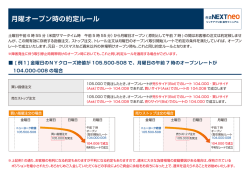
0 July 2002 日本教育工学会論文誌 英語 CALL 構築を目的とした日本人及び米国人による 読み上げ英語音声データベースの構築 峯 松 信 明†1 富 山 義 弘†2 吉 本 清 水 克 正†4 中 川 聖 一†5 壇 辻 正 剛†2 牧 野 正 三†3 啓†3 外国語学習の高度化・効率化を目的とし,近年著しく進歩を遂げた音声情報処理技術に基づく学習 支援環境構築を目指した研究が広く行なわれている。周知のように現在の音声情報処理技術は,その 多くが数理統計的な枠組みの上に構築されており,その結果,大規模音声データベース(以下,DB と略す)は技術高度化の絶対条件となっている。90 年代より音声認識研究者を中心として各種の音声 DB が構築・整備されてきたが,非母語音声 DB となるとその数は僅かなものとなり,また,発音教 育における各教育項目に対応した形での DB 数は更に制限される。更に,外国語学習支援を目的とし た場合,学習対象言語を教える教師による評定結果や,対象言語を母語とする話者による(同一読み 上げセットの)音声なども必要となる。このような観点に立った非母語音声 DB というのは筆者らの 知る限りにおいて存在しない。平成 12 年度より,科学研究費特定領域研究 (1)「メディア教育利用」 の一部において,音声・言語処理技術を用いた外国語学習支援環境の構築が推進されており,そのプ ロジェクトの一環として日本人学習者による読み上げ英語音声 DB,英語教師による発音評定ラベリ ング,米語母語話者による音声 DB を構築した。本論文では,これら DB デザインに関して行なわ れた議論の様子,構築された DB 仕様,規模,収録,評定方法などについて詳細に述べる。 キーワード:外国語学習,CALL,音声言語情報処理,音声データベース,発音評定ラベリング Development of English speech database read by Japanese and Americans for CALL system development Nobuaki Minematsu,†1 Yoshihiro Tomiyama,†2 Kei Yoshimoto,†3 Katsumasa Shimizu,†4 Seiichi Nakagawa,†5 Masatake Dantsuji†2 and Shozo Makino†3 In order to realize the educational environment for efficient foreign language learning, a lot of researches have been made based upon speech and language technology. It is well-known that the current speech and language technology is based upon statistical methods and that they naturally require large scale databases. In the early 90’s, researchers of speech recognition got aware of very high necessity of the databases and, since then, they have built various kinds of speech and language databases. But the number of non-native speech databases currently available is very small and that of the databases accordant with the syllabus of foreign language education is further restricted. To build a speech database for CALL system development, proficiency scores of the individual speakers rated by language teachers and speech samples of the same reading material spoken by native speakers should also be provided. As far as the authors know, there are no databases currently available which are designed by considering these requirements. A national project of “Advanced Utilization of Multimedia to Promote Higher Educational Reform” began in 2000 and under this project, a large English speech database read by Japanese students and a speech database containing the same material read by Americans were designed and developed with pronunciation proficiency labels assigned by English teachers. In this paper, preparations on the database design done before the development, specifications, scale, recording methods of the developed database, and adopted strategies for the labeling are described in detail. Keywords : foreign language learning, CALL, spoken language information processing, speech database, pronunciation proficiency labeling Vol. 43 No. 7 日本教育工学会論文誌 July 2002 より音声認識の研究者らによって各種の DB が開発 1. は じ め に され,LDC や ELRA などの DB 配付サイトを通し 周知のように,日本語と英語は音声学的(リズム, て広く公開されてきたが,その多くは母語を対象とし イントネーションを含む)にも言語学的にも非常に大 た DB である。非母語を対象とした技術開発における きな差異を持つ言語対である(例えば Gimson1980, 先行研究では,必要なデータを必要なだけ当該サイト 竹林 1996,川越 1996,小川 1999,深澤 2000,Ra- で収録し,他者が使えるよう公開するという例は非常 mus2002 など)。これに加え,各言語を母語とする に少なかった。先行研究において開発,公開された日 話者が持つ音声知覚プロセス間における差異(大竹ら 本人学生による英語に関する DB としては,テキス 1999,Tajima et al.2002),物事を考える発想,論理 ト DB として,日本人学生による英作文に対してタ プロセス間における差異(Kaplan1966,松本 1968), グ付けを行なった JEFLL コーパスや CEJL コーパス 更には,コミュニケーションにおける文化的差異(浅 などがあり,また,音声 DB としてはアルクが主催す 間 1997)までもが存在し,日本人学習者にとって英語 る SST(Standard Speaking Test) の様子を録音,書 の習得・運用は非常に高いハードルとなっている。事 き起こした SST コーパス(Tono et al.2001),また, 実,日本人学生の英語運用能力は,アジア諸国の他国 Foreign Accented English の一部として日本人留学 の学生のそれと比較して非常に低く位置付けられてい 生による英語音声が FAE コーパスとして収録されて る(TOEIC1998,河合 1999)。これらの状況を改善 いる。本研究では,音声 DB に焦点を当てるが,SST する試みの一つとして,2000 年度より,文部科学省科 コーパスは本来,日本人学生が発声した英語の書き起 学研究費補助金特定領域研究 (1) 「高等教育改革に資 こしを収集することが目的であり,録音条件(マイク するマルチメディアの高度利用に関する研究」が発足 特性,雑音レベル,チャネル当りの話者数など)が統 し,種々の音声・言語技術を用いた革新的な試みが検 一されず,音声情報処理技術の応用を目的として SST 討されている(特定 2001,特定 2002,特定 2003)。 コーパスを用いることは現時点では困難である。また 近年,計算機技術の飛躍的向上に支えられ,音声・言 FAE コーパスは収録の便宜を図るため,電話越しの 語情報処理技術は著しく進歩し,各種技術をツールと 音声収録を行なっており,その発話内容も自由発話と して利用することも比較的容易になってきた(Young なっている。