペレーションでも使用されます。クエリおよびスキャンオ
ペレーション中にデータを比較する場合、その比較は DynamoDB に格納されているデータに対して
行われます。
たとえば、プロパティ Dimension(DimensionType 型)を定義する、次の CatalogItem クラスが
あるとします。このプロパティには、項目の寸法として高さ、幅、厚さが格納されています。これら
の項目の寸法を、DynamoDB に文字列(8.5x11x.05 など)として格納することを決定したとします。
次の例は、DimensionType オブジェクトを文字列に変換し、文字列を DimensionType に変換する
コンバーターコードを示しています。
API Version 2012-08-10
112
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセク
ションに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード
済みであることを前提としています。
以下の例を実行するための詳しい手順については、「Java コードサンプル (p. 171)」を参照
してください。
package com.amazonaws.codesamples.datamodeling;
import
import
import
import
java.io.IOException;
java.util.Arrays;
java.util.HashSet;
java.util.Set;
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.AmazonClientException;
com.amazonaws.auth.AWSCredentials;
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.regions.Regions;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBAttribute;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBHashKey;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBMapper;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTypeConverted;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTypeConverter;
com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTable;
public class DynamoDBMapperExample {
static AmazonDynamoDBClient client;
public static void main(String[] args) throws IOException {
AWSCredentials credentials = null;
try {
credentials = new
ProfileCredentialsProvider("default").getCredentials();
} catch (Exception e) {
throw new AmazonClientException(
"Cannot load the credentials from the credential
profiles file. " +
"Please make sure that your credentials file is at the
correct " +
"location, and is in valid format.",
e);
}
// Set the AWS region you want to access.
Regions usWest2 = Regions.US_WEST_2;
client = new AmazonDynamoDBClient(credentials).withRegion(usWest2);
DimensionType dimType = new DimensionType();
dimType.setHeight("8.00");
dimType.setLength("11.0");
dimType.setThickness("1.0");
Book book = new Book();
API Version 2012-08-10
113
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
book.setId(502);
book.setTitle("Book 502");
book.setISBN("555-5555555555");
book.setBookAuthors(new HashSet<String>(Arrays.asList("Author1",
"Author2")));
book.setDimensions(dimType);
DynamoDBMapper mapper = new DynamoDBMapper(client);
mapper.save(book);
Book bookRetrieved = mapper.load(Book.class, 502);
System.out.println("Book info: " + "\n" + bookRetrieved);
bookRetrieved.getDimensions().setHeight("9.0");
bookRetrieved.getDimensions().setLength("12.0");
bookRetrieved.getDimensions().setThickness("2.0");
mapper.save(bookRetrieved);
bookRetrieved = mapper.load(Book.class, 502);
System.out.println("Updated book info: " + "\n" + bookRetrieved);
}
@DynamoDBTable(tableName="ProductCatalog")
public static class Book {
private int id;
private String title;
private String ISBN;
private Set<String> bookAuthors;
private DimensionType dimensionType;
//Partition key
@DynamoDBHashKey(attributeName = "Id")
public int getId() { return id; }
public void setId(int id) { this.id = id; }
@DynamoDBAttribute(attributeName = "Title")
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
@DynamoDBAttribute(attributeName="ISBN")
public String getISBN() { return ISBN; }
public void setISBN(String ISBN) { this.ISBN = ISBN;}
@DynamoDBAttribute(attributeName = "Authors")
public Set<String> getBookAuthors() { return bookAuthors; }
public void setBookAuthors(Set<String> bookAuthors)
{ this.bookAuthors = bookAuthors; }
@DynamoDBTypeConverted(converter = DimensionTypeConverter.class)
@DynamoDBAttribute(attributeName = "Dimensions")
public DimensionType getDimensions() { return dimensionType; }
@DynamoDBAttribute(attributeName = "Dimensions")
public void setDimensions(DimensionType dimensionType)
{ this.dimensionType = dimensionType; }
@Override
public String toString() {
API Version 2012-08-10
114
Amazon DynamoDB 開発者ガイド
Java: DynamoDBMapper
return "Book [ISBN=" + ISBN + ", bookAuthors=" + bookAuthors
+ ", dimensionType= " + dimensionType.getHeight() + " X " +
dimensionType.getLength() + " X " + dimensionType.getThickness() + ", Id=" +
id
+ ", Title=" + title + "]";
}
}
static public class DimensionType {
private String length;
private String height;
private String thickness;
public String getLength() { return length; }
public void setLength(String length) { this.length = length; }
public String getHeight() { return height; }
public void setHeight(String height) { this.height = height; }
public String getThickness() { return thickness; }
public void setThickness(String thickness) { this.thickness =
thickness; }
}
// Converts the complex type DimensionType to a string and vice-versa.
static public class DimensionTypeConverter implements
DynamoDBTypeConverter<String,DimensionType> {
@Override
public String convert(DimensionType object) {
DimensionType itemDimensions = (DimensionType)object;
String dimension = null;
try {
if (itemDimensions != null) {
dimension = String.format("%s x %s x %s",
itemDimensions.getLength(),
itemDimensions.getHeight(),
itemDimensions.getThickness());
}
} catch (Exception e) {
e.printStackTrace();
}
return dimension;
}
@Override
public DimensionType unconvert(String s) {
DimensionType itemDimension = new DimensionType();
try {
if (s != null && s.length() !=0 ) {
String[] data = s.split("x");
itemDimension.setLength(data[0].trim());
itemDimension.setHeight(data[1].trim());
itemDimension.setThickness(data[2].trim());
}
} catch (Exception e) {
e.printStackTrace();
}
API Version 2012-08-10
115
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
return itemDimension;
}
}
}
.NET ドキュメントモデル
トピック
• ドキュメントモデルでサポートされていないオペレーション (p. 116)
• AWS SDK for .NET ドキュメントモデルによる DynamoDB の項目の操作 (p. 116)
• 項目の取得 – Table.GetItem (p. 119)
• 項目の削除 – Table.DeleteItem (p. 121)
• 項目の更新 – Table.UpdateItem (p. 121)
• バッチ書き込み – 複数の項目の書き込みおよび削除 (p. 123)
• 例: AWS SDK for .NET ドキュメントモデルを使用した CRUD オペレーション (p. 125)
• 例: AWS SDK for .NET ドキュメントモデル API を使用したバッチオペレーション (p. 128)
• AWS SDK for .NET ドキュメントモデルによる DynamoDB でのテーブルのクエリ (p. 130)
AWS SDK for .NET では、低レベル DynamoDB オペレーションの一部をまとめるドキュメントモデ
ルクラスを使用して、コーディングをさらに簡略化することができます。 ドキュメントモデルのプラ
イマリクラスは Table と Document です。Table クラスでは、PutItem、GetItem、DeleteItem
などのデータオペレーション方法を使用できます。Query および Scan メソッドも使用できま
す。Document クラスは、テーブル内の単一の項目を表します。
前述のドキュメントモデルクラスは、Amazon.DynamoDBv2.DocumentModel 名前空間で使用できま
す。
ドキュメントモデルでサポートされていないオペレーション
ドキュメントモデルクラスは、テーブルの作成、更新、削除に使用することはできません。ただし、
ドキュメントモデルは、ほとんどの一般的なデータオペレーションをサポートしています。
AWS SDK for .NET ドキュメントモデルによる DynamoDB の
項目の操作
トピック
• 項目の入力 – Table.PutItem メソッド (p. 117)
• オプションパラメータの指定 (p. 119)
ドキュメントモデルを使用してデータオペレーションを実行するには、最初に Table.LoadTable
メソッドを呼び出して、特定のテーブルを表す Table クラスのインスタンスを作成します。次の C#
コードスニペットでは、DynamoDB で ProductCatalog テーブルを表す Table オブジェクトを作成し
ています。
Table table = Table.LoadTable(client, "ProductCatalog");
API Version 2012-08-10
116
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
Note
通常、LoadTable メソッドはアプリケーションの開始時に 1 回使用するだけです。このメ
ソッドによって、DynamoDB へのラウンドトリップに DescribeTable 呼び出しが追加され
るためです。
その後、テーブルオブジェクトを使用して、さまざまなデータオペレーションを実行することができ
ます。これらのデータオペレーションは、それぞれ 2 つのタイプのオーバーロードがあります。1 つ
は最小限必要なパラメータをとり、もう 1 つはそれに加えてオペレーション固有のオプション設定情
報をとります。たとえば項目を取り出すには、テーブルのプライマリキーの値を入力する必要があり
ますが、その場合は次の GetItem オーバーロードを使用できます。
// Get the item from a table that has a primary key that is composed of only
a partition key.
Table.GetItem(Primitive partitionKey);
// Get the item from a table whose primary key is composed of both a
partition key and sort key.
Table.GetItem(Primitive partitionKey, Primitive sortKey);
これらのメソッドには、オプションパラメータを渡すこともできます。たとえば前述の GetItem
では、すべての属性を含む項目全体が返されます。オプションで、取り出す属性のリストを指定す
ることもできます。その場合は、オペレーション固有の設定オブジェクトパラメータをとる、次の
GetItem オーバーロードを使用します。
// Configuration object that specifies optional parameters.
GetItemOperationConfig config = new GetItemOperationConfig()
{
AttributesToGet = new List<string>() { "Id", "Title" },
};
// Pass in the configuration to the GetItem method.
// 1. Table that has only a partition key as primary key.
Table.GetItem(Primitive partitionKey, GetItemOperationConfig config);
// 2. Table that has both a partition key and a sort key.
Table.GetItem(Primitive partitionKey, Primitive sortKey,
GetItemOperationConfig config);
設定オブジェクトを使用することで、特定の属性リストのリクエストやページサイズ(ページあたり
の項目数)の指定など、複数のオプションパラメータを指定できます。それぞれのデータオペレー
ションメソッドには、独自の設定クラスがあります。たとえば、GetItemOperationConfig クラ
スでは GetItem オペレーションのオプションを指定し、PutItemOperationConfig クラスでは
PutItem オペレーションのオプションパラメータを指定できます。
以下のセクションでは、Table クラスでサポートされているそれぞれのデータオペレーションについ
て説明します。
項目の入力 – Table.PutItem メソッド
PutItem メソッドは、入力された Document インスタンスをテーブルにアップロードします。
入力された Document で指定されているプライマリキーを持つ項目がテーブル内に存在する場合
は、PutItem オペレーションによって、既存の項目全体が置換されます。新しい項目は、PutItem
メソッドに与えた Document オブジェクトと同じになります。つまり、元の項目にそれ以外の属性が
存在していたとしても、新しい項目内には存在しないことになります。次に、AWS SDK for .NET ド
キュメントモデルを使用してテーブルに新しい項目を入力するステップを示します。
1. 項目を置くテーブル名を生成する Table.LoadTable メソッドを実行します。
API Version 2012-08-10
117
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
2. 属性名と値のリストが含まれる、Document オブジェクトを作成します。
3. Document インスタンスをパラメータとして入力して、Table.PutItem を実行します。
次の C# コードスニペットは、前述のタスクの例です。この例では、ProductCatalog テーブルに項目
がアップロードされています。
Table table = Table.LoadTable(client, "ProductCatalog");
var book = new Document();
book["Id"] = 101;
book["Title"] = "Book 101 Title";
book["ISBN"] = "11-11-11-11";
book["Authors"] = new List<string> { "Author 1", "Author 2" };
book["InStock"] = new DynamoDBBool(true);
book["QuantityOnHand"] = new DynamoDBNull();
table.PutItem(book);
前述の例では、Document インスタンスは、数値型、文字列型、文字列セット型、ブール型、Null 型
の属性を持つ項目を作成します(Null は、この製品の QuantityOnHand が不明であることを示すた
めに使用されます)。ブール値と Null の場合は、コンストラクタメソッドの DynamoDBBool および
DynamoDBNull を使用します。
DynamoDB では、データ型のうちリスト型とマップ型は、他のデータ型で構成された要素を含むこと
ができます。これらのデータ型をドキュメントモデル API にマッピングする方法を以下に示します。
• リスト - DynamoDBList コンストラクタを使用します。
• マップ - Document コンストラクタを使用します。
先にあげた例を修正して、項目にリスト属性を追加することができます。これを行うには、次のコー
ドスニペットに示すように、DynamoDBList コンストラクタを使用します。
Table table = Table.LoadTable(client, "ProductCatalog");
var book = new Document();
book["Id"] = 101;
/*other attributes omitted for brevity...*/
var relatedItems = new DynamoDBList();
relatedItems.Add(341);
relatedItems.Add(472);
relatedItems.Add(649);
item.Add("RelatedItems", relatedItems);
table.PutItem(book);
書籍にマップ属性を追加するには、別の Document を定義します。次のコードスニペットはそれを行
う方法を示しています。
Table table = Table.LoadTable(client, "ProductCatalog");
API Version 2012-08-10
118
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
var book = new Document();
book["Id"] = 101;
/*other attributes omitted for brevity...*/
var pictures = new Document();
pictures.Add("FrontView", "http://example.com/products/101_front.jpg" );
pictures.Add("RearView", "http://example.com/products/101_rear.jpg" );
item.Add("Pictures", pictures);
table.PutItem(book);
これらの例は、導入事例: ProductCatalog 項目 (p. 210) に示された項目に基づいています。ドキュメ
ントモデルを使用すると、導入事例の ProductReviews 属性のように複雑な入れ子になった属性を
作成することができます。
オプションパラメータの指定
PutItem オペレーションに PutItemOperationConfig パラメータを追加することで、オプション
パラメータを設定できます。オプションパラメータの詳細なリストについては、PutItem を参照して
ください。次の C# コードスニペットでは、ProductCatalog テーブルに項目が入力されています。次
のオプションパラメータが指定されています。
• 条件付き入力リクエストとする ConditionalExpression パラメータ。例では、置き換える項目
に ISBN 属性が存在し、それが特定の値でなくてはならないことを指定する式を作成します。
Table table = Table.LoadTable(client, "ProductCatalog");
var book = new Document();
book["Id"] = 555;
book["Title"] = "Book 555 Title";
book["Price"] = "25.00";
book["ISBN"] = "55-55-55-55";
book["Name"] = "Item 1 updated";
book["Authors"] = new List<string> { "Author x", "Author y" };
book["InStock"] = new DynamoDBBool(true);
book["QuantityOnHand"] = new DynamoDBNull();
// Create a condition expression for the optional conditional put operation.
Expression expr = new Expression();
expr.ExpressionStatement = "ISBN = :val";
expr.ExpressionAttributeValues[":val"] = "55-55-55-55";
PutItemOperationConfig config = new PutItemOperationConfig()
{
// Optional parameter.
ConditionalExpression = expr
};
table.PutItem(book, config);
項目の取得 – Table.GetItem
GetItem オペレーションでは、項目を Document インスタンスとして取り出します。次の C# コード
スニペットに示すように、取り出す項目のプライマリキーを入力する必要があります。
API Version 2012-08-10
119
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
Table table = Table.LoadTable(client, "ProductCatalog");
Document document = table.GetItem(101); // Primary key 101.
GetItem オペレーションを実行すると、項目のすべての属性が返され、デフォルトで結果整合性のあ
る読み込み(「読み込み整合性 (p. 16)」を参照)が実行されます。
オプションパラメータの指定
GetItemOperationConfig パラメータを追加することで、GetItem オペレーションに追加オプショ
ンを設定できます。オプションパラメータの詳細なリストについては、GetItem を参照してくださ
い。次の C# コードスニペットでは、ProductCatalog テーブルから項目が取り出されています。次の
オプションパラメータを使用して GetItemOperationConfig が指定されています。
• 指定された属性だけを取り出す AttributesToGet パラメータ。
• 指定されたすべての属性に対する最新の値をリクエストする ConsistentRead パラメータデータ
の整合性の詳細については、「読み込み整合性 (p. 16)」を参照してください。
Table table = Table.LoadTable(client, "ProductCatalog");
GetItemOperationConfig config = new GetItemOperationConfig()
{
AttributesToGet = new List<string>() { "Id", "Title", "Authors", "InStock",
"QuantityOnHand" },
ConsistentRead = true
};
Document doc = table.GetItem(101, config);
ドキュメントモデル API を使用して項目を取り出すと、返される Document オブジェクト内の個々の
要素にアクセスできます。
int id = doc["Id"].AsInt();
string title = doc["Title"].AsString();
List<string> authors = doc["Authors"].AsListOfString();
bool inStock = doc["InStock"].AsBoolean();
DynamoDBNull quantityOnHand = doc["QuantityOnHand"].AsDynamoDBNull();
リスト型またはマップ型の属性の場合に、属性をドキュメントモデル API にマッピングする方法を以
下に示します。
• リスト - AsDynamoDBList メソッドを使用します。
• マップ - AsDocument メソッドを使用します。
次のコードスニペットは、Document オブジェクトからリスト(RelatedItems)およびマップ
(Pictures)を取得する方法を示します。
DynamoDBList relatedItems = doc["RelatedItems"].AsDynamoDBList();
Document pictures = doc["Pictures"].AsDocument();
API Version 2012-08-10
120
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
項目の削除 – Table.DeleteItem
DeleteItem オペレーションは、テーブルから項目を削除します。次の C# コードスニペットに示
すように、項目のプライマリキーをパラメータとして渡すことができます。また、すでに項目を読
み取っていて対応する Document オブジェクトを取得している場合には、それをパラメータとして
DeleteItem メソッドに渡すこともできます。
Table table = Table.LoadTable(client, "ProductCatalog");
// Retrieve a book (a Document instance)
Document document = table.GetItem(111);
// 1) Delete using the Document instance.
table.DeleteItem(document);
// 2) Delete using the primary key.
int partitionKey = 222;
table.DeleteItem(partitionKey)
オプションパラメータの指定
DeleteItemOperationConfig パラメータを追加することで、Delete オペレーションに追加オプ
ションを設定できます。オプションパラメータの詳細なリストについては、DeleteTable を参照して
ください。次の C# コードスニペットでは、以下の 2 つのオプションパラメータを指定します。
• ISBN 属性に特定の値が含まれている書籍項目が削除されるようにする ConditionalExpression
パラメータ。
• 削除された項目が Delete メソッドによって返されることをリクエストする ReturnValues パラ
メータ。
Table table = Table.LoadTable(client, "ProductCatalog");
int partitionKey = 111;
Expression expr = new Expression();
expr.ExpressionStatement = "ISBN = :val";
expr.ExpressionAttributeValues[":val"] = "11-11-11-11";
// Specify optional parameters for Delete operation.
DeleteItemOperationConfig config = new DeleteItemOperationConfig
{
ConditionalExpression = expr,
ReturnValues = ReturnValues.AllOldAttributes // This is the only
supported value when using the document model.
};
// Delete the book.
Document d = table.DeleteItem(partitionKey, config);
項目の更新 – Table.UpdateItem
UpdateItem オペレーションは、既存の項目があればそれを更新します。プライマリキーが指定され
ている項目がない場合は、UpdateItem オペレーションによって新しい項目が追加されます。
API Version 2012-08-10
121
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
UpdateItem オペレーションを使用して、既存の属性値を更新するか、既存のコレクションに新しい
属性を追加するか、既存のコレクションから属性を削除することができます。これらの更新は、更新
を記述する Document インスタンスを作成して実行します。
UpdateItem アクションは、以下のガイドラインに従います。
• 項目が存在しない場合、UpdateItem は入力で指定されたプライマリキーを使用して、新しい項目
を追加します。
• 項目が存在する場合、UpdateItem は次のように更新を適用します。
• 既存の属性値を更新に含まれる値に置き換えます。
• 入力で指定された属性が存在しない場合は、新しい属性を項目に追加します。
• 入力された属性値が null である場合は、属性を削除します。
Note
この中間レベルの UpdateItem オペレーションでは、基層の DynamoDB オペレーションで
サポートされている Add アクション (UpdateItem を参照) はサポートされていません。
Note
PutItem オペレーション(項目の入力 – Table.PutItem メソッド (p. 117))でも更新を実行
できます。PutItem を呼び出して項目をアップロードするときにプライマリキーが存在する
場合は、PutItem オペレーションによって項目全体が置き換わります。既存の項目内に属性
があり、入力された Document でそれらの属性が指定されていない場合には、PutItem オペ
レーションによってそれらの属性が削除されます。ただし、UpdateItem が更新するのは指
定された入力属性だけです。 その項目では、その他の既存の属性は変更されません。
AWS SDK for .NET ドキュメントモデルを使用して項目を更新するステップを以下に示します。
1. 更新オペレーションを実行するテーブルの名前を入力して、Table.LoadTable メソッドを実行し
ます。
2. 実行するすべての更新を指定して、Document インスタンスを作成します。
既存の属性を削除するには、その属性値に null を指定します。
3. Table.UpdateItem メソッドを呼び出し、Document インスタンスを入力パラメータとして指定
します。
プライマリキーを、Document インスタンスで、または明示的にパラメータとして指定する必要が
あります。
次の C# コードスニペットは、前述のタスクの例です。このコードサンプルでは、Book テーブル
の項目が更新されています。UpdateItem オペレーションによって、既存の Authors 属性が更新さ
れ、PageCount 属性が削除され、新しい属性 XYZ が追加されます。Document インスタンスには、
更新する書籍のプライマリキーが含まれています。
Table table = Table.LoadTable(client, "ProductCatalog");
var book = new Document();
// Set the attributes that you wish to update.
book["Id"] = 111; // Primary key.
// Replace the authors attribute.
API Version 2012-08-10
122
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
book["Authors"] = new List<string> { "Author x", "Author y" };
// Add a new attribute.
book["XYZ"] = 12345;
// Delete the existing PageCount attribute.
book["PageCount"] = null;
table.Update(book);
オプションパラメータの指定
UpdateItemOperationConfig パラメータを追加することで、UpdateItem オペレーションに追加
オプションを設定できます。オプションパラメータの詳細なリストについては、UpdateItem を参照し
てください。
次の C# コードスニペットでは、書籍項目の価格が 25 に更新されています。次の 2 つのオプションパ
ラメータが指定されています。
• 存在することが期待される Price 属性の値が 20 であることを指定する ConditionalExpression
パラメータ。
• 更新された項目が返される UpdateItem オペレーションをリクエストする ReturnValues パラ
メータ。
Table table = Table.LoadTable(client, "ProductCatalog");
string partitionKey = "111";
var book = new Document();
book["Id"] = partitionKey;
book["Price"] = 25;
Expression expr = new Expression();
expr.ExpressionStatement = "Price = :val";
expr.ExpressionAttributeValues[":val"] = 20";
UpdateOperationConfig config = new UpdateOperationConfig()
{
ConditionalExpression = expr,
ReturnValues = ReturnValues.AllOldAttributes
};
Document d1 = table.Update(book, config);
バッチ書き込み – 複数の項目の書き込みおよび削除
バッチ書き込みは、複数の項目の書き込みと削除をバッチで行うことを意味します。このオペレー
ションでは、単一の 呼び出しの 1 つ以上のテーブルから、複数の項目の書き込みと削除を行うことが
できます。AWS SDK for .NET ドキュメントモデル API を使用して、テーブルで複数の項目の書き込
みまたは削除を行うステップを次に示します。
1. テーブルオブジェクトを作成するには、バッチオペレーションを実行するテーブルの名前を指定し
て、Table.LoadTable メソッドを実行します。
2. 前述のステップで作成したテーブルインスタンスで CreateBatchWrite メソッドを実行
し、DocumentBatchWrite オブジェクトを作成します。
3. DocumentBatchWrite オブジェクトメソッドを使用して、アップロードまたは削除するドキュメ
ントを指定します。
API Version 2012-08-10
123
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
4. DocumentBatchWrite.Execute メソッドを呼び出してバッチオペレーションを実行します。
ドキュメントモデル API を使用する場合は、1 つのバッチに任意の数のオペレーションを指定
できます。ただし DynamoDB では、1 つのバッチ内のオペレーションの数と、1 つのバッチ
オペレーションでのバッチの合計サイズが制限されています。制限の具体的な詳細について
は、BatchWriteItem を参照してください。許可されている書き込みリクエスト数をバッチ書き込み
リクエストが超えたこと、またはバッチの HTTP ペイロードサイズが BatchWriteItem で許可さ
れている制限を超えたことをドキュメントモデル API が検出した場合には、バッチが複数の小さな
バッチに分割されます。 さらに、バッチ書き込みに対する応答で、未処理の項目が返された場合に
は、ドキュメントモデル API がそれら未処理の項目を使用して、別のバッチリクエストを自動的に
送信します。
次の C# コードスニペットは、前述のステップを示しています。このコードスニペットでは、バッチ
書き込みオペレーションを使用して、書籍項目のアップロードと別の書籍項目の削除という 2 つの書
き込みが実行されています。
Table productCatalog = Table.LoadTable(client, "ProductCatalog");
var batchWrite = productCatalog.CreateBatchWrite();
var book1 = new Document();
book1["Id"] = 902;
book1["Title"] = "My book1 in batch write using .NET document model";
book1["Price"] = 10;
book1["Authors"] = new List<string> { "Author 1", "Author 2", "Author 3" };
book1["InStock"] = new DynamoDBBool(true);
book1["QuantityOnHand"] = 5;
batchWrite.AddDocumentToPut(book1);
// specify delete item using overload that takes PK.
batchWrite.AddKeyToDelete(12345);
batchWrite.Execute();
実例については、「例: AWS SDK for .NET ドキュメントモデル API を使用したバッチオペレーショ
ン (p. 128)」を参照してください。
バッチ書き込みオペレーションを使用すると、複数のテーブルで入力および削除オペレーションを実
行できます。AWS SDK for .NET ドキュメントモデルを使用して、複数のテーブルで複数の項目の書
き込みまたは削除を行うステップを次に示します。
1. 前述の手順で示したように、複数の項目の入力または削除を行う各テーブルについて
DocumentBatchWrite インスタンスを作成します。
2. MultiTableDocumentBatchWrite のインスタンスを作成し、その中に個々の
DocumentBatchWrite オブジェクトを追加します。
3. MultiTableDocumentBatchWrite.Execute メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。このコードスニペットでは、バッチ
書き込みオペレーションを使用して、次の書き込みオペレーションを実行しています。
• Forum テーブル項目内に新しい項目を入力する
• Thread テーブル内に項目を入力し、同じテーブルから項目を削除する
// 1. Specify item to add in the Forum table.
API Version 2012-08-10
124
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
Table forum = Table.LoadTable(client, "Forum");
var forumBatchWrite = forum.CreateBatchWrite();
var forum1 = new Document();
forum1["Name"] = "Test BatchWrite Forum";
forum1["Threads"] = 0;
forumBatchWrite.AddDocumentToPut(forum1);
// 2a. Specify item to add in the Thread table.
Table thread = Table.LoadTable(client, "Thread");
var threadBatchWrite = thread.CreateBatchWrite();
var thread1 = new Document();
thread1["ForumName"] = "Amazon S3 forum";
thread1["Subject"] = "My sample question";
thread1["Message"] = "Message text";
thread1["KeywordTags"] = new List<string>{ "Amazon S3", "Bucket" };
threadBatchWrite.AddDocumentToPut(thread1);
// 2b. Specify item to delete from the Thread table.
threadBatchWrite.AddKeyToDelete("someForumName", "someSubject");
// 3. Create multi-table batch.
var superBatch = new MultiTableDocumentBatchWrite();
superBatch.AddBatch(forumBatchWrite);
superBatch.AddBatch(threadBatchWrite);
superBatch.Execute();
例: AWS SDK for .NET ドキュメントモデルを使用した CRUD
オペレーション
次の C# コード例は、次のアクションを実行します。
• ProductCatalog テーブルで書籍項目を作成します。
• 書籍項目を取り出します。
• 書籍項目を更新します。このコード例は、新しい属性を追加して既存の属性を更新する、通常の更
新を示しています。また、既存の価格とコードで指定されている価格が一致する場合のみ書籍の価
格を更新する、条件付き更新も示しています。
• 書籍項目を削除します。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照
してください。
using
using
using
using
using
using
System;
System.Collections.Generic;
System.Linq;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DocumentModel;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class MidlevelItemCRUD
{
API Version 2012-08-10
125
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
private static string tableName = "ProductCatalog";
// The sample uses the following id PK value to add book item.
private static int sampleBookId = 555;
static void Main(string[] args)
{
try
{
Table productCatalog = Table.LoadTable(client, tableName);
CreateBookItem(productCatalog);
RetrieveBook(productCatalog);
// Couple of sample updates.
UpdateMultipleAttributes(productCatalog);
UpdateBookPriceConditionally(productCatalog);
// Delete.
DeleteBook(productCatalog);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
// Creates a sample book item.
private static void CreateBookItem(Table productCatalog)
{
Console.WriteLine("\n*** Executing CreateBookItem() ***");
var book = new Document();
book["Id"] = sampleBookId;
book["Title"] = "Book " + sampleBookId;
book["Price"] = 19.99;
book["ISBN"] = "111-1111111111";
book["Authors"] = new List<string> { "Author 1", "Author 2",
"Author 3" };
book["PageCount"] = 500;
book["Dimensions"] = "8.5x11x.5";
book["InPublication"] = new DynamoDBBool(true);
book["InStock"] = new DynamoDBBool(false);
book["QuantityOnHand"] = 0;
productCatalog.PutItem(book);
}
private static void RetrieveBook(Table productCatalog)
{
Console.WriteLine("\n*** Executing RetrieveBook() ***");
// Optional configuration.
GetItemOperationConfig config = new GetItemOperationConfig
{
AttributesToGet = new List<string> { "Id", "ISBN", "Title",
"Authors", "Price" },
ConsistentRead = true
};
API Version 2012-08-10
126
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
Document document = productCatalog.GetItem(sampleBookId,
config);
Console.WriteLine("RetrieveBook: Printing book retrieved...");
PrintDocument(document);
}
private static void UpdateMultipleAttributes(Table productCatalog)
{
Console.WriteLine("\n*** Executing UpdateMultipleAttributes()
***");
Console.WriteLine("\nUpdating multiple attributes....");
int partitionKey = sampleBookId;
var book = new Document();
book["Id"] = partitionKey;
// List of attribute updates.
// The following replaces the existing authors list.
book["Authors"] = new List<string> { "Author x", "Author y" };
book["newAttribute"] = "New Value";
book["ISBN"] = null; // Remove it.
// Optional parameters.
UpdateItemOperationConfig config = new UpdateItemOperationConfig
{
// Get updated item in response.
ReturnValues = ReturnValues.AllNewAttributes
};
Document updatedBook = productCatalog.UpdateItem(book, config);
Console.WriteLine("UpdateMultipleAttributes: Printing item after
updates ...");
PrintDocument(updatedBook);
}
private static void UpdateBookPriceConditionally(Table
productCatalog)
{
Console.WriteLine("\n*** Executing UpdateBookPriceConditionally()
***");
int partitionKey = sampleBookId;
var book = new Document();
book["Id"] = partitionKey;
book["Price"] = 29.99;
// For conditional price update, creating a condition expression.
Expression expr = new Expression();
expr.ExpressionStatement = "Price = :val";
expr.ExpressionAttributeValues[":val"] = 19.00;
// Optional parameters.
UpdateItemOperationConfig config = new UpdateItemOperationConfig
{
ConditionalExpression = expr,
ReturnValues = ReturnValues.AllNewAttributes
};
Document updatedBook = productCatalog.UpdateItem(book, config);
API Version 2012-08-10
127
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
Console.WriteLine("UpdateBookPriceConditionally: Printing item
whose price was conditionally updated");
PrintDocument(updatedBook);
}
private static void DeleteBook(Table productCatalog)
{
Console.WriteLine("\n*** Executing DeleteBook() ***");
// Optional configuration.
DeleteItemOperationConfig config = new DeleteItemOperationConfig
{
// Return the deleted item.
ReturnValues = ReturnValues.AllOldAttributes
};
Document document = productCatalog.DeleteItem(sampleBookId,
config);
Console.WriteLine("DeleteBook: Printing deleted just
deleted...");
PrintDocument(document);
}
private static void PrintDocument(Document updatedDocument)
{
foreach (var attribute in updatedDocument.GetAttributeNames())
{
string stringValue = null;
var value = updatedDocument[attribute];
if (value is Primitive)
stringValue = value.AsPrimitive().Value.ToString();
else if (value is PrimitiveList)
stringValue = string.Join(",", (from primitive
in
value.AsPrimitiveList().Entries
select
primitive.Value).ToArray());
Console.WriteLine("{0} - {1}", attribute, stringValue);
}
}
}
}
例: AWS SDK for .NET ドキュメントモデル API を使用した
バッチオペレーション
トピック
• 例: AWS SDK for .NET ドキュメントモデルを使用したバッチ書き込み (p. 128)
例: AWS SDK for .NET ドキュメントモデルを使用したバッチ書き込み
次の C# コード例は、単一のテーブルと複数のテーブルに対するバッチ書き込みオペレーションを示
しています。この例では次のタスクを実行しています。
• 単一のテーブルに対するバッチ書き込みを示すために、ProductCatalog テーブルに 2 つの項目を追
加しています。
• 複数のテーブルに対するバッチ書き込みを示すために、Forum テーブルと Thread テーブルの両方
に 1 つの項目を追加し、Thread テーブルから項目を削除しています。
API Version 2012-08-10
128
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
「テーブルの作成とサンプルデータのロード (p. 166)」のステップに従っていれば、ProductCatalog
テーブル、Forum テーブル、Thread テーブルは作成済みです。これらのサンプルテーブルは、プログ
ラムで作成することもできます。詳細については、「AWS SDK for .NET を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 608)」を参照してください。次のサンプルをテストするため
の詳しい手順については、「.NET コードサンプル (p. 173)」を参照してください。
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DocumentModel;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class MidLevelBatchWriteItem
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
SingleTableBatchWrite();
MultiTableBatchWrite();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void SingleTableBatchWrite()
{
Table productCatalog = Table.LoadTable(client,
"ProductCatalog");
var batchWrite = productCatalog.CreateBatchWrite();
var book1 = new Document();
book1["Id"] = 902;
book1["Title"] = "My book1 in batch write using .NET helper
classes";
book1["ISBN"] = "902-11-11-1111";
book1["Price"] = 10;
book1["ProductCategory"] = "Book";
book1["Authors"] = new List<string> { "Author 1", "Author 2",
"Author 3" };
book1["Dimensions"] = "8.5x11x.5";
book1["InStock"] = new DynamoDBBool(true);
book1["QuantityOnHand"] = new DynamoDBNull(); //Quantity is
unknown at this time
batchWrite.AddDocumentToPut(book1);
// Specify delete item using overload that takes PK.
batchWrite.AddKeyToDelete(12345);
API Version 2012-08-10
129
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
Console.WriteLine("Performing batch write in
SingleTableBatchWrite()");
batchWrite.Execute();
}
private static void MultiTableBatchWrite()
{
// 1. Specify item to add in the Forum table.
Table forum = Table.LoadTable(client, "Forum");
var forumBatchWrite = forum.CreateBatchWrite();
var forum1 = new Document();
forum1["Name"] = "Test BatchWrite Forum";
forum1["Threads"] = 0;
forumBatchWrite.AddDocumentToPut(forum1);
// 2a. Specify item to add in the Thread table.
Table thread = Table.LoadTable(client, "Thread");
var threadBatchWrite = thread.CreateBatchWrite();
var thread1 = new Document();
thread1["ForumName"] = "S3 forum";
thread1["Subject"] = "My sample question";
thread1["Message"] = "Message text";
thread1["KeywordTags"] = new List<string> { "S3", "Bucket" };
threadBatchWrite.AddDocumentToPut(thread1);
// 2b. Specify item to delete from the Thread table.
threadBatchWrite.AddKeyToDelete("someForumName", "someSubject");
// 3. Create multi-table batch.
var superBatch = new MultiTableDocumentBatchWrite();
superBatch.AddBatch(forumBatchWrite);
superBatch.AddBatch(threadBatchWrite);
Console.WriteLine("Performing batch write in
MultiTableBatchWrite()");
superBatch.Execute();
}
}
}
AWS SDK for .NET ドキュメントモデルによる DynamoDB で
のテーブルのクエリ
トピック
• AWS SDK for .NET の Table.Query メソッド (p. 130)
• AWS SDK for .NET の Table.Scan メソッド (p. 135)
AWS SDK for .NET の Table.Query メソッド
Query メソッドを使用すると、テーブルのクエリを行うことができます。複合プライマリキー (パー
ティションキーおよびソートキー) があるテーブルにのみ、クエリを実行できます。テーブルのプライ
マリキーがパーティションキーだけで構成されている場合、Query オペレーションはサポートされて
いません。デフォルトでは、Query の内部で結果整合性のあるクエリが実行されます。 整合性モデル
の詳細については、「読み込み整合性 (p. 16)」を参照してください。
API Version 2012-08-10
130
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
Query メソッドには 2 つのオーバーロードがあります。Query メソッドで最小限必要なパラメーター
は、パーティションキーの値とソートキーフィルタです。次のオーバーロードを使用して、これら最
小限必要なパラメータを指定できます。
Query(Primitive partitionKey, RangeFilter Filter);
たとえば次の C# コードスニペットでは、フォーラムで過去 15 日間に投稿されたすべての返信がクエ
リされます。
string tableName = "Reply";
Table table = Table.LoadTable(client, tableName);
DateTime twoWeeksAgoDate = DateTime.UtcNow - TimeSpan.FromDays(15);
RangeFilter filter = new RangeFilter(QueryOperator.GreaterThan,
twoWeeksAgoDate);
Search search = table.Query("DynamoDB Thread 2", filter);
これによって Search オブジェクトが作成されます。ここで次の C# コードスニペットに示すよう
に、Search.GetNextSet メソッドを反復的に呼び出して、一度に 1 ページずつ結果を取り出すこと
ができます。このコードでは、クエリによって返される各項目の属性値が出力されます。
List<Document> documentSet = new List<Document>();
do
{
documentSet = search.GetNextSet();
foreach (var document in documentSet)
PrintDocument(document);
} while (!search.IsDone);
private static void PrintDocument(Document document)
{
Console.WriteLine();
foreach (var attribute in document.GetAttributeNames())
{
string stringValue = null;
var value = document[attribute];
if (value is Primitive)
stringValue = value.AsPrimitive().Value;
else if (value is PrimitiveList)
stringValue = string.Join(",", (from primitive
in value.AsPrimitiveList().Entries
select primitive.Value).ToArray());
Console.WriteLine("{0} - {1}", attribute, stringValue);
}
}
オプションパラメータの指定
また、取り出す属性リスト、強力な整合性のある読み込み、ページサイズ、ページごとに返される項
目数などを指定する、Query のオプションパラメータを指定することもできます。 パラメータの詳細
なリストについては、Query を参照してください。オプションパラメータを指定するには、次のオー
バーロードを使用して QueryOperationConfig オブジェクトを指定する必要があります。
API Version 2012-08-10
131
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
Query(QueryOperationConfig config);
前述の例でクエリを実行する(過去 15 日間に投稿されたフォーラムの返信を取り出す)とします。
ただし、特定の属性だけを取り出し、強力な整合性のある読み込みをリクエストする、オプションの
クエリパラメータを指定するとします。次の C# コードスニペットでは、QueryOperationConfig
オブジェクトを使用してリクエストを作成しています。
Table table = Table.LoadTable(client, "Reply");
DateTime twoWeeksAgoDate = DateTime.UtcNow - TimeSpan.FromDays(15);
QueryOperationConfig config = new QueryOperationConfig()
{
HashKey = "DynamoDB Thread 2", //Partition key
AttributesToGet = new List<string>
{ "Subject", "ReplyDateTime", "PostedBy" },
ConsistentRead = true,
Filter = new RangeFilter(QueryOperator.GreaterThan, twoWeeksAgoDate)
};
Search search = table.Query(config);
例: Table.Query メソッドを使用したクエリ
次の C# コード例では、Table.Query メソッドを使用して次のサンプルクエリを実行しています。
• Reply テーブルに対して次のクエリが実行されています。
• 過去 15 日間に投稿されたフォーラムスレッドの返信を検索する。
このクエリは 2 回実行されます。最初の Table.Query の呼び出しの例では、必須のクエリパラ
メータだけが指定されています。2 回目の Table.Query の呼び出しでは、オプションのクエリパ
ラメータを指定して、強力な整合性のある読み込みと、取り出す属性のリストをリクエストして
います。
• 特定の期間中に投稿されたフォーラムスレッドの返信を検索する。
このクエリでは Between クエリ演算子を使用して、2 つの日付間に投稿された返信が検索されま
す。
• ProductCatalog テーブルから製品を取得する
ProductCatalog テーブルにはパーティションキーでしかないプライマリキーがあるため、項目の取
得だけが可能で、テーブルのクエリを行うことはできません。この例では、項目 Id を使用して特定
の製品項目を取り出しています。
using
using
using
using
using
using
using
System;
System.Collections.Generic;
System.Linq;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DocumentModel;
Amazon.Runtime;
Amazon.SecurityToken;
namespace com.amazonaws.codesamples
{
class MidLevelQueryAndScan
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
API Version 2012-08-10
132
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
{
try
{
// Query examples.
Table replyTable = Table.LoadTable(client, "Reply");
string forumName = "Amazon DynamoDB";
string threadSubject = "DynamoDB Thread 2";
FindRepliesInLast15Days(replyTable, forumName,
threadSubject);
FindRepliesInLast15DaysWithConfig(replyTable, forumName,
threadSubject);
FindRepliesPostedWithinTimePeriod(replyTable, forumName,
threadSubject);
// Get Example.
Table productCatalogTable = Table.LoadTable(client,
"ProductCatalog");
int productId = 101;
GetProduct(productCatalogTable, productId);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
private static void GetProduct(Table tableName, int productId)
{
Console.WriteLine("*** Executing GetProduct() ***");
Document productDocument = tableName.GetItem(productId);
if (productDocument != null) {
PrintDocument(productDocument);
} else {
Console.WriteLine("Error: product " + productId + " does not
exist");
}
}
private static void FindRepliesInLast15Days(Table table, string
forumName, string threadSubject)
{
string Attribute = forumName + "#" + threadSubject;
DateTime twoWeeksAgoDate = DateTime.UtcNow TimeSpan.FromDays(15);
QueryFilter filter = new QueryFilter("Id", QueryOperator.Equal,
partitionKey);
filter.AddCondition("ReplyDateTime", QueryOperator.GreaterThan,
twoWeeksAgoDate);
// Use Query overloads that takes the minimum required query
parameters.
Search search = table.Query(filter);
List<Document> documentSet = new List<Document>();
API Version 2012-08-10
133
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
do
{
documentSet = search.GetNextSet();
Console.WriteLine("\nFindRepliesInLast15Days:
printing ............");
foreach (var document in documentSet)
PrintDocument(document);
} while (!search.IsDone);
}
private static void FindRepliesPostedWithinTimePeriod(Table table,
string forumName, string threadSubject)
{
DateTime startDate = DateTime.UtcNow.Subtract(new TimeSpan(21, 0,
0, 0));
DateTime endDate = DateTime.UtcNow.Subtract(new TimeSpan(1, 0, 0,
0));
QueryFilter filter = new QueryFilter("Id", QueryOperator.Equal,
forumName + "#" + threadSubject);
filter.AddCondition("ReplyDateTime", QueryOperator.Between,
startDate, endDate);
QueryOperationConfig config = new QueryOperationConfig()
{
Limit = 2, // 2 items/page.
Select = SelectValues.SpecificAttributes,
AttributesToGet = new List<string> { "Message",
"ReplyDateTime",
"PostedBy" },
ConsistentRead = true,
Filter = filter
};
Search search = table.Query(config);
List<Document> documentList = new List<Document>();
do
{
documentList = search.GetNextSet();
Console.WriteLine("\nFindRepliesPostedWithinTimePeriod:
printing replies posted within dates: {0} and {1} ............", startDate,
endDate);
foreach (var document in documentList)
{
PrintDocument(document);
}
} while (!search.IsDone);
}
private static void FindRepliesInLast15DaysWithConfig(Table table,
string forumName, string threadName)
{
DateTime twoWeeksAgoDate = DateTime.UtcNow TimeSpan.FromDays(15);
QueryFilter filter = new QueryFilter("Id", QueryOperator.Equal,
forumName + "#" + threadName);
API Version 2012-08-10
134
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
filter.AddCondition("ReplyDateTime", QueryOperator.GreaterThan,
twoWeeksAgoDate);
// You are specifying optional parameters so use
QueryOperationConfig.
QueryOperationConfig config = new QueryOperationConfig()
{
Filter = filter,
// Optional parameters.
Select = SelectValues.SpecificAttributes,
AttributesToGet = new List<string> { "Message",
"ReplyDateTime",
"PostedBy" },
ConsistentRead = true
};
Search search = table.Query(config);
List<Document> documentSet = new List<Document>();
do
{
documentSet = search.GetNextSet();
Console.WriteLine("\nFindRepliesInLast15DaysWithConfig:
printing ............");
foreach (var document in documentSet)
PrintDocument(document);
} while (!search.IsDone);
}
private static void PrintDocument(Document document)
{
//
count++;
Console.WriteLine();
foreach (var attribute in document.GetAttributeNames())
{
string stringValue = null;
var value = document[attribute];
if (value is Primitive)
stringValue = value.AsPrimitive().Value.ToString();
else if (value is PrimitiveList)
stringValue = string.Join(",", (from primitive
in
value.AsPrimitiveList().Entries
select
primitive.Value).ToArray());
Console.WriteLine("{0} - {1}", attribute, stringValue);
}
}
}
}
AWS SDK for .NET の Table.Scan メソッド
Scan メソッドではテーブル全体のスキャンが実行されます。ここでは 2 つのオーバーロードを使用
できます。Scan メソッドで必要とされるパラメータは、次のオーバーロードを使用して指定できる、
スキャンフィルタだけです。
Scan(ScanFilter filter);
API Version 2012-08-10
135
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
たとえば、フォーラムスレッドのテーブルを維持していて、そこではスレッドの件名 (プライマリ)、
関連メッセージ、スレッドが属するフォーラムの Id、タグなどの情報を追跡しているとします。ス
レッドの件名がプライマリキーであるとします。
Thread(Subject, Message, ForumId, Tags, LastPostedDateTime, .... )
これは、AWS フォーラムで見られるフォーラムやスレッドを簡略化したものです(「Discussion
Forums」を参照)。次の C# コードスニペットでは、特定のフォーラム (ForumId = 101) 内で、
「sortkey」というタグが付加されたすべてのスレッドをクエリしています。ForumId はプライマリ
キーではないため、この例ではテーブルをスキャンしています。ScanFilter には 2 つの条件が含ま
れています。クエリによって、両方の条件を満たすすべてのスレッドが返されます。
string tableName = "Thread";
Table ThreadTable = Table.LoadTable(client, tableName);
ScanFilter scanFilter = new ScanFilter();
scanFilter.AddCondition("ForumId", ScanOperator.Equal, 101);
scanFilter.AddCondition("Tags", ScanOperator.Contains, "sortkey");
Search search = ThreadTable.Scan(scanFilter);
オプションパラメータの指定
Scan には、取り出す属性のリストや、強力な整合性のある読み込みを実行するかどうかなど、オプ
ションのパラメータを指定することもできます。オプションパラメータを指定するには、必須および
オプションのパラメータを含む ScanOperationConfig オブジェクトを作成し、次のオーバーロー
ドを使用する必要があります。
Scan(ScanOperationConfig config);
次の C# コードスニペットでは、前述のものと同じクエリ (ForumId が 101 で Tag 属性に「sortkey」
キーワードが含まれているフォーラムスレッドを検索する) を実行しています。ただしここで
は、オプションのパラメータを追加して、特定の属性リストだけを取り出すものとします。その
場合は、次のコード例に示すように、必須およびオプションのすべてのパラメータを指定して
ScanOperationConfig オブジェクトを作成する必要があります。
string tableName = "Thread";
Table ThreadTable = Table.LoadTable(client, tableName);
ScanFilter scanFilter = new ScanFilter();
scanFilter.AddCondition("ForumId", ScanOperator.Equal, forumId);
scanFilter.AddCondition("Tags", ScanOperator.Contains, "sortkey");
ScanOperationConfig config = new ScanOperationConfig()
{
AttributesToGet = new List<string> { "Subject", "Message" } ,
Filter = scanFilter
};
Search search = ThreadTable.Scan(config);
API Version 2012-08-10
136
Amazon DynamoDB 開発者ガイド
.NET ドキュメントモデル
例: Table.Scan メソッドを使用したスキャン
Scan オペレーションでは完全なテーブルスキャンが実行されるため、非効率的なオペレーションに
なる可能性があります。代わりにクエリを使用してください。ただし場合によっては、テーブルに
対してスキャンを実行しなければならないことがあります。たとえば、次の C# コード例に示すよう
に、製品価格にデータ入力エラーがあるためテーブルのスキャンを行う場合があります。この例では
ProductCatalog テーブルをスキャンして、価格の値が 0 未満である製品を検索しています。この例
は、2 つの Table.Scan オーバーロードの使い方を示しています。
• ScanFilter オブジェクトをパラメータとする Table.Scan。
必須パラメータだけを渡す場合は、ScanFilter パラメータを渡すことができます。
• ScanOperationConfig オブジェクトをパラメータとする Table.Scan。
Scan メソッドにオプションパラメータを渡す場合には、ScanOperationConfig パラメータを使
用する必要があります。
using
using
using
using
using
System;
System.Collections.Generic;
System.Linq;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DocumentModel;
namespace com.amazonaws.codesamples
{
class MidLevelScanOnly
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
Table productCatalogTable = Table.LoadTable(client,
"ProductCatalog");
// Scan example.
FindProductsWithNegativePrice(productCatalogTable);
FindProductsWithNegativePriceWithConfig(productCatalogTable);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void FindProductsWithNegativePrice(Table
productCatalogTable)
{
// Assume there is a price error. So we scan to find items priced
< 0.
ScanFilter scanFilter = new ScanFilter();
scanFilter.AddCondition("Price", ScanOperator.LessThan, 0);
Search search = productCatalogTable.Scan(scanFilter);
List<Document> documentList = new List<Document>();
do
{
documentList = search.GetNextSet();
Console.WriteLine("\nFindProductsWithNegativePrice:
printing ............");
foreach (var document in documentList)
API Version 2012-08-10
137
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
PrintDocument(document);
} while (!search.IsDone);
}
private static void FindProductsWithNegativePriceWithConfig(Table
productCatalogTable)
{
// Assume there is a price error. So we scan to find items priced
< 0.
ScanFilter scanFilter = new ScanFilter();
scanFilter.AddCondition("Price", ScanOperator.LessThan, 0);
ScanOperationConfig config = new ScanOperationConfig()
{
Filter = scanFilter,
Select = SelectValues.SpecificAttributes,
AttributesToGet = new List<string> { "Title", "Id" }
};
Search search = productCatalogTable.Scan(config);
List<Document> documentList = new List<Document>();
do
{
documentList = search.GetNextSet();
Console.WriteLine("\nFindProductsWithNegativePriceWithConfig:
printing ............");
foreach (var document in documentList)
PrintDocument(document);
} while (!search.IsDone);
}
private static void PrintDocument(Document document)
{
//
count++;
Console.WriteLine();
foreach (var attribute in document.GetAttributeNames())
{
string stringValue = null;
var value = document[attribute];
if (value is Primitive)
stringValue = value.AsPrimitive().Value.ToString();
else if (value is PrimitiveList)
stringValue = string.Join(",", (from primitive
in
value.AsPrimitiveList().Entries
select
primitive.Value).ToArray());
Console.WriteLine("{0} - {1}", attribute, stringValue);
}
}
}
}
.NET: オブジェクト永続性モデル
トピック
API Version 2012-08-10
138
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
• DynamoDB の属性 (p. 140)
• DynamoDBContext クラス (p. 142)
• サポートされているデータの種類 (p. 147)
• DynamoDB で AWS SDK for .NET オブジェクト永続性モデルを使用した、バージョン番号による
オプティミスティックロック (p. 148)
• AWS SDK for .NET オブジェクト永続性モデルを使用した、DynamoDB での任意データのマッピ
ング (p. 150)
• AWS SDK for .NET オブジェクト永続性モデルを使用したバッチオペレーション (p. 153)
• 例: AWS SDK for .NET オブジェクト永続性モデルを使用した CRUD オペレーション (p. 156)
• 例: AWS SDK for .NET オブジェクト永続性モデルを使用したバッチ書き込みオペレーショ
ン (p. 158)
• 例: AWS SDK for .NET オブジェクト永続性モデルを使用した、DynamoDB でのクエリおよびス
キャン (p. 161)
AWS SDK for .NET には、クライアント側クラスを DynamoDB テーブルにマッピングできるオブジェ
クト永続性モデルが用意されています。各オブジェクトインスタンスが、対応するテーブルの項目に
マッピングされます。クライアント側オブジェクトをテーブルに保存するために、オブジェクト永続
性モデルでは、DynamoDB のエントリポイントとなる DynamoDBContext クラスを使用できます。
このクラスでは、DynamoDB に接続してテーブルにアクセスし、各種の CRUD オペレーションやク
エリを実行することができます。
オブジェクト永続性モデルには、クライアント側クラスをテーブルにマッピングし、プロパティ/
フィールドを属性にマッピングする、属性のセットが用意されています。
Note
オブジェクト永続性モデルには、テーブルを作成、更新、または削除するための API はあ
りません。データオペレーションだけが可能になっています。テーブルを作成、更新、削除
するには、AWS SDK for .NET 低レベル API を使用する必要があります。詳細については、
「テーブルの操作 : .NET (p. 191)」を参照してください。
オブジェクト永続性モデルの機能を示すために、例を見てみましょう。まず ProductCatalog テーブル
から示します。ここでは Id がプライマリキーになっています。
ProductCatalog(Id, ...)
Title、ISBN、および Authors プロパティを持つ Book クラスがあるとします。次の C# コードスニ
ペットに示すように、オブジェクト永続性モデルで定義された属性を追加することで、Book クラスを
ProductCatalog テーブルにマッピングできます。
[DynamoDBTable("ProductCatalog")]
public class Book
{
[DynamoDBHashKey]
public int Id { get; set; }
public string Title { get; set; }
public int ISBN { get; set; }
[DynamoDBProperty("Authors")]
public List<string> BookAuthors { get; set; }
[DynamoDBIgnore]
public string CoverPage { get; set; }
API Version 2012-08-10
139
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
}
前述の例では、DynamoDBTable 属性によって、Book クラスが ProductCatalog テーブルにマッピン
グされています。
オブジェクト永続性モデルでは、クラスプロパティとテーブル属性との間で、明示的なマッピングと
デフォルトのマッピングの両方がサポートされています。
• 明示的なマッピング – プライマリキーにプロパティをマッピングするには、オブジェクト永続性モ
デル属性の DynamoDBHashKey および DynamoDBRangeKey を使用する必要があります。さらに、
非プライマリキー属性については、クラス内のプロパティ名と、マッピング先の対応するテーブル
属性が同じでない場合は、DynamoDBProperty 属性を明示的に追加してマッピングを定義する必
要があります。
前述の例では、Id プロパティが同じ名前のプライマリキーにマッピングされ、BookAuthors プロ
パティが ProductCatalog テーブル内の Authors 属性にマッピングされています。
• デフォルトのマッピング – デフォルトでは、オブジェクト永続性モデルによって、クラスプロパ
ティがテーブル内の同じ名前の属性にマッピングされます。
前述の例では、Title および ISBN プロパティが、ProductCatalog テーブル内の同じ名前の属性に
マッピングされています。
すべてのクラスプロパティをマッピングする必要はありません。これらのプロパティを特定す
るには、DynamoDBIgnore 属性を追加します。Book インスタンスをテーブルに保存する場
合、DynamoDBContext には CoverPage プロパティは含まれません。このプロパティは、書籍イン
スタンスを取り出す場合にも返されません。
int や string など、.NET プリミティブ型のプロパティをマッピングできます。また、任意データをい
ずれかの DynamoDB 型にマッピングする適切なコンバーターがある限り、任意のデータ型をマッピ
ングすることもできます。任意の型のマッピングについては、「AWS SDK for .NET オブジェクト永
続性モデルを使用した、DynamoDB での任意データのマッピング (p. 150)」を参照してください。
オブジェクト永続性モデルでは、オプティミスティックロックがサポートされています。それによっ
て、更新オペレーションで、更新する項目の最新のコピーを確実に使用することができます。詳細に
ついては、「DynamoDB で AWS SDK for .NET オブジェクト永続性モデルを使用した、バージョン番
号によるオプティミスティックロック (p. 148)」を参照してください。
DynamoDB の属性
このセクションでは、クラスとプロパティを DynamoDB のテーブルや属性にマッピングできるよう
に、オブジェクト永続性モデルで使用できる属性を示します。
Note
次の属性では、DynamoDBTable と DynamoDBHashKey だけが必須です。
DynamoDBGlobalSecondaryIndexHashKey
グローバルセカンダリインデックスのパーティションキーにクラスプロパティをマッピングします。
この属性は、グローバルセカンダリインデックス の Query を実行する必要がある場合に使用しま
す。
DynamoDBGlobalSecondaryIndexRangeKey
グローバルセカンダリインデックスのソートキーにクラスプロパティをマッピングします。この属性
は、グローバルセカンダリインデックスの Query を実行し、インデックスソートキーを使用して結果
を絞り込む必要がある場合に使用します。
API Version 2012-08-10
140
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
DynamoDBHashKey
テーブルのプライマリキーのパーティションキーにクラスプロパティをマッピングします。プライマ
リキーの属性をコレクション型にすることはできません。
次の C# コード例では、Book クラスを ProductCatalog テーブルに、Id プロパティをテーブルのプラ
イマリキーのパーティションキーにマッピングしています。
[DynamoDBTable("ProductCatalog")]
public class Book {
[DynamoDBHashKey]
public int Id { get; set; }
// Additional properties go here.
}
DynamoDBIgnore
関連するプロパティを無視するように指示します。クラスプロパティを保存しない場合は、この属
性を追加することで、テーブルにオブジェクトを保存するときにこのプロパティを含めないように
DynamoDBContext に指示できます。
DynamoDBLocalSecondaryIndexRangeKey
local secondary indexのソートキーにクラスプロパティをマッピングします。この属性は、local
secondary indexの Query を実行し、インデックスソートキーを使用して結果を絞り込む必要がある
場合に使用します。
DynamoDBProperty
テーブルの属性にクラスプロパティをマッピングします。クラスプロパティを同じ名前のテーブル属
性にマッピングする場合は、この属性を指定する必要はありません。ただし名前が異なる場合は、こ
のタグを使用してマッピングを指定できます。次の C# ステートメントでは、DynamoDBProperty に
よって、BookAuthors プロパティがテーブル内の Authors 属性にマッピングされています。
[DynamoDBProperty("Authors")]
public List<string> BookAuthors { get; set; }
DynamoDBContext はこのマッピング情報を使用して、対応するテーブルにオブジェクトデータを保
存するときに Authors 属性を作成します。
DynamoDBRenamable
クラスプロパティの代替名を指定します。これは、クラスプロパティの名前がテーブル属性と異なる
DynamoDB テーブルに任意のデータをマッピングするためのカスタムコンバーターを記述する場合に
役立ちます。
DynamoDBRangeKey
テーブルのプライマリキーのソートキーにクラスプロパティをマッピングします。テーブルに
複合プライマリキー (パーティションキーおよびソートキー) がある場合は、クラスマッピング
で、DynamoDBHashKey と DynamoDBRangeKey の両方の属性を指定する必要があります。
たとえば、サンプルテーブルの Reply には、Id パーティションキーと Replenishment ソートキーで構
成されたプライマリキーがあります。次の C# コード例では、Reply クラスを Reply テーブルにマッ
ピングしています。クラス定義では、プロパティのうち 2 つがプライマリキーにマッピングされるこ
とも示しています。
API Version 2012-08-10
141
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
サンプルテーブルの詳細については、「テーブルの作成とサンプルデータのロード (p. 166)」を参照
してください。
[DynamoDBTable("Reply")]
public class Reply {
[DynamoDBHashKey]
public int ThreadId { get; set; }
[DynamoDBRangeKey]
public string Replenishment { get; set; }
// Additional properties go here.
}
DynamoDBTable
DynamoDB でクラスがマッピングされるターゲットテーブルを識別します。たとえば次の C# コード
例では、Developer クラスを DynamoDB の People テーブルにマッピングしています。
[DynamoDBTable("People")]
public class Developer { ...}
この属性は、継承またはオーバーライドすることができます。
• DynamoDBTable 属性は継承できます。前述の例では、Developer クラスから継承された新し
いクラス Lead を追加すると、People テーブルにもマッピングされます。People テーブルに
Developer と Lead の両方のオブジェクトが格納されます。
• DynamoDBTable 属性もオーバーライドできます。次の C# コード例では、Manager クラスは
Developer クラスから継承していますが、DynamoDBTable 属性が明示的に追加されているため、
クラスが別のテーブル(Managers)にマッピングされています。
[DynamoDBTable("Managers")]
public class Manager extends Developer { ...}
オプションのパラメータ LowerCamelCaseProperties を追加すると、次の C# コードスニペッ
トに示すように、オブジェクトを格納する場合にプロパティ名の先頭文字を小文字にするよう
に、DynamoDB にリクエストできます。
[DynamoDBTable("People", LowerCamelCaseProperties=true)]
public class Developer {
string DeveloperName;
...}
Developer クラスのインスタンスを保存する場合、DynamoDBContext では DeveloperName プロ
パティが developerName として保存されます。
DynamoDBVersion
項目のバージョン番号を格納するクラスプロパティを識別します。バージョニングの詳細について
は、「DynamoDB で AWS SDK for .NET オブジェクト永続性モデルを使用した、バージョン番号によ
るオプティミスティックロック (p. 148)」を参照してください。
DynamoDBContext クラス
DynamoDBContext クラスは、DynamoDB データベースのエントリポイントです。このクラスから
DynamoDB に接続して、各種のテーブル内のデータにアクセスし、さまざまな CRUD オペレーショ
API Version 2012-08-10
142
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
ンとクエリを実行することができます。DynamoDBContext クラスでは次のメソッドを使用できま
す。
CreateMultiTableBatchGet
複数の個々の BatchGet オブジェクトで構成される MultiTableBatchGet オブジェクトを作成しま
す。各 BatchGet オブジェクトは、1 つの DynamoDB テーブルから項目を取り出すときに使用でき
ます。
1 つ以上のテーブルから項目を取り出すには、ExecuteBatchGet メソッドを使用
し、MultiTableBatchGet オブジェクトをパラメータとして渡します。
CreateMultiTableBatchWrite
複数の個々の BatchWrite オブジェクトで構成される MultiTableBatchWrite オブジェクトを作
成します。これらの BatchWrite オブジェクトはそれぞれ、1 つの DynamoDB テーブルの項目を書
き込んだり削除したりするために使用できます。
1 つ以上のテーブルに書き込むには、ExecuteBatchWrite メソッドを使用
し、MultiTableBatchWrite オブジェクトをパラメータとして渡します。
CreateBatchGet
テーブルから複数の項目を取り出すために使用できる BatchGet オブジェクトを作成します。詳細に
ついては、「バッチ取得: 複数の項目の取得 (p. 155)」を参照してください。
CreateBatchWrite
テーブルに複数の項目を入力する、またはテーブルから複数の項目を削除するために使用できる
BatchWrite オブジェクトを作成します。詳細については、「バッチ書き込み: 複数の項目の書き込
みおよび削除 (p. 153)」を参照してください。
Delete
テーブルから項目を削除します。このメソッドでは、削除する項目のプライマリキーが必要になりま
す。プライマリキーの値、またはこのメソッドのパラメータとしてプライマリキーの値を使用するク
ライアント側オブジェクトを入力できます。
• クライアント側オブジェクトをパラメータとして指定し、オプティミスティックロックを有効にす
ると、クライアント側とサーバー側のオブジェクトのバージョンが一致する場合のみ、削除が成功
します。
• プライマリキーの値だけをパラメータとして指定すると、オプティミスティックロックを有効にし
ているかどうかにかかわらず、削除が成功します。
Note
このオペレーションをバックグラウンドで実行するには、DeleteAsync メソッドを使用しま
す。
Dispose
すべてのマネージドリソースとアンマネージドリソースの Dispose を実行します。
ExecuteBatchGet
1 つ以上のテーブルからデータを読み込みます。MultiTableBatchGet 内のすべての BatchGet オ
ブジェクトを処理します。
API Version 2012-08-10
143
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
Note
このオペレーションをバックグラウンドで実行するには、ExecuteBatchGetAsync メソッ
ドを使用します。
ExecuteBatchWrite
1 つ以上のテーブルにデータを書き込むまたは削除します。MultiTableBatchWrite 内のすべての
BatchWrite オブジェクトを処理します。
Note
このオペレーションをバックグラウンドで実行するには、ExecuteBatchWriteAsync メ
ソッドを使用します。
FromDocument
Document のインスタンスと仮定すると、FromDocument メソッドは、クライアント側のクラスのイ
ンスタンスを返します。
これは、オブジェクト永続性モデルと合わせてドキュメントモデルクラスを使用してデータオペレー
ションを行う場合に役立ちます。AWS SDK for .NET で使用されるドキュメントモデルクラスの詳細
については、「.NET ドキュメントモデル (p. 116)」を参照してください。
doc という名前の Document オブジェクトがあり、Forum 項目の表現を含んでいるとします。(この
オブジェクトの構成方法については、下の ToDocument メソッドの説明を参照してください)。次の
C# コードスニペットに示すように、FromDocument を使用して Document から Forum 項目を取り出
すことができます。
forum101 = context.FromDocument<Forum>(101);
Note
Document オブジェクトで IEnumerable インターフェイスを実装している場
合、FromDocuments メソッドを使用できます。これにより、Document のすべてのクラスイ
ンスタンスを反復的に処理できます。
FromQuery
QueryOperationConfig オブジェクトに定義されたクエリパラメータを使用して、Query オペレー
ションを実行します。
Note
このオペレーションをバックグラウンドで実行するには、FromQueryAsync メソッドを使用
します。
FromScan
ScanOperationConfig オブジェクトに定義されたスキャンパラメータを使用して、Scan オペレー
ションを実行します。
Note
このオペレーションをバックグラウンドで実行するには、FromScanAsync メソッドを使用し
ます。
API Version 2012-08-10
144
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
GetTargetTable
指定した型のターゲットテーブルを取り出します。これは、任意のデータを DynamoDB テーブルに
マッピングするためのカスタムコンバーターを記述していて、カスタムデータ型に関連付けられてい
るテーブルを特定する必要がある場合に役立ちます。
Load
テーブルから項目を取り出します。このメソッドでは、取り出す項目のプライマリキーだけが必要に
なります。
デフォルトでは、DynamoDB では結果整合性のある値を持つ項目が返されます。結果整合性モデルの
詳細については、「読み込み整合性 (p. 16)」を参照してください。
Note
このオペレーションをバックグラウンドで実行するには、LoadAsync メソッドを使用しま
す。
Query
指定したクエリパラメータに基づいてテーブルのクエリが実行されます。
複合プライマリキー (パーティションキーおよびソートキー) が存在する場合にのみ、テーブルにクエ
リを実行できます。クエリを実行する場合は、パーティションキーと、ソートキーに適用される条件
を指定する必要があります。
クライアント側の Reply クラスが DynamoDB の Reply テーブルにマッピングされているとしま
す。次の C# コードスニペットでは、Reply テーブルのクエリを実行し、過去 15 日間に投稿され
たフォーラムスレッドの返信を検索しています。Reply テーブルには、Id パーティションキーと
ReplyDateTime ソートキーを持つプライマリキーがあります。Reply テーブルの詳細については、
「テーブルの作成とサンプルデータのロード (p. 166)」を参照してください。
DynamoDBContext context = new DynamoDBContext(client);
string replyId = "DynamoDB#DynamoDB Thread 1"; //Partition key
DateTime twoWeeksAgoDate = DateTime.UtcNow.Subtract(new TimeSpan(14, 0, 0,
0)); // Date to compare.
IEnumerable<Reply> latestReplies = context.Query<Reply>(replyId,
QueryOperator.GreaterThan, twoWeeksAgoDate);
これにより、Reply オブジェクトのコレクションが返されます。
Query メソッドでは、「遅延ロード」された IEnumerable コレクションが返されます。最初に結果が
1 ページのみ返され、必要に応じて、さらに次ページを要求するサービス呼び出しが行われます。一
致するすべての項目は、IEnumerable を反復的に処理するだけで取得できます。
テーブルにシンプルなプライマリキー (パーティションキー) がある場合は、Query メソッドを使用す
ることはできません。代わりに Load メソッドを使用して、パーティションキーを入力して項目を取
り出すことができます。
Note
このオペレーションをバックグラウンドで実行するには、QueryAsync メソッドを使用しま
す。
API Version 2012-08-10
145
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
Save
指定したオブジェクトがテーブルに保存されます。入力オブジェクトで指定されたプライマリキーが
テーブル内に存在しない場合は、このメソッドによって新しい項目がテーブルに追加されます。プラ
イマリキーが存在する場合は、このメソッドによって既存の項目が更新されます。
オプティミスティックロックを設定している場合には、クライアント側とサーバー側で項目のバー
ジョンが一致する場合のみ、更新が正常に実行されます。詳細については、「DynamoDB で AWS
SDK for .NET オブジェクト永続性モデルを使用した、バージョン番号によるオプティミスティック
ロック (p. 148)」を参照してください。
Note
このオペレーションをバックグラウンドで実行するには、SaveAsync メソッドを使用しま
す。
Scan
テーブル全体のスキャンを実行します。
スキャン条件を指定することで、スキャン結果にフィルタを適用することができます。この条件は、
テーブル内の任意の属性に適用することができます。クライアント側のクラス Book が、DynamoDB
の ProductCatalog テーブルにマッピングされているとします。次の C# コードスニペットでは、テー
ブルがスキャンされ、価格が 0 未満の書籍項目だけが返されています。
IEnumerable<Book> itemsWithWrongPrice = context.Scan<Book>(
new ScanCondition("Price", ScanOperator.LessThan, price),
new ScanCondition("ProductCategory", ScanOperator.Equal,
"Book")
);
Scan メソッドでは、「遅延ロード」された IEnumerable コレクションが返されます。最初に結果が
1 ページのみ返され、必要に応じて、さらに次ページを要求するサービス呼び出しが行われます。一
致するすべての項目は、IEnumerable を反復的に処理するだけで取得できます。
パフォーマンス上の理由から、テーブルについてはスキャンを避け、クエリを行うようにしてくださ
い。
Note
このオペレーションをバックグラウンドで実行するには、ScanAsync メソッドを使用しま
す。
ToDocument
クラスインスタンスから、Document ドキュメントモデルクラスのインスタンスが返されます。
これは、オブジェクト永続性モデルと合わせてドキュメントモデルクラスを使用してデータオペレー
ションを行う場合に役立ちます。AWS SDK for .NET で使用されるドキュメントモデルクラスの詳細
については、「.NET ドキュメントモデル (p. 116)」を参照してください。
クライアント側のクラスが Forum サンプルテーブルにマッピングされているとします。その場合は次
の C# コードスニペットに示すように、DynamoDBContext を使用して、Forum テーブルから項目を
Document オブジェクトとして取得することができます。
DynamoDBContext context = new DynamoDBContext(client);
API Version 2012-08-10
146
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
Forum forum101 = context.Load<Forum>(101); // Retrieve a forum by primary
key.
Document doc = context.ToDocument<Forum>(forum101);
DynamoDBContext でのオプションパラメータの指定
オブジェクト永続性モデルを使用する場合は、DynamoDBContext に次のオプションパラメータを指
定できます。
• ConsistentRead – Load、Query、または Scan オペレーションを使用してデータを取り出す場合
は、このパラメータをオプションで追加して、データの最新の値をリクエストすることができま
す。
• IgnoreNullValues – このパラメータにより、Save オペレーション時に属性の null 値を無視するよう
に DynamoDBContext に指示できます。このパラメータが false の場合(または設定されていない
場合)、null 値は、特定の属性を削除するディレクティブと見なされます。
• SkipVersionCheck – このパラメータにより、項目を保存または削除する場合にバージョンの比
較を行わないように DynamoDBContext に指示できます。バージョニングの詳細については、
「DynamoDB で AWS SDK for .NET オブジェクト永続性モデルを使用した、バージョン番号による
オプティミスティックロック (p. 148)」を参照してください。
• TableNamePrefix – すべてのテーブル名に特定の文字列をプレフィックスとして付けます。このパ
ラメータが null の場合(または設定されていない場合)、プレフィックスは使用されません。
次の C# コードスニペットでは、前述のオプションパラメータのうち、2 つを指定して、新しい
DynamoDBContext を作成しています。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
...
DynamoDBContext context =
new DynamoDBContext(client, new DynamoDBContextConfig { ConsistentRead
= true, SkipVersionCheck = true});
DynamoDBContext では、このコンテキストを使用して送信した各リクエストに、これらのオプショ
ンパラメータが含められます。
これらのパラメータを DynamoDBContext レベルで設定する代わりに、次の C# コードスニペットに
示すように、DynamoDBContext を使用して実行する個々のオペレーションに対して指定することも
できます。この例では特定の書籍項目がロードされています。DynamoDBContext の Load メソッド
では、前述のオプションパラメータを指定します。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
...
DynamoDBContext context = new DynamoDBContext(client);
Book bookItem = context.Load<Book>(productId,new
DynamoDBContextConfig{ ConsistentRead = true, SkipVersionCheck = true });
この場合 DynamoDBContext には、Get リクエストを送信する場合のみ、これらのパラメータが含ま
れます。
サポートされているデータの種類
オブジェクト永続性モデルでは、プリミティブな .NET データ型、コレクション、および任意のデー
タ型のセットがサポートされています。このモデルでは、次のプリミティブデータ型がサポートされ
ています。
• bool
API Version 2012-08-10
147
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
• byte
• char
• DateTime
• decimal
• double
• float
• Int16
• Int32
• Int64
• SByte
• string
• UInt16
• UInt32
• UInt64
オブジェクト永続性モデルでは、次の制限の下で .NET コレクション型もサポートされています。
• コレクション型は ICollection インターフェイスを実装する必要があります。
• コレクション型は、サポートされているプリミティブ型で構成されている必要があります。たとえ
ば、ICollection<string> や ICollection<bool> などです。
• コレクション型では、パラメータがないコンストラクタを使用できなければなりません。
次の表に、前述の .NET 型が DynamoDB の型にどのようにマッピングされるかを示します。
.NET プリミティブ型
DynamoDB の型
すべての数値型
N(数値型)
すべての文字列型
S (文字列型)
MemoryStream、byte[]
B(バイナリ型)
ブール
N(数値型)、0 は偽を表し 1 は真を表す。
コレクション型
BS(バイナリセット)型、SS(文字列セット)
型、NS(数値セット)型
DateTime
S(文字列型)。DateTime の値は、ISO-8601 形
式の文字列として格納されます。
オブジェクト永続性モデルでは、任意のデータ型もサポートされています。ただし、複合型を
DynamoDB 型にマッピングするためのコンバーターコードを入力する必要があります。
DynamoDB で AWS SDK for .NET オブジェクト永続性モデル
を使用した、バージョン番号によるオプティミスティックロッ
ク
オブジェクト永続性モデルではオプティミスティックロックがサポートされており、項目を更新また
は削除する前に、アプリケーションの項目バージョンとサーバー側の項目バージョンが同じになりま
す。更新する項目を取り出すとします。しかし、更新を返送する前に、他のアプリケーションが同じ
項目を更新しました。この場合、アプリケーションに項目の古いコピーが残ることになります。オプ
API Version 2012-08-10
148
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
ティミスティックロックがない場合に更新を行うと、他のアプリケーションで行われた更新が上書き
されます。
オブジェクト永続性モデルのオプティミスティックロック機能では、オプティミスティックロックを
有効にするために DynamoDBVersion タグを使用できます。この機能を使用するには、バージョン番
号を格納するためのプロパティをクラスに追加します。DynamoDBVersion 属性をプロパティに追加
します。最初にオブジェクトを保存すると、DynamoDBContext によってバージョン番号が割り当て
られ、項目を更新するたびにその値が増えていきます。
更新または削除リクエストは、クライアント側のオブジェクトのバージョンが、サーバー側の対応す
る項目のバージョン番号に一致する場合のみ成功します。アプリケーションに古いコピーがある場
合に項目を更新または削除するには、その前にサーバーから最新バージョンを取得する必要がありま
す。
次の C# コードスニペットでは、オブジェクト永続性属性と合わせて Book クラスを定義
し、ProductCatalog テーブルにマッピングしています。DynamoDBVersion 属性が指定されたクラス
の VersionNumber プロパティには、バージョン番号が格納されます。
[DynamoDBTable("ProductCatalog")]
public class Book
{
[DynamoDBHashKey]
//Partition key
public int Id { get; set; }
[DynamoDBProperty]
public string Title { get; set; }
[DynamoDBProperty]
public string ISBN { get; set; }
[DynamoDBProperty("Authors")]
public List<string> BookAuthors { get; set; }
[DynamoDBVersion]
public int? VersionNumber { get; set; }
}
Note
DynamoDBVersion 属性は、null が許容された数値プリミティブ型(int? など)に対しての
み適用できます。
オプティミスティックロックは、DynamoDBContext オペレーションに対して次のような影響があり
ます。
• 保存—DynamoDBContext は、新しい項目に対して初期バージョン番号 0 を割り当てます。
既存の項目を取り出し、その項目の 1 つ以上のプロパティを更新して変更を保存する場合
には、クライアント側とサーバー側のバージョン番号が一致する場合のみ、保存が成功しま
す。DynamoDBContext によってバージョン番号が増加します。バージョン番号を設定する必要は
ありません。
• 削除—次の C# コードスニペットに示すように、Delete メソッドでは、プライマリキーの値または
オブジェクトのいずれかをパラメータとして指定できるオーバーロードを使用できます。
DynamoDBContext context = new DynamoDBContext(client);
...
// Load a book.
Book book = context.Load<ProductCatalog>(111);
// Do other operations.
// Delete 1 - Pass in the book object.
context.Delete<ProductCatalog>(book);
API Version 2012-08-10
149
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
// Delete 2 - pass in the Id (primary key)
context.Delete<ProductCatalog>(222);
パラメータとしてオブジェクトを指定した場合には、オブジェクトのバージョンがサーバー側の対
応する項目のバージョンと一致する場合のみ、削除が可能になります。ただしパラメータとしてプ
ライマリキーの値を入力した場合には、DynamoDBContext はバージョン番号を認識せず、バー
ジョンチェックを行わずに項目を削除します。
オブジェクト永続性モデルのコードでは、オプティミスティックロックの内部実装で、DynamoDB
の条件付き更新と条件付き削除 API アクションが使用されます。
オプティミスティックロックの無効化
オプティミスティックロックを無効にするには、SkipVersionCheck 設定プロパティを使用しま
す。このプロパティは、DynamoDBContext の作成時に設定できます。この場合、このコンテキスト
を使用して作成したすべてのリクエストについて、オプティミスティックロックが無効になります。
詳細については、「DynamoDBContext でのオプションパラメータの指定 (p. 147)」を参照してく
ださい。
コンテキストレベルでプロパティを設定する代わりに、次の C# コードスニペットに示すように、
特定のオペレーションに対するオプティミスティックロックを無効にすることができます。コード
例では、このコンテキストを使用して書籍項目を削除しています。Delete メソッドはオプションの
SkipVersionCheck プロパティを true に設定し、バージョンチェックを無効にします。
DynamoDBContext context = new DynamoDBContext(client);
// Load a book.
Book book = context.Load<ProductCatalog>(111);
...
// Delete the book.
context.Delete<Book>(book, new DynamoDBContextConfig { SkipVersionCheck =
true });
AWS SDK for .NET オブジェクト永続性モデルを使用し
た、DynamoDB での任意データのマッピング
サポートされている .NET 型(「サポートされているデータの種類 (p. 147)」を参照)に加え
て、DynamoDB 型に直接マッピングされない型を、アプリケーションで使用できます。オブジェクト
永続性モデルでは、任意の型から DynamoDB 型に、またはその反対にデータを変換できるコンバー
ターがある限り、任意の型のデータを格納できます。コンバーターコードによって、オブジェクトの
保存およびロード中にデータが変換されます。
クライアント側ではどのような型でも作成できますが、テーブルに格納されているデータは
DynamoDB 型の一種であり、クエリおよびスキャンでは、データの比較は DynamoDB に格納されて
いるデータに対して行われます。
次の C# コード例では、Id、Title、ISBN、および Dimension プロパティを使用して Book クラス
を定義しています。Dimension プロパティは、Height、Width、および Thickness プロパティを
記述する DimensionType に含まれています。このコード例では、コンバーターメソッド ToEntry
および FromEntry によって、DimensionType と DynamoDB 文字列型との間でデータが変換されて
います。たとえば Book インスタンスを保存する場合には、コンバーターによって "8.5x11x.05" など
の書籍の寸法文字列が作成され、書籍を取り出す場合には、文字列が DimensionType インスタンス
に変換されます。
この例では、Book 型を ProductCatalog テーブルにマッピングしています。説明のために、サンプ
ルの Book インスタンスを保存し、取り出し、寸法を更新し、更新された Book を再度保存していま
す。
API Version 2012-08-10
150
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
次のサンプルをテストするための詳しい手順については、『.NET コードサンプル (p. 173)』を参照
してください。
using
using
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DataModel;
Amazon.DynamoDBv2.DocumentModel;
Amazon.Runtime;
Amazon.SecurityToken;
namespace com.amazonaws.codesamples
{
class HighLevelMappingArbitraryData
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
DynamoDBContext context = new DynamoDBContext(client);
// 1. Create a book.
DimensionType myBookDimensions = new DimensionType()
{
Length = 8M,
Height = 11M,
Thickness = 0.5M
};
Book myBook = new Book
{
Id = 501,
Title = "AWS SDK for .NET Object Persistence Model
Handling Arbitrary Data",
ISBN = "999-9999999999",
BookAuthors = new List<string> { "Author 1", "Author
2" },
Dimensions = myBookDimensions
};
context.Save(myBook);
// 2. Retrieve the book.
Book bookRetrieved = context.Load<Book>(501);
// 3. Update property (book dimensions).
bookRetrieved.Dimensions.Height += 1;
bookRetrieved.Dimensions.Length += 1;
bookRetrieved.Dimensions.Thickness += 0.2M;
// Update the book.
context.Save(bookRetrieved);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
API Version 2012-08-10
151
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
}
[DynamoDBTable("ProductCatalog")]
public class Book
{
[DynamoDBHashKey]
//Partition key
public int Id { get; set; }
[DynamoDBProperty]
public string Title { get; set; }
[DynamoDBProperty]
public string ISBN { get; set; }
// Multi-valued (set type) attribute.
[DynamoDBProperty("Authors")]
public List<string> BookAuthors { get; set; }
// Arbitrary type, with a converter to map it to DynamoDB type.
[DynamoDBProperty(typeof(DimensionTypeConverter))]
public DimensionType Dimensions { get; set; }
}
public class DimensionType
{
public decimal Length { get; set; }
public decimal Height { get; set; }
public decimal Thickness { get; set; }
}
// Converts the complex type DimensionType to string and vice-versa.
public class DimensionTypeConverter : IPropertyConverter
{
public DynamoDBEntry ToEntry(object value)
{
DimensionType bookDimensions = value as DimensionType;
if (bookDimensions == null) throw new
ArgumentOutOfRangeException();
string data = string.Format("{1}{0}{2}{0}{3}", " x ",
bookDimensions.Length, bookDimensions.Height,
bookDimensions.Thickness);
DynamoDBEntry entry = new Primitive { Value = data };
return entry;
}
public object FromEntry(DynamoDBEntry entry)
{
Primitive primitive = entry as Primitive;
if (primitive == null || !(primitive.Value is String) ||
string.IsNullOrEmpty((string)primitive.Value))
throw new ArgumentOutOfRangeException();
string[] data = ((string)(primitive.Value)).Split(new string[]
{ " x " }, StringSplitOptions.None);
if (data.Length != 3) throw new ArgumentOutOfRangeException();
API Version 2012-08-10
152
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
DimensionType complexData = new DimensionType
{
Length = Convert.ToDecimal(data[0]),
Height = Convert.ToDecimal(data[1]),
Thickness = Convert.ToDecimal(data[2])
};
return complexData;
}
}
}
AWS SDK for .NET オブジェクト永続性モデルを使用したバッ
チオペレーション
バッチ書き込み: 複数の項目の書き込みおよび削除
単一のリクエストでテーブルに対して複数のオブジェクトを入力または削除するには、次の手順を実
行します。
• DynamoDBContext の CreateBatchWrite メソッドを実行して、BatchWrite クラスのインスタ
ンスを作成します。
• 入力または削除する項目を指定します。
• 1 つ以上の項目を入力するには、AddPutItem または AddPutItems メソッドを使用します。
• 1 つ以上の項目を削除するには、項目のプライマリキーを指定するか、削除する項目にマッ
ピングするクライアント側オブジェクトを指定します。削除する項目のリストを指定するに
は、AddDeleteItem、AddDeleteItems、および AddDeleteKey メソッドを使用します。
• 指定したすべての項目をテーブルに入力またはテーブルから削除するには、BatchWrite.Execute
メソッドを呼び出します。
Note
オブジェクト永続性モデルを使用する場合には、バッチ内で任意の数のオペレーションを指
定できます。ただし DynamoDB では、1 つのバッチ内のオペレーションの数と、1 つのバッ
チオペレーションでのバッチの合計サイズが制限されています。制限の具体的な詳細につい
ては、BatchWriteItem を参照してください。許容されている書き込みリクエスト数、または
許容されている HTTP ペイロードの最大サイズをバッチ書き込みリクエストが超えたことを
API が検出すると、バッチが複数の小さなバッチに分割されます。さらに、バッチ書き込みに
対する応答で、未処理の項目が返された場合には、API がそれら未処理の項目を使用して、別
のバッチリクエストを自動的に送信します。
DynamoDB の ProductCatalog テーブルにマッピングされる、C# クラスの Book クラスを定
義しているとします。次の C# コードスニペットでは、BatchWrite オブジェクトを使用し
て、ProductCatalog テーブルに 2 つの項目をアップロードし、1 つの項目を削除しています。
DynamoDBContext context = new DynamoDBContext(client);
var bookBatch = context.CreateBatchWrite<Book>();
// 1. Specify two books to add.
Book book1 = new Book
{
Id = 902,
ISBN = "902-11-11-1111",
ProductCategory = "Book",
Title = "My book3 in batch write"
};
API Version 2012-08-10
153
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
Book book2 = new Book
{
Id = 903,
ISBN = "903-11-11-1111",
ProductCategory = "Book",
Title = "My book4 in batch write"
};
bookBatch.AddPutItems(new List<Book> { book1, book2 });
// 2. Specify one book to delete.
bookBatch.AddDeleteKey(111);
bookBatch.Execute();
複数のテーブルを対象にオブジェクトを入力または削除するには、次の手順を実行します。
• それぞれの型について BatchWrite クラスの 1 つのインスタンスを作成し、前述のセクションで説
明したように、入力または削除する項目を指定します。
• 次のいずれかの方法を使用して、MultiTableBatchWrite のインスタンスを作成します。
• 前述のステップで作成したいずれかの BatchWrite オブジェクトで、Combine メソッドを実行
します。
• BatchWrite オブジェクトのリストを入力して、MultiTableBatchWrite 型のインスタンスを
作成します。
• DynamoDBContext の CreateMultiTableBatchWrite メソッドを実行して、BatchWrite オ
ブジェクトのリストを渡します。
• 指定された入力および削除オペレーションを各種のテーブルで実行す
る、MultiTableBatchWrite の Execute メソッドを呼び出します。
DynamoDB で Forum および Thread テーブルにマッピングされる、Forum および Thread C# クラス
を定義しているとします。さらに、Thread クラスでバージョニングが有効になっているとします。
バッチオペレーションではバージョニングがサポートされていないため、次の C# コードスニペッ
トに示すように、バージョニングを明示的に無効にする必要があります。このコードスニペットで
は、MultiTableBatchWrite オブジェクトを使用して複数のテーブルを更新しています。
DynamoDBContext context = new DynamoDBContext(client);
// Create BatchWrite objects for each of the Forum and Thread classes.
var forumBatch = context.CreateBatchWrite<Forum>();
DynamoDBOperationConfig config = new DynamoDBOperationConfig();
config.SkipVersionCheck = true;
var threadBatch = context.CreateBatchWrite<Thread>(config);
// 1. New Forum item.
Forum newForum = new Forum
{
Name = "Test BatchWrite Forum",
Threads = 0
};
forumBatch.AddPutItem(newForum);
// 2. Specify a forum to delete by specifying its primary key.
forumBatch.AddDeleteKey("Some forum");
// 3. New Thread item.
API Version 2012-08-10
154
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
Thread newThread = new Thread
{
ForumName = "Amazon S3 forum",
Subject = "My sample question",
KeywordTags = new List<string> { "Amazon S3", "Bucket" },
Message = "Message text"
};
threadBatch.AddPutItem(newThread);
// Now execute multi-table batch write.
var superBatch = new MultiTableBatchWrite(forumBatch, threadBatch);
superBatch.Execute();
実例については、「例: AWS SDK for .NET オブジェクト永続性モデルを使用したバッチ書き込みオペ
レーション (p. 158)」を参照してください。
Note
DynamoDB バッチ API では、バッチ内の書き込み数と、バッチのサイズが制限されていま
す。詳細については、BatchWriteItem を参照してください。.NET オブジェクト永続性モデル
API を使用する場合は、任意の数のオペレーションを指定できます。ただし、バッチ内のオ
ペレーションの数またはサイズが制限を超えた場合には、.NET API がバッチ書き込みリクエ
ストを小さいバッチに分割して、複数のバッチ書き込みリクエストを DynamoDB に送信しま
す。
バッチ取得: 複数の項目の取得
単一のリクエストでテーブルから複数の項目を取り出すには、次の手順を実行します。
• CreateBatchGet クラスのインスタンスを作成します。
• 取り出すプライマリキーのリストを指定します。
• Execute メソッドを呼び出します。応答では、項目が Results プロパティによって返されます。
次の C# コードのサンプルでは、ProductCatalog テーブルから 3 つの項目を取り出しています。結果
内の項目の順序は、必ずしもプライマリキーを指定した順序と同じではありません。
DynamoDBContext context = new DynamoDBContext(client);
var bookBatch = context.CreateBatchGet<ProductCatalog>();
bookBatch.AddKey(101);
bookBatch.AddKey(102);
bookBatch.AddKey(103);
bookBatch.Execute();
// Process result.
Console.WriteLine(devBatch.Results.Count);
Book book1 = bookBatch.Results[0];
Book book2 = bookBatch.Results[1];
Book book3 = bookBatch.Results[2];
複数のテーブルからオブジェクトを取り出すには、次の手順を実行します。
• それぞれの型について CreateBatchGet 型のインスタンスを作成し、各テーブルから取り出すプ
ライマリキーの値を指定します。
• 次のいずれかの方法を使用して、MultiTableBatchGet クラスのインスタンスを作成します。
• 前述のステップで作成したいずれかの BatchGet オブジェクトで、Combine メソッドを実行しま
す。
API Version 2012-08-10
155
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
• BatchGet オブジェクトのリストを入力して、MultiBatchGet 型のインスタンスを作成しま
す。
• DynamoDBContext の CreateMultiTableBatchGet メソッドを実行して、BatchGet オブ
ジェクトのリストを渡します。
• MultiTableBatchGet の Execute メソッドを呼び出すと、個々の BatchGet オブジェクトに結
果が返されます。
次の C# コードスニペットでは、CreateBatchGet メソッドを使用して、Order および OrderDetail
テーブルから複数の項目を取り出しています。
var orderBatch = context.CreateBatchGet<Order>();
orderBatch.AddKey(101);
orderBatch.AddKey(102);
var orderDetailBatch = context.CreateBatchGet<OrderDetail>();
orderDetailBatch.AddKey(101, "P1");
orderDetailBatch.AddKey(101, "P2");
orderDetailBatch.AddKey(102, "P3");
orderDetailBatch.AddKey(102, "P1");
var orderAndDetailSuperBatch = orderBatch.Combine(orderDetailBatch);
orderAndDetailSuperBatch.Execute();
Console.WriteLine(orderBatch.Results.Count);
Console.WriteLine(orderDetailBatch.Results.Count);
Order order1 = orderBatch.Results[0];
Order order2 = orderDetailBatch.Results[1];
OrderDetail orderDetail1 = orderDetailBatch.Results[0];
例: AWS SDK for .NET オブジェクト永続性モデルを使用した
CRUD オペレーション
次の C# コード例では、Id、title、ISBN、および Authors プロパティを指定して、Book クラスを
宣言しています。これらのプロパティは、オブジェクト永続性属性を使用して、DynamoDB の
ProductCatalog テーブルにマッピングされています。さらにこのコード例では、DynamoDBContext
を使用して一般的な CRUD オペレーションを実行しています。この例では、サンプルの Book インス
タンスを作成して ProductCatalog テーブルに保存しています。さらに書籍項目を取り出し、ISBN お
よび Authors プロパティを更新しています。更新によって、既存の作成者リストが置き換えられてい
ることに注意してください。この例では最終的に書籍項目が削除されています。
この例で使用されている ProductCatalog テーブルの詳細については、「テーブルの作成とサンプル
データのロード (p. 166)」を参照してください。次のサンプルをテストするための詳しい手順につい
ては、「.NET コードサンプル (p. 173)」を参照してください。
Note
以下の例は、同期メソッドをサポートしていないため、.NET Core コアには適用されませ
ん。詳細については、「AWS の .NET 用非同期 API」を参照してください。
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DataModel;
Amazon.Runtime;
API Version 2012-08-10
156
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
namespace com.amazonaws.codesamples
{
class HighLevelItemCRUD
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
DynamoDBContext context = new DynamoDBContext(client);
TestCRUDOperations(context);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
private static void TestCRUDOperations(DynamoDBContext context)
{
int bookID = 1001; // Some unique value.
Book myBook = new Book
{
Id = bookID,
Title = "object persistence-AWS SDK for.NET SDK-Book 1001",
ISBN = "111-1111111001",
BookAuthors = new List<string> { "Author 1", "Author 2" },
};
// Save the book.
context.Save(myBook);
// Retrieve the book.
Book bookRetrieved = context.Load<Book>(bookID);
// Update few properties.
bookRetrieved.ISBN = "222-2222221001";
bookRetrieved.BookAuthors = new List<string> { " Author 1",
"Author x" }; // Replace existing authors list with this.
context.Save(bookRetrieved);
// Retrieve the updated book. This time add the optional
ConsistentRead parameter using DynamoDBContextConfig object.
Book updatedBook = context.Load<Book>(bookID, new
DynamoDBContextConfig { ConsistentRead = true });
// Delete the book.
context.Delete<Book>(bookID);
// Try to retrieve deleted book. It should return null.
Book deletedBook = context.Load<Book>(bookID, new
DynamoDBContextConfig { ConsistentRead = true });
if (deletedBook == null)
Console.WriteLine("Book is deleted");
API Version 2012-08-10
157
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
}
}
[DynamoDBTable("ProductCatalog")]
public class Book
{
[DynamoDBHashKey]
//Partition key
public int Id { get; set; }
[DynamoDBProperty]
public string Title { get; set; }
[DynamoDBProperty]
public string ISBN { get; set; }
[DynamoDBProperty("Authors")]
//String Set datatype
public List<string> BookAuthors { get; set; }
}
}
例: AWS SDK for .NET オブジェクト永続性モデルを使用した
バッチ書き込みオペレーション
次の C# コード例では、Book、Forum、Thread、および Reply クラスが宣言され、オブジェクト永続
性モデル属性を使用して、DynamoDB テーブルにマッピングされています。
このコード例ではさらに DynamoDBContext を使用して、次のバッチ書き込みオペレーションを示し
ています。
• ProductCatalog テーブルに対して書籍項目を入力または削除する BatchWrite オブジェクト。
• Forum および Thread テーブルに対して項目を入力または削除する MultiTableBatchWrite オブ
ジェクト。
この例で使用されているテーブルの詳細については、「テーブルの作成とサンプルデータのロー
ド (p. 166)」を参照してください。次のサンプルをテストするための詳しい手順については、
「.NET コードサンプル (p. 173)」を参照してください。
using
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DataModel;
Amazon.Runtime;
Amazon.SecurityToken;
namespace com.amazonaws.codesamples
{
class HighLevelBatchWriteItem
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
DynamoDBContext context = new DynamoDBContext(client);
SingleTableBatchWrite(context);
MultiTableBatchWrite(context);
}
API Version 2012-08-10
158
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void SingleTableBatchWrite(DynamoDBContext context)
{
Book book1 = new Book
{
Id = 902,
InPublication = true,
ISBN = "902-11-11-1111",
PageCount = "100",
Price = 10,
ProductCategory = "Book",
Title = "My book3 in batch write"
};
Book book2 = new Book
{
Id = 903,
InPublication = true,
ISBN = "903-11-11-1111",
PageCount = "200",
Price = 10,
ProductCategory = "Book",
Title = "My book4 in batch write"
};
var bookBatch = context.CreateBatchWrite<Book>();
bookBatch.AddPutItems(new List<Book> { book1, book2 });
Console.WriteLine("Performing batch write in
SingleTableBatchWrite().");
bookBatch.Execute();
}
private static void MultiTableBatchWrite(DynamoDBContext context)
{
// 1. New Forum item.
Forum newForum = new Forum
{
Name = "Test BatchWrite Forum",
Threads = 0
};
var forumBatch = context.CreateBatchWrite<Forum>();
forumBatch.AddPutItem(newForum);
// 2. New Thread item.
Thread newThread = new Thread
{
ForumName = "S3 forum",
Subject = "My sample question",
KeywordTags = new List<string> { "S3", "Bucket" },
Message = "Message text"
};
API Version 2012-08-10
159
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
DynamoDBOperationConfig config = new DynamoDBOperationConfig();
config.SkipVersionCheck = true;
var threadBatch = context.CreateBatchWrite<Thread>(config);
threadBatch.AddPutItem(newThread);
threadBatch.AddDeleteKey("some partition key value", "some sort
key value");
var superBatch = new MultiTableBatchWrite(forumBatch,
threadBatch);
Console.WriteLine("Performing batch write in
MultiTableBatchWrite().");
superBatch.Execute();
}
}
[DynamoDBTable("Reply")]
public class Reply
{
[DynamoDBHashKey]
//Partition key
public string Id { get; set; }
[DynamoDBRangeKey] //Sort key
public DateTime ReplyDateTime { get; set; }
// Properties included implicitly.
public string Message { get; set; }
// Explicit property mapping with object persistence model
attributes.
[DynamoDBProperty("LastPostedBy")]
public string PostedBy { get; set; }
// Property to store version number for optimistic locking.
[DynamoDBVersion]
public int? Version { get; set; }
}
[DynamoDBTable("Thread")]
public class Thread
{
// PK mapping.
[DynamoDBHashKey] //Partition key
public string ForumName { get; set; }
[DynamoDBRangeKey] //Sort key
public String Subject { get; set; }
// Implicit mapping.
public string Message { get; set; }
public string LastPostedBy { get; set; }
public int Views { get; set; }
public int Replies { get; set; }
public bool Answered { get; set; }
public DateTime LastPostedDateTime { get; set; }
// Explicit mapping (property and table attribute names are
different.
[DynamoDBProperty("Tags")]
public List<string> KeywordTags { get; set; }
// Property to store version number for optimistic locking.
[DynamoDBVersion]
public int? Version { get; set; }
}
API Version 2012-08-10
160
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
[DynamoDBTable("Forum")]
public class Forum
{
[DynamoDBHashKey] //Partition key
public string Name { get; set; }
// All the following properties are explicitly mapped,
// only to show how to provide mapping.
[DynamoDBProperty]
public int Threads { get; set; }
[DynamoDBProperty]
public int Views { get; set; }
[DynamoDBProperty]
public string LastPostBy { get; set; }
[DynamoDBProperty]
public DateTime LastPostDateTime { get; set; }
[DynamoDBProperty]
public int Messages { get; set; }
}
[DynamoDBTable("ProductCatalog")]
public class Book
{
[DynamoDBHashKey]
//Partition key
public int Id { get; set; }
public string Title { get; set; }
public string ISBN { get; set; }
public int Price { get; set; }
public string PageCount { get; set; }
public string ProductCategory { get; set; }
public bool InPublication { get; set; }
}
}
例: AWS SDK for .NET オブジェクト永続性モデルを使用し
た、DynamoDB でのクエリおよびスキャン
このセクションの C# コード例では、次のクラスを定義して、DynamoDB 内のテーブルにマッピング
しています。この例で使用されているテーブルの作成については、「テーブルの作成とサンプルデー
タのロード (p. 166)」を参照してください。
• Book クラスは ProductCatalog テーブルにマッピングされます。
• Forum、Thread、および Reply クラスは、同じ名前テーブルにマッピングされます。
この例では DynamoDBContext を使用して、さらに次のクエリとスキャンオペレーションを実行して
います。
• Id によって書籍を取得します。
ProductCatalog テーブルでは Id がプライマリキーになっています。プライマリキーの一部にソート
キーは含まれていません。したがって、テーブルのクエリを行うことはできません。項目は Id 値を
使用して取得できます。
• Reply テーブルに対して次のクエリを実行します(Reply テーブルのプライマリキーは Id および
ReplyDateTime 属性で構成されています。ReplyDateTime はソートキーです。したがってこのテー
ブルではクエリを実行できます)。
• 過去 15 日間に投稿されたフォーラムスレッドに対する返信を検索します。
API Version 2012-08-10
161
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
• 特定の日付範囲の間に投稿されたフォーラムスレッドに対する返信を検索します。
• ProductCatalog テーブルをスキャンし、価格が 0 未満である書籍を検索します。
パフォーマンス上の理由から、スキャンオペレーションではなくクエリを使用するようにしてくだ
さい。ただし、場合によってはテーブルをスキャンする必要があります。データ入力エラーがあ
り、書籍の価格の 1 つが 0 未満に設定されたとします。この例では、ProductCategory テーブルを
スキャンして、価格が 0 未満である書籍項目(ProductCategory は書籍)を検索しています。
実例を作成する手順については、「.NET コードサンプル (p. 173)」を参照してください。
using
using
using
using
using
using
using
System;
System.Collections.Generic;
System.Configuration;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DataModel;
Amazon.DynamoDBv2.DocumentModel;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class HighLevelQueryAndScan
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
DynamoDBContext context = new DynamoDBContext(client);
// Get item.
GetBook(context, 101);
// Sample forum and thread to test queries.
string forumName = "Amazon DynamoDB";
string threadSubject = "DynamoDB Thread 1";
// Sample queries.
FindRepliesInLast15Days(context, forumName, threadSubject);
FindRepliesPostedWithinTimePeriod(context, forumName,
threadSubject);
// Scan table.
FindProductsPricedLessThanZero(context);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
private static void GetBook(DynamoDBContext context, int productId)
{
Book bookItem = context.Load<Book>(productId);
API Version 2012-08-10
162
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
Console.WriteLine("\nGetBook: Printing result.....");
Console.WriteLine("Title: {0} \n No.Of threads:{1} \n No. of
messages: {2}",
bookItem.Title, bookItem.ISBN,
bookItem.PageCount);
}
private static void FindRepliesInLast15Days(DynamoDBContext context,
string forumName,
string threadSubject)
{
string replyId = forumName + "#" + threadSubject;
DateTime twoWeeksAgoDate = DateTime.UtcNow TimeSpan.FromDays(15);
IEnumerable<Reply> latestReplies =
context.Query<Reply>(replyId, QueryOperator.GreaterThan,
twoWeeksAgoDate);
Console.WriteLine("\nFindRepliesInLast15Days: Printing
result.....");
foreach (Reply r in latestReplies)
Console.WriteLine("{0}\t{1}\t{2}\t{3}", r.Id, r.PostedBy,
r.Message, r.ReplyDateTime);
}
private static void FindRepliesPostedWithinTimePeriod(DynamoDBContext
context,
string
forumName,
string
threadSubject)
{
string forumId = forumName + "#" + threadSubject;
Console.WriteLine("\nFindRepliesPostedWithinTimePeriod: Printing
result.....");
DateTime startDate = DateTime.UtcNow - TimeSpan.FromDays(30);
DateTime endDate = DateTime.UtcNow - TimeSpan.FromDays(1);
IEnumerable<Reply> repliesInAPeriod =
context.Query<Reply>(forumId,
QueryOperator.Between, startDate, endDate);
foreach (Reply r in repliesInAPeriod)
Console.WriteLine("{0}\t{1}\t{2}\t{3}", r.Id, r.PostedBy,
r.Message, r.ReplyDateTime);
}
private static void FindProductsPricedLessThanZero(DynamoDBContext
context)
{
int price = 0;
IEnumerable<Book> itemsWithWrongPrice = context.Scan<Book>(
new ScanCondition("Price", ScanOperator.LessThan, price),
new ScanCondition("ProductCategory", ScanOperator.Equal,
"Book")
);
Console.WriteLine("\nFindProductsPricedLessThanZero: Printing
result.....");
foreach (Book r in itemsWithWrongPrice)
API Version 2012-08-10
163
Amazon DynamoDB 開発者ガイド
.NET: オブジェクト永続性モデル
Console.WriteLine("{0}\t{1}\t{2}\t{3}", r.Id, r.Title,
r.Price, r.ISBN);
}
}
[DynamoDBTable("Reply")]
public class Reply
{
[DynamoDBHashKey]
//Partition key
public string Id { get; set; }
[DynamoDBRangeKey] //Sort key
public DateTime ReplyDateTime { get; set; }
// Properties included implicitly.
public string Message { get; set; }
// Explicit property mapping with object persistence model
attributes.
[DynamoDBProperty("LastPostedBy")]
public string PostedBy { get; set; }
// Property to store version number for optimistic locking.
[DynamoDBVersion]
public int? Version { get; set; }
}
[DynamoDBTable("Thread")]
public class Thread
{
// PK mapping.
[DynamoDBHashKey] //Partition key
public string ForumName { get; set; }
[DynamoDBRangeKey] //Sort key
public DateTime Subject { get; set; }
// Implicit mapping.
public string Message { get; set; }
public string LastPostedBy { get; set; }
public int Views { get; set; }
public int Replies { get; set; }
public bool Answered { get; set; }
public DateTime LastPostedDateTime { get; set; }
// Explicit mapping (property and table attribute names are
different.
[DynamoDBProperty("Tags")]
public List<string> KeywordTags { get; set; }
// Property to store version number for optimistic locking.
[DynamoDBVersion]
public int? Version { get; set; }
}
[DynamoDBTable("Forum")]
public class Forum
{
[DynamoDBHashKey]
public string Name { get; set; }
// All the following properties are explicitly mapped,
// only to show how to provide mapping.
[DynamoDBProperty]
public int Threads { get; set; }
[DynamoDBProperty]
API Version 2012-08-10
164
Amazon DynamoDB 開発者ガイド
コードサンプルの実行
public int Views { get; set; }
[DynamoDBProperty]
public string LastPostBy { get; set; }
[DynamoDBProperty]
public DateTime LastPostDateTime { get; set; }
[DynamoDBProperty]
public int Messages { get; set; }
}
[DynamoDBTable("ProductCatalog")]
public class Book
{
[DynamoDBHashKey]
//Partition key
public int Id { get; set; }
public string Title { get; set; }
public string ISBN { get; set; }
public int Price { get; set; }
public string PageCount { get; set; }
public string ProductCategory { get; set; }
public bool InPublication { get; set; }
}
}
この開発者ガイドのコードサンプルの実行
AWS SDK は、Java、JavaScript in the
browser、.NET、Node.js、PHP、Python、Rubyで、DynamoDB を広範にサポートしています。これ
らの言語をすぐに開始するには、Amazon DynamoDB 入門ガイド を参照してください。
AWS SDK は、さまざまな言語で利用できます。詳細なリストについては、「Tools for Amazon Web
Services」を参照してください。
この開発者ガイドのコードサンプルは、次のプログラミング言語を使用して DynamoDB オペレー
ションについて詳細に説明しています。
• Java (p. 171)
• .NET (p. 173)
• PHP (p. 175)
この演習を開始する前に、AWS にサインアップし、アクセスキーとシークレットキーを取得して、
コンピュータで AWS コマンドラインインターフェイスをセットアップする必要があります。この作
業を行っていない場合は、「DynamoDB (ウェブサービス) のセットアップ (p. 48)」を参照してくださ
い。
Note
DynamoDB のダウンロード可能バージョンを使用する場合は、AWS CLI を使用してテーブル
とサンプルデータを作成する必要があります。また、各 AWS CLI コマンドで --endpointurl パラメーターも指定する必要があります。詳細については、「ローカルエンドポイント
の設定 (p. 46)」を参照してください。
API Version 2012-08-10
165
Amazon DynamoDB 開発者ガイド
サンプルデータのロード
テーブルの作成とサンプルデータのロード
このセクションでは、AWS マネジメントコンソール を使用して DynamoDB にテーブルを作成しま
す。次に、AWS Command Line Interface (AWS CLI) を使用してこれらのテーブルにデータをロード
します。
これらのテーブルとそのデータは、この開発者ガイド全体で例として使用されます。
Note
アプリケーション開発者の方は、「Amazon DynamoDB 入門ガイド」も参照することをお勧
めします。
「Amazon DynamoDB 入門ガイド」では、ダウンロード可能なバージョンの DynamoDB を
使用します。これにより、スループット、ストレージ、またはデータ転送に料金を支払うこ
となく、無料で DynamoDB 低レベル API について学習できます。
トピック
• ステップ 1: サンプルテーブルの作成 (p. 166)
• ステップ 2: データをテーブルにロードする (p. 168)
• ステップ 3: データにクエリを実行する (p. 169)
• ステップ 4: (オプション) クリーンアップする (p. 170)
• 概要 (p. 171)
ステップ 1: サンプルテーブルの作成
このセクションでは、AWS マネジメントコンソール を使用して、DynamoDB で 2 つのシンプルな
ユースケース用のテーブルを作成します。
ユースケース 1: 製品カタログ
DynamoDB に製品情報を格納するとします。各製品には固有の属性があるため、これらの各製品につ
いて異なる情報を保存する必要があります。
ProductCatalog テーブルを作成できます。このテーブルでは、各項目が 1 つの数値属性 Id によって
一意に特定されます。
テーブル名
プライマリキー
ProductCatalog
パーティションキー: Id (数値)
ユースケース 2: フォーラムアプリケーション
掲示板やフォーラム用のアプリケーションを構築するとします。Amazon Web Services フォーラ
ムは、このようなアプリケーションの 1 つの例です。お客様は開発者コミュニティとやり取りし、質
問をしたり、他のお客様の投稿に返信したりできます。各 AWS サービスには専用フォーラムがあり
ます。だれでも、フォーラムでメッセージを投稿して新しいディスカッションスレッドを開始できま
す。各スレッドは、任意の数の返信を受け取ることができます。
3 つのテーブル (Forum、Thread、Reply) を作成して、このアプリケーションをモデル化できます。
テーブル名
プライマリキー
フォーラム
パーティションキー: Name (文字列)
スレッド
パーティションキー: ForumName (文字列)
API Version 2012-08-10
166
Amazon DynamoDB 開発者ガイド
サンプルデータのロード
テーブル名
プライマリキー
ソートキー: Subject (文字列)
Reply
パーティションキー: Id (文字列)
ソートキー: ReplyDateTime (文字列)
[Reply] テーブルには、PostedBy-Message-Index という名前のグローバルセカンダリインデックスが
あります。このインデックスでは、Reply テーブルの 2 つの非キー属性でのクエリを容易にします。
インデックス名
プライマリキー
PostedBy-Message-Index
パーティションキー: PostedBy (文字列)
ソートキー: Message (文字列)
ProductCatalog テーブルを作成する
1.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
2.
[Create Table] を選択します。
3.
[Create DynamoDB table] 画面で、次の操作を行います。
4.
a.
[Table name] フィールドに「ProductCatalog」と入力します。
b.
[Primary key] の [Partition key] フィールドに「Id」と入力します。データ型を [Number] に設
定します。
すべての設定が正しいことを確認したら、[Create] を選択します。
Forum テーブルを作成する
1.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
2.
[Create Table] を選択します。
3.
[Create DynamoDB table] 画面で、次の操作を行います。
4.
a.
[Table name] フィールドに「Forum」と入力します。
b.
[Primary key] の [Partition key] フィールドに「Name」と入力します。データ型を [String] に
設定します。
すべての設定が正しいことを確認したら、[Create] を選択します。
Thread テーブルを作成する
1.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
2.
[Create Table] を選択します。
3.
[Create DynamoDB table] 画面で、次の操作を行います。
a.
[Table name] フィールドに「Thread」と入力します
b.
[Primary key] ページで、以下の操作を行います。
• [Partition key] フィールドに「ForumName」と入力します。データ型を [String] に設定しま
す。
• [Add sort key] を選択します。
• [Sort key] フィールドに「Subject」と入力します。データ型を [String] に設定します。
API Version 2012-08-10
167
Amazon DynamoDB 開発者ガイド
サンプルデータのロード
4.
すべての設定が正しいことを確認したら、[Create] を選択します。
Reply テーブルを作成する
1.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
2.
3.
[Create Table] を選択します。
[Create DynamoDB table] 画面で、次の操作を行います。
a.
b.
[Table name] フィールドに「Reply」と入力します
[Primary key] ページで、以下の操作を行います。
• [Partition key] フィールドに「Id」と入力します。データ型を [String] に設定します。
• [Add sort key] を選択します。
• [Sort key] フィールドに「ReplyDateTime」と入力します。データ型を [String] に設定し
ます。
c.
[Table settings] セクションで、[Use default settings] を選択解除します。
d.
[Secondary indexes] セクションで、[Add index] を選択します。
e.
[Add index] ウィンドウで、以下の操作を行います。
• [Primary key] ページで、以下の操作を行います。
• [Partition key] フィールドに「PostedBy」と入力します。データ型を [String] に設定し
ます。
• [Add sort key] を選択します。
• [Sort key] フィールドに「Message」と入力します。データ型を [String] に設定します。
• [Index name] フィールドに「PostedBy-Message-Index」と入力します
• [Projected attributes] を [All] に設定します。
• [Add index] を選択します。
4.
すべての設定が正しいことを確認したら、[Create] を選択します。
ステップ 2: データをテーブルにロードする
このステップでは、作成したテーブルにサンプルデータをロードします。DynamoDB コンソール
にデータを手動で入力できます。ただし、時間を節約するため、代わりに AWS Command Line
Interface を使用します。
Note
まだ AWS CLI をセットアップしていない場合は、手順について「」を参照してください。
各テーブル用のサンプルデータと JSON ファイルが含まれる .zip アーカイブをダウンロードしま
す。ファイルごとに、AWS CLI を使用してデータを DynamoDB にロードします。データのロードが
成功するたびに、以下の出力が作成されます。
{
"UnprocessedItems": {}
}
サンプルデータファイルアーカイブのダウンロード
1.
次のリンクを使用してサンプルデータアーカイブ (sampledata.zip) をダウンロードします。
• sampledata.zip
API Version 2012-08-10
168
Amazon DynamoDB 開発者ガイド
サンプルデータのロード
2.
アーカイブから .json データファイルを抽出します。
3.
現在のディレクトリに .json データファイルをコピーします。
サンプルデータを DynamoDB テーブルにロードする
1.
データとともに ProductCatalog テーブルをロードするには、次のコマンドを入力します。
aws dynamodb batch-write-item --request-items file://ProductCatalog.json
2.
データとともに Forum テーブルをロードするには、次のコマンドを入力します。
aws dynamodb batch-write-item --request-items file://Forum.json
3.
データとともに Thread テーブルをロードするには、次のコマンドを入力します。
aws dynamodb batch-write-item --request-items file://Thread.json
4.
データとともに Reply テーブルをロードするには、次のコマンドを入力します。
aws dynamodb batch-write-item --request-items file://Reply.json
データロードの確認
AWS マネジメントコンソール を使用して、テーブルにロードしたデータを確認できます。
AWS マネジメントコンソールを使用してデータを確認するには
1.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
2.
ナビゲーションペインで、[ Tables] を選択します。
3.
テーブルのリストで、[ProductCatalog] を選択します。
4.
[Items] タブを選択して、テーブルにロードしたデータを表示できます。
5.
テーブルの項目を表示するには、その Id を選択します (必要に応じて、編集することもできま
す)。
6.
テーブルの一覧に返すには、[Cancel] を選択します。
作成した他のテーブルごとに、この手順を繰り返します。
• フォーラム
• スレッド
• Reply
ステップ 3: データにクエリを実行する
このステップでは、DynamoDB コンソールで作成したテーブルに対して、いくつかの単純なクエリを
試行します。
1.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
2.
ナビゲーションペインで、[ Tables] を選択します。
3.
テーブルのリストで、[Reply] を選択します。
4.
[Items] タブを選択して、テーブルにロードしたデータを表示できます。
5.
[Create item] ボタンのすぐ下にある、データフィルタリンクを選択します。
API Version 2012-08-10
169
Amazon DynamoDB 開発者ガイド
サンプルデータのロード
これを行うと、コンソールにデータフィルタリングペインが表示されます。
6.
7.
データフィルタリングペインで以下の作業を行います。
a.
オペレーションを [Scan] から [Query] に変更します。
b.
[Partition key] に値を入力します。Amazon DynamoDB#DynamoDB Thread 1
c.
[Start] を選択します。クエリ条件に一致する項目のみが Reply テーブルから返されます。
Reply テーブルには、PostedBy および Message 属性にグローバルセカンダリインデックスがあ
ります。データフィルタリングペインを使用してインデックスにクエリを実行できます。次の作
業を行います。
a.
次からクエリソースを変更します。
[Table] Reply: Id, ReplyDateTime
次のように変更する必要があります。
[Index] PostedBy-Message-Index: PostedBy, Message
b.
[Partition key] に値を入力します。User A
c.
[Start] を選択します。クエリ条件に一致する項目のみが、PostedBy-Message-Index から返
されます。
DynamoDB コンソールを使用して、他のテーブルを確認します。
• ProductCatalog
• フォーラム
• スレッド
ステップ 4: (オプション) クリーンアップする
この『Amazon DynamoDB 開発者ガイド』では、DynamoDB 低レベル API および各種 AWS SDK を
使用してテーブルと項目のオペレーションを示すため、これらのサンプルテーブルを繰り返し参照し
ます。この開発者ガイドの残りの部分を読む予定の場合、これらのテーブルが役に立ちます。
API Version 2012-08-10
170
Amazon DynamoDB 開発者ガイド
Java コードサンプル
ただし、これらのテーブルを維持する予定がない場合は、必要ないリソースに対する課金を防ぐため
に、テーブルを削除してください。
サンプルテーブルを削除するには
1.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
2.
ナビゲーションペインで、[ Tables] を選択します。
3.
テーブルのリストで、[ProductCatalog] を選択します。
4.
[Delete Table] を選択します。選択を確認する画面が表示されます。
作成した他のテーブルごとに、この手順を繰り返します。
• フォーラム
• スレッド
• Reply
概要
この演習では、DynamoDB コンソールを使用して DynamoDB で複数のテーブルを作成しました。次
に、AWS CLI を使用してテーブルにデータをロードし、DynamoDB コンソールを使用してデータで
いくつかの基本的なオペレーションを実行しました。
DynamoDB コンソールおよび AWS CLI は、すぐに使用を開始するのに便利です。ただ
し、DynamoDB の動作の詳細と、DynamoDB を使用したアプリケーションプログラムの記述の詳細
を参照することをお勧めします。この開発者ガイドの残りの部分では、これらのトピックに対応しま
す。
Java コードサンプル
トピック
• Java: AWS 認証情報の設定 (p. 172)
• Java: AWS リージョンとエンドポイントの設定 (p. 172)
この開発者ガイドには、Java コードスニペットとすぐに使用できるプログラムが含まれています。こ
れらのコードサンプルは、次のセクションで確認することができます。
• DynamoDB での項目の操作 (p. 204)
• DynamoDB でのテーブルの操作 (p. 178)
• クエリおよびスキャンの使用 (p. 287)
• セカンダリインデックスを使用したデータアクセス性の向上 (p. 333)
• Java: DynamoDBMapper (p. 78)
• DynamoDB ストリーム を使用したテーブルアクティビティのキャプチャ (p. 426)
Note
Amazon DynamoDB 入門ガイド には、追加の Java サンプルプログラムが含まれます。
Eclipse と AWS Toolkit for Eclipse を使用して、すぐに開始できます。フル機能の IDE に加えて、自
動更新で AWS SDK for Java および AWS アプリケーションの構築用に事前設定されたテンプレート
も取得できます。
API Version 2012-08-10
171
Amazon DynamoDB 開発者ガイド
Java コードサンプル
Java コードサンプルを実行するには (Eclipse を使用)
1.
Eclipse IDE をダウンロードし、インストールします。
2.
AWS Toolkit for Eclipse をダウンロードし、インストールします。
3.
Eclipse を開始し、[Eclipse] メニューから、[File]、[New]、[Other] の順に選択します。
4.
[Select a wizard] で、[AWS]、[AWS Java Project]、[Next] の順に選択します。
5.
[Create an AWS Java] で、以下の操作を行います。
a.
[Project name] で、プロジェクトの名前を入力します。
b.
[Select Account] で、リストから認証情報プロファイルを選択します。
AWS Toolkit for Eclipse を初めて使用する場合、[Configure AWS Accounts] を選択し
て、AWS 認証情報を設定します。
6.
[Finish] を選択してプロジェクトを作成します。
7.
[Eclipse] メニューから [File]、[New]、[Class] の順に選択します。
8.
[Java Class] で、[Name] にクラスの名前を入力し (実行するコードサンプルと同じ名前を使用)、
[Finish] を選択してクラスを作成します。
9.
お読みになっているドキュメントページから Eclipse エディターにコードサンプルをコピーしま
す。
10. コードを実行するには、Eclipse メニューの [Run] を選択します。
SDK for Java には、DynamoDB を操作するためにスレッドセーフなクライアントが用意されていま
す。最善の方法としては、ご利用のアプリケーションでクライアントを 1 つ作成し、そのクライアン
トをスレッド間で再利用することです。
詳細については、AWS SDK for Java を参照してください。
Note
この開発者ガイドのコードサンプルは、最新バージョンの AWS SDK for Java で使用するた
めのものです。
AWS Toolkit for Eclipse を使用している場合、SDK for Java の自動更新を設定することができ
ます。Eclipse でこれを行なうには、[Preferences] に移動し、[AWS Toolkit] --> [AWS SDK for
Java] --> [新しい SDK を自動的にダウンロード] の順に選択します。
Java: AWS 認証情報の設定
SDK for Java では、実行時にアプリケーションに AWS 認証情報を指定する必要があります。この開
発者ガイドのコードサンプルでは、『AWS SDK for Java Developer Guide』の「Set Up Your AWS
Credentials」で説明されているように、AWS 認証情報ファイルを使用することを前提としています。
~/.aws/credentials という名前の AWS 認証情報ファイルの例を次に示します。ここで、チルダ
文字 (~) はホームディレクトリを表します。
[default]
aws_access_key_id = AWS access key ID goes here
aws_secret_access_key = Secret key goes here
Java: AWS リージョンとエンドポイントの設定
デフォルトでは、米国西部 (オレゴン) リージョンで、DynamoDB にアクセスします。リージョンを変
更するには、AmazonDynamoDBClient プロパティを変更します。
API Version 2012-08-10
172
Amazon DynamoDB 開発者ガイド
.NET コードサンプル
次のコードスニペットは、新しい AmazonDynamoDBClient をインスタンス化します。その後、クラ
イアントは、別のリージョンでコードが DynamoDB に対して実行するように変更されます。
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.regions.Regions;
...
// This client will default to US West (Oregon)
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
// Modify the client so that it accesses a different region.
client.withRegion(Regions.US_EAST_1);
withRegion メソッドを使用して、利用可能な任意のリージョンで、Amazon DynamoDB を対象とし
てコードを実行します。詳細なリストについては、『アマゾン ウェブ サービス全般のリファレンス』
の「AWS Regions and Endpoints」を参照してください。
ローカルコンピュータで DynamoDB を使用しコードサンプルを実行する場合、次に示すようにエン
ドポイントを設定する必要があります。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
// Set the endpoint URL
client.withEndpoint("http://localhost:8000");
.NET コードサンプル
トピック
• .NET: AWS 認証情報の設定 (p. 174)
• .NET: AWS リージョンとエンドポイントの設定 (p. 175)
この開発者ガイドには、.NET コードスニペットとすぐに使用できるプログラムが含まれています。こ
れらのコードサンプルは、次のセクションで確認することができます。
• DynamoDB での項目の操作 (p. 204)
• DynamoDB でのテーブルの操作 (p. 178)
• クエリおよびスキャンの使用 (p. 287)
• セカンダリインデックスを使用したデータアクセス性の向上 (p. 333)
• .NET ドキュメントモデル (p. 116)
• .NET: オブジェクト永続性モデル (p. 138)
• DynamoDB ストリーム を使用したテーブルアクティビティのキャプチャ (p. 426)
Note
Amazon DynamoDB 入門ガイド には、追加の .NET サンプルプログラムが含まれます。
AWS SDK for .NET と Toolkit for Visual Studio を使用して、すぐに開始できます。
.NET コードサンプルを実行するには (Visual Studio を使用)
1.
Microsoft Visual Studio をダウンロードし、インストールします。
2.
Toolkit for Visual Studio をダウンロードし、インストールします。
API Version 2012-08-10
173
Amazon DynamoDB 開発者ガイド
.NET コードサンプル
3.
Visual Studio を起動し、[File]、[New]、[Project] の順に選択します。
4.
[New Project] で、[AWS Empty Project]、[OK] の順に選択します。
5.
[AWS アクセス認証情報] で、[既存のプロファイルを使用] を選択し、リストからご自分の認証情
報の内容を選択して、[OK] を選択します。
初めて Toolkit for Visual Studio を使用する場合は、[新しいプロファイルを使用] を選択し、AWS
の認証情報を設定します。
6.
Visual Studio プロジェクトで、プログラムソースコード (Program.cs) のタブを選択します。エ
ディターにある他のコードを置き換えて、お読みになっているドキュメントページから、Visual
Studio にコードサンプルをコピーします。
7.
The type or namespace name...could not be found 形式のエラーメッセージが表示
された場合、次のように DynamoDB の AWS SDK アセンブリをインストールする必要がありま
す。
8.
a.
ソリューションエクスプローラーで、プロジェクトのコンテキスト (右クリック) メニューを
開いて、[Manage NuGet Packages] を選択します。
b.
NuGet パッケージマネージャーで、[Browse] を選択します。
c.
検索ボックスに、「AWSSDK.DynamoDBv2」と入力し、完了するまでお待ちください。
d.
[AWSSDK.DynamoDBv2]、[Install] の順に選択します。
e.
インストールが完了したら、[Program.cs] タブを選択し、プログラムに戻ります。
コードを実行するには、Visual Studio ツールバーの [Start] ボタンを選択します。
AWS SDK for .NET には、DynamoDB を操作するためにスレッドセーフなクライアントが用意されて
います。最善の方法としては、ご利用のアプリケーションでクライアントを 1 つ作成し、そのクライ
アントをスレッド間で再利用することです。
詳細については、「AWS SDK for .NET」を参照してください。
Note
この開発者ガイドのコードサンプルは、最新バージョンの AWS SDK for .NET で使用するた
めのものです。
.NET: AWS 認証情報の設定
AWS SDK for .NET では、アプリケーションの実行時に AWS 認証情報を指定する必要があります。
この開発者ガイドのコードサンプルは、『AWS SDK for .NET 開発者ガイド』の「SDK ストアの使
用」の説明に従って、AWS の認証情報ファイルを管理している SDK ストアを使用することを前提と
しています。
Toolkit for Visual Studio では、任意数のアカウントの複数セットの認証情報がサポートされていま
す。各セットはプロファイルと呼ばれています。Visual Studio では、プロジェクトの App.config
ファイルにエントリを追加するため、アプリケーションは実行時に AWS 認証情報を見つけることが
できます。
次の例は、Toolkit for Visual Studio を使用した新しいプロジェクトの作成時に生成されたデフォルト
の App.config ファイルを示しています。
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<appSettings>
<add key="AWSProfileName" value="default"/>
<add key="AWSRegion" value="us-west-2" />
</appSettings>
API Version 2012-08-10
174
Amazon DynamoDB 開発者ガイド
PHP コードサンプル
</configuration>
実行時に、このプログラムは AWSProfileName エントリで指定されているように、AWS 認証情報
の default セットを使用します。AWS 認証情報それ自体は、暗号化されたフォームで SDK ストア
に保持されます。Toolkit for Visual Studio は、すべて Visual Studio 内からの認証情報を管理するため
のグラフィカルユーザーインターフェイスを使用します。詳細については、『AWS Toolkit for Visual
Studio ユーザーガイド』の「認証情報の指定」を参照してください。
Note
デフォルトでは、米国西部 (オレゴン) リージョンで、DynamoDB にアクセスしま
す。App.config ファイルで AWSRegion エントリを変更して、リージョンを変更できま
す。Amazon DynamoDB が利用可能なすべての AWS リージョンで、AWSRegion を設定でき
ます。詳細なリストについては、『アマゾン ウェブ サービス全般のリファレンス』の「AWS
Regions and Endpoints」を参照してください。
.NET: AWS リージョンとエンドポイントの設定
デフォルトでは、米国西部 (オレゴン) リージョンで、DynamoDB にアクセスしま
す。App.config ファイルで AWSRegion エントリを変更して、リージョンを変更できます。また
は、AmazonDynamoDBClient プロパティを変更することによってもリージョンを変更できます。
次のコードスニペットは、新しい AmazonDynamoDBClient をインスタンス化します。クライアント
は、別のリージョンでコードが DynamoDB に対して実行するように変更されます。
AmazonDynamoDBConfig clientConfig = new AmazonDynamoDBConfig();
// This client will access the US East 1 region.
clientConfig.RegionEndpoint = RegionEndpoint.USEast1;
AmazonDynamoDBClient client = new AmazonDynamoDBClient(clientConfig);
リージョンの詳細なリストについては、アマゾン ウェブ サービス全般のリファレンスのAWS のリー
ジョンとエンドポイントを参照してください。
ローカルコンピューターで DynamoDB を使用しコードサンプルを実行する場合、エンドポイントを
設定する必要があります。
AmazonDynamoDBConfig clientConfig = new AmazonDynamoDBConfig();
// Set the endpoint URL
clientConfig.ServiceURL = "http://localhost:8000";
AmazonDynamoDBClient client = new AmazonDynamoDBClient(clientConfig);
PHP コードサンプル
トピック
• PHP: AWS 認証情報の設定 (p. 176)
• PHP: AWS リージョンとエンドポイントを設定 (p. 176)
この開発者ガイドには、PHP コードスニペットとすぐに使用できるプログラムが含まれています。こ
れらのコードサンプルは、次のセクションで確認することができます。
• DynamoDB での項目の操作 (p. 204)
• DynamoDB でのテーブルの操作 (p. 178)
• クエリおよびスキャンの使用 (p. 287)
API Version 2012-08-10
175
Amazon DynamoDB 開発者ガイド
PHP コードサンプル
• セカンダリインデックスを使用したデータアクセス性の向上 (p. 333)
• DynamoDB ストリーム を使用したテーブルアクティビティのキャプチャ (p. 426)
Note
Amazon DynamoDB 入門ガイド には、追加の PHP サンプルプログラムが含まれます。
PHP の SDK を使用する方法は、環境によって、また、どのようにアプリケーションを実行するかに
よって異なります。このドキュメント内のコードサンプルは、コマンドラインから実行できますが、
異なる環境 (ウェブサーバーなど) で実行する場合は変更できます。
PHP コードサンプルを実行 (コマンドラインから)
1.
「最小要件」に説明されているように、環境が PHP の SDK の最小要件を満たしていることを確
認します。
2.
AWS SDK for PHP をダウンロードし、インストールします。
使用するインストール方法によっては、PHP 拡張モジュール間の依存性を解決するために、コー
ドを変更しなければならない場合があります。詳細については、AWS SDK for PHP のドキュメ
ントの「使用開始」の「使用開始」セクションを参照してください。
3.
(お読みになっているドキュメントページから) コードサンプルをコンピュータのファイルにコ
ピーします。
4.
