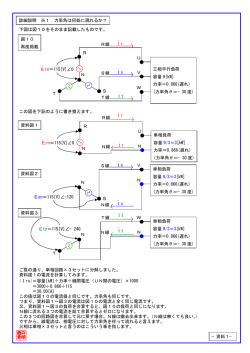
最尤法と尤度比検定について
計算特訓第5回:補助資料 1
土居正明
1 はじめに
1.1 本稿の内容など
本稿では、尤度比検定についてご説明します。実は、最尤法の詳細や尤度比検定は、
「時間もないし、きちんと理解されな
くても仕方がないかな」と思っていたのですが、尤度比検定の資料を作って欲しいというご希望があり、問題と解答を作る
のは大変ですので補助資料にしようと思ったのですが、補助資料はある程度きちんと書くのを心がけていますので、「正し
いイメージを持っていただける」ようにご説明します*1 。なお、最尤法の近辺には面白い話がたくさんありますので、適宜
「微妙に脱線」⇒「補足で解説」ということをしています。補足はやや踏み込んだ内容についても書いていますので、最初は
補足は読まず、2回目以降に補足を参照しながら読まれるとより理解が深まるかと思います。
1.2 本稿を読まれる際にあった方が良い知識
本稿は「最尤法」が肝になります。それも「2群比較のシチェーションでの最尤法」です。従いまして、計算特訓第3回そ
の3「最尤推定量の計算1」の「問題2」∼「問題6」の中の少なくとも何問かは解いてから読まれることをお勧めします。
1.3 本稿の表現について
本稿では分かりやすさを重視して、一般的に本で書かれている尤度比検定の定義とは少し異なる定義を用いています。ほ
とんど同じですが、こちらの方が理解しやすいかと思い、通常よりは1ステップ飛ばした定義をしました。
2 尤度比検定の計算方法
2.1 計算方法
理屈のご説明に入ると話がそこそこ込み入ってきますので、具体例を用いて最初に尤度比検定の計算方法のみをご紹介し
ます。
たとえば正規分布に従う1群 n 例ずつ、計2群の全て独立なデータ x11 , · · · , x1n ∼ N (µ1 , σ 2 ) x21 , · · · , x2n ∼ N (µ2 , σ 2 )
があるとします。ここで帰無仮説・対立仮説を
H0:µ1 = µ2
H1:µ1 6= µ2
(= µとおく)
c2 , σ
c2 とおきます
としたときに、H0 , H1 のもとで*2 それぞれ 最尤推定量を求めます。σ 2 の推定も各仮説のもとで行い、σ
0
1
*1
*2
数理的にあまり込み入った話はしませんのでご安心ください。
正確には「H0 のもと」と、
「H0 , H1 のどちらでもよい状況のもと」です。この点も補足で解説します。ここより下の節では正しく書きますが、こ
このみ煩雑さを避けるため「H1 のもと」という言い方をします。
1
と、各推定量は
c2
(H0 のもと): µ
b, σ
0
c2
(H1 のもと): µ
c1 , µ
c2 , σ
1
と書けます。次に、これを 尤度関数の中に入れます。仮説が異なると尤度関数も異なりますので、帰無仮説のもとでの尤度
関数を L0 (µ, σ 2 |x)、対立仮説のもとでの尤度関数を L1 (µ1 , µ2 , σ 2 |x) とおきますと(x は全データを1つの文字で表現した
もの)、
c2 |x)
(H0 のもと): L0 (b
µ, σ
0
c2 |x)
(H1 のもと): L1 (c
µ1 , µ
c2 , σ
1
となります。そして、この 2つの尤度関数の比を取ります。つまり、
c2 |x)
L1 (c
µ1 , µ
c2 , σ
1
c2 |x)
L0 (b
µ, σ
(1)
0
とします。
「広い意味の尤度比検定」は、この (1) を用いた検定全て のことを指します*3 。
一方で、
「狭い意味の尤度比検定」とは 例数が大きいとき、(1) を用いて統計量
(
T = 2 log
c2 |x)
L1 (c
µ1 , µ
c2 , σ
1
c2 |x)
L0 (b
µ, σ
)
0
が 漸近的に χ2 分布に従う ことを利用した検定です*4 *5 。このとき、χ2 分布の自由度は H0 と H1 のパラメータ数の差 で
あり、今回は「H0 : µ, σ 2 の2つ」「H1 : µ1 , µ2 , σ 2 の3つ」より、3−2=1となりますので、今回は自由度が1です。
これより、今回の場合、例数が大きいとき には
T > χ2 (1, 0.95)
で棄却すれば、有意水準5%の両側検定になります*6 。
*3
この「広い意味」
「狭い意味」は私の造語です。同じ言葉で2種類の検定が語られることがあり、まぎらわしいので区別することにしました。
n が大きいときに「大体」従う、ということを難しい言葉で「漸近的(ぜんきんてき)に」従うと言います。
*5 この T のことを
*4
(
T = −2 log
c2 |x)
L0 (b
µ, σ
0
c2 |x)
L1 (c
µ , µ
c, σ
1
(1)
*6
2
)
1
と書いてある本もありますが、− log(x) = log x ですので、全く同じものを指しています。
ここで、χ2 (1, 0.95) は「自由度1の χ2 分布の下側95%点」です。また、「これって片側検定じゃないの?」と思われる方は、私の作成資料(分
散分析講義:第1回資料1)
「正規分布・t 分布・χ2 分布・F 分布とは何か?」の χ2 分布のところをお読み下さい。
2
2.2 まとめ:尤度比検定の計算
ではとりあえず 狭い意味の方 にしておいて、尤度比検定のやり方をまとめます。データが x11 , · · · , x1n ∼ N (µ1 , σ 2 )
x21 , · · · , x2n ∼ N (µ2 , σ 2 ) として、
H0:µ1 = µ2
(= µとおく)
H1:µ1 6= µ2
における 尤度比検定(有意水準 α の両側検定)の計算手順は以下の通りです。
(i) H0 , H1 のもとでのパラメータ全て*7 の最尤推定量を求める*8 。
