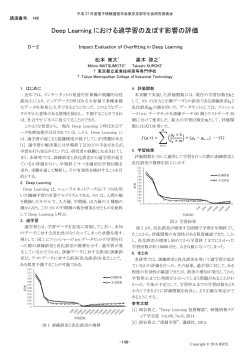
深層学習の最近の進展 稲垣祐一郎i Recent advances in deep learning Yuichiro INAGAKI 機械学習の分野で数十年に一度のブレークスルーと言われる深層学習の最近の進展について述べる.特に, 深層学習の今後の可能性の拡がりを期待させる One-shot learning,Long Short Term Memory(LSTM),word2vec を用いた自然言語処理などのトピックについて事例を紹介するとともに,特許情報処理における試行例につ いて述べる. (キーワード): Deep Learning, 深層学習,画像認識,音声認識,自然言語処理,LSTM 1 はじめに (KDD2014) と , 機 械 学 習 分 野 の 国 際 学 会 で あ る Neural 「人工知能」というテーマは,長い間技術者にと って一種のタブーとなっていたが Proccessing Systems 2014 (NIPS2014)の双方に参加してきたが,どちらの学会 1) ,この一年ほど も昨年に比べて大幅に参加者が増加したとのことで であっという間に注目される技術の一つとなってし まった Information あり,会場の雰囲気も非常に活気のあるものだった. 2) .一般的に認知されたのは,グーグルによ Kurzweil の「収穫加速の法則」とは,半導体の Moore る DeepMind 社の買収,2045 年に人間並みの人工知 の法則に典型的に見られる様に,技術と技術の結び 能が実現するとの予測 3) や「収穫加速の法則」で有 つきにより次の技術的発展が産まれるというメカニ 名な Ray Kurzweil の Google への移籍,質問応答シ ズムを通じてイノベーションが指数関数的に加速す ステム IBM ワトソンが米国のクイズ番組で優勝し るという主張であるが,これらの学会においても, 4) たこと など Google,IBM などの動きが原因と思わ 様々な新しいアイディアが統合されテストされてい れるが,技術的な面における最大の要因は,深層学 て研究の展開のスピードが速く,まさに収穫加速の 習(Deep Learning)と呼ばれる,機械学習分野の大 法則が具現化している現場に立ち会っているとの印 きなブレークスルーがあったことであろう.深層学 象を受ける. 習とは,多層のニューラルネットワークを用いて機 械学習を行う技術である 5) 6) 本稿では,これらの学会で話題となっていた深層 .多層のニューラルネッ 学習の今後の更なる発展を期待させるいくつかの最 トワークを使うというアイディア自体は古くからあ 近の進展を示す研究と,弊社で取り組んでいる特許 ったが,学習アルゴリズムの進展と入力データが大 情報処理への試行例について述べる. 量に得られるようになったことなどにより,従来の ニューラルネットワークと比べて格段に性能が進歩 2 One-shot learning した.自動運転,IoT(Internet of Things),ロボット等 の今後市場が拡大すると予想される多くの分野が, 従来の機械学習では,教師あり学習にしろ教師な 機械学習あるいは人工知能と密接な関係を持ってお し学習にしろ,学習過程においてある程度のサンプ り,今後の応用への発展が期待されている 7). ル数が必要であった.手書き文字認識を例に取ると, 筆者は今年,データマイニング分野の国際学会で あ る i Knowledge Discovery サイエンスソリューション部 and Data 新しい漢字を新たに学習するには,その字のサンプ ルは最低でも 50 程度は必要であった. Mining エレクトロニクスチーム シニアコンサルタント 41 博士(理学) ple) visual concepts, generalizing in human-like ways from just one image. W e evaluated performance on a challenging one-shot classifi cati on task, where our model achieved a human-level error rate while substantially outperforming two deep learning models. W e also tested the model on another conceptual task, generating new examples, by using a “visual Turing test” to show that our model produces human-like performance. roduction しかし,人間には,一つあるいはごく少数の例を 3 Long Short Term Memory 見ただけでその特徴を掴み,一つのカテゴリーとし て記憶し,類似の例を認識する能力が備わっている. 3.1 日本語の文脈依存性 can acquire a この能力のことは,1例で学習が可能になるという new concept from only the barest of experience – just one or a handful of s in a high-dimensional space of raw perceptual input. Although machine learning has 意味で One-shot learning と呼ばれている.