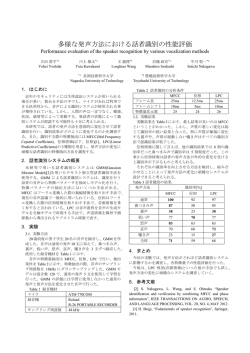
୍⯡♫ᅋἲே 㟁Ꮚሗ㏻ಙᏛ ಙᏛᢏሗٻ ٻڇڮڞڤکڪڭگڞڠڧڠٻڡڪٻڠگڰگڤگڮکڤٻڠڣگ 信学技報 ٻۏۍۊۋۀڭٻۇڼھۄۉۃھۀگٻڠڞڤڠڤ 社団法人 電子情報通信学会 ٻڮڭڠڠکڤڢکڠٻکڪڤگڜڞڤکڰڨڨڪڞٻڟکڜٻکڪڤگڜڨڭڪڡکڤ TECHNICAL ٻڄڒڋڈڎڌڋڍڃڐڐڈڎڌڋڍګڮ THE INSTITUTE OF ELECTRONICS, REPORT OF IEICE. ٻINFORMATION AND COMMUNICATION ENGINEERS 騒音環境下音声認識に対する識別的アプローチの有効性 第 2 回 CHiME チャレンジ 太刀岡勇気† 渡部 晋治†† ルルージョナトン†† ハーシージョン†† † 三菱電機株式会社 情報技術総合研究所 〒 247–8501 神奈川県鎌倉市大船 5–1–1 †† Mitsubishi Electric Research Laboratories 201, Broadway, Cambridge, MA, US E-mail: †[email protected], ††{watanabe, leroux, hershey}@merl.com あらまし 第 2 回 CHiME チャレンジは,非定常の妨害音を伴う 2 マイクロフォンでの困難な音声認識タスクである. 我々は識別学習や様々な特徴量変換,ディープニューラルネットといった先端的な音声認識の手法の残響・騒音音声認 識に対する有効性を検証した.騒音抑圧には音源到来方向を推定し,事前分布を用いてバイナリマスクを行うシンプ ルな方法を用いた.さらに任意の特徴量を識別的特徴量変換に導入可能な拡張識別的特徴量変換,識別的言語モデリ ングとベイズリスク最小化デコーディングを音声認識の後段で効率的に統合する手法を提案した.これらは CHiME チャレンジの Track2 である中程度の語彙タスクに有効であり,参加者中最も高い性能を獲得した. キーワード CHiME チャレンジ, 耐騒音音声認識, 識別的手法, 特徴量変換, 事前分布に基づくバイナリマスク Effectiveness of discriminative approaches for speech recognition under noisy environments on the 2nd CHiME Challenge Yuuki TACHIOKA† , Shinji WATANABE†† , Jonathan LE ROUX†† , and John R. HERSHEY†† † Information Technology R&D Center, Mitsubishi Electric Corporation Ofuna 5–1–1, Kamakura city, Kanagawa, 247–8501 Japan †† Mitsubishi Electric Research Laboratories 201, Broadway, Cambridge, MA, US E-mail: †[email protected], ††{watanabe, leroux, hershey}@merl.com Abstract The 2nd CHiME challenge is a difficult two-microphone speech recognition task with non-stationary interference. We investigate the effectiveness of state-of-the-art ASR techniques such as discriminative training, various feature transformations and deep neural networks for reverberated and noisy speech recognition, combined with a simple noise suppression method relying on prior-based binary masking with estimated angle of arrival. Moreover, we propose an augmented discriminative feature transformation that can introduce arbitrary features to a discriminative feature transform, an efficient combination method of discriminative language modeling and minimum Bayes risk decoding in an ASR post-processing stage. These techniques are effective for middle-vocabulary sub-task (Track 2) of CHiME challenge. Our performance is the best among participants. Key words CHiME challenge, Noise robust ASR, Discriminative methods, Feature transformation, Prior-based binary masking タスクを含む.これは音声認識の観点からは,第 1 回 CHiME 1. は じ め に チャレンジの単語発声と比べてかなり難しいタスクであるとい 第 2 回 CHiME チャレンジは,高騒音下音声認識のためのタ える. スクであり [1],家庭環境でステレオ録音された単一話者の音声 第 1 回 CHiME チャレンジでは,参加者は音源分離に重きを を認識する.収録したバイノーラルのインパルス応答を畳み込 置いていたが,我々は識別学習や種々の特徴量変換といった最 み,そこに家庭環境での騒音を重畳している.第 2 回は 5,000 新の音声認識の手法に焦点をあてることにする.