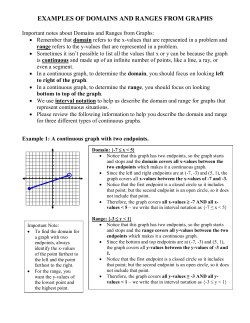
What Is Statistics?
STATISTICAL METHODS I
Ou Zhao
First Encounter To Statistics
University of South Carolina
In order to talk about statistics, or formally give a definition,
one has to mention data. I hope everybody in this room has
seen data of some sort, either from newspaper, or from your
school coursework. One possible dataset I can collect right
away is by asking you whether you like president Obama or
not, and apparently I would be interested in the proportion of
those people who indeed like the current president.
Definition: Statistics is the science of data. This involves
collecting, classifying, summarizing, organizing, analyzing,
and interpreting numerical information.
Remark: You may instantly argue with me that if your answer
to my previous question is yes, that is not numerical information. But how about coding it by 1 ?
STAT 515 – p.1
STAT 515 – p.2
More About The Definition
Sample Matters
•
There are, in general, two �kinds’ of statistics:
Descriptive Statistics uses a variety of means to look for
patterns in a data set, to summarize the information revealed
in a data set, and to present that information in a convenient
way.
Inferential Statistics utilizes something, called sample
data, to form estimates, decisions, predictions, or other
generalizations about a larger set of data, commonly referred
to as a population.
Suppose one is interested in the average age of viewers
of ABC World News Tonight, how do you best address
this question?
• Apparently this involves a big population in America (or
even worldwide), so one cannot ask everybody. The idea
of drawing �small’ sub-populations comes up naturally.
• A Statistical Inference is an estimate, prediction, or
some other generalization about a population based on
information contained in a sample.
Remark: As you can best guess, a population is a set of units
(say, people, transactions, or events) that we are interested in
studying.
STAT 515 – p.3
STAT 515 – p.4
Random Sample
EPA Car Mileage Rating Data
•
By sample, we mean a subset of the units of a
population. This subset can be big, or small, depending
on situations.
• Selection bias, nonresponse bias, measurement error.
• what is a good sample? Intuitively, we want something
representative of the population. In statistics, it is
formalized as a random sample: a sample selected from
the population in such a way that every different sample
of size n has an equal chance of selection.
• Random samples sometimes can be hard to get.
•
However, one can easily get samples like EPA. See R
output for a histogram using hist().
• This is a good time to introduce R, a free statistical
package, which is available from
http://cran.r-project.org/
on which, you can also find introductions, both quick
and comprehensive.
STAT 515 – p.5
Software Comparison
•
STAT 515 – p.6
Stem-and-Leaf Plot
Advantages of R over minitab:
(1) free; so good for students.
(2) written by research statisticians who are working at
the frontiers, which means more built-in modern
statistical packages.
(3) interactive interface; and many other features.
However, it is not as commecialized as minitab, so less
popular in industry.
STAT 515 – p.7
The EPA car Mileage data consists of 100 observations; you
may find this data set in the file �epagas.xls’ on your textbook
CD. To read them into R, you can first transport them into a
txt file, and try x<-scan(��epagas.txt’’), then x should
acquire all those observations.
Stem-and-leaf plot is very similar to the histogram plot by
purpose, it shows how the data is distributed. You may try
the command stem(x) in R, and the output is displayed on
the next slide.
STAT 515 – p.8
Stem() output
Output of hist()
> stem(x)
car mileage histogram
The decimal point is at the |
30
32
34
36
38
40
42
44
|
|
|
|
|
|
|
|
08
5799126899
02458801235667899
01233445566777888999000011122334456677899
012234567800345789
0123557002
1
9
STAT 515 – p.9
Patterns
STAT 515 – p.10
Exercise
•
For a picture like histogram, one may look for interesting
features.
• For instance, where does the observations center
around? Is the picture symmetric? If it is not symmetric,
then it is called skewed (right or left).
• We shall contrive an example by adding more
observations to the previous example.
Would you expect the following data sets to possess
histograms that are symmetric, skewed to the right, or skewed
to the left?
a The ages of automobiles on a used-car lot
b Repeated measurements of the same chemical constant
c The grades on a difficult test
STAT 515 – p.11
STAT 515 – p.12
Data Type
Mean
•
As we can see, data can come in different ways; they
may be easily identified as two types.
• Quantitive data are measurements that are recorded
on a naturally occuring numerical scale.
1. The current unemployment rate in each of the 50
states.
2. The scores of a sample of 150 law school applicants
on the LSAT, a standardized law school entrance
exam.
• Qualitive data are measurements that cannot be
measured on a natural numerical scale; they can only be
classified into one of a group of categories.
1. The political party affiliation in a sample of 100
voters.
•
Numerical measures of central tendency: One obvious
choice is the mean, which is defined as
xВЇ =
n
i=1 xi
n
,
where xi ’s are data points.
• Look at the EPA data, one can get the sample mean by
using mean(EPA). You can check that with
sum(EPA)/100. Mean tells you where most of the
observations tend to center around.
STAT 515 – p.13
STAT 515 – p.14
Mean and Median
Quick Facts
•
The other competitive notion is median: suppose you
have odd number of data points, the median is defined
to be the value right in the middle of the sorted data;
but if your sample has even number of points, the
median is the average of those two values in the center
of your sorted data.
• compare median and mean for the data: 2.3, 4.5, 6.4,
8.4, 3.4, 5.3, 4.7,3.8. Claim: median is robust to
outliers. In this regard, median is more accurate in
measuring the center.
• Indeed one may have skewed data due to measurement
error, which may bring in outliers. We will see some of
those datasets later on, so be careful when measuring
the center.
STAT 515 – p.15
Describe how the mean compares with the median for a
histogram as follows:
•
Skewed to the left
• Skewed to the right
• Symmetric
STAT 515 – p.16
Variability of Your Data
•
You may think of the range, i.e., max-min. What if there
are outliers due to measurement error. Will range reflect
the true spread out?
• Statisticians tend to use the so-called sample variance.
By formula it is given by
s2 =
•
n
i=1 (xi
в€’ xВЇ)2
.
nв€’1
As you can imagine, if the whole population is observed,
the population variance and its standard deviation would
be defined in the similar way. Statisticians tend to
denote them by Пѓ 2 , Пѓ . But keep in mind, these are
usually not available, because the population is
unmanageable. So they are parameters (or
characteristics, as you may call ) that need to be
estimated. Look at the EPA data.
Alternatively, a commonly used related quantity is the
sample standard deviation, which is the square root of
the sample variance:
в€љ
s = s2 .
STAT 515 – p.18
STAT 515 – p.17
Standard Deviation
Relative Standing
•
(a) Approximately 68% of the measurements will fall
within one standard deviation of the mean [i.e., within
the interval (ВЇ
x в€’ s, xВЇ + s) for samples and (Вµ в€’ Пѓ, Вµ + Пѓ)]
for populaions].
•
(b) Approximately 95% of the measurements will fall
within two standard deviations of the mean [i.e., within
x в€’ 2s, xВЇ + 2s) for samples and
the interval (ВЇ
(Вµ в€’ 2Пѓ, Вµ + 2Пѓ)] for populations.
•
(c) Analogously, the 3в€’deviation rule, which is about
99.7% of the measurements.
STAT 515 – p.19
•
Percentile ranking: For example, suppose you scored an
80 on a test and you want to know how do you compare
with other students in the class. If the instructor tells
you that you scored at the 90th percentile, what does
that mean?
• Definition: For any set of n measurements, the pth
percentile is a number such that p% of the
measurements fall below that number and (100-p)% fall
above it.
• It is a useful summary for a single observation if the
dataset is particularly large.
STAT 515 – p.20
Outliers
•
Another measure of relative standing is the z-score. The
sample z-score for a measurement y in a sample x is
defined as
y в€’ xВЇ
z=
;
s
and the population z-score for a measurement y is
z=
•
yв€’Вµ
.
Пѓ
So it is really measuring how many standard deviations
away is that particular measurement from the mean.
•
By outliers we mean observations which are either
unusually big or small compared to other measurements
in the sample.
• How do they appear? (1) The measurement is observed
incorrectly, recorded incorrectly, or even entered into the
computer incorrectly. (2) The measurement comes from
a different population. (3) The measurement is correct,
but represents a rare event. Like Albert Einstein, his IQ
score is incredibly high, does not belong to any
population!
• Two useful methods for detecting outliers: boxplots and
z-scores.
STAT 515 – p.21
STAT 515 – p.22
Data in CD
•
Method 1 (Boxplot): The Lower quartile QL is the
25-th percentile of a data set. The middle quartile M is
the median. The upper quartile QU is the 75th
percentile.
A box plot is based on the interquartile range
IQR = QU в€’ QL
Now look at boxplot(EPA), did you see any potential
outliers?
• More accurate ways detecting outliers is through z-score:
Observations with z-scores greater than 3 in absolute
value are considered outliers. For some highly skewed
data sets, observations with z-scores greater than 2 in
absolute value may be outliers.
STAT 515 – p.23
To make a boxplot and see whether there are potential
outliers, we shall use a data file, called LM2_126 contained in
your text CD.
• This file contains two columns, and it comes in different
formats, but not in .txt.
• So one may have to copy-paste the contents and put
them .txt format.
• Because there are two columns, the command scan()
no longer works, we may try read.table().
STAT 515 – p.24
Exercise
Exercise
Suppose a female bank employee believes that her salary is
low as a result of sex discrimination. To substantiate her
belief, she collects information on the salaries of her male
colleagues in the banking business. She finds that their
salaries have a mean of $ 54,000 and a standard deviation of
$ 2,000. Her salary is $ 47,000. Does this information
support her claim of sex discrimination?
Suppose a female bank employee believes that her salary is
low as a result of sex discrimination. To substantiate her
belief, she collects information on the salaries of her male
colleagues in the banking business. She finds that their
salaries have a mean of $ 54,000 and a standard deviation of
$ 2,000. Her salary is $ 47,000. Does this information
support her claim of sex discrimination?
z=
47, 000 в€’ 54, 000
= в€’3.5
2, 000
STAT 515 – p.25
STAT 515 – p.25
Graphing Bivariate Relationship
Quadratic Relationship
6
y
4
2
Contrived examples: x<-seq(1,3,by=.1), y<-x^2,
what is the relationship? After adding some background
noise, did the relationship change? For real data with
two variables, you can do exactly the same plot, which is
called scatterplot in statistics. It tells you quick
information about two variables.
• Add lines and colors.
plot(x,y,t="l", col="aquamarine4")
8
•
1.0
1.5
2.0
2.5
3.0
x
STAT 515 – p.26
STAT 515 – p.27
Elementary Probability
Discrete Probability Model
Probability is essential for understanding statistical inference:
•
Let pi represent the probability of sample point i. Then
(1) All sample point probabilies must lie between 0 and
1; (2) The probabilities of all the sample points within a
sample space must sum to 1 (i.e.,
pi = 1).
•
Example (Rolling a fair die): All the outcomes are
equally likely, so it is 1/6 since S = {1, 2, 3, 4, 5, 6}. You
may ask yourself the following question: what is the
probability of seeing an even number? This introduces
the notion of an event, which is more complicated than
one particular outcome.
•
Definition 1: An Experiment is an process of
observation that leads to a single outcome that cannot
be predicted with certainty.
• Like a coin tossing, the consequence may be a head, or a
tail. The likelihood may depend on the way you toss it,
and the nature of the coin. In perfect situation, it should
be equally likely. So this is a experiment, because its
outcome cannot be predicted with certainty.
• Definition 2: A Sample point is the most basic
outcome of an experiment.
• Definition 3: The Sample space of an experiment is
the collection of all its sample points.
STAT 515 – p.28
STAT 515 – p.29
Combinatorial Analysis
•
An event is a specific collection of sample points.
Generically, it can be denoted by A = {2, 4, 6}. The
probability of an event A is calculated by summing the
probabilities of the sample points in the sample space for
A.
• In order to calculate the probability of an event, it is
important to know the sample space by listing the
sample points, their respective probabilities. You should
also determine the collection of sample points contained
in that event.
