1-Q-26b
ケプストラム距離に基づく
NMF の高速化手法と VQ 手法による音楽重畳音声の認識∗
☆仲野翔一, 山本一公, 中川聖一 (豊橋技術科学大)
1
はじめに
音声認識の性能は,雑音のある環境では大きく低
下する.したがって,雑音のある音声を認識する際に
は,雑音の影響を軽減させるような前処理を行う.一
般的な雑音除去の手法としては,スペクトルサブト
ラクション法や Wiener フィルタが挙げられる.しか
し,これらの手法は定常的な雑音に対しては有効で
あるが,非定常な雑音に対しては有効でないことが
知られている.そこで本稿では非定常な信号である
音楽が背景雑音として重畳された音楽重畳音声の音
楽除去を検討する.
シングルマイクロホンによる音源分離手法として
は,ベイジアンネットワークを用いてマスクパターン
を生成し,バイナリマスキングをかけることで音源
を分離する方法 [1] が提案されている.また,話者依
存/非依存モデルと CASA(Computational Auditory
Scene Analysis)に基づくアプローチで複数話者の混
合音声から特定話者の音声を分離する研究も行われ
ている [2].マルチマイクロホンによる音源分離手法
としては,独立成分分析(ICA)に基づく手法 [3] が
広く用いられている.
我々は,シングルマイクロホンによる背景音楽を含
む入力音声に対して,ベクトル量子化(Vector Quantization:VQ)手法 [4] と非負値行列因子分解(Nonnegative Matrix Factorization: NMF) [5] の 2 つの
手法で背景音楽の除去を行い,これらの手法が音声認
識率へ与える影響について検討を行ってきた [6] [7].
文献 [6] では 2 つの手法による音楽除去によって音声
認識率の改善が得られたが,NMF による音楽除去は
非常に計算コストが高く実用的では無かった.そこ
で,文献 [7] では,NMF による分離を近似的に実現
する手法を提案し,従来の NMF による音楽除去より
も約 50 倍高速化した.本稿では,さらなる改善とし
て,従来の振幅スペクトルの距離尺度ではなく,ピッ
チの影響によるスペクトル変動を取り除いたケプス
トラムの距離尺度を導入することを提案する.
2
Fig. 1
トル領域で行う.
1. クリーン音声(音楽が重畳されていない音声)
S(i) に音楽 M (i) を重畳して,音楽重畳音声
Y (i) = S(i) + M (i) を作成する.i はフレー
ム番号を表す.
2. 音楽重畳音声とそれに対応するクリーン音声の
振幅スペクトルのペアを作成する.
{Y (i) = S(i) + M (i), S(i)}
3. スペクトルペアを特徴量として VQ コードブッ
クを作成する.{Ŷ (k), Ŝ(k)}
4. 入力音声 (音楽重畳音声) Y (j) と VQ コードブッ
クのコードベクトルの音楽重畳音声部分の振幅
スペクトルでスペクトル間の距離を計算する.
D(j, k) = ||Y (j) − Ŷ (k)||
5. 最も距離が近い VQ コードベクトルから音楽重
畳音声とクリーン音声の振幅スペクトルでフィ
ルタを構成し,入力音声にかける.C1 , C2 はス
ムージングのための定数.
Ŝ(j) = Y (j)×
∗
Ŝ(k̂) + C1
Ŷ (k̂) + C2
, k̂ = arg min D(j, k)
k
6. 音声成分だけが残ったスペクトルから音声波形
を復元する.位相は Y (j) の値を用いる.
ベクトル量子化手法による音楽除去
我々は統計的なモデルに基づく音源分離手法 [8] [9]
を簡易的に VQ による代表的なサンプルで実現する
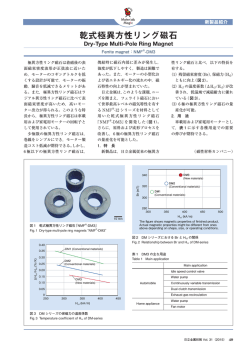
方法を提案してきた [6].Fig. 1 に VQ コードブック
マッピングによるスペクトル置換を用いた音楽除去
の概略図を示す.
手法の手順を以下に示す.以下の処理は振幅スペク
VQ 手法の概略図
学習データを用いて手順 1 ∼ 3 を予め行っておい
て,各入力音声に対して手順 4 ∼ 6 を行う.
