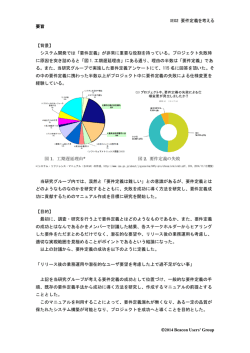
第1章 学 習 目 システム障害に対する事前対策 標 この章では、システム障害に対する事前対策を学習します。 ・長時間障害の業務への影響 ・システム障害長時間化のメカニズム ・企画、要件定義、開発工程における障害対策 ・テスト・移行工程における障害対策 ・運用・保守工程における障害対策 システム障害の長期化は、なぜ発生するのでしょうか。 その原因の一つとして、システムにまつわる各工程における要因が複合することが挙げられます。ある 業務システムが導入され、運用されるまでの工程としては、企画、要件定義、設計、開発、構築、テスト・ 移行、運用、保守などが考えられます。これらの各工程において、障害の元となる要因が発生するのです。 これらは、一つ一つは見過ごされてしまう些細なものであり、さまざまな事情によって見落とされてしまうこ とがあります。 しかし、システム障害が発生した場合、これらの小さな要因が重なり合って障害の長期間化につながりま す。 4 © 富士通ラーニングメディア 業務に必要なサービスレベルを満たすように、システム設計をするためには、次のようなフローで作業を進 めるのが効果的です。 1.サービスレベル要件の確認 業務部門からヒアリングを行い、機能的要件を定義することはもちろんですが、可用性やキャパシティ、セ キュリティや法的制限といった、非機能要件も確認します。非機能要件はヒアリングだけでは見落としてし まうこともあるため、特に注意が必要です。 2.SLAの作成 業務部門から挙がったサービスレベル要件と、情報システム部門やITベンダーが提供可能なサービスレ ベルを照合して調整し、SLAを作成します。「求めるレベル」と「可能なレベル」との折り合いをつけることが 必要です。 3.SLAの合意と設計への反映 作成したSLA案を元に、ユーザー企業とITベンダーの間でSLAを合意します。ITベンダーはこのSLAを 満たせるようシステムを設計します。SLA内容の実現にリスクを伴う場合には、必ず双方でそのリスクを共 有する必要があります。また、予算が大きく制限される場合でも、業務に必須となるサービスレベルにつ いて妥協せず、場合によっては余剰機能を削ってでも、必要なサービスレベルを満たすように調整します。 10 © 富士通ラーニングメディア 運用・保守工程における障害対策の勘所は、以下のとおりです。 1.変更に応じて、監視や障害対応手順の更新を行う 変更計画をレビューする際、そのシステム変更に伴う他の変更についても確認することが必要です。例え ば、監視や障害対応手順、ユーザーへのアナウンス内容等が挙げられます。 また、変更によっては、異常系テストや復旧テストで確認した内容が該当しなくなる場合もあります。この場 合は、変更後のテスト時にあらためて異常系テスト、復旧テストを行うことを考えます。 2.定期的に障害復旧作業の訓練を行う。 障害復旧作業の訓練は、障害が発生しなくても定期的に行うことが重要です。中でも、発生頻度の少な い障害については、日々の対応で触れる機会が少ないため、こうした項目の訓練は有用です。 訓練を通じて、障害復旧作業や体制の妥当性をチェックすることができます。訓練の結果、策定したプロ セスや体制に妥当でない部分があれば適宜修正できますし、作業員の的確かつ迅速な作業の備えとも なります。 3.定期的に障害対応手順、および体制の妥当性をチェックするルールを設ける。 障害対応手順や体制は、継続的に改善する必要があります。システム自体の変更や、システムをとりまく 環境の変化に対応する必要があるからです。定期的に妥当性確認をする際のチェック項目を準備してお き、課題を抽出し、手順、体制の維持改善を行います。 35 © 富士通ラーニングメディア 第2章 システム障害発生時の対応 学 習 目 標 この章では、システムに障害が発生した場合の対応手順について学習します。 ・障害対応に関わるメンバーを招集する ・状況の詳細を確認する ・障害箇所を特定する ・暫定対処を行い業務を復旧する ・恒久対処を行う ・事後レビューを行う 障害に対応するには、事前に障害対応の体制を決めておきます。障害に対応する場合には、作業者には 作業に集中してもらい、管理者は作業の進捗状況等を把握して、他の担当リーダーと連携・調整する必要が あります。したがって、作業する者と管理者とを分けることが必要になります。 このような体制をとらず、その時々の状況により、直接の対応者が個人で対応した場合には、その作業がト ラブルの長期化につながるおそれがあります。 上の図では、監視メンバー、ユーザーからインシデントの報告を受けたサービスデスクが、一次対応ルール によっては解決できないものと判断し、統括責任者にエスカレーションをしています。エスカレーションを受け た統括責任者は、あらかじめ定められたルールに則って、各チームリーダーを召集しています。 40 Visual InterDevによるASPを利用したWebアプリケー ションの構築© 富士通ラーニングメディア 上の図は、インターネットでコンサート等のチケットを申し込むことができるシステムの障害の根本原因をロ ジックツリーを使用して分析したものです。 まず、障害がロジックツリーのスタートになる「問題」になります。この「問題」がどのハードウェア、ソフトウェア、 ネットワークの問題なのか、「WHAT」で、考えられるものをすべてピックアップします。図では、「問題」として、 「ハードウェア」、「帯域」、「プログラム」がピックアップされました。そしてピックアップされたそれぞれの項目に つき、さらに「WHAT」を繰り返して、項目を細分化しました。 次に、細分化された個々の項目ごとに、考えられうる原因(WHY)を追究しました。考えられうる原因につい て、システムの状態がどのようになっているか、一つ一つ確認していきます。この確認の結果、障害の根本原 因は、「偶発的なトランザクション要求の偏り」と「コネクションプールが偶発的に足りなくなる状況」だと分かり ました。 このように、ロジックツリーを使用し、それぞれの考えられうる原因を確認する場合、すべての担当者の協力 を得る必要があり、結果として、客観的な判断を導くことができるだけでなく、この分析過程をドキュメント化す ることにもなり、ノウハウも蓄積できるメリットもあります。ロジックツリーを使用せず、属人的に分析してしまうと、 例えば、ネットワークの帯域だけの問題だけにしてしまったり、サーバのスペックだけの問題にしてしまったり するおそれがあり、原因が複合していることを見逃すおそれがあります。 51 Visual InterDevによるASPを利用したWebアプリケー ションの構築© 富士通ラーニングメディア
© Copyright 2026 Paperzz