後述するが,自由発話に対する現在の音 ら 2002,河原ら 2002,川本ら 2002)。これらの技術 声情報処理技術の性能は十分とは言えず,その上,音 に基づいて,外国語学習の更なる高度化・効率化を目 響的歪みの大きい非母語の音声となると,処理性能に 的とし,学習支援環境構築を目的とした研究が広く行 対する制約が更に増すことになる。本論文では,この なわれ(壇辻 2001,中川 2002,山本 2002,Swartz ような背景から読み上げ音声を対象にしている。また, el at.1992,Holland et al.1995,Jager et al.1998), 外国語学習支援を目的とした場合,学習者音声 DB だ 種々の有効な技術,ツールの提供が行なわれてきた。 けでなく,学習対象言語を教える(対象言語を母語と しかし従来の研究開発においては,共通する一つの する)教師による発音評定ラベルや,対象言語を母語 大きな問題が存在していた。それはデータベース(以 とする話者による(同一読み上げセットの)音声 DB 下 DB と略す)の欠如である。周知のように現在の なども要望されている。筆者らの知る限りおいて,こ 音声・言語情報処理技術は,その多くが数理統計的な れら音声情報処理の技術的要請,外国語(発音)学習 枠組みに基づいて構築されており,その結果,大規模 の教育的要請,システム開発における要請など,外国 DB は技術高度化の必須条件となっている。90 年代 語学習支援環境構築における各種側面からの要請を考 慮してデザイン,構築された DB は存在していない。 †1 東京大学 University of Tokyo †2 京都大学 Kyoto University †3 東北大学 Tohoku University †4 名古屋学院大学 Nagoya Gakuin University †5 豊橋技術科学大学 Toyohashi University of Technology 本論文では,構築された DB の仕様,規模,収録 方法の記載のみならず,DB デザイン時に行なわれた 種々の議論についても記述する。これは,本 DB は上 記したように外国語学習支援環境構築における多様な 側面に配慮したデザインが行なわれており,今後この ような DB 開発を行なう際における資料的価値が高 いと考えるからである。以降,第 2 節,第 3 節にお 1 2 日本教育工学会論文誌 July 2002 いて,日本人学生による読み上げ英語音声 DB に関す み上げリストに発音(音素)記号を付与し,また,母 る準備,及び構築の様子について述べる。その後,第 語話者音声を収集する必要上,英語と米語のいずれを 4 節,第 5 節において,米語を母語とする(日本人に 対象とするのかを決める必要がある。ここでは日本に 対する教育経験のある)英語教師による発音評定ラベ おける英語教育の現状を踏まえ,米語 (GA, General リングに関する準備,及びラベリングの様子について American) を対象として DB 構築することとした。な 報告する。米語話者による(同一読み上げセットに対 お,DB デザイン時の議論としては,英語を前提とし する)音声 DB 構築の様子を第 6 節で述べた後,第 7 た DB に対する高い需要があれば,それを念頭に置い 節において,本 DB の評価を行なう。DB 構築に対す た構築もすべきである,との意見が交わされた。 る評価は非常に難しいところであるが,本 DB は,技 学習者の年齢としては大学生,大学院生を対象とする。 術開発,システム開発での利用を目的として構築され 前述した科研費プロジェクトの参加者の多くは大学に ており,その意味において,本 DB を利用した各種研 在籍する工学者,語学教育者である。対象とする学生 究,開発例を紹介することで本 DB の評価に変えさせ の年齢は当然大学生,大学院生となる。また,本研究 て戴く。最後に第 8 節で本論文をまとめる。 と平行して行なわれた非日本語母語話者による日本語 2. 日本人学生による読み上げ英語音声データ ベース構築に向けた準備 音声 DB の構築では,留学生を対象として音声データ を集めている。これらを考慮し,学習者年齢としては 大学生,大学院生を対象とすることとした。 2.1 データベースデザインに対する技術的要請 音響的歪みのみを対象とし,言語的歪み(書き取り時 本 DB 構築では現在の音声情報処理の技術水準を考 の誤用など)は対象外とする。読み上げ作業を行なわ 慮して収録条件を選定した。音声 DB を構築する場 せる場合でも,学習者自らが記した英文を読み上げさ 合,その対象は「読み上げ音声」と「(疑似)自然発 せることができれば,音響的・言語的歪みの両者が含 話音声」に分類される。近年著しく進歩した音声情報 まれた読み上げ英語音声 DB が可能である。しかし, 処理技術ではあるが,自然発話は音響的・言語的変動 英作文時の誤用については先行研究(JEFLL,CEJL が非常に大きく,母語音声の場合でも,その処理精度 コーパス)において大規模な収集が行なわれており, は読み上げ音声と比較すると非常に低い(中川 2000, DB 構築作業の効率化のためにも,本研究では,与え 古井 2002)。使用言語が非母語となると,その変動は られた正しい英文を読み上げる作業を通して音声 DB 増加することが予想され,その処理精度は更に抑制さ を構築することとした。 れる。これらを考慮し本研究では,日本人学習者の英 特定の学習者に見られる「特異的な」音響的歪み,及 語読̇み̇上̇げ̇音声 DB を構築することとした。英語学習 び各学習者に見られる「一時的な」音響的歪みはなる において新出単語などについては,単語単位あるいは べく排除する。既述したように,現在の音声情報処理 該当単語が挿入された文を読み上げる形で発音練習が 技術は,比較的多くのデータサンプルに基づく統計的 行なわれることを考えると,読み上げ音声 DB を構築 手法に基づいている。この場合,特異的な発音誤りや した場合でも,発音学習への応用は十分可能である。 一時的な発音誤りにまで着眼すると,DB 規模をどこ 読み上げ音声を対象にした場合でも,非母語の発声 まで考慮すべきかという議論が難しくなる。また一時 は非常に大きな音響的・言語的「歪み」を伴う。この 的な発音誤り(言い誤り,言い淀みの類い)は,学習 歪みは学習者の母語(方言),年齢,学習歴,学習意 者がそれと気付く誤りであり,これらは対象外とする 欲などの要因により大きなばらつきを持つ。この音響 こととした。即ち,本研究で構築する DB が扱う発音 的・言語的歪みを(可能な限り)網羅する DB の構築 誤りは,英語調音知識の欠如に起因する,日本人学習 が望まれるが,例えば学習者の母語を日本語に,学習 者に比較的共通して観測される「癖」を主対象とした。 対象言語を英語に限定した場合でも,これらの歪みの 系統的記述そのものが困難であり,現時点では記述方 2.2 データベースデザインに対する教育的要請 本 DB はその構築目的が教育利用であるため,教育 式そのものが研究対象の一つとして挙げられている。 的側面からの要請を十分に考慮してデザインする必要 以上の点を考慮し,本研究では,DB 構築に対して以 がある。外国語学習(特に発音学習)の教育要項は大 下の方針を設けた(Minematsu et al.2002e)。 きく,その分節的側面と韻律的側面に分かれるが,本 学習対象言語(方言)は米語とする。後述するが,読 DB 構築でもこれに従い,各側面に焦点をあてた発声 Vol. 43 No.英語 7 CALL 構築を目的とした日本人及び米国人による読み上げ英語音声データベースの構築 3 リスト構築を行なった。この際,科研費プロジェクト に参加する英語教師に広く協力を呼びかけ,分節的, 韻律的両側面に関する発声リストを,一部,作成して 戴いた。特に本 DB 構築では,学習対象言語も,学習 者の母語も限定されている。そこで,日本人特有の発 音歪み・癖に着眼した(難音)リストも作成して戴い た。その一部は,実際の授業で使用されているリスト である。なお,具体的な文・単語リストの様子は後述 する。また,発音学習における発声を言語単位という 観点から考えると,単語,句,文に分けられる。ここ では基本的に,単語と文に着眼して各々の発声リスト を作成した。最終的に読み上げリストは, (分節,韻 律)×(文,単語)の 4 種類となっている。 一言で「読み上げ」作業と言っても,その形態は幾 つか考えられ,どれを選択するかによって,構築され た DB の利用範囲も変ってくる。例えば,発音学習を 念頭に置いた場合でも「発声時に与えられる情報」と いう観点から分類すると以下の 3 種類の「読み上げ」 形態が考えられる。 (1) 発声すべきテキスト(スペル情報)が与えられ, それを読み上げる練習 (2) スペル情報に加えて発音記号(音素情報)や, 韻律記号(リズム,イントネーションなど)も 与えられ,それを読み上げる練習 (3) モデルとなる英語音声(音響情報)が与えられ, それを聴取した上で読み上げる(真似る,復唱 する)練習 本 DB 構築では第 2.1 節で述べたように,日本人に よる英語発声において比較的共通して見られる「癖」 に着眼していること,また,発音練習時に比較的容易 に入手可能な情報は提供した形で収録をすべきである との議論から,本研究では,スペル,音素記号,韻律 記号などを提示した形での読み上げ作業を行なわせる こととした。