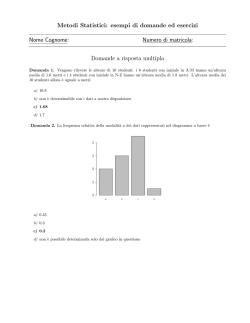
Esempio EM: apprendimento non
supervisionato delle medie di due Gaussiane
L’insieme delle variabili in considerazione `e Y = X ∪Z, dove X `e l’insieme
delle variabili osservabili e Z l’insieme delle variabili non osservabili. In
particolare, l’i-esima “variabile” `e data da
yi = hxi , zi1 , zi2 i
dove xi ∈ R `e generato o dalla Gaussiana 1 o dalla Gaussiana 2 (entrambe
con varianza conosciuta σ e medie µ1 e µ2 sconosciute), e zi1 , zi2 ∈ {0, 1}.
Vediamo come definire in questo caso
Q(h0 |h) = E[ln p(Y |h0 )|h, X]
In particolare, la probabilit`a a posteriori di yi data l’ipotesi h0 `e data da
1
0 2
0 2
1
p(yi |h0 ) = p(xi , zi1 , zi2 |h0 ) = √
e− 2σ2 (zi1 (xi −µ1 ) +zi2 (xi −µ2 ) )
2πσ 2
dove h0 = hµ01 , µ02 i. Infatti, se xi `e generato dalla Gaussiana 1, allora zi,1 = 1 ∧ zi,2 = 0,
e quindi
1
0 2
1
e− 2σ2 (xi −µ1 ) ,
p(yi |h0 ) = p(xi , 1, 0|h0 ) = √
2πσ 2
se xi `e generato dalla Gaussiana 2, allora zi,1 = 0 ∧ zi,2 = 1, e quindi
p(yi |h0 ) = p(xi , 0, 1|h0 ) = √
1
2πσ 2
1
0 2
e− 2σ2 (xi −µ2 )
Ricordando che il logaritmo (ln) `e una funzione monotona crescente e che
le istanze yi sono estratte indipendentemente, la probabilit`a a posteriori di
Y data l’ipotesi h0 `e data da
0
ln p(Y |h ) = ln
=
m
Y
p(yi |h0 )
i=1
m
X
ln p(yi |h0 )
i=1
=
m
X
(ln √
i=1
1
2πσ 2
−
1
(zi1 (xi − µ01 )2 + zi2 (xi − µ02 )2 ))
2σ 2
e il suo valore aspettato rispetto a X e l’ipotesi corrente h `e
#
" m
X
1
1
E[ln p(Y |h0 )] = E
− 2 (zi1 (xi − µ01 )2 + zi2 (xi − µ02 )2 ))
(ln √
2
2σ
2πσ
i=1
m
X
1
1
=
(ln √
− 2 (E[zi1 ](xi − µ01 )2 + E[zi2 ](xi − µ02 )2 ))
2πσ 2 2σ
i=1
Quindi il passo E dell’algoritmo EM definisce
0
Q(h |h) =
m
X
1
1
− 2 (E[zi1 ](xi − µ01 )2 + E[zi2 ](xi − µ02 )2 ))
(ln √
2
2σ
2πσ
i=1
dove E[zi1 ] e E[zi2 ] sono calcolate sulla base di h = hµ1 , µ2 i e X come
E[zi1 ] =
E[zi2 ] =
1
2
1
2
1
2
1
2
1
2
e− 2σ2 (xi −µ1 )
e− 2σ2 (xi −µ1 ) + e− 2σ2 (xi −µ2 )
1
2
e− 2σ2 (xi −µ2 )
e− 2σ2 (xi −µ1 ) + e− 2σ2 (xi −µ2 )
Il passo M deve risolvere il problema
arg max
Q(h0 |h) = arg max
0
0
h
h
m
X
i=1
(ln √
1
2πσ 2
−
1
(E[zi1 ](xi − µ01 )2 + E[zi2 ](xi − µ02 )2 ))
2σ 2
m
1 X
= arg max
(−(E[zi1 ](xi − µ01 )2 + E[zi2 ](xi − µ02 )2 ))
h0 2σ 2
i=1
= arg min
0
m
X
h
(E[zi1 ](xi − µ01 )2 + E[zi2 ](xi − µ02 )2 )
i=1
che si risolve ponendo le derivate parziali rispetto a µ01 e µ02 a zero:
P
0 2
0 2
∂ m
i=1 (E[zi1 ](xi − µ1 ) + E[zi2 ](xi − µ2 ) )
= 0
∂µ01
∂
Pm
i=1 (E[zi1 ](xi
− µ01 )2 + E[zi2 ](xi − µ02 )2 )
= 0
∂µ02
o, equivalentemente
m
X
E[zi1 ](xi − µ01 ) = 0 ⇒
m
X
E[zi1 ]xi = µ01
m
X
i=1
i=1
i=1
m
X
m
X
m
X
E[zi1 ](xi − µ02 ) = 0 ⇒
i=1
E[zi2 ]xi = µ02
i=1
da cui
µ01
µ02
Pm
E[zi1 ]xi
= Pi=1
m
E[zi1 ]
Pmi=1
E[zi2 ]xi
= Pi=1
m
i=1 E[zi2 ]
i=1
E[zi1 ]
E[zi2 ]
© Copyright 2026 Paperzz