図 1 で, 日本語は,世界の言語の中でも文脈への依存性が some of the same classifi cation and recognition problems that people solve so effortlessly, 赤四角で囲われた字と同じ字を下のパネルから選ぶ dard algorithms require hundreds or thousands of examples to reach高い言語として知られている.生成文法の立場にお good performance. ことは人間には容易である.この能力はどの様なメ いても,日本語は主題卓越型言語と分類され,主題 e standard M NIST benchmark dataset for digit recognition has 6000 training examples per ], people can カニズムで実現されているのであろうか? classify new images of a foreign handwritten character from just one example (文脈上の話題) が重視される言語とされている 10). 1b) [23, 16, 17]. Similarly, while classifi ers are generally trained on hundreds of images per 日本語の文脈依存性を示す例として良く引き合いに ing benchmark datasets such as ImageNet [4] and CIFAR-10/100 [14], people can learn a b) 出される例に, 「僕はうなぎだ」という文があるが, c) るのか?という問題である. この文は丼物屋での注文の際の発言であるという文 脈があって初めて普通の理解が可能となる文となっ ている.従って日本語の処理を行う際には,文脈を どのように取り扱うかが重要となってくる. H u m a n d r a w e r s 主題として提示されている情報に対して言及する 1 2 1 1 (=情報処理を行う)ことをニューラルネットワー 1 2 2 2 3 クで実現するには,何らかのメモリ機能を備えた再 3 3 3 帰的なものであることが必要である.しかし,その c a n o n ic a l 5 5 .1 5 .3 Can you learn a new concept from just one example? (a & b)8) W here are the other examples of the 図 1 One-shot learning による文字認識 様なモデルがまだ十分に検討されていないことが, hown in red? Answers for b) are row 4 column 3 (left) and row 2 column 4 (right). c) The learned also support many other abilities such as generating examples and parsing. 英語-日本語間の自動翻訳の精度がなかなか向上し 1 1 2 2 2 2 この問いに対する機械学習の観点からの一つの回 ないことの一因となっていると考えられる. 3 1 3 答が, 「既に学習されている特徴量を用いれば,新し 1 いパターンがどの特徴量の組合せで構成されるかを 3 6 .2 6 .2 7 .1 3.2 再帰的なニューラルネットワーク 1 3 7 .4 効率的に学習することが可能」というものである 9). Salakhutdinov ら は , Hierarchcal Bayesian Program 1 1 2 1 3 2 再帰的な構造を持ったニューラルネットの研究は, Learning (HBPL)という One-shot learning の一つのモ 3 11) 3 Elman による先駆的な研究に遡ることが出来る . 2 デルを用いた文字認識のタスクにおいて,人間によ Elman は,再帰的なモデルである Simple Recurrent 8 .2 8 .4 1 2 る誤認識率(4.5%)と同等の誤認識率(4.8%)に抑えら Network (SRN)を簡単な英語例文に適用し,文法の学 れることを示した(表 1) . 習が可能であることを示した.しかし,SRN におけ る学習では,時間的に過去へネットワークを展開し 表 1 One-shot 文字認識における HBPL と他のモデルとの比較 てバックプロパゲーションによる学習を行うために 学習器 誤認識率 人間 4.5% 層が深くなると誤差の勾配が指数関数的に減衰し, HBPL 4.8% 学習出来なくなるという問題が起こることが知られ Affine model 18.2% ており,Vanishing Gradient Problem と呼ばれている Hierarchical Deep Model 34.8% 12) (Back Propagation Through Time, BPTT) ,展開の階 . Deep Boltzman Machines 38% Simple Strokes 62.5% Long Short Term Memory(LSTM)である 12) 13).LSTM Nearest Neighbor 78.3% では,ニューラルネットワークにメモリ機能を持た SRN の発展形として最近注目されているのが, せることにより,Vanishing Gradient Problem を回避 既に習得されている特徴量や知識を用いて新しい している.日本語に LSTM を適用した研究は筆者の 概念クラスを one-shot で認識するという基本的な考 知る限りまだほとんど無いと思われるが,今後検討 え方は,今後他の分野へも適用されていくであろう すべきモデルであろう.