IBM® SPSS® Amos™ 23
ユーザーズ ガ イ ド
James L. Arbuckle
注 : 本書の情報お よ びサポー ト さ れ る 製品を使用する 前に、 「通達」 に記載 さ れてい る 情報を ご一
読 く だ さ い。
新 し いエデ ィ シ ョ ンに特に記載がない限 り 、 本エデ ィ シ ョ ンは IBM® SPSS® Amos™ 23 お よ び以
降のすべての リ リ ースお よ び改訂版に適用 さ れます。
Microsoft 製品の ス ク リ ーン シ ョ ッ ト は Microsoft Corporation か ら の許可を得て複製 さ れてい ます。
ラ イ セ ン ス資料の所有権 - IBM に帰属
© Copyright IBM Corp. 1983, 2014. 米国政府の規制付 き 権利 - 使用、 複製、 開示には、 IBM と の
「GSA ADP Schedule Contract」 で定め ら れた規制が適用 さ れます。
© Copyright 2014 Amos Development Corporation. All Rights Reserved.
AMOS は、 Amos Development Corporation 社の商標です。
目次
パー ト I: は じ めに
1
概要
1
主要な方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
チ ュ ー ト リ アルについて . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
例について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
ド キ ュ メ ン ト について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
その他の情報源 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
謝辞
2
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
チ ュー ト リ アル : Amos Graphics のス タ ー ト ア ッ プ ガ イ ド
概要
7
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Amos Graphics の起動 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
新 し いモデルの作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
デー タ フ ァ イルの指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
モデルの指定 と 変数の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
変数の命名 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
矢印の描画 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
パラ メ ー タ の制約
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
パス図の表示の変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
オブ ジ ェ ク ト を移動するには . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
オブ ジ ェ ク ト や双方向矢印の形を変更するには . . . . . . . . . . . . . . . . . . . . 14
オブ ジ ェ ク ト を削除するには . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
動作を元に戻すには . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
動作をや り 直すには . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
iii
オプ シ ョ ン出力の設定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
分析の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
出力の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
テキス ト 出力を表示するには . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
グ ラ フ ィ ッ ク ス出力を表示するには . . . . . . . . . . . . . . . . . . . . . . . . . . 19
パス図の印刷 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
パス図の コ ピー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
テキス ト 出力の コ ピー . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
パー ト II: 例
1
分散および共分散の推定
概要
21
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
デー タ の取 り 込み
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
デー タ の分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
モデルを指定する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
変数に名前を付ける . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
フ ォ ン ト の変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
共分散の設定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
分析の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
グ ラ フ ィ ッ ク出力を表示する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
テキス ト 出力の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
オプ シ ョ ン出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
標準化推定値の計算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
分析の再実行
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
相関推定値のテキス ト 出力 と し ての表示
. . . . . . . . . . . . . . . . . . . . . . . 31
Amos モデルの分布の仮定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
追加出力の生成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
C# によ る モデ リ ング . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
その他のプ ログ ラ ム開発ツール
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
iv
2
仮説の検定
概要
37
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
パラ メ ー タ 制約条件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
分散の制約 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
等 し いパラ メ ー タ の指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
共分散の制約
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
オブ ジ ェ ク ト の移動 と 書式設定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
デー タ の入力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
分析の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
テキス ト 出力の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
オプ シ ョ ン出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
分散共分散行列推定値 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
共分散および分散推定値のパス図への表示 . . . . . . . . . . . . . . . . . . . . . . 46
出力のラ ベル付け
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
仮説の検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
パス図へのカ イ 2 乗統計量の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
VB.NET でモデルを作成する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
タ イ ミ ングがすべて . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3
その他の仮説の検定
概要
53
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
デー タ の取 り 込み
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2 つの変数に相関がない と い う 仮説の検定 . . . . . . . . . . . . . . . . . . . . . . . . . 54
モデルを指定する
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
テキス ト 出力の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
グ ラ フ ィ ッ ク出力の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
v
4
従来の線型回帰
概要
61
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
デー タ の分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
モデルを指定する
特定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
係数を固定する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
テキス ト 出力を表示する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
グ ラ フ ィ ッ ク出力を表示する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
その他のテキス ト 出力を表示する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
VB.NET でモデルを作成する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
外生変数間の相関に関する仮定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
AStructure メ ソ ッ ド の式形式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5
非観測変数
概要
73
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
測定モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
構造モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
特定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
モデルを指定する
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
描画領域の方向を変更する
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
パス図を作成する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
指標を回転する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
測定モデルを複写する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
変数名を入力する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
構造モデルを完成する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
モデル A の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
グ ラ フ ィ ッ ク出力を表示する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
モデル B の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
モデル A に対する モデル B の検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
vi
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6
探索分析
概要
91
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
Wheaton デー タ 用のモデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
特定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
分析の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
棄却の処理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
修正指数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
Wheaton デー タ 用のモデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
モデル B のグ ラ フ ィ ッ ク 出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
修正指数の誤用 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
新 し い制約の追加によ っ て モデルを改良する . . . . . . . . . . . . . . . . . . . . 100
Wheaton デー タ 用のモデル C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
モデル C の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
Model C の検定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
モデル C のパラ メ ー タ 推定値 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
単一分析での複数モデルの使用
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
複数モデルによ る出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
個々のモデルのグ ラ フ ィ ッ ク出力を表示する . . . . . . . . . . . . . . . . . . . . 109
4 つのモデルすべての適合度の統計を表示する . . . . . . . . . . . . . . . . . . . 109
オプ シ ョ ン出力を取得する
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
間接効果、 直接効果、 総合効果を取得する . . . . . . . . . . . . . . . . . . . . . 112
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
モデル C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
複数のモデルを適合する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
vii
7
非再帰 モデル
概要
119
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
Felson と Bohrnstedt のモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
モデルの特定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
分析の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
標準化推定値を取得する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
重相関係数の平方を取得する . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
安定指数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
8
因子分析
概要
127
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
共通因子モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
特定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
モデルを指定する
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
モデルを作成する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
分析の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
標準化推定値を取得する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
標準化推定値を表示する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
9
共分散分析の代替分析
概要
135
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
共分散分析 と その代替分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
共分散分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
Olsson デー タ 用のモデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
viii
特定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
モデル A を指定する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
モデル A の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
よ り 適切な モデルを探す . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
修正指数を要求する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
Olsson デー タ 用のモデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
モデル B の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
Olsson デー タ 用のモデル C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
モデル C のパス図を作成する . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
モデル C の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
すべてのモデルを一度に適合する . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
モデル C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
複数のモデルを適合する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
10
複数グループの同時分析
概要
147
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
複数グループの分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
グループの相違を指定する ための規則 . . . . . . . . . . . . . . . . . . . . . . . . 148
モデル A を指定する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
複数モデルの入力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
ix
11
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
概要
161
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
Felson と Bohrnstedt のモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
女子生徒 と 男子生徒用のモデル A を指定する . . . . . . . . . . . . . . . . . . . . . . 162
図のキ ャ プ シ ョ ン を指定する . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
モデル A のテキス ト 出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
モデル A のグ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
パラ メ ー タ の差に対する検定統計量を取得する . . . . . . . . . . . . . . . . . . . 166
女子生徒 と 男子生徒のモデル B
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
モデル B の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
グ ラ フ ィ ッ ク ス出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
モデル A と B を単一の分析に適合する . . . . . . . . . . . . . . . . . . . . . . . . . 171
女子生徒 と 男子生徒のモデル C
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
モデル C の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
モデル C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
複数のモデルを適合する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 178
12
複数のグループの同時因子分析
概要
179
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
Holzinger と Swineford の少年少女のモデル A . . . . . . . . . . . . . . . . . . . . . 180
グループに名前を付ける . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
デー タ の指定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
モデル A の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
Holzinger と Swineford の少年少女のモデル B . . . . . . . . . . . . . . . . . . . . . 183
x
モデル B の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
13
平均値に関する仮説の推定および検定
概要
191
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
平均値 と 切片のモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
若者および老人の被験者のモデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
Amos Graphics の平均構造モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
モデル A の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
若者および老人の被験者のモデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
モデル B の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
モデル B と モデル A と の比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
複数のモデル入力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
VB.NET での平均構造モデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
複数のモデルを適合する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
14
明示的な切片を持つ回帰
概要
203
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203
Amos が行 う 仮定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203
モデルを指定する
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
xi
分析の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
15
構造平均によ る因子分析
概要
209
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
因子平均 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
少年 と 少女のモデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
モデルを指定する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
グループ間の制約条件について
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
モデル A の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213
少年 と 少女のモデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
モデル B の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217
モデル A お よびモデル B の比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219
複数のモデルの当てはめ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
16
共分散分析に対する Sörbom の代替案
概要
221
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
前提条件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222
デ フ ォル ト の動作の変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
モデルを指定する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
モデル A の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
xii
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
モデル B の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229
モデル C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
モデル C の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
モデル D . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
モデル D の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233
モデル E . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235
モデル E の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235
モデル A か ら モデル E を単一の分析で当てはめる
. . . . . . . . . . . . . . . . . . . 235
Sörbom の方法 と 例 9 の方法の比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . 235
モデル X . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236
Amos Graphics のモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236
モデル X の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
モデル Y . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
モデル Y の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238
モデル Z . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
モデル Z の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243
モデル C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
モデル D . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
モデル E . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246
複数のモデルを適合する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 247
モデル X、 モデル Y、 モデル Z . . . . . . . . . . . . . . . . . . . . . . . . . . . 247
17
欠損デー タ
概要
249
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249
不完全なデー タ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
モデルを指定する
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251
飽和モデルおよび独立モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
xiii
分析の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
グ ラ フ ィ ッ ク出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255
因子モデルの適合 ( モデル A) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255
飽和モデルの適合 ( モデル B) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256
尤度比カ イ 2 乗統計量 と その p 値の計算 . . . . . . . . . . . . . . . . . . . . . . 259
単一プ ログ ラ ムでの全手順の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . 260
18
欠損デー タ についてのその他の情報
概要
261
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
欠損デー タ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263
モデル A の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
グ ラ フ ィ ッ ク ス出力 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267
モデル A お よびモデル B か らの出力
. . . . . . . . . . . . . . . . . . . . . . . . . . 268
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
モデル A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
モデル B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 270
19
ブー ト ス ト ラ ッ プ
概要
271
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271
ブー ト ス ト ラ ッ プ法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272
因子分析モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272
ブー ト ス ト ラ ッ プの進行状況の監視 . . . . . . . . . . . . . . . . . . . . . . . . . . . 273
分析の結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276
xiv
20
ブー ト ス ト ラ ッ プでのモデル比較
概要
277
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 277
モデル比較における ブー ト ス ト ラ ッ プ手法 . . . . . . . . . . . . . . . . . . . . . . . . 277
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 278
5 つのモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 278
テキス ト 出力
要約
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284
21
ブー ト ス ト ラ ッ プによ る比較推定方法
概要
285
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
推定方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
モデルについて . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 286
テキス ト 出力
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 288
VB.NET でのモデル作成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 291
22
探索的モデル特定化
概要
293
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293
モデルについて . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293
xv
オプ シ ョ ン矢印が少数の探索的モデル特定化
. . . . . . . . . . . . . . . . . . . . . . 294
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294
プ ログ ラ ムのオプ シ ョ ンの選択 . . . . . . . . . . . . . . . . . . . . . . . . . . . 296
探索的モデル特定化の実行
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297
生成 さ れたモデルの表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 298
モデルのパラ メ ー タ 推定値の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . 299
BCC を使用 し たモデル比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 299
赤池ウ ェ イ ト の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 300
BIC を使用 し たモデル比較
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302
Bayes 因子を使用 し たモデル比較 . . . . . . . . . . . . . . . . . . . . . . . . . . 303
Bayes 因子の再調整 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 305
モデルの短い リ ス ト についての調査 . . . . . . . . . . . . . . . . . . . . . . . . . 306
適合度 と 複雑度についての散布図の表示
. . . . . . . . . . . . . . . . . . . . . . 307
定数の適合度を表す線の調整 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309
定数 C – df を表す線の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 310
定数 C – df を表す線の調整 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 311
定数の適合度を表すその他の線の表示 . . . . . . . . . . . . . . . . . . . . . . . . 312
C における最善の適合グ ラ フ の表示 . . . . . . . . . . . . . . . . . . . . . . . . . 312
その他の適合度に対する最善の適合グ ラ フの表示 . . . . . . . . . . . . . . . . . . 314
C のス ク リ ープ ロ ッ ト の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315
その他の適合度に対する ス ク リ ー プ ロ ッ ト の表示
オプ シ ョ ン矢印が多数の探索的モデル特定化
. . . . . . . . . . . . . . . . . 316
. . . . . . . . . . . . . . . . . . . . . . 318
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319
矢印のオプ シ ョ ン指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319
オプ シ ョ ン設定のデ フ ォル ト への リ セ ッ ト
. . . . . . . . . . . . . . . . . . . . . 320
探索的モデル特定化の実行
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 320
BIC を使用 し たモデル比較
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 321
ス ク リ ープ ロ ッ ト の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322
制限
23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322
探索的モデル特定化によ る探索的因子分析
概要
323
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323
モデルについて . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324
xvi
[ 探索的モデル特定化 ] ウ ィ ン ド ウ を開 く
すべての係数のオプ シ ョ ン指定
. . . . . . . . . . . . . . . . . . . . . . . . 324
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325
オプ シ ョ ン設定のデ フ ォル ト への リ セ ッ ト . . . . . . . . . . . . . . . . . . . . . . . . 325
探索的モデル特定化の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 327
BCC を使用 し たモデル比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 327
ス ク リ ープ ロ ッ ト の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331
モデルの短い リ ス ト の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331
発見的な探索的モデル特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332
ス テ ッ プワ イ ズ検索の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333
ス ク リ ープ ロ ッ ト の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334
発見的な探索的モデル特定化における制限 . . . . . . . . . . . . . . . . . . . . . . . . 335
24
複数グループでの因子分析
概要
337
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 337
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 337
モデル 24a: 平均値 と 切片項を使用 し ないモデル作成 . . . . . . . . . . . . . . . . . . 337
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 338
[ 複数グループの分析 ] ダ イ ア ログ ボ ッ ク ス を開 く . . . . . . . . . . . . . . . . . 338
パラ メ ー タ 部分集合の表示
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 340
生成 さ れたモデルの表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341
すべてのモデルの適合 と 、 出力の表示 . . . . . . . . . . . . . . . . . . . . . . . . 342
分析のカ ス タ マ イ ズ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343
モデル 24b: 因子の平均値の比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343
制約条件の削除 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344
グループ間制約の生成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
モデルの適合
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 346
出力の表示 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 346
xvii
25
複数グループの分析
概要
349
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 349
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 349
モデルについて . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 350
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 350
潜在変数の平均値 と 切片項の制限 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 350
グループ間制約の生成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 351
モデルの適合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352
テキス ト 出力を表示する . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353
修正指数の調査 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354
モデルの変更 と 分析の繰 り 返 し . . . . . . . . . . . . . . . . . . . . . . . . . . . 355
26
ベイズ推定
概要
357
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357
ベ イ ズ推定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357
事前分布の選択 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 358
Amos Graphics によ るベ イ ズ推定の実行 . . . . . . . . . . . . . . . . . . . . . . 359
共分散の推定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 359
最尤法解析の結果
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 360
ベ イ ジ ア ン解析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 361
ベ イ ジ ア ン解析 と デー タ 代入の結果の複製 . . . . . . . . . . . . . . . . . . . . . . . . 362
現行シー ド の調査 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363
現行シー ド の変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363
リ フ レ ッ シ ュ オプ シ ョ ンの変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . 366
収束の評価 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 366
診断の作図 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 368
2 変量相関の周辺事後分布図 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373
ベ イ ズの信頼区間
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375
信頼係数の変更 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375
ベ イ ジ ア ン推定に関する参考資料 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 376
xviii
27
非拡散事前分布によ るベイズ推定
概要
377
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 377
例について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 377
ベ イ ズ推定についてのその他の情報 . . . . . . . . . . . . . . . . . . . . . . . . . . . 377
ベ イ ジ ア ン解析 と 不適解 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378
最尤法によ る モデルの適合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 379
無情報 ( 拡散 ) 事前分布によ るベ イ ズ推定 . . . . . . . . . . . . . . . . . . . . . . . . 379
バーン イ ン オブザベーシ ョ ン数の変更 . . . . . . . . . . . . . . . . . . . . . . . 380
28
モデルのパラ メ ー タ 以外の値のベイズ推定
概要
389
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 389
例について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 389
Wheaton のデー タ の再考 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 390
間接効果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 390
間接効果の推定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 390
モデル C のベ イ ジ ア ン解析
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394
追加推定値 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395
間接効果に関する推論 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 397
29
ベイ ジア ン SEM におけるユーザー定義数量の推定
概要
403
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403
例について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403
疎外感モデルの安定性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403
数値カ ス タ ム推定値 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 409
ド ラ ッ グ ア ン ド ド ロ ッ プ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414
二値カ ス タ ム推定値 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422
二値推定値の定義 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423
xix
30
デー タ 代入
概要
427
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427
例について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427
多重代入 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 428
モデルベースの代入 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 428
Amos Graphics を使用 し た多重デー タ 代入の実行 . . . . . . . . . . . . . . . . . . . 428
31
多重代入デー タ セ ッ ト の分析
概要
435
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435
SPSS Statistics を使用 し た代入デー タ フ ァ イルの分析 . . . . . . . . . . . . . . . . . 435
手順 2 : 10 個の個別分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 436
手順 3 : 多重代入デー タ フ ァ イルの結果の結合 . . . . . . . . . . . . . . . . . . . . . 437
参考文献 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 438
32
打ち切 り デー タ
概要
439
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 439
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 439
デー タ の再 コ ー ド 化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 441
デー タ の分析
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442
回帰分析の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442
事後予測分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 445
代入
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 448
デー タ 値に対する一般的な不等式制約 . . . . . . . . . . . . . . . . . . . . . . . . . . 451
xx
33
順序 - カ テゴ リ カル デー タ
概要
453
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453
デー タ フ ァ イルの指定
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 455
Amos 内でのデー タ の再 コ ー ド 化 . . . . . . . . . . . . . . . . . . . . . . . . . . 456
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 465
モデルの適合
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 465
MCMC 診断 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 468
事後予測分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 470
潜在変数の事後予測分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474
代入
34
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 478
ト レーニ ング デー タ を使用 し た混合モデ リ ング
概要
483
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484
分析の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 486
デー タ フ ァ イルの指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 487
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 491
モデルの適合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 493
個々の ク ラ スの分類 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495
潜在構造分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 496
35
ト レーニ ング デー タ を使用 し ない混合モデ リ ング
概要
497
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 497
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 497
分析の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 498
デー タ フ ァ イルの指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 500
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 502
パラ メ ー タ の制約 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503
モデルの適合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 505
個々の ク ラ スの分類 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 508
xxi
潜在構造分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 509
ラ ベル ス イ ッ チ ング . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 510
36
混合回帰モデ リ ング
概要
513
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513
1 つ目のデー タ セ ッ ト . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513
2 つ目のデー タ セ ッ ト . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 515
デー タ セ ッ ト のグループ変数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 516
分析の実行 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 517
デー タ フ ァ イルの指定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 518
モデルの特定化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 520
モデルの適合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 522
個々の ク ラ スの分類 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 525
パラ メ ー タ 推定値の向上 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 526
グループ比率の事前分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 528
ラ ベル ス イ ッ チ ング . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 528
37
パス図を描画 し ない場合の Amos Graphics の使用
529
は じ めに . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 529
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 530
共通因子モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 530
モデルを指定する プ ラ グ イ ンの作成 . . . . . . . . . . . . . . . . . . . . . . . . . 530
元に戻す機能の制御 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534
プ ラ グ イ ンの コ ンパイル と 保存 . . . . . . . . . . . . . . . . . . . . . . . . . . . 536
プ ラ グ イ ンの使用方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 538
モデル指定以外のその他の分析機能 . . . . . . . . . . . . . . . . . . . . . . . . . . . 539
モデル変数に対応する プ ログ ラ ム変数の定義
xxii
. . . . . . . . . . . . . . . . . . . . . . 539
38
単純なユーザー定義数量 I
541
は じ めに . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 541
Wheaton のデー タ の再考 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 542
間接効果の推定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 542
パラ メ ー タ に名前を付けない間接効果の推定 . . . . . . . . . . . . . . . . . . . . 549
39
単純なユーザー定義数量 II
551
は じ めに . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 551
デー タ について . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 551
Markov モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 551
パー ト III: 付録
A
表記法
557
B
乖離度
559
C
適合度
563
倹約性の測度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564
NPAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564
DF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564
PRATIO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565
最小標本乖離度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565
CMIN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565
P . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565
CMIN/DF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 566
FMIN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 567
xxiii
母集団の乖離度に基づ く 測度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 567
NCP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 568
F0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 568
RMSEA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 569
PCLOSE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 570
情報理論的測度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 570
AIC
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 570
BCC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 571
BIC
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 571
CAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 571
ECVI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 572
MECVI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 572
ベース ラ イ ン モデル と の比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 573
NFI
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 573
RFI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574
IFI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 575
TLI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 575
CFI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 575
倹約性修正済み測度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 576
PNFI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 576
PCFI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 576
GFI および関連測度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 577
GFI
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 577
AGFI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 577
PGFI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578
その他の測度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578
HI 90 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578
HOELTER . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578
LO 90 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 579
RMR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 579
選択 さ れた適合度の リ ス ト . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 580
D
非識別可能性の数値診断
581
xxiv
E
適合度を使用 し たモデルの順位付け
583
F
記述適合度のベース ラ イ ン モデル
587
G
AIC、 BCC、 および BIC の再調整
589
ゼロ ベースの再調整 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 589
赤池ウ ェ イ ト / Bayes 因子 ( 合計 = 1) . . . . . . . . . . . . . . . . . . . . . . . . . . 590
赤池ウ ェ イ ト / Bayes 因子 (max = 1) . . . . . . . . . . . . . . . . . . . . . . . . . . 591
通達
593
参考文献
597
索引
609
xxv
第
1
章
概要
IBM® SPSS® Amos™ は、 構造方程式モデ リ ン グ (SEM) ま たは共分散構造分析や因子
モデ リ ン グ と も 呼ばれ る 一般的なデー タ 分析手法を備え てい ます。 こ の手法には、 特
別な ケース と し て、 一般線型モデルや共通因子分析な ど広 く 行われてい る 従来の方法
が含まれてい ます。
入力
1
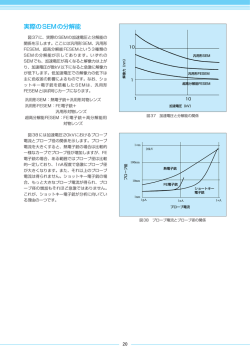
視覚的認知力
1
出力
err_v
.70
視覚的認知力
err_v
.43
視覚能力
空間視覚化力
1
err_c
視覚能力
.65
空間視覚化力
err_c
.54
方向認識力
1
.74
err_l
文書理解力
1
1
err_l
方向認識力
.49
.77
err_p
err_p
文書理解力
.88
.68
言語能力
文理解力
1
err_s
言語能力
.83
err_s
文理解力
.71
語彙力
1
.84
err_w
語彙力
err_w
Chi-square = 7.853 (8 df)
p = .448
Amos (Analysis of Moment Structures: 積率構造分析 ) は、 SEM を視覚的に示す使
いやすいプ ロ グ ラ ム です。 簡単な描画ツールを使っ て、 モデルのグ ラ フ ィ ッ ク を
素早 く 指定、 表示、 変更で き ます。 続いてモデルの適合性を評価 し 、 修正を行い、
最終モデルの グ ラ フ ィ ッ ク を 印刷物 レ ベルの品質で印刷す る こ と がで き ま す。
単にグ ラ フ ィ ッ ク でモデルを指定 し て く だ さ い ( 左側 )。 Amos に よ り 素早 く 計算
が行われ、 結果が表示 さ れ ます ( 右側 )。
1
2
第1章
構造方程式モデ リ ン グ (SEM) は し ば し ば、 難解で習得 し て使用す る のが難 し い と 考え
ら れてい ます。 こ れは大 き な間違いです。 実際、 デー タ 分析で SEM の重要性が増 し て
い る のは、 使いやす さ に よ る と こ ろ が大 き いのです。 以前は統計の専門家が必要だ っ
た推定や仮説の検定に関す る 問題が、 SEM に よ っ て専門家でな く て も 処理で き る よ う
にな っ て き ま し た。
Amos は も と も と 、 強力で基本的には単純な こ の方法を教授す る ための ツール と し
て設計 さ れ ま し た。 こ のため、 こ の方法の使いやす さ を示す こ と に力が注がれてい ま
す。 Amos は、使いやすいグ ラ フ ィ カル イ ン タ ーフ ェ イ ス に SEM 用の高度な計算エ ン
ジ ン を統合 さ せてい ます。 印刷物レベルの品質を持つ Amos のパ ス図は、 学生や同僚
の研究者に対 し てモデルを明確に示 し ます。 Amos に備わっ てい る 数値化方法は、最 も
効果的で信頼性の高い方法です。
主要な方法
構造方程式モデルを推定す る ために、 Amos には以下の方法が備わっ てい ます。
最尤法
重み付けのない最小 2 乗法
一般化 し た最小 2 乗法
Browne の漸近的分布非依存法
尺度不変最小 2 乗法
ベ イ ジ ア ン推定
欠損デー タ が あ る 場合、 Amos は、 リ ス ト ご と やペア ご と の削除や中間補完の よ う な
ア ド ホ ッ ク な方法に頼 る のではな く 、 全情報の最尤を使っ た最新の方法に よ っ て推定
を実行 し ます。 プ ロ グ ラ ムは、 複数の母集団のデー タ を一度に分析す る こ と がで き ま
す。 ま た、 回帰方程式で外因性の変数 と 切片の平均を推定す る こ と がで き ます。
プ ロ グ ラ ムは、 ブース ト ラ ッ プ標準誤差 と 信頼区間を全てのパ ラ メ ー タ 推定、 有効
推定、 標本平均、 分散、 共分散、 お よ び相関で使用可能に し ます。 ま た、 百分位数の
区間 と 偏位修正 さ れた百分位数の区間 (Stine、 1989)、 お よ びモデル検定に対す る ブー
ス ト ラ ッ プ手法 (Bollen - Stine、 1992) も 備え てい ます。
1 つの分析で複数のモデルが適合す る こ と が あ り ま す。 Amos はモデルのペア ご と
に、 他のパ ラ メ ー タ に制限を加え る こ と に よ っ て 1 つのモデルを取得 し ます。 プ ロ グ
ラ ムは、 こ う し たモデルの比較に適 し たい く つかの統計を レ ポー ト し ます。 プ ロ グ ラ
ムは、 観測 さ れ る 各変数に対す る 変量の正規分布の検定 と 多変量の正規分布の検定を
備え、 外れ値の検出を試みます。
Amos はパ ス 図 を モデル仕様 と し て受け入れ、 パ ラ メ ー タ 推定値 を パ ス 図に グ ラ
フ ィ ッ ク で表示 し ます。 モデル仕様に使われ る パ ス 図やパ ラ メ ー タ 推定値を表示す る
パ ス 図は、 プ レ ゼ ン テーシ ョ ン レベルの品質です。 直接印刷す る こ と も で き ま す し 、
ワ ープ ロ や DTP プ ロ グ ラ ム、 汎用のグ ラ フ ィ ッ ク プ ロ グ ラ ム な ど のアプ リ ケーシ ョ
ンに イ ン ポー ト す る こ と も で き ます。
3
概要
チ ュ ー ト リ アルについて
チ ュ ー ト リ アルは、 Amos Graphics を起動 し て実行で き る よ う に設計 さ れてい ま す。
基本的な機能を カバー し て あ り 、 初めての Amos 分析を ガ イ ド し ま す。
チ ュ ー ト リ アルをひ と 通 り 実行 し た ら 、 よ り 高度な機能についてはオン ラ イ ン ヘル
プで知 る こ と がで き ます。 あ る いは、 用意 さ れてい る 例を引 き 続 き 実行 し て、 Amos を
使っ た構造モデ リ ン グについて さ ら に学ぶ こ と がで き ます。
例について
多 く の人は、 実際に操作 し なが ら 学びたい と 思っ てい ます。 こ れを踏ま え て、 Amos の
使用方法を実践的に示す多数の例を用意 し ま し た。 最初の数例では、 単一の問題に対
応で き る Amos の基本機能を紹介 し ます。 ど のボ タ ン を ク リ ッ ク す る のか、 サポー ト
さ れてい る 各種デー タ 形式に ど う やっ て ア ク セ スす る のか、 出力を ど の よ う に操作す
る のか、 と いっ た こ と を学びます。 その後の例では、 プ ロ グ ラ ム イ ン タ ーフ ェ イ ス の
問題 よ り も 、 モデ リ ン グの問題を詳 し く 扱い ます。
例 1 か ら 例 4 では、 従来の分析、 つま り 標準的な統計パ ッ ケージ を使っ て実行で き
る 分析を Amos を使っ て行 う 方法を示 し ます。 こ れ ら の例では、 よ く あ る 問題に対 し
て新 し い手法を示 し なが ら 、Amos の基本機能を網羅 し てい ます。 平均や相関を推定す
る と か、 2 つの平均が同 じ であ る と い う 仮説を検定す る と い っ た単純な こ と を行 う の
に も 、 Amos を使 う と 便利な場合があ り ます。 理由の 1 つ と し て、 Amos の欠損デー タ
処理機能を使用で き る と い う こ と が挙げ ら れます。 あ る いは、Amos のブース ト ラ ッ プ
機能は、 特に信頼区間を取得す る のに役立ち ます。
例 5 か ら 例 8 は、 今日の構造モデ リ ン グで一般的に使われてい る 基本的な方法を示
し ます。
例 9 以降は、 利用価値があ り なが ら 現時点では ま だそれほ ど使用 さ れていない高度な
方法を示 し ます。 こ う し た方法 と し て、 た と えば以下の も のがあ り ます。
複数の母集団のデー タ の同時分析。
回帰方程式におけ る平均値 と 切片項の推定。
欠損デー タ があ る 場合の最尤推定。
標準誤差の推定値を取得す る ためのブー ト ス ト ラ ッ プ。 Amos では こ れ ら の方法を
特に使いやす く し てい ますので、 よ り 普及す る こ と が期待 さ れます。
探索的モデル特定化。
ベ イ ジ ア ン推定。
欠損値の代入。
打ち切 り デー タ の分析。
順序 - カ テ ゴ リ カル デー タ の分析。
混在モデル。
4
第1章
ヒ ン ト : Amos の特定の機能について質問があ る 場合はいつで も 、プ ロ グ ラ ム で提供 し
てい る 広範なオン ラ イ ン ヘルプを参照で き ます。
ド キ ュ メ ン ト について
Amos 23 には、 広範な ド キ ュ メ ン ト が付属 し てい ます。 オン ラ イ ン ヘルプ、 ユーザー
ズ ガイ ド ( 本書 )、お よ び Visual Basic ま たは C# と Amos API (Application Programming
Interface) の詳細な参考資料な ど が あ り ま す。 標準的な イ ン ス ト ール を 実行す る 場合
は、 C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Documentation¥Programming Reference.pdf
にあ る 『Amos 23 Programming Reference Guide』 を参考に し て く だ さ い。
その他の情報源
こ のユーザーズ ガ イ ド には有益な解説が記載 さ れてい ますが、 構造モデ リ ン グの正 し
く 効果的な使い方の完全な ガ イ ド ブ ッ ク と い う わけでは あ り ま せん。 多 く の優れた
SEM 解説文書が入手可能です。
『Structural Equation Modeling: A Multidisciplinary Journal』 には、 構造モデ リ ン グの
方法論的 な 記事お よ び適用例が記載 さ れ て い ま す。 発行元は Taylor and Francis
(http://www.tandf.co.uk) です。
Carl Ferguson と Edward Rigdon は、Semnet と い う 電子 メ ー リ ン グ リ ス ト を設定 し 、
構造モデ リ ン グに関連す る 議論の フ ォ ー ラ ム を提供 し てい ます。 Semnet 購読に関
す る 情報は、 www.gsu.edu/~mkteer/semnet.html で得 ら れます。
5
概要
謝辞
Amos の以前のバージ ョ ン と 現行のバージ ョ ン を テ ス ト し た多 く のユーザーの皆様か
ら い ろ い ろ な フ ィ ー ド バ ッ ク を い た だ き ま し た。 Torsten B. Neilands は、 Joseph L.
Schafer の協力の元、本ユーザーガ イ ド の例 26 か ら 31 ま で を記述 し ま し た。 Eric Loken
は例 32 お よ び 33 を レ ビ ュ ー し ま し た。 彼は ま た Amos の今後の開発におけ る 重要な
提案 と 同様に混在す る モデルに対す る 貴重な考察を提供 し て く だ さ い ま し た。
1 つ注意点があ り ます。 Amos Development Corporation と SPSS は広範なプ ロ グ ラ ム
検定を行い、 Amos が正 し く 動作す る こ と を確認 し てい ますが、 Amos を含む全ての複
雑な ソ フ ト ウ ェ アには、 未検出のバグが含ま れ る 可能性があ り ます。 我々は、 プ ロ グ
ラ ム エ ラ ーの修正に努力 し てい ます。 エ ラ ーを発見 し た場合は、 SPSS テ ク ニ カル サ
ポー ト ス タ ッ フ ま でお知 ら せ く だ さ い。
James L. Arbuckle
日本語訳監修 : 井上哲浩
(慶應義塾大学大学院経営管理研究科教授)
第
2
章
チ ュ ー ト リ アル : Amos Graphics の
スター ト ア ッ プ ガイ ド
概要
初めて統計の授業を受けた と き 、 苦労 し て公式を覚え、 紙 と 鉛筆で一生懸命計算 し て
答を出 し ま し たね。 教授の指示に従っ て そ う す る う ちに、 基本的な統計の概念を理解
す る よ う にな っ た こ と で し ょ う 。 後に、 こ う し た計算は全て、 計算機や ソ フ ト ウ ェ ア
プ ロ グ ラ ムであ っ と い う 間にで き て し ま う こ と を知 り ま し たね。
こ のチ ュ ー ト リ アルは、 統計の入門 ク ラ ス にやや似てい ます。 Amos Graphics には、
パ ス 図を描いて ラ ベルを付け る ための効率的な方法が多数あ り ますが、 こ のユーザー
ズ ガ イ ド の例を た ど っ てい く か、 オン ラ イ ン ヘルプ を参照す る う ちに、 それ ら が見つ
か る で し ょ う 。 こ のチ ュ ー ト リ アルの目的は、単に Amos Graphics の初歩的な使い方を
示す こ と です。 Amos の基本的な機能を カバー し て あ り 、 初めての Amos 分析を ガ イ ド
し ます。
チ ュ ー ト リ アルをひ と 通 り 実行 し た ら 、 よ り 高度な機能についてはオ ン ラ イ ン ヘル
プで知 る こ と がで き ます。 あ る いは、 用意 さ れてい る 例を引 き 続 き 実行 し て、 順序 よ
く 学ぶ こ と も で き ます。
標準的な イ ン ス ト ールを実行す る 場合は、 こ のチ ュ ー ト リ アルで作成す る パ ス図が
C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Tutorial¥Japanese にあ り ます。 フ ァ イ ル
Startsps.amw は、 SPSS Statistics デー タ フ ァ イ ルを使用 し てい ます。 Getstart.amw も 同
じ パ ス図ですが、 Microsoft Excel フ ァ イ ルのデー タ を使用 し てい ます。
ヒ ン ト : Amos 23 のほ と ん ど の タ ス ク には、 複数の実行方法があ り ます。 [ プ ラ グ イ ン ]
以外の全ての メ ニ ュ ー コ マ ン ド について、同 じ タ ス ク を実行す る ツールバー ボ タ ンが
あ り ます。 多 く の タ ス ク については、 キーボー ド のシ ョ ー ト カ ッ ト も 用意 さ れてい ま
す。 ユーザーズ ガ イ ド では メ ニ ュ ー パ ス を示 し てい ま す。 ツールバー ボ タ ン と キー
ボー ド シ ョ ー ト カ ッ ト については、 オン ラ イ ン ヘルプを参照 し て く だ さ い。
7
8
第2章
デー タ について
Hamilton (1990) は、 21 州のそれぞれについ て、 い く つかの測定 を 行い ま し た。 こ の
チ ュ ー ト リ アルでは、 以下の 3 つの測定を使用 し ます。
SAT の平均得点
1 人当た り の所得 ( 単位は $1,000)
25 才以上の居住者の教育の中央値
こ れ ら のデー タ は、 Tutorial デ ィ レ ク ト リ の Excel 8.0 ワ ー ク ブ ッ ク Hamilton.xls 内の
Hamilton と い う ワ ー ク シー ト にあ り ます。 デー タ は以下の と お り です。
SAT
899
896
897
889
823
857
860
890
889
888
925
869
896
827
908
885
887
790
868
904
888
所得
14.345
16.37
13.537
12.552
11.441
12.757
11.799
10.683
14.112
14.573
13.144
15.281
14.121
10.758
11.583
12.343
12.729
10.075
12.636
10.689
13.065
教育
12.7
12.6
12.5
12.5
12.2
12.7
12.4
12.5
12.5
12.6
12.6
12.5
12.5
12.2
12.7
12.4
12.3
12.1
12.4
12.6
12.4
次のパス図は、 こ れ ら のデー タ のモデルを示 し てい ます。
9
チ ュ ー ト リ アル : Amos Graphics のス タ ー ト ア ッ プ ガ イ ド
こ れは単純な回帰モデルで、 観測 さ れ る 1 つの変数 SAT は、 観測 さ れ る 他の 2 つの変
数 " 教育 " と " 所得 " の線型結合 と 予測 さ れます。 ほぼ全ての経験デー タ か ら 、 こ の予
測は完全ではあ り ません。 変数 " その他 " は、 変数 " 教育 " と " 所得 " 以外で SAT に影
響す る 変数を表 し ます。
片方向の各矢印は、 回帰係数を表わ し ま す。 図の 1 と い う 数字は、 SAT の予測で
" その他 " の係数が 1 であ る こ と を指定 し ます。 モデルを識別す る ために、 こ う し た制
約を い く つか設け る 必要があ り ます。 こ れは、 Amos に認識 さ せ る 必要のあ る モデル
の特徴の 1 つです。
Amos Graphics の起動
Amos Graphics は、 以下のいずれの方法で も 起動で き ます。
[ ス タ ー ト ] 画面で、 [Amos Graphics] を ク リ ッ ク し ま す。
Windows の タ ス ク バーで [ ス タ ー ト ] を ク リ ッ ク し 、 [ プ ログ ラ ム ][IBM SPSS
Statistics][IBM SPSS Amos 23][Amos Graphics] の順に ク リ ッ ク し ま す。
Windows のエ ク ス プ ロ ー ラ で、 パ ス図 (*.amw) を ダブル ク リ ッ ク し ます。
パ ス図 (*.amw) フ ァ イ ルを Windows エ ク ス プ ロ ー ラ か ら Amos Graphics ウ ィ ン ド
ウ に ド ラ ッ グ し ます。
SPSS Statistics 内で、 メ ニ ュ ーか ら [Add-ons]、 [Applications]、 [Amos 23] の順に
ク リ ッ ク し ます。
10
第2章
新 し いモデルの作成
E
メ ニ ュ ーか ら 、 [ フ ァ イル ] [ 新規作成 ] の順に ク リ ッ ク し ます。
作業領域が表示 さ れます。 右側の大 き な領域は、パス図を描 く 場所です。 左側の ツール
バーは、 よ く 使用 さ れ る ボ タ ンに 1 度の ク リ ッ ク でア ク セ ス で き る よ う に用意 さ れて
い ます。 ツールバーか メ ニ ュ ー コ マ ン ド を使っ て、 ほ と ん ど の操作を行 う こ と がで き
ます。
11
チ ュ ー ト リ アル : Amos Graphics のス タ ー ト ア ッ プ ガ イ ド
デー タ フ ァ イルの指定
次の ス テ ッ プは、 Hamilton のデー タ が保存 さ れてい る フ ァ イ ル を指定す る こ と です。
こ のチ ュ ー ト リ アルでは Microsoft Excel 8.0 (*.xls) フ ァ イ ル を使い ま すが、 Amos で
は、 SPSS Statistics *.sav フ ァ イ ルな ど い く つかの一般的なデー タ ベース形式を サポー
ト し てい ます。 SPSS Statistics の [Add-ons] メ ニ ュ ーか ら Amos を起動す る 場合、 SPSS
Statistics で開いてい る フ ァ イ ルが自動的に使用 さ れます。
E
メ ニ ュ ーか ら 、 [ フ ァ イル ]、 [ デー タ フ ァ イル ] の順に ク リ ッ ク し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [ フ ァ イル名 ] を ク リ ッ ク し ます。
E Tutorial フ ォ ルダ を検索 し ます。 標準的な イ ン ス ト ールを実行 し た場合、 パス は
C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Tutorial¥Japanese です。
E [ フ ァ イ ルの種類 ] リ ス ト で Excel 8.0 (*.xls) を選択 し ます。
E Hamilton.xls を選択 し 、 [ 開 く ] を ク リ ッ ク し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [OK] を ク リ ッ ク し ます。
モデルの指定 と 変数の描画
次の ス テ ッ プは、 モデルに変数を描 く こ と です。 観測 さ れ る 変数を表す 3 つの長方形
を まず描 き 、 続いて観測 さ れない変数を表す 1 つの楕円形を描 き ます。
E
メ ニ ュ ーか ら 、 [ 図 ]、 [ 観測 さ れる変数を描 く ] の順に ク リ ッ ク し ます。
E 描画領域で、" 教育 " の長方形を表示す る 場所にマ ウ ス ポ イ ン タ を移動 し ます。 ク リ ッ
ク ア ン ド ド ラ ッ グ し て長方形を描 き ます。 長方形の位置やサ イ ズは後で変更で き る の
で、 正確でな く て も か ま い ません。
E 同 じ 方法で、 " 所得 " と SAT 用に 2 つの長方形を描 き ます。
E
メ ニ ュ ーか ら 、 [ 図 ]、 [ 直接観測 さ れない変数を描 く ] の順に ク リ ッ ク し ます。
E 描画領域で、 3 つのの長方形の右にマ ウ ス ポ イ ン タ を移動 し て ク リ ッ ク し 、 ド ラ ッ グ
し て楕円を作成 し ます。
描画領域内のモデルは、 次の よ う にな る はずです。
12
第2章
変数の命名
E 描画領域で左上の長方形を右 ク リ ッ ク し 、ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト の
プ ロパテ ィ ] を選択 し ます。
E [ テキス ト ] タ ブ を ク リ ッ ク し ます。
E [ 変数名 ] テ キ ス ト ボ ッ ク ス に、 「教育」 と 入力 し ます。
E 同 じ 方法を使っ て、 残 り の変数に名前を付け ます。 [ オブジ ェ ク ト プ ロ パテ ィ ] ダ イ ア
ロ グ ボ ッ ク ス を閉 じ ます。
パ ス図は次の よ う に描かれてい る はずです。
13
チ ュ ー ト リ アル : Amos Graphics のス タ ー ト ア ッ プ ガ イ ド
矢印の描画
次の図のモデルを参考に し て、 パ ス図に矢印を加え ます。
E
メ ニ ュ ーか ら 、 [ 図 ]、 [ パス図を描 く ] の順に ク リ ッ ク し ます。
E
ク リ ッ ク ア ン ド ド ラ ッ グ し て、 " 教育 " と SAT の間に矢印を描 き ます。
E
こ の方法を使っ て、 残 り の片方向矢印を描 き ます。
E
メ ニ ュ ーか ら 、 [ 図 ]、 [ 共分散を描 く ] の順に ク リ ッ ク し ます。
E
ク リ ッ ク ア ン ド ド ラ ッ グ し て、" 所得 " と " 教育 " の間に双方向矢印を描 き ます。 矢印の
カーブは後で調整で き る ので、 正確でな く て も か ま い ません。
パラ メ ー タ の制約
回帰モデルを識別す る には、 潜在変数 " その他 " の ス ケールを定義す る 必要があ り ま
す。 そのためには、 " その他 " の分散ま たは " その他 " か ら SAT へのパ ス定数を正の値
で固定 し ます。 パ ス係数を 1 で固定す る 方法を次に示 し ます。
E 描画領域で " その他 " と SAT の間の矢印を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら
[ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
E [ パ ラ メ ー タ ] タ ブを ク リ ッ ク し ます。
E [ 係数 ] テ キ ス ト ボ ッ ク ス に 「1」 と 入力 し ます。
14
第2章
E [ オブジ ェ ク ト プ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
" その他 " と SAT の間の矢印の上に 1 が表示 さ れます。 パ ス図が完成 し ま し たが、必要
に応 じ て表示を変更で き ます。 次の よ う に描かれてい る はずです。
パス図の表示の変更
パ ス 図の表示を変更す る には、 オブジ ェ ク ト の移動やサ イ ズ変更を行い ます。 こ う し
た変更は単に視覚上の変更で、 モデルの仕様には影響 し ません。
オブ ジ ェ ク ト を移動するには
E
メ ニ ュ ーか ら 、 [ 編集 ]、 [ 移動 ] の順に ク リ ッ ク し ます。
E 描画領域で、 オブジ ェ ク ト を ク リ ッ ク し て新 し い位置に ド ラ ッ グ し ます。
オブ ジ ェ ク ト や双方向矢印の形を変更するには
E
メ ニ ュ ーか ら 、 [ 編集 ]、 [ オブ ジ ェ ク ト の形を変更 ] の順に ク リ ッ ク し ます。
E 描画領域で、 オブジェ ク ト を ク リ ッ ク し て希望のサイズ と 形にな る よ う ド ラ ッ グ し ます。
15
チ ュ ー ト リ アル : Amos Graphics のス タ ー ト ア ッ プ ガ イ ド
オブ ジ ェ ク ト を削除するには
E
メ ニ ュ ーか ら 、 [ 編集 ]、 [ 消去 ] の順に ク リ ッ ク し ます。
E 描画領域で、 削除す る オブジ ェ ク ト を ク リ ッ ク し ます。
動作を元に戻すには
E
メ ニ ュ ーか ら 、 [ 編集 ]、 [ 元に戻す ] の順に ク リ ッ ク し ます。
動作をや り 直すには
E
メ ニ ュ ーか ら 、 [ 編集 ]、 [ や り 直 し ] の順に ク リ ッ ク し ます。
オプ シ ョ ン出力の設定
Amos には、 オプシ ョ ンの出力がい く つかあ り ます。 こ の ス テ ッ プでは、 分析後に ど の
オプシ ョ ン出力部分を表示す る かを選択 し ます。
E
メ ニ ュ ーか ら 、 [ 表示 ]、 [ 分析のプ ロパテ ィ ] の順に ク リ ッ ク し ます。
E [ 出力 ] タ ブを ク リ ッ ク し ます。
E [ 最小化履歴 ]、[ 標準化推定値 ]、お よ び [ 重相関係数の平方 ] の各チ ェ ッ ク ボ ッ ク ス を オ ン
に し ます。
16
第2章
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
17
チ ュ ー ト リ アル : Amos Graphics のス タ ー ト ア ッ プ ガ イ ド
分析の実行
残っ てい る 作業は、 モデル適合の計算を実行す る こ と だけです。 パ ラ メ ー タ 推定値を
最新に保つには、 モデル、 デー タ 、 ま たは [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス
のオプシ ョ ン を変更す る たびに こ の作業を行 う 必要があ り ます。
E
メ ニ ュ ーか ら 、 [ 分析 ]、 [ 推定値を計算 ] の順に ク リ ッ ク し ます。
E ま だ フ ァ イ ルを保存 し ていないので、[ 名前を付けて保存 ] ダ イ ア ロ グ ボ ッ ク ス が表示
さ れます。 フ ァ イ ルの名前を入力 し て [ 保存 ] を ク リ ッ ク し ます。
モデル推定値が計算 さ れます。パス図の左側にあ るパネルに計算の結果が表示 さ れます。
出力の表示
計算が完了 し た ら 、 出力を表示す る オプシ ョ ン と し て、 テ キ ス ト と グ ラ フ ィ ッ ク ス の
2 つがあ り ます。
テキス ト 出力を表示するには
E
メ ニ ュ ーか ら 、 [ 表示 ]、 [ テキス ト 出力の表示 ] の順に ク リ ッ ク し ます。
[Amos 出力 ] ウ ィ ン ド ウ の左上 ウ ィ ン ド ウ 枠の ツ リ ー図で、 表示す る テ キ ス ト 出力部
分を選択 し ます。
18
第2章
E パ ラ メ ー タ 推定値を表示す る には、 [ 推定値 ] を ク リ ッ ク し ます。
19
チ ュ ー ト リ アル : Amos Graphics のス タ ー ト ア ッ プ ガ イ ド
グ ラ フ ィ ッ ク ス出力を表示するには
E [ 出力パス図の表示 ] ボ タ ン
を ク リ ッ ク し ます。
E 描画領域の左にあ る [ パラ メ ータ 形式 ] ウ ィ ン ド ウ枠で、[ 標準推定値 ] を ク リ ッ ク し ます。
パ ス図は次の よ う にな り ます。
0.49 と い う 値は、 「教育」 と 「所得」 の間の相関を示 し ます。 値 0.72 と 0.11 は、 標準
化係数です。 0.60 と い う 値は、 SAT と 「教育」 お よ び 「所得」 の重相関係数の平方を
示 し ます。
E 描画領域の左にあ る [ パ ラ メ ー タ 形式 ] ウ ィ ン ド ウ枠で、 [ 非標準化推定値 ] を ク リ ッ ク
し ます。
パ ス図は次の よ う に描かれてい る はずです。
20
第2章
パス図の印刷
E
メ ニ ュ ーか ら 、 [ フ ァ イル ]、 [ 印刷 ] の順に ク リ ッ ク し ます。
[ 印刷 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E [ 印刷 ] を ク リ ッ ク し ます。
パス図のコ ピー
Amos Graphics では、Microsoft Word な ど他のアプ リ ケーシ ョ ンにパ ス図を簡単にエ ク
ス ポー ト す る こ と がで き ます。
E
メ ニ ュ ーか ら 、 [ 編集 ]、 [ ク リ ッ プボー ド へコ ピー ] の順に ク リ ッ ク し ます。
E 他のアプ リ ケーシ ョ ンに切 り 替えて、貼 り 付け機能を使っ てパス図を挿入 し ます。 Amos
Graphics か ら エ ク ス ポー ト さ れる のは図のみで、 背景はエ ク ス ポー ト さ れません。
テキス ト 出力のコ ピー
E Amos Output ウ ィ ン ド ウ で、 コ ピーす る テ キ ス ト を選択 し ます。
E 選択 し た テ キ ス ト を右 ク リ ッ ク し 、ポ ッ プア ッ プ メ ニ ュ ーか ら [ コ ピー] を選択 し ます。
E 他のアプ リ ケーシ ョ ンに切 り 替え て、 貼 り 付け機能を使っ てテ キ ス ト を挿入 し ます。
例
1
分散および共分散の推定
概要
こ の例では、 母集団の分散 と 共分散を推定す る 方法について説明 し ます。 ま た、 Amos
の入力お よ び出力の一般的な書式について も 説明 し ます。
デー タ について
Attig (1983) は、 40 人の被験者に数ページ の広告 を含む小冊子を示 し ま し た。 次に、
各被験者に対 し て、 3 つの記憶力検定を実施 し ま し た。
変数
説明
被験者には、で き る だけ多 く の広告を思い出 し て も ら い ま し た。 こ の変数で
の被験者の ス コ アは、 正 し く 思い出せた広告の数 と し ま し た。
被験者にい く つかの ヒ ン ト を与え、 で き る だけ多 く の広告を思い出 し て も
ヒント
ら い ま し た。 被験者の ス コ アは、 正 し く 思い出せた広告の数 と し ま し た。
被験者に小冊子に掲載 さ れていた広告の リ ス ト を与え、 それぞれの広告の
掲載位置記憶 掲載ページ を思い出 し て も ら い ま し た。 こ の検定の被験者の ス コ アは、掲載
位置を正 し く 思い出せた広告の数 と し ま し た。
記憶
Attig は、 記憶力を向上 さ せ る ための ト レーニ ン グ を行っ た後で、 再び同 じ 40 名の被
験者に こ の検定を実施 し ま し た。 し たが っ て、 ト レーニ ン グの前 と 後でそれぞれ 3 つ
の成績が測定 さ れます。 さ ら に、 Attig は年齢、 性別、 教育水準に加え て、 語彙試験の
ス コア も 記録 し ま し た。Attig のデータ フ ァ イルは、Amos に付属 し てい る Examples フ ォ
ルダに入っ てい ます。
21
22
例1
デー タ の取 り 込み
E
メ ニ ュ ーか ら 、 [ フ ァ イル ] [ 新規作成 ] を選択 し ます。
E
メ ニ ュ ーか ら 、 [ フ ァ イル ] [ デー タ フ ァ イル ] を選択 し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [ フ ァ イル名 ] を ク リ ッ ク し ます。
E Examples フ ォ ルダ を参照 し ます。 通常の イ ン ス ト ールを実行 し てい る 場合、 パ ス は
C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese にな り ます。
E [ フ ァ イ ルの種類 ] リ ス ト で、 「Excel 8.0 (*.xls)」 を選択 し て [UserGuide.xls] を選択 し 、
[ 開 く ] を ク リ ッ ク し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [OK] を ク リ ッ ク し ます。
UserGuide ワ ー ク ブ ッ ク に ワ ー ク シ ー ト の 一 覧 が 表 示 さ れ ま す。 ワ ー ク シ ー ト
Attg_yng には、 こ の例のデー タ が格納 さ れてい ます。
E [ デー タ 表 を 選択 ] ダ イ ア ロ グ ボ ッ ク ス で、 [Attg_yng] を 選択 し 、 [ デー タ の表示 ] を
ク リ ッ ク し ま す。
23
分散および共分散の推定
Attg_yng デー タ フ ァ イ ルの Excel ワー ク シー ト が開 き ます。
ワ ー ク シー ト を ス ク ロ ールす る と 、 Attig の調査のすべての検定変数を参照で き ます。
こ の例では、 記憶 1 ( 事前記憶検定 )、 記憶 2 ( 事後記憶検定 )、 掲載位置記憶 1 ( 事前掲
載位置記憶検定 )、 掲載位置記憶 2 ( 事後掲載位置記憶検定 ) の変数のみを使用 し てい
ます。
E デー タ を確認 し た ら 、 デー タ ウ ィ ン ド ウ を閉 じ ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [OK] を ク リ ッ ク し ます。
デー タ の分析
こ の例の分析では、 ト レーニ ン グ前後の記憶変数 と 掲載位置記憶変数の分散お よ び共
分散の推定を行い ます。
モデルを指定する
E
メ ニ ュ ーか ら 、 [ 図 ] [ 観測 さ れる変数を描 く ] を選択 し ます。
E 描画領域で、 四角形を最初に表示す る 場所にマ ウ ス ポ イ ン タ を移動 し ます。 ク リ ッ ク
ア ン ド ド ラ ッ グ し て長方形を描 き ます。
E
メ ニ ュ ーか ら 、 [ 編集 ] [ 複写 ] を選択 し ます。
E
ク リ ッ ク し 、 最初の四角形か ら 複製を ド ラ ッ グ し ます。 マ ウ ス ボ タ ン を離 し て、 複製
を配置 し ます。
24
例1
E 4 つの四角形が並ぶま で、 さ ら に 2 つの複製の四角形を作成 し ます。
ヒ ン ト : 四角形を移動す る 場合は、 メ ニ ュ ーか ら [ 編集 ] [ 移動 ] を選択 し 、 四角形を
新 し い位置に ド ラ ッ グ し ます。
変数に名前を付ける
E
メ ニ ュ ーか ら 、 [ 表示 ] [ デー タ セ ッ ト に含まれる変数 ] を選択 し ます。
[ デー タ セ ッ ト に含まれ る 変数 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E
リ ス ト か ら 変数記憶 1 を ク リ ッ ク し て、 描画領域の最初の四角形に ド ラ ッ グ し ます。
E 同 じ 方法で、 記憶 2、 掲載位置記憶 1、 掲載位置記憶 2 の各変数に も 名前を付け ます。
E [ デー タ セ ッ ト に含まれ る 変数 ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
25
分散および共分散の推定
フ ォ ン ト の変更
E 変数を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択
し ます。
[ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E [ テキス ト ] タ ブを ク リ ッ ク し 、 希望に応 じ て フ ォ ン ト 属性を調整 し ます。
共分散の設定
パ ス図を その ま ま の状態に し た場合、 Amos Graphics は、 4 つの変数の分散を推定 し ま
すが、 変数間の共分散の推定は行われません。 Amos Graphics では、 矢印で結ばれてい
ない 2 つの変数に対 し ては相関ま たは共分散は 0 であ る と 想定 さ れます。 観測変数間
の共分散を推定す る には、最初にすべてのペア を双方向の矢印で結ぶ必要があ り ます。
E
メ ニ ュ ーか ら 、 [ 図 ] [ 共分散を描 く ] を選択 し ます。
E
ク リ ッ ク し 、 ド ラ ッ グ し て、 各変数 と 他の変数を結ぶ矢印を描画 し ます。
26
例1
パ ス図には 6 つの双方向矢印が描かれてい る 必要があ り ます。
分析の実行
E
メ ニ ュ ーか ら 、 [ 分析 ] [ 推定値を計算 ] を選択 し ます。
ま だ フ ァ イ ルを保存 し ていないので、[ 名前を付けて保存 ] ダ イ ア ロ グ ボ ッ ク ス が表示
さ れます。
E フ ァ イ ルの名前を入力 し て、 [ 保存 ] を ク リ ッ ク し ます。
グ ラ フ ィ ッ ク出力を表示する
E [ 出力パス図の表示 ] ボ タ ン
を ク リ ッ ク し ます。
出力パス図がパ ラ メ ー タ 推定値 と 共に表示 さ れます。
出力パ ス図で、 ボ ッ ク ス の横に表示 さ れ る 数が分散推定値で、 双方向矢印の横に表示
さ れ る 数が共分散推定値です。 た と えば、 記憶 1 の分散は 5.79 と 推定 さ れ、 掲載位置
記憶 1 の分散は 33.58 と 推定 さ れます。 こ の 2 つの変数間の共分散推定値は 4.34 です。
27
分散および共分散の推定
テキス ト 出力の表示
E
メ ニ ュ ーか ら 、 [ 表示 ][ テキス ト 出力の表示 ] の順に ク リ ッ ク し ます。
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ枠の ツ リ ー図で、 [ 推定値 ] を選択 し ます
最初に表示 さ れてい る 推定値は、 記憶 1 と 記憶 2 間の共分散です。 共分散は 2.56 と 推
定 さ れてい ます。 その推定値の右横の、 [ 標準誤差 ] 列に、 共分散の標準誤差の推定値、
1.16 が表示 さ れてい ます。 推定値 2.56 は、 母集団の共分散を中心に、 約 1.16 の標準偏
差でほぼ正規分散 し てい る乱数変数の観測値です。 すなわち、 セ ク シ ョ ン 32 ページの
「Amos モデルの分布の仮定」 の仮定が満た さ れてい る 場合の値です。 た と えば、 こ れ
ら の数値を使用 し て、 2.56 1.96 1.160 = 2.56 2.27 を計算す る こ と に よ っ て、
母集団共分散の 95% の信頼区間を設定す る こ と がで き ます。 こ の後で、 Amos を使用
す る と 、 共分散のほ かに も さ ま ざ ま な種類の母集団パ ラ メ ー タ を 推定で き る こ と 、
ま た、 そのいずれの信頼区間で も 同 じ 手順で設定で き る こ と を紹介 し ます。
標準誤差の隣の [検定統計量] 列には、共分散推定値を標準誤差 2.20 = 2.56 1.16
で割っ て算出 さ れた検定統計量が表示 さ れます。 こ の検定統計量は、 Attig の 40 名の被
験者が属する母集団において記憶 1 と 記憶 2 間の共分散が 0 であ る と い う 帰無仮説に関
連し ています。 こ の仮説が真であ り 、 依然 と し て 32 ページの 「Amos モデルの分布の仮
定」 セ ク シ ョ ンの仮定の下にあ る場合、 検定統計量は、 近似的に標準正規分布を持つ乱
数変数の観測値を表 し ます。 し たが っ て、 0.05 の有意確率を使用 し た場合、 1.96 よ り
大き い検定統計量を有意であ る と いいます。 こ の例では、 2.20 は 1.96 よ り 大き いため、
記憶 1 と 記憶 2 の間の共分散は 0.05 レベルでは 0 と 有意な差があ る と 言え ます。
28
例1
[ 検定統計量 ] の右の [P] 列には、 パ ラ メ ー タ 値が母集団で 0 であ る と い う 帰無仮説
を検定す る ための、 両側近似 p 値が示 さ れます。 こ の表は、p = 0.03 に よ り 、 記憶 1
と 記憶 2 間の共分散が 0 と 有意の差があ る こ と を示 し てい ます。 P の計算では、 パ ラ
メ ー タ 推定値が正規分散 し てい る と 仮定 し てい ますが、 こ れは大 き な標本でのみ正 し
い こ と です。 詳細については、 付録 A を参照 し て く だ さ い。
パ ラ メ ー タ 推定値が正規分散 し てい る と い う 断定は、 近似値に過ぎ ま せん。 ま た、
[ 標準誤差 ] 列で報告 さ れてい る 標準誤差 も 近似値に過ぎず、 最適でない場合があ り ま
す。 結果的に、 今説明 し た信頼区間お よ び仮説検定 も 近似値にな り ます。 こ れは、 こ れ
ら の結果の根拠 と な る 理論が漸近的で あ る ためです。 漸近的 と は、 希望す る 任意の精
度で適用す る こ と がで き る が、 有意に大 き な標本を使用 し た場合に限 ら れ る こ と を意
味 し ま す。 Amos を使用 し て実行で き る その他の さ ま ざ ま な種類の分析に対 し て結論
を一般化す る こ と はで き ないので、 現在の標本数で近似値が満足で き る も のであ る か
ど う かについては、検討 し ない こ と に し ます。 ただ し 、記憶 1 と 記憶 2 に相関がない と
い う 帰無仮説を再検討 し 、 近似検定の意味す る も の を確認す る す る こ と はで き ま す。
先に、 2.20 は 1.96 よ り も 大 き いため、 共分散は 0 と 有意の差があ る と い う 結論に達 し
ま し た。 2.20 の標準正規分布に関連す る p 値は 0.028 ( 両側 ) であ り 、 も ち ろん 0.05 よ
り 小 さ い値です。 こ れに対 し て、 従来の t 統計量 (Runyon & Haber, 1980, p. 226 な ど )
は自由度が 38 で 2.509 です p = 0.016 。 こ の例では、 ど ち ら の p 値 も 0.05 未満であ
る ため、 ど ち ら の検定で も 0.05 レ ベルでの帰無仮説を 棄却す る 点では一致 し てい ま
す。 ただ し 、 こ の状況では、 2 つの p 値は 0.05 の反対側にあ る 可能性があ り ます。 こ
の点は特に深刻に と ら え る 必要はあ り ません。 いずれにせ よ 、 2 つの検定では異な る
結果にな る 可能性があ る のですか ら 。 ど ち ら の検定の方が優れてい る かについては疑
いの余地があ っ てはな り ません。 t 検定は、 標本数に関係な く 、 観測値の正規性お よ び
独立性の仮定に直接基づいてい ます。 Amos では、検定統計量に基づ く 検定は同 じ 仮定
に依存 し てい ますが、 有限の標本では、 検定は近似値にな り ます。
注 : Amos の多 く のユニー ク な利用法では、 正確確率検定、 正確な標準誤差、 ま たは正
確な信頼区間は使用で き ません。
明 る い面を挙げれば、 従来の推定値が存在す る モデルの当てはめにおいて、 最尤法の
ポ イ ン ト 推定値 ([ 推定値 ] 列の数値な ど ) は一般的に従来の推定値 と 同 じ です。
29
分散および共分散の推定
E
こ こ で、 [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ枠にあ る [ モデルについての注釈 ]
を ク リ ッ ク し ます。
次の表は、 すべての Amos の分析において重要な役割を果た し ます。
異な る 標本の積率の数
推定 さ れ る 異な る パ ラ メ ー タ の数
自由度 (10 – 10)
10
10
0
[ 独立な標本積率の数 ] と は、 標本の平均値、 分散、 お よ び共分散です。 現在の分析を
含むほ と ん ど の分析において、 Amos では平均値が無視 さ れ、 標本の積率は 4 つの変
数 ( 記憶 1、 記憶 2、 掲載位置記憶 1、 掲載位置記憶 2) の標本分散お よ び標本共分散 と
な り ます。 4 つの標本分散お よ び 6 つの標本共分散があ る ため、標本の積率の数は合計
で 10 と な り ます。
[ 独立な推定パ ラ メ ー タ の数 ] は、 対応す る 母集団の分散お よ び共分散です。 4 つの
母集団分散 と 6 つの母集団共分散があ る ため、 推定パ ラ メ ー タ の数は 10 と な り ます。
[ 自由度 ] は、標本の積率が推定パ ラ メ ー タ の数 よ り も 大 き い数量です。 こ の例では、
標本の積率 と 推定パ ラ メ ー タ 間に 1 対 1 対応があ る ため、 自由度が 0 にな る のは当然
です。
例 2 で分か る よ う に、 パ ラ メ ー タ に関す る 非明示的な帰無仮説では、 推定す る 必要
のあ る パ ラ メ ー タ の数が少な く な り ます。 その結果、自由度は正の値にな り ます。 こ こ
では、 検定す る 帰無仮説はあ り ません。 検定す る 帰無仮説がない場合、 次の表はあ ま
り 意味があ り ません。
カ イ 2 乗 = 0.00
自由度 = 0
確率水準の計算はで き ません。
30
例1
こ の例で検定 さ れ る 仮説があ っ た場合、 カ イ 2 乗値は、 デー タ が仮説 と 矛盾 し てい る
度合いの測定値にな っ てい ま し た。 カ イ 2 乗値が 0 の場合、 通常は、 帰無仮説か ら 逸脱
し ていない こ と を示 し ます。 ただ し 、 こ の例では、 0 と い う 自由度お よ び 0 と い う カ イ
2 乗値は、 そ も そ も 帰無仮説がなかっ た と い う 事実を反映 し てい る に過ぎ ません。
最小値に達 し ま し た
こ の行は、 Amos が分散お よ び共分散を正常に推定で き た こ と を示 し てい ま す。 時に
よ っ ては、 Amos の よ う な構造モデ リ ン グ プ ロ グ ラ ムで推定値が検出 さ れない こ と が
あ り ます。 通常、 Amos が失敗す る のは、 解がない、 ま たは一意の解がない と い う 問題
が生 じ た場合です。 た と えば、 線型に従属 し てい る 観測変数を使用 し て最尤法の推定
を実行 し よ う と し た場合、 その よ う な分析は原理上実行で き ないため Amos は失敗 し
ます。 一意の解がない と い う 問題については、 識別可能性のテーマで こ のユーザーズ
ガ イ ド の別の場所で説明 し ます。 それほ ど多 く はあ り ませんが、 推定の問題が難解過
ぎ て Amos が失敗す る こ と も あ り ます。 こ の よ う な失敗の可能性は、 積率構造の分析
のプ ロ グ ラ ム では一般的な こ と です。 Amos で使用 し てい る 計算方法は効率の良い も
のですが、 Amos が実行す る 種類の分析を あ ら ゆ る ケー ス で約束で き る コ ン ピ ュ ー タ
プ ロ グ ラ ムはあ り ません。
オプ シ ョ ン出力
こ れま で、Amos がデフ ォ ル ト で生成す る 出力について説明 し て き ま し た。 追加の出力
も 要求で き ます。
標準化推定値の計算
Amos では相関ではな く 共分散の推定値が表示 さ れ る こ と を知 る と 、 驚 く か も し れ ま
せん。 測定尺度が任意で あ っ た り 、 実質的な関心がない場合、 相関は共分散に比べて
説明的な意味合いが強 く な り ます。 それで も なお、 Amos や類似プ ロ グ ラ ムでは、 共分
散の推定を主張 し ます。 ま た、 す ぐ に分か る よ う に、 Amos には共分散については仮説
検定用の単純な方法が用意 さ れてい ますが、 相関についてはあ り ません。 こ れは主に、
共分散の方がプ ロ グ ラ ム の記述が容易で あ る と い う 理由に よ り ます。 一方、 関連す る
分散お よ び共分散の推定が完了 し た後で、 相関推定値を導 き 出す こ と は難 し く あ り ま
せん。 標準化推定値を計算す る には、 次の操作を行い ます。
E
メ ニ ュ ーか ら 、 [ 表示 ] [ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
E [ 標準化推定値 ] チ ェ ッ ク ボ ッ ク ス を オ ンに し ます。
31
分散および共分散の推定
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
分析の再実行
[ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス でオプシ ョ ン を変更 し たため、分析を再実行
す る 必要があ り ます。
E
メ ニ ュ ーか ら 、 [ モデル適合度 ] [ 推定値を計算 ] を選択 し ます。
E [ 出力パス図の表示 ] ボ タ ン を ク リ ッ ク し ます。
E 描画領域の左の [ パ ラ メ ー タ 形式 ] ウ ィ ン ド ウ枠で、[ 標準化推定値 ] を ク リ ッ ク し ます。
相関推定値のテキス ト 出力 と し ての表示
E
メ ニ ュ ーか ら 、 [ 表示 ] [ テキス ト 出力の表示 ] を選択 し ます。
32
例1
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ 枠の ツ リ ー図で、 [ 推定値 ]、 [ ス カ ラ ー ] を
選択 し 、 [ 相関係数 ] を ク リ ッ ク し ます
Amos モデルの分布の仮定
仮説の検定手順、 信頼区間、 お よ び最尤法推定ま たは一般化最小 2 乗法推定におけ る
効率性の要求は、 特定の仮定に依存 し ます。 第一に、 観測値は独立 し てい る 必要があ
り ます。 た と えば、 Attig の調査の 40 名の若い被験者は、 若者 と い う 母集団か ら 独立
し て選択す る 必要があ り ます。 次に、 観測変数は特定の分布の要件を満たす必要があ
り ます。 観測変数に多変量の正規分散があ る 場合は、それで十分です。 すべての観測変
数の多変量正規性は、 多数の構造方程式モデ リ ン グお よ び因子分析アプ リ ケーシ ョ ン
におけ る 標準分布の仮定です。
最尤法推定を実行で き る 、 別の よ り 一般的な状況があ り ます。 一部の外生変数が固
定 さ れてい る 場合 ( すなわち、 事前に判明 し てい る か、 誤差な し で測定 さ れてい る 場
合 )、 その分布は以下の条件で、 任意の形状にな り ます。
固定変数の値パターンの場合、残 り の ( 乱数 ) 変数は ( 条件付き ) 正規分布 と な り ます。
乱数変数の ( 条件付 き ) 分散- 共分散行列は、固定変数のすべてのパ タ ーンに対 し て
同 じ です。
乱数変数の ( 条件付 き ) 期待度数は、 固定変数の値に線型に依存 し ます。
固定変数の代表的な例には、 回答者を それぞれ実験群 と 統制群に分類す る 試験的な治
療があ り ます。 その他の外生変数が調査ケー ス と 対照ケー ス で同様に正規分布 し 、 条
件付 き 分散共分散行列が同 じ で あ る 限 り 、 治療は非正規分布で あ っ て も 構い ま せん。
回帰分析におけ る 予測変数 ( 例 4 を参照 ) は、 広 く 固定変数 と も 呼ばれます。
33
分散および共分散の推定
正規性 と 独立性の観測要件は多数の従来の手順では通例の要件であ る ため、 多 く の
人が こ れ ら の要件には慣れてい ます。 ただ し 、 Amos を使用す る 場合は、 こ れ ら の要件
を満た し ていて も 、 漸近結論 ( すなわち、 大型の標本で近似的に真であ る 結論 ) につな
が る だけであ る こ と に留意す る 必要があ り ます。
VB.NET でのモデル作成
VB.NET ま たは C# でプ ロ グ ラ ム を記述する こ と に よ っ てモデルを指定 し 、 当てはめ る
こ と がで き ます。 プ ロ グ ラ ムの記述は、 Amos Graphics に よ る、 パス図を描画 し たモデ
ルの指定に代わ る も のです。 こ のセ ク シ ョ ンでは、 VB.NET プ ロ グ ラ ム を記述 し て 例 1
の分析を実行する方法について説明 し ます。 後のセ ク シ ョ ンでは、 同 じ こ と を C# で行
う 方法について説明 し ます。
Amos には、VB.NET プ ロ グ ラ ムお よ び C# プ ロ グ ラ ム用の独自の組み込みエデ ィ タ
が付随 し てい ます。 こ のエデ ィ タ には Windows の [ ス タ ー ト ] メ ニ ュ ーか ら ア ク セ ス
で き ます。 例 1 で組み込みエデ ィ タ を使用す る には
E Windows の [ ス ター ト ] メ ニューか ら 、 [ すべてのプログラム ] [IBM SPSS Statistics]
[IBM SPSS Amos 23] [Program Editor] を選択 し ます。
E [Program Editor] ウ ィ ン ド ウ か ら 、 [ フ ァ イル ] [ 新規 VB プ ログ ラ ム ] を選択 し ます。
34
例1
E 「‘Your code goes here」 と い う コ メ ン ト の代わ り に、 モデルを指定 し 当てはめ る ため
の VB.NET コ ー ド を入力 し ます。 次の図は、 プ ロ グ ラ ム を完全に入力 し た後のプ ロ グ
ラ ム エデ ィ タ を示 し てい ます。
注 : Examples デ ィ レ ク ト リ には事前に記述済みのすべての例が格納 さ れてい ます。
こ の例の VB.NET フ ァ イ ルを開 く には
E [Program Editor} ウ ィ ン ド ウ か ら 、 [ フ ァ イル ] [ 開 く ] を選択 し ます。
E Amos 23¥Examples¥Japanese デ ィ レ ク ト リ の フ ァ イ ル Ex01.vb を選択 し ます。
35
分散および共分散の推定
次の表には、 プ ロ グ ラ ムの 1 行ご と の説明が示 さ れてい ます。
プ ロ グ ラ ム の ス テー ト メ ン ト
Dim Sem As New AmosEngine
Sem.TextOutput
Sem.BeginGroup …
Sem.AStructure("recall1")
Sem.AStructure("recall2")
Sem.AStructure("place1")
Sem.AStructure("place2")
Sem.FitModel()
Sem.Dispose()
Try/Finally/End Try
説明
Sem を AmosEngine 型の オ ブ ジ ェ ク ト と し て 宣
言 し てい ます。 Sem オブジ ェ ク ト の メ ソ ッ ド と プ ロ
パテ ィ は、 モデルを指定 し 当てはめ る ために使用 さ
れます。
分析の結果を格納す る 出力フ ァ イ ル を作成 し ま す。
分析が終わ る と 、 出力フ ァ イ ルの内容が別の ウ ィ ン
ド ウ に表示 さ れます。
単一のグループ ( すなわち単一の母集団 ) のモデル
の指定 を開始 し ま す。 こ の行は、 Excel ワ ー ク ブ ッ
ク UserGuide.xls 内の Attg_yng ワ ー ク シー ト に入
力デー タ が格納 さ れてい る こ と も 指定 し てい ま す。
Sem.AmosDir() は、 Amos プロ グ ラ ム デ ィ レ ク ト リ
の場所です。
モデル を 指定 し ま す。 4 つの AStructure ス テー ト
メ ン ト は、 記憶 1、 記憶 2、 掲載位置記憶 1 お よ び
掲載位置記憶 2 の分散を フ リ ー パ ラ メ ー タ と し て
宣言 し ま す。 Attg_yng デー タ フ ァ イ ルのその他の
8 個の変数は、こ の分析では除外 さ れます。 Amos プ
ロ グ ラ ム では (Amos Graphics と は異な り )、 4 つの
変数間で 6 つの共分散を推定で き る よ う に、 観測外
生変数はデ フ ォ ル ト で相関が あ る も の と 仮定 さ れ
ます。
モデルを当てはめ ます。
Sem オブ ジ ェ ク ト に よ っ て使用 さ れた リ ソ ー ス を
解放 し ま す。 プ ロ グ ラ ム で、 別の AmosEngine オブ
ジ ェ ク ト を作成す る 前に AmosEngine オブジ ェ ク ト
の Dispose メ ソ ッ ド を 使用す る こ と は特に重要で
す。 プ ロ セ ス では、 1 度に 1 つの AmosEngine オブ
ジ ェ ク ト の イ ン ス タ ン ス し か許可 さ れ ません。
Try ブ ロ ッ ク は、 プ ロ グ ラ ム の実行中にエ ラ ーが発
生 し た場合で も 、 Dispose メ ソ ッ ド が呼び出 さ れ る
こ と を保証 し ます。
E 分析を実行す る には、 メ ニ ュ ーか ら [ フ ァ イル ] [ 実行 ] を選択 し ます。
追加出力の生成
一部の AmosEngine メ ソ ッ ド では追加出力が生成 さ れます。 た と えば、 Standardized メ
ソ ッ ド は標準化推定値を表示 し ます。 次の図は、 Standardized メ ソ ッ ド の使用を示 し
てい ます。
36
例1
C# によ る モデ リ ン グ
C# での Amos プ ロ グ ラ ムの記述 も 、 VB.NET の場合 と 同様です。 Amos の組み込みプ
ロ グ ラ ム エデ ィ タ で新 し い C# プ ロ グ ラ ム を開始す る には
E [ フ ァ イル ] [ 新規 C# プ ログ ラ ム ] を選択 し ます ([ フ ァ イル ] [ 新規 VB プ ログ ラ ム ] の
代わ り に )。
E [ フ ァ イル ] [ 開 く ] を選択 し て Ex01.cs を開 き ます。 こ れは、Ex01.vb の VB.NET プ ロ
グ ラ ムの C# バージ ョ ン です。
その他のプ ログ ラ ム開発ツール
Amos の組み込みプ ロ グ ラ ム エデ ィ タ は、 こ のユーザーズ ガ イ ド 全体で Amos プ ロ グ
ラ ム の記述お よ び実行のために使用 さ れてい ます。 ただ し 、 自分で選んだ開発ツール
を使用す る こ と も で き ます。 Examples フ ォ ルダには、 VisualStudio サブ フ ォ ルダがあ
り 、 例 1 用の Visual Studio VB.NET お よ び C# ソ リ ュ ーシ ョ ンが収録 さ れてい ます。
例
2
仮説の検定
概要
こ の例では、 Amos を使用 し て、 分散お よ び共分散に関す る 単純な仮説を検定す る 方
法について説明 し ます。 ま た、 適合度のカ イ 2 乗検定を紹介 し 、 自由度の概念につい
て も 詳 し く 説明 し ます。
デー タ について
例 1 で説明 し た Attig (1983) の空間記憶デー タ を使用 し ます。 こ こ で も 、 例 1 と 同 じ パ
ス図か ら 説明を始め ます。 さ ま ざ ま なデータ フ ォーマ ッ ト を使用で き る Amos の機能を
示すため、 こ の例では、 Excel フ ァ イ ルの代わ り に SPSS Statistics デー タ フ ァ イ ルを使
用 し ます。
パラ メ ー タ 制約条件
例 1 のパ ス図を次に示 し ます。 変数オブジ ェ ク ト は、 Amos がパ ラ メ ー タ を推定 し た ら
入力 さ れ る 小 さ な箱 ( 分散を表す ) を周囲に持っ てい る と 考え る こ と がで き ます。
Amos に入力 さ せ る のではな く 、 自分で こ れ ら の箱に入力す る こ と も で き ます。
37
38
例2
分散の制約
記憶 1 の分散を 6 に記憶 2 の分散を 8 に設定す る と し ます。
E 描画領域で、 記憶 1 を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロ
パテ ィ ] を選択 し ます。
E [ パラ メ ー タ ] タ ブ を ク リ ッ ク し ます。
E [ 分散 ] テ キ ス ト ボ ッ ク ス に 「6」 と 入力 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] を開いた ま ま で、 記憶 2 を ク リ ッ ク し 、 その分散を 「8」
に設定 し ます。
E ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
パ ス図に、 指定 し たパ ラ メ ー タ の値が表示 さ れます。
6 と 8 と い う 数字は任意に選択 し たに過ぎ ないため、 こ れはあ ま り 現実的ではあ り ま
せん。 有意なパ ラ メ ー タ 制約条件には、 おそ ら く は理論や以前の同様のデー タ の分析
に基づいた理論的な根拠が必要です。
39
仮説の検定
等 し いパラ メ ー タ の指定
母集団において 2 つのパ ラ メ ー タ が等 し いか ど う かの検定に関心を持つ こ と があ り ま
す。 た と えば、 分散に対す る 特定の値を念頭に置かずに、 記憶 1 と 記憶 2 の分散が等
し い と 考え た と し ます。 こ の可能性を調査す る には、 以下の手順を実行 し ます。
E 描画領域で、 記憶 1 を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロ
パテ ィ ] を選択 し ます。
E [ パ ラ メ ー タ ] タ ブを ク リ ッ ク し ます。
E [ 分散 ] テ キ ス ト ボ ッ ク ス に 「v_recall」 と 入力 し ます。
E 記憶 2 を ク リ ッ ク し 、 その分散に 「v_recall」 と い う ラ ベルを付け ます。
E 同 じ 方法で、 掲載位置記憶 1 と 掲載位置記憶 2 の各分散に も 「v_recall」 と い う ラ ベル
を付け ます。
ど の ラ ベルを使用す る かは問題ではあ り ません。 重要な こ と は、 強制的に等 し く す る
各分散に対 し て同 じ ラ ベル を 入力す る こ と です。 同 じ ラ ベル を 使用す る こ と の効果
は、 あ ら か じ め値を指定 し な く て も 、 ど ち ら の分散に も 同 じ 値を持たせ る こ と です。
等 し いパラ メ ー タ の指定の利点
モデル パ ラ メ ー タ に さ ら に制約条件を追加す る 前に、 記憶 1 と 記憶 2 の分散、 ま たは
掲載位置記憶 1 と 掲載位置記憶 2 の分散な ど、 2 つのパ ラ メ ー タ が等 し く な る よ う 指
定す る のか を検討 し てみま し ょ う 。 次の 2 つの利点があ り ます。
母集団で 2 つのパ ラ メ ー タ が等 し く な る よ う に指定 し 、 こ の指定を正 し く 行っ た
場合、 等 し いパ ラ メ ー タ だけでな く 、 通常は他のパ ラ メ ー タ について も 、 よ り 正
確な推定値を得 る こ と がで き ま す。 パ ラ メ ー タ が等 し い こ と が分か っ ていた場合
は、 こ れが唯一の利点です。
2 つのパ ラ メ ー タ の等 し さ が単に仮説に過ぎ ない場合、その推定値が等 し く な る よ
う に要求す る こ と に よ り 、 その仮説を検定す る こ と にな り ます。
共分散の制約
モデルにはパ ラ メ ー タ の分散以外に制限 も 含 ま れてい る 場合が あ り ま す。 た と えば、
記憶 1 と 掲載位置記憶 1 間の共分散が記憶 2 と 掲載位置記憶 2 間の共分散に等 し い と
仮定 し ます。 こ の制約を適用す る には、 次の手順を実行 し ます。
E 描画領域で、記憶 1 と 掲載位置記憶 1 を結ぶ 2 方向の矢印を右 ク リ ッ ク し 、ポ ッ プア ッ
プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
40
例2
E [ パラ メ ー タ ] タ ブ を ク リ ッ ク し ます。
E [ 共分散 ] テ キ ス ト ボ ッ ク ス に、 「cov_rp」 な ど の非数値型の文字列を入力 し ます。
E 同 じ 方法で、 記憶 2 と 掲載位置記憶 2 間の共分散を cov_rp に設定 し ます。
オブ ジ ェ ク ト の移動 と 書式設定
小 さ な例では横の レ イ ア ウ ト で十分ですが、 さ ら に複雑な分析の場合は実用的ではあ
り ません。 次に、 こ れま で使用 し て き たパス図の別の レ イ ア ウ ト を示 し ます。
以下の ツールを使用 し て、 上記の よ う な図にな る ま でパ ス図の配置を変更で き ます。
41
仮説の検定
オブジ ェ ク ト を移動す る には、 メ ニ ュ ーか ら [ 編集 ] [ 移動 ] を選択 し 、 オブジ ェ
ク ト を新 し い場所に ド ラ ッ グ し ます。 ま た、 [ オブ ジ ェ ク ト を移動 ] ボ タ ン を使用 し
て、 矢印の終点を ド ラ ッ グす る こ と も で き ます。
1 つのオブジ ェ ク ト か ら 別のオブジ ェ ク ト に書式を コ ピーす る には、 メ ニ ュ ーか ら
[ 編集 ] [ プ ロパテ ィ を ド ラ ッ グ ] を選択 し 、 適用す る プ ロ パテ ィ を選択 し て、 1 つ
のオブジ ェ ク ト か ら 別のオブジ ェ ク ト に ド ラ ッ グ し ます。
[プ ロ パテ ィ を ド ラ ッ グ ] 機能に関す る 詳細は、オ ン ラ イ ン ヘルプ を参照 し て く だ さ い。
デー タ の入力
こ の例では、 SPSS Statistics デー タ フ ァ イ ル を 使用 し ま す。 SPSS Statistics が イ ン ス
ト ール さ れてい る 場合、 ロ ー ド し てデー タ を参照す る こ と がで き ます。 SPSS Statistics
が イ ン ス ト ール さ れていない場合で も 、 Amos はデー タ を読み取 り ます。
E
メ ニ ュ ーか ら 、 [ フ ァ イル ] [ デー タ フ ァ イル ] の順に ク リ ッ ク し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [ フ ァ イル名 ] を ク リ ッ ク し ます。
E Examples フ ォ ルダ を参照 し ます。 通常の イ ン ス ト ールを実行 し てい る 場合、 パ ス は
C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese にな り ます。
E [ フ ァ イ ルの種類 ] リ ス ト で、 [ IBM SPSS Statistics (*.sav)] を 選択 し 、 [Attg_yng] を ク
リ ッ ク し て、 [ 開 く ] を ク リ ッ ク し ま す。
E SPSS Statistics が イ ン ス ト ール さ れてい る 場合、 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク
ス で [ デー タ の表示 ] ボ タ ン を ク リ ッ ク し ます。 SPSS Statistics ウ ィ ン ド ウ が開 き 、デー
タ が表示 さ れます。
E デー タ を確認 し 、 デー タ ビ ュ ーを閉 じ ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [OK] を ク リ ッ ク し ます。
42
例2
分析の実行
E
メ ニ ュ ーか ら 、 [ 分析 ] [ 推定値を計算 ] を選択 し ます。
E [ 名前を付けて保存 ] ダ イ ア ロ グ ボ ッ ク ス で フ ァ イ ルの名前を入力 し 、[ 保存 ] を ク リ ッ
ク し ます。
モデル推定値が計算 さ れます。
テキス ト 出力の表示
E
メ ニ ュ ーか ら 、 [ 表示 ] [ テキス ト 出力の表示 ] の順に ク リ ッ ク し ます。
E パ ラ メ ー タ 推定値を表示す る には、[Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ枠の ツ
リ ー図で、 [ 推定値 ] を ク リ ッ ク し ます
等 し く な る よ う に指定 さ れたパ ラ メ ー タ の推定値が実際に等 し い こ と が分か り ま す。
こ の場合の標準誤差は、例 1 で得た標準誤差 よ り も 一般的に小 さ く な り ま す。 ま た、
パ ラ メ ー タ に制約条件が設定 さ れてい る ため、 自由度は正の値にな っ てい ます。
43
仮説の検定
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ枠で、 [ モデルについての注釈 ] を ク リ ッ ク
し ます
標本の分散お よ び共分散は 10 個あ り ま すが、 推定パ ラ メ ー タ の数は 7 個だけです。
7 と い う 数は次の よ う に し て得 ら れま し た。記憶 1 と 記憶 2 の分散には v_recall と い う
ラ ベルが付け ら れ、 等 し く な る よ う に制約 さ れてい る ため、 1 つのパ ラ メ ー タ と し て
カ ウ ン ト さ れてい ます。 掲載位置記憶 1 と 掲載位置記憶 2 の分散 (v_place と い う ラ ベ
ルが付け ら れてい る ) も 、 も う 1 つの単一パ ラ メ ー タ と し て カ ウ ン ト さ れてい ま す。
3 つ目のパ ラ メ ー タ は等共分散記憶 1 <> 掲載位置記憶 1 お よ び記憶 2 <> 掲載位置記憶
2 (cov_rp と い う ラ ベル ) に相当 し ます。 こ れ ら 3 つのパ ラ メ ー タ に 4 つの ラ ベルがな
く 制限 さ れていない共分散を加え て、 推定パ ラ メ ー タ は全部で 7 つにな り ます。
自由度 ( 10 – 7 = 3 ) も 、 元の 10 個の分散お よ び共分散に設定 さ れた制約の数 と 考
え る こ と がで き ます。
オプ シ ョ ン出力
こ れ ま で説明 し た出力は、 すべてデフ ォ ル ト で生成 さ れ ます。 追加の出力 も 要求で き
ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 出力 ] タ ブを ク リ ッ ク し ます。
44
例2
E [ 最小化履歴 ]、[ 標準化推定値 ]、[ 標本の積率 ]、[ モデルの積率 ]、お よ び [ 残差積率 ] のチ ェ ッ
ク ボ ッ ク ス がオ ンにな っ てい る こ と を確認 し て く だ さ い。
E
メ ニ ュ ーか ら 、 [ 分析 ] [ 推定値を計算 ] を選択 し ます。
モデルの推定値が再計算 さ れます。
分散共分散行列推定値
E 行列に収集 さ れた標本の分散お よ び共分散 を 参照す る には、 メ ニ ュ ーか ら [ 表示 ]
[ テキス ト 出力の表示 ] を選択 し ます。
E [Amos 出力 ] ウ ィ ン ド ウ の左上隅の ツ リ ー図で、 [ 標本の積率 ] を ク リ ッ ク し ます
45
仮説の検定
標本の共分散行列を次に示 し ます。
E ツ リ ー図で、 [ 推定値 ] を展開 し 、 [ 行列 ] を ク リ ッ ク し ます。
モデルの共分散の行列を次に示 し ます。
標本の共分散行列 と モデルの共分散行列の違いに注意 し て く だ さ い。 モデルでは共分
散構造に 3 つの制約条件が設定 さ れ る ため、 モデルの分散お よ び共分散は標本の値 と
は異な っ てい ます。 た と えば、 掲載位置記憶 1 の標本の分散は 33.58 ですが、 モデルの
分散は 27.53 です。 残差共分散 ( 標本の共分散か ら モデルの共分散を引いた も の ) の行
列を得 る には、 [ 出力 ] タ ブで [ 残差積率 ] の横にチ ェ ッ ク マー ク を入れ、 分析を再実行
し ます。
残差共分散の行列を次に示 し ます。
46
例2
共分散および分散推定値のパス図への表示
例 1 の よ う に、 パ ス図に共分散お よ び分散推定値を表示す る こ と がで き ます。
E [ 出力パス図の表示 ] ボ タ ン を ク リ ッ ク し ます。
E 描画領域の左にあ る [ パ ラ メ ー タ 形式 ] ウ ィ ン ド ウ 枠で、 [ 非標準化推定値 ] を ク リ ッ ク
し ます。 ま たは、 [ 標準化推定値 ] を ク リ ッ ク し て、 パ ス図で相関推定値を要求す る こ
と も で き ます。
相関が表示 さ れたパス図を次に示 し ます。
出力のラ ベル付け
表示 さ れた値が共分散ま たは相関の ど ち ら であ る か を覚え てお く のが、 困難な場合 も
あ り ます。 こ の問題を避け る ため、Amos を使用 し て出力に ラ ベルを付け る こ と がで き
ます。
E フ ァ イ ル Ex02.amw を開 き ます。
E パ ス図でキ ャ プシ ョ ン を右 ク リ ッ ク し 、ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ
ロパテ ィ ] を選択 し ます。
47
仮説の検定
E [ テキス ト ] タ ブを ク リ ッ ク し ます。
図のキ ャ プシ ョ ンの一番下の行に 「¥format」 と い う 語が表示 さ れてい ます。 ¥format
の よ う に ¥ 記号で始ま る 語を、 テ キ ス ト マ ク ロ と いい ます。 Amos では、 テ キ ス ト マ
ク ロ は現在表示 さ れてい る モデルに関す る 情報で置 き 換え ら れます。 テ キ ス ト マ ク ロ
¥format は、 表示 さ れ る パ ス図のバージ ョ ンに よ っ て、 「モデル特定化」、 「非標準化推
定値」、 お よ び 「標準化推定値」 のいずれかの見出 し で置 き 換え ら れます。
仮説の検定
モデルの共分散は、帰無仮説の下での母集団の分散お よ び共分散の最適な推定値です。
( 帰無仮説 と は、等 し い推定値にな る よ う 要求 さ れたパ ラ メ ー タ が母集団において真に
等 し い場合です。 ) 例 1 か ら 分か る よ う に、 標本の共分散は、 母集団の値に関す る 仮定
を行わずに得 ら れ る 最適な推定値です。 こ れ ら の 2 つの行列の比較は、 帰無仮説が正
し いか ど う か と い う 問題に関連 し てい ます。 帰無仮説が正 し い場合、 モデルの共分散
と 標本の共分散は両方 と も 、 対応す る 母集団の値の最尤推定値 と な り ます ( モデルの
共分散の方が良い推定値ではあ り ますが )。 し たが っ て、 2 つの行列は互いに似てい る
と 予想 さ れ ます。 こ れに反 し て、 帰無仮説が誤っ てい る 場合、 標本の共分散のみが最
尤推定値 と な り 、 モデルの共分散 と 似てい る こ と を期待す る 根拠はあ り ません。
カ イ 2 乗統計量は、 モデルの共分散が標本の共分散 と ど の程度異な っ てい る かの全
体的な測定値 と な り ます。
カ イ 2 乗 = 6.276
自由度 = 3
確率水準 = 0.099
48
例2
一般的に、 モデルの共分散が標本の共分散か ら 異な っ ていればい る ほ ど、 カ イ 2 乗統
計量 も 大 き く な り ます。 例 1 の よ う に、 モデルの共分散が標本の共分散 と 同 じ であ る
場合は、 カ イ 2 乗統計量は 0 にな っ たはずです。 カ イ 2 乗統計量を使用 し て、 等 し い
推定値を持つ よ う 要求 さ れてい る パ ラ メ ー タ が、 実際に母集団で等 し い と い う 帰無仮
説を検定す る こ と がで き ます。 ただ し 、 単にカ イ 2 乗統計量が 0 か ど う かを確認す る
だけの問題ではあ り ません。 モデルの共分散お よ び標本の共分散は単な る 推定値に過
ぎ ないため、 同一であ る と 予想す る こ と がで き る のです ( 両方 と も 同 じ 母集団の共分
散の推定値であ っ た と し て も )。 実際には、 帰無仮説が真であ っ た場合で も 、 自由度の
近辺でカ イ 2 乗を生成す る 程度には異な る と 予想で き ます。 言い換え る と 、 帰無仮説
が真の場合で も 、 3 と い う カ イ 2 乗値は異常ではあ り ません。 それど こ ろか、 帰無仮説
が真の場合、 カ イ 2 乗値 (6.276) は、自由度が 3 の近似カ イ 2 乗分布を持つ乱数変数の
単一の観測値です。 確率は約 0.099 で、 その よ う な観測値は 6.276 と な り ま す。 し た
が っ て、 帰無仮説が真であ る か ど う かは、 0.05 レベルでは有意ではあ り ません。
パス図へのカ イ 2 乗統計量の表示
パ ス 図の図の キ ャ プ シ ョ ン に表示 さ れ る カ イ 2 乗統計量 と そ の自由度 を 得 る には、
テ キ ス ト マ ク ロ ¥cmin お よ び ¥df を使用 し ます。 こ のテ キ ス ト マ ク ロ は、 カ イ 2 乗統
計量 と その自由度の数値で置 き 換え ら れます。 テ キ ス ト マ ク ロ ¥p を使用す る と 、カ イ
2 乗分布下 の対応す る 右側の確率を表示す る こ と がで き ます。
E
メ ニ ュ ーか ら 、 [ 図 ] [ 図のキ ャ プ シ ョ ン ] を選択 し ます。
E パ ス図上で、 図のキ ャ プシ ョ ン を表示す る場所を ク リ ッ ク し ます。
[ 図のキ ャ プシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E [ 図のキ ャ プシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 次の よ う に、 「¥cmin」、 「¥df」、 「¥p」 の
各テ キ ス ト マ ク ロ を含むキ ャ プシ ョ ン を入力 し ます。
49
仮説の検定
こ のキ ャ プシ ョ ン を含むパ ス図が、 次の よ う に表示 さ れます。
50
例2
VB.NET で モデルを作成する
次のプ ロ グ ラ ムは、 例 2 の制約 さ れたモデルを当てはめ ます。
51
仮説の検定
次の表には、 プ ロ グ ラ ムの 1 行ご と の説明が示 さ れてい ます。
プ ロ グ ラ ム の ス テー ト メ ン ト
Dim Sem As New AmosEngine
Sem.TextOutput
Sem.Standardized()
Sem.ImpliedMoments()
Sem.SampleMoments()
Sem.ResidualMoments()
Sem.BeginGroup …
Sem.AStructure("recall1 (v_recall)")
Sem.AStructure("recall2 (v_recall)")
Sem.AStructure("place1 (v_place)")
Sem.AStructure("place2 (v_place)")
Sem.AStructure("recall1 <>place1
(cov_rp)")
Sem.AStructure("recall2 <>place2
(cov_rp)")
Sem.FitModel()
Sem.Dispose()
Try/Finally/End Try
説明
Sem を AmosEngine 型のオブジ ェ ク ト と し て
宣言 し てい ま す。 Sem オブジ ェ ク ト の メ ソ ッ ド
と プ ロ パテ ィ は、 モデルを指定 し 当てはめ る た
めに使用 さ れます。
分析の結果を格納す る 出力フ ァ イ ルを作成 し ま
す。 分析が終わ る と 、 出力 フ ァ イ ルの内容が別
の ウ ィ ン ド ウ に表示 さ れ ます。
標準化推定値、 モデルの共分散、 標本の共分散、
お よ び残差共分散を表示 し ます。
単一のグループ ( すなわち単一の母集団 ) のモデ
ルの特定を開始 し ます。 こ の行は、
SPSS Statistics フ ァ イ ル Attg_yng.sav に 入 力
デー タ が格納 さ れ て い る こ と も 指定 し て い ま
す。 Sem.AmosDir() は、 Amos プ ロ グ ラ ム デ ィ
レ ク ト リ の場所です。
モデルを指定 し ます。 最初の 4 つの AStructure
ス テー ト メ ン ト は、 パ ラ メ ー タ 名を か っ こ で囲
んで使用す る こ と に よ り 、 観測変数の分散を制
約 し ます。 記憶 1 と 記憶 2 の分散には両方 と も
v_recall と い う ラ ベルが付いてい る ため、 こ れ ら
は同 じ 分散に な る 必要が あ り ま す。 掲載位置記
憶 1 と 掲載位置記憶 2 の分散 も 、 同様に等 し く
な る よ う に 制約 さ れ て い ま す。 最後 の 2 つ の
AStructure 行は、 それぞれ共分散を表 し てい ま
す。 2 つの共分散は ど ち ら も cov_rp と い う 名前
です。 し た が っ て、 こ れ ら の共分散は等 し く な
る よ う 制約 さ れてい ます。
モデルを当てはめ ます。
Sem オブジ ェ ク ト に よ っ て使用 さ れた リ ソ ース
を解放 し ます。 プ ロ グ ラ ム で、 別の AmosEngine
オブ ジ ェ ク ト を作成す る 前に AmosEngine オブ
