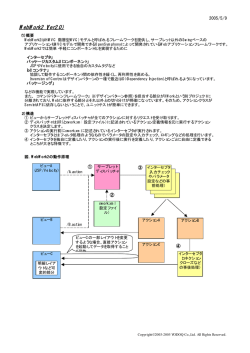
25G-08 対話システムにおける絵情報のモデル化 および対話の構造化についての検討 On Constructing Picture Information Modeling and Organizing a Structure of Conversation Module for a Chatterbot System 上野 未貴∗1 森 直樹∗1 松本 啓之亮∗1 Miki Ueno Naoki Mori Keinosuke Matsumoto ∗1 大阪府立大学, 工学研究科 College of Engineering, Osaka Prefecture University Recently, the use of various chatterbots has been proposed to simulate conversation with human users. We proposed a novel chatterbot system called picture information shared conversation agent(Pictgent) which can talk with a user utilizing picture. In our system, each picture has it own situation model with written by XML in order to prepare for communication topics. In this study, we introduced educational problems into the picture model to apply Pictgent to child education. Target child can understand situation of picture by conversation with chatterbot, as developing ability to read and understand with empathy for chatterbot. 1. はじめに 2. 従来研究 工学の大きな目的の一つとして,自然言語を理解する会話 システムが挙げられる.その実現のために,人工知能の分野で は,自然言語処理 [1] に関して多くの研究がなされてきた.し かしながら,未だに十分に人間と対話可能なシステムは実現し ていない. 一方,人工知能に対して,人工無脳 [2] と呼ばれるシステム が提案されている.人工無脳は,知能の実現に過度に拘泥する ことなく,表層的であってもユーザとシステムとの間で興味深 い会話が成立することに重点を置いた,会話の不自然さをある 程度許容した対話システムである.筆者らは,ある分野におい て深い知識を持つユーザでも満足可能な Web からの情報収集 機能を有する新しい人工無脳について提案してきた [3, 4, 5]. この人工無脳は Web 上に存在する集合知 [6] を利用すること によって,ユーザの興味を推定可能という特徴を持つ. また,近年,インターネット環境を利用した新しい学習形態 として,e-Learning[7] について多くの研究成果が報告されて いる.しかし,e-Learning のコンテンツはドリル形式になりや すく,基本的なコンピュータリテラシを持ち,年齢的にある程 度成熟した学習者を対象とするため,低年齢層の学習者に対し ては適用が難しいという問題点がある. 以上の点を背景として,著者らは人工無脳による学習支援 システムの新しいアプローチ手法として,絵情報を用いて対話 可能なシステムについて提案している.本研究では,このシス テムについて説明した後,システムの構築時に必要となる絵情 報のモデル化および対話の構造化について検討する. 以下に本研究の構成を示す.2 章で従来研究について紹介し, 3 章で提案システムの概要を述べる.4 章で絵モジュールにつ いて,5 章でシナリオ進行モジュールについて,6 章で会話モ ジュールについてそれぞれ示す.7 章で提案システムによる対 話例を示す.8 章で Pictgent の実装について述べ,9 章で今後 の課題を述べてまとめる. 人工無脳に関する従来研究としては,初の人工無脳と位置 付けられる ELIZA[8] をはじめとして,今日まで多くのシステ ムが提案されている.