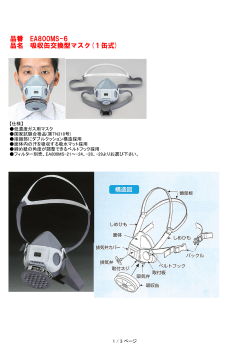
情報システム基礎論2:第 13 回 (担当: 古賀)
文書検索の高速化/ウェブページの検索
2014 年 7 月 15 日
レジュメ URL: http://sd.is.uec.ac.jp/koga/lecture/IF2/
文書検索の高速化
1
文書の類似検索では、文書を索引語のベクトルとして表現した後、cos 類似度 (式 (1)) によって類似度
を測る。cos 類似度は 2 つのベクトルの向きがどれだけ一致するかを表す。
sim(p,q) =
ap · aq
.
|ap ||aq |
(1)
クエリ q とデータベース S 内の全文書間で cos 類似度を計算すれば類似検索は実現できるが、処理負荷
が大きい。そこで、cos 類似度の計算回数を減らす手法が必要となる。以下の 2 つが代表例。どちらも明
らかに似ていない文書に対して類似度の計算を省略する。
1. cos 類似度に対する LSH
2. 転置インデックス (inverted index)
1.1
cos 類似度に対する LSH
d をベクトルの次元数とする。類似文書検索においては d は索引語の総種類数。
ハッシュ関数 h
1. 正規分布から d 個の確率変数 r1 , r2 , · · · , rd を選択し、d 次元ベクトル r を決定。
r = (r1 , r2 , · · · , rd )
2. d 次元ベクトル p のハッシュ値 h(p) は以下のように定める。
(
1 if r · p ≥ 0
h(p) =
0 if r · p < 0
(2)
式 (2) は d 次元空間を、r と直交し原点を通る超平面で 2 つに分割していることになる。
定理 1 p, q を 2 個のベクトルとし、θ(p, q) を p と q がなす角とする (0 ≤ θ ≤ π)。この時、
P [h(p) = h(q)] = 1 −
θ(p, q)
.
π
θ(p, q) が小さいほど、超平面による空間分割で p,q が違う部分空間に属する確率が低い。逆に θ(p, q) が
180 度の場合は、p,q を結ぶ線分上に原点が存在し、必ずハッシュ値が異なる。
あとは、通常の LSH と同様。複数個のハッシュ関数を用意して、ハッシュ値が一致したデータとだけ実
際に類似度を計算する。
1
h(x)=0
h(x)=1
p
r
0
図 1: h による空間分割
1.2
転置インデックス (Inverted Index)
共通の単語を全く含まない文書同士は類似データではない。それらに対して類似度を計算するのは無駄。
転置インデックスは共通の単語を含む文書を高速抽出するための自然言語処理特有のデータ構造。単語
をキーとして、当該単語を含む文書のリストを記憶。
表 1: 転置インデックスの例
T1
T2
T3
T4
T5
This pen is mine
This is a pen
This is an apple
An apple and the pen
World is mine
⇒
this
pen
is
mine
a
an
apple
and
the
world
1,2,3
1,2,4
1,2,3,5
1,5
2
3,4
3,4
4
4
5
通常の索引構造では、文書 T をキーとして T が含む索引語 VT を記憶している。文書と単語の関係が逆
転しているので転置インデックスと呼ばれる。
クエリ q が与えられた時、共通単語を含む文書集合は以下の手順で求められる。
1. q から索引語集合 Vq を取り出す。
2. ∀w ∈ Vq に対して、転置インデックスを使って w を含む文書集合 Dw を得る。
[
3.
