インテルコンパイラにおけるミドルウェア最適化に関するレポート
2010/03/31 大黒圭祐
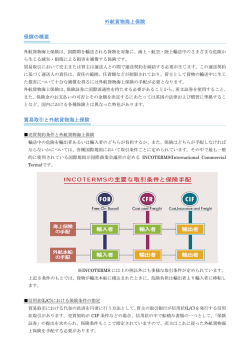
1. はじめに
インテル コンパイラー版バイナリは GCC 版バイナリよりも高速と言われている. 本稿では, その実力を普段利用
している, Apache や MySQL などのミドルウェアを対象に検証してみる.
2. インテルコンパイラについて
2.1. 使用するバージョンと特徴
今回, 利用するインテルコンパイラ ” Intel C++ Complier ( 以下, icc と呼ぶ ) ” は, 2010 年 3 月時点の最新バ
ージョンである ” 11. 1 Update 5 ” を使用する. 特色は以下のようである.
(1) 最新版の主な特徴
マルチコア開発のサポート.
C++ 例外処理における最適化の機能も向上し, また C++ クラス階層の解析や最適化も行える.
バッファー・オーバーフローなどのセキュリティー脆弱性の影響を受けにくいコードを作成できる.
アプリケーションのチューニングでインテルの高度な最適化を行えるよう, より詳細な最適化診断を行え
る.
最新のマルチコア・プロセッサーのサポート(Core i7, Atom など最新のクアッドコア, デュアルコア).
Linux 上での Eclipse 3. 3. x/3. 4. x および CDT 4. 0. 2/5. 0. 0 への統合可能.
Eclipse RCP ベースの GUI でアプリケーションの並列化や診断結果が見やすく.
GCC とのソースおよびオブジェクトの互換性により, 既存のアプリケーションを再コンパイル可能.
デバッガーが含まれており, 最適化されたコードのデバッグを行うことができる.
OpenMP プログラムを修正して 64 ビットインテル(R)アーキテクチャー・ベースのクラスターで実行でき
る.
(2) Linux インテル(R) 64 対応アプリケーションの開発に必要な環境
項目
プロセッサー
条件
インテル(R) 64 アーキテクチャー・プロセッサーをベースとするコンピューター
インテル(R) Pentium(R) 4 プロセッサー以降, または互換性のあるインテル以外のプロセッサー
推奨ディストリビューション
Red Hat Enterprise Linux 3, 4, 5
Asianux 3. 0
TurboLinux 11
Fedora 10
SUSE LINUX Enterprise Server 9, 10, 11
Debian 4. 0
Ubuntu 9. 04
RAM
必要ライブラリ郡
1GB (2GB 推奨)
Linux 開発ツール・コンポーネント (gcc, g++ および関連ツールを含む)
binutils 2. 17. 50 以降
libstdc++. so. 5 を提供する Linux コンポーネント compat-libstdc++
32 ビット・ライブラリーを含む Linux コンポーネント (ia32-libs)
(3) 付属するコンポーネント
インテル(R)デバッガー ( GUI使用するためにはJRE5. 0または6. 0が必要 )
IA-64 対応アプリケーション開発用インテル(R)アセンブラー
インテル(R)インテグレーテッド・パフォーマンス・プリミティブ ( IPP. マルチメディア・ソフトウェアに豊富
な機能と優れた性能を提供 )
インテル(R)マス・カーネル・ライブラリー ( MKL. 数学, 科学, 金融向けに最適化された演算ルーチ
ン )
インテル(R)スレッディング・ビルディング・ブロック ( TTB. スレッド化を簡素化するC++ランタイム・ライブ
ラリー )
Eclipse 統合開発環境
(4) ライセンス
確認中…
2.2. icc のインストール
intel 社 HP より ” インテル(R) C++ コンパイラーLinux* 版プロフェッショナル・エディション ” を 30 日評価ライ
センスでダウンロードし, CentoOS 5. 4 ( 詳細な環境は以降に記述 ) にインストールした. 個人利用目的であ
ればフリー ( Non-commercial, Unsupported ) バージョンも存在するのがうれしい.
