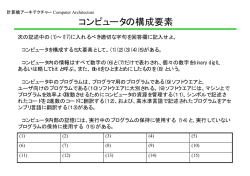
計算機アーキテクチャー Computer Architecture 1 計算機アーキテクチャー 1章:コンピュータの構成とテクノロジ(5つの構成要素、半導体、コスト) コンパイラ 2章:性能の評価 (CPU時間、CPI) 3章:命令 (MIPS命令セット) インターフェース コンピュータ 制御 記憶 4章:算術論理演算 (符号付整数、ALU) 入力 5章:データパスと制御 6章:パイプライン (ストール、フォワーディンク) 9章:並列プロセッサ (SMP) データパス プロセッサ 7章: 記憶階層 (キャッシュ、 仮想記憶) 8章: (バス) 出力 計算機アーキテクチャー Computer Architecture 2.性能の役割 2 ・ コンピュータの性能の確実な尺度は時間だけ ・ コンピュータの性能を左右する重要な要因は何か? アプリケーションの タイプが異なれば ・ 適切な性能の測定法も異なる。 ・ コンピュータ・システムのどの 要素が全体性能を決定づける かも変ってくる。 ・ 性能を測定する最善の方法、その限界の理解が重要。 ・マシン要素が性能に及ぼす影響の判定法方の理解が 各部の設計意図の理解に不可欠。 計算機アーキテクチャー Computer Architecture 3 コンピュータの性能定義 性能指標には2つの側面 ・ 応答(response)/経過(elapsed)/実行(execution)時間(time) : 作業を開始してから終了するまでの時間 ・ スループット(throughput) : 一定時間内に終了した作業の総量 応答時間 スループット コンピュータ1 ○ × コンピュータ2 × ○ 計算機アーキテクチャー Computer Architecture 4 性能(応答時間)の測定(1) タイムシェアリング方式の場合 プロセッサは同時に複数のプログラムを処理 待ち時間も含め、先にジョブを終えた計算機の方が速い 時刻 ユーザ1 ユーザ2 : : ユーザN 0 6 コンピュータの負荷は 時間帯・月日で変化 12 18 24 計算機アーキテクチャー Computer Architecture 性能(応答時間)の測定(2) 応答時間 (実行時間) 応答時間 (実行時間) CPU時間 CPU時間 ユーザCPU時間 システムCPU時間 入出力、他のプログラム 入出力、他のプログラム 待ち時間 待ち時間 実行時間 :ユーザ・プログラムの実行をシステムが制御している時間 CPU時間 :プロセッサが実際に処理に費やした時間 ユーザCPU時間 :ユーザ・プログラムで費やしたCPU時間 システムCPU時間 :OS等のシステム・プログラムで費やしたCPU時間 5 計算機アーキテクチャー Computer Architecture 性能(応答時間)の測定(3) 1 ・システム性能 = 他の負荷が掛かっていない状態での応答時間 ・ CPU性能 = 1 ユーザーCPU時間 6 計算機アーキテクチャー Computer Architecture CPU性能の測定基準(1) クロック・サイクル時間 : ハードウエア内で事象を起こす時間間隔の最小単位 そのプログラムの CPU時間 = ×クロック・サイクル時間 CPU時間 = CPUクロック・サイクル数 ×クロック・サイクル時間 そのプログラムのCPUクロック・サイクル数 = = クロック周波数 ハードウエア設計者の性能向上課題 プログラム中の 命令当たりの平均 CPUクロック・サイクル数 = × プログラムが必要とするクロック・サイクル数の削減 実行命令数 クロック・サイクル数 クロック・サイクル時間の短縮(=クロック周波数を上げる) 7 計算機アーキテクチャー Computer Architecture CPU性能の改善例 クロック周波数 プログラム実行時間 必要クロック・サイクル数比 マシンA 400MHz 10秒 1 6秒 マシンB 800MHz ? 1.2 CPU時間= CPUクロック・サイクル数 クロック周波数 ∴ CPUクロック・サイクル数=CPU時間×クロック周波数 クロック周波数= CPUクロック・サイクル数 CPU時間 CPUクロック・サイクル数A=10秒×400×106サイクル/秒 = 4000×106サイクル クロック周波数B= 1.2× 4000×106サイクル 6秒 =800MHz 8 計算機アーキテクチャー Computer Architecture CPU性能の測定基準(2) CPU時間 CPU時間= =実行命令数×CPI×クロック・サイクル時間 実行命令数×CPI×クロック・サイクル時間 そのプログラムの CPUクロック・サイクル数 実行命令数×CPI = = クロック周波数 CPI(clock cycle per instruction): 命令当りの平均クロック・サイクル数 CPI = そのプログラムのCPUクロック・サイクル数 実行命令数 9 計算機アーキテクチャー Computer Architecture 性能方程式の使用例 マシンA マシンB CPU性能A CPU性能B クロック・サイクル時間 1ns 2ns = CPI 2.0 1.2 CPU性能比 ? 