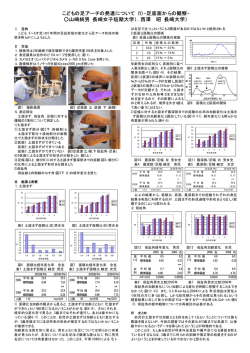
標準化変量
標準化変量
村尾博
青森公立大学
更新日:2013 年 12 月 3 日
1.はじめに
ここには標準化変量の話と共に脱線話も含まれている。書いた本人は「標準的な話」よりも「脱
線話」の方が面白いと感じているのだが、・・・。まずは標準化変量に関わる準備的な話から始
める。
ものごとの「比較」は評価や判断へ直結しており、極めて重要なことである。そして比較では「他
の事情同一条件での比較」
、いわゆる「同じ土俵での比較」が求められる。単純な話、2cm と 3Kg
とを比較し、どちらか大きいかといった判断はできない。また、2 つのテストの得点が同じ 80 点
であっても、一方のテストが 100 点満点、他方のテストが 200 点満点の場合、80 点という得点は
全く意味も評価も異なってくる。これらの例が示すように比較の場面では「他の事情同一条件で
の比較」
「同じ土俵での比較」が求められる。
「何を同じにするのか」
「どこまで同じにするのか」
といったことは具体的な内容によりけりであるが、比較や評価の場面では「同じ土俵での比較」
が求められるといった認識が大切である。
2.標準化変量
標準化変量
ここでは統計的な議論における比較・評価ということから、「異なった分布から得られる数値の
比較」について考える。具体的なイメージを得るため、次の数値例を考える。国語の試験と数学
の試験を行い、国語の試験は 120 点満点で、受験者全員の平均得点は x = 70 点、標準偏差は s x = 5
点であった。一方、数学の試験は 100 点満点で、受験者全員の平均得点は y = 50 点、標準偏差は
s y = 8 点であった。そして A 君の国語の得点は x A = 72 点、数学の得点は y A = 57 点であった。A
君はどちらの科目が良くできていたのであろうか。
このような比較では「標準化」と呼ばれる変換を行い、無単位の同じスケールで得点を比較する
のが一般的である。
n
ある量的変数 x の観測データ {( xi )}i =1 において、平均は x 、標準偏差は s x であるとする。ある観
測値 xi を標準化した値は zi と記す習慣があり、
zi =
xi − x
sx
1
「標準化係数」
「 z 値」といった具合に呼ばれる。
で与えられる。標準化した値 zi は「標準化得点」
標準化した変数の方は z と記す習慣があり、
「標準化変量」
「標準化変数」
「標準化係数」
「 z 変数」
といった具合に呼ばれる。
n
標準化したデータ {( zi )}i =1 には次の性質がある。
(1) 平均 z = 0
(2) 標準偏差 sZ = 1
(3) 無単位
(4) z 値のほとんどは ±3 の範囲に収まる(詳しくは Chebyshev の定理を参照)
。
性質(1)と(2)は「分布の位置(平均)と分布のスケール(標準偏差)とを同じにした土俵」を意
味する。試験の得点の場合であれば、「試験の難しさ(平均)とスケール(標準偏差)とを同じ
にした土俵」を意味する。性質(3)は「評価の物差し」として同然に求められる条件である。性
質(4)は標準化変量という評価の物差しのスケール感覚を得るのに役立つ。
先の数値例に関し、A 君の z 値を計算してみよう。
国語の z 値=
72 − 70
= 0.400
5
数学の z 値=
57 − 50
= 0.875
8
したがって A 君は数学の方が良くできている。試験の難しさ(平均)とスケール(標準偏差)を
制御した「同じ土俵」において、国語の得点と数学の得点とを比較し、数学の方が良くできてい
るといった意味である。
性質(4)に関しては「評価の物差しのスケール感覚を得るのに役立つ」と述べたが、もう少し詳
しく説明する。
「 z 値のほとんどは ±3 の範囲に収まる」といったスケール感覚を持っていると、
z 値を見るだけで、大雑把な判断ができることが多い。例えば試験の得点に関する z 値が +3 で
ある場合、それはトップ 5 %内と考えて良いような数値である。IQ テストの得点は正規分布に近
い形で分布することが知られている。適度に難しい試験の得点も、正規分布に近い形で分布する
ことが知られている。そこで「試験の得点が正規分布に従う」と仮定する。その場合、 +3 の z 値
