SVEUČILIŠTE U ZAGREBU
FAKULTET ELEKTROTEHNIKE I RAČUNARSTVA
DIPLOMSKI RAD br. 306
Detekcija značajki lica
Danijel Vicković
Zagreb, lipanj 2012.
Zahvaljujem kolegi i prijatelju Goranu Vidojeviću na svoj pomoći koju mi je pružio tijekom
izrade ovog rada, asistentima Nenadu Markušu i Miroslavu Frljaku na svim savjetima,
uputama i pomoći tijekom programiranja, te mentoru Igoru S. Pandžiću.
Sadržaj
Uvod ...................................................................................................................................... 1 1. Slični radovi................................................................................................................... 2 2. Način učenja .................................................................................................................. 5 2.1. Haar ....................................................................................................................... 5 2.1.1. Integralna slika .............................................................................................. 6 2.1.2. Klasifikatori ................................................................................................... 7 2.1.3. Kaskada ......................................................................................................... 8 2.2. Stabla odlučivanja ............................................................................................... 10 2.2.1. 2.3. Regresija .............................................................................................................. 12 2.3.1. 3. 4. Problemi stabla odlučivanja......................................................................... 11 Problemi kod regresijskog učenja ............................................................... 13 Skup ulaznih podataka ................................................................................................. 15 3.1. Dobivanje slika .................................................................................................... 16 3.2. Baze slika............................................................................................................. 16 3.3. FDP format .......................................................................................................... 20 Sustav za učenje .......................................................................................................... 24 4.1. Obrada ulaznih podataka ..................................................................................... 24 4.1.1. Rezači i generatori slika .............................................................................. 24 4.1.2. Konverteri .................................................................................................... 28 4.2. Aplikacija za učenje ............................................................................................ 29 4.2.1. 4.3. MPI verzija .................................................................................................. 36 Aplikacija za detekciju – FaceDetector ............................................................... 37 5. Procesi učenja .............................................................................................................. 43 6. Rezultati ....................................................................................................................... 47 Zaključak ............................................................................................................................. 51 Literatura ............................................................................................................................. 52 Popis slika ............................................................................................................................ 54 Popis tablica......................................................................................................................... 56 Sažetak ................................................................................................................................. 57 Summary.............................................................................................................................. 58 Skraćenice............................................................................................................................ 59 Privitak ................................................................................................................................ 60 Uvod
Detekcija objekata u digitaliziranim slikama relativno je novo područje koje se razvija iz
dana u dan. Mnoga se istraživanja provode kako bi se poboljšale postojeće tehnike i razvile
nove, učinkovitije. Tako se i ovaj rad može nazvati jednim istraživačkim i
eksperimentalnim radom u kojemu će se isprobati postojeće tehnike detekcije lica, te
istražiti nove. Sama detekcija lica zasniva se na tehnikama računalnog vida. No, detekcija
lica je tek početak, nužan temelj za puno delikatniju detekciju, a to je - detekcija
karakterističnih točaka lica (npr. rubovi očiju, rubovi usana, vrh nosa itd.). Kako bi se
izvršila detekcija, potrebno je provesti određeni proces strojnog učenja, a kako bi se izvršio
proces učenja, potrebno je imati veliki skup podataka za učenje. U skup podataka za učenje
spadaju slike lica i pripadne anotacije, tj. koordinate značajki lica. Kada se pribave
potrebne slike, potrebno ih je pripremiti za proces učenja, a tu spada: rezanje određenih
značajki lica (npr. izrezivanje očiju iz slika lica, izrezivanje nosa itd.), anotiranje značajki,
pretvorba anotacija iz originalnog zapisa u zapis koji će se koristiti u ovom radu itd.
Produkt učenja će se zatim ukomponirati u postojeći sustav za detekciju dostupan na
Zavodu za telekomunikacije.
Sama struktura rada može se, ugrubo, podijeliti na teorijski i praktični dio. U 1. poglavlju,
ukratko će se opisati radovi sa sličnom tematikom i sličnim tehnikama. Nakon kratkog
pregleda postojećih tehnika, u 2. poglavlju biti će pojašnjeno na koji način radi proces
učenja korišten u ovom radu. Jedna od najvažniji stvari u procesu učenja je skup ulaznih
podataka, te će se u 3. poglavlju detaljno objasniti koji su se, i kakvi ulazni podatci koristili
prilikom procesa učenja. U 4. poglavlju daje se pregled svih napravljenih alata potrebnih
za kvalitetnu pripremu i provođenje učenja. Nadalje, u 5. poglavlju detaljnije se opisuje
provođenje procesa učenja i ispitivanja parametara učenja, te se daje kratka usporedba
dobivenih rezultata učenja. Na kraju, u 6. poglavlju prikazujemo rezultate detekcije u
aplikaciji Face Detector, te usporedbu rezultata.
1
1. Slični radovi
Kao što je rečeno ranije, mnogo se istraživanja radi u području detekcije objekata u slici.
Sukladno tome, postoji mnogo članaka koji opisuju razne nove tehnike i poboljšanja starih,
te će se u ovom poglavlju, ukratko, opisati slični radovi koji su utjecali na izradu ovog
rada, te radovi koji koriste neke druge načine detekcije.
U samom radu koriste se, već naučene, Haarove kaskade i koriste se na način opisan u
članku [1].
Histogram usmjerenih gradijenata
Detekcija objekata koristeći histograme usmjerenih gradijenata (eng. Histogram of
Oriented Gradients; HoG) opisana je u članku [2]. U članku je opisan spoj dva pristupa –
koriste se kaskade i AdaBoost proces učenja za odabir značajki (kao i u Haarovoj detekciji
koja je korištena u ovom radu [1]) zajedno sa histogramima usmjerenih gradijenata.
Postupak se sastoji od toga da se pomoću AdaBoost algoritma odaberu najprikladnije
značajke. Na taj način se odabiru prikladni blokovi iz velikog skupa blokova (blok se
sastoji od ćelija, a ćelija se sastoji od piksela). Zatim se računa gradijent za svaki piksel u
slici, te se oni grupiraju za svaku ćeliju. Slika (Slika 1.1) prikazuje primjer gradijenata u
bloku koji sadrži 16 ćelija. Kada se izračunaju svi gradijenti, rezultat se serijalizira u jedan
vektor. U ovom slučaju, to je 128-dimenzionalni vektor (16 blokova * 8 mogućih
orijentacija).
Slika 1.1. Prikaz usmjerenih gradijenata u bloku
2
U radu [2] koriste se 36-dimenzionalni vektori. Poboljšanje performansi postiže se
procesom učenja kaskada u kojima svaka značajka odgovara jednom 36-dimenzionalnom
vektoru.
Ugniježđene kaskade
Detekcija i klasifikacija koristeći ugniježđene kaskade boostanih klasifikatora (eng. nested
cascades of boosted classifiers) opisana je u članku [3], te je sam sustav dosta sličan
sustavu iz članka Viole i Jonesa ([1]). Glavna razlika je u tome što se svaki jaki
klasifikator, dobiven u jednoj razini procesa učenja, tretira kao slabi klasifikator u sljedećoj
razini. Rad samog sustava vidljiv je na slici (Slika 1.2). Za proces učenja i detekciju koriste
se pravokutne Haarove značajke.
Slika 1.2. Način rada ugniježđene kaskade
Kovarijacijske matrice
U ovom postupku koriste se kovarijacijske matrice za detekciju i klasifikaciju, a postupak
je opisan u članku [4]. Postupak se sastoji od toga da se slika iz slike izvuku određene
informacije poput intenziteta, RGB komponenti i slično. Na taj način se dobije ndimenzionalni vektor (npr. intenzitet – jedna dimenzija, RGB komponente – tri dimenzije
itd.). Iz te novo-dobivene slike, odabire se pravokutna regija te se računa kovarijacijska
matrica za tu regiju. Podatci na dijagonali matrice predstavljaju varijancu svake značajke,
dok ostali podatci predstavljaju korelacije. Za uspoređivanje dvije matrice koristi se
algoritam najbližeg susjeda. Na taj način se mjere razlike između značajki. Kako bi se
postupak ubrzao, također se koriste i integralne slike (kao i u prijašnjim radovima).
Rezultat procesa učenja je kovarijacijska matrica s kojom će se uspoređivati sve matrice
3
koje se računaju u nekoj slici (u kojoj se radi detekcija). Prilikom detekcije, svaki piksel se
pretvara u 9-dimenzionalni vektor (koordinate piksela, RGB komponente, te prva i druga
derivacija intenziteta po varijabli x i po varijabli y). Nad slikom se pretražuju regije te se
za svaku regiju računa pet kovarijacijskih matrica. Na slici (Slika 1.3) prikazana je regija,
unutar cjelokupne slike, u kojoj se nalazi lice. Svaka od tih matrica se uspoređuje sa
matricom koja je naučena za prepoznavanje određenog objekta (u ovom primjeru, radi se
detekcija lica). Ukoliko se matrica u pretraživanoj slici podudara sa originalnom matricom,
objekt je detektiran.
Slika 1.3. Regije kovarijacijskih matrica
Uz navedene članke, može se spomenuti i rad [5], u kojem se koristi regresija uz boostanje,
ili [6] u kojem se radi detekcija pojedinih značajki lica te se 3D model lica prilagođava
detekciji. Osim njih, u radu [7] se opisuje detekcija značajki lica pri čemu se koristi PRFR
model (eng. Pairwise Reinforcement of Feature Responses).
4
2. Način učenja
U prošlom poglavlju navedeno je nekoliko načina strojnog učenja i detekcije. Neki od njih
imaju više sličnosti sa postupkom u ovom radu, neki manje. U ovom poglavlju dati će se
kompletan teorijski pregled načina učenja te što se zapravo koristilo za detekciju.
Za detekciju su se koristile Haarove kaskade i stabla odlučivanja. Haarova kaskada
koristila se za inicijalnu detekciju lica u slici, te se unutar te detekcije primjenjuje detekcija
pomoću šuma odlučivanja. Za detekciju lica koristila se Haarova kaskada koja je dobivena
u sklopu VisageSDK paketa. Za šume odlučivanja napravljeni su procesi učenja, te su se
šume naučile za detekciju pojedinih značajki lica. Dakle, za svaku značajku lica dobivena
je jedna šuma, no više o tome u sljedećim poglavljima.
U prvom potpoglavlju će se objasniti kako se dobivaju Haarove kaskade, te na koji način
detektiraju objekte u slici, dok će se u drugom potpoglavlju objasniti stabla odlučivanja i
regresija.
2.1. Haarove kaskade
Za shvaćanje procesa učenja Haarovih kaskada potrebno je upoznati se sa tri pojma.
No, prije toga potrebno je upoznati se sa osnovnim gradivnim elementima u Haarovoj
detekciji, a to su - Haarovi filtri. Haarov filtar je zapravo pravokutnik koji u sebi sadrži
dva susjedna pravokutnika, kao što se može vidjeti na slici (Slika 2.1), pri čemu se mogu
koristiti filtri sa 2, 3 ili 4 pravokutnika. Vrijednost jednostavnog Haarovog filtra od 2
pravokutnika se određuje tako da se suma piksela u jednom pravokutniku oduzme od sume
piksela u drugom pravokutniku te se na taj način dobije vrijednost Haarovog filtra u
pikselu koji se nalazi u donjem desnom kutu pravokutnika. Veličine tih filtara se mijenjaju
i povećavaju sve dok se ne izračuna vrijednost Haarovih filtara u svakom pikselu. Pomoću
vrijednost filtra mogu se odrediti određene karakteristike unutar slike. Svaki filtar može
odrediti prisutnost (ili odsutnost) određene karakteristike slike, kao npr. rubova, promjena
u teksturi ili odrediti gdje leži granica između tamnog i svijetlog područja. Općenito, broj
Haarovih filtara u slici je mnogo veći od broja piksela.
5
Slika 2.1. Primjer Haarovih filtara
Sada kada znamo što su Haarovi filtri, možemo se posvetiti procesu učenja.
2.1.1.
Integralna slika
Prvi bitan pojam je nova reprezentacija slike, odnosno, integralna slika, pomoću koje se
Haarovi filtri mogu vrlo brzo izračunati. Kao što je rečeno ranije, za izračun Haarovih
filtara, potrebno je izračunati sumu u jednom pravokutniku i oduzeti je od sume u drugom
pravokutniku i tu ulazi u igru integralna slika. Integralna slika na koordinatama (x,y) sadrži
sumu piksela iznad i lijevo od tih koordinata, kao što je prikazano na slici (Slika 2.2).
Integralna slika može se izračunati za cijelu sliku u samo jednom prolazu kroz sliku.