Speech recognition of mixed sound by fast nonnegative matrix factorization and vector quantization
method based on cepstrum distance. by NAKANO, Shoichi, YAMAMOTO, Kazumasa, NAKAGAWA,
Seiichi (Toyohashi University of Technology)
日本音響学会講演論文集
- 163 -
2013年3月
3
3.1
非負値行列因子分解法による音楽除去
一般的な NMF
NMF は,n × m 行列 Y を n × r 行列 W と r × m
行列 H に分解する手法である.
V ≈ WH
(1)
行列 Y ,W ,H のすべての要素は非負であるという
制約の下で,コスト関数を定義し,これを最小化する
W と H を分解結果とする.ここでは,Y と W H と
の距離であるカルバック・ライブラー・ダイバージェ
ンス DKL をコスト関数とする.DKL は次のように
定義される.
)
∑(
Yij
DKL =
Yij log
− Yij + (W H)ij
(W H)ij
Fig. 2
i,j
(2)
以下の更新式で DKL が増加しないように V と W H
を更新することができる.
∑
Wik Yij /(W H)ij
(3)
Hkj ← Hkj i ∑
i Wik
∑
j Hkj Yij /(W H)ij
∑
Wik ← Wik
(4)
j Hkj
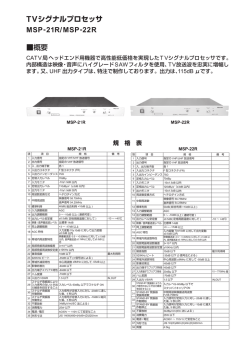
はスムージングのための定数を表す.Fig. 2 に NMF
による分離の概略図を示す.
NMF 法による音声と音楽の分離の手順をまとめる
と以下のようになる.
1. 音声と音楽の代表スペクトル Ws ,Wm を求め,
結合し行列 W とする.
2. 入力音声の振幅スペクトログラムを求め行列 V
とする.
3. 式 (3) の反復により重み行列 H を求める.
4. NMF により得られた W と H よりフィルタを構
成する.
5. 入力音声の振幅スペクトログラムにフィルタを
かけて音声と音楽へ分離する(式 (6)(7)).
DKL が収束するまで更新を繰り返して,得られた
W と H を分解結果とする.
3.2
NMF の音源分離への適用
本稿では,文献 [10] の NMF を用いた音素認識法
の考えを参考にして音楽重畳音声を音声と音楽に分
離する.行列 Y を入力音声の各フレームの振幅スペ
クトルを列ベクトルとして時系列に m 個 (発声時間
長) 並べた振幅スペクトログラムとして,これが,音
声と音楽の代表スペクトルを列ベクトルとして r 個
並べた行列 W と,各代表スペクトルに対するフレー
ムごとの重みを行ベクトルとして r 個並べた行列 H
に分解されると考える.ここで,あらかじめ音声の代
表スペクトル行列 Ws と音楽の代表スペクトル行列
Wm を求めておいて,W = [Ws Wm ] とする.この W
を使って 式 (3) の更新式で H を求める (W は固定).
Ws に対する重みを Hs ,Wm に対する重みを Hm と
すると,
Y ≈ Ws Hs + Wm Hm
(5)
3.3
Ws Hs + C1
Ws Hs + Wm Hm + C2
(6)
M̂ = Y ×
Wm Hm + C1
Ws Hs + Wm Hm + C2
(7)
ここで,Ŝ は音声の振幅スペクトログラムの推定値,
M̂ は音楽の振幅スペクトログラムの推定値,C1 , C2
日本音響学会講演論文集
NMF による音源分離の高速化手法
3.2 節で述べた手法では入力音声ごとに行列分解を
行う必要があり,計算量が多いために実用的でない.
そこで,学習データの音楽重畳音声から VQ コード
ブックを作成し,この VQ コードベクトル集合を行
列分解しておき,入力音声に対して対応する分解結
果を用いることで NMF による分離を近似的に実現す
る手法を提案した [7](以下,fastNMF).Fig. 3 に
fastNMF の概略図を示す.
手法の手順を以下に示す.
1. 音楽重畳音声,音声,音楽の代表スペクトル行
列 Ŷ ,Ws ,Wm を求める.