ジ ェ ク ト の Dispose メ ソ ッ ド を 使用す る こ と
は特に重要です。 プ ロ セ ス では、 1 度に 1 つの
AmosEngine オブ ジ ェ ク ト の イ ン ス タ ン ス し か
許可 さ れません。
Try ブ ロ ッ ク は、 プ ロ グ ラ ム の実行中にエ ラ ー
が発生 し た場合で も 、 Dispose メ ソ ッ ド が呼び
出 さ れ る こ と を保証 し ます。
E 分析を実行す る には、 メ ニ ュ ーか ら [ フ ァ イル ] [ 実行 ] を選択 し ます。
52
例2
タ イ ミ ングがすべて
AStructure 行は BeginGroup の後に来 る必要があ り ます。そ う でない と 、 AStructure 行
で指定 さ れてい る変数が attg_yng.sav データ セッ ト の観測変数であ る と 認識 さ れません。
一般的に、 Amos のプ ロ グ ラ ム では、 ス テー ト メ ン ト の順序が重要です。 Amos プ ロ
グ ラ ムの編成では、 メ ソ ッ ド は 3 つの一般的な グループに分かれます。1
グループ 1 - 宣言用の メ ソ ッ ド
Amos に 計算お よ び表示す る 結果 を 教 え る メ ソ ッ ド の グ ルー プ で す。 TextOutput、
Standardized、 ImpliedMoments、 SampleMoments、お よ び ResidualMoments はグルー
プ 1 の メ ソ ッ ド です。 こ の例で使用 さ れていない、 他のグループ 1 の メ ソ ッ ド につい
ては、 『Amos 23 Programming Reference Guide』 に記載 さ れてい ます。
グループ 2 - デー タ お よ びモデル指定用の メ ソ ッ ド
デー タ 記述 コ マ ン ド お よ びモデル特定 コ マ ン ド の グループです。 BeginGroup お よ び
AStructure は グループ 2 の メ ソ ッ ド です。 その他の メ ソ ッ ド につい ては、 『Amos 23
Programming Reference Guide』 に記載 さ れてい ます。
グループ 3 - 結果取得用の メ ソ ッ ド
結果を取得す る ための コ マ ン ド です。 こ れま で、 グループ 3 の メ ソ ッ ド は ま だ使用 し
て い ま せ ん。 グ ル ー プ 3 の メ ソ ッ ド 使 用 例 に つ い て は、 『Amos 23 Programming
Reference Guide』 に記載 さ れてい ます。
ヒ ン ト : Amos プ ロ グ ラ ム を記述す る場合、 Amos エ ン ジ ンの メ ソ ッ ド を呼び出す順序
に細心の注意を払 う こ と が重要です。 グループ 1、 グループ 2、 そ し て最後にグループ
3 の順序で記述す る 必要があ り ます。
ルールの タ イ ミ ン グの詳細 と メ ソ ッ ド お よ びその メ ソ ッ ド が ど のグループに所属す る
かについての完全な リ ス ト は、 『Amos 23 Programming Reference Guide』 を参照 し て く
だ さ い。
1 Initialize メ ソ ッ ド のみで構成 さ れ る 、 4 番目の特殊な グループ も あ り ます。 オプシ ョ ンの Initialize メ ソ ッ
ド を使用す る 場合、 グループ 1 の メ ソ ッ ド よ り 前に指定する 必要があ り ます。
例
3
その他の仮説の検定
概要
こ の例では、 2 つの変数に相関がない と い う 帰無仮説の検定方法を説明 し 、 自由度の
概念について詳 し く 解説 し 、漸近的に正確な検定の意味す る も の を具体的に示 し ます。
デー タ について
こ の例では、 Attig (1983) の空間記憶調査の被験者グループ と 、 年齢お よ びボキ ャ ブ ラ
リ の 2 つの変数 を 使用 し ま す。 タ ブ区切 り テ キ ス ト フ ァ イ ル と し て書式設定 さ れた
デー タ を使用 し ます。
デー タ の取 り 込み
E
メ ニ ュ ーか ら 、 [ フ ァ イル ][ 新規作成 ] を選択 し ます。
E
メ ニ ュ ーか ら 、 [ フ ァ イル ]、 [ デー タ フ ァ イル ] の順に ク リ ッ ク し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [ フ ァ イル名 ] を選択 し ます。
E Examples フ ォ ルダ を参照 し ます。 通常の イ ン ス ト ールを実行 し てい る 場合、 パ ス は
C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese にな り ます。
E [ フ ァ イ ルの種類 ] リ ス ト で、 [ テ キ ス ト (*.txt)] を選択 し 、 [Attg_old.txt] を ク リ ッ ク し
て、 [ 開 く ] を ク リ ッ ク し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [OK] を ク リ ッ ク し ます。
53
54
例3
2 つの変数に相関がない と い う 仮説の検定
Attig の 40 名の年長の被験者では、 年齢 と ボキ ャ ブ ラ リ 間の標本の相関は、 0.09 です
(0 か ら それほ ど乖離 し てい ません )。 と は言え、 こ の相関は著 し く 有意であ る と 言え る
で し ょ う か。 それを調べ る ために、 こ の 40 人の被験者の属す る 母集団において、 年齢
と ボ キ ャ ブ ラ リ 間の相関が 0 であ る と い う 帰無仮説を検定す る こ と に し ます。 年齢 と
ボキ ャ ブ ラ リ に相関がない と い う 制約の下で、 分散共分散行列を推定 し ます。
モデルを指定する
例 1 で学習 し た方法を使用 し て、 パス図で 2 つの観測変数年齢 と ボキ ャ ブ ラ リ を描画
し 、 名前を付け る こ と か ら 始め ます。
Amos では、年齢 と ボキ ャ ブ ラ リ 間の共分散が 0 であ る こ と を指定する ための 2 つの方
法があ り ます。 最 も 明白な方法は、単に 2 つの変数を結ぶ双方向の矢印を描画 し ない こ
と です。 2 つの外生変数を結ぶ双方向の矢印がない と い う こ と は、 相関がない こ と を意
味 し てい ます。 し たがっ て、 何 も 描かなければ、 上記の単純なパス図で指定 さ れたモデ
ルは年齢 と ボキ ャ ブ ラ リ 間の共分散 ( ひいては相関 ) が 0 であ る こ と を指定 し ます。
共分散パ ラ メ ー タ を制約す る 2 つ目の方法は、 例 1 と 例 2 で紹介 さ れた、 よ り 一般
的な手順です。
E
メ ニ ュ ーか ら 、 [ 図 ] [ 共分散を描 く ] の順に ク リ ッ ク し ます。
E
ク リ ッ ク し 、 ド ラ ッ グ し て、 ボキ ャ ブ ラ リ と 年齢を結ぶ矢印を描 き ます。
E 矢印を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択
し ます。
E [ パラ メ ー タ ] タ ブ を ク リ ッ ク し ます。
E [ 共分散 ] テ キ ス ト ボ ッ ク ス に 「0」 と 入力 し ます。
E [ オブジ ェ ク ト プ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
55
その他の仮説の検定
パ ス図は次の よ う にな り ます。
E
メ ニ ュ ーか ら 、 [ 分析 ] [ 推定値を計算 ] を選択 し ます。
[ 名前を付けて保存 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E フ ァ イ ルの名前を入力 し て、 [ 保存 ] を ク リ ッ ク し ます。
モデル推定値が計算 さ れます。
56
例3
テキス ト 出力の表示
E
メ ニ ュ ーか ら 、 [ 表示 ][ テキス ト 出力の表示 ] の順に ク リ ッ ク し ます。
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ 枠の ツ リ ー図で、 [ 推定値 ] を選択 し ます
パ ラ メ ー タ 推定値は こ の分析の主要な目的ではあ り ませんが、以下の よ う にな り ます。
こ の分析では、 年齢 と ボキ ャ ブ ラ リ に相関がない と い う 1 つの制約条件に対応す る
1 つの自由度があ り ます。 自由度 は、 次のテ キ ス ト で表示 さ れてい る 計算に よ っ て も
得 ら れます。 こ の計算を表示す る には、 次の手順を実行 し ます。
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ 枠で、 [ モデルについての注釈 ] を ク リ ッ ク
し ます
3 つの標本の積率は、 年齢の分散、 ボキ ャ ブ ラ リ の分散、 お よ び こ れ ら の共分散です。
2 つの独立な推定パ ラ メ ー タ は、 2 つの母集団の分散です。 共分散は こ のモデルでは
0 に固定 さ れてお り 、 標本の情報か ら は推定 さ れません。
57
その他の仮説の検定
グ ラ フ ィ ッ ク出力の表示
E [ 出力パス図の表示 ] ボ タ ン を ク リ ッ ク し ます。
E 描画領域の左にあ る [ パ ラ メ ー タ 形式 ] ウ ィ ン ド ウ枠で、 [ 非標準化推定値 ] を ク リ ッ ク
し ます。
非標準化推定値のパ ス図の出力、 お よ び年齢 と ボ キ ャ ブ ラ リ に相関がない と い う 帰無
仮説の検定を次に示 し ます。
こ の大 き さ の逸脱が偶発的に帰無仮説か ら 得 ら れ る 確率は 0.555 です。 従来の有意水
準では、 帰無仮説は棄却 さ れません。
こ の帰無仮説検定用の通常の t 統計量は 0.59 (df = 38 、p = 0.56 両側 ) です。 t 統
計量に関連す る 確率水準は正確です。 有限標本では正確な カ イ 2 乗分布がないため、
カ イ 2 乗統計量の確率水準 0.555 は外れてい ます。 こ の場合で も 、 0.555 と い う 確率水
準は悪 く はあ り ません。
こ こ で興味深い問題が生 じ ま す。 Amos に よ っ て表示 さ れた確率水準 を 使用 し て
0.05 レベルま たは 0.01 レベルで帰無仮説を検定 し た場合、真の帰無仮説を棄却す る 実
際の確率は ど う な る ので し ょ う か。 こ の帰無仮説の場合、 標本数に よ っ て異な り ます
が、 回答があ り ます。 次の表の第 2 列は、 複数の標本数について、 Amos を使用 し て
0.05 レベルでゼ ロ の相関の帰無仮説を検定 し た場合の、 実際の タ イ プ I の誤 り の確率
を示 し てい ます。 3 番目の列は、0.01 の有意水準を使用 し た場合の実際の タ イ プ I の誤
り の確率を示 し てい ます。 こ の表は、 標本数が多 く なればな る ほ ど、 真の有意水準が
予想値に近づ く こ と を示 し てい ます。 非常に残念なが ら 、Amos を使用 し て検定で き る
58
例3
すべての仮説について、 こ の よ う な表を作成す る こ と はで き ません。 し か し 、 次の こ
と は こ う し た表の どれについて も あ ては ま り ます。 上か ら 下に向か っ て、 0.05 列の数
値は 0.05 に近づ き 、0.01 列の数値は 0.01 に近 く な っ てい き ます。 最尤法理論に基づ く
仮説検定が漸近的に正 し い と い う のは、 こ の こ と を意味 し てい ます。
次の表は、 Amos を使用 し て 2 つの変数間に相関がない と い う 仮説を検定 し た場合
の、 タ イ プ I の誤 り の実際の確率を示 し てい ます。
標本数
3
4
5
10
20
30
40
50
100
150
200
>500
名義有意水準
0.05
0.250
0.150
0.115
0.073
0.060
0.056
0.055
0.054
0.052
0.051
0.051
0.050
0.01
0.122
0.056
0.038
0.018
0.013
0.012
0.012
0.011
0.011
0.010
0.010
0.010
59
その他の仮説の検定
VB.NET でのモデル作成
以下は、 こ の例の分析を実行す る ためのプ ロ グ ラ ムです。
Structure メ ソ ッ ド は、 共分散を定数 0 で固定 し て制約 し ます。 こ のプ ロ グ ラ ム では、
年齢 と ボ キ ャ ブ ラ リ の分散を明示的には参照 し てい ま せん。 Amos のデフ ォ ル ト の動
作は、それ ら の制約条件な し で分散を推定す る こ と です。 プロ グ ラ ムで明示的に制約 さ
れてい る 分散を除 き、 すべての外生変数の分散は フ リ ー パラ メ ータ と し て扱われます。
例
4
従来の線型回帰
概要
こ の例では、 3 個の観測変数の線型結合 と し て単一の観測変数を予測す る 、 従来の線
型回帰分析について説明 し ます。 特定可能性の概念について も 説明 し ます。
デー タ について
Warren、 White、 お よ び Fuller は、 98 名の農場共同組合長を対象に調査を行い ま し た
(1974) 。 こ こ では次の 4 つの測定値を使用 し ます。
変数
成果
知識
価値
満足度
説明
「計画、 組織、 制御、 調整、 お よ び指導」 に関す る 実績の 24 項
目の変数
「収益を目標 と し た管理の経済局面お よ び製品知識」 に関す る
知識の 26 項目の検定
「経済的目標 を 達成す る た めの手段 を 合理的に評価す る 傾向」
の 30 項目の検定
「管理的役割を果たす こ と に よ る 満足度」 の 11 項目の検定
5 つ目の測定値であ る past_training も 報告 さ れてい ますが、 こ こ では使用 し ません。
こ の例では、Examples フ ォ ルダにあ る UserGuide.xls フ ァ イ ルの Excel ワ ー ク シー ト
Warren5v を使用 し ます。 通常の イ ン ス ト ールを実行 し てい る 場合、 パス は C:¥Program
Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese にな り ます。
61
62
例4
標本分散 と 標本共分散を次に示 し ます。
Warren5v には標本の平均値 も 含まれます。 生デー タ は使用で き ませんが、 標本の積率
( 平均、 分散、 お よ び共分散 ) が提供 さ れ る 限 り 、 Amos に よ る 大部分の分析では必要
あ り ま せん。 実際に、 こ の例では標本分散 と 標本共分散のみ必要です。 差 し 当た っ て
Warren5v では標本の平均値は必要ないので、 Amos はそれ ら の値を無視 し ます。
デー タ の分析
知識、 価値、 お よ び満足度の得点を使用 し て成果を予測す る 場合を考え てみま し ょ う 。
具体的には、 知識、 価値、 お よ び満足度の線型結合に よ っ て成果の得点の近似値を求
め る こ と がで き る と 考え ます。 ただ し 、 こ の予測は完全ではないので、 モデルに誤差
変数を含め る 必要があ り ます。
こ の関係の初期パ ス図を次に示 し ます。
一方向の矢印は線型従属を表 し ます。 た と えば、 知識か ら 成果を指す矢印は、 成果の
得点が一部知識に依存す る こ と を示 し ます。 変数誤差は直接観測 さ れないため、 円で
囲 ま れてい ます。 誤差が表すのは、 測定エ ラ ーに よ る 成果の得点の ラ ン ダ ム な変動だ
けではあ り ません。 誤差は、 年齢構成、 社会経済状況、 言語能力、 その他成果が依存
63
従来の線型回帰
す る 要素で こ の調査では測定 さ れなか っ た要素 も 表 し ます。 パ ス 図には、 成果の得点
に影響す る すべての変数が示 さ れ る と 考え ら れ る ので、 こ の変数は不可欠です。 こ の
円がない場合、 こ のパ ス図は成果が知識、 価値、 お よ び満足度 と 厳密な線型結合であ
る と い う あ り え ない関係を示す こ と にな り ます。
パ ス図の双方向の矢印は、 相関す る 可能性があ る 変数を結びます。 誤差 と その他の
変数を結ぶ双方向矢印が存在 し ないのは、 誤差は他のすべての予測変数 と 無相関であ
る と 仮定 さ れ る こ と を示 し ます ( 線型回帰におけ る 基本的仮定 )。 成果 も その他の変数
と 双方向矢印で結ばれてい ませんが、 こ の理由は異な り ます。 成果はその他の変数に
依存す る ため、 必然的にそれ ら の変数 と 相関す る 可能性があ り ます。
モデルを指定する
こ れま での 3 つの例で学習 し た こ と を使用 し て、 次の操作を行い ます。
E 新 し いパ ス図を開始 し ます。
E 分析 さ れ る デー タ セ ッ ト が UserGuide.xls フ ァ イ ルの Excel ワ ー ク シー ト Warren5v に
あ る こ と を指定 し ます。
E 4 つの四角形を作成 し 、 知識、 価値、 満足度、 お よ び成果の ラ ベルを付け ます。
E 誤差変数用の楕円を作成 し ます。
E 外生 ま た は予測変数 ( 知識、 価値、 満足度、 お よ び誤差 ) か ら 内生 ま た は応答変数
( 成果 ) を指す一方向矢印を作成 し ます。
注 : 少な く と も 1 つの一方向矢印が内生変数を指し てい る必要があ り ます。 こ れに対 し
外生変数は一方向矢印の起点 と な る だけで、 指 さ れる こ と はあ り ません。
E 観測外生変数 ( 知識、 満足度、 お よ び 価値 ) を結ぶ 3 つの双方向矢印を作成 し ます。
作成 さ れたパ ス図は次の よ う にな り ます。
64
例4
特定
こ の例では、 誤差に対す る 成果の回帰の係数が推定で き ず、 誤差の分散 も 推定で き ま
せん。 こ れは、 「全部で 5 ド ルの道具を買っ た」 と 聞いただけで、 購入 し た道具それぞ
れの価格 と 購入 し た道具の数 と を推定 し よ う と す る よ う な も のです。 価格 と 数を推定
す る には情報が不十分です。
成果を予測す る 際に誤差に適用 さ れ る 係数、 ま たは誤差変数自体の分散を ゼ ロ 以外
の任意の値に固定す る こ と に よ り 、 こ の特定問題を解決で き ます。 係数を 1 に固定 し
てみま し ょ う 。 こ れに よ り 、 従来の線型回帰 と 同 じ 推定値が得 ら れます。
係数を固定する
E 誤差か ら 成果 を指す矢印を右 ク リ ッ ク し 、ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト の
プ ロパテ ィ ] を選択 し ます。
E [ パラ メ ー タ ] タ ブ を ク リ ッ ク し ます。
E [ 係数 ] ボ ッ ク ス に 「1」 と 入力 し ます。
すべての誤差変数の係数を 1 に設定す る のは面倒です。 幸いに し て、Amos Graphics に
は大部分の場合に適用で き る 方法があ ら か じ め用意 さ れてい ます。
65
従来の線型回帰
E [ 既存の変数に固有の変数を追加 ] ボ タ ン を ク リ ッ ク し ます。
E 内生変数を ク リ ッ ク し ます。
誤差変数が自動的に追加 さ れ、 係数が 1 に固定 さ れ ます。 内生変数を繰 り 返 し ク リ ッ
ク す る と 、 誤差変数の位置が変わ り ます。
テキス ト 出力を表示する
最尤法の推定値を次に示 し ます。
パ ス成果 <— 誤差の値はデフ ォ ル ト 値 1 に固定 さ れてい る ので表示 さ れません。 異な
る 定数を選択す る と 他の推定値が ど の よ う な影響を受け る か を確認 し て く だ さ い。 こ
の よ う な変更の影響を受け る のは誤差の分散の推定値だけであ る こ と がわか り ます。
次の表に、成果<—誤差 係数に さ ま ざ ま な値を選択し た場合の分散の推定値を示し ます。
固定係数
0.5
0.707
1.0
1.414
2.0
推定 さ れ る 誤差の分散
0.050
0.025
0.0125
0.00625
0.00313
66
例4
こ のパス の係数を 1 ではな く 2 に固定 し た場合を考え てみま し ょ う 。 こ の場合、 分散
の推定値は係数 4 で割 ら れ ます。 パ ス係数に固定係数を掛け る と と も に、 誤差分散を
同 じ 係数の平方根で割 る と い う 規則 を 当て はめ る こ と がで き ま す。 こ れ を 拡張す る
と 、 係数の 2 乗の積 と 誤差分散が常に一定にな り ます。 こ れが、 係数 ( と 誤差分散 ) が
特定不能で あ る と い う こ と です。 こ れ ら のいずれかに値を割 り 当て る と も う 一方を推
定で き ますが、 同時に両方を推定す る こ と はで き ません。
こ れま で説明 し た特定可能性の問題は、 変数の分散 と 、 それに関連付け ら れた係数
が、 変数の測定単位に応 じ て異な る と い う 事実に よ っ て発生 し ます。 誤差は非観測変
数なので、 自然な方法で測定単位を指定す る こ と はで き ません。 誤差の測定単位を間
接的に選択す る 方法 と し て、 誤差に関連付け ら れた係数に任意の値を割 り 当て る 方法
が考え ら れ ます。 すべての非観測変数には こ の特定不能性の問題があ り 、 測定単位を
決定す る 何 ら かの制約を設け る こ と に よ っ て問題を解決す る 必要があ り ます。
非観測変数誤差の単位 を 変更 し て も 、 全体的な モデルの適合度は変わ り ま せん。
すべての分析で、 次の出力が得 ら れます。
カ イ 2 乗 = 0.00
自由度 = 0
確率水準の計算はで き ません。
4 個の標本分散 と 6 個の標本共分散で、 合計 10 個の標本の積率があ り ます。 3 個の回
帰パ ス、 4 個のモデル分散、 3 個のモデル共分散で、 合計 10 個のパ ラ メ ー タ を推定す
る 必要があ り ます。 こ のため、モデルの自由度はゼ ロ にな り ます。 こ の よ う なモデルは
し ば し ば飽和モデル ま たは識別可能モデル と 呼ばれます。
標準化 さ れた係数の推定値には、 次の も のがあ り ます。
標準化 さ れ た係数 と 相関は、 すべて の変数 を 測定す る 単位か ら 独立 し て い る の で、
識別制約の選択に よ る 影響を受け ません。
67
従来の線型回帰
重相関の 2 乗 も 測定単位か ら 独立 し てい ます。 Amos では、内生変数ご と に重相関係
数の平方が表示 さ れます。
注 : 変数の重相関係数の平方は、 予測変数が分散に占め る 割合にな り ます。 上の例で
は、 知識、 価値、 お よ び満足度が成果の分散の 40% を占めてい ます。
グ ラ フ ィ ッ ク出力を表示する
次のパ ス図の出力には、 標準化 さ れていない値が示 さ れてい ます。
68
例4
標準化 さ れた解は次の と お り です。
その他のテキス ト 出力を表示する
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ 枠にあ る ツ リ ー図で、 [ 変数の要約 ] を ク
リ ッ ク し ます。
69
従来の線型回帰
内生変数は一方向矢印に よ っ て指 さ れ る 変数であ り 、 他の変数に依存 し ます。 外生変
数は一方向矢印に よ っ て指 さ れない変数であ り 、 他の変数に依存 し ません。
上の リ ス ト の確認は、入力フ ァ イ ルで最 も よ く 見 ら れ る ( 不注意に よ る ) エ ラ ーであ
る 、 入力エ ラ ーの検出に役立ち ます。 「成果」 と 2 回入力 し よ う と し て、 その内 1 回
は誤っ て 「製菓」 と 入力 し て し ま っ た場合、 両方の語が リ ス ト に表示 さ れます。
E
こ こ で、 [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ枠にあ る [ モデルについての注釈 ]
を ク リ ッ ク し ます。
次の出力は、 パ ス図に フ ィ ー ド バ ッ ク ループがない こ と を示 し てい ます。
後ほ ど、 変数を選択 し 、 一方向の矢印に沿っ て ト レースす る こ と に よ り 、 同 じ 変数に
戻 る パ ス を含むパス図を示 し ます。
注 : フ ィ ー ド バ ッ ク ループのあ る パ ス図は非再帰 と 呼ばれます。 フ ィ ー ド バ ッ ク ルー
プのないパス図は再帰 と 呼ばれます。
70
例4
VB.NET で モデルを作成する
こ の例のモデルは、 単一の回帰式で構成 さ れてい ます。 パ ス 図の一方向矢印は、 それ
ぞれ係数を表 し ます。 こ れ ら の係数を推定す る ためのプ ロ グ ラ ム を次に示 し ます。
Sem.BeginGroup の後の 4 行は、 Amos Graphics のパ ス図の一方向矢印に対応 し ます。
最後の AStructure 行の (1) に よ り 、 誤差係数を定数 1 に固定 し ます。
71
従来の線型回帰
外生変数間の相関に関する仮定
プ ロ グ ラ ム の実行時に、 Amos が外生変数間の相関 を 仮定 し ま す。 こ れ ら の相関は
Amos Graphics では仮定 さ れません。 こ れ ら の仮定は、 多 く のモデル、 特にパ ラ メ ー タ
が あ る モデルの指定を単純化 し ま す。 Amos Graphics でのモデルの指定 と プ ロ グ ラ ム
に よ る モデルの指定の相違は次の と お り です。
Amos Graphics は完全に WYSIWYG (What You See Is What You Get) です。 2 個の
外生変数の間に双方向矢印を作成す る 場合 ( 制約な し )、Amos Graphics はそれ ら の
共分散を推定 し ます。 2 個の外生変数が双方向矢印で接続 さ れていない場合、Amos
Graphics はそれ ら の変数は無相関であ る と 仮定 し ます。
Amos プ ロ グ ラ ムのデフ ォ ル ト の仮定は次の と お り です。
固有の変数 ( 他の 1 個の変数にのみ影響す る 非観測外生変数 ) は相互に無相関であ
り 、 他のすべての外生変数 と も 無相関であ る と 仮定 さ れます。
固有の変数以外の外生変数は、 それ ら の変数間で相関があ る と 仮定 さ れます。
Amos プ ロ グ ラ ム では、 こ れ ら のデフ ォ ル ト の仮定が、 従来の線型回帰分析の標準の
仮定に反映 さ れ ます。 こ のため、 こ の例では、 予測変数知識、 価値、 お よ び満足度は
相関があ り 、 誤差は こ れ ら の予測変数 と 無相関であ る と 仮定 さ れます。
72
例4
AStructure メ ソ ッ ド の式形式
AStructure メ ソ ッ ド では、 式形式でモデルを指定で き ます。 た と えば、 次のプ ロ グ ラ
ムに含まれ る 1 つの Sem.AStructure ス テー ト メ ン ト に よ り 、 70 ページ のプ ロ グ ラ ム
と 同 じ モデル を 1 行で指定で き ま す。 こ のプ ロ グ ラ ム は、 Examples デ ィ レ ク ト リ に
Ex04-eq.vb と い う 名前で保存 さ れてい ます。
上の AStructure 行では、 各予測変数 ( 式の右側 ) が推定 さ れ る 係数 と 関連付け ら れて
い る こ と に注意 し て く だ さ い。 次の よ う に空のか っ こ を使用す る こ と に よ り 、 こ れ ら
の係数を明示で き ます。
Sem.AStructure(" 成果 = () 知識 + () 価値 + () 満足度 + 誤差 (1)")
空のか っ こ はオプシ ョ ン です。 デフ ォ ル ト では、 各予測変数の係数が自動的に推定 さ
れます。
例
5
非観測変数
概要
こ の例では、 非観測変数を使用 し た回帰分析について説明 し ます。
デー タ について
前の例の変数は、 信頼性にあ る 程度の問題が あ る こ と は否定で き ません。 成果の信頼
性が不明であ る ため、 予測変数が成果の分散に占め る 割合が 39.9% に過ぎ ない と い う
事実の解釈において若干の問題が発生 し ます。 検定の信頼性が非常に低い場合、 その
事実自体が成果の得点を正確に予測で き ない原因にな り ます。 一方で、 予測変数の信
頼性の低 さ に よ り 、 係数の推定値が偏 る 可能性があ る ので、 よ り 深刻な問題が発生 し
ます。
Rock 等 の調査 (1977) に基づ く こ の例では、 前の分析に含まれ る 4 つの検定の信頼
性を評価 し ます。 完全に信頼で き る 、 仮想の 4 つの検定用に係数の推定値 も 取得 し ま
す。 Rock 等は、 前の例で説明 し た Warren、 White、 お よ び Fuller のデー タ (1974) を再
調査 し ま し た。 こ こ では各検定を ラ ン ダ ムに 2 分割 し 、 それぞれの得点を個別に記録
し てい ます。
入力変数の一覧を次に示 し ます。
変数名
説明
1 成果
2 成果
1 知識
2 知識
1 価値
2 価値
1 満足度
2 満足度
past_training
成果役割の 12 項目のサブセ ッ ト
成果役割の 12 項目のサブセ ッ ト
13-知識の 13 項目のサブセ ッ ト
13-知識の 13 項目のサブセ ッ ト
15-価値方向の 15 項目のサブセ ッ ト
15-価値方向の 15 項目のサブセ ッ ト
5-満足度役割の 5 項目のサブセ ッ ト
6-満足度役割の 5 項目のサブセ ッ ト
学校教育の レベル
73
74
例5
こ の例では、 Lotus デー タ フ ァ イ ルの Warren9v.wk1 を使用 し て、 こ れ ら のサブセ ッ ト
の標本分散 と 標本散を取得 し ます。 フ ァ イ ルに表示 さ れ る 標本の平均値は、 こ の例で
は使用 し ま せん。 こ の フ ァ イ ルには学校教育 (past_training) に関す る 統計 も 存在 し ま
すが、 こ の分析には使用 さ れません。 デー タ セ ッ ト の一部を次に示 し ます。
モデル A
次のパス図は、 8 つのサブセ ッ ト 用のモデルを表 し ます。
図の 4 つの楕円には、 知識、 価値、 満足度、 お よ び成果の ラ ベルが付け ら れてい ます。
こ れ ら は、2 分割 さ れた 8 つの検定に よ っ て間接的に測定 さ れる非観測変数を表 し ます。
75
非観測変数
測定モデル
モデルの中で、観測変数が非観測 ( ま たは潜在的 ) 変数に ど の よ う に依存す る か を指定
す る 部分を測定モデル と 呼ぶ場合があ り ます。 こ のモデルには、4 つの異な る 測定サブ
モデルがあ り ます。
た と えば、 知識サブモデルの例を考え てみま し ょ う 。 2 分割 さ れたサブセ ッ ト 、 1 知識
と 2 知識の得点は、 元にな る 単一の変数で、 直接観測 さ れない知識に よ っ て決ま る と
仮定 さ れます。 こ のモデルに よ る と 、2 つのサブセ ッ ト の測定エ ラ ーを表す誤差 3 と 誤
差 4 の影響に よ り 、 2 つのサブセ ッ ト の得点は一致 し ない可能性があ り ます。 1 知識 と
2 知識は、 潜在的変数知識の指標 と 呼ばれます。 知識の測定モデルが示すパ タ ーンは、
上のパ ス図で後 3 回繰 り 返 さ れます。
構造モデル
モデルの中で、 潜在的変数が ど の よ う に相互に関連す る か を指定す る 部分を構造モデ
ル と 呼ぶ場合があ り ます。
こ のモデルの構造部分は、 例 4 の構造部分 と 同 じ です。 こ の例が例 4 と 異な る のは測
定モデルだけです。
76
例5
特定
こ のモデルの 13 の非観測変数では確実な特定はで き ません。 パ ラ メ ー タ に対す る 適切
な制約に よ っ て各非観測変数の測定単位を固定す る 必要があ り ます。 こ の処理は、例 4
で非観測変数に使用 し た方法を 13 回繰 り 返す こ と に よ っ て行われ ます。 こ の方法で
は、 パス図で各非観測変数を起点 と す る 一方向の矢印を探 し 、 対応す る 係数を 1 な ど
の任意の値に固定 し ます。 非観測変数を起点 と す る 一方向矢印が複数あ る 場合、 その
いずれかで こ の処理を実行 し ます。 74 ページの 「モデル A」 のパ ス図は、 特定可能性
制約の適切な選択肢の 1 つを示 し てい ます。
モデルを指定する
パ ス図は縦長ではな く 横長にな る ので、 パ ス図に合 う よ う に描画領域の形を変更す る
こ と がで き ます。 デフ ォ ル ト では、Amos の描画領域は印刷方向が縦の場合に合わせて
幅 よ り 高 さ が大 き く な っ てい ます。
描画領域の方向を変更する
E
メ ニ ュ ーか ら 、 [ 表示 ] [ イ ン タ ー フ ェ イ スのプ ロパテ ィ ] を選択 し ます。
E [ イ ン タ ーフ ェ イ ス のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ ページ レ イ アウ ト ] タ ブを
ク リ ッ ク し ます。
77
非観測変数
E [ 用紙サ イ ズ ] を [A4 横 ] な ど の 「横方向」 用紙サ イ ズに設定 し ます。
E [ 適用 ] を ク リ ッ ク し ます。
パス図を作成する
こ れで、ページ 74 のパ ス図に示すモデルを作成す る 準備がで き ま し た。 モデルを作成
す る にはい く つかの方法があ り ます。 1 つの方法は、最初に測定モデルを作成す る 方法
で ます。 こ こ では、 潜在的変数の 1 つであ る 知識の測定モデルを作成 し 、 他の 3 つの
原型 と し て使用 し ます。
E 非観測変数知識用の楕円を作成 し ます。
E
メ ニ ュ ーか ら 、 [ 図 ] [ 指標変数を描 く ] を選択 し ます。
78
例5
E 楕円の中を 2 回 ク リ ッ ク し ます。
ク リ ッ ク す る ご と に、 知識の指標変数が 1 つ作成 さ れます。
画面か ら わか る よ う に、 [ 指標変数を描 く ] ボタ ンが有効にな っ てい る 場合、非観測変数
を複数回 ク リ ッ ク し て複数の指標を作成 し 、 固有の変数ま たはエ ラ ー変数を完成で き
ます。 Amos Graphics は指標間の適切な間隔を保持 し 、識別制約を自動的に挿入 し ます。
指標を回転する
デフ ォ ル ト では指標は知識の楕円の上に表示 さ れ ますが、 位置を変更す る こ と がで き
ます。
E
メ ニ ュ ーか ら 、 [ 編集 ] [ 回転 ] を選択 し ます。
E 知識の楕円を ク リ ッ ク し ます。
知識の楕円を ク リ ッ ク す る ご と に、 指標が時計方向に 90° 回転 し ます。 楕円を 3 回 ク
リ ッ ク す る と 、 指標は下の図の よ う にな り ます。
測定モデルを複写する
次の手順は、 価値 と 満足度の測定モデルの作成手順です。
E
メ ニ ュ ーか ら 、 [ 編集 ] [ すべて選択 ] を選択 し ます。
測定モデルが青にな り ます。
79
非観測変数
E
メ ニ ュ ーか ら 、 [ 編集 ] [ 複写 ] を選択 し ます。
E 測定モデルの任意の部分を ク リ ッ ク し 、 コ ピーを元の測定モデルの下に ド ラ ッ グ し ます。
E
こ の手順を繰 り 返 し 、 元の測定モデルの上に 3 つ目の測定モデルを作成 し ます。
パ ス図は次の よ う に描かれてい る はずです。
E 成果用に 4 つ目の コ ピーを作成 し 、 元の測定モデルの右に配置 し ます。
E
メ ニ ュ ーか ら 、 [ 編集 ] [ 反転 ] を選択 し ます。
こ れに よ り 、 成果の 2 つの指標の配置が次の よ う に変更 さ れます。
80
例5
変数名を入力する
E 各オブジ ェ ク ト を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ューか ら [ オブ ジ ェ ク ト のプ ロパ
テ ィ ] を選択 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ テキス ト ] タ ブ を ク リ ッ ク し 、
[ 変数名 ] テ キ ス ト ボ ッ ク ス に名前を入力 し ます。
ま たは、 メ ニ ュ ーか ら [ 表示 ] [ デー タ セ ッ ト に含まれる変数 ] を選択 し 、 変数名をパ
ス図内のオブジ ェ ク ト に ド ラ ッ グす る こ と も で き ます。
構造モデルを完成する
構造モデルの完成に必要な手順は残 り わずかです。
E 知識、 価値、 お よ び満足度を結ぶ 3 つの共分散パス を作成 し ます。
E 潜在的予測変数であ る 知識、 価値、 お よ び満足度のそれぞれか ら 、 潜在的従属変数で
あ る 成果へ向か っ て一方向矢印を作成 し ます。
E 非観測変数で あ る 誤差 9 を 成果の予測変数 と し て追加 し ま す ( メ ニ ュ ーか ら [ 図 ]
[ 固有の変数を描 く ] を選択 し ます )。
74 ページ に示す よ う なパ ス図が作成 さ れます。 こ のパ ス図を含む Amos Graphics の入
力フ ァ イ ルは Ex05-a.amw にな り ます。
モデル A の結果
練習 と し て、 次の自由度の計算を確認 し て く だ さ い。
モデル A が正 し い と い う 仮説が承認 さ れます。
81
非観測変数
パ ラ メ ー タ の推定値は、 識別制約の影響を受け ます。
こ れに対 し 標準化推定値は、 識別制約の影響を受け ません。 標準化推定値を計算す る
には、 次の操作を行い ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブ を ク リ ッ ク し ます。
E [ 標準化推定値 ] チ ェ ッ ク ボ ッ ク ス を オンに し ます。
82
例5
グ ラ フ ィ ッ ク出力を表示する
標準化推定値が表示 さ れたパ ス図は次の よ う にな り ます。
83
非観測変数
成果の上の値は、 純粋な知識、 価値、 お よ び満足度が、 成果の分散の 66% を占め る こ
と を示 し ます。 観測変数の上に表示 さ れ る 値は、8 つの独立 し たサブセ ッ ト の信頼性の
推定値です。 元の検定 (2 分割す る 前 ) で信頼性を求め る 式は、Rock 等の調査 (1977) ま
たは心理検定の理論に関す る 書籍に記載 さ れてい ます。
モデル B
モデル A が正 し い ( 反証がない ) と い う 仮定の上で、 1 知識 と 2 知識が並行検定であ る
と い う 追加の仮定を検討 し ます。 並行検定の仮定では、 知識に対す る 1 知識の回帰が、
知識に対す る 2 知識の回帰 と 同 じ にな る 必要があ り ます。 さ ら に、 1 知識 と 2 知識に関
連付け ら れた誤差変数の分散が等 し く な る 必要があ り ます。 1 成果 と 2 成果だけでな
く 、 1 価値 と 2 価値 も 並列検定であ る と い う 仮定か ら も 同様の結論が導かれます。 た
だ し 、 1 満足度 と 2 満足度 が並行であ る と い う 仮定は完全に正 し い と は言え ません。
元の検定の項目数が奇数であ り 、 正確に 2 分割で き ないため、 サブセ ッ ト の一方が も
う 一方 よ り やや長 く な り ます。 つま り 、 2 満足度 が 1 満足度 よ り 20% 長 く な り ます。
こ れ ら の検定は長 さ のみ異な る と い う 仮定か ら 、 次の結論が導かれます。
満足度 に対す る 2 満足度 の回帰の係数は、満足度 に対す る 1 満足度 の回帰の係数
の 1.2 倍にな る 必要があ り ます。
誤差 7 と 誤差 8 の分散が等 し い と す る と 、 誤差 8 の係数は、 誤差 7 の係数の
1.2 = 1.095445 倍の大 き さ にな る 必要があ り ます。
こ れ ら のパ ラ メ ー タ 制約を適用す る ため、 パ ス図を最初か ら 作成 し 直す必要はあ り ま
せん。 モデル A 用に作成 し たパ ス図を土台 と し て使用 し 、 2 つの係数の値を変更 し ま
す。 変更後のパ ス図は次の よ う にな り ます。
84
例5
モデル B の結果
モデル B ではパ ラ メ ー タ 制約の追加に よ り 、 次の よ う に自由度が増加 し ます。
カ イ 2 乗統計量 も 増加 し ますが、大幅な増加ではあ り ません。 こ れは、モデル B のデー
タ か ら の逸脱が大 き く ない こ と を示 し ます。
85
非観測変数
実際にモデル B が正 し い場合、 関連付け ら れたパ ラ メ ー タ 推定値は、 モデル A か ら 取
得 さ れ る 値 よ り 優先 さ れ ます。 こ こ では、 識別制約の選択に よ る 影響が大 き 過ぎ る の
で、 生のパ ラ メ ー タ 推定値は提示 さ れ ません。 ただ し 、 標準化推定値 と 重相関係数の
平方は次の よ う にな り ます。
86
例5
パ ス図に表示 さ れ る 標準化推定値 と 重相関係数の平方は次の よ う にな り ます。
モデル A に対する モデル B の検定
場合に よ っ ては、 同 じ デー タ セ ッ ト 用のモデル と し て 2 つの選択肢があ り 、 ど ち ら の
モデルがデー タ に よ り 適合す る か を判断す る 必要があ り ます。 一方のパ ラ メ ー タ に追
加の制約を適用する こ と に よ っ て も う 一方のモデルを取得で き る場合は常に、直接比較
を実行で き ます。 こ の例はその よ う なケース です。 こ こ では、 モデル A のパ ラ メ ー タ に
8 つの追加制約を適用す る こ と に よ っ てモデル B を取得 し ま し た。 た と えば、 母集団パ
ラ メ ータ に関する強い仮説を表す と い う 意味において、2 つのモデルではモデル B が強
いモデルです ( モデル A が弱いモデルです )。強いモデルほど自由度が大き く な り ます。
強いモデルのカ イ 2 乗統計量は、 少な く と も 弱いモデルのカ イ 2 乗統計量 と 同 じ 大 き
さ にな り ます。
弱いモデル ( モデル A) に対す る 強いモデル ( モデル B) の検定は、 大 き いカ イ 2 乗
統計量か ら 小 さ いカ イ 2 乗統計量を引 く こ と に よ っ て得 ら れ ます。 こ の例では、 新 し
い統計量は 16.632 (= 26.967 – 10.335 ) にな り ます。 強いモデル ( モデル B) が正 し く
指定 さ れてい る 場合、 こ の統計量はカ イ 2 乗 と 近似の分布を示 し 、 自由度は も う 一方
のモデルの自由度 と の差に等 し く な り ます。 こ の例では、 自由度の差は 8 (= 22 – 14 )
にな り ます。 モデル B では、 モデル A のすべてのパ ラ メ ー タ 制約に加え て、 8 つの制
約を適用 し ます。
87
非観測変数
要す る に、 モデル B が正 し い場合、 自由度 8 のカ イ 2 乗分布か ら 、 16.632 と い う 値
が得 ら れます。 弱いモデル ( モデル A) だけが正 し く 、 強いモデル ( モデル B) は正 し く
ない場合、 新 し い統計量が大 き く な る 傾向があ り ます。 こ のため、 新 し いカ イ 2 乗統
計量が極端に大 き く な る 場合は、 強いモデル ( モデル B) を棄却 し て弱いモデル ( モデ
ル A) を選ぶ必要があ り ます。 自由度 が 8 の場合、 15.507 以上のカ イ 2 乗値は 0.05 レ
ベルで有意 と な り ます。 こ の検定に基づいて、 こ こ ではモデル B を棄却 し ます。
カ イ 2 乗値 26.967、 自由度 22 に基づ く 、 モデル B が正 し い と い う 前の結論はど う
な っ たので し ょ う か。 2 つの結論の不一致は、 2 つの検定は仮定が異な る と い う 理由に
よ っ て説明で き ます。 自由度 8 に基づ く 検定では、 モデル B の検定時にモデル A が正
し い と 仮定 し ます。 自由度 22 に基づ く 検定では、モデル A に関す る その よ う な仮定は
行い ません。 モデル A が正 し い と 確信 し てい る 場合は、モデル A に対 し てモデル B を
比較す る 検定 ( 自由度 8 に基づ く 検定 ) を使用す る 必要があ り ます。 そ う でない場合
は、 自由度 22 に基づ く 検定を使用す る 必要があ り ます。
88
例5
VB.NET でのモデル作成
モデル A
モデル A に適合す る プ ロ グ ラ ム を次に示 し ます。
外生変数間の相関に関す る Amos の仮定に よ り ( 例 4 参照 )、 知識、 価値、 お よ び満足
度の相関が可能であ る こ と を プ ロ グ ラ ムで示す必要はあ り ません。 ま た、 誤差 1、 誤差
2.... , 誤差 9 は相互に無相関であ り 、 他のすべての外生変数 と も 無相関であ る こ と を示
す必要 も あ り ません。
89
非観測変数
モデル B
モデル B に適合す る プ ロ グ ラ ム を次に示 し ます。
例
6
探索分析
概要
こ の例では、 時間に関す る 潜在的変数を使用 し た構造モデルの作成、 探索分析での修
正指数 と 検定統計量の使用、 単一分析での複数モデルの比較方法、 お よ びモデルの積
率、 因子得点係数、 総合効果、 間接効果の計算方法について説明 し ます。
デー タ について
Wheaton 等は、1966 年か ら 1971 年にわた っ て 932 人のデー タ を長期的に追跡 し た調査
結果を報告 し ま し た (1977)。 Jöreskog お よ び Sörbom 等は以後 Wheaton のデー タ を使用
し て、 積率構造の分析を行っ てい ます (1984)。 こ の例では、 次に示す Wheaton の 6 つの
測定値を使用 し ます。
変数名
説明
anomia67 ( 失語傾向 (67 年 ))
anomia71 ( 失語傾向 (71 年 ))
powles67( 無気力感 (67 年 ))
powles71( 無気力感 (71 年 ))
education ( 教育年数 )
SEI ( 社会経済指標 )
anomia ( 失語傾向 ) 尺度の 1967 年の得点
1971 年の anomia ( 失語傾向 ) の得点
powles ( 無気力感 ) 尺度の 1967 年の得点
1971 年の powles ( 無気力感 ) の得点
1966 年に記録 さ れた就学年数
1966 年に使用 さ れた Duncan の社会経済指標
91
92
例6
こ れ ら 6 つの測定値の標本の平均値、 標準偏差、 お よ び相関を見てみま し ょ う 。 SPSS
Statistics フ ァ イ ル Wheaton.sav に次の表があ り ます。 デー タ の読み込み後、分析の必要
に応 じ て Amos が標準偏差 と 相関を分散 と 共分散に変換 し ます。 こ の分析では標本の
平均値は使用 し ません。
Wheaton デー タ 用のモデル A
Jöreskog と Sörbom は、 93 ページ に示す Wheaton デー タ 用のモデルを提示 し (1984)、
モデル A と 呼んでい ます。 こ のモデルでは、 すべての観測変数が、 元にな る 非観測変数
に依存す る と 断定 し ます。 た と えば、 anomia67 ( 失語傾向 (67 年 )) と powles67 ( 無気力
感 (67 年 )) の両方が非観測変数 67_alienation ( 疎外感 (67 年 )) に依存 し ます。 こ の変数
は、 Jöreskog と Sörbom が疎外感 と 呼ぶ仮想変数です。 非観測変数 eps1 と eps2 は、 例
5 におけ る 変数誤差 1 と 誤差 2 と 同 じ 役割を果たす よ う に見え ます。 ただ し 、 こ こ では
解釈が異な り ます。 例 5 では、 誤差 1 と 誤差 2 は測定誤差 と し て自然に解釈 さ れます。
こ の例では、 anomia ( 失語傾向 ) 尺度 と powles ( 無気力感 ) 尺度が同 じ 対象を測定す る
よ う に設計 さ れていないため、 それ ら の相違は測定誤差に よ る も のだけでない と 判断
す る 方が妥当 と 思われます。 こ のため、 こ の場合の eps1 と eps2 は、 anomia67 ( 失語傾
向 (67 年 )) と powles67 ( 無気力感 (67 年 )) の測定誤差を表すだけでな く 、 67_alienation
( 疎外感 (67 年 )) ( 両方に影響す る 変数の 1 つ ) の他に 2 つの検定の得点に影響す る 可能
性があ る すべての変数を表す と 考え る 必要があ り ます。
93
探索分析
モデルの特定化
Amos Graphics でモデル A を指定す る には、 次に示すパ ス図を作成す る か、 標本 フ ァ
イ ル Ex06–a.amw を開 き ます。 8 つの固有の変数 (delta1、 delta2、 zeta1、 zeta2、 お よ び
eps1 ~ eps4) は相互に無相関であ り 、 3 つの潜在的変数 ses、 67_alienation ( 疎外感 (67
年 ))、お よ び 71_alienation ( 疎外感 (71 年 )) と も 無相関であ る こ と に注意 し て く だ さ い。
特定
モデル A は、 各非観測変数の測定尺度が不定であ る と い う 一般的な問題を除いて特定
さ れ ます。 各非観測変数の測定尺度は、 その変数を基点 と す る パ ス のいずれかで係数
を単一の値 (1) に設定す る こ と に よ っ て自由に固定で き ます。 パ ス 図には、 単一の値
(1) に固定 さ れた 11 の係数、 つま り 、 非観測変数ご と に 1 つの制約が示 さ れてい ます。
こ れ ら の制約に よ っ て十分にモデルを特定で き ます。
94
例6
分析の結果
こ のモデルには、 推定 さ れ る 15 個のパ ラ メ ー タ (6 個の係数 と 9 個の分散 ) があ り ま
す。 ま た、21 個の標本の積率 (6 個の標本分散 と 15 個の標本共分散 ) があ り ます。 こ れ
に よ り 自由度が 6 の ま ま にな り ます。
Wheaton のデー タ はモデル A のデー タ か ら 大 き く 離れてい ます。
棄却の処理
提示 さ れたモデルを統計的な見地か ら 棄却す る 必要があ る 場合、 い く つかの方法があ
り ます。
統計仮説の検定は、 モデルの選択には不適切であ る と 言え ます。 Jöreskog は、 因子
分析において こ の問題を取 り 上げ ま し た (1967)。 モデルは、 よ く て も 近似に過ぎ
ず、 幸いに し て正確に一致 し な く て も 有効で あ る と い う 考え方が広 く 受け入れ ら
れてい ま す。 こ の考え方に よ る と 、 非常に多 く の標本を使用 し て検定を行っ た場
合、統計的な見地か ら モデルの棄却が発生す る こ と は避け ら れません。 こ の点か ら
考え る と 、 純粋に統計的な見地に よ る モデルの棄却は ( 特に標本が大 き い場合 ) 必
ず し も 問題ではあ り ません。
棄却 さ れたモデルに代わ る別のモデルを最初か ら 考案する こ と がで き ます。
棄却 さ れたモデルがデー タ に よ り 適合す る よ う に小規模な修正を加え る こ と がで
き ます。
こ の例では最後の方法について説明 し ま す。 データ に適合す る よ う にモデル を修正す
る最 も 自然な方法は、 い く つかの仮定を緩め る方法です。 た と えば、 モデル A では eps1
と eps3 が無相関であ る と 仮定 し てい ます。 eps1 と eps3 を双方向矢印で結ぶ こ と に よ
り 、 こ の制限を緩め る こ と がで き ます。 こ のモデルでは、 anomia67 ( 失語傾向 (67 年 )) は
ses に直接依存し ない こ と も 指定 さ れています。 ses か ら anomia67 ( 失語傾向 (67 年 )) に
一方向矢印を描 く こ と に よ り 、 こ の仮定を削除で き ます。 モデル A では、 制約に よ っ て
パ ラ メ ー タ を他のパ ラ メ ー タ と 等 し く す る こ と はあ り ませんが、 その よ う な制約が存
在す る 場合、 適合度を高め る ため こ の よ う な制約の削除を検討す る 場合 も あ り ま す。
当然の こ と なが ら 、 モデルの仮定を緩め る際には、 特定 さ れる モデルが特定 さ れないモ
デルにな ら ない よ う に注意する必要があ り ます。
95
探索分析
修正指数
修正の可能性ご と に個別の分析を実行す る こ と に よ り 、 モデルに対す る さ ま ざ ま な修
正を検定で き ますが、 こ の方法は時間がかか り ます。 修正指数を使用す る と 、 多 く の
修正の可能性を単一の分析で評価で き ます。 こ れに よ り 、 小 さ いカ イ 2 乗値で効果が
上が る よ う なモデル修正案が提示 さ れます。
修正指数を使用する
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブ を ク リ ッ ク し ます。
E [ 修正指数 ] チ ェ ッ ク ボ ッ ク ス を オ ンに し ます。 こ の例では、[ 修正指数の閾値 ] が [4] に
設定 さ れた ま ま に し ます。
モデル A の修正指数を次に示 し ます。
96
例6
表の列見出 し の M.I. は、 修正指数 (Modification Index) の略です。 こ の修正指数は、
Jöreskog お よ び Sörbom に よ っ て示 さ れた指数です (1984)。 最初に示 さ れてい る 修正指
数 (5.905) は、 eps2 と delta1 の相関が可能な場合に発生す る カ イ 2 乗の減少を控えめ
に推定 し た 値です。 新 し い カ イ 2 乗統計量は自由度が 5 = 6 – 1 に な り 、 65.639
( 71.544 – 5.905 ) よ り 大 き く な る こ と はあ り ません。 実際にはカ イ 2 乗統計量の減少
が 5.905 よ り 大 き く な る 可能性があ り ます。 Par Change の列は、 各パ ラ メ ー タ が 0 に
固定 さ れずに推定 さ れた場合の変化の概算値を示 し ます。 Amos は、 eps2 と delta1 の
間の共分散を – 0.424 と 推定 し ます。 小 さ い修正指数に基づ き 、 eps2 と delta1 の相関
を可能にす る こ と に よ っ て得 ら れ る も のは多 く ない と 考え ら れ ます。 ま た、 許容可能
な適合度が得 ら れた と し て も 、 理論的に見て こ の修正が正 し い と は言え ません。
修正指数の閾値を変更する
デフ ォ ル ト では 4 以上の修正指数のみ表示 さ れますが、 こ の閾値は変更で き ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
E [ 修正指数の閾値 ] テ キ ス ト ボ ッ ク ス に値を入力 し ます。 非常に低い閾値を設定す る と 、
小 さ 過ぎ て意味のない修正指数が多数表示 さ れます。
モデル A の最大修正指数は 40.911 です。 こ れは、 eps1 と eps3 の相関を可能にする と 、
カ イ 2 乗統計量が少な く と も 40.911 減少する こ と を示 し ます。 こ れ ら 2 つの変数が相
関す る 必要が あ る こ と は妥当 と 思われ る ので、 こ の修正は考慮に値 し ます。 Eps1 は、
67_alienation ( 疎外感 (67 年 )) の変化に起因 し ない anomia67 ( 失語傾向 (67 年 )) の変動
を表 し ます。同様に eps3 は、71_alienation ( 疎外感 (71 年 )) の変化に起因 し ない anomia71
( 失語傾向 (71 年 )) の変動を表 し ます。 anomia67 ( 失語傾向 (67 年 )) と anomia71 ( 失語傾
向 (71 年 )) は、同 じ 計測に よ る ( 異な る時間の ) 尺度の得点です。 anomia ( 失語傾向 ) 尺
度に よ っ て alienation 以外の測定を行 う 場合、 eps1 と eps3 の間にゼ ロ以外の相関が期
待 さ れます。 実際には正の相関が期待 さ れますが、 こ れは Par Change 列の数値が正で
あ る と い う 事実 と 合致 し ます。
eps1 と eps3 が相関す る と 予測す る 理論的な根拠は、eps2 と eps4 に も 適用 さ れます。
修正指数は、 eps2 と eps4 の相関の可能性 も 提示 し ます。 ただ し 、 こ こ では こ の修正の
可能性を無視 し 、 eps1 と eps3 の相関を可能にす る こ と に よ っ てモデル A の結果の確
認に進みます。 新 し いモデルは Jöreskog と Sörbom のモデル B にな り ます。
97
探索分析
Wheaton デー タ 用のモデル B
モデル A のパス図を基に、 eps1 と eps3 の間に双方向矢印を描 く こ と に よ り 、 モデル
B を取得で き ます。 新 し い双方向矢印が印刷領域を超え て伸び る 場合、 [ 形 ] ボ タ ン を
使用 し て双方向矢印のカーブを調整で き ます。 [ 移動 ] ボ タ ン を使用 し て双方向矢印の
終点の位置を変更す る こ と も で き ます。
モデル B のパ ス図は Ex06-b.amw フ ァ イ ルにあ り ます。
テキス ト 出力
eps1 と eps3 の間に追加 さ れた共分散に よ り 、 自由度が 1 減少 し ます。
98
例6
カ イ 2 乗統計量は、 既定の 40.911 よ り 大幅に低下 し ます。
モデル B は棄却で き ません。 モデル B の適合度に問題がないので、 eps2 と eps4 の相
関を可能にす る と い う 、 上で説明 し た可能性は追求 し ません ( モデル B に欠けてい る
対称性を実現す る ため、eps2 と eps4 の間のゼ ロ 以外の相関を可能にす る 引数を作成で
き ます )。
異な る 識別制約が適用 さ れてい る 場合、 生のパ ラ メ ー タ 推定値が異な る ので、 こ れ
ら の推定値の解釈には注意が必要です。
新 し い共分散パ ス に関連付け ら れ た検定統計量が大 き い こ と に注意 し て く だ さ い。
eps1 と eps3 の間の共分散は明 ら かにゼ ロ ではあ り ません。 こ の こ と は、 共分散が 0 に
固定 さ れたモデル A の適合度が不十分であ る こ と を示 し ます。
99
探索分析
モデル B のグ ラ フ ィ ッ ク出力
次のパ ス図に、 標準化推定値 と 重相関係数の平方を示 し ます。
モデル内の誤差変数が表すのは測定誤差だけではないため、 重相関係数の平方を信頼
性の推定値 と し て解釈す る こ と はで き ません。 む し ろ、 各重相関係数の平方は、 対応
す る 信頼性の下限の推定値にな り ます。 た と えば、 education ( 教育年数 ) の例を考え て
みま し ょ う 。 ses が分散の 72% を占めてい ます。 こ れに よ り 、信頼性が少な く と も 0.72
であ る と 推定 さ れ ます。 教育年数が就学年数で測定 さ れ る こ と を考え る と 、 その信頼
性はは る かに大 き い と 思われます。
100
例6
修正指数の誤用
モデルを改良す る 際に、 修正指数に全面的に従 う 必要はあ り ません。 理論的 ま たは常
識的に意味があ る 場合のみ修正を考え る 必要があ り ます。
その よ う な制限な し で修正指数を盲信す る と 、 適合度の大幅な向上を求めて非常に
多 く の修正の可能性を調べ る こ と にな り ます。 こ の よ う な方法は、 偶然の利用に よ り 、
許容可能な カ イ 2 乗値を含む不適切な ( 不合理な ) モデルを生成す る 傾向があ り ます。
こ の問題は、 MacCallum (1986) と 、 MacCallum、 Roznowski、 お よ び Necowitz (1992)
に よ っ て取 り 上げ ら れてい ます。
新 し い制約の追加によ っ てモデルを改良する
修正指数は、 カ イ 2 乗統計量が自由度 よ り 速 く 減少す る よ う に、 パ ラ メ ー タ 数を増加
す る こ と に よ っ てモデルを改良す る 方法を提示 し ます。 こ の技法は誤用の可能性 も あ
り ますが、 多 く の調査で適切な役割を果た し てい ます。 その他の技法を使用 し て、 許
容可能な カ イ 2 乗値を よ り 多 く 含むモデルを生成す る こ と も で き ます。 こ の技法では、
カ イ 2 乗統計量の増加が比較的少な く な る と 共に、 自由度の増加が比較的大 き く な る
よ う に追加の制約を導入 し ます。 こ の よ う な修正の多 く は、 C.R. 列の検定統計量を確
認す る こ と に よ っ て大ま かに評価で き ます。 単一の検定統計量を使用 し て、 単一の母
集団パ ラ メ ー タ が 0 に等 し く な る と い う 仮説の検定を行 う 方法については既に説明 し
ま し た ( 例 1 参照 )。 ただ し 、 検定統計量には別の解釈 も あ り ます。 パ ラ メ ー タ の検定
統計量の 2 乗は、 そのパ ラ メ ー タ を 0 に固定 し て分析を繰 り 返す場合にカ イ 2 乗統計
量が増加す る 量 と ほぼ等 し く な り ます。
検定統計量を計算する
2 つのパ ラ メ ー タ 推定値がほぼ等 し い こ と が判明 し た場合、 それ ら 2 つのパ ラ メ ー タ
が正確に等 し く な る よ う に指定 さ れた新 し いモデルを仮定す る こ と に よ り 、 適合度の
カ イ 2 乗検定を改良で き ます。 大 き な差がないパ ラ メ ー タ のペアの配置を支援す る た
め、 Amos ではパ ラ メ ー タ のペア ご と に検定統計量を提供 し ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
E [ 差に対する検定統計量 ] チ ェ ッ ク ボ ッ ク ス を ク リ ッ ク し ます。
Amos ではパ ラ メ ー タ の差に対す る 検定統計量を計算す る 際に、 モデルの指定時に名
前を付けなか っ たパ ラ メ ー タ 用に名前を生成 し ます。 名前はテ キ ス ト 出力のパ ラ メ ー
タ 推定値の横に表示 さ れます。
101
探索分析
モデル B のパ ラ メ ー タ 推定値を次に示 し ます。 Amos に よ っ て生成 さ れたパ ラ メ ー タ
名は Label 列に示 さ れます。
102
例6
パ ラ メ ー タ 名は、 次の表で検定統計量を解釈する ために必要です。
Critical Ratios for Differences between Parameters (Default model)
par_1
par_2
par_3
par_4
par_5
par_6
par_1
.000
par_2
.877
.000
par_3
9.883
9.741
.000
par_4
-4.429
-5.931
-10.579
.000
par_5
-17.943
-16.634
-12.284
-18.098
.000
par_6
-22.343
-26.471
-12.661
-17.300
-5.115
.000
par_7
3.903
3.689
-6.762
5.056
8.490
10.124
par_8
8.955
8.866
1.707
9.576
10.995
11.797
par_9
8.364
7.872
-.714
9.256
11.311
12.047
par_10
7.781
8.040
-2.362
9.470
11.683
12.629
par_11 11.106
11.705
-.186
11.969
14.039
15.431
par_12
3.826
3.336
-5.599
4.998
7.698
8.253
par_13 10.425
9.659
-.621
10.306
12.713
13.575
par_14
4.697
4.906
-4.642
6.353
8.554
9.602
par_15
3.393
3.283
-7.280
4.019
5.508
5.975
par_16 14.615
14.612
14.192
14.637
14.687
14.712
Critical Ratios for Differences between Parameters (Default model)
par_7
par_8
par_9
par_10
par_11
par_12
par_7
.000
par_8
7.128
.000
par_9
5.388
-2.996
.000
par_10
4.668
-4.112
-1.624
.000
par_11
9.773
-2.402
.548
2.308
.000
par_12
.740
-6.387
-5.254
-3.507
-4.728
.000
par_13
8.318
-2.695 . 169
1.554
-.507
5.042
par_14
1.798
-5.701
-3.909
-2.790
-4.735
.999
par_15
1.482
-3.787
-2.667
-1.799
-3.672
.855
par_16 14.563
14.506
14.439
14.458
14.387
14.544
Critical Ratios for Differences between Parameters (Default model)
par_13
par_14
par_15
par_16
par_13
.000
par_14
-3.322
.000
par_15
-3.199
.077
.000
par_16 14.400
14.518
14.293
.000
主対角線の下にあ る 0 を無視す る と 、検定統計量の表にはパラ メ ータ のペア ご と に 1 つ
ずつ、合計 120 のエン ト リ があ り ます。 表の左上付近にあ る 0.877 と い う 数値に着目 し
て く だ さ い。 こ の検定統計量は、 par_1 と par_2 と い う 名前のパラ メ ータ の差を、 こ の
差の推定標準誤差で割っ た値です。 こ れ ら 2 つのパラ メ ータ は、powles71 ( 無気力感 (71
年 )) <– 71_alienation ( 疎外感 (71 年 )) お よ び powles67 ( 無気力感 (67 年 )) <– 67_alienation
( 疎外感 (67 年 )) の係数です。
32 ページ に示す分布の仮定に基づ き 、標準正規分布の表を使用 し て検定統計量を評
価 し 、 2 つのパ ラ メ ー タ が母集団において等 し いか ど う か を 検定で き ま す。 0.877 は
1.96 よ り 小 さ いので、 2 つの係数が母集団において等 し い と い う 仮説を 0.05 レベルで
は否定 し ません。
103
探索分析
パ ラ メ ー タ 間の差に対す る 検定統計量の 2 乗は、 2 つのパ ラ メ ー タ が等 し く な る よ
う に設定 さ れた場合に カ イ 2 乗統計量が増加す る 量 と ほぼ同 じ です。 0.877 の 2 乗は
0.769 なので、 2 つの係数の推定値が等 し く な る よ う にモデル B を修正す る と 、 カ イ 2
乗値はお よ そ 6.383 + 0.769 = 7.172 にな り ま す。 新 し いモデルの自由度は 5 では
な く 6 に な り ま す。 適 合 度 は 向 上 し ま す が ( モ デ ル B の p = 0.307 に 対 し
p = 0.275 )、 それ以上の こ と はで き ません。
最小検定統計量を見てみま し ょ う 。 表の最小検定統計量は、 par_14 と par_15 と い う
名前のパ ラ メ ー タ の 0.077 です。 こ れ ら の 2 つのパ ラ メ ー タ は、 eps4 と delta1 の分散
です。 0.077 の 2 乗は約 0.006 です。 eps4 と delta1 の分散が等 し く な る と 仮定す る モデ
ル B の修正に よ り 、 カ イ 2 乗値が 6.383 を約 0.006 超え ますが、 自由度は 5 ではな く
6 です。 関連す る 確率レベルは約 0.381 にな り ます。 こ の修正の唯一の問題は、 修正に
正当な理由がない と 思われ る こ と です。 つま り 、 eps4 と delta1 の分散が等 し く な る と
予測す る 先験見的な理由がない と 思われます。
差に対する検定統計量の表の誤用については先程説明 し ま し た。 ただ し 、こ の表は少
数の仮定の迅速な調査には有効です。 こ の表の適切な使用例 と し て、 anomia67 ( 失語傾
向 (67 年 )) と anomia71 ( 失語傾向 (71 年 )) の観測値が、 2 つの状況で同 じ 計測方法を使
用 し て取得 さ れた と い う 事実を考え てみて く だ さ い。 同 じ こ と は powles67 ( 無気力感
(67 年 )) と powles71 ( 無気力感 (71 年 )) に も 当てはま り ます。 2 つの状況で検定が同様の
役割を果たす こ と は妥当であ る と 思われます。 差に対す る検定統計量は、 こ の仮定 と 一
致 し ます。 eps1 と eps3 (par_11 と par_13) の分散は、 検定統計量 –0.51 と 異な り ます。
eps2 と eps4 (par_12 と par_14) の分散は、 検定統計量 1.00 と 異な り ます。 alienation で
の powles ( 無気力感 ) の係数 (par_1 and par_2) は、 検定統計量 0.88 と 異な り ます。 個々
に見た場合、 こ れ ら の差のいずれ も 従来の有意確率で有意では あ り ま せん。 こ れは、
3 つの差がすべて 0 にな る よ う に制約 さ れ る モデルを よ り 注意 し て調査す る 価値があ
る こ と を示 し ます。 こ の新 し いモデルをモデル C と 呼びます。
104
例6
Wheaton デー タ 用のモデル C
Ex06–c.amw フ ァ イ ルにあ る モデル C のパ ス図を次に示 し ます。
path_p では、alienation ( 疎外感 ) か ら powles ( 無気力感 ) を予測す る ための係数が、1967
年 と 1971 年で同 じ にな る 必要があ り ます。 var_a を使用 し て、 eps1 と eps3 の分散が等
し く な る よ う に指定 し ます。 var_p を使用 し て、 eps2 と eps4 の分散が等 し く な る よ う
に指定 し ます。
モデル C の結果
モデル C はモデル B よ り 自由度が 3 上が り ます。
105
探索分析
Model C の検定
予想どお り モデル C は許容可能な適合度を示 し 、 確率レベルがモデル B よ り 高 く な り
ます。
モデル B に対す る モデル C の検定は、カ イ 2 乗値の差 (7.501 – 6.383 = 1.118 ) と 自
由度の差 ( 8 – 5 = 3 ) を調べ る こ と に よ っ て実行で き ます。 カ イ 2 乗値 1.118、 自由度
3 は有意ではあ り ません。
モデル C のパラ メ ー タ 推定値
モデル C の標準化推定値を次に示 し ます。
106
例6
単一分析での複数モデルの使用
Amos では単一の分析に複数のモデルを適合で き ます。 こ れに よ り 、すべてのモデルの
結果を 1 つの表に ま と め る こ と がで き ま す。 Amos では入れ子に し たモデルの比較で
カ イ 2 乗検定を実行す る こ と も 可能です。 こ の例では、 モデル B のパ ラ メ ー タ 制約に
よ っ てモデル A と C を それぞれ取得で き る よ う に指定す る こ と に よ り 、 モデル A、 B、
お よ び C を単一の分析に適合で き ます。
Ex06-all.amw フ ァ イ ルに含まれ る 次のパ ス図では、モデル A ま たはモデル C を生成
す る ために制約す る 必要があ る モデル B のパ ラ メ ー タ に次の名前が割 り 当て ら れてい
ます。
こ のパス図の 7 つのパ ラ メ ー タ には、 var_a67、 var_p67、 var_a71、 var_p71、 b_pow67、
b_pow71、 お よ び cov1 と い う 名前が付け ら れてい ます。 2 つのパ ラ メ ー タ に同 じ 名前
が付け ら れ る こ と はないので、 パ ラ メ ー タ に名前を付け る こ と に よ っ てパ ラ メ ー タ が
等 し く な る よ う に制約 さ れ る こ と はあ り ません。 ただ し 、 こ れか ら 説明す る よ う に、変
数に名前を付け る こ と に よ っ て さ ま ざ ま な方法でパ ラ メ ー タ を制約で き ます。
上に示すパ ラ メ ー タ 名を使用 し て、 cov1 = 0 を要求す る こ と に よ り 、 最 も 一般的なモ
デル ( モデル B) か ら モデル A を取得で き ます。
107
探索分析
E パ ス図の左側にあ る [ モデル ] パネルで、[ デ フ ォル ト モデル ] を ダブル ク リ ッ ク し ます。
[ モデル管理 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E [ モデル名 ] テ キ ス ト ボ ッ ク ス に、 「Model A: No Autocorrelation」 と 入力 し ます。
E 左側のパネルで cov1 を ダブル ク リ ッ ク し ます。
[ パ ラ メ ー タ 制約 ] ボ ッ ク ス に cov1 が表示 さ れ る こ と を確認 し ます。
E [ パ ラ メ ー タ 制約 ] ボ ッ ク ス に 「cov1 =0」 と 入力 し ます。
こ れでモデル A の指定が完了 し ま し た。
E [ モデル管理 ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 新規作成 ] を ク リ ッ ク し ます。
108
例6
E [ モデル名 ] テ キ ス ト ボ ッ ク ス に、 「Model B: Most General」 と 入力 し ます。
モデル B にはパ ス図に示す以外の制約がないので、直ちにモデル C に進む こ と がで き
ます。
E [ 新規作成 ] を ク リ ッ ク し ます。
E [ モデル名 ] テ キ ス ト ボ ッ ク ス に、 「Model C: Time-Invariance」 と 入力 し ます。
E [ パ ラ メ ー タ 制約 ] ボ ッ ク ス に、 次の よ う に入力 し ます。
b_pow67 = b_pow71
var_a67 = var_a71
var_p67 = var_p71
完成度を高め る ため、 4 つ目のモデル ( モデル D) を導入 し 、 モデル A の 1 つの制約 と
モデル C の 3 3 つの制約を結合 し ます。 モデル D は制約を入力 し 直 さ な く て も 指定で
き ます。
E [ 新規作成 ] を ク リ ッ ク し ます。
E [ モデル名 ] テ キ ス ト ボ ッ ク ス に、 「Model D: A and C Combined」 と 入力 し ます。
E [ パ ラ メ ー タ 制約 ] ボ ッ ク ス に、 次の よ う に入力 し ます。
Model A: No Autocorrelation
Model C: Time-Invariance
こ れ ら の行に よ り 、 Model A と Model C の両方の制約を モデル D に組み込む こ と を指
定 し ます。
こ れで 4 つのモデルすべてのパ ラ メ ー タ 制約が設定 さ れま し た。 最後の手順は、 分
析の実行 と 出力の表示です。
109
探索分析
複数モデルによ る出力
個々のモデルのグ ラ フ ィ ッ ク出力を表示する
複数のモデルを適合 し てい る 場合、 [ モデル ] パネルを使用 し て個々のモデルの図を表
示 し ます。 [ モデル ] パネルはパ ス図の左隣にあ り ます。 モデルを表示す る には、モデル
の名前を ク リ ッ ク し ます。
4 つのモデルすべての適合度の統計を表示する
E
メ ニ ュ ーか ら 、 [ 表示 ][ テキス ト 出力の表示 ] の順に ク リ ッ ク し ます。
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ枠にあ る ツ リ ー図で、[ モデルの適合度 ] を
ク リ ッ ク し ます。
カ イ 2 乗統計量を表示す る 出力の一部を次に示 し ます。
CMIN 列には、各モデルの最小乖離度が示 さ れます。 最尤法の推定値の場合 ( デフ ォ ル
ト )、 CMIN 列はカ イ 2 乗統計量にな り ます。 p 列には、 各モデルの検定用の対応す る
上側確率が示 さ れます。
モデルのペアが入れ子にな っ てい る 場合、 カ イ 2 乗比較検定 と 関連付け ら れた p 値
を含む、 モデル比較表が提供 さ れます。
110
例6
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ 枠にあ る ツ リ ー図で、 [ モデル比較 ] を ク
リ ッ ク し ます。
た と えば、 こ の表か ら モデル C の適合度はモデル B よ り 大 き く 低下 し ない こ と がわか
り ます ( p = 0.773 )。 つま り 、 モデル B が正 し い と 仮定す る と 、 時間不変性の仮説を
受け入れ る こ と にな り ます。
一方 で、 モ デル A の 適合度 は モ デル B よ り 大 き く 低下す る こ と が わ か り ま す
( p = 0.000 )。 つま り 、 Model B が正 し い と 仮定す る と 、 eps1 と eps3 が無相関であ る
と い う 仮説を否定す る こ と にな り ます。
オプ シ ョ ン出力を取得する
観測変数間の分散 と 共分散は、 モデル C が正 し い と い う 仮説の下で推定で き ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
E [ モデルの積率 ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
E モデル内の誤差変数を除 く すべての変数に対す る モデルの分散 と 共分散を取得す る に
は、 [ 全変数に対する モデルの積率 ] を選択 し ます。
111
探索分析
モデル C で [ 全変数に対する モデルの積率 ] を選択す る と 、 次の出力が得 ら れます。
観測変数に対す る モデルの分散 と 共分散は、 標本分散 と 標本共分散 と 同 じ ではあ り ま
せん。 対応す る 母集団の推定値 と し て、 モデルの分散 と 共分散は標本分散 と 標本共分
散 よ り 優れてい ます (Model C が正 し い と 仮定 し た場合 )。
[ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で [ 標準化推定値 ] と [ 全変数に関する モデ
ルの積率 ] チ ェ ッ ク ボ ッ ク ス の両方を オ ンに し てい る 場合、 モデルの共分散行列だけ
でな く 、 すべての変数のモデルの相関行列 も 提供 さ れます。
モデル内のすべての変数に対す る モデルの共分散行列を使用 し て、 観測変数に対す る
非観測変数の回帰を実行で き ます。 結果の係数推定値は、[ 因子得点ウ ェ イ ト ] チ ェ ッ ク
ボ ッ ク ス を オンにす る こ と に よ っ て取得で き ます。 モデル C の推定因子得点 ウ ェ イ ト
を次に示 し ます。
因子得点 ウ ェ イ ト の表では、 非観測変数ご と に個別の行 と 、 観測変数ご と に個別の列
が あ り ま す。 個々の ses 得点 を 推定す る 場合 を 考え てみ ま し ょ う 。 表の ses 行に あ る
6 つの ウ ェ イ ト を使用 し て、 6 つの個々の観測得点の重み付 き 合計を計算 し ます。
112
例6
間接効果、 直接効果、 総合効果を取得する
パ ス図の一方向矢印に関連付け ら れた係数を直接効果 と 呼ぶ場合があ り ます。 た と え
ばモデル C では、ses は 71_alienation ( 疎外感 (71 年 )) に対 し て直接効果が あ り ま す。
同様に、 71_alienation ( 疎外感 (71 年 )) は powles71 ( 無気力感 (71 年 )) に対 し て直接効
果があ り ます。 こ の場合、 ses は ( 疎外感 (71 年 ) を介 し て ) powles71 ( 無気力感 (71 年 ))
に対 し て間接効果があ る と 言い ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
E [ 間接、 直接または総合効果 ] チ ェ ッ ク ボ ッ ク ス を オ ンに し ます。
モデル C では、 出力に次の総合効果の表が含まれます。
表の最初の行は、 67_alienation ( 疎外感 (67 年 )) が直接的ま たは間接的に ses のみに依
存す る こ と を示 し ます。 67_alienation ( 疎外感 (67 年 )) に対す る ses の総合効果 は –0.56
です。 効果が負の値の場合、 その他の要素がすべて等 し く 、 比較的高い ses の得点が比
較的低い 67_alienation ( 疎外感 (67 年 )) の得点 と 関連す る こ と を示 し ます。 表の 5 行目
を見 る と 、 powles71 ( 無気力感 (71 年 )) が直接的ま たは間接的に ses、 67_alienation ( 疎
外感 (67 年 ))、 お よ び 71_alienation ( 疎外感 (71 年 )) に依存 し てい ます。 ses の低得点、
67_alienation ( 疎外感 (67 年 )) の高得点、お よ び 71_alienation ( 疎外感 (71 年 )) の高得点
は、 powles71 ( 無気力感 (71 年 )) の高得点 と 関連 し ます。 直接、 間接、 お よ び総合効果
の解釈の詳細については、 Fox の調査 (1980) を参照 し て く だ さ い。
113
探索分析
VB.NET でのモデル作成
モデル A
モデル A に適合す る プ ロ グ ラ ム を次に示 し ます。 こ のプ ロ グ ラ ムは Ex06–a.vb と し て
保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Mods(4)
Sem.BeginGroup(Sem.AmosDir & "Examples¥Wheaton.sav")
Sem.AStructure("anomia67 <--- 67_alienation (1)")
Sem.AStructure("anomia67 <--- eps1 (1)")
Sem.AStructure("powles67 <--- 67_alienation")
Sem.AStructure("powles67 <--- eps2 (1)")
Sem.AStructure("anomia71 <--- 71_alienation (1)")
Sem.AStructure("anomia71 <--- eps3 (1)")
Sem.AStructure("powles71 <--- 71_alienation")
Sem.AStructure("powles71 <--- eps4 (1)")
Sem.AStructure("67_alienation <--- ses")
Sem.AStructure("67_alienation <--- zeta1 (1)")
Sem.AStructure("71_alienation <--- 67_alienation")
Sem.AStructure("71_alienation <--- ses")
Sem.AStructure("71_alienation <--- zeta2 (1)")
Sem.AStructure("education <--- ses (1)")
Sem.AStructure("education <--- delta1 (1)")
Sem.AStructure("SEI <--- ses")
Sem.AStructure("SEI <--- delta2 (1)")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
114
例6
モデル B
モデル B に適合す る プ ロ グ ラ ム を次に示 し ます。 こ のプ ロ グ ラ ムは Ex06–b.vb と し て
保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.Crdiff()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Wheaton.sav")
Sem.AStructure("anomia67 <--- 67_alienation (1)")
Sem.AStructure("anomia67 <--- eps1 (1)")
Sem.AStructure("powles67 <--- 67_alienation")
Sem.AStructure("powles67 <--- eps2 (1)")
Sem.AStructure("anomia71 <--- 71_alienation (1)")
Sem.AStructure("anomia71 <--- eps3 (1)")
Sem.AStructure("powles71 <--- 71_alienation")
Sem.AStructure("powles71 <--- eps4 (1)")
Sem.AStructure("67_alienation <--- ses")
Sem.AStructure("67_alienation <--- zeta1 (1)")
Sem.AStructure("71_alienation <--- 67_alienation")
Sem.AStructure("71_alienation <--- ses")
Sem.AStructure("71_alienation <--- zeta2 (1)")
Sem.AStructure("education <--- ses (1)")
Sem.AStructure("education <--- delta1 (1)")
Sem.AStructure("SEI <--- ses")
Sem.AStructure("SEI <--- delta2 (1)")
Sem.AStructure("eps1 <---> eps3")
' Autocorrelated residual
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
115
探索分析
モデル C
モデル C に適合す る プ ロ グ ラ ム を次に示 し ます。 こ のプ ロ グ ラ ムは Ex06–c.vb と し て
保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.AllImpliedMoments()
Sem.FactorScoreWeights()
Sem.TotalEffects()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Wheaton.sav")
Sem.AStructure("anomia67 <--- 67_alienation (1)")
Sem.AStructure("anomia67 <--- eps1 (1)")
Sem.AStructure("powles67 <--- 67_alienation (path_p)")
Sem.AStructure("powles67 <--- eps2 (1)")
Sem.AStructure("anomia71 <--- 71_alienation (1)")
Sem.AStructure("anomia71 <--- eps3 (1)")
Sem.AStructure("powles71 <--- 71_alienation (path_p)")
Sem.AStructure("powles71 <--- eps4 (1)")
Sem.AStructure("67_alienation <--- ses")
Sem.AStructure("67_alienation <--- zeta1 (1)")
Sem.AStructure("71_alienation <--- 67_alienation")
Sem.AStructure("71_alienation <--- ses")
Sem.AStructure("71_alienation <--- zeta2 (1)")
Sem.AStructure("education <--- ses (1)")
Sem.AStructure("education <--- delta1 (1)")
Sem.AStructure("SEI <--- ses")
Sem.AStructure("SEI <--- delta2 (1)")
Sem.AStructure("eps3 <--> eps1")
Sem.AStructure("eps1 (var_a)")
Sem.AStructure("eps2 (var_p)")
Sem.AStructure("eps3 (var_a)")
Sem.AStructure("eps4 (var_p)")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
116
例6
複数のモデルを適合する
3 つのモデル A、 B、 お よ び C すべて を単一の分析に適合 さ せ る には、 最初に次のプ
ロ グ ラ ム を実行 し ます。 こ のプ ロ グ ラ ムは、 一部のパ ラ メ ー タ に固有の名前を割 り 当
て ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.AllImpliedMoments()
Sem.TotalEffects()
Sem.FactorScoreWeights()
Sem.Mods(4)
Sem.Crdiff()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Wheaton.sav")
Sem.AStructure("anomia67 <--- 67_alienation (1)")
Sem.AStructure("anomia67 <--- eps1 (1)")
Sem.AStructure("powles67 <--- 67_alienation (b_pow67)")
Sem.AStructure("powles67 <--- eps2 (1)")
Sem.AStructure("anomia71 <--- 71_alienation (1)")
Sem.AStructure("anomia71 <--- eps3 (1)")
Sem.AStructure("powles71 <--- 71_alienation (b_pow71)")
Sem.AStructure("powles71 <--- eps4 (1)")
Sem.AStructure("67_alienation <--- ses")
Sem.AStructure("67_alienation <--- zeta1 (1)")
Sem.AStructure("71_alienation <--- 67_alienation")
Sem.AStructure("71_alienation <--- ses")
Sem.AStructure("71_alienation <--- zeta2 (1)")
Sem.AStructure("education <--- ses (1)")
Sem.AStructure("education <--- delta1 (1)")
Sem.AStructure("SEI <--- ses")
Sem.AStructure("SEI <--- delta2 (1)")
Sem.AStructure("eps3 <--> eps1 (cov1)")
Sem.AStructure("eps1 (var_a67)")
Sem.AStructure("eps2 (var_p67)")
Sem.AStructure("eps3 (var_a71)")
Sem.AStructure("eps4 (var_p71)")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
117
探索分析
パ ラ メ ー タ 名は固有なので、 パ ラ メ ー タ に名前を付け る こ と に よ っ てパ ラ メ ー タ が制
約 さ れ る こ と はあ り ません。 ただ し 、パ ラ メ ー タ に名前を付け る こ と に よ り 、 Model メ
ソ ッ ド を使用 し て制約を適用す る こ と がで き ま す。 プ ロ グ ラ ム の Sem.FitModel 行の
代わ り に次の行を追加す る と 、 毎回異な る パ ラ メ ー タ 制約を適用 し てモデルを 4 回適
合 し ます。
Sem.Model("Model A: No Autocorrelation", "cov1 = 0")
Sem.Model("Model B: Most General", "")
Sem.Model("Model C: Time-Invariance", _
"b_pow67 = b_pow71;var_a67 = var_a71;var_p67 = var_p71")
Sem.Model("Model D: A and C Combined", _
"Model A: No Autocorrelation;Model C: Time-Invariance")
Sem.FitAllModels()
最初の行は、 Model A: No Autocorrelation と い う 名前のモデル を定義 し ま す。 こ の
モデルでは、 cov1 と い う 名前のパ ラ メ ー タ が 0 に固定 さ れてい ます。
2 行目は、 Model B: Most General と い う 名前のモデルを定義 し ます。 こ のモデルで
は、 モデル パ ラ メ ー タ に適用 さ れ る 追加の制約はあ り ません。
3 回目の Model メ ソ ッ ド では、Model C: Time-Invariance と い う 名前のモデルを定義
し ます。 こ のモデルでは、 次の同等性の制約を適用 し ます。
b_pow67 = b_pow71
var_a67 = var_a71
var_p67 = var_p71
4 回目の Model メ ソ ッ ド では、Model D: A and C Combined と い う 名前のモデルを定義
し ます。こ のモデルでは、モデル A の 1 つの制約 と モデル C の 3 つの制約を結合 し ます。
最後のモデル指定 ( モデル D) は、 それま でのモデル指定を使用 し て、 よ り 制約の多
い新 し いモデルを定義す る方法を示 し ます。
すべてのモデルを一度に適合す る には、 FitModel メ ソ ッ ド の代わ り に FitAllModels
メ ソ ッ ド を使用す る必要があ り ます。 FitModel メ ソ ッ ド は 1 つのモデル し か適合 し ま
せん。 デフ ォ ル ト では、 こ の メ ソ ッ ド は最初のモデル ( こ の例ではモデル A) を適合 し
ま す。 最初の モデル を 適合す る に は FitModel(1) 、 2 番目の モデル を 適合す る に は
FitModel(2) を使用 し ます。 FitModel( 「Model C: Time-Invariance」 ) と 指定 し てモデル C
を適合す る こ と も で き ます。
Ex06–all.vb には、 4 つのモデルすべて を適合す る プ ロ グ ラ ムが含ま れます。
例
7
非再帰 モデル
概要
こ の例では、 非再帰モデルを使用 し た構造方程式モデルの作成について説明 し ます。
デー タ について
Felson と Bohrnstedt は、 小学校 6 年生か ら 中学 2 年生の女子生徒 209 人を対象 と し た
調査を実施 し ま し た (1979)。 こ の調査では次の変数に関す る 測定値を取得 し ま し た。
変数
academic
athletic
attract
GPA
height
weight
rating
説明
認め ら れ る 学力。 最 も 学力が優れてい る 思 う 級友 3 人の名前 と い
う 項目に基づ く 計量社会学的測定値。
認め ら れ る 運動能力。 最 も 運動能力が優れてい る と 思 う 級友 3 人
の名前 と い う 項目に基づ く 計量社会学的測定値。
認め ら れ る 魅力。 最 も 外見が優れ て い る と 思 う 級友 3 人の名前
( 自分は除 く ) と い う 項目に基づ く 計量社会学的測定値。
成績平均点。
被験者の学年 と 性別の平均の高 さ か ら の偏差。
高 さ で調整 さ れた ウ ェ イ ト 。
別の市の子供た ちに被験者の写真を見せ る こ と に よ っ て得 ら れた
肉体的魅力の評価。
こ れ ら 6 つの変数の標本の相関、 平均、 お よ び標準偏差は、 SPSS Statistics フ ァ イ ル
Fels_fem.sav に保存 さ れてい ます。 SPSS Statistics デー タ エデ ィ タ に表示 さ れ る デー タ
フ ァ イ ルを次に示 し ます。
119
120
例7
こ の例では標本の平均値は使用 し ません。
Felson と Bohrnstedt のモデル
Felson と Bohrnstedt は、7 つの測定変数の内 6 つを使用する次のモデルを提示 し ま し た。
認め ら れ る academic の結果は、GPA と 認め ら れ る 魅力 (attract) の関数 と し てモデル化
さ れます。 同様に、 認め ら れ る academic の結果は、 height、 weight、 お よ び別の市の子
供た ちか ら 得 ら れた魅力の rating の関数 と し てモデル化 さ れ ます。 こ のモデルで特に
注目すべ き 点は、 認め ら れ る 学力は認め ら れ る 魅力に依存 し 、 逆 も ま た同様であ る と
い う こ と です。 こ の よ う な フ ィ ー ド バ ッ ク ループ を含むモデルを非再帰 ( 再帰 と 非再
帰の定義については例 4 を参照 ) と 呼びます。 現在のモデルは、attract か ら academic へ
のパスお よ びその逆のパス を ト レース で き る ので非再帰です。 こ のパ ス図は Ex07.amw
フ ァ イ ルに保存 さ れてい ます。
121
非再帰 モデル
モデルの特定
特定のため、 2 つの非観測変数誤差 1 と 誤差 2 の測定単位を確定す る 必要があ り ます。
上のパ ス図には、1 に固定 さ れた 2 つの係数が示 さ れてい ます。 モデルを特定す る には
こ れ ら 2 つの制約で十分です。
分析の結果
テキス ト 出力
モデルの自由度は 2 で、 モデルが不適切であ る と い う 十分な根拠はあ り ません。
ただ し 、 テ キ ス ト 出力にあ る い く つかの極端に小 さ い検定統計量に よ っ て示 さ れ る よ
う に、 こ のモデルが不必要に複雑であ る こ と を示すい く つかの根拠があ り ます。
検定統計量か ら 判断す る と 、 次に示す 3 つの帰無仮説は、 それぞれ従来の有意確率レ
ベルで許容 さ れ る こ と がわか り ます。
122
例7
認め ら れ る 魅力は高 さ に依存 し ない ( 検定統計量 = 0.050)。
認め ら れ る 学力は認め ら れ る 魅力に依存 し ない ( 検定統計量 = –0.039)。
残差変数誤差 1 と 誤差 2 は無相関であ る ( 検定統計量 = –0.382)。
厳密に言 う と 、 検定統計量を使用 し て 3 つの仮説すべて を一度に検定す る こ と はで き
ません。 代わ り に、3 つの制約すべて を同時に組み込んだモデルを作成す る 必要があ り
ます。 こ の方法については こ こ では取 り 上げません。
上に示 さ れた生のパ ラ メ ー タ 推定値は ( 誤差 1 と 誤差 2 の変数を除いて ) 識別制約の
影響を受け ません。 当然の こ と ですが、 こ れ ら の推定値は観測変数の測定単位の影響
を受け ます。 反対に、 標準化推定値はすべての測定単位か ら 独立 し てい ます。
標準化推定値を取得する
分析を実行す る 前に、 次の操作を行い ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
E [ 標準化推定値 ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
E ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
こ こ で、 こ れま でに統計的に有意でない こ と が判明 し てい る 係数 と 相関が、 記述的に
も 小 さ い こ と がわか り ます。
123
非再帰 モデル
重相関係数の平方を取得する
重相関係数の平方は、 標準化推定値 と 同様に測定単位か ら 独立 し てい ます。 重相関の
2 乗を取得す る には、 分析を実行す る 前に次の操作を行い ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブ を ク リ ッ ク し ます。
E [ 重相関係数の平方 ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
E ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
重相関係数の平方に よ り 、 こ のモデルの 2 つの内生変数はモデル内のその他の変数に
よ っ て あ ま り 正確に予測 さ れない こ と がわか り ます。 こ の こ と は、 適合度のカ イ 2 乗
検定は予測精度の測定にはな ら ない こ と を示 し ます。
グ ラ フ ィ ッ ク出力
標準化推定値 と 重相関係数の平方を表示す る パ ス図の出力を次に示 し ます。
124
例7
安定指数
非再帰モデルにはフ ィ ー ド バ ッ ク ループがあ る ため、 再帰モデルでは発生 し ない特定
の問題が発生す る 可能性があ り ます。 現在のモデルでは、 魅力が認め ら れ る 学力に依
存 し 、 認め ら れ る 学力が魅力に依存 し 、 さ ら に魅力が認め ら れ る 学力に依存す る と い
う よ う に繰 り 返 さ れ ます。 こ れは無限回帰の よ う に見え る だけでな く 、 実際に無限回
帰にな り ます。 線型従属の こ の無限シーケ ン ス に よ り 、 魅力、 学力、 お よ びモデルの
その他の変数間に明確な関係が定義 さ れ る か ど う か疑問に思われ る 方 も あ る で し ょ
う 。 その答えは、 明確な関係が定義 さ れ る 可能性 も あ り 、 さ れない可能性 も あ り ます。
すべては係数に依存 し ます。 一部の係数の値では、 線型従属の無限シーケ ン ス が一連
の明確に定義 さ れた関係に収束 し ます。 こ の よ う な場合、 線型従属のシ ス テ ム が安定
し てい る と 言い、 そ う でない場合は不安定であ る と 言い ます。
注 : パス図を見て線型シ ス テ ムが安定 し てい る か ど う かを判断す る こ と はで き ません。
係数を確認す る 必要があ り ます。
Amos では母集団に ど の よ う な係数があ る か を確認で き ませんが、 その よ う な係数を
推定 し 、 その推定値か ら 安定指数 (Fox (1980)、 Bentler お よ び Freeman (1983) に よ る )
を計算 し ます。
安定指数が –1 か ら +1 ま での間の場合、 そのシ ス テ ムは安定 し てお り 、 そ う でない
場合は不安定です。 こ の例のシ ス テ ムは安定 し てい ます。
次の変数の安定指数は 0.003 です。
魅力
学力
非再帰モデルの安定指数を表示す る には、 次の操作を行い ます。
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ウ ィ ン ド ウ 枠にあ る ツ リ ー図で、[ グループ / モデルにつ
いての注釈 ] を ク リ ッ ク し ます。
不安定なシ ス テ ム ( 安定指数が 1 以上 ) は不可能であ り 、同 じ 意味で負の分散 も 不可能
です。 安定指数 1 ( ま たは 1 以上 ) が得 ら れた場合、 モデルが不適切であ る か、 標本サ
イ ズが小 さ 過ぎ て係数の正確な推定値を提示で き ない こ と を意味 し ます。 パ ス 図にい
く つかのループがあ る 場合、Amos ではループご と に安定指数を計算 し ます。 安定指数
のいずれかが 1 以上の場合、 その線型シ ス テ ムは不安定です。
125
非再帰 モデル
VB.NET でのモデル作成
こ の例の モデルに適合す る プ ロ グ ラ ム を 次に示 し ま す。 こ の プ ロ グ ラ ム は Ex07.vb
フ ァ イ ルに保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Fels_fem.sav")
Sem.AStructure("academic <--- GPA")
Sem.AStructure("academic <--- attract")
Sem.AStructure("academic <--- error1 (1)")
Sem.AStructure("attract <--- height")
Sem.AStructure("attract <--- weight")
Sem.AStructure("attract <--- rating")
Sem.AStructure("attract <--- academic")
Sem.AStructure("attract <--- error (1)")
Sem.AStructure("error2 <--> error1")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
Felson と Bohrnstedt のモデルには最後の AStructure 行が不可欠です。 こ の行が な い
と 、 Amos は誤差 1 と 誤差 2 が無相関であ る と 仮定 し ます。
同 じ モデルを次の よ う な方程式形式で指定で き ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Fels_fem.sav")
Sem.AStructure("academic = GPA + attract + error1 (1)")
Sem.AStructure("attract = height + weight + rating + "_
& "academic + error2 (1)")
Sem.AStructure("error2 <--> error1")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
例
8
因子分析
概要
こ の例では、 確認的因子分析について説明 し ます。
デー タ について
Holzinger と Swineford は、シ カ ゴの 2 つの学校に在籍す る 中学 1 年生 と 中学 2 年生 301
人を対象 と し た心理学検定を実施 し ま し た (1939)。 こ の例では、 1 つの学校
(Grant-White 校 ) の 73 人の女子生徒か ら 取得 さ れた得点を使用 し ます。 こ の例で使用
す る 6 つの検定を次の表に示 し ます。
変数
visperc
cubes
lozenges
paragraph
sentence
wordmean
説明
視覚認知力の得点
空間視覚化力の検定
空間 ( 方向 ) の認知力の検定
文書理解力の得点
文理解力の得点
語彙力に関す る 検定の得点
127
128
例8
Grnt_fem.sav フ ァ イ ルには次の検定の得点が保存 さ れてい ます。
共通因子モデル
6 つの検定を使用す る 次のモデルを検討 し てみま し ょ う 。
こ のモデルでは、最初の 3 つの検定は spatial ( 視覚能力 ) と い う 名前の非観測変数に依
存す る と 断言 し てい ます。 spatial ( 視覚能力 ) は直接観測 さ れない基礎能力 ( 空間能力 )
と し て解釈で き ます。 こ のモデルに よ る と 、 最初の 3 つの検定の結果は こ の能力に依
存 し ます。 さ ら に、 こ れ ら の各検定の結果は、 空間能力以外の要素に も 依存す る 可能
性があ り ます。 た と えば、 visperc ( 視覚認知力 ) の場合、 固有の変数 err_v も 関連 し ま
す。 Err_v は、 パ ス図には特に示 さ れない、 visperc ( 視覚認知力 ) に対す る あ ら ゆ る 影
響を表 し ます。 Err_v は visperc ( 視覚認知力 ) の測定誤差を表 し ますが、visperc ( 視覚認
知力 ) の得点に影響を与え る 可能性があ り 、 モデルには特に示 さ れない社会経済状況、
年齢、 体力、 語彙力、 お よ びその他の特性や能力 も 表 し ます。
129
因子分析
こ こ に示すモデルは共通因子分析モデルです。 共通因子分析の用語では、 非観測変
数 spatial ( 視覚能力 ) を共通因子 と 呼び、 3 つの非観測変数 err_v、 err_c、 お よ び err_l
を独自因子 と 呼びます。 パ ス図にはその他の共通因子 verbal ( 言語能力 ) が表示 さ れて
い ま す。 最後の 3 つの検定は こ の共通因子に依存 し ま す。 パ ス 図には、 上記以外の
3 つの独自因子、 err_p、 err_s、 お よ び err_w も 表示 さ れて い ま す。 2 つの共通因子、
spatial ( 視覚能力 ) と verbal ( 言語能力 ) は相関が可能です。 一方で、 独自因子は相互に
無相関であ り 、 共通因子 と も 無相関であ る と 仮定 さ れ ます。 共通因子か ら 観測変数へ
のパス係数は、 因子負荷 と 呼ばれ る 場合があ り ます。
特定
こ のモデルは、 通常どお り 、 各非観測変数の測定尺度が不定であ る と い う 点を除いて
特定 さ れ ます。 各非観測変数の測定尺度は、 一部の回帰式で係数を 1 な ど の定数に設
定す る こ と に よ っ て自由に設定で き ます。 上のパ ス 図に こ の方法を示 し ま す。 こ のパ
ス図では、 8 つの係数が 1 に固定 さ れ、 非観測変数ご と に 1 つの係数が固定 さ れてい
ます。 こ れ ら の制約に よ っ て十分にモデルを特定で き ます。
提示 さ れたモデルは、 各非観測変数が 1 つの共通因子にのみ依存す る 、 特に単純な
共通因子分析モデルです。 共通因子分析の他の適用例では、 観測変数が任意の数の共
通因子に同時に依存で き ます。 一般的な ケー ス では、 共通因子モデルが特定 さ れ る か
ど う か を判断す る のは非常に困難です (Davis (1993)、 Jöreskog (1969、 1979) に よ る )。
こ の例お よ び前の例におけ る 特定可能性の説明は、 非観測変数の自然な測定単位の不
足が特定不能の唯一の原因であ る よ う な印象を与え、 問題を実際以上に単純化 し てい
る よ う に見え ます。 非観測変数の測定単位の不足が常に特定不能の原因にな る こ と は
事実です。 幸いに し て、 こ れ ま で何度 も 取 り 上げてい る よ う に、 こ の原因は対応が容
易です。
ただ し 、 簡単な対応策がない、 特定可能性に関す る 別の種類の問題が発生す る 可能
性 も あ り ま す。 特定可能性 の 条件 は 各 モ デル で 個別 に 設定す る 必要 が あ り ま す。
Jöreskog と Sörbom は、 パ ラ メ ー タ に同等性の制約条件を適用す る こ と に よ り 、 多数の
モデルの特定を実現す る 方法を示 し ま し た (1984)。 因子分析モデル ( お よ びその他の
多 く のモデル ) の場合、 モデル を 特定可能にす る ために何が必要か を解明す る には、
モデルに対す る 深い理解が必要です。 モデルが特定可能か ど う かわか ら ない場合は、
Amos に よ っ て特定不能 と 報告 さ れ る か ど う か を確認す る ため、 モデルを適合 し てみ
る こ と がで き ます。 実際に、 こ の実証的アプ ロ ーチは高い効果を上げてい ます。 原則
的な反論 (McDonald お よ び Krane (1979) に よ る ) も あ り ますが、 モデルの特定状態を
事前に判断す る 代替方法はあ り ません。 Bollen は、 その優れた著書の中で、 さ ま ざ ま
な種類の特定不能性の原因 と 対応について論 じ てい ます (1989)。
130
例8
モデルを指定する
Amos は、128 ページ に示すパス図か ら 直接モデルを分析 し ます。 理論的にはモデルを
spatial( 視覚能力 ) と verbal ( 言語能力 ) の枝に分離で き る こ と に注意 し て く だ さ い。
2 つの枝の構造上の類似を使用 し て、 モデルを迅速に作成で き ます。
モデルを作成する
最初の枝を作成 し た後で、 次の操作を行い ます。
E
メ ニ ュ ーか ら 、 [ 編集 ] [ すべて選択 ] を選択 し ます。
E 枝全体の コ ピーを作成す る には、 メ ニ ュ ーか ら 、 [ 編集 ] [ 複写 ] を選択 し 、 枝に含ま
れ る オブジ ェ ク ト のいずれか をパス図の別の場所に ド ラ ッ グ し ます。
spatial( 視覚能力 ) と verbal ( 言語能力 ) を結ぶ双方向矢印を必ず作成 し て く だ さ い。
こ の双方向矢印がない と 、Amos は 2 つの共通因子が無相関であ る と 仮定 し ます。 こ の
例の入力フ ァ イ ルは Ex08.amw です。
131
因子分析
分析の結果
分析の標準化 さ れていない結果を次に示 し ます。 図の右上に示す よ う に、 こ のモデル
はデー タ に非常に よ く 適合 し てい ます。
練習 と し て、 自由度の計算を確認 し てみま し ょ う 。
自由度の計算 ( デフ ォ ル ト モデル )
異な る 標本の積率の数
推定 さ れ る 異な る パ ラ メ ー タ の数
自由度 (21 – 13)
21
13
8
132
例8
パ ラ メ ー タ の推定値 ( 標準化 さ れた値 と 標準化 さ れて い な い値の両方 ) を 次に示 し
ます。 予想どお り 、 空間能力 と 語彙力の間の相関に よ り 、 係数は正にな り ます。
標準化推定値を取得する
上に示す標準化推定値を取得す る には、 分析を実行す る 前に次の操作を行い ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
133
因子分析
E [ 標準化推定値 ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
E 次の図に示す よ う に、 内生変数ご と に重相関係数の平方が必要な場合は、 [ 重相関係数
の平方 ] も 選択 し ます。
E ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
標準化推定値を表示する
E [Amos 出力 ] ウ ィ ン ド ウ で、 [ 出力パス図の表示 ] ボ タ ン を ク リ ッ ク し ます。
E パ ス図の左側にあ る [ パ ラ メ ー タ 形式 ] パネルで、 [ 標準化推定値 ] を選択 し ます。
標準化推定値が表示 さ れたパ ス図を次に示 し ます。
134
例8
重相関係数の平方は次の よ う に解釈で き ます。 wordmean ( 語彙力 ) の例を見 る と 、その
変数の 71% を語彙力が占めてい ます。 こ の変数の残 り 29% を占め る のは固有の因子
err_w です。 err_w が測定誤差のみを表す場合、 wordmean ( 語彙力 ) の信頼性の推定値
は 0.71 であ る と 言 う こ と がで き ます。 実際は、 0.71 は wordmean ( 語彙力 ) の信頼性の
下限の推定値です。
Holzinger と Swineford のデー タ は、 新 し い因子分析技法に関す る 専門書や実証で繰
り 返 し 分析 さ れて き ま し た。 こ の例で使用す る 6 つの検定は、 Jöreskog と Sörbom に よ
る 同様の例 (1984) で使用 さ れた 9 つの検定の よ り 大 き なサブセ ッ ト か ら 取得 さ れた も
のです。 こ こ で使用す る 因子分析モデル も 両者のモデル を基に し てい ま す。 因子分析
の文献に見 ら れ る 、 Holzinger と Swineford のデー タ の探求に関す る 長い歴史を考え る
と 、 現在のモデルが非常に よ く 適合す る こ と は偶然ではあ り ません。 通常の場合以上
に、 こ こ に示 さ れた結果を新た なデー タ セ ッ ト で確認す る 必要があ り ます。
VB.NET でのモデル作成
次のプ ロ グ ラ ム は、 Holzinger と Swineford のデー タ 用の因子モデル を 指定 し ま す。
こ のプ ロ グ ラ ムは Ex08.vb フ ァ イ ルに保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_fem.sav")
Sem.AStructure("visperc = (1) spatial + (1) err_v")
Sem.AStructure("cubes = spatial + (1) err_c")
Sem.AStructure("lozenges = spatial + (1) err_l")
Sem.AStructure("paragrap = (1)spatial + (1) err_p")
Sem.AStructure("sentence = spatial + (1) err_s")
Sem.AStructure("wordmean= spatial + (1) err_w")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
因子 (spatial( 視覚能力 ) と verbal ( 言語能力 )) の相関を明示的に可能にす る 必要はあ り
ません。 固有の因子は相互に無相関であ り 、 こ れ ら 2 つの因子 と も 無相関であ る こ と
を 指定す る 必要 も あ り ま せん。 こ れ ら は Amos プ ロ グ ラ ム のデ フ ォ ル ト の仮定です
(Amos Graphics ではデフ ォ ル ト ではあ り ません )。
例
9
共分散分析の代替分析
概要
こ の例では、 完全に信頼で き る 共変量を必要 と し ない、 共分散分析の単純な代替分析
について説明 し ます。 よ り 有効な、 ただ し よ り 複雑な代替分析については 例 16 で説明
し ます。
共分散分析 と その代替分析
共分散分析は、 実験研究や準実験研究で、 実験群間の既存の相違に よ る 影響を低減す
る ために し ば し ば使用 さ れ る 技法です。 実験群への無作為な割 り 当てに よ り 、 グルー
プ間で系統的な前処置が異な る 可能性が除去 さ れ る と し て も 、 共分散分析に よ っ て処
置効果の評価の精度を向上で き る と い う 利点があ り ます。
各共変量が誤差な し で測定 さ れ る と 仮定す る と 、共分散分析の有用性は低下 し ます。
こ の方法では他の仮定 も 行い ますが、 共変量が完全に信頼で き る と い う 仮定は特に注
目 さ れてい ます (Cook お よ び Cambell (1979) な ど )。 こ れは、 1 つには こ の仮定を破棄
す る と 非常に悪い結果にな る 可能性があ る か ら です。 信頼で き ない共変量を使用す る
と 、 処置の効果がない場合にあ る と 判断 し た り 、 効果があ る 場合にない と 判断す る な
ど の誤っ た結論に到達す る 可能性が あ り ます。 信頼で き ない共変量に よ っ て、 実際に
は有効な処置が有害で あ る かの よ う に見え る 場合 さ え あ り ます。 と 同時に、 残念なが
ら 、 共変量が完全に信頼で き る と い う 仮説を満たす こ と は通常は不可能です。
こ の例では、 変数を誤差な し で測定す る 必要がない共分散分析の代替分析について
説明 し ます。 こ こ に示す方法は、 Bentler と Woodward 等に よ っ て使用 さ れた方法です
(1979)。 Sörbom に よ る 別の方法 (1978) については、 例 16 で説明 し ます。 Sörbom の方
法が よ り 一般的です。 こ の方法では、 共分散分析の他の仮定を検定 し 、 い く つかの仮
定を緩和す る こ と も で き ます。 Sörbom の方法は、 その一般性に よ り 比較的複雑にな り
ます。 反対に、 こ の例で示す方法は、 共変量が誤差な し で測定 さ れ る と い う 仮定を除
いて、 共分散分析の通常の仮定を使用 し ます。 こ の方法の利点は、 比較的単純で あ る
こ と です。
135
136
例9
こ の例では、2 つの実験群 と 1 つの共変量を使用 し ます。 こ の例を任意の数の実験群
と 共変量に一般化す る こ と がで き ます。 Sörbom は、 こ の例 と 例 16 で使用す る デー タ
を使用 し てい ます (1978)。 分析は Sörbom の例に厳密に従っ てい ます。
デー タ について
Olsson は、 11 歳の生徒 213 人を対象に、 2 つの状況で一連の 8 つの検定を実施 し ま し
た (1973)。 こ の例では、 8 つの検定の内、 同意語 と 反意語の 2 つを使用 し ます。 一連の
検定を 2 回実施す る 間に、 108 人の生徒 ( 実験群 ) は検定の結果を向上 さ せ る ための ト
レーニ ン グ を受け ま し た。 それ以外の 105 人の生徒 ( 統制群 ) は特別な ト レーニ ン グ を
受けてい ません。 2 つの状況で 2 回検定を実施 し た結果、 213 人の生徒に対 し てそれぞ
れ 4 つの得点が得 ら れま し た。 実験群 と 統制群の メ ンバを識別す る ため、5 番目の 2 分
変数 も 作成 さ れてい ます。 全体 と し て、 こ の例では次の変数を使用 し ます。
変数
説明
pre_syn ( 同意語 ( 事前 ))
反意語 ( 事前 )
同意語 ( 事後 )
post_opp ( 反意語 ( 事後 ))
同意語検定の事前検定の得点。
反意語検定の事前検定の得点。
同意語検定の事後検定の得点。
反意語検定の事後検定の得点。
特別な ト レーニ ン グ ( 訓練 ) を受けた生徒は 1、 受けなか っ た
生徒は 0 の値にな る 2 分変数。 こ の変数は、 こ の例の分析用に
特に作成 さ た も のです。
treatment ( 訓練 )
5 つの測定値の相関 と 標準偏差は、 Microsoft Excel ワ ー ク ブ ッ ク UserGuide.xls の ワ ー
ク シー ト Olss_all にあ り ます。 デー タ セ ッ ト は次の と お り です。
treatment ( 訓練 ) と 各事後検定の間には正の相関があ り ます。 こ れは、 ト レーニ ン グ を
受けた生徒の方が ト レーニ ン グ を受けなか っ た生徒 よ り 事後検定の結果が良か っ た こ
と を示 し ます。 treatment ( 訓練 ) と 各事前検定の間の相関 も 正ですが、 比較的小 さ い相
関です。 こ れは、 統制群 と 実験群が、 事前検定では同等であ っ た こ と を示 し ます。 生徒
は統制群 と 実験群に無作為に割 り 当て ら れてい る ので、 こ れは予測どお り です。
137
共分散分析の代替分析
共分散分析
検定の結果に対す る ト レーニ ン グの効果を評価す る ため、 事後検定のいずれか を基準
変数 と し て、 2 つの事前検定を共変量 と し て使用す る 共分散分析の実行を検討で き ま
す。 こ の分析が適切に機能す る には、 同意語の事前検定 と 反意語の事前検定の両方が
完全に信頼で き る 必要があ り ます。
Olsson デー タ 用のモデル A
次のパ ス図に示す Olsson デー タ 用のモデルについて検討 し てみま し ょ う 。 こ のモデル
では、 pre_syn ( 同意語 ( 事前 )) と pre_opp ( 反意語 ( 事前 )) の両方が、 pre_verbal ( 言語
能力 ( 事前 )) と い う 名前の非観測能力の不完全な測定値であ る と 断言 し ます。 こ の非
観測能力は事前検定の時点での語彙力 と 考え ら れ ま す。 固有の変数 eps1 と eps2 は、
pre_syn ( 同意語 ( 事前 )) と pre_opp ( 反意語 ( 事前 )) の測定誤差だけでな く 、 こ のパス
図には示 さ れない、 2 つの検定に対す る その他の影響 も 表 し ます。
同様に、 こ のモデルでは、 post_syn ( 同意語 ( 事後 )) と post_opp ( 反意語 ( 事後 )) が、
post_verbal ( 言語能力 ( 事後 )) と い う 名前の非観測能力の不完全な測定値であ る と 断言
し ま す。 こ の非観測能力は事後検定の時点での語彙力 と 考え ら れ ま す。 Eps3 と eps4
は、 測定誤差 と 、 こ のパス図には示 さ れないその他の変動の原因を表 し ます。
モデルには、 事後検定の時点での語彙力の測定に役立つ 2 つの変数が示 さ れてい ま
す。 その よ う な予測変数の 1 つが、事前検定の時点での語彙力です。 事後検定の時点で
の語彙力が、 事前検定の時点での語彙力に依存す る こ と は予想どお り です。 過去の結
果は し ば し ば将来の結果の優れた予測変数に な る ので、 こ のモデルでは潜在的変数
pre_verbal ( 言語能力 ( 事前 )) を共変量 と し て使用 し ます。 ただ し 、 最 も 注目す る のは 2
つ目の予測変数であ る treatment ( 訓練 ) です。 こ こ では、treatment ( 訓練 ) か ら post_verbal
( 言語能力 ( 事後 )) を指す矢印に関連付け ら れた係数 と 、 それが 0 と 大 き く 異な る か ど
138
例9
う かに主に注目 し ます。 言い換えれば、 特定の係数が 0 であ る と い う 追加の仮説の下
で、 上に示すモデルが正 し い と 認め ら れ る か ど う か を確認す る こ と が最終的な目的で
す。 そのために まず、 モデル A が現状の ま ま で受け入れ ら れ る か ど う か を検討す る 必
要があ り ます。
特定
7 つの非観測変数の測定単位は不定です。 こ の問題は、上の図の各非観測変数を基点 と
す る 一方向矢印を 1 つ探 し 、 対応す る 係数を単一の値 (1) に固定す る こ と に よ っ て解
決で き ます。 上のパ ス図に示 さ れた 7 つの 1 は、 識別制約を満たすために十分であ る
こ と がわか り ます。
モデル A を指定する
モデル A を指定す る には、 137 ページ に示す よ う なパス図を作成 し ます。 こ のパ ス図
は、 Ex09-a.amw フ ァ イ ル と し て保存 さ れてい ます。
モデル A の結果
モデル A には考慮すべ き 経験的証拠があ り ます。
こ れは良 く な いデー タ です。 モデル A を 受け入れ る こ と がで き た場合、 post_verbal
( 言語能力 ( 事後 )) を treatment( 訓練 ) で回帰 さ せ る係数を 0 に固定 し て分析を繰 り 返す
次の手順を実行で き ます。 ただ し 、今それを実行 し て も 意味があ り ません。 処置の効果
がない強いモデルを検定す る 土台 と し て使用す る ため、 正 し い と 確信 さ れ る モデルか
ら 開始す る 必要があ り ます。
139
共分散分析の代替分析
よ り 適切なモデルを探す
モデル A が よ り デー タ に適合す る よ う に、 何 ら かの修正方法があ る と 考え ら れ ます。
修正指数か ら 、 適切な修正を行 う ためのい く つかの示唆が得 ら れます。
修正指数を要求する
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブ を ク リ ッ ク し ます。
E [ 修正指数 ] を選択 し 、 右に あ る フ ィ ール ド に適切な閾値を入力 し ま す。 こ の例では、
閾値はデフ ォ ル ト 値の 4 の ま ま に し ます。
閾値 4 で修正指標を要求す る と 、 次の追加出力が得 ら れます。
M.I. 列の最初の修正指数に よ る と 、 固有の変数 eps2 と eps4 の相関が可能な場合、 カ
イ 2 乗統計量が少な く と も 13.161 減少 し ます ( 実際の減少は よ り 大 き く な る 可能性が
あ り ます )。 同時に、当然の こ と ですが、追加のパ ラ メ ー タ を推定す る 必要があ る ので、
自由度が 1 下が り ま す。 13.161 が最大修正指数で あ る ため、 こ の値を最初に検討 し 、
eps2 と eps4 の相関を可能にす る こ と が妥当か ど う かを確認す る必要があ り ます。
eps2 は、 事前検定の語彙力以外のすべての pre_opp ( 反意語 ( 事前 )) 測定値を表 し ま
す。 同様に、 eps4 は事後検定の語彙力以外のすべての post_opp ( 反意語 ( 事後 )) 測定値
を表 し ます。 両方の反意語検定の実施に よ り 、 語彙力以外に何 ら かの安定 し た特性 ま
たは能力が測定 さ れ る と 考え ら れます。 こ の場合、 eps2 と eps4 の間に正の相関が予測
さ れます。 実際に、 eps2 と eps4 の共分散に関連付け ら れた、 予測 さ れ る パ ラ メ ー タ の
変化 (Par Change 列の数値 ) は正であ り 、共分散が 0 に固定 さ れていない場合は共分散
が正の推定値にな る と 考え ら れ る こ と を示 し ます。
加え て、 eps2 と eps4 の相関を可能にす る こ と を推奨す る 理由は、 eps1 と eps3 に も
ほぼ同様に適用 さ れ ます。 こ れ ら の共分散に も 非常に大 き な修正指数があ り ます。 た
だ し 、 現時点では、 モデル A に 1 つのパ ラ メ ー タ (eps2 と eps4 の共分散 ) のみ追加 し
ます。 こ の新 し いモデルを Model B と 呼びます。
140
例9
Olsson デー タ 用のモデル B
モデル B のパ ス図を下に示 し ます。 モデル B は、 モデル A のパ ス図を基に、 eps2 と
eps4 を結ぶ双方向矢印を追加す る こ と に よ っ て取得で き ます。 こ のパス図は
Ex09-b.amw フ ァ イ ルに保存 さ れてい ます。
パス 図を表示す る と わか る よ う に、 パス図の一番上に誤差変数が配置 さ れてお り 、 双
方向矢印を描 く スペース があ り ません。 こ の問題を解決する には、次の操作を行い ます。
E
メ ニ ュ ーか ら 、 [ 編集 ] [ ページ サイ ズに調整 ] を選択 し ます。
ま たは、 次の方法 も 可能です。
E 双方向矢印を描 き 、 ページ境界を越え る 場合は、 [ 画面に当てはま る よ う に パス図を拡大
/ 縮小 ] ボ タ ン ( ページに矢印が付いたボ タ ン ) ボ タ ン を ク リ ッ ク し ます。 ページ境界内
に収ま る よ う にパ ス図が縮小 さ れます。
141
共分散分析の代替分析
モデル B の結果
eps2 と eps4 の相関を可能にす る と 、 カ イ 2 乗統計量が大幅に減少 し ます。
eps1 と eps3 の共分散の修正指数が 9.788 であ っ たモデル A の結果を思い出 し て く だ
さ い。 明 ら かに、 eps2 と eps4 の共分散に加え て こ の共分散を除去 し て も 、 こ の よ う な
減少が発生す る と カ イ 2 乗統計量が負の値にな る ため、カ イ 2 乗統計量が さ ら に 9.788
減少す る こ と はあ り ません。 こ のため修正指数は、 対応す る 制約 — お よ びその制約の
み — を除去 し た場合に発生す る カ イ 2 乗統計量の減少の最小値を表 し ます。
次に示す生のパ ラ メ ー タ 推定値は、 識別制約が異な る と パ ラ メ ー タ 推定値 も 異な る
ので、 解釈が困難です。
予想どお り 、eps2 と eps4 の共分散は正にな り ます。 パラ メータ推定値 と 共に表示 さ れる
最 も 興味深い結果は、post_verbal ( 言語能力 ( 事後 )) に対する treatment ( 訓練 ) の効果の
検定統計量です。 こ の検定統計量は、 treatment ( 訓練 ) が post_verbal ( 言語能力 ( 事後 ))
に対 し て大 き な効果があ る こ と を示 し ます。 こ の係数が 0 に固定 さ れ る よ う にモデル
B を修正す る こ と に よ り 、 こ の効果の大 き さ に関す る よ り 適切な検定を容易に取得で
き ます。 一方で、 Amos Graphics に よ っ て次の よ う な標準化推定値 と 重相関係数の 2 乗
が表示 さ れます。
142
例9
こ の例では、 主に特定の仮説の検定に注目 し てお り 、 パ ラ メ ー タ 推定値には特に注意
す る 必要はあ り ません。 ただ し 、 パ ラ メ ー タ 推定値自体が特に注目 さ れない場合で も 、
と にか く 値を確認 し てそれ ら の値が妥当か ど う か を判断す る こ と は良い考えです。 た
と えば、 こ こ では eps2 と eps4 の間の相関の正確な状態には注意 し ませんが、 正であ
る と 予測 さ れます。 同様に、 こ のモデルの係数に負の推定値があ る こ と は予想外です。
ど の よ う なモデルで も 、 変数の分散が負にな ら ない こ と がわか っ てい る ので、 負の分
散推定値は常に不適切な推定値にな り ます。 標本がかな り 大 き い場合な ど、 推定値全
体の正常度チ ェ ッ ク を実行で き ない場合は、 それ ら の値が取得 さ れたモデルがデー タ
に適合 し てい る 場合で も 、 モデルの正 し さ を疑 う 必要があ り ます。
Olsson デー タ 用のモデル C
こ れで、合理的に正 し い と 確信で き る モデル ( モデル B) が作成 さ れたので、post_verbal
( 言語能力 ( 事後 )) が treatment ( 訓練 ) に依存 し ない と い う 制約を追加 し た場合に う ま く
い く かど う かを確認 し ます。 つま り 、 こ こ では新 し いモデル ( モデル C と 呼びます ) の
検定を行い ます。 モデル C の大部分はモデル B と 同 じ ですが、 post_verbal ( 言語能力
( 事後 )) で treatment ( 訓練 ) の係数が 0 にな る よ う に指定 さ れてい る点のみ異な り ます。
143
共分散分析の代替分析
モデル C のパス図を作成する
モデル C のパ ス図を作成す る には、 次の操作を行い ます。
E モデル B のパ ス図を基に作成 し ます。
E treatment ( 訓練 ) か ら post_verbal ( 言語能力 ( 事後 )) を指す矢印を右 ク リ ッ ク し 、ポ ッ プ
ア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、[ パラ メ ー タ ] タ ブ を ク リ ッ ク し 、
[ 係数 ] テ キ ス ト ボ ッ ク ス に 「0」 と 入力 し ます。
モデル C のパ ス図は、 Ex09-c.amw フ ァ イ ルに保存 さ れてい ます。
モデル C の結果
モデル C は、 従来のすべての有意水準で棄却す る 必要があ り ます。
モデル B が正 し く 、 モデル C の正 し さ のみ疑わ し い と 仮定す る 場合、 次の よ う に し て
モデル C の よ り 適切な検定を取得で き ます。 モデル B か ら モデル C を作成す る 際に、
カ イ 2 乗統計量が 52.712 (= 55.396 – 2.684 ) 増加す る 一方で、 自由度が 1 (= 3-2) 増
加 し てい ます。 モデル C が正 し い場合、 自由度 1 で近似のカ イ 2 乗分布を持つ乱数変
数の観測値が 52.712 にな り ます。 こ の よ う な乱数変数が 52.712 を超え る 確率はご く
わずかです。 treatment ( 訓練 ) は post_verbal ( 言語能力 ( 事後 )) に対 し て大 き な効果があ
り ます。
すべてのモデルを一度に適合する
標本 フ ァ イ ル Ex09-all.amw では、3 つのモデル (A か ら C) すべて を単一の分析に適合
し ます。単一の分析に複数のモデルを適合する手順については、例6 で説明 し てい ます。
144
例9
VB.NET でのモデル作成
モデル A
次のプロ グ ラ ムはモデル A を適合 し ます。 こ のプ ロ グ ラ ムは Ex09–a.vb フ ァ イ ルに保存
さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥UserGuide.xls", "Olss_all")
Sem.AStructure("pre_syn = (1) pre_verbal + (1) eps1")
Sem.AStructure("pre_opp = pre_verbal + (1) eps2")
Sem.AStructure("post_syn = (1) pre_verbal + (1) eps3")
Sem.AStructure("post_opp = pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = pre_verbal + treatment + (1) zeta")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
モデル B
次のプ ロ グ ラ ムはモデル B を適合 し ます。 こ のプ ロ グ ラ ムは Ex09–b.vb フ ァ イ ルに保
存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥UserGuide.xls", "Olss_all")
Sem.AStructure("pre_syn = (1) pre_verbal + (1) eps1")
Sem.AStructure("pre_opp = pre_verbal + (1) eps2")
Sem.AStructure("post_syn = (1) pre_verbal + (1) eps3")
Sem.AStructure("post_opp = pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = pre_verbal + treatment + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
145
共分散分析の代替分析
モデル C
次のプ ロ グ ラ ムはモデル C を適合 し ます。 こ のプ ロ グ ラ ムは Ex09–c.vb フ ァ イ ルに保
存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥UserGuide.xls", "Olss_all")
Sem.AStructure("pre_syn = (1) pre_verbal + (1) eps1")
Sem.AStructure("pre_opp = pre_verbal + (1) eps2")
Sem.AStructure("post_syn = (1) pre_verbal + (1) eps3")
Sem.AStructure("post_opp = pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = pre_verbal + (0) treatment + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
複数のモデルを適合する
次のプ ロ グ ラ ム (Ex09-all.vb) は、 3 つのモデル (A か ら C) をすべて適合 し ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥UserGuide.xls", "Olss_all")
Sem.AStructure("pre_syn = (1) pre_verbal + (1) eps1")
Sem.AStructure("pre_opp = pre_verbal + (1) eps2")
Sem.AStructure("post_syn = (1) pre_verbal + (1) eps3")
Sem.AStructure("post_opp = pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = pre_verbal + (effect) treatment + (1) zeta")
Sem.AStructure("eps2 <---> eps4 (cov2_4)")
Sem.Model("Model_A", "cov2_4 = 0")
Sem.Model("Model_B")
Sem.Model("Model_C", "effect = 0")
Sem.FitAllModels()
Finally
Sem.Dispose()
End Try
End Sub
例
10
複数グループの同時分析
概要
こ の例では、2 つのデー タ セ ッ ト に同時にモデルを適合す る 方法について説明 し ます。
Amos では、 複数のグループ ( ま たは標本 ) か ら 取得 さ れたデー タ のモデルを同時に作
成で き ます。 こ の複数グループ機能に よ り 、 次のい く つかの例に示す よ う に、 さ ら に
多 く の種類の分析を実行で き ます。
複数グループの分析
こ こ で、 例 1 か ら 例 3 で使用 さ れてい る 、 若年被験者 と 高齢被験者か ら 取得 さ れた
Attig (1983) の記憶力デー タ を も う 一度振 り 返っ てみま し ょ う 。 こ の例では、 2 つのグ
ループの結果を比較 し 、 類似性を確認 し ます。 ただ し 、 高齢者 と 若年者を個別に分析
す る こ と に よ っ て こ れ ら のグループ を比較す る こ と はあ り ません。 代わ り に、パ ラ メ ー
タ を推定 し 、両方のグループに関す る 仮説を同時に検定す る 単一の分析を実行 し ます。
こ の方法には、 若年者 と 高齢者のグループ を個別に分析す る 場合 と 比較 し て 2 つの利
点が あ り ます。 まず、 若年者 と 高齢者の間に相違が検出 さ れた場合、 その大 き さ を検
定で き ます。 次に、 若年者 と 高齢者の間に相違がない場合、 ま たはグループ間の相違
がい く つかのモデル パ ラ メ ー タ のみに関す る も のであ る 場合、 両方のグループを同時
分析す る と 、 単一グループ分析を個別に 2 回実施 し た場合に取得 さ れ る 推定値 よ り 、
正確なパ ラ メ ー タ 推定値が提供 さ れます。
デー タ について
こ こ では、若年被験者 と 高齢被験者の両方か ら 取得 さ れた Attig の記憶力デー タ を使用
し ま す。 高齢被験者のデー タ の一部 を 次に示 し ま す。 こ のデー タ は、 Microsoft Excel
ブ ッ ク UserGuide.xls の ワ ー ク シー ト Attg_old にあ り ます。
147
148
例 10
若年被験者のデー タ は ワ ー ク シー ト Attg_yng にあ り ます。 こ の例では、 測定値記憶 1
と 助成記憶 1 のみ使用 し ます。
複数グループ分析のデータ は さ ま ざ ま な方法で分類で き ます。 1 つの方法は、 グルー
プご と に 1 つのフ ァ イ ルを使用し てデータ を異な る フ ァ イ ルに保存する方法です ( こ の
例では こ の方法を使用 し ます )。 2 つ目の方法 と し て、 すべてのデー タ を 1 つの大 き い
フ ァ イ ルに保存し、 グループの所属変数を含め る方法が考え ら れます。
モデル A
こ こ では、 2 つの変数記憶 1 と 助成記憶 1 用に非常に小 さ いモデル ( モデル A) を作成
す る こ と か ら 開始 し ます。 こ のモデルでは単に、 高齢被験者 と 同様若年被験者 も 、 記
憶 1 と 助成記憶 1 がい く つかの指定 さ れない分散 と 共分散を持つ 2 つの変数であ る こ
と を示 し ます。 若年者 と 高齢者で分散 と 共分散が異な っ て も か ま い ません。
グループの相違を指定する ための規則
複数グループ分析の主な目的は、 グループが ど の程度異な る か を解明す る こ と です。
すべての グループで、 同 じ パ ラ メ ー タ 値を 含む同 じ パ ス 図を 使用 し ま すか。 ま たは、
同 じ パ ラ メ ー タ 図で グループ ご と に異な る パ ラ メ ー タ 値を 使用 し ま すか。 あ る いは、
グループご と に異な る パ ス図が必要ですか。 Amos Graphics では、複数グループ分析に
おけ る グループの相違を指定す る ため次の規則が用意 さ れてい ます。
明示的に宣言 さ れていない限 り 、 すべてのグループで同 じ パス図を使用 し ます。
名前のないパ ラ メ ー タ には異な る グループの異な る 値を使用で き ます。 こ れに よ
り 、 Amos Graphics のデフ ォ ル ト の複数グループ モデルでは、 すべてのグループで
同 じ パス図を使用 し ますが、 グループご と に異な る パ ラ メ ー タ 値を使用で き ます。
異な る グループのパ ラ メ ー タ に同 じ ラ ベル を指定す る こ と に よ り 、 こ れ ら のパ ラ
メ ー タ が同 じ 値にな る よ う に制約で き ます ( こ の方法については 158 ページのモ
デル B で説明 し ます )。
149
複数グループの同時分析
モデル A を指定する
E
メ ニ ュ ーか ら 、[ フ ァ イル ] [ 新規作成 ] を選択 し て新 し いパ ス図の作成を開始 し ます。
E
メ ニ ュ ーか ら 、 [ フ ァ イル ][ デー タ フ ァ イル ] を選択 し ます。
[ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス では、 [ グループ番号 1] と い う 名前の 1 つのグ
ループにのみデー タ フ ァ イ ルを指定で き る こ と に注意 し て く だ さ い。 こ こ では ま だ複
数グループ分析であ る こ と を指定 し てい ません。
E [ フ ァ イル名 ] を ク リ ッ ク し 、 Amos の Examples デ ィ レ ク ト リ にあ る Excel ブ ッ ク の
UserGuide.xls を選択 し て、 [ 開 く ] を ク リ ッ ク し ます。
E [ デー タ 表を選択 ] ダ イ ア ロ グ ボ ッ ク ス で、 ワー ク シー ト Attg_yng を選択 し ます。
E [OK] を ク リ ッ ク し て [ デー タ 表の選択 ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
E [OK] を ク リ ッ ク し て、 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
150
例 10
E
メ ニ ュ ーか ら 、 [ 表示 ] [ デー タ セ ッ ト に含まれる変数 ] を選択 し ます。
E 観測変数記憶 1 と 助成記憶 1 を図に ド ラ ッ グ し ます。
E 記憶 1 と 助成記憶 1 を双方向矢印で結びます。
E パ ス図にキ ャ プシ ョ ン を追加す る には、メ ニ ュ ーか ら 、[ 図 ] [ 図のキ ャ プ シ ョ ン ] を選
択 し 、 パ ス図にキ ャ プシ ョ ン を表示す る 位置を ク リ ッ ク し ます。
E [ 図のキ ャ プシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 テ キ ス ト マ ク ロ ¥group と ¥format を
含む タ イ ト ルを入力 し ます。
E [OK] を ク リ ッ ク し て若年者グループのモデル指定を完了 し ます。
E 2 つ目のグループを追加す る には、メ ニューか ら 、[ 分析 ] [ グループ管理 ] を選択 し ます。
151
複数グループの同時分析
E [ グループ管理 ] ダ イ ア ロ グ ボ ッ ク ス で、[ グループ名 ] テ キ ス ト ボ ッ ク ス の名前を 「グ
ループ番号 1」 か ら 「young subjects」 に変更 し ます。
E [ 新規作成 ] を ク リ ッ ク し て 2 つ目のグループを作成 し ます。
E [ グループ名 ] テ キ ス ト ボ ッ ク ス の名前を 「グループ番号 2」 か ら 「old subjects」 変
更 し ます。
E [ 閉 じ る ] を ク リ ッ ク し ます。
E
メ ニ ュ ーか ら 、 [ フ ァ イル ][ デー タ フ ァ イル ] を選択 し ます。
[ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス に、young subjects と old subjects と い う 名前の
2 つのグループが表示 さ れます。
E 高齢被験者のデー タ セ ッ ト を指定す る には、 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス
で [old subjects] を選択 し ます。
152
例 10
E [ フ ァ イル名 ] を ク リ ッ ク し 、 Amos の Examples デ ィ レ ク ト リ にあ る Excel ブ ッ ク の
UserGuide.xls を選択 し て、 [ 開 く ] を ク リ ッ ク し ます。
E [ デー タ 表を選択 ] ダ イ ア ロ グ ボ ッ ク ス で、 ワ ー ク シー ト Attg_old を選択 し ます。
E [OK] を ク リ ッ ク し ます。
テキス ト 出力
モデル A は自由度が 0 にな り ます。
Amos では次の よ う に し て異な る 標本の積率を計算 し ます。 若年被験者には 2 つの標
本分散 と 1 つの標本共分散があ り 、3 つの標本の積率が生成 さ れます。 高齢被験者に も
3 つの標本の積率があ り 、合計 6 つの標本の積率が生成 さ れます。 推定 さ れ る パ ラ メ ー
タ は母集団の積率であ り 、 こ の積率 も 6 つあ り ます。 自由度が 0 なので、 こ のモデル
は検定で き ません。
[Amos 出力 ] ウ ィ ン ド ウ に若年者のパ ラ メ ー タ 推定値を表示す る には、 次の操作を行
い ます。
E 左上の ウ ィ ン ド ウ 枠にあ る ツ リ ー図で、 [ 推定値 ] を ク リ ッ ク し ます。
153
複数グループの同時分析
E
ウ ィ ン ド ウ の左側にあ る [ グループ ] パネルで、 [young subjects] を ク リ ッ ク し ます。
高齢被験者のパ ラ メ ー タ 推定値を表示す る には、 次の操作を行い ます。
E [ グループ ] パネルで、 [old subjects] を ク リ ッ ク し ます。
グ ラ フ ィ ッ ク出力
次の図は、 2 つのグループの非標準化推定値を示す出力パス図です。
[Amos Graphics] ウ ィ ン ド ウ の左側にあ る パネルで、 さ ま ざ ま な表示オプシ ョ ン を選択
で き ます。
入力パ ス図ま たは出力パス図を表示す る には、[ 入力パス図の表示 ] ま たは [ 出力パス
図の表示 ] ボ タ ン を ク リ ッ ク し ます。
[ グループ ] パネルで [young subjects] または [old subjects] のいずれかを選択し ます。
154
例 10
[ パ ラ メ ー タ 形式 ] パネルで、[ 非標準化推定値 ] ま たは [ 標準化推定値 ] のいずれかを
選択 し ます。
モデル B
2 つのグループのパ ラ メ ー タ 推定値が異な る こ と を確認す る のは容易です。 では、ど の
程度異な る ので し ょ う か。 差の大 き さ を確認す る 1 つの方法 と し て、 分析を繰 り 返す
方法があ り ますが、 こ こ では若年者の各パ ラ メ ー タ を高齢者の対応す る パ ラ メ ー タ と
等 し く す る 必要があ り ます。 こ の結果作成 さ れたモデルを モデル B と 呼びます。
モデル B では、 各パ ラ メ ー タ に名前を付け、 高齢者グループ と 若年者グループで同
じ パ ラ メ ー タ 名を使用す る 必要があ り ます。
E まず、 パ ス図の左側にあ る [ グループ ] パネルで [young subjects] を ク リ ッ ク し ます。
E パ ス図で記憶 1 の四角を右 ク リ ッ ク し ます。
E ポ ッ プア ッ プ メ ニ ュ ーか ら 、 [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ パラ メ ー タ ] タ ブ を ク リ ッ ク し
ます。
155
複数グループの同時分析
E [ 分散 ] テ キ ス ト ボ ッ ク ス に、記憶 1 の分散の名前を入力 し ます。た と えば、「var_rec」
と 入力 し ます。
E [ 全グループ ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
こ こ にチ ェ ッ ク マー ク が付いてい る 場合、すべてのグループの記憶 1 の分散に var_rec
と い う 名前が割 り 当て ら れます。 こ こ にチ ェ ッ ク マー ク が付いていない場合、 var_rec
は若年者グループのみの記憶 1 の分散の名前にな り ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス が開いた状態で、 [ 助成記憶 1] を ク
リ ッ ク し 、 分散の名前 と し て 「var_cue」 と 入力 し ます。
E 双方向矢印を ク リ ッ ク し 、 共分散の名前 と し て 「cov_rc」 と 入力 し ます。 常に [ 全グ
ループ ] が選択 さ れてい る こ と を確認 し て く だ さ い。
各グループのパ ス図は次の よ う にな り ます。
156
例 10
テキス ト 出力
モデル B には制約が適用 さ れ る ため、 6 つではな く 3 つの異な る パ ラ メ ー タ のみ推定
さ れます。 こ れに よ り 、 自由度が 0 か ら 3 に増加 し ます。
モデル B は、 従来のすべての有意水準で受け入れ る こ と がで き ます。
若年被験者用のモデル B に基づいて取得 さ れたパラ メ ータ 推定値を次に示 し ます ( 高齢
被験者のパ ラ メ ー タ 推定値 も 同 じ です )。
モデル B に基づいて取得 さ れた標準誤差推定値 ( 若年被験者で 0.780、 0.909、 お よ び
0.873) は、モデル A に基づいて取得 さ れた対応す る 推定値 (0.944、1.311、お よ び 0.953).
