音声認識結果を利用した類似
TV ニュースの関連付け
Finding relation between similar TV news by using speech recognition
0312003013
感性情報学講座
指導教員: 石亀昌明
1. はじめに
伊藤慶明
伊藤洋平
小嶋和徳
3.1. 単語頻度を用いた文章比較
単語頻度を用いた従来法は比較する二つの文章に
ビデオの大容量ハードディスク化により,録画し
たデータの中から見たい場面だけを視聴できる機能
が必要になると考える. 本研究では,ニュース番組
に焦点を絞り,音声認識した結果を利用し,ニュー
スクリップの関連付けを行う方式を提案する.これ
により,TV ニュース番組中の興味のあるニュース
対し ,同じ単語の数を加算していく手法である.N
を Julius 辞書の単語数,辞書の i 番目の単語が文書
1に出現する回数を w1i と表す.L を文章の単語数,
min を二つの引数のうち,小さな方を選ぶ関数とす
ると,二つの文章の類似度 S は次の式のように一単
P
語当たりの平均重なり率となる.
N
(w1i w2i ) 2
S = i min
L1 + L2
クリップに関連したニュースクリップを視聴できる.
本論文では,ニュースクリップの構成に着目し,音
声認識の性能が高い前半部分のみを文章比較の際に
重視して利用することで,精度の高い関連付けを目
指す.従来法と比較し ,本手法の有効性を示す.
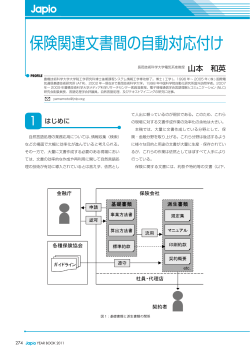
2. システム概要
自動的に複数のニュース番組を録画し ,連続音声
認識ソフトウェア Julius を用いて,音声認識を行う.
この音声認識で得られた文章を保存しておく.ユー
ザがあるニュースクリップに興味を示した場合,その
ニュースクリップの音声認識結果と保存された文章
群と比較を行う.各文章との類似度を求め,類似度
の高い順にその文章に対応しているニュースクリッ
プをユーザに提供する.また,今回は評価を簡単に
するため,ニュースクリップは事前に切出した.
3.
提案手法
3.2. tf・idf を用いた文章比較
tf・idf とはある単語 wi がどれくらいその文章を
特徴づけているか表す手法である.本研究では,単
語頻度と同様に,tf・idf により重み付けした単語を
加算する方法をとった.K を比較に使用した全ての
文章数,dfi は
wi が出現する文章数とすると,tf・
idf を用いた従来法の似度 S は次の式で表すように,
単語 wi の tf・idf の重なり部分を加算し ,平均した
PNi min(w1i
ものとなる.
S=
log dfK w2i log dfK )
L1 + L2
i
i
3.3. 提案手法
本論文では文章を先頭から可変的な単語数で区切
り,tf・idf により重み付けを行う手法を提案する.
大別することができる.アナウンサーの原稿読み上
L 単語までで二つの文章とも打ち切り,そこまでに
3.1 同様に w i1 ,w i2 と
すると,提案手法の二つの文章の類似度 S は次の式
で表すように,L 単語までの単語 w i の tf・idf の重
げによる部分は背景の音が少なく,音声認識の認識
なり部分を加算し ,平均したものとなる.
ニュースクリップは主にアナウンサーの原稿読み
上げによる部分と生中継や現地での VTR の部分に
率も高い傾向を示した.しかし,生中継や現地での
VTR の部分は臨場感を出すためにわざと背景の音
を含め音声を収録している.このため,音声認識の
0
0
S=
PNi min(w i1
0
log dfK w i2 log dfK )
2L
認識率が低くなる傾向にあった.また,ニュース番
4. 実験と考察
組の基本的な構成として,前半にアナウンサーの原
4.1. 実験データと実験条件
稿読み上げ,後半に生中継や現地での VTR という
0
出現した単語の出現回数を
本論文では
0
i
i
50 ペア 100 個のニュースクリップよ
構成が多い.したがって,音声認識の性能が高い前
り実験を行った.実験に使用したニュースクリップ
半部分のみの音声認識結果を文章比較の際に利用す
の単語数は
ることで精度の向上を目指す.以下,代表的な二つ
本研究ではニュースクリップの音声認識結果から得
の類似度算出手法と提案手法を述べる.
