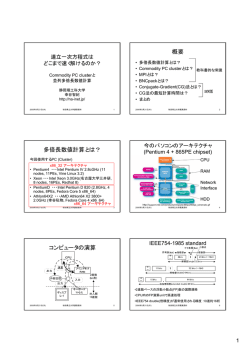
PC Cluster 上における 多倍長数値計算ライブラリ BNCpack の並列分散化 ーMPIBNCpackについてー 幸谷智紀 静岡理工科大学 [email protected] 講演概要 1. 2. 3. 4. 数値計算ソフトウェアの高速化 BNCpackとは? BNCpack + MPI = MPIBNCpack MPIBNCpackのプログラミングお作法 5. ベンチマークテスト 6. 今後の(アテにならない)予定 7. 蛇足 8. 参考文献 数値計算ソフトウェアの高速化 (1/2) Applications (5)行列の固有値・固有 ベクトル計算 (4)連立一次方程式の 解法 (3)基本線型計算 LAPACK BNCpack BLAS (2)四則演算・ 初等関数 Floating-point Units in CPUs (1)浮動小数点数形式 IEEE754 Standard GMP + MPFR 数値計算ソフトウェアの高速化 (2/2) どのレベルでの高速化を図るか? • 1CPU環境での高速化 – 下部Layerの高速化は限界に近い – LAPACK/BLAS ・・・Cache Hit率の向上→ATLAS • 複数CPU環境での高速化 – SMP環境での高速化(共有メモリ) – PC Clusterでの高速化(分散メモリ) BNCpackとは? • 固定長・可変長浮動小数点演算両方のサポート – IEEE754 単精度・倍精度 – GMP(GNU MP)+MPFRによる多倍長浮動小数点 • 主な機能 – – – – – – 基本線型計算 連立一次方程式 固有値問題 非線型方程式 代数方程式 数値積分 ・・・詳細は,LC2002の資料参照。 BNCpack + MPI = MPIBNCpack (1/3) BNCpack + MPI (mpich 1.2.5) ↓ MPIBNCpack – IEEE754倍精度と多倍長精度をサポート – 基本線型計算 • 実ベクトル演算 • 実正方行列演算 http://na-inet.jp/na/bnc/ – 台形則(数値積分) – CG法(連立一次方程式) – DKA法(代数方程式) BNCpack + MPI = MPIBNCpack(2/3) 実装方法 1. コミュニケータにおい て多倍長データ型 (MPI_MPF)を宣言 2. 送受信の際は pack_mpf/unpack_mpf 関数をかませる。 メリット 1. 既存の多倍長演算ラ イブラリがそのまま利 用できる 2. 実装が簡単 BNCpack + MPI = MPIBNCpack (3/3) Pallalell and Distributed Computation Environment MPIBNCpack BNCpack IEEE754 floatingpoint arithmetic GMP MPF/MPFR Hardware Serial Computation Environment mpich TCP & UDP/IP Ethernet MPIBNCpackのプログラミングお作法 • 入出力はPE0で行う(そうしておくと楽)。 • データの分割・集約処理は関数にお任せ。 vec1.c with BNCpack 1. 2. 3. 4. 5. ベクトル初期化 ベクトル要素の 代入 計算 表示 ベクトル消去 1. mpi_vec1.c with MPIBNCpack @PE0 1. 2. 2. 3. 4. 5. 6. 7. 初期化 ベクトル要素の代入 各PEで使用するベクトルの初期化 ベクトル要素の分散配置 計算 ベクトル要素をPE0へ集約 ベクトル消去 @PE0 1. 2. ベクトル表示 ベクトル消去 ベンチマークテスト 1. 2. 3. 4. 5. 実験環境 1対1通信,集団通信 行列積(_mpi_mul_mpfmatrix関数) CG法(_mpi_MPFCG関数) DKA法(_mpi_mpf_dka関数) 実験環境 cs-pccluster 192.168.1.0/24 Default GW: 192.168.1.1 学内LANへ 16 Port l OSは全てVine Switching Hub Linux 2.6r1 l NFS/NISでディレ export /home クトリとユーザア /usr cs-southpole カウントの共有を 192.168.1.1 行う l PCはIntel cs-room443-b03 cs-room443-b01 Pentium 192.168.1.23 192.168.1.21 cs-room443-b04 cs-room443-b02 III/Celeronの 192.168.1.24 192.168.1.22 1GHzマシン cs-room443-s03 cs-room443-s01 192.168.1.33 192.168.1.31 cs-room443-s04 cs-room443-s02 192.168.1.34 192.168.1.32 1対1通信 1.40E-01 1.20E-01 Millisec 1.00E-01 Add Mul Div Send/Recv 8.00E-02 6.00E-02 4.00E-02 2.00E-02 0.00E+00 128 256 512 1024 Precision(bits) 2048 4096 Bit数が長くなるほど,粒度が上がり,並列分散処理向き。 