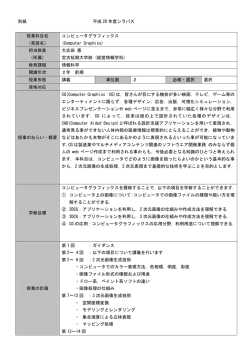
計算機アーキテクチャー Computer Architecture 1 柔軟性の高いブロック配置 ダイレクト・マップ方式 特定の一箇所に配置 ブロック タグ データ 0 1 2 3 4 5 6 7 フル・アソシアティブ方式 メモリ・ブロックをキャッシュ内の任意のロケーションに配置 タグ データ タグ データ タグ データ タグ データ タグ データ タグ データ タグ データ タグ △ 要求されたデータを引き出すには、キャッシュ内の全ブロックを検索要 データ 計算機アーキテクチャー Computer Architecture 2 mウェイ・セット・アソシアティブ方式 セット・アソシアティブ方式 ダイレクト・マップとフル・アソシアティブの中間 (配置可能な場所がm個存在) インデックスによって選択されたセット内の要素だけを検索すればよい セットの位置=メモリのブロック・アドレス modulo キャッシュ・セット数 1ウェイ・セット・アソシアティブ方式 2ウェイ・セット・アソシアティブ方式 (ダイレクト・マップ方式) ブロック タグ セット タグ データ タグ データ 0 1 2 3 データ 0 1 2 3 4 5 6 7 4ウェイ・セット・アソシアティブ方式 セット タグ データ タグ データ タグ データ タグ データ データ タグ データ 0 1 8ウェイ・セット・アソシアティブ方式(フル・アソシアティブ方式) タグ データ タグ データ タグ データ タグ データ タグ データ タグ データ タグ 計算機アーキテクチャー Computer Architecture キャッシュの連想度例(1) 1語のブロック4つから成る以下の3つの方式キャッシュがある。 (1)ダイレクト・マップ方式 (2)2ウェイ・セット・アソシアティブ方式 (3)フル・アソシアティブ方式 メモリのブロック・アドレスを0, 8, 0, 6, 8の順にアクセスするとき、各方式でミスの発生数 を求めよ。 (1)ダイレクト・マップ方式 メモリ・ブロック・アドレス 0 6 8 メモリ・ブロック のアドレス 0 8 0 6 8 キャッシュ・ブロック (0 mod 4) = 0 (6 mod 4) = 2 (8 mod 4) = 0 ヒット/ミス ミス ミス ミス ミス ミス ブロック 0 1 2 3 タグ データ 参照後の各キャッシュ・ブロックの内容 0 1 2 3 メモリ[0] メモリ[8] メモリ[0] メモリ[0] メモリ[6] メモリ[8] メモリ[6] 3 計算機アーキテクチャー Computer Architecture 4 キャッシュの連想度例(2) (2)2ウェイ・セット・アソシアティブ方式 メモリ・ブロック・アドレス 0 6 8 メモリ・ブロック のアドレス 0 8 0 6 8 キャッシュ・ブロック (0 mod 2) = 0 (6 mod 2) = 0 (8 mod 2) = 0 ヒット/ミス ミス ミス ヒット ミス ミス セット 0 1 タグ データ タグ 参照後の各キャッシュ・ブロックの内容 セット0 セット0 セット1 セット1 メモリ[0] メモリ[0] メモリ[8] メモリ[0] メモリ[8] メモリ[0] メモリ[6] メモリ[8] メモリ[6] データ 計算機アーキテクチャー Computer Architecture キャッシュの連想度例(3) (3)フル・アソシアティブ方式 タグ データ メモリ・ブロック のアドレス 0 8 0 6 8 タグ ヒット/ミス ミス ミス ヒット ミス ヒット データ タグ データ タグ データ 参照後の各キャッシュ・ブロックの内容 セット0 セット0 セット1 セット1 メモリ[0] メモリ[0] メモリ[8] メモリ[0] メモリ[8] メモリ[0] メモリ[8] メモリ[6] メモリ[0] メモリ[8] 5 計算機アーキテクチャー Computer Architecture mウェイ・セット・アソシアティブ方式 連想度: 1セットのブロック数 連想度mを増やすと、○ミス率が低下、△ヒット時間が増大 セット・アソシアティブ方式のコスト ・比較器の増加 ・キャッシュ・ブロック当たりのタグのビット数増大 ・セットの中から比較および選択するための時間が余分にかかる 置き換えブロックの選択 LRU(least recently used)方: 使用されずにいた時間が最も長いブロックを置換 ・使われた時間の情報を持つ必要有り ・連想度があがるも実現が難しくなる 6 計算機アーキテクチャー Computer Architecture マルチ・レベル・キャッシュ マルチ・レベル・キャッシュ 1次キャッシュと主記憶の間に、大きな2次キャッシュを追加して 1次キャッシュのミスを処理 ⇒ ミス・ペナルティ削減 ・1次キャッシュはCPUを構成するマイクロプロセッサと同じチップ上に搭載 ・シリコン容量の制限およびクロック周波数を高くしたい場合、 1次キャッシュは大きく出来ない ・2次キャッシュはメイン・チップとは別のSRAMで構成 (1次キャッシュの10倍程度の容量) 7 計算機アーキテクチャー Computer Architecture マルチ・レベル・キャッシュの性能例 データの参照は全て1次キャッシュに対してなされる下記のプロセッサがある。 