コマンドラインからコードを実行します。以下に例を示します。php myProgram.php
Note
この開発者ガイドのコードサンプルは、最新バージョンの AWS SDK for PHP で使用するため
のものです。
PHP: AWS 認証情報の設定
PHP の SDK では、アプリケーションの実行時に AWS 認証情報を指定する必要があります。この開
発者ガイドのコードサンプルは、AWS SDK for PHP ドキュメントの「Credentials」で説明されてい
るように、AWS 認証情報ファイルを使用することを前提としています。
~/.aws/credentials という名前の AWS 認証情報ファイルの例を次に示します。ここで、チルダ
文字 (~) はホームディレクトリを表します。
[default]
aws_access_key_id = AWS access key ID goes here
aws_secret_access_key = Secret key goes here
PHP: AWS リージョンとエンドポイントを設定
DynamoDB クライアントを作成するときに、AWS のリージョンを指定する必要があります。これを
行うには、使用するリージョンとAws\Sdk オブジェクトを指定します。
次のコードスニペットは 米国西部 (オレゴン) リージョンを使用して、新しい Aws\Sdk オブジェク
トをインスタンス化します。次に、このリージョンを使用する DynamoDB クライアントを作成しま
す。
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2', // US West (Oregon) Region
API Version 2012-08-10
176
Amazon DynamoDB 開発者ガイド
PHP コードサンプル
'version'
=> 'latest'
// Use the latest version of the AWS SDK for PHP
]);
// Create a new DynamoDB client
$dynamodb = $sdk->createDynamoDb();
ローカルコンピュータで DynamoDB を使用しコードサンプルを実行する場合、次に示すようにエン
ドポイントを設定する必要があります。
$sdk = new Aws\Sdk([
'endpoint'
=> 'http://localhost:8000', // Use DynamoDB running locally
'region'
=> 'us-west-2', // US West (Oregon) Region
'version' => 'latest' // Use the latest version of the AWS SDK for PHP
]);
// Create a new DynamoDB client
$dynamodb = $sdk->createDynamoDb();
API Version 2012-08-10
177
Amazon DynamoDB 開発者ガイド
テーブルの操作
DynamoDB の操作
ここでは、次のトピックについて詳しく説明します。
トピック
• DynamoDB でのテーブルの操作 (p. 178)
• DynamoDB での項目の操作 (p. 204)
• クエリおよびスキャンの使用 (p. 287)
• セカンダリインデックスを使用したデータアクセス性の向上 (p. 333)
• DynamoDB ストリーム を使用したテーブルアクティビティのキャプチャ (p. 426)
DynamoDB でのテーブルの操作
トピック
• プライマリキーの指定 (p. 179)
• テーブルの読み書き要件の指定 (p. 179)
• キャパシティーユニットの計算 (p. 181)
• テーブルのリストと情報を取得する (p. 183)
• DynamoDB のタグ付け (p. 184)
• テーブルの操作 : Java (p. 186)
• テーブルの操作 : .NET (p. 191)
• テーブルの操作 : PHP (p. 198)
Amazon DynamoDB でテーブルを作成するときには、テーブル名、プライマリキー、および必須
の読み書きスループット値を指定する必要があります。テーブル名に指定できる文字は、a-z、AZ、0-9、'_' (アンダースコア)、'-' (ハイフン)、'.' (ドット)です。名前は 3~255 文字で指定しま
す。リレーショナルデータベースでは、テーブルは事前定義されたスキーマを保持しています。こ
のスキーマには、テーブル名、プライマリキー、列名、データ型などのプロパティが記述されてい
ます。テーブルに保存されているすべてのレコードは、同じ一連の列で構成されている必要がありま
す。DynamoDB は NoSQL データベースです。必要なプライマリキーを除き、DynamoDB テーブルに
はスキーマがありません。DynamoDB テーブル内の個々の項目には多数の属性があります。ただし、
項目サイズに対する 400 KB の制限があります。
ベストプラクティスについては、テーブルの操作のガイドライン (p. 566) を参照してください。
オプションでタグを使用して、既存の DynamoDB リソースにラベルを付けることができます。詳細
については、「DynamoDB のタグ付け (p. 184)」を参照してください。
API Version 2012-08-10
178
Amazon DynamoDB 開発者ガイド
プライマリキーの指定
プライマリキーの指定
テーブルを作成する場合には、テーブル名に加えて、テーブルのプライマリキーを指定する必要があ
ります。プライマリキーは各項目を一意に識別するため、テーブル内の 2 つの項目が同じプライマリ
キーを持つことはありません。
DynamoDB は 2 種類の異なるプライマリキーをサポートします。
• パーティションキー — パーティションキーという 1 つの属性で構成されたシンプルなプライマリ
キー。DynamoDB は内部ハッシュ関数への入力として、パーティションキーの値を使用します。
ハッシュ関数からの出力により、項目が保存されるパーティションが決まります。テーブルの 2 つ
の項目が、同じパーティションキー値を持つことはできません。
• パーティションキーとソートキー — 2 つの属性で構成された複合プライマリキー。最初の属性
はパーティションキーであり、2 番目の属性はソートキーです。DynamoDB は内部ハッシュ関数
への入力として、パーティションキーの値を使用します。ハッシュ関数からの出力により、項目が
保存されるパーティションが決まります。同じパーティションキーを持つすべての項目は、ソート
キー値でソートされてまとめて保存されます。2 つの項目でパーティションキー値を同じにするこ
とは可能ですが、これらの 2 つの項目のソートキー値は異なっている必要があります。
テーブルの読み書き要件の指定
DynamoDB は、予測可能で低レイテンシーの応答時間を実現するあらゆる規模のワークロードをサ
ポートするように構築されています。
高可用性と低レイテンシーの応答を実現するために、DynamoDB では、テーブル作成時に必須の読み
書きスループット値を指定する必要があります。DynamoDB はこの情報を使用して十分なハードウェ
アリソースを予約し、また、複数のサーバーにまたがるデータを適切に分割してスループット要件を
満たしています。アプリケーションデータとアクセスの要件が変化した場合は、DynamoDB コンソー
ルまたは API を使用して、プロビジョニングされたスループットを簡単に増減できます。
DynamoDB はリソースの割り当てと予約を行い、持続性のある低レイテンシーを実現することで、ス
ループット要件に対応します。お客様は、これらのリソースの時間単位の予約に対して代金を支払い
ます。支払いは貴社の成長に応じて行うことができ、スループット要件の引き上げや引き下げも簡単
です。たとえば、既存のデータストアからの大量のデータを新しいテーブルに入力しなければならな
い場合があります。この場合、大容量の書き込みスループットを設定したテーブルを作成できます。
また、初回のデータアップロード後には、その書き込みスループットを下げ、アプリケーションの要
件に合うように読み込みスループットを高めます。
テーブル作成時には、以下のキャパシティーユニットによってスループット要件を指定しま
す。UpdateTable リクエスト内でこれらのユニットを指定して、既存テーブルのプロビジョニング
されたスループットを増減することもできます。
• 読み込みキャパシティーユニット – 最大 4 KB のサイズの項目に対する、強い整合性のある読み込
みの 1 秒あたりの数です。たとえば、読み込みキャパシティーユニット 10 をリクエストすると、
該当するテーブルに対して 4 KB の強い整合性のある読み込みのスループットを、1 秒あたり 10
回リクエストします。結果整合性のある読み込みの場合、1 つの読み込みキャパシティーユニット
は、最大 4 KB の項目を 1 秒あたり 2 回読み込むことになります。読み込み整合性の詳細について
は、「読み込み整合性 (p. 16)」を参照してください。
• 書き込みキャパシティーユニット – 1 秒あたりの 1 KB の書き込み数たとえば、書き込みキャパシ
ティーユニット 10 をリクエストすると、該当するテーブルに対して 1 KB のサイズを 1 秒あたり
10 回書き込むスループットをリクエストします。
DynamoDB はこれらのキャパシティーユニットを使用して、リクエストされたスループットを提供す
るための十分なリソースをプロビジョニングします。
テーブルのキャパシティーユニットを決定するときは、以下の点を考慮する必要があります。
API Version 2012-08-10
179
Amazon DynamoDB 開発者ガイド
テーブルの読み書き要件
• 項目サイズ – DynamoDB は、指定するキャパシティーユニットの読み書き数に従って、テーブル
にリソースを割り当てます。これらのキャパシティーユニットは、データ項目のサイズ(1 回の読
み込みで 4 KB または 1 回の書き込みで 1 KB)に基づいています。たとえば、テーブル内の項目
が 4 KB 以下の場合、各項目の読み込みオペレーションでは、読み込みキャパシティーユニット 1
が消費されます。項目が 4 KB を超える場合は、各読み込みオペレーションでは、追加のキャパシ
ティーユニットが消費されます。この場合、1 秒あたりに実行できるデータベース読み込みオペ
レーションの数は、プロビジョニング済みの読み込みキャパシティーユニットの数よりも少なくな
ります。たとえば、テーブルに対して読み込みキャパシティーユニット 10 のスループットをリク
エストする場合に項目のサイズが 8 KB であれば、そのテーブルに対して強い整合性のある読み込
みが 1 秒あたり最大 5 回確保されます。
• 読み書きリクエストの期待値 – アプリケーションからテーブルに対して 1 秒あたりに実行される読
み書きオペレーションの期待数も決定する必要があります。この期待値は、推定の項目サイズとと
もに、読み書きキャパシティーユニットの値を決定する際に役立ちます。
• 整合性 – 読み込みキャパシティーユニットは、強い整合性のある読み込みオペレーションに基づい
ています。ただし、このオペレーションには、より多くの手間がかかり、データベースリソースの
消費量は結果整合性のある読み込みの 2 倍になります。たとえば、プロビジョニングされたスルー
プットの 10 の読み込みキャパシティーユニットを持つテーブルは、4 KB の項目に対する 1 秒あた
り 10 の強い整合性のある読み込み、または、同じ項目に対する 1 秒あたり 20 の結果整合性のある
読み込みのいずれかを提供します。アプリケーションでどちらの整合性読み込みが必要かは、テー
ブルにプロビジョニングする必要のある読み込みキャパシティーユニットの数の決定要因となりま
す。DynamoDB では、読み込みオペレーションのデフォルトは、結果整合性のある読み込みとな
ります。これらのオペレーションの中には、強い整合性のある読み込みを指定できるものもありま
す。
• Secondary indexes – インデックスに対するクエリは、プロビジョニングされた読み込みスループッ
トを消費します。DynamoDB は 2 種類の セカンダリインデックスes (グローバルセカンダリイン
デックスes と local secondary indexes) をサポートします。インデックスおよびプロビジョニング
されたスループットに関する詳細については、「セカンダリインデックスを使用したデータアクセ
ス性の向上 (p. 333)」を参照してください。
これらの要因は、テーブル作成時に指定する、アプリケーションのスループット要件を決定する際
に役立ちます。CloudWatch のメトリクスを使用して、パフォーマンスをモニタリングできます。ま
た、アラームを設定し、消費されたキャパシティーユニットの特定のしきい値に到達した場合に通
知することもできます。DynamoDB コンソールでは、デフォルトのメトリクスをいくつか利用でき
ます。このメトリクスを確認して、テーブルパフォーマンスをモニタリングし、必要に応じてスルー
プット要件を調整できます。詳細については、DynamoDB コンソールにアクセスしてください。
DynamoDB では、自動的にテーブルパーティション全体にデータが分散され、複数のサーバーに格
納されます。最適なスループットを実現するために、これらのパーティション全体にできるだけ均一
に読み込みリクエストを分散する必要があります。たとえば、1 秒あたり 100 万の読み込みキャパシ
ティーユニットでテーブルをプロビジョニングする必要があるとします。テーブル内の単一の項目に
100 万のリクエストを発行すると、すべての読み込みアクティビティが単一のパーティションに集中
します。しかし、テーブル内の全項目にリクエストを分散すると、DynamoDB はテーブルパーティ
ションに並列でアクセスできます。これにより、テーブルのプロビジョニングされたスループットの
目標を実現できます。
読み込みの場合、異なる平均項目サイズ、リクエスト率、および整合性の組み合わせに対応する、プ
ロビジョニングされたスループットの値が、以下のテーブルで比較されます。
期待される項目サイズ
整合性
1 秒あたりの期待され
る読み込み数
必須のプロビジョニン
グされたスループット
4 KB
強い整合性
50
50
8 KB
強い整合性
50
100
4 KB
結果整合性
50
25
API Version 2012-08-10
180
Amazon DynamoDB 開発者ガイド
キャパシティーユニットの計算
期待される項目サイズ
整合性
1 秒あたりの期待され
る読み込み数
必須のプロビジョニン
グされたスループット
8 KB
結果整合性
50
50
読み込みの項目サイズは、次の 4 KB の倍数に切り上げられます。たとえば、3,500 バイトの項目
は、4 KB の項目と同じスループットを消費します。
書き込みの場合、異なる平均項目サイズおよび書き込みリクエスト率に対応する、プロビジョニング
されたスループットの値が、以下のテーブルで比較されます。
期待される項目サイズ
1 秒あたりの期待される書き込
み数
必須のプロビジョニングされた
スループット
1 KB
50
50
2 KB
50
100
書き込みの項目サイズは、次の 1 KB の倍数に切り上げられます。たとえば、500 バイトの項目は、1
KB の項目と同じスループットを消費します。
DynamoDB は、リクエストされた読み込みと書き込みのキャパシティーユニットにリソースをコミッ
トします。その結果として、リクエストされた率内にとどまることが予想されます。プロビジョニン
グされたスループットは、リクエストされるデータのサイズにも依存します。読み込みまたは書き込
みのリクエスト率が、リクエストされるデータの累積的なサイズに組み合わされ、現在確保されてい
る容量を超える場合、DynamoDB は、プロビジョニングされたスループットレベルが超過したことを
示すエラーを返します。
ProvisionedThroughput パラメータを使用して、プロビジョニングされたスループットを設定し
ます。ProvisionedThroughput パラメータの設定については、Amazon DynamoDB API Reference
の CreateTable を参照してください。
プロビジョニングされたスループットの使用に関する詳細については、「テーブルの操作のガイドラ
イン (p. 566)」を参照してください。
Note
ワークロードの急上昇(新製品の発売など)により、スループットがテーブルの現在のプロ
ビジョニングされたスループットを超過する可能性が予想される場合は、UpdateTable オペ
レーションを使用して、ProvisionedThroughput 値を大きくすることをお勧めします。
テーブル単位またはアカウント単位の、現在の最大のプロビジョニングされたスループット
値については、「DynamoDB での制限 (p. 558)」を参照してください。
UpdateTable リクエストを発行すると、テーブルのステータスが AVAILABLE から
UPDATING に変わります。テーブルは UPDATING 中も全面的に利用できます。この期間
中、DynamoDB は必要なリソースを割り当てて、新しいプロビジョニングされたスループッ
トレベルをサポートします。この処理が完了すると、テーブルのステータスが UPDATING か
ら AVAILABLE に変わります。
キャパシティーユニットの計算
DynamoDB では、キャパシティーユニットは、以下のように定義されます。
• 最大サイズ 4 KB の項目について、1 つの読み込みキャパシティーユニット = 1 秒あたり 1 回の強力
な整合性のある読み込み、あるいは 1 秒あたり 2 回の結果整合性のある読み込み。
API Version 2012-08-10
181
Amazon DynamoDB 開発者ガイド
キャパシティーユニットの計算
• 最大サイズ 1 KB の項目について、1 つの書き込みキャパシティーユニット = 1 秒あたり 1 回の書き
込み
項目サイズは、属性名と属性値の長さの合計です。(キャパシティーユニットの消費を最適化するに
は、属性名の長さをできるだけ短くすることをお勧めします。)
Null またはブール属性値のサイズは、属性名の長さ + 1 バイトです。
リスト型またはマップ型の属性は、その内容にかかわらず、余分な 3 バイトが必要です。空のリスト
またはマップのサイズは、属性名の長さ + 3 バイトです。属性が空でない場合、サイズは、属性名の
長さ + 属性値の長さの合計 + 3 バイトです。
読み取り操作
DynamoDB 読み込みオペレーションが読み込みキャパシティーユニットを消費する仕組みについて次
に説明します。
• GetItem – テーブルから単一の項目を読み取ります。キャパシティーユニットの計算では、項目サ
イズは、次の 4 KB 境界に切り上げられます。たとえば、3.5 KB の項目を読み取ると、DynamoDB
は項目サイズを 4 KB まで切り上げます。10 KB の項目を読み取ると、DynamoDB は項目サイズを
12 KB まで切り上げます。
• BatchGetItem – 1 つ以上のテーブルから 100 個の項目を読み取ります。DynamoDB はバッチ内の
各項目を個別の GetItem リクエストとして処理するため、DynamoDB は、まず各項目のサイズを
次の &read_size; 境界に切り上げ、次に合計サイズを算出します。この結果は、すべての項目の合
計サイズと必ずしも同じではありません。たとえば、BatchGetItem が 1.5 KB の項目と 6.5 KB の
項目を読み込むと、DynamoDB は、サイズを 8 KB(1.5 KB + 6.5 KB)ではなく、12 KB(4 KB + 8
KB)と算出します。
• Query - 同じパーティションキー値を持つ複数の項目を読み取ります。返されるすべての項目は単
一の読み取りオペレーションとして扱われ、DynamoDB はすべての項目の合計サイズを計算し、次
の 4 KB 境界に切り上げます。たとえば、クエリの結果、合計サイズが 40.8 KB になる 10 項目が返
されるとします。DynamoDB はオペレーションの項目サイズを 44 KB まで切り上げます。クエリ
の結果、64 バイトの項目が 1,500 項目返されると、累積サイズは 96 KB になります。
• Scan - テーブルのすべての項目を読み取ります。DynamoDB は、スキャンにより返される項目のサ
イズではなく、評価される項目のサイズを考慮します。
存在しない項目に対して読み込みオペレーションを実行しても、DynamoDB ではやはりプロビジョ
ンド読み込みスループットが消費されます。強力な整合性のある読み込みオペレーションでは、1 つ
の読み込みキャパシティーユニットが消費されますが、結果整合性のある読み込みオペレーションで
は、半分の読み込みキャパシティーユニットが消費されます。
項目を返すオペレーションの場合、取り出す属性の一部をリクエストできます。ただし、項目サイズ
の計算には影響を及ぼしません。また、Query と Scan は、属性値の代わりに項目数を返します。項
目数の取得には、同じ量の読み込みキャパシティーユニットが使用され、その結果は同じ項目サイズ
の計算の影響を受けます。これは、DynamoDB では、項目数を増加させるために各項目を読み込む必
要があるからです。
読み取りオペレーションと読み取り整合性
前出の計算によって、強い整合性のある読み込みリクエストが仮定されます。結果整合性のある読み
込みリクエストでは、このオペレーションによってキャパシティーユニットの半分のみが消費されま
す。結果整合性のある読み込みでは、合計項目サイズが 80 KB の場合、オペレーションによって 10
キャパシティーユニットのみが消費されます。
書き込み操作
DynamoDB 書き込みオペレーションが書き込みキャパシティーユニットを消費する仕組みについて次
に説明します。
API Version 2012-08-10
182
Amazon DynamoDB 開発者ガイド
テーブルのリストと情報を取得する
• PutItem – テーブルに単一の項目を書き込みます。同じプライマリキーを持つ項目がテーブル内に
存在する場合、このオペレーションによって項目が置き換えられます。プロビジョニングされたス
ループットの消費量を算出する場合、重要な項目サイズは 2 つのうち大きい方となります。
• UpdateItem - テーブル内の単一の項目を変更します。DynamoDB は更新前後に表示される項目の
サイズを考慮します。プロビジョニングされたスループットの消費は、これらの項目サイズの大き
い方を反映しています。項目の属性の一部だけを更新した場合でも、UpdateItem は、プロビジョ
ニングされたスループットの総量 ("前" の項目サイズと "後" の項目サイズで、より大きい方) を消費
します。
• DeleteItem – テーブルから単一の項目を削除します。プロビジョニングされたスループットの消
費量は、削除された項目のサイズに基づいています。
• BatchWriteItem – 1 つ以上のテーブルに最大 25 個の項目を書き込みます。DynamoDB はバッ
チの各項目を個別の PutItem または DeleteItem リクエスト (更新はサポートされない) とし
て処理するため、DynamoDB は各項目のサイズを 1 KB 境界にまず切り上げてから、合計サイズ
を計算します。この結果は、すべての項目の合計サイズと必ずしも同じではありません。たとえ
ば、BatchWriteItem が 500 バイトと 3.5 KB の項目を書き込んだ場合、DynamoDB はサイズ
を、4 KB (500 bytes + 3.5 KB) ではなく、5 KB (1 KB + 4 KB) と計算します。
PutItem、UpdateItem、および DeleteItem オペレーションでは、DynamoDB は項目のサイズを
次の 1 KB に切り上げます。たとえば、1.6 KB の項目を入力または削除すると、DynamoDB は項目サ
イズを 2 KB まで切り上げます。
PutItem、UpdateItem、DeleteItem では、条件付き書き込みが可能です。これは指定した条件が
true と評価された場合のみ書き込みオペレーションが行われるというものです。式が false と評価さ
れた場合でも、DynamoDB はテーブルの書き込みキャパシティーユニットを消費します。
• 項目が存在する場合、消費される書き込みキャパシティーユニットの数は、項目のサイズによっ
て異なります (たとえば、1 KB の項目の条件付き書き込みが失敗すると、1 つの書き込みキャパシ
ティーユニットが消費されます。項目のサイズがその倍である場合、条件付き書き込みが失敗する
と、2 つの書き込みキャパシティーユニットが消費されます)。
• 項目が存在しない場合、DynamoDB は 1 つの書き込みキャパシティーユニットを消費します。
テーブルのリストと情報を取得する
すべてのテーブルのリストを取得するには、ListTables オペレーションを使用しま
す。ListTables の 1 回の 呼び出しで、最大 100 個のテーブル名を取得できます。テーブルの数が
100 個を超える場合は、ListTables によってページ分割された結果が返されるようにリクエストす
ることで、すべてのテーブル名を取得できます。
任意のテーブルの構造を調べるには、DescribeTable オペレーションを使用しま
す。DescribeTable によって返されるメタデータには、テーブル作成時のタイムスタンプ、キース
キーマ、プロビジョンドスループット設定、推定サイズ、既存のすべての セカンダリインデックス が
含まれています。
Note
CreateTable のリクエスト直後に DescribeTable リクエストを発行した場
合、DynamoDB によって ResourceNotFoundException が返されることがありま
す。DescribeTable で結果整合性のあるクエリが使用されており、テーブルのメタデータが
その時点で使用できない可能性があるためです。数秒間待ってから、再び DescribeTable
リクエストを試してみてください。
テーブルで使用されるストレージの計算時に、DynamoDB は、100 bytes のオーバーヘッド
をインデックス化の目的で各項目に追加します。DescribeTable オペレーションは、この
オーバーヘッドを含むテーブルサイズを返します。また、このオーバーヘッドは、ストレー
ジ費用に算入されます。ただし、この余分な 100 bytes は、キャパシティーユニットの計算に
は使用されません。価格の詳細については、「DynamoDB Pricing」を参照してください。
API Version 2012-08-10
183
Amazon DynamoDB 開発者ガイド
DynamoDB のタグ付け
DynamoDB のタグ付け
DynamoDB リソースにタグでラベルを付けることができます。タグを使用すると、リソースを目的、
所有者、環境、その他の条件などさまざまな方法で分類することができます。タグは次のことに役立
ちます。
• リソースに割り当てたタグに基づいてリソースをすばやく特定する。
• タグ別に分類された AWS 請求を表示する。
Note
タグが付けられたテーブルに関連するローカルセカンダリインデックス (LSI) およびグロー
バルセカンダリインデックス (GSI) は、自動的に同じタグでラベルが付けられます。現在の
ところ、DynamoDB Streams の使用にタグを付けることはできません。
タグ付けは、Amazon EC2、Amazon S3、DynamoDB などの AWS のサービスでサポートされていま
す。効率的なタグ付けを行うと、特定のタグを持つサービス間でレポートを作成でき、コストインサ
イトを得ることができます。
タグ付けを開始するには、次の操作を実行します。
1. タグ付けの制限 (p. 184) について理解します。
2. タグ付けオペレーション (p. 184) を使用してタグを作成します。
3. コスト配分レポート (p. 185) を使用して、アクティブなタグごとに AWS のコストを追跡しま
す。
最後に、最適のタグ付け手法に従うことをお勧めします。詳細については、「AWS Tagging
Strategies」を参照してください。
タグ付けの制限
タグはそれぞれ、1 つのキーと 1 つの値で構成されており、どちらもお客様側が定義します。以下の
制限が適用されます。
• 各 DynamoDB テーブルは同じキーを含む 1 つのタグのみを持つことができます。既存のタグ (同じ
キー) を追加しようとすると、既存のタグの値は新しい値に更新されます。
• タグのキーと値は大文字と小文字が区別されます。
• キーの最大長: 128 文字(Unicode)
• 値の最大長: 256 文字(Unicode)
• 使用できる文字は、文字、ホワイトスペース、数字、および特殊文字 +、-、= です。_ : /
• リソースあたりのタグの最大数: 50
• AWS 側で割り当てたタグ名と値には自動的に aws: というプレフィックスが付けられますが、これ
を割り当てることはできません。AWS 側で割り当てたタグ名は、50 個というタグ数の制限には含
まれません。ユーザー側で割り当てたタグ名は、user: というプレフィックスを付けてコスト配分
レポートに表示されます。
• リソースの作成と同時にタグを付けることはできません。タグ付けは、リソースが作成された後で
のみ実行できる別のアクションです。
• 過去にさかのぼってタグを適用することはできません。
タグ付けオペレーション
このセクションでは、DynamoDB コンソールまたは CLI を使用してタグを追加、リスト、編集、また
は削除する方法について説明します。次に、これらのユーザー定義タグをアクティブ化し、コスト配
API Version 2012-08-10
184
Amazon DynamoDB 開発者ガイド
DynamoDB のタグ付け
分の追跡のため、Billing and Cost Management コンソールに表示できます。詳細については、「コス
ト配分レポート (p. 185)」を参照してください。
一括編集の場合は、AWS マネジメントコンソールのタグエディターを使用することもできます。詳細
については、「Tag Editor の使用」を参照してください。
代わりに API を使用する場合は、「Amazon DynamoDB API Reference」を参照してください。
トピック
• タグ付け (コンソール) (p. 185)
• タグ付け (CLI) (p. 185)
タグ付け (コンソール)
コンソールを使用してタグを追加、リスト、編集、または削除するには:
1. https://console.aws.amazon.com/dynamodb/home にある DynamoDB コンソールを開きます。
2. テーブルを選択し、[Settings] タブを選択します。
ここでタグを追加、リスト、編集、または削除できます。この例で、Movies タグは、映画テーブ
ル用に値 moviesProd で作成されました。
タグ付け (CLI)
映画テーブル用に値 blueTeam で Owner タグを追加するには:
aws dynamodb tag-resource \
--resource-arn arn:aws:dynamodb:us-east-1:123456789012:table/Movies \
--tags Key=Owner,Value=blueTeam
映画テーブルに関連付けられているすべてのタグをリストするには:
aws dynamodb list-tags-of-resource \
--resource-arn arn:aws:dynamodb:us-east-1:123456789012:table/Movies
コスト配分レポート
AWS ではタグを使用して、コスト配分レポートでリソースのコストが整理されます。AWS は 2 種類
のコスト配分タグを提供しています。
• AWS が生成したタグ。AWS は、お客様に代わってこのタグを定義、作成、適用します。
• ユーザー定義タグ。これらのタグは、お客様が定義、作成、適用します。
コストエクスプローラーまたはコスト配分レポートで使用するには、事前に両方のタイプのタグを
別々にアクティブ化しておく必要があります。
AWS が生成したタグをアクティブ化するには:
1. https://console.aws.amazon.com/billing/home#/ で AWS マネジメントコンソールにサインインし、
[Billing and Cost Management] コンソールを開きます。
2. ナビゲーションペインで、[Cost Allocation Tags] を選択します。
3. [AWS-Generated Cost Allocation Tags] で、[Activate] を選択します。
API Version 2012-08-10
185
Amazon DynamoDB 開発者ガイド
テーブルの操作 : Java
ユーザー定義タグをアクティブ化するには:
1. https://console.aws.amazon.com/billing/home#/ で AWS マネジメントコンソールにサインインし、
[Billing and Cost Management] コンソールを開きます。
2. ナビゲーションペインで、[Cost Allocation Tags] を選択します。
3. [User-Defined Cost Allocation Tags] で、[Activate] を選択します。
タグを作成し、アクティブ化すると、アクティブなタグによってグループ化された使用量とコストを
含むコスト配分レポートが AWS によって生成されます。コスト配分レポートには、ご利用の AWS
サービスのコストすべてが請求期間別に出力されます。タグ付きとタグなしのどちらのリソースもこ
のレポートに出力されるので、リソース別の請求額を明確に分類できます。
Note
現在のところ、DynamoDB から転送されるすべてのデータが、コスト配分レポートでタグ別
に分類されるわけではありません。
詳細については、「コスト配分タグの使用」を参照してください。
テーブルの操作 : Java
トピック
• テーブルの作成 (p. 186)
• テーブルの更新 (p. 187)
• テーブルの削除 (p. 188)
• テーブルの一覧表示 (p. 188)
• 例: AWS SDK for Java ドキュメント API を使用したテーブルの作成、更新、削除、一覧表
示 (p. 189)
AWS SDK for Java を使用して、テーブルの作成、更新、削除、アカウント内の全テーブルの一覧表
示、特定のテーブルに関する情報収集を実行できます。
次に、AWS SDK for Java ドキュメント API を使用したテーブルオペレーションの一般的なステップ
を示します。
テーブルの作成
テーブルを作成するには、テーブル名、プライマリキー、およびプロビジョニングされたスループッ
ト値を指定する必要があります。以下の コードスニペットでは、数値型の属性 Id をプライマリキー
として使用するサンプルテーブルを作成します。
AWS SDK for Java API を使用してテーブルを作成するには:
1. DynamoDB クラスのインスタンスを作成します。
2. CreateTableRequest をインスタンス化して、リクエスト情報を指定します。
テーブル名、属性定義、キースキーマ、プロビジョニングされたスループット値を指定する必要が
あります。
3. リクエストオブジェクトをパラメータとして指定して、createTable メソッドを実行します。
以下の コードスニペットは、前述のステップの例です。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
API Version 2012-08-10
186
Amazon DynamoDB 開発者ガイド
テーブルの操作 : Java
new ProfileCredentialsProvider()));
ArrayList<AttributeDefinition> attributeDefinitions= new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new
AttributeDefinition().withAttributeName("Id").withAttributeType("N"));
ArrayList<KeySchemaElement> keySchema = new ArrayList<KeySchemaElement>();
keySchema.add(new
KeySchemaElement().withAttributeName("Id").withKeyType(KeyType.HASH));
CreateTableRequest request = new CreateTableRequest()
.withTableName(tableName)
.withKeySchema(keySchema)
.withAttributeDefinitions(attributeDefinitions)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits(5L)
.withWriteCapacityUnits(6L));
Table table = dynamoDB.createTable(request);
table.waitForActive();
DynamoDB によりテーブルが作成され、そのステータスが ACTIVE に設定されるまでは、テーブルを
使用する準備ができません。 createTable リクエストは、テーブルについての詳細情報を取得する
ために使用できる Table オブジェクトを返します。
TableDescription tableDescription =
dynamoDB.getTable(tableName).describe();
System.out.printf("%s: %s \t ReadCapacityUnits: %d \t WriteCapacityUnits:
%d",
tableDescription.getTableStatus(),
tableDescription.getTableName(),
tableDescription.getProvisionedThroughput().getReadCapacityUnits(),
tableDescription.getProvisionedThroughput().getWriteCapacityUnits());
クライアントの describe メソッドを呼び出せば、いつでもテーブル情報を収集できます。
TableDescription tableDescription = dynamoDB.getTable(tableName).describe();
テーブルの更新
既存のテーブルのプロビジョニングされたスループット値のみを更新できます。ご利用のアプリケー
ションの要件によっては、これらの値を更新する必要があります。
Note
読み込みキャパシティーユニットと書き込みキャパシティーユニットは、いつでも増やせま
す。ただし、これらの値を減らすことができるのは、24 時間で 4 回 だけです。詳細なガイド
ラインおよび制限については、「テーブルの読み書き要件の指定 (p. 179)」を参照してくだ
さい。
AWS SDK for Java API を使用してテーブルを更新するには:
1. Table クラスのインスタンスを作成します。
API Version 2012-08-10
187
Amazon DynamoDB 開発者ガイド
テーブルの操作 : Java
2. ProvisionedThroughput クラスのインスタンスを作成して、新しいスループット値を指定しま
す。
3. ProvisionedThroughput インスタンスをパラメータとして指定して、updateTable メソッドを
実行します。
以下の コードスニペットは、前述のステップの例です。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductCatalog");
ProvisionedThroughput provisionedThroughput = new ProvisionedThroughput()
.withReadCapacityUnits(15L)
.withWriteCapacityUnits(12L);
table.updateTable(provisionedThroughput);
table.waitForActive();
テーブルの削除
テーブルを削除するには:
1. Table クラスのインスタンスを作成します。
2. DeleteTableRequest クラスのインスタンスを作成し、削除するテーブル名を指定します。
3. Table インスタンスをパラメータとして指定して、deleteTable メソッドを実行します。
以下の コードスニペットは、前述のステップの例です。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductCatalog");
table.delete();
table.waitForDelete();
テーブルの一覧表示
アカウントのテーブルを一覧表示するには、DynamoDB のインスタンスを作成し、listTables メ
ソッドを実行します。ListTables オペレーションはパラメータを必要としません。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
TableCollection<ListTablesResult> tables = dynamoDB.listTables();
Iterator<Table> iterator = tables.iterator();
while (iterator.hasNext()) {
Table table = iterator.next();
System.out.println(table.getTableName());
API Version 2012-08-10
188
Amazon DynamoDB 開発者ガイド
テーブルの操作 : Java
}
例: AWS SDK for Java ドキュメント API を使用したテーブル
の作成、更新、削除、一覧表示
次のコード例では、AWS SDK for Java ドキュメント API を使用して、テーブル(ExampleTable)
を作成、更新、削除します。 このテーブル更新の一環として、プロビジョニングされたスループッ
ト値が増加します。この例では、アカウント内にすべてのテーブルが一覧表示され、固有のテーブ
ルの説明が取得されます。以下の例を実行するための詳しい手順については、「Java コードサンプ
ル (p. 171)」を参照してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import java.util.ArrayList;
import java.util.Iterator;
import
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Table;
com.amazonaws.services.dynamodbv2.document.TableCollection;
com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
com.amazonaws.services.dynamodbv2.model.KeyType;
com.amazonaws.services.dynamodbv2.model.ListTablesResult;
com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
com.amazonaws.services.dynamodbv2.model.TableDescription;
public class DocumentAPITableExample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tableName = "ExampleTable";
public static void main(String[] args) throws Exception {
createExampleTable();
listMyTables();
getTableInformation();
updateExampleTable();
deleteExampleTable();
}
static void createExampleTable() {
try {
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Id")
API Version 2012-08-10
189
Amazon DynamoDB 開発者ガイド
テーブルの操作 : Java
.withAttributeType("N"));
ArrayList<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new KeySchemaElement()
.withAttributeName("Id")
.withKeyType(KeyType.HASH)); //Partition key
CreateTableRequest request = new CreateTableRequest()
.withTableName(tableName)
.withKeySchema(keySchema)
.withAttributeDefinitions(attributeDefinitions)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits(5L)
.withWriteCapacityUnits(6L));
System.out.println("Issuing CreateTable request for " +
tableName);
Table table = dynamoDB.createTable(request);
System.out.println("Waiting for " + tableName
+ " to be created...this may take a while...");
table.waitForActive();
getTableInformation();
} catch (Exception e) {
System.err.println("CreateTable request failed for " +
tableName);
System.err.println(e.getMessage());
}
}
static void listMyTables() {
TableCollection<ListTablesResult> tables = dynamoDB.listTables();
Iterator<Table> iterator = tables.iterator();
System.out.println("Listing table names");
while (iterator.hasNext()) {
Table table = iterator.next();
System.out.println(table.getTableName());
}
}
static void getTableInformation() {
System.out.println("Describing " + tableName);
TableDescription tableDescription =
dynamoDB.getTable(tableName).describe();
System.out.format("Name: %s:\n" + "Status: %s \n"
+ "Provisioned Throughput (read capacity units/sec): %d \n"
+ "Provisioned Throughput (write capacity units/sec): %d \n",
tableDescription.getTableName(),
tableDescription.getTableStatus(),
tableDescription.getProvisionedThroughput().getReadCapacityUnits(),
API Version 2012-08-10
190
Amazon DynamoDB 開発者ガイド
テーブルの操作 : .NET
tableDescription.getProvisionedThroughput().getWriteCapacityUnits());
}
static void updateExampleTable() {
Table table = dynamoDB.getTable(tableName);
System.out.println("Modifying provisioned throughput for " +
tableName);
try {
table.updateTable(new ProvisionedThroughput()
.withReadCapacityUnits(6L).withWriteCapacityUnits(7L));
table.waitForActive();
} catch (Exception e) {
System.err.println("UpdateTable request failed for " +
tableName);
System.err.println(e.getMessage());
}
}
static void deleteExampleTable() {
Table table = dynamoDB.getTable(tableName);
try {
System.out.println("Issuing DeleteTable request for " +
tableName);
table.delete();
System.out.println("Waiting for " + tableName
+ " to be deleted...this may take a while...");
table.waitForDelete();
} catch (Exception e) {
System.err.println("DeleteTable request failed for " +
tableName);
System.err.println(e.getMessage());
}
}
}
テーブルの操作 : .NET
トピック
• テーブルの作成 (p. 192)
• テーブルの更新 (p. 193)
• テーブルの削除 (p. 194)
• テーブルの一覧表示 (p. 194)
• 例: AWS SDK for .NET の低レベル API を使用した、テーブルの作成、更新、削除、一覧表
示 (p. 195)
AWS SDK for .NET を使用して、テーブルの作成、更新、削除、アカウント内の全テーブルの一覧表
示、特定のテーブルに関する情報収集を実行できます。
以下に、AWS SDK for .NET を使用したテーブルオペレーションの一般的な手順を示します。
API Version 2012-08-10
191
Amazon DynamoDB 開発者ガイド
テーブルの操作 : .NET
1. AmazonDynamoDBClient クラスのインスタンス(クライアント)を作成します。
2. 対応するリクエストオブジェクトを作成して、オペレーションについて必要なパラメータとオプ
ションパラメータを入力します。
たとえば、テーブルを作成するには CreateTableRequest オブジェクトを作成し、既存のテーブ
ルを更新するには UpdateTableRequest オブジェクトを作成します。
3. 前述のステップで作成したクライアントから提供された適切なメソッドを実行します。
テーブルの作成
テーブルを作成するには、テーブル名、プライマリキー、およびプロビジョニングされたスループッ
ト値を指定する必要があります。
以下に、.NET 低レベル API を使用してテーブルを作成する手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. リクエスト情報を指定する CreateTableRequest クラスのインスタンスを作成します。
テーブル名、プライマリキー、およびプロビジョニングされたスループット値を指定する必要があ
ります。
3. リクエストオブジェクトをパラメータとして指定して、AmazonDynamoDBClient.CreateTable
メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。このサンプルでは、Id をプライマリ
キーとして使用するテーブル(ProductCatalog)、およびプロビジョニングされたスループット値の
セットを作成します。ご利用のアプリケーションの要件によっては、UpdateTable API を使用して、
プロビジョニングされたスループット値を更新できます。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ProductCatalog";
var request = new CreateTableRequest
{
TableName = tableName,
AttributeDefinitions = new List<AttributeDefinition>()
{
new AttributeDefinition
{
AttributeName = "Id",
AttributeType = "N"
}
},
KeySchema = new List<KeySchemaElement>()
{
new KeySchemaElement
{
AttributeName = "Id",
KeyType = "HASH" //Partition key
}
},
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = 10,
WriteCapacityUnits = 5
}
};
API Version 2012-08-10
192
Amazon DynamoDB 開発者ガイド
テーブルの操作 : .NET
var response = client.CreateTable(request);
DynamoDB がテーブルを作成し、テーブルのステータスを ACTIVE に設定するまで待機する必要が
あります。CreateTable 応答には、必要なテーブル情報が記載された TableDescription プロパ
ティが含まれます。
var result = response.CreateTableResult;
var tableDescription = result.TableDescription;
Console.WriteLine("{1}: {0} \t ReadCapacityUnits: {2} \t WriteCapacityUnits:
{3}",
tableDescription.TableStatus,
tableDescription.TableName,
tableDescription.ProvisionedThroughput.ReadCapacityUnits,
tableDescription.ProvisionedThroughput.WriteCapacityUnits);
string status = tableDescription.TableStatus;
Console.WriteLine(tableName + " - " + status);
また、クライアントの DescribeTable メソッドを呼び出せば、いつでもテーブル情報を収集できま
す。
var res = client.DescribeTable(new DescribeTableRequest{TableName =
"ProductCatalog"});
テーブルの更新
既存のテーブルのプロビジョニングされたスループット値のみを更新できます。ご利用のアプリケー
ションの要件によっては、これらの値を更新する必要があります。
Note
読み込みキャパシティーユニットと書き込みキャパシティーユニットは、いつでも増やせ
ます。また、読み込みキャパシティーユニットは、いつでも減らせます。ただし、書き込み
キャパシティーユニットを減らすことができるのは、24 時間で 4 回 だけです。変更する場合
は、必ず現在の値から 10% 以上は変更してください。詳細なガイドラインおよび制限につい
ては、「テーブルの読み書き要件の指定 (p. 179)」を参照してください。
以下に、.NET 低レベル API を使用してテーブルを更新する手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. リクエスト情報を指定する UpdateTableRequest クラスのインスタンスを作成します。
テーブル名およびプロビジョニングされたスループット値を指定する必要があります。
3. リクエストオブジェクトをパラメータとして指定して、AmazonDynamoDBClient.UpdateTable
メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ExampleTable";
var request = new UpdateTableRequest()
{
TableName = tableName,
API Version 2012-08-10
193
Amazon DynamoDB 開発者ガイド
テーブルの操作 : .NET
ProvisionedThroughput = new ProvisionedThroughput()
{
// Provide new values.
ReadCapacityUnits = 20,
WriteCapacityUnits = 10
}
};
var response = client.UpdateTable(request);
テーブルの削除
以下に、.NET 低レベル API を使用してテーブルを削除する手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. DeleteTableRequest クラスのインスタンスを作成し、削除するテーブル名を指定します。
3. リクエストオブジェクトをパラメータとして指定して、AmazonDynamoDBClient.DeleteTable
メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ExampleTable";
var request = new DeleteTableRequest{ TableName = tableName };
var response = client.DeleteTable(request);
テーブルの一覧表示
アカウント内にテーブルを一覧表示するには、AWS SDK for .NET 低レベル API を使用し
て、AmazonDynamoDBClient のインスタンスを作成し、ListTables メソッドを実行しま
す。ListTables オペレーションはパラメータを必要としません。ただし、オプションパラメータ
を指定できます。たとえば、ページングを使用して 1 ページあたりのテーブル名を制限する場
合には、Limit パラメータを設定できます。この場合は、以下の C# コードスニペットに示すよ
うに、ListTablesRequest オブジェクトを作成し、オプションパラメータを指定する必要が
あります。ページサイズに加え、このリクエストでは、ExclusiveStartTableName パラメー
タを設定します。ただし、初めは、ExclusiveStartTableName は null です。最初のページ
の結果を取り出した後に次ページの結果を取り出すには、このパラメータ値を、現在の結果の
LastEvaluatedTableName プロパティに設定する必要があります。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
// Initial value for the first page of table names.
string lastEvaluatedTableName = null;
do
{
// Create a request object to specify optional parameters.
var request = new ListTablesRequest
{
Limit = 10, // Page size.
ExclusiveStartTableName = lastEvaluatedTableName
};
var response = client.ListTables(request);
ListTablesResult result = response.ListTablesResult;
foreach (string name in result.TableNames)
Console.WriteLine(name);
API Version 2012-08-10
194
Amazon DynamoDB 開発者ガイド
テーブルの操作 : .NET
lastEvaluatedTableName = result.LastEvaluatedTableName;
} while (lastEvaluatedTableName != null);
例: AWS SDK for .NET の低レベル API を使用した、テーブル
の作成、更新、削除、一覧表示
次の C# の例では、テーブル (ExampleTable) を作成、更新、および削除します。 アカウント内にす
べてのテーブルが一覧表示され、固有のテーブルの説明が取得されます。このテーブル更新によっ
て、プロビジョニングされたスループット値が増加します。次のサンプルをテストするための詳しい
手順については、「.NET コードサンプル (p. 173)」を参照してください。
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class LowLevelTableExample
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
private static string tableName = "ExampleTable";
static void Main(string[] args)
{
try
{
CreateExampleTable();
ListMyTables();
GetTableInformation();
UpdateExampleTable();
DeleteExampleTable();
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
private static void CreateExampleTable()
{
Console.WriteLine("\n*** Creating table ***");
var request = new CreateTableRequest
{
AttributeDefinitions = new List<AttributeDefinition>()
{
new AttributeDefinition
API Version 2012-08-10
195
Amazon DynamoDB 開発者ガイド
テーブルの操作 : .NET
{
AttributeName = "Id",
AttributeType = "N"
},
new AttributeDefinition
{
AttributeName = "ReplyDateTime",
AttributeType = "N"
}
},
KeySchema = new List<KeySchemaElement>
{
new KeySchemaElement
{
AttributeName = "Id",
KeyType = "HASH" //Partition key
},
new KeySchemaElement
{
AttributeName = "ReplyDateTime",
KeyType = "RANGE" //Sort key
}
},
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = 5,
WriteCapacityUnits = 6
},
TableName = tableName
};
var response = client.CreateTable(request);
var tableDescription = response.TableDescription;
Console.WriteLine("{1}: {0} \t ReadsPerSec: {2} \t WritesPerSec:
{3}",
tableDescription.TableStatus,
tableDescription.TableName,
tableDescription.ProvisionedThroughput.ReadCapacityUnits,
tableDescription.ProvisionedThroughput.WriteCapacityUnits);
string status = tableDescription.TableStatus;
Console.WriteLine(tableName + " - " + status);
WaitUntilTableReady(tableName);
}
private static void ListMyTables()
{
Console.WriteLine("\n*** listing tables ***");
string lastTableNameEvaluated = null;
do
{
var request = new ListTablesRequest
{
Limit = 2,
API Version 2012-08-10
196
Amazon DynamoDB 開発者ガイド
テーブルの操作 : .NET
ExclusiveStartTableName = lastTableNameEvaluated
};
var response = client.ListTables(request);
foreach (string name in response.TableNames)
Console.WriteLine(name);
lastTableNameEvaluated = response.LastEvaluatedTableName;
} while (lastTableNameEvaluated != null);
}
private static void GetTableInformation()
{
Console.WriteLine("\n*** Retrieving table information ***");
var request = new DescribeTableRequest
{
TableName = tableName
};
var response = client.DescribeTable(request);
TableDescription description = response.Table;
Console.WriteLine("Name: {0}", description.TableName);
Console.WriteLine("# of items: {0}", description.ItemCount);
Console.WriteLine("Provision Throughput (reads/sec): {0}",
description.ProvisionedThroughput.ReadCapacityUnits);
Console.WriteLine("Provision Throughput (writes/sec): {0}",
description.ProvisionedThroughput.WriteCapacityUnits);
}
private static void UpdateExampleTable()
{
Console.WriteLine("\n*** Updating table ***");
var request = new UpdateTableRequest()
{
TableName = tableName,
ProvisionedThroughput = new ProvisionedThroughput()
{
ReadCapacityUnits = 6,
WriteCapacityUnits = 7
}
};
var response = client.UpdateTable(request);
WaitUntilTableReady(tableName);
}
private static void DeleteExampleTable()
{
Console.WriteLine("\n*** Deleting table ***");
var request = new DeleteTableRequest
{
TableName = tableName
};
API Version 2012-08-10
197
Amazon DynamoDB 開発者ガイド
テーブルの操作 : PHP
var response = client.DeleteTable(request);
Console.WriteLine("Table is being deleted...");
}
private static void WaitUntilTableReady(string tableName)
{
string status = null;
// Let us wait until table is created. Call DescribeTable.
do
{
System.Threading.Thread.Sleep(5000); // Wait 5 seconds.
try
{
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
status = res.Table.TableStatus;
}
catch (ResourceNotFoundException)
{
// DescribeTable is eventually consistent. So you might
// get resource not found. So we handle the potential
exception.
}
} while (status != "ACTIVE");
}
}
}
テーブルの操作 : PHP
トピック
• テーブルの作成 (p. 199)
• テーブルの更新 (p. 200)
• テーブルの削除 (p. 200)
• テーブルの一覧表示 (p. 201)
• 例: AWS SDK for PHP の低レベル API を使用した、テーブルの作成、更新、削除、一覧表
示 (p. 202)
AWS SDK for PHP を使用して、テーブルの作成、更新、削除、アカウント内の全テーブルの一覧表
示、特定のテーブルに関する情報収集を実行できます。
以下に、PHP の SDK を使用した DynamoDB オペレーションの一般的な手順を示します。
1. DynamoDB クライアントのインスタンスを作成します。
2. オプションのパラメーターを含む DynamoDB オペレーションのパラメーターを指定します。
3. DynamoDB からの応答をアプリケーションのローカル変数にロードします。
API Version 2012-08-10
198
Amazon DynamoDB 開発者ガイド
テーブルの操作 : PHP
テーブルの作成
テーブルを作成するには、テーブル名、プライマリキー、およびプロビジョニングされたスループッ
ト値を指定する必要があります。以下の PHP コードサンプルでは、数値型の属性 Id をプライマリ
キーとして使用する ExampleTable を作成します。
次の PHP コードスニペットでは、Id をプライマリキーとして使用するテーブル (ProductCatalog)、お
よびプロビジョニングされたスループット値のセットを作成します。ご利用のアプリケーションの要
件によっては、updateTable メソッドを使用して、プロビジョニングされたスループット値を更新
できます。
require 'vendor/autoload.php';
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'ExampleTable';
echo "# Creating table $tableName...\n";
$result = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[ 'AttributeName' => 'Id', 'AttributeType' => 'N' ]
],
'KeySchema' => [
[ 'AttributeName' => 'Id', 'KeyType' => 'HASH' ]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits'
=> 5,
'WriteCapacityUnits' => 6
]
]);
print_r($result->getPath('TableDescription'));
データをテーブル内に配置するには、DynamoDB がテーブルを作成し、テーブルのステータスを
ACTIVE に設定するまで待機する必要があります。クライアントの waitUntil 関数を使用して、
テーブルのステータスが ACTIVE になるまで待機することができます。
次の コードスニペットはそれを行う方法を示しています。連想配列 @waiter はオプションであ
り、waitUntil のポーリングオプションを指定することができます。
$dynamodb->waitUntil('TableExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
]);
API Version 2012-08-10
199
Amazon DynamoDB 開発者ガイド
テーブルの操作 : PHP
テーブルの更新
既存のテーブルを更新し、プロビジョニングされたスループット値またはセカンダリインデックスを
変更できます。
UpdateTable リクエストが成功するとすぐに、テーブルのステータスは UPDATING になります。オ
ペレーションが完了すると、テーブルの状態は ACTIVE に戻ります。
以下の PHP コードスニペットは、テーブルのプロビジョニングされたスループット設定を変更しま
す。次に、テーブルが再度 ACTIVE になるまで待機します。
$tableName = 'ExampleTable';
echo "Updating provisioned throughput settings on $tableName...\n";
$result = $dynamodb->updateTable([
'TableName' => $tableName,
'ProvisionedThroughput'
=> [
'ReadCapacityUnits'
=> 6,
'WriteCapacityUnits' => 7
]
]);
$dynamodb->waitUntil('TableExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
]);
echo "New provisioned throughput settings:\n";
echo "Read capacity units: "
. $result['TableDescription']['ProvisionedThroughput']
['ReadCapacityUnits']
. "\n";
echo "Write capacity units: "
. $result['TableDescription']['ProvisionedThroughput']
['WriteCapacityUnits']
. "\n";
テーブルの削除
不要になったテーブルは削除できます。
DeleteTable リクエストが成功するとすぐに、テーブルのステータスは DELETING になります。オ
ペレーションが完了すると、テーブルは存在しなくなります。
以下の PHP コードスニペットはテーブルを削除し、オペレーションが完了するまで待機します。
$tableName = 'ExampleTable';
echo "Deleting the table...\n";
API Version 2012-08-10
200
Amazon DynamoDB 開発者ガイド
テーブルの操作 : PHP
$result = $dynamodb->deleteTable([
'TableName' => $tableName
]);
$dynamodb->waitUntil('TableNotExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
]);
echo "The table has been deleted.\n";
テーブルの一覧表示
ListTables オペレーションを使用して、現在の AWS リージョン内のすべてのテーブルの名前を返
します。
オプションのパラメーターを指定できます。たとえば、ページングを使用して 1 ページあたりの
テーブル名を制限する場合には、Limit パラメータを設定できます。ExclusiveStartTableName
パラメータも設定できます。最初のページの結果を取り出すと、DynamoDB は
LastEvalutedTableName 値を返します。ExclusiveStartTableName パラメータに
LastEvalutedTableName の値を使用すると、次のページの結果を取得できます。
次の PHP コードスニペットは、現在の AWS リージョンで所有しているすべてのテーブルをリスト表
示します。ページごとに、2 つのテーブル名の Limit 値を使用して、LastEvalutedTableName の
値を ExclusiveStartTableName パラメーターに使用します。
$tables = [];
unset($response);
do {
if (isset($response)) {
$params = [
'Limit' => 2,
'ExclusiveStartTableName' => $response['LastEvaluatedTableName']
];
}else {
$params = ['Limit' => 2];
}
$response = $dynamodb->listTables($params);
foreach ($response['TableNames'] as $key => $value) {
echo "$value\n";
}
$tables = array_merge($tables, $response['TableNames']);
} while ($response['LastEvaluatedTableName']);
// Print total number of tables
echo "Total number of tables: ";
print_r(count($tables));
echo "\n";
API Version 2012-08-10
201
Amazon DynamoDB 開発者ガイド
テーブルの操作 : PHP
例: AWS SDK for PHP の低レベル API を使用した、テーブル
の作成、更新、削除、一覧表示
次の PHP コード例では、テーブル (ExampleTable) を作成、更新、および削除します。このテーブル
更新の一環として、プロビジョニングされたスループット値が増加します。この例では、現在のリー
ジョンのすべてのテーブルが一覧表示され、固有のテーブルの説明が取得されます。終了時に、この
例ではテーブルが削除されます。
Note
次に示すコード例を実行するための詳しい手順については、「PHP コードサンプ
ル (p. 175)」を参照してください。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'ExampleTable';
echo "# Creating table $tableName...\n";
try {
$response = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[
'AttributeName' => 'Id',
'AttributeType' => 'N'
]
],
'KeySchema' => [
[
'AttributeName' => 'Id',
'KeyType' => 'HASH' //Partition key
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits'
=> 5,
'WriteCapacityUnits' => 6
]
]);
$dynamodb->waitUntil('TableExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
API Version 2012-08-10
202
Amazon DynamoDB 開発者ガイド
テーブルの操作 : PHP
]
]);
print_r($response->getPath('TableDescription'));
echo "table $tableName has been created.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to create table $tableName\n");
}
####################################################################
# Updating the table
echo "# Updating the provisioned throughput of table $tableName.\n";
try {
$response = $dynamodb->updateTable([
'TableName' => $tableName,
'ProvisionedThroughput'
=> [
'ReadCapacityUnits'
=> 6,
'WriteCapacityUnits' => 7
]
]);
$dynamodb->waitUntil('TableExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
]);
echo "New provisioned throughput settings:\n";
$response = $dynamodb->describeTable(['TableName' => $tableName]);
echo "Read capacity units: " .
$response['Table']['ProvisionedThroughput']['ReadCapacityUnits']."\n";
echo "Write capacity units: " .
$response['Table']['ProvisionedThroughput']['WriteCapacityUnits']."\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to update table $tableName\n");
}
####################################################################
# Deleting the table
try {
echo "# Deleting table $tableName...\n";
$response = $dynamodb->deleteTable([ 'TableName' => $tableName]);
$dynamodb->waitUntil('TableNotExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
API Version 2012-08-10
203
Amazon DynamoDB 開発者ガイド
項目の操作
'maxAttempts' => 20
]
]);
echo "The table has been deleted.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to delete table $tableName\n");
}
####################################################################
# List all table names for this AWS account, in this region
echo "# Listing all of your tables in the current region...\n";
$tables = [];
// Walk through table names, two at a time
unset($response);
do {
if (isset($response)) {
$params = [
'Limit' => 2,
'ExclusiveStartTableName' => $response['LastEvaluatedTableName']
];
}else {
$params = ['Limit' => 2];
}
$response = $dynamodb->listTables($params);
foreach ($response['TableNames'] as $key => $value) {
echo "$value\n";
}
$tables = array_merge($tables, $response['TableNames']);
} while ($response['LastEvaluatedTableName']);
// Print total number of tables
echo "Total number of tables: ";
print_r(count($tables));
echo "\n";
?>
DynamoDB での項目の操作
トピック
• 概要 (p. 205)
• 項目を読み込む (p. 206)
• 項目を書き込む (p. 206)
API Version 2012-08-10
204
Amazon DynamoDB 開発者ガイド
概要
• バッチオペレーション (p. 207)
• アトミックカウンタ (p. 207)
• 条件付きの書き込み (p. 208)
• 式を使用した項目の読み取りと書き込み (p. 210)
• 項目の操作 : Java (p. 228)
• 項目の操作 : .NET (p. 250)
• 項目の操作 : PHP (p. 274)
DynamoDB では、項目は属性の集まりです。各属性には名前と値があります。属性値はスカラー型、
セット型、ドキュメント型のいずれかです。詳細については、「データ型 (p. 12)」を参照してくださ
い。
DynamoDB では、項目の読み取りおよび書き込みをするオペレーションを実行できます。これらのオ
ペレーションでは、操作する項目と属性を指定する必要があります。項目を記述するとき、true と評
価される必要のある条件を 1 つ以上指定できます。たとえば、同じキーを持つ既存の項目がない場合
にのみ、書き込みが成功するようにできます。
このセクションでは、Amazon DynamoDB の項目を操作する方法について説明します。項目の読
み込みと書き込み、条件付き更新、アトミックカウンターも取り上げています。このセクションに
は、AWS SDK を使用するサンプルコードも含まれています。ベストプラクティスについては、項目
の操作のガイドライン (p. 577) を参照してください。
概要
1 つの項目は 1 つ以上の属性で構成されます。各属性は名前、データ型、値で構成されます。項目の
読み込みまたは書き込み時、必須の属性はプライマリキーを構成する属性のみです。
Important
プライマリキーでは、その属性をすべて指定する必要があります。たとえば、シンプルなプ
ライマリキーの場合は、パーティションキーを指定する必要があります。複合プライマリ
キー (パーティションキーおよびソートキー) の場合、パーティションキーおよびソートキー
の両方を指定する必要があります。詳細については、次を参照してください。 プライマリ
キー (p. 5)。
プライマリキーの場合を除き、テーブル内の項目には事前定義されたスキーマはありません。たとえ
ば、製品情報を格納するには、ProductCatalog テーブルを作成し、書籍や自転車など、さまざまな製
品項目をこのテーブルに格納できます。以下のテーブルに、書籍と自転車の 2 つの項目を示します。
これらは、ProductCatalog テーブルに格納できます。この例では JSON に似た構文を使用して、属性
値を表しています。
Id(プライマリキー)
101
その他の属性
{
Title = "Book 101 Title"
ISBN = "111-1111111111"
Authors = "Author 1"
Price = "-2"
Dimensions = "8.5 x 11.0 x 0.5"
PageCount = "500"
InPublication = true
ProductCategory = "Book"
}
API Version 2012-08-10
205
Amazon DynamoDB 開発者ガイド
項目を読み込む
Id(プライマリキー)
201
その他の属性
{
Title = "18-Bicycle 201"
Description = "201 description"
BicycleType = "Road"
Brand = "Brand-Company A"
Price = "100"
Color = [ "Red", "Black" ]
ProductCategory = "Bike"
}
個々の項目には多数の属性がありますが、項目サイズに対する 400 KB の制限があります。項目のサ
イズは、属性名と値の長さの合計です(バイナリおよび UTF-8 の長さ)です。したがって、属性名は
短く保つことをお勧めします。
項目を読み込む
DynamoDB テーブルから項目を読み込むには、GetItem オペレーションを使用します。必要な項目
のプライマリキーと共にテーブルの名前を指定する必要があります。
プライマリキーでは、一部ではなくすべての属性を指定する必要があります。たとえば、テーブルに
複合プライマリキー (パーティションキーおよびソートキー) がある場合、パーティションキーおよび
ソートキーの値を指定する必要があります。
次に示しているのは、GetItem のデフォルトの動作です。
• GetItem は、結果整合性のある読み込みを行います。
• GetItem は、項目のすべての属性を返します。
• GetItem は、消費されるプロビジョンドキャパシティーユニットについて情報を返しません。
GetItem にはオプションのパラメーターが用意されているため、必要に応じてこれらのデフォルトを
上書きすることができます。
読み込み整合性
DynamoDB では、堅牢性を確保するために各項目のコピーが複数保持されます。それぞれの書き込み
リクエストを成功させるために、DynamoDB では複数台のサーバーでの書き込みの堅牢性を保証して
います。ただし、書き込みがすべてのコピーに伝達されるには時間がかかります。DynamoDB では、
データに結果整合性があります。つまり、ある項目を書き込み、すぐに読み込もうとすると、その書
き込みの結果が表示されない可能性があります。
デフォルトでは、GetItem オペレーションは結果整合性のある読み込みを行います。必要に応じて、
強力な整合性のある読み込みを代わりにリクエストできます。これにより、追加の読み込みキャパシ
ティーユニットが消費されますが、最新の項目が返されます。
結果整合性のある GetItem リクエストによって消費される読み込みキャパシティーユニットは、強
い整合性のあるリクエストの半分だけです。このため、可能な限り、結果整合性のある読み込みを使
用できるようにアプリケーションを設計することが賢明です。データのすべてのコピーにわたる整合
性は、普通、1 秒以内に確保されます。
項目を書き込む
DynamoDB テーブルの項目を作成、更新、削除するには、次のオペレーションを使用します。
API Version 2012-08-10
206
Amazon DynamoDB 開発者ガイド
バッチオペレーション
• PutItem - 新しい項目を作成します。同じキーを持つ項目がテーブルにすでに存在する場合は、新
しい項目に置き換えられます。テーブル名と書き込む項目を指定する必要があります。
• UpdateItem - 項目が存在しない場合、このオペレーションは新しい項目を作成します。すでに存
在する場合は、既存の項目の属性を変更します。テーブル名と変更する項目のキーを指定する必要
があります。更新する属性ごとに、新しい値を指定する必要があります。
• DeleteItem - 項目を削除します。テーブル名と削除する項目のキーを指定する必要があります。
これらの各オペレーションで、プライマリキーの一部の属性ではなくすべての属性を指定する必要が
あります。たとえば、テーブルに複合プライマリキー (パーティションキーおよびソートキー) がある
場合、パーティションキーおよびソートキーの値を指定する必要があります。
既存の項目が誤って上書きされたり削除されたりしないように、条件式をこれらのどのオペレーショ
ンでも使用できます。条件式を使用すると、オペレーションを続行する前に条件が true かどうか(項
目がテーブルにすでに存在するかどうかなど)を確認できます。すでに存在しない場合にのみ項目を
書き込むには、attribute_not_exists 関数と、テーブルのパーティションキーの名前を使用する
条件式とともに PutItem を使用します。これは、存在する項目にはパーティションキーがあるため
です。詳細については、「条件付き書き込みオペレーション (p. 227)」を参照してください。
場合によっては、ある属性値を変更する前後に、その属性値を DynamoDB で表示することをお勧め
します。たとえば、UpdateItem オペレーションでは、更新前に既存の属性値が返されるようにリ
クエストできます。PutItem、UpdateItem、および DeleteItem には、ReturnValues パラメー
ターがあります。このパラメーターを使用することで、属性の変更前後に、その属性値を返すことが
できます。
デフォルトでは、これらのオペレーションはどれも、消費されるプロビジョンドキャパシティーユ
ニットについて情報を返しません。ReturnConsumedCapacity パラメーターを使用すると、この情
報を取得できます。
バッチオペレーション
アプリケーションで複数の項目を読み込む必要がある場合は、BatchGetItem を使用できま
す。BatchGetItem の 1 回のリクエストで、最大 16 MB のデータ(最大 100 の項目)を取得できま
す。さらに、BatchGetItem の 1 回のリクエストで、複数のテーブルから項目を取得できます。
BatchWriteItem オペレーションでは、複数の項目を入力したり削除したりできま
す。BatchWriteItem オペレーションでは、最大 25 の入力または削除リクエストにより、最
大 16 MB のデータを書き込むことができます。個々の項目の最大サイズは 400 KB です。さら
に、BatchWriteItem の 1 回のリクエストで、複数のテーブルの項目を入力したり削除したり
できます(ただし BatchWriteItem で項目を更新することはできません。項目を更新するに
は、UpdateItem を代わりに使用してください)
バッチは 1 つ以上のリクエストで構成されます。リクエストごとに、DynamoDB によってそのリク
エストに適切なオペレーションが呼び出されます。たとえば、BatchGetItem リクエストに 5 つの項
目が含まれている場合、DynamoDB によって 5 回の GetItem オペレーションが暗黙的に実行されま
す。同様に、BatchWriteItem リクエストに 2 つの入力リクエストと 4 つの削除リクエストが含ま
れている場合、DynamoDB によって 2 つの PutItem リクエストと 4 つの DeleteItem リクエスト
が暗黙的に実行されます。
バッチの個々のリクエストが失敗しても(テーブルのプロビジョンドスループット設定を超えている
ためなどで)、バッチ全体が失敗することはありません。代わりに、バッチオペレーションでは、失
敗した個々のリクエストのキーとデータが返されるため、そのオペレーションを再試行できるように
なります。一般的に、バッチのすべてのリクエストが失敗しない限り、バッチオペレーションは失敗
しません。
アトミックカウンタ
DynamoDB では、アトミックカウンターがサポートされています。そのため、UpdateItem オペレー
ションを使用して、他の書き込みリクエストを妨げることなく既存の属性値をインクリメントまたは
API Version 2012-08-10
207
Amazon DynamoDB 開発者ガイド
条件付きの書き込み
デクリメントできます。(すべての書き込みリクエストは、受信された順に適用されます)。たと
えば、あるウェブアプリケーションでサイトの訪問者数を示すカウンタを保持するとします。この場
合、アプリケーションはこのカウンタを、現在値に関係なくインクリメントする必要があります。
アトミックカウンターの更新はべき等のオペレーションではありません。つまり、カウンターは
UpdateItem の呼び出しごとにインクリメントされます。前のリクエストの失敗が疑われる場合、ア
プリケーションは UpdateItem オペレーションを再試行しますが、カウンターが 2 回更新される恐れ
があります。ウェブサイトのカウンタの場合には許容できる可能性があります。というのも、訪問者
のカウントがわずかに上下しても大きな問題にはならないからです。 銀行業務用のアプリケーション
の場合は、アトミックカウンターよりも条件付き更新を使用したほうが安全です。
アトミックカウンターを更新するには、UpdateItem オペレーションの UpdateExpression パラ
メータで数値型の属性を使用し、実行する更新アクションとして SET を使用します。カウンターは正
の数を使用してインクリメント、負の数を使用してデクリメントできます。詳細については、「数値
属性の増減 (p. 224)」を参照してください。.
条件付きの書き込み
マルチユーザー環境では、複数のクライアントが同じ項目にアクセスし、その項目の属性値の変更を
同時に実行する可能性があります。しかし、各クライアントでは、他のクライアントが項目をすでに
変更していることに気が付かない可能性があります。この点について、次の図に示します。ここで、
クライアント 1 とクライアント 2 は項目(Id=1)のコピーを取得しています。クライアント 1 は、価
格を 10 USD から 8 USD に変更します。その後で、クライアント 2 が同じ項目の価格を 12 USD に
変更します。この結果、クライアント 1 による前の変更内容は失われます。
クライアントによるデータ項目への書き込みを調整できるように、DynamoDB では、条件付き書き込
みが PutItem、DeleteItem、UpdateItem のオペレーションでサポートされています。条件付き書
き込みを使用すると、オペレーションが成功するのは、項目の属性が 1 つ以上の想定条件を満たす場
合のみです。それ以外の場合は、エラーが返されます。次の例では、クライアント 1 とクライアント
2 が項目(Id=1)のコピーを取得しています。まず、クライアント 1 は、サーバー上の既存の項目の
価格が 10 USD であるという条件で、項目の価格を 8 USD に更新しようとします。その条件が満たさ
れるため、このオペレーションは成功します。その後、クライアント 2 は、サーバー上の既存の項目
の価格が 10 USD であるという条件で、項目の価格を 12 USD に更新しようとします。現在の価格が
8 USD ドルになっているため、その条件が満たされず、したがってクライアント 2 のリクエストは失
敗します。
API Version 2012-08-10
208
Amazon DynamoDB 開発者ガイド
条件付きの書き込み
条件付き書き込みがべき等のオペレーションであることに注意してください。つまり、同じ条件付き
書き込みリクエストを何度も送信できますが、指定した更新が最初に DynamoDB によって実行され
た後は、更新のリクエストがあってもそれ以上項目への影響はありません。たとえば、現在の価格が
20 USD であるという条件で、書籍項目の価格を 10% 更新するリクエストを発行するとします。しか
し、応答を得る前にネットワークエラーが発生したため、リクエストが成功したかどうかがわからな
くなってしまいました。条件付き更新は、べき等のオペレーションであるため、同じリクエストを再
度送信することができます。DynamoDB は、現在の価格がまだ 20 USD である場合にのみ価格を更新
します。
条件付きの PutItem、DeleteItem、または UpdateItem をリクエストするに
は、ConditionExpression パラメーターで条件(複数可)を指定します。ConditionExpression
は、属性名、条件付き演算子および組み込み関数を含む文字列です。式全体の評価結果が true になる
必要があります。そうでない場合、オペレーションは失敗します。
Tip
詳細については、「条件付き書き込みオペレーション (p. 227)」を参照してください。
ReturnConsumedCapacity パラメータを指定した場合、条件書き込み中に使用された書き込み容
量ユニットの数が DynamoDB により返されます。(書き込みオペレーションでは、書き込み容量ユ
ニットだけが使用される点に注意してください。読み込み容量ユニットが使用されることはありませ
ん)。ReturnConsumedCapacity を TOTAL に設定すると、テーブルに対して消費された書き込み
キャパシティーとすべてのグローバルセカンダリインデックスが返されます。INDEXES はグローバ
ルセカンダリインデックスによって消費された書き込みキャパシティーのみを返し、NONE は、消費
されたキャパシティーの統計情報を一切返さないことを意味します。
条件付き書き込み中に ConditionExpression が false と評価された場合でも、DynamoDB はテー
ブルから書き込みキャパシティーユニットを引き続き消費します。
• 項目が存在する場合、消費される書き込みキャパシティーユニットの数は、項目のサイズによっ
て異なります (たとえば、1 KB の項目の条件付き書き込みが失敗すると、1 つの書き込みキャパシ
ティーユニットが消費されます。項目のサイズがその倍である場合、条件付き書き込みが失敗する
と、2 つの書き込みキャパシティーユニットが消費されます)。
• 項目が存在しない場合、DynamoDB は 1 つの書き込みキャパシティーユニットを消費します。
失敗した条件付き書き込みでは、書き込みオペレーションから予期される応答ではなく
ConditionalCheckFailedException が返されます。したがって、消費された書き込みキャパシ
ティーユニットに関する情報は受け取りません。ただし、Amazon CloudWatch でテーブルの
ConsumedWriteCapacityUnits メトリクスを表示して、テーブルから消費された、プロビジョ
API Version 2012-08-10
209
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
ニングされた書き込みキャパシティーを判断することができます。詳細については、「Amazon
DynamoDB のモニタリング (p. 495)」の「DynamoDB Metrics (p. 497)」を参照してください。
Note
local secondary indexは、グローバルセカンダリインデックスとは異なり、プロビジョニング
されたスループット容量をそのテーブルと共有します。local secondary indexでの読み取りと
書き込みのアクティビティは、テーブルからプロビジョニングされたスループット容量を消
費します。
式を使用した項目の読み取りと書き込み
DynamoDB では、式を使用して、項目から読み取る属性を示します。また、項目を書き込むときも式
を使用して、満たす必要がある条件(条件付き更新とも呼ばれます)と、属性を更新する方法を示し
ます。更新の例として、属性を新しい値で置き換えたり、新しいデータをリストやマップに追加した
りします。このセクションでは、利用可能なさまざまな種類の式について説明します。
Note
下位互換性のために、DynamoDB は式を使用しない条件パラメータもサポートします。詳細
については、「レガシー条件パラメータ (p. 678)」を参照してください。
新しいアプリケーションでは、レガシーパラメータではなく式を使用する必要があります。
トピック
• 導入事例: ProductCatalog 項目 (p. 210)
• プロジェクト式を使用した項目属性へのアクセス (p. 211)
• 属性の名前および値でのプレースホルダーの使用 (p. 213)
• 条件式を使用した条件付きの書き込みの実行 (p. 215)
• 更新式を使用した項目および属性の変更 (p. 222)
導入事例: ProductCatalog 項目
このセクションでは、ProductCatalog テーブルの項目について検討します(このテーブルについては、
「サンプルテーブルとデータ (p. 589)」でいくつかの項目とともに説明します)。項目の表現を次に
示します。
{
Id: 206,
Title: "20-Bicycle 206",
Description: "206 description",
BicycleType: "Hybrid",
Brand: "Brand-Company C",
Price: 500,
Color: ["Red", "Black"],
ProductCategory: "Bike",
InStock: true,
QuantityOnHand: null,
RelatedItems: [
341,
472,
649
],
Pictures: {
API Version 2012-08-10
210
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
FrontView: "http://example.com/products/206_front.jpg",
RearView: "http://example.com/products/206_rear.jpg",
SideView: "http://example.com/products/206_left_side.jpg"
},
ProductReviews: {
FiveStar: [
"Excellent! Can't recommend it highly enough!
"Do yourself a favor and buy this."
],
OneStar: [
"Terrible product! Do not buy this."
]
}
Buy it!",
}
次の点に注意してください。
• パーティションキー値 (Id) は 206 です。ソートキーはありません。
• ほとんどの属性に、文字列、数値、ブール値、NULL などのスカラーデータ型があります。
• 1 つの属性(Color)は文字列セットです。
• 次の属性はドキュメントデータ型です。
• RelatedItems のリスト。各要素は関連製品の Id です。
• Pictures のマップ。各要素は対応するイメージファイルの URL と、写真の短い説明です。
• ProductReviews のマップ。各要素は、レーティングと、そのレーティングに対応する評価のリ
ストを表します。最初に、このマップには 5 つ星と 1 つ星の評価が入力されます。
プロジェクト式を使用した項目属性へのアクセス
テーブルからデータを読み取るには、GetItem、Query、Scan などの オペレーションを使用しま
す。DynamoDB はデフォルトですべての項目属性を返します。すべての属性ではなく、一部の属性だ
けを取得するには、プロジェクション式を使用します。
Note
以下のセクションの例は、「導入事例: ProductCatalog 項目 (p. 210)」の ProductCatalog 項
目に基づいています。
トピック
• プロジェクション式 (p. 211)
• ドキュメントパス (p. 212)
プロジェクション式
プロジェクション式は、任意の属性を識別する文字列です。1 つの属性を取得するには、名前を指定
します。複数の属性の場合、名前をカンマで区切る必要があります。
プロジェクション式のいくつかの例を次に示します。
• 1 つの最上位属性。
Title
• 3 つの最上位属性。DynamoDB は Color セット全体を取得します。
Title, Price, Color
API Version 2012-08-10
211
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
• 4 つの最上位属性。DynamoDB は RelatedItems および ProductReviews のコンテンツ全体を返
します。
Title, Description, RelatedItems, ProductReviews
最初の文字が a-z または A-Z であり、2 番目の文字(ある場合)が a-z、A-Z、または 0-9 である場
合は、投影式で任意の属性値を使用できます。属性名がこの要件を満たさない場合は、式の属性名を
プレースホルダーとして定義する必要があります。詳細については、「式の属性名 (p. 213)」を参照
してください。
Note
プロジェクション式を指定する方法は、使用するプログラミング言語によって異なります。
サンプルコードについては、該当言語の Amazon DynamoDB 入門ガイド のセクションを参照
してください。
ドキュメントパス
式は、最上位属性に加えて、任意のドキュメントタイプ属性の個別の要素にアクセスできます。これ
を行うには、項目内で要素の場所またはドキュメントパスを指定する必要があります。ドキュメント
パスにより、DynamoDB は、複数のリストやマップ内で深くネストされている場合でも、属性の場所
を見つけることができます。
最上位属性の場合、ドキュメントパスは単純に属性名になります。
ネストされた属性の場合は、間接参照演算子を使用してドキュメントパスを構築します。
リスト要素へのアクセス
リスト要素の間接参照演算子は [n] で、n は要素数です。リストの要素はゼロベースであるため、[0]
はリスト内の最初の要素、[1] は 2 番目の要素、という順番で表されます。
• MyList[0]
• AnotherList[12]
• ThisList[5][11]
要素 ThisList[5] は、それ自体がネストされたリストです。したがって、ThisList[5][11] は、
そのリストの 12 番目の要素を参照します。
リストの間接参照のインデックスは、ゼロ以外の整数である必要があります。そのため、次の式は無
効です。
• MyList[-1]
• MyList[0.4]
マップ要素へのアクセス
マップ要素の間接参照演算子は .(ドット)です。マップの要素間の区切り文字として、ドットを使用
します。
• MyMap.nestedField
• MyMap.nestedField.deeplyNestedField
ドキュメントパスの例
ドキュメントパスを使用したプロジェクション式のいくつかの例を次に示します。
API Version 2012-08-10
212
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
• RelatedItems リストの 3 番目の要素(このリスト要素はゼロベースであることに注意してくださ
い)。
RelatedItems[2]
• 項目の価格、色、製品の正面の写真。
Price, Color, Pictures.FrontView
• すべての 5 つ星の評価。
ProductReviews.FiveStar
• 最初の 5 つ星の評価。
ProductReviews.FiveStar[0]
Note
ドキュメントパスの最大深度は 32 です。したがって、任意のパスの間接参照の数はこの制限
を超えることはできません。
最初の文字が a-z または A-Z であり、2 番目の文字(ある場合)が a-z、A-Z、または 0-9 であ
る場合は、ドキュメントパスで任意の属性値を使用できます。属性名がこの要件を満たさない場合
は、式の属性名をプレースホルダーとして定義する必要があります。詳細については、「式の属性
名 (p. 213)」を参照してください。
属性の名前および値でのプレースホルダーの使用
このセクションでは、DynamoDB 式で使用できるプレースホルダー(置換変数)について説明しま
す。
トピック
• 式の属性名 (p. 213)
• 式の属性値 (p. 215)
式の属性名
場合によっては、DynamoDB 予約語と競合する属性名を含む式を書く必要が生じることがあります。
予約語の一覧については、「DynamoDB の予約語 (p. 668)」を参照してください。
たとえば、SESSION は予約語であるため、次のプロジェクション式は無効です。
• Classroom, Session, StartTime
この問題に対処するには、式の属性名を定義できます。式の属性名は、実際の属性名の代わりとして
式で使用するプレースホルダーです。式の属性名は # で始まり、1 つ以上の英数字が続きます。
上記の式では、Session を、#s などの式の属性名と置き換えることができます。#(シャープ記号)
は必須であり、これが属性名のプレースホルダーであることを示します。変更された式は次のように
なります。
• Classroom, #s, StartTime
Tip
属性名が数値で始まるか、スペース、特殊文字、または予約語を含む場合、式の属性名を使
用して式のその属性名を置き換えなければなりません。
API Version 2012-08-10
213
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
式では、ドット(".")はドキュメントパスの区切り文字として解釈されます。ただし、DynamoDB で
は属性名の一部としてドット文字を使用することもできます。これは、あいまいな意味を持つことが
あります。例として、DynamoDB テーブル内の次の項目について考えます。
{
Id: 1234,
My.Scalar.Message: "Hello",
MyMap: {
MyKey: "My key value",
MyOtherKey: 10
}
}
次のプロジェクション式を使用して、My.Scalar.Message にアクセスするとします。
My.Scalar.Message
DynamoDB は、予想される Hello 文字列ではなく空の結果を返します。これは、DynamoDB が式の
ドットをドキュメントパスの区切り文字として解釈するためです。この場合、My.Scalar.Message
の置換として式の属性名(#msm など)を定義する必要があります。その後、次のプロジェクション式
を使用します。
#msm
次に、DynamoDB が目的の結果を返します。Hello
Tip
式のドットは、ドキュメントパスの区切り文字を表します。
属性名にドット文字が含まれる場合、その式属性名を定義します。その場合、式でその名前
を使用できます。
ここでは、次のプロジェクション式を使用して、埋め込み属性 MyMap.MyKey にアクセスするとしま
す。
MyMap.MyKey
結果は、予想される My key value になります。
ただし、代わりに式属性名を使用することにした場合はどうなるでしょうか。たとえ
ば、MyMap.MyKey の置換として #mmmk を定義した場合はどうなるでしょうか。DynamoDB は、予
想される文字列ではなく空の結果を返します。これは、DynamoDB が式属性値のドットを属性名内の
文字として解釈するためです。DynamoDB は、式属性名 #mmmk を評価すると、MyMap.MyKey がスカ
ラー属性(これは意図されたものではありません)を参照していると判断します。
2 つの式属性名(ドキュメントパス内の要素ごとに 1 つずつ)を定義するのが正しい方法です。
• #mm — MyMap
• #mk — MyKey
その後、次のプロジェクション式を使用します。
#mm.#mk
次に、DynamoDB が目的の結果を返します。My key value
API Version 2012-08-10
214
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
Note
式属性名のドットは、属性名内の有効な文字を表します。
入れ子になった属性にアクセスするには、ドキュメントパス内の各要素の式属性名を定義し
ます。その後、これらの名前を式で使用できます。各名前はドットで区切ります。
式の属性名は、同じ属性名を繰り返し参照する必要がある場合にも役立ちます。たとえ
ば、ProductCatalog 項目からいくつかの評価を取得する次の式を考えてみます。
• ProductReviews.FiveStar, ProductReviews.ThreeStar, ProductReviews.OneStar
これをより簡潔にするために、ProductReviews を、#pr などの式の属性名で置き換えることができ
ます。変更された式は次のようになります。
• #pr.FiveStar, #pr.ThreeStar, #pr.OneStar
式属性名を定義した場合、式全体で一貫して使用する必要があります。さらに、# 記号を省略するこ
とはできません。
Note
式の属性名を指定する方法は、使用するプログラミング言語によって異なります。 サンプル
コードについては、該当言語の Amazon DynamoDB 入門ガイド のセクションを参照してくだ
さい。
式の属性値
属性を値と比較する必要がある場合は、式の属性値をプレースホルダーとして定義します。式の属性
値は、比較する実際の値(実行時までわからないことがある値)の置換です。式の属性値は : で始ま
り、1 つ以上の英数字が続きます。
たとえば、価格が特定の値より低い製品を示し、実際の値はユーザーが入力するアプリケーションが
あるとします。:p などの式の属性値を、プレースホルダーとして定義できます。: が必須であり、こ
れは属性値のプレースホルダーであることを示します。このような式は次のようになります。
• Price < :p
アプリケーションは、実行時に希望の価格を入力するようにユーザーに求めることができます。この
価格は式で使用され、DynamoDB は必要な結果を取得します。
式属性値を定義した場合、式全体で一貫して使用する必要があります。さらに、: 記号を省略するこ
とはできません。
Note
式の属性値を指定する方法は、使用するプログラミング言語によって異なります。 サンプル
コードについては、該当言語の Amazon DynamoDB 入門ガイド のセクションを参照してくだ
さい。
条件式を使用した条件付きの書き込みの実行
テーブルの項目を確認するには、Query や Scan などの オペレーションを使用します。これらの
オペレーションにより、選択条件およびフィルタリングの独自の条件を指定することができます。
DynamoDB は、条件に一致する項目のみを評価して返します。
API Version 2012-08-10
215
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
項目を書き込むには、PutItem、UpdateItem、DeleteItem などの オペレーションを使用します。
これらのオペレーションとともに条件式を使用すると、項目を変更できる方法と条件を管理できま
す。 項目が事前に一部の条件を満たさない場合、更新が発生しないようにすることができます。たと
えば、PutItem が既存の項目を上書きしないようにできます。
Note
このセクションの例は、「導入事例: ProductCatalog 項目 (p. 210)」の ProductCatalog 項目
に基づいています。
トピック
• 条件式 (p. 216)
• 条件式リファレンス (p. 217)
条件式
条件式は、テーブルの項目を読み書きするときに適用する制限を表します。条件式は、属性名、ド
キュメントパス、論理演算子、および関数を含むフリーフォームの文字列です。条件式で使用できる
要素の一覧については、「条件式リファレンス (p. 217)」を参照してください。
条件式のいくつかの例を次に示します。 これらの式の一部では、属性の名前と値にプレースホルダー
が使用されている点に注意してください。詳細については、「属性の名前および値でのプレースホル
ダーの使用 (p. 213)」を参照してください。
• PutItem が既存の項目を上書きしないようにするには、項目のパーティションキーが存在しないこ
とを指定する条件式を使用します。テーブルのすべての項目にはパーティションキーが必要である
ため、これにより、既存の項目が上書きされるのを回避できます。たとえば、パーティションキー
の名前が「town」の場合は、次のコードを使用できます。
attribute_not_exists(town)
この条件式は PutItem で使用されます。DynamoDB は、書き込む項目のプライマリキーとプライ
マリキーが一致する項目を最初に探します。結果にパーティションキーが含まれないのは、検索で
何も返されない場合のみです。それ以外の場合、上記の attribute_not_exists 関数は失敗し、
書き込みは禁止されます。
• RearView の写真があるすべての項目。
attribute_exists(Pictures.RearView)
• 1 つ星の評価がない項目のみ。式の属性名 #pr, は、ProductReviews の置換です。
attribute_not_exists (#pr.OneStar)
# 文字の詳細については、「式の属性名 (p. 213)」を参照してください。
• 単純なスカラー比較である :p は数値を表し、:bt は文字列を表します。
Price <= :p
BicycleType = :bt
• 2 つの条件はどちらも true でなければなりません。#P と #PC は、Price および
ProductCategory 属性名のプレースホルダーです。:lo と :hi は、数値型の値を表してお
り、:cat1 と :cat2 は文字列型の値を表しています。
(#P between :lo and :hi) and (#PC in (:cat1, :cat2))
最初の文字が a-z または A-Z であり、残りの文字 (ある場合) が a-z、A-Z、または 0-9 である場合
は、条件式で任意の属性名を使用できます。属性名がこの要件を満たさない場合は、式の属性名をプ
API Version 2012-08-10
216
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
レースホルダーとして定義する必要があります。詳細については、「式の属性名 (p. 213)」を参照し
てください。
条件式リファレンス
このセクションでは、DynamoDB の条件式の基本的な構成要素について説明します。
Note
ConditionExpression の構文は FilterExpression パラメータと同じで
す。FilterExpression はデータのクエリ時とスキャン時に使用されます。詳細について
は、「クエリまたはスキャンからの結果のフィルタリング (p. 289)」を参照してください。
トピック
• 条件式の構文 (p. 217)
• 比較の実行 (p. 218)
• 関数 (p. 218)
• 論理評価 (p. 221)
• 括弧 (p. 222)
• 条件の優先順位 (p. 222)
条件式の構文
以下の構文の概要で、operand は次のいずれかです。
• 最上位の属性名(Id、Title、Description、ProductCategory など)
• 入れ子の属性を参照するドキュメントパス
condition-expression ::=
operand comparator operand
| operand BETWEEN operand AND operand
| operand IN ( operand (',' operand (, ...) ))
| function
| condition AND condition
| condition OR condition
| NOT condition
| ( condition )
comparator ::=
=
| <>
| <
| <=
| >
| >=
function ::=
attribute_exists (path)
| attribute_not_exists (path)
| attribute_type (path, type)
| begins_with (path, substr)
| contains (path, operand)
| size (path)
API Version 2012-08-10
217
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
比較の実行
これらのコンパレータを使用して、値の範囲または値の列挙リストに対してオペランドを比較しま
す。
• a = b - a が b と等しい場合、true
• a <> b - a が b と等しくない場合、true
• a < b - a が b より小さい場合、true
• a <= b - a が b 以下である場合、true
• a > b - a が b より大きい場合、true
• a >= b - a が b 以上である場合、true
値の範囲または値の列挙リストに対してオペランドを比較するには、BETWEEN および IN キーワード
を使用します。
• a BETWEEN b AND c - a が b 以上で、c 以下である場合、true。
• a IN (b, c, d) - a がリスト内の任意の値(例では、b、c、d のいずれか)と等しい場
合、true。リストには、コンマで区切って最大 100 個の値を指定できます。
関数
以下の関数を使用して、ある属性が項目に存在するか判定したり、属性の値を評価したりします。こ
れらの関数名では大文字と小文字が区別されます。入れ子の属性では、フルパスを指定する必要があ
ります。詳細については、「ドキュメントパス (p. 212)」を参照してください。
関数
説明
attribute_exists (path)
項目に、path で指定した属性が含まれる場
合、true。
例: Product テーブルの項目に側面図があるかど
うかを確認します。
• attribute_exists
(Pictures.SideView)
attribute_not_exists (path)
path で指定した属性が項目に存在しない場
合、true。
例: 項目に Manufacturer 属性があるかどうか
を確認します。
• attribute_not_exists (Manufacturer)
attribute_type (path, type)
指定したパスの属性が、特定のデータ型のもの
である場合、true。type パラメータは次のいず
れかである必要があります。
• S — 文字列
• SS — 文字列セット
• N — 数値
• NS — 数値セット
• B — バイナリ
• BS — バイナリセット
• BOOL — Boolean
API Version 2012-08-10
218
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
関数
説明
• NULL — Null
• L — リスト
• M — マップ
type パラメータには、式の属性値を使用する必
要があります。
例: QuantityOnHand 属性がリスト型のも
のであるかどうかを確認します。この例で
は、:v_sub は文字列 L のプレースホルダーで
す。
• attribute_type
(ProductReviews.FiveStar, :v_sub)
2 番目のパラメータには、式の属性値を使用する
必要があります。
begins_with (path, substr)
path で指定された属性が特定のサブ文字列から
始まる場合、true。
例: 正面図 URL の最初の数文字が http:// かど
うかを確認します。
• begins_with
(Pictures.FrontView, :v_sub)
式の属性値 :v_sub は、http:// のプレースホ
ルダ―です。
API Version 2012-08-10
219
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
関数
説明
contains (path, operand)
path で指定された属性が次の属性である場
合、true。
• 特定のサブ文字列を含む文字列。
• 設定の中に特定の要素を含む設定。
いずれの場合でも、operand は文字列である必
要があります。
パスとオペランドは異なっている必要がありま
す。つまり contains (a, a) はエラーを返し
ます。
例: ブランド属性にサブ文字列 Company が含ま
れているかどうかを確認します。
• contains (Brand, :v_sub)
式の属性値 :v_sub は、Company のプレースホ
ルダ―です。
例: 製品が赤で入手可能かどうかを確認します。
• contains (Color, :v_sub)
式の属性値 :v_sub は、Red のプレースホルダ―
です。
API Version 2012-08-10
220
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
関数
説明
size (path)
属性のサイズを表す数値を返します。以下
は、size で使用できる有効なデータ型です。
属性は文字列型で、size は文字列の長さを返し
ます。
例: 文字列ブランドが 20 文字以下であるかどう
かを確認します。式の属性値 :v_sub は、20 の
プレースホルダ―です。
• size (Brand) <= :v_sub
属性がバイナリ型の場合、size は属性値のバイ
ト数を返します。
例: ProductCatalog 項目に VideoClip という
名前のバイナリ属性があるとします。この属性
には使用中の製品の短いビデオが含まれます。
次の式は、VideoClip が 64,000 バイトを超え
るかどうかを確認します。式の属性値 :v_sub
は、64000 のプレースホルダ―です。
• size(VideoClip) > :v_sub
属性がセットデータ型の場合、size は設定の要
素数を返します。
例: 製品が複数の色で入手可能かどうかを確認し
ます。式の属性値 :v_sub は、1 のプレースホ
ルダ―です。
• size (Color) < :v_sub
属性がリスト型またはマップのものである場
合、size は子要素の数を返します。
例: OneStar のレビューの数が特定のしきい値
を超えたかどうかを確認します。式の属性値
:v_sub は、3 のプレースホルダ―です。
• size(ProductReviews.OneStar)
> :v_sub
論理評価
論理評価を実行するには、AND、OR、NOT キーワードを使用します。以下のリストでは、a と b は評
価される条件を示しています。
• a AND b - a と b の両方が true である場合、true。
• a OR b - a または b のどちらか(または両方)が true の場合、true。
API Version 2012-08-10
221
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
• NOT a - a が false の場合、true。a が true の場合、false。
括弧
論理評価の優先順位を変更するには括弧を使用します。たとえば、条件 a と b が true で、条件 c が
false であるとします。次の式は true と評価されます。
• a OR b AND c
しかし、条件を括弧で囲むと、それが最初に評価されます。たとえば、次の式は false と評価されま
す。
• (a OR b) AND c
Note
式では括弧を入れ子にできます。最も内側の括弧が最初に評価されます。
条件の優先順位
DynamoDB では、条件は次の優先順位ルールを使用して左から右に評価されます。
• = <> < <= > >=
• IN
• BETWEEN
• attribute_exists attribute_not_exists begins_with contains
• 括弧
• NOT
• AND
• OR
更新式を使用した項目および属性の変更
テーブルから項目を削除するには、DeleteItem オペレーションを使用します。削除する項目のキー
を指定する必要があります。
テーブルの既存の項目を更新するには、UpdateItem オペレーションを使用します。更新する項目の
キーを指定する必要があります。また、変更する属性を示す更新式と、その式に割り当てる値も指定
する必要があります。詳細については、「更新式 (p. 223)」を参照してください。
DeleteItem および UpdateItem オペレーションは条件付き書き込みをサポートします。条件付き
書き込みでは、条件式を指定して、オペレーションが成功するために満たす必要がある条件を示しま
す。詳細については、「条件付き書き込みオペレーション (p. 227)」を参照してください。
DynamoDB が項目を正常に変更する際は、HTTP 200 ステータスコード(OK)でこれを通知しま
す。応答でそれ以上のデータは返されませんが、項目またはその属性を返すようにリクエストするこ
とができます。これは、更新前または更新後の表示どおりにリクエストできます。詳細については、
「戻り値 (p. 228)」を参照してください。
Note
以下のセクションの例は、「導入事例: ProductCatalog 項目 (p. 210)」の ProductCatalog 項
目に基づいています。
API Version 2012-08-10
222
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
トピック
• 更新式 (p. 223)
• 条件付き書き込みオペレーション (p. 227)
• 戻り値 (p. 228)
更新式
更新式は、変更する属性を、それらの属性用の新しい値とともに指定します。更新式は、スカラー値
の設定、リストやマップでの要素の削除など、属性を変更する方法も指定します。これは、属性名、
ドキュメントパス、演算子、および関数を含めることができるフリーフォームの文字列です。これに
は、属性を変更する方法を示すキーワードも含まれます。
PutItem、UpdateItem、DeleteItem の各オペレーションではプライマリキー値が必要で、その
キーを持つ項目のみが変更されます。条件付き更新を実行する場合、更新式と条件式の両方を指定す
る必要があります。条件式では、更新が成功するために満たす必要がある条件を指定します。更新式
の構文の概要を次に示します。
update-expression ::=
SET set-action , ...
| REMOVE remove-action , ...
| ADD add-action , ...
| DELETE delete-action , ...
更新式は、セクションで構成されます。各セクションは、SET、REMOVE、ADD、または DELETE キー
ワードで始まります。これらのいずれのセクションも、任意の順序で更新式に含めることができま
す。ただし、各セクションキーワードは 1 回のみ表示できます。同時に複数の属性を変更できます。
更新式のいくつかの例を次に示します。
• SET list[0] = :val1
• REMOVE #m.nestedField1, #m.nestedField2
• ADD aNumber :val2, anotherNumber :val3
• DELETE aSet :val4
以下の例は、複数のセクションを持つ 1 つの更新式を示しています。
• SET list[0] = :val1 REMOVE #m.nestedField1, #m.nestedField2 ADD
aNumber :val2, anotherNumber :val3 DELETE aSet :val4
最初の文字が a-z または A-Z であり、2 番目の文字(ある場合)が a-z、A-Z、または 0-9 である場
合は、更新式で任意の属性値を使用できます。属性名がこの要件を満たさない場合は、式の属性名を
プレースホルダーとして定義する必要があります。詳細については、「式の属性名 (p. 213)」を参照
してください。
更新式でリテラル値を指定するには、式の属性値を使用します。詳細については、「式の属性
値 (p. 215)」を参照してください。
トピック
• Set (p. 224)
• REMOVE (p. 225)
• ADD (p. 226)
• DELETE (p. 227)
API Version 2012-08-10
223
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
Set
1 つ以上の属性と値を項目に追加するには、更新式で SET アクションを使用します。これらのいずれ
かの属性が既に存在する場合、新しい値で置き換えられます。ただし、SET を使用して、数値型であ
る属性を増減することもできます。複数の属性に SET を使用するには、属性をカンマで区切ります。
次の構文の概要について説明します。
• path 要素は、項目へのドキュメントパスです。詳細については、「ドキュメントパス (p. 212)」
を参照してください。
• operand 要素は、項目へのドキュメントパスまたは関数とすることができます。詳細については、
「属性を更新するための関数 (p. 225)」を参照してください。
set-action ::=
path = value
value ::=
operand
| operand '+' operand
| operand '-' operand
operand ::=
path | function
SET アクションを使用した更新式のいくつかの例を次に示します。
• 以下の例では、Brand および Price 属性を更新します。式の属性値 :b は文字列で、:p は数値で
す。
SET Brand = :b, Price = :p
• 以下の例では、RelatedItems リストの属性を更新します。式の属性値 :ri は数値です。
SET RelatedItems[0] = :ri
• 以下の例では、いくつかのネストされたマップ属性を更新します。式の属性名 #pr は
ProductReviews で、属性値 :r1 および :r2 は文字列です。
SET #pr.FiveStar[0] = :r1, #pr.FiveStar[1] = :r2
数値属性の増減
既存の数値属性は増減することができます。これを行うには、+(プラス)および -(マイナス)演算
子を使用します。
以下の例では、項目の Price 値を減らします。式の属性値 :p は数値です。
• SET Price = Price - :p
Price を増やすには、代わりに + 演算子を使用します。
リスト要素での SET の使用
SET を使用してリスト要素を更新すると、その要素のコンテンツは、指定した新しいデータで置き換
えられます。要素が既に存在していない場合、SET は配列の末尾に新しい要素を追加します。
API Version 2012-08-10
224
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
1 つの SET オペレーションに複数の要素を追加すると、要素は要素番号で順にソートされます。たと
えば、次のリストを考えてみます。
MyNumbers: { ["Zero","One","Two","Three","Four"] }
リストには、要素 [0]、[1]、[2]、[3]、[4] があります。ここでは、SET アクションを使用して 2
つの新しい要素を追加します。
set MyNumbers[8]="Eight", MyNumbers[10] = "Ten"
リストには、要素 [0]、[1]、[2]、[3]、[4]、[5]、[6] が、各要素で次のデータとともに含まれ
るようになりました。
MyNumbers: { ["Zero","One","Two","Three","Four","Eight","Ten"] }
Note
リストの末尾に新しい要素が追加され、使用可能な次の要素番号が割り当てられます。
属性を更新するための関数
SET アクションは、次の関数をサポートします。
• if_not_exists (path, operand) - 指定された path で項目が属性を含まない場
合、if_not_exists は operand に評価されます。それ以外の場合は、path に評価されます。こ
の関数を使用して、既に項目に存在する属性への上書きを防ぐことができます。
• list_append (operand, operand) – この関数は、追加された新しい要素でリストに対して評
価を実行します。新しい要素がリストに含まれている必要があります。たとえば、2 をリストに追
加するには、オペランドを [2] にします。オペランドの順序を入れ替えて、リストの先頭または末
尾に新しい要素を追加できます。
Important
これらの関数名では大文字と小文字は区別されません。
以下に、これらの関数とともに SET アクションを使用するいくつかの例を示します。
• 属性が既に存在する場合、以下の例では何も実行されません。それ以外の場合は、属性がデフォル
ト値に設定されます。
SET Price = if_not_exists(Price, 100)
• 以下の例では、FiveStar 評価リストに新しい要素を追加します。式の属性名 #pr は
ProductReviews で、属性値 :r は 1 つの要素のリストです。リストに以前に 2 つの要素([0] およ
び [1])があった場合、新しい要素は [2] になります。
SET #pr.FiveStar = list_append(#pr.FiveStar, :r)
• 以下の例では、FiveStar 評価リストに別の要素を追加しますが、今回、要素は [0] でリストの先頭
に追加されます。リストのその他のすべての要素は、1 つずつ変わります。
SET #pr.FiveStar = list_append(:r, #pr.FiveStar)
REMOVE
1 つ以上の属性を項目から削除するには、更新式で REMOVE アクションを使用します。複数の
REMOVE オペレーションを実行するには、オペレーションをカンマで区切ります。
API Version 2012-08-10
225
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
更新式の REMOVE の構文の概要を次に示します。唯一のオペランドは、削除する属性のドキュメント
パスです。
remove-action ::=
path
以下に、REMOVE アクションを使用した更新式の例を示します。 項目から複数の属性が削除されま
す。
• REMOVE Title, RelatedItems[2], Pictures.RearView
リスト要素での REMOVE の使用
既存のリスト要素を削除すると、残りの要素は変わります。たとえば、次のリストを考えてみます。
• MyNumbers: { ["Zero","One","Two","Three","Four"] }
リストには、要素 [0]、[1]、[2]、[3]、[4] があります。ここで、REMOVE アクションを使用して
2 つの要素を削除してみましょう。
• REMOVE MyNumbers[1], MyNumbers[3]
残りの要素は右に移り、要素 [0]、[1]、[2] が、各要素で次のデータとともに残ります。
• MyNumbers: { ["Zero","Two","Four"] }
Note
REMOVE を使用して、リストの最後の要素以降の存在しない項目を削除しても、何も起こりま
せん。これは、削除するデータがないためです。たとえば、次の式は MyNumbers リストに対
して効果がありません。
• REMOVE MyNumbers[11]
ADD
Important
ADD アクションでは、数値とセットデータ型のみがサポートされます。通常は、ADD ではな
く SET を使用することをお勧めします。
更新式で ADD アクションを使用して、次のいずれかを行います。
• 属性が既に存在しない場合は、新しい属性とその値を項目に追加します。
• 属性が既に存在する場合、ADD の動作は属性のデータ型によって決まります。
• 属性が数値で、追加する値も数値である場合、値は既存の属性に数学的に追加されます(値が負
の数値である場合は、既存の属性から減算されます)。
• 属性が設定され、追加する値も設定された場合、値は既存のセットに付加されます。
複数の ADD オペレーションを実行するには、オペレーションをカンマで区切ります。
次の構文の概要について説明します。
API Version 2012-08-10
226
Amazon DynamoDB 開発者ガイド
式を使用した項目の読み取りと書き込み
• path 要素は、属性へのドキュメントパスです。属性は数値またはセットデータ型である必要があり
ます。
• value 要素は、属性に追加する数値(数値データ型の場合)、または属性に付加するセット(セッ
トデータ型の場合)です。
add-action ::=
path value
add アクションを使用した更新式のいくつかの例を次に示します。
• 以下の例では、数値を増やします。式の属性値 :n は数値で、この値は Price に追加されます。
ADD Price :n
• 以下の例では、Color セットに 1 つ以上の値を追加します。式の属性値 :c は文字列セットです。
ADD Color :c
DELETE
Important
DELETE アクションは、セットデータ型のみをサポートします。
セットから要素を削除するには、更新式で DELETE アクションを使用します。複数の DELETE オペ
レーションを実行するには、オペレーションをカンマで区切ります。
次の構文の概要について説明します。
• path 要素は、属性へのドキュメントパスです。属性はセットデータ型である必要があります。
• value 要素は、セットで削除する要素です。
delete-action ::=
path value
以下の例では、DELETE アクションを使用して Color セットから要素を削除します。式の属性値 :c
は文字列セットです。
DELETE Color :c
条件付き書き込みオペレーション
条件付き削除を実行するには、条件式とともに DeleteItem オペレーションを使用します。条件式
は、オペレーションが成功するためには true に評価される必要があります。それ以外の場合、オペ
レーションは失敗します。
項目を削除したいが、関連項目がない場合のみにするとします。これを行うには、次の式を使用でき
ます。
• 条件式: attribute_not_exists(RelatedItems)
API Version 2012-08-10
227
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
条件付き更新を実行するには、UpdateItem オペレーションを更新式と条件式の両方とともに使用し
ます。条件式は、オペレーションが成功するためには true に評価される必要があります。それ以外の
場合、オペレーションは失敗します。
「:amt」で定義されているように、項目の価格を特定量上げたいが、結果が上限価格を超えない場合
のみにするとします。これは、増加が許可される現在の最大価格を計算し、最大額から増加分 :amt
を引くことで行うことができます。結果を :limit として定義し、次の条件式を使用します。
• 条件式: Price <= :limit)
• 更新式: SET Price = Price + :amt
項目の正面の写真を設定したいが、その項目が既にそのような写真を持っていない場合のみにする
(既存の要素の上書きは避けたい)とします。これを行うには、次の式を使用できます。
• 更新式: SET Pictures.FrontView = :myURL
(:myURL は、http://example.com/picture.jpg のような、項目の写真の場所であるとします。)
• 条件式: attribute_not_exists(Pictures.FrontView)
戻り値
DeleteItem または UpdateItem オペレーションを実行するときに、DynamoDB はオプションで一
部またはすべての項目を応答で返すことができます。これを行うには、ReturnValues パラメータを
設定します。ReturnValues のデフォルト値は NONE であるため、データは返されません。この動作
は以下のように変更できます。
項目の削除
DeleteItem オペレーションでは、ReturnValues を ALL_OLD に設定できます。この操作を行う
と、DynamoDB は、削除オペレーションが発生した前に表示されたように、項目全体を返します。
項目の更新
UpdateItem オペレーションでは、ReturnValues を次のいずれかに設定できます。
• ALL_OLD - 更新の発生前に表示されたように、項目全体が返されます。
• ALL_NEW – 更新後に表示されるように、項目全体が返されます。
• UPDATED_OLD – 更新の発生前に表示されたように、更新した値のみが返されます。
• UPDATED_NEW – 更新後に表示されるように、更新した値のみが返されます。
項目の操作 : Java
トピック
• 項目の置換 (p. 229)
• 項目の取得 (p. 232)
• バッチ書き込み: 複数の項目の書き込みおよび削除 (p. 234)
• バッチ取得: 複数の項目の取得 (p. 235)
• 項目の更新 (p. 236)
• 項目の削除 (p. 238)
• 例: AWS SDK for Java ドキュメント API を使用した CRUD オペレーション (p. 238)
• 例: AWS SDK for Java ドキュメント API を使用したバッチオペレーション (p. 243)
• 例: AWS SDK for Java ドキュメント API を使用したバイナリタイプ属性の処理 (p. 247)
API Version 2012-08-10
228
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
AWS SDK for Java ドキュメント API を使用して、テーブル内の項目に対して、一般的な作成、読み
込み、更新、削除(CRUD)のオペレーションを実行できます。
Note
SDK for Java には、オブジェクト永続性モデルも用意されています。このモデルにより、ク
ライアント側のクラスを DynamoDB テーブルにマッピングすることができます。この方法
により、記述する必要のあるコードの量を減らすことができます。詳細については、「Java:
DynamoDBMapper (p. 78)」を参照してください。
項目の置換
putItem メソッドによって、項目をテーブルに格納します。項目が存在する場合、その項目全体が置
き換えられます。項目全体を置き換える代わりに固有の属性のみを更新する場合は、updateItem メ
ソッドを使用できます。詳細については、「項目の更新 (p. 236)」を参照してください。
以下の手順に従ってください:
1. DynamoDB クラスのインスタンスを作成します。
2. 操作対象のテーブルを表すために、Table クラスのインスタンスを作成します。
3. 新しい項目を表す Item クラスのインスタンスを作成します。新しい項目のプライマリキーと属性
を指定する必要があります。
4. 前の手順で作成した Item を使用して、Table オブジェクトの putItem メソッドを呼び出しま
す。
次の Java コードスニペットは、前述のタスクの例です。このスニペットでは、ProductCatalog
テーブルに新しい自転車項目を書き込みます。(これは、「導入事例: ProductCatalog 項
目 (p. 210)」で説明した項目と同じです)。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductCatalog");
// Build a list of related items
List<Number> relatedItems = new ArrayList<Number>();
relatedItems.add(341);
relatedItems.add(472);
relatedItems.add(649);
//Build a map of product pictures
Map<String, String> pictures = new HashMap<String, String>();
pictures.put("FrontView", "http://example.com/products/206_front.jpg");
pictures.put("RearView", "http://example.com/products/206_rear.jpg");
pictures.put("SideView", "http://example.com/products/206_left_side.jpg");
//Build a map of product reviews
Map<String, List<String>> reviews = new HashMap<String, List<String>>();
List<String> fiveStarReviews = new ArrayList<String>();
fiveStarReviews.add("Excellent! Can't recommend it highly enough!
fiveStarReviews.add("Do yourself a favor and buy this");
reviews.put("FiveStar", fiveStarReviews);
List<String> oneStarReviews = new ArrayList<String>();
oneStarReviews.add("Terrible product! Do not buy this.");
API Version 2012-08-10
229
Buy it!");
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
reviews.put("OneStar", oneStarReviews);
// Build the item
Item item = new Item()
.withPrimaryKey("Id", 206)
.withString("Title", "20-Bicycle 206")
.withString("Description", "206 description")
.withString("BicycleType", "Hybrid")
.withString("Brand", "Brand-Company C")
.withNumber("Price", 500)
.withStringSet("Color", new HashSet<String>(Arrays.asList("Red",
"Black")))
.withString("ProductCategory", "Bike")
.withBoolean("InStock", true)
.withNull("QuantityOnHand")
.withList("RelatedItems", relatedItems)
.withMap("Pictures", pictures)
.withMap("Reviews", reviews);
// Write the item to the table
PutItemOutcome outcome = table.putItem(item);
前の例では、項目はスカラー(文字列、数値、ブール値、Null)、セット(文字列セット)、ドキュ
メント型(リスト、マップ)を持っています。
オプションパラメータの指定
必須のパラメータに加え、putItem メソッドにはオプションパラメータも指定できます。
たとえば、以下の Java コードスニペットでは、オプションパラメータを使用して、項目
のアップロード条件を指定します。指定した条件を満たさない場合は、AWS Java SDK が
ConditionalCheckFailedExceptionをスローします。このコードスニペットでは、putItem メ
ソッドに以下のオプションパラメータを指定します。
• リクエストの条件を定義する ConditionExpression。このスニペットでは、特定の値に等しい
ISBN 属性が既存の項目にある場合にのみ同じプライマリキーを持つ既存の項目を置き換えるという
条件を定義します。
• 条件で使用される ExpressionAttributeValues のマップ。この場合、必要な置き換えは 1 つだ
けです。条件式のプレースホルダー :val が、実行時に、チェックする実際の ISBN 値に置き換え
られます。
以下の例では、これらのオプションパラメータを使用して新しい書籍項目を追加します。
Item item = new Item()
.withPrimaryKey("Id", 104)
.withString("Title", "Book 104 Title")
.withString("ISBN", "444-4444444444")
.withNumber("Price", 20)
.withStringSet("Authors",
new HashSet<String>(Arrays.asList("Author1", "Author2")));
Map<String, Object> expressionAttributeValues = new HashMap<String,
Object>();
expressionAttributeValues.put(":val", "444-4444444444");
PutItemOutcome outcome = table.putItem(
item,
"ISBN = :val", // ConditionExpression parameter
API Version 2012-08-10
230
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
null,
// ExpressionAttributeNames parameter - we're not using it
for this example
expressionAttributeValues);
PutItem および JSON ドキュメント
JSON ドキュメントは、DynamoDB テーブルに属性として格納できます。これを行うには、項目
の withJSON メソッドを使用します。このメソッドは、JSON ドキュメントを解析し、各要素を
DynamoDB のネイティブデータ型にマッピングします。
特定の製品の注文を処理できるベンダーを含む、次の JSON ドキュメントを格納するとします。
{
"V01": {
"Name": "Acme Books",
"Offices": [ "Seattle" ]
},
"V02": {
"Name": "New Publishers, Inc.",
"Offices": ["London", "New York"
]
},
"V03": {
"Name": "Better Buy Books",
"Offices": [ "Tokyo", "Los Angeles", "Sydney"
]
}
}
withJSON メソッドを使用して、VendorInfo という名前のマップ属性でこれを ProductCatalog
テーブルに格納することができます。次の Java コードスニペットはそれを行う方法を示していま
す。
// Convert the document into a String. Must escape all double-quotes.
String vendorDocument = "{"
+ "
\"V01\": {"
+ "
\"Name\": \"Acme Books\","
+ "
\"Offices\": [ \"Seattle\" ]"
+ "
},"
+ "
\"V02\": {"
+ "
\"Name\": \"New Publishers, Inc.\","
+ "
\"Offices\": [ \"London\", \"New York\"" + "]" + "},"
+ "
\"V03\": {"
+ "
\"Name\": \"Better Buy Books\","
+
"\"Offices\": [ \"Tokyo\", \"Los Angeles\", \"Sydney\""
+ "
]"
+ "
}"
+ "
}";
Item item = new Item()
.withPrimaryKey("Id", 210)
.withString("Title", "Book 210 Title")
.withString("ISBN", "210-2102102102")
.withNumber("Price", 30)
.withJSON("VendorInfo", vendorDocument);
PutItemOutcome outcome = table.putItem(item);
API Version 2012-08-10
231
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
項目の取得
単一の項目を取り出すには、Table オブジェクトの getItem メソッドを使用します。以下の手順に
従ってください:
1. DynamoDB クラスのインスタンスを作成します。
2. 操作対象のテーブルを表すために、Table クラスのインスタンスを作成します。
3. Table インスタンスの getItem メソッドを呼び出します。取り出す項目のプライマリキーを指定
する必要があります。
次の Java コードスニペットは、前述のステップを示しています。このコードスニペットでは、指定
したパーティションキーを持つ項目を取得します。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductCatalog");
Item item = table.getItem("Id", 101);
オプションパラメータの指定
必須のパラメータに加え、getItem メソッドにはオプションパラメータも指定できます。たとえば、
以下の Java コードスニペットでは、オプションメソッドを使用して、特定の属性リストのみを取り
出します。また、強い整合性のある戻り値をリクエストします。読み込み整合性の詳細については、
「読み込み整合性 (p. 16)」を参照してください。
ProjectionExpression を使用すると、項目全体ではなく特定の属性または要素のみを取り出すこ
とができます。ProjectionExpression は、ドキュメントのパスを使用して最上位の属性または入
れ子になった属性を指定できます。詳細については、プロジェクション式 (p. 211) および ドキュメ
ントパス (p. 212) を参照してください。
getItem メソッドのパラメーターでは、読み込み整合性を指定することはできません。ただし、すべ
ての低レベル GetItem オペレーションの入力へのフルアクセスを提供する GetItemSpec を作成で
きます。 以下のコード例では、GetItemSpec を作成し、その仕様を getItem メソッドへの入力と
して使用します。
GetItemSpec spec = new GetItemSpec()
.withPrimaryKey("Id", 206)
.withProjectionExpression("Id, Title, RelatedItems[0], Reviews.FiveStar")
.withConsistentRead(true);
Item item = table.getItem(spec);
System.out.println(item.toJSONPretty());
Tip
Item を人間が読める形式で出力するには、toJSONPretty メソッドを使用します。上の例に
よる出力は次のようになります。
{
"RelatedItems" : [ 341 ],
"Reviews" : {
API Version 2012-08-10
232
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
"FiveStar" : [ "Excellent! Can't recommend it highly enough!
it!", "Do yourself a favor and buy this" ]
},
"Id" : 206,
"Title" : "20-Bicycle 206"
Buy
}
GetItem および JSON ドキュメント
PutItem および JSON ドキュメント (p. 231) セクションでは、VendorInfo という名前のマップ属
性に JSON ドキュメントを格納しました。getItem メソッドを使用して JSON 形式のドキュメント
全体を取り出すか、ドキュメントパス表記を使用してドキュメント内の一部の要素のみ取り出しま
す。次の Java コードスニペットは、この手法を示しています。
GetItemSpec spec = new GetItemSpec()
.withPrimaryKey("Id", 210);
System.out.println("All vendor info:");
spec.withProjectionExpression("VendorInfo");
System.out.println(table.getItem(spec).toJSON());
System.out.println("A single vendor:");
spec.withProjectionExpression("VendorInfo.V03");
System.out.println(table.getItem(spec).toJSON());
System.out.println("First office location for this vendor:");
spec.withProjectionExpression("VendorInfo.V03.Offices[0]");
System.out.println(table.getItem(spec).toJSON());
上の例による出力は次のようになります。
All vendor info:
{"VendorInfo":{"V03":{"Name":"Better Buy Books","Offices":["Tokyo","Los
Angeles","Sydney"]},"V02":{"Name":"New Publishers, Inc.","Offices":
["London","New York"]},"V01":{"Name":"Acme Books","Offices":["Seattle"]}}}
A single vendor:
{"VendorInfo":{"V03":{"Name":"Better Buy Books","Offices":["Tokyo","Los
Angeles","Sydney"]}}}
First office location for a single vendor:
{"VendorInfo":{"V03":{"Offices":["Tokyo"]}}}
Tip
toJSON メソッドを使用して、任意の項目(またはその属性)を JSON 形式文字列に変
換できます。次のコードスニペットは、最上位の属性と入れ子になった属性を複数取り出
し、JSON として結果を出力します。
GetItemSpec spec = new GetItemSpec()
.withPrimaryKey("Id", 210)
.withProjectionExpression("VendorInfo.V01, Title, Price");
Item item = table.getItem(spec);
System.out.println(item.toJSON());
API Version 2012-08-10
233
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
出力は次のようになります。
{"VendorInfo":{"V01":{"Name":"Acme Books","Offices":
["Seattle"]}},"Price":30,"Title":"Book 210 Title"}
バッチ書き込み: 複数の項目の書き込みおよび削除
バッチ書き込みは、複数の項目の書き込みと削除をバッチで行うことを意味しま
す。batchWriteItem メソッドによって、単一の コール内にある 1 つまたは複数のテーブルから複
数の項目を置換および削除できます。以下に、AWS SDK for Java ドキュメント API を使用して複数
の項目を入力および削除する手順を示します。
1. DynamoDB クラスのインスタンスを作成します。
2. テーブルのすべての入力および削除オペレーションを記述する TableWriteItems クラスのイン
スタンスを作成します。1 つのバッチ書き込みオペレーションで複数のテーブルに書き込む場合、
テーブルごとに TableWriteItems インスタンスを 1 つずつ作成する必要があります。
3. 前の手順で作成した TableWriteItems オブジェクトを指定して、batchWriteItem メソッドを
呼び出します。
4. 応答を処理します。返された未処理のリクエスト項目が応答内に存在していたかどうかをチェック
する必要があります。これは、プロビジョニングされたスループットの制限または他の何らかの一
時的エラーに達する場合に、発生する可能性があります。また、DynamoDB によって、リクエスト
のサイズ、およびリクエスト内で指定できるオペレーションの数が制限されます。これらの制限を
超えると、DynamoDB によってリクエストが却下されます。詳細については、「DynamoDB での
制限 (p. 558)」を参照してください。
次の Java コードスニペットは、前述のステップを示しています。この例では、2 つのテーブル
(Forum と Thread)で batchWriteItem オペレーションを実行します。対応する TableWriteItems
オブジェクトは、次のアクションを定義します。
• Forum テーブル内で項目を入力
• Thread テーブル内で項目を入力および削除
その後、コードは batchWriteItem を呼び出してオペレーションを実行します。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
TableWriteItems forumTableWriteItems = new TableWriteItems("Forum")
.withItemsToPut(
new Item()
.withPrimaryKey("Name", "Amazon RDS")
.withNumber("Threads", 0));
TableWriteItems threadTableWriteItems = new TableWriteItems(Thread)
.withItemsToPut(
new Item()
.withPrimaryKey("ForumName","Amazon RDS","Subject","Amazon RDS
Thread 1")
.withHashAndRangeKeysToDelete("ForumName","Some partition key value",
"Amazon S3", "Some sort key value");
BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem(forumTableWriteItems,
threadTableWriteItems);
API Version 2012-08-10
234
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
// Code for checking unprocessed items is omitted in this example
実例については、「例: AWS SDK for Java ドキュメント API を使用したバッチ書き込みオペレーショ
ン (p. 243)」を参照してください。
バッチ取得: 複数の項目の取得
batchGetItem メソッドによって、1 つまたは複数のテーブルから複数の項目を取得できます。単一
の項目を取り出すために、getItem メソッドを使用できます。
以下の手順に従ってください:
1. DynamoDB クラスのインスタンスを作成します。
2. テーブルから取り出すプライマリキーのリストを記述する TableKeysAndAttributes クラスの
インスタンスを作成します。1 つのバッチ取得オペレーションで複数のテーブルから読み込む場
合、テーブルごとに TableKeysAndAttributes インスタンスを 1 つずつ作成する必要がありま
す。
3. 前の手順で作成した TableKeysAndAttributes オブジェクトを指定して、batchGetItem メ
ソッドを呼び出します。
次の Java コードスニペットは、前述のステップを示しています。この例では、Forum テーブル内の
2 つの項目、および Thread テーブル内の 3 つの項目を取り出します。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
TableKeysAndAttributes forumTableKeysAndAttributes = new
TableKeysAndAttributes(forumTableName);
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys("Name",
"Amazon S3",
"Amazon DynamoDB");
TableKeysAndAttributes threadTableKeysAndAttributes = new
TableKeysAndAttributes(threadTableName);
threadTableKeysAndAttributes.addHashAndRangePrimaryKeys("ForumName",
"Subject",
"Amazon DynamoDB","DynamoDB Thread 1",
"Amazon DynamoDB","DynamoDB Thread 2",
"Amazon S3","S3 Thread 1");
BatchGetItemOutcome outcome = dynamoDB.batchGetItem(
forumTableKeysAndAttributes, threadTableKeysAndAttributes);
for (String tableName : outcome.getTableItems().keySet()) {
System.out.println("Items in table " + tableName);
List<Item> items = outcome.getTableItems().get(tableName);
for (Item item : items) {
System.out.println(item);
}
}
オプションパラメータの指定
必須のパラメータに加え、batchGetItem を使用する場合はオプションパラメータも指定できます。
たとえば、定義した TableKeysAndAttributes ごとに ProjectionExpression を指定できま
す。これにより、テーブルから取り出す属性を指定することができます。
API Version 2012-08-10
235
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
次のコードスニペットでは、Forum テーブルの 2 つの項目を取り出しま
す。withProjectionExpression パラメータは、Threads 属性のみを取得することを指定しま
す。
TableKeysAndAttributes forumTableKeysAndAttributes = new
TableKeysAndAttributes("Forum")
.withProjectionExpression("Threads");
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys("Name",
"Amazon S3",
"Amazon DynamoDB");
BatchGetItemOutcome outcome =
dynamoDB.batchGetItem(forumTableKeysAndAttributes);
項目の更新
Table オブジェクトの updateItem メソッドは、既存の属性値の更新、新しい属性の追加、または既
存の項目からの属性の削除を実行できます。
updateItem メソッドは、以下のように動作します。
• 項目が存在しない(指定されたプライマリキーを持つ項目がテーブル内にない)場
合、updateItem はテーブルに新しい項目を追加します
• 項目が存在する場合、updateItem は UpdateExpression パラメータで指定されたとおりに更新
を実行します。
Note
putItem を使用して項目を「更新」することもできます。たとえば、putItem を呼び出して
項目をテーブルに追加したが、指定されたプライマリーキーを持つ項目がすでに存在する場
合、putItem は項目全体を置き換えます。入力で指定されていない属性が既存の項目内にあ
る場合、putItem は項目からそれらの属性を削除します。
一般に、項目属性を変更するときは必ず updateItem を使用することをお勧めしま
す。updateItem メソッドは、入力で指定した項目属性のみを変更し、項目内の他の属性は
変更されません。
以下の手順に従ってください:
1. 操作対象のテーブルを表すために、Table クラスのインスタンスを作成します。
2. Table インスタンスの updateTable メソッドを呼び出します。変更する属性とその変更方法を記
述する UpdateExpression と同時に、取り出す項目のプライマリーキーを指定する必要がありま
す。
次の Java コードスニペットは、前述のタスクの例です。このスニペットでは、ProductCatalog テー
ブルで書籍項目を更新します。この例では、Authors のセットに著者を追加し、既存の ISBN 属性を削
除します。また、価格を 1 引き下げます。
ExpressionAttributeValues マップは UpdateExpression で使用されます。プレースホルダー
:val1 および :val2 は、実行時に、Authors と Price の実際の値に置き換えられます。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductCatalog");
API Version 2012-08-10
236
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#A", "Authors");
expressionAttributeNames.put("#P", "Price");
expressionAttributeNames.put("#I", "ISBN");
Map<String, Object> expressionAttributeValues = new HashMap<String,
Object>();
expressionAttributeValues.put(":val1",
new HashSet<String>(Arrays.asList("Author YY","Author ZZ")));
expressionAttributeValues.put(":val2", 1);
//Price
UpdateItemOutcome outcome = table.updateItem(
"Id",
// key attribute name
101,
// key attribute value
"add #A :val1 set #P = #P - :val2 remove #I", // UpdateExpression
expressionAttributeNames,
expressionAttributeValues);
オプションパラメータの指定
必須のパラメータに加えて、更新を実行するために満たす必要がある条件も含めて、updateItem メ
ソッドのオプションパラメータを指定することもできます。指定した条件を満たさない場合は、AWS
Java SDK が ConditionalCheckFailedExceptionをスローします。たとえば、以下の Java コー
ドスニペットでは、書籍項目の価格を条件付きで 25 に更新します。現在の価格が 20 である場合にの
み価格を更新する必要があることを示す ConditionExpression を指定します。
Table table = dynamoDB.getTable("ProductCatalog");
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#P", "Price");
Map<String, Object> expressionAttributeValues = new HashMap<String,
Object>();
expressionAttributeValues.put(":val1", 25); // update Price to 25...
expressionAttributeValues.put(":val2", 20); //...but only if existing Price
is 20
UpdateItemOutcome outcome = table.updateItem(
new PrimaryKey("Id",101),
"set #P = :val1", // UpdateExpression
"#P = :val2",
// ConditionExpression
expressionAttributeNames,
expressionAttributeValues);
アトミックカウンター
updateItem を使用してアトミックカウンターを実装できます。アトミックカウンターでは、他の書
き込みリクエストを妨げることなく、既存の属性の値をインクリメントまたはデクリメントします。
アトミックカウンターをインクリメントするには、UpdateExpression を使用して、set アクショ
ンで既存の数値型の属性に数値を加算します。
次のコード例はアトミックカウンターを示しており、Quantity 属性を 1 ずつインクリメントさせてい
ます。さらに、UpdateExpression での ExpressionAttributeNames パラメータの使用方法も示
します。
Table table = dynamoDB.getTable("ProductCatalog");
API Version 2012-08-10
237
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
Map<String,String> expressionAttributeNames = new HashMap<String,String>();
expressionAttributeNames.put("#p", "PageCount");
Map<String,Object> expressionAttributeValues = new HashMap<String,Object>();
expressionAttributeValues.put(":val", 1);
UpdateItemOutcome outcome = table.updateItem(
"Id", 121,
"set #p = #p + :val",
expressionAttributeNames,
expressionAttributeValues);
項目の削除
deleteItem メソッドによって、テーブルから項目を削除します。削除する項目のプライマリキーを
指定する必要があります。
以下の手順に従ってください:
1. DynamoDB クライアントのインスタンスを作成します。
2. 削除する項目のキーを指定して、deleteItem メソッドを呼び出します。
次の Java コードスニペットは、このタスクを示しています。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductCatalog");
DeleteItemOutcome outcome = table.deleteItem("Id", 101);
オプションパラメータの指定
deleteItem のオプションパラメータを指定できます。たとえば、次の Java コードスニペット
は、ProductCatalog 内の書籍項目は書籍が絶版になった(InPublication 属性が false)場合のみ削
除可能であることを示す ConditionExpression を指定します。
Map<String,Object> expressionAttributeValues = new HashMap<String,Object>();
expressionAttributeValues.put(":val", false);
DeleteItemOutcome outcome = table.deleteItem("Id",103,
"InPublication = :val",
null, // ExpressionAttributeNames - not used in this example
expressionAttributeValues);
例: AWS SDK for Java ドキュメント API を使用した CRUD オ
ペレーション
以下のコード例は、項目に対する CRUD オペレーションの例です。 この例では、項目の作成、項目
の取得、さまざまな更新の実行、さらに項目の削除を行います。
Note
SDK for Java には、オブジェクト永続性モデルも用意されています。このモデルにより、ク
ライアント側のクラスを DynamoDB テーブルにマッピングすることができます。この方法
API Version 2012-08-10
238
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
により、記述する必要のあるコードの量を減らすことができます。詳細については、「Java:
DynamoDBMapper (p. 78)」を参照してください。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。
以下の例を実行するための詳しい手順については、「Java コードサンプル (p. 171)」を参照
してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import
import
import
import
import
java.io.IOException;
java.util.Arrays;
java.util.HashMap;
java.util.HashSet;
java.util.Map;
import
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.Table;
com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
com.amazonaws.services.dynamodbv2.document.utils.NameMap;
com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class DocumentAPIItemCRUDExample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tableName = "ProductCatalog";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Perform various updates.
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Delete the item.
deleteItem();
API Version 2012-08-10
239
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
}
private static void createItems() {
Table table = dynamoDB.getTable(tableName);
try {
Item item = new Item()
.withPrimaryKey("Id", 120)
.withString("Title", "Book 120 Title")
.withString("ISBN", "120-1111111111")
.withStringSet( "Authors",
new HashSet<String>(Arrays.asList("Author12",
"Author22")))
.withNumber("Price", 20)
.withString("Dimensions", "8.5x11.0x.75")
.withNumber("PageCount", 500)
.withBoolean("InPublication", false)
.withString("ProductCategory", "Book");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", 121)
.withString("Title", "Book 121 Title")
.withString("ISBN", "121-1111111111")
.withStringSet( "Authors",
new HashSet<String>(Arrays.asList("Author21", "Author
22")))
.withNumber("Price", 20)
.withString("Dimensions", "8.5x11.0x.75")
.withNumber("PageCount", 500)
.withBoolean("InPublication", true)
.withString("ProductCategory", "Book");
table.putItem(item);
} catch (Exception e) {
System.err.println("Create items failed.");
System.err.println(e.getMessage());
}
}
private static void retrieveItem() {
Table table = dynamoDB.getTable(tableName);
try {
Item item = table.getItem("Id", 120,
"Id, ISBN, Title, Authors",
null);
System.out.println("Printing item after retrieving it....");
System.out.println(item.toJSONPretty());
} catch (Exception e) {
System.err.println("GetItem failed.");
System.err.println(e.getMessage());
}
}
API Version 2012-08-10
240
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
private static void updateAddNewAttribute() {
Table table = dynamoDB.getTable(tableName);
try {
Map<String, String> expressionAttributeNames = new
HashMap<String, String>();
expressionAttributeNames.put("#na", "NewAttribute");
UpdateItemSpec updateItemSpec = new UpdateItemSpec()
.withPrimaryKey("Id", 121)
.withUpdateExpression("set #na = :val1")
.withNameMap(new NameMap()
.with("#na", "NewAttribute"))
.withValueMap(new ValueMap()
.withString(":val1", "Some value"))
.withReturnValues(ReturnValue.ALL_NEW);
UpdateItemOutcome outcome =
table.updateItem(updateItemSpec);
// Check the response.
System.out.println("Printing item after adding new
attribute...");
System.out.println(outcome.getItem().toJSONPretty());
}
catch (Exception e) {
System.err.println("Failed to add new attribute in " +
tableName);
System.err.println(e.getMessage());
}
}
private static void updateMultipleAttributes() {
Table table = dynamoDB.getTable(tableName);
try {
UpdateItemSpec updateItemSpec = new UpdateItemSpec()
.withPrimaryKey("Id", 120)
.withUpdateExpression("add #a :val1 set #na=:val2")
.withNameMap(new NameMap()
.with("#a", "Authors")
.with("#na", "NewAttribute"))
.withValueMap(new ValueMap()
.withStringSet(":val1", "Author YY", "Author ZZ")
.withString(":val2", "someValue"))
.withReturnValues(ReturnValue.ALL_NEW);
UpdateItemOutcome outcome = table.updateItem(updateItemSpec);
// Check the response.
System.out
.println("Printing item after multiple attribute update...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Failed to update multiple attributes in "
API Version 2012-08-10
241
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
+ tableName);
System.err.println(e.getMessage());
}
}
private static void updateExistingAttributeConditionally() {
Table table = dynamoDB.getTable(tableName);
try {
// Specify the desired price (25.00) and also the condition
(price =
// 20.00)
UpdateItemSpec updateItemSpec = new UpdateItemSpec()
.withPrimaryKey("Id", 120)
.withReturnValues(ReturnValue.ALL_NEW)
.withUpdateExpression("set #p = :val1")
.withConditionExpression("#p = :val2")
.withNameMap(new NameMap()
.with("#p", "Price"))
.withValueMap(new ValueMap()
.withNumber(":val1", 25)
.withNumber(":val2", 20));
UpdateItemOutcome outcome = table.updateItem(updateItemSpec);
// Check the response.
System.out
.println("Printing item after conditional update to new
attribute...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Error updating item in " + tableName);
System.err.println(e.getMessage());
}
}
private static void deleteItem() {
Table table = dynamoDB.getTable(tableName);
try {
DeleteItemSpec deleteItemSpec = new DeleteItemSpec()
.withPrimaryKey("Id", 120)
.withConditionExpression("#ip = :val")
.withNameMap(new NameMap()
.with("#ip", "InPublication"))
.withValueMap(new ValueMap()
.withBoolean(":val", false))
.withReturnValues(ReturnValue.ALL_OLD);
DeleteItemOutcome outcome = table.deleteItem(deleteItemSpec);
// Check the response.
API Version 2012-08-10
242
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
System.out.println("Printing item that was deleted...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Error deleting item in " + tableName);
System.err.println(e.getMessage());
}
}
}
例: AWS SDK for Java ドキュメント API を使用したバッチオ
ペレーション
トピック
• 例: AWS SDK for Java ドキュメント API を使用したバッチ書き込みオペレーション (p. 243)
• 例: AWS SDK for Java ドキュメント API を使用したバッチ取得オペレーション (p. 245)
このセクションでは、AWS SDK for Java ドキュメント API を使用したバッチ書き込みおよびバッチ
取得オペレーションの例を示します。
Note
SDK for Java には、オブジェクト永続性モデルも用意されています。このモデルにより、ク
ライアント側のクラスを DynamoDB テーブルにマッピングすることができます。この方法
により、記述する必要のあるコードの量を減らすことができます。詳細については、「Java:
DynamoDBMapper (p. 78)」を参照してください。
例: AWS SDK for Java ドキュメント API を使用したバッチ書き込みオペレー
ション
以下の Java コード例では、batchWriteItem メソッドを使用して、以下の置換および削除のオペ
レーションを実行します。
• Forum テーブル内で 1 つの項目を置換
• Thread テーブルに対して 1 つの項目を置換および削除
バッチの書き込みリクエストを作成すると、1 つまたは複数のテーブルに対して多数の置換リクエス
トと削除リクエストを指定できます。ただし、batchWriteItem では、1 回のバッチ書き込みオペ
レーションで可能なバッチ書き込みリクエストのサイズ、置換および削除のオペレーションの数を制
限しています。 これらの制限を超えるリクエストは却下されます。プロビジョニングされたスルー
プットがテーブルに不足しているためにこのリクエストを処理できない場合は、応答時に未処理のリ
クエスト項目が返されます。
以下の例では、未処理のリクエスト項目がないか、応答を確認します。未処理のリクエスト項目があ
る場合は、batchWriteItem リクエストをループバックして再送信します。「テーブルの作成とサン
プルデータのロード (p. 166)」セクションの手順に従っていれば、Forum テーブルと Thread テーブル
は作成済みです。プログラムで、これらのテーブルを作成し、サンプルデータをアップロードするこ
ともできます。詳細については、「AWS SDK for Java を使用した、サンプルテーブルの作成とデー
タのアップロード (p. 600)」を参照してください。
次のサンプルをテストするための詳しい手順については、「Java コードサンプル (p. 171)」を参照し
てください。
API Version 2012-08-10
243
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import
import
import
import
import
java.io.IOException;
java.util.Arrays;
java.util.HashSet;
java.util.List;
java.util.Map;
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.BatchWriteItemOutcome;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.TableWriteItems;
com.amazonaws.services.dynamodbv2.model.WriteRequest;
public class DocumentAPIBatchWrite {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String forumTableName = "Forum";
static String threadTableName = "Thread";
public static void main(String[] args) throws IOException {
writeMultipleItemsBatchWrite();
}
private static void writeMultipleItemsBatchWrite() {
try {
// Add a new item to Forum
TableWriteItems forumTableWriteItems = new
TableWriteItems(forumTableName) //Forum
.withItemsToPut(new Item()
.withPrimaryKey("Name", "Amazon RDS")
.withNumber("Threads", 0));
// Add a new item, and delete an existing item, from Thread
// This table has a partition key and range key, so need to
specify both of them
TableWriteItems threadTableWriteItems = new
TableWriteItems(threadTableName)
.withItemsToPut(new Item()
.withPrimaryKey("ForumName","Amazon RDS","Subject","Amazon
RDS Thread 1")
.withString("Message", "ElastiCache Thread 1 message")
.withStringSet("Tags", new HashSet<String>(
Arrays.asList("cache", "in-memory"))))
.withHashAndRangeKeysToDelete("ForumName","Subject", "Amazon S3",
"S3 Thread 100");
System.out.println("Making the request.");
API Version 2012-08-10
244
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
BatchWriteItemOutcome outcome =
dynamoDB.batchWriteItem(forumTableWriteItems, threadTableWriteItems);
do {
// Check for unprocessed keys which could happen if you
exceed provisioned throughput
Map<String, List<WriteRequest>> unprocessedItems =
outcome.getUnprocessedItems();
if (outcome.getUnprocessedItems().size() == 0) {
System.out.println("No unprocessed items found");
} else {
System.out.println("Retrieving the unprocessed items");
outcome =
dynamoDB.batchWriteItemUnprocessed(unprocessedItems);
}
} while (outcome.getUnprocessedItems().size() > 0);
}
catch (Exception e) {
System.err.println("Failed to retrieve items: ");
e.printStackTrace(System.err);
}
}
}
例: AWS SDK for Java ドキュメント API を使用したバッチ取得オペレーショ
ン
以下の Java コード例では、batchGetItem メソッドを使用して、Forum テーブルおよび Thread
テーブルから複数の項目を取り出します。BatchGetItemRequest は、取得する各項目のテーブル名
とキーのリストを指定します。この例では、取得した項目を印刷して応答を処理します。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。
以下の例を実行するための詳しい手順については、「Java コードサンプル (p. 171)」を参照
してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
API Version 2012-08-10
245
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
import
import
import
import
import
com.amazonaws.services.dynamodbv2.document.BatchGetItemOutcome;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.TableKeysAndAttributes;
com.amazonaws.services.dynamodbv2.model.KeysAndAttributes;
public class DocumentAPIBatchGet {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String forumTableName = "Forum";
static String threadTableName = "Thread";
public static void main(String[] args) throws IOException {
retrieveMultipleItemsBatchGet();
}
private static void retrieveMultipleItemsBatchGet() {
try {
TableKeysAndAttributes forumTableKeysAndAttributes = new
TableKeysAndAttributes(forumTableName);
//Add a partition key
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys("Name",
"Amazon S3", "Amazon DynamoDB");
TableKeysAndAttributes threadTableKeysAndAttributes = new
TableKeysAndAttributes(threadTableName);
//Add a partition key and a sort key
threadTableKeysAndAttributes.addHashAndRangePrimaryKeys("ForumName",
"Subject",
"Amazon DynamoDB","DynamoDB Thread 1",
"Amazon DynamoDB","DynamoDB Thread 2",
"Amazon S3","S3 Thread 1");
System.out.println("Making the request.");
BatchGetItemOutcome outcome =
dynamoDB.batchGetItem(forumTableKeysAndAttributes,
threadTableKeysAndAttributes);
Map<String, KeysAndAttributes> unprocessed = null;
do {
for (String tableName : outcome.getTableItems().keySet()) {
System.out.println("Items in table " + tableName);
List<Item> items =
outcome.getTableItems().get(tableName);
for (Item item : items) {
System.out.println(item.toJSONPretty());
}
}
// Check for unprocessed keys which could happen if you
exceed provisioned
API Version 2012-08-10
246
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
// throughput or reach the limit on response size.
unprocessed = outcome.getUnprocessedKeys();
if (unprocessed.isEmpty()) {
System.out.println("No unprocessed keys found");
} else {
System.out.println("Retrieving the unprocessed keys");
outcome = dynamoDB.batchGetItemUnprocessed(unprocessed);
}
} while (!unprocessed.isEmpty());
}
catch (Exception e) {
System.err.println("Failed to retrieve items.");
System.err.println(e.getMessage());
}
}
}
例: AWS SDK for Java ドキュメント API を使用したバイナリ
タイプ属性の処理
以下の Java コード例は、バイナリタイプ属性の処理の例です。この例では、Reply テーブルに項目
を追加します。この項目には、圧縮データを格納するバイナリタイプ属性(ExtendedMessage)な
どがあります。また、この例では、項目を取得し、すべての属性値を印刷します。説明のため、こ
の例では GZIPOutputStream クラスを使用して、サンプルストリームを圧縮し、圧縮したデータを
ExtendedMessage 属性に割り当てます。バイナリ属性が取得されると、GZIPInputStream クラス
を使用して展開されます。
Note
SDK for Java には、オブジェクト永続性モデルも用意されています。このモデルにより、ク
ライアント側のクラスを DynamoDB テーブルにマッピングすることができます。この方法
により、記述する必要のあるコードの量を減らすことができます。詳細については、「Java:
DynamoDBMapper (p. 78)」を参照してください。
「テーブルの作成とサンプルデータのロード (p. 166)」セクションの手順に従っていれば、Reply テー
ブルは作成済みです。このテーブルは、プログラムで作成することもできます。詳細については、
「AWS SDK for Java を使用した、サンプルテーブルの作成とデータのアップロード (p. 600)」を参
照してください。
次のサンプルをテストするための詳しい手順については、「Java コードサンプル (p. 171)」を参照し
てください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import
import
import
import
java.io.ByteArrayInputStream;
java.io.ByteArrayOutputStream;
java.io.IOException;
java.nio.ByteBuffer;
API Version 2012-08-10
247
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
import
import
import
import
import
java.text.SimpleDateFormat;
java.util.Date;
java.util.TimeZone;
java.util.zip.GZIPInputStream;
java.util.zip.GZIPOutputStream;
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.Table;
com.amazonaws.services.dynamodbv2.document.spec.GetItemSpec;
public class DocumentAPIItemBinaryExample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tableName = "Reply";
static SimpleDateFormat dateFormatter = new SimpleDateFormat("yyyy-MMdd'T'HH:mm:ss.SSS'Z'");
public static void main(String[] args) throws IOException {
try {
// Format the primary key values
String threadId = "Amazon DynamoDB#DynamoDB Thread 2";
dateFormatter.setTimeZone(TimeZone.getTimeZone("UTC"));
String replyDateTime = dateFormatter.format(new Date());
// Add a new reply with a binary attribute type
createItem(threadId, replyDateTime);
// Retrieve the reply with a binary attribute type
retrieveItem(threadId, replyDateTime);
// clean up by deleting the item
deleteItem(threadId, replyDateTime);
} catch (Exception e) {
System.err.println("Error running the binary attribute type
example: " + e);
e.printStackTrace(System.err);
}
}
public static void createItem(String threadId, String replyDateTime)
throws IOException {
Table table = dynamoDB.getTable(tableName);
// Craft a long message
String messageInput = "Long message to be compressed in a lengthy
forum reply";
// Compress the long message
ByteBuffer compressedMessage =
compressString(messageInput.toString());
API Version 2012-08-10
248
Amazon DynamoDB 開発者ガイド
項目の操作 : Java
table.putItem(new Item()
.withPrimaryKey("Id", threadId)
.withString("ReplyDateTime", replyDateTime)
.withString("Message", "Long message follows")
.withBinary("ExtendedMessage", compressedMessage)
.withString("PostedBy", "User A"));
}
public static void retrieveItem(String threadId, String replyDateTime)
throws IOException {
Table table = dynamoDB.getTable(tableName);
GetItemSpec spec = new GetItemSpec()
.withPrimaryKey("Id", threadId, "ReplyDateTime", replyDateTime)
.withConsistentRead(true);
Item item = table.getItem(spec);
// Uncompress the reply message and print
String uncompressed =
uncompressString(ByteBuffer.wrap(item.getBinary("ExtendedMessage")));
System.out.println("Reply message:\n"
+ " Id: " + item.getString("Id") + "\n"
+ " ReplyDateTime: " + item.getString("ReplyDateTime") + "\n"
+ " PostedBy: " + item.getString("PostedBy") + "\n"
+ " Message: " + item.getString("Message") + "\n"
+ " ExtendedMessage (uncompressed): " + uncompressed + "\n");
}
public static void deleteItem(String threadId, String replyDateTime) {
Table table = dynamoDB.getTable(tableName);
table.deleteItem("Id", threadId, "ReplyDateTime", replyDateTime);
}
private static ByteBuffer compressString(String input) throws IOException
{
// Compress the UTF-8 encoded String into a byte[]
ByteArrayOutputStream baos = new ByteArrayOutputStream();
GZIPOutputStream os = new GZIPOutputStream(baos);
os.write(input.getBytes("UTF-8"));
os.close();
baos.close();
byte[] compressedBytes = baos.toByteArray();
// The following code writes the compressed bytes to a ByteBuffer.
// A simpler way to do this is by simply calling
ByteBuffer.wrap(compressedBytes);
// However, the longer form below shows the importance of resetting
the position of the buffer
// back to the beginning of the buffer if you are writing bytes
directly to it, since the SDK
// will consider only the bytes after the current position when
sending data to DynamoDB.
// Using the "wrap" method automatically resets the position to zero.
API Version 2012-08-10
249
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
ByteBuffer buffer = ByteBuffer.allocate(compressedBytes.length);
buffer.put(compressedBytes, 0, compressedBytes.length);
buffer.position(0); // Important: reset the position of the
ByteBuffer to the beginning
return buffer;
}
private static String uncompressString(ByteBuffer input) throws
IOException {
byte[] bytes = input.array();
ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
GZIPInputStream is = new GZIPInputStream(bais);
int chunkSize = 1024;
byte[] buffer = new byte[chunkSize];
int length = 0;
while ((length = is.read(buffer, 0, chunkSize)) != -1) {
baos.write(buffer, 0, length);
}
String result = new String(baos.toByteArray(), "UTF-8");
is.close();
baos.close();
bais.close();
return result;
}
}
項目の操作 : .NET
トピック
• 項目の置換 (p. 251)
• 項目の取得 (p. 252)
• 項目の更新 (p. 253)
• アトミックカウンター (p. 255)
• 項目の削除 (p. 256)
• バッチ書き込み: 複数の項目の書き込みおよび削除 (p. 257)
• バッチ取得: 複数の項目の取得 (p. 259)
• 例: AWS SDK for .NET の低レベル API を使用した CRUD オペレーション (p. 261)
• 例: AWS SDK for .NET の低レベル API を使用した、バッチオペレーション (p. 265)
• 例: AWS SDK for .NET の低レベル API を使用した、バイナリタイプ属性の処理 (p. 271)
AWS SDK for .NET 低レベル API を使用して、テーブル内の項目に対して、一般的な作成、読み込
み、更新、削除(CRUD)のオペレーションを実行できます。
以下に、.NET の低レベル API を使用してデータ CRUD オペレーションを実行する手順を示します。
1. AmazonDynamoDBClient クラスのインスタンス(クライアント)を作成します。
2. 対応するリクエストオブジェクト内に、オペレーション固有の必須パラメータを指定します。
たとえば、項目をアップロードするには PutItemRequest リクエストオブジェクトを使用し、既
存の項目を取り出すには GetItemRequest リクエストオブジェクトを使用します。
API Version 2012-08-10
250
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
リクエストオブジェクトを使用して、必須パラメータとオプションパラメータの両方を指定できま
す。
3. 前の手順で作成したリクエストオブジェクト内でパスすることにより、クライアントから提供され
た適切なメソッドを実行します。
AmazonDynamoDBClient クライアントは、CRUD オペレーション用のメソッドとし
て、PutItem、GeItem、UpdateItem、DeleteItem を提供します。
項目の置換
PutItem メソッドによって、項目をテーブルにアップロードします。項目が存在する場合、その項目
全体が置き換えられます。
Note
項目全体を置き換える代わりに固有の属性のみを更新する場合は、UpdateItem メソッドを
使用できます。詳細については、「項目の更新 (p. 253)」を参照してください。
以下に、低レベルの .NET SDK API を使用して項目をアップロードする手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. PutItemRequest クラスのインスタンスを作成し、必須パラメータを指定します。
項目を置き換えるには、テーブル名と項目を指定する必要があります。
3. 前の手順で作成した PutItemRequest オブジェクトを指定して、PutItem メソッドを実行しま
す。
次の C# コードスニペットは、前述のステップを示しています。この例では、ProductCatalog テーブ
ルに項目がアップロードされています。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ProductCatalog";
var request = new PutItemRequest
{
TableName = tableName,
Item = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { N = "201" }},
{ "Title", new AttributeValue { S = "Book 201 Title" }},
{ "ISBN", new AttributeValue { S = "11-11-11-11" }},
{ "Price", new AttributeValue { S = "20.00" }},
{
"Authors",
new AttributeValue
{ SS = new List<string>{"Author1", "Author2"}
}
}
}
};
client.PutItem(request);
上記の例では、Id、Title、ISBN、Authors の属性を持つ書籍項目をアップロードしています。Id は数
値型の属性で、それ以外の属性はすべて文字列型です。Authors は文字列セットです。
API Version 2012-08-10
251
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
オプションパラメータの指定
以下の C# コードスニペットに示すように、PutItemRequest オブジェクトを使用してオプションの
パラメータを指定することもできます。このサンプルでは、次のオプションパラメータが指定されて
います。
• ExpressionAttributeNames、ExpressionAttributeValues、および
ConditionExpression は、特定の値が設定された ISBN 属性が既存の項目にある場合にのみ項目
を置き換えるという条件を指定します。
• ReturnValues パラメータ。応答内で古い項目をリクエストします。
var request = new PutItemRequest
{
TableName = tableName,
Item = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { N = "104" }},
{ "Title", new AttributeValue { S = "Book 104 Title" }},
{ "ISBN", new AttributeValue { S = "444-4444444444" }},
{ "Authors",
new AttributeValue { SS = new List<string>{"Author3"}}}
},
// Optional parameters.
ExpressionAttributeNames = new Dictionary<string,string>()
{
{"#I", "ISBN"}
},
ExpressionAttributeValues = new Dictionary<string, AttributeValue>()
{
{":isbn",new AttributeValue {S = "444-4444444444"}}
},
ConditionExpression = "#I = :isbn"
};
var response = client.PutItem(request);
詳細については、PutItem を参照してください。
項目の取得
GetItem メソッドにより、項目を取り出します。
Note
複数の項目を取り出すために、BatchGetItem メソッドを使用できます。詳細については、
「バッチ取得: 複数の項目の取得 (p. 259)」を参照してください。
以下に、低レベルの .NET SDK API を使用して既存の項目を取り出す手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. GetItemRequest クラスのインスタンスを作成し、必須パラメータを指定します。
項目を取得するには、その項目のテーブル名とプライマリキーを指定する必要があります。
3. 前の手順で作成した GetItemRequest オブジェクトを指定して、GetItem メソッドを実行しま
す。
API Version 2012-08-10
252
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
次の C# コードスニペットは、前述のステップを示しています。ProductCatalog テーブルから項目を
取り出す例を以下に示します。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ProductCatalog";
var request = new GetItemRequest
{
TableName = tableName,
Key = new Dictionary<string,AttributeValue>() { { "Id", new AttributeValue
{ N = "202" } } },
};
var response = client.GetItem(request);
// Check the response.
var result = response.GetItemResult;
var attributeMap = result.Item; // Attribute list in the response.
オプションパラメータの指定
以下の C# コードスニペットに示すように、GetItemRequest オブジェクトを使用してオプションの
パラメータを指定することもできます。このサンプルでは、次のオプションパラメータが指定されて
います。
• 取得対象の属性を指定する ProjectionExpression パラメータ。
• 強力な整合性のある読み込みを実行する ConsistentRead パラメータ。読み込みの整合性に関す
る詳細については、「読み込み整合性 (p. 16)」を参照してください。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ProductCatalog";
var request = new GetItemRequest
{
TableName = tableName,
Key = new Dictionary<string,AttributeValue>() { { "Id", new AttributeValue
{ N = "202" } } },
// Optional parameters.
ProjectionExpression = "Id, ISBN, Title, Authors",
ConsistentRead = true
};
var response = client.GetItem(request);
// Check the response.
var result = response.GetItemResult;
var attributeMap = result.Item;
詳細については、GetItem を参照してください。
項目の更新
既存の項目がある場合に、UpdateItem メソッドにより、その項目を更新します。UpdateItem オペ
レーションを使用して、既存の属性値の更新、新しい属性の追加、または既存のコレクションからの
属性の削除ができます。指定のプライマリキーのある項目が見つからない場合は、新しい項目を追加
します。
API Version 2012-08-10
253
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
UpdateItem オペレーションは、以下のガイドラインに従います。
• 項目が存在しない場合、UpdateItem は入力で指定されたプライマリキーを使用して、新しい項目
を追加します。
• 項目が存在する場合、UpdateItem は次のように更新を適用します。
• 既存の属性値を更新内の値に置き換えます。
• 入力内で指定した属性が存在しない場合は、項目に新しい属性を追加します。
• 入力属性が null の場合、属性がある場合は、削除します。
• Action に ADD を使用すると、既存のセット(文字列または数セット)に値を追加できます。ある
いは、既存の数値属性の値に対して足し算(正の数を使用)したり、引き算(負の数を使用)す
ることもできます。
Note
また、PutItem オペレーションにより、更新を実行できます。詳細については、「項目の置
換 (p. 251)」を参照してください。たとえば、PutItem を呼び出して項目をアップロードし
た場合にプライマリキーが存在すれば、PutItem オペレーションによって項目全体が置き換
えられます。既存の項目内に属性がある場合、入力に指定されていない属性は、PutItem オ
ペレーションによって削除されます。ただし、UpdateItem は指定された入力属性のみを更
新します。その項目の他の既存の属性は変更されません。
以下に、低レベルの .NET SDK API を使用して既存の項目を更新する手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. UpdateItemRequest クラスのインスタンスを作成し、必須パラメータを指定します。
これは、属性の追加、既存の属性の更新、属性の削除など、すべての更新を記述するリクエストオ
ブジェクトです。既存の属性を削除するには、null 値の属性名を指定します。
3. 前の手順で作成した UpdateItemRequest オブジェクトを指定して、UpdateItem メソッドを実
行します。
次の C# コードスニペットは、前述のステップを示しています。ProductCatalog テーブルで書籍項目
を更新する例を以下に示します。この例では、Authors コレクションに著者を追加し、既存の ISBN 属
性を削除します。また、価格を 1 引き下げます。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ProductCatalog";
var request = new UpdateItemRequest
{
TableName = tableName,
Key = new Dictionary<string,AttributeValue>() { { "Id", new
AttributeValue { N = "202" } } },
ExpressionAttributeNames = new Dictionary<string,string>()
{
{"#A", "Authors"},
{"#P", "Price"},
{"#NA", "NewAttribute"},
{"#I", "ISBN"}
},
ExpressionAttributeValues = new Dictionary<string, AttributeValue>()
{
{":auth",new AttributeValue { SS = {"Author YY","Author ZZ"}}},
{":p",new AttributeValue {N = "1"}},
API Version 2012-08-10
254
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
{":newattr",new AttributeValue {S = "someValue"}},
},
// This expression does the following:
// 1) Adds two new authors to the list
// 2) Reduces the price
// 3) Adds a new attribute to the item
// 4) Removes the ISBN attribute from the item
UpdateExpression = "ADD #A :auth SET #P = #P - :p, #NA = :newattr REMOVE
#I"
};
var response = client.UpdateItem(request);
オプションパラメータの指定
以下の C# コードスニペットに示すように、UpdateItemRequest オブジェクトを使用してオプショ
ンのパラメータを指定することもできます。以下のオプションパラメータを指定します。
• ExpressionAttributeValues および ConditionExpression パラメータ。既存の価格が 20.00
USD である場合にのみ価格を更新できることを指定します。
• ReturnValues パラメータ。応答内で更新された項目をリクエストします。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ProductCatalog";
var request = new UpdateItemRequest
{
Key = new Dictionary<string,AttributeValue>() { { "Id", new
AttributeValue { N = "202" } } },
// Update price only if the current price is 20.00.
ExpressionAttributeNames = new Dictionary<string,string>()
{
{"#P", "Price"}
},
ExpressionAttributeValues = new Dictionary<string, AttributeValue>()
{
{":newprice",new AttributeValue {N = "22"}},
{":currprice",new AttributeValue {N = "20"}}
},
UpdateExpression = "SET #P = :newprice",
ConditionExpression = "#P = :currprice",
TableName = tableName,
ReturnValues = "ALL_NEW" // Return all the attributes of the updated
item.
};
var response = client.UpdateItem(request);
詳細については、UpdateItem を参照してください。
アトミックカウンター
updateItem を使用してアトミックカウンターを実装できます。アトミックカウンターでは、他の書
き込みリクエストを妨げることなく、既存の属性の値をインクリメントまたはデクリメントします。
アトミックカウンターを更新するには、updateItem の UpdateExpression パラメータで数値型の属
性を使用し、Action として ADD を使用します。
API Version 2012-08-10
255
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
次のコード例はアトミックカウンターを示しており、Quantity 属性を 1 ずつインクリメントさせてい
ます。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ProductCatalog";
var request = new UpdateItemRequest
{
Key = new Dictionary<string, AttributeValue>() { { "Id", new
AttributeValue { N = "121" } } },
ExpressionAttributeNames = new Dictionary<string, string>()
{
{"#Q", "Quantity"}
},
ExpressionAttributeValues = new Dictionary<string, AttributeValue>()
{
{":incr",new AttributeValue {N = "1"}}
},
UpdateExpression = "SET #Q = #Q + :incr",
TableName = tableName
};
var response = client.UpdateItem(request);
項目の削除
DeleteItem メソッドによって、テーブルから項目を削除します。
以下に、低レベルの .NET SDK API を使用して項目を削除する手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. DeleteItemRequest クラスのインスタンスを作成し、必須パラメータを指定します。
項目を削除するには、テーブル名とその項目のプライマリキーが必要です。
3. 前の手順で作成した DeleteItemRequest オブジェクトを指定して、DeleteItem メソッドを実
行します。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "ProductCatalog";
var request = new DeleteItemRequest
{
TableName = tableName,
Key = new Dictionary<string,AttributeValue>() { { "Id", new
AttributeValue { N = "201" } } },
};
var response = client.DeleteItem(request);
オプションパラメータの指定
以下の C# コードスニペットに示すように、DeleteItemRequest オブジェクトを使用してオプショ
ンのパラメータを指定することもできます。以下のオプションパラメータを指定します。
• ExpressionAttributeValues および ConditionExpression パラメータ。廃刊になっている
(InPublication の属性値が false)場合にのみ書籍項目を削除するという条件を指定します。
API Version 2012-08-10
256
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
• ReturnValues パラメータ。応答内で削除済みの項目をリクエストします。
var request = new DeleteItemRequest
{
TableName = tableName,
Key = new Dictionary<string,AttributeValue>() { { "Id", new
AttributeValue { N = "201" } } },
// Optional parameters.
ReturnValues = "ALL_OLD",
ExpressionAttributeNames = new Dictionary<string, string>()
{
{"#IP", "InPublication"}
},
ExpressionAttributeValues = new Dictionary<string, AttributeValue>()
{
{":inpub",new AttributeValue {BOOL = false}}
},
ConditionExpression = "#IP = :inpub"
};
var response = client.DeleteItem(request);
詳細については、DeleteItem を参照してください。
バッチ書き込み: 複数の項目の書き込みおよび削除
バッチ書き込みは、複数の項目の書き込みと削除をバッチで行うことを意味しま
す。BatchWriteItem メソッドによって、単一の コール内にある 1 つまたは複数のテーブルから複
数の項目を置換および削除できます。以下に、低レベルの .NET SDK API を使用して複数の項目を取
り出す手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. BatchWriteItemRequest クラスのインスタンスを作成して、置換および削除のすべてのオペ
レーションを説明します。
3. 前の手順で作成した BatchWriteItemRequest オブジェクトを指定して、BatchWriteItem メ
ソッドを実行します。
4. 応答を処理します。返された未処理のリクエスト項目が応答内に存在していたかどうかをチェック
する必要があります。これは、プロビジョニングされたスループットの制限または他の何らかの一
時的エラーに達する場合に、発生する可能性があります。また、DynamoDB によって、リクエスト
のサイズ、およびリクエスト内で指定できるオペレーションの数が制限されます。これらの制限を
超えると、DynamoDB によってリクエストが却下されます。詳細については、BatchWriteItem を
参照してください。
次の C# コードスニペットは、前述のステップを示しています。この例で
は、BatchWriteItemRequest を作成して、以下の書き込みオペレーションを実行します。
• Forum テーブル内で項目を置換します。
• Thread テーブルに対して項目の置換および削除を実行します。
コードにより、BatchWriteItem が実行され、バッチオペレーションが行われます。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
API Version 2012-08-10
257
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
string table1Name = "Forum";
string table2Name = "Thread";
var request = new BatchWriteItemRequest
{
RequestItems = new Dictionary<string, List<WriteRequest>>
{
{
table1Name, new List<WriteRequest>
{
new WriteRequest
{
PutRequest = new PutRequest
{
Item = new Dictionary<string,AttributeValue>
{
{ "Name", new AttributeValue { S = "Amazon S3 forum" } },
{ "Threads", new AttributeValue { N = "0" }}
}
}
}
}
} ,
{
table2Name, new List<WriteRequest>
{
new WriteRequest
{
PutRequest = new PutRequest
{
Item = new Dictionary<string,AttributeValue>
{
{ "ForumName", new AttributeValue { S = "Amazon S3
forum" } },
{ "Subject", new AttributeValue { S = "My sample
question" } },
{ "Message", new AttributeValue { S = "Message Text." } },
{ "KeywordTags", new AttributeValue { SS = new List<string>
{ "Amazon S3", "Bucket" } } }
}
}
},
new WriteRequest
{
DeleteRequest = new DeleteRequest
{
Key = new Dictionary<string,AttributeValue>()
{
{ "ForumName", new AttributeValue { S = "Some forum
name" } },
{ "Subject", new AttributeValue { S = "Some subject" } }
}
}
}
}
}
}
};
API Version 2012-08-10
258
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
response = client.BatchWriteItem(request);
実例については、「例: AWS SDK for .NET の低レベル API を使用した、バッチオペレーショ
ン (p. 265)」を参照してください。
バッチ取得: 複数の項目の取得
BatchGetItem メソッドによって、1 つまたは複数のテーブルから複数の項目を取得できます。
Note
単一の項目を取り出すために、GetItem メソッドを使用できます。
以下に、低レベルの .NET SDK API を使用して複数の項目を取り出す手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. BatchGetItemRequest クラスのインスタンスを作成し、必須パラメータを指定します。
複数の項目を取り出すには、テーブル名、およびプライマリキー値のリストが必要です。
3. 前の手順で作成した BatchGetItemRequest オブジェクトを指定して、BatchGetItem メソッド
を実行します。
4. 応答を処理します。未処理キーがなかったかどうかをチェックする必要があります。これは、プロ
ビジョニングされたスループットの制限または他の何らかの一時的エラーに達する場合に、発生す
る可能性があります。
次の C# コードスニペットは、前述のステップを示しています。この例では、Forum と Thread の 2
つのテーブルから項目を取り出します。このリクエストには、Forum テーブル内の 2 つの項目、およ
び Thread テーブル内の 3 つの項目を指定します。応答には、両方のテーブルの項目が含まれます。
このコードには、応答を処理する方法が示されます。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string table1Name = "Forum";
string table2Name = "Thread";
var request = new BatchGetItemRequest
{
RequestItems = new Dictionary<string, KeysAndAttributes>()
{
{ table1Name,
new KeysAndAttributes
{
Keys = new List<Dictionary<string, AttributeValue>>()
{
new Dictionary<string, AttributeValue>()
{
{ "Name", new AttributeValue { S = "DynamoDB" } }
},
new Dictionary<string, AttributeValue>()
{
{ "Name", new AttributeValue { S = "Amazon S3" } }
}
}
}
API Version 2012-08-10
259
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
},
{
table2Name,
new KeysAndAttributes
{
Keys = new List<Dictionary<string, AttributeValue>>()
{
new Dictionary<string, AttributeValue>()
{
{ "ForumName", new AttributeValue { S = "DynamoDB" } },
{ "Subject", new AttributeValue { S = "DynamoDB Thread 1" } }
},
new Dictionary<string, AttributeValue>()
{
{ "ForumName", new AttributeValue { S = "DynamoDB" } },
{ "Subject", new AttributeValue { S = "DynamoDB Thread 2" } }
},
new Dictionary<string, AttributeValue>()
{
{ "ForumName", new AttributeValue { S = "Amazon S3" } },
{ "Subject", new AttributeValue { S = "Amazon S3 Thread 1" } }
}
}
}
}
}
};
var response = client.BatchGetItem(request);
// Check the response.
var result = response.BatchGetItemResult;
var responses = result.Responses; // The attribute list in the response.
var table1Results = responses[table1Name];
Console.WriteLine("Items in table {0}" + table1Name);
foreach (var item1 in table1Results.Items)
{
PrintItem(item1);
}
var table2Results = responses[table2Name];
Console.WriteLine("Items in table {1}" + table2Name);
foreach (var item2 in table2Results.Items)
{
PrintItem(item2);
}
// Any unprocessed keys? could happen if you exceed ProvisionedThroughput or
some other error.
Dictionary<string, KeysAndAttributes> unprocessedKeys =
result.UnprocessedKeys;
foreach (KeyValuePair<string, KeysAndAttributes> pair in unprocessedKeys)
{
Console.WriteLine(pair.Key, pair.Value);
}
API Version 2012-08-10
260
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
オプションパラメータの指定
以下の C# コードスニペットに示すように、BatchGetItemRequest オブジェクトを使用してオプ
ションのパラメータを指定することもできます。このサンプルコードでは、Forum テーブルの 2 つの
項目を取り出します。次のオプションパラメータが指定されています。
• 取得対象の属性を指定する ProjectionExpression パラメータ。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string table1Name = "Forum";
var request = new BatchGetItemRequest
{
RequestItems = new Dictionary<string, KeysAndAttributes>()
{
{ table1Name,
new KeysAndAttributes
{
Keys = new List<Dictionary<string, AttributeValue>>()
{
new Dictionary<string, AttributeValue>()
{
{ "Name", new AttributeValue { S = "DynamoDB" } }
},
new Dictionary<string, AttributeValue>()
{
{ "Name", new AttributeValue { S = "Amazon S3" } }
}
}
},
// Optional - name of an attribute to retrieve.
ProjectionExpression = "Title"
}
}
};
var response = client.BatchGetItem(request);
詳細については、BatchGetItem を参照してください。
例: AWS SDK for .NET の低レベル API を使用した CRUD オ
ペレーション
以下の C# コード例は、項目に対する CRUD オペレーションの例です。この例では、ProductCatalog
テーブルへの項目の追加、項目の取得、さまざまな更新の実行、さらに項目の削除を行います。
「テーブルの作成とサンプルデータのロード (p. 166)」のステップに従っていれば、ProductCatalog
テーブルは作成済みです。これらのサンプルテーブルは、プログラムで作成することもできます。
詳細については、「AWS SDK for .NET を使用した、サンプルテーブルの作成とデータのアップロー
ド (p. 608)」を参照してください。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using System;
using System.Collections.Generic;
using Amazon.DynamoDBv2;
API Version 2012-08-10
261
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
using Amazon.DynamoDBv2.Model;
using Amazon.Runtime;
using Amazon.SecurityToken;
namespace com.amazonaws.codesamples
{
class LowLevelItemCRUDExample
{
private static string tableName = "ProductCatalog";
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
CreateItem();
RetrieveItem();
// Perform various updates.