STAT 515 – p.30
•
Since calculating probabilities usually involve counting,
let us review some combinatorial analysis, the art of
counting in mathematics. Suppose a sample of n
elements is to be drawn from a set of N elements. The
the number of different samples possible is denoted by
N
n and is equal to
N
n
=
N!
.
n!(N в€’ n)!
note that n! = 1 В· 2 В· В· В· n
• If a fair die is rolled 5 times, the probability of getting
exactly 1 spot on the first and last rolls and more than 1
spot on the other three rolls is
. What if,
additionally we require all those rolls give different spots?
STAT 515 – p.31
Unions and Intersections
•
The union of two events A and B is the event that
occurs if either A or B (or both) occurs on a single
performance of the experiment. We denote the union of
events A and B by A в€Є B . The intersection is defined
to be the event that occurs if both A and B occur on a
single performance, denoted by A ∩ B .
• Using Venn diagrams, you can see more easily.
• Problem: Consider a die-toss experiment in which the
following events are defined: A=Toss an even number.
B=toss a number less than or equal to 3.
(a) Describe A в€Є B for this experiment
(b) what about A ∩ B ?
(c) Calculate P (A ∩ B), P (A ∪ B), assuming the die is
balanced.
•
•
The Complement of an event A is the event that A
does not occur— that is, the event consisting of all
sample points that are not in event A. We denote the
complement by Ac . So P (A в€Є Ac ) = 1.
It is easy to hypothesize P (A ∩ B) = 0 if A and B are
mutually exclusive, i.e., A ∩ B contains no sample
points. Using Venn diagram, one can show
P (A ∪ B) = P (A) + P (B) − P (A ∩ B).
It follows easily that P (A) + P (Ac ) = 1
STAT 515 – p.33
STAT 515 – p.32
Conditional Probability
•
Given today is a rainy day, what is the chance that it is
going to rain tomorrow? This likelihood presumably
should be higher than asking without any conditioning
knowledge. Given two events A and B in a sample space
S , what is the probability A occurs given that B already
occurred. It is defined to be
P (A|B) =
•
Independent Events
P (A ∩ B)
.
P (B)
•
There are situations where two events A and B are both
empirically believed, or theoretically calculated as being
independent of each other. By definition, if
P (A) = P (A|B), then A and B are said to be
independent; otherwise, they are dependent.
• Consequently, for independent events, the multiplicative
rule holds, i.e., P (A ∩ B) = P (A)P (B). In many
applications, this will simplify the calculations to a great
extent.
When rolling a fair die, what is the likelihood of seeing
2? It is certainly different than the probability of seeing
2 given that we already knew the outcome is an even
number. So A = {2}, B = {2, 4, 6}; P (A) = 1/6,
however P (A|B) = 1/3.
STAT 515 – p.34
STAT 515 – p.35
Die example revisited
Bayes Rule
Problem: Consider the experiment of tossing a fair die , let
Given k mutually exclusive and exhaustive events,
B1 , B2 , . . . , Bk such that P (B1 ) + P (B2 ) + В· В· В· + P (Bk ) = 1,
and given an observed event A, it follows that
A = {observe an even number},
and
B = {observe a number less than or equal to 4}.
Are A and B independent events?
P (Bi |A) =
P (Bi ∩ A)
P (A)
which is equal to
P (Bi )P (A|Bi )
.
P (B1 )P (A|B1 ) + В· В· В· + P (Bk )P (A|Bk )
Solution: P (A) = 1/2, P (B) = 2/3, P (A ∩ B) = 1/3. What is
the conditional probability P (A|B)? ( one may be inclined to
check P (B|A) as well).
The preceding statement is called the Bayes Theorem.
STAT 515 – p.36
Problem Setup: An unmanned monitoring system uses
high-tech equipment and microprocessors to detect intruders.
One such system has been used outdoors at a weapons
munitions plant. The system is designed to detect intruders
with a probability of .90, however, its performance may vary
with the weather. Naturally design engineers want to test
how reliable the system is. Suppose after a long sequence of
tests, the following information has been available: Given that
the intruder was indeed detected by the system, the weather
was clear 75% of the time, cloudy 20% of the time, and
raining 5% of the time. When the system failed to detect the
intruder, 60% of the days were clear, 30% cloudy, and 10%
rainy. Use this information to find the probability of detecting
an intruder, given rainy weather. (Assume an intruder has
already been released)
STAT 515 – p.38
STAT 515 – p.37
•
So what is the experiment? More importantly, what is a
possible outcome? (detected, rainy), or (nondetected,
clear) .... etc.
• Let D denote the event that the intruder is detected,
then D is the collection of possible outcomes (detected,
* ), with the second component unconstrained. Similarly
we can define: Clear be the event that includes all those
outcomes with the second component being clear; and
also those events for Cloudy, Rainy.
STAT 515 – p.39
•
From the problem setup, P (D) = .90, P (Clear|D) =
.75, P (Cloudy|D) = .20, P (Rainy|D) = .05; moreover,
P (Clear|Dc ) = .60, P (Cloudy|Dc ) = .30, P (Rainy|Dc ) =
.10
• It follows from conditional probability that
P (Rainy ∩ D) = P (D)P (Rainy|D) = .9 ∗ .05 = .045.
Simultaneously,
P (Rainy ∩ Dc ) = P (Dc )P (Rainy|Dc ) = .1 ∗ .1 = .01 .
•
By Bayes Rule, P (D|Rainy) should be equal to
P (D)P (Rainy|D)
,
P (D)P (Rainy|D) + P (Dc )P (Rainy|Dc )
and it can be computed as
(.90)(.05)
= .818.
(.90)(.05) + (.10)(.10)
So, the system is not that reliable, but not too bad!
STAT 515 – p.40
STAT 515 – p.41
Homework Question
Homework Question
A straight flush in poker. Consider 5-card poker hands
dealt from a standard 52-card bridge deck. Two important
events are
A straight flush in poker. Consider 5-card poker hands
dealt from a standard 52-card bridge deck. Two important
events are
A = {You draw a flush},
B = {You draw a straight}.
Note: an ace may be considered as having a value of 1 or,
alternatively, a value higher than a king.
1. How many different 5-card hands can be dealt from a
52-card bridge deck?
2. Find P (A).
3. Find P (B).
4. The event that both A and B occur is called a straight
flush. Find P (A ∩ B).
STAT 515 – p.42
A = {You draw a flush},
B = {You draw a straight}.
Note: an ace may be considered as having a value of 1 or,
alternatively, a value higher than a king.
1. How many different 5-card hands can be dealt from a
52-card bridge deck?
2. Find P (A).
3. Find P (B).
4. The event that both A and B occur is called a straight
flush. Find P (A ∩ B).
Ans: 2,598,960; .002; .00394; .0000154.
STAT 515 – p.42
Random Variables
Discrete random variables
•
Definition: A random variable is a variable that
assumes numerical values associated with the random
outcomes of an experiment, where one numerical value
is assigned to each sample point.
• One easy random variable would be the so called
Bernoulli random variable, which assigns 1 to a head,
and 0 to a tail for a coin-tossing experiment.
•
Another one may be from the following experiment: A
panel of 10 experts for the Wine Spectator is asked to
evaluate a new wine and give their ratings of 0,1,2, or 3.
A score is then obtained by adding those ratings
together. What is the random variable of interest here?
Can you justify the wording, random, here?
• Note: there is some common feature for the previous
two examples; that is, those random variables can only
assume some countable values. These random variables
certainly inherited the randomness from the
corresponding experiments because they depend on the
outcomes which are not certain.
STAT 515 – p.43
Probability Distributions
•
Let us toss two coins, and let X be the number of heads
observed. Can you find the probability associated with
each value of the random variable assuming that the two
coins are fair?
• The foregoing description of the random variable is
called the probability mass function, it is a complete
characterization for a discrete random variable. By
notation, we use p(x) := P (X = x), where x is any
possible value X . So naturally, we have (i) p(x) ≥ 0;
and (ii)
p(x) = 1.
STAT 515 – p.45
STAT 515 – p.44
One Example
Suppose you roll two balanced dice, and you are interested in
the summation of upper face values. Can you identify a
random variable and quantify its randomness?
STAT 515 – p.46
One Example
Exercise
Suppose you roll two balanced dice, and you are interested in
the summation of upper face values. Can you identify a
random variable and quantify its randomness?
Five men and 5 women are ranked according to their scores
on an examination. Assume that no two scores are alike and
all 10! possible rankings are equally likely. Let X denote the
highest ranking achieved by a woman ( for instance, X = 2 if
the top ranked person was male and the next ranked person
was female). Find P (X = i), for i = 1, 2, 3, . . . , 8, 9, 10.
0.10
0.08
0.04
0.06
Mass Function
0.12
0.14
0.16
Summation of Two Dice
2
4
6
8
10
12
STAT 515 – p.46
STAT 515 – p.47
Exercise
Mean and Variance
Five men and 5 women are ranked according to their scores
on an examination. Assume that no two scores are alike and
all 10! possible rankings are equally likely. Let X denote the
highest ranking achieved by a woman ( for instance, X = 2 if
the top ranked person was male and the next ranked person
was female). Find P (X = i), for i = 1, 2, 3, . . . , 8, 9, 10.
5 Г— 9!
P (X = 1) =
,
10!
P (X = 3) =
5 Г— 5 Г— 8!
P (X = 2) =
,
10!
5 Г— 4 Г— 3 Г— 5 Г— 6!
5 Г— 4 Г— 5 Г— 7!
, P (X = 4) =
,
10!
10!
5! Г— 5 Г— 5!
,
P (X = 5) =
10!
5! Г— 5!
P (X = 6) =
.
10!
STAT 515 – p.47
•
The mean (or expected value) of a discrete random
variable X is Вµ = E[X] = xp(x). As you can see, the
mean comes out of a summation, so it may not be a
possible value for X at all; but it certainly tells roughly
where X would very much like to take values.
• The variance of a random variable X is
Пѓ 2 = E[(X в€’ Вµ)2 ] =
(x в€’ Вµ)2 p(x),
does that equal
x2 p(x) в€’ Вµ2 ?
Again, the standard deviation is defined to be
в€љ
Пѓ2.
STAT 515 – p.48
One Toy Example
•
Real problem on the mean
Example: Consider the mass function shown below:
•
x
1 2 4 10
p(x) .2 .4 .2 .2
what is the mean and variance?
Suppose you work for an insurance company and you sell
a $ 10,000 one-year term insurance policy at an annual
premium of $ 290. This premium is targeted on those
customers (with certain age, sex, health, etc), for whom
the probability of death in the forthcoming year is
calculated as .001 based on actuarial tables. What is the
expected gain in the next year for a policy of this type?
STAT 515 – p.49
STAT 515 – p.50
Real problem on the mean
•
Suppose you work for an insurance company and you sell
a $ 10,000 one-year term insurance policy at an annual
premium of $ 290. This premium is targeted on those
customers (with certain age, sex, health, etc), for whom
the probability of death in the forthcoming year is
calculated as .001 based on actuarial tables. What is the
expected gain in the next year for a policy of this type?
Ans = $280
STAT 515 – p.50
Some Empirical Rule
•
Just like the sample case, for random variables one also
has the relationship
• P (µ − σ < X < µ + σ) ≈ .68
• P (µ − 2σ < X < µ + 2σ) ≈ .95
• P (µ − 3σ < X < µ + 3σ) ≈ 1.00
• Some commands to revisit the summation of dice
x<-2:12
y<-c((1:6)/36,5/36,4/36,3/36,2/36,1/36)
me<-sum(x*y)
stdv<-sqrt(sum((x^2)*y)-me^2)
low<-me-2*stdv
up<-me+2*stdv
c(low,up)
sum(y[c(-1,-11)])
STAT 515 – p.51
Fitness Test Example
Binomial Random Variables
The Heart Association claims that only 10% of U.S. adults
over 30 years of age meet the President’s Physical Fitness
Commission’s minimum requirements. Suppose three adults
are randomly selected and each is given the fitness test.
• Find the probability that none of the adults pass the test.
• Find the probability that two of the three adults pass the
test.
• Let X denote the number of passes, what is the mean
and variance of X .
• Can you verify mean=np, variance=np(1-p)?
•
Consider n independent Bernoulli trials, let us count the
number of heads in those trials. Apparently, it will be a
random quantity, what is the probability mass function?