よ り 小 さ い こ と がわか り ます。 モデル B が正 し い と 考え る 限 り 、 モデル A の推定値 よ
り モデル B の推定値の方が適 し てい る と 言え ます。
グ ラ フ ィ ッ ク出力
モデル B では、 両方のグループの出力パス図が同 じ にな り ます。
157
複数グループの同時分析
VB.NET でのモデル作成
モデル A
モデル A を適合す る プ ロ グ ラ ム (Ex10-a.vb) を次に示 し ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.BeginGroup(Sem.AmosDir & "Examples¥UserGuide.xls", "Attg_yng")
Sem.GroupName("young subjects")
Sem.AStructure("recall1")
Sem.AStructure("cued1")
Sem.BeginGroup(Sem.AmosDir & "Examples¥UserGuide.xls", "Attg_old")
Sem.GroupName("old subjects")
Sem.AStructure("recall1")
Sem.AStructure("cued1")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
こ の 2 つ の グ ル ー プ 分 析 で は BeginGroup メ ソ ッ ド を 2 回 使 用 し ま す。 最 初 の
BeginGroup 行は、 Attg_yng データ セ ッ ト を指定 し ます。 その後の 3 行に よ っ てそのグ
ループの名前 と モデルを示 し ます。 2 番目の BeginGroup 行は Attg_old デー タ セ ッ ト
を指定 し 、 その後の 3 行に よ っ てそのグループの名前 と モデルを示 し ます。 各グルー
プのモデルは単に、 記憶 1 と 助成記憶 1 が、 制約 さ れない分散 と 指定 さ れない共分散
を持つ 2 つの変数で あ る こ と を示 し ます。 GroupName メ ソ ッ ド はオプシ ョ ン ですが、
Amos に よ る 出力への ラ ベル付けに役立つので、 複数グループ分析では有効です。
158
例 10
モデル B
次に示すモデル B のためのプ ロ グ ラ ムは、 Ex10-b.vb に保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Dim dataFile As String = Sem.AmosDir & "Examples¥UserGuide.xls"
Sem.Standardized()
Sem.TextOutput()
Sem.BeginGroup(dataFile, "Attg_yng")
Sem.GroupName("young subjects")
Sem.AStructure("recall1
(var_rec)")
Sem.AStructure("cued1
(var_cue)")
Sem.AStructure("recall1 <>cued1 (cov_rc)")
Sem.BeginGroup(dataFile, "Attg_old")
Sem.GroupName("old subjects")
Sem.AStructure("recall1
(var_rec)")
Sem.AStructure("cued1
(var_cue)")
Sem.AStructure("recall1 <>cued1 (cov_rc)")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
パ ラ メ ー タ 名の var_rec、 var_cue、 お よ び cov_rc ( かっ こ 内 ) を使用 し て、 一部のパ ラ
メ ー タ が若年者 と 高齢者で同 じ 値にな る よ う に指定 し ます。 var_rec と い う 名前を 2 回
使用す る には、 記憶 1 が両方の グループで同 じ 分散を持つ必要が あ り ま す。 同様に、
var_cue と い う 名前を 2 回使用す る には、助成記憶 1 が両方のグループで同 じ 分散を持
つ必要があ り ます。 cov_rc と い う 名前を 2 回使用す る には、記憶 1 と 助成記憶 1 が両方
のグループで同 じ 共分散を持つ必要があ り ます。
159
複数グループの同時分析
複数モデルの入力
モデル A と B の両方を適合す る プ ロ グ ラ ム (Ex10-all.vb) を次に示 し ます。1
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.Standardized()
Sem.TextOutput()
Sem.BeginGroup(Sem.AmosDir & "Examples¥UserGuide.xls", "Attg_yng")
Sem.GroupName("young subjects")
Sem.AStructure("recall1
(yng_rec)")
Sem.AStructure("cued1
(yng_cue)")
Sem.AStructure("recall1 <>cued1 (yng_rc)")
Sem.BeginGroup(Sem.AmosDir & "Examples¥UserGuide.xls", "Attg_old")
Sem.GroupName("old subjects")
Sem.AStructure("recall1
(old_rec)")
Sem.AStructure("cued1
(old_cue)")
Sem.AStructure("recall1 <>cued1 (old_rc)")
Sem.Model("Model A")
Sem.Model("Model B", "yng_rec=old_rec", "yng_cue=old_cue", _
"yng_rc=old_rc")
Sem.FitAllModels()
Finally
Sem.Dispose()
End Try
End Sub
Sem.Model ス テー ト メ ン ト は、最後のグループの AStructure 指定の直後に く る 必要が
あ り ます。 ど の Model ス テー ト メ ン ト が最初に き て も 問題はあ り ません。
1 例 6 (Ex06-all.vb) では、 複数のモデル制約が単一の文字列で指定 さ れ、 個々の制約はセ ミ コ ロ ンで区切 ら れ
てい ます。 こ の例では、 各制約が独自の文字列で指定 さ れ、 個々の文字列はカ ン マで区切 ら れてい ます。 ど
ち ら の唆文 も 使用で き ます。
例
11
Felson と Bohrnstedt の女子生徒 と
男子生徒のデー タ
概要
こ の例では、 同時方程式モデルを 2 つのデー タ セ ッ ト に一度に適合す る方法について
説明 し ます。
Felson と Bohrnstedt のモデル
例 7 では、 209 人の女子生徒の標本を使用 し て、 認め ら れ る 魅力 と 認め ら れ る 学力に
関す る Felson と Bohrnstedt のモデル (1979) を検証 し ま し た。 こ こ では、 同 じ モデルを
使用 し て、 例 7 のデー タ と 207 人の男子生徒の別の標本か ら 取得 さ れたデー タ に同時
に適用 し ま す。 測定 さ れた変数の相互の関連が、 男子生徒 と 女子生徒で同様か ど う か
と い う 問題を検証 し ます。
デー タ について
Felson と Bohrnstedt に よ る 女子生徒のデー タ (1979) については 例 7 で説明 し ま し た。
SPSS Statistics フ ァ イ ル Fels_mal.sav か ら 取得 さ れた男子生徒のデー タ を次の表に示 し
ます。
161
162
例 11
男子生徒のデー タ フ ァ イ ルには 8 つの変数があ る のに、女子生徒のデー タ フ ァ イ ルに
は 7 つの変数 し かない こ と に注意 し て く だ さ い。 追加の変数 skills は こ の例の ど のモ
デルで も 使用 し ないので、 デー タ フ ァ イ ルに存在 し て も 無視 さ れます。
女子生徒 と 男子生徒用のモデル A を指定する
認め ら れ る 魅力 と 学力に関す る Felson と Bohrnstedt のモデルを、 女子生徒だけでな く
男子生徒に も 拡張す る こ と を検討 し てみま し ょ う 。 こ れを行 う には、 例 7 に示す女子
生徒のみのモデル指定を基に し て、 2 つのグループに適合す る よ う に修正 し ます。 例 7
のパ ス図を既に作成 し てい る 場合は、 こ の例の出発点 と し てそのパ ス図を使用で き ま
す。 追加のパ ス図を作成す る 必要はあ り ません。
複数グループ分析では、 パ ス 図にパ ラ メ ー タ 推定値 を 表示で き る のは一度に 1 グ
ループだけです。 ど のグループのパ ラ メ ー タ 推定値が表示 さ れてい る か を確認す る た
め、 図のキ ャ プシ ョ ン を表示す る と 便利です。
図のキ ャ プ シ ョ ン を指定する
グ ループ名 を 表示す る 図の キ ャ プ シ ョ ン を 作成す る には、 キ ャ プ シ ョ ン に ¥group
テ キ ス ト マ ク ロ を配置 し ます。
E
メ ニ ュ ーか ら 、 [ 図 ] [ 図のキ ャ プ シ ョ ン ] を選択 し ます。
E パ ス図にキ ャ プシ ョ ン を表示す る 位置を ク リ ッ ク し ます。
E [ 図のキ ャ プシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、テ キ ス ト マ ク ロ ¥group を含む タ イ ト ル
を入力 し ます。 次に例を示 し ます。
例 7 では 1 つのグループ し かないので、 グループの名前に注意す る 必要はあ り ません
で し た。 デ フ ォ ル ト の グループ番号 1 と い う 名前を その ま ま 使用で き ま し た。 今回は
2 つの グ ループ を 管理す る ので、 グ ループにわか り やすい名前 を 付け る 必要が あ り
ます。
163
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
E
メ ニ ュ ーか ら [ 分析 ] [ グループ管理 ] を選択 し ます。
E [ グループ管理 ] ダ イ ア ロ グ ボ ッ ク ス で、 [ グループ名 ] に 「girls」 と 入力 し ます。
E [ グループ管理 ] ダ イ ア ロ グ ボ ッ ク ス が開いた ま ま の状態で、[ 新規作成 ] を ク リ ッ ク し
て 2 つ目のグループ を作成 し ます。
E [ グループ名 ] テ キ ス ト ボ ッ ク ス に 「boys」 と 入力 し ます。
E [ 閉 じ る ] を ク リ ッ ク し て [ グループ管理 ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
E
メ ニ ュ ーか ら 、 [ フ ァ イル ] [ デー タ フ ァ イル ] を選択 し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、[girls] を ダブル ク リ ッ ク し 、デー タ フ ァ イ
ル Fels_fem.sav を選択 し ます。
E 次に、 [boys] を ダブル ク リ ッ ク し 、 デー タ フ ァ イ ル Fels_mal.sav を選択 し ます。
E [OK] を ク リ ッ ク し て、 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
164
例 11
男子生徒の標本用のパ ス図は次の よ う にな り ます。
女子生徒 と 男子生徒のパ ス 図は同 じ にな り ますが、 2 つのグループでパ ラ メ ー タ の値
が等 し く な る 必要はない こ と に注意 し て く だ さ い。 こ の こ と は、 係数、 共分散、 お よ
び分散の推定値が男子生徒 と 女子生徒では異な る 可能性があ る こ と を意味 し ます。
モデル A のテキス ト 出力
例 7 の 1 つのグループの代わ り に こ こ では 2 つのグループ を使用す る ので、 推定す る
標本の積率 と パ ラ メ ー タ の数が 2 倍にな り ます。 こ のため、 自由度 も 例 7 の 2 倍にな
り ます。
こ のモデルは、 両方のグループのデー タ に非常に よ く 適合 し てい ます。
カ イ 2 乗 = 3.183
自由度 = 4
確率水準 = 0.528
こ れに よ り 、 Felson と Bohrnstedt のモデルが男子生徒 と 女子生徒の両方で正 し い と い
う 仮説を受け入れます。 次に注意す る のはパ ラ メ ー タ 推定値です。 こ こ では、女子生徒
の推定値を男子生徒の推定値 と ど の よ う に比較す る かに注目 し ます。 女子生徒のパ ラ
メ ー タ 推定値は次の と お り です。
165
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
こ れ ら のパ ラ メ ー タ 推定値は例 7 と 同 じ も のです。 標準誤差、検定統計量、お よ び p 値
も 同 じ です。 男子生徒の非標準化推定値は次の と お り です。
166
例 11
モデル A のグ ラ フ ィ ッ ク出力
非標準化推定値が表示 さ れた女子生徒のパ ス図を次に示 し ます。
男子生徒の推定値が表示 さ れたパス図を次に示 し ます。
モデル A の女子生徒 と 男子生徒の推定値 を 視覚的に検査 し 、 性差 を 確認で き ま す。
1 つの パ ラ メ ー タ の値が女子生徒 と 男子生徒で大幅に異 な る か ど う か を 確認す る
には、 自由なパ ラ メ ー タ のすべてのペア間の差に対す る 検定統計量の表を調べます。
パラ メ ー タ の差に対する検定統計量を取得する
E
メ ニ ュ ーか ら 、 [ 表示 ] [ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
167
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
E [ パ ラ メ ー タ の差に対する検定統計量 ] を選択 し ます。
ただ し 、 こ の例では差に対す る 検定統計量は使用せず、 グループの差を確認す る 代替
方法を使用 し ます。
女子生徒 と 男子生徒のモデル B
こ こ では主に係数に注目 し 、( モデル B では ) 女子生徒 と 男子生徒が同 じ 係数にな る と
仮定 し ます。 こ のモデルでは、 外生変数の分散 と 共分散がグループに よ っ て異な る 可
能性があ り ます。
こ のモデルでは、 変数間の線型従属がすべてのグループで不変であ る 必要があ る 一
方で、 height や weight な ど の変数の分布が男子生徒 と 女子生徒で異な る 可能性があ り
ます。 モデル B では、 各グループで 6 つの係数を制約す る 必要があ り ます。
E 最初に、パス図の左側にあ る [ グループ ] パネルで [girls] を ク リ ッ ク し 、女子生徒のパ
ス図を表示 し ます。
E 一方向矢印のいずれかを右 ク イ ッ ク し 、ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ
ロパテ ィ ] を選択 し ます。
E [オブジェ ク ト のプロパテ ィ ] ダイ ア ロ グ ボ ッ ク ス の [パラ メ ー タ ] タ ブを ク リ ッ ク し ます。
E [ 係数 ] テ キ ス ト ボ ッ ク ス に名前を入力 し ます。
168
例 11
E [ 全グループ ] を選択 し ます。 [ 全グループ ] の横にチ ェ ッ ク マー ク が表示 さ れます。
チ ェ ッ ク マー ク が付いてい る 場合、 すべてのグループで こ の係数に同 じ 名前が割 り 当
て ら れます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス が開いた状態で、別の一方向矢印を
ク リ ッ ク し 、 [ 係数 ] テ キ ス ト ボ ッ ク ス に別の名前を入力 し ます。
E すべての係数に名前を付け る ま で こ の操作を繰 り 返 し ます。 常に [ 全グループ ] を選択
( チ ェ ッ ク マー ク を付け る ) し て く だ さ い。
すべての係数に名前を付けた ら 、 各標本のパ ス図は次の よ う にな り ます。
169
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
モデル B の結果
テキス ト 出力
モデル B はデー タ に非常に よ く 適合 し てい ます。
カ イ 2 乗 = 9.493
自由度 = 10
確率水準 = 0.486
モデル A と モデル B を比較す る と 、 有意でないカ イ 2 乗 ( 9.493 – 3.183 = 6.310 )
と 自由度 ( 10 – 4 = 6 ) が得 ら れます。 モデル B が正 し い と 仮定す る と 、 モデル B の推
定値がモデル A の推定値 よ り 適 し てい る と 考え ら れます。
女子生徒の標本の非標準化パ ラ メ ー タ 推定値は次の と お り です。
170
例 11
男子生徒の非標準化パ ラ メ ー タ 推定値は次の と お り です。
モデル B の指定に よ り 、男子生徒の推定係数は女子生徒の推定係数 と 同 じ にな り ます。
グ ラ フ ィ ッ ク ス出力
女子生徒の出力パ ス図は次の と お り です。
171
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
男子生徒の出力は次の と お り です。
モデル A と B を単一の分析に適合する
モデル A と モデル B を同一の分析に適合す る こ と がで き ます。 Amos の Examples デ ィ
レ ク ト リ にあ る Ex11-ab.amw フ ァ イ ルに、 こ の方法が示 さ れてい ます。
女子生徒 と 男子生徒のモデル C
すべてのパ ラ メ ー タ を男子生徒 と 女子生徒で同 じ 値にす る な ど、 モデル B に制約を追
加す る こ と も 検討で き ます。 つま り 、 Felson と Bohrnstedt のモデルが両方のグループ
で正 し く な る 必要があ る と 同時に、観測変数の分散 / 共分散行列全体が男子生徒 と 女子
生徒で同 じ に な る と 仮定 し ま す。 こ の コ ー ス を 進め る 代わ り に、 こ こ で Felson と
Bohrnstedt のモデルか ら 離れて、観測変数が女子生徒 と 男子生徒で同 じ 分散 / 共分散行
列にな る と い う 仮定に注目 し てみま し ょ う 。 こ の仮定を具象化す る モデル ( モデル C)
を作成 し ます。
172
例 11
E モデル A ま たはモデル B のパ ス図を基に し て、 6 つの観測変数を除 く すべてのオブ
ジ ェ ク ト をパス図か ら 削除 し ます ([ 編集 ] [ 消去 ] を選択 し ます )。 パ ス図は次の よ う
にな り ます。
四角形の各ペア を双方向矢印で結ぶ必要があ り ます。合計 15 の双方向矢印が必要です。
E 出力結果の外観を改善す る には、 メ ニ ュ ーか ら [ 編集 ] [ 移動 ] を選択 し 、 マ ウ ス を使
用 し て 6 つの四角形を次の よ う に一列に並べます。
[ プ ロパテ ィ を ド ラ ッ グ ] オプシ ョ ン を使用す る と 、四角形を一直線上に整列で き ます。
173
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
E
メ ニ ュ ーか ら 、 [ 編集 ] [ プ ロパテ ィ を ド ラ ッ グ ] を選択 し ます。
E [ プ ロ パテ ィ を ド ラ ッ グ ] ダ イ ア ロ グ ボ ッ ク ス で、[ 高 さ ]、[ 幅 ]、お よ び [X 座標 ] を選択
し ます。 各項目の横にチ ェ ッ ク マー ク が表示 さ れます。
E マ ウ ス を使用 し て、 こ れ ら のプ ロ パテ ィ を academic か ら attract に ド ラ ッ グ し ます。
こ れに よ り 、 attract の x 座標が academic と 同 じ にな り ます。 つま り 、 一直線上に整列
し ます。 attract と academic のサ イ ズが異な る 場合は、 サ イ ズ も 同 じ にな り ます。
E 次に、 attract か ら GPA へ、 GPA か ら height へ、 以下同様にプ ロ パテ ィ を ド ラ ッ グ し
ます。 6 つの変数がすべて一直線上に整列す る ま で こ の操作を続け ます。
E 四角形の間隔を均等にする には、 メ ニ ューか ら 、 [ 編集 ] [ すべて選択 ] を選択 し ます。
E 次に、 [ 編集 ] [ 垂直に配置 ] を選択 し ます。
多数の双方向矢印を一度に作成す る ための特殊なボ タ ンがあ り ます。 前の手順で 6 つ
の変数がすべて選択 さ れた状態で、 次の操作を行い ます。
174
例 11
E
メ ニ ュ ーか ら 、 [ プ ラ グ イ ン ] [ 共分散を描 く (Draw Covariances)] を選択 し ます。
選択 し た変数間で使用可能なすべての共分散パス が作成 さ れます。
E すべての分散 と 共分散に適切な名前の ラ ベルを付け ます。 た と えば、 a か ら u の ラ ベ
ルを付け ます。 [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 パ ラ メ ー タ に名
前を付け る 際には常に [ 全グループ ] にチ ェ ッ ク マー ク が付いてい る こ と を確認 し て く
だ さ い。
E
メ ニ ュ ーか ら 、[ 分析 ] [ モデル管理 ] を選択 し 、男子生徒用の 2 つ目のグループ を作成
し ます。
E [ フ ァ イル ] [ デー タ フ ァ イル ] を選択 し 、 こ のグループに男子生徒のデー タ セ ッ ト
(Fels_mal.sav) を指定 し ます。
175
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
Ex11-c.amw フ ァ イ ルには、モデル C のモデル指定が含まれます。 入力パ ス図は次の と
お り です。 こ のパス図は両方のグループで同 じ にな り ます。
モデル C の結果
モデル C は、 従来のすべての有意水準で棄却す る 必要があ り ます。
カ イ 2 乗 = 48.977
自由度 = 21
確率水準 = 0.001
こ の結果は、 男子生徒 と 女子生徒の相違が ま っ た く ないモデルの提示に よ っ て時間を
浪費 し てはいけない こ と を示 し てい ます。
176
例 11
VB.NET でのモデル作成
モデル A
モデル A に適合す る プ ロ グ ラ ム を次に示 し ます。 こ のプ ロ グ ラ ムは Ex11-a.vb と し て
保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Fels_fem.sav")
Sem.GroupName("girls")
Sem.AStructure("academic = GPA + attract + error1 (1)")
Sem.AStructure _
("attract = height + weight + rating + academic + error2 (1)")
Sem.AStructure("error2 <--> error1")
Sem.BeginGroup(Sem.AmosDir & "Examples¥Fels_mal.sav")
Sem.GroupName("boys")
Sem.AStructure("academic = GPA + attract + error1 (1)")
Sem.AStructure _
("attract = height + weight + rating + academic + error2 (1)")
Sem.AStructure("error2 <--> error1")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
177
Felson と Bohrnstedt の女子生徒 と 男子生徒のデー タ
モデル B
次のプ ロ グ ラ ムはモデル B を適合 し ま す。 こ のプ ロ グ ラ ム では、 パ ラ メ ー タ ラ ベル
p1 か ら p6 を使用 し て グループ全体に同等性の制約条件を適用 し ます。 こ のプ ロ グ ラ
ムは Ex11-b.vb に保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Fels_fem.sav")
Sem.GroupName("girls")
Sem.AStructure("academic = (p1) GPA + (p2) attract + (1) error1")
Sem.AStructure("attract = "& _
"(p3) height + (p4) weight + (p5) rating + (p6) academic + (1) error2")
Sem.AStructure("error2 <--> error1")
Sem.BeginGroup(Sem.AmosDir & "Examples¥Fels_mal.sav")
Sem.GroupName("boys")
Sem.AStructure("academic = (p1) GPA + (p2) attract + (1) error1")
Sem.AStructure("attract = "& _
"(p3) height + (p4) weight + (p5) rating + (p6) academic + (1) error2")
Sem.AStructure("error2 <--> error1")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
モデル C
モデル C 用の VB.NET プ ロ グ ラ ムは こ こ には示 し ません。 こ のプ ロ グ ラ ムは
Ex11-c.vb フ ァ イ ルに保存 さ れてい ます。
178
例 11
複数のモデルを適合する
次のプ ロ グ ラ ム はモデル A と B の両方を適合 し ま す。 こ のプ ロ グ ラ ムは Ex11-ab.vb
フ ァ イ ルに保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Fels_fem.sav")
Sem.GroupName("girls")
Sem.AStructure("academic = (g1) GPA + (g2) attract + (1) error1")
Sem.AStructure("attract = "& _
"(g3) height + (g4) weight + (g5) rating + (g6) academic + (1) error2")
Sem.AStructure("error2 <--> error1")
Sem.BeginGroup(Sem.AmosDir & "Examples¥Fels_mal.sav")
Sem.GroupName("boys")
Sem.AStructure("academic = (b1) GPA + (b2) attract + (1) error1")
Sem.AStructure("attract = "& _
"(b3) height + (b4) weight + (b5) rating + (b6) academic + (1) error2")
Sem.AStructure("error2 <--> error1")
Sem.Model("Model_A")
Sem.Model("Model_B", _
"g1=b1", "g2=b2", "g3=b3", "g4=b4", "g5=b5", "g6=b6")
Sem.FitAllModels()
Finally
Sem.Dispose()
End Try
End Sub
例
12
複数のグループの同時因子分析
概要
こ の例は、 複数の母集団のそれぞれに対 し て、 同 じ 因子分析モデルが適用 さ れ る か ど
う か を検定す る 方法を示 し ます。 異な る 母集団に対 し ては、 パ ラ メ ー タ も 異な る 可能
性があ り ます (Jöreskog, 1971 年 )。
デー タ について
こ こ では、例 8 で説明 し た Holzinger と Swineford (1939 年 ) のデー タ を使用 し ます。 た
だ し 、 今回は Grant-White の標本か ら 、 例 8 で調べた 73 人の少女のデー タ だけでな く 、
72 人の少年のデー タ も 分析 し ま す。 Grnt_fem.sav フ ァ イ ルに保存 さ れて い る 少女の
デー タ については、 例 8 で説明 し ま し た。 以下に、 Grnt_mal.sav フ ァ イ ルに保存 さ れて
い る 少年の標本 デー タ を示 し ます。
179
180
例 12
Holzinger と Swineford の少年少女のモデル A
例 8 の共通因子分析モデルは、 少女の場合 と 同 じ く 、 少年の場合に も 適用 さ れ る と い
う 仮説を考え ます。 例 8 のパス図は、 こ の 2 グループのモデルの出発点 と し て使用で
き ます。 Amos Graphics では、デフ ォ ル ト で両方のグループが同 じ パ ス図を持っ てい る
と 仮定 さ れ ます。 そのため、 2 つのグループに対 し てパ ス図を 2 回描 く 必要はあ り ま
せん。
例 8 では、 グループは 1 つ し かないため、 グループの名前は重要ではあ り ませんで
し た。デフ ォ ル ト のグループ番号 1 と い う 名前を その ま ま使用で き ま し た。 今回は 2 つ
のグループを管理す る ので、 グループにわか り やすい名前を付け る 必要があ り ます。
グループに名前を付ける
E
メ ニ ュ ーか ら [ 分析 ] [ グループ管理 ] を選択 し ます。
E [ グループ管理 ] ダ イ ア ロ グ ボ ッ ク ス で、 [ グループ名 ] に 「Girls」 と 入力 し ます。
E [ グループ管理 ] ダ イ ア ロ グ ボ ッ ク ス を開いた ま ま、[ 新規作成 ] を ク リ ッ ク し て別のグ
ループ を作成 し ます。
E [ グループ名 ] テ キ ス ト ボ ッ ク ス に 「Boys」 と 入力 し ます。
E [ 閉 じ る ] を ク リ ッ ク し て [ グループ管理 ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
181
複数のグループの同時因子分析
デー タ の指定
E
メ ニ ュ ーか ら 、 [ フ ァ イル ][ デー タ フ ァ イル ] を選択 し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 Girls を ダブル ク リ ッ ク し て、 デー タ フ ァ
イ ルに grnt_fem.sav を指定 し ます。
E 次に Boys を ダブル ク リ ッ ク し て、 デー タ フ ァ イ ルに grnt_mal.sav を指定 し ます。
E [OK] を ク リ ッ ク し て、 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
少女の標本のパ ス図は次の よ う にな り ます。
少年のパ ス図 も 同 じ です。 ただ し 、 パ ラ メ ー タ 推定値は 2 つのグループで異な る 場合
も あ る こ と に注意 し て く だ さ い。
182
例 12
モデル A の結果
テキス ト 出力
こ のモデルの自由度の計算では、 例 8 のすべての数値がち ょ う ど 2 倍にな り ます。
自由度の計算 ( デフ ォ ル ト モデル )
異な る 標本の積率の数
推定 さ れ る 異な る パ ラ メ ー タ の数
自由度 (42 – 26)
42
26
16
通常の有意水準では、 モデル A は適合 し ます。 モデル A が棄却 さ れ る 場合は、 2 つの
グループの う ち少な く と も 1 つのパス図を変更す る 必要があ り ます。
カ イ 2 乗 = 16.480
自由度 = 16
確率水準 = 0.420
グ ラ フ ィ ッ ク出力
こ こ に示すのは、 73 人の少女の ( 標準化 さ れていない ) パ ラ メ ー タ 推定値です。 こ れ
は、 少女だけ を調べた例 8 で得 ら れた も の と 同 じ 推定値です。
183
複数のグループの同時因子分析
72 人の少年の出力パ ス図は、 次の よ う にな り ます。
推定 さ れた係数は、 グループ間でほ と ん ど 変わ っ ていない こ と に注意 し て く だ さ い。
2 つの母集団は同 じ 係数を持っ てい る よ う に思われます。 モデル B では、 こ の仮説を
検定 し ます。
Holzinger と Swineford の少年少女のモデル B
こ こ では、 少年 と 少女のパ ス図は同 じ であ る と い う 仮説を使用 し ます。 次に、 少年 と
少女が同 じ パ ラ メ ー タ 値 を 持つか ど う か を 調べ ま す。 次のモデル ( モデル B) では、
少年の母集団のすべてのパ ラ メ ー タ が、 少女の対応す る パ ラ メ ー タ と 等 し く な る こ と
ま では要求 し ません。 要求す る のは、 因子パ タ ーン ( つま り 、 係数 ) が、 両方のグルー
プで等 し く な る こ と です。 モデル B では、 少年 と 少女は異な る 固有の分散を持つ こ と
がで き ます。 共通因子の分散お よ び共分散 も 、 グループ間で異な る 場合があ り ます。
E モデル A を モデル B の出発点 と し て使用 し ます。
E まず、 パ ス図の左にあ る [ グループ ] パネルで Girls を ク リ ッ ク し て、 少女のパ ス図を
表示 し ます。
E spatial ( 視覚能力 ) か ら cubes ( 空間視覚化力 ) へ伸び る 矢印を右 ク リ ッ ク し て、 ポ ッ プ
ア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
E [オブジェ ク ト のプロパテ ィ ] ダイ ア ロ グ ボ ッ ク ス の [パラ メ ー タ ] タ ブを ク リ ッ ク し ます。
184
例 12
E [ 係数 ] テ キ ス ト ボ ッ ク ス に 「cube_s」 と 入力 し ます。
E [ 全グループ ] を選択 し ます。 [ 全グループ ] の横にチ ェ ッ ク マー ク が表示 さ れます。
チ ェ ッ ク マー ク を付け る こ と に よ り 、 両方のグループで こ の係数に同 じ 名前が割 り 当
て ら れます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダイ ア ロ グ ボ ッ ク ス を開いた ま ま、 残 り の片矢印を順に
ク リ ッ ク し 、 それぞれ [ 係数 ] テキス ト ボ ッ ク ス に名前を入力 し ます。 こ の操作を繰 り
返 し て、 すべての係数に名前を付け ます。 常に [ 全グループ ] を選択 ( チ ェ ッ ク マー ク
を付け る ) し て く だ さ い。 ( 既に 1 に固定 さ れてい る 係数は、その ま ま に し て く だ さ い。)
2 つの標本のパ ス図は、 いずれ も 次の よ う にな り ます。
185
複数のグループの同時因子分析
モデル B の結果
テキス ト 出力
モデル B で追加 さ れた制約条件のため、 デー タ か ら 推定 さ れ る パ ラ メ ー タ の数は 4 つ
少な く な り 、 自由度の数は 4 だけ増え ます。
自由度の計算 ( デフ ォ ル ト モデル )
異な る 標本の積率の数
推定 さ れ る 異な る パ ラ メ ー タ の数
自由度 (42 – 20)
42
22
20
カ イ 2 乗適合度統計量は許容可能です。
カ イ 2 乗 = 18.292
自由度 = 20
確率水準 = 0.568
モデル A と モデル B のカ イ 2 乗の差 18.292 – 16.480 = 1.812 も 、 通常の有意水準
では大 き な差ではあ り ません。 し たが っ て、 グループに よ ら ない因子パ タ ーン を指定
し たモデル B は、 Holzinger と Swineford のデー タ に適合 し ます。
グ ラ フ ィ ッ ク出力
こ こ に示すのは、 73 人の少女のパ ラ メ ー タ 推定値です。
186
例 12
こ こ に示すのは、 72 人の少年のパ ラ メ ー タ 推定値です。
予想 さ れ る と お り 、 モデル B のパ ラ メ ー タ 推定値は、 モデル A の推定値 と は異な っ て
い ます。 次の表に、 2 つのモデルの推定値 と 標準誤差を並べて示 し てい ます。
[ パラ メ ー タ ]
モデル A
少女の標本
推定値
g: cubes ( 空間視覚化力 ) <--- spatial ( 視覚能力 )
g: lozenges ( 方向認識力 ) <--- spatial ( 視覚能力 )
g: sentence ( 文理解力 ) <--- verbal ( 言語能力 )
g: wordmean ( 語彙力 ) <--- verbal ( 言語能力 )
g: spatial ( 視覚能力 ) <---> verbal ( 言語能力 )
g: var(spatial)
g: var(verbal)
g: var(err_v)
g: var(err_c)
g: var(err_l)
g: var(err_p)
g: var(err_s)
g: var(err_w)
少年の標本
b: cubes ( 空間視覚化力 ) <--- spatial ( 視覚能力 )
b: lozenges ( 方向認識力 ) <--- spatial ( 視覚能力 )
b: sentence ( 文理解力 ) <--- verbal ( 言語能力 )
b: wordmean ( 語彙力 ) <--- verbal ( 言語能力 )
b: spatial ( 視覚能力 ) <---> verbal ( 言語能力 )
b: var(spatial)
b: var(verbal)
b: var(err_v)
b: var(err_c)
b: var(err_l)
b: var(err_p)
b: var(err_s)
b: var(err_w)
0.610
1.198
1.334
2.234
7.315
23.302
9.682
23.873
11.602
28.275
2.834
7.967
19.925
推定値
0.450
1.510
1.275
2.294
6.840
16.058
6.904
31.571
15.693
36.526
2.364
6.035
19.697
モデル B
標準誤差
0.143
0.272
0.160
0.263
2.571
8.124
2.159
5.986
2.584
7.892
0.869
1.869
4.951
標準誤差
0.176
0.461
0.171
0.308
2.370
7.516
1.622
6.982
2.904
11.532
0.726
1.433
4.658
推定値
0.557
1.327
1.305
2.260
7.225
22.001
9.723
25.082
12.382
25.244
2.835
8.115
19.550
推定値
0.557
1.327
1.305
2.260
6.992
16.183
6.869
31.563
15.245
40.974
2.363
5.954
19.937
標準誤差
0.114
0.248
0.117
0.200
2.458
7.078
2.025
5.832
2.481
8.040
0.834
1.816
4.837
標準誤差
0.114
0.248
0.117
0.200
2.090
5.886
1.465
6.681
2.934
9.689
0.681
1.398
4.470
187
複数のグループの同時因子分析
2 つを除いて、 すべての標準誤差の推定値がモデル B の方が小 さ く な っ てい ます。 こ
れには、 制約条件のないパラ メ ータ も 含まれます。 こ れが、 モデル B が正 し い と い う こ
と を仮定 し て、 モデル A ではな く モデル B のパラ メ ータ 推定値を使用す る 理由です。
188
例 12
VB.NET でのモデル作成
モデル A
次のプ ロ グ ラ ム (Ex12-a.vb) は、 モデル A の少年少女を表 し てい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_fem.sav")
Sem.GroupName("Girls")
Sem.AStructure("visperc = (1) spatial + (1) err_v")
Sem.AStructure("cubes = spatial + (1) err_c")
Sem.AStructure("lozenges = spatial + (1) err_l")
Sem.AStructure("paragrap = (1)spatial + (1) err_p")
Sem.AStructure("sentence = spatial + (1) err_s")
Sem.AStructure("wordmean= spatial + (1) err_w")
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_mal.sav")
Sem.GroupName("Boys")
Sem.AStructure("visperc = (1) spatial + (1) err_v")
Sem.AStructure("cubes = spatial + (1) err_c")
Sem.AStructure("lozenges = spatial + (1) err_l")
Sem.AStructure("paragrap = (1)spatial + (1) err_p")
Sem.AStructure("sentence = spatial + (1) err_s")
Sem.AStructure("wordmean= spatial + (1) err_w")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
少年について も 、 少女 と 同 じ モデルを指定 し ます。 ただ し 、 少年のパ ラ メ ー タ 値は対
応す る 少女のパ ラ メ ー タ 値 と は異な る 場合があ り ます。
189
複数のグループの同時因子分析
モデル B
こ こ では、 モデル B に適合す る プ ロ グ ラ ム を示 し ます。 モデル B では、 い く つかのパ
ラ メ ー タ に同 じ 名前を付け、 等 し く な る よ う に制約条件を設定 し てい ます。 こ のプ ロ
グ ラ ムは、 Ex12-b.vb と い う 名前で保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_fem.sav")
Sem.GroupName("Girls")
Sem.AStructure("visperc = (1) spatial + (1) err_v")
Sem.AStructure("cubes = (cube_s) spatial + (1) err_c")
Sem.AStructure("lozenges = (lozn_s) spatial + (1) err_l")
Sem.AStructure("paragrap = (1)spatial + (1) err_p")
Sem.AStructure("sentence = (sent_v)spatial + (1) err_s")
Sem.AStructure("wordmean= (word_v)spatial + (1) err_w")
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_mal.sav")
Sem.GroupName("Boys")
Sem.AStructure("visperc = (1) spatial + (1) err_v")
Sem.AStructure("cubes = (cube_s) spatial + (1) err_c")
Sem.AStructure("lozenges = (lozn_s) spatial + (1) err_l")
Sem.AStructure("paragrap = (1)spatial + (1) err_p")
Sem.AStructure("sentence = (sent_v)spatial + (1) err_s")
Sem.AStructure("wordmean= (word_v)spatial + (1) err_w")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
例
13
平均値に関する仮説の推定および検定
概要
こ の例は、 平均値の推定方法お よ び平均値に関す る 仮説の検定方法を示 し ます。 大規
模な標本では、 こ こ で示す方法は多変量分散分析 と 同等です。
平均値 と 切片のモデル作成
Amos や同様の プ ロ グ ラ ム を 使用す る 場合、 通常は分散、 共分散、 係数 を 推定 し 、
こ れ ら のパ ラ メ ー タ に関す る 仮説 を 検定 し ま す。 平均値 と 切片は通常は推定せず、
平均値 と 切片に関す る 仮説は通常は検定 し ません。 平均値 と 切片は、こ れ ら のパ ラ メ ー
タ を含むモデルの指定は比較的難 し いため、 構造モデルの方程式か ら 外 さ れ る 場合 も
少な く あ り ません。
し か し 、 Amos は平均値 と 切片のモデル作成が容易にな る よ う に設計 さ れてい ます。
こ こ で示す例は、 平均値 と 切片を推定 し 、 仮説を検定す る 方法を示す最初の例です。
こ の例では、 モデルのパ ラ メ ー タ は分散、 共分散、 平均値のみか ら 構成 さ れ ま す。
後の例では、 回帰式に係数 と 切片を導入 し ます。
デー タ について
こ の例では、例 1 で説明 し た Attig (1983 年 ) の メ モ リ デー タ を使用 し ます。 こ こ では、
若者お よ び老人両方の被験者のデー タ を 使用 し ま す。 2 つの グ ループの生デー タ は、
UserGuide.xls と い う Microsoft Excel ワークブッ ク の Attg_yng および Attg_old ワークシー
ト に含まれてい ます。 こ の例で使用す る 測定値は、 記憶 1 お よ び助成記憶 1 だけです。
191
192
例 13
若者および老人の被験者のモデル A
例 10 のモデル B の分析では、 記憶 1 および助成記憶 1 は、 若者 と 老人の両方のグループ
について、 分散および共分散が同じ であ る と い う 結論にな り ま し た。 少な く と も、 見つ
かった仮説の反証は有意な も のではあ り ませんで し た。 こ の例でのモデル A は、 例 10 の
モデル B の分析に手を加えた も のです。 今回は、 2 つの変数 ( 記憶 1 および助成記憶 1) の
平均値 も推定し ます。
Amos Graphics の平均構造モデル
Amos Graphics では、 平均値に関す る 仮説の推定 と 検定は、 分散お よ び共分散構造の
分析 と それほ ど違い ません。 例 10 のモデル B を出発点に し ます。 若者 と 老人の被験者
は、 次の よ う な同 じ パ ス図を持っ てい ます。
両方のグループで、 同 じ パ ラ メ ー タ 名を使用 し ます。 こ れに よ り 、 必要なパ ラ メ ー タ
推定値が両グループで同 じ にな り ます。
例 10 には、平均値 と 切片はあ り ません。 こ のモデルに平均値 と 切片を導入す る には、
次の操作を実行 し ます。
E
メ ニ ュ ーか ら 、 [ 表示 ] [ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 推定 ] タ ブを ク リ ッ ク し ます。
193
平均値に関する仮説の推定および検定
E [ 平均値 と 切片を推定 ] を選択 し ます。
パ ス図は次の よ う にな り ます ( ど ち ら のグループ も 同 じ パ ス図です )。
パ ス図には、 各外生変数について、 パ ラ メ ー タ の平均値、 分散の組が表示 さ れてい ま
す。 こ のモデルには内生変数がないため、 切片はあ り ま せん。 パ ス 図の各変数につい
て、 カ ン マの後に分散の名前が続 き ます。 モデルの平均値は ま だ名前を付け ていない
ため、 カ ン マの前は空白にな っ てい ます。
[ 分析 ] メ ニ ュ ーか ら [ 推定値を計算 ] を選択す る と 、 Amos は 2 つの平均値、 2 つの
分散、 お よ び各グループの共分散を推定 し ます。 分散 と 共分散はグループ間で等 し く
な る と い う 制約条件があ り ますが、 平均値には制約条件はあ り ません。
194
例 13
[ 平均値 と 切片を推定 ] を選択 ( チ ェ ッ ク マー ク を付け る ) す る と 、 Amos Graphics の動
作は次の よ う に変わ り ます。
平均値 と 切片の フ ィ ール ド が [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス の
[ パラ メ ー タ ] タ ブに表示 さ れます。
係数、 分散、 共分散だけでな く 、 平均値 と 切片に も 制約条件を適用す る こ と がで
き ます。
メ ニ ュ ーか ら [ 分析 ] [ 推定値を計算 ] を選択す る と 、平均値 と 切片 — が推定 さ れま
す。 制約条件があ る 場合は適用 さ れます。
標本の共分散を入力 と し て与え る 場合、 標本の平均値を与え る 必要があ り ます。
[ 平均値 と 切片を推定 ] にチ ェ ッ ク マー ク を 「付けない」 場合は次の よ う にな り ます。
分散、 共分散、 お よ び係数の フ ィ ール ド だけが [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ
ア ロ グ ボ ッ ク ス の [ パ ラ メ ー タ ] タ ブに表示 さ れ ま す。 制約条件は こ れ ら のパ ラ
メ ー タ にのみ指定で き ます。
[ 推定値を 計算 ] を 選択す る 場合、 Amos は分散、 共分散、 係数は推定 し ま すが、
平均値 と 切片は推定 「 し ません」。
標本の平均値を与えずに、標本の共分散を入力 と し て与え る こ と がで き ます。 標本
の平均値を与え て も 無視 さ れます。
平均モデルを当てはめた後に [ 平均値 と 切片を推定 ] のチ ェ ッ ク マー ク を外 し た場
合、出力パ ス図には平均値 と 切片が残 り ます。 平均値 と 切片のない正 し い出力パ ス
図を表示す る には、 [ 平均値 と 切片を推定 ] のチ ェ ッ ク マー ク を外 し てか ら モデル
の推定値を 「再計算」 し ます。
以上の規則に従っ て [ 平均値 と 切片を推定 ] チ ェ ッ ク ボ ッ ク ス を使用 し て、 従来のパ ス
モデル と 同様に、 簡単に平均モデルの推定お よ び検定がで き ます。
モデル A の結果
テキス ト 出力
こ のモデルの自由度の数は、 例 10 のモデル B と 同 じ です。 こ こ では、 異な る 方法で
自由度を求め ます。 今回は、 独立な標本積率の数には標本の平均値だけでな く 、 標本
の分散お よ び共分散 も 含まれます。 若者の標本には、 2 つの分散、 1 つの共分散、 2 つ
の平均値があ り 、 合計 5 つの標本積率があ り ます。 同様に、 老人の標本に も 5 つの標
本積率があ り ます。 し たが っ て、両方の標本を合わせ る と 10 個の標本積率があ り ます。
推定パ ラ メ ー タ は 7 つあ り ます。 それぞれ、 var_rec ( 記憶 1 の分散 )、 var_cue ( 助成記
憶 1 の分散 )、 cov_rc ( 記憶 1 と 助成記憶 1 の共分散 )、 若者 と 老人の中での記憶 1 の平
均値 (2 つ )、 若者 と 老人の中での助成記憶 1 の平均値 (2 つ ) です。
195
平均値に関する仮説の推定および検定
し たが っ て、 自由度の数は次の よ う に計算 さ れます。
こ こ でのカ イ 2 乗統計量 も 、 例 10 のモデル B と 同 じ です。 通常の有意水準では、 若者
と 老人が同 じ 分散 と 共分散を持つ と い う 仮説は適用で き ます。
カ イ 2 乗 = 4.588
自由度 = 3
確率水準 = 0.205
こ こ に示すのは、 40 人の若者の被験者のパ ラ メ ー タ 推定値です。
こ こ に示すのは、 40 人の老人の被験者の推定値です。
平均値 を 除い て、こ れ ら の推定値は例 10 のモデル B で得 ら れた推定値 と 同 じ です。
標準誤差お よ び検定統計量の推定値 も 同 じ です。 こ の こ と は、 平均値に制約条件を指
定せずに平均値を推定 し て も 、 残 り のパ ラ メ ー タ や標準誤差の推定値には影響 し ない
こ と を示 し てい ます。
196
例 13
グ ラ フ ィ ッ ク出力
2 つのグループのパ ス図の出力を次に示 し ます。 各変数の隣に、平均値 と 分散の組が表
示 さ れてい ます。 た と えば、若者の被験者の場合、変数記憶 1 の平均の推定値は 10.25、
分散の推定値は 5.68 です。
若者および老人の被験者のモデル B
こ こ か ら は、 モデル A が正 し い と 仮定 し て、 両方のグループの記憶 1 お よ び助成記憶
1 の平均値が同 じ であ る と い う 、 よ り 限定的な仮説を考え ます。
記憶 1 お よ び助成記憶 1 の平均値に制約条件を指定す る には、 次の操作を実行 し ます。
E 記憶 1 を右 ク リ ッ ク し て、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を
選択 し ます。
E [オブジェ ク ト のプロパテ ィ ] ダ イ ア ロ グ ボ ッ ク ス の [ パラ メ ータ ] タ ブ を ク リ ッ ク し ます。
[ 平均値 ] テ キ ス ト ボ ッ ク ス には、 数値か名前のいずれかを入力で き ます。 こ こ では、
「mn_rec」 と い う 名前を入力 し ます。
197
平均値に関する仮説の推定および検定
E [ 全グループ ] を選択 し ます。 ([ 全グループ ] の隣にチ ェ ッ ク マー ク が表示 さ れます。
チ ェ ッ ク マー ク を付け る と 、 すべてのグループの記憶 1 の平均値に mn_rec と い う 名
前を割 り 当て、すべてのグループで記憶 1 の平均値が同 じ であ る こ と が要求 さ れます。)
E 記憶 1 の平均値に mn_rec と い う 名前を付けた後、 同 じ 手順で助成記憶 1 の平均値に
mn_cue と い う 名前を付け ます。
2 つのグループのパ ス図は、 次の よ う にな り ます。
こ のパ ス図は、 Ex13-b.amw フ ァ イ ルに保存 さ れてい ます。
モデル B の結果
平均値に新 し い制約条件を指定す る と 、 モデル B の自由度は 5 にな り ます。
通常の有意水準では、 モデル B は棄却 さ れます。
カ イ 2 乗 = 19.267
自由度 = 5
確率水準 = 0.002
198
例 13
モデル B と モデル A と の比較
モデル A が正 し く 、 モデル B が誤 り であ る 場合 ( こ れは、 モデル A は適用で き、 モデ
ル B は棄却 さ れた こ と か ら 理に適っ てい ます )、 平均値が等 し い と い う 仮定が誤っ て
い る こ と にな り ます。 分散 と 共分散が等 し い と い う 仮定の下で平均値が等 し い と い う
仮説を さ ら に検定す る には、 次の方法が あ り ま す。 モデル B を モデル A と 比較す る
と 、 カ イ 2 乗統計量の差は 14.679、 自由度の差は 2 です。 モデル B は、 モデル A に制
約条件を追加 し て得 ら れた ため、 モデル B が正 し い場合、 差の 14.679 は、 自由度の差
2 に よ る カ イ 2 乗変数についての観測値です。 こ の大 き さ のカ イ 2 乗値を得 ら れ る 確
率は 0.001 です。 し たが っ て、モデル A を受け入れてモデル B は棄却 し 、2 つのグルー
プの平均値は異な る と 結論す る こ と がで き ます。
モデル B を モデル A と 比較す る こ と は、 Amos の通常の多変量分散分析に非常に近
い方法です。 実際、 Amos の カ イ 2 乗検定は漸近的にのみ正 し い と い う 点 を 除いて、
Amos の検定は通常の MANOVA と 同等です。 対照的に、 こ の例の場合、 MANOVA で
は正確な検定を行 う こ と がで き ます。
複数のモデル入力
単一の分析でモデル A およびモデル B を両方当てはめ る こ と がで き ます。 Ex13-all.amw
フ ァ イ ルで こ の方法を示し ます。 単一の分析で両方のモデルを当てはめ る利点のひ と つ
は、 2 つのモデルが入れ子になっ てい る こ と を Amos が認識し、 カ イ 2 乗値の差だけで
な く 、 モデル B をモデル A に対し て検定する場合の p 値を自動的に計算する こ と です。
199
平均値に関する仮説の推定および検定
VB.NET での平均構造モデル作成
モデル A
こ こ で示すプ ロ グ ラ ム (Ex13-a.vb) は、 モデル A に適合 し ます。 こ のプ ロ グ ラ ムでは、
例 10 のモデル B で使用 し た分散 と 共分散の制限を保持 し 、 さ ら に平均値について も
制約条件を指定 し ます。
ModelMeansAndIntercepts メ ソ ッ ド を使用 し て、 ( 外生変数の ) 平均値お よ び ( 内生変
数の予測におけ る ) 切片が明示的なモデル パ ラ メ ー タ と し て推定 さ れ る よ う に指定 し
ます。
Mean メ ソ ッ ド は、記憶 1 お よ び助成記憶 1 の平均値を推定す る ために各グループで
2 回使用 し ます。 こ のプ ロ グ ラ ムで Mean メ ソ ッ ド を使用 し ない場合、記憶 1 お よ び助
成記憶 1 の平均値は 0 で固定 さ れます。 Amos プ ロ グ ラ ムで ModelMeansAndIntercepts
メ ソ ッ ド を使用す る 場合、 別の平均値を指定 し ない と 、 Amos では各外生変数の平均
値が 0 と 仮定 さ れます。 平均値を推定す る 外生変数につ き 1 回 Model メ ソ ッ ド を使用
す る 必要があ り ます。 ModelMeansAndIntercepts メ ソ ッ ド を使用す る 場合は、Amos プ
ロ グ ラ ムが こ の よ う に動作す る こ と を考慮す る 必要はあ り ません。
200
例 13
注 : Amos プ ロ グ ラ ムで Sem.ModelMeansAndIntercepts メ ソ ッ ド を使用する場合、平均
値を推定する外生変数ご と に 1 回、 Mean メ ソ ッ ド を呼び出す必要があ り ます。 Mean メ
ソ ッ ド を使用し て明示的に推定し ない外生変数は、 平均値が 0 と 仮定 さ れます。
こ の点が Amos Graphics と 違い ます。 Amos Graphics では、 [ 平均値 と 切片を推定 ] に
チ ェ ッ ク マー ク を 付け る と 、 平均値に明示的な制約条件が指定 さ れて い な い限 り 、
すべての外生変数の平均値が制約条件のないパ ラ メ ー タ と し て扱われます。
モデル B
次のプ ロ グ ラ ム (Ex13-b.vb) は、モデル B に適合 し ます。 グループに よ ら ない分散 と 共
分散が要求 さ れ る こ と に加え、 こ のプ ロ グ ラ ムではグループ間で等 し い平均値を持つ
こ と も 要求 さ れます。
201
平均値に関する仮説の推定および検定
複数のモデルを適合する
次のプ ロ グ ラ ムは、モデル A お よ びモデル B の両方に適合 し ます。 こ のプ ロ グ ラ ムは、
Ex13-all.vb と い う 名前で保存 さ れてい ます。
例
14
明示的な切片を持つ回帰
概要
こ の例は、 通常の回帰分析で切片を推定す る 方法を示 し ます。
Amos が行 う 仮定
通常、 あ る 変数が他の変数に線形従属す る と 指定す る 場合、 Amos では付加定数、
つ ま り 切片を含む従属を表す線形方程式を仮定 し ま すが、 切片の推定は行い ま せん。
た と えば例 4 では、 変数成果を他の 3 つの変数 ( 知識、 価値、 満足度 ) に線形従属す る
よ う に指定 し ま し た。 Amos では、 次の形式の回帰方程式を仮定 し ます。
成果 = a + b1 知識 + b2 価値 + b3 満足度 + error
こ こ で、b 1 、b 2 、b 3 は係数、 a は切片です。 例 4 では、 係数 b 1 か ら b 3 を推定 し ま し た。
Amos では、 例 4 の a は推定せず、 パス図に も 現れません。 それで も 、 回帰方程式に a
が存在する と 仮定 し て b 1 、b 2 、b 3 を推定 し ま し た。 同様に、 知識、 価値、 満足度 が平
均値を持つ と 仮定 し ま し たが、 平均値は推定せず、 パス図に も 現れません。 通常は回帰
方程式の平均値 と 切片を こ の方法で扱えば十分です。 し か し 、場合に よ っ ては切片を推
定 し た り 、 切片に関す る 仮説を検定 し た り す る必要があ る こ と も あ り ます。 その場合、
こ の例で示す手順に従 う 必要があ り ます。
デー タ について
こ こ では、 例 4 で最初に使用 し た Warren, White, Fuller (1974 年 ) のデー タ を も う 一度
使用 し ます。 こ こ では、 Examples デ ィ レ ク ト リ にあ る UserGuide.xls の Warren5v と い
う Excel ワ ー ク シー ト を使用 し ます。 以下に、 標本の積率 ( 平均値、 分散、 共分散 ) を
示 し ます。
203
204
例 14
モデルを指定する
例 4 で指定 し た も の と 同 じ 回帰モデルを指定で き ます。 例 4 の操作を行っ てい る 場合、
そのパ ス 図を こ の例の出発点 と し て使用で き ます。 Amos で平均値 と 切片を推定す る
には、 1 つだけ変更す る 必要があ り ます。
E
メ ニ ュ ーか ら [ 表示 ] [ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス の [ 推定 ] タ ブを ク リ ッ ク し ます。
E [ 平均値 と 切片を推定 ] を選択 し ます。
パ ス図は次の よ う にな り ます。
変数誤差の上に、 0, と い う 文字列が表示 さ れてい る こ と に注意 し て く だ さ い。 カ ン マ
の左の 0 は、 変数誤差の平均値が 0 で固定 さ れてい る こ と を示 し ます。 こ れは、 線形
回帰モデルでは通常の仮定です。 0, のカ ン マの右に何 も ないのは、 誤差の分散が定数
ではな く 、 名前を付け ら れていない こ と を表 し ます。
[ 平均値 と 切片を推定 ] にチ ェ ッ ク マー ク を付け る と 、 Amos では各予測変数につい
て平均値を推定 し 、 成果を予測す る回帰方程式の切片を推定 し ます。
205
明示的な切片を持つ回帰
分析の結果
テキス ト 出力
現在の分析では例 4 と 同 じ 結果にな り ますが、 3 つの平均値 と 1 つの切片が明示的に
推定 さ れます。 自由度の数は こ こ で も 0 ですが、自由度の計算は少 し 異な り ます。 標本
の平均値が こ の分析に必要です。 し たが っ て、 独立な標本積率の数には標本の分散 と
共分散だけでな く 平均値 も 含 ま れ ます。 標本には 4 つの平均値、 4 つの分散、 6 つの
共分散があ り 、 合計で 14 個の標本の積率があ り ます。 パ ラ メ ー タ 推定値については、
3 つの係数 と 1 つの切片があ り ます。 ま た、 3 つの予測変数には 3 つの平均値、 3 つの
分散、 3 つの共分散があ り ます。 最後に、 1 つの誤差分散があ り ます。 合計で 14 個の
パ ラ メ ー タ 推定値があ り ます。
自由度が 0 であ る ため、 検定す る 仮説はあ り ません。
カ イ 2 乗 = 0.000
自由度 = 0
確率水準の計算はで き ません。
206
例 14
係数、 分散、 共分散の推定は例 4 と 同 じ です。 ま た、 関係す る 標準誤差、 検定統計量、
p 値 も 同 じ です。
グ ラ フ ィ ッ ク出力
こ の例の標準化 さ れていない推定値を示すパ ス図を、 以下に示 し ます。 内生変数成果
の真上に切片 –0.83 が表示 さ れてい ます。
207
明示的な切片を持つ回帰
VB.NET でのモデル作成
参照用に、 例 4 の Amos プ ロ グ ラ ム ( 方程式版 ) を こ こ に示 し ます。
次の例 14 のモデルのプ ロ グ ラ ムは、 同 じ 結果に加え て、 平均値 と 切片の推定値を与え
ます。 こ のプ ロ グ ラ ムは、 Ex14.vb と い う 名前で保存 さ れてい ます。
Sem.ModelMeansAndIntercepts ス テー ト メ ン ト に よ り Amos が平均値 と 切片を明示的
なモデル パ ラ メ ー タ と し て扱 う こ と に注意 し て く だ さ い。 も う 1 つの例 4 と の違いは、
AStructure の行に、1 組の空のかっ こ と プ ラ ス記号を追加 し てい る こ と です。 追加 し た
空のか っ こ は、 回帰方程式の切片を表 し ます。
208
例 14
Sem.Mean ス テー ト メ ン ト に よ り 、 知識、 価値、 満足度 の平均の推定値を求め ます。
Mean メ ソ ッ ド の呼び出 し では、0 以外の平均値を持つ外生変数を それぞれ引数 と し て
指定す る 必要があ り ます。 こ のプ ロ グ ラ ムで Mean メ ソ ッ ド を使用 し ない場合、 Amos
では外生変数の平均値は 0 で固定 さ れます。
切片パ ラ メ ー タ は、( こ の例で示 し た よ う に ) Sem.AStructure コ マ ン ド で 1 組のかっ
こ を追加す る こ と で指定で き ますが、 Intercept メ ソ ッ ド を使用 し て指定す る こ と も で
き ます。 次のプ ロ グ ラ ム では、 Intercept メ ソ ッ ド を使用 し て、 成果を予測す る 回帰方
程式に切片が存在す る こ と を指定 し ます。
例
15
構造平均によ る因子分析
概要
こ の例は、複数の母集団のデータ の共通因子分析で因子平均を推定する方法を示し ます。
因子平均
伝統的に、 共通因子分析モデルでは、 変数の平均値に関す る 仮定は行い ません。 特に、
モデルでは共通因子の平均に関す る 仮定は行い ません。 実際、 因子平均を推定 し た り 、
従来の単一標本の因子分析で仮説を検定 し た り す る こ と は不可能です。
し か し 、 Sörbom (1974 年 ) は、 複数の母集団のデー タ を分析す る 限 り 、 適切な仮定
の下で因子平均について推論す る こ と が可閥であ る こ と を示 し ま し た。 Sörbom の手法
を使用す る と 、すべての母集団のすべての因子の平均を推定す る こ と はで き ませんが、
母集団間の因子平均の差を推定す る こ と はで き ます。 た と えば、 共通因子分析モデル
を少女の標本 と 少年の標本に同時に当てはめた例 12 を考え ます。 各グループに 2 つの
共通因子があ り 、言語能力 (verbal) お よ び空間能力 (spatial) と 解釈 さ れま し た。 例 12 で
使用 し た方法では、 言語能力の平均や空間能力の平均を調査で き ません。 Sörbom の方
法では こ れが可能です。 Sörbom の方法では、 少女ま たは少年の ど ち ら について も 平均
値を推定す る こ と はで き ませんが、 各因子について、 少女 と 少年の平均値の差を推定
す る こ と はで き ます。 こ の方法では、 因子平均の差についての有意確率の検定 も で き
ます。
因子分析モデルの状態の特定は、 因子平均を推定す る 場合の難 し い問題です。 実際、
Sörbom の業績は、 パ ラ メ ー タ に制約条件を課 し て、 因子分析モデルを特定 し て因子平
均の差を推定す る 方法を示 し た こ と です。 こ こ では、Sörbom のガ イ ド ラ イ ンに従っ て、
こ の例のモデルを特定 し ます。
209
210
例 15
デー タ について
こ こ では、例 12 の Holzinger と Swineford (1939 年 ) のデー タ を使用 し ます。 少女のデー
タ セ ッ ト は Grnt_fem.sav にあ り ます。 少年のデータ セ ッ ト は Grnt_mal.sav にあ り ます。
少年 と 少女のモデル A
モデルを指定する
こ の例では、 少年 と 少女の空間能力の平均は同 じ であ り 、 言語能力の平均 も 同 じ であ
る と い う 帰無仮説を検定す る ためのモデルを構成す る 必要があ り ます。 こ こ で、 空間
能力お よ び言語能力は共通因子 で す。 こ の仮説に意味 を 持 た せ る に は、 視覚能力
(spatial) お よ び言語能力 (verbal) を、少年に対 し て も 少女に対 し て も 同様に観測変数に
関連付け る 必要があ り ます。 こ れは、 少女の係数 と 切片を、 少年の係数 と 切片に等 し
く す る 必要があ る と い う こ と です。
例 12 のモデル B は、 こ の例のモデル A を指定す る ための出発点 と し て使用で き ま
す。 例 12 のモデル B を出発点 と し て、 以下の操作を実行 し ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 推定 ] タ ブを ク リ ッ ク し ます。
E [ 平均値 と 切片を推定 ] を選択 し ます ( 隣にチ ェ ッ ク マー ク が表示 さ れます )。
係数は既にグループ間で等 し い と い う 制約条件を指定 さ れてい ます。 切片がグループ
間で等 し い と い う 制約条件を設定す る には、 次の操作を実行 し ます。
E visperc ( 視覚認知力 ) な ど の観測変数の 1 つを右 ク リ ッ ク し ます。
E ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
E [オブジェ ク ト のプロパテ ィ ] ダイ ア ロ グ ボ ッ ク ス で、[パラ メ ータ ] タブを ク リ ッ ク し ます。
E [ 切片 ] テ キ ス ト ボ ッ ク ス に、 「int_vis」 な ど のパ ラ メ ー タ 名を入力 し ます。
E [ 全グループ ] を選択 し 、 両方のグループで切片の名前を 「int_vis」 に し ます。
E 同 じ 操作を繰 り 返 し て、 残 り の 5 つの切片に も 名前を付け ます。
Sörbom が示 し た よ う に、1 つのグループの因子平均を定数に固定す る 必要があ り ます。
こ こ では、 少年の視覚能力 (spatial) お よ び言語能力 (verbal) を 0 に固定 し ます。 例 13
では、 変数の平均値を定数値に固定す る 方法を示 し てい ます。
211
構造平均によ る因子分析
注 : [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を使用 し て少年の因子平均を 0
に固定す る 場合、[ 全グループ ] のチ ェ ッ ク マー ク を付けない よ う に注意 し て く だ さ い。
少年の因子平均を 0 に固定 し てか ら 、 同 じ 手順に従っ て、 少女の因子平均に も 名前を
割 り 当て ます。 こ の時点で、 少女のパ ス図は次の よ う にな り ます。
少年のパ ス図は次の よ う にな り ます。
212
例 15
グループ間の制約条件について
切片お よ び係数に関す る グループ間の制約条件は、 母集団に よ っ て満た さ れ る 場合 と
満た さ れない場合があ り ます。 モデルを当てはめた結果の 1 つが、 こ れ ら の制約条件
が少女 と 少年の母集団で保持 さ れ る か ど う かの検定にな り ます。 こ れ ら の制約条件か
ら 始めた理由は、 (Sörbom が指摘 し てい る よ う に ) 因子平均を推定す る 場合、 モデルを
特定す る ためには切片お よ び係数に関す る 制約条件のい く つかを課す必要があ る ため
です。 こ れ ら の制約条件だけがモデル を特定す る ための制約条件では あ り ま せんが、
妥当 と 思われ る も のです。
少年 と 少女のパス図の唯一の違いは、2 つの因子平均の制約条件にあ り ます。 少年の
場合、 平均は 0 で固定 さ れてい ま す。 少女の場合、 両方の因子平均が推定 さ れ ま す。
少女の因子平均には mn_s お よ び mn_v と い う 名前が付け ら れてい ますが、それぞれの
因子平均に固有の名前が付け ら れてい る ため、 因子平均には制約条件はあ り ません。
少年の因子平均は、 モデル を 特定す る た めに 0 に固定 さ れて い ま す。 Sörbom は、
こ こ で ま っ た く 違 う 制約条件を課 し た と し て も 、 少年 と 少女の因子平均を同時に推定
す る こ と は不可能であ る こ と を示 し ま し た。 例 と し て、言語能力を考え ます。 少年の言
語能力の平均を あ る 定数 (0 な ど ) に固定す る 場合、 少女の言語能力の平均を推定す る
こ と が で き ま す。 別の方法 と し て、 少女の言語能力の平均 を あ る 定数に固定 し て、
少年の言語能力の平均を推定す る こ と も で き ます。 残念なが ら 、 両方の平均を同時に
推定す る こ と はで き ません。 その代わ り 、 ど ち ら の平均を固定 し た場合 も 、 その平均
を ど んな値に固定 し た場合 も 、 少年の平均 と 少女の平均の差は同 じ にな り ます。
モデル A の結果
テキス ト 出力
通常の有意水準では、 モデル A を棄却す る 理由はあ り ません。
カ イ 2 乗 = 22.593
自由度 = 24
確率水準 = 0.544
213
構造平均によ る因子分析
グ ラ フ ィ ッ ク出力
こ こ で関心があ る のは、 主に言語能力の平均 と 空間能力の平均の推定値です。 他のパ
ラ メ ー タ の推定値にはあ ま り 関心はあ り ません。 し か し 、 通常どお り 、 すべての推定
値が妥当であ る か確かめ る必要があ り ます。 こ こ に示すのは、 73 人の少女の標準化 さ
れていないパ ラ メ ー タ 推定値です。
214
例 15
こ こ に示すのは、 少年の推定値です。
少女の空間能力の平均の推定値は –1.07 です。 少年の空間能力の平均は 0 で固定 し て
い ます。 し たが っ て、 少女の空間能力の平均は、 少年の空間能力の平均 よ り も 1.07 単
位だけ低い と 推定 さ れてい ます。 こ の差は、 最初に少年の平均を 0 に固定 し た こ と に
は影響 さ れません。 少年の平均を 10.000 に固定 し ていた場合、 少女の平均は 8.934 と
推定 さ れてい ま し た。 少女の平均を 0 に固定 し ていた場合、 少年の平均は 1.07 と 推定
さ れてい ま し た。
空間能力は ど の よ う な単位で表 さ れてい る ので し ょ う か。 空間能力の 1.07 単位の
差は、 単位の大 き さ に応 じ て大 き な差に も 小 さ い差に も な り ます。 空間能力の visperc
( 視覚認知力 ) を回帰す る 係数は 1 に等 し いので、 空間能力は visperc ( 視覚認知力 ) の
検定の得点 と 同 じ 単位で表 さ れてい る と い う こ と がで き ます。 も ち ろ ん、 こ れはユー
ザーが visperc ( 視覚認知力 ) の検定に詳 し く ない と 有用な情報にはな り ません。 visperc
( 視覚認知力 ) に関係な く 1.07 と い う 平均の差を評価す る 別の方法 も あ り ます。 こ こ に
は載せてい ませんが、 テ キ ス ト 出力の一部に、 少年の spatial ( 視覚能力 ) の分散の推定
値は 15.752 で あ り 、 標準偏差は約 4.0 で あ る こ と が示 さ れ て い ま す。 少女の場合、
spatial ( 視覚能力 ) の分散の推定値は 21.188、 標準偏差は約 4.6 です。 こ の大 き さ の標
準偏差では、 通常は 1.07 と い う 差はあ ま り 大 き い と は考え ら れません。
少女 と 少年の間の、 1.07 単位の差の統計上の有意性は容易に評価で き ます。 少年の
平均は 0 に固定 さ れてい る ため、 必要なのは少女の平均が 0 か ら 大 き く 離れてい る か
ど う か を調べ る こ と だけです。
215
構造平均によ る因子分析
こ こ に、 テ キ ス ト 出力の少女の因子平均の推定値を示 し ます。
少女の空間能力の平均の検定統計量は –1.209 で、 0 か ら 大 き く 離れ て は い ま せん
( p = 0.226 )。 言い換え る と 、 少年の平均か ら 大 き く 離れてはい ません。
言語能力に注目す る と 、 少女の平均は、 少年の平均 よ り 0.96 単位高い と 推定 さ れ
ま す。 言語能力の標準偏差は、 少年では約 2.7、 少女では約 3.15 です。 し たが っ て、
言語能力の 0.96 単位は、 一方のグループの標準偏差の約 1/3 です。 少年 と 少女の間の
差は、 0.05 レベルで有意 と な り ます ( p = 0.066 )。
少年 と 少女のモデル B
モデル A の議論では、 検定統計量を使用 し て 2 回の有意差検定を行い ま し た。 空間能
力におけ る 性別の違いについての検定 と 、 言語能力におけ る 性別の違いについての検
定です。 こ こ では、 空間能力 ま たは言語能力のいずれにおいて も 性別に よ る 違いはな
い と い う 帰無仮説の検定を行い ます。 こ のため、 少年 と 少女が空間能力で も 言語能力
で も 同 じ 平均値を持つ と い う 制約条件を追加 し て分析を繰 り 返 し ます。 少年の平均値
は既に 0 に固定 さ れてい る ため、 少女の平均値を少年の平均値 と 同 じ にす る と い う こ
と は、 少女の平均値 も 0 にす る と い う こ と です。
少女の因子平均には、 mn_s お よ び mn_v と い う 名前が付け ら れてい ます。 平均値を 0
に固定す る には、 次の操作を実行 し ます。
E
メ ニ ュ ーか ら [ 分析 ] [ モデルを管理 ] の順に選択 し ます。
E [ モデル管理 ] ダ イ ア ロ グ ボ ッ ク ス の [ モデル名 ] テ キ ス ト ボ ッ ク ス に 「Model A」 と
入力 し ます。
216
例 15
E [ パ ラ メ ー タ 制約 ] ボ ッ ク ス は空白の ま ま残 し てお き ます。
E [ 新規作成 ] を ク リ ッ ク し ます。
E [ モデル名 ] テ キ ス ト ボ ッ ク ス に 「Model B」 と 入力 し ます。
E [ パ ラ メ ー タ 制約 ] テ キ ス ト ボ ッ ク ス に 「mn_s = 0」 お よ び 「mn_v = 0」 と い う 制約
条件を入力 し ます。
E [ 閉 じ る ] を ク リ ッ ク し ます。
こ こ で [ 分析 ] [ 推定値を計算 ] を選択す る と 、 Amos はモデル A お よ びモデル B の両
方を当てはめ ます。 Ex15-all.amw フ ァ イ ルには、 こ の 2 つのモデルの設定があ り ます。
217
構造平均によ る因子分析
モデル B の結果
モデル A を比較の基準 と し て使用 し ない場合、 通常の有意水準を使用す る と 、 モデル
B は適用可能です。
カ イ 2 乗 = 30.624
自由度 = 26
確率水準 = 0.243
モデル A およびモデル B の比較
モデル B の検定の別の方法 と し て、 モデル A が正 し い と 仮定 し て、 モデル B がモデ
ル A よ り も 大 き く 劣っ た適合を し ないか ど う かを検定す る こ と も で き ます。 こ の比較
についてのカ イ 2 乗検定はテ キ ス ト 出力で与え ら れます。
E [Amos 出力 ] ウ ィ ン ド ウ で、左上のペ イ ンの ツ リ ー図にあ る [ モデル比較 ] を ク リ ッ ク し
ます。
こ の表は、モデル B にはモデル A よ り も 2 多い自由度があ り 、カ イ 2 乗統計量は 8.030
だけ大 き い こ と を示 し てい ます。 モデル B が正 し い場合、 カ イ 2 乗の値が こ の よ う な
大 き い差にな る 確率は 0.018 であ り 、 モデル B に対す る 反証 と な り ます。
218
例 15
VB.NET でのモデル作成
モデル A
モデル A に適合す る プ ロ グ ラ ム を次に示 し ます。 こ のプ ロ グ ラ ムは Ex15-a.vb と し て
保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_fem.sav")
Sem.GroupName("Girls")
(1) spatial + (1) err_v")
Sem.AStructure("visperc = (int_vis) +
Sem.AStructure("cubes = (int_cub) + (cube_s) spatial + (1) err_c")
Sem.AStructure("lozenges = (int_loz) + (lozn_s) spatial + (1) err_l")
(1)spatial + (1) err_p")
Sem.AStructure("paragrap = (int_par) +
Sem.AStructure("sentence = (int_sen) + (sent_v)spatial + (1) err_s")
Sem.AStructure("wordmean= (int_wrd) + (word_v)spatial + (1) err_w")
Sem.Mean("spatial ", "mn_s")
Sem.Mean("verbal", "mn_v")
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_mal.sav")
Sem.GroupName("Boys")
(1) spatial + (1) err_v")
Sem.AStructure("visperc = (int_vis) +
Sem.AStructure("cubes = (int_cub) + (cube_s) spatial + (1) err_c")
Sem.AStructure("lozenges = (int_loz) + (lozn_s) spatial + (1) err_l")
Sem.AStructure("paragrap = (int_par) +
(1)spatial + (1) err_p")
Sem.AStructure("sentence = (int_sen) + (sent_v)spatial + (1) err_s")
Sem.AStructure("wordmean= (int_wrd) + (word_v)spatial + (1) err_w")
Sem.Mean("spatial ", "0")
Sem.Mean("verbal", "0")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
AStructure メ ソ ッ ド は、 各内生変数につ き 1 回呼び出 さ れ ま す。 少女の グ ループで
Mean メ ソ ッ ド を使用 し て、 言語能力お よ び空間能力の因子が制約な く 推定 さ れ る よ
う に指定 し ます。 プ ロ グ ラ ムでは、 Mean メ ソ ッ ド を使用 し て、 少年のグループにおけ
る 言語能力お よ び空間能力の平均が 0 にな る と い う 指定 も 行っ てい ま す。 実際には、
Amos ではデフ ォ ル ト で平均を 0 と 仮定 し ます。 し たが っ て、 少年に対す る Mean メ
ソ ッ ド は必要あ り ません。
219
構造平均によ る因子分析
モデル B
モデル B に適合す る プ ロ グ ラ ム を次に示 し ます。 こ のモデルでは、 少年 と 少女の両方
の因子平均が 0 に固定 さ れてい ます。 こ のプ ロ グ ラ ムは、 Ex15-b.vb と し て保存 さ れて
い ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Dim dataFile As String = Sem.AmosDir & "Examples¥userguide.xls"
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(dataFile, "grnt_fem")
Sem.GroupName("Girls")
(1) spatial + (1) err_v")
Sem.AStructure("visperc = (int_vis) +
Sem.AStructure("cubes = (int_cub) + (cube_s) spatial + (1) err_c")
Sem.AStructure("lozenges = (int_loz) + (lozn_s) spatial + (1) err_l")
Sem.AStructure("paragraph = (int_par) +
(1)spatial + (1) err_p")
Sem.AStructure("sentence = (int_sen) + (sent_v)spatial + (1) err_s")
Sem.AStructure("wordmean= (int_wrd) + (word_v)spatial + (1) err_w")
Sem.Mean("spatial ", "0")
Sem.Mean("verbal", "0")
Sem.BeginGroup(dataFile, "grnt_mal")
Sem.GroupName("Boys")
(1) spatial + (1) err_v")
Sem.AStructure("visperc = (int_vis) +
Sem.AStructure("cubes = (int_cub) + (cube_s) spatial + (1) err_c")
Sem.AStructure("lozenges = (int_loz) + (lozn_s) spatial + (1) err_l")
(1)spatial + (1) err_p")
Sem.AStructure("paragraph = (int_par) +
Sem.AStructure("sentence = (int_sen) + (sent_v)spatial + (1) err_s")
Sem.AStructure("wordmean= (int_wrd) + (word_v)spatial + (1) err_w")
Sem.Mean("spatial ", "0")
Sem.Mean("verbal", "0")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
220
例 15
複数のモデルの当てはめ
次のプ ロ グ ラ ム (Ex15-all.vb) は、 モデル A と モデル B の両方に適合 し ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_fem.sav")
Sem.GroupName("Girls")
(1) spatial + (1) err_v")
Sem.AStructure("visperc = (int_vis) +
Sem.AStructure("cubes = (int_cub) + (cube_s) spatial + (1) err_c")
Sem.AStructure("lozenges = (int_loz) + (lozn_s) spatial + (1) err_l")
Sem.AStructure("paragrap = (int_par) +
(1)spatial + (1) err_p")
Sem.AStructure("sentence = (int_sen) + (sent_v)spatial + (1) err_s")
Sem.AStructure("wordmean= (int_wrd) + (word_v)spatial + (1) err_w")
Sem.Mean("spatial ", "mn_s")
Sem.Mean("verbal", "mn_v")
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_mal.sav")
Sem.GroupName("Boys")
(1) spatial + (1) err_v")
Sem.AStructure("visperc = (int_vis) +
Sem.AStructure("cubes = (int_cub) + (cube_s) spatial + (1) err_c")
Sem.AStructure("lozenges = (int_loz) + (lozn_s) spatial + (1) err_l")
(1)spatial + (1) err_p")
Sem.AStructure("paragrap = (int_par) +
Sem.AStructure("sentence = (int_sen) + (sent_v)spatial + (1) err_s")
Sem.AStructure("wordmean= (int_wrd) + (word_v)spatial + (1) err_w")
Sem.Mean("spatial ", "0")
Sem.Mean("verbal", "0")
Sem.Model("Model A")
' 因子平均の性別によ る差
Sem.Model("Model B", "mn_s=0", "mn_v=0") ' 因子平均を等 し く する
Sem.FitAllModels()
Finally
Sem.Dispose()
End Try
End Sub
例
16
共分散分析に対する Sörbom の代替案
概要
こ の例は、 2 つ以上のグループでの長期的な観測に よ る 潜在的な構造方程式モデルの
作成、 潜在変数 と 自己相関残差を取 り 入れて従来の共分散分析技術を一般化す る モデ
ル (1978 年の Sörbom と 比較 し ます )、 お よ び従来の共分散分析で行われた仮定の検定
方法を示 し ます。
前提条件
例 9 では、 従来の共分散分析に対 し て、 信頼で き ない共変量があ る 場合で も 使用で き
る 代替案を示 し ま し た。 残念なが ら 、 共分散分析は完全に信頼で き る 共変量を仮定す
る 以外に も 前提条件が必要で、例 9 の方法は他の前提条件に も 依存 し てい ます。Sörbom
(1978 年 ) は、 こ れ ら の前提条件の多 く を検定 し 、 前提条件の一部を緩和す る こ と がで
き る 、 よ り 一般的な方法を開発 し ま し た。
こ の例では、Sörbom が自分の方法を紹介す る ために使用 し たの と 同 じ デー タ を使用
し ます。 説明 も Sörbom の解説に厳密に従い ます。
221
222
例 16
デー タ について
こ こ では、 例 9 で紹介 し た Olsson (1973 年 ) のデー タ を も う 一度使用 し ます。 108 人の
実験被験者か ら 得た標本の平均値、 分散、 共分散は、 UserGuide.xls と い う Microsoft
Excel ワ ー ク ブ ッ ク の Olss_exp ワ ー ク シー ト に格納 さ れてい ます。
105 人の統制群の被験者か ら 得た標本の平均値、 分散、 共分散は、 Olss_cnt ワ ー ク シー
ト に格納 さ れてい ます。
両方のデー タ セ ッ ト に、分散 と 共分散の通例の不偏推定値が含まれてい ます。 つま り 、
共分散行列の要素は ( N – 1 ) で割 る こ と で得 ら れます。 こ れは、 Amos が共分散行列を
読み込むために使用す る デフ ォ ル ト の設定で も あ り ます。 ただ し 、 モデルの当てはめ
の場合は、 デフ ォ ル ト の動作は (N で割っ て得 ら れ る ) 母集団共分散行列の最尤法の推
定を標本の共分散行列 と し て使用 し ます。 Amos では、不偏推定値か ら 最尤法の推定値
に自動的に移行 し ます。
223
共分散分析に対する Sörbom の代替案
デ フ ォル ト の動作の変更
E
メ ニ ュ ーか ら 、 [ 表示 ] [ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス の [ 分散 タ イ プ ] タ ブを ク リ ッ ク し ます。
Amos で使用 さ れ る デフ ォ ル ト の設定では、 デー タ モデルの欠損値に一致す る 結果を
得 ら れます ( 例 17 お よ び例 18 で解説 し ます )。 LISREL (Jöreskog と Sörbom、 1989 年 )
や EQS (Bentler、 1985 年 ) な ど の他の SEM プ ロ グ ラ ムでは、 代わ り に不偏積率を分析
し 、 標本のサ イ ズが小 さ い場合はわずかに異な る 結果にな り ます。 [ 分散 タ イ プ ] タ ブ
の [ 不偏推定値共分散 ] オプシ ョ ン を両方選択す る と 、 Amos では LISREL や EQS と 同
じ 推定値を生成 し ます。 付録 B では、 共分散行列の最尤法の推定値 と 不偏推定値の ど
ち ら を選択 し て当てはめを行 う かに関す る ト レー ド オ フ について、詳 し く 解説 し ます。
224
例 16
モデル A
モデルを指定する
Olsson のデー タ に対 し て、 Sörbom の最初のモデル ( モデル A) を考え ます。 統制群の
パ ス図は次の よ う にな り ます。
次のパス図は、 実験群のモデル A です。
こ のモデルでは平均値 と 切片が重要であ る ため、 次の操作を し っ か り と 実行 し て く だ
さ い。
E
メ ニ ュ ーか ら 、 [ 表示 ] [ 分析のプ ロパテ ィ ] を選択 し ます。
225
共分散分析に対する Sörbom の代替案
E [ 推定 ] タ ブを ク リ ッ ク し ます。