到来時間差に 語彙の Wall Street Journal (WSJ0) の中規模語彙の読み上げ 基づく騒音抑圧処理は行うものの,主目的は音声認識の手法に - 13 - —1— This article is a technical report without peer review, and its polished and/or extended version may be published elsewhere. Copyright ©2013 by IEICE よって,どの程度性能が向上するか調べることにある.最新の 基づく信号処理に関しても検討する [19]. 音声認識の手法の実環境下での性能を,音声認識の専門家以外 2. システムの概観 に伝えることもできる. 近年の音声認識技術の進展により,音声認識の性能は飛躍的 全体システムの概要図を Fig. 1 に示す.提案法は 3 つの要 に向上した [2].この 10 年間で,音声認識のモデル学習法は,最 素からなっている.1 つめは,3. 節に示す騒音抑圧部で,事前 大尤度法 (ML) から識別学習へと移り変わった [3], [4].加えて 分布に基づくバイナリマスクにより,方向性の妨害音を抑圧す 種々の特徴量変換が提案され,その有効性が示されてきた [5]∼ る.2 つめは,特徴量変換部で,特徴量レベルでの特徴量変換 [10]. これらの最新の音声認識の手法が,クリーン音声に対し (LDA, MLLT, fMLLR) と,4. 2 に述べる識別的特徴量変換が て非常に有効なことはよく知られているものの,残響や騒音と ある [20].3 つめは,デコード部で,音声認識には 4. 1 節に述 いった環境で効果がみられるかはさらなる検討が必要である. べる相互情報量最大化法 (MMI) と boosted MMI による識別 本報では,特徴量変換と識別学習を主に扱う.まず,元の 的音響モデルを使っている.N 位までの音声認識結果は,4. 3 特徴量から新しい特徴量に線形変換に基づき変換するいくつ 節の識別的言語モデリング (DLM) により並び替えられる.4. 4 かの特徴量変換を扱う.線形判別分析 (LDA) [5], 最尤線形変 節に示すように,DLM の 1 位とラティス上の仮説を用いてベ 換 (MLLT) [6], [7], 話者適応化学習 (SAT) [8], 識別的特徴量変 イズリスク最小化デコーディング (MBR) を行う. 換 [9] を検討した.LDA はコンテクスト拡張により,例えば連 3. 事前分布に基づくバイナリマスク 続した 9 フレームといった長いコンテクストを使って,特徴量の 動的性質を引き出し,非定常騒音の影響を低減する.MLLT は, CHiME チャレンジではステレオ録音のデータが提供され, 状態で条件づけられた特徴量の相関を減らすような線形特徴 目的話者の方向はマイクの正面とされている.到来時間差に基 量変換を見つける.SAT と特徴量空間最尤線形回帰 (fMLLR) づくバイナリマスク [21] は,マイクの個数が少ない環境では は,未知の変化する騒音条件に適応することで音声認識性能を ビームフォーミングよりも効果的であることが知られている. 向上させる. 正面方向の設定では,残響とダミーヘッドの回折の影響が無視 識別的特徴量変換は,デコーダーの認識結果に基づき,認識 できれば,目的話者からの信号の位相差は零になるはずである. 誤りを削減するように最適化するため [11],通常の特徴量変換 それゆえ,マイク間の位相差がゼロから離れた時間周波数ビン に加えて性能の向上が期待できる.基本的な識別的特徴量変 では目的話者以外の妨害音のエネルギーが大きいと考えられる. 換は,特徴量の線形変換に加えてガウス分布の事後確率に基 しかしながら,残響と回折の影響により,目的話者からの信号 づく特徴量を用いる.我々はこの基本的な手法を拡張し,領域 であっても位相差が零にならないこともある.例として,残響 に基づく特徴量に騒音の条件に関連するであろう非線形の特 音声に対する 250 Hz と 1 kHz の場合の位相差のヒストグラム 徴量を含める.この方法を拡張識別的特徴量変換と呼ぶ.識別 を Fig. 2 に示す.250 Hz の場合はヒストグラムはおおむね零 的特徴量変換の代替として,ディープニューラルネットワーク 対称で分散も小さいものの,1 kHz の場合には平均は 0 からず (DNN) [10] の有効性の予備的な検討も行う. れ,分散も大きい.位相差がどの程度騒音や残響の影響を受け これらの手法の有効性を個別に検証するのに加え,バイノー るかは各周波数ビンによって大きく異なるので,物理情報に基 ラル録音の利点を活かすために,フロントエンドに信号処理 (バ づく単純なバイナリマスクはうまくいかない.実際,予備的な イナリマスク) を行った.これはマイク間の位相差と目的話者 実験では単語誤り率はベースラインよりも低下した.騒音がな 位置に期待される位相差の相違を考慮してマスク関数を構築し, い場合からの位相差のずれや分散の広がりを考慮するためには, 騒音を抑圧する.音声認識の後段では,識別的言語モデリング 統計的モデルが必要である [22].ここでは事前分布に基づくバ (DLM) [12], [13] に基づく N-best の並び替え手法と,ベイズリ イナリマスク推定法を提案する.周波数ビン ω ,時間フレーム スク最小化 (MBR) デコーディング [14]∼[16] を扱う.DLM と t の時間周波数ビンの位相差 θω,t は MBR デコーディングを効率的に結合し,音声認識性能をさら L R Xω,t /Xω,t = Aω,t ejθω,t , に向上させる方法を提案する(注 1). まとめると,本報の目的は特徴量変換と識別学習の残響・騒 (1) のように表される.ここで,j は虚数単位,Aω,t は正の実数, 音音声認識への有効性を,第 2 回 CHiME チャレンジの Track2 X L と X R はそれぞれ左チャネルと右チャネルの短時間フーリ を使って評価することにある.また,コミュニティーで共有で エ変換である.通常のバイナリマスクでは,マスク W は以下 きる公開ツールを CHiME チャレンジのベンチマークとして構 のように閾値を用いて設定される. 