Paper
zz
Explore Categories
Log in
Create new account
No category
論文 - Takeichi Lab
Download
Report
社会保険届書の電子媒体申請について
ボタン一発! Excelより 断然速い自動グラフ作成 ツールFreeG
スライド 1 - 株式会社ミウラ
による流星の自動観測 UFOCapture 司馬康生 望遠鏡が不要な流星
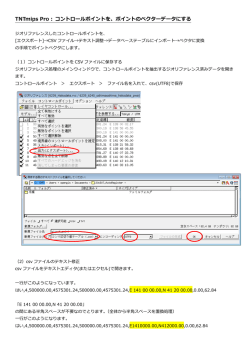
TNTmips Pro : コントロールポイントを、ポイントのベクターデータにする
2012年8月16日 ITインフラの適格性への対応が必須へ!
SISCONSTと他製品との違い
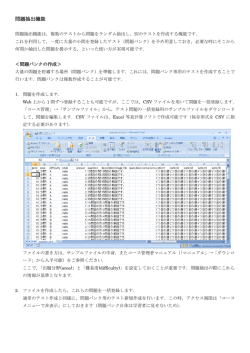
問題抽出機能
© Copyright 2026 Paperzz
About Paperzz
DMCA / GDPR
Report