通信時間はBit数に比例(但し,集団通信は別)。 集団通信(1/3) • Bcast8 Gather8 a=1 PE0 a=1 b a=1 a=1 PE1 b a=2 PE2 PE2 a=1 PE3 PE0 PE1 PE2 b a[0]=0 a[1]=1 a[2]=2 a[3]=3 a=0 b[0] b[1] b[2] b[3] PE0 PE1 Scatter8 b a=3 PE3 PE3 集団通信 (2/3) • Allgather8 a=0 b[0]=0, b[1]=1, b[2]=2, b[3]=3 a=0 PE0 PE0 a=1 a=1 b[0]=0, b[1]=1, b[2]=2, b[3]=3 Allgather PE1 PE1 a=2 PE2 a=2 b[0]=0, b[1]=1, b[2]=2, b[3]=3 PE2 a=3 PE3 a=3 b[0]=0, b[1]=1, b[2]=2, b[3]=3 PE3 • Alltoall8 a[0]=0, a[1]=1, a[2]=2, a[3]=3 b[0]=?, b[1]=?, b[2]=?, b[3]=? a[0]=0, a[1]=1, a[2]=2, a[3]=3 b[0]=0, b[1]=0, b[2]=0, b[3]=0 PE0 PE0 a[0]=0, a[1]=1, a[2]=2, a[3]=3 b[0]=?, b[1]=?, b[2]=?, b[3]=? PE1 a[0]=0, a[1]=1, a[2]=2, a[3]=3 b[0]=1, b[1]=1, b[2]=1, b[3]=1 Alltoall PE1 a[0]=0, a[1]=1, a[2]=2, a[3]=3 b[0]=?, b[1]=?, b[2]=?, b[3]=? PE2 a[0]=0, a[1]=1, a[2]=2, a[3]=3 b[0]=2, b[1]=2, b[2]=2, b[3]=2 PE2 a[0]=0, a[1]=1, a[2]=2, a[3]=3 b[0]=?, b[1]=?, b[2]=?, b[3]=? PE3 a[0]=0, a[1]=1, a[2]=2, a[3]=3 b[0]=3, b[1]=3, b[2]=3, b[3]=3 PE3 集団通信(3/3) 0.007 0.006 0.005 Bcast8 Scatter8 Gather8 Allgather8 Alltoall8 Sec 0.004 0.003 0.002 0.001 0 128 256 512 1024 2048 4096 8192 16384 32768 Precision(bits) Bcastを除けば,同じ程度で通信時間が増加する。 この程度の長さのデータでは大差が出ない? 行列積(1/2) Cij = Ai1 B1 j + Ai 2 B2 j + Ai 3 B3 j + Ai 4 B4 j ・行列Aの回転は 添字のみで良い。 A11 A12 A13 A14 B11 B12 B13 B14 PE0 A21 A22 A23 A24 B21 B22 B23 B24 PE1 A31 A32 A33 A34 B31 B32 B33 B34 PE2 A41 A42 A43 A44 B41 B42 B43 B44 PE3 A11 A12 A13 A14 B11 B22 B33 B44 PE0 A22 A23 A24 A21 B21 B32 B43 B14 PE1 C131 C132 C133 C134 A33 A34 A31 A32 B31 B42 B13 B34 PE2 C141 C142 C143 C144 A44 A41 A42 A43 B41 B12 B23 B44 PE3 ・行列Bの回転は PE間の通信が発 生。 C111 C112 C113 C114 C121 C122 C123 C124 = 行列積(2/2) Dimension: 256 160 140 • 256次実正方行列 の行列積を計算 120 Sec 100 128 256 512 1024 80 60 40 20 0 1 2 4 Dimension: 256 8 # of PEs 10 MPI_Send/Recvによる実装 がよろしくない? 128 256 512 1024 Ratio 精度が大きくなると通信の オーバーヘッドが大きい? 