Slika 2.2. Integralna slika
Koristeći integralnu sliku, suma bilo kojeg pravokutnika može se izračunati preko 4
vrijednosti, kao što se može vidjeti na slici (Slika 2.3).
6
Slika 2.3. Računanje sume piksela unutar pravokutnika D
Slika (Slika 2.3) prikazuje računanje sume unutar pravokutnika D. Vrijednost integralne
slike u točci 1 je suma piksela u pravokutniku A. Vrijednost u točci 2 je A+B, u točci 3 je
A+C, dok je vrijednost u točci 4 A+B+C+D. Suma unutar pravokutnika D je tada jednaka:
4+1-2-3.
2.1.2.
Klasifikatori
Druga bitna stvar u učenju sa Haarovim kaskadama, a time i u detekciji, je izgradnja
jednostavnog i efikasnog klasifikatora odabirući mali broj bitnih filtara iz velikog skupa
potencijalnih filtara. Kao što je ranije rečeno, unutar slike postoji vrlo veliki broj Haarovih
filtara, puno veći od broja piksela. Kako bi ubrzali klasifikator, proces učenja mora
odbaciti veliku većinu filtara i koncentrirati se na mali broj krucijalnih filtara. Odabir
filtara postiže se procesom strojnog učenja AdaBoost ograničavajući svaki slabi
klasifikator tako da ovisi samo o jednom filtru. Slabi klasifikator je onaj koji je malo bolji
od pukog pogađanja (očekujemo da dobro klasificira 51 % testnih uzoraka). Jaki
klasifikator je onaj koji vrlo dobro može raspoznati i klasificirati pozitivne primjere
(pozitivni primjeri su oni koji sadrže objekt koji detektiramo). Kao rezultat takvog učenja,
odabir novog klasifikatora u svakoj razini može se smatrati odabirom novog filtra.
Dakle, iako se svaki filtar može izračunati vrlo brzo i efikasno, računanje cijelog skupa je
prilično skupo (vremenski i sistemski). Zato je glavna hipoteza ta da se vrlo mali broj
filtara može kombinirati kako bi se napravio efektivan klasifikator. AdaBoost proces
učenja se koristi i kako bi se odabrali filtri i kako bi se naučili klasifikatori. AdaBoost
proces učenja se obično koristi kako bi se poboljšala (eng. boost) klasifikacija
jednostavnog algoritma učenja. To se jednostavno radi kombinirajući određeni broj slabih
7
klasifikatora kako bi se napravio jaki klasifikator. Kako bi se slabi klasifikator poboljšao,
mora riješiti niz problema u procesu učenja. Nakon prve razine učenja primjerima, na
kojima se provelo učenje, se mijenjaju težine kako bi se stavio naglasak na one koji su bili
pogrešno klasificirani u prethodnom koraku.
2.1.3.
Kaskada
Treći bitan dio je izgradnja kaskade kojom se postiže bolja detekcija i kojom se smanjuje
vrijeme računanja. Glavna ideja je da se slabiji klasifikatori koriste tako da odbacuju
većinu negativnih prozora i propuštaju gotovo sve pozitive. Jednostavniji klasifikatori se
koriste kako bi se odbacila većina prozora prije nego što se počnu koristiti kompleksniji
klasifikatori kojima se postiže mala razina krivih pozitiva (eng. false positive). Slabi
klasifikatori na početku procesa propuštaju gotovo sve pozitive, a time i puno krivih
pozitiva. Svi ti pozitivi idu dalje na sljedeću razinu klasifikatora koji su stroži i propuštaju
manje pozitiva nego oni sa niže razine. Na taj način se u svakoj razini odbacuju krivi
pozitivi, odnosno, proglašavaju se negativima te se odbacuju. Oni pozitivi koji dođu do
zadnje razine i zadnjeg klasifikatora (koji je najstroži) i prođu su vrlo vjerojatno pravi
pozitivi (eng. true positive).
Razine kaskada se izgrađuju učeći klasifikatore pomoću AdaBoost algoritma. Performanse
detekcije klasifikatora sa filtrom sa dva pravokutnika je daleko od prihvatljivog za sustava
za detekciju lica. No, klasifikator može značajno smanjiti broj prozora koji idu u daljnju
obradu koristeći vrlo malo operacija. Te operacije su: izračunaj vrijednosti filtra, izračunaj
slabi klasifikator za svaki filtar, kombiniraj slabe klasifikatore.
Sveukupni oblik procesa detekcije sličan je stablu odlučivanja, kao što se može vidjeti na
slici (Slika 2.4).
8
Slika 2.4. Prikaz procesa učenja kaskade
Pozitivan rezultat (strelica sa oznakom T) iz prvog klasifikatora pokreće računanje drugog
klasifikatora koji je također podešen da postiže vrlo visoke razine pozitiva. Pozitivni
rezultat iz drugog klasifikatora pokreće treći klasifikator i tako dalje. Negativni ishod u
bilo kojem trenutku rezultira odbacivanjem prozora (strelica sa oznakom F). Sama
struktura kaskade napravljena je sa pretpostavkom da je velika većina prozora negativna
(što i jest tako). Kao takva, kaskada pokušava odbaciti što je više moguće negativa u ranim
fazama, dok će pravi pozitiv pokrenuti izračune u svakom klasifikatoru kaskade, što je
zapravo vrlo rijedak događaj unutar slike. Kao i u stablu odluke, kasniji klasifikatori se uče
koristeći one primjere koji se prošli kroz sve ranije faze. Kao rezultat toga, drugi
klasifikator je suočen sa težim zadatkom nego prvi. Primjeri koji prođu kroz prvu razinu su
teži od običnih primjera.
Za provedbu procesa učenja potreban je veliki broj slika na kojima će se učiti kaskada. Te
slike nazivaju se pozitivi ili pozitivni primjeri. Kvaliteta završne kaskade uvelike ovisi o
broju pozitiva te o njihovoj kvaliteti. Za učenje se uobičajeno koristi od 5 do 10 tisuća
pozitiva, no može se koristiti i puno više. Prilikom učenja, vrlo bitan faktor je i trajanje
istog. Kao primjer može se navesti proces učenja sa 7 000 pozitiva, na računalu sa
procesorom Intel Xeon od 2 GHz i sa 1 GB memorije, koji je trajao 3 dana ([16]). Dakle,
bitna je i dostupna memorija za proces učenja.
Kao što je rečeno ranije, u ovom radu korištena je Haarova kaskada dobivena uz paket
VisageSDK.
9
2.2. Stabla odlučivanja
Stabla odlučivanja vrlo su moćne i popularne tehnike modeliranja za klasifikacijske i
regresijske probleme. Privlačnost stabla odlučivanja leži u činjenici da, u odnosu na npr.
neuralne mreže nude modela podataka u „čitljivom“, razumljivom obliku – u stvari u
obliku pravila. Ta pravila se lako mogu direktno interpretirati običnim jezikom, ili pak
koristiti u nekom od jezika za rad s bazama podataka (SQL), tako da se određeni primjeri
iz baze mogu izdvojiti korištenjem pravila generiranih stablom odlučivanja.
Stablo odlučivanja je algoritam u formi stablaste strukture (Slika 2.5), u kojoj se razlikuju
dva tipa čvorova povezanih granama:
•
krajnji čvor (eng. leaf node) - kojim završava određena grana stabla. Krajnji čvorovi
definiraju klasu kojoj pripadaju primjeri koji zadovoljavaju uvjete na toj grani stabla;
•
čvor odluke ("decision node") - ovaj čvor definira određeni uvjet u obliku vrijednosti
određenog atributa (varijable), iz kojeg izlaze grane koje zadovoljavaju određene
vrijednosti tog atributa.
Slika 2.5. Primjer stabla odlučivanja
10
Stablo odlučivanja može se koristiti za klasifikaciju primjera, tako da se krene od prvog
čvora odlučivanja u korijenu stabla i kreće po onim granama stabla koja primjer sa svojim
vrijednostima zadovoljava sve do krajnjeg čvora koji klasificira primjer u jednu od
postojećih klasa problema.
Osnovni preduvjeti za korištenje tehnike stabla odlučivanja su:
•
Opis u obliku parova vrijednosti-atributa - podaci o primjeru moraju biti opisani u
obliku konačnog broja atributa;
•
Prethodno definiran konačan broj klasa (vrijednosti ciljnog atributa) - kategorije
kojima primjeri pripadaju moraju biti definirane unaprijed i treba ih biti konačan broj;
•
Klase moraju biti diskretne - svaki primjer mora pripadati samo jednoj od postojećih
klasa, kojih mora biti znatno manje negoli broja primjera;
•
Značajan broj primjera - obično je poželjno da u skupu primjera za generiranje stabla
odlučivanja postoji barem nekoliko stotina primjera.
Stabla odlučivanja mogu se koristiti za rješavanje dva tipa problema: problem klasifikacije
i problem regresije. Kod klasifikacije određuje se kojoj klasi pripada rezultat, dok se kod
problema regresije rezultat može smatrati realnim brojem.
Stablo se može „naučiti“ tako da se ulazni podatci dijele na temelju vrijednosti atributa.
Podatci se dijele na podskupove ili particije. Proces podjele ulaznih podataka se ponavlja
na svakom čvoru, te se taj proces naziva rekurzivno particioniranje (eng. recursive
partitioning). Rekurzija se zaustavlja kada dodatno particioniranje ne daje nikakve dodatne
informacije (tj. kada je cijeli podskup ima istu vrijednost) ili kada bi čvorovi sadržavali
manje od npr. 5% ukupnog skupa. Ovaj proces primjer je „pohlepnog algoritma“, te se vrlo
često koristi u učenju pomoću stabla odlučivanja.
2.2.1.
Problemi stabla odlučivanja
Jedan od najvećih problema stabla odlučivanja je kada se stablo „prenauči“ (eng.
overfitting). To zapravo znači da se stablo (ili bilo što drugo u drugim tehnikama učenja,
kao npr. kaskade) naučilo samo na primjere iz skupa podataka za učenje. Takvo stablo bi
davalo savršene rezultate za primjere koji su sastavni dio skupa za učenje, no vrlo loše za
bilo koje druge primjere. Naravno, cilj učenja je da stablo nauči dobro generalizirati sve
ostale primjere na temelju naučenoga.
11
U principu može se generirati stablo, dovoljno kompleksno da točno klasificira sve
primjere iz skupa podataka za učenje. Iako je to u određenim slučajevima razumna
strategija, u većini situacija to rađa dodatne probleme, bilo zbog „šuma“ u podacima, ili
pak nedovoljno velikog uzorka podataka koji bi trebao reprezentirati populaciju primjera
za određeni klasifikacijski problem. Bez obzira da li se radi o prvom ili drugom slučaju,
jednostavni algoritam prikazan na slici (Slika 2.5), bi generirao stablo koje „pretjerano
dobro“ aproksimira odnose u podacima.
Ako primjera za učenje ima premalo, stablo će se vrlo loše naučiti generalizirati ostale
primjere (skup za validaciju) jednostavno zato jer ima premalo različitih primjera da se
stablo kvalitetno nauči. S druge strane, ako primjera ima previše, vrlo lako bi moglo doći
do „prenaučenosti“ jer će stablo naučiti donositi odluke samo nad skupom slika za učenje,
dok će kod ostalih primjera davati vrlo loše rezultate.
2.3. Regresija
Linearna regresija se odnosi na svaki pristup modeliranju relacija između jedne ili više
varijabli označene sa Y, te jedne ili više varijabli označene sa X, na način da takav model
linearno ovisi o nepoznatim parametrima estimiranih iz podataka. Najčešće se linearna
regresija odnosi na model u kojem je uvjetna srednja vrijednost od Y, uz danu vrijednost X,
afina funkcija od X.
Linearna regresija ima mnogo praktičnih primjena. Većina aplikacija linearne regresije
pada u jednu od sljedeće dvije široke kategorije:
•
Ako je cilj predviđanje ili prognoza, linearna regresija se može koristiti za
podešavanje preditivnog modela prema promatranom skupu podataka vrijednosti Y i
X. Nakon razvoja ovakvog modela, ako je data vrijednost za X bez pripadajuće
vrijednosti Y, podešeni model se može koristiti za predviđanje vrijednosti Y.
•
Ako imamo varijablu Y i veći broj varijabli X1, ..., Xn koje mogu biti povezane sa Y,
možemo koristiti linearnu regresijsku analizu za kvantificiranje jačine relacije između
Y i Xj, za procjenu koji je Xj uopće vezan za Y, te da bi identificirali koji podskupovi
od Xj sadrže redundantne informacije o Y, tako da, kad je jedan od njih poznat, ostali
više ne daju korisne informacije.