インストールはいたって簡単で, ダウンロードした tar ボールを展開し, install. sh を実行すれば対話形式でインス
トールが開始される( デフォルトの設定で全てインストールされるので迷うこともない ).
2.3. Vtune のインストール
今回の検証では使用しないが, インストールと簡単に動作確認をしてみたので少し取り上げる.
Vtune とは, その名の通りアプリケーションのパフォーマンス解析ツールで Eclipse 開発環境をベースに作られて
いる ( 図 a ). また, リモートプロセスを起動すれば, Linux または Windows マシンからリモートで Linux マシン上
での診断の実行及び結果見ることも可能 ( 図 b ).
図 a:Eclipse 開発環境上での Vtune(Linux 上のローカル)
図 b:Windows 上での Vtune(Visual Studio に組み込み可)
他のアナライザーと大きく異なるのは, CPU 上で実行されるすべての命令についてサンプリングしてくれるところか
と思う. 高機能で且つ, 視覚的に見やすくなっているのには違いないが使い勝手はもう少し利用してみないと何と
も言えない. しかしながら, Eclipse 組み込みなので ubuntu 等の Linux 上で開発を行っているエンジニアにとって
は有用かもしれない.
2.4. icc の最適化オプション
特に有効と思われる最適化オプションを以下に挙げる ( マニュアルより抜粋 ) .
(1) 基本的な最適化オプション
オプション
-O1
内容
サイズの最適化を行います.
オブジェクトのサイズを増やす傾向がある最適化を省略します. 多くの場合, 最小限のサイズで最適化
されたコードが作成されます. コードサイズが大きいために, メモリーページングが問題になっている巨
大なサーバー/ データベース・アプリケーションにおいて, このオプションは効果的です
-O2
最速化します ( デフォルト設定 ). ベクトル化を含む多くの最適化を有効にします.
-O3
-O2 の最適化に加えて, スカラー置換, ループアンロール, 分岐を除去するコード反復, より効率的に
キャッシュを使用するループ・ブロッキング, さらに IA-64 ベースのシステムにはデータ・プリフェッチ機
能など, 強力なループの最適化およびメモリーアクセスの最適化を行います.
特に浮動小数点演算を多用するループや大きなデータセットを処理するループを含むアプリケーション
に推奨します. これらの強力な最適化は, 場合によっては-O2 の最適化よりもアプリケーションの実行が
遅くなることがあります.
(2) 並列パフォーマンスに関する最適化オプション
オプション
内容
-parallel
安全に並列実行可能な単純構造のループを検出し, そのループに対するマルチスレッド・コードを自動
的に生成します.
-parthreshold[n]
ループ並列化による効果の可能性に基づいて, ループの自動並列化のしきい値を設定します ( n=0
から n=100. デフォルト: n=100 ) .
0 :計算量にかかわらず並列化を行います.
100 :ループは並列実行が有効であることが確実な場合にのみ並列化されます.
(3) プロセッサーに関する最適化オプション
オプション
内容
-x { sse4. 2 | sse4. 1 | sse3_atom | ssse3 |
対象とするプロセッサー ( 命令セット SSE※1 ) を指定します. host の場合コ
sse3 | sse2 | host }
ンパイルホストでサポートされている命令を生成し, 最適化します.
-ax
特定の CPU 以外(AMD など Intel 以外の SSE2 をサポートするもの)でも動作
{ sse4. 2 | sse4. 1 | ssse3 | sse3 | sse2 }
するプログラムを作成したい場合. SSE バージョンに応じた複数のコードが生
成され, CPU に最 適なコードが選択・実行される. -x と -m {ia32|sse3|sse2}
の組み合わせも同様. このオプションを指定することで若干のオーバーヘッ
ドが発生するほか, バイナリサイズが大きくなる.
1
SSE ( Streaming SIMD Extensions ) とは, 一つの命令で複数のデータを一気に処理できる ” SIMD ” という
処理方式を実装したマイクロプロセッサに内蔵されている拡張命令セット
(4) プロシージャー間の最適化オプション※2
オプション
-ip
-ipo [ value ]
内容
単一ファイル内でのプロシージャー間の最適化を行います.