はトップ 0.1 %ぐらいになる。つまり、千人の受験者の中でトップに相当するような良い得点を
意味する。分布形が分からない場合でも、前述の如く、 +3 の z 値はトップ 5 %内と考えて良いよ
うな数値である。このようなスケール感覚は、後述する「2tルール」にも繋がってくる。
3.標準化のバリエーション
標準化のバリエーション
回帰分析において、説明変数から従属変数への影響力を説明変数間で比較する場合は、
「t 値」に
基づき比較するのが普通である。その t 値は次の形をしている。
2
t値 =
係数推定値
標準誤差
この t 値は次の解釈ができる数値になっている。
t値 =
影響力の計測値
上の影響力の分布の標準偏差
つまり、t 値は一種の標準化得点である。
「影響力なし」の点を基準点(ゼロ)として影響力を標
準化したものが上のt値である。したがって説明変数の影響力は t 値で比較することになる。一
方、係数推定値は影響力を「生のスケール」で計測したものであり、
「単位が異なる」
「スケール
が異なる」等々の理由により、影響力を「比較」
「評価」する場面では用いない。係数推定値は
影響力を「解釈」する場面で用いる。
ところで、データの大きさが 30 を超えるぐらいに大きくなると「 z分布 ≈ t分布 」
「 z値 ≈ t 値 」と
なり、先の性質(4)が役立つ。その結果、絶対値で 3 を超えるような t 値は 1000 回中 1 回くらい
にしか起きないような極めて稀な数値であり、絶対値で 2 を超えるような t 値は 100 回中 5 回く
らいにしか起きないような稀な数値になる。
「影響力なし」の点が 0 となっている視点(仮定)
から見ると、絶対値で 2 よりも大きな影響力は偶然とは思えないほど大きいな影響力となる。し
たがって次のような大雑把な判断ルールが成り立つ。
t 値の絶対値が 2 ぐらいよりも大きい場合は影響力ありと判断する。
この大雑把な判断ルールは「2tルール」と呼ばれている。t 値が 3 や 6 ともなると、極めて大き
な影響力を意味する。正式には「t検定」と呼ばれる仮説検定が必要であるが、回帰分析の現場
において即決するのに役立つ大雑把な判断ルールである。
上の t 値は標準化のバリエーションである。統計学に関する計測値は
・生のスケールの数値
・比較用の数値(評価用の数値)
に大別できると考えるのが良い。比較の場面では比較用の数値で比較するといった単純な話であ
る。一方、比較用の数値(評価用の数値)であってもデータの大きさによってスケールが異なっ
てくるものもあり、このあたりの実情は多種多様であり、一筋縄ではいかない。そうであるから
こそ、単純に整理する考え方を自分で得ることが大切である。
3
4.
「他の事情同一の条件での比較」に関する
「他の事情同一の条件での比較」に関するコメント
に関するコメント
話が「脱線」するが、次の内容は様々な科学分野での学習に役立つと考える。
「他の事情同一条
件での比較」
「同じ土俵での比較」の重要性を一般論として理解していたとしても、
「同じ土俵で
の比較を達成するための工夫」といった視点から、次に示す様々な事例を見ていたであろうか。
科学分野
統計学
金融学
医学
議論の対象
分布から得られる数値
異時点間の金額
治療効果の検証方法
多次元の比較になっている
(数値、単位、レベル、
(金額、時期、リスク) ある治療の成果は「治療
といった共通性がある。
スケール)といった 4 次
といった 3 次元の比較
の有無」のみならず様々
元の比較を考える。
を考える。
な影響要因の影響を受け
ていると考えられる。
どうするのか。
(単位、レベル、スケー
(時期、リスク)を制御
様々な影響要因を「同じ
比較する対象物を除き、他は
ル)を制御した同じ土俵
した同じ土俵において、 に」できないが、
「ランダ
「固定」
「同じ」にする。な
において、変換後の数値
変換後の評価額(現在価
マイゼーション(攪乱
いしは類似の工夫を施す。
を比較する。
値)を比較する。
化)
」という方法により、
治療の有無だけが浮き彫
りになるようにする。
その結果
現在価値
標準化変量(z 値)
zi =
xi − x
sx
V0 =
Vt
(1 + r )t
「対照実験」や「コント
ロール実験」と呼ばれる
方法。医学に限らず、様々
な科学分野で広く利用さ
れている。
科学分野