12
Linearni regresijski modeli se često podešavaju uz pomoć metode najmanjih kvadrata, iako
se mogu koristit i drugi načini, kao što je minimiziranje "nedostatka podešenja" (eng. lack
of fit) u nekim drugim normama, ili minimiziranjem penalizirane verzije funkcije gubitaka
najmanjih kvadrata.
U radu je, za učenje, korištena metoda strojnog učenja koja se primjenjuje u problemima
regresije - gradient boosting. Produkt te metode je model koji u sebi sadrži skup slabih
predikcijskih modela (slabih klasifikatora), a ti slabi modeli su često stabla odlučivanja.
Metodom gradient boosting gradi se model od više razina (kao i kod ostalih metoda
boostanja, poput AdaBoost metode), te se radi generalizacija tih razina tako da se
optimizira određena funkcija gubitka.
Prilikom učenja modelira se model koji ima izlaznu varijablu y i vektor ulaznih varijabli x
koje su povezane preko distribucije vjerojatnosti P(x, y). Koristeći skup za učenje (x1, y1,),
…, (xn, yn), pri čemu su vrijednosti varijable x i odgovarajuće vrijednosti y poznate, cilj je
pronaći aproksimaciju Fˆ ( x) funkcije F * ( x) koja minimizira očekivanu vrijednost
funkcije gubitka L(y, F(x)) i predviđanja Ex,y (1).
F * ( x) = arg min E x , y L( y, F ( x))
(1)
F
Metodom gradient boosting pretpostavimo vrijednost y i tražimo aproksimaciju Fˆ ( x) u
obliku težinske sume funkcija hi (x) iz klase H (2).
M
F ( x) = ∑ γ i hi ( x) + const
(2)
i =1
2.3.1.
Problemi kod regresijskog učenja
Ulazne vrijednosti kod učenja (xi) mogu imati više dimenzija (npr. otvorenost oka – jedna
dimenzija, koordinate točke – dvije dimenzije, koordinate 7 točaka – 14 dimenzija itd.). U
idealnom slučaju, broj primjera za učenje bi trebao rasti eksponencijalno sa brojem ulaznih
varijabli. No, u praksi je broj primjera za proces učenja vrlo oskudan, te može doći do
„overfittinga“.
Sljedeći problem može biti vrlo čest u regresijskom učenju, a to je različiti prikaz objekata.
Pošto se u ovom radu obavlja proces učenja nad značajkama lica koje su anotirane i imamo
13
njihove koordinate, ovaj problem je donekle izbjegnut. No, inače mnogo faktora utječe na
prikaz objekta od interesa u slici. Neki od njih su jednostavno razlika između objekata
(npr. u detekciji tumora), korištenje različitih kamera, različita osvjetljenja, šminka itd.
Druge varijacije koje mogu raditi probleme su različite pozadine u slikama i različita
poravnavanja u slikama. U ovom radu sve slike su dobivene iz baza koje sadrže različite
slike ljudi. No, nekih slika ima manje od ostalih, poput slika ljudi sa brkovima i bradom, sa
naočalama itd. Zbog toga, takvo naučena šuma neće raditi dobro kada se susretne sa
primjerima kojih je bilo malo (ili ih uopće nije bilo) u skupu slika za učenje.
Još jedan od problema je višedimenzionalnost izlaznih varijabli. Većina regresijskih
pristupa, poput SVR-a (eng. Support Vector Regression), mogu se nositi sa jednom
izlaznom varijablom, no proširenje istih na više dimenzija može biti vrlo kompleksno, kao
što je u slučaju SVR-a.
Sljedeći problem može se vrlo lako previdjeti, te kasnije snositi posljedice, a to je problem
pohrane i računske složenosti. Proces učenja zahtjeva vrlo velike količine podataka za
samo učenje, a pošto su ti podatci u našem slučaju slike različitih rezolucija (malih i
velikih) zajedno sa anotacijskim datotekama, vrlo brzo može doći do zasićenja što se tiče
memorije. Nadalje, računanje uvelike raste sa brojem primjera, brojem ulaznih i izlaznih
varijabli te jednostavno sa promjenom parametara (što će biti objašnjeno u kasnijem
poglavlju), te sve to kao rezultat daje vrlo dugo trajanje procesa učenja.
U ovom radu korištene su regresijske tehnike gdje se, kao slabi klasifikatori, koriste stabla
odlučivanja sa jednom, tj. sa malim brojem razina. Vrlo velika količina tih stabala čini
šumu odlučivanja. Prilikom procesa učenja parametri na koje se može utjecati su: broj
stabala, težina stabala i dubina stabala.
14
3. Skup ulaznih podataka
Kako bi se lakše objasnio skup podataka, na slici (Slika 3.1) prikazan je sustav koji će
detaljno biti objašnjen u sljedećem poglavlju. U ovom poglavlju biti će pojašnjeni svi
ulazni podatci i formati korišteni za proces učenja. Općenito, može se reći da su ulazni
podatci slike i anotacije. Negdje su ulazni podatci cijele slike iz baze, negdje izrezane
slike, negdje anotacije u .fdp formatu itd.
Slika 3.1. Arhitektura sustava
15
3.1. Dobivanje slika
Za obavljanje procesa učenja potrebno je osigurati vrlo veliki broj primjera za učenje. No,
broj slika koji se koristi u učenju ne smije biti premalen jer se može dogoditi da se,
procesom strojnog učenja, šuma jednostavno neće dovoljno dobro naučiti prepoznavati
značajke za koje provodimo proces učenja. S druge strane, skup primjera za učenje ne
smije biti ni prevelik jer može doći do ranije spominjanog problema „overfittinga“. Kako
bi dobili dovoljno slika za provedbu procesa učenja bilo je potrebno iscrpno traženje baza
slika lica, te se u sljedećem poglavlju opisuju baze koje su pronađene za ovaj rad.
3.2. Baze slika
Postoji mnogo baza slika sa raznih sveučilišta i iz raznih istraživanja, no u velikoj većini
slučajeva te baze sadrže samo slike lica. Tokom izrade ovog rada, pronađeno je, otprilike,
30-tak baza slika lica. Osim samog traženja baza, potrebno je klasificirati baze i zabilježiti
kakve sve slike sadrže (Slika 3.2) jer su, zapravo, slike najbitnije za proces učenja.
Slika 3.2. Prikaz baza
16
Dakle, za korištenje baza bitne su nam sljedeće informacije. Zabilježeno je ime baze, te sva
imena „podskupova“ baze, jer su neke baze još podijeljene u različite strukture (npr.
podjela baze po orijentaciji lica, podjela na slike koje su jako osvijetljene i na slike koje su
lošije osvijetljene itd.). Neke baze, osim podjele na strukture, sadrže parametre u samom
imenu slike, kao npr. baza HeadPose Image Database. Na primjer, ime slike
„person01100-90+0.jpg“ označava osobu, kao prvo, dok su druga sva broja stupnjevi za
koje je zakrenuta glava u vertikalnom i horizontalnom smjeru. Navedeni primjer bi značio
da je osoba na slici zakrenula glavu za 90°prema dolje.
Broj slika je od velike važnosti, te je i to zabilježeno, zajedno sa brojem različitih osoba.
Za proces učenja je od izrazite važnosti koliko se slika koristi te koliko je različitih osoba
na tim slikama. Proces učenja nije jednak ako se koristi 4 000 slika sa 200 različitih osoba
ili 4 000 slika sa 10 različitih osoba. Naravno, onaj koji ima manje različitih osoba će dati
lošije rezultate.
Rezolucija je također bitna i njezina važnost se može izraziti u dva segmenta. Prvi segment
je jednostavno količina memorije koju sliku zauzima. Što je veća rezolucija, slika sadrži
više piksela (što je bitno u procesu učenja, kao što će biti objašnjeno kasnije) i zauzima
više memorijskog prostora. S druge strane, ako je slika lica premala, prilikom izrezivanja,
npr. oka iz slike (za proces učenja za detekciju zjenice), rezultirajuća slika može biti
premale rezolucije za kvalitetno obavljanje procesa učenja.
Kao što je već rečeno, za proces učenja je važna raznolikost slika koje se nalaze u skupu za
učenje. U skladu s tim potrebno je zabilježiti i kakve orijentacije glave sadrže slike u
pojedinim bazama. Neke baze mogu sadržavati samo frontalne slike lica, dok druge mogu
sadržavati po 90 slika jednog lica koje se okraće u koracima od 2°.
Osim rotacije, bitan je također spol. Potrebno je imati podjednake primjere ženskim i
muških lica.
Kao što je ranije rečeno, više se koncentriramo na baze koje već imaju anotacije jer to
znači da ih nećemo morati anotirati prije samog procesa učenja (Slika 3.1). Neke od baza
sadrže anotacije, no svaka od tih baza ima svoj vlastiti format zapisivanja tih anotacija, te
je potrebno provesti konverziju u FDP format (koji će biti pojašnjen u sljedećem
poglavlju). Općenito, vrlo malo baza ima anotacije.
Za svaku bazu je također zabilježen kratki komentar. Zadnja dva stupca u primjeru na slici
(Slika 3.2) označuju da li je baza preuzeta, te da li su anotacije konvertirane.
17
Slika 3.3. Primjeri slika iz baza: a) MUCT Database; b) Franck – Talking Face; c) FEI face
database; d) Face Recognition Data; e) Indian Face Database; f) Faces in the Wild; g) BioID Face
Database; h) FacePix; i) Bao Face Database
Na slici (Slika 3.3) je vrlo zorno prikazana različitost između baza. Neke baze imaju slike
u boji, dok druge imaju crno-bijele slike (što je bitno jer se za proces učenja koriste samo
crno-bijele slike), neke baze imaju samo frontalne slike lica, neke lica pod različitim
kutovima, dok neke baze uopće ne vode računa o orijentaciji lica. Također, neke baze
sadrže jednostavno slike ljudi (primjer na gornjoj slici pod i)). Još jedna bitna razlika
između baza, koja se također može vidjeti na gornjoj slici, je vrlo velika razlika između
rezolucija pojedinih slika. Neke baze sadrže sve slike jednake rezolucije, dok se kod nekih
18
baza uopće ne vodi računa koje su rezolucije slike. Neke baze sadrže samo slike
muškaraca, dok neke sadrže slike oba spola. Neke baze sadrže i slike ljudi sa brkovima i
bradom, sa naočalama i sličnim dodatcima i varijacijama (npr. ćelavi ljudi, različite frizure,
različite rase, sa otvorenim i zatvorenim očima itd.) Osim toga, velika većina baza uopće
nema zabilježene sve informacije, što je vrlo problematično prilikom klasifikacije. Tako
neke baze uopće nemaju zabilježeno koju se im veličine slika, da li sadrže slike muških i
ženskih osoba, te koliko je takvih slika, koliko je različitih osoba korišteno prilikom
stvaranja baze, koje su sve rotacije lica itd. Nedostatak tih podataka je još jedan dodatan
problem.
Naravno, za ovaj rad nisu sve baze slika jednako interesantne. Prioritet baza koje će se
koristiti u ovom radu može se podijeliti na sljedeći način. Baze koje imaju anotacije će se
koristiti prve po redu, jer se njihove anotacije mogu pretvoriti u nama prihvatljiv format
(FDP), te na taj način izbjegavamo ručno anotiranje slika, što je, zapravo, vrlo iscrpljujući i
dugotrajan posao. Sljedeće baze od interesa su baze koje sadrže slike lice i, na kraju, baze
koje sadrže slike osoba, kao npr. na gornjoj slici pod i). Slike osoba se, uglavnom, mogu
koristiti za testiranje, dok su za proces učenja vrlo vjerojatno neprikladne.
Sve u svemu, baze slika lica vrlo su raznolike i svaka je napravljena po svojim vlastitim
pravilima. Kao dio ovog diplomskog rada, napravljena je jedna velika baza slika. Sve baze
koje su bile dostupne, preuzete su i pohranjene lokalno na računalu u labosu Mobility na
Zavodu za telekomunikacije, te je preuzeto oko 65 000 slika lica. Također, za neke baze su
napravljeni konverteri koje pretvaraju anotacije iz njihovog originalnog zapisa u FDP
format. Pretraživanje baza slika je rađena tokom cijelog trajanja izrade ovog rada, te su, u
svrhu provođenja procesa učenja, korištene sljedeće baze (Tablica 3.1):
•
BioID v1.2
•
FEI Face Database (spatially normalized)
•
Franck – Talking Face Database
Tablica 3.1. Baze korištene pri procesu učenja
Ime
# slika
# osoba
Rezolucija
Rotacije
Dob
Spol
Anotacije
P
K
BioID
v1.2
1 521
23
384 x 286
0°
20 – 50
miž
Ima (20 točaka)
9 9
FEI
400
200
250 x 300
0°
19 – 40
50 % m
Ima (46 točaka)
9 9
Talking
Face
5 000
1
720 x 576
Oko 0°
30
m
Ima (68 točaka)
9 9
19
Potrebno je naglasiti da, iako zadnja baza ima 5 000 slika, to su slike samo jedne osobe, te
korištenje svih tih slika ne bi dalo dobre rezultate.
