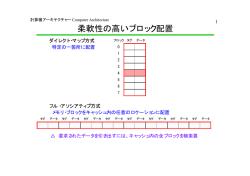
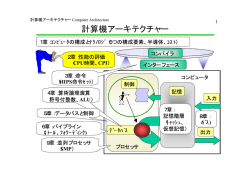
計算機アーキテクチャー Computer Architecture 1 7.容量と速度の両立:記憶階層の利用 ・記憶階層 時間的局所性・空間的局所性、メモリの基本 ・キャッシュ ダイレクト・マップ方式 コンパイラ キャッシュの性能測定 インタフェース コンピュータ セット・アソシアティブ方式 マルチ・レベル・キャッシュ 制 御 ・仮想記憶 記 憶 データ TLB パ ス プロセッサ 入 力 出 力 計算機アーキテクチャー Computer Architecture 記憶階層の基本原理 局所性の法則 時間的局所性:ある項目が参照された場合、 その項目がまもなく再び参照される確率が高い 空間的局所性:ある項目が参照された場合、 その項目の近くにある項目がまもなく再び参照される確率が高い 記憶階層を構成するために使用される主要テクノロジ 1997時点の メモリ 代表的なアクセス時間 テクノロジ 1Mバイト当りのコスト 1 SRAM 1〜25 ns ( ) 100〜250ドル ( 1,000 ) 50 ) DRAM 60〜120 ns ( 5〜10ドル ( 50 ) 磁気ディスク 10〜20 ms ( 5,000,000 ) 0.1〜0.2ドル ( 1 ) 2 計算機アーキテクチャー Computer Architecture 3 記憶階層の構造 CPU 記 憶 階 層 1次キャッシュ 2次キャッシュ 主記憶 磁気ディスク レベル1 レベル 2 ・ ・ ・ CPUから離れるほど アクセス時間が増大 SRAM DRAM レベル n CPUから離れるほど記憶容量が増大 ・隣接する2レベル間で、ブロックと呼ぶ単位でデータを取り交わす ・プロセッサ(CPU)に近い方の上位ベルのメモリは、 遠い方の下位レベルのメモリよりも、容量は小さいが高速 計算機アーキテクチャー Computer Architecture 4 キャッシュメモリによる計算機性能向上 • 年々広がるプロセッサ対DRAMの性能格差 • キャッシュメモリによるコンピュータ性能向上の効果大 1ns プロセッサ(1.5年で2倍;60%/年) Mooreの法則 10ns 100 較差は50%/年 で広がる一方 10 100ns DRAM (10年で2倍;10%/年) 1 1980 1000ns 1985 1990 1995 2000 2005 レイテンシ 周波数 (MHz) 1000 計算機アーキテクチャー Computer Architecture 5 メモリの基本: SRAMとDRAM RAMは、「SRAM(Static RAM)」と「DRAM(Dynamic RAM)」に大きく分け られる。その違いは、データの記憶方法である。 SRAMはトランジスタによるフリップフロップ回路で構成され、この回路 に“1” 、 “0”という論理値レベルでデータを記憶する。 DRAMはトランジスタ1個とキャパシタ1個で構成され、このキャパシタに 電荷を蓄えるか否かで"1"、"0"を記憶する。 このノードの電圧で情報を保持する ビット線(内部データ線) V DD キャパシタ データ線 データ線 SRAMのメモリセル構造 ワード線 DRAMのメモリセル構造 計算機アーキテクチャー Computer Architecture 6 SRAMとDRAMの比較 ビット線(内部データ線) V DD キャパシタ データ線 SRAMの特徴 ・トランジスタ回路で構成 データ線 ワード線 DRAMの特徴 ・キャパシタに蓄えられた微小な電荷 でデータを記憶 ・リード(読み出し)・ライト(書き込み) の動 ・記憶を維持するための「リフレッシュ」が 作シンプル 必要。リード動作は2段階アドレッシング。 ・高速動作が可能 ・高速動作がしにくい ・大容量化が難しい ・大容量化が可能 ・高速性が要求されるキャッシュメモリ ・大容量が要求されるメインメモリ 計算機アーキテクチャー Computer Architecture 7 DRAMの動作 記憶の保持(リフレッシュ) DRAMはその構造上、キャパシタに蓄えた電荷が時間とともに消滅してしまう という弱点がある。 MOSトランジスタはGNDに接続されたP型半導体、ソース、ドレインにあたるN 型半導体、ゲート電極により構成されているが、N型半導体に存在する電荷は P型半導体に接続されたGNDに微小ながら流れ出す(リークする)特性がある。 したがってキャパシタ電圧は徐々に低下してしまう。そのためDRAMでは記憶 を保持するためにキャパシタ電圧を復帰させるリフレッシュ動作を定期的に行 なう必要がある。 リフレッシュはリード動作と同じ処理で行なわれる。 