1.2 1 CPU時間B CPU時間A CPU時間=CPUクロック・サイクル数×クロック・サイクル時間 CPUクロック・サイクル数=実行命令数×CPI CPUクロック・サイクル数A=実行命令数×2.0 CPUクロック・サイクル数B=実行命令数×1.2 CPU時間A=実行命令数×2.0×1ns CPU時間B=実行命令数×1.2×2ns CPU性能A/CPU性能B=CPU時間B/CPU時間A =1.2 10 計算機アーキテクチャー Computer Architecture CPU性能の測定基準(3) 11 CPU時間 CPU時間= =実行命令数×CPI×クロック・サイクル時間 実行命令数×CPI×クロック・サイクル時間 実行命令数×CPI = = クロック周波数 性能を決める要因 CPU(実行)時間 実行命令数 命令当たりのクロック・サイクル数(CPI) 尺度 プログラムの実行にかかった時間 (秒) プログラム内で実行された命令の数 平均クロック・サイクル数/実行命令数 クロック・サイクル時間 CPU時間/クロック・サイクル数 コンピュータの性能を表す完全かつ信頼性のある唯一の尺度は時間 ・実行命令数を少なくしようとすると、クロック・サイクル時間を長くせざる おえなくなることがある。 ・命令ミックスに依存するので、実行命令数が最小のプログラムの 実行速度が最速とは限らない。 計算機アーキテクチャー Computer Architecture 12 コード系列の比較例 コード系列 1 2 命令クラスごとの実行命令数 (Ci) 実行 CPUクロック・ A B C 命令数 サイクル数 10 2 1 2 5 4 1 1 6 9 n 実行命令数 = ΣC i=1 i n CPUクロック・サイクル数 = Σ(CPI i ×Ci ) i=1 CPI = CPUクロック・サイクル数 実行命令数 CPUクロック・サイクル数2=(1×4) + (2×1) + (3×1)=9 CPI2=9/6=1.5 2 1.5 命令クラス 各命令クラスのCPI(CPIi) A 1 B 2 C 3 CPUクロック・サイクル数1 =(1×2) + (2×1) + (3×2)=10 CPI1=10/5=2 CPI 計算機アーキテクチャー Computer Architecture 測定基準値の算出方法 13 クロック・サイクル時間 ← マシン性能諸元 実行命令数 ← プログラム実行状況分析集計ソフトウエア・ツール アーキテクチャシュミレーター、ハードウエアカウンタ CPI ← シュミレーター(+ハードウエアカウンタ) 命令タイプ別に観測して計算 n CPI = CPUクロック・サイクル数 実行命令数 = Σ(CPI i ×Ci ) i=1 n ΣC i=1 i Ci : 実行されたクラスiの実行命令数 CPIi :そのクラスの命令当たりのクロック・サイクル数の平均値 n:命令クラスの数 計算機アーキテクチャー Computer Architecture 性能評価用プログラムの選定 14 ベンチマーク (コンピュータの性能測定を目的としたプログラム) ・実際のアプリケーションをいくつかまとめたもの ・ベンチマークの実行を高速化する方法を見つけにくいもの (小さいプログラムを採用すると、それを対象とした最適化を誘発し易い) ・例:Whetstone,Dhrystone,Livemore,Linpack,toy program, SPECINT,SPECFP,Perfect Club 代表的なベンチマーク: SPEC*** ・SPEC(Standard Performance Evaluation Corp.)