3.3. FDP format
Jedan od zadataka ovog rada je napraviti aplikaciju za detekciju značajki lica. Kako bi se
mogle detektirati značajke, potrebno je zapisati koordinate tih značajki u neki format. U tu
svrhu koristi se format propisan normom MPEG-4, FDP format (eng. Feature Point
Definition). Struktura .fdp datoteka može se vidjeti na sljedećoj slici (Slika 3.4).
Slika 3.4. Primjer .fdp datoteke
Prvi redak .fdp datoteka sadrži jednostavno oznaku tipa datoteke, a to je FDP. Ponekad
može sadržavati i dodatne informacije poput: tko je kreirao .fdp datoteku (npr. created by
visage|life software.). Nakon toga se, u sljedećem retku, nalazi verzija, ime datoteke (može
biti i putanja, ovisi o načinu na koji se stvara konkretna datoteka), te sljedeće informacije
vezane uz 3D modele: ime datoteke sa 3D mrežom, ime datoteke sa teksturama i SGI RGB
format. Ako se ne koristi zapis vezan uz 3D modele, stavlja se nula. U ovom radu se
20
koriste samo koordinate točaka, a ne 3D modeli, dakle stavljamo nule. Oznakom „#“ se
mogu pisati komentari. Nakon toga slijedi zapis značajki (eng. feature points) i to u
sljedećem formatu:
<int grupa značajke>.<int indeks značajke> <float x> <float y> <float z>
Gornja linija se ponavlja za svaku značajku. Nakon toga se zapisuju indeksi površina (eng.
surface) i točaka (eng. vertex). Sljedeće linije su opcionalne i koriste se za gornju i donju
usnicu kod 3D modela:
NUL <int broj točaka gornje usnice>
UL <float x> <float y> <float z> <int indeks površine>.<int indeks točke>
NLL <int broj točaka donje usnice>
LL <float x> <float y> <float z> <int indeks površine>.<int indeks točke>
Pošto se u ovom radu ne koriste 3D modeli, ovi parametri su postavljeni na nulu (Slika
3.4).
Do sada je opisana općenita struktura .fdp datoteke, te je već rečeno da je za ovaj rad bitan
samo zapis značajki i njihove koordinate, što je i prikazano na slici (Slika 3.4). Značajke se
zapisuju u apsolutnim koordinatama. Dakle, koordinate točke u slici je potrebno podijeliti
sa dužinom, odnosno širinom slike kako bi se dobile apsolutne koordinate za zapis u FDP
format. Osim toga, u slici postoje samo x i y koordinate, te se zbog toga za z koordinatu
svake značajke stavlja nula.
Sve značajke lica podijeljene su po grupama (Slika 3.5):
−
−
−
−
−
−
−
−
−
−
−
grupa 2 – brada i unutrašnja strana usana
grupa 3 – oči
grupa 4 – obrve
grupa 5 – obrazi
grupa 6 – jezik
grupa 7 – rub čeljusti
grupa 8 – usta
grupa 9 – nos
grupa 10 – uši
grupa 11 – tjeme, potiljak i vrh glave
grupa 12 – posebna grupa sa dodatnim točkama
21
Slika 3.5. Prikaz FDP točaka
Na gornjoj slici su također, crvenom bojom, označene točke nad kojima će se raditi
obavljati procesi učenja. Dakle, učenje će se raditi nad sljedećim točkama:
22
−
−
−
−
−
−
vrh brade (2.1)
rubovi očiju i zjenice (3.5, 3.6, 3.7, 3.8, 3.11, 3.12, )
rubovi obrva (4.1, 4.2, 4.5, 4.6)
gornji i donji rubovi usana (8.1, 8.2, 8.3, 8.4)
vrh nosa (9.3)
nosnice (12.18, 12.19)
Dakle, sveukupno će aplikacija za detekciju moći detektirati 18 točaka na licu i to su točke
od
interesa u ovom radu. Ove točke su odabrane jer su to točke koje su zapravo
najkarakterističnije za ljudsko lice te se najlakše mogu detektirati. Razne baze sadrže razne
anotirane točke, te je to još jedna prepreka za učenje (npr. jedna baza može imati anotiran
položaj zjenice, dok neke druge ne moraju), no o tome će se više reći u poglavlju o
konverterima formata.
23
4. Sustav za učenje
Slika cijelog sustava može se vidjeti na slici (Slika 3.1). Sve potrebne komponente za
izradu sustava programirane su u programskom jeziku C++ koristeći razvojnu platformu
Microsoft Visual Studio 2008. Za baratanje sa slikama, dodatno su se koristile OpenCV
biblioteke. OpenCV biblioteke sadrže već ugrađene funkcije za manipuliranje slikama,
videima, slikom iz kamere, prikazom prozora na ekranu i još mnogo drugih funkcija
potrebnih za računalnu grafiku. Osim toga, za baratanje sa .fdp datotekama, te za izradu
same aplikacije za detekciju su se koristile i biblioteke koje nam pruža VisageSDK.
Kompletan programski kod je odražavan preko SVN repozitorija.
4.1. Obrada ulaznih podataka
Učenje za pojedine točke se provodi u određenom prozoru oko te točke. To znači da ulazni
podatci za učenje FDP točke zjenice 3.5 neće biti kompletne slike lica kao što su prikazane
na slici (Slika 3.3), već je potrebno izrezati područje interesa (eng. Region of Interest;
ROI). Da se učenje za, npr. zjenicu, radilo koristeći cijele slike lica, rezultirajuća šuma
odlučivanja bi radila iznimno loše. U tu svrhu je napravljena pomoćna aplikacija za rezanje
slika (Slika 3.1). Unutar ovog poglavlja biti će pojašnjeni svi alati koji su bili korišteni u
svrhu procesa učenja.
4.1.1.
Rezači i generatori slika
Da bi se mogao obaviti proces učenja za pojedinu točku, potrebno je izrezati regiju od
interesa iz slike. U tu svrhu napravljena je aplikacija za generiranje slika. Aplikacija za
generiranje slika zapravo radi puno više uz samo generiranje slika. Napravljeno je nekoliko
verzija alata za generiranje slika, te će ovdje najviše biti objašnjen onaj koji se najviše
koristio. Slike korištene u ovom radu, same po sebi, nisu dovoljne za kvalitetno učenje, te
je potrebno generirati nove iz postojećih. To je zapravo vrlo uobičajena praksa kod
pripreme slika za procese učenja i to se postiže na sljedeći način. Iz jedne originalne slike
se prvo odredi područje gdje će se slika izrezati, te se taj pravokutnik nasumično pomiče i
na taj način se dobivaju različite slike istog objekta. (Slika 4.1) prikazuje primjer odabira
regije.
24
Slika 4.1. Primjer odabira regije
Način rada aplikacije
Kako bi se uopće došlo do slika, prvo je potrebno pozicionirati se u direktorij u kojemu se
nalaze slike. To se radi koristeći funkcije: _chdir() za pozicioniranje, _findfirst()
za traženje prve datoteke sa određenom ekstenzijom u direktoriju i findnext() za
traženje sljedećih datoteka sa određenom ekstenzijom u direktoriju. Traženje datoteka
određene ekstenzije (npr. .jpg, .png, itd.) provodi se u while petlji koje se izvršava dokle
god ima određenih ekstenzija u zadanom direktoriju. Ta while petlja je unutar for petlje
koja ima 6 iteracija i prolazi kroz 6 definiranih ekstenzija. To su: .jpg, .jpeg, .bmp, .png,
.tif, .pgm. Svi ti formati su razumljivi od strane OpenCV-a i mogu se raditi operacije nad
njima (otvaranje, mijenjanje piksela, rezanje itd.).
Nadalje, postoje dvije grane programa. Za detekciju se koristi Haarova kaskada, te se
program grana na dva dijela: ako je Haarova detekcija uspjela i ako Haarova detekcija nije
uspjela, tj. ako se nije detektiralo lice. Neki dijelovi su isti pa će se posebno naglasiti
različitosti između ta dva načina rezanja.
Ako je Haarova detekcija uspjela, onda se jednostavno geometrijski odredi gdje bi mogle
biti značajke unutar tog pravokutnika. Na primjer, za oko: gornja lijeva točka ROI-a –
(2/20 cjelokupne dužine Haarovog pravokutnika, 6/20 cjelokupne visine Haarovog
pravokutnika), donja desna točka – (9/20 cjelokupne dužine Haarovog pravokutnika, 10/20
cjelokupne visine Haarovog pravokutnika). Nakon toga se određuje granica unutar ROI
pravokutnika kako točke koje učimo detektirati ne bi bile direktno uz rub ROI-a, te nakon
toga slijede perturbacije.
25
Perturbacijama se nasumično mijenja veličina i pozicija ROI pravokutnika, te se zatim
slika pretvara iz RGB formata u crno-bijelu sliku. Nakon toga slijedi stvaranje nove .fdp
datoteke i zapisivanje koordinata u istu.
Naravno, prije zapisivanja, koordinate moraju biti pretvorene u apsolutne koordinate
gledajući koordinatni sustav unutar ROI pravokutnika. Nakon toga se ispituje da li su sve
točke koje će se zapisivati u .fdp datoteku unutar dozvoljene granice. To se radi tek sada
zato jer, ako točke nisu dobre, izaći će se iz petlje i ponovno stvoriti nova .fdp datoteka
koja će prebrisati staru. Na kraju se rade dodatna ispitivanja kako pomicanje ROI
pravokutnika ne bi zapelo u beskonačnoj petlji. Jedan od graničnika je maksimalni broj
pokušaja nasumičnog pomicanja pravokutnika.
U bazama ima svakakvih slika i može se dogoditi da ROI pravokutnik uopće ne pokriva
točke. U tom slučaju se jednostavno prelazi na novu sliku.
Potrebno je naglasiti da svi postupci u kojima se koristi Haarova kaskada jako puno ovise o
toj detekciji. Pravokutnik Haarove detekcije na jednom licu može biti izvan lica, dok je na
licu na drugoj slici unutar lica (Slika 4.2). Ovo je jedan od glavnih problema u ovom radu
koji jako utječe na sve aspekte ovog rada, od pripreme slika do detekcije značajki u
aplikaciji FaceDetector.
Slika 4.2. Prikaz nekonzistentnosti Haarovog pravokutnika
U slučaju da Haarova detekcija nije uspjela, onda se sve radi isto osim određivanja ROI
pravokutnika. I u ovom slučaju će se provoditi perturbacije i pretvaranje koordinata,
dobivanje granice, spremanje .fdp točaka i ostalo, isto kao i u slučaju da je Haarova
detekcija uspjela. No, u ovom slučaju regija interesa se određuje na drugačiji način.
26
Određuje se tako da se prvo odredi koja je maksimalna i minimalna x i y koordinata.
Nakon toga se x koordinate pomoću za određeni postotak, npr. 4%, od dužine slike, te se u
skladu s tim pomiču i y koordinate, pri čemu se mora paziti da omjer svih slika uvijek bude
sličan. Omjer je jako bitan i na njega se mora paziti bez obzira kako se reže.
Za proces učenja se obično generiralo deset slika iz jedne, tj. isprobavalo se sa
generiranjem od pet do deset slika iz jedne. . Slika (Slika 4.3) prikazuje primjer dobivanja
deset slika iz jedne. Sve slike su slike očiju, ali svaka ima male razlike u sebi, bilo da se
tiče položaja značajke za koju se radi proces učenja, rezolucije slike ili okolnih informacija
(blizina obrve, zatamnjenja oko oka itd.).
Slika 4.3. Generiranje novih deset slika iz jedne originalne
27
Osim opisanog alata, napravljena je i verzija u kojoj uopće nema Haarove detekcije, već se
ROI pravokutnik određuje samo na temelju točaka iz .fdp datoteke (na sličan način kao i u
opisanoj verziji). Može se postaviti pitanje, zašto to nije odmah napravljeno. Kao prvo, ovo
je eksperimentalni rad i ne zna se koji način je najbolji. Zato se testira i isprobava. Drugi
razlog, i važniji, je to da se u aplikaciji za detekciju značajki koristi Haarova detekcija
kako bi se napravila inicijalna detekcija, te se unutar nje radi detekcija značajki. Ideja
vodilja je da način izrezivanja u aplikaciji za detekciju bude isti kao i način izrezivanja kod
pripreme slika za proces učenja.
4.1.2.