築する.Kaldi ツールキット [17] により先進的な音声認識のシ Wω,t = ステムを提供し,CHiME チャレンジ標準の HTK [18] ベース の最尤学習法と比較する.加えて,提案法である拡張識別的特 徴量変換,DLM と MBR デコーディングの連結,音源方向に 1 if |θω,t | > θc , < θc , if |θω,t | = (2) は十分小さい定数,θc は事前に定めておく閾値であり,事前 分布に基づくバイナリマスクでは,マスク W は周波数依存の (注 1):文献 [16] は DLM を MBR 基準で行っているが,我々は DLM と MBR デコーディングを直列に結合していることに注意されたい. ヒストグラムを正規化した事前分布 qω を用いて以下のように 定める. - 14 - —2— Lch lattice Binary masking Feature transform. Feature extraction ASR decoding (LDA, MLLT, fMLLR, feature-space MMI/bMMI) Reranking MBR results 1-best N-best Rch TDOA histogram Discriminative acoustic model Transform. matrix Discriminative language model (MMI, bMMI) Fig. 1 Schematic diagram of the proposed system. Normalized count 250Hz ht を加え,新しい特徴量 yt を得る方法を提案する. 1kHz 0.06 0.04 0.02 0 yt = xt + M M −π 0 Phase difference π −π π 0 Phase difference = Faf-MMI (qω (θω,t )/q̄ω )α if qω (θω,t )/q̄ω < qc , if qω (θω,t )/q̄ω > = qc , スク (以下の場合は音声データが与えられた際の単語系列の事 後確率を用いて設計される) を最小化する.本報では boosted MMI (bMMI) [23] を用いる.これは音素正解率に依存する重 みである増幅係数 b > = 0 を用いる.目的関数は (5) M M = R κ pλ ({yt }r |Hsr ) pL (sr ) . log p ({yt }r |Hs )κ pL (s) s λ 徴量変換を扱うことができる.例えばバイナリマスクの値や, 音声区間検出の際の情報などが考えられる. アを補正する.スコアは,デコーダーの仮説 Hs から得られる 素性ベクトル φ(Hs )(例えば N-gram の出現個数) と重みベクト ル w の内積で補正される.重みベクトルは,学習データの各 発話ごとにオンライン学習により求める.パーセプトロン手法 では,学習則は w = w + (φ(Hsr ) − φ(Hs )) のようになる. 平均化パーセプトロン手法では,すべての発話に対して集積 pλ ({xt }r |Hsr ) pL (sr ) , p ({xt }r |Hs )κ pL (s)e−bA(s,sr ) s λ log れる誤りパターンを学習し,誤りを削減するように仮説のスコ κ された重みベクトルを平均化する.DLM は N 位までのリスト で与えられる.R は学習データの発話数,{xt }r は r 番目の発 話の特徴量系列である.音響モデルパラメータ λ は拡張 Baum- Welch アルゴリズムで最適化される.Hsr と Hs は,それぞれ の並び替えを行うために用いられ,Hsr は,識別学習における 正解仮説とは違い,N 位までのリスト中の単語誤り率最低の仮 説 (オラクル) から選択される. 4. 4 識別的言語モデリングとベイズリスク最小化デコーディ 正解ラベル sr と認識結果 s に対応する HMM 系列である.pλ ングの接続 は音響モデル尤度,κ は音響スケール,pL は言語モデル尤度 である.A(s, sr ) は,正解 sr に対する s の音素正解率である. MMI(b = 0 の場合) と bMMI の性能を,ML と比較する. ベイズリスク最小化 (MBR) デコーディングでは,おおよそ ベイズリスクを最小化する仮説をラティスに基づき編集距離の 観点から見つけ出す.いくつかのアルゴリズムが提案されてい 4. 2 付加特徴量による識別的特徴量変換 識別学習の指標に基づく特徴量変換は,f-MMI [9] と呼ばれ る.以下のように,豊富な情報を持つスパースな高次元特徴量 を低次元特徴量に写像する行列 M を学習する. yt = xt + Mht , . 識別的言語モデリング (DLM) はデコーダーの出力仮説に現 識別学習は,正解ラベルと認識結果の情報から,ベイズリ r=1 ht 4. 3 識別的言語モデリング 4. 1 識 別 学 習 拡張識別的特徴量変換では,拡張特徴量の選択により幅広い特 4. 識別的手法に基づく後段の処理 FbMMI (λ) = ht r=1 (3) q̄ω = maxθ qω (θ) で,qc は閾値の確率,α は歪み係数である. R M と M の結合行列は,F を最大にするよう最適化する. Fig. 2 Histogram of phase differences for two frequency bins. Wω,t るが,本報では文献 [15] のアルゴリズムを用いる.これは 1 位 の仮説とラティス上の仮説との間の編集距離を最小にするよう に単語系列を選ぶものである. Hŝ = arg min s (4) xt は元の I 次元特徴量,ht は J 次元特徴量で xt に依存してい pλ {yt }|Hs κ pL (s)L(Hs , Hs ), (6) s∈L ここで,L(Hs , Hs ) はラティス中の仮説 Hs と最小化の対象と る.yt は変換された特徴量である.M は I × J (J I) の行 なる仮説である Hs の間の編集距離である.編集距離は,( シ 列である.本報では,特徴量空間 MMI(f-MMI) とその拡張で ンボルを含む) シンボル u が単語列 Hŝ の位置 q におかれた時 ある特徴量空間 boosted MMI(f-bMMI) の有効性を検討する. の確率 γ(q, u) から計算され,目的関数は反復的に更新される. 