絵情報の工学的な利用については,二次 元的に配置された絵文字間の位置関係と既存のオントロジー をマッピングすることで,絵文字の作成や理解を支援し,コ ミュニケーションへの支援などの応用を見込んだ手法が提案 されている [9].絵情報を用いた学習に関しては,物語生成に 学習者を参加させることによって学習意欲の向上を図る,物 語自動生成システムが報告されている [10].絵に限らず,特定 のコンテンツに対するユーザの興味や感情を推定する感情推 定 (Sentiment Analysis) も,近年特に注目されており,多くの 成果が報告されている [11].しかしながら,低年齢層の学習者 を対象とした,絵情報を用いた学習支援システムについては, ほとんど研究がなされていない. 3. 提案システムの概要 3.1 提案システムの基本方針 本研究では,学習者が絵の情報を教師役である人工無脳と 共有しながら会話することによって,学習が可能なシステムを 提案する. 今回は,唯一の答えが存在する問題を解かせることのみを 目的とはせずに,低年齢層の児童に有用と思われる典型的な場 面について示した絵を見ながら,登場人物間の関係や気持ちを 推測させることも重要な目的とする.このような推測には明示 的な答えはないが,道徳的な見地から正しいと考えられる答え を事前に用意しておき,児童がその答えに到達した場合には人 工無脳が賛同する発言をすることで,学習者が人工無脳に共感 を持ちながら,感受性を培い,状況判断能力を高めることがで きる.これにはまず児童の飽き防止の効果がある.また,提案 システムは,学習者の発言が絵や学習意図から完全に離れた場 合でも,何らかの会話を続けることができる点が特徴として挙 げられる.一見,学習には関係のない会話の中にも,学習者が 抱える問題点が含まれている場合もあるため,提案システムは 学習支援システムでありながら,児童の抱える問題点を事前に 察知するカウンセリングシステム的要素も併せ持つ. 連絡先: 上野 未貴,大阪府立大学工学研究科,〒 599-8531 堺 市中区学園町 1 番 1,E-mail: [email protected] 1 3.2 提案システムの構成 提案システムは,絵モジュール,シナリオ進行モジュールお よび会話モジュールの 3 つの構成要素からなる.以下に各モ ジュールの概要を示す. 3.2.1 絵モジュール 本研究の中心的な要素である,絵を示すモジュールである. 単純な絵だけでは計算機が内容を理解することができないた め,事前に絵の内容を表すモデルを与える.モデルには,登場 人物に関する情報および登場人物間の関係が記載される.な お,モデルは XML 形式で保存され,必要に応じて編集が可能 であるとする.絵モジュールを用いることによって,絵の情報 をユーザと共有しながら会話が可能なエージェントを絵情報共 有型会話エージェント (Picture Information Shared Conversation Agent: Pictgent) と呼ぶ. 3.2.2 シナリオ進行モジュール 学習者の学習進度を内部状態として保持し,事前に作成さ れた学習シナリオを持つモジュールである.学習者の入力に応 じて,適切なシナリオ進行を実現する. 学習者が学習シナリオ に従っている場合には,会話モジュールに適切な応答用の情報 を渡す. 3.2.3 会話モジュール 人工無脳に基づき会話をするモジュールである. ただし, 学 習者が学習シナリオに従っている間は,主として定型的な会話 だけをするため,人工無脳的要素は少ない.学習者が何らかの 理由で学習シナリオから外れた場合には普通の人工無脳として 会話をするが,この場合でも可能な限り学習シナリオへの復帰 を促すものとする. 図 1: 対話に用いる絵の例 <?xml version="1.0" encoding="UTF-8"?> <picture> <id scenario="1" page="1" /> <title>pict_math</title> <size width="512" height="512" /> <character> <base id="1" type="人" name="はな" sex="女" age="28" /> <scene> <position>真ん中</position> <expression>微笑み</expression> <emotion target="2">心配</emotion> <action name="見る" target="2" /> <state> <physical></physical> <mental></mental> </state> </scene> <relation