基本CPI=1.0、クロック周波数=1GHz、主記憶へのアクセス=100ns 1次キャッシュにおける命令当たりのミス率=5% このマシンに2次キャッシュを追加した場合、マシンの速度はどのくらい向上す るか?ただし、2次キャッシュのアクセス時間=10ns、主記憶へのミス率=2%。 主記憶に対するミス・ペナルティ =100ns/(1/1GHz)=100ns/(1ns/クロック・サイクル)=100クロック・サイクル 合計CPI1次キャッシュのみ=基本CPI+命令当たりのメモリ・ストール・サイクル数 =1.0+5%×100=6.0 2次キャッシュを追加した場合、 2次キャッシュに対するミス・ペナルティ =10ns/(1ns/クロック・サイクル)=10クロック・サイクル 合計CPI2次キャッシュ追加=基本CPI+命令当たりのメモリ・ストール・サイクル数1次キャッシュ +命令当たりのメモリ・ストール・サイクル数2次キャッシュ =1.0+5%×10+2%×100=1.0+0.5+2.0=3.5 合計CPI1次キャッシュのみ/合計CPI2次キャッシュ追加=6.0/3.6=1.7倍 8 計算機アーキテクチャー Computer Architecture 9 キャッシュメモリによる計算機性能向上 • 年々広がるプロセッサ対DRAMの性能格差 • キャッシュメモリによるコンピュータ性能向上の効果大 1ns ターゲット プロセッサ(1.5年で2倍;60%/年) Mooreの法則 10ns 100 較差は50%/年 で広がる一方 10 100ns DRAM (10年で2倍;10%/年) 1 1980 1000ns 1985 1990 1995 年 2000 2005 レイテンシ 周波数 (MHz) 1000 計算機アーキテクチャー Computer Architecture 10 キャッシュメモリの効果 サーバーの特徴 - 複数 CPU 搭載 - 高い動作周波数 - 小容量オンチップキャッシュ CPU L1 L2 CPU L1 L2 ノード制御 ボトルネック メインメモリとのデータスルー プットが性能アップの鍵 CPU L1 L2 CPU L1 L2 ノード制御 - 広いバンド幅 - 狭いインターフェース L3 キャッシュ - 高速アクセス - 大容量 バンド幅 L3 キャッシュにより - 遅いアクセス時間 メインメモリ 30%の性能向上 メインメモリ L3キャッシュなし L3キャッシュあり 計算機アーキテクチャー Computer Architecture 11 高速性と大容量の両立 2003年2月10日 世界最高速の動作クロック周波数750MHzと大容量 144Mbitを実現した「キャッシュDRAM LSI」を開発 このたび、次世代の高性能サーバ用に、世界最高速の動作クロック周波 数750MHzと144Mbitの大容量を実現した「キャッシュDRAM LSI」を開発し ました。本LSI開発技術は、高速SRAMに取って代わりキュッシュメモリの 大容量化を行うことで、今後のIT社会の基盤となる次世代サーバの高性 能化に道を拓くものです。(以下、略) • 0.18µm Logic-DRAM混載プロセス • DRAM 144Mb/chip, SRAM 108Kb, 論理800KGを集積 •動作クロック周波数 750MHz •DRAMアクセス性能 ランダム(tRAC): 8.0ns シーケンシャル(tCAC): 5.3ns •内部バンド幅48GB/s DRAM DRAM DRAM DRAM SOG SRAM SRAM SOG I/O回路 SRAM I/O回路 DRAM DRAM DRAM DRAM 計算機アーキテクチャー Computer Architecture 12 7.容量と速度の両立:記憶階層の利用 ・記憶階層 時間的局所性・空間的局所性、メモリの基本 ・キャッシュ ダイレクト・マップ方式 コンパイラ キャッシュの性能測定 インタフェース コンピュータ セット・アソシアティブ方式 マルチ・レベル・キャッシュ 制 御 ・仮想記憶 記 憶 データ TLB パ ス プロセッサ 入 力 出 力 計算機アーキテクチャー Computer Architecture 仮想記憶 仮想記憶 : 通常は磁気ディスクでできている2次記憶に対して、 主記憶にキャッシュの役割を果たさせる技法 ○複数プログラム間でメモリを効率よく共有 ○主記憶容量の限界に対処するプログラミング上の負荷を軽減 1つのマシン上で複数のプログラムが稼動しているケースでは ・全プログラムが要求するメモリの合計量は、 マシン上の利用可能な主記憶の量よりもはるかに大きくなりうる ・主記憶には各プログラムの実働している一部分だけを置けばよい ↓ 仮想記憶では ・キャッシュと基本的に同じ概念である ・各プログラム独自のアドレス空間を実アドレスに変換する機能と、 