騒音下音声認識のためには,タンデム手法のように,異なる 種類の特徴量を用いるのが有効なので,ここでは ht に特徴量 N 位までのリストの並び替えを行う DLM と,ラティスに基 づく MBR デコーディングを効率的に結合する方法を提案する. - 15 - —3— 従来法はラティス上の 1 位の仮説を初期値として,ラティス中 を行う.本報では,LDA と MLLT,SAT の有効性を検討する. の系列のアライメントをとるが,上記手法には初期値依存性が 5. 3 識別的手法 ある.そこで提案法では,初期値をラティス上の 1 位ではなく, 識別的特徴量変換 (4. 2 節) では,400 個のガウス分布を使 DLM により並び替えられた N 位までのリストの 1 位で置き換 い,特徴量には,その事後確率とオフセット特徴量 (39 次元の えることで性能改善を目指す.γ(q, u) は,元の (スケールされ MFCC) の計 40 次元から計算される.特徴量は連続 9 フレーム ていない)DLM の 1-best 結果のアークのスコアからおおよそ でコンテクスト拡張される.特徴量 ht の次元は,400 × 40 × 9 計算される(注 2). である.特徴量のうち上位 2 つの事後確率を持つ特徴量だけを 選択し,残りは無視する. 5. 実験の設定 識別的特徴量変換の代替となる DNN では,Kaldi の CPU 5. 1 タスクの記述 バージョンのニューラルネットワークの学習ツールを使い,3 提案法の残響騒音下の音声に対する有効性を検証するために, つの隠れ層と 1,000,000 のパラメータを学習した.初期の学習 第 2 回 CHiME チャレンジ [1] の Track2 を評価した.Track2 率は 0.01 とし,学習の終盤には 0.001 になるように低減した. は残響騒音下における中程度の語彙サイズのタスクで,発話 5. 4 実 験 手 順 は Wall Street Journal のデータベース (WSJ0) から取られて 以下に上述の設定に基づく実験の手順を述べる.初めにク いる.学習セット (si tr s) は,83 話者の 7138 発話 (si84),評 リーンの音響モデルを学習した.モノフォンのモデル数は,無 価セットは (si et 05) は,12 話者の 330 発話 (Nov’92),開発 音のモデル (“sil”) を含み 40 とした.トライフォンモデルで セットは (si dt 05) は,10 話者の 409 発話である.音響モデ は,状態数は 2500 とし,ガウス分布の全体数は 15000 とした. ルは si tr s を用いて学習し,言語モデル重みといったいくつ 次に,クリーンモデルによるアライメントと,トライフォン かのパラメータは si dt 05 の単語誤り率 (WER) を元に調整し モデルの木構造を使って,“reverberated” セットにより残響音 た.言語モデルのサイズは 5 k である.データベースは現実 響モデルを学習した.その後,信号処理による前処理無しに に起こりうる状況を模擬しており,2 種類のデータからなる. “isolated” セットにより,騒音音響モデルをマルチコンディショ “reverberated” は,クリーン発話に居間におけるマイクの 2 m ン学習で学習した.最後に,ML モデルを用いて識別学習と特 前方話者に対応するバイノーラルの室内のインパルス応答を畳 徴量変換の有効性を “isolated” のデータセットに対して評価し みこんだものである.“isolated” は,“reverberated” と同じ部 た.実験に用いた設定は,Kaldi ツールキットに付属の WSJ 屋で録音した実環境での騒音を適当に選択して,信号対雑音比 のチュートリアルを参考に決定した. (SNR) が −6,−3,0,3,6,9 dB になるように,正規化せず 6. 結果と考察 に重畳したものである.騒音は他の話者の発話や,家庭内の騒 6. 1 識別学習と特徴量変換 音,音楽といった非定常性のものである. 5. 2 特徴量抽出および特徴量変換 初めに,MFCC 特徴量において識別学習による ML からの ここでは音響的な特徴量と特徴量変換の設定について述べ WER の向上を Table 1 (上段) に示す.騒音と音声が混ざる る.基本となる音響特徴量は MFCC と PLP である.(1-13 次 ことで,誤り音素に対する尤度が向上し,誤認識が起こるが, の MFCC (PLP) + Δ + ΔΔ) よく知られているように,LDA このような誤りを識別学習によって修正できたと考えられる. は特徴量のクラスが他のクラスの特徴量に対してできるだけ識 (f-)boosted MMI は,(f-)MMI と比べて WER を 1%改善した. 別性が高くなるように変換行列を決定する.連続する 9 フレー この実験では,増幅係数は 0.1 としたが,性能は増幅係数にそ ムの 1-13 次元の静的 MFCC 特徴量を結合したのちに,全体で れほど依存せず,おおよそ 0.1∼0.2 が最適であることが分かっ 117 次元の特徴量を LDA によって 40 次元に圧縮する.その た.一方で,特徴量空間手法は WER を 3%改善した.特徴量 際の LDA のクラスはトライフォンの状態 (2500 状態) とした. 空間を目的話者に適応させることで,他の騒音の影響が低減さ 音響特徴量は高次元なので,全共分散モデルを取り扱うことは れ,WER の改善が図られたと考えられる.なお本実験におい 現実的でなく,対角共分散モデルが広く使われている.この単 て,識別学習の分母のラティスは,ML モデルにより生成した. 純化により,次元間の相関が問題となりモデルの性能を低下さ 次に,MFCC 特徴量を LDA と MLLT を用いて変換した. せるため,特徴量空間を変換して,次元間の相関を低減するい Table 1 (中段) に WER を示す.LDA のみの場合には,54.37% くつかの手法が提案されており,MLLT が広く使われている. (ML) であった.LDA によって,他の音素との混同性を低減さ さらに,話者間の特徴量のばらつきが大きいと音響モデルの せるような特徴量が得られたと考えられる.