name="親子" role="母" target="2" /> </character> <character> <base id="2" type="人" name="たろう" sex="男" age="6" /> <scene> <position>下</position> <expression>しかめっつら</expression> <emotion>困る</emotion> <action name="勉強" target="-1" /> <state> <physical>座る</physical> <mental></mental> </state> </scene> <relation name="親子" role="息子" target="1" /> </character> </picture> 4. 絵モジュール 4.1 絵モデルの表現 本研究では,絵モデルをオブジェクト指向モデリング [12] に基づき構成する.各オブジェクトは内部状態と他オブジェク トとの関係を持ち, ユーザの問いに答えるための基本的な情報 となる.今回は,特に主要な登場人物のみをオブジェクトとし て定義したが,シナリオに直接的には関わらない人物や無生物 をオブジェクトとすることも可能である.絵モデルは,XML 形式で保存され,必要に応じて異なるモデルを用いることやモ デルの編集も可能とする. 図 1 に今回用いる絵の一例を,図 2 に図 1 の絵モデルを表 す XML の例を示す.表 1 にオブジェクトの属性を表す主要な タグを示す. 図 2: 絵モデルを表す XML 表 1: 絵モデルで用いる主要タグ タグ名 <id> <title> <size> <character> <base> <scene> <position> <expression> <emotion> <action> <state> <physical> <mental> <relation> 5. シナリオ進行モジュール 5.1 シナリオ構造 シナリオ進行モジュールは,具体的な学習目標を持つ.学 習目標とは,例えば, 「絵中の算数の問題が解ける」 「登場人物 [S1] が何をしているかわかる」 「登場人物 [S2] が何をしている かわかる」などである.各学習目標ごとに,個別のサブシナリ オが準備されており,最終的に学習目標が達成されるとその目 標に関するサブシナリオは終了する.サブシナリオ間の状態 遷移は,基本的には自由であるが,事前に特定のサブシナリオ を達成しないと遷移できないサブシナリオも存在する.また, 明示的な順序関係を付与することによって,あるサブシナリオ が終了した直後に遷移するシナリオを定めることもできる. また,システムは学習者であるユーザの内部状態を,各学習 目標の達成度を表す学習進度ベクトル uL と各サブシナリオに 説明 各ページごとのオブジェクトの ID. 絵のタイトル. 絵のサイズ.単位は px. 人物オブジェクト. 登場人物に付随し,場面転換で一般的に変わらない特徴. 絵・場面に応じての情報. 絵の中での位置. 表情. 感情.複数保持可.対象を持つ. 動作.対象を必ず付す. オブジェクトの内部状態や付帯状況.対象をもたない. 身体的な状態.ex:病気である,怪我をしている 精神的な状態.ex:迷っている,落ち込んでいる 他のキャラクタとの社会的・静的な関係性.複数保持可. 対する親和度を表すシナリオ親和ベクトル uS として保持する. ここで, N s = |uL | = |uS | はサブシナリオの総数を表す.今回 は,学習進度ベクトルの各要素は (-1: 未学習,0:学習中, 1:学 習済み),シナリオ親和ベクトルの各要素は (0: 興味なし,1:シ 2 ナリオ進行中) とする.システムの状態は,ただ一つのサブシ ナリオに属するか,すべてのサブシナリオに属さないかのいず れかである.サブシナリオの決定は,選択可能なサブシナリオ の中から,何らかのアルゴリズムを用いてなされる. 各サブシナリオは以下の構成をとる.以下では,サブシナリ オ i について考えるものとし,学習進度ベクトルおよびシナリ オ親和ベクトルの要素 i は以下の値であるとする. uLi = −1, uSi = 0 提案システムによる対話例 7. 図 3 に状態遷移の例を,表 2 に,実際の対話例を表す.ま ず,全体導入によりシナリオが始まり,サブシナリオへと遷移 する.サブシナリオからサブシナリオへの遷移は,学習進度ベ クトルやサブシナリオ親和ベクトルから決定する.