We denote the number of heads by X , then for
x = 0, 1, . . . , n
p(x) := P (X = x) =
n
x
1
2
nв€’x
n k nв€’k
a b
.
k
STAT 515 – p.52
1. The experiment consists of n identical trials.
2. There are only two possible outcomes on each trial. We
can denote by S for success, and by F for failure; or just
simply code them by 1 and 0.
3. The probability of seeing S remains the same from trial
to trial.
4. The trials are independent.
5. The binomial random variable X is the number of S ’s in
n trials.
1
2
It is easy to see
p(x) = 1 because of the Binomial
Theorem, as given below
(a + b)n =
Characteristics of a Binomial
x
STAT 515 – p.53
Is it binomial?
Before marketing a new product on a large scale, many companies conduct a consumer-preference survey to determine
whether the product is likely to be successful. Suppose a company develops a new diet soda and then conduct a survey in
which 100 randomly chosen consumers state their preferences
among the new soda and two other leading sellers. Let X be
the number of those people who choose the new brand over
the two others. Is X binomial?
STAT 515 – p.54
STAT 515 – p.55
Binomial cont’d
•
Properties of Binomial
Noting that the Binomial theorem is true for any
a, b в€€ R, we can generalize those Bernoulli trials to the
bias coin design situation; in other words, we can
consider the experiments of tossing an unbalanced coin
such that the probability of getting head is p в€€ (0, 1).
After repeating n times, we can still count the number
of heads which yields the so-called Binomial random
variable, with mass function given by
P (X = k) =
•
Mean: E[X] = np;
• Variance:
Var[X] = E[(X в€’ np)2 ]
= E[X 2 ] + n2 p2 в€’ 2npE[X]
= E[X 2 ] в€’ n2 p2 ,
where
n k
p (1 в€’ p)nв€’k
k
n
E[X ] =
k=0
for k = 0, 1, . . . , n.
•
STAT 515 – p.56
R Commands
•
k2
2
n k
p (1 в€’ p)nв€’k = p2 n(n в€’ 1) + pn
k
Very useful, and very common in real life, particularly in
survey sampling where many questions only involve yes
or no answers.
STAT 515 – p.57
Cumulative Binomial Probabilities
In R you can easily compute the mass function of a
Binomial random variable. For example, you can try
dbinom(3,20,0.6), which should return the value of
20
(0.6)3 (0.4)17 ,
3
or pbinom(6,20,0.6), for the value of
•
Recall Binomial random variable:
1. an experiment consisting of n independent identical
trials, say n = 20;
2. depends on a parameter p, the success probability;
3. counting the number of successes.
• Usually denoted by X ∼ Binomial(n, p).
P (X ≤ 6) = P (X = 0) + · · · + P (X = 6).
•
Can you verify from the table?
STAT 515 – p.58
STAT 515 – p.59
Table II on page 785
•
How do we describe a discrete random variable? Use
mass function
p(x) := P (X = x).
•
For X в€ј Binomial(20, .6), what is its mass function
p(x)?
20
p(x) =
(0.6)x (0.4)20в€’x
x
where
20
x
and x! = 1 в€— 2 в€— 3 В· В· В· x.
=
20!
x!(20 в€’ x)!
•
Because of the significance of Binomial distributions,
their mass functions are usually well known and very well
tabulated.
• Those listed values are cumulative probabilities,
P (X ≤ k) = P (X = 1) + · · · + P (X = k).
•
Remark: Knowing mass function is equivalent to
knowing cumulative probabilities.
• Suppose X ∼ Binomial(6, 0.3), by looking at the table
(P.785 in the textbook) please find out P (X = 4), what
about P (X ≤ 3) and P (X ≤ 4)?
STAT 515 – p.60
STAT 515 – p.61
Assigning a passing grade
Assigning a passing grade
A literature professor decides to give a 20-question true-false
quiz to determine who has read an assigned novel. She wants
to choose the passing grade such that the probability of
passing a student who guesses on every question is less than
.05. What score should she set as the lowest passing grade?
A literature professor decides to give a 20-question true-false
quiz to determine who has read an assigned novel. She wants
to choose the passing grade such that the probability of
passing a student who guesses on every question is less than
.05. What score should she set as the lowest passing grade?
Ans=15.
STAT 515 – p.62
STAT 515 – p.62
Mean of Binomial (revisited)
•
What is the mean of Binomial R.V.
X в€ј Binomial(n, p)?
• Recall Bernoulli random variable Y1 , namely its mass
function is given by
x
0 1
p(x) 1-p p
•
Mean of Binomial (continued)
•
If Y1 , Y2 , . . . are from independent trials, what should be
the expected value
E[Y1 + Y2 ] =
?
•
In this way can you easily compute the mean of X ,
which is Binomial(n,p) ?
•
If not, try Binomial(10,0.6) first.
Suppose there is another Bernoulli trial with its outcome
?
denoted by Y2 , compute the mean of E[Y2 ] =
STAT 515 – p.63
STAT 515 – p.64
Exercise 2
•
Simulation setup
Suppose a poll of 20 voters is taken in a large city. The
purpose is to determine X , the number who favor a
certain candidate for mayor. Suppose that 60% of all the
city’s voters favor the candidate.
a. Find the mean and standard deviation of X .
b. Use the binomial probability tables to find the
probability that X ≤ 10.
c. Use the table to find the probability that X > 12.
d. What is the likelihood of seeing 8 ≤ X ≤ 16.
STAT 515 – p.65
•
If X в€ј Binomial(10, 0.6), then X = Y1 + Y2 + В· В· В· + Y10
where all those Y s are independent Bernoulli trials with
success probability .6.
• Population mean can be approximated by sample mean;
we will check that.
• Computer can help us to draw samples by using the
so-called simple random sampling algorithm.
STAT 515 – p.66
Getting Bernoulli Observations
•
Recall that soda-drink example, suppose the company
was targeting the southern states. Let us imagine the
situation that the whole population has been perfectly
surveyed, and 60% said yes. Now if you randomly came
across somebody on a street of Columbia, and ask the
question. How likely you will have an answer, yes? If yes,
then you code it by 1.
• You can draw samples like this in R easily, Using
rbinom(1,size=1,p=.6) .
Computer Experiment
•
Based on the very nature of Binomial experiment, one
can approximate the mean of Binomial(10,0.6), say, by
setting up a small computer experiment.
• One can draw many samples, with each sample
consisting of 10 observations from independent Bernoulli
trials (with success probability .6).
• For each sample, we can count the number of successes,
then average across samples.
STAT 515 – p.67
What about continuous?
•
Continuous random variables certainly abound. For
example, the length of time between arrivals at a
hospital clinic: 0 ≤ x < ∞; or the length of time it takes
a student to complete a one-hour exam.
• Definition: Random variables that assume values
corresponding to any of the points contained in an
interval are called continuous.
STAT 515 – p.69
STAT 515 – p.68
Cumulative Distribution Function
•
Sometimes you may find it is easier to work with
P (X ≤ x), the cumulative distribution function (CDF)
of X . It is particularly true when X is continuous as we
will see in the future.
• Probability distribution is a notion to characterize a
Random variable. It can mean a variety of things, but in
this course we will be referring to CDF mostly.
STAT 515 – p.70
Uniform Distribution
Probability Density Function
•
The most simplest continuous random variable.
• A random quantity may assume values in an interval
[c,d] equally likely, say [c,d]=[0,1].
• How to describe the distribution for a continuous
random variable? This is not too difficult; recall
histogram. On the top, there is usually a curve. How
would you interpret it?
•
It is usually some kind of curve, with area underneath
equal to 1.
• We tend to denote the density function by f (x), as
plotted in the picture.
• What is the probability that X = a, a ≤ X ≤ b, for
0 ≤ a ≤ b ≤ 7, and X ≤ 7?
0
50
100
150
f(x)
200
250
300
350
Density Curve
0
1
2
3
4
5
6
7
x
STAT 515 – p.71
STAT 515 – p.72
Density Function of Uniform
•
Suppose you are shooting at an interval [c, d], with equal
chance of getting one position in the interval. How
would you expect your curve should be?
• Can someone draw a picture of this density function?
• What is the probability that you hit a point in
[a, b] вЉ‚ [c, d] ?
Density Function of Uniform
•
Suppose you are shooting at an interval [c, d], with equal
chance of getting one position in the interval. How
would you expect your curve should be?
• Can someone draw a picture of this density function?
• What is the probability that you hit a point in
[a, b] вЉ‚ [c, d] ?
0.00
0.05
0.10
f(x)
0.15
0.20
0.25
Uniform Density Curve
0
1
2
3
4
5
6
x
STAT 515 – p.73
STAT 515 – p.73
Mean and standard deviation
•
For the previous example, please compute the mean and
the standard deviation.
• If you have learned calculus, then it is true that
b
f (x)dx,
P (a < X < b) =
a
and always remember, the area underneath any density
curve is 1.
• Indeed, by calculus one may verify, for X ∼Uniform(c,d),
E[X] =
c+d
2
Var[X] =
Exercise
•
An unprincipled used-car dealer sells a car to an
unsuspecting buyer, even though the dealer knows that
the car will have a major breakdown within the next 6
months. The dealer provides a warranty of 45 days on all
cars sold. Let X represent the length of time until the
breakdown occurs. Assume that X is a uniform random
variable with values between 0 and 6 months.
(a). Calculate the mean and standard deviation of X .
(b). Calculate the probability that the breakdown occurs
while the car is still under warranty.
(d в€’ c)2
12
STAT 515 – p.74
Normal Distribution
STAT 515 – p.75
How normal density looks like?
•
0.2
f(x)
0.3
0.4
mean=0,variance=1
0.1
One of the most commonly used distribution in both
probability and statistics. It was first discovered by Carl
F. Gauss, so Gaussian distribution can also be used in
place of normal.
• The probability density function is given by
0.0
2
1
f (x) = в€љ eв€’(1/2)[(xв€’Вµ)/Пѓ] ,
Пѓ 2ПЂ
в€’4
and it is perfectly bell shaped. This fact is very useful to
fit the data, because most of the errors occurring in real
life assume a bell-shaped distribution. For example, the
error made in measuring somebody’s blood pressure, or
the distribution of yearly rainfall data in a certain region.
STAT 515 – p.76
в€’2
0
2
4
x<-seq(-5,5,by=0.01)
x
y<-(1/sqrt(2*pi))*exp(-(.5)*(x^2))
plot(x,y,xlab="x",ylab="f(x)",main="mean=0,
variance=1",t="l")
history()
When $\mu=0, \sigma^2=1$, it is called a
standard normal distribution.
STAT 515 – p.77
Some Comments
•
EPA data
In the normal density function, Вµ=mean of the
ditribution, Пѓ is the standard deviation. ПЂ = 3.1416 . . .
and e = 2.71828 . . ..
•
Histogram of two samples with size 100 each for car
mileage ratings.
Histogram of EPA
Histogram of EPAn06
30
20
Frequency
0
37
39
41
35
37
39
41
EPAn06
density.default(x = EPA)
density.default(x = EPAn06)
0
5
Density
0.2
Density
0.0
0.1
0.1
0.0
0.00
в€’5
в€’5
0
36
5
38
40
42
N = 100 Bandwidth = 0.3743
STAT 515 – p.78
0.0 0.1 0.2 0.3 0.4
EPA
0.3
0.2
0.10
normal density
0.3
0.15
35
0.05
normal density
10
20
0
0.4
10
mean=0,standard deviation=1
0.20
mean=1,standard deviation=2
Frequency
30
40
Below is another plot:
34
36
38
40
42
N = 100 Bandwidth = 0.3275
STAT 515 – p.79
Properties of Normal
•
Plotting its density in R:
x<-seq(-4,4,by=.01); dnorm(x,mean=0,sd=1);
plot(x,y,t="l",col="red").
• How do you get probabilities like P (X ≤ x), when X is
normal? Use pnorm()
• The cumulative probabilities for Normal distribution are
very important, but not easily computable in any
analytic way. They are usually numerically computed,
and very well documented in tables.
STAT 515 – p.80
•
Find the probability that a standard normal random
variable exceeds 1.96 in absolute value.