特徴量変換によっ 性能が低下する.この問題に対処するのに,話者適応化学習 て性能が大幅に向上した一つの要因としては,CHiME データ (SAT) がよく用いられる.SAT では,学習データを標準話者 ベースの特性が考えられる. 「はじめに」で述べたとおり,LDA 空間に変換し,話者間の特徴量のばらつきを低減した後に学習 と MLLT は通常の騒音条件であってもモデルの性能を向上さ せる.CHiME データベースの騒音には,他者の多数の妨害発 (注 2):アークに割り当てられている正確な確率は,推定された DLM の重みを ラティス中のアークの重みへと変換することで得ることができる.しかしながら, 話を含んでおり,この種の騒音には LDA が適している.なぜ DLM は未知の N-gram 素性やより広範な素性を含みうることから,対応する なら,音源が混合し複数の音素が同一フレームに存在する場合 DLM 重みをアークスコアに直接的に変換できず,この変換は自明ではない. にも,これらの音素を別々に識別できるようにモデルが学習さ - 16 - —4— Table 1 WER[%] for isolated speech (si dt 05) without noise suppression. Table 3 WER[%] for isolated speech (si dt 05) with noise sup- Tri-phone model, discriminative train- pression by prior-based binary masking. Tri-phone ing with MFCC features (upper), MFCC+LDA+MLLT model, discriminative training with MFCC features (up- (middle), MFCC+LDA+MLLT+SAT (lower). per), MFCC+LDA+MLLT (middle), MFCC+LDA+MLLT −6dB −3dB 0dB 3dB 6dB 9dB Avg. +SAT (lower). ML 74.20 66.57 58.24 51.84 46.73 40.64 56.37 −6dB −3dB 0dB 3dB 6dB 9dB Avg. MMI 73.40 65.60 56.88 51.17 45.40 41.20 55.61 ML 66.82 57.87 48.86 42.29 38.18 31.86 47.65 bMMI 72.78 64.71 55.69 50.83 44.00 40.27 54.71 (+MBR) 66.16 57.09 48.15 41.47 37.16 31.23 46.88 f-MMI 69.94 62.50 54.51 48.74 42.73 38.34 52.79 bMMI 65.73 56.98 46.95 41.57 36.27 31.02 46.42 f-bMMI 68.64 61.56 53.11 47.65 41.73 36.98 51.61 f-bMMI 63.40 54.05 44.28 38.87 33.72 29.90 44.04 ML 70.95 62.62 53.98 47.37 40.27 34.84 51.67 ML 64.64 54.24 46.35 37.91 32.75 28.96 44.14 MMI 68.55 61.12 53.41 46.32 39.52 34.30 50.54 bMMI 63.39 52.54 44.56 35.60 30.98 28.10 42.53 bMMI 68.74 60.98 51.95 45.86 38.16 32.85 49.76 f-bMMI 60.92 50.41 41.76 33.59 29.56 25.90 40.36 f-MMI 66.19 58.24 49.23 43.58 36.89 31.35 47.58 DNN 57.21 45.85 36.21 30.61 26.36 23.31 36.59 f-bMMI 66.65 57.46 48.25 42.99 35.71 31.07 47.02 ML 59.94 47.93 39.83 33.01 28.00 23.47 38.70 ML 68.36 58.30 48.80 40.73 35.09 28.54 46.64 bMMI 56.90 45.79 37.60 30.31 26.15 21.74 36.42 MMI 65.13 55.27 45.89 39.64 33.12 27.29 44.39 f-bMMI 52.93 42.62 34.59 27.63 24.27 20.24 33.71 bMMI 64.60 55.10 45.82 39.05 32.72 26.86 44.03 (+DLM) 53.16 42.93 34.36 27.26 23.72 19.47 33.48 f-MMI 63.09 52.62 42.44 36.29 31.01 25.52 41.83 (+MBR) 52.65 42.04 33.75 27.05 23.74 19.91 33.19 (both) 52.54 42.09 33.72 27.02 23.66 19.66 33.11 f-bMMI 62.43 52.23 42.17 35.31 29.84 24.72 41.12 Table 2 WER[%] for isolated speech (si dt 05) without noise suppression. Tri-phone model, discriminative feature transformation with PLP (P) features. くつかの α で実験し,α = 0.25 のときにもっともよい WER を得た.これにより方向性雑音はある程度取り除くことができ るが,音楽のような拡散性雑音は依然として残っている. −6dB −3dB 0dB 3dB 6dB 9dB Avg. ML(M) 74.20 66.57 58.24 51.84 46.73 40.64 56.37 DNN の WER を,MFCC+LDA+MLLT (中段) の ML の ML(P) 74.57 67.50 59.76 53.02 47.00 42.23 57.35 ベースラインとともに Table 3 に載せた.DNN は,bMMI と f-MMI 69.94 62.50 54.51 48.74 42.73 38.34 52.79 69.52 62.31 54.48 48.59 42.94 37.90 52.62 (+P) 6. 