音素記号については多くの話者が不慣れ であると予測されるので,各記号と「音」との対応に ついては図 1 に示すように別途 web を用意し,必要 に応じて参照するよう指示した。但し,音素記号が振 られた文を読み上げる場合,付与された記号が不自然 な読み上げを誘発する恐れもあるため,一部の文セッ トに対しては,発音練習時(後述するが,事前の発音 練習も許可している)のみ各種記号を付与し,読み上 げ時のリストには付与しないなどの方法をとった。 2.3 学習者音声収録に関する準備 外国語学習支援環境構築用の DB である以上,収録 図 1 発音記号と音との対応を確認するために設け られた web 画面 された音声の中に発音誤りが存在していなければ意味 がない。その意味で,音声収録に対して,収録直前に 読み上げリストを配付して収録を開始する方法も考え られる。しかし,本 DB 構築では音素バランス文など の発声も予定しており,そのような文には使用頻度の 低い単語も存在する。このような単語に起因する発音 誤りは第 2.1 節で述べた方針に反するものである。ま た,言い誤り・言い淀みなど一時的な発音誤りが多発 する恐れもある。そこで音声収録に関しては,事前に, 読み上げリスト(発音記号,韻律記号などが付与され ている)を配付し,発音練習を許可した。更に,収録 中に発声者自身が発音誤りに気付いた場合は(「一時 的」歪みである場合が多いので)発声を繰り返すよう 指示した(ただし最大 3 回まで。3 回連続して誤った 場合は,その発声をスキップすることを許可した)。 即ち,本音声 DB は原則的に,発声者本人が「正しく 発声できた」と判断した音声のみが収録されているこ とになる。このような「読み上げ」作業を学習者に課 した場合,得られた音声 DB には発音誤りを含む音声 試料が少なくなることが危惧されたが,最終的に得ら れた音声 DB に対する自動発音誤り分析によれば(大 崎ら 2002,峯松ら 2002c),発音誤りは非常に多く混 入していることが示されている。なお,事前の発声練 習量については発声者に一任しており,その練習量の 違いによって,本来その話者が持つ真の発音習熟度と は異なる発音が行なわれる可能性がある。しかし,本 研究では収録された音声と,それに対する教師の発音 評定結果を対にして提供することが目的であり,各話 4 日本教育工学会論文誌 July 2002 表 3 音素バランスを考慮した単語・文セット 表 1 音声試料のファイル化における音響条件 録音場所 カテゴリ 最低限「静かな居室」を準備する。 音素バランス単語 300 平均録音レベル ミニマル単語対 600 [使用機器の最大レベル]−15dB 音素バランス文 460 ファイル化条件 発音困難な音素列を含む文 32 16kHz/16bit,ビックエンディアン 音素学習に対する評価文 100 サイズ 背景雑音 50dB 以下を目安。ゼロ詰めは禁止。 表 4 韻律バリエーションを考慮した単語・文セット 音声の前後に 300msec 相当の背景雑音を付与 カテゴリ 使用マイク 種々の強勢パターンを含む単語 サイズ Senheiser 社の HMD25-1(あるいは同等品) 種々のイントネーションパターンを含む文 94 最終的なファイルフォーマット 種々のリズムパターンを含む文 109 120 マイクロソフト WAV す。なお,市販されている英語辞書の発音記号と若干 表 2 発音記号表記に採用した音素体系 B, D, G, P, T, K, JH, CH, S, SH, Z, ZH, F, TH, 異なり,schwa (相当の音)の発音を全て音素 /AX/ V, DH, M, N, NG, L, R, W, Y, HH, IY, IH, EH, て同一記号となる。この場合発声者の中には,schwa EY, AE, AA, AW, AY, AH, AO, OY, OW, UH, 音の音響的実現に混乱を来す可能性が示唆されるが, UW, ER, AXR, AX 付与された音素記号及び図 1 による web 上の指示だ で統一した。その結果,/AH/, /IH/, /UH/の弱勢は全 けではどのような発音が要求されているのか不明であ 者の本来の発音習熟度に沿った発音がされているかど うかは全く考慮していない。 2.4 音声試料のファイル化作業に関する準備 る場合は,各自の英語辞書を参照するよう指示した。 韻律記号に関しては,まず単語強勢を,無強勢 (0), 第一強勢 (1),第二強勢 (2) の 3 段階に分類し,母音記 音声試料は一端 DAT(Digital Audio Tape) に収録 号に対する添え字として定義した。また,イントネー され(サンプリング周波数 48kHz,量子化ビット数 ションパターンは矢印を用いて表現し,リズムに関し 16bit),その後各収録サイトの音響機器を用いて計算 機に取り入れられ,最終的にはファイル化される。ファ イル化の際の音響条件としては,JNAS データベース (Itou1999)構築時における音響条件を踏襲した。表 1 に主な音響条件について示す。各収録サイトにおい て防音室を準備することは不可能であるため,収録環 境としては「静かな居室」という緩やかな条件を課す 一方で,使用するマイクは Senheiser 社の HMD25-1 (あるいはその同等品)を指定するなどの条件を課し ては文強勢を,無強勢 (-),強勢 (+),核強勢 (@) の 3 段階に分類し,該当するシラブル位置に付与すること で視覚提示とした。韻律境界 (phrase break) につい ても記号 “/”を用いて示した。なお,これらの表記は 各種発音教材を参考にした。また,文に対するイント ネーションパターン・リズムパターンの付与は一意に 定めることは困難であるが,ここでは,米語を母語と する英語教師 1 名に,最も一般的と思われるパターン を提示させ,各種記号を付与した。 た。また,音声ファイリングに関しては人工的なゼロ 3.2 作成した読み上げリスト 詰め(波形振幅値としてゼロを入れる)は禁止し,前 3.2.1 音素バランスに着眼したリスト 後に 300 msec ほどの背景雑音を残すよう指示した。 音素バランスに着眼して作成したリストを表 3 に示 3. 日本人学生による読み上げ英語音声データ ベースの構築 す。音素バランス単語セットは 50 単語で 1 セットと 3.1 付与した音素記号と韻律記号 音素記号としては,TIMIT DB の音素体系,CMU 発音辞書の音素体系をベースとし,多少の修正を施し たものを使用した。利用した音素記号一覧を表 2 に示 なる単語セットを 6 セット用いている。ミニマル単語 対セットの中には,ある特定の音素系列の発声を意図 したものもあり,未知単語が含まれている。この場合 は当然「与えられた音素記号列の読み上げ」となる。 音素バランス文セットは TIMIT DB をベースとした Vol. 43 No.英語 7 CALL 構築を目的とした日本人及び米国人による読み上げ英語音声データベースの構築 5 460 文を採用し,日本人にとってその発音が困難な文 各単語は約 20 人の話者に読み上げられる。なお,収 セット,評価文セットは実際に英語教師によって作成 録手順に関しては第 2.3 節で述べた通りである。 された文セットである。これら文セットに対しては, 音素記号が付与されたリストと付与されないリストを 用意し,前者は事前の発音練習用,後者を収録時の参 4. 英語教師による発音評定ラベリングに関す る準備 照用として利用した。これは,収録時における音素記 4.1 評定者の選定 号の参照が不自然な発音を誘発することが予想された 発音評定者としては,英語音声学の知識を有し,対 からである。単語リストについては未知語の問題もあ 象言語を母語とし,日本人学生に対しての教育経験を り,発音記号が付与されたもののみを用意した。しか 持つ(対象言語の)語学教師のみを採用した。文音声 し単語リスト中の既知単語はその殆どが容易な単語で の評定には 5 名の教師(但し韻律セットは 4 人)が, あり,音素記号付与による不自然な発声は考え難い。 単語音声の評定には 2 名(5 名中 2 名)が参加した。 3.2.2 韻律バリエーションに着眼したリスト 4.2 評定尺度と評定基準 表 4 に韻律バリエーションに着眼して作成した発声 複数の教師に評定を依頼する場合,事前に評定尺度 リストを示す。まず,第一強勢位置や第二強勢の有無 (どのような観点からの評定を行なうのか),及び評定 などに着眼して単語セットを構成した。このセットに 基準(各観点からの評定において,どのような発音に は,複数の箇所に強勢が許される単語(所謂名前動後 どの程度のスコアを与えるのか)を厳密に議論した上 の単語)や,複合語や名詞句も含まれており,white で評定作業に移ることが考えられる。しかし, (実践的 house など,強勢の置き方で意味が異なる句なども含 な)英語教育において評定基準の統一化が十分に図ら まれている。文イントネーションは,カンマの有無に れていないように,基準の統一化は種々の問題を含ん よるイントネーションの差異,焦点が置かれる単語の でいる。