Solution:
P (|Z| > 1.96) = P (Z < в€’1.96 or Z > 1.96).
•
For the command pnorm(), you have the choice of
specifying mean and variance for your normal
distribution, in standard notation N (Вµ, Пѓ 2 ).
• Find the probability that the standard normal random
variable Z falls between -1.33 and 1.33.
STAT 515 – p.81
Transformation
•
Normal Quantiles
Let X в€ј N (Вµ, Пѓ 2 ), so it has density
(x в€’ Вµ)2
exp в€’
f (x) = в€љ
2Пѓ 2
2ПЂПѓ 2
1
.
•
It is best to introduce this notion by doing an example.
•
Example: Find the value of z —call it z0 – in the standard
normal distribution that will be exceeded only 10% of
the time. That is, find z0 such that P (Z ≥ z0 ) = .10 .
Can you tell me the distribution of
z0 = 1.28
X в€’Вµ
?
Пѓ
•
or in other words, what is its density?
Upper О±-percentile (quantile).
qnorm(.1,lower.tail=F)
STAT 515 – p.82
STAT 515 – p.83
Normal Curve Areas
Exercise
•
STAT 515 – p.84
Problem: Suppose the scores x on a college entrance
examination are normally distributed with a mean of 550
and a standard deviation of 100. A certain prestigious
university will consider for admission only those
applicants whose scores exceed the 90th percentile of
the distribution. Find the minimum score an applicant
must achieve in order to receive consideration for
admission to the university.
STAT 515 – p.85
Assessing Normality
Methods Assessing Normality
•
Many future chapters will talk about statistical inference
methods for normal populations. These procedures will
perform well only when you have reasonable populations.
•
So it is important for us to determine whether the
sample data come from a normal population, before we
apply those techniques properly.
•
A natural method you may think of would be using a
histogram, or a stem-and-leaf plot, and look at the
shape. One should be cautious though it may not be
that reliable.
•
Method 1: Find the interquartile range IQR and
standard deviation s for the sample, then calculate the
ratio IQR/s. If the data (sample) come from a normal
population, then IQR/s≈1.34. Why? ... Because for a
standard normal random variable, the 25th and 75th
percentiles are -.67 and .67. So what is the theoretical
IQR/Пѓ ?
•
Method 2: Q-Q normal plot, comparing sample quantiles
with theoretical normal quantiles.
STAT 515 – p.86
STAT 515 – p.87
Sample Test Problem
1.6
8.4
3.5
6.5
7.4
5.9
3.1
1.1
8.6
6.7
4.3
5.0
3.2
4.5
3.3
9.4
2.1
6.3
8.4
6.4
Normal Qв€’Q Plot
45
5.3
7.3
9.7
8.2
35
30
1. Construct a stem-and-leaf plot to assess whether the
data are from an approximately normal distribution.
2. Compute s for the sample data. Ans: s = 2.353.
3. Find the values of QL and QU , then use the value of s
to assess whether the data come from an approximately
normal distribution. Note: 1.34 В± 0.04=very good
Sample Quantiles
40
5.9
4.0
6.0
4.6
Gas Mileage Data
в€’2
в€’1
0
1
2
Theoretical Quantiles
STAT 515 – p.88
STAT 515 – p.89
Point Estimation
Population vs Sample
•
Recall that mayor-voters example, for which we
hypothesized that the proportion of all voters who would
favor the candidate is 60% in a particular city. However,
in practice it is usually unknown, and needs to be
estimated by sample data.
•
Definition: In statistics, a parameter is a numerical
measure of a population . Since it is based on the
observations in the whole population, its value is usually
unknown.
•
Definition: A sample statistic is a numerical
descriptive measure of a sample. It is calculated from
the observations in the sample.
• List of population parameters and corresponding sample
statistics.
Mean:
Вµ
Variance:
Пѓ2
Standard deviation: Пѓ
Binomial proportion: p
•
xВЇ
s2
s
pˆ
Note: the term statistic refers to a sample quantity and
the term parameter refers to a population quantity.
STAT 515 – p.90
STAT 515 – p.91
Die Tossing
Sampling Distribution
•
When you sit down, and toss a balanced die; you know
in principle you may get 6 different values on the upper
face. If you toss it three times, and the observations
appear as 2,3,6; this may be considered as a sample.
•
But what is the relevant population here, in other words,
what is the mechanism generating your data? The
population here can be best described using a random
variable with the uniform distribution on {1, 2, 3, 4, 5, 6}.
This random variable is responsible for generating a
potentially infinite population.
•
How about using sample mean to estimate population
mean? This is particularly relevent if the die is not
known to be balanced a priori. So the mean is unknown!
STAT 515 – p.92
•
Definition: The sampling distribution of a sample
statistic calculated from a sample of n measurements is
the probability distribution of the statistic.
•
How to find a sampling distribution? Answer: It is
usually difficult and sometimes impossible. Why do we
want to find it? In short: Compare estimators for a
population parameter, draw inference at some confidence
level.
STAT 515 – p.93
Estimating Population Mean
Challenging Question
•
Median
Consider a game played with a standard 52-card bridge
deck in which you can score 0,3, or 12 points on any one
hand. Suppose the population of points scored per hand
is described by the probability distribution shown here. A
random sample of n=3 hands is selected from the
population.
Points, x 0
3
12
p(x)
1/2 1/4 1/4
Mean
a. Find the sampling distribution of the mean xВЇ.
b. Find the sampling distribution of sample median M .
Вµ
STAT 515 – p.94
STAT 515 – p.95
Another Exercise
The probability distribution shown here describes a population
of measurements that can assume values of 0,2,4, and 6, each
of which occurs with the same relative frequency:
x
p(x)
• How many
possibilities for xВЇ ?
• Is M discrete?
•
Watch the typo on
bottom row.
STAT 515 – p.96
0
2
4
6
1
4
1
4
1
4
1
4
(a). List all the different samples of n = 2 measurements
that can be selected from this population.
(b). Calculate the mean of each different sample listed in
part (a).
(c). If a sample of n = 12 measurements is randomly
selected from the population, what is the probability
that a specific sample will be selected?
STAT 515 – p.97
What is a sampling distribution?
•
It is a distribution about a sample statistic, like the
mean xВЇ, and the sample variance s2 .
•
Sampling distribution usually depends on the size of a
sample.
•
It also depends on the population where samples are
drawn.
•
If population is simple, and the potential possible
samples are finite, then we can get a very good idea of
the sampling distribution.
•
In general we may appeal to central limit theorem.
Exercise
Suppose one can design a rule of counting points for a hand
in a bridge game, such that for any given hand the points can
only be one of the following three possibilities:
x
0
1
4
p(x) 1/3 1/3 1/3
a. Find the population mean and variance.
b. For the sample statistic, s2 with sample size n = 2, find its
sampling distribution. Is it biased while estimating Пѓ 2 ?
STAT 515 – p.98
STAT 515 – p.99
Comparing Estimators
What if both are unbiased?
•
The same population parameter can sometimes be
estimated in two (or more) different ways, i.e., several
estimators. What is the useful procedure to compare
them?
•
If the sampling distribution of a sample statistic has a
mean equal to the population parameter the statistic is
intended to estimate, the statistic is said to be an
unbiased estimate of the parameter.
•
If the mean of the sampling distribution is not equal to
the parameter, the statistic is said to be a biased
estimate of the parameter.
STAT 515 – p.100
•
If both estimators are unbiased, then we will look at the
spread-out of the sampling distributions. The smaller the
standard deviation is the better.
•
The standard deviation of the sampling distribution of a
statistic is also called the standard error of the
statistic.
STAT 515 – p.101
Which one is unbiased?
•
Following that bridge game example, suppose we change
the rule of counting points of a hand a little bit, we have
the following possibilities for each hand.
x
0
3
12
p(x) 1/3, 1/3, 1/3
The sampling distributions of ВЇx (n=3) and M are:
ВЇx
0
1
2
3
4
p(ВЇx) 1/27 3/27 3/27 1/27 3/27
ВЇx
5
6
8
9
12
p(ВЇx) 6/27 3/27 3/27 3/27 1/27
Further Considerations
•
If you still have some doubt choosing the right
estimator, let us look at the standard deviations of their
sampling distributions.
•
2 = 20.9136
Solution: Пѓx2ВЇ = 8.6667 vs ПѓM
•
As we can see, sample mean xВЇ is usually better than the
sample median M in estimating the population mean.
•
Summary: Ideally we want to find an estimator that is
unbiased and has the smallest variance among all
unbiased estimators. We call this statistic the
minimum-variance unbiased estimator (MVUE).
M
0
3
12
p(m) 7/27 13/27 7/27
STAT 515 – p.102
Sampling distribution again
STAT 515 – p.103
Sample Mean Diagram
Assuming a random sample x of n observations has been
selected from any population. Then the following are true:
(1) The mean of the sampling distribution equals the mean
x]) = Вµ.
of the sampled population. That is, ВµxВЇ (:= E[ВЇ
(2) The standard deviation of the sampling distribution
equals
Population
Standard deviation of sampled population
Square root of sample size
в€љ
That is, ПѓxВЇ = Пѓ/ n (also called the standard error of
the mean).
sampling distribution
x
sample mean
0
STAT 515 – p.104
7
STAT 515 – p.105
Another Example
Central Limit Theorem
Consider the following distribution:
•
Theorem 6.1 (in the book): If a random sample of n
observations is selected from a population with a normal
distribution (normal population), the sampling
distribution of xВЇ will be a normal distribution.
•
Theorem 6.2 (Central Limit Theorem): Consider a
random sample of n observations selected from a
population (any population) with mean Вµ and
standard deviation Пѓ . Then, when n is sufficiently large,
the sampling distribution of xВЇ will be approximately a
normal distributionв€љwith mean ВµxВЇ = Вµ and standard
deviation ПѓxВЇ = Пѓ/ n. The larger the sample size, the
better will be the normal approximation to the sampling
distribution of xВЇ. n = 30 is usually good enough.
x
1 2 3 8
p(x) .1 .4 .4 .1
a. Can someone find the population mean Вµ and variance Пѓ 2 ?
b. Consider drawing samples of size 2 from the population,
can you work out the sampling distribution of the mean xВЇ?
Can you confirm E[ВЇ
x] = Вµ, and compute ПѓxВЇ ?
STAT 515 – p.106
STAT 515 – p.107
Sample Test Problem
•
The left column gives
four different kinds of
populations, from
which the samples
could be drawn.
• Can you observe the
patterns of those
curves when sample
size increases?
• This shows the central
limit behavior.
STAT 515 – p.108
•
Question: Suppose we have selected a random sample
of n = 36 observations from a population with mean
equal to 80 and standard deviation equal to 6. It is
known that the population is not extremely skewed.
a. Sketch the relative frequency distribution for the
sampling distribution of the sample mean xВЇ.
b. Find the probability that xВЇ will be larger than 82.
STAT 515 – p.109
Exercise
One Sample Inference
Question: A manufacturer of automobile batteries claims
that the distribution of the lengths of life of its best battery
has a mean of 54 months and a standard deviation of 6
months. Suppose a consumer group decides to check the
claim by purchasing a sample of 50 of the batteries and
subjecting them to tests that estimate the battery’s life.
•
Confidence interval for population mean
•
The idea is to give an interval such that you can claim
with certain probability, the true population parameter is
going to be in the interval.
a. Assuming that the manufacturer’s claim is true, describe
the sampling distribution of the mean lifetime of a sample
of 50 batteries.
b. Assuming that the manufacturer’s claim is true, what is
the probability that the consumer group’s sample has a
mean life of 52 or fewer months?
•
In the large sample case,
2Пѓ
xВЇ В± 2ПѓxВЇ = xВЇ В± в€љ
n
has good coverage probabilities. Why?
STAT 515 – p.110
STAT 515 – p.111
Hospital patients
•
Confidence Coefficient
•
Definition 7.2: An interval estimator or ( confidence
interval) is a formula that tells us how to use sample
data to calculate an interval that estimates a population
parameter.
•
= 4.53В±.74.
Definition 7.3: The confidence coefficient is the
probability that an interval estimator encloses the
population parameter – that is, the relative frequency
with which the interval estimator encloses the population
parameter when the estimator is used repeatedly a very
large number of times. The confidence level is the
confidence coefficient expressed as a percentage.