(ii) (i) で得られた最尤推定量を、それぞれの尤度関数に入れます。
(iii) (ii) で得られた尤度関数の比をとり、そこから統計量
(
)
c2 |x)
L1 (c
µ1 , µ
c2 , σ
1
T = 2 log
c2 |x)
L0 (b
µ, σ
0
(
)
c2 |x) − l0 (b
c2 |x)
= 2 l1 (c
µ1 , µ
c2 , σ
µ
,
σ
1
0
を作ります*9 。
(iv) 自由度 m= (「H1 のパラメータ数」−「H0 のパラメータ数」) とした χ2 分布を用いて、
T > χ2 (m, 1 − α)
のときに棄却します。
以上がやり方です。なお、ここでは正規分布の場合だけを見てきましたが、他の分布でも同様に「帰無仮説のもとでの最
尤推定」
「対立仮説のもとでの最尤推定」を別々に行い、尤度関数の比をとって T を構成すれば、それが漸近的に χ2 分布に
従います。自由度も同様に「H1 のもとでのパラメータ数」−「H0 のもとでのパラメータ数」で求まります。
次に例題を1問解いて、それから「最尤法とはどういう推定方法か」というところから入って、ある程度のところまで理
論をご説明します。
3 例題
では、1問だけ例題を解いてみましょう。
「例題」
ある検査値のデータを考えます。1群 5 例ずつ、計2群の全て独立な正規分布に従うデータがあるとしまして、実薬群を
x11 , · · · , x15 ∼ N (µ1 , σ 2 )、プラセボ群 x21 , · · · , x25 ∼ N (µ2 , σ 2 ) とします*10 。いま、実薬にはこの検査値の値を下げる
効果が期待されているとしまして、帰無仮説・対立仮説を
H0:µ1 = µ2
H1:µ1 6= µ2
(= µとおく)
とします。データが
x11 = 10, x12 = 13, x13 = 14, x14 = 8, x15 = 15
x21 = 13, x22 = 21, x23 = 18, x24 = 25, x25 = 13
であったとします。このとき、有意水準 0.05 の両側検定を、(狭い意味の)尤度比検定を用いて行ってください。
*7
*8
知りたいのが平均 µ だけでも、分散 σ 2 まで推定します。
今回のように仮に平均にしか興味ない場合でも、分散の推定量も求めます。
c2 |x), l0 (b
c2 |x) はそれぞれ対立仮説・帰無仮説のもとでの対数尤度関数です。
µ
c2 , σ
µ, σ
1
0
本当は、10 例程度では漸近的な検定を用いるのは妥当ではない と思われます。今回は手計算を楽にするために、練習として 10 例でやっているだ
*9 l1 (c
µ1 ,
*10
けです。ご注意ください。
3
「解答」
まず、尤度関数と最尤推定量を求めます。
(帰無仮説のもとでの計算)
帰無仮説 H0:µ1 = µ2 (= µ) のもとでは 10 個のデータの全てが N (µ, σ 2 ) に従いますので、尤度関数は
(
))
(xij − µ)2
√
L (µ, σ |x) =
exp −
2σ 2
2πσ 2
i=1 j=1
(
)10
2 ∑
5
∑
1
1
= √
exp − 2
(xij − µ)2
2σ i=1 j=1
2πσ 2
0
2
2 ∏
5 (
∏
1
であり、対数尤度関数は
l0 (µ, σ 2 |x) = −
2
5
(
)
1 ∑∑
10
log 2πσ 2 − 2
(xij − µ)2
2
2σ i=1 j=1
となります。最尤推定量*11 は
1 ∑∑
1
xij =
(10 + 13 + 14 + 8 + 15 + 13 + 21 + 18 + 25 + 13) = 15
10 i=1 j=1
10
2
µ
b=
5
∑∑
c2 = 1
σ
(xij − µ
b)2
0
10 i=1 j=1
2
5
1 {
(10 − 15)2 + (13 − 15)2 + (14 − 15)2 + (8 − 15)2 + (15 − 15)2
10
}
+(13 − 15)2 + (21 − 15)2 + (18 − 15)2 + (25 − 15)2 + (13 − 15)2
= 23.2
=
となります。これより、対数尤度関数にパラメータを代入したものは
2
5
(
)
10
1 ∑∑
c
c
2
2
(xij − µ
b)2
l (b
µ, σ0 |x) = − log 2π σ0 −
c2
2
2σ
0 i=1 j=1
∑
0
となります。ここで直接値を代入してもよいですが、少しショートカットします。右の
2 ∑
5
∑
(2)
の部分について
(xij − µ
b)2
i=1 j=1
となっていますが、これは
∑∑
c2 = 1
σ
(xij − µ
b)2
0
10 i=1 j=1
2
5
を用いて書き直すと、
2 ∑
5
∑
c2
(xij − µ
b)2 = 10σ
0
i=1 j=1
となります。これより、(2) は
(
)
c2 − 1 · 10σ
c2 |x) = − 10 log 2π σ
c2
l0 (b
µ, σ
0
0
0
c2
2
2σ
0
= −5 log (46.4π) − 5
*11
最尤推定量の求め方は今回省略しています。忘れた方は、第3回資料3「最尤推定量の計算 1」を復習してください。
4
となります。
(対立仮説のもとでの計算)*12
このとき、尤度関数は
(
)} ∏
(
)}
5 {
(x1j − µ1 )2
1
(x2j − µ2 )2
√
exp −
·
exp
−
2σ 2
2σ 2
2πσ 2
2πσ 2
j=1
j=1
(
)10
5
5
∑
∑
1
1
= √
exp − 2 (x1j − µ1 )2 +
(x2j − µ2 )2
2σ
2πσ 2
j=1
j=1
L1 (µ1 , µ2 , σ 2 |x) =
5 {
∏
√
1
であり、対数尤度関数は