1 1 2 4 # of PEs 8 連立一次方程式 Ax = b CG法(1/3) 内積,スカラー倍,ノルム,行 列・ベクトル積を並列分散化 n − 1 L 1 0 n 1 n − 1 n − 1 L 1 , x = A= M M M M − 1 1 L 1 n 1 CG法(2/3) • 64次元∼512次元の収束履歴 Dimension: 128 Dimension: 64 ||r_k||_2/||r_0||_2 1.E-08 1.E-12 1.E-20 1.E-20 double 256bits 192bits Dimension: 256 99 106 92 85 78 71 64 57 50 43 36 64bits 512bits 128bits 1024bits 192bits Dimension: 512 1.E+00 1 20 39 58 77 96 115 134 153 172 191 210 229 248 267 286 305 324 121 1.E-04 1.E-08 1.E-12 1.E-16 64bits 512bits 128bits 1024bits 192bits ↓ 最短計算時 間は? 1.E-08 1.E-12 1.E-20 double 256bits 多倍長で計 算すると,反 復回数が少 なくなる。 Iterative Times 1.E-16 1.E-20 double 256bits 113 97 105 89 81 73 65 57 Iterative Times ||r_k||_2/||r_0||_2 1.E-04 49 41 33 25 17 9 1 1.E+00 ||r_k||_2/||r_0||_2 29 1.E-12 1.E-16 128bits 1024bits Iterative Times 1.E-08 1.E-16 64bits 512bits 22 1.E-04 Iterative Times double 256bits 8 1 13 17 21 25 29 33 37 41 45 49 53 57 61 5 9 1 ||r_k||_2/||r_0||_2 1.E-04 15 1.E+00 1.E+00 64bits 512bits 128bits 1024bits 192bits CG法(3/3) • IEEE754倍精度の3倍強が限界。 • もっと次元数を上げると? • PE数がもっと多ければ? DKA法(1/3) 今回は次の代数方程式を解いてみる。 但し,奇数次の係数は0。 ↑複素数演 算! DKA法(2/3) • Gauss平面の第1 象限のみ,会を表 示している。 • 大部分が複素数 解となる。 DKA法(3/3) • 128次元の場合 Degree: 128 700 600 128bits 256bits 512bits 1024bits 400 300 200 Degree: 128 100 10 0 1 2 4 8 # of PEs 128bits 256bits 512bits 1024bits Ratio Sec 500 並列化効率はほぼMAX値。 1 1 2 4 # of PEs 8 今後の(アテにならない)予定 • 多倍長計算を生かす数値計算アルゴリズムの研 究 • ライバルとの比較検討・・・計算効率・使い勝手 – [1CPU] FMLIB, ARPREC(MPFUN) v.s. GMP+MPFR – [MPI] PETSc v.s. MPIBNCpack with ScaLAPACK • MPIBNCpackの機能強化 – – – – 精度のスコープの明確化(必須!) SMP/MTへの対応・・・local scalability 超多倍長への対応・・・global scalability 可視化ツールへの対応(Patch?) 蛇足(1/2) • 大学院「 分散処理」(前半)を担当 – MPIBNCpackを使った並列数値アルゴリズム を教える ↓ • MPIは主要な機能のみ解説 • 数値計算に集中できる!!( 分散化を自 動化したおかげ) 蛇足(2/2) http://na-inet.jp/tutorial/にて公開。 参考文献 • BNCpack/MPIBNCpack, http://na-inet.jp/na/bnc/ • Try! MPFR, http://www.jpsearch.net/try_mpfr.html • A Tutorial of BNCpack and MPIBNCpack, http://nainet.jp/tutorial/ • G.H.Golub/C.F. Van Loan, Matrix Computations 3rd ed. , Johns Hopkins Univ. Press, 1996. • P.Paccheco/秋葉博・訳, MPI並列プログラミング, 培風館, 2001. • mpich, http://www-unix.mcs.anl.gov/mpi/mpich/ • GNU MP, http://swox.com/gmp/ • MPFR Project , http://www.mpfr.org/
© Copyright 2026 Paperzz