UpdateMultipleAttributes();
UpdateExistingAttributeConditionally();
// Delete item.
DeleteItem();
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (Exception e)
{
Console.WriteLine(e.Message);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
}
private static void CreateItem()
{
var request = new PutItemRequest
{
TableName = tableName,
Item = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { N = "1000" }},
{ "Title", new AttributeValue { S = "Book 201 Title" }},
{ "ISBN", new AttributeValue { S = "11-11-11-11" }},
{ "Authors", new AttributeValue { SS = new List<string>{"Author1",
"Author2" }}},
{ "Price", new AttributeValue { N = "20.00" }},
{ "Dimensions", new AttributeValue { S = "8.5x11.0x.75" }},
{ "InPublication", new AttributeValue { BOOL = false } }
}
};
client.PutItem(request);
}
private static void RetrieveItem()
{
API Version 2012-08-10
262
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
var request = new GetItemRequest
{
TableName = tableName,
Key = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { N = "1000" } }
},
ProjectionExpression = "Id, ISBN, Title, Authors",
ConsistentRead = true
};
var response = client.GetItem(request);
// Check the response.
var attributeList = response.Item; // attribute list in the
response.
Console.WriteLine("\nPrinting item after retrieving
it ............");
PrintItem(attributeList);
}
private static void UpdateMultipleAttributes()
{
var request = new UpdateItemRequest
{
Key = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { N = "1000" } }
},
// Perform the following updates:
// 1) Add two new authors to the list
// 1) Set a new attribute
// 2) Remove the ISBN attribute
ExpressionAttributeNames = new Dictionary<string,string>()
{
{"#A","Authors"},
{"#NA","NewAttribute"},
{"#I","ISBN"}
},
ExpressionAttributeValues = new Dictionary<string,
AttributeValue>()
{
{":auth",new AttributeValue {SS = {"Author YY", "Author
ZZ"}}},
{":new",new AttributeValue {S = "New Value"}}
},
UpdateExpression = "ADD #A :auth SET #NA = :new REMOVE #I",
TableName = tableName,
ReturnValues = "ALL_NEW" // Give me all attributes of the
updated item.
};
var response = client.UpdateItem(request);
// Check the response.
var attributeList = response.Attributes; // attribute list in the
response.
// print attributeList.
API Version 2012-08-10
263
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
Console.WriteLine("\nPrinting item after multiple attribute
update ............");
PrintItem(attributeList);
}
private static void UpdateExistingAttributeConditionally()
{
var request = new UpdateItemRequest
{
Key = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { N = "1000" } }
},
ExpressionAttributeNames = new Dictionary<string,string>()
{
{"#P", "Price"}
},
ExpressionAttributeValues = new Dictionary<string,
AttributeValue>()
{
{":newprice",new AttributeValue {N = "22.00"}},
{":currprice",new AttributeValue {N = "20.00"}}
},
// This updates price only if current price is 20.00.
UpdateExpression = "SET #P = :newprice",
ConditionExpression = "#P = :currprice",
TableName = tableName,
ReturnValues = "ALL_NEW" // Give me all attributes of the
updated item.
};
var response = client.UpdateItem(request);
// Check the response.
var attributeList = response.Attributes; // attribute list in the
response.
Console.WriteLine("\nPrinting item after updating price value
conditionally ............");
PrintItem(attributeList);
}
private static void DeleteItem()
{
var request = new DeleteItemRequest
{
TableName = tableName,
Key = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { N = "1000" } }
},
// Return the entire item as it appeared before the update.
ReturnValues = "ALL_OLD",
ExpressionAttributeNames = new Dictionary<string,string>()
{
{"#IP", "InPublication"}
},
ExpressionAttributeValues = new Dictionary<string,
AttributeValue>()
API Version 2012-08-10
264
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
{
{":inpub",new AttributeValue {BOOL = false}}
},
ConditionExpression = "#IP = :inpub"
};
var response = client.DeleteItem(request);
// Check the response.
var attributeList = response.Attributes; // Attribute list in the
response.
// Print item.
Console.WriteLine("\nPrinting item that was just
deleted ............");
PrintItem(attributeList);
}
private static void PrintItem(Dictionary<string, AttributeValue>
attributeList)
{
foreach (KeyValuePair<string, AttributeValue> kvp in
attributeList)
{
string attributeName = kvp.Key;
AttributeValue value = kvp.Value;
Console.WriteLine(
attributeName + " " +
(value.S == null ? "" : "S=[" +
(value.N == null ? "" : "N=[" +
(value.SS == null ? "" : "SS=["
value.SS.ToArray()) + "]") +
(value.NS == null ? "" : "NS=["
value.NS.ToArray()) + "]")
);
}
value.S + "]") +
value.N + "]") +
+ string.Join(",",
+ string.Join(",",
Console.WriteLine("************************************************");
}
}
}
例: AWS SDK for .NET の低レベル API を使用した、バッチオ
ペレーション
トピック
• 例: AWS SDK for .NET の低レベル API を使用した、バッチ書き込みオペレーション (p. 266)
• 例: AWS SDK for .NET の低レベル API を使用した、バッチ取得オペレーション (p. 269)
このセクションでは、DynamoDB でサポートするバッチオペレーションの例(バッチの書き込み、取
得)を説明します。
API Version 2012-08-10
265
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
例: AWS SDK for .NET の低レベル API を使用した、バッチ書き込みオペレー
ション
以下の C# コード例では、BatchWriteItem メソッドを使用して、以下の置換および削除のオペレー
ションを実行します。
• Forum テーブル内で 1 つの項目を置換
• Thread テーブルに対して 1 つの項目を置換および削除
バッチの書き込みリクエストを作成すると、1 つまたは複数のテーブルに対して多数の置換リクエス
トと削除リクエストを指定できます。ただし、DynamoDB BatchWriteItem では、1 回のバッチ書
き込みオペレーションで可能なバッチ書き込みリクエストのサイズ、置換および削除のオペレーショ
ンの数を制限しています。 詳細については、BatchWriteItem を参照してください。これらの制限を超
えるリクエストは却下されます。プロビジョニングされたスループットがテーブルに不足しているた
めにこのリクエストを処理できない場合は、応答時に未処理のリクエスト項目が返されます。
以下の例では、未処理のリクエスト項目がないか、応答を確認します。未処理のリクエスト項目があ
る場合は、BatchWriteItem リクエストをループバックして再送信します。「テーブルの作成とサン
プルデータのロード (p. 166)」のステップに従っていれば、Forum テーブルと Thread テーブルは作
成済みです。プログラムで、これらのサンプルテーブルを作成し、サンプルデータをアップロードす
ることもできます。詳細については、「AWS SDK for .NET を使用した、サンプルテーブルの作成と
データのアップロード (p. 608)」を参照してください。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class LowLevelBatchWrite
{
private static string table1Name = "Forum";
private static string table2Name = "Thread";
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
TestBatchWrite();
}
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void TestBatchWrite()
{
API Version 2012-08-10
266
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
var request = new BatchWriteItemRequest
{
ReturnConsumedCapacity = "TOTAL",
RequestItems = new Dictionary<string, List<WriteRequest>>
{
{
table1Name, new List<WriteRequest>
{
new WriteRequest
{
PutRequest = new PutRequest
{
Item = new Dictionary<string, AttributeValue>
{
{ "Name", new AttributeValue { S = "S3 forum" } },
{ "Threads", new AttributeValue { N = "0" }}
}
}
}
}
},
{
table2Name, new List<WriteRequest>
{
new WriteRequest
{
PutRequest = new PutRequest
{
Item = new Dictionary<string, AttributeValue>
{
{ "ForumName", new AttributeValue { S = "S3 forum" } },
{ "Subject", new AttributeValue { S = "My sample
question" } },
{ "Message", new AttributeValue { S = "Message
Text." } },
{ "KeywordTags", new AttributeValue { SS = new
List<string> { "S3", "Bucket" } } }
}
}
},
new WriteRequest
{
// For the operation to delete an item, if you provide a
primary key value
// that does not exist in the table, there is no error, it
is just a no-op.
DeleteRequest = new DeleteRequest
{
Key = new Dictionary<string, AttributeValue>()
{
{ "ForumName", new AttributeValue { S = "Some partition
key value" } },
{ "Subject", new AttributeValue { S = "Some sort key
value" } }
}
}
}
}
}
API Version 2012-08-10
267
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
}
};
CallBatchWriteTillCompletion(request);
}
private static void
CallBatchWriteTillCompletion(BatchWriteItemRequest request)
{
BatchWriteItemResponse response;
int callCount = 0;
do
{
Console.WriteLine("Making request");
response = client.BatchWriteItem(request);
callCount++;
// Check the response.
var tableConsumedCapacities = response.ConsumedCapacity;
var unprocessed = response.UnprocessedItems;
Console.WriteLine("Per-table consumed capacity");
foreach (var tableConsumedCapacity in
tableConsumedCapacities)
{
Console.WriteLine("{0} - {1}",
tableConsumedCapacity.TableName, tableConsumedCapacity.CapacityUnits);
}
Console.WriteLine("Unprocessed");
foreach (var unp in unprocessed)
{
Console.WriteLine("{0} - {1}", unp.Key,
unp.Value.Count);
}
Console.WriteLine();
// For the next iteration, the request will have unprocessed
items.
request.RequestItems = unprocessed;
} while (response.UnprocessedItems.Count > 0);
Console.WriteLine("Total # of batch write API calls made: {0}",
callCount);
}
}
}
API Version 2012-08-10
268
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
例: AWS SDK for .NET の低レベル API を使用した、バッチ取得オペレーショ
ン
以下の C# コード例では、BatchGetItem メソッドを使用して、Forum テーブルおよび Thread テー
ブルから複数の項目を取り出します。BatchGetItemRequest は、各テーブルにテーブル名とプライ
マリキーのリストを指定します。この例では、取得した項目を印刷して応答を処理します。
「テーブルの作成とサンプルデータのロード (p. 166)」のステップに従っていれば、サンプルデータ
を使用したこれらのテーブルは作成済みです。プログラムで、これらのサンプルテーブルを作成し、
サンプルデータをアップロードすることもできます。詳細については、「AWS SDK for .NET を使用
した、サンプルテーブルの作成とデータのアップロード (p. 608)」を参照してください。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class LowLevelBatchGet
{
private static string table1Name = "Forum";
private static string table2Name = "Thread";
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
RetrieveMultipleItemsBatchGet();
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
private static void RetrieveMultipleItemsBatchGet()
{
var request = new BatchGetItemRequest
{
RequestItems = new Dictionary<string, KeysAndAttributes>()
{
{ table1Name,
new KeysAndAttributes
{
Keys = new List<Dictionary<string, AttributeValue>>()
{
new Dictionary<string, AttributeValue>()
{
{ "Name", new AttributeValue { S = "Amazon DynamoDB" } }
},
API Version 2012-08-10
269
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
new Dictionary<string, AttributeValue>()
{
{ "Name", new AttributeValue { S = "Amazon S3" } }
}
}
}
},
{
table2Name,
new KeysAndAttributes
{
Keys = new List<Dictionary<string, AttributeValue>>()
{
new Dictionary<string, AttributeValue>()
{
{ "ForumName", new AttributeValue { S = "Amazon
DynamoDB" } },
{ "Subject", new AttributeValue { S = "DynamoDB Thread
1" } }
},
new Dictionary<string, AttributeValue>()
{
{ "ForumName", new AttributeValue { S = "Amazon
DynamoDB" } },
{ "Subject", new AttributeValue { S = "DynamoDB Thread
2" } }
},
new Dictionary<string, AttributeValue>()
{
{ "ForumName", new AttributeValue { S = "Amazon S3" } },
{ "Subject", new AttributeValue { S = "S3 Thread 1" } }
}
}
}
}
}
};
BatchGetItemResponse response;
do
{
Console.WriteLine("Making request");
response = client.BatchGetItem(request);
// Check the response.
var responses = response.Responses; // Attribute list in the
response.
foreach (var tableResponse in responses)
{
var tableResults = tableResponse.Value;
Console.WriteLine("Items retrieved from table {0}",
tableResponse.Key);
foreach (var item1 in tableResults)
{
PrintItem(item1);
}
}
API Version 2012-08-10
270
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
// Any unprocessed keys? could happen if you exceed
ProvisionedThroughput or some other error.
Dictionary<string, KeysAndAttributes> unprocessedKeys =
response.UnprocessedKeys;
foreach (var unprocessedTableKeys in unprocessedKeys)
{
// Print table name.
Console.WriteLine(unprocessedTableKeys.Key);
// Print unprocessed primary keys.
foreach (var key in unprocessedTableKeys.Value.Keys)
{
PrintItem(key);
}
}
request.RequestItems = unprocessedKeys;
} while (response.UnprocessedKeys.Count > 0);
}
private static void PrintItem(Dictionary<string, AttributeValue>
attributeList)
{
foreach (KeyValuePair<string, AttributeValue> kvp in
attributeList)
{
string attributeName = kvp.Key;
AttributeValue value = kvp.Value;
Console.WriteLine(
attributeName + " " +
(value.S == null ? "" : "S=[" +
(value.N == null ? "" : "N=[" +
(value.SS == null ? "" : "SS=["
value.SS.ToArray()) + "]") +
(value.NS == null ? "" : "NS=["
value.NS.ToArray()) + "]")
);
}
value.S + "]") +
value.N + "]") +
+ string.Join(",",
+ string.Join(",",
Console.WriteLine("************************************************");
}
}
}
例: AWS SDK for .NET の低レベル API を使用した、バイナリ
タイプ属性の処理
以下の C# コード例は、バイナリタイプ属性の処理の例です。この例では、Reply テーブルに項目
を追加します。この項目には、圧縮データを格納するバイナリタイプ属性(ExtendedMessage)
などがあります。また、この例では、項目を取得し、すべての属性値を印刷します。説明のため、
この例では GZipStream クラスを使用して、サンプルストリームを圧縮し、圧縮したデータを
ExtendedMessage 属性に割り当て、属性値の印刷時に展開します。
「テーブルの作成とサンプルデータのロード (p. 166)」のステップに従っていれば、Reply テーブルは
作成済みです。これらのサンプルテーブルは、プログラムで作成することもできます。詳細について
は、「AWS SDK for .NET を使用した、サンプルテーブルの作成とデータのアップロード (p. 608)」
を参照してください。
API Version 2012-08-10
271
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using
using
using
using
using
using
using
System;
System.Collections.Generic;
System.IO;
System.IO.Compression;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class LowLevelItemBinaryExample
{
private static string tableName = "Reply";
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
// Reply table primary key.
string replyIdPartitionKey = "Amazon DynamoDB#DynamoDB Thread
1";
string replyDateTimeSortKey = Convert.ToString(DateTime.UtcNow);
try
{
CreateItem(replyIdPartitionKey, replyDateTimeSortKey);
RetrieveItem(replyIdPartitionKey, replyDateTimeSortKey);
// Delete item.
DeleteItem(replyIdPartitionKey, replyDateTimeSortKey);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
private static void CreateItem(string partitionKey, string sortKey)
{
MemoryStream compressedMessage = ToGzipMemoryStream("Some long
extended message to compress.");
var request = new PutItemRequest
{
TableName = tableName,
Item = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { S = partitionKey }},
{ "ReplyDateTime", new AttributeValue { S = sortKey }},
{ "Subject", new AttributeValue { S = "Binary type " }},
{ "Message", new AttributeValue { S = "Some message about the
binary type" }},
{ "ExtendedMessage", new AttributeValue { B = compressedMessage }}
}
};
API Version 2012-08-10
272
Amazon DynamoDB 開発者ガイド
項目の操作 : .NET
client.PutItem(request);
}
private static void RetrieveItem(string partitionKey, string
sortKey)
{
var request = new GetItemRequest
{
TableName = tableName,
Key = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { S = partitionKey } },
{ "ReplyDateTime", new AttributeValue { S = sortKey } }
},
ConsistentRead = true
};
var response = client.GetItem(request);
// Check the response.
var attributeList = response.Item; // attribute list in the
response.
Console.WriteLine("\nPrinting item after retrieving
it ............");
PrintItem(attributeList);
}
private static void DeleteItem(string partitionKey, string sortKey)
{
var request = new DeleteItemRequest
{
TableName = tableName,
Key = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { S = partitionKey } },
{ "ReplyDateTime", new AttributeValue { S = sortKey } }
}
};
var response = client.DeleteItem(request);
}
private static void PrintItem(Dictionary<string, AttributeValue>
attributeList)
{
foreach (KeyValuePair<string, AttributeValue> kvp in
attributeList)
{
string attributeName = kvp.Key;
AttributeValue value = kvp.Value;
Console.WriteLine(
attributeName + " " +
(value.S == null ? "" : "S=[" +
(value.N == null ? "" : "N=[" +
(value.SS == null ? "" : "SS=["
value.SS.ToArray()) + "]") +
(value.NS == null ? "" : "NS=["
value.NS.ToArray()) + "]") +
API Version 2012-08-10
273
value.S + "]") +
value.N + "]") +
+ string.Join(",",
+ string.Join(",",
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
(value.B == null ? "" : "B=[" +
FromGzipMemoryStream(value.B) + "]")
);
}
Console.WriteLine("************************************************");
}
private static MemoryStream ToGzipMemoryStream(string value)
{
MemoryStream output = new MemoryStream();
using (GZipStream zipStream = new GZipStream(output,
CompressionMode.Compress, true))
using (StreamWriter writer = new StreamWriter(zipStream))
{
writer.Write(value);
}
return output;
}
private static string FromGzipMemoryStream(MemoryStream stream)
{
using (GZipStream zipStream = new GZipStream(stream,
CompressionMode.Decompress))
using (StreamReader reader = new StreamReader(zipStream))
{
return reader.ReadToEnd();
}
}
}
}
項目の操作 : PHP
トピック
• 項目の置換 (p. 275)
• 項目の取得 (p. 276)
• バッチ書き込み: 複数の項目の書き込みおよび削除 (p. 277)
• バッチ取得: 複数の項目の取得 (p. 278)
• 項目の更新 (p. 279)
•
•
•
•
アトミックカウンター (p. 281)
項目の削除 (p. 281)
例: AWS SDK for PHP の低レベル API を使用した CRUD オペレーション (p. 283)
例: AWS SDK for PHP を使用した、バッチオペレーション (p. 285)
AWS SDK for PHP を使用して、テーブル内の項目に対して、一般的な作成、読み込み、更新、削除
(CRUD)のオペレーションを実行できます。SDK オペレーションは、基盤となる DynamoDB の低
レベルアクションにマッピングされます。 詳細については、「PHP コードサンプル (p. 175)」を参照
してください。
以下に、AWS SDK for PHP を使用してデータ CRUD オペレーションを実行する一般的な手順を示し
ます。
1. DynamoDB クライアントのインスタンスを作成します。
API Version 2012-08-10
274
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
2. オプションのパラメーターを含む DynamoDB オペレーションのパラメーターを指定します。
3. DynamoDB からの応答をアプリケーションのローカル変数にロードします。
項目の置換
PHP putItem 関数によって、項目をテーブルにアップロードします。項目が存在する場合、そ
の項目全体が置き換えられます。項目全体を置き換える代わりに固有の属性のみを更新する場合
は、updateItem 関数を使用できます。詳細については、「項目の更新 (p. 279)」を参照してくだ
さい。
以下の PHP コードスニペットは、前述のタスクの例です。このコードでは、ProductCatalog テーブ
ルに項目をアップロードします。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。あるいは、「AWS SDK for PHP を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 617)」のトピックに記載されている手順に従って
データをロードすることもできます。
以下の例を実行するための詳しい手順については、「PHP コードサンプル (p. 175)」を参照
してください。
require 'vendor/autoload.php';
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$response = $dynamodb->putItem([
'TableName' => 'ProductCatalog',
'Item' => [
'Id'
=> ['N'
=> '104'
], // Primary Key
'Title'
=> ['S'
=> 'Book 104 Title' ],
'ISBN'
=> ['S'
=> '111-1111111111' ],
'Price'
=> ['N'
=> '25' ],
'Authors' => ['SS' => ['Author1', 'Author2'] ]
]
]);
print_r($response);
オプションパラメータの指定
必須のパラメータに加え、putItem 関数にはオプションパラメータも指定できます。た
とえば、以下の PHP コードスニペットでは、オプションパラメータを使用して、項目の
アップロード条件を指定します。指定した条件を満たさない場合は、AWS PHP SDK が
ConditionalCheckFailedException をスローします。このコードでは、putItem に以下のオプ
ションパラメータを指定します。
• ConditionExpression パラメータ。特定の値に等しい ISBN 属性が既存の項目にある場合にのみ
既存の項目を置き換えるという条件など、リクエストに対する条件を定義します。
API Version 2012-08-10
275
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
• ReturnValue パラメータに対応する ALL_OLD 値。項目に対するすべての属性値を、PutItem オペ
レーションの前に提供します。この場合、古い項目には 2 人の著者のみが含まれ、新しい項目値に
は 3 人の著者が含まれています。
$tableName = 'ProductCatalog';
$result = $dynamodb->putItem ([
'TableName' => $tableName,
'Item' => [
'Id' => [ 'N' => '104' ], // Primary Key
'Title' => [ 'S' => 'Book 104 Title' ],
'ISBN' => [ 'S' => '333-3333333333' ],
'Price' => [ 'N' => '2000' ],
'Authors' => [ 'SS' => [
'Author1', 'Author2', 'Author3' ]
]
],
'ExpressionAttributeNames' => [
'#I' => 'ISBN'] ,
'ExpressionAttributeValues' => [
':val1' => ['S' => '333-3333333333']] ,
'ConditionExpression' => '#I = :val1',
'ReturnValues' => 'ALL_OLD'
]);
print_r ($result);
詳細については、PutItem を参照してください。
項目の取得
getItem 関数によって、単一の項目を取り出します。複数の項目を取り出すために、batchGetItem
メソッドを使用できます(「バッチ取得: 複数の項目の取得 (p. 278)」参照)。
以下の PHP コードスニペットは、前述のステップの例です。このコードでは、指定したパーティショ
ンキーを持つ項目を取得します。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。あるいは、「AWS SDK for PHP を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 617)」のトピックに記載されている手順に従って
データをロードすることもできます。
以下の例を実行するための詳しい手順については、「PHP コードサンプル (p. 175)」を参照
してください。
$response = $dynamodb->getItem([
'TableName' => 'ProductCatalog',
'Key' => [
'Id' => [ 'N' => '104' ]
]
]);
API Version 2012-08-10
276
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
print_r ($response['Item']);
オプションパラメータの指定
必須のパラメータに加え、getItem 関数にはオプションパラメータも指定できます。たとえば、以下
の PHP コードスニペットでは、オプションメソッドを使用して、特定の属性リストのみを取り出し
ます。また、強い整合性のある戻り値をリクエストします。このコードでは、以下のオプションパラ
メータを指定します。
• 属性名の特定のリスト(Id や Authors など)。
• 強い整合性のある読み込み値をリクエストするブール値。読み込み結果は、デフォルトで結果整合
性があります。読み込み結果が強い整合性を持つようにリクエストできます。読み込み整合性の詳
細については、「読み込み整合性 (p. 16)」を参照してください。
$response = $dynamodb->getItem([
'TableName' => 'ProductCatalog',
'Key' => [
'Id' => ['N' => '104'],
],
'ProjectionExpression' => 'Id, Authors',
'ConsistentRead' => true
]);
詳細については、GetItem を参照してください。
バッチ書き込み: 複数の項目の書き込みおよび削除
AWS SDK for PHP batchWriteItem 関数を使用すると、単一のリクエスト内にある複数のテーブル
に対して、複数の項目の置換または削除を実行することができます。
以下の PHP コードスニペットは、次の書き込みオペレーションを実行します。
• Forum テーブル内で項目を置換。
• Thread テーブルに対して項目の置換および削除を実行。
詳細については、BatchWriteItem を参照してください。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。あるいは、「AWS SDK for PHP を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 617)」のトピックに記載されている手順に従って
データをロードすることもできます。
以下の例を実行するための詳しい手順については、「PHP コードサンプル (p. 175)」を参照
してください。
$tableNameOne = 'Forum';
$tableNameTwo = 'Thread';
$response = $dynamodb->batchWriteItem([
'RequestItems' => [
API Version 2012-08-10
277
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
$tableNameOne => [
[
'PutRequest' => [
'Item' => [
'Name'
=> ['S' => 'Amazon S3 Forum'],
'Threads' => ['N' => '0']
]]
]
],
$tableNameTwo => [
[
'PutRequest' => [
'Item' => [
'ForumName'
=> ['S' => 'Amazon S3 Forum'],
'Subject' => ['S' => 'My sample question'],
'Message'=> ['S' => 'Message Text.'],
'KeywordTags'=>['SS' => ['Amazon S3', 'Bucket']]
]]
],
[
'DeleteRequest' => [
'Key' => [
'ForumName' =>['S' => 'Some partition key value'],
'Subject' => ['S' => 'Some sort key value']
]]
]
]
]
]);
print_r ($response['Item']);
バッチ取得: 複数の項目の取得
AWS SDK for PHP の batchGetItem 関数を使用すると、1 つまたは複数のテーブルから複数の項目
を取得できます。単一の項目を取り出すために、getItem メソッドを使用できます。
次の PHP コードスニペットでは、Forum テーブル内の 2 つの項目、および Thread テーブル内の 3
つの項目を取り出します。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。あるいは、「AWS SDK for PHP を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 617)」のトピックに記載されている手順に従って
データをロードすることもできます。
以下の例を実行するための詳しい手順については、「PHP コードサンプル (p. 175)」を参照
してください。
date_default_timezone_set('UTC');
$sevenDaysAgo = date('Y-m-d H:i:s', strtotime('-7 days'));
$twentyOneDaysAgo = date('Y-m-d H:i:s', strtotime('-21 days'));
$response = $dynamodb->batchGetItem([
'RequestItems' => [
API Version 2012-08-10
278
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
'Forum' => [
'Keys' => [
[
'Name' => [ 'S' => 'DynamoDB' ]
]
]
],
'Reply' => [
'Keys' => [
[
'Id' => [ 'S' => 'DynamoDB#DynamoDB Thread 2'],
'ReplyDateTime' => [ 'S' => $sevenDaysAgo],
],
[
'Id' => [ 'S' => 'DynamoDB#DynamoDB Thread 2'],
'ReplyDateTime' => [ 'S' => $twentyOneDaysAgo],
],
]
]
]
]);
print_r($response['Responses']);
オプションパラメータの指定
必須のパラメータに加え、batchGetItem 関数にはオプションパラメータも指定できます。たとえ
ば、以下の PHP コードスニペットに示すように、取り出す属性のリストを指定することができます。
このコードでは、Forum テーブル内の 2 つの項目を取得し、ProjectionExpression パラメータを
使用して、各テーブル内のスレッド数を取り出します。
$response = $dynamodb->batchGetItem([
'RequestItems' => [
'Forum' => [
'Keys' => [
[
'Name' => [ 'S' => 'Amazon S3' ]
],
[
'Name' => [ 'S' => 'DynamoDB' ]
]
],
'ProjectionExpression' => 'Threads'
],
]
]);
print_r($response);
詳細については、BatchGetItem を参照してください。
項目の更新
updateItem 関数を使用して、既存の属性値の更新、既存のコレクションへの新しい属性の追加、ま
たは既存のコレクションからの属性の削除を実行します。
updateItem 関数は、以下のガイドラインに従います。
API Version 2012-08-10
279
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
• 項目が存在しない場合、updateItem 関数が、入力で指定したプライマリキーを使用して新しい項
目を追加します。
• 項目が存在する場合、updateItem 関数が以下のように更新を適用します。
• 既存の属性値を更新に含まれる値に置き換えます。
• 入力内で指定した属性が存在しない場合は、項目に新しい属性を追加します。
• Action に ADD を使用すると、既存のセット(文字列または数セット)に値を追加できます。ある
いは、既存の数値属性の値に対して足し算(正の数を使用)したり、引き算(負の数を使用)す
ることもできます。
Note
putItem 関数(項目の置換 (p. 275))は項目も更新します。たとえば、putItem を使用し
て項目をアップロードした場合にプライマリキーが存在すれば、 オペレーションによって項
目全体が置き換えられます。既存の項目内に属性がある場合、入力に指定されていない属性
は、putItem オペレーションによって削除されます。ただし、updateItem は指定された入
力属性のみを更新するため、その項目の他の既存の属性は変更されません。
次の PHP コードスニペットでは、ProductCatalog テーブルの書籍項目を更新します。この例で
は、Authors のセットに著者を追加し、既存の ISBN 属性を削除します。また、価格を 1 引き下げま
す。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。あるいは、「AWS SDK for PHP を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 617)」のトピックに記載されている手順に従って
データをロードすることもできます。
以下の例を実行するための詳しい手順については、「PHP コードサンプル (p. 175)」を参照
してください。
$response = $dynamodb->updateItem([
'TableName' => 'ProductCatalog',
'Key' => [
'Id' => [ 'N' => '201' ]
],
'ExpressionAttributeValues' => [
':val1' => [
'S' => 'Author YY',
'S' => 'Author ZZ'],
':val2' => ['N' => '1']
] ,
'UpdateExpression' => 'set Authors = :val1, Price = Price - :val2 remove
ISBN'
]);
print_r($response);
オプションパラメータの指定
必須のパラメータに加え、updateItem 関数にはオプションパラメータも指定できます。これには、
更新が発生する場合に属性に必要な期待値も含まれます。指定した条件を満たさない場合は、AWS
SDK for PHP が ConditionalCheckFailedException をスローします。たとえば、以下の PHP
API Version 2012-08-10
280
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
コードスニペットでは、書籍項目の価格を条件付きで 25 に更新します。以下のオプションパラメー
タを指定します。
• ConditionExpression パラメータ。現在の価格が 20.00 USD である場合にのみ価格を更新する
という条件を設定します。
• ReturnValues パラメータに対応する ALL_NEW 値。項目の更新後の現在の全属性値を応答に含め
るよう指定します。
$response = $dynamodb->updateItem([
'TableName' => 'ProductCatalog',
'Key' => [
'Id' => [
'N' => '201'
]
],
'ExpressionAttributeValues' => [
':val1' => ['N' => '22'],
':val2' => ['N' => '20']
] ,
'UpdateExpression' => 'set Price = :val1',
'ConditionExpression' => 'Price = :val2',
'ReturnValues' => 'ALL_NEW'
]);
print_r($response);
詳細については、UpdateItem を参照してください。
アトミックカウンター
updateItem を使用してアトミックカウンターを実装できます。アトミックカウンターでは、他の書
き込みリクエストを妨げることなく、既存の属性の値をインクリメントまたはデクリメントします。
アトミックカウンタを更新するには、適切な UpdateExpression と共に updateItem を使用しま
す。
次のコード例はアトミックカウンターを示しており、Quantity 属性を 1 ずつインクリメントさせてい
ます。
$response = $dynamodb->updateItem([
'TableName' => 'ProductCatalog',
'Key' => [
'Id' => ['N' => '201']
],
'ExpressionAttributeValues' => [
':val1' => ['N' => '1']
] ,
'UpdateExpression' => 'set Quantity = Quantity + :val1',
'ReturnValues' => 'ALL_NEW'
]);
print_r($response['Attributes']);
項目の削除
deleteItem 関数によって、テーブルから項目を削除します。
API Version 2012-08-10
281
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。あるいは、「AWS SDK for PHP を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 617)」のトピックに記載されている手順に従って
データをロードすることもできます。
以下の例を実行するための詳しい手順については、「PHP コードサンプル (p. 175)」を参照
してください。
$response = $dynamodb->deleteItem([
'TableName' => 'ProductCatalog',
'Key' => [
'Id' => [
'N' => '101'
]
]
]);
print_r($response);
オプションパラメータの指定
必須のパラメータに加え、deleteItem 関数にはオプションパラメータも指定できます。たとえば、
以下の PHP コードスニペットでは、以下のオプションパラメータを指定します。
• Expected パラメーター。対象の書籍が廃刊になっている場合にのみ ProductCatalog テーブル内の
Id 値が「103」の Book 項目を削除するように指定します。具体的には、InPublication の属性が
false の場合に、書籍を削除します。
• ReturnValues パラメータに対応する RETURN_ALL_OLD 列挙値。削除された項目およびその項目
の削除前の属性を応答に含めるようリクエストします。
$$tableName = 'ProductCatalog';
$response = $dynamodb->deleteItem ([
'TableName' => $tableName,
'Key' => [
'Id' => [
'N' => '103'
]
],
'ExpressionAttributeValues' => [
':val1' => ['BOOL' => false]
],
'ConditionExpression' => 'InPublication = :val1',
'ReturnValues' => 'ALL_OLD'
]);
print_r($response);
詳細については、DeleteItem を参照してください。
API Version 2012-08-10
282
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
例: AWS SDK for PHP の低レベル API を使用した CRUD オペ
レーション
以下の PHP コード例は、項目に対する CRUD(作成、読み込み、更新、削除)オペレーションの例
です。この例では、項目の作成、項目の取得、さまざまな更新の実行、さらに項目の削除を行いま
す。
Note
次に示すコード例を実行するための詳しい手順については、「PHP コードサンプ
ル (p. 175)」を参照してください。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'ProductCatalog';
// ###################################################################
// Adding data to the table
echo "# Adding data to table $tableName...\n";
$response = $dynamodb->putItem([
'TableName' => $tableName,
'Item' => [
'Id' => ['N' => '120'],
'Title' => ['S' => 'Book 120 Title'],
'ISBN' => ['S' => '120-1111111111'],
'Authors' => ['SS' => ['Author12', 'Author22']],
'Price' => ['N' => '20'],
'Category' => ['S' => 'Book'],
'Dimensions' => ['S' => '8.5x11.0x.75'],
'InPublication' => ['BOOL' => false],
],
'ReturnConsumedCapacity' => 'TOTAL'
]);
echo "Consumed capacity: " . $response ["ConsumedCapacity"]
["CapacityUnits"] . "\n";
$response = $dynamodb->putItem([
'TableName' => $tableName,
'Item' => [
'Id' => ['N' => '121'],
'Title' => ['S' => 'Book 121 Title'],
API Version 2012-08-10
283
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
'ISBN' => ['S' => '121-1111111111'],
'Authors' => ['SS' => ['Author21', 'Author22']],
'Price' => ['N' => '20'],
'Category' => ['S' => 'Book'],
'Dimensions' => ['S' => '8.5x11.0x.75'],
'InPublication' => ['BOOL' => true],
],
'ReturnConsumedCapacity' => 'TOTAL'
]);
echo "Consumed capacity: " . $response ["ConsumedCapacity"]
["CapacityUnits"] . "\n";
// ###################################################################
// Getting an item from the table
echo "\n\n";
echo "# Getting an item from table $tableName...\n";
$response = $dynamodb->getItem ([
'TableName' => $tableName,
'ConsistentRead' => true,
'Key' => [
'Id' => [
'N' => '120'
]
],
'ProjectionExpression' => 'Id, ISBN, Title, Authors'
] );
print_r ( $response ['Item'] );
// ###################################################################
// Updating item attributes
echo "\n\n";
echo "# Updating an item and returning the whole new item in table
$tableName...\n";
$response = $dynamodb->updateItem ( [
'TableName' => $tableName,
'Key' => [
'Id' => [
'N' => '120' //was 121
]
],
'ExpressionAttributeNames' => [
'#NA' => 'NewAttribute',
'#A' => 'Authors'
],
'ExpressionAttributeValues' => [
':val1' => ['S' => 'Some Value'],
':val2' => ['SS' => ['Author YY','Author ZZ']]
] ,
'UpdateExpression' => 'set #NA = :val1, #A = :val2',
'ReturnValues' => 'ALL_NEW'
]);
print_r ( $response ['Attributes'] );
// ###################################################################
API Version 2012-08-10
284
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
// Conditionally updating the Price attribute, only if it has not changed.
echo "\n\n";
echo "# Updating an item attribute only if it has not changed in table
$tableName...\n";
$response = $dynamodb->updateItem ( [
'TableName' => $tableName,
'Key' => [
'Id' => [
'N' => '121'
]
],
'ExpressionAttributeNames' => [
'#P' => 'Price'
],
'ExpressionAttributeValues' => [
':val1' => ['N' => '25'],
':val2' => ['N' => '20'],
],
'UpdateExpression' => 'set #P = :val1',
'ConditionExpression' => '#P = :val2',
'ReturnValues' => 'ALL_NEW'
]);
print_r ( $response ['Attributes'] );
// ###################################################################
// Deleting an item
echo "\n\n";
echo "# Deleting an item and returning its previous values from in table
$tableName...\n";
$response = $dynamodb->deleteItem ( [
'TableName' => $tableName,
'Key' => [
'Id' => [
'N' => '121'
]
],
'ReturnValues' => 'ALL_OLD'
]);
print_r ( $response ['Attributes']);
?>
例: AWS SDK for PHP を使用した、バッチオペレーション
例: AWS SDK for PHP を使用した、バッチ書き込みオペレーション
次の PHP コード例は、次のタスクを実行します。
• Forum テーブル内で項目を入力。
• Thread テーブル内で項目を入力および削除。
API Version 2012-08-10
285
Amazon DynamoDB 開発者ガイド
項目の操作 : PHP
バッチ書き込みオペレーションの詳細については、「バッチ書き込み: 複数の項目の書き込みおよび削
除 (p. 277)」を参照してください。
このコード例では、「テーブルの作成とサンプルデータのロード (p. 166)」のステップに従って
Forum テーブルと Thread テーブルを作成済みであると仮定します。あるいは、「AWS SDK for PHP
を使用した、サンプルテーブルの作成とデータのアップロード (p. 617)」のトピックに記載する手順
に従って、プログラムでデータをロードすることもできます。
Note
次に示すコード例を実行するための詳しい手順については、「PHP コードサンプ
ル (p. 175)」を参照してください。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableNameOne = 'Forum';
$tableNameTwo = 'Thread';
$response = $dynamodb->batchWriteItem([
'RequestItems' => [
$tableNameOne => [
[
'PutRequest' => [
'Item' => [
'Name'
=> ['S' => 'Amazon S3 Forum'],
'Threads' => ['N' => '0']
]]
]
],
$tableNameTwo => [
[
'PutRequest' => [
'Item' => [
'ForumName'
=> ['S' => 'Amazon S3 Forum'],
'Subject' => ['S' => 'My sample question'],
'Message'=> ['S' => 'Message Text.'],
'KeywordTags'=>['SS' => ['Amazon S3', 'Bucket']]
]]
],
[
'DeleteRequest' => [
'Key' => [
'ForumName' =>['S' => 'Some partition key value'],
'Subject' => ['S' => 'Some sort key value']
]]
API Version 2012-08-10
286
Amazon DynamoDB 開発者ガイド
クエリおよびスキャンの使用
]
]
]
]);
print_r($response);
?>
クエリおよびスキャンの使用
トピック
• Query (p. 287)
• スキャン (p. 289)
• クエリまたはスキャンからの結果のフィルタリング (p. 289)
• クエリおよびスキャンオペレーションによって消費されるキャパシティーユニット (p. 290)
• ページ単位の出力件数を指定 (p. 290)
• 制限 (p. 290)
• 応答での項目のカウント (p. 291)
• 読み込み整合性 (p. 291)
• クエリおよびスキャンのパフォーマンス (p. 292)
• 並列スキャン (p. 292)
• DynamoDB のクエリ (p. 294)
• DynamoDB のスキャン (p. 310)
Amazon DynamoDB では、プライマリキーを使用した項目へのアクセスに加えて、データの検索用に
Query および Scan という 2 つのオペレーションも用意されています。
Tip
テーブルのクエリと同じ方法で セカンダリインデックス のクエリまたはスキャンを実行で
きます。これを行うには、Query または Scan に、パラメーターとして IndexName および
TableName を指定する必要があります。詳細については、「セカンダリインデックスを使用
したデータアクセス性の向上 (p. 333)」を参照してください。
ベストプラクティスについては、クエリおよびスキャンのガイドライン (p. 581) を参照してくださ
い。
Query
Query オペレーションでは、プライマリキーの属性値を使用してテーブルまたは セカンダリインデッ
クス の項目を検索します。パーティションキーの名前と検索対象の値を指定する必要があります。必
要に応じて、ソートキーの名前と値を指定し、比較演算子を使用して、検索結果をさらに絞り込むこ
とができます。デフォルトでは、Query オペレーションは、指定したプライマリキーを持つ項目のす
べてのデータ属性を返します。ただし、ProjectionExpression パラメーターを使用して、Query
オペレーションがすべての属性ではなく一部の属性のみを返すようにすることもできます。
Query オペレーションでは、KeyConditionExpression パラメータを使用してテーブルまたはイン
デックスから読み込む項目を決定します。等価条件としてパーティションキーの名前と値を指定する
API Version 2012-08-10
287
Amazon DynamoDB 開発者ガイド
Query
必要があります。オプションで、ソートキーに 2 番目の条件を指定できます (存在する場合)。ソート
キーの条件では、次の比較演算子の 1 つを使用する必要があります。
• a = b - 属性 a が値 b と等しい場合、true
• a < b - a が b より小さい場合、true
• a <= b - a が b 以下である場合、true
• a > b - a が b より大きい場合、true
• a >= b - a が b 以上である場合、true
• a BETWEEN b AND c - a が b 以上で、c 以下である場合、true。
次の関数もサポートされます。
• begins_with (a, substr) - 属性の値 a が特定のサブ文字列から始まる場合、true。
キー条件式のいくつかの例を次に示します。これらの式では、実際の値の代わりにプレースホルダー
(:name や :subj など)を使用しています。詳細については、「式の属性名 (p. 213)」および「式
の属性値 (p. 215)」を参照してください。
• Thread テーブルに対して、特定の ForumName (パーティションキー) についてのクエリを実行し
ます。その ForumName の値を持つすべての項目はクエリによって読み込まれます。これはソート
キー (Subject) が KeyConditionExpression に含まれないためです。
ForumName = :name
• Thread に対して、特定の ForumName (パーティションキー) についてのクエリを実行しますが、今
回は指定の Subject (ソートキー) を持つ項目のみを返します。
Forum = :name and Subject = :subj
• Reply テーブルに対して、特定の Id (パーティションキー) についてのクエリを実行します
が、ReplyDateTime (ソートキー) が特定の文字で始まる項目のみを返します。
Id = :id and begins_with(ReplyDateTime, :dt)
最初の文字が a-z または A-Z であり、2 番目の文字(ある場合)が a-z、A-Z、または 0-9 である場
合は、キー条件式で任意の属性値を使用できます。さらに、属性名は DynamoDB の予約語ではない
必要があります(フィールドの一覧については、「DynamoDB の予約語 (p. 668)」を参照してくだ
さい)。属性名がこれらの要件を満たさない場合は、式の属性名をプレースホルダーとして定義する
必要があります。詳細については、「式の属性名 (p. 213)」を参照してください。
特定のパーティションキー値を持つ項目は、DynamoDB によって、ソートキーの値で並べ替えられた
順序で近くに配置されて保存されます。Query オペレーションでは、DynamoDB は並べ替えられた順
序で項目を取得し、KeyConditionExpression や存在する任意の FilterExpression を使用して
項目を処理します。その後、Query の結果がクライアントに返されます。
Query オペレーションは常に結果セットを返します。一致する項目が見つからない場合、結果セット
は空になります。
Query の結果は常にソートキーの値によってソートされます。ソートキーのデータ型が Number であ
る場合は、結果が番号順で返されます。その他の場合は、UTF-8 バイトの順序で結果が返されます。
デフォルトの並べ替え順序は昇順です。順序を反転させるには、ScanIndexForward パラメーター
を false に設定します。
1 回の Query または Scan オペレーションで、最大 1 MB のデータを取得できます。この制限は、
結果への FilterExpression の適用前に適用されます。レスポンスに LastEvaluatedKey が存
在し、Null 以外の場合、結果セットをページ分割する必要があります (ページ単位の出力件数を指
定 (p. 290) を参照)。
API Version 2012-08-10
288
Amazon DynamoDB 開発者ガイド
スキャン
スキャン
Scan オペレーションは、テーブルまたは セカンダリインデックス のすべての項目を読み込みます。
デフォルトでは、Scan オペレーションはテーブルまたはインデックスのすべての項目のデータ属性を
返します。ProjectionExpression パラメータを使用し、Scan がすべての属性ではなく一部のみを
返すようにできます。
Scan は常に結果セットを返します。一致する項目がない場合、結果セットは空になります。
1 回の Scan リクエストで、最大 1 MB のデータを取得できます。DynamoDB では、必要に応じて
このデータにフィルタ式を適用して、結果をユーザーに返す前に絞り込むことができます。(フィル
ターの詳細については「クエリまたはスキャンからの結果のフィルタリング (p. 289)」を参照)。
クエリまたはスキャンからの結果のフィルタリング
Query または Scan オペレーションでは、必要に応じてフィルタ式を指定して、返された結果を絞り
込むことができます。フィルタ式では、データに条件を適用できます。条件は、データをクエリまた
はスキャンした後、ユーザーに返す前に適用されます。条件を満たす項目のみが返されます。
フィルタ式のいくつかの例を次に示します。これらの式では、実際の値の代わりにプレースホルダー
(:num や :name など)を使用しています。詳細については、「式の属性名 (p. 213)」および「式
の属性値 (p. 215)」を参照してください。
• Thread テーブルで特定の ForumName (パーティションキー) および Subject (ソートキー) に対する
クエリを実行します。見つかった項目のうち、最も一般的なディスカッションスレッドだけを返し
ます(たとえば、Views が特定の数を超えるスレッド)。
#V > :num
Views は DynamoDB の予約語であるため(「DynamoDB の予約語 (p. 668)」を参照)、代わりに
式の属性名を使用していることに注意してください。
• Thread テーブルをスキャンして、特定のユーザーによって最後に投稿された項目のみを返します。
LastPostedBy = :name
Note
FilterExpression の構文は ConditionExpression と同じです。ま
た、FilterExpression は、ConditionExpression と同じコンパレータ、関数、および
論理演算子を使用します。
Query オペレーションの場合、パーティションキーまたはソートキーに基づいて
FilterExpression を定義することはできません (これは Sort オペレーションには適用さ
れません)。
ConditionExpression 構文の詳細については、「条件式リファレンス (p. 217)」を参照
してください。
1 回の Query または Scan オペレーションで、最大 1 MB のデータを取得できます。この制限は、結
果への任意のフィルタ式の適用前に適用されます。
API Version 2012-08-10
289
Amazon DynamoDB 開発者ガイド
クエリおよびスキャンオペレーションに
よって消費されるキャパシティーユニット
クエリおよびスキャンオペレーションによって消費
されるキャパシティーユニット
テーブルを作成する場合には、読み込みおよび書き込みキャパシティーユニット要件を指定します。
テーブルにグローバルセカンダリインデックスを追加する場合、そのインデックスのスループット要
件も指定する必要があります。
Query および Scan オペレーションは、テーブルで使用するのと同じ方法でセカンダリインデックス
で使用することができます。local secondary index で Query または Scan を実行する場合、キャパ
シティーユニットはテーブルのプロビジョンドスループットから消費されます。ただし、これらのオ
ペレーションをグローバルセカンダリインデックスで行うと、キャパシティーユニットは、インデッ
クスのプロビジョニングされたスループットから消費されます。これは、グローバルセカンダリイン
デックス には独自のプロビジョンドスループット設定があり、テーブルのものとは別になっているた
めです。
オペレーションによって消費されるキャパシティーユニットを DynamoDB が計算する方法の詳細に
ついては、「キャパシティーユニットの計算 (p. 181)」を参照してください。
Note
Query と Scan のオペレーションの場合、DynamoDB では、アプリケーションに返
されるデータの量ではなく項目のサイズに基づいて、消費されるプロビジョンドス
ループットの量が計算されます。このため、消費されるキャパシティーユニットの数
は、ProjectionExpression パラメーターで属性のすべてをリクエストしても(デフォル
トの動作)一部をリクエストしても、同じになります。
消費されるキャパシティーユニットの数も、FilterExpression オペレーションを指定して
も指定しなくても、同じになります。
ページ単位の出力件数を指定
DynamoDB では、Query および Scan オペレーションで得られた結果のページ分割を行うことができ
ます。ページ分割を行うことで Query および Scan の結果が分割されるため、アプリケーションでは
結果の最初のページ、次に 2 番目のページというように、順次処理していくことができます。Query
または Scan オペレーションによって返されるデータは、1 MB に限定されます。これは、結果セット
のデータが 1 MB を超えた場合、新たに Query または Scan オペレーションを実行して次のデータを
1 MB 取得する必要があることを意味しています。
特定の属性に対するクエリまたはスキャンを実行して、一致する値の合計データが 1 MB を超える
場合には、次の 1 MB のデータに対する Query または Scan リクエストを別に実行する必要があり
ます。そのためには、前のリクエストから LastEvaluatedKey の値を取得し、次のリクエストで
ExclusiveStartKey として使用します。このアプローチにより、新しいデータを 1 MB ずつインク
リメントさせて段階的にクエリまたはスキャンできるようになります。
Query または Scan からの結果セット全体が処理されると、LastEvaluatedKey は null になりま
す。これは、結果セットが完了したこと(つまり、オペレーションによってデータの「最後のペー
ジ」が処理されたこと)を意味します。
LastEvaluatedKey が null 以外の値の場合、結果セットにまだ値があることを必ずしも意味するわ
けではありません。結果セットの最後まで到達したことを確認できるのは、LastEvaluatedKey が
null になったときだけです。
制限
DynamoDB の Query および Scan API では、Limit の値によって結果のサイズを制限できます。
リクエストでは、Limit パラメータに、DynamoDB が結果を返す前に処理する項目数を設定します。
API Version 2012-08-10
290
Amazon DynamoDB 開発者ガイド
応答での項目のカウント
応答では、DynamoDB は Limit の値の範囲で一致したすべての結果を返します。たとえば、Limit
値が 6 でフィルタ式のない Query リクエストまたは Scan リクエストを発行した場合、DynamoDB
は、リクエストで指定されたキー条件に一致するテーブル内の最初の 6 つの項目を返します(また
は、フィルタのない Scan の場合はそのまま最初の 6 つの項目)。FilterExpression 値も指定し
た場合、DynamoDB は、フィルタ要件にも一致する最初の 6 つの中から項目を返します(返される結
果の数は 6 以下です)。
Query または Scan オペレーションでは、テーブル内で一致する項目の一部が返されるとき
は、DynamoDB によって LastEvaluatedKey の値が返される場合があります。一致する項目の
総数を取得するには、前のリクエストから LastEvaluatedKey の値を取得し、次のリクエストで
ExclusiveStartKey の値として使用します。DynamoDB から LastEvaluatedKey の値が返されな
くなるまで、この処理を繰り返します。
応答での項目のカウント
Query または Scan オペレーションからの応答には、条件に一致する項目に加えて次の要素が含まれ
ます。
• ScannedCount — フィルタ式が結果に適用される前にクエリまたはスキャンされた項目の数。
• Count — 応答で返された項目の数。
FilterExpression を使用しない場合、ScannedCount と Count は同じ値を持ちます。
1000 項目がある TestTable というテーブルがあり、各項目のサイズは正確に 250 バイトであると
します。このテーブルに Scan (フィルタなし) を実行する場合、ScannedCount と Count は同じ
値 (1000) を持ちます。ここで、FilterExpression を追加し、300 項目のみが返されるとしま
す。DynamoDB はそれでも 1000 個の項目を TestTable からすべて読み込みますが、条件に一致す
る 300 項目を除くこれらのすべての結果を破棄します。この場合、ScannedCount は 1000 になりま
すが、Count は 300 になります。
結果セットのサイズが 1 MB を超えた場合、ScannedCount および Count は、合計項目数の一部の
数のみを表します。TestTable に 100 万の項目があり、各項目のサイズが 250 KB であるとします。
この場合、テーブル全体をスキャンするために、複数の Scan リクエストを実行する必要がありま
す。(詳細については、「ページ単位の出力件数を指定 (p. 290)」を参照してください)。各応答
には、特定の Scan リクエストによって処理された項目の ScannedCount および Count が含まれま
す。すべての Scan リクエストの合計を取得するには、ScannedCount および Count の実行中の集
計を維持することができます。
読み込み整合性
クエリの読み込み整合性
Query の結果は結果整合性のある読み込みですが、必要に応じて強力な整合性のある読み込みを
リクエストすることもできます。結果整合性のある読み込みには、最近完了した PutItem または
UpdateItem オペレーションの結果が反映されない可能性があります。詳細については、「読み込み
整合性 (p. 16)」を参照してください。
スキャンの読み込み整合性
Scan リクエストを発行すると、DynamoDB は結果的に整合性のある読み込みを使用します。
つまり、テーブルでスキャンの実行直前に加えられたデータの変更は、スキャン結果に含まれ
ない可能性があります。データの整合性のあるコピーが必要な場合は、Scan が開始する時間
に、ConsistentRead パラメーターを true に設定できます。これにより、Scan が開始する前に完了
した書き込みオペレーションがすべて Scan 応答に含められます。これは、 DynamoDB ストリーム
と同時に使用すると、テーブルのバックアップまたはレプリケーションシナリオで役立ちます。最初
に、テーブル内のデータの整合性のあるコピーを取得するため、ConsistentRead を true に設定し
API Version 2012-08-10
291
Amazon DynamoDB 開発者ガイド
クエリおよびスキャンのパフォーマンス
て Scan を使用します。Scan の実行中、DynamoDB ストリーム はテーブルで発生した追加の書き込
みアクティビティをすべて記録します。Scan が完了したら、ストリームからテーブルへの書き込みア
クティビティを適用できます。
ConsistentRead を true に設定した Scan オペレーションでは、ConsistentRead をデフォルト値
(false) のままにした場合と比較して、2 倍の読み込みキャパシティーユニットが使用されます。
クエリおよびスキャンのパフォーマンス
一般的に、Query オペレーションは Scan オペレーションよりも効率的です。
Scan オペレーションでは常にテーブル全体またはセカンダリインデックスがスキャンされ、目的の結
果を得るために値にフィルタが適用され、基本的に結果セットからデータを削除するステップが追加
されます。フィルタによって多数の結果が除外されるようなサイズの大きいテーブルまたはインデッ
クスでは、可能な限り Scan オペレーションを使用しないことをお勧めします。また、テーブルやイ
ンデックスが大きくなるに従って、Scan オペレーションは低速になります。Scan オペレーションで
は、リクエストした値に対するすべての項目が調べられるため、サイズの大きいテーブルまたはイン
デックスでは、プロビジョニングされたスループットが 1 回のオペレーションで枯渇する可能性があ
ります。高速な応答時間を得るには、アプリケーションが Scan ではなく Query を使用できるように
テーブルとインデックスを設計します(テーブルの場合は、GetItem および BatchGetItem API の
使用を検討することもできます)。
または、Scan オペレーションを使用してもリクエスト率に対する影響が最小になるように、アプリ
ケーションを設計します。詳細については、「クエリおよびスキャンのガイドライン (p. 581)」を参
照してください。
Query オペレーションは、指定した一連のキー条件を満たす特定範囲のキーを検索します。フィルタ
式を指定した場合、DynamoDB は結果セットからデータを削除する追加の手順を実行する必要があり
ます。Query オペレーションでは、次のいずれかのイベントが発生するまで、指定された複合プライ
マリキーまたは一定範囲のキーが検索されます。
• 結果セットが枯渇する。
• 取り出した項目数が、指定した Limit パラメータの値に達する。
• 取り出したデータの量が、結果セットの最大サイズ制限 1 MB に達する。
Query のパフォーマンスは、テーブルまたはセカンダリインデックス内のプライマリキーの全体数
ではなく、取り出されたデータの量によって決まります。クエリのパフォーマンスは、Query オペ
レーションのパラメータ(および結果的に一致したキーの数)によって決まります。たとえば、1 つ
のパーティションキー値に対するソートキー値の数が少ないテーブルに対するクエリよりも、1 つの
パーティションキー値に対する多量のソートキー値が含まれる別のテーブルに対するクエリのほう
が、最初のテーブルで一致するキーの数が 2 番目のテーブルよりも少ない場合には効率的です。どち
らのテーブルでも、プライマリキーの合計数によって、Query オペレーションの効率性が決まること
はありません。フィルタ式は Query オペレーションの効率に影響を与えることがあります。フィルタ
に一致しない項目を結果セットから削除する必要があるためです。フィルタによって多数の結果が除
外されるようなサイズの大きいテーブルまたはセカンダリインデックスでは、可能な限り Query オペ
レーションを使用しないことをお勧めします。
特定のパーティションキー値にサイズの大きいソートキー値のセットがあり、1 つの Query リクエス
トでは結果を取り出せない場合には、ExclusiveStartKey 継続パラメーターによって、最後に取り
出した項目から新しいクエリリクエストを送信できます。すでに取り出されたデータを再処理する必
要はありません。
並列スキャン
デフォルトでは、Scan オペレーションはデータを連続的に処理します。DynamoDB は 1 MB の増分
でアプリケーションにデータを返し、アプリケーションは追加の Scan オペレーションを実行して、
次の 1 MB 分のデータを取り出します。
API Version 2012-08-10
292
Amazon DynamoDB 開発者ガイド
並列スキャン
スキャンされるテーブルまたはインデックスが大きいほど、Scan の完了に要する時間は長くなりま
す。さらに、シーケンシャルな Scan では、プロビジョニングされた読み込みスループットキャパシ
ティーが完全に利用されない場合があります。DynamoDB がサイズの大きいテーブルのデータを複
数の物理パーティションに分散しても、Scan オペレーションでは一度に 1 つのパーティションしか
読み込むことができません。そのため Scan のスループットは、単一のパーティションの最大スルー
プットによって制限されます。
これらの問題に対処するために、Scan オペレーションではテーブルまたはセカンダリインデックスを
複数のセグメントに論理的に分割して、複数のアプリケーションワーカーがセグメントに対する並列
スキャンを行うことができます。各ワーカーは、スレッド(マルチスレッドをサポートするプログラ
ミング言語を使用)またはオペレーティングシステムのプロセスにすることができます。並列スキャ
ンを実行するには、各ワーカーが次のパラメータを使用して、別個に Scan リクエストを行います。
• Segment — 特定のワーカーがスキャンするセグメント。各ワーカーは Segment にそれぞれ異なる
値を指定します。
• TotalSegments — 並列スキャンの対象となるセグメントの合計数。この値は、アプリケーション
で使用されるワーカーの数と同じでなければなりません。
次の図は、マルチスレッドアプリケーションが 3 段階の並列処理で実行する並列 Scan を示していま
す。
API Version 2012-08-10
293
Amazon DynamoDB 開発者ガイド
クエリ
この図では、アプリケーションが 3 つのスレッドをスポーンして、各スレッドに番号を割り当ててい
ます(セグメントはゼロベースであるため、最初の数字は必ず 0 になります)。各スレッドは Scan
リクエストを発行し、Segment を指定された数値に設定して、TotalSegments を 3 に設定します。
各スレッドは指定されたセグメントをスキャンし、一度に 1 MB のデータを取り出し、アプリケー
ションのメインスレッドにデータを返します。
Segment および TotalSegments の値は個々の Scan リクエストに適用され、また異なる値をいつ
でも使用できます。これらの値、および使用するワーカー数を決定するには、アプリケーションのパ
フォーマンスが最高になるまで実験を行う必要があるかもしれません。
Note
多数のワーカーで行う並列スキャンでは、スキャンされるテーブルまたはインデックスのた
めにプロビジョニングされたスループットがすぐにすべて使用されます。テーブルまたはイ
ンデックスでも他のアプリケーションからの重い読み込みや書き込みが発生させる場合は、
このようなスキャンは避けるのが最善です。
リクエストごとに返されるデータの量を制御するには、Limit パラメータを使用します。そ
れによって、1 つのワーカーがプロビジョニングされたスループットを使い果たして、他の
ワーカーが制約を受ける状況が避けられます。詳細については、「読み込みアクティビティ
の急激な増大の回避 (p. 581)」の「ページサイズを小さくする」を参照してください。
DynamoDB のクエリ
トピック
• テーブルおよびインデックスにクエリを実行 : Java (p. 294)
• テーブルおよびインデックスにクエリを実行: .NET (p. 300)
• テーブルおよびインデックスにクエリを実行 : PHP (p. 307)
このセクションでは、基本的なクエリとその結果を示します。
テーブルおよびインデックスにクエリを実行 : Java
Query オペレーションを使用すると、テーブルまたは セカンダリインデックス をクエリできます。
この関数ではパーティションキー値と等価条件を指定する必要があります。テーブルまたはインデッ
クスにソートキーがある場合は、ソートキー値と条件を指定することで結果を絞り込むことができま
す。
Note
SDK for Java には、オブジェクト永続性モデルも用意されています。このモデルにより、ク
ライアント側のクラスを DynamoDB テーブルにマッピングすることができます。この方法
により、記述する必要のあるコードの量を減らすことができます。詳細については、「Java:
DynamoDBMapper (p. 78)」を参照してください。
次に、AWS SDK for Java ドキュメント API を使用して項目を取り出すステップを示します。
1. DynamoDB クラスのインスタンスを作成します。
2. 操作対象のテーブルを表すために、Table クラスのインスタンスを作成します。
3. Table インスタンスの query メソッドを呼び出します。任意のオプションクエリパラメーターと
ともに、取得する項目のパーティションキー値を指定する必要があります。
応答には、クエリによって返されたすべての項目を示す ItemCollection オブジェクトが含まれて
います。
API Version 2012-08-10
294
Amazon DynamoDB 開発者ガイド
クエリ
次の Java コードスニペットは、前述のタスクの例です。このスニペットでは、フォーラムスレッド
の返信を格納する Reply テーブルがあることを前提としています。詳細については、「テーブルの作
成とサンプルデータのロード (p. 166)」を参照してください。
Reply ( Id, ReplyDateTime, ... )
各フォーラムスレッドには一意の ID があり、0 またはそれ以上の返信を受け取ることができます。つ
まり、Reply テーブルの Id 属性は、フォーラム名とフォーラムの件名の両方で構成されています。Id
(パーティションキー) と ReplyDateTime (ソートキー) が、テーブルの複合プライマリキーを構成して
います。
次のクエリでは、特定のスレッド件名に対するすべての返信を取り出します。このクエリでは、テー
ブル名と件名の両方が必要になります。
DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("Reply");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Id = :v_id")
.withValueMap(new ValueMap()
.withString(":v_id", "Amazon DynamoDB#DynamoDB Thread 1"));
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
Item item = null;
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.toJSONPretty());
}
オプションパラメータの指定
query メソッドでは、複数のオプションパラメータがサポートされています。たとえば、必要に応じ
て条件を指定して前述のクエリの結果を絞り込み、過去 2 週間の返信が返されるようにできます。こ
の条件をソートキー条件と呼びます。指定したクエリ条件が DynamoDB によってプライマリキーの
ソートキーに対して評価されるためです。その他のオプションパラメータを指定して、クエリ結果の
項目から特定の属性のリストだけを取り出すこともできます。
次の Java コードスニペットでは、過去 15 日間に投稿されたフォーラムスレッドの返信が取り出され
ます。このスニペットでは、次のものを使用してオプションパラメータを指定しています。
• KeyConditionExpression - 特定のディスカッションフォーラムからの返信を取得し (パーティ
ションキー)、その項目のセット内では、過去 15 日の間に投稿された返信を取得します (ソート
キー)。
• FilterExpression - 特定のユーザーからの返信だけを返します。フィルタは、クエリの処理の終
了後、ユーザーに結果が返される前に適用されます。
• ValueMap - KeyConditionExpression プレースホルダーの実際の値を定義します。
• ConsistentRead - true に設定すると、強力な整合性のある読み込みをリクエストします。
このスニペットでは、すべての低レベルクエリ入力パラメータにアクセスできる QuerySpec オブ
ジェクトを使用します。
API Version 2012-08-10
295
Amazon DynamoDB 開発者ガイド
クエリ
Table table = dynamoDB.getTable("Reply");
long twoWeeksAgoMilli = (new Date()).getTime() - (15L*24L*60L*60L*1000L);
Date twoWeeksAgo = new Date();
twoWeeksAgo.setTime(twoWeeksAgoMilli);
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'");
String twoWeeksAgoStr = df.format(twoWeeksAgo);
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Id = :v_id and ReplyDateTime
> :v_reply_dt_tm")
.withFilterExpression("PostedBy = :v_posted_by")
.withValueMap(new ValueMap()
.withString(":v_id", "Amazon DynamoDB#DynamoDB Thread 1")
.withString(":v_reply_dt_tm", twoWeeksAgoStr)
.withString(":v_posted_by", "User B"))
.withConsistentRead(true);
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
また、withMaxPageSize メソッドを使用して、ページあたりの項目数を制限することもできま
す。query メソッドを呼び出すと、結果の項目が含まれている ItemCollection が返されます。そ
の後、結果を 1 ページずつ、最後のページまで処理していくことができます。
次の Java コードスニペットは、上記のクエリの仕様を変更します。今回、クエリの仕様は
withMaxPageSize メソッドを使用します。Page クラスには、コードが各ページの項目を処理でき
るようにするイテレータがあります。
spec.withMaxPageSize(10);
ItemCollection<QueryOutcome> items = table.query(spec);
// Process each page of results
int pageNum = 0;
for (Page<Item, QueryOutcome> page : items.pages()) {
System.out.println("\nPage: " + ++pageNum);
// Process each item on the current page
Iterator<Item> item = page.iterator();
while (item.hasNext()) {
System.out.println(item.next().toJSONPretty());
}
}
例 – Java を使用したクエリ
以下のテーブルには、フォーラムのコレクションに関する情報が格納されています。詳細について
は、「テーブルの作成とサンプルデータのロード (p. 166)」を参照してください。
API Version 2012-08-10
296
Amazon DynamoDB 開発者ガイド
クエリ
Note
SDK for Java には、オブジェクト永続性モデルも用意されています。このモデルにより、ク
ライアント側のクラスを DynamoDB テーブルにマッピングすることができます。この方法
により、記述する必要のあるコードの量を減らすことができます。詳細については、「Java:
DynamoDBMapper (p. 78)」を参照してください。
Forum ( Name, ... )
Thread ( ForumName, Subject, Message, LastPostedBy, LastPostDateTime, ...)
Reply ( Id, ReplyDateTime, Message, PostedBy, ...)
この Java コード例では、"DynamoDB" フォーラムで "DynamoDB Thread 1" スレッドに対する返信を
検索するのバリエーションを実行します。
• スレッドに対する返信を検索します。
• 結果のページあたりの項目数に対する制限を指定して、スレッドへの返信を探します。結果セット
の項目数がページサイズを超えた場合は、結果の最初のページだけが得られます。このコーディン
グパターンによって、確実にクエリ結果の全ページがコードで処理されます。
• 過去 15 日間の返信を検索します。
• 特定の日付範囲の返信を検索します。
前述の 2 つのクエリはどちらも、ソートキー条件を指定してクエリ結果を絞り込む方法、必要に応
じてその他のクエリパラメーターを使用する方法を示しています。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。
以下の例を実行するための詳しい手順については、「Java コードサンプル (p. 171)」を参照
してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Iterator;
import
import
import
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.ItemCollection;
com.amazonaws.services.dynamodbv2.document.Page;
com.amazonaws.services.dynamodbv2.document.QueryOutcome;
com.amazonaws.services.dynamodbv2.document.Table;
com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class DocumentAPIQuery {
API Version 2012-08-10
297
Amazon DynamoDB 開発者ガイド
クエリ
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(new
ProfileCredentialsProvider()));
static String tableName = "Reply";
public static void main(String[] args) throws Exception {
String forumName = "Amazon DynamoDB";
String threadSubject = "DynamoDB Thread 1";
findRepliesForAThread(forumName, threadSubject);
findRepliesForAThreadSpecifyOptionalLimit(forumName, threadSubject);
findRepliesInLast15DaysWithConfig(forumName, threadSubject);
findRepliesPostedWithinTimePeriod(forumName, threadSubject);
findRepliesUsingAFilterExpression(forumName, threadSubject);
}
private static void findRepliesForAThread(String forumName, String
threadSubject) {
Table table = dynamoDB.getTable(tableName);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Id = :v_id")
.withValueMap(new ValueMap()
.withString(":v_id", replyId));
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\nfindRepliesForAThread results:");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
private static void findRepliesForAThreadSpecifyOptionalLimit(String
forumName, String threadSubject) {
Table table = dynamoDB.getTable(tableName);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Id = :v_id")
.withValueMap(new ValueMap()
.withString(":v_id", replyId))
.withMaxPageSize(1);
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\nfindRepliesForAThreadSpecifyOptionalLimit
results:");
API Version 2012-08-10
298
Amazon DynamoDB 開発者ガイド
クエリ
// Process each page of results
int pageNum = 0;
for (Page<Item, QueryOutcome> page : items.pages()) {
System.out.println("\nPage: " + ++pageNum);
// Process each item on the current page
Iterator<Item> item = page.iterator();
while (item.hasNext()) {
System.out.println(item.next().toJSONPretty());
}
}
}
private static void findRepliesInLast15DaysWithConfig(String forumName,
String threadSubject) {
Table table = dynamoDB.getTable(tableName);
long twoWeeksAgoMilli = (new Date()).getTime() (15L*24L*60L*60L*1000L);
Date twoWeeksAgo = new Date();
twoWeeksAgo.setTime(twoWeeksAgoMilli);
SimpleDateFormat df = new SimpleDateFormat("yyyy-MMdd'T'HH:mm:ss.SSS'Z'");
String twoWeeksAgoStr = df.format(twoWeeksAgo);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withProjectionExpression("Message, ReplyDateTime, PostedBy")
.withKeyConditionExpression("Id = :v_id and ReplyDateTime
<= :v_reply_dt_tm")
.withValueMap(new ValueMap()
.withString(":v_id", replyId)
.withString(":v_reply_dt_tm", twoWeeksAgoStr));
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\nfindRepliesInLast15DaysWithConfig results:");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
private static void findRepliesPostedWithinTimePeriod(String forumName,
String threadSubject) {
Table table = dynamoDB.getTable(tableName);
long startDateMilli = (new Date()).getTime() (15L*24L*60L*60L*1000L);
long endDateMilli = (new Date()).getTime() - (5L*24L*60L*60L*1000L);
java.text.SimpleDateFormat df = new java.text.SimpleDateFormat("yyyyMM-dd'T'HH:mm:ss.SSS'Z'");
String startDate = df.format(startDateMilli);
API Version 2012-08-10
299
Amazon DynamoDB 開発者ガイド
クエリ
String endDate = df.format(endDateMilli);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withProjectionExpression("Message, ReplyDateTime, PostedBy")
.withKeyConditionExpression("Id = :v_id and ReplyDateTime
between :v_start_dt and :v_end_dt")
.withValueMap(new ValueMap()
.withString(":v_id", replyId)
.withString(":v_start_dt", startDate)
.withString(":v_end_dt", endDate));
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\nfindRepliesPostedWithinTimePeriod results:");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
private static void findRepliesUsingAFilterExpression(String forumName,
String threadSubject) {
Table table = dynamoDB.getTable(tableName);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withProjectionExpression("Message, ReplyDateTime, PostedBy")
.withKeyConditionExpression("Id = :v_id")
.withFilterExpression("PostedBy = :v_postedby")
.withValueMap(new ValueMap()
.withString(":v_id", replyId)
.withString(":v_postedby", "User B"));
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\nfindRepliesUsingAFilterExpression results:");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
テーブルおよびインデックスにクエリを実行: .NET
Query オペレーションを使用すると、テーブルまたは セカンダリインデックス をクエリできます。
この関数ではパーティションキー値と等価条件を指定する必要があります。テーブルまたはインデッ
クスにソートキーがある場合は、ソートキー値と条件を指定することで結果を絞り込むことができま
す。
API Version 2012-08-10
300
Amazon DynamoDB 開発者ガイド
クエリ
次に、低レベル .NET SDK API を使用してテーブルのクエリを行うステップを示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. QueryRequest クラスのインスタンスを作成して、クエリオペレーションパラメータを指定しま
す。
3. Query メソッドを実行し、前述のステップで作成した QueryRequest オブジェクトを指定しま
す。
応答には、クエリによって返されたすべての項目を示す QueryResult オブジェクトが含まれてい
ます。
次の C# コードスニペットは、前述のタスクの例です。このスニペットでは、フォーラムスレッドの
返信を格納する Reply テーブルがあることを前提としています。詳細については、「テーブルの作成
とサンプルデータのロード (p. 166)」を参照してください。
Reply ( <emphasis role="underline">Id</emphasis>, <emphasis
role="underline">ReplyDateTime</emphasis>, ... )
各フォーラムスレッドには一意の ID があり、0 またはそれ以上の返信を受け取ることができます。し
たがってプライマリキーは、Id (パーティションキー) と ReplyDateTime (ソートキー) の両方で構成さ
れます。
次のクエリでは、特定のスレッド件名に対するすべての返信を取り出します。このクエリでは、テー
ブル名と件名の両方が必要になります。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
var request = new QueryRequest
{
TableName = "Reply",
KeyConditionExpression = "Id = :v_Id",
ExpressionAttributeValues = new Dictionary<string, AttributeValue> {
{":v_Id", new AttributeValue { S = "Amazon DynamoDB#DynamoDB Thread
1" }}}
};
var response = client.Query(request);
foreach (Dictionary<string, AttributeValue> item in response.Items)
{
// Process the result.
PrintItem(item);
}
オプションパラメータの指定
Query メソッドでは、複数のオプションパラメータがサポートされています。たとえば、必要に応じ
て条件を指定して前述のクエリの結果を絞り込み、過去 2 週間の返信が返されるようにできます。こ
の条件をソートキー条件と呼びます。指定したクエリ条件が Amazon DynamoDB によってプライマリ
キーのソートキーに対して評価されるためです。その他のオプションパラメータを指定して、クエリ
結果の項目から特定の属性のリストだけを取り出すこともできます。詳細については、Query を参照
してください。
次の C# コードスニペットでは、過去 15 日間に投稿されたフォーラムスレッドの返信が取り出されま
す。このスニペットでは、次のオプションパラメータが指定されています。
• 過去 15 日間の返信だけを取り出す KeyConditionExpression。
API Version 2012-08-10
301
Amazon DynamoDB 開発者ガイド
クエリ
• クエリ結果内の項目について取得する属性のリストを指定する ProjectionExpression パラメー
タ。
• 強力な整合性のある読み込みを実行する ConsistentRead パラメータ。
DateTime twoWeeksAgoDate = DateTime.UtcNow - TimeSpan.FromDays(15);
string twoWeeksAgoString =
twoWeeksAgoDate.ToString(AWSSDKUtils.ISO8601DateFormat);
var request = new QueryRequest
{
TableName = "Reply",
KeyConditionExpression = "Id = :v_Id and ReplyDateTime > :v_twoWeeksAgo",
ExpressionAttributeValues = new Dictionary<string, AttributeValue> {
{":v_Id", new AttributeValue { S = "Amazon DynamoDB#DynamoDB Thread
2" }},
{":v_twoWeeksAgo", new AttributeValue { S = twoWeeksAgoString }}
},
ProjectionExpression = "Subject, ReplyDateTime, PostedBy",
ConsistentRead = true
};
var response = client.Query(request);
foreach (Dictionary<string, AttributeValue> item in response.Items)
{
// Process the result.
PrintItem(item);
}
また、オプションの Limit パラメータを追加することで、ページサイズ、またはページあたりの項
目数を制限することもできます。Query メソッドを実行するたびに、指定された数の項目が含まれる
結果が 1 ページ取得されます。次のページをフェッチするには、前ページの最後の項目のプライマリ
キーの値を入力して次の項目のセットが返されるようにし、Query メソッドを再度実行します。この
情報は、ExclusiveStartKey プロパティを設定することでリクエストに含めます。このプロパティ
は最初は null である場合があります。以降のページを取り出すには、このプロパティ値を更新して、
前ページの最後の項目のプライマリキーにする必要があります。
次の C# コードスニペットでは、Reply テーブルのクエリを実行しています。リクエストでは、オ
プションの Limit および ExclusiveStartKey パラメータを指定しています。do/while ループ
は、LastEvaluatedKey から null 値が返されるまで、一度に 1 ページのスキャンを継続します。
Dictionary<string,AttributeValue> lastKeyEvaluated = null;
do
{
var request = new QueryRequest
{
TableName = "Reply",
KeyConditionExpression = "Id = :v_Id",
ExpressionAttributeValues = new Dictionary<string, AttributeValue> {
{":v_Id", new AttributeValue { S = "Amazon DynamoDB#DynamoDB
Thread 2" }}
},
// Optional parameters.
Limit = 1,
API Version 2012-08-10
302
Amazon DynamoDB 開発者ガイド
クエリ
ExclusiveStartKey = lastKeyEvaluated
};
var response = client.Query(request);
// Process the query result.
foreach (Dictionary<string, AttributeValue> item in response.Items)
{
PrintItem(item);
}
lastKeyEvaluated = response.LastEvaluatedKey;
} while (lastKeyEvaluated != null && lastKeyEvaluated.Count != 0);
例 – AWS SDK for .NET を使用したクエリ
以下のテーブルには、フォーラムのコレクションに関する情報が格納されています。詳細について
は、「テーブルの作成とサンプルデータのロード (p. 166)」を参照してください。
Forum ( <emphasis role="underline">Name</emphasis>, ... )
Thread ( <emphasis role="underline">ForumName</emphasis>, <emphasis
role="underline">Subject</emphasis>, Message, LastPostedBy,
LastPostDateTime, ...)
Reply ( <emphasis role="underline">Id</emphasis>, <emphasis
role="underline">ReplyDateTime</emphasis>, Message, PostedBy, ...)
この C# コード例では、"DynamoDB" フォーラムで "DynamoDB Thread 1" スレッドに対する返信を検
索するのバリエーションを実行します。
• スレッドに対する返信を検索します。
• スレッドに対する返信を検索します。Limit クエリパラメータを指定してページサイズを設定しま
す。
この機能は、ページ分割を使用した、複数ページのクエリ結果の処理を示しています。Amazon
DynamoDB にはページサイズ制限があり、クエリ結果がページサイズを超えた場合には、結果のう
ち最初の 1 ページ分だけが得られます。このコーディングパターンによって、確実にクエリ結果の
全ページがコードで処理されます。
• 過去 15 日間の返信を検索します。
• 特定の日付範囲の返信を検索します。
前述の 2 つのクエリはどちらも、ソートキー条件を指定してクエリ結果を絞り込む方法、必要に応
じてその他のクエリパラメーターを使用する方法を示しています。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
Amazon.Util;
namespace com.amazonaws.codesamples
{
API Version 2012-08-10
303
Amazon DynamoDB 開発者ガイド
クエリ
class LowLevelQuery
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
// Query a specific forum and thread.
string forumName = "Amazon DynamoDB";
string threadSubject = "DynamoDB Thread 1";
FindRepliesForAThread(forumName, threadSubject);
FindRepliesForAThreadSpecifyOptionalLimit(forumName,
threadSubject);
FindRepliesInLast15DaysWithConfig(forumName,
threadSubject);
FindRepliesPostedWithinTimePeriod(forumName,
threadSubject);
Console.WriteLine("Example complete. To continue, press
Enter");
Console.ReadLine();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); Console.ReadLine(); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); Console.ReadLine(); }
catch (Exception e) { Console.WriteLine(e.Message);
Console.ReadLine(); }
}
private static void FindRepliesPostedWithinTimePeriod(string
forumName, string threadSubject)
{
Console.WriteLine("*** Executing
FindRepliesPostedWithinTimePeriod() ***");
string replyId = forumName + "#" + threadSubject;
// You must provide date value based on your test data.
DateTime startDate = DateTime.UtcNow - TimeSpan.FromDays(21);
string start =
startDate.ToString(AWSSDKUtils.ISO8601DateFormat);
// You provide date value based on your test data.
DateTime endDate = DateTime.UtcNow - TimeSpan.FromDays(5);
string end = endDate.ToString(AWSSDKUtils.ISO8601DateFormat);
var request = new QueryRequest
{
TableName = "Reply",
ReturnConsumedCapacity = "TOTAL",
KeyConditionExpression = "Id = :v_replyId and ReplyDateTime
between :v_start and :v_end",
ExpressionAttributeValues = new Dictionary<string,
AttributeValue> {
{":v_replyId", new AttributeValue { S = replyId }},
{":v_start", new AttributeValue { S = start }},
API Version 2012-08-10
304
Amazon DynamoDB 開発者ガイド
クエリ
{":v_end", new AttributeValue { S = end }}
}
};
var response = client.Query(request);
Console.WriteLine("\nNo. of reads used (by query in
FindRepliesPostedWithinTimePeriod) {0}",
response.ConsumedCapacity.CapacityUnits);
foreach (Dictionary<string, AttributeValue> item
in response.Items)
{
PrintItem(item);
}
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void FindRepliesInLast15DaysWithConfig(string
forumName, string threadSubject)
{
Console.WriteLine("*** Executing
FindRepliesInLast15DaysWithConfig() ***");
string replyId = forumName + "#" + threadSubject;
DateTime twoWeeksAgoDate = DateTime.UtcNow TimeSpan.FromDays(15);
string twoWeeksAgoString =
twoWeeksAgoDate.ToString(AWSSDKUtils.ISO8601DateFormat);
var request = new QueryRequest
{
TableName = "Reply",
ReturnConsumedCapacity = "TOTAL",
KeyConditionExpression = "Id = :v_replyId and ReplyDateTime
> :v_interval",
ExpressionAttributeValues = new Dictionary<string,
AttributeValue> {
{":v_replyId", new AttributeValue { S = replyId }},
{":v_interval", new AttributeValue { S =
twoWeeksAgoString }}
},
// Optional parameter.
ProjectionExpression = "Id, ReplyDateTime, PostedBy",
// Optional parameter.
ConsistentRead = true
};
var response = client.Query(request);
Console.WriteLine("No. of reads used (by query in
FindRepliesInLast15DaysWithConfig) {0}",
response.ConsumedCapacity.CapacityUnits);
foreach (Dictionary<string, AttributeValue> item
in response.Items)
{
PrintItem(item);
}
API Version 2012-08-10
305
Amazon DynamoDB 開発者ガイド
クエリ
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void FindRepliesForAThreadSpecifyOptionalLimit(string
forumName, string threadSubject)
{
Console.WriteLine("*** Executing
FindRepliesForAThreadSpecifyOptionalLimit() ***");
string replyId = forumName + "#" + threadSubject;
Dictionary<string, AttributeValue> lastKeyEvaluated = null;
do
{
var request = new QueryRequest
{
TableName = "Reply",
ReturnConsumedCapacity = "TOTAL",
KeyConditionExpression = "Id = :v_replyId",
ExpressionAttributeValues = new Dictionary<string,
AttributeValue> {
{":v_replyId", new AttributeValue { S = replyId }}
},
Limit = 2, // The Reply table has only a few sample
items. So the page size is smaller.
ExclusiveStartKey = lastKeyEvaluated
};
var response = client.Query(request);
Console.WriteLine("No. of reads used (by query in
FindRepliesForAThreadSpecifyLimit) {0}\n",
response.ConsumedCapacity.CapacityUnits);
foreach (Dictionary<string, AttributeValue> item
in response.Items)
{
PrintItem(item);
}
lastKeyEvaluated = response.LastEvaluatedKey;
} while (lastKeyEvaluated != null && lastKeyEvaluated.Count !
= 0);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void FindRepliesForAThread(string forumName, string
threadSubject)
{
Console.WriteLine("*** Executing FindRepliesForAThread() ***");
string replyId = forumName + "#" + threadSubject;
var request = new QueryRequest
{
TableName = "Reply",
ReturnConsumedCapacity = "TOTAL",
API Version 2012-08-10
306
Amazon DynamoDB 開発者ガイド
クエリ
KeyConditionExpression = "Id = :v_replyId",
ExpressionAttributeValues = new Dictionary<string,
AttributeValue> {
{":v_replyId", new AttributeValue { S = replyId }}
}
};
var response = client.Query(request);
Console.WriteLine("No. of reads used (by query in
FindRepliesForAThread) {0}\n",
response.ConsumedCapacity.CapacityUnits);
foreach (Dictionary<string, AttributeValue> item in
response.Items)
{
PrintItem(item);
}
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void PrintItem(
Dictionary<string, AttributeValue> attributeList)
{
foreach (KeyValuePair<string, AttributeValue> kvp in
attributeList)
{
string attributeName = kvp.Key;
AttributeValue value = kvp.Value;
Console.WriteLine(
attributeName + " " +
(value.S == null ? "" : "S=[" +
(value.N == null ? "" : "N=[" +
(value.SS == null ? "" : "SS=["
value.SS.ToArray()) + "]") +
(value.NS == null ? "" : "NS=["
value.NS.ToArray()) + "]")
);
}
value.S + "]") +
value.N + "]") +
+ string.Join(",",
+ string.Join(",",
Console.WriteLine("************************************************");
}
}
}
テーブルおよびインデックスにクエリを実行 : PHP
query 関数を使用すると、テーブルまたは セカンダリインデックス をクエリできます。この関数で
はパーティションキー値と等価条件を指定する必要があります。テーブルまたはインデックスにソー
トキーがある場合は、ソートキー値と条件を指定することで結果を絞り込むことができます。
以下に、AWS SDK for PHP を使用した一般的な手順を示します。
1. DynamoDB クライアントのインスタンスを作成します。
2. オプションのパラメーターを含む DynamoDB オペレーションのパラメーターを指定します。
3. DynamoDB からの応答をアプリケーションのローカル変数にロードします。
API Version 2012-08-10
307
Amazon DynamoDB 開発者ガイド
クエリ
フォーラムスレッドに対する返信を格納する、次のような Reply テーブルがあるとします。
Reply ( Id, ReplyDateTime, ... )
各フォーラムスレッドには一意の ID があり、0 またはそれ以上の返信を受け取ることができます。し
たがってプライマリキーは、Id (パーティションキー) と ReplyDateTime (ソートキー) の両方で構成さ
れます。
次のクエリでは、特定のスレッド件名に対するすべての返信を取り出します。このクエリでは、テー
ブル名と件名が必要になります。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。あるいは、「AWS SDK for PHP を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 617)」のトピックに記載されている手順に従って
データをロードすることもできます。
以下の例を実行するための詳しい手順については、「PHP コードサンプル (p. 175)」を参照
してください。
require 'vendor/autoload.php';
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$response = $dynamodb->query([
'TableName' => 'Reply',
'KeyConditionExpression' => 'Id = :v_id',
'ExpressionAttributeValues' => [
':v_id' => ['S' => 'Amazon DynamoDB#DynamoDB Thread 1']
]
]);
print_r($response['Items']);
オプションパラメータの指定
query 関数では、複数のオプションパラメータがサポートされています。たとえば、必要に応じて
ソートキー条件を指定して前述のクエリの結果を絞り込み、過去 2 週間の返信が返されるようにでき
ます。条件は、ソートキー条件と呼ばれます。これは、指定したクエリ条件を DynamoDB がソート
キーに対して評価するためです。その他のオプションパラメータを指定して、クエリ結果の項目から
特定の属性のリストを取り出すこともできます。パラメータの詳細については、Query を参照してく
ださい。
次の PHP コード例では、過去 7 日間に投稿されたフォーラムスレッドの返信が取り出されます。こ
のサンプルでは、次のオプションパラメータが指定されています。
• 過去 7 日間の返信だけを取り出す、KeyConditionExpression パラメーターのソートキー。
この条件によって、日付の比較に使用する ReplyDateTime の値と比較演算子を指定します。
API Version 2012-08-10
308
Amazon DynamoDB 開発者ガイド
クエリ
• クエリ結果内の項目について取り出す属性を指定する ProjectionExpression パラメータ。
• 強力な整合性のある読み込みを実行する ConsistentRead パラメータ。これにより、結果整合性
のある読み込みを実行するデフォルトの動作がオーバーライドされます。読み込み整合性の詳細に
ついては、「読み込み整合性 (p. 16)」を参照してください。
$sevenDaysAgo = date('Y-m-d H:i:s', strtotime('-7 days'));
$response = $dynamodb->query([
'TableName' => 'Reply',
'KeyConditionExpression' => 'Id = :v_id and ReplyDateTime
>= :v_reply_dt',
'ExpressionAttributeValues' => [
':v_id' => ['S' => 'Amazon DynamoDB#DynamoDB Thread 2'],
':v_reply_dt' => ['S' => $sevenDaysAgo]
],
// optional parameters
'ProjectionExpression' => 'Subject, ReplyDateTime, PostedBy',
'ConsistentRead' => true
]);
print_r($response['Items']);
Limit パラメータを追加することで、ページサイズ、またはページあたりの項目数を制限することも
できます。query 機能を実行するたびに、指定された数の項目が含まれる結果が 1 ページ取得されま
す。次のページをフェッチするには、前ページの最後の項目のプライマリキーの値を入力して次の項
目のセットが返されるようにし、query 機能を再度実行します。この情報は、ExclusiveStartKey
プロパティを設定することでリクエストに含めます。このプロパティは最初は null である場合があり
ます。以降のページを取り出すには、このプロパティ値を更新して、前ページの最後の項目のプライ
マリキーにする必要があります。
次の PHP コード例では、14 日を経過したエントリについて、Reply テーブルのクエリを行っていま
す。リクエストでは、オプションの Limit および ExclusiveStartKey パラメータを指定していま
す。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$fourteenDaysAgo = date('Y-m-d H:i:s', strtotime('-14 days'));
$tableName = 'Reply';
# The Query API is paginated. Issue the Query request multiple times.
do {
echo "Querying table $tableName\n";
$request = [
'TableName' => $tableName,
API Version 2012-08-10
309
Amazon DynamoDB 開発者ガイド
スキャニング
'KeyConditionExpression' => 'Id = :v_id and ReplyDateTime
>= :v_reply_dt',
'ExpressionAttributeValues' => [
':v_id' => ['S' => 'Amazon DynamoDB#DynamoDB Thread 2'],
':v_reply_dt' => ['S' => $fourteenDaysAgo]
],
'ProjectionExpression' => 'Id, ReplyDateTime, Message, PostedBy',
'ConsistentRead' => true,
'Limit' => 1
];
# Add the ExclusiveStartKey if we got one back in the previous response
if(isset($response) && isset($response['LastEvaluatedKey'])) {
$request['ExclusiveStartKey'] = $response['LastEvaluatedKey'];
}
$response = $dynamodb->query($request);
foreach ($response['Items'] as $key => $value) {
echo 'Id: ' . $value['Id']['S'] . "\n";
echo 'ReplyDateTime: ' . $value['ReplyDateTime']['S'] . "\n";
echo 'Message: ' . $value['Message']['S'] . "\n";
echo 'PostedBy: ' . $value['PostedBy']['S'] . "\n";
echo "\n";
}
# If there is no LastEvaluatedKey in the response, then
# there are no more items matching this Query
} while(isset($response['LastEvaluatedKey']));
?>
DynamoDB のスキャン
トピック
• テーブルおよびインデックスのスキャン: Java (p. 310)
• テーブルおよびインデックスのスキャン: .NET (p. 318)
• スキャンテーブルとインデックス : PHP (p. 327)
このセクションでは、基本的なスキャンとその結果を示します。
テーブルおよびインデックスのスキャン: Java
Scan オペレーションは、テーブルまたはインデックスの全項目を読み込みます。 スキャンおよび
クエリオペレーションに関するパフォーマンスの詳細については、「クエリおよびスキャンの使
用 (p. 287)」を参照してください。
以下に、AWS SDK for Java ドキュメント API を使用してテーブルをスキャンする手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. ScanRequest クラスのインスタンスを作成し、スキャンパラメータを指定します。
必須のパラメータは、テーブル名だけです。
3. scan メソッドを実行し、前述のステップで作成した ScanRequest オブジェクトを指定します。
API Version 2012-08-10
310
Amazon DynamoDB 開発者ガイド
スキャニング
以下の Reply テーブルに、フォーラムスレッドに対する応答が格納されます。
Reply ( Id, ReplyDateTime, Message, PostedBy )
このテーブルには、さまざまなフォーラムスレッドに対するすべての応答が保持されています。
したがってプライマリキーは、Id (パーティションキー) と ReplyDateTime (ソートキー) の両方で
構成されます。以下の Java コードスニペットは、テーブル全体をスキャンする例を示していま
す。ScanRequest インスタンスで、スキャン対象のテーブルの名前を指定します。
AmazonDynamoDBClient client = new AmazonDynamoDBClient(
new ProfileCredentialsProvider());
ScanRequest scanRequest = new ScanRequest()
.withTableName("Reply");
ScanResult result = client.scan(scanRequest);
for (Map<String, AttributeValue> item : result.getItems()){
printItem(item);
}
オプションパラメータの指定
scan メソッドでは、複数のオプションパラメータがサポートされています。たとえば、オプション
として、フィルタ式を使用してスキャン結果をフィルタリングすることができます。フィルタ式で、
条件や、条件の評価対象となる属性名と値を指定できます。詳細については、Scan を参照してくださ
い。
以下の Java コードスニペットは、ProductCatalog テーブルをスキャンして、価格が 0(ゼロ)未満
の項目を検索する例を示しています。このスニペットでは、次のオプションパラメータが指定されて
います。
• 価格が 0 未満の項目のみを取り出すフィルタ式(エラー条件)。
• クエリ結果内の項目について取り出す属性のリスト。
Map<String, AttributeValue> expressionAttributeValues =
new HashMap<String, AttributeValue>();
expressionAttributeValues.put(":val", new AttributeValue().withN("0"));
ScanRequest scanRequest = new ScanRequest()
.withTableName("ProductCatalog")
.withFilterExpression("Price < :val")
.withProjectionExpression("Id")
.withExpressionAttributeValues(expressionAttributeValues);
ScanResult result = client.scan(scanRequest);
for (Map<String, AttributeValue> item : result.getItems()) {
printItem(item);
}
スキャンリクエストの withLimit メソッドを使用し、ページサイズまたはページごとの項目数を必
要に応じて制限することもできます。scan メソッドを実行するたびに、指定された数の項目が含ま
API Version 2012-08-10
311
Amazon DynamoDB 開発者ガイド
スキャニング
れる結果が 1 ページ取得されます。次のページを取り出すには、前のページで最終項目のプライマリ
キーの値を指定して、scan メソッドを再度実行します。これにより、scan メソッドで、次の項目の
セットを返すことができます。この情報は、withExclusiveStartKey メソッドを使用することでリ
クエストに含めます。初期状態では、このメソッドのパラメータは null になる場合があります。以降
のページを取り出すには、このプロパティ値を更新して、前ページの最後の項目のプライマリキーに
する必要があります。
以下の Java コードスニペットは、ProductCatalog テーブルをスキャンする例を示しています。リ
クエストでは、withLimit および withExclusiveStartKey メソッドが使用されています。do/
while ループは、結果の getLastEvaluatedKey メソッドが null の値を返すまでの時間で、1 ペー
ジをスキャンし続けます。
Map<String, AttributeValue> lastKeyEvaluated = null;
do {
ScanRequest scanRequest = new ScanRequest()
.withTableName("ProductCatalog")
.withLimit(10)
.withExclusiveStartKey(lastKeyEvaluated);
ScanResult result = client.scan(scanRequest);
for (Map<String, AttributeValue> item : result.getItems()){
printItem(item);
}
lastKeyEvaluated = result.getLastEvaluatedKey();
} while (lastKeyEvaluated != null);
例 – Java を使用したスキャン
以下の Java コードは、ProductCatalog テーブルをスキャンして、価格が 100(ゼロ)未満の項目を
検索するという、作業サンプル例を示しています。
Note
SDK for Java には、オブジェクト永続性モデルも用意されています。このモデルにより、ク
ライアント側のクラスを DynamoDB テーブルにマッピングすることができます。この方法
により、記述する必要のあるコードの量を減らすことができます。詳細については、「Java:
DynamoDBMapper (p. 78)」を参照してください。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。
以下の例を実行するための詳しい手順については、「Java コードサンプル (p. 171)」を参照
してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
API Version 2012-08-10
312
Amazon DynamoDB 開発者ガイド
スキャニング
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.ItemCollection;
com.amazonaws.services.dynamodbv2.document.ScanOutcome;
com.amazonaws.services.dynamodbv2.document.Table;
public class DocumentAPIScan {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(new
ProfileCredentialsProvider()));
static String tableName = "ProductCatalog";
public static void main(String[] args) throws Exception {
findProductsForPriceLessThanZero();
}
private static void findProductsForPriceLessThanZero() {
Table table = dynamoDB.getTable(tableName);
Map<String, Object> expressionAttributeValues = new HashMap<String,
Object>();
expressionAttributeValues.put(":pr", 100);
ItemCollection<ScanOutcome> items = table.scan(
"Price < :pr", //FilterExpression
"Id, Title, ProductCategory, Price", //ProjectionExpression
null, //ExpressionAttributeNames - not used in this example
expressionAttributeValues);
System.out.println("Scan of " + tableName + " for items with a price
less than 100.");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
例 – Java を使用したパラレルスキャン
以下の Java コード例は、パラレルスキャンの例です。プログラムは、ParallelScanTest という名前の
テーブルを削除して再作成し、テーブルにデータをロードします。データのロードが終了すると、複
数のスレッドが生成され、並列の Scan リクエストが発行されます。プログラムは、各並列リクエス
トのランタイム統計を表示します。
Note
SDK for Java には、オブジェクト永続性モデルも用意されています。このモデルにより、ク
ライアント側のクラスを DynamoDB テーブルにマッピングすることができます。この方法
により、記述する必要のあるコードの量を減らすことができます。詳細については、「Java:
DynamoDBMapper (p. 78)」を参照してください。
API Version 2012-08-10
313
Amazon DynamoDB 開発者ガイド
スキャニング
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。
以下の例を実行するための詳しい手順については、「Java コードサンプル (p. 171)」を参照
してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import
import
import
import
import
import
import
import
java.util.ArrayList;
java.util.Arrays;
java.util.HashSet;
java.util.Iterator;
java.util.List;
java.util.concurrent.ExecutorService;
java.util.concurrent.Executors;
java.util.concurrent.TimeUnit;
import
import
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.AmazonServiceException;
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.ItemCollection;
com.amazonaws.services.dynamodbv2.document.ScanOutcome;
com.amazonaws.services.dynamodbv2.document.Table;
com.amazonaws.services.dynamodbv2.document.spec.ScanSpec;
com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
com.amazonaws.services.dynamodbv2.model.KeyType;
com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
public class DocumentAPIParallelScan {
// total number of sample items
static int scanItemCount = 300;
// number of items each scan request should return
static int scanItemLimit = 10;
// number of logical segments for parallel scan
static int parallelScanThreads = 16;
// table that will be used for scanning
static String parallelScanTestTableName = "ParallelScanTest";
static DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
public static void main(String[] args) throws Exception {
try {
// Clean up the table
API Version 2012-08-10
314
Amazon DynamoDB 開発者ガイド
スキャニング
deleteTable(parallelScanTestTableName);
createTable(parallelScanTestTableName, 10L, 5L, "Id", "N");
// Upload sample data for scan
uploadSampleProducts(parallelScanTestTableName, scanItemCount);
// Scan the table using multiple threads
parallelScan(parallelScanTestTableName, scanItemLimit,
parallelScanThreads);
}
catch (AmazonServiceException ase) {
System.err.println(ase.getMessage());
}
}
private static void parallelScan(String tableName, int itemLimit, int
numberOfThreads) {
System.out.println("Scanning " + tableName + " using " +
numberOfThreads
+ " threads " + itemLimit + " items at a time");
ExecutorService executor =
Executors.newFixedThreadPool(numberOfThreads);
// Divide DynamoDB table into logical segments
// Create one task for scanning each segment
// Each thread will be scanning one segment
int totalSegments = numberOfThreads;
for (int segment = 0; segment < totalSegments; segment++) {
// Runnable task that will only scan one segment
ScanSegmentTask task = new ScanSegmentTask(tableName, itemLimit,
totalSegments, segment);
// Execute the task
executor.execute(task);
}
shutDownExecutorService(executor);
}
// Runnable task for scanning a single segment of a DynamoDB table
private static class ScanSegmentTask implements Runnable {
// DynamoDB table to scan
private String tableName;
// number of items each scan request should return
private int itemLimit;
// Total number of segments
// Equals to total number of threads scanning the table in parallel
private int totalSegments;
// Segment that will be scanned with by this task
private int segment;
public ScanSegmentTask(String tableName, int itemLimit, int
totalSegments, int segment) {
API Version 2012-08-10
315
Amazon DynamoDB 開発者ガイド
スキャニング
this.tableName = tableName;
this.itemLimit = itemLimit;
this.totalSegments = totalSegments;
this.segment = segment;
}
@Override
public void run() {
System.out.println("Scanning " + tableName + " segment " +
segment + " out of " + totalSegments + " segments " + itemLimit + " items at
a time...");
int totalScannedItemCount = 0;
Table table = dynamoDB.getTable(tableName);
try {
ScanSpec spec = new ScanSpec()
.withMaxResultSize(itemLimit)
.withTotalSegments(totalSegments)
.withSegment(segment);
ItemCollection<ScanOutcome> items = table.scan(spec);
Iterator<Item> iterator = items.iterator();
Item currentItem = null;
while (iterator.hasNext()) {
totalScannedItemCount++;
currentItem = iterator.next();
System.out.println(currentItem.toString());
}
} catch (Exception e) {
System.err.println(e.getMessage());
} finally {
System.out.println("Scanned " + totalScannedItemCount
+ " items from segment " + segment + " out of "
+ totalSegments + " of " + tableName);
}
}
}
private static void uploadSampleProducts(String tableName, int itemCount)
{
System.out.println("Adding " + itemCount + " sample items to " +
tableName);
for (int productIndex = 0; productIndex < itemCount; productIndex++)
{
uploadProduct(tableName, productIndex);
}
}
private static void uploadProduct(String tableName, int productIndex) {
Table table = dynamoDB.getTable(tableName);
try {
System.out.println("Processing record #" + productIndex);
API Version 2012-08-10
316
Amazon DynamoDB 開発者ガイド
スキャニング
Item item = new Item()
.withPrimaryKey("Id", productIndex)
.withString("Title", "Book " + productIndex + " Title")
.withString("ISBN", "111-1111111111")
.withStringSet(
"Authors",
new HashSet<String>(Arrays.asList("Author1")))
.withNumber("Price", 2)
.withString("Dimensions", "8.5 x 11.0 x 0.5")
.withNumber("PageCount", 500)
.withBoolean("InPublication", true)
.withString("ProductCategory", "Book");
table.putItem(item);
}
catch (Exception e) {
System.err.println("Failed to create item " + productIndex + " in
" + tableName);
System.err.println(e.getMessage());
}
}
private static void deleteTable(String tableName){
try {
Table table = dynamoDB.getTable(tableName);
table.delete();
System.out.println("Waiting for " + tableName
+ " to be deleted...this may take a while...");
table.waitForDelete();
} catch (Exception e) {
System.err.println("Failed to delete table " + tableName);
e.printStackTrace(System.err);
}
}
private static void createTable(
String tableName, long readCapacityUnits, long writeCapacityUnits,
String partitionKeyName, String partitionKeyType) {
createTable(tableName, readCapacityUnits, writeCapacityUnits,
partitionKeyName, partitionKeyType, null, null);
}
private static void createTable(
String tableName, long readCapacityUnits, long writeCapacityUnits,
String partitionKeyName, String partitionKeyType,
String sortKeyName, String sortKeyType) {
try {
System.out.println("Creating table " + tableName);
List<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new KeySchemaElement()
.withAttributeName(partitionKeyName)
.withKeyType(KeyType.HASH)); //Partition key
API Version 2012-08-10
317
Amazon DynamoDB 開発者ガイド
スキャニング
List<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName(partitionKeyName)
.withAttributeType(partitionKeyType));
if (sortKeyName != null){
keySchema.add(new KeySchemaElement()
.withAttributeName(sortKeyName)
.withKeyType(KeyType.RANGE)); //Sort key
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName(sortKeyName)
.withAttributeType(sortKeyType));
}
Table table = dynamoDB.createTable(tableName,
keySchema,
attributeDefinitions,
new ProvisionedThroughput()
.withReadCapacityUnits(readCapacityUnits)
.withWriteCapacityUnits(writeCapacityUnits));
System.out.println("Waiting for " + tableName
+ " to be created...this may take a while...");
table.waitForActive();
} catch (Exception e) {
System.err.println("Failed to create table " + tableName);
e.printStackTrace(System.err);
}
}
private static void shutDownExecutorService(ExecutorService executor) {
executor.shutdown();
try {
if (!executor.awaitTermination(10, TimeUnit.SECONDS)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
// Preserve interrupt status
Thread.currentThread().interrupt();
}
}
}
テーブルおよびインデックスのスキャン: .NET
Scan オペレーションは、テーブルまたはインデックスの全項目を読み込みます。 スキャンおよび
クエリオペレーションに関するパフォーマンスの詳細については、「クエリおよびスキャンの使
用 (p. 287)」を参照してください。
以下に、AWS SDK for .NET の低レベル API を使用してテーブルをスキャンする手順を示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
API Version 2012-08-10
318
Amazon DynamoDB 開発者ガイド
スキャニング
2. ScanRequest クラスのインスタンスを作成し、スキャンオペレーションのパラメータを指定しま
す。
必須のパラメータは、テーブル名だけです。
3. Scan メソッドを実行し、前述のステップで作成した QueryRequest オブジェクトを指定します。
以下の Reply テーブルに、フォーラムスレッドに対する応答が格納されます。
>Reply ( <emphasis role="underline">Id</emphasis>, <emphasis
role="underline">ReplyDateTime</emphasis>, Message, PostedBy )
このテーブルには、さまざまなフォーラムスレッドに対するすべての応答が保持されています。
したがってプライマリキーは、Id (パーティションキー) と ReplyDateTime (ソートキー) の両方
で構成されます。以下の C# コードスニペットは、テーブル全体をスキャンする例を示していま
す。ScanRequest インスタンスで、スキャン対象のテーブルの名前を指定します。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
var request = new ScanRequest
{
TableName = "Reply",
};
var response = client.Scan(request);
var result = response.ScanResult;
foreach (Dictionary<string, AttributeValue> item in
response.ScanResult.Items)
{
// Process the result.
PrintItem(item);
}
オプションパラメータの指定
Scan メソッドでは、複数のオプションパラメータがサポートされています。たとえば、オプション
として、スキャンフィルタを使用してスキャン結果をフィルタリングすることができます。スキャン
フィルタを使用すると、条件、およびその条件を評価するための属性名を指定できます。詳細につい
ては、Scan を参照してください。
以下の C# コードは、ProductCatalog テーブルをスキャンして、値が 0(ゼロ)未満の項目を検索す
る例を示しています。このサンプルでは、次のオプションパラメータが指定されています。
• 値が 0 未満(エラー状態)の項目のみを取り出す FilterExpression パラメータ。
• クエリ結果内の項目について取り出す属性のリストを指定する ProjectionExpression パラメー
タ。
以下の C# コードスニペットは、ProductCatalog テーブルをスキャンして、値が 0(ゼロ)未満の項
目をすべて検索する例を示しています。
var forumScanRequest = new ScanRequest
{
TableName = "ProductCatalog",
// Optional parameters.
API Version 2012-08-10
319
Amazon DynamoDB 開発者ガイド
スキャニング
ExpressionAttributeValues = new Dictionary<string,AttributeValue> {
{":val", new AttributeValue { N = "0" }}
},
FilterExpression = "Price < :val",
ProjectionExpression = "Id"
};
また、オプションの Limit パラメータを追加することで、ページサイズ、またはページあたりの項目
数を制限することもできます。Scan メソッドを実行するたびに、指定された数の項目が含まれる結果
が 1 ページ取得されます。次のページを取り出すには、前のページで最終項目のプライマリキーの値
を指定して、Scan メソッドを再度実行します。これにより、Scan メソッドで、次の項目のセットを
返すことができます。この情報は、ExclusiveStartKey プロパティを設定することでリクエストに
含めます。このプロパティは最初は null である場合があります。以降のページを取り出すには、この
プロパティ値を更新して、前ページの最後の項目のプライマリキーにする必要があります。
以下の C# コードスニペットは、ProductCatalog テーブルをスキャンする例を示しています。リク
エストでは、オプションの Limit および ExclusiveStartKey パラメータを指定しています。do/
while ループは、LastEvaluatedKey から null 値が返されるまで、一度に 1 ページのスキャンを継
続します。
Dictionary<string, AttributeValue> lastKeyEvaluated = null;
do
{
var request = new ScanRequest
{
TableName = "ProductCatalog",
Limit = 10,
ExclusiveStartKey = lastKeyEvaluated
};
var response = client.Scan(request);
foreach (Dictionary<string, AttributeValue> item
in response.Items)
{
PrintItem(item);
}
lastKeyEvaluated = response.LastEvaluatedKey;
} while (lastKeyEvaluated != null && lastKeyEvaluated.Count != 0);
例 – .NET を使用したスキャン
以下の C# コードは、ProductCatalog テーブルをスキャンして、値が 0(ゼロ)未満の項目を検索す
るという、作業サンプル例を示しています。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class LowLevelScan
API Version 2012-08-10
320
Amazon DynamoDB 開発者ガイド
スキャニング
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
FindProductsForPriceLessThanZero();
Console.WriteLine("Example complete. To continue, press
Enter");
Console.ReadLine();
}
catch (Exception e) {
Console.WriteLine(e.Message);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
}
private static void FindProductsForPriceLessThanZero()
{
Dictionary<string, AttributeValue> lastKeyEvaluated = null;
do
{
var request = new ScanRequest
{
TableName = "ProductCatalog",
Limit = 2,
ExclusiveStartKey = lastKeyEvaluated,
ExpressionAttributeValues = new
Dictionary<string,AttributeValue> {
{":val", new AttributeValue { N = "0" }}
},
FilterExpression = "Price < :val",
ProjectionExpression = "Id, Title, Price"
};
var response = client.Scan(request);
foreach (Dictionary<string, AttributeValue> item
in response.Items)
{
Console.WriteLine("\nScanThreadTableUsePaging printing.....");
PrintItem(item);
}
lastKeyEvaluated = response.LastEvaluatedKey;
} while (lastKeyEvaluated != null && lastKeyEvaluated.Count !=
0);
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void PrintItem(
API Version 2012-08-10
321
Amazon DynamoDB 開発者ガイド
スキャニング
Dictionary<string, AttributeValue> attributeList)
{
foreach (KeyValuePair<string, AttributeValue> kvp in
attributeList)
{
string attributeName = kvp.Key;
AttributeValue value = kvp.Value;
Console.WriteLine(
attributeName + " " +
(value.S == null ? "" : "S=[" +
(value.N == null ? "" : "N=[" +
(value.SS == null ? "" : "SS=["
value.SS.ToArray()) + "]") +
(value.NS == null ? "" : "NS=["
value.NS.ToArray()) + "]")
);
}
value.S + "]") +
value.N + "]") +
+ string.Join(",",
+ string.Join(",",
Console.WriteLine("************************************************");
}
}
}
例 – .NET を使用したパラレルスキャン
以下の C# コード例は、パラレルスキャンの例です。このプログラムにより、ProductCatalog テーブ
ルが削除後に再作成され、このテーブルにデータがロードされます。データのロードが終了すると、
複数のスレッドが生成され、並列の Scan リクエストが発行されます。最後に、ランタイム統計の要
約が印刷されます。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using
using
using
using
using
using
using
System;
System.Collections.Generic;
System.Threading;
System.Threading.Tasks;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
namespace com.amazonaws.codesamples
{
class LowLevelParallelScan
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
private static string tableName = "ProductCatalog";
private static int exampleItemCount = 100;
private static int scanItemLimit = 10;
private static int totalSegments = 5;
static void Main(string[] args)
{
try
{
API Version 2012-08-10
322
Amazon DynamoDB 開発者ガイド
スキャニング
DeleteExampleTable();
CreateExampleTable();
UploadExampleData();
ParallelScanExampleTable();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
private static void ParallelScanExampleTable()
{
Console.WriteLine("\n*** Creating {0} Parallel Scan Tasks to scan
{1}", totalSegments, tableName);
Task[] tasks = new Task[totalSegments];
for (int segment = 0; segment < totalSegments; segment++)
{
int tmpSegment = segment;
Task task = Task.Factory.StartNew(() =>
{
ScanSegment(totalSegments, tmpSegment);
});
tasks[segment] = task;
}
Console.WriteLine("All scan tasks are created, waiting for them
to complete.");
Task.WaitAll(tasks);
Console.WriteLine("All scan tasks are completed.");
}
private static void ScanSegment(int totalSegments, int segment)
{
Console.WriteLine("*** Starting to Scan Segment {0} of {1} out of
{2} total segments ***", segment, tableName, totalSegments);
Dictionary<string, AttributeValue> lastEvaluatedKey = null;
int totalScannedItemCount = 0;
int totalScanRequestCount = 0;
do
{
var request = new ScanRequest
{
TableName = tableName,
Limit = scanItemLimit,
ExclusiveStartKey = lastEvaluatedKey,
Segment = segment,
TotalSegments = totalSegments
};
var response = client.Scan(request);
lastEvaluatedKey = response.LastEvaluatedKey;
totalScanRequestCount++;
API Version 2012-08-10
323
Amazon DynamoDB 開発者ガイド
スキャニング
totalScannedItemCount += response.ScannedCount;
foreach (var item in response.Items)
{
Console.WriteLine("Segment: {0}, Scanned Item with Title:
{1}", segment, item["Title"].S);
}
} while (lastEvaluatedKey.Count != 0);
Console.WriteLine("*** Completed Scan Segment {0} of {1}.
TotalScanRequestCount: {2}, TotalScannedItemCount: {3} ***", segment,
tableName, totalScanRequestCount, totalScannedItemCount);
}
private static void UploadExampleData()
{
Console.WriteLine("\n*** Uploading {0} Example Items to {1}
Table***", exampleItemCount, tableName);
Console.Write("Uploading Items: ");
for (int itemIndex = 0; itemIndex < exampleItemCount; itemIndex+
+)
{
Console.Write("{0}, ", itemIndex);
CreateItem(itemIndex.ToString());
}
Console.WriteLine();
}
private static void CreateItem(string itemIndex)
{
var request = new PutItemRequest
{
TableName = tableName,
Item = new Dictionary<string, AttributeValue>()
{
{ "Id", new AttributeValue { N = itemIndex }},
{ "Title", new AttributeValue { S = "Book " + itemIndex + "
Title" }},
{ "ISBN", new AttributeValue { S = "11-11-11-11" }},
{ "Authors", new AttributeValue { SS = new
List<string>{"Author1", "Author2" }}},
{ "Price", new AttributeValue { N = "20.00" }},
{ "Dimensions", new AttributeValue { S = "8.5x11.0x.75" }},
{ "InPublication", new AttributeValue { BOOL = false } }
}
};
client.PutItem(request);
}
private static void CreateExampleTable()
{
Console.WriteLine("\n*** Creating {0} Table ***", tableName);
var request = new CreateTableRequest
{
AttributeDefinitions = new List<AttributeDefinition>()
{
new AttributeDefinition
{
AttributeName = "Id",
AttributeType = "N"
API Version 2012-08-10
324
Amazon DynamoDB 開発者ガイド
スキャニング
}
},
KeySchema = new List<KeySchemaElement>
{
new KeySchemaElement
{
AttributeName = "Id",
KeyType = "HASH" //Partition key
}
},
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = 5,
WriteCapacityUnits = 6
},
TableName = tableName
};
var response = client.CreateTable(request);
var result = response;
var tableDescription = result.TableDescription;
Console.WriteLine("{1}: {0} \t ReadsPerSec: {2} \t WritesPerSec:
{3}",
tableDescription.TableStatus,
tableDescription.TableName,
tableDescription.ProvisionedThroughput.ReadCapacityUnits,
tableDescription.ProvisionedThroughput.WriteCapacityUnits);
string status = tableDescription.TableStatus;
Console.WriteLine(tableName + " - " + status);
WaitUntilTableReady(tableName);
}
private static void DeleteExampleTable()
{
try
{
Console.WriteLine("\n*** Deleting {0} Table ***", tableName);
var request = new DeleteTableRequest
{
TableName = tableName
};
var response = client.DeleteTable(request);
var result = response;
Console.WriteLine("{0} is being deleted...", tableName);
WaitUntilTableDeleted(tableName);
}
catch (ResourceNotFoundException)
{
Console.WriteLine("{0} Table delete failed: Table does not
exist", tableName);
}
}
API Version 2012-08-10
325
Amazon DynamoDB 開発者ガイド
スキャニング
private static void WaitUntilTableReady(string tableName)
{
string status = null;
// Let us wait until table is created. Call DescribeTable.
do
{
System.Threading.Thread.Sleep(5000); // Wait 5 seconds.
try
{
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
status = res.Table.TableStatus;
}
catch (ResourceNotFoundException)
{
// DescribeTable is eventually consistent. So you might
// get resource not found. So we handle the potential
exception.
}
} while (status != "ACTIVE");
}
private static void WaitUntilTableDeleted(string tableName)
{
string status = null;
// Let us wait until table is deleted. Call DescribeTable.
do
{
System.Threading.Thread.Sleep(5000); // Wait 5 seconds.
try
{
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
status = res.Table.TableStatus;
}
catch (ResourceNotFoundException)
{
Console.WriteLine("Table name: {0} is not found. It is
deleted", tableName);
return;
}
} while (status == "DELETING");
}
}
}
API Version 2012-08-10
326
Amazon DynamoDB 開発者ガイド
スキャニング
スキャンテーブルとインデックス : PHP
Scan オペレーションは、テーブルまたはインデックスの全項目を読み込みます。 スキャンおよび
クエリオペレーションに関するパフォーマンスの詳細については、「クエリおよびスキャンの使
用 (p. 287)」を参照してください。
以下に、AWS SDK for PHP を使用した一般的な手順を示します。
1. DynamoDB クライアントのインスタンスを作成します。
2. オプションのパラメーターを含む DynamoDB オペレーションのパラメーターを指定します。
3. DynamoDB からの応答をアプリケーションのローカル変数にロードします。
さまざまなフォーラムスレッドに対する応答を格納する、以下の Reply テーブルを考慮します。
Reply ( Id, ReplyDateTime, Message, PostedBy )
このテーブルには、さまざまなフォーラムスレッドに対するすべての応答が保持されています。した
がってプライマリキーは、Id (パーティションキー) と ReplyDateTime (ソートキー) の両方で構成され
ます。以下の PHP コードスニペットは、テーブルをスキャンする例を示しています。
Note
このサンプルコードでは、「テーブルの作成とサンプルデータのロード (p. 166)」のセクショ
ンに記載されている手順に従ってユーザーのアカウントで DynamoDB にデータがロード済み
であることを前提としています。あるいは、「AWS SDK for PHP を使用した、サンプルテー
ブルの作成とデータのアップロード (p. 617)」のトピックに記載されている手順に従って
データをロードすることもできます。
以下の例を実行するための詳しい手順については、「PHP コードサンプル (p. 175)」を参照
してください。
require 'vendor/autoload.php';
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$response = $dynamodb->scan([
'TableName' => 'Reply'
]);
foreach ($response['Items'] as $key => $value) {
echo 'Id: ' . $value['Id']['S'] . "\n";
echo 'ReplyDateTime: ' . $value['ReplyDateTime']['S'] . "\n";
echo 'Message: ' . $value['Message']['S'] . "\n";
echo 'PostedBy: ' . $value['PostedBy']['S'] . "\n";
echo "\n";
}
API Version 2012-08-10
327
Amazon DynamoDB 開発者ガイド
スキャニング
オプションパラメータの指定
scan 関数では、複数のオプションパラメータがサポートされています。たとえば、オプションとし
て、フィルタ式を使用してスキャン結果をフィルタリングすることができます。フィルタ式では、条
件、およびその条件を評価するための属性名を指定します。詳細については、Scan を参照してくださ
い。
以下の PHP コードでは、ProductCatalog テーブルをスキャンし、(誤って) ゼロ以下の価格になって
いる項目を見つけます。このサンプルでは、次のオプションパラメータが指定されています。
• ゼロ以下の価格となっている項目のみを取得する FilterExpression。
• クエリ結果内の項目について取り出す属性を指定する ProjectionExpression パラメータ。
$response = $dynamodb->scan([
'TableName' => 'ProductCatalog',
'ProjectionExpression' => 'Id, Price',
'ExpressionAttributeValues' => [
':val1' => ['N' => '0']] ,
'FilterExpression' => 'Price <= :val1',
]);
foreach ($response['Items'] as $key => $value) {
echo 'Id: ' . $value['Id']['N'] . ' Price: ' . $value['Price']['N'] .
"\n";
echo "\n";
}
オプションの Limit パラメータを追加し、ページサイズまたはページごとの項目数を必要に応じて
制限することもできます。scan 関数を実行するたびに、指定した数の項目が付属する 1 ページの結
果が得られます。次のページを取り出すには、前のページで最終項目のプライマリキーの値を指定し
て、scan 関数を再度実行します。これにより、scan 関数で、次の項目のセットを返すことができま
す。この情報は、ExclusiveStartKey プロパティを設定することでリクエストに含めます。このプ
ロパティは最初は null である場合があります。以降のページを取り出すには、このプロパティ値を更
新して、前ページの最後の項目のプライマリキーにする必要があります。
以下の PHP コードスニペットは、ProductCatalog テーブルをスキャンする例を示しています。リク
エストでは、オプションの Limit および ExclusiveStartKey パラメータを指定しています。
$tableName = 'ProductCatalog';
# The Scan operation is paginated. Issue the Scan request multiple times.
do {
echo "Scanning table $tableName\n";
$request = [
'TableName' => $tableName,
'ExpressionAttributeValues' => [
':val1' => ['N' => '201']
],
'FilterExpression' => 'Price < :val1',
'Limit' => 2
];
# Add the ExclusiveStartKey if we got one back in the previous response
if(isset($response) && isset($response['LastEvaluatedKey'])) {
API Version 2012-08-10
328
Amazon DynamoDB 開発者ガイド
スキャニング
$request['ExclusiveStartKey'] = $response['LastEvaluatedKey'];
}
$response = $dynamodb->scan($request);
foreach ($response['Items'] as $key => $value) {
echo 'Id: ' . $value['Id']['N'] . "\n";
echo 'Title: ' . $value['Title']['S'] . "\n";
echo 'Price: ' . $value['Price']['N'] . "\n";
echo "\n";
}
}
# If there is no LastEvaluatedKey in the response, there are no more items
matching this Scan
while(isset($response['LastEvaluatedKey']));
例 – PHP を使用したデータのロード
以下の PHP コード例では、以降の例で使用するサンプルデータを作成します。このプログラムによ
り、ProductCatalog テーブルが削除後に再作成され、このテーブルにデータがロードされます。
Note
これらのコード例を実行するための詳しい手順については、「PHP コードサンプ
ル (p. 175)」を参照してください。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'ProductCatalog';
// Delete an old DynamoDB table
echo "Deleting the table...\n";
try {
$response = $dynamodb->deleteTable([
'TableName' => $tableName
]);
$dynamodb->waitUntil('TableNotExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
API Version 2012-08-10
329
Amazon DynamoDB 開発者ガイド
スキャニング
]);
echo "The table has been deleted.\n";
echo "The table {$tableName} has been deleted.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to delete table $tableName\n");
}
// Create a new DynamoDB table
echo "# Creating table $tableName...\n";
try {
$response = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[
'AttributeName' => 'Id',
'AttributeType' => 'N'
]
],
'KeySchema' => [
[
'AttributeName' => 'Id',
'KeyType'
=> 'HASH'
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 5,
'WriteCapacityUnits' => 6
]
]);
//Partition key
$dynamodb->waitUntil('TableExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
]);
echo "Table {$tableName} has been created.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to create table $tableName\n");
}
// Populate DynamoDB table
echo "# Populating Items to $tableName...\n";
for ($i = 1; $i <= 100; $i++) {
$response = $dynamodb->putItem([
'TableName' => $tableName,
'Item' => [
'Id'
=> [ 'N'
=> "$i" ], // Primary Key
'Title'
=> [ 'S'
=> "Book {$i} Title" ],
API Version 2012-08-10
330
Amazon DynamoDB 開発者ガイド
スキャニング
'ISBN'
=> [ 'S'
=> '111-1111111111' ],
'Price'
=> [ 'N'
=> "25" ],
'Authors' => [ 'SS' => ['Author1', 'Author2']]
]
]);
$response = $dynamodb->getItem([
'TableName' => 'ProductCatalog',
'Key' => [
'Id' => [ 'N' => "$i" ]
]
]);
echo "Item populated: {$response['Item']['Title']['S']}\n";
sleep(1);
}
echo "{$tableName} is populated with items.\n";
?>
例 – PHP を使用したスキャン
以下の PHP コード例は、ProductCatalog テーブル上でシリアルスキャンを実行する例を示していま
す。
Note
このプログラムを実行する前に、ProductTable にデータを設定する必要があります。詳細に
ついては、「例 – PHP を使用したデータのロード (p. 329)」を参照してください。
これらのコード例を実行するための詳しい手順については、「PHP コードサンプ
ル (p. 175)」を参照してください。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'ProductCatalog';
$params = [
'TableName' => $tableName,
'ExpressionAttributeValues' => [
':val1' => ['S' => 'Book']
],
'FilterExpression' => 'contains (Title, :val1)',
API Version 2012-08-10
331
Amazon DynamoDB 開発者ガイド
スキャニング
'Limit' => 10
];
// Execute scan operations until the entire table is scanned
$count = 0;
do {
$response = $dynamodb->scan ( $params );
$items = $response->get ( 'Items' );
$count = $count + count ( $items );
// Do something with the $items
foreach ( $items as $item ) {
echo "Scanned item with Title \"{$item['Title']['S']}\".\n";
}
// Set parameters for next scan
$params ['ExclusiveStartKey'] = $response ['LastEvaluatedKey'];
} while ( $params ['ExclusiveStartKey'] );
echo "{$tableName} table scanned completely. {$count} items found.\n";
?>
例 – PHP を使用したパラレルスキャン
以下の PHP コード例は、パラレルスキャンの例です。複数の Scan リクエストが同時に実行されま
す。最後に、ランタイム統計の要約が印刷されます。
Note
このプログラムを実行する前に、ProductTable にデータを設定する必要があります。詳細に
ついては、「例 – PHP を使用したデータのロード (p. 329)」を参照してください。
これらのコード例を実行するための詳しい手順については、「PHP コードサンプ
ル (p. 175)」を参照してください。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
use Aws\CommandPool;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'ProductCatalog';
$totalSegments = 5;
$params = array(
'TableName' => $tableName,
API Version 2012-08-10
332
Amazon DynamoDB 開発者ガイド
インデックスの使用
'ExpressionAttributeValues' => array (
':val1' => array('S' => 'Book')
) ,
'FilterExpression' => 'contains (Title, :val1)',
'Limit' => 10,
'TotalSegments' => $totalSegments
);
// Build an array of Scan commands - one for each segment
$commands = [];
for ($segment = 0; $segment < $totalSegments; $segment++) {
$params['Segment'] = $segment;
$commands[] = $dynamodb->getCommand('Scan',$params);
}
// Setup a command pool to run the Scan commands concurrently
// The 'fulfilled' callback will process the results from each command
// The 'rejected' callback will tell why the command failed
$pool = new CommandPool($dynamodb,$commands,[
'fulfilled' => function($result, $iterKey, $aggregatePromise) {
echo "\nResults from segment $iterKey\n";
// Do something with the items
foreach ($result['Items'] as $item) {
echo "Scanned item with Title \"" . $item['Title']['S'] . "\"\n";
}
},
'rejected' => function ($reason, $iterKey, $aggregatePromise) {
echo "Failed {$iterKey}: {$reason}\n";
}
]);
$promise = $pool->promise();
$promise->wait();
?>
セカンダリインデックスを使用したデータアクセ
ス性の向上
トピック
• グローバルセカンダリインデックス (p. 336)
• ローカルセカンダリインデックス (p. 383)
Amazon DynamoDB は、プライマリキーの値を指定して、テーブルの項目への高速なアクセスを可能
にします。しかし多くのアプリケーションでは、プライマリキー以外の属性を使って、データに効率
的にアクセスできるようにセカンダリ(または代替)キーを 1 つ以上設定することで、メリットが得
られることがあります。これに対応するために、1 つのテーブルで 1 つ以上のセカンダリインデック
スを作成して、それらのインデックスに対して Query または Scan リクエストを実行することができ
ます。
セカンダリインデックス は、テーブルからの属性のサブセットと、Query オペレーションをサポート
する代替キーで構成されるデータ構造です。Query をテーブルで使用する場合と同じように、Query
を使用してインデックスからデータを取得できます。テーブルには、複数の セカンダリインデック
API Version 2012-08-10
333
Amazon DynamoDB 開発者ガイド
インデックスの使用
ス を作成できます。これにより、アプリケーションは複数の異なるクエリパターンにアクセスできま
す。
Note
また、テーブルを Scan するのと同じように、インデックスも Scan できます。
すべてのセカンダリインデックスは完全に 1 つのテーブルに関連付けられ、そこからデータを取得
します。これはインデックスのベーステーブルと呼ばれます。インデックスを作成する場合は、イン
デックスの代替キー (パーティションキーおよびソートキー) を定義します。また、ベーステーブルか
らインデックスに射影 (コピー) する属性も定義します。DynamoDB は、これらの属性とベーステーブ
ルからのプライマリキー属性をインデックスにコピーします。次に、テーブルに対してクエリまたは
スキャンを実行する場合と同様に、インデックスに対してクエリまたはスキャンを実行します。
すべての セカンダリインデックス は、DynamoDB によって自動的に維持されます。ベーステーブル
の項目を追加、変更、または削除すると、そのテーブルのインデックスも更新され、この変更が反映
されます。
DynamoDB では、次の 2 種類の セカンダリインデックス をサポートしています。
• Global secondary index — ベーステーブルと異なるパーティションキーとソートキーを持つイン
デックス。グローバルセカンダリインデックスは、そのインデックスのクエリは、すべてのパー
ティションにわたって、ベーステーブルのすべてのデータを対象に実行できるので、「グローバ
ル」と見なされます。
• ローカルセカンダリインデックス — ベーステーブルと同じパーティションキーと、異なるソート
キーを持つインデックス。local secondary indexは、local secondary indexのすべてのパーティショ
ンの範囲が、同じパーティションキーの値を持つベーステーブルパーティションに限定されるとい
う意味で「ローカル」です。
使用するインデックスの種類を決定するときは、アプリケーションの要件を考慮する必要がありま
す。次の表は、グローバルセカンダリインデックスとlocal secondary indexの主な違いを示していま
す。
特徴
グローバルセカンダリインデッ
クス
ローカルセカンダリインデック
ス
キースキーマ
グローバルセカンダリインデッ
クスのプライマリキーはシンプ
ル (パーティションキー) また
は複合 (パーティションキーと
ソートキー) のいずれかとする
ことができます。
local secondary indexのプライ
マリキーは複合 (パーティショ
ンキーとソートキー) である必
要があります。
キーの属性
インデックスパーティション
キーとソートキー (存在する場
合) は、文字列、数値、または
バイナリ型の任意のベーステー
ブル属性とすることができま
す。
インデックスのパーティション
キーは、ベーステーブルのパー
ティションキーと同じ属性で
す。ソートキーは、文字列、数
値、またはバイナリ型の任意の
ベーステーブル属性とすること
ができます。
パーティションキー値ごとのサ
イズ制限
グローバルセカンダリインデッ
クス にサイズ制限はありませ
ん。
パーティションキーの値ごと
に、すべてのインデックス付き
項目の合計サイズが、10 GB 以
下である必要があります。
オンラインインデックスオペ
レーション
Global secondary indexは、
テーブルの作成と同時に作成
ローカルセカンダリインデック
スは、テーブルの作成と同時
API Version 2012-08-10
334
Amazon DynamoDB 開発者ガイド
インデックスの使用
特徴
グローバルセカンダリインデッ
クス
ローカルセカンダリインデック
ス
できます。また、既存のテーブ
ルに新しいグローバルセカンダ
リインデックスを追加したり、
既存のグローバルセカンダリイ
ンデックスを削除したりできま
す。詳細については、「グロー
バルセカンダリインデックスの
管理 (p. 344)」を参照してく
ださい。
に作成されます。既存のテーブ
ルにlocal secondary indexを追
加したり、現在存在するlocal
secondary indexを削除したりす
ることはできません。
クエリとパーティション
グローバルセカンダリインデッ
クス では、すべてのパーティ
ションでテーブル全体に対して
クエリを実行できます。
local secondary indexでは、ク
エリのパーティションキー値で
指定された 1 つのパーティショ
ンに対してクエリを実行できま
す。
読み込み整合性
グローバルセカンダリインデッ
クス のクエリでは、結果整合
性のみがサポートされます。
local secondary index のクエリ
を実行するとき、結果整合性ま
たは強い整合性のどちらかを選
択できます。
プロビジョニングされたスルー
プットの消費
各 グローバルセカンダリイン
デックス には、読み込みおよ
び書き込みアクティビティに対
する独自のプロビジョニングさ
れたスループット設定がありま
す。グローバルセカンダリイン
デックスのクエリまたはスキャ
ンでは、ベーステーブルからで
はなく、インデックスからキャ
パシティーユニットを消費しま
す。同じことが、テーブルへの
書き込みによる グローバルセ
カンダリインデックス の更新
にも当てはまります。
local secondary indexのクエリ
またはスキャンでは、ベース
テーブルから読み込みキャパシ
ティーユニットを消費します。
テーブルに書き込むと、その
local secondary indexも更新さ
れます。この更新では、ベース
テーブルから書き込みキャパシ
ティーユニットを消費します。
射影される属性
グローバルセカンダリインデッ
クスのクエリまたはスキャンで
は、インデックスに射影された
属性だけをリクエストできま
す。DynamoDB は、テーブル
から属性をフェッチしません。
local secondary indexのクエリ
またはスキャンを実行する場
合、インデックスに射影されて
いない属性をリクエストできま
す。DynamoDB は、その属性を
テーブルから自動的にフェッチ
します。
セカンダリインデックス を持つテーブルを複数作成する場合は、連続的に作成する必要があります。
たとえば、最初のテーブルを作成し、そのテーブルが ACTIVE になるまで待ちます。次のテーブルを
作成し、そのテーブルが ACTIVE になるまで待ちます。セカンダリインデックス を持つ複数のテーブ
ルを同時に作成しようとすると、DynamoDB は LimitExceededException を返します。
各 セカンダリインデックス には、以下を指定する必要があります。
• 作成するインデックスの種類 – グローバルセカンダリインデックスまたはlocal secondary index。
• インデックスの名前。インデックスの名前付けルールは、「DynamoDB での制限 (p. 558)」に示
すようにテーブルの場合と同じです。名前は関連付けられているベーステーブルに対して一意であ
API Version 2012-08-10
335
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
る必要がありますが、別のベーステーブルに関連付けられているインデックスでも同じ名前を使用
できます。
• インデックスのキースキーマ。インデックスキースキーマの各属性は、型が String、Number、また
は Binary の最上位属性である必要があります。ドキュメントとセットを含むその他のデータ型は使
用できません。キースキーマのその他の要件は、インデックスの種類によって異なります。
• グローバルセカンダリインデックスの場合、パーティションキーはベーステーブルの任意のスカ
ラー属性にすることができます。ソートキーはオプションです。このキーもベーステーブルの任
意のスカラー属性にすることができます。
• local secondary indexの場合、パーティションキーは、ベーステーブルのパーティションキーと同
じである必要があります。ソートキーは、非キーベーステーブル属性である必要があります。
• ベーステーブルからインデックスに射影する追加の属性 (ある場合)。この属性は、すべてのイン
デックスに自動的に射影されるテーブルのキー属性とは別の属性です。スカラー、ドキュメント、
およびセットを含む任意のデータ型の属性を射影できます。
• インデックスのプロビジョニングされたスループット設定(必要な場合):
• グローバルセカンダリインデックス の場合、読み込みおよび書き込みキャパシティーユニット設
定を指定する必要があります。このプロビジョニングされたスループット設定は、ベーステーブ
ルの設定から独立しています。
• local secondary index の場合、読み込みおよび書き込みキャパシティーユニット設定を指定する
必要はありません。local secondary indexに対する読み込みおよび書き込みオペレーションは、そ
のベーステーブルのプロビジョニングされたスループット設定から消費します。
クエリで最大の柔軟性を得るには、1 テーブルあたり最大 5 個のグローバルセカンダリインデックス
および最大 5 個のlocal secondary indexを作成できます。
テーブルの セカンダリインデックスes の詳細なリストを取得するには、DescribeTable オペレー
ションを使用します。DescribeTable によって、テーブルのすべての セカンダリインデックス につ
いて、名前、ストレージサイズ、および項目数が返されます。これらの値はリアルタイムでは更新さ
れませんが、約 6 時間ごとに更新されます。
セカンダリインデックスのデータには、Query または Scan オペレーションを使用してアクセスでき
ます。使用するベーステーブル名とインデックス名、結果で返される属性、および適用する条件式ま
たはフィルタを指定する必要があります。DynamoDB で返される結果は、昇順にも降順にもすること
ができます。
テーブルを削除すると、そのテーブルに関連付けられているすべてのインデックスも削除されます。
ベストプラクティスについては、ローカルセカンダリインデックス のガイドライン (p. 584) と グ
ローバルセカンダリインデックス のガイドライン (p. 586) をそれぞれ参照してください。
グローバルセカンダリインデックス
トピック
• 属性の射影 (p. 339)
• グローバルセカンダリインデックス のクエリ (p. 340)
• グローバルセカンダリインデックスのスキャン (p. 341)
• テーブルと グローバルセカンダリインデックス 間のデータ同期 (p. 341)
• プロビジョニングされたスループットに関する考慮事項(グローバルセカンダリインデック
ス) (p. 342)
• グローバルセカンダリインデックス のストレージに関する考慮事項 (p. 343)
• グローバルセカンダリインデックスの管理 (p. 344)
• グローバルセカンダリインデックス の使用 : Java (p. 356)
• グローバルセカンダリインデックスes: .NET の使用 (p. 364)
• グローバルセカンダリインデックス の操作 : PHP (p. 375)
API Version 2012-08-10
336
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
アプリケーションによっては、さまざまな属性をクエリ基準に使用して、いろいろな種類のクエリ
を実行する必要があります。このような要件に対応するために、1 つ以上の グローバルセカンダリ
インデックス を作成して、そのインデックスに対して Query リクエストを発行できます。たとえ
ば、GameScores という名前のテーブルがあり、モバイルゲームアプリケーションのユーザーとスコ
アを記録しているとします。GameScores の各項目は、パーティションキー (UserId) とソートキー
(GameTitle) で識別します。次の図は、テーブル内の項目の構成を示しています。一部表示されていな
い属性もあります。
ここで、各ゲームの最高スコアを表示する順位表アプリケーションを作成すると仮定します。キー
属性(UserId と GameTitle)を指定したクエリは非常に効率的ですが、GameTitle だけに基づいて
GameScores からデータを取り出す必要があるアプリケーションでは、Scan オペレーションを使用
する必要があります。テーブルに追加される項目が増えるにつれ、すべてのデータのスキャンは低速
で非効率的になり、次のような質問に答えることが難しくなります。
• ゲーム Meteor Blasters で記録された最高スコアはいくつですか?
• Galaxy Invaders で最高スコアを獲得したユーザーは誰ですか?
• 勝敗の最も高い比率は何ですか?