例では,サ ブシナリオ 1 から 2 へと遷移しており,その後,サブシナリ オ 2 を達成していることを条件として,達成対話へと遷移し ている.また,分岐 1 で正例と判定されたとして対話が進行し ている. (1) 導入部 ユーザにこれからどのような問題に取り組むのかを理 解させる.ここで,ユーザから問題解決について肯定的 な意見を得られた場合は,uLi = 0, uSi = 1 とする.否定 的な答えの場合は事前に定められた回数回サブシナリオ i への導入を試み,それでも否定的な答えしか得られない 場合は,ベクトルの要素はそのままで,このサブシナリ オを抜け,これ以外の選択可能サブシナリオの中から次 のサブシナリオを一つ決める. 7.1 対話例における学習目標 例での学習目標は, 「登場人物 [S1] が何をしているかわかる」 「絵中の足し算に正解する」「登場人物 [S2] の気持ちを答える ことができる」などである. 7.2 質問の種類 質問には,目標質問と共感質問の 2 種類がある.以下に各 質問について述べる. 7.2.1 目標質問 主に学習目標に基づいたもので,明確な解を用意し,正例 もしくは負例の判定をするものである.すなわち, 「絵中の足 し算に正解する」に対しては, 「13+28=」の答えを「41」を意 味する形で答えることが正例となる.また, 「登場人物 [S1] が 何をしているかわかる」では, 「勉強している」 「算数をしてい る」を意味する答えを正例とみなす. 7.2.2 共感質問 教育効果を上げるため,ユーザに登場人物の気持ちに共感す るように促すような内容の質問を共感質問とする.これには正 例,負例といった明確な解は用意しない.例として, 「[S1] は 今どう思っているかな?」といったような質問である. 議論部 問題に明確な答えがない場合には,ここで議論をする. 議論の途中でユーザの興味がなくなってきた場合や十分 な議論がなされた場合には解答部に遷移する.解答前にサ ブシナリオ i に対する興味を失った場合,uLi = 0, uSi = 0 として,これ以外のサブシナリオを選択する.将来的に このサブシナリオが再び選ばれた場合には,学習進度ベ クトルが [学習中] を示しているため,導入部はスキップ 可能とする. 解答部 ユーザから提示した問題に対する解答を得る.計算問 題のように,明示的に正解が存在する場合には,正解不 正解に応じて応答を返す.明確な答えがない問題の場合 には,システムの解答例を示し,それに対するユーザの 意見を聞く.解答部が完了すると,問題が終了したこと を告げ,uLi = 1, uSi = 0 として,サブシナリオ選択モー ドに戻る.各ユーザの入力は,サブシナリオごとにログ として保存され,後から保護者や教育者が,学習者の入 力を体系立てて取得することを可能とする. 表 2: 対話例 シナリオ名 全体導入 話者 b 種別 < 導入対話 > サブシナリオ 1 b < 導入対話 > < 目標質問 1> < 入力 1> u なお,サブシナリオは内部的にサブシナリオを持つことが 可能であり,階層的な構造を取ることができる. サブシナリオ 2 5.2 状態遷移 図 3 にサブシナリオ間の状態遷移の例を表すアクティビティ 図 [12] を示す.図中の類似度とは,ユーザの入力と解答の近 さを表す. 提案システムでは,事前に用意したシナリオに沿ってサブシ ナリオ間を状態遷移する.ユーザの状態遷移がどのサブシナリ オにも適合しない場合は「雑談モード」と呼ばれ,任意の話題 について人工無脳と会話可能となる.これにより,エキスパー トシステムのように想定した入力しか処理できないという問題 点は提案システムにはない.一方,人工無脳の持つ対話が発散 してしまうという問題点は豊富なサブシナリオを準備すること で解決できる. b < 正 1> b c b u b < 導入対話 > < 共感質問 1> < 自由入力 1> < 目標質問 2> 達成対話 u < 入力 2> c < 正 2> b u b < 共感質問 2> < 自由入力 2> < 共感質問 3> u < 自由入力 3> b u: ユーザ,b: 人工無脳, c: 登場人物 文章 こんにちは. この絵を見て. 遷移 男の子とお母さんがいるね. 男の子は何をしているかな? 勉強している. [分岐 1] そうだね. 遷移 あれ?男の子が何か言っているよ. うーん.どう解くんだっけ? 男の子はどんな気持ちかな? 困っている. そうかな. 問題は, 13+28= と書いてあるね. 答えの数字を入力して男の子を助けてあげよう. 