E [ 平均値 と 切片を推定 ] を選択 し ます ( 隣にチ ェ ッ ク マー ク が表示 さ れます )。
モデル A の各グループで、 pre_syn ( 同意語 ( 事前 )) と pre_opp ( 反意語 ( 事前 )) が
pre_verbal ( 言語能力 ( 事前 )) と い う 単一の潜在変数の指標で あ り 、 post_syn ( 同意語
( 事後 )) と post_opp ( 反意語 ( 事後 )) が post_verbal ( 言語能力 ( 事後 )) と い う 別の潜在変
数の指標であ る こ と が指定 さ れます。 潜在変数 pre_verbal ( 言語能力 ( 事前 )) は学習開
始時の言語能力、 post_verbal ( 言語能力 ( 事後 )) は学習終了時の言語能力 と 解釈 さ れま
す。 こ れが Sörbom の測定モデルです。 構造モデルでは、 post_verbal ( 言語能力 ( 事後 ))
は pre_verbal ( 言語能力 ( 事前 )) に線形従属す る と 指定 さ れます。
opp_v1 と opp_v2 の ラ ベルに よ り 、 測定モデルの係数が両方のグループで同 じ であ
る こ と が要求 さ れ ま す。 同様に、 a_syn1 、 a_opp1、 a_syn2、 a_opp2 ラ ベルに よ り 、
測定モデルの切片が両方のグループで同 じ であ る こ と が要求 さ れ ます。 こ の等質性の
制約条件は、 誤っ た仮定で あ る 可能性 も あ り ます。 実際、 こ れか ら 行 う 分析の結果の
1 つは、 こ れ ら の仮定の検定にな り ます。 Sörbom が指摘 し てい る よ う に、 構造モデル
のパ ラ メ ー タ に関す る 仮説を推定お よ び検定で き る よ う にす る ためには、 測定モデル
のパ ラ メ ー タ に関す る い く つかの仮定を行 う 必要があ り ます。
統制群の被験者については、pre_verbal ( 言語能力 ( 事前 )) の平均値お よ び post_verbal
( 言語能力 ( 事後 )) の切片が 0 に固定 さ れてい ます。 こ れに よ り 、 グループの比較を行
う 場合は統制群が参照す る 群にな り ま す。 潜在変数の平均値 と 切片を特定す る には、
こ の よ う な統制群を選ぶ必要があ り ます。
実験被験者の場合、 潜在因子のパ ラ メ ー タ の平均値 と 切片は、 0 以外の値を と る こ
と が可能です。 pre_diff ラ ベルの付いた潜在変数の平均値は試験前の言語能力の差を
表 し 、 effect ラ ベルの付いた切片は統制群 と 比較 し た実験群の向上度を表 し ます。 こ の
例のパ ス図は、 Ex16-a.amw フ ァ イ ルに保存 さ れてい ます。
Sörbom のモデルでは、 6 つの観測 さ れない外生変数の分散にグループ間の制約条件
を課 し ていない こ と に注意 し て く だ さ い。 つま り 、4 つの観測変数は統制状態 と 実験状
態で異な る 固有の分散を持ち、 pre_verbal ( 言語能力 ( 事前 )) お よ び zeta の分散 も 2 つ
のグループで異な る場合があ り ます。 モデル X、 モデル Y、 お よ びモデル Z を作成す
る と き に、 こ れ ら の仮定を よ り 厳密に調査 し ます。
モデル A の結果
テキス ト 出力
[Amos 出力 ] ウ ィ ン ド ウ で、左上のペ イ ンのツ リ ー図にあ る [ モデルについての注釈 ] を
ク リ ッ ク す る と 、 モデル A は通常の有意水準では適用で き ない こ と が示 さ れます。
カ イ 2 乗 = 34.775
自由度 = 6
確率水準 = 0.000
226
例 16
モデル A が誤 り であ る こ と を示す次の メ ッ セージ も 出力 さ れます。
実験群 と 統制群を意味のあ る 比較がで き る よ う に し た ま ま、 デー タ に適合す る よ う に
モデル A を修正す る こ と は可能で し ょ う か。 こ こ では、 分析を繰 り 返 し て修正指数を
要求す る こ と が有効です。 修正指数を得 る には、 次の操作を実行 し ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ]
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス の [ 出力 ] タ ブを ク リ ッ ク し ます。
E [ 修正指数 ] を選択 し 、[ 修正指数 ] の右にあ る テ キ ス ト ボ ッ ク ス に適切な し き い値を入
力 し ます。 こ の例では、 し き い値はデフ ォ ル ト 値の 4 の ま ま に し ます。
こ こ に示すのは、 実験群か ら 出力 さ れた修正指数です。
統制群では、 し き い値の 4 よ り 大 き い修正指数を持つパ ラ メ ー タ はあ り ません。
227
共分散分析に対する Sörbom の代替案
モデル B
モデル A で得 ら れた修正指数の最大値か ら 、 実験群の eps2 と eps4 の間の共分散を追
加す る こ と が示唆 さ れます。 修正指数が示すのは、 eps2 と eps4 が 0 でない共分散を持
つ こ と がで き る 場合、 カ イ 2 乗統計量は少な く と も 10.508 下が る と い う こ と です。
変更パ ラ メ ー タ の統計量 4.700 は、 共分散の推定値が任意の値を と る こ と がで き る 場
合、 共分散の推定値が正の値にな る こ と を示 し てい ます。 提示 さ れた修正値は妥当な
値です。 eps2 は pre_opp ( 反意語 ( 事前 )) の固有の分散を表 し 、 eps4 は post_opp ( 反意
語 ( 事後 )) の固有の分散 を 表 し ま す。 pre_opp ( 反意語 ( 事前 )) と post_opp ( 反意語
( 事後 )) の測定値は、 2 つの異な る 状況で同 じ 検定 ( 反意語 ) を実施 し て得 ら れ ま す。
し たが っ て、 eps2 お よ び eps4 が正の相関関係を持つ と 考え る のは妥当です。
次に、 変更 さ れたモデルを考え ます。 こ のモデル B では、 eps2 および eps4 は、 実験
群内で相関関係を持つ こ と がで き ます。 モデル A か ら モデル B を得る には、次の操作を
実行し ます。
E eps2 と eps4 を結ぶ両矢印を引 き ます。
矢印を引 く こ と で、 eps2 と eps4 は両グループで相関関係を持つ こ と がで き ます。 統制
群では相関 さ せた く な いので、 統制群では共分散 を 0 に固定す る 必要が あ り ま す。
手順は次の と お り です。
E ( パ ス図の左にあ る ) [ グループ ] パネルで control を ク リ ッ ク し て、 統制群のパ ス図を
表示 し ます。
E 両矢印を右 ク リ ッ ク し て、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を
選択 し ます。
E [ オブジェ ク ト のプロパテ ィ ] ダ イ ア ロ グ ボ ッ ク ス の [ パラ メ ー タ ] タブを ク リ ッ ク し ます。
E [ 共分散 ] テ キ ス ト ボ ッ ク ス に 「0」 と 入力 し ます。
E [ 全グループ ] のチ ェ ッ ク ボ ッ ク ス が空であ る こ と を確認 し ます。 チ ェ ッ ク ボ ッ ク ス が
空の場合、 共分散の制約条件は統制群にのみ適用 さ れます。
228
例 16
モデル B の統制群のパ ス図を こ こ に示 し ます。
実験群のパ ス図は次の よ う にな り ます。
229
共分散分析に対する Sörbom の代替案
モデル B の結果
モデル A か ら モデル B に移行す る と 、 カ イ 2 乗統計量は ( 見込みの 10.508 よ り 大 き く )
17.712 下が り 、 自由度の数は 1 だけ下が り ます。
カ イ 2 乗 = 17.063
自由度 = 5
確率水準 = 0.004
モデル B はモデル A よ り は改善 さ れてい ますが、 十分な改善ではあ り ません。 モデル
B は、 ま だデー タ に う ま く 適合 し ません。 さ ら に、 統制群の zeta の分散は、 モデル A
の場合 と 同 じ く 負の推定値を持ち ます ( こ こ では示 し ません )。 こ れ ら の 2 つの事実は、
モデル B に対す る 強力な反証にな り ます。 し か し 、 修正指数はモデル B を さ ら に修正
で き る こ と を示 し てい る ので、 ま だ望みはあ り ます。 統制群の修正指数は次の よ う に
な り ます。
修正指数の最大値 (4.727) は、 eps2 と eps4 を統制群で相関 さ せ る こ と を提示 し てい ま
す。 (eps2 と eps4 は実験群では既に相関 し てい ます。) こ の修正を行 う と モデル C にな
り ます。
230
例 16
モデル C
モデル C は、 項 eps2 と eps4 が統制群 と 実験群の両方で相関関係を持つ と い う 点を除
いてモデル B と 同様です。
モデル C を指定す る には、 モデル B を取 り 上げて、 統制群で eps2 と eps4 の間の共
分散に関す る 制約条件 を 削除す る だ け です。 統制群の新 し いパ ス 図 を こ こ に示 し ま
す。 こ のパ ス図は、 Ex16-c.amw フ ァ イ ルにあ り ます。
モデル C の結果
こ こ でついに適合す る モデルを得 ら れます。
カ イ 2 乗 = 2.797
自由度 = 4
確率水準 = 0.592
231
共分散分析に対する Sörbom の代替案
統計的な適合度の観点か ら 見 る と 、 モデル C を棄却す る 理由はあ り ません。 分散の推
定値がすべて正の値で あ る こ と に も 注意 し て く だ さ い。 105 人の統制群の被験者のパ
ラ メ ー タ 推定値を次に示 し ます。
次のパ ス図は、 108 人の実験被験者のパ ラ メ ー タ 推定値を表示 し てい ます。
パ ラ メ ー タ 推定値の大部分はあ ま り 興味を引 き ませんが、 推定値が妥当であ る こ と を
確認す る こ と がで き ま す。 分散の推定値が正で あ る こ と は既に確認 し ま し た。 測定モ
デルのパ ス係数は正であ る こ と が保証 さ れ ます。 測定モデルの係数に正の値 と 負の値
が混在す る と 、 解釈す る のが困難で、 モデルに疑問が生 じ ます。 eps2 と eps4 の間の共
分散は、 期待どお り 両方のグループで正です。
232
例 16
こ こ で主に興味があ る のは、pre_verbal ( 言語能力 ( 事前 )) に対す る post_verbal ( 言語
能力 ( 事後 )) の回帰です。 切片は、 統制群では 0 に固定 さ れてい ますが、 実験群では
3.71 と 推定 さ れます。 係数の推定値は、 統制群では 0.95、 実験群では 0.85 です。 2 つ
のグループの係数は非常に近 く 、2 つの母集団で同 じ 値であ る よ う に見え ます。 係数が
同 じ 場合、 2 つのグループの比較を切片の比較に限定す る こ と で、 試験の評価を大幅
に簡略化で き ます。 し たが っ て、 両方のグループの係数が同 じ であ る モデルは試行す
る 価値があ り ます。 こ れがモデル D にな り ます。
モデル D
モデル D は、 両方のグループで pre_verbal ( 言語能力 ( 事前 )) か ら post_verbal ( 言語能力
( 事後 )) を予測す る ための係数が同 じ であ る こ と が要求 さ れ る 点を除いて、モデル C と
同様です。 両方の グループの係数に同 じ 名前 ( た と えば、 pre2post) を付け る こ と で、
こ の制約条件を指定す る こ と がで き ます。 次に示すのは、 実験群についてのモデル D
のパ ス図です。
233
共分散分析に対する Sörbom の代替案
次に、 統制群についてのモデル D のパス図を示 し ます。
モデル D の結果
通常の有意水準では、 モデル D は適合 し ます。
カ イ 2 乗 = 3.976
自由度 = 5
確率水準 = 0.553
モデル C に対 し て、 モデル D の検定では 1.179 (= 3.976 – 2.797) 大 き いカ イ 2 乗値 と
1 ( つ ま り 、 5 – 4) 多い自由度が得 ら れ ま し た。 こ こ で も 、 係数が等 し い と い う 仮説
( モデル D) を受け入れ る こ と がで き ます。
234
例 16
係数が等 し い場合、 試験前 と 試験後の被験者の比較は、 切片の差に依存 し ま す。
こ こ に示すのは、 105 人の統制群の被験者のパ ラ メ ー タ 推定値です。
108 人の実験被験者の推定値は次の よ う にな り ます。
実験群の切片は 3.63 と 推定 さ れます。 テ キ ス ト 出力 ( こ こ では示 し ません ) に よ る と 、
推定値 3.63 の検定統計量は 7.59 です。 し た が っ て、 実験群の切片は統制群の切片
(0 に固定 ) と 大 き く 異な っ てい ます。
235
共分散分析に対する Sörbom の代替案
モデル E
切片 post_verbal ( 言語能力 ( 事後 )) の差の有意確率を検定す る 別の方法に、 グループ間
で切片が等 し い と い う 制約条件を追加 し て モデル D の分析を繰 り 返す方法が あ り ま
す。 統制群の切片は既に 0 に固定 さ れてい る ので、 必要な手順は実験群の切片 も 同様
に 0 にす る と い う 条件を追加す る だけです。 モデル E では こ の制約を使用 し ます。
モデル E のパ ス図は、 pre_verbal ( 言語能力 ( 事前 )) に対す る 回帰の切片 post_verbal
( 言語能力 ( 事後 )) が両方のグループで 0 に固定 さ れてい る こ と を除いて、モデル D の
パ ス図 と 同 じ です。 パ ス図は こ こ には載せません。 Ex16-e.amw にパ ス図が含まれてい
ます。
モデル E の結果
モデル E は棄却 さ れます。
カ イ 2 乗 = 55.094
自由度 = 6
確率水準 = 0.000
モデル E を モデル D と 比較す る と 、51.018 (= 55.094 – 3.976) 大 き い カ イ 2 乗値 と 1
(= 6 – 5) 多い自由度が得 ら れます。 モデル D が支持 さ れ、 モデル E は棄却 さ れます。
モデル E の適合度はモデル D の適合度 よ り 大幅に低いため、切片が等 し い と い う 仮説
は棄却 さ れ ます。 言い換え る と 、 試験後の時点での統制群 と 実験群には、 試験前の時
点で存在 し た差か ら は計算で き ない差があ り ます。
こ れが Olsson のデー タ に対す る Sörbom (1978 年 ) の分析の結論です。
モデル A から モデル E を単一の分析で当てはめる
Ex16-a2e.amw フ ァ イ ルの例は、5 つすべてのモデル ( モデル A か ら モデル E) を単一の
分析で当てはめ ます。 単一の分析で複数のモデルを当てはめ る 手順の詳細は、 例 6 で
示 し ま し た。
Sörbom の方法 と 例 9 の方法の比較
共分散分析に対す る Sörbom の代替案は例 9 の方法 よ り も 適用す る のが困難です。 その
一方で、 Sörbom の方法は よ り 一般的で あ る た め、 例 9 の方法 よ り も 優れてい ま す。
つま り 、適切なパ ラ メ ー タ 制約を用いて Sörbom の方法を使用す る こ と で、例 9 の方法
を再現で き ます。
236
例 16
モデル X、 モデル Y、 モデル Z と い う 3 つのモデルを示 し て、 こ の例を終わ り ます。
こ れ ら の新 し いモデルの比較に よ り 、 例 9 の結果を再現す る こ と がで き ます。 ただ し 、
例 9 で使用 し た方法が不適切だ っ た と い う 証拠 も 見つか り ます。 こ の非常に複雑な演
習の目的は、 例 9 の手法の制限に注目 し 、 Sörbom の手法ではその方法の前提条件の一
部を検定お よ び緩和で き る こ と を示す こ と です。
モデル X
最初に、 観測変数の分散 と 共分散が統制状態お よ び実験状態で同 じ であ る こ と が要求
さ れ る 新 し いモデル ( モデル X) を考え ます。 観測変数の平均値は、 2 つの母集団の間
で異な る 場合 も あ り ま す。 モデル X では、 変数の間に線形従属性は指定 し ま せん。
モデル X はそれ自体はあ ま り 興味深い も のではあ り ませんが、( 後か ら 作成す る ) モデ
ル Y お よ びモデル Z は興味深いモデルです。 モデル X と 比べて、 こ れ ら のモデルが
どれだけデー タ に適合す る か を調べます。
Amos Graphics のモデル作成
推定する切片や平均値がないため、 [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス の [ 推定 ]
タ ブにあ る [ 平均値 と 切片を推定 ] にチ ェ ッ ク マー ク がない こ と を確認 し て く だ さ い。
次に示すのは、 統制群についてのモデル X のパス図です。
実験群のパ ス図 も 同 じ です。 両方のグループで同 じ パ ラ メ ー タ 名を使用す る と 、2 つの
グループが同 じ パ ラ メ ー タ 値を持つ こ と が要求 さ れます。
237
共分散分析に対する Sörbom の代替案
モデル X の結果
通常の有意水準では、 モデル X は棄却 さ れます。
カ イ 2 乗 = 29.145
自由度 = 10
確率水準 = 0.001
実際には、 モデル X が不適切であ る こ と がわかっ た時点で、 こ の後の分析 ( モデル Y
お よ びモデル Z) も 不適切なモデルです。 例 9 で得 ら れた結果 と 同 じ 結果にな る こ と を
示すため、 演習 と し て分析を実行 し ます。
モデル Y
モデル D に次の制約条件を追加 し たモデルを考え ます。
試験前の言語能力 ( 言語能力 ( 事前 )) が、 統制群 と 実験群で同 じ 分散を持つ。
eps1、 eps2、 eps3、 eps4、 お よ び zeta の分散が、 両方のグループで等 し い。
eps2 と eps4 の間の共分散が、 両方のグループで等 し い。
eps2 と eps4 の相関関係 を 除い て、 モデル D では、 eps1、 eps2、 eps3、 eps4、 お よ び
zeta が、 こ れ ら の変数同士 と も 他のすべての外生変数 と も 相関 し ない こ と が要求 さ れ
ま し た。 こ れ ら の新 し い制約条件に よ り 、 すべての外生変数の分散 と 共分散が両方の
グループで同 じ にな る こ と が要求 さ れます。
要す る に、 新 し いモデルでは次の 2 種類の制約条件が課 さ れます。
すべて の係数 と 切片は両方の グ ループで等 し い。 た だ し 、 pre_verbal ( 言語能力
( 事前 )) か ら post_verbal ( 言語能力 ( 事後 )) を予測す る ために使用す る 切片は異な る
場合があ り ます ( モデル D の条件 )。
外生変数の分散 と 共分散は両方のグループで等 し い ( モデル Y で追加 さ れた条件 )。
こ れ ら は例 9 のモデル B で行っ た も の と 同 じ 仮定です。 今回は、明示的に仮定を行い、
検定で き る と い う こ と が違い ます。 モデル Y のパ ス図を下に示 し ます。 こ のモデルで
は平均値 と 切片を推定す る ので、 次の操作を し っ か り と 実行 し て く だ さ い。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 推定 ] タ ブを ク リ ッ ク し ます。
E [ 平均値 と 切片を推定 ] を選択 し ます ( 隣にチ ェ ッ ク マー ク が表示 さ れます )。
238
例 16
実験群のパ ス図を こ こ に示 し ます。
統制群のパ ス図を こ こ に示 し ます。
モデル Y の結果
モデル Y は棄却 さ れます。
カ イ 2 乗 = 31.816
自由度 = 12
確率水準 = 0.001
例 9 の分析は、 モデル Y ( 例 9 のモデル B) が正 し い と い う こ と に依存 し てい る ため、
適合 し なかっ たの も 当然です。 振 り 返っ てみ る と 、 例 9 のモデル B が適合す る こ と が
わか り ます (2= 2.684、 df = 2、 p = 0.261)。 では、 ど う し て こ こ では同 じ モデルが棄却
さ れ る ので し ょ う か (2 = 31.816、 df = 1、 p = 0.001)。 その答えは、 帰無仮説は両方の
239
共分散分析に対する Sörbom の代替案
ケース ( 例 9 のモデル B と こ の例のモデル Y) で同 じ ですが、対立仮説が異な る ためで
す。 例 9 では、 モデル B を検定 し た対立仮説には、 観測変数の分散 と 共分散が試験変
数の両方の値 と 同 じ であ る と い う 仮定が含まれてい ます (32 ページで も 仮定 し てい ま
す )。 言い換え る と 、 例 9 のモデル B の検定は、 統制群 と 実験群の母集団で分散 と 共分
散の等質性を暗に仮定 し て実行 さ れま し た。 こ れは ま さ に、 こ の例のモデル X で明示
的に行っ た仮定です。
モデル Y は、 モデル X に制約を追加 し たモデルです。 モデル Y の仮定 (2 つの母集
団で係数が等 し く 、 外生変数の分散 と 共分散が等 し い ) は、 モデル X の仮定 ( 観測変
数の共分散が等 し い ) を包含す る こ と を示す こ と がで き ます。 し たが っ て、 モデル X
と モデル Y は入れ子にな っ たモデルです。 そ し て、 モデル X が正 し い と い う 仮定の下
でモデル Y の条件付 き 検定を実行す る こ と が可能です。 当然、 検定が意味を持つのは
モデル X が本当に正 し い場合のみですが、既にモデル X は誤 り だ と い う 結論が出てい
ます。 それで も 、 モデル X に対す る モデル Y の検定を行い ま し ょ う 。 カ イ 2 乗値の差
は 2.671 ( つま り 、 31.816 – 29.145)、 自由度の差は 2 (= 12 – 10) です。 こ れ ら の数値は、
例 9 のモデル B の値 と ( 丸め誤差の範囲内で ) 同 じ です。 違 う のは、 例 9 では検定が適
切であ る と 仮定 し た こ と です。 こ こ では、 ( モデル X を棄却 し た こ と か ら ) 検定が不適
切であ る こ と は よ く わか っ てい ます。
現在のモデル Y が例 9 のモデル B と 同 じ であ る こ と に疑問があ る 場合、 2 つの分析
のパ ラ メ ー タ 推定値を比較 し て く だ さ い。 108 人の実験被験者のモデル Y のパ ラ メ ー
タ 推定値を こ こ に示 し ます。 例 9 のモデル B か ら 得た標準化 さ れていないパ ラ メ ー タ
推定値が、 表示 さ れ る 推定値 と 一致す る か ど う か確認 し て く だ さ い。
240
例 16
モデル Z
最後に、 pre_verbal ( 言語能力 ( 事前 )) か ら post_verbal ( 言語能力 ( 事後 )) を予測す る た
めの方程式の切片が、 両方の母集団で等 し い と い う 条件を モデル Y に追加 し て、 新 し
いモデル ( モデル Z) を 作成 し ま す。 こ のモデルは例 9 の モデル C と 同 じ も のです。
モデル Z のパ ス図は次の よ う にな り ます。
モデル Z の実験群のパス図を こ こ に示 し ます。
統制群のパ ス図を こ こ に示 し ます。
241
共分散分析に対する Sörbom の代替案
モデル Z の結果
こ のモデルは棄却 さ れます。
カ イ 2 乗 = 84.280
自由度 = 13
確率水準 = 0.000
モデル Y と 比較す る と 、モデル Z も 棄却 さ れ ま す ( 2 = 84.280 – 31.816 = 52.464 、
df = 13 – 12 = 1)。 丸め誤差の範囲内で、 こ れは例 9 でモデル C を モデル B と 比較 し た
と き のカ イ 2 乗値 と 自由度の差 と 同 じ です。
242
例 16
VB.NET でのモデル作成
モデル A
モデル A に適合す る プ ロ グ ラ ム を次に示 し ます。 こ のプ ロ グ ラ ムは Ex16-a.vb と し て
保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Dim dataFile As String = Sem.AmosDir & "Examples¥UserGuide.xls"
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(dataFile, "Olss_cnt")
Sem.GroupName("control")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (0) + () pre_verbal + (1) zeta")
Sem.BeginGroup(dataFile, "Olss_exp")
Sem.GroupName("experimental")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (effect) + () pre_verbal + (1) zeta")
Sem.Mean("pre_verbal ", "pre_diff")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
243
共分散分析に対する Sörbom の代替案
モデル B
モデル B を当てはめ る には、 モデル A のプ ロ グ ラ ムの実験群のモデル指定に
Sem.AStructure("eps2 <---> eps4")
と い う 行を追加 し ます。 完成 し たモデル B のプ ロ グ ラ ム を こ こ に示 し ます。 こ のプ ロ
グ ラ ムは、 Ex16-b.vb と し て保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Dim dataFile As String = Sem.AmosDir & "Examples¥UserGuide.xls"
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(dataFile, "Olss_cnt")
Sem.GroupName("control")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (0) + () pre_verbal + (1) zeta")
Sem.BeginGroup(dataFile, "Olss_exp")
Sem.GroupName("experimental")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (effect) + () pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.Mean("pre_verbal ", "pre_diff")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
244
例 16
モデル C
モデル C に適合す る プ ロ グ ラ ム を次に示 し ます。 こ のプ ロ グ ラ ムは、Ex16-c.vb と し て
保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Dim dataFile As String = Sem.AmosDir & "Examples¥UserGuide.xls"
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(dataFile, "Olss_cnt")
Sem.GroupName("control")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (0) + () pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.BeginGroup(dataFile, "Olss_exp")
Sem.GroupName("experimental")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (effect) + () pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.Mean("pre_verbal ", "pre_diff")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
245
共分散分析に対する Sörbom の代替案
モデル D
次のプ ロ グ ラ ムはモデル D に適合 し ます。 こ のプ ロ グ ラ ムは、Ex16-d.vb と し て保存 さ
れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Dim dataFile As String = Sem.AmosDir & "Examples¥UserGuide.xls"
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(dataFile, "Olss_cnt")
Sem.GroupName("control")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (0) + (pre2post) pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.BeginGroup(dataFile, "Olss_exp")
Sem.GroupName("experimental")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure( _
"pre_verbal = (effect) + (pre2post) pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.Mean("pre_verbal ", "pre_diff")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
246
例 16
モデル E
次のプ ロ グ ラ ムはモデル E に適合 し ます。 こ のプ ロ グ ラ ムは、 Ex16-e.vb と し て保存 さ
れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Dim dataFile As String = Sem.AmosDir & "Examples¥UserGuide.xls"
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(dataFile, "Olss_cnt")
Sem.GroupName("control")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (0) + (pre2post) pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.BeginGroup(dataFile, "Olss_exp")
Sem.GroupName("experimental")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (0) + (pre2post) pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4")
Sem.Mean("pre_verbal ", "pre_diff")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
247
共分散分析に対する Sörbom の代替案
複数のモデルを適合する
次のプ ロ グ ラ ムは、 モデル A か ら モデル E ま で 5 つすべてのモデルに適合 し ます。 こ
のプ ロ グ ラ ムは、 Ex16-a2e.vb と し て保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Dim dataFile As String = Sem.AmosDir & "Examples¥UserGuide.xls"
Sem.TextOutput()
Sem.Mods(4)
Sem.Standardized()
Sem.Smc()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(dataFile, "Olss_cnt")
Sem.GroupName("control")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (0) + (c_beta) pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4 (c_e2e4)")
Sem.BeginGroup(dataFile, "Olss_exp")
Sem.GroupName("experimental")
pre_verbal + (1) eps1")
Sem.AStructure("pre_syn = (a_syn1) + (1)
Sem.AStructure( _
"pre_opp = (a_opp1) + (opp_v1) pre_verbal + (1) eps2")
pre_verbal + (1) eps3")
Sem.AStructure("post_syn= (a_syn2) + (1)
Sem.AStructure( _
"post_opp = (a_opp2) + (opp_v2) pre_verbal + (1) eps4")
Sem.AStructure("pre_verbal = (effect) + (e_beta) pre_verbal + (1) zeta")
Sem.AStructure("eps2 <---> eps4 (e_e2e4)")
Sem.Mean("pre_verbal ", "pre_diff")
Sem.Model("Model A", "c_e2e4 = 0", "e_e2e4 = 0")
Sem.Model("Model B", "c_e2e4 = 0")
Sem.Model("Model C")
Sem.Model("Model D", "c_beta = e_beta")
Sem.Model("Model E", "c_beta = e_beta", "effect = 0")
Sem.FitAllModels()
Finally
Sem.Dispose()
End Try
End Sub
モデル X、 モデル Y、 モデル Z
こ こ では、 モデル X、 モデル Y、 モデル Z の VB.NET のプ ロ グ ラ ムは説明 し ません。
プ ロ グ ラ ムは、 Ex16-x.vb、 Ex16-y.vb、 お よ び Ex16-z.vb と い う フ ァ イ ルに保存 さ れて
い ます。
例
17
欠損デー タ
概要
こ の例は、 デー タ の一部に欠損値があ る デー タ セ ッ ト の分析方法を示 し ます。
不完全なデー タ
調査を計画 し た と き に期待 し たデー タ 値が、 実際には得 る こ と がで き ない こ と が し ば
し ば発生 し ま す。 被験者が調査の一部に参加で き ない こ と も あ り ま す。 ま たは、 ア ン
ケー ト の回答者がい く つかの質問を飛ばす こ と も あ り ます。 年齢を教え ない人、 収入
を答え ない人、 反応時間を測定す る 日に現れない人な ど がい る 場合 も あ り ます。 ど の
よ う な理由にせ よ 、 し ば し ば欠損値のあ る デー タ セ ッ ト を処理す る こ と にな り ます。
不完全なデー タ を処理す る 標準的な方法の 1 つは、 デー タ の一部に欠損値があ る 観
測値 を 分析か ら 除外す る こ と です。 こ れ を リ ス ト ご と の削除 と 呼ぶ こ と が あ り ま す。
た と えばあ る 人が収入を答え なか っ た場合、 その人を調査か ら 除外 し 、 サ イ ズは小 さ
く な り ま すが、 完全なデー タ の あ る 標本に基づいて通常の分析を行い ます。 こ の方法
は、 答え なか っ た回答のために、 答え た回答に含まれ る 情報を捨て る 必要があ る ため、
満足ので き る 方法ではあ り ません。 欠損値が多い と 、 こ の方法では標本の大部分を捨
て る 必要があ る 場合 も あ り ます。
標本積率に基づ く 分析の場合の も う 1 つの標準的な方法は、 各標本積率を個別に計
算 し 、 特定の積率の計算に必要な値が欠損 し てい る 場合にのみ観測値を計算か ら 除外
す る 方法です。 た と えば、 標本の平均収入の計算では、 収入がわか ら ない人だけ を除
外 し ま す。 同様に、 標本の年齢 と 収入の間の共分散の計算では、 年齢 ま たは収入が欠
損 し てい る 場合にだけ観測値を除外 し ます。 こ の欠損デー タ の処理方法は、 ペア ご と
の削除 と 呼ばれ る こ と も あ り ます。
249
250
例 17
3 つ目の方法はデー タ の代入です。 こ れは、 欠損値を何 ら かの推測値で置 き 換え、
完全なデー タ に対す る 通常の分析を行 う 方法です。 た と えば、 収入を答え た人の平均
収入を計算 し 、 その平均収入を収入を答え なかっ た人全員の収入 と 考え ます。 Beale と
Little (1975 年 ) は、 多 く の統計パ ッ ケージで実装 さ れてい る デー タ の代入方法を解説
し てい ます。
Amos では こ れ ら の方法はどれ も 使用 し ません。 欠損デー タ があ る場合で も 、 最尤法
に よ る推定値 (Anderson, 1957 年 ) を計算し ます。 こ のため、 欠損データ があ る場合は常
に Amos を使用すれば、 簡単な回帰分析 ( 例 4) や平均値の推定 ( 例 13) な ど、 従来の分
析を行 う こ と がで き ます。
Amos で処理で き ない種類の欠損デー タ があ る こ と に も 注意 し て く だ さ い。 ( 上記の
3 つの方法な ど、 他の一般的な欠損デー タ 処理方法で も 処理で き ません。 ) 場合に よ っ
ては、 欠損値の存在自体が情報を持てい る こ と も あ り ます。 た と えば、 収入が非常に
高い人は ( 他の人 と 比べて ) 収入に関す る 質問に答え ない傾向が あ る こ と な ど です。
こ の よ う に、 観測デー タ か ら 得 ら れ る 情報に加え て、 質問に答え なか っ た こ と か ら そ
の人の収入レベルについての確率的な情報が得 ら れます。 こ の よ う な場合には、 Amos
が使用す る 欠損デー タ の処理方法は不適切です。
Amos では、欠損 し たデー タ 値は ラ ン ダ ムに欠損 し た と 仮定 さ れます。 こ の仮定が妥
当であ る か ど う かや、 欠損デー タ が実際に意味す る こ と がいつ も 簡単にわか る と は限
り ません (Rubin, 1976 年 )。 一方で、ラ ン ダ ムに欠損 し た と い う 条件が満た さ れ る 場合、
Amos では有効で堅実な推定値が得 ら れ ます。 対照的に、 前述の方法では有効な推定
値を得 ら れ ません。 ま た、 欠損デー タ が完全に ラ ン ダ ム に欠損 し てい る と い う 強い条
件の下でのみ推定値が一致 し ます (Little と Rubin, 1989 年 )。
デー タ について
こ の例では、 例 8 で使用 し た Holzinger と Swineford (1939 年 ) のデー タ を修正 し ます。
元のデー タ セ ッ ト (SPSS Statistics フ ァ イ ル Grnt_fem.sav に格納 さ れてい ます ) には 73
人の少女の 6 つの検定の得点が含まれ、 合計 438 個のデー タ 値があ り ます。 欠損値の
あ る デー タ セ ッ ト を得 る には、Grnt_fem.sav の 438 個のデー タ 値を それぞれ 0.30 の確
率で削除 し ます。
その結果のデー タ セ ッ ト が SPSS Statistics フ ァ イ ル Grant_x.sav に格納 さ れてい ます。
下に示 し てい る のは、 こ の フ ァ イ ルの最初のい く つかのデー タ です。 ピ リ オ ド (.) は欠
損値を表 し ます。
251
欠損デー タ
Amos では、 SPSS Statistics デー タ セ ッ ト の ピ リ オ ド を認識 し 、 欠損デー タ と し て処理
し ます。
Amos は他に も 多 く のデー タ 形式で欠損デー タ を認識で き ます。 た と えば ASCII 形
式のデー タ セ ッ ト では、 区切 り 文字が 2 つ連続す る と 欠損値を示 し ます。 上に示 し た
7 つのデー タ は、 ASCII 形式では次の よ う にな り ます。
visperc,cubes,lozenges,paragraph,sentence,wordmean
33,,17,8,17,10
30,,20,,,18
,33,36,,25,41
28,,,10,18,11
,,25,,11,,8
20,25,6,9,,,,
17,21,6,5,10,10
Grant_x.sav のデー タ の約 27% が欠損 し てい ます。 完全なデー タ が利用で き る のは、
7 人分のデー タ だけです。
モデルを指定する
こ こ では、 Grant_x.sav フ ァ イ ルの Holzinger と Swineford のデー タ に対 し て、 例 8 の
共通因子分析モデル (251 ページで示 し ま し た ) を当てはめ ます。 こ の分析 と 例 8 の分
析の違いは、 今回はデー タ の 27% が欠損 し てい る こ と です。
デー タ フ ァ イ ルに Grant_x.sav を指定 し て上のパ ス図を描いてか ら 、 次の操作を実行
し ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 推定 ] タ ブ を ク リ ッ ク し ます。
E [ 平均値 と 切片を推定 ] を選択 し ます ( 隣にチ ェ ッ ク マー ク が表示 さ れます )。
252
例 17
こ れに よ り 、 測定変数を予測す る 6 つの回帰方程式それぞれの切片を推定す る こ と が
で き ます。 欠損値があ る 場合の最尤法に よ る 推定は、 平均値 と 切片を推定す る と き の
み機能 し ます。 そのため、 推定値が必要でない場合に も 平均値 と 切片を推定す る 必要
があ り ます。
飽和モデルおよび独立モデル
一部の適合度の計算には、 ユーザーのモデルに加え て、 飽和モデル と 独立モデルを当
てはめ る必要があ り ます。 完全なデー タ があれば こ れは問題にな り ませんが、欠損値が
あ る 場合には、 飽和モデル と 独立モデルの適合に大量の計算が必要にな る 場合があ り
ます。 飽和モデルは特に問題にな り ます。 p 個の観測変数があ る場合、 飽和モデルには
p p + 3 2 個のパ ラ メ ー タ があ り ます。 た と えば、観測変数が 10 個の場合は 65 個
のパ ラ メ ー タ 、 20 個の変数の場合は 230 個のパ ラ メ ー タ 、 40 個の変数の場合は 860 個
のパ ラ メ ー タ な ど と な り ます。 パ ラ メ ー タ の数が多 く な る と 、飽和モデルを当てはめ る
のは現実的ではない場合があ り ます。 さ ら に、 欠損値のパ タ ーンに よ っ ては、 ユーザー
のモデルを当てはめ る こ と は可能で も 、 飽和モデルを当てはめ る こ と は原理的に不可
能であ る場合 も あ り ます。
不完全なデー タ の場合、 Amos Graphics はユーザーのモデルに加え て、 飽和モデル
お よ び独立モデル を当てはめ よ う と し ま す。 Amos が独立モデルの適合に失敗 し た場
合、 CFI な ど、 独立モデルの適合に依存す る 適合度が計算で き ません。 Amos が飽和モ
デルを当てはめ る こ と がで き ない場合、 通常のカ イ 2 乗統計量は計算で き ません。
分析の結果
テキス ト 出力
こ の例では、 Amos は飽和モデルお よ び独立モデルを両方当てはめ る こ と がで き ます。
結果 と し て、 カ イ 2 乗統計量を含め、 すべての適合度が示 さ れ ます。 適合度を見 る に
は、 次の操作を実行 し ます。
E [Amos 出力 ] ウ ィ ン ド ウ の左上の ツ リ ー図にあ る [ モデル適合 ] を ク リ ッ ク し ます。
次に示すのは、 因子分析モデル ( デフ ォ ル ト モデル と 呼びます )、 飽和モデル、 独立モ
デルのカ イ 2 乗統計量を示す出力の一部です。
カ イ 2 乗値 11.547 は、例 8 の完全なデー タ セ ッ ト で得 ら れた値 7.853 か ら あ ま り 離れ
てい ません。 両方の分析で、 p 値は 0.05 以上です。
253
欠損デー タ
パ ラ メ ー タ 推定値、 標準誤差、 お よ び検定統計量は完全なデー タ の分析の場合 と 同
じ 解釈がで き ます。
標準化推定値 と 重相関係数の平方は次の よ う にな り ます。
254
例 17
グ ラ フ ィ ッ ク出力
こ のパス図は、 内生変数の標準化推定値 と 重相関係数の平方を示 し てい ます。
標準化パ ラ メ ー タ 推定値は、例 8 で完全なデー タ か ら 得 ら れた推定値 と 比較で き ます。
2 組の推定値は小数点以下 1 桁ま で同 じ です。
255
欠損デー タ
VB.NET でのモデル作成
不完全なデー タ を分析す る ために Amos プ ロ グ ラ ム を書 く 場合、 Amos では独立モデ
ルお よ び飽和モデルは自動的には当てはめ ません。 (Amos Graphics では こ れ ら のモデ
ルを自動的に当てはめ ます。 ) Amos プ ロ グ ラ ムで独立モデルお よ び飽和モデルを当て
はめ る には、プ ロ グ ラ ムに こ れ ら のモデルを指定す る コ ー ド を含め る 必要があ り ます。
特に、 通常の尤度比カ イ 2 乗統計量を計算す る には、 プ ロ グ ラ ムに飽和モデルを当て
はめ る コ ー ト を含め る 必要があ り ます。
こ のセ ク シ ョ ンでは、 尤度比カ イ 2 乗統計量の計算に必要な次の 3 つの手順を説明 し
ます。
因子モデルの適合
飽和モデルの適合
尤度比カ イ 2 乗統計量 と その p 値の計算
最初に、 こ の 3 つの手順を、 3 つの別々のプ ロ グ ラ ム で実行 し ます。 その後、 3 つの手
順を単一のプ ロ グ ラ ムに ま と め ます。
因子モデルの適合 ( モデル A)
次のプ ロ グ ラ ムは確認のための因子モデル ( モデル A) に適合 し ます。 こ のプ ロ グ ラ ム
は、 Ex17-a.vb と し て保存 さ れてい ます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.Title("Example 17 a: Factor Model")
Sem.TextOutput()
Sem.Standardized()
Sem.Smc()
Sem.AllImpliedMoments()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grant_x.sav")
Sem.AStructure("visperc = ( ) + (1) spatial + (1) err_v")
Sem.AStructure("cubes = ( ) + spatial + (1) err_c")
Sem.AStructure("lozenges = ( ) + spatial + (1) err_l")
Sem.AStructure("paragrap = ( ) + (1)spatial + (1) err_p")
Sem.AStructure("sentence = ( ) + spatial + (1) err_s")
Sem.AStructure("wordmean= ( ) + spatial + (1) err_w")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
256
例 17
ModelMeansAndIntercepts メ ソ ッ ド を使用 し て平均値 と 切片がモデルのパ ラ メ ー タ と
し て指定 さ れてい る こ と と 、 6 つの回帰方程式のそれぞれに切片を表す 1 組の空のかっ
こ が含まれてい る こ と に注意 し て く だ さ い。 欠損値のあ るデー タ を分析する場合、平均
値 と 切片はモデルの明示的なパ ラ メ ー タ と し て示す必要が あ り ま す。 こ れは完全な
デー タ の分析 と は異な り ます。 完全なデー タ の分析では、 平均値 と 切片は、 推定する か
制約条件を設定する場合を除いて、 モデルに示す必要はあ り ません。
モデル A の適合を要約す る と 、 次の よ う にな り ます。
対数尤度関数 = 1375.133
パ ラ メ ー タ 数 = 19
対数尤度関数の値は、 完全なデー タ の場合に得 ら れ る カ イ 2 乗統計量の代わ り に表示
さ れます。 加え て、 テ キ ス ト 出力のモデルの要約セ ク シ ョ ンの先頭に、 Amos は次の警
告を表示 し ます。
少 な く と も 1 つの グ ループ のデー タ に対 し て 飽和モデルは適合 し ま せん で
し た。 こ のため、 「対数尤度関数」 、 AIC、 BCC のみが出力 さ れ ま す。 尤度比
カ イ 2 乗統計量やその他の適合度測度は出力 さ れ ま せん。
Amos が こ の注記を表示す る と き は常に、 モデルの要約セ ク シ ョ ンの cmin 列の値には
見慣れた適合度カ イ 2 乗統計量が含まれません。 因子モデルの適合度を評価す る には、
対数尤度関数の値を、 飽和モデルな ど の制約条件の少ない基準モデルの値 と 比較す る
必要があ り ます。
飽和モデルの適合 ( モデル B)
飽和モデルには、1 次お よ び 2 次の積率 と 同 じ 数の自由なパ ラ メ ー タ があ り ます。 完全
なデー タ を分析す る 場合、 飽和モデルは常に標本のデー タ に完全に適合 し ます ( カ イ
2 乗 = 0.00、 df = 0)。 同 じ 6 つの観測変数があ る 構造方程式モデルはすべて、 飽和モデ
ル と 同等か、 飽和モデルに制約条件を指定 し たモデルのいずれかです。 飽和モデルは、
少な く と も 制約条件のあ る モデル と 同程度には標本のデー タ に適合 し ます。 対数尤度
関数の値は制約条件のあ る モデル よ り 大 き く はな く 、 通常は小 さ く な り ます。
257
欠損デー タ
次のプ ロ グ ラ ムは飽和モデル ( モデル B) に適合 し ます。 こ のプ ロ グ ラ ムは、 Ex17-b.vb
と し て保存 さ れてい ます。
Sub Main()
Dim Saturated As New AmosEngine
Try
' 飽和モデルの設定 と 推定
Saturated.Title("Example 17 b: Saturated Model")
Saturated.TextOutput()
Saturated.AllImpliedMoments()
Saturated.ModelMeansAndIntercepts()
Saturated.BeginGroup(Saturated.AmosDir & "Examples¥Grant_x.sav")
Saturated.Mean("visperc")
Saturated.Mean("cubes")
Saturated.Mean("lozenges")
Saturated.Mean("paragrap")
Saturated.Mean("sentence ")
Saturated.Mean("wordmean")
Saturated.FitModel()
Finally
Saturated.Dispose()
End Try
End Sub
BeginGroup の行以降では、 Mean メ ソ ッ ド を 6 回使用 し 、 6 つの変数の平均の推定値
を要求 し てい ます。 Amos が平均値を推定す る 場合、プ ロ グ ラ ム で明示的に分散 と 共分
散を制約 し ていない限 り 、 自動的に分散 と 共分散 も 推定 し ます。
258
例 17
次に示すのは、 飽和モデル B の標準化 さ れていないパ ラ メ ー タ 推定値です。
プ ロ グ ラ ムの中の AllImpliedMoments メ ソ ッ ド は、 次の推定値の表を表示 し ます。
259
欠損デー タ
こ れ ら の推定値は、 平均の推定値 も 含め、 ペア ご と ま たは リ ス ト ご と の削除方法を使
用 し て 計 算 さ れ た 標本 の 値 と は 異 な り ま す。 た と え ば、 53 人 が 視 覚認識 の 検定
(visperc) を受け ま し た。 こ の 53 人の visperc ( 視覚認知力 ) の得点の平均は 28.245 です。
Amos に よ る 視覚認識の平均得点の推定値 も 28.245 だ と 予想す る か も し れ ま せん。
こ れ ら の推定値は、 推定平均で さ え、 ペア ご と の削除ま たは リ ス ト ご と の削除のいず
れか を使用 し て標本の値を計算 し た場合 と 異な り ます。
こ の 53 人の visperc ( 視覚認知力 ) の得点の平均は 28.245 です。
対数尤度関数 = 1363.586
パ ラ メ ー タ 数 = 27
対数尤度関数の値は、 入れ子にな っ たモデルの適合度の計算に使用で き ます。 こ の場
合、 モデル A ( 適合度の統計量 1375.133、パラ メ ータ 数 19) はモデル B ( 適合度の統計量
1363.586、 パ ラ メ ー タ 数 27) の中に入れ子にな っ てい ます。 強い方のモデル ( モデル A)
を弱いモデル ( モデル B) と 比較 し 、 強い方のモデルが正 し い場合、 次の こ と が言え ま
す。 弱いモデルか ら 強いモデルに切 り 替え る と き の対数尤度関数の増加量は、 2 つの
モデルのパ ラ メ ー タ 数の差に等 し い自由度を持つ、 カ イ 2 乗 ラ ン ダ ム変数の観測値で
す。 こ の例で は、 モデル A の対数尤度関数は、 モデル B の対数尤度関数 を 11.547
(= 1375.133 – 1363.586) 上回っ てい ます。 同時に、 モデル A は 19 個のパ ラ メ ー タ し か
推定す る 必要があ り ません。 一方でモデル B は 27 個のパ ラ メ ー タ を推定す る 必要が
あ り 、 その差は 8 です。 言い換え る と 、 モデル A が正 し い場合、 11.547 は 8 自由度の
カ イ 2 乗変数の観測値です。 カ イ 2 乗の表で、 こ のカ イ 2 乗統計量が有意な値か ど う
か を参照す る こ と がで き ます。
尤度比カ イ 2 乗統計量 と その p 値の計算
カ イ 2 乗の表を参照す る 代わ り に、 ChiSquareProbability メ ソ ッ ド を使用 し て、 11.547
と い う 大 き さ のカ イ 2 乗値が正 し い因子モデルで発生す る 確率を求め る こ と がで き ま
す。 次のプ ロ グ ラ ムは、 ChiSquareProbability メ ソ ッ ド の使用方法を示 し てい ます。 こ
のプ ロ グ ラ ムは、 Ex17-c.vb と し て保存 さ れてい ます。
Sub Main()
Dim ChiSquare As Double, P As Double
Dim Df As Integer
ChiSquare = 1375.133 - 1363.586 ' 対数尤度関数の差
Df = 27 - 19
' パ ラ メ ー タ 数の差
P = AmosEngine.ChiSquareProbability(ChiSquare, CDbl(Df))
Debug.WriteLine( "Fit of factor model:")
Debug.WriteLine( "Chi Square = " & ChiSquare.ToString("#,##0.000"))
Debug.WriteLine("DF = " & Df)
Debug.WriteLine("P = " & P.ToString("0.000"))
End Sub
260
例 17
プ ロ グ ラ ムの出力は、 プ ロ グ ラ ム エデ ィ タ の [ デバ ッ グ ] 出力パネルに表示 さ れます。
p 値は 0.173 です。 し たがっ て、 モデル A が 0.05 レベルで正 し い と い う 仮説を受け入
れ る こ と がで き ます。
こ の例で説明 し た よ う に、 不完全なデー タ のモデルを検定す る には、 適合度を別の
代替モデルの適合度 と 比較する必要があ り ます。 こ の例では、検定 し たいのはモデル A
ですが、 モデル A を比較す る基準 と し てモデル B も 当てはめ る必要があ り ます。 代替
モデルは 2 つの条件を満たす必要があ り ます。 1 つ目は、 代替モデルが正 し い こ と を確
かめ る 必要があ り ます。 モデル B では明示的でない積率に制約条件を課 し てはい ませ
ん し 、 誤 り であ る可能性がないため、 モデル B は確かに こ の条件を満た し ます。 2 つ目
は、検定する モデル よ り も 一般的であ る必要があ り ます。 検定する モデルのパ ラ メ ータ
に対す る 制約条件の一部を削除す る こ と で得 ら れたモデルは、 こ の 2 つ目の条件を満
た し ます。 代替モデルを考え出す こ と がで き ない場合は、 こ こ で使用 し た よ う に、 いつ
で も 飽和モデルを使用で き ます。
単一プ ログ ラ ムでの全手順の実行
両方のモデル ( 因子モデルお よ び飽和モデル ) を適合す る 単一のプ ロ グ ラ ム を書 き 、
カ イ 2 乗統計量 と その p 値を計算す る こ と がで き ます。 Ex17-all.vb フ ァ イ ルのプ ロ グ
ラ ムで こ の方法を示 し ます。
例
18
欠損デー タ についてのその他の情報
概要
こ の例では、 一部の値を故意に欠損 さ せたデー タ を分析 し た後、 不完全なデー タ を意
図的に収集す る 際の利点について調べます。
欠損デー タ
通常、 デー タ の欠損を歓迎す る 研究者はい ま せん。 普通は可能な限 り 、 細心の注意を
払っ てデー タ の欠損に よ る 誤差を回避 し よ う と し ま す。 し か し 実際には、 各状況にお
け る すべての変数を観察 し ない 方がいい場合 も あ り ます。 Matthai(1951) と Lord(1955)
は、 特定のデー タ 値を意図的に観察 し ない と い う デザ イ ン を設計 し ま し た。
こ のデザ イ ン で採用 さ れてい る 基本原則 と は、 あ る 変数について十分な観察が得 ら
れない、 ま たは コ ス ト がかか り 過ぎ る と い う 場合には、 相関関係のあ る 他の変数を別
に観察す る こ と で、 よ り 精度の高い推定値が得 ら れ る と い う も のです。
こ のデザ イ ンは非常に便利ですが、 計算が難 し い と い う 理由か ら 、 以前はご く 単純
な条件下で し か用い ら れ ませんで し た。 こ こ では、 一部のデー タ が意図的に収集 さ れ
なか っ たデザ イ ン について、 考え ら れ る 多数の例の中か ら 一例を紹介 し ま す。 分析の
方法は、 例 17 と 同 じ です。
261
262
例 18
デー タ について
こ の例では、 Attig に よ る デー タ ( 例 1 を参照 ) か ら 一部のデー タ 値を除去 し 、 欠損 と
し て扱っ てい ます。 以下に、 SPSS Statistics デー タ エデ ィ タ で表示 し た、 若年層におけ
る 変更済みデー タ フ ァ イ ル Atty_mis.sav の一部を示 し ます。 こ の フ ァ イ ルには、 40 名
の若年被験者が、 Attig に よ る v_short お よ び vocab と い う 2 種類の語彙検定を受けた
際の得点が記載 さ れてい ます。 変数 vocab は、WAIS 語彙の得点です。 V_short は、WAIS
語彙検定での、 項目の小規模なサブセ ッ ト におけ る 得点です。 Vocab 得点では、 ラ ン
ダ ムに抽出 し た 30 名の被験者のデー タ を削除 し て あ り ます。
2 番目のデー タ フ ァ イ ル Atto_mis.sav には、 40 名の老年被験者に よ る 語彙検定の得点
が記載 さ れてい ます。 こ こ で も 、 ラ ン ダ ムに抽出 し た 30 名分の vocab 得点が削除 さ れ
てい ます。
も ち ろん、 常識的な人間な ら ば、 収集済みのデー タ を削除 し た り し ません。 こ こ では、
例を説明す る にあ た り 、 こ のデー タ 欠損パ タ ーン が次の よ う な状況下で発生 し た と し
ます。
vocab は、自分が知 る 限 り 最良の語彙検定であ る と 仮定 し ます。 こ の検定は非常に信
頼性が高 く 有効なので、 あ な たは こ の語彙検定を実施 し たい と 考え てい ます。 ただ残
念な こ と に、 実施には費用が高 く つ き ま す。 実施には長時間 を 要す る で し ょ う し 、
被験者ご と に個別に実施す る 必要があ り ます。 ま た、 採点には訓練を積んだ人間があ
た る 必要があ る か も し れません。 一方、 V_short は、 語彙検定 と し て良い も の と は言え
ませんが、 短時間で済み、 コ ス ト も 抑え ら れ、 一回で多数の被験者に対 し て簡単に実
施で き ます。 若年層 と 老年層それぞれ 40 名ずつに対 し て廉価な検定であ る v_short を
実施 し ます。 その後で、 若年層 と 老年層か ら それぞれ ラ ン ダ ムに 10 名を抽出 し 、 高価
な検定であ る vocab を受けて も ら い ます。
263
欠損デー タ についてのその他の情報
こ の研究の目的は、 次の と お り であ る と し ます。
若年層の母集団におけ る vocab 検定の得点の平均値を推定す る 。
老年層の母集団におけ る vocab 検定の得点の平均値を推定す る 。
vocab の得点におけ る 平均値は、 若年層 と 老年層で等 し い と い う 仮説を検定す る 。
こ のシナ リ オでは、 あ な たは v_short の得点の平均値には関心を持っ てい ません。 ただ
し 、 次に示す と お り 、 こ の得点には vocab の得点についての仮説を推定 し て検定す る
ために役立つ情報が含まれてい る ため、 v_short の得点は こ こ で も 有用です。
意図的に欠損値を発生 さ せた と い う 事実が、 分析の方法に影響す る こ と はあ り ませ
ん。 こ のデー タ には、 2 つのモデルが適用 さ れます。 両方のモデルで、 2 つの語彙検定
間の平均値、 分散、 共分散が、 若年層だけで な く 、 老年層において も 推定 さ れ ま す。
モデル A では、 グループ間でのパ ラ メ ー タ 推定値が等 し い必要があ る と い う 制約条件
はあ り ません。 モデル B では、 vocab の平均値が、 両方のグループで等 し く な る こ と
が求め ら れます。
モデル A
vocab と v_short 間の平均値、 分散、 お よ び共分散を推定す る には、 若年層 と 老年層の
2 つのグループ モデルを設定 し ます。
E パ ス図を作成 し ます。 こ の図では、 vocab と v_short を、 双方向矢印でつながれた 2 つ
の四角形で表 し ます。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 推定 ] タ ブ を ク リ ッ ク し ます。
E [ 平均値 と 切片を推定 ] を選択 し ます ( 横にチ ェ ッ ク マー ク が表示 さ れます )。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス が開いてい る 状態で、[ 出力 ] タ ブを ク リ ッ ク
し ます。
E [ 標準化推定値 ] と [ 差に対する検定統計量 ] を選択 し ます。
こ の例では、 グループ間におけ る vocab の平均値の差に注目 し てい る ため、 若年層グ
ループ と 老年層グループのそれぞれの平均値に名前を付け てお く と 便利です。 若年層
グループの vocab 平均値に名前を付け る 方法は、 次の と お り です。
E 若年層グループのパ ス図内にあ る vocab 四角形を右 ク リ ッ ク し ます。
E ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
E [オブジェ ク ト のプロパテ ィ ] ダイ ア ロ グ ボ ッ ク ス で、[パラ メ ータ ] タブを ク リ ッ ク し ます。
264
例 18
E [ 平均値 ] テ キ ス ト ボ ッ ク ス で、 m1_yng な ど の名前を入力 し ます。
E 老年層グループについて も 同様の手順を と り ます。 老年層グループの平均値に も 、
m1_old な ど の一意の名前を付けて く だ さ い。
それぞれの名前が一意であれば、 名前を付けた こ と で平均値の値が制約 さ れ る こ と は
あ り ません。 平均値に名前が付 く と 、 こ の 2 つのグループのパ ス図は次の よ う にな り
ます。
モデル A の結果
グ ラ フ ィ ッ ク ス出力
若年被験者 と 老年被験者のそれぞれに平均値、 分散、 お よ び共分散が表示 さ れた 2 つ
のパ ス図です。
265
欠損デー タ についてのその他の情報
テキス ト 出力
E [Amos 出力 ] ウ ィ ン ド ウ の左上隅の ウ ィ ン ド ウ 枠にあ る [ モデルについての注釈 ] を ク
リ ッ ク し ます。
モデル A は飽和状態にあ る と い う こ と がテ キ ス ト 出力 さ れます。 つま り 、 こ のモデル
は検定で き ない と い う こ と です。
異な る 標本の積率の数
推定 さ れ る 異な る パ ラ メ ー タ の数
自由度 (10 – 10)
10
10
0
若年被験者のパ ラ メ ー タ 推定値 と 標準誤差は、 次の と お り です。
老年被験者のパ ラ メ ー タ 推定値 と 標準誤差は、 次の と お り です。
vocab の平均値におけ る 推定値は、 若年層の母集団では 56.891、 老年層の母集団では
65.001 です。 こ れ ら の値が、 vocab 検定を受けた若年層 と 老年層各 10 名か ら 得 ら れ る
と し た標本の平均値 と は異な る 点に注意 し て く だ さ い。 標本の平均値で あ る 58.5 と
62 は母集団の平均値 と し ては良い推定値です (サイ ズが 10 の 2 つの標本か ら 得 ら れ る
と さ れ る 最良の値)。 ただ し 、 Amos に よ る推定値 (56.891 と 65.001) には、 v_short の
得点に関す る 情報が使用 さ れてい る と い う 利点があ り ます。
266
例 18
それでは、 v_short の得点におけ る 情報を含む推定値は、 ど の程度精度を増 し てい る
こ と に な る ので し ょ う か。 こ れは、標準誤差の推定値に注目す る と 大体わか り ま す。
若年被験者では、 表中の 56.891 に対す る 標準誤差は約 1.765 です。 こ れに対 し 、 標本
の平均値 58.5 に対す る 標準誤差は、 約 2.21 です。 老年被験者では、 65.001 に対す る 標
準誤差は約 2.167 です。 こ れに対 し 、 標本の平均値 62 に対す る 標準誤差は、 約 4.21 で
す。 こ こ で取 り 上げた標準誤差は近似値に過ぎ ませんが、 おお よ その比較基準にな り
ます。 若年被験者の ケー ス では、 v_short での得点に含 ま れ る 情報を使用す る こ と で、
vocab 平均値の推定値におけ る 標準誤差が約 21% 減少 し てい ます。 老年被験者の例で
は、 約 49% の標準誤差が減少 し てい ます。
v_short での得点か ら 得 ら れ る 追加情報を評価す る には、標本サ イ ズの要件を評価す
る と い う 方法 も あ り ます。 v_short での得点に関す る 情報を使用 し なかっ た と 仮定 し ま
す。 平均値におけ る 標準誤差を 21% 減少 さ せ る には、 あ と 何名の若年被験者が vocab
検定を受け る 必要があ っ たで し ょ う か。 同様に、 平均値におけ る 標準誤差を 49% 減少
さ せ る には、あ と 何名の老年被験者が vocab 検定を受け る 必要があ っ たで し ょ う か。 こ
の平均値におけ る 標準誤差は標本 サ イ ズの平方根に反比例す る ため、 答えは、 若年層
で約 1.6 倍、 老年層で約 3.8 倍の被験者が必要だ っ た こ と にな り ます。 つま り 、 各層で
10 名ずつが両方の検定を受け、 30 名ずつが短時間の検定のみを受け る のではな く 、 若
年層で約 16 名、 老年層では約 38 名の被験者が vocab 検定を受け る 必要があ っ た と い
う こ と です。 も ち ろ ん、 こ の計算で扱っ てい る のはあ く ま で も 標準誤差の推定値であ
り 、 正確な標準誤差の値ではあ り ません。 こ のため、 こ こ でわか る こ と は、 v_short 検
定の得点を使用す る こ と で得 ら れ る精度についての概略に過ぎ ません。
若年層 と 老年層の各母集団では、 vocab の得点におけ る 平均値が異な る で し ょ う か。
こ の平均値の差におけ る 推定値は、8.110(65.001 - 56.891) です。 こ の有意確率の差を検
定す る にあ た っ ての検定統計量を、 次のテーブルに示 し ます。
「m1_yng」 お よ び 「m1_old」 と い う ラ ベルがついた上か ら の 2 行 と 左か ら の 2 列は、
vocab 検定のグループ平均値を参照 し ます。 長時間の検定では、老年層の母集団の得点
は若年層の母集団 よ り も 高 く 、 両者の平均値には 0.05 レ ベルでの有意差がみ ら れ ま
す。 こ れに よ っ て、 こ の平均値の差に対す る 検定統計量は 2.901 と な っ てい ます。
ま た、 vocab でのグループ平均値が等 し い と い う 仮説の検定は、 両者の平均値に設
けた同等性の制約条件を モデルに対 し て最適合す る こ と で も 得 ら れ ます。 次に こ の方
法について説明 し ます。
267
欠損デー タ についてのその他の情報
モデル B
モデル B では、 vocab の平均値が、 若年層 と 老年層 と で等 し く な る こ と が求め ら れま
す。 こ の制約条件を設け る には、 2 つの方法があ り ます。 1 つは、 平均値の名前を変更
す る と い う 方法です。 モデル A では、 各平均値には一意の名前が付け ら れてい ま す。
こ の名前は変更す る こ と がで き 、 両方の平均値に同 じ 名前を付け る こ と がで き ま す。
こ れに よ っ て、 2 つの平均値は同 じ 値であ る 必要が生 じ る こ と にな り ます。
こ こ では、 別の方法を使用 し て平均値を制約 し ます。 平均値の名前 m1_yng お よ び
m1_old は変更 さ れません。 Amos では [ モデルを管理 ] を使用 し て、単一の分析にモデ
ル A と モデル B の両方を適合 さ せます。 こ の手法を使用す る には、 次の手順を実行 し
ます。
E モデル A か ら 開始 し ます。
E
メ ニ ュ ーか ら [ 分析 ] [ モデルを管理 ] の順に選択 し ます。
E [ モデル管理 ] ダ イ ア ロ グ ボ ッ ク ス の [ モデル名 ] テ キ ス ト ボ ッ ク ス に 「モデル A」 と
入力 し ます。
E [ パ ラ メ ー タ 制約 ] ボ ッ ク ス は空白の ま ま残 し てお き ます。
E モデル B を指定す る には、 [ 新規作成 ] を ク リ ッ ク し ます。
E [ モデル名 ] テ キ ス ト ボ ッ ク ス で、 「モデル番号 2」 を 「モデル B」 に変更 し ます。
268
例 18
E [ パ ラ メ ー タ 制約 ] テ キ ス ト ボ ッ ク ス に、 「m1_old = m1_yng」 と 入力 し ます。
E [ 閉 じ る ] を ク リ ッ ク し ます。
Ex18-b.amw と い う フ ァ イ ルに、 モデル A と モデル B の両方に適合す る パ ス図が保存
さ れます。
モデル A およびモデル B からの出力
E モデル A と モデル B の両方におけ る 適合度を調べ る には、 [Amos 出力 ] ウ ィ ン ド ウ の
左上隅の ウ ィ ン ド ウ 枠にあ る ツ リ ー図で、 [ モデルの適合度 ] を ク リ ッ ク し ます。
カ イ 2 乗の値のあ る 出力部分を次に示 し ます。
モデル B が正 し い ( 若年層 と 老年層の両方の母集団において vocab の得点の平均値が
等 し い ) 場合、 7.849 は、 自由度 1 のカ イ 2 乗分布がみ ら れ る 乱数変数におけ る 観測値
と な り ます。 7.849 と 同 じ 大 き さ の値を偶然に得 る 確率は低いので (p = 0.005)、 モデル
B は棄却 さ れます。 こ の結果、 若年被験者 と 老年被験者では、 vocab の得点におけ る 平
均値が有意に異な る と 言え ます。
269
欠損デー タ についてのその他の情報
VB.NET でのモデル作成
モデル A
モデル A に適合す る プ ロ グ ラ ム を次に示 し ます。 両方の被験者グループにおけ る 両方
の語彙検定につい て、 制約 を 設けずに平均値、 分散、 お よ び共分散 を 推定 し ま す。
こ のプ ロ グ ラ ムは、 Ex18-a.vb フ ァ イ ル と し て保存 さ れます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Crdiff()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(Sem.AmosDir & "Examples¥atty_mis.sav")
Sem.GroupName("young_subjects")
Sem.Mean("vocab", "m1_yng")
Sem.Mean("v_short")
Sem.BeginGroup(Sem.AmosDir & "Examples¥atto_mis.sav")
Sem.GroupName("old_subjects")
Sem.Mean("vocab", "m1_old")
Sem.Mean("v_short")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
Crdiff メ ソ ッ ド は、 前述 し たパ ラ メ ー タ の差に対す る 検定統計量を表示 し ます。
後で参照す る ために、 モデル A の 対数尤度関数 の値を控え ておいて く だ さ い。
対数尤度関数 = 429.963
パ ラ メ ー タ 数 = 10
270
例 18
モデル B
モデル B に適合す る プ ロ グ ラ ム は次の と お り です。 こ のプ ロ グ ラ ム では、 若年層グ
ル ー プ の vocab 平 均 値 と 老 年 層 グ ル ー プ の vocab 平 均 値 と で 同 じ パ ラ メ ー タ 名
(mn_vocab) が使用 さ れてい ます。 こ の方法では、 若年層グループ と 老年層グループに
おけ る vocab 平均値が同 じ であ る 必要があ り ます。 こ のプ ロ グ ラ ムは、 Ex18-b.vb フ ァ
イ ル と し て保存 さ れます。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Crdiff()
Sem.ModelMeansAndIntercepts()
Sem.BeginGroup(Sem.AmosDir & "Examples¥atty_mis.sav")
Sem.GroupName("young_subjects")
Sem.Mean("vocab", "mn_vocab")
Sem.Mean("v_short")
Sem.BeginGroup(Sem.AmosDir & "Examples¥atto_mis.sav")
Sem.GroupName("old_subjects")
Sem.Mean("vocab", "mn_vocab")
Sem.Mean("v_short")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
Amos が報告す る モデル B の適合度は、 次の と お り です。
対数尤度関数 = 437.813
パラ メ ータ数 = 9
モデル B と モデル A と の適合度の差は 7.85(= 437.813 - 429.963)、パ ラ メ ー タ 数の差は
1(= 10 - 9) です。 こ れ ら の数値は、 先に Amos Graphics で得た数値 と 同 じ です。
例
19
ブー ト ス ト ラ ッ プ
概要
こ の例では、 ブー ト ス ト ラ ッ プ法に よ っ て頑健な標準誤差の推定値を得 る 方法につい
て示 し ます。
ブー ト ス ト ラ ッ プ法
ブー ト ス ト ラ ッ プ (Efron, 1982) は、 パ ラ メ ー タ 推定値の標本分布の推定に汎用で き る
方法です。 特に、標準誤差の近似を求め る 場合に使用す る こ と がで き ます。 先に示 し た
例の と お り 、 Amos は推定対象のパ ラ メ ー タ について、 標準誤差の近似を自動表示 し
ます。 Amos では、 こ う し た近似値の計算に、 32 ページ での仮定に依存 し た公式を使
用 し ます。
ブー ト ス ト ラ ッ プでは、 標準誤差の推定におけ る 問題に対 し 、 ま っ た く 異な る 手法
を と り ます。 別の手法が必要 と さ れ る 理由 と は何で し ょ う か。 第一に、 Amos には、 重
相関の 2 乗におけ る 標準誤差な ど、 必要 と さ れ る 標準誤差のすべてに公式が備わ っ て
い る わけではあ り ません。 ただ し 、 ブー ト ス ト ラ ッ プでは、 標準誤差に対す る 公式を
使用で き な く て も ま っ た く 問題あ り ません。 ブー ト ス ト ラ ッ プ を使用すれば、 標準誤
差に対す る 公式がわか っ てい る か ど う かにかかわ ら ず、 Amos が計算す る すべての推
定値に対す る 標準誤差の近似 を 生成す る こ と がで き ま す。 標準誤差に対す る 公式が
Amos に備わ っ てい る 場合で も 、 公式が役立つのは 32 ページ での仮定においてのみ
です。 加え て、 公式が機能す る のは、 正 し いモデルを使用 し てい る 場合に限 ら れ ます。
ブー ト ス ト ラ ッ プに よ っ て求め ら れた標準誤差の近似は、 こ う し た制限を受け る こ と
はあ り ません。
ブー ト ス ト ラ ッ プには、 かな り 大 き な標本を必要 と す る な ど、 特有の欠点 も あ り ま
す。 ブー ト ス ト ラ ッ プについて初めて学習す る 場合は、 『Scientific American』 誌に掲載
の、 Diaconis と Efron(1983) に よ る 論文を一読 さ れ る こ と をお勧め し ます。
271
272
例 19
こ の例では因子分析モデルを適用 し たブー ト ス ト ラ ッ プについて紹介 し ますが、 も
ち ろん任意のモデルを使用 し て も か ま い ません。 なお、 Amos は 例 1 の よ う な単純な
推定におけ る 問題を解決で き る こ と を覚え ていて く だ さ い。 Amos のブー ト ス ト ラ ッ
プ機能 を 使用で き る よ う に な る こ と だ け を 目的に、 こ う し た 単純 な 問題に あ え て
Amos を使用 し てみ る の も いいで し ょ う 。
デー タ について
こ の例では、 例 8 で紹介 し た Holzinger と Swineford(1939) のデー タ を使用 し ま す。
こ のデー タ は、 Grnt_fem.sav フ ァ イ ルに入っ てい ます。
因子分析モデル
こ のモデルのパ ス図 (Ex19.amw) は、 例 8 と 同 じ です。
E 500 回のブー ト ス ト ラ ッ プ反復を求めるには、 メ ニ ューか ら [ 表示 ] [ 分析のプロパテ ィ ]
の順に選択し ます。
E [ ブー ト ス ト ラ ッ プ ] タ ブ を ク リ ッ ク し ます。
E [ ブー ト ス ト ラ ッ プの実行 ] を選択 し ます。
273
ブー ト ス ト ラ ッ プ
E [ ブー ト ス ト ラ ッ プ標本の数 ] テ キ ス ト ボ ッ ク ス に 「500」 と 入力 し ます。
ブー ト ス ト ラ ッ プの進行状況の監視
パ ス図の左側にあ る [ 計算の要約 ] パネルを見 る こ と で、ブー ト ス ト ラ ッ プ アルゴ リ ズ
ムの進行状況を監視で き ます。
分析の結果
モデルの適合度は、 も ち ろん 例 8 と 同 じ です。
カ イ 2 乗 = 7.853
自由度 = 8
確率水準 = 0.448
274
例 19
パ ラ メ ー タ 推定値 も 、 例 8 と 同 じ です。 ただ し 、 こ こ では最尤法の理論に基づ く 標準
誤差の推定値に注目 し 、 ブー ト ス ト ラ ッ プに よ っ て得 ら れた標準誤差 と 比較 し ま す。
こ のため、 最尤法に よ る パ ラ メ ー タ の推定値 と 標準誤差は次の よ う にな り ます。
ブー ト ス ト ラ ッ プ出力は、 診断情報が以下の と お り のテーブルか ら 開始 さ れます。
275
ブー ト ス ト ラ ッ プ
特異な分散共分散行列が、 1 つ以上のブー ト ス ト ラ ッ プ標本に見 ら れ る こ と があ り ま
す。 ま た、 Amos が一部のブー ト ス ト ラ ッ プ標本の解を求め ら れない こ と も あ り ます。
上記のいずれかの標本が出現 し た場合、 Amos は出現について報告 し 、 ブー ト ス ト ラ ッ
プ分析か ら こ の標本を除外 し ます。 こ の例では、特異な分散共分散行列が見 ら れ る ブー
ト ス ト ラ ッ プはな く 、 500 のブー ト ス ト ラ ッ プ標本すべての解が求め ら れ ま し た。 標準
誤差のブー ト ス ト ラ ッ プ推定値は、 次の と お り です。
276
例 19
「S.E.」 と い う ラ ベルが付いた 1 列目には、 標準誤差のブー ト ス ト ラ ッ プ推定値が
表示 さ れてい ます。 こ れ ら の推定値は、最尤法に よ っ て得 ら れた標準誤差の近似 と
比較 さ れます。
「S.E.-S.E.」 と い う ラ ベルが付いた 2 列目には、 ブー ト ス ト ラ ッ プにおけ る 標準誤
差の推定値自身に対す る 標準誤差の近似が表示 さ れてい ます。
「Mean」 と い う ラ ベルが付いた列にあ る 値は、 ブー ト ス ト ラ ッ プ標本に対 し て計算
さ れたパ ラ メ ー タ 推定値の平均値です。 ブー ト ス ト ラ ッ プ平均値は、元の推定値 と
同 じ であ る 必要はあ り ません。
「Bias」 と い う ラ ベルが付いた列にあ る 値は、 元の推定値 と 、 ブー ト ス ト ラ ッ プ標
本に対する推定値の平均 と の差です。 ブー ト ス ト ラ ッ プ標本に対する推定値の平均
が元の推定値 よ り も 大き い場合、 「Bias」 は正の値 と な り ます。
「S.E.-Bias」 と い う ラ ベルが付いた最後の列には、 推定値の偏 り に対す る 標準誤差
の近似が表示 さ れてい ます。
VB.NET でのモデル作成
次のプ ロ グ ラ ム (Ex19.vb) は 例 19 のモデルに適合 し 、 500 のブー ト ス ト ラ ッ プ標本で
ブー ト ス ト ラ ッ プを実行 し ます。 こ れは、 Bootstrap 行が追加 さ れてい る 点以外は 例 8
でのプ ロ グ ラ ム と 同 じ です。
Sub Main()
Dim Sem As New AmosEngine
Try
Sem.TextOutput()
Sem.Bootstrap(500)
Sem.Standardized()
Sem.Smc()
Sem.BeginGroup(Sem.AmosDir & "Examples¥Grnt_fem.sav")
Sem.AStructure("visperc = (1) spatial + (1) err_v")
Sem.AStructure("cubes = spatial + (1) err_c")
Sem.AStructure("lozenges = spatial + (1) err_l")
Sem.AStructure("paragrap = (1)spatial + (1) err_p")
Sem.AStructure("sentence = spatial + (1) err_s")
Sem.AStructure("wordmean= spatial + (1) err_w")
Sem.FitModel()
Finally
Sem.Dispose()
End Try
End Sub
Sem.Bootstrap(500) と い う 行で、500 のブー ト ス ト ラ ッ プ標本に基づ く ブー ト ス ト ラ ッ
プの標準誤差を求めてい ます。
例
20
ブー ト ス ト ラ ッ プ でのモデル比較
概要
こ の例では、 ブー ト ス ト ラ ッ プを モデル比較に使用す る 方法について示 し ます。
モデル比較における ブー ト ス ト ラ ッ プ手法
こ の方法で扱 う のは、 個々のモデルを絶対的に評価す る 際の問題ではな く 、 競合す る
2 つ以上の モデル か ら モデル を 選択す る 際の問題です。 Bollen と Stine の共同研究
(1992) お よ び、 Bollen(1982)、 Stine(1989) の各研究では、 積率構造分析でのモデル選択
に お け る ブ ー ト ス ト ラ ッ プ 使 用 の 可 能 性 に つ い て 述 べ ら れ て い ま す。 Linhart と
Zucchini の共同研究 (1986) では、 構造モデ リ ン グ な ど の大 き なモデル ク ラ ス に適 し た
ブー ト ス ト ラ ッ プ と モデル選択に向けた、 一般的な ス キーマについて述べ ら れてい ま
す。 こ こ では、 こ の Linhart と Zucchini に よ る 手法を採用 し てい ます。
モデル比較におけ る ブー ト ス ト ラ ッ プ手法について要約す る と 、次の よ う にな り ます。
元の標本を置換 し て標本を抽出す る こ と で、 複数のブー ト ス ト ラ ッ プ 標本を生成
し ます。 つま り 、 元の標本 が、 ブー ト ス ト ラ ッ プの標本抽出のための 母集団 と な
り ます。
競合す る すべてのモデルを各ブー ト ス ト ラ ッ プ標本に当てはめ ます。 個々の分析
が済んだ ら 、 ブー ト ス ト ラ ッ プ標本か ら 得 ら れたモデルの積率 と 、 ブー ト ス ト ラ ッ
プ母集団の積率 と の乖離度を計算 し ます。
先述の手順におけ る 各モデルについて、乖離度の ( ブー ト ス ト ラ ッ プ標本に対す る )
平均値を計算 し ます。
乖離度の平均値が最 も 小 さ いモデルを選択 し ます。
277
278
例 20
デー タ について
こ の例では、 先に例 8、 例 12、 例 15、 例 17、 お よ び 例 19 で紹介 し た Holzinger と
Swineford に よ る 研究 (1939) におけ る 、 Grant-White 高校の男子生徒 と 女子生徒が混
ざ っ た標本を使用 し ます。 男子生徒 と 女子生徒を合わせて 145 の観測値が、 Grant.sav
フ ァ イ ルに入っ てい ます。
5 つのモデル
5 つの尺度モデルが、 6 種類の心理検定に適用 さ れます。 モデル 1 は、 因子数が 1 の因
子分析モデルです。
279
ブー ト ス ト ラ ッ プ でのモデル比較
モデル 2 は、 制約のない因子分析です。 因子数は 2 です。 回帰 ウ ェ イ ト の う ちの 2 つ
を 0 に固定す る こ と でモデルを制約す る のではな く 、 モデルを特定す る だけであ る こ
と に注意 し て く だ さ い (Anderson, 1984; Bollen お よ び Jöreskog, 1985; Jöreskog, 1979)。
モデル 2R は、 制限つ き の因子分析モデルで、 因子数は 2 です。 こ のモデルでは、
最初の 3 つの検定は因子の う ちの 1 つのみに依存 し ていて、 残 り の 3 つの検定は も う
一方の因子のみに依存 し てい ます。
280
例 20
残 る 2 つのモデルか ら は、 先述のモデルの適合度を評価す る ための、 慣例に よ る 基準
点を設定す る こ と がで き ます。 飽和モデルでは、 観測変数の分散 と 共分散は制限 さ れ
ません。
独立モデルでは、 観測変数の分散は制限 さ れませんが、 共分散は 0 にな る こ と が求め
ら れます。
分析のたびに、 Amos に よ っ て こ の 2 つのモデルの適合度が自動的に報告 さ れ る ため、
通常、 飽和モデル と 独立モデルを別々に当てはめ る こ と はあ り ません。 ただ し 、 こ の
2 つのモデルについてのブー ト ス ト ラ ッ プ結果を得 る には、 飽和モデル と 独立モデル
を明示的に指定す る 必要があ り ます。 異な る 5 つのブー ト ス ト ラ ッ プ分析は、1 つのモ
デルに対 し て 1 つずつ実施す る 必要があ り ます。 こ の 5 つの分析を実施す る 方法は、い
ずれ も 次の と お り です。
E
メ ニ ュ ーか ら [ 表示 ] [ 分析のプ ロパテ ィ ] の順に選択 し ます。
281
ブー ト ス ト ラ ッ プ でのモデル比較
E [ 分析のプロパテ ィ ] ダイ ア ロ グ ボ ッ ク ス で、[ ブー ト ス ト ラ ッ プ ] タ ブを ク リ ッ ク し ます。
E [ ブー ト ス ト ラ ッ プの実行 ] を選択 し ます ( 横にチ ェ ッ ク マー ク が表示 さ れます )。
E [ ブー ト ス ト ラ ッ プ標本の数 ] テ キ ス ト ボ ッ ク ス に 「1000」 と 入力 し ます。
E [ 乱数 ] タ ブを ク リ ッ ク し てか ら 、 [ 乱数のシー ド ] に値を入力 し ます。
シー ド には任意の値を設定で き ますが、 複数あ る Amos の各セ ッ シ ョ ン と ま っ た く 同
じ 標本群を抽出す る には、 毎回同 じ シー ド 数を設定す る 必要があ り ます。 こ の例では、
シー ド 数を 3 に設定 し ます。
場合に よ っ ては、 ブー ト ス ト ラ ッ プ 標本に対 し 、 最小化アルゴ リ ズ ムが収束 し な く な
る こ と があ り ます。 全体の計算時間を抑制す る 方法は、 次の と お り です。
E [ 数値解析 ] タ ブを ク リ ッ ク し てか ら 、 [ 反復回数の制限 ] フ ィ ール ド で、 反復回数を 40
な ど の現実的な数に制限 し ます。
こ の 5 つのモデルに対す る Amos Graphics の入力フ ァ イ ルは、 それぞれ Ex20-1.amw、
Ex20-2.amw、 Ex20-2r.amw、 Ex20-sat.amw、 Ex20-ind.amw と い う 名前で保存 さ れてい
ます。
282
例 20
テキス ト 出力
E モデル 1 のテ キ ス ト 出力の表示を表示す る には、 [Amos 出力 ] ウ ィ ン ド ウ の左上隅の
ウ ィ ン ド ウ 枠にあ る ツ リ ー図で [ ブー ト ス ト ラ ッ プ反復の要約 ] を ク リ ッ ク し ます。
次の メ ッ セージは、 いずれのブー ト ス ト ラ ッ プ 標本について も 破棄す る 必要はない と
い う こ と を表 し てい ます。 1,000 のブー ト ス ト ラ ッ プ 標本すべてが利用 さ れま し た。
共分散行列が特異なため、 0 個のブー ト ス ト ラ ッ プ標本が利用 さ れ ませんで し た。
解を求め る こ と がで き なか っ たため、 0 個のブー ト ス ト ラ ッ プ標本が利用 さ れ ませ
んで し た。
1000 個の利用可能なブー ト ス ト ラ ッ プ標本が得 ら れま し た。
E ツ リ ー図で [ ブー ト ス ト ラ ッ プ分布 ] を ク リ ッ ク し て、次の ヒ ス ト グ ラ ム を表示 し ます。
C
ML
ˆb ,a CKL ˆb ,a CKL a,a ,
b 1, K ,1000
a には、Grant-White 高校の生徒 145 名分の元の標本か ら の標本積率 ( ブー ト ス ト ラ ッ プ
母集団の積率 ) が含まれてい ます。̂ b には、 モデル 1 を b-th ブー ト ス ト ラ ッ プ標本に当
てはめ る こ と で得 ら れたモデルの積率が含まれてい ます。 し たが っ て、C ML ̂ b a は、
母集団の積率が、 モデル 1 を使用 し た b-th 標本か ら 推定 し た積率か ら ど の程度離れて
い る か を表す測度であ る こ と にな り ます。
283
ブー ト ス ト ラ ッ プ でのモデル比較
1,000 を超え る ブー ト ス ト ラ ッ プ 標本に対す る C ML ̂ b a の平均値は 64.162、 標準誤
差は 0.292 で し た。 残 り の 4 つのモデルについて も 、 同様の ヒ ス ト グ ラ ムが平均値 と
標準誤差 と と も に表示 さ れてい ますが、こ こ では再現 し てい ません。 5 つの競合モデル
におけ る 乖離度の平均値は、 BCC、 AIC、 お よ び CAIC と い う 値 と と も に下記のテー
ブルに表示 さ れてい ます。 こ のテーブルか ら 、5 つの競合モデルにおけ る モデルの適合
度 ( かっ こ 内は標準誤差 ) がわか り ます。
モデル
1
2
2R
Sat.
Indep.