非キー属性に対するクエリの速度を上げるために、グローバルセカンダリインデックス を作成できま
す。グローバルセカンダリインデックスには、ベーステーブルからの属性の一部が格納されますが、
テーブルのプライマリキーとは異なるプライマリキーによって構成されます。インデックスキーは、
テーブルからのキー属性を持つ必要がありません。また、テーブルと同じキースキーマを使用する必
要もありません。
たとえば、パーティションキーに GameTitle を使用し、ソートキーに TopScore を使用し
て、GameTitleIndex という名前のグローバルセカンダリインデックスを作成できます。ベーステー
ブルのプライマリキー属性は必ずインデックスに射影されるので、UserId 属性も存在します。次の図
は、GameTitleIndex インデックスを示しています。
API Version 2012-08-10
337
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
これで、GameTitleIndex に対してクエリを実行し、Meteor Blasters のスコアを簡単に入手できるよう
になります。結果は、ソートキーの値 TopScore 別に並べられます。ScanIndexForward パラメータ
を false に設定した場合、結果は降順で返されます。つまり、最高スコアが最初に返されます。
すべてのグローバルセカンダリインデックスには、パーティションキーが必要で、オプションのソー
トキーを指定できます。インデックスキースキーマは、ベーステーブルスキーマとは異なるものにす
ることができます。シンプルなプライマリキー (パーティションキー) のあるテーブルを作成したり、
複合プライマリキー (パーティションキーおよびソートキー) のあるグローバルセカンダリインデッ
クスを作成でき、その逆も可能です。インデックスキー属性は、ベーステーブルの任意の最上位文字
列、数値、またはバイナリ属性で構成できます。他のスカラー型、ドキュメント型、およびセット型
は使用できません。
必要な場合、他のベーステーブル属性をインデックスに射影できます。インデックスに対してクエリ
を実行すると、DynamoDB は、この射影された属性を効率的に取り出すことができますが、グローバ
ルセカンダリインデックスのクエリでは、ベーステーブルから属性をフェッチできません。上記の図
に示すように、GameTitleIndex にクエリを実行した場合、クエリは TopScore 以外の非キー属性にア
クセスすることはできません (キー属性 GameTitle と UserId は自動的に射影されます)。
DynamoDB テーブルでは、各キー値は一意である必要があります。ただし、グローバルセカンダリイ
ンデックス のキー値は一意である必要がありません。たとえば、Comet Quest という名前のゲームが
特に難しく、多くの新しいユーザーが試しても、ゼロを上回るスコアを獲得することができないとし
ます。ここに、それを表すのに使用できるいくつかのデータがあります。
UserId
GameTitle
TopScore
123
Comet Quest
0
201
Comet Quest
0
301
Comet Quest
0
このデータを GameScores テーブルに追加すると、DynamoDB はそのデータを GameTitleIndex に伝
達します。GameTitle として Comet Quest を、TopScore として 0 を指定してインデックスに対する
クエリを実行すると、次のデータが返されます。
API Version 2012-08-10
338
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
指定したキー値を持つ項目だけがレスポンスに表示されます。その一連のデータ内では、項目は特定
の順に並んでいません。
グローバルセカンダリインデックス は、キー属性が実際に存在するデータ項目のみを記録します。た
とえば、別の新しい項目を GameScores テーブルに追加し、必須のプライマリキー属性だけを指定し
たとします。
UserId
GameTitle
400
Comet Quest
TopScore 属性を指定していないので、DynamoDB は、この項目を GameTitleIndex に反映しません。
このため、すべての Comet Quest 項目を対象に、GameScores に対してクエリを実行した場合、次の
4 つの項目が返されます。
GameTitleIndex に対して同様のクエリを実行すると、4 つではなく 3 つの項目が返されます。これ
は、TopScore が存在しない項目はインデックスに反映されないためです。
属性の射影
射影は、テーブルからセカンダリインデックスにコピーされる属性セットです。テーブルのパーティ
ションキーとソートキーは必ずインデックスに射影されます。アプリケーションのクエリ要件をサ
ポートするために、他の属性を射影することができます。インデックスのクエリを行うと、Amazon
DynamoDB は射影内の属性に、それらの属性が独立したテーブル内にあるかのようにアクセスできま
す。
セカンダリインデックス を作成する場合は、インデックスに射影される属性を指定する必要がありま
す。DynamoDB にはこのための 3 つのオプションが用意されています。
• KEYS_ONLY – インデックスの各項目は、テーブルのパーティションキーとソートキー値、および
インデックスキー値のみで構成されます。KEYS_ONLY オプションを使用すると、セカンダリイン
デックス は最小になります。
• INCLUDE – KEYS_ONLY の属性に加えて、セカンダリインデックス にその他の非キー属性が含まれ
るように指定できます。
API Version 2012-08-10
339
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
• ALL – セカンダリインデックス にソーステーブルのすべての属性が含まれます。テーブルの全デー
タがインデックスで複製されるため、ALL の射影により、セカンダリインデックス は最大になりま
す。
前の図の GameTitleIndex には、追加の射影された属性がありません。アプリケーションは、クエリ
で GameTitle と TopScore を使用できます。ただし、特定のゲームで最高スコアを獲得したユーザー
や、勝率が最も高いユーザーを効率的に特定することはできません。このデータに対するクエリをサ
ポートする最も効率的な方法は、次の図に示すように、これらの属性をベーステーブルからグローバ
ルセカンダリインデックスに射影する方法です。
非キー属性 Wins と Losses がインデックスに射影されるので、アプリケーションは、任意のゲーム、
またはゲームとユーザー ID の任意の組み合わせに対して、勝敗の比率を特定できます。
グローバルセカンダリインデックス に射影する属性を選択する場合には、プロビジョニングされるス
ループットコストとストレージコストのトレードオフを考慮する必要があります。
• ごく一部の属性だけに最小のレイテンシーでアクセスする必要がある場合は、それらの属性だけを
グローバルセカンダリインデックス に射影することを検討してください。インデックスが小さいほ
ど少ないコストで格納でき、書き込みコストも低くなります。
• アプリケーションが非キー属性に頻繁にアクセスする場合には、それらの属性を グローバルセカン
ダリインデックス に射影することを検討してください。グローバルセカンダリインデックス の追加
のストレージコストは、頻繁なテーブルスキャンを実行するコストを相殺します。
• ほとんどの非キー属性に頻繁にアクセスする場合は、それらの属性、さらにはベーステーブル全体
をグローバルセカンダリインデックスに射影することができます。これにより、最大限の柔軟性が
得られますが、ストレージコストは増加するか、倍になります。
• アプリケーションでテーブルのクエリを頻繁に行う必要がなく、テーブル内のデータに対する書き
込みや更新が多数になる場合は、KEYS_ONLY を射影することを検討してください。グローバルセ
カンダリインデックス のサイズは最小になりますが、クエリに必要なサイズは確保されます。
グローバルセカンダリインデックス のクエリ
Query オペレーションを使用して、グローバルセカンダリインデックスの 1 つ以上の項目にアクセス
することができます。クエリでは、使用するベーステーブル名とインデックス名、クエリ結果で返さ
API Version 2012-08-10
340
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
れる属性、および適用するクエリ条件を指定する必要があります。DynamoDB で返される結果は、昇
順にも降順にもすることができます。
順位表アプリケーションのゲームデータをリクエストする Query から返される次のデータについて考
えます。
{
"TableName": "GameScores",
"IndexName": "GameTitleIndex",
"KeyConditionExpression": "GameTitle = :v_title",
"ExpressionAttributeValues": {
":v_title": {"S": "Meteor Blasters"}
},
"ProjectionExpression": "UserId, TopScore",
"ScanIndexForward": false
}
このクエリでは次のようになっています。
• DynamoDB が GameTitle パーティションキーを使用して GameTitleIndex にアクセスし、Meteor
Blasters のインデックス項目を特定します。このキーを持つすべてのインデックス項目が、すばや
く取り出せるように隣り合わせに格納されます。
• このゲーム内で、DynamoDB はインデックスを使用して、このゲームのすべてのユーザー ID と最
高スコアにアクセスします。
• ScanIndexForward パラメータが false に設定されているので、結果は降順で返されます。
グローバルセカンダリインデックスのスキャン
Scan オペレーションを使用して、グローバルセカンダリインデックス からすべてのデータを取得
できます。 リクエストにはベーステーブル名とインデックス名を指定する必要があります。Scan で
は、DynamoDB はインデックスのすべてのデータを読み取り、それをアプリケーションに返します。
また、データの一部のみを返し、残りのデータを破棄するようにリクエストすることもできます。こ
れを行うには、Scan オペレーションの FilterExpression パラメーターを使用します。 詳細につ
いては、「クエリまたはスキャンからの結果のフィルタリング (p. 289)」を参照してください。
テーブルと グローバルセカンダリインデックス 間のデータ同
期
DynamoDB は、各グローバルセカンダリインデックスをそのベーステーブルと自動的に同期します。
アプリケーションがテーブルに項目を書き込むか、削除すると、そのテーブルのすべての グローバル
セカンダリインデックス は、結果整合性のあるモデルを使用して、非同期で更新されます。アプリ
ケーションがインデックスに直接書き込むことはありません。ただし、DynamoDB でこれらのイン
デックスがどのように維持されるかを理解することは重要です。
グローバルセカンダリインデックスを作成するときは、1 つ以上のインデックスキー属性およびそ
れらのデータ型を指定します。つまり、ベーステーブルに項目を書き込むとき、それらの属性の
データ型が、インデックスキースキーマのデータ型に一致する必要があります。GameTitleIndex の
場合、インデックスの GameTitle パーティションキーは文字列データ型として定義され、インデッ
クス内の TopScore ソートキーは数値型になります。GameScores テーブルに項目を追加すると
きに、GameTitle または TopScore に対して別のデータ型を指定すると、データ型の不一致により
DynamoDB によって ValidationException が返されます。
テーブルに項目を入力するか、削除すると、そのテーブルの グローバルセカンダリインデックス は、
結果整合性のある方法で更新されます。テーブルデータへの変更は、通常は、瞬時に グローバルセカ
ンダリインデックス に伝達されます。ただし、万が一障害が発生した場合は、長い伝達遅延が発生す
API Version 2012-08-10
341
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
ることがあります。このため、アプリケーションでは、グローバルセカンダリインデックス に対する
クエリによって、最新でない結果が返される状況を予期し、それに対応する必要があります。
テーブルに項目を書き込む場合には、グローバルセカンダリインデックスソートキーに対して属性を
指定する必要はありません。GameTitleIndex を例にとると、GameScores テーブルに新しい項目を書
き込むために、TopScore 属性に値を指定する必要はありません。この場合、Amazon DynamoDB は
この特定の項目のインデックスにデータを書き込むことはありません。
多数の グローバルセカンダリインデックス があるテーブルは、インデックス数が少ないテーブルに比
べて書き込みアクティビティに多くのコストを要します。詳細については、「プロビジョニングされ
たスループットに関する考慮事項(グローバルセカンダリインデックス) (p. 342)」を参照してくだ
さい。
プロビジョニングされたスループットに関する考慮事項(グ
ローバルセカンダリインデックス)
グローバルセカンダリインデックス を作成するときには、そのインデックスに対して予想されるワー
クロードに応じた読み込みおよび書き込みキャパシティーユニットを指定する必要があります。グ
ローバルセカンダリインデックスのプロビジョニングされたスループット設定は、そのベーステーブ
ルの設定から独立しています。グローバルセカンダリインデックスに対する Query オペレーション
では、ベーステーブルではなく、インデックスから読み込みキャパシティーユニットを消費します。
テーブルで項目を入力、更新、または削除すると、そのテーブルのグローバルセカンダリインデック
スも更新されます。このインデックスの更新では、ベーステーブルからではなく、インデックスから
書き込みキャパシティーユニットを消費します。
たとえば、グローバルセカンダリインデックス に対して Query を実行し、そのプロビジョニングさ
れた読み込みキャパシティーを超えた場合、リクエストは調整されます。多量の書き込みアクティビ
ティをテーブルに対して実行するときに、そのテーブルの グローバルセカンダリインデックス に十分
な書き込みキャパシティーがない場合、そのテーブルに対する書き込みアクティビティは調整されま
す。
グローバルセカンダリインデックス のプロビジョニングされたスループット設定を表示するに
は、DescribeTable オペレーションを使用します。テーブルのすべての グローバルセカンダリイン
デックス に関する詳細が返されます。
読み込みキャパシティーユニット
Global secondary index では、結果整合性のある読み込みをサポートしており、各読み込みで、1 読み
込みキャパシティーユニットの半分を消費します。つまり、1 回の グローバルセカンダリインデック
ス のクエリでは、1 読み込みキャパシティーユニットあたり最大 2 × 4 KB = 8 KB を取り出すことが
できます。
グローバルセカンダリインデックス のクエリの場合、DynamoDB は、プロビジョニングされた読み
込みアクティビティを、テーブルに対するクエリと同じ方法で計算します。唯一の違いは、ベース
テーブル内の項目のサイズではなくインデックスエントリのサイズに基づいて計算が行われることで
す。読み込みキャパシティーユニットの数は、返されたすべての項目について射影されたすべての属
性のサイズの合計です。結果は、次の 4 KB 境界まで切り上げられます。DynamoDB がプロビジョ
ニング済みスループットの利用率を計算する方法の詳細については、「テーブルの読み書き要件の指
定 (p. 179)」を参照してください。
Query オペレーションによって返される結果の最大サイズは、1 MB です。これには、返されるすべ
ての項目にわたる、すべての属性の名前と値のサイズが含まれます。
たとえば、各項目に 2000 バイトのデータが格納されている グローバルセカンダリインデックス があ
るとします。このインデックスに対して Query を実行し、そのクエリによって 8 項目返されるとし
ます。一致する項目の合計サイズは、2000 バイト × 8 項目 = 16,000 バイトです。これは、最も近い
4 KB 境界に切り上げられます。グローバルセカンダリインデックス のクエリは結果整合性があるの
で、合計コストは、0.5 ×(16 KB/4 KB)、つまり、2 読み込みキャパシティーユニットです。
API Version 2012-08-10
342
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
書き込みキャパシティーユニット
テーブルの項目が追加、更新、または削除されたときに、グローバルセカンダリインデックス がこの
影響を受ける場合、グローバルセカンダリインデックス は、そのオペレーションに対してプロビジョ
ニングされた書き込みキャパシティーユニットを消費します。書き込み用にプロビジョニングされた
スループットの合計コストは、ベーステーブルに対する書き込みと、グローバルセカンダリインデッ
クスの更新で消費された書き込みキャパシティーユニットの合計になります。テーブルへの書き込み
には、グローバルセカンダリインデックス の更新は必要ないので、インデックスから消費される書き
込みキャパシティーはありません。
テーブルへの書き込みを正常に実行するために、テーブルとそのすべての グローバルセカンダリイン
デックス に対するプロビジョニングされたスループット設定は、書き込みに対応できるだけの十分な
書き込みキャパシティーを備えている必要があります。十分でない場合、書き込みは調整されます。
グローバルセカンダリインデックス に項目を書き込むコストは、いくつかの要因に左右されます。
• インデックス付き属性が定義されたテーブルに新しい項目を書き込む場合、または既存の項目を更
新して未定義のインデックス付き属性を定義する場合には、インデックスへの項目の挿入に 1 回の
書き込みオペレーションが必要です。
• テーブルに対する更新によってインデックス付きキー属性の値が(A から B に)変更された場合に
は、インデックスから既存の項目を削除し、インデックスに新しい項目を挿入するために、2 回の
書き込みが必要です。 • インデックス内に既存の項目があって、テーブルに対する書き込みによってインデックス付き属性
が削除された場合は、インデックスから古い項目の射影を削除するために、1 回の書き込みが必要
です。
• 項目の更新の前後にインデックス内に項目が存在しない場合は、インデックスで追加の書き込みコ
ストは発生しません。
• テーブルに対する更新によってインデックスキースキーマの射影された属性の値のみが変更され、
インデックス付きキー属性の値は変更されない場合は、インデックスに射影された属性の値を更新
するために、1 回の書き込みが必要です。
これらすべての要因は、インデックス内の各項目のサイズが 1 KB 以下であるという前提で書き込み
キャパシティーユニット数を算出します。インデックスエントリがそれよりも大きい場合は、書き込
みキャパシティーユニットを追加する必要があります。クエリが返す必要がある属性を特定し、それ
らの属性だけをインデックスに射影することで、書き込みコストは最小になります。
グローバルセカンダリインデックス のストレージに関する考
慮事項
アプリケーションがテーブルに項目を書き込むと、DynamoDB では正しい属性のサブセットが、それ
らの属性が現れる必要がある グローバルセカンダリインデックス に自動的にコピーされます。AWS
アカウントでは、テーブル内の項目のストレージと、そのベーステーブルのグローバルセカンダリイ
ンデックスにある属性のストレージに対して課金されます。
インデックス項目が使用するスペースの量は、次の量の合計になります。
• ベーステーブルのプライマリキー (パーティションキーとソートキー) のサイズのバイト数
• インデックスキー属性のサイズのバイト数
• 射影された属性(存在する場合)のサイズのバイト数
• インデックス項目あたり 100 bytes のオーバーヘッド
グローバルセカンダリインデックスのストレージ要件の見積もりは、インデックス内の 1 項目の平均
サイズの見積もり値に、ベーステーブル内のグローバルセカンダリインデックスキー属性を持つ項目
の数を掛けて算出します。
API Version 2012-08-10
343
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
特定の属性が定義されていない項目がテーブルに含まれていて、その属性がインデックスパーティ
ションキーまたはソートキーとして定義されている場合、DynamoDB はその項目のデータをインデッ
クスに書き込みません。
グローバルセカンダリインデックスの管理
このセクションでは、グローバルセカンダリインデックスを作成、変更、および削除する方法につい
て説明します。
トピック
• テーブルとグローバルセカンダリインデックスの作成 (p. 344)
• テーブルでのグローバルセカンダリインデックスの説明 (p. 344)
• 既存のテーブルへのグローバルセカンダリインデックスの追加 (p. 345)
• インデックス作成の変更 (p. 347)
• テーブルからのグローバルセカンダリインデックスの削除 (p. 348)
• インデックスキー違反の検出と修正 (p. 348)
テーブルとグローバルセカンダリインデックスの作成
1 つ以上のグローバルセカンダリインデックスがあるテーブルを作成するに
は、GlobalSecondaryIndexes オペレーションを CreateTable パラメータと共に使用します。最
大限のクエリの柔軟性を得るために、テーブルごとに最大 5 個のグローバルセカンダリインデックス
を作成できます。
インデックスパーティションキーとなる 1 つの属性を指定する必要があります。必要に応じて、イ
ンデックスソートキーに別の属性を指定できます。これらのキー属性は、テーブルのキー属性と同
じである必要はありません。たとえば、GameScores テーブル (「グローバルセカンダリインデック
ス (p. 336)」を参照) で、TopScore も TopScoreDateTime もキー属性ではありませんが、パーティ
ションキーに TopScore を使用し、ソートキーに TopScoreDateTime を使用して、グローバルセカン
ダリインデックスを作成できます。このようなインデックスを使用して、高いスコアとゲームをプレ
イする時間帯の間に相関関係があるかどうかを判断できます。
各インデックスキー属性は、文字列型、数値型、またはバイナリ型である必要があります (ドキュメン
トまたはセットにすることはできません)。任意のデータ型の属性をグローバルセカンダリインデック
スに射影できます。これには、スカラー、ドキュメント、およびセットが含まれます。データ型の詳
細なリストについては、「データ型 (p. 12)」を参照してください。
ReadCapacityUnits および ProvisionedThroughput で構成される、インデックス用の
WriteCapacityUnits 設定を指定する必要があります。このプロビジョニングされたスループット
設定は、テーブルに対するその設定から独立していますが、同じように動作します。詳細について
は、「プロビジョニングされたスループットに関する考慮事項(グローバルセカンダリインデック
ス) (p. 342)」を参照してください。
テーブルでのグローバルセカンダリインデックスの説明
テーブルのすべての グローバルセカンダリインデックスes のステータスを表示するに
は、DescribeTable オペレーションを使用します。応答の GlobalSecondaryIndexes 部分は、そ
れぞれの現在のステータス(IndexStatus)と共に、テーブルのすべてのインデックスを示します。
グローバルセカンダリインデックスの IndexStatus は次のいずれかになります。
• CREATING - インデックスは現在作成中で、まだ使用することはできません。
• ACTIVE - インデックスは使用する準備が整っていて、アプリケーションはインデックスで Query
オペレーションを実行できます。
• UPDATING - インデックスのプロビジョニングされたスループット設定を変更中です。
• DELETING - インデックスは現在削除中で、使用できなくなりました。
API Version 2012-08-10
344
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
DynamoDB がグローバルセカンダリインデックスの作成を終了すると、インデックスのステータスは
CREATING から ACTIVE に変わります。
既存のテーブルへのグローバルセカンダリインデックスの追加
既存のテーブルにグローバルセカンダリインデックスを追加するには、UpdateTable オペレーショ
ンを GlobalSecondaryIndexUpdates パラメータと共に使用します。以下を指定する必要がありま
す。
• インデックス名。名前は、テーブルのすべてのインデックス間で一意である必要があります。
• インデックスのキースキーマ。インデックスパーティションキー用の 1 つの属性を指定する必要
があります。必要に応じて、インデックスソートキーに別の属性を指定できます。これらのキー属
性は、テーブルのキー属性と同じである必要はありません。各スキーマ属性のデータ型はスカラー
(文字列、数値、またはバイナリ)である必要があります。
• テーブルからインデックスに射影する属性:
• KEYS_ONLY – インデックスの各項目は、テーブルのパーティションキーとソートキー値、および
インデックスキー値のみで構成されます。
• INCLUDE - KEYS_ONLY の属性に加えて、セカンダリインデックスにその他の非キー属性が含まれ
るように指定できます。
• ALL - インデックスにソーステーブルのすべての属性が含まれます。
• ReadCapacityUnits および WriteCapacityUnits で構成される、インデックスのプロビジョニ
ングされたスループット設定。これらのプロビジョニングされたスループット設定は、テーブルの
設定から独立しています。
UpdateTable オペレーションごとに、1 つのグローバルセカンダリインデックスを作成または削除で
きます。ただし、複数の UpdateTable オペレーションを同時に実行すれば、複数のインデックスを
同時に作成できます。テーブルでこれらの UpdateTable オペレーションを一度に 5 つまで実行でき
ます。各オペレーションは厳密に 1 つのインデックスを作成できます。
Note
処理中のグローバルセカンダリインデックスの作成をキャンセルすることはできません。
インデックス作成のフェーズ
既存のテーブルに新しいグローバルセカンダリインデックスを追加すると、テーブルはインデックス
の作成中も引き続き使用可能になります。ただし、Query オペレーションの新しいインデックスは、
そのステータスが CREATING から ACTIVE に変わるまで使用できません。
バックグラウンドでは、DynamoDB が次の 2 つの段階でインデックスを作成します。
リソースの割り当て
DynamoDB はインデックスの作成に必要なコンピューティングリソースおよびストレージリソー
スを割り当てます。
リソースの割り当てフェーズ中は、IndexStatus 属性は CREATING になり、Backfilling 属
性は false になります。テーブルのステータスとそのすべてのセカンダリインデックスを取得する
には、DescribeTable オペレーションを使用します。
インデックスがリソースの割り当てフェーズにあるときは、その親テーブルを削除したり、イン
デックスまたはテーブルのプロビジョニングされたスループットを変更したりすることはできま
せん。テーブルの他のインデックスを追加または削除することはできませんが、これらの他のイ
ンデックスのプロビジョニングされたスループットを変更することができます。
バックフィリング
DynamoDB は、テーブルの各項目については、射影(KEYS_ONLY、INCLUDE、または ALL)に
基づいて、インデックスに書き込む一連の属性を決定します。次に、これらの属性をインデック
スに書き込みます。DynamoDB はバックフィルフェーズ中に、テーブルで追加、削除、または更
API Version 2012-08-10
345
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
新中の項目を追跡します。また、これらの項目の属性は、必要に応じてインデックスで追加、削
除、または更新されます。
バックフィリングフェーズ中に、IndexStatus 属性は CREATING になり、Backfilling 属性
は true になります。テーブルのステータスとそのすべてのセカンダリインデックスを取得するに
は、DescribeTable オペレーションを使用します。
インデックスのバックフィリング中に親テーブルを削除することはできません。ただし、テーブ
ルと任意のグローバルセカンダリインデックスのプロビジョニングされたスループットを変更す
ることはできます。
Note
バックフィリングフェーズ中に、違反のある項目の書き込みは、成功するものと、拒否
されるものがあります。バックフィリング後に、新しいインデックスのキースキーマに
違反する、項目へのすべての書き込みは拒否されます。バックフィリングフェーズが完了
したら、Violation Detector ツールを実行して、発生した可能性のあるキーの違反を検出
し、解決することをお勧めします。詳細については、「インデックスキー違反の検出と修
正 (p. 348)」を参照してください。
リソースの割り当てフェーズとバックフィリングフェーズの進行中は、インデックスは CREATING 状
態になります。この間、DynamoDB はテーブルで読み取りオペレーションを実行します。この読み取
りオペレーションには課金されません。
インデックスの作成が完了すると、そのステータスは ACTIVE に変わります。状態が ACTIVE になる
まで、インデックスに対して Query や Scan を実行することはできません。
Note
場合によっては、DynamoDB は、インデックスキーの違反のため、テーブルからインデック
スにデータを書き込めない場合があります。これは、属性値のデータ型がインデックスキー
スキーマのデータ型と一致しない場合や、属性のサイズがインデックスキー属性の最大長を
超える場合に発生することがあります。インデックスキーの違反によって、グローバルセカ
ンダリインデックスの作成に影響はありません。ただし、インデックスが ACTIVE になる
と、違反のあるキーはインデックスに存在しません。
DynamoDB には、これらの問題を見つけて解決するためのスタンドアロンツールが用意され
ています。詳細については、「インデックスキー違反の検出と修正 (p. 348)」を参照してく
ださい。
大きなテーブルへのグローバルセカンダリインデックスの追加
グローバルセカンダリインデックスの作成に必要な時間は、次のようないくつかの要因によって異な
ります。
• テーブルのサイズ
• インデックスへの組み込みの対象になるテーブルの項目数
• インデックスに射影される属性の数
• インデックスのプロビジョニングされた書き込みキャパシティー
• インデックス作成中のメインテーブルでの書き込みアクティビティ
非常に大きなテーブルにグローバルセカンダリインデックスを追加する場合、作成プロセスが完了す
るまでに長い時間がかかることがあります。進捗状況を監視し、インデックスに十分な書き込みキャ
パシティーがあるかどうか判断するには、次の Amazon CloudWatch メトリクスを確認します。
• OnlineIndexPercentageProgress
• OnlineIndexConsumedWriteCapacity
API Version 2012-08-10
346
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
• OnlineIndexThrottleEvents
Note
DynamoDB に関連する CloudWatch メトリクスの詳細については、「DynamoDB
Metrics (p. 497)」を参照してください。
インデックスでプロビジョニングされた書き込みスループット設定が低すぎる場合、インデックスの
作成にはより多くの時間がかかります。新しいグローバルセカンダリインデックスの作成に要する時
間を短くするため、プロビジョニングされる書き込みキャパシティーを一時的に増やすことができま
す。
Note
一般的なルールとして、インデックスのプロビジョニングされる書き込みキャパシティー
を、テーブルの書き込みキャパシティーの 1.5 倍に設定することをお勧めします。これは多く
のユースケースに適した設定ですが、実際の要件はこれ以上またはこれ以下である可能性が
あります。
DynamoDB は、インデックスのバックフィリング中に内部的なシステムキャパシティーを使用して
テーブルからの読み取りを行います。これは、インデックス作成の影響を最小化し、テーブルの読み
取りキャパシティーが不足しないようにするためです。
ただし、受信書き込みアクティビティのボリュームが、インデックスのプロビジョニングされた書き
込みキャパシティーを超える可能性があります。これは、インデックスへの書き込みアクティビティ
が調整されているため、インデックス作成により多くの時間がかかるボトルネックのシナリオです。
インデックスの作成中に、インデックスの Amazon CloudWatch のメトリクスを監視して、消費され
た書き込みキャパシティーが、プロビジョニングされたキャパシティーを超えているかどうか判断す
ることをお勧めします。ボトルネックのシナリオでは、インデックスでプロビジョニングされた書き
込みキャパシティーを増やし、バックフィルフェーズ中の書き込み調整を避ける必要があります。
インデックスが作成されたら、アプリケーションの通常の使用を反映するように、プロビジョニング
された書き込みキャパシティーを設定します。
インデックス作成の変更
インデックスの作成中に、DescribeTable オペレーションを使用して、そのフェーズを判断できま
す。インデックスの説明には、現在、DynamoDB がテーブルから項目と共にインデックスを読み込
んでいるかどうかを示すためのブール属性 Backfilling が含まれます。Backfilling が true の場
合、リソースの割り当てフェーズは完了していて、インデックスはバックフィル中です。
バックフィルの進行中は、インデックス用にプロビジョニングされたスループットパラメータを更新
できます。インデックス作成を高速化するために、これを行うことがあります。作成中にインデック
スの書き込みキャパシティーを増やし、その後で減らすことができます。インデックスのプロビジョ
ニングされたスループット設定を変更するには、UpdateTable オペレーションを使用します。イン
デックスのステータスは UPDATING に変わり、Backfilling はインデックスの使用準備ができるま
で true になります。
バックフィリングフェーズ中は、テーブルの他のインデックスを追加または削除することはできませ
ん。
Note
CreateTable オペレーションの一部として作成されたインデックスについ
て、Backfilling 属性は DescribeTable 出力に表示されません。詳細については、「イン
デックス作成のフェーズ (p. 345)」を参照してください。
API Version 2012-08-10
347
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
テーブルからのグローバルセカンダリインデックスの削除
グローバルセカンダリインデックスが不要になった場合は、UpdateTable オペレーションを使用し
て削除することができます。
UpdateTable オペレーションごとに、1 つのグローバルセカンダリインデックスのみを削除できま
す。ただし、複数の UpdateTable オペレーションを同時に実行することにより、一度に複数のイン
デックスを削除できます。テーブルでこれらの UpdateTable オペレーションを一度に 5 つまで実行
できます。各オペレーションは厳密に 1 つのインデックスを削除できます。
グローバルセカンダリインデックスの削除中に、親テーブルの読み取りアクティビティまたは書き込
みアクティビティに影響はありません。削除が進行中でも、その他のインデックスでプロビジョニン
グされたスループットを変更できます。
Note
DeleteTable アクションを使用してテーブルを削除すると、そのテーブルのすべてのグロー
バルセカンダリインデックスも削除されます。
インデックスキー違反の検出と修正
グローバルセカンダリインデックス作成のバックフィルフェーズの間、DynamoDB はテーブルの各項
目を調べ、インデックスに含めるかどうかを判断します。一部の項目は、インデックスキーの違反を
引き起こすため、この対象とはならない場合があります。このような場合、項目はテーブルに残りま
すが、インデックスにはその項目に対応するエントリは作成されません。
次の場合に、インデックスキーの違反が発生します。
• 属性値とインデックスキースキーマのデータ型の間にデータ型の不一致がある。たとえ
ば、GameScores テーブルのいずれかの項目に、文字列型の値 TopScore があるとします。数値型
のパーティションキー TopScore をグローバルセカンダリインデックスに追加すると、テーブルの
項目はインデックスキーに違反します。
• テーブルの属性値が、インデックスキー属性の最大長を超えている。パーティションキーの最大長
は 2048 バイト で、ソートキーの最大長は 1024 バイト です。テーブルに対応する属性値のいずれ
かがこれらの制限を超えた場合は、テーブルの項目がインデックスキーに違反します。
インデックスキーの違反が発生した場合、バックフィルフェーズは中断なく続行しますが、違反のあ
る項目はインデックスには含まれません。バックフィルフェーズが完了すると、新しいインデックス
のキースキーマに違反する項目へのすべての書き込みは拒否されます。
インデックスキーに違反したテーブルの属性値を特定し、修正するには、Violation Detector ツールを
使用します。Violation Detector を実行するには、スキャンするテーブルの名前、グローバルセカン
ダリインデックスパーティションキーとソートキーの名前とデータ型、およびインデックスキーの違
反が見つかった場合に実行するアクションを指定する設定ファイルを作成します。Violation Detector
は、次の 2 つのモードのどちらかで実行できます。
• 検出モード - インデックスキーの違反を検出します。グローバルセカンダリインデックスでキー違
反を発生させるようなテーブル項目を報告するには、検出モードを使用します(オプションで、こ
れらのテーブル項目が見つかったらすぐに削除するようリクエストできます)。検出モードの出力
はファイルに書き込まれ、詳細な分析に使用できます。
• 修正モード - インデックスキーの違反を修正します。修正モードでは、Violation Detector は検出
モードからの出力ファイルと同じ形式の入力ファイルを読み取ります。修正モードでは入力ファイ
ルからレコードを読み取り、レコードごとに、テーブルの対応する項目を削除または更新します
(項目の更新を選択する場合は、入力ファイルを編集し、更新の適切な値を設定する必要がありま
す)。
API Version 2012-08-10
348
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
Violation Detector のダウンロードと実行
Violation Detector は、実行可能 Java アーカイブ(.jar ファイル)の形で入手で
き、Windows、Mac、または Linux コンピュータで動作します。Violation Detector には Java 1.7(ま
たはそれ以降)と Maven が必要です。
• https://github.com/awslabs/dynamodb-online-index-violation-detector
README.md ファイルの手順に従い、Maven を使用して Violation Detector をダウンロードし、イン
ストールします
Violation Detector を起動するには、ViolationDetector.java を作成したディレクトリに移動し、
次のコマンドを入力します。
java -jar ViolationDetector.jar [options]
Violation Detector コマンドラインでは、次のオプションを使用できます。
• -h | --help – Violation Detector の使用方法の概要とオプションを出力します。
• -p | --configFilePath value - Violation Detector の設定ファイルの完全修飾名。詳細について
は、「Violation Detector の設定ファイル (p. 349)」を参照してください。
• -t | --detect value - テーブルのインデックスキー違反を検出し、Violation Detector の出力
ファイルに書き込みます。このパラメータ値を keep に設定すると、キーの違反がある項目は変更
されません。値を delete に設定すると、キーの違反がある項目はテーブルから削除されます。
• -c | --correct value - 入力ファイルからインデックスキーの違反を読み取り、テーブルの項目
で修正アクションを実行します。このパラメータの値を update に設定すると、キーの違反がある
項目は、違反がない新しい値で更新されます。値を delete に設定すると、キーの違反がある項目
はテーブルから削除されます。
Violation Detector の設定ファイル
実行時に、Violation Detector ツールには設定ファイルが必要です。このファイルのパラメータによ
り、Violation Detector がアクセスできる DynamoDB リソースと、消費できるプロビジョニングされ
たスループットが決まります。次の表は、これらのパラメータを示しています。
パラメータ名
説明
必須?
awsCredentialsFile
AWS 認証情報を含むファイル
の完全修飾名。認証情報ファイ
ルは次の形式である必要があり
ます。
はい
accessKey
= access_key_id_goes_here
secretKey
= secret_key_goes_here
dynamoDBRegion
テーブルが存在する AWS リー
ジョン。例: us-west-2。
はい
tableName
スキャンする DynamoDB テー
ブルの名前。
はい
gsiHashKeyName
インデックスパーティション
キーの名前。
はい
API Version 2012-08-10
349
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
パラメータ名
説明
必須?
gsiHashKeyType
インデックスパーティション
キーのデータ型 (文字列、数
値、またはバイナリ):
はい
S | N | B
gsiRangeKeyName
インデックスソートキーの名
前。インデックスにシンプルな
プライマリキー (パーティショ
ンキー) のみがある場合は、こ
のパラメーターを指定しないで
ください。
いいえ
gsiRangeKeyType
インデックスソートキーのデー
タ型 (文字列、数値、またはバ
イナリ):
いいえ
S | N | B
インデックスにシンプルなプ
ライマリキー (パーティション
キー) のみがある場合は、この
パラメーターを指定しないでく
ださい。
出力ファイルにインデックス
キーの違反の完全な詳細を書き
込むかどうか。true(デフォ
ルト)に設定した場合、違反の
ある項目に関する完全な情報が
報告されます。false に設定
した場合、違反数のみが報告さ
れます。
いいえ
recordGsiValueInViolationRecord
違反のあるインデックスキーの
値を出力ファイルに書き込むか
どうか。true(デフォルト)
に設定した場合、キーの値が報
告されます。false に設定し
た場合、キーの値は報告されま
せん。
いいえ
recordDetails
API Version 2012-08-10
350
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
パラメータ名
説明
必須?
detectionOutputPath
Violation Detector 出力ファ
イルの完全なパス。このパラ
メータは、ローカルディレクト
リや Amazon Simple Storage
Service (Amazon S3) への書き
込みをサポートします。次に例
を示します。
いいえ
detectionOutputPath
= //local/path/
filename.csv
detectionOutputPath =
s3://bucket/filename.csv
出力ファイルの情報
が、CSV 形式(カンマ
区切り値)で表示されま
す。detectionOutputPath
を設定しない場合、
出力ファイルは
violation_detection.csv
という名前になり、現在の作
業ディレクトリに書き込まれま
す。
numOfSegments
Violation Detector がテーブル
をスキャンするときに使用する
並列スキャンセグメントの数。
デフォルト値は 1 です。この
場合、テーブルはシーケンシャ
ルにスキャンされます。値が 2
以上の場合、Violation Detector
はテーブルを多数の論理セグメ
ントと同数のスキャンスレッド
に分割します。
numOfSegments の最大設定は
4096 です。
通常、大きなテーブルの場合、
並列スキャンはシーケンシャル
スキャンより高速です。また、
テーブルが複数のパーティショ
ンにまたがるほど大きい場合、
並列スキャンでは複数のパー
ティションにわたって均等に読
み取りアクティビティが分散さ
れます。
DynamoDB での並列スキャン
の詳細については、「並列ス
キャン (p. 292)」を参照して
ください。
API Version 2012-08-10
351
いいえ
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
パラメータ名
説明
必須?
numOfViolations
出力ファイルに書き込むイ
ンデックスキーの違反の上
限。-1(デフォルト)に設定
された場合、テーブル全体が
スキャンされます。正の整数に
設定されている場合、Violation
Detector はその数の違反が発生
すると停止します。
いいえ
numOfRecords
スキャンするテーブルの項目
数。-1(デフォルト)に設定さ
れた場合、テーブル全体がス
キャンされます。正の整数に
設定されている場合、Violation
Detector はテーブルでその数の
項目をスキャンした後に停止し
ます。
いいえ
readWriteIOPSPercent
テーブルのスキャン中に消費さ
れた、プロビジョニングされた
読み込みキャパシティーユニッ
トの割合を管理します。有効
な値の範囲は 1~100 です。デ
フォルト値(25)は、Violation
Detector が、プロビジョニング
された読み取りスループットの
25% 以上を消費しないことを
意味します。
いいえ
correctionInputPath
Violation Detector の修正
入力ファイルの完全なパ
ス。Violation Detector を修正
モードで実行すると、このファ
イルのコンテンツは、テーブ
ルでグローバルセカンダリイン
デックスに違反するデータ項目
を変更または削除するために使
用されます。
いいえ
correctionInputPath
ファイルの形式
は、detectionOutputPath
ファイルの形式と同じです。こ
れにより、検出モードからの出
力を修正モードで入力として処
理することができます。
API Version 2012-08-10
352
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
パラメータ名
説明
必須?
correctionOutputPath
Violation Detector の修正出力
ファイルの完全なパス。この
ファイルは、更新エラーがある
場合にのみ作成されます。
いいえ
このパラメータは、ローカ
ルディレクトリや Amazon
Simple Storage Service
(Amazon S3) への書き込みをサ
ポートします。次に例を示しま
す。
correctionOutputPath
= //local/path/
filename.csv
correctionOutputPath =
s3://bucket/filename.csv
出力ファイルの情報
が、CSV 形式(カンマ
区切り値)で表示されま
す。correctionOutputPath
を設定しない場合、
出力ファイルは
violation_update_errors.csv
という名前になり、現在の作業
ディレクトリに書き込まれま
す。
検出
インデックスキーの違反を検出するには、Violation Detector を --detect コマンドラインオプショ
ンと共に使用します。このオプションの動作を確認するには、「テーブルの作成とサンプルデータの
ロード (p. 166)」の ProductCatalog の表を検討してください。次に示すのは、テーブル項目のリス
トです。プライマリキー(Id)および Price 属性のみが表示されています。
Id(プライマリキー)
価格
101
-2
102
20
103
200
201
100
202
200
203
300
204
400
205
500
API Version 2012-08-10
353
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
Price のすべての値は数値型です。ただし、DynamoDB はスキーマレスであるため、数値以外の
Price を持つ項目を追加することができます。たとえば、別の項目を ProductCatalog テーブルに
追加するとします。
Id(プライマリキー)
価格
999
"Hello"
テーブルには、これで合計 9 個の項目があります。
ここで、テーブルに新しいグローバルセカンダリインデックス PriceIndex を追加します。このイン
デックスのプライマリキーは、数値型のパーティションキー Price です。インデックスの作成後、8
個の項目が含まれますが、ProductCatalog テーブルには 9 個の項目があります。この不一致の理由
は、値 "Hello" は文字列型ですが、PriceIndex には数値型のプライマリキーがあることです。文
字列値はグローバルセカンダリインデックスキーに違反するので、インデックスには存在しません。
このシナリオで Violation Detector を使用するには、まず次のような設定ファイルを作成します。
# Properties file for violation detection tool configuration.
# Parameters that are not specified will use default values.
awsCredentialsFile = /home/alice/credentials.txt
dynamoDBRegion = us-west-2
tableName = ProductCatalog
gsiHashKeyName = Price
gsiHashKeyType = N
recordDetails = true
recordGsiValueInViolationRecord = true
detectionOutputPath = ./gsi_violation_check.csv
correctionInputPath = ./gsi_violation_check.csv
numOfSegments = 1
readWriteIOPSPercent = 40
次に、この例のように Violation Detector を実行します。
$
java -jar ViolationDetector.jar --configFilePath config.txt --detect keep
Violation detection started: sequential scan, Table name: ProductCatalog, GSI
name: PriceIndex
Progress: Items scanned in total: 9,
Items scanned by this thread: 9,
Violations found by this thread: 1, Violations deleted by this thread: 0
Violation detection finished: Records scanned: 9, Violations found: 1,
Violations deleted: 0, see results at: ./gsi_violation_check.csv
recordDetails 設定パラメータが true に設定されている場合、Violation Detector は次の例のよう
に、出力ファイルにそれぞれの違反の詳細を書き込みます。
Table Hash Key,GSI Hash Key Value,GSI Hash Key Violation Type,GSI Hash Key
Violation Description,GSI Hash Key Update Value(FOR USER),Delete Blank
Attributes When Updating?(Y/N)
999,"{""S"":""Hello""}",Type Violation,Expected: N Found: S,,
出力ファイルはカンマ区切り値(CSV)形式です。ファイルの最初の行はヘッダーで、インデックス
キーに違反する項目ごとに、1 つのレコードが続きます。これら違反レコードのフィールドは次のと
おりです。
API Version 2012-08-10
354
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
• Table Hash Key - テーブルの項目のパーティションキー値。
• Table Range Key - テーブルの項目のソートキーの値。
• GSI Hash Key Value - グローバルセカンダリインデックスのパーティションキー値。
• GSI Hash Key Violation Type - Type Violation または Size Violation。
• GSI Hash Key Violation Description - 違反の原因。
• GSI Hash Key Update Value(FOR USER) - 修正モードで、属性に対してユーザーが指定した新しい
値。
• GSI Range Key Value - グローバルセカンダリインデックスのソートキーの値
• GSI Range Key Violation Type - Type Violation または Size Violation。
• GSI Range Key Violation Description - 違反の原因。
• GSI Range Key Update Value(FOR USER) - 修正モードで、属性に対してユーザーが指定した新し
い値。
• Delete Blank Attribute When Updating(Y/N) - 修正モードで、テーブルの違反項目を削除する(Y)
か維持する(N)かを決定します。ただし、次のフィールドのどちらが空白である場合のみです。
• GSI Hash Key Update Value(FOR USER)
• GSI Range Key Update Value(FOR USER)
これらのうち、いずれかのフィールドが空でない場合、Delete Blank Attribute When
Updating(Y/N) の効果はありません。
Note
出力形式は、設定ファイルおよびコマンドラインツールオプションによって異なることがあ
ります。たとえば、テーブルにシンプルなプライマリキー (ソートキーなし) がある場合、出
力にソートキーフィールドは含まれません。
ファイルの違反レコードは、ソート順にならない可能性があります。
修正
インデックスキーの違反を修正するには、Violation Detector を --correct コマンドラインオプショ
ンと共に使用します。修正モードでは、Violation Detector は correctionInputPath パラメータで
指定された入力ファイルを読み取ります。このファイルは、detectionOutputPath ファイルと同じ
形式であるため、検出からの出力は修正用の入力として使用できます。
Violation Detector には、インデックスキーの違反を修正するために 2 つの異なる方法が用意されてい
ます。
• 違反の削除 - 違反のある属性値を持つテーブル項目を削除します。
• 違反の更新 - テーブル項目を更新し、違反のある属性を違反のない値で置き換えます。
どちらの場合も、修正モードの入力として検出モードの出力ファイルを使用できます。
ProductCatalog の例を引き続き使用し、違反のある項目をテーブルから削除するとします。これを
行うには、次のコマンドラインを使用します。
$
java -jar ViolationDetector.jar --configFilePath config.txt --correct
delete
この時点で、違反のある項目を削除するかどうか確認が求められます。
API Version 2012-08-10
355
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
Are you sure to delete all violations on the table?y/n
y
Confirmed, will delete violations on the table...
Violation correction from file started: Reading records from file: ./
gsi_violation_check.csv, will delete these records from table.
Violation correction from file finished: Violations delete: 1, Violations
Update: 0
これで、ProductCatalog と PriceIndex の両方に同じ数の項目の数が含まれました。
グローバルセカンダリインデックス の使用 : Java
AWS SDK for Java ドキュメント API を使用して、1 つ以上の グローバルセカンダリインデックス を
持つテーブルを作成し、テーブルのインデックスについて説明し、インデックスを使用してクエリを
実行することができます。
以下に、テーブルオペレーションの一般的な手順を示します。
1. DynamoDB クラスのインスタンスを作成します。
2. 対応するリクエストオブジェクトを作成して、オペレーションについて必要なパラメータとオプ
ションパラメータを入力します。
3. 前述のステップで作成したクライアントから提供された適切なメソッドを呼び出します。
グローバルセカンダリインデックス を使用したテーブルの作成
グローバルセカンダリインデックス は、テーブルの作成と同時に作成できます。そのために
は、CreateTable を使用して、1 つ以上の グローバルセカンダリインデックス の仕様を指定しま
す。次の Java コードスニペットでは、気象データに関する情報を格納するテーブルを作成します。
パーティションキーは Location で、ソートキーは Date です。PrecipIndex という名前の グローバル
セカンダリインデックス は、さまざまな場所の降水量データに高速アクセスできます。
次に、DynamoDB ドキュメント API を使用して、グローバルセカンダリインデックス があるテーブ
ルを作成するステップを示します。
1. DynamoDB クラスのインスタンスを作成します。
2. リクエスト情報を指定する CreateTableRequest クラスのインスタンスを作成します。
テーブル名、プライマリキー、プロビジョニング済みスループットの値を指定する必要がありま
す。グローバルセカンダリインデックスについては、インデックス名、そのプロビジョニングされ
たスループット設定、インデックスソートキーの属性定義、インデックスのキースキーマ、属性射
影を指定する必要があります。
3. リクエストオブジェクトをパラメータとして指定して、createTable メソッドを呼び出します。
次の Java コードスニペットは、前述のステップを示しています。このスニペットでは、グローバル
セカンダリインデックス(PrecipIndex)を持つテーブル(WeatherData)を作成します。インデック
スパーティションキーは Date で、そのソートキーは Precipitation です。すべてのテーブル属性がイ
ンデックスに射影されます。ユーザーは、このインデックスに対してクエリを実行して、特定の日付
の気象データを取得でき、必要に応じて、降水量別にデータを並べ替えることができます。
Precipitation はテーブルのキー属性ではないので、必須ではありません。ただし、Precipitation のない
WeatherData 項目は PrecipIndex に現れません。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
API Version 2012-08-10
356
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
// Attribute definitions
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Location")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Date")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Precipitation")
.withAttributeType("N"));
// Table key schema
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Location")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Date")
.withKeyType(KeyType.RANGE)); //Sort key
// PrecipIndex
GlobalSecondaryIndex precipIndex = new GlobalSecondaryIndex()
.withIndexName("PrecipIndex")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 10)
.withWriteCapacityUnits((long) 1))
.withProjection(new
Projection().withProjectionType(ProjectionType.ALL));
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Date")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Precipitation")
.withKeyType(KeyType.RANGE)); //Sort key
precipIndex.setKeySchema(indexKeySchema);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName("WeatherData")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 5)
.withWriteCapacityUnits((long) 1))
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(tableKeySchema)
.withGlobalSecondaryIndexes(precipIndex);
Table table = dynamoDB.createTable(createTableRequest);
System.out.println(table.getDescription());
DynamoDB がテーブルを作成し、テーブルのステータスを ACTIVE に設定するまで待機する必要があ
ります。その後は、データ項目をテーブルに書き込むことが可能になります。
API Version 2012-08-10
357
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
グローバルセカンダリインデックス のあるテーブルの説明
テーブルの グローバルセカンダリインデックス に関する情報を取得するには、DescribeTable を使
用します。各インデックスについて、名前、キースキーマ、射影された属性にアクセスできます。
次に、テーブルの グローバルセカンダリインデックス 情報にアクセスするステップを示します。
1. DynamoDB クラスのインスタンスを作成します。
2. 操作対象のインデックスを表すために、Table クラスのインスタンスを作成します。
3. Table オブジェクトで describe メソッドを呼び出します。
次の Java コードスニペットは、前述のステップを示しています。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("WeatherData");
TableDescription tableDesc = table.describe();
Iterator<GlobalSecondaryIndexDescription> gsiIter =
tableDesc.getGlobalSecondaryIndexes().iterator();
while (gsiIter.hasNext()) {
GlobalSecondaryIndexDescription gsiDesc = gsiIter.next();
System.out.println("Info for index "
+ gsiDesc.getIndexName() + ":");
Iterator<KeySchemaElement> kseIter = gsiDesc.getKeySchema().iterator();
while (kseIter.hasNext()) {
KeySchemaElement kse = kseIter.next();
System.out.printf("\t%s: %s\n", kse.getAttributeName(),
kse.getKeyType());
}
Projection projection = gsiDesc.getProjection();
System.out.println("\tThe projection type is: "
+ projection.getProjectionType());
if (projection.getProjectionType().toString().equals("INCLUDE")) {
System.out.println("\t\tThe non-key projected attributes are: "
+ projection.getNonKeyAttributes());
}
}
グローバルセカンダリインデックス のクエリ
グローバルセカンダリインデックス では、テーブルの Query を実行するのと同様の方法で、Query
を使用できます。インデックス名、インデックスパーティションキーとソートキー (存在する場合) の
クエリ基準、および返されるようにする属性を指定する必要があります。この例では、インデックス
は PrecipIndex で、そのパーティションキーは Date で、ソートキーは Precipitation です。インデック
スクエリは、特定の日付を対象に、降水量がゼロよりも大きい気象データをすべて返します。
以下に、AWS SDK for Java ドキュメント API を使用して グローバルセカンダリインデックス のクエ
リを行う手順を示します。
1.
2.
3.
4.
DynamoDB クラスのインスタンスを作成します。
操作対象のインデックスを表すために、Table クラスのインスタンスを作成します。
クエリを実行するインデックスの Index クラスのインスタンスを作成します。
Index オブジェクトで query メソッドを呼び出します。
API Version 2012-08-10
358
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
属性名 Date は、DynamoDB の予約語です。したがって、式の属性名を KeyConditionExpression
のプレースホルダーとして使用する必要があります。
次の Java コードスニペットは、前述のステップを示しています。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("WeatherData");
Index index = table.getIndex("PrecipIndex");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("#d = :v_date and Precipitation = :v_precip")
.withNameMap(new NameMap()
.with("#d", "Date"))
.withValueMap(new ValueMap()
.withString(":v_date","2013-08-10")
.withNumber(":v_precip",0));
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
System.out.println(iter.next().toJSONPretty());
}
例: AWS SDK for Java ドキュメント API を使用した グローバルセカンダリイ
ンデックス
次の Java コード例では、グローバルセカンダリインデックス の操作方法を示します。この例で
は、Issues という名前のテーブルを作成します。このテーブルは、ソフトウェア開発の単純なバグ
追跡システムで使用される可能性があります。パーティションキーは IssueId で、ソートキーは
Title です。このテーブルには 3 つの グローバルセカンダリインデックス があります。
• CreateDateIndex — パーティションキーは CreateDate で、ソートキーは IssueId です。テーブ
ルキーに加えて、属性 Description と Status がインデックスに射影されます。
• TitleIndex — パーティションキーは IssueId で、ソートキーは Title です。テーブルキー以外の
属性は、インデックスに射影されません。
• DueDateIndex — パーティションキーは DueDate で、ソートキーはありません。すべてのテーブル
属性がインデックスに射影されます。
Issues テーブルを作成した後、プログラムによって、ソフトウェアバグレポートを表すデータがテー
ブルにロードされ、グローバルセカンダリインデックス を使用してそのデータに対してクエリが実行
されます。最後に、プログラムによって Issues テーブルが削除されます。
次のサンプルをテストするための詳しい手順については、「Java コードサンプル (p. 171)」を参照し
てください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import java.util.ArrayList;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
API Version 2012-08-10
359
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Index;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.ItemCollection;
com.amazonaws.services.dynamodbv2.document.QueryOutcome;
com.amazonaws.services.dynamodbv2.document.Table;
com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
com.amazonaws.services.dynamodbv2.model.GlobalSecondaryIndex;
com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
com.amazonaws.services.dynamodbv2.model.KeyType;
com.amazonaws.services.dynamodbv2.model.Projection;
com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
public class DocumentAPIGlobalSecondaryIndexExample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
public static String tableName = "Issues";
public static void main(String[] args) throws Exception {
createTable();
loadData();
queryIndex("CreateDateIndex");
queryIndex("TitleIndex");
queryIndex("DueDateIndex");
deleteTable(tableName);
}
public static void createTable() {
// Attribute definitions
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("IssueId")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Title")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("CreateDate")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("DueDate")
.withAttributeType("S"));
// Key schema for table
API Version 2012-08-10
360
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("IssueId")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Title")
.withKeyType(KeyType.RANGE)); //Sort key
// Initial provisioned throughput settings for the indexes
ProvisionedThroughput ptIndex = new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L);
// CreateDateIndex
GlobalSecondaryIndex createDateIndex = new GlobalSecondaryIndex()
.withIndexName("CreateDateIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema( new KeySchemaElement()
.withAttributeName("CreateDate")
.withKeyType(
KeyType.HASH), //Partition key
new KeySchemaElement()
.withAttributeName("IssueId")
.withKeyType(KeyType.RANGE)) //Sort key
.withProjection(new Projection()
.withProjectionType("INCLUDE")
.withNonKeyAttributes("Description", "Status"));
// TitleIndex
GlobalSecondaryIndex titleIndex = new GlobalSecondaryIndex()
.withIndexName("TitleIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("Title")
.withKeyType(KeyType.HASH), //Partition key
new KeySchemaElement()
.withAttributeName("IssueId")
.withKeyType(KeyType.RANGE)) //Sort key
.withProjection(new Projection()
.withProjectionType("KEYS_ONLY"));
// DueDateIndex
GlobalSecondaryIndex dueDateIndex = new GlobalSecondaryIndex()
.withIndexName("DueDateIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema( new KeySchemaElement()
.withAttributeName("DueDate")
.withKeyType(KeyType.HASH)) //Partition key
.withProjection(new Projection()
.withProjectionType("ALL"));
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withProvisionedThroughput( new ProvisionedThroughput()
.withReadCapacityUnits( (long) 1)
.withWriteCapacityUnits( (long) 1))
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(tableKeySchema)
API Version 2012-08-10
361
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
.withGlobalSecondaryIndexes(createDateIndex, titleIndex,
dueDateIndex);
System.out.println("Creating table " + tableName + "...");
dynamoDB.createTable(createTableRequest);
// Wait for table to become active
System.out.println("Waiting for " + tableName + " to become
ACTIVE...");
try {
Table table = dynamoDB.getTable(tableName);
table.waitForActive();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void queryIndex(String indexName) {
Table table = dynamoDB.getTable(tableName);
System.out.println
("\n***********************************************************\n");
System.out.print("Querying index " + indexName + "...");
Index index = table.getIndex(indexName);
ItemCollection<QueryOutcome> items = null;
QuerySpec querySpec = new QuerySpec();
if (indexName == "CreateDateIndex") {
System.out.println("Issues filed on 2013-11-01");
querySpec.withKeyConditionExpression("CreateDate = :v_date and
begins_with(IssueId, :v_issue)")
.withValueMap(new ValueMap()
.withString(":v_date","2013-11-01")
.withString(":v_issue","A-"));
items = index.query(querySpec);
} else if (indexName == "TitleIndex") {
System.out.println("Compilation errors");
querySpec.withKeyConditionExpression("Title = :v_title and
begins_with(IssueId, :v_issue)")
.withValueMap(new ValueMap()
.withString(":v_title","Compilation error")
.withString(":v_issue","A-"));
items = index.query(querySpec);
} else if (indexName == "DueDateIndex") {
System.out.println("Items that are due on 2013-11-30");
querySpec.withKeyConditionExpression("DueDate = :v_date")
.withValueMap(new ValueMap()
.withString(":v_date","2013-11-30"));
items = index.query(querySpec);
} else {
System.out.println("\nNo valid index name provided");
return;
}
Iterator<Item> iterator = items.iterator();
API Version 2012-08-10
362
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
System.out.println("Query: printing results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
public static void deleteTable(String tableName) {
System.out.println("Deleting table " + tableName + "...");
Table table = dynamoDB.getTable(tableName);
table.delete();
// Wait for table to be deleted
System.out.println("Waiting for " + tableName + " to be deleted...");
try {
table.waitForDelete();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void loadData() {
System.out.println("Loading data into table " + tableName + "...");
//
//
//
//
IssueId, Title,
Description,
CreateDate, LastUpdateDate, DueDate,
Priority, Status
putItem("A-101","Compilation error",
"Can't compile Project X - bad version number. What does this
mean?",
"2013-11-01", "2013-11-02", "2013-11-10",
1, "Assigned");
putItem("A-102","Can't read data file",
"The main data file is missing, or the permissions are
incorrect",
"2013-11-01", "2013-11-04", "2013-11-30",
2, "In progress");
putItem("A-103", "Test failure",
"Functional test of Project X produces errors",
"2013-11-01", "2013-11-02", "2013-11-10",
1, "In progress");
putItem("A-104", "Compilation error",
"Variable 'messageCount' was not initialized.",
"2013-11-15", "2013-11-16", "2013-11-30",
3, "Assigned");
putItem("A-105", "Network issue",
"Can't ping IP address 127.0.0.1. Please fix this.",
API Version 2012-08-10
363
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
"2013-11-15", "2013-11-16", "2013-11-19",
5, "Assigned");
}
public static void putItem(
String issueId, String title, String description, String createDate,
String lastUpdateDate, String dueDate, Integer priority,
String status) {
Table table = dynamoDB.getTable(tableName);
Item item = new Item()
.withPrimaryKey("IssueId", issueId)
.withString("Title", title)
.withString("Description", description)
.withString("CreateDate", createDate)
.withString("LastUpdateDate", lastUpdateDate)
.withString("DueDate", dueDate)
.withNumber("Priority", priority)
.withString("Status", status);
table.putItem(item);
}
}
グローバルセカンダリインデックスes: .NET の使用
トピック
• グローバルセカンダリインデックス を使用したテーブルの作成 (p. 364)
• グローバルセカンダリインデックス のあるテーブルの説明 (p. 366)
• グローバルセカンダリインデックス のクエリ (p. 367)
• 例: AWS SDK for .NET 低レベル API を使用した グローバルセカンダリインデックス (p. 368)
AWS SDK for .NET 低レベル API を使用して、1 つ以上の グローバルセカンダリインデックス を持つ
テーブルを作成し、テーブルのインデックスについて説明し、インデックスを使用してクエリを実行
することができます。これらのオペレーションは、対応する DynamoDB オペレーションにマッピン
グされます。詳細については、『Amazon DynamoDB API Reference』を参照してください。
次に、.NET 低レベル API を使用したテーブルオペレーションの一般的なステップを示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. 対応するリクエストオブジェクトを作成して、オペレーションについて必要なパラメータとオプ
ションパラメータを入力します。
たとえば、CreateTableRequest オブジェクトを作成してテーブルと QueryRequest オブジェク
トを作成し、テーブルまたはインデックスのクエリを行います。
3. 前述のステップで作成したクライアントから提供された適切なメソッドを実行します。
グローバルセカンダリインデックス を使用したテーブルの作成
グローバルセカンダリインデックス は、テーブルの作成と同時に作成できます。そのために
は、CreateTable を使用して、1 つ以上の グローバルセカンダリインデックス の仕様を指定しま
API Version 2012-08-10
364
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
す。次の C# コードスニペットでは、気象データに関する情報を格納するテーブルを作成します。
パーティションキーは Location で、ソートキーは Date です。PrecipIndex という名前の グローバル
セカンダリインデックス は、さまざまな場所の降水量データに高速アクセスできます。
次に、.NET 低レベル API を使用して、グローバルセカンダリインデックス があるテーブルを作成す
るステップを示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. リクエスト情報を指定する CreateTableRequest クラスのインスタンスを作成します。
テーブル名、プライマリキー、プロビジョニング済みスループットの値を指定する必要がありま
す。グローバルセカンダリインデックスについては、インデックス名、そのプロビジョニングされ
たスループット設定、インデックスソートキーの属性定義、インデックスのキースキーマ、属性射
影を指定する必要があります。
3. リクエストオブジェクトをパラメータとして指定して、CreateTable メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。このスニペットでは、グローバルセ
カンダリインデックス(PrecipIndex)を持つテーブル(WeatherData)を作成します。インデックス
パーティションキーは Date で、そのソートキーは Precipitation です。すべてのテーブル属性がイン
デックスに射影されます。ユーザーは、このインデックスに対してクエリを実行して、特定の日付の
気象データを取得でき、必要に応じて、降水量別にデータを並べ替えることができます。
Precipitation はテーブルのキー属性ではないので、必須ではありません。ただし、Precipitation のない
WeatherData 項目は PrecipIndex に現れません。
client = new AmazonDynamoDBClient();
string tableName = "WeatherData";
// Attribute definitions
var attributeDefinitions = new List<AttributeDefinition>()
{
{new AttributeDefinition{
AttributeName = "Location",
AttributeType = "S"}},
{new AttributeDefinition{
AttributeName = "Date",
AttributeType = "S"}},
{new AttributeDefinition(){
AttributeName = "Precipitation",
AttributeType = "N"}
}
};
// Table key schema
var tableKeySchema = new List<KeySchemaElement>()
{
{new KeySchemaElement {
AttributeName = "Location",
KeyType = "HASH"}}, //Partition key
{new KeySchemaElement {
AttributeName = "Date",
KeyType = "RANGE"} //Sort key
}
};
// PrecipIndex
var precipIndex = new GlobalSecondaryIndex
{
API Version 2012-08-10
365
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
IndexName = "PrecipIndex",
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = (long)10,
WriteCapacityUnits = (long)1
},
Projection = new Projection { ProjectionType = "ALL" }
};
var indexKeySchema = new List<KeySchemaElement> {
{new KeySchemaElement { AttributeName = "Date", KeyType = "HASH"}}, //
Partition key
{new KeySchemaElement{AttributeName = "Precipitation",KeyType = "RANGE"}}
//Sort key
};
precipIndex.KeySchema = indexKeySchema;
CreateTableRequest createTableRequest = new CreateTableRequest
{
TableName = tableName,
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = (long)5,
WriteCapacityUnits = (long)1
},
AttributeDefinitions = attributeDefinitions,
KeySchema = tableKeySchema,
GlobalSecondaryIndexes = { precipIndex }
};
CreateTableResponse response = client.CreateTable(createTableRequest);
Console.WriteLine(response.CreateTableResult.TableDescription.TableName);
Console.WriteLine(response.CreateTableResult.TableDescription.TableStatus);
DynamoDB がテーブルを作成し、テーブルのステータスを ACTIVE に設定するまで待機する必要があ
ります。その後は、データ項目をテーブルに書き込むことが可能になります。
グローバルセカンダリインデックス のあるテーブルの説明
テーブルの グローバルセカンダリインデックス に関する情報を取得するには、DescribeTable を使
用します。各インデックスについて、名前、キースキーマ、射影された属性にアクセスできます。
次に、.NET 低レベル API を使用して、テーブルの グローバルセカンダリインデックス 情報にアクセ
スするステップを示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. リクエスト情報を指定する DescribeTableRequest クラスのインスタンスを作成します。テーブ
ル名を入力する必要があります。
3. リクエストオブジェクトをパラメータとして指定して、describeTable メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。
client = new AmazonDynamoDBClient();
string tableName = "WeatherData";
DescribeTableResponse response = client.DescribeTable(new
DescribeTableRequest { TableName = tableName});
API Version 2012-08-10
366
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
List<GlobalSecondaryIndexDescription> globalSecondaryIndexes =
response.DescribeTableResult.Table.GlobalSecondaryIndexes;
// This code snippet will work for multiple indexes, even though
// there is only one index in this example.
foreach (GlobalSecondaryIndexDescription gsiDescription in
globalSecondaryIndexes) {
Console.WriteLine("Info for index " + gsiDescription.IndexName + ":");
foreach (KeySchemaElement kse in gsiDescription.KeySchema) {
Console.WriteLine("\t" + kse.AttributeName + ": key type is " +
kse.KeyType);
}
Projection projection = gsiDescription.Projection;
Console.WriteLine("\tThe projection type is: " +
projection.ProjectionType);
if (projection.ProjectionType.ToString().Equals("INCLUDE")) {
Console.WriteLine("\t\tThe non-key projected attributes are: "
+ projection.NonKeyAttributes);
}
}
グローバルセカンダリインデックス のクエリ
グローバルセカンダリインデックス では、テーブルの Query を実行するのと同様の方法で、Query
を使用できます。インデックス名、インデックスパーティションキーとソートキー (存在する場合) の
クエリ基準、および返されるようにする属性を指定する必要があります。この例では、インデックス
は PrecipIndex で、そのパーティションキーは Date で、ソートキーは Precipitation です。インデック
スクエリは、特定の日付を対象に、降水量がゼロよりも大きい気象データをすべて返します。
次に、.NET 低レベル API を使用して グローバルセカンダリインデックス のクエリを行うステップを
示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. リクエスト情報を指定する QueryRequest クラスのインスタンスを作成します。
3. リクエストオブジェクトをパラメータとして指定して、query メソッドを実行します。
属性名 Date は、DynamoDB の予約語です。したがって、式の属性名を KeyConditionExpression
のプレースホルダーとして使用する必要があります。
次の C# コードスニペットは、前述のステップを示しています。
client = new AmazonDynamoDBClient();
QueryRequest queryRequest = new QueryRequest
{
TableName = "WeatherData",
IndexName = "PrecipIndex",
KeyConditionExpression = "#dt = :v_date and Precipitation > :v_precip",
ExpressionAttributeNames = new Dictionary<String, String> {
{"#dt", "Date"}
},
ExpressionAttributeValues = new Dictionary<string, AttributeValue> {
API Version 2012-08-10
367
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
{":v_date", new AttributeValue { S = "2013-08-01" }},
{":v_precip", new AttributeValue { N = "0" }}
},
ScanIndexForward = true
};
var result = client.Query(queryRequest);
var items = result.Items;
foreach (var currentItem in items)
{
foreach (string attr in currentItem.Keys)
{
Console.Write(attr + "---> ");
if (attr == "Precipitation")
{
Console.WriteLine(currentItem[attr].N);
}
else
{
Console.WriteLine(currentItem[attr].S);
}
}
Console.WriteLine();
}
例: AWS SDK for .NET 低レベル API を使用した グローバルセカンダリイン
デックス
次の C# コード例では、グローバルセカンダリインデックス の操作方法を示します。この例で
は、Issues という名前のテーブルを作成します。このテーブルは、ソフトウェア開発の単純なバグ追
跡システムで使用される可能性があります。パーティションキーは IssueId で、ソートキーは Title で
す。このテーブルには 3 つの グローバルセカンダリインデックス があります。
• CreateDateIndex – パーティションキーは CreateDate で、ソートキーは IssueId です。テーブル
キーに加えて、属性 Description と Status がインデックスに射影されます。
• TitleIndex – パーティションキーは IssueId で、ソートキーは Title です。テーブルキー以外の属性
は、インデックスに射影されません。
• DueDateIndex – パーティションキーは DueDate で、ソートキーはありません。すべてのテーブル
属性がインデックスに射影されます。
Issues テーブルを作成した後、プログラムによって、ソフトウェアバグレポートを表すデータがテー
ブルにロードされ、グローバルセカンダリインデックス を使用してそのデータに対してクエリが実行
されます。最後に、プログラムによって Issues テーブルが削除されます。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using
using
using
using
using
using
using
using
System;
System.Collections.Generic;
System.Linq;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DataModel;
Amazon.DynamoDBv2.DocumentModel;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
API Version 2012-08-10
368
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
using Amazon.SecurityToken;
namespace com.amazonaws.codesamples
{
class LowLevelGlobalSecondaryIndexExample
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
public static String tableName = "Issues";
public static void Main(string[] args)
{
CreateTable();
LoadData();
QueryIndex("CreateDateIndex");
QueryIndex("TitleIndex");
QueryIndex("DueDateIndex");
DeleteTable(tableName);
Console.WriteLine("To continue, press enter");
Console.Read();
}
private static void CreateTable()
{
// Attribute definitions
var attributeDefinitions = new List<AttributeDefinition>()
{
{new AttributeDefinition {AttributeName = "IssueId",
AttributeType = "S"}},
{new AttributeDefinition {AttributeName = "Title",
AttributeType = "S"}},
{new AttributeDefinition {AttributeName = "CreateDate",
AttributeType = "S"}},
{new AttributeDefinition {AttributeName = "DueDate",
AttributeType = "S"}}
};
// Key schema for table
var tableKeySchema = new List<KeySchemaElement>() {
{
new KeySchemaElement {
AttributeName= "IssueId",
KeyType = "HASH" //Partition key
}
},
{
new KeySchemaElement {
AttributeName = "Title",
KeyType = "RANGE" //Sort key
}
}
};
API Version 2012-08-10
369
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
// Initial provisioned throughput settings for the indexes
var ptIndex = new ProvisionedThroughput
{
ReadCapacityUnits = 1L,
WriteCapacityUnits = 1L
};
// CreateDateIndex
var createDateIndex = new GlobalSecondaryIndex()
{
IndexName = "CreateDateIndex",
ProvisionedThroughput = ptIndex,
KeySchema = {
new KeySchemaElement {
AttributeName = "CreateDate", KeyType = "HASH" //
Partition key
},
new KeySchemaElement {
AttributeName = "IssueId", KeyType = "RANGE" //Sort
key
}
},
Projection = new Projection
{
ProjectionType = "INCLUDE",
NonKeyAttributes = { "Description", "Status" }
}
};
// TitleIndex
var titleIndex = new GlobalSecondaryIndex()
{
IndexName = "TitleIndex",
ProvisionedThroughput = ptIndex,
KeySchema = {
new KeySchemaElement {
AttributeName = "Title", KeyType = "HASH" //
Partition key
},
new KeySchemaElement {
AttributeName = "IssueId", KeyType = "RANGE" //Sort
key
}
},
Projection = new Projection
{
ProjectionType = "KEYS_ONLY"
}
};
// DueDateIndex
var dueDateIndex = new GlobalSecondaryIndex()
{
IndexName = "DueDateIndex",
ProvisionedThroughput = ptIndex,
KeySchema = {
new KeySchemaElement {
AttributeName = "DueDate",
KeyType = "HASH" //Partition key
API Version 2012-08-10
370
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
}
},
Projection = new Projection
{
ProjectionType = "ALL"
}
};
var createTableRequest = new CreateTableRequest
{
TableName = tableName,
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = (long)1,
WriteCapacityUnits = (long)1
},
AttributeDefinitions = attributeDefinitions,
KeySchema = tableKeySchema,
GlobalSecondaryIndexes = { createDateIndex, titleIndex,
dueDateIndex }
};
Console.WriteLine("Creating table " + tableName + "...");
client.CreateTable(createTableRequest);
WaitUntilTableReady(tableName);
}
private static void LoadData()
{
Console.WriteLine("Loading data into table " + tableName +
"...");
//
//
//
//
IssueId, Title,
Description,
CreateDate, LastUpdateDate, DueDate,
Priority, Status
putItem("A-101", "Compilation error",
"Can't compile Project X - bad version number. What does this
mean?",
"2013-11-01", "2013-11-02", "2013-11-10",
1, "Assigned");
putItem("A-102", "Can't read data file",
"The main data file is missing, or the permissions are
incorrect",
"2013-11-01", "2013-11-04", "2013-11-30",
2, "In progress");
putItem("A-103", "Test failure",
"Functional test of Project X produces errors",
"2013-11-01", "2013-11-02", "2013-11-10",
1, "In progress");
API Version 2012-08-10
371
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
putItem("A-104", "Compilation error",
"Variable 'messageCount' was not initialized.",
"2013-11-15", "2013-11-16", "2013-11-30",
3, "Assigned");
putItem("A-105", "Network issue",
"Can't ping IP address 127.0.0.1. Please fix this.",
"2013-11-15", "2013-11-16", "2013-11-19",
5, "Assigned");
}
private static void putItem(
String issueId, String title,
String description,
String createDate, String lastUpdateDate, String dueDate,
Int32 priority, String status)
{
Dictionary<String, AttributeValue> item = new Dictionary<string,
AttributeValue>();
item.Add("IssueId", new AttributeValue { S = issueId });
item.Add("Title", new AttributeValue { S = title });
item.Add("Description", new AttributeValue { S = description });
item.Add("CreateDate", new AttributeValue { S = createDate });
item.Add("LastUpdateDate", new AttributeValue { S =
lastUpdateDate });
item.Add("DueDate", new AttributeValue { S = dueDate });
item.Add("Priority", new AttributeValue { N =
priority.ToString() });
item.Add("Status", new AttributeValue { S = status });
try
{
client.PutItem(new PutItemRequest
{
TableName = tableName,
Item = item
});
}
catch (Exception e)
{
Console.WriteLine(e.ToString());
}
}
private static void QueryIndex(string indexName)
{
Console.WriteLine
("\n***********************************************************\n");
Console.WriteLine("Querying index " + indexName + "...");
QueryRequest queryRequest = new QueryRequest
{
TableName = tableName,
IndexName = indexName,
API Version 2012-08-10
372
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
ScanIndexForward = true
};
String keyConditionExpression;
Dictionary<string, AttributeValue> expressionAttributeValues =
new Dictionary<string, AttributeValue>();
if (indexName == "CreateDateIndex")
{
Console.WriteLine("Issues filed on 2013-11-01\n");
keyConditionExpression = "CreateDate = :v_date and
begins_with(IssueId, :v_issue)";
expressionAttributeValues.Add(":v_date", new AttributeValue
{ S = "2013-11-01" });
expressionAttributeValues.Add(":v_issue", new AttributeValue
{ S = "A-" });
}
else if (indexName == "TitleIndex")
{
Console.WriteLine("Compilation errors\n");
keyConditionExpression = "Title = :v_title and
begins_with(IssueId, :v_issue)";
expressionAttributeValues.Add(":v_title", new AttributeValue
{ S = "Compilation error" });
expressionAttributeValues.Add(":v_issue", new AttributeValue
{ S = "A-" });
// Select
queryRequest.Select = "ALL_PROJECTED_ATTRIBUTES";
}
else if (indexName == "DueDateIndex")
{
Console.WriteLine("Items that are due on 2013-11-30\n");
keyConditionExpression = "DueDate = :v_date";
expressionAttributeValues.Add(":v_date", new AttributeValue
{ S = "2013-11-30" });
// Select
queryRequest.Select = "ALL_PROJECTED_ATTRIBUTES";
}
else
{
Console.WriteLine("\nNo valid index name provided");
return;
}
queryRequest.KeyConditionExpression = keyConditionExpression;
queryRequest.ExpressionAttributeValues =
expressionAttributeValues;
var result = client.Query(queryRequest);
var items = result.Items;
API Version 2012-08-10
373
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
foreach (var currentItem in items)
{
foreach (string attr in currentItem.Keys)
{
if (attr == "Priority")
{
Console.WriteLine(attr + "---> " +
currentItem[attr].N);
}
else
{
Console.WriteLine(attr + "---> " +
currentItem[attr].S);
}
}
Console.WriteLine();
}
}
private static void DeleteTable(string tableName)
{
Console.WriteLine("Deleting table " + tableName + "...");
client.DeleteTable(new DeleteTableRequest { TableName =
tableName });
WaitForTableToBeDeleted(tableName);
}
private static void WaitUntilTableReady(string tableName)
{
string status = null;
// Let us wait until table is created. Call DescribeTable.
do
{
System.Threading.Thread.Sleep(5000); // Wait 5 seconds.
try
{
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
status = res.Table.TableStatus;
}
catch (ResourceNotFoundException)
{
// DescribeTable is eventually consistent. So you might
// get resource not found. So we handle the potential
exception.
}
} while (status != "ACTIVE");
}
private static void WaitForTableToBeDeleted(string tableName)
API Version 2012-08-10
374
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
{
bool tablePresent = true;
while (tablePresent)
{
System.Threading.Thread.Sleep(5000); // Wait 5 seconds.
try
{
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
}
catch (ResourceNotFoundException)
{
tablePresent = false;
}
}
}
}
}
グローバルセカンダリインデックス の操作 : PHP
トピック
• グローバルセカンダリインデックス を使用したテーブルの作成 (p. 375)
• グローバルセカンダリインデックス のあるテーブルの説明 (p. 377)
• グローバルセカンダリインデックス のクエリ (p. 377)
• 例: AWS SDK for PHP 低レベル API を使用した グローバルセカンダリインデックス (p. 378)
AWS SDK for PHP 低レベル API を使用して、1 つ以上の グローバルセカンダリインデックス を持つ
テーブルを作成し、テーブルのインデックスについて説明し、インデックスを使用してクエリを実行
することができます。これらのオペレーションは、対応する DynamoDB アクションにマッピングさ
れます。 詳細については、「PHP コードサンプル (p. 175)」を参照してください。
以下に、AWS SDK for PHP を使用したテーブルオペレーションの一般的な手順を示します。
1. DynamoDB クライアントのインスタンスを作成します。
2. オプションのパラメーターを含む DynamoDB オペレーションのパラメーターを指定します。
3. DynamoDB からの応答をアプリケーションのローカル変数にロードします。
グローバルセカンダリインデックス を使用したテーブルの作成
グローバルセカンダリインデックス は、テーブルの作成と同時に作成できます。そのために
は、CreateTable を使用して、1 つ以上の グローバルセカンダリインデックス の仕様を指定しま
す。次の PHP コードスニペットでは、気象データに関する情報を格納するテーブルを作成します。
パーティションキーは Location で、ソートキーは Date です。PrecipIndex という名前の グローバル
セカンダリインデックス は、さまざまな場所の降水量データに高速アクセスできます。
API Version 2012-08-10
375
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
次のコードスニペットでは、グローバルセカンダリインデックス (PrecipIndex) を持つテーブル
(WeatherData) を作成します。インデックスパーティションキーは Date で、そのソートキーは
Precipitation です。すべてのテーブル属性がインデックスに射影されます。ユーザーは、このイン
デックスに対してクエリを実行して、特定の日付の気象データを取得でき、必要に応じて、降水量別
にデータを並べ替えることができます。
Precipitation はテーブルのキー属性ではないので、必須ではありません。ただし、Precipitation のない
WeatherData 項目は PrecipIndex に現れません。
require 'vendor/autoload.php';
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'WeatherData';
$result = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[ 'AttributeName' => 'Location', 'AttributeType' => 'S' ],
[ 'AttributeName' => 'Date', 'AttributeType' => 'S' ],
[ 'AttributeName' => 'Precipitation', 'AttributeType' => 'N' ]
],
'KeySchema' => [
[ 'AttributeName' => 'Location', 'KeyType' => 'HASH' ], //Partition
key
[ 'AttributeName' => 'Date', 'KeyType' => 'RANGE' ] //Sort key
],
'GlobalSecondaryIndexes' => [
[
'IndexName' => 'PrecipIndex',
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 5,
'WriteCapacityUnits' => 5
],
'KeySchema' => [
[ 'AttributeName' => 'Date', 'KeyType' => 'HASH' ], //
Partition key
[ 'AttributeName' => 'Precipitation', 'KeyType' => 'RANGE' ]
//Sort key
],
'Projection' => [ 'ProjectionType' => 'ALL' ]
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 5,
'WriteCapacityUnits' => 5
]
]);
DynamoDB がテーブルを作成し、テーブルのステータスを ACTIVE に設定するまで待機する必要があ
ります。その後は、データ項目をテーブルに書き込むことが可能になります。
API Version 2012-08-10
376
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
グローバルセカンダリインデックス のあるテーブルの説明
テーブルの グローバルセカンダリインデックス に関する情報を取得するには、DescribeTable を使
用します。各インデックスについて、名前、キースキーマ、射影された属性にアクセスできます。
$tableName = 'WeatherData';
$result = $dynamodb->describeTable([
'TableName' => $tableName
]);
foreach ($result['Table']['GlobalSecondaryIndexes'] as $key => $value) {
echo "Info for index " . $value['IndexName'] . ":\n";
foreach ($value['KeySchema'] as $attribute => $keyschema) {
echo "\t" .
$value['KeySchema'][$attribute]['AttributeName'] . ': ' .
$value['KeySchema'][$attribute]['KeyType'] . "\n";
}
echo "\tThe projection type is: " . $value['Projection']
['ProjectionType'] . "\n";
}
グローバルセカンダリインデックス のクエリ
グローバルセカンダリインデックス では、テーブルの Query を実行するのと同様の方法で、Query
を使用できます。インデックス名、インデックスパーティションキーとソートキー (存在する場合) の
クエリ基準、および返されるようにする属性を指定する必要があります。この例では、インデックス
は PrecipIndex で、そのパーティションキーは Date で、ソートキーは Precipitation です。インデック
スクエリは、特定の日付を対象に、降水量がゼロよりも大きい気象データをすべて返します。
属性名 Date は、DynamoDB の予約語です。したがって、式の属性名を KeyConditionExpression
のプレースホルダーとして使用する必要があります。
$tableName = 'WeatherData';
$response = $dynamodb->query([
'TableName' => $tableName,
'IndexName' => 'PrecipIndex',
'KeyConditionExpression' => '#dt = :v_dt and Precipitation > :v_precip',
'ExpressionAttributeNames' => ['#dt' => 'Date'],
'ExpressionAttributeValues' => [
':v_dt' => ['S' => '2014-08-01'],
':v_precip' => ['N' => '0']
],
'Select' => 'ALL_ATTRIBUTES',
'ScanIndexForward' => true,
]);
foreach ($response['Items'] as $item) {
echo "Date ---> " . $item['Date']['S'] . "\n";
echo "Location ---> " . $item['Location']['S'] . "\n";
echo "Precipitation ---> " . $item['Precipitation']['N'] . "\n";
echo "\n";
}
API Version 2012-08-10
377
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
例: AWS SDK for PHP 低レベル API を使用した グローバルセカンダリイン
デックス
次の PHP コード例では、グローバルセカンダリインデックス の操作方法を示します。この例で
は、Issues という名前のテーブルを作成します。このテーブルは、ソフトウェア開発の単純なバグ追
跡システムで使用される可能性があります。パーティションキーは IssueId で、ソートキーは Title で
す。このテーブルには 3 つの グローバルセカンダリインデックス があります。
• CreateDateIndex – パーティションキーは CreateDate で、ソートキーは IssueId です。テーブル
キーに加えて、属性 Description と Status がインデックスに射影されます。
• TitleIndex – パーティションキーは IssueId で、ソートキーは Title です。テーブルキー以外の属性
は、インデックスに射影されません。
• DueDateIndex – パーティションキーは DueDate で、ソートキーはありません。すべてのテーブル
属性がインデックスに射影されます。
Issues テーブルを作成した後、プログラムによって、ソフトウェアバグレポートを表すデータがテー
ブルにロードされ、グローバルセカンダリインデックス を使用してそのデータに対してクエリが実行
されます。最後に、プログラムによって Issues テーブルが削除されます。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'Issues';
echo "# Creating table $tableName...\n";
try {
$response = $dynamodb->createTable ( [
'TableName' => $tableName,
'AttributeDefinitions' => [
[ 'AttributeName' => 'IssueId', 'AttributeType' => 'S' ],
[ 'AttributeName' => 'Title', 'AttributeType' => 'S' ],
[ 'AttributeName' => 'CreateDate', 'AttributeType' => 'S' ],
[ 'AttributeName' => 'DueDate', 'AttributeType' => 'S' ]
],
'KeySchema' => [
[ 'AttributeName' => 'IssueId', 'KeyType' => 'HASH' ], //
Partition key
[ 'AttributeName' => 'Title', 'KeyType' => 'RANGE' ] //Sort key
],
'GlobalSecondaryIndexes' => [
[
'IndexName' => 'CreateDateIndex',
'KeySchema' => [
[ 'AttributeName' => 'CreateDate', 'KeyType' => 'HASH' ],
//Partition key
API Version 2012-08-10
378
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
[ 'AttributeName' => 'IssueId', 'KeyType' => 'RANGE' ]
//Sort key
],
'Projection' => [
'ProjectionType' => 'INCLUDE',
'NonKeyAttributes' => [ 'Description', 'Status' ]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 1, 'WriteCapacityUnits' => 1
]
],
[
'IndexName' => 'TitleIndex',
'KeySchema' => [
[ 'AttributeName' => 'Title', 'KeyType' => 'HASH' ], //
Partition key
[ 'AttributeName' => 'IssueId', 'KeyType' => 'RANGE' ]
//Sort key
],
'Projection' => [ 'ProjectionType' => 'KEYS_ONLY' ],
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 1, 'WriteCapacityUnits' => 1
]
],
[
'IndexName' => 'DueDateIndex',
'KeySchema' => [
[ 'AttributeName' => 'DueDate', 'KeyType' => 'HASH' ]
Partition key
],
'Projection' => [
'ProjectionType' => 'ALL'
],
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 1, 'WriteCapacityUnits' => 1 ]
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 1, 'WriteCapacityUnits' => 1 ]
]);
echo " Waiting for table $tableName to be created.\n";
$dynamodb->waitUntil('TableExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
]);
echo " Table $tableName has been created.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to create table $tableName\n");
}
// ########################################
// Add items to the table
API Version 2012-08-10
379
//
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
echo "# Loading data into $tableName...\n";
$response = $dynamodb->putItem ([
'TableName' => $tableName,
'Item' => [
'IssueId' => [ 'S' => 'A-101' ],
'Title' => [ 'S' => 'Compilation error' ],
'Description' => [
'S' => 'Can\'t compile Project X - bad version number. What does
this mean?' ],
'CreateDate' => [ 'S' => '2014-11-01' ],
'LastUpdateDate' => [ 'S' => '2014-11-02' ],
'DueDate' => [ 'S' => '2014-11-10' ],
'Priority' => [ 'N' => '1' ],
'Status' => [ 'S' => 'Assigned' ]
]
]);
$response = $dynamodb->putItem ([
'TableName' => $tableName,
'Item' => [
'IssueId' => [ 'S' => 'A-102' ],
'Title' => [ 'S' => 'Can\'t read data file' ],
'Description' => [
'S' => 'The main data file is missing, or the permissions are
incorrect' ],
'CreateDate' => [ 'S' => '2014-11-01' ],
'LastUpdateDate' => [ 'S' => '2014-11-04' ],
'DueDate' => [ 'S' => '2014-11-30' ],
'Priority' => [ 'N' => '2' ],
'Status' => [ 'S' => 'In progress' ]
]
]);
$response = $dynamodb->putItem ([
'TableName' => $tableName,
'Item' => [
'IssueId' => [ 'S' => 'A-103' ],
'Title' => [ 'S' => 'Test failure' ],
'Description' => [
'S' => 'Functional test of Project X produces errors.' ],
'CreateDate' => [ 'S' => '2014-11-01' ],
'LastUpdateDate' => [ 'S' => '2014-11-02' ],
'DueDate' => [ 'S' => '2014-11-10' ],
'Priority' => [ 'N' => '1' ],
'Status' => [ 'S' => 'In progress' ]
]
]);
$response = $dynamodb->putItem ([
'TableName' => $tableName,
'Item' => [
'IssueId' => [ 'S' => 'A-104' ],
'Title' => [ 'S' => 'Compilation error' ],
'Description' => [
'S' => 'Variable "messageCount" was not initialized.' ],
'CreateDate' => [ 'S' => '2014-11-15' ],
'LastUpdateDate' => [ 'S' => '2014-11-16' ],
'DueDate' => [ 'S' => '2014-11-30' ],
API Version 2012-08-10
380
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
'Priority' => [ 'N' => '3' ],
'Status' => [ 'S' => 'Assigned' ]
]
]);
$response = $dynamodb->putItem ([
'TableName' => $tableName,
'Item' => [
'IssueId' => [ 'S' => 'A-105' ],
'Title' => [ 'S' => 'Network issue' ],
'Description' => [
'S' => 'Can\'t ping IP address 127.0.0.1. Please fix this.' ],
'CreateDate' => [ 'S' => '2014-11-15' ],
'LastUpdateDate' => [ 'S' => '2014-11-16' ],
'DueDate' => [ 'S' => '2014-11-19' ],
'Priority' => [ 'N' => '5' ],
'Status' => [ 'S' => 'Assigned' ]
]
]);
// ########################################
// Query for issues filed on 2014-11-01
$response = $dynamodb->query ( [
'TableName' => $tableName,
'IndexName' => 'CreateDateIndex',
'KeyConditionExpression' =>
'CreateDate = :v_dt and begins_with(IssueId, :v_issue)',
'ExpressionAttributeValues' => [
':v_dt' => ['S' => '2014-11-01'],
':v_issue' => ['S' => 'A-']
]
]);
echo '# Query for issues filed on 2014-11-01:' . "\n";
foreach ( $response ['Items'] as $item ) {
echo ' - ' . $item ['CreateDate'] ['S'] .
' ' . $item ['IssueId'] ['S'] .
' ' . $item ['Description'] ['S'] .
' ' . $item ['Status'] ['S'] .
"\n";
}
echo "\n";
// ########################################
// Query for issues that are 'Compilation errors'
$response = $dynamodb->query ( [
'TableName' => $tableName,
'IndexName' => 'TitleIndex',
'KeyConditionExpression' =>
'Title = :v_title and IssueId >= :v_issue',
'ExpressionAttributeValues' => [
':v_title' => ['S' => 'Compilation error'],
':v_issue' => ['S' => 'A-']
]
]);
API Version 2012-08-10
381
Amazon DynamoDB 開発者ガイド
グローバルセカンダリインデックス
echo '# Query for issues that are compilation errors: ' . "\n";
foreach ( $response ['Items'] as $item ) {
echo ' - ' . $item ['Title'] ['S'] .
' ' . $item ['IssueId'] ['S'] .
"\n";
}
echo "\n";
// ########################################
// Query for items that are due on 2014-11-30
$response = $dynamodb->query ( [
'TableName' => $tableName,
'IndexName' => 'DueDateIndex',
'KeyConditionExpression' => 'DueDate = :v_dt',
'ExpressionAttributeValues' => [
':v_dt' => ['S' => '2014-11-30']
]
]);
echo "# Querying for items that are due on 2014-11-30:\n";
foreach ( $response ['Items'] as $item ) {
echo ' - ' . $item ['DueDate'] ['S'] .
' ' . $item ['IssueId'] ['S'] .
' ' . $item ['Title'] ['S'] .
' ' . $item ['Description'] ['S'] .
' ' . $item ['CreateDate'] ['S'] .
' ' . $item ['LastUpdateDate'] ['S'] .
' ' . $item ['Priority'] ['N'] .
' ' . $item ['Status'] ['S'] . "\n";
}
echo "\n";
// ########################################
// Delete the table
try {
echo "# Deleting table $tableName...\n";
$dynamodb->deleteTable(['TableName' => $tableName]);
echo " Waiting for table $tableName to be deleted.\n";
$dynamodb->waitUntil('TableNotExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
]);
echo "
Table $tableName has been deleted.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to delete table $tableName\n");
}
API Version 2012-08-10
382
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
?>
ローカルセカンダリインデックス
トピック
• 属性の射影 (p. 385)
• ローカルセカンダリインデックス の作成 (p. 387)
• ローカルセカンダリインデックス のクエリ (p. 387)
• ローカルセカンダリインデックスの実行 (p. 388)
• 項目の書き込みと ローカルセカンダリインデックス (p. 389)
• プロビジョニングされたスループットに関する考慮事項(ローカルセカンダリインデック
ス) (p. 389)
• ローカルセカンダリインデックス のストレージに関する考慮事項 (p. 391)
• 項目コレクション (p. 391)
• ローカルセカンダリインデックス の使用 : Java (p. 394)
• ローカルセカンダリインデックスes: .NET の使用 (p. 405)
• ローカルセカンダリインデックス の操作 : PHP (p. 418)
ベーステーブルのプライマリキーを使用してデータのクエリを実行する必要があるのは、一部のアプ
リケーションだけですが、代替のソートキーが役に立つ場合があります。アプリケーションにソート
キーという選択肢を提供するために、テーブルに 1 つ以上のlocal secondary indexを作成して、それ
らのインデックスに対して Query または Scan リクエストを実行できます。
たとえば、テーブルの作成とサンプルデータのロード (p. 166) で定義した Thread テーブルがありま
す。このテーブルは、AWS フォーラムのようなアプリケーションで役立ちます。次の図は、テーブル
内の項目の構成を示しています。一部表示されていない属性もあります。
DynamoDB には、同じパーティションキー値を持つすべての項目が隣接して保存されます。この
例では、特定の ForumName を指定すると、Query オペレーションはそのフォーラムのすべての
スレッドをすばやく見つけることができます。同じパーティションキー値を持つ項目のグループで
は、項目がソートキーの値によって並べ替えられます。クエリにソートキー (Subject) も指定した場
API Version 2012-08-10
383
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
合、DynamoDB では、返された結果をすばやく絞り込むことができます。たとえば、"S3" フォーラム
の中から、Subject の先頭が文字 "a" であるすべてのスレッドを返すことができます。
リクエストによっては、より複雑なデータアクセスパターンが要求される場合があります。以下に例
を示します。
• ビューと返信の数が最も多いのはどのフォーラムか?
• 特定のフォーラムでメッセージ数が最も多いのはどのスレッドか?
• 特定の期間中に特定のフォーラムに投稿されたスレッド数は?
これらの質問に答えるには、Query アクションでは十分ではありません。代わりに、テーブル全体の
Scan を実行する必要があります。膨大な数の項目があるテーブルでは、これにより、プロビジョニン
グされた読み込みスループットが大量に消費されることになり、完了するまでに長時間かかります。
ただし、Replies や LastPostDateTime などの非キー属性に 1 つ以上のlocal secondary indexを指定す
ることができます。
local secondary index は特定のパーティションキー値の代替ソートキーを維持します。またlocal
secondary indexでは、そのベーステーブルの一部またはすべての属性のコピーが保持されます。テー
ブルを作成する際に、local secondary indexに射影する属性を指定します。local secondary indexの
データは、ベーステーブルと同じパーティションキーと、異なるソートキーで構成されます。これに
より、この異なるディメンションにわたってデータ項目に効率的にアクセスできます。クエリまたは
スキャンの柔軟性を向上するために、テーブルごとに最大 5 つのlocal secondary indexを作成できま
す。
たとえば、あるアプリケーションで過去 3 か月以内に投稿されたすべてのスレッドを検索する必要
があるとします。local secondary index がない場合は、アプリケーションでは Thread テーブル全体
の Scan を実行して、指定された時間枠から外れた投稿を破棄する必要があります。local secondary
indexがあれば、Query オペレーションでは LastPostDateTime をソートキーとして使用して、データ
をすばやく特定することができます。
次の図は、LastPostIndex という名前の local secondary index を示しています。パーティションキー
は Thread テーブルのパーティションキーと同じですが、ソートキーは LastPostDateTime です。
local secondary index は、すべて次の条件を満たす必要があります。
• パーティションキーはそのベーステーブルのパーティションキーと同じである。
API Version 2012-08-10
384
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
• ソートキーは完全に 1 つのスカラー属性で構成されている。
• ベーステーブルのソートキーがインデックスに射影され、非キー属性として機能する。
この例では、パーティションキーは ForumName で、local secondary indexのソートキーは
LastPostDateTime です。さらに、ベーステーブルのソートキーの値 (この例では Subject) がイン
デックスに射影されますが、その値はインデックスキーの一部ではありません。アプリケーション
が ForumName と LastPostDateTime に基づくリストを必要とする場合は、LastPostIndex に対して
Query リクエストを実行できます。クエリ結果は LastPostDateTime によって並べ替えられ、昇順ま
たは降順で返すことができます。このクエリは、特定の時間枠内に LastPostDateTime がある項目だ
けを返すなどのキー条件を適用することもできます。
すべてのlocal secondary indexには、そのベーステーブルからのパーティションキーとソートキーが
自動的に格納されます。必要に応じて、非キー属性をインデックスに射影できます。インデックスの
クエリを行うと、DynamoDB ではこれらの射影された属性を効率的に取り出すことができます。local
secondary index のクエリを行うと、クエリでは、インデックスに射影されていない属性も取り出すこ
とができます。DynamoDB では、これらの属性をベーステーブルから自動的にフェッチしますが、レ
イテンシーが大きくなり、プロビジョニングされたスループットコストが高くなります。
任意のlocal secondary indexについて、異なるパーティションキーの値ごとに最大 10 GB のデータを
保存できます。この数字には、ベーステーブル内のすべての項目に加えて、同じパーティションキー
の値を持つインデックス内のすべての項目も含まれています。詳細については、「項目コレクショ
ン (p. 391)」を参照してください。
属性の射影
LastPostIndex があるので、アプリケーションは、ForumName と LastPostDateTime をクエリ基準と
して使用できますが、追加の属性を取り出すには、DynamoDB は、Thread テーブルに対して追加の
読み込みオペレーションを実行する必要があります。このような追加の読み込みをフェッチと言い、
それによってクエリにプロビジョニングするスループットの合計量が増加することがあります。
ウェブページに "S3" 内のすべてのスレッドと各スレッドの返信のリストを表示し、最新の返信の最後
の返信日時で並べ替えるとします。このリストに入力するには、次の属性が必要になります。
• 件名
• Replies
• LastPostDateTime
このデータのクエリを最も効率的に行い、フェッチオペレーションを回避するには、次の図に示すよ
うに、local secondary indexにテーブルからの Replies 属性を射影します。
API Version 2012-08-10
385
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
射影は、テーブルからセカンダリインデックスにコピーされる属性セットです。テーブルのパーティ
ションキーとソートキーは必ずインデックスに射影されます。アプリケーションのクエリ要件をサ
ポートするために、他の属性を射影することができます。インデックスのクエリを行うと、Amazon
DynamoDB は射影内の属性に、それらの属性が独立したテーブル内にあるかのようにアクセスできま
す。
セカンダリインデックス を作成する場合は、インデックスに射影される属性を指定する必要がありま
す。DynamoDB にはこのための 3 つのオプションが用意されています。
• KEYS_ONLY – インデックスの各項目は、テーブルのパーティションキーとソートキー値、および
インデックスキー値のみで構成されます。KEYS_ONLY オプションを使用すると、セカンダリイン
デックス は最小になります。
• INCLUDE – KEYS_ONLY の属性に加えて、セカンダリインデックス にその他の非キー属性が含まれ
るように指定できます。
• ALL – セカンダリインデックス にソーステーブルのすべての属性が含まれます。テーブルの全デー
タがインデックスで複製されるため、ALL の射影により、セカンダリインデックス は最大になりま
す。
前の図では、非キー属性の Replies が LastPostIndex に射影されています。アプリケーション
では Thread テーブル全体ではなく LastPostIndex に対するクエリを実行し、ウェブページに
Subject、Replies、LastPostDateTime を表示することができます。他の非キー属性がリクエストされ
た場合には、DynamoDB はそれらの属性を Thread テーブルからフェッチする必要があります。
アプリケーションの観点から見ると、ベーステーブルから追加の属性をフェッチする処理は、自動
的で透過的なので、アプリケーションロジックを書き直す必要はありません。ただし、このような
フェッチによって、local secondary index を使用することで得られるパフォーマンスの利点が大幅に
小さくなる可能性があります。
local secondary index に射影する属性を選択する場合には、プロビジョニングされるスループットコ
ストとストレージコストのトレードオフを考慮する必要があります。
• ごく一部の属性だけに最小のレイテンシーでアクセスする必要がある場合は、それらの属性だけ
を local secondary index に射影することを検討してください。インデックスが小さいほど少ないコ
ストで格納でき、書き込みコストも低くなります。まれにしかフェッチされない属性がある場合に
は、それらの属性を格納するコストよりも、プロビジョニングされるスループットのコストのほう
が長期的に大きくなる可能性があります。
API Version 2012-08-10
386
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
• アプリケーションが非キー属性に頻繁にアクセスする場合には、それらの属性を local secondary
index に射影すると効果的です。local secondary index の追加のストレージコストは、頻繁なテーブ
ルスキャンを実行するコストを相殺します。
• ほとんどの非キー属性に頻繁にアクセスする場合は、それらの属性、さらにはベーステーブル全体
をlocal secondary indexに射影することができます。それによってフェッチが不要になるため、柔軟
性が最大になり、プロビジョニングされるスループットが最小限になります。ただしストレージコ
ストが増加し、すべての属性を射影する場合には 2 倍にまで増大します。
• アプリケーションでテーブルのクエリを頻繁に行う必要がなく、テーブル内のデータに対する
書き込みや更新が多数になる場合は、KEYS_ONLY を射影することを検討してください。local
secondary index のサイズは最小になりますが、クエリに必要なサイズは確保されます。
ローカルセカンダリインデックス の作成
テーブルで 1 つ以上の local secondary index を作成するには、CreateTable オペレーションの
LocalSecondaryIndexes パラメータを使用します。テーブルの ローカルセカンダリインデックス
は、テーブルが作成された時点で作成されます。テーブルを削除すると、そのテーブルにある local
secondary index も削除されます。
local secondary indexのソートキーにとなる 1 つの非キー属性を指定する必要があります。選択し
た属性は、スカラー文字列、数値、またはバイナリである必要があります。他のスカラー型、ド
キュメント型、およびセット型は使用できません。データ型の詳細なリストについては、「データ
型 (p. 12)」を参照してください。
Important
local secondary indexがあるテーブルには、パーティションキーの値ごとに 10 GB のサイズ
制限があります。local secondary indexがあるテーブルには、1 つのパーティションキー値
の合計サイズが 10 GB を超えない限り、任意の数の項目を保存できます。詳細については、
「項目コレクションのサイズ制限 (p. 393)」を参照してください。
local secondary index には、任意のデータ型の属性を射影できます。これには、スカラー、ドキュメ
ント、およびセットが含まれます。データ型の詳細なリストについては、「データ型 (p. 12)」を参照
してください。
ローカルセカンダリインデックス のクエリ
DynamoDB テーブルでは、各項目のパーティションキーとソートキーを結合した値が一意である必要
があります。ただし、local secondary indexでは、ソートキーの値は、特定のパーティションキーの値
に対して一意である必要がありません。local secondary indexにソートキーの値が同じである複数の項
目がある場合、Query オペレーションは、同じパーティションキーの値を持つすべての項目を返しま
す。レスポンスでは、一致する項目は特定の順序で返されません。
結果整合性のある読み込みまたは強力な整合性のある読み込みを使用して、local secondary index
のクエリを行うことができます。必要な整合性のタイプを指定するには、Query オペレーションの
ConsistentRead パラメータを使用します。local secondary index からの強力な整合性のある読み込み
では、常に最新の更新された値が返されます。クエリがベーステーブルからさらに属性をフェッチす
る必要がある場合、それらの属性はインデックスについて整合性があることになります。
API Version 2012-08-10
387
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
Example
特定のフォーラムのディスカッションスレッドにあるデータをリクエストする Query から返される次
のデータを考えてみます。
{
"TableName": "Thread",
"IndexName": "LastPostIndex",
"ConsistentRead": false,
"ProjectionExpression": "Subject, LastPostDateTime, Replies, Tags",
"KeyConditionExpression":
"ForumName = :v_forum and LastPostDateTime between :v_start
and :v_end",
"ExpressionAttributeValues": {
":v_start": {"S": "2015-08-31T00:00:00.000Z"},
":v_end": {"S": "2015-11-31T00:00:00.000Z"},
":v_forum": {"S": "EC2"}
}
}
このクエリでは次のようになっています。
• DynamoDB が ForumName パーティションキーを使用して LastPostIndex にアクセスし、「EC2」
のインデックス項目を特定します。このキーを持つすべてのインデックス項目が、すばやく取り出
せるように隣り合わせに格納されます。
• このフォーラム内で、DynamoDB はインデックスを使用して、指定された LastPostDateTime 条件
に一致するキーを検索します。
• Replies 属性はインデックスに射影されているため、DynamoDB は追加でプロビジョニングされた
スループットを消費することなく、この属性を取り出すことができます。
• Tags 属性はインデックスに射影されていないため、DynamoDB は Thread テーブルにアクセスして
この属性をフェッチする必要があります。
• 結果が、LastPostDateTime によって並べ替えられ、返されます。インデックスのエントリはまず
パーティションキーの値によって、次にソートキーの値によって並べ替えられ、保存される順序
で Query から返されます(ScanIndexForward パラメータを使用すると、結果が降順で返されま
す)。
local secondary indexには Tags 属性が射影されていないため、DynamoDB は、読み込みキャパシ
ティーユニットをさらに消費して、ベーステーブルからこの属性をフェッチする必要があります。こ
のクエリを頻繁に実行する必要がある場合は、Tags 属性を LastPostIndex に射影して、ベーステーブ
ルからフェッチされないようにする必要があります。ただし、Tags 属性をまれにしか使用しない場合
は、Tags 属性をインデックスに射影するためにストレージを追加することが有効でない可能性があり
ます。
ローカルセカンダリインデックスの実行
Scan を使用して、local secondary index からすべてのデータを取得できます。 リクエストにはベー
ステーブル名とインデックス名を指定する必要があります。Scan では、DynamoDB はインデック
スのすべてのデータを読み取り、それをアプリケーションに返します。また、データの一部のみを返
し、残りのデータを破棄するようにリクエストすることもできます。これを行うには、Scan API の
FilterExpression パラメータを使用します。詳細については、「クエリまたはスキャンからの結
果のフィルタリング (p. 289)」を参照してください。
API Version 2012-08-10
388
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
項目の書き込みと ローカルセカンダリインデックス
DynamoDB によって、すべてのlocal secondary indexがそれぞれのベーステーブルと自動的に同期さ
れます。アプリケーションがインデックスに直接書き込むことはありません。ただし、DynamoDB で
これらのインデックスがどのように維持されるかを理解することは重要です。
local secondary indexを作成する場合は、インデックスのソートキーになる属性を指定します。その
属性のデータ型も指定します。つまり、ベーステーブルに項目を書き込むとき、その項目にインデッ
クスキー属性が定義されている場合は、その型がインデックスキースキーマのデータ型に一致する
必要があります。LastPostIndex の場合、インデックス内の LastPostDateTime ソートキーは、文字
列データ型として定義されています。Thread テーブルに項目を追加するときに、LastPostDateTime
に対して別のデータ型 (数値など) を指定すると、データ型の不一致により DynamoDB によって
ValidationException が返されます。
テーブルに項目を書き込む場合には、local secondary indexソートキーに対して属性を指定する
必要はありません。LastPostIndex を例にとると、Thread テーブルに新しい項目を書き込むため
に、LastPostDateTime 属性の値を指定する必要はありません。その場合、DynamoDB はこの特定の
項目のインデックスにデータを書き込むことはありません。
ベーステーブル内の項目とlocal secondary index内の項目を 1 対 1 の関係にする必要はありません。
この振る舞いは、多くのアプリケーションにとってメリットになります。詳細については、「スパー
スなインデックスの利用 (p. 585)」を参照してください。
多数の local secondary index があるテーブルは、インデックス数が少ないテーブルに比べて書き込み
アクティビティに多くのコストを要します。詳細については、「プロビジョニングされたスループッ
トに関する考慮事項(ローカルセカンダリインデックス) (p. 389)」を参照してください。
Important
local secondary indexがあるテーブルには、パーティションキーの値ごとに 10 GB のサイズ
制限があります。local secondary indexがあるテーブルには、1 つのパーティションキー値
の合計サイズが 10 GB を超えない限り、任意の数の項目を保存できます。詳細については、
「項目コレクションのサイズ制限 (p. 393)」を参照してください。
プロビジョニングされたスループットに関する考慮事項(ロー
カルセカンダリインデックス)
DynamoDB でテーブルを作成する場合には、テーブルで予想されるワークロードに応じた読み込みお
よび書き込みキャパシティーユニットをプロビジョニングします。このワークロードには、テーブル
の local secondary index の読み込みおよび書き込みアクティビティが含まれます。
プロビジョンドスループット性能の現在の料金を確認するには、https://aws.amazon.com/dynamodb/
pricing を参照してください。
読み込みキャパシティーユニット
local secondary index に対してクエリを実行する場合には、消費される読み込みキャパシティーユ
ニットの数は、データのアクセス方法によって異なります。
テーブルに対するクエリと同様に、インデックスクエリでは ConsistentRead の値に応じて、結果整
合性のある読み込みまたは強力な整合性のある読み込みを実行できます。1 回の強力な整合性のある
読み込みでは、1 つの読み込みキャパシティーユニットが消費され、結果整合性のある読み込みでは
その半分が消費されます。したがって結果整合性のある読み込みを選択することで、読み込みキャパ
シティーユニットのコストを削減できます。
インデックスキーと射影された属性だけをリクエストするインデックスクエリの場合、DynamoDB は
テーブルに対するクエリの場合と同じ計算方法で、プロビジョニングされた読み込みアクティビティ
API Version 2012-08-10
389
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
を計算します。唯一の違いは、ベーステーブル内の項目のサイズではなくインデックスエントリのサ
イズに基づいて計算が行われることです。読み込みキャパシティーユニットの数は、返されたすべて
の項目について射影されたすべての属性のサイズの合計です。結果は、次の 4 KB 境界まで切り上げ
られます。DynamoDB がプロビジョニング済みスループットの利用率を計算する方法の詳細について
は、「テーブルの読み書き要件の指定 (p. 179)」を参照してください。
local secondary indexに射影されていない属性を読み取るインデックスクエリの場合、DynamoDB
は射影された属性をインデックスから読み取るのに加えて、それらの属性をベーステーブルから
フェッチする必要があります。これらのフェッチは、Query オペレーションの Select または
ProjectionExpression パラメータに、射影されていない属性を含めた場合に実行されます。
フェッチによってクエリ応答のレイテンシーが増加し、プロビジョニングされるスループットのコス
トも増加します。前述のlocal secondary indexからの読み込みに加えて、フェッチされるベーステーブ
ル項目それぞれについて、読み込みキャパシティーユニットの料金がかかります。この料金は、リク
エストした属性だけでなく、項目全体をテーブルから読み取るために発生するものです。
Query オペレーションによって返される結果の最大サイズは、1 MB です。これには、返されるすべ
ての項目にわたる、すべての属性の名前と値のサイズが含まれます。ただし、local secondary indexに
対するクエリによって、DynamoDB がテーブルから項目の属性をフェッチする場合には、結果で示さ
れるデータの最大サイズが小さくなる可能性があります。この場合、結果のサイズは次の合計になり
ます。
• インデックス内で一致する項目のサイズ(次の 4 KB に切り上げ)
• ベーステーブル内で一致する各項目のサイズ (項目ごとに次の 4 KB に切り上げ)
この式を使用すると、クエリオペレーションによって返される結果の最大サイズは依然として 1 MB
になります。
たとえば、各項目のサイズが 300 バイトであるテーブルがあるとします。そのテーブルには local
secondary index がありますが、各項目のうち 200 バイトだけがインデックスに射影されます。この
インデックスに対して Query を行うときに各項目についてテーブルのフェッチが必要で、クエリに
よって 4 つの項目が返されるとします。DynamoDB では次のように合計されます。
• インデックス内で一致する項目のサイズは 200 バイト × 4 項目 = 800 バイトになり、それが 4 KB
に切り上げられます。
• ベーステーブル内で一致する項目のサイズ: (300 バイト、4 KB に切り上げ) × 4 項目 = 16 KB。
それによって、結果データの合計サイズは 20 KB になります。
書き込みキャパシティーユニット
テーブル内の項目が追加、更新、または削除された場合に local secondary index を更新すると、テー
ブルにプロビジョニングされた書き込みキャパシティーユニットが消費されます。書き込み用にプ
ロビジョニングされたスループットの合計コストは、テーブルに対する書き込みと、local secondary
index の更新で消費された書き込みキャパシティーユニットの合計になります。
local secondary index に項目を書き込むコストは、いくつかの要因によって異なります。
• インデックス付き属性が定義されたテーブルに新しい項目を書き込む場合、または既存の項目を更
新して未定義のインデックス付き属性を定義する場合には、インデックスへの項目の挿入に 1 回の
書き込みオペレーションが必要です。
• テーブルに対する更新によってインデックス付きキー属性の値が(A から B に)変更された場合に
は、インデックスから既存の項目を削除し、インデックスに新しい項目を挿入するために、2 回の
書き込みが必要です。 • インデックス内に既存の項目があって、テーブルに対する書き込みによってインデックス付き属性
が削除された場合は、インデックスから古い項目の射影を削除するために、1 回の書き込みが必要
です。
API Version 2012-08-10
390
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
• 項目の更新の前後にインデックス内に項目が存在しない場合は、インデックスで追加の書き込みコ
ストは発生しません。
これらすべての要因は、インデックス内の各項目のサイズが 1 KB 以下であるという前提で書き込み
キャパシティーユニット数を算出します。インデックスエントリがそれよりも大きい場合は、書き込
みキャパシティーユニットを追加する必要があります。クエリが返す必要がある属性を特定し、それ
らの属性だけをインデックスに射影することで、書き込みコストは最小になります。
ローカルセカンダリインデックス のストレージに関する考慮
事項
アプリケーションがテーブルに項目を書き込むと、DynamoDB では正しい属性のサブセットが、それ
らの属性を表示する必要がある local secondary index に自動的にコピーされます。AWS アカウント
では、テーブル内の項目のストレージと、そのベーステーブルのlocal secondary indexにある属性のス
トレージに対して課金されます。
インデックス項目が使用するスペースの量は、次の量の合計になります。
• ベーステーブルのプライマリキー (パーティションキーとソートキー) のサイズのバイト数
• インデックスキー属性のサイズのバイト数
• 射影された属性(存在する場合)のサイズのバイト数
• インデックス項目あたり 100 bytes のオーバーヘッド
local secondary indexのストレージ要件の見積もりは、インデックス内の 1 項目の平均サイズの見積
もり値にベーステーブルの項目数を掛けて算出します。
特定の属性が定義された項目がテーブルに含まれておらず、その属性がインデックスソートキーとし
て定義されている場合、DynamoDB はその項目に関連するデータをインデックスに書き込みません。
この動作の詳細については、「スパースなインデックスの利用 (p. 585)」を参照してください。
項目コレクション
Note
次のセクションは、local secondary index があるテーブルだけに関係します。
DynamoDB では、項目コレクションとは、テーブルおよびテーブルのlocal secondary index全体
で同じパーティションキーの値を持つ任意の項目グループです。このセクションで使用する例で
は、Thread テーブルのパーティションキーは ForumName で、LastPostIndex のパーティションキー
も ForumName です。同じ ForumName を持つテーブルとインデックス項目は、すべて同じ項目コレ
クションの一部です。たとえば Thread テーブルと LastPostIndex local secondary index には、フォー
ラム EC2 用の項目コレクションと、フォーラム RDS 用の別の項目コレクションがあります。
次の図は、フォーラム S3 の項目コレクションを示しています。
API Version 2012-08-10
391
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
この図では、項目コレクションは、ForumName パーティションキーの値が「S3」である Thread お
よび LastPostIndex 内のすべての項目で構成されています。テーブルにその他のlocal secondary index
があった場合には、ForumName が「S3」であるそれらのインデックス内の項目も、項目コレクショ
ンの一部になります。
DynamoDB では次のオペレーションのいずれかを使用して、項目コレクションに関する情報を得るこ
とができます。
• BatchWriteItem
• DeleteItem
• PutItem
• UpdateItem
API Version 2012-08-10
392
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
これらのオペレーションでは、それぞれ ReturnItemCollectionMetrics パラメータがサポートさ
れています。このパラメータを SIZE に設定すると、インデックス内の各項目コレクションのサイズ
に関する情報が表示されます。
Example
UpdateItemThread テーブルでの オペレーションの出力に含まれる スニペットを示しま
す。ReturnItemCollectionMetrics が SIZE に設定されています。更新された項目には
ForumName 値「EC2」があったため、出力にはその項目コレクションに関する情報が含まれていま
す。
{
ItemCollectionMetrics: {
ItemCollectionKey: {
ForumName: "EC2"
},
SizeEstimateRangeGB: [0.0, 1.0]
}
}
SizeEstimateRangeGB オブジェクトは、項目コレクションのサイズが 0~1 GB の間であることを
示します。DynamoDB ではこのサイズ見積りが定期的に更新されるため、項目を次に変更したときに
は数字が異なる場合があります。
項目コレクションのサイズ制限
1 つの項目コレクションのサイズは最大 10 GB までです。この制限は、local secondary index を含ま
ないテーブルには適用されません。1 つ以上の local secondary index を含むテーブルのみに影響しま
す。
項目コレクションが 10 GB を超えると、DynamoDB は
ItemCollectionSizeLimitExceededException を返します。こうなると、その項目コレクショ
ンに項目を追加することも、項目サイズを大きくすることもできません。(項目コレクションのサイ
ズを小さくする読み込みおよび書き込みオペレーションは、引き続き実行できます)。その他の項目
コレクションには項目を追加することができます。
項目コレクションのサイズを小さくするには、次のいずれかを実行します。
• 問題になっているパーティションキーの値を持つ不要な項目を削除します。ベーステーブルからこ
れらの項目を削除すると、DynamoDB では同じパーティションキーの値を持つインデックスエント
リも削除されます。
• 属性を削除するか属性のサイズを小さくすることで、項目を更新します。これらの属性が local
secondary index に射影されている場合には、DynamoDB では対応するインデックスエントリのサ
イズも小さくなります。
• 同じパーティションキーおよびソートキーを使用して新しいテーブルを作成し、古いテーブルから
新しいテーブルに項目を移動します。これは、頻繁にアクセスされない履歴データがテーブルに含
まれている場合に適した方法です。この履歴データを Amazon Simple Storage Service(Amazon
S3)にアーカイブすることもできます。
項目コレクションの合計サイズが 10 GB 未満になると、再び同じパーティションキーの値を使用して
項目を追加できるようになります。
項目コレクションのサイズを監視するようにアプリケーションを設定することをお勧めします。1 つ
の方法としては、BatchWriteItem、DeleteItem、PutItem、または UpdateItem を使用する場合
に、ReturnItemCollectionMetrics パラメータを SIZE に設定するというものがあります。アプ
リケーションで出力内の ReturnItemCollectionMetrics オブジェクトを調査し、項目コレクショ
API Version 2012-08-10
393
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
ンがユーザー定義の制限(たとえば 8 GB)を超えた場合にエラーメッセージを記録するようにしま
す。制限を 10 GB より低く設定すれば早期警告システムになり、項目コレクションが上限に達する前
に余裕をもって何らかの対処をとることができます。
項目コレクションおよびパーティション
各項目コレクションのテーブルおよびインデックスデータは、単一のパーティションに格納されま
す。Thread テーブルの例では、同じ ForumName 属性を持つすべてのベーステーブルとインデックス
項目が、同じパーティション内に格納されます。「S3」項目コレクションが 1 つのパーティションに
格納され、「EC2」が別のパーティションに格納され、「RDS」が 3 つ目のパーティションに格納さ
れます。
アプリケーションを設計する場合は、テーブルデータが異なるパーティションキー値に均一に分配さ
れるようにする必要があります。local secondary index を持つテーブルについては、単一のパーティ
ション内の単一の項目コレクションに読み込みおよび書き込みアクティビティの「ホットスポット」
が作られないように、アプリケーションを設計します。
ローカルセカンダリインデックス の使用 : Java
トピック
• ローカルセカンダリインデックス を使用したテーブルの作成 (p. 394)
• ローカルセカンダリインデックス のあるテーブルの説明 (p. 396)
• ローカルセカンダリインデックスのクエリ (p. 397)
• 例: Java ドキュメント API を使用した ローカルセカンダリインデックス (p. 398)
AWS SDK for Java ドキュメント API を使用して、1 つ以上の local secondary index を持つテーブル
を作成し、テーブルのインデックスについて説明し、インデックスを使用してクエリを実行すること
ができます。
次に、AWS SDK for Java ドキュメント API を使用したテーブルオペレーションの一般的なステップ
を示します。
1. DynamoDB クラスのインスタンスを作成します。
2. 対応するリクエストオブジェクトを作成して、オペレーションについて必要なパラメータとオプ
ションパラメータを入力します。
3. 前述のステップで作成したクライアントから提供された適切なメソッドを呼び出します。
ローカルセカンダリインデックス を使用したテーブルの作成
ローカルセカンダリインデックス は、テーブルの作成と同時に作成する必要があります。そのために
は、createTable メソッドを使用して、1 つ以上の local secondary index の仕様を指定します。次
の Java コードスニペットでは、音楽コレクション内の曲に関する情報を保存するテーブルを作成し
ています。パーティションキーは Artist で、ソートキーは SongTitle です。セカンダリインデックスの
AlbumTitleIndex は、アルバムのタイトルによるクエリを容易にします。
次に、DynamoDB ドキュメント API を使用して、local secondary index があるテーブルを作成するス
テップを示します。
1. DynamoDB クラスのインスタンスを作成します。
2. リクエスト情報を指定する CreateTableRequest クラスのインスタンスを作成します。
テーブル名、プライマリキー、プロビジョニング済みスループットの値を指定する必要がありま
す。local secondary indexについては、インデックス名、インデックスソートキーの名前とデータ
型、インデックスのキースキーマ、属性射影を指定する必要があります。
API Version 2012-08-10
394
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
3. リクエストオブジェクトをパラメータとして指定して、createTable メソッドを呼び出します。
次の Java コードスニペットは、前述のステップを示しています。このスニペットでは、AlbumTitle
属性のセカンダリインデックスによって、テーブル(Music)が作成されています。インデックスに射
影される属性は、テーブルのパーティションキーおよびソートキーと、インデックスのソートキーだ
けです。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Music";
CreateTableRequest createTableRequest = new
CreateTableRequest().withTableName(tableName);
//ProvisionedThroughput
createTableRequest.setProvisionedThroughput(new
ProvisionedThroughput().withReadCapacityUnits((long)5).withWriteCapacityUnits((long)5));
//AttributeDefinitions
ArrayList<AttributeDefinition> attributeDefinitions= new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new
AttributeDefinition().withAttributeName("Artist").withAttributeType("S"));
attributeDefinitions.add(new
AttributeDefinition().withAttributeName("SongTitle").withAttributeType("S"));
attributeDefinitions.add(new
AttributeDefinition().withAttributeName("AlbumTitle").withAttributeType("S"));
createTableRequest.setAttributeDefinitions(attributeDefinitions);
//KeySchema
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new
KeySchemaElement().withAttributeName("Artist").withKeyType(KeyType.HASH));
//Partition key
tableKeySchema.add(new
KeySchemaElement().withAttributeName("SongTitle").withKeyType(KeyType.RANGE));
//Sort key
createTableRequest.setKeySchema(tableKeySchema);
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new
KeySchemaElement().withAttributeName("Artist").withKeyType(KeyType.HASH));
//Partition key
indexKeySchema.add(new
KeySchemaElement().withAttributeName("AlbumTitle").withKeyType(KeyType.RANGE));
//Sort key
Projection projection = new
Projection().withProjectionType(ProjectionType.INCLUDE);
ArrayList<String> nonKeyAttributes = new ArrayList<String>();
nonKeyAttributes.add("Genre");
nonKeyAttributes.add("Year");
API Version 2012-08-10
395
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
projection.setNonKeyAttributes(nonKeyAttributes);
LocalSecondaryIndex localSecondaryIndex = new LocalSecondaryIndex()
.withIndexName("AlbumTitleIndex").withKeySchema(indexKeySchema).withProjection(projection);
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
localSecondaryIndexes.add(localSecondaryIndex);
createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes);
Table table = dynamoDB.createTable(createTableRequest);
System.out.println(table.getDescription());
DynamoDB がテーブルを作成し、テーブルのステータスを ACTIVE に設定するまで待機する必要があ
ります。その後は、データ項目をテーブルに書き込むことが可能になります。
ローカルセカンダリインデックス のあるテーブルの説明
テーブルの local secondary index に関する情報を取得するには、describeTable メソッドを使用し
ます。各インデックスについて、名前、キースキーマ、射影された属性にアクセスできます。
次に、AWS SDK for Java ドキュメント API を使用して、テーブルの local secondary index 情報にア
クセスするステップを示します。
1. DynamoDB クラスのインスタンスを作成します。
2. Table クラスのインスタンスを作成します。テーブル名を入力する必要があります。
3. Table オブジェクトで describeTable メソッドを呼び出します。
次の Java コードスニペットは、前述のステップを示しています。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Music";
Table table = dynamoDB.getTable(tableName);
TableDescription tableDescription = table.describe();
List<LocalSecondaryIndexDescription> localSecondaryIndexes
= tableDescription.getLocalSecondaryIndexes();
// This code snippet will work for multiple indexes, even though
// there is only one index in this example.
Iterator<LocalSecondaryIndexDescription> lsiIter =
localSecondaryIndexes.iterator();
while (lsiIter.hasNext()) {
LocalSecondaryIndexDescription lsiDescription = lsiIter.next();
System.out.println("Info for index " + lsiDescription.getIndexName() +
":");
Iterator<KeySchemaElement> kseIter =
lsiDescription.getKeySchema().iterator();
while (kseIter.hasNext()) {
KeySchemaElement kse = kseIter.next();
API Version 2012-08-10
396
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
System.out.printf("\t%s: %s\n", kse.getAttributeName(),
kse.getKeyType());
}
Projection projection = lsiDescription.getProjection();
System.out.println("\tThe projection type is: " +
projection.getProjectionType());
if (projection.getProjectionType().toString().equals("INCLUDE")) {
System.out.println("\t\tThe non-key projected attributes are: " +
projection.getNonKeyAttributes());
}
}
ローカルセカンダリインデックスのクエリ
local secondary index では、テーブルの Query を実行するのと同様の方法で、Query オペレーション
を使用できます。 インデックス名、インデックスソートキーのクエリ基準、および返されるようにす
る属性を指定する必要があります。この例では、インデックスが AlbumTitleIndex で、インデックス
ソートキーが AlbumTitle です。
返される属性は、インデックスに射影された属性だけです。このクエリを変更して非キー属性も選択
するように設定することもできますが、その場合は比較的コストがかかるテーブルフェッチアクティ
ビティが必要になります。テーブルのフェッチの詳細については、「属性の射影 (p. 385)」を参照し
てください。
以下に、AWS SDK for Java ドキュメント API を使用して local secondary index のクエリを行う手順
を示します。
1. DynamoDB クラスのインスタンスを作成します。
2. Table クラスのインスタンスを作成します。テーブル名を入力する必要があります。
3. Index クラスのインスタンスを作成します。インデックス名を提供しなければなりません。
4. Index クラスの query メソッドを呼び出します。
次の Java コードスニペットは、前述のステップを示しています。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Music";
Table table = dynamoDB.getTable(tableName);
Index index = table.getIndex("AlbumTitleIndex");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Artist = :v_artist and AlbumTitle
= :v_title")
.withValueMap(new ValueMap()
.withString(":v_artist", "Acme Band")
.withString(":v_title", "Songs About Life"));
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> itemsIter = items.iterator();
while (itemsIter.hasNext()) {
Item item = itemsIter.next();
System.out.println(item.toJSONPretty());
API Version 2012-08-10
397
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
}
例: Java ドキュメント API を使用した ローカルセカンダリインデックス
次の Java コード例では、local secondary index の操作方法を示します。この例では、パーティション
キーとして CustomerId、ソートキーとして OrderId を使用して、CustomerOrders という名前のテー
ブルが作成されます。このテーブルには次の 2 つの local secondary index があります。
• OrderCreationDateIndex — ソートキーは OrderCreationDate で、次の属性がインデックスに射影さ
れます。
• ProductCategory
• ProductName
• OrderStatus
• ShipmentTrackingId
• IsOpenIndex — ソートキーは IsOpen で、すべてのテーブル属性がインデックスに射影されていま
す。
CustomerOrders テーブルを作成すると、プログラムによってカスタマーの注文を表すデータがテー
ブルにロードされ、local secondary index を使用してデータのクエリが行われます。最後に、プログ
ラムによって CustomerOrders テーブルが削除されます。
次のサンプルをテストするための詳しい手順については、「Java コードサンプル (p. 171)」を参照し
てください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.document;
import java.util.ArrayList;
import java.util.Iterator;
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Index;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.ItemCollection;
com.amazonaws.services.dynamodbv2.document.PutItemOutcome;
com.amazonaws.services.dynamodbv2.document.QueryOutcome;
com.amazonaws.services.dynamodbv2.document.Table;
com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
com.amazonaws.services.dynamodbv2.model.KeyType;
com.amazonaws.services.dynamodbv2.model.LocalSecondaryIndex;
com.amazonaws.services.dynamodbv2.model.Projection;
com.amazonaws.services.dynamodbv2.model.ProjectionType;
com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
com.amazonaws.services.dynamodbv2.model.ReturnConsumedCapacity;
com.amazonaws.services.dynamodbv2.model.Select;
public class DocumentAPILocalSecondaryIndexExample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
API Version 2012-08-10
398
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
new ProfileCredentialsProvider()));
public static String tableName = "CustomerOrders";
public static void main(String[] args) throws Exception {
createTable();
loadData();
query(null);
query("IsOpenIndex");
query("OrderCreationDateIndex");
deleteTable(tableName);
}
public static void createTable() {
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 1)
.withWriteCapacityUnits((long) 1));
// Attribute definitions for table partition and sort keys
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("CustomerId")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OrderId")
.withAttributeType("N"));
// Attribute definition for index primary key attributes
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OrderCreationDate")
.withAttributeType("N"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("IsOpen")
.withAttributeType("N"));
createTableRequest.setAttributeDefinitions(attributeDefinitions);
// Key schema for table
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerId")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("OrderId")
.withKeyType(KeyType.RANGE)); //Sort key
createTableRequest.setKeySchema(tableKeySchema);
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
API Version 2012-08-10
399
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
// OrderCreationDateIndex
LocalSecondaryIndex orderCreationDateIndex = new
LocalSecondaryIndex()
.withIndexName("OrderCreationDateIndex");
// Key schema for OrderCreationDateIndex
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerId")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("OrderCreationDate")
.withKeyType(KeyType.RANGE)); //Sort key
orderCreationDateIndex.setKeySchema(indexKeySchema);
// Projection (with list of projected attributes) for
// OrderCreationDateIndex
Projection projection = new Projection()
.withProjectionType(ProjectionType.INCLUDE);
ArrayList<String> nonKeyAttributes = new ArrayList<String>();
nonKeyAttributes.add("ProductCategory");
nonKeyAttributes.add("ProductName");
projection.setNonKeyAttributes(nonKeyAttributes);
orderCreationDateIndex.setProjection(projection);
localSecondaryIndexes.add(orderCreationDateIndex);
// IsOpenIndex
LocalSecondaryIndex isOpenIndex = new LocalSecondaryIndex()
.withIndexName("IsOpenIndex");
// Key schema for IsOpenIndex
indexKeySchema = new ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerId")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("IsOpen")
.withKeyType(KeyType.RANGE)); //Sort key
// Projection (all attributes) for IsOpenIndex
projection = new Projection()
.withProjectionType(ProjectionType.ALL);
isOpenIndex.setKeySchema(indexKeySchema);
isOpenIndex.setProjection(projection);
localSecondaryIndexes.add(isOpenIndex);
// Add index definitions to CreateTable request
createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes);
System.out.println("Creating table " + tableName + "...");
System.out.println(dynamoDB.createTable(createTableRequest));
API Version 2012-08-10
400
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
// Wait for table to become active
System.out.println("Waiting for " + tableName + " to become
ACTIVE...");
try {
Table table = dynamoDB.getTable(tableName);
table.waitForActive();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void query(String indexName) {
Table table = dynamoDB.getTable(tableName);
System.out
.println("\n***********************************************************\n");
System.out.println("Querying table " + tableName + "...");
QuerySpec querySpec = new QuerySpec()
.withConsistentRead(true)
.withScanIndexForward(true)
.withReturnConsumedCapacity(ReturnConsumedCapacity.TOTAL);
if (indexName == "IsOpenIndex") {
System.out.println("\nUsing index: '" + indexName
+ "': Bob's orders that are open.");
System.out.println(
"Only a user-specified list of attributes are returned\n");
Index index = table.getIndex(indexName);
querySpec.withKeyConditionExpression("CustomerId = :v_custid and
IsOpen = :v_isopen")
.withValueMap(new ValueMap()
.withString(":v_custid", "[email protected]")
.withNumber(":v_isopen", 1));
querySpec.withProjectionExpression(
"OrderCreationDate, ProductCategory, ProductName,
OrderStatus");
ItemCollection<QueryOutcome> items = index.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Query: printing results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
} else if (indexName == "OrderCreationDateIndex") {
System.out.println("\nUsing index: '" + indexName
+ "': Bob's orders that were placed after 01/31/2015.");
System.out.println("Only the projected attributes are returned
\n");
Index index = table.getIndex(indexName);
API Version 2012-08-10
401
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
querySpec.withKeyConditionExpression("CustomerId = :v_custid and
OrderCreationDate >= :v_orddate")
.withValueMap(new ValueMap()
.withString(":v_custid", "[email protected]")
.withNumber(":v_orddate", 20150131));
querySpec.withSelect(Select.ALL_PROJECTED_ATTRIBUTES);
ItemCollection<QueryOutcome> items = index.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Query: printing results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
} else {
System.out.println("\nNo index: All of Bob's orders, by OrderId:
\n");
querySpec.withKeyConditionExpression("CustomerId = :v_custid")
.withValueMap(new ValueMap()
.withString(":v_custid", "[email protected]"));
ItemCollection<QueryOutcome> items = table.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Query: printing results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
public static void deleteTable(String tableName) {
Table table = dynamoDB.getTable(tableName);
System.out.println("Deleting table " + tableName + "...");
table.delete();
// Wait for table to be deleted
System.out.println("Waiting for " + tableName + " to be deleted...");
try {
table.waitForDelete();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void loadData() {
Table table = dynamoDB.getTable(tableName);
System.out.println("Loading data into table " + tableName + "...");
API Version 2012-08-10
402
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
Item item = new Item()
.withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 1)
.withNumber("IsOpen", 1)
.withNumber("OrderCreationDate", 20150101)
.withString("ProductCategory", "Book")
.withString("ProductName", "The Great Outdoors")
.withString("OrderStatus", "PACKING ITEMS");
// no ShipmentTrackingId attribute
PutItemOutcome putItemOutcome = table.putItem(item);
item = new Item()
.withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 2)
.withNumber("IsOpen", 1)
.withNumber("OrderCreationDate", 20150221)
.withString("ProductCategory", "Bike")
.withString("ProductName", "Super Mountain")
.withString("OrderStatus", "ORDER RECEIVED");
// no ShipmentTrackingId attribute
putItemOutcome = table.putItem(item);
item = new Item()
.withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 3)
// no IsOpen attribute
.withNumber("OrderCreationDate", 20150304)
.withString("ProductCategory", "Music")
.withString("ProductName", "A Quiet Interlude")
.withString("OrderStatus", "IN TRANSIT")
.withString("ShipmentTrackingId", "176493");
putItemOutcome = table.putItem(item);
item = new Item()
.withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 1)
// no IsOpen attribute
.withNumber("OrderCreationDate", 20150111)
.withString("ProductCategory", "Movie")
.withString("ProductName", "Calm Before The Storm")
.withString("OrderStatus", "SHIPPING DELAY")
.withString("ShipmentTrackingId", "859323");
putItemOutcome = table.putItem(item);
item = new Item()
.withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 2)
// no IsOpen attribute
.withNumber("OrderCreationDate", 20150124)
.withString("ProductCategory", "Music")
.withString("ProductName", "E-Z Listening")
.withString("OrderStatus", "DELIVERED")
.withString("ShipmentTrackingId", "756943");
putItemOutcome = table.putItem(item);
API Version 2012-08-10
403
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
item = new Item()
.withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 3)
// no IsOpen attribute
.withNumber("OrderCreationDate", 20150221)
.withString("ProductCategory", "Music")
.withString("ProductName", "Symphony 9")
.withString("OrderStatus", "DELIVERED")
.withString("ShipmentTrackingId", "645193");
putItemOutcome = table.putItem(item);
item = new Item().withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 4).withNumber("IsOpen", 1)
.withNumber("OrderCreationDate", 20150222)
.withString("ProductCategory", "Hardware")
.withString("ProductName", "Extra Heavy Hammer")
.withString("OrderStatus", "PACKING ITEMS");
// no ShipmentTrackingId attribute
putItemOutcome = table.putItem(item);
item = new Item().withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 5)
/* no IsOpen attribute */
.withNumber("OrderCreationDate", 20150309)
.withString("ProductCategory", "Book")
.withString("ProductName", "How To Cook")
.withString("OrderStatus", "IN TRANSIT")
.withString("ShipmentTrackingId", "440185");
putItemOutcome = table.putItem(item);
item = new Item()
.withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 6)
// no IsOpen attribute
.withNumber("OrderCreationDate", 20150318)
.withString("ProductCategory", "Luggage")
.withString("ProductName", "Really Big Suitcase")
.withString("OrderStatus", "DELIVERED")
.withString("ShipmentTrackingId", "893927");
putItemOutcome = table.putItem(item);
item = new Item().withPrimaryKey("CustomerId", "[email protected]")
.withNumber("OrderId", 7)
/* no IsOpen attribute */
.withNumber("OrderCreationDate", 20150324)
.withString("ProductCategory", "Golf")
.withString("ProductName", "PGA Pro II")
.withString("OrderStatus", "OUT FOR DELIVERY")
.withString("ShipmentTrackingId", "383283");
putItemOutcome = table.putItem(item);
assert putItemOutcome != null;
}
API Version 2012-08-10
404
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
}
ローカルセカンダリインデックスes: .NET の使用
トピック
• ローカルセカンダリインデックス を使用したテーブルの作成 (p. 405)
• ローカルセカンダリインデックス のあるテーブルの説明 (p. 407)
• ローカルセカンダリインデックス のクエリ (p. 408)
• 例: AWS SDK for .NET 低レベル API を使用した ローカルセカンダリインデックス (p. 409)
AWS SDK for .NET 低レベル API を使用して、1 つ以上の local secondary index を持つテーブルを作
成し、テーブルのインデックスについて説明し、インデックスを使用してクエリを実行することがで
きます。 これらのオペレーションは、対応する低レベル DynamoDB API アクションにマッピングし
ます。 詳細については、「.NET コードサンプル (p. 173)」を参照してください。
次に、.NET 低レベル API を使用したテーブルオペレーションの一般的なステップを示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. 対応するリクエストオブジェクトを作成して、オペレーションについて必要なパラメータとオプ
ションパラメータを入力します。
たとえば、テーブルを作成するための CreateTableRequest オブジェクトと、テーブルまたはイ
ンデックスのクエリを行うための QueryRequest オブジェクトを作成します。
3. 前述のステップで作成したクライアントから提供された適切なメソッドを実行します。
ローカルセカンダリインデックス を使用したテーブルの作成
ローカルセカンダリインデックス は、テーブルの作成と同時に作成する必要があります。そのた
めには、CreateTable を使用して、1 つ以上の local secondary index の仕様を指定します。 次の
C# コードスニペットでは、音楽コレクション内の曲に関する情報を保存するテーブルを作成してい
ます。パーティションキーは Artist で、ソートキーは SongTitle です。セカンダリインデックスの
AlbumTitleIndex は、アルバムのタイトルによるクエリを容易にします。
次に、.NET 低レベル API を使用して、local secondary index があるテーブルを作成するステップを示
します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. リクエスト情報を指定する CreateTableRequest クラスのインスタンスを作成します。
テーブル名、プライマリキー、プロビジョニング済みスループットの値を指定する必要がありま
す。local secondary indexについては、インデックス名、インデックスソートキーの名前とデータ
型、インデックスのキースキーマ、属性射影を指定する必要があります。
3. リクエストオブジェクトをパラメータとして指定して、CreateTable メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。このスニペットでは、AlbumTitle 属
性のセカンダリインデックスによって、テーブル(Music)が作成されています。インデックスに射影
される属性は、テーブルのパーティションキーおよびソートキーと、インデックスのソートキーだけ
です。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "Music";
CreateTableRequest createTableRequest = new CreateTableRequest()
{
API Version 2012-08-10
405
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
TableName = tableName
};
//ProvisionedThroughput
createTableRequest.ProvisionedThroughput = new ProvisionedThroughput()
{
ReadCapacityUnits = (long)5,
WriteCapacityUnits = (long)5
};
//AttributeDefinitions
List<AttributeDefinition> attributeDefinitions = new
List<AttributeDefinition>();
attributeDefinitions.Add(new AttributeDefinition()
{
AttributeName = "Artist",
AttributeType = "S"
});
attributeDefinitions.Add(new AttributeDefinition()
{
AttributeName = "SongTitle",
AttributeType = "S"
});
attributeDefinitions.Add(new AttributeDefinition()
{
AttributeName = "AlbumTitle",
AttributeType = "S"
});
createTableRequest.AttributeDefinitions = attributeDefinitions;
//KeySchema
List<KeySchemaElement> tableKeySchema = new List<KeySchemaElement>();
tableKeySchema.Add(new KeySchemaElement() { AttributeName = "Artist", KeyType
= "HASH" }); //Partition key
tableKeySchema.Add(new KeySchemaElement() { AttributeName = "SongTitle",
KeyType = "RANGE" }); //Sort key
createTableRequest.KeySchema = tableKeySchema;
List<KeySchemaElement> indexKeySchema = new List<KeySchemaElement>();
indexKeySchema.Add(new KeySchemaElement() { AttributeName = "Artist", KeyType
= "HASH" }); //Partition key
indexKeySchema.Add(new KeySchemaElement() { AttributeName = "AlbumTitle",
KeyType = "RANGE" }); //Sort key
Projection projection = new Projection() { ProjectionType = "INCLUDE" };
List<string> nonKeyAttributes = new List<string>();
nonKeyAttributes.Add("Genre");
nonKeyAttributes.Add("Year");
projection.NonKeyAttributes = nonKeyAttributes;
LocalSecondaryIndex localSecondaryIndex = new LocalSecondaryIndex()
{
API Version 2012-08-10
406
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
IndexName = "AlbumTitleIndex",
KeySchema = indexKeySchema,
Projection = projection
};
List<LocalSecondaryIndex> localSecondaryIndexes = new
List<LocalSecondaryIndex>();
localSecondaryIndexes.Add(localSecondaryIndex);
createTableRequest.LocalSecondaryIndexes = localSecondaryIndexes;
CreateTableResponse result = client.CreateTable(createTableRequest);
Console.WriteLine(result.CreateTableResult.TableDescription.TableName);
Console.WriteLine(result.CreateTableResult.TableDescription.TableStatus);
DynamoDB がテーブルを作成し、テーブルのステータスを ACTIVE に設定するまで待機する必要があ
ります。その後は、データ項目をテーブルに書き込むことが可能になります。
ローカルセカンダリインデックス のあるテーブルの説明
テーブルの local secondary index に関する情報を取得するには、DescribeTable API を使用しま
す。各インデックスについて、名前、キースキーマ、射影された属性にアクセスできます。
次に、.NET 低レベル API を使用して、テーブルの local secondary index 情報にアクセスするステッ
プを示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. リクエスト情報を指定する DescribeTableRequest クラスのインスタンスを作成します。テーブ
ル名を入力する必要があります。
3. リクエストオブジェクトをパラメータとして指定して、describeTable メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。
AmazonDynamoDBClient client = new AmazonDynamoDBClient();
string tableName = "Music";
DescribeTableResponse response = client.DescribeTable(new
DescribeTableRequest() { TableName = tableName });
List<LocalSecondaryIndexDescription> localSecondaryIndexes =
response.DescribeTableResult.Table.LocalSecondaryIndexes;
// This code snippet will work for multiple indexes, even though
// there is only one index in this example.
foreach (LocalSecondaryIndexDescription lsiDescription in
localSecondaryIndexes)
{
Console.WriteLine("Info for index " + lsiDescription.IndexName + ":");
foreach (KeySchemaElement kse in lsiDescription.KeySchema)
{
Console.WriteLine("\t" + kse.AttributeName + ": key type is " +
kse.KeyType);
}
Projection projection = lsiDescription.Projection;
Console.WriteLine("\tThe projection type is: " +
projection.ProjectionType);
API Version 2012-08-10
407
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
if (projection.ProjectionType.ToString().Equals("INCLUDE"))
{
Console.WriteLine("\t\tThe non-key projected attributes are:");
foreach (String s in projection.NonKeyAttributes)
{
Console.WriteLine("\t\t" + s);
}
}
}
ローカルセカンダリインデックス のクエリ
local secondary index では、テーブルの Query を実行するのと同様の方法で、Query を使用できま
す。 インデックス名、インデックスソートキーのクエリ基準、および返されるようにする属性を指定
する必要があります。この例では、インデックスが AlbumTitleIndex で、インデックスソートキーが
AlbumTitle です。
返される属性は、インデックスに射影された属性だけです。このクエリを変更して非キー属性も選択
するように設定することもできますが、その場合は比較的コストがかかるテーブルフェッチアクティ
ビティが必要になります。テーブルのフェッチの詳細については、「属性の射影 (p. 385)」を参照し
てください。
次に、.NET 低レベル API を使用して local secondary index のクエリを行うステップを示します。
1. AmazonDynamoDBClient クラスのインスタンスを作成します。
2. リクエスト情報を指定する QueryRequest クラスのインスタンスを作成します。
3. リクエストオブジェクトをパラメータとして指定して、query メソッドを実行します。
次の C# コードスニペットは、前述のステップを示しています。
QueryRequest queryRequest = new QueryRequest
{
TableName = "Music",
IndexName = "AlbumTitleIndex",
Select = "ALL_ATTRIBUTES",
ScanIndexForward = true,
KeyConditionExpression = "Artist = :v_artist and AlbumTitle = :v_title",
ExpressionAttributeValues = new Dictionary<string, AttributeValue>()
{
{":v_artist",new AttributeValue {S = "Acme Band"}},
{":v_title",new AttributeValue {S = "Songs About Life"}}
},
};
QueryResponse response = client.Query(queryRequest);
foreach (var attribs in response.Items)
{
foreach (var attrib in attribs)
{
Console.WriteLine(attrib.Key + " ---> " + attrib.Value.S);
}
Console.WriteLine();
API Version 2012-08-10
408
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
}
例: AWS SDK for .NET 低レベル API を使用した ローカルセカンダリインデッ
クス
次の C# コード例では、local secondary index の操作方法を示します。この例では、パーティション
キーとして CustomerId、ソートキーとして OrderId を使用して、CustomerOrders という名前のテー
ブルが作成されます。このテーブルには次の 2 つの local secondary index があります。
• OrderCreationDateIndex — ソートキーは OrderCreationDate で、次の属性がインデックスに射影さ
れます。
• ProductCategory
• ProductName
• OrderStatus
• ShipmentTrackingId
• IsOpenIndex — ソートキーは IsOpen で、すべてのテーブル属性がインデックスに射影されていま
す。
CustomerOrders テーブルを作成すると、プログラムによってカスタマーの注文を表すデータがテー
ブルにロードされ、local secondary index を使用してデータのクエリが行われます。最後に、プログ
ラムによって CustomerOrders テーブルが削除されます。
次のサンプルをテストするための詳しい手順については、「.NET コードサンプル (p. 173)」を参照し
てください。
using
using
using
using
using
using
using
using
using
System;
System.Collections.Generic;
System.Linq;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DataModel;
Amazon.DynamoDBv2.DocumentModel;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
Amazon.SecurityToken;
namespace com.amazonaws.codesamples
{
class LowLevelLocalSecondaryIndexExample
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
private static string tableName = "CustomerOrders";
static void Main(string[] args)
{
try
{
CreateTable();
LoadData();
Query(null);
Query("IsOpenIndex");
Query("OrderCreationDateIndex");
DeleteTable(tableName);
API Version 2012-08-10
409
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
Console.WriteLine("To continue, press Enter");
Console.ReadLine();
}
catch (AmazonDynamoDBException e)
{ Console.WriteLine(e.Message); }
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
private static void CreateTable()
{
var createTableRequest =
new CreateTableRequest()
{
TableName = tableName,
ProvisionedThroughput =
new ProvisionedThroughput()
{
ReadCapacityUnits = (long)1,
WriteCapacityUnits = (long)1
}
};
var attributeDefinitions = new List<AttributeDefinition>()
{
// Attribute definitions for table primary key
{ new AttributeDefinition() {AttributeName = "CustomerId",
AttributeType = "S"} },
{ new AttributeDefinition() {AttributeName = "OrderId",
AttributeType = "N"} },
// Attribute definitions for index primary key
{ new AttributeDefinition() {AttributeName =
"OrderCreationDate", AttributeType = "N"} },
{ new AttributeDefinition() {AttributeName = "IsOpen",
AttributeType = "N" }}
};
createTableRequest.AttributeDefinitions = attributeDefinitions;
// Key schema for table
var tableKeySchema = new List<KeySchemaElement>()
{
{ new KeySchemaElement() {AttributeName = "CustomerId", KeyType
= "HASH"} }, //Partition key
{ new KeySchemaElement() {AttributeName = "OrderId", KeyType =
"RANGE"} } //Sort key
};
createTableRequest.KeySchema = tableKeySchema;
var localSecondaryIndexes = new List<LocalSecondaryIndex>();
// OrderCreationDateIndex
LocalSecondaryIndex orderCreationDateIndex = new
LocalSecondaryIndex()
{
IndexName = "OrderCreationDateIndex"
API Version 2012-08-10
410
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
};
// Key schema for OrderCreationDateIndex
var indexKeySchema = new List<KeySchemaElement>()
{
{ new KeySchemaElement() {AttributeName = "CustomerId",
KeyType = "HASH"} }, //Partition key
{ new KeySchemaElement() {AttributeName =
"OrderCreationDate", KeyType = "RANGE"} } //Sort key
};
orderCreationDateIndex.KeySchema = indexKeySchema;
// Projection (with list of projected attributes) for
// OrderCreationDateIndex
var projection = new Projection() { ProjectionType = "INCLUDE" };
var nonKeyAttributes = new List<string>()
{
"ProductCategory",
"ProductName"
};
projection.NonKeyAttributes = nonKeyAttributes;
orderCreationDateIndex.Projection = projection;
localSecondaryIndexes.Add(orderCreationDateIndex);
// IsOpenIndex
LocalSecondaryIndex isOpenIndex
= new LocalSecondaryIndex() { IndexName = "IsOpenIndex" };
// Key schema for IsOpenIndex
indexKeySchema = new List<KeySchemaElement>()
{
{ new KeySchemaElement() {AttributeName = "CustomerId",
KeyType = "HASH" }}, //Partition key
{ new KeySchemaElement() {AttributeName = "IsOpen", KeyType =
"RANGE" }} //Sort key
};
// Projection (all attributes) for IsOpenIndex
projection = new Projection() { ProjectionType = "ALL" };
isOpenIndex.KeySchema = indexKeySchema;
isOpenIndex.Projection = projection;
localSecondaryIndexes.Add(isOpenIndex);
// Add index definitions to CreateTable request
createTableRequest.LocalSecondaryIndexes = localSecondaryIndexes;
Console.WriteLine("Creating table " + tableName + "...");
client.CreateTable(createTableRequest);
WaitUntilTableReady(tableName);
}
public static void Query(string indexName)
{
API Version 2012-08-10
411
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
Console.WriteLine("\n***********************************************************
\n");
Console.WriteLine("Querying table " + tableName + "...");
QueryRequest queryRequest = new QueryRequest()
{
TableName = tableName,
ConsistentRead = true,
ScanIndexForward = true,
ReturnConsumedCapacity = "TOTAL"
};
String keyConditionExpression = "CustomerId = :v_customerId";
Dictionary<string, AttributeValue> expressionAttributeValues =
new Dictionary<string, AttributeValue> {
{":v_customerId", new AttributeValue { S =
"[email protected]" }}
};
if (indexName == "IsOpenIndex")
{
Console.WriteLine("\nUsing index: '" + indexName
+ "': Bob's orders that are open.");
Console.WriteLine("Only a user-specified list of attributes
are returned\n");
queryRequest.IndexName = indexName;
keyConditionExpression += " and IsOpen = :v_isOpen";
expressionAttributeValues.Add(":v_isOpen", new AttributeValue
{ N = "1" });
// ProjectionExpression
queryRequest.ProjectionExpression = "OrderCreationDate,
ProductCategory, ProductName, OrderStatus";
}
else if (indexName == "OrderCreationDateIndex")
{
Console.WriteLine("\nUsing index: '" + indexName
+ "': Bob's orders that were placed after 01/31/2013.");
Console.WriteLine("Only the projected attributes are returned
\n");
queryRequest.IndexName = indexName;
keyConditionExpression += " and OrderCreationDate > :v_Date";
expressionAttributeValues.Add(":v_Date", new AttributeValue
{ N = "20130131" });
// Select
queryRequest.Select = "ALL_PROJECTED_ATTRIBUTES";
}
else
{
Console.WriteLine("\nNo index: All of Bob's orders, by
OrderId:\n");
}
API Version 2012-08-10
412
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
queryRequest.KeyConditionExpression = keyConditionExpression;
queryRequest.ExpressionAttributeValues =
expressionAttributeValues;
var result = client.Query(queryRequest);
var items = result.Items;
foreach (var currentItem in items)
{
foreach (string attr in currentItem.Keys)
{
if (attr == "OrderId" || attr == "IsOpen"
|| attr == "OrderCreationDate")
{
Console.WriteLine(attr + "---> " +
currentItem[attr].N);
}
else
{
Console.WriteLine(attr + "---> " +
currentItem[attr].S);
}
}
Console.WriteLine();
}
Console.WriteLine("\nConsumed capacity: " +
result.ConsumedCapacity.CapacityUnits + "\n");
}
private static void DeleteTable(string tableName)
{
Console.WriteLine("Deleting table " + tableName + "...");
client.DeleteTable(new DeleteTableRequest() { TableName =
tableName });
WaitForTableToBeDeleted(tableName);
}
public static void LoadData()
{
Console.WriteLine("Loading data into table " + tableName +
"...");
Dictionary<string, AttributeValue> item = new Dictionary<string,
AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "1" };
item["IsOpen"] = new AttributeValue { N = "1" };
item["OrderCreationDate"] = new AttributeValue { N =
"20130101" };
item["ProductCategory"] = new AttributeValue { S = "Book" };
item["ProductName"] = new AttributeValue { S = "The Great
Outdoors" };
item["OrderStatus"] = new AttributeValue { S = "PACKING ITEMS" };
/* no ShipmentTrackingId attribute */
PutItemRequest putItemRequest = new PutItemRequest
{
TableName = tableName,
Item = item,
API Version 2012-08-10
413
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "2" };
item["IsOpen"] = new AttributeValue { N = "1" };
item["OrderCreationDate"] = new AttributeValue { N =
"20130221" };
item["ProductCategory"] = new AttributeValue { S = "Bike" };
item["ProductName"] = new AttributeValue { S = "Super
Mountain" };
item["OrderStatus"] = new AttributeValue { S = "ORDER
RECEIVED" };
/* no ShipmentTrackingId attribute */
putItemRequest = new PutItemRequest
{
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "3" };
/* no IsOpen attribute */
item["OrderCreationDate"] = new AttributeValue { N =
"20130304" };
item["ProductCategory"] = new AttributeValue { S = "Music" };
item["ProductName"] = new AttributeValue { S = "A Quiet
Interlude" };
item["OrderStatus"] = new AttributeValue { S = "IN TRANSIT" };
item["ShipmentTrackingId"] = new AttributeValue { S = "176493" };
putItemRequest = new PutItemRequest
{
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "1" };
/* no IsOpen attribute */
item["OrderCreationDate"] = new AttributeValue { N =
"20130111" };
item["ProductCategory"] = new AttributeValue { S = "Movie" };
item["ProductName"] = new AttributeValue { S = "Calm Before The
Storm" };
item["OrderStatus"] = new AttributeValue { S = "SHIPPING
DELAY" };
item["ShipmentTrackingId"] = new AttributeValue { S = "859323" };
putItemRequest = new PutItemRequest
API Version 2012-08-10
414
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
{
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "2" };
/* no IsOpen attribute */
item["OrderCreationDate"] = new AttributeValue { N =
"20130124" };
item["ProductCategory"] = new AttributeValue { S = "Music" };
item["ProductName"] = new AttributeValue { S = "E-Z Listening" };
item["OrderStatus"] = new AttributeValue { S = "DELIVERED" };
item["ShipmentTrackingId"] = new AttributeValue { S = "756943" };
putItemRequest = new PutItemRequest
{
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "3" };
/* no IsOpen attribute */
item["OrderCreationDate"] = new AttributeValue { N =
"20130221" };
item["ProductCategory"] = new AttributeValue { S = "Music" };
item["ProductName"] = new AttributeValue { S = "Symphony 9" };
item["OrderStatus"] = new AttributeValue { S = "DELIVERED" };
item["ShipmentTrackingId"] = new AttributeValue { S = "645193" };
putItemRequest = new PutItemRequest
{
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "4" };
item["IsOpen"] = new AttributeValue { N = "1" };
item["OrderCreationDate"] = new AttributeValue { N =
"20130222" };
item["ProductCategory"] = new AttributeValue { S = "Hardware" };
item["ProductName"] = new AttributeValue { S = "Extra Heavy
Hammer" };
item["OrderStatus"] = new AttributeValue { S = "PACKING ITEMS" };
/* no ShipmentTrackingId attribute */
putItemRequest = new PutItemRequest
{
API Version 2012-08-10
415
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "5" };
/* no IsOpen attribute */
item["OrderCreationDate"] = new AttributeValue { N =
"20130309" };
item["ProductCategory"] = new AttributeValue { S = "Book" };
item["ProductName"] = new AttributeValue { S = "How To Cook" };
item["OrderStatus"] = new AttributeValue { S = "IN TRANSIT" };
item["ShipmentTrackingId"] = new AttributeValue { S = "440185" };
putItemRequest = new PutItemRequest
{
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "6" };
/* no IsOpen attribute */
item["OrderCreationDate"] = new AttributeValue { N =
"20130318" };
item["ProductCategory"] = new AttributeValue { S = "Luggage" };
item["ProductName"] = new AttributeValue { S = "Really Big
Suitcase" };
item["OrderStatus"] = new AttributeValue { S = "DELIVERED" };
item["ShipmentTrackingId"] = new AttributeValue { S = "893927" };
putItemRequest = new PutItemRequest
{
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
item = new Dictionary<string, AttributeValue>();
item["CustomerId"] = new AttributeValue { S =
"[email protected]" };
item["OrderId"] = new AttributeValue { N = "7" };
/* no IsOpen attribute */
item["OrderCreationDate"] = new AttributeValue { N =
"20130324" };
item["ProductCategory"] = new AttributeValue { S = "Golf" };
item["ProductName"] = new AttributeValue { S = "PGA Pro II" };
item["OrderStatus"] = new AttributeValue { S = "OUT FOR
DELIVERY" };
item["ShipmentTrackingId"] = new AttributeValue { S = "383283" };
putItemRequest = new PutItemRequest
{
API Version 2012-08-10
416
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
TableName = tableName,
Item = item,
ReturnItemCollectionMetrics = "SIZE"
};
client.PutItem(putItemRequest);
}
private static void WaitUntilTableReady(string tableName)
{
string status = null;
// Let us wait until table is created. Call DescribeTable.
do
{
System.Threading.Thread.Sleep(5000); // Wait 5 seconds.
try
{
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
status = res.Table.TableStatus;
}
catch (ResourceNotFoundException)
{
// DescribeTable is eventually consistent. So you might
// get resource not found. So we handle the potential
exception.