41 かな. [分岐 2] えーっと. あ,僕もちゃんと 41 って答えになったよ. 遷移 良かったね. 君のおかげでうまくいったみたい. お母さんはどんな気持ちかな? 嬉しがってる. お母さんが男の子を褒めているよ! 男の子はどんな気持ちかな? 喜んでいる. ありがとう!二人とも嬉しそうだね. 6. 会話モジュール 本章では会話モジュールの構成について述べる.現在,会話 モジュールは雑談時には従来の人工無脳を用い,学習時には単 純な質問応答モジュールを用いている.今回の提案システムで は低年齢層の児童を対象とすることから,ユーザの意図を解釈 しにくい入力が少ないことを前提としている. 8. Pictgent の実装 本章では提案する Pictgent の具体的な実装を述べる.以下 に,システム構築時に必要となる絵情報のモデル化および対話 の構造化および,インタフェースの実装について検討する. 3 એ㒠⋭⇛ 図 3: サブシナリオ 1 から 2 への状態遷移例 8.1 会話モジュール 情報モデル,XML を対話的に生成する必要もあると考える. そこで,言語と絵を結びつけた絵情報のモデルを作成するに あたって,有用なインタフェースについて詳述する.図 4 に Pictgent の概観を示す. 簡単な対話モジュールを作成し,その組合せで高次の処理を する対話モジュールを構築する.この対話モジュール自体もま たより高次なモジュールの部分となり得る.質問に対する肯定 と否定の返事を判断する Yes-No Question モジュール,5W1H Question モジュールを作成し,対話をなるべく簡単な形で捉え る.そしてこのモジュールの組合せにより,再利用性を高めた 対話処理を目指す. 8.2.1 入力支援インタフェース 調査を進める中で,児童にとってはキーボード入力が難し いという意見が多かった.また,大体の文は作ることができる が,絵の中の一部の物に対して,語彙を獲得できていない可能 性がある.そこで,特別なツールを使わず,なるべく多くの児 童を対象としたいことから,補助入力パレットインタフェース を実装した.使用するかしないかはユーザが決めることができ る.以下にそのインタフェースのアルゴリズムを記載する. 8.2 絵情報のモデル化 絵の中の登場人物や登場人物間の関係といったものを記述す る際,工学での UML におけるオブジェクト図とソシオグラム を融合した内容を XML で記述する.オブジェクト図としてモ デル化することの利点として,再利用性の高さを挙げる.例え ば,子が足し算を解いている様子を母が心配そうに見守ってい る絵がある.その絵に紐付ける情報をモデルとして抽象化して おくことで,母と子という絵の関係性であったり,問題を変え た絵を作った際に,具体的な属性である名前や問題内容を追加 して記述するだけで,そのモデルに対する学習目標やシナリオ を選ぶことができる. モデルは作成者側の知識だけではなく,児童の語彙から絵 1. 絵中の情報を取得して,人物名や動作で列を分けて入力 候補として表示する.また,関連する単語を取得できる 場合は同様に表示する. 2. 選択された単語が,テキストフィールドのカーソルの箇 所に入力される. また,絵情報をすべて用意するのは困難なため,児童の入力 からの絵情報モデルの生成を考える.A という名前だけの記述 4 された絵情報のモデルに対して以下の手順を例として考える. 8.3 複数枚の絵の遷移と対話からの絵生成 絵本では,複数の絵の遷移が順番に進む.しかし,実際に児 童に絵本を読み聞かせる際には,次の展開を児童に問いかけ て,絵本通りではないお話を作ることもある.そこで,システ ムと対話することにより,次の場面の絵が生成され,絵本の中 の人物と対話することにより展開が変わる新しい絵本コンテン ツの創造を考えている. 1. A の位置を問う. (例:A はどこにいるかな?丸で囲んで みて) 2. 指ツールもしくは範囲指定ツールで囲まれた部分の座標 を取得し,位置情報を絵情報のモデルに追加する. このように,絵を利用した入力を促して,モデルを生成する. 8.2.2 顔パーツと児童の語彙の結びつけ 以前会った人の顔の特徴など,視覚を主とした記憶を説明 する際に用いる語彙について考える.例えば, 「大きくてくり くりした目をしていた」など,人は形容詞やオノマトペを使っ て説明することがあるが,互いの言語と概念や視覚の結びつき により頭の中で思い描くものは異なる.そこで,言語からの絵 の生成を考える.まず,児童にとって最も馴染みやすい画像情 報であると思われる,人物の表情を例に挙げる.