失敗
0
19
0
0
0
乖離度の平均値
64.16 (0.29)
29.14 (0.35
26.57 (0.30)
32.05 (0.37)
334.32 (0.24)
BCC
AIC
CAIC
68.17
36.81
30.97
44.15
333.93
66.94
35.07
29.64
42.00
333.32
114.66
102.68
81.34
125.51
357.18
こ のテーブルの 「失敗」 列は、 モデル 2 の尤度関数が、 1,000 個のブー ト ス ト ラ ッ プ 標
本中 19 個で最大化 さ れなかっ た こ と を示 し てい ます。 少な く と も 、 反復回数の制限値
40 は適用 さ れてい ません。 ブー ト ス ト ラ ッ プ 標本の総数を タ ーゲ ッ ト の 1,000 に合わ
せ る ため、 モデル 2 には新たに 19 個のブー ト ス ト ラ ッ プ 標本が生成 さ れま し た。 モ
デル 2 を正常に適合で き なかっ た 19 個の標本は、残 り の 4 つのモデルでは問題 と な り
ませんで し た。 し たが っ て、 5 つのモデルすべてに共通す る ブー ト ス ト ラ ッ プ 標本は
981 個で し た。
19 個のブー ト ス ト ラ ッ プ 標本においてモデル 2 の推定値を計算で き なか っ た理由
については、 特に調べ ら れてい ません。 一般に、 積率構造分析でのアルゴ リ ズ ムは、 適
合が不十分なモデルに対 し て失敗 し がちです。 た と えば、 開始値を厳密に設定 し た り 、
優れた アルゴ リ ズ ム を使用す る な ど、モデル 2 を こ の 19 個の標本に正常に適合 さ せ る
方法を見つけ ら れた と し て も 、 乖離度が大 き く な る も の と 予想 さ れ ます。 こ の理由か
ら 、 推定に失敗 し たブー ト ス ト ラ ッ プ 標本を破棄すれば、 乖離度の平均値におけ る 偏
り を減少 さ せ る こ と がで き る と 考え ら れ ます。 こ のため、 ブー ト ス ト ラ ッ プ実行中に
おけ る 推定の失敗について考慮す る 必要があ り ます。 乖離度の平均値が最 も 小 さ いモ
デルに対 し て こ の失敗が起 き た場合には、 特に注意 し ます。
こ の例では、 モデル 2R で乖離度の平均値が最小 (26.57) と な り 、 BCC、 AIC、 CAIC
基準に基づいたモデル選択が確認 さ れ ます。 乖離度の平均値におけ る 差は、 標準誤差
に比べて大 き いです。 すべてのモデルが同一のブー ト ス ト ラ ッ プ 標本に適合 し ていた
ため ( モデル 2 を正常に適合で き なか っ た標本を除 く )、ブー ト ス ト ラ ッ プ 標本におい
て、 同一モデルに対す る 乖離度間で正の相関が見 ら れ る だ ろ う と 予想す る こ と も で き
る で し ょ う 。 し か し あいに く なが ら 、Amos か ら こ の相関が報告 さ れ る こ と はあ り ませ
ん。 こ の相関を手計算 し てみ る と 、 ほぼ 1 近 く にな り ます。 こ のため、 全体的にテー
ブル内の平均値の差におけ る 標準誤差は、 平均値の標準誤差 よ り も かな り 小 さ い と 言
え ます。
284
例 20
要約
ブ ー ト ス ト ラ ッ プ は、 積率構造分析 で の モ デル選択 に お い て 実際 に 役立 ち ま す。
Linhart と Zucchini (1986) の手法では、 モデル比較の基準 と し て、 モデルの積率 と 母集
団の積率 と の間で予測 さ れ る 乖離度を使用 し ます。 こ の方法は理論上は単純で、 適用
し やすい も のです。 こ の方法では、 有意確率な ど の特別な数を任意に使用す る こ と は
で き ま せん。 も ち ろ ん、 競合モデルの理論的な妥当性や、 モデルに関連付け ら れた
パ ラ メ ー タ 推定値の合理性は、 ブー ト ス ト ラ ッ プ手続 き では考慮 さ れ ま せん。 ま た、
モデル評価プ ロ セ ス での別の段階では、 適切な重みを指定す る 必要があ り ます。
VB.NET でのモデル作成
こ の例が記述 さ れた Visual Basic プ ロ グ ラ ム は、 Ex20-1.vb、 Ex20-2.vb、 Ex20-2r.vb、
Ex20-ind.vb、 お よ び Ex20-sat.vb フ ァ イ ルに入っ てい ます。
例
21
ブー ト ス ト ラ ッ プに よ る比較推定方法
概要
こ の例では、 競合す る 推定基準を ブー ト ス ト ラ ッ プに よ っ て選択す る 方法について示
し ます。
推定方法
母集団の積率 と モデルの積率 と の乖離度は、 モデルだけではな く 推定方法に も 依存 し
ます。 モデルを比較す る ために 例 20 で使用 し た手法は、推定方法の比較に も 適用で き
ます。 こ の手法が特に必要 と さ れ る のは、 選択対象 と な る 推定方法が漸近的にのみ最
適 と な る こ と が わ か っ て い て、 こ の推定方法の有限標本におけ る 相対的な 利点が、
モデル、 標本 サ イ ズ、 お よ び母集団の分布に依存す る と 予測 さ れ る 場合です。 推定方
法 を 選択す る こ のプ ロ グ ラ ム を 実行す る 際に最 も 問題 と な る のは、 母集団の積率 と
モデルの積率 と の間の乖離度を測定す る 方法を あ ら か じ め決定す る 必要があ る と い う
こ と です。 こ の決定に あ た っ ては、 他の対象への推定基準を肯定す る し か方法がない
よ う です。 も ち ろ ん、 すべての母集団の乖離度が同 じ 結果 と なれば、 適切な母集団の
乖離度は どれか と い う 問題について理論的に考察で き る よ う にな り ます。 こ の例では、
こ う し た明確な例を紹介 し ます。
デー タ について
こ の例では、 例 20 (Grant.sav フ ァ イ ル ) での Holzinger-Swineford(1939) デー タ を使用
し ます。
285
286
例 21
モデルについて
こ の例では先の例 と は替わ り 、 漸近的分布非依存法 (ADF)、 最尤法 (ML)、 一般化最小
2 乗法 (GLS)、 重み付けのない最小 2 乗法 (ULS) の 4 つの方法で、 例 20 のモデル 2R
のパ ラ メ ー タ を推定 し ます。 こ の 4 つのモデルを比較す る には、Amos を 4 回実行す る
必要があ り ます。
推定方法 と ブー ト ス ト ラ ッ プ パ ラ メ ー タ を指定す る 方法は、 次の と お り です。
E
メ ニ ュ ーか ら [ 表示 ][ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 乱数 ] タ ブを ク リ ッ ク し ます。
E [ 乱数のシー ド ] に値を入力 し ます。
例 20 で述べた と お り 、 シー ド には任意の値を選択で き ますが、 複数あ る Amos の各
セ ッ シ ョ ン と ま っ た く 同 じ 標本群を抽出す る には、 毎回同 じ シー ド 数を設定す る 必要
があ り ます。 こ の例では、 シー ド 数を 3 に設定 し ます。
E 次に、 [ 推定 ] タ ブ を ク リ ッ ク し ます。
E [ 漸近的分布非依存法 ] 乖離度を選択 し ます。
こ の乖離度は、 各ブー ト ス ト ラ ッ プ 標本へのモデル適合に、 ADF に よ る 推定方法を使
用す る こ と を設定 し ます。
287
ブー ト ス ト ラ ッ プによ る比較推定方法
E 最後に、 [ ブー ト ス ト ラ ッ プ ] タ ブを ク リ ッ ク し ます。
E [ ブー ト ス ト ラ ッ プの実行 ] を選択 し て、 [ ブー ト ス ト ラ ッ プ標本の数 ] に 「1000」 と 入力
し ます。
E [ ブ ー ト ス ト ラ ッ プ ADF] 、 [ ブ ー ト ス ト ラ ッ プ ML] 、 [ ブ ー ト ス ト ラ ッ プ GLS] 、 お よ び
[ ブー ト ス ト ラ ッ プ ULS]。
[ ブー ト ス ト ラ ッ プ ADF]、 [ ブー ト ス ト ラ ッ プ ML]、 [ ブー ト ス ト ラ ッ プ GLS]、 [ ブー ト ス
ト ラ ッ プ SLS] お よ び [ ブー ト ス ト ラ ッ プ ULS] の選択に よ っ て、元の標本での標本積率
と 各ブー ト ス ト ラ ッ プ標本か ら のモデル積率 と の乖離度 を 測定す る 際に、 それぞれ
CADF 、 CML、 CGLS、 お よ び CULS を使用す る こ と が設定 さ れます。
集計のため、 分析 ([ 分析 ][ 推定値を計算 ]) の実行中に、 Amos は ADF 乖離度を使
用 し てい る 1,000 のブー ト ス ト ラ ッ プ 標本のそれぞれにモデルを適合 し ます。 各ブー
ト ス ト ラ ッ プ 標本について、 モデル積率の母集団積率に対す る 近似値は、 CADF 、 CML、
CGLS、 お よ び CULS と い う 異な る 4 つの方法に よ っ て測定 さ れます。
288
例 21
E [ 最尤法 ] 乖離度を選択 し て、 分析を繰 り 返 し ます。
E [ 一般化最小 2 乗法 ] 乖離度を選択 し て、 さ ら に分析を繰 り 返 し ます。
E [ 重み付けのない最小 2 乗法 ] 乖離度を選択 し て、 最後の分析を実行 し ます。
こ の 例 に つ い て の Amos Graphics 入 力 フ ァ イ ル は、 Ex21-adf.amw、 Ex21-ml.amw、
Ex21-gls.amw、 お よ び Ex21-uls.amw の 4 フ ァ イ ルです。
テキス ト 出力
4 つの分析の う ちの最初の分析 (Ex21-adf.amw にあ り ます ) では、 ADF を使用 し た推
定に よ っ て、 次の ヒ ス ト グ ラ ム出力が得 ら れ ます。 こ の ヒ ス ト グ ラ ム を表示す る 方法
は、 次の と お り です。
289
ブー ト ス ト ラ ッ プによ る比較推定方法
E [Amos 出力 ] ウ ィ ン ド ウ の左上隅の ウ ィ ン ド ウ枠にあ る ツ リ ー図で、[ ブー ト ス ト ラ ッ プ
分布 ] [ADF 乖離度 ( モデル対母集団 )] の順に ク リ ッ ク し ます。
こ の出力部分には、 1,000 個のブー ト ス ト ラ ッ プ 標本におけ る 母集団の乖離度の分布
C ADF ̂ b a が表示 さ れてい ます。 こ こ で、̂ b には C ADF ̂ b a b の最小化に よ っ て得
ら れた モデル積率、 つ ま り 、 標本の乖離度が含 ま れてい ま す。 1,000 個のブー ト ス ト
ラ ッ プ 標本におけ る C ADF ̂ b a の平均値は 20.601 で、 標準誤差は 0.218 です。
次の ヒ ス ト グ ラ ムは、C ML ̂ b a の分布を表 し てい ます。 こ の ヒ ス ト グ ラ ム を表示する
方法は、 次の と お り です。
E [Amos 出力 ] ウ ィ ン ド ウ の左上隅の ウ ィ ン ド ウ枠にあ る ツ リ ー図で、[ ブー ト ス ト ラ ッ プ
分布 ] [ML 乖離度 ( モデル対母集団 )] の順に ク リ ッ ク し ます。
次の ヒ ス ト グ ラ ムは、 C GLS ̂ b a の分布を表 し てい ます。 こ の ヒ ス ト グ ラ ム を表示す
る方法は、 次の と お り です。
290
例 21
E [Amos 出力 ] ウ ィ ン ド ウ の左上隅の ウ ィ ン ド ウ枠にあ る ツ リ ー図で、[ ブー ト ス ト ラ ッ プ
分布 ] [GLS 乖離度 ( モデル対母集団 )] の順に ク リ ッ ク し ます。
次の ヒ ス ト グ ラ ムは、 C ULS ̂ b a の分布を表 し てい ます。 こ の ヒ ス ト グ ラ ム を表示す
る方法は、 次の と お り です。
E [Amos 出力 ] ウ ィ ン ド ウ の左上隅の ウ ィ ン ド ウ枠にあ る ツ リ ー図で、[ ブー ト ス ト ラ ッ プ
分布 ] [ULS 乖離度 ( モデル対母集団 )] の順に ク リ ッ ク し ます。
291
ブー ト ス ト ラ ッ プによ る比較推定方法
次のテーブルには、1,000 個のブー ト ス ト ラ ッ プ 標本におけ る C ̂ b a の平均値が表
示 さ れてい ます。 か っ こ 内は標準誤差です。 先ほ ど示 し た 4 つの分布は、 テーブルの
最初の行に集計 さ れてい ます。 残 る 3 行には、 CML、 CGLS、 お よ び CULS を それぞれ最
小化 し た推定結果が表示 さ れてい ます。
推定に使用 し
た、 標本の乖
離度
CADF
CML
CGLS
評価に使用 し た、 母集団の乖離度 : C ̂ b a b
CADF
CML
CGLS
CULS
20.60 (0.22)
36.86 (0.57)
21.83 (0.26)
43686 (1012)
19.19 (0.20)
26.57 (0.30)
18.96 (0.22)
34760 (830)
19.45 (0.20)
31.45 (0.40)
19.03 (0.21)
37021 (830)
C ̂ b a b
CULS
24.89 (0.35)
31.78 (0.43)
24.16 (0.33)
35343 (793)
「CADF 」 と い う ラ ベルが付いた 1 列目には、 母集団の乖離度 CADF に応 じ た 4 つの推
定方法の相対的なパフ ォ ーマ ン ス が表示 さ れてい ます。 CADF 列では、 19.19 が乖離度
の平均値 と し て最小なので、 CADF 基準におけ る 最適な推定方法は CML であ る と 言え
ます。 同様に、 テーブルの CML 列を調べ る と 、 CML 基準において も 、 CML が最適な推
定方法であ る こ と がわか り ます。
テーブルの 4 つの列は 4 つの推定方法の正確な順序 と は一致 し ませんが、 すべての
ケース において、 乖離度の平均値が最 も 小 さ いのは ML です。 ML に よ る 推定 と GLS
に よ る 推定 と の差がわずかな ケー ス も あ り ます。 当然の こ と なが ら 、 使用 し た母集団
の乖離度すべてにおいて、 ULS に よ る 推定は う ま く い き ませんで し た。 さ ら に興味深
いのは、 ADF に よ る 推定が う ま く いかなかっ た こ と です。 ADF に よ る 推定はモデル、
母集団、 標本 サ イ ズ と い う 組み合わせには適 さ ない と 言え ます。
VB.NET でのモデル作成
こ の例についての Visual Basic プ ロ グ ラ ムは、 Ex21-adf.vb、 Ex21-gls.vb、 Ex21-ml.vb、
お よ び Ex21-uls.vb フ ァ イ ルにあ り ます。
例
22
探索的モデル特定化
概要
こ の例では、 2 種類の探索的モデル特定化を紹介 し ます。 一方は概 し て確認的 ( オプ
シ ョ ン矢印が少数 ) で、 他方は概 し て探索的 ( オプシ ョ ン矢印が多数 ) です。
デー タ について
こ の例では、 例 7 で紹介 し た、 Felson と Bohrnstedt(1979) に よ る女子のデー タ を使用 し
ます。
モデルについて
こ の探索的モデル特定化での初期モデルには、 Felson と Bohrnstedt(1979) の研究での
モデルを使用 し てい ます。 図 22-1 を参照 し て く だ さ い。
図 22-1 Felson と Bohrnstedt の研究における女子のモデル
293
294
例 22
オプ シ ョ ン矢印が少数の探索的モデル特定化
Felson と Bohrnstedt が主に関心 を 向け て い た のは、 academic ← attract と 、 attract ←
academic と い う 2 つの一方向矢印で し た。 こ こ での論点は、 こ の 2 つの一方向矢印の
う ち、 必要 と さ れてい る のは片方だけなのか両方なのか、 あ る いは ど ち ら も 必要 と さ
れていないのか と い う こ と で し た。 こ の理由か ら 、探索的モデル特定化の実行中は、両
方の矢印を オプシ ョ ンに し ます。 ま た、 誤差 1 と 誤差 2 を結ぶ双方向矢印に よ っ て、 一
方向矢印で表示 さ れてい る 効果の解釈が複雑にな り 、 こ れはモデルに と っ て望ま し く
ない機能です。 こ のため、 こ の双方向矢印 も 省略可能に し ます。 探索的モデル特定化
は、 こ の 3 つのオプシ ョ ン矢印の う ち必要な矢印があ る 場合に、 どれがモデルに と っ
て必要なのか を決定す る 手助け と な り ます。
こ の探索的モデル特定化では、 ほ と ん ど の矢印がモデルに必要で、 オプ シ ョ ン は
3 つだけなので、 概 し て確認的 と 言え ます。
モデルの特定化
E Ex22a.amw を開 き ます。 通常の イ ン ス ト ールを実行 し てい る 場合、 パ ス は C:¥Program
Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese¥Ex22a.amw にな り ます。
描画領域にパス図が開かれます。 最初は、 図 22-1 に見 ら れ る オプシ ョ ン矢印は表示 さ
れてい ません。
E
メ ニ ュ ーか ら [ 分析 ] → [ 探索的モデル特定化 ] の順に選択 し ます。
[ 探索的モデル特定化 ] ウ ィ ン ド ウ が表示 さ れます。 最初は、 ツールバーだけが表示 さ
れてい ます。
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し てか ら 、誤差 1 と 誤差 2 を結ぶ
双方向矢印を ク リ ッ ク し ます。 矢印の色が、 オプシ ョ ン であ る こ と を表す色に変わ り
ます。
295
探索的モデル特定化
ヒ ン ト : 次の図の よ う に、オプ シ ョ ン矢印の色 を 変え た り 破線に し た り す る には、 メ
ニ ュ ーか ら [ 表示 ] [ イ ン タ ー フ ェ イ スのプ ロパテ ィ ] の順に選択 し てか ら 、 [ ア ク セ
ス ] タ ブを ク リ ッ ク し て [ 色の選択 ] チ ェ ッ ク ボ ッ ク ス を選択 し ます。
E 矢印を必須に戻すには、[ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し てか ら
目的の矢印を ク リ ッ ク し ます。 ポ イ ン タ を離す と 、 必須の矢印 と し て矢印が再表示 さ
れます。
E 再度
を ク リ ッ ク し てか ら 、 パ ス図が次の よ う にな る ま で、 図中の矢印を ク リ ッ ク
し ます。
後で探索分析を実行す る 際に、 プ ロ グ ラ ムは こ の 3 つの色付 き 矢印を オプシ ョ ン と し
て扱い、 こ れ ら の矢印の可能なサブグループ をすべて使用 し てモデルを適合 し よ う と
し ます。
296
例 22
プ ログ ラ ムのオプ シ ョ ンの選択
E [ 探索的モデル特定化 ] ツールバーの [ オプ シ ョ ン ] ボ タ ン
を ク リ ッ ク し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 結果 ] タ ブ を ク リ ッ ク し ます。
E [ リ セ ッ ト ] を ク リ ッ ク し て、 設定 し たオプシ ョ ンが こ の例 と 同 じ であ る こ と を確認 し
ます。
E 次に、 [ 次を検索 ] タ ブ を ク リ ッ ク し ま す。 先頭のテ キ ス ト には、 こ の探索分析が 8 つ
( つま り 23) のモデルに適合す る こ と が表示 さ れてい ます。
E [ 最善の ___ モデルのみを保存 ] ボ ッ ク ス で、 値を 10 か ら 0 に変更 し ます。
デフ ォ ル ト 値 10 で探索的モデル特定化を実行す る と 、 最大 10 の一方向矢印モデル、
最大 10 の双方向矢印モデル、 な ど が報告 さ れます。 値を 0 に設定す る と 、 報告対象モ
デル数に対す る 制限がな く な り ます。
297
探索的モデル特定化
報告対象モデル数を制限す る こ と で、 探索的モデル特定化が大幅に速 く な り ま す。
ただ し 、 こ の例での探索的モデル特定化に出現す る モデルは、 合計 8 つ し かあ り ませ
ん。 ま た、 [ 最善の ___ モデルのみを保存 ] に 0 以外の値を指定す る こ と で、 後述す る
よ う に、 プ ロ グ ラ ムが赤池 ウ ェ イ ト や Bayes 因子を正規化 し て、 すべてのモデルの合
計を 1 にす る と い う こ と がで き な く な る と い う 、 望ま し く ない効果が生 じ る こ と があ
り ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
探索的モデル特定化の実行
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。
こ のプ ロ グ ラ ムでは、 オプシ ョ ン矢印の各サブグループを使用 し て、 モデルを 8 回適
合 さ せます。 完了す る と 、 [ 探索的モデル特定化 ] ウ ィ ン ド ウ が拡張 し て、 結果が表示
さ れます。
298
例 22
次のテーブルには、 こ の 8 つのモデル と 飽和モデルについての適合度が集計 さ れてい
ます。
「モデル」 列には、 探索的モデル特定化で適合 さ れたモデルに対す る 、 1 か ら 8 ま での
任意の索引番号が表示 さ れてい ます。 「飽和モデル」 は、 飽和モデルを表 し てい ます。
最初の行を見 る と 、 モデル 1 には 19 のパ ラ メ ー タ と 2 の自由度があ り ます。 乖離度関
数 ( こ のケース では尤度比カ イ 2 乗統計量 ) は 2.761 です。 Amos 出力の別の箇所では、
乖離度関数におけ る 最小値を CMIN と 呼び ます。 こ こ では略 し て 「C」 と い う ラ ベル
が付け ら れてい ます。 テーブル内の列についての説明を表示す る には、 列の上で右 ク
リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ 用語のヘルプ ] を選択 し ます。
「モデル」 列 と 「注釈」 列を除 き、 各列での最良の値には下線が引かれてい る こ と に
注意 し て く だ さ い。
こ のテーブルでは、 よ く 知 ら れてい る 適合度 (CFI や RMSEA な ど ) が多数省かれて
い ます。 表示 さ れてい る 適合度の選択理由については、 付録 E を参照 し て く だ さ い。
生成 さ れたモデルの表示
E テーブル内の任意の行を ダブル ク リ ッ ク し て ( 「飽和モデル」 行を除 き ます )、 描画領
域にあ る 対応す る パ ス図を表示す る こ と がで き ます。 例 と し て、 モデル 7 の行を ダブ
ル ク リ ッ ク し てパ ス図を表示 し てみま し ょ う 。
図 22-2 モデル 7 のパス図
299
探索的モデル特定化
モデルのパラ メ ー タ 推定値の表示
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。
E [ 探索的モデル特定化 ] ウ ィ ン ド ウ で、 モデル 7 の行を ダブル ク リ ッ ク し ます。
描画領域にモデル 7 のパ ラ メ ー タ 推定値が表示 さ れます。
図 22-3 モデル 7 のパラ メ ー タ 推定値
BCC を使用 し たモデル比較
E [ 探索的モデル特定化 ] ウ ィ ン ド ウ で、「BCC0」 と い う 見出し のついた列を ク リ ッ ク し ます。
「BCC」 を基準にテーブルが並べ替え ら れ、BCC におけ る 最善モデル (BCC の値が最 も
小 さ いモデル ) が リ ス ト の先頭に配置 さ れます。
300
例 22
Burnham と Anderson(1998) に よ る 提言に基づ き 、 BCC の最小値が 0 に な る よ う 、
すべての BCC 値に定数が挿入 さ れてい ます。 BCC0 の下付 き 文字 0 は、 こ の再調整が
行われた こ と を表 し てい ます。 AIC ( 上図には表示 さ れてい ません ) と BIC も 、 同様に
再調整 さ れ て い ま す。 おお ま か な ガ イ ド ラ イ ン と し て、 Burnham と Anderson 1998,
p. 128) は、 AIC0 について、 次の よ う な解釈を提言 し てい ます。 BCC0 について も 同様
に解釈で き ます。
AIC0 ま たは BCC0
0–2
2–4
4–7
7 – 10
10
Burnham と Anderson に よ る 解釈
こ のモデル を、 可能な標本母集団におけ る 実際の K-L 最善モデルか
ら 除外すべ き 確実な証拠が何 も あ り ま せん (Burnham と Anderson に
よ る K-L の最善 についての定義を参照 し て く だ さ い )。
こ のモデルが K-L 最善モデルではない と す る 証拠は弱いです。
こ のモデルが K-L 最善モデルではない と す る 確実な証拠があ り ます。
こ のモデルが K-L 最善モデルではない と す る 強力な証拠があ り ます。
こ のモデルが K-L 最善モデルではない こ と は明 ら かです。
Burnham と Anderson に よ る ガ イ ド ラ イ ン ではモデル 7 が最善モデル と 推定 さ れてい
ますが、 モデル 6 と モデル 8 も 除外すべ き ではあ り ません。
赤池ウ ェ イ ト の表示
E [ 探索的モデル特定化 ] ツールバーの [ オプ シ ョ ン ] ボ タ ン
を ク リ ッ ク し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 結果 ] タ ブ を ク リ ッ ク し ます。
E [BCC, AIC, BIC] で、 [ 赤池ウ ェ イ ト / Bayes 因子 ( 合計 = 1)] を選択 し ます。
301
探索的モデル特定化
適合度のテーブルでは、 「BCC0」 と い う ラ ベルが付いていた列が 「BCCp」 に替わ り 、
値に赤池 ウ ェ イ ト が挿入 さ れま し た。 ( 付録 G を参照 し て く だ さ い )。
赤池 ウ ェ イ ト ( 赤池 , 1978; Bozdogan, 1987; Burnham お よ び Anderson, 1998) は、 デー
タ を与え ら れたモデルの尤度 と し て解釈 さ れて き ま し た。 こ の解釈に よ る と 、 推定 さ
れた K-L 最善モデル ( モデル 7) の可能性は、モデル 6 の約 2.4 倍 (0.494 / 0.205 = 2.41)
に過ぎ ません。 Bozdogan(1987) は、 候補モデルに事前確率を割 り 当て る こ と がで き れ
ば、こ の事前確率を ( モデルの尤度 と し て解釈 さ れてい る ) 赤池 ウ ェ イ ト と と も に使用
し て、事後確率を得 る こ と がで き る と 指摘 し てい ます。 同 じ 値の事前確率 と と も に、赤
池 ウ ェ イ ト 自身が事後確率 と な り ます。 こ れに よ っ て、 モデル 7 は確率 0.494 の K-L
最善モデル、 モデル 6 は確率 0.205 の K-L 最善モデル、 な ど と 表す こ と がで き ます。
可能性が高いモデルは、 モデル 7、 6、 8、 お よ び 1 の 4 つです。 各モデルの確率を合
計 (0.494 + 0.205 + 0.192 + 0.073 = 0.96) す る と 、 こ の 4 つのモデルの う ちいずれかが
K-L 最善モデルにな る 確率は 96% であ る と 言え ます (Burnham お よ び Anderson, 1998、
pp. 127-129)。 BCCp の下付 き 文字 p は、 BCCp を、 あ る 状況下での確率 と 解釈で き る こ
と を表 し てい ます。
302
例 22
BIC を使用 し たモデル比較
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 結果 ] プ ロ パテ ィ ページで、[BCC, AIC, BIC] か
ら [ ゼロベース (min = 0) ] を選択 し ます。
E [ 探索的モデル特定化 ] ウ ィ ン ド ウ で、「BIC0」 と い う 見出し のついた列を ク リ ッ ク し ます。
「BIC」 を基準にテーブルが並べ替え ら れ、BIC におけ る 最善モデル (BIC の値が最 も 小
さ いモデル ) が リ ス ト の先頭に配置 さ れます。
303
探索的モデル特定化
BIC の値が最 も 小 さ いモデル 7 が、 事後確率の近似値 ( モデル間で同 じ 値の事前確率
を使用 し た う えで、 個々のモデルのパ ラ メ ー タ におけ る 特定の事前分布を使用 ) が最
も 高いモデルです。 Raftery(1995) は、 競合モデルに対す る モデル 7 についての証拠の
判断にあ た り 、 BIC0 値の解釈を次の よ う に提言 し てい ます。
BIC0
Raftery(1995) に よ る 解釈
0–2
2–6
6 – 10
10
弱い
陽性
強い
非常に強い
こ のガ イ ド ラ イ ンに よ る と 、 モデル 6 と 8 では 「陽性」 の証拠が得 ら れ、 その他のモ
デルについてはモデル 7 に比べて 「非常に強い」 証拠が得 ら れます。
Bayes 因子を使用 し たモデル比較
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 結果 ] プ ロ パテ ィ で、[BCC, AIC, BIC] か ら [ 赤池
ウ ェ イ ト / Bayes 因子 ( 合計 = 1) ] を選択 し ます。
304
例 22
適合度の テーブルでは、 「 BIC0」 と い う ラ ベルが付い て い た列が 「 BIC p」 に替わ り 、
合計が 1 と な る よ う 調整 さ れた Bayes 因子が値に挿入 さ れま し た。
モデル間で同 じ 値の事前確率を使用 し た う えで、 個々のモデルのパ ラ メ ー タ におけ る
特定の事前分布を使用 (Raftery, 1995; Schwarz, 1978) し た BICp 値は、 事後確率の近似
値です。 モデル 7 は、 確率 0.860 の正 し いモデルです。 モデル 7、 6、 8 のいずれかが正
し いモデルで あ る と い う こ と は、 99% (0.860 + 0.069 + 0.065 = 0.99) 確信で き ま す。
下付 き 文字 p は、 BICp 値を確率 と 解釈で き る こ と を表 し てい ます。
Madigan と Raftery(1994) は、モデルの平均化 ( こ こ での説明は省 き ます ) には Occam
の ウ ィ ン ド ウ におけ る モデルのみが使用 さ れ る と い う こ と を提言 し てい ます。 対称的
な Occam の ウ ィ ン ド ウ は、 最 も 可能性が高い モデルに比べ て 可能性が か な り 低い
(Madigan と Raftery は、 お よ そ 20 分の 1 の可能性 と い う 例を挙げてい ます ) モデルを
除外す る こ と で得 ら れ る 、 モデルのサブグループです。 こ の例では、 対称的な Occam
の ウ ィ ン ド ウ には、 モデル 7、 6、 8 が含ま れてい ます。 こ れ ら のモデルは確率 (BICp
値 ) が 0.860 20 = 0.043 よ り も 高いためです。
305
探索的モデル特定化
Bayes 因子の再調整
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 結果 ] プ ロ パテ ィ ページで、[BCC, AIC, BIC] か
ら [ 赤池ウ ェ イ ト / Bayes 因子 (max = 1) ] を選択 し ます。
適合度の テーブルでは、 「 BICp」 と い う ラ ベルが付い て いた列が 「 BIC L」 に替わ り 、
最大値が 1 と な る よ う 調整 さ れた Bayes 因子が値に含まれま し た。 こ れに よ り 、Occam
の ウ ィ ン ド ウ を抽出 し やす く な り ます。 こ れは、 BICL 値が 1 20 = 0.05 よ り も 大 き
いモデルで構成 さ れてい ます。 つま り はモデル 7、 6、 8 の こ と です。 BICL の下付 き 文
字 L は、 BCCL と 似た統計量を尤度 と 解釈で き る と い う こ と を表 し てい ます。
306
例 22
モデルの短い リ ス ト についての調査
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。 こ れに よ り 、 モデルにつ
いての短い リ ス ト が表示 さ れます。
次の図の と お り 、 こ の短い リ ス ト には、 各パ ラ メ ー タ 数に対す る 最善モデルが表示 さ
れてい ます。 こ こ では、 パ ラ メ ー タ 数 16 個での最善モデル、 パ ラ メ ー タ 数 17 個での
最善モデル、 な ど が表示 さ れてい ます。 パ ラ メ ー タ 数の固定 さ れたモデルに対 し て こ
の比較が制限 さ れた場合、 すべての基準が最善モデルについて一致す る と い う こ と に
注意 し て く だ さ い。 選択す る 基準に関係な く 、 こ の リ ス ト には全体におけ る 最善モデ
ルが掲載 さ れてい る はずです。
図 22-4 各パ ラ メ ー タ 数に対する最善モデル
こ のテーブルは、 パ ラ メ ー タ 数 17 個での最善モデルが、 パ ラ メ ー タ 数 16 個での最善
モデル よ り も 大幅に適合度が高い こ と を表 し てい ます。 パ ラ メ ー タ が 17 個を超す と 、
さ ら にパ ラ メ ー タ を追加 し て も 適合度の向上は比較的にゆ る やかです。 費用対効果の
分析では、 16 個のパ ラ メ ー タ を 17 個に増やす場合には比較的大 き な対費用効果が得
ら れますが、 パ ラ メ ー タ が 17 個を超す と 対費用効果は比較的小 さ いです。 こ の こ と か
ら 、 発見的な収穫逓減点引数の使用に よ っ て、 パ ラ メ ー タ 数 17 個での最善モデルが採
用で き る こ と がわか り ます。 パ ラ メ ー タ 数の決定におけ る こ の手法については、 こ の
例の後半で詳 し く 紹介 し ます (312 ページの 「C におけ る 最善の適合グ ラ フ の表示」 と
315 ページの 「C の ス ク リ ープ ロ ッ ト の表示」 を参照 し て く だ さ い )。
307
探索的モデル特定化
適合度 と 複雑度についての散布図の表示
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。[ プ ロ ッ ト ] ウ ィ ン ド ウ が
開 き 、 次のグ ラ フ が表示 さ れます。
こ のグ ラ フは、 複雑度 (ÉpÉâÉÅÅ[ タ 数の測定に よ る ) に対す る適合度 (C の測定に よ る )
についての散布図を表 し てい ます。 各点はモデルを表 し ます。 グ ラ フ か ら 、 適合度 と
複雑度が ト レ ー ド オ フ の関係に あ る こ と が わか り ま す。 こ の関係の特質につい て、
Steiger は次の よ う に述べてい ます。
複雑度 と 適合度の間の数値的に最良の妥協点は あ る 程度個人の好みの
問題であ る ため、 最終分析において複雑 さ の測度 と 適合度の測度を単一
の数値指標に組み合わせ る 1 つの最良の方法を定義す る こ と は、 あ る 意
味では不可能であ る と も 言え ます。 モデルの選択は、 嗜好についての 2
次元分析におけ る 昔か ら の課題です (Steiger, 1990、 p. 179)。
E 散布図中の任意の点を ク リ ッ ク し て、 こ の点や、 重な り 合 う 点が表すモデルを示す メ
ニ ュ ーを表示 し ます。
E ポ ッ プア ッ プ メ ニ ュ ーか ら モデルを 1 つ選択 し 、 こ のモデルが強調表示 さ れてい る モ
デルの適合度統計量についてのテーブル と 、 同時に、 描画領域でのモデルのパ ス図 と
を参照 し ます。
308
例 22
次の図では、 カー ソ ルが、 重な り 合 う 2 点を指 し てい ます。 こ の 2 点は、 モデル 6 ( 乖
離度 2.76) と モデル 8 ( 乖離度 2.90) を それぞれ表 し てい ます。
こ のグ ラ フ の水平線は、 C の値が一定で あ る こ と を表 し てい ます。 最初は、 こ の線の
中心は、 縦軸の 0 に あ り ま す。 左下に あ る [ 適合度 ] パネルでは、 水平線上の点が、
C = 0、 お よ び F = 0 (F は、 Amos 出力では FMIN と 呼ばれます ) と 表 さ れてい ます。
NFI1 と NFI2 はいずれ も NFI の一種で、 2 つの異な る ベー ス ラ イ ン モデル を使用 し
ます ( 付録 F を参照 し て く だ さ い )。
最初は、 NFI1 と NFI2 の両方が、 水平線上の点での 1 と 等 し いです。 水平線の位置
は調整す る こ と がで き ます。 こ の線は、マ ウ ス で ド ラ ッ グすれば移動で き ます。 線を移
動す る と 、 左下のパネル内の適合度の値が、 線の移動先の位置に変更 さ れてい る こ と
を確認で き ます。
309
探索的モデル特定化
定数の適合度を表す線の調整
E 調整可能な線の上にマ ウ ス を移動 し ま す。 ポ イ ン タ が手の形に変わ っ た ら 、 NFI1 の
値が 0.900 の位置ま で線を ド ラ ッ グ し ます ( 左下のパネルで NFI1 の値を追いなが ら 、
調整可能な線を移動 し ます )。
NFI1 は、 NFI 統計量で よ く 使用 さ れ る 形式です。 こ の形式におけ る ベース ラ イ ン モデ
ルでは、 観測変数の平均値 と 分散に制約を設けずに、 観測変数が互いに相関 し ない こ
と が必要 と さ れます。 線の下にあ る 点の値は NFI1 > 0.900 であ り 、 線 よ り 上にあ る 点
については NFI1 < 0.900 です。 こ の こ と か ら 、 調整可能な線に よ っ て、 適用で き る モ
デルが適用で き ないモデル と 分け ら れてい る こ と がわか り ます。 こ れは、 一般に使用
さ れてい る 、 Bentler と Bonett(1980) の発言を基に し た規則に よ る も のです。
310
例 22
定数 C – df を表す線の表示
E [ プ ロ ッ ト ] ウ ィ ン ド ウ で、[ 適合度 ] の [C - df] を選択 し ます。次の よ う に表示 さ れます。
調整可能な線の位置の他には、 散布図に変更はあ り ません。 こ こ では、 調整可能な線
に、 C - df の値が一定であ る 点が含まれてい ます。 先の例では こ の線は水平で し たが、
こ こ では下方に傾いてい ます。 こ れは、 C - df に よ っ て、 モデルの適正の評価におけ
る 複雑度に重みが付け ら れ て い る こ と を 示 し て い ま す。 最初は、 調整可能 な線は、
C - df の値が最小の点を通過 し ます。
E
こ の点を ク リ ッ ク し てか ら 、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ モデル 7] を選択 し ます。
適合度を表すテーブルでモデル 7 が強調表示 さ れ、 描画領域にはモデル 7 のパス図が
表示 さ れます。
左下隅のパネルには、 C - df だけに依存す る 適合度の値が表示 さ れ ます。 し たが っ
て、 こ れ ら の適合度値は、 C - df 自身の よ う に、 調整可能な線に沿っ て一定の値を と
り ます。 CFI1 と CFI2 はいずれ も CFI の一種で、2 つの異な る ベース ラ イ ン モデルを使
用 し ます ( 付録 G を参照 し て く だ さ い )。 最初は、 CFI1 と CFI2 の両方が、 調整可能な
線上の点での 1 と 等 し いです。 調整可能な線を移動す る と 、 左下のパネル内の適合度
の値が、 線の移動先の位置に変更 さ れます。
311
探索的モデル特定化
定数 C – df を表す線の調整
E 調整可能な線を、 CFI1 の値が 0.950 の位置ま で ド ラ ッ グ し ます。
CFI1 は、 通常の CFI 統計量です。 こ の CFI 統計量におけ る ベース ラ イ ン モデルでは、
平均値 と 分散に制約を設けずに、観測変数が互いに相関 し ない こ と が必要 と さ れます。
線の下にあ る 点の値は CFI1 > 0.950 であ り 、線 よ り 上にあ る 点については CFI1 < 0.950
です。 こ の こ と か ら 、 Hu と Bentler(1999) の提言を基に し た規則を基準に、 調整可能な
線に よ っ て、 適用で き る モデルが適用で き ないモデル と 分け ら れてい る こ と がわか り
ます。
312
例 22
定数の適合度を表すその他の線の表示
E [AIC]、 [BCC]、 [BIC] を順番に ク リ ッ ク し ます。
調整可能な線が次第に負に傾いてい く こ と に注意 し て く だ さ い。 こ れには、5 つの測定
値 (C、 C - df、 AIC、 BCC、 お よ び BIC) が、 モデルの複雑度に対 し て重みを増加 さ せ
てい る と い う 事実が反映 さ れてい ます。 こ の 5 つの測定値それぞれについて、 調整可
能な線の傾 き は一定です。 こ の こ と は、 線を マ ウ ス で ド ラ ッ グす る と 確認で き ま す。
一方、 C / df の調整可能な線におけ る 傾 き は一定ではあ り ません ( マ ウ ス で ド ラ ッ グす
る と 線の傾 き が変わ り ます )。 こ のため、 C / df の傾 き は、 C、 C – df、 AIC、 BCC、 お
よ び BIC のそれぞれの傾 き と 比較す る こ と がで き ません。
C における最善の適合グ ラ フ の表示
E [ プ ロ ッ ト ] ウ ィ ン ド ウ で、 [ プ ロ ッ ト タ イ プ ] の [ 最善の適合 ] を選択 し ます。
E [ 適合度 ] か ら [C] を選択 し ます。
図 22-5 各パ ラ メ ー タ 数に対する C の最小値
313
探索的モデル特定化
こ のグ ラ フ上の各点は、 C の値が、 パ ラ メ ー タ 数の等 し い他のモデルの値以下であ る
モ デル を 表 し て い ま す。 グ ラ フ か ら 、 パ ラ メ ー タ 数 16 個 で の 最善 モ デル の 値 は
C = 67.342 、 グ ラ フ か ら 、 パ ラ メ ー タ 数 17 個での最善モデルの値は C = 3.071 、
な ど がわか り ます。 [ 最善の適合 ] が選択 さ れてい る と 、適合度のテーブルに、パ ラ メ ー
タ 数ご と の最善モデルが表示 さ れます。 こ のテーブルは、 先に 306 ページ で紹介 し て
い ます。
固定 さ れたパ ラ メ ー タ 数に対す る 最善モデルは、 適合度の選択に依存 し ない こ と に注
意 し て く だ さ い。 た と えばモデル 7 は、 C - df だけでな く 、 C / df や他の各適合度を基
準に し て も 、 パ ラ メ ー タ 数 17 個での最善モデル と な り ます。 モデルの選択基準に使用
し た適合度の種類 と は関係な く 、 最善モデルについての こ の短い リ ス ト には、 全体的
に判断 さ れた最善モデルが必ず含まれてい ます。
を ク リ ッ ク すれば、 いつで も こ の短い リ ス ト を表示す る こ と がで き ます。 最善
の適合グ ラ フ か ら 、 発見的な見地においては、 収穫逓減点であ る 17 を正 し いパ ラ メ ー
タ 数 と し て選択すべ き であ る こ と がわか り ます。 つ ま り 、 パ ラ メ ー タ 数を 16 か ら 17
に増やす と C ( 67.342 – 3.071 = 64.271 ) の値は比較的大 き く 増加 し ま すが、 パ ラ
メ ー タ 数が 17 を超え る と 、 その後の変化は比較的ゆ る やかにな り ます。
314
例 22
その他の適合度に対する最善の適合グ ラ フの表示
E [ 最善の適合 ] を選択 し てい る 状態で、[ 適合度 ] か ら 他の選択肢を選んでみ ま し ょ う 。
選択肢には、 C - df、 AIC、 BCC、 BIC、 お よ び C / df があ り ます。 た と えば、 [BIC] を ク
リ ッ ク す る と 、 次の よ う に表示 さ れます。
BIC は、 C、 C - df、 AIC、 BCC、 お よ び BIC の う ち、 複雑度に対 し て最 も 大 き なペナ
ルテ ィ を課す測定値です。 複雑度に対す る ペナルテ ィ の高 さ は、 パ ラ メ ー タ 数 17 以降
で急勾配を描 く 正の傾 き に表れてい ます。 こ のグ ラ フ か ら は、 BIC を基準に し た場合、
パ ラ メ ー タ 数 17 個での最善モデルが他の候補モデル よ り も 優れてい る と い う こ と が
明 ら かです。
別の適合度を ク リ ッ ク す る と 、 最善の適合グ ラ フ の縦軸や、 点の設定内容が変更 さ
れ る こ と に注意 し て く だ さ い。1 た だ し 、 各点の同一性は保持 さ れ ま す。 た と え ば、
パ ラ メ ー タ 数 16 個での最善モデルは常にモデル 4 であ り 、 パ ラ メ ー タ 数 17 個での最
善モデルは常にモデル 7 であ る、 と い う こ と です。 こ れは、 パ ラ メ ー タ 数が固定 さ れ
てい る 場合、 各適合度に対す る モデルの ラ ン ク 順位は同 じ だか ら です。
1 C / df グ ラ フか ら は飽和モデルが欠損し ていますが、こ れは C / df で飽和モデルが定義 さ れていないためです。
315
探索的モデル特定化
C のス ク リ ープ ロ ッ ト の表示
E [ プ ロ ッ ト ] ウ ィ ン ド ウ で、 [ プ ロ ッ ト タ イ プ ] の [ ス ク リ ー プ ロ ッ ト ] を選択 し ます。
E [ 適合度 ] か ら [C] を選択 し ます。
[ プ ロ ッ ト ] ウ ィ ン ド ウ に、 次のグ ラ フ が表示 さ れます。
図 22-6 C のス ク リ ープ ロ ッ ト
こ のス ク リ ー プロ ッ ト では、 横軸の座標が 17 の位置にあ る点の縦軸の座標は、 64.271 で
す。 これは、 パラ メ ータ数 17 個での最善モデル ( C = 3.071 ) は、 パラ メ ータ数 16 個で
の最善モデル ( C = 67.342 ) よ り も適合度が高 く 、こ の差は 67.342 – 3.071 = 64.271
であ る こ と を示し ています。 同様に、 18 個のパ ラ メ ータ でのグ ラ フの高 さ か ら は、 パ ラ
メ ータ数 17 個での最善モデルか ら パラ メ ータ数 18 個での最善モデルに移動し た こ と で
得 ら れ る C の向上な どがわか り ます。 ただ し 、 横軸の値が 21 を超え る 点については、
別の説明が必要です。 パ ラ メ ータ数 21 個での最善モデル と 比較で き る、 パラ メ ータ数が
20 個のモデルはあ り ません ( 実際、 唯一のパラ メ ータ数が 21 個のモデルは、 飽和モデル
です )。 パラ メ ータ数 21 個での最善モデル ( C = 0 ) は、 これによ り パラ メ ータ数 19 個で
の最善モデル ( C = 2.761 ) と 比較 さ れ ま す。 21 個のパ ラ メ ー タ の点の高 さ は、
2.761 – 0 2 と 計算さ れます。 つま り 、 パ ラ メ ータ数 19 個のモデルか ら パラ メ ータ
数 21 個のモデルに移動し た こ と で得られる C の向上は、 パラ メ ータ あた り の C の減少量
と し て表されます。
316
例 22
312 ページ と 315 ページ の図はいずれ も 、 17 個のパ ラ メ ー タ を肯定す る 、 発見的
な収穫逓減点引数についての裏付け と し て使用す る こ と がで き ます。 こ の 2 つの図に
は、 次の よ う な違いがあ り ます。 最善の適合グ ラ フ (312 ページ ) では、 線が L 字 に
な っ てい る 箇所、 つま り 、 比較的急な傾斜か ら 比較的ゆ る やかな傾斜に変化す る 箇所
が注目 さ れます。 こ こ で述べてい る 問題に よ り 、 こ の変化はパ ラ メ ー タ 数 17 個で発生
し ま す。 こ の こ と は、 パ ラ メ ー タ 数 17 個での最善モデルの裏付け と な り ま す。 ス ク
リ ー プ ロ ッ ト (315 ページ ) で も 、 L 字箇所が注目 さ れますが、 こ の例ではパ ラ メ ー タ
数 18 個で発生 し ます。 こ の こ と も ま た、 パ ラ メ ー タ 数 17 個での最善モデルの裏付け
と な り ます。 ス ク リ ー プ ロ ッ ト では、 パ ラ メ ー タ 数 k 個で発生 し た L 字は、 パ ラ メ ー
タ 数 ( k – 1 ) 個での最善モデルの裏付け と な り ます。
ス ク リ ー プ ロ ッ ト と い う 名は、主成分分析で ス ク リ ー プ ロ ッ ト と し て知 ら れ る グ ラ
フ (Cattell, 1966) と 類似 し てい る こ と か ら 付け ら れてい ます。 主成分分析で、 ス ク リ ー
プ ロ ッ ト は、 成分を 1 つずつモデルに追加 し た こ と で得 ら れ る モデルの適合度の向上
を表 し ます。 こ こ で紹介 し てい る SEM についての ス ク リ ー プ ロ ッ ト は、 モデルのパ
ラ メ ー タ 数を増分 さ せ る こ と で得 ら れ る モデルの適合度の向上を表 し てい ます。 こ の
SEM についての ス ク リ ー プ ロ ッ ト は、 主成分分析についての ス ク リ ー プ ロ ッ ト と 完
全に同 じ ではあ り ません。 た と えば、 主成分分析では、 成分を 1 つずつ取 り 入れ る 際
に、一連の入れ子モデルを得 る こ と にな り ます。 SEM についての ス ク リ ー プ ロ ッ ト で
は、 こ の限 り ではあ り ません。 パ ラ メ ー タ 数 17 個での最善モデルやパ ラ メ ー タ 数 18
個での最善モデルな ど では、 入れ子にな る か ど う かは不明です ( こ の例では入れ子に
な っ てい ます )。 さ ら に、 主成分分析では ス ク リ ー プ ロ ッ ト は常に単調で、 増加す る こ
と はないのですが、 SEM についての ス ク リ ー プ ロ ッ ト の ケー ス では、 入れ子モデル
であ っ たに も かかわ ら ず、 こ の こ と を確証で き ません。 実際、 こ の例での ス ク リ ー プ
ロ ッ ト は単調ではあ り ません。
従来の ス ク リ ー プロ ッ ト と こ こ での ス ク リ ー プロ ッ ト には違いがあ る のですが、新 し
い ス ク リ ー プロ ッ ト を従来の ス ク リ ー プロ ッ ト と 同様の発見的方法で使用す る こ と が
提唱 さ れてい ます。 モデル選択におけ る 2 段階の手法が勧め ら れてい ます。 第 1 段階
では、 ス ク リ ー プ ロ ッ ト と モデルの短い リ ス ト のいずれかを調べ る こ と に よ り 、 パ ラ
メ ー タ 数が選択 さ れます。 第 2 段階では、 第 1 段階で決定 さ れた数のパ ラ メ ー タ を持
つモデルの中か ら 、 最善モデルが選択 さ れます。
その他の適合度に対する ス ク リ ー プ ロ ッ ト の表示
E [ プ ロ ッ ト タ イ プ ] で [ ス ク リ ー プ ロ ッ ト ] を選択 し てい る 状態で、[ 適合度 ] か ら 他の選
択肢を選択 し ます。 選択肢には、 C - df、 AIC、 BCC、 お よ び BIC があ り ます (C / df は
あ り ません )。
317
探索的モデル特定化
た と えば、 [BIC] を選択す る と 、 次の よ う に表示 さ れます。
C - df、 AIC、 BCC、 お よ び BIC で、 縦軸の単位 と 原点が C と は異な る こ と を 除 き 、
すべて同 じ グ ラ フ です。 こ の こ と か ら 、 ス ク リ ー プ ロ ッ ト の検定に よ っ て選択 さ れ る
最終モデルは、 使用す る 適合度の種類 と は独立 し てい る こ と がわか り ます (C / df を使
用す る 場合を除 く )。 こ の こ と は、 こ の例で先に紹介 し た (312 ページの 「C におけ る 最
善の適合グ ラ フ の表示」 と 314 ページの 「その他の適合度に対す る 最善の適合グ ラ フ
の表示」 を参照 し て く だ さ い ) 最善の適合プ ロ ッ ト についての ス ク リ ー プ ロ ッ ト にお
け る 利点です。 最良の適合プ ロ ッ ト と ス ク リ ー プ ロ ッ ト には、 ほぼ同 じ 情報が含まれ
ます。 ただ し 、 最良の適合プ ロ ッ ト の形が適合度の選択に依存す る 一方、 ス ク リ ー プ
ロ ッ ト では こ れに依存 し ません (C / df を除 く )。
標本積率を変更せずに標本 サ イ ズ を変更 し て も 、 縦軸が再調整 さ れ る だけで何 も 影
響 し ない と い う 点で、最良の適合図 と ス ク リ ー プ ロ ッ ト は標本 サ イ ズ と は独立 し てい
ます。
318
例 22
オプ シ ョ ン矢印が多数の探索的モデル特定化
先述の探索的因子分析は、 オプシ ョ ン矢印が 3 つのみの、 概 し て確認的な も ので し た。
Felson と Bohrnstedt に よ る デー タ におけ る モデルを構築す る にあ た っ ては、 こ れ よ り
も は る かに探索的な手法を と る こ と がで き ます。 測定 さ れた 6 つの変数についての唯
一の仮説は次の と お り であ る と し ます。
academic は他の 5 つの変数に依存 し 、 かつ、
attract は他の 5 つの変数に依存す る
図 22-7 のパス図では、こ の仮説が 11 のオプシ ョ ン矢印で表 さ れてい ます。 こ の図では、
ど の変数が内生変数であ る かが指定 さ れてい る だけです。 仮説を なす各観測変数モデ
ルは、 探索的モデル特定化に含 ま れてい ます。 観測変数 と 外生変数 と の共分散を オプ
シ ョ ンにする こ と も で き ますが、 その場合、 オプシ ョ ン矢印の数が 11 か ら 17 に増え、
候補モデルは 2,048(211) か ら 131,072(217) に ま で増えて し ま い ます。 観測変数 と 外生変
数 と の共分散をオプシ ョ ンにする と コ ス ト がかか る う え、相関がない変数のペア を含む
モデルを検索する のは、 興味深い作業 と は言いがたいです。
図 22-7 Felson と Bohrnstedt に よ る女子のデー タ における、 高度に探索的な モデル
319
探索的モデル特定化
モデルの特定化
E Ex22b.amw を開 き ます。 通常の イ ン ス ト ールを実行 し てい る 場合、 パ ス は C:¥Program
Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese¥Ex22b.amw にな り ます。
ヒ ン ト : 直前に開いた フ ァ イ ルが Examples フ ォ ルダ内にあ る 場合、描画領域の左側に
あ る [ フ ァ イ ル ] リ ス ト で フ ァ イ ルを ダブル ク リ ッ ク すれば開 く こ と がで き ます。
矢印のオプ シ ョ ン指定
E
メ ニ ュ ーか ら [ 分析 ] [ 探索的モデル特定化 ] の順に選択 し ます。
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し てか ら 、パ ス図が 318 ページ の
よ う にな る ま で、 パ ス図内の矢印を ク リ ッ ク し ます。
ヒ ン ト : 複数の矢印を一度に変更す る には、 マ ウ ス ポ イ ン タ を ク リ ッ ク し てか ら 目的
の矢印に向けて ド ラ ッ グ し ます。
320
例 22
オプ シ ョ ン設定のデ フ ォル ト への リ セ ッ ト
E [ 探索的モデル特定化 ] ツールバーの [ オプ シ ョ ン ] ボ タ ン
を ク リ ッ ク し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 次を検索 ] タ ブ を ク リ ッ ク し ます。
E [ 最善の ___ モデルのみを保存 ] ボ ッ ク ス で、 値を 0 か ら 10 に変更 し ます。
こ れに よ り 、 先に こ の例で変更 し たデフ ォ ル ト 設定が復元 さ れ ます。 デフ ォ ル ト 設定
では、 プ ロ グ ラ ムはモデル リ ス ト の列の並べ替えに使用す る 基準に応 じ て、 最善モデ
ル を 10 だけ表示 し ま す。 こ の探索的モデル特定化では多数のモデルが生成 さ れ る の
で、 こ の制限は必要です。
E [ 結果 ] タ ブ を ク リ ッ ク し ます。
E [BCC、 AIC、 BIC] で、 [ ゼロベース (min=0)] を選択 し ます。
探索的モデル特定化の実行
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。
こ の検索には、 1.8 GHz の Pentium 4 で 10 秒ほ ど かか り ます。 完了す る と 、 [ 探索的モ
デル特定化 ] ウ ィ ン ド ウ が拡張 し て、 結果が表示 さ れます。
321
探索的モデル特定化
BIC を使用 し たモデル比較
E [ 探索的モデル特定化 ] ウ ィ ン ド ウ で、 「BIC0」 と い う 見出 し のついた列を ク リ ッ ク し ま
す。 こ れに よ っ て、 BIC0 を基準にテーブルが並べ替え ら れます。
図 22-8 BIC0 を基準に し た 10 の最善モデル
並べ替え ら れたテーブルか ら 、 BIC0 を基準に し た場合、 モデル 22 が最善モデルであ
る こ と がわか り ます ( モデルの番号は、 パ ス図にオブジ ェ ク ト が描画 さ れた順序に も
多少依存 し ます。 こ のため、 独自のパ ス図を作成す る 場合、 モデルの番号が こ こ での
番号 と 異な る こ と があ り ます )。 BIC0 を基準 と し た場合に 2 番目に適合 し ていたモデ
ル 32 は、BCC0 を基準にす る と 最善モデル と な り ます。 上記のモデルを次に示 し ます。
モデル 22
モデル 32
322
例 22
ス ク リ ープ ロ ッ ト の表示
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。
E [ プ ロ ッ ト ] ウ ィ ン ド ウ で、 [ プ ロ ッ ト タ イ プ ] の [ ス ク リ ー プ ロ ッ ト ] を選択 し ます。
ス ク リ ー プ ロ ッ ト では、 モデルの適合度 と 倹約性 と の ト レー ド オ フ が最適なモデル と
し て、 パ ラ メ ー タ 数 15 個のモデルを強 く 推奨 し てい ます。
E 横軸 15 の点を ク リ ッ ク す る と ポ ッ プア ッ プが表示 さ れ、 こ の点がモデル 22 を表す こ
と が示 さ れます。 こ のモデルのカ イ 2 乗の変化は 46.22 です。
E 22 (46.22) を ク リ ッ ク し て、 描画領域にモデル 22 を表示 し ます。
制限
探索的モデル特定化手続 き は、 単一グループか ら のデー タ を分析す る 場合にのみ実行
で き ます。
例
23
探索的モデル特定化によ る探索的因子
分析
概要
こ の例では、 探索的モデル特定化に よ る 探索的因子分析について説明 し ま す。 こ こ で
の探索的因子分析に向けた手法では、 測定 さ れた変数は任意の因子に ( オプシ ョ ンで )
依存す る こ と がで き ま す。 探索的モデル特定化は、 単純性 と 適合度の最適な組み合わ
せを示す、 一方向矢印のサブグループ を検索す る ために実行 し ます。 ま た、 モデルが
多数あ る ために網羅的な探索的モデル特定化を実行で き ない場合に役立つ、 発見的な
探索的モデル特定化について も 説明 し ます。
デー タ について
こ の例では、 例 8 で紹介 し た、 Holzinger と Swineford(1939) に よ る 女子のデー タ を使
用 し ます。
モデルについて
初期モデルについては、 324 ページ の図 23-1 を参照 し て く だ さ い。 探索的モデル特定
化では、 因子か ら 測定 さ れた変数に向け た一方向矢印は、 すべて オプ シ ョ ン と さ れ
ま す。 こ の探索的モデル特定化では、 モデルに必要な一方向矢印は ど れか、 つ ま り 、
あ る 変数が ど の因子に依存 し てい る のか と い う こ と について把握す る こ と を目的 と し
てい ます。
323
324
例 23
こ の 2 つの因子分散は、 残差変数に関連付け ら れたすべての係数 と 同様に、 ど ち ら
も 1 に固定 さ れて い ま す。 こ の制約 を 設け な い と 、探索的モデル特定化に出現す る 、
いずれのモデル も 識別で き な く な り ます。
図 23-1 2 つの因子での探索的因子分析モデル
モデルの特定化
E Ex23.amw フ ァ イ ルを開 き ます。 標準 イ ン ス ト ールを行っ た場合、 パ ス は C:¥Program
Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese¥Ex23.amw です。
最初は、 図 23-1 でのパス図が表示 さ れます。 因子分散が 1 に固定 さ れていて も 、 こ の
状態ではモデルを識別で き ないため、こ のモデルを適合 さ せ よ う と し て も 意味があ り ま
せん。
[ 探索的モデル特定化 ] ウ ィ ン ド ウ を開 く
E [ 探索的モデル特定化 ] ウ ィ ン ド ウ を開 く には、[ 分析 ] → [ 探索的モデル特定化 ] の順に選
択 し ます。
最初は、 次の よ う に ツールバーだけが表示 さ れてい ます。
325
探索的モデル特定化によ る探索的因子分析
すべての係数のオプ シ ョ ン指定
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し てか ら 、パ ス図内のすべての一
方向矢印を ク リ ッ ク し ます。
図 23-2 すべての係数を オプ シ ョ ン に し た 2 因子モデル
探索的モデル特定化の実行中、 プ ロ グ ラ ムは、 オプシ ョ ン矢印の可能なサブグループ
をすべて使用 し てモデルを適合 し よ う と し ます。
オプ シ ョ ン設定のデ フ ォル ト への リ セ ッ ト
E [ 探索的モデル特定化 ] ツールバーの [ オプ シ ョ ン ] ボ タ ン
を ク リ ッ ク し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 結果 ] タ ブを ク リ ッ ク し ます。
326
例 23
E [ リ セ ッ ト ] を ク リ ッ ク し て、 設定 し たオプシ ョ ンが こ の例 と 同 じ であ る こ と を確認 し
ます。
E 次に、 [ 次を検索 ] タ ブを ク リ ッ ク し ます。 [ 最善の ___ モデルのみを保存 ] のデフ ォ ル ト
値が 10 であ る こ と に注意 し て く だ さ い。
こ の設定では、 プ ロ グ ラ ム はモデル リ ス ト の列の並べ替えに使用す る 基準に応 じ て、
最善モデルを 10 だけ表示 し ます。 た と えば、「C / df」 と い う 見出 し のついた列を ク リ ッ
ク す る と 、 C / df を基準に並べ替えが行われ、 C / df の値が小 さ い順に 10 のモデルが
テーブルに表示 さ れます。 散布図には、 上位 10 位ま での 1 因子モデル、 上位 10 位ま
での 2 因子モデル と い う よ う に表示 さ れ ます。 オプシ ョ ンのパ ラ メ ー タ が多数あ る 場
合には、 表示パ ラ メ ー タ 数を制限 し てお く と 便利です。
327
探索的モデル特定化によ る探索的因子分析
12
こ の例ではオプシ ョ ンのパ ラ メ ー タ が 12 あ る ので、 候補モデルの数は 2 = 4096
と な り ます。 多数のモデルに対 し て結果を保存 し てい く と 、 パ フ ォ ーマ ン ス に影響す
る こ と が あ り ま す。 パ ラ メ ー タ 数ご と に上位 10 位 ま でのモデル を表示す る と い う 制
限に よ っ て、 プ ロ グ ラ ムでは、 お よ そ 10 Þ 13 = 130 モデル分だけの リ ス ト を保持すれ
ばいい こ と にな り ま す。 パ ラ メ ー タ 数ご と に上位 10 位 ま でのモデル を検索す る ため
には、 プ ロ グ ラ ムは 130 をは る かに超え る モデルを適合 さ せ る 必要はあ り ませんが、
4,096 よ り は少な く て済み ま す。 こ のプ ロ グ ラ ム ではモデル を不必要に適合 し ないた
め、 アルゴ リ ズ ムに総当た り 回帰 (Furnival お よ び Wilson, 1974) で使用 さ れてい る ア
ルゴ リ ズ ム と 同 じ 、 分岐限界法を使用 し てい ます。
探索的モデル特定化の実行
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。
こ の検索には、 1.8 GHz の Pentium 4 で 12 秒ほ ど かか り ます。 完了す る と 、 [ 探索的モ
デル特定化 ] ウ ィ ン ド ウ が拡張 し て、 結果が表示 さ れます。
最初は、 モデルの リ ス ト はあ ま り 詳細にわた っ てい ません。 モデルは出現 し た順に
リ ス ト に掲載 さ れ る ので、 検索の早期に出現 し たモデルは識別 さ れ ません。 識別で き
ないモデルの分類方法については、 付録 D で説明 さ れてい ます。
BCC を使用 し たモデル比較
E [ 探索的モデル特定化 ] ウ ィ ン ド ウ で、 「BCC0」 と い う 見出 し のついた列を ク リ ッ ク し
ます。
328
例 23
「BCC」 を基準にテーブルが並べ替え ら れ、BCC におけ る 最善モデル (BCC の値が最 も
小 さ いモデル ) が リ ス ト の先頭に配置 さ れます。
図 23-3 BCC0 を基準に し た 10 の最善モデル
BCC0 を基準に し た場合の 2 つの最善モデル ( モデル 52 と モデル 53) の適合度は同 じ
です ( こ こ では値が 0 ですが、小数以下 3 桁ま で指定 さ れます )。 こ の こ と については、
こ の 2 つのモデルのそれぞれのパ ス図か ら の説明を得 る こ と がで き ます。
E [ 探索的モデル特定化 ] ウ ィ ン ド ウ で、モデル 52 の行を ダブル ク リ ッ ク し ます。 描画領
域にパス図が表示 さ れます。
E モデル 53 のパ ス図を参照す る には、 モデル 53 の行を ダブル ク リ ッ ク し ます。
モデル 52
図 23-4 F1 と F2 を逆にする と 、 候補モデルが入れ替わる
モデル 53
329
探索的モデル特定化によ る探索的因子分析
こ れは、F1 と F2 の役割を逆にす る と 、一方のペアの メ ンバーが他方のペアの メ ンバー
と 入れ替わ る と い う 、 単な る 1 組のモデルのペアに過ぎ ません。 こ う し たペアは他に
も あ り ます。 モデル 52 と モデル 53 は同 じ も のですが、4,096 の候補モデル リ ス ト では
別の も の と し て数え ら れてい ます。 328 ページ の図 23-3 での 10 のモデルは 5 組のペ
アにな っ てい ますが、 図 23-5 で示す よ う に、 候補モデルが常に同 じ ペアで出現す る と
は限 り ません。 こ の図のモデルは、 パ ラ メ ー タ 数 6 個での上位 10 位のモデルに入 ら な
いだけでな く 、 識別 さ れ る こ と も あ り ません。 ただ し 、 こ のモデルか ら は、 F1 と F2
を逆に し た場合に、 ど の よ う に し て 4,096 の候補モデルか ら 別の メ ンバーの抽出に失
敗 し う る か と い う こ と がわか り ます。
図 23-5 F1 と F2 を逆にする と 、 同 じ 候補モデルが発生する
同 じ 候補モデルが発生す る こ と で、 こ の例でのモデル選択におけ る ベ イ ズの計算の適
用方法が不明確に な り ま す。 同様に、赤池 ウ ェ イ ト の使用方法 も 不明確に な り ま す。
さ ら に、 BCC0 の解釈におけ る Burnham と Anderson に よ る ガ イ ド ラ イ ン (300 ページ
を参照 し て く だ さ い ) は赤池 ウ ェ イ ト についての推論に基づいてい る ので、 こ のガ イ
ド ラ イ ン が こ の例に適用で き る か ど う かが明確では あ り ま せん。 一方、 Burnham と
Anderson に よ る ガ イ ド ラ イ ン を無視 し て BCC0 を使用すれば、 問題が発生 し ない も の
と 考え ら れます。 モデル 52 ( お よ び、 こ れ と 同 じ であ る モデル 53) は、 BCC0 を基準に
し た場合の最善モデルです。
330
例 23
BCC0 は、例 8 で使用 さ れた Jöreskog と Sörbom (1996) に よ る モデルを基に し たモデ
ルを選択 し ますが、 モデル 62 ( お よ び、 こ れ と 同 じ であ る モデル 63) は BCC0 の基準に
おいて僅差で 2 位であ り 、 別の適合度を基準に し た場合は最善モデルにな っ てい る こ
と も あ る と い う こ と には注意すべ き で し ょ う 。 モデル 63 のパ ス図は次の と お り です。
図 23-6 モデル 63
モデル 53 と モデル 63 の両方において、 因子 F1 と 因子 F2 は、 それぞれ大ま かに空間
能力 と 言語能力であ る と 解釈で き ます。 こ の 2 つのモデルでは、 cubes ( 空間視覚化力 )
検定の得点におけ る 解釈が異な り ます。 モデル 53 では、 cubes ( 空間視覚化力 ) の得点
は空間能力に全面的に依存 し てい ます。 モデル 63 では、 cubes ( 空間視覚化力 ) の得点
は空間能力 と 言語能力の両方に依存 し てい ます。 すべての基準が適合度 と 倹約性に基
づいてい る こ と は危険性が高いため、 モデルの選択基準におけ る 解釈の問題に注意す
る こ と が特に必要です。 ただ し 、 次の手順での ス ク リ ー プ ロ ッ ト の検定では、 最善モ
デルが どれであ る かが明確にわか り ます。
331
探索的モデル特定化によ る探索的因子分析
ス ク リ ープ ロ ッ ト の表示
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。
E [ プ ロ ッ ト ] ウ ィ ン ド ウ で、 [ プ ロ ッ ト タ イ プ ] の [ ス ク リ ー プ ロ ッ ト ] を選択 し ます。
ス ク リ ー プ ロ ッ ト では、 パ ラ メ ー タ 数 13 個のモデルの使用を強 く 推奨 し てい ま す。
13 番目のパ ラ メ ー タ の直後でグ ラ フ が突然落ち込み、 その後勾配がゆ る やかにな る た
めです。 横軸の座標 13 にあ る 点を ク リ ッ ク し ます。 ポ ッ プア ッ プが表示 さ れ、 こ の点
が 328 ページ の図 23-4 におけ る モデル 52 と モデル 53 を表す こ と が示 さ れます。
モデルの短い リ ス ト の表示
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。 後か ら 参照で き る よ う
に、 モデルの短い リ ス ト の控え を と っ てお き ます。
332
例 23
発見的な探索的モデル特定化
オプシ ョ ン矢印の数が増え る に し たが っ て、 網羅的な探索的モデル特定化で適合す る
必要のあ る モデルの数が急速に増え ます。 325 ページ の図 23-2 には 12 のオプシ ョ ン
12
矢印があ り ます。 こ のため、 網羅的な探索的モデル特定化では、2 = 4096 のモデル
を適合す る 必要があ り ます ([ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 次を検索 ] プ ロ パ
テ ィ ページにあ る [ 最善の ___ モデルのみを保存 ] に、 小 さ な正の数が指定 さ れてい る
場合は、 モデルの数は 4096 よ り も 少な く な り ます )。 適合す る 必要があ る モデルの数
を減 ら すために、多数の発見的な検索手続 き が提案 さ れて き ま し た (Salhi, 1998)。 いず
れ も 必ず最善モデルを検索で き る と は限 り ませんが、オプシ ョ ン矢印の数が 20 を超え
た あ た り か ら 網羅的な探索的モデル特定化がで き な く な る と い う 問題に対 し 、 実際の
計算に役立つ と い う 利点があ り ます。
Amos には、 発見的検索のオプシ ョ ンの他に、 発見的検索の方略が 3 つ備わ っ てい
ます。 特定の適合度におけ る 最小 と 最大の意味において、 最善についての定義を選択
す る こ と が必要 と な る ため、 発見的な方略では、 全体におけ る 最善モデルの検索が試
み ら れ る こ と はあ り ません。 その代わ り 、発見的な方略では、乖離度が最小のパ ラ メ ー
タ 数 1 個のモデル、 乖離度が最小のパ ラ メ ー タ 数 2 個のモデル、 と いっ たモデルの検
索を試み ます。 こ の手法を採 り 入れ る こ と で、 適合度の選択か ら 独立 し た検索手続 き
を設計す る こ と がで き ます。 [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 次を検索 ] プ ロ パ
テ ィ ページで、 適用が可能な検索方略を選択で き ます。 選択肢は、 次の と お り です。
全ての部分集合網羅的検索が実行 さ れます。 こ れがデフ ォ ル ト と な り ます。
変数増加法プ ロ グ ラ ムは、オプシ ョ ン矢印のないモデルを最初に適合 し ます。 その
後、 乖離度の減少が最 も 大 き い矢印を常に追加 し なが ら 、 オプシ ョ ン矢印を 1 つ
ずつ追加 し てい き ます。
変数減少法プ ロ グ ラ ムは、 モデル内の矢印がすべてオプシ ョ ン矢印で あ る モデル
を最初に適合 し ま す。 その後、 乖離度の増加が最 も 小 さ い矢印を常に削除 し なが
ら 、 オプシ ョ ン矢印を 1 つずつ削除 し てい き ます。
ス テ ッ プ ワ イ ズ法プ ロ グ ラ ムは、 変数増加法 と 変数減少法を切 り 替え なが ら 検索
を行い ます。 最初は変数増加法か ら 始め ます。プ ロ グ ラ ムはオプシ ョ ン矢印 1 つの
最善モデルの出現、 オプシ ョ ン矢印 2 つの最善モデルの出現、 と い う よ う に経過
を追い ます。 変数増加法に よ る 検索後、変数増加法 と 変数減少法 と の切 り 替え アル
ゴ リ ズ ムが、 一定の規則の も と で変更 さ れます。 こ の規則では、 プ ロ グ ラ ムは、 出
現 し たモデルの乖離度が、 こ れ よ り 前に出現 し た同 じ 数の矢印を持つど のモデル
よ り も 小 さ い場合にのみ、 矢印の追加や削除を行 う こ と に な っ てい ま す。 た と え
ば、 オプシ ョ ン矢印 5 つのモデルに対 し てプ ロ グ ラ ムが矢印を 1 つ追加す る のは、
出現 し たオプシ ョ ン矢印 6 つのモデルの乖離度が、 こ れ よ り も 前に出現 し たオプ
シ ョ ン矢印 6 つのモデルのいずれ と 比べて も 小 さ い場合のみです。 変数増加法 と
変数減少法 と の切 り 替え検索では、変数増加法ま たは変数減少法のいずれかが、改
善のない ま ま に完了 し た時点で一方に切 り 替わ り ます。
333
探索的モデル特定化によ る探索的因子分析
ス テ ッ プワ イ ズ検索の実行
E [ 探索的モデル特定化 ] ツールバーの [ オプ シ ョ ン ] ボ タ ン
を ク リ ッ ク し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 次を検索 ] タ ブを ク リ ッ ク し ます。
E [ ス テ ッ プワ イ ズ法 ] を選択 し ます。
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。
図 23-7 では、パ ラ メ ー タ 数 13 個のモデルであ る モデル 7 の調査が推奨 さ れてい ます。
こ のモデルの乖離度 C は、 パ ラ メ ー タ 数 12 個での最善モデルの乖離度 よ り も は る か
に小 さ く 、 パ ラ メ ー タ 数 14 個での最善モデルを大 き く 上回っ て も い ません。 モデル 7
は、 BCC と BIC の ど ち ら を基準に し て も 最善モデル と な り ます。 ( 発見的な探索的モ
デル特定化アルゴ リ ズ ム での確率的要素に よ っ て、 図中の数値 と は異な る 結果が生 じ
る 場合があ り ます。 変数増加法での検索中に矢印が追加 さ れた り 、 変数減少法での検
索中に矢印が削除 さ れた り す る と 、 最善モデルの選択が一意ではな く な る こ と があ り
ます。 こ の場合、最善モデルに結び付け ら れた矢印か ら 1 本が無作為に抽出 さ れます。)
図 23-7 ス テ ッ プワ イ ズ法での検索結果
334
例 23
ス ク リ ープ ロ ッ ト の表示
E [ 探索的モデル特定化 ] ツールバーの
を ク リ ッ ク し ます。
E [ プ ロ ッ ト ] ウ ィ ン ド ウ で、 [ プ ロ ッ ト タ イ プ ] の [ ス ク リ ー プ ロ ッ ト ] を選択 し ます。
ス ク リ ー プ ロ ッ ト か ら 、 13 番目のパ ラ メ ー タ を追加す る と 、 乖離度が大幅に減少 し 、
13 番目のパ ラ メ ー タ を超え る と 、 それ以上パ ラ メ ー タ を追加 し て も ほんの少 し し か減
少 し ない と い う こ と が確認で き ます。
図 23-8 ス テ ッ プワ イ ズ法に よ る検索後のス ク リ ー プ ロ ッ ト
E ス ク リ ー プ ロ ッ ト で、横軸の座標が 13 の点 ( 図 23-8 を参照 ) を ク リ ッ ク し ます。 ポ ッ
プア ッ プが表示 さ れ、モデル 7 がパ ラ メ ー タ 数 13 個での最善モデルであ る こ と が示 さ
れます。
E ポ ッ プア ッ プ メ ニ ュ ーか ら 7 (25.62) を ク リ ッ ク し ます。 描画領域にモデル 7 のパ ス図
が表示 さ れます。
ヒ ン ト : [ 探索的モデル特定化 ] ウ ィ ン ド ウ でモデル 7 の行を ダブル ク リ ッ ク し て も 同
じ 結果が得 ら れます。
335
探索的モデル特定化によ る探索的因子分析
発見的な探索的モデル特定化における制限
発見的な探索的モデル特定化では、 特定のパ ラ メ ー タ 数の最善モデルを検索で き ない
場合があ り ます。 実際、 こ の例での ス テ ッ プ ワ イ ズ検索では、 パ ラ メ ー タ 数 11 個での
最善モデルを 1 つ も 検索で き ませんで し た。 333 ページの図 23-7 では、 ス テ ッ プ ワ イ
ズ検索に よ っ て検索 さ れた、パ ラ メ ー タ 数 11 個での最善モデルの乖離度 (C) は 97.475
で し た。 と こ ろが網羅的検索では、乖離度 55.382 の 2 つのモデルが検索 さ れてい ます。
各パラ メ ータ 数に対 し 、ステ ッ プワ イ ズ検索では最善モデルか ら 1 つが検索 さ れま し た。
当然なが ら 、 発見的検索が成功だ っ たのか ど う かがわか る のは、 網羅的検索を実行
し て、 発見的検索の結果を再調査で き た場合だけです。 使用で き る 手法が発見的検索
のみであ る 場合の問題 と し て、 各パ ラ メ ー タ 数に対 し て最善モデルの 1 つを検索で き
る か ど う かが不確かであ る と い う こ と だけでな く 、 検索が成功 し たのか ど う か を知 る
方法がない と い う こ と も 挙げ ら れます。
発見的検索に よ っ て、 特定のパ ラ メ ー タ 数に対す る 最善モデルの 1 つを検索で き た
場合において も 、 適合度が同 じ か、 差がわずかな他のモデルについての情報を得 る こ
と がで き ません (Amos では こ の よ う に実装 さ れてい ます )。
例
24
複数グループ での因子分析
概要
こ の例では、 複数グループに ま たが る 制約条件の自動指定に よ る 、 2 つの グループで
の因子分析を紹介 し ます。
デー タ について
こ の例では、 例 12 と 例 15 で紹介 し た、 Holzinger と Swineford(1939) に よ る 女子 と 男
子のデー タ を使用 し ます。
モデル 24a: 平均値 と 切片項を使用 し ないモデル作成
明示的なモデルパ ラ メ ー タ に平均値 と 切片項が含ま れてい る と 、 複数グループの分析
が困難にな り ます。 平均値 と 切片項の処理については、 追っ てモデル 24b で説明 し ま
す。 こ こ では、 明示的な平均値 と 切片項のない次の因子分析モデル を、 女子 と 男子の
デー タ に適合 さ せ る こ と について考察 し ます。
337
338
例 24
図 24-1 女子 と 男子の 2 因子モデル
こ れは、 例 12 で考察 し た、 2 つの グループでの因子分析におけ る 問題 と 同 じ です。
こ こ では例 12 での結果が自動的に得 ら れます。
モデルの特定化
E
メ ニ ュ ーか ら [ フ ァ イル ] [ 開 く ] の順に選択 し ます。
E [ 開 く ] ダ イ ア ロ グ ボ ッ ク ス で、 Ex24a.amw フ ァ イ ルを ダブル ク リ ッ ク し ます。 標準 イ
ンス ト ールの場合、 パスは C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese¥
Ex24a.amw です。
パ ス図は 図 24-1 に表示の と お り で、男子 も 女子 も 同 じ です。 回帰 ウ ェ イ ト の う ちのい
く つかは、 値が 1 に固定 さ れてい ます。 こ の回帰 ウ ェ イ ト の値は、 続 く 分析が完了す
る ま で 1 に固定 さ れ た ま ま です。 こ の補助が付い た複数 グ ループの分析に よ っ て、
指定 し たモデルに制約条件が設け ら れ る こ と はあ っ て も 、 制約条件が削除 さ れ る こ と
はあ り ません。
[ 複数グループの分析 ] ダ イ ア ログ ボ ッ ク ス を開 く
E
メ ニ ュ ーか ら [ 分析 ] → [ 複数グループの分析 ] の順に選択 し ます。
339
複数グループ での因子分析
E 表示 さ れ る ダ イ ア ロ グ ボ ッ ク ス で [OK] を ク リ ッ ク し ま す。 [ 複数グ ループの分析 ]
ダ イ ア ロ グ ボ ッ ク ス が開 き ます。
図 24-2 [ 複数グループの分析 ] ダ イ ア ロ グ ボ ッ ク ス
ほ と ん ど の場合、 [OK] を ク リ ッ ク す る だけです。 し か し 、 こ こ では [ 複数グループの
分析 ] ダ イ ア ロ グ ボ ッ ク ス の一部を見てみ る こ と に し ま し ょ う 。
チ ェ ッ ク ボ ッ ク ス が 8 列に並んでい ます。 チ ェ ッ ク ボ ッ ク ス がオ ンにな っ てい る の
は、 [1]、 [2]、 お よ び [3] と い う ラ ベルが付いた列だけです。 こ れは、 プ ロ グ ラ ムに よ っ
て、 グループ間制約がそれぞれ異な る 3 つのモデルが生成 さ れ る と い う こ と を意味 し
てい ます。
列 1 では、 モデルの測定部分におけ る回帰 ウ ェ イ ト の略であ る 、 [ 測定モデルのウ ェ
イ ト ] と い う ラ ベルの付いた行だけがオンにな っ てい ます。 こ れは、因子分析モデルで
の因子負荷に当た り ます。 次の項で、 測定モデルの ウ ェ イ ト をパ ス 図に表示す る 方法
について説明 し ます。 列 1 よ り 、 測定モデルの ウ ェ イ ト がグループ間で一定 (男子 と
女子 と で等 し い) のモデルが生成 さ れます。
列 2 では、 [ 測定モデルのウ ェ イ ト ] だけでな く 、 モデルの構造部分におけ る 分散 と
共分散の略であ る [ 構造モデルの共分散 ] も オンにな っ てい ます。 こ れ ら はそれぞれ、因
子分析モデルでの因子分散 と 因子共分散に当た り ます。 次の項で、 構造モデルの共分
散をパ ス図に表示す る 方法について説明 し ます。 列 2 よ り 、 測定モデルの ウ ェ イ ト と 、
構造モデルの共分散がグループ間で一定のモデルが生成 さ れます。
列 3 では、 列 2 でのすべてのチ ェ ッ ク ボ ッ ク ス に加え て、 モデルの測定部分におけ
る 残差 ( 誤差 ) 変数の分散 と 共分散の略であ る 、[ 測定モデルの残差 ] チ ェ ッ ク ボ ッ ク ス
も オ ンにな っ てい ます。 次の項で、 測定モデルの残差をパ ス 図に表示す る 方法につい
て説明 し ます。 黒の フ ォ ン ト ( 灰色ではあ り ません ) で表示 さ れた 3 つのパ ラ メ ー タ の
グループは、 相互に排他的かつ網羅的です。 こ のため、 列 3 に よ り 、 すべてのパ ラ メ ー
タ がグループ間で一定のモデルが生成 さ れます。
340
例 24
上記を要約す る と 、 列 1 か ら 列 3 に よ り 、 モデルの階層が生成 さ れます。 こ の階層
では、 前のモデルの制約条件が各モデルに引 き 継がれ ます。 最初に、 因子負荷の値が
グループ間で固定 さ れ ま す。 次に、 因子分散 と 因子共分散の値が固定 さ れ ま す。 最後
に、 残差 ( 独自 ) 分散の値が固定 さ れます。
パラ メ ー タ 部分集合の表示
E [複数グループの分析] ダイ ア ロ グ ボ ッ ク ス の [測定モデルのウェ イ ト ] を ク リ ッ ク し ます。
測定モデルの ウ ェ イ ト が、描画領域に色付 き で表示 さ れます。 [ イ ン ターフ ェ イ ス のプロ
パテ ィ ] ダイ ア ロ グ ボ ッ ク ス の [ ア ク セス ] プ ロ パテ ィ ページにあ る [ 色の選択 ] チ ェ ッ
ク ボ ッ ク ス がオ ンにな っ てい る 場合、 測定モデルの ウ ェ イ ト は次の よ う な太線で表示
さ れます。
E [ 構造モデルの共分散 ] を ク リ ッ ク し て、因子分散 と 因子共分散が強調表示 さ れてい る こ
と を確認 し ます。
E [ 測定モデルの残差 ] を ク リ ッ ク し て、誤差変数が強調表示 さ れてい る こ と を確認し ます。
グループ間制約のそれぞれが、 ど のパ ラ メ ー タ に影響 し てい る か を簡単に視覚化す る
方法があ り ます。
341
複数グループ での因子分析
生成 さ れたモデルの表示
E [ 複数グループの分析 ] ダ イ ア ロ グ ボ ッ ク ス で [OK] を ク リ ッ ク し ます。
パ ス 図にすべて のパ ラ メ ー タ の名前が表示 さ れ ま す。 パ ス 図の左側に あ る パネルか
ら 、 グループ間制約が設け ら れていない [ 制約な し ] モデルの他に、 プ ロ グ ラ ムに よ っ
て 3 つの新規モデルが作成 さ れた こ と がわか り ます。
図 24-3 自動制約後の Amos Graphics のウ ィ ン ド ウ
342
例 24
E [XX: 測定モデルのウ ェ イ ト ] を ダブル ク リ ッ ク し ます。 [ モデルを管理 ] ダ イ ア ロ グ ボ ッ
ク ス が開 き 、 因子負荷の値を グループ間で一定にす る 必要があ る と い う 制約条件が表
示 さ れます。
すべてのモデルの適合 と 、 出力の表示
E
メ ニ ュ ーか ら [ 分析 ] [ 推定値を計算 ] の順に選択 し て、すべてのモデルを適合 し ます。
E
メ ニ ュ ーか ら 、 [ 表示 ] [ テキス ト 出力の表示 ] を選択 し ます。
E 出力ビ ュ ーアの概念ツ リ ー図で [ モデルの適合度 ] ノード を ク リ ッ ク し て拡張 し てか ら 、
[CMIN] を ク リ ッ ク し ます。
CMIN テーブルには、各適合モデルに対す る 尤度比カ イ 2 乗統計量が表示 さ れます。 こ
のデー タ は、 いずれのモデルか ら も 著 し く 逸脱す る こ と はあ り ません。 加え て、 [ 制約
な し ] モデルか ら [ 測定モデルの残差 ] モデルに向けての階層において、 あ る 段階か ら
次の段階へのカ イ 2 乗の増加分が、自由度の増加分を大 き く 上回 る こ と はあ り ません。
女子のパ ラ メ ー タ 値が男子のパ ラ メ ー タ 値 と 異な る こ と を示す有意な証拠はない よ う
です。
CMIN テーブルを次に示 し ます。
モデル
NPAR
CMIN
DF
P
CMIN/DF
制約な し
測定モデルの ウ ェ イ ト
構造モデルの共分散
測定モデルの残差
飽和モデル
独立モデル
26
22
19
13
42
12
16.48
18.29
22.04
26.02
0.00
337.55
16
20
23
29
0
30
0.42
0.57
0.52
0.62
1.03
0.91
0.96
0.90
0.00
11.25
343
複数グループ での因子分析
E 概念ツ リ ー図で、 [ モデルの適合度 ] ノ ー ド の下にあ る [AIC] を ク リ ッ ク し ます。
[AIC] 値 と [BCC] 値は、 すべてのパ ラ メ ー タ がグループ間で等 し く な る よ う に制約 し
た こ と で ([ 測定モデルの残差 ] モデル )、 モデルの適合度 と 倹約性におけ る 最適な ト
レー ド オ フ が得 ら れた こ と を示 し てい ます。
AIC テーブルを次に示 し ます。
モデル
AIC
BCC
制約な し
測定モデルの ウ ェ イ ト
構造モデルの共分散
測定モデルの残差
飽和モデル
独立モデル
68.48
62.29
60.04
52.02
84.00
361.55
74.12
67.07
64.16
54.84
93.12
364.16
BIC
CAIC
分析のカ ス タ マ イ ズ
自動生成 さ れ た グ ループ間制約は、 次の 2 箇所におい て変更す る こ と も で き ま す。
339 ページ の図 24-2 では、 列 1、 2、 3 のチ ェ ッ ク ボ ッ ク ス のオン / オ フ を変更で き ま
す。 ま た、 列 4 か ら 列 8 ま でのチ ェ ッ ク ボ ッ ク ス を オ ンにす る こ と で、 別のモデルを
生成す る こ と も で き ます。 その後、 341 ページ の図 24-3 で、 パ ス図の左側にあ る パネ
ルに一覧表示 さ れた任意の自動生成モデルについて、 名前を変更 し た り 、 モデル自体
を変更す る こ と がで き ます。
モデル 24b: 因子の平均値の比較
明示的 な平均値 と 切片項が モデルに加わ る と 、 ど の グ ループ間パ ラ メ ー タ 制約 を 、
ど の よ う な順番で検定す る べ き か と い う 問題が発生 し ま す。 こ の例では、 338 ページ
の図 24-1 におけ る 因子分析モデルを、女子 と 男子に分かれた グループのデー タ に適合
す る 際に、 Amos が ど の よ う に平均値 と 切片項を制限す る かについて説明 し ます。
こ れは、 例 15 で考察 し た、 2 つのグループでの因子分析におけ る 問題 と 同 じ です。
こ こ では例 15 での結果が自動的に得 ら れます。
モデルの特定化
E
メ ニ ュ ーか ら [ フ ァ イル ] [ 開 く ] の順に選択 し ます。
E [ 開 く ] ダ イ ア ロ グ ボ ッ ク ス で、Ex24b.amw フ ァ イ ルを ダブル ク リ ッ ク し ます。 標準 イ
ン ス ト ールの場合、 パ ス は C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Examples¥
Japanese¥Ex24b.amw です。
344
例 24
パ ス 図は次の と お り で、 男子 も 女子 も 同 じ です。 回帰 ウ ェ イ ト の う ちのい く つかは、
値が 1 に固定 さ れてい ます。 観測 さ れない変数の平均値は、 すべて 0 に固定 さ れてい
ます。 次の項で、女子におけ る 因子の平均値に対す る 制約条件を削除 し ます。 その他の
制約条件 (削除 し ない制約条件) は、 分析が完了す る ま で有効の ま ま です。
図 24-4 明示的な平均値 と 切片項を含む 2 因子モデル
制約条件の削除
最初は、 因子の平均値は男子 と 女子の両方で 0 に固定 さ れてい ます。 両方のグループ
におけ る 因子の平均値を推定す る こ と はで き ません。 ただ し 、 Sörbom (1974) は、 1 つ
のグループの因子の平均値を一定の値に固定 し 、 因子モデルの回帰 ウ ェ イ ト と 切片項
に適切な制約条件を設け る こ と で、 他のすべてのグループにおけ る 因子の平均につい
て、 有意な推定値を得 る こ と がで き る と 述べてい ます。 こ の例では、 上記での 1 つの
グループ を男子 と し 、 こ の因子の平均値を 0 に固定す る こ と に し ます。 その後、 残 り
のグループであ る 女子におけ る 因子の平均値に対す る 制約条件を削除 し ます。 Sörbom
に よ る 手法で必要 と さ れ る 、回帰 ウ ェ イ ト と 切片項に対す る 制約条件は、 Amos に よ っ
て自動生成 さ れます。
男子におけ る 因子の平均値はすでに 0 に固定 さ れてい ます。 女子におけ る 因子の平
均値に対す る 制約条件を削除す る 方法は、 次の と お り です。
E Amos Graphics の ウ ィ ン ド ウ の描画領域で視覚能力 を右 ク リ ッ ク し て、ポ ッ プア ッ プ メ
ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ パラ メ ー タ ] タ ブ を ク リ ッ ク し
ます。
E [ 平均 ] ボ ッ ク ス で 0 を選択 し てか ら 、 Del キーを押 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス が開いてい る 状態で、描画領域の言
語能力 を ク リ ッ ク し ます。 [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス に、 言語
因子のプ ロ パテ ィ が表示 さ れます。
345
複数グループ での因子分析
E [ パ ラ メ ー タ ] プ ロ パテ ィ ページの [ 平均 ] ボ ッ ク ス で 0 を選択 し てか ら 、Del キーを押
し ます。
E [ オブジ ェ ク ト プ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
女子におけ る 因子の平均値に対す る 制約条件が削除 さ れ、 女子 と 男子の各パ ス図は次
の よ う にな り ます。
女子
男子
ヒ ン ト : 描画領域のパ ス図を切 り 替え る には、 左側の [ グループ ] 枠で [Boys] ま たは
[Girls] を ク リ ッ ク し て く だ さ い。
グループ間制約の生成
E
メ ニ ュ ーか ら [ 分析 ] [ 複数グループの分析 ] の順に選択 し ます。
E 表示 さ れ る ダ イ ア ロ グ ボ ッ ク ス で [OK] を ク リ ッ ク し ま す。 [ 複数グ ループの分析 ]
ダ イ ア ロ グ ボ ッ ク ス が開 き ます。
346
例 24
上記のデフ ォ ル ト 設定では、 次の よ う な 5 つのモデルについての入れ子状の階層が生
成 さ れます。
モデル
モデル 1 ( 列 1)
モデル 2 ( 列 2)
モデル 3 ( 列 3)
モデル 4 ( 列 4)
モデル 5 ( 列 5)
制約条件
測定モデルの ウ ェ イ ト ( 因子負荷 ) の値は、 グループ間で
同 じ です。
上記に加え、 測定モデルの切片項 ( 測定変数を予測す る 方
程式での切片項 ) も 、 グループ間で同 じ です。
上記に加 え 、 構造モデル の平均値 ( 因子の平均値 ) も 、
グループ間で同 じ です。
上記に加え、 構造モデルの共分散 ( 因子の分散 と 共分散 )
も 、 グループ間で同 じ です。
すべてのパ ラ メ ー タ の値がグループ間で同 じ です。
E [OK] を ク リ ッ ク し ます。
モデルの適合
E
メ ニ ュ ーか ら [ 分析 ] [ 推定値を計算 ] の順に選択 し ます。
パ ス図の左側にあ る パネルに、 2 つのモデルをデー タ に適合で き なか っ た こ と が表示
さ れます。 適合で き なか っ た 2 つのモデル と は、 グループ間制約のない [ 制約な し ] モ
デル と 、 因子負荷がグループ間で等 し く な る よ う 固定 さ れた [ 測定モデルのウ ェ イ ト ]
モデルです。 こ の 2 つのモデルは識別 さ れてい ません。
出力の表示
E
メ ニ ュ ーか ら [ 表示 ] [ テキス ト 出力の表示 ] の順に選択 し ます。
E 出力ビ ュ ーアの概念ツ リ ー図で、 [ モデルの適合度 ] ノ ー ド を拡張 し ます。
自動生成 さ れ、 識別 さ れた 4 つのモデルについての適合度の一部が、 飽和モデル と 独
立モデルの適合度 と と も に表示 さ れます。
E [ モデルの適合度 ] ノ ー ド の下にあ る [CMIN] を ク リ ッ ク し ます。
347
複数グループ での因子分析
CMIN テーブルか ら 、 飽和モデルに対 し て検定を行っ た場合、 いずれの生成モデル も
棄却で き ない と い う こ と がわか り ます。
モデル
NPAR
CMIN
DF
P
CMIN/DF
測定モデルの切片項
構造モデルの平均値
構造モデルの共分散
測定モデルの残差
飽和モデル
独立モデル
30
28
25
19
54
24
22.593
30.624
34.381
38.459
0.00
337.553
24
26
29
35
0
30
0.544
0.243
0.226
0.316
0.941
1.178
1.186
1.099
0.00
11.252
一方、因子の平均値を等 し く する と い う 制約条件を設けた こ と に よ る カ イ 2 乗値の変化
( 30.62 – 22.59 = 8.03 ) は、 自由度の変化 ( 26 – 24 = 2 ) に比べて大 き い よ う です。
E 概念ツ リ ー図で、 [ モデルの適合度 ] ノ ー ド を ク リ ッ ク し ます。
モデルの [ 測定モデルの切片項 ] が正 し い場合、 次のテーブルか ら 、 カ イ 2 乗値の差が
有意であ る こ と がわか り ます。
NFI
Delta-1
モデル
DF
CMIN
P
構造モデルの平均値
構造モデルの共分散
測定モデルの残差
2
5
11
8.030
11.787
15.865
0.018 0.024
0.038 0.035
0.146 0.047
IFI
Delta-2
RFI
rho-1
TLI
rho2
0.026
0.038
0.051
0.021
0.022
0.014
0.023
0.024
0.015
上の 2 つのテーブルでは、 2 つのカ イ 2 乗統計量 と 、 こ れに関連す る 自由度が特に重
2
要です。 最初のテーブルでの、 = 22.59 と df = 24 か ら 、 測定モデルにおけ る 切
片項 と 回帰 ウ ェ イ ト がそれぞれ等 し い と い う 仮説を採択で き る こ と にな り ま し た。 切
片項 と 回帰 ウ ェ イ ト がそれぞれ等 し く ない限 り 、 男子 と 女子で因子が同 じ 意味を持つ
と い う こ と が不明確にな り 、 各平均値を比較す る 意味がな く な る ため、 こ の仮説の信
2
頼性を確立す る こ と は重要です。 も う 1 つの重要な カ イ 2 乗統計量 であ る = 8.03
と df = 2 か ら は、 男子 と 女子で因子の平均値が等 し い と い う 仮説が棄却 さ れ る こ と
にな り ます。
男子 と 女子での因子の平均値に見 ら れ る グループ間の差は、 [ 測定モデルの切片項 ]
モデルでの女子の推定値か ら 決定す る こ と がで き ます。
E 出力ビ ュ ーアの左下の ウ ィ ン ド ウ 枠で、 [ 測定モデルの切片項 ] モデルを選択 し ます。
E 概念ツ リ ー図で、 [ 推定値 ] を ク リ ッ ク し てか ら 、 [ ス カ ラ ー ]、 [ 平均値 ] の順に ク リ ッ ク
し ます。
男子の平均値は 0 に固定 さ れてい る ので、 次のテーブルに表 さ れ る と お り 、 女子の平
均値だけが推定 さ れます。
spatial ( 視覚能力 )
言語
推定値
–1.066
0.956
標準誤差 検定統計量 P
ラ ベル
0.881
–1.209
0.226 m1_1
0.521
1.836
0.066 m2_1
348
例 24
上記の推定値は、 例 15 のモデル A において述べ ら れてい ます。 こ のモデルは、 こ こ
での [ 測定モデルの切片項 ] モデル と 同 じ です ( 例 15 のモデル B は、 こ こ での [ 構造
モデルの平均値 ] モデル と 同 じ です )。
例
25
複数グループの分析
概要
こ の例では、 Sörbom に よ る 代替案を、 共分散の分析において自動的に実装す る 方法に
ついて説明 し ます。
例 16 では、 潜在変数のあ る 共分散の分析におけ る、 Sörbom に よ る 手法の利点につ
いて紹介 し てい ます。 ただ し 残念な こ と に、 例 16 で も 説明 し てい る と お り 、 Sörbom に
よ る 手法は多数の手順を必要 と す る ため、 適用が困難です。 こ の例では、 例 16 と 同 じ
結果を自動的に取得 し ます。
デー タ について
こ こ で は、 例 16 で の Olsson(1973) に よ る デ ー タ を 使 用 し ま す。 標 本 の 積 率 は、
UserGuide.xls と い う ワ ー ク ブ ッ ク にあ り ます。 実験群での標本の積率は、 Olss_exp と
い う ワ ー ク シー ト にあ り ます。 統制群での標本の積率は、Olss_cnt と い う ワ ー ク シー ト
にあ り ます。
349
350
例 25
モデルについて
モデルについては、例 16 で説明 し てい ます。 Sörbom に よ る 手法では、 パス図が実験群
と 統制群で同 じ であ る こ と が必要 と さ れます。
図 25-1 Olsson のデー タ における Sörbom のモデル
モデルの特定化
E Ex25.am を開 き ます。 通常の イ ン ス ト ールを実行 し てい る 場合、 パ ス は C:¥Program
Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese¥Ex25.amw にな り ます。
パ ス図は図 25-1 に表示の と お り で、 統制群 も 実験群 も 同 じ です。 回帰 ウ ェ イ ト の う ち
のい く つかは、 値が 1 に固定 さ れてい ます。 すべての残差 ( 誤差 ) 変数の平均値の平均
値は、0 に固定 さ れています。 こ れ ら の制約条件は、分析が完了する まで有効のま まです。
潜在変数の平均値 と 切片項の制限
Olsson のデー タ におけ る Sörbom のモデルを表 し た、 図 25-1 のモデルは識別 さ れませ
ん。 Amos に よ っ て自動生成 さ れ る 各グループ間制約において も 識別 さ れない ま ま で
す。 各グループ間制約において、 pre_verbal ( 言語能力 ( 事前 )) の平均値 と 、 post_verbal
( 言語能力 ( 事後 )) を予測す る 方程式での切片項は、 識別 さ れません。 少な く と も 一部
のグループ間制約でモデルが識別 さ れ る よ う にす る には、統制群な ど の 1 つのグループ
を抽出 し て、 pre_verbal ( 言語能力 ( 事前 )) の平均値 と 、 post_verbal ( 言語能力 ( 事後 ))
の切片項を、 0 な ど の数に固定す る 必要があ り ます。
E パス図の左側にあ る [ グループ ] 枠で、「control」 が選択 さ れてい る こ と を確認 し て く だ
さ い。 こ の こ と は、 統制群のパ ス図が描画領域に表示 さ れてい る こ と を示 し てい ます。
E 描画領域で pre_verbal ( 言語能力 ( 事前 )) を右 ク リ ッ ク し て、ポ ッ プア ッ プ メ ニ ュ ーか
ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し ます。
351
複数グループの分析
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ パラ メ ー タ ] タ ブ を ク リ ッ ク し
ます。
E [ 平均 ] テ キ ス ト ボ ッ ク ス に、 「0」 と 入力 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス が開いてい る 状態で、 描画領域の
post_verbal ( 言語能力 ( 事後 )) を ク リ ッ ク し ます。
E [ テーブル プ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス の [ 切片 ] テ キ ス ト ボ ッ ク ス に、 「0」 と 入
力 し ます。
E [ オブジ ェ ク ト プ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
統制群のパス図が次の よ う に表示 さ れます。
実験群のパス図は図 25-1 での ま ま です。
グループ間制約の生成
E
メ ニ ュ ーか ら [ 分析 ] [ 複数グループの分析 ] の順に選択 し ます。
E 表示 さ れ る ダ イ ア ロ グ ボ ッ ク ス で [OK] を ク リ ッ ク し ます。
352
例 25
[ 複数グループの分析 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E [OK] を ク リ ッ ク す る と 、 8 つのモデルに よ る 、 次の よ う な入れ子状の階層が生成 さ れ
ます。
モデル
モデル 1 ( 列 1)
モデル 2 ( 列 2)
モデル 3 ( 列 3)
モデル 4 ( 列 4)
モデル 5 ( 列 5)
モデル 6 ( 列 6)
モデル 7 ( 列 7)
モデル 8 ( 列 8)
制約条件
測定モデルの ウ ェ イ ト ( 因子負荷 ) の値は、 グループ間で一定
です。
上記に加え、 測定モデルの切片項 ( 測定変数を予測す る 方程式
での切片項 ) も 、 グループ間で一定です。
上記に加え、 構造モデルの ウ ェ イ ト ( 言語能力 ( 事後 ) を予測
す る ための回帰 ウ ェ イ ト ) も 、 グループ間で一定です。
上記に加え、 構造モデルの切片項 ( 言語能力 ( 事後 ) を予測す
る 方程式での切片項 ) も 、 グループ間で一定です。
上記に加え、 構造モデルの平均値 ( 言語能力 ( 事後 ) の平均値 )
も 、 グループ間で一定です。
上記に加え、 構造モデルの共分散 ( 言語能力 ( 事前 ) の分散 )
も 、 グループ間で一定です。
上記に加え、 構造モデルの残差 (zeta の分散 ) も 、 グループ間
で一定です。
すべてのパ ラ メ ー タ の値がグループ間で一定です。
モデルの適合
E
メ ニ ュ ーか ら [ 分析 ] [ 推定値を計算 ] の順に選択 し ます。
353
複数グループの分析
パ ス図の左側にあ る パネルに、 2 つのモデルをデー タ に適合で き なか っ た こ と が表示
さ れます。 適合で き なか っ たモデルは、 [ 制約な し ] モデル と 、 [ 測定モデルのウ ェ イ ト ]
モデルです。 こ の 2 つのモデルは識別 さ れてい ません。
テキス ト 出力を表示する
E
メ ニ ュ ーか ら 、 [ 表示 ] [ テキス ト 出力の表示 ] を選択 し ます。
E 出力ビ ューアの概念ツ リ ー図で [ モデルの適合度 ] ノード を拡張し てか ら 、 [CMIN] を ク
リ ッ ク し ます。 自動生成 さ れ、 識別 さ れた 7 つのモデルについての一部の適合度が、 飽
和モデル と 独立モデルの適合度 と と も に、CMIN テーブルに次の よ う に表示 さ れます。
モデル
NPAR
CMIN
DF
P
CMIN/DF
測定モデルの切片項
構造モデルの ウ ェ イ ト
構造モデルの切片項
構造モデルの平均値
構造モデルの共分散
構造モデルの残差
測定モデルの残差
飽和モデル
独立モデル
22
21
20
19
18
17
13
28
16
34.775
36.340
84.060
94.970
99.976
112.143
122.366
0.000
682.638
6
7
8
9
10
11
15
0
12
0.000
0.000
0.000
0.000
0.000
0.000
0.000
5.796
5.191
10.507
10.552
9.998
10.195
8.158
0.000
56.887
こ の テーブルには多数の カ イ 2 乗統計量が あ り ま すが、 重要な のは 2 つだ け です。
Sörbom の手続 き か ら 、 2 つの基本的な問題に行 き当た り ます。 1 つは、 [ 構造モデルの
ウ ェ イ ト ] モデルを適合で き る か ど う かについてです。 こ のモデルでは、pre_verbal ( 言
語能力 ( 事前 )) か ら post_verbal ( 言語能力 ( 事後 )) を予測す る ための回帰 ウ ェ イ ト の値
が、 グループ間で一定にな る よ う 指定 し てい ます。
[ 構造モデルの ウ ェ イ ト ] モデルが採択 さ れ る と な る と 、 階層での次のモデルであ る
[ 構造モデルの切片項 ] モデルの適合度は大幅に低 く な る のではないか と 考え ら れ ま
す。 一方、 [ 構造モデルの ウ ェ イ ト ] モデルを棄却す る 必要があ る 場合は、 [ 構造モデル
の切片項 ] モデルが問題に上 ら な く な っ て し ま い ます。 残念なが ら 、こ こ では こ のケー
2
ス が発生 し てい ます。 = 36.34 、df = 7 の [ 構造モデルの ウ ェ イ ト ] モデルは、 従
来のいずれの有意水準において も 棄却 さ れます。
354
例 25
修正指数の調査
[ 構造モデルの ウ ェ イ ト ] モデルの適合度を改善で き る か ど う か を調べ る 方法は、 次の
と お り です。
E 出力ビ ュ ーア を閉 じ ます。
E Amos Graphics メ ニ ュ ーか ら 、 [ 表示 ] [ 分析のプ ロパテ ィ ] の順に選択 し ます。
E [ 出力 ] タ ブ を ク リ ッ ク し てか ら 、 [ 修正指数 ] チ ェ ッ ク ボ ッ ク ス を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
E
メ ニ ュ ーか ら [ 分析 ] [ 推定値を計算 ] の順に選択 し て、すべてのモデルを適合 し ます。
こ のモデルは分析に適合度が必要な唯一のモデルであ る ため、 調査が必要 と な る のは
[ 構造モデルの ウ ェ イ ト ] モデルの修正指数だけです。
E
メ ニ ューか ら 、[ 表示 ] → [ テキス ト 出力の表示 ] の順に選択 し てか ら 、出力ビ ューアの概
念ツ リ ー図で [ 修正指数 ] を選択 し ます。 さ ら に、 左下のパネルで [ 構造モデルのウェ イ
ト ] を選択 し ます。
E [ 修正指数 ] ノ ー ド を拡張 し て、 [ 共分散 ] を選択 し ます。
統制群におけ る 次の共分散テーブルに見 ら れ る と お り 、 デフ ォ ル ト の し き い値であ る
4 を上回っ てい る 修正指数は 1 つだけです。
M.I.
eps2 <--> eps4
4.553
改善度
2.073
E 左のパネルで、 [experimental] を ク リ ッ ク し ます。 実験群におけ る 次の共分散テーブ
ルに見 ら れ る と お り 、 4 を上回っ てい る 修正指数は 4 つあ り ます。
M.I.