l1 (µ1 , µ2 , σ 2 |x) = −
(
10
log 2πσ
2
)
2
−
5
∑
5
∑
1
(x1j − µ1 )2 +
(x2j − µ2 )2
2σ 2 j=1
j=1
(3)
となります。これより、最尤推定量は
µ
c1 =
1∑
1
x1j = (10 + 13 + 14 + 8 + 15) = 12
5 j=1
5
µ
c2 =
1∑
1
x2j = (13 + 21 + 18 + 25 + 13) = 18
5 j=1
5
5
5
5
5
∑
∑
1
2
2
c2 =
σ
(x1j − µ
c1 ) +
(x2j − µ
c2 )
1
10 j=1
j=1
1 {
(10 − 12)2 + (13 − 12)2 + (14 − 12)2 + (8 − 12)2 + (15 − 12)2
10
}
(13 − 18)2 + (21 − 18)2 + (18 − 18)2 + (25 − 18)2 + (13 − 18)2
= 14.2
=
これを (3) の対数尤度関数に代入します。
5
5
(
)
∑
∑
10
1
c2 |x) = − log 2π σ
c2 −
(x1j − µ
l1 (c
µ1 , µ
c2 , σ
c1 )2 +
(x2j − µ
c2 )2
1
1
c2
2
2σ
j=1
j=1
1
となりますが、ここで帰無仮説のときと同じようにショートカットをします。
5
∑
5
∑
c2 = 1 (x − µ
c1 )2 +
(x2j − µ
c2 )2
σ
1j
1
10 j=1
j=1
より、(4) は
(
)
10
c2 − 1 · 10σ
c2
log 2π σ
1
1
c2
2
2σ
1
= −5 log (28.4π) − 5
c2 |x) = −
l1 (c
µ1 , µ
c2 , σ
1
*12
実際は「帰無仮説と対立仮説のどちらでもよい状況のもとでの計算」です。気になる方は補足をご覧ください。
5
(4)
(尤度比検定統計量と尤度比検定)
これより、尤度比検定統計量は
(
T = 2 log
(
c2 |x)
L1 (c
µ1 , µ
c2 , σ
1
c
2
0
L (b
µ, σ |x)
)
0
)
c2 |x) − l0 (b
c2 |x)
= 2 l (c
µ1 , µ
c2 , σ
µ, σ
1
0
1
= 2 {(−5 log (28.4π) − 5) − (−5 log (46.4π) − 5)}
(
)
46.4π
28.4π
(
)
46.4
= 10 log
≒ 4.9
28.4
= 10 log
となります*13 。χ2 分布の自由度は「H1 のパラメータ数は µ1 , µ2 , σ 2 の3つ」「H0 のパラメータ数は µ, σ 2 の2つ」より、
3−2=1です。これより、棄却限界は χ2 (1, 0.95) ≒ 3.84 より、
T ≒ 4.9 > 3.84 ≒ χ2 (1, 0.95)
となり、帰無仮説は棄却されます*14 。
4 最尤法について
では、これから理論のご説明に入ります。まず最尤法について整理しましょう。お伝えしたいことは2点で
(i) 尤度関数の定義は確率(密度)関数の積ではない ということ*15
(ii) 最尤法の考え方
です。
4.1 (i) 尤度関数の定義
では最初に尤度関数の定義についてです。前回の「最尤推定量の計算 1」などでは、尤度関数を「確率(密度)関数の積」
として定義しましたが、一般のデータの場合それは正しくありません。正確には、データ (x1 , · · · , xn ) が与えられたときの
尤度関数 とは、(x1 , · · · , xn ) の従う同時確率(密度)関数に、データを入れたものです*16 。しかし、データ (x1 , · · · , xn )
が 全て独立のとき、独立性の定義から同時確率(密度)関数は x1 , · · · , xn のそれぞれの変数の従う確率(密度)関数の積
で表現できます。これより、今まで扱ってきたような 独立なデータ に対しては結果的に「尤度関数」=「確率(密度)関数
の積」となっただけなのです*17 。これの成り立たない例を1つ補足にあげておきました*18 。
本稿で重要なのは「尤度関数を確率(密度)関数と考える」ということです。強調したいのは、一般に「尤度関数」6=「確
率(密度)関数の積」ということではなく、「尤度関数がそれ自身確率(密度)関数である」と解釈できることです。この
点さえ押さえておいていただければ十分です*19 。
*13
log の計算は PC でしました。
*14
もう一度お断りしておきますが、両群合わせて例数 10 程度の集団に対して漸近的な検定をするのはお薦めできません。あくまで計算の練習として
出題していますのでご注意ください。
*15 「確率(密度)関数」という書き方は、離散分布 の場合「確率関数」、連続分布 の場合「確率密度関数」を指すものとします。
*16 さらに正確には、
「データは定数で、パラメータの関数である」という点も特徴(というか、確率(密度)関数との立場の違い)ですが、この点には
今回踏み込みません。
*17 「最尤推定量の計算1」では「独立」であることを強調しています。
*18 少し面倒ですので、興味のある方や2回目・3回目に本稿を読まれる際にお読みください。
*19 「確率(密度)関数の積」という見方をしてしまうと、「それ自身が確率」という解釈が、直感的には成り立ちません。そうではなくて、
「それ自身
が確率」なものをもってきてやるのです。それが(データが独立の時は)
「結果的にそれぞれの確率の積で表わされる」というだけであり、
「積」は
「確率(密度)関数の値が大きい」=
尤度関数にとって本質ではありません。なお、連続分布の場合は「確率(密度)関数の値」6=「確率」ですが、
「その近くのデータが取れる確率が高い」ですので、「(本稿の話題に関しては)大体同じようなもの」と考えていただいて問題ありません。