複数ファイルにわたるプロシージャー間の最適化を行います. オプションの value 引数には, コン
パイル時に生成するオブジェクト・ファイルの最大数を指定します. デフォルトの value は 0 です
(コンパイラーが選択). 条件によってはコンパイル時間とコードサイズが大幅に増加する場合があ
ります.
(5) 浮動小数点演算に関する最適化オプション
オプション
-fp-model name
内容
最適化を制限して浮動小数点結果の一貫性を制御する.
浮動小数点演算の一貫性や再現性が必要な多くの状況では, -fp-model precise -fp-model
source を推奨します.
-[ no ] prec-div
精度の高い浮動小数点除算を使用します.
(6) その他の最適化オプション
オプション
内容
-unroll [ n ]
ループをアンロールする最大回数を設定します. -unroll0 はループアンロールを無効にします. デ
フォルトは, -unroll で, デフォルトのヒューリスティックを使用します.
- [ no ] restrict
ポインターの一義化が有効 [ 無効 ] になります. デフォルトではオフです. ( C++ のみ )
2.5. icc へのコンパイラーの切替
iccを利用するために, 以下のスクリプトを実行することで必要な環境変数やライブラリ郡を読み込むことが出来る.
shell> source <install-dir>/bin/iccvars. sh <arg>
例) source /opt/intel/Compiler/11. 1/069/bin/iccvars. sh intel64
2
関数のインライン化を制御することで, 関数呼び出しで発生するオーバーヘッドを減少させ, 最適化の機会を増やし
ます.
3. 検証内容と環境
3.1.
ミドルウェア
評価するミドルウェアは以下とした.
(1) apache 2. 2. 15 ( 2010/03/15 時点で最新 )
(2) MySQL 4. 1. 21 ( 余裕があれば 5.0.90 も )
(3) memcache 1. 4. 4 ( 2010/03/15 時点で最新 )
(4) redis 1. 2. 5 ( 2010/03/15 時点で最新 )
3.2.
最適化オプション
以下のパターンの最適化オプションで性能を評価する.
ミドルウェア
gcc 最適化オプション
icc 最適化オプション ( CFLAGS および CXXFLAGS )
apache
1) -O2
1) -O2
MySQL
2) -O3
2) -O3
3) -O2 -parallel
memcached
4) –O2 -xSSE4. 1
redis
5) –O2 -ip
6) –O2 -fp-model precise
7) –O2 –xSSE4.1 -ip
8) –O3 –xSSE4.1 -ip
3.3.
方法
下記のクライアント上からベンチマークソフトを用いて, gcc バイナリと icc バイナリの性能を比較する. ベンチマーク
の詳細な内容は, 後述. 尚, なるべく誤差がでないように, 測定前後でページキャッシュはクリアすることとする※3.
ミドルウェア
3.4.
ベンチマークツール
apache
apache bench ( 付属ツール )
MySQL
sql-bench および mysqlslap (付属ツール )
memcached
memslap ( libmemcached 付属ツール )
redis
redis-benchmark ( 付属ツール )
環境
コンパイルを行い, ベンチマークをかけたサーバーは以下. クライアントは x3650(Quad Core / 4G memory)を使
用.
スペック
OS
3
R200 / Intel(R) Xeon(R) X3330 2. 66GHz (Quad Core) / 4G memory
Centos 5. 4 x86_64 / 2. 6. 18-164. el5 / gcc 4. 1. 2
echo 1 > /proc/sys/vm/drop_caches
3.5.
ミドルウェアの configure と設定
configure の例と起動時の設定を以下に示す. CFLAGS および CXXFLAGS を前述の検証する最適化オプション
に置き換えることになる.