}
} while (status != "ACTIVE");
}
private static void WaitForTableToBeDeleted(string tableName)
{
bool tablePresent = true;
while (tablePresent)
{
System.Threading.Thread.Sleep(5000); // Wait 5 seconds.
try
{
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
}
catch (ResourceNotFoundException)
{
tablePresent = false;
}
}
}
API Version 2012-08-10
417
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
}
}
ローカルセカンダリインデックス の操作 : PHP
トピック
• ローカルセカンダリインデックス を使用したテーブルの作成 (p. 418)
• ローカルセカンダリインデックス のクエリ (p. 419)
• 例: AWS SDK for PHP 低レベル API を使用した ローカルセカンダリインデックス (p. 420)
AWS SDK for PHP 低レベル API を使用して、1 つ以上の local secondary index を持つテーブルを作
成し、テーブルのインデックスについて説明し、インデックスを使用してクエリを実行することがで
きます。これらのオペレーションは、対応する DynamoDB API にマッピングされます。詳細について
は、「PHP コードサンプル (p. 175)」を参照してください。
以下に、AWS SDK for PHP を使用したテーブルオペレーションの一般的な手順を示します。
1. DynamoDB クライアントのインスタンスを作成します。
2. オプションのパラメーターを含む DynamoDB オペレーションのパラメーターを指定します。
3. DynamoDB からの応答をアプリケーションのローカル変数にロードします。
ローカルセカンダリインデックス を使用したテーブルの作成
ローカルセカンダリインデックス は、テーブルの作成と同時に作成する必要があります。そのために
は、CreateTable を使用して、1 つ以上の local secondary index の仕様を指定します。
次の PHP コードスニペットでは、音楽コレクション内の曲に関する情報を保存するテーブルを作成し
ています。パーティションキーは Artist で、ソートキーは SongTitle です。セカンダリインデックスの
AlbumTitleIndex は、アルバムのタイトルによるクエリを容易にします。インデックスに射影される属
性は、テーブルのパーティションキーおよびソートキーと、インデックスのソートキーだけです。
require 'vendor/autoload.php';
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'Music';
$result = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[ 'AttributeName' => 'Artist', 'AttributeType' => 'S' ],
[ 'AttributeName' => 'SongTitle', 'AttributeType' => 'S' ],
[ 'AttributeName' => 'AlbumTitle', 'AttributeType' => 'S'
]
],
'KeySchema' => [
[ 'AttributeName' => 'Artist', 'KeyType' => 'HASH' ],
[ 'AttributeName' => 'SongTitle', 'KeyType' => 'RANGE' ]
],
API Version 2012-08-10
418
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
'LocalSecondaryIndexes' => [
[
'IndexName' => 'AlbumTitleIndex',
'KeySchema' => [
[ 'AttributeName' => 'Artist', 'KeyType' => 'HASH' ],
[ 'AttributeName' => 'AlbumTitle', 'KeyType' => 'RANGE' ]
],
'Projection' => [
'ProjectionType' => 'INCLUDE',
'NonKeyAttributes' => ['Genre', 'Year']
]
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 5,
'WriteCapacityUnits' => 5
]
]);
DynamoDB がテーブルを作成し、テーブルのステータスを ACTIVE に設定するまで待機する必要があ
ります。その後は、データ項目をテーブルに書き込むことが可能になります。
ローカルセカンダリインデックス のクエリ
local secondary index では、テーブルの Query を実行するのと同様の方法で、Query オペレーション
を使用できます。 インデックス名、インデックスソートキーのクエリ基準、および返されるようにす
る属性を指定する必要があります。この例では、インデックスが AlbumTitleIndex で、インデックス
ソートキーが AlbumTitle です。
返される属性は、インデックスに射影された属性だけです。このクエリを変更して非キー属性も選択
するように設定することもできますが、その場合は比較的コストがかかるテーブルフェッチアクティ
ビティが必要になります。テーブルのフェッチの詳細については、「属性の射影 (p. 385)」を参照し
てください。
$tableName='Music';
$response = $dynamodb->query([
'TableName' => $tableName,
'IndexName' => 'AlbumTitleIndex',
'KeyConditionExpression' => 'Artist = :v_artist and AlbumTitle
>= :v_title',
'ExpressionAttributeValues' => [
':v_artist' => ['S' => 'Acme Band'],
':v_title' => ['S' => 'Songs About Life']
],
'Select' => 'ALL_ATTRIBUTES'
]);
echo "Acme Band's Songs About Life:\n";
foreach($response['Items'] as $item) {
echo "
- " . $item['SongTitle']['S'] . "\n";
}
API Version 2012-08-10
419
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
例: AWS SDK for PHP 低レベル API を使用した ローカルセカンダリインデッ
クス
次の PHP コード例では、local secondary index の操作方法を示します。この例では、パーティション
キーとして CustomerId、ソートキーとして OrderId を使用して、CustomerOrders という名前のテー
ブルが作成されます。このテーブルには次の 2 つの local secondary index があります。
• OrderCreationDateIndex — ソートキーは OrderCreationDate で、次の属性がインデックスに射影さ
れます。
• ProductCategory
• ProductName
• OrderStatus
• ShipmentTrackingId
• IsOpenIndex — ソートキーは IsOpen で、すべてのテーブル属性がインデックスに射影されていま
す。
CustomerOrders テーブルを作成すると、プログラムによってカスタマーの注文を表すデータがテー
ブルにロードされ、local secondary index を使用してデータのクエリが行われます。最後に、プログ
ラムによって CustomerOrders テーブルが削除されます。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'CustomerOrders';
echo "# Creating table $tableName...\n";
try {
$response = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[ 'AttributeName' => 'CustomerId', 'AttributeType' => 'S' ],
[ 'AttributeName' => 'OrderId', 'AttributeType' => 'N' ],
[ 'AttributeName' => 'OrderCreationDate', 'AttributeType' =>
'N' ],
[ 'AttributeName' => 'IsOpen', 'AttributeType' => 'N' ]
],
'KeySchema' => [
[ 'AttributeName' => 'CustomerId', 'KeyType' => 'HASH' ], //
Partition key
[ 'AttributeName' => 'OrderId', 'KeyType' => 'RANGE' ] //Sort key
],
'LocalSecondaryIndexes' => [
[
'IndexName' => 'OrderCreationDateIndex',
API Version 2012-08-10
420
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
'KeySchema' => [
[ 'AttributeName' => 'CustomerId', 'KeyType' => 'HASH' ],
//Partition key
[ 'AttributeName' => 'OrderCreationDate', 'KeyType' =>
'RANGE' ] //Sort key
],
'Projection' => [
'ProjectionType' => 'INCLUDE',
'NonKeyAttributes' => ['ProductCategory', 'ProductName']
]
],
[
'IndexName' => 'IsOpenIndex',
'KeySchema' => [
[ 'AttributeName' => 'CustomerId', 'KeyType' => 'HASH' ],
//Partition key
[ 'AttributeName' => 'IsOpen', 'KeyType' => 'RANGE' ] //
Sort key
],
'Projection' => [ 'ProjectionType' => 'ALL' ]
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits' => 5, 'WriteCapacityUnits' => 5
]
]);
echo " Waiting for table $tableName to be created.\n";
$dynamodb->waitUntil('TableExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
]);
echo " Table $tableName has been created.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to create table $tableName\n");
}
#########################################
# Add items to the table
echo "# Loading data into $tableName...\n";
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '1'],
'IsOpen' => ['N' => '1'],
'OrderCreationDate' => ['N' => '20140101'],
'ProductCategory' => ['S' => 'Book'],
'ProductName' => ['S' => 'The Great Outdoors'],
'OrderStatus' => ['S' => 'PACKING ITEMS']
]
]);
API Version 2012-08-10
421
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '2'],
'IsOpen' => ['N' => '1'],
'OrderCreationDate' => ['N' => '20140221'],
'ProductCategory' => ['S' => 'Bike'],
'ProductName' => ['S' => 'Super Mountain'],
'OrderStatus' => ['S' => 'ORDER RECEIVED']
]
]);
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '3'],
// no IsOpen attribute
'OrderCreationDate' => ['N' => '20140304'],
'ProductCategory' => ['S' => 'Music'],
'ProductName' => ['S' => 'A Quiet Interlude'],
'OrderStatus' => ['S' => 'IN TRANSIT'],
'ShipmentTrackingId' => ['N' => '176493']
]
]);
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '1'],
// no IsOpen attribute
'OrderCreationDate' => ['N' => '20140111'],
'ProductCategory' => ['S' => 'Movie'],
'ProductName' => ['S' => 'Calm Before The Storm'],
'OrderStatus' => ['S' => 'SHIPPING DELAY'],
'ShipmentTrackingId' => ['N' => '859323']
]
]);
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '2'],
// no IsOpen attribute
'OrderCreationDate' => ['N' => '20140124'],
'ProductCategory' => ['S' => 'Music'],
'ProductName' => ['S' => 'E-Z Listening'],
'OrderStatus' => ['S' => 'DELIVERED'],
'ShipmentTrackingId' => ['N' => '756943']
]
]);
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
API Version 2012-08-10
422
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '3'],
// no IsOpen attribute
'OrderCreationDate' => ['N' => '20140221'],
'ProductCategory' => ['S' => 'Music'],
'ProductName' => ['S' => 'Symphony 9'],
'OrderStatus' => ['S' => 'DELIVERED'],
'ShipmentTrackingId' => ['N' => '645193']
]
]);
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '4'],
'IsOpen' => ['N' => '1'],
'OrderCreationDate' => ['N' => '20140222'],
'ProductCategory' => ['S' => 'Hardware'],
'ProductName' => ['S' => 'Extra Heavy Hammer'],
'OrderStatus' => ['S' => 'PACKING ITEMS']
]
]);
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '5'],
// no IsOpen attribute
'OrderCreationDate' => ['N' => '20140309'],
'ProductCategory' => ['S' => 'Book'],
'ProductName' => ['S' => 'How To Cook'],
'OrderStatus' => ['S' => 'IN TRANSIT'],
'ShipmentTrackingId' => ['N' => '440185']
]
]);
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '6'],
// no IsOpen attribute
'OrderCreationDate' => ['N' => '20140318'],
'ProductCategory' => ['S' => 'Luggage'],
'ProductName' => ['S' => 'Really Big Suitcase'],
'OrderStatus' => ['S' => 'DELIVERED'],
'ShipmentTrackingId' => ['N' => '893927']
]
]);
$response = $dynamodb->putItem ( [
'TableName' => $tableName,
'Item' => [
'CustomerId' => ['S' => '[email protected]'],
'OrderId' => ['N' => '7'],
// no IsOpen attribute
'OrderCreationDate' => ['N' => '20140324'],
API Version 2012-08-10
423
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
'ProductCategory' => ['S' => 'Golf'],
'ProductName' => ['S' => 'PGA Pro II'],
'OrderStatus' => ['S' => 'OUT FOR DELIVERY'],
'ShipmentTrackingId' => ['N' => '383283']
]
]);
#########################################
# Query for Bob's 5 most recent orders in 2014, retrieving attributes which
# are projected into the index
$response = $dynamodb->query([
'TableName' => $tableName,
'IndexName' => 'OrderCreationDateIndex',
'KeyConditionExpression' => 'CustomerId = :v_id and OrderCreationDate
>= :v_dt',
'ExpressionAttributeValues' => [
':v_id' => ['S' => '[email protected]'],
':v_dt' => ['N' => '20140101']
],
'Select' => 'ALL_PROJECTED_ATTRIBUTES',
'ScanIndexForward' => false,
'ConsistentRead' => true,
'Limit' => 5,
'ReturnConsumedCapacity' => 'TOTAL'
]);
echo "# Querying for Bob's 5 most recent orders in 2014:\n";
foreach($response['Items'] as $item) {
echo '
- ' . $item['CustomerId']['S'] .
' ' . $item['OrderCreationDate']['N'] .
' ' . $item['ProductName']['S'] .
' ' . $item['ProductCategory']['S'] .
"\n";
}
echo ' Provisioned Throughput Consumed: ' .
$response['ConsumedCapacity']['CapacityUnits'] . "\n";
#########################################
# Query for Bob's 5 most recent orders in 2014, retrieving some attributes
# which are not projected into the index
$response = $dynamodb->query([
'TableName' => $tableName,
'IndexName' => 'OrderCreationDateIndex',
'KeyConditionExpression' => 'CustomerId = :v_id and OrderCreationDate
>= :v_dt',
'ExpressionAttributeValues' => [
':v_id' => ['S' => '[email protected]'],
':v_dt' => ['N' => '20140101']
],
'Select' => 'SPECIFIC_ATTRIBUTES',
'ProjectionExpression' =>
'CustomerId, OrderCreationDate, ProductName, ProductCategory,
OrderStatus',
'ScanIndexForward' => false,
'ConsistentRead' => true,
'Limit' => 5,
API Version 2012-08-10
424
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス
'ReturnConsumedCapacity' => 'TOTAL'
]);
echo "# Querying for Bob's 5 most recent orders in 2014:" . "\n";
foreach($response['Items'] as $item) {
echo '
- ' . $item['CustomerId']['S'] .
' ' . $item['OrderCreationDate']['N'] .
' ' . $item['ProductName']['S'] .
' ' . $item['ProductCategory']['S'] .
' ' . $item['OrderStatus']['S'] .
"\n";
}
echo ' Provisioned Throughput Consumed: ' .
$response['ConsumedCapacity']['CapacityUnits'] . "\n";
#########################################
# Query for Alice's open orders, fetching all attributes
# (which are already projected into the index)
$response = $dynamodb->query([
'TableName' => $tableName,
'IndexName' => 'IsOpenIndex',
'KeyConditionExpression' => 'CustomerId = :v_id',
'ExpressionAttributeValues' => [
':v_id' => ['S' => '[email protected]']
],
'Select' => 'ALL_ATTRIBUTES',
'ScanIndexForward' => false,
'ConsistentRead' => true,
'Limit' => 5,
'ReturnConsumedCapacity' => 'TOTAL'
]);
echo "# Querying for Alice's open orders:" . "\n";
foreach($response['Items'] as $item) {
echo '
- ' . $item['CustomerId']['S'].
' ' . $item['OrderCreationDate']['N'] .
' ' . $item['ProductName']['S'] .
' ' . $item['ProductCategory']['S'] .
' ' . $item['OrderStatus']['S'] .
"\n";
}
echo ' Provisioned Throughput Consumed: ' .
$response['ConsumedCapacity']['CapacityUnits'] . "\n";
#########################################
# Delete the table
try {
$dynamodb->deleteTable(['TableName' => $tableName]);
echo " Waiting for table $tableName to be deleted.\n";
$dynamodb->waitUntil('TableNotExists', [
'TableName' => $tableName,
'@waiter' => [
'delay'
=> 5,
'maxAttempts' => 20
]
API Version 2012-08-10
425
Amazon DynamoDB 開発者ガイド
ストリームの使用
]);
echo " Table $tableName has been deleted.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to delete table $tableName\n");
}
?>
DynamoDB ストリーム を使用したテーブルアク
ティビティのキャプチャ
多くのアプリケーションでは、DynamoDB テーブルに保存された項目の変更を、変更の発生時にキャ
プチャできると役立ちます。ユースケースは次のとおりです。
• ある AWS リージョンのアプリケーションが、DynamoDB テーブルのデータを変更します。別の
AWS リージョンの 2 番目のアプリケーションがそのデータ変更を読み込み、データを別のテーブ
ルに書き込みます。このとき、元のテーブルと同期されたレプリカを作成します。
• 人気のモバイルアプリは、1 秒あたり数千件の更新速度で、DynamoDB テーブルのデータを変更し
ます。別のアプリケーションは、これらの更新に関するデータをキャプチャして保存し、モバイル
アプリの使用状況メトリクスをほぼリアルタイムで提供します。
• グローバルなマルチプレーヤーゲームには、データを複数の AWS リージョンに保存するマルチマ
スタートポロジがあります。各マスターは、リモートリージョンで発生した変更を使用および再現
することにより同期されます。
• アプリケーションは、友人の 1 人が新しい画像をアップロードするとすぐに、グループ内のすべて
の友人のモバイルデバイスに通知を自動送信します。
• 新しいお客様がデータを DynamoDB テーブルに追加します。このイベントにより、新しいお客様
にようこそメールを送信する別のアプリケーションが起動されます。
DynamoDB ストリーム では、このようなソリューションに加えて、他にも多くのソリューションを
実現できます。DynamoDB ストリーム は、DynamoDB テーブル内の項目レベルの変更の時系列シー
ケンスをキャプチャし、この情報を最大 24 時間ログに保存します。アプリケーションは、このログ
にアクセスし、データ項目の変更前および変更後の内容をほぼリアルタイムで参照できます。
DynamoDB ストリームは、Amazon DynamoDB テーブル内の項目に加えられた変更に関する情報の
順序付けされた情報です。テーブルでストリームを有効にすると、DynamoDB はテーブル内のデータ
項目に加えられた各変更に関する情報をキャプチャします。
アプリケーションがテーブル内の項目を作成、更新、または削除するたびに、DynamoDB ストリーム
は変更された項目のプライマリキー属性を付けてストリームレコードを書き込みます。ストリームレ
コードには、DynamoDB テーブル内の単一の項目に加えれたデータ変更についての情報が含まれてい
ます。ストリームレコードが追加情報(変更された項目の前後のイメージ)をキャプチャするように
ストリームを設定できます。
DynamoDB ストリーム では、以下の点が保証されます。
• 各ストリームレコードは、ストリームに 1 回だけ出現します。
• DynamoDB テーブルで変更された各項目について、ストリームレコードは項目に対する実際の変更
と同じ順序で出現します。
DynamoDB ストリーム は、ストリームレコードをほぼリアルタイムで書き込むため、これらのスト
リームを使用し、内容に基づいてアクションを実行するアプリケーションを構築できます。
API Version 2012-08-10
426
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム におけるエンドポイント
DynamoDB ストリーム におけるエンドポイント
AWS では、DynamoDB と DynamoDB ストリーム に別個のエンドポイントが維持されます。データ
ベースのテーブルとインデックスを使用するには、アプリケーションが DynamoDB エンドポイント
にアクセスする必要があります。DynamoDB ストリーム レコードを読み込んで処理するには、アプ
リケーションが同じリージョンの DynamoDB ストリーム エンドポイントにアクセスする必要があり
ます。
DynamoDB ストリーム エンドポイントの命名規則は
streams.dynamodb.<region>.amazonaws.com です。たとえば、エンドポイント dynamodb.uswest-2.amazonaws.com を使用して DynamoDB にアクセスする場合、エンドポイント
streams.dynamodb.us-west-2.amazonaws.com を使用して DynamoDB ストリーム にアクセス
する必要があります。
Note
DynamoDB と DynamoDB ストリーム のリージョンおよびエンドポイントの詳細なリストに
ついては、『AWS General Reference』の「リージョンとエンドポイント」を参照してくだ
さい。
AWS SDK は、さまざまなクライアントに DynamoDB また DynamoDB ストリーム を提供します。要
件によっては、アプリケーションは、DynamoDB エンドポイント、DynamoDB ストリーム エンドポ
イント、または両方に同時にアクセスできます。両エンドポイントに接続するには、アプリケーショ
ンは、DynamoDB 用と DynamoDB ストリーム 用の 2 つのクライアントをインスタンス化する必要が
あります。
API Version 2012-08-10
427
Amazon DynamoDB 開発者ガイド
ストリームの有効化
ストリームの有効化
新しいテーブルでは、そのテーブルの作成時にストリームを有効にできます。既存のテーブルでスト
リームを有効または無効にしたり、ストリームの設定を変更することもできます。DynamoDB スト
リーム は非同期的に動作するため、ストリームを有効にしてもテーブルのパフォーマンスに影響は与
えません。
DynamoDB ストリーム を管理するには、AWS マネジメントコンソール を使用するのが最も簡単な方
法です。
1.
2.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
DynamoDB コンソールのダッシュボードから、[Tables] を選択します。
3.
[Overview] タブで、[Manage Stream] を選択します。
4.
[Manage Stream] ウィンドウで、テーブルのデータが変更されるたびにストリームに書き込まれ
る情報を選択します。
• [Keys only] — 変更された項目のキー属性のみ。
• [New image] — 変更後に表示される項目全体。
• [Old image] — 変更前に表示されていた項目全体。
• [New and old images] — 項目の新しいイメージと古いイメージの両方。
5.
すべての設定が正しいことを確認したら、[Enable] を選択します。
(オプション) 既存のストリームを無効にするには、[Manage Stream] を選択し、[Disable] を選択
します。
CreateTable または UpdateTable API を使用して、ストリームを有効にするか、変更することもで
きます。ストリームの設定内容は、StreamSpecification パラメータにより決まります。
• StreamEnabled - テーブルでストリームが有効(true)か無効(false)かを指定します。
• StreamViewType - テーブル内のデータが変更されるたびにストリームに書き込まれる情報を指定
します。
• KEYS_ONLY - 変更された項目のキー属性のみ。
• NEW_IMAGE – 変更後に表示される項目全体。
• OLD_IMAGE – 変更前に表示されていた項目全体。
• NEW_AND_OLD_IMAGES - 項目の新しいイメージと古いイメージの両方。
ストリームはいつでも有効または無効にできます。ただし、既にストリームがあるテーブルでスト
リームを有効にしようとした場合は ResourceInUseException を受け取り、ストリームのないテーブ
ルでストリームを無効にしようとすると ValidationException を受け取る点に注意してください。
StreamEnabled を true に設定すると、一意のストリーム記述子が割り当てられた新しいストリー
ムが DynamoDB により作成されます。テーブルでストリームを無効にして再度有効にすると、新し
いストリームは異なるストリーム記述子で作成されます。
各ストリームは、Amazon リソースネーム(ARN)により一意に識別されます。TestTable という
DynamoDB テーブルにあるストリームのサンプル ARN を次に示します。
arn:aws:dynamodb:us-west-2:111122223333:table/TestTable/
stream/2015-05-11T21:21:33.291
テーブルの最新のストリーム記述子を調べるには、DynamoDB DescribeTable リクエストを発行
し、レスポンスで LatestStreamArn 要素を探します。
API Version 2012-08-10
428
Amazon DynamoDB 開発者ガイド
ストリームの読み込みと処理
ストリームの読み込みと処理
ストリームを読み込んで処理するには、アプリケーションが DynamoDB ストリーム エンドポイント
に接続して API リクエストを発行する必要があります。
ストリームは、ストリームレコードで構成されています。各ストリームレコードは、ストリームが
属する DynamoDB テーブル内の 1 件のデータ変更を表しています。各ストリームレコードには、レ
コードがストリームに発行された順序を反映したシーケンス番号が割り当てられます。
ストリームレコードは、グループ(つまり、シャード)に整理されます。各シャードは、複数のスト
リームレコードのコンテナとして機能し、これらのレコードへのアクセスと反復処理に必要な情報が
含まれています。シャード内のストリームレコードは 24 時間後に自動的に削除されます。
シャードはエフェメラルであり、必要に応じて自動的に作成および削除されます。また、任意の
シャードは複数の新しいシャードに分割できます。これもまた自動的に行われます (親シャードが 1
つの子シャードのみを持つ場合もあります)。アプリケーションが複数のシャードからレコードを並列
処理できるように、シャードは親テーブルで高レベルな書き込みアクティビティに応じて分割される
場合があります。
ストリームを無効にすると、開かれているシャードは閉じられます。
シャードには系列 (親と子) があるため、アプリケーションは子シャードを処理する前に、必ず親
シャードを処理する必要があります。これにより、ストリームレコードも正しい順序で処理されるよ
うになります。DynamoDB ストリーム Kinesis Adapter を使用している場合、これは自動的に処理さ
れます。アプリケーションは、シャードとストリームレコードを正しい順序で処理し、新しいシャー
ド、期限切れのシャード、およびアプリケーションの実行中に分割されたシャードを自動的に処理し
ます。詳細については、「DynamoDB ストリーム Kinesis Adapter を使用したストリームレコードの
処理 (p. 430)」を参照してください。
次の図は、ストリーム、ストリーム内のシャード、シャード内のストリームレコードの関係を示して
います。
Note
項目内のデータを何も変更しないPutItemまたはUpdateItem オペレーションを実行した場
合、そのオペレーションのストリームレコードは DynamoDB ストリーム によって書き込ま
れません。
API Version 2012-08-10
429
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
ストリームにアクセスしてその中のストリームレコードを処理するには、以下の操作を実行する必要
があります。
• アクセスするストリームの一意の Amazon リソースネーム(ARN)を調べます。
• 目的のストリームレコードがストリーム内のどのシャードに含まれているかを調べます。
• シャードにアクセスし、目的のストリームレコードを取得します。
Note
最大でも 2 つを超えるプロセスが、同時に同じストリームシャードから読み取りを行うこと
はできません。シャードごとに 2 つを超えるリーダーがあると、スロットリングが発生する
場合があります。
DynamoDB ストリーム API は、アプリケーションプログラムが使用する次のアクションを提供しま
す。
• ListStreams - 現在のアカウントおよびエンドポイントのストリーム記述子のリストを返します。
必要に応じて、特定のテーブル名のストリーム記述子だけをリクエストできます。
• DescribeStream - 特定のストリームに関する詳細情報を返します。出力には、ストリームに関連
付けられたシャードのリストが含まれています(シャード ID を含む)。
• GetShardIterator - シャード内の場所を表すシャードイテレーターを返します。イテレータがス
トリーム内の最も古いポイント、最も新しいポイント、特定のポイントへのアクセスを提供するこ
とをリクエストできます。
• GetRecords - 特定のシャード内からストリームレコードを返します。GetShardIterator リクエ
ストから返されたシャードイテレーターを指定する必要があります。
リクエストやレスポンスの例など、これらの API アクションの詳細な説明については、「DynamoDB
ストリーム API リファレンス」を参照してください。
DynamoDB ストリーム のデータ保持期限
DynamoDB ストリーム 内のすべてのデータは、24 時間保持されます。特定のテーブルの直近 24 時
間のアクティビティを取得して分析できますが、24 時間を超えたデータはすぐにトリミング(削除)
される可能性があります。
テーブルのストリームを無効にした場合、ストリーム内のデータは 24 時間読み込み可能な状態にな
ります。この時間が経過すると、データは期限切れになり、ストリームレコードは自動的に削除され
ます。既存のストリームを手動で削除するためのメカニズムはないことに注意してください、保持期
限が切れて(24 時間)、すべてのストリームレコードが削除されるまで待つ必要があります。
DynamoDB ストリーム Kinesis Adapter を使用した
ストリームレコードの処理
DynamoDB から Streams を消費するには、Kinesis Adapter の使用をお勧めします。
DynamoDB ストリーム API は、Amazon Kinesis Streams (大規模なストリーミングデータをリアル
タイムで処理するためのサービス) の API と意図的に似たものになっています。 どちらのサービスで
も、データストリームはシャード(ストリームレコードのコンテナ)で構成されています。どちらの
サービスの API にも、ListStreams、DescribeStream、GetShards、GetShardIterator の各
アクションが含まれています(DynamoDB ストリーム のアクションは Amazon Kinesis Streams のア
クションと似ていますが、100% 同じではありません。)
Amazon Kinesis Streams のアプリケーションは、Amazon Kinesis Client Library (KCL) を使用して
記述できます。KCL は、低レベルの Amazon Kinesis Streams API の上で役に立つ抽象化を提供す
API Version 2012-08-10
430
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
ることによりコーディングを簡素化します。KCL の詳細については、「Amazon Kinesis Developer
Guide」を参照してください。
DynamoDB ストリーム ユーザーは、KCL 内で見つかった設計パターンを活用して、DynamoDB スト
リーム のシャードとストリームレコードを活用できます。 これを行うには、DynamoDB ストリーム
Kinesis Adapter を使用します。 DynamoDB ストリーム からのレコードの使用と処理に KCL を使用
できるように、Kinesis Adapter には Amazon Kinesis Streams インターフェイスが実装されます。
次の図に、これらのライブラリがどのように相互に作用するかを示します。
DynamoDB ストリーム Kinesis Adapter が用意されたら、DynamoDB ストリーム エンドポイントで
シームレスに指示された API 呼び出しを行って、KCL インターフェイスを対象とした開発を開始でき
ます。
アプリケーションは起動時に KCL を呼び出してワーカーをインスタンス化します。ワーカーには、
アプリケーションの設定情報(ストリームの記述子や AWS 認証情報など)と、お客様が指定したレ
コードプロセッサクラス名を提供する必要があります。ワーカーは、コードをレコードプロセッサで
実行するため、以下のタスクを実行します。
API Version 2012-08-10
431
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
• ストリームに接続する.
• ストリーム内のシャードを列挙します。
• シャードと他のワーカー(存在する場合)の関連付けを調整します。
• レコードプロセッサで管理する各シャードのレコードプロセッサをインスタンス化する.
• ストリームからレコードを取得します。
• 対応するレコードプロセッサにレコードを送信する.
• 処理されたレコードのチェックポイントを作成する.
• ワーカーのインスタンス数が変化したときに、シャードとワーカーの関連付けを調整する.
• シャードが分割されたときに、シャードとワーカーの関連付けを調整する.
Note
上記の KCL の概念の説明については、『Amazon Kinesis Developer Guide』の「Amazon
Kinesis クライアントライブラリを使用した Amazon Kinesis コンシューマーの開発」を参照
してください。
チュートリアル : DynamoDB ストリーム Kinesis Adapter
このセクションは、Kinesis Client Library と DynamoDB ストリーム Kinesis Adapter を使用する Java
アプリケーションのチュートリアルです。 アプリケーションには、データレプリケーションの例が表
示されます。データレプリケーションでは、1 つのテーブルからの書き込みアクティビティが 2 番目
のテーブルに適用され、両方のテーブルの内容が同期されます。ソースコードについては、「完成し
たプログラム: DynamoDB ストリーム Kinesis Adapter (p. 435)」を参照してください。
このプログラムでは、次のような処理を実行します。
1. KCL-Demo-src と KCL-Demo-dst という 2 つの DynamoDB テーブルを作成します。これらの各
テーブルでは、ストリームが有効になっています。
2. 項目を追加、更新、削除することで、ソーステーブルで更新アクティビティを生成します。これに
より、データがテーブルのストリームに書き込まれます。
3. ストリームからレコードを読み込んで、DynamoDB リクエストとして再構築し、ターゲットテーブ
ルにリクエストを適用します。
4. ソーステーブルとターゲットテーブルをスキャンし、内容が同じであることを確認します。
5. テーブルを削除してクリーンアップします。
これらのステップについては次のセクションで説明します。完成したアプリケーションは、チュート
リアルの最後に示します。
トピック
• ステップ 1: DynamoDB テーブルを作成する (p. 432)
• ステップ 2: ソーステーブルに更新アクティビティを生成する (p. 433)
• ステップ 3: ストリームを処理する (p. 433)
• ステップ 4: 両方のテーブルの内容が同じであることを確認する (p. 434)
• ステップ 5: クリーンアップ (p. 435)
• 完成したプログラム: DynamoDB ストリーム Kinesis Adapter (p. 435)
ステップ 1: DynamoDB テーブルを作成する
最初のステップでは、2 つの DynamoDB テーブル(ソーステーブルとターゲットテーブル)を作成し
ます。ソーステーブルのストリームにある StreamViewType は NEW_IMAGE です。これは、このテー
API Version 2012-08-10
432
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
ブルで項目が変更されると必ず、イメージの "後の" 項目がストリームに書き込まれることを意味しま
す。このようにして、ストリームはテーブル内のすべての書き込みアクティビティを記録します。
次のコードスニペットは、両方のテーブルを作成するためのコードを示しています。
java.util.List<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new
AttributeDefinition().withAttributeName("Id").withAttributeType("N"));
java.util.List<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new
KeySchemaElement().withAttributeName("Id").withKeyType(KeyType.HASH));
Partition key
//
ProvisionedThroughput provisionedThroughput = new ProvisionedThroughput()
.withReadCapacityUnits(2L).withWriteCapacityUnits(2L);
StreamSpecification streamSpecification = new StreamSpecification();
streamSpecification.setStreamEnabled(true);
streamSpecification.setStreamViewType(StreamViewType.NEW_IMAGE);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(keySchema)
.withProvisionedThroughput(provisionedThroughput)
.withStreamSpecification(streamSpecification);
ステップ 2: ソーステーブルに更新アクティビティを生成する
次のステップでは、ソーステーブルにいくつかの書き込みアクティビティを生成します。このアク
ティビティの実行中、ソーステーブルのストリームもほぼリアルタイムで更新されます。
アプリケーションは、データを書き込むための PutItem、UpdateItem、および DeleteItem API ア
クションを呼び出すメソッドを持つヘルパークラスを定義します。次のコードスニペットは、これら
のメソッドの使用方法を示しています。
StreamsAdapterDemoHelper.putItem(dynamoDBClient, tableName, "101", "test1");
StreamsAdapterDemoHelper.updateItem(dynamoDBClient, tableName, "101",
"test2");
StreamsAdapterDemoHelper.deleteItem(dynamoDBClient, tableName, "101");
StreamsAdapterDemoHelper.putItem(dynamoDBClient, tableName, "102", "demo3");
StreamsAdapterDemoHelper.updateItem(dynamoDBClient, tableName, "102",
"demo4");
StreamsAdapterDemoHelper.deleteItem(dynamoDBClient, tableName, "102");
ステップ 3: ストリームを処理する
ここでは、プログラムがストリームの処理を開始します。DynamoDB ストリーム Kinesis Adapter
は、コードが低レベルの DynamoDB ストリーム 呼び出しを行わなくても KCL を十分に活用できるよ
うに、KCL と DynamoDB ストリーム エンドポイントの間の透過的なレイヤーとして機能します。 こ
のプログラムでは次のタスクを実行しています。
API Version 2012-08-10
433
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
• KCL インターフェイス定義に従ったメソッド(initialize、processRecords、shutdown)
を使用して、レコードプロセッサクラス StreamsRecordProcessor を定義しま
す。processRecords メソッドには、ソーステーブルのストリームからの読み込みとターゲット
テーブルへの書き込みに必要なロジックが含まれています。
• レコードプロセッサクラスのクラスファクトリを定義します
(StreamsRecordProcessorFactory)。これは、KCL を使用する Java プログラムに必要で
す。
• クラスファクトリに関連付けられた新しい KCL Worker をインスタンス化します。
• レコード処理が完了すると、Worker をシャットダウンします。
KCL インターフェイス定義の詳細については、『Amazon Kinesis Developer Guide』の「Amazon
Kinesis クライアントライブラリを使用した Amazon Kinesis コンシューマーの開発」を参照してくだ
さい。
次のコードスニペットは、StreamsRecordProcessor におけるメインループを示しています。case
ステートメントは、ストリームレコードに出現する OperationType に基づいて、実行するアクショ
ンを決定します。
for(Record record : records) {
String data = new String(record.getData().array(),
Charset.forName("UTF-8"));
System.out.println(data);
if(record instanceof RecordAdapter) {
com.amazonaws.services.dynamodbv2.model.Record streamRecord =
((RecordAdapter) record).getInternalObject();
switch(streamRecord.getEventName()) {
case "INSERT" : case "MODIFY" :
StreamsAdapterDemoHelper.putItem(dynamoDBClient, tableName,
streamRecord.getDynamodb().getNewImage());
break;
case "REMOVE" :
StreamsAdapterDemoHelper.deleteItem(dynamoDBClient,
tableName, streamRecord.getDynamodb().getKeys().get("Id").getN());
}
}
checkpointCounter += 1;
if(checkpointCounter % 10 == 0) {
try {
checkpointer.checkpoint();
} catch(Exception e) {
e.printStackTrace();
}
}
}
}
ステップ 4: 両方のテーブルの内容が同じであることを確認する
この時点で、ソーステーブルとターゲットテーブルの内容が同期されています。アプリケーション
は、両方のテーブルに対して Scan リクエストを発行し、内容が実際に同じであることを確認しま
す。
DemoHelper クラスには、低レベルのスキャン API を呼び出す ScanTable メソッドが含まれていま
す。次のコードスニペットは、このクラスの使用方法を示しています。
API Version 2012-08-10
434
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
if(StreamsAdapterDemoHelper.scanTable(dynamoDBClient,
srcTable).getItems().equals(StreamsAdapterDemoHelper.scanTable(dynamoDBClient,
destTable).getItems())) {
System.out.println("Scan result is equal.");
} else {
System.out.println("Tables are different!");
}
ステップ 5: クリーンアップ
デモは完了したため、アプリケーションによりソーステーブルとターゲットテーブルが削除されま
す。次のコードスニペットを参照してください。
テーブルが削除されても、そのストリームは最大 24 時間使用可能です。その後、自動的に削除され
ます。
dynamoDBClient.deleteTable(new DeleteTableRequest().withTableName(srcTable));
dynamoDBClient.deleteTable(new
DeleteTableRequest().withTableName(destTable));
完成したプログラム: DynamoDB ストリーム Kinesis Adapter
このチュートリアルで説明したタスクを実行する、完成した Java プログラムを次に示します。実行
すると、次のような出力が表示されます。
Creating table KCL-Demo-src
Creating table KCL-Demo-dest
Table is active.
Creating worker for stream: arn:aws:dynamodb:us-west-2:111122223333:table/
KCL-Demo-src/stream/2015-05-19T22:48:56.601
Starting worker...
Scan result is equal.
Done.
Important
このプログラムを実行するには、クライアントアプリケーションがポリシーを使用して
DynamoDB および CloudWatch にアクセスできることを確認します。詳細については、
「Amazon DynamoDB でアイデンティティベースのポリシー (IAM ポリシー) を使用す
る (p. 465)」を参照してください。
ソースコードは、4 つの .java ファイルから構成されています。
StreamsAdapterDemo.java
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.gsg;
import com.amazonaws.ClientConfiguration;
import com.amazonaws.auth.AWSCredentialsProvider;
API Version 2012-08-10
435
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.cloudwatch.AmazonCloudWatchClient;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.model.DeleteTableRequest;
import com.amazonaws.services.dynamodbv2.model.DescribeTableResult;
import
com.amazonaws.services.dynamodbv2.streamsadapter.AmazonDynamoDBStreamsAdapterClient;
import
com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessorFactory;
import
com.amazonaws.services.kinesis.clientlibrary.lib.worker.InitialPositionInStream;
import
com.amazonaws.services.kinesis.clientlibrary.lib.worker.KinesisClientLibConfiguration;
import com.amazonaws.services.kinesis.clientlibrary.lib.worker.Worker;
public class StreamsAdapterDemo {
private static Worker worker;
private static KinesisClientLibConfiguration workerConfig;
private static IRecordProcessorFactory recordProcessorFactory;
private static AmazonDynamoDBStreamsAdapterClient adapterClient;
private static AWSCredentialsProvider streamsCredentials;
private static AmazonDynamoDBClient dynamoDBClient;
private static AWSCredentialsProvider dynamoDBCredentials;
private static AmazonCloudWatchClient cloudWatchClient;
private
private
private
private
private
static
static
static
static
static
String
String
String
String
String
serviceName = "dynamodb";
dynamodbEndpoint = "DYNAMODB_ENDPOINT_GOES_HERE";
streamsEndpoint = "STREAMS_ENDPOINT_GOES_HERE";
tablePrefix = "KCL-Demo";
streamArn;
/**
* @param args
*/
public static void main(String[] args) throws Exception {
System.out.println("Starting demo...");
String srcTable = tablePrefix + "-src";
String destTable = tablePrefix + "-dest";
streamsCredentials = new ProfileCredentialsProvider();
dynamoDBCredentials = new ProfileCredentialsProvider();
recordProcessorFactory = new
StreamsRecordProcessorFactory(dynamoDBCredentials, dynamodbEndpoint,
serviceName, destTable);
/* ===== REQUIRED =====
* Users will have to explicitly instantiate and configure the
adapter, then pass it to
* the KCL worker.
*/
adapterClient = new
AmazonDynamoDBStreamsAdapterClient(streamsCredentials, new
ClientConfiguration());
adapterClient.setEndpoint(streamsEndpoint);
API Version 2012-08-10
436
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
dynamoDBClient = new AmazonDynamoDBClient(dynamoDBCredentials, new
ClientConfiguration());
dynamoDBClient.setEndpoint(dynamodbEndpoint);
cloudWatchClient = new AmazonCloudWatchClient(dynamoDBCredentials,
new ClientConfiguration());
setUpTables();
workerConfig = new KinesisClientLibConfiguration("streams-adapterdemo",
streamArn, streamsCredentials, "streams-demo-worker")
.withMaxRecords(1000)
.withIdleTimeBetweenReadsInMillis(500)
.withInitialPositionInStream(InitialPositionInStream.TRIM_HORIZON);
System.out.println("Creating worker for stream: " + streamArn);
worker = new Worker(recordProcessorFactory, workerConfig,
adapterClient, dynamoDBClient, cloudWatchClient);
System.out.println("Starting worker...");
Thread t = new Thread(worker);
t.start();
Thread.sleep(25000);
worker.shutdown();
t.join();
if(StreamsAdapterDemoHelper.scanTable(dynamoDBClient,
srcTable).getItems().equals(StreamsAdapterDemoHelper.scanTable(dynamoDBClient,
destTable).getItems())) {
System.out.println("Scan result is equal.");
} else {
System.out.println("Tables are different!");
}
System.out.println("Done.");
cleanupAndExit(0);
}
private static void setUpTables() {
String srcTable = tablePrefix + "-src";
String destTable = tablePrefix + "-dest";
streamArn = StreamsAdapterDemoHelper.createTable(dynamoDBClient,
srcTable);
StreamsAdapterDemoHelper.createTable(dynamoDBClient, destTable);
awaitTableCreation(srcTable);
performOps(srcTable);
}
private static void awaitTableCreation(String tableName) {
Integer retries = 0;
Boolean created = false;
while(!created && retries < 100) {
DescribeTableResult result =
StreamsAdapterDemoHelper.describeTable(dynamoDBClient, tableName);
API Version 2012-08-10
437
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
created = result.getTable().getTableStatus().equals("ACTIVE");
if (created) {
System.out.println("Table is active.");
return;
} else {
retries++;
try {
Thread.sleep(1000);
} catch(InterruptedException e) {
// do nothing
}
}
}
System.out.println("Timeout after table creation. Exiting...");
cleanupAndExit(1);
}
private static void performOps(String tableName) {
StreamsAdapterDemoHelper.putItem(dynamoDBClient, tableName, "101",
"test1");
StreamsAdapterDemoHelper.updateItem(dynamoDBClient, tableName, "101",
"test2");
StreamsAdapterDemoHelper.deleteItem(dynamoDBClient, tableName,
"101");
StreamsAdapterDemoHelper.putItem(dynamoDBClient, tableName, "102",
"demo3");
StreamsAdapterDemoHelper.updateItem(dynamoDBClient, tableName, "102",
"demo4");
StreamsAdapterDemoHelper.deleteItem(dynamoDBClient, tableName,
"102");
}
private static void cleanupAndExit(Integer returnValue) {
String srcTable = tablePrefix + "-src";
String destTable = tablePrefix + "-dest";
dynamoDBClient.deleteTable(new
DeleteTableRequest().withTableName(srcTable));
dynamoDBClient.deleteTable(new
DeleteTableRequest().withTableName(destTable));
System.exit(returnValue);
}
}
StreamsRecordProcessor.java
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.gsg;
import java.nio.charset.Charset;
import java.util.List;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.streamsadapter.model.RecordAdapter;
import
com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessor;
API Version 2012-08-10
438
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
import
com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessorCheckpointer;
import com.amazonaws.services.kinesis.clientlibrary.types.ShutdownReason;
import com.amazonaws.services.kinesis.model.Record;
public class StreamsRecordProcessor implements IRecordProcessor {
private Integer checkpointCounter;
private final AmazonDynamoDBClient dynamoDBClient;
private final String tableName;
public StreamsRecordProcessor(AmazonDynamoDBClient dynamoDBClient, String
tableName) {
this.dynamoDBClient = dynamoDBClient;
this.tableName = tableName;
}
@Override
public void initialize(String shardId) {
checkpointCounter = 0;
}
@Override
public void processRecords(List<Record> records,
IRecordProcessorCheckpointer checkpointer) {
for(Record record : records) {
String data = new String(record.getData().array(),
Charset.forName("UTF-8"));
System.out.println(data);
if(record instanceof RecordAdapter) {
com.amazonaws.services.dynamodbv2.model.Record streamRecord =
((RecordAdapter) record).getInternalObject();
switch(streamRecord.getEventName()) {
case "INSERT" : case "MODIFY" :
StreamsAdapterDemoHelper.putItem(dynamoDBClient,
tableName, streamRecord.getDynamodb().getNewImage());
break;
case "REMOVE" :
StreamsAdapterDemoHelper.deleteItem(dynamoDBClient,
tableName, streamRecord.getDynamodb().getKeys().get("Id").getN());
}
}
checkpointCounter += 1;
if(checkpointCounter % 10 == 0) {
try {
checkpointer.checkpoint();
} catch(Exception e) {
e.printStackTrace();
}
}
}
}
@Override
public void shutdown(IRecordProcessorCheckpointer checkpointer,
ShutdownReason reason) {
API Version 2012-08-10
439
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
if(reason == ShutdownReason.TERMINATE) {
try {
checkpointer.checkpoint();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
StreamsRecordProcessorFactory.java
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.gsg;
import com.amazonaws.ClientConfiguration;
import com.amazonaws.auth.AWSCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import
com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessor;
import
com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessorFactory;
public class StreamsRecordProcessorFactory implements
IRecordProcessorFactory {
private final AWSCredentialsProvider dynamoDBCredentials;
private final String dynamoDBEndpoint;
private final String tableName;
public StreamsRecordProcessorFactory(
AWSCredentialsProvider dynamoDBCredentials,
String dynamoDBEndpoint,
String serviceName,
String tableName) {
this.dynamoDBCredentials = dynamoDBCredentials;
this.dynamoDBEndpoint = dynamoDBEndpoint;
this.tableName = tableName;
}
@Override
public IRecordProcessor createProcessor() {
AmazonDynamoDBClient dynamoDBClient = new
AmazonDynamoDBClient(dynamoDBCredentials, new ClientConfiguration());
dynamoDBClient.setEndpoint(dynamoDBEndpoint);
return new StreamsRecordProcessor(dynamoDBClient, tableName);
}
}
StreamsAdapterDemoHelper.java
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
API Version 2012-08-10
440
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
package com.amazonaws.codesamples.gsg;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.model.AttributeAction;
com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
com.amazonaws.services.dynamodbv2.model.AttributeValue;
com.amazonaws.services.dynamodbv2.model.AttributeValueUpdate;
com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
com.amazonaws.services.dynamodbv2.model.CreateTableResult;
com.amazonaws.services.dynamodbv2.model.DeleteItemRequest;
com.amazonaws.services.dynamodbv2.model.DescribeTableRequest;
com.amazonaws.services.dynamodbv2.model.DescribeTableResult;
com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
com.amazonaws.services.dynamodbv2.model.KeyType;
com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
com.amazonaws.services.dynamodbv2.model.PutItemRequest;
com.amazonaws.services.dynamodbv2.model.ResourceInUseException;
com.amazonaws.services.dynamodbv2.model.ScanRequest;
com.amazonaws.services.dynamodbv2.model.ScanResult;
com.amazonaws.services.dynamodbv2.model.StreamSpecification;
com.amazonaws.services.dynamodbv2.model.StreamViewType;
com.amazonaws.services.dynamodbv2.model.UpdateItemRequest;
public class StreamsAdapterDemoHelper {
/**
* @return StreamArn
*/
public static String createTable(AmazonDynamoDBClient client, String
tableName) {
java.util.List<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new
AttributeDefinition().withAttributeName("Id").withAttributeType("N"));
java.util.List<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new
KeySchemaElement().withAttributeName("Id").withKeyType(KeyType.HASH)); //
Partition key
ProvisionedThroughput provisionedThroughput = new
ProvisionedThroughput()
.withReadCapacityUnits(2L).withWriteCapacityUnits(2L);
StreamSpecification streamSpecification = new StreamSpecification();
streamSpecification.setStreamEnabled(true);
streamSpecification.setStreamViewType(StreamViewType.NEW_IMAGE);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(keySchema)
.withProvisionedThroughput(provisionedThroughput)
.withStreamSpecification(streamSpecification);
API Version 2012-08-10
441
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム Kinesis Adapter
を使用したストリームレコードの処理
try {
System.out.println("Creating table " + tableName);
CreateTableResult result =
client.createTable(createTableRequest);
return result.getTableDescription().getLatestStreamArn();
} catch(ResourceInUseException e) {
System.out.println("Table already exists.");
return describeTable(client,
tableName).getTable().getLatestStreamArn();
}
}
public static DescribeTableResult describeTable(AmazonDynamoDBClient
client, String tableName) {
return client.describeTable(new
DescribeTableRequest().withTableName(tableName));
}
public static ScanResult scanTable(AmazonDynamoDBClient client, String
tableName) {
return client.scan(new ScanRequest().withTableName(tableName));
}
public static void putItem(AmazonDynamoDBClient client, String tableName,
String id, String val) {
java.util.Map<String, AttributeValue> item = new HashMap<String,
AttributeValue>();
item.put("Id", new AttributeValue().withN(id));
item.put("attribute-1", new AttributeValue().withS(val));
PutItemRequest putItemRequest = new PutItemRequest()
.withTableName(tableName)
.withItem(item);
client.putItem(putItemRequest);
}
public static void putItem(AmazonDynamoDBClient client, String tableName,
java.util.Map<String, AttributeValue> items) {
PutItemRequest putItemRequest = new PutItemRequest()
.withTableName(tableName)
.withItem(items);
client.putItem(putItemRequest);
}
public static void updateItem(AmazonDynamoDBClient client, String
tableName, String id, String val) {
java.util.Map<String, AttributeValue> key = new HashMap<String,
AttributeValue>();
key.put("Id", new AttributeValue().withN(id));
Map<String, AttributeValueUpdate> attributeUpdates = new
HashMap<String, AttributeValueUpdate>();
AttributeValueUpdate update = new AttributeValueUpdate()
.withAction(AttributeAction.PUT)
.withValue(new AttributeValue().withS(val));
attributeUpdates.put("attribute-2", update);
UpdateItemRequest updateItemRequest = new UpdateItemRequest()
API Version 2012-08-10
442
Amazon DynamoDB 開発者ガイド
チュートリアル : DynamoDB ス
トリーム の低レベルの API
.withTableName(tableName)
.withKey(key)
.withAttributeUpdates(attributeUpdates);
client.updateItem(updateItemRequest);
}
public static void deleteItem(AmazonDynamoDBClient client, String
tableName, String id) {
java.util.Map<String, AttributeValue> key = new HashMap<String,
AttributeValue>();
key.put("Id", new AttributeValue().withN(id));
DeleteItemRequest deleteItemRequest = new DeleteItemRequest()
.withTableName(tableName)
.withKey(key);
client.deleteItem(deleteItemRequest);
}
}
チュートリアル : DynamoDB ストリーム の低レベ
ルの API
このセクションは、動作中の DynamoDB ストリーム を示す Java プログラムのチュートリア
ルです。 ソースコードについては、「完成したプログラム: 低レベルの DynamoDB ストリーム
API (p. 446)」を参照してください。
このプログラムでは、次のような処理を実行します。
1. ストリームが有効になった DynamoDB テーブルを作成します。
2. このテーブルのストリーム設定を記述します。
3. テーブル内のデータを変更します。
4. ストリーム内のシャードを記述します。
5. シャードからストリームレコードを読み込みます。
6. クリーンアップ.
Note
このコードではすべての例外は処理されず、高トラフィックの条件下では確実に動作しませ
ん。DynamoDB からストリームレコードを使用する推奨の方法は、「DynamoDB ストリー
ム Kinesis Adapter を使用したストリームレコードの処理 (p. 430)」で説明しているよう
に、Amazon Kinesis Client Library (KCL) を使用し、Kinesis Adapter を介して行うことです。
これらのステップについては次のセクションで説明します。完成したアプリケーションは、チュート
リアルの最後に示します。
トピック
• ステップ 1: ストリームが有効になったテーブルを作成する (p. 444)
• ステップ 2: テーブルのストリーム設定を記述する (p. 444)
• ステップ 3: テーブル内のデータを変更する (p. 445)
• ステップ 4: ストリーム内のシャードを記述する (p. 445)
• ステップ 5: ストリーム レコードを読み込む (p. 445)
API Version 2012-08-10
443
Amazon DynamoDB 開発者ガイド
チュートリアル : DynamoDB ス
トリーム の低レベルの API
• ステップ 6: クリーンアップ (p. 446)
• 完成したプログラム: 低レベルの DynamoDB ストリーム API (p. 446)
ステップ 1: ストリームが有効になったテーブルを作成する
最初のステップでは、次のコードスニペットに示すように、DynamoDB にテーブルを作成し
ます。テーブルではストリームが有効になっています。ストリームは、変更された各項目の
NEW_AND_OLD_IMAGES をキャプチャします。
ArrayList<AttributeDefinition> attributeDefinitions =
new ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Id")
.withAttributeType("N"));
ArrayList<KeySchemaElement> keySchema = new ArrayList<KeySchemaElement>();
keySchema.add(new KeySchemaElement()
.withAttributeName("Id")
.withKeyType(KeyType.HASH)); //Partition key
StreamSpecification streamSpecification = new StreamSpecification();
streamSpecification.setStreamEnabled(true);
streamSpecification.setStreamViewType(StreamViewType.NEW_AND_OLD_IMAGES);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withKeySchema(keySchema)
.withAttributeDefinitions(attributeDefinitions)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L))
.withStreamSpecification(streamSpecification);
ステップ 2: テーブルのストリーム設定を記述する
DescribeTable API を使用すると、テーブルの現在のストリーム設定を表示することができます。
次のコードスニペットは、ストリームが有効になっていることと、適切なデータがキャプチャされる
ことを確認するのに役立ちます。
DescribeTableResult describeTableResult =
dynamoDBClient.describeTable(tableName);
String myStreamArn = describeTableResult.getTable().getLatestStreamArn();
StreamSpecification myStreamSpec =
describeTableResult.getTable().getStreamSpecification();
System.out.println("Current stream ARN for " + tableName + ": "+
myStreamArn);
System.out.println("Stream enabled: "+ myStreamSpec.getStreamEnabled());
System.out.println("Update view type: "+ myStreamSpec.getStreamViewType());
API Version 2012-08-10
444
Amazon DynamoDB 開発者ガイド
チュートリアル : DynamoDB ス
トリーム の低レベルの API
ステップ 3: テーブル内のデータを変更する
次のステップでは、テーブル内のデータにいくつかの変更を加えます。次のコードスニペットは、
テーブルに新しい項目を追加して、その項目の属性を更新し、項目を削除します。
// Add a new item
int numChanges = 0;
System.out.println("Making some changes to table data");
Map<String, AttributeValue> item = new HashMap<String, AttributeValue>();
item.put("Id", new AttributeValue().withN("101"));
item.put("Message", new AttributeValue().withS("New item!"));
dynamoDBClient.putItem(tableName, item);
numChanges++;
// Update the item
Map<String, AttributeValue> key = new HashMap<String, AttributeValue>();
key.put("Id", new AttributeValue().withN("101"));
Map<String, AttributeValueUpdate> attributeUpdates =
new HashMap<String, AttributeValueUpdate>();
attributeUpdates.put("Message", new AttributeValueUpdate()
.withAction(AttributeAction.PUT)
.withValue(new AttributeValue().withS("This item has changed")));
dynamoDBClient.updateItem(tableName, key, attributeUpdates);
numChanges++;
// Delete the item
dynamoDBClient.deleteItem(tableName, key);
numChanges++;
ステップ 4: ストリーム内のシャードを記述する
テーブル内のデータを変更すると、ストリームレコードがテーブルのストリームに書き込まれます。
「 ステップ 2: テーブルのストリーム設定を記述する (p. 444)」では、現在のストリーム ARN を
調べ、それを変数 myStreamArn に割り当てました。これを DescribeStream アクションで使用する
と、ストリーム内のシャードを取得できます。
DynamoDB テーブル内のデータを大きく変更したわけではないため、リストにはシャードが 1 つしか
ありません。次のコードスニペットは、この情報を取得する方法を示しています。
DescribeStreamResult describeStreamResult =
streamsClient.describeStream(new DescribeStreamRequest()
.withStreamArn(myStreamArn));
String streamArn =
describeStreamResult.getStreamDescription().getStreamArn();
List<Shard> shards =
describeStreamResult.getStreamDescription().getShards();
ステップ 5: ストリーム レコードを読み込む
リスト内のシャードごとに、シャードイテレーターを取得し、そのイテレーターを使用することでス
トリームレコードを取得して印刷します。
API Version 2012-08-10
445
Amazon DynamoDB 開発者ガイド
チュートリアル : DynamoDB ス
トリーム の低レベルの API
次のコードスニペットは、シャード 1 つしかない場合でもループを使用してシャードリストを処理し
ます。
for (Shard shard : shards) {
String shardId = shard.getShardId();
System.out.println(
"Processing " + shardId + " from stream "+ streamArn);
// Get an iterator for the current shard
GetShardIteratorRequest getShardIteratorRequest = new
GetShardIteratorRequest()
.withStreamArn(myStreamArn)
.withShardId(shardId)
.withShardIteratorType(ShardIteratorType.TRIM_HORIZON);
GetShardIteratorResult getShardIteratorResult =
streamsClient.getShardIterator(getShardIteratorRequest);
String nextItr = getShardIteratorResult.getShardIterator();
while (nextItr != null && numChanges > 0) {
// Use the iterator to read the data records from the shard
GetRecordsResult getRecordsResult =
streamsClient.getRecords(new GetRecordsRequest().
withShardIterator(nextItr));
List<Record> records = getRecordsResult.getRecords();
System.out.println("Getting records...");
for (Record record : records) {
System.out.println(record);
numChanges--;
}
nextItr = getRecordsResult.getNextShardIterator();
}
}
ステップ 6: クリーンアップ
デモが完了したため、テーブルを削除できます。テーブルが削除されても、このテーブルに関連付け
られたストリームは引き続き読み込み可能である点に注意してください。ストリームは 24 時間後に
自動的に削除されます。
dynamoDBClient.deleteTable(tableName);
完成したプログラム: 低レベルの DynamoDB ストリーム API
このチュートリアルで説明したタスクを実行する、完成した Java プログラムを次に示します。実行
すると、各ストリームレコードがすべて表示されます。
Issuing CreateTable request for TestTableForStreams
Waiting for TestTableForStreams to be created...
Current stream ARN for TestTableForStreams: arn:aws:dynamodb:uswest-2:111122223333:table/TestTableForStreams/stream/2015-05-19T23:03:50.641
Stream enabled: true
Update view type: NEW_AND_OLD_IMAGES
Making some changes to table data
API Version 2012-08-10
446
Amazon DynamoDB 開発者ガイド
チュートリアル : DynamoDB ス
トリーム の低レベルの API
Processing shardId-00000001415575208348-98d954b6 from stream
arn:aws:dynamodb:us-west-2:111122223333:table/TestTableForStreams/
stream/2015-05-19T23:03:50.641
Getting records...
{eventID: 7f6ba6f037b9fdd5a43af22cb726f0cd,eventName: INSERT,eventVersion:
1.0,eventSource: aws:dynamodb,awsRegion: us-west-2,dynamodb: {Keys: {Id={N:
101,}},NewImage: {Message={S: New item!,}, Id={N: 101,}},SequenceNumber:
100000000000000507337,SizeBytes: 26,StreamViewType: NEW_AND_OLD_IMAGES}}
{eventID: 8f546e78ab6183d1441c0680ec03dcfc,eventName: MODIFY,eventVersion:
1.0,eventSource: aws:dynamodb,awsRegion: us-west-2,dynamodb: {Keys:
{Id={N: 101,}},NewImage: {Message={S: This item has changed,}, Id={N:
101,}},OldImage: {Message={S: New item!,}, Id={N: 101,}},SequenceNumber:
200000000000000507338,SizeBytes: 59,StreamViewType: NEW_AND_OLD_IMAGES}}
{eventID: d9bb1e7a1684dfd66c8a3fb8ca2f6977,eventName: REMOVE,eventVersion:
1.0,eventSource: aws:dynamodb,awsRegion: us-west-2,dynamodb: {Keys:
{Id={N: 101,}},OldImage: {Message={S: This item has changed,}, Id={N:
101,}},SequenceNumber: 300000000000000507339,SizeBytes: 38,StreamViewType:
NEW_AND_OLD_IMAGES}}
Deleting the table...
Demo complete
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples.gsg;
import
import
import
import
java.util.ArrayList;
java.util.HashMap;
java.util.List;
java.util.Map;
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreamsClient;
com.amazonaws.services.dynamodbv2.model.AttributeAction;
com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
com.amazonaws.services.dynamodbv2.model.AttributeValue;
com.amazonaws.services.dynamodbv2.model.AttributeValueUpdate;
com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
com.amazonaws.services.dynamodbv2.model.DescribeStreamRequest;
com.amazonaws.services.dynamodbv2.model.DescribeStreamResult;
com.amazonaws.services.dynamodbv2.model.DescribeTableResult;
com.amazonaws.services.dynamodbv2.model.GetRecordsRequest;
com.amazonaws.services.dynamodbv2.model.GetRecordsResult;
com.amazonaws.services.dynamodbv2.model.GetShardIteratorRequest;
com.amazonaws.services.dynamodbv2.model.GetShardIteratorResult;
com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
com.amazonaws.services.dynamodbv2.model.KeyType;
com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
com.amazonaws.services.dynamodbv2.model.Record;
com.amazonaws.services.dynamodbv2.model.Shard;
com.amazonaws.services.dynamodbv2.model.ShardIteratorType;
com.amazonaws.services.dynamodbv2.model.StreamSpecification;
com.amazonaws.services.dynamodbv2.model.StreamViewType;
com.amazonaws.services.dynamodbv2.util.Tables;
public class StreamsLowLevelDemo {
API Version 2012-08-10
447
Amazon DynamoDB 開発者ガイド
チュートリアル : DynamoDB ス
トリーム の低レベルの API
private static AmazonDynamoDBClient dynamoDBClient =
new AmazonDynamoDBClient(new ProfileCredentialsProvider());
private static AmazonDynamoDBStreamsClient streamsClient =
new AmazonDynamoDBStreamsClient(new ProfileCredentialsProvider());
public static void main(String args[]) {
dynamoDBClient.setEndpoint("DYNAMODB_ENDPOINT_GOES_HERE");
streamsClient.setEndpoint("STREAMS_ENDPOINT_GOES_HERE");
// Create the table
String tableName = "TestTableForStreams";
ArrayList<AttributeDefinition> attributeDefinitions =
new ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Id")
.withAttributeType("N"));
ArrayList<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new KeySchemaElement()
.withAttributeName("Id")
.withKeyType(KeyType.HASH)); //Partition key
StreamSpecification streamSpecification = new StreamSpecification();
streamSpecification.setStreamEnabled(true);
streamSpecification.setStreamViewType(StreamViewType.NEW_AND_OLD_IMAGES);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withKeySchema(keySchema)
.withAttributeDefinitions(attributeDefinitions)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L))
.withStreamSpecification(streamSpecification);
System.out.println("Issuing CreateTable request for " + tableName);
dynamoDBClient.createTable(createTableRequest);
System.out.println("Waiting for " + tableName + " to be created...");
try {
Tables.awaitTableToBecomeActive(dynamoDBClient, tableName);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Determine the Streams settings for the table
DescribeTableResult describeTableResult =
dynamoDBClient.describeTable(tableName);
String myStreamArn =
describeTableResult.getTable().getLatestStreamArn();
API Version 2012-08-10
448
Amazon DynamoDB 開発者ガイド
チュートリアル : DynamoDB ス
トリーム の低レベルの API
StreamSpecification myStreamSpec =
describeTableResult.getTable().getStreamSpecification();
System.out.println("Current stream ARN for " + tableName + ": "+
myStreamArn);
System.out.println("Stream enabled: "+
myStreamSpec.getStreamEnabled());
System.out.println("Update view type: "+
myStreamSpec.getStreamViewType());
// Add a new item
int numChanges = 0;
System.out.println("Making some changes to table data");
Map<String, AttributeValue> item = new HashMap<String,
AttributeValue>();
item.put("Id", new AttributeValue().withN("101"));
item.put("Message", new AttributeValue().withS("New item!"));
dynamoDBClient.putItem(tableName, item);
numChanges++;
// Update the item
Map<String, AttributeValue> key = new HashMap<String,
AttributeValue>();
key.put("Id", new AttributeValue().withN("101"));
Map<String, AttributeValueUpdate> attributeUpdates =
new HashMap<String, AttributeValueUpdate>();
attributeUpdates.put("Message", new AttributeValueUpdate()
.withAction(AttributeAction.PUT)
.withValue(new AttributeValue().withS("This item has changed")));
dynamoDBClient.updateItem(tableName, key, attributeUpdates);
numChanges++;
// Delete the item
dynamoDBClient.deleteItem(tableName, key);
numChanges++;
// Get the shards in the stream
DescribeStreamResult describeStreamResult =
streamsClient.describeStream(new DescribeStreamRequest()
.withStreamArn(myStreamArn));
String streamArn =
describeStreamResult.getStreamDescription().getStreamArn();
List<Shard> shards =
describeStreamResult.getStreamDescription().getShards();
// Process each shard
for (Shard shard : shards) {
String shardId = shard.getShardId();
System.out.println(
"Processing " + shardId + " from stream "+ streamArn);
// Get an iterator for the current shard
API Version 2012-08-10
449
Amazon DynamoDB 開発者ガイド
クロスリージョン レプリケーション
GetShardIteratorRequest getShardIteratorRequest = new
GetShardIteratorRequest()
.withStreamArn(myStreamArn)
.withShardId(shardId)
.withShardIteratorType(ShardIteratorType.TRIM_HORIZON);
GetShardIteratorResult getShardIteratorResult =
streamsClient.getShardIterator(getShardIteratorRequest);
String nextItr = getShardIteratorResult.getShardIterator();
while (nextItr != null && numChanges > 0) {
// Use the iterator to read the data records from the shard
GetRecordsResult getRecordsResult =
streamsClient.getRecords(new GetRecordsRequest().
withShardIterator(nextItr));
List<Record> records = getRecordsResult.getRecords();
System.out.println("Getting records...");
for (Record record : records) {
System.out.println(record);
numChanges--;
}
nextItr = getRecordsResult.getNextShardIterator();
}
// Delete the table
System.out.println("Deleting the table...");
dynamoDBClient.deleteTable(tableName);
System.out.println("Demo complete");
}
}
}
クロスリージョン レプリケーション
Important
AWS では、以前は AWS CloudFormation に基づいてクロスリージョンのレプリケーションソ
リューションを提供していました。このソリューションは、オープンソースのコマンドライ
ンツールを優先して廃止されています。詳細については、GitHub で詳細な手順を参照してく
ださい。
• https://github.com/awslabs/dynamodb-cross-region-library/blob/master/README.md
DynamoDB のクロスリージョンレプリケーションソリューションでは、Amazon DynamoDB のクロ
スリージョンレプリケーションライブラリが使用されます。このライブラリは、DynamoDB ストリー
ム を使用して、複数のリージョンにまたがる DynamoDB テーブルをほぼリアルタイムで同期しま
す。 あるリージョンの DynamoDB テーブルに書き込みを行うと、クロスリージョンレプリケーショ
ンライブラリによりその変更が他のリージョンのテーブルに自動的に反映されます。
お客様のアプリケーションでクロスリージョンレプリケーションライブラリを使用して、DynamoDB
ストリーム による独自のレプリケーションソリューションを構築することができます。 詳細について
とソースコードのダウンロードについてには、次の GitHub リポジトリを参照してください。
• https://github.com/awslabs/dynamodb-cross-region-library
API Version 2012-08-10
450
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
DynamoDB ストリーム と AWS Lambda のトリ
ガー
トピック
• チュートリアル: DynamoDB テーブルの新しい項目の処理 (p. 451)
• ベストプラクティス (p. 458)
Amazon DynamoDB は AWS Lambda と統合されているため、トリガー (DynamoDB ストリーム 内の
イベントに自動的に応答するコード) を作成できます。トリガーを使用すると、DynamoDB テーブル
内のデータ変更に対応するアプリケーションを構築できます。
テーブルで DynamoDB ストリーム を有効にした場合、書き込む Lambda 関数にストリーム ARN を
関連付けることができます。 テーブルの項目が変更されるとすぐに、新しいレコードがテーブルのス
トリームに表示されます。AWS Lambda はストリームをポーリングし、新しいストリームレコードを
検出すると Lambda 関数を同期的に呼び出します。
Lambda 関数は、通知の送信やワークフローの開始など、指定したアクションを実行できます。
たとえば、Lambda 関数を記述すると、各ストリームレコードを Amazon Simple Storage Service
(Amazon S3) などの永続的ストレージにコピーしたり、書き込みアクティビティの永続的な監査証跡
をテーブルに作成したりすることが簡単にできます。または、GameScores テーブルに書き込みを行
うモバイルゲームアプリがあるとします。GameScores テーブルの TopScore 属性が更新されるたび
に、対応するストリームレコードがテーブルのストリームに書き込まれます。その後、このイベント
によって Lambda 関数をトリガーし、ソーシャルメディアネットワークにおめでとうメッセージを投
稿できます (この関数は、GameScores の更新でないストリームレコードや、TopScore 属性を変更
しないストリームレコードを無視します)。
AWS Lambda の詳細については、「AWS Lambda Developer Guide」を参照してください。
チュートリアル: DynamoDB テーブルの新しい項目の処理
トピック
• ステップ 1: ストリームが有効になった DynamoDB テーブルを作成する (p. 452)
• ステップ 2: Lambda 実行ロールを作成する (p. 452)
• ステップ 3: Amazon SNS トピックを作成する (p. 454)
• ステップ 4: Lambda 関数を作成してテストする (p. 454)
• ステップ 5: トリガーを作成してテストする (p. 457)
このチュートリアルでは、AWS Lambda トリガーを作成して、DynamoDB テーブルからのストリー
ムを処理します。
このチュートリアルのシナリオは、シンプルなソーシャルネットワークである Woofer です。Woofer
ユーザーは、他の Woofer ユーザーに送信される bark (短いテキストメッセージ) を使用して通信しま
す。次の図は、このアプリケーションのコンポーネントとワークフローを示しています。
1. ユーザーは DynamoDB テーブル (BarkTable) に項目を書き込みます。テーブルの各項目は bark を
表します。
2. 新しいストリームレコードが書き込まれ、新しい項目が BarkTable に追加されたことを反映しま
す。
3. 新しいストリームレコードは AWS Lambda 関数 (publishNewBark) をトリガーします。
4. ストリームレコードに、新しい項目が BarkTable に追加されたことが示された場合、Lambda 関数
はストリームレコードからデータを読み取り、Amazon Simple Notification Service (Amazon SNS)
のトピックにメッセージを発行します。
API Version 2012-08-10
451
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
5. メッセージは Amazon SNS トピックの受信者によって受信されます (このチュートリアルでは、唯
一の受信者は E メールアドレスです)。
開始する前に
このチュートリアルでは AWS Command Line Interface を使用します。まだ行っていない場合は、
「AWS Command Line Interface ユーザーガイド」の手順に従って AWS CLI をインストールおよび設
定します。
ステップ 1: ストリームが有効になった DynamoDB テーブルを作成する
このステップでは、Woofer ユーザーからのすべての bark を保存する DynamoDB テーブル
(BarkTable) を作成します。プライマリキーは Username (パーティションキー) と Timestamp (ソート
キー) で構成されます。これらの属性は両方とも文字列型になります。
BarkTable ではストリームが有効になります。このチュートリアルの後半では、AWS Lambda 関数を
ストリームと関連付けてトリガーを作成します。
1.
次のコマンドを入力してテーブルを作成します。
aws dynamodb create-table \
--table-name BarkTable \
--attribute-definitions AttributeName=Username,AttributeType=S
AttributeName=Timestamp,AttributeType=S \
--key-schema AttributeName=Username,KeyType=HASH
AttributeName=Timestamp,KeyType=RANGE \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 \
--stream-specification
StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES
2.
出力で、LatestStreamArn を探します。
...
"LatestStreamArn": "arn:aws:dynamodb:region:acccountID:table/BarkTable/
stream/timestamp
...
region と accountID をメモしておきます。これらは、このチュートリアルの他のステップで必
要になります。
ステップ 2: Lambda 実行ロールを作成する
このステップでは、IAMロール (WooferLambdaRole) を作成し、それにアクセス権限を割り当て
ます。このロールは、「ステップ 4: Lambda 関数を作成してテストする (p. 454)」で作成する
Lambda 関数で使用されます。
また、ロールのポリシーを作成します。このポリシーには、Lambda 関数が実行時に必要とするすべ
てのアクセス権限が含まれます。
1.
次の内容で、trust-relationship.json というファイルを作成します。
{
"Version": "2012-10-17",
"Statement": [
API Version 2012-08-10
452
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
2.
次のコマンドを入力して WooferLambdaRole を作成します。
aws iam create-role --role-name WooferLambdaRole \
--path "/service-role/" \
--assume-role-policy-document file://trust-relationship.json
3.
次の内容で、role-policy.json というファイルを作成します (region および accountID を
AWS リージョンとアカウント ID に置き換えます)。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource":
"arn:aws:lambda:region:accountID:function:publishNewBark*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:region:accountID:*"
},
{
"Effect": "Allow",
"Action": [
"dynamodb:DescribeStream",
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:ListStreams"
],
"Resource": "arn:aws:dynamodb:region:accountID:table/
BarkTable/stream/*"
},
{
"Effect": "Allow",
"Action": [
"sns:Publish"
],
"Resource": [
"*"
]
API Version 2012-08-10
453
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
}
]
}
ポリシーには 4 つのステートメントがあり、これにより WooferLambdaRole は以下を実行するこ
とができます。
• Lambda 関数 (publishNewBark) を実行する。このチュートリアルの後半で、この関数を作成し
ます。
• CloudWatch Logs にアクセスする。Lambda 関数は実行時に診断を CloudWatch Logs に書き込
みます。
• BarkTable の DynamoDB ストリームからデータを読み取る。
• Amazon SNS にメッセージを発行する。
4.
次のコマンドを入力して、WooferLambdaRole にポリシーをアタッチします。
aws iam put-role-policy --role-name WooferLambdaRole \
--policy-name WooferLambdaRolePolicy \
--policy-document file://role-policy.json
ステップ 3: Amazon SNS トピックを作成する
このステップでは、Amazon SNS トピック (wooferTopic) を作成し、そのトピックに E メールアドレ
スを受信登録します。Lambda 関数はこのトピックを使用して、Woofer ユーザーからの新しい bark
を公開します。
1.
次のコマンドを入力して、新しい Amazon SNS トピックを作成します。
aws sns create-topic --name wooferTopic
2.
次のコマンドを入力して、wooferTopic に E メールアドレスを受信登録します (region および
accountID は AWS リージョンとアカウント ID に置き換え、[email protected] は有効な
E メールアドレスと置き換えます)。
aws sns subscribe \
--topic-arn arn:aws:sns:region:accountID:wooferTopic \
--protocol email \
--notification-endpoint [email protected]
3.
Amazon SNS は E メールアドレスに確認メッセージを送信します。そのメッセージの [Confirm
subscription] リンクをクリックして、受信登録プロセスを完了します。
ステップ 4: Lambda 関数を作成してテストする
このステップでは、AWS Lambda 関数 (publishNewBark) を作成して BarkTable からのストリームレ
コードを処理します。
publishNewBark 関数は、BarkTable の新しい項目に対応するストリームイベントのみを処理します。
この関数は、そのようなイベントからデータを読み取ってから、Amazon SNS を呼び出してデータを
公開します。
1.
次の内容で、publishNewBark.js というファイルを作成します (region および accountID を
AWS リージョンとアカウント ID に置き換えます)。
API Version 2012-08-10
454
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
'use strict';
var AWS = require("aws-sdk");
var sns = new AWS.SNS();
exports.handler = (event, context, callback) => {
event.Records.forEach((record) => {
console.log('Stream record: ', JSON.stringify(record, null, 2));
if (record.eventName == 'INSERT') {
var who = JSON.stringify(record.dynamodb.NewImage.Username.S);
var when =
JSON.stringify(record.dynamodb.NewImage.Timestamp.S);
var what = JSON.stringify(record.dynamodb.NewImage.Message.S);
var params = {
Subject: 'A new bark from ' + who,
Message: 'Woofer user ' + who + ' barked the following at
' + when + ':\n\n ' + what,
TopicArn: 'arn:aws:sns:region:accountID:wooferTopic'
};
sns.publish(params, function(err, data) {
if (err) {
console.error("Unable to send message. Error JSON:",
JSON.stringify(err, null, 2));
callback(err, null);
} else {
console.log("Results from sending message: ",
JSON.stringify(data, null, 2));
callback(null, data);
}
});
}
});
callback(null, `Successfully processed ${event.Records.length}
records.`);
};
2.
publishNewBark.js を含める zip ファイルを作成します。zip コマンドラインユーティリティが
ある場合は、次のコマンドを入力してこれを行うことができます。
zip publishNewBark.zip publishNewBark.js
3.
Lambda 関数を作成するときに、「ステップ 2: Lambda 実行ロールを作成する (p. 452)」で作
成した WooferLambdaRole の ARN を指定する必要があります。この ARN を取得するには、次
のコマンドを入力します。
aws iam get-role --role-name WooferLambdaRole
出力で、WooferLambdaRole の ARN を探します。
...
"Arn": "arn:aws:iam::region:role/service-role/WooferLambdaRole"
...
API Version 2012-08-10
455
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
ここで、次のコマンドを入力して Lambda 関数を作成します (roleARN を WooferLambdaRole の
ARN に置き換えます)。
aws lambda create-function \
--region us-east-1 \
--function-name publishNewBark \
--zip-file fileb://publishNewBark.zip \
--role roleARN \
--handler publishNewBark.handler \
--timeout 5 \
--runtime nodejs4.3
4.
ここで、publishNewBark をテストして、これが動作することを確認します。これを行うに
は、DynamoDB ストリーム の地域レコードに似た情報を入力します。
次の内容で、payload.json というファイルを作成します。
{
"Records": [
{
"eventID": "7de3041dd709b024af6f29e4fa13d34c",
"eventName": "INSERT",
"eventVersion": "1.1",
"eventSource": "aws:dynamodb",
"awsRegion": "us-west-2",
"dynamodb": {
"ApproximateCreationDateTime": 1479499740,
"Keys": {
"Timestamp": {
"S": "2016-11-18:12:09:36"
},
"Username": {
"S": "John Doe"
}
},
"NewImage": {
"Timestamp": {
"S": "2016-11-18:12:09:36"
},
"Message": {
"S": "This is a bark from the Woofer social
network"
},
"Username": {
"S": "John Doe"
}
},
"SequenceNumber": "13021600000000001596893679",
"SizeBytes": 112,
"StreamViewType": "NEW_IMAGE"
},
"eventSourceARN": "arn:aws:dynamodb:useast-1:123456789012:table/BarkTable/stream/2016-11-16T20:42:48.104"
}
]
}
API Version 2012-08-10
456
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
publishNewBark 関数をテストするには、次のコマンドを入力します。
aws lambda invoke --function-name publishNewBark --payload file://
payload.json output.txt
テストが成功すると、次の出力が表示されます。
{
"StatusCode": 200
}
さらに、output.txt ファイルには次のテキストが含まれます。
"Successfully processed 1 records."
また、数分以内に新しい E メールメッセージが届きます。
Note
AWS Lambda は診断情報を Amazon CloudWatch Logs に書き込みます。Lambda 関数で
エラーが発生した場合、この診断情報をトラブルシューティングに使用できます。
1. https://console.aws.amazon.com/cloudwatch/にある CloudWatch コンソールを開きま
す。
2. ナビゲーションペインで [Logs] を選択します。
3. 次のロググループを選択: /aws/lambda/publishNewBark
4. 最新のログストリーミングを選択して、関数からの出力 (およびエラー) を表示しま
す。
ステップ 5: トリガーを作成してテストする
「ステップ 4: Lambda 関数を作成してテストする (p. 454)」で、Lambda 関数をテストして、正し
く実行されたことを確認しました。このステップでは、Lambda 関数 (publishNewBark) をイベント
ソース (BarkTable ストリーム) に関連付けて、トリガーを作成します。
1.
トリガーを作成するときは、BarkTable ストリーム用の ARN を指定する必要があります。この
ARN を取得するには、次のコマンドを入力します。
aws dynamodb describe-table --table-name BarkTable
出力で、LatestStreamArn を探します。
...
"LatestStreamArn": "arn:aws:dynamodb:region:acccountID:table/BarkTable/
stream/timestamp
...
2.
次のコマンドを入力してトリガーを作成します (streamARN を l ストリーム ARN に置き換えま
す)。
aws lambda create-event-source-mapping \
API Version 2012-08-10
457
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
--region us-east-1 \
--function-name publishNewBark \
--event-source streamARN \
--batch-size 1 \
--starting-position TRIM_HORIZON
3.
ここで、トリガーをテストします。次のコマンドを入力して、BarkTable に項目を追加します。
aws dynamodb put-item \
--table-name BarkTable \
--item Username={S="Jane
Doe"},Timestamp={S="2016-11-18:14:32:17"},Message={S="Testing...1...2...3"}
数分以内に新しい E メールメッセージが届きます。
4.
DynamoDB コンソールに移動し、さらにいくつかの項目を BarkTable に追加します。Username
および Timestamp 属性の値を指定する必要があります (必須ではないものの、Message の値を
指定する必要があります)。BarkTable に追加した各項目について、新しい E メールメッセージが
届きます。
Lambda 関数は、BarkTable に追加した新しい項目のみを処理します。テーブル内の項目を更新
または削除すると、この関数は何も行いません。
Note
AWS Lambda は診断情報を Amazon CloudWatch Logs に書き込みます。Lambda 関数でエ
ラーが発生した場合、この診断情報をトラブルシューティングに使用できます。
1. https://console.aws.amazon.com/cloudwatch/にある CloudWatch コンソールを開きます。
2. ナビゲーションペインで [Logs] を選択します。
3. 次のロググループを選択: /aws/lambda/publishNewBark
4. 最新のログストリーミングを選択して、関数からの出力 (およびエラー) を表示します。
ベストプラクティス
AWS Lambda 関数はコンテナ内で実行されます。これは他の関数から分離された実行環境です。この
関数を初めて実行すると、AWS Lambda は新しいコンテナを作成し、関数のコードを実行し始めま
す。
Lambda 関数には、呼び出しごとに 1 回実行されるハンドラがあります。ハンドラには、関数用の
主要なビジネスロジックが含まれます。たとえば、「ステップ 4: Lambda 関数を作成してテストす
る (p. 454)」に示す Lambda 関数には、DynamoDB ストリームのレコードを処理できるハンドラが
あります。
コンテナの作成後に 1 回のみ実行される初期化コードを提供することもできますが、AWS
Lambda がハンドラを初めて実行する前のみです。「ステップ 4: Lambda 関数を作成してテストす
る (p. 454)」に示す Lambda 関数には、Node.js 内の SDK for JavaScript をインポートし、Amazon
SNS 用のクライアントを作成する初期化コードがあります。これらのオブジェクトはハンドラの外部
で 1 回のみ定義します。
関数の実行後、AWS Lambda は関数のそれ以降の呼び出しに対してコンテナを再利用する場合があり
ます。この場合、関数ハンドラは、初期化コードで定義したリソースを再利用できる可能性がありま
す (AWS Lambda がコンテナを保持する期間や、コンテナを再利用するかどうかを制御することはで
きません)。
AWS Lambda を使用した DynamoDB トリガーの場合は、次のことをお勧めします。
API Version 2012-08-10
458
Amazon DynamoDB 開発者ガイド
DynamoDB ストリーム と AWS Lambda のトリガー
• AWS のサービスのクライアントは、ハンドラではなく初期化コードでインスタンス化する必要があ
ります。これにより、AWS Lambda コンテナは、コンテナの有効期間中は既存の接続を再利用する
ことができます。
• 通常、お客様が明示的に接続を管理したり、接続プールを実装したりする必要はありません。これ
は AWS Lambda によって自動的に管理されます。
詳細については、AWS Lambda Developer Guideの「AWS Lambda 関数を使用する際のベストプラク
ティス」を参照してください。
API Version 2012-08-10
459
Amazon DynamoDB 開発者ガイド
認証
Amazon DynamoDB に対する認証
とアクセスコントロール
Amazon DynamoDB へのアクセスには、認証情報が必要です。これらの認証情報には、Amazon
DynamoDB table や Amazon Elastic Compute Cloud (Amazon EC2) インスタンスなどの AWS リソー
スに対するアクセス権限が含まれている必要があります。次のセクションでは、AWS Identity and
Access Management (IAM) と DynamoDB を使用して、リソースへのアクセスをセキュリティで保護
する方法について詳しく説明します。
• 認証 (p. 460)
• アクセスコントロール (p. 461)
認証
AWS には、次のタイプのアイデンティティでアクセスできます。
• AWS アカウントのルートユーザー – AWS にサインアップするときは、AWS アカウントに関連付
けられた E メールアドレスとパスワードを指定します。これらは ルート認証情報であり、これらの
情報を使用すると、すべての AWS リソースへの完全なアクセスが可能になります。
Important
セキュリティ上の理由から、AWS アカウントへの完全なアクセス権限を持つ管理者ユー
ザー (IAM ユーザー) を作成するためにのみ、ルート認証情報を使用することをお勧めし
ます。その後、この管理者ユーザーを使用して、制限されたアクセス権限を持つ他の IAM
ユーザーとロールを作成できます。詳細については、『IAM ユーザーガイド』の「IAM の
ベストプラクティス」および「管理者のユーザーおよびグループの作成」を参照してくだ
さい。
• IAM ユーザー – IAM ユーザーは、特定のカスタム権限 (たとえば、DynamoDB で a table を作成す
るアクセス権限) を持つ AWS アカウント内のアイデンティティです。IAM のユーザー名とパスワー
ドを使用して、AWS マネジメントコンソール、AWS ディスカッションフォーラム、AWS Support
Center などのセキュリティ保護された AWS ウェブページにサインインできます。
ユーザー名とパスワードに加えて、各ユーザーのアクセスキーを生成することもできます。いくつ
かの SDK の 1 つまたは AWS Command Line Interface (CLI) を使ってプログラムで AWS サービス
にアクセスするときに、これらのキーを使用します。SDK と CLI ツールでは、アクセスキーを使用
してリクエストが暗号で署名されます。AWS ツールを使用しない場合は、リクエストを自分で署名
API Version 2012-08-10
460
Amazon DynamoDB 開発者ガイド
アクセスコントロール
する必要があります。DynamoDB supports では、署名バージョン 4 がサポートされています。こ
れは、インバウンド API リクエストを認証するためのプロトコルです。リクエストの認証の詳細に
ついては、『AWS General Reference』の「署名バージョン 4 の署名プロセス」を参照してくださ
い。
• IAM ロール – IAM ロールは、特定のアクセス権限を持ち、アカウントで作成できるもう 1 つの IAM
アイデンティティです。これは IAM ユーザーに似ていますが、特定のユーザーに関連付けられてい
ません。IAM ロールでは、AWS サービスおよびリソースにアクセスするために使用できる一時的な
アクセスキーを取得することができます。IAM ロールと一時的な認証情報は、次の状況で役立ちま
す。
• フェデレーティッドユーザーアクセス – IAM ユーザーを作成するのではなく、AWS Directory
Service、エンタープライズユーザーディレクトリ、またはウェブアイデンティティプロバイダー
の既存のユーザーアイデンティティを使用することもできます。このようなユーザーはフェデ
レーティッドユーザーと呼ばれます。AWS では、アイデンティティプロバイダーを通じてアク
セスがリクエストされたときに、フェデレーティッドユーザーにロールを割り当てます。フェデ
レーティッドユーザーの詳細については、『IAM ユーザーガイド』の「フェデレーティッドユー
ザーとロール」を参照してください。
• クロスアカウントアクセス – アカウントで IAM ロールを使って、お客様のアカウントのリソース
へのアクセス権を別の AWS アカウントに付与できます。この例については、『IAM ユーザーガ
イド』の「チュートリアル: AWS アカウント間の IAM ロールを使用したアクセスの委任」を参照
してください。
• AWS サービスアカウント – アカウントで IAM ロールを使って、お客様のアカウントのリソース
にアクセスする AWS サービスのアクセス権限を付与できます。たとえば、Amazon Redshift が
お客様に代わって Amazon S3 バケットにアクセスし、バケットに保存されたデータを Amazon
Redshift クラスターにロードすることを許可するロールを作成できます。 詳細については、
『IAM ユーザーガイド』の「AWS ユーザーにアクセス権限を委任するロールの作成」を参照して
ください。
• Amazon EC2 で実行されるアプリケーション – インスタンスで実行し、AWS API リクエストを
作成するアプリケーションで使用されるアクセスキーを EC2 インスタンス内に保存する代わり
に、IAM ロールを使用して、これらのアプリケーション用の一時認証情報を管理できます。AWS
ロールを EC2 インスタンスに割り当て、そのすべてのアプリケーションで使用できるようにする
には、インスタンスにアタッチされたインスタンスプロファイルを作成できます。インスタンス
プロファイルにはロールが含まれ、EC2 インスタンスで実行されるプログラムは一時認証情報を
取得することができます。詳細については、『IAM ユーザーガイド』の「Amazon EC2 上のアプ
リケーションに対するロールの使用」を参照してください。
アクセスコントロール
有効な認証情報があればリクエストを認証できますが、許可を持っていないかぎり Amazon
DynamoDB リソースの作成やアクセスはできません。たとえば、Amazon DynamoDB table を作成す
るためのアクセス権限が必要です。
以下のセクションでは、Amazon DynamoDB のアクセス権限を管理する方法について説明します。最
初に概要のセクションを読むことをお勧めします。
API Version 2012-08-10
461
Amazon DynamoDB 開発者ガイド
アクセス管理の概要
• アクセス管理の概要 (p. 462)
• アイデンティティベースのポリシー (IAM ポリシー) を使用する (p. 465)
• DynamoDB API の権限リファレンス (p. 473)
• 条件の使用 (p. 477)
Amazon DynamoDB リソースへのアクセス権限
の管理の概要
すべての AWS リソースは AWS アカウントによって所有され、となり、リソースの作成またはアク
セスは、アクセス権限のポリシーによって管理されます。アカウント管理者は、アクセス権限ポリ
シーを IAM アイデンティティ (ユーザー、グループ、ロール) にアタッチできます。一部のサービス
(AWS Lambda など) では、アクセス権限ポリシーをリソースにアタッチすることもできます。
Note
アカウント管理者 (または管理者ユーザー) は、管理者権限を持つユーザーです。詳細につい
ては、IAM ユーザーガイド の「IAM のベストプラクティス」を参照してください。
アクセス権限を付与する場合、アクセス権限を取得するユーザー、取得するアクセス権限の対象とな
るリソース、およびそれらのリソースに対して許可される特定のアクションを決定します。
トピック
• Amazon DynamoDB リソースおよびオペレーション (p. 462)
• リソース所有権について (p. 463)
• リソースへのアクセスの管理 (p. 463)
• ポリシー要素の指定 : アクション、効果、プリンシパル (p. 464)
• ポリシーでの条件の指定 (p. 465)
Amazon DynamoDB リソースおよびオペレーション
DynamoDB では、プライマリ リソースはテーブルです。DynamoDB では、追加リソースタイプとし
てインデックスとストリームもサポートされています。ただし、既存の DynamoDB テーブルのコン
テキストでのみ、インデックスやストリームを作成できます。これらはサブリソースと呼ばれます。
これらのリソースとサブリソースには、次の表に示すとおり、一意の Amazon リソースネーム (ARN)
が関連付けられています。
リソースタイプ
ARN 形式
表
arn:aws:dynamodb:region:account-id:table/table-name
索引
arn:aws:dynamodb:region:account-id:table/table-name/
index/index-name
ストリーム
arn:aws:dynamodb:region:account-id:table/table-name/
stream/stream-label
DynamoDB には、DynamoDB リソースを操作するための一連のオペレーションが用意されていま
す。可能なオペレーションのリストについては、Amazon DynamoDB Actions を参照してください。
API Version 2012-08-10
462
Amazon DynamoDB 開発者ガイド
リソース所有権について
リソース所有権について
AWS アカウントは、誰がリソースを作成したかにかかわらず、アカウントで作成されたリソースを所
有します。 具体的には、リソース所有者は、リソースの作成リクエストを認証するプリンシパルエン
ティティ (ルートアカウント、IAM ユーザー、または IAM ロール) の AWS アカウントです。以下の例
では、このしくみを示しています。
• AWS アカウントのルートアカウント認証情報を使用して a table を作成する場合、この AWS アカ
ウントがリソースの所有者です (DynamoDB では、リソースは a table です)。
• AWS アカウントに IAM ユーザーを作成し、そのユーザーに a table を作成するためのアクセス権
限を付与する場合、そのユーザーは a table リソースを作成できます。ただし、ユーザーが属する
AWS アカウントは table リソースを所有しています。
• a table リソースを作成するためのアクセス権限を持つ AWS アカウントに IAM ロールを作成する場
合は、ロールを引き受けることのできるいずれのユーザーも a table を作成できます。ユーザーが属
する AWS アカウントは table リソースを所有しています。
リソースへのアクセスの管理
アクセスポリシーでは、誰が何にアクセスできるかを記述します。以下のセクションで、アクセス権
限のポリシーを作成するために使用可能なオプションについて説明します。
Note
このセクションでは、DynamoDB のコンテキストでの IAM の使用について説明します。こ
れは、IAM サービスに関する詳細情報を取得できません。完全な IAM ドキュメントについて
は、「IAM とは?」 (IAM ユーザーガイド ) を参照してください。IAM ポリシー構文の詳細お
よび説明については、IAM ユーザーガイド の「AWS IAM ポリシーリファレンス」を参照して
ください。
IAM アイデンティティにアタッチされたポリシーはアイデンティティベースのポリシー (IAM ポ
リシー) と呼ばれ、リソースにアタッチされたポリシーはリソースベースのポリシーと呼ばれま
す。DynamoDB では、アイデンティティベースのポリシー (IAM ポリシー) のみサポートされます。
トピック
• アイデンティティベースのポリシー (IAM ポリシー) (p. 463)
• リソースベースのポリシー (p. 464)
アイデンティティベースのポリシー (IAM ポリシー)
ポリシーを IAM アイデンティティにアタッチできます。たとえば、次の操作を実行できます。
• アカウントのユーザーまたはグループにアクセス権限ポリシーをアタッチする – a table などの
Amazon DynamoDB リソースを作成するためのアクセス権限を付与するには、ユーザーまたはユー
ザーが所属するグループにアクセス権限ポリシーをアタッチできます。
• アクセス権限ポリシーをロールにアタッチする (クロスアカウントのアクセス権限を付与) – アイデ
ンティティベースのアクセス権限ポリシーを IAM ロールにアタッチして、クロスアカウントのアク
セス権限を付与することができます。たとえば、アカウント A の管理者は、次のように他のまたは
AWS にクロスアカウントのアクセス権限を別の AWS アカウント (アカウント B) または AWS サー
ビスに付与するロールを作成することができます。
1. アカウント A の管理者は、IAM ロールを作成して、アカウント A のリソースに権限を付与する
ロールに権限ポリシーをアタッチします。
2. アカウント A の管理者は、アカウント B をそのロールを引き受けるプリンシパルとして識別する
ロールに、信頼ポリシーをアタッチします。
API Version 2012-08-10
463
Amazon DynamoDB 開発者ガイド
ポリシー要素の指定 : アクション、効果、プリンシパル
3. アカウント B の管理者は、アカウント B のユーザーにロールを引き受ける権限を委任できるよう
になります。これにより、アカウント B のユーザーにアカウント A のリソースの作成とアクセス
が許可されます。AWS サービスのアクセス権限を付与してロールを引き受けさせたい場合は、
信頼ポリシー内のプリンシパルも、AWS サービスのプリンシパルとなることができます。
IAM を使用したアクセス権限の委任の詳細については、「アクセス管理」 (IAM ユーザーガイド) を
参照してください。
DynamoDB アクション (dynamodb:ListTables) に許可を付与するポリシーの例を次に示しま
す。Resource 値のワイルドカード文字 (*) は、このアクションを使用して、現在の AWS リージョン
の AWS アカウントで所有されているすべてのテーブルの名前を取得できることを意味します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListTables",
"Effect": "Allow",
"Action": [
"dynamodb:ListTables"
],
"Resource": "*"
}
]
}
DynamoDB でアイデンティティベースのポリシーを使用する詳細については、「Amazon DynamoDB
でアイデンティティベースのポリシー (IAM ポリシー) を使用する (p. 465)」を参照してください。
ユーザー、グループ、ロール、アクセス権限の詳細については、「アイデンティティ (ユーザー、グ
ループ、ロール)」 (IAM ユーザーガイド) を参照してください。
リソースベースのポリシー
Amazon S3 などの他のサービスでは、リソースベースのアクセス権限ポリシーもサポートされていま
す。たとえば、ポリシーを S3 バケットにアタッチして、そのバケットに対するアクセス権限を管理
できます。DynamoDB では、リソースベースのポリシーはサポートされていません。
ポリシー要素の指定 : アクション、効果、プリンシ
パル
DynamoDB リソースの種類ごとに、このサービスは、一連の API オペレーションを定義します。これ
らの API オペレーションのアクセス権限を付与するために、DynamoDB は、ポリシー内に指定できる
一連のアクションを定義します。一部の API オペレーションは、API オペレーションを実行するため
に複数のアクションに対するアクセス許可を要求できます。 リソースおよび API オペレーションの詳
細については、「Amazon DynamoDB リソースおよびオペレーション (p. 462)」および DynamoDB
Actions を参照してください。
以下は、最も基本的なポリシーの要素です。
• リソース – Amazon Resource Name (ARN) を使用して、ポリシーを適用するリソースを識別しま
す。詳細については、「Amazon DynamoDB リソースおよびオペレーション (p. 462)」を参照し
てください。
• アクション – アクションのキーワードを使用して、許可または拒否するリソースオペレーショ
ンを識別します。たとえば、dynamodb:Query を allows the user permissions to perform the
DynamoDB Query operation に使用できます。
API Version 2012-08-10
464
Amazon DynamoDB 開発者ガイド
ポリシーでの条件の指定
• 効果 – ユーザーが特定のアクションをリクエストする際の効果を指定します。許可または拒否のい
ずれかになります。リソースへのアクセスを明示的に許可していない場合、アクセスは暗黙的に拒
否されます。また、明示的にリソースへのアクセスを拒否すると、別のポリシーによってアクセス
が許可されている場合でも、ユーザーはそのリソースにアクセスできなくなります。
• プリンシパル – アイデンティティベースのポリシー (IAM ポリシー) で、ポリシーがアタッチされて
いるユーザーが黙示的なプリンシパルとなります。リソースベースのポリシーでは、権限 (リソース
ベースのポリシーにのみ適用) を受け取りたいユーザー、アカウント、サービス、またはその他のエ
ンティティを指定します。DynamoDB doesn't support リソースベースのポリシー。
IAM ポリシーの構文と説明についての詳細については、IAM ユーザーガイド の「AWS IAM ポリシー
の参照」を参照してください。
すべての Amazon DynamoDB API オペレーションとそれらが適用されるリソースのリストについて
は、「DynamoDB API のアクセス権限: アクション、リソース、条件リファレンス (p. 473)」を参照
してください。
ポリシーでの条件の指定
アクセス権限を付与するとき、アクセスポリシー言語を使用して、ポリシーが有効になる必要がある
条件を指定できます。たとえば、特定の日付の後にのみ適用されるポリシーが必要になる場合があり
ます。ポリシー言語での条件の指定の詳細については、IAM ユーザーガイド の「条件」を参照してく
ださい。
条件を表すには、あらかじめ定義された条件キーを使用します。AWS 全体の条件キーと DynamoDB
固有のキーがあり、必要に応じて使用できます。AWS 全体を対象とするすべてのキーのリストにつ
いては、『IAM ユーザーガイド』の「条件に利用可能なキー」を参照してください。DynamoDB 固有
のキーの一覧については、「詳細に設定されたアクセスコントロールのための IAM ポリシー条件の使
用 (p. 477)」を参照してください。
Amazon DynamoDB でアイデンティティベース
のポリシー (IAM ポリシー) を使用する
このトピックでは、アカウント管理者が IAM アイデンティティ (ユーザー、グループ、ロール) にアク
セス権限ポリシーをアタッチし、それによって Amazon DynamoDB リソースでオペレーションを実行
するアクセス権限を付与する方法を示すアイデンティティベースのポリシーの例を示します。
Important
初めに、Amazon DynamoDB リソースへのアクセスを管理するための基本概念と使用可能
なオプションについて説明する概要トピックを読むことをお勧めします。詳細については、
「Amazon DynamoDB リソースへのアクセス権限の管理の概要 (p. 462)」を参照してくださ
い。
このセクションでは、次のトピックを対象としています。
• Amazon DynamoDB コンソールを使用するために必要なアクセス権限 (p. 466)
• Amazon DynamoDB での AWS 管理 (事前定義) ポリシー (p. 466)
• お客様が管理するポリシーの例 (p. 467)
以下に示しているのは、アクセス権限ポリシーの例です。
{
API Version 2012-08-10
465
Amazon DynamoDB 開発者ガイド
コンソールのアクセス許可
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DescribeQueryScanBooksTable",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeTable",
"dynamodb:Query",
"dynamodb:Scan"
],
"Resource": "arn:aws:dynamodb:us-west-2:account-id:table/Books"
}
]
}
このポリシーには、us-west-2 リージョンのテーブルで 3 つの DynamoDB アクション
(dynamodb:DescribeTable、dynamodb:Query、dynamodb:Scan) を許可する 1 つのステートメ
ントがあります。これは、account-id で指定される AWS アカウントで所有されています。 値の
Amazon リソースネーム (ARN)Resource では、アクセス権限が適用されるテーブルを指定します。
Amazon DynamoDB コンソールを使用するために必
要なアクセス権限
DynamoDB コンソールを使用して作業するユーザーに対しては、ユーザーに AWS アカウントの
DynamoDB リソースの使用を許可する最小限のアクセス許可が必要です。これらの DynamoDB アク
セス許可に加えて、コンソールでは次のサービスからのアクセス許可が必要になります。
• メトリクスとグラフを表示する Amazon CloudWatch アクセス許可。
• DynamoDB データをエクスポートおよびインポートする AWS Data Pipeline アクセス許可。
• エクスポートおよびインポートに必要なロールにアクセスする AWS Identity and Access
Management アクセス許可。
• CloudWatch アラームがトリガーされるたびに通知する Amazon Simple Notification Service アクセ
ス許可。
• DynamoDB ストリーム レコードを処理する AWS Lambda アクセス許可。
これらの最小限必要なアクセス権限よりも制限された IAM ポリシーを作成している場合、その IAM
ポリシーを使用するユーザーに対してコンソールは意図したとおりには機能しません。「Amazon
DynamoDB での AWS 管理 (事前定義) ポリシー (p. 466)」で説明されているとおり、ユーザーが
DynamoDB コンソールを使用できること、および、AmazonDynamoDBReadOnlyAccess 管理対象ポ
リシーがユーザーにアタッチされていることを確認してください。
AWS CLI または Amazon DynamoDB API のみを呼び出すユーザーには、最小限のコンソールアクセ
ス権限を付与する必要はありません。
Amazon DynamoDB での AWS 管理 (事前定義) ポ
リシー
AWS は、AWS によって作成され管理されるスタンドアロンの IAM ポリシーが提供する多くの一般的
ユースケースに対応します。これらの AWS 管理ポリシーは、一般的ユースケースに必要なアクセス
権限を付与することで、どの権限が必要なのかをユーザーが調査する必要をなくすことができます。
詳細については、IAM ユーザーガイド の「AWS 管理ポリシー」を参照してください。
アカウントのユーザーにアタッチ可能な以下の AWS 管理ポリシーは、DynamoDB に固有のもので、
ユースケースシナリオ別にグループ化されます。
API Version 2012-08-10
466
Amazon DynamoDB 開発者ガイド
お客様が管理するポリシーの例
• AmazonDynamoDBReadOnlyAccess – AWS マネジメントコンソール を使用して DynamoDB リ
ソースへ読み取り専用アクセスを付与します。
• AmazonDynamoDBFullAccess – AWS マネジメントコンソール を使用して DynamoDB リソースへ
のフルアクセスを付与します。
• AmazonDynamoDBFullAccesswithDataPipeline – AWS マネジメントコンソール を使用して、AWS
Data Pipeline によるエクスポートおよびインポートを含む、DynamoDB リソースへのフルアクセス
を付与します。
Note
IAM コンソールにサインインし、特定のポリシーを検索することで、これらのアクセス権限
ポリシーを確認することができます。
独自のカスタム IAM ポリシーを作成して、DynamoDB アクションとリソースのための権限を許可す
ることもできます。これらのカスタムポリシーは、それらのアクセス権限が必要な IAM ユーザーまた
はグループにアタッチできます。
お客様が管理するポリシーの例
このセクションでは、さまざまな DynamoDB アクションのアクセス権限を付与するユーザーポリ
シー例を示しています。これらのポリシーは、AWS SDK または AWS CLI を使用しているときに機能
します。コンソールを使用している場合は、「Amazon DynamoDB コンソールを使用するために必要
なアクセス権限 (p. 466)」で説明しているコンソールに固有の追加のアクセス権限を付与する必要が
あります。
Note
すべての例で、us-west-2 リージョンを使用し、架空のアカウント ID を含めています。
例
• 例 1: ユーザーがテーブルで任意の DynamoDB アクションを実行することを許可する (p. 467)
• 例 2: テーブル内の項目の読み取り専用アクセスを許可する (p. 468)
• 例 3: 特定のテーブルでの入力、更新、および削除オペレーションを許可する (p. 468)
• 例 4: 特定のテーブルおよびそのテーブルのすべてのインデックスにアクセスを許可す
る (p. 469)
• 例 5: 別のテスト環境および運用環境のアクセス権限ポリシーの設定 (p. 469)
• 例 6: リザーブドキャパシティーのサービス購入をユーザーに禁止する (p. 471)
• 例 7: DynamoDB ストリームのみの読み取りアクセスを許可する (テーブルを除く) (p. 472)
• 例 8: AWS Lambda 関数が DynamoDB ストリームレコードを処理できるようにする (p. 472)
例 1: ユーザーがテーブルで任意の DynamoDB アクションを
実行することを許可する
以下のアクセス権限のポリシーでは、テーブルでのすべての DynamoDB アクションのアクセス権限
を付与します。Resource で指定された ARN 値は、特定のリージョンのテーブルを識別します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllAPIActionsOnBooks",
API Version 2012-08-10
467
Amazon DynamoDB 開発者ガイド
お客様が管理するポリシーの例
"Effect": "Allow",
"Action": "dynamodb:*",
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:table/Books"
}
]
}
Note
リソース ARN のテーブル名 (Books) をワイルドカード文字 (*) に置き換える場合、アカウン
トのすべてのテーブルで、任意の DynamoDB アクションが許可されます。これを行う場合
は、セキュリティへの影響について慎重に考慮してください。
例 2: テーブル内の項目の読み取り専用アクセスを許可する
以下のアクセス権限のポリシーでは、GetItem および BatchGetItem DynamoDB アクションのみの
アクセス権限を付与し、それによってテーブルへの読み取り専用アクセスを設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadOnlyAPIActionsOnBooks",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:BatchGetItem"
],
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:table/Books"
}
]
}
例 3: 特定のテーブルでの入力、更新、および削除オペレー
ションを許可する
次のアクセス権限ポリシーでは、特定の DynamoDB テーブルで、PutItem、UpdateItem、および
DeleteItem アクションのアクセス権限を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PutUpdateDeleteOnBooks",
"Effect": "Allow",
"Action": [
"dynamodb:PutItem",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem"
],
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:table/Books"
}
]
}
API Version 2012-08-10
468
Amazon DynamoDB 開発者ガイド
お客様が管理するポリシーの例
例 4: 特定のテーブルおよびそのテーブルのすべてのインデッ
クスにアクセスを許可する
以下のアクセス権限ポリシーでは、テーブル (Book) のすべての DynamoDB アクションと、そのテー
ブルのすべてのインデックスにアクセス権限を付与します。インデックスの動作の詳細については、
「セカンダリインデックスを使用したデータアクセス性の向上 (p. 333)」を参照してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AccessAllIndexesOnBooks",
"Effect": "Allow",
"Action": [
"dynamodb:*"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/Books",
"arn:aws:dynamodb:us-west-2:123456789012:table/Books/index/*"
]
}
]
}
例 5: 別のテスト環境および運用環境のアクセス権限ポリシー
の設定
たとえば、テスト環境と本番環境が別々にあり、各環境で、ProductCatalog という名前のテーブル
を独自のバージョンで維持するとします。これらの ProductCatalog テーブルを同じ AWS アカウン
トから作成する場合、アクセス権限の設定方法により、本番環境に対してテスト作業の影響が発生す
る可能性があります。この理由として、同時発生の作成アクションと削除アクションに対する制限が
AWS アカウントレベルで設定されていることなどが挙げられます。この結果、テスト環境内の各ア
クションによって、本番環境で利用可能なアクションの数が減少します。また、テスト環境内のコー
ドが本番環境内のテーブルに偶然にアクセスしてしまう危険性もあります。このような問題を防ぐに
は、本番環境とテスト環境に別々の AWS アカウントを作成することを検討します。
さらに、Bob と Alice という 2 人の開発者が ProductCatalog テーブルをテストしているとし
ます。開発者ごとに別々の AWS アカウントを作成する代わりに、開発者間で同じテストアカウ
ントを共有することができます。このテスト用アカウントでは、Alice_ProductCatalog や
Bob_ProductCatalog など、対象の開発者ごとに、同じテーブルのコピーを作成できます。この場
合、テスト環境用に作成した AWS アカウント内で、IAM ユーザーの Alice と Bob を作成できます。
このとき、所有するテーブルに対して DynamoDB アクションを実行できるように、この 2 人のユー
ザーにアクセス権限を付与することができます。
これらのユーザーアクセス権限を付与するには、次のいずれかを実行します。
• 各ユーザーに別々のポリシーを作成し、各ユーザーに個別に割り当てます。たとえば、以下の
ポリシーをユーザー Alice に割り当てることで、Alice_ProductCatalog テーブルに対する
DynamoDB アクションをすべて許可することができます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllAPIActionsOnAliceTable",
"Effect": "Allow",
API Version 2012-08-10
469
Amazon DynamoDB 開発者ガイド
お客様が管理するポリシーの例
"Action": [
"dynamodb:*"
],
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:table/
Alice_ProductCatalog"
}
]
}
次に、ユーザー Bob に対して、同様のポリシーを異なるリソース (Bob_ProductCatalog テーブ
ル) で作成できます。
• 個々のユーザーにポリシーを付与する代わりに、IAM ポリシー変数を使用して単一のポリ
シーを記述し、グループに付与することができます。この例では、グループを作成し、そ
のグループにユーザー Alice とユーザー Bob の両者を追加する必要があります。次の例で
は、${aws:username}_ProductCatalog テーブルのすべての DynamoDB アクションを実行で
きる権限を付与します。ポリシーが評価されると、ポリシー変数 ${aws:username} はリクエス
ターのユーザー名に置き換えられます。たとえば、Alice が項目の追加要求を送信する場合、Alice
が Alice_ProductCatalog テーブルにアイテムを追加する場合にのみ、そのアクションが許可さ
れます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllAPIActionsOnUserSpecificTable",
"Effect": "Allow",
"Action": [
"dynamodb:*"
],
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:table/
${aws:username}_ProductCatalog"
},
{
"Sid": "AdditionalPrivileges",
"Effect": "Allow",
"Action": [
"dynamodb:ListTables",
"dynamodb:DescribeTable",
"cloudwatch:*",
"sns:*"
],
"Resource": "*"
}
]
}
Note
IAM ポリシー変数を使用する場合、ポリシーで明示的にアクセスポリシー言語の
2012-10-17 バージョンを指定する必要があります。アクセスポリシー言語のデフォルト
バージョン (2008-10-17) では、ポリシー変数をサポートしていません。
具体的なテーブルをリソースとして特定する代わりに、ワイルドカード文字 (*) を使用して、すべての
テーブルに権限を付与することができます。次に示すように、各テーブル名の先頭には、リクエスト
を行っている IAM ユーザーの名前が付きます。
API Version 2012-08-10
470
Amazon DynamoDB 開発者ガイド
お客様が管理するポリシーの例
"Resource":"arn:aws:dynamodb:us-west-2:123456789012:table/${aws:username}_*"
例 6: リザーブドキャパシティーのサービス購入をユーザーに
禁止する
DynamoDB のお客様は、「Amazon DynamoDB 料金表」に説明されているように、リザーブドキャ
パシティーを購入することができます。リザーブドキャパシティーでは、1 回限りの前払い料金を支
払い、期間中、大幅な節約ができる最小使用レベルを支払う契約を結びます。AWS マネジメントコ
ンソール を使用して、リザーブドキャパシティーを表示し、購入できます。ただし、組織のすべての
ユーザーに、同じレベルのアクセスを付与しないことをお勧めします。
DynamoDB は、リザーブドキャパシティー管理へのアクセスの制御のために、次の API オペレーショ
ンを提供します。
• dynamodb:DescribeReservedCapacity – 現在有効なリザーブドキャパシティーの購入を返しま
す。
• dynamodb:DescribeReservedCapacityOfferings – AWS で現在提供されているリザーブド
キャパシティープランについての詳細を返します。
• dynamodb:PurchaseReservedCapacityOfferings – リザーブドキャパシティーの実際の注文
を実行します。
AWS マネジメントコンソール はこれらの API オペレーションを使用してリザーブドキャパシティー
の情報を表示し、購入を行います。アプリケーションプログラムからこれらのオペレーションを呼
び出すことはできません。オペレーションはコンソールからのみアクセス可能であるためです。ただ
し、IAM アクセス権限ポリシーでこれらのオペレーションへのアクセスを許可または拒否することが
できます。
次のポリシーでは、ユーザーは AWS マネジメントコンソール を使用してリザーブドキャパシティー
のサービスと現在の購入を確認できます。ただし、新しい購入は拒否されます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowReservedCapacityDescriptions",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeReservedCapacity",
"dynamodb:DescribeReservedCapacityOfferings"
],
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:*"
},
{
"Sid": "DenyReservedCapacityPurchases",
"Effect": "Deny",
"Action": "dynamodb:PurchaseReservedCapacityOfferings",
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:*"
}
]
}
API Version 2012-08-10
471
Amazon DynamoDB 開発者ガイド
お客様が管理するポリシーの例
例 7: DynamoDB ストリームのみの読み取りアクセスを許可す
る (テーブルを除く)
テーブルで DynamoDB ストリーム を有効にすると、テーブル内のデータ項目に加えられた各変更に
関する情報がキャプチャされます。詳細については、「DynamoDB ストリーム を使用したテーブル
アクティビティのキャプチャ (p. 426)」を参照してください。
場合によっては、アプリケーションが DynamoDB テーブルからデータを読み取らないようにする一
方で、そのテーブルのストリームへのアクセスは許可したいことがあります。たとえば、項目の更新
が検出されたときにストリームをポーリングし、Lambda 関数を呼び出して、追加の処理を実行する
よう AWS Lambda を設定できます。
DynamoDB ストリーム へのアクセスを制御するために、以下のアクションを使用できます。
• dynamodb:DescribeStream
• dynamodb:GetRecords
• dynamodb:GetShardIterator
• dynamodb:ListStreams
これらのアクションは、DynamoDB ストリーム API に対応します。詳細については、「DynamoDB
ストリーム API リファレンス」を参照してください。
次の例では、GameScores という名前のテーブルでストリームにアクセスするアクセス権限をユー
ザーに付与するポリシーを作成します。ARN の最後のワイルドカード (*) は、そのテーブルに関連付
けられた任意のストリーム ID に一致します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AccessGameScoresStreamOnly",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeStream",
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:ListStreams"
],
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:table/
GameScores/stream/*"
}
]
}
このポリシーは GameScores テーブルのストリームへのアクセスを許可しますが、テーブル自体への
アクセスは許可しないことに注意してください。
例 8: AWS Lambda 関数が DynamoDB ストリームレコードを
処理できるようにする
DynamoDB ストリームの新しいイベントに基づいて特定のアクションを実行する場合、それらの新
しいイベントによってトリガーされる AWS Lambda 関数を記述できます。ストリームイベントでの
Lambda の使用の詳細については、「DynamoDB ストリーム と AWS Lambda のトリガー (p. 451)」
API Version 2012-08-10
472
Amazon DynamoDB 開発者ガイド
DynamoDB API の権限リファレンス
を参照してください。このような Lambda 関数には、DynamoDB ストリームからデータを読み取るア
クセス権限が必要です。
Lambda にアクセス権限を付与するには、Lambda 関数の IAM ロール (実行ロール) に関連付けられた
アクセス権限ポリシーを使用します。これは、Lambda 関数を作成するときに指定します。
たとえば、次のアクセス権限ポリシーを実行ロールに関連付けて、リストされた DynamoDB スト
リーム アクションを実行するアクセス権限を Lambda に付与できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowLambdaFunctionInvocation",
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": [
"*"
]
},
{
"Sid": "AllAPIAccessForDynamoDBStreams",
"Effect": "Allow",
"Action": [
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:DescribeStream",
"dynamodb:ListStreams"
],
"Resource": "*"
}
]
}
詳細については、『AWS Lambda Developer Guide』の「AWS Lambda のアクセス権限モデル」を参
照してください。
DynamoDB API のアクセス権限: アクション、リ
ソース、条件リファレンス
アクセスコントロール (p. 461) をセットアップし、IAM アイデンティティにアタッチできるアクセ
ス権限ポリシー (アイデンティティベースのポリシー) を作成するときは、以下のリストをリファレン
スとして使用できます。 リストには各 DynamoDB API オペレーション、アクションを実行するため
のアクセス権限を付与できる対応するアクション、およびアクセス権限を付与できる AWS リソース
が掲載されています。ポリシーの Action フィールドでアクションを指定し、ポリシーの Resource
フィールドでリソースの値を指定します。
DynamoDB ポリシーで AWS 全体の条件キーを使用して、条件を表現することができます。AWS 全
体を対象とするすべてのキーのリストについては、IAM ユーザーガイド の「利用可能なキー」を参照
してください。
AWS 全体を対象とする条件キーに加え、DynamoDB には条件内で使用可能な独自の固有のキーもあ
ります。詳細については、「詳細に設定されたアクセスコントロールのための IAM ポリシー条件の使
用 (p. 477)」を参照してください。
API Version 2012-08-10
473
Amazon DynamoDB 開発者ガイド
DynamoDB API の権限リファレンス
Note
アクションを指定するには、API オペレーション名 (dynamodb:CreateTable など) の前に
dynamodb: プレフィックスを使用します。
DynamoDB API のアクセス権限: アクション、リソース、および条件キーリファレンス
BatchGetItem
アクション: dynamodb:BatchGetItem
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
BatchWriteItem
アクション: dynamodb:BatchWriteItem
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
CreateTable
アクション: dynamodb:CreateTable
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
DeleteItem
アクション: dynamodb:DeleteItem
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
DeleteTable
アクション: dynamodb:DeleteTable
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
DescribeReservedCapacity
アクション: dynamodb:DeleteTable
リソース:
API Version 2012-08-10
474
Amazon DynamoDB 開発者ガイド
DynamoDB API の権限リファレンス
arn:aws:dynamodb:region:account-id:*
DescribeReservedCapacityOfferings
アクション: dynamodb:DescribeReservedCapacityOfferings
リソース:
arn:aws:dynamodb:region:account-id:*
DescribeStream
アクション: dynamodb:DescribeStream
リソース:
arn:aws:dynamodb:region:account-id:table/table-name/stream/stream-label
または
arn:aws:dynamodb:region:account-id:table/table-name/stream/*
DescribeTable
アクション: dynamodb:DescribeTable
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
GetItem
アクション: dynamodb:GetItem
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
GetRecords
アクション: dynamodb:GetRecords
リソース:
arn:aws:dynamodb:region:account-id:table/table-name/stream/stream-label
または
arn:aws:dynamodb:region:account-id:table/table-name/stream/*
GetShardIterator
アクション: dynamodb:GetShardIterator
リソース:
arn:aws:dynamodb:region:account-id:table/table-name/stream/stream-label
または
arn:aws:dynamodb:region:account-id:table/table-name/stream/*
ListStreams
アクション: dynamodb:ListStreams
リソース:
API Version 2012-08-10
475
Amazon DynamoDB 開発者ガイド
DynamoDB API の権限リファレンス
arn:aws:dynamodb:region:account-id:table/table-name/stream/*
または
arn:aws:dynamodb:region:account-id:table/*/stream/*
ListTables
アクション: dynamodb:ListTables
リソース:
*
PurchaseReservedCapacityOfferings
アクション: dynamodb:PurchaseReservedCapacityOfferings
リソース:
arn:aws:dynamodb:region:account-id:*
PutItem
アクション: dynamodb:PutItem
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
Query
アクション: dynamodb:Query
リソース:
テーブルに対してクエリを実行するには:arn:aws:dynamodb:region:accountid:table/table-name
または:
arn:aws:dynamodb:region:account-id:table/table-name
インデックスでクエリを実行するには
arn:aws:dynamodb:region:account-id:table/table-name/index/index-name
または:
arn:aws:dynamodb:region:account-id:table/table-name/index/*
Scan
アクション: dynamodb:Scan
リソース:
テーブルをスキャンするには
arn:aws:dynamodb:region:account-id:table/table-name
または:
arn:aws:dynamodb:region:account-id:table/table-name
インデックスをスキャンするには
arn:aws:dynamodb:region:account-id:table/table-name/index/index-name
API Version 2012-08-10
476
Amazon DynamoDB 開発者ガイド
関連トピック
または:
arn:aws:dynamodb:region:account-id:table/table-name/index/*
UpdateItem
アクション: dynamodb:UpdateItem
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
UpdateTable
アクション: dynamodb:UpdateTable
リソース:
arn:aws:dynamodb:region:account-id:table/table-name
または
arn:aws:dynamodb:region:account-id:table/*
関連トピック
• アクセスコントロール (p. 461)
• 詳細に設定されたアクセスコントロールのための IAM ポリシー条件の使用 (p. 477)
詳細に設定されたアクセスコントロールのための
IAM ポリシー条件の使用
DynamoDB でアクセス権限を付与するときは、アクセス権限ポリシーを有効にする方法を決める条件
を指定できます。
概要
DynamoDB では、IAM ポリシー (「アクセスコントロール (p. 461)」を参照) を使用してアクセス権
限を付与するとき、条件を指定することもできます。たとえば、次のようにすることができます。
• テーブルまたはセカンダリインデックス内の項目と属性に対する読み取り専用アクセスをユーザー
に許可するアクセス権限を付与します。
• ユーザーのアイデンティティに基づいて、テーブルの特定の属性への書き込み専用アクセスをユー
ザーを許可するアクセス権限を付与します。
DynamoDB では、次のセクションのユースケースに示すように、条件キーを使用して IAM ポリシー
の条件を指定できます。
Note
一部の AWS サービスはタグベースの条件もサポートしますが、DynamoDB はサポートしま
せん。
API Version 2012-08-10
477
Amazon DynamoDB 開発者ガイド
概要
アクセス権限のユースケース
DynamoDB API アクションへのアクセスを制御するだけでなく、個別のデータ項目と属性へのアクセ
スも制御できます。たとえば、次の操作を実行できます。
• テーブルでアクセス権限を付与しますが、特定のプライマリキー値に基づいて、そのテーブル内の
特定の項目へのアクセスを制限します。この例として、ゲーム用のソーシャルネットワーキングア
プリケーションがあります。次の図に示すように、すべてのユーザーのゲームデータは 1 つのテー
ブルに保存されますが、いずれのユーザーも、自分が所有していないデータ項目にアクセスするこ
とはできません。
• 属性のサブセットのみがユーザー表示されるように、情報を非表示にします。この例として、ユー
ザーの位置に基づいて、近くの空港の運航便データを表示するアプリケーションがあります。航空
会社名、到着時間、出発時間、および運航便番号がすべて表示されます。ただし、次の図に示すよ
うに、パイロット名や乗客数などの属性は非表示になります。
このような種類のきめ細かなアクセス制御を実装するには、セキュリティ認証情報と関連する権限に
アクセスするための条件を指定した IAM アクセス権限ポリシーを作成します。次に、IAM コンソール
を使用して作成する IAM ユーザー、グループ、またはロールにそのポリシーを適用します。IAM ポリ
シーによって、テーブルの個別の項目へのアクセス、その項目の属性へのアクセス、またはその両方
へのアクセスを同時に制御できます。
必要に応じて、ウェブ ID フェデレーションを使用して、Login with Amazon、Facebook、または
Google によって認証されるユーザーによるアクセスを制御できます。詳細については、「ウェブアイ
デンティティフェデレーションの使用 (p. 488)」を参照してください。
IAM の Condition 要素を使用して、詳細なアクセスコントロールポリシーを実装できま
す。Condition 要素をアクセス権限ポリシーに追加することで、特定のビジネス要件に基づい
て、DynamoDB テーブルとインデックスの項目と属性へのアクセスを許可または拒否できます。
例として、プレーヤーがさまざまなゲームを選択してプレイできるモバイルゲームアプリケーション
を考えてみます。このアプリケーションでは、GameScores という名前の DynamoDB テーブルを使
用して、高スコアなどのユーザーデータを記録します。テーブルの各項目は、ユーザー ID とユーザー
がプレイしたゲームの名前で一意に識別されます。GameScores テーブルには、パーティションキー
(UserId) およびソートキー (GameTitle) で構成されているプライマリキーがあります。ユーザー
は、そのユーザー ID に関連付けられたゲームデータだけにアクセスできます。ゲームをプレイする
API Version 2012-08-10
478
Amazon DynamoDB 開発者ガイド
概要
ユーザーは、GameRole という名前の IAM ロールに属する必要があります。このロールには、セキュ
リティポリシーが関連付けられています。
このアプリケーションのユーザーアクセス権限を管理するには、次のようなアクセス権限ポリシーを
記述できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowAccessToOnlyItemsMatchingUserID",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:BatchGetItem",
"dynamodb:Query",
"dynamodb:PutItem",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem",
"dynamodb:BatchWriteItem"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores"
],
"Condition": {
"ForAllValues:StringEquals": {
"dynamodb:LeadingKeys": [
"${www.amazon.com:user_id}"
],
"dynamodb:Attributes": [
"UserId",
"GameTitle",
"Wins",
"Losses",
"TopScore",
"TopScoreDateTime"
]
},
"StringEqualsIfExists": {
"dynamodb:Select": "SPECIFIC_ATTRIBUTES"
}
}
}
]
}
GameScores テーブル (Resource 要素) の特定の DynamoDB アクション (Action 要素) に対するア
クセス権限の付与に加えて、Condition 要素は、次のようにアクセス権限を制限する DynamoDB に
固有の次の条件キーを使用します。
• dynamodb:LeadingKeys – この条件キーにより、ユーザーはパーティションキーの値がユー
ザー ID に一致する項目にのみアクセスできます。この ID、${www.amazon.com:user_id} は、
置換変数です。置換変数の詳細については、「ウェブアイデンティティフェデレーションの使
用 (p. 488)」を参照してください。
• dynamodb:Attributes – この条件キーは指定された属性へのアクセスを制限し、アクセス権限
ポリシーに示されたアクションのみが、これらの属性の値を返すことができるようにします。さら
に、StringEqualsIfExists 句は、アプリケーションが常に対象となる特定の属性のリストを提
供し、すべての属性をリクエストできないようにします。
API Version 2012-08-10
479
Amazon DynamoDB 開発者ガイド
条件の指定: 条件キーの使用
IAM ポリシーが評価されると、結果は必ず true (アクセス許可) または false (アクセス拒否) になりま
す。Condition 要素のいずれかの部分が false の場合、ポリシー全体が false と評価され、アクセス
は拒否されます。
Important
dynamodb:Attributes を使用する場合、ポリシーでリストに記載されているテーブルとす
べてのセカンダリインデックスについて、すべてのプライマリキー属性とインデックスキー
属性の名前を指定する必要があります。指定しなかった場合、DynamoDB は、このキー属性
を使用して、リクエストされたアクションを実行できません。
IAM ポリシードキュメントには、次の Unicode 文字のみを含めることができます。水平タブ (U
+0009)、ラインフィード (U+000A)、キャリッジリターン (U+000D)、および U+0020~U+00FF の範
囲内の文字。
条件の指定: 条件キーの使用
AWS には、アクセスコントロールのために IAM をサポートするすべての AWS サービスに合わ
せて事前定義された一連の条件キー (AWS 全体に対する条件キー) が用意されています。たとえ
ば、aws:SourceIp 条件キーを使用して、リクエスタの IP アドレスを確認してから、アクションの
実行を許可できます。AWS 全体に対するキーの詳細とリストについては、『IAM ユーザーガイド』の
「条件に利用可能なキー」を参照してください。
Note
条件キーは大文字と小文字が区別されます。
以下の表では、DynamoDB に適用される DynamoDB サービス固有の条件キーを示しています。
DynamoDB 条件キー
説明
dynamodb:LeadingKeysテーブルの最初のキー属性、つまりパーティションキーを表します。キー
が 1 つの項目のアクションで使用される場合も、キー名 LeadingKeys は
複数形であることに注意してください。また、条件で ForAllValues を
使用するときには、LeadingKeys 修飾子を使用する必要があります。
dynamodb:Select
Select または Query リクエストの Scan パラメータを表しま
す。Select には次のいずれかの値を指定できます。
• ALL_ATTRIBUTES
• ALL_PROJECTED_ATTRIBUTES
• SPECIFIC_ATTRIBUTES
• COUNT
dynamodb:Attributes リクエストの属性名、またはリクエストから返される属性のリストを表し
ます。次に示すように、Attributes 値は、特定の DynamoDB API アク
ション用のパラメーターと同じ方法で名前が付けられ、同じ意味を持ちま
す。
• AttributesToGet
用途: BatchGetItem, GetItem, Query, Scan
• AttributeUpdates
用途: UpdateItem
API Version 2012-08-10
480
Amazon DynamoDB 開発者ガイド
条件の指定: 条件キーの使用
DynamoDB 条件キー
説明
• Expected
用途: DeleteItem, PutItem, UpdateItem
• Item
用途: PutItem
• ScanFilter
用途: Scan
dynamodb:ReturnValues
リクエストの ReturnValues パラメータを表します。ReturnValues に
は次のいずれかの値を指定できます。
• ALL_OLD
• UPDATED_OLD
• ALL_NEW
• UPDATED_NEW
• NONE
dynamodb:ReturnConsumedCapacity
リクエストの ReturnConsumedCapacity パラメータを表しま
す。ReturnConsumedCapacity には、次のいずれかの値を指定できま
す。
• TOTAL
• NONE
ユーザーアクセスの制限
多くの IAM アクセス権限ポリシーでは、パーティションキーの値がユーザー識別子
と一致するテーブルの項目へのアクセスのみをユーザーに許可します。たとえば、
前述のゲームアプリケーションは、この方法でアクセスを制限し、ユーザーは自分の
ユーザー ID に関連付けらたゲームデータのみにアクセスできるようにします。IAM
置換変数 ${www.amazon.com:user_id}、${graph.facebook.com:id}、および
${accounts.google.com:sub} には、Login with Amazon、Facebook、および Google のユーザー
識別子が格納されます。アプリケーションがこのようなアイデンティティプロバイダーのいずれかに
ログインし、この識別子を取得する方法については、「ウェブアイデンティティフェデレーションの
使用 (p. 488)」を参照してください。
Note
以下のセクションの各例では、Effect 句を Allow に設定して、許可されるアクション、リ
ソース、およびパラメーターだけを指定します。IAM ポリシーで明示的に指定されたものへ
のアクセスだけが許可されます。
場合によっては、拒否ベースとなるようにこのポリシーを書き直すことができます。つ
まり、Effect 句を Deny に設定して、ポリシーのすべてのロジックを逆にします。ただ
し、拒否ベースのポリシーを DynamoDB で使用しないことをお勧めします。このような
ポリシーは、許可ベースのポリシーと比べて、正しく記述することが難しいためです。ま
た、DynamoDB API への将来の変更(または、既存の API 入力への変更)が原因で、拒否
ベースのポリシーが機能しなくなる可能性があります。
API Version 2012-08-10
481
Amazon DynamoDB 開発者ガイド
条件の指定: 条件キーの使用
ポリシー例: きめ細かなアクセスコントロールのための IAM ポ
リシー条件の使用
このセクションでは、DynamoDB テーブルとインデックスに対してきめ細かなアクセス制御を実装す
るためのポリシーについて説明します。
Note
すべての例で、us-west-2 リージョンを使用し、架空のアカウント ID を含めています。
1: 特定のパーティションのキー値を持つ項目へのアクセスを制限するアクセ
ス権限の付与
以下のアクセス権限ポリシーは、GamesScore テーブルで DynamoDB アクションのセットを許
可するアクセス権限を付与します。このポリシーは dynamodb:LeadingKeys 条件キーを使用し
て、UserID パーティションキーの値が、このアプリケーション用の Login with Amazon の一意の
ユーザー ID と一致する項目のみでユーザーアクションを制限します。
Important
Scan 用のアクセス権限は、アクションのリストに含まれていません。これは、Scan が主要
なキーにかかわらずすべての項目を返すためです。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "FullAccessToUserItems",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:BatchGetItem",
"dynamodb:Query",
"dynamodb:PutItem",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem",
"dynamodb:BatchWriteItem"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores"
],
"Condition": {
"ForAllValues:StringEquals": {
"dynamodb:LeadingKeys": [
"${www.amazon.com:user_id}"
]
}
}
}
]
}
API Version 2012-08-10
482
Amazon DynamoDB 開発者ガイド
条件の指定: 条件キーの使用
Note
ポリシー変数を使用する場合は、2012-10-17 をポリシー内で明示的に指定する必要があり
ます。アクセスポリシー言語のデフォルトバージョン、2008-10-17 では、ポリシー変数を
サポートしていません。
読み取りアクセスを実装するには、データを変更可能なアクションを削除します。次のポリシーで
は、読み込み専用アクセスを提供するアクションだけが条件に追加されています。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadOnlyAccessToUserItems",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:BatchGetItem",
"dynamodb:Query"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores"
],
"Condition": {
"ForAllValues:StringEquals": {
"dynamodb:LeadingKeys": [
"${www.amazon.com:user_id}"
]
}
}
}
]
}
Important
dynamodb:Attributes を使用する場合、ポリシーでリストに記載されているテーブルとす
べてのセカンダリインデックスについて、すべてのプライマリキー属性とインデックスキー
属性の名前を指定する必要があります。指定しなかった場合、DynamoDB は、このキー属性
を使用して、リクエストされたアクションを実行できません。
2: テーブルの特定の属性へのアクセスを制限するアクセス権限の付与
次のアクセス権限ポリシーは、dynamodb:Attributes 条件キーを追加して、テーブルの 2 つの特定
の属性のみへアクセスを許可します。この属性に対して、読み込み、書き込み、または条件付き書き
込みまたはスキャンフィルタでの評価を実行できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LimitAccessToSpecificAttributes",
"Effect": "Allow",
"Action": [
"dynamodb:UpdateItem",
"dynamodb:GetItem",
API Version 2012-08-10
483
Amazon DynamoDB 開発者ガイド
条件の指定: 条件キーの使用
"dynamodb:Query",
"dynamodb:BatchGetItem",
"dynamodb:Scan"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores"
],
"Condition": {
"ForAllValues:StringEquals": {
"dynamodb:Attributes": [
"UserId",
"TopScore"
]
},
"StringEqualsIfExists": {
"dynamodb:Select": "SPECIFIC_ATTRIBUTES",
"dynamodb:ReturnValues": [
"NONE",
"UPDATED_OLD",
"UPDATED_NEW"
]
}
}
}
]
}
Note
このポリシーでは、ホワイトリスト手法を使用し、名前の付いた一連の属性へのアクセスを
許可します。代わりに、他の属性へのアクセスを拒否する同等のポリシーを記述できます (ブ
ラックリスト手法)。このブラックリスト 手法は、お勧めしません。それは、ユーザーが、す
べての考えられる属性名を使用してリクエストを繰り返し発行し、最終的に、アクセスが許
可されていない属性を見つけることで、ブラックリストに記載されている属性の名前を特定
できる可能性があるためです。これを回避するには、Wikipedia (http://en.wikipedia.org/wiki/
Principle_of_least_privilege) で説明されているように、最小権限の原則に従ってホワイトリス
ト手法を使用し、拒否される属性を指定するのではなく、許可されるすべての値を列挙しま
す。
このポリシーでは、PutItem、DeleteItem、または BatchWriteItem は許可されません。これら
のアクションでは常に前の項目全体が置き換えられ、アクセスが許可されていない属性の以前の値
を、ユーザーが削除できる可能性があるためです。
アクセス権限ポリシーの StringEqualsIfExists 句により、以下を実施することができます。
• ユーザーが Select パラメータを指定する場合、その値は SPECIFIC_ATTRIBUTES である必要が
あります。この要件により、インデックスの射影からなど、API アクションが許可されていない属
性を返さないようにします。
• ユーザーが ReturnValues パラメータを指定する場合、その値は、NONE、UPDATED_OLD、ま
たは UPDATED_NEW にする必要があります。これが必要なのは、UpdateItem アクションでは、
置換する前に項目が存在するかどうかをチェックするために、および、リクエストされた場合
に前の属性値を返すことができるように、暗黙的な読み込みオペレーションが実行されるためで
す。ReturnValues をこのように制限することで、確実にユーザーが許可された属性だけを読み込
むまたは書き込むことができるようにします。
• StringEqualsIfExists 節により、許可されたアクションのコンテキストで、リクエストごとに
Select または ReturnValues パラメータのいずれか 1 つだけを使用できるようにすることができ
ます。
API Version 2012-08-10
484
Amazon DynamoDB 開発者ガイド
条件の指定: 条件キーの使用
次に、このポリシーのバリエーションをいくつか示します。
• 読み込みアクションだけを許可するには、許可されるアクションのリストから UpdateItem
を削除できます。残りのどのアクションも ReturnValues を受け付けないので、条件から
ReturnValues を削除できます。また、Select パラメーターには必ず値 (特に指定のない限
り、ALL_ATTRIBUTES) があるので、StringEqualsIfExists を StringEquals に変更できま
す。
• 書き込みアクションだけを許可するには、許可されるアクションのリストから、UpdateItem を除
くすべてのアクションを削除します。UpdateItem では Select パラメーターを使用しないので、
条件から Select を削除できます。また、ReturnValues パラメーターには必ず値 (特に指定のな
い限り、NONE) があるので、StringEqualsIfExists を StringEquals に変更する必要がありま
す。
• 名前がパターンに一致するすべての属性を許可するには、StringEquals ではなく StringLike
を使用し、複数文字パターン照合ワイルドカード文字 (*) を使用します。
3: 特定の属性で更新を回避するアクセス権限の付与
以下のアクセス権限のポリシーでは、dynamodb:Attributes 条件キーによって識別される特定の属
性のみを更新するようユーザーアクセスを制限します。StringNotLike 条件によって、アプリケー
ションが、dynamodb:Attributes 条件キーを使用して指定された属性を更新できないようになりま
す。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PreventUpdatesOnCertainAttributes",
"Effect": "Allow",
"Action": [
"dynamodb:UpdateItem"
],
"Resource": "arn:aws:dynamodb:us-west-2:123456789012:table/
GameScores",
"Condition": {
"ForAllValues:StringNotLike": {
"dynamodb:Attributes": [
"FreeGamesAvailable",
"BossLevelUnlocked"
]
},
"StringEquals": {
"dynamodb:ReturnValues": [
"NONE",
"UPDATED_OLD",
"UPDATED_NEW"
]
}
}
}
]
}
次の点に注意してください。
• UpdateItem アクションは、他の書き込みアクションと同じように、更新前の値と更新後
の値を返すことができるように、項目への読み取りアクセスを必要とします。ポリシーで
は、dynamodb:ReturnValues 条件キーを指定して、更新が許可される属性のみにアクセ
API Version 2012-08-10
485
Amazon DynamoDB 開発者ガイド
条件の指定: 条件キーの使用
スするようアクションを制限します。条件キーは、リクエストの ReturnValues を制限して
NONE、UPDATED_OLD、または UPDATED_NEW のみを指定し、ALL_OLD または ALL_NEW は含まれ
ません。
• PutItem および DeleteItem アクションは項目全体を置き換えるため、アプリケーションは任意
の属性を変更することができます。したがって、特定の属性のみを更新するようアプリケーション
を制限するときは、それらの API 用のアクセス権限を付与しないようにします。
4: インデックスで射影された属性のみのクエリを許可するアクセス権限の付
与
以下のアクセス権限ポリシーでは、dynamodb:Attributes 条件キーを使用して、セカンダリイン
デックス (TopScoreDateTimeIndex) でクエリを許可します。また、このポリシーでは、インデック
スに射影された特定の属性だけをリクエストするようクエリを制限します。
アプリケーションがクエリで属性のリストを指定するよう要求するには、ポリシーで
dynamodb:Select 条件キーを指定して、DynamoDB の Query アクションの Select パラメーター
が SPECIFIC_ATTRIBUTES であることを要求します。属性のリストは、dynamodb:Attributes 条
件キーを使用して提供される特定のリストに制限されます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "QueryOnlyProjectedIndexAttributes",
"Effect": "Allow",
"Action": [
"dynamodb:Query"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores/
index/TopScoreDateTimeIndex"
],
"Condition": {
"ForAllValues:StringEquals": {
"dynamodb:Attributes": [
"TopScoreDateTime",
"GameTitle",
"Wins",
"Losses",
"Attempts"
]
},
"StringEquals": {
"dynamodb:Select": "SPECIFIC_ATTRIBUTES"
}
}
}
]
}
次のアクセス権限ポリシーは、似ていますが、クエリでは、インデックスに射影されたすべての属性
をリクエストする必要があります。
{
"Version": "2012-10-17",
"Statement": [
{
API Version 2012-08-10
486
Amazon DynamoDB 開発者ガイド
条件の指定: 条件キーの使用
"Sid": "QueryAllIndexAttributes",
"Effect": "Allow",
"Action": [
"dynamodb:Query"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores/
index/TopScoreDateTimeIndex"
],
"Condition": {
"StringEquals": {
"dynamodb:Select": "ALL_PROJECTED_ATTRIBUTES"
}
}
}
]
}
5: 特定の属性とパーティションキー値へのアクセスを制限するアクセス権限
の付与
以下のアクセス権限ポリシーでは、特定の DynamoDB アクション (Action 要素で指定)
をテーブルとテーブルインデックス (Resource 要素で指定) で許可します。このポリシー
は、dynamodb:LeadingKeys 条件キーを使用して、パーティションキーの値がユーザーの
Facebook ID に一致する項目のみにアクセス権限を制限します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LimitAccessToCertainAttributesAndKeyValues",
"Effect": "Allow",
"Action": [
"dynamodb:UpdateItem",
"dynamodb:GetItem",
"dynamodb:Query",
"dynamodb:BatchGetItem"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores",
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores/
index/TopScoreDateTimeIndex"
],
"Condition": {
"ForAllValues:StringEquals": {
"dynamodb:LeadingKeys": [
"${graph.facebook.com:id}"
],
"dynamodb:Attributes": [
"attribute-A",
"attribute-B"
]
},
"StringEqualsIfExists": {
"dynamodb:Select": "SPECIFIC_ATTRIBUTES",
"dynamodb:ReturnValues": [
"NONE",
"UPDATED_OLD",
API Version 2012-08-10
487
Amazon DynamoDB 開発者ガイド
関連トピック
"UPDATED_NEW"
]
}
}
}
]
}
次の点に注意してください。
• ポリシー (UpdateItem) によって許可された書き込みアクションでは、attribute-A または
attribute-B のみを変更できます。
• ポリシーでは UpdateItem が許可されるため、アプリケーションは新しい項目を挿入でき、その非
表示の属性は、新しい項目では null として表示されます。この属性が TopScoreDateTimeIndex
に射影されている場合、テーブルからのフェッチを引き起こすクエリを防止するという利点がポリ
シーに追加されます。
• アプリケーションは、dynamodb:Attributes に列挙されている属性以外の属性を読み込むこ
とができません。このポリシーにより、アプリケーションは、読み込みリクエストで Select パ
ラメーターを SPECIFIC_ATTRIBUTES に設定する必要があり、ホワイトリストに記載されてい
る属性だけをリクエストすることができます。書き込みリクエストの場合、アプリケーション
は、ReturnValues を ALL_OLD または ALL_NEW に設定できません。また、他の属性に基づく条件
付き書き込みオペレーションを実行できません。
関連トピック
• アクセスコントロール (p. 461)
• DynamoDB API のアクセス権限: アクション、リソース、条件リファレンス (p. 473)
ウェブアイデンティティフェデレーションの使用
多数のユーザーを対象とするアプリケーションを記述している場合、必要に応じて、ウェブアイデン
ティティフェデレーションを使用して、認証と認可を実行できます。ウェブアイデンティティフェデ
レーションを使用すると、IAM ユーザーを作成する必要がなくなります。ユーザーは、アイデンティ
ティプロバイダーにサインインして、AWS Security Token Service(AWS STS)から一時的なセキュ
リティ認証情報を取得できます。アプリケーションでは、この認証情報を使用して AWS サービスに
アクセスできます。
ウェブアイデンティティフェデレーションでは、次のアイデンティティプロバイダーをサポートして
います。
• Login with Amazon
• Facebook
• Google
ウェブアイデンティティフェデレーションに関する
その他のリソース
ウェブアイデンティティフェデレーションの詳細を理解するのに、次のリソースが役に立ちます。
• 「Web Identity Federation Playground」は、インタラクティブなウェブサイトで、Login with
Amazon、Facebook、または Google を介して認証を行い、一時的なセキュリティ認証情報を取得
し、その認証情報を使用して AWS にリクエストを行うプロセスを体験できます。
API Version 2012-08-10
488
Amazon DynamoDB 開発者ガイド
ウェブアイデンティティフェデレーションのポリシー例
• AWS .NET Development ブログの記事「Web Identity Federation using the AWS SDK for .NET」で
は、ウェブ ID フェデレーションと Facebook を使用する方法について説明し、ウェブ ID を使用し
て IAM ロールを前提とする方法を示す C# コード例と、一時的なセキュリティ認証情報を使用して
AWS リソースにアクセスする方法を示す C# コード例を掲載しています。
• 「AWS SDK for iOS」と「AWS SDK for Android」には、サンプルアプリケーションが用意されて
います。このアプリケーションには、アイデンティティプロバイダーを呼び出す方法、そのプロ
バイダーからの情報を使用して、一時的なセキュリティ認証情報を取得および使用する方法を示す
コードが含まれています。
• 記事「Web Identity Federation with Mobile Applications」では、ウェブアイデンティティフェデレー
ションについて説明し、ウェブアイデンティティフェデレーションを使用して AWS リソースにア
クセスする例を挙げています。
ウェブアイデンティティフェデレーションのポリ
シー例
ウェブアイデンティティフェデレーションを DynamoDB で使用する方法を説明するために、「詳
細に設定されたアクセスコントロールのための IAM ポリシー条件の使用 (p. 477)」で示した
GameScores テーブルをもう一度取り上げます。次に、GameScores のプライマリキーを示します。
テーブル名
プライマリキーのタイ
プ
GameScores(UserId、GameTitle、...)
複合
パーティションキーの
名前と型
ソートキーの名前と型
属性名: UserId
属性名: GameTitle
型: 文字列
型: 文字列
ここで、あるモバイルゲームアプリケーションがこのテーブルを使用し、そのアプリケーションで
は、数千人、数百万人のユーザーをサポートする必要があるとします。この規模では、個別のアプリ
ケーションユーザーを管理し、各ユーザーが GameScores テーブルの自分のデータにだけアクセス
できることを確実にするのは非常に難しいです。多くのユーザーは、Facebook、Google、Login with
Amazon などのサードパーティのアイデンティティプロバイダーのアカウントを持っているので、こ
のようなプロバイダーのいずれかを利用して、認証タスクを行うことができます。
ウェブアイデンティティフェデレーションを使用して認証を行うには、アプリケーション開発者は、
そのアプリケーションをアイデンティティプロバイダー(Login with Amazon など)に登録して、一
意のアプリケーション ID を取得する必要があります。次に、IAM ロールを作成する必要があります。
(この例では、このロールに GameRole という名前を付けます)。このロールには、IAM ポリシード
キュメントを関連付ける必要があります。このドキュメントでは、アプリケーションが GameScores
テーブルにアクセスできるように条件を指定します。
ユーザーは、ゲームをプレイするとき、ゲームアプリケーション内から Login with Amazon アカウン
トにサインインします。アプリケーションは、AWS Security Token Service(AWS STS)を呼び出
し、Login with Amazon アプリケーション ID を提供し、GameRole のメンバーシップをリクエスト
します。AWS STS は、一時的な AWS 認証情報をアプリケーションに返し、GameRolel ポリシード
キュメントに従って GameScores テーブルへのアクセスをアプリケーションに許可します。
次の図は、これらの要素を組み合わせるとどのようになるかを示しています。
API Version 2012-08-10
489
Amazon DynamoDB 開発者ガイド
ウェブアイデンティティフェデレーションのポリシー例
ウェブ ID フェデレーションの概要
1. アプリケーションは、サードパーティのアイデンティティプロバイダーを呼び出して、ユーザーと
アプリケーションを認証します。アイデンティティプロバイダーは、ウェブアイデンティティトー
クンをアプリケーションに返します。
2. アプリケーションは、AWS STS を呼び出し、ウェブアイデンティティトークンを入力として渡し
ます。AWS STS は、アプリケーションを認可し、一時的な AWS アクセス認証情報をアプリケー
ションに渡します。アプリケーションは、IAM ロール(GameRole)を想定し、そのロールのセ
キュリティポリシーに従って AWS リソースにアクセスすることが許可されます。
3. アプリケーションは、DynamoDB を呼び出して、GameScores テーブルにアクセスします。アプ
リケーションは GameRole を想定しているので、そのロールに関連付けられたセキュリティポリ
シーの影響を受けます。ポリシードキュメントによって、ユーザーに属していないデータにアプリ
ケーションはアクセスできません。
もう一度、「詳細に設定されたアクセスコントロールのための IAM ポリシー条件の使用 (p. 477)」
で示した GameRole のセキュリティポリシーを示します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowAccessToOnlyItemsMatchingUserID",
API Version 2012-08-10
490
Amazon DynamoDB 開発者ガイド
ウェブアイデンティティフェデ
レーションを使用するための準備
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:BatchGetItem",
"dynamodb:Query",
"dynamodb:PutItem",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem",
"dynamodb:BatchWriteItem"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/GameScores"
],
"Condition": {
"ForAllValues:StringEquals": {
"dynamodb:LeadingKeys": [
"${www.amazon.com:user_id}"
],
"dynamodb:Attributes": [
"UserId",
"GameTitle",
"Wins",
"Losses",
"TopScore",
"TopScoreDateTime"
]
},
"StringEqualsIfExists": {
"dynamodb:Select": "SPECIFIC_ATTRIBUTES"
}
}
}
]
}
Condition 節によって、アプリケーションに表示される GameScores の項目が決まります。Login
with Amazon ID と GameScores の UserId パーティションキーの値を比較することで、これを行
います。このポリシーに列挙されている DynamoDB アクションのいずれかを使用して処理できるの
は、現在のユーザーに属する項目だけです。テーブルのその他の項目にはアクセスできません。さら
に、ポリシーに列挙されている特定の属性にだけアクセスできます。
ウェブアイデンティティフェデレーションを使用す
るための準備
アプリケーション開発者がアプリケーションにウェブアイデンティティフェデレーションを使用する
場合、次の手順に従います。
1. 開発者としてサードパーティのアイデンティティプロバイダーにサインアップします。次の外部リ
ンクには、サポートされるアイデンティティプロバイダーにサインアップする方法に関する情報が
記載されています。
• Login with Amazon 開発者センター
• Facebook サイトの登録
• Google サイトの Using OAuth 2.0 to Access Google APIs
2. アプリケーションをアイデンティティプロバイダーに登録します。登録すると、プロバイダーから
アプリケーションに固有の ID が提供されます。複数のアイデンティティプロバイダーで機能する
API Version 2012-08-10
491
Amazon DynamoDB 開発者ガイド
ウェブアイデンティティフェデレーショ
ンを使用するアプリケーションの記述
ようにアプリケーションを構築する場合は、各プロバイダーからアプリケーション ID を取得する
必要があります。
3. 1 つ以上の IAM ロールを作成します。各アプリケーションのアイデンティティプロバイダーごと
に 1 つのロールが必要です。たとえば、ユーザーが Login with Amazon を使用してサインインする
アプリケーションで想定できるロール、ユーザーが Facebook を使用してサインインする同じアプ
リケーションの 2 つ目のロール、およびユーザーが Google を使用してサインインするアプリケー
ションの 3 つ目のロールを作成します。
ロール作成プロセスの中で、IAM ポリシーをロールに関連付ける必要があります。ポリシードキュ
メントでは、アプリケーションに必要な DynamoDB リソース、そのリソースにアクセスするため
の権限を定義する必要があります。
詳細については、『IAM ユーザーガイド』の「ウェブ ID フェデレーションの詳細について」を参照し
てください。
Note
AWS Security Token Service の代わりに、Amazon Cognito を使用することもできま
す。Amazon Cognito の方が、モバイルアプリの一時的認証情報の管理用としては望ましい
サービスです。詳細については、次のページを参照してください。
• 「ユーザーの認証方法(AWS Mobile SDK for iOS)」
• 「ユーザーの認証方法(AWS Mobile SDK for Android)」
DynamoDB コンソールを使用した IAM ポリシーの生成
DynamoDB コンソールでは、ウェブアイデンティティフェデレーションで使用する IAM ポリシーを
作成できます。作成するには、DynamoDB テーブルを選択し、ポリシーに追加するアイデンティティ
プロバイダー、アクション、および属性を指定します。DynamoDB コンソールによって、IAM ロール
に関連付けることができるポリシーが生成されます。
1.