Konverteri
Kao što je rečeno u poglavlju o bazama, sve baze koje imaju anotacije, imaju ih zapisane u
svojim internim formatima. Pošto se u ovom radu koristi standardni FDP format, potrebno
je provesti konverziju formata. Slika (Slika 4.4) prikazuje koje su sve točke anotirane u
bazama koje se koriste u ovom radu.
Slika 4.4. Anotirane točke iz baza: a) FEI; b) Talking Face; c) BioID v1.2
Dakle, napravljena su tri alata za konverziju. Na gornjoj slici vidljivo je da neke baze
imaju puno više anotiranih točaka nego za što će se raditi procesi učenja u ovom radu.
Istina, neke baze imaju više točaka, no, razne baze imaju razne točke anotirane. Kao
primjer može se navesti FEI baza slika koja nema anotirani vrh nosa. Također je vidljivo
da samo baza Talking Face ima anotirane točke unutarnjih rubova usana. Osim toga, neke
točke su zanimljivije od drugih. Obrazi i druge točke na rubu glave nam nisu toliko
zanimljive, a osim toga, rezultat učenja za te točke bi vjerojatno bio loš.
28
Slika 4.5. Originalni formati zapisa točaka iz baza: a) BioID; b) Talking Face; c) FEI
Slika (Slika 4.5) prikazuje format u kojem su zapisane koordinate točaka u pojedinim
bazama. Svi formati su isti, te je isti kod iskorišten u sva tri slučaja. Jedina razlika je u
preslikavanju pojedinih točaka iz originalnog formata u FDP točke.
4.2. Aplikacija za učenje
Nakon što je obrada slika gotova i imamo spreman skup slika za učenje, može se započeti
sa procesom učenja. Sama aplikacija koristi principe stabala odlučivanja i regresiju za
učenje. Sam algoritam za učenje, osnovne strukture stabala, te osnovne funkcije za
manipuliranje šumama (izračunavanje koordinata pomoću šume odlučivanja, spremanje
šuma, brisanje šuma itd.) napisao je mag. ing. inf. et. Nenad Markuš.
Kako bi se taj algoritam iskoristio, u sklopu ovog rada napravljeno je sučelje kako bi se
najbolje mogao iskoristiti algoritam učenja i u ovom poglavlju će biti objašnjeno što je sve
napravljeno u tu svrhu.
29
Sam proces učenja se provodi kao što je opisano u poglavljima 2.2 i 2.3. Dakle, koristi se
određeni broj slabih klasifikatora, koji su u ovom slučaju stabla odlučivanja sa vrlo malim
brojem razina. Ovisno o parametrima, u ovom radu su korištena stabla od jedne pa do
osam razina. Koristeći vrlo veliki broj tih slabih klasifikatora, tj. stabla odlučivanja
stvaramo šumu odlučivanja.
Način rada aplikacije
Aplikacija za učenje ima tri načina rada koji se mogu odabrati na početku:
1.
2.
3.
učenje
učenje pomoću batch datoteke
validacija
Prva dva načina rada provode učenje, samo što se u prvom radi samo jedan proces učenja,
dok se u drugom iščitava batch datoteka te se provode procesi učenja u ovisnosti što piše u
istoj. Kada se pokrene učenje, potrebno je definirati parametre učenja, a to su:
−
−
−
broj stabala
težina stabala
dubina stabala
Što je broj stabala veći i što je dubina stabala veća, to će proces učenja trajati duže. Sam
proces učenja ima vrlo varijabilno vrijeme trajanja. Općenito, bilo kakvi procesi strojnog
učenja mogu trajati po par sati ili čak po par tjedana. No, procesi učenja u ovom radu, na
svu sreću, nisu trajali toliko dugo. Općenito su procesi učenja trajali od sat-dva do otprilike
dvadeset četiri sata, no više o provođenju učenja u sljedećem poglavlju.
1.) Učenje
Kada se pokrene proces učenja, potrebno je upisati putanju do skupa slika za učenje.
Nakon toga se upisuju parametri učenja. Naravno, jedan od parametara učenja je i broj
slika, iako se to ne upisuje u aplikaciju, jer nije isto ako se učenje napravi nad 100 slika ili
nad 4 000 slika.
Nakon toga slijedi učitavanje svih potrebnih podataka za proces učenja u funkciji
LoadSet(). U toj funkciji će se čitati sve konfiguracijske datoteke, sve slike i pripadne
anotacije, te će se pretvarati u oblik pogodan za algoritam učenja.
Dakle, prvo se iščitava konfiguracijska datoteka čiji primjeri se mogu vidjeti na slici (Slika
4.6). Potrebno je napomenuti da se u aplikaciji koriste dvije konfiguracijske datoteke: .conf
30
i .cfg. Dakle, na donjoj slici je prikaz .conf konfiguracijske datoteke. U toj konfiguracijskoj
datoteci korisnik upisuje nad čime sve želi provesti proces učenja. Na primjer, na slici
(Slika 4.6) pod a) je definirano da se učenje izvrši nad FDP točkama 3.7 i 3.11, te da se
koriste dodatne anotacije (koje će se iščitati iz .ann anotacijske datoteke) i provede proces
učenja nad time. Dakle, rezultat tog učenja bi bio: predviđanje koordinata dvije točke (4
izlazna parametra), jedan skalar (1 izlazni parametar) i jedan 3D vektor (3 izlazna
parametra). Sveukupno, učenje bi se provodilo nad 8 ulaznih varijabli.
Slika 4.6. Primjeri .conf konfiguracijskih datoteka: a) Dvije FDP točke i još dva tipa anotacija; b)
sedam FDP točaka; c) jedna FDP točka
Na slici (Slika 3.1) prikazana je arhitektura sustava i vidljivo je koje se sve vrste datoteka
mogu koristiti u učenju. Datoteke tipa .ann nisu korištene u ovom radu, no koristio ih je
kolega Vidojević u svojem radu, te aplikacija za provedbu učenja mora podržavati i taj tip
datoteka. Te datoteke sadrže dodatne anotacije (u koje ne spadaju FDP točke) poput
otvorenosti oka ili smjer pogleda. To su dodatne, nešto apstraktnije anotacije. Primjer
anotacijske datoteke može se vidjeti na slici (Slika 4.7).
31
Slika 4.7. Primjer .ann datoteke
Prvi redak .ann datoteke sadrži putanju do .cfg konfiguracijske datoteke (ili samo ime ako
se obje datoteke nalaze u istom direktoriju). Nakon toga slijede sve anotacije koje su
anotirane u alatu FDPanotator. Dakle, njihova imena, raspon i vrijednost.
Datoteke tipa .cfg su također konfiguracijske datoteke koje se koriste u posebnom alatu
kolege Vidojevića – FDPanotator. Ta datoteka sadrži popis svih mogućih varijabli koje se
mogu anotirati. Slika (Slika 4.8) prikazuje primjer jedne .cfg datoteke.
Slika 4.8. Primjer .cfg datoteke
U .cfg konfiguracijskoj datoteci se, dakle, definiraju sve dodatne anotacije koje će se
koristiti prilikom anotacije u alatu FDPanotator. Definiraju se njihove veličine (npr. skalar,
2D vektor i slično), raspon (npr. Range: 0, 100) i ime (npr. Eye_Open) te se pruža
32
mogućnost da se i te anotacije anotiraju. Prvi redak ove datoteke sadrži koliko tipova
podataka će se koristiti u alatu FDPanotator. Za izradu ovog rada nisu korištene nikakve
dodatne anotacije, no bilo je potrebno osigurati da alat za učenje može interpretirati sve do
sada opisano i normalno obaviti proces učenja nad bilo kojim anotacijama.
Dakle, alat za učenje će iščitati sve do sada opisane datoteke, te iz njih izvući što se ući.
Korisnik definira nad čime će se obaviti proces učenja u .conf datoteci. Nakon toga slijedi
alokacija memorije za sve slike, za sve integralne slike i za sve prave vrijednosti (eng.
ground truth) anotacija koje će se koristiti u učenju. Sam algoritam učenja prima crnobijele slike zapisane u matričnom obliku. Dakle, vrijednosti svakog piksela slike iznose od
0 do 255. Zbog toga je još potrebno pretvoriti svaku sliku u matrični oblik, te svaku sliku
spremiti u memoriju zajedno sa svim vrijednostima anotacija. To se radi na sličan način
kao i kod aplikacije za generiranje novih slika. Prolazi se kroz direktorij, traže se slike, .fdp
datoteke i dodatne anotacije (ako se koriste u učenju) koristeći sličan mehanizam petlji kao
i kod aplikacije za generiranje novih slika. Jedan vrlo ozbiljan problem koji se tu pojavljuje
je ograničenost memorije. Spremanje svih slika i svih pravih vrijednosti zauzima dosta
memorije. Naravno, to uvelike ovisi nad koliko se značajki provodi učenje, te koliko su
velike slike.
Tek nakon što se sve slike učitaju u memoriju, zajedno sa vrijednostima anotacija koje će
se koristiti u učenju, slijedi sam proces učenja. Trajanje procesa učenja jako ovisi o
zadanim parametrima i broju slika. Kada je učenje završeno, generirana šuma odlučivanja
će se spremiti u direktorij gdje se nalazi skup za učenje. Prilikom pokretanja programa,
upisuje se ime šume, te se na to ime dodaju odabrani parametri učenja. Šuma se, dakle,
sprema pod tako dobivenim imenom.
2.) Učenje pomoću batch datoteke
U ovom slučaju proces učenja se izvršava na isti način kao i ranije. Učitavanje podataka se
također vrši na isti način. Jedina razlika je što u ovom načinu rada, aplikaciji za izvedbu
učenja šaljemo još jedan parametar, a to je putanja do batch datoteka. Primjer batch
datoteke može se vidjeti na slici (Slika 4.9).
33
Slika 4.9. Primjer batch datoteke
Batch datoteka se sastoji od parova parametara. Prvo se zapisuje relativna putanja do skupa
slika za učenje (na gornjoj slici je primjer putanje do skupa za učenja FDP točke 4.1), a
zatim, u novom redu, parametri učenja. Alat za učenje u ovom načinu rada će prvo
pročitati prvi redak (putanju) i pozicionirati se u definirani direktorij. Zatim će se učitati
sve potrebne datoteke (prvo .conf datoteka u kojoj piše nad čime će se vršiti učenje, a
zatim ostatak), te će se provesti proces učenja sa parametrima koji su definirani u
sljedećem retku batch datoteke. Kada se taj proces učenja završi, prelazi se na sljedeći par
putanja-parametri, i tako dok se ne provedu svi procesi učenja do kraja batch datoteke.
Naravno, za svaki proces učenja će se spremiti odgovarajuća šuma odlučivanja u direktorij
sa slikama za učenje. Na ovaj način se može definirati nekoliko procesa učenja, te se može
pustiti da alat radi nekoliko dana (npr. preko vikenda).
3.) Validacija
Treći način rada aplikacije za učenje je jednostavno validacija šume odlučivanja. Kako bi
lakše mogli uspoređivati šume odlučivanja, za svaku šumu odlučivanja računa se korijen
srednje kvadratne pogreške – RMSE (eng. root mean square error). RMSE je jedna od
procjena kojom se određuje razlika između procijenjene vrijednosti i prave vrijednosti.
Način na koji se izračunava RMSE je:
34
1 n ⎛ m
2⎞
* ∑ ⎜⎜ ∑ (Y j − y j ) ⎟⎟
n i =1 ⎝ j =1
⎠
(3)
n – broj slika
m – broj izlaza (jedna značajka → jedna točka → dvije koordinate)
Y – prava vrijednost (iščitana iz .fdp datoteke; ground truth)
y – predviđana vrijednost (rezultat šume odlučivanja)
Alat u ovom načinu rada ne provodi proces učenja, već se samo učitaju svi podatci kao i
ranije. Nakon toga se učita određena šuma (tako da se jednostavno upiše njezino ime), te se
upiše putanja do skupa za validaciju, odnosno testiranje. Na ekranu se, zatim, ispišu RMSE
vrijednosti, te se otvara prozor u kojem su iscrtane prave vrijednosti i procijenjene
vrijednosti koristeći odabranu šumu odlučivanja. Na slici (Slika 4.10) crvenim (manjim)
kružićem je prikazana detekcija koju je procijenila određena šuma odlučivanja, a zelenim
kružićem je prikazana je stvarna pozicija zapisana u .fdp datoteci. Konkretno, ispituje se
detekcija točke 3.8 – unutarnji rub desnog oka.
