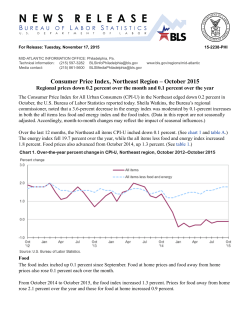
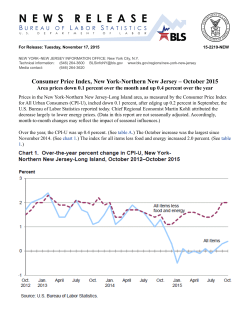
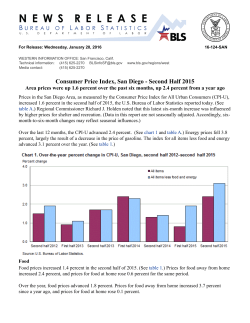
Loss Functions for Detecting Outliers in Panel Data Charles D. Coleman Thomas Bryan Jason E. Devine U.S. Census Bureau Prepared for the Spring 2000 meetings of the Federal-State Cooperative Program for Population Estimates, Los Angeles, CA, March, 2000 Panel Data A.k.a. “longitudinal data.” xit: – i indexes cross-sectional units: retain identities over time. Exx: Geographic areas, persons, households, companies, autos. – t indexes time. – Chronological or nominal. – Chronological time measures time elapsed between two dates. – Nominal time indexes different sets of estimates, can also index true values. Notation • • • • • • Bi is base value for unit i. Fi is “future” value for unit i. Fit is future value for unit i at time t. Bi, Fi, Fit > 0. i=|Fi-Bi| is absolute difference for unit i. Subscripts will be dropped when not needed. What is an Outlier? “[An outlier is] an observation which deviates so much from other observations as to arouse suspicions that it was generated by a different mechanism.” D.M. Hawkins, Identification of Outliers, 1980, p. 1. Meaning of an Outlier • Either – Indication of a problem with the data generation process. • Or – A true, but unusual, statement about reality. Loss Functions • Motivations: The i come from unknown distributions. Want to compare multiple size classes on same basis. • L(Fi;Bi)(i,Bi) is loss function for observation i. • Loss functions measure “badness.” • Loss functions produce rankings of observations to be examined. • Loss functions are empirically based, except for one special case in nominal time. Assumption 1 Loss is symmetric in error: L(B+; B) = L(B–; B) Assumption 2 Loss increases in difference: / > 0 Assumption 3 Loss decreases in base value: /B < 0 Property 1 Loss associated with given absolute percentage difference (| / B|) increases in B. Simplest Loss Function L(F;B) = |F – B|Bq (1a) or (,B) = Bq with 0 > q > –1. (1b) Loss as Weighted Combination of Absolute Difference and Absolute Percentage Difference ~ r F B L ( F; B) F B B s • This generates loss function with q = –s/(r + s). • Infinite number of pairs (r, s) correspond to any given q. Outlier Criterion • Outlier declared whenever L(F;B)(,B) > C • C is “critical value.” • C can be determined in advance, or as function of data (e.g., quantile or multiple of scale measure). Loss Function Variants • Time-Invariant Loss Function • Signed Loss Function • Nominal Time Time-Invariant Loss Function • Idea: Compare multiple dates of data on same basis. • Time need not be round number. • L(Fit;Bi,t) = |Fit – Bi|Btq • Property 1 satisfied as long as t < –1/q. • Thus, useful horizon is limited. Signed Loss Function • Idea: Account for direction and magnitude of loss. S(F;B) = (F – B) Bq • Can use asymmetric critical values and “q”s: – Declare outliers whenever S+(F;B) = (F – B) Bq > C+ or S–(F;B) = (F – B) Bq < C– + – with C+ –C–, q+ q–. Nominal Time • Compare 2 sets of estimates, one set can be actual values, Ai. • Assumptions: – Unbiased: EBi = EFi = Ai. – Proportionate variance: Var(Bi) = Var(Fi) = 2Ai. • q = –1/2. • Either set of estimates can be used for Bi, Fi. – Exception: Ai can only be substituted for Bi. How to Use: No Preexisting Outlier Criteria • Start with q = – 0.5. – Adjust by increments of 0.1 to get “good” distribution of outliers. • Alternative: Start with q = log(range)/25 – 1, where range is range of data. (Bryan, 1999) – Can adjust. How to Use: Preexisting Discrete Outlier Criteria • Start with schedule of critical pairs (j, Bj). – These pairs (approximately) satisfy equation Bq = C for some q and C. They are the cutoffs between outliers and nonoutliers. • Run regression log j = –q log Bj + K • Then, C = eK. Loss Functions and GIS • Loss functions can be used with GIS to focus analyst’s attention on problem areas. • Maps compare tax method county population estimates to unconstrained housing unit method estimates. • q = –0.5 in loss function map. Map 1 Absolute between Differences betweenthe the TwoPopulation Sets of Population Estimates Absolute Differences Estimates Persons Note: The tax method estimates are the base 0 - 5000 5000 - 25000 25000 - 50000 Over 50000 No Data Map 2 Absolute Percent Differences between the Two Sets ofthe Population Estimates Percent Absolute Differences between Population Estimates Percent Note: The tax method estimates are the base 0-5 5 - 10 10 - 20 Above 20 No Data Map 3 LossLoss Function Values Function Values Loss Note: The tax method estimates are the base 0 - 1000 1000 - 2000 2000 - 4000 Above 4000 No Data Outliers Classified by Another Variable • Di is function of 2 successive observations. • Ri is “reference” variable, used to classify outliers. • Start with schedule of critical pairs (Dj, Rj). • Run regression log Dj = a + log Rj • Then, L(D, R) = DRb and C = ea. What to Do with Negative Data • From Coleman and Bryan (2000): L(F,B) = |F–B|(|F|+|B|)q, B 0 or F 0, 0 , B = F = 0. S(F,B) = (F–B)(|F|+|B|)q, B 0 or F 0, 0 , B = F = 0. • 0 > q > –1. Suggest q –0.5. Summary • Defined panel data. • Defined outliers. • Created several types of loss functions to detect outliers in panel data. • Loss functions are empirical (except for nominal time.) • Showed several applications, including GIS. URL for Presentation http://chuckcoleman.home.dhs.org/fscpela.ppt
© Copyright 2026 Paperzz