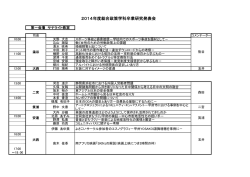
確率・統計(電子2年) 第1講 担当:鶴 ([email protected]) 1. はじめに 確率・統計とは?(参考書1.1章) 本講義では,不確実(不規則,非決定論的)な現象(「確率的現象」)を,数学的 に扱うための道具である「確率論」の基本と, 「統計的推定(推計統計学)」および 「確率過程」の各々初歩を学ぶ.つまり,現象の起きやすさ(起きるかどうか)を 予測する方法や観測(データ)から何が起きているかを解析する方法を学ぶ.た だし,本質的に不確実な現象な場合もあれば,我々が現象を正確に確定・断定する のに必要な情報を持たないだけの場合もある.そして,起きるかどうかの「予測」 は必ずしも「未来」のことに対して行うとは限らず, (対象者にとって)「未知」の ことであればよい.例えば, • 今から振るサイコロの目が1である「確率」とか,自分が買った(当選発表 前の)宝くじが当る「確率」→典型的な確率的現象と思える. • 伏せたお椀の中に入っているサイコロの目が1である「確率」→お椀を開け るまでは確率的現象と思いたい,知ってる情報に依存する. • サイコロを無限回投げ続ける時,ある回以降はずっと1が出続ける「確率」 →対象としてる現象が無限回の試行に関する性質. • 容疑者 A が真犯人である「確率」→知ってる情報に依存する. • 自宅周辺で雨が降る「確率」→「自宅周辺で雨が降る」をどう定義するか? • ルパン三世がコナンに逮捕される「確率」→仮想実験上の確率.何を仮定で きるのか? これらが「確率論」で扱えるかどうかは,適切な「仮定」が成り立つようなモ デル化ができるかに依存している.この講義では,応用数学の一分野として「確 率論」を学習し, 「現実問題に正しく適用できる」ようになることを目標にする. 1. 現実世界の現象のほとんどすべてにおいて,それを理解するのに必要な情報 は「不十分・不完全」であり,よって「不確実」である.そのため,確率論は, • 面白い.特に条件付確率や無限が絡むと直感に反する場合がある. • 役に立つ.よって,専門分野で必ず使う.また,詐欺に遭わないための基礎知 識とも言える.天気予報はもとより,あらゆる種類のシステムやネットワー クの設計・運転・制御から,株の売買,犯罪捜査,生命保険設計,スポーツ 戦術,等々,人間の勘(だけ)に頼らない客観的な「戦術・意思決定」には, 確率・統計が不可欠. 1 – 確率論とそれに基づく統計的推定は,既にあらゆる分野において必須の 道具である.近年「ビッグデータ」という言葉も流行しているが,誤差 を含む膨大な観測データから人間が気付かない新しい知見・法則を「発 見」することが試みられている. – アクチュアリー会試験:http://www.actuaries.jp/examin/info.html は,有名な資格の1つ. – EMaT(工学系数学統一試験:http://www.aemat.jp/exam/)は大学 資格試験のようなもので,第 4 分野が「確率・統計」である.本講義受 講後には容易に解けるはず. 2. 確率論はひらめき・直感クイズではなく数学である.そのため, • 理論とそれに基づく計算を用いる.離散的現象なら組み合わせの数や数列和, 連続的現象なら積分が基本. • 解析数学がどれもそうであるように,納得・理解には時間をかけた勉強(自 分の手で計算してみること)が必要. さらに確率論を考える時,以下の3つを区別(意識)する必要がある. 1. 現実の確率的現象の直感的説明 2. 数学的な厳密な論理展開 3. 正しい適用と正しい計算 高校までの「確率」は,1番目のものと3番目の一部を学んできた(学んでな い人も居るかも知れないが, , , ). それに対して,本講義の目的は,主に2番目,3番目の話である. • 数学的な厳密な論理展開∼数学的なモデル(定義)から出発して,現実の確 率的現象に関する経験則を論理的に導く.ただし,本当に「厳密」な数学的 扱いは, 「測度論(ルベーグ積分論)」を必要とするので,諦め,ある程度の 許容範囲内の仮定・前提を使いながら,数学的論理を展開する.本講義での 到達目標は,大数の法則と中心極限定理である. • 正しい応用∼これから実際の工学的・理学的な対象を学ぶ中で,そのような 対象の振舞いに確率論を適用し,様々な確率や統計量を計算する必要がある. そこで困らないような計算技術や考え方に慣れることも,本講義の大きな目 的である. このように確率論の理解を深め,その結果として,直感だけでは正しい答えが 得られないような確率的現象も扱えること,を目指す. 2 授業の進め方 • 資料(プリント)配付.