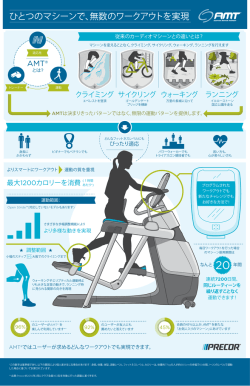
計測工学II 【第13回】Excelによる有意差の検定 今日の内容 • 【第13回】Excelによる有意差の検定 • 「危険率や統計検定」を学習します。 有意差とは? • 計測して、データを取りました。 • データ処理して、特性を調べました。 • それで、何がわかるの? • ある治療法だと、病気の治癒率が高い! • なぜ、そう言い切ることができるの? • 有意差があることを示す。 • 意味の有る差 (Significant Difference) • 意味のない差があるの? • 「偶然」差が出てしまった。 • 偶然何かが起きる確率を計算して、その確率が「十分小さい」ことが示 せれば、「意味があった」と言える。 帰無仮説 • 帰無仮説って何? • 無に帰る仮説・・・ (有意差と同様、読んで字の如く) • 「この治療法が役に立つなんて、間違いさ!」という仮説 • 「どちらも差がない」(同じ母集団に属する)という仮説 • 通常、証明したい事実を否定する仮説のことを言います。 • 実際のデータを処理して、普通の治療法と、新しい治療法を比べる。 • 比べて、「両方の結果に違いが出たのは偶然である」確率を計算する。 • その確率が 5% だったしたらと、「5%の危険率で、帰無仮説が棄却さ れた」と言う。 危険率 • 危険率とは? • うっかり間違えて、帰無仮説を棄却してしまう確率。 • 偶然いい結果がでる確率が 5% はあるのだから、「この 治療法は効果がある」と言ってしまっても、 5% は「偶然 の結果」で、間違っているかも知れない。 • 本当は帰無仮説が正しかったのだけど、偶然違いが出てし まう確率 • どの程度「意味があると言えるか」ということで、有意水準 ともいいます。 対立仮説 • 帰無仮説に対して、「これから証明したいこと」を対立仮説と言 います。 • 仮説のことを英語でHypothesis (ハイポセシス)と言います。 • 帰無仮説を通常H0で表し、 • 対立仮説を通常H1で表します。 「偶然」をどうやって証明する? • 平均値から極端に外れたデータは、「発生確率」が小さい。 • この値なら、人口1万人に一人くらい、この値だと、人口1億人に一人、と いう性質がわかる。 • 身長2m10cmの人が、電車に乗り合わせる確率は?(かなり小さい) • それが、もし、乗り換えた電車でも3回連続したら、単なる偶然と言える か? • 「一つの集団」の統計的な性質は、正規分布する、ということ を前提にする。 • 異なる二つの集団の「統計的な性質」は、異なる。 • 日本人の集団で、60歳のグループの身長と、20歳のグループの身長は、 異なる。 母集団と標本 • 例:「全日本人の、20代男子の集団」を「母集団」とする。 このクラスの男子を、「標本」とする。 母集団と標本で、身長を比較する。 • 標本数が大きければ、その統計的な性質は、母集団の統計的な性 質に近づく。 • 救急救命の学生と、臨床工学の学生で、身長の平均を比較する。 • どちらも、同じ母集団のはず。 • 「標本」が偏っていると、母集団と統計的な性質が異なることがある。 • 例:バレーボール部に所属する人と、母集団とを比較すると、平均値が異なる場 合が多い。 • 測定データAと、条件を変えて測定したデータBを比較し、それぞれ の「標本」が、「同じ母集団に属する」確率を求める。 • → これが「危険率」 • 元々同じ母集団に属するのに、偶然差があるという結果がでる確率。 生物学的・医学的統計の例 • サイトの引用です。 • 下図のデータは、40歳代男性の透析患者9名、同年代の病院 職員の健常者7名のIgG値(mg/100ml)を測定した結果です。 IgGとは免疫グロブリンタンパクの一種です。(出典;「新版 医 学への統計学」朝倉書店) • 分析の目的 • 透析患者のIgG値が健常者に比べて高いか どうかを調べます。有意水準1%で片側検定を 行います。 • 帰無仮説 H0:透析患者と健常者の母平均は等しい • 対立仮説 H1:透析患者の母平均は健常者の 母平均よりも大きい http://software.ssri.co.jp/statweb2/sample/example_3.html 統計的処理(前期、第4回) • 平均値 • データの総和をNで割る • 計算が容易 • 正規分布の場合の中心の値 を推定 • 標準偏差 • 正規分布を仮定した場合、 データが平均値の周囲にどの 程度分散しているかを示す値。 • X±σに、68.26%が集中 • X±2σに、95.44%が集中 • X±3σに、99.74%が集中 標本群の比較 • 「統計的な性質」が同じかどうかは、「平均」と「標準偏差」で比 較する。 • 標準偏差が大きい → 裾野が広がっているので、平均から値が離れ ているデータが多くある可能性が高い。 • 標本群の平均が離れていても、同じ母集団に属する可能性が高くなる。 • 母集団が同じであるなら、平均値が近いはず。 • 平均値と、標準偏差を用いて、 複数の「標本群」が同じ母集団に 属するかを検証する。 このグラフの見方、 わかりますよね!? 分布の種類 • 正規分布 • 最も一般的な分布で、生物・医学的データなどはほとんどこれだけで処理で きる。(と思う・・・) • 二項分布 • これもよく用いる。「コインの表が出た」「裏が出た」など、二律背反の場合の 統計的な分布 • ポアソン分布 • 二律背反でも、発生確率が小さく、母集団も大きい場合の確率を処理する 分布。(アルビノ[色素がない個体]が発生する確率、など。) • データを処理するときは、どの分布に従うデータなのかは、性質をよ く考える必要がある。(パラメトリックな検定) • ただ、スケーラブルなデータでは、ほとんど正規分布を考えます。 様々な検定方法 • t検定 • 二つのグループの平均値の違いに、有意な差があるかどうかの検定 • F検定 • 二つのグループの分散の違いに、有意な差があるかどうかの検定 • χ2検定 (カイ2乗検定) • ピアソンのカイ二乗検定:頻度分布の比較に用いる。 • 事象は互いに排他的でなければならない(例えば「さいころの目」、「あ る人が男か女か」など)。 • コンピュータの乱数が本当に「ランダム」か、頻度分布に置き換えて検定 を行う場合などに使う。 参考ページ:Wikipedia データの性質で方法が異なる • 「度数」と「連続量」とで、処理方法を変えます。 • 度数 → 度数分布:ヒストグラムで表す。 • サイコロの目が出た回数。 • Countable な(数えることができる)データ • 度数分布を処理すると、「Aである確率」と「Aでない確率」(二律背反)に分 けられるため、二項分布に従う。 • 連続量 • 身長や体重など • Scalableな(計測で数値を出せる)データ • 今回は、これだけを扱う • 順序尺度 (1位、2位という序列が与えられたデータ) • AKB48の人気順位(ランキング)の統計的分析! • とにかく、これらによって「処理方法が違う」ということをしっかり思い 出して、後は統計の専門書へ! 自由度 • 正規分布で検定を行う際に、「自由度」という概念が出てきま す。(degree of freedom) • 「自由」って何? • → 一つ一つが型にはめられていなくて、独立の(外部から制御されて いない)値を持つことができている。 • その度合い? → 簡単には、データの個数(それぞれが独立変数) • 全変数の数から、それら相互間に成り立つ関係式(束縛条件、拘束条 件)の数を引いたものである。 [引用元:Wikipedia] • 近似的には「データ数」ですが、「データ数=自由度」ではあり ません。さらに、個々のデータ間の条件式があるため、例えば Welchの方法では「整数値」ではなく、実数値を持ちます。 不偏分散 n 1 2 2 s = (x − x) • 例えば、不偏分散 ∑ i n −1 i=1 • については、 n x= 1 xi ∑ n i=1 • という関係式(ここで は母集団平均 µ の推定量である)があ るから、自由度は1少ないn - 1となる。 • このため、標準偏差ではなく、不偏分散が使われることが多い。 • 標準偏差だと「標本分散」が「母集団の分散」よりも小さくなる ことが多いが、「標本の不偏分散」の期待値は、母集団の分 散に等しくなる。 引用元:Wikipedia Excelと不偏分散 • 標準偏差 σ は、分散の平方根で、以下の式で計算されます。 1 n 2 σ= (x − x) ∑ i n i=1 • この式は、「母集団」の標準偏差の計算に用いて、EXCELで は = STDEV.P() 関数になります。