ゲート N+ソース P基板 メモリセル電荷のリーク N+ドレイン 計算機アーキテクチャー Computer Architecture 8 高速キャッシュSRAMのアクセス時間推移 100 DRAM 1.3um 最大アクセス時間 (ns) 0.8um CMOS 10 0.5um バイポーラ 0.35um SR2201 M-680 0.18um M-880 1 0.25um S3800 SRAM MP5800 SR8000 MP6000 バイポーラCMOS マイクロプロセッサ 内蔵キャッシュ 0.1 1984 1986 1988 1990 1992 1994 年 1996 1998 2000 2002 計算機アーキテクチャー Computer Architecture 9 メモリセルサイズの推移 100 デザインルール(um) 最小デザインルール DRAMセル面積 10 SRAMセル面積 1 0.1 DRAM 3年で4倍の集積化 0.01 1985 1987 1989 1991 1993 1995 (年) 1997 1999 2001 2003 2005 計算機アーキテクチャー Computer Architecture 10 DRAMの3次元キャパシタ構造の例 PL ポリSi1 WL ポリSi2 PL2 ポリSi3 BL ポリサイド PL1 ポリSi2 BL ポリサイド Vdd/2 Vdd/2 n+ 溝キャパシタ (トレンチ) (A)トレンチタイプ n+ n+ WL,ポリSi1 積層キャパシタ (スタック) (B)スタックタイプ n+ 計算機アーキテクチャー Computer Architecture 11 DRAMの3次元キャパシタ構造の例 Ta2O5 Capacitor Bit line Word line 計算機アーキテクチャー Computer Architecture 12 International Technology Roadmap for Semiconductors 2002 (μm) Process Technology 2.0 32G Process 5.0 3.0 2.0 1.0 1G 1.3 256M 64M 0.8 0.5 0.5 0.2 Memory 0.1 2G 276M 0.35 16M 0.25 0.18 4M 0.13 1M 0.05 256K 64K 4G (Trs) 64G 8G 16G 4.4G 697M 2.2G 1.1G CPU 439M 0.065 0.09 0.045 0.032 1G 1M 0.02 1980 1990 2000 2010 (Year) 計算機アーキテクチャー Computer Architecture 90nmノードCMOSデバイス技術 13 低消費電力対応チャネル構造 (SSC: Super Steep Channel、 IEDM2001にて発表) 特徴1 低表面濃度 特徴2 高基板定数 高移動度・低ノイズ オフ電流制御 SSC Inイオン打込み Ioff(A/um) 10 -7 高移動度化 NMOS 10 -8 10 -9 従来 (Bチャネル) Inチャネル 10-10 65nm 10 -11 200 400 Ion(uA/um) 600 計算機アーキテクチャー Computer Architecture 20nm CMOSデバイス技術 14 世界最高速のCOMS技術を開発 オフセット・スペーサ ゲート長 20nm 世界最高速の動作速度 280fs ゲート 20nm 窒化膜系ゲート絶縁膜 ゲートリーク電流を一桁低減 ゲート絶縁膜 (2002 VLSI Symposiumで発表) 計算機アーキテクチャー Computer Architecture 15 7.容量と速度の両立:記憶階層の利用 ・記憶階層 時間的局所性・空間的局所性、メモリの基本 ・キャッシュ ダイレクト・マップ方式 コンパイラ キャッシュの性能測定 インタフェース コンピュータ セット・アソシアティブ方式 マルチ・レベル・キャッシュ 制 御 ・仮想記憶 記 憶 データ TLB パ ス プロセッサ 入 力 出 力 計算機アーキテクチャー Computer Architecture 記憶階層の構造 ○ヒット率: プロセッサから要求されたデータが上位レベルで見つかる割合 ●ミス率: アクセスしたデータが上位レベルで見つからない割合 △ヒット時間: 記憶階層の上位レベルのアクセスにかかる時間 (アクセスがヒットするかミスするかの判定に必要な時間を含む) ▲ミス・ペナルティ: 下位レベル中の求めるデータ・ブロックで上位レベルの対応する ブロックを置き換え、プロセッサに取り込むのに要する時間 データアクセス時間=ヒット時間+ミス・ペナルティ時間*ミス率 16 計算機アーキテクチャー Computer