AWS マネジメントコンソール にサインインし、DynamoDB コンソール (https://
console.aws.amazon.com/dynamodb/) を開きます。
2.
ナビゲーションペインで、[ Tables] を選択します。
3.
テーブルの一覧で、IAM ポリシーを作成するテーブルを選択します。
4.
[Access control] タブを選択します。
5.
ポリシーの ID プロバイダー、アクション、および属性を選択します。
ポリシーの設定が正しいことを確認したら、[Create policy] をクリックします。生成されたポリ
シーが表示されます。
6.
[Attach policy instructions] をクリックし、必要な手順に従って、生成されたポリシーを IAM ロー
ルにアタッチします。
ウェブアイデンティティフェデレーションを使用す
るアプリケーションの記述
ウェブアイデンティティフェデレーションを使用するには、アプリケーションで、作成した IAM ロー
ルを想定する必要があります。その時点から、アプリケーションは、そのロールに関連付けられたア
クセスポリシーに従います。
実行時、アプリケーションがウェブアイデンティティフェデレーションを使用する場合、次の手順に
従う必要があります。
API Version 2012-08-10
492
Amazon DynamoDB 開発者ガイド
ウェブアイデンティティフェデレーショ
ンを使用するアプリケーションの記述
1. サードパーティのアイデンティティプロバイダーと認証を行います。アプリケーションは、アイデ
ンティティプロバイダーが提供するインターフェイスを使用してそのプロバイダーを呼び出す必要
があります。ユーザーを認証するときの正確な方法は、プロバイダーおよびアプリケーションを実
行しているプラットフォームによって異なります。一般的に、ユーザーがまだサインインしていな
い場合、アイデンティティプロバイダーはそのプロバイダーのサインインページを表示するように
対処します。
アイデンティティプロバイダーはユーザーを認証した後、ウェブアイデンティティトークンをアプ
リケーションに返します。このトークンの形式は、プロバイダーによって異なりますが、通常は、
非常に長い文字列です。
2. 一時的な AWS セキュリティ認証情報を取得します。取得するために、アプリケーションは
AssumeRoleWithWebIdentity リクエストを AWS Security Token Service(AWS STS)に送信
します。このリクエストでは以下を指定します。
• 前の手順からのウェブアイデンティティトークン
• アイデンティティプロバイダーからのアプリケーション ID
• このアプリケーションのこのアイデンティティプロバイダー用に作成した IAM ロールの Amazon
リソースネーム(ARN)
AWS STS は、一定の時間(デフォルトでは、3600 秒)経過した後に失効する AWS セキュリティ
認証情報のセットを返します。
次に、AWS STS で AssumeRoleWithWebIdentity アクションを実行するときのサンプルリクエ
ストとレスポンスを示します。ウェブアイデンティティトークンは、Login with Amazon アイデン
ティティプロバイダーから取得しました。
GET / HTTP/1.1
Host: sts.amazonaws.com
Content-Type: application/json; charset=utf-8
URL: https://sts.amazonaws.com/?ProviderId=www.amazon.com
&DurationSeconds=900&Action=AssumeRoleWithWebIdentity
&Version=2011-06-15&RoleSessionName=web-identity-federation
&RoleArn=arn:aws:iam::123456789012:role/GameRole
&WebIdentityToken=Atza|IQEBLjAsAhQluyKqyBiYZ8-kclvGTYM81e...(remaining
characters omitted)
<AssumeRoleWithWebIdentityResponse
xmlns="https://sts.amazonaws.com/doc/2011-06-15/">
<AssumeRoleWithWebIdentityResult>
<SubjectFromWebIdentityToken>amzn1.account.AGJZDKHJKAUUSW6C44CHPEXAMPLE</
SubjectFromWebIdentityToken>
<Credentials>
<SessionToken>AQoDYXdzEMf//////////wEa8AP6nNDwcSLnf+cHupC...
(remaining characters omitted)</SessionToken>
<SecretAccessKey>8Jhi60+EWUUbbUShTEsjTxqQtM8UKvsM6XAjdA==</
SecretAccessKey>
<Expiration>2013-10-01T22:14:35Z</Expiration>
<AccessKeyId>06198791C436IEXAMPLE</AccessKeyId>
</Credentials>
<AssumedRoleUser>
<Arn>arn:aws:sts::123456789012:assumed-role/GameRole/web-identityfederation</Arn>
<AssumedRoleId>AROAJU4SA2VW5SZRF2YMG:web-identity-federation</
AssumedRoleId>
</AssumedRoleUser>
API Version 2012-08-10
493
Amazon DynamoDB 開発者ガイド
ウェブアイデンティティフェデレーショ
ンを使用するアプリケーションの記述
</AssumeRoleWithWebIdentityResult>
<ResponseMetadata>
<RequestId>c265ac8e-2ae4-11e3-8775-6969323a932d</RequestId>
</ResponseMetadata>
</AssumeRoleWithWebIdentityResponse>
3. AWS リソースにアクセスします。AWS STS からのレスポンスには、DynamoDB リソースにアク
セスするためにアプリケーションに必要な情報が格納されています。
• AccessKeyID、SecretAccessKey、および SessionToken フィールドには、このユーザーと
このアプリケーションにのみ有効なセキュリティ認証情報が入っています。
• Expiration フィールドは、この認証情報の時間制限を示します。この時間を経過すると、認証
情報は無効になります。
• AssumedRoleId フィールドには、アプリケーションによって想定されたセッション固有の IAM
ロールの名前が入っています。アプリケーションは、このセッションの期間中、IAM ポリシード
キュメントのアクセスコントロールに従います。
• SubjectFromWebIdentityToken フィールドには、この特定のアイデンティティプロバイダー
用の IAM ポリシー変数に表示される一意の ID が入っています。次に、サポートされるプロバイ
ダーの IAM ポリシー変数と、その値の例を示します。
ポリシー変数
値の例
${www.amazon.com:user_id}
amzn1.account.AGJZDKHJKAUUSW6C44CHPEXAMPLE
${graph.facebook.com:id}
123456789
${accounts.google.com:sub}
123456789012345678901
このポリシー変数が使用される IAM ポリシーの例については、「ポリシー例: きめ細かなアクセスコ
ントロールのための IAM ポリシー条件の使用 (p. 482)」を参照してください。
AWS Security Token Service が一時的なアクセス認証情報を生成する方法については、『IAM ユー
ザーガイド』の「一時的セキュリティ認証情報のリクエスト」を参照してください。
API Version 2012-08-10
494
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB のモニタリン
グ
モニタリングは、Amazon DynamoDB と AWS ソリューションの信頼性、可用性、パフォーマンスを
維持する上で重要な部分です。マルチポイント障害が発生した場合は、その障害をより簡単にデバッ
グできるように、AWS ソリューションのすべての部分からモニタリングデータを収集する必要があり
ます。Amazon DynamoDB のモニタリングを開始する前に、以下の質問に対する回答を反映したモニ
タリング計画を作成する必要があります。
• どのような目的でモニタリングしますか?
• モニタリングの対象となるリソースとは ?
• どのくらいの頻度でこれらのリソースをモニタリングしますか?
• 使用するモニタリングツールは?
• 誰がモニタリングタスクを実行しますか?
• 誰が問題が発生したときに通知を受け取りますか?
次のステップは、さまざまなタイミングと負荷条件でパフォーマンスを測定することにより、お客様
の環境で通常の Amazon DynamoDB パフォーマンスのベースラインを確定することです。Amazon
DynamoDB を監視するには、モニタリングデータの履歴を保存することを検討します。保存データ
を、最新のパフォーマンスデータと比較するベースラインとして使用し、通常のパフォーマンスのパ
ターンやパフォーマンスの異常を検出して、問題への対応を検討することができます。
ベースラインを確立するには、少なくとも、次の項目をモニタリングする必要があります。
• 指定の期間内に消費された読み取りおよび書き込み容量ユニットの数。これにより、どれだけのプ
ロビジョンドスループットが使用されたかをトラックすることができます。
• テーブルにプロビジョニングされた書き込みまたは読み取り容量を指定期間で超えたリクエスト
で、テーブルにプロビジョニングされたスループット制限をどのリクエストが超えたかを判断でき
ます。
• システムエラーで、いずれかのリクエストでエラーが発生したかどうかを判断できます。
トピック
• モニタリングツール (p. 496)
API Version 2012-08-10
495
Amazon DynamoDB 開発者ガイド
モニタリングツール
• Amazon CloudWatch でのモニタリング (p. 497)
• AWS CloudTrail を使用した DynamoDB オペレーションのログ記録 (p. 511)
モニタリングツール
AWS では、Amazon DynamoDB のモニタリングに使用できるツールを提供しています。これらの中
には、自動モニタリングを設定できるものもあれば、手操作を必要とするものもあります。モニタリ
ングタスクをできるだけ自動化することをお勧めします。
自動モニタリングツール
以下に示す自動化されたモニタリングツールを使用すると、Amazon DynamoDB がモニタリングさ
れ、問題が検出されたときにレポートされます。
• Amazon CloudWatch Alarms – Watch a single metric over a time period that you specify, and
perform one or more actions based on the value of the metric relative to a given threshold over a
number of time periods. The action is a notification sent to an Amazon Simple Notification Service
(Amazon SNS) topic or Auto Scaling policy. CloudWatch alarms do not invoke actions simply
because they are in a particular state; the state must have changed and been maintained for a
specified number of periods. For more information, see Amazon CloudWatch でのモニタリン
グ (p. 497).
• Amazon CloudWatch Logs – Monitor, store, and access your log files from AWS CloudTrail or other
sources. For more information, see Monitoring Log Files in the Amazon CloudWatch ユーザーガイ
ド.
• Amazon CloudWatch Events – Match events and route them to one or more target functions
or streams to make changes, capture state information, and take corrective action. For more
information, see Using Events in the Amazon CloudWatch ユーザーガイド.
• AWS CloudTrail Log Monitoring – Share log files between accounts, monitor CloudTrail log files
in real time by sending them to CloudWatch Logs, write log processing applications in Java, and
validate that your log files have not changed after delivery by CloudTrail. For more information, see
Working with CloudTrail Log Files in the AWS CloudTrail User Guide.
手動モニタリングツール
Amazon DynamoDB のモニタリングにおけるもう 1 つの重要な部分は、CloudWatch アラームで網羅
されていない項目を手動でモニタリングすることです。Amazon DynamoDB、CloudWatch、Trusted
Advisor、その他の AWS コンソールのダッシュボードには、AWS 環境の状態が一目でわかるビュー
が表示されます。Amazon DynamoDB のログファイルを確認することもお勧めします。
• Amazon DynamoDB ダッシュボードは以下のように表示されます。
• 最近のアラート
• 合計容量
• サービス状態
• CloudWatch ホーム ページは以下のように表示されます。
• 現在のアラームとステータス
• アラームとリソースのグラフ
• サービス状態ステータス
さらに、CloudWatch を使用して次のことが行えます。
• 重視するサービスをモニタリングするためのカスタマイズしたダッシュボードを作成する
• メトリクスデータをグラフ化して、問題のトラブルシューティングを行い、傾向を確認する
API Version 2012-08-10
496
Amazon DynamoDB 開発者ガイド
Amazon CloudWatch でのモニタリング
• AWS リソースのすべてのメトリクスを検索して参照する
• 問題があることを通知するアラームを作成/編集する
Amazon CloudWatch でのモニタリング
CloudWatch を使用して Amazon DynamoDB をモニタリングすることで、Amazon DynamoDB から
未加工データを収集し、リアルタイムに近い読み取り可能なメトリクスに加工することができます。
これらの統計は 2 週間記録されるため、履歴情報にアクセスしてウェブアプリケーションまたはサー
ビスの動作をより的確に把握することができます。デフォルトでは、Amazon DynamoDB メトリック
スデータは CloudWatch に自動的に送信されます。詳細については、「Amazon CloudWatch とは何
ですか?」を参照してください。」 (Amazon CloudWatch ユーザーガイド) を参照してください。
トピック
• Amazon DynamoDB のメトリクスとディメンション (p. 497)
• Amazon DynamoDB のメトリクスの使用方法 (p. 508)
• Amazon DynamoDB をモニタリングする CloudWatch アラームの作成 (p. 509)
Amazon DynamoDB のメトリクスとディメンション
DynamoDB を操作するとき、以下のメトリックスとディメンションが CloudWatch に送信されます。
以下の手順を使用して、Amazon DynamoDB のメトリクスを表示できます。
メトリックスを表示するには (コンソール)
メトリクスはまずサービスの名前空間ごとにグループ化され、次に各名前空間内のさまざまなディメ
ンションの組み合わせごとにグループ化されます。
1.
https://console.aws.amazon.com/cloudwatch/にある CloudWatch コンソールを開きます。
2.
ナビゲーションペインで メトリクスを選択します。
3.
名前空間に [DynamoDB] を選択します。
メトリックスを表示するには (CLI)
•
コマンドプロンプトで、次のコマンドを使用します。
aws cloudwatch list-metrics --namespace "AWS/DynamoDB"
CloudWatch では、Amazon DynamoDB の以下のメトリクスが表示されます。
Amazon DynamoDB のディメンションとメトリックス
Amazon DynamoDB が Amazon CloudWatch に送信するメトリックスおよびディメンションは次のと
おりです。
DynamoDB Metrics
The following metrics are available from Amazon DynamoDB. Note that DynamoDB only sends metrics
to CloudWatch when they have a non-zero value. For example, the UserErrors metric is incremented
whenever a request generates an HTTP 400 status code. If no HTTP 400 errors were encountered
during a time period, CloudWatch will not provide metrics for UserErrors during that period.
API Version 2012-08-10
497
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Note
Amazon CloudWatch aggregates the following DynamoDB metrics at one-minute intervals:
• ConditionalCheckFailedRequests
• ConsumedReadCapacityUnits
• ConsumedWriteCapacityUnits
• ReadThrottleEvents
• ReturnedBytes
• ReturnedItemCount
• ReturnedRecordsCount
• SuccessfulRequestLatency
• SystemErrors
• ThrottledRequests
• UserErrors
• WriteThrottleEvents
For all other DynamoDB metrics, the aggregation granularity is five minutes.
Not all statistics, such as Average or Sum, are applicable for every metric. However, all of these values
are available through the Amazon DynamoDB console, or by using the CloudWatch console, AWS
CLI, or AWS SDKs for all metrics. In the following table, each metric has a list of Valid Statistics that is
applicable to that metric.
Metric
Description
ConditionalCheckFailedRequests
The number of failed attempts to perform conditional writes.
The PutItem, UpdateItem, and DeleteItem operations let
you provide a logical condition that must evaluate to true before
the operation can proceed. If this condition evaluates to false,
ConditionalCheckFailedRequests is incremented by one.
Note
A failed conditional write will result in an HTTP 400
error (Bad Request). These events are reflected in the
ConditionalCheckFailedRequests metric, but not in
the UserErrors metric.
Units: Count
Dimensions: TableName
Valid Statistics:
• Minimum
• Maximum
• Average
• SampleCount
• Sum
ConsumedReadCapacityUnits The number of read capacity units consumed over the specified
time
period,
so you can track how much of your provisioned
API
Version
2012-08-10
498
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
throughput is used. You can retrieve the total consumed read
capacity for a table and all of its global secondary indexes, or for
a particular global secondary index. For more information, see
Provisioned Throughput in Amazon DynamoDB.
Note
Use the Sum statistic to calculate the consumed
throughput. For example, get the Sum value over a
span of one minute, and divide it by the number of
seconds in a minute (60) to calculate the average
ConsumedReadCapacityUnits per second
(recognizing that this average will not highlight any large
but brief spikes in read activity that occurred during that
minute). You can compare the calculated value to the
provisioned throughput value you provide DynamoDB.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• Minimum – Minimum number of read capacity units consumed
by any individual request to the table or index.
• Maximum – Maximum number of read capacity units consumed
by any individual request to the table or index.
• Average – Average per-request read capacity consumed.
• Sum – Total read capacity units consumed. This is the most
useful statistic for the ConsumedReadCapacityUnits metric.
• SampleCount – Number of requests to DynamoDB that
consumed read capacity.
API Version 2012-08-10
499
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
ConsumedWriteCapacityUnits The number of write capacity units consumed over the specified
time period, so you can track how much of your provisioned
throughput is used. You can retrieve the total consumed write
capacity for a table and all of its global secondary indexes, or for
a particular global secondary index. For more information, see
Provisioned Throughput in Amazon DynamoDB.
Note
Use the Sum statistic to calculate the consumed
throughput. For example, get the Sum value over a
span of one minute, and divide it by the number of
seconds in a minute (60) to calculate the average
ConsumedWriteCapacityUnits per second
(recognizing that this average will not highlight any large
but brief spikes in write activity that occurred during that
minute). You can compare the calculated value to the
provisioned throughput value you provide DynamoDB.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• Minimum – Minimum number of write capacity units consumed
by any individual request to the table or index.
• Maximum – Maximum number of write capacity units consumed
by any individual request to the table or index.
• Average – Average per-request write capacity consumed.
• Sum – Total write capacity units consumed. This is the most
useful statistic for the ConsumedWriteCapacityUnits metric.
• SampleCount – Number of requests to DynamoDB that
consumed write capacity.
API Version 2012-08-10
500
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
OnlineIndexConsumedWriteCapacity
The number of write capacity units consumed when adding a
new global secondary index to a table. If the write capacity of
the index is too low, incoming write activity during the backfill
phase might be throttled; this can increase the time it takes to
create the index. You should monitor this statistic while the index
is being built to determine whether the write capacity of the index
is underprovisioned.
You can adjust the write capacity of the index using the
UpdateTable operation, even while the index is still being built.
Note that the ConsumedWriteCapacityUnits metric for the
index does not include the write throughput consumed during
index creation.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• Minimum
• Maximum
• Average
• SampleCount
• Sum
OnlineIndexPercentageProgress
The percentage of completion when a new global secondary
index is being added to a table. DynamoDB must first allocate
resources for the new index, and then backfill attributes from the
table into the index. For large tables, this process might take a
long time. You should monitor this statistic to view the relative
progress as DynamoDB builds the index.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• Minimum
• Maximum
• Average
• SampleCount
• Sum
API Version 2012-08-10
501
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
OnlineIndexThrottleEvents The number of write throttle events that occur when adding a new
global secondary index to a table. These events indicate that the
index creation will take longer to complete, because incoming
write activity is exceeding the provisioned write throughput of the
index.
You can adjust the write capacity of the index using the
UpdateTable operation, even while the index is still being built.
Note that the WriteThrotttleEvents metric for the index does
not include any throttle events that occur during index creation.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• Minimum
• Maximum
• Average
• SampleCount
• Sum
ProvisionedReadCapacityUnits
The number of provisioned read capacity units for a table or a
global secondary index.
The TableName dimension returns the
ProvisionedReadCapacityUnits for the table,
but not for any global secondary indexes. To view
ProvisionedReadCapacityUnits for a global
secondary index, you must specify both TableName and
GlobalSecondaryIndex.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• Minimum – Lowest setting for provisioned read capacity. If you
use UpdateTable to increase read capacity, this metric shows
the lowest value of provisioned ReadCapacityUnits during
this time period.
• Maximum – Highest setting for provisioned read capacity. If
you use UpdateTable to decrease read capacity, this metric
shows the highest value of provisioned ReadCapacityUnits
during this time period.
• Average – Average provisioned read capacity. The
ProvisionedReadCapacityUnits metric is published
at five-minute intervals. Therefore, if you rapidly adjust the
provisioned read capacity units, this statistic might not reflect
the true average.
API Version 2012-08-10
502
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
ProvisionedWriteCapacityUnits
The number of provisioned write capacity units for a table or a
global secondary index
The TableName dimension returns the
ProvisionedWriteCapacityUnits for the table,
but not for any global secondary indexes. To view
ProvisionedWriteCapacityUnits for a global
secondary index, you must specify both TableName and
GlobalSecondaryIndex.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• Minimum – Lowest setting for provisioned write capacity. If you
use UpdateTable to increase write capacity, this metric shows
the lowest value of provisioned WriteCapacityUnits during
this time period.
• Maximum – Highest setting for provisioned write capacity. If
you use UpdateTable to decrease write capacity, this metric
shows the highest value of provisioned WriteCapacityUnits
during this time period.
• Average – Average provisioned write capacity. The
ProvisionedWriteCapacityUnits metric is published
at five-minute intervals. Therefore, if you rapidly adjust the
provisioned write capacity units, this statistic might not reflect
the true average.
ReadThrottleEvents
Requests to DynamoDB that exceed the provisioned read
capacity units for a table or a global secondary index.
A single request can result in multiple events. For example, a
BatchGetItem that reads 10 items is processed as ten GetItem
events. For each event, ReadThrottleEvents is incremented
by one if that event is throttled. The ThrottledRequests metric
for the entire BatchGetItem is not incremented unless all ten of
the GetItem events are throttled.
The TableName dimension returns the ReadThrottleEvents
for the table, but not for any global secondary indexes. To view
ReadThrottleEvents for a global secondary index, you must
specify both TableName and GlobalSecondaryIndex.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• SampleCount
• Sum
API Version 2012-08-10
503
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
ReturnedBytes
The number of bytes returned by GetRecords operations
(Amazon DynamoDB Streams) during the specified time period.
Units: Bytes
Dimensions: Operation, StreamLabel, TableName
Valid Statistics:
• Minimum
• Maximum
• Average
• SampleCount
• Sum
ReturnedItemCount
The number of items returned by Query or Scan operations
during the specified time period.
Note that the number of items returned is not necessarily the
same as the number of items that were evaluated. For example,
suppose you requested a Scan on a table that had 100 items, but
specified a FilterExpression that narrowed the results so that
only 15 items were returned. In this case, the response from Scan
would contain a ScanCount of 100 and a Count of 15 returned
items.
Units: Count
Dimensions: TableName
Valid Statistics:
• Minimum
• Maximum
• Average
• SampleCount
• Sum
ReturnedRecordsCount
The number of stream records returned by GetRecords
operations (Amazon DynamoDB Streams) during the specified
time period.
Units: Count
Dimensions: Operation, StreamLabel, TableName
Valid Statistics:
• Minimum
• Maximum
• Average
• SampleCount
• Sum
API Version 2012-08-10
504
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
SuccessfulRequestLatency
Successful requests to DynamoDB or Amazon
DynamoDB Streams during the specified time period.
SuccessfulRequestLatency can provide two different kinds of
information:
• The elapsed time for successful requests (Minimum, Maximum,
Sum, or Average).
• The number of successful requests (SampleCount).
SuccessfulRequestLatency reflects activity only within
DynamoDB or Amazon DynamoDB Streams, and does not take
into account network latency or client-side activity.
Units: Milliseconds
Dimensions: TableName, Operation
Valid Statistics:
• Minimum
• Maximum
• Average
• SampleCount
SystemErrors
Requests to DynamoDB or Amazon DynamoDB Streams that
generate an HTTP 500 status code during the specified time
period. An HTTP 500 usually indicates an internal service error.
Units: Count
Dimensions: All dimensions
Valid Statistics:
• Sum
• SampleCount
API Version 2012-08-10
505
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
ThrottledRequests
Requests to DynamoDB that exceed the provisioned throughput
limits on a resource (such as a table or an index).
ThrottledRequests is incremented by one if any event within
a request exceeds a provisioned throughput limit. For example,
if you update an item in a table with global secondary indexes,
there are multiple events—a write to the table, and a write to
each index. If one or more of these events are throttled, then
ThrottledRequests is incremented by one.
Note
In a batch request (BatchGetItem or
BatchWriteItem), ThrottledRequests is only
incremented if every request in the batch is throttled.
If any individual request within the batch is throttled, one
of the following metrics is incremented:
• ReadThrottleEvents – For a throttled GetItem
event within BatchGetItem.
• WriteThrottleEvents – For a throttled PutItem or
DeleteItem event within BatchWriteItem.
To gain insight into which event is throttling a request, compare
ThrottledRequests with the ReadThrottleEvents and
WriteThrottleEvents for the table and its indexes.
Note
A throttled request will result in an HTTP 400
status code. All such events are reflected in the
ThrottledRequests metric, but not in the UserErrors
metric.
Units: Count
Dimensions: TableName, Operation
Valid Statistics:
• Sum
• SampleCount
API Version 2012-08-10
506
Amazon DynamoDB 開発者ガイド
メトリクスとディメンション
Metric
Description
UserErrors
Requests to DynamoDB or Amazon DynamoDB Streams that
generate an HTTP 400 status code during the specified time
period. An HTTP 400 usually indicates a client-side error such
as an invalid combination of parameters, attempting to update a
nonexistent table, or an incorrect request signature.
All such events are reflected in the UserErrors metric, except
for the following:
• ProvisionedThroughputExceededException – See the
ThrottledRequests metric in this section.
• ConditionalCheckFailedException – See the
ConditionalCheckFailedRequests metric in this section.
UserErrors represents the aggregate of HTTP 400 errors for
DynamoDB or Amazon DynamoDB Streams requests for the
current region and the current AWS account.
Units: Count
Valid Statistics:
• Sum
• SampleCount
WriteThrottleEvents
Requests to DynamoDB that exceed the provisioned write
capacity units for a table or a global secondary index.
A single request can result in multiple events. For example, a
PutItem request on a table with three global secondary indexes
would result in four events—the table write, and each of the
three index writes. For each event, the WriteThrottleEvents
metric is incremented by one if that event is throttled. For
single PutItem requests, if any of the events are throttled,
ThrottledRequests is also incremented by one. For
BatchWriteItem, the ThrottledRequests metric for the
entire BatchWriteItem is not incremented unless all of the
individual PutItem or DeleteItem events are throttled.
The TableName dimension returns the WriteThrottleEvents
for the table, but not for any global secondary indexes. To view
WriteThrottleEvents for a global secondary index, you must
specify both TableName and GlobalSecondaryIndex.
Units: Count
Dimensions: TableName, GlobalSecondaryIndexName
Valid Statistics:
• Sum
• SampleCount
API Version 2012-08-10
507
Amazon DynamoDB 開発者ガイド
メトリクスの使用
Dimensions for DynamoDB Metrics
The metrics for DynamoDB are qualified by the values for the account, table name, global secondary
index name, or operation. You can use the CloudWatch console to retrieve DynamoDB data along any
of the dimensions in the table below.
Dimension
Description
GlobalSecondaryIndexName
This dimension limits the data to a global secondary index on a
table. If you specify GlobalSecondaryIndexName, you must also
specify TableName.
Operation
This dimension limits the data to one of the following DynamoDB
operations:
• PutItem
• DeleteItem
• UpdateItem
• GetItem
• BatchGetItem
• Scan
• Query
• BatchWriteItem
In addition, you can limit the data to the following Amazon
DynamoDB Streams operation:
• GetRecords
StreamLabel
This dimension limits the data to a specific stream label. It is
used with metrics originating from Amazon DynamoDB Streams
GetRecords operations.
TableName
This dimension limits the data to a specific table. This value can be
any table name in the current region and the current AWS account.
Amazon DynamoDB のメトリクスの使用方法
Amazon DynamoDB によってレポートされるメトリクスが提供する情報は、さまざまな方法で分析で
きます。以下のリストは、メトリクスの一般的な利用方法をいくつか示しています。ここで紹介する
のは開始するための提案事項です。すべてを網羅しているわけではありません。
どのように
関連するメトリクス
How can I determine how
much of my provisioned
throughput is being
used?
指定した期間に ConsumedReadCapacityUnits または
ConsumedWriteCapacityUnits をモニタリングして、プロビ
ジョニングしたスループットがどれだけ使用されているかトラッ
キングできます。
How can I determine
which requests exceed
the provisioned
throughput limits of a
table?
リクエスト内で任意のイベントがプロビジョンドスループッ
トの制限を超過した場合、ThrottledRequests は 1 ずつ増
加します。その後、どのイベントがリクエストをスロットリ
ングしているかを確認するには、ThrottledRequests と、
そのテーブルとインデックスの ReadThrottleEvents と
WriteThrottleEvents メトリックスを比較してください。
API Version 2012-08-10
508
Amazon DynamoDB 開発者ガイド
アラームの作成
どのように
関連するメトリクス
How can I determine
if any system errors
occurred?
SystemErrors をモニタリングして、リクエストが HTTP 500
(サーバーエラー) コードを生じさせたかを確認できます。通常、
このメトリックスはゼロと等しくなります。ゼロでない場合、調
査が必要な可能性があります。
Note
項目の操作中に内部サーバーエラーが発生することがあ
ります。これはテーブルの存続期間中に発生すると予想
されます。失敗したリクエストは速やかに再試行できま
す。
Amazon DynamoDB をモニタリングする
CloudWatch アラームの作成
CloudWatch アラームを作成できます。これは、アラームの状態が変わったときに Amazon SNS メッ
セージを送信します。 アラームは、指定期間にわたって単一のメトリクスを監視し、その値と複
数期間に対するしきい値との比較結果に基づいて 1 つ以上のアクションを実行します。アクション
は、Amazon SNS トピックまたは Auto Scaling ポリシーに送信される通知です。 アラームは、持続
している状態変化に対してのみアクションを呼び出します。CloudWatch アラームはそれが特定の状
態にあるという理由だけではアクションを呼び出しません。アクションを呼び出すには、状態が変更
され、その状態が特定の期間にわたって維持されている必要があります。
読み取り容量全体を使い切る前にどのように通知を受け取るこ
とができますか。
1.
Amazon SNS トピック arn:aws:sns:us-east-1:123456789012:capacity-alarm を作成し
ます。
詳細については、「Amazon Simple Notification Service をセットアップする」を参照してくださ
い。
2.
アラームを作成します。この例では、5 つの読み込みキャパシティーユニットがプロビジョニン
グされた容量を前提としています。
Prompt>aws cloudwatch put-metric-alarm \
--alarm-name ReadCapacityUnitsLimitAlarm \
--alarm-description "Alarm when read capacity reaches 80% of my
provisioned read capacity" \
--namespace AWS/DynamoDB \
--metric-name ConsumedReadCapacityUnits \
--dimensions Name=TableName,Value=myTable \
--statistic Sum \
--threshold 240 \
--comparison-operator GreaterThanOrEqualToThreshold \
--period 60 \
--evaluation-periods 1 \
--alarm-actions arn:aws:sns:us-east-1:123456789012:capacity-alarm
3.
アラームのテストを行います。
API Version 2012-08-10
509
Amazon DynamoDB 開発者ガイド
アラームの作成
Prompt>aws cloudwatch set-alarm-state --alarm-name
ReadCapacityUnitsLimitAlarm --state-reason "initializing" --state-value
OK
Prompt>aws cloudwatch set-alarm-state --alarm-name
ReadCapacityUnitsLimitAlarm --state-reason "initializing" --state-value
ALARM
Note
アラームは、消費された読み取り容量が 1 分間 (60 秒) で少なくとも毎秒 4 ユニット (プロ
ビジョニングされた 5 つの読み取り容量の 80%) になるとアクティブ化されます。ですか
ら、threshold は 240 読み取りキャパシティーユニット (4ユニット/秒 * 60 秒) です。読み
取り容量が更新されるたびに、アラーム計算を適切に更新する必要があります。DynamoDB
コンソールを使用してアラームを作成すると、このプロセスを回避することができます。そ
うすることで、アラームが自動的に更新されます。
テーブルにプロビジョニングされたスループット制限をリクエ
ストが超えた場合にどのように通知を受け取ることができます
か。
1.
Amazon SNS トピック arn:aws:sns:us-east-1:123456789012:requests-exceedingthroughput を作成します。
詳細については、「Amazon Simple Notification Service をセットアップする」を参照してくださ
い。
2.
アラームを作成します。
Prompt>aws cloudwatch put-metric-alarm \
--alarm-name RequestsExceedingThroughputAlarm\
--alarm-description "Alarm when my requests are exceeding provisioned
throughput limits of a table" \
--namespace AWS/DynamoDB \
--metric-name ThrottledRequests \
--dimensions Name=TableName,Value=myTable \
--statistic Sum \
--threshold 0 \
--comparison-operator GreaterThanThreshold \
--period 300 \
--unit Count \
--evaluation-periods 1 \
--alarm-actions arn:aws:sns:us-east-1:123456789012:requests-exceedingthroughput
3.
アラームのテストを行います。
Prompt>aws cloudwatch set-alarm-state --alarm-name
RequestsExceedingThroughputAlarm --state-reason "initializing" --statevalue OK
API Version 2012-08-10
510
Amazon DynamoDB 開発者ガイド
AWS CloudTrail を使用した
DynamoDB オペレーションのログ記録
Prompt>aws cloudwatch set-alarm-state --alarm-name
RequestsExceedingThroughputAlarm --state-reason "initializing" --statevalue ALARM
システムエラーが発生した場合にどのように通知を受け取るこ
とができますか。
1.
Amazon SNS トピック arn:aws:sns:us-east-1:123456789012:notify-on-systemerrors を作成します。
詳細については、「Amazon Simple Notification Service をセットアップする」を参照してくださ
い。
2.
アラームを作成します。
Prompt>aws cloudwatch put-metric-alarm \
--alarm-name SystemErrorsAlarm \
--alarm-description "Alarm when system errors occur" \
--namespace AWS/DynamoDB \
--metric-name SystemErrors \
--dimensions Name=TableName,Value=myTable \
--statistic Sum \
--threshold 0 \
--comparison-operator GreaterThanThreshold \
--period 60 \
--unit Count \
--evaluation-periods 1 \
--alarm-actions arn:aws:sns:us-east-1:123456789012:notify-on-systemerrors
3.
アラームのテストを行います。
Prompt>aws cloudwatch set-alarm-state --alarm-name SystemErrorsAlarm -state-reason "initializing" --state-value OK
Prompt>aws cloudwatch set-alarm-state --alarm-name SystemErrorsAlarm -state-reason "initializing" --state-value ALARM
AWS CloudTrail を使用した DynamoDB オペレー
ションのログ記録
DynamoDB は CloudTrail と統合されています。CloudTrail は、AWS アカウントで DynamoDB に
よって行われたか、それに代わって行われた 低レベル API リクエストをキャプチャし、指定した
Amazon S3 バケットにログファイルを渡すサービスです。CloudTrail は、DynamoDB コンソールま
たは DynamoDB 低レベル API から行われた呼び出しをキャプチャします。CloudTrail によって収集
された情報を使用して、DynamoDB に対してどのようなリクエストが行われたか(リクエストの実行
元 IP アドレス、実行者、実行日時など)を判断できます。CloudTrail の詳細(設定して有効にする方
法など)については、AWS CloudTrail User Guideを参照してください。
API Version 2012-08-10
511
Amazon DynamoDB 開発者ガイド
CloudTrail での DynamoDB 情報
CloudTrail での DynamoDB 情報
AWS アカウントで CloudTrail のログ記録を有効にすると、DynamoDB アクションに対する低レベル
API 呼び出しがログファイルに記録されます。DynamoDB レコードは、他の AWS サービスレコー
ドと一緒にログファイルに記録されます。CloudTrail は、期間とファイルサイズに基づいて、新しい
ファイルをいつ作成して書き込むかを決定します。
以下の DynamoDB アクションがサポートされています。
• CreateTable
• DeleteTable
• DescribeTable
• ListTables
• UpdateTable
• DescribeReservedCapacity
• DescribeReservedCapacityOfferings
• PurchaseReservedCapacityOfferings
以下の DynamoDB ストリーム アクションもサポートされています。
• DescribeStream
• ListStreams
各ログエントリには、誰がリクエストを生成したかに関する情報が含まれます。ログのユーザー ID 情
報は、リクエストが、ルートまたは IAM ユーザーの認証情報を使用して送信されたか、ロールまたは
フェデレーションユーザーの一時的なセキュリティ認証情報を使用して送信されたか、あるいは別の
AWS サービスによって送信されたかを確認するのに役立ちます。詳細については、CloudTrail Event
Reference の userIdentity フィールドを参照してください。
必要な場合はログファイルを自身のバケットに保管できますが、ログファイルを自動的にアーカイブ
または削除するにように Amazon S3 ライフサイクルルールを定義することもできます。デフォルト
では Amazon S3 のサーバー側の暗号化 (SSE) を使用して、ログファイルが暗号化されます。
ログファイルの配信時にすぐにアクションを実行する場合、新しいログファイルの配信時に
CloudTrail により Amazon SNS 通知を発行することを選択できます。詳細については、「Amazon
SNS 通知の構成」を参照してください。
また、複数の AWS リージョンと複数の AWS アカウントからの DynamoDB ログファイルを 1 つの
Amazon S3 バケットに集約することもできます。詳細については、「Receiving CloudTrail Log Files
from Multiple Regions」を参照してください。
DynamoDB ログファイルエントリの概要
CloudTrail ログファイルには、複数の JSON 形式イベントで構成される 1 つ以上のログエントリを
記録できます。ログエントリは任意の送信元からの単一のリクエストを表し、リクエストされたアク
ション、パラメーター、アクションの日時などに関する情報を含みます。ログエントリは、特定の順
序になるように生成されるわけではありません。つまり、低レベル DynamoDB API 呼び出しの順序付
けられたスタック トレースではありません。
CloudTrail ログの例を次に示します。
{"Records": [
{
"eventVersion": "1.03",
"userIdentity": {
API Version 2012-08-10
512
Amazon DynamoDB 開発者ガイド
DynamoDB ログファイルエントリの概要
"type": "AssumedRole",
"principalId": "AKIAIOSFODNN7EXAMPLE:bob",
"arn": "arn:aws:sts::111122223333:assumed-role/users/bob",
"accountId": "111122223333",
"accessKeyId": "AKIAIOSFODNN7EXAMPLE",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2015-05-28T18:06:01Z"
},
"sessionIssuer": {
"type": "Role",
"principalId": "AKIAI44QH8DHBEXAMPLE",
"arn": "arn:aws:iam::444455556666:role/admin-role",
"accountId": "444455556666",
"userName": "bob"
}
}
},
"eventTime": "2015-05-01T07:24:55Z",
"eventSource": "dynamodb.amazonaws.com",
"eventName": "CreateTable",
"awsRegion": "us-west-2",
"sourceIPAddress": "192.0.2.0",
"userAgent": "console.aws.amazon.com",
"requestParameters": {
"provisionedThroughput": {
"writeCapacityUnits": 10,
"readCapacityUnits": 10
},
"tableName": "Music",
"keySchema": [
{
"attributeName": "Artist",
"keyType": "HASH"
},
{
"attributeName": "SongTitle",
"keyType": "RANGE"
}
],
"attributeDefinitions": [
{
"attributeType": "S",
"attributeName": "Artist"
},
{
"attributeType": "S",
"attributeName": "SongTitle"
}
]
},
"responseElements": {"tableDescription": {
"tableName": "Music",
"attributeDefinitions": [
{
"attributeType": "S",
"attributeName": "Artist"
},
API Version 2012-08-10
513
Amazon DynamoDB 開発者ガイド
DynamoDB ログファイルエントリの概要
{
"attributeType": "S",
"attributeName": "SongTitle"
}
],
"itemCount": 0,
"provisionedThroughput": {
"writeCapacityUnits": 10,
"numberOfDecreasesToday": 0,
"readCapacityUnits": 10
},
"creationDateTime": "May 1, 2015 7:24:55 AM",
"keySchema": [
{
"attributeName": "Artist",
"keyType": "HASH"
},
{
"attributeName": "SongTitle",
"keyType": "RANGE"
}
],
"tableStatus": "CREATING",
"tableSizeBytes": 0
}},
"requestID": "KAVGJR1Q0I5VHF8FS8V809EV7FVV4KQNSO5AEMVJF66Q9ASUAAJG",
"eventID": "a8b5f864-480b-43bf-bc22-9b6d77910a29",
"eventType": "AwsApiCall",
"apiVersion": "2012-08-10",
"recipientAccountId": "111122223333"
},
{
"eventVersion": "1.03",
"userIdentity": {
"type": "AssumedRole",
"principalId": "AKIAIOSFODNN7EXAMPLE:bob",
"arn": "arn:aws:sts::111122223333:assumed-role/users/bob",
"accountId": "444455556666",
"accessKeyId": "AKIAIOSFODNN7EXAMPLE",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2015-05-28T18:06:01Z"
},
"sessionIssuer": {
"type": "Role",
"principalId": "AKIAI44QH8DHBEXAMPLE",
"arn": "arn:aws:iam::444455556666:role/admin-role",
"accountId": "444455556666",
"userName": "bob"
}
}
},
"eventTime": "2015-05-04T02:43:11Z",
"eventSource": "dynamodb.amazonaws.com",
"eventName": "DescribeTable",
"awsRegion": "us-west-2",
"sourceIPAddress": "192.0.2.0",
API Version 2012-08-10
514
Amazon DynamoDB 開発者ガイド
DynamoDB ログファイルエントリの概要
"userAgent": "console.aws.amazon.com",
"requestParameters": {"tableName": "Music"},
"responseElements": null,
"requestID": "DISTSH6DQRLCC74L48Q51LRBHFVV4KQNSO5AEMVJF66Q9ASUAAJG",
"eventID": "c07befa7-f402-4770-8c1b-1911601ed2af",
"eventType": "AwsApiCall",
"apiVersion": "2012-08-10",
"recipientAccountId": "111122223333"
},
{
"eventVersion": "1.03",
"userIdentity": {
"type": "AssumedRole",
"principalId": "AKIAIOSFODNN7EXAMPLE:bob",
"arn": "arn:aws:sts::111122223333:assumed-role/users/bob",
"accountId": "111122223333",
"accessKeyId": "AKIAIOSFODNN7EXAMPLE",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2015-05-28T18:06:01Z"
},
"sessionIssuer": {
"type": "Role",
"principalId": "AKIAI44QH8DHBEXAMPLE",
"arn": "arn:aws:iam::444455556666:role/admin-role",
"accountId": "444455556666",
"userName": "bob"
}
}
},
"eventTime": "2015-05-04T02:14:52Z",
"eventSource": "dynamodb.amazonaws.com",
"eventName": "UpdateTable",
"awsRegion": "us-west-2",
"sourceIPAddress": "192.0.2.0",
"userAgent": "console.aws.amazon.com",
"requestParameters": {"provisionedThroughput": {
"writeCapacityUnits": 25,
"readCapacityUnits": 25
}},
"responseElements": {"tableDescription": {
"tableName": "Music",
"attributeDefinitions": [
{
"attributeType": "S",
"attributeName": "Artist"
},
{
"attributeType": "S",
"attributeName": "SongTitle"
}
],
"itemCount": 0,
"provisionedThroughput": {
"writeCapacityUnits": 10,
"numberOfDecreasesToday": 0,
"readCapacityUnits": 10,
API Version 2012-08-10
515
Amazon DynamoDB 開発者ガイド
DynamoDB ログファイルエントリの概要
"lastIncreaseDateTime": "May 3, 2015 11:34:14 PM"
},
"creationDateTime": "May 3, 2015 11:34:14 PM",
"keySchema": [
{
"attributeName": "Artist",
"keyType": "HASH"
},
{
"attributeName": "SongTitle",
"keyType": "RANGE"
}
],
"tableStatus": "UPDATING",
"tableSizeBytes": 0
}},
"requestID": "AALNP0J2L244N5O15PKISJ1KUFVV4KQNSO5AEMVJF66Q9ASUAAJG",
"eventID": "eb834e01-f168-435f-92c0-c36278378b6e",
"eventType": "AwsApiCall",
"apiVersion": "2012-08-10",
"recipientAccountId": "111122223333"
},
{
"eventVersion": "1.03",
"userIdentity": {
"type": "AssumedRole",
"principalId": "AKIAIOSFODNN7EXAMPLE:bob",
"arn": "arn:aws:sts::111122223333:assumed-role/users/bob",
"accountId": "111122223333",
"accessKeyId": "AKIAIOSFODNN7EXAMPLE",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2015-05-28T18:06:01Z"
},
"sessionIssuer": {
"type": "Role",
"principalId": "AKIAI44QH8DHBEXAMPLE",
"arn": "arn:aws:iam::444455556666:role/admin-role",
"accountId": "444455556666",
"userName": "bob"
}
}
},
"eventTime": "2015-05-04T02:42:20Z",
"eventSource": "dynamodb.amazonaws.com",
"eventName": "ListTables",
"awsRegion": "us-west-2",
"sourceIPAddress": "192.0.2.0",
"userAgent": "console.aws.amazon.com",
"requestParameters": null,
"responseElements": null,
"requestID": "3BGHST5OVHLMTPUMAUTA1RF4M3VV4KQNSO5AEMVJF66Q9ASUAAJG",
"eventID": "bd5bf4b0-b8a5-4bec-9edf-83605bd5e54e",
"eventType": "AwsApiCall",
"apiVersion": "2012-08-10",
"recipientAccountId": "111122223333"
},
API Version 2012-08-10
516
Amazon DynamoDB 開発者ガイド
DynamoDB ログファイルエントリの概要
{
"eventVersion": "1.03",
"userIdentity": {
"type": "AssumedRole",
"principalId": "AKIAIOSFODNN7EXAMPLE:bob",
"arn": "arn:aws:sts::111122223333:assumed-role/users/bob",
"accountId": "111122223333",
"accessKeyId": "AKIAIOSFODNN7EXAMPLE",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2015-05-28T18:06:01Z"
},
"sessionIssuer": {
"type": "Role",
"principalId": "AKIAI44QH8DHBEXAMPLE",
"arn": "arn:aws:iam::444455556666:role/admin-role",
"accountId": "444455556666",
"userName": "bob"
}
}
},
"eventTime": "2015-05-04T13:38:20Z",
"eventSource": "dynamodb.amazonaws.com",
"eventName": "DeleteTable",
"awsRegion": "us-west-2",
"sourceIPAddress": "192.0.2.0",
"userAgent": "console.aws.amazon.com",
"requestParameters": {"tableName": "Music"},
"responseElements": {"tableDescription": {
"tableName": "Music",
"itemCount": 0,
"provisionedThroughput": {
"writeCapacityUnits": 25,
"numberOfDecreasesToday": 0,
"readCapacityUnits": 25
},
"tableStatus": "DELETING",
"tableSizeBytes": 0
}},
"requestID": "4KBNVRGD25RG1KEO9UT4V3FQDJVV4KQNSO5AEMVJF66Q9ASUAAJG",
"eventID": "a954451c-c2fc-4561-8aea-7a30ba1fdf52",
"eventType": "AwsApiCall",
"apiVersion": "2012-08-10",
"recipientAccountId": "111122223333"
}
]}
API Version 2012-08-10
517
Amazon DynamoDB 開発者ガイド
Amazon Redshift との統合
他の AWS のサービスと
DynamoDB の統合
Amazon DynamoDB は他の AWS サービスと統合して、繰り返しタスクを自動化したり、複数のサー
ビスにまたがるアプリケーションを作成したりできます。以下に例を示します。
• 同じリージョン内で、またはリージョン間で、DynamoDB データを Amazon S3 に定期的にエクス
ポートします。
• Amazon EMR を使用して DynamoDB データに対する複雑なクエリを実行します。
• 完全なデータウェアハウジングソリューションのために、DynamoDB から Amazon Redshift にデー
タをロードします。
トピック
• DynamoDB から Amazon Redshift へのデータのロード (p. 518)
• Amazon EMR 上の Apache Hive を使用した DynamoDB の処理 (p. 519)
• AWS Data Pipeline を使用して DynamoDB データをエクスポートおよびインポートす
る (p. 548)
DynamoDB から Amazon Redshift へのデータの
ロード
Amazon Redshift は、高度なビジネスインテリジェンス機能と強力な SQL ベースのインターフェイス
を使用して Amazon DynamoDB を補完します。DynamoDB テーブルのデータを Amazon Redshift に
コピーすると、Amazon Redshift クラスター内の他のテーブルとの結合など、複雑なデータ分析のク
エリを実行することができます。
プロビジョニングされたスループットの面から見ると、DynamoDB テーブルからのコピーオペ
レーションによって、テーブルの読み込み容量が低下します。いずれにせよ、データをコピーし
た後は、Amazon Redshift 内で SQL クエリを実行しても DynamoDB に影響はありません。これ
は、DynamoDB 自身に対してではなく、DynamoDB からのデータのコピーに対してクエリが実行さ
れるためです。
DynamoDB テーブルからデータをロードするには、まずデータのロード先として Amazon Redshift
テーブルを作成する必要があります。注意していただきたいのは、NoSQL 環境から SQL 環境にデー
タをコピーしていることと、1 つの環境での特定のルールが他の環境には適用されないことです。考
慮すべき相違点の例を以下に示します。
API Version 2012-08-10
518
Amazon DynamoDB 開発者ガイド
Amazon EMR との統合
• DynamoDB テーブル名には、最大 255 文字を指定できます。これには、"."(ドット)および
"-"(ダッシュ)を含み、大文字と小文字が区別されます。Amazon Redshift テーブル名は 127 文字
に制限され、ドットおよびダッシュは含まず、大文字と小文字は区別されません。さらに、テーブ
ル名には、Amazon Redshift の予約語と重複しない値を指定する必要があります。
• DynamoDB では、SQL の NULL の概念がサポートされません。Amazon Redshift におい
て、DynamoDB 内の空白またはブランクの属性値をどのように解釈するか、つまり、NULL と空白
フィールドのどちらで処理するかを指定する必要があります。
• DynamoDB のデータ型は、Amazon Redshift のデータ型と直接には対応していません。Amazon
Redshift テーブルの各列において、データ型が正しく、DynamoDB からのデータに対応したサイズ
であることを確認する必要があります。
Amazon Redshift SQL からの COPY コマンドの例を以下に示します。
copy favoritemovies from 'dynamodb://my-favorite-movies-table'
credentials 'aws_access_key_id=<Your-Access-KeyID>;aws_secret_access_key=<Your-Secret-Access-Key>'
readratio 50;
この例では、DynamoDB 内のソーステーブルは、my-favorite-movies-table です。Amazon
Redshift 内のターゲットテーブルは、favoritemovies です。readratio 50 節により、プロビ
ジョニングされたスループットの消費される割合が制限されます。この場合、COPY コマンドで
は、my-favorite-movies-table用にプロビジョニングされた読み込みキャパシティーの 50% 以下
しか使用されません。この割合については、未使用のプロビジョニングされたスループットの平均よ
りも小さい値に設定することを強くお勧めします。
DynamoDB から Amazon Redshift へのデータロードに関する詳細な説明については、Amazon
Redshift Database Developer Guide 内の以下のセクションを参照してください。
• DynamoDB テーブルからのデータのロード
• The COPY command
• COPY の例
Amazon EMR 上の Apache Hive を使用した
DynamoDB の処理
Amazon EMR 上で実行するデータウェアハウスアプリケーション、Apache Hive と Amazon
DynamoDB を統合します。Hive は DynamoDB テーブルのデータの読み込みと書き込みができ、以下
を許可します。
• SQL のような言語 (HiveQL) を使用してライブ DynamoDB データにクエリを実行します。
• DynamoDB テーブルから Amazon S3 バケット (またはその逆) にデータをコピーします。
• DynamoDB テーブルから Hadoop Distributed File System (HDFS) (またはその逆) にデータをコピー
します。
• DynamoDB テーブルで結合操作を実行します。
トピック
• 概要 (p. 520)
• チュートリアル: Amazon DynamoDB および Apache Hive の使用 (p. 520)
• Hive に外部テーブルを作成します。 (p. 527)
• HiveQL ステートメントの処理 (p. 529)
API Version 2012-08-10
519
Amazon DynamoDB 開発者ガイド
概要
• DynamoDB でのデータのクエリ (p. 530)
• Amazon DynamoDB でデータを出し入れする (p. 532)
• パフォーマンスの調節 (p. 544)
概要
Amazon EMR は、大量のデータを高いコスト効率で素早くかつ簡単に処理するためのサービスで
す。Amazon EMR を使用するには、Hadoop オープンソースフレームワークを実行する Amazon EC2
インスタンスのマネージド型クラスターを起動します。Hadoop は、タスクがクラスター内の複数の
ノードにマップされる MapReduce アルゴリズムを実装する分散アプリケーションです。各ノード
は、指定された作業を他のノードと並列に処理します。最後に、出力は単一のノードにまとめられ、
最終結果を提供します。
永続的または一時的となるように、Amazon EMR クラスターの起動を選択できます。
• 永続的なクラスターはシャットダウンするまで実行されます。永続的なクラスターはデータ分析、
データウェアハウス、または他のインタラクティブな使用などに最適です。
• 一時的なクラスターは、ジョブフローが処理されるまでの間実行され、自動的にシャットダウンさ
れます。一時的なクラスターは、スクリプトの実行などの定期的な処理タスクに最適です。
Amazon EMR アーキテクチャーおよび管理の詳細については、「Amazon EMR 管理ガイド」を参照
してください。
Amazon EMR クラスターを起動する場合、Amazon EC2 インスタンスの開始値とタイプを指定しま
す。また、クラスターで実行する他の分散アプリケーション (Hadoop 自体に加えて) も指定します。
これらのアプリケーションには Hue、Mahout、Pig、Spark などが含まれます。
Amazon EMR 用アプリケーションの詳細については、「Amazon EMR リリースガイド」を参照して
ください。
クラスター構成によっては、次のノードタイプのうちの 1 つ以上を持つことができます。
• マスターノード – クラスターの管理、コアおよびタスクインスタンスグループへの MapReduce 実
行可能ファイルおよび raw データのサブセットのディストリビューションを調整します。また、実
行される各タスクのステータスを追跡し、インスタンスグループの状態を監視します。クラスター
にマスターノードは 1 つしか存在しません。
• コアノード – Hadoop Distributed File System (HDFS) を使用して MapReduce タスクを実行し、
データを格納します。
• タスクノード (オプション) — MapReduce タスクを実行します。
チュートリアル: Amazon DynamoDB および
Apache Hive の使用
このチュートリアルでは、Amazon EMR クラスターを起動し、DynamoDB テーブルに格納されてい
るデータを処理するため Apache Hive を使用します。
Hive は、複数のソースからのデータを処理して分析できる Hadoop 用のデータウェアハウスアプ
リケーションです。Hive は、SQL のような言語である HiveQL を提供し、この言語を使用する
と、Amazon EMR クラスターでローカルに保存されたデータ、または外部データソース (Amazon
DynamoDB など) のデータを操作できます。
詳細については、「Hive のチュートリアル」を参照してください。
トピック
API Version 2012-08-10
520
Amazon DynamoDB 開発者ガイド
チュートリアル: Amazon DynamoDB
および Apache Hive の使用
• 開始する前に (p. 521)
• ステップ 1: Amazon EC2 キーペアの作成 (p. 521)
• ステップ 2: Amazon EMR クラスターの起動 (p. 522)
• ステップ 3: マスターノードに接続する (p. 522)
• ステップ 4: HDFS にデータをロードする (p. 523)
• ステップ 5: DynamoDB にデータをコピーします。 (p. 525)
• ステップ 6: DynamoDB テーブル内のデータにクエリを実行する (p. 526)
• ステップ 7: (オプション) クリーンアップする (p. 526)
開始する前に
このチュートリアルでは、以下が必要になります。
• AWS アカウント。アカウントがない場合は、「AWS にサインアップする (p. 48)」を参照してくだ
さい。
• SSH クライアント (Secure Shell)。SSH クライアントを使用して Amazon EMR クラスターのマス
ターノードに接続して、インタラクティブコマンドを実行します。デフォルトでは、SSH クライ
アントはほとんどの Linux、Unix、および Mac OS X インストールで使用できます。Windows ユー
ザーは、SSH サポートがある PuTTY クライアントをダウンロードしてインストールできます。
次のステップ
ステップ 1: Amazon EC2 キーペアの作成 (p. 521)
ステップ 1: Amazon EC2 キーペアの作成
このステップでは、Amazon EMR マスターノードへの接続に必要な Amazon EC2 キーペアを作成し
て、Hive コマンドを実行します。
1.
AWS マネジメントコンソールにサインインをしたあと、https://console.aws.amazon.com/ec2/ に
ある Amazon EC2 コンソールを開きます。
2.
リージョンを選択します (US West (Oregon) など)。これは DynamoDB テーブルがあるのと同
じリージョンです。
3.
ナビゲーションペインで、[Key Pairs] を選択します。
4.
[Create Key Pair] を選択します。
5.
[キーペア名] で、キーペアの名前を入力し (mykeypair など)、[作成] を選択します。
6.
プライベートキーファイルをダウンロードします。ファイル名は .pem で終わります
(mykeypair.pem など)。このプライベートキーファイルを安全な場所に保存します。このキー
ファイルは、このキーペアで起動する Amazon EMR クラスターにアクセスするときに必要で
す。
Important
キーペアを紛失した場合は、Amazon EMR クラスターのマスターノードに接続できませ
ん。
キーペアの詳細については、『Linux インスタンス用 Amazon EC2 ユーザーガイド』の
「Amazon EC2 のキーペア」を参照してください。
次のステップ
ステップ 2: Amazon EMR クラスターの起動 (p. 522)
API Version 2012-08-10
521
Amazon DynamoDB 開発者ガイド
チュートリアル: Amazon DynamoDB
および Apache Hive の使用
ステップ 2: Amazon EMR クラスターの起動
このステップでは、Amazon EMR クラスターを設定して起動します。Hive と DynamoDB のストレー
ジハンドラはクラスターにインストールされています。
1.
2.
Amazon EMR コンソール(https://console.aws.amazon.com/elasticmapreduce/)を開きます。
[Create Cluster] を選択します。
3.
[クラスターの作成 - クイックオプション] ページで、次の作業を行います。
4.
a.
[クラスター名] で、クラスターの名前を入力します (My EMR cluster など)。
b.
[EC2 キーペア] で、先に作成したキーペアを選択します。
その他の設定はデフォルトのままにしておきます。
[Create cluster] を選択します。
クラスターが起動されるまで数分かかる場合があります。Amazon EMR コンソールの [クラスターの
詳細] ページを使用して、進捗状況を監視できます。
ステータスが [Waiting] に変わると、クラスターは使用可能です。
クラスター上のログファイルと Amazon S3
Amazon EMR クラスターは、クラスターのステータス、およびデバッグ情報に関する情報を含むロ
グファイルを生成します。デフォルトの [クラスターの作成 - クイックオプション] 設定には Amazon
EMR ログの設定が含まれます。
存在しない場合、AWS マネジメントコンソール は Amazon S3 バケットを作成します。バケット名
は、aws-logs-account-id-region で、 account-id は AWS アカウント番号、region はクラ
スターを起動したリージョンです (aws-logs-123456789012-us-west-2 など)。
Note
Amazon S3 コンソールを使用して、ログファイルを表示できます。詳細については、
「Amazon EMR 管理ガイド」の「ログファイルを表示する」を参照してください。
このバケットをロギングに加えて他の目的のために使用できます。たとえば、データを Amazon
DynamoDB から Amazon S3 にエクスポートする場合に、Hive スクリプトを保存する場所または送信
先としてバケットを使用できます。
次のステップ
ステップ 3: マスターノードに接続する (p. 522)
ステップ 3: マスターノードに接続する
Amazon EMR クラスターのステータスが [Waiting] に変わると、SSH およびコマンドラインオペ
レーションを使用してマスターノードに接続できます。
1.
2.
3.
Amazon EMR コンソールで、ステータスを表示するにはクラスターの名前を選択します。
[クラスターの詳細] ページで、[マスターパブリック DNS] フィールドを見つけます。これ
は、Amazon EMR クラスターのマスターノードのパブリック DNS 名です。
DNS 名の右側で、[SSH] リンクを選択します。
4.
[SSH を使用してマスターノードに接続する] の手順に従います。
オペレーティングシステムに応じて、[Windows] タブまたは [Mac/Linux] タブを選択し、マスター
ノードに接続する手順に従います。
API Version 2012-08-10
522
Amazon DynamoDB 開発者ガイド
チュートリアル: Amazon DynamoDB
および Apache Hive の使用
SSH または PuTTY を使用してマスターノードに接続すると、次のようなコマンドプロンプトが表示
されます。
[hadoop@ip-192-0-2-0 ~]$
次のステップ
ステップ 4: HDFS にデータをロードする (p. 523)
ステップ 4: HDFS にデータをロードする
このステップでは、Hadoop Distributed File System (HDFS) にデータファイルをコピーし、データ
ファイルにマッピングされる外部 Hive テーブルを作成します。
サンプルデータをダウンロードします。
1.
サンプルデータアーカイブをダウンロードします (features.zip)。
wget http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/
samples/features.zip
2.
アーカイブから features.txt ファイルを抽出します。
unzip features.zip
3.
features.txt ファイルの最初の数行を表示します。
head features.txt
結果は以下のようになります。
1535908|Big Run|Stream|WV|38.6370428|-80.8595469|794
875609|Constable Hook|Cape|NJ|40.657881|-74.0990309|7
1217998|Gooseberry Island|Island|RI|41.4534361|-71.3253284|10
26603|Boone Moore Spring|Spring|AZ|34.0895692|-111.410065|3681
1506738|Missouri Flat|Flat|WA|46.7634987|-117.0346113|2605
1181348|Minnow Run|Stream|PA|40.0820178|-79.3800349|1558
1288759|Hunting Creek|Stream|TN|36.343969|-83.8029682|1024
533060|Big Charles Bayou|Bay|LA|29.6046517|-91.9828654|0
829689|Greenwood Creek|Stream|NE|41.596086|-103.0499296|3671
541692|Button Willow Island|Island|LA|31.9579389|-93.0648847|98
データファイルには、アメリカ地名委員会が提供するデータのサブセットが含まれています
(http://geonames.usgs.gov/domestic/download_data.htm)。
API Version 2012-08-10
523
Amazon DynamoDB 開発者ガイド
チュートリアル: Amazon DynamoDB
および Apache Hive の使用
features.txt ファイルには、アメリカ地名委員会からのデータのサブセットが含まれています
(http://geonames.usgs.gov/domestic/download_data.htm)。各行のフィールドは以下を表します。
• 地物 ID (一意の識別子)
• 名前
• クラス (湖、森、川など)
• 状態
• 緯度 (度)
• 経度 (度)
• 高さ (フィート)
4.
コマンドプロンプトで、次のコマンドを入力します。
hive
コマンドプロンプトがこれに変わります: hive>
5.
次の HiveQL ステートメントを入力して、ネイティブ Hive テーブルを作成します。
CREATE TABLE hive_features
(feature_id
BIGINT,
feature_name
STRING ,
feature_class
STRING ,
state_alpha
STRING,
prim_lat_dec
DOUBLE ,
prim_long_dec
DOUBLE ,
elev_in_ft
BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
LINES TERMINATED BY '\n';
6.
次の HiveQL ステートメントを入力して、テーブルにデータをロードします。
LOAD DATA
LOCAL
INPATH './features.txt'
OVERWRITE
INTO TABLE hive_features;
7.
これで、features.txt ファイルからのデータが入力されたネイティブ Hive テーブルが作成さ
れました。確認するには、次の HiveQL ステートメントを入力します。
SELECT state_alpha, COUNT(*)
FROM hive_features
GROUP BY state_alpha;
出力には、状態のリストとそれぞれの地理的特徴の数が表示されます。
次のステップ
API Version 2012-08-10
524
Amazon DynamoDB 開発者ガイド
チュートリアル: Amazon DynamoDB
および Apache Hive の使用
ステップ 5: DynamoDB にデータをコピーします。 (p. 525)
ステップ 5: DynamoDB にデータをコピーします。
このステップでは、Hive テーブル (hive_features) から DynamoDB の新しいテーブルにデータを
コピーします。
1.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
2.
[Create Table] を選択します。
3.
[DynamoDB テーブルの作成] ページで、次の操作を行います。
a.
[テーブル] で、「##」を入力します。
b.
[パーティションキー] フィールドの、[プライマリキー] に、「ID」を入力します。データ型
を [Number] に設定します。
[デフォルト設定の使用] をクリアします。[プロビジョニングされた容量] に、次を入力しま
す。
• 読み込みキャパシティーユニット—10
• 書き込みキャパシティーユニット—10
[Create] を選択します。
4.
Hive プロンプトでは、次の HiveQL ステートメントを入力します。
CREATE EXTERNAL TABLE ddb_features
(feature_id
BIGINT,
feature_name STRING,
feature_class STRING,
state_alpha
STRING,
prim_lat_dec DOUBLE,
prim_long_dec DOUBLE,
elev_in_ft
BIGINT)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES(
"dynamodb.table.name" = "Features",
"dynamodb.column.mapping"="feature_id:Id,feature_name:Name,feature_class:Class,state_al
);
これで、Hive と DynamoDB の地物テーブルとの間のマッピングが確立されました。
5.
次の HiveQL ステートメントを入力して、DynamoDB にデータをインポートします。
INSERT OVERWRITE TABLE ddb_features
SELECT
feature_id,
feature_name,
feature_class,
state_alpha,
prim_lat_dec,
prim_long_dec,
elev_in_ft
FROM hive_features;
API Version 2012-08-10
525
Amazon DynamoDB 開発者ガイド
チュートリアル: Amazon DynamoDB
および Apache Hive の使用
Hive は Amazon EMR クラスターによって処理される MapReduce ジョブを送信します。ジョブ
を完了するまでに数分かかります。
6.
DynamoDB にデータがロードされたことを確認してください。
a.
DynamoDB コンソールのナビゲーションペインで、[テーブル] を選択します。
b.
地物テーブルを選択し、[項目] タブを選択してデータを表示します。
次のステップ
ステップ 6: DynamoDB テーブル内のデータにクエリを実行する (p. 526)
ステップ 6: DynamoDB テーブル内のデータにクエリを実行す
る
このステップでは、HiveQL を使用して DynamoDB 内の地物テーブルにクエリを実行します。次の
Hive クエリを試してください。
1.
アルファベット順のすべての地物タイプ (feature_class)。
SELECT DISTINCT feature_class
FROM ddb_features
ORDER BY feature_class;
2.
「M」から始まるすべての湖。
SELECT feature_name, state_alpha
FROM ddb_features
WHERE feature_class = 'Lake'
AND feature_name LIKE 'M%'
ORDER BY feature_name;
3.
少なくとも 3 つの地物が 1 マイルより高い州 (5,280 フィート)。
SELECT state_alpha, feature_class, COUNT(*)
FROM ddb_features
WHERE elev_in_ft > 5280
GROUP by state_alpha, feature_class
HAVING COUNT(*) >= 3
ORDER BY state_alpha, feature_class;
次のステップ
ステップ 7: (オプション) クリーンアップする (p. 526)
ステップ 7: (オプション) クリーンアップする
チュートリアルは完了したので、続けてこのセクションから Amazon EMR の DynamoDB データの使
用方法の詳細について学ぶことができます。その間 Amazon EMR クラスターを維持して実行するこ
ともできます。
API Version 2012-08-10
526
Amazon DynamoDB 開発者ガイド
Hive に外部テーブルを作成します。
クラスターが不要になった場合は、それを終了し、関連するリソースを削除する必要があります。こ
れは、不要なリソースに料金が発生しないようにするのに役立ちます。
1.
2.
3.
Amazon EMR クラスターを終了します。
a.
Amazon EMR コンソール(https://console.aws.amazon.com/elasticmapreduce/)を開きま
す。
b.
Amazon EMR クラスターを選択して、[終了] を選択し、確認します。
DynamoDB の地物テーブルを削除します。
a.
https://console.aws.amazon.com/dynamodb/ にある DynamoDB コンソールを開きます。
b.
ナビゲーションペインで、[ Tables] を選択します。
c.
地物テーブルを選択します。[アクション] メニューから、[テーブルの削除] を選択します。
Amazon EMR ログファイルを含む Amazon S3 バケットを削除します。
a.
https://console.aws.amazon.com/s3/ にある Amazon S3 コンソールを開きます。
b.
バケットのリストから、aws-logs- accountID-region を選択します。accountID は
AWS アカウント番号で、#####はクラスターを起動したリージョンです。
c.
[アクション] メニューから、[削除] を選択します。
Hive に外部テーブルを作成します。
チュートリアル: Amazon DynamoDB および Apache Hive の使用 (p. 520) で、DynamoDB テーブル
にマッピングした外部 Hive テーブルを作成しました。外部テーブルに対して HiveQL ステートメント
を発行すると、DynamoDB テーブルに読み取りと書き込みのオペレーションが渡されます。
外部テーブルは、他の場所で管理され格納されているデータソースへのポインタと考えることができ
ます。この場合、基盤となるデータソースは DynamoDB テーブルです。(テーブルはすでに存在して
いる必要があります。Hive 内から DynamoDB テーブルを作成、更新、または削除することはできま
せん。)CREATE EXTERNAL TABLE ステートメントを使用して外部テーブルを作成します。その後、
データが Hive 内でローカルに保管されている DynamoDB のデータの操作に HiveQL を使用できま
す。
Note
外部テーブルにデータを挿入するために INSERT ステートメントを使用でき、そこからデー
タを選択するために SELECT ステートメントを使用できます。ただし、テーブル内のデータ
の操作に UPDATE または DELETE ステートメントを使用することはできません。
外部テーブルが不要になった場合には、DROP TABLE ステートメントを使用してそれを削除できま
す。この場合、DROP TABLE は Hive の外部テーブルのみを削除します。基盤となる DynamoDB テー
ブルやそのいずれのデータも影響を受けません。
トピック
• CREATE EXTERNAL TABLE の構文 (p. 527)
• データ型マッピング (p. 528)
CREATE EXTERNAL TABLE の構文
DynamoDB にマッピングされる外部 Hive テーブルを作成するための HiveQL の構文を以下に示しま
す。
API Version 2012-08-10
527
Amazon DynamoDB 開発者ガイド
Hive に外部テーブルを作成します。
CREATE EXTERNAL TABLE hive_table
(hive_column1_name hive_column1_datatype, hive_column2_name hive_column2_datatype...)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES (
"dynamodb.table.name" = "dynamodb_table",
"dynamodb.column.mapping" =
"hive_column1_name:dynamodb_attribute1_name,hive_column2_name:dynamodb_attribute2_name..."
);
行 1 は、CREATE EXTERNAL TABLE ステートメントの開始で、作成する Hive テーブル (hive_table)
の名前を指定します。
行 2 では、hive_table の列およびデータ型を指定します。DynamoDB テーブルの属性に対応する列お
よびデータ型を定義する必要があります。
行 3 は STORED BY 句で、Hive と DynamoDB テーブル間のデータ管
理を処理するクラスを指定します。DynamoDB では、STORED BY は
'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler' のように設定する必要があ
ります。
行 4 は TBLPROPERTIES 句の開始で、DynamoDBStorageHandler に次のパラメーターを定義しま
す。
• dynamodb.table.name— DynamoDB テーブルの名前。
• dynamodb.column.mapping— Hive テーブルの列名と DynamoDB テーブルの対応する属性のペ
ア。各ペアは hive_column_name:dynamodb_attribute_name の形式で、ペアはカンマで区切られま
す。
次の点に注意してください。
• Hive テーブルの名前は、DynamoDB テーブル名と同じである必要はありません。
• Hive テーブルの列名は、DynamoDB テーブルの列名と同じである必要はありません。
• dynamodb.table.name で指定されたテーブルは DynamoDB 内にある必要があります。
• 複数 dynamodb.column.mapping:
• DynamoDB テーブルのキースキーマ属性をマッピングする必要があります。これには、パーティ
ションキーおよびソートキーが含まれます (存在する場合)。
• DynamoDB テーブルの非キー属性をマッピングする必要はありません。ただし、Hive テーブル
のクエリを実行する場合は、これらの属性のデータは表示されません。
• Hive テーブルの列と DynamoDB 属性のデータ型は互換性があり、Hive テーブルのクエリを実行
する場合、これらの列に NULL が表示されます。
Note
CREATE EXTERNAL TABLE ステートメントは TBLPROPERTIES 句で検証を実行しませ
ん。dynamodb.table.name および dynamodb.column.mapping に指定した値は、テー
ブルにアクセスを試みるときに DynamoDBStorageHandler クラスによってのみ評価されま
す。
データ型マッピング
次の表は、DynamoDB データ型および互換性のある Hive データ型を示しています。
API Version 2012-08-10
528
Amazon DynamoDB 開発者ガイド
HiveQL ステートメントの処理
DynamoDB データ型
Hive データ型
文字列
STRING
数値
BIGINT または DOUBLE
バイナリ
BINARY
文字列セット
ARRAY<STRING>
数値セット
ARRAY<BIGINT> または ARRAY<DOUBLE>
バイナリセット
ARRAY<BINARY>
Note
以下の DynamoDB データ型は、DynamoDBStorageHandler クラスでサポートされていない
ため、dynamodb.column.mapping には使用できません。
• マップ
• リスト
• ブール
• Null
数値型の DynamoDB 属性をマッピングする場合、適切な Hive の型を選択する必要があります。
• Hive BIGINT 型は 8 バイトの符号付き整数です。これは、Java の long データ型と同じです。
• Hive DOUBLE 型は 8 ビット倍精度浮動小数点数です。これは、Java の double データ型と同じで
す。
DynamoDB に格納されている数値データが選択した Hive データよりも高精度な場合、DynamoDB
データにアクセスすると精度が低下する場合があります。
バイナリ型のデータを DynamoDB から (Amazon S3) または HDFS にエクスポートすると、データは
Base64 エンコード文字列として格納されます。Amazon S3 または HDFS から DynamoDB バイナリ
型にデータをインポートする場合、データが Base64 エンコード文字列であることを確認する必要が
あります。
HiveQL ステートメントの処理
Hive は、MapReduce ジョブを実行するバッチ志向のフレームワークで、Hadoop 上で実行するアプ
リケーションです。HiveQL ステートメントを発行すると、Hive はすぐに結果を返すことができる
か、MapReduce ジョブを送信する必要があるかを決定します。
たとえば、(チュートリアル: Amazon DynamoDB および Apache Hive の使用 (p. 520) からの)
ddb_features テーブルについて検討します。次の Hive クエリは州の略称と各山頂の数を表示します。
SELECT state_alpha, count(*)
FROM ddb_features
WHERE feature_class = 'Summit'
GROUP BY state_alpha;
Hive はすぐに結果を返しません。代わりに、Hadoop フレームワークによって処理される
MapReduce ジョブを送信します。Hive はクエリからの結果を参照する前に、ジョブが完了するまで
待機します。
API Version 2012-08-10
529
Amazon DynamoDB 開発者ガイド
DynamoDB でのデータのクエリ
AK 2
AL 2
AR 2
AZ 3
CA 7
CO 2
CT 2
ID 1
KS 1
ME 2
MI 1
MT 3
NC 1
NE 1
NM 1
NY 2
OR 5
PA 1
TN 1
TX 1
UT 4
VA 1
VT 2
WA 2
WY 3
Time taken: 8.753 seconds, Fetched: 25 row(s)
ジョブのモニタリングとキャンセル
Hive が Hadoop ジョブを起動すると、そのジョブの出力を表示します。ジョブの完了ステータスは
ジョブの進行に合わせて更新されます。場合によっては、ステータスは長い間更新されない場合があ
ります。(これは読み込みキャパシティーが小さく設定された大きな DynamoDB テーブルにクエリを
実行しているときに発生することがあります。)
ジョブが完了する前にキャンセルすることが必要な場合は、Ctrl+C と入力することができます。
DynamoDB でのデータのクエリ
次の例は、HiveQL を使用して DynamoDB のデータにクエリを行う方法を示します。
これらの例では、チュートリアル (ステップ 5: DynamoDB にデータをコピーします。 (p. 525)) の
ddb_features テーブルを参照します。
トピック
• 集計関数の使用 (p. 530)
• GROUP BY 句および HAVING 句の使用 (p. 531)
• 2 つの DynamoDB テーブルの結合 (p. 531)
• 異なるソースのテーブルの結合 (p. 532)
集計関数の使用
HiveQL は、データ値をまとめるための組み込み関数を提供します。たとえば、MAX 関数を使用して
選択した列の最大値を見つけることができます。次の例では、コロラド州の最高地物の標高を返しま
す。
API Version 2012-08-10
530
Amazon DynamoDB 開発者ガイド
DynamoDB でのデータのクエリ
SELECT MAX(elev_in_ft)
FROM ddb_features
WHERE state_alpha = 'CO';
GROUP BY 句および HAVING 句の使用
GROUP BY 句を使用して、複数のレコードのデータを収集できます。多くの場合、これは
SUM、COUNT、MIN、またはMAX のような集計関数とともに使用されます。HAVING 句を使用して、特
定の基準を満たさない結果を破棄することもできます。
次の例では、ddb_features テーブルに 5 つ以上の地物のある州からの最高標高のリストを返します。
SELECT state_alpha, max(elev_in_ft)
FROM ddb_features
GROUP BY state_alpha
HAVING count(*) >= 5;
2 つの DynamoDB テーブルの結合
次の例では、別の Hive テーブル (east_coast_states) を DynamoDB. のテーブルにマッピングしま
す。SELECT ステートメントは、これらの 2 つのテーブルの結合です。結合がクラスターで計算され
て返されます。join は DynamoDB では発生しません。
以下のデータを含む EastCoastStates という名前の DynamoDB テーブルについて検討します。
StateName
StateAbbrev
Maine
New Hampshire
Massachusetts
Rhode Island
Connecticut
New York
New Jersey
Delaware
Maryland
Virginia
North Carolina
South Carolina
Georgia
Florida
ME
NH
MA
RI
CT
NY
NJ
DE
MD
VA
NC
SC
GA
FL
そのテーブルは、east_coast_states という名前の Hive 外部テーブルとして実行可能であると仮定し
ます。
CREATE EXTERNAL TABLE ddb_east_coast_states (state_name STRING, state_alpha
STRING)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
API Version 2012-08-10
531
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
TBLPROPERTIES ("dynamodb.table.name" = "EastCoastStates",
"dynamodb.column.mapping" = "state_name:StateName,state_alpha:StateAbbrev");
次の結合は、少なくとも 3 つの地物のある米国東海岸の州を返します。
SELECT ecs.state_name, f.feature_class, COUNT(*)
FROM ddb_east_coast_states ecs
JOIN ddb_features f on ecs.state_alpha = f.state_alpha
GROUP BY ecs.state_name, f.feature_class
HAVING COUNT(*) >= 3;
異なるソースのテーブルの結合
次の例では、s3_east_coast_states は、Amazon S3 に格納された CSV ファイルに関連付けられた
Hive テーブルです。ddb_features テーブルは DynamoDB のデータと関連付けられます。次の例で
は、これらの 2 つのテーブルを結合し、名前が「New」で始まる州の地理的特徴を返します。
create external table s3_east_coast_states (state_name STRING, state_alpha
STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION 's3://bucketname/path/subpath/';
SELECT ecs.state_name, f.feature_name, f.feature_class
FROM s3_east_coast_states ecs
JOIN ddb_features f
ON ecs.state_alpha = f.state_alpha
WHERE ecs.state_name LIKE 'New%';
Amazon DynamoDB でデータを出し入れする
チュートリアル: Amazon DynamoDB および Apache Hive の使用 (p. 520) で、データをネイティブ
Hive テーブルから外部 DynamoDB テーブルにコピーして、外部 DynamoDB テーブルにクエリを実行
しました。テーブルは Hive の外に存在するため、外部にあります。それにマッピングする Hive テー
ブルを削除しても、DynamoDB のテーブルは影響を受けません。
Hive は DynamoDB テーブル、Amazon S3 バケット、ネイティブ Hive テーブル、および Hadoop
Distributed File System (HDFS) 間でデータをコピーするのに優れたソリューションです。このセク
ションでは、これらの操作の例を示します。
トピック
• DynamoDB とネイティブ Hive テーブルの間でデータをコピーする (p. 533)
• DynamoDB と Amazon S3 間のデータのコピー (p. 534)
• DynamoDB と HDFS 間のデータのコピー (p. 538)
• データ圧縮の使用 (p. 543)
• 印刷不可の UTF-8 文字データを読み取る (p. 544)
API Version 2012-08-10
532
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
DynamoDB とネイティブ Hive テーブルの間でデータをコピー
する
DynamoDB テーブルにデータが存在する場合は、ネイティブ Hive テーブルにデータをコピーできま
す。それをコピーした時点でデータのスナップショットを得られます。
多くの HiveQL クエリを実行する必要があり、DynamoDB からプロビジョニングされたスループッ
ト容量を消費したくない場合、これを行うことがあります。ネイティブ Hive テーブルのデータ
は、DynamoDB からのデータのコピーであり、ライブデータではないため、クエリはデータが最新の
状態であると期待できません。
このセクションの例は、チュートリアル: Amazon DynamoDB および Apache Hive の使用 (p. 520)
の手順に従ったこと、また DynamoDB (ddb_features) でマスターされている外部テーブルがあること
を前提にしています。
ネイティブ Hive テーブルから DynamoDB へ
ネイティブ Hive テーブルを作成し、このような、ddb_features からのデータを入力することができま
す。
CREATE TABLE features_snapshot AS
SELECT * FROM ddb_features;
データはいつでも更新できます。
INSERT OVERWRITE TABLE features_snapshot
SELECT * FROM ddb_features;
Note
これらの例では、サブクエリ SELECT * FROM ddb_features は、ddb_features からのす
べてのデータを取得します。データのサブセットのみをコピーする場合は、サブクエリ内の
WHERE 句を使用できます。
次の例は湖および山頂の属性の一部のみを含むネイティブ Hive テーブルを作成します。
CREATE TABLE lakes_and_summits AS
SELECT feature_name, feature_class, state_alpha
FROM ddb_features
WHERE feature_class IN ('Lake','Summit');
DynamoDB からネイティブ Hive テーブルへ
次の HiveQL ステートメントを使用して、ネイティブ Hive テーブルから ddb_features にデータをコ
ピーします。
API Version 2012-08-10
533
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
INSERT OVERWRITE TABLE ddb_features
SELECT * FROM features_snapshot;
DynamoDB と Amazon S3 間のデータのコピー
DynamoDB テーブルにデータが存在する場合は、Hive を使用して Amazon S3 バケットにデータをコ
ピーできます。
DynamoDB テーブルのデータのアーカイブを作成する場合、これを行う場合があります。たとえ
ば、DynamoDB の一連のベースラインテストデータを使用する必要のあるテスト環境があるとしま
す。ベースラインデータを Amazon S3 バケットにコピーでき、それからテストを実行します。その
後、ベースラインデータを Amazon S3 バケットから DynamoDB に復元して、テスト環境をリセット
できます。
チュートリアル: Amazon DynamoDB および Apache Hive の使用 (p. 520) を完了している場合、既
に Amazon EMR ログを含む Amazon S3 バケットがあります。バケットのルートパスが分かっている
場合は、このセクションの例では、このバケットを使用します。
1.
Amazon EMR コンソール(https://console.aws.amazon.com/elasticmapreduce/)を開きます。
2.
[Name] には、クラスターを選択します。
3.
URI は、[設定の詳細] の [Log URI] に一覧表示されます。
4.
バケットのルートパスを書きとめておきます。命名規則は次のとおりです。
s3://aws-logs-accountID-region
accountID が、AWS アカウント ID であり、リージョンがバケットの AWS リージョンである場
合です。
Note
これらの例では、この例のように、バケット内のサブパスを使用します。
s3://aws-logs-123456789012-us-west-2/hive-test
次の手順は、チュートリアルのステップに従ったこと、DynamoDB (ddb_features) でマスターされて
いる外部テーブルがあることを前提にしています。
トピック
• Hive のデフォルト形式を使用してデータをコピーする (p. 534)
• ユーザー指定の形式でのデータのコピー (p. 535)
• 列のマッピングなしでのデータのコピー (p. 536)
• Amazon S3 のデータを表示する (p. 538)
Hive のデフォルト形式を使用してデータをコピーする
DynamoDB から Amazon S3 へ
INSERT OVERWRITE ステートメントを使用して Amazon S3 に直接書き込みます。
INSERT OVERWRITE DIRECTORY 's3://aws-logs-123456789012-us-west-2/hive-test'
API Version 2012-08-10
534
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
SELECT * FROM ddb_features;
Amazon S3 のデータファイルは次のようになります。
920709^ASoldiers Farewell Hill^ASummit^ANM^A32.3564729^A-108.33004616135
1178153^AJones Run^AStream^APA^A41.2120086^A-79.25920781260
253838^ASentinel Dome^ASummit^ACA^A37.7229821^A-119.584338133
264054^ANeversweet Gulch^AValley^ACA^A41.6565269^A-122.83614322900
115905^AChacaloochee Bay^ABay^AAL^A30.6979676^A-87.97388530
各フィールドは SOH 文字 (ヘッダーの開始、0x01) で区切ります。ファイルで、SOH は ^A と表示さ
れます。
Amazon S3 から DynamoDB へ
1.
Amazon S3 の未フォーマットデータをポイントする外部テーブルを作成します。
CREATE EXTERNAL TABLE s3_features_unformatted
(feature_id
BIGINT,
feature_name
STRING ,
feature_class
STRING ,
state_alpha
STRING,
prim_lat_dec
DOUBLE ,
prim_long_dec
DOUBLE ,
elev_in_ft
BIGINT)
LOCATION 's3://aws-logs-123456789012-us-west-2/hive-test';
2.
データを DynamoDB にコピーします。
INSERT OVERWRITE TABLE ddb_features
SELECT * FROM s3_features_unformatted;
ユーザー指定の形式でのデータのコピー
独自のフィールド区切り文字を指定する場合は、Amazon S3 バケットにマッピングされる外部テーブ
ルを作成できます。カンマ区切り値 (CSV) を使用したデータファイルを作成するためにこの手法を使
用する場合があります。
DynamoDB から Amazon S3 へ
1.
Amazon S3. にマッピングする Hive 外部テーブルを作成します。これを行うとき、データ型
が、DynamoDB 外部テーブルのデータ型に準拠していることを確認します。
CREATE EXTERNAL TABLE s3_features_csv
(feature_id
BIGINT,
feature_name
STRING,
API Version 2012-08-10
535
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
feature_class
STRING,
state_alpha
STRING,
prim_lat_dec
DOUBLE,
prim_long_dec
DOUBLE,
elev_in_ft
BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION 's3://aws-logs-123456789012-us-west-2/hive-test';
2.
DynamoDB からデータをコピーします。
INSERT OVERWRITE TABLE s3_features_csv
SELECT * FROM ddb_features;
Amazon S3 のデータファイルは次のようになります。
920709,Soldiers Farewell Hill,Summit,NM,32.3564729,-108.3300461,6135
1178153,Jones Run,Stream,PA,41.2120086,-79.2592078,1260
253838,Sentinel Dome,Summit,CA,37.7229821,-119.58433,8133
264054,Neversweet Gulch,Valley,CA,41.6565269,-122.8361432,2900
115905,Chacaloochee Bay,Bay,AL,30.6979676,-87.9738853,0
Amazon S3 から DynamoDB へ
単一の HiveQL ステートメントを使用すると、Amazon S3 からのデータを使用して DynamoDB テー
ブルに入力できます。
INSERT OVERWRITE TABLE ddb_features
SELECT * FROM s3_features_csv;
列のマッピングなしでのデータのコピー
RAW 形式で DynamoDB からデータをコピーし、データ型または列マッピングを指定しないで
Amazon S3 に書き込めます。この方法を使用すると、DynamoDB データのアーカイブを作成し
て、Amazon S3 に保存できます。
Note
DynamoDB テーブルに Map 型、List、Boolean、または Null の属性が含まれる場合、この方
法でのみ Hive を使用してデータを DynamoDB から Amazon S3 へコピーできます。
DynamoDB から Amazon S3 へ
1.
DynamoDB テーブルに関連付けられる外部テーブルを作成します。(この HiveQL ステートメント
には dynamodb.column.mapping はありません。)
API Version 2012-08-10
536
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
CREATE EXTERNAL TABLE ddb_features_no_mapping
(item MAP<STRING, STRING>)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES ("dynamodb.table.name" = "Features");
2.
Amazon S3 バケットに関連付けられた別の外部テーブルを作成します。
CREATE EXTERNAL TABLE s3_features_no_mapping
(item MAP<STRING, STRING>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
LOCATION 's3://aws-logs-123456789012-us-west-2/hive-test';
3.
DynamoDB から Amazon S3 へデータをコピーします。
INSERT OVERWRITE TABLE s3_features_no_mapping
SELECT * FROM ddb_features_no_mapping;
Amazon S3 のデータファイルは次のようになります。
Name^C{"s":"Soldiers Farewell
Hill"}^BState^C{"s":"NM"}^BClass^C{"s":"Summit"}^BElevation^C{"n":"6135"}^BLatitude^C{"n":"
Name^C{"s":"Jones
Run"}^BState^C{"s":"PA"}^BClass^C{"s":"Stream"}^BElevation^C{"n":"1260"}^BLatitude^C{"n":"4
Name^C{"s":"Sentinel
Dome"}^BState^C{"s":"CA"}^BClass^C{"s":"Summit"}^BElevation^C{"n":"8133"}^BLatitude^C{"n":"
Name^C{"s":"Neversweet
Gulch"}^BState^C{"s":"CA"}^BClass^C{"s":"Valley"}^BElevation^C{"n":"2900"}^BLatitude^C{"n":
Name^C{"s":"Chacaloochee
Bay"}^BState^C{"s":"AL"}^BClass^C{"s":"Bay"}^BElevation^C{"n":"0"}^BLatitude^C{"n":"30.6979
各フィールドは STX 文字 (テキスト開始 0x02) で始まり ETX 文字 (テキスト終了 0x03) で終わりま
す。ファイルで、STX は ^B、ETX は ^C と表示されます。
Amazon S3 から DynamoDB へ
単一の HiveQL ステートメントを使用すると、Amazon S3 からのデータを使用して DynamoDB テー
ブルに入力できます。
INSERT OVERWRITE TABLE ddb_features_no_mapping
SELECT * FROM s3_features_no_mapping;
API Version 2012-08-10
537
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
Amazon S3 のデータを表示する
SSH を使用してマスターノードに接続する場合、AWS Command Line Interface (AWS CLI) を使用し
て、Hive が Amazon S3 に 書き込んだデータにアクセスできます。
次のステップは、このセクションの手順の 1 つを使用して DynamoDB から Amazon S3 にデータをコ
ピーしたことを前提にしています。
1.
現在 Hive コマンドプロンプトである場合は、Linux コマンドプロンプトに戻ります。
hive> exit;
2.
Amazon S3 バケットで Hive テストディレクトリのコンテンツを一覧表示します。(これは、Hive
が DynamoDB からデータをコピーした場所です。)
aws s3 ls s3://aws-logs-123456789012-us-west-2/hive-test/
レスポンスは以下のようになります。
2016-11-01 23:19:54 81983 000000_0
ファイル名 (000000_0) は、システムで生成されます。
3.
(オプション) Amazon S3 から マスターノードのローカルファイルシステムにデータファイルを
コピーできます。その後、ファイルのデータを運用するために Linux 標準コマンドラインユー
ティリティを使用できます。
aws s3 cp s3://aws-logs-123456789012-us-west-2/hive-test/000000_0 .
レスポンスは以下のようになります。
download: s3://aws-logs-123456789012-us-west-2/hive-test/000000_0
to ./000000_0
Note
マスターノードのローカルファイルシステムは容量が限定されています。ローカルファ
イルシステムで利用可能なスペースより大きなファイルでこのコマンドを使用しないで
ください。
DynamoDB と HDFS 間のデータのコピー
DynamoDB テーブルにデータが存在する場合は、Hive を使用して、Hadoop Distributed File System
(HDFS) にデータをコピーできます。
DynamoDB からのデータを必要とする MapReduce ジョブを実行しているなら、これを行う場合があ
ります。HDFS からのデータを DynamoDB コピーする場合、Hadoop はクラスターで利用可能なすべ
てのノードを使用して、並列 Amazon EMR 処理できます。MapReduce ジョブが完了すると、HDFS
から DDB に結果を記述できます。
次の例では、Hive は次の HDFS ディレクトリで読み取りと書き込みを行います。/user/hadoop/
hive-test
API Version 2012-08-10
538
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
このセクションの例は、チュートリアル: Amazon DynamoDB および Apache Hive の使用 (p. 520)
の手順に従ったこと、また DynamoDB (ddb_features) でマスターされている外部テーブルがあること
を前提にしています。
トピック
• Hive のデフォルト形式を使用してデータをコピーする (p. 539)
• ユーザー指定の形式でのデータのコピー (p. 540)
• 列のマッピングなしでのデータのコピー (p. 541)
• HDFS でデータにアクセスする (p. 542)
Hive のデフォルト形式を使用してデータをコピーする
DynamoDB から HDFS へ
INSERT OVERWRITE ステートメントを使用して HDFS に直接書き込みます。
INSERT OVERWRITE DIRECTORY 'hdfs:///user/hadoop/hive-test'
SELECT * FROM ddb_features;
HDFS のデータファイルは次のようになります。
920709^ASoldiers Farewell Hill^ASummit^ANM^A32.3564729^A-108.33004616135
1178153^AJones Run^AStream^APA^A41.2120086^A-79.25920781260
253838^ASentinel Dome^ASummit^ACA^A37.7229821^A-119.584338133
264054^ANeversweet Gulch^AValley^ACA^A41.6565269^A-122.83614322900
115905^AChacaloochee Bay^ABay^AAL^A30.6979676^A-87.97388530
各フィールドは SOH 文字 (ヘッダーの開始、0x01) で区切ります。ファイルで、SOH は ^A と表示さ
れます。
HDFS から DynamoDB へ
1.
HDFS で未フォーマットデータにマッピングされる外部テーブルを作成します。
CREATE EXTERNAL TABLE hdfs_features_unformatted
(feature_id
BIGINT,
feature_name
STRING ,
feature_class
STRING ,
state_alpha
STRING,
prim_lat_dec
DOUBLE ,
prim_long_dec
DOUBLE ,
elev_in_ft
BIGINT)
LOCATION 'hdfs:///user/hadoop/hive-test';
2.
データを DynamoDB にコピーします。
API Version 2012-08-10
539
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
INSERT OVERWRITE TABLE ddb_features
SELECT * FROM hdfs_features_unformatted;
ユーザー指定の形式でのデータのコピー
別のフィールド区切り文字を使用する場合は、HDFS ディレクトリにマッピングされる外部テーブル
を作成します。カンマ区切り値 (CSV) を使用したデータファイルを作成するためにこの手法を使用す
る場合があります。
DynamoDB から HDFS へ
1.
HDFS にマッピングする Hive 外部テーブルを作成します。これを行うとき、データ型
が、DynamoDB 外部テーブルのデータ型に準拠していることを確認します。
CREATE EXTERNAL TABLE hdfs_features_csv
(feature_id
BIGINT,
feature_name
STRING ,
feature_class
STRING ,
state_alpha
STRING,
prim_lat_dec
DOUBLE ,
prim_long_dec
DOUBLE ,
elev_in_ft
BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION 'hdfs:///user/hadoop/hive-test';
2.
DynamoDB からデータをコピーします。
INSERT OVERWRITE TABLE hdfs_features_csv
SELECT * FROM ddb_features;
HDFS のデータファイルは次のようになります。
920709,Soldiers Farewell Hill,Summit,NM,32.3564729,-108.3300461,6135
1178153,Jones Run,Stream,PA,41.2120086,-79.2592078,1260
253838,Sentinel Dome,Summit,CA,37.7229821,-119.58433,8133
264054,Neversweet Gulch,Valley,CA,41.6565269,-122.8361432,2900
115905,Chacaloochee Bay,Bay,AL,30.6979676,-87.9738853,0
HDFS から DynamoDB へ
単一の HiveQL ステートメントを使用すると、HDFS からのデータを DynamoDB テーブルに表示する
ことができます。
INSERT OVERWRITE TABLE ddb_features
API Version 2012-08-10
540
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
SELECT * FROM hdfs_features_csv;
列のマッピングなしでのデータのコピー
RAW 形式で DynamoDB からデータをコピーし、データ型または列マッピングを指定しないで HDFS
に書き込めます。この方法を使用すると、DynamoDB データのアーカイブを作成して、HDFS に保存
できます。
Note
DynamoDB テーブルにタイプ Map、List、Boolean、または Null の属性が含まれる場合、こ
の方法でのみ Hive を使用してデータを DynamoDB から HDFS へコピーできます。
DynamoDB から HDFS へ
1.
DynamoDB テーブルに関連付けられる外部テーブルを作成します。(この HiveQL ステートメント
には dynamodb.column.mapping はありません。)
CREATE EXTERNAL TABLE ddb_features_no_mapping
(item MAP<STRING, STRING>)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES ("dynamodb.table.name" = "Features");
2.
HDFS ディレクトリに関連付けられた別の外部テーブルを作成します。
CREATE EXTERNAL TABLE hdfs_features_no_mapping
(item MAP<STRING, STRING>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
LOCATION 'hdfs:///user/hadoop/hive-test';
3.
DynamoDB から HDFS へデータをコピーします。
INSERT OVERWRITE TABLE hdfs_features_no_mapping
SELECT * FROM ddb_features_no_mapping;
HDFS のデータファイルは次のようになります。
Name^C{"s":"Soldiers Farewell
Hill"}^BState^C{"s":"NM"}^BClass^C{"s":"Summit"}^BElevation^C{"n":"6135"}^BLatitude^C{"n":"
Name^C{"s":"Jones
Run"}^BState^C{"s":"PA"}^BClass^C{"s":"Stream"}^BElevation^C{"n":"1260"}^BLatitude^C{"n":"4
Name^C{"s":"Sentinel
Dome"}^BState^C{"s":"CA"}^BClass^C{"s":"Summit"}^BElevation^C{"n":"8133"}^BLatitude^C{"n":"
API Version 2012-08-10
541
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
Name^C{"s":"Neversweet
Gulch"}^BState^C{"s":"CA"}^BClass^C{"s":"Valley"}^BElevation^C{"n":"2900"}^BLatitude^C{"n":
Name^C{"s":"Chacaloochee
Bay"}^BState^C{"s":"AL"}^BClass^C{"s":"Bay"}^BElevation^C{"n":"0"}^BLatitude^C{"n":"30.6979
各フィールドは STX 文字 (テキスト開始 0x02) で始まり ETX 文字 (テキスト終了 0x03) で終わりま
す。ファイルで、STX は ^B、ETX は ^C と表示されます。
HDFS から DynamoDB へ
単一の HiveQL ステートメントを使用すると、HDFS からのデータを DynamoDB テーブルに表示する
ことができます。
INSERT OVERWRITE TABLE ddb_features_no_mapping
SELECT * FROM hdfs_features_no_mapping;
HDFS でデータにアクセスする
HDFS は、Amazon EMR クラスターのすべてのノードにアクセス可能な分散ファイルシステムで
す。SSHを使用してマスターノードに接続する場合、コマンドラインツールを使用して、Hive が
HDFS に書き込んだデータにアクセスできます。
HDFS は、マスターノードのローカルファイルシステムと同じものではありません。標準 Linux コマ
ンド (cat、cp、mv、rm など) を使用して HDFS のファイルとディレクトリで作業することはできま
せん。代わりに、hadoop fs コマンドを使用してこれらのタスクを実行します。
次のステップは、このセクションの手順の 1 つを使用して DynamoDB から HDFS にデータをコピー
したと想定しています。
1.
現在 Hive コマンドプロンプトである場合は、Linux コマンドプロンプトに戻ります。
hive> exit;
2.
/user/hadoop/hive-testディレクトリの内容を HDFS に表示します。(これは、Hive が DynamoDB
からデータをコピーした場所です。)
hadoop fs -ls /user/hadoop/hive-test
レスポンスは以下のようになります。
Found 1 items
-rw-r--r-- 1 hadoop hadoop 29504 2016-06-08 23:40 /user/hadoop/hivetest/000000_0
ファイル名 (000000_0) は、システムで生成されます。
3.
ファイルのコンテンツを表示します。
hadoop fs -cat /user/hadoop/hive-test/000000_0
API Version 2012-08-10
542
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB でデータを出し入れする
Note
この例では、ファイルは比較的小さくなっています (約29 KB)。大きなファイルまたは
印刷不可の文字を含むファイルでこのコマンドを使用する場合は注意する必要がありま
す。
4.
(オプション) HDFS から マスターノードのローカルファイルシステムにデータファイルをコピー
できます。その後、ファイルのデータを運用するために Linux 標準コマンドラインユーティリ
ティを使用できます。
hadoop fs -get /user/hadoop/hive-test/000000_0
このコマンドはファイルを上書きしません。
Note
マスターノードのローカルファイルシステムは容量が限定されています。ローカルファ
イルシステムで利用可能なスペースより大きなファイルでこのコマンドを使用しないで
ください。
データ圧縮の使用
さまざまなデータソース間で Hive を使用してデータをコピーする場合、オンザフライのデータ圧縮を
リクエストできます。Hive は複数の圧縮コーデックを提供します。Hive セッション中に 1 つを選択
できます。選択すると、データは指定した形式で圧縮されます。
次の例では、LZO (Lempel-Ziv-Oberhumer) アルゴリズムを使用して、データを圧縮します。
SET hive.exec.compress.output=true;
SET io.seqfile.compression.type=BLOCK;
SET mapred.output.compression.codec = com.hadoop.compression.lzo.LzopCodec;
CREATE EXTERNAL TABLE lzo_compression_table (line STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
LOCATION 's3://bucketname/path/subpath/';
INSERT OVERWRITE TABLE lzo_compression_table SELECT *
FROM hiveTableName;
Amazon S3 内のファイルにはシステム生成された名前が付けられ、最後に .lzo が付けられます (例:
8d436957-57ba-4af7-840c-96c2fc7bb6f5-000000.lzo)。
以下の圧縮コーデックを利用できます。
• org.apache.hadoop.io.compress.GzipCodec
• org.apache.hadoop.io.compress.DefaultCodec
• com.hadoop.compression.lzo.LzoCodec
• com.hadoop.compression.lzo.LzopCodec
• org.apache.hadoop.io.compress.BZip2Codec
API Version 2012-08-10
543
Amazon DynamoDB 開発者ガイド
パフォーマンスの調節
• org.apache.hadoop.io.compress.SnappyCodec
印刷不可の UTF-8 文字データを読み取る
Hive テーブル作成時に STORED AS SEQUENCEFILE 句を使用すると、印刷不可の UTF-8 文字デー
タを読み取り、書き込むことができます。SequenceFile は Hadoop バイナリファイル形式です。こ
のファイルを読み取るには Hadoop を使用する必要があります。次の例は、DynamoDB のデータを
Amazon S3 にエクスポートする方法を示しています。この機能を使用して印刷不可の UTF-8 でエン
コードされた文字を処理できます。
CREATE EXTERNAL TABLE s3_export(a_col string, b_col bigint, c_col
array<string>)
STORED AS SEQUENCEFILE
LOCATION 's3://bucketname/path/subpath/';
INSERT OVERWRITE TABLE s3_export SELECT *
FROM hiveTableName;
パフォーマンスの調節
DynamoDB にマップする Hive の外部テーブルを作成する場合、DynamoDB で読み取り容量または
書き込み容量を消費しません。ただし、Hive テーブルでの読み取りおよび書き込み作業 (INSERT や
SELECT など) は、基盤となる DynamoDB テーブルでの読み取りおよび書き込みオペレーションに直
接変換されます。
Amazon EMR の Apache Hive は DynamoDB テーブルの I/O 負荷のバランスを取るために独自のロ
ジックを導入し、テーブルのプロビジョンドスループットを超過する可能性を最小限に抑えるよう
に努めます。それぞれの Hive クエリの最後に、Amazon EMR はプロビジョンドスループットを超
過した回数など、ランタイムメトリックスを返します。この情報に加えて、DynamoDB テーブルの
CloudWatch メトリックスを使用して、続くリクエストのパフォーマンスを向上させることができま
す。
Amazon EMR コンソールでは、クラスターの基本モニタリングツールが用意されています。詳細につ
いては、Amazon EMR 管理ガイドのクラスターを表示し、モニタリングするを参照してください。
クラスターや Hadoop ジョブは、Hue、Ganglia、Hadoop ウェブインターフェイスなどのウェブベー
スのツールでモニタリングできます。詳細については、Amazon EMR 管理ガイドのAmazon EMR ク
ラスターでホストされているウェブインターフェイスの表示を参照してください。
このセクションでは、外部 DynamoDB テーブルで Hive オペレーションのパフォーマンス調整を行う
ための手順について説明します。
トピック
• DynamoDB プロビジョンドスループット (p. 544)
• マッパーの調整 (p. 546)
• その他のトピック (p. 547)
DynamoDB プロビジョンドスループット
外部 DynamoDB テーブルに対して HiveQL ステートメントを発行する
と、DynamoDBStorageHandler クラスは適切な低レベル DynamoDB API リクエストを行い、プロ
API Version 2012-08-10
544
Amazon DynamoDB 開発者ガイド
パフォーマンスの調節
ビジョンドスループットを消費します。DynamoDB テーブルに十分な読み取りまたは書き込み容量が
ない場合、リクエストは調整され、HiveQL のパフォーマンスが遅くなります。そのため、テーブルに
十分な容量があることを確認する必要があります。
例えば、DynamoDB テーブルに対して 100 ユニットの読み取りキャパシティーをプロビジョニングし
ているとします。この場合、1 秒間に 409,600 バイトの読み取り (100 × 4 KB 読み取り容量ユニット
サイズ) を実行できます。ここで、テーブルに 20 GB のデータ (21,474,836,480 バイト) が含まれてお
り、HiveQL を使っているすべてのデータを SELECT ステートメントで選択するとします。クエリの
実行時間を次のように推定できます。
21,474,836,480 / 409,600 = 52,429 秒 = 14.56 時間
このシナリオでは、DynamoDB テーブルがボトルネックとなります。Amazon EMR ノードを追
加しても解決にはなりません。Hive スループットは毎秒 409,600バイトに制限されているからで
す。SELECT ステートメントに必要な時間を短縮する唯一の方法は、DynamoDB テーブルにプロビ
ジョニングされた読み取り容量を増やすことです。
また同様の計算を実行して、DynamoDB テーブルにマップされた Hive 外部テーブルにデータを一括
読み込みするのに必要な時間を推定することもできます。読み込むデータの合計バイト数を特定し
て、1 つの DynamoDB 書き込み容量ユニットのサイズ (1 KB) で割ります。これでテーブルを読み込
む秒数が得られます。
テーブルの CloudWatch メトリックスを定期的にモニタリングする必要があります。DynamoDB コン
ソールの概要については、テーブルを選択し、[Metrics] タブを選択します。その後、消費された読み
取りおよび書き込み容量ユニット、および調整された読み取りおよび書き込みリクエストを確認でき
ます。
読み込みキャパシティー
Amazon EMR はテーブルのプロビジョニング済みスループットに基づいて、DynamoDB
テーブルに対するリクエスト負荷を管理します。ただし、ジョブ出力に大量の
ProvisionedThroughputExceeded メッセージがあることに気付いた場合、デフォルトの読み取り
レートを調整することができます。これを行うには、dynamodb.throughput.read.percent 設定
変数を変更します。SET コマンドを使って Hive コマンドプロンプトでこの変数を設定できます:
SET dynamodb.throughput.read.percent=1.0;
この変数は、現在の Hive セッションでのみ維持されます。Hive を終了して、あとで戻った場
合、dynamodb.throughput.read.percent はデフォルト値に戻ります。
dynamodb.throughput.read.percent の値は 0.1 以上 1.5 以下にできます。0.5 はデフォルト
の読み取りレートを示します。つまり、Hive はテーブルの読み取り容量の半分を消費しようと試みま
す。値が 0.5 を上回ると、Hive はリクエストレートを増やします。値が 0.5 を下回ると、読み取り
リクエストレートを減らします。(実際の読み取りレートは、DynamoDB テーブルに統一キーディス
トリビューションがあるかどうかなどの要因によって変わります。)
Hive が頻繁にテーブルにプロビジョニングされた読み取り容量を使い切ってい
ることに気付いた場合、または読み取りリクエストが過度に調整されている場合
は、dynamodb.throughput.read.percent を 0.5 未満にしてみます。テーブルで十分な読み取り
容量があり、HiveQL オペレーションの応答性を高める場合、0.5 を超える値に設定できます。
書き込みキャパシティー
Amazon EMR はテーブルのプロビジョニング済みスループットに基づいて、DynamoDB
テーブルに対するリクエスト負荷を管理します。ただし、ジョブ出力に大量の
ProvisionedThroughputExceeded メッセージがあることに気付いた場合、デフォルトの書き込み
API Version 2012-08-10
545
Amazon DynamoDB 開発者ガイド
パフォーマンスの調節
レートを調整することができます。これを行うには、dynamodb.throughput.write.percent 設定
変数を変更します。SET コマンドを使って Hive コマンドプロンプトでこの変数を設定できます:
SET dynamodb.throughput.write.percent=1.0;
この変数は、現在の Hive セッションでのみ維持されます。Hive を終了して、あとで戻った場
合、dynamodb.throughput.write.percent はデフォルト値に戻ります。
dynamodb.throughput.write.percent の値は 0.1 以上 1.5 以下にできます。0.5 はデフォルト
の読み取りレートを示します。つまり、Hive はテーブルの読み取り容量の半分を消費しようと試みま
す。値が 0.5 を上回ると、Hive はリクエストレートを増やします。値が 0.5 を下回ると、読み取り
リクエストレートを減らします。(実際の読み取りレートは、DynamoDB テーブルに統一キーディス
トリビューションがあるかどうかなどの要因によって変わります。)
Hive が頻繁にテーブルにプロビジョニングされた書き込み容量を使い切ってい
ることに気付いた場合、または書き込みリクエストが過度に調整されている場合
は、dynamodb.throughput.write.percent を 0.5 未満にしてみます。テーブルで十分な書き込
み容量があり、HiveQL オペレーションの応答性を高める場合、0.5 を超える値に設定できます。
Hive を使用してデータを DynamoDB に書き込む場合は、書き込みキャパシティーユニットの数をク
ラスター内のマッパーの数より大きくする必要があります。たとえば、10 の m1.xlarge ノードで構成
される Amazon EMR クラスターについて考えます。m1.xlarge ノードタイプは 8 つのマッパータスク
が可能なので、クラスターには合計 80 のマッパー (10 × 8) があります。DynamoDB テーブルの書き
込み容量ユニットが 80 未満の場合、Hive 書き込みオペレーションは、テーブルのすべての書き込み
スループットを消費する可能性があります。
Amazon EMR ノードタイプのマッパーの数を決定するには、Amazon EMR 開発者ガイドのタスクの
設定を参照してください。
マッパーの詳細については、マッパーの調整 (p. 546)を参照してください。
マッパーの調整
Hive が Hadoop ジョブが起動すると、ジョブは 1 つ以上のマッパータスクによって処理されま
す。DynamoDB テーブルに十分なスループット容量があると仮定して、クラスター内のマッパーの数
を調整すると、パフォーマンスが向上する可能性があります。
Note
Hadoop ジョブで使用されるマッパーの数は、Hadoop がデータを論理ブロックに分割する入
ロ分割によって左右されます。Hadoop が十分な入力分割を実行しないと、書き込みオペレー
ションは DynamoDB テーブルで利用可能なすべての書き込みスループットを処理できない可
能性があります。
マッパーの数を増やす
Amazon EMR の各マッパーの最大読み取りレートは毎秒 1 MiB です。クラスターにあるマッパーの数
は、クラスターのノードのサイズによって決まります。(ノードサイズとノードあたりのマッパーの数
については、Amazon EMR 開発者ガイドにあるタスクの設定を参照してください。)
DynamoDB テーブルに十分な読み取りスループット容量がある場合、次のいずれかの方法でマッパー
の数を増やしてみることができます。
• クラスターのノードのサイズを拡張する。たとえば、クラスターで m1.large ノード (ノードあたり
3 つのマッパー) を使用している場合、m1.xlarge ノード (ノードあたり 8 つのマッパー) にアップグ
レードすることを検討できます。
API Version 2012-08-10
546
Amazon DynamoDB 開発者ガイド
パフォーマンスの調節
• クラスターのノード数を増やす。たとえば、m1.xlarge ノードの 3 ノードクラスターを使用してい
る場合、合計 24 のマッパーがあります。同じタイプのノードでクラスターのサイズを 2 倍にする
と、マッパーは 48 になります。
AWS マネジメントコンソール を使用して、lクラスター内のノードの数またはサイズを管理できま
す。(変更を有効にするには、場合によってはクラスターを再起動する必要があります。)
マッパーの数を増やすもう 1 つの方法は、mapred.tasktracker.map.tasks.maximum
Hadoop 設定パラメーターを変更することです。(これは Hadoop パラメーターで、Hive パラ
メーターではありません。コマンドプロンプトからインタラクティブに変更することはできませ
ん。)mapred.tasktracker.map.tasks.maximum の値を増やすと、ノードのサイズや数を増やさ
ずに、マッパーの数を増やすことができます。ただし、値が大きすぎると、クラスターノードのメモ
リが不足する可能性があります。
Amazon EMR クラスターを最初に起動するときに mapred.tasktracker.map.tasks.maximum
の値をブートストラップアクションとして設定します。詳細については、Amazon EMR 管理ガイ
ドの(オプション) 追加のソフトウェアをインストールするためのブートストラップアクションの作
成を参照してください。
マッパーの数を減らす
SELECT ステートメントを使用して DynamoDB にマッピングする外部 Hive テーブルからデータを選
択する場合、Hadoop のジョブは、クラスター内のマッパー数の上限まで、必要な数のタスクを使用
できます。このシナリオでは、長時間の Hive クエリが、DynamoDB テーブルにプロビジョニングさ
れたすべての読み取り容量を使い切り、他のユーザーにマイナスの影響を与える可能性があります。
dynamodb.max.map.tasks パラメーターを使用して、マップタスクの上限を設定できます。
SET dynamodb.max.map.tasks=1
この値は、1 以上にする必要があります。Hive がクエリを処理すると、Hadoop のジョブで
は、DynamoDB テーブルからの読み取りで dynamodb.max.map.tasks より多くは使用しません。
その他のトピック
Hive を使って DynamoDB にアクセスするアプリケーションの他の調整方法について取り上げます。
再試行の期間
デフォルトで、Hadoop ジョブが 2 分以内に DynamoDB から結果を返さない場合、Hive はそのジョ
ブを再実行します。この間隔は、dynamodb.retry.duration パラメーターを変更して調整できま
す。
SET dynamodb.retry.duration=2;
値はゼロ以外の整数にする必要があり、これは再試行間隔の分数を表しま
す。dynamodb.retry.duration のデフォルト値は 2 (分) です。
並列データリクエスト
複数のユーザーまたは複数のアプリケーションから単一のテーブルに複数のデータリクエストが行わ
れると、プロビジョニング済み読み込みスループットが減少し、パフォーマンス速度が低下します。
API Version 2012-08-10
547
Amazon DynamoDB 開発者ガイド
Amazon Data Pipeline との統合
処理間隔
DynamoDB のデータ整合性は、各ノードでの読み書きオペレーションの順序に依存します。Hive ク
エリの進行中に、別のアプリケーションが DynamoDB テーブルに新しいデータをロードしたり、既
存のデータの変更や削除を行ったりする場合があります。この場合、クエリの実行中にデータに対し
て行われた変更は Hive クエリの結果に反映されないことがあります。
リクエスト時間
DynamoDB テーブルの需要が低いときに DynamoDB テーブルにアクセスする Hive クエリをスケ
ジュールすると、パフォーマンスが向上します。例えば、アプリケーションのほとんどのユーザーが
サンフランシスコに住んでいる場合、大部分のユーザーが睡眠中で DynamoDB データベースを更新
していない毎朝 4 時 (PST) にデータをエクスポートするように選択することができます。
AWS Data Pipeline を使用して DynamoDB デー
タをエクスポートおよびインポートする
AWS Data Pipeline を使用して、DynamoDB テーブルから Amazon S3 バケット内のファイルにデー
タをエクスポートできます。コンソールを使用して、Amazon S3 から同じまたは異なる AWS リー
ジョンにある DynamoDB テーブルにデータをインポートできます。
データのエクスポートおよびインポート機能は多くシナリオで役立ちます。たとえば、テスト目的で
一連のベースラインデータを保守するとします。ベースラインデータを DynamoDB テーブルに入力
し、Amazon S3 にエクスポートできます。続いて、テストデータを変更するアプリケーションを実行
した後、Amazon S3 から DynamoDB テーブルにインポートして戻すことで、ベースラインデータを
「リセット」できます。別の例としては、データの誤った削除や誤った DeleteTable オペレーショ
ンもあります。このような場合は、Amazon S3 にある前回のエクスポートファイルからデータを復
元できます。ある AWS リージョン内の DynamoDB テーブルからデータをコピーし、Amazon S3 に
保存し、続いて Amazon S3 から別のリージョン内の同じ DynamoDB テーブルにインポートすること
もできます。別のリージョン内のアプリケーションは、最も近い DynamoDB エンドポイントにアク
セスし、データの独自のコピーを操作できるため、同時に、ネットワークレイテンシーが短くなりま
す。
次の図に、AWS Data Pipeline を使用した DynamoDB データのエクスポートおよびインポートの概要
を示します。
API Version 2012-08-10
548
Amazon DynamoDB 開発者ガイド
Amazon Data Pipeline との統合
DynamoDB テーブルをエクスポートするには、AWS Data Pipeline コンソールを使用して新しいパイ
プラインを作成します。パイプラインによって、実際のエクスポートを実行する Amazon EMR クラ
スターが起動されます。Amazon EMR は、DynamoDB からデータを読み込み、Amazon S3 バケット
内のエクスポートファイルにデータを書き込みます。
このプロセスは、データが Amazon S3 バケットから読み込まれて DynamoDB テーブルに書き込まれ
ること以外、インポートでも同様です。
Important
DynamoDB データのエクスポートまたはインポート時、基礎となる次の AWS サービスの使
用に対して追加コストが発生します。
• AWS Data Pipeline - インポート/エクスポートのワークフローを管理します。
• Amazon S3 - DynamoDB に対してエクスポートまたはインポートするデータを格納しま
す。
API Version 2012-08-10
549
Amazon DynamoDB 開発者ガイド
データをエクスポートおよびイン
ポートデータするための前提条件
• Amazon EMR - マネージド型 Hadoop クラスターを実行して、Amazon S3 と DynamoDB
の間で読み込みと書き込みを行います。 クラスター構成は、1 つの m1.medium インスタン
スマスターノードと 1 つの m1.medium インスタンスコアノードです。
詳細については、「AWS Data Pipeline Pricing」、「Amazon EMR Pricing」、「Amazon S3
Pricing」を参照してください。
データをエクスポートおよびインポートデータする
ための前提条件
データのエクスポートとインポートに AWS Data Pipeline を使用するときは、パイプラインによっ
て実行できるアクションと消費できるリソースを指定する必要があります。許可されるそれらのアク
ションとリソースは AWS Identity and Access Management (IAM) ロールを使用して定義します。
また、IAM ポリシーを作成し、IAM ユーザーまたはグループにアタッチすることで、アクセスを制御
できます。これらのポリシーでは、DynamoDB データに対してインポートおよびエクスポートが許可
されるユーザーを指定できます。
Important
エクスポートとインポートを実行する IAM ユーザーには、アクティブな AWS アクセスキー
ID とシークレットキーが必要です。詳細については、『IAM ユーザーガイド』の「IAM ユー
ザーのアクセスキーの管理」を参照してください。
AWS Data Pipeline の IAM ロールを作成する
AWS Data Pipeline を使用するには、次の IAM ロールが AWS アカウントにあることが必要です。
• DataPipelineDefaultRole - パイプラインによって自動的に実行されるアクション。
• DataPipelineDefaultResourceRole - パイプラインによって自動的にプロビジョニングされる AWS
リソース。DynamoDB データのエクスポートとインポートの場合、これらのリソースには Amazon
EMR クラスターと、そのクラスターに関連付けられている Amazon EC2 インスタンスが含まれま
す。
これまでに AWS Data Pipeline を使用したことがない場合は、DataPipelineDefaultRole と
DataPipelineDefaultResourceRole を自分で作成する必要があります。作成したそれらのロールを使用
して、必要に応じていつでも DynamoDB データをエクスポートしたりインポートしたりできます。
Note
以前に AWS Data Pipeline コンソールを使用してパイプラインを作成した場
合、DataPipelineDefaultRole と DataPipelineDefaultResourceRole はその時点で自動的
に作成されています。これ以上の操作は必要ありません。このセクションをスキップ
し、DynamoDB コンソールを使用したパイプラインの作成を開始できます。詳細につい
ては、「DynamoDB から Amazon S3 にデータをエクスポートする (p. 554)」および
「Amazon S3 から DynamoDB にデータをインポートする (p. 555)」を参照してください。
1.
https://console.aws.amazon.com/iam/ で Identity and Access Management (IAM) コンソールにサ
インインします。
2.
IAM コンソールダッシュボードで [Roles] をクリックします。
3.
[Create New Role] をクリックし、次の操作を実行します。
API Version 2012-08-10
550
Amazon DynamoDB 開発者ガイド
データをエクスポートおよびイン
ポートデータするための前提条件
4.
a.
[Role Name] フィールドに「DataPipelineDefaultRole」と入力し、[Next Step] をクリッ
クします。
b.
[Select Role Type] パネルの [AWS Service Roles] リストで、[AWS Data Pipeline] に移動し、
[Select] をクリックします。
c.
[Attach Policy] パネルで [AWSDataPipelineRole] ポリシーの横にあるボックスをクリック
し、[Next Step] をクリックします。
d.
[Review] パネルで [Create Role] をクリックします。
[Create New Role] をクリックし、次の操作を実行します。
a.
[Role Name] フィールドに「DataPipelineDefaultResourceRole」と入力し、[Next
Step] をクリックします。
b.
[Select Role Type] パネルの [AWS Service Roles] リストで、[Amazon EC2 Role for Data
Pipeline] に移動し、[Select] をクリックします。
c.
[Attach Policy] パネルで [AmazonEC2RoleforDataPipelineRole] ポリシーの横にあるボックス
をクリックし、[Next Step] をクリックします。
d.
[Review] パネルで [Create Role] をクリックします。
これらのロールを作成できたので、DynamoDB コンソールを使用したパイプラインの作成を開始でき
ます。詳細については、「DynamoDB から Amazon S3 にデータをエクスポートする (p. 554)」お
よび「Amazon S3 から DynamoDB にデータをインポートする (p. 555)」を参照してください。
IAM ユーザーおよびグループへのエクスポートおよびイン
ポートタスクを実行するためのアクセス権限の付与
他の IAM ユーザーまたはグループにその DynamoDB テーブルのデータのエクスポートとインポート
を許可するには、IAM ポリシーを作成し、指定したユーザーまたはグループにアタッチできます。ポ
リシーには、これらのタスクを実行するために必要なアクセス権限のみが含まれます。
AWS 管理ポリシーを使用したフルアクセスの付与
次の手順は、AWS 管理ポリシー AmazonDynamoDBFullAccesswithDataPipeline を IAM ユー
ザーにアタッチする方法を説明しています。この管理ポリシーは、AWS Data Pipeline および
DynamoDB リソースへのフルアクセスを提供します。
1.
https://console.aws.amazon.com/iam/ で Identity and Access Management (IAM) コンソールにサ
インインします。
2.
IAM コンソールダッシュボードで、[Users] をクリックし、変更するユーザーを選択します。
3.
[Permissions] タブで [Attach Policy] をクリックします。
4.
[Attach Policy] パネルで AmazonDynamoDBFullAccesswithDataPipeline を選択し、[Attach
Policy] をクリックします。
Note
同様の手順を使用して、この管理ポリシーをユーザーではなくグループにアタッチできま
す。
特定の DynamoDB テーブルへのアクセスの制限
アクセスを制限し、ユーザーがテーブルのサブセットのエクスポートまたはインポートのみできるよ
うにするには、カスタマイズした IAM ポリシードキュメントを作成する必要があります。AWS 管理
ポリシー AmazonDynamoDBFullAccesswithDataPipeline をカスタムポリシーの開始点として使
用し、このポリシーを変更して、ユーザーが、指定されたテーブルのみを操作するようにできます。
API Version 2012-08-10
551
Amazon DynamoDB 開発者ガイド
データをエクスポートおよびイン
ポートデータするための前提条件
たとえば、IAM ユーザーに Forum、Thread、Reply のテーブルに対してのみエクスポートまたはイン
ポートを許可するとします。この手順では、ユーザーがそれらテーブルを操作できるが、それ以外は
操作できないようにするカスタムポリシーを作成する方法を示します。
1.
https://console.aws.amazon.com/iam/ で Identity and Access Management (IAM) コンソールにサ
インインします。
2.
IAM コンソールダッシュボードから [Policies] をクリックし、[Create Policy] をクリックします。
3.
[Create Policy] パネルで、[Copy an AWS Managed Policy] に移動し、[Select] をクリックしま
す。
4.
[Copy an AWS Managed Policy] パネルで、AmazonDynamoDBFullAccesswithDataPipeline
に移動し、[Select] をクリックします。
5.
[Review Policy] パネルで、以下の作業を行います。
a.
自動生成される [Policy Name] および [Description] を確認します。必要に応じて、これらの
値を変更できます。
b.
[Policy Document] テキストボックスで、特定のテーブルへのアクセスを制限するポリシー
を編集します。デフォルトでは、ポリシーはすべてのテーブルのすべての DynamoDB アク
ションを許可します。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"cloudwatch:DeleteAlarms",
"cloudwatch:DescribeAlarmHistory",
"cloudwatch:DescribeAlarms",
"cloudwatch:DescribeAlarmsForMetric",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics",
"cloudwatch:PutMetricAlarm",
"dynamodb:*",
"sns:CreateTopic",
"sns:DeleteTopic",
"sns:ListSubscriptions",
"sns:ListSubscriptionsByTopic",
"sns:ListTopics",
"sns:Subscribe",
"sns:Unsubscribe"
],
"Effect": "Allow",
"Resource": "*",
"Sid": "DDBConsole"
},
...remainder of document omitted...
ポリシーを制限するには、最初に次の行を削除します。
"dynamodb:*",
次に、Forum、Thread、および Reply のテーブルのみへのアクセスを許可する新しい
Action を作成します。
API Version 2012-08-10
552
Amazon DynamoDB 開発者ガイド
データをエクスポートおよびイン
ポートデータするための前提条件
{
"Action": [
"dynamodb:*"
],
"Effect": "Allow",
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/Forum",
"arn:aws:dynamodb:us-west-2:123456789012:table/Thread",
"arn:aws:dynamodb:us-west-2:123456789012:table/Reply"
]
},
Note
us-west-2 は DynamoDB テーブルがあるリージョンに置き換えてくださ
い。123456789012 は AWS アカウント番号に置き換えてください。
最後に、ポリシードキュメントに新しい Action を追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"dynamodb:*"
],
"Effect": "Allow",
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789012:table/Forum",
"arn:aws:dynamodb:us-west-2:123456789012:table/Thread",
"arn:aws:dynamodb:us-west-2:123456789012:table/Reply"
]
},
{
"Action": [
"cloudwatch:DeleteAlarms",
"cloudwatch:DescribeAlarmHistory",
"cloudwatch:DescribeAlarms",
"cloudwatch:DescribeAlarmsForMetric",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics",
"cloudwatch:PutMetricAlarm",
"sns:CreateTopic",
"sns:DeleteTopic",
"sns:ListSubscriptions",
"sns:ListSubscriptionsByTopic",
"sns:ListTopics",
"sns:Subscribe",
"sns:Unsubscribe"
],
"Effect": "Allow",
"Resource": "*",
"Sid": "DDBConsole"
},
API Version 2012-08-10
553
Amazon DynamoDB 開発者ガイド
DynamoDB から Amazon S3 に
データをエクスポートする
...remainder of document omitted...
6.
ポリシーの設定が正しいことを確認したら、[Create Policy] をクリックします。
ポリシーを作成したら、IAM ユーザーにポリシーをアタッチできます。
1.
IAM コンソールダッシュボードで、[Users] をクリックし、変更するユーザーを選択します。
2.
3.
[Permissions] タブで [Attach Policy] をクリックします。
[Attach Policy] パネルでポリシー名を選択し、[Attach Policy] をクリックします。
Note
同様の手順を使用して、ポリシーをユーザーではなくグループにアタッチできます。
DynamoDB から Amazon S3 にデータをエクスポー
トする
このセクションでは、1 つ以上の DynamoDB テーブルから Amazon S3 バケットにデータをエクス
ポートする方法について説明します。エクスポートを実行する前に、Amazon S3 バケットを作成する
必要があります。
Important
これまでに AWS Data Pipeline を使用したことがない場合は、この手順を実行する前に 2 つ
の IAM ロールを設定する必要があります。詳細については、「AWS Data Pipeline の IAM
ロールを作成する (p. 550)」を参照してください。
1.
2.
Sign in to the AWS マネジメントコンソール and open the AWS Data Pipeline console at https://
console.aws.amazon.com/datapipeline/.
すでに現在の AWS リージョンにパイプラインがない場合は、[Get started now] を選択します。
3.
それ以外の場合、少なくとも 1 つのパイプラインがある場合は、[Create new pipeline] を選択し
ます。
[Create Pipeline] ページで、次の操作を実行します。
a.
[Name] フィールドで、パイプラインの名前を入力します。例:
MyDynamoDBExportPipeline。
b.
[Source] パラメーターで、[Build using a template] を選択します。ドロップダウンテンプ
レートのリストから、[Export DynamoDB table to S3] を選択します。
c.
[Source DynamoDB table name] フィールドに、エクスポートする DynamoDB テーブルの名
前を入力します。
d.
[Output S3 Folder] テキストボックスに、エクスポートファイルが書き込まれる Amazon S3
の URI を入力します。以下に例を示します。s3://mybucket/exports
この URI の形式は s3://bucketname/folder で、次のような構成になっています。
e.
• bucketname は Amazon S3 バケットの名前です。
• folder はそのバケット内のフォルダーの名前です。フォルダーが存在し
ない場合は、自動的に作成されます。フォルダーの名前を指定しない場合
は、s3://bucketname/region/tablename という形式で名前が付けられます。
[S3 location for logs] テキストボックスに、エクスポート用のログファイルが書き込まれる
Amazon S3 の URI を入力します。以下に例を示します。s3://mybucket/logs/
API Version 2012-08-10
554
Amazon DynamoDB 開発者ガイド
Amazon S3 から DynamoDB にデータをインポートする
[S3 Log Folder] の URI 形式は [Output S3 Folder] のものと同じです。URI はフォルダに解
決される必要があります。ログファイルを S3 バケットの最上位に書き込むことはできませ
ん。
4.
すべての設定が正しいことを確認したら、[Activate] をクリックします。
これで、パイプラインが作成されます。このプロセスが完了するまでに数分かかることがありま
す。AWS Data Pipeline コンソールで進捗状況をモニターすることができます。
エクスポートが完了したら、Amazon S3 コンソールに移動して、エクスポートファイルを表示できま
す。ファイルはテーブルと同じ名前のフォルダーに置かれ、YYYY-MM-DD_HH.MM という形式で名前
が付けられます。このファイルの内部形式については、AWS Data Pipeline 開発者ガイド の「Verify
Data Export File」を参照してください。
Amazon S3 から DynamoDB にデータをインポート
する
このセクションでは、すでに DynamoDB テーブルからデータをエクスポートし、エクスポート
ファイルが Amazon S3 バケットに書き込まれているとします。このファイルの内部形式について
は、AWS Data Pipeline 開発者ガイド の「Verify Data Export File」を参照してください。これは
DynamoDB が AWS Data Pipeline を使用してインポートできる唯一のファイル形式であることに注意
してください。
ソーステーブルという用語は、データのエクスポート元となったテーブルに使用します。インポート
先テーブルという用語は、データのインポート先となるテーブルに使用します。エクスポートファイ
ルから Amazon S3 にデータをインポートできます。ただし、次のすべての条件を満たしていること
が前提です。
• インポート先テーブルがすでに存在する(インポートプロセスによってテーブルは作成されませ
ん)
• インポート先テーブルとソーステーブルのキースキーマが同じ
インポート先テーブルは空である必要はありません。ただしインポートプロセスでは、インポート先
テーブルのデータ項目のうち、エクスポートファイルの項目とキーが同じものはすべて置き換えら
れます。たとえば、Customer テーブルに CustomerId というキーがあり、そのテーブルに 3 つの項
目(CustomerId 1、2、3)のみがあるとします。エクスポートファイルにも CustomerID 1、2、3 の
データ項目がある場合、インポート先テーブルの項目はエクスポートファイルのものと置き換えられ
ます。エクスポートファイルに CustomerId 4 のデータ項目もある場合、その項目がインポート先テー
ブルに追加されます。
インポート先テーブルは異なる AWS リージョンに置くことができます。たとえば、米国西部 (オレ
ゴン) リージョンに Customer テーブルがあり、そのデータを Amazon S3 にエクスポートするとしま
す。エクスポートしたデータは 欧州 (アイルランド) リージョン内の同じ Customer テーブルにイン
ポートできます。これは、クロスリージョンのエクスポートとインポートと呼ばれています。AWS
リージョンのリストについては、『AWS General Reference』の「リージョンとエンドポイント」を
参照してください。
AWS マネジメントコンソール では、一度に複数のソーステーブルをエクスポートできます。ただ
し、一度にインポートできるのは 1 つのテーブルのみです。
1.
Sign in to the AWS マネジメントコンソール and open the AWS Data Pipeline console at https://
console.aws.amazon.com/datapipeline/.
2.
(省略可能) クロスリージョンのインポートを実行する場合、ウィンドウの右上隅にあるインポー
ト先リージョンを選択します。
3.
[Create new pipeline] を選択します。
API Version 2012-08-10
555
Amazon DynamoDB 開発者ガイド
トラブルシューティング
4.
[Create Pipeline] ページで、次の操作を実行します。
a.
[Name] フィールドで、パイプラインの名前を入力します。例:
MyDynamoDBImportPipeline。
b.
[Source] パラメーターで、[Build using a template] を選択します。ドロップダウンテンプ
レートのリストから、[Import DynamoDB backup data from S3] を選択します。
c.
[Input S3 Folder] テキストボックスに、エクスポートファイルが見つかる Amazon S3 の URI
を入力します。以下に例を示します。s3://mybucket/exports
この URI の形式は s3://bucketname/folder で、次のような構成になっています。
• bucketname は Amazon S3 バケットの名前です。
• folder はエクスポートファイルを含むフォルダーの名前です。
インポートジョブでは、指定した Amazon S3 の場所にファイルが見つかることが想定さ
れます。このファイルの内部形式については、AWS Data Pipeline 開発者ガイド の「Verify
Data Export File」を参照してください。
d.
[Target DynamoDB table name] フィールドに、データをインポートする DynamoDB テーブ
ルの名前を入力します。
e.
[S3 location for logs] テキストボックスに、インポート用のログファイルが書き込まれる
Amazon S3 の URI を入力します。以下に例を示します。s3://mybucket/logs/
[S3 Log Folder] の URI 形式は [Output S3 Folder] のものと同じです。URI はフォルダに解
決される必要があります。ログファイルを S3 バケットの最上位に書き込むことはできませ
ん。
5.