6
4.2 (ii) 最尤法の考え方
4.2.1 「尤度関数の値が大きい」ことの意味
たとえば二項分布で考えてみましょう。二項分布の確率関数は
f (x|n, p) = n Cx px (1 − p)n−x
と書けます。ここで、ある病気に 10 人中 3 人発症したとします。このとき、尤度関数は
L(p|10, 3) = 10 C3 p3 (1 − p)7
(5)
となります。
さてこのデータをもとに、p はどのくらいの値なのかを考えてみましょう。 手始めに p = 0.1, 0.3, 0.5 の3つの中でど
れが最もふさわしいのか を検討してみます。(5) の p にそれぞれの値を入れてみますと、
(p = 0.1) : L(0.1|10, 3) = 10 C3 · 0.13 · 0.97 ≒ 0.057
(p = 0.3) : L(0.3|10, 3) = 10 C3 · 0.33 · 0.77 ≒ 0.287
(p = 0.5) : L(0.5|10, 3) = 10 C3 · 0.53 · 0.57 ≒ 0.117
となります。「尤度関数は確率(密度)関数と考えてよい」ということですので、尤度関数のが大きいとき、確率が大きい
ということになります。
さて、尤度関数に値を代入したものを言葉で解釈すると以下の通りになります。
(p=0.1):「p = 0.1(発生割合1割)」であれば、「10 人中 3 人発症する」というデータは 6 %くらいの確率で得られる。
(p=0.3):「p = 0.3(発生割合3割)」であれば、
「10 人中 3 人発症する」というデータは 29 %くらいの確率で得られる。
(p=0.5):「p = 0.5(発生割合5割)」であれば、
「10 人中 3 人発症する」というデータは 11 %くらいの確率で得られる。
つまり、「p = 0.3 のとき、p = 0.1, 0.5 のときに比べて『このデータが得られる確率が高い』」ということになります。
言いかえると、
「p = 0.3 が(3 つの候補の中で)最もこのデータにフィットしている」と見ることもできます。最尤法 とは
このように、「データが得られたときに、そのデータが得られる確率が最も高くなるようなパラメータを探す」、言いかえ
れば「パラメータがいくつであれば、そのデータが最も『よくあるデータ』とみなせるか」を考える方法なのです*20 。
4.2.2 最尤法の計算方法
では次に、最尤法の計算方法です。先ほど「尤度関数の値が大きい」=「確率が大きい」ということをみました。そして、
上では p = 0.1, 0.3, 0.5 の3つの値の中で「p = 0.3 が最大」ということを見ました。実際の p の値としては 0∼1 までの
無限の値がありますので、この無限個の中で L(p|10, 3) が最大となる値を求めると、それが「最もデータにフィットした」
p の値となります。この最大値を与える p を求めるには、L(p|10, 3) を p で微分 して、
dL(p|10, 3)
=0
dp
*20
(6)
これは「よいこと」のように聞こえるかもしれませんが、実はここから、逆に最尤法のデメリットが1つでてくるのです。それは、たとえば例数が
少なく、外れ値が含まれる場合などの「ちょっと変なデータ」に対しても、「そのデータが普通のデータである」ようなパラメータを探し出してし
まう、ということです。つまり、ばらつき(分散)を過小評価してしまう、ということが起こります。これについては本稿の本題とは違いますの
で、補足で述べることにします。
7
を解いて、その 解を求めればよい、ということになります*21 。ところが実際計算しようとすると、たとえば (5) では p の
10 次関数で、大変になります。そこで、計算の面倒くささを緩和するために log をとるのです*22 。そうして対数尤度関数
l(p|10, 3) = log (L(p|10, 3))
を求め、実際の最尤法ではこの l(p|10, 3) の方を p で微分して
dl(p|10, 3)
=0
dp
(7)
を解くことになります*23 。これによって、
「最も(対数)尤度関数が大きくなる」p を求め、これを pb と書き、これを「p の
最尤推定量」と言います。
5 尤度比検定とは
では次に尤度比検定のご説明に入ります。しつこいようですが繰り返しておきますと、例数が多い場合を考えています。
そのため、推定の精度がよく 最尤推定量はかなり真の値に近い ものだということを前提にしておいてください。
たとえば正規分布に従う1群 n 例ずつ、計2群の全て独立なデータ x11 , · · · , x1n ∼ N (µ1 , σ 2 ) x21 , · · · , x2n ∼ N (µ2 , σ 2 )
があるとします。ここで帰無仮説・対立仮説を
H0:µ1 = µ2
(= µとおく)
H1:µ1 6= µ2
とします。このとき、「どちらが正しいか」ということを「どちらの尤度関数がより大きいか」でとらえることにします。
尤度関数が同時確率(密度)関数である、ということはご説明しました。したがってこれは、おおざっぱに言いますと、
「 H0 と H1 の
場合で、そのデータが得られる確率を比較している」ととらえることができます。なお、詳細は補足で述べますが、実際に
は「帰無仮説 H0 のもとでの尤度関数」と「帰無仮説 H0 と対立仮説 H1 のどちらのもとでもよい場合の尤度関数」を比較
します。
ところが、比較したくても、パラメータ µ1 , µ2 , σ 2 などが分からなければ尤度関数は数字になりません。そこで、これら
のパラメータを推定値で置き換えるのです。この際に最尤法によって得られる推定値を入れてやるのです。データを全てま
とめて x と1文字で書きますと、