Slika 4.10. Primjeri detekcije nad skupom za validaciju
35
Kao što se može vidjeti, na nekim slikama detekcija pomoći šume odlučivanja radi vrlo
dobro, dok se koji put znaju dogoditi pogreške. No, u problemu raspoznavanja neke se
pogreške toleriraju. Na primjer, detekcija nad prvom, trećom i osmom slikom nije baš
dobra, no ostale su vrlo dobre, a ponekad i potpuno točne. Naravno, stvarnih primjera ima
jako mnogo i sa mnogim varijacijama tako da se zapravo nikada ne može dobiti točna
mjera koliko je koja šuma dobra. Ovaj način se koristio jednostavno kako bi dobili, barem
nekakvu, mjeru kvalitete po kojoj bi mogli klasificirati šume.
4.2.1.
MPI verzija
Osim opisane verzije, napravljena je i MPI (eng. message passing interface) verzija alata
za učenje u kojoj se može definirati koliko procesorskih jezgri će se koristiti za proces
učenja. Osim toga, za proces učenja se može koristiti i više računala, te se na taj način
može dodatno povećati procesorska snaga i ubrzati proces učenja.
Za izvedbu MPI verzije koristi se alat mpiexec. Kompletan način rada je isti kao što je
opisano u prethodnom potpoglavlju, jedino što se ovdje koriste dodatne funkcije za
dozvole prilikom korištenja više procesa. Na slici (Slika 4.11) može se vidjeti primjer
programa pokrenutog u alatu mpiexec, u kojem se koristi pet procesora.
Slika 4.11. Alat mpiexec
36
U ovoj verziji aplikacije za učenje može se koristiti jedino način rada sa batch datotekom,
te se ne može zadati ime šume koja će se spremiti na kraju. Za učenje se najčešće koristilo
oko 8 jezgri, te se procesi učenja trajali kraće. Sama izrada ovog alata bila je dodatno
zakomplicirana jer se u ovom načinu rada program ne mogu normalno ispitivati i
ispravljati greške (eng. debug). U svrhu ispravljanja greški koristili su se jednostavni ispisi.
4.3. Aplikacija za detekciju – FaceDetector
Nakon što su obavljeni procesi učenja i nakon što dobijemo šume odlučivanja, te šume
koristimo u aplikaciji FaceDetector, unutar VisageSDK paketa, kako bi obavili detekciju
značajki lica. Aplikacija radi tako da se prvo detektira lice u slici koristeći Haarovu
kaskadu, te se unutar te detekcije određuju i izrezuju pojedina područja, ROI (oči, obrve,
nos, usta i brada). Unutar tih područja se rade finije detekcije pojedinih značajki. Slika
(Slika 4.12) prikazuje unutar kojih područja se vrše detekcije. Ova slika je samo prikaz
područja. Više o samim rezultatima biti će rečeno u kasnijem poglavlju.
Slika 4.12. Područja unutar kojih se vrše detekcije
37
Unutar aplikacije rađeno je puno ispitivanja što se tiče detekcije. Detekcija uvelike ovisi o
rezanju područja, a osim toga, isprobana su i dva načina detekcije:
−
−
detekcija pomoću Haarove kaskade
detekcija pomoću inicijalnih 7 točaka
Detekcija pomoću Haarove kaskade
U ovoj verziji koristi se Haarova kaskada za inicijalnu detekciju lica. Nakon toga se
jednostavnim aritmetičkim operacijama određuju pozicije prozora unutar kojih će se raditi
finije detekcije. Potrebno je naglasiti da se pozicija unutarnjeg prozora određuje isključivo
na temelju Haarovog pravokutnika, npr. koordinate prozora za detekciju značajki lijevog
oka dobivene su na sljedeći način:
•
gornji lijevi kut
−
•
x koordinata: (x koordinata gornjeg kuta Haarovog pravokutnika) + 11/20 *
(širina Haarovog pravokutnika)
− y koordinata: (y koordinata gornjeg kuta Haarovog pravokutnika) + 6/20 * (visina
Haarovog pravokutnika)
donji desni kut
−
−
x koordinata: (x koordinata gornjeg kuta Haarovog pravokutnika) + 17/20 *
(širina Haarovog pravokutnika)
y koordinata: (y koordinata gornjeg kuta Haarovog pravokutnika) + 10/20 *
(visina Haarovog pravokutnika)
Na isti način, samo sa drugim omjerima, su određeni prozori za oči, obrve, nos, usta i
bradu. Za pojedinu detekciju se zatim učitavaju sve šume koje mislimo koristiti unutar
pojedinog prozora, npr. unutar prozora za lijevo oko će se raditi detekcija točaka 3.5, 3.7 i
3.11 (rubovi oka i zjenica) te je potrebno učitati tri šume. Nakon toga se samo obavlja
pretvorba koordinata i iscrtavanje. Shematski prikaz određivanja unutarnjeg prozora
prikazan je na slici (Slika 4.13). Konkretno, prikazan je primjer određivanja prozora za
detekciju značajki lijevog oka.
38
Slika 4.13. Shematski prikaz određivanja prozora kod Haarove detekcije
Primjer detekcije sa Haarovom kaskadom vidljiv je na slici (Slika 4.14). Vidljivo je da je
detekcija prilično dobra.
Slika 4.14. Detekcija koristeći samo Haarovu kaskadu
39
Detekcija pomoću inicijalnih 7 točaka
Kod ovog načina detekcije se također koristi Haarova kaskada za detekciju lica u slici. No,
nakon toga se stvari mijenjaju. U ovom ispitivanju se sada detektira inicijalnih sedam
točaka lica unutar Haarovog pravokutnika koristeći jednu šumu odlučivanja. Na slici (Slika
4.15) je prikazana detekcija inicijalnih sedam točaka. To su sljedeće točke:
−
−
−
rubovi desnog i lijevog oka: 3.7, 3.8, 3.11, 3.12
vrh nosa: 9.3
horizontalni rubovi usnica: 8.3, 8.4
Slika 4.15. Inicijalna detekcija sa sedam točaka
Dakle, za ovu detekciju je proveden proces učenja nad sedam točaka. Na slici (Slika 4.6)
pod b) je vidljiva .conf konfiguracijska datoteka koja se koristila pri tim procesima učenja.
Nakon inicijalne detekcije, pojedini prozori za finije detekcije sa određuju na temelju
inicijalnih sedam točaka. Primjer određivanja prozora za detekciju značajki lijevog oka:
40
•
gornji lijevi kut
−
•
x koordinata: (x koordinata unutarnjeg ruba oka, točka 3.11) - 1/10 * (širina
Haarovog pravokutnika)
− y koordinata: (y koordinata unutarnjeg ruba oka, točka 3.11) - 1/10 * (visina
Haarovog pravokutnika)
donji desni kut
−
−
x koordinata: (x koordinata vanjskog ruba oka, točka 3.7) + 1/10 * (širina
Haarovog pravokutnika)
y koordinata: (y koordinata vanjskog ruba oka, točka 3.7) + 7/100 * (visina
Haarovog pravokutnika)
Ne postoji neko pravilo kako izrezati prozor za detekciju, i za određivanje tih prozora su se
jednostavno radila mnoga testiranja.
Shematski prikaz određivanja unutarnjeg prozora kod inicijalne detekcije sa sedam točaka
prikazan je na slici (Slika 4.16).
Slika 4.16. Shematski prikaz određivanja unutarnjeg prozora koristeći inicijalnu detekciju sa sedam
točaka
Plave točke na gornjoj slici predstavljaju dvije točke od sedam inicijalnih točaka.
Konkretno, prikazan je primjer za određivanje prozora za detekciju značajki lijevog oka.
Primjer finije detekcije značajki vidljiv je na slici (Slika 4.17).
41
Slika 4.17. Detekcija značajki pomoću inicijalnih 7 točaka
Dakle, ideja je da se inicijalnom detekcijom sedam točaka što bolje proba detektirati tih
sedam točaka. Ta detekcija gotov uvijek neće biti dobra, no, ovom detekcijom nam nije ni
cilj točno detektirati značajke. Cilj nam je detektirati što je bolje moguće, a prava detekcija
će se obaviti unutar izrezanih prozora. Na gornjoj slici je vidljivo da inicijalna detekcija
(zelene točke) nije točna, ali je dovoljno dobra. Na temelju tih točaka se izrezuju pojedine
regije, te se odrađuje finija detekcija značajki (uključujući i sedam točaka u inicijalnoj
detekciji). Može se primijetiti da su finije detekcije puno bolje od inicijalne detekcije, što
nam je i bio cilj. Dakle, inicijalnu detekciju koristimo samo za određivanje područja u
kojima će se raditi finija detekcija.
Naravno, ni prva ni druga metoda nisu savršene i ima dosta primjera gdje zakažu, no više o
tome biti će riječi u poglavlju o rezultatima.
42
5. Procesi učenja
Za provedbu učenja potrebne su velike količine slika za učenje, kao što je rečeno u
poglavlju bazama slika. Prilikom provođenja procesa učenja u svrhu ovog rada za pojedine
procese je korišteno između 5 i 10 tisuća slika. Slike su dobivene na način opisan u
poglavlju o obradi ulaznih podataka. Slika (Slika 5.1) prikazuje originalne primjere, iz
baza slika, koje će se koristiti za proces učenja. Kažemo originalne jer se te slike trebaju
pretvoriti u crno-bijele (ako već nisu), te je potrebno izrezati dijelove lica za koje će se
provoditi proces učenja.
Slika 5.1. Primjeri originalnih slika
Slike nad kojima su se provodili procesi učenja vidljivi su na sljedećim slikama. Na slici
(Slika 5.2) vidljivi su primjeri lijevog oka. Na takvim slikama su se provodili procesi
učenja za rubove očiju i za zjenicu, tj. za FDP točke 3.5, 3.7 i 3.11. Slike desnog oka su
43
napravljene na isti način, te su se one koristile također za učenje značajki rubova očiju i
zjenice, tj. FDP točke 3.6, 3.8 i 3.12.
Slika 5.2. Primjeri iz skupa za učenje značajki lijevog oka
Slika (Slika 5.3) prikazuje primjere koji su se koristili za učenje značajki obrve. Slične
slike su se koristile i za desnu obrvu, te su nad tim slikama obavljeni procesi učenja za
rubove obrva, tj. za FDP točke 4.1, 4.2, 4.5 i 4.6.
Slika 5.3. Primjeri iz skupa za učenje značajki lijeve obrve
Slika (Slika 5.4) prikazuje primjere koji su se koristili za učenje značajki nosa. Procesi
učenja su napravljeni nad vrhom nosa, te nad nosnicama, odnosno nad FDP točkama 9.3,
12.18 i 12.19.
Slika 5.4. Primjeri iz skupa za učenje značajki nosa
Slika (Slika 5.5) prikazuje primjere koji su korišteni u procesima učenja značajki lica.
Značajke nad kojima su se vršili procesi učenja su: horizontalni i vertikalni rubovi usana,
odnosno FDP točke 8.1, 8.2, 8.3, 8.4.
Slika 5.5. Primjeri iz skupa za učenje značajki usta
Slika (Slika 5.6) prikazuje primjere koji su korišteni u procesima učenja značajki brade. U
ovom slučaju proces učenja se vršio samo za vrh brade, a to označava FDP točka 2.1.
44
Slika 5.6. Primjeri iz skupa za učenje značajki brade
Slika (Slika 5.7) prikazuje primjere koji su se koristili za proces učenja šume koja se
koristila za inicijalnu detekciju sa sedam točaka. Dakle, ovo je jedini skup, i jedini proces
učenja, u kojem se koristio broj točaka veći od jedne. Proces učenja se provodio nad sedam
točaka za jednu šumu, i te točke su: 3.7, 3.8, 3.11, 3.12, 9.3, 8.3 i 8.4.
Slika 5.7. Primjeri iz skupa za učenje sedam inicijalnih točaka
Dakle, u procesu učenja se koriste tri parametra: broj stabala, te težina i dubina stabala.
Pošto je ovo istraživački rad, izvedeno je mnogo procesa učenja, te je isprobano mnogo
kombinacija parametara kako bi se dobili najbolji rezultati. Tablica (Tablica 5.1) prikazuje
primjer određenih parametara procesa učenja.