Architecture 17 キャッシュ(Cache) インデックス キャッシュ CPUとメモリとの間に 挿入された記憶階層レベル キャッシュ メモリ 000 001 010 011 100 101 110 111 キャッシュ内のどこに存在するか、 それとも、どこにも存在しないのか アドレス 00 000 00 001 00 010 00 011 00 100 00 101 00 110 00 111 01 000 01 001 01 010 01 011 01 100 01 101 01 110 01 111 10 000 10 001 10 010 10 011 10 100 10 101 10 110 10 111 11 000 11 001 11 010 ブロック ↓ ・メモリ中のアドレスから一意的に キャッシュ中のブロックのインデックス が決まるように対応付ける ダイレクト・マップ方式 タグ 計算機アーキテクチャー Computer Architecture 18 ダイレクト・マップ方式(1) データのメモリ中アドレス 31 12 11 (30−n)ビット 2 1 0 31 バイト オフセット n ビット キャッシュ容量 1024=2 10 データ → n=10 有効ビット インデックス ↓ タグ 0 1 ・・・ 1 20ビット ・・・ ・・・ 1022 1023 データ 32ビット ブロック長 53ビット 0 計算機アーキテクチャー Computer Architecture ダイレクト・マップ方式(2) ダイレクト・マップ方式 : 語単位データのメモリ中アドレスに基づいて、 キャッシュに入れる位置を割当てる方法 キャッシュに付加する情報 インデックス: メモリ中アドレスの該当下位ビット キャッシュのブロックを選択するために使用 ブロック位置=メモリのブロック・アドレス modulo キャッシュ・ブロック数 タグ: メモリ中アドレスのキャッシュ中インデックスに当る部分より 上位のビット部分 求める語がキャッシュ中にあるか否かを判断するために使用 有効ビット: データの有効性を示す 19 計算機アーキテクチャー Computer Architecture キャッシュのビット数例 64Kバイトのデータを保持するダイレクト・マップ方式のキャシュに必要な総ビット数は? ブロック・サイズ:1語(4バイト)、メモリのアドレス:32ビット アドレス:32ビット メモリ タグ(16ビット) キャッシュ インデックス(14ビット) バイト・オフセット(2ビット) 有効(1ビット) タグ(16ビット) データ(32ビット) 有効(1ビット) タグ(16ビット) データ(32ビット) 214 ブロック長: ブロック数(2n): タグ長: 有効ビット: 1語=32ビット 64Kバイト=16K語=214語=214ブロック アドレス長−n−バイト・オフセット長=32−14−2ビット=16ビット 1ビット キャッシュ総容量=2n×(ブロック長+タグ長+有効ビット長) =214×(32+16+1)=214×49=784×210=784Kビット 20 計算機アーキテクチャー Computer Architecture 21 キャッシュへのアクセス例 インデックス 有効 タグ 000 001 010 011 100 101 110 111 データ N N N N N N N N 000 001 010 011 100 101 110 111 a. 電源を入れた後の初期状態 インデックス 有効 タグ 000 001 010 011 100 101 110 111 Y N Y Y N N Y N インデックス 有効 タグ データ 102 メモリ(100002) 112 002 メモリ(110102) メモリ(000112) 102 メモリ(101102) c. アドレス(000112)のミスを処理した後 N N N N N N Y N 102 データ メモリ(101102) b. アドレス(101102)のミスを処理した後 インデックス 有効 タグ 000 001 010 011 100 101 110 111 Y N Y Y N N Y N データ 102 メモリ(100002) 102 002 メモリ(100102) メモリ(000112) 102 メモリ(101102) d. アドレス(100102)のミスを処理した後 計算機アーキテクチャー Computer Architecture キャッシュ・ミスの取扱い 22 キャッシュ・ミスの取扱い(基本アプローチ) (1) CPUをストールさせ、すべてのレジスタの内容を凍結する (2) 専用の制御ユニットによってキャッシュ・ミスの処理を行い、 メモリからキャッシュにデータをコピーする (3) キャッシュ・ミスの発生した時点から処理を再開 命令の参照に対するミスが発生した場合の マルチサイクル/パイプライン・データーパスにおける処理 1.