(帰無仮説のもと)
c2 |x):帰無仮説のもとでこのデータが得られる確率(パラメータは最尤法で求めた推定値を代入)
L0 (b
µ, σ
0
(帰無仮説でも対立仮説のどちらでもよい)
c2 |x):帰無仮説でも対立仮説でもどちらでもよい状況のもとでこのデータが得られる確率
L1 (c
µ1 , µ
c2 , σ
1
(パラメータは最尤法で求めた推定値を代入)
の2つを比較することになります。
y = f (x) の最大・最小を求めるときは「f 0 (x) = 0」を解いて、増減表を書いて・・・ということを高校時代にされたと思います。その際、
「f 0 (x) = 0 だからといって、最大・最小とは限らない」(たとえば f (x) = x3 において x = 0 のとき) ということは習われたと思います。しかし通
常は暗黙のうちに「(6) を解けば最大値が求まる」ことは前提としています。厳密には結構大変な議論が必要なはずですが、そこには踏み入りませ
*21
*22
ん。
実際に
L(p | 10, 3) = 10 C3 p3 (1 − p)7
l(p | 10, 3) = log (10 C3 ) + 3 log p + 7 log (1 − p)
をそれぞれ p
*23
(b
p)
で微分して、 dL
dp
= 0,
dl
(b
p)
dp
= 0 を解かれると、後者が以下に楽かが実感していただけると思います。
ただし、x = 0, n などの「端っこ」の状況ではデリケートな取扱いが必要になります。その点は「第3回資料3:最尤推定量の計算1」の追加問題
で取り扱っています。
8
5.1 「尤度関数を比べる」ということ
上で見ました通り、実際比べるのは以下の2つです。
c2 |x)(パラメータは最尤法で求めた推定値を代入)
(i) H0 のもとでの尤度関数 L0 (b
µ, σ
0
c2 |x)(パラメータは最尤法で求めた推定値を代入)
(ii) H , H のどちらでもよい状況での尤度関数 L1 (c
µ ,µ
c, σ
0
1
1
2
1
上でも述べましたが、例数が多い場合の最尤推定量は「ほぼパラメータの真の値」ととらえることができますので、こ
れは「H0 で考える場合と H0 , H1 どちらでもよい状況で考える場合に、データのフィット具合がどの程度違うか」を調べて
いることになります。
ここで (a)「帰無仮説が正しいとき」(b)「対立仮説が正しいとき」のそれぞれに、尤度関数の比がどのようになるか を
見ていきましょう。
まずは (a)「帰無仮説 H0:µ1 = µ2 (= µ) が正しいとき」です。このとき、「H0 でも H1 でもよい状況」での最尤推定量
は、各群別々に µ
c1 , µ
c2 と推定されますが、帰無仮説 H0:µ1 = µ2 が正しいので、この2つの推定値はほぼ等しく、µ
c1 ≒ µ
c2
となります。さらにこれは帰無仮説のもとでの推定値 µ
b ともほぼ等しくなる、ということが分かります。そうなると、
∑∑
c2 = 1
σ
(xij − µ
b)2
0
n i=1 j=1
2
n
n
∑
n
∑
c2 = 1 (x − µ
σ
c1 )2 +
(x2j − µ
c2 )2
1j
1
n j=1
j=1
の値もほぼ同じになってきます。つまりこのとき、「H0 で考えようが、H0 でも H1 でもどちらでもよい状況で考えよう
が、同じような状況」ということになります。したがって、「どちらの仮説のもとで考えようともこのデータの起こりやす
さはほぼ同じ」となります。これより、2つの尤度関数もほぼ同じ値であり、
c2 |x)
L1 (c
µ1 , µ
c2 , σ
1
≒1
c2 |x)
L0 (b
µ, σ
0
となります。
次に、(b)「対立仮説 H1:µ1 6= µ2 が正しいとき」です。このとき、対立仮説 H1:µ1 6= µ2 が成り立ちますので、各群
の推定値もそれなりに異なる、つまり µ
c1 6= µ
c2 (結構違う)ということが想定されます。このときどうなるかと言います
と、H0 のもとでは「本当は対立仮説が正しく平均値が群ごとで異なるのに、無理やり『両群同じ µ
b』として推定してい
る」から、「このデータが発生する確率はそれほど高くない」つまり「データにあまりフィットしていない」ことが想定さ
c2 |x) の値はそれほど大きくならない でしょう。一方で、H でも H でもどちらでもよ
れます。つまり、尤度関数 L0 (b
µ, σ
0
1
0
い状況下での推定量の方は「正しい仮説 H1 通りに、群ごとに別々の µ
c1 , µ
c2 で推定している」ということで、これは「こ
のデータが出てくる確率が結構高い」つまり「データにフィットしている」ということになります。そのため、尤度関数
c2 |x) は L0 (b
c2 |x) よりも大きくなる ことが想定されます。つまり、
L1 (c
µ1 , µ
c2 , σ
µ, σ
1
0
c2 |x)
L1 (c
µ1 , µ
c2 , σ
1
>> 1
c
2
0
L (b
µ, σ |x)
0
となります。
つまり、尤度関数の比が大きくなればなるほど、「対立仮説が正しい」ことを示すのです*24 。これが尤度比検定の原理
です。
*24
当たり前ですが、
「分母が帰無仮説」のときです。これを間違えると話がさかさまになります。
9
6 (狭い意味での)尤度比検定の統計量と棄却限界について
6.1 (狭い意味での)尤度比検定統計量
(狭い意味での)尤度比検定の統計量は、尤度比の log をとって 2 倍した
(
T = 2 log
(
c2 |x)
L1 (c
µ1 , µ
c2 , σ
1
c2 |x)
L0 (b
µ, σ
)
0
c2 |x) − l0 (b
c2 |x)
= 2 l1 (c
µ1 , µ
c2 , σ
µ, σ
1
0
)