られた文章を利用する.参考のため書き起こしから
54 個から 1258 個,平均 290 個だった.
得られた文章との比較を行う.今回の実験では名詞
だけを抽出し,Julius に含まれる単語のみを文章比
較に用いる.提案手法の有効性を検証するために,
従来法と提案手法との比較実験を行う.
4.2. 予備実験
ニュースクリップの前半部分の音声認識結果を文
章比較の際に利用するために,以下の予備実験を行
い,文章比較に用いる先頭からの単語数( L )の適切
な値を求めた.50 ペア 100 個のニュースクリップを
10 ペアずつそれぞれ A,B,C,D,E とし,クロス
バリデーション法により評価する.学習用 40 ペア
に対し ,先頭から文章比較に用いる単語数( L )を
変化させた際の正解ペア抽出性能を図 1 に示す.
図
1
比較単語数( L )による正解の抽出性能
4.3. 評価実験と考察
図
2
開始単語( L )による認識率の変化
4.4. 代表手法との比較実験
単語頻度と tf・idf の両手法を用いて,提案手法と
従来法の比較実験を行った.実験は音声認識結果か
ら得られた文章と,書き起こしから得られた文章に
対して行い,各々の正解率を図 3 に示す.
図
3
正解ペア抽出性能の比較
音声認識結果を用いた場合,提案手法は従来法よ
りも高い正解率が得られ,提案手法の有効性が検証
all は文章に含まれる全ての単語を用いたときの正
できた.また,書き起こしを用いた場合,提案手法
解率を示す.この学習結果から,全ての学習データ
は従来法より低い正解率となった.これは正確な情
における正解率の最大値は比較単語数 60 から 150 の
報ならば 情報量の多い方が有利であるためである.
間にあることが分かる.以上の学習結果と評価デー
提案手法は音声認識の認識率が高い部分のみを利用
タを用いて実験を行った.その結果を表 1 に示す.
各学習セットで正解率が高い三つの単語数( L )に
おける正解率を太字で示した.
y
表
A
B
C
D
E
平均
1
評価実験結果( %)
60
(85)
(80)
80
100
150
75
85
85
85
80
80
80
85
80
55
65
65
90
90
80
78
80
78
(80)
(65)
(75)
77
all
80
70
65
50
80
69
表 1 の正解率の平均より,ニュースクリップの全
ての単語を用いるよりも,本方式により高い正解率
が得られた.ニュースクリップの単語数( L )まで
の単語認識率を図 2 に示す.この図から,ニュース
クリップの音声認識の単語認識率は 100 単語を境に
大きく低下することが分かる.これは,中継放送等
への切り替わりが原因だと考える.この結果から提
案手法が有効に働く理由が分かる.
し,誤認識による悪影響を受けにくいため,音声認
識結果で正解率が高くなったと考える.
5. おわりに
本論文ではニュースクリップの構成に着目し ,音
声認識の性能が高い前半部分のみを文章比較の際に
重視して利用する文章比較手法を提案した.音声認
識結果を用いた場合に従来法との比較により,高い
正解率が得られ,本手法の有効性を検証した.今後
は類似度の算出精度の向上と,ニュースクリップ毎
の自動抽出法を検討したい.
参考文献
1 )川原達也,李晃伸:連続音声認識ソフトウェア
Julius
,
人工知能学会誌, Vol.20, No.1, pp.41{49, 2005.
2 )石田英敬 記号の知/メディアの知 日常生活批判のた
:
めのレッスン,東京大学出版会
3 )高橋伸弥,森元逞,入江由紀/
2003
Web
年刊
上の類似記事自
動収集による音声認識用言語モデルの適応と学習用
ニュース記事コーパスの分析,福岡大学工学集報,第
77
号,2006 年 9 月.
© Copyright 2026 Paperzz