が開発 ・測定プロセスを管理した現実性の高いベンチマークの提供により CPU性能の測定と報告の方法の改善を目的 ・SPECint(整数の演算),SPECfp(浮動小数点の演算 ) ・SPEC比: 基準マシンと測定対象マシンの実行時間比 計算機アーキテクチャー Computer Architecture 15 SPECintのクロック周波数依存 ③ Pentium Proの方が クロック周波数を上げた時 の性能改善効果が高い 10 ① Pentium Proの方が 1.4∼1.5倍高速 SPECint 8 6 4 ② クロック周波数を上げた 割合に比べ、 性能の改善率が下回る 2 Pentium Pentium Pro 0 50 100 150 200 クロック周波数 [MHz] 250 計算機アーキテクチャー Computer Architecture 16 SPECfpのクロック周波数依存 10 ① Pentium Proの方が 1.7∼1.8倍高速 SPECfp 8 ③ Pentium Proの方が クロック周波数を上げた時 の性能改善効果が高い 6 4 2 Pentium Pentium Pro 0 50 100 ② クロック周波数を上げた 割合に比べ、 性能の改善率が下回る 150 200 クロック周波数 [MHz] 250 計算機アーキテクチャー Computer Architecture 17 CPU性能の改善方法 1.クロック周波数を上げる 2.CPIを下げるようにプロセッサの構成を改善する 3.クロック・サイクル数を削減するようにコンパイラを改善する - 命令数を減らす - 平均CPIの低い命令を生成する(例:単純な命令セットを使用) そのプログラムのCPUクロック・サイクル数 CPU時間 = CPU時間 = クロック周波数 実行命令数×CPI = = クロック周波数 計算機アーキテクチャー Computer Architecture 18 最近のプロセッサの例(1) 1600 SPECint_base2000 1400 1200 MHz vs. SPECint, SPECft Intel 1000 Itanium2 800 HP PA-8700 600 MIPS R14000 400 200 IBM Power4 Alpha 21264C Sun UltraSPARCⅢ AMD Athlon XP Intel Xeon Intel Itanium 0 0 500 1000 1500 2000 Clock Rate [MHz] 2500 3000 計算機アーキテクチャー Computer Architecture 19 最近のプロセッサの例(2) 1600 Intel Itanium2 SPECfp_base2000 1400 IBM Power4 1200 MHz vs. SPECint, SPECft 1000 Intel Itanium 800 Alpha 21264C AMD Athlon XP Intel Xeon Sun UltraSPARCⅢ 600 MIPS R14000 400 200 HP PA-8700 0 0 500 1000 1500 2000 Clock Rate [MHz] 2500 3000 計算機アーキテクチャー Computer Architecture 性能の比較とまとめ方 合計実行時間 算術平均実行時間 1 n 算術平均 = n Σ時間 i i=1 加重算術平均実行時間 加重算術平均 =Σwi×時間i n i=1 幾何平均実行時間 n 幾何平均 = Π実行時間比 i i=1 n 時間i : i番目のプログラムの実行時間 wi: i番目のプログラムが実行される頻度の割合 実行時間比i: i番目のプログラムの基準マシンに対して正規化した実行時間 20 計算機アーキテクチャー Computer Architecture 21 性能の比較とまとめ方 実行時間 Aを基準に正規化 Bを基準に正規化 マシンA マシンB A B A B プログラム1 1 10 1 10 0.1 1 プログラム2 1000 100 1 0.1 10 1 正規化 算術平均 結果の 幾何平均 − − 1 5.05 5.05 1 − − 1 1 1 1 算術平均 実行 時間の 幾何平均 500.5 55 1 0.11 9.1 1 31.6 31.6 1 1 1 1 正規化した実行時間 の算術平均は、基準 に選択したマシンに 左右される 幾何平均は、 正規化に左右 されない 計算機アーキテクチャー Computer Architecture コンピュータの性能尺度 MIPS(million instruction per second) :1秒当りの実行命令数を100万単位で数えた命令実行速度 MIPS=クロック周波数/(CPI×106) 速いマシンほどMIPS値が大きい→直感的に分かりやすい 【問題点】 (1)命令セットの異なるコンピュータ(実行命令数が違う)の比較不可 相対MIPS:実行時間比×基準マシンMIPS値 1980年代 基準マシン VAX-11/780 1MIPS (2)1機種のマシンにMIPS値がいくつもある 同じコンピュータでも、プログラムが違えばMIPS値も違ってくる (3)CPIが平均値のため、MIPS値は性能とは逆に変化することがある