4 ディープニューラルネットワーク f-bMMI を最大で 2.8%上回り,下段の SAT を行ったシステム と同程度の性能であった.これは,残響騒音下の音声認識にお れるためである.また,長いコンテキストを使うことも非定常 ける DNN の潜在的な有効性を示すものといえる.現在のとこ 騒音と残響の影響を低減するのに有効である.さらに,騒音は ろ,DNN は我々のシステム全体には組み込まれていないが, MFCC 特徴量の次元間の相関を高めるが,MLLT により相関 DNN と我々のシステムの統合によりさらなる音声認識性能の が低減され,認識性能が向上したと考えられる.なお識別学習 向上を図ることができるであろう. 6. 5 識別的言語モデリングおよびベイズリスク最小化デ 用の分母のラティスは MFCC+LDA+MLLT の特徴量による ML のモデルにより再生成した. コーディング 識別的言語モデリングの重み w は,学習データの 100 位ま 第 3 に,SAT と fMLLR を上述のモデルに加えた.Table 1 (下段) に,WER を示す.学習データの量が限られているため, での認識候補を用いて学習した.学習時の元のスコアに関連付 標準話者空間への変換は実質的な学習データの増加をもたらし, けられる重み w0 は 20 とした.これらの重みベクトルを用い 音響モデルの推定精度を向上させる.加えて,fMLLR の話者 て,結果を並び替えた.その際には重み w0 は 13 とした.重 適応により,騒音の影響を低減できる.なお分母のラティスは みベクトルは平均化パーセプトロン手法 (3 回繰り返し) により ML モデルにより再生成した. 求めた.素性は,ユニグラム,バイグラム,トライグラムの出 6. 2 拡張識別的特徴量変換 現個数とした.DLM により WER は平均で 0.23%,特に 9dB Table 2 は,ML と拡張特徴量空間 MMI において Eq. (5) の の場合には 0.77%向上した.誤り傾向は SNR によって異なる 加える特徴量 ht として PLP (13 次元) を用いた結果を示して が,DLM の学習は全 SNR を含む学習セット全体を使っている いる.ML では,絶対値で 1%,PLP の方が MFCC より性能 ため,SNR によっては これが学習と認識の間にミスマッチを が低下したものの,PLP を識別的特徴量変換に加えた場合に もたらし,性能が低下することもあった. は,WER の向上がみられた.よって,特徴量 ht だけでは得ら れない情報を含む新しい特徴量を使うことが有効である. MBR により,WER は ML (MFCC) から 0.77%改善し,fbMMI (MFCC+LDA+MLLT+SAT) に対しても 0.52%改善 6. 3 騒 音 抑 圧 した.MBR は SNR によらず効果がみられた.さらに 4. 4 節 Table 3 は,事前分布に基づくバイナリマスキングによる騒音 に述べた DLM と MBR の結合により性能が向上した.これは 抑圧を行った後の WER である.バイナリマスキングは WER DLM により初期値の仮説が改善できたためと考えられる. をすべての SNR の場合で絶対値で 7%から 9%向上させた.い - 17 - —5— Table 4 WER[%] for isolated speech (si et 05) without noise suppression. The baseline is ML (MFCC), whereas on た.MBR と DLM の組み合わせにより,デコーダーに固有の top of MFCC+LDA+MLLT+SAT, “Best 1” is ML and 誤り傾向を考慮でき性能が向上した.今回構築したシステム “Best 2” is feature-space boosted MMI. は,残響と非定常騒音に有効であり,第 2 回 CHiME チャレン −6dB −3dB 0dB 3dB 6dB 9dB Avg. Baseline 69.79 62.71 55.86 46.89 42.07 37.49 52.47 Best 1 60.83 52.14 43.51 34.28 29.22 23.82 40.63 ジ Track 2 において首位を獲得した.音声強調手法と音声認識 手法の統合により,さらに認識性能を改善できると考えられる. 54.70 45.11 35.98 28.64 24.38 21.39 35.04 Best 2 Table 5 WER[%] for isolated speech (si et 05) with noise suppression. The baseline is ML (MFCC), whereas on top of 文 [1] [2] MFCC+LDA+MLLT+SAT, “Best 1” is ML and “Best 2” is feature-space boosted MMI. [3] −6dB −3dB 0dB 3dB 6dB 9dB Avg. Baseline 60.58 52.87 45.60 37.70 33.38 29.24 43.23 Best 1 50.91 41.64 33.89 26.30 21.61 18.85 32.20 Best 2 44.54 35.91 29.24 22.31 17.77 15.88 27.61 (+DLM) 44.27 35.48 28.75 21.61 17.34 15.37 27.14 (+MBR) 44.51 35.42 28.81 21.46 17.41 14.98 27.10 [6] (both) 44.12 35.46 28.12 21.20 17.43 14.83 26.86 [7] Table 6 WER[%] for isolated speech with noise suppression [4] [5] [8] by prior-based binary masking (tri-phone model) using HTK with MFCC features. si dt 05 [9] −6dB −3dB 0dB denoised 72.18 66.16 57.95 53.99 48.36 43.58 57.04 noisy 74.67 68.08 61.12 56.61 51.33 47.65 59.91 3dB 6dB 9dB Avg. [10] [11] si et 05 −6dB −3dB 0dB denoised 68.56 61.97 56.34 48.76 43.51 40.58 53.29 noisy 72.00 65.27 59.05 52.34 48.57 44.14 56.90 3dB 6dB 9dB Avg. [12] [13] 6. 