これらを考慮すると,本プロジェクトの評定 違いに起因するイントネーションの差異,統語構造に 作業の為に早急に結論を出すことは危険であると考え 基づく差異,提示情報の新旧による差異などに着目し られる。また,後述するように評定尺度そのものは従 てサブセットが構成されている。リズム文に関しては 来より用いられてきた一般的な尺度であり,また,各 基本的に,文構造が徐々に複雑化していく文をサブセッ 評定者の評定結果を比較することで,評定作業が本来 トとして用意し,それに対して米語を母語とする英語 もつ問題,困難さについて議論可能となり,評定基準 教師にリズムパターンを付与させる形で作成した。 の統一化に対する情報提供も可能となる。以上の判断 3.3 発声リスト例 から,本評定作業では,評定者間の事前議論は行なわ 図 2∼8 に文リストの例を示す。全ての例において なかった。また,評定者にも上記意図を理解して戴い 音素記号が振られ,単語強勢は母音の添え字として表 た上で,従来各自が採用してきた評定基準に基づいて 現されている。文強勢は記号 -, +, @,韻律境界は/で, 採点するよう依頼した。具体的には以下の評定尺度を イントネーションパターンは矢印を用いて示している。 用い,5 段階評定(1∼5,5 が最高点)を行なわせた。 3.4 発声者の選択と一話者当たりの発声量 幅広い英語習熟度の話者による音声を収録する必要 があるため「発音習熟度が意図的に偏るような選定 はしない」という方針の下,各収録サイトに対して話 者を(準)ランダム抽出するよう指示した。特に「希 望者を募る」などの操作は行なわないよう,注意した • 発声者が意図した音素が適切に生成されているか 否か。 • 発声者が意図した単語強勢,文強勢(リズム)が 適切に生成されているか否か。 • 発声者が意図したイントネーションが適切に生成 されているか否か。 (希望者を募ると比較的発音能力の高い話者のみによ 当然,単語音声に対しては第二尺度まで,文音声につ る DB が構築される恐れがある)。最終的に,20 の大 いては第三尺度まで考慮した評定となる。発声者が意 学・高専機関の協力の下,男性 100 人,女性 101 人の 図した音素,リズム,イントネーションであるが,図 音声を収録した。なお,全文から 8 サブセット(各々 2∼8 にあるように,各々の記号が発声リストには明 約 120 文),全単語から 5 サブセット(各々約 220 単 示されており,発声者の意図は自明である。即ちこの 語)を構成し,1 サブセットずつを一人当たりの発声 意図(音素,韻律の各種記号)を評定者に示した上で タスク量とした。その結果,各文は約 12 人の話者に, 学習者音声を聴取させ,その適切さを評定させた。な 6 July 2002 日本教育工学会論文誌 Ambidextrous pickpockets accomplish more. [AE2 M B AX0 D EH1 K S T R AX0 S] [P IH1 K P AA2 K AX0 T S] [AX0 K AA1 M P L AX0 SH] [M AO1 R] Her classical repertoire gained critical acclaim. [HH ER1] [K L AE1 S AX0 K AX0 L] [R EH1 P AXR0 T W AA2 R] [G EY1 N D] [K R IH1 T AX0 K AX0 L] [AX0 K L EY1 M] Even a simple vocabulary contains symbols. [IY1 V AX0 N] [AX0] [S IH1 M P AX0 L] [V OW0 K AE1 B Y AX0 L EH2 R IY0] [K AX0 N T EY1 N Z] [S IH1 M B AX0 L Z] The eastern coast is a place for pure pleasure and excitement. [DH IH1] [IY1 S T AXR0 N] [K OW1 S T] [IH1 Z] [AX0] [P L EY1 S] [F AO1 R] [P Y UH1 R] [P L EH1 ZH AXR0] [AE1 N D] [AX0 K S AY1 T M AX0 N T] The lack of heat compounded the tenant’s grievances. [DH AX0] [L AE1 K] [AH1 V] [HH IY1 T] [K AX0 M P AW1 N D AX0 D] [DH AX0] [T EH1 N AX0 N T S] [G R IY1 V AX0 N S AX0 Z] 図 2 音素記号及び単語強勢記号が振られた音素バランス文セットの一例 San Francisco is one-eighth as populous as New York. [S AE1 N] [F R AE0 N S IH1 S K OW0] [IH1 Z] [W AH1 N EY1 TH] [AE1 Z] [P AA1 P Y AX0 L AX0 S] [AE1 Z] [N Y UW1] [Y AO1 R K] Its extreme width was eighteen inches. [IH1 T S] [AX0 K S T R IY1 M] [W IH1 D TH] [W AA1 Z] [EY0 T IY1 N] [IH1 N CH AX0 Z] Who ever saw his old clothes ? [HH UW1] [EH1 V AXR0] [S AO1] [HH IH1 Z] [OW1 L D] [K L OW1 DH Z] I could be telling you the five-fifths of it in two-three words. [AY1] [K UH1 D] [B IY1] [T EH1 L AX0 NG] [Y UW1] [DH AX0] [F AY1 V F IH1 F TH S] [AH1 V] [IH1 T] [IH1 N] [T UW1 TH R IY1] [W ER1 D Z] 図 3 日本人にとって発音が困難な音素列を含む文セットの一例 rub [R AH1 B] slip [S L IH1 P] smile [S M AY1 L] strife [S T R AY1 F] such [S AH1 CH] then [DH EH1 N] there [DH EH1 R] toe [T OW1] use [Y UW1 S] 図 4 音素記号及び単語強勢記号が振られた音素バランス単語セットの一例 luck robe sink burn selling stuck meat pitch [L [R [S [B [S [S [M [P AH1 K] OW1 B] IH1 NG K] ER1 N] EH1 L AX0 NG] T AH1 K] IY1 T] IH1 CH] lack rope sing barn sailing stock mitt bitch [L [R [S [B [S [S [M [B AE1 K] OW1 P] IH1 NG] AA1 R N] EY1 L AX0 NG] T AA1 K] IH1 T] IH1 CH] 図 5 音素記号及び単語強勢記号が振られたミニマル単語対セットの一例 お,韻律的な文評定において英語教師より「意図した おり,発音教育における韻律指導の問題点の一つとし 韻律パターンの視覚提示と学習者音声の聴覚提示のみ て捉えることができる。なお,単語強勢に関してはモ では, (文脈の情報が無いために)評価が困難である」 デル音声の提示はしていない。 との意見が出された。そこで,英語教師 1 名に韻律文 セットの各文を,付与された記号に沿って読み上げさ 4.3 評定用 web の構築 評定者の中には米国在住の英語教師も含まれており, せた(モデル音声)。韻律評定時には,モデル音声を 評定作業の効率化を図るため,発音評定用の web を 逐次聴取させ,その音声を(音響的な)正解とした場 構築した(図 9 参照)。文音声については 3 種類の評 合の評定を行なわせた。読み上げリスト作成時に付与 定尺度,単語音声については 2 種類の評定尺度があり, した韻律記号であるが,英語発音に関する関連書籍を 基本的には 5 つのページにおいて評定を行なわせた。 調査し,一般的な表現方法を採用している。しかし上 各ページは更にサブページに分割されるが,サブペー 記意見は,視覚的表現のみでは「その表現が意図する ジ毎の評価が終了すると,それを通知する E メールが 音響的対象物が一意に特定できない」ことを示唆して 実験者側に通知されるようにし,評定作業の進捗状況 Vol. 43 No.