資料内の「練習 」は復習用として必ず次回までに 解いて来て下さい.その次の授業で時間の許す範囲で簡単に解答・解説する. 出席確認も兼ねて, 「練習」のうちの数回を「小レポート」として次週の授業 で提出してもらう(用紙は A4,様式は自由,氏名・学生番号を忘れない). • 授業の最後の 10 分程度を使って配布する問題をその場で解いて提出しても らうこともある(演習). • 前半まとめの模擬試験を課し,その解答を「中間レポート」として提出して もらい(回収までの期間は 1 週間以上取る),部分評価を行う.期末試験に よって前半・後半の総合評価を行う. • 基準参考書(購入は自由)は, – 「はじめての確率論」(小杉のぶ子,久保幹雄共著),近代科学社. 1 章∼4 章は本講義とほぼ同じ範囲を扱うが,面白い具体例(例題)が 載っている.5, 6 章には確率過程が深入りしない範囲で載っている. 確率や統計に関する市販本は際限なく多数あるが,その中で以下の本は,本 講義受講と並行して,あるいは後で読んでみるとさらに世界が広がるものと してぜひお勧めしたい. – 「統計と確率の基礎」(服部哲弥著),学術図書出版社. 本講義の一部はこの本(の元になった古い公開資料)を参考にしてい る.読んで面白く自習書として最適.少し確率過程の例も扱っている. – 「入門 統計学」(栗原伸一著),オーム社. 本講義では推計統計学のごく一部しか学ぶ時間がない.この本はその全 体を見渡すための入門書. なお,総務省統計局(国勢調査などを企画する機関)が提供している「な るほど統計学園高等部」 :http://www.stat.go.jp/koukou/index.htm もこれから推計統計学を学ぶ人は一見の価値あり. – 「確率と確率過程」(宮沢政清著).近代科学社(現代数学ゼミナール 17). 本講義の資料は,元々この本の前半の内容に合わせ,それを簡易に解説 する意図で作成した.より深い内容を学びたい人に勧めたい.特に後半 の確率過程は著者の専門性に依存した非常に高度な内容を含む. – 「マルコフ解析」(森村英典,高橋幸雄著),日科技連. 実際の動的なシステムを確率過程を使ってモデル化する際に重要なマル コフ連鎖に関しても,本講義では簡単な例を通じてさわりしか学ぶ時間 3 がない.この本はマルコフ連鎖を使ったモデル化・解析手法の全体を見 渡す有名な教科書. – 「マルチンゲールによる確率論」(D. Williams 著,赤堀次郎;原啓介; 山田俊雄訳),培風館. 前半は本講義の範囲に関して数学的な厳密さを勉強することができ,そ の厳密な理論に基づいて後半は条件付き期待値と確率過程を学ぶこと で, (本講義のレベルを超えているが,しかし大変面白い)高度な確率 的問題を扱えるようになる. – 「ビッグデータの正体」 (V. Mayer-Schonberger 他著,齊藤 栄一郎訳), 講談社. 膨大な情報(観測データ)が利用可能な現代における,確率・統計の新 しい活用の事例と方向性を論じた読み物で,大変面白い. • 授業中の携帯電話禁止,マナーモードにすること.説明途中でも,声を上げ て質問などの割り込み可.なお,休講が入る場合は,どこかで補講を行う. • 確率論は解析数学の応用の一種であり,解析数学は,自分の計算過程を追体 験(例えば紙と鉛筆を使って)して納得するのが,唯一の理解の方法である. 授業時間内にすべての計算を確認することは不可能なので,必ず復習するこ と.例題や練習問題は必ず自分でノートに解いてみて下さい. 第 2 クォータの「応用解析学」に関連する部分も多い.数学的な詳細のうち 「応用解析学」に任せることが可能な部分はそのように進めるので,是非応 用解析学も受講してみてほしい. • 資料の間違いは,授業中でもメールでもいいので,指摘して下さい. 一方,白板に書くことは大体資料にも書いてあるので,それを丸写しする必 要はない.ただし,資料に書ききれないことをポンチ絵や言葉で補うので, それを見逃さない,聞き逃さないようにして下さい. 講義の中身はシラバス参照のこと.大雑把に言えば以下のことを学ぶ. • 確率的現象は通常, 「確率変数」で表わされる.これをどのような数学的実体 として定義するかが最初の問題になる.