Tablica 5.1. Primjeri parametara učenja
Značajka
Br. slika
Br. stabala
Težina
Dubina
RMSE
3.5
5 500
80
0,12
4
0,0808
3.5
5 500
70
0,13
4
0,0802
3.5
5 500
70
0,15
4
0,0792
3.5
7 000
80
0,14
4
0,0592
3.5
7 000
80
0,15
4
0,0601
3.5
7 000
80
0,17
4
0,0606
3.5
7 000
80
0,2
4
0,0609
45
U gornjoj tablici dani su primjeri samo za jedan mali dio provedenih procesa učenja, no i
tu je vidljivo da se sa različitim postavljenim parametrima dobivaju šume odlučivanje
različite kvalitete. Prilikom provođenja procesa učenja također je otkriveno da nema
univerzalno dobrih parametara. Najbolji (otkriveni) parametri za jednu značajku ne moraju
biti najbolji za neku drugu. Naravno, na procese učenja utječe i broj slika koji se koristi u
procesu, no osim toga i sama kvaliteta slika je bitna. Procesi učenja su isprobani sa
različitim varijacijama slika, različite rezolucije, različite veličine značajki unutar slike ,
npr. testiranje sa slikama gdje oko zauzima skoro cijelu sliku za učenje, sa slikama gdje je
oko manje, pa kombinirano itd. Osim toga, trajanje procesa je od praktične važnosti za
ovaj rad. U tablici (Tablica 5.2) je vidljivo da su procesi učenja uobičajeno trajali oko 4 i 5
sati, no bilo je i kraćih i dužih procesa (od otprilike 2 sata pa do 8 sati).
Tablica 5.2. Primjer parametara učenja i trajanje učenja
Značajka
Br. slika
Br. stabala
Težina
Dubina
RMSE
Trajanje
(min)
8.4
5 000
80
0,1
5
0,0813
326
8.4
5 000
80
0,15
5
0,0836
335
8.4
5 000
80
0,18
5
0,0739
343
8.4
5 000
80
0,12
5
0,0823
341
8.4
5 000
80
0,25
5
0,0868
273
Sveukupno je dobiveno oko 150 šuma odlučivanja i, one koje su odabrane kao najbolje, su
korištene u aplikaciji FaceDetector.
46
6. Rezultati
U ovom poglavlju biti će predstavljeni rezultati detekcije koristeći aplikaciju FaceDetector
i šume odlučivanja dobivene ranije opisanim procesom učenja.
Na slici (Slika 6.1) prikazani su rezultati detekcija. Pod a) su prikazani primjeri detekcija
gdje su se unutarnji prozori rezali na temelju Haarovog pravokutnika, dok su pod b)
prikazani primjeri detekcije kod kojih su se unutarnji prozori rezali na temelju inicijalne
detekcije sa sedam točaka. Na prvoj slici detekcija je uglavnom podjednaka, no ima
razlika. Kod detekcije sa sedam točaka, brada je detektirana malo previše udesno, no nos i
nosnice su bolje detektirane nego kod detekcije samo sa Haarovom kaskadom. Osim toga,
detekcija unutarnjeg ruba desnog oka je kod detekcije sa sedam točaka nešto lošija nego
kod druge detekcije.
Što se tiče druge slike, kod inicijalne detekcije sa sedam točaka, nos i desno oko su previše
loše detektirani i prozori su, na temelju toga, loše odrezani. Zbog toga je detekcija tih
značajki dosta lošija nego kod detekcija sa Haarovom kaskadom. Ova slika je inače jedan
od težih primjera.
Treća slika je direktno frontalno lice. Na takvim slikama obje detekcije rade najbolje. To je
jednostavno zato jer je takvih primjera bilo najviše tijekom učenja. Može se vidjeti da su
obje detekcije vrlo dobre, no detekcija kod koje se prozori režu na temelju inicijalnih
sedam točaka bolje je detektirala značajke očiju.
47
Slika 6.1. Primjer detekcije: a) Rezanje na temelju Haarove kaskade; b) Rezanje na temelju
inicijalnih sedam točaka
48
Na slici (Slika 6.2) vidljivi su još neki primjeri detekcija, no ovaj put bez iscrtavanja
unutrašnjeg prozora.
Slika 6.2. Primjeri detekcije bez iscrtavanja prozora rezanja: a) Detekcija kod koje se rezalo na
temelju Haarove detekcije; b) Detekcija kod koje se rezalo na temelju inicijalne detekcije sedam
točaka
Prva prikazana slika je jedan od najtežih primjera i tu niti jedna detekcija ne radi dobro. Ne
rade dobro jednostavno zato jer je na slici čovjek dosta zakrenuo glavu. Haarova detekcija
je detektirala lice, ali takvih primjera nije bilo u skupu za učenje, i očekivano je da
detekcija radi loše. Zapravo, detekcija kod koje se unutrašnji prozori režu na temelju
Haarove detekcije nije ni teoretski imala šanse dobro detektirati značajke na ovom licu
jednostavno zato jer će se prozori izrezati na krivim mjestima. U tim slučajevima, detekcija
49
koja se temelji na inicijalnoj detekciji sedam točaka bi trebala raditi bolje. U ovom slučaju
ne radi zato jer, kao što je rečeno, takvih primjera nije bilo u skupu za učenje.
Drugi primjer je također zakrenuto lice, no ovaj put nešto manje i detekcija radi bolje. Ni
jedna ni druga nije savršena, no u ovom primjeru je bolja detekcija kod koje su se prozori
rezali na temelju Haara (vidljivo po detekciji značajki usana).
Treća prikazana slika je također jedan od najtežih primjera i vidljivo je da niti jedna
detekcija tu ne radi baš dobro.
Četvrti i peti primjer su frontalne slike i tu detekcija značajki radi gotovo savršeno. Skoro
sve značajke su dobro detektirane.
50
Zaključak
Detekcija značajki lica je vrlo delikatni proces. Ovaj rad pokazao se kao rad u kojem je
bilo potrebno mnogo istraživanja i još više isprobavanja. Počevši od tražnja pravih slika
lica, što je zapravo jako bitno, kao što smo vidjeli i poglavlju o rezultatima. Da bi detekcija
što bolje radila, potrebno je jako dobro pripremiti skup za učenje. U idealnom slučaju, taj
skup ne bi bio niti prevelik niti premali. Trebao bi sadržavat jako mnogo različitih osoba,
različite rase sa različitim karakteristikama i dodatcima (naočale, brkovi, brade, duga kosa,
kratka kosa itd.) i sa orijentacijom glave u raznim položajima (malo nalijevo, malo više, pa
još više i tako u svim smjerovima). Ovaj proces je sam za sebe teži nego što bi se
očekivalo.
Nakon toga, potrebno je sve te slike obraditi i izrezati regije interesa nad kojima će se
provoditi procesi učenja. Samo rezanje je novi problem jer sve slike trebaju imati isti
omjer, te objekti nad kojima će se provoditi proces učenja trebaju biti raznoliki (npr. za
slike oka potrebni su primjeri: oko zauzima cijelu sliku, oko zauzima oko 50% slike itd.,
oko je u gornjem lijevom kutu, u donjem, u gornjem desnom, oko je nadesno, oko je
nalijevo itd.).
Kada je priprema gotova, dolazimo do procesa učenja. Tek tu dolazi do izražaja pravo
isprobavanje jer se ne zna koji će parametri davati najbolje rezultate. No, ako su radnje
opisane ranije loše napravljene, proces učenja će također obaviti loš posao. Potrebno je
obaviti nekoliko procesa učenja nad jednom značajkom kako bi se dobili dobri rezultati.
Kada imamo naučenu šumu odlučivanja, možemo je iskoristiti za detekciju značajki. Ovdje
također nije sve definirano i potrebno je dosta isprobavanja kako bi se odredio najbolji
prozor unutar kojeg će se izvršavati detekcija značajki. Postupak rezanja daje vrlo različite
rezultate za male promjene u rezanju. Na primjer, rezanje Haarovog pravokutnika na 10/20
i 11/20 može davati dosta različite rezultate.
Sve u svemu, detekcija značajki lica je vrlo kompleksan postupak koji se sastoji od mnogih
radnji (Slika 3.1), a sve zahtijevaju isprobavanja i točnost. Kada se jednom nauče dobre
šume odlučivanja i kada se dobro odrede područja detekcije, sama detekcija značajki
mogla bi raditi impresivno dobro.
51
Literatura
[1]
PAUL VIOLA, MICHAEL J. JONES: Robust Real-Time Face Detection, International
Journal of Computer Vision, 2004.
[2]
QIANG ZHU, SHAI AVIDAN I OSTALI: Fast Human Detection Using a Cascade of
Histograms of Oriented Gradients, Computer Vision and Pattern Recognition, 2006.
[3]
RODRIGO VERSCHAE, JAVIER RUIZ-DEL-SOLAR, MAURICIO CORREA: A unified
learning framework for object detection and calssification using nesteed cascades of
boosted calssifiers, Machine Vision and Aplication, 2008.
[4]
ONCEL TUZEL, FATIH PORIKLI I PETER MEER: REGION COVARIANCE: A Fast
Descriptor for Detection and Classification, Computer Vision – ECCV, 2006.
[5]
SHAOHUA K. ZHOU, BOGDAN GEOGESCU, XIANG S. ZHOU I DORIN COMANICIU: Image
based Regression Using Boosting Method, Computer Vision, 2005.
[6]
LIN LIANG, RONG XIAO, FANG WEN, JIAN SUN: Face Alignment via Componentbased Discriminative Search, 2008.
[7]
DAVID CRISTIANCCE, TIM COOTES, IAN SCOTT: A Multi-Stage Approach to Facial
Feature Detection, 2004.
[8]
PHILIP IAN WILSON, DR. JOHN FERNANDEZ: Facial Feature Detection Using Haar
Classifiers, Journal of Computing Sciences in Colleges, Volume 21 Issue 4, travanj
2006.
[9]
NAVNEET DALAL, BILL TRIGGS: Histogram of Oriented Gradients fo Human
Detection, Computer Vision and Pattern Recognition, 2005.
[10] JONAS LUNDBERG: MPEG-4 Facial Feature Point Editor, Master thesis at the Image
Coding Group at Linkoping University, listopad 2002.
[11] SHAOHUA K. ZHOU, JINGHAO ZHOU, DORIN COMANICIU: A boosting regression
approach to medical anatomy detection, Computer Vision and Pattern Recognition,
2007.
[12] ZHIFENG LI, UNSENG PARK, ANIL K. JAIN: A Discriminative model for Age Invariant
Face Recognition, Information Forensics and Security, 2011.
[13] HUA GU, GUANGDA SU, CHENG DU: Feature points Extraction from Faces, 2003.
[14] LIYA DING, ALEX M. MARTINEZ: Precise Detailed Detection of Faces and Facial
Features, Computer Vision and Pattern Recognition, 2008.
[15] S. KEVIN ZHOU, DORIN COMANCIU: Shape Regression Machine, IPMI’07
proceedings of the 20th international conference on Information, Berlin, 2007.
[16] NAOTOSHI SEO: Tutorial-openCV haartraining (Rapid Object Detection With A
Cascade of Boosted Classifiers Based on Haar-like Features),
http://note.sonots.com/SciSoftware/haartraining.html
[17] Stabla odlučivanja, Institut Ruđer Bošković, 2012.,
http://dms.irb.hr/tutorial/hr_tut_dtrees.php
52
[18] Wikipedia: Decision Tree, http://en.wikipedia.org/wiki/Decision_tree
[19] Wikipedia: Decision tree learning,
http://en.wikipedia.org/wiki/Decision_tree_learning
[20] Wikipedia: Gradient Boosting, http://en.wikipedia.org/wiki/Gradient_boosting
[21] Wikipedia: Regression analysis, http://en.wikipedia.org/wiki/Regression_analysis
[22] Wikipedia: Linearna regresija, http://hr.wikipedia.org/wiki/Linearna_regresija
[23] VISAGE TECHNOLOGIES: VisageSDK 6.3 documentation
[24] VIDIT JAIN, AMITABHA MUKHERJEE: The Indian Face Database, http://viswww.cs.umass.edu/~vidit/IndianFaceDatabase/ , 2002.
[25] GARY B. HUANG, MANU RAMESH, TAMARA BERG, AND ERIK LEARNED-MILLER:
Labeled Faces in the Wild: A Database for Studying Face Recognition in
Unconstrained Environments, University of Massachusetts, Amherst, Technical
Report 07-49, October, http://vis-www.cs.umass.edu/lfw/, 2007.
[26] DAVID ALDAVERT MIRO: Pixel Level Object Categorization using Bag of Features,
http://www.cvc.uab.cat/~aldavert/plor/, 2010.
[27] UTKARSH SINHA: Scale Invariant Feature Transform,
http://www.aishack.in/2010/05/sift-scale-invariant-feature-transform/7/, 14. 5.2010.
