Paper
zz
Explore Categories
Log in
Create new account
No category
t+1
Download
Report
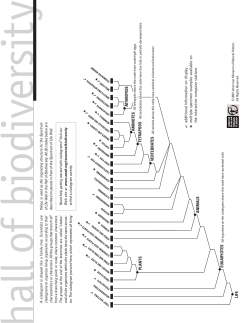
Hall of Biodiversity Insert - American Museum of Natural History
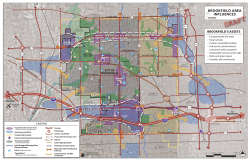
Community Wide Assets (08.11.08).ai
download
产品规格书 - Shenzhen leynew technology Co., LTD
final!!!1
PPT2
Statistical Inference for Some Network Models
An introduction to Big Data and Hadoop
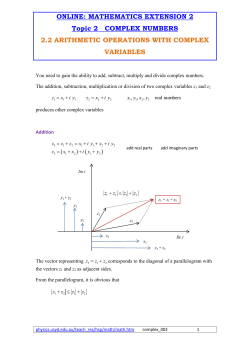
Mathematics Extension 2 Complex Numbers
View the slides
A UNIFIED PROOF FOR THE CONVERGENCE OF JACOBI AND
Distributed Clustering in Ad-hoc Sensor Networks: A
© Copyright 2026 Paperzz
About Paperzz
DMCA / GDPR
Report