eps2 <--> eps4
eps2 <--> eps3
eps1 <--> eps4
eps1 <--> eps3
9.314
9.393
8.513
6.192
改善度
4.417
–4.117
–3.947
3.110
こ の中で、 明 ら か な論理的調整が見 ら れ る のは、 eps2 を eps4 と 相関 さ せ る 修正 と 、
eps1 を eps3 と 相関 さ せ る 修正の 2 つだけです。 こ の 2 つの う ち修正指数が大 き いの
は、 eps2 を eps4 と 相関 さ せ る 修正の方です。 こ れに よ り 、 統制群 と 実験群の ど ち ら の
修正指数か ら も 、 eps2 を eps4 と 相関 さ せ る こ と が推奨 さ れます。
355
複数グループの分析
モデルの変更 と 分析の繰 り 返 し
E 出力ビ ュ ーア を閉 じ ます。
E
メ ニ ュ ーか ら [ 図 ] → [ 共分散を描 く ] の順に選択 し ます。
E
ク リ ッ ク し た ま ま ド ラ ッ グ し て、 eps2 と eps4 の間に双方向矢印を描 き ます。
E
メ ニ ュ ーか ら [ 分析 ] → [ 複数グループの分析 ] の順に選択 し 、 表示 さ れ る メ ッ セージ
ボ ッ ク ス で [OK] を ク リ ッ ク し ます。
E [ 複数グループの分析 ] ダ イ ア ロ グ ボ ッ ク ス で [OK] を ク リ ッ ク し ます。
E
メ ニ ュ ーか ら [ 分析 ] → [ 推定値を計算 ] の順に選択 し て、すべてのモデルを適合 し ます。
E
メ ニ ュ ーか ら [ 表示 ] → [ テキス ト 出力の表示 ] の順に選択 し ます。
E 出力ビ ュ ーアの概念ツ リ ー図を使用 し て、[ 構造モデルのウ ェ イ ト ] モデルの適合度を表
示 し ます。
eps2 と eps4 を結ぶ双方向矢印が追加 さ れた こ と で、 次の CMIN テーブルに表 さ れ る
2
よ う に、 [ 構造モデルの ウ ェ イ ト ] モデルの適合度 ( = 3.98 、df = 5 ) が適切な値
と な り ま し た。
モデル
NPAR
CMIN
DF
P
CMIN/DF
測定モデルの切片項
構造モデルの ウ ェ イ ト
構造モデルの切片項
構造モデルの平均値
構造モデルの共分散
構造モデルの残差
測定モデルの残差
飽和モデル
独立モデル
24
23
22
21
20
19
14
28
16
2.797
3.976
55.094
63.792
69.494
83.194
93.197
0.000
682.638
4
5
6
7
8
9
14
0
12
0.59
0.55
0.00
0.00
0.00
0.00
0.00
0.699
0.795
9.182
9.113
8.687
9.244
6.657
0.00
56.887
[ 構造モデルの ウ ェ イ ト ] モデルがデー タ に適合す る よ う に な っ た た め、 今度は、
[ 構造モデルの切片項 ] モデルの適合度が大幅に低 く な る のではないか と い う こ と が考
え ら れます。 [ 構造モデルの ウ ェ イ ト ] モデルが正 し い場合、 次の よ う にな り ます。
モデル
DF
CMIN
P
NFI
Delta-1
IFI
Delta-2
RFI
rho-1
TLI
rho2
構造モデルの切片項
構造モデルの平均値
構造モデルの共分散
構造モデルの残差
測定モデルの残差
1
2
3
4
9
51.118
59.816
65.518
79.218
89.221
0.000
0.000
0.000
0.000
0.000
0.075
0.088
0.096
0.116
0.131
0.075
0.088
0.097
0.117
0.132
0.147
0.146
0.139
0.149
0.103
0.150
0.149
0.141
0.151
0.105
356
例 25
[ 構造モデルの切片項 ] モデルの適合度は、 確かに [ 構造モデルの ウ ェ イ ト ] モデルを
大 き く 下回っ てい ます。 post_verbal ( 言語能力 ( 事後 )) を予測す る 方程式におけ る 切片
項を グループ間で一定にす る 必要があ る 場合、 自由度が 1 し か増加 し ていないのに対
し 、 カ イ 2 乗統計量は 51.12 増加 し てい ます。 つま り 、実験群の切片項が統制群の切片
項 と 大 き く 異な る と い う こ と です。 実験群の切片項は 3.627 と 推定 さ れます。
言語能力 ( 事後 )
pre_syn ( 同意語 ( 事前 ))
反意語 ( 事前 )
同意語 ( 事後 )
post_opp ( 反意語 ( 事後 ))
推定値
3.627
18.619
19.910
20.383
21.204
標準誤差
0.478
0.594
0.541
0.535
0.531
検定統計量
7.591
31.355
36.781
38.066
39.908
P
<0.001
<0.001
<0.001
<0.001
<0.001
ラ ベル
j1_2
i1_1
i2_1
i3_1
i4_1
統制群の切片が 0 に固定 さ れていた こ と を思い出す と 、 こ れに よ っ て、 pre_verbal ( 言語
能力 ( 事前 )) の得点を固定 し た状態では、 post_verbal ( 言語能力 ( 事後 )) の得点は 3.63
増加す る と 推定 さ れます。
こ の例か ら 得 ら れた結果は、 例 16 での結果 と 同 じ です。 [ 構造モデルの ウ ェ イ ト ]
モデルは、 例 16 のモデル D と 同 じ です。 [ 構造モデルの切片項 ] モデルは、 例 16 のモ
デル E と 同 じ です。
例
26
ベ イ ズ推定
概要
こ の例は、 Amos でのベ イ ズ推定について説明 し ます。
ベ イ ズ推定
最尤法の推定 と 仮説検定では、モデル パ ラ メ ー タ の真の値は固定だが未知 と 考え ら れ、
こ の よ う なパ ラ メ ー タ の所定の標本か ら の推定は ラ ン ダ ム だが既知 と 考え ら れ ま す。
ベ イ ズ ・ アプ ロ ーチ と 呼ばれ る 別の統計的推論では、 未知の数量を ラ ン ダ ム な変数 と
見な し て、 確率分布に割 り 当て ます。 ベ イ ズ法の観点では、 真のモデル パ ラ メ ー タ は
未知なので ラ ン ダ ム で あ る と 見な し 、 同時確率分布に割 り 当て ます。 こ の分布は、 何
ら かの方式でパ ラ メ ー タ が変化す る こ と を示すわけではあ り ま せん。 む し ろ こ の分布
は、 収集 し た情報の状態、 すなわちパ ラ メ ー タ について現在わか っ てい る 情報を要約
す る ための も のです。 デー タ が観測 さ れ る 前のパ ラ メ ー タ の分布を事前分布 と いい ま
す。 デー タ の観測後、 デー タ か ら 得 ら れ る 証拠は、 ベ イ ズの定理 と い う 有名な公式に
よ っ て事前分布 と 結合 さ れ ます。 その結果、 更新 さ れたパ ラ メ ー タ の分布で あ る 事後
分布には、 事前の確信 と 経験的な証拠が反映 さ れてい ます (Bolstad, 2004)。
モデルの複数のパ ラ メ ー タ の同時事後分布を視覚的に と ら え た り 解釈 し た り す る の
は、 人間には難 し い も のです。 し たが っ て、 ベ イ ジ ア ン解析を実行す る 際には、 解釈
が容易にな る よ う 事後分布を要約す る 必要があ り ます。 は じ めに各パ ラ メ ー タ の周辺
事後密度を一度に 1 つずつ作図す る のが よ い方法です。 特に、 デー タ 標本が多い場合
には、 パ ラ メ ー タ の周辺事後分布は正規分布に近似す る 傾向があ り ます。 周辺事後分
布の平均は事後平均 と いい、 パ ラ メ ー タ 推定 と し て報告で き ます。 分布の標準偏差で
あ る事後の標準偏差は、 従来の標準誤差に似た、 不確実性を測定す る 有用な方法です。
357
358
例 26
周辺事後分布のパーセ ン タ イ ルか ら 信頼区間に類似す る 値を計算で き ます。2.5 パー
セ ン タ イ ルか ら 97.5 パーセ ン タ イ ルの範囲の区間は、95% のベ イ ズの信頼区間を形成
し ます。 周辺事後分布はほぼ正規分布に近似 し 、 95% のベ イ ズの信頼区間は事後平均
± 1.96 事後標準偏差にほぼ等 し く な り ます。 こ の場合、ベ イ ズの信頼区間は、パ ラ メ ー
タ 推定値の正規標本分布を前提 と す る 通常の信頼区間 と 基本的に同 じ にな り ます。 事
後分布が正規分布でない場合、 区間は事後平均に関 し て対称にな り ません。 こ の場合、
ベ イ ズ推定の特性のほ う が従来の手法 よ り も 適切な こ と があ り ます。
従来の信頼区間 と は異な り 、 ベ イ ズの信頼区間はパ ラ メ ー タ 自体に関す る 確率分布
と し て解釈 さ れます。 Prob ( a b = 0.95 ) は、 文字どお り 、 の真の値が a と
b の間にあ る 確率が 95% であ る こ と を意味 し ます。 周辺事後分布の両裾の部分をベ イ
ズの p 値の一種 と し て仮説検定に使用す る こ と も で き ます。 に対す る 周辺事後密度
の領域の 96.5% が a 値の右側にあ る 場合、 帰無仮説 a の検定のベ イ ズの p 値は対
立仮説 a に対 し て 0.045 です。 こ の場合、 「対立仮説が真であ る 確率は 96.5% であ
る 」 と 言 う こ と も で き ます。
ベ イ ジ ア ン推論の考え方は 18 世紀後半ま で さ かのぼ り ますが、統計には近年ま でほ
と ん ど使用 さ れてい ませんで し た。 ベ イ ズの手法の適用に抵抗があ る のは、 確率を確
信の状態 と し て示す こ と への哲学的な嫌悪や、 事前分布の選択に主観が付 き ま と う こ
と に由来 し てい ます。 し か し 、 ベ イ ジ ア ン解析があ ま り 使用 さ れなか っ た理由の大半
は、 同時事後分布を要約す る 計算方法が困難で あ る か利用不可能で あ っ た こ と です。
し か し 、 マルコ フ連鎖モンテカルロ (MCMC) 法 と 呼ばれ る 新 し いシ ミ ュ レーシ ョ ン技法
を使用 し て、 高次元の同時事後分布や複合的な問題において も パ ラ メ ー タ の ラ ン ダ ム
値を作図で き る よ う にな り ま し た。 MCMC では、 事後分布の要約の作成が、 ヒ ス ト グ
ラ ムの作図や標本の平均値お よ びパーセ ン タ イ ルの計算 と 同様に簡単にな り ま し た。
事前分布の選択
事前分布では、 不明のパ ラ メ ー タ があ る 場合の研究者の確信を数量化 し ます。 母集団
で変数が ど の よ う に分布す る かの知識があ る と 、 対象 と な る パ ラ メ ー タ の妥当な事前
分布を選択す る 上で研究者の助けにな る こ と があ り ます。 Hox (2002) は、 一般的な母
集団におけ る 平均が 100 で標準偏差が 15 の ノ ルム に準拠 し た知能検定の例を挙げて
い ます。 一般的な母集団を代表す る のは誰か と い う 調査で被験者に検定を実施す る 場
合、検定ス コ アの平均が 100 で標準偏差が 15 であ る 事前分布の中心に位置す る と 考え
る のが妥当です。 観察対象の変数に限界があ る こ と を知 る と 、 パ ラ メ ー タ に境界を設
定す る 上で役立つ こ と があ り ます。 た と えば、 リ ッ カー ト 法で 0、 1 …10 の値を と る 調
査項目の平均は 0 か ら 10 の間にあ る はずであ り 、 最大分散は 25 です。 こ の項目の平
均 と 分散の事前分布を こ れ ら の限界に準拠す る よ う 設定で き ます。
多 く の場合、 取 り 入れ る 情報がで き る だけ少ない事前分布を設定 し 、 デー タ がそれ
自体 を 表せ る よ う にす る 傾向が あ り ま す。 事前分布の確率が非常に広い範囲のパ ラ
メ ー タ 値を と る場合、 拡散 し てい る と いい ます。 Amos ではデフ ォ ル ト で、 各パ ラ メ ー
– 38
38
タ に対 し て – 3.4 10 か ら 3.4 10 の一様分布を適用 し ます。
359
ベ イ ズ推定
拡散事前分布は、 無情報事前分布 と 呼ばれ る こ と も 多いので、 こ の用語 も 同様に使
用 し ます。 し か し 、 厳密な意味では、 事前分布は完全に無情報で あ る こ と も 、 許容 さ
れ る 値の全範囲にわた る 一様分布にな る こ と も あ り ません。 パ ラ メ ー タ が変換 さ れた
場合に一様でな く な っ て し ま う ためです。 ( た と えば、 変数の分散が 0 か ら ま で均
等に分布す る と 仮定 し ます。 こ の と き 、 標準偏差は均一に分布 し ません。 ) すべての事
前分布は、 少な く と も なん ら かの情報を伴い ます。 デー タ セ ッ ト のサ イ ズが大 き く な
る と 、 結果的にデー タ か ら の証拠が こ の情報を上回 る ため、 事前分布の影響は小 さ く
な り ます。 標本が非常に少ない場合やモデル ま たは事前分布がデー タ と 矛盾 し てい る
場合を除 き 、 事前分布を変え て も ベ イ ジ ア ン解析か ら の解はほ と ん ど変わ ら ない傾向
があ り ます。 Amos では、任意のパ ラ メ ー タ の事前分布を容易に変え る こ と がで き る た
め、 こ の よ う な感度のチ ェ ッ ク が簡単に行え ます。
Amos Graphics によ るベ イ ズ推定の実行
Amos Graphics に よ る ベ イ ズ推定を説明す る ために、 例 3 を再度取 り 上げ ます。 こ の
例では、 2 つの変数間の共分散が、 年齢 と ボ キ ャ ブ ラ リ の間の共分散の値を 0 に固定
す る こ と に よ っ て 0 にな る 帰無仮説の検定方法を示 し てい ます。
共分散の推定
現在の例に対 し て最初に行 う 必要があ る のは、 共分散を推定で き る よ う に共分散のゼ
ロ 制約を除去す る こ と です。
E Ex03.amw を開 き ます。 通常の イ ン ス ト ールを実行 し てい る 場合、 パ ス は C:¥Program
Files¥IBM¥SPSS¥Amos¥23¥Examples¥Japanese にな り ます。
E パ ス図の 2 方向の矢印を右 ク リ ッ ク し 、ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト のプ
ロパテ ィ ] を選択 し ます。
360
例 26
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ パラ メ ー タ ] タ ブ を ク リ ッ ク し
ます。
E [ 共分散 ] テ キ ス ト ボ ッ ク ス で 「0」 を削除 し ます。
E [ オブジ ェ ク ト プ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
こ の結果得 ら れ る パス図は次の よ う にな り ます (Ex26.amw で も 参照で き ます )。
最尤法解析の結果
こ のモデルのベ イ ジ ア ン解析を実行す る 前に、 比較目的で最尤法解析を実行 し ます。
E
メ ニ ュ ーか ら [ 分析 ] [ 推定値を計算 ] を選択す る と 、次のパ ラ メ ー タ 推定値 と 標準誤
差が表示 さ れます。
共分散 : ( グループ番号 1 - デフ ォ ル ト モデル )
年齢 <--> ボキ ャ ブ ラ リ
推定値
–5.014
標準誤差
8.560
検定統計量 P
–0.586
0.558
ラ ベル
検定統計量 P
4.416
***
4.416
***
ラ ベル
分散 : ( グループ番号 1 - デフ ォ ル ト モデル )
年齢
ボキ ャ ブ ラ リ
推定値
21.574
131.294
標準誤差
4.886
29.732
361
ベ イ ズ推定
ベ イ ジ ア ン解析
ベ イ ジ ア ン解析では、明示的な平均値お よ び切片の推定が必要です。 Amos でベ イ ジ ア
ン解析を実行す る には、 まず、 平均値お よ び切片を推定す る よ う 指定 し ます。
E
メ ニ ュ ーか ら [ 表示 ] [ 分析のプ ロパテ ィ ] を選択 し ます。
E [ 平均値 と 切片を推定 ] を選択 し ます。 ( 横にチ ェ ッ ク マー ク が表示 さ れます。 )
E ベ イ ジ ア ン解析を実行す る には、 メ ニ ュ ーか ら [ モデル適合度 ] [ ベ イ ズ推定 ] を選択
す る か、 キーボー ド で Ctrl+B キーを同時に押 し ます。
362
例 26
[ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ が表示 さ れ、 MCMC アルゴ リ ズ ムに よ っ て即座に標本
が生成 さ れます。
[ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ には、 ウ ィ ン ド ウ上部近 く に ツールバーがあ り 、 その下
に結果の要約表が表示 さ れます。 要約表の各行は、 単一のモデル パ ラ メ ー タ の周辺事
後分布を表 し ます。 [ 平均値 ] と い う ラ ベルの付いた最初の列には、 事後分布の中央ま
たは平均で あ る 、 事後平均が表示 さ れ ます。 こ れは、 デー タ と 事前分布に基づ く 、 ベ
イ ジ ア ン のパ ラ メ ー タ ポ イ ン ト 推定 と し て使用で き ま す。 デー タ セ ッ ト が大 き い場
合、 事後平均は最尤推定値に近づ く 傾向があ り ます。 ( こ の場合、 2 つの値はあ る 程度
近い値です。 年齢 - ボ キ ャ ブ ラ リ の共分散の事後平均 –6.536 と 前出の最尤推定値
–5.014 を比較 し て く だ さ い。 )
ベ イ ジ ア ン解析 と デー タ 代入の結果の複製
Amos に実装 さ れてい る 多重代入 と ベ イ ジ ア ン推定のアルゴ リ ズ ムは、 初期の乱数の
シー ド に よ っ て変わ る 一連の乱数を多用 し ます。 Amos のデフ ォ ル ト の動作では、ベ イ
ジ ア ン推定、 ベ イ ジ ア ン法デー タ 代入、 ま たは確率的回帰法デー タ 代入を実行す る た
びに乱数シー ド を変更 し ます。 その結果、 こ の よ う な解析のいずれかを複製す る と 、異
な る 乱数シー ド を使用 し てい る ため、若干異な る 結果が得 ら れ る こ と が予想で き ます。
何 ら かの理由で前の解析 と ま っ た く 同 じ 複製が必要な場合は、 前の解析で使用 し た
も の と 同 じ 乱数シー ド で開始 し ます。
363
ベ イ ズ推定
現行シー ド の調査
現行の乱数シー ド が何であ る かを調べた り 、 値を変更 し た り す る には、 次の よ う に し
ます。
E
メ ニ ュ ーか ら [ ツール ][ 乱数シー ド マネジ ャ ー ] を選択 し ます。
デフ ォ ル ト で、Amos では、乱数を使用す る シ ミ ュ レーシ ョ ン メ ソ ッ ド ( ベイ ジアン SEM、
確率的回帰法デー タ 代入、 ま たはベイ ジアン法データ 代入のいずれか ) の呼び出 し ご と
に現行の乱数シード に 1 ずつ加算 し ます 。 Amos では、以前に使用 し たシード の ロ グ を
保持 し てい る ので、 前に生成 し た解析結果ま たは代入 さ れたデータ セ ッ ト の フ ァ イ ル
作成日 と 、 乱数シー ド マネジ ャ ーで報告 さ れた日付を突 き 合わせ る こ と がで き ます。
現行シー ド の変更
E [ 変更 ] を ク リ ッ ク し 、 以前に使用 し た シー ド を入力 し てか ら 解析を実行 し ます。
Amos では、 そのシー ド を用いて最後に開始 し た と き に使用 し た も の と 同 じ 一連の乱
数が使用 さ れます。 た と えば、 こ の例の解析を実行 し た と き 、 Amos が使用 し た シー ド
14942405 を調べ る ために乱数シー ド マネ ジ ャ ーを使用 し ま し た。 その時 と 同 じ ベ イ
ジ ア ン解析の結果を生成す る には、 次の よ う に し ます。
E [ 変更 ] を ク リ ッ ク し 、 現在のシー ド を 14942405 に変更 し ます。
364
例 26
次の図は、 変更後の [ 乱数シー ド マネジ ャ ー ] ダ イ ア ロ グ ボ ッ ク ス を示 し てい ます。
先を見越 し て、 ベ イ ジ ア ン解析ま たはデー タ 代入解析の実行前に固定のシー ド 値を選
択す る 方法 も あ り ます。 [ 常に同一シー ド 使用 ] オプシ ョ ン を選択す る と 、 Amos ですべ
ての解析に同 じ シー ド 値を使用す る こ と も で き ます。
こ のシー ド の値を確実な場所に記録 し てお く と 、 解析の結果を後日再現す る こ と がで
き ます。
ヒ ン ト : こ のガ イ ド では、 すべての例で同 じ シー ド 値 14942405 を使用 し てい る ので、
こ の結果を再現す る こ と がで き ます。
365
ベ イ ズ推定
前述 し た よ う に、 Amos で採用 し てい る MCMC アルゴ リ ズ ムでは、 パ ラ メ ー タ の事後
分布のモ ン テ カル ロ シ ミ ュ レーシ ョ ン を経た、 高次元の同時事後分布か ら のパ ラ メ ー
タ の乱数値を描画 し ます。 た と えば、 [ 平均値 ] 列に示 さ れ る 値は、 厳密な事後平均で
はな く 、 MCMC の手続 き か ら 生成 さ れ る 乱数の標本を平均 し て得 ら れ る 推定値です。
事後平均の不確実性が ど の程度モ ン テ カル ロ 法のサンプ リ ン グに起因す る か、 大ま か
にで も 理解す る こ と が重要です。
[ 標準誤差 ] と い う ラ ベルの付いた第 2 列は、 モ ン テ カル ロ 法で推定 さ れ る 事後平均
が実際の事後平均か ら ど の程度隔た っ てい る 可能性があ る か を示唆す る 標準誤差の推
定値を示 し てい ます。 MCMC の手続 き で さ ら に多 く の標本が生成 さ れ る につれ、 事後
平均の推定の精度が向上 し 、 [ 標準誤差 ] は徐々に低下 し ます。 こ の標準誤差は、 事後
平均がパ ラ メ ー タ の実際の未知の値か ら ど の程度隔た っ てい る か を推定す る も のでは
ないので注意が必要です。 つま り 、 パ ラ メ ー タ の 95% の区間の幅 と し て、 ± の標準誤
差の値を使用す る こ と はあ り ません。
事後平均 と 実際の未知のパ ラ メ ー タ の間の考え う る 隔た り は、 [ 標準偏差 ] と い う ラ
ベルの付いた第 3 列に示 さ れます。こ の数値は最尤推定値の標準誤差に近 く な り ます。
そのほかの列には、 [ 収束統計量 ] (C.S.) 、 各パ ラ メ ー タ の中央値、 各パ ラ メ ー タ 分布
の 50% の上限 と 下限、 各パ ラ メ ー タ の歪度、 尖度、 最小値、 最大値が示 さ れます。 50%
の上限 と 下限はベ イ ズの 50% の信頼セ ッ ト の終点であ り 、 従来の手法の 50% の信頼
区間に類似 し てい ます。 信頼係数は 95% を使用す る のが一般的なので、 95% に変更す
る 方法を後述 し ます。
[ 分析 ] [ ベ イ ズ推定 ] を選択す る と 、 MCMC アルゴ リ ズ ムに よ っ て即座にサンプ
リ ン グが開始 さ れ、 ユーザーが [ サン プ リ ングの一時停止 ] ボ タ ン を ク リ ッ ク し て処理
を 停止す る ま で続け ら れ ま す。 362 ページ の図は、500 + 5831 = 6331 のサ ン プ リ ン
グが完了 し た後で、 サンプ リ ン グが停止 し てい ます。 Amos では、 解析用に保存 さ れた
最初の標本を描画す る 前に、500 のバーン イ ン 標本を生成 し て破棄 し ま し た。 Amos で
は、 MCMC 手続 き が実際の同時事後分布に収束で き る よ う にす る バーン イ ン 標本を
描画 し ます。 バーン イ ン標本を描画 し て破棄 し た後で、 こ の同時事後分布の外観を際
立たせ る ための追加の標本を描画 し ます。 362 ページに示す例では、 Amos が 5,831 の
こ の よ う な解析標本を描画 し た後で、 要約表の結果が基にす る 解析標本の上に描画 さ
れてい ます。 実際に、 表示 さ れ る 結果は 500 のバーン イ ン 標本 と 5,500 の解析標本で
す。 Amos が使用す る サン プ リ ン グ アルゴ リ ズ ムは非常に高速なので、 サン プ リ ン グ
のたびに要約表を更新す る と 、 [ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ に表示 さ れ る 結果は、 急
速に変化す る 意味不明のに じ んだ画像に な り ま す。 こ れは解析の速度 も 低下 さ せ ま
す。 2 つの問題を回避す る ため、 Amos では 1,000 回のサンプ リ ン グ ご と に結果を リ フ
レ ッ シ ュ し ます。
366
例 26
リ フ レ ッ シ ュ オプ シ ョ ンの変更
リ フ レ ッ シ ュ の間隔を変更す る には
E
メ ニ ュ ーか ら [ 表示 ][ オプ シ ョ ン ] を選択 し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で [ リ フ レ ッ シ ュ ] タ ブを ク リ ッ ク す る と 、 リ フ レ ッ
シ ュ オプシ ョ ンが表示 さ れます。
リ フ レ ッ シ ュ の間隔 を デ フ ォ ル ト の 1,000 オブザベーシ ョ ン 以外の値に変更で き ま
す。 あ る いは、 指定 し た一定の時間間隔で表示を リ フ レ ッ シ ュ す る こ と も で き ます。
[ 画面表示を手作業で リ フ レ ッ シ ュ ] を選択す る と 、表示は自動的に更新 さ れな く な り
ます。[ リ フ レ ッ シ ュ ] タ ブで何を選択す る かに関わ ら ず、[ ベ イ ジ ア ン SEM] ツールバー
の [ リ フ レ ッ シ ュ ] ボ タ ン を ク リ ッ ク す る こ と に よ っ て、 手作業でいつで も 画面表示を
リ フ レ ッ シ ュ で き ます。
収束の評価
パ ラ メ ー タ の安定 し た推定を得 る ための十分な標本があ り ますか ? こ の質問に答え る
前に、 手続 き が収束す る と はど う い う 意味か を簡潔に説明 し ます。 MCMC アルゴ リ ズ
ムの収束は、 最尤法な ど無作為でない方法の収束 と は ま っ た く 異な り ます。 MCMC の
収束を正 し く 理解す る には、 2 つの異な る タ イ プ を区別す る 必要があ り ます。
第 1 の タ イ プは、 分布の収束 と いい、 分析標本がパ ラ メ ー タ の実際の同時事後分布
か ら 引 き 出 さ れ る こ と を意味 し ます。 分布の収束は、 アルゴ リ ズ ム が徐々に初期値か
ら 離れてい く バーン イ ン の期間に発生 し ます。 こ の段階の標本は実際の事後分布を表
し ていない可能性があ る ため、 破棄 さ れ ます。 デフ ォ ル ト の 500 のバーン イ ン期間は
保守的な見積 り なので、 ほ と ん ど の問題に必要な期間 よ り ずっ と 長 く な っ てい ま す。
バーン イ ン期間が終わ り 、 Amos が分析標本の収集を開始す る と 、 事後平均な ど の要
約統計量を正確に推定す る のに十分な標本があ る か ど う かが問題にな り ます。
367
ベ イ ズ推定
問題は事後分布の要約の収束 と 呼ばれ る 第 2 の タ イ プの収束に関係 し ます。 分析標
本が独立 し てい る のではな く 、 実際は自己相関性があ る 時系列にな っ てい る と い う 事
実に よ っ て、事後分布の要約の収束は複雑です。 1001 番目の標本は 1000 番目 と 、 1000
番目は 999 番目 と 、 順々に相関 し てい ます。 こ の よ う な相関は MCMC の固有の機能
で、 こ の相関のために、5,500 ( ま たは任意の数 ) の分析標本か ら の要約統計量は、5,500
の標本が独立 し てい る 場合 よ り も 変動が大 き く な り ます。 し か し 、 分析標本を引 き 続
き 累積 し てい く と 、 事後分布の要約は徐々に安定 し ます。
Amos は、 収束のチ ェ ッ ク を支援す る い く つかの診断を備え てい ます。 362 ページの
[ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ の ツールバー上の 1.0025 と い う 値に注目 し て く だ さ い。
こ れは、 Gelman、 Carlin、 Stern お よ び Rubin に よ っ て提唱 さ れた基準に基づ く 全体の
収束統計量です (2004)。 画面を リ フ レ ッ シ ュ す る たびに、 要約表で各パ ラ メ ー タ の収
束統計量が更新 さ れ ます。 ツールバー上の収束統計量の値は個々の収束統計量の値の
最大値です。 デフ ォ ル ト で、 収束統計量の最大値が 1.002 未満の場合に、 Amos は手続
き が収束 し た と 判断 し ます。 こ の基準では、 1.0025 と い う 最大収束統計量は、 十分小
が
さ く はあ り ません。 全体の収束統計量が十分小 さ く ない場合には、 不機嫌な顔
表示 さ れ ます。 収束統計量では、 分析標本の部分の範囲内の変動 と 、 複数の部分に ま
たが っ た変動 を比較 し ま す。 1.000 の値は完全な収束を表 し ま す。 それ よ り 大 き い値
は、 よ り 多 く の分析標本を作成す る こ と に よ っ て事後分布の要約を さ ら に正確にで き
る こ と を示 し ます。
[ サン プ リ ングの一時停止 ] ボ タ ン を 2 回めに ク リ ッ ク する と 、サンプ リ ン グ処理が再
開 さ れます。 [ 分析 ] メ ニ ュ ーか ら [ サン プ リ ングの一時停止 ] を選択 し た り 、 キーボー
ド か ら Ctrl+E キーを同時に押 し た り す る こ と に よ っ て も 、 サンプ リ ン グの一時停止お
よ び再開が可能です。 次の図は、 し ば ら く の間サンプ リ ン グ を再開 し 、 再度停止 し た後
の結果を示 し てい ます。
368
例 26
こ の時点で 74,501 の分析標本があ り ますが、 表示が直近で更新 さ れたのは 74,500 番
目の標本の時点です。 最大の収束統計量は 1.0005 で、 許容 さ れ る 収束基準の 1.002 を
が表示 さ れてい ます。 Gelman
下回っ てい ます。 満足で き る 収束を示す上機嫌の顔
ほか (2004) は、 多 く の分析において、 1.10 以下の値で十分であ る と 提言 し てい ます。
デフ ォ ル ト 基準の 1.002 は保守的な値です。 こ の基準に よ っ て MCMC が収束 し た こ と
を判断 し て も 、 要約表の変化が停止す る わけではあ り ません。 MCMC アルゴ リ ズ ム を
実行 し てい る 限 り 、 要約表は変化 し 続け ます。 ただ し 、 ツールバー上の全体の収束統
計量の値が 1.000 に近づ く につれて、 標本を追加 し て も 精度はそれほ ど上が ら な く な
る ので、 分析を停止 し ます。
診断の作図
収束統計量の値に加え て、Amos はベ イ ジ ア ンの MCMC 手法の収束のチ ェ ッ ク を支援
す る い く つかの作図機能を備え てい ます。 各種の作図を表示す る には、 次の よ う に し
ます。
E
メ ニ ュ ーか ら [ 表示 ] [ 事後分布 ] を選択 し ます。
[ 事後分布 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
369
ベ イ ズ推定
E [ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ か ら [ 年齢 < - > ボキ ャ ブ ラ リ ] パ ラ メ ー タ を選択 し ます。
こ こ で、 [ 事後分布 ] ダ イ ア ロ グ ボ ッ ク ス に、 22,500 標本での年齢 - ボキ ャ ブ ラ リ の共
分散の分布を表す頻度多角形 ( ポ リ ゴ ン ) が表示 さ れます。
事後分布に収束 し た可能性を視覚的に判断す る ために、 累積 さ れた標本の最初の 3 分
の 1 か ら 得た分布の推定 と 、 最後の 3 分の 1 か ら 得た分布の推定を 2 つ同時に表示す
る 方法があ り ます。 周辺事後分布 2 つの推定を同 じ グ ラ フ上に表示す る には、 次の よ
う に し ます。
370
例 26
E [ 最初 と 最後の分布 ] を選択 し ます。( オプシ ョ ンの横にチェ ッ ク マーク が表示 さ れます。)
こ の例では、分析標本の最初の 3 分の 1 と 最後の 3 分の 1 の分布はほ と ん ど同 じ です。
こ れは、 年齢 - ボキ ャ ブ ラ リ の共分散の事後分布の重要な特徴を Amos で う ま く 特定
で き た こ と を示 し てい ます。 こ の事後分布は、 –6 に近い値を中心に し てい る よ う に見
え ます。 こ れは、 こ のパ ラ メ ー タ の [ 平均値 ] の値に一致 し ます。 視覚的にみて、 標準
偏差はほぼ 10 であ る こ と がわか り ます。 こ れは [ 標準偏差 ] の値に一致 し ます。
サン プ リ ン グ さ れた値の過半数が 0 の左側にあ り ます。 こ れは、 共分散パ ラ メ ー タ
の真の値が負数であ る こ と の緩やかな証拠にはな り ますが、 0 の右側の比率 も かな り
大 き いため、 こ の結果が統計上有意であ る こ と にはな り ません。 サ ン プ リ ン グ さ れた
値の 0 の右側の部分に対す る 比率が非常に小 さ ければ ( た と えば、 5% 未満 )、 共分散
パ ラ メ ー タ が 0 以上であ る と い う 帰無仮説を棄却で き ますが、こ の場合はで き ません。
収束の評価に役立つ作図 と し て、 ほかに ト レー ス図があ り ます。 時系列図 と も 呼ば
れ る ト レー ス図は、 パ ラ メ ー タ のサ ン プ リ ン グ さ れた値を時間 と 共に表示 し ます。 こ
の図では、 分布で MCMC の手続 き が どれだけ早 く 収束す る か、 つま り 、 どれだけ早
く 開始値に依存 し な く な る か を判断す る 上で役立ち ます。
371
ベ イ ズ推定
E
ト レース図を表示す る には、 [ ト レース ] を選択 し ます。
こ こ に示す図はかな り 典型的な も のです。 急速な上下の変動を示 し 、 長期間の傾向や
動向は見 ら れ ま せん。 こ の図を 目分量で横方向にい く つかのセ ク シ ョ ン に分け て も 、
任意のセ ク シ ョ ンの ト レース の外観は別のセ ク シ ョ ンの ト レース と それほ ど変わ り ま
せん。 こ れは、分布の収束が急速に起 こ っ てい る こ と を示 し ます。 図の中に長期間の傾
向や動向があ る 場合は、 収束が遅い こ と を示 し ます。 ( 長期間 と は、 こ の図の水平方向
の ス ケールに対 し て相対的な も のであ り 、 標本数に依存 し ます。 多 く のサン プ リ ン グ
を行 う と 、 ト レース ス ポ ッ ト はア コ ーデ ィ オ ンの よ う に縮み、 やがて、 急速に上下に
変動す る よ う な外観の動向ま たは傾向が現れます。急速な上下の動 き が意味す る のは、
k の値が標本の総数 と 比べて小 さ い場合に、 任意の反復でサ ン プ リ ン グ さ れ る 値が k
回後の反復でサンプ リ ン グ さ れ る 値 と 関連 し ていない と い う こ と です。
標本間の相関が低下す る ま で どれだけ長 く かか る か を知 る には、 自己相関図 と 呼ぶ
第 3 の図を調べます。 こ の図では、任意の反復でサンプ リ ング さ れ る 値 と 、k = 1, 2, 3,…
の場合に k 回後の反復でサンプ リ ング さ れ る 値の間の推定 さ れ る 相関が表示 さ れます。
372
例 26
E
こ の図を表示す る には、 [ 自己相関 ] を選択 し ます。
水平方向の軸に沿っ た ラ グ は、相関を推定す る 間隔を意味 し ます。 通常の状態では、自
己相関係数が低下す る と 0 に近づ き 、 一定の ラ グ を超え る と 0 の近 く に留 ま り ます。
上の自己相関図では、 ラ グ- 10 の相関 ( 任意のサンプ リ ン グ さ れた値 と 10 回後の反復
か ら 得 ら れた値の相関 ) は、 お よ そ 0.50 です。 ラ グ- 35 の相関は 0.20 未満で、 ラ グ 90
以上では相関は実質的に 0 です。 こ れは、 少な く と も こ の共分散パ ラ メ ー タ に関す る
限 り 、 90 の反復に よ っ て MCMC の手続 き が実質的に開始値に依存 し な く な る こ と を
表 し てい ます。 開始値に依存 し な く な る と は、分布が収束す る の と 同 じ です。 モデルの
他のパ ラ メ ー タ の自己相関図を調べ る と 、ほぼ 90 回の反復で実質的に 0 に低下す る こ
と がわか り ます。 こ の事実か ら 、500 標本のバーン イ ン期間は分布の収束に到達す る の
に十分であ り 、 分析標本は実際の事後分布の標本であ る と い う 確信が得 ら れます。
あ る 種の病理学上の条件では、 MCMC の手続 き は非常に緩やかに収束す る か、 ま っ
た く 収束 し ない こ と があ り ます。 こ れは、デー タ セ ッ ト 内に高い比率で欠損値があ り 、
その欠損値が特殊なパ タ ーン を形成 し てい る 場合や、 モデルの一部のパ ラ メ ー タ の推
定が正確でない場合な ど に起 こ り ます。 こ の よ う な状況では、 モデル内の 1 つ以上の
パ ラ メ ー タ の ト レース図に長期間の動向ま たは傾向があ り 、 標本を増や し て も 減少 し
ません。 ト レー ス図がア コ ーデ ィ オ ン の よ う に縮んで も 、 動向 と 傾向はな く な り ませ
ん。 こ の よ う な場合、パ ラ メ ー タ のサンプ リ ン グ さ れた値の範囲 ( ト レース図の垂直方
向の ス ケールに よ っ て、 あ る いは [ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ の [ 標準偏差 ] ま たは
[ 最小値 ] と [ 最大値 ] の差に よ っ て示 さ れ る ) が非常に大 き い可能性があ り ます。 自己
相関は、 大 き い ラ グで高い ま ま にな っ た り 、 長い間、 正の値 と 負の値の間で揺れ動 く
373
ベ イ ズ推定
よ う に見え た り す る こ と があ り ます。 こ の よ う な現象が起 こ る 場合は、 モデルが複雑
すぎ て手元のデー タ では対処で き ない こ と を示唆 し てい る ので、 よ り 単純なモデルに
適合 さ せ る か、 さ ら に情報の多い事前分布を指定 し てパ ラ メ ー タ に関す る 情報を付加
す る こ と を検討 し ます。
2 変量相関の周辺事後分布図
[ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ の要約表 と 各 [ 事後分布 ] ダ イ ア ロ グ ボ ッ ク ス のポ リ ゴ
ンは、1 度に 1 つの推定値の周辺事後分布を表 し てい ます。 周辺事後分布は非常に重要
ですが、 推定値ど う し に関連があ る こ と を明 ら かにす る も のではあ り ません。 た と え
ば、 共分散ま たは回帰の 2 つの係数が、 いずれか 1 つが 0 であ る 可能性が高い と い う
意味で同 じ 有意性を持つ こ と はあ り ますが、 両方 と い う こ と はあ り え ません。 推定値
のペアの間の関連性を視覚的に表すために、 Amos は 2 変量相関の周辺事後分布図機
能を備え てい ます。
E 2 つのパ ラ メ ー タ の周辺事後分布を表示す る には、 まず、 パ ラ メ ー タ のいずれか 1 つ
の事後分布を表示 し ます ( た と えば、 年齢の分散 )。
E キーボー ド で Ctrl キーを押 し なが ら 、 要約表の第 2 のパ ラ メ ー タ を選択 し ます ( た と
えば、 ボキ ャ ブ ラ リ の分散 )。
374
例 26
す る と 、年齢 と ボキ ャ ブ ラ リ の分散の周辺事後分布を表す 3 次元面図が表示 さ れます。
E [ ヒス ト グラム ] を選択する と 、 垂直方向のブ ロ ッ ク を使用する同様の図が表示 さ れます。
375
ベ イ ズ推定
E [2-D 等高線 ] を選択する と 、2 変量相関の周辺事後密度を表す 2 次元の図が表示されます。
3 つの灰色の網かけは、 暗い色か ら 明 る い色に順にそれぞれ、 50%、 90%、 95% の信
頼領域を表 し ます。 こ の信頼領域は、 従来の統計的推論の手法を用いた大部分のデー
タ 分析でな じ みのあ る 2 変量相関の信頼領域 と 概念的に似てい ます。
ベ イ ズの信頼区間
[ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ の要約表には、各推定値に対す る ベ イ ズの信頼区間の上
限お よ び下限の終点が表示 さ れます。 デフ ォ ル ト で、 Amos は 50% の間隔を表示 し ま
す。 こ れは、 従来の手法の 50% の信頼区間 と 同様です。
研究者は、 95% の信頼区間を報告す る こ と が多いので、事後確率の内容の 95% に相
当す る よ う に境界を変更す る こ と も で き ます。
信頼係数の変更
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で [ 表示 ] タ ブ を ク リ ッ ク し ます。
376
例 26
E [ 信頼係数 ] の値 と し て 「95」 と 入力 し ます。
E [ 閉 じ る ] ボ タ ン を ク リ ッ ク し ます。 こ れで、95% のベ イ ズの信頼区間が表示 さ れます。
ベ イ ジ ア ン推定に関する参考資料
Gill (2004) は 『Political Analysis』 の特別号で、 ベ イ ジ ア ン推定 と その利点を読みやす
い概要に ま と めてい ます。 Jackman (2000) はジ ャ ーナルの論文で、ト ピ ッ ク の よ り 技術
的 な 取 り 扱い方につい て 例 を 挙げ て 提案 し て い ま す。 Gelman, Carlin, Stern, お よ び
Rubin (2004) に よ る 書籍では、 膨大な例を持つ実際の問題を数多 く 取 り 扱っ てい ます。
例
27
非拡散事前分布によ るベ イ ズ推定
概要
こ の例では、 非拡散事前分布を使用す る 例を説明 し ます。
例について
例 26 では、 Amos がデフ ォ ル ト で使用す る 一様事前分布に よ っ て、 単純なモデルにベ
イ ズ推定を実行す る 方法を示 し ま し た。 こ の章の例では、 さ ら に複雑なモデルについ
て考察 し 、 非拡散事前分布を用い ます。 特に、 分散推定値が負の値やその他の不適切
な値を と ら ない事前分布を設定す る 方法を示 し ます。
ベ イ ズ推定についてのその他の情報
前章の例の説明で は、 ベ イ ズ 推定は分析者がデー タ と と も に与 え る 情報に依存す
る こ と に注目 し ま し た 。 そ れに対 し て 、 最尤法の推定では、 観測デー タ が関係
L(|y) (y|q) を通 し て与え ら れ る 場合に未知のパ ラ メ ー タ q の尤度を最大に し 、ベ イ
ズ推定では y の事後密度 p(q|y) (q)(q|y) を見積 も り ます。 こ こ で、 p(q) は q の事前
分布で、 p(q|y) は y を所与 と し た q の事後密度です。 概念 と し て、 こ れは q を所与 と
す る y の事後密度が q の事前分布 と 観測デー タ の尤度の積で あ る こ と を 意味 し ま す
(Jackman2000p. 377)。
サンプルのサ イ ズが大 き く な る につれ、 尤度関数は ML 推定値の付近に、 よ り 高密
度に集中 し ま す。 その場合、 拡散事前分布は尤度が高い領域ではほぼ平 ら 、 すなわち
一定にな る 傾向があ り 、 事後分布の形状は主に尤度 ( つま り 、 デー タ その も の ) に よ っ
て決定 さ れます。
377
378
例 27
の一様な事前分布では、 (q) は完全に平 ら であ り 、 事後分布は尤度を単純に再正
規化 し た も のです。 一様でない事前分布で も 、 事前分布の影響はサ ン プルのサ イ ズが
大 き く な る に従っ て小 さ く な り ます。 さ ら に、 サンプル サ イ ズが増大す る と 、 の同
時事後分布は正規分布に近似 し ます。 こ の理由で、 ベ イ ズ法 と 古典的な最尤法の分析
では同等の漸近的結果が得 ら れます (Jackman 2000)。 サンプル数が小 さ い と 、 ベ イ ズ
法の手続 き に合理的な事前情報を与え ら れ る 場合は、 ベ イ ジ ア ン解析か ら のパ ラ メ ー
タ 推定値のほ う が正確にな る 可能性があ り ます。 ( 逆にい う と 、 適切でない事前情報は
偏 り を持ち込む こ と で悪い影響を及ぼ し ます。 )
ベ イ ジ ア ン解析 と 不適解
潜在変数モデル を当てはめ る 際に よ く あ る 問題の 1 つが、 不適解の出現です (Chen、
BollenPaxtonCurranKirby2001)。 た と えば、 分散の推定値が負数であ る 場合に不適
解が出現 し ます。 分散が 0 よ り 小 さ く な る こ と はないため、 その よ う な解は不適解 と
呼ばれ ます。 不適解はサ ン プルが小 さ すぎ る か、 モデルが不適切であ る こ と を示す場
合があ り ます。 ベ イ ズ推定に よ っ て、 不適切なモデルを改善す る こ と はで き ませんが、
使用す る サ ン プルが少ない こ と か ら 生 じ る 不適解を回避す る こ と はで き ま す。 Martin
と McDonald (1975) は、 探索的因子分析のためのベ イ ズ推定について論 じ 、 不適解に
ゼ ロ の確率を割 り 当て る 事前分布を選ぶ こ と に よ っ て、 推定を改善 し 、 不適解を回避
で き る と 示唆 し てい ます。 こ の章の例は、 事前分布を適切に選択す る こ と に よ り 不適
解を回避す る Martin と McDonald の手法を説明 し てい ます。
デー タ について
Jamison と Scogin (1995) は、 う つ病の被験者に自宅で課題を読んで完成 さ せて も ら う 、
新 し い治療法の有効性についての実験的な研究を実施 し ま し た ( 「Feeling Good: The
New Mood Therapy」 (Burns, 1999))。 Jamison と Scogin は、 被験者に対照条件ま たは実
験条件を ラ ン ダ ムに割 り 当て、 被験者の う つ病の レベルを測定 し 、 実験群に治療を施
し た後で レベルを再度測定 し ま し た。 う つ病の測定は、1 つの測定方法には依存す る の
ではな く 、 ベ ッ ク う つ病評価尺度 (Beck Depression Inventory) (Beck, 1967) と ハ ミ ル ト
ン う つ病評価尺度 (Hamilton Rating Scale for Depression) (Hamilton, 1960) と い う よ く 知
ら れた 2 つの う つ病評価尺度を使用 し ま し た。 こ こ では、 それぞれ BDI お よ び HRSD
と 略す こ と と し ます。 デー タ は、 フ ァ イ ル feelinggood.sav にあ り ます。
379
非拡散事前分布によ るベ イ ズ推定
最尤法によ る モデルの適合
次の図は、 最尤法の推定を用いて、 時間 2 の う つ病での治療効果 (COND) にモデルを
適合 さ せた結果を表 し てい ます。 時間 1 の う つ病は、 共変量 と し て使用 し ます。 時間 1
と 時間 2 で、 BDI お よ び HRSD は、 基礎 と な る 単一の変数であ る う つ病 (DEPR) を示
す指標 と し てモデ リ ン グ さ れます。
こ のモデルのパ ス図は、 Ex27.amw にあ り ます。 自由度 1 のカ イ 2 乗統計量 0.059 は良
好な適合を示 し ますが、 治療後の HRSD に対す る 負の残差分散は、 解が不適であ る こ
と を示 し ます。
無情報 ( 拡散 ) 事前分布によ るベ イ ズ推定
拡散事前分布 を 用い たベ イ ジ ア ン解析では、 最尤法の解 と 同様の結果が得 ら れ る で
し ょ う か ? こ れを確かめ る ため、 同 じ モデルでベ イ ジ ア ン解析を実行 し ます。 最初に、
バーン イ ン オブザベーシ ョ ン数を増やす方法について説明 し ます。 こ こ ではデフ ォ ル
ト のバーン イ ン オブザベーシ ョ ン数の 500 を変更す る 必要はあ り ませんが、 手順のみ
説明 し ます。
380
例 27
バーン イ ン オブザベーシ ョ ン数の変更
バーン イ ン オブザベーシ ョ ン数を 1,000 に変更す る には、 次の よ う に し ます。
E
メ ニ ュ ーか ら [ 表示 ] [ オプ シ ョ ン ] を選択 し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で [MCMC] タ ブ を選択 し ます。
E [ バーン イ ン ・ オブザベーシ ョ ン数 ] を 1000 に変更 し ます。
381
非拡散事前分布によ るベ イ ズ推定
E [ 閉 じ る ] を ク リ ッ ク し 、不機嫌な顔が
上機嫌な顔に変わ る
ま で MCMC サンプ リ
ン グ を続け ます。
要約表は次の よ う にな り ます。
こ こ では、 Amos が MCMC サンプルのデフ ォ ル ト の制限であ る 100,000 に到達す る ま
で解析を続け ま し た。 Amos が こ の制限に達す る と 、細線化 と 呼ばれ る 処理が始ま り ま
す。 細線化 と は、すべてのサンプルの代わ り に、等間隔に配置 し たサンプルのサブセ ッ
ト を保持す る 処理です。 Amos は、 MCMC サンプ リ ン グ処理を開始す る と 、 100,000 サ
ン プルの制限に達す る ま ですべてのサ ン プルを保持 し ます。 制限に達 し た時点でデー
タ の分析者がサン プ リ ン グ処理を停止 し ていない場合、 Amos は 1 つお き にサ ンプル
を削除す る こ と に よ っ てサンプルの半分を破棄す る ので、 残っ た系列の ラ グ- 1 の従属
は、元の細線化 し ていない系列の ラ グ- 2 の従属 と 同 じ にな り ます。 こ れ以降、Amos は
生成 さ れ る 2 つのサン プルか ら 1 つを保持 し なが ら 、 100,000 の上限に再び達す る ま
でサ ンプ リ ン グ処理を継続 し ます。 再び上限に達 し た時点で Amos はサン プルを再び
細線化 し 、 4 つお き に 1 つのサンプルを保持 し 、 ... と 続いてい き ます。
382
例 27
Amos ではなぜ細線化を実行す る ので し ょ う か ? 細線化に よ っ て連続す る サン プル
間の自己相関が低 く な る ため、 細線化 さ れた連続す る 100,000 のサンプルは、 同 じ 長
さ の細線化 さ れていない系列 よ り も 多 く の情報を提供 し ます。 現在の例で表示 さ れて
い る 結果は、 1,000 のバーン イ ン サンプルの後に収集 さ れた 53,000 サンプルを基に し
た、 合計 54,000 サンプルの結果です。 ただ し 、 こ れはサンプルの系列が 3 回細線化 さ
れた後であ る ため、 保持 さ れてい る 1 つのサンプルご と に 8 つのサンプルが生成 さ れ
てい ます。 細線化が実行 さ れなか っ た と すれば、1 000 8 = 8 000 のバーン イ ン サ
ンプル と 53 000 8 = 424 000 の分析サンプルがあ る こ と にな り ます。
ベ イ ジ ア ン解析の結果は、 最尤法の結果 と 非常に よ く 似てい ます。 e5 の残差分散の
事後平均は、最尤法の推定値 と 同様に負数です。 事後分布自体が 0 の左側にかな り 寄っ
てい ます。
こ の問題には解消す る 方法があ り ます。 e5 の分散が負数にな る 任意のパ ラ メ ー タ のベ
ク ト ルに 0 の事前密度を割 り 当て る こ と です。 e5 の分散の事前分布を変更す る には、
次の よ う に し ます。
383
非拡散事前分布によ るベ イ ズ推定
E
メ ニ ュ ーか ら [ 表示 ] [ 事前分布 ] を選択 し ます。
あ る いは、 [ ベ イ ジ ア ン SEM] ツールバーの [ 事前分布 ] ボ タ ン
を ク リ ッ ク す る か、
キーボー ド で Ctrl+R キーを同時に押 し ます。 [ 事前分布 ] ダ イ ア ロ グ ボ ッ ク ス が表示
さ れます。
E [ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ で e5 の分散を選択す る と 、 e5 のデフ ォ ル ト の事前分布
が表示 さ れます。
384
例 27
E デフ ォ ル ト の下限値の – 3.4 10
– 38
を 0 に置 き 換え ます。
E [ 適用 ] を ク リ ッ ク す る と 、 変更が保存 さ れます。
385
非拡散事前分布によ るベ イ ズ推定
累積 さ れた MCMC サン プルは直ちに破棄 さ れ、 サ ン プ リ ン グは初めか ら 再び開始 さ
れます。 し ば ら く し た ら 、[ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ の表示が次の よ う にな り ます。
386
例 27
e5 の分散の事後平均が正数にな っ てい ます。 事後分布を調べ る と 、 サンプ リ ン グ さ れ
た値に 0 以下の も のがない こ と が確認で き ます。
こ の解は適切で し ょ う か ? 各分散の事後平均は正数ですが、 [ 最小値 ] 列を見 る と 、 e2
の分散 と e3 の分散に対 し てサ ン プ リ ン グ さ れた値の一部が負数で あ る こ と がわか り
ます。 e2 と e3 の分散が負の値にな る の を避け る ため、 e5 に対 し て実施 し たの と 同様
に事前分布を変更で き ます。
こ の例の よ う な小規模のモデルで、 パ ラ メ ー タ 単位に こ の よ う な制約条件を設定す
る のはそれほ ど困難ではあ り ません。 し か し 、 不適切な値を と る 任意のパ ラ メ ー タ 値
に対 し て自動的に事前密度を 0 に設定す る 方法 も あ り ます。 こ の機能を使用す る には、
次の よ う に し ます。
E
メ ニ ュ ーか ら [ 表示 ] [ オプ シ ョ ン ] を選択 し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 事前分布 ] タ ブ を ク リ ッ ク し ます。
387
非拡散事前分布によ るベ イ ズ推定
E [ 許容性テ ス ト ] を選択 し ます。 ( 横にチ ェ ッ ク マー ク が表示 さ れます。 )
[ 許容性テ ス ト ] を選択す る と 、 任意の分散共分散行列が正値定符号でないモデルにな
る パ ラ メ ー タ 値の事前密度が 0 に設定 さ れます。 特に、 正の値でない分散の事前密度
が 0 に設定 さ れます。
Amos は、 許容性テ ス ト オプシ ョ ン と 同 じ よ う に機能す る 安定性テ ス ト オプシ ョ ン
も 備え てい ます。 [ 安定性テ ス ト ] を選択す る と 、 線型方程式の不安定な体系にな る パ
ラ メ ー タ 値の事前密度が 0 に設定 さ れます。
388
例 27
[ 許容性テ ス ト ] を選択す る と 、 前に累積 さ れたサンプルが破棄 さ れ、 直ちに MCMC
サンプ リ ン グが再び開始 さ れます。 少 し 経つ と 、 次の よ う な結果が表示 さ れます。
解析には、 すべての推定値の収束基準を満たす 73,000 のオブザベーシ ョ のみが使用 さ
れてい る こ と に注意 し て く だ さ い。 すべての分散推定値の最小値が正の値にな っ てい
ます。
例
28
モデルのパラ メ ー タ 以外の値のベ イ ズ
推定
概要
こ の例では、 ベ イ ズ推定でモデルのパ ラ メ ー タ 以外の数量を推定す る 方法について示
し ます。
例について
例 26 と 例 27 ではベ イ ジ ア ン解析について説明 し ま し た。 いずれの例で も 、モデルのパ
ラ メ ー タ の推定のみを取 り 扱い ま し た。 時には、 モデル パ ラ メ ー タ の関数以外の数量
の推定が必要にな る こ と も あ り ます。 た と えば、 構造方程式モデ リ ン グ を最 も よ く 使
用す る ケー ス に、 直接効果 と 間接効果の同時推定が あ り ます。 こ の例では、 間接効果
の事後分布を推定す る 方法について説明 し ます。
389
390
例 28
Wheaton のデー タ の再考
例 6 で、 Wheaton ほか (1977) の疎外デー タ を紹介 し 、 デー タ の 3 つの代替モデルを示
し ま し た。 こ こ では、 例 6 のモデル C を再度取 り 上げ ます。 次のパス図は、 フ ァ イ ル
Ex28.amw にあ り ます。
間接効果
こ こ で、 あ る 研究者が疎外感 (67 年 ) を介 し た社会的地位か ら 疎外感 (71 年 ) への間接
効果に着目 し てい る と 仮定 し ます。 言い換え る と 、 研究者は、 社会経済的地位が 1967
年時点での疎外感に影響を及ぼ し 、その結果 1971 年時点での疎外感に影響を及ぼすの
ではないか と 考え てい ます。
間接効果の推定
E ベ イ ジ ア ン解析を開始す る 前に、 Amos Graphics の メ ニ ュ ーか ら [ 表示 ] [ 分析のプ ロ
パテ ィ ] を選択 し ます。
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 出力 ] タ ブを ク リ ッ ク し ます。
391
モデルのパラ メ ー タ 以外の値のベ イ ズ推定
E [ 間接、 直接、 または総合効果 ] と [ 標準化推定値 ] を選択 し 、 標準化間接効果を推定 し ま
す。 ( オプシ ョ ンの横にチ ェ ッ ク マー ク が表示 さ れます。 )
E [ 分析のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
392
例 28
E
メ ニ ュ ーか ら [ 分析 ][ 推定値を計算 ] を選択す る と 、 モデル適合度 と パ ラ メ ー タ 推定
値の最尤法のカ イ 2 乗検定が実行 さ れます。
結果は、 例 6-6 の Model C で示 し た も の と 同 じ にな り ます。 社会的地位か ら 疎外感 (71
年 ) への標準化直接効果は -0.19 です。 社会的地位か ら 疎外感 (71 年 ) への標準化間接効
果は、 社会的地位か ら 疎外感 (67 年 ) への標準化直接効果 (-0.56) と 疎外感 (67 年 ) か ら
疎外感 (71 年 ) への標準化直接効果 (0.58) の 2 つの標準化直接効果の積 と し て定義 さ れ
ています。 こ れ ら の 2 つの標準化直接効果の積は – 0.56 0.58 = – 0.32 と な り ます。
標準化間接効果を手動で求め る 必要はあ り ません。 すべての標準化間接効果を表示
す る には、 次の よ う に し ます。
E
メ ニ ュ ーか ら 、 [ 表示 ] [ テキス ト 出力の表示 ] の順に ク リ ッ ク し ます。
393
モデルのパラ メ ー タ 以外の値のベ イ ズ推定
E [Amos 出力 ] ウ ィ ン ド ウ の左上隅か ら [ 推定値 ]、[ 行列 ]、[ 標準化間接効果 ] を選択 し ます。
394
例 28
モデル C のベ イ ジ ア ン解析
モデル C のベ イ ズ推定を開始す る には、 次の よ う に し ます。
E
メ ニ ュ ーか ら [ 分析 ] [ ベ イ ズ推定 ] を選択 し ます。
MCMC アルゴ リ ズ ムは、 MCMC サンプル 22,000 以内に非常に急速に収束 し ます。
395
モデルのパラ メ ー タ 以外の値のベ イ ズ推定
追加推定値
要約表には、 モデル パ ラ メ ー タ のみの結果が表示 さ れます。 間接効果な ど、 モデル パ
ラ メ ー タ か ら 求め ら れた数量の事後分布を推定す る には、 次の よ う に し ます。
E
メ ニ ュ ーか ら [ 表示 ] [ 追加推定値 ] を選択 し ます。
追加推定値 の 周辺事後分布 を 推定す る に は、 少 し 時間 が か か る こ と が あ り ま す。
ス テー タ ス ウ ィ ン ド ウ に進行状況が表示 さ れます。
結果は [ 追加推定値 ] ウ ィ ン ド ウ に表示 さ れます。 標準化間接効果ご と の事後平均を表
示す る には、 次の よ う に し ます。
E
ウ ィ ン ド ウ の左側のパネルか ら [ 標準化間接効果 ] と [ 平均値 ] を選択 し ます。
396
例 28
E 結果を印刷す る には、 印刷す る 項目を選択 し ます。 ( 横にチ ェ ッ ク マー ク が表示 さ れ
ます。 )
E
メ ニ ュ ーか ら [ フ ァ イル ] [ 印刷 ] を選択 し ます。
大量の印刷出力が生成 さ れ る 可能性があ る ので注意 し て く だ さ い。 こ の例ですべての
チ ェ ッ ク ボ ッ ク ス にチ ェ ッ ク マー ク を付け る と 、1 8 11 = 88 の行列が印刷 さ れ
ます。
E 標準化直接効果の事後平均を表示す る には、左側のパネルか ら [ 標準化直接効果 ] と [ 平
均値 ] を選択 し ます。
社会経済的地位か ら 1971 年時点での疎外感への標準化直接効果お よ び標準化間接効
果の事後平均は、 最尤推定値 と ほぼ同 じ です。
397
モデルのパラ メ ー タ 以外の値のベ イ ズ推定
間接効果に関する推論
間接効果の信頼区間を見つけた り 、 間接効果の有意性検定を行っ た り す る には、 2 つ
の方法があ り ます。 Sobel (1982、 1986) は、 間接効果が正規分布す る と 仮定す る 方法を
提唱 し ま し た。 こ の仮定に異議を と な え る 統計シ ミ ュ レーシ ョ ン の論文は増え てい ま
すが、よ り 良い ( 通常は非対称の ) 信頼区間を構築す る ブー ト ス ト ラ ッ プの使用は支持
さ れ て い ま す (MacKinnon, Lockwood, お よ び Williams, 2004, Shrout お よ び Bolger,
2002)。 こ れ ら の研究に よ り 、 Amos で利用可能なバ イ ア ス修正済のブー ト ス ト ラ ッ プ
信頼区間は、 間接効果の信頼で き る 推論を導 き 出す こ と がわか り ま し た。
Sobel の手法 と 信頼区間 を 見つ け る た め の ブー ト ス ト ラ ッ プ の代替手段 と し て、
Amos では、 標準化間接効果ま たは標準化 さ れていない間接効果の ( 通常、 非対称の )
信頼区間を求め る こ と がで き ます。 次の図は、 モデル内の各標準化間接効果の 95% の
信頼区間の下限値を示 し ます。 [ 追加推定値 ] ウ ィ ン ド ウ の左側のパネルで [95% 下限 ]
が選択 さ れてい ます。 ( ベ イ ジ ア ン SEM の [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス か ら 95%
以外の値 も 指定で き ます。 )
398
例 28
社会経済的地位か ら 1971 年時点での疎外感への間接効果の 95% の信頼区間の下限値
は、 –0.382 です。 対応す る 上限値は、 次の図が示す よ う に –0.270 です。
こ の標準化間接効果の実際の値が –0.382 と –0.270 の範囲内にあ る こ と の確信は 95%
です。 事後分布を表示す る には、 次の よ う に し ます。
399
モデルのパラ メ ー タ 以外の値のベ イ ズ推定
E [ 追加推定値 ] ウ ィ ン ド ウ の メ ニ ュ ーか ら [ 表示 ] [ 事後分布 ] を選択 し ます。
最初に、 空の事後分布の ウ ィ ン ド ウ が表示 さ れます。
400
例 28
E [ 追加推定値 ] ウ ィ ン ド ウ で [ 平均値 ] と [ 標準化間接効果 ] を選択 し ます。
401
モデルのパラ メ ー タ 以外の値のベ イ ズ推定
その後、社会経済的地位か ら 1971 年時点での疎外感への間接効果の事後分布が表示 さ
れます。 間接効果の分布は、 厳密ではあ り ませんが、 ほぼ正規分布にな り ます。
例
29
ベイジアン SEM におけるユーザー定義
数量の推定
概要
こ の例では、ユーザー定義の数量 ( 直接効果 と 間接効果の差異 ) を推定す る 方法を示 し
ます。
例について
前の例では、 Amos ベ イ ジ ア ン分析の追加推定値機能を使用 し て間接効果を推定す る
方法を示 し ま し た。 分析を も う 1 歩進め、 「間接効果を、 対応す る直接効果 と 比較す る
には ど う すれば よ いですか」 と い う 、 調査で よ く 聞かれ る 質問に対応す る も の と 仮定
し ます。
疎外感モデルの安定性
カ ス タ ム推定値機能を使用 し て、 モデル パ ラ メ ー タ の任意の関数について推論を導い
た り 推定 し た り で き ま す。 カ ス タ ム推定機能について説明す る ために、 も う 一度前の
例に戻 っ てみ ま し ょ う 。 モデルのパ ス 図 を 405 ページ に示 し ま す。 ま た、 フ ァ イ ル
Ex29.amw に も 記載 し て あ り ます。 こ のモデルでは、 1971 年に見 ら れた疎外感に対す
る 社会経済的地位に よ る 直接効果を確認で き ます。 ま た、 1967 年に見 ら れた疎外感に
よ っ て媒介 さ れ る 間接効果 も 確認で き ます。
403
404
例 29
こ の例の残 り の部分では、 直接効果、 間接効果、 お よ び こ の 2 つの比較に焦点を当
ててい ます。 直接効果に対 し てパ ラ メ ータ ラ ベル ( 「c」 ) を指定 し 、 間接効果の 2 つの
コ ンポーネ ン ト ( 「a」 お よび 「b」 ) を指定 し た こ と に注目 し て く だ さ い。 必須ではあ り
ませんが、 パ ラ メ ー タ ラ ベルを使用する と カ ス タ ム推定値の指定が容易にな り ます。
405
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
こ のモデルのベ イ ジ ア ン分析を開始す る には
E
メ ニ ュ ーか ら [ 分析 ] [ ベ イ ズ推定 ] を選択 し ます。
し ば ら く し た ら 、 [ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ の表示が次の よ う にな り ます。
E
メ ニ ュ ーか ら [ 表示 ] [ 追加推定値 ] を選択 し ます。
406
例 29
E [ 追加推定値 ] ウ ィ ン ド ウ で、[ 標準化直接効果 ] チ ェ ッ ク ボ ッ ク スお よ び [ 平均値 ] チ ェ ッ
ク ボ ッ ク ス を オ ンに し ます。
疎外感 (71 年 ) に対す る 社会的地位の直接効果の事後分布平均値は、 -0.195 です。
407
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
E [ 標準化間接効果 ] チェ ッ ク ボ ッ ク スお よ び [ 平均値 ] チ ェ ッ ク ボ ッ ク ス を オンに し ます。
1971 年にけお る 疎外感に対す る 社会経済的地位の直接効果は、 –0.322 です。
408
例 29
間接効果の事後分布は完全に 0 よ り も 左に位置す る ため、 間接効果は 0 未満であ る と
考え て差 し 支え あ り ません。
ま た、 直接効果の事後分布 も 表示で き ます。 ただ し 、 こ のプ ロ グ ラ ム には、 間接効果
と 直接効果の差異 ( ま たはその比率) の事後分布を確かめ る 機能は組み込まれてい ませ
ん。 こ のケー ス では、 プ ロ グ ラ ム の開発者が想定 し ていなか っ た数量を推定 し た り 推
論 を導 く 必要が あ り ま す。 こ の場合、 独自の カ ス タ ム推定値を定義す る こ と に よ り 、
Amos の機能を拡張す る 必要があ り ます。
409
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
数値カ ス タ ム推定値
こ のセ ク シ ョ ンでは、直接効果 と 間接効果の数値の差異を推定す る Visual Basic プ ロ グ
ラ ムの記述方法を示 し ます (Visual Basic の代わ り に C# を使用す る こ と も で き ます )。
最終的な Visual Basic プ ロ グ ラ ムは、 フ ァ イ ル Ex29.vb に記載 さ れてい ます。
カ ス タ ム推定値を定義す る プ ロ グ ラ ム を記述す る 最初の手順では、 カ ス タ ム推定値
ウ ィ ン ド ウ を開 き ます。
E [ ベイ ジアン SEM] ウ ィ ン ド ウ の メ ニ ュ ーか ら [ 表示 ] [ カ ス タ ム推定値 ] を選択 し ます。
こ の ウ ィ ン ド ウ には Visual Basic の ス ケル ト ン プ ロ グ ラ ムが表示 さ れますので、 Amos
で推定す る 新 し い数量を定義す る コ ー ド 行を追加 し ます。
注 : Visual Basic の代わ り に C# を使用す る 場合は、 メ ニ ュ ーか ら [ フ ァ イル ] [ 新規
C# プ ラ グ イ ン ] を選択 し ます。
スケル ト ン プロ グ ラ ムにはサブルーチン と 関数が含まれてい ます。 サブルーチン と 関数
の呼び出 し を制御す る こ と はで き ません。 こ れ ら は、 Amos に よ っ て呼び出 さ れます。
Amos は、作成 し た DeclareEstimands サブルーチン を 1 度呼び出 し 、推定す る 新 し
い数量 ( 推定値 ) の数を確認 し ます。
410
例 29
Amos は、 作成 し た CalculateEstimands 関数を繰 り 返 し 呼び出 し ます。 Amos は
CalculateEstimands 関数を呼び出すたびに、 指定 さ れたパ ラ メ ー タ 値について カ
ス タ ム推定値の値を計算す る 必要があ り ます。
最初は、 DeclareEstimands サブルーチンの 1 行目のみ表示 さ れます。
E すべての行を表示す る には、 Sub DeclareEstimands を ダブル ク リ ッ ク す る か、 行の
先頭にあ る 小 さ なボ ッ ク ス内の + 記号を ク リ ッ ク し ます。
411
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
プ レース ホルダ ‘TODO: Your code goes here を、 推定す る 新 し い数量 ( 推定値 ) の数
と その名前を指定す る 行で置 き 換え ます。 こ の例 と し て、疎外感 (71 年 ) に対す る 社会
的地位 の直接効果 と こ れに対応す る間接効果の差異を推定 し ます。 ま た、 直接効果 と
間接効果を個別に計算す る コ ー ド を記述 し ま すが、 こ こ ではその方法のみ示 し ま す。
直接効果 と 間接効果は、 カ ス タ ム推定値 と し て定義 し な く て も 、 個別に推定で き ます。
各推定値を定義す る には、 次に示す よ う に newestimand キー ワー ド を使用 し ます。
「direct」、 「indirect」、 お よ び 「difference」 と い う 語は、 推定値の ラ ベルです。 別の ラ
ベルを使用す る こ と も で き ます。
関数 CalculateEstimands は、 DeclareEstimands サブルーチン で定義 し た推定値の値
を計算 し ます。 関数の 1 行目のみ表示 さ れます。
412
例 29
E すべての行を表示す る には、 Function CalculateEstimands を ダブル ク リ ッ ク す る か、
行の先頭にあ る 小 さ なボ ッ ク ス内の + 記号を ク リ ッ ク し ます。
413
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
プ レース ホルダ ‘TODO: Your code goes here を 「direct」、 「indirect」、 お よ び
「difference」 と い う 推定値を評価す る 行で置 き 換え る 必要があ り ます。
まず、 直接効果を計算す る Visual Basic コ ー ド を記述 し ます。 次の図では、 Visual
Basic ス テー ト メ ン ト の一部であ る estimand( 「direct」 ) .value = が入力済みにな っ て
い ます。
等号 (=) の右側に コ ー ド を追加 し て、ス テー ト メ ン ト を完成す る 必要があ り ます。 直接
効果は、 CalculateEstimands 関数の引数 と し て指定 さ れ る AmosEngine オブジ ェ ク ト
を 介 し て ア ク セ ス で き る パ ラ メ ー タ 値のセ ッ ト につい て計算 さ れ ま す。 AmosEngine
オブジ ェ ク ト の使用方法を知 る には Amos に精通 し たプ ロ グ ラ マであ る 必要があ り ま
すが、 必要な Visual Basic シ ン タ ッ ク ス は ド ラ ッ グ ア ン ド ド ロ ッ プで簡単に取得で き
ます。
414
例 29
ド ラ ッ グ アン ド ド ロ ッ プ
E [ ベ イ ジ ア ン SEM] ウ ィ ン ド ウ で直接効果を見つけ、 その行を ク リ ッ ク し ます ( こ の行
は次の図では強調表示 さ れてい ます )。
E マ ウ ス ポ イ ン タ を選択 し た行の端に移動 し ます。 上端で も 下端で も か ま い ません。
ヒ ン ト : マ ウ ス ポ イ ン タ を適当な位置に配置す る と 、 マ ウ ス ポ イ ン タ の横にプ ラ ス符
号 (+) が表示 さ れます。
415
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
E マ ウ ス の左ボ タ ン を押 し た ま ま、 マ ウ ス ポ イ ン タ を Visual Basic の ウ ィ ン ド ウ 内の、
直接効果を表す式を配置す る 位置に ド ラ ッ グ し ます。
こ の操作が完了す る と 、 次の図に示す よ う に、 適切なパ ラ メ ー タ 式が入力 さ れます。
等号の右側のパ ラ メ ー タ は、 前述のパ ス図で使用 し ていた ラ ベル ( 「c」 ) で識別 さ れ
ます。
次に、 1971 年におけ る 疎外に対す る 社会経済的地位の間接効果の計算に目を向けて
み ま し ょ う 。 こ の間接効果は、 2 つの直接効果の積 と し て定義 さ れてい ま す。 1 つは
1967 年におけ る 疎外感に対す る 社会経済的地位の直接効果 ( パ ラ メ ー タ a) で、 も う
1 つは 1971 年におけ る 疎外感に対す る 1967 年の疎外の直接効果 ( パ ラ メ ー タ b) です。
416
例 29
E 間接効果を計算す る Visual Basic 割 り 当て ス テー ト メ ン ト の左側には、
estimand(“indirect”) .value = と 入力 し ます。
上記 と 同 じ ド ラ ッ グ ア ン ド ド ロ ッ プの処理を使用 し て、 まず [ ベ イ ジ ア ン SEM] ウ ィ
ン ド ウ か ら [ 無題 .vb] ウ ィ ン ド ウ に行を ド ラ ッ グ し ます。
417
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
E 最初に、 1967 年におけ る 疎外に対す る 社会経済的地位の直接効果を、 未完成の ス テー
ト メ ン ト の等号の右側に ド ラ ッ グ し ます。
E 次に、 1971 年の疎外に対す る 1967 年の疎外感の直接効果を ド ラ ッ グ ア ン ド ド ロ ッ プ
し ます。
418
例 29
こ の 2 つ目の直接効果は、 [ 無題 .vb] ウ ィ ン ド ウ に sem.ParameterValue( 「b」 ) と 表
示 さ れます。
419
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
E 最後に、キーボード を使用 し て、2 つのパラ メ ータ の間にアス タ リ ス ク (*) を挿入 し ます。
ヒ ン ト : 複雑な カ ス タ ム推定値については、 [ 追加推定値 ] ウ ィ ン ド ウ か ら [ カ ス タ ム
推定値 ] ウ ィ ン ド ウ に ド ラ ッ グ ア ン ド ド ロ ッ プす る こ と も で き ます。
420
例 29
直接効果 と 間接効果の差異を計算す る には、 次の図に示す よ う に、 Visual Basic シ ン
タ ッ ク ス の 3 番目の行を追加 し ます。
E 3 つのカ ス タ ム推定値すべての事後分布を確認す る には、 [ 実行 ] を ク リ ッ ク し ます。
結果が表示 さ れ る ま で数秒かか り ます。 ス テー タ ス ウ ィ ン ド ウ に進行状況が表示 さ れ
ます。
421
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
3 つのカ ス タ ム推定値の周辺事後分布は、 次の表に集計 さ れます。
direct の結果は [ ベ イ ジ ア ン SEM] 要約表で も 確認で き ます。 ま た、 indirect の結果は
[ 追加推計値 ] 表で も 確認で き ます。 こ こ で確認す る 必要があ る のは、 difference の結果
です。 差異の事後分布平均値は –0.135 です。 最小値は –0.377 で、最大値は 0.096 です。
E 差異の周辺事後分布を確認す る には、 [ 表示 ] [ 事後分布 ] を選択 し ます。
E [ カ ス タ ム推定値 ] 表の difference 行を選択 し ます。
422
例 29
ほ と ん ど の領域が 0 よ り も 左にあ る ため、 差異はほぼ負であ る と 考え る こ と がで き ま
す。 つま り 、 間接効果は直接効果 よ り も 負であ る と 言っ て も ほぼ差 し 支え あ り ません。
事後分布を目測 し てみ る と 、 おそ ら く 95 % 程度の領域が 0 よ り 左に存在す る よ う に
思われます。 し たが っ て、 約 95% の公算で、 間接効果が直接効果 よ り も 大 き い と 言 う
こ と がで き ます。 し か し 、 事後分布を目測 に頼 る 必要はあ り ません。 周辺事後分布の
任意の領域を確認す る 方法、 よ り 一般的には、 パ ラ メ ー タ に関す る 任意の命題が真で
あ る 確率を推定す る 方法があ り ます。
二値カ ス タ ム推定値
ポ リ ゴ ン を視覚的に調査 し てみれば、 difference 値の大部分が負であ る こ と がわか り ま
すが、 ど の く ら いの比率の値が負であ る のか を正確には確認で き ません。 こ の比率は、
間接効果が直接効果を超え る と い う 確率の推定値です。 こ の よ う な確率を推定す る 場
合、 二値推定値を使用で き ます。 Visual Basic ( ま たは C#) プ ロ グ ラ ム では、 二値推定
値は、 真 と 偽 と い う 2 つの値のみを取 る と い う 点を除けば、 数値推定値 と ま っ た く 同
じ です。 間接効果が直接効果 よ り も 負であ る 確率を推定す る には、 間接効果が直接効
果 よ り も 負であ る 場合に真 と な り 、 それ以外の場合は偽 と な る モデル パ ラ メ ー タ の関
数を定義す る 必要があ り ます。
423
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
二値推定値の定義
E DeclareEstimands サブルーチンで各二値推定値に名前を付け ます。 わか り やす く す る
ために、 2 つの二値推定値にそれぞれ 「indirect is less than zero」 と 「indirect is
smaller than direct」 と い う 名前を付けて宣言 し ます。
424
例 29
E CalculateEstimates 関数に コ ー ド 行を追加 し て、 二値推定値の計算方法を指定 し ます。
こ の例では、 最初の二値カ ス タ ム推定値は、 間接効果の値が 0 未満の場合に真 と な り
ます。 2 番目の二値カ ス タ ム推定値は、間接効果が直接効果 よ り も 小 さ い場合に真 と な
り ます。
425
ベ イ ジ ア ン SEM におけるユーザー定義数量の推定
E [ 実行 ] を ク リ ッ ク し ます。
Amos は、 抽出 さ れた各 MCMC 標本について各論理式の真偽を評価 し ます。 分析が終
了す る と 、各式の評価が真 と な っ た MCMC 標本の比率が報告 さ れます。 こ れ ら の比率
は、 [ カ ス タ ム推定値 ] 要約表の [ 二値推定値 ] セ ク シ ョ ンに表示 さ れます。
P 列は、 MCMC 標本の全系列の う ち、 各式が真 と 評価 さ れた回数の比率を示 し ます。
こ の例では、 MCMC 標本数が 29,501 であ っ たため、 P の値はお よ そ 30,000 の標本に
基づいてい ます。 P1、 P2、 お よ び P3 は、 それぞれ、 MCMC 標本の最初の 3 分の 1、 真
ん中の 3 分の 1、 最後の 3 分の 1 で各論理式の評価が真であ っ た回数の比率を示 し ま
す。 こ の図では、こ れ ら の各比率は、お よ そ 10,000 の MCMC 標本が基にな っ てい ます。
[ カ ス タ ム推定値 ] ウ ィ ン ド ウ の [ 二値推定値 ] 領域の比率に基づいて、 ほぼ間違い
な く 間接効果が負であ る と い う 結論を下す こ と がで き ます。 こ れは、 間接効果の値が
0 以上であ る MCMC 標本が存在 し ない こ と を示 し た 408 ページ のポ リ ゴ ン と 一致 し
てい ます。
同様に、 間接効果は直接効果 よ り も 大 ( 負 ) であ る 確率は約 0.970 であ る と 言え ま
す。 0.970 は確率の推定に過ぎ ません。 こ れは、29,501 の相関観測値の基づ く 比率です。
ただ し 、 最初の 3 分の 1 (0.968)、 真ん中の 3 分の 1 (0.970)、 最後の 3 分の 1 (0.972) の
比率が近接 し てい る ため、 こ れは適切な推定であ る よ う に思われます。
例
30
デー タ 代入
概要
こ の例では、 因子分析モデルにおけ る 多重代入について説明 し ます。
例について
例 17 では、 デー タ に欠損値が含まれ る 場合に最尤法を使用 し てモデル適合を行 う 方法
を示 し ます。 ま た、Amos では欠損値に値を代入す る こ と も で き ます。 デー タ 代入では、
各欠損値はなん ら かの推測数値に置 き 換え ら れ ます。 各欠損値を代入値に置 き 換え た
ら 、 その結果得 ら れ る 完全デー タ セ ッ ト を、 完全デー タ 用に設計 さ れたデー タ 分析方
法で分析で き ます。 Amos には 3 つのデー タ 代入方法が用意 さ れてい ます。
回帰法代入では、 まず最尤法を使用 し てモデル適合を行い ます。 その後、 モデル パ
ラ メ ー タ を最尤推定値 と 等 し く な る よ う に設定 し 、 線型回帰を使用 し て、 各ケース
の未観測値を、 同 じ ケース についての観測値の線型結合 と し て予測 し ます。 こ の予
測値を欠損値に当てはめ ます。
確率的回帰法代入 (Little お よ び Rubin, 2002 年 ) では、 未知のモデル パ ラ メ ー タ を
最尤推定値 と 等 し く な る よ う に設定 し 、観測値に基づ く 欠損値の条件付 き 分布か ら
無作為に抽出 し て、 各ケース の値を代入 し ます。 確率的回帰法代入には ラ ン ダ ム な
要素が存在す る ため、 代入プ ロ セ ス を繰 り 返すたびに、 異な る完全デー タ セ ッ ト が
生成 さ れます。
ベ イ ジ ア ン法代入は、 確率的回帰法代入に似てい ますが、 パ ラ メ ー タ 値が推定に過
ぎず未知であ る と い う 事実を考慮す る 点が異な り ます。
427
428
例 30
多重代入
多重代入 (Schafer, 1997 年 ) では、 非決定性の代入方法 ( 確率的回帰法代入ま たはベ イ
ジ ア ン法代入 ) を使用 し て複数の完全デー タ セ ッ ト を作成 し ます。 観測値が変化す る
こ と はあ り ませんが、 代入値は完全デー タ セ ッ ト ご と に異な り ます。 複数の完全デー
タ セ ッ ト を作成 し た ら 、 完全デー タ セ ッ ト ご と に分析 し ます。 た と えば、 m 個の完全
デー タ セ ッ ト があ る 場合、 m 個の異な る 結果セ ッ ト が存在 し 、 それぞれの結果セ ッ ト
には さ ま ざ ま な数量の推定値 と 標準誤差の推定値が含 ま れ ま す。 m 個の完全デー タ
セ ッ ト は互いに異な る ため、 m 個の結果セ ッ ト も 互いに異な り ます。
デー タ 分析者は m 個の完全デー タ セ ッ ト を個別に分析 し た後、得 ら れた m セ ッ ト の
推定値 と 標準誤差を単一の結果セ ッ ト に結合す る 必要があ り ます。 Rubin (1987 年 ) の
有名な公式を使用 し て、複数の完全デー タ セ ッ ト の結果を結合で き ます。 こ れ ら の公式
は、 例 31 で使用 し ます。
モデルベースの代入
こ の例では、 因子分析モデルを使用 し て代入を実行 し ます。 モデルベー ス の代入には
2 つの利点があ り ます。 まず、 モデル内の任意の潜在的変数に値を代入で き る 点です。
2 番目の利点は、 モデルが的確で正の自由度を持っ てい る 場合、 モデルの共分散行列
と 平均値は飽和モデルのそれ よ り も 正確であ る と 推定 さ れ る こ と です ( 代入はモデル
の共分散行列 と 平均値に基づ き ます )。 ただ し 、 例 1 のモデルの よ う な飽和モデルは、
他に適切なモデルが存在 し ない場合に代入に使用で き ます。
Amos Graphics を使用 し た多重デー タ 代入の実行
こ の例では、例 17 の確認的因子分析モデルを使用 し てベ イ ジ ア ン法多重代入を実行 し
ま す。 使用す る デー タ セ ッ ト は、 フ ァ イ ル grant_x.sav に あ る Holzinger と Swineford
(1939 年 ) に よ る 不完全デー タ セ ッ ト です。 欠損値の代入は、 多重代入か ら 有用な結果
を得 る ための最初の手順に過ぎ ません。 最終的には、 次の 3 つの手順すべて を実行す
る 必要があ り ます。
手順 1 : Amos のデータ代入機能を使用し て、m 個の完全データ フ ァ イルを作成する 。
手順 2 : m 個の各完全デー タ フ ァ イ ルを個別に分析す る 。
こ の分析は自分で行い ます。 Amos で も 分析を行 う こ と はで き ますが、 通常は他の
プ ロ グ ラ ム を使用 し ます。 こ の例 と 次の例では、 SPSS Statistics を使用 し て回帰分
析を実行 し ます。 こ こ では、 1 つの変数 (Sentence) を使用 し て別の変数 ( 語彙力 )
を予測 し ます。 特に、 回帰の重み付け と その標準誤差の推定に重点を置 き ます。
手順 3 : m 個のデー タ フ ァ イ ルの分析結果を結合す る。
こ の例では、 最初の手順を行い ます。 手順 2 と 3 は、 例 31 で行い ます。
429
デー タ 代入
E 完全デー タ フ ァ イ ルを生成す る には、 Amos Graphics フ ァ イ ル Ex30.amw を開 き ます
E
メ ニ ュ ーか ら [ 分析 ] [ デー タ 代入 ] を選択 し ます。
[Amos デー タ 代入 ] ウ ィ ン ド ウ が表示 さ れます。
430
例 30
E [ ベ イ ジ ア ン法代入 ] が選択 さ れてい る こ と を確認 し ます。
E [ 完了デー タ セ ッ ト 数 ] を 「10」 に設定 し ます ( こ れに よ り m = 10 と 設定 さ れます )。
完全デー タ フ ァ イ ルは多数必要 と 思え る か も し れません。 し か し 、 ほ と ん ど のアプ リ
ケーシ ョ ンでは完全デー タ フ ァ イ ルは少 し し か必要あ り ません。 正確なパ ラ メ ー タ 推
定値 と 表示順誤差を得 る には、 通常、 5 つか ら 10 の完全デー タ フ ァ イ ルで十分です
(Rubin, 1987 年 )。 10 を超え る 代入を使用 し て も 問題はあ り ませんが、 手順 2 と 3 での
計算作業が増え て し ま い ます。
Amos では、 完全データセ ッ ト を積み重ね る こ と に よ り 、 単一の フ ァ イル ([ 単一出力
フ ァ イル ]) に完全データセ ッ ト を保存す る こ と も 、 個別の フ ァ イル ([ 多重出力フ ァ イル ])
に各完全デー タ セ ッ ト を保存す る こ と も で き ます。 単一グループの分析の場合、 [ 単一
出力 フ ァ イル ] を選択す る と 、 1 つの出力データ フ ァ イルが生成 さ れ、 [ 多重出力フ ァ イ
ル ] を選択す る と m 個の個別デー タ フ ァ イ ルが生成 さ れます。
複数グループの分析の場合、 [ 単一出力フ ァ イル ] を選択する と 、 分析グループご と に
1 つの出力フ ァ イ ルが生成 さ れ、 [ 多重出力フ ァ イル ] を選択す る と グループご と に m 個
の出力フ ァ イ ルが生成 さ れ ます。 た と えば、 グループが 4 つあ り 、 5 つの完全デー タ
セ ッ ト を要求 し た場合、 [ 単一出力フ ァ イル ] を選択する と 4 つの出力フ ァ イ ルが生成 さ
れ、 [ 多重出力 フ ァ イ ル ] を選択す る と 20 の出力フ ァ イ ルが生成 さ れ ます。 こ こ では
SPSS Statistics を使用 し て完全デー タ セ ッ ト を分析する ので、 最 も 簡単な方法を選択す
る のであれば [ 単一出力フ ァ イル ] と い う こ と にな り ます。 次に、手順 2 で SPSS Statistics
の分割フ ァ イ ル機能を使用 し て、 完全データ セ ッ ト を個別に分析 し ます。 ただ し 、 どの
回帰プ ロ グ ラ ム を使用 し て も こ の例を再現で き る よ う にする には、 次の よ う に し ます。
E [ 多重出力 フ ァ イル ] を選択 し ます。
代入データ は 2 つのフ ァ イル形式 ( テキス ト 形式 と SPSS Statistics 形式 ) で保存で き ます。
E [ フ ァ イル名 ] を ク リ ッ ク し 、 [ 名前を付けて保存 ] ダ イ ア ロ グ ボ ッ ク ス を表示 し ます。
431
デー タ 代入
E [ フ ァ イ ル名 ] ボ ッ ク ス で、 代入デー タ セ ッ ト の接頭辞名を指定で き ます。 こ こ では、
「Grant_Imp」 と 指定 し ます。
代入デー タ フ ァ イ ルには、 Grant_Imp1、 Grant_Imp2、 か ら 以降順番に Grant_Imp10 ま
で名前が付け ら れます。
E [ 名前を付けて保存 ] ボ ッ ク ス の一覧で、テ キ ス ト 形式 ([.txt]) ま たは IBM SPSS Statistics
デー タ フ ァ イ ル形式 ([.sav]) を選択 し ます。
E [ 保存 ] を ク リ ッ ク し ます。
E [ デー タ 代入 ] ウ ィ ン ド ウ の [ オプ シ ョ ン ] を ク リ ッ ク し 、使用可能な代入オプシ ョ ン を
表示 し ます。
こ れ ら のオプシ ョ ンについては、 オ ン ラ イ ン ヘルプを参照 し て く だ さ い。 オプシ ョ ン
の説明を表示す る には、 対象のオプシ ョ ン の上にマ ウ ス ポ イ ン タ を置いた状態で F1
キーを押 し ます。 下図では、 観測値の数を 10,000 ( デフ ォ ル ト ) か ら 30,000 に変更 し
てい ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ て、 [ デー タ 代入 ] ウ ィ ン ド ウ の [ 代入 ] を ク
リ ッ ク し ます。 し ば ら く す る と 、 次の メ ッ セージが表示 さ れます。
432
例 30
E [OK] を ク リ ッ ク し ます。
完全デー タ フ ァ イ ルの名前が一覧表示 さ れます。
各完全デー タ フ ァ イ ルには 73 の完全な ケース が含まれます。 最初の完全デー タ フ ァ
イ ル Grant_Imp1.sav の先頭の レ コ ー ド のい く つかを次に示 し ます。
433
デー タ 代入
下に示 し て あ る のは、2 番目の完全デー タ フ ァ イ ル Grant_Imp2.sav の同 じ ビ ュ ーです。
visperc ( 視覚認知力 ) の最初の 2 つのケース の値は、 元のデー タ フ ァ イ ルで も 観測 さ
れてい る ため、 代入デー タ フ ァ イ ル全体で同一です。 こ れに対 し て、 cubes ( 空間視覚
化力 ) の こ れ ら のケース の値は、元のデー タ フ ァ イ ル Grant_x.sav では欠損 し てい る た
め、 cubes ( 空間視覚化力 ) の こ れ ら 2 つのケース については、 代入デー タ フ ァ イ ル全
体で さ ま ざ ま な値が代入 さ れてい ます。
元の観測変数に加え、 代入デー タ フ ァ イ ルには 4 つの新 し い変数が追加 さ れてい ま
す。 spatial ( 視覚能力 ) と verbal ( 言語能力 ) は、代入 さ れた潜在的変数得点です。 Caseno
と imputeno は、 それぞれケース番号 と 完全デー タ セ ッ ト 番号です。
例
31
多重代入デー タ セ ッ ト の分析
概要
こ の例では、 多重代入デー タ セ ッ ト の分析について説明 し ます。
SPSS Statistics を使用 し た代入デー タ フ ァ イルの分析
例 30 では 10 個の完全デー タ セ ッ ト を作成 し ま し た。 こ れは、 3 段階のプ ロ セ ス の う
ち、 Amos のデー タ 代入機能を使用 し て、 m 個の完全デー タ セ ッ ト を補完す る と い う
最初の手順で し た ( こ こ では、 m = 10)。 残 り の 2 つの手順は次の と お り です。
手順 2 : m 個の各完全デー タ フ ァ イ ルを個別に分析す る 。
手順 3 : m 個のデー タ フ ァ イ ルの分析結果を結合す る。
手順 2 の分析は、 Amos、 SPSS Statistics、 ま たは他の任意のプ ロ グ ラ ム を使用 し て実
行で き ます。 手順 2 と 3 を自動化す る には、 完全デー タ セ ッ ト の分析に使用す る プ ロ
グ ラ ム を あ ら か じ め把握 し てお く 必要があ り ます。
具体的な問題を解決す る ために、 手順 2 と 3 では SPSS Statistics を使用 し て回帰分
析を実行 し 、 完全デー タ セ ッ ト を分析 し ます。 こ こ では、 1 つの変数 (Sentence) を使用
し て別の変数 (Wordmean) を予測 し ます。 特に、 回帰の重み付け と その標準誤差の推定
に重点を置 き ます。
435
436
例 31
手順 2 : 10 個の個別分析
例 30 で生成 し た 10 個の完全デー タ セ ッ ト のそれぞれについて、 回帰分析を実行す る
必要が あ り ま す。 こ の回帰分析では、 Sentence を 使用 し て Wordmean を 予測 し ま す。
まず、 最初の完全デー タ セ ッ ト であ る Grant_Imp1.sav を SPSS Statistics で開 き ます。
E SPSS Statistics メ ニ ュ ーか ら [ 分析 ] [ 回帰 ] [ 線型 ] を選択 し 、回帰分析を実行 し ます
( こ の手順の詳細については省略 し ます )。
結果は次の よ う にな り ます。
回帰 ウ ェ イ ト 付けの推定値 と (1.106) と 標準誤差の推定値 (0.160) に注目 し ます。 先ほ
ど実行 し た分析を、 他の 9 個の完全デー タ セ ッ ト について も 繰 り 返す と 、 回帰 ウ ェ イ
ト 付け と その標準誤差の推定値が 9 個ずつ得 ら れます。 次の表に、 計 10 個の推定値 と
標準誤差を示 し ます。
代入
1
2
3
4
5
6
7
8
9
10
ML 推定値
1.106
1.080
1.118
1.273
1.102
1.286
1.121
1.283
1.270
1.081
ML 標準誤差
0.160
0.160
0.151
0.155
0.154
0.152
0.139
0.140
0.156
0.157
437
多重代入デー タ セ ッ ト の分析
手順 3 : 多重代入デー タ フ ァ イルの結果の結合
1 つの完全デー タ セ ッ ト の分析か ら 得 ら れた標準誤差は、 欠損デー タ 値を代入 し た た
めに生 じ る 不確実性が考慮 さ れていないため正確 と は言え ません。 完全デー タ セ ッ ト
の個別分析か ら 推定値 と 標準誤差を収集 し 、 単一の要約値 ( パ ラ メ ー タ 推定値の要約
値お よ びパ ラ メ ー タ 推定値の標準誤差の要約値 ) に結合す る 必要があ り ます。 こ れを
実行す る ための公式 (Rubin, 1987 年 ) は さ ま ざ ま な文献に記載 さ れてい ます。 下記の公
式の出典は、 Schafer の論文 (1997 年、 109 ページ ) です。 こ のセ ク シ ョ ンの以下の部
分では、 こ れ ら の公式を、 上記の 10 個の推定値 と 標準誤差の表に適用 し ます。 以下に
おいて、
m を、 完全デー タ セ ッ ト の数 と し ます ( こ のケース では、 m = 10)。
Q̂
t
を標本 t の推定値 と し ます。し たがって、 Q̂
1
= 1.106、 Q̂
2
= 1.080、など と な り ます。
U t を 標 本 t の 標 準 誤 差 の 推 定 値 と し ま す。 し た が っ て、 U 1
U 2 = 0.160、 な ど と な り ます。
= 0.160、
回帰 ウ ェ イ ト 付けの多重代入推定値は、次の よ う に 10 個の完全デー タ セ ッ ト か ら 得 ら
れ る 10 個の推定値の平均に過ぎ ません。
1 m ˆ t
Q Q 1.172
m t 1
結合 さ れたパ ラ メ ー タ 推定値の標準誤差を得 る には、 次の手順を実行 し ます。
E 代入内分散の平均を計算 し ます。
m
1
U = --- U t = 0.0233
mt = 1
E 代入間分散を計算 し ます。
1
B = -----------m–1
m
Q̂
t
2
– Q = 0.0085
t=1
E 全分散を計算 し ます。
1
T = U + 1 + 1--- B = 0.0233 + 1 + ----- 0.0085 = 0.0326
m
10
複数グループの標準誤差は、 次の よ う にな り ます。
T =
0.0326 = 0.1807
438
例 31
母集団において回帰 ウ ェ イ ト 付けが 0 にな る と い う 帰無仮説の検定は、 統計量
1.172
Q
------- = ------------------ = 6.49
0.1807
T
に基づ き ます。 回帰 ウ ェ イ ト 付けが 0 の場合、 こ の統計量は、 次の式に よ っ て得 ら れ
る 自由度を持つ t 分布を持ち ます。
2
0.0233
U - = 10 – 1 1 + -------------------------------------v = m – 1 1 + -------------------1
1 + --1- B
1 + ----- 0.0085
m
10
2
= 109
Joseph Schafer の NORM プ ロ グ ラ ムで、 こ れ ら の計算を行 う こ と がで き ます。 NORM
は、 http://www.stat.psu.edu/~jls/misoftwa.html#win か ら ダ ウ ン ロ ー ド で き ます。
参考文献
Amos には、 FIML ( 例 17 を参照 )、 多重代入、 ベ イ ズ推定な ど、 欠損デー タ を処理す
る 高度な メ ソ ッ ド がい く つか用意 さ れてい ま す。 各 メ ソ ッ ド の詳細を 確認す る 場合、
FIML お よ び多重代入の概要については Schafer と Graham (2002 年 ) の論文を参照 し て
く だ さ い。 Allison は FIML と 多重代入の両方を扱っ た簡潔でわか り やすいモ ノ グ ラ フ
(Allison, 2002 年 ) を発表 し てい ます。 こ の論文には、 数多 く の機能例 と 、 多変量正規
性を想定 し た多重代入法の文脈内で非正規変数お よ びカ テ ゴ リ 変数を処理す る 方法に
関す る 優れた論考が示 さ れてい ます。 Schafer (1997 年 ) は、多重代入について詳細かつ
技術的に論 じ てい ま す。 Schafer と Olsen (1998 年 ) は、 多重代入を実行す る ための、
わか り やす く 段階的なガ イ ド を発表 し てい ます。
構造方程式モデルにおけ る FIML と 多重代入の統計パ フ ォ ーマ ン ス を 比較 し た、
SEM 固有の研究 も 入手可能です (Olinsky, Chen, お よ び Harlow, 2003 年 )。 最後に、 例
例 26 か ら 例 29 で説明 し たベ イ ズ推定アプ ロ ーチが、 欠損デー タ の処理方法において
FIML に似てい る 点に注目 し てお く 必要があ り ます。 Ibrahim ら は、最近、不完全なデー
タ の問題に対処す る ための、 FIML、 ベ イ ズ推定、 確率の重み付け、 お よ び多重代入の
各アプ ロ ーチのパフ ォーマ ン ス を比較 し 、欠損値が ラ ン ダ ム な欠損 (MAR) プ ロ セ ス か
ら 生 じ る 、 不完全なデー タ の問題 を 処理す る う え で、 こ れ ら 4 つの ア プ ロ ーチのパ
フ ォ ー マ ン ス が おおむね同様 に 良好 で あ っ た と 結論付 け て い ま す (Ibrahim, Chen,
Lipsitz, お よ び Herring, 2005 年 )。 彼 ら の報告では SEM ではな く 一般線型モデルが検討
さ れてい ますが、 彼 ら の調査結果 と 結論は、 一般に、 SEM を含む広範な統計モデル と
デー タ 分析シナ リ オに も 適用で き ます。
例
32
打ち切 り デー タ
概要
こ こ では、 打ち切 り デー タ を使用 し たパ ラ メ ー タ の推定、 事後予測分布の推定、 お よ
びデー タ 代入について説明 し ます。
デー タ について
こ の例では、 1967 年か ら 1974 年の間に ス タ ン フ ォ ー ド 心臓移植プ ロ グ ラ ムに登録 さ
れた 103 人の患者か ら 得た打ち切 り デー タ を使用 し ます。 こ のデー タ は Crowley お よ
び Hu に よ っ て収集 さ れた も ので (1977 年 )、 Kalbfleisch お よ び Prentice な ど が再分析
を行っ てい ます (2002 年 )。 こ のデー タ セ ッ ト は transplant-a.sav フ ァ イ ルに保存 さ れて
い ます。
439
440
例 32
上の図で 1 番上に表示 さ れてい る 行を左か ら 順に説明 し ます。 患者 17 は 1968 年にプ
ロ グ ラ ムに登録 さ れ、 当時の年齢は 20.33 才で し た。 こ の患者は 35 日後に死亡 し ま し
た。 次の数字 5.916 は、 35 の平方根です。 Amos では、 打ち切 り 変数を正規分布 と 仮定
し ます。 こ の例では、 生存期間の平方根の分布は生存期間自体の分布 よ り も 正規分布
に近 く な る と い う 前提の下に、 生存期間の平方根を使用 し ます。 [ 非打ち切 り ] は、 患
者の生存期間がわか っ てい る こ と を表 し ます。 言い換えれば、 患者がすでに死亡 し て
いた と い う こ と です。 こ の こ と か ら 、 こ の患者はプ ロ グ ラ ムに登録 さ れた後 35 日間生
存 し た と い う こ と がで き ます。
一部の患者は、 最後の観察時 も 生存 し てい ま し た。 た と えば、 患者 25 は、 1969 年、
33.22 才の と き にプ ロ グ ラ ムに登録 さ れま し た。 こ の患者を最後に観察 し たのは 1,799
日後です。 42.415 は 1,799 の平方根です。 [ ス テー タ ス ] 列の [ 打ち切 り ] は、 こ の患者
がプ ロ グ ラ ムに登録 さ れてか ら 1,799 日後に生存 し ていた こ と 、 かつ、 その日が こ の
患者を最後に観察 し た と き であ る こ と を意味 し ます。 そのため、 こ の患者の生存期間
が 1,799 日間であ る と はいえ ません。 実際、 こ の患者は さ ら に長生 き を し ま し たが、 そ
の期間はわか り ません。 こ の よ う な ケース は他に も あ り ます。 患者番号 26 を最後に観
察 し たのはプ ロ グ ラ ムへの登録後 1,400 日後の こ と で、 当時 も ま だ生存 し てい ま し た。
し たが っ て、 こ の患者が少な く と も 1,400 日間は生存 し た こ と がわか り ます。
患者 25 の生存期間 1,799 日な ど、 打ち切 り 値はど の よ う に扱えば良いで し ょ う か。
1,799 お よ び他の打ち切 り 値をすべて破棄す る と 、長期間生存 し た患者のデー タ を破棄
す る こ と にな る ため、 値を破棄す る こ と はで き ません。 他方、 こ の患者は 1,799 日 よ り
も 長 く 生存 し ていた こ と がわかっ てい る ので、1,799 の ま ま通常の ス コ ア と 同様に処理
す る こ と も で き ません。
Amos では、 「患者 25 が 1,799 日 よ り も 長 く 生存 し た」 と い う 情報を使用で き ます。
こ の情報を破棄 し た り 、 こ の患者の生存期間が正確にわか っ てい る と 仮定 し た り す る
必要はあ り ません。 も ち ろん、 生存期間が 218 日間だ っ た こ と がわかっ てい る 患者 24
の よ う に、 正確な数値があ る デー タ については、 その数値が使用 さ れます。
441
打ち切 り デー タ
デー タ の再 コ ー ド 化
デー タ フ ァ イ ルは、 Amos で読み込みを実行す る 前に再 コ ー ド 化す る 必要があ り ます。
次の図は、再 コ ー ド 化 し た後のデー タ セ ッ ト の一部を示 し てい ます ( 完全なデー タ セ ッ
ト は transplant-a.sav フ ァ イ ルにあ り ます )。
観測値が非打ち切 り のデー タ は、新 し いデー タ フ ァ イ ルで も 元のデー タ フ ァ イ ル と 同
じ 様に表示 さ れてい ます。 し か し 、打ち切 り 値は、元のデー タ フ ァ イ ル と は異な る コ ー
ド 化処理が行われてい ます。 た と えば、患者 25 の生存期間 (1,799 日 よ り も 長い と し か
わか っ ていない ) は、 新 し いデー タ フ ァ イ ルでは [> 1799] と コ ー ド 化 さ れてい ま す
([> 1799] の よ う な文字列中の スペース は省略可能です )。 ま た、 生存期間の平方根は
42.415 よ り も 大 き い こ と がわか っ てい る ため、こ のデー タ フ ァ イ ルでは患者 25 の [ 経
過平方根 ] 列に [> 42.415] と 表示 さ れてい ます。 数値変数 と 文字列変数を区別す る デー
タ フ ァ イ ル形式 (SPSS Statistics 形式な ど ) のために、 経過日数 と 経過平方根は文字列
変数 と し て コ ー ド 化す る 必要があ り ます。
442
例 32
デー タ の分析
次の手順に従っ て、 Amos Graphics でデー タ フ ァ イ ルを指定 し ます。
E
メ ニ ュ ーか ら 、 [ フ ァ イル ]、 [ デー タ フ ァ イル ] の順に ク リ ッ ク し ます。
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で、 [ フ ァ イル名 ] ボ タ ン を ク リ ッ ク し ます。
E デー タ フ ァ イ ル transplant-a.sav を選択 し ます。
E [ 数値でないデー タ を許可する ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
前述 し たデー タ の再 コ ー ド 化、 お よ び [ 数値で な いデー タ を 許可す る ] の有効化は、
打ち切 り デー タ を分析す る 場合に限 り 必要 と な る 手順です。 こ の 2 点を除けば、 打ち
切 り デー タ を使用 し たモデルの適用 と 結果の解釈の方法は、 デー タ がすべて数値デー
タ の場合 と ま っ た く 変わ り ません。
回帰分析の実行
それでは、 年齢お よ び登録年度 ( 開始年 ) を予測変数 と し て、 経過平方根を予測 し てみ
ま し ょ う 。 まず、 次の よ う なパ ス図を描 き ます。
443
打ち切 り デー タ
次のいずれかの方法でモデルを適用 し ます。
E ツールバーの
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 分析 ]、 [ ベ イ ズ推定 ] の順に選択 し ます。
注 : 非数値デー タ を使用す る 場合はベ イ ズ推定 し か実行で き ないため、
無効化 さ れてい ます。
のボ タ ンは
[ ベ イ ズ SEM] ウ ィ ン ド ウ が開いた ら 、不機嫌な顔
が上機嫌の顔
に変わ る ま で
待ち ます。 [ ベ イ ズ SEM] ウ ィ ン ド ウ に、 次の よ う な推定値の表が表示 さ れます。
こ の図は表の一部です。 [ 平均値 ] 列には、 パ ラ メ ー タ のポ イ ン ト 推定値が表示 さ れて
い ます。 開始年を使用 し て経過平方根を予測す る 係数は 1.45 です。 つま り 、 登録年度
が 1 年あ と だ と 、生存期間の平方根の値が 1.45 増加す る と 予測で き ます。 こ の予測は、
調査期間中に移植プ ロ グ ラ ム が改善 し てい っ た可能性が あ る こ と を示唆 し てい ま す。
年齢を使用 し て経過平方根を予測す る 係数は -0.29 です。 つ ま り 、 移植プ ロ グ ラ ム登
録時の患者の年齢が 1 才上が る ご と に、生存期間の平方根の値が 0.29 ずつ減少す る と
予測で き ます。 -0.29 と い う 係数推定値は、 実際は係数の事後分布の平均値です。
E 事後分布全体を確認す る には、 推定値 -0.29 を含む行を右 ク リ ッ ク し て、 ポ ッ プア ッ
プ メ ニ ュ ーか ら [ 事後分布の表示 ] を選択 し ます。
444
例 32
[ 事後分布 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れ、 係数の事後分布が表示 さ れます。
係数の事後分布は確かに -0.29 付近が最 も 高 く な っ てい ます。 -0.75 ~ 0.25 の範囲にほ
と ん どすべてが分布 し てい る ので、こ の範囲内に係数があ る と 考え て問題あ り ません。
さ ら に分布の大部分が -0.5 ~ 0 の範囲にあ る こ と か ら 、 係数は -0.5 ~ 0 の間だ と ほぼ
確定で き ます。
445
打ち切 り デー タ
事後予測分布
こ のデー タ セ ッ ト には、 患者 25 の生存期間の よ う な打ち切 り 値が含まれてい ま し た。
患者 25 の生存期間についてわか っ てい る のは、 1,799 日 よ り も 長い こ と 、 し たが っ て
生存期間の平方根は 42.415 よ り も 大 き い と い う こ と です。 こ の患者の経過平方根が
42.415 よ り どれだけ大 き いかはわか り ませんが、 その事後分布を求め る こ と はで き ま
す。 経過平方根が 42.415 を超え る こ と を考慮 し 、 モデルが正確だ と い う 前提で、 患者
25 の年齢 と 開始年か ら 生存期間について ど の よ う な こ と がわか る で し ょ う か。 こ れを
確かめ る には、 次の操作を行い ます。
E [ 事後予測分布 ] ボ タ ン
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 表示 ]、 [ 事後予測分布 ] の順に選択 し ます。
[ 事後予測分布 ] ウ ィ ン ド ウ に表が表示 さ れます。 こ の表では、 行が各患者に対応 し て
お り 、列がモデルの観測変数に対応 し てい ます。 25 行目を見 る と 、患者 25 の年齢 と 開
始年の ス コ アがわか り ます。 患者 25 の経過平方根には、 << と い う 記号が表示 さ れて
い ます。 こ れは、 こ のデー タ では経過平方根の ス コ アに不等式制約が適用 さ れていて
実際の数値ではない と い う こ と を表 し てい ます。
446
例 32
患者 25 の経過平方根の事後分布を表示す る には、 次の よ う に し ます。
E [<<] を ク リ ッ ク し ます。 [ 事後分布 ] ウ ィ ン ド ウ に事後分布が表示 さ れます。
患者 25 の経過平方根の事後分布は、 完全に 42.415 の右側に分布 し てい ます。 デー タ
だけ見て も 経過平方根が 42.415 を超え てい る こ と は明 ら かで し たが、 こ の分布か ら
は、 患者 25 の経過平方根が 70 を超え る 可能性がほ と ん ど ない と わか り ます。 さ ら に、
経過平方根が 55 を超え る 確率が非常に低い こ と も わか り ます。
447
打ち切 り デー タ
患者 25 の事後予測分布 と は分布の形状が異な る 場合について見てみま し ょ う 。
E 事後予測分布表の 100 行目の [<<] の記号を ク リ ッ ク し ます。
患者 100 が最後に観察 さ れたのはプ ロ グ ラ ム に登録 さ れてか ら 38 日後で、 こ の時点
で ま だ生存 し てい ま し た。 つま り 、 経過平方根は 6.164 以上であ る こ と がわか っ てい
ます。 患者の経過平方根の事後分布をみ る と 、 6.164 ~ 70 の範囲であ る と 考え て良い
し 、さ ら には 6.164 ~ 50 の範囲内であ る 確率が高い こ と がわか り ます。 平均値は 27.36
で、 経過平方根のポ イ ン ト 推定値 と な り ます。 27.36 を 2 乗 し た値 748 が、 患者 100 の
生存期間 ( 日数 ) の推定値 と な り ます。
448
例 32
代入
こ のモデルを使用 し て、 打ち切 り 値に値を代入す る こ と がで き ます。
E [ ベ イ ズ SEM] ウ ィ ン ド ウ が開いてい る 場合は こ れを閉 じ ます。
E Amos Graphics メ ニ ュ ーか ら 、 [ 分析 ]、 [ デー タ 代入 ] の順に選択 し ます。
[ 回帰法代入 ] と [ 確率的回帰法代入 ] は選択で き ない状態にな っ てい る はずです。 打ち
切 り デー タ の よ う な非数値デー タ を使用 し てい る 場合は、 [ ベ イ ズ法代入 ] し か選択で
き ません。
上の図に表示 さ れてい る 設定に従い、 10 個の完全デー タ セ ッ ト を作成 し てそのすべ
て を transplant-b_C.sav と い う 1 つの SPSS Statistics デー タ フ ァ イ ルに保存 し ます。 代
入を開始す る 手順は次の と お り です。
449
打ち切 り デー タ
E [ 代入 ] ボ タ ン を ク リ ッ ク し ます。
[ ベ イ ズ SEM] ウ ィ ン ド ウ と と も に [ デー タ 代入 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E [ デー タ 代入 ] ダ イ ア ロ グ ボ ッ ク ス に上機嫌の顔
(10 個の各完全デー タ セ ッ ト の間
に実質的な相関がない こ と を示す ) が表示 さ れ る ま で待ち ます。
注 : 上機嫌の顔が表示 さ れた後 [OK] を ク リ ッ ク す る前に、[ ベ イ ズ SEM] ウ ィ ン ド ウ内
の任意のパ ラ メ ー タ を右 ク リ ッ ク し て、 ポ ッ プア ッ プ メ ニ ューか ら [ 事後分布の表示 ]
を選択す る こ と も で き ます。 こ れに よ り 、 ト レース図や自己相関図を確認で き ます。
E [ デー タ 代入 ] ダ イ ア ロ グ ボ ッ ク ス で、 [OK] を ク リ ッ ク し ます。
[ 要約 ] ウ ィ ン ド ウ に、 作成 さ れた完全デー タ フ ァ イ ルの一覧が表示 さ れます。 こ こ で
は、 作成 さ れた完全デー タ フ ァ イ ルは 1 つだけです。
450
例 32
E フ ァ イ ル名を ダブル ク リ ッ ク し て、 単一の完全デー タ フ ァ イ ルの内容を表示 し ます。
こ の フ ァ イ ルには 10 個の完全デー タ セ ッ ト が含まれてい ます。
10 個あ る 完全デー タ セ ッ ト のそれぞれには 103 のケース が含まれてい ます。 し たがっ
て、 フ ァ イ ルに含まれ る ケー ス数は 1,030 です。 新 し いデー タ フ ァ イ ルの最初の 103
行は、 1 番目の完全デー タ セ ッ ト に対応 し ます。 1 番目の完全デー タ セ ッ ト の各行の
imputeno 変数は 1、 caseno 変数はそれぞれ 1 ~ 103 と な っ てい ます。
完全デー タ フ ァ イ ルの最初の行の経過平方根の値は 7 です。 こ の値は打ち切 り 値では
ないので、 7 は代入値ではあ り ません。 こ の値は、 元のデー タ フ ァ イ ルに含まれてい
た通常の数値です。 一方、 患者 25 の経過平方根は打ち切 り 値だ っ たため、 こ の患者の
経過平方根の値 ( こ の例では 49.66) は代入値です。 49.66 と い う 値は、 446 ページ の図
にあ る 事後予測分布か ら 無作為に抽出 さ れた値です。
451
打ち切 り デー タ
通常、 こ の後に行 う 手順では、 打ち切 り デー タ を適用で き ない他のプ ロ グ ラ ムへの
入力用に、 transplant-b_C.sav 内の 10 個の完全デー タ セ ッ ト を使用 し ます。 こ の場合、
そのプ ロ グ ラ ムでは、 10 個の完全デー タ セ ッ ト を 1 つずつ順番に使っ て 10 回の分析
を個別に実行す る こ と にな り ます。 その後、 例 31 で行っ た よ う に、 さ ら に計算を実行
し 10 回分の分析結果を 1 つの結果セ ッ ト に ま と め ます。 こ の例では、 こ れ ら の手順は