以下では,LSTM モデルと, と考えられる. NIPS2014 で発表されていた適用例について述べる. 42 3.3 LSTM モデル LSTM では,Vanishing Gradient Problem の解決策 NIPS 2014 においても,Google の研究者である として,BPTT により時間的に展開しても誤差が減 Sutskever らが LSTM を用いた発表をしており,注目 衰しない様な構造を導入する.LSTM のネットワー を集めた 13).図 3 は,LSTM による学習後,いくつ ク構造は,Constant Error Carrousel (CEC)と CEC への かの文を入力した際の隠れ層の状態を連結して多次 入力と出力をコントロールするゲートを含む単位セ 元のベクトルとして表現したものを,主成分分析に ルが連なった構造をしている(図 2).CEC は,自 より第1主成分と第2主成分の 2 次元上に射影した 分自身に重み1で結合しており,これにより,誤差 ものである.隠れ層は,各時点でのモデルの内部状 が減衰することなく重み1でループすることが可能 態を保持していることから,このベクトルは文脈の となり,時系列上で離れた単語の間の関係(例えば, 意味を表現していると言える.意味の相似(admire 長い関係節の前後など)を捉えることが可能となっ と in love と respect),反対の意味になる構文("Mary ている.また,メモリ機能には,情報を入力するタ admires John"と"John admires Mary"など),異なる構 イミングと忘却するタイミングを制御することも必 文で示された内容の一致("I was given a card by her in 要であり,これを gating ユニットとして導入する(図 the garden."と"In the garden, she gave me a card."など) 2 の●) .また,入力と出力にそれぞれ活性化関数が の構造が捉えられていることが判る. 導入される(図 2 の g と h). Sutskever らは,英語-フランス語間の自動翻訳に LSTM を適用した結果を示している.入力側(英語) と出力側(フランス語)のそれぞれに LSTM を 4 層 ずつ配置した構造を用いている.非常にシンプルな 構造であるにも関わらず,今までの最良の方法に近 い成績が得られている. 4 特許情報処理への適用試行例 4.1 word2vec と doc2vec 2013 年に,Mikolov らは単語の意味をベクトル空 間 に 射 影す る ア ルゴ リ ズム を 考 案し , そ の実 装 word2vec と共に発表して大変話題となった 14) 15). 図 2 LSTM の単位セル 意味の相似 同一内容構文 逆の意味の構文 図 3 LSTM による構文と意味の把握 43 Le らは,このモデルを更に拡張し,パラグラフや文 5 まとめ 書全体の意味を表現するベクトルを単語のベクトル 本稿では,NIPS2014 等の学会で話題となっていた と 一 緒 に 学 習 す る Distributed Memory Model of .Le らは, 深層学習の今後の更なる発展を期待させるいくつか PV-DM を,映画のレビュー文章の内容が好意的か否 の最近の進展を示す研究について,概説を行った. かを判定するセンチメント解析 17)と呼ばれるタスク 紹介した以外にも,重要と思われる研究も多い.通 に適用し,従来の研究に比べてエラー率を低減させ 常の Recurrent Neural Network では deep さが足りな ている(7.42%).Le らの PV-DM アルゴリズムは, いとする論文 20),Recurrent Neural Network を使って doc2vec としてフリーソフトウェア gensim18)に実装 時系列データのパターンを学習するアルゴリズム されている. Conceptor21)22),ロボットの学習などに適用可能と考 Paragraph Vectors (PV-DM)を開発した 16) えられる強化学習と深層学習を組み合わせた deep Q-network23)など興味深い論文は多い. 4.2 類似文献検索 弊社では,深層学習の最新の成果の科学技術論文 これらの部分的な理解が順に統合され,さらに実 や特許情報の処理へ適用を試みている.その第一歩 世界とのインターフェース・情報プラットフォーム として,word2vec と doc2vec を用いた特許の類似文 としてのロボットやインターネットと結合されると, 献検索のシステムを開発している. 本格的な人工知能の実現も Kurzweil の予想よりも意 外に早いのではと思われる. 凡そ 1,000 億単語を含む Google ニュースのデータ 弊社においても,今後深層学習の日本語への適用, セットを用いて 300 万の単語とフレーズのベクトル 表現を学習したデータ 19)を用い,米国特許庁の特許 各種センサーデータへの適用など,深層学習の応用 文献に対する類義語まで含めた検索を可能にした. 展開へ取り組んで行きたい. gensim を用いて,米国特許庁からオープンデータと 引 用 文 献 して提供されている米国特許の検索を試みた. 1) ジェルリー・A・ムーア著,川又政治訳:キャズム, 従来の通常の検索では,何らかの単語に関連する 翔泳社(2002). 文献を検索する場合,類義後のリストを手動で作成 2) 日経コンピュータ: ビッグデータは人工知能に する必要があった.