ピークMIPS:CPIを最小にするように命令出現頻度を仮定したMIPS値 MFLOPS(million floating-point operation per second) :1秒間に実行される浮動小数点演算数を 100万単位で数えた演算実行速度 22 計算機アーキテクチャー Computer Architecture 23 性能尺度としてのMIPS値例 使用した 命令クラス別の実行命令数 (Ci) [×109] A B C コンパイラ 1 5 1 1 2 10 1 1 実行時間 = CPUクロック・サイクル数 クロック周波数 n CPUクロック・サイクル数 = Σ(CPI i ×Ci ) i=1 MIPS = 命令数 実行時間×106 実行時間 MIPS 20秒 30秒 350 400 命令クラス 各命令クラスのCPI(CPIi) A 1 B 2 C 3 クロック周波数=500MHz 実行時間1=(1×5+2×1+3×1)×109/(500×106)=(10×109)/(500×106)=20 実行時間2=(1×10+2×1+3×1)×109/(500×106)=(15×109)/(500×106)=30 MIPS1=(5+1+1)×109/(20×106)=350 MIPS2=(10+1+1)×109/(30×106)=400 計算機アーキテクチャー Computer Architecture 24 スーパーコンピュータの性能諸元の例 SR8000 コンパクトモデル モデル名 A B C D 理論ピーク性能 [GFLOPS] 4 8 12 14.4 メモリー容量[GB] 2/4/8 2/4/8/16 外部インターフェース Ultra SCSI, Fibre Channel,Ethernet/Fast Ethernet, Gigabit Ethernet, HIPPI, ATM I/Oインターフェース数 最大8 システム拡張機構 寸法 [mm] (WxDxH) あり 500 x 910 x 1,500 計算機アーキテクチャー Computer Architecture 25 スーパーコンピュータ用CPUの例 浮動小数点演算器 レジスタファイル 診断ユニット レジスタ ファイル 演算制御 アドレス 加算器 アドレス キャッシュ シノニムRAM データキャッシュ ル ー ロ ト ン コ ュ シ ッ ャ キ 整数演算器 レジスタファイル データキャッシュ 命令ユニット 分岐 キャッシュ アドレス キャッシュ 分岐予測 ユニット 命令キャッシュ 命令キャッシュ データキャッシュ メモリインターフェイス - Area: 18.5x18.5mm2 - Logic gate: 8M Trs. 64bitアドレッシング 4-wayスーパースカラー - RAM’s: 20M Trs. 命令キャッシュ 64KB データキャッシュ 128KB - 0.2umCMOSプロセス 配線7層 - クロック周波数: 450MHz 計算機アーキテクチャー Computer Architecture スーパーコンピュータ用CPUの例(2) 浮動小数点演算性能: 450MHz×2演算器×2[operation/演算器] = 1.8GFLOPS 命令実行性能: 450MHz×4[命令/cyc] = 1800MIPS 26 計算機アーキテクチャー Computer Architecture 27 スーパーコンピュータ用CPUの例(3) 70 60 SPE Cin t9 5b+ 50 MHz vs. SPECint, SPECft 40 30 20 HP PA-8000 IBM IBM PowerPC 620 Intel Pentium pro Power2 P2CS MIPS R10000 Sun UltraSparc 10 0 0 10 0 HITACHI SR8000 Digital 21164 200 30 0 400 Cloc k Rate [MHz] 50 0 600 計算機アーキテクチャー Computer Architecture 28 スーパーコンピュータ用CPUの例(4) 70 HITACHI SR8000 60 SPE Cfp95 b+ 50 MHz vs. SPECint, SPECft 40 30 20 HP PA-8000 IBM Power2 IBM P2CS 10 0 0 1 00 Sun UltraSparc MIPS R10000 PowerPC 620 Intel Pentium pro 200 3 00 400 Clock Rate [MHz] Digital 21164 500 600 計算機アーキテクチャー Computer Architecture 2002/12/6 円周率計算の世界記録を更新 スーパーコンピュータシステム「HITACHI SR8000/MPP」を用いて、東京大 学 情報基盤センタースーパーコンピューティング研究部門 金田康正教授 が、円周率計算の桁数で約1兆2,400億桁の世界記録を樹立しました。 