また,無限個の確率変数の振る舞い (特に,時刻 t をパラメタとする確率変数の集合)を扱うのが「確率過程」. 確率計算:確率モデル→観測データの振る舞いの予測. 1) 現象をモデル化する(基本確率変数に分布を与える). 2) モデルから,複雑な現象の分布を導出(計算)し,複雑な現象の発生に 関する特性を予測する. 4 – 例1:いんちきのないコインを2回投げる時,2回とも表が出る確率 は?高校までの「確率」で,この値を 0.5 × 0.5 = 0.25 と計算すること を学んだ(はず). – 例2:福岡県で 1 日平均 100 件の交通事故が起きるとする.今の瞬間に ある事故が起きた.10 分以内に県内で次の事故が起きる確率は?高校 までの「確率」では扱えない問題である. – 賭け事(ポーカー等)の戦術の議論が,確率計算の本格的な研究の起源 と言われている.しかし,数学的なモデルが整備されたのは 20 世紀に なってからである(ロシアのコルモゴロフら). • 一方,実際の現象を確率変数でモデル化する際に,現象の観測データとの関 係を論じるのが統計.観測値からモデルを抽出することを統計的推定と呼ぶ. 統計的推定:観測データ→確率モデルの推定 1) 現象を未知のパラメタ付きでモデル化する. 2) 現象を観測する(無作為に観測された結果を「サンプルデータ」と呼ぶ). 3) サンプルデータから,未知パラメタ(未知分布)を推定する. – 例1:テレビの視聴率を調査したいが,もちろん全世帯を調査すること はできない.そこで無作為に選んだ 1000 世帯で視聴率を調査した.そ のデータから何がどの程度の信頼性?で推定(予測)できるか? – 例2:血圧を下げる効果がある(はずの)新薬を開発した.どういう実 験をすればそのデータからどの程度の信頼性?で「この薬がそもそも効 果があること」を示せる?さらに「既に市販されているある薬に比べて 効果が高いこと」を示すにはどうすればよいか? – (確率論に基づく)数学的な厳密化とは別に,経験則的に発展し,理論 的裏付けは後で行われたようである. 確率論の中で出てくる2つの重要な事実,ベイズの公式(条件付き確率)と 中心極限定理(および大数の法則)がその根幹にある. • それらを組み合わせ,実現象の観測 ⇒ 現象のモデルの推定・検定 ⇒ モデル に基づく現象の予想や観測 ⇒ .... が繰り返され, 「今日はかさを持って外出 すべきか?」, 「この株は今売るべきか?」, 「生命保険の掛け金はどのように 決定すべきか?」から, 「地球温暖化は本当に進行しているか?」, 「10 年以内 にM8級地震が起きるか?」まで,様々な判断の根拠を与える. 予備的練習問題 問1 < 1 > あなたならどちらを選ぶか? 理由を付けて答えよ. 5 A 80 万円必ずもらえる B 100 万円もらえる可能性が高いが,15%の確率で全くもらえない < 2 > あなたならどちらを選ぶか? 理由を付けて答えよ. A 80 万円必ず支払わねばならない. B 100 万円支払わねばならない可能性が高いが, 15%の確率で全く支払わ なくてもよい. 問2 1 から n までの(相異なる)数字の書かれた n 枚のカードをよく切ってから,一 列に並べる時,それが順単峰数列になる確率を計算せよ.ただし,順単峰とは, (並 べた列の中で)j 番目のカードの数字を aj として,ある番号 k(2 ≤ k ≤ n − 1) が あって,a1 < . . . < ak > ak+1 > . . . an が成り立つこととする. 問3 的当てを繰り返し行う.1回の投てきで当る確率を p として,この値は何回投 げても変化しない(つまり上達しない!).また,前回の結果が次の回の確率に影 響しない(調子のいい時は続けて当たるような現象は起きないとする). <1> 運悪く最初の 100 回が続けて(全部)外れたとする.この状況で次の 101 回 目が当たる確率は,p か,それとも,p ではないか? <2> n 回目で初めて的に当る確率を n と p の式で表せ. <3> 永久に的に当たらない確率はいくらか? 問4 <1> 乱数 X, Y は,互いに無関係(「独立」※定義は講義で※)で,どちらも,値 1 または 2 を各々確率 0.5 で出力する.例えばコイン A, B を投げ,X(Y ) の 値を,A(B) の目が表なら 1,裏なら 2 として決めればよい.一回の実験で X と Y の値を各々一個出力し,i 回目の実験での出力値を Xi , Yi と置く.