を用います*25 。
6.2 尤度比検定の棄却域
詳しいご説明は省略しますが*26 、この尤度比検定統計量に対して漸近的に、
(
)
c2 |x) − l0 (b
c2 |x) ∼ χ2 (1)
T = 2 l1 (c
µ1 , µ
c2 , σ
µ, σ
1
0
が成り立ちます。ここで、χ2 分布の自由度は「H1 のパラメータ数」−「H0 のパラメータ数」で決まります。今回は H1 の
パラメータは µ1 , µ2 , σ 2 の3つであり、H0 のパラメータが µ, σ 2 の2つであったため、(自由度)=3−2=1となったの
です。そして、帰無仮説が棄却されるのは、有意水準 α の両側検定のとき
(
)
c2 |x) − l0 (b
c2 |x) > χ2 (1, 1 − α)
T = 2 l1 (c
µ1 , µ
c2 , σ
µ
,
σ
1
0
となるときです。
なお、「尤度関数の比を考えるときにどちらを上にしたらよいか忘れる」という方がよくいらっしゃるかと思います。こ
の点に関しては覚えるよりは「毎回考える」方がよいかと思います。
今までの理屈をたどっていきますと、
「H0 を棄却」⇔「『H0 』より『H0 または H1 』の方がデータによくフィットする」
(a)
⇔「『H0 』より『H0 または H1 』のもとの方が尤度関数が大きい」
(b)
となります。一方で、
「H0 を棄却」⇔「T が大きい」
(c)
となりますので、これらを合わせると結局
「T が大きい」⇔「H0 を棄却」
(∵ (c))
⇔「『H0 』より『H0 または H1 』の方がデータによくフィットする」
(∵ (a))
⇔「『H0 』より『H0 または H1 』のもとの方が尤度関数が大きい」
(∵ (b))
となります。T が大きくなるのは分子が大きくなるときですので、結局「『H0 または H1 』のもとの方が分子」となります。
*25
*26
したがって、帰無仮説が正しいとき T ≒ 0 となります。
「中心極限定理」が必要になりますので、結構大変です。
10
7 補足
7.1 補足1:尤度関数が確率(密度)関数の積にならない例
最初に、
「尤度関数は同時確率(密度)関数にデータを入れたものであり、一般には確率(密度)関数の積ではない」とい
うお話をしました。この具体例を1つ見てみましょう。
同一の症例に対して繰り返し測定したデータのような場合、同一症例のデータ同士は独立ではないと仮定する方が妥当で
しょう。数式で見てみますと、同じ人にある測定を2回するときの測定値が確率変数 X1 , X2 で表現できるとします。そし
て、記号を
(
X=
X1
X2
)
(
, µ=
µ1
µ2
)
(
, Σ=
σ12
ρσ1 σ2
ρσ1 σ2
σ22
)
(ρ 6= 0)
として、X は 2 変量正規分布
X ∼ N (µ, Σ)
に従うとします。このとき、データ(X1 , X2 )= (x1 , x2 ) が与えられたときの尤度関数は
L(µ1 , µ2 , ρ, σ12 , σ22 |x1 , x2 )
))
(
(
2ρ(x1 − µ1 )(x2 − µ2 ) (x2 − µ2 )2
1
1
(x1 − µ1 )2
√
−
=
exp −
+
2(1 − ρ2 )
σ12
σ1 σ2
σ22
2πσ1 σ2 1 − ρ2
と表現されます。
一方このとき X1 ∼ N (µ1 , σ12 ), X2 ∼ N (µ2 , σ22 ) となりますので、確率密度関数の積は
)) (
))
(
1
(x1 − µ1 )2
(x2 − µ2 )2
= √
· √
exp −
exp −
2σ12
2σ22
2πσ12
2πσ22
)
(
)2
(
(x2 − µ2 )2
1
(x1 − µ1 )2
−
= √
exp −
2σ12
2σ22
2πσ 2
(
f (x1 |µ1 , σ12 )
·
f (x2 |µ2 , σ22 )
1
(
となり、これは尤度関数 L(µ1 , µ2 , ρ, σ12 , σ22 |x1 , x2 ) とは異なっています。
このように、一般に尤度関数と確率(密度)関数の積は一致せず「データが独立なとき」のみ一致するのです。
7.2 補足2:最尤推定量の弱点
7.2.1 分散の過小評価について
本稿では、最尤推定量が「データにフィットしすぎている」というお話をしました。それをもとに最尤法の弱点について
も述べておきましょう。
最尤法とは、データが得られたときに「それに最もフィットするように」パラメータを選ぶ手法でした。これは一見する
とよいことに思えるのですが、実際はそうとばかりは言い切れません。たとえば「データに外れ値が入っていた場合」を考
えてみましょう。このとき、本当は外れ値ですので、ばらつきが結構大きくなるはずです。一方、最尤法で考えると「外れ
値を外れ値でない、よくある値」としてとらえてしまうのです*27 。
µ)」は「外れ値に引っ張られる」という性質があります。
具体的に何が起こるかといいますと、まず「平均の最尤推定量 (b
そのため、真のパラメータ µ の値よりも µ
b は外れ値の方に近くなります。その結果、外れ値の外れ具合が小さくなり、結局
*27
「外れ値」とは「分布にあまりフィットしないデータ」ですので、本来は「あまりフィットしてないですよね」と言いたいところですが、最尤法で
はこのデータに対しても「フィットした」パラメータを探してしまうのです。
11
「データのばらつきが過小評価される」ということが起こるのです*28 。これについて、具体例はご存知の方が多いと思いま
すが、x1 , · · · , xn ∼ N (µ, σ 2 ) のときに、分散の最尤推定量は
1∑
2
[
σ
(xi − x̄)2
ML =
n i=1
n
と書きますが、通常我々が使うのはこれではなく
c2 =
σ
1 ∑
(xi − x̄)2