STAT 515 – p.112
STAT 515 – p.113
For this dataset, we can read from the book (page 307)
that xВЇ = 4.53 days and s = 3.68 days. So we can
construct the interval
Пѓ
,
xВЇ В± 2ПѓxВЇ = 4.53 В± 2 в€љ
100
but we do not know Пѓ , how can we approximate it?
s
Пѓ
≈ x¯ ±2 √
= 4.53В±2
xВЇ В±2 в€љ
100
100
3.68
10
99 % confidence interval
•
How do you find it?
•
Choose О± such that 100(1 в€’ О±) = 99, solving it gives
О± = 0.01
•
•
Then look at the normal table, find out the upper О±/2
percentile, zО±/2 .
•
Then use the standard formula to find out that
confidence interval.
100(1 в€’ О±)% C.I. for Вµ
The large-sample 100(1 в€’ О±)% confidence interval for Вµ
is
Пѓ
xВЇ В± zО±/2 ПѓxВЇ = xВЇ В± zО±/2 в€љ
n
where zО±/2 is the z value with an area О±/2 to its right
в€љ
and ПѓxВЇ = Пѓ/ n. The parameter Пѓ is the standard
deviation of the sampled population and n is the sample
size.
•
Remark: When Пѓ is unknown and n is large (say,
n ≥ 30), the confidence interval is approximately equal
to
s
xВЇ В± zО±/2 в€љ
n
where s is the sample standard deviation.
STAT 515 – p.114
STAT 515 – p.115
Example
•
Exercise
Problem: Unoccupied seats on flights cause airlines to
lose revenue. Suppose a large airline wants to estimate
its average number of unoccupied seats per flight over
the past year. To accomplish this, the records of 225
flights are randomly selected, and the number of
unoccupied seats is noted for each of the sampled flights.
Descriptive statistics for the data are displayed below
Variable
N
Mean
StDev SE Mean
NOSHOWS 225 11.5956 4.1026 0.2735
•
A random sample of 90 observations produced a mean
xВЇ = 25.9 and a standard deviation s = 2.7.
a. Find a 90% confidence interval for Вµ
b. Find a 99% confidence interval for Вµ
Can you construct a 90% confidence interval for Вµ, the
population mean?
STAT 515 – p.116
STAT 515 – p.117
Confidence Interval Interpretation
•
•
•
Sampled Intervals
When we form a 100(1 в€’ О±)% confidence interval for Вµ,
we usually express our confidence in the interval with a
statement such as “ We can be 100(1 − α)% confident
that Вµ lies between the lower and upper bounds of the
confidence interval.
The statement reflects our confidence in the estimation
procedure, rather than in the particular interval that is
calculated from the sample data.
We know that repeated applications of the same
procedure will result in different lower and upper bounds
on the interval. Furthermore, we know that 100(1 в€’ О±)%
of the resulting intervals will contain Вµ.
•
Decrease the confidence level.
• Following up the previous example, a 90% confidence
interval for Вµ is
в€љ
в€љ
x¯±1.645(σ/ n) ≈ 4.53±(1.645)(3.68)/ 100 = 4.53±.61
STAT 515 – p.120
Вµ
Вµ
STAT 515 – p.119
Small-sample confidence interval
•
There are many actual needs to address small samples.
For example, Federal legislation requires pharmaceutical
companies to perform extensive tests on new drugs
before they can be marketed. After testing on animals,
and if it seems safe, then the company can try it out on
humans. However, it is unlikely you will have large
sample due to ethical standards.
•
Suppose a pharmaceutical company must estimate the
average increase in blood pressure of patients who take a
certain new drug. Assume only 6 patients can be used in
the initial phase of human testing. How do you make
confidence interval for that average increase in blood
pressure?
•
This interval (3.92,5.14) is narrower than the previously
calculated 95% confidence interval, (3.79,5.27).
• Remark: although the interval is narrower,
simultaneously we are having “less confidence” for the
narrower interval to cover the true population parameter.
• The other way of decreasing the width of an interval
without sacrificing “confidence” is to increase the sample
size n.
10 samples
Confidence intervals are meant to be at certain confidence levels.
STAT 515 – p.118
Narrow the width of a C.I.
10 samples
STAT 515 – p.121
Two Remarks
•
•
t-statistic
Remark 1: The sampling distribution of xВЇ may not be
normal, if the population is far from being normal (say,
very skewed). But remember, xВЇ has (approximately)
normal distribution if the population is (approximately)
normal, no matter how small the sample size is.
•
t=
the approximation of Пѓ by s would be very poor, if the
sample size is small.
xВЇ в€’ Вµ
в€љ
s/ n
•
It is also called Student’s t-statistic, because William
Gosset (1876-1937) first found its distribution in a paper
published under his pen name, Student.
•
Degrees of freedom of t-statistic: Apparently, the
amount of variability in the sampling distribution
depends on the sample size. To capture this relationship,
we call n в€’ 1 the degrees of freedom.
Remark 2: In the formula
Пѓ
ПѓxВЇ = в€љ ,
n
t-statistic is defined in the following way
STAT 515 – p.122
Variability of the t-statistic
STAT 515 – p.123
t-distribution
•
The bigger the number of degrees of freedom associated
with the t-statistic, the less variable will be its sampling
distribution. see the Table on page 318.
• Compared to the standard normal statistic
z=
xВЇ в€’ Вµ
xВЇ в€’ Вµ
= в€љ ,
ПѓxВЇ
Пѓ/ n
standar normal
t with df=4
в€’3
the t-statistic is more variable. For example, when n = 5
which means degrees of freedom is 4, the standard
normal z-score is z.025 = 1.96, but t.025 = 2.776.
• When sample size is about 30, there is no real difference
in the distributions of t-statistic and the standard normal
statistic.
STAT 515 – p.124
в€’2
в€’1
0
1
2
3
•
Critical values
• One parameter
family
• Courtesy
textbook, P.796
STAT 515 – p.125
Drug Testing Example
•
•
Summary of the procedure
Remember n в€’ 1 = 5 which is way less than 30, so we
use t-statistic to construct confidence intervals. Read
from the table, t.025 = 2.571.
•
xВЇ В± tО±/2
From the text p.319, the actual data gives us xВЇ = 2.283
and s = .950, so
2.283 В± (2.571)
.950
в€љ
6
= 2.283 В± .997
The small-sample confidence interval for Вµ is
s
в€љ
n
where tО±/2 is based on (n в€’ 1) degrees of freedom.
•
gives us the 95% confidence interval (1.286,3.280).
It is required the population has a relative frequency
distribution that is approximately normal. (It has been
empirically found that t-distribution is not very sensitive
to the departure from normality in the population.)
STAT 515 – p.126
STAT 515 – p.127
Example
•
Exercise
Some quality control experiments require destructive
sampling in order to measure a particular characteristic
of the product. The cost is usually high, so only small
samples are available. Suppose a manufacturer of
printers for personal computers wishes to estimate the
mean number of characters printed before the printhead
fails. The manufacturer tests n = 15 printheads and
records the number of characters printed until failure for
each. The actual data and its summary are located on
p.320.
(1) Form a 99% confidence interval for the mean number
of characters printed before the printhead fails.
(2) What assumption is required for the interval you
found in part (1) to be valid? is that assumption
reasonably satisfied?
STAT 515 – p.128
•
The following sample of 16 measurements was selected
from a population that is approximately normally
distributed:
91 80 99 110 95 106 78 121
106 100 97 82 100 83 115 104
(a). Construct an 80% confidence interval for the
population mean.
(b). Construct a 95% confidence interval for the
population mean, and compare the width of this
interval with that of part (a).
(c). Carefully interpret each of the confidence intervals,
and explain why the 80% confidence interval is
narrower.
STAT 515 – p.129
Population Proportion
•
Confidence Interval for p
Question: Public-opinion polls are conducted regularly
to estimate the fraction of U.S. citizens who trust the
president. Suppose 1,000 people are randomly chosen
and 637 answer that they trust the president. How
would you estimate the true fraction of all U.S. citizens
who trust the president?
pˆ =
637
= .637
1, 000
1. The mean of the sampling distribution of pˆ is p; that is,
pˆ is an unbiased estimator of p.
2. The standard deviation of the sampling distribution of pˆ
is pq/n, where q = 1 в€’ p.
3. distribution? large sample scenario.
4. The large-sample confidence interval for p is
pˆ ± zα/2 σpˆ = pˆ ± zα/2
This is a point estimate (can we say estimator?), what
about an interval estimator?
pq
≈ pˆ ± aα/2
n
where pˆ = x/n and qˆ = 1 − pˆ. Note: x is counting the
number of successes, like those people who trust their
president.
STAT 515 – p.130
STAT 515 – p.131
Some Conditions for C.I.
1. A random sample is selected from the target population
2. The sample size n is large, say bigger than 30. (In
particular, either nˆ
p ≥ 15 or nˆ
q ≥ 15)
Getting back to the president example, we can construct the
95% confidence interval for the proportion of all U.S. citizens
who trust the president
pˆ ± zα/2 σpˆ = .637 ± 1.96
pq
1, 000
where p can be estimated by pˆ, and q ≈ qˆ = 1 − pˆ.
STAT 515 – p.132
pˆqˆ
n
Interesting Example
•
Problem: Many public polling agencies conduct surveys
to determine the current consumer sentiment concerning
the state of the economy. For example, the Bureau of
Economic and Business Research at the University of
Florida conducts quarterly surveys to gauge consumer
sentiment in the sunshine state. Suppose that BEBR
randomly samples 484 consumers and finds that 257 are
optimistic about the state of the economy. Use a 90%
confidence interval to estimate the proportion of all
consumers in Florida who are optimistic about the state
of economy. Based on the confidence interval, can
BEBR infer that the majority of Florida consumers are
optimistic about the economy?
STAT 515 – p.133
Wilson’s adjustment for p
•
Sometimes the true population parameter is near 0 or 1;
for example, suppose one wants to estimate the
proportion of people of who die from a bee sting. This
proportion may very likely be near 0 (say, p ≈ .0013).
Can you estimate the parameter based on a sample of
size 50, or even 200? The answer is: NO.
• Wilson’s adjustment: An adjusted (1 − α)100%
confidence interval for p is
pЛњ В± zО±/2
pЛњ(1 в€’ pЛњ)
n+4
Quick Application
•
Application of Wilson’s adjustment
• Problem: According to an article, the probability of
being the victim of a violent crime is less than .01.
Suppose that, in a random sample of 200 Americans, 3
were victims of a violent crime. Use a 95% confidence
interval to estimate the true proportion of Americans
who were victims of a violent crime.
• How does Wilson’s adjusted confidence interval compare
with (в€’.0.002, 0.032)?
x+2
where pЛњ = n+4
is the adjusted sample proportion, and
x =# of successes.
STAT 515 – p.134
STAT 515 – p.135
Determining the sample size
•
Recall that one alternative way of reducing the width of
a confidence interval, while maintaining the confidence
level, is to increase the sample size.
• This is a real issue faced by an experiment designer, who
would like to decide how big the sample size he or she
would like.
• For example, to estimate a population mean by a
potential large sample, one may want a 95% confidence
interval with a certain narrow width to satisfy some
agency requirements. In this situation a sampling
scheme has to be worked out.
Sampling Error
•
Let us introduce the notion, sampling error, which
should be distinguished from the standard error of the
sampling distribution.
• The sampling error is defined to be the half length of a
100(1 в€’ О±)% confidence interval. In formula, it is given
by
Пѓ
zО±/2 в€љ
= SE,
n
solving it gives us
(zО±/2 )2 Пѓ 2
n=
.
(SE)2
If n above is not an integer, you should round it up to
make the sample size sufficient.
STAT 515 – p.136
STAT 515 – p.137
Value of Пѓ
Sample Size Calculation
•
To calculate the sample size n, we need to know Пѓ . In
practice, one may estimate it using current available
sample as data collection goes.
•
Or conservatively, we may use the approximate
relationship, σ ≈ R/4. You may still remember the 2σ or
3Пѓ rule.
•
If you would use R/4 approximation, by all means you
should conservatively make your sample size a little
bigger than the actual numerical value.