すべての設定が正しいことを確認したら、[Activate] をクリックします。
これで、パイプラインが作成されます。このプロセスが完了するまでに数分かかることがあります。
インポートジョブはパイプラインの作成直後に開始されます。
トラブルシューティング
このセクションでは、DynamoDB のエクスポートについていくつかの基本的な障害モードとトラブル
シューティングを取り上げます。
エクスポートまたはインポート時にエラーが発生した場合、AWS Data Pipeline コンソールのパイプ
ラインステータスは「ERROR」として表示されます。この場合は、エラーの発生したパイプラインの
名前をクリックして、その詳細ページに移動します。これにより、パイプラインのすべてのステップ
の詳細と、各ステップのステータスが表示されます。特に、表示される実行スタックトレースを確認
します。
最後に、Amazon S3 バケットに移動し、そこに書き込まれたすべてのエクスポートまたはインポート
ログファイルを探します。
次に示しているのは、パイプラインのエラーの原因として考えられるいくつかの一般的な問題とその
対処方法です。パイプラインを診断するには、表示されたエラーと次に示している問題を比較しま
す。
• インポートの場合は、インポート先テーブルがすでに存在すること、インポート先テーブルにソー
ステーブルと同じキースキーマがあることを確認します。これらの条件が満たされていない場合、
インポートは失敗します。
• 指定した Amazon S3 バケットが作成されていること、そのバケットに対する読み込みと書き込み
のアクセス許可があることを確認します。
• パイプラインがその実行タイムアウトを超えている可能性があります(このパラメーターはパイプ
ラインの作成時に設定しています)。たとえば、1 時間の実行タイムアウトを設定している場合が
API Version 2012-08-10
556
Amazon DynamoDB 開発者ガイド
AWS Data Pipeline と DynamoDB
用の定義済みテンプレート
ありますが、エクスポートジョブでこれより長い時間が必要だった可能性があります。パイプライ
ンを削除して作成し直してみてください。ただし実行タイムアウト間隔は前回よりも長くします。
• エクスポートまたはインポートを実行するための正しいアクセス許可がない可能性があります。詳
細については、「データをエクスポートおよびインポートデータするための前提条件 (p. 550)」を
参照してください。
• AWS アカウントのリソース制限(Amazon EC2 インスタンスの最大数や AWS Data Pipeline パイ
プラインの最大数など)に達した可能性があります。これらの上限の増加をリクエストする方法な
ど、詳細については、AWS General Reference の「AWS Service Limits」を参照してください。
Tip
パイプラインのトラブルシューティングの詳細については、『AWS Data Pipeline 開発者ガイ
ド』の「Troubleshooting」を参照してください。
AWS Data Pipeline と DynamoDB 用の定義済みテ
ンプレート
AWS Data Pipeline のしくみをより深く理解するには、『AWS Data Pipeline 開発者ガイド』を参照
することをお勧めします。このガイドには、パイプラインを作成して操作する手順について説明した
チュートリアルが含まれています。これらのチュートリアルは、独自のパイプラインの作成を開始す
るときに参考になります。また、DynamoDB のチュートリアルを参照することをお勧めします。この
チュートリアルでは、要件に合わせてカスタマイズ可能なインポートおよびエクスポートパイプライ
ンを作成する手順について説明しています。『AWS Data Pipeline 開発者ガイド』の「チュートリア
ル: AWS Data Pipeline を使用した Amazon DynamoDB のエクスポートとインポート」を参照してく
ださい。
AWS Data Pipeline には、パイプラインを作成するためのテンプレートがいくつか用意されていま
す。次のテンプレートは DynamoDB に関連しています。
DynamoDB と Amazon S3 の間のデータのエクスポート
AWS Data Pipeline コンソールには、DynamoDB と Amazon S3 間でデータをエクスポートするため
の定義済みテンプレートが 2 つ用意されています。これらのテンプレートの詳細については、『AWS
Data Pipeline 開発者ガイド』の次のセクションを参照してください。
• Export DynamoDB to Amazon S3
• Export Amazon S3 to DynamoDB
API Version 2012-08-10
557
Amazon DynamoDB 開発者ガイド
キャパシティーユニットとプロ
ビジョニングされるスループット
DynamoDB での制限
このセクションでは、Amazon DynamoDB 内の現在の制限について説明します (制限がない場合もあ
ります)。以下に示す各制限は、指定がない限り、リージョン単位で適用されます。
トピック
• キャパシティーユニットとプロビジョニングされるスループット (p. 558)
• テーブル (p. 560)
• セカンダリインデックス (p. 560)
• パーティションキーおよびソートキー (p. 560)
• 名前付けルール (p. 561)
• データ型 (p. 561)
• アイテム (p. 562)
• 属性 (p. 562)
• 式パラメーター (p. 563)
• DynamoDB ストリーム (p. 563)
• API 固有の制限 (p. 564)
キャパシティーユニットとプロビジョニングされ
るスループット
キャパシティーユニットサイズ
最大サイズ 4 KB の項目について、1 つの読み込みキャパシティーユニット = 1 秒あたり 1 回の強力な
整合性のある読み込み、あるいは 1 秒あたり 2 回の結果整合性のある読み込み。
最大サイズ 1 KB の項目について、1 つの書き込みキャパシティーユニット = 1 秒あたり 1 回の書き込
み
API Version 2012-08-10
558
Amazon DynamoDB 開発者ガイド
プロビジョニングされたスループットの最小値と最大値
プロビジョニングされたスループットの最小値と最
大値
テーブルまたはグローバルセカンダリインデックスについて、プロビジョニングされるスループット
の最小設定は 1 つの読み込みキャパシティーユニットと 1 つの書き込みキャパシティーユニットで
す。
AWS アカウントでは、プロビジョニングできるスループットについて、いくつかの初期的な最大制限
があります。
• 米国東部(バージニア北部) リージョン:
• テーブル単位 – 読み込みキャパシティーユニット数 40,000 および書き込みキャパシティーユ
ニット数 40,000
• アカウント単位 – 読み込みキャパシティーユニット数 80,000 および書き込みキャパシティーユ
ニット数 80,000
• その他すべてのリージョン:
• テーブル単位 – 読み込みキャパシティーユニット数 10,000 および書き込みキャパシティーユ
ニット数 10,000
• アカウント単位 – 読み込みキャパシティーユニット数 20,000 および書き込みキャパシティーユ
ニット数 20,000
プロビジョニングされたスループット制限には、すべてのグローバルセカンダリインデックスの容量
とともに、テーブルの容量の合計が含まれます。
これらの制限はリクエストによって増加させることができます。詳細については、https://
aws.amazon.com/ サポートを参照してください。
AWS マネジメントコンソールでは、特定のリージョンでプロビジョニングされた現在の容量を
表示し、制限に近づきすぎていないことを確認できます。デフォルトの制限を増加させた場合
は、DescribeLimits オペレーションを使用して現在の制限値を確認できます。
プロビジョニングされるスループットを増やす
AWS マネジメントコンソール または UpdateTable オペレーションを使用して、必要な回数だけ
ReadCapacityUnits または WriteCapacityUnits を増やすことができます。1 回の呼び出し
で、テーブル、そのテーブルの任意の グローバルセカンダリインデックス、またはこれらの任意の
組み合わせに対して、プロビジョニングされるスループットを増やすことができます。新しい設定
は、UpdateTable オペレーションが完了するまでは有効になりません。
プロビジョニングされた容量を追加する場合、アカウントごとの制限を超えることはできません。ま
た、DynamoDB では、プロビジョニングされた容量を急速に増やすことはできません。これらの制
限とは別に、テーブルにプロビジョニングされた容量はどれだけでも増やすことができます。アカウ
ントごとの制限の詳細については、前述の「プロビジョニングされたスループットの最小値と最大
値 (p. 559)」セクションを参照してください。
プロビジョニングされるスループットを減らす
テーブルの ReadCapacityUnits または WriteCapacityUnits 設定を減らすことができますが、1
UTC 暦日にテーブルあたり 4 回 以上減らすことはできません。1 回のオペレーションで、テーブル、
そのテーブルの任意のグローバルセカンダリインデックス、またはテーブルとグローバルセカンダリ
インデックスの任意の組み合わせに対して、プロビジョニングされるスループットを減らすことがで
きます。
API Version 2012-08-10
559
Amazon DynamoDB 開発者ガイド
テーブル
UpdateTable オペレーションのすべてのテーブルと グローバルセカンダリインデックス につい
て、ReadCapacityUnits または WriteCapacityUnits(あるいはその両方)を減らすことができ
ます。新しい設定は、UpdateTable オペレーションが完了するまでは有効になりません。
テーブル
テーブルのサイズ
テーブルのサイズには実用的な制限はありません。テーブルは項目数やバイト数について制限があり
ません。
アカウントあたりのテーブル数
AWS アカウントについては、リージョンごとに 256 個のテーブルという初期制限があります。
この制限の増加をリクエストすることができます。詳細については、「https://aws.amazon.com/サ
ポート」を参照してください。
セカンダリインデックス
テーブルごとのセカンダリインデックス
1 つのテーブルで、最大 5 のlocal secondary indexと 5 のグローバルセカンダリインデックスを定義
できます。
テーブルあたりの射影されたセカンダリインデック
ス属性
1 つのテーブルのすべてのローカルおよびグローバル セカンダリインデックス に対して、合計で最大
20 個の属性を射影することができます。これは、ユーザー指定の射影された属性だけに適用されま
す。
CreateTable オペレーションでは、ProjectionType として INCLUDE を指定した場合に
は、NonKeyAttributes で指定した属性の数をすべての セカンダリインデックス で集計した合計値
が 20 を超えてはいけません。同じ属性名を 2 つの異なるインデックスに射影した場合には、合計を
計算する際に 2 つの異なる属性として計算されます。
この制限は、ProjectionType が KEYS_ONLY または ALL である セカンダリインデックス には適用
されません。
パーティションキーおよびソートキー
パーティションキーの長さ
パーティションキーと値の最小長は 1 バイトです。最大長は 2048 バイト です。
パーティションキーの値
テーブルまたはセカンダリインデックスについて、パーティションキー値の明確な数に関する実質的
な制限はありません。
API Version 2012-08-10
560
Amazon DynamoDB 開発者ガイド
ソートキーの長さ
ソートキーの長さ
ソートキーと値の最小長は 1 バイトです。最大長は 1024 バイト です。
ソートキー値
一般的に、パーティションキーの値ごとのソートキーの値の数について、実質的に制限はありませ
ん。
テーブルの例外はlocal secondary indexです。local secondary indexでは、項目コレクションのサイズ
に制限があります。異なるパーティションキーの値について、すべてのテーブルおよびインデックス
項目の合計サイズは、10 GB を超えることはできません。これにより、パーティションキー値あたり
のソートキーの数が制約を受ける可能性があります。詳細については、「項目コレクションのサイズ
制限 (p. 393)」を参照してください。
名前付けルール
テーブル名およびセカンダリインデックス名
テーブルとセカンダリインデックスの名前は、3 文字以上、255 文字以下である必要があります。使
用できる文字は次のとおりです。
• A-Z
• a-z
• 0-9
• _ (下線)
• - (ハイフン)
• . (ドット)
属性名
一般的に、属性名は 1 文字以上、64 KB 以下である必要があります。
例外は次のとおりです。これらの属性名は 255 文字以下である必要があります。
• Secondary indexパーティションキー名。
• Secondary indexソートキー名。
• ユーザー指定の射影された属性の名前(local secondary index のみに適用)。CreateTable オペ
レーションでは、ProjectionType を INCLUDE に指定した場合には、NonKeyAttributes パラ
メータの属性名の長さが制限されます。射影タイプ KEYS_ONLY および ALL には影響しません。
これらの属性名は UTF-8 を使用してエンコードする必要があり、それぞれの名前の合計サイズが (エ
ンコード後に) 255 バイトを超えることはできません。
データ型
文字列
文字列の長さは、最大項目サイズ 400 KB によって制限されます。
API Version 2012-08-10
561
Amazon DynamoDB 開発者ガイド
数値
文字列は、UTF-8 バイナリエンコードの Unicode です。UTF-8 は可変幅のエンコードであるた
め、DynamoDB により、UTF-8 バイトを使用して文字列の長さが決まります。
数値
数値は、最大 38 桁の精度であり、正、負、または 0 のいずれかです。
• 正の範囲: 1E-130~9.9999999999999999999999999999999999999E+125
• 負の範囲: -9.9999999999999999999999999999999999999E+125~-1E-130
DynamoDB は JSON 文字列を使用してリクエストと返信の数値データを表します。詳細については、
「DynamoDB 低レベル API (p. 68)」を参照してください。
数値の精度が重要な場合は、数値型から変換する文字列を使用して、DynamoDB に数値を渡します。
バイナリ
バイナリの長さは、最大項目サイズ 400 KB によって制限されます。
バイナリ属性を操作するアプリケーションは、データを DynamoDB に送信する前に、それを Base64
形式でエンコードする必要があります。DynamoDB は、受信したデータを署名なしバイト配列にデ
コードし、それを属性の長さとして使用します。
アイテム
項目のサイズ
DynamoDB の最大項目のサイズ 400 KB で、属性名バイナリの長さ (UTF-8 長) と属性値の長さ (これ
もバイナリ長) を含みます。属性名はサイズ制限に反映されます。
たとえば、2 つの属性を持つ項目があり、1 つの属性は名前が "shirt-color" で値が "R"、別の属性は名
前が "shirt-size" で値が "M" であるとします。この項目の合計サイズは 23 バイトです。
ローカルセカンダリインデックスを持つテーブルの
項目サイズ
テーブルの local secondary index ごとに、以下を合計したサイズに関して 400 KB の制限がありま
す。
• テーブルの項目データのサイズ。
• その項目に対応する local secondary index エントリのサイズ。キーの値と射影された属性を含みま
す。
属性
項目あたりの属性名と値のペア
項目あたりの属性の累積サイズは、DynamoDB の最大項目サイズ (400 KB) 内である必要がありま
す。
API Version 2012-08-10
562
Amazon DynamoDB 開発者ガイド
リスト、マップ、またはセットの値の最大数
リスト、マップ、またはセットの値の最大数
値を含む項目が 400 KB のサイズ制限内である限り、リスト、マップ、またはセットの値の最大数の
制限はありません。
属性値
属性値は空の文字列または空のセット (文字列セット、数値セット、またはバイナリセット) にするこ
とはできません。ただし、空のリストおよびマップは許可されます。
入れ子の属性の深さ
DynamoDB は深さが最大 32 レベルの入れ子の属性をサポートします。
式パラメーター
式パラメーターには、ProjectionExpression、ConditionExpression、UpdateExpression、
および FilterExpression があります。
長さ
任意の式の最大長は 4 KB です。たとえば、ConditionExpression a=b のサイズは 3 バイトです。
1 つの式属性名または式属性値の最大長は 255 バイトです。たとえば、#name は 5 バイト、:val は
4 バイトです。
式のすべての置換変数の最大長は 2 MBです。これはすべての ExpressionAttributeNames および
ExpressionAttributeValues の長さの合計です。
演算子およびオペランド
UpdateExpression で許容される演算子または関数の最大数は 300 です。たとえ
ば、UpdateExpression SET a = :val1 + :val2 + :val3 は 2 つの "+" 演算子を含みます。
IN コンパレータのオペランドの最大数は 100 です。
予約語
DynamoDB に、予約語と競合する名前の使用を防止する機構はありません (詳細な一覧については、
「DynamoDB の予約語 (p. 668)」を参照してください)。
ただし、式パラメーターで予約語を使用する場合は、ExpressionAttributeNames も指定する必要
があります。詳細については、「属性の名前および値でのプレースホルダーの使用 (p. 213)」を参照
してください。
DynamoDB ストリーム
DynamoDB ストリーム のシャードの同時リーダー
同じ DynamoDB ストリーム シャードから同時に複数のプロセスの読み取りを許可しないでくださ
い。この制限を超えると、リクエストのスロットリングが発生する場合があります。
API Version 2012-08-10
563
Amazon DynamoDB 開発者ガイド
ストリームが有効なテーブル
の最大書き込みキャパシティー
ストリームが有効なテーブルの最大書き込みキャパ
シティー
次の書き込みキャパシティーの制限が、DynamoDB ストリームを有効にしたテーブルに適用されま
す。
• 米国東部 (バージニア北部) リージョン:
• テーブル単位 – 40,000 書き込みキャパシティーユニット
• アカウント単位– 80,000 書き込みキャパシティーユニット
• その他すべてのリージョン:
• テーブル単位 – 10,000 書き込みキャパシティーユニット
• アカウント単位– 20,000 書き込みキャパシティーユニット
API 固有の制限
CreateTable/UpdateTable/DeleteTable
一般的に、最大 10 の CreateTable、UpdateTable、および、 DeleteTable リクエストを同
時に実行できます (任意の組み合わせ)。つまり、CREATING、UPDATING、または DELETING の状
態のテーブルの合計数が 10 を超えることはできません。
唯一の例外は、1 つ以上の セカンダリインデックス を持つテーブルを作成する場合です。そのよ
うなリクエストは一度に 5 件まで実行できます。ただしテーブルまたはインデックスの仕様が複
雑な場合は、DynamoDB によって同時リクエスト数が一時的に 5 件未満に減らされることがあり
ます。
BatchGetItem
1 回の BatchGetItem オペレーションで、最大 100 項目を取得できます。取得するすべての項目
の合計サイズは 16 MB を超えることはできません。
BatchWriteItem
単一の BatchWriteItem オペレーションは、最大 25 の PutItem または DeleteItem リクエス
トを含むことができます。書き込むすべての項目の合計サイズは 16 MB を超えることはできませ
ん。
DescribeLimits
DescribeLimits は定期的に呼び出すのみにする必要があります。1 分以内に複数回呼び出す
と、スロットリングエラーが発生する可能性があります。
Query
Query の結果セットは、呼び出しあたり 1 MB に制限されます。クエリ応答から
LastEvaluatedKey を使用して、結果をさらに取り出すこともできます。
Scan
Scan の結果セットは、呼び出しあたり 1 MB に制限されます。スキャン応答から
LastEvaluatedKey を使用して、結果をさらに取り出すこともできます。
API Version 2012-08-10
564
Amazon DynamoDB 開発者ガイド
テーブルのベストプラクティス
DynamoDB のベストプラクティス
このセクションを使用して、パフォーマンスを最大にしてスループットコストを最小にするための推
奨事項をすばやく見つけてください。
テーブルのベストプラクティス
DynamoDB テーブルは複数のパーティションに分散されています。最良の結果を得るには、パフォー
マンスを低下させる可能性がある I/O の「ホットスポット」を発生させないために、読み込みおよび
書き込みアクティビティがテーブル内のすべての項目に均一に分散されるように、テーブルとアプリ
ケーションを設計します。
• テーブル内のすべての項目に対して均一なデータアクセスを実現する設計 (p. 567)
• パーティションの動作について (p. 569)
• 急激に増大するキャパシティーは控えめに使用する (p. 573)
• データアップロード時に書き込みアクティビティを分散する (p. 573)
• 時系列データへのアクセスパターンを理解する (p. 574)
• 人気の高い項目をキャッシュに格納する (p. 575)
• プロビジョニングされたスループットを調整するときにワークロードの均一性を考慮する (p. 575)
• 大規模環境でのアプリケーションのテスト (p. 576)
項目のベストプラクティス
DynamoDB 項目はサイズが限定されています(「DynamoDB での制限 (p. 558)」を参照)。ただし、
テーブル内の項目数に制限はありません。大きなデータ属性値を項目内に格納する代わりに、ここに
示すアプリケーション設計方法を検討してください。
• 大規模な設定属性の代わりに 1 対多のテーブルを使用する (p. 577)
• 複数テーブルの使用による多様なアクセスパターンのサポート (p. 578)
• 大量の属性値を圧縮する (p. 579)
• Amazon S3 に大量の属性値を格納する (p. 580)
API Version 2012-08-10
565
Amazon DynamoDB 開発者ガイド
クエリとスキャンのベストプラクティス
• 大量の属性を複数の項目に分割する (p. 580)
クエリとスキャンのベストプラクティス
予期しない突然の読み込みアクティビティがあると、テーブルやグローバルセカンダリインデックス
のプロビジョニングされている読み込みキャパシティーが急速に消費されます。またそのようなアク
ティビティは、複数のテーブルパーティションに均一に分散されていないと、効率が低下する可能性
があります。
• 読み込みアクティビティの急激な増大の回避 (p. 581)
• 並列スキャンの利用 (p. 583)
ローカルセカンダリインデックス のベストプラク
ティス
local secondary indexでは、データ用の代替ソートキーを定義することができます。テーブルのクエリ
と同じ方法でlocal secondary indexのクエリを実行できます。local secondary index を使用する前に、
プロビジョニングされたスループットコスト、ストレージコスト、クエリの効率性について、固有の
トレードオフがあることを認識する必要があります。
• インデックスの使用は控えめにする (p. 584)
• 射影を慎重に選択する (p. 584)
• フェッチを回避するための頻繁なクエリの最適化 (p. 585)
• スパースなインデックスの利用 (p. 585)
• 項目コレクションの拡張の監視 (p. 586)
グローバルセカンダリインデックス のベストプラ
クティス
グローバルセカンダリインデックスでは、データ用の代替パーティションキーとソートキーの属性を
定義することができます。これらの属性は、テーブルパーティションのキーおよびソートキーと同じ
である必要はありません。テーブルのクエリと同じ方法でグローバルセカンダリインデックスのクエ
リを実行できます。local secondary index と同様、グローバルセカンダリインデックス にも、アプリ
ケーションを設計するときに考慮する必要があるトレードオフがあります。
• ワークロードが均一になるようにキーを選択する (p. 586)
• スパースなインデックスの利用 (p. 587)
• グローバルセカンダリインデックス を使用したすばやい検索 (p. 587)
• 結果整合性のある読み込みレプリカを作成する (p. 587)
テーブルの操作のガイドライン
トピック
• テーブル内のすべての項目に対して均一なデータアクセスを実現する設計 (p. 567)
• パーティションの動作について (p. 569)
• 急激に増大するキャパシティーは控えめに使用する (p. 573)
API Version 2012-08-10
566
Amazon DynamoDB 開発者ガイド
テーブル内のすべての項目に対して
均一なデータアクセスを実現する設計
• データアップロード時に書き込みアクティビティを分散する (p. 573)
• 時系列データへのアクセスパターンを理解する (p. 574)
• 人気の高い項目をキャッシュに格納する (p. 575)
• プロビジョニングされたスループットを調整するときにワークロードの均一性を考慮す
る (p. 575)
• 大規模環境でのアプリケーションのテスト (p. 576)
このセクションでは、模範的なテーブルの操作方法について説明します。
テーブル内のすべての項目に対して均一なデータア
クセスを実現する設計
テーブルのプロビジョニングされたスループットを最適に使用するには、次の要因が影響します。
• プライマリキーの選択
• 個々の項目に対するワークロードパターン
プライマリキーは、テーブルの各項目を一意に識別します。プライマリキーはシンプル (パーティショ
ンキー) または複合 (パーティションキーとソートキー) とすることができます。
データを保存するとき、DynamoDB はテーブルの項目を複数のパーティションに分割し、主にパー
ティションキー値に基づいて、データを分散します。そのため、テーブルにプロビジョニング済みの
十分な量のリクエストスループットを得るには、ワークロードをパーティションキー値全体に均一に
分散します。パーティションキー値全体にリクエストを分散すると、パーティション全体にリクエス
トが分散されます。
たとえば、1 つのテーブルに、頻繁にアクセスされるパーティションキー値がごく少数含まれる場合
(非常に頻繁に使用されるパーティションキー値が 1 つだけの場合もあります)、少数のパーティショ
ン (場合によっては 1 つのパーティションだけ) にリクエストトラフィックが集中します。1 つまたは
一部のパーティションに偏ってしまうなど、ワークロードのバランスが極端に悪いと、リクエストで
は、プロビジョニングされたスループットの全体的なレベルが達成されません。DynamoDB のスルー
プットを最大限に活用するには、テーブルを作成するときに、パーティションキーに個別の値が多数
含まれ、できるだけランダムかつ均一に値がリクエストされるようにします。
この操作によって、スループットレベルを達成するために、すべてのパーティションキー値にアクセ
スする必要があるというわけではありません。また、アクセスされるパーティションキー値の割合を
高くする必要があるというわけでもありません。ただし、より明確に区別できるパーティションキー
値にワークロードがアクセスするとき、それらのリクエストは、割り当てられたスループットレベ
ルを十分に活用する方法で、分割されたスペース全体に展開されることに注意してください。一般的
に、テーブルのパーティションキー値の合計数に対する、アクセスされたパーティションキー値の割
合が大きくなるほど、スループットをより効率的に活用することができます。
パーティションキーの選択
一般的なパーティションキースキーマをいくつか比較し、プロビジョニングされたスループットの効
率について次の表に示します。
パーティションキーの値
均一性
ユーザー ID(アプリケーションに多くのユー
ザーがある場合)
良い
ステータスコード(可能性のあるステータス
コードが少しだけある場合)
不良
API Version 2012-08-10
567
Amazon DynamoDB 開発者ガイド
テーブル内のすべての項目に対して
均一なデータアクセスを実現する設計
パーティションキーの値
均一性
項目の作成日(直近の期間(日、時、分など)
に切り上げられます)
不良
デバイス ID(各デバイスが比較的類似した間隔
でデータにアクセスする場合)
良い
デバイス ID(追跡中のデバイスが大量にある場
不良
合でも、1 つのデバイスが他のすべてのデバイス
よりもずっと人気がある場合)
単一のテーブル内にあるパーティションキー値の数が非常に少ない場合は、より明確に区別できる
パーティションキー値全体を対象として、書き込みオペレーションを分散するように検討してくださ
い。つまり、"ホット" パーティションキー値 (何度もリクエストされるパーティションキー値) を回避
するように、プライマリキー要素を構築してください。このようなパーティションキー値が原因で、
全体のパフォーマンス速度が低下する場合があります。
たとえば、複合プライマリキーを持つテーブルがあるとします。パーティションキーは項目の作成
日を表します (直近の日付に切り上げられます)。ソートキーは項目の識別子を表します。特定の日付
(2014-07-09 など) で、すべての新しい項目が同じパーティションキー値として書き込まれます。
テーブル全体が単一のパーティションに収まり(時間の経過に伴うデータの増加を考慮します)、ア
プリケーションで必要となる読み込みスループットと書き込みスループットが単一のパーティション
における読み込みと書き込みの容量を超過しない場合は、パーティション分割をしても、アプリケー
ションが予想外の制限を受けることはありません。
ただし、テーブル全体が単一のパーティションには収まらないことが予想される場合は、テーブルの
完全にプロビジョニングされたスループットをより多く使用できるように、アプリケーションを設計
する必要があります。
複数のパーティションキー値を対象としたランダム化
アプリケーションの書き込みスループットを向上させる方法の 1 つとして、複数のパーティション
キー値を対象とした書き込みをランダム化する方法があります。固定された数値のセット(たとえ
ば、1~200)からランダムな数値を選択し、その数値をサフィックスとして日付に連結します。これ
により、2014-07-09.1、2014-07-09.2 などのパーティションキー値が生成されます。この場合、
最大のパーティションキー値は 2014-07-09.200 になります。パーティションキーをランダム化す
るため、毎日行われるテーブルへの書き込みは、すべてのパーティションキー値に均一に分散されま
す。これにより、並列処理が向上し、全体的なスループットが高まります。
特定の日付についてすべての項目を読み込むには、各サフィックスのすべての項目を取得する必要が
あります。たとえば、最初にパーティションキー値 2014-07-09.1 に対する Query リクエストを発
行し、次に 2014-07-09.2 に対する Query を発行します。この処理を 2014-07-09.200 まで繰り
返します。最終的には、アプリケーションですべての Query リクエストの結果をマージする必要があ
ります。
算出された値の使用
ランダム化の方法によって、書き込みスループットを大幅に向上させることができます。ただし、特
定の項目を読み込むことは難しくなります。これは、項目を書き込むときにどのサフィックスが使用
されたかを把握できないためです。個々の項目を簡単に読み込むことができるようにするには、別の
方法を使用します。ランダムな数値を使用して項目をパーティションに分散するのではなく、項目が
持つ固有の情報に基づいて算出できる数値を使用します。
これまでの例を引き続き使用します。ここでは、各項目に OrderId があるとします。アプリケー
ションで項目をテーブルに書き込む前に、この OrderId に基づいてパーティションキーのサフィック
スを計算します。この計算では、1~200 の範囲の数値が算出される必要があります。これらの各数値
は、指定の名前のセット(またはユーザー ID のセット)を対象として、完全に均一に分散されます。
API Version 2012-08-10
568
Amazon DynamoDB 開発者ガイド
パーティションの動作について
この計算はシンプルな計算で十分です (OrderId の各文字の UTF-8 コードポイント値を乗算して、そ
れを 200 + 1 で割った余りなど)。 パーティションキー値は、日付に計算結果がサフィックスとして連
結された値になります。この方法を使用すると、書き込みがパーティションキー値全体に均一に分散
され、パーティション全体にも均一に分散されます。これで、GetItem オペレーションを実行して、
特定の項目を簡単に読み込むことができます。これは、特定の OrderId 値を取得するときに、必要
となるパーティションキー値を計算できるためです。
特定の日付についてすべての項目を読み込むには、2014-07-09.N キー(N は 1~200 の数値)に対
する Query を発行し、アプリケーションですべての結果をマージする必要があります。ただし、すべ
てのワークロードを利用する単一の "ホット" パーティションキー値の使用は回避してください。
パーティションの動作について
DynamoDB によって自動的にテーブルパーティションが管理され、必要に応じて新しいパーティショ
ンが追加されます。また、パーティション間で均等にプロビジョンドスループット性能が分散されま
す。
テーブルに対して DynamoDB で最初に割り当てられるパーティションの数を予測することができま
す。また、その予測と、使用する規模およびアクセスパターンを比較することもできます。また、増
えたストレージまたはプロビジョニングされたスループット要件に応じて、DynamoDB で割り当て
られる追加のパーティションの数を見積もることもできます。これらの予測は、アプリケーションの
ニーズに最適なテーブル設計を決める場合に役立ちます。
Note
パーティションサイズとスループットに関する以下の詳細は、変更される場合があります。
パーティションの最初の割り当て
新しいテーブルを作成するときに、DynamoDB は指定のプロビジョニングされたスループット設定に
従ってテーブルのパーティションを割り当てます。
1 つのパーティションは、最大 3,000 個の読み込みキャパシティーユニットまたは 1,000 個の書き込
みキャパシティーユニットをサポートできます。新しいテーブルを作成するときに、パーティション
の初期値は次のように表すことができます。
( readCapacityUnits / 3,000 ) + ( writeCapacityUnits / 1,000 )
= initialPartitions (rounded up)
たとえば、1,000 個の読み込みキャパシティーユニットと 500 個の書き込みキャパシティーユニット
を使用してテーブルを作成したとします。この場合、パーティションの初期数は次のようになりま
す。
( 1,000 / 3,000 ) + ( 500 / 1,000 ) = 0.8333 --> 1
このため、単一のパーティションで、テーブルのすべてのプロビジョニングされたスループット要件
に対応できます。
ただし、1,000 個の読み込みユニットと 1,000 個の書き込みユニットがあるテーブルを作成した場
合、1 つのパーティションは指定されたスループット容量をサポートすることができません。
( 1,000 / 3,000 ) + ( 1,000 / 1,000 ) = 1.333 --> 2
この場合、テーブルでは 2 つのパーティションが必要になり、各パーティションは 500 個の読み込み
キャパシティーユニットと 500 個の書き込みキャパシティーユニットを保持します。
API Version 2012-08-10
569
Amazon DynamoDB 開発者ガイド
パーティションの動作について
パーティションのその後の割り当て
1 つのパーティションに約 10 GB 個のデータを保持でき、最大 3,000 個の読み込みキャパシティーユ
ニットまたは 1,000 個の書き込みキャパシティーユニット数をサポートできます。
DynamoDB は、必要に応じて既存のパーティションを分割することによって、テーブルに追加のパー
ティションを割り当てることができます。テーブルのパーティションの 1 つ (P) が、ストレージの制
限 (10 GB) を超えたとします。この場合、DynamoDB は次のようにパーティションを分割します。
1. 2 つの新しいパーティション (P1 および P2) を割り当てます。
2. P からのデータを P1 と P2 の間で均等に分散します。
3. テーブルから P を割り当て解除します。
次の図は、DynamoDB がパーティション分割を実行する方法を示しています。大きな四角形はパー
ティションを示し、小さい四角形はテーブルのデータ項目を表します。
パーティションの分割中に、DynamoDB は古いパーティションからのデータを 2 つの新しいパーティ
ションに均等に分散します (他のパーティションのデータは影響を受けません)。古いパーティション
のプロビジョンドスループット性能は二つの新しいパーティション間で、均等に分散されます (パー
ティションあたりのスループット容量 (p. 572) を参照)。
DynamoDB はバックグラウンドでパーティションの分割を自動的に実行することに注意してくださ
い。テーブルは、指定されたスループットレベルで、読み込みおよび書き込みアクティビティに対し
て完全に使用可能な状態のままになります。
パーティション分割は、以下に応じて発生します。
• プロビジョニングされたスループット設定の引き上げ
• ストレージ要件の引き上げ
プロビジョニングされたスループット設定の引き上げ
テーブルのプロビジョンドされたスループットを引き上げ、テーブルの現在のパーティショニングス
キームが新しい要件に対応できない場合、DynamoDB はパーティションの現在の数を 2 倍にします。
たとえば、5,000 個の読み込みキャパシティーユニットと 2,000 個の書き込みキャパシティーユニッ
トを使用して新しいテーブルを作成したとします。パーティションの最初の割り当て (p. 569) の情
報を使用して、この新しいテーブルで 4 つのパーティションを必要とすることを決定できます。
( 5,000 / 3,000 ) + ( 2,000 / 1,000 ) = 3.6667 --> 4
API Version 2012-08-10
570
Amazon DynamoDB 開発者ガイド
パーティションの動作について
4 つの各パーティションは、1 秒あたり 1,250 個の読み込み (5,000 読み込みキャパティシーユニッ
ト / 4 パーティション) および 1 秒あたり 500 個の書き込み (2,000 書き込みキャパティシーユニット /
4 パーティション) に対応できます。
ここで、テーブルの読み込みキャパシティーユニットを 5,000 から 8,000 に引き上げたとします。既
存の 4 つのパーティションは、この要件をサポートできません。応答 (「パーティションのその後の
割り当て (p. 570)」を参照) で、DynamoDB はパーティション数を 2 倍の 8 にします (4 * 2 = 8)。結
果の各パーティションは、1 秒あたり 1,000 個の読み込み (8,000 読み込みキャパティシーユニット /
8 パーティション) および 1 秒あたり 250 個の書き込み (2,000 書き込みキャパティシーユニット / 8
パーティション) に対応できます。
次の図は、テーブルの元の 4 つのパーティションと、DynamoDB によってパーティション数が 2 倍に
なった後のパーティションスキームを示します。大きな四角形はパーティションを示し、小さい四角
形はテーブルのデータ項目を表します。
ストレージ要件の引き上げ
既存のパーティションがデータでいっぱいになると、DynamoDB によってそのパーティションが分割
されます。結果は 2 つのパーティションになり、古いパーティションからのデータは新しいパーティ
ション間で均等に分割されます。
「プロビジョニングされたスループット設定の引き上げ (p. 570)」で説明するテーブルには 8 個の
パーティションがあるため、最大容量は、次に示すように約 80 GB になります。
8 partitions * 10 GB = 80 GB
これらのパーティションで容量がいっぱいになる場合、DynamoDB によってそのパーティションが分
割されます。その結果、次に示すように合計 9 個のパーティションになり、容量全体は 90 GB になり
ます。
API Version 2012-08-10
571
Amazon DynamoDB 開発者ガイド
パーティションの動作について
9 partitions * 10 GB = 90 GB
次の図は、容量がいっぱいになった元のパーティションの 1 つと、DynamoDB によってそのパーティ
ションが分割された後のパーティションスキームを示します。大きな四角形はパーティションを示
し、小さい四角形はテーブルのデータ項目を表します。
パーティションあたりのスループット容量
テーブルのパーティション数を予測すると、パーティションごとの概算のスループット容量を判断
することができます。5,000 個の読み込みキャパシティーユニットと 2,000 個の書き込みキャパシ
ティーユニットを使用してテーブルを作成するとします。DynamoDB により、新しいテーブルに 4 個
のパーティションが割り当てられます。
( 5,000 / 3,000 ) + ( 2,000 / 1,000 ) = 3.6667 --> 4
次のようにして、パーティションごとの読み込みキャパシティーと書き込みキャパシティーの量を判
断できます。
5,000 read capacity units / 4 partitions = 1,250 read capacity units per
partition
2,000 write capacity units / 4 partitions = 500 write capacity units per
partition
ここで、これら 4 つのパーティションの 1 つの容量がいっぱいになるとします。DynamoDB はその
パーティションを分割し、それによりテーブルに 5 つのパーティションが割り当てられます。次に、
API Version 2012-08-10
572
Amazon DynamoDB 開発者ガイド
急激に増大するキャパシティーは控えめに使用する
パーティションごとの読み込みキャパシティーと書き込みキャパシティーは次のように分散されま
す。
1,250 read capacity units / 2 partitions = 625 read capacity units per child
partition
500 write capacity units / 2 partitions = 250 write capacity units per child
partition
上の結果 :
• 5 つのパーティションのうち 3 つは、それぞれ読み込み容量 1,250 ユニットと書き込み容量 500 ユ
ニットとなります。
• 残りの 2 つのパーティションは、それぞれ読み込み容量 625 ユニットと書き込み容量 250 ユニット
となります。
テーブルのパーティションの数が増えると、各パーティションで利用できる読み込みキャパシティー
と書き込みキャパシティーユニットの数が減ります。ただし、テーブルのプロビジョニングされたス
ループットの合計は同じままです。
急激に増大するキャパシティーは控えめに使用する
DynamoDB によって、パーティションごとのスループットを柔軟にプロビジョニングすることがで
きます。 パーティションのスループットを十分に活用していない場合、後でスループットの利用率
が急激に増加した場合に備えて、DynamoDB では未使用のキャパシティーの一部を保持します。現在
DynamoDB は、未使用の読み込みおよび書き込みキャパシティーについて、最大 5 分 (300 秒) を保
持します。読み込みや書き込みのアクティビティの急激な増加が頻繁に発生しないときは、これらの
追加のキャパシティーユニットはすぐに消費されます (テーブルに対して定義した 1 秒あたりのプロ
ビジョンドスループット性能よりも速く消費されます)。ただし、急激に増大するキャパシティーが常
に使用可能であることを前提としてアプリケーションを設計しないでください。DynamoDB は、急激
に増大するキャパシティーをバックグラウンドでのメンテナンスや他のタスクで使用します。このと
き、事前の通知はありません。
Note
今後、急激に増大するキャパシティーに関する上記の仕様は、変更される可能性がありま
す。
データアップロード時に書き込みアクティビティを
分散する
他のデータソースから DynamoDB にデータをロードする場合があります。一般に、DynamoDB は
テーブルデータを複数のサーバーに分配します。データをテーブルにアップロードする場合は、配分
されたサーバーすべてに同時にデータをアップロードすると、パフォーマンスが向上します。たとえ
ば、ユーザーメッセージを DynamoDB テーブルにアップロードするとします。UserID がパーティ
ションキーで、MessageID がソートキーである複合プライマリキーを使用するテーブルを設計すると
します。ソースからのデータをアップロードするときは、特定のユーザーのすべてのメッセージ項目
を読み込み、DynamoDB にアップロードしてしまいがちです。以下のテーブルのシーケンスを参照し
てください。
UserId
MessageID
U1
1
U1
2
API Version 2012-08-10
573
Amazon DynamoDB 開発者ガイド
時系列データへのアクセスパターンを理解する
UserId
MessageID
U1
...
U1
... 最大 100
U2
1
U2
2
U2
...
U2
... 最大 200
この場合の問題は、DynamoDB への書き込みリクエストをパーティションキー値全体に分散して
いないことです。一度に 1 つのパーティションキー値を使用し、そのすべての項目をアップロー
ドしてから、次のパーティションキー値に移動し、同じ処理を実行します。バックグラウンドで
は、DynamoDB によって複数のサーバーのテーブルにデータが分配されています。テーブル用にプロ
ビジョニングされたすべてのスループット容量を十分に活用するには、パーティションキー値全体に
ワークロードを分散する必要があります。この場合、不均一のアップロード作業量が、同じパーティ
ションキー値を持つ項目に向けられています。このため、DynamoDB によってテーブル用にプロビ
ジョニングされたリソースすべてを十分に活用できない可能性があります。アップロード作業は、最
初に各パーティションキーの値から 1 つの項目をアップロードすることで分散できます。次に、以下
のテーブルのアップロードシーケンスの例に示すすべてのデータをアップロードするまで、すべての
項目について、次のセットのソートキー値に対応するパターンを繰り返します。
UserId
MessageID
U1
1
U2
1
U3
1
...
....
U1
2
U2
2
U3
2
...
...
このシーケンスのすべてのアップロードでは、異なるパーティションキー値が使用され、より多くの
DynamoDB サーバーが同時にビジー状態になり、スループットパフォーマンスが向上します。
時系列データへのアクセスパターンを理解する
作成する各テーブルに対して、スループット要件を指定します。DynamoDB はリソースの割り当てを
行い、持続性のある低レイテンシーを実現することで、スループット要件に対応します。 アプリケー
ションおよびテーブルの設計時には、テーブルのリソースを最も効率よく活用するためにアプリケー
ションのアクセスパターンを考慮する必要があります。
拠点での顧客の行動(URL のクリックなど)を追跡するテーブルを設計するとします。Customer ID
をパーティションキー、日付/時刻をソートキーとして構成される複合プライマリキーを持つテーブ
ルを設計するとします。このアプリケーションでは、顧客データが時間とともに無制限に大きくなり
ます。ただし、アプリケーションは、テーブル内のすべての項目にわたって不均一のアクセスパター
API Version 2012-08-10
574
Amazon DynamoDB 開発者ガイド
人気の高い項目をキャッシュに格納する
ンを示す可能性があります。この場合、最新の顧客データのほうが適切であり、アプリケーションは
最新の項目に頻繁にアクセスできます。時間の経過とともに、これらの項目へのアクセスは減少し、
結果的に古い項目はほとんどアクセスされなくなります。これが既知のアクセスパターンである場合
は、テーブルスキーマの設計時に考慮することができます。すべての項目を単一のテーブルに格納す
る代わりに、複数のテーブルに格納できます。たとえば、月単位のデータまたは週単位のデータを格
納するテーブルを作成できます。最新の月または週のデータを格納するテーブルの場合、データアク
セス率は高く、より高いスループットが要求されます。これに対し、古いデータを格納するテーブル
については、スループットの調整が可能であり、リソースを節約できます。
"ホット" な項目を高いスループットが設定された 1 つのテーブルに格納し、"コールド" な項目を低
いスループットが設定された他のテーブルに格納することによって、リソースを節約できます。古い
項目を削除するには、単純にテーブルを削除します。これらのテーブルは、Amazon Simple Storage
Service(Amazon S3)など、他のストレージオプションに任意にバックアップできます。テーブル
全体を削除するほうが、項目を 1 つずつ削除するよりもはるかに効率的です。これにより、削除オペ
レーションを置換オペレーションと同じくらいの回数実行するときに、書き込みスループットは基本
的に 2 倍になります。
人気の高い項目をキャッシュに格納する
テーブル内の一部の項目が他の項目よりも人気が高い場合があります。たとえば、「テーブルの作成
とサンプルデータのロード (p. 166)」で説明している ProductCatalog テーブルの場合を考えます。こ
のテーブルに数百万点のさまざまな商品が格納されているとします。一部の商品が顧客の間で非常に
人気が高い場合があり、したがってそれらの項目は他の項目よりも一貫してアクセス数が多くなりま
す。その結果、ProductCatalog に対する読み込みアクティビティの分布は、これらの人気の高い項目
に大きく偏ったものになります。
1 つの解決策は、アプリケーション層でこれらの読み込みをキャッシュに格納することです。キャッ
シュはスループットの高い多くのアプリケーションに使用されている手法であり、アクセス数の多い
項目に対する読み込みアクティビティをデータベースではなくキャッシュにオフロードします。アプ
リケーションはメモリ内の最も人気の高い項目をキャッシュに格納できます。または、同様の処理に
ElastiCache のような製品を使用できます。
引き続き ProductCatalog の例で、顧客がそのテーブルに項目をリクエストすると、アプリケーショ
ンはまずキャッシュに問い合わせて、キャッシュにその項目のコピーが存在するかどうかを確認しま
す。存在する場合は、キャッシュヒットです。それ以外の場合は、キャッシュミスです。キャッシュ
ミスがあると、アプリケーションは DynamoDB から項目を読み込み、その項目のコピーをキャッ
シュに格納する必要があります。時間の経過と共に、キャッシュが人気の高い項目で満たされるた
め、キャッシュミスは減ります。つまり、アプリケーションはこれらの項目に探して DynamoDB に
アクセスする必要はなくなります。
キャッシュによる解決策により、読み込みアクティビティの分布で人気の高い項目への偏りを小さ
くできます。さらに、テーブルに対する読み込みアクティビティの量が減るため、キャッシュは
DynamoDB 使用の全体的なコストを削減するために役立ちます。
プロビジョニングされたスループットを調整すると
きにワークロードの均一性を考慮する
テーブルのデータ量が増加したり、追加の読み込みおよび書き込みキャパシティーをプロビジョニン
グしたりするときに、DynamoDB によって、データが複数のパーティション全体に自動的に分散さ
れます。アプリケーションでそれほど多くのスループットを必要としない場合、UpdateTable オペ
レーションを使用してスループットを減らし、プロビジョニングしたスループットに対してのみお支
払いいただくことができます。
均一なワークロードで使用するように設計されたアプリケーションでは、DynamoDB のパーティショ
ン割り当てアクティビティによる目立った効果を確認することはできません。通常、ワークロードの
一時的な不均一性は、「急激に増大するキャパシティーは控えめに使用する (p. 573)」で説明され
ているように、急激に増大するキャパシティーに対応した機能によって緩和されます。ただし、アプ
リケーションで不均一なワークロードに定期的に対応する必要がある場合、DynamoDB でのパーティ
API Version 2012-08-10
575
Amazon DynamoDB 開発者ガイド
大規模環境でのアプリケーションのテスト
ション分割の動作(「パーティションの動作について (p. 569)」を参照)を考慮して、テーブルを設
計してください。また、そのテーブルに対してプロビジョニングされるスループットを増減させるタ
イミングにも留意してください。
テーブルのプロビジョニングされたスループットの量を減らしても、DynamoDB はパーティション
の数を減らしません。アプリケーションで実際に必要となるよりも多くのプロビジョニングされたス
ループットを使用して、テーブルを作成し、その後で、プロビジョニングされたスループットの量を
減らしたとします。このシナリオでは、パーティションごとのプロビジョニングされたスループット
の量は、初めから少ない量のスループットを使用してテーブルを作成した場合のパーティションごと
のスループットの量と比べると、少なくなります。
たとえば、2,000 万個の項目を DynamoDB テーブルにバルクロードする必要がある状況を考えてみ
ましょう。各項目のサイズを 1 KB と仮定した場合、このバルクロードにおけるデータのサイズは 20
GB になります。このバルクロードタスクでは、合計 2,000 万個の書き込みキャパシティーユニット
が必要になります。このデータロードを 30 分以内に実行するには、テーブルのプロビジョニングさ
れた書き込みスループットを 11,000 個の書き込みキャパシティーユニットに設定する必要がありま
す。
パーティションの最大書き込みスループットは、1,000 個の書き込みキャパシティーユニットになり
ます(「パーティションの動作について (p. 569)」を参照)。このため、DynamoDB では 11 個の
パーティションが作成され、各パーティションには 1,000 個のプロビジョニングされた書き込みキャ
パシティーユニットが割り当てられます。
データをバルクロードした後、安定した状態の書き込みスループットの要件では、書き込みキャパシ
ティーユニットの量はかなり少なくなります。たとえば、アプリケーションで 1 秒あたり 200 回の書
き込みが必要になるとします。テーブルのプロビジョニングされたスループットをこのレベルに減ら
す場合、11 個のパーティションそれぞれについて、1 秒あたり約 20 個のキャパティーユニットがプ
ロビジョニングされます。パーティションごとのプロビジョニングされたスループットがこのレベル
に減少しても、DynamoDB の急激に増大するキャパシティーに対応した動作と組み合わされて、アプ
リケーションに十分に対応したスループットとなります。
ただし、アプリケーションで、パーティションごとに 1 秒あたり 20 回の書き込みを超える持続的な
書き込みスループットが必要になる場合、次のいずれかを行う必要があります。(a) パーティション
キー値ごとの 1 秒あたりの書き込み数がより少なくても対応できるスキーマを設計します。(b) より
遅いペースで実行され、初期スループット要件が少なくなるようにデータのバルクロードを設計しま
す。たとえば、30 分ちょうどではなく3 時間を超える一括インポートの実行が許可されていたとしま
す。このシナリオでは、11,000 個ではなく、1 秒あたり 1,900 個の書き込みキャパシティーユニット
のみをプロビジョニングする必要があります。その結果、DynamoDB ではテーブルに対して 2 つの
パーティションのみが作成されます。
大規模環境でのアプリケーションのテスト
多くのテーブルでは、最初に格納されているデータ量は少量です。その後、アプリケーションでの書
き込みアクティビティの実行に伴って、データ量は多くなっていきます。このデータ量の増加は段階
的に発生する場合があり、テーブルに対して定義したプロビジョニングされたスループット設定を超
えることはありません。テーブルが大きくなると、DynamoDB では、より多くのパーティションに
データを分散することで、テーブルを自動的に拡張します。こうした処理が実行されると、作成され
る各パーティションに割り当てられるプロビジョニングされたスループットは、元のパーティション
に割り当てられるスループットよりも少なくなります。
アプリケーションでは、すべてのパーティションキー値に分散されているテーブルのデータにアクセ
スするが、不均一な方法でアクセスするとします (少数のパーティションキー値にのみ頻繁にアクセ
スする)。テーブルに十分な量のデータがなくても、アプリケーションは適切に動作する場合がありま
す。ただし、テーブルが大きくなると、パーティションが増加し、パーティションごとのスループッ
トは減少します。過去に動作したものと同じ不均一なアクセスパターンがアプリケーションで使用さ
れると、アプリケーションが制限されることに気付くことがあります。
テーブルが大きくなった場合の "ホット" なキーに関連する問題を回避するには、大規模環境でアプリ
ケーション設計をテストしてください。大規模環境で実行する場合のスループットに対するストレー
API Version 2012-08-10
576
Amazon DynamoDB 開発者ガイド
項目の操作のガイドライン
ジの比率、および DynamoDB でパーティションをテーブルに割り当てる方法を検討します。(詳し
くは、パーティションの動作について (p. 569) を参照してください)。
大量のテストデータを生成できない場合は、非常に高いスループット設定にプロビジョニングされた
テーブルを作成できます。これにより、多くのパーティションを持つテーブルが作成されます。そ
の後で、UpdateTable を使用して設定値を減らすことができます。ただし、大規模環境でアプリケー
ションを実行する場合に決定した、スループットに対するストレージの比率は維持してください。こ
れで、テーブルの拡張後に必要となるパーティションごとのスループットの割合を備えたテーブルが
作成されます。実際のワークロードを使用し、このテーブルに対してアプリケーションをテストして
ください。
時系列データが格納されるテーブルは、際限なく大きくなる可能性があります。このようなテーブル
が原因となって、アプリケーションのパフォーマンスが時間の経過に伴って低下する場合がありま
す。時系列データを使用する場合、通常、アプリケーションはテーブルに格納されている以前の項
目よりも最新の項目を頻繁に読み書きします。リアルタイムテーブルから以前の時系列データを削除
し、そのデータを他の場所にアーカイブできる場合は、パーティションごとのスループットの割合を
高い値に維持できます。
時系列データを使用したベストプラクティスについては、「時系列データへのアクセスパターンを理
解する (p. 574)」を参照してください。
項目の操作のガイドライン
トピック
• 大規模な設定属性の代わりに 1 対多のテーブルを使用する (p. 577)
• 複数テーブルの使用による多様なアクセスパターンのサポート (p. 578)
• 大量の属性値を圧縮する (p. 579)
• Amazon S3 に大量の属性値を格納する (p. 580)
• 大量の属性を複数の項目に分割する (p. 580)
DynamoDB 内の項目を操作するときは、最高のパフォーマンスを得る方法、プロビジョニングされた
スループットのコストを削減する方法、読み込みと書き込みのキャパシティーユニット内にとどまる
ことによる調整を回避する方法を検討する必要があります。処理中の項目が最大の項目サイズを超え
るようであれば(「DynamoDB での制限 (p. 558)」参照)、この状況にどのように対処するかを検討
する必要があります。このセクションでは、このような問題に対処する最善の方法を示します。
大規模な設定属性の代わりに 1 対多のテーブルを使
用する
テーブルに大規模な設定タイプ属性(数字セットや文字列セットなど)を格納する項目がある場合
は、属性を削除し、テーブルを 2 つに分割することを検討してください。これらのテーブル間に 1 対
多の関係を形成するには、プライマリキーを使用します。
「テーブルの作成とサンプルデータのロード (p. 166)」セクションに記載の Forum、Thread、Reply
の各テーブルは、この 1 対多の関係を示す良い例です。たとえば、Thread テーブルには、各フォーラ
ムのスレッドに対応する項目が 1 つあり、Reply テーブルには、各スレッドに対応する 1 つまたは複
数の応答が格納されています。
別々のテーブルに項目として応答を格納する代わりに、スレッドと応答の両方を同じテーブルに格納
できます。各スレッドについて、文字列セットタイプの 1 つの属性にすべての応答を格納できます。
ただし、スレッドと応答データを別々のテーブルに保持することは、いくつかの点で有益です。
• 応答をテーブル内の項目として格納する場合、任意の数の応答を格納できます。DynamoDB のテー
ブルには任意の数の項目を格納できるためです。
API Version 2012-08-10
577
Amazon DynamoDB 開発者ガイド
複数テーブルの使用による多様
なアクセスパターンのサポート
応答を Thread テーブル内の属性値として格納する場合は、最大項目サイズの制約を受けるため、
格納可能な応答数が制限されます(「DynamoDB での制限 (p. 558)」参照)。
• Thread 項目を取り出す場合、取り出す対象がスレッドデータとそのスレッドに対応する一部の応答
に限られるため、プロビジョニングされたスループットに対する支払額が少なくなります。
• クエリを使用すると、一部の項目のみをテーブルから取り出せます。応答を別々の Reply テーブル
に格納することで、一部の応答のみを取り出せます。たとえば、Reply テーブルをクエリして、特
定の日付範囲内の応答を取り出せます。
応答を設定タイプの属性値として格納する場合、すべての応答を常に取り出す必要があります。こ
の結果、必要でない可能性のあるデータに対して、プロビジョニングされたスループットの消費量
が多くなります。
• 新しい応答をスレッドに追加するときは、項目のみを Reply テーブルに追加します。この結果、そ
の単一の Reply 項目に対してのみ、プロビジョニングされたスループットの費用が発生します。
応答を Thread テーブルに格納する場合は、単一のユーザー応答をスレッドに追加するたびに、お
客様が全 Thread 項目(すべての応答を含む)の書き込みにかかる総費用を負担することになりま
す。
複数テーブルの使用による多様なアクセスパターン
のサポート
DynamoDB テーブル内のサイズの大きい項目に頻繁にアクセスしており、項目の大きめの属性を常に
すべて使用するのでなければ、小さめで、より頻繁にアクセスする属性を別のテーブルの別の項目と
して格納します。これにより、効率を改善し、ワークロードをさらに均一化することができます。
たとえば、ProductCatalog テーブル(「テーブルの作成とサンプルデータのロード (p. 166)」セク
ション参照)を検討してください。このテーブルの項目には、製品の名前や説明など、製品の基本情
報が含まれています。この情報はめったに変更されませんが、アプリケーションによって製品が表示
されるたびに使用されます。
変化の激しい製品属性(価格や可用性など)の追跡情報をアプリケーションで保持する必要もある場
合は、この情報を ProductAvailability という別のテーブルに格納できます。この手法によって、更新
時のスループットにかかる費用が最小限に抑えられます。説明のため、ProductCatalog 項目のサイズ
を 3 KB、この項目に対応する価格および可用性の属性を 300 バイトと仮定します。この場合、この
ような変化の激しい属性を更新すると、費用は 3 になります。これは、他の製品属性を更新する場合
と同額の費用です。ここで、その代わりに、価格と可用性の情報が ProductAvailability テーブルに格
納されているとします。この場合、情報を更新すると、書き込みキャパシティーユニット 1 つにのみ
かかる費用と同額になります。
Note
キャパシティーユニットの説明については、「プロビジョニングされたスループッ
ト (p. 16)」を参照してください。
表示頻度の低い製品データをアプリケーションで格納する必要もある場合は、この情報を
ExtendedProductCatalog という別のテーブルに格納できます。このようなデータには、製品寸法、音
楽アルバムの曲名リスト、基本的な製品データほど頻繁にはアクセスされないその他の属性が含まれ
る可能性があります。このようにして、アプリケーションは、基本的な製品情報を表示するときにの
みスループットを消費します。また、追加のスループットについては、ユーザーが広範囲に及ぶ製品
詳細をリクエストする場合にのみ消費します。
前述のテーブルインスタンスの例を以下に示します。すべてのテーブルには、プライマリキーとして
Id 属性があります。
ProductCatalog
API Version 2012-08-10
578
Amazon DynamoDB 開発者ガイド
大量の属性値を圧縮する
ID
役職
説明
21
"有名な書籍"
"去年のベストセラーリストか
ら..."
302
"赤い自転車"
"赤いクラシック自転車..."
58
"音楽アルバム"
"今週の人気ニューアルバム..."
ID
価格
QuantityOnHand
21
"5.00 USD"
3750
302
"125.00 USD"
8
58
"5.00 USD"
"無限(デジタル項目)"
ID
AverageCustomerRating
TrackListing
21
5
302
3.5
58
4
{"Track1#3:59", "Track2#2:34",
"Track3#5:21", ...}
ProductAvailability
ExtendedProductCatalog
1 つの項目の属性を別のテーブル内の複数の項目に分割する場合には、以下のように、メリットと問
題点がいくつかあります。
• これらの属性の読み込みまたは書き込みにかかるスループット費用が削減されます。項目の単一
の属性を更新する場合にかかる費用は、項目の実際のサイズに基づいています。項目が少量の場合
は、各項目にアクセスするとスループットが低下します。
• 頻繁にアクセスする項目を少量に維持すれば、I/O ワークロードはより均一に分散されます。大量の
項目を取り出すと、テーブルの同一のパーティションから一度に大量の読み込みキャパシティーが
消費されます。この結果、ワークロードは不均一になり、調整が発生する可能性があります。詳細
については、「読み込みアクティビティの急激な増大の回避 (p. 581)」を参照してください。
• 単一項目の読み込みオペレーション(GetItem など)の場合、スループットの計算値は、次の 4
KB 境界に切り上げられます。項目のサイズが 4 KB よりも小さく、プライマリキーのみで項目を
取り出す場合、項目の属性を別項目として格納すると、スループットの低下を避けることができま
す。それでも、Query や Scan などのオペレーションのスループット費用は、別々に計算されま
す。返されたすべての項目のサイズが合計され、その総計は次の 4 KB 境界に切り上げられます。
これらのオペレーションの場合は、大量の属性を別項目に移動することによってスループット費用
を削減できます。詳細については、「キャパシティーユニットの計算 (p. 181)」を参照してくださ
い。
大量の属性値を圧縮する
大量の属性値は、DynamoDB に格納する前に圧縮できます。圧縮することで、このようなデータを格
納および取り出す費用を削減できます。圧縮アルゴリズム(GZIP、LZO など)により、バイナリ出力
が生成されます。この結果、この出力をバイナリ属性タイプで格納できます。
API Version 2012-08-10
579
Amazon DynamoDB 開発者ガイド
Amazon S3 に大量の属性値を格納する
たとえば、「テーブルの作成とサンプルデータのロード (p. 166)」セクションの Reply テーブルに、
フォーラムユーザーの書いたメッセージが格納されます。これらのユーザー応答は、非常に長い文字
列で構成される場合があるため、圧縮の立派な候補になります。
DynamoDB での長いメッセージの圧縮方法を示すコード例については、次の場所を参照してくださ
い。
• 例: AWS SDK for Java ドキュメント API を使用したバイナリタイプ属性の処理 (p. 247)
• 例: AWS SDK for .NET の低レベル API を使用した、バイナリタイプ属性の処理 (p. 271)
Amazon S3 に大量の属性値を格納する
DynamoDB は、現在、テーブルに格納する項目のサイズを制限しています。詳細については、
「DynamoDB での制限 (p. 558)」を参照してください。ただし、アプリケーションは、DynamoDB の
サイズ制限で許可されているよりも多くのデータを 1 つの項目に格納しなければならない場合もあり
ます。この問題を回避するために、大量の属性を Amazon Simple Storage Service(Amazon S3)の
オブジェクトとして格納し、項目にオブジェクト ID を格納できます。Amazon S3 のオブジェクトメ
タデータのサポートを利用して、対応する項目のプライマリキー値を Amazon S3 オブジェクトのメ
タデータとして格納できます。メタデータの使用は、Amazon S3 オブジェクトを将来的にメンテナン
スする際に役立ちます。
たとえば、ProductCatalog テーブル(「テーブルの作成とサンプルデータのロード (p. 166)」セク
ション参照)を検討してください。ProductCatalog テーブル内の項目は、項目の価格、説明、書籍の
著者、その他の製品の寸法に関する情報を格納します。各製品の画像を格納する場合は、対象の画像
を拡大できます。画像は DynamoDB ではなく Amazon S3 に格納するのが賢明です。
この手法には重要な考慮事項があります。
• DynamoDB は Amazon S3 と DynamoDB 間のトランザクションをサポートしていません。このた
め、失敗が発生する状況や、親のない Amazon S3 オブジェクトの削除に、アプリケーションで対
処する必要があります。
• Amazon S3 では、オブジェクト ID の長さを制限しています。このため、データをまとめる際
には、この制限および Amazon S3 の他の制約を考慮する必要があります。詳細については、
「Amazon Simple Storage Service 開発者ガイド」を参照してください。
大量の属性を複数の項目に分割する
DynamoDB での許容量を超えるデータを単一の項目に格納する必要がある場合は、そのデータをより
大きな「仮想項目」のチャンクとして、複数の項目に格納できます。最良の結果を得るには、シンプ
ルなプライマリキー (パーティションキー) がある別のテーブルにチャンクを保存し、バッチオペレー
ション (BatchGetItem および BatchWriteItem) を使用してチャンクの読み取りと書き込みを行い
ます。この手法は、ワークロードをテーブルパーティションの全体に均一に分散するときに役立ちま
す。
たとえば、「テーブルの作成とサンプルデータのロード (p. 166)」セクションで説明した
Forum、Thread、Reply の各テーブルを検討します。Reply テーブル内の項目には、フォーラムユー
ザーの書いたフォーラムメッセージが格納されています。DynamoDB では 400 KB の項目サイズ制限
があるため、各応答の長さも制限されます。大量の応答の場合は、1 つの項目を Reply テーブルに保
存するのではなく、応答メッセージを複数のチャンクに分割します。続いて各チャンクを、シンプル
なプライマリキー (パーティションキー) がある新しい ReplyChunks テーブルに、各チャンク専用の
独立した項目として書き込みます。
各チャンクのプライマリキーは、「親」応答項目、バージョン番号、およびシーケンス番号のプライ
マリキーを連結したものになります。シーケンス番号によってチャンクの順序が決定します。バー
ジョン番号によって、大量の応答が後で更新される場合に、確実にアトミックに更新されます。さら
に、更新前に作成されたチャンクは、更新後に作成されたチャンクと混合されることはありません。
API Version 2012-08-10
580
Amazon DynamoDB 開発者ガイド
クエリおよびスキャンのガイドライン
また、「親」応答項目をチャンクの数で更新する必要もあります。このため、応答のすべてのチャン
クを取り出す必要がある場合に、検索するチャンクの数がわかります。
以下に、これらの項目が Reply テーブルおよび ReplyChunks テーブルにどのように現れるかを示しま
す。
Reply
ID
ReplyDateTime
メッセージ
ChunkCount
ChunkVersion
"DynamoDB#Thread1"
"2012-03-15T20:42:54.023Z"
3
1
"DynamoDB#Thread2"
"2012-03-21T20:41:23.192Z"
"短いメッセージ"
ReplyChunks
ID
メッセージ
"DynamoDB#Thread1#2012-03-15T20:42:54.023Z#1#1"
"長いメッセージテキストの最初の部分..."
"DynamoDB#Thread1#2012-03-15T20:42:54.023Z#1#3"
"長いメッセージテキストの 3 番目の部分..."
"DynamoDB#Thread1#2012-03-15T20:42:54.023Z#1#2"
"長いメッセージテキストの 2 番目の部分..."
この手法には重要な考慮事項があります。
• DynamoDB は項目間のトランザクションをサポートしていないため、複数項目の書き込みが失敗す
る状況や、複数項目の読み込み時に発生する項目間の不一致に、アプリケーションで対処する必要
があります。
• アプリケーションが一度に大量のデータを取り出すと、不均一のワークロードが生成され、その結
果、予想外の調整が発生する可能性があります。このことは、特にパーティションキーの値を共有
する項目を取り出す場合に当てはまります。
シンプルなプライマリキー (パーティションキー) がある別々のテーブルを使用して大量のデータ項目
をチャンクに分割することで、この問題が回避されます。このため、大量の各チャンクがテーブル全
体に分散されます。
有力なソリューション (最善ではありませんが) は、複合キーのあるテーブルや、「親」項目のプライ
マリキーとなっているパーティションキーのあるテーブルに各チャンクを保存することです。この設
計上の選択により、同じ「親」項目のチャンクすべてを取り出すアプリケーションによって不均一な
ワークロードが生成され、パーティション全体での I/O の量が不均一になります。
クエリおよびスキャンのガイドライン
このセクションでは、クエリおよびスキャンオペレーションのベストプラクティスを示します。
読み込みアクティビティの急激な増大の回避
テーブルを作成する場合には、読み込みおよび書き込みキャパシティーユニット要件を設定します。
読み込みの場合、キャパシティーユニットは、強力な整合性のある 1 秒あたり 4 KB のデータ読み込
みリクエスト数として表されます。結果整合性のある読み込みの場合、読み込みキャパシティーユ
ニットは、1 秒あたり 2 回の 4 KB の読み込みリクエストになります。Scan オペレーションでは結果
整合性のある読み込みがデフォルトで実行され、最大 1 MB(1 ページ)のデータが返されます。した
がって、1 回の Scan リクエストでは、(1 MB のページサイズ/ 4 KB の項目サイズ)/ 2(結果整合性
API Version 2012-08-10
581
Amazon DynamoDB 開発者ガイド
読み込みアクティビティの急激な増大の回避
のある読み込み)= 128 の読み込みオペレーションが実行されます。もし、代わりに強い整合性のあ
る読み込みをリクエストすると、Scan オペレーションはプロビジョニングされたスループットを 2
倍消費します(256 の読み込みオペレーション)。
これはテーブルに設定済みの読み込みキャパシティーに比べて、使用量が急激に増大することを意味
します。このようにスキャンが使用するキャパシティーユニットが増大すると、同じテーブルに対す
るその他の重要なリクエストがキャパシティーユニットを使用する妨げになります。その結果、それ
らのリクエストについて ProvisionedThroughputExceeded 例外が発生する可能性があります。
問題なのは、Scan が使用するキャパシティーユニットの急激な増大だけではありません。スキャンで
はパーティション内で隣接する読み込み項目がリクエストされるため、スキャンによって、同じパー
ティションのキャパシティーユニットがすべて消費される可能性があります。つまり同じパーティ
ションがリクエストの対象になるため、キャパシティーユニットがすべて消費され、そのパーティ
ションに対する他のリクエストが制限されることになります。データ読み込みのリクエストを複数の
パーティションに分散させれば、オペレーションによって特定のパーティションが制限されることは
ありません。
次の図は、Query および Scan オペレーションによるキャパシティーユニットの使用量の急激な増大
の影響と、同じテーブルに対する他のリクエストに及ぼす影響を示しています。
大がかりな Scan オペレーションの代わりに次の手法を使用すれば、テーブルのプロビジョニングさ
れたスループットに対するスキャンの影響を最小限に抑えることができます。
API Version 2012-08-10
582
Amazon DynamoDB 開発者ガイド
並列スキャンの利用
• ページサイズを小さくする
スキャンオペレーションではページ全体(デフォルトでは 1 MB)を読み込むため、設定するペー
ジサイズを小さくすることで、スキャンの影響を軽減させることができます。Scan オペレーショ
ンには、リクエストのページサイズの設定に使用できる Limit パラメータがあります。Scan または
Query リクエストのページサイズが小さい場合は、読み込みオペレーションの数が少なくなり、各
リクエストの間に間隔ができます。たとえば、各項目が 4 KB で、ページサイズを 40 項目に設定し
た場合に Query リクエストで使用されるのは、40 回の強力な整合性のある読み込みオペレーショ
ン、または 20 回の結果整合性のある読み込みオペレーションです。Scan または Query オペレー
ションのサイズが小さくなって回数が増えれば、他の重要なリクエストが制限されることなく実行
されるようになります。
• スキャンオペレーションを分離する
DynamoDB は容易に拡張できるように設計されています。そのため、アプリケーションでは明確な
目的でテーブルを作成できます。コンテンツを複数のテーブルに複製することも可能です。「ミッ
ションクリティカル」なトラフィックを扱わないテーブルに対するスキャンを実行するとします。
アプリケーションによっては、(重要なトラフィック用と記録用の)2 つのテーブル間で 1 時間ご
とにトラフィックを分担することで、この負荷が処理されます。また別のアプリケーションでは、
すべての書き込みを 2 つのテーブル(「ミッションクリティカル」なテーブルと「シャドウ」テー
ブル)に対して行うことで処理されます。
アプリケーションのリクエストに対しプロビジョニングされたスループットを超えたことを示す応答
コードが返された場合にはそのリクエストを再試行するか、UpdateTable オペレーションを使用し
てテーブルにプロビジョニングされたスループットを増やすようにアプリケーションを設定します。
ワークロードが一時的に急増して、プロビジョニングされたレベルをスループットが超えることがあ
る場合には、エクスポネンシャルパックオフによってリクエストを再試行します。エクスポネンシャ
ルパックオフの実装の詳細については、「エラーの再試行とエクスポネンシャルバックオフ (p. 76)」
を参照してください。
並列スキャンの利用
多くのアプリケーションでは、シーケンシャルスキャンよりも並列 Scan オペレーションのほうが有
効です。たとえば、サイズの大きい履歴データテーブルを処理するアプリケーションでは、シーケン
シャルスキャンよりも並列スキャンのほうが大幅に速く実行できます。バックグラウンドの "スイー
パー" プロセスで複数のワーカースレッドを使用することで、プロダクショントラフィックに影響す
ることなく、低いプライオリティでテーブルをスキャンできます。これらの例では、他のアプリケー
ションが使用するプロビジョニングされたスループットリソースが枯渇しないように、並列 Scan が
使用されています。
並列スキャンは有益ですが、プロビジョニングされたスループットが多量に消費される可能性があり
ます。並列スキャンでは、複数のワーカーがアプリケーションを使用して Scan オペレーションを同
時に実行するため、テーブルにプロビジョニングされた読み込みキャパシティーが急速に消費されま
す。その場合は、テーブルにアクセスする必要がある他のアプリケーションが制限される可能性があ
ります。
並列スキャンが適しているのは、次の条件に当てはまる場合です。
• テーブルのサイズが 20 GB 以上である。
• テーブルにプロビジョニングされている読み込みスループットが完全に使用されていない。
• シーケンシャル Scan オペレーションでは遅すぎる。
TotalSegments の選択
TotalSegments の最適な設定は、使用するデータ、テーブルにプロビジョニングされるスループッ
ト設定、パフォーマンス要件によって異なります。最適な設定は実験を通じて明らかになる場合もあ
ります。2 GB のデータにつき 1 セグメントなど、単純な比率から始めることをお勧めします。たと
えば 30 GB のテーブルでは、TotalSegments を 15(30 GB / 2 GB)に設定できます。アプリケー
API Version 2012-08-10
583
Amazon DynamoDB 開発者ガイド
ローカルセカンダリインデックス のガイドライン
ションでは 15 のワーカーを使用して、各ワーカーが異なるセグメントをスキャンするようにしま
す。
TotalSegments の値は、クライアントのリソースに基づいて選択することもできま
す。TotalSegments を 1~1000000 の範囲の任意の数値に設定すると、DynamoDB ではその数のセ
グメントをスキャンできます。たとえば、クライアントで同時に実行できるスレッド数が制限されて
いる場合には、アプリケーションで Scan のパフォーマンスが最高になるまで、TotalSegments を
徐々に増やすことができます。
プロビジョニングされたスループットの使用率を最適にするには、並列スキャンをモニタリングする
とともに、他のアプリケーションが使用するリソースが枯渇しないようにする必要があります。プ
ロビジョニングされたスループットをすべて消費しないうちに Scan リクエストが制限される場合に
は、TotalSegments の値を増やします。Scan リクエストによって、プロビジョニングされたスルー
プットが必要以上に消費される場合には、TotalSegments の値を減らします。
ローカルセカンダリインデックス のガイドライン
トピック
• インデックスの使用は控えめにする (p. 584)
• 射影を慎重に選択する (p. 584)
• フェッチを回避するための頻繁なクエリの最適化 (p. 585)
• スパースなインデックスの利用 (p. 585)
• 項目コレクションの拡張の監視 (p. 586)
このセクションでは、local secondary index についていくつかのベストプラクティスを示します。
インデックスの使用は控えめにする
頻繁にクエリを行わない属性では、local secondary index を作成しないようにします。頻繁に更新さ
れず、多数の異なる基準を使用してクエリが行われるテーブルは、複数のインデックスを作成して維
持するのに適しています。ただし使用されていないインデックスは、ストレージおよび I/O のコスト
増大の一因になり、アプリケーションのパフォーマンスには効果がありません。
データキャプチャアプリケーションで使用するテーブルのように、多量の書き込みアクティビティが
発生するテーブルには、インデックスを設定しないようにしてください。インデックスを維持するた
めに必要な I/O オペレーションのコストが多大になる可能性があります。そのようなテーブルでデー
タにインデックスを設定する必要がある場合は、データを別のテーブルにコピーして必要なインデッ
クスを設定し、そこでクエリを行います。
射影を慎重に選択する
local secondary index はストレージとプロビジョニング済みのスループットを消費するため、イン
デックスのサイズは可能な限り小さくすべきです。またインデックスが小さいほど、テーブル全体に
対してクエリを行うのに比べてパフォーマンスが向上します。使用するクエリが属性の一部しか返さ
ないことが多く、それらの属性のサイズを合計しても項目全体より大幅に小さい場合には、頻繁にリ
クエストを行う属性だけを射影するようにします。
テーブルでの書き込みアクティビティが読み込みに比べて多くなることが予想される場合には、次の
ようにします。
• 射影される属性が少なくなるようにします。インデックスに書き込まれる項目のサイズが最小にな
ります。ただしこれらの項目が 1 つの書き込みキャパシティーユニット(1 KB)よりも小さい場合
は、書き込みキャパシティーユニットに関する節約効果はありません。たとえば、インデックスエ
API Version 2012-08-10
584
Amazon DynamoDB 開発者ガイド
フェッチを回避するための頻繁なクエリの最適化
ントリのサイズが 200 バイトである場合、DynamoDB ではこれが 1 KB に切り上げられます。 言い
換えれば、インデックス項目のサイズが小さい間は、追加コストが発生することなく、より多くの
属性を射影することができます。
• そのテーブルの属性の一部に、クエリでほとんど使用されない属性があることがわかっている場合
は、それらの属性を射影する理由はありません。その後インデックス内にない属性を更新しても、
インデックス更新による追加コストは発生しません。クエリでは射影されない属性を取り出すこと
はできますが、プロビジョニングされるスループットのコストは増加します。
ALL は、クエリによってテーブル項目全体が返されるとともに、異なるソートキーによってテーブル
を並べ替えるようにする場合のみ指定します。すべての属性にインデックスを付けることでテーブル
フェッチの必要がなくなりますが、ほとんどの場合、ストレージおよび書き込みアクティビティに要
するコストが倍加します。
フェッチを回避するための頻繁なクエリの最適化
レイテンシーを可能な限り小さくしてクエリを最速にするには、クエリによって返されるようにする
すべての属性を射影します。インデックスのクエリを行った場合に、リクエストした属性が射影され
ていないと、DynamoDB はリクエストされた属性をテーブルからフェッチします。その場合、テーブ
ルから項目全体を読み込む必要があるため、レイテンシーが発生し、I/O オペレーションが増加しま
す。
特定のクエリを臨時的に実行するだけで、リクエストされたすべての属性を射影する必要がない場
合、そのような「臨時的な」クエリが「不可欠な」クエリに変わることがよくあるので注意が必要で
す。それらの属性の射影を行うべきだったと後で気づく可能性もあります。
テーブルのフェッチの詳細については、「プロビジョニングされたスループットに関する考慮事項
(ローカルセカンダリインデックス) (p. 389)」を参照してください。
スパースなインデックスの利用
テーブル内の項目について、DynamoDB は項目内にインデックスソートキーの値がある場合のみ、対
応するインデックスエントリを書き込みます。ソートキーが必ずしもすべてのテーブル項目に現れな
い場合、そのインデックスはスパースであるといえます。
スパースなインデックスは、ほとんどのテーブル項目に現れない属性のクエリに役立ちます。たとえ
ば、すべての注文を格納する CustomerOrders というテーブルがあるとします。このテーブルのキー
属性は次のようになります。
• パーティションキー: CustomerId
• ソートキー: OrderId
オープンな注文だけを追跡する場合は、IsOpen という属性を指定できます。注文の受信を待機して
いる場合、アプリケーションでは、テーブル内の特定の項目について「X」(またはその他の任意の
値)と書き込むことで、IsOpen を定義できます。注文を受信すると、アプリケーションでは IsOpen
属性を削除して、注文が履行されたことを示します。
オープンな注文を追跡するために、CustomerId (パーティションキー) および IsOpen (ソートキー) に
インデックスを作成できます。インデックスに現れるのは、IsOpen が定義されたテーブルの注文だ
けです。アプリケーションでは、インデックスのクエリを実行することで、オープンになっている
注文をすばやく効率的に検索することができます。膨大な注文があって、そのうちオープンになっ
ているのが少数だけである場合、アプリケーションでインデックスに対するクエリを実行し、オー
プンになっている各注文の OrderId を返すことができます。アプリケーションが実行する読み込み
は、CustomerOrders テーブル全体をスキャンする場合に比べて大幅に少なくなります。
IsOpen 属性に任意の値を書き込む代わりに、別の属性を使用して、インデックス内に使いやすい並
べ替え順序を持つことも可能です。その場合は、OrderOpenDate 属性を作成して注文が行われた日
API Version 2012-08-10
585
Amazon DynamoDB 開発者ガイド
項目コレクションの拡張の監視
付に設定し (注文が処理された時点で属性を削除)、スキーマの CustomerId (パーティションキー) と
OrderOpenDate (ソートキー) と合わせて OpenOrders インデックスを作成します。それによって、
インデックスのクエリを行ったときに、より使いやすい並べ替え順序で項目が返されるようになりま
す。
項目コレクションの拡張の監視
項目コレクションとは、テーブルとそのインデックス内で、同じパーティションキーを持つすべての
項目を意味します。項目コレクションは 10 GB を超えることができないため、パーティションキー値
によってはスペースが不足する可能性があります。
テーブル項目を追加または更新すると、DynamoDB は影響を受ける local secondary index を更新しま
す。テーブル内でインデックスが付けられた属性が定義されている場合は、テーブルの拡張とともに
インデックスも増加します。
インデックスを作成する場合は、インデックスに書き込まれるデータの量と、そのうちパーティショ
ンキー値が同じデータがどの程度になるかを考慮します。特定のパーティションキー値に対するテー
ブルおよびインデックス項目の合計が 10 GB を超えると予想される場合は、そのインデックスの作成
を回避できないかどうかを検討すべきです。
インデックスの作成を回避できない場合は、項目コレクションのサイズ制限を超える前に対処する必
要があります。制限の範囲内での作業と是正措置のための戦略については、「項目コレクションのサ
イズ制限 (p. 393)」を参照してください。
グローバルセカンダリインデックス のガイドライ
ン
トピック
• ワークロードが均一になるようにキーを選択する (p. 586)
• スパースなインデックスの利用 (p. 587)
• グローバルセカンダリインデックス を使用したすばやい検索 (p. 587)
• 結果整合性のある読み込みレプリカを作成する (p. 587)
このセクションでは、グローバルセカンダリインデックス についていくつかのベストプラクティスを
示します。
ワークロードが均一になるようにキーを選択する
DynamoDB テーブルを作成するとき、読み込みアクティビティと書き込みアクティビティをテーブル
全体に均一に分散することが重要です。これを行うには、データが複数のパーティションに均一に分
かれるように、プライマリキーの属性を選択します。
このガイダンスは グローバルセカンダリインデックス にも当てはまります。インデックスの項目数
に比べて、値の数が多いパーティションキーとソートキーを選択します。また、グローバルセカンダ
リインデックス は一意であることを強制しないので、キー属性の濃度について理解する必要がありま
す。濃度とは、項目の数を基準とした、特定の属性にある値の個別の数のことです。
たとえば、Employee というテーブルに、Name、Title、Address、PhoneNumber、Salary、PayLevel
などの属性があるとします。PayLevel をパーティションキーに指定した、PayLevelIndex という名前
のグローバルセカンダリインデックスがあるとします。多くの企業では、給与コードの数は非常に少
なく、通常、従業員数が百人単位または千人単位の企業でも、10 個未満です。このようなインデック
スがアプリケーションにもたらすメリットは、あまりありません。
API Version 2012-08-10
586
Amazon DynamoDB 開発者ガイド
スパースなインデックスの利用
PayLevelIndex には、個別の値の分散が均一でないという別の問題もあります。たとえば、最高経営
幹部は数人で、時給労働者が非常に多い場合があります。PayLevelIndex に対してクエリを実行する
と、読み込みアクティビティがパーティション全体に均一に分散されないので、あまり効率的ではあ
りません。
スパースなインデックスの利用
テーブル内の項目について、DynamoDB は項目内にインデックスキー値がある場合のみ、対応するエ
ントリを グローバルセカンダリインデックス に書き込みます。グローバルセカンダリインデックス
の場合、これは、インデックスパーティションキーとそのソートキー (存在する場合) です。インデッ
クスキー値が一部のテーブル項目に存在しない場合、そのインデックスは、スパースであるといえま
す。
スパースな グローバルセカンダリインデックス を使用すると、一般的でない属性を持つテーブル
項目を効率的に見つけることができます。これを行うには、グローバルセカンダリインデックス 属
性が存在しないテーブル項目には、まったくインデックスが付けられないという点を利用します。
たとえば、GameScores テーブルで、あるプレーヤーは、ゲームで "チャンピオン (Champ)" などの
特別な成績を収め、ほとんどのプレーヤーは収めていない場合があります。チャンピオンについて
GameScores テーブル全体をスキャンするのではなく、パーティションキーに Champ、ソートキーに
UserId を指定したグローバルセカンダリインデックスを作成します。こうすることで、テーブルをス
キャンするのではなくインデックスに対してクエリを実行し、すべてのチャンピオンを簡単に見つけ
ることができます。
インデックス内の項目数は、テーブル内の項目数よりも大幅に少ないので、このようなクエリは非常
に効率的です。さらに、インデックスに射影するテーブル属性の数が少ないほど、インデックスから
消費する読み込みキャパシティーユニットも少なくなります。
グローバルセカンダリインデックス を使用したすば
やい検索
任意のテーブル属性をインデックスパーティションキーとソートキーに使用してグローバルセカンダ
リインデックスを作成できます。テーブルとまったく同じキー属性を持つインデックスを作成して、
非キー属性のサブセットだけを射影できます。
まったく同じキースキーマを持つ グローバルセカンダリインデックス のユースケースとして、最小限
のプロビジョニングされたスループットでテーブルデータをすばやく検索することが挙げられます。
テーブルに多数の属性があり、その属性自体が大きい場合、そのテーブルに対する各クエリによっ
て、大量の読み込みキャパシティーが消費される可能性があります。ほとんどのクエリで、返される
データのほとんどが必要ない場合は、最小限の射影された属性を使用して、つまり、テーブルのキー
以外は射影された属性をまったく含まない グローバルセカンダリインデックス を作成できます。これ
により、非常に小さい グローバルセカンダリインデックス に対してクエリを実行できます。追加の属
性が本当に必要な場合に、同じキー値を使用してテーブルに対してクエリを実行できます。
結果整合性のある読み込みレプリカを作成する
テーブルと同じキースキーマがある グローバルセカンダリインデックス を作成して、テーブルからイ
ンデックスに一部(またはすべて)の非キー属性を射影できます。アプリケーションでは、一部(ま
たすべて)の読み込みアクティビティをテーブルではなくこのインデックスに振り分けることができ
ます。これにより、テーブルに対するプロビジョンド読み込みキャパシティーを、読み込みアクティ
ビティの増加に応じて変更せずに済みます。テーブルに書き込んでからそのデータがインデックスに
反映されるまでの間に短い伝達遅延があることに注意してください。この場合、アプリケーションで
は結果整合性を想定する必要があります。
アプリケーションの特性をサポートするために複数のグローバルセカンダリインデックスを作成でき
ます。2 つアプリケーション間で読み込み特性が大きく異なるとします。たとえば、最高レベルの読
み込みパフォーマンスが必要な優先度の高いアプリケーションと、読み込みアクティビティの臨時
API Version 2012-08-10
587
Amazon DynamoDB 開発者ガイド
結果整合性のある読み込みレプリカを作成する
の調整を許容できる優先度の低いアプリケーションの場合です。これらのアプリケーションの両方が
同じテーブルから読み込む場合は、互いに干渉する可能性があります。優先度の低いアプリケーショ
ンからの高い読み込み負荷によって、テーブルの使用可能なすべての読み込みキャパシティーが消費
される可能性があります。その場合、結果的に優先度の高いアプリケーションの読み込みアクティビ
ティが制限されることになります。2 つの グローバルセカンダリインデックス を作成する場合、つ
まり、1 つは高い読み込みスループット設定にプロビジョニングし、もう 1 つは低い読み込みスルー
プット設定にプロビジョニングする場合、これらのワークロードの格差は、各アプリケーションから
の読み込みアクティビティをそれぞれのインデックスに振り分けることで効果的に縮小できます。こ
の方法では、プロビジョンド読み込みスループットの量を、各アプリケーションの読み込み特性に合
わせて調整できます。
状況によっては、テーブルから読み込むことができるアプリケーションを制限することもできます。
たとえば、あるアプリケーションがウェブサイトからのクリックストリームアクティビティをキャ
プチャし、DynamoDB テーブルに頻繁に書き込んでいるとします。このテーブルへの大部分のア
プリケーションからの読み込みアクセスを禁止することで、このテーブルを分離する場合がありま
す。(詳細については、「詳細に設定されたアクセスコントロールのための IAM ポリシー条件の使
用 (p. 477)」を参照してください)。ただし、他のアプリケーションでデータに対してアドホックク
エリを実行する必要がある場合は、その目的で 1 つ以上の グローバルセカンダリインデックス を作
成できます。このようなインデックスを作成するときは、必ずアプリケーションで実際に必要にな
る属性のみを射影するようにしてください。アプリケーションでは、読み込めるデータが増える一
方で、消費するプロビジョンド読み込みキャパシティーは減ります。テーブルからサイズの大きい項
目を読み込まずに済むためです。その結果、時間の経過と共に大幅なコスト削減になることがありま
す。
API Version 2012-08-10
588
Amazon DynamoDB 開発者ガイド
サンプルテーブルとデータ
DynamoDB 付録
トピック
• サンプルテーブルとデータ (p. 589)
• サンプルテーブルの作成とデータのアップロード (p. 599)
• AWS SDK for Python (Boto) を使用した DynamoDB サンプルアプリケーション: Tic-TacToe (p. 626)
• DynamoDB 用の追加のツールとリソース (p. 644)
• DynamoDB の予約語 (p. 668)
• レガシー条件パラメータ (p. 678)
• 現在の低レベル API バージョン (2012-08-10) (p. 696)
• 前バージョンの低レベル API (2011-12-05) (p. 697)
サンプルテーブルとデータ
『Amazon DynamoDB 開発者ガイド』では、サンプルテーブルを使用して DynamoDB のさまざまな
側面を示します。
テーブル名
プライマリキー
ProductCatalog
シンプルなプライマリキー:
• Id (数値)
フォーラム
シンプルなプライマリキー:
• Name (文字列)
スレッド
複合プライマリキー:
• ForumName (文字列)
• Subject (文字列)
Reply
複合プライマリキー:
• Id (文字列)
• ReplyDateTime (文字列)
[Reply] テーブルには、PostedBy-Message-Index という名前のグローバルセカンダリインデックスが
あります。このインデックスでは、Reply テーブルの 2 つの非キー属性でのクエリを容易にします。
API Version 2012-08-10
589
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
インデックス名
プライマリキー
PostedBy-Message-Index
複合プライマリキー:
• PostedBy (文字列)
• Message (文字列)
これらのテーブルの詳細については、「ユースケース 1: 製品カタログ (p. 166)」および「ユースケー
ス 2: フォーラムアプリケーション (p. 166)」を参照してください。
サンプルデータファイル
トピック
• ProductCatalog のサンプルデータ (p. 590)
• Forum のサンプルデータ (p. 595)
• Thread のサンプルデータ (p. 596)
• Reply サンプルデータ (p. 598)
以下のセクションでは、ProductCatalog、Forum、Thread、および Reply の各テーブルの読み込みに
使用されるサンプルデータファイルを示します。
各データファイルには複数の PutRequest 要素が含まれ、それぞれに 1 つの項目が含まれます。これ
らの PutRequest 要素は、AWS Command Line Interface (AWS CLI) を使用して BatchWriteItem
オペレーションへの入力として使用されます。
詳細については、「テーブルの作成とサンプルデータのロード (p. 166)」の「ステップ 2: データを
テーブルにロードする (p. 168)」を参照してください。
ProductCatalog のサンプルデータ
{
"ProductCatalog": [
{
"PutRequest": {
"Item": {
"Id": {
"N": "101"
},
"Title": {
"S": "Book 101 Title"
},
"ISBN": {
"S": "111-1111111111"
},
"Authors": {
"L": [
{
"S": "Author1"
}
]
},
"Price": {
"N": "2"
},
"Dimensions": {
API Version 2012-08-10
590
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
"S": "8.5 x 11.0 x 0.5"
},
"PageCount": {
"N": "500"
},
"InPublication": {
"BOOL": true
},
"ProductCategory": {
"S": "Book"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"N": "102"
},
"Title": {
"S": "Book 102 Title"
},
"ISBN": {
"S": "222-2222222222"
},
"Authors": {
"L": [
{
"S": "Author1"
},
{
"S": "Author2"
}
]
},
"Price": {
"N": "20"
},
"Dimensions": {
"S": "8.5 x 11.0 x 0.8"
},
"PageCount": {
"N": "600"
},
"InPublication": {
"BOOL": true
},
"ProductCategory": {
"S": "Book"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"N": "103"
API Version 2012-08-10
591
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
},
"Title": {
"S": "Book 103 Title"
},
"ISBN": {
"S": "333-3333333333"
},
"Authors": {
"L": [
{
"S": "Author1"
},
{
"S": "Author2"
}
]
},
"Price": {
"N": "2000"
},
"Dimensions": {
"S": "8.5 x 11.0 x 1.5"
},
"PageCount": {
"N": "600"
},
"InPublication": {
"BOOL": false
},
"ProductCategory": {
"S": "Book"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"N": "201"
},
"Title": {
"S": "18-Bike-201"
},
"Description": {
"S": "201 Description"
},
"BicycleType": {
"S": "Road"
},
"Brand": {
"S": "Mountain A"
},
"Price": {
"N": "100"
},
"Color": {
"L": [
{
API Version 2012-08-10
592
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
"S": "Red"
},
{
"S": "Black"
}
]
},
"ProductCategory": {
"S": "Bicycle"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"N": "202"
},
"Title": {
"S": "21-Bike-202"
},
"Description": {
"S": "202 Description"
},
"BicycleType": {
"S": "Road"
},
"Brand": {
"S": "Brand-Company A"
},
"Price": {
"N": "200"
},
"Color": {
"L": [
{
"S": "Green"
},
{
"S": "Black"
}
]
},
"ProductCategory": {
"S": "Bicycle"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"N": "203"
},
"Title": {
"S": "19-Bike-203"
},
API Version 2012-08-10
593
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
"Description": {
"S": "203 Description"
},
"BicycleType": {
"S": "Road"
},
"Brand": {
"S": "Brand-Company B"
},
"Price": {
"N": "300"
},
"Color": {
"L": [
{
"S": "Red"
},
{
"S": "Green"
},
{
"S": "Black"
}
]
},
"ProductCategory": {
"S": "Bicycle"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"N": "204"
},
"Title": {
"S": "18-Bike-204"
},
"Description": {
"S": "204 Description"
},
"BicycleType": {
"S": "Mountain"
},
"Brand": {
"S": "Brand-Company B"
},
"Price": {
"N": "400"
},
"Color": {
"L": [
{
"S": "Red"
}
]
},
API Version 2012-08-10
594
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
"ProductCategory": {
"S": "Bicycle"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"N": "205"
},
"Title": {
"S": "18-Bike-204"
},
"Description": {
"S": "205 Description"
},
"BicycleType": {
"S": "Hybrid"
},
"Brand": {
"S": "Brand-Company C"
},
"Price": {
"N": "500"
},
"Color": {
"L": [
{
"S": "Red"
},
{
"S": "Black"
}
]
},
"ProductCategory": {
"S": "Bicycle"
}
}
}
}
]
}
Forum のサンプルデータ
{
"Forum": [
{
"PutRequest": {
"Item": {
"Name": {"S":"Amazon DynamoDB"},
"Category": {"S":"Amazon Web Services"},
"Threads": {"N":"2"},
"Messages": {"N":"4"},
"Views": {"N":"1000"}
API Version 2012-08-10
595
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
}
}
},
{
"PutRequest": {
"Item": {
"Name": {"S":"Amazon S3"},
"Category": {"S":"Amazon Web Services"}
}
}
}
]
}
Thread のサンプルデータ
{
"Thread": [
{
"PutRequest": {
"Item": {
"ForumName": {
"S": "Amazon DynamoDB"
},
"Subject": {
"S": "DynamoDB Thread 1"
},
"Message": {
"S": "DynamoDB thread 1 message"
},
"LastPostedBy": {
"S": "User A"
},
"LastPostedDateTime": {
"S": "2015-09-22T19:58:22.514Z"
},
"Views": {
"N": "0"
},
"Replies": {
"N": "0"
},
"Answered": {
"N": "0"
},
"Tags": {
"L": [
{
"S": "index"
},
{
"S": "primarykey"
},
{
"S": "table"
}
]
}
API Version 2012-08-10
596
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
}
}
},
{
"PutRequest": {
"Item": {
"ForumName": {
"S": "Amazon DynamoDB"
},
"Subject": {
"S": "DynamoDB Thread 2"
},
"Message": {
"S": "DynamoDB thread 2 message"
},
"LastPostedBy": {
"S": "User A"
},
"LastPostedDateTime": {
"S": "2015-09-15T19:58:22.514Z"
},
"Views": {
"N": "3"
},
"Replies": {
"N": "0"
},
"Answered": {
"N": "0"
},
"Tags": {
"L": [
{
"S": "items"
},
{
"S": "attributes"
},
{
"S": "throughput"
}
]
}
}
}
},
{
"PutRequest": {
"Item": {
"ForumName": {
"S": "Amazon S3"
},
"Subject": {
"S": "S3 Thread 1"
},
"Message": {
"S": "S3 thread 1 message"
},
"LastPostedBy": {
API Version 2012-08-10
597
Amazon DynamoDB 開発者ガイド
サンプルデータファイル
"S": "User A"
},
"LastPostedDateTime": {
"S": "2015-09-29T19:58:22.514Z"
},
"Views": {
"N": "0"
},
"Replies": {
"N": "0"
},
"Answered": {
"N": "0"
},
"Tags": {
"L": [
{
"S": "largeobjects"
},
{
"S": "multipart upload"
}
]
}
}
}
}
]
}
Reply サンプルデータ
{
"Reply": [
{
"PutRequest": {
"Item": {
"Id": {
"S": "Amazon DynamoDB#DynamoDB Thread 1"
},
"ReplyDateTime": {
"S": "2015-09-15T19:58:22.947Z"
},
"Message": {
"S": "DynamoDB Thread 1 Reply 1 text"
},
"PostedBy": {
"S": "User A"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"S": "Amazon DynamoDB#DynamoDB Thread 1"
},
API Version 2012-08-10
598
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード
"ReplyDateTime": {
"S": "2015-09-22T19:58:22.947Z"
},
"Message": {
"S": "DynamoDB Thread 1 Reply 2 text"
},
"PostedBy": {
"S": "User B"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"S": "Amazon DynamoDB#DynamoDB Thread 2"
},
"ReplyDateTime": {
"S": "2015-09-29T19:58:22.947Z"
},
"Message": {
"S": "DynamoDB Thread 2 Reply 1 text"
},
"PostedBy": {
"S": "User A"
}
}
}
},
{
"PutRequest": {
"Item": {
"Id": {
"S": "Amazon DynamoDB#DynamoDB Thread 2"
},
"ReplyDateTime": {
"S": "2015-10-05T19:58:22.947Z"
},
"Message": {
"S": "DynamoDB Thread 2 Reply 2 text"
},
"PostedBy": {
"S": "User A"
}
}
}
}
]
}
サンプルテーブルの作成とデータのアップロード
トピック
• AWS SDK for Java を使用した、サンプルテーブルの作成とデータのアップロード (p. 600)
• AWS SDK for .NET を使用した、サンプルテーブルの作成とデータのアップロード (p. 608)
API Version 2012-08-10
599
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – Java
• AWS SDK for PHP を使用した、サンプルテーブルの作成とデータのアップロード (p. 617)
「テーブルの作成とサンプルデータのロード (p. 166)」では、最初に DynamoDB コンソールを使用し
てテーブルを作成し、AWS CLI を使用してデータをテーブルに追加します。この付録では、テーブル
の作成とデータの追加の両方をプログラムによって実行するためのコードを示します。
AWS SDK for Java を使用した、サンプルテーブル
の作成とデータのアップロード
次の Java コードの例では、テーブルを作成して、そのテーブルにデータをアップロードしてい
ます。結果として得られるテーブル構造とデータを「テーブルの作成とサンプルデータのロー
ド (p. 166)」に示します。このコードを Eclipse を使用して実行するための詳しい手順については、
「Java コードサンプル (p. 171)」を参照してください。
// Copyright 2012-2015 Amazon.com, Inc. or its affiliates. All Rights
Reserved.
// Licensed under the Apache License, Version 2.0.
package com.amazonaws.codesamples;
import
import
import
import
import
import
java.text.SimpleDateFormat;
java.util.ArrayList;
java.util.Arrays;
java.util.Date;
java.util.HashSet;
java.util.TimeZone;
import
import
import
import
import
import
import
import
import
import
import
import
import
com.amazonaws.auth.profile.ProfileCredentialsProvider;
com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
com.amazonaws.services.dynamodbv2.document.DynamoDB;
com.amazonaws.services.dynamodbv2.document.Item;
com.amazonaws.services.dynamodbv2.document.Table;
com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
com.amazonaws.services.dynamodbv2.model.KeyType;
com.amazonaws.services.dynamodbv2.model.LocalSecondaryIndex;
com.amazonaws.services.dynamodbv2.model.Projection;
com.amazonaws.services.dynamodbv2.model.ProjectionType;
com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
public class CreateTablesLoadData {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static SimpleDateFormat dateFormatter = new SimpleDateFormat(
"yyyy-MM-dd'T'HH:mm:ss.SSS'Z'");
static
static
static
static
String
String
String
String
productCatalogTableName = "ProductCatalog";
forumTableName = "Forum";
threadTableName = "Thread";
replyTableName = "Reply";
public static void main(String[] args) throws Exception {
try {
API Version 2012-08-10
600
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – Java
deleteTable(productCatalogTableName);
deleteTable(forumTableName);
deleteTable(threadTableName);
deleteTable(replyTableName);
// Parameter1: table name // Parameter2: reads per second //
// Parameter3: writes per second // Parameter4/5: partition key
and data type
// Parameter6/7: sort key and data type (if applicable)
createTable(productCatalogTableName, 10L, 5L, "Id", "N");
createTable(forumTableName, 10L, 5L, "Name", "S");
createTable(threadTableName, 10L, 5L, "ForumName", "S",
"Subject", "S");
createTable(replyTableName, 10L, 5L, "Id", "S", "ReplyDateTime",
"S");
loadSampleProducts(productCatalogTableName);
loadSampleForums(forumTableName);
loadSampleThreads(threadTableName);
loadSampleReplies(replyTableName);
} catch (Exception e) {
System.err.println("Program failed:");
System.err.println(e.getMessage());
}
System.out.println("Success.");
}
private static void deleteTable(String tableName) {
Table table = dynamoDB.getTable(tableName);
try {
System.out.println("Issuing DeleteTable request for " +
tableName);
table.delete();
System.out.println("Waiting for " + tableName
+ " to be deleted...this may take a while...");
table.waitForDelete();
} catch (Exception e) {
System.err.println("DeleteTable request failed for " +
tableName);
System.err.println(e.getMessage());
}
}
private static void createTable(
String tableName, long readCapacityUnits, long writeCapacityUnits,
String partitionKeyName, String partitionKeyType) {
createTable(tableName, readCapacityUnits, writeCapacityUnits,
partitionKeyName, partitionKeyType, null, null);
}
private static void createTable(
String tableName, long readCapacityUnits, long writeCapacityUnits,
String partitionKeyName, String partitionKeyType,
String sortKeyName, String sortKeyType) {
API Version 2012-08-10
601
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – Java
try {
ArrayList<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new KeySchemaElement()
.withAttributeName(partitionKeyName)
.withKeyType(KeyType.HASH)); //Partition key
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName(partitionKeyName)
.withAttributeType(partitionKeyType));
if (sortKeyName != null) {
keySchema.add(new KeySchemaElement()
.withAttributeName(sortKeyName)
.withKeyType(KeyType.RANGE)); //Sort key
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName(sortKeyName)
.withAttributeType(sortKeyType));
}
CreateTableRequest request = new CreateTableRequest()
.withTableName(tableName)
.withKeySchema(keySchema)
.withProvisionedThroughput( new ProvisionedThroughput()
.withReadCapacityUnits(readCapacityUnits)
.withWriteCapacityUnits(writeCapacityUnits));
// If this is the Reply table, define a local secondary index
if (replyTableName.equals(tableName)) {
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("PostedBy")
.withAttributeType("S"));
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
localSecondaryIndexes.add(new LocalSecondaryIndex()
.withIndexName("PostedBy-Index")
.withKeySchema(
new
KeySchemaElement().withAttributeName(partitionKeyName).withKeyType(KeyType.HASH),
//Partition key
new
KeySchemaElement() .withAttributeName("PostedBy") .withKeyType(KeyType.RANGE))
//Sort key
.withProjection(new
Projection() .withProjectionType(ProjectionType.KEYS_ONLY)));
request.setLocalSecondaryIndexes(localSecondaryIndexes);
}
request.setAttributeDefinitions(attributeDefinitions);
System.out.println("Issuing CreateTable request for " +
tableName);
API Version 2012-08-10
602
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – Java
Table table = dynamoDB.createTable(request);
System.out.println("Waiting for " + tableName
+ " to be created...this may take a while...");
table.waitForActive();
} catch (Exception e) {
System.err.println("CreateTable request failed for " +
tableName);
System.err.println(e.getMessage());
}
}
private static void loadSampleProducts(String tableName) {
Table table = dynamoDB.getTable(tableName);
try {
System.out.println("Adding data to " + tableName);
Item item = new Item()
.withPrimaryKey("Id", 101)
.withString("Title", "Book 101 Title")
.withString("ISBN", "111-1111111111")
.withStringSet("Authors", new HashSet<String>(
Arrays.asList("Author1")))
.withNumber("Price", 2)
.withString("Dimensions", "8.5 x 11.0 x 0.5")
.withNumber("PageCount", 500)
.withBoolean("InPublication", true)
.withString("ProductCategory", "Book");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", 102)
.withString("Title", "Book 102 Title")
.withString("ISBN", "222-2222222222")
.withStringSet( "Authors", new HashSet<String>(
Arrays.asList("Author1", "Author2")))
.withNumber("Price", 20)
.withString("Dimensions", "8.5 x 11.0 x 0.8")
.withNumber("PageCount", 600)
.withBoolean("InPublication", true)
.withString("ProductCategory", "Book");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", 103)
.withString("Title", "Book 103 Title")
.withString("ISBN", "333-3333333333")
.withStringSet( "Authors", new HashSet<String>(
Arrays.asList("Author1", "Author2")))
// Intentional. Later we'll run Scan to find price error.
Find
// items > 1000 in price.
.withNumber("Price", 2000)
.withString("Dimensions", "8.5 x 11.0 x 1.5")
.withNumber("PageCount", 600)
.withBoolean("InPublication", false)
API Version 2012-08-10
603
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – Java
.withString("ProductCategory", "Book");
table.putItem(item);
// Add bikes.
item = new Item()
.withPrimaryKey("Id", 201)
.withString("Title", "18-Bike-201")
// Size, followed by some title.
.withString("Description", "201 Description")
.withString("BicycleType", "Road")
.withString("Brand", "Mountain A")
// Trek, Specialized.
.withNumber("Price", 100)
.withStringSet("Color", new HashSet<String>(
Arrays.asList("Red", "Black")))
.withString("ProductCategory", "Bicycle");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", 202)
.withString("Title", "21-Bike-202")
.withString("Description", "202 Description")
.withString("BicycleType", "Road")
.withString("Brand", "Brand-Company A")
.withNumber("Price", 200)
.withStringSet( "Color", new HashSet<String>(
Arrays.asList("Green", "Black")))
.withString("ProductCategory", "Bicycle");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", 203)
.withString("Title", "19-Bike-203")
.withString("Description", "203 Description")
.withString("BicycleType", "Road")
.withString("Brand", "Brand-Company B")
.withNumber("Price", 300)
.withStringSet( "Color", new HashSet<String>(
Arrays.asList("Red", "Green", "Black")))
.withString("ProductCategory", "Bicycle");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", 204)
.withString("Title", "18-Bike-204")
.withString("Description", "204 Description")
.withString("BicycleType", "Mountain")
.withString("Brand", "Brand-Company B")
.withNumber("Price", 400)
.withStringSet("Color", new HashSet<String>(
Arrays.asList("Red")))
.withString("ProductCategory", "Bicycle");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", 205)
.withString("Title", "20-Bike-205")
.withString("Description", "205 Description")
API Version 2012-08-10
604
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – Java
.withString("BicycleType", "Hybrid")
.withString("Brand", "Brand-Company C")
.withNumber("Price", 500)
.withStringSet("Color", new HashSet<String>(
Arrays.asList("Red", "Black")))
.withString("ProductCategory", "Bicycle");
table.putItem(item);
} catch (Exception e) {
System.err.println("Failed to create item in " + tableName);
System.err.println(e.getMessage());
}
}
private static void loadSampleForums(String tableName) {
Table table = dynamoDB.getTable(tableName);
try {
System.out.println("Adding data to " + tableName);
Item item = new Item().withPrimaryKey("Name", "Amazon DynamoDB")
.withString("Category", "Amazon Web Services")
.withNumber("Threads", 2).withNumber("Messages", 4)
.withNumber("Views", 1000);
table.putItem(item);
item = new Item().withPrimaryKey("Name", "Amazon S3")
.withString("Category", "Amazon Web Services")
.withNumber("Threads", 0);
table.putItem(item);
} catch (Exception e) {
System.err.println("Failed to create item in " + tableName);
System.err.println(e.getMessage());
}
}
private static void loadSampleThreads(String tableName) {
try {
long time1 = (new Date()).getTime() - (7 * 24 * 60 * 60 *
1000); // 7
// days
// ago
long time2 = (new Date()).getTime() - (14 * 24 * 60 * 60 *
1000); // 14
// days
// ago
long time3 = (new Date()).getTime() - (21 * 24 * 60 * 60 *
1000); // 21
// days
// ago
Date date1 = new Date();
date1.setTime(time1);
Date date2 = new Date();
API Version 2012-08-10
605
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – Java
date2.setTime(time2);
Date date3 = new Date();
date3.setTime(time3);
dateFormatter.setTimeZone(TimeZone.getTimeZone("UTC"));
Table table = dynamoDB.getTable(tableName);
System.out.println("Adding data to " + tableName);
Item item = new Item()
.withPrimaryKey("ForumName", "Amazon DynamoDB")
.withString("Subject", "DynamoDB Thread 1")
.withString("Message", "DynamoDB thread 1 message")
.withString("LastPostedBy", "User A")
.withString("LastPostedDateTime",
dateFormatter.format(date2))
.withNumber("Views", 0)
.withNumber("Replies", 0)
.withNumber("Answered", 0)
.withStringSet( "Tags", new HashSet<String>(
Arrays.asList("index", "primarykey", "table")));
table.putItem(item);
item = new Item()
.withPrimaryKey("ForumName", "Amazon DynamoDB")
.withString("Subject", "DynamoDB Thread 2")
.withString("Message", "DynamoDB thread 2 message")
.withString("LastPostedBy", "User A")
.withString("LastPostedDateTime",
dateFormatter.format(date3))
.withNumber("Views", 0)
.withNumber("Replies", 0)
.withNumber("Answered", 0)
.withStringSet( "Tags", new HashSet<String>(
Arrays.asList("index", "partitionkey", "sortkey")));
table.putItem(item);
item = new Item()
.withPrimaryKey("ForumName", "Amazon S3")
.withString("Subject", "S3 Thread 1")
.withString("Message", "S3 Thread 3 message")
.withString("LastPostedBy", "User A")
.withString("LastPostedDateTime",
dateFormatter.format(date1))
.withNumber("Views", 0)
.withNumber("Replies", 0)
.withNumber("Answered", 0)
.withStringSet( "Tags", new HashSet<String>(
Arrays.asList("largeobjects", "multipart upload")));
table.putItem(item);
} catch (Exception e) {
System.err.println("Failed to create item in " + tableName);
System.err.println(e.getMessage());
}
}
API Version 2012-08-10
606
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – Java
private static void loadSampleReplies(String tableName) {
try {
// 1 day ago
long time0 = (new Date()).getTime() - (1 * 24 * 60 * 60 * 1000);
// 7 days ago
long time1 = (new Date()).getTime() - (7 * 24 * 60 * 60 * 1000);
// 14 days ago
long time2 = (new Date()).getTime() - (14 * 24 * 60 * 60 *
1000);
// 21 days ago
long time3 = (new Date()).getTime() - (21 * 24 * 60 * 60 * 1000);
Date date0 = new Date();
date0.setTime(time0);
Date date1 = new Date();
date1.setTime(time1);
Date date2 = new Date();
date2.setTime(time2);
Date date3 = new Date();
date3.setTime(time3);
dateFormatter.setTimeZone(TimeZone.getTimeZone("UTC"));
Table table = dynamoDB.getTable(tableName);
System.out.println("Adding data to " + tableName);
// Add threads.
Item item = new Item()
.withPrimaryKey("Id", "Amazon DynamoDB#DynamoDB Thread 1")
.withString("ReplyDateTime", (dateFormatter.format(date3)))
.withString("Message", "DynamoDB Thread 1 Reply 1 text")
.withString("PostedBy", "User A");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", "Amazon DynamoDB#DynamoDB Thread 1")
.withString("ReplyDateTime", dateFormatter.format(date2))
.withString("Message", "DynamoDB Thread 1 Reply 2 text")
.withString("PostedBy", "User B");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", "Amazon DynamoDB#DynamoDB Thread 2")
.withString("ReplyDateTime", dateFormatter.format(date1))
.withString("Message", "DynamoDB Thread 2 Reply 1 text")
.withString("PostedBy", "User A");
table.putItem(item);
item = new Item()
.withPrimaryKey("Id", "Amazon DynamoDB#DynamoDB Thread 2")
.withString("ReplyDateTime", dateFormatter.format(date0))
.withString("Message", "DynamoDB Thread 2 Reply 2 text")
.withString("PostedBy", "User A");
API Version 2012-08-10
607
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
table.putItem(item);
} catch (Exception e) {
System.err.println("Failed to create item in " + tableName);
System.err.println(e.getMessage());
}
}
}
AWS SDK for .NET を使用した、サンプルテーブル
の作成とデータのアップロード
次の C# コードの例では、テーブルを作成して、そのテーブルにデータをアップロードしています。
結果として得られるテーブル構造とデータを「テーブルの作成とサンプルデータのロード (p. 166)」
に示します。このコードを Visual Studio を使用して実行するための詳しい手順については、「.NET
コードサンプル (p. 173)」を参照してください。
using
using
using
using
using
using
using
System;
System.Collections.Generic;
Amazon.DynamoDBv2;
Amazon.DynamoDBv2.DocumentModel;
Amazon.DynamoDBv2.Model;
Amazon.Runtime;
Amazon.SecurityToken;
namespace com.amazonaws.codesamples
{
class CreateTablesLoadData
{
private static AmazonDynamoDBClient client = new
AmazonDynamoDBClient();
static void Main(string[] args)
{
try
{
//DeleteAllTables(client);
DeleteTable("ProductCatalog");
DeleteTable("Forum");
DeleteTable("Thread");
DeleteTable("Reply");
// Create tables (using the AWS SDK for .NET low-level API).
CreateTableProductCatalog();
CreateTableForum();
CreateTableThread(); // ForumTitle, Subject */
CreateTableReply();
// Load data (using the .NET SDK document API)
LoadSampleProducts();
LoadSampleForums();
LoadSampleThreads();
LoadSampleReplies();
Console.WriteLine("Sample complete!");
Console.WriteLine("Press ENTER to continue");
API Version 2012-08-10
608
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
Console.ReadLine();
}
catch (AmazonServiceException e)
{ Console.WriteLine(e.Message); }
catch (Exception e) { Console.WriteLine(e.Message); }
}
private static void DeleteTable(string tableName)
{
try
{
var deleteTableResponse = client.DeleteTable(new
DeleteTableRequest() { TableName = tableName });
WaitTillTableDeleted(client, tableName,
deleteTableResponse);
}
catch (ResourceNotFoundException)
{
// There is no such table.
}
}
private static void CreateTableProductCatalog()
{
string tableName = "ProductCatalog";
var response = client.CreateTable(new CreateTableRequest
{
TableName = tableName,
AttributeDefinitions = new List<AttributeDefinition>()
{
new AttributeDefinition
{
AttributeName = "Id",
AttributeType = "N"
}
},
KeySchema = new List<KeySchemaElement>()
{
new KeySchemaElement
{
AttributeName = "Id",
KeyType = "HASH"
}
},
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = 10,
WriteCapacityUnits = 5
}
});
WaitTillTableCreated(client, tableName, response);
}
private static void CreateTableForum()
{
string tableName = "Forum";
API Version 2012-08-10
609
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
var response = client.CreateTable(new CreateTableRequest
{
TableName = tableName,
AttributeDefinitions = new List<AttributeDefinition>()
{
new AttributeDefinition
{
AttributeName = "Name",
AttributeType = "S"
}
},
KeySchema = new List<KeySchemaElement>()
{
new KeySchemaElement
{
AttributeName = "Name", // forum Title
KeyType = "HASH"
}
},
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = 10,
WriteCapacityUnits = 5
}
});
WaitTillTableCreated(client, tableName, response);
}
private static void CreateTableThread()
{
string tableName = "Thread";
var response = client.CreateTable(new CreateTableRequest
{
TableName = tableName,
AttributeDefinitions = new List<AttributeDefinition>()
{
new AttributeDefinition
{
AttributeName = "ForumName", // Hash attribute
AttributeType = "S"
},
new AttributeDefinition
{
AttributeName = "Subject",
AttributeType = "S"
}
},
KeySchema = new List<KeySchemaElement>()
{
new KeySchemaElement
{
AttributeName = "ForumName", // Hash attribute
KeyType = "HASH"
},
new KeySchemaElement
{
AttributeName = "Subject", // Range attribute
API Version 2012-08-10
610
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
KeyType = "RANGE"
}
},
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = 10,
WriteCapacityUnits = 5
}
});
WaitTillTableCreated(client, tableName, response);
}
private static void CreateTableReply()
{
string tableName = "Reply";
var response = client.CreateTable(new CreateTableRequest
{
TableName = tableName,
AttributeDefinitions = new List<AttributeDefinition>()
{
new AttributeDefinition
{
AttributeName = "Id",
AttributeType = "S"
},
new AttributeDefinition
{
AttributeName = "ReplyDateTime",
AttributeType = "S"
},
new AttributeDefinition
{
AttributeName = "PostedBy",
AttributeType = "S"
}
},
KeySchema = new List<KeySchemaElement>()
{
new KeySchemaElement()
{
AttributeName = "Id",
KeyType = "HASH"
},
new KeySchemaElement()
{
AttributeName = "ReplyDateTime",
KeyType = "RANGE"
}
},
LocalSecondaryIndexes = new List<LocalSecondaryIndex>()
{
new LocalSecondaryIndex()
{
IndexName = "PostedBy_index",
KeySchema = new List<KeySchemaElement>() {
API Version 2012-08-10
611
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
new KeySchemaElement() {AttributeName = "Id", KeyType =
"HASH"},
new KeySchemaElement() {AttributeName = "PostedBy",
KeyType = "RANGE"}
},
Projection = new Projection() {ProjectionType =
ProjectionType.KEYS_ONLY}
}
},
ProvisionedThroughput = new ProvisionedThroughput
{
ReadCapacityUnits = 10,
WriteCapacityUnits = 5
}
});
WaitTillTableCreated(client, tableName, response);
}
private static void WaitTillTableCreated(AmazonDynamoDBClient client,
string tableName,
CreateTableResponse
response)
{
var tableDescription = response.TableDescription;
string status = tableDescription.TableStatus;
Console.WriteLine(tableName + " - " + status);
// Let us wait until table is created. Call DescribeTable.
while (status != "ACTIVE")
{
System.Threading.Thread.Sleep(5000); // Wait 5 seconds.
try
{
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
status = res.Table.TableStatus;
}
// Try-catch to handle potential eventual-consistency issue.
catch (ResourceNotFoundException)
{ }
}
}
private static void WaitTillTableDeleted(AmazonDynamoDBClient client,
string tableName,
DeleteTableResponse
response)
{
var tableDescription = response.TableDescription;
API Version 2012-08-10
612
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
string status = tableDescription.TableStatus;
Console.WriteLine(tableName + " - " + status);
// Let us wait until table is created. Call DescribeTable
try
{
while (status == "DELETING")
{
System.Threading.Thread.Sleep(5000); // wait 5 seconds
var res = client.DescribeTable(new DescribeTableRequest
{
TableName = tableName
});
Console.WriteLine("Table name: {0}, status: {1}",
res.Table.TableName,
res.Table.TableStatus);
status = res.Table.TableStatus;
}
}
catch (ResourceNotFoundException)
{
// Table deleted.
}
}
private static void LoadSampleProducts()
{
Table productCatalogTable = Table.LoadTable(client,
"ProductCatalog");
// ********** Add Books *********************
var book1 = new Document();
book1["Id"] = 101;
book1["Title"] = "Book 101 Title";
book1["ISBN"] = "111-1111111111";
book1["Authors"] = new List<string> { "Author 1" };
book1["Price"] = -2; // *** Intentional value. Later used to
illustrate scan.
book1["Dimensions"] = "8.5 x 11.0 x 0.5";
book1["PageCount"] = 500;
book1["InPublication"] = true;
book1["ProductCategory"] = "Book";
productCatalogTable.PutItem(book1);
var book2 = new Document();
book2["Id"] = 102;
book2["Title"] = "Book 102 Title";
book2["ISBN"] = "222-2222222222";
book2["Authors"] = new List<string> { "Author 1", "Author
2" }; ;
book2["Price"] = 20;
book2["Dimensions"] = "8.5 x 11.0 x 0.8";
book2["PageCount"] = 600;
book2["InPublication"] = true;
book2["ProductCategory"] = "Book";
API Version 2012-08-10
613
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
productCatalogTable.PutItem(book2);
var book3 = new Document();
book3["Id"] = 103;
book3["Title"] = "Book 103 Title";
book3["ISBN"] = "333-3333333333";
book3["Authors"] = new List<string> { "Author 1", "Author2",
"Author 3" }; ;
book3["Price"] = 2000;
book3["Dimensions"] = "8.5 x 11.0 x 1.5";
book3["PageCount"] = 700;
book3["InPublication"] = false;
book3["ProductCategory"] = "Book";
productCatalogTable.PutItem(book3);
// ************ Add bikes. *******************
var bicycle1 = new Document();
bicycle1["Id"] = 201;
bicycle1["Title"] = "18-Bike 201"; // size, followed by some
title.
bicycle1["Description"] = "201 description";
bicycle1["BicycleType"] = "Road";
bicycle1["Brand"] = "Brand-Company A"; // Trek, Specialized.
bicycle1["Price"] = 100;
bicycle1["Color"] = new List<string> { "Red", "Black" };
bicycle1["ProductCategory"] = "Bike";
productCatalogTable.PutItem(bicycle1);
var bicycle2 = new Document();
bicycle2["Id"] = 202;
bicycle2["Title"] = "21-Bike 202Brand-Company A";
bicycle2["Description"] = "202 description";
bicycle2["BicycleType"] = "Road";
bicycle2["Brand"] = "";
bicycle2["Price"] = 200;
bicycle2["Color"] = new List<string> { "Green", "Black" };
bicycle2["ProductCategory"] = "Bicycle";
productCatalogTable.PutItem(bicycle2);
var bicycle3 = new Document();
bicycle3["Id"] = 203;
bicycle3["Title"] = "19-Bike 203";
bicycle3["Description"] = "203 description";
bicycle3["BicycleType"] = "Road";
bicycle3["Brand"] = "Brand-Company B";
bicycle3["Price"] = 300;
bicycle3["Color"] = new List<string> { "Red", "Green",
"Black" };
bicycle3["ProductCategory"] = "Bike";
productCatalogTable.PutItem(bicycle3);
var bicycle4 = new Document();
bicycle4["Id"] = 204;
bicycle4["Title"] = "18-Bike 204";
bicycle4["Description"] = "204 description";
bicycle4["BicycleType"] = "Mountain";
bicycle4["Brand"] = "Brand-Company B";
bicycle4["Price"] = 400;
bicycle4["Color"] = new List<string> { "Red" };
API Version 2012-08-10
614
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
bicycle4["ProductCategory"] = "Bike";
productCatalogTable.PutItem(bicycle4);
var bicycle5 = new Document();
bicycle5["Id"] = 205;
bicycle5["Title"] = "20-Title 205";
bicycle4["Description"] = "205 description";
bicycle5["BicycleType"] = "Hybrid";
bicycle5["Brand"] = "Brand-Company C";
bicycle5["Price"] = 500;
bicycle5["Color"] = new List<string> { "Red", "Black" };
bicycle5["ProductCategory"] = "Bike";
productCatalogTable.PutItem(bicycle5);
}
private static void LoadSampleForums()
{
Table forumTable = Table.LoadTable(client, "Forum");
var forum1 = new Document();
forum1["Name"] = "Amazon DynamoDB"; // PK
forum1["Category"] = "Amazon Web Services";
forum1["Threads"] = 2;
forum1["Messages"] = 4;
forum1["Views"] = 1000;
forumTable.PutItem(forum1);
var forum2 = new Document();
forum2["Name"] = "Amazon S3"; // PK
forum2["Category"] = "Amazon Web Services";
forum2["Threads"] = 1;
forumTable.PutItem(forum2);
}
private static void LoadSampleThreads()
{
Table threadTable = Table.LoadTable(client, "Thread");
// Thread 1.
var thread1 = new Document();
thread1["ForumName"] = "Amazon DynamoDB"; // Hash attribute.
thread1["Subject"] = "DynamoDB Thread 1"; // Range attribute.
thread1["Message"] = "DynamoDB thread 1 message text";
thread1["LastPostedBy"] = "User A";
thread1["LastPostedDateTime"] = DateTime.UtcNow.Subtract(new
TimeSpan(14, 0, 0, 0));
thread1["Views"] = 0;
thread1["Replies"] = 0;
thread1["Answered"] = false;
thread1["Tags"] = new List<string> { "index", "primarykey",
"table" };
threadTable.PutItem(thread1);
// Thread 2.
var thread2 = new Document();
thread2["ForumName"] = "Amazon DynamoDB"; // Hash attribute.
API Version 2012-08-10
615
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – .NET
thread2["Subject"] = "DynamoDB Thread 2"; // Range attribute.
thread2["Message"] = "DynamoDB thread 2 message text";
thread2["LastPostedBy"] = "User A";
thread2["LastPostedDateTime"] = DateTime.UtcNow.Subtract(new
TimeSpan(21, 0, 0, 0));
thread2["Views"] = 0;
thread2["Replies"] = 0;
thread2["Answered"] = false;
thread2["Tags"] = new List<string> { "index", "primarykey",
"rangekey" };
threadTable.PutItem(thread2);
// Thread 3.
var thread3 = new Document();
thread3["ForumName"] = "Amazon S3"; // Hash attribute.
thread3["Subject"] = "S3 Thread 1"; // Range attribute.
thread3["Message"] = "S3 thread 3 message text";
thread3["LastPostedBy"] = "User A";
thread3["LastPostedDateTime"] = DateTime.UtcNow.Subtract(new
TimeSpan(7, 0, 0, 0));
thread3["Views"] = 0;
thread3["Replies"] = 0;
thread3["Answered"] = false;
thread3["Tags"] = new List<string> { "largeobjects", "multipart
upload" };
threadTable.PutItem(thread3);
}
private static void LoadSampleReplies()
{
Table replyTable = Table.LoadTable(client, "Reply");
// Reply 1 - thread 1.
var thread1Reply1 = new Document();
thread1Reply1["Id"] = "Amazon DynamoDB#DynamoDB Thread 1"; //
Hash attribute.
thread1Reply1["ReplyDateTime"] = DateTime.UtcNow.Subtract(new
TimeSpan(21, 0, 0, 0)); // Range attribute.
thread1Reply1["Message"] = "DynamoDB Thread 1 Reply 1 text";
thread1Reply1["PostedBy"] = "User A";
replyTable.PutItem(thread1Reply1);
// Reply 2 - thread 1.
var thread1reply2 = new Document();
thread1reply2["Id"] = "Amazon DynamoDB#DynamoDB Thread 1"; //
Hash attribute.
thread1reply2["ReplyDateTime"] = DateTime.UtcNow.Subtract(new
TimeSpan(14, 0, 0, 0)); // Range attribute.
thread1reply2["Message"] = "DynamoDB Thread 1 Reply 2 text";
thread1reply2["PostedBy"] = "User B";
replyTable.PutItem(thread1reply2);
// Reply 3 - thread 1.
var thread1Reply3 = new Document();
thread1Reply3["Id"] = "Amazon DynamoDB#DynamoDB Thread 1"; //
Hash attribute.
API Version 2012-08-10
616
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
thread1Reply3["ReplyDateTime"] = DateTime.UtcNow.Subtract(new
TimeSpan(7, 0, 0, 0)); // Range attribute.
thread1Reply3["Message"] = "DynamoDB Thread 1 Reply 3 text";
thread1Reply3["PostedBy"] = "User B";
replyTable.PutItem(thread1Reply3);
// Reply 1 - thread 2.
var thread2Reply1 = new Document();
thread2Reply1["Id"] = "Amazon DynamoDB#DynamoDB Thread 2"; //
Hash attribute.
thread2Reply1["ReplyDateTime"] = DateTime.UtcNow.Subtract(new
TimeSpan(7, 0, 0, 0)); // Range attribute.
thread2Reply1["Message"] = "DynamoDB Thread 2 Reply 1 text";
thread2Reply1["PostedBy"] = "User A";
replyTable.PutItem(thread2Reply1);
// Reply 2 - thread 2.
var thread2Reply2 = new Document();
thread2Reply2["Id"] = "Amazon DynamoDB#DynamoDB Thread 2"; //
Hash attribute.
thread2Reply2["ReplyDateTime"] = DateTime.UtcNow.Subtract(new
TimeSpan(1, 0, 0, 0)); // Range attribute.
thread2Reply2["Message"] = "DynamoDB Thread 2 Reply 2 text";
thread2Reply2["PostedBy"] = "User A";
replyTable.PutItem(thread2Reply2);
}
}
}
AWS SDK for PHP を使用した、サンプルテーブル
の作成とデータのアップロード
次の PHP コードの例では、テーブルを作成しています。結果として得られるテーブル構造とデータを
「テーブルの作成とサンプルデータのロード (p. 166)」に示します。このコードを実行するための詳
しい手順については、「PHP コードサンプル (p. 175)」を参照してください。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
$tableName = 'ProductCatalog';
echo "Creating table $tableName...";
API Version 2012-08-10
617
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
try {
$response = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[
'AttributeName' => 'Id',
'AttributeType' => 'N'
]
],
'KeySchema' => [
[
'AttributeName' => 'Id',
'KeyType' => 'HASH' //Partition key
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits'
=> 10,
'WriteCapacityUnits' => 5
]
]);
echo "CreateTable request was successful.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to create table $tableName\n");
}
$tableName = 'Forum';
echo "Creating table $tableName...";
try {
$response = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[
'AttributeName' => 'Name',
'AttributeType' => 'S'
]
],
'KeySchema' => [
[
'AttributeName' => 'Name',
'KeyType' => 'HASH' //Partition key
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits'
=> 10,
'WriteCapacityUnits' => 5
]
]);
echo "CreateTable request was successful.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to create table $tableName\n");
}
$tableName = 'Thread';
echo "Creating table $tableName...";
API Version 2012-08-10
618
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
try {
$response = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[
'AttributeName' => 'ForumName',
'AttributeType' => 'S'
],
[
'AttributeName' => 'Subject',
'AttributeType' => 'S'
]
],
'KeySchema' => [
[
'AttributeName' => 'ForumName',
'KeyType' => 'HASH' //Partition key
],
[
'AttributeName' => 'Subject',
'KeyType' => 'RANGE' //Sort key
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits'
=> 10,
'WriteCapacityUnits' => 5
]
]);
echo "CreateTable request was successful.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to create table $tableName\n");
}
$tableName = 'Reply';
echo "Creating table $tableName...";
try {
$response = $dynamodb->createTable([
'TableName' => $tableName,
'AttributeDefinitions' => [
[
'AttributeName' => 'Id',
'AttributeType' => 'S'
],
[
'AttributeName' => 'ReplyDateTime',
'AttributeType' => 'S'
],
[
'AttributeName' => 'PostedBy',
'AttributeType' => 'S'
]
],
'LocalSecondaryIndexes' => [
[
'IndexName' => 'PostedBy-index',
'KeySchema' => [
API Version 2012-08-10
619
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
[
'AttributeName' => 'Id',
'KeyType' => 'HASH' //Partition key
],
[
'AttributeName' => 'PostedBy',
'KeyType' => 'RANGE' //Sort key
],
],
'Projection' => [
'ProjectionType' => 'KEYS_ONLY',
],
],
],
'KeySchema' => [
[
'AttributeName' => 'Id',
'KeyType' => 'HASH' //Partition key
],
[
'AttributeName' => 'ReplyDateTime',
'KeyType' => 'RANGE' //Sort key
]
],
'ProvisionedThroughput' => [
'ReadCapacityUnits'
=> 10,
'WriteCapacityUnits' => 5
]
]);
echo "CreateTable request was successful.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to create table $tableName\n");
}
?>
次の PHP コードの例では、テーブルにデータをアップロードしています。結果として得られるテーブ
ル構造とデータを「テーブルの作成とサンプルデータのロード (p. 166)」に示します。
<?php
require 'vendor/autoload.php';
date_default_timezone_set('UTC');
use Aws\DynamoDb\Exception\DynamoDbException;
$sdk = new Aws\Sdk([
'region'
=> 'us-west-2',
'version' => 'latest'
]);
$dynamodb = $sdk->createDynamoDb();
# Setup some local variables for dates
$oneDayAgo = date('Y-m-d H:i:s', strtotime('-1 days'));
$sevenDaysAgo = date('Y-m-d H:i:s', strtotime('-7 days'));
API Version 2012-08-10
620
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
$fourteenDaysAgo = date('Y-m-d H:i:s', strtotime('-14 days'));
$twentyOneDaysAgo = date('Y-m-d H:i:s', strtotime('-21 days'));
$tableName = 'ProductCatalog';
echo "Adding data to the $tableName table...\n";
try {
$response = $dynamodb->batchWriteItem([
'RequestItems' => [
$tableName => [
[
'PutRequest' => [
'Item' => [
'Id'
'Title'
'ISBN'
'Authors'
'Price'
'Dimensions'
=>
=>
=>
=>
=>
=>
['N' => '1101'],
['S' => 'Book 101 Title'],
['S' => '111-1111111111'],
['SS' => ['Author1']],
['N' => '2'],
['S' => '8.5 x 11.0 x 0.5'],
'PageCount'
=> ['N' => '500'],
'InPublication'
=> ['N' => '1'],
'ProductCategory' => ['S' => 'Book']
]
],
],
[
'PutRequest' => [
'Item' => [
'Id'
'Title'
'ISBN'
'Authors'
=>
=>
=>
=>
['N' => '102'],
['S' => 'Book 102 Title'],
['S' => '222-2222222222'],
['SS' => ['Author1',
'Author2']],
'Price'
'Dimensions'
=> ['N' => '20'],
=> ['S' => '8.5 x 11.0 x
0.8'],
'PageCount'
=> ['N' => '600'],
'InPublication'
=> ['N' => '1'],
'ProductCategory' => ['S' => 'Book']
]
],
],
[
'PutRequest' => [
'Item' => [
'Id'
'Title'
'ISBN'
'Authors'
=>
=>
=>
=>
['N' => '103'],
['S' => 'Book 103 Title'],
['S' => '333-3333333333'],
['SS' => ['Author1',
'Author2']],
'Price'
'Dimensions'
=> ['N' => '2000'],
=> ['S' => '8.5 x 11.0 x
1.5'],
'PageCount'
=> ['N' => '600'],
'InPublication'
=> ['N' => '0'],
'ProductCategory' => ['S' => 'Book']
API Version 2012-08-10
621
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
]
],
],
[
'PutRequest' => [
'Item' => [
'Id'
'Title'
'Description'
'BicycleType'
'Brand'
'Price'
'Color'
'ProductCategory'
=>
=>
=>
=>
=>
=>
=>
=>
['N' => '201'],
['S' => '18-Bike-201'],
['S' => '201 Description'],
['S' => 'Road'],
['S' => 'Mountain A'],
['N' => '100'],
['SS' => ['Red', 'Black']],
['S' => 'Bicycle']
=>
=>
=>
=>
=>
=>
=>
['N' => '202'],
['S' => '21-Bike-202'],
['S' => '202 Description'],
['S' => 'Road'],
['S' => 'Brand-Company A'],
['N' => '200'],
['SS' => ['Green',
]
],
],
[
'PutRequest' => [
'Item' => [
'Id'
'Title'
'Description'
'BicycleType'
'Brand'
'Price'
'Color'
'Black']],
'ProductCategory' => ['S' => 'Bicycle']
]
],
],
[
'PutRequest' => [
'Item' => [
'Id'
'Title'
'Description'
'BicycleType'
'Brand'
'Price'
'Color'
=>
=>
=>
=>
=>
=>
=>
['N' => '203'],
['S' => '19-Bike-203'],
['S' => '203 Description'],
['S' => 'Road'],
['S' => 'Brand-Company B'],
['N' => '300'],
['SS' => ['Red', 'Green',
'Black']],
'ProductCategory' => ['S' => 'Bicycle']
]
],
],
[
'PutRequest' => [
'Item' => [
'Id'
'Title'
'Description'
'BicycleType'
'Brand'
'Price'
'Color'
API Version 2012-08-10
622
=>
=>
=>
=>
=>
=>
=>
['N' => '204'],
['S' => '18-Bike-204'],
['S' => '204 Description'],
['S' => 'Mountain'],
['S' => 'Brand-Company B'],
['N' => '400'],
['SS' => ['Red']],
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
'ProductCategory' => ['S' => 'Bicycle']
]
],
],
[
'PutRequest' => [
'Item' => [
'Id'
'Title'
'Description'
'BicycleType'
'Brand'
'Price'
'Color'
'ProductCategory'
=>
=>
=>
=>
=>
=>
=>
=>
['N' => '205'],
['S' => '20-Bike-205'],
['S' => '205 Description'],
['S' => 'Hybrid'],
['S' => 'Brand-Company C'],
['N' => '500'],
['SS' => ['Red', 'Black']],
['S' => 'Bicycle']
]
]
]
],
],
]);
echo "done.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to load data into $tableName\n");
}
$tableName = 'Forum';
echo "Adding data to the $tableName table...\n";
try {
$response = $dynamodb->batchWriteItem([
'RequestItems' => [
$tableName => [
[
'PutRequest' => [
'Item' => [
'Name'
=> ['S'
'Category' => ['S'
'Threads' => ['N'
'Messages' => ['N'
'Views'
=> ['N'
]
]
],
[
'PutRequest' => [
'Item' => [
'Name'
=> ['S'
'Category' => ['S'
'Threads' => ['N'
]
]
],
]
API Version 2012-08-10
623
=>
=>
=>
=>
=>
'Amazon DynamoDB'],
'Amazon Web Services'],
'0'],
'0'],
'1000']
=> 'Amazon S3'],
=> 'Amazon Web Services'],
=> '0']
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
]
]);
echo "done.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to load data into $tableName\n");
}
$tableName = 'Thread';
echo "Adding data to the $tableName table...\n";
try {
$response = $dynamodb->batchWriteItem([
'RequestItems' => [
$tableName => [
[
'PutRequest' => [
'Item' => [
'ForumName'
'Subject'
1'],
'Message'
message'],
'LastPostedBy'
'LastPostedDateTime'
'Views'
'Replies'
'Answered'
'Tags'
'primarykey', 'table']]
]
],
'PutRequest' => [
'Item' => [
'ForumName'
'Subject'
2'],
'Message'
message'],
'LastPostedBy'
'LastPostedDateTime'
'Views'
'Replies'
'Answered'
'Tags'
'partitionkey', 'sortkey']]
]
],
'PutRequest' => [
'Item' => [
'ForumName'
'Subject'
'Message'
message'],
'LastPostedBy'
'LastPostedDateTime'
'Views'
'Replies'
API Version 2012-08-10
624
=> ['S'=>'Amazon DynamoDB'],
=> ['S'=> 'DynamoDB Thread
=> ['S'=>'DynamoDB thread 1
=>
=>
=>
=>
=>
=>
['S'=>'User A'],
['S'=>$fourteenDaysAgo],
['N'=>'0'],
['N'=>'0'],
['N'=>'0'],
['SS' => ['index',
=> ['S'=>'Amazon DynamoDB'],
=> ['S'=> 'DynamoDB Thread
=> ['S'=>'DynamoDB thread 2
=>
=>
=>
=>
=>
=>
['S'=>'User A'],
['S'=>$twentyOneDaysAgo],
['N'=>'0'],
['N'=>'0'],
['N'=>'0'],
['SS' => ['index',
=> ['S'=>'Amazon S3'],
=> ['S'=> 'S3 Thread 1'],
=> ['S'=>'S3 Thread 3
=>
=>
=>
=>
['S'=>'User A'],
['S'=>$sevenDaysAgo],
['N'=>'0'],
['N'=>'0'],
Amazon DynamoDB 開発者ガイド
サンプルテーブルの作成とデータのアップロード – PHP
'Answered'
'Tags'
=> ['N'=>'0'],
=> ['SS' => ['largeobjects',
'multipart upload']]
]
]
]
]
]
]);
echo "done.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to load data into $tableName\n");
}
$tableName = 'Reply';
echo "Adding data to the $tableName table...\n";
try {
$response = $dynamodb->batchWriteItem([
'RequestItems' => [
$tableName => [
[
'PutRequest' => [
'Item' => [
'Id'
DynamoDB#DynamoDB Thread 1'],
'ReplyDateTime'
'Message'
Reply 2 text'],
'PostedBy'
]
]
],
[
'PutRequest' => [
'Item' => [
'Id'
DynamoDB#DynamoDB Thread 2'],
'ReplyDateTime'
'Message'
Reply 3 text'],
'PostedBy'
]
]
],
[
'PutRequest' => [
'Item' => [
'Id'
DynamoDB#DynamoDB Thread 2'],
'ReplyDateTime'
'Message'
Reply 2 text'],
'PostedBy'
]
]
],
API Version 2012-08-10
625
=> ['S' => 'Amazon
=> ['S' => $fourteenDaysAgo],
=> ['S' => 'DynamoDB Thread 1
=> ['S' => 'User B']
=> ['S' => 'Amazon
=> ['S' => $twentyOneDaysAgo],
=> ['S' => 'DynamoDB Thread 2
=> ['S' => 'User B']
=> ['S' => 'Amazon
=> ['S' => $sevenDaysAgo],
=> ['S' => 'DynamoDB Thread 2
=> ['S' => 'User A']
Amazon DynamoDB 開発者ガイド
AWS SDK for Python(Boto)を使
用したサンプルアプリケーション
[
'PutRequest' => [
'Item' => [
'Id'
=> ['S' =>
DynamoDB#DynamoDB Thread 2'],
'ReplyDateTime' => ['S' =>
'Message'
=> ['S' =>
Reply 1 text'],
'PostedBy'
=> ['S' =>
]
]
]
],
]
]);
'Amazon
$oneDayAgo],
'DynamoDB Thread 2
'User A']
echo "done.\n";
} catch (DynamoDbException $e) {
echo $e->getMessage() . "\n";
exit ("Unable to load data into $tableName\n");
}
?>
AWS SDK for Python (Boto) を使用した
DynamoDB サンプルアプリケーション: Tic-TacToe
トピック
• ステップ 1: ローカルにデプロイおよびテストを実行する (p. 627)
• ステップ 2: データモデルと実装の詳細を調べる (p. 630)
• ステップ 3: DynamoDB サービスを使用して本稼働環境でデプロイする (p. 637)
• ステップ 4: リソースをクリーンアップする (p. 644)
Tic-Tac-Toe ゲームは、Amazon DynamoDB 上に構築されたサンプルウェブアプリケーションです。
このアプリケーションは AWS SDK for Python (Boto) を使用して、DynamoDB テーブルにゲームデー
タを格納するために必要な DynamoDB 呼び出しを行い、Python ウェブフレームワーク Flask を使用
して、データのモデル化の方法を含む DynamoDB でのアプリケーション開発のすべてを示します。
また、DynamoDB でのデータのモデル化に関するベストプラクティスを示します。これには、ゲーム
アプリケーション用に作成するテーブル、ユーザーが定義するプライマリキー、クエリ要件に基づい
て必要になる追加のインデックス、および連結された属性値の使用が含まれます。
Tic-Tac-Toe アプリケーションは、次のようにしてウェブ上でプレイします。
1. アプリケーションのホームページにログインします。
2. 次に、他のユーザーを対戦相手としてゲームに招待します。
他のユーザーが招待を受け入れるまで、ゲームのステータスは PENDING となります。対戦相手が
招待を受け入れると、ステータスは IN_PROGRESS に変わります。
3. ゲームは、対戦相手がログインして招待を受け入れてから開始されます。
4. アプリケーションはゲームのすべての動きやステータス情報を DynamoDB テーブルに格納しま
す。
API Version 2012-08-10
626
Amazon DynamoDB 開発者ガイド
ステップ 1: ローカルにデプロイおよびテストを実行する
5. ゲームは優勝または引き分けで終わり、これによりゲームのステータスは FINISHED に設定されま
す。
アプリケーション構築についてすべて網羅した演習を各ステップで示します。
• ステップ 1: ローカルにデプロイおよびテストを実行する (p. 627) - このセクションでは、アプリ
ケーションをローカルコンピュータにダウンロード、デプロイ、およびテストします。DynamoDB
のダウンロード可能バージョンで、必要なテーブルを作成します。
• ステップ 2: データモデルと実装の詳細を調べる (p. 630) - このセクションでは、最初にインデッ
クスと連結属性値の使用を含めて、データモデルについて詳細に説明します。次に、アプリケー
ションの動作について説明します。
• ステップ 3: DynamoDB サービスを使用して本稼働環境でデプロイする (p. 637) – このセクショ
ンでは、本稼働環境でのデプロイの考慮事項について説明します。このステップでは、Amazon
DynamoDB サービスを使用してテーブルを作成し、AWS Elastic Beanstalk を使用してアプリケー
ションをデプロイします。本稼働環境にアプリケーションがある場合は、アプリケーションが
DynamoDB テーブルにアクセスできるように、適切なアクセス許可を付与します。このセクション
の手順では、本稼働デプロイについて詳細に説明します。
• ステップ 4: リソースをクリーンアップする (p. 644) – このセクションでは、この例で説明されて
いない分野を取り上げます。また、料金が発生しないようにするため、前のステップで作成した
AWS リソースを削除するためのステップについても説明します。
ステップ 1: ローカルにデプロイおよびテストを実
行する
トピック
• 1.1: 必要なパッケージのダウンロードとインストール (p. 627)
• 1.2: ゲームアプリケーションをテストする (p. 628)
このステップでは、Tic-Tac-Toe ゲームアプリケーションをローカルコンピュータにダウンロー
ド、デプロイ、およびテストします。Amazon DynamoDB ウェブサービスを使用する代わり
に、DynamoDB をコンピュータにダウンロードして必要なテーブルを作成します。
1.1: 必要なパッケージのダウンロードとインストール
このアプリケーションをローカルでテストするには、次のものが必要です。
• Python
• Flask(Python 用のマイクロフレームワーク)
• AWS SDK for Python(Boto)
• コンピュータ上で実行される DynamoDB
• Git
これらのツールを入手するには、以下の作業を実行します。
1. Python をインストールします。詳しい手順については、「Python のダウンロード」を参照してく
ださい。
Tic-Tac-Toe アプリケーションは、Python バージョン 2.7 を使用してテスト済みです。
2. Python パッケージインストーラ(PIP)を使用して Flask および AWS SDK for Python(Boto)を
インストールします。
• PIP をインストールします。
API Version 2012-08-10
627
Amazon DynamoDB 開発者ガイド
ステップ 1: ローカルにデプロイおよびテストを実行する
手順については、「PIP のインストール」を参照してください。インストールページで、[getpip.py] リンクを選択して、ファイルを保存します。次に、管理者としてコマンドターミナルを開
き、コマンドプロンプトで以下のように入力します。
python.exe get-pip.py
Linux では、.exe 拡張子を指定しません。python get-pip.py のみを指定します。
• PIP で、次に示すコードを使用して Flask と Boto パッケージをインストールします。
pip install Flask
pip install boto
pip install configparser
3. DynamoDB をコンピュータにダウンロードします。その実行方法については、「DynamoDB (ダウ
ンロード可能バージョン) のセットアップ (p. 44)」を参照してください。
4. Tic-Tac-Toe アプリケーションをダウンロードします。
a. Git をインストールします。手順については、「Git のダウンロード」を参照してください。
b. アプリケーションをダウンロードするには、次のコードを実行します。
git clone https://github.com/awslabs/dynamodb-tictactoe-example-app.git
1.2: ゲームアプリケーションをテストする
Tic-Tac-Toe アプリケーションをテストするには、ローカルコンピュータで DynamoDB を実行する必
要があります。
Tic-Tac-Toe アプリケーションを実行するには
1.
DynamoDB を起動します。
2.
Tic-Tac-Toe アプリケーション用のウェブサーバーを起動します。
そのためには、コマンドターミナルを開き、Tic-Tac-Toe アプリケーションをダウンロードした
フォルダに移動し、次に示すコードを使用してアプリケーションをローカルに実行します。
python.exe application.py --mode local --serverPort 5000 --port 8000
Linux では、.exe 拡張子を指定しません。
3.
ウェブブラウザを開き、次のように入力します。
http://localhost:5000/
ブラウザにホームページが表示されます。
API Version 2012-08-10
628
Amazon DynamoDB 開発者ガイド
ステップ 1: ローカルにデプロイおよびテストを実行する
4.
[Log in] ボックスに「user1」と入力し、user1 としてログインします。
Note
このサンプルアプリケーションは、ユーザー認証を実行しません。ユーザー ID のみがプ
レーヤーを識別するために使用されます。2 人のプレーヤーが同じエイリアスでログイン
すると、アプリケーションは 2 つの別のブラウザでプレイしているかのように動作しま
す。
5.
初めてゲームを実行する場合、DynamoDB で必要なテーブル(Games)を作成するようにリクエ
ストするページが表示されます。[CREATE TABLE] を選択します。
6.
[CREATE] を選択して、最初の Tic-Tac-Toe ゲームを作成します。
7.
[Choose an Opponent] ボックスに「user2」と入力し、[Create Game!] を選択します。
この操作を行うと、Games テーブルに項目を追加してゲームが作成されます。これにより、ゲー
ムのステータスが PENDING に設定されます。
8.
別のブラウザウィンドウを開き、次のように入力します。
http://localhost:5000/
ブラウザは Cookie を通じて情報を渡すので、Cookie を引き継がないように、匿名モードまたは
プライベートブラウジングを使用します。
9.
user2 としてログインします。
API Version 2012-08-10
629
Amazon DynamoDB 開発者ガイド
ステップ 2: データモデルと実装の詳細を調べる
user1 からの保留中の招待を示すページが表示されます。
10. [accept] を選択して招待を受け入れます。
ゲームページが、空の Tic-Tac-Toe グリッドとともに表示されます。このページには、ゲーム
ID、誰の番か、ゲームのステータスなど、関連するゲーム情報も表示されます。
11. ゲームをプレイします。
ユーザーが動くたびに、ウェブサービスは Games テーブルのゲーム項目を条件付きで更新するリク
エストを DynamoDB に送信します。たとえば、条件により、動きが有効で、ユーザーが選択した四
角形が利用可能で、動いたユーザーの番であったことを確認できます。動きが有効な場合、更新操作
により、ボードでの選択に対応する新しい属性が追加されます。また、既存の属性値が、次に動くこ
とができるユーザーに設定されます。
アプリケーションは、ゲームページで非同期 JavaScript 呼び出しを毎秒行い、最大 5 分にわた
り、DynamoDB のゲーム状態が変わったかどうかを確認します。変わった場合、アプリケーション
は新しい情報でページを更新します。5 分後に、アプリケーションはリクエストを中止します。ユー
ザーはページを更新して、更新された情報を取得する必要があります。
ステップ 2: データモデルと実装の詳細を調べる
トピック
• 2.1: 基本的なデータモデル (p. 630)
• 2.2: 実行中のアプリケーション(コードのウォークスルー) (p. 632)
2.1: 基本的なデータモデル
このサンプルアプリケーションでは、次の DynamoDB データモデルの概念を説明します。
API Version 2012-08-10
630
Amazon DynamoDB 開発者ガイド
ステップ 2: データモデルと実装の詳細を調べる
• テーブル – DynamoDB では、テーブルは項目(レコード)の集合であり、各項目は属性と呼ばれる
名前と値のペアの集合です。
この Tic-Tac-Toe の例では、アプリケーションは、Games テーブル内のすべてのゲームデータを格
納します。アプリケーションはゲームごとにテーブルで 1 つの項目を作成し、すべてのゲームデー
タを属性として格納します。Tic-Tac-Toe ゲームでは最大 9 回の移動が可能です。DynamoDB テー
ブルは、プライマリキーのみが必須属性である場合はスキーマを持たないので、アプリケーション
は 1 ゲーム項目あたり異なる数の属性を格納できます。
Games テーブルには、文字列型の 1 つの属性 GameId で構成されるシンプルなプライマリキーが
あります。アプリケーションは各ゲームに一意の ID を割り当てます。DynamoDB プライマリキー
の詳細については、「プライマリキー (p. 5)」を参照してください。
ユーザーが他のユーザーを招待して Tic-Tac-Toe ゲームを開始すると、アプリケーションは、次の
ようなゲームメタデータを格納する属性で、Games テーブルに新しい項目を作成します。
• ゲームを開始したユーザーである HostId。
• ゲームに招待されたユーザーである Opponent。
• プレイする番のユーザー。最初にゲームを開始したユーザー。
• ボードで O 記号を使用するユーザー。ゲームを開始するユーザーは O 記号を使用します。
さらに、アプリケーションは StatusDate 連結属性を作成し、ゲームの初期状態を PENDING とし
てマークします。次のスクリーンショットは、DynamoDB コンソールに表示されるサンプル項目を
示しています。
アプリケーションは、ゲームの進行に合わせて、ゲームで動きがあるたびに 1 つの属性をテーブル
に追加します。属性名はボードの位置(TopLeft、BottomRight など)です。たとえば、動きに
は値 Oの TopLeft 属性、値 O の TopRight 属性、および値 Xの BottomRight 属性があるなどで
す。属性値は、動いたユーザーに応じて、O または X になります。たとえば、次のボードを考えて
みます。
• 連結属性値 – StatusDate 属性が、連結値属性を示します。この手法では、ゲームのステータス
(PENDING、IN_PROGRESS、FINISHED)および日付(最後の動き)を格納する個別の属性を作成
API Version 2012-08-10
631
Amazon DynamoDB 開発者ガイド
ステップ 2: データモデルと実装の詳細を調べる
する代わりに、IN_PROGRESS_2014-04-30 10:20:32 などの単一の属性としてそれらを組み合わ
せます。
次に、アプリケーションは、インデックスのソートキーとして StatusDate を指定して、セカンダ
リインデックスの作成で StatusDate 属性を使用します。StatusDate 連結値属性を使用する利点
について、さらに次のインデックスの説明で示します。
• グローバルセカンダリインデックス - テーブルのプライマリキー GameId を使用すると、テーブル
を効率的に照会してゲーム項目を検索できます。プライマリキー属性以外の属性でテーブルを照会
するため、DynamoDB はセカンダリインデックスの作成をサポートしています。このサンプルアプ
リケーションでは、次の 2 つのセカンダリインデックスを構築します。
• HostId-StatusDate-index. このインデックスはパーティションキーとして HostId を、ソートキー
として StatusDate を持ちます。このインデックスを使用して、たとえば特定のユーザーによっ
てホストされたゲームを検索するなど、HostId でクエリを実行できます。
• OpponentId-StatusDate-index. このインデックスはパーティションキーとして OpponentId を、
ソートキーとして StatusDate を持ちます。たとえば、特定のユーザーが対戦相手であるゲーム
を検索するなど、このインデックスを使用して Opponent でクエリを実行できます。
これらのインデックスは、グローバルセカンダリインデックスと呼ばれます。これは、インデック
スのパーティションキーが、テーブルのプライマリキーで使用されるパーティションキー (GameId)
とは同じでないためです。
両方のインデックスがソートキーとして StatusDate を指定することに注意してください。これを
行うと、次のことが可能になります。
• BEGINS_WITH 比較演算子を使用してクエリを実行できます。たとえば、特定のユーザー
によってホストされた IN_PROGRESS 属性を持つすべてのゲームを検索できます。この場
合、BEGINS_WITH 演算子は、IN_PROGRESS で始まる StatusDate 値を確認します。
• DynamoDB は、インデックスでソートキー値によってソートして項目を保存します。したがっ
て、すべてのステータスのプレフィックスは同じ(たとえば、IN_PROGRESS)になり、日付部
分に使用される ISO 形式には、最も古いものから最も新しいものの順にソートされた項目が含ま
れます。この手法により、たとえば次のように特定のクエリを効率的に実行できるようになりま
す。
• ログインしているユーザーによってホストされている最新の IN_PROGRESS のゲームを最大 10
個取得します。このクエリでは、HostId-StatusDate-index インデックスを指定します。
• ログインしているユーザーが対戦相手である最新の IN_PROGRESS のゲームを最大 10 個取得
します。このクエリでは、OpponentId-StatusDate-index インデックスを指定します。
セカンダリインデックスの詳細については、「セカンダリインデックスを使用したデータアクセス性
の向上 (p. 333)」を参照してください。
2.2: 実行中のアプリケーション(コードのウォークスルー)
このアプリケーションには 2 つのメインページがあります。
API Version 2012-08-10
632
Amazon DynamoDB 開発者ガイド
ステップ 2: データモデルと実装の詳細を調べる
• ホームページ – このページには、簡単なログイン、新しい Tic-Tac-Toe ゲームを作成する
[CREATE] ボタン、進行中のゲームのリスト、ゲームの履歴、およびアクティブな保留中のゲーム
の招待が表示されます。
ホームページは自動的に更新されません。リストを更新するには、ユーザーがページを更新する必
要があります。
• ゲームページ - このページには、ユーザーがプレイする Tic-Tac-Toe グリッドが表示されます。
アプリケーションは、毎秒ゲームページを自動的に更新します。ブラウザの JavaScript が毎秒
Python ウェブサーバーを呼び出して、テーブルのゲーム項目が変更されたかどうかを Games テー
ブルに照会します。変更された場合、JavaScript はページ更新をトリガーし、更新されたボードが
ユーザーに表示されるようにします。
アプリケーションの動作について詳細に説明します。
ホームページ
ユーザーがログインすると、アプリケーションには、以下の 3 つの情報のリストが表示されます。
• 招待 – このリストには、ログインしているユーザーが受け入れを保留中の、他のユーザーからの最
新の招待が最大 10 個表示されます。前のスクリーンショットで、user1 は user5 および user2 から
の招待を保留中です。
• 進行中のゲーム - このリストには、進行中の最新のゲームが最大 10 個表示されます。これらは、
ユーザーがアクティブに実行中のゲームで、そのステータスは IN_PROGRESS です。スクリーン
ショットでは、user1 は user3 および user4 と Tic-Tac-Toe ゲームをアクティブにプレイ中です。
• 最近の履歴 – このリストには、ユーザーが終了した最近のゲームが最大 10 個表示されます。その
ステータスは FINISHED です。スクリーンショットに示したゲームで、user1 は以前に user2 とプ
レイしています。完了した各ゲームについて、ゲームの結果がリストに表示されます。
コードで、index 関数は(application.py で)次の 3 つの呼び出しを行い、ゲームのステータス
情報を取得します。
inviteGames
= controller.getGameInvites(session["username"])
inProgressGames = controller.getGamesWithStatus(session["username"],
"IN_PROGRESS")
finishedGames
= controller.getGamesWithStatus(session["username"],
"FINISHED")
これらは呼び出しはそれぞれ、Game オブジェクトでラップされた、DynamoDB からの項目のリスト
を返します。ビューでこれらのオブジェクトからデータを抽出することは簡単です。インデックス関
数は、HTML を表示するため、これらのオブジェクトリストをビューに渡します。
API Version 2012-08-10
633
Amazon DynamoDB 開発者ガイド
ステップ 2: データモデルと実装の詳細を調べる
return render_template("index.html",
user=session["username"],
invites=inviteGames,
inprogress=inProgressGames,
finished=finishedGames)
Tic-Tac-Toe アプリケーションは、主に DynamoDB から取得したゲームデータを格納するた
め、Game クラスを定義します。これらの関数は、Amazon DynamoDB 項目に関連するコードからア
プリケーションの他の部分を分離できるようにする Game オブジェクトのリストを返します。これら
の関数により、このようにしてデータストア層の詳細からアプリケーションコードを切り離すことが
できます。
ここで説明するアーキテクチャーパターンは、model-view-controller(MVC)UI パターンとも呼
ばれます。この場合、Game オブジェクトのインスタンス(データを表す)はモデルで、HTML
ページはビューです。コントローラーは 2 つのファイルに分割されます。application.py
ファイルには Flask フレームワーク用のコントローラーロジックがあり、ビジネスロジックは
gameController.py ファイルに分離されます。つまり、アプリケーションは、DynamoDB SDK で
行う必要があるすべてを、dynamodb フォルダの独自の個別ファイルに格納します。
3 つの関数と、それらが該当データを取得するためにグローバルセカンダリインデックスを使用して
Games テーブルを照会する方法について説明します。
getGameInvites を使用した保留中のゲームの招待リストの取得
getGameInvites 関数は保留中の最新の 10 個の招待リストを取得します。これらのゲームはユー
ザーによって作成されましたが、対戦相手はゲームの招待を受け入れていません。これらのゲームの
場合、対戦相手が招待を受け入れるまでステータスは PENDING のままになります。対戦相手が招待
を辞退した場合、アプリケーションは、対応する項目をテーブルから削除します。
関数は、以下のようなクエリを指定します。
• 関数は、以下のキー値および比較演算子とともに使用する OpponentId-StatusDate-index イン
デックスを指定します。
• パーティションキーは OpponentId で、インデックスキー user ID を受け取ります。
• ソートキーは StatusDate で、比較演算子およびインデックスキー値
beginswith="PENDING_" を受け取ります。
OpponentId-StatusDate-index インデックスを使用して、ログインしたユーザーが招待される
ゲーム(ログインしたユーザーが対戦相手であるゲーム)を取得します。
• クエリは結果を 10 項目に制限します。
gameInvitesIndex = self.cm.getGamesTable().query(
Opponent__eq=user,
StatusDate__beginswith="PENDING_",
index="OpponentId-StatusDateindex",
limit=10)
インデックスで、DynamoDB は OpponentId (パーティションキー) ごとに、StatusDate (ソート
キー) でソートして項目を保持します。そのため、クエリが返すゲームは最新の 10 個のゲームになり
ます。
getGamesWithStatus を使用した特定のステータスのゲームリストの取得
対戦相手がゲームの招待を受け入れると、ゲームのステータスは IN_PROGRESS に変わります。ゲー
ムが完了すると、ステータスは FINISHED に変わります。
API Version 2012-08-10
634
Amazon DynamoDB 開発者ガイド
ステップ 2: データモデルと実装の詳細を調べる
進行中または終了済みのゲームを検索するクエリは、ステータス値が異なる場合を除いて同じです。
したがって、アプリケーションは getGamesWithStatus 関数を定義し、この関数はステータス値を
パラメータとして受け取ります。
inProgressGames = controller.getGamesWithStatus(session["username"],
"IN_PROGRESS")
finishedGames
= controller.getGamesWithStatus(session["username"],
"FINISHED")
次のセクションでは進行中のゲームについて説明しますが、終了済みのゲームにも同じ説明が当ては
まります。
特定のユーザーの進行中のゲームのリストには、次の両方が含まれます。
• ユーザーによってホストされた進行中のゲーム
• ユーザーが対戦相手である進行中のゲーム
getGamesWithStatus 関数は、毎回適切なセカンダリインデックスを使用して次の 2 つのクエリを
実行します。
• この関数は HostId-StatusDate-index インデックスを使用して Games テーブルを照会しま
す。インデックスについて、クエリでは比較演算子とともにプライマリキーの値 (パーティション
キー (HostId) およびソートキー (StatusDate) の値の両方) を指定します。
hostGamesInProgress = self.cm.getGamesTable ().query(HostId__eq=user,
StatusDate__beginswith=status,
index="HostId-StatusDateindex",
limit=10)
比較演算子の Python の構文に注意してください。
• HostId__eq=user は等価比較演算子を指定します。
• StatusDate__beginswith=status は BEGINS_WITH 比較演算子を指定します。
• この関数は OpponentId-StatusDate-index インデックスを使用して Games テーブルを照会し
ます。
oppGamesInProgress = self.cm.getGamesTable().query(Opponent__eq=user,
StatusDate__beginswith=status,
index="OpponentId-StatusDateindex",
limit=10)
• 次に、この関数は 2 つのリストを組み合わせ、ソートし、最初の 0~10 項目について Game オブ
ジェクトのリストを作成して、呼び出し元関数(インデックス)にリストを返します。
games = self.mergeQueries(hostGamesInProgress,
oppGamesInProgress)
return games
API Version 2012-08-10
635
Amazon DynamoDB 開発者ガイド
ステップ 2: データモデルと実装の詳細を調べる
ゲームページ
ゲームページは、ユーザーが Tic-Tac-Toe ゲームをプレイする場所です。このページには、ゲームの
関連情報とともに、ゲームグリッドが表示されます。次のスクリーンショットは、進行中のサンプル
ゲームを示しています。
アプリケーションは次の状況でゲームページを表示します。
• ユーザーは他のユーザーを招待してゲームを作成します。
この場合、ページはホストやゲームのステータスを PENDING としてユーザーに表示し、対戦相手
が受け入れるのを待ちます。
• ユーザーは、ホームページで保留中の招待の 1 つを受け入れます。
この場合、ページではユーザーは対戦相手として、ゲームのステータスは IN_PROGRESS として表
示されます。
ボード上でのユーザーによる選択操作により、アプリケーションへのフォーム POST リクエ
ストが生成されます。つまり、Flask は HTML フォームデータとともに selectSquare 関数
を(application.py で)呼び出します。次に、この関数は updateBoardAndTurn 関数を
(gameController.py で)呼び出して、次のようにゲーム項目を更新します。
• これにより、動きに固有の新しい属性が追加されます。
• Turn 属性が、次の番のユーザーに更新されます。
controller.updateBoardAndTurn(item, value, session["username"])
項目の更新が成功した場合、関数は true を返します。それ以外の場合は、false を返しま
す。updateBoardAndTurn 関数について、以下の点に注意してください。
• この関数は、既存の項目に対する更新の一定のセットを作成するため、AWS SDK for Python の
update_item 関数を呼び出します。この関数は、DynamoDB の UpdateItem オペレーションに対
応します。詳細については、「UpdateItem」を参照してください。
Note
UpdateItem オペレーションと PutItem オペレーションの違いは、PutItem が項目全体
を置き換えることです。詳細については、「PutItem」を参照してください。
API Version 2012-08-10
636
Amazon DynamoDB 開発者ガイド
ステップ 3: 本稼働環境でのデプロイ
update_item 呼び出しでは、コードは以下を識別します。
• Games テーブルのプライマリキー(ItemId)。
key = { "GameId" : { "S" : gameId } }
• 現在のユーザーの動きに固有の、追加する新しい属性とその値(例: TopLeft="X")。
attributeUpdates = {
position : {
"Action" : "PUT",
"Value" : { "S" : representation }
}
}
• 更新が実行されるために満たされる必要がある条件
• ゲームは進行中である必要があります。つまり、StatusDate 属性値は IN_PROGRESS で始まる
必要があります。
• 現在の番は、Turn 属性で指定されている有効なユーザーの番である必要があります。
• ユーザーが選択した四角形は使用可能である必要があります。つまり、四角形に対応する属性は
存在していてはなりません。
expectations = {"StatusDate" : {"AttributeValueList": [{"S" :
"IN_PROGRESS_"}],
"ComparisonOperator": "BEGINS_WITH"},
"Turn" : {"Value" : {"S" : current_player}},
position : {"Exists" : False}}
ここで、関数は update_item を呼び出して項目を更新します。
self.cm.db.update_item("Games", key=key,
attribute_updates=attributeUpdates,
expected=expectations)
関数に戻ると、selectSquare 関数呼び出しは次の例に示すようにリダイレクトされます。
redirect("/game="+gameId)
この呼び出しにより、ブラウザが更新されます。この更新の一環として、アプリケーションはゲーム
が優勝または引き分けで終了したかどうかを確認します。終了した場合、アプリケーションはそれに
応じてゲーム項目を更新します。
ステップ 3: DynamoDB サービスを使用して本稼働
環境でデプロイする
トピック
• 3.1: Amazon EC2 向けの IAM ロールを作成する (p. 639)
• 3.2: Amazon DynamoDB での Games テーブルの作成 (p. 639)
• 3.3: Tic-Tac-Toe アプリケーションコードのバンドルとデプロイ (p. 639)
• 3.4: AWS Elastic Beanstalk 環境のセットアップ (p. 641)
API Version 2012-08-10
637
Amazon DynamoDB 開発者ガイド
ステップ 3: 本稼働環境でのデプロイ
前のセクションでは、DynamoDB Local を使用してコンピュータでローカルに Tic-Tac-Toe アプリ
ケーションをデプロイし、テストしました。ここでは、次のようにして本稼働環境でアプリケーショ
ンをデプロイします。
• ウェブアプリケーションやサービスをデプロイ、スケーリングするための使いやすいサービスであ
る Elastic Beanstalk を使用して、アプリケーションをデプロイします。詳細については、「AWS
Elastic Beanstalk への Flask アプリケーションのデプロイ」を参照してください。
Elastic Beanstalk は 1 つ以上の Amazon Elastic Compute Cloud(Amazon EC2)インスタンスを起
動します。これは、Tic-Tac-Toe アプリケーションが実行される Elastic Beanstalk を通じて設定し
ます。
• Amazon DynamoDB サービスを使用して、コンピュータにローカルに存在するのではなく、AWS
に存在する Games テーブルを作成します。
さらに、アクセス許可も設定する必要があります。DynamoDB の Games テーブルなど、作成する
AWS リソースは、デフォルトでプライベートになります。リソース所有者(Games テーブルを作
成した AWS アカウント)のみが、このテーブルにアクセスできます。したがって、デフォルトでは
Tic-Tac-Toe アプリケーションは Games テーブルを更新することはできません。
必要なアクセス許可を付与するには、AWS Identity and Access Management(IAM)のロールを作成
し、Games テーブルへのアクセス許可をこのロールに付与します。Amazon EC2 インスタンスは最
初にこのロールを引き受けます。AWS は、その応答として Tic-Tac-Toe アプリケーションに代わって
Amazon EC2 インスタンスが Games テーブルを更新するために使用できる一時的なセキュリティ認
証情報を返します。Elastic Beanstalk アプリケーションを設定するときは、Amazon EC2 インスタン
スが引き受けることができる IAM ロールを指定します。IAM ロールの詳細については、『Linux イン
スタンス用 Amazon EC2 ユーザーガイド』の「Amazon EC2 向けの IAM ロール」を参照してくださ
い。
Note
Tic-Tac-Toe 用の Amazon EC2 インスタンスを作成する前に、Elastic Beanstalk がインスタ
ンスを作成する AWS リージョンを最初に決定する必要があります。Elastic Beanstalk アプ
リケーションを作成したら、設定ファイルで同じリージョン名とエンドポイントを指定しま
す。Tic-Tac-Toe アプリケーションはこのファイルの情報を使用して Games テーブルを作成
し、それ以降のリクエストを特定の AWS リージョンに送信します。DynamoDB Games テー
ブルと Elastic Beanstalk が起動する Amazon EC2 インスタンスの両方は、同じ AWS リー
ジョンにある必要があります。使用可能なリージョンのリストについては、『アマゾン ウェ
ブ サービス全般のリファレンス』の「Amazon DynamoDB 」を参照してください。
要約すると、Tic-Tac-Toe アプリケーションを本稼働環境にデプロイするには、以下の作業を行いま
す。
1. AWS IAM サービスを使用して IAM ロールを作成します。DynamoDB アクションが Games テーブ
ルにアクセスするためのアクセス許可を付与するポリシーを、このロールにアタッチします。
2. Tic-Tac-Toe アプリケーションコードおよび設定ファイルをバンドルし、.zip ファイルを作成しま
す。この .zip ファイルを使用して、サーバーに配置する Tic-Tac-Toe アプリケーションコードを
Elastic Beanstalk に渡します。バンドル作成の詳細については、『AWS Elastic Beanstalk 開発者ガ
イド』の「アプリケーションソースバンドルを作成する」を参照してください。
設定ファイル(beanstalk.config)で、AWS リージョンおよびエンドポイント情報を指定しま
す。Tic-Tac-Toe アプリケーションは、この情報を使用して、通信する DynamoDB リージョンを決
定します。
3. Elastic Beanstalk 環境をセットアップします。Elastic Beanstalk は 1 つ以上の Amazon EC2 インス
タンスを起動して、Tic-Tac-Toe アプリケーションバンドルをそれらのインスタンス上でデプロイ
します。Elastic Beanstalk 環境の準備が整ったら、CONFIG_FILE 環境変数を追加して設定ファイ
ル名を指定します。
API Version 2012-08-10
638
Amazon DynamoDB 開発者ガイド
ステップ 3: 本稼働環境でのデプロイ
4. DynamoDB テーブルを作成します。Amazon DynamoDB サービスを使用して、コンピュータ上
にローカルにではなく AWS 上に Games テーブルを作成します。このテーブルは、文字列型の
GameId パーティションキーで構成されたシンプルなプライマリキーを持ちます。
5. 本稼働環境でゲームをテストします。
3.1: Amazon EC2 向けの IAM ロールを作成する
Amazon EC2 型の IAM ロールを作成すると、Tic-Tac-Toe アプリケーションを実行中の Amazon EC2
インスタンスは正しい IAM ロールを引き受け、Games テーブルにアクセスするアプリケーションリ
クエストを行えるようになります。ロールを作成するときに、[Custom Policy] オプションを選択し、
次のポリシーをコピーして貼り付けます。
{
"Version":"2012-10-17",
"Statement":[
{
"Action":[
"dynamodb:ListTables"
],
"Effect":"Allow",
"Resource":"*"
},
{
"Action":[
"dynamodb:*"
],
"Effect":"Allow",
"Resource":[
"arn:aws:dynamodb:us-west-2:922852403271:table/Games",
"arn:aws:dynamodb:us-west-2:922852403271:table/Games/index/*"
]
}
]
}
詳細な手順については、『IAM ユーザーガイド』の「AWS サービス用のロールを作成する (AWS
Management Console)」を参照してください。
3.2: Amazon DynamoDB での Games テーブルの作成
DynamoDB の Games テーブルはゲームデータを格納します。テーブルが存在しない場合、アプリ
ケーションによって自動的にテーブルが作成されます。この例では、アプリケーションで Games
テーブルを作成します。
3.3: Tic-Tac-Toe アプリケーションコードのバンドルとデプロ
イ
この例のステップを実行した場合、既に Tic-Tac-Toe アプリケーションをダウンロードしています。
そうでない場合は、アプリケーションをダウンロードし、すべてのファイルをローカルコンピュータ
上のフォルダに展開します。手順については、「ステップ 1: ローカルにデプロイおよびテストを実行
する (p. 627)」を参照してください。
すべてのファイルを展開すると、code フォルダが作成されます。このフォルダを Electric Beanstalk
に渡すには、このフォルダのコンテンツを .zip ファイルとしてバンドルします。最初に、そのフォ
ルダに設定ファイルを追加する必要があります。アプリケーションは、リージョンとエンドポイント
API Version 2012-08-10
639
Amazon DynamoDB 開発者ガイド
ステップ 3: 本稼働環境でのデプロイ
情報を使用して、指定されたリージョンで DynamoDB テーブルを作成し、指定されたエンドポイン
トを使用して、それ以降のテーブルオペレーションのリクエストを行います。
1.