n − 1 i=1
n
2
[
c2 は不偏推定量ですが、σ
の方です*29 。σ
M L にはバイアスが入っています。例数が大きければ気にならなくなるのですが、
小さいときには注意が必要です。たとえば、n = 10 で
n
∑
(xi − x̄)2 = 270 のときには
i=1
270
2
[
c2 = 270 = 30
σ
= 27, σ
ML =
10
9
2
[
*30 。ただし、繰り返しておきますが、例数が多い場合はこのバイア
となり、σ
M L が過小評価されている ことが分かります
スは問題になりません。例数が多いとき、最尤推定量は最適と呼んでよい推定量となります。
なお、この補足の内容は(狭い意味での)尤度比検定の文脈では、例数が多い場合を考えますので、本稿の本題に対して
は関係ないと考えていただいて結構です。
7.2.2 平均・分散の不偏性について
2
[
上で流れをお話したことから、σ
M L にはバイアスが入っていて、不偏推定量ではありません。一方、先ほど「平均の最尤
推定量 µ
b = x̄ は外れ値に引っ張られる」というお話をしました。しかしこの µ
b は µ の不偏推定量 なのです。これは一見す
ると奇妙なことのように思われますので、「不偏性」について少し考えてみることにしましょう。不偏推定量とは何か、と
いうのは意外と定義からはつかみにくいので、私は「大数の法則」とペアにしてご説明することが多いです*31 。
つまり、今回の µ
b = x̄ が 不偏推定量 である、とは、同じような試験をたくさん繰り返し、µ
b と同様な手順で最尤推定量
を 9,999 個の µ
c1 , · · · , µd
b と合わせて 10,000 個にしておいて、その 10,000 個の平均をとると、µ にほとん
9999 を考え、µ
ど一致することだと考えていただくのがよいかと思います。つまり、
µ
b+µ
c1 + · · · + µ[
9999
≒µ
10000
が成り立つ、というのが「µ
b が µ の不偏推定量」ということです。
今、
「外れ値が出た場合」というのが話題の中心でしたので、外れ値について考えましょう。たしかに、データを採ったと
きに外れ値が入っていれば、µ
b は外れ値の方に偏った値かもしれません。しかし、正規分布であれば左右均等にばらついて
いますので、そのうち(適当ですが)たとえば µ
c1 , · · · , µd
100 くらいまで眺めていると、そのうちのいくつかは「右側の外れ
値」によって影響を受けている、という風に考えるのは不自然ではないでしょう。
このようにして、「1回の測定で外れ値に影響されたとしても、『何回も試験をくり返して µ
b を作り、その平均をとった
ら』きちんと µ が推定できる」というのが不偏性の重要な点です。
では一方、分散 の方です。残念ながらこちらは平均ほど丸くおさまってはくれません。というのは、分散は「値の大きい
これは「外れ値」に限らず、たとえば「データが偶然真の平均 µ よりも大きい方にたくさん出てしまった」場合など、
「平均の推定値 µ
b = x̄ は真の
平均 µ より大きく」なることがあります。そのため、「真の平均 µ よりは結構離れている(ばらついている)」データが「平均の推定値 µ
b からはそ
れほど離れていない(ばらついていない)
」となって、ばらつきが過小評価されるのです。
*29 このことの証明は省略します。
*30 分散を過小評価すると、
「差がないものに有意差がつきやすくなる」ため、開発の人間は絶対にしてはいけません。
*31 この点については、私の以前作成した資料(分散分析講義第1回:資料2「不偏推定量・UMVU と大数の法則」
)の中にも書きました。興味がおあ
りの方はそちらもお読みください。
*28
12
方向に外れ値が出たとき、過小評価」されますが、困ったことに「値の小さい方向に外れ値が出た場合も、過小評価」して
しまうからです。つまり、どのようなデータに対しても「過剰にフィットする」ように推定してしまうため、
「何回くり返し
測定しても、毎回小さい値」ということになります。そのため、先と同様に 10,000 回のくり返しをしたとしても、
2
2
2\
[
\
σ
M L + σM L,1 + · · · + σM L,9999
10000
< σ2
となってしまうのです。ただし、これは「試験のくり返し回数を増やすことで偏りが是正されない」という風に言っている
だけです。
「1回あたりの試験の例数を増やす」ことには意味があります*32 。この点は混乱しやすいのでご注意ください。
直感的なご説明にとどめますが、要は「例数が多かったら、外れ値の1つや2つ入っていても『自然なデータ』と呼んで
いいでしょう」ということです。「外れ値が入った状態が普通」であり、「それ以外のデータが、きちんと外れ値の補正をし
てくれる」ので、毎回の過小評価具合がほとんどなくなるのです。
さて、分散が不偏にならないことを式で捉えてみるとこういうことになります。真の平均値 µ が分かっている場合*33
∑
f2 = 1
σ
(xi − µ)2
n i=1
n
(8)
は σ 2 の不偏推定量になります。これに対して、µ を最尤推定量 µ
b = x̄ で置き換えたものが分散の最尤推定量となります
ので、
1∑
2
[
(xi − µ
b)2
σ
ML =
n i=1
n
(9)
が分散を過小評価している、ということでした。(8) と (9) の2式は真の平均 µ を使うか平均値の推定値 µ
b を使うか、以外
の点は全く同じです。これらを見比べて解釈します。
(8):「真の平均 µ」を用いている ⇒ 「外れ値」があれば「平均から結構離れた値」と的確に評価される。
⇒ 分散 σ 2 が正しく推定できる*34 。
(9):「平均の推定値 µ
b」を用いている ⇒ µ