実行 し ません。
デー タ 値に対する一般的な不等式制約
こ の例では、 > 1799 の よ う な不等式制約だけ取 り 上げ ま し た。 他に も 不等式制約を示
す文字列値があ り 、 次の よ う な も のが、 元の数値変数の値に対す る 不等式制約を示す
文字列値 と し てデー タ フ ァ イ ルで使用で き ます。
文字列値 <5 は、 元にな る 数値が 5 未満であ る こ と を表 し ます。
文字列値 4<<5 は、 元にな る 数値が 4 ~ 5 の範囲内にあ る こ と を表 し ます。
例
33
順序 - カ テ ゴ リ カル デー タ
概要
こ の例では、 因子分析モデルを順序 - カ テ ゴ リ カル デー タ に適合 さ せ る方法について
説明 し ま す。 ま た、 カ テ ゴ リ 化 さ れた回答の基礎 と な る 数値変数の事後予測分布を求
め る 方法や、 カ テ ゴ リ 化 さ れた回答に数値を代入す る 方法について も 説明 し ます。
デー タ について
こ の例では、 オ ラ ン ダ国内で 1,017 人を対象に行っ た環境問題に関す る 意識ア ン ケー
ト 調査の回答をデー タ と し て使用 し ます。 こ のデー タ は、 European Values Study Group
が ま と め た も の で す ( 参 考 文 献 の 一 覧 を 参 照 し て く だ さ い )。 デ ー タ フ ァ イ ル
environment-nl-string.sav には、6 つの質問項目に対す る それぞれの回答が保存 さ れてい
ます。 回答は、 「強 く 同意で き ない」 (SD)、 「同意で き ない」 (D)、 「同意す る 」 (A)、 「強
く 同意す る 」 (SA) のいずれかのカ テ ゴ リ か ら 選択 さ れた も のです。
453
454
例 33
こ れ ら のデー タ を分析す る 手段 と し て、 4 つにカ テ ゴ リ 化 さ れた回答のそれぞれに数
値を割 り 当て る こ と がで き ます (1 = SD、 2 = D、 3 = A、 4 = SA な ど )。 こ の方法で各
カ テ ゴ リ に数値を割 り 当て る と 、 environment-nl-numeric.sav のデー タ セ ッ ト を取得で
き ます。
Amos の分析では、 上記の よ う な、 カ テ ゴ リ に数値を割 り 当て る 方法を使用 し な く て
も 、分析は実行で き ます。 4 つにカ テ ゴ リ 化 さ れた回答の順序だけ を扱 う こ と も で き ま
す。 デ ー タ の 順 序 だ け を 扱 う 場 合 は、 environment-nl-string.sav と environment-nlnumeric.sav の ど ち ら のデー タ セ ッ ト を使用 し て も か ま い ません。
environment-nl-numeric.sav は比較的簡単に使用で き ます。 こ のデー タ セ ッ ト を使用
す る と 、 Amos では、 数値のカ テ ゴ リ に対 し て、 順位の低い方か ら 1、 2、 3、 4 の順に
デフ ォ ル ト で番号が割 り 当て ら れ る ためです。 こ の場合は、正 し い順序 と な り ます。 こ
れに対 し environment-nl-string.sav を使用 し た場合、 Amos では、 カ テ ゴ リ がアルフ ァ
ベ ッ ト の昇順 (A、 D、 SA、 SD) にデフ ォ ル ト で順序付け さ れます。 こ の場合、 順序は
正 し く あ り ません。 し たが っ て、 Amos におけ る デフ ォ ル ト の カ テ ゴ リ 順序を変更す
る 必要があ り ます。
こ の例では、 デー タ フ ァ イ ル environment-nl-string.sav を使用 し ます。 こ れは、 デー
タ の順序だけ を扱 う と い う こ と を明瞭化す る だけでな く 、 カ テ ゴ リ の正 し い順序の指
定方法について も 説明す る ためです。
455
順序 - カ テ ゴ リ カル デー タ
デー タ フ ァ イルの指定
E Amos Graphics メ ニ ュ ーか ら 、 [ フ ァ イル ]、 [ デー タ フ ァ イル ] の順に ク リ ッ ク し ます。
E [ デー タ フ ァ イ ル ] ウ ィ ン ド ウ で、 [ フ ァ イル名 ] ボ タ ン を ク リ ッ ク し ます。
E デー タ フ ァ イ ル environment-nl-string.sav を選択 し ます。
E [ 数値でないデー タ を許可する ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
E [OK] を ク リ ッ ク し ます。
456
例 33
Amos 内でのデー タ の再 コ ー ド 化
デー タ の順序は、 デー タ フ ァ イ ルだ け か ら 特定す る こ と はで き ま せん。 デー タ の値
(SD、 D、 A、 お よ び SA) の解釈に必要な補足情報を Amos に対 し て指定す る 手順は次
の と お り です。
E Amos Graphics メ ニ ュ ーか ら 、 [ ツール ]、 [ デー タ の再コ ー ド 化 ] の順に選択 し ます。
E [ データ の再 コ ー ド 化 ] ウ ィ ン ド ウ の左上にあ る変数 リ ス ト か ら [item 1] を選択 し ます。
こ れに よ り 、 [item 1] に対す る 回答の度数分布が ウ ィ ン ド ウ の下部に表示 さ れます。
[ 再 コ ー ド 化ルール ] ボ ッ ク ス で [ 再 コ ー ド 化な し ] を選択す る と 、 [item 1] に対す る 回
答がその ま ま の形で Amos に読み込まれ ます。 つま り 、 SD、 D、 A、 SA、 空の文字列
のいずれかが読み込まれます。 し か し Amos は、SD や D な ど を その ま ま処理す る こ と
がで き ないため、 なん ら かの対処が必要 と な り ます。
457
順序 - カ テ ゴ リ カル デー タ
E [ 再 コ ー ド 化な し ] を ク リ ッ ク し 、ド ロ ッ プダ ウ ン リ ス ト か ら [ 順序 - カ テ ゴ リ カル ] を選
択 し ます。
458
例 33
ウ ィ ン ド ウ 下部の度数表には [ 新 し い値 ] 列が作成 さ れ、 デー タ フ ァ イ ル内の [item 1]
の値が、 Amos に読み込まれ る 前に ど の よ う に再 コ ー ド 化 さ れ る のかが表示 さ れます。
度数表の先頭行に表示 さ れ る 内容は、 元のデー タ フ ァ イ ル内に含まれ る 空の文字列が
欠損 値 と し て 処 理 さ れ る こ と を 表 し て い ま す。 ま た 2 行目 の 内容 は、 回答 A が
<0.0783345405060296 と い う 文字列に変換 さ れ る こ と を 表 し てい ま す。 Amos では こ
れを基に、 [item 1] に対す る 回答が連続型数値変数に よ っ て表 さ れ、 かつ A と 回答 し
た回答者の ス コ アは、基礎 と な る 変数上では 0.0783345405060296 未満にな る と 判断 し
ます。 同様に 3 行目の内容は、 回答 D が 0.0783345405060296<<0.442569286522029 と
い う 文字列に変換 さ れ る こ と を表 し てお り 、 Amos では、 基礎 と な る 変数上の ス コ ア
が 0.0783345405060296 と 0.442569286522029 の間の値にな る と 判断 し ます。
0.0783345405060296 や 0.442569286522029 な ど の数値は、 回答の基礎 と な る 数値変数
上の ス コアが、 平均値 0、 標準偏差 1 の正規分布に従っ てい る と の仮定の下に、 [ 度数 ]
列の度数か ら 求め ら れます。
[ 元の値 ] 列のカ テ ゴ リ の順序は変更す る 必要があ り ます。 順序を変更す る 手順は次
の と お り です。
459
順序 - カ テ ゴ リ カル デー タ
E [ 詳細 ] ボ タ ン を ク リ ッ ク し ます。[ 順序 - カ テ ゴ リ カルの詳細 ] ダ イ ア ロ グ ボ ッ ク ス が表
示 さ れます。
[ 順序カ テ ゴ リ ] リ ス ト ボ ッ ク ス には、 4 つの回答カ テ ゴ リ がそれぞれ点線 (<---->)
をは さ んで、 A、 D、 SA、 SD の順に表示 さ れます。 こ の 3 つの点線は、 実数を、 回答
カ テ ゴ リ に関連す る 4 つの区間に分け る 際の境界を表 し ます。 観測 さ れない数値変数
について、 最 も 小 さ い境界値を下回 る ス コ ア を持つ回答者は、 回答が A であ る と 見な
さ れ ます。 最 も 小 さ い境界値 と 中央の境界値 と の間に ス コ ア を持つ回答者は、 回答が
D であ る と 見な さ れ ます。 中央の境界値 と 最 も 大 き い境界値の間に ス コ ア を持つ回答
者は、回答が SA であ る と 見な さ れます。 最 も 大 き い境界値を上回 る ス コ ア を持つ回答
者は、 回答が SD であ る と 見な さ れます。
プ ロ グ ラ ム側の処理は、 カ テ ゴ リ ( 区間 ) が 4 つ と 境界が 3 つ存在す る こ と につい
ては正 し く 行われてい ますが、 カ テ ゴ リ の順序については正 し く あ り ません。 プ ロ グ
ラ ム の処理では、 カ テ ゴ リ がアル フ ァ ベ ッ ト 順に並べ ら れてい ます。 そのため、 こ れ
ら 4 つのカ テ ゴ リ と 3 つの境界はその ま ま維持 し て、 順序だけ を変更す る 必要があ り
ます。 こ こ では、 SD を先頭の区間 ( 最 も 小 さ い境界値を上限 と す る 区間 ) に移動す る
な ど、 順序の入れ替え を い く つか行い ます。
460
例 33
カ テ ゴ リ と 境界の順序は、 変更す る こ と がで き ます。 手順は次の と お り です。
E マ ウ ス を使っ て カ テ ゴ リ ま たは境界を直接 ド ラ ッ グ ア ン ド ド ロ ッ プす る 。
ま たは
E マ ウ ス を使っ て カ テ ゴ リ ま たは境界を選択 し 、 [ 上へ ] ボ タ ンや [ 下へ ] ボ タ ン を ク リ ッ
クする。
次に示すのは、 カ テ ゴ リ お よ び境界を正 し い順序に並べ終わ っ た時点での、 [ 順序 カ テ ゴ リ カルの詳細 ] ダ イ ア ロ グ ボ ッ ク ス の表示内容です。
[ 順序な し カ テ ゴ リ ] リ ス ト ボ ッ ク ス には、 Amos に よ り 欠損値 と し て処理 さ れ る 値の
リ ス ト が表示 さ れます。 こ こ では、 ただ 1 つのエ ン ト リ [ 空の文字列 ] が表示 さ れてい
ます。 空の文字列は、 Amos に よ り 欠損値 と し て処理 さ れます。 空の文字列 と し て コ ー
ド 化 さ れた回答が、 実際には SD、 D、 A、 ま たは SA に対応す る 意味のあ る 回答であ
る 場合には、 [ 順序な し カ テ ゴ リ ] リ ス ト ボ ッ ク ス の [ 空の文字列 ] を選択 し 、 [ 下へ ]
ボ タ ン を ク リ ッ ク し て、 [ 空の文字列 ] を [ 順序カ テ ゴ リ ] リ ス ト ボ ッ ク ス に移動で き
ます。
同様に、 [ 順序カ テ ゴ リ ] リ ス ト ボ ッ ク ス内の回答 ( た と えば SD) が、 他の回答 と 比
較 し た と き に意味のない回答であ る場合には、 マ ウ ス で [SD] を選択 し [ 上へ ] ボ タ ン
を ク リ ッ ク す る と 、 [ 順序な し カ テ ゴ リ ] リ ス ト ボ ッ ク ス に移動で き ます。 こ の場合、
SD は欠損値 と し て処理 さ れます。
注 : [ 順序カ テ ゴ リ ] リ ス ト ボ ッ ク ス と [ 順序な し カ テ ゴ リ ] リ ス ト ボ ッ ク ス と の間で
エン ト リ を移動す る 場合は、ド ラ ッ グ ア ン ド ド ロ ッ プ操作を使用す る こ と はで き ませ
ん。 2 つの リ ス ト ボ ッ ク ス間でカ テ ゴ リ を移動す る には、 [ 上へ ] ボ タ ン ま たは [ 下へ ]
ボ タ ン を使用 し ます。
461
順序 - カ テ ゴ リ カル デー タ
すでに適切な数の境界 と カ テ ゴ リ が設定 さ れ、 カ テ ゴ リ が正 し い順序に並べ ら れてい
る ため、 こ の時点で [ 順序 - カ テ ゴ リ カルの詳細 ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ 、 作業を
終了 し て も か ま い ません。 し か し こ こ では、Croon (2002) の提言に従っ て さ ら に変更を
加え ます。 Croon は こ のデー タ セ ッ ト を実際に使用 し た上で、 SD カ テ ゴ リ は出現の
頻度が非常に低いため、D カ テ ゴ リ と ひ と ま と めにす る べ き であ る と 提言 し てい ます。
こ れ ら 2 つのカ テ ゴ リ を 1 つのカ テ ゴ リ に ま と め る ための手順は次の と お り です。
E ま と め ら れ る 2 つのカ テ ゴ リ の境界を選択 し ます。
E [ 境界を削除 ] ボ タ ン を ク リ ッ ク し ます。 [ 順序カ テ ゴ リ ] リ ス ト の表示内容は次の よ う
にな り ます。
こ れで、 回答 SD と D は区別で き な く な り ます。 ど ち ら の回答を し た回答者 も 、 基礎
と な る 数値変数上の ス コ アは、 先頭の区間に属す る ス コ アにな り ます。
3 つあ る 各区間を隔て てい る 2 つの境界には、 ま だ値が設定 さ れてい ません。 境界
に値を指定 し ない場合は、 基礎 と な る 数値変数上の ス コ アが、 平均値 0 お よ び標準偏
差 1 の正規分布に従っ てい る と の仮定に基づいて、 Amos で境界値が推定 さ れ ま す。
Amos で推定を実行 し ない場合は、値を境界に直接割 り 当て る こ と がで き ます。 値を割
り 当て る 手順は次の と お り です。
E マ ウ ス で境界を選択 し ます。
E テ キ ス ト ボ ッ ク ス に数値を入力 し ます。
462
例 33
次の図は、2 つの境界にそれぞれ 0 およ び 1 の値が割 り 当て ら れた状態を示 し てい ます。
順序が先の境界の値 よ り 順序が後の境界の値の方が大 き い と い う 条件が満た さ れてい
る 限 り 、 こ の 2 つの境界には 0 と 1 でな く と も 任意の 1 組の数値を割 り 当て る こ と が
で き ます。 境界の数がい く つであ っ て も ( ただ し 2 つ以上 )、 その う ちの 2 つの境界に
値を割 り 当て る こ と に よ り 、 基礎 と な る 数値変数に対 し て 0 と な る 点お よ び測定単位
を選択す る こ と にな り ます。 基礎 と な る 数値変数の尺度設定については、 ヘルプ フ ァ
イ ルの ト ピ ッ ク 「Choosing boundaries when there are three categories」 で さ ら に詳 し く
説明 し ます。
E [OK] を ク リ ッ ク し て [ 順序 - カ テ ゴ リ カルの詳細 ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
463
順序 - カ テ ゴ リ カル デー タ
こ の時点で、 カ テ ゴ リ お よ び区間の境界に対す る 変更内容が、 [ デー タ の再 コ ー ド 化 ]
ウ ィ ン ド ウ の度数表に反映 さ れます。
度数表には、 Amos に読み込まれ る 前に行われ る デー タ フ ァ イ ルの値の再 コ ー ド 化方
法が表示 さ れます。 度数表を上か ら 順に説明 し ます。
空の文字列は欠損値 と し て処理 さ れます。
文字列 SD と D は <0 と し て再 コ ー ド 化 さ れます。 こ れは、 基礎 と な る 数値ス コ ア
が 0 未満にな る こ と を表 し てい ます。
A は 0<<1 と し て再 コ ー ド 化 さ れます。 こ れは、 基礎 と な る 数値ス コ アが 0 と 1 の
間の値にな る こ と を表 し てい ます。
SA は >1 と し て再 コ ー ド 化 さ れます。 こ れは、 基礎 と な る 数値ス コ アが 1 よ り 大
き く な る こ と を表 し てい ます。
464
例 33
こ こ ま では、 [item 1] に対す る 処理について説明 し ま し た。 [item 1] に対 し て行っ たの
と 同様の処理を、残 り 5 つの各観測変数に対 し て も 行 う 必要があ り ます。 6 つの観測変
数すべてに対 し て再 コ ー ド 化を指定 し た ら 、 元のデー タ セ ッ ト と 再 コ ー ド 化 さ れた変
数 と を並べて表示す る こ と がで き ます。 手順は次の と お り です。
E [ デー タ の表示 ] ボ タ ン を ク リ ッ ク し ます。
左側の表には、 再 コ ー ド 化 さ れ る 前の、 元のデー タ フ ァ イ ルの内容が表示 さ れ ます。
右側の表には、再 コ ー ド 化 さ れた後の再 コ ー ド 化変数が表示 さ れます。 Amos で分析が
実行 さ れ る 際には、 元の値ではな く 再 コ ー ド 化 さ れた値が読み込まれます。
注 : デー タ の再 コ ー ド 化実行済みの原デー タ フ ァ イ ルを作成で き ます。 つま り 、 上図
の右側に表示 さ れてい る よ う な不等号を含む原デー タ フ ァ イ ルを作成で き ます。 こ の
場合、 Amos の [ デー タ の再 コ ー ド 化 ] ウ ィ ン ド ウ を使用す る 必要はあ り ません。 こ の
方法は、 例 32 で実際に使用 し てい ます。
E 最後に、[ データ の再 コード 化 ] ウ ィ ン ド ウ を閉 じ 、モデルを特定化す る 作業に移 り ます。
465
順序 - カ テ ゴ リ カル デー タ
モデルの特定化
こ れ ま での説明に従 っ てデー タ の再 コ ー ド 化ルール を 指定 し た後は、 ベ イ ズ解析 と
同 じ 要領で分析を進め ます。 こ の例では、 環境問題に関す る デー タ セ ッ ト に含 ま れ る
6 つの質問事項に因子分析モデルを適合 し ます。 初めの 3 項目は、環境保全のために費
用を負担す る 意志が ど の程度あ る かを調べ る ための質問です。 一方、 残 り の 3 項目は、
環境問題に ど の程度の関心が あ る か を 調べ る た めの質問です。 こ う し た質問の意図
は、 次に示す因子分析モデルに反映 さ れてい ます。 こ の因子分析モデルは Ex33-a.amw
フ ァ イ ルに保存 さ れてい ます。
パ ス図は、 数値デー タ の場合 と ま っ た く 同様に作成 さ れます。 こ れは、 順序 - カ テ ゴ リ
カル変数ご と に最低 3 つのカ テ ゴ リ が存在す る 場合の利点の 1 つです。 つま り 、 変数
がすべて数値型であ る 場合 と 同 じ 方法でモデルを特定化す る こ と がで き 、 なおかつそ
のモデルは数値変数 と 順序 - カ テ ゴ リ カル変数の任意の組み合わせに対 し て適用で き
ます。 変数が二値変数の場合は、 モデルを識別で き る よ う にパ ラ メ ー タ に関す る 制約
を追加す る 必要があ り ます。 こ れについては、 オン ラ イ ン ヘルプの ト ピ ッ ク 「Parameter
identification with dichotomous variables」 で詳 し く 説明 し ます。
モデルの適合
E ツールバーの
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 分析 ]、 [ ベ イ ズ推定 ] の順に選択 し ます。
注 : 非数値デー タ を使用す る 場合はベ イ ズ推定 し か実行で き ないため、
無効化 さ れてい ます。
のボ タ ンは
466
例 33
[ ベ イ ズ SEM] ウ ィ ン ド ウ が開いた ら 、ア イ コ ンが不機嫌な顔か ら 上機嫌な顔に変わ る
ま で待ち ます。 [ ベ イ ズ SEM] ウ ィ ン ド ウ の表示内容が次の よ う にな り ます。
上図には、 パ ラ メ ー タ 推定値の一部だけが表示 さ れてい ます。 [ 平均値 ] 列には、 各パ
ラ メ ー タ のポ イ ン ト 推定値が表示 さ れます。 た と えば、WILLING か ら 項目 1 を予測す
る 場合の係数は 0.59 です。 事後分布の歪度 (0.09) お よ び尖度 (-0.01) は 0 に近い値であ
り 、事後分布がほぼ正規分布にな っ てい る こ と と 一致 し ます。 標準偏差 ([S.D.]) は 0.03
であ り 、 係数は約 67% の確率で 0.59±0.03 の範囲内に収ま り ます。 標準偏差を 2 倍の
0.06 にす る と 、 係数は約 95% の確率で 0.59±0.06 の範囲内に収ま り ます。
係数の事後分布を表示す る 手順は次の と お り です。
E 目的の行を右 ク リ ッ ク し 、ポ ッ プア ッ プ メ ニ ュ ーか ら [ 事後分布の表示 ] を選択 し ます。
467
順序 - カ テ ゴ リ カル デー タ
[ 事後分布 ] ウ ィ ン ド ウ に事後分布が表示 さ れます。 分布の形状に よ り 、分布の平均値、
標準偏差、 歪度、 お よ び尖度を基に判断 し た先の結果を再確認す る こ と がで き ま す。
分布の形状は正規分布に近 く 、 領域の 95% は 0.53 と 0.65 の間 ( つま り 0.59±0.06) に
含まれてい る と 考え ら れます。
468
例 33
MCMC 診断
MCMC アルゴ リ ズ ム (Gelman 他 (2004) を参照 ) に よ る 診断の出力結果を理解す る 知識
があ る 場合は、 [ ト レース ] 図や [ 自己相関 ] 図を活用す る こ と がで き ます。
469
順序 - カ テ ゴ リ カル デー タ
470
例 33
[ 最初 と 最後の分布 ] 図か ら は、別の診断内容を読み取 る こ と がで き ます。 こ の図には、
事後分布の 2 つの推定値 (2 つを重ね合わせた図 ) が表示 さ れます。 一方は MCMC 標
本の最初の 3 分の 1 についての推定値、 も う 一方は MCMC 標本の最後の 3 分の 1 に
ついての推定値です。
事後予測分布
推定 と 言えば通常は、 標準化係数や間接効果な ど、 モデル パ ラ メ ー タ ま たはその関数
の推定 を 思い浮かべ ま す。 し か し こ の分析では、 それ以外に も 未知量が存在 し ま す。
454 ページにあ る デー タ 表の各エ ン ト リ は、 未知の数値 ま たは一部が未知の数値を表
し てい ます。 た と えば、 回答者 1 は項目 2 に対 し て無回答であ る ため、 回答者 1 の基
礎 と な る 数値変数上の ス コ アは推測 ( 推定 ) す る し かあ り ません。 一方、 その他の項目
に関す る 回答者 1 の回答や、 モデルが適切であ る と い う 仮定か ら 得 ら れ る 結果を考慮
すれば、 基礎 と な る 数値変数については、 かな り 確度の高い推測が可能だ と 考え ら れ
ます。
471
順序 - カ テ ゴ リ カル デー タ
回答者 1 は、 項目 1 に対 し ては回答 し てい る ため、 項目 1 の基礎 と な る 数値変数上
の回答者 1 の ス コ アについて推測を行 う こ と は非常に容易です。 回答者 1 の ス コ アは、
その回答か ら 、 2 つの境界の間にあ る 中央の区間に属 し てい る と 判断 さ れます。 2 つの
境界にはすでに 0 お よ び 1 と い う 値が割 り 当て ら れてい る ため、 回答者 1 の ス コ アは
0 と 1 の間の値を取 る こ と は明 ら かですが、 さ ら に、 その他の項目に関す る 回答や、 モ
デルが適切であ る と い う 仮定を考慮す る こ と に よ っ て、 よ り 詳 し い値を求め る こ と が
で き ます。
ベ イ ズ推定では、 未知量はすべて同 じ 方法で処理 さ れ ます。 未知デー タ の値は、 未
知パ ラ メ ー タ の値 を 推定す る 場合 と ま っ た く 同様に、 その事後分布 を 与え る こ と に
よ っ て推定が行われ ます。 未知デー タ の値に関す る 事後分布は事後予測分布 と 呼ばれ
ますが、 解釈の方法は他の事後分布 と ま っ た く 同 じ です。 未知デー タ の値に関す る 事
後予測分布を表示す る 手順は次の と お り です。
E [ 事後予測分布 ] ボ タ ン
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 表示 ]、 [ 事後予測分布 ] の順に選択 し ます。
[ 事後予測分布 ] ウ ィ ン ド ウ が表示 さ れます。
472
例 33
[ 事後予測分布 ] ウ ィ ン ド ウ には、 行を各回答者、 列を モデルの各観測変数 と す る 表が
表示 さ れます。 ア ス タ リ ス ク (*) は欠損値であ る こ と を表 し ます。 ま た << は、 元の数
値変数に不等式制約を適用す る 回答であ る こ と を表 し ます。 各項目に対 し て事後分布
を表示す る 手順は次の と お り です。
E 表の左上のエ ン ト リ ( 項目 1 に対す る 回答者 1 の回答 ) を ク リ ッ ク し ます。
[ 事後分布 ] ウ ィ ン ド ウ が開 き 、 回答者 1 の基礎 と な る数値ス コ アの事後分布が表示 さ
れます。 事後分布は最初、 起伏が激 し く 不規則な形状を示 し ます。
こ れは、 プ ロ グ ラ ムに よ る 事後分布の推定が、 MCMC サンプ リ ン グ を実行 し なが ら 順
次行われてい る ためです。 し か し 時間が経過す る につれて、 事後分布の推定値は修正
さ れてい き ます。 し ば ら く す る と 推定値はそれ以上変化 し な く な り 、 次の図の よ う な
形状にな り ます。
事後分布を見 る と 、 回答者 1 の項目 1 に対す る回答の基礎 と な る 数値変数の ス コ アは
0 と 1 の間にあ り ( こ れは既知の事実 )、 かつ 0 よ り も 1 に近い値を取 る 可能性が高い
こ と がわか り ます。
473
順序 - カ テ ゴ リ カル デー タ
E 次に、 表の 22 行目の第 1 列にあ る エ ン ト リ を ク リ ッ ク し 、 回答者 22 の項目 1 に対す
る 回答の基礎 と な る数値変数の ス コ ア を推定 し ます。
し ば ら く す る と 推定値が確定 し 、 事後分布が次の図の よ う な形状にな り ます。
回答者 1 と 回答者 22 はど ち ら も 、 項目 1 に対 し て 「同意す る 」 と 回答 し てい ます。 し
たが っ て ど ち ら の回答者 も 、 基礎 と な る 数値変数上の ス コ アは 0 と 1 の間の値を取 り
ますが、 それぞれの事後分布は ま っ た く 異な っ てい ます。
事後予測分布の例を も う 1 つ見 る ために、 欠損値 ( 回答者 1 の項目 2 に対す る 回答
な ど ) をいずれか 1 つ選択 し ます。 MCMC サンプ リ ン グが十分に実行 さ れ る と 、 事後
分布の推定値は次の図の よ う な形状にな り ます。
ポ イ ン ト 推定値が必要な場合は、 事後分布の平均値 (0.52) を、 基礎 と な る 数値変数に
おけ る 回答者 1 の ス コ アの推定値 と し て使用で き ます。 事後分布の図を見 る と 、 ス コ
アはほぼ 100% の確率で -1 と 2 の間の値を取 る こ と がわか り ます。 ま た、 事後分布の
領域は大半が 0 と 1 の間に存在す る ため、 ス コ アは 0 と 1 の間の値を取 る 確率が高 く
な り ます。
474
例 33
潜在変数の事後予測分布
WILLING 因子についての回答者 1 の ス コ ア を推定す る 場合を考え ます。 Amos で未知
ス コ アの事後予測分布を推定で き る のは、 観測変数に対 し てだけです。 潜在変数に対
す る ス コ アの事後予測分布を推定す る こ と はで き ません。 ただ し 、 WILLING に対す る
ス コ アの事後予測分布を推定す る ための方法は存在 し ます。 WILLING を、潜在変数で
はな く 、 ケー スすべてに欠損値を持つ観測変数 と 見なす こ と に よ り 、 観測変数に変更
で き ます。 その際、 パ ス図お よ びデー タ の 2 つを変更す る 必要があ り ます。
パス図では、 WILLING を囲む楕円を長方形に変更 し ます。 手順は次の と お り です。
E WILLING を囲む楕円を右 ク リ ッ ク し 、ポ ッ プア ッ プ メ ニ ュ ーか ら [ 直接観測 さ れる / さ
れない変数を交替 ] を選択 し ます。
E WILLING を囲む楕円を ク リ ッ ク し ます。
パ ス図では次の よ う に WILLING を囲む楕円が長方形に変更 さ れます。
こ こ ま では、 パス図に対する処理について説明 し ま し た。 WILLING が観測変数にな る
と 、 データ フ ァ イル内に WILLING 列が必要にな る ため、 データ も 変更する必要があ り
ます。 データ フ ァ イルは直接修正で き ます。 こ のフ ァ イ ルは SPSS Statistics データ フ ァ
イルであ る ため、SPSS Statistics を使用 し て WILLING 変数を追加する こ と も で き ます。
ただ し 、 WILLING に対する ス コ アがすべて欠損値にな る よ う 注意 し て く だ さ い。
元のデー タ フ ァ イ ルの内容を維持 し た ま まデー タ を変更す る 手順は次の と お り です。
E パ ス図の WILLING 変数を右 ク リ ッ ク し ます。
E ポ ッ プア ッ プ メ ニ ュ ーか ら [ デー タ の再コ ー ド 化 ] を選択 し 、 [ デー タ の再 コ ー ド 化 ]
ウ ィ ン ド ウ を開 き ます。
475
順序 - カ テ ゴ リ カル デー タ
E [ デー タ の再 コ ー ド 化 ] ウ ィ ン ド ウ で、[ 変数を作成 ] を ク リ ッ ク し ます。 新 し い変数 と そ
のデフ ォ ル ト 名 V1 が、 [ 新規作成変数 と 再 コ ー ド 化変数 ] リ ス ト ボ ッ ク ス に表示 さ れ
ます。
476
例 33
E V1 を WILLING に変更 し ます ( 必要であれば、[ 変数名を変更 ] ボタ ン を ク リ ッ ク し ます )。
E 新 し い WILLING 変数を含む再 コ ー ド 化 さ れたデー タ セ ッ ト を表示す る 必要があ る 場
合は、 [ デー タ の表示 ] ボ タ ン を ク リ ッ ク し ます。
左側の表には元のデー タ セ ッ ト が表示 さ れます。 一方、 右側の表には、 Amos に読み込
ま れ る 再 コ ー ド 化 さ れたデー タ セ ッ ト が表示 さ れ ま す。 こ のデー タ セ ッ ト には、 再
コ ー ド 化後の項目 1 か ら 項目 6 ま での各項目 と 、 新たに追加 さ れた WILLING 変数が
含まれてい ます。
477
順序 - カ テ ゴ リ カル デー タ
E [ デー タ の再 コー ド 化 ] ウ ィ ン ド ウ を閉 じ ます。
E Amos Graphics ツールバーの
を ク リ ッ ク し てベ イ ジ ア ン解析を開始 し ます。
E [ ベ イ ズ SEM] ウ ィ ン ド ウ で、ア イ コ ンが不機嫌な顔
た ら 、 [ 事後予測分布 ] ボ タ ン
か ら 上機嫌な顔
に変わ っ
を ク リ ッ ク し ます。
E 表の右上にあ る エン ト リ を ク リ ッ ク す る と 、 WILLING 因子に関す る 回答者 1 の ス コ ア
の事後分布が表示 さ れます。
478
例 33
代入
順序 - カ テ ゴ リ カル デー タ でのデー タ 代入は、 数値デー タ でのデー タ 代入 と 同 じ 方法
で行われます。 順序 - カ テ ゴ リ カル デー タ を使用す る 場合、 代入で き る 数値は、 欠損
値、 潜在変数の ス コ ア、 お よ び観測 さ れ る 順序 - カ テ ゴ リ カル測定値の基礎 と な る 非
観測数値変数の ス コ アの値にな り ます。
代入を実行す る にはモデルが必要です。 モデルには、 すでに使用 し た因子分析モデ
ルを使用 し て も か ま い ません。 代入に因子分析モデルを使用す る 場合、 い く つかの長
所があ り ますが、 短所 も 1 つだけあ り ます。 長所の 1 つは、 モデルが適切であれば因
子に値を代入で き る こ と です。 つま り 、 WILLING お よ び AWARE を観測変数 と す る
デー タ セ ッ ト を新規作成す る こ と がで き ます。 も う 1 つの長所は、 モデルが適切であ
れば、 項目 1 か ら 項目 6 ま での各項目に対 し 、 制約が少ないモデル よ り も 的確な代入
が期待で き る 点です。 因子分析モデルを使用す る 短所は、 モデルが不適切にな る 可能
性があ る と い う 点です。 こ の例では確実性を重視 し て、 適切であ る 確率が最 も 高い飽
和モデル ( 下図参照 ) を使用 し ます ( フ ァ イ ル Ex33-c.amw を参照 し て く だ さ い )。
飽和モデルに対す る パ ス図を作成 し た ら 、 代入を開始で き ます。
479
順序 - カ テ ゴ リ カル デー タ
E Amos Graphics メ ニ ュ ーか ら 、 [ 分析 ]、 [ デー タ 代入 ] の順に選択 し ます。
[Amos デー タ 代入 ] ウ ィ ン ド ウ では、 [ 回帰法代入 ] と [ 確率的回帰法代入 ] は無効化 さ
れてい る こ と に注意 し て く だ さ い。 非数値デー タ を使用 し てい る 場合は、 [ ベ イ ズ法代
入 ] し か選択で き ません。
こ こ では上の図に表示 さ れてい る 設定内容を その ま ま使用 し ます。 こ れに よ り 、 10
個の完全デー タ セ ッ ト が作成 さ れ、 それ ら すべてが environment-nl-string_C.sav と い う
1 つのデー タ フ ァ イ ルに保存 さ れます。 代入を開始す る 手順は次の と お り です。
E [ 代入 ] ボ タ ン を ク リ ッ ク し ます。
[ ベ イ ズ SEM] ウ ィ ン ド ウ と と も に [ デー タ 代入 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
480
例 33
E [ デー タ 代入 ] ダ イ ア ロ グ ボ ッ ク ス に上機嫌な顔
(10 個の各完全デー タ セ ッ ト の間
に実質的な相関がない こ と を示す ) が表示 さ れ る ま で待ち ます。
注 : 上機嫌な顔が表示 さ れた後 [OK] を ク リ ッ ク す る 前に、 [ ベ イ ズ SEM] ウ ィ ン ド ウ
内の任意のパ ラ メ ー タ を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ 事後分布の表示 ]
を選択す る こ と も で き ます。 こ れに よ り 、 ト レース図や自己相関図を確認で き ます。
E [ デー タ 代入 ] ダ イ ア ロ グ ボ ッ ク ス で、 [OK] を ク リ ッ ク し ます。
[ 要約 ] ウ ィ ン ド ウ に、 作成 さ れた完全デー タ フ ァ イ ルの一覧が表示 さ れます。 こ こ で
は、 作成 さ れた完全デー タ フ ァ イ ルは 1 つだけです。
E [ 要約 ] ウ ィ ン ド ウ で フ ァ イ ル名を ダブル ク リ ッ ク し て、完全デー タ フ ァ イ ルの内容を
表示 し ます。 こ の フ ァ イ ルには 10 個の完全デー タ セ ッ ト が含まれてい ます。
481
順序 - カ テ ゴ リ カル デー タ
10 個あ る 完全デー タ セ ッ ト のそれぞれには 1,017 の ケー ス が含 ま れてい ま す。 し た
が っ て、 フ ァ イ ルに含まれ る ケース数は 10,170 です。 新 し いデー タ フ ァ イ ルの最初の
1,017 行は、 1 番目の完全デー タ セ ッ ト に対応 し ます。 1 番目の完全デー タ セ ッ ト にお
け る imputeno 変数は各行で 1 にな っ てい ます。 ま た caseno 変数には 1 か ら 1,017 ま
での値が順番に並んでお り 、 1,017 に達す る と 再び 1 か ら 繰 り 返 さ れます。
通常、 こ の後に行 う 手順では、 数値 ( 順序 - カ テ ゴ リ カルでない ) デー タ を必要 と す る
他のプ ロ グ ラ ムへの入力用に、environment-nl-string_C.sav 内の 10 個の完全デー タ セ ッ
ト を使用 し ます。 こ の場合、 そのプ ロ グ ラ ムでは、 10 個の完全デー タ セ ッ ト を 1 つず
つ順番に使っ て 10 回の分析を個別に実行す る こ と にな り ます。 その後、 例 31 で行っ
た よ う に、 さ ら に計算を実行 し 10 回分の分析結果を 1 つの結果セ ッ ト に ま と め ます。
こ の例では、 こ れ ら の手順は実行 し ません。
例
34
ト レーニング データ を使用 し た
混合モデ リ ング
概要
混合モデ リ ン グは、 あ る モデルを母集団全体に当てはめ る のは不適切であ る けれど も 、
各サブグループに当てはめ る こ と がで き る よ う に、 母集団を サブグループに分け る こ
と がで き る 場合に適 し てい ます。
混合モデ リ ン グ は、 構造方程式モデ リ ン グ の分脈では、 Arminger、 Stein、 お よ び
Wittenberg (1999 年 )、 星野 (2001 年 )、 Lee (2007 年 , 11 章 )、 Loken (2004 年 )、 Vermunt
お よ び Magidson (2005 年 )、Zhu お よ び Lee (2001 年 ) な ど に よ っ て解説 さ れてい ます。
こ の例では、 グループに割 り 当て済みのケース と 割 り 当て ら れていないケース があ
る 場合の混合モデ リ ン グについて説明 し ます。 すでに分類 さ れてい る ケース か ら 学び、
他のケース を分類す る のは、 Amos が行い ます。
例 10、 例 11、 例 12 の よ う な通常の複数グループの分析の設定 と ほぼ同 じ なので、 こ
こ では一部のケース がすでに分類 さ れてい る 例を使っ て混合モデ リ ング を実行 し ます。
混合モデ リ ン グは、 事前にケース が分類 さ れていな く て も 実行で き ます。 その場合
はプ ロ グ ラ ムがすべてのケース を分類す る 必要があ り ます。 例 35 では、 こ の タ イ プの
分析について説明 し ます。
483
484
例 34
デー タ について
こ の例のデー タ は Anderson (1935 年 ) に よ っ て収集 さ れ、 Fisher (1936 年 ) が こ のデー
タ を使っ て判別分析を示 し ま し た。 元のデー タ は、 iris.sav フ ァ イ ルにあ り ます。 こ こ
ではその一部を示 し ます。
デー タ セ ッ ト には、150 の異な る 植物の花に関す る 4 つの測定値が含まれてい ます。 最
初の 50 の花は、setosa ( セ ト サ ) と い う 種類のア イ リ ス で し た。 次の 50 の花は、versicolor
( ベルシ カ ラ ー ) と い う 種類のア イ リ ス で し た。 最後の 50 の花は、 virginica ( ベルジニ
カ ) と い う 種類のア イ リ ス で し た。
485
ト レーニ ング デー タ を使用 し た 混合モデ リ ン グ
PetalLength ( 花び ら の長 さ ) と PetalWidth ( 花び ら の幅 ) と い う 2 つの測定値の散布
図は、 種類に よ る 花の分類では、 こ れ ら 2 つの測定値だけで も 有用であ る こ と 示 し て
い ます。
散布図の左下角にあ る のは、setosa の花だけです。 し たが っ て、Amos では、PetalLength
と PetalWidth を使っ て、他の花 と setosa の花を容易に区別す る こ と がで き る はずです。
一方、 versicolor と virginica は一部が重複 し てい る ので、 PetalLength と PetalWidth だ
けで、 花の種類が versicolor なのか virginica なのか を区別す る のは難 し い場合があ る
こ と が予想 さ れます。
486
例 34
こ の例では、 すべての花の種類が含 ま れてい る iris.sav デー タ セ ッ ト は使用 し ま せ
ん。 代わ り に、数種類の花だけが含まれてい る iris3.sav デー タ セ ッ ト を使用 し ます。 次
の図は、 iris3.sav デー タ セ ッ ト の一部を示 し てい ます。
種類については、 setosa の花 10 個、 versicolor の花 10 個、 virginica の花 10 個がわかっ
てい ます。 残 り の 120 の花の種類は不明です。 こ れ ら のデー タ を Amos で分析す る と 、
花の種類ご と に 10 の例を使用 し て、 残 り の花の分類を行ない ます。
分析の実行
E
メ ニ ュ ーか ら 、[ フ ァ イル ][ 新規作成 ] を選択 し て新 し いパ ス図の作成を開始 し ます。
E
メ ニ ュ ーか ら [ 分析 ] [ グループ管理 ] を選択 し ます。
E [ グループ管理 ] ダ イ ア ロ グ ボ ッ ク ス で、[ グループ名 ] テ キ ス ト ボ ッ ク ス の名前を 「グ
ループ番号 1」 か ら 「PossiblySetosa ( セ ト サの可能性 )」 に変更 し ます。
E [ 新規作成 ] を ク リ ッ ク し て 2 つ目のグループ を作成 し ます。
487
ト レーニ ング デー タ を使用 し た 混合モデ リ ン グ
E [ グループ名 ] テ キ ス ト ボ ッ ク ス の名前を 「グループ番号 2」 か ら 「PossiblyVersicolor
( バーシ カ ラ ーの可能性 )」 に変更 し ます。
E [ 新規作成 ] を ク リ ッ ク し て 3 つ目のグループを作成 し ます。
E [ グループ名 ] テ キ ス ト ボ ッ ク ス の名前を 「グループ番号 3」 か ら 「PossiblyVirginica
( バージ ニ カの可能性 )」 に変更 し ます。
E [ 閉 じ る ] を ク リ ッ ク し ます。
デー タ フ ァ イルの指定
E
メ ニ ュ ーか ら 、 [ フ ァ イル ][ デー タ フ ァ イル ] を選択 し ます。
488
例 34
E [PossiblySetosa] を ク リ ッ ク し て行を選択 し ます。
E [ フ ァ イル名 ] を ク リ ッ ク し 、 Amos の Examples デ ィ レ ク ト リ にあ る iris3.sav フ ァ イ ル
を選択 し て、 [ 開 く ] を ク リ ッ ク し ます。
E [ グループ化変数 ] を ク リ ッ ク し 、 [ グループ化変数を選択 ] ダ イ ア ロ グ ボ ッ ク ス で
[species] を ダブル ク リ ッ ク し ます。 こ れで、変数 [species] が花の分類に使用 さ れます。
489
ト レーニ ング デー タ を使用 し た 混合モデ リ ン グ
E [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス で [ グループ値 ] を ク リ ッ ク し 、[ グループの識
別値の選択 ] ダ イ ア ロ グ ボ ッ ク ス で [setosa] を ダブル ク リ ッ ク し ます。
[ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス は、 次の よ う にな り ます。
E [PossiblyVersicolor] グループについて前述の手順を繰 り 返 し ますが、 今回は [ グルー
プの識別値の選択 ] ダ イ ア ロ グ ボ ッ ク ス で [versicolor] を ダブル ク リ ッ ク し ます。
490
例 34
E [PossiblyVirginica] グループについて前述の手順を も う 一度繰 り 返 し ますが、 今回は
[ グループの識別値の選択 ] ダ イ ア ロ グ ボ ッ ク ス で [virginica] を ダブル ク リ ッ ク し ま
す。 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス は、 次の よ う にな り ます。
こ こ ま では、 すべての花の種類が判明 し てい る 、 通常の 3 グループ分析の よ う に設定
し て き ま し た。 次に行 う 手順は、 混合モデ リ ン グ特有の も のです。
E [ ケース を グループに割 り 当て る ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。 こ の
チ ェ ッ ク マー ク が表示 さ れてい る と 、 ケース が属 し てい る グループがデー タ セ ッ ト で
指定 さ れていない場合、 ケース はグループに割 り 当て ら れます。
E [OK] を ク リ ッ ク し て、 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
491
ト レーニ ング デー タ を使用 し た 混合モデ リ ン グ
モデルの特定化
変数 [PetalLength] お よ び [PetalWidth] の飽和モデルを使用 し ます。 先に示 し た散布図
は、 種類に基づいて花の分類を行な う のに、 こ れ ら 2 つの変数が有用であ る こ と を示
し てい ます。
混合モデ リ ン グ を行な う と き には、 飽和モデルに限定 さ れない こ と に注意 し て く だ
さ い。 因子分析モデルや回帰モデルな ど、 ど の タ イ プのモデルで も 使用す る こ と がで
き ます。 回帰モデルを使っ た混合モデ リ ン グの実証については、 例 36 を参照 し て く だ
さ い。
E 次のパ ス図を描 き ます ( こ のパ ス図は、 Ex34-a.amw と し て保存 さ れてい ます )。
E
メ ニ ュ ーか ら [ 表示 ] [ 分析のプ ロパテ ィ ] の順に選択 し ます。
492
例 34
E [ 平均値 と 切片を推定 ] を選択 し ます ( 隣にチ ェ ッ ク マー ク が表示 さ れます )。
493
ト レーニ ング デー タ を使用 し た 混合モデ リ ン グ
モデルの適合
E ツールバーの
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 分析 ] [ ベ イ ズ推定 ] の順に選択 し ます。
注 : 混合モデ リ ン グではベ イ ズ推定 し か実行で き ないため、
てい ます。
のボ タ ンは無効化 さ れ
[ ベ イ ズ SEM] ウ ィ ン ド ウ が開いた ら 、不機嫌な顔
が上機嫌の顔
に変わ る ま で
待ち ます。 [ ベ イ ズ SEM] ウ ィ ン ド ウ に、 次の よ う な推定値の表が表示 さ れます。
[ ベ イ ズ SEM] ウ ィ ン ド ウ に、通常の 3 グループ分析で取得 さ れ る すべてのパ ラ メ ー タ
推定が表示 さ れます。 表には、 1 度に 1 つのグループの結果が表示 さ れます。 表の上部
にあ る タ ブ を ク リ ッ ク す る と 、 別のグループに切 り 替え る こ と がで き ます。 こ の例で
は、 モデルのパ ラ メ ー タ には平均値、 分散、 お よ び共分散が含ま れてい ます。 さ ら に
複雑なモデルにな る と 、 係数 と 切片項の推定値 も 含まれます。
混合モデ リ ン グ分析では、各グループの母集団におけ る 比率の推定値 も 取得 し ます。
前の図は、 母集団での setosa の花の推定比率が 0.333 と 示 し てい ます ( ただ し 、 標本
には、 意図的に setosa、 versicolor、 virginica の花がそれぞれ同 じ 数だけ含 ま れてい る
こ と を指摘 し てお く 必要があ る で し ょ う 。 し たが っ て、 こ の例では、 標本か ら 母集団
の比率について推論を導 き 出す こ と は有意ではあ り ませんが、 その よ う な推論を導 き
出す方法を示すために、 こ こ では species を確率変数 と し て扱い ます )。
494
例 34
母集団の比率の事後分布を確認す る には、比率が表示 さ れいて る 行を右 ク リ ッ ク し て、
ポ ッ プア ッ プ メ ニ ュ ーか ら [ 事後分布の表示 ] を選択 し ます。
[ 事後分布 ] ウ ィ ン ド ウ は、 setosa の種類に属す る花の比率が、 ほぼ確実に 0.25 ~ 0.45
の範囲にな る こ と を示 し てい ます。 比率が 0.3 ~ 0.35 の間にな る確率は、半々(約 50%)
の よ う です。
495
ト レーニ ング デー タ を使用 し た 混合モデ リ ン グ
個々のク ラ スの分類
各花のグループ所属の確率を取得す る には、 次の よ う に し ます。
E [ 事後予測分布 ] ボ タ ン
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 表示 ] [ 事後予測分布 ] の順に選択 し ます。
[ 事後予測分布 ] ウ ィ ン ド ウ では、 それぞれの花が setosa、 versicolor、 ま たは virginica
であ る 確率が示 さ れてい ます。
最初の 50 の花 ( 実際に setosa であ る も の ) については、 setosa グループに属す る 確
率がほぼ 1 にな っ てい ます。 先に示 し た散布図において、 setosa の花は明 ら かに他の
種類の花 と は分離 し ていたので、 こ の結果は予想 し た と お り です。
versicolor の花 ( ケース番号 51 以降 ) も ほ と ん ど が正 し く 分類 さ れま し た。 た と えば、
花番号 51 が versicolor であ る 事後確率は 0.95 にな っ てい ます。 し か し 、 分類エ ラ ーは
実際に起 こ り ます。 た と えば、 ケース番号 71 は間違っ て分類 さ れてい ます。 versicolor
の花であ る のに、 0.75 の確率で virginica であ る こ と が推定 さ れてい ます。
496
例 34
潜在構造分析
混合モデ リ ン グ を行な う と き には、飽和モデルに限定 さ れない こ と は先に述べま し た。
因子分析モデルや回帰モデルな ど、ど の タ イ プのモデルで も 使用す る こ と がで き ます。
こ こ で、 飽和モデルの重要なバ リ エーシ ョ ンについて理解 し てお く こ と をお勧め し ま
す。 潜在構造分析 (Lazarsfeld お よ び Henry, 1968 年 ) は、 混合モデ リ ン グが変化 し た も
ので、 各グループ内において測定変数が独立 し てい る 必要があ り ます。 測定変数が多
変量の正規変数の場合、 こ れ ら の変数は無相関であ る こ と が必要です。
E 測定変数が無相関であ る こ と を要求す る には、 飽和モデルのパ ス図か ら 双方向矢印を
削除 し ます ( こ のパ ス図は Ex34-b.amw と し て保存 さ れてい ます )。
E [ ベイ ジアン ] ボ タ ン
を ク リ ッ ク し て、潜在構造分析を実行 し ます。 こ こ では、潜在
構造分析の結果は示 し ません。
例
35
ト レーニ ング デー タ を
使用 し ない混合モデ リ ング
概要
混合モデ リ ン グは、 あ る モデルを母集団全体に当てはめ る のは不適切であ る けれど も 、
各サブグループに当てはめ る こ と がで き る よ う に、 母集団を サブグループに分け る こ
と がで き る 場合に適 し てい ます。
Amos で混合モデ リ ン グ を実行す る と き には、 分析を開始す る 前に一部の ケー ス を
グループに割 り 当て る こ と がで き ます。 こ の方法については、例 34 で説明 し てい ます。
こ の例では、混合モデ リ ング分析の開始時には、すべてのケース が分類 さ れてい ません。
デー タ について
こ の例では、例 34 で使っ た Anderson (1935 年 ) に よ る ア イ リ ス のデー タ を使用 し ます。
ただ し 、今回は、150 の花の う ち 30 についての種類の情報が含まれてい る iris3.sav デー
タ セ ッ ト は使用 し ま せ ん。 代 わ り に、 種類 に つい て の 情報 が 一切含 ま れ て い な い
iris2.sav デー タ セ ッ ト を使用 し ます。 例 34 と こ の例が異な る のは、 例 34 では、 一部の
ケー ス があ ら か じ め分類 さ れてい る のに対 し 、 こ の例ではあ ら か じ め分類 さ れてい る
ケース がない と い う 点です。 次の図は、 iris2.sav デー タ セ ッ ト の一部を示 し てい ます。
497
498
例 35
デー タ セ ッ ト には、 [species] 列が含 ま れてい ま すが、 こ の列は空白にな っ てい ま す。
Amos では、 一部のケース の種類がすでにわかっ てい る ( 例 34 の よ う な ) 場合があ る
こ と を考慮す る ので、 数値がな く て も [species] 列があ る こ と が重要です。 ケース の分
類に使用 さ れ る 変数は、 「species」 と い う 名前でな く て も 構い ません。 ど の よ う な変数
名で も 使用で き ますが、 文字列 ( 非数値 ) 変数でなければな り ません。
分析の実行
E
メ ニ ュ ーか ら 、[ フ ァ イル ] [ 新規作成 ] を選択 し て新 し いパ ス図の作成を開始 し ます。
E
メ ニ ュ ーか ら [ 分析 ] [ グループ管理 ] を選択 し ます。
499
ト レーニ ング デー タ を 使用 し ない混合モデ リ ン グ
E [ 新規作成 ] を ク リ ッ ク し て 2 つ目のグループを作成 し ます。
E [ 新規作成 ] を も う 1 度 ク リ ッ ク し て 3 つ目のグループを作成 し ます。
E [ 閉 じ る ] を ク リ ッ ク し ます。
こ の例では、3 グループの混合モデルを当てはめ ます。 存在す る グループの数がわか ら
ない場合は、 プ ロ グ ラ ム を複数回実行で き ます。 プ ロ グ ラ ム を実行 し て 2 グループの
モデルを当てはめた後、 も う 1 度実行 し て 3 グループのモデルを当てはめた り す る こ
と がで き ます。
500
例 35
デー タ フ ァ イルの指定
E
メ ニ ュ ーか ら 、 [ フ ァ イル ] [ デー タ フ ァ イル ] を選択 し ます。
E [ グループ番号 1] を ク リ ッ ク し て 1 行目を選択 し ます。
E [ フ ァ イル名 ] を ク リ ッ ク し 、 Amos の Examples デ ィ レ ク ト リ にあ る iris2.sav フ ァ イ ル
を選択 し て、 [ 開 く ] を ク リ ッ ク し ます。
E [ グループ化変数 ] を ク リ ッ ク し 、 [ グループ化変数を選択 ] ダ イ ア ロ グ ボ ッ ク ス で
[species] を ダブル ク リ ッ ク し ます。 こ れで、変数 species を使っ て グループが区別 さ れ
ます。
501
ト レーニ ング デー タ を 使用 し ない混合モデ リ ン グ
E 同 じ デー タ フ ァ イ ル (iris2.sav) と グループ変数 (species) を指定 し 、 グループ番号 2 に
ついて前述の手順を繰 り 返 し ます。
E 同 じ デー タ フ ァ イ ル (iris2.sav) と グループ変数 (species) を指定 し 、 グループ番号 3 に
ついて前述の手順を も う 1 度繰 り 返 し ます。
E [ ケース を グループに割 り 当て る ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
[ ケース をグループに割 り 当て る ] の横にチ ェ ッ ク マー ク があ る の を除 き 、 こ こ ま では
通常の複数グループの分析 と 同 じ です。 こ のチ ェ ッ ク マー ク に よ っ て、 こ れが混合モ
デ リ ン グ分析にな り ます。 こ のチ ェ ッ ク マー ク が表示 さ れてい る と 、 デー タ フ ァ イ ル
のグループ変数がグループに割 り 当て ら れていない場合、 花はグループに割 り 当て ら
れます。 [ グループ値 ] を ク リ ッ ク し て グループ変数の値を指定す る 必要がなか っ た こ
と に注意 し て く だ さ い。 デー タ フ ァ イ ルには、 グループ変数 (Species) の値が含まれて
いないので、 3 つのグループの [species] の値 と し て、 Cluster1、 Cluster2、 Cluster3 が
自動的に作成 さ れます。
E [OK] を ク リ ッ ク し て、 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
502
例 35
モデルの特定化
変数 [PetalLength] お よ び [PetalWidth] の飽和モデルを使用 し ます。 例 34 の散布図は、
種類に基づいて花の分類を行な う のに、 こ れ ら 2 つの変数が有用であ る こ と を示 し て
い ます。
混合モデ リ ン グ を行な う と き には、 飽和モデルに限定 さ れない こ と に注意 し て く だ
さ い。 因子分析モデルや回帰モデルな ど、 ど の タ イ プのモデルで も 使用す る こ と がで
き ます。 例 36 では、 回帰モデルを使用 し た混合モデ リ ン グ を説明 し てい ます。
E 次の よ う なパス図を描 き ます。
E
メ ニ ュ ーか ら [ 表示 ] [ 分析のプ ロパテ ィ ] を選択 し ます。
503
ト レーニ ング デー タ を 使用 し ない混合モデ リ ン グ
E [ 平均値 と 切片を推定 ] を選択 し ます ( 隣にチ ェ ッ ク マー ク が表示 さ れます )。
パラ メ ー タ の制約
こ の例では、 分散 と 共分散がすべてのグループにおいて変わ ら ない こ と が要求 さ れ ま
す。 こ れは、 判別分析やあ る 種の ク ラ ス タ リ ン グ で多 く 使用 さ れ る 、 分散お よ び共分
散の等質性の仮定です。 原理上、 分散お よ び共分散の等質性の仮定は混合モデ リ ン グ
では必要あ り ません。 こ こ でそれを仮定す る のは、 こ の例の場合、 こ の仮定がな けれ
ば Amos のアルゴ リ ズ ムが う ま く いかないか ら です ( 例 34 の散布図は、 仮定が破 ら れ
てい る こ と を示 し てい ます )。
504
例 35
E パ ス図の [PetalLength] を右 ク リ ッ ク し て、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ オブ ジ ェ ク ト
のプ ロパテ ィ ] を選択 し 、 [ 分散 ] テ キ ス ト ボ ッ ク ス にパ ラ メ ー タ 名を 「v1」 と 入力 し
ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ]
ダイアログ
ボ ッ ク ス が開いてい る 状態で、 パス図の
PetalWidth を ク リ ッ ク し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 分散 ] テ キ ス ト ボ ッ ク ス にパ
ラ メ ー タ 名を 「v2」 と 入力 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス が開いてい る 状態で、PetalLength と
PetalWidth の間の共分散を表す 2 方向矢印を ダブル ク リ ッ ク し ます。
505
ト レーニ ング デー タ を 使用 し ない混合モデ リ ン グ
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 共分散 ] テ キ ス ト ボ ッ ク ス に
パ ラ メ ー タ 名を 「c12」 と 入力 し ます。
パ ス図は次の図の よ う にな り ます。 ( こ のパ ス図は、 Ex35-a.amw と し て保存 さ れてい
ます )。
モデルの適合
E ツールバーの
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 分析 ] [ ベ イ ズ推定 ] の順に選択 し ます。
注 : 混合モデ リ ン グではベ イ ズ推定 し か実行で き ないため、
てい ます。
のボ タ ンは無効化 さ れ
506
例 35
[ ベ イ ズ SEM] ウ ィ ン ド ウ が開いた ら 、不機嫌な顔
が上機嫌の顔
に変わ る ま で
待ち ます。 [ ベ イ ズ SEM] ウ ィ ン ド ウ に、 次の よ う な推定値の表が表示 さ れます。
[ ベ イ ズ SEM] ウ ィ ン ド ウ に、通常の 3 グループ分析で取得 さ れ る すべてのパ ラ メ ー タ
推定が表示 さ れます。 表には、 1 度に 1 つのグループの推定値が表示 さ れます。 表の上
部にあ る タ ブ を ク リ ッ ク す る と 、 別のグループに切 り 替え る こ と がで き ます。 こ の例
では、 モデルのパ ラ メ ー タ には平均値、 分散、 お よ び共分散が含 ま れてい ます。 さ ら
に複雑なモデルにな る と 、 係数 と 切片項の推定値 も 含まれます。
混合モデ リ ン グ分析では、 各グループの母集団におけ る 比率の推定値 も 取得 し ま す。
前の図は、 母集団での setosa の花の推定比率が 0.360 であ る こ と 示 し てい ます。
507
ト レーニ ング デー タ を 使用 し ない混合モデ リ ン グ
E 母集団の比率の事後分布を確認す る には、比率が表示 さ れいて る 行を右 ク リ ッ ク し て、
ポ ッ プア ッ プ メ ニ ュ ーか ら [ 事後分布の表示 ] を選択 し ます。
[ 事後分布 ] ウ ィ ン ド ウ の事後分布グ ラ フ は、 グループ番号 1 に属す る 花の比率が、
確実に 0.23 ~ 0.50 の範囲にな る こ と を示 し てい ます。 比率が 0.30 ~ 0.40 の範囲にな
る 確率は非常に高 く な っ てい ます。
508
例 35
個々のク ラ スの分類
各花のグループ所属の確率を取得す る には、 次の よ う に し ます。
E [ 事後予測分布 ] ボ タ ン
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 表示 ] [ 事後予測分布 ] の順に選択 し ます。
[ 事後予測分布 ] ウ ィ ン ド ウ に は、 そ れ ぞ れ の 花 の 変数 [species] の 値 が Cluster1、
Cluster2、 ま たは Cluster3 であ る 確率が表示 さ れてい ます。
509
ト レーニ ング デー タ を 使用 し ない混合モデ リ ン グ
setosa の例であ る こ と がわかっ てい る 最初の 50 のケース は、確率が 1 でグループ番号
3 に含まれ る ので、グループ番号 3 には明 ら かに setosa の花が含まれてい ます。 ケース
51 か ら 100 ま では、 主にグループ番号 1 に含まれ る ので、 グループ番号 1 には明 ら か
に versicolor の花が含まれてい ます。 同様に、 上の図には示 さ れてい ませんが、 ケース
101 か ら 150 ま では、 主にグループ番号 1 に割 り 当て ら れてい る ので、 グループ番号
2 には明 ら かに virginica の花が含まれてい ます。
潜在構造分析
観測変数が各グループ内で独立 し てい る 必要があ る 、 潜在構造分析 と 呼ばれ る 混合モ
デ リ ン グのバ リ エーシ ョ ンがあ り ます。
E PetalLength と PetalWidth が無相関、し たが っ て ( 多変量の正規分布なので ) 独立 し てい
る こ と を要求す る には、 パ ス図で こ れ ら を結んでい る 2 方向矢印を削除 し ます。 その
結果得 ら れ る パ ス図は次の よ う にな り ます ( こ のパ ス図は、 Ex35-b.amw と し て保存 さ
れてい ます )。
E ま たは、 パ ラ メ ー タ 名の [v1] と [v2] を削除 し て、 分散に対す る 制約を削除す る こ と も
で き ます ( その結果得 ら れ る パ ス図は、 Ex35-c.amw と し て保存 さ れてい ます )。
E 2 方向矢印を削除 し 、分散に対す る 制約を削除 し た ら 、[ ベイジアン ] ボタ ン
をク リ ッ
ク し て潜在構造分析を実行 し ます。 こ こ では、 潜在構造分析の結果は報告 し ません。
510
例 35
ラ ベル ス イ ッ チ ング
こ の例で分析を再現 し よ う と す る と 、 こ こ で報告す る 結果を得ますが、 グループ名の
順序が変わ り ます。 こ こ でグループ番号 1 について報告 さ れ る 結果は、 グループ番号
2 ま たはグループ番号 3 について得 ら れ る 結果の場合があ り ます。 こ れは、 ラ ベル ス
イ ッ チン グ (Chung, Loken お よ び Schafer, 2004 年 ) と 呼ばれ る 場合があ り ます。 ラ ベル
ス イ ッ チン グは、 1 つの分析を行っ てい る 途中で起 こ ら ない限 り 、 特に問題ではあ り
ません。 し か し 残念なが ら 、 ラ ベル ス イ ッ チン グが分析の最中に起 こ る こ と があ り ま
す。 ラ ベル ス イ ッ チン グが起 こ る 場合、 通常は個々のパ ラ メ ー タ の ト レース図に よ っ
て明 ら かにな り ます。 ベ イ ズ推定の実行時に ト レー ス図を表示す る には、 次の よ う に
し ます。
E [ ベ イ ズ SEM] ウ ィ ン ド ウ でパ ラ メ ー タ を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら
[ 事後分布の表示 ] を選択 し ます。
E [ 事後分布 ] ウ ィ ン ド ウ で、 [ ト レース ] を選択 し ます。
こ の例の分析では、 ラ ベル ス イ ッ チン グは起 こ っ てい ません。 別の分析か ら 得た次の
図は、ラ ベル ス イ ッ チン グに典型的な ト レース図を示 し てい ます。 こ の ト レース図は、
2 つのケース ク ラ ス タ があ る デー タ の分析か ら 得た も のです。 一方の ク ラ ス タ では X
と 呼ばれ る 変数の平均値は約 4、他方の ク ラ ス タ では変数 X の平均値は約 17 にな っ て
い ま し た。 こ の ト レース図は、 お よ そ 5,000 回目の MCMC アルゴ リ ズ ムの反復ま でほ
と ん ど の間、 グループ番号 1 と 呼ばれ る グループでは X の平均値のサンプ リ ン グ さ れ
た値が 4 に近い数値の ま ま だ っ た こ と を示 し てい ます。 お よ そ 5,000 回目の反復で、サ
ン プ リ ン グ さ れた値が 17 の辺 り で変動 し 始め ま し た。 ト レ ー ス 図の こ の突然の変化
は、 グループ ラ ベル ( グループ番号 1 と グループ番号 2) が約 5,000 回目の反復時に入
れ替わ っ た証拠を示 し てい ます。 ト レース図は、 MCMC アルゴ リ ズ ムの最初の 20,000
回の反復中に、 こ の ラ ベル ス イ ッ チン グが数回起 こ っ た こ と を示 し てい ます。
511
ト レーニ ング デー タ を 使用 し ない混合モデ リ ン グ
ラ ベル ス イ ッ チン グは、1 つま たは複数のパ ラ メ ー タ の、複数モデルの事後分布に よ っ
て明 ら かにな る こ と があ り ます。 上の ト レー ス図は、 次の事後分布推定に対応 し てい
ます。
上のグ ラ フは、 パ ラ メ ー タ の事後分布の平均値を表 し た も のです。 ラ ベル ス イ ッ チン
グ が起 こ っ た と き の混合モデ リ ン グ分析では、 有意な推定ではない場合が あ り ま す。
ラ ベル ス イ ッ チン グ を防止す る 方法は、 い く つか提案 さ れてい ます (Celeux, Hurn お
よ び Robert, 2000 年 ; Frühwirth-Schnatter, 2004 年 ; Jasra, Holmes お よ び Stephens, 2005
年 ; Stephens, 2000 年 )。 Chung、 Loken お よ び Schafer (2004 年 ) は、 1 つま たは 2 つの
ケース だけで も あ ら か じ めグループに割 り 当て る と 、 ラ ベル ス イ ッ チン グの解消に有
効な場合があ る と 提案 し てい ます。 Amos では、例 34 で示 し た よ う に、あ ら か じ めケー
ス を グループに割 り 当て る こ と がで き ます。 Amos 23 では、 ラ ベル ス イ ッ チン グ を防
止す る ための他の方法は実行 さ れません。
例
36
混合回帰モデ リ ング
概要
混合回帰モデ リ ン グ (Ding, 2006 年 ) は、 あ る 回帰モデルを母集団全体に当てはめ る の
は不適切であ る けれど も 、 各サブグループに当てはめ る こ と がで き る よ う に、 母集団
を サブグループに分け る こ と がで き る 場合に適 し てい ます。
デー タ について
2 つの人為的なデー タ セ ッ ト を使っ て、 混合回帰について説明 し ます。
1 つ目のデー タ セ ッ ト
次 の デ ー タ セ ッ ト は DosageAndPerformance1.sav フ ァ イ ル に 保 存 さ れ て い ま す。
Dosage ( 投与量 ) は、一部の治療の強度を指 し ます。 Performance ( パフ ォーマ ン ス ) は、
あ る 達成度の尺度です。 Group ( グループ ) は、 文字列 ( 非数値 ) 変数です。 混合回帰分
析での こ の変数の役割については後で説明 し ます。
513
514
例 36
dosage と performance の散布図は、 標本には 2 つの異な る 被験者グループがあ る こ と
を示 し てい ます。 一方のグループでは、 dosage が増え る につれ、 performance が向上 し
てい ます。他方のグループでは、dosage が増え る につれ、performance が低下 し ています。
こ の場合、1 本の回帰直線を標本全体に当てはめ よ う と す る のは間違いです。 こ のデー
タ には、 それぞれのグループに 1 本ずつ、 2 本の直線が う ま く 当ては ま り ます。 こ れ
は、 混合回帰モデ リ ン グで行な う こ と がで き ます。 混合回帰分析では、 標本を グルー
プに分割 し 、 それぞれのグループに別々の回帰直線を当てはめ ます。
515
混合回帰モデ リ ン グ
2 つ目のデー タ セ ッ ト
DosageAndPerformance2.sav フ ァ イ ルにあ る 次のデー タ セ ッ ト に も 、 dosage 、
performance 、 お よ び group と い う 変数についてのデー タ が含まれてい ます。
ま た同 じ く 、 デー タ の散布図は、 グループ ご と に固有の回帰直線を必要 と す る 、 2 つ
のグループが存在す る 証拠を示 し てい ます。 ど ち ら のグループにおいて も 、 dosage の
1 単位の増加は、 performance の約 2 単位の向上に関連 し てい る ので、 各グループ内で
の回帰直線の傾 き は約 2 にな っ てい ます。 一方、2 つのグループには異な る 切片があ り
ます。 ど の dosage レベルにおいてで も 、一方のグループの performance は他方のグルー
プ よ り も 5 ポ イ ン ト 程度高 く な っ てい ます。 こ のデー タ セ ッ ト の混合回帰分析では、標
本を グループに分割 し 、 それぞれのグループに別々の回帰直線を当てはめ ます。
516
例 36
デー タ セ ッ ト のグループ変数
前述 し た ど ち ら のデー タ セ ッ ト に も 、 group と 呼ばれ る 、 デー タ が含 ま れていない文
字列 ( 非数値 ) 変数が含まれてい ます。 Amos では、 混合モデル回帰分析で group 変数
を使っ て個々のケース を分類 し ます ( こ こ で変数が group と 呼ばれてい る こ と は重要
ではあ り ません。 文字列変数であれば、 ど の変数名で も 使用で き ます )。
分析を開始す る 前に一部の ケー ス がすでに グループに割 り 当て ら れてい る 場合は、
デー タ セ ッ ト の [group] 列にグループ名を入力で き ます。 た と えば、 混合モデル回帰分
析を開始す る 前に、パフ ォーマ ン ス の高い被験者 と 低い被験者が標本に含まれていて、
標本の最初の 2 人が高パフ ォーマ ン ス、 その次の 3 人が低パフ ォーマ ン ス の被験者 と
わかっ てい る 場合、 デー タ 表の [group] 列にその情報を次の よ う に入力で き ます。
プ ロ グ ラ ムでは、 あ ら か じ め分類 さ れた こ の 5 つのケース を使用 し て、 残 り のケース
の分類を行ない ます。 選択 し た個々のケー ス を グループにあ ら か じ め割 り 当て る 作業
は、 こ こ では単な る 可能性 と し て述べてい る だけです。 こ の例では、 ケー ス を グルー
プにはあ ら か じ め割 り 当て ません。
517
混合回帰モデ リ ン グ
分析の実行
こ の例では、 DosageAndPerformance2.sav デー タ セ ッ ト のみを分析 し ます。
E
メ ニ ュ ーか ら 、[ フ ァ イル ][ 新規作成 ] を選択 し て新 し いパ ス図の作成を開始 し ます。
E
メ ニ ュ ーか ら [ 分析 ] [ グループ管理 ] を選択 し ます。
E [ 新規作成 ] を ク リ ッ ク し て 2 つ目のグループを作成 し ます。
E [ 閉 じ る ] を ク リ ッ ク し ます。
こ の例では、2 グループの混合回帰モデルを当てはめ ます。 存在す る グループの数がわ
か ら ない場合は、 プ ロ グ ラ ム を複数回実行で き ます。 プ ロ グ ラ ム を実行 し て 2 グルー
プのモデルを当てはめた後、 も う 1 度実行 し て 3 グループのモデルを当てはめた り す
る こ と がで き ます。
518
例 36
デー タ フ ァ イルの指定
E
メ ニ ュ ーか ら 、 [ フ ァ イル ][ デー タ フ ァ イル ] を選択 し ます。
E [ グループ番号 1] を ク リ ッ ク し て行を選択 し ます。
E [ フ ァ イル名 ] を ク リ ッ ク し 、 Amos の Examples デ ィ レ ク ト リ にあ る
DosageAndPerformance2.sav フ ァ イ ルを選択 し て、 [ 開 く ] を ク リ ッ ク し ます。
E [ グループ化変数 ] を ク リ ッ ク し 、 [ グループ化変数を選択 ] ダ イ ア ロ グ ボ ッ ク ス で
[group] を ダブル ク リ ッ ク し ます。 こ れで、 group と い う 変数を使っ て グループが区別
さ れます。
519
混合回帰モデ リ ン グ
E 同 じ デー タ フ ァ イ ル (DosageAndPerformance2.sav) と グループ変数 (group) を指定 し 、
グループ番号 2 について前述の手順を繰 り 返 し ます。
E [ ケース を グループに割 り 当て る ] を選択 し ます ( チ ェ ッ ク マー ク が表示 さ れます )。
[ ケース をグループに割 り 当て る ] の横にチ ェ ッ ク マー ク があ る の を除 き 、 こ こ ま では
通常の複数グループの分析 と 同 じ です。 こ のチ ェ ッ ク マー ク に よ っ て、 こ れが混合モ
デ リ ン グ分析にな り ます。 こ のチ ェ ッ ク マー ク が表示 さ れてい る と 、 デー タ フ ァ イ ル
のグループ変数がグループに割 り 当て ら れていない場合、 ケース はグループに割 り 当
て ら れます。 [ グループ値 ] を ク リ ッ ク し て グループ変数の値を指定す る 必要がなかっ
た こ と に注意 し て く だ さ い。 デー タ フ ァ イ ルには、 グループ変数 (group) の値が含 ま
れて い な いので、 [group] 変数の値 と し て、 グループ番号 1 の ケー ス に Cluster1、 グ
ループ番号 2 のケース に Cluster2 が自動的に作成 さ れます。
E [OK] を ク リ ッ ク し て、 [ デー タ フ ァ イ ル ] ダ イ ア ロ グ ボ ッ ク ス を閉 じ ます。
520
例 36
モデルの特定化
E 回帰モデルのパ ス図を次の よ う に作成 し ます。 ( こ のパ ス図は Ex07.amw と し て保存 さ
れてい ます )。
E
メ ニ ュ ーか ら [ 表示 ] [ 分析のプ ロパテ ィ ] の順に選択 し ます。
521
混合回帰モデ リ ン グ
E [ 平均値 と 切片を推定 ] を選択 し ます ( 隣にチ ェ ッ ク マー ク が表示 さ れます )。
522
例 36
モデルの適合
E ツールバーの
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら [ 分析 ] [ ベ イ ズ推定 ] を選択 し ます。
注 : 混合モデ リ ン グではベ イ ズ推定 し か実行で き ないため、
てい ます。
のボ タ ンは無効化 さ れ
[ ベ イ ズ SEM] ウ ィ ン ド ウ が開いた ら 、不機嫌な顔
が上機嫌の顔
に変わ る ま で
待ち ます。 [ ベ イ ズ SEM] ウ ィ ン ド ウ に、 次の よ う な推定値の表が表示 さ れます。
[ ベ イ ズ SEM] ウ ィ ン ド ウ に、通常の複数グループの回帰分析で取得 さ れ る すべてのパ
ラ メ ー タ 推定が表示 さ れ ま す。 グループ ご と に個別の推定値表があ り ま す。 推定値の
表の上部にあ る タ ブ を ク リ ッ ク す る と 、 別のグループに切 り 替え る こ と がで き ます。
523
混合回帰モデ リ ン グ
表の一番下の行には、 各グループの母集団におけ る 比率の推定値が表示 さ れ ま す。
グループ番号 1 の推定値を表示 し てい る 上の図では、 グループ番号 1 の母集団の比率
が 0.247 と 推定 さ れてい ます。 母集団の比率の推定事後分布を確認す る には、比率の行
を右 ク リ ッ ク し て、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ 事後分布の表示 ] を選択 し ます。
[ 事後分布 ] ウ ィ ン ド ウ のグ ラ フは、グループ番号 1 の母集団の比率が実質的に 0.15 ~
0.35 の範囲にな る こ と を保証 し てい ます。
524
例 36
こ こ で、 グループ番号 1 の係数 と 切片を グループ番号 2 の対応す る推定値 と 比較 し て
みま し ょ う 。 グループ番号 1 では、係数の推定値は 2.082、切片の推定値は 5.394 です。
グループ番号 2 では、 係数の推定値 (1.999) はグループ番号 1 と ほぼ同 じ ですが、 切片
の推定値 (9.955) はグループ番号 1 よ り 大幅に大 き く な っ てい ます。
525
混合回帰モデ リ ン グ
個々のク ラ スの分類
各ケース のグループ所属の確率を取得す る には、 次の よ う に し ます。
E [ 事後予測分布 ] ボ タ ン
を ク リ ッ ク し ます。
ま たは
E
メ ニ ュ ーか ら 、 [ 表示 ][ 事後予測分布 ] の順に選択 し ます。
[ 事後予測分布 ] ウ ィ ン ド ウ には、 それぞれのケース の変数 [group] が Cluster1 ま たは
Cluster2 の値を取 る 確率が表示 さ れてい ます。 ケース 1 は、 グループ番号 1 に属す る 確
率が 0.88、 グループ 2 に属す る 確率が 0.12 と 推定 さ れてい ます。 1 つ目のグループの
切片が約 5.394 なのに対 し て、 2 つ目のグループの切片が約 9.955 なの を考え る と 、 グ
ループ番号 1 がパフ ォーマンス の低いグループだ と 言え ます。 し たが っ て、 標本の 1 人
目の被験者がパフ ォ ーマ ン ス の低いグループに属す る 確率は 88 パーセン ト 、 パフ ォー
マンス の高いグループに属す る 確率は 12 パーセ ン ト です。
526
例 36
パラ メ ー タ 推定値の向上
推定に必要なパ ラ メ ー タ の数を減 ら す こ と に よ っ て、 パ ラ メ ー タ 推定値 ( お よ び Amos
の ク ラ ス タ 形成力 ) を向上で き ます。 先に確認 し た よ う に、 2 つのグループの回帰直線
の傾 き はほぼ同 じ です。 ま た、 各回帰直線のば ら つ き も 、 2 つのグループにおいてほぼ
同 じ に見え ます。 し たが っ て、 傾 き と 誤差分散は 2 つのグループで同 じ であ る と い う
仮説を混合モデ リ ン グ分析に取 り 入れ、 その結果、 推定 さ れ る 異な る パ ラ メ ー タ の数
を減 ら す こ と が可能です。 手順は次の と お り です。
E パ ス図で dosage と performance を結ぶ一方向矢印を右 ク リ ッ ク し て、 ポ ッ プア ッ プ メ
ニ ュ ーか ら [ オブ ジ ェ ク ト のプ ロパテ ィ ] を選択 し 、 [ 係数 ] テ キ ス ト ボ ッ ク ス にパ ラ
メ ー タ 名を 「b」 と 入力 し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス が開いてい る 状態で、 パ ス図の E1
を ク リ ッ ク し ます。
E [ オブジ ェ ク ト のプ ロ パテ ィ ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 分散 ] テ キ ス ト ボ ッ ク ス にパ
ラ メ ー タ 名を 「v」 と 入力 し ます。
527
混合回帰モデ リ ン グ
パ ス図は次の図の よ う にな り ます。 ( こ のパ ス図は Ex36-b.amw と し て保存 さ れてい
ます )。
傾 き と 誤差分散が 2 つのグループで同 じ にな る よ う に制約 し た ら 、 [ ベイ ジアン ] ボタ
ン
を ク リ ッ ク し て混合モデ リ ン グ分析を繰 り 返す こ と がで き ます。 こ こ では、 そ
の分析の結果は示 し ません。
528
例 36
グループ比率の事前分布
グループ比率の事前分布では、 ユーザーが指定で き る パラ メ ータ に よ る デ ィ リ シュ レ分
布を使用 し ます。 デフ ォ ル ト では、デ ィ リ シュ レ パラ メ ータ は 4, 4, … にな っ てい ます。
E デ ィ リ シュ レ パラ メ ータ を指定す る には、 [ ベ イ ズ SEM] ウ ィ ン ド ウ でグループ比率の
推定値を右 ク リ ッ ク し 、 ポ ッ プア ッ プ メ ニ ュ ーか ら [ 事前分布の表示 ] を選択 し ます。
ラ ベル ス イ ッ チ ング
こ こ でグループ番号 1 について報告 さ れ る 結果が、 グループ番号 2 について得 ら れ る
結果 と 一致 し 、 グループ 2 について報告 さ れ る 結果が、 グループ 1 について得 ら れ る
結果 と 一致す る 場合があ り ます。 つ ま り 、 ユーザーが得 る 結果 と こ こ で報告 さ れ る 結
果は一致す る が、 グループ名が反対にな っ てい る 場合があ る と い う こ と です。 こ れは、
ラ ベル ス イ ッ チン グ (Chung, Loken お よ び Schafer, 2004 年 ) と 呼ばれ る 場合があ り ま
す。 ラ ベル ス イ ッ チン グについては、 例 35 の最後に詳 し く 説明 し てい ます
例
37
パス図を描画 し ない場合の Amos
Graphics の使用
は じ めに
Amos Graphics では、 通常、 パ ス図を描画 し てモデルを指定 し ますが、 グ ラ フ ィ ッ ク を
使用 し ない方法 も 提供 さ れてい ます。 パ ス図を描画 し ない場合は、 Visual Basic ま たは
C# プ ロ グ ラ ムの形式でテ キ ス ト を指定で き ます。 こ の よ う なプ ロ グ ラ ムでは、 パ ス図
の各オブジ ェ ク ト ( 四角形、 楕円形、 片方向矢印、 双方向矢印、 図のキ ャ プシ ョ ン ) は、
単一のプ ロ グ ラ ム の ス テー ト メ ン ト に対応 し ます。 通常、 プ ロ グ ラ ム の ス テー ト メ ン
ト は、 1 行のテ キ ス ト です。
以下は、 パ ス図を描画す る 代わ り にテ キ ス ト を入力 し てモデルを指定す る 場合があ
る 理由です。
モデルが大 き すぎ る ため、 そのパ ス図を描画す る のが困難であ る
マ ウ ス よ り も キーボー ド の使用を好んでい る 、ま たはグ ラ フ ィ ッ ク よ り も テ キ ス ト
での作業を好んでい る
変数の数や変数名な ど のわずかな情報が異な る 類似 し た多数のモデル を生成す る
必要が あ る 。 こ の よ う な モデル を 頻繁に生成す る 必要が あ る 場合、 テ キ ス ト 出力
が、 IBM SPSS Amos を 当て はめ る 特定の モデル を 指定す る 、 カ ス タ ム の Visual
Basic ま たは C# プ ロ グ ラ ム と な る スーパー プ ロ グ ラ ム を作成 し 、 作業を自動化す
る と 効率的です。
こ の例は、 パ ス図を描画す る 代わ り にテ キ ス ト を入力 し て Amos Graphics でモデルを
指定す る 方法を示 し ます。
529
530
例 37
デー タ について
こ の例では、 例 8 の Holzinger and Swineford (1939) デー タ セ ッ ト を使用 し ます。
共通因子モデル
こ の例では、 例 8 の因子分析モデルを使用 し ます。 例 8 ではパ ス図の描画に よ っ てモ
デルを指定 し ま し たが、 こ の例では Visual Basic プ ロ グ ラ ム の記述に よ っ て同 じ モデ
ルを指定 し ます。
モデルを指定する プ ラ グ イ ンの作成
E
メ ニ ュ ーか ら 、 [ プ ラ グ イ ン ][ プ ラ グ イ ン ] を選択 し ます。
E [ プ ラ グ イ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 作成 ] を ク リ ッ ク し ます。
531
パス図を描画 し ない場合の Amos Graphics の使用
[ プ ロ グ ラ ム エデ ィ タ ] ウ ィ ン ド ウ が開 き ます。
E [ プ ロ グ ラ ム エデ ィ タ ] ウ ィ ン ド ウ で、 Name 関数 と Description 関数を有意義な文字
列を戻す よ う に変更 し ます。
こ の時点では、 例 8 の最初のパス図を参照す る と 役立ち ます。 パ ス図の各四角形、 楕
円形、 お よ び矢印の Mainsub 関数に 1 行を追加 し ます。
532
例 37
E プ ロ グ ラ ム エデ ィ タ で、 次の行
pd.Observed("visperc")
を Mainsub 関数の最初の行に入力 し ます。
こ こ でプ ラ グ イ ン を保存す る と 、 後で 「visperc」 と い う 変数を表す四角形の描画に使
用で き ます。 こ の四角形は、 パ ス 図の無作為の位置に、 任意の高 さ と 幅で描画 さ れ ま
す。 高 さ 、 幅、 お よ び位置を指定で き ます。 例を次に示 し ます。
pd.Observed("visperc", 400, 300, 200, 100)
こ れは、 「visperc」 と い う 変数の四角形 を 描画 し ま す。 四角形は、 パ ス 図の左端か ら
400 論理ピ ク セル、上端か ら 300 論理ピ ク セルの位置を中心に配置 さ れます。 ま た、幅
200 論理ピ ク セル、 高 さ 100 論理ピ ク セルの大 き さ です。 ( 論理ピ ク セルは、 1/96 イ ン
チです。 ) 他の Observed 方法の種類は、 オン ラ イ ンヘルプを ご覧 く だ さ い。
こ の例では、 パ ス図のオブジ ェ ク ト に高 さ と 幅を指定 し ません。
E プ ラ グ イ ンが残 り の 5 つの Observed 変数に対す る 四角形を描画す る よ う に、 Mainsub
関数に以下の行を追加入力 し ます。
pd.Observed("cubes")
pd.Observed("lozenges")
pd.Observed("paragrap")
pd.Observed("sentence")
pd.Observed("wordmean")
533
パス図を描画 し ない場合の Amos Graphics の使用
E プ ラ グ イ ンが 8 つの Unobserved 変数に対す る 8 つの楕円形を描画す る よ う に、以下の
行を入力 し ます。
pd.Unobserved("err_v")
pd.Unobserved("err_c")
pd.Unobserved("err_l")
pd.Unobserved("err_p")
pd.Unobserved("err_s")
pd.Unobserved("err_w")
pd.Unobserved("spatial")
pd.Unobserved("verbal")
E プ ラ グ イ ンが 12 個の片方向矢印を描画す る よ う に、 以下の行を入力 し ます。
pd.Path("visperc", "spatial", 1)
pd.Path("cubes", "spatial")
pd.Path("lozenges", "spatial")
pd.Path("paragrap", "verbal", 1)
pd.Path("sentence", "verbal")
pd.Path("wordmean", "verbal")
pd.Path("visperc", "err_v", 1)
pd.Path("cubes", "err_c", 1)
pd.Path("lozenges", "err_l", 1)
pd.Path("paragrap", "err_p", 1)
pd.Path("sentence", "err_s", 1)
pd.Path("wordmean", "err_w", 1)
上記の一部の行には、 Path 方法に 1 と 同等に設定 さ れた 3 つ目の引数があ り ますが、
こ の よ う に し て、 回帰の太 さ を定数値 1 に固定 し てい ま す。 他の Path 方法について
は、 オン ラ イ ン ヘルプを参照 し て く だ さ い。
534
例 37
E プ ラ グ イ ンが双方向矢印を描画す る よ う に、 以下の行を入力 し ます。
pd.Cov("spatial", "verbal")
E パ ス図でのオブジ ェ ク ト の位置を調整 し 、 見栄え を改善す る ために、 以下の行を入力
し ます。
pd.Reposition()
前述の と お り 、こ の例で使用 さ れてい る 単純な Observed、Unobserved、お よ び Caption
方法は、パ ス図の無作為な位置にオブジ ェ ク ト を配置 し ますが、 Reposition 方法は、オ
ブジ ェ ク ト の位置を再調整 し 、 パ ス図の見栄え を良 く し ます。 し か し 、 プ レ ゼ ン テー
シ ョ ン品質のパ ス 図を生成す る わけではあ り ません。 実際には、 その品質に及び も し
ま せん。 一方、 Reposition は通常パ ス 図の見栄え を 大幅に改善 し ま す。 パ ス 図のオブ
ジ ェ ク ト のサ イ ズ と 位置を希望どお り に変更す る には、 以下の手法があ り ます。
E pd ク ラ ス の Observed、 Unobserved、 お よ び Caption 方法を使用す る たびに、 高 さ 、 幅、
お よ び位置を指定 し ます。 (Observed、 Unobserved、 お よ び Caption 方法については、 オ
ン ラ イ ン ヘルプ を参照 し て く だ さ い。 )
ま たは
E プ ラ グ イ ンで、 Reposition 方法を使用 し て、 オブジ ェ ク ト の位置を調整 し ます。 プ ラ グ
イ ン を実行後、 Amos Graphics ツールボ ッ ク ス の描画ツールを使用 し て、 パ ス 図のオ
ブジ ェ ク ト を イ ン タ ラ ク テ ィ ブに移動お よ びサ イ ズの変更を行い ます。
元に戻す機能の制御
E 次の行を Mainsub 関数の最初の行に入力 し ます。
pd.UndoToHere
E 次の行を Mainsub 関数の最後の行に入力 し ます。
pd.UndoResume
UndoToHere 方法 と UndoResume 方法は、 [ 元に戻す ] ボ タ ン を 1 回 ク リ ッ ク す る こ
と でプ ラ グ イ ンの実行の効果が取 り 消 さ れ る よ う に、 セ ッ ト で使用 し ます。
535
パス図を描画 し ない場合の Amos Graphics の使用
こ れで、 プ ロ グ ラ ム エデ ィ タ の Mainsub 関数は次の よ う にな り ます。
こ れで、 例 8 の因子分析モデルを指定す る ためのプ ラ グ イ ンが完成 し ま し た。 記述済
みのプ ラ グ イ ンは、 Amos の plugins フ ォ ルダの フ ォ ルダにあ る 「Ex37a-plugin.vb」 と
い う フ ァ イ ル に あ り ま す。 IBM SPSS Amos を 通常 イ ン ス ト ール し た 場合、 Ex37aplugin.vb は、 C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Plugins¥<language> にあ り ます。
536
例 37
プ ラ グ イ ンの コ ンパイル と 保存
E [ プ ロ グ ラ ム エデ ィ タ ] ウ ィ ン ド ウ の [ コ ンパイル ] を ク リ ッ ク し ます。 [ プ ロ グ ラ ム エ
デ ィ タ ] ウ ィ ン ド ウ の [ コ ンパ イ ル エ ラ ー] タ ブに コ ンパ イ ル エ ラ ーが表示 さ れます。
E
コ ンパ イ ル エ ラ ーを修正 し た ら 、 [ プ ロ グ ラ ム エデ ィ タ ] ウ ィ ン ド ウ の [ 閉 じ る ] を ク
リ ッ ク し ます。 フ ァ イ ルを保存す る か ど う か を問われます。
E [ はい ] を ク リ ッ ク し ます。 [ 名前を付けて保存 ] ダ イ ア ロ グ ボ ッ ク ス が表示 さ れます。
E [ 名前を付けて保存 ] ダ イ ア ロ グ ボ ッ ク ス で、プ ラ グ イ ンの名前を入力 し て [ 保存 ] を ク
リ ッ ク し ます。 プ ラ グ イ ンは、 [ 名前を付けて保存 ] ダ イ ア ロ グのデフ ォ ル ト の フ ォ ル
ダに保存す る 必要があ り ます。 Amos の通常 イ ン ス ト ールの場合、デフ ォ ル ト の フ ォ ル
ダの場所は C:¥Program Files¥IBM¥SPSS¥Amos¥23¥Plugins です。
537
パス図を描画 し ない場合の Amos Graphics の使用
プ ラ グ イ ン を保存 し た ら 、プ ラ グ イ ン名 Example 37a が [ プ ラ グ イ ン ] ウ ィ ン ド ウ のプ
ラ グ イ ン リ ス ト に表示 さ れます。 (Example 37a は、 プ ラ グ イ ンの Name 関数を使用 し
て戻 さ れ る 文字列です。 )
E [ プ ラ グ イ ン ] ウ ィ ン ド ウ を閉 じ ます。
538
例 37
プ ラ グ イ ンの使用方法
E
メ ニ ュ ーか ら 、 [ フ ァ イル ][ 新規作成 ] を選択 し ます。
作業を保存す る か ど う かを問われた場合は、 [ はい ] ま たは [ いいえ ] を選択 し ます。
E
メ ニ ュ ーか ら 、 [ プ ラ グ イ ン ][Example 37a] を選択 し ます。 プ ラ グ イ ンに よ っ て、 モ
デルのパ ス図が生成 さ れ、 パ ス 図 ウ ィ ン ド ウ にモデルが表示 さ れ ます。 以下は、 こ の
例の準備中に生成 さ れたパス図です。( パ ス図内の要素の位置付けは乱数ジ ェ ネ レー タ
に よ っ て決定 さ れ る ため、 こ れ と は異な る パ ス図が表示 さ れ る 場合があ り ます )
539
パス図を描画 し ない場合の Amos Graphics の使用
モデル指定以外のその他の分析機能
例 8 では、 デー タ フ ァ イ ル Gmt_fem.sav を イ ン タ ラ ク テ ィ ブに指定 し ま し た ( メ
ニ ュ ーか ら 、 [ フ ァ イル ][ デー タ フ ァ イル ] を選択 )。 こ こ で も 、 同 じ 操作を実行で き
ま す。 ま た は、 Mainsub 関数に以下の行 を 追加す る こ と に よ っ て、 プ ラ グ イ ン 内で
Gmt_fem.sav デー タ フ ァ イ ルを指定す る こ と も で き ます。
pd.SetDataFile(1, MiscAmosTypes.cDatabaseFormat.mmSPSS, _
"C:\Program Files\IBM\SPSS\Amos\23\Examples\English\grnt_fem.sav", "", "", "")
同様に、 例 8 では、 標準化推定値は、 イ ン タ ラ ク テ ィ ブに要求 さ れて い ま し た ( メ
ニ ュ ーの [ 表示 ] [ 分析プ ロパテ ィ ] を選択 )。 標準化推定値を イ ン タ ラ ク テ ィ ブに要
求す る 代替手法 と し て、 Mainsub 関数に以下の行を追加す る こ と に よ っ て、 プ ラ グ イ
ン内で要求す る こ と がで き ます。
pd.GetCheckBox("AnalysisPropertiesForm", "StandardizedCheck").Checked = True
一般的に、 イ ン タ ラ ク テ ィ ブに指定で き る 分析の機能は、 pd ク ラ ス の方法 と プ ロ パ
テ ィ を使用 し てプ ラ グ イ ン内で指定で き ます。
モデル変数に対応する プ ログ ラ ム変数の定義
パ ス 図にオブジ ェ ク ト を作成す る 方法には、 Oserved、 Unobserved、 Path、 Cov、 お よ
び Caption の 5 つがあ り ます。 こ れ ら の各方法は、それが作成す る オブジ ェ ク ト への参
照を返 し ます。 た と えば、 Observed 方法は、 パ ス図に観測変数を作成 し 、 さ ら にその
観測変数に参照を返 し ます。 以下の行
pd.Observed("wordmean")
pd.Unobserved("verbal")
を 記述 し て観測変数 wordmean と 非観測変数 verbal を 作成す る 代わ り に、 以下の行
(Visual Basic) を記述で き ます。
Dim wordmean As PDElement = pd.Observed("wordmean")
Dim verbal As PDElement = pd.Unobserved("verbal")
それか ら 、 プ ロ グ ラ ム変数 wordmean を使用 し てモデル変数 wordmean を参照 し 、 プ
ロ グ ラ ム 変数 verbal を 使用 し て モデル変数 verbal を 参照で き ま す。 verbal 変数か ら
wordmean 変数に片方向矢印を描画す る には、 以下のいずれか を記述で き ます。
pd.Path(wordmean, verbal)
ま たは
pd.Path(ìwordmeanî, "verbal")
540
例 37
引用符を使用 し ない記述方法には、 引用符を使用 し ない場合にプ ラ グ イ ン を コ ンパ イ
ル し た と き ([ プ ロ グ ラ ム エデ ィ タ ] ウ ィ ン ド ウ で [ コ ンパイル ] を ク リ ッ ク し た と き )
に入力エ ラ ーが検出 さ れやすい と い う と こ ろ に、 利点があ り ます。 引用符を使用す る
と 、 入力エ ラ ーがあ る場合に、 プ ラ グ ラ イ ン を使用す る ま でエ ラ ーは検出 さ れません。
フ ァ イ ル Ex37b-plubin.vb には、Ex37a-plugin.vb と 同 じ 機能を持つプ ラ グ イ ンが含まれ
ますが、 Ex37b-plugin.vb は Visual Basic 変数を使用 し てモデル変数を参照 し てい る 点
が異な り ま す。 Amos を通常 イ ン ス ト ール し た場合、 Ex37b-plugin.vb は、 C:¥Program
Files¥IBM¥SPSS¥Amos¥23¥Plugins¥ にあ り ます。
例
38
単純なユーザー定義数量 I
は じ めに
こ の例では、 ブー ト ス ト ラ ッ プ標準誤差、 信頼区間、 有意検査を使用 し てモデル パ ラ
メ ー タ のユーザー定義関数を推定す る 方法を示 し てい ま す。 こ の例では、 1 つのユー
ザー定義関数が推定 さ れます。 こ れは間接効果です。
こ の例では、 パ ラ メ ー タ のユーザー定義関数を推定す る 簡略化 さ れた方法を示 し て
い ます。 簡略化 さ れた方法では、 単一の式で定義で き る 数量 も 限定 さ れます。 Amos の
ユーザー定義数量機能の よ り 一般的なバージ ョ ン ( こ こ では示 し てい ません ) では、任
意の長 さ と 複雑 さ のプ ロ グ ラ ム 1 つで数量を定義で き ます。 よ り 一般的なバージ ョ ン
については、 オン ラ イ ン ヘルプの ト ピ ッ ク 「CValue Class Reference (CValue ク ラ ス参
照 )」 を参照 し て く だ さ い。 http://amosdevelopment.com/video/index.htm では動画で
も 説明 し てい ます。
541
542
例 38
Wheaton のデー タ の再考
例 6 では、 Wheaton ら (1977) のデー タ の 3 つの代替モデルについて説明 し ま し た。 こ
こ では、 例 6 のモデル B を再度取 り 上げます。 フ ァ イ ル Ex38.amw にあ る次のパス図
は、 例 6 のモデル B にい く つかのパ ラ メ ー タ 名を追加 し た も のです。
例 6 で 67alienation と い う 名前だ っ た潜在的変数は、 こ こ では alienation67 と い う 名前
にな っ てい ます。 同様に、 71alienation も alienation71 に変更 さ れてい ます。 変数名を
変更 し た理由は、 こ れ ら の名前が、 名前の先頭に数値を使用で き ない式で表示 さ れ る
こ と にな る ためです。
間接効果の推定
こ のモデルの 5 つの回帰の重み付けが A、 B、 C、 D、 E と い う 名前にな っ てい る のは、
powles71 に対す る ses の間接効果について説明 し やす く す る ためです。 こ の よ う な間
接効果には、 積 AB お よ び積 CDB の 2 つがあ り ます。 2 つの間接効果の和 AB + CDB
は、 [ 表示 ] > [ 分析のプ ロパテ ィ ] > [ 出力 ] を ク リ ッ ク し て [ 間接、 直接、 または総合効
果 ] の横にチ ェ ッ ク マー ク を付け る こ と で推定で き ます。 こ の機能は Amos に組み込
まれてい る ため、 ユーザー定義数量を指定す る 必要はあ り ません。 ただ し 、 た と えば
AB と CDB な ど の個々の間接効果を その和 と 共に推定 し たい場合 も あ り ます。 こ れは
次の方法でユーザー定義数量 と し て推定で き ます。
543
単純なユーザー定義数量 I
E [Amos Graphics] ウ ィ ン ド ウ の左下にあ る ス テー タ スバーで [ ユーザー定義数量を推定 し
ない ] を ク リ ッ ク し ます。次に、 ポ ッ プア ッ プ メ ニ ューで [ 新 し い数量を定義 ] を ク リ ッ
ク し ます。
E 新 し い ウ ィ ン ド ウ が開いた ら 、 3 行に入力 し て 3 つのカ ス タ ム数量を定義 し ます。
3 つのカ ス タ ム数量の名前は、 Indirect_AB、 Indirect_CDB、 Sum です。 別の名前を指
定す る こ と も で き ます。 数量の名前は英数字 と 下線で構成す る 必要があ り ます。 先頭
文字は英字でなければな り ません。 大文字小文字は区別 さ れません。 つま り 、 Abc と
い う 数量がすでにあ る 場合、 abc と い う 名前は使え ません。
544
例 38
パ ラ メ ー タ 名には、 接頭辞 「p.」 と 1 文字を組み合わせます。 た と えば、 「p.A」 は 「A
と い う 名前のパ ラ メ ー タ 」 を意味 し ます。 読みやす く す る ために、 「p.」 接頭辞は省略
さ れ る こ と も あ り ます。
ただ し 、 「p.」 を使用す る と 、 「p.」 と 入力すればパ ラ メ ー タ 名の一覧が表示 さ れて、 簡
単にパ ラ メ ー タ を選択で き る と い う 利点があ り ます。以下の ス ク リ ーン シ ョ ッ ト では、
パ ラ メ ー タ リ ス ト の A を ダブル ク リ ッ ク す る と 、 キーボー ド で 「A」 と 入力 し たの と
同 じ 結果にな り ます。
「p.」 を使用す る 必要のあ る 状況が 1 つあ り ます。 A と い う 名前のパ ラ メ ー タ と A と
い う 名前の変数の両方が あ る と 、 単に 「A」 と 入力す る と あい ま いにな り ま す。 こ の
よ う な場合、 「A」 と い う 名前のパ ラ メ ー タ には 「p.A」 、 「A」 と い う 名前の変数には
「v.A」 と 入力す る 必要があ り ます。
545
単純なユーザー定義数量 I
E ま た、 次の よ う に行 と コ メ ン ト を入力す る こ と も で き ます。
E [ 閉 じ る ] ボ タ ン を ク リ ッ ク し ます。
E 次のダ イ ア ロ グで [ はい ] を ク リ ッ ク し ます。
546
例 38
E [ 名前を付けて保存 ] ダ イ ア ロ グで、 [ フ ァ イ ル名 ] ボ ッ ク ス に 「indirect effects」 と 入
力 し ます。 次に、 [ 保存 ] ボ タ ン を ク リ ッ ク し ます。
E [ 表示 ] > [ 分析のプ ロパテ ィ ] > [ ブー ト ス ト ラ ッ プ ] を ク リ ッ ク し 、[ ブー ト ス ト ラ ッ プの実
行 ] お よ び [ バイ ア ス修正済信頼区間) ] の横にチ ェ ッ ク マー ク を付け ます。 ま た、 デー
タ フ ァ イ ルに標本積率が含まれていて生デー タ は含まれていないため、 [ モ ン テ カルロ
( パラ メ ト リ ッ ク ブー ト ス ト ラ ッ プ )] の横に も チ ェ ッ ク マー ク を付け ます。
E [ 分析 ] > [ 推定値を計算 ] を ク リ ッ ク し ます。
E [ 表示 ] > [ テキス ト 出力の表示 ] を ク リ ッ ク し ます。
547
単純なユーザー定義数量 I
E [Amos 出力 ] ウ ィ ン ド ウ で [ 推定値 ] を ダブル ク リ ッ ク し てか ら [ ス カ ラ ー] を ダブル ク
リ ッ ク し 、 [ ユーザー定義数量 ] を ク リ ッ ク し ます。
Indirect_AB と い う 名前の数量は -0.205 と 推定 さ れてい ます。 こ れは。 回帰の重み付け
A (–0.212) と 回帰の重み付け B (0.971) の積です。
E [ ブー ト ス ト ラ ッ プの標準誤差 ] を ク リ ッ ク し ます。
Indirect_AB は、 おお よ そ正規分布に従っ ていて、 標準誤差は約 0.048 です。
548
例 38
E [ ブー ト ス ト ラ ッ プの信頼度 ] を ク リ ッ ク し ます。
Indirect_AB の母集団値は、 90% の信頼度で -0.283 ~ -0.118 です。 推定値が –0.205 の
場合、 p 値は 0.013 にな り ます。 0.05 の水準ではゼ ロ か ら 有意な差があ り ますが、 0.01
の水準では有意な差はあ り ません。
549
単純なユーザー定義数量 I
パラ メ ー タ に名前を付けない間接効果の推定
パ ラ メ ー タ の関数を推定 し よ う と 考え てい る 場合、 上記の よ う に、 こ れ ら のパ ラ メ ー
タ に名前を付け る と い う 方法が便利です。 ただ し 、 パ ラ メ ー タ に名前を付け る 必要が
あ る わけではあ り ません。 次の手順は、 推定 し たばか り の同 じ 間接効果を推定す る 方
法を示 し てい ますが、 パ ラ メ ー タ 名を使用 し てい ません。
E [Amos Graphics] ウ ィ ン ド ウ の左下にあ る ス テー タ ス バーで [Simple indirect effect の
推定 ] を ク リ ッ ク し ます。 次に、 ポ ッ プア ッ プ表示 さ れ る メ ニ ュ ーで [Simple indirect
effects の編集 ] を ク リ ッ ク し ます。
パ ラ メ ー タ を名前で参照す る 場合には、パ ラ メ ー タ の説明を次の よ う に置 き 換え ます。
E 「p.A」 を 「e.DirectEffect(alienation71,ses)」 に変更 し ます。
E 「p.B」 を 「e.DirectEffect(powles71,alienation71)」 に変更 し ます。
E 「p.C」 を 「e.DirectEffect(alienation67,ses)」 に変更 し ます。
550
例 38
E 「p.D」 を 「e.DirectEffect(alienation71,alienation67)」 に変更 し ます。
置換を終え る と 、 カ ス タ ム数量の指定は次の よ う にな り ます。
E [ 閉 じ る ] ボ タ ン を ク リ ッ ク し ます。
E 表示 さ れ る ダ イ ア ロ グ ボ ッ ク ス で [ はい ] を ク リ ッ ク し ます。
E [ 分析 ] > [ 推定値を計算 ] を ク リ ッ ク し ます。
E [ 表示 ] > [ テキス ト 出力の表示 ] を ク リ ッ ク し ます。( テ キ ス ト 出力は、前回 と 同 じ です )。
例
39
単純なユーザー定義数量 II
は じ めに
こ の例では、 ブー ト ス ト ラ ッ プ標準誤差、 信頼区間、 差の有意検査を使用 し て 2 つの
標準化 さ れた回帰の重み付けの差を推定す る 方法を示 し てい ます。
デー タ について
39 人の生徒がい る ク ラ ス に対 し て 4 回の小テ ス ト が行われま し た。 小テ ス ト は、 学期
中、 ほぼ一定の間隔を空けて行われま し た。 フ ァ イ ル QuizComplete.txt には、 4 回の小
テ ス ト をすべて受けた生徒 22 人の点数が記載 さ れてい ます。
Markov モデル
フ ァ イ ル Ex39.amw には、4 回の小テ ス ト の点数の Markov モデルが記載 さ れてい ます。
551
552
例 39
次のパ ス図は、 こ のモデルについて推定 さ れ る 標準化 さ れた回帰の重み付け を示 し て
い ます。
2 つの標準化 さ れた回帰の重み付け を比較 し てみま し ょ う 。 た と えば、 q3 を予測す る
ための q2 を使用 し た重み付け と q4 を予測す る ための q3 を使用 し た重み付け を比較
し ます。 2 つの推定値の差は約0.39 – 0.35 = 0.04 です。 その差の標準誤差を求め、
信頼区間 と その差の有意検査を求め ま し ょ う 。
E [Amos Graphics] ウ ィ ン ド ウ の左下にあ る ス テー タ ス バーで [ ユーザー定義数量を推定
し ない ] を ク リ ッ ク し ます。 次に、 ポ ッ プア ッ プ表示 さ れ る メ ニ ュ ーで [ 新 し い数量を
定義 ] を ク リ ッ ク し ます。
553
単純なユーザー定義数量 II
E 新 し い ウ ィ ン ド ウ が開いた ら 、 次の よ う に 1 行に入力 し て新 し い数量を定義 し ます。
StandardizedWeightDiff 以外の名前を選ぶ こ と も で き ます。
E [ シ ン タ ッ ク ス を検証 ] ボ タ ン を ク リ ッ ク し ます。入力に間違いがなければ、[ 説明 ] ボ ッ
ク ス に 「 シ ン タ ッ ク スは OK です。」 と 表示 さ れます。
E [ 閉 じ る ] ボ タ ン を ク リ ッ ク し ます。
E 次のダ イ ア ロ グで [ はい ] を ク リ ッ ク し ます。
554
例 39
E [ 名前を付けて保存 ] ダ イ ア ロ グで、[ フ ァ イ ル名 ] ボ ッ ク ス に StandardizedDifference
と 入力 し ます。 次に、 [ 保存 ] ボ タ ン を ク リ ッ ク し ます。
E [ 表示 ] > [ 分析のプ ロパテ ィ ] > [ ブー ト ス ト ラ ッ プ ] を ク リ ッ ク し 、[ ブー ト ス ト ラ ッ プの実
行 ] お よ び [ バイ ア ス修正済信頼区間) ] の横にチ ェ ッ ク マー ク を付け ます。
E [ 分析 ] > [ 推定値を計算 ] を ク リ ッ ク し ます。
E [ 表示 ] > [ テキス ト 出力の表示 ] を ク リ ッ ク し ます
555
単純なユーザー定義数量 II
E [Amos 出力 ] ウ ィ ン ド ウ で [ 推定値 ] を ダブル ク リ ッ ク し てか ら [ ス カ ラ ー] を ダブル ク
リ ッ ク し 、 [ ユーザー定義数量 ] を ク リ ッ ク し ます。
StandardizedWeightDiff と い う 名前の数量は 0.047 と 推定 さ れてい ます。
E [ ブー ト ス ト ラ ッ プの標準誤差 ] を ク リ ッ ク し ます。
こ の差は、 おお よ そ正規分布に従っ ていて、 標準誤差は約 0.426 です。
556
例 39
E [ ブー ト ス ト ラ ッ プの信頼度 ] を ク リ ッ ク し ます。
差の母集団値は、 90% の信頼度で -0.679 ~ 0.688 です。 0.047 と い う 推定値は、 従来
の ど の有意水準で も ゼ ロ か ら 有意な差があ り ません (p = 0.934)。
付録
A
表記法
q = パラ メ ータ数
= パ ラ メ ー タ のベ ク ト ル ( 次の q)
G = グループ数
N
g
= グループ g のオブザベーシ ョ ン数
G
N =
N
g
= 全グループを統合 し たオブザベーシ ョ ン総数
g=1
p
g
p
*g
= グループ g の観測変数の数
= グループ g の標本の積率数。 平均 と 定数項が明示的なモデル パ ラ メ ー タ であ る
場合、 関連す る 標本の積率は、 平均、 分散、 お よ び共分散であ り 、
g
g
g
p * = p p + 3 2 と な り ます。 それ以外の場合は、 標本分散 と 共分散
g
g
g
= p p + 1 2 と な り ます。
のみがカ ウ ン ト さ れ、p *
G
p =
p
*g
= 全グループ を統合 し た標本の積率数
g=1
d = p – q = モデルの検定のための自由度の数
g
x ir = グループ g の i 番目の変数の r 番目のオブザベーシ ョ ン
g
xr
S
g
= グループ g の r 番目のオブザベーシ ョ ン
= グループ g の標本共分散行列
g
= モデルに従っ た、 グループ g の共分散行列
g
= モデルに従っ た、 グループ g の平均ベ ク ト ル
g
0
= グループ g の母集団共分散行列
557
558
付録 A
g
0
s
g
= グループ g の母集団平均ベ ク ト ル
g
= vec S = 単一の列ベ ク ト ルに配列 さ れた p *
g
g
のS
g
の異な る 要素
g
= vec
r = ChiCorrect 方 式 で 指 定 さ れ た 負 で な い 整 数 値。 デ フ ォ ル ト で は、 r = G で す。
Emulisrel6 方式を使用 し た場合、 r = G であ り 、 ChiCorrect を使用 し て変更す
る こ と はで き ません。
n=N–r
a = す べ て の グ ル ー プ の 標本 の 積率 を 含 む、 p 次 の ベ ク ト ル、 す な わ ち a に は
1
G
S S の要素 と ( 平均 と 定数項が明示的なモデル パ ラ メ ー タ であ る 場
1
G
も 含まれます。
合 ) x x
␣ 0 = すべての グループの母集団の積率を含む、 p 次のベ ク ト ル、 すなわち ␣ 0 には
1
G
0 0 の要素 と ( 平均 と 定数項が明示的なモデル パ ラ メ ー タ であ る 場
1
G
合 ) 0 0 も 含まれます。 ␣ の要素の順序は、a の要素の順序 と 一致
し てい る 必要があ り ます。
␣ = モデルに従っ て、 すべてのグループの母集団の積率を含む、 p 次のベ ク ト ル、
1
G
すなわち ␣ には の要素 と ( 平均 と 定数項が明示的な
1
G
モデル パ ラ メ ー タ であ る 場合 ) も 含まれます。 ␣ の要
素の順序は、a の要素の順序 と 一致 し てい る 必要があ り ます。
F ␣ a = モデルの標本への当てはめで最小化 さ れ る 関数 (␥) の )
̂ = F ␣ a を最小化す る ␥ の値
ˆ g
g
= ̂
̂
g
g
= ̂
␣ˆ = ␣ ̂
付録
B
乖離度
Amos は次の形式の乖離度 (Browne, 1982, 1984) を最小化 し ます。
(D1)
G g
N f g , g ;x g , S g
g 1
C ,a N r
N
N r F ,a
f の定義方法を変更す る こ と に よ り 、 さ ま ざ ま な乖離度が得 ら れます。 平均 と 定数項に
g
g
と は省
制約条件がな く 、 明示的モデル パ ラ メ ー タ と し て表示 さ れない場合、x
g
g
略 さ れ、 f は f ; S と 表 さ れます。
乖離度
C KL と F KL は、 f を次の よ う にす る こ と に よ っ て得 ら れます。
1
1
f KL g , g ; x g , S g log g tr S g g x g g g x g g
標本サ イ ズにのみ依存す る 付加定数を除 き 、f KL は、 Kullback-Leibler の情報量の - 2 倍
です (Kullback & Leibler, 1951)。 厳密に言 う と 、 C KL と F KL は、F KL a a 0 であ る た
め、 Browne の定義に よ る と 乖離度 と はみな さ れません。
最尤法推定値 (ML) では、 C ML および
F ML は f を次のよ う にする こ と によ って得られます。
(D2)
f ML g , g ; x g , S g f KL g , g ; x g , S g f KL x g , S g ; x g , S g
1
1
log g tr S g g log S g p g x g g g x g g .
559
560
付録 B
一般化最小 2 乗法推定値 (GLS) では、 C GLS お よ び
よ っ て得 ら れます。
F GLS は f を次の よ う にす る こ と に
(D3)
f GLS g ;S g 12 tr S g S g g
1
漸近的分布非依存推定値 (ADF) の場合、 C ADF お よ び
に よ っ て得 ら れます。
2
F ADF は f を次の よ う にす る こ と
(D4)
G
1
f ADF g ;S g s g g ( ) U g s g g ( )
g 1
U
g
の要素は、 Browne (1984, Equations 3.1 - 3.4) に よ っ て次の よ う に表 さ れます。
(g)
i
x
wij( g )
(g)
ij , kl
w
1
Ng
x
Ng
r 1
(g)
ir
1
Ng
1
Ng
x
Ng
r 1
(g)
ir
Ng
x
(g)
ir
r 1
xi( g ) x (jrg ) x (j g )
xi( g ) x (jrg ) x (j g ) xkr( g ) xk( g ) xlr( g ) xl( g )
U
g
ij , kl
wij( g,kl) wij( g ) wkl( g )
尺度不変最小 2 乗推定値 (SLS) では、 C SLS お よ び
よ っ て得 ら れます。
(D5)
F SLS は f を次の よ う にす る こ と に
f SLS g ;S g 12 tr D g S g g
こ の と き 、D
g
1
2
g
= diag(S ) と な り ます。
重み付けのない最小 2 乗法 推定値 (ULS) では、 C ULS お よ び
る こ と に よ っ て得 ら れます。
F ULS は f を次の よ う にす
561
乖離度
(D6)
fULS g ;S g 12 tr S g g
2
Amos の Emulisrel6 方式は、 (D1) を以下で置 き 換え る のに使用で き ます。
(D1a)
G
C N g 1 F g
g 1
F は、 F = C N – G と し て計算 さ れます。
G = 1 かつ r = 1 の場合、 (D1) お よ び (D1a) は等 し く 、 次の よ う に表 さ れます。
C N 1 1 F 1 ( N 1) F
最尤法、 漸近的分布非依存、 お よ び一般化最小 2 乗法推定値では、 (D1) お よ び (D2)
共、 適切な分布の仮定の下で正 し く 指定 さ れたモデルに対 し て カ イ 2 乗分布 と な り ま
す。 漸近的には、 (D1) と (D2) は等価ですが、 ど ち ら の式で も 、 有限標本ではあ る 程度
の不一致が見 ら れます。
2 つの独立 し た標本があ り 、 それぞれに 1 つのモデルを使用す る と し ます。 さ ら に、
こ の 2 つの標本を同時に分析 し ますが、 その場合に、 1 つのモデルの任意のパ ラ メ ー
タ が も う 1 つのモデルのパ ラ メ ー タ と 等 し い こ と を要求す る 制約条件を課 さ ない こ と
と し ま す。 次に、 (D1a) を最小化 し た場合、 両グループの同時分析か ら 得 ら れたパ ラ
メ ー タ 推定値は、 各グループの別々の分析か ら 得 ら れた も の と 同 じ にな り ます。
さ ら に、 同時分析か ら 得 ら れた乖離度 (D1a) は、 2 つの個別の分析か ら 得 ら れた乖
離度の合計にな り ます。 r がゼ ロ 以外の場合、 公式 (D1) には こ のプ ロ パテ ィ があ り ま
せん。 公式 (D1) を使用 し て 2 つのグループの同時分析を実行す る と 、 2 つの別々の分
析 と 同 じ パ ラ メ ー タ 推定値が得 ら れ ますが、 同時分析か ら の乖離度は、 個別の乖離度
の合計にはな り ません。
一方、Amos を使用 し てモデルを当てはめた単一の標本があ る と し ます。 こ の標本を
任意にサ イ ズの異な る 2 つのグループに分割 し 、 それ ら のグループの同時分析を実行
す る と し ます。 こ の と き 、 両グループの元のモデルを採用 し 、 第 1 グループの各パ ラ
メ ー タ が第 2 グループの対応す る パ ラ メ ー タ と 等 し く な る よ う に制約条件を設定 し ま
す。 両方の分析で (D1) を最小化 し た場合、 両方 と も 同 じ 結果が得 ら れ ま す。 ただ し 、
両方の分析で (D1a) を使用 し た場合、 2 つの分析では異な る 推定値 と F に対す る 異な
る 最小値が生成 さ れます。
こ こ で指摘 さ れた不一致はすべて、 r = 0 を選択 し 、 (D1) が次の よ う にな る よ う に し
て (D1) を使用す る こ と に よ っ て回避で き ます。
G
C N g F g N F
g 1
付録
C
適合度
モデル評価は、 構造モデ リ ン グ に関連す る 、 最 も 難 し い未解決 な 問題の 1 つです。
Bollen & Long (1993)、 MacCallum (1990)、 Mulaik 他 (1989)、 お よ び Steiger (1990) は、
こ の問題について さ ま ざ ま な見解や推奨案を提唱 し てい ます。 少な く と も 乖離度の値
の ほ か に、 多数の統計量が モデルの メ リ ッ ト の測定値 と し て 提唱 さ れ て き ま し た。
Amos は こ れ ら のほ と ん ど の統計量を算出 し ます。
適合度は、 ユーザーに よ っ て指定 さ れた各モデルに対 し て、 ま た、 飽和モデルお よ
び独立モデル と 呼ばれ る 2 つの追加のモデルに対 し て使用 さ れます。
飽和モデルでは、 母集団の積率に制約条件が設定 さ れません。 飽和モデルは、 最 も
一般的なモデルです。 あ ら ゆ る デー タ セ ッ ト に完全に適合す る こ と が保障 さ れて
い る と い う 意味では、 空疎なモデルです。 すべての Amos モデルは、 飽和モデルに
制約条件が付け ら れた も のです。
独立モデルは こ れ と 正反対の性格を持っ てい ます。 独立モデルでは、 観測変数に相
関はない も の と 仮定 さ れます。 平均値が推定ま たは制約 さ れてい る場合、 すべての
観測変数の平均値は 0 に固定 さ れます。 独立モデルは信 じ 難いほど厳密に制約 さ れ
る ため、 いかな る興味あ るデー タ セ ッ ト に も あ ま り 適合 し ません。
指定 し た各モデルが、独立モデルに等 し く な る よ う に制約 さ れ る 場合が良 く あ り ます。
こ の場合、 飽和モデル と 独立モデルは、 2 つの極値で あ り 、 提案 し たモデルは こ の間
に位置す る と みなす こ と がで き ます。
最尤法以外のすべての推定法の場合、 Amos は、 すべてのパ ラ メ ー タ が 0 に固定 さ
れ る ゼ ロ モデルの適合度 も 報告 し ます。
563
564
付録 C
倹約性の測度
比較的パ ラ メ ー タ の少ない ( かつ、 比較的自由度の多い ) モデルは、 倹約性、 すなわち
単純性が高い と 考え ら れます。 パ ラ メ ー タ の多い ( かつ、 自由度の少ない ) モデルは、
複雑であ り 、 倹約性に欠け てい る と 考え ら れ ます。 こ の単純 と 複雑 と い う 言葉の用法
は、 必ず し も 日常の用法には適合 し てい ません。 た と えば、 飽和モデルは複雑であ り 、
線形従属の凝っ たパ タ ーン を持ち、 パ ラ メ ー タ 値が高度に制約 さ れてい る モデルは単
純であ る と い う こ と にな り ます。
単純で、 倹約性の高いモデルが好ま し い (Mulaik 他、 1989) と い う 根拠を調べ る こ と
はで き ますが、 倹約性の高いモデルが複雑なモデル よ り も 好ま し い と い う 点では異論
はない よ う に思われ ます。 他がすべて同 じ であ る と す る と 、 パ ラ メ ー タ と い う 点では
少ない方が好ま し い と 言え ます。 同時に、 適合性の高いモデルは適合性の低いモデル
よ り も 好ま し い も のです。 多 く の適合度は、 こ の相反す る 2 つの目的、 すなわち単純
さ と 適合度のバ ラ ン ス を と ろ う と し てい ます。
複雑度 と 適合度の間の数値的に最良の妥協点はあ る 程度個人の好みの問題で あ
る ため、最終分析において複雑 さ の測度 と 適合度の測度を単一の数値指標に組み
合わせ る 1 つの最良の方法を定義す る こ と は、あ る 意味では不可能であ る と も 言
え ます。 モデルの選択は、 嗜好についての 2 次元分析におけ る 昔か ら の課題です
(Steiger, 1990、 p. 179)。
NPAR
NPAR は、 推定 さ れ る 異な る パ ラ メ ー タ (q) の数です。 た と えば、 相互に等 し い こ と が
求め ら れ る 2 つの係数は 1 つのパ ラ メ ー タ と し て数え ら れます。
注 : 出力パス図にパ ラ メ ー タ の数を表示す る には、¥npar テキス ト マ ク ロ を使用 し ます。
DF
DF はモデルの検定のための自由度の数です。
df d p q
p は標本の積率数であ り 、 q は異な る パ ラ メ ー タ の数です。 Rigdon (1994a) は、 自由度
の計算 と 解釈について詳 し く 説明 し てい ます 。
注 : 出力パス図に自由度を表示す る には、 ¥df テ キ ス ト マ ク ロ を使用 し ます。
565
適合度
PRATIO
倹約率 (James, Mulaik, お よ び Brett, 1982。 Mulaik 他 , 1989) は、 評価対象のモデルの制
約条件の数を、 独立モデルの制約条件数の割合 と し て表 し た も のです。
PRATIO
d
di
こ こ で、 d は評価 さ れ る モデルの自由度を表 し 、d i は独立モデルの自由度を表 し ます。
倹約率は PNFI お よ び PCFI の計算で使用 さ れます (576 ページの 「倹約性修正済み測
度」 を参照 )。
注 : 出力パ ス図に倹約率を表示す る には、 ¥pratio テ キ ス ト マ ク ロ を使用 し ます。
最小標本乖離度
以下の適合度は、 乖離度の最小値を基に し てい ます。
CMIN
CMIN は、 乖離度 C の最小値、 Ĉ です ( 付録 B を参照 )。
注 : 出力パ ス図に乖離度 C の最小値
し ます。
Ĉ を表示す る には、 ¥cmin テキス ト マ ク ロ を使用
P
P は、 現在の標本で発生す る 大 き さ の乖離度が得 ら れ る 確率です ( 適切な分布の仮定
の下で、 適正に指定 さ れたモデルを想定 し た場合 )。 すなわち、 P は、 モデルが完全に
母集団に適合 し てい る と い う 仮説を検定す る ための "p 値 " です。
モデルを選択す る 1 つの方法では、統計的な仮説の検定を採用 し て、使用可能なデー
タ と 矛盾す る モデルを分析か ら 除外 し ます。 仮説の検定は広範に受け入れ ら れてい る
手順であ り 、 多 く の使用経験があ り ます。 ただ し 、 モデル選択手段 と し ては不適切で
あ る こ と が、 積率構造の分析の開発におい て 早 く か ら 指摘 さ れ て い ま す (Jöreskog,
1969)。 母集団に完全には適合 し ないほ と ん ど のモデルが有効な近似値で あ る こ と は、
一般的に認め ら れてい ます。 言い換え る と 、 完全適合 と い う 帰無仮説か ら 始め る こ と
は信頼性が低 く 、 最終的には標本の過度の肥大化が許可 さ れていない場合にのみ使用
さ れます。
モデルの当てはめにおいて、 仮説の検定の役割についての上記の よ う な見解に抵抗
があ っ た場合、 次の引用が便利で し ょ う 。 最初の 2 つは構造モデ リ ン グの開発以前の
も ので、 他のモデル当てはめ問題を指 し てい る のです。
566
付録 C
理論 と デー タ の基本的な食い違いを検出す る 検定の検出力は、主に標本のサ イ ズ
に よ っ て制御 さ れます。 標本のサ イ ズが小 さ い場合、 帰無仮説か ら 著 し く 逸脱 し
てい る 代替仮説で も 、 有意値の 2 が得 ら れ る 可能性はわずかなが ら あ り ます。
標本が非常に大 き く な る と 、 帰無仮説か ら の小 さ な、 重要でない逸脱 も 、 ほぼ間
違いな く 検出 さ れます。 (Cochran, 1952)
標本が小 さ い場合、 2 検定では、デー タ が広範囲の多様な理論か ら " 著 し く 逸脱
し ていない " こ と が示 さ れますが、 標本が大 き い場合、 2 検定では、 差が他の基
準では無視で き る か取 る に足 ら ないほ ど わずかな も のであ っ て も 、特定の理論で
期待 さ れたデー タ か ら 著 し く 逸脱 し てい る と い う 結果が示 さ れ ます。 (Gulliksen
& Tukey, 1958, p. 95 ~ 96)
こ の よ う な " 完全に適合す る " 仮説は、 検定デー タ での経験作業においては極め
て非現実的です。 十分に大 き なサ イ ズの標本が得 ら れた場合、 こ の 2 統計に よ
れば、 間違いな く 、 こ の よ う な自明でない仮説は統計的に受け入れ難い も のであ
る こ と が示 さ れます。 (Jöreskog, 1969, p. 200)
... 非常に大 き な標本では、 実質的にすべてのモデルが、 統計的に受け入れ難い と
し て棄却すべ き であ る と みな さ れ る ... 実際は、 有意でないカ イ 2 乗値が望まれ、
モデル と デー タ 間の差がない と い う 仮説の有効性 を推定 し よ う と し ま す。 こ の
よ う な論理は、 各種の統計的な見せかけにおいて、 帰無仮説を証明 し よ う と す る
試み と し て よ く 知 ら れてい ます。 カ イ 2 乗分布 v は、 標本のサ イ ズ を単純に小 さ
く す る だ け で小 さ く で き る た め、 こ の 試みは一般的に は正当化 で き ま せ ん。
(Bentler & Bonett, 1980, p. 591)
こ こ では、 こ の帰無仮説 ( 完全適合 ) は極めて信頼性が乏 し い も のであ り 、 統計
検定で偽で あ る こ と を検出で き たか ど う か を把握 し て も それほ ど役に立た ない
も のであ る と い う 立場を支持 し ます。 (Browne & Mels, 1992, p. 78).
570 ページの 「PCLOSE」 も 参照 し て く だ さ い。
注 : 出力パス図に こ の p 値を表示す る には、 ¥p テ キ ス ト マ ク ロ を使用 し ます。
CMIN/DF
CMIN/DF は、 最小乖離度 Ĉ ( 付録 B を参照 ) を自由度で割っ た値です。
Ĉ
d
一部の著者は、 こ の比率を適合度 と し て使用す る こ と を提言 し てい ます。 ULS と SLS
以外のすべての推定基準では、 こ の比率は正 し いモデルでは 1 に近 く な り ます。 問題
は、 こ の比率が 1 か ら ど の程度逸脱 し た値になれば、 モデルが十分でない と 結論付け
る こ と がで き る かが明確でない こ と です。
567
適合度
経験則
...Wheaton 他 (1977) は、 研究者が相対的な カ イ 2 乗 ( 2 df ) も 計算す る よ う 勧
め ま し た。 彼 ら は、妥当な値 と し て最初約 5 以下の比率を提案 し ま し た。ただ し 、
弊社では、 2 ~ 1 ま たは 3 ~ 1 の範囲の自由度の比率ま での 2 が仮説モデル と
標本 デー タ 間 で 許容可能 な 適合度 で あ る こ と が 示 さ れ て い ま す。 (Bentler &
Bonett、 1981、 p. 80)
... 別の研究者は、 2 と い う 低い比率、 あ る いは 5 と い う 高い比率が妥当な適合を
示す と し て提唱 し てい ます。 (Marsh & Hocevar, 1985).
...2.00 よ り 大 き い 2 df 比率は、 不十分な適合を示す こ と は明 ら かな よ う です
(Byrne, 1989, p. 55)。
注 : 出力パス図に CMIN/DF の数を表示す る には、¥cmindf テキス ト マ ク ロ を使用 し ます。
FMIN
FMIN は、 乖離度 F の最小値、F̂ です ( 付録 B を参照 )。
注 : 出力パ ス図に乖離度 F の最小値
し ます。
F̂ を表示す る には、 ¥fmin テ キ ス ト マ ク ロ を使用
母集団の乖離度に基づ く 測度
Steiger & Lind (1980) は、モデルの妥当性の測度 と し て母集団の乖離度を使用す る こ と
を提唱 し ま し た。 母集団の乖離度、F 0 は、 モデルを標本の積率ではな く 、 母集団の積
率に当てはめて得 ら れ る 乖離度の値です。 すなわち、 次の式の よ う にな り ます。
F 0 = min F , 0
に対 し て
F̂ = min F ,a
Steiger, Shapiro, お よ び Browne (1985) は、 一定の条件下では、 Ĉ = nF̂ は、 自由度が
d で非心度パ ラ メ ー タ が = C = nF の非心度カ イ 2 乗分布にな る こ と を示 し ま し
た。 Steiger-Lind のモデル評価の手法は、F 0 お よ び関連す る 数量の推定を中心に し てい
ます。
こ こ では、 主に、 Steiger & Lind (1980) お よ び Steiger, Shapiro, Browne (1985) を基に
し てい ます。 表記法は、 Browne & Mels (1992) の も の を採用 し てい ます。
568
付録 C
NCP
NCP = max(Ĉ – d 0) は非心度パ ラ メ ー タ の推定値です。 = C 0 = nF 0 .
LO90 お よ び HI 90 と い う ラ ベルの付いた列には、 の 90% の信頼区間の下限値 ( L )
と 上限値 ( U ) が含まれてい ます。 L は、 について次を解 く と 得 ら れ、
Cˆ , d .95
U は、 について次を解 く と 得 ら れ、
Cˆ | , d .05
(x d) は、非心度パラ メータ が で自由度 d の非心度カ イ 2 乗分布の分布関数です。
注 : パ ス図に非心度パ ラ メ ー タ 推定値を表示す る には、¥ncp テ キ ス ト マ ク ロ を使用 し 、
90% 信頼下限値 を 表示す る には ¥ncplo を 使用 し 、 90% 信頼上限値 を 表示す る には
¥ncphi を使用 し ます。
F0
Ĉ – d
F0 = F̂ 0 = max ------------ 0 = NCP
--------- は --- = F 0 の推定値です。
n
n
n
LO 90 お よ び HI 90 と い う ラ ベルの付いた列には、F 0 の 90% の信頼区間の下限値 と 上
限値が含まれてい ます。
LO 90
L
HI 90
U
n
n
注 : 出力パ ス図に F̂ 0 の値を表示す る には、 ¥f0 テキス ト マ ク ロ を使用 し 、 90% の信頼
下限推定値を表示す る には ¥f0lo を使用 し 、90% の信頼上限推定値を表示す る には ¥f0hi
を使用 し ます。
569
適合度
RMSEA
F 0 は、 モデルの複雑度に対 し てペナルテ ィ を含まず、 多数のパ ラ メ ー タ を持つモデル
が有利にな り やすい傾向があ り ます。 2 つの入れ子モデル を比較 し た場合、F 0 では単
純なモデルの方が有利にはな り ません。 Steiger & Lind (1980) は、 モデルの検定におい
て、F 0 を自由度の数で割 る こ と に よ っ て、 モデルの複雑度の効果を補正す る こ と を提
案 し てい ます。 結果の比率の平方根を と る と 、 母集団の近似誤差平均平方根 (Steiger &
Lind に よ れば RMS 、 Browne & Cudeck (1993) に よ れば RMSEA ) が生成 さ れます。
population RMSEA
F0
d
estimated RMSEA
Fˆ0
d
LO 90 お よ び HI 90 と い う ラ ベルの付いた列には、 RMSEA の 90% の信頼区間の下限
値 と 上限値が含まれてい ます。 こ れ ら の上下限値は、 次の式で求め ら れます。
LO 90
L n
HI 90
U n
d
d
経験則
実際の経験か ら 、 RMSEA の値が約 0.05 以下であれば、 自由度に関 し てモデルの
高い適合性 を示 し てい る よ う に思われ ま す。 こ の数字は主観的判断に基づ く も
のです。 絶対確実ま たは正確であ る と みなす こ と はで き ませんが、 RMSEA = 0.0
の厳密な適合の要件に比べれば妥当な値です。 ま た、 RMSEA が約 0.08 以下の値
は妥当な近似誤差を示す も のであ る と 考え、 RMSEA が 0.1 を超え る モデルは採
用 し ない こ と と し ます。 (Browne & Cudeck、 1993)
注 : 出力パ ス図に推定近似誤差平均平方根を表示す る には、 ¥rmsea テ キ ス ト マ ク ロ を
使用 し 、 90% 信頼下限推定値を表示す る には ¥rmsealo を使用 し 、 90% 信頼上限推定値
を表示す る には ¥rmseahi を使用 し ます。
570
付録 C
PCLOSE
2
PCLOSE = 1 – Ĉ .05 nd d は、母集団 RMSEA が 0.05 以下の帰無仮説検定用の
p 値です。
H 0 : RMSEA .05
こ れに反 し て、 P 列の p 値 (565 ページの 「P」 を参照 ) は、 母集団 RMSEA が 0 の仮
説の検定用です。
H 0 : RMSEA 0
RMSEA の使用経験に基づ き 、 Browne & Cudeck (1993) は、 RMSEA が 0.05 以下の場
合は高い適合度を示す こ と を提唱 し てい ます。 高適合度の こ の定義に従 う と 、PCLOSE
は高適合度の検定 と な り 、 P は厳密な適合の検定 と な り ます。
注 : 出力パス図に母集団 RMSEA の高適合度用の p 値を表示す る には、 ¥pclose テ キ ス
ト マ ク ロ を使用 し ます。
情報理論的測度
Amos は複数の統計を Ĉ + kq ま たは F̂ + kq の形式で報告 し ま す。 k は正の定数で
す。 こ れ ら の各統計か ら 、 適合性 ( Ĉ ま たは F̂ ) と 複雑 さ (q) の重み付 き 合計を求め る
こ と に よ っ て、 両者の合成測度が形成 さ れ ます。 適合性の高い単純なモデルは、 こ の
よ う な基準に従 う と ス コアが低 く な り ます。 複雑で、適合性の低いモデルの ス コアは高
く な り ます。 定数 k は、 適合性 と 複雑 さ に付加 さ れ る 相対的ペナルテ ィ を決定 し ます。
こ の項で述べ る 統計量は、 モデルの比較のための も のであ り 、 分離モデルの評価の
ための も のではあ り ません。
こ れ ら のすべ て の統計量は、 最尤法推定で使用す る た め に開発 さ れ た も の です。
Amos は GLS お よ び ADF 推定 も 報告 し ますが、 それ ら を使用す る こ と が適切であ る
か ど う かは不明です。
AIC
赤池情報量基準 (Akaike, 1973, 1987) は次の式で表 さ れます。
AIC Cˆ 2q
572 ページの 「ECVI」 も 参照 し て く だ さ い。
注 : 出力パス図に赤池情報量基準の値を表示す る には、 ¥aic テ キ ス ト マ ク ロ を使用 し
ます。
571
適合度
BCC
Browne-Cudeck (1989) 基準は次の式で表 さ れます。
BCC Cˆ 2q
p g p g 3
G
bg N g p g 2
g 1
p g p g 3
G
g 1
こ こ で Emulisrel6 コ マ ン ド が使用 さ れた場合
た場合、b
g
g
b
g
= N
g
– 1 であ り 、使用 さ れなか っ
N
= n -------- です。
N
BCC ではモデルの複雑 さ に対 し 、 AIC よ り も わずかに大 き なペナルテ ィ が課 さ れま
す。 BCC は、特に積率構造分析のために開発 さ れた、こ の項で唯一の測度です。 Browne
と Cudeck は、 BCC が よ り 一般的に適用可能な測度に比べて優れてい る こ と を示す、
経験的証拠を提供 し ま し た。 Arbuckle ( 準備中 ) は、 BCC の正当性についての代替的根
拠を示 し 、 複数のグループに対 し て上記の式を導 き 出 し ま し た。
572 ページの 「MECVI」 も 参照 し て く だ さ い。
注 : 出力パ ス図に Browne-Cudeck 基準の値を表示す る には、¥bcc テ キ ス ト マ ク ロ を使
用 し ます。
BIC
ベ イ ズ情報量基準 (Schwarz, 1978, Raftery, 1993) は、 次の式で表 さ れます。
BIC Cˆ q ln N 1
AIC、 BCC、 お よ び CAIC に比べて、 BIC はモデルの複雑 さ に大 き なペナルテ ィ を与
え る ため、 倹約性の高いモデルを採用す る 傾向が強 く な り ます。 BIC は、 平均 と 定数
項が明示的なモデル パ ラ メ ー タ でない単一のグループの場合にのみ報告 さ れます。
注 : 出力パ ス図にベ イ ズ情報量基準の値を表示す る には、 ¥bic テ キ ス ト マ ク ロ を使用
し ます。
CAIC
Bozdogan (1987) の CAIC (consistent AIC) は次の式で表 さ れます。
CAIC Cˆ q ln N 1 1
CAIC はモデルの複雑 さ に AIC や BCC よ り も 大 き なペナルテ ィ を課 し ますが、BIC ほ
ど大 き く はあ り ません。 CAIC は、 平均 と 定数項が明示的なモデル パ ラ メ ー タ でない
単一のグループの場合にのみ報告 さ れます。
572
付録 C
注 : 出力パ ス図に一致 AIC 統計量の値を表示す る には、 ¥caic テ キ ス ト マ ク ロ を使用
し ます。
ECVI
一貫 し た目盛 り の単位以外、 ECVI は AIC と 同 じ です。
ECVI
1
AIC Fˆ 2q
n
n
LO 90 お よ び HI 90 と い う ラ ベルの付いた列には、 ECVI の 90% の信頼区間の下限値
と 上限値が含まれてい ます。
LO 90
L d 2q
HI 90
U d 2q
n
n
570 ページの 「AIC」 も 参照 し て く だ さ い。
注 : 出力パス図に期待交差確認指標の値を表示す る には、 ¥ecvi テ キ ス ト マ ク ロ を使用
し 、 90% 信頼下限期待値を表示す る には ¥ecvilo を使用 し 、 90% 信頼上限期待値を表
示す る には ¥ecvihi を使用 し ます。
MECVI
ス ケール因子以外、 MECVI は BCC と 同 じ です。
G
MECVI
1
BCC Fˆ 2q g 1
n
a g
p g p g 3
N g p g 2
p g p g 3
G
g 1
こ こ で Emulisrel6 コ マ ン ド が使用 さ れた場合、a
か っ た場合、a
g
g
= N
-------- です。
g
g
N –1
= ----------------- であ り 、 使用 さ れな
N–G
N
571 ページの 「BCC」 も 参照 し て く だ さ い。
注 : 出力パ ス図に変更 さ れた ECVI 統計量を表示す る には、 ¥mecvi テ キ ス ト マ ク ロ を
使用 し ます。
573
適合度
ベース ラ イ ン モデル と の比較
い く つかの適合度では、 どれほ ど モデルが適合 し ていて も 、 事態は常に悪化す る 可能
性があ る と い う 事実について熟考を促 さ れます。
Bentler と Bonett (1980) お よ び Tucker と Lewis (1973) は、 独立モデルま たはその他
の非常に適合性の低いベース ラ イ ン モデルの適合を、 乖離度が どれほ ど大 き く な る か
を調べ る 課題 と し て提案 し ま し た。 こ の課題の目的は、 独自のモデルの適合性に何 ら
かの見通 し を持たせ る こ と です。 ど のモデル も う ま く 適合 し ない場合、 真に不良なモ
デルを確認す る こ と は勇気付け ら れ る こ と です。 た と えば、 次の出力が示 し てい る よ
う に、 例 6 のモデル A は自由度に関 し て大 き な乖離度 ( Ĉ = 71.544 ) を持っ てい ま
す。 こ れに反 し て、71.544 は 2131.790 ( 独立モデルの乖離度 ) と 比べ る と それほ ど悪 く
ない よ う に見え ます。
モデル
NPAR
CMIN
DF
P
CMIN/DF
モデル A: 自己相関な し
モデル B: 最も一般的
モデル C: 時間不変
モデル D: A と C の合成
飽和モデル
独立モデル
15
16
13
12
21
6
71.544
6.383
7.501
73.077
0.000
2131.790
6
5
8
9
0
15
0.000
0.271
0.484
0.000
11.924
1.277
0.938
8.120
0.000
142.119
こ の、 モデル評価におけ る 「状況は さ ら に悪化す る 可能性があ る」 と い う 原理は、 多
数の適合度に組み入れ ら れてい ます。 すべての測度は 0 ~ 1 の範囲にな る 傾向があ り 、
1 に近い値は適合度が高い こ と を示 し ます。 NFI ( 下記 ) のみが、0 ~ 1 の範囲にな る こ
と が保証 さ れてお り 、 1 は完全な適合を示 し ます。 (1 よ り 大 き い値 も 1 と し て報告 さ
れ、 0 未満の値 も 0 と し て報告 さ れ る ため、 CFI も 0 ~ 1 の範囲にな る こ と が保証 さ
れてい ます。 )
独立モデルは最 も 多 く 使用 さ れ、 Amos で も 使用 し てい ますが、 ベース ラ イ ン モデル
と し て選択で き る モデルの唯一の例です。 Sobel と Bohrnstedt (1985) は、ベース ラ イ ン
モデル と し て独立モデル を選択す る こ と は、 不適切な場合が多い と 主張 し てい ま す。
彼 ら は代替案を提案 し 、 Bentler と Bonett (1980) が行っ た よ う に、 い く つかの例を挙げ
てベース ラ イ ン モデルの選択に対す る NFI の感度を示 し ま し た。
NFI
Bentler-Bonett (1980) 標準適合指標 (NFI) ま たは Bollen (1989b) の表記法では 1 は、次
の よ う に表 さ れます。
NFI 1 1
Cˆ
1
Cˆ
b
Fˆ
Fˆ
b
こ こ で Ĉ = nF̂ は、 評価 さ れ る モデルの最小乖離度であ り 、 Cˆb =
ン モデルの最小乖離度です。
nFˆb はベース ラ イ
574
付録 C
例 6 では、 他の任意のモデルに制約条件 を 付加す る こ と に よ っ て、 独立モデルが
得 ら れます。 すべてのモデルは、 飽和モデルに制約を設け る こ と に よ っ て得 ら れます。
た と えば、 モデル A は、 2 = 71.544 であ り 、 完全に適合す る 飽和モデル ( 2 = 0 )
と 独立モデル ( 2 = 2131.790 ) と の明 ら かに中間に位置 し ます。
モデル
NPAR
CMIN
DF
P
CMIN/DF
モデル A: 自己相関な し
モデル B: 最も 一般的
モデル C: 時間不変
モデル D: A と C の合成
飽和モデル
独立モデル
15
16
13
12
21
6
71.544
6.383
7.501
73.077
0.000
2131.790
6
5
8
9
0
15
0.000
0.271
0.484
0.000
11.924
1.277
0.938
8.120
0.000
142.119
こ の よ う に見 る と 、 モデル A の適合度は、 独立モデルの適合度 よ り も 飽和モデルの
適合度に近い と 言え ます。 事実、 モデル A の乖離度は、 ( 適合度の低い ) 独立モデル と
( 完全に適合す る ) 飽和モデル と の間の 96.6% であ る こ と がわか り ます。
NFI
2131.790 71.54
71.54
1
.966
2131.790
2131.790
経験則
適合度の目盛 り は必ず し も 解釈が容易ではない ( 指標が重相関の 2 乗ではない )
ため、 結果の さ ま ざ ま な度合いの優位性に関連付け ら れ る指標の値を定義す る に
は、 経験が必要です。 弊社の経験では、 全体の適合指標が 0.9 未満のモデルは、
通常、 実質的に改善 さ れます。 こ れ ら の指標や先に説明 し た一般的な階層的比較
については、 例を挙げ る こ と に よ っ て よ く 理解 さ れます。 (Bentler & Bonett, 1980,
p. 600、 NFI と TLI の両方を参照 )
注 : 出力パ ス図に標準適合指標の値を表示す る には、¥nfi テキス ト マ ク ロ を使用 し ます。
RFI
Bollen (1986) の相対適合指標 (RFI) は次の式で表 さ れます。
RFI 1 1
Cˆ d
Fˆ d
1
Fˆb d b
Cˆ b d b
こ こ で Ĉ と d は評価 さ れ る モデルの自由度であ り 、 Ĉ b お よ び d b は、 ベース ラ イ ン
モデルの乖離度 と 自由度です。
RFI は、 F の代わ り に F / d を置 き 換え る こ と に よ っ て、 NFI か ら 得 ら れます。 1 に近
い RFI 値は、 適合度が非常に高い こ と を示 し てい ます。
注 : 出力パス図に相対適合指標を表示す る には、 ¥rfi テ キ ス ト マ ク ロ を使用 し ます。
575
適合度
IFI
Bollen (1989b) の増分適合指標 (IFI) は次の式で表 さ れます。
IFI 2
Cˆ b Cˆ
Cˆ b d
こ こ で Ĉ お よ び d は評価 さ れ る モデルの乖離度 と 自由度で あ り 、 Ĉ b お よ び d b は、
ベース ラ イ ン モデルの乖離度 と 自由度です。 1 に近い IFI 値は、適合度が非常に高い こ
と を示 し てい ます。
注 : 出力パ ス図に増分適合指標を表示す る には、 ¥ifi テ キ ス ト マ ク ロ を使用 し ます。
TLI
Tucker-Lewis 係数 (Bollen, 1989b の表記法では 2) については、Bentler と Bonett (1980)
に よ っ て積率の構造の分析の文脈で解説 さ れてお り 、 Bentler-Bonett 非標準適合指標
(NNFI) と も 呼ばれます。
TLI 2
Cˆ b
db
Cˆ
ˆ
Cd
b
db
1
TLI の一般的な範囲は 0 ~ 1 の間ですが、 こ の範囲には限定 さ れません。 1 に近い TLI
値は、 適合度が非常に高い こ と を示 し てい ます。
注 : 出力パ ス図に Tucker-Lewis 指標の値を表示す る には、¥tli テ キ ス ト マ ク ロ を使用 し
ます。
CFI
比較適合指標 (CFI, Bentler, 1990) は次の式で表 さ れます。
CFI 1
NCP
max Cˆ d , 0
1
ˆ
NCP b
max Cb d b , 0
こ こ で Ĉ 、 d お よ び NCP は評価 さ れ る モデルの乖離度、自由度お よ び非心度パ ラ メ ー
タ 推定値であ り 、 Ĉ b 、d b お よ び NCP b は、 ベース ラ イ ン モデルの乖離度 と 自由度、 お
よ び非心度パ ラ メ ー タ 推定値です。
CFI は 0 ~ 1 の範囲に収 ま る よ う に切 り 捨て ら れ る 点以外、 CFI は McDonald と
Marsh (1990) の相対非心度指標 (RNI) と 同 じ です。
RNI 1
Cˆ d
Cˆ d
b
b
1 に近い CFI 値は、 適合度が非常に高い こ と を示 し てい ます。
576
付録 C
注 : 出力パ ス図に相対適合指標の値を表示す る には、¥cfi テキス ト マ ク ロ を使用 し ます。
倹約性修正済み測度
James 他 (1982) は、 評価対象のモデル と ベース ラ イ ン モデルの両方の検定において自
由度 の 数 が 考慮 さ れ る よ う に、 NFI に 倹約性指標 を か け る こ と を 提唱 し ま し た。
Mulaik 他 (1989) は、 GFI に も 同 じ 修正を適用す る こ と を提案 し ま し た。 Amos で も 、
CFI に倹約性修正を適用 し てい ます。
578 ページの 「PGFI」 も 参照 し て く だ さ い。
PNFI
PNFI は、 James 他 (1982) の倹約性修正を NFI に適用 し た結果です。
PNFI NFIPRATIO NFI
d
db
こ こ で d は評価 さ れ る モデルの自由度です。 d b はベース ラ イ ン モデルの自由度です。
注 : 出力パス図に倹約性標準適合指標の値を表示す る には、 ¥pnfi テ キ ス ト マ ク ロ を使
用 し ます。
PCFI
PCFI は、 James 他 (1982) の倹約性修正を CFI に適用 し た結果です。
PCFI CFI PRATIO = CFI
d
db
こ こ で d は評価 さ れ る モデルの自由度です。 d b はベース ラ イ ン モデルの自由度です。
注 : 出力パス図に倹約性比較適合指標の値を表示す る には、 ¥pcfi テ キ ス ト マ ク ロ を使
用 し ます。
577
適合度
GFI および関連測度
こ こ では、 GFI と 関連測度について説明 し ます。
GFI
GFI ( 適合度指標 ) は、 ML お よ び ULS 推定のために Jöreskog と Sörbom (1984) に よ っ
て考案 さ れ、 Tanaka and Huba (1985) に よ っ て他の推定基準に一般化 さ れま し た。
GFI は次の式で表 さ れます。
GFI 1
Fˆ
Fˆ
b
g
こ こ で F̂ は、付録 B に定義 さ れてい る 最小乖離度であ り 、Fˆb は
= 0 , g = 1, 2,...,G
g
で F を評価す る と 得 ら れます。 (D2) は 付録 B では
= 0 について定義 さ れていな
いため、 最尤法推定値について例外を設け る 必要があ り ます。 最尤法推定値の場合の
g
g
g
g
GFI を計算す る ため、 付録 B の f ; S は K
= ̂ ML で次の よ う に計算
さ れます。
f g ; S g 12 tr K g
1
S
g
g
2
こ こ で、 ̂ ML は の最尤法推定値です。 GFI は常に 1 未満です。 GFI = 1 は完全な適合
を示 し ます。
注 : 出力パ ス図に適合度指標の値を表示す る には、 ¥gfi テ キ ス ト マ ク ロ を使用 し ます。
AGFI
AGFI ( 修正済み適合度指標 ) は、 モデルの検定で使用可能な自由度 を 考慮 し ま す。
次の式で表 さ れます。
AGFI 1 1 GFI
db
d
こ こで
db
G
p*g
g 1
AGFI の上限値は 1 で、 こ の場合完全な適合を示 し ます。 ただ し 、 GFI の よ う に下限値
は 0 ではあ り ません。
注: 出力パス図に修正済み GFI の値を表示する には、¥agfi テキス ト マク ロ を使用 し ます。
578
付録 C
PGFI
Mulaik 他 (1989) に よ っ て提唱 さ れた PGFI ( 倹約性適合度指標 ) は、モデルの検定で使
用可能な自由度を考慮 し て GFI を修正 し た も のです。
PGFI GFI
d
db
d は評価 さ れ る モデルの自由度であ り 、
db
G
p*g
g 1
はベース ラ イ ン ゼ ロ モデルの自由度です。
注 : 出力パ ス図に倹約性 GFI の値を表示す る には、¥pgfi テ キ ス ト マ ク ロ を使用 し ます。
その他の測度
その他の適合測度について説明 し ます。
HI 90
Amos は、 複数の統計量の母集団の値に対 し て 90% 信頼区間を報告 し ます。 上限値 と
下限値は、 HI 90 お よ び LO 90 と い う ラ ベルの列で表 さ れます。
HOELTER
Hoelter (1983) の ク リ テ ィ カル N は、モデルが正 し い と い う 仮説を受け入れ る ための最
大標本サ イ ズです。 Hoelter は、 ク リ テ ィ カル N を決定す る ために使用す る 有意水準を
指定 し てい ませんが、 彼の例では 0.05 を使用 し てい ます。 Amos は、 0.05 お よ び 0.01
の有意水準に対 し て ク リ テ ィ カル N を報告 し ます。
例 6 の各モデルについて Amos に よ っ て表示 さ れ る ク リ テ ィ カル N を示 し ます。
モデル
HOELTER
0.05
HOELTER
0.01
モデル A: 自己相関な し
モデル B: 最も 一般的
モデル C: 時間不変
モデル D: A と C の合成
独立モデル
164
1615
1925
216
11
219
2201
2494
277
14
579
適合度
た と えば、 モデル A は、 標本の積率が Wheaton の研究で検出 さ れたの と ま っ た く 同 じ
で 標本 サ イ ズが 164 であれば、0.05 レベルで使用 さ れたはずです。 標本 サ イ ズが 165
の場合、 モデル A は棄却 さ れた こ と にな り ます。 Hoelter は、 200 以上の ク リ テ ィ カル
N は十分な適合度を示す と 主張 し てい ます。 複数のグループの分析において、 Hoelter
はグループ数の 200 倍の し き い値を提唱 し てい ます。 おそ ら く 、 こ の し き い値は 0.05
の有意水準 と 共に使用 さ れ る 値です。 こ の標準では、 例 6 のモデル A と 独立モデルは
除外 さ れ ます。 Hoelter の基準に よ れば、 モデル B は満足のい く も のです。 私自身は、
Hoelter に よ る 200 の標準の主張の正当性は確信 し てい ません。 残念なが ら 、 ク リ テ ィ
カル N を モデルの選択に実際に役立て る には、 こ の よ う な標準が必要です。 Bollen と
Liang (1988) は、 ク リ テ ィ カル N の統計量に関す る 研究を報告 し てい ます。
注 : 出力パ ス 図に Hoelter の ク リ テ ィ カル N を表示す る には、 = 0.05 については
¥hfive テ キ ス ト マ ク ロ を使用 し 、 = 0.01 については ¥hone を使用 し ます。
LO 90
Amos は、 複数の統計量の母集団の値に対 し て 90% 信頼区間を報告 し ます。 上限値 と
下限値は、 HI 90 お よ び LO 90 と い う ラ ベルの列で表 さ れます。
RMR
RMR ( 残差平均平方根 ) は、 平均平方量の平方根であ り 、 こ の値だけ、 標本分散 お よ
び共分散は、 モデルが正 し い と い う 仮定の下に得 ら れた推定値か ら 相違 し てい ます。
RMR
pg
g 1
i 1
sˆ
G
j i
(g)
ij
j 1
ij( g )
p *
G
g
g 1
RMR が小 さ ければ小 さ いほ ど、 適合度は高 く な り ます。 RMR が 0 の場合は、 完全な
適合度を示 し ます。
例 6 か ら の以下の出力は、 RMR に よ る と 、 飽和モデルを除けばモデル A が検討対
象のモデルの中で最適であ る こ と を示 し てい ます。
モデル
RMR
GFI
AGFI
PGFI
モデル A: 自己相関な し
モデル B: 最も一般的
モデル C: 時間不変
モデル D: A と C の合成
飽和モデル
独立モデル
0.284
0.757
0.749
0.263
0.000
12.342
0.975
0.998
0.997
0.975
1.000
0.494
0.913
0.990
0.993
0.941
0.279
0.238
0.380
0.418
0.292
0.353
注 : 出力パ ス図に残差平均平方根の値を表示す る には、 ¥rmr テ キ ス ト マ ク ロ を使用 し
ます。
580
付録 C
選択 さ れた適合度の リ ス ト
少数の適合度に集中す る 場合、 以下の適合度のみを選出 し て報告 し た Browne と Mels
(1992) の暗黙の推奨を検討 し てみて く だ さ い。
565 ページの 「CMIN」
565 ページの 「P」
567 ページの 「FMIN」
568 ページの 「F0」、 90% 信頼区間
570 ページの 「PCLOSE」
569 ページの 「RMSEA」、 90% 信頼区間
572 ページの 「ECVI」、 90% 信頼区間 ( 570 ページの 「AIC」 ) も 参照 )
最尤法推定の場合、Browne と Cudeck (1989、1993) が ECVI に代え て MECVI (572 ペー
ジ ) を提唱 し てい ます。
付録
D
非識別可能性の数値診断
パ ラ メ ー タ を識別す る のか、 あ る いはモデル全体を識別す る のか を判定す る ために、
Amos では近似二次導関数の行列お よ び関連す る 行列の順位を調べ ま す。 使用 さ れ る
手法は、 McDonald & Krane (1977) の手法に似てい ます。 こ の方法には原理的な難点 も
あ り ます (Bentler &Weeks, 1980McDonald, 1982)。 ま た、 境界線上にあ る行列の順位の
判定には実務的な問題 も あ り ま す。 こ う し た困難のため、 可能で あれば、 事前にモデ
ルの識別可能性を判定 し てお く 必要があ り ます。 複雑なモデルでは、 事前判定が不可
能であ る ため、 Amos の数値判定に依存す る 必要があ り ます。 幸いな こ と に、 Amos は
現実の識別可能性の評価に大変優れてい ます。
581
付録
E
適合度を使用 し たモデルの順位付け
一般的に、 選択肢が多過ぎ る ため、 1 つの適合度を選択す る こ と は困難です。 適合度の
目的が、 絶対的な標準に よ っ てモデルの長所を判定す る のではな く 、 モデルを相互に
比較す る こ と であ る 場合には、 選択が容易にな り ます。 た と えば、 モデルの集合の ラ ン
ク 順を決め る 場合は、 RMSEA、 RFI、 ま たは TLI の どれを使用 し て も 問題はない こ と
が分か り ます。 こ れ ら の各測度は、 Ĉ お よ び Ĉ d のみに よ る d に依存 し てお り 、それ
ぞれ単調に Ĉ d に依存 し てい ます。 し たが っ て、各測度に よ る モデルの ラ ン ク 順は同
じ にな り ます。 こ のため、探索的モデル特定化手順では、RMSEA のみが報告 さ れます。
RMSEA =
Ĉ----------–d =
nd
1--- Ĉ
--- – 1
nd
Ĉ d
RFI = 1 = 1 – -------------Ĉ b d b
Ĉ b Ĉ
----- – --db d
TLI = 2 = ------------Ĉ b
----- – 1
db
次の適合度は、 Ĉ お よ び Ĉ – d のみに よ る d に依存 し てお り 、単調に Ĉ – d に依存 し
てい ます。探索的モデル特定化手順では、すべての代表 と し て CFI のみが報告 さ れます。
583
584
付録 E
NCP = max Ĉ – d 0
Ĉ – d
F0 = F̂ 0 = max ------------ 0
n
max Ĉ – d 0
CFI = 1 – --------------------------------------------------ˆ
max C b – d b Ĉ – d 0
Ĉ – d
RNI = 1 – ---------------- (Amos では報告 さ れない )
ˆ
Cb – db
次の適合度は、 単調に Ĉ に依存 し てお り 、 d には全 く 依存 し てい ません。 探索的モデ
ル特定化手順では、 すべての代表 と し て Ĉ が報告 さ れます。
CMIN = Ĉ
Ĉ
n
FMIN = ---
Ĉ
Ĉ b
NFI = 1 – -----
次の各適合度は Ĉ と d の重み付け合計で あ り 、 モデルの ラ ン ク 順を生成で き ま す。
探索的モデル特定化手順では、 CAIC 以外の各適合度が報告 さ れます。
BCC
AIC
BIC
CAIC
585
適合度を使用 し たモデルの順位付け
次の各適合度は、 独自のモデルの ラ ン ク 順を提供 し ます。 ラ ン ク 順はベース ラ イ ン モ
デルの選択に も 依存 し てい ます。 探索的モデル特定化手順では、 こ れ ら の測度は報告
さ れません。
IFI = 2
PNFI
PCFI
次の適合度は、 最尤法の推定の場合に Amos に よ っ て報告 さ れ る 、 Ĉ お よ び d の関数
ではない速度です。 探索的モデル特定化手順では、 こ れ ら の測度は報告 さ れません。
GFI
AGFI
PGFI
付録
F
記述適合度のベース ラ イ ン モデル
7 つの適合度 (NFI、 RFI、 IFI、 TLI, CFI、 PNFI、 お よ び PCFI) では、 他のモデル と 比
較す る ための、帰無 ま たは ベース ラ イ ン 不良モデルが必要です。 探索的モデル特定化
手順では、 4 つの帰無モデル ま たはベース ラ イ ン モデルか ら 選択で き ます。
帰無モデル 1: 観測変数間に相関がない こ と が必要です。 観測変数の平均値 と 分散は制
約 さ れ ません。 こ れは、 探索的モデル特定化を実行 し ない、 通常の Amos 分析におけ
る 独立モデルです。
帰無モデル 2: 観測変数間の相関度が等 し い こ と が必要です。 観測変数の平均値 と 分散
は制約 さ れません。
帰無モデル 3: 観測変数間に相関がな く 、 平均値が 0 であ る こ と が必要です。 観測変数
の分散は制約 さ れません。 こ れは、 平均値 と 定数項が明示的なモデル パ ラ メ ー タ であ
る 、 Amos 4.0.1 以前で使用 さ れ る ベース ラ イ ン独立モデルです。
帰無モデル 4: 観測変数間の相関度が等 し い こ と が必要です。 観測変数の分散は制約 さ
れません。 平均値は 0 であ る こ と が必要です。
各帰無モデルは、 NFI、 RFI、 IFI、 TLI、 CFI、 PNFI、 PCFI に対 し て異な る 値を生成 し
ます。 帰無モデル 3 と 帰無モデル 4 は、 平均値 と 定数項が指定 し たモデルで明示的に
推定 さ れない場合にのみ、 探索的モデル特定化で当てはめ ら れ ます。 帰無モデル 3 と
帰無モデル 4 は、平均値 と 定数項が制約 さ れ る モデルの評価に適 し てい る と 言え ます。
平均値 と 定数項は制約 さ れないが、 欠損デー タ に よ る 最尤法を許可す る ためだけに推
定 さ れ る よ う な一般的な状況で、 帰無モデル 3 と 帰無モデル 4 を当てはめ る 理由はほ
と ん ど あ り ません。
587
588
付録 F
探索的モデル特定化で当てはめ る ベース ラ イ ン モデルを指定す る には
E
メ ニ ュ ーか ら [ 分析 ] [ 探索的モデル特定化 ] の順に選択 し ます。
E [ 探索的モデル特定化 ] ツールバーの [ オプ シ ョ ン ] ボ タ ン
を ク リ ッ ク し ます。
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス で、 [ 次を検索 ] タ ブ を ク リ ッ ク し ます。
4 つの帰無モデル と 飽和モデルが、 [ ベンチマー ク モデル ] グループに表示 さ れます。
付録
G
AIC、 BCC、 および BIC の再調整
適合度 AIC、BCC、お よ び BIC は、付録 C に定義 さ れてい ます。 各測度の形式は Ĉ + kq
で、 k はすべてのモデルで同 じ 値にな り ます。 小 さ い値の方が優れてお り 、 デー タ への
高い適合度 ( 小 さ い Ĉ ) と 倹約性 ( 小 さ い q) の組み合わせを示 し てい ます。 測度は単一
のモデルの長所を判定す る ためではな く 、 モデルの相互比較のために使用 さ れます。
Amos の探索的モデル特定化手順では、 こ れ ら の測度の 3 通 り の再調整方法が用意
さ れてお り 、 例 22 お よ び 例 23 に示 さ れてい ます。 こ の付録では、 再調整 さ れた適合
度の公式を示 し ます。
i
i
i
以下では、AIC 、 BCC 、 お よ び BIC を モデル i の適合度 と し ます。
ゼロ ベースの再調整
AIC、 BCC、 お よ び BIC は、 モデルの相互比較のみに使用 さ れ、 小 さ い値の方が大 き
い値 よ り も 優れてい る ため、 以下の よ う に定数を追加 し て も 弊害はあ り ません。
AIC
i
0
= AIC
i
BCC
i
0
= BCC
i
BIC
i
0
= BIC
i
i
– min AIC
i
i
– min BCC
i
i
– min BIC
i
再調整 さ れた値は 0 ま たは正の値です。 た と えば、 AIC に従っ た場合の最適なモデル
では AIC 0 = 0 と な り 、 こ れ よ り 劣 る モデルでは、 最適なモデル よ り どれだけ劣 る か
を示す、 正の AIC 0 値が生成 さ れます。
589
590
付録 G
AIC 0 、 BCC 0 、お よ び BIC0 を表示す る には、 [ 探索的モデル
を ク リ ッ ク し ます。
E 探索的モデル特定化後に
特定化 ] バーで
E [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 結果 ] タ ブで、[ ゼロベース (min=0)] を ク リ ッ ク し
ます。
赤池ウ ェ イ ト / Bayes 因子 ( 合計 = 1)
E 以下の再調整を得 る には、 [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 結果 ] タ ブで、 [ 赤池
ウ ェ イ ト / Bayes 因子 ( 合計 = 1)] を ク リ ッ ク し ます。
i
AIC p
i
2
e
= --------------------------– AIC
e
– AIC
m
2
m
i
BCC p
i
2
e
= --------------------------– BCC
e
– BCC
m
2
m
i
BIC p
i
2
e
= --------------------------– BIC
e
– BIC
m
2
m
各再調整 さ れた測度の合計は、 モデル全体で 1 にな り ます。 再調整は、 包括的な探索
的モデル特定化の後にのみ実行 さ れ ます。 発見的探索を実行す る か、 [ 最善の_モデル
のみを保存 ] に正の値を指定 し た場合、 分母での総和は計算 さ れず、 再調整 も 実行 さ れ
i
ません。 AIC p は、Burnham & Anderson (1998) に よ っ て赤池 ウ ェ イ ト と 名付け ら れま
i
i
し た。 BCC p は AIC p と 同 じ に解釈 さ れ ま す。 ベ イ ジ ア ン法フ レーム ワ ー ク 内お よ
i
びモデルに対 し て同 じ 事前確率を指定 し た適切な仮定の下では、BIC p は 事後確率の
近似値 と な り ます。
591
AIC、 BCC、 および BIC の再調整
赤池ウ ェ イ ト / Bayes 因子 (max = 1)
E 以下の再調整を得 る には、 [ オプシ ョ ン ] ダ イ ア ロ グ ボ ッ ク ス の [ 結果 ] タ ブで、 [ 赤池
ウ ェ イ ト / Bayes 因子 (max = 1)] を ク リ ッ ク し ます。
i
AIC L
i
BCC L
i
BIC L
e –AIC
i
2
= ----------------------------------m
– AIC 2
max
e
m
e –BCC
i
2
= ----------------------------------m
– BCC 2
max
e
m
e –BIC
i
2
= ----------------------------------m
– BIC 2
max
e
m
た と えば、 AIC に従っ た場合の最適なモデルでは AIC L = 1 と な り 、 こ れ よ り 劣 る モ
デルでは、 0 ~ 1 の AIC L 値が生成 さ れ ま す。 AIC L の詳細については、 Burnham &
Anderson (1998) を、ま た、BIC L の詳細については、Raftery (1993, 1995) お よ び Madigan
& Raftery (1994) を参照 し て く だ さ い。
通達
こ こ に記載の情報は、 米国内で提供 さ れ る 製品 と サービ ス を対象に作成 さ れてい ます。
本書に記載 さ れた製品、 サービ ス、 ま たは機能は、 他の国で提供 さ れていない場合があ り ま
す。 お客様のお住ま いの地域で現在提供 さ れてい る 製品お よ びサービ ス に関す る 情報は、 現
地の IBM カ ス タ マーサービ ス にお問い合わせ く だ さ い。 IBM 製品、プ ロ グ ラ ム、 ま たはサー
ビ ス を言及 し てい る 場合、 それ ら の IBM 製品、 プ ロ グ ラ ム ま たはサービ ス のみが使用 さ れ
てい る こ と を陳述 ま たは暗示 し てい る わけではあ り ま せん。 IBM の知的財産権を侵害 し な
い、 機能的に同等の製品、 プ ロ グ ラ ム、 ま たはサービ ス が代わ り に使用 さ れてい る 場合 も あ
り ます。 ただ し 、 IBM 以外の製品、プ ロ グ ラ ム、 ま たはサービ ス の機能の評価や検証は、ユー
ザーの責任にゆだね ら れます。
IBM は、 本書に記述 さ れた内容について、 特許を有 し てい る か、 申請中であ る場合があ り ま
す。 本書を提供す る こ と に よ っ て、こ れ ら の特許の使用権が認め ら れ る わけではあ り ません。
使用権については、 以下にお問い合わせ く だ さ い。
IBM Director of Licensing
IBM Corporation
North Castle Drive
Armonk, NY 10504-1785
U.S.A.
ダブルバ イ ト 文字セ ッ ト (DBCS) に関す る ラ イ セ ン ス については、 現地の IBM Intellectual
Property Department ( 知的財産部門 ) にお問い合わせ く だ さ い。
知的財産権 ラ イ セ ン ス係
法務お よ び知的財産法
日本 IBM
郵便番号 242-8502
神奈川県大和市下鶴間 1623-14
593
594
次の文言は英国ま たは以下の規約が現地法 と 矛盾す る 国には適用 さ れません。
INTERNATIONAL BUSINESS MACHINES CORPORATION は、 本書を、 第三者の権利を侵
害 し ていない こ と 、 市販性、 ま たは特定目的 と の適合性を含む ( ただ し こ れ ら に限定 さ れな
い ) 明示ま たは暗示の保証をす る こ と な く 、 「現状の ま ま」 提供す る と し ます。 一部の国は、
特定の取引におけ る 明示的ま たは暗示的な保証の放棄を認めていないため、上述の文言がお
客様に適用 さ れない場合があ り ます。
こ の情報には、 技術的に不正確な情報ま たは誤字や誤植が含まれ る こ と があ り ます。 こ こ に
示 さ れ る 情報は定期的に変更 さ れてい ま すが、 こ れ ら の変更は本書の改訂版で適用 さ れ ま
す。 IBM は、 予告な く いつで も 、 本書に記載の製品やプ ロ グ ラ ムに機能改善や機能変更を提
供す る 場合があ り ます。
本書中の IBM 以外の Web サ イ ト に対す る参照は、 便宜上の目的でのみ参照 さ れてお り 、 い
かな る 意味で も こ れ ら の Web サ イ ト を推奨す る も のではあ り ません。 こ れ ら の Web サ イ ト
で提供 さ れてい る 資料は本 IBM 製品のための資料ではな く 、 お客様の自己責任の下、 こ れ
ら の Web サ イ ト を ご利用 く だ さ い。
IBM は、 お客様への義務を発す る こ と な く 、 IBM が適切であ る と 判断 し た方法で、 お客様
か ら の情報を使用ま たは配布す る 場合があ り ます。
本プ ロ グ ラ ム の使用許諾 ラ イ セ ン ス取得者の う ち、 (i) 独立 し て作成 さ れたプ ロ グ ラ ム と 他
のプ ロ グ ラ ム ( 本プ ロ グ ラ ム を含む ) の間の情報の交換、 お よ び (ii) 交換 さ れた情報の相互
使用を行 う 目的で、 使用許諾 ラ イ セ ン ス に関す る 情報を必要 と す る お客様は、 以下にお問い
合わせ く だ さ い。
IBM Software Group
Attention: Licensing
200 W. Madison St
Chicago, IL 60606
U.S.A.
その よ う な情報は、 該当す る 諸条件の下、 一部のケース では有償に よ っ て、 提供で き る 場合
があ り ます。
本書に記載 さ れた使用許諾 ラ イ セ ン ス取得のプ ロ グ ラ ム、お よ びそれに提供 さ れ る すべての
使用許諾 ラ イ セ ン ス 取得 の 資料は、 IBM Customer Agreement、 IBM International Program
License Agreement、ま たはお客様 と 当社の間で締結す る 同等のすべての契約に よ っ て提供 さ
れます。
IBM 以外の製品に関す る 情報は、 それ ら の製品の提供業者、 提供業者の公開告示、 ま たは
他の一般提供情報 よ り 取得 さ れて ま す。 IBM は、 それ ら の製品を検証 し て ないため、 IBM
以外の製品に関す る パ フ ォ ーマ ン ス、 互換性、 ま たは他の主張を裏付け る こ と はで き ま せ
ん。 IBM 以外の製品の機能に関す る ご質問は、 それ ら の製品の提供業者にお問い合わせ く
だ さ い。
IBM の将来の方向性 ま たは意向に関す る すべての記述は、 目標お よ び目的のみを示す も の
であ り 、 予告な く 変更ま たは取 り 消 さ れます。
595
通達
こ の情報には、 日常の取引で使用 さ れ る デー タ やレ ポー ト の例が含まれます。 こ れ ら を可能
な限 り 完全に説明す る ために、 例には個人、 会社、 ブ ラ ン ド 、 お よ び製品の名前が含まれま
す。 こ れ ら はすべて架空の名前であ り 、 実際の ビ ジネ ス エン タ ープ ラ イ ズに使用 さ れ る 名前
や呼称に類似す る 場合は、 完全な偶然です。
こ の情報の ソ フ ト コ ピーを ご覧にな っ てい る 場合、写真やカ ラ ーに よ る 説明は表示 さ れない
場合があ り ます。
商標
IBM、 IBM ロ ゴ、 ibm.com、 お よ び SPSS は、 世界 の 多数 の 管轄区 に お け る International
Business Machines Corp 社の商標ま たは登録商標です。 他の製品お よ びサービ ス名は、 IBM
ま たは各社の商標です。 現時点におけ る IBM の商標の一覧については
http://www.ibm.com/legal/copytrade.shtml を ご覧 く だ さ い。
AMOS は、 Amos Development Corporation 社の商標です。
Microsoft、 Windows、 Windows NT、 お よ び Windows ロ ゴは、 米国お よ び他の国、 ま たはそ
の両方の Microsoft Corporation 社の商標です。
参考文献
Akaike, H. 1973. Information theory and an extension of the maximum likelihood principle.
Proceedings of the 2nd International Symposium on Information Theory, B. N. Petrov and F.
Csaki, eds. Budapest: Akademiai Kiado. 267–281 よ り 。
______. 1978. A Bayesian analysis of the minimum AIC procedure. Annals of the Institute of
Statistical Mathematics, 30: 9–14.
______. 1987. Factor analysis and AIC. Psychometrika, 52: 317–332.
Allison, P. D. 2002. Missing data. Thousand Oaks, CA: Sage Publications.
Anderson, E. 1935. The irises of the Gaspe Peninsula. Bulletin of the American Iris Society, 59: 2–5.
Anderson, T. W. 1957. Maximum likelihood estimates for a multivariate normal distribution when
some observations are missing. Journal of the American Statistical Association, 52: 200–203.
______. 1984. An introduction to multivariate statistical analysis. New York: John Wiley and Sons.
Arbuckle, J. L. Unpublished, 1991. Bootstrapping and model selection for analysis of moment
structures.
______. 1994a. Advantages of model-based analysis of missing data over pairwise deletion. RMD
Conference on Causal Modeling (West Lafayette, IN) において発表。
______. 1994b. A permutation test for analysis of covariance structures. Psychometric Society,
University of Illinois, Champaign, IL の年次総会において発表。
______. 1996. Full information estimation in the presence of incomplete data. Advanced structural
equation modeling, G. A. Marcoulides and R. E. Schumacker, eds. Mahwah, New Jersey:
Lawrence Erlbaum Associates. よ り 。
Arminger, G., P. Stein, and J. Wittenberg. 1999. Mixtures of conditional mean- and covariancestructure models. Psychometrika, 64:4, 475–494.
Attig, M. S. 1983. The processing of spatial information by adults. The Gerontological Society, San
Francisco の年次総会において発表。
Beale, E. M. L., and R. J. A. Little. 1975. Missing values in multivariate analysis. Journal of the Royal
Statistical Society Series B, 37: 129–145.
597
598
Beck, A. T. 1967. Depression: causes and treatment. Philadelphia, PA: University of Pennsylvania
Press.
Bentler, P. M. 1980. Multivariate analysis with latent variables: Causal modeling. Annual Review of
Psychology, 31: 419–456.
______. 1985. Theory and Implementation of EQS: A Structural Equations Program. Los Angeles,
CA: BMDP Statistical Software.
______. 1989. EQS structural equations program manual. Los Angeles, CA: BMDP Statistical
Software.
______. 1990. Comparative fit indexes in structural models. Psychological Bulletin, 107: 238–246.
Bentler, P. M., and D. G. Bonett. 1980. Significance tests and goodness of fit in the analysis of
covariance structures. Psychological Bulletin, 88: 588–606.
Bentler, P. M., and C. Chou. 1987. Practical issues in structural modeling. Sociological Methods and
Research, 16: 78–117.
Bentler, P. M., and E. H. Freeman. 1983. Tests for stability in linear structural equation systems.
Psychometrika, 48: 143–145.
Bentler, P. M., and D. G. Weeks. 1980. Linear structural equations with latent variables.
Psychometrika, 45: 289–308.
Bentler, P. M., and J. A. Woodward. 1979. Nonexperimental evaluation research: Contributions of
causal modeling. Improving Evaluations, L. Datta and R. Perloff, eds. Beverly Hills: Sage
Publications よ り 。
Bollen, K. A. 1986. Sample size and Bentler and Bonett’s non-normed fit index. Psychometrika, 51:
375–377.
______. 1987. Outliers and improper solutions: A confirmatory factor analysis example.
Sociological Methods and Research, 15: 375–384.
______. 1989a. Structural equations with latent variables. New York: John Wiley and Sons.
______. 1989b. A new incremental fit index for general structural equation models. Sociological
Methods and Research, 17: 303–316.
Bollen, K. A., and K. G. Jöreskog. 1985. Uniqueness does not imply identification: A note on
confirmatory factor analysis. Sociological Methods and Research, 14: 155–163.
Bollen, K. A., and J. Liang. 1988. Some properties of Hoelter’s CN. Sociological Methods and
Research, 16: 492–503.
Bollen, K. A., and J. S. Long, eds. 1993. Testing structural equation models. Newbury Park, CA:
Sage Publications.
Bollen, K. A., and R. A. Stine. 1992. Bootstrapping goodness-of-fit measures in structural equation
models. Sociological Methods and Research, 21: 205–229.
Bolstad, W. M. 2004. Introduction to Bayesian Statistics. Hoboken, NJ: John Wiley and Sons.
Boomsma, A. 1987. The robustness of maximum likelihood estimation in structural equation models.
Structural Modeling by Example: Applications in Educational, Sociological, and Behavioral
Research, P. Cuttance and R. Ecob, eds. Cambridge University Press, 160–188. よ り 。
599
参考文献
Botha, J. D., A. Shapiro, and J. H. Steiger. 1988. Uniform indices-of-fit for factor analysis models.
Multivariate Behavioral Research, 23: 443–450.
Bozdogan, H. 1987. Model selection and Akaike’s information criterion (AIC): The general theory
and its analytical extensions. Psychometrika, 52: 345–370.
Brown, C. H. 1983. Asymptotic comparison of missing data procedures for estimating factor
loadings. Psychometrika, 48:2, 269–291.
Brown, R. L. 1994. Efficacy of the indirect approach for estimating structural equation models with
missing data: A comparison of five methods. Structural Equation Modeling: A Multidisciplinary
Journal, 1: 287–316.
Browne, M. W. 1982. Covariance structures. Topics in applied multivariate analysis, D. M. Hawkins,
ed. Cambridge: Cambridge University Press, 72–141 よ り 。
______. 1984. Asymptotically distribution-free methods for the analysis of covariance structures.
British Journal of Mathematical and Statistical Psychology, 37: 62–83.
Browne, M. W., and R. Cudeck. 1989. Single sample cross-validation indices for covariance
structures. Multivariate Behavioral Research, 24: 445–455.
______. 1993. Alternative ways of assessing model fit. Testing structural equation models, K. A.
Bollen and J. S. Long, eds. Newbury Park, CA: Sage Publications, 136–162 よ り 。
Browne, M. W., and G. Mels. 1992. RAMONA user’s guide. The Ohio State University, Columbus,
OH.
Burnham, K. P., and D. R. Anderson. 1998. Model selection and inference: A practical informationtheoretic approach. New York: Springer-Verlag.
Burnham, K. P., and D. R. Anderson. 2002. Model selection and multimodel inference: A practical
information-theoretic approach. 2nd ed. New York: Springer-Verlag.
Burns, D. D. 1999. Feeling good: the new mood therapy. New York: Avon Books.
Byrne, B. M. 1989. A primer of LISREL: Basic applications and programming for confirmatory
factor analytic models. New York: Springer-Verlag.
______. 2001. Structural equation modeling with Amos: Basic concepts, applications, and
programming. Mahwah, New Jersey: Erlbaum.
Carmines, E. G., and J. P. McIver. 1981. Analyzing models with unobserved variables. Social
measurement: Current issues, G. W. Bohrnstedt and E. F. Borgatta, eds. よ り 。 Beverly Hills: Sage
Publications.
Cattell, R. B. 1966. The scree test for the number of factors. Multivariate Behavioral Research,
1: 245–276.
Celeux, G., M. Hurn, and C. P. Robert. 2000. Computational and inferential difficulties with mixture
posterior distributions. Journal of the American Statistical Association, 95:451, 957–970.
Chen, F., K. A. Bollen, P. Paxton, P. J. Curran, and J. B. Kirby. 2001. Improper solutions in structural
equation models: Causes, consequences, and strategies. Sociological Methods and Research,
29:4, 468–508.
Chung, H., E. Loken, and J. L. Schafer. 2004. Difficulties in drawing inferences with finite-mixture
models: A simple example with a simple solution. American Statistician, 58:2, 152–158.
600
Cliff, N. 1973. Scaling. Annual Review of Psychology, 24: 473–506.
______. 1983. Some cautions concerning the application of causal modeling methods. Multivariate
Behavioral Research, 18: 115–126.
Cochran, W. G. 1952. The 2 test of goodness of fit. Annals of Mathematical Statistics, 23: 315–345.
Cook, T. D., and D. T. Campbell. 1979. Quasi-experimentation: Design and analysis issues for field
settings. Chicago: Rand McNally.
Croon, M. 2002. Ordering the classes. Applied Latent Class Analysis: 137–162, J. A. Hagenaars and
A. L. McCutcheon, eds. よ り 。 Cambridge, UK: Cambridge University Press.
Crowley, J., and M. Hu. 1977. Covariance analysis of heart transplant data. Journal of the American
Statistical Association, 72: 27–36.
Cudeck, R., and M. W. Browne. 1983. Cross-validation of covariance structures. Multivariate
Behavioral Research, 18: 147–167.
Davis, W. R. 1993. The FC1 rule of identification for confirmatory factor analysis: A general
sufficient condition. Sociological Methods and Research, 21: 403–437.
Diaconis, P., and B. Efron. 1983. Computer-intensive methods in statistics. Scientific American,
248:5, 116–130.
Ding, C. 2006. Using regression mixture analysis in educational research. Practical Assessment
Research and Evaluation, 11:11. http://pareonline.net/getvn.asp?v=11&n=11 で入手可能。
Dolker, M., S. Halperin, and D. R. Divgi. 1982. Problems with bootstrapping Pearson correlations in
very small samples. Psychometrika, 47: 529–530.
Draper, N. R., and H. Smith. 1981. Applied regression analysis. 2nd ed. New York: John Wiley and
Sons.
Edgington, E. S. 1987. Randomization Tests. 2nd ed. New York: Marcel Dekker.
Efron, B. 1979. Bootstrap methods: Another look at the jackknife. Annals of Statistics, 7: 1–26.
______. 1982. The jackknife, the bootstrap, and other resampling plans. (SIAM Monograph #38)
Philadelphia: Society for Industrial and Applied Mathematics.
______. 1987. Better bootstrap confidence intervals. Journal of the American Statistical Association,
82: 171–185.
Efron, B., and G. Gong. 1983. A leisurely look at the bootstrap, the jackknife, and cross-validation.
American Statistician, 37: 36–48.
Efron, B., and D. V. Hinkley. 1978. Assessing the accuracy of the maximum likelihood estimator:
Observed versus expected Fisher information. Biometrika, 65: 457–87.
Efron, B., and R. J. Tibshirani. 1993. An introduction to the bootstrap. New York: Chapman and Hall.
European Values Study Group and World Values Survey Association. European and world values
surveys four-wave integrated data file, 1981–2004. Vol. 20060423. 2006.
Felson, R.B., and G. W. Bohrnstedt 1979. “Are the good beautiful or the beautiful good?” The
relationship between children’s perceptions of ability and perceptions of physical attractiveness.
Social Psychology Quarterly, 42: 386–392.
601
参考文献
Fisher, R. A. 1936. The use of multiple measurements in taxonomic problems. Annals of Eugenics,
7: 179–188.
Fox, J. 1980. Effect analysis in structural equation models. Sociological Methods and Research, 9:
3–28.
Fraley, C., and A. E. Raftery. 2002. Model-based clustering, discriminant analysis, and density
estimation. Journal of the American Statistical Association, 97:458, 611–631.
Frühwirth-Schnatter, S. 2004. Estimating marginal likelihoods for mixture and Markov switching
models using bridge sampling techniques. The Econometrics Journal, 7: 143–167.
Furnival, G. M., and R. W. Wilson. 1974. Regression by leaps and bounds. Technometrics, 16:
499–511.
Gelman, A., J. B. Carlin, H. S. Stern, and D. B. Rubin. 2004. Bayesian Data Analysis. 2nd ed. Boca
Raton: Chapman and Hall/CRC.
Gill, J. 2004. Introduction to the special issue. Political Analysis, 12:4, 323–337.
Graham, J. W., S. M. Hofer, S. I. Donaldson, D. P. MacKinnon, and J. L. Schafer. 1997. Analysis
with missing data in prevention research. The science of prevention: Methodological advances
from alcohol and substance abuse research, K. Bryant, M. Windle, and S. West, eds. よ り 。
Graham, J. W., S. M. Hofer, and D. P. MacKinnon. 1996. Maximizing the usefulness of data obtained
with planned missing value patterns: An application of maximum likelihood procedures.
Multivariate Behavorial Research, 31: 197–218.
Gulliksen, H., and J. W. Tukey. 1958. Reliability for the law of comparative judgment.
Psychometrika, 23: 95–110.
Hamilton, L. C. 1990. Statistics with Stata. Pacific Grove, CA: Brooks/Cole.
Hamilton, M. 1960. A rating scale for depression. Journal of Neurology, Neurosurgery, and
Psychiatry, 23: 56–62.
Hayduk, L. A. 1987. Structural equation modeling with LISREL. Baltimore: Johns Hopkins
University Press.
Hoelter, J. W. 1983. The analysis of covariance structures: Goodness-of-fit indices. Sociological
Methods and Research, 11: 325–344.
Hoeting, J. A., D. Madigan, A. E. Raftery, and C. T. Volinsky. 1999. Bayesian model averaging: a
tutorial. Statistical Science, 14: 382–417.
Holzinger, K. J., and F. A. Swineford. 1939. A study in factor analysis: The stability of a bi-factor
solution. Supplementary Educational Monographs, No. 48. Chicago: University of Chicago, Dept.
of Education.
Hoshino, T. 2001. Bayesian inference for finite mixtures in confirmatory factor analysis.
Behaviormetrika, 28:1, 37–63.
Hu, L., and P. M. Bentler. 1999. Cutoff criteria for fit indices in covariance structure analysis:
conventional criteria versus new alternatives. Structural Equation Modeling, 6: 1–55.
Hubert, L. J., and R. G. Golledge. 1981. A heuristic method for the comparison of related structures.
Journal of Mathematical Psychology, 23: 214–226.
Huitema, B. E. 1980. The analysis of covariance and alternatives. New York: John Wiley and Sons.
602
Ibrahim, J. G., M-H Chen, S. R. Lipsitz, and A. H. Herring. 2005. Missing data methods for
generalized linear models: A review. Journal of the American Statistical Association, 100:469,
332–346.
Jackman, S. 2000. Estimation and inference via Bayesian simulation: An introduction to Markov
chain Monte Carlo. American Journal of Political Science, 44:2, 375–404.
James, L. R., S. A. Mulaik, and J. M. Brett. 1982. Causal analysis: Assumptions, models, and data.
Beverly Hills: Sage Publications.
Jamison, C., and F. Scogin. 1995. The outcome of cognitive bibliotherapy with depressed adults.
Journal of Consulting and Clinical Psychology, 63: 644–650.
Jasra, A., C. C. Holmes, and D. A. Stephens. 2005. Markov chain Monte Carlo methods and the label
switching problem in Bayesian mixture modeling. Statistical Science, 20:1, 50–67.
Jöreskog, K. G. 1967. Some contributions to maximum likelihood factor analysis. Psychometrika, 32:
443–482.
______. 1969. A general approach to confirmatory maximum likelihood factor analysis.
Psychometrika, 34: 183–202.
______. 1971. Simultaneous factor analysis in several populations. Psychometrika, 36: 409–426.
______. 1979. A general approach to confirmatory maximum likelihood factor analysis with
addendum. Advances in factor analysis and structural equation models, K. G. Jöreskog and D.
Sörbom, eds. Cambridge, MA: Abt Books, 21–43 よ り 。
Jöreskog, K. G., and D. Sörbom. 1984. LISREL-VI user’s guide. 3rd ed. Mooresville, IN: Scientific
Software.
______. 1989. LISREL-7 user’s reference guide. Mooresville, IN: Scientific Software.
______. 1996. LISREL-8 user’s reference guide. Chicago: Scientific Software.
Judd, C. M., and M. A. Milburn. 1980. The structure of attitude systems in the general public:
Comparisons of a structural equation model. American Sociological Review, 45: 627–643.
Kalbfleisch, J. D., and R. L. Prentice. 2002. The statistical analysis of failure time data. Hoboken,
NJ: John Wiley and Sons.
Kaplan, D. 1989. Model modification in covariance structure analysis: Application of the expected
parameter change statistic. Multivariate Behavioral Research, 24: 285–305.
Kendall, M. G., and A. Stuart. 1973. The advanced theory of statistics. Vol. 2, 3rd ed. New York:
Hafner.
Kline, R. B. 2005. Principles and practice of structural equation modeling. 2nd ed. New York: The
Guilford Press.
Kullback, S., and R. A. Leibler. 1951. On information and sufficiency. Annals of Mathematical
Statistics, 22: 79–86.
Lazarsfeld, P. F., and N. W. Henry. 1968. Latent structure analysis. Boston: Houghton Mifflin.
Lee, S., and S. Hershberger. 1990. A simple rule for generating equivalent models in covariance
structure modeling. Multivariate Behavioral Research, 25: 313–334.
603
参考文献
Lee, S. Y. 2007. Structural equation modeling: A Bayesian approach. Chichester, UK: John Wiley
and Sons.
Lee, S. Y., and X. Y. Song. 2004. Evaluation of the Bayesian and maximum likelihood approaches in
analyzing structural equation models with small sample sizes. Multivariate Behavioral Research,
39:4, 653–686.
Lee, S. Y., and X. Y. Song. 2003. Bayesian analysis of structural equation models with dichotomous
variables. Statistics in Medicine, 22: 3073–3088.
Linhart, H., and W. Zucchini. 1986. Model selection. New York: John Wiley and Sons.
Little, R. J. A., and D. B. Rubin. 1987. Statistical analysis with missing data. New York: John Wiley
and Sons.
______. 1989. The analysis of social science data with missing values. Sociological Methods and
Research, 18: 292–326.
______. 2002. Statistical analysis with missing data. New York: John Wiley and Sons.
Little, R. J. A., and N. Schenker. 1995. Missing data. Handbook of statistical modeling for the social
and behavioral sciences, G. Arminger, C. C. Clogg, and M. E. Sobel, eds. New York: Plenum.
よ り。
Loehlin, J. C. 1992. Latent variable models: An introduction to factor, path, and structural analysis.
2nd ed. Mahwah, New Jersey: Lawrence Erlbaum Associates.
Loken, E. 2004. Using latent class analysis to model temperament types. Multivariate Behavioral
Research, 39:4, 625–652.
Lord, F. M. 1955. Estimation of parameters from incomplete data. Journal of the American Statistical
Association, 50: 870–876.
Lubke, G. H., and B. Muthén. 2005. Investigating population heterogeneity with factor mixture
models. Psychological Methods, 10:1, 21–39.
MacCallum, R. C. 1986. Specification searches in covariance structure modeling. Psychological
Bulletin, 100: 107–120.
______. 1990. The need for alternative measures of fit in covariance structure modeling. Multivariate
Behavioral Research, 25: 157–162.
MacCallum, R. C., M. Roznowski, and L. B. Necowitz. 1992. Model modifications in covariance
structure analysis: The problem of capitalization on chance. Psychological Bulletin, 111:
490–504.
MacCallum, R. C., D. T. Wegener, B. N. Uchino, and L. R. Fabrigar. 1993. The problem of equivalent
models in applications of covariance structure analysis. Psychological Bulletin, 114: 185–199.
MacKay, D. J. C. 2003. Information theory, inference and learning algorithms. Cambridge, UK:
Cambridge University Press.
MacKinnon, D. P., C. M. Lockwood, and J. Williams. 2004. Confidence limits for the indirect effect:
distribution of the product and resampling methods. Multivariate Behavioral Research, 39:1,
99–128.
604
Madigan, D., and A. E. Raftery. 1994. Model selection and accounting for model uncertainty in
graphical models using Occam’s window. Journal of the American Statistical Association, 89:
1535–1546.
Manly, B. F. J. 1991. Randomization and Monte Carlo Methods in Biology. London: Chapman and
Hall.
Mantel, N. 1967. The detection of disease clustering and a generalized regression approach. Cancer
Research, 27: 209–220.
Mantel, N., and R. S. Valand. 1970. A technique of nonparametric multivariate analysis. Biometrics,
26: 47–558.
Mardia, K. V. 1970. Measures of multivariate skewness and kurtosis with applications. Biometrika,
57: 519–530.
______. 1974. Applications of some measures of multivariate skewness and kurtosis in testing
normality and robustness studies. Sankhya, Series B, 36: 115–128.
Marsh, H. W., and D. Hocevar. 1985. Application of confirmatory factor analysis to the study of selfconcept: First- and higher-order factor models and their invariance across groups. Psychological
Bulletin, 97: 562–582.
Martin, J. K., and R. P. McDonald. 1975. Bayesian estimation in unrestricted factor analysis: A
treatment for Heywood cases. Psychometrika, 40: 505–517.
Matsumoto, M., and T. Nishimura. 1998. Mersenne twister: A 623-dimensionally equidistributed
uniform pseudo-random number generator. ACM Transactions on Modeling and Computer
Simulation, 8: 3–30.
Matthai, A. 1951. Estimation of parameters from incomplete data with application to design of
sample surveys. Sankhya, 11: 145–152.
McArdle, J. J., and M. S. Aber. 1990. Patterns of change within latent variable structural equation
models. Statistical methods in longitudinal research, Volume I: Principles and structuring change,
A. von Eye, ed. New York: Academic Press, 151–224 よ り 。
McDonald, R. P. 1978. A simple comprehensive model for the analysis of covariance structures.
British Journal of Mathematical and Statistical Psychology, 31: 59–72.
______. 1982. A note on the investigation of local and global identifiability. Psychometrika, 47:
101–103.
______. 1989. An index of goodness-of-fit based on noncentrality. Journal of Classification, 6:
97–103.
McDonald, R. P., and W. R. Krane. 1977. A note on local identifiability and degrees of freedom in
the asymptotic likelihood ratio test. British Journal of Mathematical and Statistical Psychology,
30: 198–203.
______. 1979. A Monte-Carlo study of local identifiability and degrees of freedom in the asymptotic
likelihood ratio test. British Journal of Mathematical and Statistical Psychology, 32: 121–132.
McDonald, R. P., and H. W. Marsh. 1990. Choosing a multivariate model: Noncentrality and
goodness of fit. Psychological Bulletin, 107: 247–255.
605
参考文献
Mulaik, S. A. 1990. An analysis of the conditions under which the estimation of parameters inflates
goodness of fit indices as measures of model validity. Psychometric Society の年次総会
(Princeton, New Jersey, June 28–30, 1990) で論文発表。
Mulaik, S. A., L. R. James, J. Van Alstine, N. Bennett, S. Lind, and C. D. Stilwell. 1989. Evaluation
of goodness-of-fit indices for structural equation models. Psychological Bulletin, 105: 430–445.
Muth 始 , B., D. Kaplan, and M. Hollis. 1987. On structural equation modeling with data that are not
missing completely at random. Psychometrika, 52: 431–462.
Olinsky, A., S. Chen, and L. Harlow. 2003. The comparitive efficacy of imputation methods for
missing data in structural equation modeling. European Journal of Operational Research, 151:
53–79.
Olsson, S. 1973. An experimental study of the effects of training on test scores and factor structure.
Uppsala, Sweden: University of Uppsala, Department of Education.
Raftery, A. E. 1993. Bayesian model selection in structural equation models. In: Testing structural
equation models, K. A. Bollen and J. S. Long, eds. Newbury Park, CA: Sage Publications,
163–180.
______. 1995. Bayesian model selection in social research. Sociological Methodology, P. V.
Marsden, ed. San Francisco: Jossey-Bass, 111–163 よ り 。
Rigdon, E. E. 1994a. Calculating degrees of freedom for a structural equation model. Structural
Equation Modeling, 1: 274–278.
______. 1994b. Demonstrating the effects of unmodeled random measurement error. Structural
Equation Modeling, 1: 375–380.
Rock, D. A., C. E. Werts, R. L. Linn, and K. G. Jöreskog. 1977. A maximum likelihood solution to
the errors in variables and errors in equations model. Journal of Multivariate Behavioral Research,
12: 187–197.
Rubin, D. B. 1976. Inference and missing data. Biometrika, 63: 581–592.
______. 1987. Multiple imputation for nonresponse in surveys. New York: John Wiley and Sons.
Runyon, R. P., and A. Haber. 1980. Fundamentals of behavioral statistics, 4th ed. Reading, Mass.:
Addison-Wesley.
Salhi, S. 1998. Heuristic search methods. Modern methods for business research, G. A. Marcoulides,
ed. Mahwah, NJ: Erlbaum, 147–175 よ り 。
Saris, W. E., A. Satorra, and D. Sörbom. 1987. The detection and correction of specification errors in
structural equation models. Sociological methodology, C. C. Clogg, ed. San Francisco: JosseyBass よ り 。
Schafer, J. L. 1997. Analysis of incomplete multivariate data. London, UK: Chapman and Hall.
Schafer, J. L., and J. W. Graham. 2002. Missing data: Our view of the state of the art. Psychological
Methods, 7:2, 147–177.
Schafer, J. L., and M. K. Olsen. 1998. Multiple imputation for multivariate missing-data problems:
A data analyst's perspective. Multivariate Behavioral Research, 33:4, 545–571.
Schwarz, G. 1978. Estimating the dimension of a model. The Annals of Statistics, 6: 461–464.
606
Scheines, R., H. Hoijtink, and A. Boomsma. 1999. Bayesian estimation and testing of structural
equation models. Psychometrika, 64: 37–52.
Shrout, P. E., and N. Bolger. 2002. Mediation in experimental and nonexperimental studies: New
procedures and recommendations. Psychological Methods, 7:4, 422–445.
Sobel, M. E. 1982. Asymptotic confidence intervals for indirect effects in structural equation models.
Sociological methodology, S. Leinhart, ed. San Francisco: Jossey-Bass, 290–312 よ り 。
______. 1986. Some new results on indirect effects and their standard errors in covariance structure
models. Sociological methodology, S. Leinhart, ed. San Francisco: Jossey-Bass, 159–186 よ り 。
Sobel, M. E., and G. W. Bohrnstedt. 1985. Use of null models in evaluating the fit of covariance
structure models. Sociological methodology, N. B. Tuma, ed. San Francisco: Jossey-Bass, 152178 よ り 。
Sörbom, D. 1974. A general method for studying differences in factor means and factor structure
between groups. British Journal of Mathematical and Statistical Psychology, 27: 229–239.
______. 1978. An alternative to the methodology for analysis of covariance. Psychometrika, 43:
381–396.
Spirtes, P., R. Scheines, and C. Glymour. 1990. Simulation studies of the reliability of computeraided model specification using the TETRAD II, EQS, and LISREL programs. Sociological
Methods and Research, 19: 3–66.
Steiger, J. H. 1989. EzPATH: Causal modeling. Evanston, IL: Systat.
______. 1990. Structural model evaluation and modification: An interval estimation approach.
Multivariate Behavioral Research, 25: 173–180.
Steiger, J. H., and J. C. Lind. 1980, May 30. Statistically-based tests for the number of common
factors. Psychometric Society の Annual Spring Meeting (Iowa City) で論文発表。
Steiger, J. H., A. Shapiro, and M. W. Browne. 1985. On the multivariate asymptotic distribution of
sequential chi-square statistics. Psychometrika, 50: 253–263.
Stelzl, I. 1986. Changing a causal hypothesis without changing the fit: Some rules for generating
equivalent path models. Multivariate Behavioral Research, 21: 309–331.
Stephens, M. 2000. Dealing with label switching in mixture models. Journal of the Royal Statistical
Society, Series B, 62:4, 795–809.
Stine, R. A. 1989. An introduction to bootstrap methods: Examples and ideas. Sociological Methods
and Research, 18: 243–291.
Swain, A. J. 1975. Analysis of parametric structures for variance matrices. Unpublished Ph.D. thesis,
University of Adelaide.
Tanaka, J. S., and G. J. Huba. 1985. A fit index for covariance structure models under arbitrary GLS
estimation. British Journal of Mathematical and Statistical Psychology, 38: 197–201.
______. 1989. A general coefficient of determination for covariance structure models under arbitrary
GLS estimation. British Journal of Mathematical and Statistical Psychology, 42: 233–239.
Tucker, L. R., and C. Lewis. 1973. A reliability coefficient for maximum likelihood factor analysis.
Psychometrika, 38: 1–10.
607
参考文献
Verleye, G. 1996. Missing at random data problems in attitude measurements using maximum
likelihood structural equation modeling. Unpublished dissertation. Frije Universiteit Brussels,
Department of Psychology.
Vermunt, J. K., and J. Magidson. 2005. Structural equation models: Mixture models. Encyclopedia
of statistics in behavioral scientce, B. Everitt and D. Howell, eds. Chichester, UK: John Wiley and
Sons, 1922–1927 よ り 。
Warren, R. D., J. K. White, and W. A. Fuller. 1974. An errors-in-variables analysis of managerial role
performance. Journal of the American Statistical Association, 69: 886–893.
Wheaton, B. 1987. Assessment of fit in overidentified models with latent variables. Sociological
Methods and Research, 16: 118–154.
Wheaton, B., B. Muthén, D. F. Alwin, and G. F. Summers. 1977. Assessing reliability and stability
in panel models. Sociological methodology, D. R. Heise, ed. San Francisco: Jossey-Bass, 84–136
よ り。
Wichman, B. A., and I. D. Hill. 1982. An efficient and portable pseudo-random number generator.
Algorithm AS 183. Applied Statistics, 31: 188–190.
Winer, B. J. 1971. Statistical principles in experimental design. New York: McGraw-Hill.
Wothke, W. 1993. Nonpositive definite matrices in structural modeling. In: Testing structural
equation models, K. A. Bollen and J. S. Long, eds. Newbury Park, CA: Sage Publications,
256–293.
______. 1999 Longitudinal and multi-group modeling with missing data. Modeling longitudinal and
multiple group data: Practical issues, applied approaches and specific examples, T. D. Little, K.
U. Schnabel, and J. Baumert, eds. よ り 。 Mahwah, New Jersey: Lawrence Erlbaum Associates.
Zhu, H. T., and S. Y. Lee. 2001. A Bayesian analysis of finite mixtures in the LISREL model.
Psychometrika, 66:1, 133–152.
608
索引
A
ADF, 漸近的分布非依存 , 560
AGFI, 修正済み適合度指標 , 577
AIC
Burnham と Anderson に よ る ガイ ド ラ イ ン , 300
赤池情報量基準 , 283, 570
Amos Graphics、 起動 , 9
AmosEngine メ ソ ッ ド , 52
Amos に よ る 仮定
回帰について , 203
外生変数間の相関について , 71
共分散分析について , 221
欠損デー タ について , 250
測定モデル内のパ ラ メ ー タ について , 225
分布に関す る , 32
Amos モデルの分布の仮定 , 32
Anderson のア イ リ ス のデー タ , 484, 497
AStructure メ ソ ッ ド の式形式 , 72
CMIN
最小乖離度関数 , 109, 565
テーブル , 342
CMIN/DF, 最小乖離度を自由度で割っ た値 , 566
Cov
パ ス図を描画す る ための pd 方法 , 534
C におけ る
オプシ ョ ン矢印 , 313
探索的因子分析 , 312
適合度 , 314
D
DF, 自由度 , 564
E
ECVI, 期待交差確認指標 , 572
EQS (SEM プ ロ グ ラ ム ), 223
European Values Study Group, 453
B
F
Bayes 因子 , 590, 591
再調整 , 305
BCC
Browne-Cudeck 基準 , 283, 571
Burnham と Anderson に よ る ガイ ド ラ イ ン , 300
モデル比較 , 299
BCC を使用 し たモデル比較 , 327
BIC
ベ イ ズ情報量基準 , 571
モデル比較 , 321
F0
C
CAIC, 一貫 し た AIC, 571
Caption
パス図を描画す る ための pd 方法 , 534
CFI, 比較適合指標 (comparative fit index), 575
テ キ ス ト マ ク ロ , 568
F0, 母集団の乖離度 , 568
Fisher のア イ リ ス のデー タ , 484, 497
FMIN, 乖離度 F の最小値 , 567
G
GetCheckBox
pd 方法 , 539
GFI, 倹約性適合度指標 , 578
GFI, 適合度指標 , 577
GLS, 一般化 し た最小 2 乗法 , 560
GroupName メ ソ ッ ド , 157
H
HOELTER, ク リ テ ィ カル N, 578
609
610
索引
L
R
LISREL (SEM プ ロ グ ラ ム ), 223
Reposition
パ ス図を描画す る ための pd 方法 , 534
RFI, 相対非心度指標 (relative noncentrality index),
M
Mainsub 関数 , 531
MCMC 診断 , 468
MECVI, 変更 さ れた期待交差確認指標 , 572
ML, 最尤法推定値 , 559
N
NCP, 非心度パ ラ メ ー タ , 568
NFI, 相対適合指標 (relative fit index), 574
NFI, 増分適合指標 (incremental fit index), 575
NFI, 標準適合指標 (normed fit index), 573
NNFI, 非標準適合指標 (non-normed fit index), 575
NPAR, パ ラ メ ー タ 数 , 564
O
Observed
パス図を描画す る ための pd 方法 , 532
Occam の ウ ィ ン ド ウ、 対称 , 304
P
P, 確率 , 565
Path
パス図を描画す る ための pd 方法 , 533
PCFI, 倹約性比較適合指標 (parsimonious
comparative fit index), 576
PCLOSE, 母集団 RMSEA の高い適合性 , 570
pd 方法
Caption, 534
Cov, 534
GetCheckBox, 539
Observed, 532
Path, 533
Reposition, 534
SetDataFile, 539
UndoResume, 534
UndoToHere, 534
Unobserved, 533
PNFI, 倹約性標準適合指標 (parsimonious normed
fit index), 576
PRATIO, 倹約率 , 565
575
RMR, 残差平均平方根 , 579
RMSEA, 近似誤差平均平方根 , 569
S
Semnet, 4
SetDataFile
pd 方法 , 539
SLS, 尺度不変最小 2 乗 , 560
T
TLI, Tucker-Lewis 指標 , 575
U
ULS, 重み付けのない最小 2 乗法 , 560
UndoResume
pd 方法 , 534
UndoToHere
pd 方法 , 534
Unobserved
パ ス図を描画す る ための pd 方法 , 533
あ
ア イ リ ス のデー タ , 484, 497
赤池 ウ ェ イ ト , 590, 591
解釈 , 301
表示 , 300
新 し いグループ , 51, 70, 157
安定指数 , 124
安定 し たモデル , 124
い
一貫 し た AIC(CAIC), 283
入れ子にな っ たモデル , 239
因子得点 ウ ェ イ ト , 111
因子の平均値
制約条件の削除 , 344
比較 , 343
因子負荷 , 339
611
索引
因子分析 , 127
構造平均 , 209
探索的 , 323
モデル , 209
う
打ち切 り デー タ , 439
お
オブジ ェ ク ト の移動 , 14
オブジ ェ ク ト の形変更 , 14
オプシ ョ ン出力 , 15, 30, 43, 110
オプシ ョ ン矢印 , 306, 313, 316
か
カ イ 2 乗確率 メ ソ ッ ド , 259
カ イ 2 乗統計量 , 47
図のキ ャ プシ ョ ンへの表示 , 48
回帰法代入 , 427
回帰モデル , 9, 13, 442
外生変数 , 35, 63, 69, 71
外生変数間の相関 , 71
乖離度 , 559
取得
重相関係数の平方 , 123
パ ラ メ ー タ の差に対す る 検定統計量 , 166
標準化推定値 , 122, 132
確率 , 28
確率的回帰法代入 , 427
カ ス タ ム推定値 , 403
仮説の検定 , 47
カ テ ゴ リ の境界 , 459
間接効果 , 112
信頼区間の発見 , 397
推定 , 390
表示、 標準化 , 393
き
記述適合度 , 587
帰無モデル , 587
境界。 「カ テ ゴ リ の境界」 を参照
共通因子 , 129
共通因子モデル , 128
共分散
構造 , 339
描画 , 174
不偏推定値 , 222
ラ ベル , 174
共分散の設定 , 25
共分散分析 , 137
代替 , 135, 221
方法の比較 , 235
共分散分析の代替分析 , 135, 221
共分散を描 く , 174
く
グ ラ フ ィ ッ ク を使用 し ないモデルの指定 , 529
グループ間制約 , 212
影響 さ れ る パ ラ メ ー タ , 340
手動設定 , 343
生成 , 351
グループ間制約の生成 , 351
グループの相違の指定
規則 , 148
グループの相違を指定す る ための規則 , 148
け
計算
検定統計量 , 100
標準化推定値 , 30
係数 , 581
結果取得用の メ ソ ッ ド , 52
結果の結合、 多重代入デー タ フ ァ イ ル , 437
結果を含むテ キ ス ト フ ァ イ ル , 51
欠損デー タ , 249–270
検定統計量 , 27
計算 , 100
倹約性 , 564
倹約性指標 , 576
こ
構造指定 , 72
パ ラ メ ー タ の推定 , 72
構造方程式モデ リ ン グ , 2
雑誌 , 4
推定方法 , 2
構造方程式モデ リ ン グに関す る 雑誌 , 4
構造モデル , 75
構造モデルの共分散 , 339
固定変数 , 32
612
索引
コ ピー
テ キ ス ト 出力の表示 , 20
パス図 , 20
固有の変数 , 71
混合モデ リ ン グ , 483
さ
再帰モデル , 69
再 コ ー ド 化デー タ , 441, 456, 474
最小乖離度関数 , 109
細線化 , 381
再調整 さ れた測度 , 589
作成
2 つ目のグループ , 174
パス図 , 77
散布図
C - df を表す線 , 310
C - df を表す線の調整 , 311
定数の適合度を表す線 , 309
定数の適合度を表す線の調整 , 309
定数の適合度を表すその他の線 , 312
適合度 と 複雑度 , 307
し
シー ド 、 乱数 , 362
閾値。 「カ テ ゴ リ の境界」 を参照
識別可能モデル , 66, 252, 255, 280, 563
識別制約 , 138
時系列図 , 370
事後
標準偏差 , 357
分布 , 357
平均 , 357
自己相関図 , 371, 469
事後予測分布 , 445, 470, 495, 508, 525
潜在変数 , 474
事前分布 , 357, 358, 377
グループ比率 , 528
指定
図のキ ャ プシ ョ ンのグループ名 , 162
等 し いパ ラ メ ー タ , 39
等 し いパ ラ メ ー タ の利点 , 39
指標の回転 , 78
修正指数 , 95, 100, 354
誤用 , 100
要求 , 139
修正指数の誤用 , 100
修正指数の要求 , 139
収束
事後分布の要約の , 367
分布の , 366
ベ イ ズ推定におけ る , 366
自由度 , 29
従来の線型回帰 , 61
順序 - カ テ ゴ リ カル デー タ , 453
条件付 き 検定 , 239
情報理論的適合度 , 570
診断
MCMC, 468
信頼区間 , 578, 579
信頼領域 , 375
す
垂直に配置 , 173
推定
間接効果 , 390
分散 と 共分散 , 21
平均値 , 191
数値カ ス タ ム推定値 , 409
数量 , 541
ス ク リ ー プロ ッ ト
最善の適合グ ラ フ の表示 , 314
探索的モデル特定化 , 315
すべてのモデルの適合 , 342
単一の分析 , 171
せ
正規分布 , 32
生成 さ れたモデル , 341
生存期間 , 440
制約
共分散 , 39
追加に よ る モデルの改良 , 100
パ ラ メ ー タ , 13
分散 , 38
平均値 と 切片項 , 350
ゼ ロ ベース の再調整 , 589
ゼ ロ モデル , 563
描画領域
共分散パ ス の追加 , 80
測定モデルの ウ ェ イ ト の表示 , 340
非観測変数の追加 , 80
方向の変更 , 76
漸近 , 28
613
索引
線型従属 , 62
宣言用の メ ソ ッ ド , 52
潜在構造分析 , 496, 509
潜在変数
事後予測分布 , 474
そ
相関がない変数 , 54
相関がない変数の検定 , 54
総合効果 , 112
測定エ ラ ー , 62
測定モデル , 75, 278
測定モデルの ウ ェ イ ト , 339
描画領域での表示 , 340
測定モデルの残差 , 340
測定モデルの複写 , 78
た
対称的な Occam の ウ ィ ン ド ウ , 304
代入
回帰 , 427
確率的回帰法 , 427
多重 , 428
デー タ , 427, 448, 478
ベ イ ジ ア ン , 427
モデルベース の , 428
多重代入 , 428
多重代入デー タ セ ッ ト , 435
多重代入デー タ フ ァ イ ルの結果の結合 , 437
多変量分散分析 , 198
単一分析での複数モデル , 106
探索的因子分析 , 318, 323
ス ク リ ー プ ロ ッ ト , 312
探索的モデル特定化 , 315
適合度 と 複雑度についての散布図 , 307
探索的モデル特定化 , 293–322
Bayes 因子を使用 し たモデル比較 , 303
BCC を使用 し たモデル比較 , 299
BIC を使用 し たモデル比較 , 302
CAIC, 584
CFI, 583
RMSEA, 583
赤池 ウ ェ イ ト , 300
オプシ ョ ン矢印 , 306, 319
オプシ ョ ン矢印が少数 , 294
確証的 , 294
高速化 , 297
実行 , 297
使用す る パ ラ メ ー タ 数 , 306
生成 さ れたモデル , 298
探索的因子分析 , 315, 318, 323
適合度の表示 , 297
デフ ォ ル ト に戻す , 296, 320
発見的 , 323, 332
パ ラ メ ー タ 推定値 , 299
必須の矢印 , 295
プ ロ グ ラ ムのオプシ ョ ン , 296
保持す る モデルの制限 , 296
探索分析 , 91
単純モデル , 564
ち
直接効果 , 112
て
デー タ お よ びモデル指定用の メ ソ ッ ド , 52
デー タ 代入 , 250, 427, 448, 478
デー タ の再 コ ー ド 化 , 441, 456, 474
デー タ の入力 , 41
デー タ フ ァ イ ル , 11
適合度 , 563, 580, 583
テ キ ス ト 出力 と し ての相関推定値 , 31
テ キ ス ト 出力の表示
コ ピー , 20
テ キ ス ト マ ク ロ , 47, 564–579
デフ ォ ル ト 、 変更 , 223
と
統計仮説の検定 , 94
同時因子分析 , 179
同時方程式モデル , 161
同等性の制約条件 , 129
独自因子 , 129
特定可能性 , 61, 129, 581
条件 , 129
特定可能性の条件 , 129
独立モデル , 252, 255, 280, 563
ト レース図 , 370, 468, 510
ト レーニ ン グ デー タ , 483
614
索引
な
内生変数 , 66
名前を付け る
グループ , 180
変数 , 24
は
バーン イ ン 標本 , 365
パス図 , 2
印刷 , 20
オブジ ェ ク ト の移動 , 14, 40
オブジ ェ ク ト の形変更 , 14
オブジ ェ ク ト の削除 , 15
オブジ ェ ク ト の書式設定 , 40
カ イ 2 乗統計量の表示 , 48
キ ャ プシ ョ ンのグループ名の指定 , 162
コ ピー , 20
作成 , 77
指標の回転 , 78
新規 , 22
測定モデルの複写 , 78
デー タ フ ァ イ ルの添付 , 22, 41
動作のや り 直 し , 15
動作を元に戻す , 15
パ ラ メ ー タ の制約 , 13
表示の変更 , 14
矢印の描画 , 13
発見的な探索的モデル特定化 , 323, 332
ス テ ッ プ ワ イ ズ法 , 332, 333
制限 , 335
変数減少法 , 332
変数増加法 , 332
パラ メ ータ
グループ間制約に よ る 影響 , 340
等 し い、 指定の利点 , 39
等 し いパ ラ メ ー タ の指定 , 39
パ ラ メ ー タ 制約条件 , 37
パ ラ メ ー タ の推定
構造指定 , 72
ひ
非拡散事前分布 , 377
非観測変数 , 73
非再帰モデル , 69, 119, 120
表示
グ ラ フ ィ ッ ク ス出力 , 19, 26
生成 さ れたモデル , 341
テ キ ス ト 出力の表示 , 17, 27
パ ラ メ ー タ 部分集合 , 340
標準化間接効果 , 393
標準化推定値 , 133
標準化推定値 , 30, 122
取得 , 132
表示 , 133
ふ
ブー ト ス ト ラ ッ プ , 271–276
ADF, 287
GLS, 287
ML, 287
ULS, 287
欠点 , 271
失敗 , 283
進行状況の監視 , 273
診断情報のあ る テーブル , 274
推定方法の比較 , 285–291
標本 , 277
標本の数 , 273, 281
モデル比較におけ る 手法 , 277–284
不安定なモデル , 124
付加定数 ( 切片 ), 203
複雑モデル , 564
複数グループでの因子分析 , 337
複数グループの同時分析 , 147
複数グループの分析 , 349
不適解 , 378
不等式制約、 デー タ , 445, 451
負の分散 , 142
フ リ ー パ ラ メ ー タ , 35
[ プ ロ パテ ィ を ド ラ ッ グ ] オプシ ョ ン , 173
分散
不偏推定値 , 222
ラ ベル , 174
分散 と 共分散の等質性 , 503
分散 と 共分散の不偏推定値 , 222
分類エ ラ ー , 495
へ
ベース ラ イ ン モデル , 587
指定 , 588
比較 , 573
ペア ご と の削除 , 249
615
索引
平均値 と 切片
モデル作成 , 191
平均値 と 切片項
制限 , 343, 350
[ 平均値 と 切片を推定 ] オプシ ョ ン
選択 し ない場合 , 194
選択す る 場合 , 194
平均値に関す る 仮説の検定 , 191
ベ イ ジ ア ン推定 , 357
追加推定値の , 395
ベ イ ジ ア ン法代入 , 427
ベ イ ズ推定におけ る 安定性テ ス ト , 387
ベ イ ズ推定におけ る 許容性テ ス ト , 387
ベ イ ズの信頼区間 , 358
ベ イ ズの定理 , 357
変更
描画領域の方向 , 76
デフ ォ ル ト , 223
デフ ォ ル ト の動作 , 223
フ ォ ン ト , 25
変数
外生 , 63, 69, 71
固有 , 71
名前の入力 , 80
非観測 , 73
変数減少法に よ る 発見的な探索的モデル特定化
, 332
変数増加法に よ る 発見的な探索的モデル特定化
, 332
ほ
飽和 , 66
飽和モデル
オプシ ョ ン指定 , 325
特定不能な係数 , 64
モデル , 66
母集団の乖離度
モデルの妥当性の測度 , 567
も
網羅的な探索的モデル特定化 , 332
モデル
新 し い制約の追加に よ る 改良 , 100
安定 , 124
一方に対す る も う 一方の検定 , 86
入れ子 , 239
因子分析 , 209
回帰 , 9
棄却 , 94
共通因子 , 128
構造 , 75
個別、 グ ラ フ ィ ッ ク 出力の表示 , 109
再帰 , 69
識別可能 , 66, 252, 255, 280, 563
指定 , 11, 35
修正 , 94
新規 , 10
生成 , 341
ゼ ロ , 563
描画 , 130
測定 , 75, 278
単一分析での複数 , 106
単純 , 564
同時方程式 , 161
特定 , 61, 64, 76, 93, 121, 129, 138, 209
独立 , 252, 255, 280, 563
内生 , 66
非再帰 , 69, 119, 120
不安定 , 124
複雑 , 564
複数、 統計の表示 , 109
平均値 と 切片項を使用 し ない , 337
変数の描画 , 11
変数の命名 , 12
矢印の描画 , 13
モデルの指定、 グ ラ フ ィ ッ ク を使用 し ない , 529
モデル比較
Bayes 因子の使用 , 303
BCC の使用 , 299
BIC の使用 , 302, 321
モデルベース の代入 , 428
よ
予測分布。 「事後予測分布」 を参照
予測変数 , 32
ら
ラ ベル
出力 , 46
分散 と 共分散 , 174
ラ ベル ス イ ッ チン グ , 510, 528
乱数のシー ド , 362
乱数変数 , 32
り
リ ス ト ご と の削除 , 249
616
索引
© Copyright 2026 Paperzz