登場人物が途 中で姿を隠すようなシナリオを使い,顔を当てるよう指示し, 以下のステップに沿って対話および入力を進める. 9. まとめと今後の課題 本研究では,絵の情報をユーザと共有しながら会話が可能な人 工無脳として絵情報共有型会話エージェント (Picture Information Shared Conversation Agent, Pictgent) を提案し,Pictgent を用い た学習支援システムの紹介と,その構築に関わる絵モデルと対 話構造などを検討した.今後の課題として,実際に児童がシス テムを使用した場合の教育効果の測定および各モジュールの改 善,とりわけ会話モジュールの精度向上が挙げられる. 今後は,ログの解析により適切なサブシナリオに自動的に 状態遷移するアルゴリズムの考案や,対話型進化型計算による 文生成についても考慮し,柔軟な応答が可能な学習システムの 実現を目指す. 1. 顔の特徴を問いかける. (例:どんな顔をしていたかな?) 2. 1. の質問で得られる入力が十分な場合は 4. へ進み,不十 分な場合は,3. の誘導質問へと進む.この場合の十分と は,一定数の顔パーツについて特徴が入力されているこ とである. LCCII に寄せて 既存の概念を壊した,新しい学際領域の創出を目指す研究 会とのことで,既存の論文体系に捉われず本節を書く.正確に 人の知識を文法構造を再現できたら,果たして人らしいものが できるのだろうか.私たちは何を一番作りたいのだろうか. これほど多くの研究が続く中,未だに ELIZA を超えるドメ インを限定しない対話システムは難しい.人は対話システムに 何を求めているのだろう.外国語を学習している相手と対話す るとき文法にこだわらずとも,単語を並べればある程度言いた いことを伝えることができる.間違っていても,相手は勉強中 だからという配慮から,分からなかったところを聞こうと問い 返す.つまり,相手の発言すなわち入力に答える際に,完璧な 一文である必要も,一度の出力で全てに答える必要もない. また,情報が多くなった今,多くの言語データを集めて統計 的に処理をすれば良い結果が出るのではないかという方向に時 代は進んでいるように思われる.統計量はある一定の期間にお いて,多くの人の平均としてならされた量である.そこに時間 の流れや個性や感情はない. 私たちの生活で切り離せない時間や個性や感情,人はきち んとそこで息をしているものに人らしさを見出す.Twitter bot が 同じようなことしかツイートしていなくとも,時間の流れ を付加すると,とたんに Twitter の中で生活しているように錯 覚する人もいる.感情を機械において擬似的に表現することが 悪いことだとも思わない.時に人を和ませ笑わせる. そういう個性や感情から生まれるモデルを絵を使って引き出 せないだろうか.絵はそれだけを与えてしまうと,人の表現を 逆に奪ってしまうこともある.言語だけの方が,ずっと人の表 現を広げることもある.言語から絵を,絵から言語を,その間 の広がりを丁寧に追うことで,言語や絵だけに収まりきらない 人の内部の複雑なように見えて単純な状態や人のコミュニケー ションをきちんと拾い上げたい. 私は,無機質なものの中に有機性を見出すことに魅力を感 じる.ロボットのようなハードがなくとも,表現次第でコード から立ち上がり,動いていく.それは小説の中の人物が徐々に 読み手の中に形作られていくモデルと似ているかもしれない. 3. パーツに対する一つの要素ごとに質問をする. (例:目が 大きかった?小さかった?,どんな形の目をしていた?) 4. 入力中の単語をもとに用意された顔パーツから全体の顔 を生成し提示する.この単語とは,例えば形容詞やオノ マトペをさす. 5. 4. で生成された顔が児童の意図に沿わない場合はどの パーツが違うかを尋ねる.意図に沿う場合は 9. へ進む. 6. ペイントできるウィンドウを表示し,5. で指定されたパー ツを自由に描かせる. 7. 入力された単語と共にパーツを保存する. 8. 児童の納得が得られるか,もしくは設定した入力回数に 達するまで,各パーツについて,3.∼7. のステップを繰 り返す. 9. 顔全体と入力された単語,生成されたパーツの情報を保 存する. このようにパーツごとに絵と言語を結びつけた情報を蓄え ることにより,言語からの絵生成のプロトタイプを作る予定で ある.また,これは 8.1 で述べたモジュールの一つとして顔生 成(人相問い合わせ)モジュールとして実装予定である.