しかし,gensim を使えば,例え 任せた!,日経 BP 社 2014.10.2 号. ば,"nanotube"と類似性の高い単語とフレーズのリス 3) レイ・カーツワイル著,井上健ほか訳: ポスト・ トを抽出することが出来る(表 2).これにより, nanotube と 関 係 の 深 い 言 葉 と し て , nanowire , ヒューマン誕生 graphene,quantum_dot などナノテクノロジーの分野 超えるとき,日本放送出版協会(2007). コンピュータが人類の知性を 4) http://www-06.ibm.com/ibm/jp/lead/ideasfromibm/w で重要な単語が認識されている.これにより,ユー atson/ ザーが様々な関連の深い文献を抽出することが可能 5) 人工知能学会誌連載記事参照(2013 年 5 月~2014 となった. 年 7 月). 表 2 1 2 3 4 5 6 7 8 9 10 6) 「特集:機械学習」 ,みずほ情報総研 nanotube と類似の単語(類似性上位 20) nanotubes carbon_nanotube carbon_nanotubes nanowire nanowires graphene quantum_dot nanoscale nanostructures nanometer_scale 11 12 13 14 15 16 17 18 19 20 技報,Vol.6, No.1(2014). CNTs quantum_dots silicon_nanowires polymer semiconducting nanostructure nanoparticle nanocrystals nano_scale graphene_layers 7) Manyika, J. et al. :Distructive technologies:Advances that will transform life, business, and the global economy, McKinsey Global Institute(2013). 8) Lake, B. M., Salakhutdinov, R. R., Tenenbaum, J.:One-shot learning by inverting a compositional causal process, Proc. Neural Information Processing Systems(2013). 9) Salakhutdinov, R., Tenenbaum, J. B. , Torralba, A.: Learning with Hierarchical-Deep Models, IEEE Transactions on Pattern Analysis and Machine 44 Intelligence, 35, 8, 1958-1971(2013). 10) ベイカー,M.C.著,郡司隆男訳:言語のレシピ-多様 性にひそむ普遍性をもとめて,岩波書店(2010). 11) Elman, J. L.: Finding Structure in Time, Congnitive Science, 14, pp.179-211 (1990). 12) Hochreiter, S., and Schmidhuber, J.:Long Short-Term Memory, Neural Computation 9(8),pp.1735-1780 (1997). 13) Sutskever, I., Vinyals, O. V., Le, Q.:Sequence to Sequence Learning with Neural Networks, Proc. NIPS(2014). 14) Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient Estimation of Word Representations in Vector Space, arXiv 1301.3781v3 (2013). 15) https://code.google.com/p/word2vec/ 16) Le, Q., Mikolov, T.,:Distributed Representations of Sentences and Documents, arXiv1405.4053v2(2014). 17) http://ai.stanford.edu/~amaas/data/sentiment/ 18) http://radimrehurek.com/gensim/index.html 19) 上記 15)のページの以下のファイル: GoogleNews-vectors-negative300.bin.gz 20) Pascanu, R.: How to Construct Deep Reccurrent Neural Networks, arXiv1312.6026v5(2014). 21) Jaeger, H.: Conceptors: an easy introduction, arXiv 1406.2671(2014). 22) Jaeger, H.: Controlling Recurrent Neural Networks by Conceptors, arXiv 1403.3369(2014). 23) Minih, V. et al.:Human-level control through deep reinforcement learning, Nature, 518, 529-533 (2015). 45
© Copyright 2026 Paperzz