例 えば, i Xi Yi Xi /Yi def Si = i k=1 Xk /Yk Si /i 6 1 1 1 1 2 1 2 0.5 3 2 1 2 ··· ··· ··· ··· 1 1 1.5 0.75 3.5 1.167 ··· ··· n 1 Xi という値,すなわち比 X/Y の n 個(回) n i=1 Yi の算術平均(相加平均)は,n を増やしていくとどうなるか? 実験を繰り返すとして, 1. いつかは,1 に収束 2. いつかは,1.125 に収束 3. 「多数回繰り返す実験」というものを機会を変えて行う毎に収束先が違 う(場合によっては収束しないことも) <2> 乱数 X, Y は,互いに「独立」で,どちらも実数区間 [1, 2] の範囲から無作為 に1つの「実数」を出力する.一回の実験で X と Y の値を各々一個出力し, i 回目の実験での出力値を Xi , Yi と置く.実験を繰り返すとして,Xi と Yi の n 1 Xi : という値は,n の増加に 比の n 個(回)の算術平均(相加平均) n i=1 Yi 伴い収束するか? 1. いつかは,1 に収束 2. いつかは,約 1.035 . . .(1.5 log 2) に収束 3. 「多数回繰り返す実験」というものを機会を変えて行う毎に収束先が違 う(場合によっては収束しないことも) 解説(解答) def 本資料では,A = B は,左辺の記号 A を右辺の既に定義されたもの(式や数) B で定義する,という意味で使う. 問 1 の解説 <1>の場合の期待値が,Aは 80 万,Bは 85 万.<2>の場合の期待値が,Aは80 万,Bは-85 万.また,分散が,Aは 0,Bは 1275 万(標準偏差が,Aは 0,Bは約 35.7 万),というのが確率論による「期待値」や「分散」や「標準偏差」の定義である. ちなみに,この場合の分散の計算は,(100 − 85)2 × 0.85 + (0 − 85)2 × 0.15 = 1275 である.それをわかった上で,どちらを選ぶかは,状況や性格に依存する. 問 2 の解説 これは,みなさんが高校(大学入試)で見たはずの組み合わせ的確率の典型的 な問題である.念のために復習すると, 7 • 異なる n 個の要素が与えられた時,異なる m 個を取り出して並べる並べ方 (順列)の数は n! def = n(n − 1) · · · (n − m + 1) n Pm = (n − m)! • 異なる n 個の要素が与えられた時,異なる m 個を取り出す組み合わせの数は n Cm def = n(n − 1) · · · (n − m + 1) n! = m!(n − m)! m(m − 1) · · · 1 なお,P は Permutation の,C は Combination の頭文字. • n = 3, m = 2 の例:X, Y, Z の 3 名が居る時, – 2 名の組合わせは 3 C2 = 3 通り∼{X, Y }, {Y, Z}, {X, Z} – 2 名の並び方は 3 P2 = 6 通り∼(X, Y ), (Y, X), (Y, Z), (Z, Y ), (X, Z), (Z, X) 問題に戻る. • すべての可能な並べ方は n Pn = n! 通り.1 から n! までの通し番号で区別す ることにしよう. • その中のどの並べ方も同じ確率で出現すると仮定できる.つまり,j 番目の並 べ方が出る確率を pj と置くと,pj = c(j によらない値).この時, (確率の満たすべき性質.次講参照)より, pj = 1 . n! n! j=1 pj = 1 M n! M を求めよう.一番大きいカード (数字= n) を k 番目の位置に置く場合,1, · · · , k− 1 の位置に置く (k − 1) 枚のカードを,n 以外の (n − 1) 枚のカードから選べば一意 に配列が決まり,あとは,その (k − 1) 枚を昇順に並べたり,残りに (n − k) 枚を 降順に並べたりするだけである.もちろん,k = 2, 3, . . . , n − 1.よって, • よって, 「順単峰」な並べ方が M 通りならば,順単峰に並ぶ確率は M= n−1 k=2 n−1 Ck−1 = n−2 j=1 n−1 Cj = n−1 j=0 n−1 Cj m − n−1 C0 − n−1 Cn−1 = 2n−1 − 2 ただし,最後の等式は,2項定理:(a + b) = m j=0 合の関係を用いた. j m−j m Cj a b で,a = b = 1 の場 2n−1 − 2 .