2. 音楽重畳音声の代表スペクトル行列 Ŷ を NMF
により分解し,重み行列 H を求める.
3. 入力音声 Y と Ŷ の各列との距離を計算し,距離
が最も近い列のインデックスを求める.
4. 得られたインデックスに対応する H と基底 W
よりフィルタを構成する.
5. 入力音声の振幅スペクトログラムにフィルタを
かけて音声と音楽へ分離する(式 (6)(7)).
となり,Ws Hs が音声,Wm Hm が音楽となるように
分離できる.ここでは,以下に示すように分離結果か
らフィルタを構成して,入力音声にかけることで音声
と音楽のスペクトログラムの推定値を得る.
Ŝ = Y ×
NMF による分離
手順 1,2 を予め行っておいて,各入力音声に対して
フレーム・バイ・フレームで手順 3 ∼ 5 を行う.NMF
による分解を予め 1 度だけ行っておけばよい(手順
2)ので計算量が大幅に削減される.
- 164 -
2013年3月
新式の導出が困難で,近似式を用いて更新すると却っ
て悪くなってしまったので,今回は使用していない.
5
孤立単語認識実験
5.1
Fig. 3 fastNMF の概略図
4
ケプストラム距離尺度の導入
2, 3 章で説明した従来法では,特徴量として振幅ス
ペクトルのみを用いていた.しかし,振幅スペクト
ルは,ピッチの影響によるスペクトルの変動が多い
ため,その影響を軽減する枠組みが課題であった.そ
こで本稿では,VQ コードブックの作成・検索の際に
ピッチの影響が取り除かれた特徴量であるケプスト
ラムの距離尺度を導入することを提案する.
4.1
VQ 手法への導入
従来法では,音楽重畳音声と対応するクリーン音
声の振幅スペクトルのペアをコードベクトルとして,
音楽重畳音声の振幅スペクトル部分でクラスタリン
グを行い VQ コードブックを作成していた.
提案法では,音楽重畳音声とクリーン音声の振幅ス
ペクトルに加えて,音楽重畳音声の低次ケプストラム
を含めてコードベクトルとし,音楽重畳音声の低次ケ
プストラム部分でクラスタリングを行い VQ コード
ブックを作成する.そして,音楽除去フェーズでは,
入力音声の低次ケプストラムと VQ コードブックの
音楽重畳音声の低次ケプストラム部分との距離を計
算し,最も近いものに対応する音楽重畳音声とクリー
ン音声の振幅スペクトルでフィルタを構成する.
4.2
fastNMF への導入
音楽重畳音声の代表ベクトルを VQ により作成す
る際に,低次ケプストラムと振幅スペクトルの結合ベ
クトルをコードベクトルとして,低次ケプストラム部
分でクラスタリングを行い VQ コードブックを作成
する.そして,音楽除去フェーズでは,入力音声の低
次ケプストラムと VQ コードブックの低次ケプスト
ラム部分との距離を計算し,最も近いものに対応する
振幅スペクトルの分解結果からフィルタを作成する.
ただし,音声と音楽の代表ベクトルを VQ で作成す
る際には,従来法と同じ振幅スペクトルのユークリッ
ド距離尺度を用いた.なお,式 (2) の代わりに,ケプ
ストラム距離尺度に変更することも考えられるが,更
日本音響学会講演論文集
実験条件
本実験では,東北大–松下単語音声データベースか
ら 200 単語,20 話者分について,15 話者分を学習,
5 話者分をテストに使用した.音声データはサンプリ
ング周波数 12kHz,サンプリング精度 16bit のモノラ
ル音声である.背景音楽はピアノ三重奏曲 1 曲(ピ
アノ,バイオリン,チェロ)を学習用とテスト用に分
割して用いた.単語区間は目視により手動で切り出
した.