元のPC値(PC−4)をメモリに送る。 2.主記憶から読出しをおこなうように指示し、完了を待つ。 3.キャッシュの該当ブロックに書き込みを行う。 (データの格納、アドレスの上位ビットをALUからタグ・フィールドへ 格納、有効ビットON) 4.実行命令を最初のステップから再開する。(命令をフェッチし直す) 計算機アーキテクチャー Computer Architecture キャッシュとメモリの一貫性 データの書込みもキャッシュで高速に行う。 しかし、キャッシュのみに書込みを行うとすると、 キャッシュの内容と対応するメモリの内容が異なることになる。 キャッシュと主記憶が一貫性をなくした 23 計算機アーキテクチャー Computer Architecture キャッシュとメモリの一貫性 24 キャッシュと主記憶に一貫性を持たせる方法 ライト・スルー方式 書込み発生時に、キャッシュとメモリの両方にデータを書込む。 ○ 単純処理 △ 書き込みに時間がかかる ライト・バッファ方式: メモリ書込み待ちデータを一時蓄えておく場所であるバッファを設け、 バッファが満杯になった時点で、バッファ内容をメモリに書込む。 ○ キャッシュとライト・バッファに書き込んだら処理を続行可能 △ 書き込もうとした時ライト・バッファが満杯だと、空きができるまでストール要 ライト・バック方式 書込み発生時には、キャッシュにのみデータを書込む。 キャッシュ内容の置換発生時に、置換前のキャッシュ内容をメモリに書込む。 △ 実現方法が複雑 計算機アーキテクチャー Computer Architecture 25 空間的局所性の利用 空間的局所性の利用 ー キャッシュ・ミス率の低減 ブロックサイズ=1語 → 複数語 データのメモリ中アドレス 31 データのメモリ中アドレス 16 15 16ビット 2 14ビット 1 0 バイト オフセット 31 16ビット インデックス 32ビット 49ビット 有効ビット ↓ タグ 16K エントリ 1 16ビット 32ビット 4 12ビット インデックス 有効ビット データ ↓ タグ (1語/ブロック) 1 16ビット 16 15 3 2 1 0 バイト 2ビット オフセット ブロック内 オフセット データ(4語/ブロック) 32ビット 145ビット 32ビット 32ビット 4K エントリ 計算機アーキテクチャー Computer Architecture 26 ミス率とブロックサイズの関係 40% 35% Miss rate 30% 25% 20% 15% 10% 5% 0% 4 16 64 B lock size (bytes) 256 1 KB 8 KB 16 KB 64 KB 256 KB 計算機アーキテクチャー Computer Architecture キャッシュを支援する記憶システム CPU 1cyc/adr キャッシュ 4w/block 1cyc/w ブロックサイズ=1語 → 複数語 ○空間的局所性の利用 ー キャッシュ・ミス率の低減 ○キャッシュ中のメモリ使用効率も向上 △ミス・ペナルティ増大 ⇒ データ幅拡張、インターリーブ方式 CPU CPU バス マルチプレクサ キャッシュ キャッシュ バス メモリ 1w/bank 15cyc/w a. 1語幅 27 1cyc/4w バス メモリ メモリ メモリ メモリ メモリ バンク0 バンク1 バンク2 バンク3 b. データ幅拡張 c. インターリーブ方式 キャッシュミスペナルティ: 1+4x1+4x15=65cyc 1+1+15=17 1+4x1+15 =20 計算機アーキテクチャー Computer Architecture キャッシュの性能測定 28 CPU時間 =(CPU実行クロック数+メモリ・ストール・クロック数)×クロック・サイクル時間 メモリ・ストール・クロック数 =読出しストール・クロック数+書込みストール・クロック数 読出しストール・クロック数 =プログラム当たりの読出し件数×読出しミス率×読出しミス・ペナルティ 書込みストール・クロック数 =(プログラム当たりの読出し件数×読出しミス率×読出しミス・ペナルティ) +書込みバッファ・ストール 計算機アーキテクチャー Computer Architecture キャッシュの性能測定 ライト・スルー方式の場合 読出しストール・クロック数=書込みストール・クロック数 メモリ・ストール・クロック数 =プログラム当たりのメモリ・アクセス件数×ミス率×ミス・ペナルティ =プログラム当たりの命令アクセス件数×1命令アクセス当たりのミス率 ×ミス・ペナルティ 29
© Copyright 2026 Paperzz