Tic-Tac-Toe アプリケーションをダウンロードしたフォルダに切り替えます。
2.
アプリケーションのルートフォルダで、次のコンテンツを使用して beanstalk.config という
名前のテキストファイルを作成します。
[dynamodb]
region=<AWS region>
endpoint=<DynamoDB endpoint>
たとえば、次のコンテンツを使用します。
[dynamodb]
region=us-west-2
endpoint=dynamodb.us-west-2.amazonaws.com
利用可能なリージョンのリストについては、『アマゾン ウェブ サービス全般のリファレンス』の
「Amazon DynamoDB」を参照してください。
Important
設定ファイルで指定されたリージョンは、Tic-Tac-Toe アプリケーションが DynamoDB
で Games テーブルを作成する場所です。次のセクションで説明する Elastic Beanstalk ア
プリケーションを、同じリージョンで作成する必要があります。
Note
Elastic Beanstalk アプリケーションを作成するときは、環境タイプを選択できる環境を起
動するようにリクエストします。Tic-Tac-Toe サンプルアプリケーションをテストするに
は、[Single Instance] 環境タイプを選択し、それ以降をスキップして、次のステップに進
みます。
ただし、[Load balancing, autoscaling] 環境タイプでは、高可用性でスケーラブルな環境
が提供されます。これは、他のアプリケーションを作成、デプロイする場合に検討して
ください。この環境タイプを選択する場合、UUID を生成し、次に示すように設定ファイ
ルに追加する必要があります。
[dynamodb]
region=us-west-2
endpoint=dynamodb.us-west-2.amazonaws.com
[flask]
secret_key= 284e784d-1a25-4a19-92bf-8eeb7a9example
クライアント/サーバー通信でサーバーが応答を送信するときは、セキュリティのため、
サーバーは、クライアントが次のリクエストでサーバーに送り返す署名済み Cookie を送
信します。サーバーが 1 台のみの場合、サーバーは、起動時にローカルに暗号化キーを
生成できます。多くのサーバーがある場合、それらのサーバーはすべて同じ暗号化キー
を知る必要があります。そうしない場合、ピアサーバーによって設定された Cookie を読
み取ることができません。secret_key を設定ファイルに追加することで、この暗号化
キーを使用するようにすべてのサーバーに伝えます。
3.
アプリケーションのルートフォルダのコンテンツ(beanstalk.config ファイルを含む)を、
たとえば TicTacToe.zip のように zip ファイルとしてバンドルします。
API Version 2012-08-10
640
Amazon DynamoDB 開発者ガイド
ステップ 3: 本稼働環境でのデプロイ
4.
Amazon Simple Storage Service(Amazon S3)バケットに .zip ファイルをアップロードしま
す。次のセクションでは、この .zip ファイルを、1 つ以上のサーバーにアップロードするため
に Elastic Beanstalk に渡します。
Amazon S3 バケットにアップロードする方法の手順については、『Amazon Simple Storage
Service 入門ガイド』の「バケットの作成」および「バケットへのオブジェクトの追加」トピック
を参照してください。
3.4: AWS Elastic Beanstalk 環境のセットアップ
このステップでは、環境を含むコンポーネントの集合である Elastic Beanstalk アプリケーションを作
成します。この例では、1 つの Amazon EC2 インスタンスを起動して、Tic-Tac-Toe アプリケーショ
ンをデプロイ、実行します。
1.
環境をセットアップするには、次のカスタム URL を入力して Elastic Beanstalk コンソールを
セットアップします。
https://console.aws.amazon.com/elasticbeanstalk/?region=<AWS-Region>#/
newApplication
?applicationName=TicTacToeyour-name
&solutionStackName=Python
&sourceBundleUrl=https://s3.amazonaws.com/<bucket-name>/TicTacToe.zip
&environmentType=SingleInstance
&instanceType=t1.micro
カスタム URL の詳細については、『AWS Elastic Beanstalk 開発者ガイド』の「Launch Now
URL の作成」を参照してください。URL については、次の点に注意してください。
• (設定ファイルで指定したものと同じ)AWS リージョン名、Amazon S3 バケット名、および
オブジェクト名を指定する必要があります。
• テストでは、URL は SingleInstance 環境タイプ、および t1.micro をインスタンスタイプとして
リクエストします。
• アプリケーション名は一意である必要があります。そのため、前の URL で
は、applicationName の前に名前を追加することをお勧めします。
この操作を行うと、Elastic Beanstalk コンソールが開きます。場合によっては、サインインが必
要にあることがあります。
2.
Elastic Beanstalk コンソールで、[Review and Launch] を選択し、[Launch] を選択します。
3.
今後の参照用に URL を書き留めてください。この URL により、Tic-Tac-Toe アプリケーション
のホームページが開きます。
4.
Tic-Tac-Toe アプリケーションを設定し、設定ファイルの場所を指定します。
Elastic Beanstalk がアプリケーションを作成したら、[Configuration] を選択します。
API Version 2012-08-10
641
Amazon DynamoDB 開発者ガイド
ステップ 3: 本稼働環境でのデプロイ
a.
次のスクリーンショットに示すように、[Software Configuration] の横にある歯車のボックス
を選択します。
b.
[Environment Properties] セクションの最後で、「CONFIG_FILE」とその値
「beanstalk.config」を入力し、[Save] を選択します。
この環境の更新が完了するには数分かかる場合があります。
更新が完了したら、ゲームをプレイできます。
5.
ブラウザで、前のステップでコピーした URL を、以下の例に示すように入力します。
http://<pen-name>.elasticbeanstalk.com
これにより、アプリケーションのホームページが開きます。
API Version 2012-08-10
642
Amazon DynamoDB 開発者ガイド
ステップ 3: 本稼働環境でのデプロイ
6.
testuser1 としてログインし、[CREATE] を選択して新しい Tic-Tac-Toe ゲームを開始します。
7.
[Choose an Opponent] ボックスに「testuser2」と入力します。
8.
別のブラウザウィンドウを開きます。
ブラウザウィンドウのすべての Cookie を消去し、同じユーザーとしてログインしないようにし
ます。
9.
以下の例に示すように、同じ URL を入力してアプリケーションのホームページを開きます。
http://<env-name>.elasticbeanstalk.com
10. testuser2 としてログインします。
11. 保留中の招待のリストで、testuser1 からの招待に対して [accept] を選択します。
12. ゲームページが表示されます。
API Version 2012-08-10
643
Amazon DynamoDB 開発者ガイド
ステップ 4: リソースをクリーンアップする
testuser1 と testuser2 の両者がゲームをプレイできます。動きがあるごとに、アプリケーション
は Games テーブルの対応する項目に動きを保存します。
ステップ 4: リソースをクリーンアップする
これで Tic-Tac-Toe アプリケーションのデプロイとテストを完了しました。このアプリケーション
は、ユーザー認証を除いて、Amazon DynamoDB でのウェブアプリケーション開発をすべて網羅して
います。このアプリケーションは、ゲームの作成時にプレーヤーの名前を追加するためにのみ、ホー
ムページのログイン情報を使用します。本稼働アプリケーションでは、ユーザーログインおよび認証
を実行するために必要なコードを追加します。
テストを終了したら、料金が発生しないようにするため、Tic-Tac-Toe アプリケーションのテスト用
に作成したリソースを削除できます。
作成したリソースを削除するには
1.
DynamoDB で作成した Games テーブルを削除します。
2.
3.
Elastic Beanstalk 環境を終了し、Amazon EC2 インスタンスを解放します。
作成した IAM ロールを削除します。
4.
Amazon S3 で作成したオブジェクトを削除します。
DynamoDB 用の追加のツールとリソース
トピック
• Amazon DynamoDB Storage Backend for Titan (p. 645)
• Amazon DynamoDB 用 Logstash プラグイン (p. 668)
このセクションでは、Amazon DynamoDB でアプリケーションを開発するときに役立ついくつかの追
加のツールとリソースについて説明します。
Tip
ベストプラクティス、使用方法、およびツールの詳細については、DynamoDB 開発者用リ
ソースページを参照してください。
API Version 2012-08-10
644
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
• http://aws.amazon.com/dynamodb/developer-resources/
Amazon DynamoDB Storage Backend for Titan
DynamoDB Storage Backend for Titan パッケージは、Amazon DynamoDB 上で実装される Titan グ
ラフデータベース用のストレージバックエンドです。Titan は、グラフの保存とクエリ用に最適化さ
れたスケーラブルなグラフデータベースです。DynamoDB Storage Backend for Titan パッケージは
GitHub で入手できます。Titan: 分散グラフデータベース は GitHub (Titan バージョン0.4.4、Titanバー
ジョン0.5.4、Titanバージョン1.0.0) でも入手できます。
以下のセクションでは、グラフデータベース、グラフデータベースのいくつかのユースケース、およ
び Titan: 分散グラフデータベース を DynamoDB Storage Backend で使用する方法について説明しま
す。
トピック
• グラフデータベースの使用 (p. 645)
• Titan と DynamoDB Storage Backend for Titan (p. 646)
• Titan の機能 (p. 647)
• DynamoDB Storage Backend for Titan の使用開始 (p. 649)
• DynamoDB の Titan グラフモデリング (p. 655)
• DynamoDB Storage Backend for Titan メトリクス (p. 662)
グラフデータベースの使用
グラフデータベースとは、頂点と、これらの頂点をつなぐ有向辺を保存したものです。頂点と辺はい
ずれも、キーと値のペアとして保存されたプロパティを持ちます。
グラフデータベースは隣接関係のリストやマトリックスを使用して辺を保存し、探索を容易にしま
す。グラフデータベースのグラフは特定の辺のタイプによって、またはグラフ全体にかけて探索でき
ます。
グラフデータベースはアクション、所有権、親子関係などによって、エンティティ同士の関係性を表
すことができます。モデル化するデータの核となるのがエンティティ同士のつながりまたは関係性
である場合は、グラフデータベースが適しています。したがって、グラフデータベースはソーシャル
ネットワーク、ビジネス関係、依存関係、船舶移動などの項目をモデル化およびクエリするのに便利
です。
グラフデータベースの辺を使用して、エンティティ (頂点またはノードとも呼ばれます) 間のタイプ
ドリレーションシップを表示できます。辺は、親子関係、アクション、製品の推奨、購入などを表す
ことができます。関係または辺は、常に開始ノード、終了ノード、タイプ、および方向を持つ 2 つの
頂点間の接続です。グラフデータベースの重要なルールは、壊れたリンクは許可されないことです。
各リンクは 2 つのノード間の関係を表します。ノードを削除すると、そのすべてのインシデント関係
(つまり、削除されるノードで開始または終了する関係) が削除されます。
ソーシャルネットワークグラフの例を次に示します。
API Version 2012-08-10
645
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
この例では、友だちのグループとその趣味をグラフとしてモデリングします。
Note
各辺には方向があり、矢印によって示されますが、辺の情報は "入力" ノードと "出力" ノード
の両方に保存されます。
このグラフの単純な探索により、Justin の友だちについて知ることができます。
Titan と DynamoDB Storage Backend for Titan
Titan には、グラフの多くのストレージバックエンドの 1 つを使用できるようにするプラグインアー
キテクチャがあります。DynamoDB Storage Backend for Titan はそれらのプラグインの 1 つです。
次の表では、Titan の [Storage Backend Overview] ページで利用できるパリティマトリックスに
DynamoDB Storage Backend を追加します。
ストレージバックエンドの比較
名前
ストレージ
バックエン
ドの設定値
整合性
可用性
DynamoDB
com.amazon.titan.diskstorage.dynamodb.DynamoDBStoreManager
結果的に
可用性が高
線形のス
はい、マ
整合性があ い、マネー
ケーラビ
ネージド
る、マネー ジド
リティ、マ
ジド
ネージド
SSD、マ
ネージド
Cassandra
cassandra
結果整合性
高い可用性
線形のス
ケーラビリ
ティ
はい
ディスク
HBase
hbase
頂点整合性
フェイル
オーバー復
旧
線形のス
ケーラビリ
ティ
はい
ディスク
BerkeleyDB
berkeleyje
ACID
単一障害点
単一のマシ
ン
HA モード
が使用可能
ディスク
Persistit
persistit
ACID
単一障害点
単一のマシ
ン
なし
ディスク
InMemory
inmemory
ACID
単一障害点
単一のマシ
ン
なし
なし
API Version 2012-08-10
646
スケーラビ
リティ
レプリケー
ション
永続性
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
グラフストレージでの DynamoDB の使用により、データベースクラスターを管理する負担なしで、
高度にスケーラブルな分散グラフデータベースを得ることができます。DynamoDB は任意のサイズ
にスケーリングでき、高速で予測可能なパフォーマンスを提供し、AWS リージョンの 3 つのアベイ
ラビリティーゾーン間で自動データレプリケーションによる高可用性が確保されます。また、プレ
フィックスを Titan グラフテーブルの前に追加して、1 つのアカウントとリージョンで AWS が管理す
る認証と複数のグラフが提供されます。
Titan の機能
DynamoDB Storage Backend for Titan プラグインは Titan バージョン 0.4.4、0.5.4、および 1.0.0 をサ
ポートします。
DynamoDB Storage Backend for Titan 1.0.0 の使用をお勧めしますが、Titan 0.4.4 および 0.5.4 のプラ
グインバージョンもまだ利用できます。
Titan には次の機能があります。
• 指定された辺のタイプに沿った高速なトラバーサルと任意のトラバーサル
• 有向で型付けされた辺
• 保存された関係
Titan 0.4.4 は、Blueprints API を実装して TinkerPop 2.4 スタックをサポートします。TinkerPop には
以下のコンポーネントが含まれます。
• Rexster グラフサーバー
• Furnace グラフアルゴリズム
• Frames オブジェクトグラフマッパー
• Gremlin トラバーサル言語
• Pipes データフロー
• Blueprints 汎用グラフ API
Gremlin、Rexster、Furnace、Frames、および Blueprints を含む TinkerPop スタックについて
は、TinkerPop のホームページを参照してください。
Titan バージョン 0.5.4 では、いくつかの重要な変更点や追加機能が提供されています。
• TinkerPop 2.5 のスタックのサポート
• 頂点のパーティション化のサポート
• 頂点ラベルのサポート
• ユーザー定義のトランザクションログ
• 2 つの新しいシステムトランザクションログテーブル: (txlog および systemlog)
• edgeindex および vertexindex は単一の graphindex テーブルにマージされます
Titan バージョン 0.5.4 の機能は、Titan バージョン 0.4.4 の機能のスーパーセットです。Titan の変更
の詳細については、「Titan 0.5.4 リリースノート」を参照してください。
Titan バージョン 1.0.0 では、以下の変更と追加機能が提供されます。
• TinkerPop 3.0 のスタックのサポート。
• TinkerPop 用の Titan 固有の TraversalStrategies。
• クエリ実行エンジンの最適化。
API Version 2012-08-10
647
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
Titan バージョン 1.0.0 の機能は、Titan バージョン 0.5.4 の機能のスーパーセットです。Titan の変更
の詳細については、「Titan 1.0 リリースノート」を参照してください。
Titan 機能の詳細については、Titan のドキュメントページを参照してください。
他の Titan ストレージバックエンドと同様に、Java ネイティブ API または Blueprints API の使用に加
えて、Gremlin シェルおよび Groovy 言語を使用して Titan グラフを操作できます。
次の表では、Titan ストレージバックエンドで使用できる機能を比較しています。
機能名
dynamodb
cassandra
berkeleyje
hbase
persistit
(0.4.4 のみ)
in memory
(0.5.4 および
1.0.0)
batchMutation はい
はい
いいえ
はい
いいえ
いいえ
distributed
はい
はい
いいえ
はい
いいえ
いいえ
keyConsistent はい
はい
いいえ
構成によっ
て異なる
いいえ
構成によっ
て異なる
keyOrdered
いいえ
パーティ
ショナーに
よって異な
る
はい
はい
はい
はい
localKeyPartition
いいえ
パーティ
ショナーに
よって異な
る
いいえ
いいえ
いいえ
いいえ
locking
はい
いいえ
はい
いいえ
はい
いいえ
multiQuery
はい
は
いいえ
い、cassandra
埋め込みを
除く
はい
いいえ
いいえ
orderedScan いいえ
パーティ
ショナーに
よって異な
る
はい
はい
はい
はい
transactional いいえ
いいえ
はい
いいえ
はい
いいえ
unorderedScanはい
パーティ
ショナーに
よって異な
る
いいえ
はい
いいえ
はい
optimisticLocking
はい
はい
いいえ
はい
はい
cellTTL
(0.5.4 のみ)
いいえ
はい
いいえ
いいえ
いいえ
storeTTL
(0.5.4 のみ)
いいえ
いいえ
いいえ
はい
いいえ
MILLI
preferredTimestamps
(0.5.4 のみ)
API Version 2012-08-10
648
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
timestamps
(0.5.4 のみ)
いいえ
はい
いいえ
はい
いいえ
visibility
(0.5.4 のみ)
いいえ
いいえ
いいえ
いいえ
いいえ
Cassandra パーティショナー
パーティショナー
RANDOM
BYTEORDER
keyOrdered / localKeyPartition
いいえ
はい
orderedScan
いいえ
はい
unorderedScan
はい
いいえ
次のステップ
• DynamoDB Storage Backend for Titan の使用開始 (p. 649)
DynamoDB Storage Backend for Titan の使用開始
DynamoDB Storage Backend for Titan の使用を開始するには、このセクションの最初の 2 つのトピッ
クのいずれかの手順に従って、次の操作を行うことができます。
• Download, install, and run Titan with the DynamoDB Storage Backend for Titan (p.
)
• Launch DynamoDB Storage Backend for Titan with Gremlin Server on Amazon EC2 (p. 652)
このセクションの「ローカルの DynamoDB と Amazon DynamoDB サービス (p. 655)」トピックで
は、ローカルに実行している DynamoDB (初期テストに最適です) の使用から、本稼働環境での使用の
ための Amazon DynamoDB サービスの使用に DynamoDB Storage Backend for Titan を切り替える方
法を示します。
トピック
• DynamoDB Storage Backend for Titan のインストールおよび実行 (p. 649)
• AWS CloudFormation テンプレートを使用して、Gremlin Server とともに DynamoDB Storage
Backend for Titan サーバーを Amazon EC2 で起動する (p. 652)
• ローカルの DynamoDB と Amazon DynamoDB サービス (p. 655)
DynamoDB Storage Backend for Titan のインストールおよび実行
DynamoDB Storage Backend for Titan は GitHub 上の Apache Maven プロジェクトとして利用で
き、Windows、Mac、または Linux コンピュータ上で実行されます。DynamoDB Storage Backend
for Titan では、Java 1.7 (またはそれ以降) および Apache Maven が必要になります。Java を入手
するには、http://java.com/download/ に移動してください。Apache Maven を取得するには、http://
maven.apache.org/ に移動してください。次の手順に従ってローカルの Maven リポジトリに
DynamoDB Storage Backend for Titan をインストールし、インストールをテストします。
Important
このドキュメントは DynamoDB Storage Backend for Titan バージョン 1.0 用です。以前の
バージョンの詳細については、Titan 0.4.4 用 README.md ファイルおよび Titan 0.5.4 用
README.md ファイルを参照してください。
API Version 2012-08-10
649
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
最初の例では、Marvel Universe Social Graph を使用します。このグラフには頂点に漫画のキャラク
ターがあり、辺にはキャラクターが登場する漫画本があります。Marvel Universe Social Graph の詳細
については、Marvel Universe Social Graph データセットのウェブページを参照してください。
Marvel Universe Social Graph のサブセットを読み込むには
1.
Git プロジェクトをセットアップするフォルダで、次のコマンドを実行して Git プロジェクトのク
ローンを作成します。
git clone https://github.com/awslabs/dynamodb-titan-storage-backend.git
Note
この git コマンドは Titan Version 1.0.0 用です。Titan 0.4.4 git コマンドについて
は、Titan 0.4.4 用の README.md ファイルを参照してください。Titan 0.5.4 git コマンド
については、Titan 0.5.4 用の README.md ファイルを参照してください。
2.
dynamodb-titan-storage-backend フォルダに切り替え、次のコマンドを入力し、Maven を
使用してパッケージをインストールします。
mvn install
Maven をインストールすると、Titan パッケージを含む追加の依存関係が Maven リポジトリから
ダウンロードされます。
3.
別のコマンドプロンプトウィンドウを開き、次のコマンドを入力して、お使いのコンピュータで
DynamoDB を起動します (グラフデータベースをテストします)。
mvn test -Pstart-dynamodb-local
4.
前のコマンドプロンプトウィンドウで、次のコマンドを入力して古い Elasticsearch インデックス
をクリーンアップします。
rm -rf /tmp/searchindex
5.
次のコマンドを入力して、Gremlin Server と DynamoDB Storage Backend for Titan をインストー
ルします。
src/test/resources/install-gremlin-server.sh
6.
次のコマンドを入力して、Gremlin Server のホームディレクトリにディレクトリを変更します。
cd server/dynamodb-titan100-storage-backend-1.0.0-hadoop1
7.
次のコマンドを入力して、ローカルマシンで DynamoDB を使用するように設定された Gremlin
Server を起動します。
bin/gremlin-server.sh ${PWD}/conf/gremlin-server/gremlin-server-local.yaml
8.
別のコマンドプロンプトウィンドウで、Gremlin Server ホームにディレクトリを変更します。
続いて、次のように入力して Gremlin シェルを開始します。
bin/gremlin.sh
9.
Gremlin シェルで、次のように入力して Gremlin Server に接続します。
API Version 2012-08-10
650
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
:remote connect tinkerpop.server conf/remote.yaml
Note
コロン (:) は、コマンドで必須の部分です。
10. 次のコマンドを入力して、Marvel Universe Social Graph の最初の 100 行を読み込みます。
:> com.amazon.titan.example.MarvelGraphFactory.load(graph, 100, false)
Important
コマンドの先頭にある : > 文字は必須です。これらの文字は、前のコマンドで接続した
Gremlin Server でこれらのコマンドが実行されることをシェルに対して示します。
残りの手順では、すべてこの同じ構文を使用します。
テスト行の数を増やして大きなグラフを作成するには、MarvelGraphFactory.load() メソッ
ドの 2 番目の引数の値を増やします。
11. 次のように入力して、キャラクターと、盾または爪の武器を持ってキャラクターが登場した漫画
本を出力します。
:> g.V().as('character').has('weapon',
within('shield','claws')).out('appeared').as('comicbook').select('character','comic-book')
12. 次のように入力して、キャラクターと、盾または爪ではない武器を持ってキャラクターが登場し
た漫画本を出力します。
:> g.V().as('character').has('weapon',
without('shield','claws')).out('appeared').as('comicbook').select('character','comic-book')
13. 次のように入力して、漫画本 AVF 4 に登場するキャラクターのソートされたリストを出力しま
す。
:> g.V().has('comic-book', 'AVF
4').in('appeared').values('character').order()
14. 盾または爪ではない武器を持って漫画本 AVF 4 に登場したキャラクターのソートされた一覧を出
力します。
:> g.V().has('comic-book', 'AVF 4').in('appeared').has('weapon',
without('shield','claws')).values('character').order()
Graph of the Gods を読み込むには
Graph of the Gods は、Titan に組み込まれ、Titan ドキュメントで使用されているグラフの例です。こ
の手順では、DynamoDB Storage Backend for Titan で Graph of the Gods を読み込み、「Titan 入門ガ
イド」ドキュメントのチュートリアルを実行できるようにする方法を示します。
1.
「Marvel グラフセクション (p. 650)」のステップ 1~9 に従います。
2.
次のように入力して、Graph of the Gods を読み込みます。
API Version 2012-08-10
651
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
:> com.thinkaurelius.titan.example.GraphOfTheGodsFactory.load(graph)
3.
「Titan 入門ガイド」ドキュメントに移動し、「グローバルグラフインデックス」セクションか
ら、残りのセットアッププロセスに従います。
Important
Gremlin Server エンドポイントでリモートにコマンドを実行するには、各コマンドの前
に :> を付ける必要があります。
また、ローカル変数を含むトラバーサルと同じ行の先頭に、ローカルの変数定義を付ける必要が
あります。
たとえば、トラバーサル g.V(hercules).out('father', 'mother').values('name') を
リモートで実行するには、その前に Hercules の定義を付ける必要があります。
:> hercules = g.V(saturn).repeat(__.in('father')).times(2).next();
g.V(hercules).out('father', 'mother').values('name')
ただし、saturn はローカル変数でもあるため、これも定義する必要があります。
:> saturn = g.V().has('name', 'saturn').next(); hercules
= g.V(saturn).repeat(__.in('father')).times(2).next();
g.V(hercules).out('father', 'mother').values('name')
これを前に付ける必要があるのは、Gremlin サーバーがオンのときに実行されるスクリプトで定義さ
れた変数を除き、各リモートスクリプトの実行でローカル変数の状態は引き継がれないためです。詳
細については、Gremlin Server YAML ファイルの scriptEngines/gremlin-groovy/scripts リ
スト要素を参照してください。
AWS CloudFormation テンプレートを使用して、Gremlin Server とともに
DynamoDB Storage Backend for Titan サーバーを Amazon EC2 で起動する
AWS マネジメントコンソールを使用して、テンプレートから AWS CloudFormation スタックを起動
し、Amazon EC2 でユーザーが選択するインスタンスタイプで Gremlin Server とともに Titan を起動
できます。このスタックでは、gremlin-server.yaml 設定ファイルへの Amazon S3 読み取りアクセス
権、およびテーブルを作成し、テーブルの項目を読み取り、書き込むための DynamoDB のフルアク
セス権がある既存の IAM ロールが必要です。
VPC のネットワーク ACL には、次を許可するための必要十分なアクセスが含まれます。
• インスタンスへの SSH 接続。
• セントラルリポジトリから yum の更新をダウンロードする EC2 インスタンス (HTTP アウトバウン
ド)。
• S3 から gremlin-server.yaml と Gremlin Server パッケージをダウンロードする EC2 インスタンス
(HTTPS アウトバウンド)。
• DynamoDB (HTTPS アウトバウンド) に接続する EC2 インスタンス。
前提条件
• Amazon EC2 インスタンスの SSH キーは、Gremlin Server スタックを作成する計画のリージョン
に存在する必要があります。
API Version 2012-08-10
652
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
• Amazon S3読み取りアクセスと DynamoDB フルアクセスがあるリージョンの IAM ロールの名前と
パスで、この CloudFormation スタックを実行するには、最小限のポリシーが必要です。cloud-init
のスタックに dynamodb.properties ファイルを提供するには、Amazon S3 読み取りアクセスが
必要です。DynamoDB フルアクセスが必要なのは、DynamoDB Storage Backend for Titan がテー
ブルを作成および削除し、それらのテーブルでデータを読み取り、書き込む必要があるためです。
• 設定を含む gremlin-server および dynamodb.properties を持つ Amazon S3 バケット。これ
らのファイルは、server/dynamodb-titan100-storage-backend-1.0.0-hadoop1/conf/gremlin-server に
あります。
作成と Amazon S3 へのアップロードの詳細については、「Working with Amazon S3 Buckets」を
参照してください。
Note
AWS CloudFormation テンプレートは再パッケージ化されたバージョンの titan-1.0.0hadoop1.zip、titan-dynamodb-0.5.4-hadoop2.zip、および titan-dynamodb-server-0.4.4.zip を
ダウンロードします。
DynamoDB Storage Backend for Titan およびその依存関係が、デフォルトのディストリ
ビューションに追加されています。これらは次のウェブサイトからダウンロードできます。
• 0.4.4: dynamodb-titan044-storage-backend-server-1.0.0.zip (SHA256 ハッシュ:
a3bbd0e5eb0b71bbadf6762def516f5836c8032c442d5f39799c56c5345cb14b)
• 0.5.4: dynamodb-titan054-storage-backend-1.0.0-hadoop2.zip (SHA256 ハッシュ:
612979bc0c3c4ced3d01c2366c3a95888a40931d3dea72c47284653cdcc1)
• 1.0.0: dynamodb-titan100-storage-backend-1.0.0-hadoop1.zip (SHA256 ハッシュ:
5e8c31c97227ebc19eb6ac555d914de950ebbcd93b8eb5439b6f28a1990)
AWS CloudFormation を使用して Amazon EC2 で Gremlin Server を起動するには
1.
次のリンクを選択し、DynamoDB Storage Backend for Titan を使用して Gremlin Server スタック
を作成する AWS CloudFormation テンプレートを表示します。
バージョン 1.0.0 テンプレートの表示
2.
スタックを起動する準備ができたら、このボタンを選択します。
3.
[Select Template] ページで、[Next] を選択します。
Note
このチュートリアルでは、デフォルト設定を使用します。ただし、このページで AWS
CloudFormation スタックの名前をカスタマイズするか、別のテンプレートを使用するこ
とができます。
4.
[Specify Parameters] ページで、次のように指定します。
• EC2 インスタンスタイプ
• Gremlin Server Websockets ポートのネットワークホワイトリストパターン
• Gremlin Server ポート、デフォルトは 8182。
• dynamodb.properties 設定ファイルへの S3 URL
• 既存の EC2 SSH キーの名前
• SSH プロトコル用のネットワークホワイトリスト。SSH 経由の着信接続を許可し、Gremlin
Server への Websockets 接続を保護する
SSH トンネルを有効にする必要があります。
API Version 2012-08-10
653
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
Note
デフォルトの CIDR である 0.0.0.0/32 は、すべての IP アドレスからの SSH アクセ
スをブロックします。適切なアドレス範囲を指定する必要があります。詳細について
は、「Linux インスタンス用の受信トラフィックの認可」を参照してください。
• この CloudFormation スクリプトを実行し、DynamoDB Storage Backend for Titan で
Gremlin Server を実行する最小限の権限を持つ IAM ロールへのパス。このロールで
は、dynamodb.properties ファイルを取得する S3 読み取りと、テーブルを作成し、項目を読み
取って書き込むための DynamoDB のフルアクセスが必要です。
5.
Network ホワイトリストおよび Amazon EC2 インスタンスタイプは変更できます。
[Options] ページで、[Next] を選択します。
Note
6.
このチュートリアルでは、デフォルト設定を使用します。
[Review] ページで、[I acknowledge that this template might cause AWS CloudFormation to create
IAM resources] を選択し、[Create] を選択します。
Note
7.
8.
9.
この AWS CloudFormation テンプレートでは IAM リソースは作成されません。
スタックのデプロイ中は、AWS CloudFormation コンソールに移動し、Amazon EC2 インスタン
スの [Status] 列を参照することで、進捗状況をモニタリングできます。
スタックの作成が完了したら、新しいスタックの [Outputs] タブに移動します。
CloudFormation スクリプトの Outputs から SSH トンネルコマンドをコピーし、それを使用し
て、スタックのデプロイが完了した後で、localhost ポート 8182 から EC2 ホストの Gremlin
Server ポート (8182) への SSH トンネルを作成します。
10. 前のトピックの「Marvel Universe Social Graph のサブセットを読み込むには (p. 650)」セク
ションをステップ 5 から続行します。
次のステップ
これで EC2 に Gremlin Server が作成されたため、Titan の作業を開始できます。継続するためのいく
つかのオプションを示します。
「Titan 入門ガイド」チュートリアルに従います
「Titan 入門ガイド」ドキュメントに移動し、「グローバルグラフインデックス」セクションか
ら、残りのセットアッププロセスに従います。
Gremlin の例に従います
Gremlin の詳細については、このセクションの手順を繰り返し、Gremlin ドキュメントの例に従っ
てください。
Important
Gremlin Server エンドポイントでリモートにコマンドを実行するには、各コマンドの前に
:> を付ける必要があります。
Marvel グラフを試す
Marvel Social Graph データを操作するには、このセクションの手順を繰り返し、「Marvel グラ
フ」セクションのステップ 5~14 に従います。
DynamoDB Storage Backend for Titan の詳細について学ぶ
詳細については、最初に「ローカルの DynamoDB と Amazon DynamoDB サービス (p. 655)」
セクションを参照してください。
API Version 2012-08-10
654
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
ローカルの DynamoDB と Amazon DynamoDB サービス
DynamoDB Storage Backend for Titan はデフォルトで DynamoDB のダウンロード可能バージョ
ンをストレージに使用します。DynamoDB のこのエディションは、最初にアプリケーションを
DynamoDB Storage Backend for Titan でテストするのに便利ですが、実稼働環境のパフォーマンスを
正確に表すには、テストプロセスの早い段階で Amazon DynamoDB に切り替えることをお勧めしま
す。
ローカル DynamoDB から Amazon DynamoDB ウェブサービスにストレージバックエンドを
切り替えるには
1.
デフォルトのリージョンは 米国東部(バージニア北部) です。別のリージョンが必要な場合は、
設定ファイルでこれを変更する必要があります。それ以外の場合は、ステップ 2 に進みます。
src/test/resources/dynamodb.properties の設定ファイルで、リージョンのエンドポイン
トを https://dynamodb.us-east-1.amazonaws.com から DynamoDB に変更します。たと
えば、リージョンが 米国西部 (オレゴン) である場合は、次のエンドポイント設定を使用します。
storage.dynamodb.client.endpoint=https://dynamodb.us-west-2.amazonaws.com
使用可能なリージョンとエンドポイントのリストについては、『アマゾン ウェブ サービス全般の
リファレンス』の「Amazon DynamoDB」セクションを参照してください。
2.
次のコマンドで Gremlin Server を起動します。
bin/gremlin-server.sh ${PWD}/conf/gremlin-server/gremlin-server.yaml
コンピュータで DynamoDB を実行することなく、Titan を実行できます。Titan DynamoDB Storage
バックエンドは、DynamoDB のローカルインスタンスではなく、エンドポイントの DynamoDB リー
ジョンのテーブルを使用します。
関連トピック
DynamoDB の Titan グラフモデリング (p. 655)
DynamoDB の Titan グラフモデリング
Titan は、頂点と一意のキーに関連付けられた列と値のペアとして、辺とプロパティを保存しま
す。DynamoDB Storage Backend for Titan は列と値の各ペアを、DynamoDB の 1 つの属性に保存し
ます。列と値のペアのシリアル化の詳細については、「Titan データモデル」ドキュメントの「個別の
辺のレイアウト」セクションを参照してください。
次のセクションでは、DynamoDB Storage Backend for Titan のグラフモデリングについて説明しま
す。
トピック
• 単一項目データモデル (p. 657)
• 複数項目データモデル (p. 657)
• Titan バージョン 0.5.4 以降のストレージの変更 (p. 659)
• DynamoDB Storage Backend for Titan の制限 (p. 659)
• バックエンドデータの使用 (p. 660)
• メトリックス (p. 661)
API Version 2012-08-10
655
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
Titan は KeyColumnValueStore インターフェイスを使用して、バックエンドデータベースに列と値の
ペアを保存します。DynamoDB Storage Backend for Titan には、このインターフェイスについて次の
2 つの具体的な実装があります。
実装クラス
設定プロパティ
説明
DynamoDBSingleRowStore
SINGLE
キーのすべての列と値のペアを
1 つの項目に保存します。
DynamoDBStore
MULTI
キーの列と値の各ペアを、複合
プライマリキー (パーティショ
ンキーとソートキー) を持つ
テーブルの別の項目に保存しま
す。
両方の実装では、edgestore という名前の DynamoDB テーブルに情報が保存されます。
edgestore を含めて、Titan バージョン 0.4.4 では、保存のために次の DynamoDB テーブルが使用さ
れます。
表
説明
edgestore
すべてのプロパティと辺 (列の値のペア) を保存
します。頂点ごとに 1 つの項目。
edgeindex
辺のインデックス。
vertexindex
すべての頂点のインデックス。
titan_ids
プラグインの各インスタンスのクライアント
ID。
system_properties
ストレージバックエンドのプロパティ。
Titan バージョン 0.5.4 以降では、異なるバックエンドテーブルが使用されます。edgestore を含め
て、Titan バージョン 0.5.4 以降では、保存のために次の DynamoDB テーブルが使用されます。
表
説明
edgestore
すべてのプロパティと辺 (列の値のペア) を保存
します。頂点ごとに 1 つの項目。
graphindex
辺と頂点のインデックス。
systemlog
Titan システムログ。
txlog
トランザクションログ。
titan_ids
プラグインの各インスタンスのクライアント
ID。
system_properties
ストレージバックエンドのプロパティ。
Note
Titan バージョン 0.5.4 以降では、それぞれがテーブルに保存される、ユーザー定義のトラン
ザクションログもサポートされます。
API Version 2012-08-10
656
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
DynamoDB Storage Backend for Titan プロパティファイルで、1 つまたは複数の項目のストレージオ
プションを選択できます。以下のセクションでは、2 つの実装について説明します。
単一項目データモデル
単一項目データモデルでは、すべての列と値のペアが、1 つの DynamoDB 項目の特定のキーに保存
されます。 edgestore テーブルでは、頂点のすべてのプロパティと辺が 1 つの項目に保存されます。
ここで、パーティションキーは KeyColumnValueStore ストア (KCV) のキーです。詳細については、
「KeyColumnValueStore」を参照してください。
次の表は、前述の「グラフデータベースの使用 (p. 645)」セクションのソーシャルネットワークグラ
フが、単一項目データモデルの edgestore DynamoDB テーブルにどのように保存されるかを示してい
ます。また、非表示のプロパティも示します。Titan は、非表示のプロパティを各ノードに追加し、そ
れが存在していることを示します。
Note
これは、テーブルに保存されているデータを表したものです。実際のデータは圧縮メタデー
タでシリアル化され、人間が読み取ることはできません。
パーティショ
ンキー (pk)
属性
属性
属性
属性
属性
Vertex id 1
Property Name: Justin
Edge (out) Friend: Anna
Edge (out) Friend: Kris
Edge (out) Likes: Movies
Hidden
Property Exists
Vertex id 2
Property Name: Anna
Edge (in) Friend: Justin
Edge (out) Likes: Books
Hidden
Property Exists
Vertex id 3
Property Name: Kris
Edge (in) Friend: Justin
Edge (out) Likes: Movies
Hidden
Property Exists
Vertex id 4
Property Name: Movie
Edge (in) Likes: Justin
Edge (in) Likes: Kris
Hidden
Property Exists
Vertex id 5
Property Name: Books
Edge (in) Likes: Anna
Hidden
Property Exists
この表は、各属性に保存されたすべてのデータを示していません。属性に保存される辺とプロパティ
のデータおよびデータ形式の詳細については、「Titan データモデル」ページを参照してください。
このモデルの制限として、すべてを単一の項目に保存すると、各頂点に対するプロパティと辺の数が
制限されます。これは、DynamoDB には 400 KB という項目サイズの制限があるためです。
複数項目データモデル
400 KB の項目サイズの制限を回避するため、DynamoDB Storage Backend for Titan は複数項目のス
トレージを代替モデルとして提供します。グラフに次のいずれかの特徴がある場合、複数項目のスト
レージを使用することをお勧めします。
• 各頂点に多くの辺がある
• 多数の頂点プロパティがある
API Version 2012-08-10
657
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
• 項目サイズの制限に近いサイズの個別のプロパティ値がある
これらの場合、少なくとも edgestore と インデックスストア (0.4.4 の edgeindex および
vertexindex、および 0.5.4 の graphindex) について、複数項目モデルを使用することをお勧めしま
す。edgestore とインデックスストアは、項目サイズの制限の影響を受ける可能性が高くあります。
複数項目データモデルでは、列と値の各ペアが個別の DynamoDB 項目に保存されます。列と値の各
ペアは、パーティションキーが KCV のキーで、ソートキーが KCV の列である項目として保存されま
す。特定のキーの列と値のすべてのペアは、edgestore テーブルの異なる項目に保存されます。
次の表は、前述の「グラフデータベースの使用 (p. 645)」セクションのソーシャルネットワークグラ
フが、複数項目データモデルの edgestore DynamoDB テーブルにどのように保存されるかを示してい
ます。また、非表示のプロパティも示します。Titan は、非表示のプロパティを各ノードに追加し、そ
れが存在していることを示します。
Note
これは、テーブルに保存されているデータを表したものです。実際のデータは圧縮メタデー
タでシリアル化され、人間が読み取ることはできません。
パーティションキー (pk)
ソートキー (sk)
値 (v)
Vertex id 1
ソートキー
Vertex id 1
Property id
Property - Name: Justin
Vertex id 1
Edge id
Edge (out) - Friend: Anna
Vertex id 1
Edge id
Edge (out) - Friend: Kris
Vertex id 1
Edge id
Edge (out) - Likes: Movies
Vertex id 1
Property id
Hidden Property - Exists
Vertex id 2
ソートキー
Vertex id 2
Property id
Property - Name: Anna
Vertex id 2
Edge id
Edge (in) - Friend: Justin
Vertex id 2
Edge id
Edge (out) - Likes: Books
Vertex id 2
Property id
Hidden Property - Exists
Vertex id 3
ソートキー
Vertex id 3
Property id
Property - Name: Kris
Vertex id 3
Edge id
Edge (in) - Friend: Justin
Vertex id 3
Edge id
Edge (out) - Likes: Movies
Vertex id 3
Property id
Hidden Property - Exists
Vertex id 4
ソートキー
Vertex id 4
Property id
Property - Name: Movies
Vertex id 4
Edge id
Edge (in) - Likes: Justin
Vertex id 4
Edge id
Edge (in) - Likes: Kris
API Version 2012-08-10
658
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
Vertex id 4
Property id
Hidden Property - Exists
Vertex id 5
ソートキー
Vertex id 5
Property id
Property - Name: Books
Vertex id 5
Edge id
Edge (in) - Likes: Anna
Vertex id 5
Property id
Hidden Property - Exists
この表は、各属性に保存されたすべてのデータを示していません。属性に保存される辺とプロパティ
のデータおよびデータ形式の詳細については、「Titan データモデル」ページを参照してください。
複数項目データモデルでは 400 KB 項目の制限を回避できますが、パフォーマンスが低下します。基
本テーブルのスキャンによる edgestore テーブルの頂点の反復的な処理は、単一項目のデータモデル
よりも複数項目のデータモデルで長い時間がかかる可能性があります。
複数項目のデータモデルは、ストアの 1 つのエンティティをキーで列ごとに 1 つの項目に非正規化す
ることで、400 KB の制限を解消します。この機能では、1 つのキーが複数項目のデータストアの行ご
とに 1 回表示されます。このモデルでスキャン時間が長くなるのは、各辺ラベル、頂点プロパティ、
および辺プロパティに対して、別の項目がこのモデルで存在するためです。edgestore_key テーブル
は、ストアエンティティのキーと改訂番号を保存するため、スキャンでは変化のオペレーションごと
に 1 回のみ KCV キーにアクセスします。この機能は、KCV ストアへの変化では少なくとも 2 つの
HTTP ラウンドトリップが必要になります。その対象の 1 つはキーテーブルで、少なくとももう 1 つ
はベーステーブル、変化に列の削除のみが関連する場合はさらに多くのラウンドトリップが必要にな
ります。
Titan バージョン 0.5.4 以降のストレージの変更
DynamoDB Storage Backend for Titan バージョン 0.5.4 以降では、バージョン 0.4.4 と同じ方法でグ
ラフデータが保存されますが、以下の違いがあります。
• パーティション化された頂点を使用できます。頂点のパーティションはすべて並行して読み取り、
書き込まれます。
• vertexindex と edgeindex テーブルは、graphindex という名前の 1 つのインデックスストアに結合
されます。
• Titan 0.5.4 は、ユーザー定義のトランザクションログをサポートします。各ユーザー定義のトラン
ザクションログは、.properties/rexster.xml で設定する必要がある追加の DynamoDB テーブ
ルに対応します。
• Titan 1.0.0 も、ユーザー定義のトランザクションログをサポートします。各ユーザー定義のトラ
ンザクションログは、dynamodb-properties ファイルで設定する必要がある追加の DynamoDB
テーブルに対応します。
DynamoDB Storage Backend for Titan の制限
DynamoDB は、パーティションキーのサイズ (2048 バイト)、ソートキーのサイズ (1024 バイト)、
および合計項目サイズ (400 KB) に制限を適用しています。したがって、Titan DynamoDB BigTable
の実装には、次のリストに示すいくつかの制限があります。BigTable は Titan バックエンド用のスト
レージの抽象概念の名前です。Titan BigTable の抽象化の詳細については、BigTable を参照してくだ
さい。
• 組み込みのインデックスを使用する場合、インデックスを作成したプロパティ値は、パーティショ
ンキーの最大サイズによって制限されます。2048 バイトドキュメントなど、より大きな値のイン
デックスを作成する必要がある場合、複合インデクサ (Elasticsearch、Solr、Lucene など) を使用し
て、全文検索を有効にします。
• 列の最大値のサイズは、可変の ID エンコードスキーマと Titan の圧縮オブジェクトのシリアル化
によって異なりますが、これが DynamoDB の最大項目サイズであるため、項目の表現では 400 KB
API Version 2012-08-10
659
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
に制限されます。単一項目のデータモデルでは、KCVStore の 1 つのキー (edgestore の out-vertex)
に保存されたすべての列が、400 KB 未満でなければならないことを意味します。複数項目のデー
タモデルでは、1 つの列に保存されたすべて (頂点プロパティ、辺などの 1 つのキーと列のペア)
は、400 KB 以下のサイズである必要があります。頂点からのすべての辺は単一項目のデータモデル
の 1 つの項目に保存されるため、1 つの項目モデルは、出力度合が小さいグラフでのみ使用できま
す。
• DynamoDB テーブルのプレフィックスを使用して、ユーザー定義のトランザクションログがない限
り、バージョン 0.4.4 ではリージョンあたり 51 のグラフ、バージョン 0.5.4 以降ではリージョンあ
たり 42 のグラフを持つことができます。ユーザー定義トランザクションログを使用する場合、各
ログに追加のテーブルがあるため、リージョンに保存できるグラフの数は少なくなります。詳細に
ついては、Titan ドキュメントの「ユーザー定義トランザクションログ」を参照してください。デ
フォルトでは、DynamoDB のテーブル数は、リージョンあたり 256 テーブルに制限されています。
リージョンでさらに多くのグラフを作成する場合は、アカウント制限の引き上げをリクエストでき
ます。アカウントの制限の詳細については、「DynamoDB の制限」ページを参照してください。
前述の制限は、Titan の制限に加えて適用されます。Titan の制限の詳細については、Titan ドキュメン
トの「技術的な制限」ページを参照してください。
バックエンドデータの使用
TitanDB バックエンドストレージ用のプロビジョニングは、グラフの設計 (多くの頂点と多くのプロパ
ティ)、使用量 (読み取り、書き込み、更新)、ストレージデータモデル (単一と複数) に応じて異なりま
す。
どのグラフでも、edgestore テーブルにほとんどのデータがあり、最も使用されます。
次の表は、edgestore テーブルに対するプロビジョニング量の予測に役立ちます。毎秒、処理 (読み取
り、書き込み、更新) する次のグラフオブジェクトの数を予測する必要があります。
• 頂点: 頂点の数。単一および複数項目モデルに適用されます。
• 頂点あたりのプロパティ: 各頂点のプロパティの数。複数項目モデルに適用されます。
• 頂点ごとの外部方向の辺: 頂点から他の頂点への辺の数。単一および複数項目モデルに適用されま
す。
Note
辺はデフォルトでは双方向になります。一方向 (外部方向のみ) の辺を作成しない限り、外
部方向と内部方向の辺は等しくなります。
• 頂点への辺: 頂点に入る辺の数。
• 非表示のプロパティ: Titan によって保存されるプロパティ。各頂点には、少なくとも exists プロ
パティがあります。Inn Titan バージョン 0.4.4 には、頂点あたり少なくとも 1 つの非表示のプロパ
ティがあり、Titan 0.5.4 には頂点あたり少なくとも 2 つの非表示プロパティがあります。
Note
単一項目データモデルでは、多くのグラフオブジェクトは頂点を持つ単一の項目にシリアル
化されるため、使用量の予測には必要ありません。
タイプ
edgestore に対する Update/
edgestore に対する Update/
DeleteItem 呼び出し、単一項目 DeleteItem 呼び出し、複数項目
モデル
モデル
作成
vertices * edgesOutOfVertex
API Version 2012-08-10
660
vertices * (vertexProperties
+ edgesIntoVertex +
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
edgesOutOfVertex +
titanHiddenProperties)
更新
vertices * edgesOutOfVertex
vertices + vertexProperties
+ edgesIntoVertex +
edgesOutOfVertex +
titanHiddenProperties
読み取り
頂点
vertices + vertexProperties
+ edgesIntoVertex +
edgesOutOfVertex +
titanHiddenProperties
前の表は、ストレージモデルとオペレーションタイプ別に、キャパシティー予測を分けています。次
のリストは、さまざまなオペレーションタイプについて DynamoDB アクティビティの詳細と、イン
デックスの影響を示しています。
データのロード
データの一括ロードは、書き込みに大きな負荷がかかります。グラフへの新しいデータのロード
では、バックエンドデータベースで項目を作成する必要があります。複数項目モデルの作成で
は、各頂点、プロパティ、および辺が個別の項目として書き込まれるため、より大きな負荷が発
生します。
データの更新
データの更新は、複数項目ストレージモデルでは負荷が低くなります。これは、更新中の特定の
プロパティまたは辺に対して項目を更新するだけで済むためです。単一項目ストレージモデルで
は、項目全体を更新する必要があります。
データの読み取り
複数項目モデルでは、プロパティまたは辺のサブセットの読み取りは、単一モデルよりも効率が
高い場合があります。これは、項目全体ではなくリクエストした項目のみが読み取られるためで
す。
graphindex テーブルでの操作
単一項目モデルでは、graphindex テーブルの項目は一意の頂点/辺のプロパティの名前と値の組
み合わせでキーが付けられ、その他の項目属性 (列) は、このプロパティ値が持つ頂点/辺の ID を
表します。複数項目モデルには、graphindex の項目は引き続きプロパティの名前と値の組み合
わせでキーが付けられますが、そのプロパティの名前と値の組み合わせを持つ頂点/辺ごとに異
なる項目があります。したがって、単一項目モデルでは、プロパティと値の組み合わせごとに 1
つの項目が graphindex に書き込まれます。複数項目モデルでは、vertices * vertexProperties +
edges * edgeProperties の項目が graphindex に書き込まれます。
メトリックス
Titan は Metrics core パッケージを使用してメトリクスを記録、出力します。Metrics core
は、JMX、HTTP、STDOUT、CSV、SLF4j、Ganglia、および Graphite を介したメトリクスの報告
をサポートします。サードパーティーのプラグインとして使用できるその他のレポーターがありま
す。Metrics core パッケージの詳細については、Metrics ウェブサイトを参照してください。
次のプロパティを使用して Metrics を有効にできます。
metrics.enabled=true
# prefix for metrics from titan-core. Optional. If not specified,
com.thinkaurelius.titan will be used.
# Currently, the prefix for Titan system stores (system log, txlog,
titan_ids, system_properties, and all user logs)
# is set to com.thinkaurelius.titan.sys and cannot be changed.
metrics.prefix=titan
API Version 2012-08-10
661
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
# polling interval in milliseconds
metrics.csv.interval=500
# the directory where to write metrics in CSV files
metrics.csv.directory=metrics
# The metrics prefix in titan-dynamodb allows you to change what gets
prepended to the codahale metric names.
#storage.dynamodb.metrics-prefix=dynamodb
Note
プロパティは、クラスパスのプロパティファイルで設定できます。直接 Gremlin シェルで設
定オブジェクトを使用するか、rexster.xml ファイル内で設定できます。
Gremlin シェルでメトリクス設定プロパティを設定するには、次のように入力します。
conf = new BaseConfiguration()
conf.setProperty("metrics.enabled", "true")
conf.setProperty("metrics.prefix", "titan")
conf.setProperty("metrics.csv.interval", 1000)
conf.setProperty("metrics.csv.directory", "metrics")
conf.setProperty("storage.dynamodb.metrics-prefix", "dynamodb")
Metrics core は、さまざまな数量の測定をサポートします。Timer は、コードのレイテン
シーのレートとヒストグラムの Meter です。ヒストグラムでは、特定の値の分布を測定
し、count、max、mean、min、stddev、p50、p75、p95、p98、p99、および p999 を出力しま
す。Meter は呼び出しレート (tps) を測定し、count、mean_rate、m1_rate、m5_rate、および
m15_rate を出力します。Gauge はさまざまなスレッドの値を測定し、値を出力します。Counter は
コードが呼び出された回数をカウントし、カウントを出力します。
Titan は「Titan メトリクス (p. 663)」ページの表に示したメトリクスを出力します。
Amazon DynamoDB Storage Backend for Titan は、Titan によって出力されたものに加えてメトリ
クスを出力します。これらは、「追加の Amazon DynamoDB Storage Backend for Titan メトリク
ス (p. 666)」の表に説明されている、低レベルの DynamoDB オペレーションの統計に関連します。
DynamoDB Storage Backend for Titan メトリクス
Titan は Metrics core パッケージを使用してメトリクスを記録、出力します。Metrics core
は、JMX、HTTP、STDOUT、CSV、SLF4j、Ganglia、および Graphite を介したメトリクスの報告
をサポートします。サードパーティーのプラグインとして使用できるその他のレポーターがありま
す。Metrics ウェブサイト (https://dropwizard.github.io/metrics/3.1.0/manual/core/) で、Metrics core
パッケージの詳細を参照できます。
DynamoDB Storage Backend for Titan は、Titan によって生成されるものに加えてメトリクスを生成
します。
これらは、以下の表に説明されている、低レベルの DynamoDB オペレーションの統計に関連しま
す。
トピック
• Titan メトリクス (p. 663)
• 追加の Amazon DynamoDB Storage Backend for Titan メトリクス (p. 666)
API Version 2012-08-10
662
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
Titan メトリクス
Titan 1.0.0 および 0.5.4 のメトリクスは、Titan 0.4.4 によって生成されるメトリクスのスーパーセッ
トです。
Note
• <store> は、メトリクスが関連付けられているグラフストアを示します。
メトリクス名
Titan のバージョン
スコープ
計器のタイプ
db.getVertexByID
0.4.4、0.5.4、1.0.0
グローバル
Counter
db.getVerticesByID
0.4.4、0.5.4、1.0.0
グローバル
Counter
<store>.acquireLock.calls
0.4.4、0.5.4、1.0.0
Graph Store
Counter
<store>.acquireLock.time
0.4.4、0.5.4、1.0.0
Graph Store
Timer (Histogram
+Meter)
<store>.getKeys.calls
Graph Store
Counter
<store>.getKeys.iterator.hasNext.calls
0.5.4、1.0.0
Graph Store
Counter
<store>.getKeys.iterator.hasNext.time
0.5.4、1.0.0
Graph Store
Timer (Histogram
+Meter)
<store>.getKeys.iterator.next.calls
0.5.4、1.0.0
Graph Store
Counter
<store>.getKeys.iterator.next.time
0.5.4、1.0.0
Graph Store
Timer (Histogram
+Meter)
<store>.getKeys.time
0.5.4、1.0.0
Graph Store
Timer (Histogram
+Meter)
<store>.getSlice.calls
0.4.4、0.5.4、1.0.0
Graph Store
Counter
<store>.getSlice.entries-0.4.4、0.5.4、1.0.0
histogram
Graph Store
Histogram
<store>.getSlice.entries-0.4.4、0.5.4、1.0.0
returned
Graph Store
Counter
<store>.getSlice.time
Graph Store
Timer (Histogram
+Meter)
<store>.storeManager.mutate.calls
1.0.0
Graph Store
Counter
<store>.storeManager.mutate.time
1.0.0
Graph Store
Timer
global.storeManager.closeManager.calls
1.0.0
グローバル
Counter
global.storeManager.openDatabase.calls
1.0.0
グローバル
Counter
global.storeManager.startTransaction.calls
1.0.0
グローバル
Counter
query.graph.execute.calls0.4.4、0.5.4、1.0.0
グローバル
Counter
query.graph.execute.exceptions
0.5.4
グローバル
Counter
query.graph.execute.time 0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
0.5.4、1.0.0
0.4.4、0.5.4、1.0.0
API Version 2012-08-10
663
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
query.graph.getNew.calls 0.4.4、0.5.4、1.0.0
グローバル
Counter
query.graph.getNew.time 0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
query.graph.hasDeletions.calls
0.4.4、0.5.4、1.0.0
グローバル
Counter
query.graph.hasDeletions.time
0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
query.graph.isDeleted.calls
0.4.4、0.5.4
グローバル
Counter
query.graph.isDeleted.time
0.4.4、0.5.4
グローバル
Timer (Histogram
+Meter)
query.vertex.execute.calls0.4.4、0.5.4、1.0.0
グローバル
Counter
query.vertex.execute.time0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
query.vertex.getNew.calls0.4.4、0.5.4、1.0.0
グローバル
Counter
query.vertex.getNew.time0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
query.vertex.hasDeletions.calls
0.4.4、0.5.4、1.0.0
グローバル
Counter
query.vertex.hasDeletions.time
0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
query.vertex.isDeleted.calls
0.5.4
グローバル
Counter
query.vertex.isDeleted.time
0.5.4
グローバル
Timer (Histogram
+Meter)
schemacache.name.misses
0.5.4
グローバル
Counter
schemacache.name.retrievals
0.5.4
グローバル
Counter
schemacache.relations.misses
0.5.4
グローバル
Counter
schemacache.relations.retrievals
0.5.4
グローバル
Counter
stores.acquireLock.calls 0.4.4、0.5.4、1.0.0
グローバル
Counter
stores.acquireLock.time 0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
stores.getKeys.calls
0.5.4、1.0.0
グローバル
Counter
stores.getKeys.iterator.hasNext.calls
0.5.4、1.0.0
グローバル
Counter
stores.getKeys.iterator.hasNext.time
0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
stores.getKeys.iterator.next.calls
0.5.4、1.0.0
グローバル
Counter
stores.getKeys.iterator.next.time
0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
stores.getKeys.time
グローバル
Timer (Histogram
+Meter)
0.5.4、1.0.0
API Version 2012-08-10
664
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
stores.getSlice.calls
0.4.4、0.5.4、1.0.0
グローバル
Counter
stores.getSlice.entrieshistogram
0.4.4、0.5.4、1.0.0
グローバル
Histogram
stores.getSlice.entriesreturned
0.4.4、0.5.4、1.0.0
グローバル
Counter
stores.getSlice.time
0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
sys.schemacache.name.misses
1.0.0
グローバル
Counter
sys.schemacache.name.retrievals
1.0.0
グローバル
Counter
sys.schemacache.relations.misses
1.0.0
グローバル
Counter
sys.schemacache.relations.retrievals
1.0.0
グローバル
Counter
sys.<store>.getSlice.calls
0.4.4、0.5.4、1.0.0
System Store
Counter
sys.<store>.getSlice.entries0.4.4、0.5.4、1.0.0
histogram
System Store
Histogram
sys.<store>.getSlice.entries0.4.4、0.5.4、1.0.0
returned
System Store
Counter
sys.<store>.getSlice.time0.4.4、0.5.4、1.0.0
System Store
Timer (Histogram
+Meter)
sys.<store>.mutate.calls0.4.4、0.5.4、1.0.0
System Store
Counter
sys.<store>.mutate.time0.4.4、0.5.4、1.0.0
System Store
Timer (Histogram
+Meter)
sys.stores.getSlice.calls 0.4.4、0.5.4、1.0.0
グローバル
Counter
sys.stores.getSlice.entries0.4.4、0.5.4、1.0.0
histogram
グローバル
Histogram
sys.stores.getSlice.entries0.4.4、0.5.4、1.0.0
returned
グローバル
Counter
sys.stores.getSlice.time 0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
sys.stores.mutate.calls
0.4.4、0.5.4、1.0.0
グローバル
Counter
sys.stores.mutate.time
0.4.4、0.5.4、1.0.0
グローバル
Timer (Histogram
+Meter)
sys.storeManager.mutate.calls
1.0.0
グローバル
Counter
sys.storeManager.mutate.time
1.0.0
グローバル
Timer
sys.schema.query.graph.execute.calls
1.0.0
グローバル
Counter
sys.schema.query.graph.execute.time
1.0.0
グローバル
Timer
sys.schema.query.graph.getNew.calls
1.0.0
グローバル
Counter
sys.schema.query.graph.getNew.time
1.0.0
グローバル
Timer
API Version 2012-08-10
665
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
sys.schema.query.graph.hasDeletions.calls
1.0.0
グローバル
Counter
sys.schema.query.graph.hasDeletions.time
1.0.0
グローバル
Timer
sys.schema.stores.getSlice.calls
1.0.0
グローバル
Counter
sys.schema.stores.getSlice.entries1.0.0
histogram
グローバル
Histogram
sys.schema.stores.getSlice.entries1.0.0
returned
グローバル
Counter
sys.schema.stores.getSlice.time
1.0.0
グローバル
Timer
sys.schema.tx.begin
1.0.0
グローバル
Counter
sys.schema.tx.rollback
1.0.0
グローバル
Counter
sys.schema.v100_edgestore.getSlice.calls
1.0.0
グローバル
Counter
sys.schema.v100_edgestore.getSlice.entries1.0.0
histogram
グローバル
Histogram
sys.schema.v100_edgestore.getSlice.entries1.0.0
returned
グローバル
Counter
sys.schema.v100_edgestore.getSlice.time
1.0.0
グローバル
Timer
sys.schema.v100_graphindex.getSlice.calls
1.0.0
グローバル
Counter
sys.schema.v100_graphindex.getSlice.entries1.0.0
histogram
グローバル
Histogram
sys.schema.v100_graphindex.getSlice.entries1.0.0
returned
グローバル
Counter
sys.schema.v100_graphindex.getSlice.time
1.0.0
グローバル
Timer
tx.begin
0.4.4、0.5.4、1.0.0
グローバル
Counter
tx.commit
0.4.4、0.5.4、1.0.0
グローバル
Counter
tx.commit.exceptions
0.5.4
グローバル
Counter
tx.rollback
0.5.4
グローバル
Counter
追加の Amazon DynamoDB Storage Backend for Titan メトリクス
Note
• <prefix> は、プロパティファイルで設定されるテーブルのプレフィックスです。
• <ddb> は、プロパティファイルで設定される DynamoDB メトリクスのプレフィックスで
す。
• <store> は、メトリクスが関連付けられているグラフストアを示します。
メトリクス名
Titan のバージョン
計器のタイプ
<ddb>.<prefix>_executorqueue-size
0.4.4、0.5.4、1.0.0
Gauge
API Version 2012-08-10
666
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB Storage Backend for Titan
<ddb>.<prefix>_ListTablesPagesTimer
0.4.4、0.5.4、1.0.0
Histogram
<ddb>.<prefix>_ListTablesHistogram
0.4.4、0.5.4、1.0.0
Timer (Histogram+Meter)
<ddb>.<prefix>_mutateManyGauge
0.4.4、0.5.4
Timer (Histogram+Meter)
<ddb>.<prefix>_mutateMany
Timer (Histogram+Meter)
1.0.0
<ddb>.<prefix>_mutateManyKeys
1.0.0
Meter
<ddb>.<prefix>_mutateManyStores
1.0.0
Meter
<ddb>.<prefix>_mutateManyUpdateOrDeleteItemCalls
1.0.0
Meter
<ddb>.CreateTable.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Timer (Histogram+Meter)
<ddb>.DeleteItem.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Timer (Histogram+Meter)
<ddb>.DeleteItemConsumedCapacity.
0.4.4、0.5.4、1.0.0
<prefix>_<store>
Meter
<ddb>.DeleteItemRetries.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Meter
<ddb>.DeleteItemThrottling.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Timer (Histogram+Meter)
<ddb>.DeleteTable.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Timer (Histogram+Meter)
<ddb>.DescribeTable.<prefix>_0.4.4、0.5.4、1.0.0
<store>
Timer (Histogram+Meter)
<ddb>.GetItem.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Timer (Histogram+Meter)
<ddb>.GetItemConsumedCapacity.
0.4.4、0.5.4、1.0.0
<prefix>_<store>
Meter
<ddb>.GetItemRetries.<prefix>_0.4.4、0.5.4、1.0.0
<store>
Meter
<ddb>.GetItemThrottling.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Timer (Histogram+Meter)
<ddb>.Query.<prefix>_<store>0.4.4、0.5.4、1.0.0
Timer (Histogram+Meter)
<ddb>.QueryConsumedCapacity.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Meter
<ddb>.QueryItemCountCounter.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Counter
<ddb>.QueryItemCountHistogram.0.4.4、0.5.4、1.0.0
<prefix>_<store>
Histogram
<ddb>.QueryPages.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Histogram
<ddb>.QueryRetries.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Meter
<ddb>.QueryThrottling.<prefix>0.4.4、0.5.4、1.0.0
_<store>
Timer (Histogram+Meter)
<ddb>.Scan.<prefix>_<store>0.4.4、0.5.4、1.0.0
Timer (Histogram+Meter)
<ddb>.ScanConsumedCapacity.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Meter
<ddb>.ScanItemCountCounter.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Counter
<ddb>.ScanItemCountHistogram.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Histogram
<ddb>.ScanPages.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Histogram
<ddb>.ScanRetries.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Meter
<ddb>.ScanThrottling.<prefix>_0.4.4、0.5.4、1.0.0
<store>
Timer (Histogram+Meter)
API Version 2012-08-10
667
Amazon DynamoDB 開発者ガイド
Amazon DynamoDB 用 Logstash プラグイン
<ddb>.UpdateItem.<prefix>_<store>
0.4.4、0.5.4、1.0.0
Timer (Histogram+Meter)
<ddb>.UpdateItemBytes.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Histogram
<ddb>.UpdateItemConsumedCapacity.
0.4.4、0.5.4、1.0.0
<prefix>_<store>
Meter
<ddb>.UpdateItemRetries.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Meter
<ddb>.UpdateItemThrottling.<prefix>
0.4.4、0.5.4、1.0.0
_<store>
Timer (Histogram+Meter)
Amazon DynamoDB 用 Logstash プラグイン
Amazon DynamoDB 用 Logstash プラグイン は、DynamoDB テーブルでデータにほぼリアルタイムで
表示します。DynamoDB 用 Logstash プラグイン は DynamoDB ストリーム を使用して、DynamoDB
テーブルに追加されるデータを解析および出力します。 DynamoDB 用 Logstash プラグイン をインス
トールしてアクティブにすると、指定されたテーブルでデータをスキャンし、DynamoDB ストリーム
を使用して更新の消費を開始し、Elasticsearch に出力するか、ユーザーが選択した Logstash に出力
します。
詳細についてとソースコードのダウンロードについてには、次の GitHub リポジトリを参照してくだ
さい。
• https://github.com/awslabs/logstash-input-dynamodb
DynamoDB の予約語
以下のキーワードは、DynamoDB で予約されています。式の中で属性名としてこれらの単語を使用し
ないでください。
DynamoDB の予約語と競合する属性名を含む式を書き込む必要がある場合、予約語の代わりに使用す
る式の属性名を定義できます。詳細については、「式の属性名 (p. 213)」を参照してください。
ABORT
ABSOLUTE
ACTION
ADD
AFTER
AGENT
AGGREGATE
ALL
ALLOCATE
ALTER
ANALYZE
AND
ANY
ARCHIVE
ARE
ARRAY
AS
ASC
ASCII
ASENSITIVE
ASSERTION
ASYMMETRIC
AT
ATOMIC
API Version 2012-08-10
668
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
ATTACH
ATTRIBUTE
AUTH
AUTHORIZATION
AUTHORIZE
AUTO
AVG
BACK
BACKUP
BASE
BATCH
BEFORE
BEGIN
BETWEEN
BIGINT
BINARY
BIT
BLOB
BLOCK
BOOLEAN
BOTH
BREADTH
BUCKET
BULK
BY
BYTE
CALL
CALLED
CALLING
CAPACITY
CASCADE
CASCADED
CASE
CAST
CATALOG
CHAR
CHARACTER
CHECK
CLASS
CLOB
CLOSE
CLUSTER
CLUSTERED
CLUSTERING
CLUSTERS
COALESCE
COLLATE
COLLATION
COLLECTION
COLUMN
COLUMNS
COMBINE
COMMENT
COMMIT
COMPACT
COMPILE
COMPRESS
CONDITION
CONFLICT
API Version 2012-08-10
669
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
CONNECT
CONNECTION
CONSISTENCY
CONSISTENT
CONSTRAINT
CONSTRAINTS
CONSTRUCTOR
CONSUMED
CONTINUE
CONVERT
COPY
CORRESPONDING
COUNT
COUNTER
CREATE
CROSS
CUBE
CURRENT
CURSOR
CYCLE
DATA
DATABASE
DATE
DATETIME
DAY
DEALLOCATE
DEC
DECIMAL
DECLARE
DEFAULT
DEFERRABLE
DEFERRED
DEFINE
DEFINED
DEFINITION
DELETE
DELIMITED
DEPTH
DEREF
DESC
DESCRIBE
DESCRIPTOR
DETACH
DETERMINISTIC
DIAGNOSTICS
DIRECTORIES
DISABLE
DISCONNECT
DISTINCT
DISTRIBUTE
DO
DOMAIN
DOUBLE
DROP
DUMP
DURATION
DYNAMIC
EACH
ELEMENT
API Version 2012-08-10
670
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
ELSE
ELSEIF
EMPTY
ENABLE
END
EQUAL
EQUALS
ERROR
ESCAPE
ESCAPED
EVAL
EVALUATE
EXCEEDED
EXCEPT
EXCEPTION
EXCEPTIONS
EXCLUSIVE
EXEC
EXECUTE
EXISTS
EXIT
EXPLAIN
EXPLODE
EXPORT
EXPRESSION
EXTENDED
EXTERNAL
EXTRACT
FAIL
FALSE
FAMILY
FETCH
FIELDS
FILE
FILTER
FILTERING
FINAL
FINISH
FIRST
FIXED
FLATTERN
FLOAT
FOR
FORCE
FOREIGN
FORMAT
FORWARD
FOUND
FREE
FROM
FULL
FUNCTION
FUNCTIONS
GENERAL
GENERATE
GET
GLOB
GLOBAL
GO
API Version 2012-08-10
671
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
GOTO
GRANT
GREATER
GROUP
GROUPING
HANDLER
HASH
HAVE
HAVING
HEAP
HIDDEN
HOLD
HOUR
IDENTIFIED
IDENTITY
IF
IGNORE
IMMEDIATE
IMPORT
IN
INCLUDING
INCLUSIVE
INCREMENT
INCREMENTAL
INDEX
INDEXED
INDEXES
INDICATOR
INFINITE
INITIALLY
INLINE
INNER
INNTER
INOUT
INPUT
INSENSITIVE
INSERT
INSTEAD
INT
INTEGER
INTERSECT
INTERVAL
INTO
INVALIDATE
IS
ISOLATION
ITEM
ITEMS
ITERATE
JOIN
KEY
KEYS
LAG
LANGUAGE
LARGE
LAST
LATERAL
LEAD
LEADING
API Version 2012-08-10
672
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
LEAVE
LEFT
LENGTH
LESS
LEVEL
LIKE
LIMIT
LIMITED
LINES
LIST
LOAD
LOCAL
LOCALTIME
LOCALTIMESTAMP
LOCATION
LOCATOR
LOCK
LOCKS
LOG
LOGED
LONG
LOOP
LOWER
MAP
MATCH
MATERIALIZED
MAX
MAXLEN
MEMBER
MERGE
METHOD
METRICS
MIN
MINUS
MINUTE
MISSING
MOD
MODE
MODIFIES
MODIFY
MODULE
MONTH
MULTI
MULTISET
NAME
NAMES
NATIONAL
NATURAL
NCHAR
NCLOB
NEW
NEXT
NO
NONE
NOT
NULL
NULLIF
NUMBER
NUMERIC
API Version 2012-08-10
673
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
OBJECT
OF
OFFLINE
OFFSET
OLD
ON
ONLINE
ONLY
OPAQUE
OPEN
OPERATOR
OPTION
OR
ORDER
ORDINALITY
OTHER
OTHERS
OUT
OUTER
OUTPUT
OVER
OVERLAPS
OVERRIDE
OWNER
PAD
PARALLEL
PARAMETER
PARAMETERS
PARTIAL
PARTITION
PARTITIONED
PARTITIONS
PATH
PERCENT
PERCENTILE
PERMISSION
PERMISSIONS
PIPE
PIPELINED
PLAN
POOL
POSITION
PRECISION
PREPARE
PRESERVE
PRIMARY
PRIOR
PRIVATE
PRIVILEGES
PROCEDURE
PROCESSED
PROJECT
PROJECTION
PROPERTY
PROVISIONING
PUBLIC
PUT
QUERY
QUIT
API Version 2012-08-10
674
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
QUORUM
RAISE
RANDOM
RANGE
RANK
RAW
READ
READS
REAL
REBUILD
RECORD
RECURSIVE
REDUCE
REF
REFERENCE
REFERENCES
REFERENCING
REGEXP
REGION
REINDEX
RELATIVE
RELEASE
REMAINDER
RENAME
REPEAT
REPLACE
REQUEST
RESET
RESIGNAL
RESOURCE
RESPONSE
RESTORE
RESTRICT
RESULT
RETURN
RETURNING
RETURNS
REVERSE
REVOKE
RIGHT
ROLE
ROLES
ROLLBACK
ROLLUP
ROUTINE
ROW
ROWS
RULE
RULES
SAMPLE
SATISFIES
SAVE
SAVEPOINT
SCAN
SCHEMA
SCOPE
SCROLL
SEARCH
SECOND
API Version 2012-08-10
675
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
SECTION
SEGMENT
SEGMENTS
SELECT
SELF
SEMI
SENSITIVE
SEPARATE
SEQUENCE
SERIALIZABLE
SESSION
SET
SETS
SHARD
SHARE
SHARED
SHORT
SHOW
SIGNAL
SIMILAR
SIZE
SKEWED
SMALLINT
SNAPSHOT
SOME
SOURCE
SPACE
SPACES
SPARSE
SPECIFIC
SPECIFICTYPE
SPLIT
SQL
SQLCODE
SQLERROR
SQLEXCEPTION
SQLSTATE
SQLWARNING
START
STATE
STATIC
STATUS
STORAGE
STORE
STORED
STREAM
STRING
STRUCT
STYLE
SUB
SUBMULTISET
SUBPARTITION
SUBSTRING
SUBTYPE
SUM
SUPER
SYMMETRIC
SYNONYM
SYSTEM
API Version 2012-08-10
676
Amazon DynamoDB 開発者ガイド
DynamoDB の予約語
TABLE
TABLESAMPLE
TEMP
TEMPORARY
TERMINATED
TEXT
THAN
THEN
THROUGHPUT
TIME
TIMESTAMP
TIMEZONE
TINYINT
TO
TOKEN
TOTAL
TOUCH
TRAILING
TRANSACTION
TRANSFORM
TRANSLATE
TRANSLATION
TREAT
TRIGGER
TRIM
TRUE
TRUNCATE
TTL
TUPLE
TYPE
UNDER
UNDO
UNION
UNIQUE
UNIT
UNKNOWN
UNLOGGED
UNNEST
UNPROCESSED
UNSIGNED
UNTIL
UPDATE
UPPER
URL
USAGE
USE
USER
USERS
USING
UUID
VACUUM
VALUE
VALUED
VALUES
VARCHAR
VARIABLE
VARIANCE
VARINT
VARYING
API Version 2012-08-10
677
Amazon DynamoDB 開発者ガイド
レガシー条件パラメータ
VIEW
VIEWS
VIRTUAL
VOID
WAIT
WHEN
WHENEVER
WHERE
WHILE
WINDOW
WITH
WITHIN
WITHOUT
WORK
WRAPPED
WRITE
YEAR
ZONE
レガシー条件パラメータ
このセクションでは、DynamoDB のレガシー条件パラメータを式パラメータを比較します。
式パラメーター (「式を使用した項目の読み取りと書き込み (p. 210)」を参照) の導入に伴って、旧パ
ラメーターがいくつか廃止されました。新しいアプリケーションでは、これらのレガシーパラメー
ターではなく、式パラメーターを使用する必要があります。(詳しくは、式を使用した項目の読み取
りと書き込み (p. 210) を参照してください)。
Note
DynamoDB では、単一の 呼び出しにレガシー条件パラメータと式パラメータを混在させる
ことはできません。たとえば、Query オペレーションの呼び出しで AttributesToGet と
ConditionExpression を使用すると、エラーになります。
次の表に、これらのレガシーパラメーターを引き続きサポートしている DynamoDB API と、代わりに
使用される式パラメーターを示します。この表は、アプリケーションを更新して式パラメーターを使
用することを検討する際に役立ちます。
この API を使用する場合
使用しているレガシーパラメー
ター
代わりに使用する式パラメー
ター
BatchGetItem
AttributesToGet
ProjectionExpression
DeleteItem
Expected
ConditionExpression
GetItem
AttributesToGet
ProjectionExpression
PutItem
Expected
ConditionExpression
Query
AttributesToGet
ProjectionExpression
KeyConditions
KeyConditionExpression
QueryFilter
FilterExpression
AttributesToGet
ProjectionExpression
ScanFilter
FilterExpression
Scan
API Version 2012-08-10
678
Amazon DynamoDB 開発者ガイド
AttributesToGet
この API を使用する場合
使用しているレガシーパラメー
ター
代わりに使用する式パラメー
ター
UpdateItem
AttributeUpdates
UpdateExpression
Expected
ConditionExpression
以下のセクションでは、レガシー条件パラメータについて詳しく説明します。
トピック
• AttributesToGet (p. 679)
• AttributeUpdates (p. 680)
• ConditionalOperator (p. 681)
• Expected (p. 682)
• KeyConditions (p. 685)
• QueryFilter (p. 687)
• ScanFilter (p. 689)
• レガシー パラメータを使用した条件書き込み (p. 690)
AttributesToGet
AttributesToGet は、DynamoDB から取得する 1 つ以上の属性の配列です。属性名を省略した場
合、すべての属性が返されます。リクエストされた属性のうち見つからなかったものは、結果には表
示されません。
AttributesToGet リスト型またはマップ型の属性を取得できます。ただし、リストまたはマップ内
の個別要素は取得できません。
AttributesToGet はプロビジョニングされたスループットの消費量には影響しないことに留意し
てください。アプリケーションに返されるデータ量ではなく、項目のサイズに基づいて、消費される
キャパシティーユニットが DynamoDB で決定されます。
代替として ProjectionExpression を使用する
Music テーブルから項目を取得するとします。ただし、返す属性は一部のみとします。次のように
AttributesToGet パラメーターを指定して GetItem リクエストを使用できます。
{
TableName: "Music",
AttributesToGet:
["Artist", "Genre"],
Key: {
SongTitle: {"Call Me Today"},
Artist: {"No One You Know"}
}
ただし、代わりに ProjectionExpression を使用できます。
{
TableName: "Music",
ProjectionExpression: "Artist, Genre",
Key: {
API Version 2012-08-10
679
Amazon DynamoDB 開発者ガイド
AttributeUpdates
SongTitle: {"Call Me Today"},
Artist: {"No One You Know"}
}
AttributeUpdates
UpdateItem オペレーションでは、AttributeUpdates は変更する属性の名前、それぞれで実行す
るアクション、およびそれぞれの新しい値です。そのテーブルの任意のインデックスのインデックス
キー属性である属性を更新する場合は、属性タイプがテーブルの説明の AttributesDefinition で
定義されたインデックスキーのタイプに一致する必要があります。UpdateItem を使用して、キーで
はない属性を更新できます。
属性値を null にすることはできません。文字列タイプおよびバイナリタイプの属性は、ゼロより大
きい長さが必要です。セットタイプの属性は空にする必要があります。空白の値があるリクエスト
は、ValidationException 例外で拒否されます。
各 AttributeUpdates 要素は、次と併せて、変更する属性名で構成されます。
• Value - 該当する場合、この属性の新しい値。
• Action - 更新の実行方法を指定する値。このアクションは、データ型が数値型またはセットである
既存の属性でのみ有効です。他のデータ型で ADD を使用しないでください。
指定のプライマリキーを持つ項目がテーブル内に存在する場合、以下の値で以下のアクションが実
行されます。
• PUT - 指定された属性を項目に追加します。属性がすでに存在する場合、新しい値に置き換えま
す。
• DELETE - DELETE に値を指定しなかった場合、属性とその値が削除されます。指定した値のデー
タ型は、既存の値のデータ型に一致する必要があります。
値のセットを指定すると、これらの値が古いセットから減算されます。たとえば、属性値が
[a,b,c] のセットで、DELETE アクションが [a,c] を指定する場合、最終的な属性値は [b] で
す。空白のセットを指定するとエラーになります。
• ADD - 属性が存在しない場合、指定された値を項目に追加します。属性が存在する場合は、ADD
の動作は属性のデータ型によって決まります。
• 既存の属性が数値で、Value も数値である場合、Value は既存の属性に数学的に追加されま
す。Value が負の数値である場合は、既存の属性から減算されます。
Note
ADD を使用して、更新前に存在しない項目の数値を増やすまたは減らす場
合、DynamoDB は初期値として 0 を使用します。
同様に、既存の項目に ADD を使用して、更新前に存在しない項目の属性値を加算また
は減算する場合、DynamoDB は初期値として 0 を使用します。たとえば、更新する項
目に itemcount という名前の属性がないが、この属性に ADD で数字 3 を加算するとし
ます。DynamoDB は itemcount 属性を作成し、初期値を 0 に設定して、最後に 3 を加
算します。結果として、3 という値を持つ新しい itemcount 属性ができます。
• 既存のデータ型がセットであり、Value もセットもある場合、Value は既存のセットに付けら
れます。たとえば、属性値が [1,2] のセットで、ADD アクションで [3] を指定する場合、最
終的な属性値は [1,2,3] です。ADD アクションをセット属性に対して指定し、指定した属性
の型が既存のセット型と一致しない場合、エラーが発生します。
両方のセットが同じプリミティブデータ型である必要があります。たとえば、既存のデータ型
が一連の文字列の場合、Value も一連の文字列である必要があります。
指定のキーを持つ項目がテーブル内に存在しない場合、以下の値で以下のアクションが実行されま
す。
API Version 2012-08-10
680
Amazon DynamoDB 開発者ガイド
ConditionalOperator
• PUT - DynamoDB で指定のプライマリキーを持つ新しい項目が作成され、属性が追加されます。
• DELETE - 存在しない項目から属性を削除できないので、何も起こりません。オペレーションは成
功しますが、DynamoDB によって新しい項目は作成されません。
• ADD - DynamoDB によって、提供されたプライマリキーと属性値に対する数値 (または数値のセッ
ト) で項目が作成されます。使用できるデータ型は数値型および数値セットのみです。
インデックスキーの一部である任意の属性を指定した場合、それらの属性のデータ型はテーブルの属
性定義のスキーマのデータ型に一致する必要があります。
代替として UpdateExpression を使用する
Music テーブルの項目を変更するとします。次のように AttributeUpdates パラメーターを指定し
て UpdateItem リクエストを使用できます。
{
TableName: "Music",
Key: {
"SongTitle": "Call Me Today",
"Artist": "No One You Know"
},
AttributeUpdates: {
"Genre": {
"Action": "PUT",
"Value": "Rock"
}
}
}
ただし、代わりに UpdateExpression を使用できます。
{
TableName: "Music",
Key: {
"SongTitle": "Call Me Today",
"Artist": "No One You Know"
},
UpdateExpression: "SET Genre = :g",
ExpressionAttributeValues: {
":g": "Rock"
}
}
ConditionalOperator
Expected、QueryFilter、または ScanFilter マップで条件に適用される論理演算子:
• AND - すべての条件が true として評価された場合、マップ全体が true として評価されます。
• OR - 条件の少なくとも 1 つが true として評価された場合、マップ全体が true として評価されま
す。
ConditionalOperator を省略する場合は、AND がデフォルトです。
オペレーションはマップ全体が true である場合のみ成功します。
API Version 2012-08-10
681
Amazon DynamoDB 開発者ガイド
Expected
Note
このパラメーターはリスト型またはマップ型の属性をサポートしていません。
Expected
Expected は UpdateItem オペレーションの条件ブロックです。Expected は属性と条件のペ
アのマップです。マップの各要素は、属性名、比較演算子、および 1 つ以上の値で構成されま
す。DynamoDB で比較演算子を使用して提供された属性と値が比較されます。各 Expected 要素で、
評価の結果が true または false になります。
Expected マップ内の複数のエレメントを指定すると、デフォルトではすべての条件が true である必
要があります。言い換えると、条件は AND で結ばれます。(ConditionalOperator パラメーターを
使用して、条件を OR で結ぶこともできます。その場合、条件のすべてではなく、そのうち少なくと
も 1 つが true である必要があります。)
Expected マップが true であると評価されると、条件演算が成功します。そうでない場合、失敗しま
す。
Expected には以下が含まれています。
• AttributeValueList - 提供された属性に対して評価する 1 つまたは複数の値。リストの値の数値
は使用される ComparisonOperator によって異なります。
数値型の場合、値比較は数値です。
大なり、等しい、小なりの文字列値比較は、UTF-8 バイナリエンコードを使用した Unicode に基づ
きます。たとえば、a は A より大きく、a は B より大きい文字列です。
バイナリ型では、DynamoDB は、バイナリ値を比較する際にバイナリデータの各バイトを符号なし
として扱います。
• ComparisonOperator - AttributeValueList の属性を評価するコンパレータ。比較を実行する
際、DynamoDB は強力な整合性のある読み込みを使用します。
次の比較演算子を使用できます。
EQ | NE | LE | LT | GE | GT | NOT_NULL | NULL | CONTAINS | NOT_CONTAINS |
BEGINS_WITH | IN | BETWEEN
各比較演算子の説明は、以下のとおりです。
• EQ : 等しい。EQ は、リストおよびマップを含むすべてのデータ型でサポートされています。
AttributeValueList に指定できるのは、文字列型、数値型、バイナリ型、文字列セット型、
数値セット型、またはバイナリセット型の AttributeValue 要素 1 つのみです。リクエストで
指定した型とは異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しませ
ん。たとえば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} と {"NS":
["6", "2", "1"]} も等しくありません。
• NE : 等しくない。NE は、リストおよびマップを含むすべてのデータ型でサポートされています。
AttributeValueList に指定できるのは、文字列型、数値型、バイナリ型、文字列セット型、
数値セット型、またはバイナリセット型の AttributeValue 1 つのみです。リクエストで指定し
た型とは異なる型の AttributeValue が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} と {"NS":["6", "2",
"1"]} も等しくありません。
• LE : 以下。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 要素 1 つのみです (セット型は指定できません)。リクエストで指定した型と
API Version 2012-08-10
682
Amazon DynamoDB 開発者ガイド
Expected
は異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} は {"NS":["6", "2",
"1"]} と同等ではありません。
• LT : 未満。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 1 つのみです (セット型は指定できません)。リクエストで指定した型とは
異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} は {"NS":["6", "2",
"1"]} と同等ではありません。
• GE : 以上。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 要素 1 つのみです (セット型は指定できません)。リクエストで指定した型と
は異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} は {"NS":["6", "2",
"1"]} と同等ではありません。
• GT : より大きい。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 要素 1 つのみです (セット型は指定できません)。リクエストで指定した型と
は異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} は {"NS":["6", "2",
"1"]} と同等ではありません。
• NOT_NULL : 属性がある。NOT_NULL は、リストおよびマップを含むすべてのデータ型でサポート
されています。
Note
この演算子はデータ型ではなく、属性の存在をテストします。属性「a」のデータ型が
null の場合、NOT_NULL を使用して評価すると、結果はブール値 true になります。これ
は、属性「a」が存在し、そのデータ型が NOT_NULL 比較演算子に関係ないためです。
• NULL : 属性が存在しない。NULL は、リストおよびマップを含むすべてのデータ型でサポートさ
れています。
Note
この演算子はデータ型ではなく、属性の非存在をテストします。属性「a」のデータ型が
null の場合、NULL を使用して評価すると、結果はブール値 false になります。これは、
属性「a」が存在し、そのデータ型が NULL 比較演算子に関係ないためです。
• CONTAINS : サブシーケンスまたはセットの値のチェック。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 要素 1 つのみです (セット型は指定できません)。比較する属性が文字列型
の場合、部分文字列の一致があることが確認されます。比較する属性がバイナリ型の場合、入
力に一致する対象の属性のサブシーケンスがあることが確認されます。比較する属性がセット
(「SS」、「NS」、または「BS」) の場合、セットのいずれかの値と完全一致すると、演算子は
true と評価されます。
CONTAINS はリストでサポートされます。「a CONTAINS b」を評価する場合、「a」をリスト
型にはできますが、「b」をセット型、マップ型、リスト型にはできません。
• NOT_CONTAINS : サブシーケンスがない、またはセットの値がないことのチェック。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 要素 1 つのみです (セット型は指定できません)。比較する属性が文字列型
の場合、部分文字列の一致がないことが確認されます。比較する属性がバイナリ型の場合、入
API Version 2012-08-10
力に一致する対象の属性のサブシーケンスがないことが確認されます。比較する属性がセット
683
Amazon DynamoDB 開発者ガイド
Expected
(「SS」、「NS」、または「BS」) の場合、セットのいずれの値とも完全一致しない (does not)
と、演算子は true と評価されます。
NOT_CONTAINS はリストでサポートされます。「a NOT CONTAINS b」を評価する場合、
「a」をリスト型にはできますが、「b」をセット型、マップ型、リスト型にはできません。
• BEGINS_WITH : プレフィックスのチェック。
AttributeValueList に指定できるのは、文字列型またはバイナリ型の AttributeValue 1 つ
のみです (数値型またはセット型は指定できません)。比較対象の属性は、(数値型またはセット型
ではなく) 文字列型またはバイナリ型である必要があります。
• IN : 2 つのセット内での要素の一致のチェック。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つ以上の
AttributeValue 要素です (セット型は指定できません)。これらの属性は、項目の既存のセット
型の属性に対して比較されます。入力セットのいずれかの要素が項目の属性に含まれる場合、式
は true と評価されます。
• BETWEEN : 最初の値以上、かつ 2 番目の値以下。
AttributeValueList には、同じ型 (文字列、数値、またはバイナリ) の AttributeValue
要素を 2 つ指定する必要があります (セット型は指定できません)。対象の属性が一致するの
は、対象の値が最初の要素以上かつ 2 番目の要素以下の場合です。リクエストで指定した型と
は異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} は {"N":"6"} と同等ではありません。また、{"N":"6"} は {"NS":["6",
"2", "1"]} と同等ではありません。
次のパラメーターを AttributeValueList および ComparisonOperator の代わりに使用できま
す。
• Value - 属性と比較する DynamoDB の値。
• Exists - DynamoDB で条件付き演算を実行する前に値を評価するブール値。
• Exists が true の場合、DynamoDB はその属性値がすでにテーブルに存在するかどうかを
チェックします。存在する場合は、条件の評価結果が true になります。存在しない場合は条件は
false に評価されます。
• Exists が false の場合、DynamoDB はその属性値がテーブルに存在しない (not) とみなしま
す。実際に値が存在しない場合は、みなしが有効であり、条件の評価結果が true になります。値
が存在しないとみなされていたにもかかわらず値が見つかった場合は、条件は false と評価され
ます。
Exists のデフォルト値は true であることに注意してください。
Value および Exists パラメーターは、AttributeValueList および ComparisonOperator
との互換性はありません。両方のパラメーターのセットを同時に使用すると、DynamoDB が
ValidationException 例外を返すことに注意してください。
Note
このパラメーターはリスト型またはマップ型の属性をサポートしていません。
代替として ConditionExpression を使用する
特定の条件が true の場合のみ Music テーブルの項目を変更するとします。次のように Expected パ
ラメーターを指定して UpdateItem リクエストを使用できます。
{
TableName: "Music",
API Version 2012-08-10
684
Amazon DynamoDB 開発者ガイド
KeyConditions
Key: {
"SongTitle": "Call Me Today",
"Artist": "No One You Know"
},
AttributeUpdates: {
"Price": {
Action: "PUT",
Value: 1.98
},
Expected: {
"Price": {
"ComparisonOperator": "LE",
"AttributeValueList": [ 2.00 ]
}
}
}
}
ただし、代わりに ConditionExpression を使用できます。
{
TableName: "Music",
Key: {
"SongTitle": "Call Me Today",
"Artist": "No One You Know"
},
UpdateExpression: "SET Price = :p1",
ConditionExpression: "Price <= :p2",
ExpressionAttributeValues: {
":p1": 1.98,
":p2": 2.00
}
}
KeyConditions
KeyConditions は Query オペレーションの選択条件です。テーブルに対するクエリの場合、テーブ
ルのプライマリキー属性のみの条件を持つことができます。EQ 条件としてパーティションキーの名
前と値を提供する必要があります。オプションで、ソートキーを参照する 2 番目の条件を指定できま
す。
Note
ソートキー条件を指定しない場合、パーティションキーと一致するすべての項目が取得され
ます。FilterExpression または QueryFilter が存在する場合、項目が取得された後に適
用されます。
インデックスのクエリでは、インデックスキー属性のみの条件を持つことができます。EQ 条件として
インデックスパーティションキーの名前と値を提供する必要があります。オプションで、インデック
スソートキーを参照する 2 番目の条件を指定できます。
各 KeyConditions 要素は、次と併せて、比較する属性名で構成されます。
• AttributeValueList - 提供された属性に対して評価する 1 つまたは複数の値。リストの値の数値
は使用される ComparisonOperator によって異なります。
数値型の場合、値比較は数値です。
API Version 2012-08-10
685
Amazon DynamoDB 開発者ガイド
KeyConditions
大なり、等しい、小なりの文字列値比較は、UTF-8 バイナリエンコードを使用した Unicode に基づ
きます。たとえば、a は A より大きく、a は B より大きい文字列です。
バイナリ型では、DynamoDB は、バイナリ値を比較する際にバイナリデータの各バイトを符号なし
として扱います。
• ComparisonOperator - 属性を評価するコンパレータ。たとえば、等しい、大なり、小なりなどで
す。
KeyConditions の場合、次の比較演算子のみがサポートされています。
EQ | LE | LT | GE | GT | BEGINS_WITH | BETWEEN
比較演算子の説明は、以下のとおりです。
• EQ : 等しい。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 1 つのみです (セット型は指定できません)。リクエストで指定した型とは
異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} と {"NS":["6", "2",
"1"]} も等しくありません。
• LE : 以下。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 要素 1 つのみです (セット型は指定できません)。リクエストで指定した型と
は異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} は {"NS":["6", "2",
"1"]} と同等ではありません。
• LT : 未満。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 1 つのみです (セット型は指定できません)。リクエストで指定した型とは
異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} は {"NS":["6", "2",
"1"]} と同等ではありません。
• GE : 以上。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 要素 1 つのみです (セット型は指定できません)。リクエストで指定した型と
は異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} は {"NS":["6", "2",
"1"]} と同等ではありません。
• GT : より大きい。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の
AttributeValue 要素 1 つのみです (セット型は指定できません)。リクエストで指定した型と
は異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} と {"N":"6"} は等しくありません。また、{"N":"6"} は {"NS":["6", "2",
"1"]} と同等ではありません。
• BEGINS_WITH : プレフィックスのチェック。
AttributeValueList に指定できるのは、文字列型またはバイナリ型の AttributeValue 1 つ
のみです (数値型またはセット型は指定できません)。比較対象の属性は、(数値型またはセット型
ではなく) 文字列型またはバイナリ型である必要があります。
• BETWEEN : 最初の値以上、かつ 2 番目の値以下。
AttributeValueList には、同じ型 (文字列、数値、またはバイナリ) の AttributeValue
要素を 2 つ指定する必要があります (セット型は指定できません)。対象の属性が一致するの
API Version 2012-08-10
686
Amazon DynamoDB 開発者ガイド
QueryFilter
は、対象の値が最初の要素以上かつ 2 番目の要素以下の場合です。リクエストで指定した型と
は異なる型の AttributeValue 要素が項目に含まれている場合、値は一致しません。たとえ
ば、{"S":"6"} は {"N":"6"} と同等ではありません。また、{"N":"6"} は {"NS":["6",
"2", "1"]} と同等ではありません。
代替として KeyConditionExpression を使用する
Music テーブルから、同じパーティションキーを持つ複数の項目を取得するとします。次のように
KeyConditions パラメーターを指定して Query リクエストを使用できます。
{
TableName: "Music",
KeyConditions: {
"SongTitle": {
ComparisonOperator:
AttributeValueList:
},
"Artist": {
ComparisonOperator:
AttributeValueList:
}
}
"BETWEEN",
["A", "M"]
"EQ",
["No One You Know"]
}
ただし、代わりに KeyConditionExpression を使用できます。
{
TableName: "Music",
KeyConditionExpression: "Artist = :a AND SongTitle BETWEEN :t1 AND :t2",
ExpressionAttributeValues: {
":a": "No One You Know",
":t1": "A",
":t2": "M"
}
}
QueryFilter
Query オペレーションでは、QueryFilter は項目が読み込まれ目的の値のみが返された後にクエリ
結果を評価する条件です。
このパラメーターはリスト型またはマップ型の属性をサポートしていません。
Note
QueryFilter は項目が読み込まれた後に適用されます。フィルタ処理は追加の読み込みキャ
パシティーユニットを消費しません。
QueryFilter マップ内の複数の条件を指定すると、デフォルトではすべての条件が true である必
要があります。言い換えると、条件は AND で結ばれます。(ConditionalOperator (p. 681) パラメー
ターを使用して、条件を OR で結ぶこともできます。その場合、条件のすべてではなく、そのうち少
なくとも 1 つが true である必要があります。)
ただし、QueryFilter ではキー属性を使用できないことに注意してください。パーティションキー
またはソートキーにフィルタ条件を定義することはできません。
API Version 2012-08-10
687
Amazon DynamoDB 開発者ガイド
QueryFilter
各 QueryFilter 要素は、次と併せて、比較する属性名で構成されます。
• AttributeValueList - 提供された属性に対して評価する 1 つまたは複数の値。リストの値の数値
は ComparisonOperator で指定される演算子によって異なります。
数値型の場合、値比較は数値です。
大なり、等しい、小なりの文字列値比較は、UTF-8 バイナリエンコードに基づきます。たとえ
ば、a は A より大きく、a は B より大きい文字列です。
バイナリ型では、DynamoDB は、バイナリ値を比較する際にバイナリデータの各バイトを符号なし
として扱います。
JSON でデータ型を指定する方法については、「DynamoDB 低レベル API (p. 68)」を参照してくだ
さい。
• ComparisonOperator - 属性を評価するコンパレータ。たとえば、等しい、より大きい、より小さ
い、などです。
次の比較演算子を使用できます。
EQ | NE | LE | LT | GE | GT | NOT_NULL | NULL | CONTAINS | NOT_CONTAINS |
BEGINS_WITH | IN | BETWEEN
代替として FilterExpression を使用する
Music テーブルにクエリして、項目が返される前に条件を適用するとします。次のように
QueryFilter パラメーターを指定して Query リクエストを使用できます。
{
TableName: "Music",
KeyConditions: {
"Artist": {
ComparisonOperator:
AttributeValueList:
}
},
QueryFilter: {
"Price": {
ComparisonOperator:
AttributeValueList:
}
}
"EQ",
[ "No One You Know" ]
"GT",
[ 1.00 ]
}
ただし、代わりに FilterExpression を使用できます。
{
TableName: "Music",
KeyConditionExpression: "Artist = :a",
FilterExpression: "Price > :p",
ExpressionAttributeValues: {
":p": 1.00,
":a": "No One You Know"
}
}
API Version 2012-08-10
688
Amazon DynamoDB 開発者ガイド
ScanFilter
ScanFilter
Scan オペレーションでは、ScanFilter がスキャン結果を評価して目的の値のみを返す条件です。
Note
このパラメーターはリスト型またはマップ型の属性をサポートしていません。
ScanFilter マップ内の複数の条件を指定すると、デフォルトではすべての条件が true である必要が
あります。言い換えると、条件は AND で結ばれます。(ConditionalOperator (p. 681) パラメーター
を使用して、条件を OR で結ぶこともできます。その場合、条件のすべてではなく、そのうち少なく
とも 1 つが true である必要があります。)
各 ScanFilter 要素は、次と併せて、比較する属性名で構成されます。
• AttributeValueList - 提供された属性に対して評価する 1 つまたは複数の値。リストの値の数値
は ComparisonOperator で指定される演算子によって異なります。
数値型の場合、値比較は数値です。
大なり、等しい、小なりの文字列値比較は、UTF-8 バイナリエンコードに基づきます。たとえ
ば、a は A より大きく、a は B より大きい文字列です。
バイナリ型では、DynamoDB は、バイナリ値を比較する際にバイナリデータの各バイトを符号なし
として扱います。
JSON でデータ型を指定する方法については、「DynamoDB 低レベル API (p. 68)」を参照してくだ
さい。
• ComparisonOperator - 属性を評価するコンパレータ。たとえば、等しい、より大きい、より小さ
い、などです。
次の比較演算子を使用できます。
EQ | NE | LE | LT | GE | GT | NOT_NULL | NULL | CONTAINS | NOT_CONTAINS |
BEGINS_WITH | IN | BETWEEN
代替として FilterExpression を使用する
Music テーブルをスキャンして、項目が返される前に条件を適用するとします。次のように
ScanFilter パラメーターを指定して Scan リクエストを使用できます。
{
TableName:"Music",
ScanFilter:{
"Genre":{
AttributeValueList:[ "Rock" ],
ComparisonOperator:"EQ"
}
}
}
ただし、代わりに FilterExpression を使用できます。
{
TableName:"Music",
FilterExpression:"Genre = :g",
API Version 2012-08-10
689
Amazon DynamoDB 開発者ガイド
レガシー パラメータを使用した条件書き込み
ExpressionAttributeValues:{
":g":"Rock"
}
}
レガシー パラメータを使用した条件書き込み
このセクションでは、Expected、QueryFilter、および ScanFilter などのレガシーパラメータを
使用して条件を書き込む方法を説明します。
Note
新しいアプリケーションでは代わりに式パラメータを使用してください。詳細については、
「式を使用した項目の読み取りと書き込み (p. 210)」を参照してください。
単純な条件
属性値を使用して、テーブル属性に対する比較のための条件を記述できます。条件は常に true または
false と評価され、次の演算子と値で構成されます。
• ComparisonOperator - 「より大きい」、「より小さい」、「等しい」などの演算子。
• AttributeValueList(省略可能) - 比較対象の属性値。使用する ComparisonOperator に応じ
て、AttributeValueList に 1 つ、2 つ、またはそれ以上の値を指定できます。値を指定しない
場合もあります。
この後のセクションでは、さまざまな比較演算子について説明し、それらの演算子を条件に使用する
例を示します。
属性値を指定しない比較演算子
• NOT_NULL - 属性が存在する場合に true。
• NULL - 属性が存在しない場合に true。
これらの演算子を使用して、属性が存在するかどうかを確認します。比較対象の値がないた
め、AttributeValueList を指定しないでください。
例
次の式では、Dimensions 属性が存在する場合に true と評価されます。
{
"Dimensions": {
ComparisonOperator: "NOT_NULL"
}
}
1 つの属性値を指定する比較演算子
• EQ - 属性が値と等しい場合に true。
AttributeValueList に指定できるのは、文字列型、数値型、バイナリ型、文字列セット、数値
セット、またはバイナリセットの 1 つの値だけです。リクエストで指定した型とは異なる型の値が
項目に含まれている場合、値は一致しません。たとえば、文字列 "3" は数値 3 と等しくありませ
ん。また、数値 3 は数値セット [3, 2, 1] と等しくありません。
• NE - 属性が値に等しくない場合に true。
API Version 2012-08-10
690
Amazon DynamoDB 開発者ガイド
レガシー パラメータを使用した条件書き込み
AttributeValueList に指定できるのは、文字列型、数値型、バイナリ型、文字列セット、数値
セット、またはバイナリセットの 1 つの値だけです。リクエストで指定した型とは異なる型の値が
項目に含まれている場合、値は一致しません。
• LE - 属性が値以下の場合に true。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つの値だけ
です(セット型は指定できません)。リクエストで指定した型とは異なる型の AttributeValue
が項目に含まれている場合、値は一致しません。
• LT - 属性が値より小さい場合に true。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つの値だけ
です(セット型は指定できません)。リクエストで指定した型とは異なる型の値が項目に含まれて
いる場合、値は一致しません。
• GE - 属性が値以上の場合に true。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つの値だけ
です(セット型は指定できません)。リクエストで指定した型とは異なる型の値が項目に含まれて
いる場合、値は一致しません。
• GT - 属性が値よりも大きい場合に true。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つの値だけ
です(セット型は指定できません)。リクエストで指定した型とは異なる型の値が項目に含まれて
いる場合、値は一致しません。
• CONTAINS - 値がセットに含まれる場合、または値が別の値を含む場合に true。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つの値だけ
です(セット型は指定できません)。比較する属性が文字列型の場合、部分文字列の一致があるこ
とが確認されます。比較する属性がバイナリ型の場合、入力に一致する対象の属性のサブシーケン
スがあることが確認されます。比較する属性がセットの場合、セットのいずれかの値と完全一致す
ると、演算子は true と評価されます。
• NOT_CONTAINS - 値がセットに含まれない場合、または値が別の値を含まない場合に true。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つの値だけ
です(セット型は指定できません)。比較する属性が文字列型の場合、部分文字列の一致がない
ことが確認されます。比較する属性がバイナリ型の場合、入力に一致する対象の属性のサブシーケ
ンスがないことが確認されます。比較する属性がセットの場合、セットのどの値とも完全一致しな
いと、演算子は true と評価されます。
• BEGINS_WITH - 属性の先頭からの数文字が指定した値と一致した場合に true。この演算子を数値の
比較に使用しないでください。
AttributeValueList に指定できるのは、文字列型またはバイナリ型の 1 つの値だけです(数値
型またはセット型は指定できません)。比較対象の属性は、(数値型またはセット型ではなく)文
字列型またはバイナリ型である必要があります。
これらの演算子は属性と値の比較に使用してください。1 つの値で構成される
AttributeValueList を指定する必要があります。ほとんどの演算子では、この値はスカラーであ
ることが必要ですが、EQ と NE 演算子では、セットもサポートされています。
例
ここで示している式は次の場合に true と評価されます。
• 商品の価格が 100 より大きい。
{
"Price": {
API Version 2012-08-10
691
Amazon DynamoDB 開発者ガイド
レガシー パラメータを使用した条件書き込み
ComparisonOperator: "GT",
AttributeValueList: [ 100 ]
}
}
• 商品のカテゴリが「Bo」で始まる。
{
"ProductCategory": {
ComparisonOperator: "BEGINS_WITH",
AttributeValueList: [ "Bo" ]
}
}
• 商品の色が「Red」、「Green」、「Black」のいずれか。
{
"Color": {
ComparisonOperator: "EQ",
AttributeValueList: [
[ "Black", "Red", "Green" ]
]
}
}
Note
セットデータ型を比較するとき、要素の順序は重要ではありません。DynamoDB では、リ
クエストで指定した順序に関係なく、同じ値のセットを持つ項目のみが返されます。
2 つの属性値を指定する比較演算子
• BETWEEN - 値が下限から上限の範囲内にある場合に true(上限または下限に一致する場合も含
む)。
AttributeValueList には、同じ型(文字列、数値、またはバイナリ)の要素を 2 つ指定する必
要があります(セット型は指定できません)。対象の属性が一致するのは、対象の値が最初の要素
以上かつ 2 番目の要素以下の場合です。リクエストで指定した型とは異なる型の値が項目に含まれ
ている場合、値は一致しません。
この演算子は、属性値が範囲内にあるかどうかを調べるために使用します。AttributeValueList
には、同じ型(文字列、数値、またはバイナリ)のスカラー要素を 2 つ指定する必要があります。
例
商品の価格が 100~200 の範囲内にある場合、次の式は true と評価されます。
{
"Price": {
ComparisonOperator: "BETWEEN",
AttributeValueList: [ 100, 200 ]
}
}
API Version 2012-08-10
692
Amazon DynamoDB 開発者ガイド
レガシー パラメータを使用した条件書き込み
N 個の属性値を指定する比較演算子
• IN - 値が列挙リスト内のいずれかの値と等しい場合に true。列挙リストではスカラー値のみがサ
ポートされています。セットはサポートされていません。比較する属性と一致するには、同じ型と
値であることが必要です。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つ以上の要
素です(セット型は指定できません)。これらの属性は、項目の既存のセット型以外の属性に対し
て比較されます。入力セットのいずれかの要素が項目の属性に含まれる場合、式は true と評価され
ます。
AttributeValueList に指定できるのは、文字列型、数値型、またはバイナリ型の 1 つ以上の値
です(セット型は指定できません)。比較対象の属性は、同じ型と正確な値に一致する必要があり
ます。文字列は文字列セットには一致しません。
この演算子は、指定した値が列挙リストに含まれるかどうかを調べるために使用しま
す。AttributeValueList には任意の個数のスカラー値を指定できますが、それらの値はすべて同
じデータ型であることが必要です。
例
Id の値が 201、203、または 205 の場合、次の式は true と評価されます。
{
"Id": {
ComparisonOperator: "IN",
AttributeValueList: [ 201, 203, 205 ]
}
}
複数条件の使用
DynamoDB では、複数の条件を組み合わせて複雑な式を構成できます。そのためには、必要に応じて
ConditionalOperator (p. 681) で複数の式を指定します。
デフォルトでは、複数の条件を指定した場合に式全体が true と評価されるには、すべての条件が true
と評価される必要があります。つまり、暗黙的な AND 演算が行われます。
例
商品が 600 ページ以上の書籍(Book)である場合、次の式は true と評価されます。暗黙的な AND 演
算が行われるため、両方の条件が true と評価される必要があります。
{
"ProductCategory": {
ComparisonOperator:
AttributeValueList:
},
"PageCount": {
ComparisonOperator:
AttributeValueList:
}
"EQ",
[ "Book" ]
"GE",
[ 600 ]
}
ConditionalOperator (p. 681) を使用して AND 演算を明示的に行うこともできます。次の例では、前
の例と同じ結果になります。
API Version 2012-08-10
693
Amazon DynamoDB 開発者ガイド
レガシー パラメータを使用した条件書き込み
{
ConditionalOperator : "AND",
"ProductCategory": {
ComparisonOperator: "EQ",
AttributeValueList: [ "Book" ]
},
"PageCount": {
ComparisonOperator: "GE",
AttributeValueList: [ 600 ]
}
}
ConditionalOperator を OR に設定することもできます。この場合、少なくとも 1 つの条件が true
と評価される必要があります。
例
次の式は、商品がマウンテンバイク(Mountain)であるか、その名前が特定のブランド名であるか、
その価格が 100 よりも大きい場合に、true と評価されます。
{
ConditionalOperator : "OR",
"BicycleType": {
ComparisonOperator: "EQ",
AttributeValueList: [ "Mountain" ]
},
"Brand": {
ComparisonOperator: "EQ",
AttributeValueList: [ "Brand-Company A" ]
},
"Price": {
ComparisonOperator: "GT",
AttributeValueList: [ 100 ]
}
}
Note
複雑な式では、条件は最初のものから最後のものまで順に処理されます。
AND と OR の両方を 1 つの式で使用することはできません。
その他の条件付き演算子
DynamoDB の以前のリリースでは、Expected パラメーターの動作は条件付き書き込みに対して異
なっていました。Expected マップの各項目は、確認する DynamoDB の属性名を表しており、次のオ
プションと共に使用していました。
• Value - 属性に対して比較する値。
• Exists - オペレーションの試行前に値が存在するかどうかを調べます。
Value と Exists のオプションは引き続き DynamoDB でサポートされますが、可能なのは等価
条件、つまり属性が存在するかどうかのテストのみです。代わりに ComparisonOperator と
AttributeValueList を使用することをお勧めします。これらのオプションを使用すると、より広
範な条件を作成できるためです。
API Version 2012-08-10
694
Amazon DynamoDB 開発者ガイド
レガシー パラメータを使用した条件書き込み
Example
DeleteItem では、書籍が絶版になっているかどうかを確認し、この条件が true と評価された場合に
のみ、その書籍を削除できます。次に示すのは、レガシー条件を使用した例です。
{
TableName: "Product",
Item: {
"Id": 600,
"Title": "Book 600 Title"
},
Expected: {
"InPublication": {
Exists: true,
Value : false
}
}
}
次の例でも、同じ結果になりますが、レガシー条件を使用していません。
{
TableName: "Product",
Item: {
"Id": 600,
"Title": "Book 600 Title"
},
Expected: {
"InPublication": {
ComparisonOperator: "EQ",
AttributeValueList: [ false ]
}
}
}
API Version 2012-08-10
695
Amazon DynamoDB 開発者ガイド
現在の低レベル API バージョン (2012-08-10)
Example
PutItem オペレーションでは、同じプライマリキー属性を持つ既存の項目が上書きされないようにで
きます。次に示すのは、レガシー条件を使用した例です。
{
TableName: "Product",
Item: {
"Id": 500,
"Title": "Book 500 Title"
},
Expected: {
"Id": {
Exists: false
}
}
}
次の例でも、同じ結果になりますが、レガシー条件を使用していません。
{
TableName: "Product",
Item: {
"Id": 500,
"Title": "Book 500 Title"
},
Expected: {
"Id": {
ComparisonOperator: "NULL"
}
}
}
Note
Expected マップの条件には、レガシーオプションである Value および Exists
を、ComparisonOperator および AttributeValueList と一緒に使用しないでくださ
い。一緒に使用すると、条件付き書き込みが失敗します。
現在の低レベル API バージョン (2012-08-10)
低レベル &DDB; API の現在のバージョンは 2012-08-10 です。 完全なドキュメントについては、
『Amazon DynamoDB API Reference』を参照してください
以下のオペレーションがサポートされています。
• BatchGetItem
• BatchWriteItem
• CreateTable
• DeleteItem
• DeleteTable
• DescribeLimits
• DescribeTable
API Version 2012-08-10
696
Amazon DynamoDB 開発者ガイド
前バージョンの低レベル API (2011-12-05)
• GetItem
• ListTables
• ListTagsOfResource
• PutItem
• Query
• Scan
• TagResource
• UpdateItem
• UpdateTable
• UntagResource
前バージョンの低レベル API (2011-12-05)
ここでは、前バージョンの DynamoDB 低レベル API (2011-12-05) で利用可能なオペレーションを文
書化します。 この 低レベル API のバージョンは、既存のアプリケーションとの下位互換性を確保す
るために保持されています。
新しいアプリケーションでは、現在の API バージョン(2012-08-10)を使用してください。詳細につ
いては、「現在の低レベル API バージョン (2012-08-10) (p. 696)」を参照してください。
Note
新しい DynamoDB の機能は前の API のバージョンにはバックポートされないため、アプリ
ケーションを最新の API バージョン(2012-08-10)に移行することをお勧めします。
トピック
• BatchGetItem (p. 697)
• BatchWriteItem (p. 703)
• CreateTable (p. 708)
• DeleteItem (p. 713)
• DeleteTable (p. 717)
• DescribeTables (p. 721)
• GetItem (p. 724)
• ListTables (p. 726)
• PutItem (p. 728)
• Query (p. 734)
• スキャン (p. 743)
• UpdateItem (p. 754)
• UpdateTable (p. 760)
BatchGetItem
Important
############## API ##### 2011-12-05 ##################################
現在の低レベル API のドキュメントについては、Amazon DynamoDB API Referenceを参照
してください。
API Version 2012-08-10
697
Amazon DynamoDB 開発者ガイド
BatchGetItem
説明
BatchGetItem オペレーションは、プライマリキーを使用して複数のテーブルから複数の項目の属性
を返します。1 回のオペレーションで取り出すことができる項目の最大数は 100 です。また、取り出
される項目の数は、1 MB のサイズ制限を受けます。レスポンスサイズの制限を超えた場合、または、
テーブルのプロビジョニングされたスループットの超過や内部処理エラーが原因で一部の結果しか返
されなかった場合、DynamoDB は UnprocessedKeys 値を返します。この場合、オペレーションを
やり直して次の項目から取得を再開することができます。DynamoDB は、ページごとに返される項目
の数を自動的に調整し、この制限を適用します。たとえば、100 項目を取り出すように指示した場合
でも、各項目のサイズが 50 KB の場合、20 個の項目と、結果の次のページを取得できるように適切
な UnprocessedKeys 値が返されます。必要に応じて、アプリケーションに独自のロジックを追加し
て、結果のページを 1 つのセットにまとめることができます。
リクエストに含まれる各テーブルのプロビジョニングされたスループットが不十
分であることが原因で、項目をまったく処理できなかった場合、DynamoDB は
ProvisionedThroughputExceededException エラーを返します。
Note
デフォルトでは、BatchGetItem は、リクエストのすべてのテーブルに対して結果整合
性のある読み込みを実行します。整合性のある読み込みが必要な場合は、テーブル単位で
ConsistentRead パラメータを true に設定できます。
BatchGetItem は、並列で項目をフェッチして、レスポンスのレイテンシーを最小限に抑え
ます。
アプリケーションの設計にあたっては、DynamoDB によって返される属性の順序が保証され
ないことに注意してください。リクエストで項目の AttributesToGet にプライマリキーの
値を追加すると、項目別にレスポンスを解析しやすくなります。
リクエストした項目が存在しない場合、レスポンスではその項目に関して何も返されませ
ん。存在しない項目のリクエストは、読み込みのタイプに応じて最小の読み込みキャパシ
ティーユニットを消費します。詳細については、「キャパシティーユニットの計算 (p. 181)」
を参照してください。
リクエスト
構文
// This header is abbreviated. For a sample of a complete header,
see DynamoDB #### API (p. 68).
POST / HTTP/1.1
x-amz-target: DynamoDB_20111205.BatchGetItem
content-type: application/x-amz-json-1.0
{"RequestItems":
{"Table1":
{"Keys":
[{"HashKeyElement": {"S":"KeyValue1"}, "RangeKeyElement":
{"N":"KeyValue2"}},
{"HashKeyElement": {"S":"KeyValue3"}, "RangeKeyElement":
{"N":"KeyValue4"}},
{"HashKeyElement": {"S":"KeyValue5"}, "RangeKeyElement":
{"N":"KeyValue6"}}],
"AttributesToGet":["AttributeName1", "AttributeName2",
"AttributeName3"]},
"Table2":
{"Keys":
[{"HashKeyElement": {"S":"KeyValue4"}},
API Version 2012-08-10
698
Amazon DynamoDB 開発者ガイド
BatchGetItem
{"HashKeyElement": {"S":"KeyValue5"}}],
"AttributesToGet": ["AttributeName4", "AttributeName5",
"AttributeName6"]
}
}
}
名前
説明
必須
RequestItems
テーブル名とプライマリキーに
よって取得する対応する項目の
コンテナ。項目をリクエスト
しているとき、各テーブル名
は、1 回のオペレーションにつ
き一度だけ呼び出すことができ
ます。
型: String
デフォルト: なし
はい
Table
取得する項目を含んでいるテー
ブルの名前。エントリは、ラベ
ルなしで既存のテーブルを指定
する文字列です。
型: 文字列
デフォルト: なし
はい
Table:Keys
指定したテーブルの項目を定義
するプライマリキーの値。プラ
イマリキーの詳細については、
「プライマリキー (p. 5)」を参
照してください。
型: キー
はい
Table:AttributesToGet
指定したテーブル内の属性名の
配列。属性名を省略した場合、
すべての属性が返されます。見
つからなかった属性は、結果に
は表示されません。
型: 配列
いいえ
Table:ConsistentRead
true に設定した場合、整合性
のある読み込みが実行されま
す。それ以外の場合は、結果整
合性が使用されます。
タイプ: ブール値
いいえ
レスポンス
構文
HTTP/1.1 200
x-amzn-RequestId: 8966d095-71e9-11e0-a498-71d736f27375
content-type: application/x-amz-json-1.0
content-length: 855
API Version 2012-08-10
699
Amazon DynamoDB 開発者ガイド
BatchGetItem
{"Responses":
{"Table1":
{"Items":
[{"AttributeName1": {"S":"AttributeValue"},
"AttributeName2": {"N":"AttributeValue"},
"AttributeName3": {"SS":["AttributeValue", "AttributeValue",
"AttributeValue"]}
},
{"AttributeName1": {"S": "AttributeValue"},
"AttributeName2": {"S": "AttributeValue"},
"AttributeName3": {"NS": ["AttributeValue", "AttributeValue",
"AttributeValue"]}
}],
"ConsumedCapacityUnits":1},
"Table2":
{"Items":
[{"AttributeName1": {"S":"AttributeValue"},
"AttributeName2": {"N":"AttributeValue"},
"AttributeName3": {"SS":["AttributeValue", "AttributeValue",
"AttributeValue"]}
},
{"AttributeName1": {"S": "AttributeValue"},
"AttributeName2": {"S": "AttributeValue"},
"AttributeName3": {"NS": ["AttributeValue",
"AttributeValue","AttributeValue"]}
}],
"ConsumedCapacityUnits":1}
},
"UnprocessedKeys":
{"Table3":
{"Keys":
[{"HashKeyElement": {"S":"KeyValue1"}, "RangeKeyElement":
{"N":"KeyValue2"}},
{"HashKeyElement": {"S":"KeyValue3"}, "RangeKeyElement":
{"N":"KeyValue4"}},
{"HashKeyElement": {"S":"KeyValue5"}, "RangeKeyElement":
{"N":"KeyValue6"}}],
"AttributesToGet":["AttributeName1", "AttributeName2",
"AttributeName3"]}
}
}
名前
説明
Responses
テーブル名とテーブルからの各項目の属性。
タイプ: マップ
Table
項目を含んでいるテーブルの名前。エントリ
は、ラベルなしでテーブルを指定する文字列で
す。
タイプ: 文字列
Items
オペレーションパラメータを満たす属性名と値
のコンテナ。
型: 属性名とそのデータ型と値のマップ。
API Version 2012-08-10
700
Amazon DynamoDB 開発者ガイド
BatchGetItem
名前
説明
ConsumedCapacityUnits
各テーブルの消費された読み込みキャパシ
ティーユニットの数。この値は、プロビジョ
ニングされたスループットに対して適用され
た数を示します。存在しない項目のリクエス
トは、読み込みのタイプに応じて最小の読み
込みキャパシティーユニットを消費します。詳
細については、「テーブルの読み書き要件の指
定 (p. 179)」を参照してください。
型: 数値
UnprocessedKeys
テーブルと、現在のレスポンスで処理さ
れなかった個別のキーの配列を含んでいま
す。レスポンスサイズの制限に達したこと
が原因で処理されなかった可能性がありま
す。UnprocessedKeys 値は、RequestItems
パラメータと同じフォームです(これにより、
この値を後続の BatchGetItem オペレーション
でそのまま使用できます)。詳細については、
前述の RequestItems パラメータを参照してく
ださい。
型: 配列
UnprocessedKeys: Table: Keys
項目と項目に関連付けられた属性を定義するプ
ライマリキー属性値。プライマリキーの詳細に
ついては、「プライマリキー (p. 5)」を参照して
ください。
型: 属性名と値のペアの配列
UnprocessedKeys: Table: AttributesToGet
指定したテーブル内の属性名。属性名を省略し
た場合、すべての属性が返されます。見つから
なかった属性は、結果には表示されません。
型: 属性名の配列
UnprocessedKeys: Table: ConsistentRead
true に設定した場合、指定したテーブルに対し
て整合性のある読み込みが使用されます。それ
以外の場合、結果整合性のある読み込みが使用
されます。
型: ブール値
特殊なエラー
エラー
説明
ProvisionedThroughputExceededException プロビジョニングされたスループットの許容さ
れている最大値を超えました。
例
次の例は、BatchGetItem オペレーションを使用した HTTP POST リクエストとレスポンスで
す。AWS SDK を使用した例については、「DynamoDB での項目の操作 (p. 204)」を参照してくださ
い。
API Version 2012-08-10
701
Amazon DynamoDB 開発者ガイド
BatchGetItem
リクエスト例
次のリクエスト例では、2 つの異なるテーブルから属性を取得します。
// This header is abbreviated.
// For a sample of a complete header, see DynamoDB #### API (p. 68).
POST / HTTP/1.1
x-amz-target: DynamoDB_20111205.BatchGetItem
content-type: application/x-amz-json-1.0
content-length: 409
{"RequestItems":
{"comp2":
{"Keys":
[{"HashKeyElement":{"S":"Julie"}},{"HashKeyElement":
{"S":"Mingus"}}],
"AttributesToGet":["user","friends"]},
"comp1":
{"Keys":
[{"HashKeyElement":{"S":"Casey"},"RangeKeyElement":
{"N":"1319509152"}},
{"HashKeyElement":{"S":"Dave"},"RangeKeyElement":
{"N":"1319509155"}},
{"HashKeyElement":{"S":"Riley"},"RangeKeyElement":
{"N":"1319509158"}}],
"AttributesToGet":["user","status"]}
}
}
レスポンス例
次の例はレスポンスです。
HTTP/1.1 200 OK
x-amzn-RequestId: GTPQVRM4VJS792J1UFJTKUBVV4KQNSO5AEMVJF66Q9ASUAAJG
content-type: application/x-amz-json-1.0
content-length: 373
Date: Fri, 02 Sep 2011 23:07:39 GMT
{"Responses":
{"comp2":
{"Items":
[{"status":{"S":"online"},"user":{"S":"Casey"}},
{"status":{"S":"working"},"user":{"S":"Riley"}},
{"status":{"S":"running"},"user":{"S":"Dave"}}],
"ConsumedCapacityUnits":1.5},
"comp2":
{"Items":
[{"friends":{"SS":["Elisabeth", "Peter"]},"user":{"S":"Mingus"}},
{"friends":{"SS":["Dave", "Peter"]},"user":{"S":"Julie"}}],
"ConsumedCapacityUnits":1}
},
"UnprocessedKeys":{}
}
API Version 2012-08-10
702
Amazon DynamoDB 開発者ガイド
BatchWriteItem
BatchWriteItem
Important
############## API ##### 2011-12-05 ##################################
現在の低レベル API のドキュメントについては、Amazon DynamoDB API Referenceを参照
してください。
説明
このオペレーションでは、1 回の コールで複数のテーブルにまたがる複数の項目を入力または削除で
きます。
1 つの項目をアップロードするには、PutItem を使用します。また、1 つの項目を削除するに
は、DeleteItem を使用します。 ただし、大量のデータを Amazon EMR(Amazon EMR)からアッ
プロードしたり、別のデータベースから DynamoDB にデータを移行したりするなど、大量のデータ
をアップロードまたは削除する場合は、BatchWriteItem を使用すると効率的に実行できます。
Java などの言語を使用する場合、スレッドを使用して項目を並列でアップロードできます。この場
合、アプリケーションの処理はスレッド処理が加わってより複雑なものになります。他の言語はス
レッド処理をサポートしていません。たとえば、PHP を使用している場合、項目を 1 つずつアップ
ロードまたは削除する必要があります。どちらの場合でも、BatchWriteItem では、指定された入力
および削除オペレーションが並列で処理されるので、アプリケーションの処理を複雑なものにするこ
となく、スレッドプールの利点に浴することができます。
BatchWriteItem オペレーションで指定された各入力と削除のコストは、消費されるキャパシティー
ユニットの点では同じです。 ただし、BatchWriteItem は、指定されたオペレーションを並列で実
行するので、レイテンシーが短縮されます。 存在しない項目に対する削除オペレーションでは、1 書
き込みキャパシティーユニットを消費します。消費されるキャパシティーユニットの詳細について
は、「DynamoDB でのテーブルの操作 (p. 178)」を参照してください。
BatchWriteItem を使用するときは、次の制限事項に注意してください。
• 1 つのリクエストの最大オペレーション数 – 合計で最大 25 個の入力または削除オペレーションを指
定できます。ただし、リクエストサイズの合計は 1 MB(HTTP ペイロード)以下にする必要があり
ます。
• BatchWriteItem オペレーションは、項目を入力および削除する場合にのみ使用できます。既存の
項目を更新する場合は使用できません。
• アトミックオペレーションではありません – BatchWriteItem に指定する各オペレーションは
アトミックですが、BatchWriteItem 全体では、アトミックオペレーションではなく、"ベスト
エフォート" オペレーションです。つまり、BatchWriteItem リクエストでは、成功するオペ
レーションと失敗するオペレーションがあります。失敗したオペレーションは、レスポンスの
UnprocessedItems フィールドで返されます。失敗の原因として、テーブルに対して設定され
たプロビジョニングされたスループットを超過したか、ネットワークエラーなどの一時的なエ
ラーが考えられます。調査して、必要に応じてリクエストを再送信できます。通常、ループで
BatchWriteItem を呼び出し、各反復で、未処理の項目の有無を確認し、その未処理の項目を指定
した新しい BatchWriteItem リクエストを送信します。
• 項目を返しません – BatchWriteItem は、大量のデータを効率的にアップロードすることを目的に
設計されています。これには、PutItem や DeleteItem などによって提供される高度な機能の一
部が備わっていません。 たとえば、DeleteItem では、レスポンスで削除された項目をリクエスト
するためにリクエストの本文に ReturnValues フィールドを指定することをサポートしています。
BatchWriteItem オペレーションでは、レスポンスで項目を返しません。
• PutItem や DeleteItem とは異なり、BatchWriteItem では、オペレーションの各書き込みリク
エストに条件を指定できません。
API Version 2012-08-10
703
Amazon DynamoDB 開発者ガイド
BatchWriteItem
• 属性値を null にすることはできません。文字列型およびバイナリ型の属性の長さは、ゼロより大き
くする必要があります。セット型属性を空白にすることはできません。空白の値があるリクエスト
は、ValidationException で拒否されます。
DynamoDB は、次の条件のいずれか 1 つでも当てはまる場合、バッチ書き込みオペレーション全体を
拒否します。
• BatchWriteItem リクエストに指定された 1 つ以上のテーブルが存在しない。
• リクエストの項目に指定されたプライマリキー属性が、対応するテーブルのプライマリキースキー
マと一致しない。
• 同じ BatchWriteItem リクエストで、同じ項目に対して複数のオペレーションを実行しようとし
ている。たとえば、同じ BatchWriteItem リクエストで、同じ項目を入力および削除することは
できません。
• リクエストサイズの合計が 1 MB リクエストサイズ(HTTP ペイロード)制限を超えている。
• バッチの項目のいずれかが 64 KB 項目サイズ制限を超えている。
リクエスト
構文
// This header is abbreviated. For a sample of a complete header,
see DynamoDB #### API (p. 68).
POST / HTTP/1.1
x-amz-target: DynamoDB_20111205.BatchGetItem
content-type: application/x-amz-json-1.0
{
"RequestItems" :
RequestItems
}
RequestItems
{
"TableName1" :
"TableName2" :
...
}
[ Request, Request, ... ],
[ Request, Request, ... ],
Request ::=
PutRequest | DeleteRequest
PutRequest ::=
{
"PutRequest" : {
"Item" : {
"Attribute-Name1" : Attribute-Value,
"Attribute-Name2" : Attribute-Value,
...
}
}
}
DeleteRequest ::=
{
"DeleteRequest" : {
"Key" : PrimaryKey-Value
API Version 2012-08-10
704
Amazon DynamoDB 開発者ガイド
BatchWriteItem
}
}
PrimaryKey-Value ::= HashTypePK | HashAndRangeTypePK
HashTypePK ::=
{
"HashKeyElement" : Attribute-Value
}
HashAndRangeTypePK
{
"HashKeyElement" : Attribute-Value,
"RangeKeyElement" : Attribute-Value,
}
Attribute-Value ::= String | Numeric| Binary | StringSet | NumericSet
| BinarySet
Numeric ::=
{
"N": "Number"
}
String ::=
{
"S": "String"
}
Binary ::=
{
"B": "Base64 encoded binary data"
}
StringSet ::=
{
"SS": [ "String1", "String2", ... ]
}
NumberSet ::=
{
"NS": [ "Number1", "Number2", ... ]
}
BinarySet ::=
{
"BS": [ "Binary1", "Binary2", ... ]
}
リクエストの本文で、RequestItems JSON オブジェクトは、実行するオペレーションを記述しま
す。オペレーションはテーブル別にグループ化されます。BatchWriteItem を使用して、複数のテー
ブルにまたがる複数の項目を更新または削除できます。 書き込みリクエストごとに、リクエストのタ
イプ(PutItem、DeleteItem)とその後にオペレーションの詳細を指定する必要があります。
• PutRequest の場合、項目(つまり、属性とその値のリスト)を指定します。
• DeleteRequest の場合、プライマリキーの名前と値を指定します。
API Version 2012-08-10
705
Amazon DynamoDB 開発者ガイド
BatchWriteItem
レスポンス
構文
次に、レスポンスで返される JSON 本文の構文を示します。
{
"Responses" :
"UnprocessedItems" :
ConsumedCapacityUnitsByTable
RequestItems
}
ConsumedCapacityUnitsByTable
{
"TableName1" : { "ConsumedCapacityUnits", : NumericValue },
"TableName2" : { "ConsumedCapacityUnits", : NumericValue },
...
}
RequestItems
This syntax is identical to the one described in the JSON syntax in the
request.
特殊なエラー
このオペレーションに固有のエラーはありません。
例
次の例は、BatchWriteItem オペレーションの HTTP POST リクエストとレスポンスです。リクエス
トでは、Reply テーブルと Thread テーブルに対して次のオペレーションを指定しています。
• Reply テーブルで項目を入力し、項目を削除する
• Thread テーブルに項目を入力する
AWS SDK を使用した例については、「DynamoDB での項目の操作 (p. 204)」を参照してください。
リクエスト例
// This header is abbreviated. For a sample of a complete header,
see DynamoDB #### API (p. 68).
POST / HTTP/1.1
x-amz-target: DynamoDB_20111205.BatchGetItem
content-type: application/x-amz-json-1.0
{
"RequestItems":{
"Reply":[
{
"PutRequest":{
"Item":{
"ReplyDateTime":{
"S":"2012-04-03T11:04:47.034Z"
},
"Id":{
"S":"DynamoDB#DynamoDB Thread 5"
}
API Version 2012-08-10
706
Amazon DynamoDB 開発者ガイド
BatchWriteItem
}
}
},
{
"DeleteRequest":{
"Key":{
"HashKeyElement":{
"S":"DynamoDB#DynamoDB Thread 4"
},
"RangeKeyElement":{
"S":"oops - accidental row"
}
}
}
}
],
"Thread":[
{
"PutRequest":{
"Item":{
"ForumName":{
"S":"DynamoDB"
},
"Subject":{
"S":"DynamoDB Thread 5"
}
}
}
}
]
}
}
レスポンス例
次のレスポンス例は、Thread テーブルと Reply テーブルの両方に対する入力オペレーションが成功
し、(テーブルのプロビジョニングされたスループットを超過したときに発生する調整などが原因
で)Reply テーブルに対する削除オペレーションが失敗したことを示しています。JSON レスポンス
の次の点に注意してください。
• Responses オブジェクトは、Thread テーブルと Reply テーブルに対する入力オペレーションが
成功した結果、両方のテーブルで 1 キャパシティーユニットが消費されたことを示しています。
• UnprocessedItems オブジェクトは、Reply テーブルに対する削除オペレーションが失敗したこ
とを示しています。新しい BatchWriteItem コールを実行して、この未処理のリクエストに対応
できます。
HTTP/1.1 200 OK
x-amzn-RequestId: G8M9ANLOE5QA26AEUHJKJE0ASBVV4KQNSO5AEMVJF66Q9ASUAAJG
Content-Type: application/x-amz-json-1.0
Content-Length: 536
Date: Thu, 05 Apr 2012 18:22:09 GMT
{
"Responses":{
"Thread":{
"ConsumedCapacityUnits":1.0
},
API Version 2012-08-10
707
Amazon DynamoDB 開発者ガイド
CreateTable
"Reply":{
"ConsumedCapacityUnits":1.0
}
},
"UnprocessedItems":{
"Reply":[
{
"DeleteRequest":{
"Key":{
"HashKeyElement":{
"S":"DynamoDB#DynamoDB Thread 4"
},
"RangeKeyElement":{
"S":"oops - accidental row"
}
}
}
}
]
}
}
CreateTable
Important
############## API ##### 2011-12-05 ##################################
現在の低レベル API のドキュメントについては、Amazon DynamoDB API Referenceを参照
してください。
説明
CreateTable オペレーションは、新しいテーブルをアカウントに追加します。
テーブル名は、リクエストを発行している AWS アカウントに関連付けられたテーブルおよびリクエ
ストを受け取る AWS リージョン(dynamodb.us-west-2.amazonaws.com) を使用する場合、Amazon
S3 は仮想ホスティング形式のリクエストをデフォルトで米国東部 (バージニア北部) リージョンに
ルーティングします。各 DynamoDB エンドポイントは完全に独立しています。たとえば、"MyTable"
という名前のテーブルが 2 つあり、その 1 つが dynamodb.us-west-2.amazonaws.com にあり、もう
1 つが dynamodb.us-west-1.amazonaws.com にある場合、この 2 つのテーブルは完全に独立してお
り、データを共有しません。
CreateTable オペレーションは、非同期ワークフローをトリガーして、テーブルの作成を開始しま
す。DynamoDB は、テーブルが ACTIVE 状態になるまで、すぐにテーブルの状態(CREATING)を返
します。テーブルが ACTIVE 状態になると、データプレーンオペレーションを実行できます。
DescribeTables (p. 721) オペレーションを使用して、テーブルのステータスを確認します。
リクエスト
構文
// This header is abbreviated.
// For a sample of a complete header, see DynamoDB #### API (p. 68).
POST / HTTP/1.1
x-amz-target: DynamoDB_20111205.CreateTable
API Version 2012-08-10
708
Amazon DynamoDB 開発者ガイド
CreateTable
content-type: application/x-amz-json-1.0
{"TableName":"Table1",
"KeySchema":
{"HashKeyElement":
{"AttributeName":"AttributeName1","AttributeType":"S"},
"RangeKeyElement":
{"AttributeName":"AttributeName2","AttributeType":"N"}},
"ProvisionedThroughput":{"ReadCapacityUnits":5,"WriteCapacityUnits":10}
}
名前
説明
必須
TableName
作成するテーブルの名前。
使用できる文字は、a~z、A
~Z、0~9、'_'(アンダースコ
ア)、'-'(ダッシュ)、および
'.'(ドット)です。名前は 3~
255 文字で指定します。
タイプ: 文字列
はい
KeySchema
テーブルのプライマリ
キー(単純または複合)構
造。HashKeyElement の
名前と値のペアは必須で
す。RangeKeyElement の名
前と値のペアはオプションです
(複合プライマリキーの場合の
み、必須)。プライマリキーの
詳細については、「プライマリ
キー (p. 5)」を参照してくださ
い。
プライマリキー要素の名前
は、1~255 文字の長さで、文
字に関する制限はありません。
AttributeType の有効な値
は、"S"(文字列)、"N"(数
値)、または "B"(バイナリ)
です。
型: HashKeyElement のマッ
プ、または複合プライマリキー
の場合、HashKeyElement と
RangeKeyElement のマップ
はい
API Version 2012-08-10
709
Amazon DynamoDB 開発者ガイド
CreateTable
名前
説明
必須
ProvisionedThroughput
指定したテーブル
の新しいスループッ
ト。ReadCapacityUnits と
WriteCapacityUnits の値で
構成されます。詳細について
は、「テーブルの読み書き要件
の指定 (p. 179)」を参照してく
ださい。
はい
Note
現在の最大値および
最小値については、
「DynamoDB での制
限 (p. 558)」を参照し
てください。
型: 配列
ProvisionedThroughput:
ReadCapacityUnits
DynamoDB が他のオペレー
はい
ションと負荷のバランスをとる
までの、指定したテーブルに関
して 1 秒間に消費され
© Copyright 2026 Paperzz