b が外れ値の方に引っ張られる
⇒ 外れ値から「µ までの距離」よりも「µ
b までの距離」の方が短くなる
⇒ 外れ値のばらつきを過小評価する
⇒ 全体的にばらつきを過小評価する*35
と解釈できます*36 。
7.3 補足3:H0 , H1 のどちらでもよい状況のもとでの最尤推定量 にする理由
尤度比検定統計量の分子において「対立仮説 H1 」ではなく「帰無仮説 H0 と対立仮説 H1 のどちらでもよい」のもとでの
尤度関数を考えます。これを奇妙に感じられる方も多いと思いますが、具体例をご紹介すれば簡単にご理解いただけると思
います。
データが正規分布に従う、1群3例の場合を考えます。x11 , x12 , x13 ∼ N (µ1 , σ 2 ), x21 , x22 , x23 ∼ N (µ2 , σ 2 ) として、
*32
*33
*34
*35
*36
[
2
この点少しややこしいですが、「例数の小さい試験をくり返し回数を増やす」ことでは、σ
「例数の大きい試験
M L のバイアスは消去されませんが、
をくり返し回数を増やす」ことで、バイアスはほとんどなくなります。
現実的にはあり得ませんが、
「仮に」というお話です。
ここで「正しく」というのは「偏りなく」つまり不偏な推定になっている、という意味で使っています。
全体のばらつきの大きさは外れ値は大きく影響を受けますので、これは「大体」大丈夫です。
ご説明のわかりやすさのため「外れ値」ばかり取り上げていますが、これは「1つの点に注目してご説明した方が分かりやすい」という点に加え
て、「外れ値が分散(ばらつき)の大きさに大きく寄与している」という点もあります。そのため、外れ値を基本としてイメージを持っておいてい
b の選び方
ただければ十分なのではないか、と考えています。なお、外れ値がない場合の普通のデータのばらつきも同様に過小評価されています。µ
が「データに最もフィットするように」=「ばらつきが少なくなるように」となっているため、結果的に分散を過小評価している、ということです。
13
仮説を
H0 : µ1 = µ2
H1 : µ1 6= µ2
(= µとおく)
とします。このとき、たとえば
x11 = 20, x12 = 30, x13 = 22
x21 = 25, x22 = 18, x23 = 29
となったとき、H1 のもと では、
µ
c1 =
1
1
(20 + 30 + 22) = 24, µ
c2 = (25 + 18 + 29) = 24
3
3
となり、µ
c1 と µ
c2 が同じ値 になってしまいます。ところが H1 は µ1 6= µ2 なので、これは 推定値として妥当な値ではなく
なってしまいます。
このようなことが起きてしまうと面倒くさいので「H0 でも H1 でもよい」としておいて、µ
c1 = µ
c2 となってしまったと
きには「H0:µ1 = µ2 も含んでいるから大丈夫」という風に対応しているのです。
c1 = µ
c2 の状況において、明らかに帰無仮説 H0:µ1 = µ2 は棄却
ちなみに、検定ベースで考えると、このような 点推定値 µ
されません*37 。ですので、分子を「H1 」にしたところで「H0 でも H1 でもよい」にしたところで、「帰無仮説が棄却され
ない部分を整備しただけ」で、
「こうしたおかげで何かが棄却されやすくなる」などということは決して起こりません。従っ
て、このようなことをしても誰かの不当な利益にはつながらないので、問題ないなのです。
8 おまけ:Holmes と最尤法
実は、かの Sharlock Holmes*38 氏の推理方法(のうちの1つ)が最尤法に近い、ということが彼自身の言葉から分かって
います。小説「バスカヴィル家の犬」の中で、自身の推理方法について彼はこう語っています*39 。
we balance the probabilies and choose the most likely
(確率をはかりにかけて、最も確からしいものを選ぶのです*40 )
これは我々が 4.2 最尤法の考え方で見ました「p = 0.1, 0.3, 0.5 を入れて尤度関数(≒確率)が最も大きいものを選ぶ」
というのとほとんど同じことを言っています。このように、最尤法は人間の思考方法のモデルとしても使用可能な理論なの
です*41 。
*37
5.1「尤度関数を比べる」ということ で見ました通り、このとき
c2 |x)
L1 (c
µ1 , µ
c2 , σ
1
≒1
c2 |x)
L0 (b
µ, σ
0
となります(厳密には「=1」が成り立ちます)
。
シャーロック・ホームズ。欧米人の人名は基本的にアルファベット表記にします。
*39 出典は「シャーロック・ホームズの推理学」
(講談社現代新書:内井惣七 著)です。英文はそのまま持ってきましたが、和訳は私がアレンジしまし
た。この本には「科学的思考」というものの本質的な部分に確率・統計がいかに深く関与しているか、ということが丁寧に書いてあります。統計を
仕事にしている(勉強している)ことを誇りに思いたい(誇りを強めたい)方はぜひご一読ください。
*40 Holmes の場合の大雑把な例をあげますと、たとえば「A さんが犯人」
「B さんが犯人」「C さんが犯人」の確率をそれぞれ計算して、「確率が最も
大きい人が犯人」ということになります。
*41 ちなみに、Holmes は推理の際に「知識」の重要性をよく説いています。これより、彼の推理は最尤法というよりその一般化と考えられる Bayes
(ベイズ)統計を用いている、と考える方が厳密だと思われます。つまり、
「尤度関数」と「事前分布(事前情報)
」から「事後分布」を求めて、事後
分布に対して「確率をはかりにかけて、最も確からしいものを選ぶ」という方法です。
*38
14
© Copyright 2026 Paperzz