•
Suppose the manufacturer of official NFL footballs uses
a machine to inflate the new balls to a pressure of 13.5
pounds. When the machine is properly calibrated, the
mean inflation pressure is 13.5 pounds, but
uncontrollable factors cause the pressures of individual
footballs to vary randomly from about 13.3 to 13.7
pounds. For quality control purposes, the manufacturer
wishes to estimate the mean inflation pressure to within
.025 pound of its true value with a 99% confidence
interval. What sample size should be specified for the
experiment?
Solution: Note z.005 = 2.575. If by calculation n = 107
after rounding up, we may very well require a sample
size n = 110 to be more certain to obtain 99%
confidence level.
STAT 515 – p.138
Test of a Hypothesis
STAT 515 – p.139
Null hypothesis and alternative
•
In estimation, we have seen how to make inference
about one single parameter, where the goal was to get
an estimate as exact as possible. There are other
situations, in which we may only want to know some
qualitative relationship. For example, one may want to
know whether the mean of a driver’s blood alcohol
exceeds the legal limit after two drinks.
• One characteristic of this inference is that we are making
inference about how the value of a parameter relates to
a specific numerical value. Is it less than, equal to, or
greater than the specified number? This type of
inference is called a test of hypothesis.
STAT 515 – p.140
•
Pipe manufacturer example: Suppose a certain city
requires the residential sewer pipe to be more than 2,400
pounds per foot of length. Each manufacturer that
wants to sell pipe will have to pass the inspection. So
there is a testing problem here, and we are still interested
in the population mean Вµ; but we are less interested in
estimating the value of Вµ than we are in testing a
hypothesis about its value. What is the hypotheis?
Whether the mean breaking strength of the pipe exceeds
2,400 pounds per linear foot?
STAT 515 – p.141
How to Set Up?
•
•
Taking care of sampling variability
•
Null hypothesis (H0 ): µ ≤ 2, 400
Alternative hypothesis (Ha ): Вµ > 2, 400.
• Suppose you have a data set from one manufacturer
company, how can you decide whether the company will
meet the requirement? In other words, how can you test
whether the mean pipe breaking strength from this
company is bigger than 2,400? You may say, compute
the sample mean x¯ for this data set, if it’s bigger than
2,400, then reject the null hypothesis. Would this be fair
to the company? You want to show convincing evidence.
Generally speaking, we want to find a procedure to take
care of the sampling variability.
• The rational is that: Suppose the null is true, you look
at your data, and ask, does the data support the belief?
• In practice, we may compute a test statistic (a sample
statistic for testing purpose), under the null the test
statistic may have a sampling distribution. As we know
the sampling distribution tells us the sampling variability.
If the test statistic evaluated on your particular dataset
is too far away from the center of the sampling
distribution. That means you should reject the null
hypothesis, in this case we say the testing is significant.
STAT 515 – p.142
Pipe example
•
How to find convincing evidence?
Observation: For the null hypothesis, µ ≤ 2, 400, if we
can reject the hypothesis Вµ = 2, 400 in favor of
µ > 2, 400, then µ ≤ 2, 400 is automatically rejected. So
we may look at the test statistic
•
Remember we are testing: H0 : Вµ = 2, 400 against
Ha : Вµ > 2, 400. If H0 is true, then z has a standard
normal distribution if sample size n is reasonably big. If
z=
xВЇ в€’ 2, 400
xВЇ в€’ 2, 400
в€љ
=
z=
ПѓxВЇ
Пѓ/ n
•
STAT 515 – p.143
How large must z be before the city can be convinced
that the null hypothesis can be rejected in favor of the
alternative hypothesis and conclude that the pipe meets
the requirement?
STAT 515 – p.144
xВЇ в€’ 2, 400
xВЇ в€’ 2, 400
в€љ
в€љ
≈
Пѓ/ n
s/ n
is bigger than 1.645, this is indeed convincing evidence
H0 should be rejected in favor of Ha .
• Of course, there is some probability of making mistakes
if we do this.
STAT 515 – p.145
Type I decision error
•
Example
Following the previous procedure, we may make some
mistakes by falsely rejecting the null hypothesis. But
that probability is small; if the null hypothesis is indeed
true, and we reject it by realizing z > 1.645. What is the
probability we are making a mistake? This is called a
Type I decision error. Denote
•
Suppose we test 50 sections of sewer pipe and find the
mean and standard deviation for these 50 measurements
to be, respectively,
xВЇ = 2, 460 pounds per linear foot
and
s = 200 pounds per linear foot,
О± = P (Type I error)
= P (rejecting Null when it is indeed true).
what is the z value? Can we reject the null hypothesis
Вµ = 2, 400 in favor of Вµ > 2, 400? How about
H0 ≤ 2, 400 ? what’s the Type I error probability if we
are comparing z-value with 1.645?
So in our example,
О± = P (z > 1.645 when in fact Вµ = 2, 400) = .05
STAT 515 – p.146
STAT 515 – p.147
Summary
Challenging a claim
•
Null hypothesis: usually something you have doubt, but
of interest.
• Alternative: what you are really interested in.
• Test statistic: for example
z=
•
xВЇ в€’ 2, 400
ПѓxВЇ
Rejection region: for example z > 1.645 is one rejection
region if we allow Type I error probability to be О± = .05
STAT 515 – p.148
•
Exercise: A University of Florida economist conducted a
study of Virginia elementary school lunch menus. During
the state-mandated testing period, school lunches
averaged 863 calories (findings available in National
Bureau of Economic Research, Nov. 2002). The
economist claimed that after the testing period end, the
average caloric content of Virginia school lunches
dropped significantly. Set up the null and alternative
hypothesis to test the economist’s claim.
STAT 515 – p.149
Test of a hypothesis
•
•
•
•
•
Level of a test
A sewer pipe manufacturer claim that, on average their
pipes have breaking strength beyond 2,400 pounds.
Suppose you have a dataset consisting 50
measurements, namely the breaking strength measured
on 50 sections of a sewer pipe the company produced.
Can you test the claim in a �convincing’ way?
Null hypothesis: H0 : µ ≤ 2, 400, where µ is the mean
breaking strength of the sewer pipe the company can
produce.
Alternative hypothesis: Ha : Вµ > 2, 400.
Does the data show convincing evidence to reject H0 in
favor of Ha .
From the actual data y , yВЇ = 2, 460 pounds per linear
foot, and s = 200 pounds per linear foot.
•
Also known as type I error probability
• For the z-value of that particular dataset, if we are
comparing it with the value 1.645, and decide to reject
H0 whenever the sample z -value exceeding 1.645. This
is called a level-О± test, and the О± is given by .05.
Another interpretation for this value is the type I error
probability. Why? remember we are using the rejection
region (1.645, +в€ћ); if the null is indeed true, we may
still have О± probability of seeing z -values in that region.
Since we have decided that’s the rejection region, then
can you figure out the implication?
• Description above gives us the type I error probability.
STAT 515 – p.150
Type II error probability
•
Suppose we got another sample (dataset), a, with size
n = 50, and it gives us aВЇ = 2, 430 and s = 200. For this
dataset, we have the test statistic
z=
2430 в€’ 2400
30
в€љ
= 1.06.
=
28.28
200/ 50
If we continue to test the original claim at the .05 level,
the result is not significant here for this dataset.
• Note our estimate a
ВЇ here does exceed 2,400 quite a bit,
but somehow we fail to reject H0 : µ ≤ 2, 400 at the
significance level .05.
STAT 515 – p.152
STAT 515 – p.151
Type II error probability (cont’d)
•
what will happen if we accept the null hypothesis? we
may be making some mistake again with certain
probability ОІ , Type II error probability. This probability is
usually very difficult to compute, statisticians tend to try
to avoid this issue by claiming �the sample evidence is
insufficient to reject H0 .
• Rule of thumb: Since β , the type II error probability, is
very difficult to compute, we will generally avoid the
decision to accept H0 , preferring instead to say the
sample evidence is insufficient to reject H0 when the
sample test statistic is not in the rejection region.
• There may indeed exist situations where you can
compute ОІ . In a formal statistical report, it is acceptable
to say you want to accept H0 , then give the О± and ОІ
values.
STAT 515 – p.153
Summary–PP. 355-356, Chapter 8
•
Null hypothesis: usually something you have doubt, but
of interest.
•
Alternative: what you are really interested in.
•
Test statistic: for example
z=
xВЇ в€’ 2, 400
ПѓxВЇ
•
rejection region: for example z > 1.645 is one rejection
region if we allow Type I error probability to be О± = .05
•
Type II error probability.
Challenging a claim (cont’d)
•
Exercise: A University of Florida economist conducted a
study of Virginia elementary school lunch menus. During
the state-mandated testing period, school lunches
averaged 863 calories (findings available in National
Bureau of Economic Research, Nov. 2002). The
economist claimed that after the testing period end, the
average caloric content of Virginia school lunches
dropped significantly. Set up the null and alternative
hypothesis to test the economist’s claim. What is the
test statistic you may want to look at?
STAT 515 – p.154
Further example
•
STAT 515 – p.155
Two-sided test
According to a researcher at the Univ. of Florida wildlife
ecology and conservation center, the average level of
mercury uptake in wading birds in the everglades has
declined over the past several years (UF News,
December 15, 2000). Five years ago, the average level
was 15 parts per million.
a. Give the null and alternative hypothesis for testing
whether the average level today is less than 15 ppm.
b. Describe a Type I error for this test
c. Describe a Type II error for this test.
d. Describe the rejection region for a .01-level test.
e. For a sample y of 100 measurements, suppose
yВЇ = 14.6 and s = 2, can you reject this 0.01-level test?
What about yВЇ = 12, s = 2 ?
STAT 515 – p.156
• H0 : µ ≤ 2, 400
against Ha : Вµ > 2, 400 is called
one-sided test, because the alternative hypothesis only
has one direction.
• a. One tailed (upper tailed)
b. One tailed, (lower tailed)
c. Two tailed.
• Remark: The tail is in the direction of the alternative
hypothesis.
• The real difference from one-sided test is the rejection
region.
STAT 515 – p.157
Problem–P.360 Chapter 8
•
Problem: (The effect of drugs and alcohol on the
nervous system ) Suppose a research neurologist is
testing the effect of a drug on response time by injecting
100 rats with a unit dose of the drug, subjecting each
rat to a neurological stimulus, and recording its response
time. The neurologist knows that the mean response
time for rats not injected with drug is 1.2 seconds. She
wishes to test whether the mean response time for
drug-injected rats differs from 1.2 seconds. Set up the
test of hypothesis for this experiment, using О± = .01.
• Can somebody guess what the rejection region should
be? one-sided or two-sided?
Some comments and p-value
•
Rejection region: For a two-sided test with level О±, the
critical values (percentiles) are found using О±/2, instead
of О±. This is very important to keep in mind.
• What is a p-value? Definition from the book: The
p-value, also called the observed significance level, for a
specific statistical test is the probability (assuming that
H0 is true) of observing a value of the test statistic that
is at least as contradictory to the null hypothesis, and
supportive of the alternative hypothesis, as the actual
one computed from the sample data.
• For example, in the testing of sewer pipes we computed
zˆ = 2.12 from one particular sample. So the observed
significance level (p-value) for this test is
p − value = P (z ≥ 2.12) = 0.5 − 0.4830 = 0.0170.
STAT 515 – p.159
STAT 515 – p.158
p-value for two-sided test
•
Step 1: Determine the value of the test statistic (say, z)
corresponding to the result of the sampling experiment.
• Step 2: If the test is two-sided, the p-value is equal to
twice the tail area beyond the observed z-value in the
direction of the sign of z .
• Reporting p-value: when the test level is chosen, if the
observed significance level (p-value) is less than the
chosen value of О±, the reject the null hypothesis.
Otherwise, do not reject the null hypothesis.
STAT 515 – p.160
Problem – Chapter 8, P. 368
•
The lengths of stay (in days) for 100 randomly selected
hospital patients are observed and recorded, as shown in
the book. Suppose we want to test the hypothesis that
the true mean length of stay (LOS) at the hospital is
less than 5 days; that is
H0 : Вµ = 5 versus Ha : Вµ < 5.
Assuming that Пѓ = 3.68, use the data in the table to
conduct the test at О± = .05. Can you reject the null
hypothesis?