単に, 画像を生成するだけであれば,画像を直接クリックして選ぶ手 法の方が児童にとって容易であり,直感的だが,言葉で説明す ることにより,思わぬ絵ができることで児童の好奇心を刺激す ることができると考えている.また,このインタフェースの実 装により言語から想像するイメージのユーザ間の違いを考察す ることも可能である.つまり,XML の入力支援と対話の動機 付けを兼ねたインタフェースである.また,このツールによっ て,児童が自分の絵に容易に文字情報を付加することができる ため,児童同士で作成した絵を相互に用いることによって,よ り共感を伴った対話を実現することも可能となる. 5 ⛗ᖱႎߩਛߩන⺆߿㑐ㅪേߩឭ␜ ኻࠪࠬ࠹ࡓ ⛗ᖱႎࡕ࠺࡞ߣࠝࡉࠫࠚࠢ࠻ Person1 DOM Person2 ߅ߣߎߩߎ ߚࠈ߁ ߴࠎ߈ࠂ߁ ߽ࠎߛ ߒߡࠆ ߣߡࠆ ࡑࡑ ߅߆ߐࠎ ߐࠎߔ߁ ߚߒߑࠎ ߆ߡࠆ ߺߡࠆ ߅ࠎߥߩ߭ߣ ߆ߺ ߪߥ XML ࠠࡖࡦࡃࠬߣࡄ࠶࠻ ⛗ߩਛߩੱ‛ࠍ ޟਣߢ࿐ޠ ޟᜰࠍᜰߔ࡞࠷ޠ ᣢߦࠆ⛗ߦ ߅߅߈ ߊࠅߊࠅ ߜߐ ߜࠂߎࠎ ߹ࠆ ߹ࠆ ߈ࠄ߈ࠄ ߆߇߿ߚ ᒛ㧦⸒⪲ߣ⚿߮ߟߚ㗻ࡄ࠷ࠍឭ␜ߔࠆ ઃߌ⿷ߒߡឬߊߎߣ߽ߢ߈ࠆ 図 4: Pictgent の概観 人らしさが滲み出ているものに愛着を感じる.それは,きちん と人々の中に溶け込んでゆくように思われる. [5] 上野 未貴, 森 直樹, 松本 啓之亮 : 人工無脳システムにおけ る Web 情報を用いた興味推定-II, 計測自動制御学会若手研 究特別発表会講演論文集, 105-108 (2011) 謝辞 [6] Toby Segaran : 集合知プログラミング, オライリー・ジャパ ン (2008) なお,本研究は一部,日本学術振興会科学研究補助金基盤研 究 (C) (課題番号 2500208) の補助を得て行われたものである. また本研究は一部,財団法人科学技術融合振興財団の助成を得 て行われたものである. [7] 日本イーラーニングコンソシアム (編集): e ラーニング白 書〈2008/2009 年版〉東京電機大学出版局 (2008) [8] J. Weizenbaum : ELIZA–A Computer Program For the Study of Natural Language Communication Between Man and Machine, Commun. ACM 9[1], 36-45 (1966) 参考文献 [1] S. Bird, E. Klein, E. Loper (萩原,中山,水野 (訳)) : 入門 自 然言語処理, オライリージャパン (2010) [9] 伊藤 一成, 橋田 浩一:絵文字の作成と理解を促進するた めのオントロジーマッピング, 報処理学会研究報告. データ ベース・システム研究会報告 2006(78), 505-510 (2006) [2] 秋山智俊 : 恋するプログラム -Ruby でつくる人工無脳-, 毎 日コミュニケーションズ (2005) [10] 岩垣 守彦, 小方 孝 : コンピュータとインターネットに「物 語生成」を組み合わせた言語学習プログラム, 電子情報通 信学会技術研究報告. TL, 思考と言語 107(323), 7-12, (2007) [3] Miki Ueno, Naoki Mori, Keinosuke Matsumoto : Novel Chatterbot System Utilizing Web Information, Distributed Computing and Artificial Intelligence Advances in Soft Computing, Volume 79, 605-612 (2010) [11] 徳久 雅人, 村上 仁一, 池原 悟 : テキスト対話コーパスか らの発話対と情緒の分析, 電子情報通信学会技術研究報告. TL, 思考と言語 108(50), 41-46 (2008) [4] Miki Ueno, Naoki Mori, Keinosuke Matsumoto : Novel Chatterbot System Utilizing BBS Information for Estimating User Interests, Distributed Computing and Artificial Intelligence Advances in Soft Computing, Volume 79, 237-240 (2010) [12] 松本 啓之亮: ソフトウェア工学,森北出版 (2005) 6
© Copyright 2026 Paperzz