Dw : q と共通単語を含む文書集合
w∈Vq
2
ウェブページの検索
一般ユーザが最も馴染みがあるのはウェブページのキーワードによる検索である。そこで、本講義でウェ
ブページの検索を実現する検索エンジンについて講義する。
2
• 入力: ユーザが指定したキーワード
• 出力: キーワードにマッチしたウェブページの集合
出力されるウェブページの集合にはランクが付与される。ユーザに有益なページが上位に提示されるのが
望ましい。ウェブページの検索は以下の 3 ステップによって実現される。
1. クローリング (crawling): 世界中のウェブページを収集する。
2. インデクシング (indexing): 収集したウェブページを解析し、どの単語を含むかをまとめる。
3. ランキング (ranking): 検索キーワードとマッチしたページに順位を付けて出力する。
• インデクシング
クエリを高速に処理できるように、収集したウェブページの単語情報をあらかじめ抽出する。前処
理によりウェブページから索引語を抽出。その後、転置インデックスを作成。キーワードを含む文
書に高速アクセスできる。
• ランキング
キーワードとマッチしたページをユーザに順位を付けて提示。
1. キーワードとのマッチ具合: キーワードの出現回数、キーワードの出現位置
– 出現回数:多すぎても少なすぎても駄目。 – 出現位置:前の方でマッチすると得点大。
2. ページの重要性
の 2 つを考慮してランキングを決定。
3
ページの重要性
直感的に
他のページからリンク(つまり引用)されるページは重要性が高い
⇓
リンクをページの重要性判定に使えないか?
u をウェブページとする。
• forward link: u から外に出るリンク。u 内に直接記述される。
• backward link: u を指すリンク。u 内には記述されていないが、クローリングによって見つけられる。
• Fu : u の forward リンクの集合
• Bu : u の backward リンクの集合
3
3.1
単純な方法
backward link 数 |Bu | でウェブページ u の重要性を測る。backward link 数=被参照回数。
欠点: リンク元の重要性を反映できない。Yahoo からのリンクと無名サイトからのリンクが同じ価値。
4
PageRank
Google によって提唱された重要性に基づくページの順位付け手法。
4.1
基本アイデア
PageRank では重要性 (=ページランク) の高いページのリンクに高い価値を持たせる。以下ではウェブ
ページ v のページランクを P R(v) と記す。
• v から u へのリンクは「v が u を支持するという信任投票」
• ページ u のページランク P R(u) = u への投票数の合計。
• ページ v は P R(v) だけの投票数を持つ。つまり、重要度大 → 投票数多い。v はその投票数を forward
link に均等に投票。
以上をまとめると関係式 (3) が得られる。しかし、P R が左辺と右辺の両方に出現する。
P R(u) =
X P R(v)
.
|Fv |
(3)
v∈Bu
v2
v1
v3
図 2: ウェブページのリンク
例: 図 2 では以下の連立方程式が得られる。
P R(v1 )
0
1
P R(v2 ) = 2
P R(v3 )
0 1
P R(v1 )
0 0 P R(v2 )
1 0
P R(v3 )
1
2
P R(v1 )
0 0 1
x = P R(v2 ) , A = 21 0 0 とおくと、式 (4) は x = Ax と書ける。
1
P R(v3 )
2 1 0
これを一般化すると以下のようにまとめられる。
4
(4)
• d: ウェブページ数
(
• A: 大きさ d × d の行列。auv =
0
1
|Fv |
if v から u にリンクなし
if v から u にリンクあり
• x: 各ページのページランクが並んだベクトル。Ax = x を満たすので、A の固有ベクトルとなる。
以下では、一般性を失わず x の要素の合計は 1 と仮定する。
4.2
固有ベクトル x の計算
一般に A は非常に大きなサイズになるので固有ベクトルの計算は簡単ではない。しかし、A は
• 全ての要素が非負
• 任意の列の要素の和=1.