[28] CHI-CHEN RAXLE WANG: AdaBoost Learning for Human Detection Based on
Histograms of Oriented Gradients,
http://robotics.csie.ncku.edu.tw/Students/PHD/92/Raxle/raxle_project_HumanDetect
ion_Publication_2007ACCV492.html
[29] ANKIT GUPTA: Feature Detection, Description and Matching,
http://www.cs.washington.edu/homes/ankit/course_projects/files/vision/features/feat
ures.html
[30] OPENCV: Installation Guide, http://opencv.willowgarage.com/wiki/InstallGuide
[31] BIOID FACE DATABASE, http://www.bioid.com/downloads/software/bioid-facedatabase.html
[32] FEI FACEDATABASE, http://fei.edu.br/~cet/facedatabase.html
[33] TALKING FACE VIDEO, http://www-prima.inrialpes.fr/FGnet/data/01TalkingFace/talking_face.html
53
Popis slika
Slika 1.1. Prikaz usmjerenih gradijenata u bloku .................................................................. 2 Slika 1.2. Način rada ugniježđene kaskade ........................................................................... 3 Slika 1.3. Regije kovarijacijskih matrica ............................................................................... 4 Slika 2.1. Primjer Haarovih filtara ........................................................................................ 6 Slika 2.2. Integralna slika ...................................................................................................... 6 Slika 2.3. Računanje sume piksela unutar pravokutnika D ................................................... 7 Slika 2.4. Prikaz procesa učenja kaskade .............................................................................. 9 Slika 2.5. Primjer stabla odlučivanja ................................................................................... 10 Slika 3.1. Arhitektura sustava .............................................................................................. 15 Slika 3.2. Prikaz baza .......................................................................................................... 16 Slika 3.3. Primjeri slika iz baza: a) MUCT Database; b) Franck – Talking Face; c) FEI face
database; d) Face Recognition Data; e) Indian Face Database; f) Faces in the Wild; g)
BioID Face Database; h) FacePix; i) Bao Face Database ................................................... 18 Slika 3.4. Primjer .fdp datoteke ........................................................................................... 20 Slika 3.5. Prikaz FDP točaka ............................................................................................... 22 Slika 4.1. Primjer odabira regije .......................................................................................... 25 Slika 4.2. Prikaz nekonzistentnosti Haarovog pravokutnika ............................................... 26 Slika 4.3. Generiranje novih deset slika iz jedne originalne ............................................... 27 Slika 4.4. Anotirane točke iz baza: a) FEI; b) Talking Face; c) BioID v1.2 ....................... 28 Slika 4.5. Originalni formati zapisa točaka iz baza: a) BioID; b) Talking Face; c) FEI ..... 29 Slika 4.6. Primjeri .conf konfiguracijskih datoteka: a) Dvije FDP točke i još dva tipa
anotacija; b) sedam FDP točaka; c) jedna FDP točka ......................................................... 31 Slika 4.7. Primjer .ann datoteke........................................................................................... 32 Slika 4.8. Primjer .cfg datoteke ........................................................................................... 32 54
Slika 4.9. Primjer batch datoteke......................................................................................... 34 Slika 4.10. Primjeri detekcije nad skupom za validaciju..................................................... 35 Slika 4.11. Alat mpiexec ...................................................................................................... 36 Slika 4.12. Područja unutar kojih se vrše detekcije ............................................................. 37 Slika 4.13. Shematski prikaz određivanja prozora kod Haarove detekcije ......................... 39 Slika 4.14. Detekcija koristeći samo Haarovu kaskadu....................................................... 39 Slika 4.15. Inicijalna detekcija sa sedam točaka ................................................................. 40 Slika 4.16. Shematski prikaz određivanja unutarnjeg prozora koristeći inicijalnu detekciju
sa sedam točaka ................................................................................................................... 41 Slika 4.17. Detekcija značajki pomoću inicijalnih 7 točaka ................................................ 42 Slika 5.1. Primjeri originalnih slika ..................................................................................... 43 Slika 5.2. Primjeri iz skupa za učenje značajki lijevog oka ................................................ 44 Slika 5.3. Primjeri iz skupa za učenje značajki lijeve obrve ............................................... 44 Slika 5.4. Primjeri iz skupa za učenje značajki nosa ........................................................... 44 Slika 5.5. Primjeri iz skupa za učenje značajki usta ............................................................ 44 Slika 5.6. Primjeri iz skupa za učenje značajki brade ......................................................... 45 Slika 5.7. Primjeri iz skupa za učenje sedam inicijalnih točaka .......................................... 45 Slika 6.1. Primjer detekcije: a) Rezanje na temelju Haarove kaskade; b) Rezanje na temelju
inicijalnih sedam točaka ...................................................................................................... 48 Slika 6.2. Primjeri detekcije bez iscrtavanja prozora rezanja: a) Detekcija kod koje se
rezalo na temelju Haarove detekcije; b) Detekcija kod koje se rezalo na temelju inicijalne
detekcije sedam točaka ........................................................................................................ 49 Sl. 1. Primjer izvedbe programa za rezanje i generiranje novih slika ................................. 61 Sl. 2. Primjer alata za konverziju......................................................................................... 62 Sl. 3. Primjer izvođenja aplikacije za učenje ....................................................................... 63 55
Popis tablica
Tablica 3.1. Baze korištene pri procesu učenja ................................................................... 19 Tablica 5.1. Primjeri parametara učenja .............................................................................. 45 Tablica 5.2. Primjer parametara učenja i trajanje učenja .................................................... 46 56
Sažetak
Detekcija značajki lica
U radu je opisan cjelokupni proces koji je potrebno obaviti kako bi se mogla napraviti
detekcija značajki lica. Prvo se objašnjavaju potrebni teoretski temelji, a nakon toga slijedi
opis kompletnog sustava, alata koji su korišteni, te opis procesa učenja i detekcije. Sam
sustav započinje sa dobavljanjem potrebnih slika za izvedbu procesa učenja, nastavlja se sa
obradom tih slika, te se slike, nakon toga, koriste za učenje šuma odlučivanja. Kada je
proces učenja završen, sve šume odlučivanja se koriste u aplikaciji za detekciju značajka
lica.
Ključne riječi: detekcija, lice, značajke, učenje, FDP točke, rezanje, skup slika za učenje,
skup slika za validaciju, baze slika, značajke lica, Haarove značajke, kaskade, regresija,
stabla odlučivanja, šume odlučivanja
57
Summary
Facial features detection
In this paper a complete system for facial features detection is proposed. In the first part of
the paper, we describe the necessary theoretical background so we can later describe the
complete system, together with the tools used in it, the process of training (learning) and
the process of detection. The system's inputs are the pictures necessary for training. After
we acquire the necessary pictures, we must process them for the training with appropriate
tools. We then use the training tool to train decision forests. The resulting forests from the
training are then used in the Face Detector application for detecting facial features.
Keywords: detection, face, feature, learning (training), FDP points, cropping, training set,
validation set, picture database, facial features, Haar features, cascade, regression, decision
tree, decision forest
58
Skraćenice
HoG
Histogram of Oriented Gradients
RGB
Red, Green, Blue
PRFR
Pairwise Reinforcement of Feature Responses
SVR
Support Vector Regression
FDP
Feature Point Definition
SVN
Subversion
ROI
Region of Interest
RMSE Root mean square error
MPI
Message passing interface
59
Privitak
U ovom poglavlju biti će opisano što je sve potrebno instalirati kako bi se mogli pokretati
alati napravljeni u svrhu ovog rada. Osim toga, biti će opisano i kako se koriste isti.
Instalacija potrebnih biblioteka
Svi alati napravljeni su u razvojnom okruženju MS Visual Studio 2008 u programskom
jeziku C++. Osim uobičajenih biblioteka (time.h, direct.h, io.h, windows.h itd.), koristile
su se i biblioteke OpenCV-a koje omogućuju obrađivanje slika (cv.h, highgui.h). Osim
njih, koristile su se i biblioteke VisageSDK paketa. Konkretno, biblioteke koje su potrebne
za baratanje .fdp datotekama (FDP.h).
Za instalaciju OpenCV biblioteka, potrebno je preuzeti pripadnu instalacijsku datoteku (u
ovom radu je korištena verzija za Visual Studio 2008) sa [30] i instalirati je na lokalnom
računalu. Osim toga, potrebno je imati pristup Visage Technologies repozitoriju i
tehnologijama.
Svi alati napravljeni u svrhu ovog diplomskog rada dostupni su na SVN repozitoriju
Visage Technologies-a (konkretno u bin direktoriju), te se mogu koristiti direktno iz
repozitorija.
Način rada svih alata objašnjen je u poglavlju u kojem se opisuje kompletan sustav za
učenje (4).
Alat za rezanje i generiranje slika – FDPImageCropper
Kada se pokrene alat za generiranje slika, prvo je potrebno upisati putanju do direktorija
koji sadrži ulazne slike u program (originalne slike iz kojih će se dalje rezati i generirati
nove) i putanju do direktorija gdje će se spremiti rezultat, tj. generirane i izrezane slike.
Na slici (Sl. 1) prikazan je primjer rada programa. Nakon što se upišu putanje, potrebno je
odabrati način rada. Program može raditi tako da automatski učitava slike iz ulaznog
60
direktorija sve dok ne dođe do zadnje, ili može učitati sliku, prikazati je (kao što je
prikazano na slici dolje) i čekati da korisnik pritisne tipku za nastavak na sljedeću sliku. Na
taj način korisnik može pogledati da li sve radi kako treba.
Sl. 1. Primjer izvedbe programa za rezanje i generiranje novih slika
Nakon odabira načina rada, bira se područje rezanja (cijelo lice, desno oko, desna obrva
itd.), te se, zatim odabire koliko lika želimo generirati i koliko slika odabrane značajke
želimo generirati iz jedne originalne. Naravno, ako u ulaznom direktoriju nema dovoljno
slika za generiranje novih, alat će generirati najviše što može. Na gornjoj slici može se
vidjeti veći pravokutnik oko lica koji predstavlja Haarov pravokutnik. Unutar Haarovog
pravokutnika nalazi se prozor za rezanje i FDP točke koje će se zapisati u pripadnu .fdp
datoteku. Taj prozor se nasumično pomiče i na taj način se dobiva više slika značajke (npr.
oka) iz jedne originalne slike.
Rezultat ovog alata su slike odabrane značajke (npr. oka) i pripadne .fdp datoteke (koje
sadrže koordinate značajki).
61
Alati za konverziju
Alati za konverziju napravljeni su kako bi se zapis koordinata iz originalnog formata
pretvorio u FDP format. Svi alati su slični, te se primjer alata, koji pretvara koordinate iz
zapisa BioID, može vidjeti na slici (Sl. 2).
Sl. 2. Primjer alata za konverziju
Za provedbu konverzije, potrebno je samo upisati putanju do direktorija koji sadrži slike i
pripadne datoteke u kojima su zapisane koordinate (u slučaju BioID baze, to su .pts
datoteke). Rezultat konverzije su .fdp datoteke koje se spremaju u isti direktorij gdje se
nalaze i originalne datoteke.
U svrhu ovog rada, napravljene su tri aplikacije za konverziju. Dakle, za konvertiranje
zapisa iz BioID baze, FEI baze i Talking Face baze.
62
Aplikacija za učenje
Na slici (Sl. 3) može se vidjeti primjer izvođenja aplikacije za učenje. Kada se aplikacija
pokrene, prvo je potrebno odabrati u kojem će načinu rada raditi (načini rada su opisani u
poglavlju o sustavu za učenje). Dakle, može se raditi učenje, učenje i nakon toga
validacija, ili samo validacija. Osim toga, može se odabrati hoće li se parametri upisivati
preko konzole ili će se upisivati iz batch datoteke (pri čemu će onda trebati upisati putnju
do batch datoteke).
Sl. 3. Primjer izvođenja aplikacije za učenje
Nakon što je odabran način rada, upisuje se ime šume i parametri učenja. Nakon toga,
aplikacija prolazi kroz sve slike u direktoriju, ispisuje koliko ih je (u gornjem slučaju,
proces učenja će se provesti nad 119 slika) i započinje se sa procesom učenja. Tijekom
procesa učenja ispisuje se na kojem je trenutno stablu proces.
Na kraju, rezultat aplikacije je jedna ili više šuma odlučivanja koje se spremaju u direktorij
gdje se nalazi skup za učenje.
63
Aplikacija za detekciju - FaceDetector
Primjeri rada aplikacije za detekcije dani su u poglavlju o rezultatima. Kada se pokrene
aplikacija, pojavljuje se mali prozor sa izbornikom. U izborniku se može odabrati hoće li
se raditi detekcija značajki nad jednom slikom ili će se koristiti batch datoteka i provesti
detekcija nad više slika. Ako se odabere detekcija nad više slika, rezultirajuće slike će se
spremiti kako je definirano u batch datoteci.
64
© Copyright 2026 Paperzz







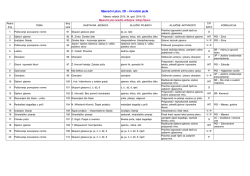
!["[Kliknite ovdje i unesite ime]"](http://s3.paperzz.com/store/data/005137337_1-775aeab23a62e4e08a17a775abe33c1d-250x500.png)