英語 7 CALL 構築を目的とした日本人及び米国人による読み上げ英語音声データベースの構築 7 That’s from my brother who lives in London. [DH AE1 T S] [F R AH1 M] [M AY1] [B R AH1 DH AXR0] [HH UW1] [L IH1 V Z] [AX0 N] [L AH1 N D AX0 N] That’s from my brother, who lives in London. [DH AE1 T S] [F R AH1 M] [M AY1] [B R AH1 DH AXR0] [HH UW1] [L IH1 V Z] [AX0 N] [L AH1 N D AX0 N] Cauliflower, broccoli, cabbage, sprouts, and onions. [K AA1 L AX0 F L AW2 AXR0] [B R AA1 K AX0 L IY0] [K AE1 B AX0 JH] [S P R AW1 T S] [AE1 N D] [AH1 N Y AX0 N Z] Is this elevator going up or down ? [IH1 Z] [DH IH1 S] [EH1 L AX0 V EY2 T AXR0] [G OW1 AX0 NG] [AH1 P] [AO1 R] [D AW1 N] She knows you, doesn’t she ? [SH IY1] [N OW1 Z] [Y UW1] [D AH1 Z AX0 N T] [SH IY1] 図 6 音素記号及び韻律記号が付与されたイントネーション文セットの一例 Come to tea. / + - @ / [K AH1 M] [T UW1] [T IY1] Come to tea with John. / + - + @ / [K AH1 M] [T UW1] [T IY1] Come to tea with John and / + - @ / + [K AH1 M] [T UW1] [T IY1] Come to tea with John and / + - @ / + [K AH1 M] [T UW1] [T IY1] [W IH1 DH] [JH AA1 N] Mary. @ -/ [W IH1 DH] [JH AA1 N] [AE1 N D] [M EH1 R IY0] Mary at ten. + @ / [W IH1 DH] [JH AA1 N] [AE1 N D] [M EH1 R IY0] [AE1 T] [T EH1 N] 図 7 音素記号と韻律記号が付与されたリズム文セットの一例 a dark room [AX0][D AA1 R K][R UW1 M] a darkroom [AX0][D AA1 R K R UW2 M] a light housekeeper [AX0][L AY1 T][HH AW1 S K IY2 P AXR0] a lighthouse keeper [AX0][L AY1 T HH AW2 S][K IY1 P AXR0] the brief case [DH AX0][B R IY1 F][K EY1 S] the briefcase [DH AX0][B R IY1 F K EY2 S] almond-eyed [AA2 M AX0 N D AY1 D] broad-minded [B R AO1 D M AY1 N D AX0 D] free-range [F R IY1 R EY1 N JH] blue-black [B L UW1 B L AE1 K] forward-looking [F AO1 R W AXR0 D L UH2 K AX0 NG] built-in [B IH1 L T IH1 N] 図 8 音素記号と単語強勢記号が付与された単語アクセントに着眼した単 語セットの一例 をモニタリングできるよう Web デザインを行なった。 発声者の各種意図(音素記号,韻律記号)や,韻律文 5. 英語教師による発音評定ラベリング 評定におけるモデル話者音声についても確実に評定者 5.1 評定用音声の選択 に参照されるよう配置し,また,連続する 2 音声試料 DB 中に含まれる全音声に対して評定を行なうのは が同一話者の音声とならないよう注意し,更には,各 現実的には不可能である。そこで単語音声に対しては, 評定者の(自分自身の)過去の評価履歴を参照できる 音素,強勢の両尺度に対して各々20 単語/人,10 単 よう配慮した。評定者の中には,評定作業を一端中止 語/人を選んだ。最終的に,300 語の音素バランス単 し,数週間後に再開するケースもあり,このような場 語セットに対して約 13 人/単語,約 100 語の強勢単 合は過去の履歴(及び音声試料)を参照し,自らの評 語セットに対して約 19 人/単語の音声資料が選択さ 定基準を確認して作業を開始するよう依頼した。 れた。文音声に関しては,音素,リズム,イントネー ションの各尺度に対して,10 文/人,5 文/人,5 文 8 July 2002 日本教育工学会論文誌 50 音素生成 リズム生成 イントネーション生成 40 発 30 声 者 20 数 10 0 ∼1.5 ∼2.0 図 10 図 9 評定作業用 web 画面 /人を選んだ。リズム,イントネーション文に対して も,事前の発音練習時の文リストには音素記号が振ら れているのでこれらの文を音素生成評定に利用するこ とができる。そこで音素尺度に対してのみ全文を対象 として選択した。最終的に,120 文のリズム文セット に対して約 8 人/文,60 文のイントネーション文セッ トに対して約 16 人/文,460 文の音素バランス文セッ ト及び 180 文の韻律文セットから約 2 人/文,約 5 人 /文の音声試料が選択された。なお,本評定作業時に 収集が完了した音声は男女 95 人ずつであり,その結 果,評定作業もこれらの話者を対象に行なわれた。評 定者 1 人当りの評定タスクは,3,800 文音声,5,700 単語音声であった。 5.2 評定結果に対する分析と考察 本論文の主旨は,日本人及び米国人による,英語 CALL 構築を目的とした読み上げ英語音声 DB,英語 教師による発音評定ラベリングの報告である。しかし 第 4.2 節で述べたように,本評定作業は,評定基準に おける事前の協議を行なわずに 5 段階評定を依頼し た。そこで本節において,評定結果を分析し,評定作 業の持つ問題点について考察する(峯松ら 2002f)。本 来ならば,男女の別,文単語の別など種々の観点から 本評定結果を分析し,その問題点を明らかにすること が可能であるが,前述したように本論文の主旨はあく までも DB 構築の報告であり,また,紙面も限られて いるため,男声の文音声に着眼した分析結果のみにつ いて示す。なお,女声や単語音声についての分析結果 については別途報告の機会を設けたいと考えている。 ∼2.5 ∼3.0 ∼3.5 ∼4.0 ∼4.5 ∼5.0 話者別平均スコア 評定尺度別に見た話者平均点ヒストグラム 500 音素生成 400 頻 300 度 200 100 0 2 1 250 リズム生成 200 頻 150 度 100 50 0 2 1 250 イントネーション生成 200 頻 150 度 100 50 0 2 1 評定者1 評定者2 評定者3 評定者4 評定者5 3 4 5 3 4 5 3 4 5 図 11 評定者別に見た評定点ヒストグラム まず,各評価尺度において話者毎にその平均点を求 めた。ヒストグラムを図 10 に示す。本 DB 収録に際 して,話者の準ランダム選択を行なったが,どの尺度 においても幅広く話者平均スコアが分布している様 子が分かる。次に,各評価者が与えたスコア値に対す るヒストグラムを評価尺度別に算出した。図 11 に示 す。音素生成に対するスコア付与に対しては,頻度が 最も高いスコア値は評価者間で相違があるが,いずれ も 2/3 点が多く,1/5 点は少ないという山の分布をし ている。しかし,特にイントネーションに対しては, 点数付与の傾向が大きく異なる評価者が存在すること が分かる。例えば評価者 2 は 3 点以下の評定が多い が,評価者 4 は 4 点以上の評定が多い。これらの違い は,評定における「甘さ,辛さ」に起因するのか,あ るいは,そもそもイントネーションという言葉の定義 が評定者毎に異なるのか,などの理由が考えられる。 イントネーション,リズムという言葉の音響的実体に 関しては,英語発音教材の中にもその混同が見受けら れる。言葉の定義の問題は外国語教育以前の問題であ Vol. 43 No.英語 7 CALL 構築を目的とした日本人及び米国人による読み上げ英語音声データベースの構築 9 り,早急の解決を図る必要がある。また「甘さ,辛さ」 として米語を母語とする話者による音声データを収集 に起因する場合は,スコアの高低が評定者に依存する した。ここで問題となるのが「どの方言話者を採択する ような音声試料を具体的に提示した上で,発音評定基 のか」ということであるが,ここでは Giegerich(1992) 準について評定者間で検討する場を提供する必要があ における GA(General American) の定義☆ を参照し ろう。今後の研究課題の一つである。 て話者を募った。なお当初,音声学或いは語学教育・指 5 人の評定者(うち一人は音素生成のみを評定)に 導の経験者のみを募ることも考慮したが,発声者の数 対して,任意の 2 評定者間のスコアの一致の様子につ が大幅に制限されるため,ここでは「対象方言 (GA) いて分析した。本実験では,5 段階評価を採用してい が母語である」という条件で話者を選定した。但し, るので,2 評定者間のスコア一致の様子は 5×5 の行 語学教師の音声も一部収録されている。本収録では, 列として示すことができる。全ての音声試料の評定値 男性 8 名,女性 12 名の音声を収録した。