なのでマルコフ連鎖の状態遷移に対応する確率行列となる。図 3 に図 1 の例に対するマルコフ連鎖の状態
遷移図を示す。
• 状態数=ページ数
• 遷移確率=forward リンクの重み
したがって、Ax = x を満たす固有ベクトル x は、マルコフ連鎖の極限分布として求められる。具体的
には、適当な大きさ1の初期ベクトル x0 を与え、x = limk→∞ Ak x0 より、x を計算する (図 4)。
注:極限分布が収束するためには A にある条件が成立している必要がある。この事に関しては 4.3 節で
後述。x0 には依存しない。
S2
1/2
S1
1
1
1/2
S3
図 3: マルコフ連鎖の状態遷移図
4.3
PageRank の直観的な意味
ネットサーフィンをしている状況を考えると、aji はページ i を見ている条件で、次にページ j を見る確
率を表す。
• i から j への forward リンクがない。→ aji = 0.
• i から j への forward リンクがある。→ aji > 0.
5
PR(v1)
PR(v2)
PR(v3)
0.4
0.333
0.2
0
0
2
4
6
8
10
12
14
図 4: 極限分布 (固有ベクトル) への収束
となっており、ネットサーフィンを合理的にモデル化できている。さらに
• ページ i の forward リンクの重みは同じ → 次のページをリンク先を等確率で選択して読む。
極限分布 x =
x1
x2
..
.
は、上記のようなランダムなネットサーフィンに長時間おこなった後でユーザ
xd
が各ページを見ている確率を表す。
xi : ページ i を見ている確率。
4.4
damping factor
マルコフ連鎖が極限分布に収束するための必要条件の一つに既約性がある。
• (既約性) 任意の状態から任意の状態に到達可能。
しかし、web ページはこの条件を必ずしも満足しない。例えば、
1. forward リンクを持たないページ
2. 外部への forward リンクを持たないループ (図 5 の BC) からは、任意のページに到達できない。
A
B
C
図 5: 外部への forward リンクを持たないループ
6
Si
C1i
S1
Cni
Cji
S2 .....
.........
Sj
Sn
図 6: 遷移確率
この問題を解決するために、A に全要素が正である行列 B を混合し、式 (5) のマルコフ連鎖を考える。
x = (αA + (1 − α)B)x
(5)
つまり、ページランクは行列 (αA + (1 − α)B) の固有ベクトル。
• α:0 < α < 1 を満たす実数。行列 A と B の混合率であり damping factor と呼ばれる。α = 0.85 が
よく用いられる。
1
d
1
d
1
d
1
d
..
.
···
···
..
.
1
d
1
d
1
d
1
d
···
1
d
B=
..
.
..
.
(αA + (1 − α)B) は確率行列。なぜならば B は各列の要素和が 1。よって、∀j (1 ≤ j ≤ d) に対して、
αA + (1 − α)B の第 j 列の要素和 = αA の第 j 列の要素和 + (1 − α)B の第 j 列の要素和
= α + (1 − α) = 1.
(αA + (1 − α)B) はすべての要素が真に正なので明らかに既約。よって、(αA + (1 − α)B) によって表現
されるマルコフ連鎖の定常状態は必ず存在。
Appendix: マルコフ連鎖
時間とともに値が変化する確率変数 X を考える。X は n 個の値 {S1 , S2 , · · · , Sn } のどれかの値を取る。
時刻 t における X の値を Xt と記載する。
マルコフ連鎖では現在 (時刻 t) の値が Si (1 ≤ i ≤ n) である時、次の時刻 (t + 1) に Sj に変化する確率
を状態 i から状態 j への遷移確率という。遷移確率を表す式を (6) に示す。
P (Xt+1 = Sj |Xt = Si ) = Cji
Pn
j=1 Cji
(6)
= 1 を満足する(図 6)。マルコフ連鎖では Cji は t に依存しない定数であると仮定する。
マルコフ連鎖において状態遷移を繰り返し、時刻 t → ∞ における X の分布をマルコフ連鎖の極限分布
という。極限分布の実応用例としては市場シェアの予測などがある。
7
© Copyright 2026 Paperzz