STAT 515 – p.161
Exercise
•
When sample size is small
Consider a test of H0 : Вµ = 75 performed with the
computer. SPSS reports a two-sided p-value of .1032.
Make the appropriate conclusion for each of the
following situations:
a. Ha : Вµ < 75, z = в€’1.63, О± = 0.05
b. Ha : Вµ < 75, z = 1.63, О± = .10
c. Ha : Вµ > 75, z = 1.63, О± = .10
d. Ha : Вµ = 75, z = в€’1.63, О± = .01
• z -statistic
is no longer very normally distributed.
• Remember confidence interval situation, we can work
out the sampling distribution of the following statistic
t=
xВЇ в€’ Вµ0
в€љ ,
s/ n
but watch for the degrees of freedom.
STAT 515 – p.162
STAT 515 – p.163
Small-Sample test of Вµ
•
•
One sided test
1. H0 : Вµ = Вµ0
In the text there is a water-quality monitoring
experiment, where the goal is to watch whether the pH
value measured in the drinking water would fall below
7.0, which is considered dangerous to human health.
One water-treatment plant has a target pH of 8.5, but
only collected 17 water samples, can you test the claim?
Note: for these 17 water samples, it is known
xВЇ = 8.42, s = .16 .
• Solution: On page 372-373 of the textbook.
2. Ha : Вµ < Вµ0 (or Ha : Вµ > Вµ0 )
3. Test statistic: t =
x
ВЇв€’Вµ
в€љ0
s/ n
4. Rejection region: t < в€’tО±
•
One Example
Two-tailed test
1. H0 : Вµ = Вµ0
2. Ha : Вµ = Вµ0
3. Test statistic: t =
x
ВЇв€’Вµ
в€љ 0
s n
4. Rejection region: t < в€’tО±/2 or t > tО±/2
STAT 515 – p.164
STAT 515 – p.165
One more exercise
•
C.I. in action
A car manufacturer wants to test a new engine to
determine whether it meets new air pollution standards.
The mean emission Вµ of all engines of this type must be
less than 20 parts per million of carbon. Ten engines are
manufactured for testing purposes, and the emission
level of each is determined. The data (in parts per
million) are listed below.
•
A random sample of 90 observations produced a mean
xВЇ = 25.9 and a standard deviation s = 2.7. Find a 95%
confidence interval for the population mean Вµ. Suppose
another sample of 15 observations is obtained, and it has
a mean xВЇ = 23, and a standard deviation s = 3.5; can
you construct a 97% confidence interval for Вµ?
15.6 16.2 22.5 20.5 16.4
19.4 19.6 17.9 12.7 14.9
Do the data supply sufficient evidence to allow the
manufacturer to conclude that this type of engine meets
the population standard? Assume that the manufacturer
is willing to risk a Type I error with probability О± = .01.
STAT 515 – p.166
STAT 515 – p.167
Determining sample size again
•
How to determine sample size for estimating proportion?
• A gigantic warehouse located in Atlanta, GA, stores
approximately 60 million empty aluminum beer and soda
cans. Recently, a fire occurred at the warehouse. The
smoke from the fire contaminated many of the cans with
blackspot, rendering them unusable. A University of
South Florida statistician was hired by the insurance
company to estimate p, the true proportion of cans in
the warehouse that were contaminated by the fire. How
many aluminum cans should be randomly sampled to
estimate the true proportion to within .02 with 90%
confidence.
STAT 515 – p.168
Some Ideas
•
Remember the formula for Confidence Interval
pˆ ± zα/2
pq
.
n
In this problem we do not have a pˆ available, so being
conservative, we can estimate pq = 1/4 because this is
the biggest possible for product p в€— q
в€љ
( pq ≤ (p + q)/2 = 1/2).
•
The allowable sampling error SE= .02, soв€љwe should pick
n to solve the following equation zО±/2 /2 n = .02, where
О± = 0.1, z0.1 being the upper .1 percentile for the
standard normal. Make sure round up n.
STAT 515 – p.169
Hypothesis Testing
Solution
•
BusinessWeek.com provides consumers with retail prices
of new cars at dealers from across the country. The July
2006 prices for the hybrid Toyota Prius were obtained
from a sample of 160 dealers. These 160 prices are
saved in the HYBRIDCARS file. Preliminary analysis
showed that the mean of these 160 prices is $ 25476.7.
Suppose one is interested in knowing whether the mean
July 2006 dealer price of the Toyota Prius differs from $
25,000, and after a two-sided analysis in MINITAB, the
p-value is reported to be .014. Can you decide the
sample standard deviation for this sample? If you are
willing to risk a Type I error probability .05, can you
reject the null hypothesis?
• Yes, we can reject H0 because p-value = .014 ≤ .05.
•
Hypothesis setup: H0 : Вµ = 25, 000 vs Ha : Вµ = 25, 000
Use z-statistic: z = xВЇв€’25,000
; for this dataset, after a
ПѓxВЇ
two-sided testing, the reported p-value is .014.
• So under H0 ,
P (z > observed z-value) = 0.014/2 = 0.007
• We need to find z0 such that
P (0 < z < z0 ) = 0.5 в€’ 0.007 = 0.493, from the standard
normal curve table z0 = 2.45.
• Then we have the relationship
•
observed z-value =
25476.7 в€’ 25, 000
в€љ
= z0 = 2.45
s/ n
plugging in n = 160 gives s = 2461.156.
STAT 515 – p.170
STAT 515 – p.171
Simple Linear Regression
•
Deterministic model vs Probabilistic model
• Simple regression model (first coined by Francis
Galton) is about the relationship of two variables in
the population. say, Height vs IQ index
• Here is a more interesting example, it is known that the
response time to certain stimulus is related to the
percentage of a certain drug in the bloodstream.
• One may believe this relationship is deterministic, but
after some careful thinking, you may change your mind.
Given a certain percentage of the drug, there may still
be some variability in the response time, either due to
some other hidden causes, or just simply to individual
difference.
STAT 515 – p.172
The Typical Model
•
So we shall be mostly interested in the mean of certain
variable, given the other variable. In statistics, you may
often hear response variable and predictors.
•
In symbols,
•
A first-order probabilistic model
y = 1.5x + random error
y = ОІ0 + ОІ1 x + Оµ
where y = Dependent or response variable, x =
Independent or predictor variable.
STAT 515 – p.173
Hello, Mr. Euclid
•
In the previous slide, Оµ is the random error component,
which has mean 0, ОІ0 = y-intercept of the line, and ОІ1 is
the slope.
• It turns out that this is a very useful model, and the goal
is to estimate ОІ0 and ОІ1 as accurately as possible using
observations on x and y.
• Please notice that E[y] = β0 + β1 x , and this
relationship is deterministic.
• A major focus will be trying to figure out ways
estimating ОІ0 and ОІ1 , regression serves a good ground
for both parameter estimation and testing.
•
Below is something you need to know, and I am willing
to bet you already knew.
•
Suppose a line
y = ОІ0 + ОІ1 x
passes through the point (-2,3) and (4,6), what should
be ОІ0 and ОІ1 .
STAT 515 – p.174
STAT 515 – p.175
Scatter plot
3.5
3.0
2.5
2.0
1.0
1.5
Is there any linear relationship between x and y .
Reaction time
Subject Percent x of Drug Reaction time y (seconds)
1
1
1
2
2
1
3
3
2
4
4
2
5
5
4
4.0
The Data
1
2
3
4
5
Percent of Durg
STAT 515 – p.176
STAT 515 – p.177
Fitted with visual line
Errors of prediction=distance between the fitted value
and the actual observation
•
It is easy to see: sum of errors=0, but sum of squared
errors (SSE)=2.
•
By playing with this, you can see there are many lines
which may give you sum of errors=0, but there is only
one line which will give you minimum SSE.
3.0
2.5
2.0
1.0
1.5
Reaction time
3.5
4.0
•
1
2
3
4
5
Percent of Durg
STAT 515 – p.178
STAT 515 – p.179
Least Squares Estimate
•
To find the linear relationship of two variables, suppose
we observe a sample of n data points, say,
(x1 , y1 ), (x2 , y2 ), . . . , (xn , yn ). We want to find out the
least squares line, in other words, to find out ОІ0 , ОІ1
minimizing
Some Formulas
•
Solving this optimization problem, we get:
Slope:
SSxy
ОІЛ†1 =
SSxx
where
n
SSE =
i=1
[yi в€’ (ОІ0 + ОІ1 xi )]2 .
SSxy =
The minimizers, denoted by ОІЛ†0 and ОІЛ†1 , are called the
least squares estimates of the population parameters ОІ0
and ОІ1 .
STAT 515 – p.180
(xi в€’ xВЇ)(yi в€’ yВЇ) =
SSxx =
•
(xi в€’ xВЇ)2 =
xi y i в€’
x2i в€’
(
(
xi )(
n
yi )
xi ) 2
n
y-intercept: ОІЛ†0 = yВЇ в€’ ОІЛ†1 xВЇ.
STAT 515 – p.181
Example 11.1 – Page 566
Refer to the reaction data presented in the previous
table. Consider the straight-line model E(y) = ОІ0 + ОІ1 x,
where y =reaction time and x=percent of drug received.
a. Use the method of least squares to estimate the
values of ОІ0 and ОІ1 .
b. Predict the reaction time when x = 2%.
c. Find SSE for the analysis.
d. Give practical interpretations of ОІЛ†0 and ОІЛ†1 .
•
It is easy to compute
xi = 15, yi = 10,
SSxy = 7
x2i = 55,
SSxx =
x2i в€’
xi yi = 37, so
(
xi ) 2
= 10.
5
It follows
ОІЛ†1 = .7,
•
10
ОІЛ†0 = yВЇ в€’ ОІЛ†1 xВЇ =
в€’ (.7)
5
15
5
= в€’0.1
The least squares line is given by:
yˆ = βˆ0 + βˆ1 x = −.1 + .7x
STAT 515 – p.183
STAT 515 – p.182
Least Squares Line
Fun Exercise
•
Consider the following pairs of measurements:
3.5
4.0
x 5 3 -1 2 7 6 4
y 4 3 0 1 8 5 3
1.5
2.0
2.5
3.0
a. Construct a scattergram (scatter-plot) of these data.
b. What does the scattergram suggest about the
relationship
c. Can you calculate the least squares estimate of ОІ0
and ОІ1 ?
d. Plot the least squares line on your scattergram.
Does the line appear to fit the data well?
e. Interpret the y-intercept and slope of the least
squares line.
1.0
y
•
Solutions
1
2
3
4
5
x
STAT 515 – p.184
Figure 1: SSE=1.1
STAT 515 – p.185
Regression Inference
•
Ground Assumptions
•
Recall the model
y = ОІ0 + ОІ1 x + Оµ
•
The least squares estimators for ОІ1 and ОІ0 are given by
SSxy
,
ОІЛ†1 =
SSxx
•
•
•
ОІЛ†0 = yВЇ в€’ ОІЛ†1 xВЇ
By fitting this model, we know the estimates are too
much focused on the sample data. Can we say
something about these estimates on different samples?
In other words, how reliable are they?
•
•
In order to pursue statistical inference, some
assumptions are needed for the random component.
Оµ is assumed to have a probability distribution with mean
0
The variance of the probability distribution of Оµ is
constant for all settings of the independent x. By
notation, we assume Var[Оµ] в‰Ў Пѓ 2 .
Оµ has a normal distribution.
The values of Оµ associated with any two observed values
of y are independent.
STAT 515 – p.186
STAT 515 – p.187
Estimating Пѓ 2
•
Recall SSE=
algebra
in which
Example
(yi − yˆi )2 , expanding it out and by some
SSE = SSyy в€’ ОІЛ†1 SSxy
SSyy =
yi2 в€’
(
Referring to the drug reaction time example, please
compute an estimate of Пѓ ; below is the data.
Subject Percent x of Drug Reaction time y (seconds)
1
1
1
2
2
1
3
3
2
4
4
2
5
5
4
yi )2
n
One estimator for Пѓ 2 is given by
s2 =
•
SSE
nв€’2
where n is the sample size.
STAT 515 – p.188
STAT 515 – p.189
Making inference on the slope
•
In previous study, we have tried to visually inspect the
scattergram, and try to see whether there is some
convincing evidence for linear relationship.