(1) apache
configure 例
gcc
./configure --prefix=/usr/local/apache2-gccO2 –-with-mpm=worker CFLAGS="-O2 –m64"
icc
./configure --prefix=/usr/local/apache2-iccO2 –-with-mpm=worker CC=icc CXX=icpc CFLAGS="-O2" CXXFLAGS="-O2"
設定
MaxClient を 200, Keep Alive ON とした
(2) MySQL
configure 例
gcc
./configure --with-charset=utf8 \
--with-mysqld-user=mysql \
--prefix=/usr/local/mysql-gccO2 \
--localstatedir=/usr/local/mysql/data \
CFLAGS="-O2 -m64" \
CXXFLAGS="-O2 -m64"
icc
./configure \
--with-charset=utf8 \
--with-mysqld-user=mysql \
--prefix=/usr/local/mysql-iccO2 \
--localstatedir=/usr/local/mysql/data \
CC=icc \
CXX=icpc \
CFLAGS="-O2" \
CXXFLAGS="-O2"
設定
key_buffer_size = 1G, innodb_buffer_pool_size = 1G, innodb_flush_log_at_trx_commit = 0, innodb_flush_method = O_DSYNC
とした.
(3) memcached
configure 例
gcc
./configure --prefix=/usr/local/memcached-gccO2 --with-libevent=/usr/local/lib --enable-64bit CFLAGS="-O2"
icc
./configure --prefix=/usr/local/memcached-iccO2 --with-libevent=/usr/local/lib CC=icc CFLAGS="-O2"
設定
memcached -u cy_memcache -p 11211 -l 172. xxx. xxx. xxx -d -c 4096 -m 2048 /* メモリ割当て 2G とする */
で起動
(4) redis
configure 例
configure は用意されていないので Makefile を直接書き換える※4.
CC=icc /*icc の場合追記*/
CFLAGS?= -std=c99 -O2 -Wall $(ARCH) $(PROF)
設定
redis-server redis. conf /* redis. conf はデフォルトを使用(特に変更しなくてよい) */
で起動
4
icc では gcc 固有のオプションは無視されるが, 念のため実際は不要なオプションは削除した. 問題がある場合は
警告やエラーとなる.
4. 結果
(1) apache
ベンチマーク内容
[ データ ]
静的ページまたは動的ページ ( CGI )※5を用意
[ クライアント数 ]
100.
[ 計測内容 ]
apache bench による 1 万リクエストした結果のスループットを計測.
[ ベンチマークツール実行例 ]
ab -n 10000 -c 100 http://172.xxx.xxx.xxx/index.html
結果
それほど大きな違いは見られなかった.何度か実施した平均値を取っているが, 最大と最小の差が大きかった
ため参考程度. 実際の web アプリケーションを乗せて Jmeter 等で負荷をかけるべきだろう.
5
mod_perl は使用していない…
(2) MySQL
ベンチマーク内容 ( sql-bench )
[ データ ]
sql-bench による自動生成
[ スレッド数 ]
1
[ 計測内容 ]
sql-bench による DML および DDL 文実行のトータル実行時間を計測
[ ベンチマークツール実行例 ]
perl run-all-tests --user=bench
ベンチマーク内容 ( mysqlslap※6 )
[ データ ]
mysqlslap による自動生成 ( varchar(128)が 2 カラム int(32)が 2 カラムのテーブルを使うよう指定 )
※ ディスクは別で検証中だった Intel 製の SSD (X-25E) を使用した
[ スレッド ]
100
[ 計測内容 ]
mysqlslap にて各スレッド 10 万回 select, insert 混合の負荷をかけ,スレッドあたりの平均実行時間を測定
連続 5 回試行した平均値をとる.
[ ベンチマークツール実行例 ] mysqlslap \
--no-defaults \
--create-schema=mysqlslap \
--host=172.xxx.xxx.xxx \
--user=bench \
--auto-generate-sql \
--auto-generate-sql-guid-primary \
--auto-generate-sql-write-number=100000 \
--auto-generate-sql-execute-number=100000 \
--auto-generate-sql-load-type=mixed \
--number-int-cols=2 \
--number-char-cols=2 \
--iterations=5 \
--concurrency=100
6
結果 ( sql-bench )
mysqlslap は mysql5.1 以上で付属するツールで, 一部 mysql4.1 では利用できないコマンドがあったためソースを書
き換えた
結果 ( mysqlslap MyISAM )
結果 ( mysqlslap InnoDB )
sql-bench と MyISAM での mysqlslap については icc の方がパフォーマンスが良い ( 実行時間が短い ) 結
果となっているが, InnoDB での mysqlslap はパフォーマンスが落ちる結果となった. もう少し詳細に検証する必
要がありそうだ.