標本の場合には、不偏 分散の式を用いるので、標準偏差は n 1 2 s= (x − x) ∑ i n −1 i=1 の式になり、EXCELの関数は = STDEV.S () になります。 両側検定と片側検定 調べたい現象で、平均が大きくなるか小さくなるかわからない 場合には、平均が大きい方と小さい方の「両側」を調べます。 • 例:ある薬品を使うと、血圧が上がるか下がるか、よくわかっていない 場合、「正常な平均値」からの上と下の両方を調べます • 「血圧が下がる」ことがわかっている際に、「こんな使い方で 効果が出るか」を調べる場合には、「片側」を調べます。 画像引用元: http://homepage2.nifty.com/nandemoarchive/toukei_hosoku/ryougawa_katagawa.htm 棄却域って何? • 前のページのスライドで、グラフの端の方を「棄却域」と書きま した。 • 帰無仮説が「仮説として正しくない」と判断することを「仮説を 棄却する」と言います。帰無仮説が棄却されるということは、 「対立仮説が正しい」ということなので、「証明したい内容が証 明された」という意味になります。 • 分布のグラフで、面積が小さいということは、確率的に起こり にくいことを意味し、「この薬に効果があったなんて、単なる偶 然さ」という、その「偶然の起きる確率」がものすごく小さいこと を示していることになります。 今回は、計算しないの? • 前回まで、Excelの「お任せ」機能を使わずに、Σを計算して相 関係数などを求めました。 • 今回は、有意水準の推定で、ガンマ関数やベータ関数という 特殊関数を使いますが、有意水準ごとに、計算量の多い積分 計算を行う必要があります。 • このため、一般には計算済みの数表を使い数表を読んで、検 定値を判断します。 • できれば、「t値」などを計算し、その「t値」での「有意水準が何%か」わか ればいいのですが、ガンマ関数の積分の逆関数がとにかくやっかいな ので、とにかく従来は数表を使いました。 今回は、計算しないの?(Part 2) • 級数展開、積分など計算式を設定するのは内容的にも時間 的にも困難なので、今回はこの部分はExcelの関数を使いま す。 • ガンマ関数やベータ関数は数学科などの皆さんにお任せしましょう。 • そのものズバリの検定用関数を使います。 • 重要な概念や用語が大量に出て来るので、とにかく言葉の意 味をしっかり覚え、「こういう時は処理法を変える」ということだ けは覚えておいて下さい。 • そして、実際にデータを処理する時に、統計の本などで確認して下さい。 t検定の種類 • t検定では、平均の違いを比べる。 • ですが、そのt検定だけでも「どんな時にこんな計算式を使う」 というのが分かれてきます。 • paired-t(データに対応がある時のt検定) • 「使用前」 → 「使用後」みたいなデータ • 対応はないが、分散が等しい時 • 対応がなく、分散も等しくない場合。 • Excelの =TTEST()関数で、引数を 変えます。 図引用元:http://www.geisya.or.jp/~mwm48961/statistics/bunsan1.htm 検定の行い方(従来の方法) • データの種類(度数、量、順序尺度)などによって、検定方法 を選ぶ。 • その検定による「検定値」を計算する。 • 例: t値、 F値、 χ2値 など • 統計分布関数から、「ある有意水準」で、その「自由度」でのt 値、F値、χ2値などを数表から調べる。 • その「有意水準」での検定値よりも、調べる検定値が大きけれ ば、その有意水準では、同じ母集団に属さない(有意差があ る)と判断する。(t値、F値、χ2値の場合) Excelを使っての検定 • 数表を調べる、という部分がExcelの関数になり、計算したF値 やt値をとる場合の「確率」が計算できるようになりました。 • この場合には、計算で求めた「確率」が、調べたい有意水準よ りも大きければ、計測データにおいて帰無仮説が起きることは 「確率的にも大きい」、つまり、統計的に違いがない、つまり、 「治療法が有効」などとは言えない、などという結果になります。 • 逆に言えば、論文として成り立ちやすいのは、「偶然の確率」 が有意水準よりも小さいから、帰無仮説は棄却できる、つまり、 「この治療法の有効性が統計的に証明された」という流れで論 証します。 