なお,韻律 が,この行列の対角成分上に存在していれば 2 人の評 文収録に際して,本収録においても, 「記号のみでは 定者は全く同一の評定を下したこととなる。2 人の評 (記号が)意図した韻律パターンを生成できるか不明 定値の対角成分上への集中度(A),及び,(i, i ± 1) である」との意見が母語話者より出たため,韻律文評 まで含めた領域への集中度(B)を算出した。比較対 定で用いたモデル音声を聴取させ,その直後に復唱さ 照として,FAE データベースにおける日本人英語に せる方法をとった(日本人による英語収録では,モデ 対する評定値(全体的な発音能力を 4 段階で評定)か ル音声の提示はしていない)。英語指導書(テキスト) ら同様の集中度を計算した。なお,段階数の違いを吸 には,視覚的記号のみで韻律を表記しているものがあ 収する必要があるので,FAE の結果を 5 段階評定相 るが,記号の意図が学習者にどの程度理解されている 当となるよう換算した。本実験における集中度 A,B のか検討する必要があろう。 を任意の 2 評定者間で計算し,平均値をとったところ, 音素生成時に対して 38.5%,85.2%,リズム生成に対 7. 構築した DB を用いた研究例 して 32.7%,79.2%,イントネーション生成に対して DB は構築しただけでは意味を持たない。DB を用 21.3%,69.7%となった。一方 FAE(評定者 3 名)で いた分析,研究,開発などを通して初めてその DB の は平均 46.5%,80.3%となった。FAE における評価 存在に意義が生まれる。しかし,各種研究成果が DB 尺度は発音の全体的な評定を行なわせており,本評定 と直接的に関係するのか否かについての判断は困難を 作業よりも容易なタスク設定であり,その一致率も高 極める。このように DB 構築の評価は非常に難しい問 くなることが考えられる。その意味において,本評定 題であるが,本 DB が技術開発,システム開発での利 作業における音素生成に関する一致率は FAE におけ 用を目的として構築されており,その意味において, る一致率と同等あるいはそれ以上のものが得られてい 本 DB を利用した各種工学研究,開発例を紹介するこ ると言える。その一方で,図 11 にあるようにリズム, とで本 DB の評価に変えさせて戴く。その中には,本 イントネーションに関しては評価者の採点方針に違い DB の存在によって初めて可能となった研究例もある。 が見られるため,一致度も低くなっている。韻律的要 第 1 節に示したように,比較的統一された音響条件 素の評定は,教師の言語的背景(どの方言話者か,な ど)や,音声の韻律的要素に対する sensitivity などに も依存するため,統一した評定基準を教師の耳に期待 するのは困難な側面があるのも事実である。音声情報 処理技術導入対象の一つであろう。 6. 米語 (GA) 話者による読み上げ音声デー タベースの構築 発音教育システムには,学習者が教師音声と同一文 を読み上げ,その比較に基づいて評定を行なうものが ある。そこで表 3,4 に示した文,単語セットを各々2 等分し,各 1 セットずつを一人当たりの発声タスク量 ☆ General American (GA) is a cover term used for the group of accents in the United States that do not bear the marked regional characteristics of either the East (more precisely, Eastern New England and New York City) or the South (mainly ranging from Virginia, the Carolinas and Georgia to Lousiana and Texas). These two areas easily perceived as linguistically distinct from the rest of the United States, while the rest – the GA area – appears to be the variety that has no marked regional characteristics, except the negative ones of being non-eastern and non-southern. GA is, then, one of at least three “standard accents” found in the United States; it is by far the most widespread one. It has the largest geographical spread and is the accent commonly used in the television networks covering the whole of the United States. 10 日本教育工学会論文誌 July 2002 の下で,これだけ幅広い発音習熟度分布を網羅する日 ワー,ピッチ,継続長の観点からモデル化している。 本人英語発声を収録した DB は,本プロジェクトによっ 井本ら (2001) は同様の強/弱勢モデルとその時間長 て初めて利用可能となったと言える。その意味におい モデルを用いて英語リズムの学習システムを構築し, て,システム開発に先立ち,日本人英語の特徴分析を Minematsu et al.(2002a) は,強勢の本質が前後シラ 目的とした研究例がある(大崎ら 2002,峯松ら 2002c, ブルより「目立つ」ことであるとの着眼から,隣接シ 真下ら 2003)。大崎ら (2002) は本 DB 中の文音声を ラブル間差分特徴量を用いたより高精度なモデル化を 利用し,日本人英語の特徴を考慮した認識文法に基づ 実現している。一方,中島ら (2003) は,強勢シラブ く母音挿入,子音置換分析を行なっている。また,母 ル検出を明示的に行なわずに,音声のパワー,ピッチ 語話者音響モデルを用いた自動評定についても検討し パターンに着眼することで,着眼する音声中にどの程 ており,既存の自動スコアリング手法(Witt1997)を 度等時な(韻律)イベントがあるのか,を自動推定す 用いて,本 DB 中の評定ラベル間の相関分析をしてい る手法を提案している。更に,本 DB における日本人 る。峯松ら (2002c) は,まず音声認識技術を用いて日 による発声,母語話者による発声を用いて,リズムに 本人英語と米語の音素モデルを構築し,各モデル間距 対する評定スコアリングについても検討している。 離のみに着眼することで音素樹型図を構成している。 以上は,基本的に学習者音声と母語話者音声を比較 即ち,音声データから音声学的な音韻の階層構造を自 するという方法論に基づく分析,開発例である。外国 動抽出し,両者の違いを構造的に論じている。そこに 語学習における発音指導では,音声学的知見に根づ は,母音挿入,子音混同,母音混同,schwa の不適切 く方法論が多く,上記の研究例は音声学(及び音声工 な発声など,広く認知された日本人英語の癖が克明に 学)に基づく方法論である。一方,英語教育の現場で 観測されている。真下ら (2003) は,本 DB における は「native-like な英語から intelligible な英語へ」とい リズム文発声を日本人,米語話者間で韻律的特徴の分 う,目指す英語の転換が議論されているのも事実であ 析を行ない,その差異について定量的に論じている。 る(Crystal 1995)。 (本論文では両者の善し悪しを議 CALL システムを目的とした技術開発,システム 論することはしないが)後者の立場を採るならば「日 開発例としては,まず,発音の分節的側面に着眼した 本人アクセントは残っているが十分通じる英語」は是 研究例を紹介する(森ら 2002,阿部ら 2001,坪田ら とすることになる。これは「聞き手」となる「人間」 2002)。大崎ら (2002) は,既存のスコアリング手法を の高度な適応・正規化能力を前提とした議論であり, 検討していたが,森ら (2002) は,本 DB 中の英単語 この場合の発音の善し悪しは,聞き手が(適応・正規 発声に着眼し,音声認識技術を用いて算出される各種 化能力を通して)学習者音声からその言語メッセージ 音響スコアの重み付き線形和によって最終的な発音ス を抽出する際に感じる知覚タスク量の大小についても コアを計算する方法を提案している。阿部ら (2001), 着眼する必要がある。つまり,従来の音声学的議論に 坪田ら (2002) は音韻的誤りを検出する目的でシステ 対して認知科学的な側面まで考慮した検討が必要とな ム開発を行なっているが,ここでは,入力文の制約を る。このような観点から本 DB を用いた研究も行なわ 緩め,音声認識することにより意図された単語系列を れている(峯松ら 2002d,Guo et al.2003)。 抽出している。この場合日本人英語を自動認識する必 峯松ら (2002d) は,峯松ら (2002c) による発音の 要があるが,日本人英語認識用の音響モデルを本 DB 階層構造抽出が,音響パラメータから静的な音響歪み 及び話者適応技術を用いて構築している。 