例えば,n = 3 の場合,確率は 1/3.し n! かし,n が大きくなると,この確率は急速に 0 に近づく.つまり,n が大きいなら ば,滅多に「順単峰」には並ばない. ただし,この問題の本質は条件を満たす「場合の数」を効率よく(賢く)数え 上げるテクニックであり,そこは確率論の問題ではなく,よって本講義の目標もこ のようなテクニックの勉強ではない. 結局,順単峰に並ぶ確率は, 8 練習1 壷に r 個の赤玉(当たり)と b 個の黒玉(はずれ),計 r + b 個の同じ形・大きさ の玉が入っている.無作為に m 個を掴んで取り出すとする.以下を計算せよ.た だし,r ≤ m ≤ b の場合に限定して考える. • 取り出した m 個中に r 個の当たり全部が含まれている確率 • 取り出した m 個中に少なくとも1個の当たりが含まれている確率 問 3 の解説 <1> 「何回投げても変化せず」「前回の結果が次の回の確率に影響しない」と仮 定しているのだから,もちろん,p である. しかし, (自分がギャンブルをしている時などは)悪いことが続いたらそろそ ろ良いことが起きるだろう,という気になってしまうことがある.例えば, 前回の結果が次回に影響しないにもかかわらず,10 回続けて負けた後は, 「11 回目はそろそろ勝つ(勝つ可能性が高くなってる)だろう」と思いたくなる. これを,Gambler’s fallacy (ギャンブラーの誤謬)と呼ぶ. <2> 「何回投げても変化せず」「前回の結果が次の回の確率に影響しない」なら ば,2 回続けて当たる確率,2 回続けて外れる確率,最初当たって次が外れる 確率,最初外れて次が当たる確率,は各々,は p2 , (1 − p)2 , p(1 − p), p(1 − p) と考えるのが自然である(実はこれが「独立」の定義).よって,n 回目で 初めて的に当る確率は,(1 − p)n−1 p <3> 直感的に 0 だが,その「証明」には理論が必要.※講義で吟味する. 練習2 (小レポート課題1) 前問の状況で,p = 0.5 として以下に答えよ.電卓やプログラミング利用可. • 10回投げてちょうど1回当る確率と,30回投げてちょうど3回当る確率 はどちらが高いか? • 10回投げて1回以上当る確率と,30回投げて3回以上当る確率はどちら が高いか? 問 4 の解説 現実には「無限回」実験は続けられないので,思考実験になるが,まず<1> X の「期待値(※定義は講義で)」に収束することが も<2>も,n → ∞ で値が Y 証明できる(※詳しい吟味は講義).そこで,各々の期待値を計算すると, 9 X の値は,(0.5, 1, 2) の 3 通りであ Y り,それらの起きる確率が (0.25, 0.5, 0.25) なので,期待値は, 1> X も Y も,値として 1 か 2 を取るので, 0.5 × 0.25 + 1 × 0.5 + 2 × 0.25 = 1.125 2> X の「期待値」の理論的な正解は, , , ,実は,1.5 log 2 = 1.035 . . .. Y ※詳しい吟味は講義やる.直感では解けない. ただし,C でプログラムを書けば,容易に実験的に確認できる.以下の図は,以 下の C プログラムを使って,2つの異なる「1000 回繰り返す実験」を行ってみた n 1 Xi の値).自分で,擬似 結果である(x 軸は繰り返し回数 n,y 軸は実際の n i=1 Yi 乱数の初期値を変えていろいろ試して(実験して)みても,やはり 1.035 付近に 近づくことが体験できる「はず」である. #include <math.h> #include <stdlib.h> #include <stdio.h> #include <time.h> main() { int i; double x, y, s; srand48(time(NULL)); s = 0.0; for (i=1;i<=1000;i++) { x = drand48(); y = drand48(); s += (1.0 + x)/(1.0 + y); printf("%d %f\n", i, s/i); }} 1.1 1.05 1 0.95 a sample path another sample path 1.5 * log(2) 0.9 0 200 400 10 600 800 1000
© Copyright 2026 Paperzz