F検定の両側、片側 • t検定の場合には、平均が大きくなるか、小さくなるか(片側) がわかっているか、平均が異なるか、(両側)で、検定の読み 方に「両側」「片側」があります。 • F検定の場合、もちろん分散が大きいか、小さいか(片側)、 違っているか、という差がありますが、F値を計算する際に、分 散が大きい方を分母とする、という方法をとりますので、必ず 「片側」になります。 • F検定で、分散が大きいか、小さいかを問題にする場合には、両側の場 合の式を参考にして下さい。 • 別途、統計の資料やサイトなどを参照して式を組み直して下さい。 統計計算の実際 下図のデータは、AクラスとBクラス(全員)の定期試験の結果で す。(架空)この二つのクラスに、実力の差があると言えるか、 5%の有意水準で検証して下さい。 • 分析の目的 • 二つのクラスのテストの結果が 統計的に差があると言えるか 検証する。 • 帰無仮説 H0:両クラスの平均は等しい (違いは、偶然の範囲内である。) • 対立仮説 H1:両クラスの平均は統計的に 異なると言える。 平均と標準偏差を求める • 平均は、=average(範囲) で入力できます。 • 分散は・・・ • 今回のデータは、「Aクラス」と「Bクラス」の全体ですので、母集団です。 母集団の分散の場合には、 標準偏差σ=STDEV.P(範囲)を使います。 • もし、検証がスライドの 9 ページのように、「全ての透析患者」と「全ての健 常者」を母集団とし、データを取ったのがその一部である(ほとんどの生 物・医学的な統計は、こちら)である場合には、不偏分散の標準偏差 s=STDEV.S()を使います。 • この時は、母集団ではなく、標本集団という言い方をします。 分散、データ数、自由度 • 分散には、標準偏差の二乗 =count(範囲) 関数 • 自由度には、データ数−1を入力します。 • Aクラスのデータの場合 • データ数には、 • C14 =AVERAGE(C4:C12) • C15 =STDEV.P(C4:C12) • C16 =C15*C15 • C17 =COUNT(C4:C12) • C18 =C17-1 • という式を入力する。 • C列に数式は、 オートフィルで D列にコピーできます。 F値 • F値は、二つの分散値のうち、大きい方を分子とする比を計算 します。(これにより、F値は片側検定になります。) • C19の分散比(F値)では、 =IF(C16>D16,C16/D16,D16/C16) • という式を使ってみました。 • C20には、有意水準の値を入力しました。 F検定 • F検定の関数は、F.TEST()です。 • 古いバージョンのEXCELでは、FTEST()として下さい。 • FTESTの戻り値は、両側検定の確率です。片側検定にするた めに、2で割ります。 • この数値を有意水準と比較します。 • 片側検定の結果(C22)が、「分散が等しい」確率です。この確 率が有意水準よりも小さければ、「分散が等しい」という帰無 仮説が棄却され、不等分散であると言えます。 昔ながらの数表確認 • 現在のやり方(直接確率を計算する方法)では、もう使いませ んが、有意水準0.05の時に、与えられた自由度でF値がいくつ になるか、念のために表示してみます。 • 両側検定の場合には、有意水準を2で割って0.025として数表 から読みます。 • 現在は、数表を使わなくても、Excelで計算できます。 • C24のセルには =IF(C16>D16,F.INV(1-$C$20/2,C18,D18),F.INV(1-$C$20/2,D18,C18)) • C25のセルには =IF(C16>D16,F.INV(1-$C$20,C18,D18),F.INV(1-$C$20,D18,C18)) • を入力します。 t値の計算 • t値を計算します。t値の計算式は、文献により何通りかありま すが、ここでは以下の式を用いました。 x1 − x2 t= 1 1 s + n1 n2 • ここで、計算に用いた分散Sは、二つの事象の分散から合成 しました。 s12 (n1 −1) + s22 (n2 −1) s= n1 + n2 − 2 t検定 • Excelでのt検定は、T.TEST()です。 • 第一引数と第二引数は、データ配列です。 • 第三パラメータは、1ならば片側検定、2ならば両側検定です。 • 第四パラメータは、1ならば paired-t(対応のあるt検定)、2なら ば等分散の独立2変数、3ならば、不等分散の検定です。 • ここでは、F検定の結果から第4パラメータを与えるようにして =T.TEST(C4:C12,D4:D12,1,IF($C$20>$C$22,2,3)) • の式を入力しました。 検定結果の判定 • t検定の結果は、T.TESTの値が有意水準の確率と比べて大き いか、小さいかで判断します。 • T.TESTの結果は、「二つの標本集団が、平均値が同じ母集 団の一部である(データの統計的性質が同じ)確率」を表して います。この値が小さい、ということは、二つの統計的な性質 は違う、ということを意味します。 • 両側検定の結果が1%だったということは、1%の確率で両方 のデータが同じである、つまり、(1%というのは小さい値なの で)、二つの統計データは異なる、つまり、この課題では、「Aク ラスと、Bクラスとでは、実力が異なる」:という結果が、1%の 危険率で示されたことになります。 昔ながらの数表検索 • 直接確率を計算してしまっているので、0.05(5%)の危険率 を設定しても、全然意味がなかった、ということにはなりますが、 棄却域が5%に設定されているならば、この確率と比較して有 意差のあり、なしが求められます。 • そもそも、昔は数表で調べていましたが、有意水準と、自由度 (二つの和)を与えて、数表から検索しました。 • この値を計算したt値と比べて、t値の絶対値の方が大きかった ら「有意差あり」と判定していました。 • 現在は、以下のような関数式で計算できます。 計算部分のEXCEL関数式 STDEV.Pか STDEV.Sか、 注意深く選ぼう 危険率の値 • 昔のやり方の場合には、数表が不可欠でした。 • 現在は、直接確率を求めることができるので、元のデータから、 前ページの色塗りした部分の式を入力するだけで、有意差の 判定ができます。 • 論文などを読むと、危険率の値として1%とか5%などが使わ れていますが、これは、統計数表にこれらの値しか用意されて いなかったためです。 • 現在は、1.3%でも0.41%でも、任意の値に危険率を設定する ことができます。棄却水準という言い方ではなく、「帰無仮説の 成立確率が0.23%なので」などという言い方をしても正しいは ずですが、論文などを書く場合には昔からの言い方の方が無 難かもしれません。 今日の授業課題 • 今日の授業スライドのP9の、免疫グロブリンのデータを処理して、 有意差の有無を論じて下さい。 • EXCELのシートに数式を入れて、結論を出すだけではなく、論文調 に、「目的」と、「仮説」、「計算結果」、「結論」をできればデータシート とは別のシートに記して下さい。 • ここまでの課題で数式が入れてあれば、データ部分を行拡張してデータを 入れ替えるだけで結果は出せます。 • 最高点6点で計算します。 • 標準偏差の計算式などに誤りがあった場合には、減点します。 • また、「結論」に使われている言葉(帰無仮説や、対立仮説など)の使い方に 誤りがあったり、あるいは、言葉できちんと結論を出していない場合にも、減 点します。 • 課題ファイル名は、「学籍番号-13.xlsx」でお願いします。 次回の予告 • 【第14回】計測と伝達関数、論文に見るデータ処理 • シラバスより以下の部分を変更して扱います。 • 【第14回】論文に見る計測データの処理 • 学術論文における「計測データ」の処理方法を読む。計測データは適切な処理を行わないと結 論を導くことが困難であるため、どんなデータから何が言えるか、危険率や統計検定、回帰直線 や、相関係数を実際に求めている論文を読んで、それらの指標の重要性を学ぶ。 • コンパートメント・モデルを紹介し、計測データから特性を調べる計 算処理を行います。また、時間に余裕があれば、最新の学会誌から 論文を紹介して、実際のデータ処理を読みます。 • コンピュータ演習室の使用は、今回だけです。 • 次回から、一般教室に戻ります。 欠席した人は・・・ • 今日の授業課題を提出して下さい。 • 提出があれば、出席に切り換えて、レポートも採点評価します。
© Copyright 2026 Paperzz