を除去(正規化)する処理となっている点に着眼し, 一方韻律的側面においても,本 DB を用いた多く 得られた構造に対して音声知覚モデルの一つであるコ の研究が行なわれている。特にリズムに着眼した研究 ホートモデル(Marslen-Wilson1980)を適用し,母語 例が多い(Minematsu et al.2002a,井本ら 2001,中 話者,学習者音声各々の発音構造に基づく心的辞書検 島ら 2003,近藤ら 2003)。英語のリズムは文中の強 索時のタスク量の差異(発音音響空間における語彙密 勢シラブルが(知覚的に)等間隔に配列することによ 度の大小)を定量的に論じている。Guo et al.(2003) り生成されると言われる(強勢シラブルの知覚等時 は,本 DB の日本人文音声を米語母語話者に書き取ら 性)。Minematsu et al.(2002a) は,強/弱勢シラブ せる,という実験を行なっている。と同時に音響分析・ ルの音響的モデリングを本 DB 中の母語話者音声を 言語分析より,各単語(発声)毎に多様なパラメータ 用いて検討している。強弱の違いを,スペクトル,パ 値を抽出し,これらを説明変数として各単語の書き取 Vol. 43 No.英語 7 CALL 構築を目的とした日本人及び米国人による読み上げ英語音声データベースの構築 11 り率を予測している。即ち「intelligibility を最も低減 分利用可能である。教育の現場では「きれいな英語」 させる発音/言語歪み」を直接的に検討している。 の例のみが学生に提供されるが, 「きたない英語」の例 本 DB は,外国語学習以外においても活用されてい として本 DB(の一部)を使うこともできる。更には, る。Minematsu et al.(2002b) 及び大崎ら (2003) は, 発音評定上位者の外国語学習履歴を追跡調査すること 聴覚障害者を対象とした国際会議講演の自動字幕化を も非常に興味深く,意義深いものである。このように, 念頭に置き,日本人英語の自動音声認識性能向上を検 外国語学習に関与する様々な場で本 DB が利用,活用 討している。日本人英語に特有の癖に着眼し,音響モ されることを切に願っている。と同時に本 DB 利用者 デリング技術,適応技術を日本人英語用に修正,改良 からのフィードバックを基に,更なる発話データの拡 し,高精度化を実現している。音声認識技術は大規模 充,タグ付けも検討したい。なお,本 DB に関する連 音声 DB を前提とした技術体系であり,これらの研究 絡先は [email protected] である。 において,本 DB の存在価値は非常に大きい。 以上,本 DB を使用した研究例について(筆者らの 謝辞 本 DB の構築は,科研費プロジェクト以外の機 知る)一部を紹介したが,ここに挙げた研究例だけで 関を含む,非常に多くの方々に支えられて行なわれた。 も,日本人英語の特性分析,発音の分節的側面に着眼 一連の作業に協力して戴いた機関をここに示し,あわ した技術開発,発音の韻律的側面に着眼した技術開発, せて,感謝の意を表する。 更には発音(聴取)の認知科学的側面に着眼した研究 DB 構築協力機関:岩手大学,山形大学,東北大学,東 例など,その利用範囲は多岐に及ぶ。と同時に,講演 京大学,東京工業大学,早稲田大学,帝京平成大学, 音声の自動字幕化に対して研究基盤を与えるなど,本 東海大学,金沢大学,石川高専,静岡大学,豊橋科学 DB の存在価値は極めて高いと言える。 技術大学,名古屋大学,名古屋学院大学,京都大学, 8. ま と め 同志社大学,立命館大学,龍谷大学,奈良先端科学技 術大学院大学,和歌山大学,広島女子大学 文部科学省科学研究費補助金特定領域研究 (1)「メ ディア教育利用」プロジェクトにおいて構築された「日 本人及び米国人による読み上げ英語音声 DB」につい て,その設計,構築,規模,収録などについて詳説し た。また,日本人英語音声に対する,英語教師による 発音評定ラベリングの様子についても報告した。更に, 発音評定結果を分析することで,発音評定作業が持つ 問題点についてその一部を明らかにした。本 DB(及 び評定ラベル)の評価として,その利用状況を調査し たところ,日本人英語の特性分析,発音の分節的側面, 韻律的側面,更には認知科学的側面に対する技術・シ ステム開発において利用されていることが分かった。 と同時に,字幕作成への応用など,語学教育利用以外 の研究における利用例もあり,本 DB の存在意義は極 めて高いと考えることができる。 本 DB は当初,技術・システム開発を念頭に置いて デザインされたが,各関係者との意見交流を通して, 工学以外の利用可能性についても検討すべきであると の認識を持つようになった。例えば本 DB は非常に幅 広い発音習熟度の話者の音声を,およそ統制された録 音環境下で収録しているが, 「どのような発音に対して, どのような評定・指導を行なうべきか」という評価基 準,指導戦略を議論する際の音声サンプルとしても十 参考文献 阿部一彦,鍋島良紀,河原達也,田中和世,壇辻正剛 (2001),日本人英語の特性に基づく音声認識システム を用いた英会話学習支援システム,日本音響学会講演 論文集,3-1-9,pp.109–110 淺間正通 (1997),英語教育における「異文化コミュニ ケーション」の普遍的視点をめぐって,静岡大学情報 学研究,vol.3,pp.1–10 D. Crystal(1995), English as a global language, Cambridge University Press, New York 壇辻正剛 (2001),道しるべ:IT 化時代の語学環境とし ての CALL,情報処理,vol.42,no.10,pp.1001–1005 深澤俊昭 (2000),英語の発音パーフェクト辞典,アル ク,東京 古井貞煕 (2002), 『話し言葉工学』プロジェクトのこれ までの成果と展望,話し言葉の科学と工学ワークショッ プ講演予稿集,pp.1–6 H. J. Giegerich(1992), English Phonology : An introduction, Cambridge University Press, New York A. C. Gimson(1980), An introduction to the pronunciation of English, Edward Arnold Ltd., London C. Guo, N. Minematsu, and K. Hirose(2003), Prediction of American listeners’ misrecognition of En- 12 日本教育工学会論文誌 glish words spoken by Japanese, Technical report of IEICE, SP2002-179, pp.1–6 V. M. Holland, J. D. Kaplan, and M. R. Sames(1995), Intelligent Language Tutors, Lawrence Erlbaum Associates Inc., New Jergey 井本和範,壇辻正剛,河原達也 (2001),文強勢と等 時性の自動検出に基づく英語韻律学習支援システム, 電子情報通信学会音声研究会資料,SP2001-133,pp. 63–70 K. Itou, M. Yamamoto, K. Takeda, T. Takezawa, T. Matsuoka, T. Kobayashi, K. Shikano, and S. Itahashi(1999), JNAS : Japanese speech corpus for large vocabulary continuous speech recognition research, The Journal of the Acoustic Society of Japan (E), vol.20, no.3, pp.199–206 S. Jager, J. Nerbonne, and A. V. Essen(1998), Language teaching & language technology, Swets & Zeitlinger, Netherland R. B. Kaplan (1966), Cultural thought patterns in inter-cultural education, Language Learning, vol.16, pp.1–20 川越いつえ (1996),英語の音声を科学する,大修館書 店,東京 河原達也,住吉貴志,李晃伸,坂野秀樹,武田一哉, 三村正人,山田武志,西浦敬信,伊藤克亘,伊藤彰則, 鹿野清宏 (2002),連続音声認識コンソーシアム 2001 年度版ソフトウエアの概要,情報処理学会音声言語情 報処理研究会資料,SLP-43-3,pp.1–6 河合剛 (1999),英語が話せる日本人,話せない日本 人,日本音響学会誌,vol.55,no.1,pp.45–50 川本真一,下平博,新田恒雄,西本卓也,中村哲,伊 藤克亘,森島繁生,四倉達夫,甲斐充彦,李晃伸,山 下洋一,小林隆夫,徳田恵一,広瀬啓吉,峯松信明, 山田篤,伝康晴,宇津呂武仁,嵯峨山茂樹 (2002),カ スタマイズ性を考慮した擬人化音声対話エージェント のソフトウェアツールキットの設計,情報処理学会論 文誌,vol.43,no.7,pp.2249–2263 近藤亜希,前木大樹,内藤拓郎,白井克彦,匂坂芳典 (2003),日本人発話英語のリズム客観評価モデル,日 本音響学会講演論文集 (発表予定) W. D. Marslen-Wilson and L. K. Tyler(1980), The temporal structure of spoken language understanding, Cognition, vol.8, pp.1–71 (1980) 真 下 美 紀 子 ,柏 岡 秀 紀 ,N. Campbell,鹿 野 清 宏 (2003),日本人による英語フレーズ音声の韻律的特 徴の分析,日本音響学会講演論文集 (発表予定) 松本亨 (1968),英語で考える本,英友社,東京 N. Minematsu, S. Kobashikawa, K. Hirose, and D. Erickson(2002a), Acoustic modeling of sentence July 2002 stress using differential features between syllables for English rhythm learning system development, Proc. Int. Conf. Spoken Language Processing, pp.745–748 N. Minematsu, G. Kurata, and K. Hirose(2002b), Integration of MLLR Adaptation with Pronunciation Proficiency Adaptation for Non-native Speech Recognition, Proc. Int. Conf. Spoken Language Processing, pp.529–532 峯松信明,倉田岳人,広瀬啓吉 (2002c),英語音素体 系及び語彙体系を考慮した日本人英語の発音と聴取に 関するコーパス分析,日本音声学会全国大会予稿集, pp.97–102 峯松信明,倉田岳人,広瀬啓吉 (2002d),コホート理 論に基づく日本人英語とアメリカ英語の知覚タスク量 に関するシミュレーション,日本音響学会講演論文集, 2-2-10,pp.435–436 N. Minematsu, Y. Tomiyama, K. Yoshimoto, K. Shimizu, S. Nakagawa, M. Dantsuji, and S. Makino(2002e), English Speech Database Read by Japanese Learners for CALL System Development, Proc. Int. Conf. Language Resources and Evaluation, pp.896–903 峯松信明,富山義弘,吉本啓,清水克正,中川聖一, 壇辻正剛,牧野正三 (2002f),日本人英語音声に対す る母国語話者英語英語教師による評価ラベリング,日 本音響学会講演論文集,1-6-4,pp.215–216 森一将,中川聖一 (2002),日本人の英単語発音の評価 法,日本音響学会講演論文集,1-6-2,pp.211–212 中川聖一 (2000),音声認識研究の動向,電子情報通信 学会論文誌,J83-DII,vol.2,pp.433–457 中川聖一 (2002),語学学習における音声言語処理技術 の利用,電子情報通信学会誌,vol.85,no.12,pp.942– 943 中島丈晴,小林聡,中川聖一 (2003),日本人英語とネ イティブ英語音声の強勢等時性の自動評価法,日本音 響学会講演論文集 (発表予定) 小川直樹 (1999),理屈で分かる英語の発音,ノヴァ・ エンタープライズ,東京 大崎功一,峯松信明,広瀬啓吉 (2002),非母語音声認 識を目的とした誤発音モデリングに関する実験的検討, 日本音響学会秋季論文予稿集,2-9-22,pp.105–106 大崎功一,峯松信明,広瀬啓吉 (2003),日本人英語発 声に観測される発音上の癖を考慮した音声認識,電子 情報通信学会音声研究会資料,SP2002-180,pp.7–12 大竹孝司,米山聖子 (1999),心内辞書における音節と モーラの認識,日本音声学会全国大会予稿集,pp.77– 83 F. Ramus(2002), Acoustic correlates of linguistic Vol. 43 No.英語 7 CALL 構築を目的とした日本人及び米国人による読み上げ英語音声データベースの構築 13 rhythm: Perspectives, Proc. Int. Conf. Speech Prosody, pp.115–11 tono/jefll.html M. L. Swartz and M. Yazdam(1992), Intelligent Tutoring Systems for Foreign Language Learning, Springer-Verlag, Heidelberg TIMIT: TIMIT database: http://www.ldc.upenn. edu/Catalog/LDC93S1.html K. Tajima, R. Yamada, and T. Yamada(2002), Perceptual learning of English syllable rhythm by young and elderly Japanese listeners, Proc. General Meeting of the Phonetic Society of Japan, pp. 103–108 竹林滋 (1996),英語音声学,研究社,東京 特定 (2001),文部科学省科学研究費補助金特定領域研 究 (1) 「高等教育改革に資するマルチメディアの高度 利用に関する研究」平成 12 年度研究成果報告書 特定 (2002),文部科学省科学研究費補助金特定領域研 究 (1) 「高等教育改革に資するマルチメディアの高度 利用に関する研究」平成 13 年度研究成果報告書 特定 (2003),文部科学省科学研究費補助金特定領域研 究 (1) 「高等教育改革に資するマルチメディアの高度 利用に関する研究」平成 14 年度研究成果報告書 Y. Tono, T. Kaneko, H, Isahara, T. Saiga, and E. Izumi(2001), The Standard Speaking Test (SST) corpus: a 1 million-word spoken corpus of Japanese learners of English and its implications for L2 lexicography, Proc. Int. Cong. Asian Association for Lexicography, pp.257–262 Y. Tsubota, T. Kawahara, and M. Dantsuji(2002), Recognition and verification of English by Japanese students for computer-assisted language learning system, Proc. Int. Conf. Spoken Language Processing, pp.1205–1208 S. Witt and S. Young(1997), Language learning based on non-native speech recognition, Proc. European Conf. Speech Communication and Technology, pp.633–636 山本秀樹 (2002),音声メディアを利用した教育システ ム,人工知能学会誌,vol.17,no.4,pp.452–457 S. Young, G. Evermann, D. Kershaw, G. Moore, J. Odel, D. Ollason, D. Povey, V. Valtchev, P. Woodland (2002), The HTK Book version 3.2, Cambridge University Engineering Department, London CEJL Corpus: http://www.lb.u-tokai.ac.jp/ lcorpus/index-j.html CMU: http://www.speech.cs.cmu.edu/cgi-bin/ cmudict ELRA: http://www.icp.inpg.fr/ELRA/home.html FAE: FAE database: http://cslu.cse.ogi.edu/ corpora/fae JEFLL Corpus: http://www.lb.u-tokai.ac.jp/ LDC: http://www.ldc.upenn.edu TOEIC(1998): http://www.toeic.or.jp/toeic/data/ Worldwide%20Data.pdf
© Copyright 2026 Paperzz