(3) memcached
ベンチマーク内容
[ データ ]
memslap による自動生成 ( key はランダム. value は 1024byte )
[ スレッド数 ]
100
[ 計測内容 ]
memslap にて get および set コマンドをそれぞれ 10 分間行ったスループットを計測.
連続 5 回試行した平均値をとる.
[ ベンチマークツール実行例 ] memslap -s 172.xxx.xxx.xxx:11211 -F memslap.conf -c 100 –t 600s
結果
set, get ともに icc のパフォーマンスが良好. 各最適化オプションでの傾向がつかめないが測定誤差の範囲内
ではないかと考えられる.
(4) redis
ベンチマーク内容
[ データ ]
redis-benchmark による自動生成 ( key はランダム. value は 1024byte )
[ スレッド数 ]
100.
[ 計測内容 ]
redis-benchmark にて get および set コマンドを各スレッド 10 万回行ったスループットを計測.
連続 5 回試行した平均値を取る.
[ ベンチマークツール実行例 ] redis-benchmark -h 172.xxx.xxx.xxx -p 6379 -q -c 100 -n 100000 -d 1024
結果
get については, icc と gcc にそれほど違いは見られない. setについては, gcc に比べ icc のほうが勝る傾向に
はあるが, memcached と同様に各最適化オプションでの傾向がつかめない.
5. 考察
今回の評価では, icc と gcc でそれほど大きなパフォーマンスの差は見られなかった.
簡易的なベンチマークツールを使用したことや, 最適化オプションも不十分であったことが原因なのか, 同じミドル
ウェアでも, icc のバイナリのほうが gcc より処理が高速となる場合も逆のパターンも見られた. 特に, MySQL のよう
に, c++のコードが多い場合や複雑な処理を含むプログラムは最適化が活かされる場合と, そうでない場合がある
と推測している. ストレージエンジンによりコンパイラーや最適化オプションを変更するのも有効かもしれない. また,
MySQL4.1 は 2 コアまでしかスケールしないと言われており, マルチコアに関する最適化が有効に働かない可能性
もある(5.0 以上で再検証したい). ましてや, redis に関してはシングルスレッド(将来は libevent の対応が入る)であ
る.
結論として, 単純に icc でコンパイルしたからと言って一概に高速になるわけでもなさそうだ. 本来, Vtune などでボ
トルネックを見つたり, プログラムの性質を考慮して最適化オプションを付ける付けないを判断するなど, もう一歩
踏み込んだ計画的な最適化が必要であろう.
6. 最後に
今回の検証は完全ではなかったが, よりオープンソースの内側に入り込むきっかけになったように思う. コンパイル
一つにしてもベンチマークにしても探求しなければならない箇所は無数にあるという面白さを感じた. 今後も検証
は続けていこうと思う.
参
考
文
献
[1]
インテル(R) C++ コンパイラー 11. 1 Linux* 版 プロフェッショナル・エディション インストール・ガイドおよびリリースノート.
[2]
インテル(R) C++ コンパイラー 11. 1 Linux* OS 版プロフェッショナル・エディション 入門ガイド.
[3]
"Using the GNU Compiler Collection (GCC)".
[4]
"Intel(R) compiler options for SSE generation (SSE2,
<http://gcc. gnu. org/onlinedocs/gcc-4. 1. 2/gcc. pdf>
SSE3,
SSSE3,
SSE4. 1,
SSE4. 2) and processor-specific optimizations".
<http://software.
intel.
com/en-us/articles/performance-tools-for-software-developers-intel-compiler-options-for-sse-generation-and-processor-specific
-optimizations/#1>
© Copyright 2026 Paperzz


![遊戯空間としてのメディア - NTT InterCommunication Center [ICC]](http://s3.paperzz.com/store/data/005571347_1-c8695ee4e4c0b992f525d4b896b15794-250x500.png)