6 評価セット Table 4 は,開発セットでチューニングしたモデルで評価セッ [14] トを認識した場合の WER である.“Baseline” は ML (MFCC) であり,MFCC+LDA+MLLT+SAT 特徴量での “Best 1” は ML であり,“Best 2” は特徴量変換と識別学習の両方を使った [15] [16] f-bMMI である.“Best 2” は,“Baseline” と比べて 33.2%誤 りを削減した.これによって,特徴量変換と識別学習が残響騒 [17] 音環境下において有効であることが示された.騒音抑圧後の WER を Table 5 に示す.こちらは,37.9%の誤りを削減した. [18] 参考までに,我々のフロントエンドを使った場合の si dt 05 と si et 05 に対する HTK のベースラインの WER を Table 6 [19] に示す.“Denoised” は,騒音抑圧後の学習データで再学習し た音響モデルによる結果である.“Noisy” は,騒音の学習デー [20] タによって学習した元の音響モデルによる結果である.性能は Kaldi よりも低いが,設定が異なり HTK の方は十分な調整を [21] していないことも影響していると考えられる. [22] 7. ま と め 実際に起こりうる残響・騒音環境に対して,事前分布に基づ くバイナリマスキングを行った後に,最新の音声認識システム を構築することで,特徴量変換と識別学習の有効性を確かめ - 18 - [23] 献 E. Vincent, J. Barker, S. Watanabe, J. Le Roux, F. Nesta, and M. Matassoni, “The 2nd ‘CHiME’ speech separation and recognition challenge: Datasets, tasks and baselines,” in Proc. ICASSP, pp. 126-130, 2013. J.M. Baker, L. Deng, J. Glass, S. Khudanpur, C.H. Lee, N. Morgan, and D. O’Shaughnessy, “Research developments and directions in speech recognition and understanding part 1,” IEEE Signal Process. Mag., vol. 26, pp. 75–80, May 2009. D. Povey and P.C. Woodland, “Minimum phone error and Ismoothing for improved discriminative training,” in Proc. ICASSP, 2002, pp. 105–108. E. McDermott, T.J. Hazen, J. Le Roux, A. Nakamura, and S. Katagiri, “Discriminative training for large-vocabulary speech recognition using minimum classification error,” IEEE Trans. Audio, Speech, Language Process., vol. 15, pp. 203–223, Jan. 2007. R. Haeb-Umbach and H. Ney, “Linear discriminant analysis for improved large vocabulary continuous speech recognition,” in Proc. ICASSP, 1992, pp. 13–16. R.A. Gopinath, “Maximum likelihood modeling with Gaussian distributions for classification,” in Proc. ICASSP, 1998, pp. 661–664. M.J.F. Gales, “Semi-tied covariance matrices for hidden Markov models,” IEEE Trans. Speech Audio Process., vol. 7, pp. 272–281, Jul. 1999. T. Anastasakos, J. McDonough, R. Schwartz, and J. Makhoul, “A Compact Model for Speaker-Adaptive Training,” in Proc. ICSLP, 1996, pp. 1137–1140. D. Povey, B. Kingsbury, L. Mangu, G. Saon, H. Soltau, and G. Zweig, “fMPE: Discriminatively trained features for speech recognition,” in Proc. ICASSP, 2005, pp. 961–964. G. Hinton, L. Deng, D. Yu, G. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, and T. Sainath, and B. Kingsbury, “Deep Neural Networks for Acoustic Modeling in Speech Recognition,” IEEE Signal Process. Mag., vol. 28, pp. 82-97, Nov. 2012. S. Renals, T. Hain, and H. Bourlard, “Recognition and understanding of meetings the AMI and AMIDA projects,” in Proc. ASRU, 2007, pp. 238–247. B. Roark, M. Saraçlar, M. Collins, and M. Johnson, “Discriminative language modeling with conditional random fields and the perceptron algorithm,” in Proc. ACL, 2004, pp. 47-54. E. Dikici, M. Semarci, M. Saraçlar, and E. Alpaydin, “Classification and ranking approaches to discriminative language modeling for ASR,” IEEE Trans. Audio, Speech, Language Process., vol. 21, pp. 291–300, Feb. 2013. V. Goel and W.J. Byrne, “Minimum Bayes-risk automatic speech recognition,” Computer Speech & Language, vol. 14, pp. 115–135, Apr. 2000. H. Xu, D. Povey, L. Mangu, and J. Zhu, “An Improved Consensuslike method for minimum Bayes risk decoding and lattice Combination,” in Proc. ICASSP, 2010, pp. 4938-4941. H. Kuo, L. Mangu, E. Arisoy, and G. Saon, “Minimum Bayes risk discriminative language models for Arabic speech recognition,” in Proc. of ASRU, 2011, pp. 208-213. D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, M. Petr, Y. Qian, P. Schwarz, J. Silovský, G. Stemmer, and K. Veselý, “The Kaldi speech recognition toolkit,” in Proc. ASRU, 2011, pp. 1–4. S. Young, G. Evermann, M. Gales, T. Hain, D. Kershaw, X. Liu, G. Moore, J. Odell, D. Ollason, D. Povey, V. Valtchev, and P. Woodland, “The HTK Book (for HTK Version 3.4.1),” http://htk.eng.cam.ac.uk, March 2009. Y. Tachioka, S. Watanabe, J. Le Roux, and J. R. Hershey, “Discriminative methods for noise robust speech recognition: A CHiME Challenge benchmark,” in CHiME workshop, pp. 19-24, 2013. Y. Tachioka, S. Watanabe, and J. R. Hershey, “Effectiveness of discriminative training and feature transformation for reverberated and noisy speech,” in Proc. ICASSP, pp. 6935-6939, 2013. H. Sawada, S. Araki, and S. Makino, “Underdetermined convolutive blind source separation via frequency bin-wise clustering and permutation alignment,” IEEE Trans. Audio, Speech, Language Process., vol. 19, pp. 516–527, Mar. 2011. M. Delcroix, K. Kinoshita, T. Nakatani, S. Araki, A. Ogawa, T. Hori, S. Watanabe, M. Fujimoto, T. Yoshioka, T. Oba, Y. Kubo, M. Souden, S. Hahm, and A. Nakamura, “Speech recognition in the presence of highly non-stationary noise based on spatial, spectral and temporal speech/noise modeling combined with dynamic variance adaptation,” in Proc. CHiME, 2011, pp. 12-17. D. Povey, D. Kanevsky, B. Kingsbury, B. Ramabhadran, G. Saon, and K. Visweswariah, “Boosted MMI for model and feature-space discriminative training,” in Proc. ICASSP, 2008, pp. 4057–4060. —6—
© Copyright 2026 Paperzz