• More formally, based on data we can perform a
two-sided test
H0 : ОІ1 = 0
•
vs Ha : ОІ1 = 0
To perform this test, we must first find an appropriate
test statistic.
Sampling Distribution of ОІЛ†1
•
Research efforts suggest that one such test statistic may
be formed based upon ОІЛ†1 ; but its sampling distribution is
needed.
• Under those assumptions about ε, it can be shown that
the sampling distribution of the least squares estimator
ОІЛ†1 of the slope is normal with mean ОІ1 and the standard
deviation
Пѓ
ПѓОІЛ†1 = в€љ
;
SSxx
the formula above is called the standard error
в€љ of the
slope estimator, it can be estimated by s/ SSxx .
STAT 515 – p.190
STAT 515 – p.191
Test Statistic
•
Since the sampling distribution of ОІЛ†1 is known, the
approriate test statistic is a t-statistic, formed as
t=
where
•
Exercise
ОІЛ†1 в€’ Hypothesized value of ОІ1
sОІЛ†1
•
For the drug reaction time example, conduct a .01-level
test to determine whether the reaction time (y) is
linearly related to the amount of drug (x).
• Solution to be applied.
s
sОІЛ†1 = в€љ
.
SSxx
The t-statistic above has a t-distribution with df=n-2
STAT 515 – p.192
STAT 515 – p.193
R Demo on linear regression
The Fitted Model
25
15
20
final
30
35
library(faraway)
data(stat500)
ls()
names(stat500)
attach(stat500)
plot(midterm,final)
abline(0,1)
g $<$-- lm(final~midterm,stat500)
summary(g)
g\$coef
abline(g\$coef,col="red")
Remark: One may have to install the faraway package first.
10
15
20
25
30
midterm
STAT 515 – p.194
Summary on Testing ОІ1
•
One-tailed test: H0 : ОІ1 = 0 vs Ha : ОІ1 < 0 (or
Ha : ОІ1 > 0).
Test statistic:
ОІЛ†1
ОІЛ†1
t=
= в€љ
sОІЛ†1
s/ SSxx
Rejection region: t < в€’tО± (or t > tО± when Ha : ОІ1 > 0).
• Two-tailed test: H0 : β1 = 0 vs Ha : β1 = 0, and the
rejection region is given by |t| > tО±/2
•
where tО± and tО±/2 are based on (n в€’ 2) degrees of
freedom.
STAT 515 – p.196
STAT 515 – p.195
t-statistic for drug reaction time
•
As we can compute, ОІЛ†1 = .7, s = .61, and SSxx = 10.
Thus
t=
.7
ОІЛ†1
.7
в€љ =
в€љ
= 3.7
=
.19
s/ SSxx
.61/ 10
If we are willing to risk a Type-I error probability,
О± = 0.05, then the rejection region for t will be
|t| > t.025 = 3.182.
Apparently, 3.7 is in the upper rejection region, so we
reject the null hypothesis and conclude that the slope ОІ1
is not 0. What is the observed p-value for this two-sided
test, approximately ?
STAT 515 – p.197
Reading Output
Confidence Interval for ОІ1
•
Major statistical software packages, like R, Minitab,
SPSS, will report a two-tailed p-value for each of the
ОІ -parameters in the regression fitting. For example, in
simple linear regression, the p-value for the two-sided
test H0 : ОІ1 = 0 versus Ha : ОІ1 = 0 is given on the
printout. If you want to perform a one-sided test of
hypothesis, you need to make the adjustment.
• Upper-tailed test Ha : β1 > 0, p-value=p/2 if the
observed t > 0, and 1 в€’ p/2 if t < 0.
•
•
A 100(1 в€’ О±)% confidence interval for the simple linear
regression slope is given by
ОІЛ†1 В± tО±/2 sОІЛ†1
where the estimated standard error of ОІЛ†1 is computed as
sОІЛ†1 = в€љ
s
SSxx
and tО±/2 is based on (n-2) degrees of freedom.
Lower-tailed test Ha : ОІ1 < 0, p-value=p/2 if the
observed t < 0, and 1 в€’ p/2 if t > 0.
STAT 515 – p.198
STAT 515 – p.199
Drug Reaction Time Data
•
What is a 95% confidence interval for ОІ1 ?
• tα/2 is based on (n-2)=3 degrees of freedom. Reading
from the t-table, t.025 = 3.182.
• So a 95% confidence interval is given by
ОІЛ†1 В± t.025 sОІЛ†1 = .7 В± 3.182
s
в€љ
SSxx
.61
= .7 В± 3.182 в€љ
10
which gives .7 В± .61. So the estimate of the interval for
the slope parameter ОІ1 is from .09 to 1.31, and one can
be 95% confident there is a positive correlation between
the response time and drug percentage.
STAT 515 – p.200
Exercise
•
Consider the following pairs of observations:
y 4 2 5 3 2 4
x 1 4 5 3 2 4
a). Construct a scattergram of the data.
b). Use the method of least squares to fit a straight line
to the 6 data points.
c). Plot the least squares lines on the scattergram of
part a.
d). Compute the test statistic for determining whether x
and y are linearly related.
e). Carry out the test you set up in part d, using О± = .01.
f). Find a 99% confidence interval for ОІ1 .
STAT 515 – p.201
Correlation Coefficients
The (Pearson) correlation coefficient is defined as
в€’2.0
5
в€’1.0
6
SSxy
SSxx SSyy
2
в€’3.0
3
r=
4
•
Data Clouds
for a sample of n paired measurements.
• It can be shown that −1 ≤ r ≤ 1, and r is scaleless. So
this is much better than ОІЛ†1 . If r = 0, then ОІЛ†1 = 0, and
vice versa. So r = 0 means there is no linear relationship
at all. Can you guess what r = 1 (or r = в€’1) would
mean?
0
1
2
3
4
5
6
0
1
2
3
4
5
12
4
3
6 8
2
0
1
2
3
4
5
r=0, no linear relationship
6
0
1
2
3
4
5
•
STAT 515 – p.203
The coefficient of determination
•
For the data,
y 4 2 5 3 2 4
x 1 4 5 3 2 4
It turns out if you would square r, there is a relation
r2 =
•
How much is its r?
• Using x <-c(1,4,5,3,2,4) and y <-c(4,2,5,3,2,4), we
know
SSxy = sum(x в€— y) в€’
6
r>0, some positive relationship
STAT 515 – p.202
Example
6
r=в€’1, perfect negative linear relationship
16
r=1, perfect positive linear relationship
•
SSyy в€’ SSE
SSE
=1в€’
SSyy
SSyy
This is an important measure of goodness of fit in linear
regression. Perfect fit gives r = 1.
sum(x) в€— sum(y)
= 2.67
n
similarly, SSyy = 7.33, SSxx = 10.83; so r = 0.3.
STAT 515 – p.204
STAT 515 – p.205
Prediction
Prediction Intervals
•
One important goal for regression analysis is for
prediction.
• For the drug reaction example, if somebody comes in
with a measure of the drug percentage, 5%; can you
predict what the response time for this individual would
be?
• Recall the least squares line
•
Instead of looking at point estimates, one may derive
confidence intervals for prediction.
• A 100(1 − α)% prediction interval for an individual new
value of y at x = xp is
yˆ ± tα/2 (Estimated standard error of prediction)
or
yˆ = βˆ0 + βˆ1 x = −.1 + .7x,
yˆ ± tα/2 s
so the predicted value would be yˆ = −.1 + .7(5) = 3.4
seconds. But how reliable is this estimate? What would
other samples tell you about this value?
1+
1 (xp в€’ xВЇ)2
+
n
SSxx
where tО±/2 is based on (n-2) degrees of freedom.
STAT 515 – p.206
Example
•
STAT 515 – p.207
Something of less importance
Refer again to the drug reaction regression. Predict the
reaction time for the next performance of the experiment
for a subject with a drug concentration of 4%. Use a
95% prediction interval.
•
Along with prediction interval for a new subject at
x = xp , one can talk about estimating the mean of y in
that subpopulation with characteristic (predictor) xp .
•
The confidence interval is going to be different from the
prediction interval because
σyˆ = σ
1 (xp в€’ xВЇ)2
+
n
SSxx
is different from
Пѓ(yв€’Л†y) = Пѓ
STAT 515 – p.208
1+
1 (xp в€’ xВЇ)2
+
n
SSxx
STAT 515 – p.209
A walk through linear regression
•
Based on empirical ground, and look at the scattergram,
hypothesize the model
E(y) = ОІ0 + ОІ1 x
•
Estimate the β ’s, using least squares estimation
• Keep in mind the assumptions on random errors: (i)
mean(ε)=0; (ii) Var(ε) = σ 2 stays constant; and (iii)ε’s
are independent, with normal distribution.
• t-test for β0 and β1 , to check model adequacy. Look for
quantities like s, p-values, and F statistic.
• Estimation and/or prediction. (using interval estimation)
Estimability
•
There are many causes for non-estimability
• Textbook gives us a very simple one
• Suppose you want to fit a model relating annual crop
yield y to the total expenditure for fertilizer, x. Let us
propose the following the model
E(y) = ОІ0 + ОІ1 x.
If you observe a data with only one single x, the
parameters in the model cannot be estimated.
STAT 515 – p.210
Outlier
STAT 515 – p.211
Comparing two population means
•
In regression analysis, it is very important to identify
outliers because they may make your findings spurious.
An outlier is defined to be the observation whose
residual is larger than 3s (in absolute values).
• Example: Consider the following 10 data points.
x 3 5 6 4 3 7 6 5 4 1
y 4 3 2 1 2 3 3 5 4 7
(a) Is there sufficient evidence to indicate that x and y
are linearly correlated?
(b) Can you find any outlier?
(c) Can you compute R2 and Ra2 ? which one is bigger?
Is it always true?
STAT 515 – p.212
•
Problem: A study published in the Journal of American
Academy of Business, examined whether the
perception of the quality of service at five-star hotels in
Jamaica differed by gender. Hotel guests were randomly
selected from the lobby and restaurant areas and asked
to rate 10 service-related items. Each item was rated on
a five-point scale (1=“much worse than I expected,”
5=“much better than I expected”), and the sum of the
items for each guest was determined. A summary of the
guest scores are provided in the following table:
Gener
Sample size
Mean Score
Males
127
39.08
Standard Deviation
6.73
Females
114
38.79
6.94
STAT 515 – p.213
Question
Is there any gender difference for rating the hotel? Can you
construct a 90% confidence interval for that difference?
•
To answer this question, let Вµ1 denote the mean score
for male population, and let Вµ2 denote the mean score
for female population. Suppose we have sample x1 from
the male population, and x2 from the female population,
a natural point estimator for Вµ1 в€’ Вµ2 is xВЇ1 в€’ xВЇ2 . In order
to construct confidence interval, we need to work out
the sampling distribution. As most of you can imagine,
it is
, with mean=Вµ1 в€’ Вµ2 , and variance=combined
variability from xВЇ1 and xВЇ2 .
STAT 515 – p.214
•
Problem: In an experiment to improve the Japanese
reading comprehension levels at the University of Hawaii,
14 students participated in a 10-week extensive reading
program in a second-semester Japanese course. The
numbers of books read by each student and the student’s
course grade are reported in the following table:
# of Books
Course Grade
# of books
Course Grade
53
A
30
A
42
A
28
B
40
A
24
A
40
B
22
C
39
A
21
B
34
A
20
B
34
A
16
B
STAT 515 – p.216
•
In other words,
Пѓ(ВЇx1 в€’ВЇx2 ) =
Пѓ12 Пѓ22
+ ;
n1 n2
and the 100(1 в€’ О±)% confidence interval here is of the
form
(ВЇ
x1 в€’ xВЇ2 ) В± zО±/2 Пѓ(ВЇx1 в€’ВЇx2 ) .
STAT 515 – p.215
Question: Consider two populations of students who
participate in the reading program prior to taking a
second-semester Japanese course: those who earn an A grade
and those who earn a B or C grade. Of interest is the
difference in the mean number of books read by the two
populations of students. Can you draw inference on how
many more books a B student should read in order to get A?
STAT 515 – p.217
© Copyright 2026 Paperzz