VQ 手法のコードブックは,15 話者分の学習データ
に SNR が 20dB,10dB,0dB,−5dB となるように
音楽を重畳したもので作成した.特徴抽出は窓長 512
点(256 次元のスペクトル),フレームシフト 256 点
である.従来法は,スペクトル領域において均等帯
域で 4 分割したコードベクトル(64(混合音) + 64(音
声) = 128 次元)で,コードブックサイズは 8192 と
した.従って,81944 通りのベクトル表現が可能であ
る.一方,提案法では対応するケプストラムとの結合
ベクトルのため,分割は行わず,低次ケプストラムと
スペクトルの結合ベクトル(20 + 256 + 256 = 532 次
元)をコードベクトルとし,サイズは 8192 とした.
fastNMF の混合音の代表ベクトル集合は,低次ケプ
ストラムとスペクトルの結合ベクトル(20+256 = 276
次元)をコードベクトルとし,サイズは 4096.行列
W の代表スペクトルは VQ 手法により音声,音楽と
もに 512 個ずつ選んだ.特徴抽出は窓長 512 点,フ
レームシフト 256 点である.
また,スムージングのための定数 C1 , C2 は VQ 手
法,NMF ともに 1 とした.
音声認識の音響モデルは,状態数 14,ガウス分布
の混合数 8(対角共分散行列) の単語 HMM である.特
徴パラメータは MFCC38 次元 (MFCC + ∆MFCC +
∆∆MFCC + ∆パワー + ∆∆パワー) で,窓長 25ms,
フレームシフト 10ms で抽出した.
テストデータは,5 話者分の音声に SNR が 20dB,
10dB,0dB,−5dB になるように音楽を重畳して用い
た.また,VQ 手法と NMF の併用として, VQ 手法
で音楽除去してから認識した尤度と NMF で音楽除去
してから認識した尤度を以下の式のように重み付き
の線形結合でリスコアリングを行った (α を 0.0 ∼ 1.0
まで 0.1 刻みで変化させ最大値を結果とした).
P = (1 − α)PV Q + αPN M F
5.2
5.2.1
(8)
実験結果
クリーン音声によるモデル
クリーン音声で学習した HMM で認識した場合の
結果を Table 1 に示す.VQ 手法の提案法は,20dB で
90.9% から 93.4%,10dB で 74.1% から 74.8%,0dB
- 165 -
2013年3月
Table 1
クリーン音声のモデルでの認識率 [%]
入力・手法
処理なし
VQ 手法 (従来)
VQ 手法 (提案)
NMF
fastNMF(従来)
fastNMF(提案)
両手法の併用 (従来)
両手法の併用 (提案)
クリーン音声
−5dB
2.2
8.0
9.4
20.6
5.2
8.2
8.0
10.4
SNR
0dB 10dB
7.8
53.4
20.0
74.1
27.3
74.8
42.7
83.2
17.6
71.4
17.5
66.1
21.9
74.7
28.4
75.1
98.8
20dB
86.1
90.9
93.4
92.9
90.4
91.5
91.8
93.4
で 20.0% から 27.3%,−5dB で 8.0% から 9.4% と全
ての SNR において従来法から改善が得られた.そし
て,fastNMF の提案法は,20dB で 90.4% から 91.5%,
−5dB で 5.2% から 8.2% と従来法から改善が得られ
たが,10dB で 71.4% から 66.1%,0dB で 17.6% か
ら 17.5% と改善が得られない SNR もあった.特に,
10dB では従来法から大きく低下してしまっている.
これが,手法とテストデータのどちらに起因するも
のかどうか調査する必要がある.尤度結合による両
手法の併用では,20dB を除く SNR でそれぞれ単独
よりもさらなる改善が得られ,処理なしの場合から
比べて,20dB で 7.3%(誤り削減率約 53%),10dB
で 21.7% (誤り削減率約 47%)の改善が得られた.
5.2.2
マッチド条件によるモデル
次に,マッチド条件での認識率を Table 2 に示す.
“音楽重畳音声” は,SNR が ∞dB,20dB,10dB,
0dB,−5dB の音楽重畳音声で学習した HMM で音楽
重畳音声を認識した場合の結果を示している.“VQ
手法” は,SNR が 20dB,10dB,0dB,−5dB の音楽
重畳音声を VQ 手法で音楽除去を行った後の音声 +
クリーン音声で学習した HMM で,VQ 手法で音楽除
去を行った後の音声を認識した場合の結果を示してい
る.“fastNMF” も同様である.VQ 手法の提案法は,
全ての SNR で従来法から改善が得られ,特に 0dB で
66.6% から 72.6%,−5dB で 35.4% から 42.3% と低
い SNR で大きな改善が得られ,全ての SNR で音楽
重畳音声を上回る結果が得られた.一方,fastNMF
の提案法では,クリーン音声のモデルの場合と同様
に改善が得られない場合もあった.尤度結合による両
手法の併用では,fastNMF の提案法が 20dB と 10dB
で改善が得られなかった影響で従来法からの改善は
得られなかったが,0dB と −5dB では改善が得られ
た.また,音楽重畳音声を含む 3 手法を併用でも同
様の傾向であった.