数学
経済学
ミクロ経済学
議論の対象
微分
比較静学
価格変化に対する需要量
の変化
多次元の比較になっている
相互依存関係の内生変
価格の変化による需要量
数が複数個あり、内生変
の変化(価格効果)は、相対
y は複
数へ影響する外生変数
価格と購買力との双方が
数の独立変数の影響を受
が多数個ある連立方程
変化した結果になってい
ける構図になっている。
式モデルを想定する。
る。
どうするのか。
x1 の変化に対する y の
一度に変化させる外生
相対価格のみの変化に対
比較する対象物を除き、他は
反応を調べるときには、
変数は 1 個(ないしは 2
応する「代替効果」と、
「固定」
「同じ」にする。な
他の影響要因 ( x2 , x3 ) を
個)に限定する。他の外
購買力のみの変化に対応
いしは類似の工夫を施す。
固定する。
生変数は変化させない。 する「所得効果」とに 2
といった共通性がある。
多変数関数
y = f ( x1 , x2 , x3 )
における従属変数
分割する。
その結果
偏微分
ほとんどの経済分析は
スルツキ―方程式
∂y ∂f ( x1 , x2 , x3 )
=
∂x1
∂x1
このタイプである。
価格効果 = 代替効果
+ 所得効果
4
比較や評価に関わる手法や道具に接したときは、
・どのような意味で同じ土俵の比較になっているのか
・同じ土俵にするための具体的な工夫は何なのか
といったことに関し、自問自答するぐらいのことが求められる。そのことは手法や道具を作った
先人の工夫を探る楽しみにつながり、そして先人の知恵に驚かされることがある。これが「脱線」
で述べたかったことである。
5.先の治療効果の検証方法の続き
脱線話の続きになるが、本来の話「標準化変量」へ戻していこう。具体的には先の治療効果に関
する検証の話を標準化変量や 2t ルールの話へ結びつける。具体性を持たせるため治療効果の話
になっているが、統計的な評価法においてポピュラーな手法の話でもある。
治療を施すグループは「トリートメントグループ」と呼ばれ、
「偽の治療を施す」
「従前の治療法
を施す」など、比較の基準となるグループは「コントロールグループ」と呼ばれる。このような
2 グループに被験者をランダム(無作為)に振り分ける。
「トリートメントグループ」に属するメ
「コントロールグループ」に属するメンバーの結果の平均を xC と記し、
ンバーの結果の平均を xT 、
治療の効果は、
xT − xC
といった差の形で計測できるとする。これは生のスケールで計測した効果である。生のスケール
の計測値は「単位があること」
「スケールが異なること」等々の理由で比較や評価に適していな
い。したがって標準化した数値へ変換し、標準化した計測値に基づき判断を行うことになる。
一方、治療の結果に影響する様々な他の要因はランダム化されており、小さい様々な影響力の集
合と考えることができる。つまり、
「治療効果に対する誤差」と考えることができる。小さい様々
な影響力の集合は正規分布に近くなるとする定理(中心極限定理)がある。このような理論的根
拠もあり、誤差の分布としては正規分布が良く用いられる。また、平均は
x=
1
1
1
x1 + x2 + ⋯ + xn
n
n
n
といった形をしており、データの大きさ n が大きい場合は、
「小さい様々な影響力の集合」となっ
ており、先の定理(中心極限定理)から、変数としての平均は正規分布に従うとすることがきる。
このような結果、正規分布やt分布に基づく仮説検定が多く、
・前述の標準化変量に関する性質(4)
・前述の 2tルール
といったスケール感覚が役立つ。例えば標準正規分布に基づく「z 検定」においても、2tルール
が意味するところの大雑把な判断ルールは有効である。
このようなスケール感覚が役立つ話へ直行するため、
5
・実際の仮説検定は、もっと込み入った話になっている
等々、枝葉的なことはスキップした。
ここで述べた統計的な検証法は
・新しい肥料の効果に関する検証
・新しい社会的プログラムの効果に関する検証
等々へ適用できることは自明であろう。
ものごとの検証は比較の話であり、比較のための計測値が使われる。その際には標準化得点( z 値)
や類似の計測値が頻繁に出てくる。話が標準化変量へ戻ったところで、話を終えよう。
おわり
6
© Copyright 2026 Paperzz