今回の円周率計算においては、新たに共同開発した分割有理数化法 (DRM法)*1 という計算アルゴリズムを用い、金田教授が1999年9月にスー パーテクニカルサーバ「HITACHI SR8000」(128ノード、1TFLOPS*2)を用い て樹立した約2,061億桁の円周率計算世界記録の約6倍と、初めて1兆桁を 超える桁数を達成しました。 *1) 分割有理数化法(DRM法):Divide and Rationalize Method.、情報処理学会 論文誌 第41巻 第6号(2002年6月) P.1,811∼1,819「級数に基づく多数計算の演 算量削減を実現する分割有理数化法」(後 保範、金田康正、高橋大介)にて発表 *2) TFLOPS:Tera FLoating Operations Per Second、1秒当たり、1兆回の64ビット 浮動小数点演算を行う性能 29 計算機アーキテクチャー Computer Architecture スーパーコンピュータの動向 30 http://www.top500.org/ 計算機アーキテクチャー Computer Architecture 地球シミュレータ 31 http://www.es.jamstec.go.jp/ ・640台の計算ノード(PN: Processor Node)を、640×640の単段 クロスバネットワークで結合させた分散メモリ型並列計算機 ・各PNは、ピーク性能8Gflopsのベクトル型計算プロセッサ(AP: Arithmetic Processor)8台が主記憶装置16GBを共有 ・全体ではAPが5120台でピーク性能は40Tflops、主記憶容量は 10TB 計算機アーキテクチャー Computer Architecture 32 計算機アーキテクチャー Computer Architecture コンピュータの性能評価 コンピュータの性能を表す完全かつ信頼性のある唯一の尺度は時間 ・システム性能 = ・ CPU性能 = 1 他の負荷が掛かっていない状態での応答時間 1 ユーザーCPU時間 ・・CPU時間 CPU時間= =実行命令数×CPI×クロック・サイクル時間 実行命令数×CPI×クロック・サイクル時間 実行命令数×CPI CPI(clock cycle per instruction): = = 命令当りの平均クロック・サイクル数 クロック周波数 コンピュータ・システム全体の性能評価は一様ではない ベンチマーク(benchmark):性能測定を目的としたプログラム [弊害]ベンチマークで効果が出る改善をしても、 実際に使用しているプログラムでは全然効果が出ない場合が多い。 33 計算機アーキテクチャー Computer Architecture 34 ハードウエア/ソフトウエアの性能改善 Amdahlの法則 ある面を改善したことによる性能の向上は、 その改善された機能が使用される割合に制約される ・たとえ改善部分の高速化率が∞でも、 (現状全体時間/非改善部分時間)倍 以上の全体高速化は不可能 ・改善に伴い追加される前処理、後処理の 時間を足し忘れて高速化率を見積りがち 改善前 改善部分 t n倍高速化 改善後 t/n r ↑ 改善に伴う追加 a r t+r t/n+a+r ──── < n 稀な場合に対して最適化を施すよりも、 一般的な場合を高速化する方が、性能が改善される割合は高い。 ・初期バージョンは改善箇所の宝庫→10倍、100倍も夢でない ・バージョンアップ後の10倍、100倍の高速化は、 全体の方式から根本的に見直して初めて実現可能 →旧版との互換性を100%維持するという条件も加えると実現困難 計算機アーキテクチャー Computer Architecture コストと性能比 35 高性能設計: 性能最優先 (例:スーパーコンピューター) コスト/性能比設計: コストと性能のトレードオフ (例:ワークステーション) 低コスト設計: コスト重視 (例:ローエンドのIBM PC互換機) コストと性能の最適バランス点の見出しが、コンピュータ設計の極意 いろいろな設計案の性能とコストへの影響の正確な判定が必要 (予想以上に困難) なぜなら、マシンのコストに影響を与える要因は、 ・構成要素のコストだけでなく、組立作業者の人件費、 研究開発費営業経費、粗利etcも含む ・製造技術の急速な進歩(現時点の高コスト効率な方式が、 半年、一年先にそれほどでも無くなってしまう)
© Copyright 2026 Paperzz