6
まとめ
本稿では非定常な信号である音楽を背景雑音とす
る音楽重畳音声の音声認識のための NMF による音楽
除去の高速化手法および VQ 手法に対して,ピッチの
影響によるスペクトル変動の多さを軽減するために,
ケプストラム距離尺度を導入することを提案した.
クリーン音声のモデルでの孤立単語認識では,VQ
日本音響学会講演論文集
Table 2
マッチド条件での認識率 [%]
入力・手法
(a) 音楽重畳音声
(b) VQ 手法 (従来)
(c) VQ 手法 (提案)
NMF
(d) fastNMF(従来)
(e) fastNMF(提案)
併用 (b + d)
併用 (c + e)
併用 (a + b)
併用 (a + c)
併用 (a + b + d)
併用 (a + c + e)
−5dB
25.0
35.4
42.3
48.3
22.1
37.3
37.7
45.9
37.5
43.4
39.6
47.2
SNR
0dB 10dB
59.3
94.4
66.6
95.7
72.6
96.0
76.1
94.0
61.1
94.1
66.1
93.3
72.1
97.2
76.2
96.8
73.6
96.7
76.3
97.4
77.3
97.9
78.7
97.4
20dB
98.5
98.5
99.0
97.1
98.6
98.6
99.4
99.0
98.7
99.5
99.6
99.5
手法の提案手法は,従来法から改善が得られ,音楽除
去を行わない場合に比べて約 47% の単語誤り削減率
が得られた(10dB の場合).マッチド条件では併用
法で,10dB でもクリーン音声の認識と同程度,0dB
でも約 80% の高い認識率が得られた.
今後の課題としては,fastNMF の提案法で改善が
得られなかった場合について,それが手法とテスト
データのどちらに起因するのかどうか調査する必要
がある.また,時系列情報を考慮した枠組みを考える
こと,学習とテストで別の曲を使うなど,より複雑な
タスクへの適用や単語区間の切り出しを自動で行う
ことなども今後の課題である.
参考文献
[1] 伊藤 他, “ベイジアンネットワークを用いたバイ
ナリマスキングに基づく音源分離,” 情報処理学
会研究報告, vol.2008, no.72, pp.51–56, 2008.
[2] M. Cooke et al., “Monaural speech separation
and recognition challenge,” Computer Speech
and Language, vol.24, no.1, pp.1–15, 2010.
[3] M. A. Casey, and A. Westner, “Separation of
mixed audio sources by independent subspace
analysis” Proc. International Computer Music
Conference, 2000.
[4] K. Yamamoto, S. Nakagawa, “Evaluation of
privacy protection techniques for speech signals,” Proc. IPMU 2010, pp.653–662, 2010.
[5] D. D. Lee, H. S. Seung, “Algorithms for Nonnegative Matirix Factorization,” Proc. NIPS
2000, pp.556–562, 2000.
[6] 仲野 他,“NMF と VQ 手法による音楽重畳音声
の音声認識,” 信学技報, vol.111, no.97, SP201134, pp.23-28, 2011.
[7] 仲野 他,“音楽重畳音声の音声認識のための
NMF による音楽除去の高速化および VQ 手法の
改善,” 音講論(春), 1-P-18, pp.165–168, 2012.
[8] L. Benaroya et al., “Audio source separation with a single sensor” IEEE Trans. Audio,
speech and Language Processing, vol.14, no.1,
pp.191-199, 2006.
[9] R. Blouet et al., “Evaluation of several strategies for single sensor speech/music separation,”
Proc. ICASSP 2008, pp.37–40, 2008.
[10] B. Schuller, F. Weninger, “Discrimination of
speech and non-linguistic vocalizations by nonnegative matrix factorization,” Proc. ICASSP
2010, pp.5054–5057, 2010.
- 166 -
2013年3月
© Copyright 2026 Paperzz