他のプログラムのアドレス空間を保護する機能を備えねばならない 13 計算機アーキテクチャー Computer Architecture 14 仮想記憶 変換 物理アドレス 仮想アドレス 仮想ページ番号 ページ内オフセット ページサイズ 決定 物理ページ番号 ページ内オフセット ディスク上でのアドレス 計算機アーキテクチャー Computer Architecture ページの配置と検索 ページ・フォールト: キャッシュでのミスに相当 ・ディスクのアクセスは遅いので、ミス・ペナルティが途方も無く大きい ミスの発生低減 → ページ配置はフル・アソシアティブ方式 エントリの検索容易化 → ページ表 ページの所在を突き止める為の メモリを全面的にインデックス付 けした表 15 計算機アーキテクチャー Computer Architecture 16 ページ表 仮想アドレス(232=4Gバイト空間) 31 仮想ページ番号 ページ表 レジスタ 20 有効ビット 12 11 0 ページ内オフセット 12 ページ表 物理ページ番号 2 20 =1M ページ 1 0 2 12バイト =4Kバイト /ページ 18 29 物理ページ番号 ディスク装置 12 11 0 ページ内オフセット 物理アドレス(230=1Gバイト空間) 計算機アーキテクチャー Computer Architecture アドレス変換バッファ(translation-lookaside buffer:TLB) TLB:主記憶に格納されるページ表の上位階層にある キャッシュ ページ表の 仮想ページ番号 有効 タグ TLB 物理ページ・アドレス 物理メモリ 1 1 0 1 ページ表 有効 物理ページorディスク上アドレス 1 1 1 1 0 1 1 0 1 ディスク装置 17 計算機アーキテクチャー Computer Architecture 18 TLBとキャッシュの構成 仮想 アドレス 31 12 11 仮想ページ番号 有効 ビット 0 ページ内オフセット TLBインデックス タグ 物理ページ番号 仮想アドレス・タグ 1 TLB 29 物理 アドレス 12 11 0 物理ページ番号 ページ内オフセット 物理アドレス・タグ キャッシュ・インデックス 31 16 15 有効 ビット タグ 1 物理アドレス・タグ キャッシュ 2 データ 0 バイト オフセット 計算機アーキテクチャー Computer Architecture 19 記憶階層のデータ参照手順 データ存在場所 キャッシュヒット TLBアクセス キャッシュアクセス キャッシュ TLBミス キャッシュミス 仮想記憶ヒット 主メモリ・ページ ページ表アクセス 仮想記憶ミス=ページフォールト ディスク装置 TLBヒット TLB 仮想ページ番号 タグ TLB インデックス t ページ表 インデックス p t 有効 ビット ページ内 オフセット タグ p 有効 ビット 主メモリ・ページ インデックス m 物理ページ番号 キャッシュ ページ内 オフセット キャッシュ インデックス c 物理ページ番号 ページ表 ページ内 オフセット 物理アドレス 物理ページ番号 タグ c 有効 ビット バイト オフセット タグ 主メモリ・ページ m データ データ ディスク装置 データ 計算機アーキテクチャー Computer Architecture マルチ・レベル・キャッシュの性能(2) 20 2レベルのキャッシュ、1レベルのDRAM、およびディスクを備えた1GHzのプロセッサが ある。メモリ・システムは下記の性能を持つ。 構成要素 ヒット時間 ミス率 ブロック・サイズ 1st キャッシュ 1サイクル 5% (data), 1% (inst) 64 bytes 2nd キャッシュ 20サイクル+1サイクル/64bits 2% 128 bytes DRAM 50ns+25ns/8bytes 0.1% (Page Fault) 16K bytes (Page Size) TLB 1サイクル 0.1% (data), 0% (inst) ディスクの平均アクセス時間(AMATdisk)は20msec、TLBのミス・ペナルティを100cycleと して、命令の平均メモリ・アクセス時間(AMATinst)およびデータの平均メモリ・アクセス時 間(AMATdata)を求めよ。 AMATdram=(50ns+25ns×128bytes/8bytes)+0.001×AMATdisk =(50ns+25ns×16)+0.001×20msec=20.45μsec⇒20.45μsec×1GHz=20450cycle AMAT2lev=(20cycle+1cycle×64bytes/64bit)+0.02×AMATdram =(20cycle+1cycle×8)+0.02×20450=437cycle AMATinst=1cycle+0.01×AMAT2lev=5.37cycle AMATdata=1cycle+0.05×AMAT2lev+1cycle+0.001×100cycle=23.95cycle
© Copyright 2026 Paperzz